
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
An Ontology-Based Question Answering System for University Admissions Advising
School of Computer Science and Engineering, International University, VNU-HCMC, Vietnam National University, Ho Chi Minh City, Vietnam
* Corresponding Author: Thi Thanh Sang Nguyen. Email:
Intelligent Automation & Soft Computing 2023, 36(1), 601-616. https://doi.org/10.32604/iasc.2023.032080
Received 06 May 2022; Accepted 01 July 2022; Issue published 29 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Question-Answer systems are now very popular and crucial to support human in automatically responding frequent questions in many fields. However, these systems depend on learning methods and training data. Therefore, it is necessary to prepare such a good dataset, but it is not an easy job. An ontology-based domain knowledge base is able to help to reason semantic information and make effective answers given user questions. This study proposes a novel chatbot model involving ontology to generate efficient responses automatically. A case study of admissions advising at the International University–VNU HCMC is taken into account in the proposed chatbot. A domain ontology is designed and built based on the domain knowledge of university admissions using Protégé. The Web user interface of the proposed chatbot system is developed as a prototype using NetBeans. It includes a search engine reasoning the ontology and generating answers to users’ questions. Two experiments are carried out to test how the system reacts to different questions. The first experiment examines questions made from some templates, and the second one examines normal questions taken from frequent questions. Experimental results have shown that the ontology-based chatbot can release meaningful and long answers. The results are analysed to prove the proposed chatbot is usable and promising.Keywords
As known, social networks are very popular nowadays and data analysis jobs help much in enhancing marketing strategies [1,2]. In social network sites, automatic supports, e.g., interacting with customers or web users, are crucial and attracting more users. A chatbot is now not strange in social networks, it becomes a friend, a consultant, or an assistant answering problems in some specific fields. In other words, a chatbot is able to understand and communicate with people and perform specific tasks. In natural language processing, it is used in applications that offer automatic verbal interactions. For example, a chatbot [3] has been developed alongside an E-learning platform in order to answer questions relevant to course materials, and chitchat as well. This makes online classes more interesting, especially, nowadays, online courses/classes are very popular. Depending on different architectures, these smart entities can communicate in many ways, whether to provide instructions, answers to questions, or to entertain users.
According to [4], there are many types of chatbots, classified based on: the knowledge domain, the service provided, the goals, the input processing and response generation method, the human-aid, and the build method. Basing on the knowledge domain, a retrieval-based model can be used, in that, a domain ontology is able to be built for information retrieval since it is a powerful expression tool [5,6]. Some ontology-based chatbots have been built to support answering automatically questions in specific domains, e.g., shopping in e-commerce [7], drug information consultant in medical [8], and educational and professional orientation [9]. Theses chatbots help human much nowadays because of an overload of consultative jobs in many fields or being impracticable to access to a person in charge. In another way, the input processing and response generation methods take into account the generative models which are more human-like. In generative models, some usable methods are machine learning or deep learning, e.g., Recurrent neural network (RNN) [10], Long short-term memory (LSTM) [11], Qanats [12], Sequence-to-sequence (Seq2seq) [13], Hierarchical Recurrent Encoder–decoder (HRED) [14], SPHRED [15], XLNet [16], etc. Using generative models brings some positive achievements, for example, by improving the QANet model to be combined with the retrieval-based model, a hybrid model K-12 e-learning assistant chatbot [3] was built and better than a teacher counselling service. However, the generative model-based chatbots often return short answers and need to train a large dataset. This makes building a chatbot more difficult if training data is not enough at the beginning.
As we can see, the generative model is more interesting and effective for open domain chatbots, but it requires a large amount of well-prepared question-answer data for training the model. In many cases, this kind of data is not available at the beginning, so domain data is necessary to be collected to construct a knowledge base for a chatbot model, e.g., an ontology-based chatbot. Therefore, this study concerns building a domain knowledge base for a closed domain chatbot, focusing on the case study of university admissions advising. Particularly, it proposes a chatbot model for admissions advising at the International University (IU) belonging to the Vietnam National University–Hochiminh City (VNU-HCMC). A domain ontology is constructed given the information of university admissions at the university admissions website of IU. Based on the domain ontology, we can make a response reasoner of the specified domain.
The study focuses on building an ontology-based chatbot which can help response frequent questions of university admissions automatically. The source of the ontology is from the admissions information of the International University (VNU-HCMC). Moreover, the proposed chatbot model is developed dynamically so that it can be extended by adding more data into the ontology to enrich the knowledge base. In this manner, the performance of the chatbot will be improved significantly.
The following sections will present related work (Section 2), research methodology (Section 3), experimental results with evaluation (Section 4) and conclusions (Section 5).
As mentioned in the Introduction Section, this section presents related techniques and the concerning chatbot models which are based on ontology.
According to Antoniou et al. [5], Ontology is a fundamental Semantic Web technology, it defines the formal semantics of the terms used for describing data, and the relations between these terms. It is efficient to express the semantic information of knowledge bases in different domains. That is why ontology is used to represent semantic knowledge bases for automatic inference or information retrieval in a specific domain. OWL (Web ontology language, http://www.w3.org/TR/owl-features/) is a main Web ontology language which satisfies the requirements of building a domain ontology, including a well-defined syntax, a well-defined semantics, efficient reasoning support, sufficient expressive power, and convenience. Therefore, an ontology can be used efficiently in a search engine of a chatbot.
2.2 Existing Ontology-based Chatbot Models
Ontology is a solution for understanding what utterances are about. That is the reason the ontology-based chatbot models were born. It is also driven domain knowledge so that it can create domain-driven conversations. Ontology is used to store the domain knowledge and navigate through it [17]. Therefore, this ontology-based knowledge base can provide information for answer generation in dialogs. The benefit of the ontology-based approach is to “keep conversation memory explicitly throughout the conversation”. Because of the benefits of ontology, it has been adopted into closed domain chatbots and provides very specific answers given questions.
There are many kinds of question answering systems (QAS) (known as chatbots) emerging [18]. Most QAS have three main subtasks: questions analysis, search of documents/database containing the answers, and extraction of answers. Their goal is to response users’ questions in natural language using their own terminology. The databases used in QAS are able to be structured databases, unstructured free text, or semantic knowledge bases. In that, the ontology-based QAS use ontology to build semantic knowledge bases which can infer information semantically within the ontology-based domain knowledge in order to response user queries. The benefits of these systems are they do not require training data and the user does not need to learn the vocabulary or the structure of the ontology. Therefore, the user can ask questions in a natural way in a specific domain.
The ontology-based QAS have been developed in many fields, for example, an e-learning bot built by Clarizia et al. [19] allows dealing with students’ questions of subjects in lectures. Its knowledge base is an ontology containing “users” and “learning objects” which is a collection of content items, practice items, and assessment items. It plays a role as an education support system for students. Experimental results show that the chatbot can furnish about 71% correct suggestions. On the other hand, ontology could help recommend interesting courses to the prospective students, for instance, in a personalized course recommendation system proposed by [20]. It combined collaborative-based filtering with content-based filtering by using ontology to map the course profiles and student profiles with job profiles. In that way, the system could produce recommendation results better than traditional collaborative-filtering methods considering only keyword similarity. In another application domain, such as medical, an ontology of drugs and their relevant information has been constructed for MediBot [8], which is Portuguese Speakers Drug. The knowledge base of the ontology is a combination of many data sources and expert knowledge. The bot is responsible for converting natural language to SPARQL query, processing the query, and sending a response to users.
Recently, an educational program counseling system [21] has been proposed using ontology. It has achieved higher performance than the Apache Lucene system using a keyword-based text search engine. University admissions counseling or advising is very crucial, nowadays, since many future students want to know how to choose a suitable major out of many majors at universities. Especially, admissions advising at Vietnamese universities is very time and labor-consuming. Advisors need to update admissions information regularly so that they can help future students to decide on the most suitable academic program. However, there has not been a QAS yet to support these jobs at Vietnam universities. Therefore, developing a QA system of advising university admissions is very significant at Vietnamese universities.
As known, the ontology-based model is limited to a specific knowledge domain, but able to be built from the real-world data sources with domain experts’ support and achieve significant outcomes. Therefore, this study considers using ontology to build a QA system of admissions advising at the International University as a case study.
The proposed chatbot framework, namely IUOntoBase Chatbot, consists of three steps: data preparation, ontology construction and reasoning (Fig. 1). The ontology construction is the main process step, an ontology of university admissions information is constructed for understanding input queries in natural language and reasoning relevant things in order to generate most suitable answers. The following subsections will give more details of the proposed framework.
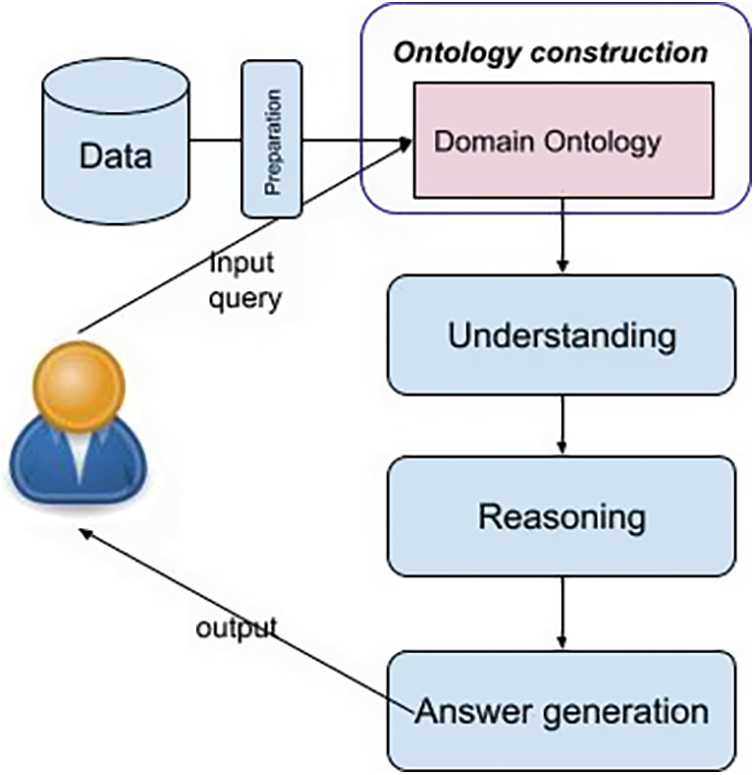
Figure 1: The proposed chatbot framework
As known, ontology is an expressive powerful expressive tool in semantic knowledge representation. Based on that, this study proposes building an ontology of a knowledge domain of university admissions as a case study. Particularly, the raw data is collected from the admissions website of the International University (https://tuyensinh.hcmiu.edu.vn/). It is cleaned to remove meaningless words, then analysed to construct ontology concepts and relationships among concepts in the preparation step before modelling a domain ontology.
To model the domain ontology, domain entities are first identified, and then data and object properties are added. Fig. 2 depicts the ontology model of the International University (IU), including Major, Unit, Employee, etc. This study focuses on the enrollment and academic advising, so the information on curricula is considered along with subjects.
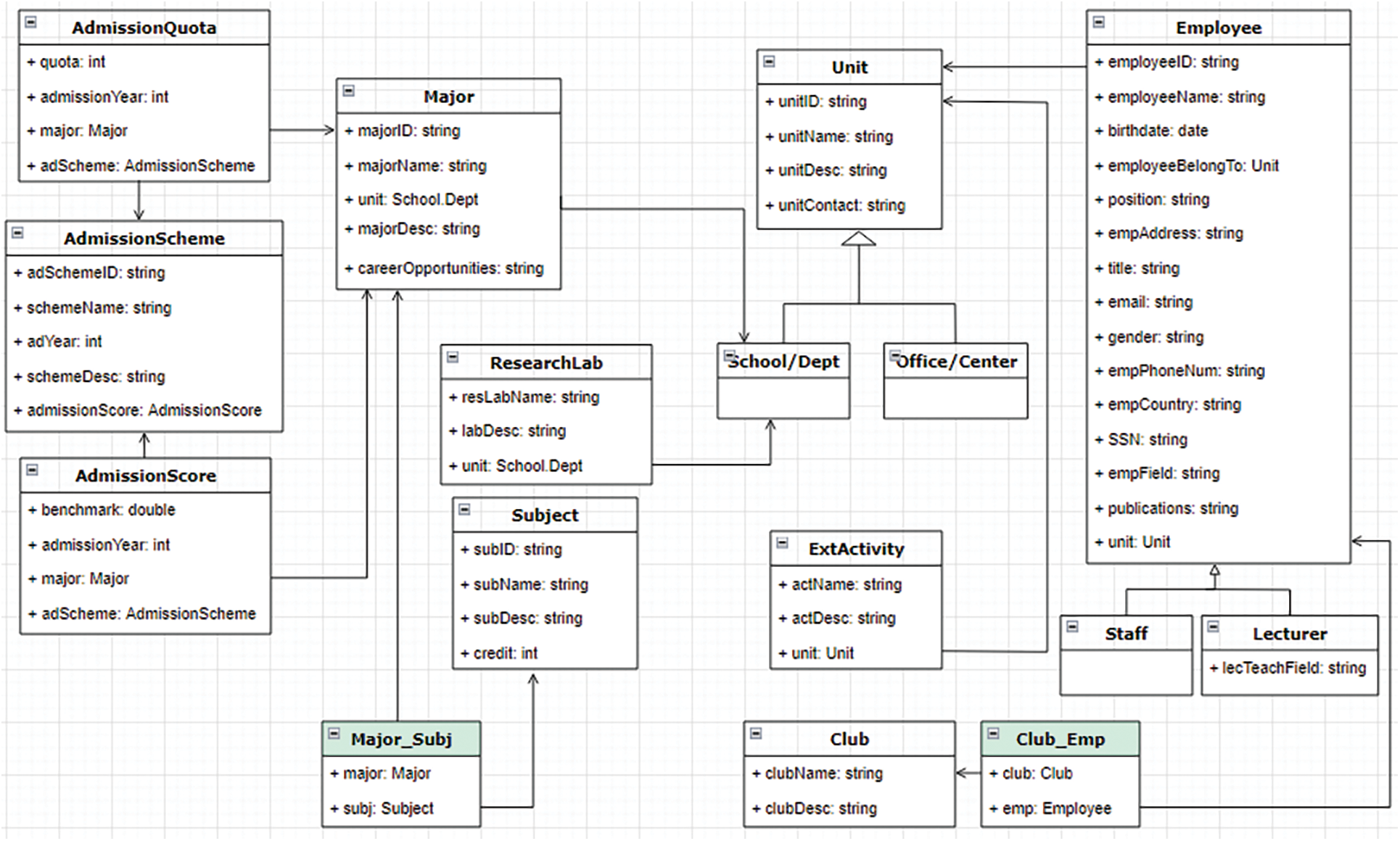
Figure 2: Ontology model of the International University
The following is the definition of the domain ontology model, namely IUOnto.
Definition 1. (Domain ontology model of the International University) A domain ontology structure of IU is defined as a four-tuple:
Based on IUOnto, the IU ontology is built using Protégé tool, as shown in Fig. 3.

Figure 3: The admissions ontology of the International University
To quickly seek instances in the IU ontology, some keywords are added into each instance. Therefore, a multivalued keywordName property is added into the Thing class. Moreover, some keywords are commonly used in many instances, hence we have the Keyword class. Besides, keywords categorized in groups are presented by the KeywordByClass class.
From this ontology, we can construct a full ontology-based knowledge base by populating the data collected from the IU into the built ontology. For instances, Fig. 4 shows some instances of AdmissionScore and Subject classes. For classes that do not have a Name property, e.g., AdmissionScore, their IDs must be meaningful names.
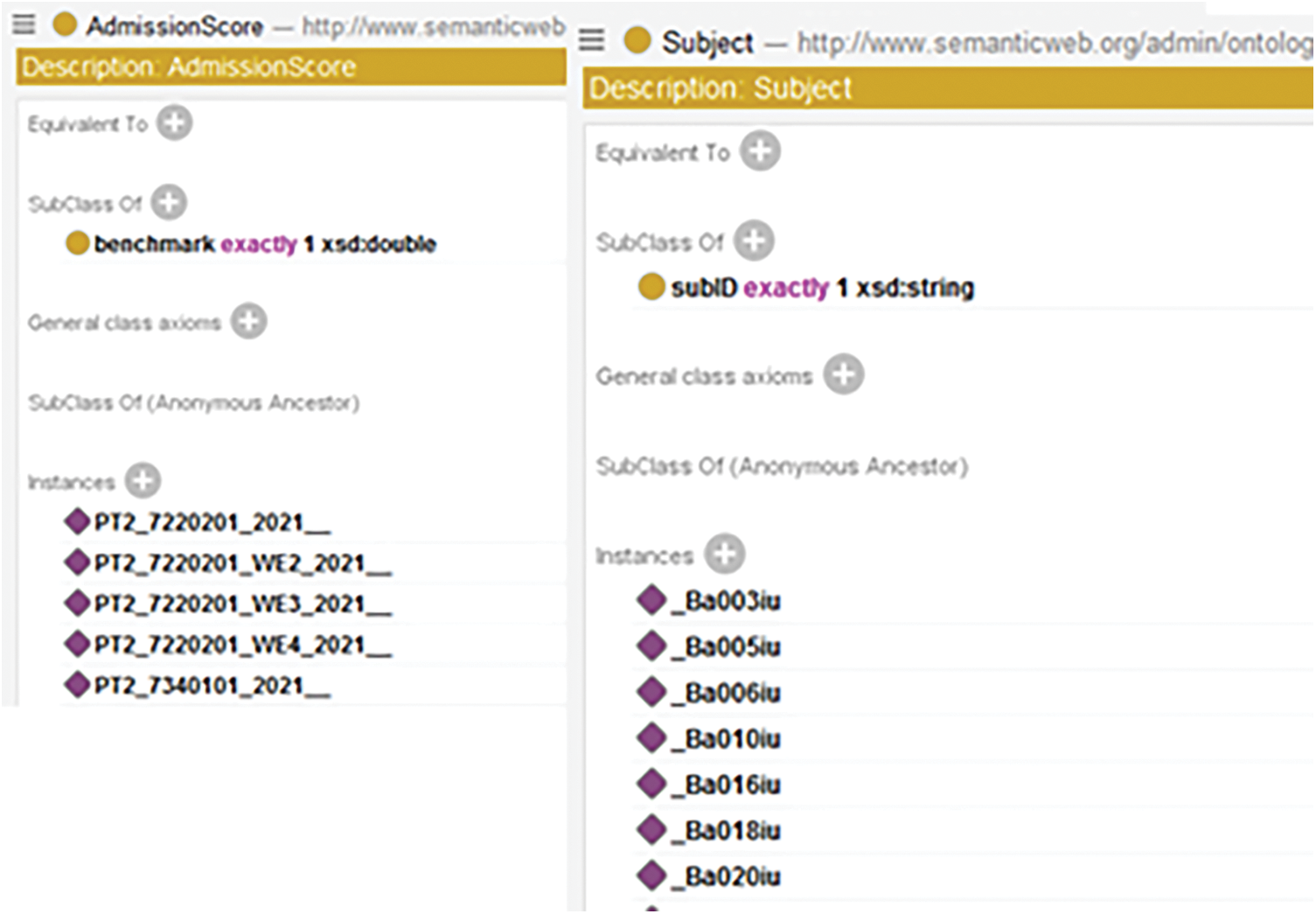
Figure 4: The partial instances of AdmissionScore and subject classes
Fig. 5 shows some keywords added into the instances of Major class. It is noted that the data values in the ontology are in Vietnamese, since the IU admissions data is in Vietnamese. In Fig. 5, the “Quản trị Kinh Doanh” (Business Administration) Major has some keywords “kinh doanh” (business), “quản trị” (administration), and “quản trị kinh doanh” (business administration).
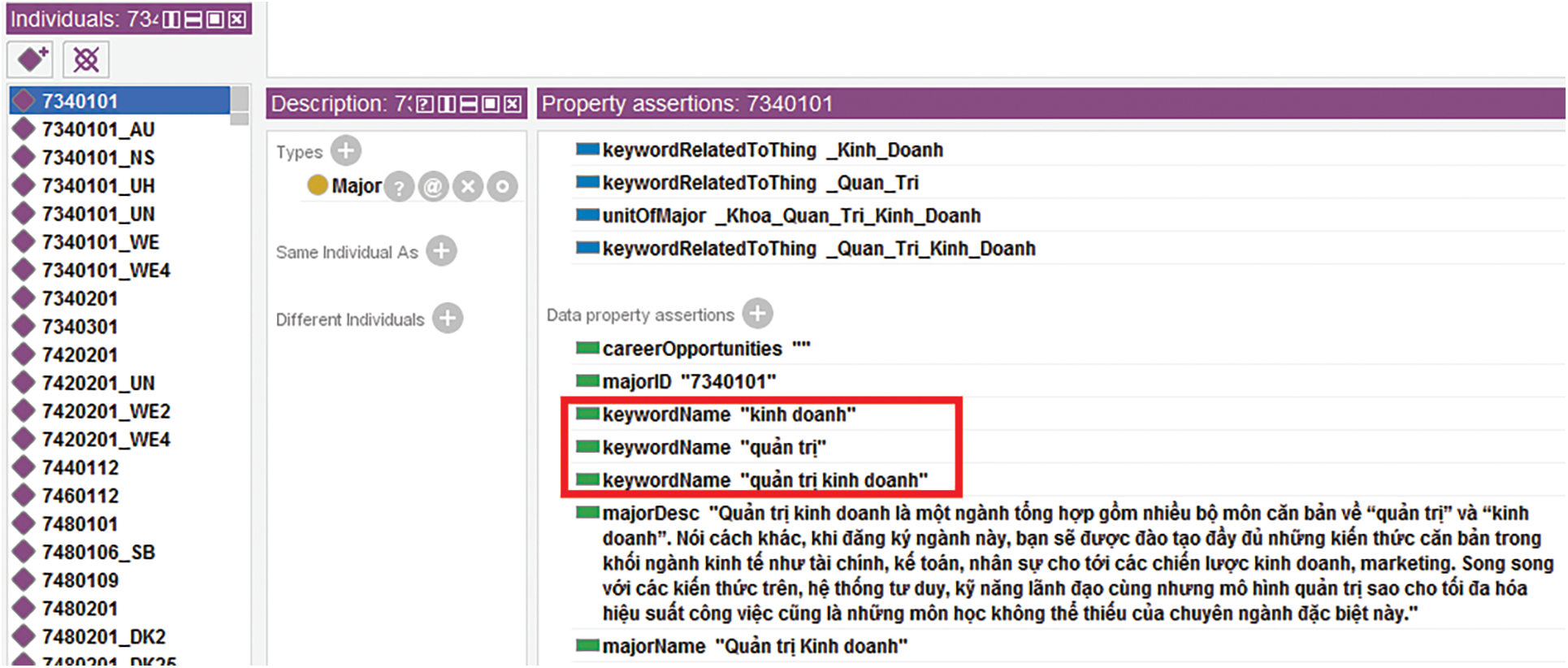
Figure 5: The partial instances of the major class and relevant keywords
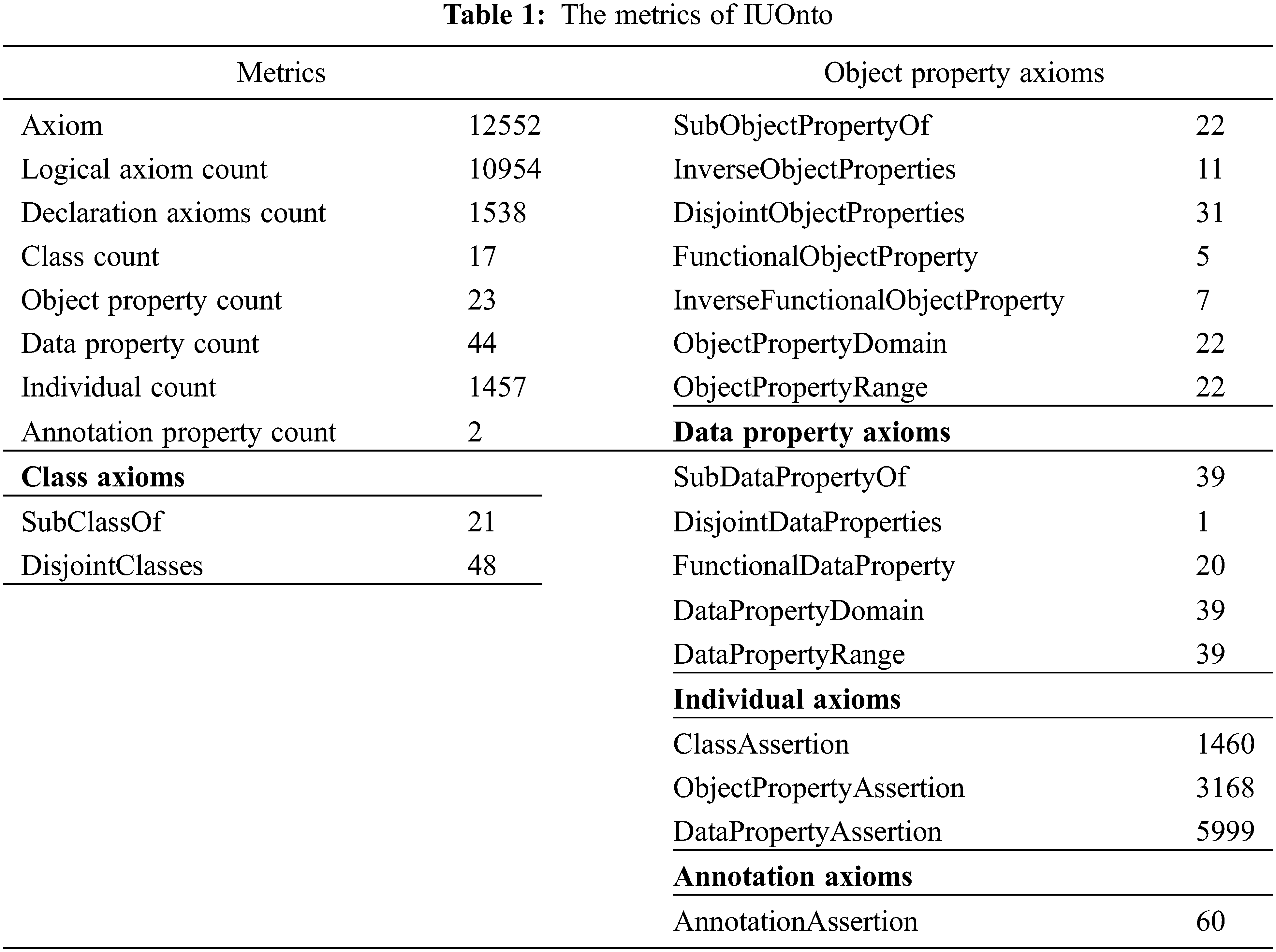
Tab. 1 shows the metrics of IUOnto after populating the IU admissions data. Totally, there are 17 classes, 23 object properties, 44 data properties, 12552 axioms, and 1457 individuals created.
3.2 Reasoning and Answer Generation
Based on the above ontology, the machine can reason information of instances so that it can understand the meaning of a keyword if that one is found in the list of keywords or instance names/IDs. By ontology reasoning, the IUOntoBase chatbot can generate answers to users’ questions. Algorithm 1 presents how to generate answers given a question. Keywords from questions are extracted by using the VNcoreNLP library [22]. The output answer is the information or description of the returned instance.

Algorithm 1 has shown that relevant things are returned if any userKeywords match owlKeywords. That means there is no response if not matched. There are 747 keywords which are typical and various in the domain of university admissions are added to the IUOnto. Therefore, the chatbot can response most questions related to the university admissions.
By the IUOntoBase chatbot framework, a QA system is implemented in Java. NetBeans is used to design and develop the Web interface of the chatbot using Spring Boot, the IU ontology population and reasoner. Fig. 6 shows the QA system framework. By using Protégé, the IU ontology is built and saved as an Ontology.owl file; Java classes of the IUOnto model are generated from the IUOnto model. To program the aforementioned IU ontology population and reasoner, Protege-OWL API is imported into the system so that new terms or admissions information can be updated, and queries can be automatically responses.
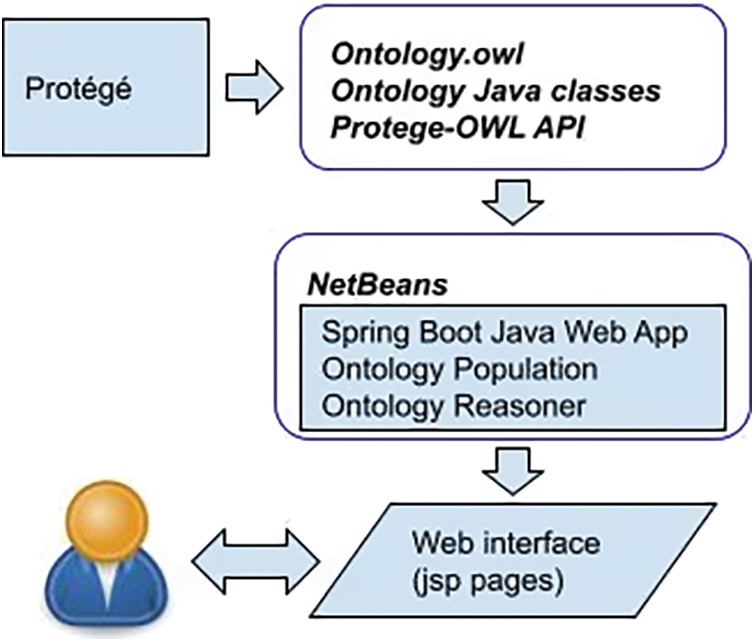
Figure 6: Integrated framework of the QA system
Since the IUOntoBase chatbot is used for admissions advising at IU, the used dataset is collected the IU admissions website. Given the IU data, the IU ontology is constructed. The programmes of 21 majors at IU along with their subjects are added into the ontology. The admission score and quota of each major are also modified. There are six admissions schemes, 12 schools/departments and 17 offices/centers appended into the ontology.
Some web interface pages of the chatbot are depicted in Figs. 7 and 8. User queries are input into the chat box, and responses are generated by the IUOntoBase chatbot. For example, two sequential questions are answered correctly in Figs. 7 and 8.
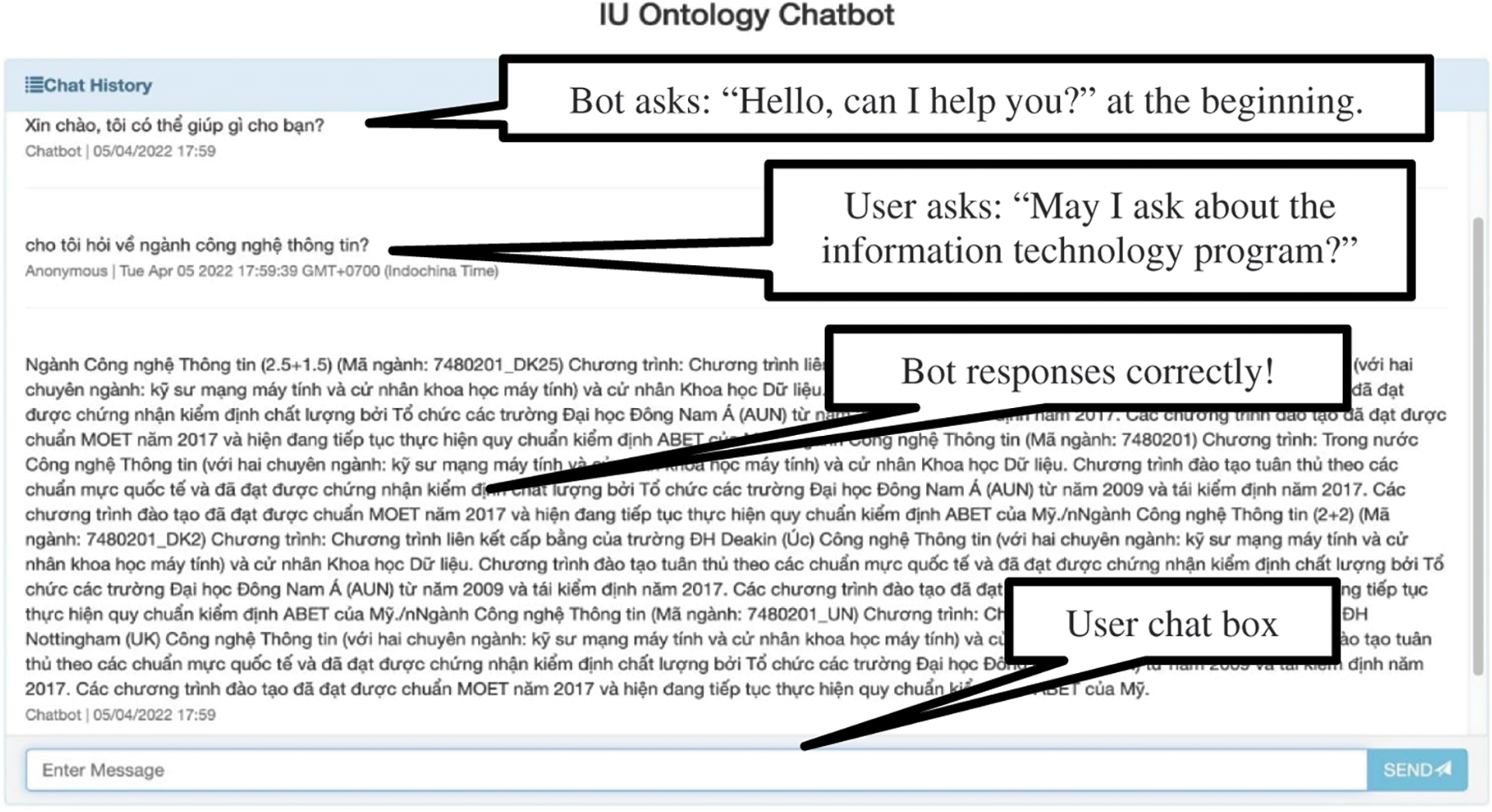
Figure 7: Web interface page of the chatbot
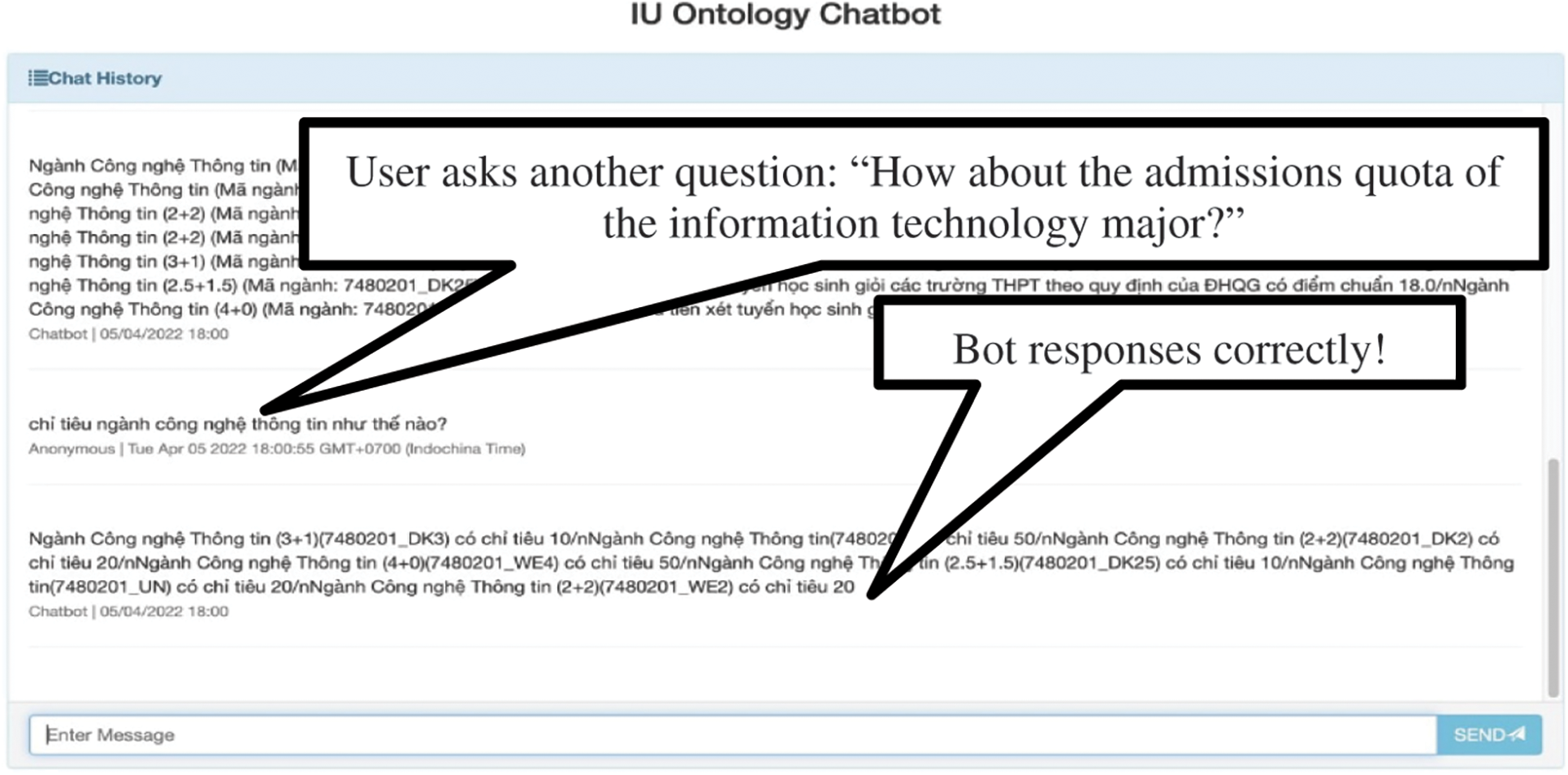
Figure 8: Web interface page of the chatbot (cont.)
The following presents experiments run on a MacBook Pro with 6-Core Intel Core i7 processor, 2.2 GHz and 16 GB of RAM.
4 Experimental Results and Evaluation
In this study, two experiments are carried out to validate the proposed chatbot model. Testing questions at different levels of difficulty are made for the experiments. According to [18], the evaluation criteria of responses are able to be the rates of satisfactory, correctness and usefulness represented by scores from 1 to 5. These metrics can be defined as follows by the Cambridge Dictionary:
Satisfactory: good or good enough for a particular need or purpose.
Correctness: the quality of being in agreement with the true facts or with what is generally accepted.
Usefulness: effective; helping you to do or achieve something.
The responses from the chatbot are remarked by domain experts who are in charge of developing the admissions advising website at the International University. The highest score (5) means the response is completely satisfied, correct or useful. The medium score (3) means somehow the response may give some acceptable, meaningful, useful information. The lowest score (0) means the response is completely not relevant or useful.
In the first experiment, 78 questions covering nine topics in the IUOnto are made for evaluating the chatbot model. The templates of testing questions are: “May I ask about <major name>|<unit name>?”, “What is the admissions quota of <major name>?”, “What is the admissions score of <major name>?”. In that, 11 questions are medium, i.e., relatively related to the application domain, and the rest questions are directly related to the domain. Fig. 9 shows the evaluations of answers responded by the model.
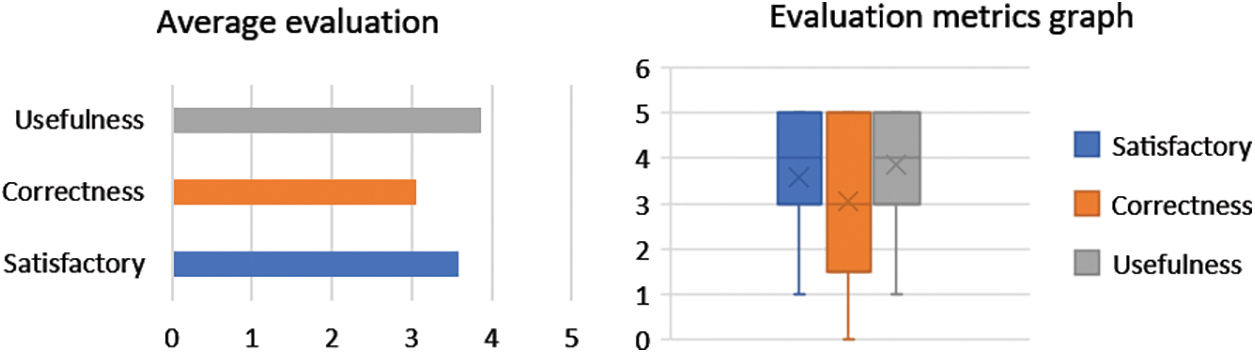
Figure 9: Evaluation metrics of the proposed model in experiment 1
As seen, the distributions of satisfactory, correctness and usefulness scores are left-skewed, and all means are greater than 3. It shows that most responses are satisfied, correct and useful. The scores of satisfactory and usefulness are quite high, greater than 3.5. Furthermore, the proportion of answers having scores equal or greater than 3 is considered as the acceptable evaluation rate. Fig. 10 shows the acceptable rates of satisfactory, correctness and usefulness are higher than 74%. The success rates (scores >= 4) of satisfactory and usefulness are higher than 70%.
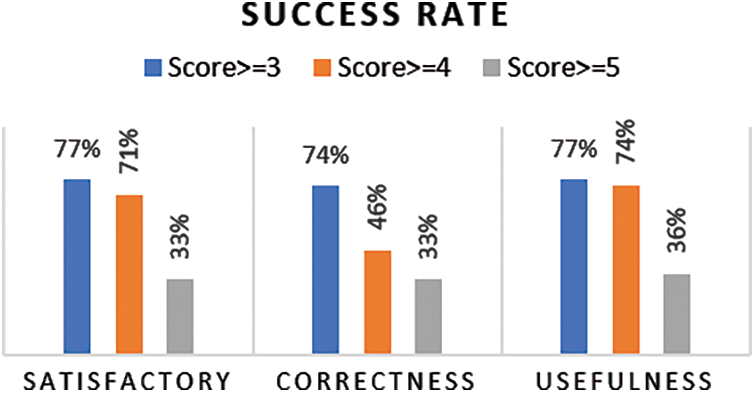
Figure 10: Successful evaluation rate of the proposed model in experiment 1
Fig. 11 shows evaluation metrics for 11 medium questions, average evaluation scores are greater than 2.5, and the distributions of scores are also left-skewed. In that, the scores of satisfactory and usefulness are higher than 3. These results have proved that the performance of the proposed model is acceptable.
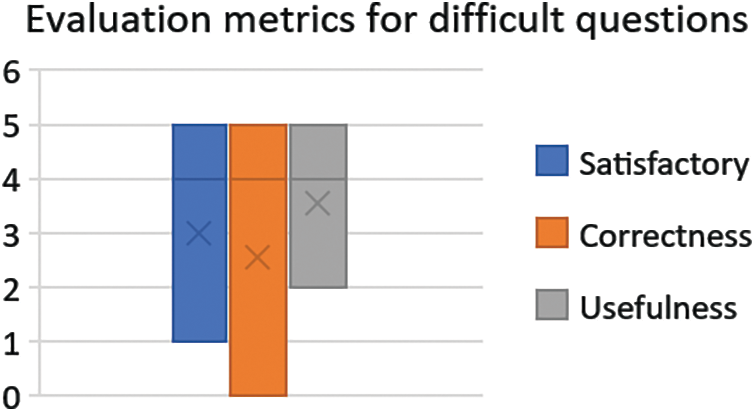
Figure 11: Evaluation metrics for difficult question in experiment 1
For further validating the proposed models, a set of 16 questions related to the domain information in the learning sources are suggested as listed in Tab. 2. These questions were collected by the domain experts in the web team developing the admissions advising website at IU in 2021. These questions are frequent and typical when advising admissions at IU. These questions are classified at three level of difficulty: (1) Easy (directly related to the application domain), (2) Medium (relatively related to the application domain), (3) Difficult (not relevant much to the domain).

Tab. 3 presents the evaluation scores of responses to the above questions in Experiment 2.
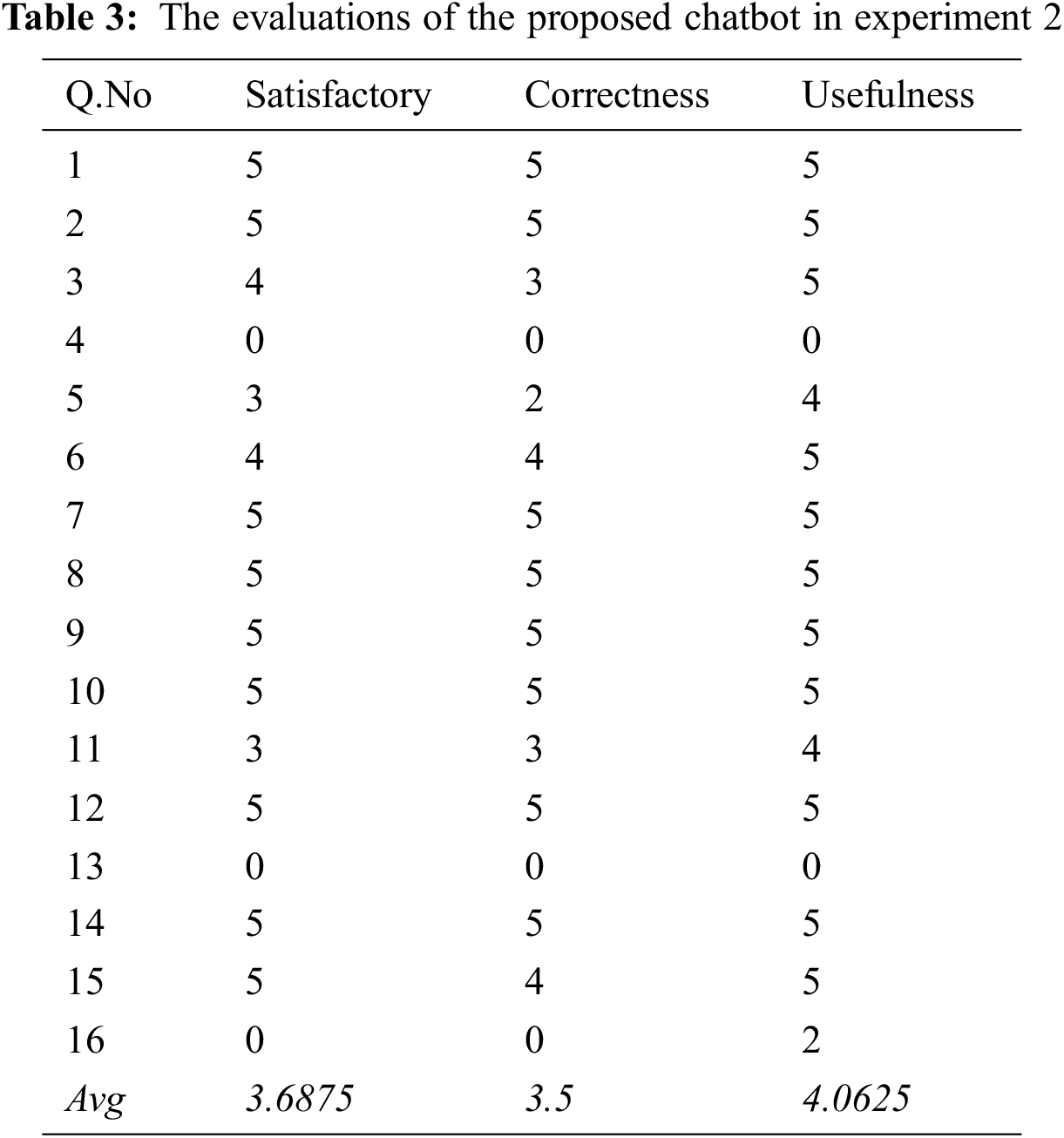
As shown in Tab. 3, the ontology-based chatbot model can provide most of the responses satisfied high, except for difficult questions (4, 13, 16). Moreover, the responses are meaningful and useful. Question 4 is challenging, Question 13 is out of domain, so the bot could not provide any answer. However, Question 16 has some relevant keywords, e.g., “extracurricular activities”, hence the bot can reason and respond some useful information. This is reasonable in practice.
In the context of the ontology model, the IUOnto contains essential concepts for university admissions, more variety than the ontology of educational program counseling built in [21] which has only the concepts of City/Capital, Program, DeptProgram and Type. Moreover, this ontology can be extended with more data so that more responses can be generated. Tab. 4 presents the features of the developed QA system compared with the existing educational program counseling system [21]. The developed system has similar features as the existing system, and is richer with more classes, object properties and data properties. Therefore, its inference ability is better, and its answers will be more information.

The ontology-based chatbot model can achieve high performance in answering questions in the learned application domain. The experimental results have shown the proposed chatbot framework is promising and acceptable. It can provide meaningful and long answers, while existing chatbots could not give long answers. Especially, this chatbot is useful for counseling educational programs for future students at Vietnamese universities. In the future, the reasoning algorithm of the chatbot will be improved to generate more accurate answers. A synonym database might be used to extend the ability to understand different words in queries.
Funding Statement: This research is funded by International University, VNU-HCM under Grant Number T2020-03-IT.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. U. Nasir, U. Rehmat and I. Ahmad, “Social media analysis of customer emotions in pizza industry,” The Computer Journal, 2022. https://doi.org/10.1093/comjnl/bxac042. [Google Scholar]
2. U. Rehmat, A. Javed, M. U. Nasir and M. M. Bashir, “Sentimental analysis of beauty brands on social media,” in Proc. GS Int. Conf. on Computer Science on Engineering 2020 (GSICCSE 2020), Dubai, no. 37, 2020. [Google Scholar]
3. E. H. Wu, C. Lin, Y. Ou, C. Liu, W. Wang et al., “Advantages and constraints of a hybrid model K-12 e-learning assistant chatbot,” IEEE Access, vol. 8, pp. 77788–77801, 2020. [Google Scholar]
4. E. Adamopoulou and L. Moussiades, “An overview of chatbot technology,” in Proc. AIAI 2020. IFIP Advances in Information and Communication Technology, Cham, pp. 373–383, 2020. [Google Scholar]
5. G. Antoniou and F. v. Harmelen, A Semantic web Primer, 3rd ed., Cambridge, MA 02142: MIT Press, 2012. https://mitpress.mit.edu/books/semantic-web-primer-third-edition. [Google Scholar]
6. U. Rehmat, A. Javed, M. M. Bashir and M. U. Nasir, “An ontology-based sentimental analysis: Review,” in Proc. GS Int. Conf. on Computer Science on Engineering 2020 (GSICCSE 2020), Dubai, no. 4, 2020. [Google Scholar]
7. A. Hallili, “Toward an ontology-based chatbot endowed with natural language processing and generation,” in 26th European Summer School in Logic, Language & Information, Tübingen, Germany, 2014. [Google Scholar]
8. C. V. S. Avila, A. B. Calixto, T. V. Rolim, W. Franco, A. D. P. Venceslau et al., “MediBot: An ontology based chatbot for Portuguese speakers drug’s users,” in Proc. 21st Int. Conf. on Enterprise Information Systems Heraklion, Crete, Greece, pp. 25–36, 2019. [Google Scholar]
9. O. Zahour, E. H. Benlahmar, A. Eddaoui, H. Ouchra and O. Hourrane, “A system for educational and vocational guidance in Morocco: Chatbot e-orientation,” Procedia Computer Science, vol. 175, pp. 554–559, 2020. [Google Scholar]
10. K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares et al., “Learning phrase representations using rnn encoder–decoder for statistical machine translation,” in Proc. the 2014 Conf. on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, pp. 1724–1734, 2014. [Google Scholar]
11. S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, pp. 1735–1780, 1997. [Google Scholar]
12. A. W. Yu, D. Dohan, M. -T. Luong, R. Zhao, K. Chen et al., “QANet: Combining local convolution with global self-attention for reading comprehension,” in Proc. ICLR, Vancouver, BC, Canada, pp. 1–18, 2018. [Google Scholar]
13. D. Jurafsky and J. H. Martin, Speech and Language Processing, 3rd ed. draft, 2020. [Online]. Available: https://web.stanford.edu/~jurafsky/slp3/. [Google Scholar]
14. I. V. Serban, A. Sordoni, Y. Bengio, A. Courville and J. Pineau, “Building end-to-end dialogue systems using generative hierarchical neural network models,” in Proc. 30th AAAI Conf. on Artificial Intelligence, Phoenix, Arizona, pp. 3776–3783, 2016. [Google Scholar]
15. X. Shen, H. Su, Y. Li, W. Li, S. Niu et al., “A conditional variational framework for dialog generation,” in Proc. 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, Canada, pp. 504–509, 2017. [Google Scholar]
16. Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov et al., “XLNet: Generalized autoregressive pretraining for language understanding,” in Proc. 33rd Int. Conf. on Neural Information Processing Systems, Red Hook, NY, USA, pp. 1–18, 2019. [Google Scholar]
17. D. Altinok, “An ontology-based dialogue management system for banking and finance dialogue systems,” in Proc. 11th Int. Conf. on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 2018. [Google Scholar]
18. A. Bouziane, D. Bouchiha, N. Doumi and M. Malki, “Question answering systems: Survey and trends,” Procedia Computer Science, vol. 73, pp. 366–375, 2015. [Google Scholar]
19. F. Clarizia, F. Colace, M. Lombardi, F. Pascale and D. Santaniello, “Chatbot: An education support system for student,” In: Castiglione, A., Pop, F., Ficco, M., Palmieri, F. (eds) Cyberspace Safety and Security. CSS 2018. Lecture Notes in Computer Science, Springer, Cham, vol. 11161, pp. 291–302, 2018. https://doi.org/10.1007/978-3-030-01689-0_23. [Google Scholar]
20. M. E. Ibrahim, Y. Yang, D. L. Ndzi, G. Yang and M. Al-Maliki, “Ontology-based personalized course recommendation framework,” IEEE Access, vol. 7, pp. 5180–5199, 2019. [Google Scholar]
21. M. Majid, M. -F. Hayat, F. -Z. Khan, M. Ahmad, N. Jhanjhi et al., “Ontology-based system for educational program counseling,” Intelligent Automation & Soft Computing, vol. 30, pp. 373–386, 2021. [Google Scholar]
22. T. Vu, D. Q. Nguyen, D. Q. Nguyen, M. Dras and M. Johnson, “VnCoreNLP: A Vietnamese natural language processing toolkit,” in Proc. 2018 Conf. of the North American Chapter of the Association for Computational Linguistics: Demonstrations, New Orleans, Louisiana, Association for Computational Linguistics, pp. 56–60, 2018. https://aclanthology.org/N18-5012/. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools