
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Auto-Weighted Neutrosophic Fuzzy Clustering for Multi-View Data
1 College of Mathematics and Computer, Xinyu University, Xinyu, 338004, China
2 School of Computer Sciences, Universiti Sains Malaysia, Penang, 11800, Malaysia
3 College of Computer Science and Technology, Harbin Engineering University, Harbin, 150001, China
4 Department of Mathematics and Sciences, Prince Sultan University, Riyadh, 11586, Saudi Arabia
* Corresponding Author: Zhe Liu. Email:
(This article belongs to the Special Issue: Algorithms, Models, and Applications of Fuzzy Optimization and Decision Making)
Computer Modeling in Engineering & Sciences 2025, 144(3), 3531-3555. https://doi.org/10.32604/cmes.2025.071145
Received 01 August 2025; Accepted 03 September 2025; Issue published 30 September 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The increasing prevalence of multi-view data has made multi-view clustering a crucial technique for discovering latent structures from heterogeneous representations. However, traditional fuzzy clustering algorithms show limitations with the inherent uncertainty and imprecision of such data, as they rely on a single-dimensional membership value. To overcome these limitations, we propose an auto-weighted multi-view neutrosophic fuzzy clustering (AW-MVNFC) algorithm. Our method leverages the neutrosophic framework, an extension of fuzzy sets, to explicitly model imprecision and ambiguity through three membership degrees. The core novelty of AW-MVNFC lies in a hierarchical weighting strategy that adaptively learns the contributions of both individual data views and the importance of each feature within a view. Through a unified objective function, AW-MVNFC jointly optimizes the neutrosophic membership assignments, cluster centers, and the distributions of view and feature weights. Comprehensive experiments conducted on synthetic and real-world datasets demonstrate that our algorithm achieves more accurate and stable clustering than existing methods, demonstrating its effectiveness in handling the complexities of multi-view data.Keywords
As data continues to grow across diverse domains, it is often gathered from numerous heterogeneous sources or perspectives, each contributing unique and complementary information about the underlying structure. Multi-view datasets are ubiquitous, found in areas such as multimedia applications (e.g., image-text data), the Internet of Things (e.g., sensor readings), and healthcare (e.g., clinical records). These datasets consist of data from different sources, modalities, or feature sets that describe the same set of entities. Each view brings unique strengths and weaknesses and often differs in completeness, consistency, and relevance. Although widely applied in practice, algorithms such as
To tackle the challenges posed by such heterogeneous data, multi-view clustering is now regarded as a powerful approach that jointly utilizes information from all available views so as to achieve better clustering results. In contrast to using a single view, multi-view clustering integrates complementary information across views, thereby improving data understanding and clustering accuracy. Among various strategies, partition-based hard clustering methods are widely adopted for their simplicity and computational efficiency. For example, Ref. [6] introduced a robust variant using the
In contrast, fuzzy clustering methods offer a more adaptive framework by allowing samples to be associated with several clusters at different membership levels, which is particularly suitable for ambiguous or overlapping area in multi-view contexts. Among them, fuzzy
To address such limitations, neutrosophic set theory (NST) has been increasingly applied to clustering. Ref. [38] first introduced the neutrosophic
We introduce a more granular and effective algorithm: auto-weighted multi-view neutrosophic fuzzy clustering (AW-MVNFC). The proposed algorithm not only adaptively learns view-level weights but also integrates feature-level weighting within each view, enabling a more refined representation of intra-view structure. AW-MVNFC is formulated as a unified optimization problem, simultaneously learning cluster prototypes, neutrosophic memberships, view weights, and feature weights. The main contributions are summarized as follows:
• We propose a novel AW-MVNFC clustering algorithm that jointly models uncertainty and imprecision across multiple views.
• A new auto-weighted strategy is introduced, incorporating feature-level importance learning within each view in addition to view-level weighting, thereby achieving finer-grained modeling of intra-view contributions.
• Comprehensive experiments on both simulated and real-world datasets demonstrate that the proposed method consistently outperforms existing multi-view clustering techniques.
The structure of the study is outlined below. Section 2 gives an overview of NCM and MVNCM, Section 3 introduces the AW-MVNFC framework, Section 4 discusses the experimental findings, and Section 5 closes with the conclusions.
In this section, we will take a brief review of NCM [38] and MVNCM [42].
2.1 Neutrosophic
Consider a multi-view dataset
with
where the terms
• Update neutrosophic partition matrix:
where
• Update view cluster centers matrix
2.2 Multi-View Neutrosophic
Consider a multi-view dataset
with
where
• Update neutrosophic partition matrix:
where
• Update cluster centers matrix
• Update view weights:
where
3 A Novel Multi-View Clustering Algorithm
Although the previous work, MVNCM, adaptively learns view-level weights and achieves promising results, it is fundamentally limited by its inability to account for heterogeneity at the feature level. Real-world multi-view data often contains noisy, redundant, or irrelevant features within each view, which can significantly degrade clustering performance. To solve this critical limitation, we propose an improved algorithm, AW-MVNFC, which introduces a hierarchical dual-weighting strategy. For the first time, this algorithm integrates feature-level weighting into the neutrosophic clustering framework, enabling the algorithm to not only assess the importance of each view but also the relevance of individual features within that view. This finer-grained control allows for a more robust and effective clustering solution, especially in complex environments.
Given a multi-view dataset denoted by
with
Let
We follow the Lagrange multiplier method used in NCM [38] to optimize neutrosophic partition matrix, cluster centers, view weights matrix, and feature weights in turn. The following is the derivation process:
(1) Updating
Since the derivation process of this step is highly similar to the method in NCM, the proof process is omitted. We give the final optimization formula as follows:
where the normalizing term
(2) Updating
To minimize
Then we obtain:
(3) Updating
Lagrange multipliers
To derive the necessary conditions, we set the partial derivatives of the Lagrangian function
Thus, we obtain from (29):
Returning in (31), we have:
where
(4) Updating
The minimization of
Then we set the derivatives of the Lagrangian function with respect to
Thus, we obtain:
Returning in (39), we have:
where
Fig. 1 and Algorithm 1 summarize AW-MVNFC algorithm in detail.
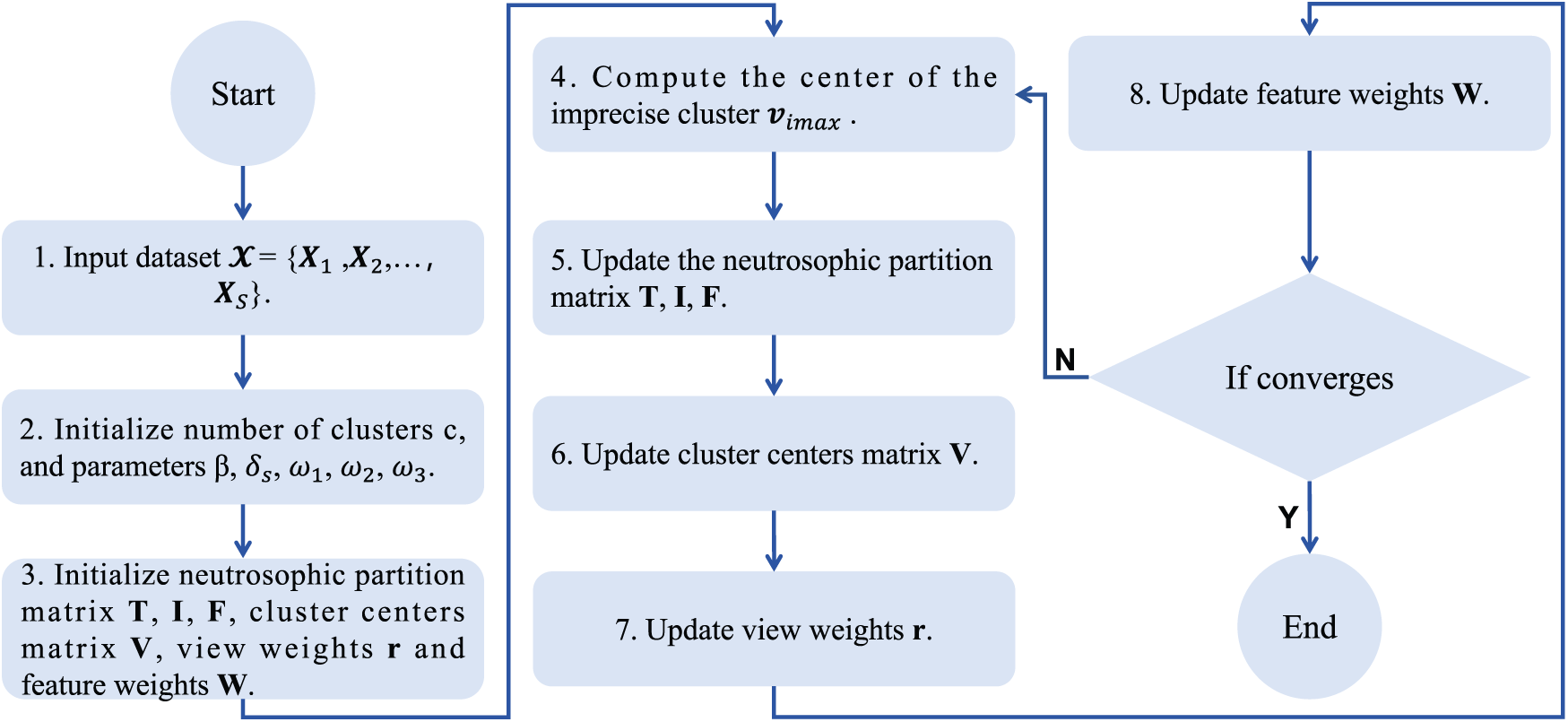
Figure 1: Flow diagram of AW-MVNFC
3.3 Computational Complexity Analysis
In this section, we provide a time complexity analysis for the AW-MVNFC algorithm, summarized in Algorithm 1. The computational bottleneck is associated with updating the neutrosophic partition matrix, which operates in

For evaluation, the AW-MVNFC algorithm is benchmarked against nine contemporary multi-view clustering techniques: Co-FCM [30], WV-Co-FCM [30], TW-Co-
The optimal parameters are determined via a grid-search procedure, based on achieving the maximum clustering performance. For the comparative algorithms mentioned above, the parameter search ranges and default configurations are set in accordance with the recommendations provided in their respective original papers. More precisely, the weighting exponent
For a comprehensive assessment of AW-MVNFC and the comparative algorithms on multi-view data, we utilize six standard evaluation metrics: Accuracy (ACC), Normalized Mutual Information (NMI), Rand Index (RI), F1 score (
4.2 Experimental Results on Synthetic Multi-View Datasets
To rigorously evaluate the effectiveness of AW-MVNFC, we construct a synthetic dataset (SD) and conduct a comparative analysis against eight representative multi-view clustering algorithms, comprising Co-FCM, WV-Co-FCM, TW-Co-
As illustrated in Fig. 2, we construct a synthetic dataset consisting of two distinct views, each comprising three clusters of unequal sizes, denoted as

Figure 2: Synthetic dataset from two views
View 1: The clusters are assumed to follow Gaussian distributions, each with distinct mean vectors
Additionally, three outliers are added at coordinates
View 2: In a similar manner, each cluster is modeled as a Gaussian distribution characterized with the following parameters:
Three additional outliers are placed at positions
Figs. 3 and 4 provide a visual representation of the clustering results obtained by the eight algorithms under evaluation, enabling a comparative analysis of their performance on the constructed dataset.

Figure 3: Clustering results of nine clustering algorithms in view 1

Figure 4: Clustering results of nine clustering algorithms in view 2
As illustrated in Figs. 3a and 4a, Co-FCM exhibits a clear performance deficiency due to its equal treatment of all views, failing to leverage view-specific information. The results presented in Figs. 3c,f,g and 4c,f,g indicate that clustering methods based on hard partitions tend to misclassify samples near cluster boundaries. In contrast, soft partition-based methods, shown in Figs. 3b,d,e and 4b,d,e, offer improved interpretability by accommodating uncertainty during assignment. However, despite this advantage, they still encounter difficulties in resolving overlapping clusters and often misallocate outliers.
Within the framework of neutrosophic partition, Figs. 3h,i and 4h,i demonstrate that the MVNCM and AW-MVNFC algorithms exhibit superior capability in managing both the imprecision and uncertainty arising from overlapping clusters. These algorithms proficiently assign ambiguous samples to an imprecise cluster-visualized by yellow plus markers, while simultaneously identifying and labeling the three outliers using magenta pentagram symbols. Notably, this ability to effectively detect outliers is a distinct advantage of the proposed neutrosophic clustering and is not observed in the compared algorithms. Compared to MVNCM, the proposed AW-MVNFC incorporates not only view-specific weights but also adaptive feature weighting. This enhancement leads to a notable reduction in mis-assignments relative to MVNCM and other competing algorithms.
4.3 Experimental Results on Real-World Multi-View Datasets
An extensive experimental study was performed to assess the performance of the newly proposed AW-MVNFC algorithm in comparison with thirteen state-of-the-art multi-view clustering algorithms. The experiment is carried out using five diverse real-world datasets: IS [43], Forest Type [13], Prokaryotic Phyla [36], MSRCv1 [31], Seeds1 and Caltech101-7 [31], with the basic details provided in Table 1. We normalize all raw data to make the values between 0 and 1.

Clustering performance is evaluated using six distinct metrics: ACC, NMI, RI,






First, the proposed AW-MVNFC achieves superior performance compared to most baseline methods with respect to ACC, NMI, RI,
Second, compared with MVNCM, the proposed AW-MVNFC algorithm not only retains the original view-level weighting mechanism but also introduces a novel feature-level weighting strategy. This enhancement enables AW-MVNFC to assess the contribution of each individual feature with finer granularity. By capturing the differential importance of features within and across views, the method demonstrates heightened sensitivity to feature relevance, leading to more accurate clustering outcomes. Consequently, AW-MVNFC exhibits improved efficiency and effectiveness in handling complex multi-view data where both inter-view and intra-view information play critical roles.
To validate the effectiveness of the proposed auto-weighted mechanism, AW-MVNFC is evaluated on datasets including MSRCv1, Seeds and Caltech101-7, with its ability to jointly assign view weights and feature weights. As depicted in Figs. 5–8, the model allocates varying weights to different views based on their global discriminative relevance, while simultaneously learning fine-grained feature weights that capture the local importance of individual attributes. This hierarchical weighting strategy enables more nuanced representation learning and contributes to improved clustering accuracy.

Figure 5: The view weights generated by AW-MVNFC on real-world datasets

Figure 6: The feature weights generated by AW-MVNFC on MSRCv1

Figure 7: The feature weights generated by AW-MVNFC on Seeds


Figure 8: The feature weights generated by AW-MVNFC on Caltech101-7
In this section, we investigate the impact of variations in the parameter
To assess the impact of the parameter

Figure 9: Clustering results of different
In order to determine the statistical significance of performance differences between the proposed AW-MVNFC algorithm and competing approaches, we employ the Friedman–Nemenyi test following the procedure in [43]. The average ranks (AR) of the ten algorithms across all multi-view datasets, evaluated by Across all multi-view datasets, the ten algorithms were evaluated and their average ranks (AR) determined by ACC, NMI, RI, F1, FMI, and JI, are reported in Table 8.

To begin, the value of
In this context,
Subsequently, a Nemenyi post-hoc test is conducted following the Friedman test. The outcomes are illustrated in Fig. 10, where each horizontal line represents a clustering algorithm: the midpoint indicates its average rank, while the line length corresponds to the critical difference (CD). The CD is computed as follows:

Figure 10: Friedman test graph in terms of ACC, NMI, RI,
The critical value
In this study, we present AW-MVNFC, a new auto-weighted multi-view neutrosophic fuzzy clustering algorithm designed with adaptive learning of view and feature weights. Building upon the MVNCM algorithm, the proposed clustering algorithm incorporate feature-level weights, effectively learning the varying contributions of views and features. This fine-grained weighting enhances the algorithm’s ability to handle imprecision and uncertainty in cluster assignments. We formulate the objective functions for the proposed methods and introduce an iterative optimization strategy to obtain their solutions efficiently. Experiments conducted on synthetic and real-world datasets confirm the performance of the proposed methods, along with a sensitivity analysis of key parameters, which provide strong evidence of the efficiency and stability of our proposed methods. However, to avoid excessive computational burden, we only consider the imprecise clusters between two different singleton clusters, but not the imprecise clusters that may occur between multiple clusters. In future work, we aim to propose an adaptive multi-view clustering that includes different imprecise clusters, and explore its performance in real-world application scenarios.
Acknowledgement: The authors Dania Sanatina and Nabil Mlaiki would like to thank Prince Sultan University for paying the APC and for the support through the TAS research lab.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Conceptualization, Zhe Liu; methodology, Zhe Liu; validation, Dania Santina, Yulong Huang and Nabil Mlaiki; formal analysis, Jiahao Shi and Yulong Huang; investigation, Zhe Liu, Dania Santina and Nabil Mlaiki; visualization, Jiahao Shi; software: Jiahao Shi; writing—original draft preparation, Zhe Liu, Dania Santina and Jiahao Shi; writing—review and editing, Zhe Liu, Yulong Huang and Nabil Mlaiki; supervision, Nabil Mlaiki. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data information is included in this paper.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
1https://archive.ics.uci.edu/ml/datasets/seeds (accessed on 02 September 2025).
References
1. Naz H, Saba T, Alamri FS, Almasoud AS, Rehman A. An improved robust fuzzy local information k-means clustering algorithm for diabetic retinopathy detection. IEEE Access. 2024;12:78611–23. doi:10.1109/access.2024.3392032. [Google Scholar] [CrossRef]
2. Naz H, Nijhawan R, Ahuja NJ, Saba T, Alamri FS, Rehman A. Micro-segmentation of retinal image lesions in diabetic retinopathy using energy-based fuzzy C-Means clustering (EFM-FCM). Microsc Res Techn. 2024;87(1):78–94. doi:10.1002/jemt.24413. [Google Scholar] [PubMed] [CrossRef]
3. Jia H, Ding S, Xu X, Nie R. The latest research progress on spectral clustering. Neural Comput Appl. 2014;24(7):1477–86. doi:10.1007/s00521-013-1439-2. [Google Scholar] [CrossRef]
4. Liu Z, Letchmunan S. Representing uncertainty and imprecision in machine learning: a survey on belief functions. J King Saud Univ-Comput Inf Sci. 2024;36(1):101904. doi:10.1016/j.jksuci.2023.101904. [Google Scholar] [CrossRef]
5. Mahmood T, Saba T, Alamri FS, Tahir A, Ayesha N. MVLA-Net: a multi-view lesion attention network for advanced diagnosis and grading of diabetic retinopathy. Comput Mater Contin. 2025;83(1):1173–93. doi:10.32604/cmc.2025.061150. [Google Scholar] [CrossRef]
6. Cai X, Nie F, Huang H. Multi-view k-means clustering on big data. In: Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence; 2013 Aug 3–9; Beijing, China. p. 2598–604. [Google Scholar]
7. Pan B, Li C, Che H, Leung MF, Yu K. Low-rank tensor regularized graph fuzzy learning for multi-view data processing. IEEE Transact Cons Electr. 2024;70(1):2925–38. doi:10.1109/tce.2023.3301067. [Google Scholar] [CrossRef]
8. Chen X, Xu X, Huang JZ, Ye Y. TW-(k)-means: automated two-level variable weighting clustering algorithm for multiview data. IEEE Trans Knowl Data Eng. 2013;25(4):932–44. doi:10.1109/tkde.2011.262. [Google Scholar] [CrossRef]
9. Zhang GY, Wang CD, Huang D, Zheng WS, Zhou YR. TW-Co-k-means: two-level weighted collaborative k-means for multi-view clustering. Knowl-Based Syst. 2018;150(12):127–38. doi:10.1016/j.knosys.2018.03.009. [Google Scholar] [CrossRef]
10. Pedrycz W. Collaborative fuzzy clustering. Pattern Recognit Lett. 2002;23(14):1675–86. doi:10.1016/s0167-8655(02)00130-7. [Google Scholar] [CrossRef]
11. Deng Z, Liu R, Xu P, Choi KS, Zhang W, Tian X, et al. Multi-view clustering with the cooperation of visible and hidden views. IEEE Transact Knowl Data Eng. 2022;34(2):803–15. [Google Scholar]
12. Xing L, Zhao H, Lin Z, Chen B. Mixture correntropy based robust multi-view K-means clustering. Knowl Based Syst. 2023;262(1):110231. doi:10.1016/j.knosys.2022.110231. [Google Scholar] [CrossRef]
13. Liu Z, Zhu S, Lyu S, Letchmunan S. Multi-view alternative hard c-means clustering. Int J Data Sci Anal. 2024;110(2):104743. doi:10.1007/s41060-024-00685-9. [Google Scholar] [CrossRef]
14. Liu Z, Aljohani S, Zhu S, Senapati T, Ulutagay G, Haque S, et al. Robust vector-weighted and matrix-weighted multi-view hard c-means clustering. Intell Syst Appl. 2025;25(3):200470. doi:10.1016/j.iswa.2024.200470. [Google Scholar] [CrossRef]
15. Yang B, Wu J, Zhang X, Zheng X, Nie F, Chen B. Discrete correntropy-based multi-view anchor-graph clustering. Inf Fusion. 2024;103(8):102097. doi:10.1016/j.inffus.2023.102097. [Google Scholar] [CrossRef]
16. Wang R, Li L, Tao X, Wang P, Liu P. Contrastive and attentive graph learning for multi-view clustering. Inform Process Manag. 2022;59(4):102967. doi:10.1016/j.ipm.2022.102967. [Google Scholar] [CrossRef]
17. Chen Z, Li L, Zhang X, Wang H. Deep graph clustering via aligning representation learning. Neural Netw. 2025;183(6):106927. doi:10.1016/j.neunet.2024.106927. [Google Scholar] [PubMed] [CrossRef]
18. Chen J, Ling Y, Xu J, Ren Y, Huang S, Pu X, et al. Variational graph generator for multiview graph clustering. IEEE Trans Neural Netw Learn Syst. 2025;36(6):11078–91. doi:10.1109/tnnls.2024.3524205. [Google Scholar] [PubMed] [CrossRef]
19. Zhang C, Fu H, Hu Q, Cao X, Xie Y, Tao D, et al. Generalized latent multi-view subspace clustering. IEEE Transact Pattern Anal Mach Intell. 2020;42(1):86–99. doi:10.1109/tpami.2018.2877660. [Google Scholar] [PubMed] [CrossRef]
20. Dong A, Wu Z, Zhang H. Multi-view subspace clustering based on adaptive search. Knowl Based Syst. 2024;289(1):111553. doi:10.1016/j.knosys.2024.111553. [Google Scholar] [CrossRef]
21. Wang J, Wu B, Ren Z, Zhang H, Zhou Y. Multi-scale deep multi-view subspace clustering with self-weighting fusion and structure preserving. Expert Syst Appl. 2023;213(6):119031. doi:10.1016/j.eswa.2022.119031. [Google Scholar] [CrossRef]
22. Wang Q, Zhang Z, Feng W, Tao Z, Gao Q. Contrastive multi-view subspace clustering via tensor transformers autoencoder. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence; 2025 Feb 25–Mar 4; Philadelphia, PA, USA. p. 21207–15. [Google Scholar]
23. Houthuys L, Langone R, Suykens JAK. Multi-view kernel spectral clustering. Inform Fusion. 2018;44(5):46–56. doi:10.1016/j.inffus.2017.12.002. [Google Scholar] [CrossRef]
24. Khan A, Maji P. Multi-manifold optimization for multi-view subspace clustering. IEEE Transact Neural Netw Learn Syst. 2022;33(8):3895–907. doi:10.1109/tnnls.2021.3054789. [Google Scholar] [PubMed] [CrossRef]
25. Yan X, Zhong G, Jin Y, Ke X, Xie F, Huang G. Binary spectral clustering for multi-view data. Inf Sci. 2024;677(2):120899. doi:10.1016/j.ins.2024.120899. [Google Scholar] [CrossRef]
26. Wu Y, Lan S, Cai Z, Fu M, Li J, Wang S. SCHG: spectral clustering-guided hypergraph neural networks for multi-view semi-supervised learning. Expert Syst Appl. 2025;277(1):127242. doi:10.1016/j.eswa.2025.127242. [Google Scholar] [CrossRef]
27. Ruspini EH, Bezdek JC, Keller JM. Fuzzy clustering: a historical perspective. IEEE Comput Intell Mag. 2019;14(1):45–55. doi:10.1109/mci.2018.2881643. [Google Scholar] [CrossRef]
28. Cleuziou G, Exbrayat M, Martin L, Sublemontier JH. CoFKM: a centralized method for multiple-view clustering. In: 2009 Ninth IEEE International Conference on Data Mining; 2009 Dec 6–9; Miami, FL, USA. p. 752–7. [Google Scholar]
29. Zhang W, Deng Z, Zhang T, Choi KS, Wang S. One-step multiview fuzzy clustering with collaborative learning between common and specific hidden space information. IEEE Transact Neural Netw Learn Syst. 2024;35(10):14031–44. doi:10.1109/tnnls.2023.3274289. [Google Scholar] [PubMed] [CrossRef]
30. Jiang Y, Chung FL, Wang S, Deng Z, Wang J, Qian P. Collaborative fuzzy clustering from multiple weighted views. IEEE Trans Cybern. 2015;45(4):688–701. doi:10.1109/tcyb.2014.2334595. [Google Scholar] [PubMed] [CrossRef]
31. Yang MS, Sinaga KP. Collaborative feature-weighted multi-view fuzzy c-means clustering. Pattern Recognit. 2021;119:108064. doi:10.1016/j.patcog.2021.108064. [Google Scholar] [CrossRef]
32. Thong PH, Canh HT, Lan LTH, Huy NT, Giang NL. Multi-view picture fuzzy clustering: a novel method for partitioning multi-view relational data. Comput Mater Contin. 2025;83(3):5461–85. doi:10.32604/cmc.2025.065127. [Google Scholar] [CrossRef]
33. Han J, Xu J, Nie F, Li X. Multi-view K-means clustering with adaptive sparse memberships and weight allocation. IEEE Transact Knowl Data Eng. 2022;34(2):816–27. doi:10.1109/tkde.2020.2986201. [Google Scholar] [CrossRef]
34. Hu X, Qin J, Shen Y, Pedrycz W, Liu X, Liu J. An efficient federated multiview fuzzy c-means clustering method. IEEE Transact Fuzzy Syst. 2024;32(4):1886–99. doi:10.1109/tfuzz.2023.3335361. [Google Scholar] [CrossRef]
35. Liu Z, Qiu H, Deveci M, Letchmunan S, Martinez L. Robust multi-view fuzzy clustering with exponential transformation and automatic view weighting. Knowl Based Syst. 2025;315(7):113314. doi:10.1016/j.knosys.2025.113314. [Google Scholar] [CrossRef]
36. Benjamin JBM, Yang MS. Weighted multiview possibilistic c-means clustering with L2 regularization. IEEE Transact Fuzzy Syst. 2021;30(5):1357–70. doi:10.1109/tfuzz.2021.3058572. [Google Scholar] [CrossRef]
37. Liu Z, Qiu H, Letchmunan S, Deveci M, Abualigah L. Multi-view evidential c-means clustering with view-weight and feature-weight learning. Fuzzy Sets Syst. 2025;498(12):109135. doi:10.1016/j.fss.2024.109135. [Google Scholar] [CrossRef]
38. Guo Y, Sengur A. NCM: neutrosophic c-means clustering algorithm. Pattern Recogni. 2015;48(8):2710–24. doi:10.1016/j.patcog.2015.02.018. [Google Scholar] [CrossRef]
39. Akbulut Y, Sengür A, Guo Y, Polat K. KNCM: kernel neutrosophic c-means clustering. Appl Soft Comput. 2017;52(2):714–24. doi:10.1016/j.asoc.2016.10.001. [Google Scholar] [CrossRef]
40. Thong PH, Smarandache F, Huan PT, Tuan TM, Ngan TT, Thai VD, et al. Picture-neutrosophic trusted safe semi-supervised fuzzy clustering for noisy data. Comput Syst Sci Eng. 2023;46(2):1981–97. doi:10.32604/csse.2023.035692. [Google Scholar] [CrossRef]
41. Qiu H, Liu Z, Letchmunan S. INCM: neutrosophic c-means clustering algorithm for interval-valued data. Granul Comput. 2024;9(2):34. doi:10.1007/s41066-024-00452-y. [Google Scholar] [CrossRef]
42. Liu Z, Qiu H, Deveci M, Pedrycz W, Siarry P. Multi-view neutrosophic c-means clustering algorithms. Expert Syst Appl. 2025;260:125454. doi:10.1016/j.eswa.2024.125454. [Google Scholar] [CrossRef]
43. Deng Z, Liang L, Yang H, Zhang W, Lou Q, Choi KS, et al. Enhanced multiview fuzzy clustering using double visible-hidden view cooperation and network LASSO constraint. IEEE Transact Fuzzy Syst. 2022;30(11):4965–79. doi:10.1109/tfuzz.2022.3164796. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools