
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Railway Track Defect Detection Based on Dynamic Multi-Modal Fusion and Challenging Object Enhanced Perception
1 Institute of Technological Innovation, Beijing Subway Operation Co. Ltd., Beijing, 100044, China
2 Technical Department, Beijing Subway Operation Co. Ltd., Beijing, 100044, China
3 State Key Laboratory of Advanced Rail Autonomous Operation, Beijing Jiaotong University, Beijing, 100044, China
* Corresponding Author: Yang Gao. Email:
(This article belongs to the Special Issue: AI-Enhanced Low-Altitude Technology Applications in Structural Integrity Evaluation and Safety Management of Transportation Infrastructure Systems)
Structural Durability & Health Monitoring 2026, 20(2), 10 https://doi.org/10.32604/sdhm.2025.072538
Received 29 August 2025; Accepted 27 October 2025; Issue published 31 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The fasteners employed in the railway tracks are susceptible to defects arising from their intricate composition. Foreign objects are frequently observed on the track bed in an open environment. These two types of defects pose potential threats to high-speed trains, thus necessitating timely and accurate track inspection. The majority of extant automatic inspection methods are predicated on the utilization of single visible light data, and the efficacy of the algorithmic processes is influenced by complex environments. Furthermore, due to the single information dimension, the detection accuracy of defects in similar, occluded, and small object categories is low. To address the aforementioned issues, this paper proposes a track defect detection method based on dynamic multi-modal fusion and challenging object enhanced perception. First, in light of the variances in the representation dimensions of multimodal information, this paper proposes a dynamic weighted multi-modal feature fusion module. The fused multi-modal features are assigned weights, and then multiplied with the extracted single-modal features at multiple levels, achieving adaptive adjustment of the response degree of fusion features. Second, a novel stepwise multi-scale convolution feature aggregation module is proposed for challenging objects. The proposed method employs depth separable convolution and cross-scale aggregation operations of different receptive fields to enhance feature extraction and reuse, thereby reducing the degree of progressive loss of effective information. The experimental results demonstrate the efficacy of the proposed method in comparison to eight established methods, encompassing both single-modal and multi-modal methods, as evidenced by the extensive findings within the constructed RGBD dataset.Keywords
The track is the core component of the rail transit infrastructure system and the physical foundation for carrying out transportation activities. Its safety should be given top priority [1]. Fasteners are a crucial component in track construction. They are positioned laterally on either side of the rails, and their primary function is to provide structural integrity to the rails. It should be noted that throughout the operation of the running train, the fastener is exposed to both vibration and impact. Its structure is complex, composed of elastic strips, nuts, plate washers, plates, baffles, and so forth, and all parts are susceptible to displacement, loss, and breakage. Consequently, it is imperative to meticulously monitor the fastener’s status over time. Furthermore, the presence of natural stationary foreign objects within the track bed is a common occurrence. The rapid and accurate identification and location of foreign objects are conducive to timely clearance by the operation and maintenance department, thus avoiding potential hazards to the safe operation of trains [2].
The majority of extant methods for track inspection are manual inspections. Inspection workers are tasked with the responsibility of making subjective judgments based on their historical experience, and the content of the inspection is relatively comprehensive. However, it is imperative to note that this inspection method must be conducted during optimal weather conditions, and the associated workload is notably elevated. The advent of artificial intelligence and sensor technology has precipitated the gradual adoption of vision-based intelligent track inspection methodologies in on-site settings. Deep learning-based object detection methods, such as the single-stage YOLO series, with typical algorithms including YOLOV3 [3], YOLOV5 [4], YOLOV7 [5], etc., can automatically extract the features of the object to obtain category and location information. Therefore, many scholars make specific improvements to the object detection algorithm for track scenarios to achieve the detection of fastener defects and foreign objects under good lighting conditions [6–10]. Transformer-based methods are also applied to track defect detection due to their excellent multi-scale feature fusion capability [11–13]. The data source of these methods is a single visible light image, which contains the primary information regarding color, edge contour, and texture features. However, there is no obvious distinction between the components of the fastener in the above features. The high degree of similarity between different objects can result in classification errors. In addition, the rail transit scenario is an open and complex environment. The quality of visible light data is subject to the influence of lighting conditions. It has been demonstrated that both overexposure and shadow areas can result in the loss of object features. This, in turn, has the potential to have a detrimental effect on the performance of the algorithm. The single visible image is devoid of depth information, and occlusion can destroy the geometric integrity of the object, resulting in the loss of key features. Consequently, existing single-modal inspection methods may be subject to misjudgment. It is evident that the specific task of detecting fastener defects based on a single visible light image is challenging due to the following factors.
(1) Compared with the other components, the pixels representing the nut and plate washer are relatively small in the track image. Their corresponding defect categories, miss and loose, also belong to small objects.
(2) There is little difference in the features of defects such as loose nut, missing nut, and missing plate washer.
(3) Baffle miss, baffle loose, and other defects occur due to the mutual occlusion of components. These defects result in unobvious characteristics and are prone to misjudgment and oversight.
The two-dimensional planar information contained in a single visible light image is insufficient to overcome the above difficulties and requires the assistance of additional information.
In recent years, the sensor field has been constantly undergoing technological and equipment iterations. Three-dimensional sensors attract extensive attention due to their ability to extract high-precision three-dimensional spatial information of objects, such as lidar, millimeter-wave radar, and three-dimensional structured light cameras. Among them, structured light cameras have a shorter working distance, higher precision, and lower cost, and are widely used in industrial measurement and inspection fields. They utilize the principle of active triangulation to store three-dimensional perception information in depth images, which have the same data format and storage method as visible light images. Moreover, structured light cameras have strong anti-light interference performance, which can effectively compensate for the deficiencies of single visible light in track scenes and may significantly improve the detection accuracy of challenging objects. Consequently, within the domain of track inspection, the utilization of a multi-modal intelligent detection method that integrates visible light images and depth images has the potential to emerge as the prevailing approach.
The fusion method of multi-modal data is extremely crucial. An unreasonable fusion method may lead to ineffective information redundancy and mutual interference of key information [14]. The existing fusion methods can be classified into three categories: data layer, feature layer, and decision-making layer. In track inspection, there are relatively few studies on the detection of fastener defects and foreign objects based on grayscale and depth images. The specific fusion methods mainly focus on the data layer and the decision-making layer. Gao et al. [15] propose a pixel-level attention RGBD data layer fusion method, inputting the fusion image into the object detection network to achieve the detection of fastener defects and foreign objects. Ge et al. [16] propose a decision-level detection architecture that integrates the detection results of object detection and unsupervised detection methods to achieve the detection of loose fastener bolts. Yuan et al. [17] propose an effective method based on the bimodal fusion of RGB depth images and point clouds (RGB-P) to achieve simultaneous recognition of visual defects and structural defects of fasteners. The detection methods of fastener defects and foreign objects on the track bed based on the feature layer still need to be explored.
In the task of rail surface defect detection, some feature-layer detection frameworks based on RGBD can be referred to. Yang et al. [18] propose a fusion network with bidirectional feature alignment for rail grayscale and depth images, and conduct research on cross-modal feature consistency representation from both edge and semantic levels. Wang et al. [19] propose a depth-assisted semi-supervised RGBD rail surface defect detection method, which utilizes depth information for multi-scale exploration and cross-modal complementary fusion. Zhou and Hong [20] propose a cross-modal detection module and a multi-feature integration module to deeply mine grayscale information and depth information in order to achieve precise detection of rail surface defects. The above-mentioned methods provide a feature-layer processing paradigm, but directly migrating it to the tasks of fastener defect and foreign object detection may lead to a decline in algorithm performance. This is because rail surface defect detection focuses on fine surface texture and edge contour abnormalities, while fastener defects and foreign objects focus more on obvious morphological differences and the distinction between presence and absence.
To address the above issues, this paper proposes a track defect detection method based on dynamic multi-modal fusion and challenging object enhanced perception (DMCEP). A novel dynamic weighted multi-modal feature fusion module (DWMFF module) is designed to effectively achieve unified representation and enhancement of multi-modal features. Additionally, a stepwise multi-scale convolution feature aggregation module (SMCFA module) is proposed to effectively improve the detection accuracy of challenging objects. The main contributions of this paper can be summarized as follows.
(1) This paper constructs a track defect detection network based on multi-modal data, achieving the best joint detection accuracy for fastener defects and foreign objects on the self-collected track RGBD dataset, while maintaining real-time performance.
(2) The DWMFF module is proposed to dynamically fuse multi-modal features with differences in information representation dimensions. It adopts a weight allocation strategy to flexibly adjust the contribution degree of each modality feature at different fusion levels.
(3) To address the three detection difficulties of challenging objects, a novel SMCFA module is proposed, emphasizing the focus on local fine texture features, global spatial relationship features, and cross-scale feature aggregation.
This paper proposes a multi-modal object detection framework to achieve precise detection of track fastener defects and foreign objects, as shown in Fig. 1. First, the backbone network of YOLOV7 [5], known for its excellent performance, is selected to perform single-modal shallow detail feature extraction and deep semantic feature generation. Second, the DWMFF module is designed to dynamically align and fuse the feature information of RGB mode and depth mode at the multi-layer feature level. Third, to address the difficulties of challenging object detection in track scenes, such as the difficulty in distinguishing between similar defect categories and the tendency to overlook small objects, the SMCFA module is introduced to mitigate information loss and enhance feature representation. Finally, by constructing the neck and head structure, the accurate detection of fastener defects and foreign objects on the track bed is realized.
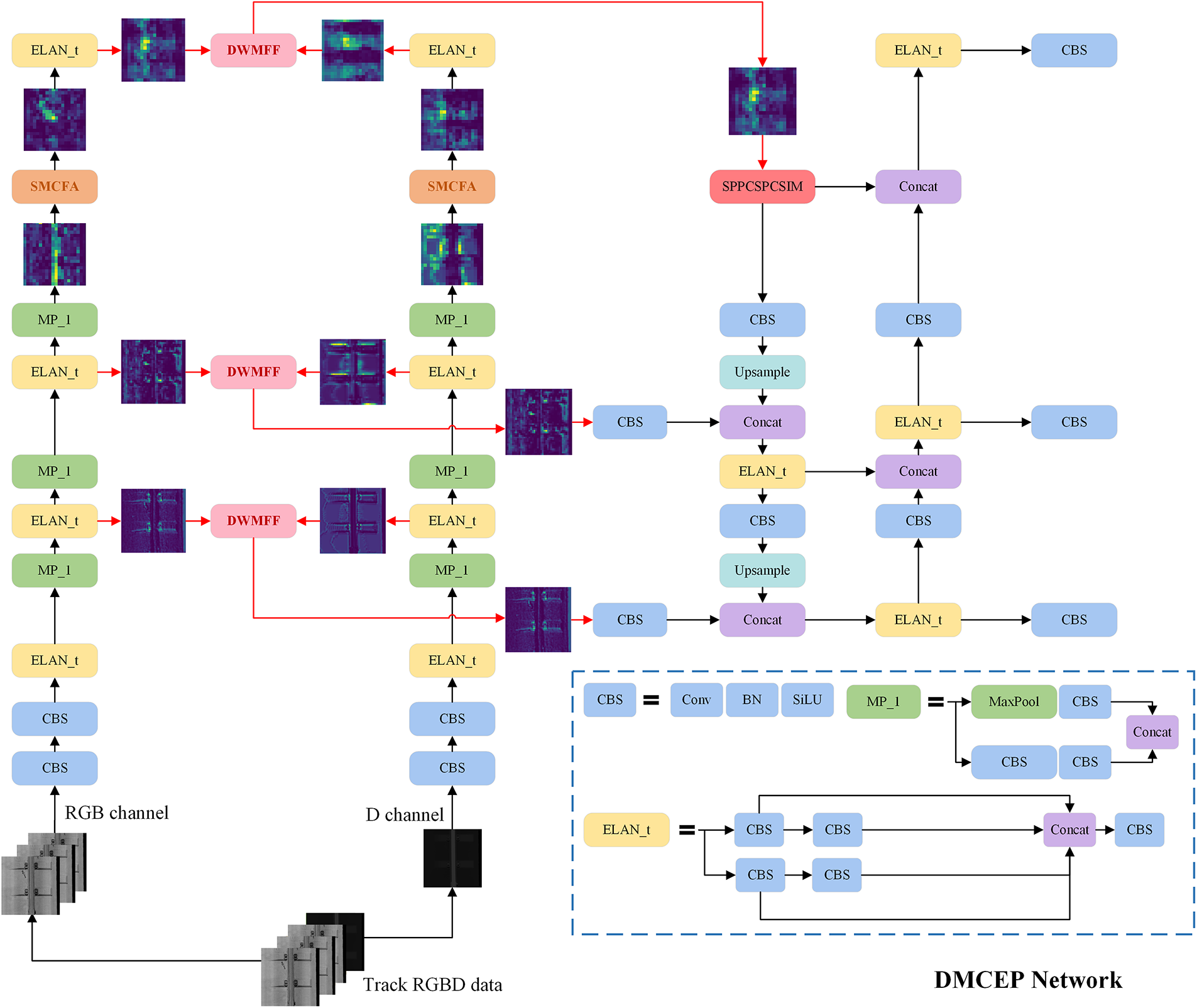
Figure 1: Overview of DMCEP network. There is dual-stream backbone for RGB and depth inputs, consisting of two key modules: DWMFF and SMCFA. The DWMFF module facilitates comprehensive fusion of multi-modal features across multiple fusion levels. The SMCFA module is designed to enhance feature representation for challenging object
A significant disparity exists in the manner in which dimensions are represented in RGB images and depth images. The former focuses on texture and contour details, while the latter contains spatial height and geometric topological information. In response to this characteristic, this paper proposes the DWMFF module, which performs a multi-level fusion operation on the rich semantic features of the RGB modality and the geometric perception features of the depth modality extracted by the dual-backbone network. It realizes the semantic alignment and effective fusion of complementary modal features and minimizes the adverse impact of modal differences on feature fusion. The specific structure is shown in Fig. 2.
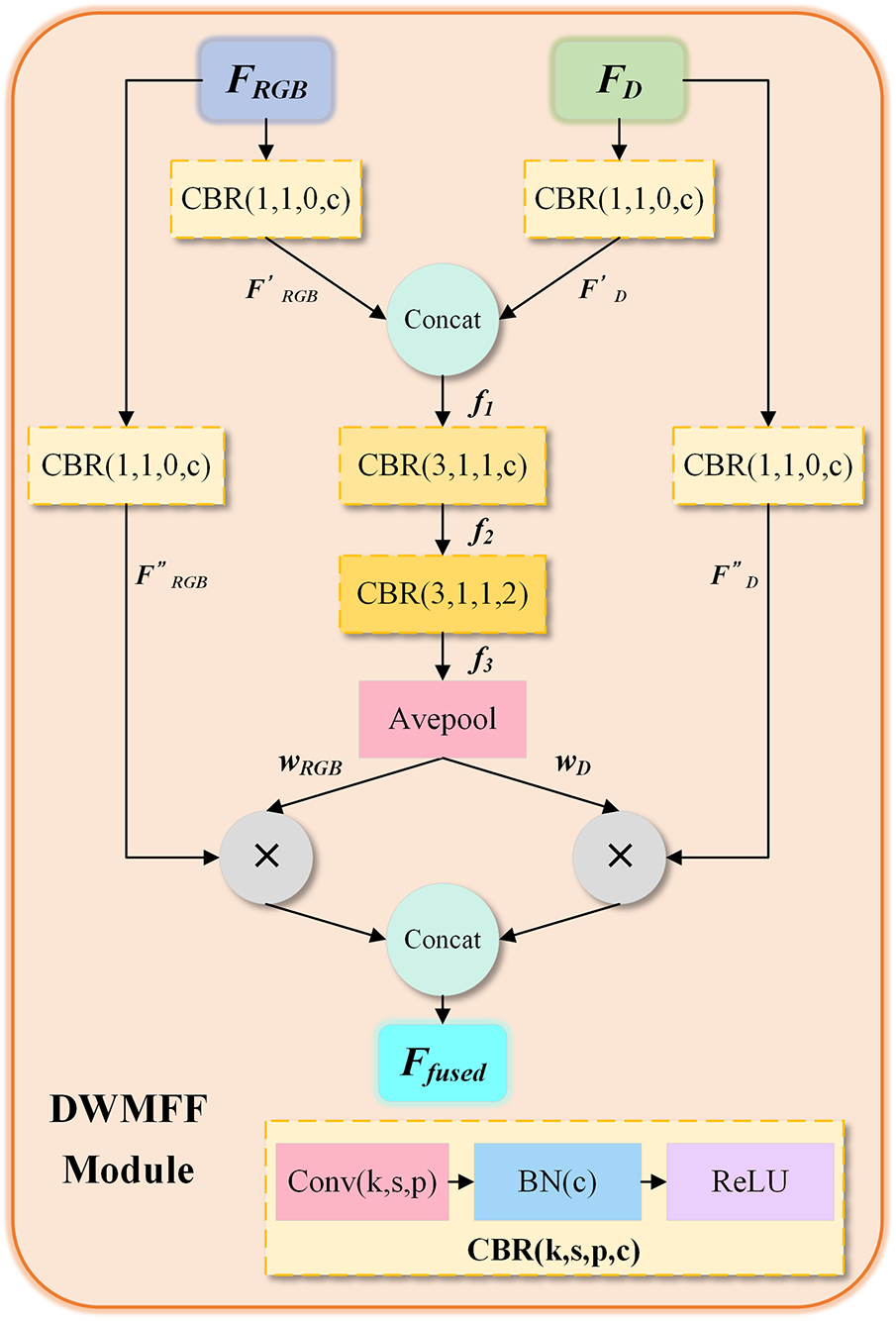
Figure 2: The structure of DWMFF module. It performs multi-level fusion operation on the rich semantic features of RGB mode and the geometric perception features of depth mode extracted by the dual-backbone network
The input of this module is a pair of RGBD feature maps FRGB and FD extracted from the backbone network at the same level. We use dynamic weight calculation and allocation strategies to achieve effective information integration.
First, perform 1 × 1 convolution operations on the RGBD features respectively to initially complete the dynamic selection of features within a single modality, and screen out the more representative and discriminative feature information
where Conv1×1,1,0 refers to the convolution operation with a 1 × 1 kernel size. The stride size is set to 1, and padding is set to 0. BN is the batch normalization operation, c is the number of channels, and ReLU is the rectified linear unit activation function.
where Concat(,) refers to the concatenation operation.
Second, as the backbone network deepens, the semantic information contained in RGB images becomes increasingly prominent, while the effective information contained in relatively simple depth images gradually becomes sparse. In view of this, the contribution degree of the bimodal features to the fusion features should be dynamically adjusted at different levels. By adopting two layers of 3 × 3 convolution operations, normalization operations, and ReLU activation functions, the potential correlations among multi-modal features are deeply explored, and feature dimension adaptation is achieved, as shown in Eqs. (4) and (5).
where, Conv3 × 3,1,1 refers to the convolution operation with a 3 × 3 kernel size. The stride size is set to 1, and padding is set to 1. f2 and f3 are the deeply explored fused feature maps.
Combined with adaptive average pooling, dynamic weights representing the prominent object features are obtained to flexibly adjust the proportion of bimodal features in the fused features, as shown in Eq. (6). This ensures that the fused features can fully integrate the advantageous information from different modalities.
where wRGB and wD are weights corresponding to RGB and depth modes. Avepool(.) is an adaptive average pooling operation.
Third, to further enhance the feature representation of different modalities and reduce the loss of original information, an independent modal feature extraction operation is added to the initial RGBD feature map pairs to improve the integrity and distinguishability of the features, as shown in Eqs. (7) and (8).
where,
Finally, the deep interaction of multi-modal weighted features is accomplished by using element-wise multiplication and channel concatenation, and the final fused feature map Ffused is obtained, as shown in Eq. (9). By dynamically adjusting the contributions of different modal features in the final fused features through learnable weights, this module achieves adaptive adjustment of the response degree of multi-modal fused features.
There are three main detection difficulties in fastener defect detection based on visible light track images. (1) Scale extremity: The proportion of pixels occupied by fasteners is significantly lower than that of track plates. Nuts and plate washers are typical small objects. There are multi-level scale differences among the detected objects. (2) Spatial complexity: There are mutual obstructions among the components of the fasteners. For instance, the partial baffle is located beneath the plate, which leads to damage to the geometric integrity of defects such as baffle miss and baffle loose. (3) Feature ambiguity: The components of the fastener are similar in material and color. The similarity between different defects is relatively high.
To solve the above challenging object detection difficulties, we designed a novel SMCFA module, and the structure is shown in Fig. 3. We designed depthwise separable convolution [21] operations with different receptive fields to adapt to objects of different scales and establish cross-scale spatial relationships. The visibility and separation degree of challenging objects in the feature extraction process of the backbone network are significantly improved. The SMCFA module consists of one main branch and three skip connections. The main branch concatenates three DWCBS blocks to fully extract features. Feature reuse and dimension alignment are achieved by combining the skip connection with the upsampling operation, and the feature fusion is realized by pixel addition.
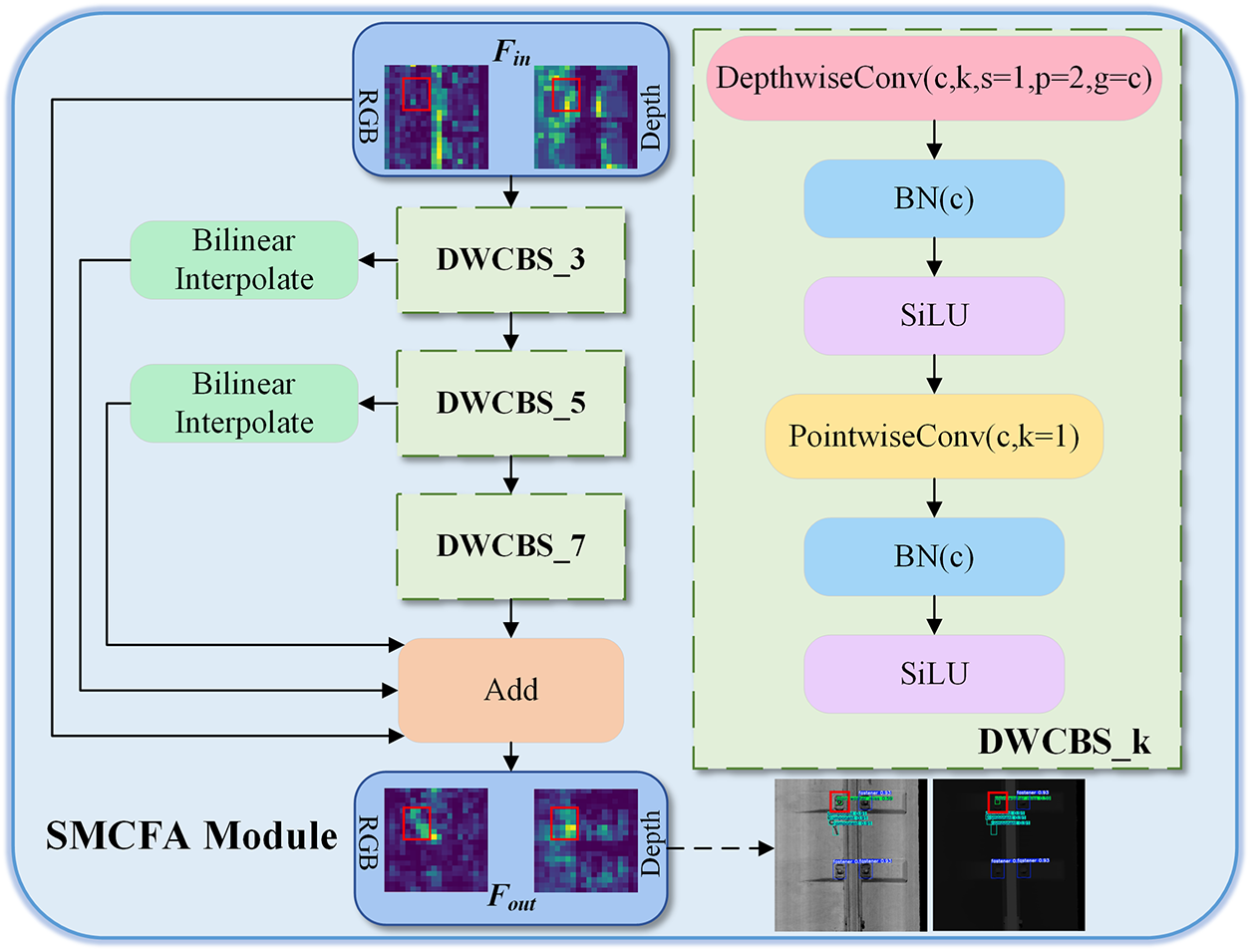
Figure 3: The structure of SMCFA module
Depthwise separable Convolution is an efficient convolution operation. It decomposes the standard convolution into two steps: Depthwise Convolution and Pointwise Convolution. It can significantly reduce the amount of computation and the number of parameters while maintaining the expressive ability of the model.
With the deepening of the backbone network, the effective information of small objects is gradually lost. Therefore, a 3 × 3 depthwise separable convolution block is designed to capture the local texture of small objects such as nuts and plate washers. It aims to enhance the response concentration of small object regions in the feature space, thereby effectively alleviating the problem of information loss that tends to occur as the network deepens.
Then, to focus on the global structural information of larger components such as plates and elastic strips, 5 × 5 and 7 × 7 depth-separable convolution block operations are introduced. These convolutional kernels with larger receptive fields can aggregate context information more effectively. They provide a rich global perspective for understanding component relationships in complex scenarios. The calculation is shown in Eq. (10).
where Fin is the input feature map, and X is the intermediate feature map.
Finally, through the cross-scale feature addition strategy, the fine texture features and the global semantic features extracted at different scales are fused, as shown in Eq. (11). This feature aggregation method retains unique information at each scale and generates more discriminative feature representations. It provides for the subsequent precise identification and location of challenging objects.
where Fout is the output feature map and BI is the bilinear interpolation operation.
The total loss function consists of three parts: classification loss, regression loss, and distribution focal loss.
Our method adopts an anchor-free structure, and each box directly predicts the category probability. Due to the handling of multiple category tasks, the binary cross-entropy function is adopted as the measurement function for classification losses. The calculation is shown in Eq. (12).
where N represents the total number of prediction boxes, yi represents the true labels, and pi represents the predicted category probabilities.
The regression loss is calculated by the CIOU function [22], which takes into account the distance of the center point and the aspect ratio of the bounding box, resulting in faster convergence and more accurate positioning. The calculation is shown in Eq. (13).
where IoU refers to the intersection over union ratio of the prediction box to the ground truth, and b and bgt are the center point coordinates of the prediction box and the ground truth. ρ is the square of the Euclidean distance. c is the diagonal length of the minimum bounding rectangle that encloses the prediction box and the ground truth. ν is an indicator for measuring the consistency of the aspect ratio. α is the equilibrium coefficient.
The distributed focal loss aims to optimize the prediction of the discrete distribution of bounding box coordinates and improve the localization ability for blurred or occluded objects. The calculation is shown in Eq. (14).
where y is the true label, yl and yr are the two nearest integer coordinates from y, and pi and pi + 1 are the probabilities at yl and yr predicted by the model.
The weighted sum of the three constitutes the total loss function, which optimizes the model’s performance during the training stage. The calculation is shown in Eq. (15).
where λcls, λbox and λdfl are 0.5, 7.5 and 1.5, respectively.
The three-dimensional structured light camera, which is integrated into the track inspection car, is used to collect track images and obtain one-to-one corresponding track grayscale and depth images, as shown in Fig. 4.

Figure 4: The track inspection car with three-dimensional structured light camera
The original size of the image is 2048 × 2048. The image frame includes rails, fasteners, sleepers and track plates, as shown in Fig. 5.

Figure 5: (a) is the track RGB image, and (b) is its corresponding depth image
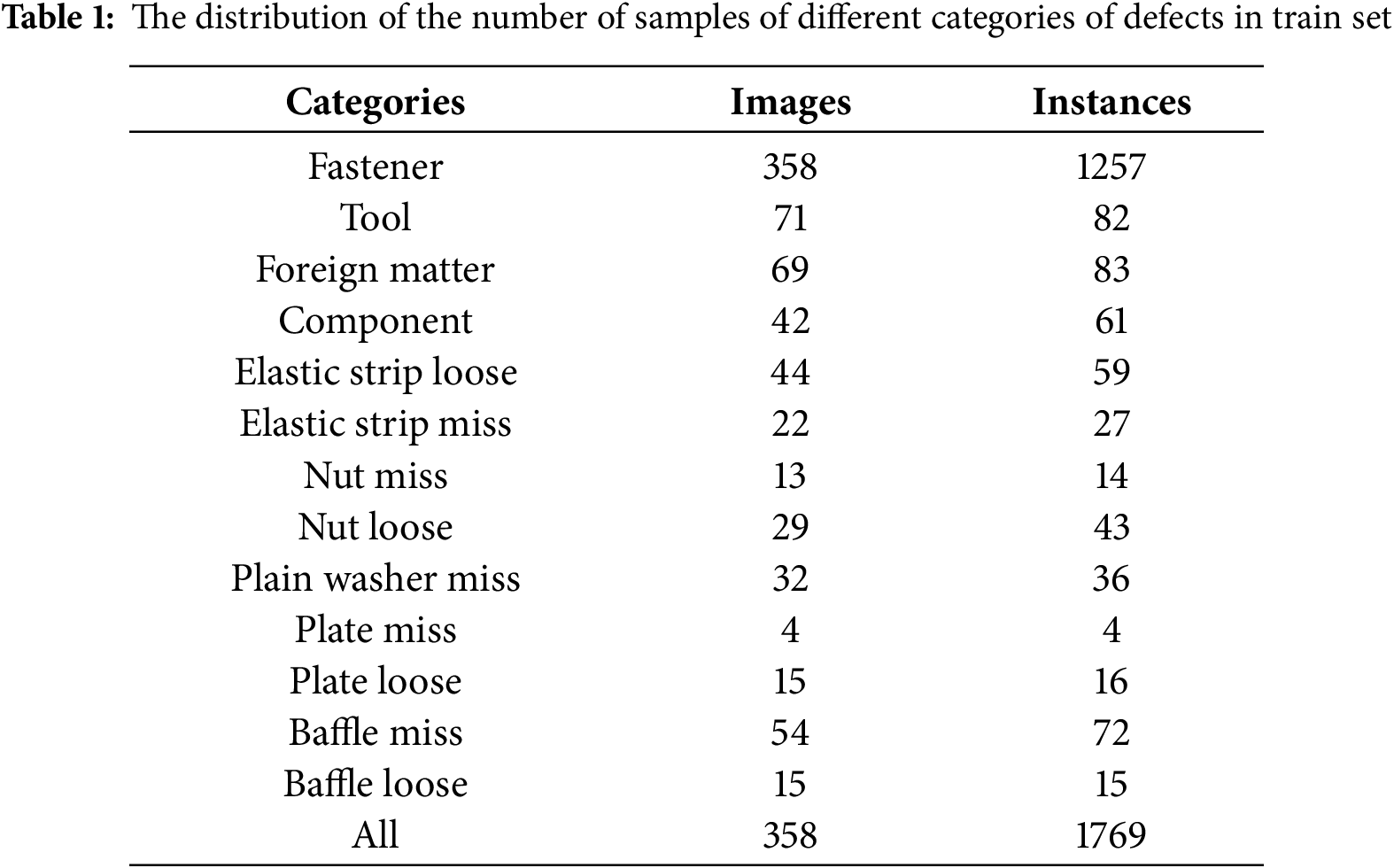
This paper constructs a track RGBD dataset to verify the performance of intelligent detection methods. It contains 3579 pairs of matching grayscale images and depth images, which are randomly divided into the training set, validation set, and test set in a ratio of 8:1:1. This dataset covers 13 categories of fastener defects and foreign objects on the track bed, and the specific categories are shown in Fig. 6. The distribution of the number of samples of different categories of defects in the training set is shown in Table 1. The number of normal fastener samples is the largest, while the distribution of the defect samples is relatively uniform, which is in line with the actual distribution of railway scene data.

Figure 6: The categories of defects in the track multi-modal dataset. From (a) to (m), they are respectively are fastener, plain washer miss, elastic strip miss, elastic strip loose, nut miss, nut loose, baffle miss, baffle loose, plate miss, plate loose, foreign matter, component, tool
In this paper, the training epoch for all algorithms is 300, and the batch-size is set to 16. The input image is uniformly resized to 640 × 640, the momentum is set to 0.937, and the weight decay is set to 0.0005. The initial learning rate is 0.01, and a warm-up learning rate strategy is used. The SGD optimizer is adopted. Our method is based on the PyTorch architecture and CUDA is set to version 11.3. All methods are trained and tested on the NVIDIA GeForce RTX 4090 GPU. The hyperparameter tuning strategy adopts the grid search algorithm.
The detection accuracy is measured by four indicators: Precision (P), Recall (R), mAP0.5 and mAP0.5:0.95. The calculation is as shown in Eqs. (16)–(18). TP represents true positive, FP represents false positive, FN represents false negative, and TN represents true negative.
where, K is the total number of categories, and APi is the AP of the ith category.
The detection speed of the algorithm is quantified by inference speed (FPS), with higher FPS values indicating better real-time performance.
3.4 Comparative Experimental Results
We compare DMCEP with several state-of-the-art single-modal and multi-modal object detection methods on the track RGBD dataset. The representative single-modal methods are YOLOV7 [5], YOLOV8 [23], YOLO11 [24], and YOLO12 [25]. The multi-modal methods are the feature-level fusion of YOLOV7, YOLOV8, YOLO11 YOLO10, YOLO12, and DEYOLO [26]. We present both qualitative and quantitative analyses of the results.
3.4.1 Quantitative Results and Analysis
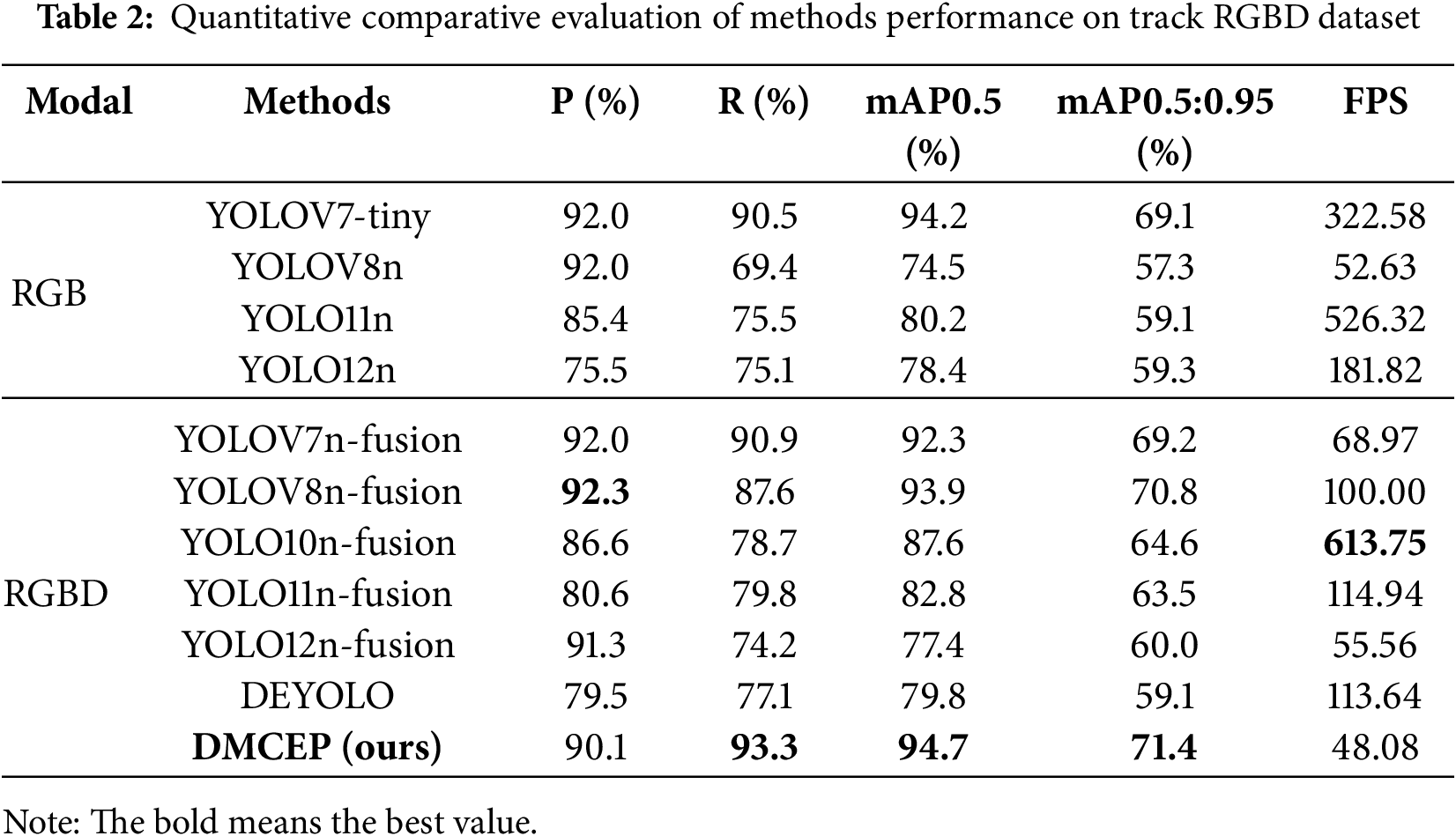
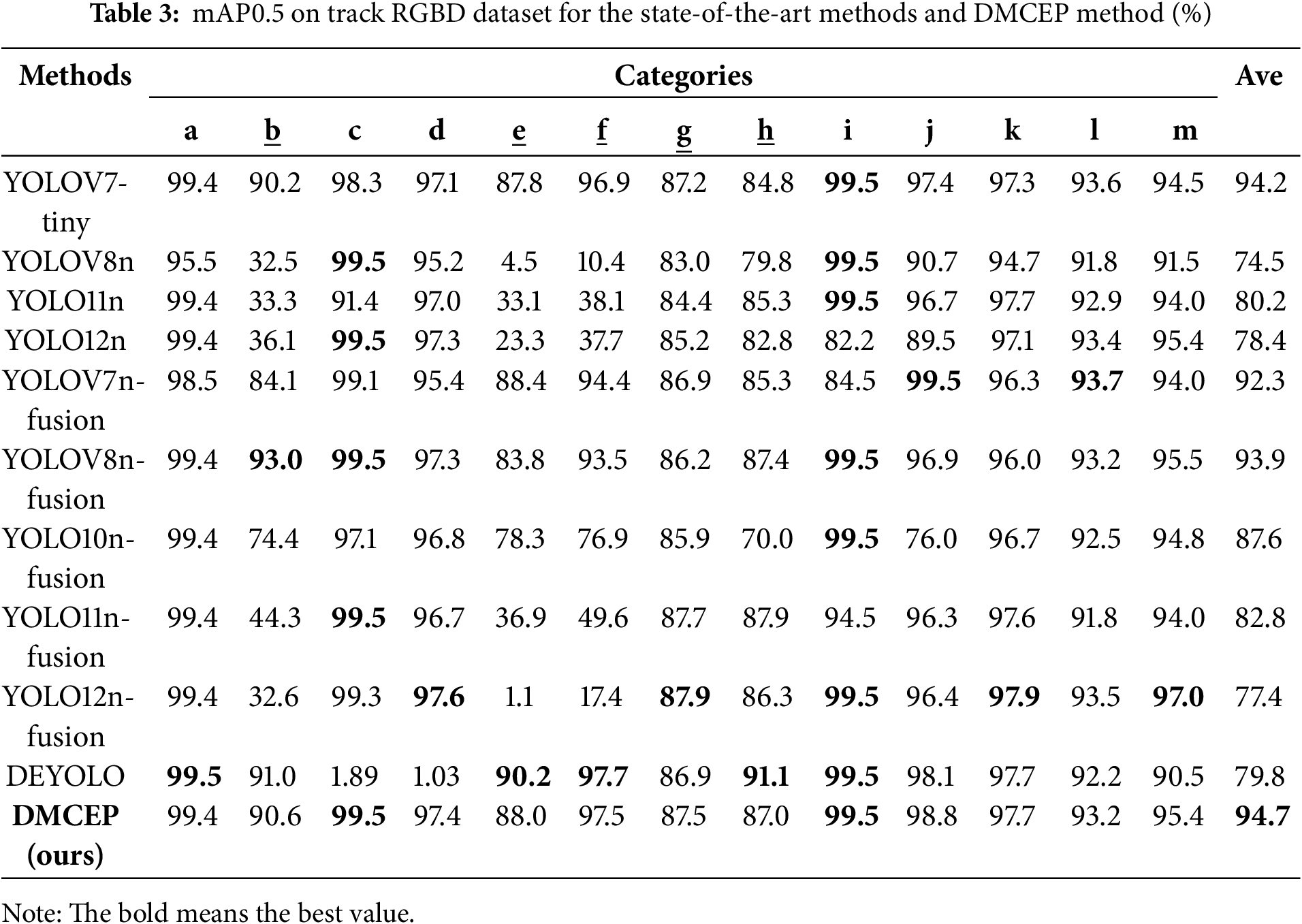
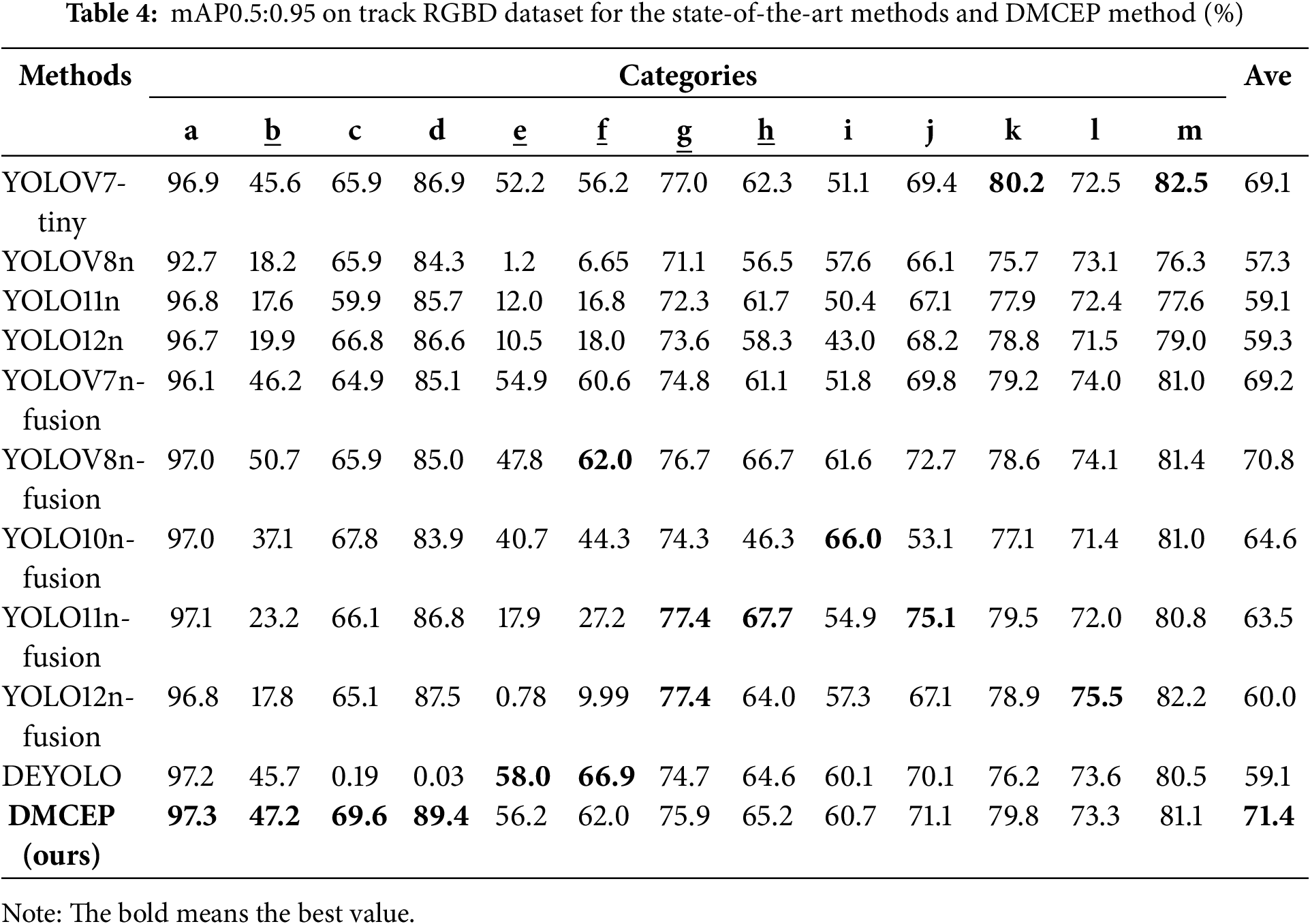
The quantitative results of the comparative experiment are shown in Table 2. The proposed method achieves optimal results in terms of three detection accuracy metrics while concurrently attaining real-time performance in terms of detection speed. Concurrently, the multi-modal fusion method consistently exhibits superior performance compared to the single-modal method. Furthermore, this paper presents the mAP0.5 and mAP0.5:0.95 for each category, with the objective of facilitating a more intuitive comparison of the detection effects of each type of defect, as illustrated in Tables 3 and 4. The underlined categories in Tables 3 and 4 are challenging objects, namely b (plain washer miss), e (nut miss), f (nut loose), g (baffle miss), and h (baffle loose). It is evident that the method’s capacity to detect challenging objects is notably deficient, with mAP0.5 consistently falling below 90% and mAP0.5:0.95 reaching a mere 50%. The detection effect of the DMCEP method on challenging objects is significantly improved, which also confirms the effectiveness of the method. The categories k (foreign matter), l (component), and m (tool) are not fasteners’ structural defects but rather separate objects of various shapes that do not belong to the normal track. In the context of challenging objects, the SMCFA module is specially designed to emphasize the detailed features of small size and similar form, while the global features remain relatively unaffected. However, the detection accuracy of these three categories is slightly lower than the optimal value, which is also attributed to the powerful feature extraction and multi-modal fusion abilities of the DWMFF module.
3.4.2 Qualitative Results and Analysis
The following visualization results are presented to verify the superiority of the DMCEP method, as shown in Fig. 7. Fig. 8 highlights the sections with significant differences in the detection results shown in Fig. 7. The DMCEP method demonstrates superiority over alternative approaches in identifying challenging objects. It is important to note that alternative methods may result in erroneous conclusions, as evidenced by the category e defect of the top-left fastener in the first-row figure and the category l defect of the bottom-left fastener in the fifth-row figure. It is evident that alternative methods have also been unsuccessful in detecting certain defects. These include category f defects of the right fasteners in the second-row figure, category g defects of the bottom-left fastener in the third-row figure, and category b defects of the bottom-right fastener in the fourth-row figure. The DWMFF and SMCFA modules make a significant contribution to the excellent detection performance. Additionally, incorporating depth information has been shown to enhance the detection performance of multi-modal methods compared to single-modal methods.

Figure 7: Visualization results of the state-of-the-art methods and DMCEP method

Figure 8: The parts of detection results with obvious differences in the Fig. 7
To verify the effectiveness of each module of the DMCEP, we conducted a series of ablation experiments, objectively demonstrating the effectiveness and focus of each core module. Our baseline model adopts the YOLOV7 feature-level fusion framework for processing multi-modal information, without the DWMFF module and the SMCFA module. We successively added the DWMFF module and the SMCFA module to the baseline network to verify their functionality, and the results are shown in Table 5.
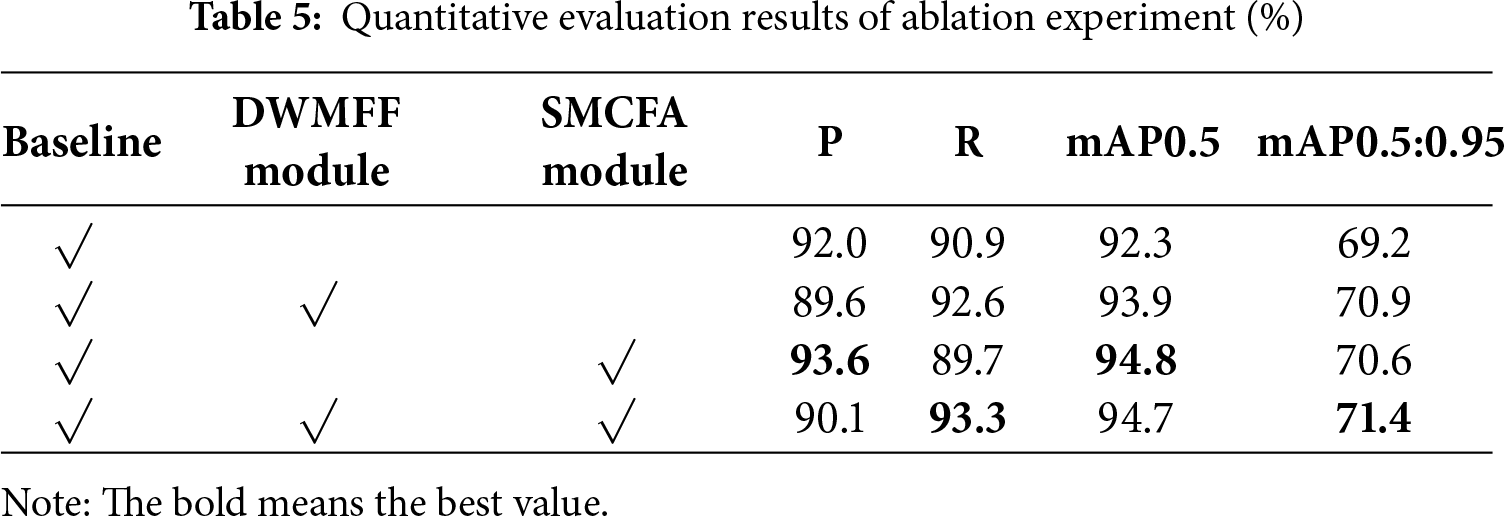
It can be seen that adding the two key modules can effectively improve detection accuracy. Adding only the DWMFF module increases recall by 1.7%, and mAP0.5:0.95 also increases by 1.7%. This indicates that the reasonable integration of multi-modal information enhances the coverage of effective information, significantly reducing missed detections. Adding only the SMCFA module increases precision by 1.6%, and mAP0.5 is significantly improved by 2.5%. The algorithm has fewer misjudgments because the SMCFA module can enhance the feature visibility and separability of similar category defects. The synergistic application of the two modules enables the DMCEP method to achieve optimal performance.
To elaborate on the effectiveness of the SMCFA module, we present mAP0.5 and mAP0.5:0.95 for each specific category, as shown in Table 6. It can be seen that adding the SMCFA module can effectively improve the detection accuracy of the most challenging objects. The mAP0.5 of category b defect increased by 5.6%. The mAP0.5 of category f defect increased by 3.5%, and its mAP0.5:0.95 increased by 4.2%. The mAP0.5 of category g defect increased by 3.6%, and its mAP0.5:0.95 increased by 4.5%. The detection outcomes pertaining to categories e and h defects have not undergone substantial enhancement. The rationale behind this phenomenon is that categories e and h defects are analogous to categories f and g defects. However, the number of training samples is lower in the former than in the latter. Consequently, the features of categories e and h defects are readily misclassified into the analogous category feature space, thereby hindering the enhancement of detection accuracy. Furthermore, the SMCFA module possesses a certain degree of complexity. The model consists of multiple separable convolutional blocks and specific parameter settings. For categories e and h, where the sample number is relatively small, this complexity may be excessive, resulting in overfitting of the model. It is important to note that, during the training process, the model may overlearn the noise and specific patterns present in the training samples. This may result in the model failing to learn features that possess generalization ability. When applied to the test data, the objects of categories e and h cannot be accurately detected, rendering the improvement effect indistinct.
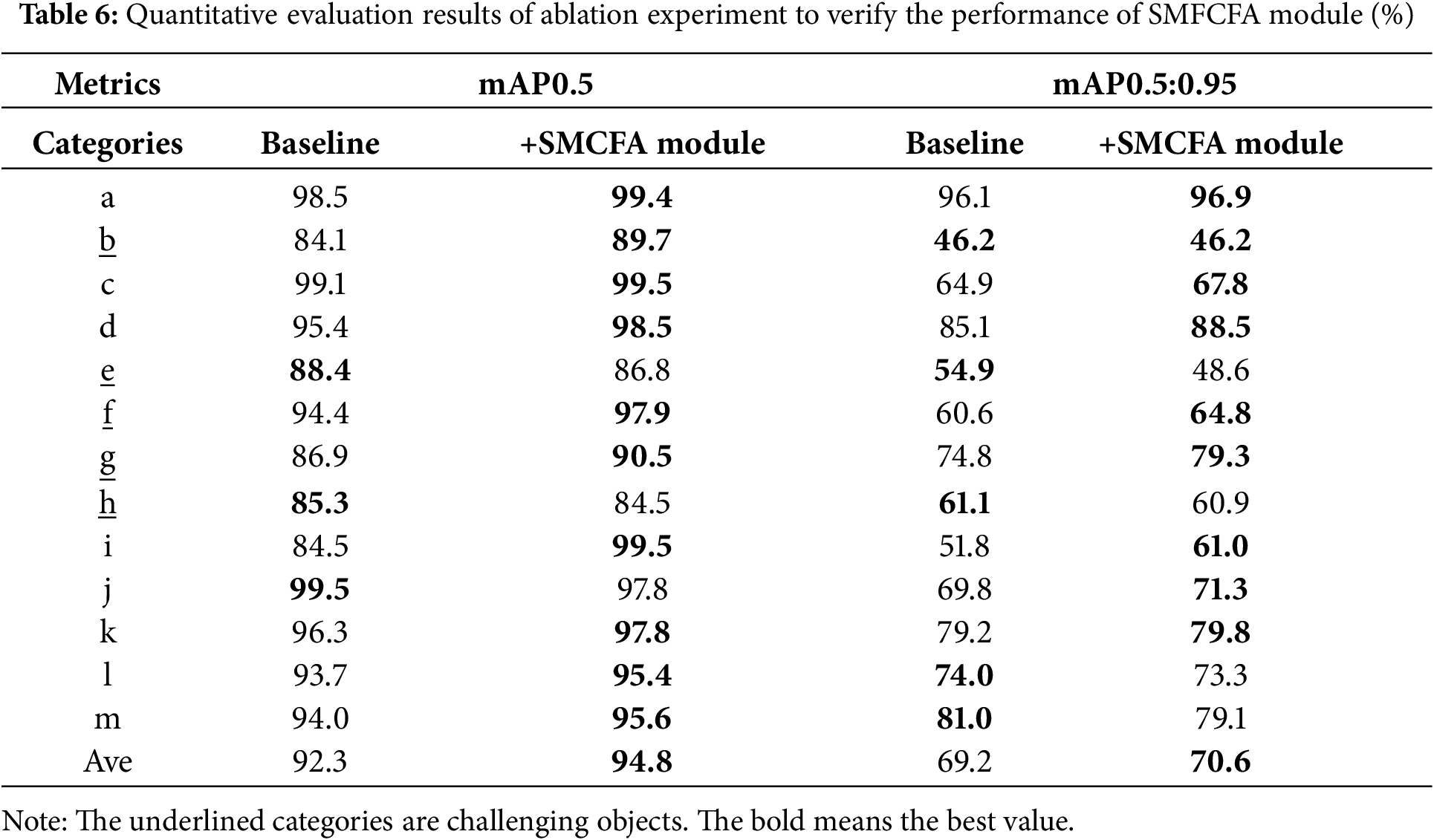
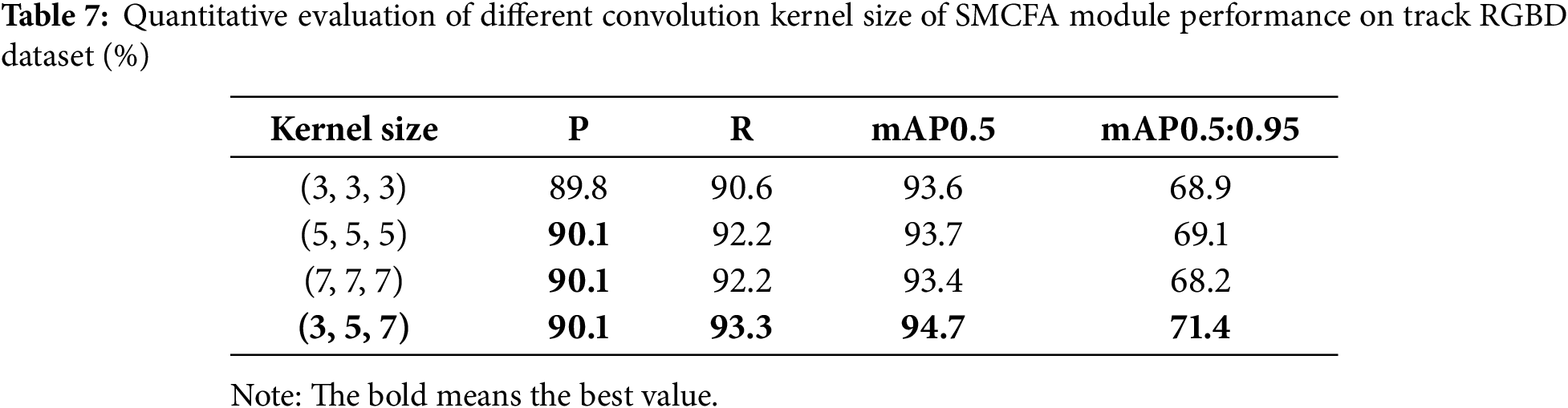
To verify the rationality of the depthwise separable convolutional block of the SMACFA module, we conduct experiments on combinations of different convolutional kernel sizes, and the results are shown in Table 7. It can be seen that three identical convolutional receptive fields that are either too large or too small have mediocre effects and cannot achieve the extraction of multi-scale features.
This paper addresses the challenging task of detecting fastener defects and foreign objects on the track bed. First, a multi-modal RGBD data fusion object detection framework is constructed to achieve complementary information supplementation and effectively reduce the impact of complex environments on data quality. Second, the DWMFF module is innovatively designed to address the problem of cross-dimensional modal feature fusion. It does this by dynamically adjusting the dual-modal response degree at different levels. Finally, the proposal of the SMCFA module is intended to enhance the perception of challenging objects. The module is designed to effectively act on the extracted object features at different scales, thereby making them significantly more visible and separable. The experimental results demonstrate that the proposed method attains optimal accuracy in detecting fastener defects and foreign objects by utilizing a feature-level fusion detection network. The proposed method provides a new detection paradigm for track inspection, thereby enhancing the efficiency and accuracy of intelligent railway operation and maintenance, and thus improving the level of intelligence.
The DMCEP method is predicated on one-to-one matched on-board multi-modal track data. In the context of railway scenarios, sensors are susceptible to shock and vibration, emphasizing the necessity for automatic hardware registration correction. In future research, a dual data acquisition guarantee mechanism will be considered. This mechanism will be based on camera mechanical registration and algorithm correction, and it will be studied to avoid algorithm failure problems caused by data quality.
Sensor calibration errors, such as the distortion coefficient of RGB cameras and the scale factor of depth sensors, can cause pixel-level misalignment between depth images and RGB images. In feature-level fusion, such misalignment can disrupt cross-modal semantic associations. For instance, the fastener area is clear in RGB but shifts in the depth image, leading to confusion in fused features. In practical applications, online self-calibration can be utilized; that is, real-time calibration and correction can be carried out by using known geometric structures in the track scene (such as rail edges) to reduce the potential sensitivity of this method to hardware and calibration changes.
Moreover, in real railway scenarios, adverse weather conditions such as rain, snow, and fog can affect the imaging quality of sensors, causing noise interference and blurring of effective information, thus resulting in a decline in the performance of the method. In future studies, a multi-modal data augmentation strategy and domain adaptive learning can be applied to reduce the impact of adverse weather on the performance of the algorithm.
Acknowledgement: Not applicable.
Funding Statement: This research was funded by Beijing Natural Science Foundation, grant number L241078.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Yaguan Wang, Yang Gao and Yong Qin; methodology, Yaguan Wang and Yang Gao; software, Yaguan Wang; validation, Yaguan Wang; formal analysis, Yaguan Wang; investigation, Yaguan Wang; resources, Yaguan Wang; data curation, Yang Gao; writing—original draft preparation, Yaguan Wang; writing—review and editing, Yang Gao and Genwang Peng; visualization, Yaguan Wang; supervision, Yang Gao, Qiang Sun; project administration, Linlin Kou; funding acquisition, Linlin Kou. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Qin Y, Cao Z, Sun Y, Kou L, Zhao X, Wu Y, et al. Research on active safety methodologies for intelligent railway systems. Engineering. 2023;27(1):266–79. doi:10.1016/j.eng.2022.06.025. [Google Scholar] [CrossRef]
2. Cao Z, Qin Y, Jia L, Xie Z, Gao Y, Wang Y, et al. Railway intrusion detection based on machine vision: a survey, challenges, and perspectives. IEEE Trans Intell Transp Syst. 2024;25(7):6427–48. doi:10.1109/TITS.2024.3412170. [Google Scholar] [CrossRef]
3. Redmon J, Farhadi A. YOLOv3: an incremental improvement. arXiv:1804.02767. 2018. [Google Scholar]
4. Ultralytics. YOLOv5 [Internet]. [cited 2025 Oct 1]. Available from: https://github.com/ultralytics/ultralytics. [Google Scholar]
5. Wang CY, Bochkovskiy A, Liao HM. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. IEEE; 2023. p. 7464–75. doi:10.1109/CVPR52729.2023.00721. [Google Scholar] [CrossRef]
6. Qiu S, Cai B, Wang W, Wang J, Zaheer Q, Liu X, et al. Automated detection of railway defective fasteners based on YOLOv8-FAM and synthetic data using style transfer. Autom Constr. 2024;162(7):105363. doi:10.1016/j.autcon.2024.105363. [Google Scholar] [CrossRef]
7. Ye W, Ren J, Zhang AA, Lu C. Automatic pixel-level crack detection with multi-scale feature fusion for slab tracks. Comput Aided Civ Infrastruct Eng. 2023;38(18):2648–65. doi:10.1111/mice.12984. [Google Scholar] [CrossRef]
8. Fan Y, Dai P, Song H, Li H. Detection of high-speed railway track bed foreign object based on contrastive learning and adversarial training. In: 2025 IEEE 5th International Conference on Power, Electronics and Computer Applications (ICPECA); 2025 Jan 17–19; Shenyang, China. IEEE; 2025. p. 73–7. doi:10.1109/ICPECA63937.2025.10928813. [Google Scholar] [CrossRef]
9. An Y, Li X, Cao Y, Su S, Sun Y, Wang F, et al. A T-YOLO and overlapping reconstruction-based method for rail fastener defect detection in heavy-haul railway. IEEE Trans Instrum Meas. 2025;74:2546912. doi:10.1109/TIM.2025.3602605. [Google Scholar] [CrossRef]
10. Ye W, Ren J, Lu C, Zhang AA, Zhan Y, Liu J. Intelligent detection of fastener defects in ballastless tracks based on deep learning. Autom Constr. 2024;159(1):105280. doi:10.1016/j.autcon.2024.105280. [Google Scholar] [CrossRef]
11. He J, Wang W, Jin X, Li H, Liu J, Chen B. Multiscale cross-attention CNN-transformer two-branch fusion network for detecting railway U-shaped bolts & nuts defects. IEEE/ASME Trans Mechatron. 2025;1–12. doi:10.1109/TMECH.2025.3587940. [Google Scholar] [CrossRef]
12. Qiu Y, Liu J, Liu H. Railway track multicomponent segmentation based on residual contextual transformer. IEEE Sens J. 2024;24(14):22575–87. doi:10.1109/JSEN.2024.3403137. [Google Scholar] [CrossRef]
13. Zhao J, Yeung AW, Ali M, Lai S, Ng VT. CBAM-SwinT-BL: small rail surface defect detection method based on swin transformer with block level CBAM enhancement. IEEE Access. 2024;12:181997–2009. doi:10.1109/access.2024.3509986. [Google Scholar] [CrossRef]
14. Long K, Xie G, Ma L, Liu J, Lu Z. Revisiting multimodal fusion for 3D anomaly detection from an architectural perspective. Proc AAAI Conf Artif Intell. 2025;39(12):12273–81. doi:10.1609/aaai.v39i12.33337. [Google Scholar] [CrossRef]
15. Gao Y, Cao Z, Qin Y, Ge X, Lian L, Bai J, et al. Railway fastener anomaly detection via multisensor fusion and self-driven loss reweighting. IEEE Sens J. 2024;24(2):1812–25. doi:10.1109/JSEN.2023.3336962. [Google Scholar] [CrossRef]
16. Ge X, Cao Z, Qin Y, Gao Y, Lian L, Bai J, et al. An anomaly detection method for railway track using semisupervised learning and vision-lidar decision fusion. IEEE Trans Instrum Meas. 2024;73:5023215. doi:10.1109/TIM.2024.3417537. [Google Scholar] [CrossRef]
17. Yuan X, Kang B, Wang Y, Liu W, Liu B, Hou D, et al. Rapid detection of visual and structural defects of railway fasteners via RGB-P bimodal data fusion. IEEE Sens J. 2025;25(20):38092–108. doi:10.1109/JSEN.2025.3602275. [Google Scholar] [CrossRef]
18. Yang J, Zhou W, Wu R, Fang M. CSANet: contour and semantic feature alignment fusion network for rail surface defect detection. IEEE Signal Process Lett. 2023;30:972–6. doi:10.1109/LSP.2023.3299218. [Google Scholar] [CrossRef]
19. Wang J, Li G, Qiu G, Ma G, Xi J, Yu N. Depth-assisted semi-supervised RGB-D rail surface defect inspection. IEEE Trans Intell Transp Syst. 2024;25(7):8042–52. doi:10.1109/TITS.2024.3387949. [Google Scholar] [CrossRef]
20. Zhou W, Hong J. FHENet: lightweight feature hierarchical exploration network for real-time rail surface defect inspection in RGB-D images. IEEE Trans Instrum Meas. 2023;72:5005008. doi:10.1109/TIM.2023.3237830. [Google Scholar] [CrossRef]
21. Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, et al. MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861.2017. [Google Scholar]
22. Zheng Z, Wang P, Liu W, Li J, Ye R, Ren D. Distance-IoU loss: faster and better learning for bounding box regression. Proc AAAI Conf Artif Intell. 2020;34(7):12993–3000. doi:10.1609/aaai.v34i07.6999. [Google Scholar] [CrossRef]
23. Ultralytics. YOLOv8 [Internet]. [cited 2025 Oct 1]. Available from: https://github.com/ultralytics/ultralytics. [Google Scholar]
24. Ultralytics. YOLOv11 [Internet]. [cited 2025 Oct 1]. Available from: https://github.com/ultralytics/ultralytics. [Google Scholar]
25. Tian Y, Ye Q, Doermann D. YOLOv12: attention-centric real-time object detectors. arXiv:2502.12524.2025. [Google Scholar]
26. Chen Y, Wang B, Guo X, Zhu W, He J, Liu X, et al. DEYOLO: dual-feature-enhancement YOLO for cross-modality object detection. In: Pattern recognition. Cham, Switzerland: Springer Nature; 2024. p. 236–52. doi:10.1007/978-3-031-78447-7_16. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools