
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
A New Extension Odd Generalized Exponential Model Using Type-II Progressive Censoring and Its Applications in Engineering and Medicine
1 Mathematics Department, Faculty of Science, Mansoura University, Mansoura, 35516, Egypt
2 Department of Mathematics and Statistics, Faculty of Science, Imam Mohammad Ibn Saud Islamic University (IMSIU), Riyadh, 11432, Saudi Arabia
* Corresponding Author: Alia M. Magar. Email:
(This article belongs to the Special Issue: Frontiers in Parametric Survival Models: Incorporating Trigonometric Baseline Distributions, Machine Learning, and Beyond)
Computer Modeling in Engineering & Sciences 2025, 144(2), 2063-2097. https://doi.org/10.32604/cmes.2025.065604
Received 17 March 2025; Accepted 15 July 2025; Issue published 31 August 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
A new extended distribution called the Odd Exponential Generalized Exponential-Exponential distribution is proposed based on generalization of the odd generalized exponential family (OEGE-E). The statistical properties of the proposed distribution are derived. The study evaluates the accuracy of six estimation methods under complete samples. Estimation techniques include maximum likelihood, ordinary least squares, weighted least squares, maximum product of spacing, Cramer von Mises, and Anderson-Darling methods. Two methods of estimation for the involved parameters are considered based on progressively type II censored data (PTIIC). These methods are maximum likelihood and maximum product of spacing. The proposed distribution’s effectiveness was evaluated using different data sets from various fields. The proposed distribution provides a better fit for these datasets than existing probability distributions.Keywords
Researchers and statisticians have been focusing close attention to new normalized distributions in recent years due to their flexibility in statistical modeling and wide use in nearly all scientific domains. Marshall and Olkin [1] proposed adding a parameter to the survival function
As per Gupta and Kundu, Gupta [3] explored the two-parameter generalized-exponential
Olabad conducted a series of studies [4–7] exploring various types of extended generalized logistic distributions, including type I extended forms [4], negatively skewed versions [5], symmetric distributions [6], and extended generalized exponential formulations [7], highlighting the flexibility of logistic-type models in capturing a wide range of distributional shapes.
Alizadeh et al. [8] further expanded this framework by introducing the Kumaraswamy odd log-logistic family, which demonstrated greater flexibility in modeling complex hazard shapes and tail behaviors in applied datasets. Cordeiro and de Castro [9] contributed by proposing a new family of generalized distributions through innovative transformation techniques, opening new directions for statistical inference and distribution theory. Similarly, Maiti [10] introduced the odd generalized exponential–exponential distribution, emphasizing its mathematical properties and usefulness in fitting real data.
Finally, Tahir et al. [11] introduced a new generalization of the odd generalized exponential family
where
and the probability density function (PDF) is given by:
where
Recent studies have proposed compound and transformed versions of the GE distribution to better model skewed, heavy-tailed, or multimodal data:
Andrade et al. [12] introduced the Exponentiated Generalized Extended Exponential (EGEE) distribution, a four-parameter model capable of modeling diverse hazard functions, including bathtub and unimodal shapes.
Sah Telee et al. [13] developed the Exponentiated Generalized Exponential Geometric (EGEG) distribution, which compounds the GE and geometric distributions. This model offers improved goodness-of-fit for count and reliability data, and supports various estimation methods such as MLE, LSE, and Cramér–von Mises.
Abonongo [14] presented the Exponentiated Generalized Weibull Exponential (EGWE) model, combining features of the Weibull and GE distributions to address more complex hazard structures.
On the other hand, lifetime distributions are crucial in modelling real-world phenomena. As a result, many lifetime distributions have been used to model various types of data in various branches of applied sciences (medicine, engineering, and finance, for example). Existing distributions may not be suitable for certain real-life data sets due to various issues. Researchers can propose new or improve existing lifetime distributions to better match real-world data. Recent advances in distribution modeling [15–17] highlight the need for flexible models like EOEGE–E. In this paper, the flexible Odd Exponential Generalized Exponential-Exponential distribution.
Statisticians have devoted significant effort to studying the failure of components and units, which are the fundamental elements of operational systems in industrial and mechanical engineering. Their research involves monitoring the performance of these units until failure, recording their lifespans, utilizing statistical inference methods on the collected data, and estimating the system’s overall reliability and hazard functions based on this information. However, in cases where experimental units are costly and highly reliable, it becomes necessary to minimize both the number of units tested and the duration of the experiments. The progressive type-II censoring (PTIIC) scheme addresses this need by enabling the collection of reliable estimators while preserving some units from failure during the testing process. There are several types of censorship systems, including right, left, interval, single, and multiple censoring. For this reason, we consider a PTIIC scheme, which is a more general censoring method. Several sources, including [18] and [19], provide additional information on the PTIIC data. The stages of PTIIC scheme is depicted in Fig. 1.

Figure 1: PTIIC scheme
Statistical modeling of lifetime data in engineering and medicine requires flexible distributions to capture complex behaviors like non-monotonic hazard rates and heavy-tailed distributions. Existing models, such as Weibull and Generalized Exponential, often fail to fit datasets with diverse shapes. EOEGE–E distribution offers unique advantages over existing models like Weibull and Generalized Exponential distributions. Its ability to model both monotonic and non-monotonic hazard rates (e.g., bathtub-shaped) makes it suitable for complex datasets in engineering (e.g., reliability analysis) and medicine (e.g., survival analysis). Unlike simpler models, the EOEGE–E captures heavy-tailed and skewed data, providing superior fit, as demonstrated in Section 6.
The remainder of the paper is structured as follows: Section 2 outlines the cumulative distribution function, density function, survival function, and hazard rate function of the extended odd exponential generalized exponential-exponential
In this section, we develop a new class of odd generalized exponential-exponential model, known as Extended Odd Exponential Generalized Exponential distribution
where
where
The survival function (SF) is given by
The hazard rate function (HRF) is given by
The graphical representations in Figs. 2 and 3 illustrate the remarkable flexibility and adaptability of the EOEGE–E distribution, driven by its parameters
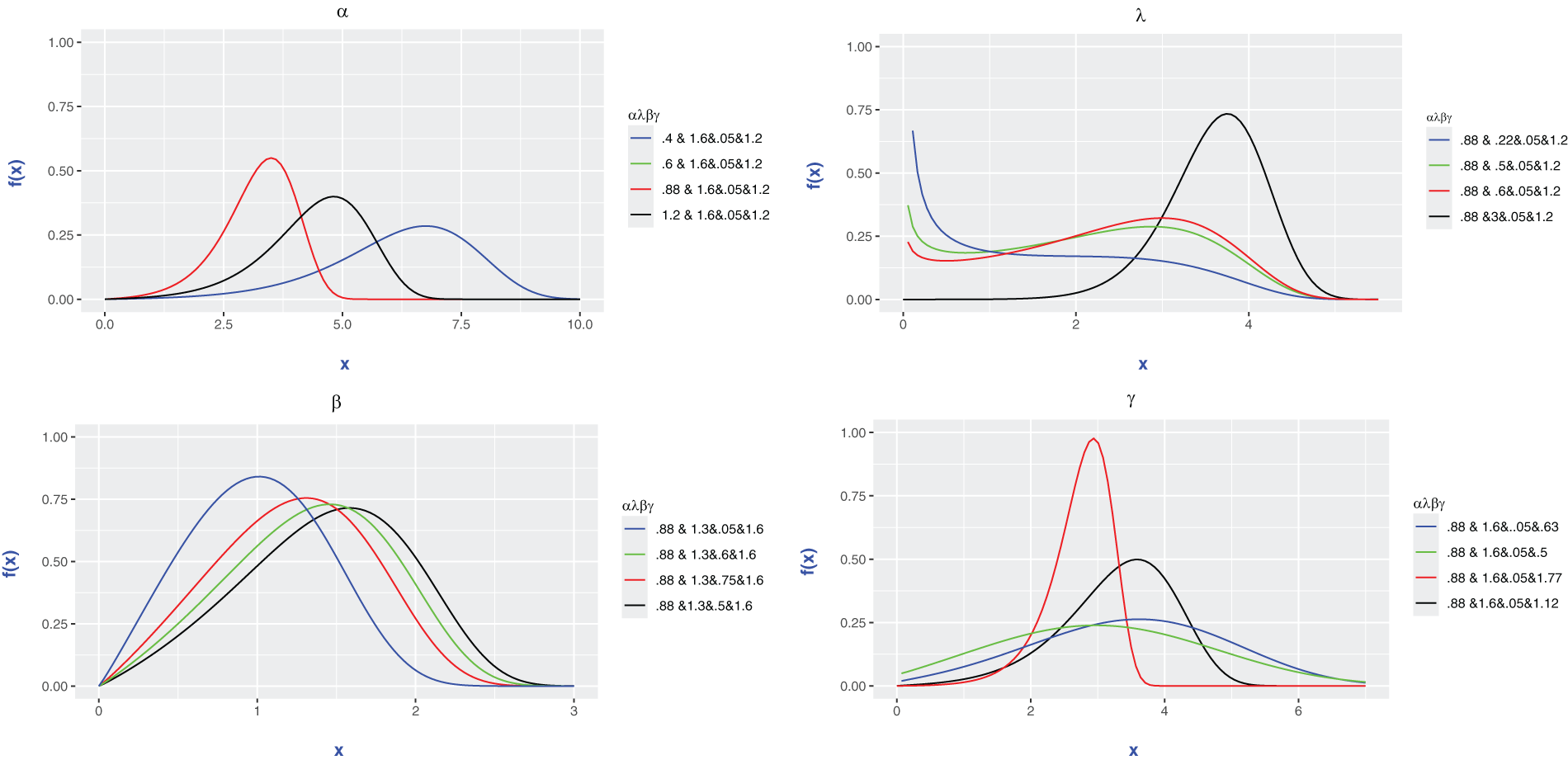
Figure 2: Shape and behaviour of pdf plots with several values of parameters
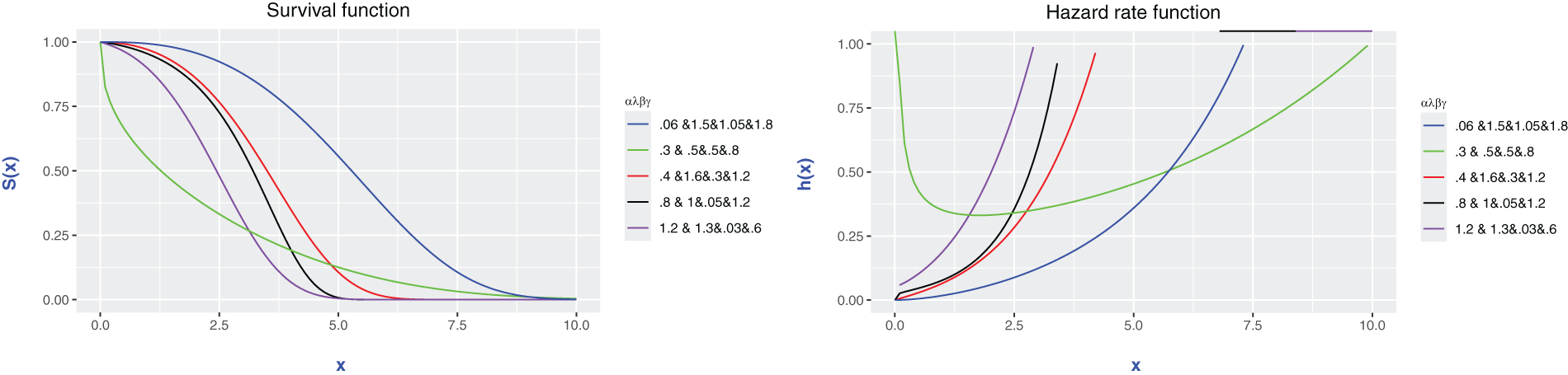
Figure 3: Survival function and Hazard rate function
3 Several Statistical Properties
In the beginning of this section, several useful expansions of the PDF and CDF of the new EOEGE − E distribution are shown below using a well-known generalized binomial and power series expansion. It is presented to justify the analytical divergence of some basic distribution features. The expansions of the generalized binomial and power series are as follows:
The EOEGE − E distribution’s PDF and CDF are then displayed as follows:
The quantile function of the EOEGE–E distribution is derived in Appendix A.
In particular, the Galton skewness coefficient and Moors kurtosis coefficient is applicable for calculating skewness and kurtosis as following
Figs. 4–9 display the skewness and kurtosis plot for the EOEGE–E distribution with different parameter values. The EOEGE–E distribution is found to be symmetric, positively skewed, and slightly negatively skewed. It could also be mesokurtic, platykurtic, or leptokurtic.
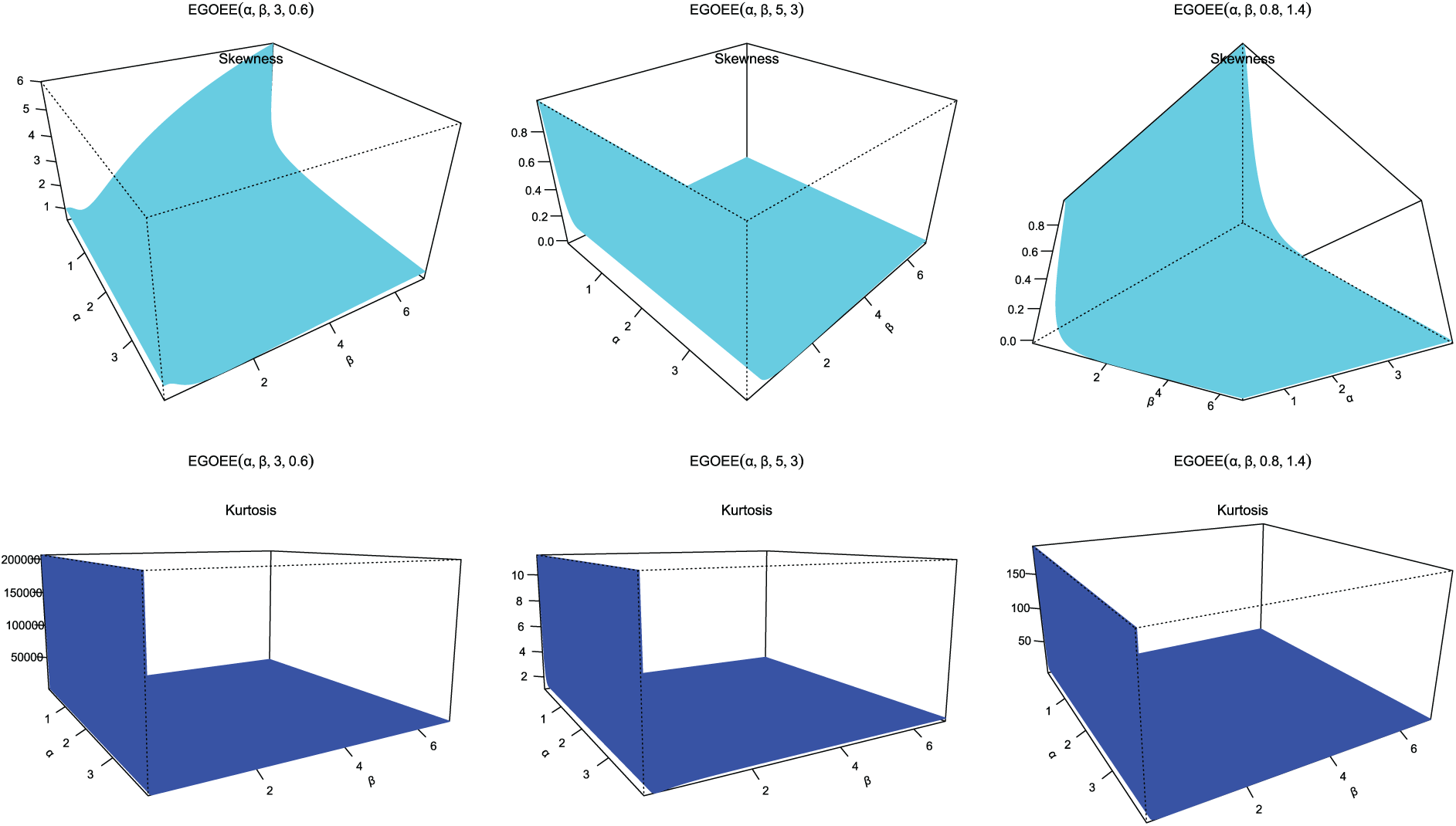
Figure 4: Skewness and kurtosis plots for EOEGE-E parameters
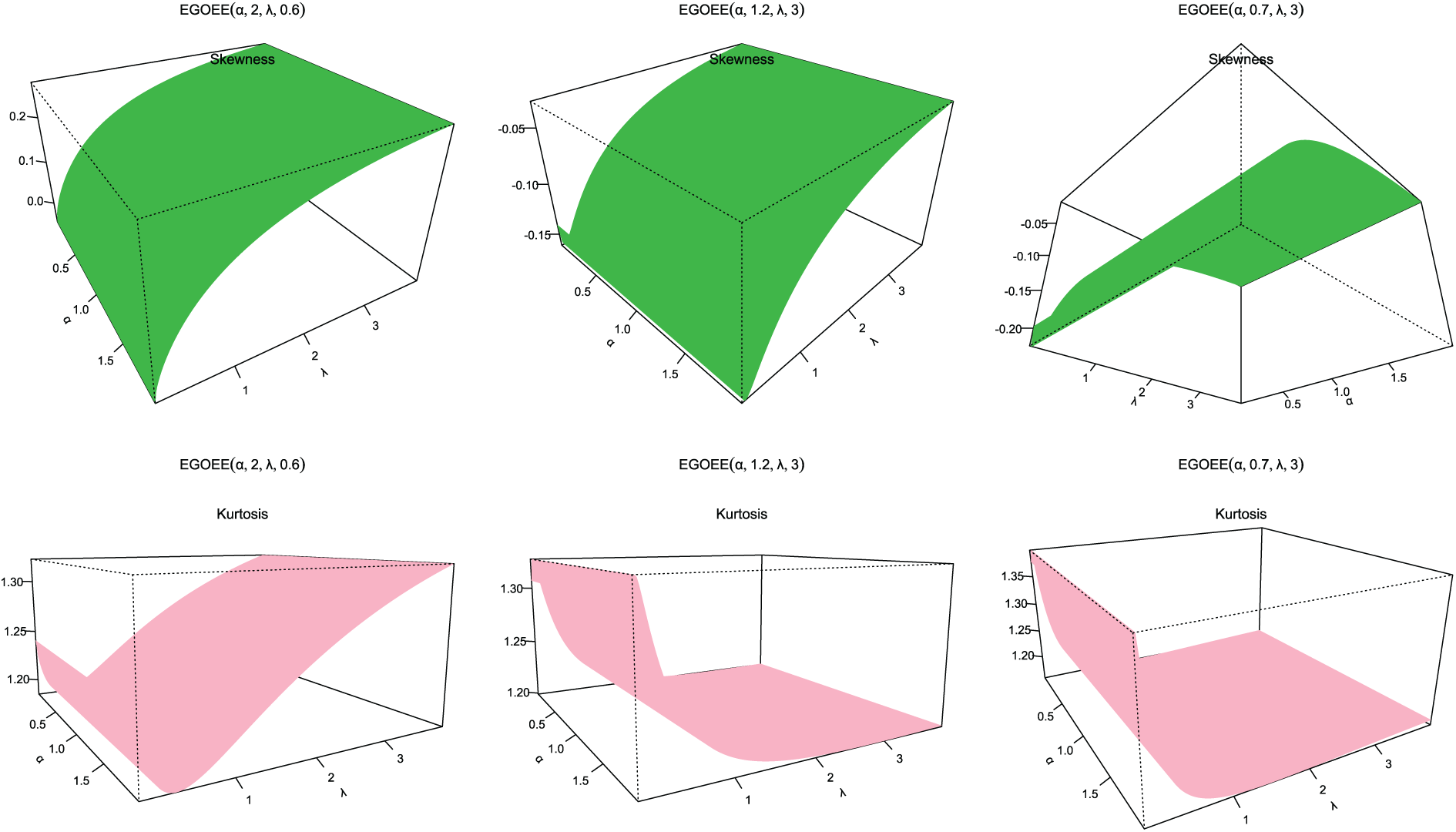
Figure 5: Skewness and kurtosis plots for EOEGE-E parameters
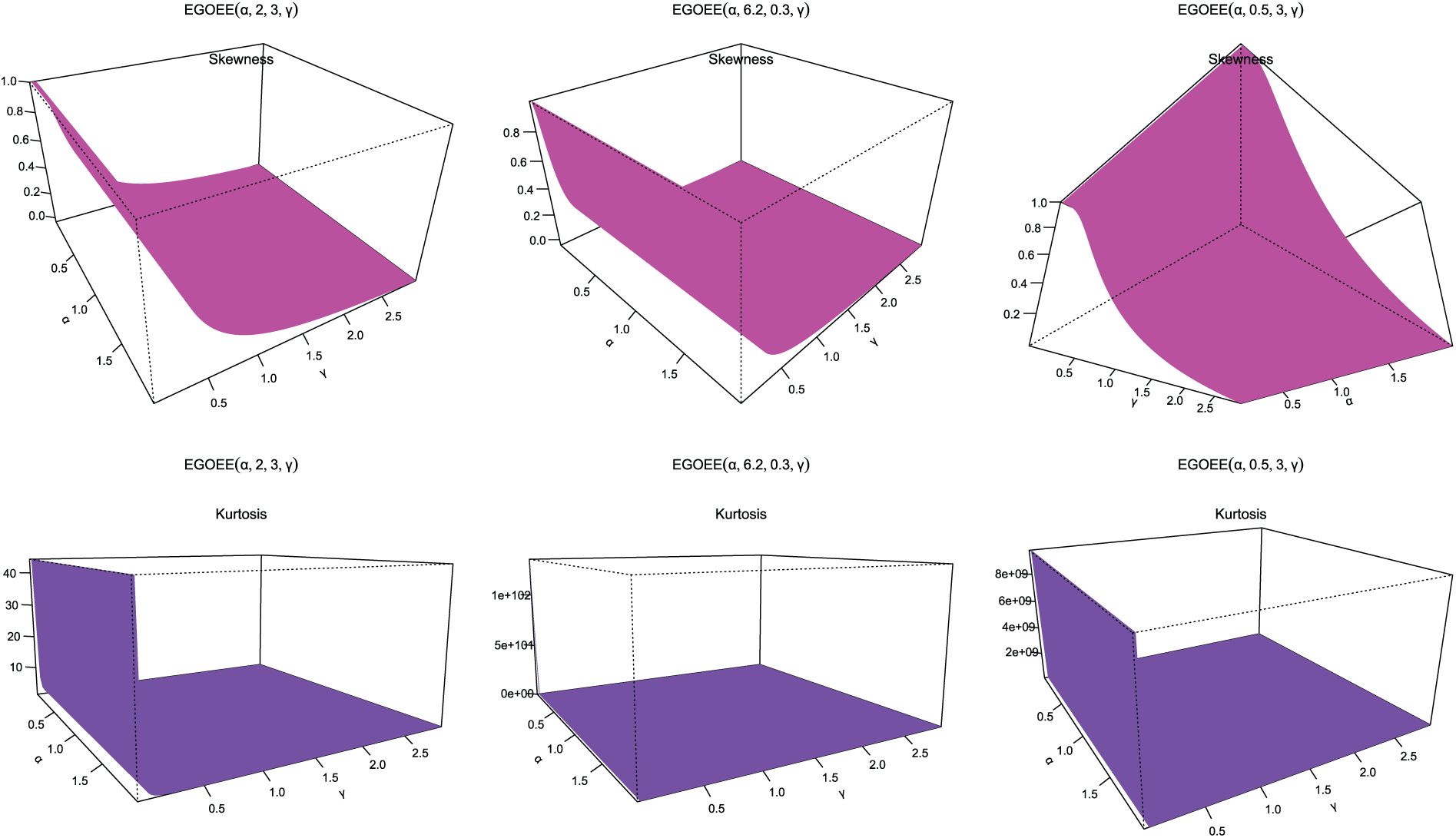
Figure 6: Skewness and kurtosis plots for EOEGE-E parameters
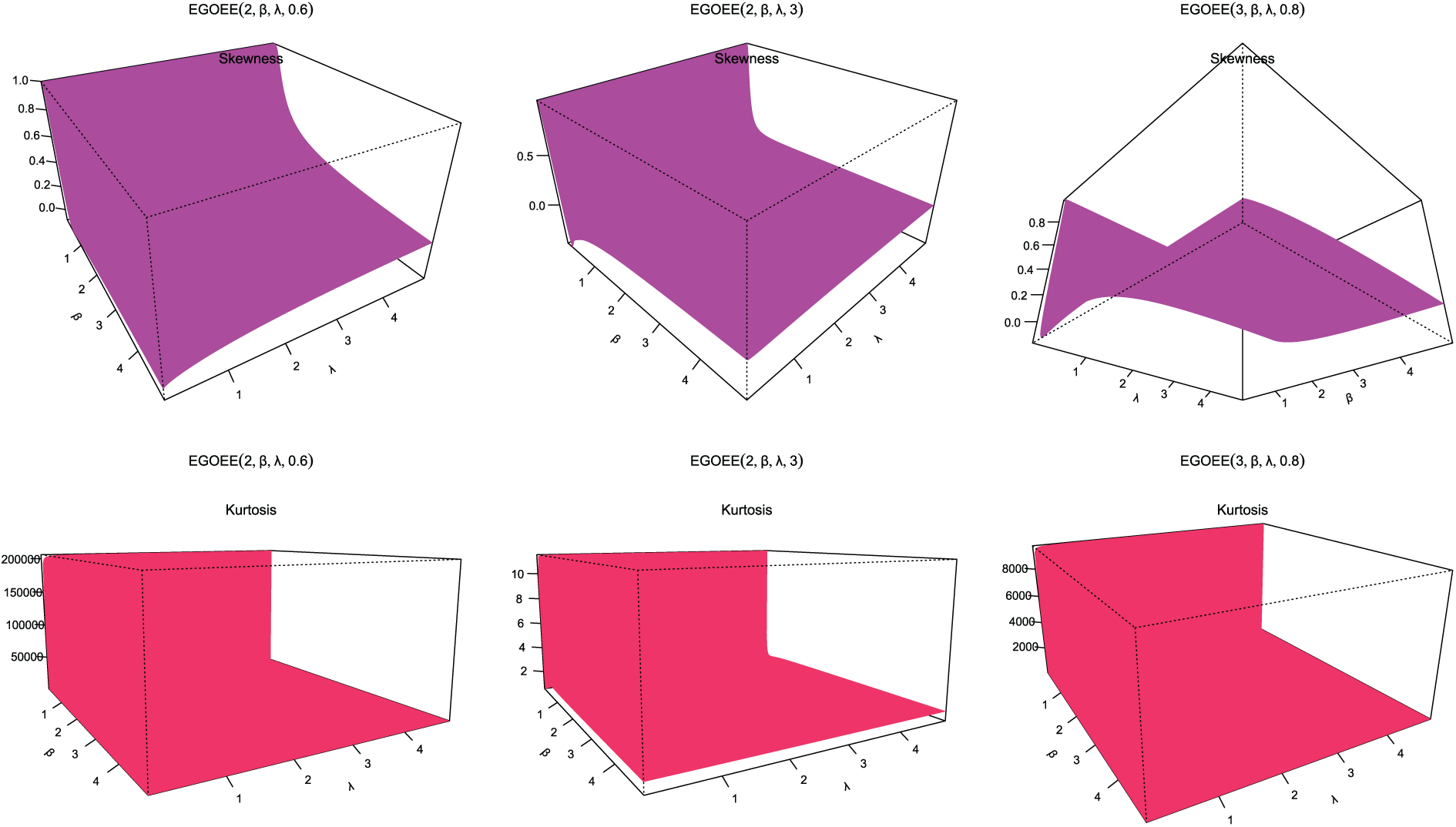
Figure 7: Skewness and kurtosis plots for EOEGE-E parameters
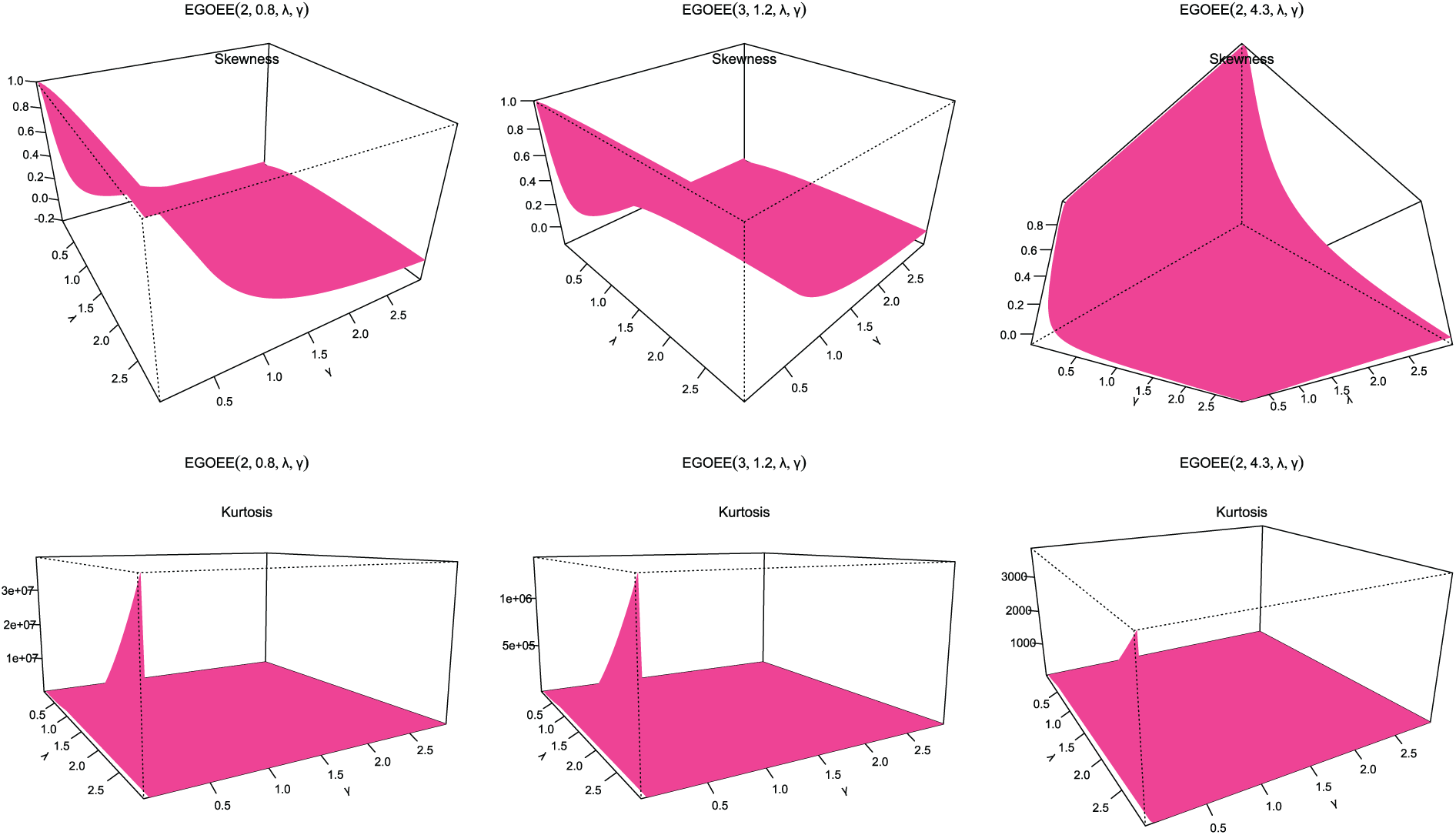
Figure 8: Skewness and kurtosis plots for EOEGE-E parameters
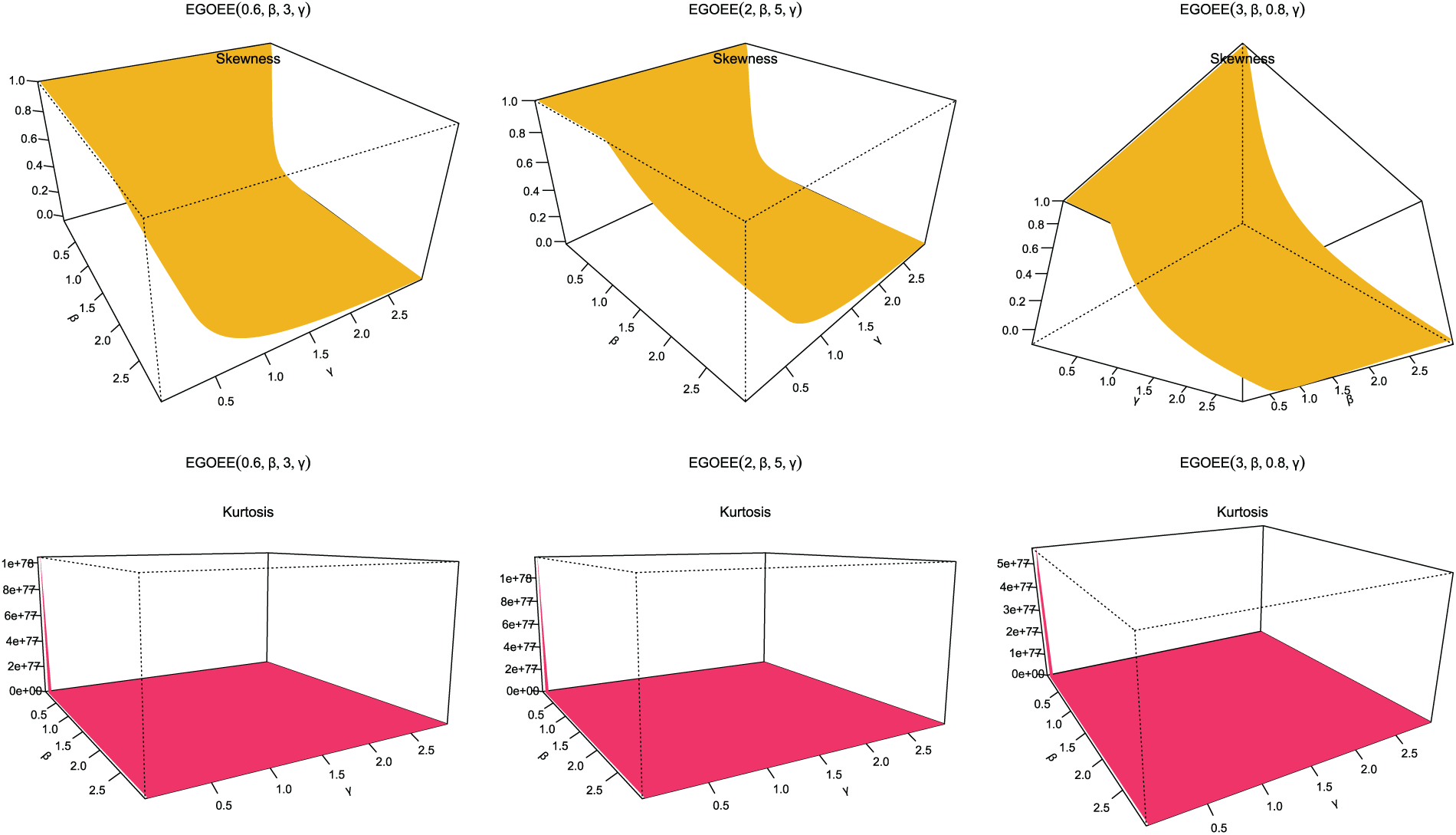
Figure 9: Skewness and kurtosis plots for EOEGE-E parameters
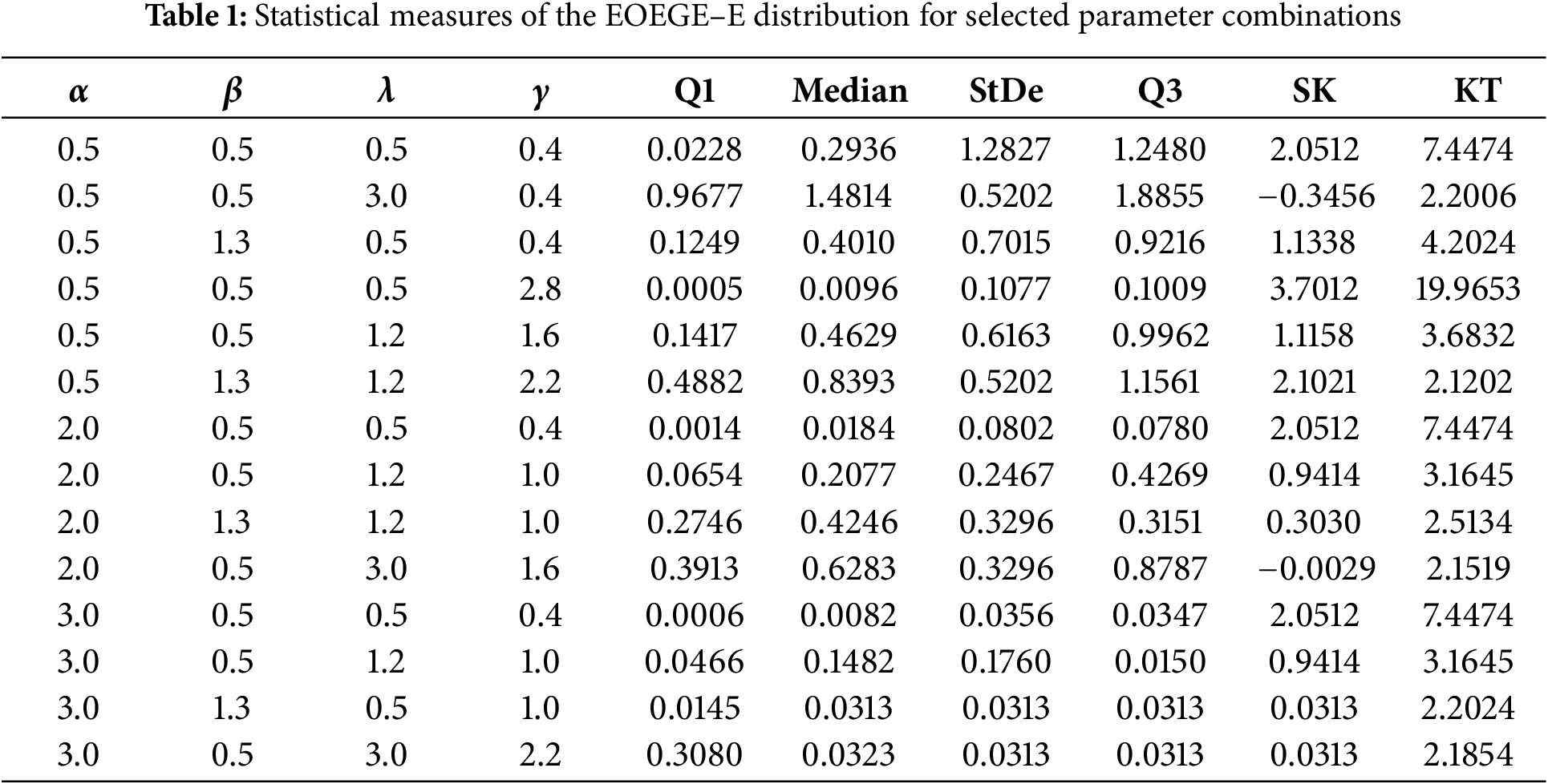
Table 1 displays key statistical measures for the EOEGE–E distribution across 14 parameter combinations with
r-th moments of the EOEGE–E distribution are derived in Eq. (A1).
3.3 The Moment Generating Function
We derive the moment generating function using an infinite expansion of the EOEGE−E distribution, as follows: The moment generating functions of random variable
using series expansion
Substiuting from Eq. (5), we get The moment generating function
for any
Consider
where
Substituting cdf and pdf given by Eqs. (4) and (5) in Eq. (16), respectively, then the rth order statistics of EOEGE−E distribution is
where
In this context, six estimation methods are employed to estimate the parameters

4.1 Maximum Likelihood Estimation (MLE)
Let
The function expressing the natural logarithm of the likelihood is provided as follows:
Partial derivatives of previous equation for (
Estimators of maximum likelihood
4.2 Ordinary Least Squares (OLS) and Weighted Least Squares (WLS)
Consider a random sample
where
where
and
4.3 Maximum Product of Spacing (MPS)
Let
with respect to
and
Consider a random sample
with respect to
where
Consider a random samples
with respect to
where
The non-linear equations derived from the log-likelihood are solved using the Newton-Raphson method. For parameters
where
A Monto Carlo (MC) simulation study is carried out to explore and assess the behavior of MLEs of EOEGE–E model via R program. We consider 1000 MC-replicates under different sample sizes n = 50, 100, 200, and 300.
The samples have been drawn for different cases as follows:
• Case 1:
• Case 2:
• Case 3:
• Case 4:
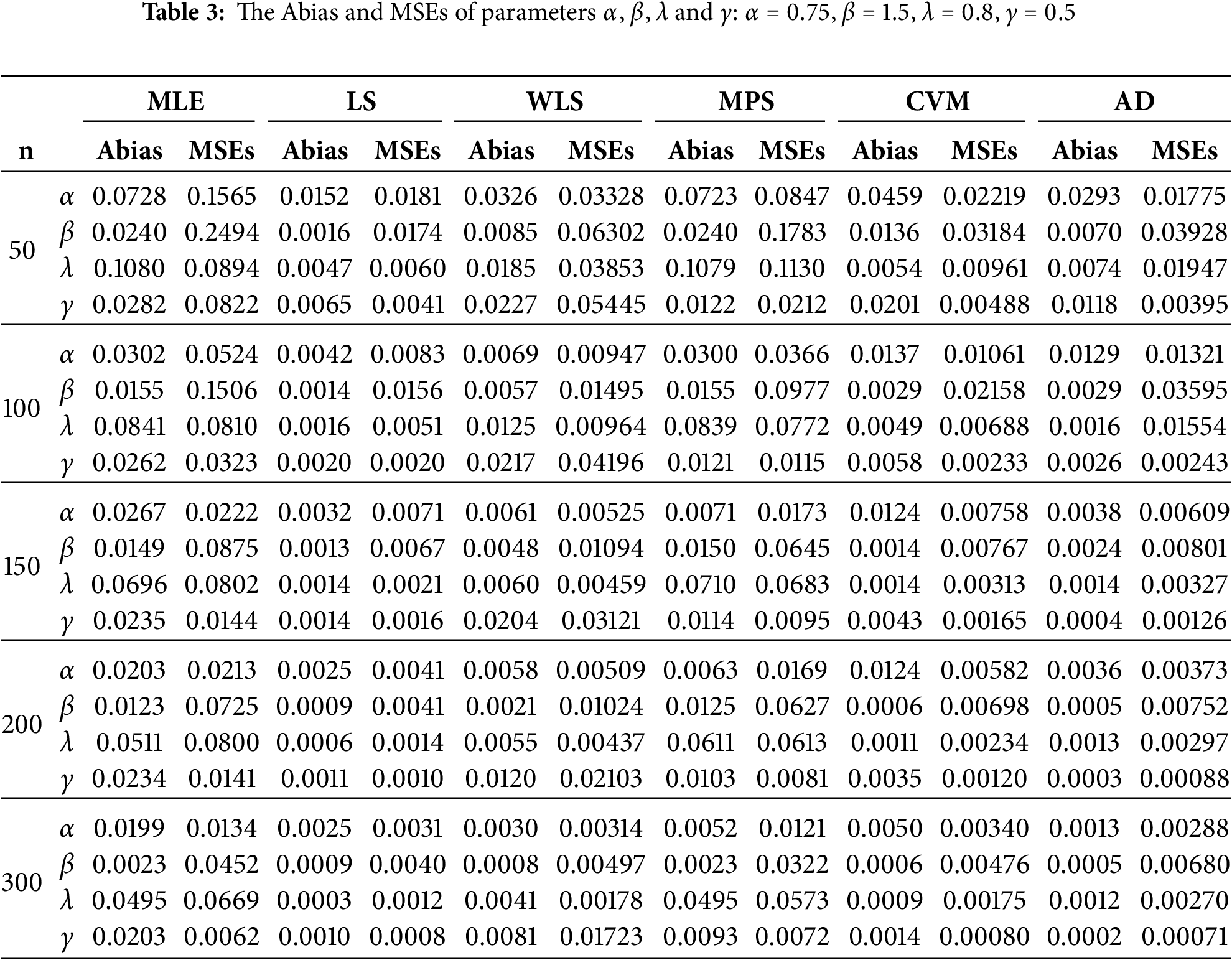
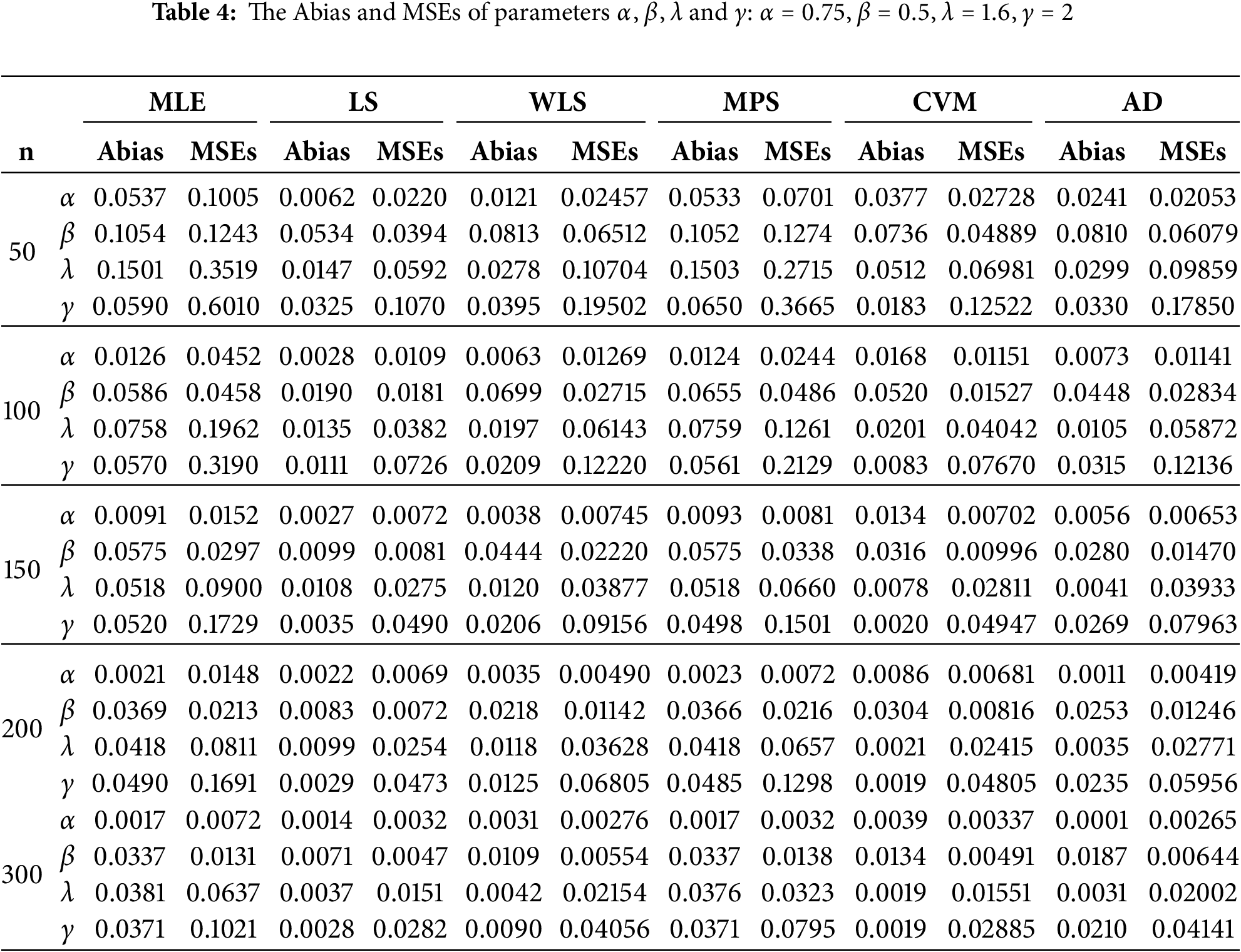
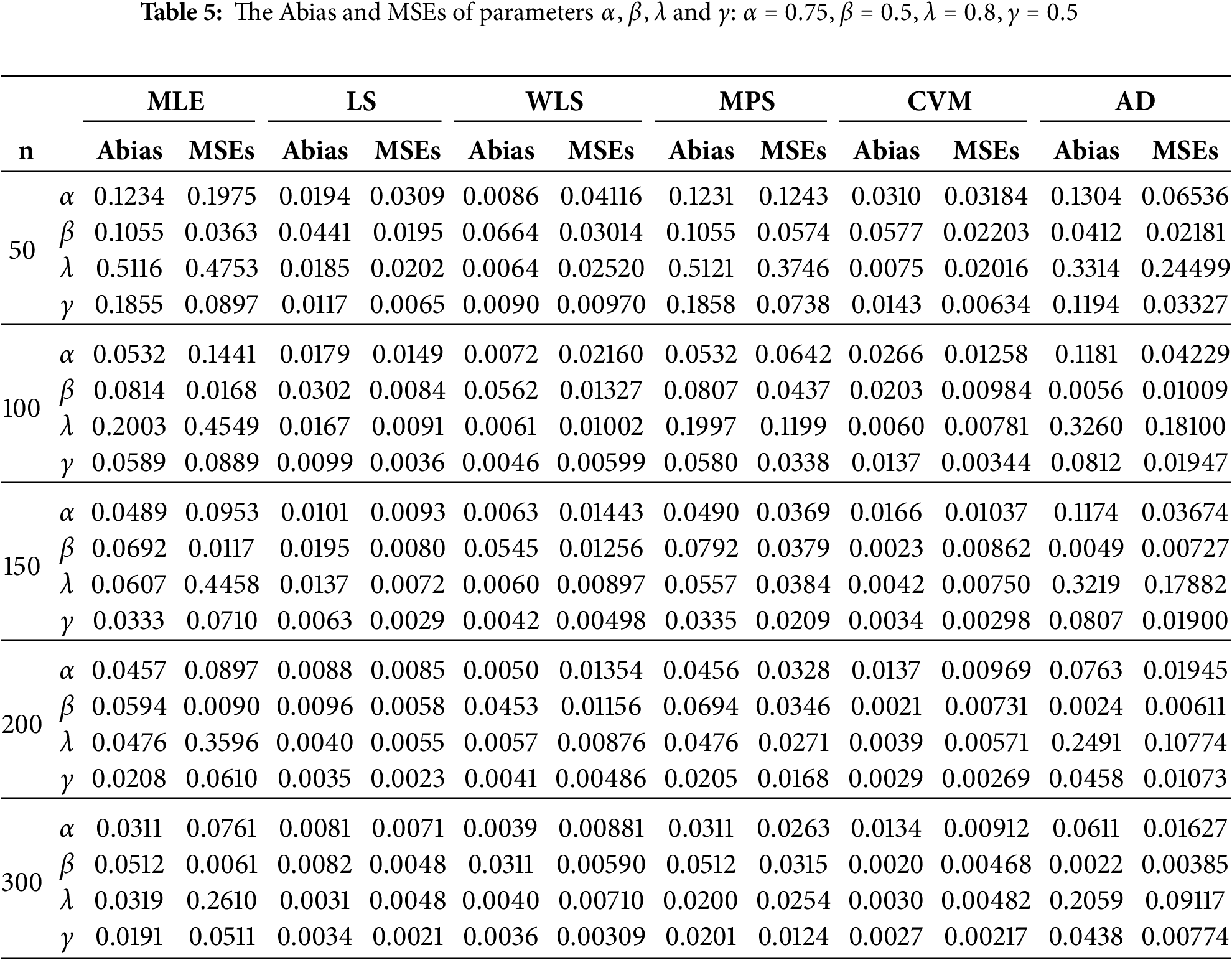
For each sample size, we compute the MLE, LS, WLS, MPS, CVM, and AD with different measures as Absolute Biases (ABias) and mean square error (MSEs) for all estimates methods. All simulation experiments were conducted using the R software. The likelihood function was optimized using the optim function with the Nelder-Mead algorithm. These methods are well-established in statistical analysis and contribute to the reliability and accuracy of the obtained results. The results obtained after performing the MC simulation and ABias and MSEs are presented in Tables 2–5. The following conclusions can be made based on the data presented in Tables 2–5:
• With larger sample sizes (n), there is a decrease in both the Abias and MSEs of all estimators, indicating better precision in estimating model parameters, indicating consistency behaviour.
• The methods yielding the least biased parameters across different sample sizes (n) are CVM, and WLS methods.
• Across all n’s, the Abias of the estimators tends to approach zero, indicating unbiased estimation.
The simulation results indicate that the MPSE often provides more accurate estimates in terms of both bias and mean squared error, particularly for small and moderate sample sizes. This can be attributed to the spacing-based nature of the MPSE, which tends to perform better under skewed or heavy-tailed distributions—features that characterize the proposed EOEGE–E distribution. While the MLE is asymptotically efficient, its performance may deteriorate when the likelihood function is complex or when the sample size is small. The OLSE and WLSE exhibit sensitivity to heteroscedasticity in the transformed data, leading to less stable estimates. The CVME and ADE methods show balanced performance, with ADE particularly effective in the presence of extreme values due to its emphasis on tail behavior. These findings suggest that the choice of estimation method should be informed by the sample size and the underlying characteristics of the data.
Three real data sets applications to illustrate the importance and flexibility of the family are presented.
Data set 1. Failure time of 69 components. Badar and Priest [20] discussed the data set of sample size 69 observed failure times, the dataset is represented the data measured in GPA (Gigapascals), for single carbon fibers and impregnated 1000 carbon fiber The data set values are: 0.562, 0.564, 0.729, 1.216, 1.474, 1.632, 1.816, 2.020, 2.317, 1.247, 1.490, 1.676, 1.824, 2.023, 2.334, 1.256, 1.503, 1.684, 1.836, 2.050, 2.340, 0.802, 1.271, 1.520, 1.685, 1.879, 2.059, 2.346, 0.950, 1.277, 1.522, 1.728, 1.883, 2.068, 2.378, 1.053, 1.305, 1.524, 1.740, 1.892, 2.071, 2.483, 1.111, 1.348, 1.551, 1.764, 1.934, 2.130, 2.835, 1.115, 1.313, 1.551, 1.761, 1.898, 2.098, 2.683, 1.194, 1.390, 1.609, 1.785, 1.947, 2.204, 2.835, 1.208, 1.429, 1.632, 1.804, 1.976, 2.262. For data set 1, the MLEs of the parameters, Kolmogorov-Smirnov (KS) and the p value are calculated and displayed in Table 6 demonstrated the commonly used well-known model selection information criterion, namely, AIC, CAIC (Consistent Akaike Information Criterion), BIC, and HQIC with important measures including Anderson-Darling (AD) and Cramer-von Mises (CVM). The EOEGE–E distribution is compared with other competitive models as: Alpha power exponential (APEx) [21], The exponentiated generalized alpha power family (EGAPEx) [22], Half logistic exponentiated inverse Rayleigh distribution (HLEIRD) [23], the exponentiated generalized exponential (EGEx) [24], alpha power generalized exponential (APGEx) [25] and exponential (Ex) distributions. Fig. 10 includes six diagnostic plots (A–F) assessing the EOEGE–E distribution’s fit to the 69 failure times in Dataset I.
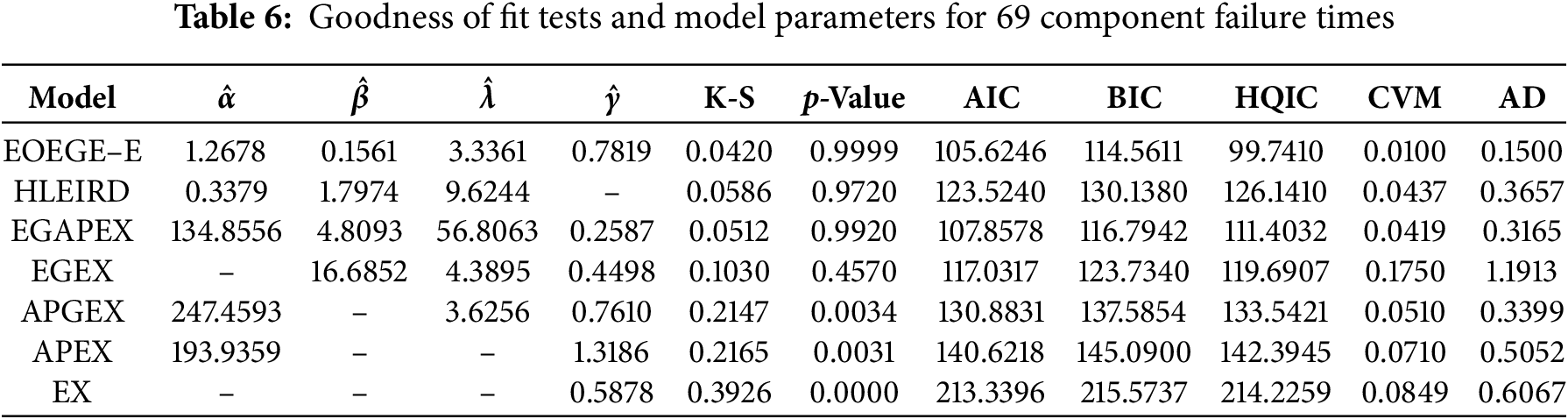
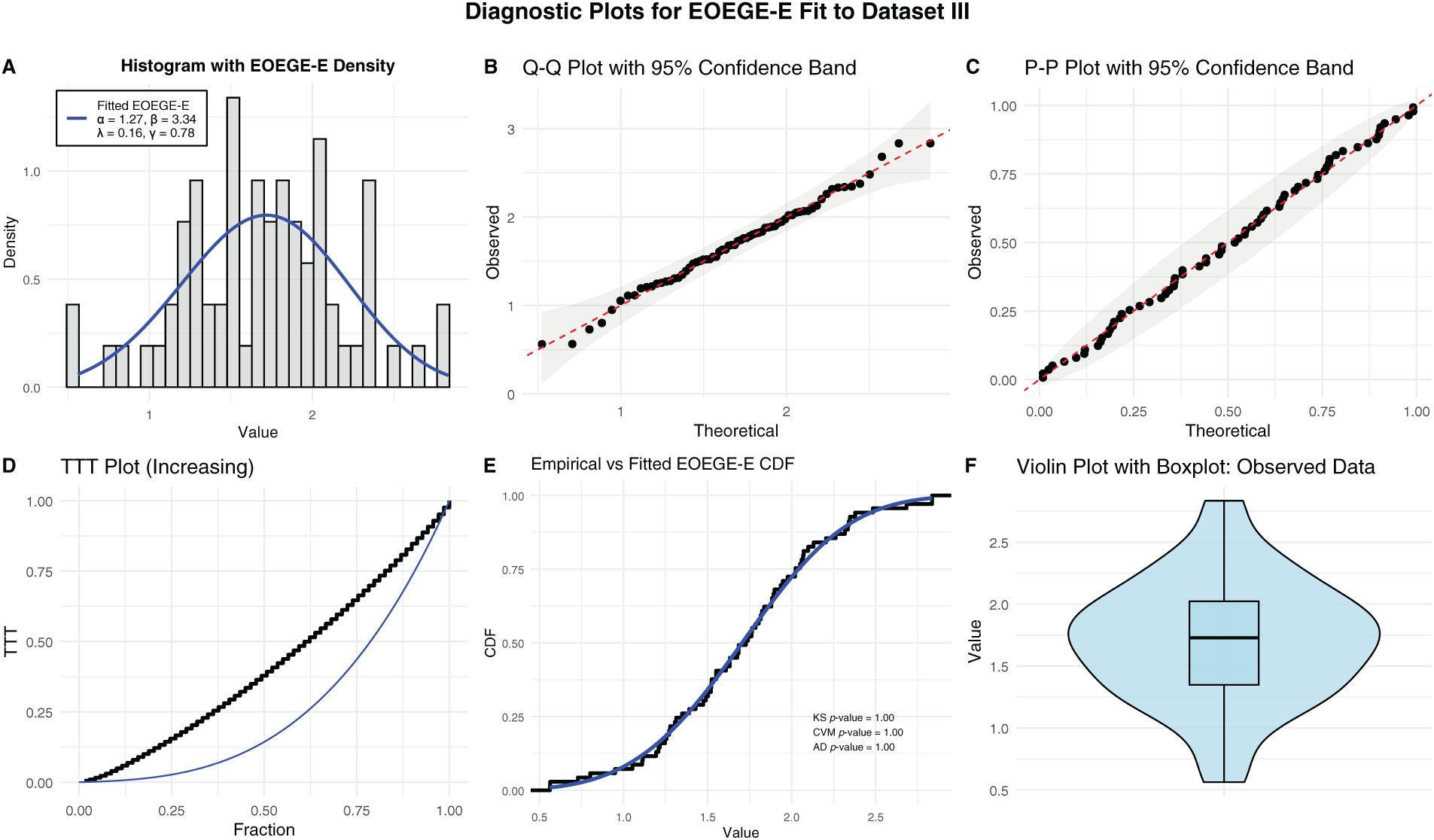
Figure 10: Diagnostic plots for EOEGE-E Fit to dataset I
The EOEGE–E distribution provides an exceptional fit to Dataset I, numerically, Table 6 shows EOEGE–E’s lowest Kolmogorov-Smirnov (K-S) statistic (0.0420), highest p-value (0.9999), and lowest Akaike Information Criterion (AIC, 105.6246), Bayesian Information Criterion (BIC, 114.5611), Hannan-Quinn Information Criterion (HQIC, 99.7410), Cramér-von Mises (CVM, 0.0100), and Anderson-Darling (AD, 0.1568) values, outperforming HLEIRD, EGAPEX, EGEX, APGEX, APEX, and EX. Visually, Fig. 10’s diagnostic plots confirm this:
• The histogram and violin plots (A, F) show EOEGE–E capturing the right-skewed, heavy-tailed distribution.
• Q-Q and P-P plots (B, C) validate quantile and probability alignment within 95% confidence bands.
• The Total Time on Test (TTT) plot (D) confirms an increasing hazard rate, which EOEGE–E models accurately.
• The cumulative distribution function (CDF) plot (E) shows near-perfect overlap with the empirical CDF.
Dataset I’s right-skewed failure times and increasing hazard rate, indicative of carbon fiber fatigue under stress, are ideally suited to EOEGE–E’s four-parameter flexibility. This makes EOEGE–E a powerful tool for reliability engineering, enabling accurate failure predictions and material design optimization. Competing models, especially EX, fail to capture these characteristics, highlighting EOEGE–E’s superiority.
Data set 2. Service times of 50 aircraft windshields. The second data presents the contains information on the “service times” of 50 aircraft windshields. Murthy et al.’s study [24] contains this information. Data are as follows: 1.0030, 1.436, 0.1400, 0.2800, 1.7940, 2.819, 2.592, 0.3130, 0.0460, 1.9150, 2.820, 0.3890, 1.9200, 2.878, 3.1020, 0.9520, 2.0650, 3.3040, 0.9960, 2.1170, 3.483, 1.0030, 2.1370, 3.500, 0.487, 1.9630, 2.950, 0.6220, 1.978, 3.0030, 0.9000, 2.0530, 1.0100, 2.141, 3.6220, 1.492, 2.600, 0.150, 1.580, 2.163, 3.6650, 1.092, 2.183, 3.6950, 1.1520, 2.2400, 4.015, 2.670, 0.248, 1.7190. Table 7 defines the parameter estimates, their standard errors (SE), are enclosed in bracket, Anderson-Darling (AD), Cram’er-von Mises (CVM), and Kolmogrov-Smirnov (K-S) tests and p values. The EOEGE–E distribution is compared with the well-known models in publications Al-Essa et al. [26], Chesneau and Yousof [27], Cordeiro et al. [28], Lemonte et al. [29] and Yousof et al. [30].
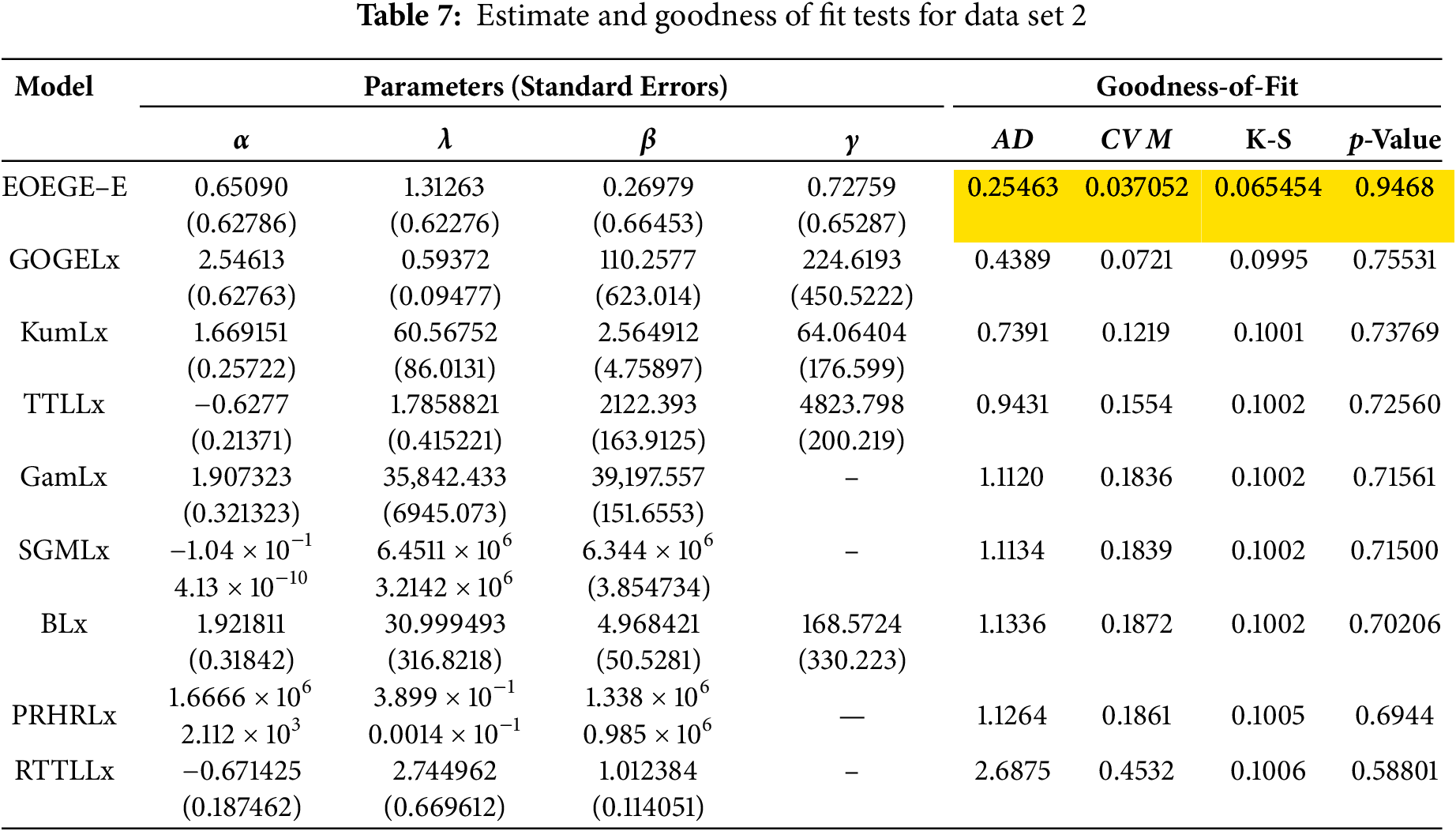
Fig. 11 and Table 7 demonstrate that the EOEGE–E distribution provides an excellent fit to Dataset II (service times of 50 aircraft windshields). Numerically, Table 7 shows EOEGE–E’s lowest Anderson-Darling (AD, 0.25463), Cramér-von Mises (CVM, 0.037052), and Kolmogorov-Smirnov (K-S, 0.065454) statistics, and highest p-value (0.9468), outperforming GOGELx, KumLx, TTLLx, GamLx, SGMLx, BLx, PRHRLx (Proportional Reversed Hazard Rate Lomax), and RTTLLx. Visually, Fig. 11’s diagnostic plots confirm this:
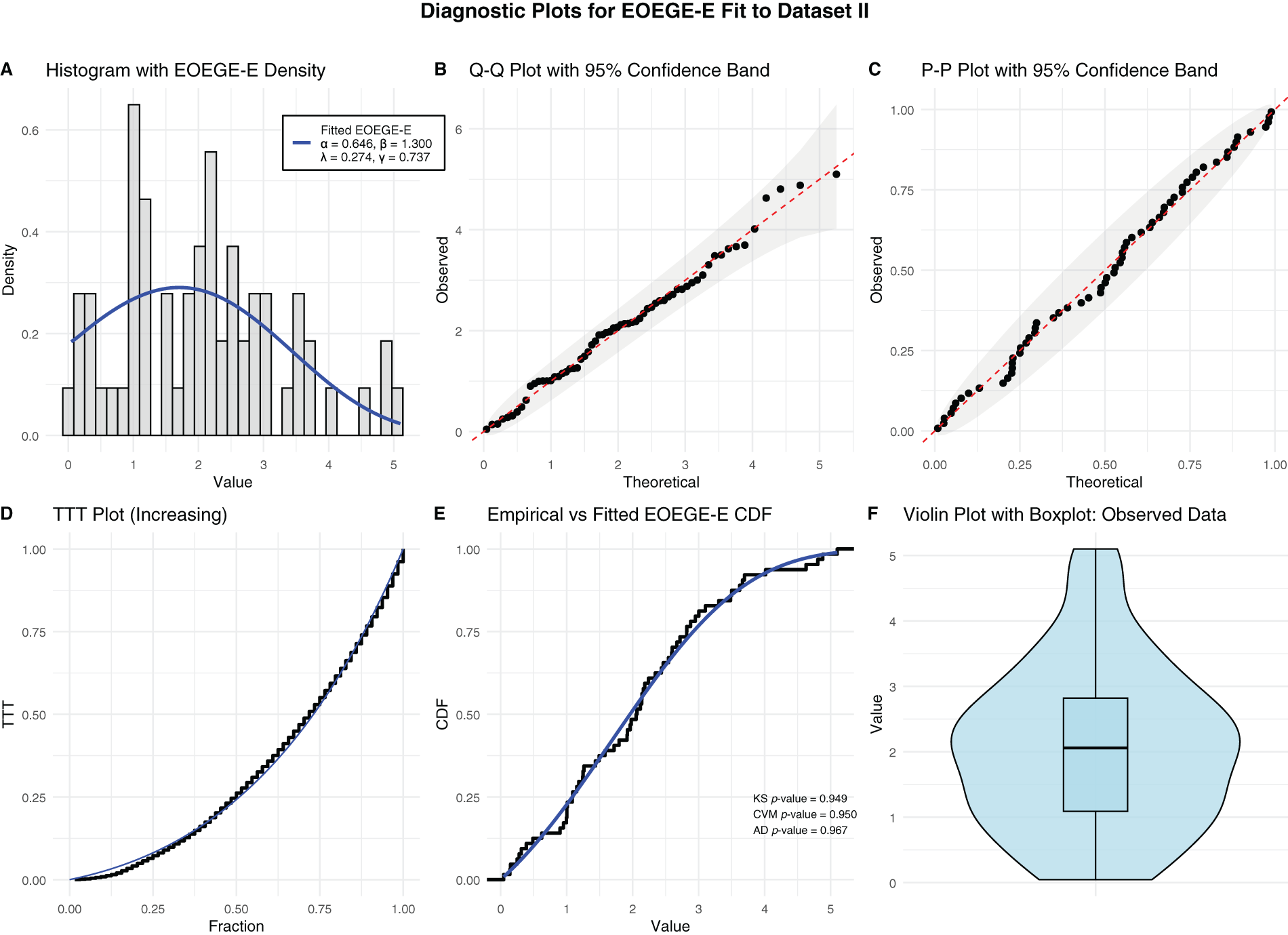
Figure 11: Diagnostic plots for EOEGE–E fit to dataset II
• The histogram and violin plots (A, F) show EOEGE–E capturing the slightly left-skewed, long-tailed distribution.
• Q-Q and P-P plots (B, C) validate quantile and probability alignment within 95% confidence bands.
• The Total Time on Test (TTT) plot (D) confirms an increasing hazard rate, accurately modeled by EOEGE–E.
• The cumulative distribution function (CDF) plot (E) shows near-perfect overlap with the empirical CDF.
Compared to Dataset I (right-skewed carbon fiber failure times), Dataset II’s different skewness and smaller sample size result in a slightly less precise fit, but EOEGE–E’s four-parameter flexibility ensures superior performance in both cases. This makes EOEGE–E a powerful tool for reliability engineering.
Data set 3. Blood cancer data set. The life time (in years) of a 40 blood cancer (leukemia) patients from one of Ministry of health hospitals in Saudi Arabia. This actual data are as follows: ‘0.315, 0.496, 0.616, 1.145, 1.208, 1.263, 1.414, 2.025, 2.036, 2.162, 2.211, 2.370, 2.532, 2.693, 2.805, 2.910, 2.912, 3.192, 3.263, 3.348, 3.348, 3.427, 3.499, 3.534, 3.767, 3.751, 3.858, 3.986, 4.049, 4.244, 4.323, 4.381, 4.392, 4.397, 4.647, 4.753, 4.929, 4.973, 5.074, 5.381’. For data set 3, the MLEs of the parameters, the commonly used wellknown model selection information criterion, namely, AIC and BIC with important measures including Anderson–Darling (AD), Cram’er–von Mises (CVM), and Kolmogrov–Smirnov (K–S) test and p value are computed and displayed in Table 8. The EOEGE–E distribution is compared with other some competitive models, including the exponentiated generalized Weibull Rayleigh distribution (EGWR) (Alsulami, 2025) [31], gamma log-logistic Weibull (GmLLW) (Foya et al., 2017) [32], Burr III Extended Exponentiated Weibull Distribution (BIIIEEW) (Hussian et al., 2023) [33], generalized odd beta prime Weibull (GOBPW) (Suleiman et al., 2022) [34], gamma generalized modified Weibull (GmGMoW) (Oluyede et al., 2015) [35] and beta modified Weibull (BMoW) (Silva et al., 2010) [36].
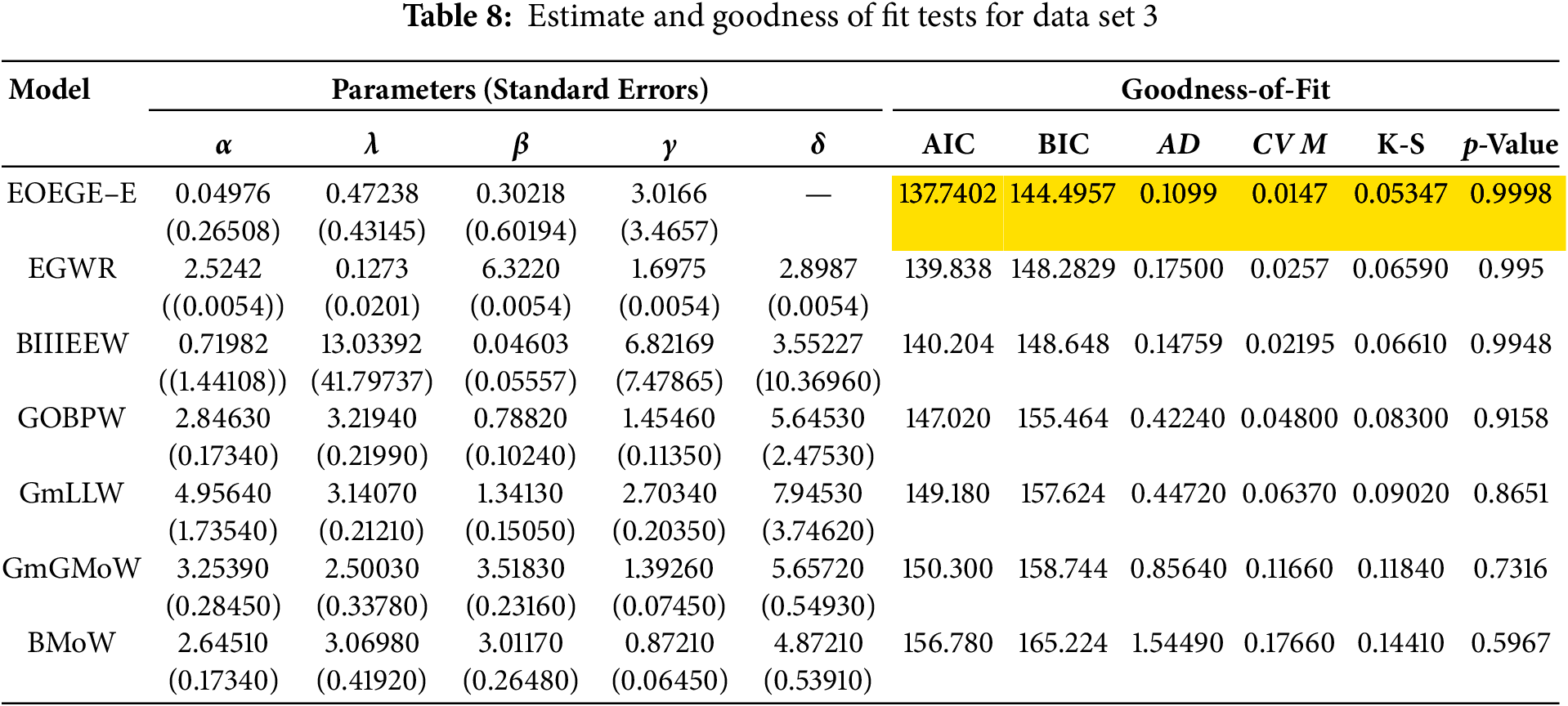
Table 8 demonstrates that the EOEGE–E distribution provides an exceptional fit to Dataset 3 and shows EOEGE–E’s lowest Akaike Information Criterion (AIC, 137.7402), Bayesian Information Criterion (BIC, 144.4957), Anderson-Darling (AD, 0.1099), Cramér-von Mises (CVM, 0.0147), and Kolmogorov-Smirnov (K-S, 0.05347) statistics, and highest p-value (0.9998), outperforming EGWR, BIIIEEW, GOBPW, GmLLW, GmGMoW, and BMoW. Accorging Fig. 12, EOEGE–E is expected to capture the left-skewed distribution (mean = 3.0859 < median = 3.3055) and likely increasing hazard rate, similar to Datasets 1 and 2, with:
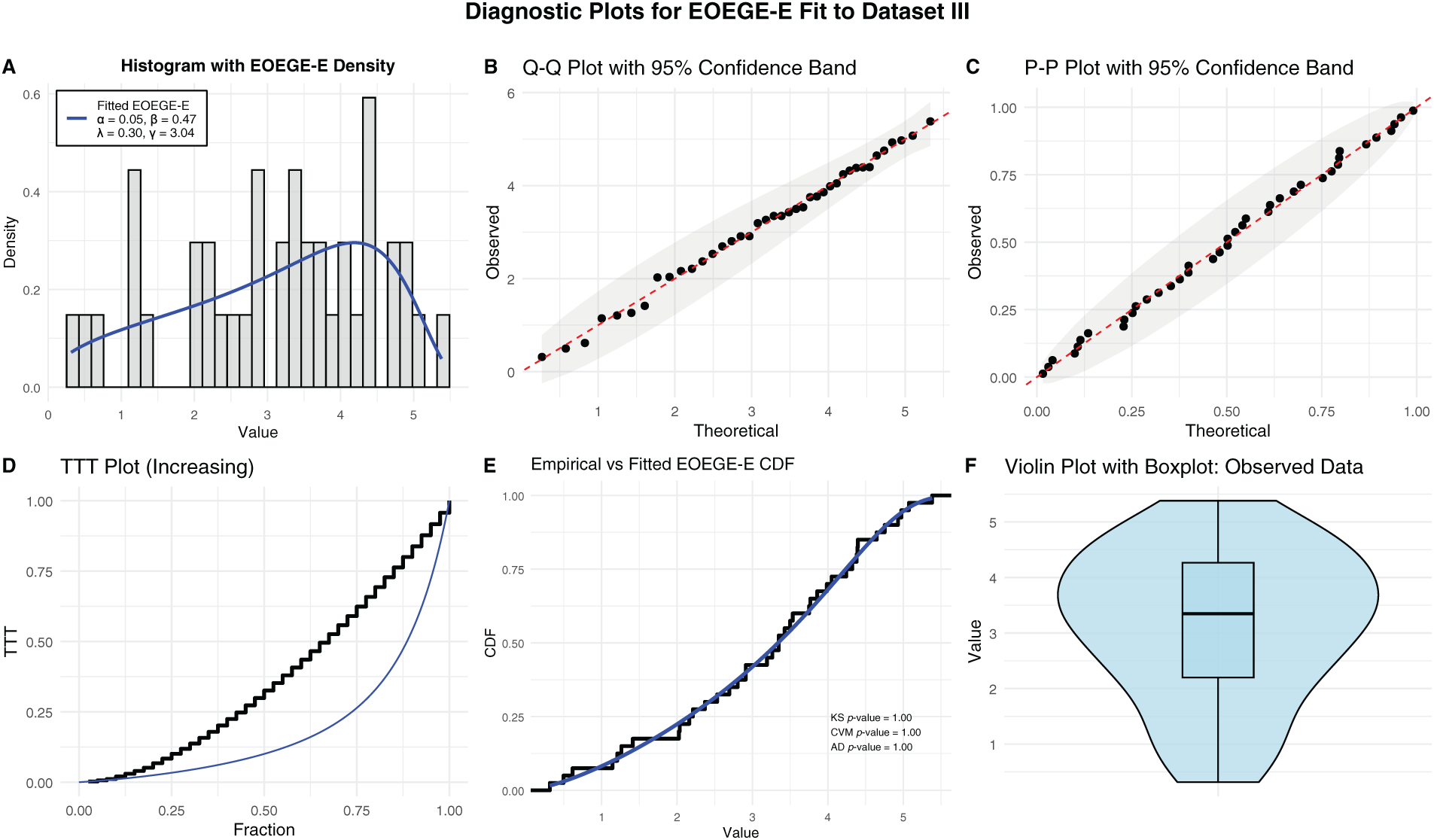
Figure 12: Diagnostic plots for EOEGE–E fit to dataset III
• Histogram and violin plots showing alignment with the left-skewed, moderate-tailed distribution.
• Q-Q and P-P plots validating quantile and probability alignment within 95% confidence bands.
• A Total Time on Test (TTT) plot confirming an increasing hazard rate, reflecting disease progression.
• A cumulative distribution function (CDF) plot showing near-perfect overlap with the empirical CDF.
Compared to Dataset 1 (right-skewed carbon fiber failure times, K-S = 0.0420, p-value = 0.9999) and Dataset 2 (slightly left-skewed windshield service times, K-S = 0.065454, p-value = 0.9468), Dataset 3’s fit is comparable to Dataset 1’s and superior to Dataset 2’s, despite the smaller sample size (n = 40 vs. 69 and 50). EOEGE–E’s four-parameter flexibility ensures robust modeling of diverse distributions and increasing hazard rates across material durability (Dataset 1), aviation maintenance (Dataset 2), and medical survival (Dataset 3). This makes EOEGE–E a powerful tool for reliability and survival analysis, enabling accurate prognosis prediction in healthcare and failure modeling in engineering.
Data set 4. Lifetime Data of Electronic Components The lifetimes of twenty electronic components, as reported by Murthy (2004, p. 100), are given in appropriate units as follows: 0.03, 0.12, 0.22, 0.35, 0.73, 0.79, 1.25, 1.41, 1.52, 1.79, 1.80, 1.94, 2.38, 2.40, 2.87, 2.99, 3.14, 3.17, 4.72, 5.09. These data represent the durations until failure for each component. For data set 4, the MLEs of the parameters, the commonly used wellknown model measures including Anderson–Darling (AD), Cram’er–von Mises (CVM), and Kolmogrov–Smirnov (K–S) test and p value are computed and displayed in Table 9. The EOEGE–E distribution is compared with other some competitive the extended odd weibull Lindley (ExOW-Li) (Alizadeh et al., 2018) [37], the new odd log-logistic (NOLL-L) model (Alizadeh et al., 2019) [38], the Topp-Leone Lindley distribution (TL-Li) (Al-Shomarni et al., 2016) [39], Odd log-logistic Lindley (OLL-Li) model (Ozel et al, 2017) [40], the Modefied half logistic (MHL) model (Mohammad, 2021) [41] and the Weighted Exponentiated class of Distributions (WExp-G) (Shaheed, 2025) [42].
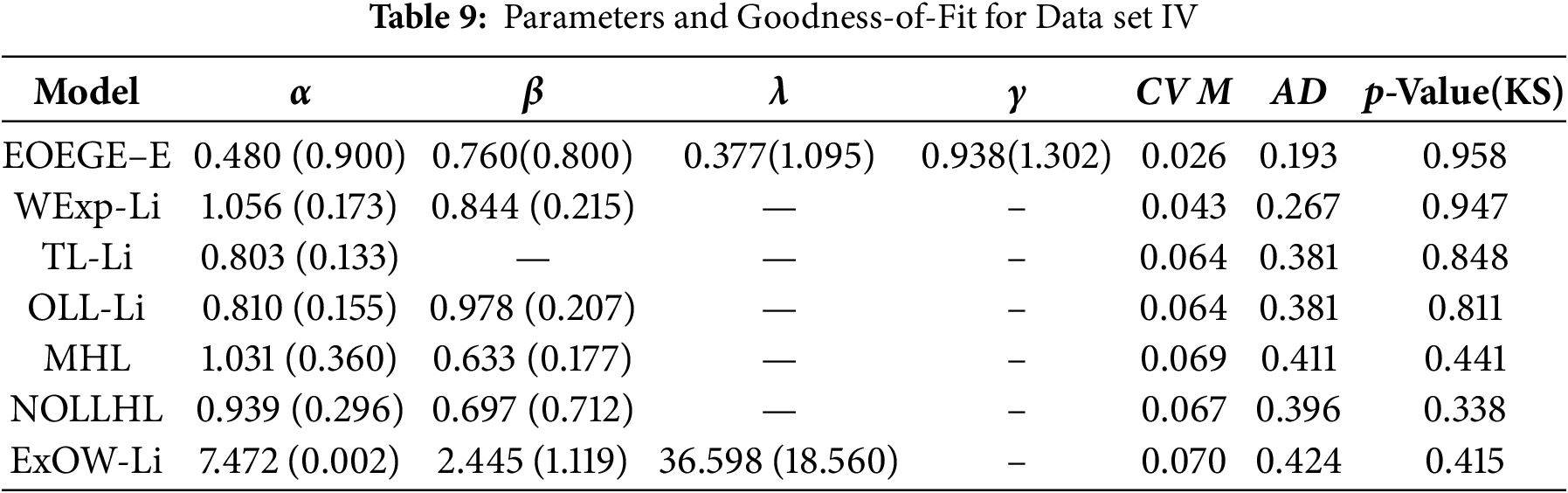
The Dataset IV lifetimes, with their right-skewed distribution, are best modeled by the EOEGE–E distribution, which achieves the lowest CVM (0.026), AD (0.193), and highest KS p-value (0.958). The EOEGE–E model’s fit is validated through six diagnostic plots in Fig. 13, which confirm its ability to capture Dataset IV’s characteristics:
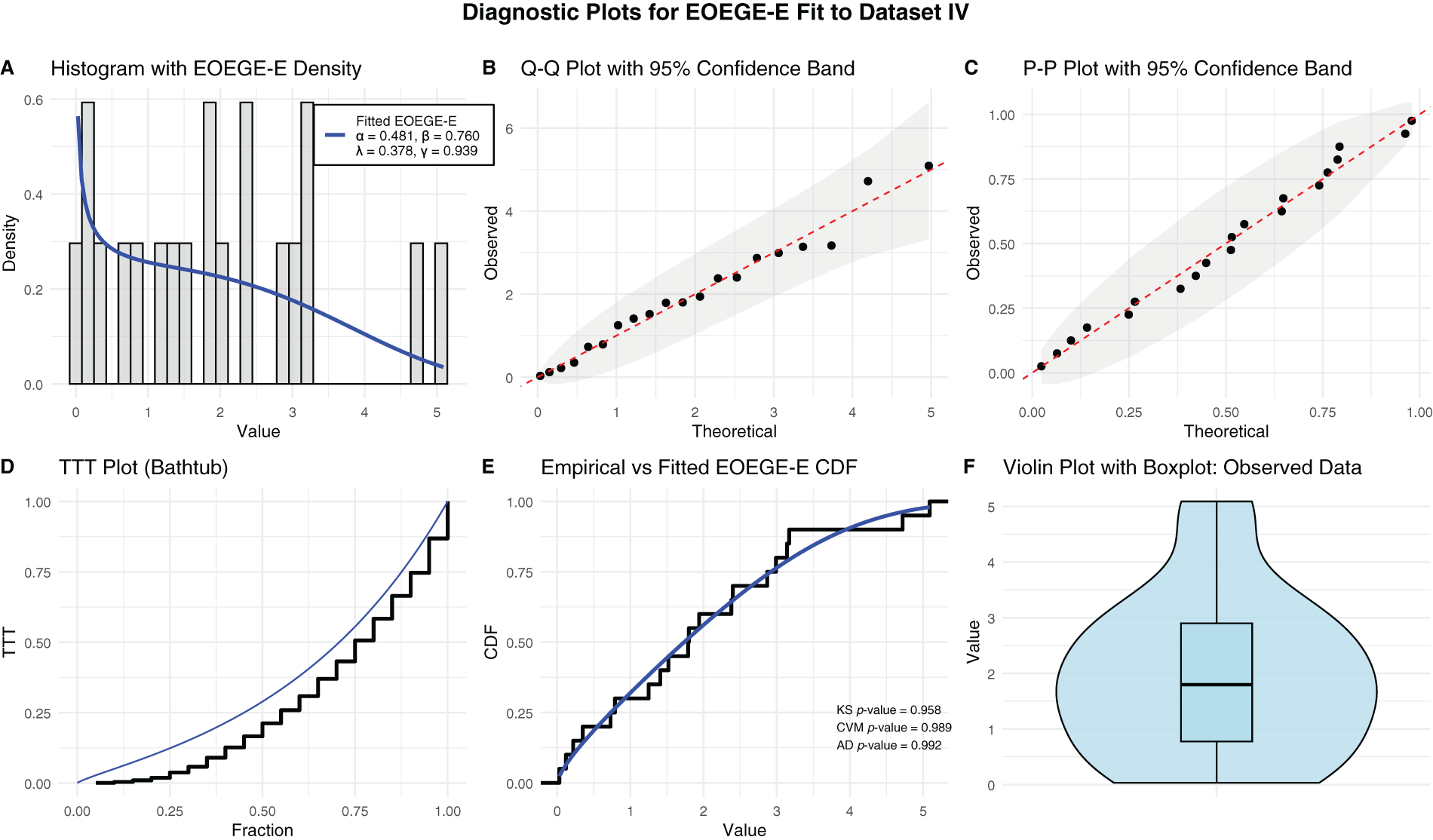
Figure 13: Diagnostic plots for EOEGE–E fit to dataset IV
• Histogram and violin plots show alignment with the right-skewed, moderate-tailed distribution, capturing early failures and longer lifetimes effectively.
• Q-Q and P-P plots validate quantile and probability alignment, with most points within 95% confidence bands, indicating minimal deviation from the observed data.
• A Total Time on Test (TTT) plot confirms a bathtub-shaped hazard rate, reflecting electronic components’ early burn-in failures, stable operational period, and late wear-out, which EOEGE–E models accurately.
• A cumulative distribution function (CDF) plot shows near-perfect overlap with the empirical CDF, consistent with the KS p-value of 0.958.
7 Progressive Type-II Censored Sample
The progressive type-II censoring scheme is commonly described as follows: Initially,
where C may be a constant defined as
We discussed the MLE and MPS for parameter estimator of the EOEGE-E distribution based on progressive type-II censored sample. Let
7.1 Maximum-Likelihood Estimation
From Eq. (22) the likelihood function of is then given by
where
The corresponding log-likelihood function for the parameters
Since, derivatives of Eq. (23) for parameters does not has closed-form solution, the MLEs of
To solve the system of nonlinear likelihood equations for the parameters
where
7.2 Maximum Product of Spacing Method
According to [44], the MPS under progressive type-II censored sample as:
Let
Further, the log-MPS of the EOEGE-E parameter can also be obtained by solving the first partial derivatives of log-MPS with relation to
In this section, Monte Carlo simulations are conducted using progressive Type-II censored samples to compare the performance of MLE, and MPS estimates of the EOEGE-E parameter. The simulations are designed to evaluate and report the results in terms of Abias, MSE, and length of asymptotic confidence intervales (LACI). Moreover, 95% confidence intervals for the parameters were obtained based on the estimated variances derived from the inverse of the observed Fisher information matrix. These functions and tools are standard in statistical analysis and ensure the accuracy and reliability of the obtained results. For various parameter combinations, 10,000 random samples are generated from the EOEGE-E distribution, considering sample sizes of
• Scheme 2:
• Scheme 1:
To Generate an ordinary progressive Type-II censored samples
1. Generate H independent observations of size
2. Given the values of
3. Define
where
4. Invert Eq. (4) for a given value of
thus generating the progressive Type-II censored sample from the EOEGE − E distribution
All simulation experiments were carried out using R software. The optimization of the likelihood function was implemented using the optim function with the Nelder-Mead algorithm. To obtain the maximum likelihood estimates via the Newton-Raphson (NR) method, we used the “maxlike” package, and the Hessian matrix was computed to assess the precision of the estimates. These functions and tools are standard in statistical analysis and ensure the accuracy and reliability of the obtained results. The 95% confidence interval (CI) for each parameter estimate
where
The most straightforward estimation method is often the one that minimizes Abias, MSE, and LACI. The simulation results, including values for Abias, and MSE are presented in Tables 10 and 11. These tables summarize the findings for different parameter scenarios.
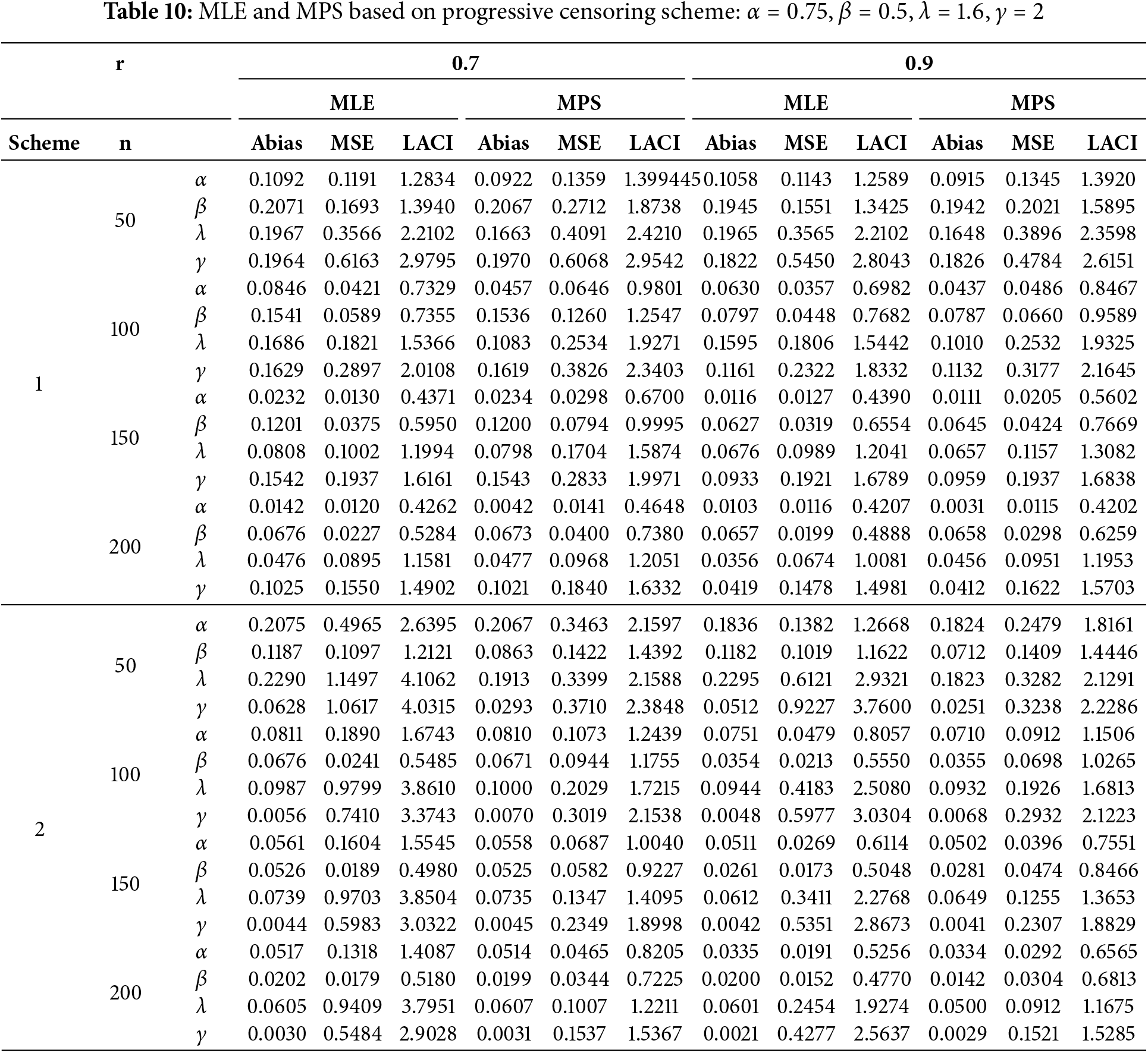
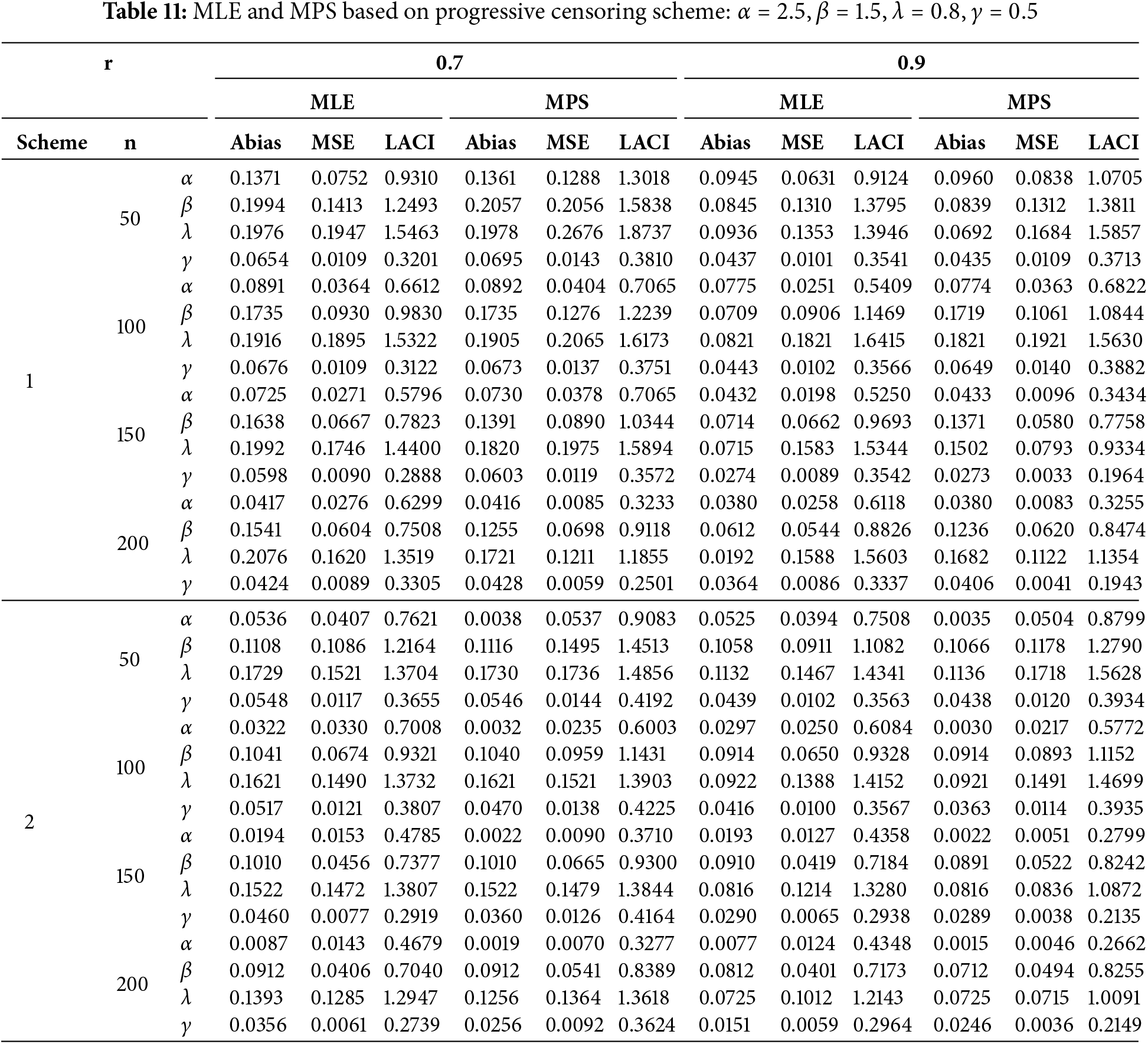
The key observations derived from Tables 10 and 11 are summarized as follows:
1. Effect of Sample Size: ABias, and MSE decrease as the sample size (
2. Effect of Stages (
3. Comparison of Methods: The MLE estimates outperform other methods in most studied cases of the EOEGE-E distribution under progressive Type-II censored samples.
This subsection presents the application of Maximum Likelihood Estimation (MLE) to estimate the parameters of the EOEGE–E using progressively Type II censored data under different schemes and datasets. Table 12 provides a comprehensive summary of the estimates and their standard errors (StEr) for various parameter values, sample sizes, and censoring schemes.
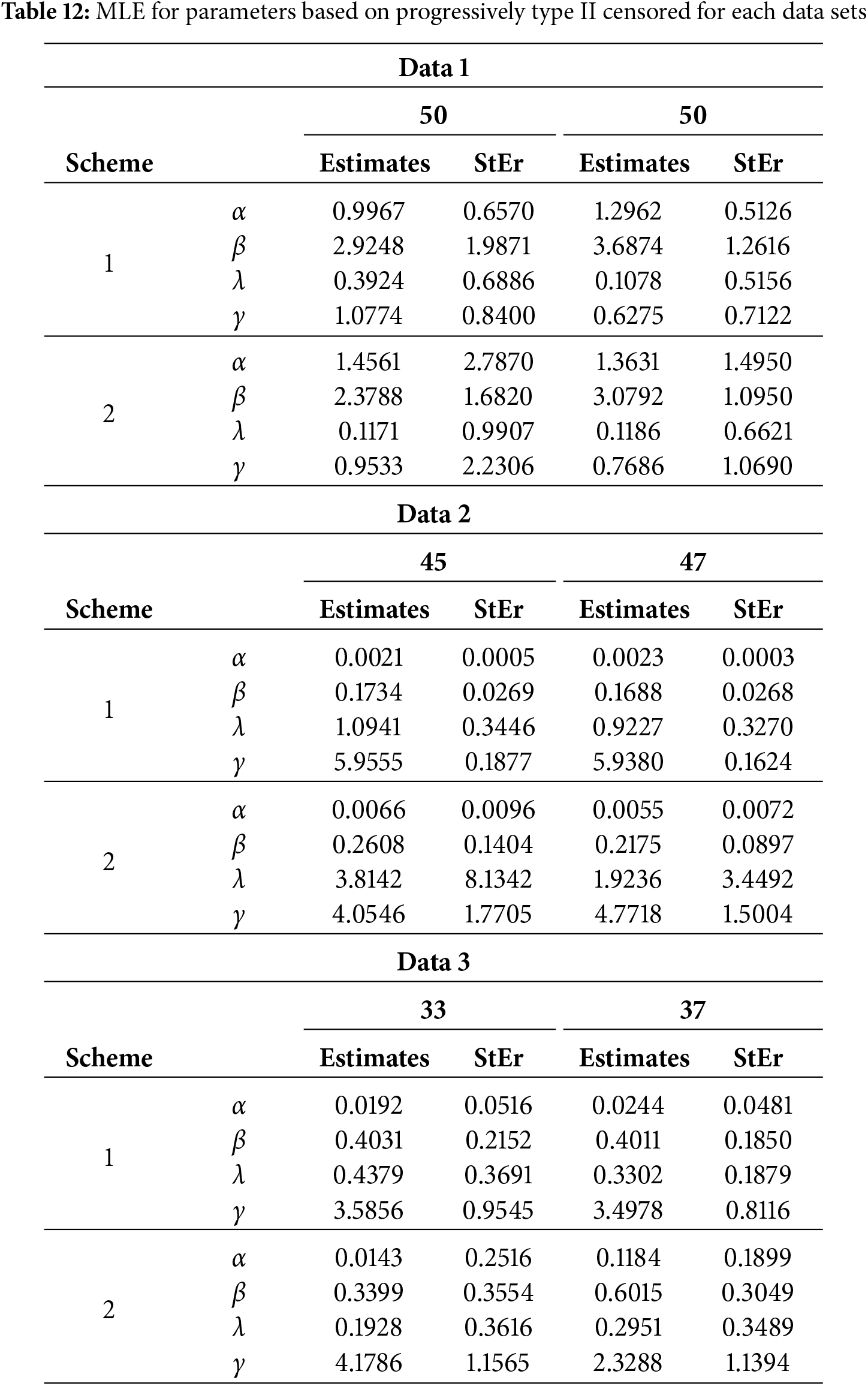
Table 12 presents the application of Maximum Likelihood Estimation (MLE) for parameter estimation under progressively Type II censored schemes across three datasets (Data 1, Data 2, and Data 3) with varying sample sizes and two censoring schemes. The parameters
The Exponentiated Odd Generalized Exponential-Exponential (EOEGE–E) distribution, parameterized by
Acknowledgement: We express our sincere gratitude to the anonymous reviewers and editors for their insightful and valuable comments, which significantly improved the quality and clarity of this manuscript.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: Study conception and design: Zohra A. Esaadi, Rabab S. Gomaa; Data collection: Rabab S. Gomaa, Ehab M. Almetwally; Analysis and interpretation of results: Alia M. Magar, Rabab S. Gomaa, Beih S. El-Desouky; Draft manuscript preparation: Rabab S. Gomaa, Alia M. Magar, Ehab M. Almetwally. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: All data generated or analyzed during this study are included in this published article.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
Quantile Function
By inverting the (4), we obtain EOEGE–E quantile function as follows:
where
Moments
r-th moments of the EOEGE–E distribution are derived by Eq. (9).
If, we put
Then,
Substituting
By Substituting Eq. (4) in Eq. (3), the
References
1. Marshall AN, Olkin I. A new method for adding a parameter to a family of distributions with applications to the exponential and Weibull families. Biometrika. 1997;84(3):641–52. doi:10.1093/biomet/84.3.641. [Google Scholar] [CrossRef]
2. Ordeiro GM, Lemonté AJ, Cunha DCC. The exponentiated generalized class of distributions. J Data Sci. 2013;11:1–27. [Google Scholar]
3. Gupta RD, Kundu D. Generalized exponential distributions. Aust N Z J Stat. 1999;41(2):173–88. [Google Scholar]
4. Olabad AK. On extended type I generalized logistic distribution. Int J Math Math Sci. 2004;57(57):3069–74. doi:10.1155/s0161171204309014. [Google Scholar] [CrossRef]
5. Olabad AK. On negatively skewed extended generalized logistic distribution. KragujevacJ Math. 2005;27:175–82. [Google Scholar]
6. Olabad AK. On symmetric extended generalized logistic distribution. J Statist Res Iran. 2006;3:177–90. [Google Scholar]
7. Olabad AK. On extended generalized exponential distribution. Br J Math Comput Sci. 2014;4(9):1280–9. [Google Scholar]
8. Alizadeh M, Emadi M, Doostparast M, Cordeiro GM, Ortega EMM, Pescim RR. Kumaraswamy odd log-logistic family of distributions: properties and applications. Hacet J Math Stat. 2014. [Google Scholar]
9. Cordeiro GM, de Castro M. A new family of generalized distributions. J Stat Comput Simul. 2011;81:883–93. [Google Scholar]
10. Maiti S. Odd generalized exponential-exponential distributin. J Data Sci. 2015;13(4):733–54. [Google Scholar]
11. Tahir MH, Cordeiro GM, Alizadeh M, Mansoor M, Zubair M, Hamedani GG. The odd generalized exponential family of distributions with applications. J Stat Distrib Appl. 2015;2(1):1. doi:10.1186/s40488-014-0024-2. [Google Scholar] [CrossRef]
12. de Andrade TA, Bourguignon M, Cordeiro GM. The exponentiated generalized extended exponential distribution. J Data Sci. 2022;14(3):393–413. [Google Scholar]
13. Telee LBS, Karki M, Kumar V. Exponentiated generalized exponential geometric distribution: model, properties and applications. Interdiscip J Manag Soc Sci. 2022;3(2):37–60. doi:10.3126/ijmss.v3i2.50261. [Google Scholar] [CrossRef]
14. Abonongo AIL, Abonongo J. Exponentiated generalized weibull exponential distribution: properties, estimation and applications. Comput J Math Stat Sci. 2024;3(1):57–84. doi:10.21608/cjmss.2023.243845.1023. [Google Scholar] [CrossRef]
15. Aboul-Fotouh Salem S, Abo-Kasem OE, Abdelgaied Khairy A. Inference for generalized progressive hybrid type-II censored weibull lifetimes under competing risk data. Comput J Math Stat Sci. 2024;3(1):177–202. doi:10.21608/cjmss.2024.256760.1035. [Google Scholar] [CrossRef]
16. Almetwally EM, Khaled OM, Barakat HM. Inference based on progressive-stress accelerated life-testing for extended distribution via the marshall-olkin family under progressive type-II censoring with optimality techniques. Axioms. 2025;14(4):244. doi:10.3390/axioms14040244. [Google Scholar] [CrossRef]
17. Elsherpieny EA, Abdel-Hakim A. Statistical analysis of Alpha-Power exponential distribution using unified Hybrid censored data and its applications. Comput J Math Stat Sci. 2025;4(1):283–315. doi:10.21608/cjmss.2025.346134.1094. [Google Scholar] [CrossRef]
18. Balakrishnan N, Cramer E. The art of progressive censoring, statistics for industry and technology. Birkhauser, NY, USA: Springer; 2014. [Google Scholar]
19. Balakrishnan N. Progressive censoring methodology: an appraisal. Test. 2007;16(2):211–59. doi:10.1007/s11749-007-0061-y. [Google Scholar] [CrossRef]
20. Bader MG, Priest AM. Statistical aspects of fibre and bundle strength in hybrid composites. Progress Sci Eng Compos. 1986;1129–36. [Google Scholar]
21. Alotaibi R, Mutairi AA, Almetwally EM, Park C, Rezk H. Optimal design for a bivariate step-stress accelerated life test with alpha power exponential distribution based on type-i progressive censored samples. Symmetry. 2022;14(4):830. doi:10.3390/sym14040830. [Google Scholar] [CrossRef]
22. El-Sherpieny EA, Almetwally EM. The exponentiated generalized alpha power family of distribution: properties and applications. Pak J Stat Oper Res. 2022;18(2):349–67. [Google Scholar]
23. Kamnge JS, Chacko M. Half logistic exponentiated inverse Rayleigh distribution: properties and application to life time data. PLoS One. 2025;20(1):e0310681. doi:10.1371/journal.pone.0310681. [Google Scholar] [PubMed] [CrossRef]
24. Sarhan AM, EL-Baset Abd AA, Alasbahi IA. Exponentiated generalized linear exponential distribution. Appl Math Model. 2013;37(5):2838–49. [Google Scholar]
25. Yan Z, Wang N. Statistical analysis based on adaptive progressive hybrid censored sample from alpha power generalized exponential distribution. IEEE Access. 2020;8:54691–7. doi:10.1109/access.2020.2981497. [Google Scholar] [CrossRef]
26. Al-Essa LA, Eliwa MS, El-Morshedy M, Alqifari H, Yousof HM. Flexible extension of the lomax distribution for asymmetric data under different failure rate profiles: characteristics with applications for failure modeling and service times for aircraft windshields. Processes. 2023;11(7):2197. doi:10.3390/pr11072197. [Google Scholar] [CrossRef]
27. Chesneau C, Yousof HM. On a special generalized mixture class of probabilistic models. J Nonlinear Model Anal. 2021;3:71–92. [Google Scholar]
28. Cordeiro GM, Ortega EM, Popovi’c BV. The gamma-Lomax distribution. J Stat Comput Simul. 2015;85:305–19. [Google Scholar]
29. Lemonte AJ, Cordeiro GM. An extended Lomax distribution. Statistics. 2013;47(4):800–16. doi:10.1080/02331888.2011.568119. [Google Scholar] [CrossRef]
30. Yousof HM, Alizadeh M, Jahanshahiand SMA, Ramires TG, Ghosh I, Hamedani GG. The Transmute-Topp-Leone G family of distributions: theory, characterizations and applications. J Data Sci. 2017;15:723–40. [Google Scholar]
31. Alsulami D. A new extension of the Rayleigh distribution: properties, different methods of estimation, and an application to medical data. AIMS Math. 2025;10(4):7636–63. doi:10.3934/math.2025350. [Google Scholar] [CrossRef]
32. Foya S, Oluyede BO, Fagbamigbe AF, Makubate B. The gamma log-logisticWeibull distribution: model, properties, and application. Electron J Appl Stat Anal. 2017;10:206–41. [Google Scholar]
33. Hussain S, Ul Hassan M, Rashid MS, Ahmed R. Families of extended exponentiated generalized distributions and applications of medical data using burr III extended exponentiated weibull distribution. Mathematics. 2023;11(14):3090. doi:10.3390/math11143090. [Google Scholar] [CrossRef]
34. Suleiman AA, Othman M, Ishaq AI, Abdullah ML, Indawati R, Daud H, et al. A new statistical model based on the novel generalized odd beta prime family of continuous probability distributions with applications to cancer disease data sets. Comput Sci Math. 2022;71:20. doi:10.3390/iocma2023-14429. [Google Scholar] [CrossRef]
35. Oluyede BO, Huang S, Yang T. A new class of generalized modified weibull distribution with applications. Aust J Stat. 2015;44(3):45–68. doi:10.17713/ajs.v44i3.36. [Google Scholar] [CrossRef]
36. Silva GO, Ortega EM, Cordeiro GM. The beta modified Weibull distribution. Lifetidata Anal. 2010;16(3):409–30. doi:10.1007/s10985-010-9161-1. [Google Scholar] [PubMed] [CrossRef]
37. Alizadeh M, Emadi M, Doostparast M. A modified half-logistic distribution: properties and applications. J Stat Res Iran. 2018;15(1):1–20. [Google Scholar]
38. Alizadeh M, MirMostafaee SMTK, Ghosh I. A new odd log-logistic half-logistic distribution with applications to lifetime data. Commun Stat Simul Comput. 2019;50(11):3911–34. [Google Scholar]
39. Al-Shomarni AA, Arif OH, Shawky AI. The Topp-Leone Lindley distribution. J Stat Theory Appl. 2016;15(4):351–66. [Google Scholar]
40. Ozel G, Alizadeh M, Cakmakyapan S. The odd log-logistic Lindley distribution. Commun Stat-Theory Methods. 2017;46(24):12347–64. [Google Scholar]
41. Shaheed G. A new two-parameter modified half-logistic distribution: properties and applications. Stat, Optimiz Inf Comput. 2021;10(2):589–605. doi:10.19139/soic-2310-5070-1210. [Google Scholar] [CrossRef]
42. Shaheed G. A Weighted exponentiated class of distributions: properties with applications for modelling reliability data. Stat, Optimiz Inf Comput. 2025;13(3):1144–61. doi:10.19139/soic-2310-5070-1858. [Google Scholar] [CrossRef]
43. Balakrishnan, Aggarwala R. Progressive censoring: theory, methods, and applications. Berlin/Heidelberg, Germany: Springer Science & Business Media; 2000. [Google Scholar]
44. Ng HKT, Luo L, Hu Y, Duan F. Parameter estimation of three-parameter Weibull distribution based on progressively type-II censored samples. J Stat Comput Simul. 2012;82(11):1661–78. doi:10.1080/00949655.2011.591797. [Google Scholar] [CrossRef]
45. Balakrishnan N, Sandhu RA. A simple simulational algorithm for generating progressive Type-II censored samples. Am Stat. 1995;49(2):229–30. doi:10.1080/00031305.1995.10476150. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools