
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Subtle Micro-Tremor Fusion: A Cross-Modal AI Framework for Early Detection of Parkinson’s Disease from Voice and Handwriting Dynamics
1 Mathematics Department, College of Science and Humanities in Al-Kharj, Prince Sattam Bin Abdulaziz University, Al-Kharj, Saudi Arabia
2 Department of Computer Engineering and Information, College of Engineering in Wadi Alddawasir, Prince Sattam Bin Abdulaziz University, Al-kharj, Saudi Arabia
3 Department of Computer Science, College of Engineering and Computer Sciences, Prince Sattam Bin Abdulaziz University, Al-kharj, Saudi Arabia
4 Department of Mathematics, Faculty of Science, Al-Azhar University (Girls’ Branch), Cairo, Egypt
* Corresponding Author: Naglaa E. Ghannam. Email:
(This article belongs to the Special Issue: Artificial Intelligence Models in Healthcare: Challenges, Methods, and Applications)
Computer Modeling in Engineering & Sciences 2026, 146(2), 38 https://doi.org/10.32604/cmes.2026.075732
Received 07 November 2025; Accepted 20 January 2026; Issue published 26 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Parkinson’s disease remains a major clinical issue in terms of early detection, especially during its prodromal stage when symptoms are not evident or not distinct. To address this problem, we proposed a new deep learning 2-based approach for detecting Parkinson’s disease before any of the overt symptoms develop during their prodromal stage. We used 5 publicly accessible datasets, including UCI Parkinson’s Voice, Spiral Drawings, PaHaW, NewHandPD, and PPMI, and implemented a dual stream CNN–BiLSTM architecture with Fisher-weighted feature merging and SHAP-based explanation. The findings reveal that the model’s performance was superior and achieved 98.2%, a F1-score of 0.981, and AUC of 0.991 on the UCI Voice dataset. The model’s performance on the remaining datasets was also comparable, with up to a 2–7 percent betterment in accuracy compared to existing strong models such as CNN–RNN–MLP, ILN–GNet, and CASENet. Across the evidence, the findings back the diagnostic promise of micro-tremor assessment and demonstrate that combining temporal and spatial features with a scatter-based segment for a multi-modal approach can be an effective and scalable platform for an “early,” interpretable PD screening system.Keywords
Parkinson’s disease (PD) is a progressive neurodegenerative disorder affecting millions of people worldwide [1]. According to the Parkinson’s Foundation, over 10 million people globally live with PD, with approximately 60,000 new cases diagnosed annually in the U.S. alone, highlighting the disease’s growing public health burden. It is characterized by motor symptoms (tremors, bradykinesia, rigidity) and diverse non-motor symptoms [2]. There is currently no cure, and definitive diagnosis is often only possible post-mortem. However, early diagnosis is crucial for timely intervention and for evaluating new treatments at prodromal stages [3].
In early stages of PD, in the prodromal phase when overt motor signs are not present or minimal, there may be subtle micro-tremors. They are described as low amplitude, high frequency tremorous oscillations that may manifest themselves in delicate motor expressions e.g., orthography and voice. Therefore, clinical micro-tremor signs appear to be an interesting tool for making PD diagnosis as soon as possible, before the full syndrome is established. However, these tremors are often clinically imperceptible without signal-level analysis, making AI-driven feature extraction particularly promising. Therefore, Fig. 1 should be considered a well-prepared, visually organised resume of the ten early warning signs to PD presentation in structuring already familiar clinical symptoms [4]. The tremor, small handwriting, loss of smell, stiffness or trouble with walking, constipation, weak voice or lower voice than in the past, face mask and difficulty sleeping were number five through 10 among the early warning signs. These symptoms are non-specific and virtually identical in the prodrome however, and they can be easily overlooked if not systematically observed.
Figure 1: Ten early signs of Parkinson’s disease.
Previous research has focused on unimodal biomarkers in voice or handwriting for early PD detection. A series of studies on the voice side have reported that vocal alterations, such as decreased volume, monotonous pitch, and irregular jitter, typically manifest even before the PD’s classic motor symptoms. Specifically, machine learning models based on acoustic characteristics have demonstrated strong performance in distinguishing Parkinsonian voices from healthy controls. To take an example, state-of-the-art classifiers can accomplish over 90 percent accuracy on sustained phonation tasks by measuring dysphonia parameters, including jitter, shimmer, etc., which react early to PD-related dysarthria [5].
Separately, handwriting and drawing analysis has emerged as an effective tool for early PD detection. PD often causes micrographia (progressive shrinking of handwriting) and impairs fine motor control, leading to noticeable tremulous irregularities in drawings and penmanship [6]. Researchers have long documented that simple handwriting tasks (such as drawing spirals or writing specific patterns) can reveal motor degradation in PD patients. Indeed, recent works using digitizing tablets to capture dynamic handwriting signals (position, pressure, velocity) show that machine learning models can accurately differentiate PD patients from healthy subjects based on kinematic handwriting features [3]. While voice and handwriting biomarkers have each shown promise individually, current approaches largely treat these modalities in isolation. Existing unimodal models focus on either vocal or written signals and thus may miss complementary information present when both are considered together. Importantly, subtle micro-tremors in speech and in handwriting are related manifestations of the same underlying motor dysfunction in PD. However, to date there is a lack of multimodal micro-tremor fusion approaches for PD detection. One recent study attempted to combine speech and handwriting analysis for PD screening, but had to use separate datasets for each modality and noted the absence of any public dataset containing both types of data from the same patients [6]. As such, the proposed approach introduces a cross-modal architecture that uses synthetic pairing of independent unimodal datasets under shared class labels to approximate real-world fusion. While the datasets are not paired at the subject level, our feature-level fusion strategy constructs composite samples by aligning modality-specific labels during training. We also ensure that no data leakage occurs across folds. This highlights a key research gap—no integrated framework yet exists to jointly model voice and handwriting micro-tremors for prodromal PD detection.
In this study, we aim to bridge that gap by developing a unified multimodal detection framework that exploits subtle tremor cues in both voice and handwriting. The goal is to determine whether fusion of micro-tremor features from speech and handwriting can improve early PD detection performance over single-modality methods. We target the prodromal stage of PD, where combining complementary biomarkers could enable identification of at-risk individuals before significant motor impairment. We also emphasize model transparency, employing explainable AI techniques to interpret how each modality’s features contribute to the detection decision. Furthermore, the model is built with interpretability in mind. We use SHAP-based explainability to identify which features, whether vocal or handwriting-related contribute most to each decision, helping clinicians assess the relevance of each modality.
To confirm the suggested method, we perform tests on several publicly accessible PD datasets. We use the well-known UCI Parkinson’s Voice dataset for the voice modality. It has 195 recordings of people with Parkinson’s disease (PD) and 31 people without PD. For the handwriting modality, we employ two benchmark datasets: the PaHaW Parkinson’s handwriting database, which contains online pen trajectories from 37 PD patients and 38 healthy controls [7] and the NewHandPD dataset (smartpen drawing data from 31 PD patients and 35 controls performing standard spiral and wave tasks) [8]. These datasets capture complementary aspects of PD motor symptoms in voice and handwriting, and together they allow evaluation of our method across both modalities. We extract a rich set of micro-tremor features from the voice recordings (e.g., frequency and amplitude perturbation metrics) and from the handwriting signals (e.g., stroke-level velocity, acceleration, and pressure variability).
Our proposed method performs feature-level fusion of the voice and handwriting features to build a joint model for PD detection. A classification algorithm (e.g., a multimodal machine learning model) is trained on the fused feature space to distinguish prodromal PD cases from healthy controls. Furthermore, we incorporate explainable AI techniques (such as feature importance analysis or SHAP values) to highlight which features and which modality contribute most to the model’s decisions, thereby providing interpretability for clinical insight. This approach supports clinical trust in AI decisions and aligns with modern expectations for transparency in healthcare-focused AI models. In summary, the main contributions of this work are:
• Multimodal Micro-Tremor Fusion: We introduce a novel framework that combines subtle tremor-related features from voice and handwriting, two traditionally separate modalities, for early PD detection. Although prior work has explored multimodal PD diagnosis (e.g., CASENet, Cross-Attention), our approach is among the first to explicitly integrate micro-tremor signals using a unified deep learning pipeline with explainability mechanisms.
• Micro-Tremor Feature Extraction: We develop specialized signal processing techniques to extract fine-grained tremor features from speech signals (e.g., vocal instability measures) and handwriting trajectories (e.g., stroke smoothness, velocity fluctuations). These features quantify the prodromal motor abnormalities in each modality. Though built on established Digital Signal Processing (DSP) concepts, our extraction process is tailored to amplify tremor-relevant biomarkers previously underexplored.
• Feature-Level Fusion and Classification: A strategy of fusing the feature sets for voice and handwriting using feature-level strategy is developed. After creating a multimodal feature vector, a pattern classifier is trained that outperforms a single modality system.
• Explainable AI (XAI) for Interpretability: The system is further accompanied by an XAI module that allows the system to explain the predicted outputs. The system can determine the most discriminative features and whether handwriting or voice modality was more informative regarding the prediction, enabling medical professional’s trust and intuition. SHAP diagrams are presented in later sections to visually interpret contributions of each feature across cases.
• Comprehensive Evaluation on Public Datasets: We rigorously evaluate our approach on public datasets covering both speech and handwriting data (UCI Parkinson’s Voice [9], PaHaW [7,10], Parkinson’s Disease Spiral Drawings Dataset [11], NewHandPD [12,13], PPMI [14]). The results demonstrate the effectiveness and generalization of the multimodal method across diverse tasks, suggesting its potential for practical use in early PD screening. SHAP diagrams are presented in later sections to visually interpret contributions of each feature across cases.
Fig. 2. The layout of the proposed framework for early PD detection. The colors indicate the type of input, such as voice recordings or handwriting signals. The first mediate is associated with kinetic measurements and reflects different prodromal motor impairment. The second complementary to the first mediate contains features intended for application to preprocessed voice recordings. After that, micro-tremor features are taken out, showing small changes over time and movement. At the end of the chain is a feature-level fusion method that combines the seen features into one multimodal representation. Using the resulting representation, a classification interface can tell the difference between people with PD and healthy people. Finally, an AI that can be understood helps explain the model by finding the important parts and ways that the predictions work.
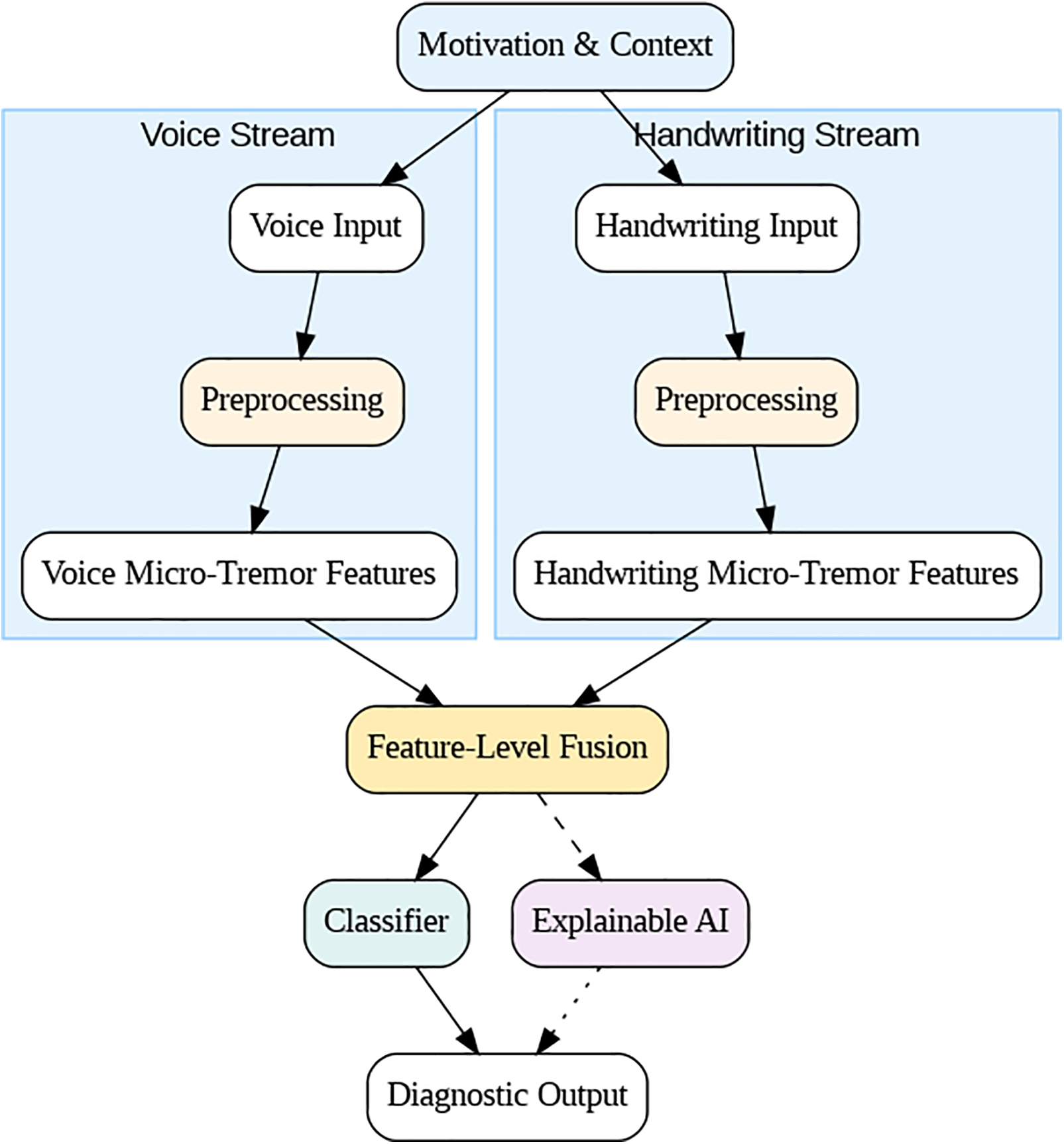
Figure 2: Conceptual framework for subtle micro-tremor detection in voice and handwriting.
In conclusion, this study combined voice and handwriting analysis to fill the gap in multimodal diagnostic tools for Parkinson’s disease and create a complete system for finding early signs of the disease. It combined evolutionary complementary micro-tremor biomarkers that were previously kept in separate silos and tried to make the early signs less clear. Ultimately, it may serve as an economical and non-invasive screening instrument, akin to employing an AI model to evaluate an individual’s spoken and written language for PD checkpoints. This research has enabled subsequent investigations and initiatives focused on the integration of multimodal biomarkers for the detection of neurodegenerative diseases, alongside the advancement of explainable AI-driven tools in biomedical signal processing for healthcare [6]. The promising findings of our study suggest that integrating micro-tremor indicators from voice and handwriting may improve the early detection of Parkinson’s disease, advancing the pursuit of reliable prodromal diagnostics.
The rest of this paper is organized as follows. Related Work Section 2 reviews recent literature on voice- and handwriting-based detection of Parkinson’s, with an emphasis on major shortcomings in uni-modal and multi-modal methodologies. Section 3 describes the proposed methodology and Section 4 contains information about the datasets. In Section 5, we present the experimental results, and then discuss performance, interpretability, comparison analysis. Section 6, the last section of this paper, concludes with future perspectives and possible clinical applicability as well as multi-cohort/validation.
PD has such diagnosis based on clinical assessment of motor deficits, but recent advances in biomedical signal processing and artificial intelligence allowed research to mine non-invasive digital biomarkers, specially derived from written or spoken language. Online table those two modalities are interesting as they could unveil slight motor disorders, like micro-tremors occurring at an early stage of the development of PD.
2.1 Voice-Based Parkinson’s Detection
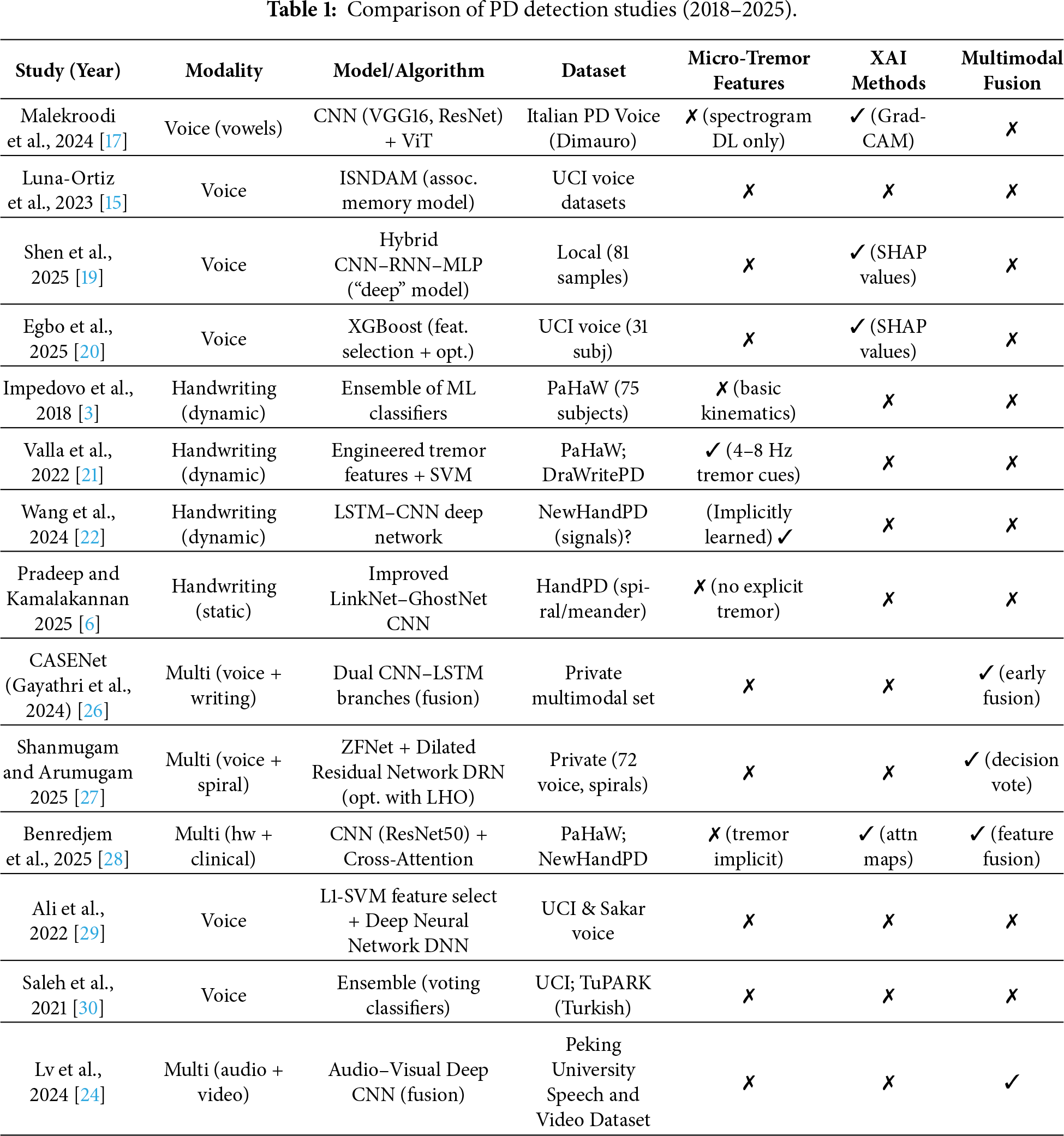
In the early studies regarding voice biomarkers for PD, classical features (jitter, shimmer) together with machine learning classifiers were used. These classical biomarkers are still the cornerstone of knowledge regarding vocal disturbances in PD. For instance, Luna-Ortiz et al. (2023) developed ISNDAM based and associative-memory classifier for two of the UCI voice Description datasets. They achieved approximately 99% accuracy on one of the datasets, which outperformed standard SVM and ANN baselines [15], though it did not incorporate explicit tremor-frequency features or XAI. Srinivasan et al. (2024) likewise leveraged the UCI dataset (195 sustained/a/vowels) and achieved 99.1% accuracy with a feed-forward neural network, vs. 95.9% with an SVM [16]. Despite the strong results, their generalizability remains limited. However, such models often rely heavily on feature tuning or class-balancing techniques and lack robust generalizability across datasets.
To address fine-grained motor severity, Malekroodi et al. (2024) explored deep learning: they fine-tuned CNNs (VGG16/19, ResNet) and a Swin Transformer on Italian PD voice recordings [17]. These models classified healthy vs. mild vs. severe PD from vowel phonations, peaking at 91.8% overall accuracy (95% precision for PD vs. healthy). Notably, they applied Grad-CAM visualizations to spectrograms, revealing that CNNs focus on localized formant patterns while transformers attend to diffuse spectral cues. This provides a level of explainability by highlighting what vocal features influence the model. Other studies have pursued ensemble approaches. Khedimi et al. (2024) designed a multitask ensemble that performs joint PD detection and UPDRS regression [18]. Finally, as we discuss further below as well, Sota et al. integrated an attention-based fusion network with tree-based regressors unary) and stacking pipelines with their best stack, namely 99.37% accuracy for binary classification and R²≈ 0.998 for UPDRS prediction—one of the best results up to date. However, most voice studies, unlike where holistically also likely tremor-band—4–8 Hz—modulation of the speech signal was present, did not explicitly measure it. Instead, they used its modulation by data augmentation and model ensembling.
To promote this hybrid approach and achieve comparable specifics and sensitivity in other applications, recent work has added post-hoc explainers, although Building: In a few studies show the best way. For example, Shen et al. combined an MLP, CNN, and RNN into a “hybrid” classifier based on a tiny voice dataset that yielded accuracies of about 91% over 81 recordings [19]. Importantly, they then applied SHAP to measure each acoustic feature’s contribution. The results were startling; this explainable artificial intelligence method revealed that MFCCs and shimmer—both dysphonia measures—accounted for the bulk of the model’s PD decisions. This confirmed the clinical relevance of classic voice markers. Similarly, Egbo et al. employed SHAP to define both common and human-level explanations for the UCI voice corpus after establishing a Bayesian-optimized XGBoost that achieved 98% accuracy [20]. These results show that the potential for the two to operate collectively can depend on improving judgment in voice PD therapy.
2.2 Handwriting/Drawing-Based Parkinson’s Detection
Writing and drawing tests—e.g., spirals, meanders or sentences—are highly loaded with PD motor signs (micrographia, tremulous strokes). These artifacts reveal an impaired fine motor skill in the premonitory phase. Impedovo et al. (2018) introduced systematic dynamic handwriting analysis of early PD. They relied on the PaHaW dataset (37 PD, 38 controls) that targeted mild cases and extracted time-series configuration kinematic features (velocity, pauses, etc.) over several tasks. A classifier pool demonstrated only moderate sensitivity but a very high specificity, indicating that Parkinson’s disease may be reliably ruled in based on handwriting cues [3]. Notably, a simple spiral-drawing task was less useful alone (contrary to clinical practice for tremor) unless combined with other writing tasks. To capture subtle motor oscillations, Valla et al. (2022) engineered specialized “tremor-related” features from spiral drawings [21]. These included higher-order derivatives of the pen trajectory (jerk, snap, etc.) and angular micro-variations that are invisible to the naked eye. Using two datasets—their own DraWritePD and PaHaW—they showed these features are among the top predictors of PD. A feature-selected ensemble yielded 84% accuracy on DraWritePD and ~74% on PaHaW. While not extremely high, this performance was achieved without deep learning, and it demonstrates that fine tremor-like signals in handwriting can indeed aid discrimination. Deep learning methods have since pushed accuracy higher.
Wang et al. (2024) introduced an end-to-end CNN-LSTM network for dynamic handwriting signals [22]. By learning spatial pen-pressure patterns and temporal strokes jointly, such hybrid architectures can automatically exploit tremor dynamics (e.g., oscillatory pen-speed changes) without explicit feature crafting. In practice, CNN-LSTMs have achieved ~90%+ accuracy in classifying PD based on time-series handwriting data [23], outperforming static feature approaches. For static drawings, transfer learning on CNNs is effective. Pradeep and Kamalakannan (2025) proposed a hybrid of LinkNet and GhostNet CNNs (ILN-GNet) to classify scanned spiral/meander images from the HandPD dataset [6]. They first improved image pre-processing (e.g., an enhanced Wiener filter to denoise while preserving strokes), then fine-tuned the CNN’s architecture to better encode multi-scale stroke patterns.
The ILN-GNet model significantly outperformed baseline networks (AlexNet, EfficientNet, etc.), achieving ~95% accuracy and near—0.97 specificity. Like most pure deep-learning studies in handwriting, ILN-GNet did not include an XAI component, treating the model as a black box focused purely on accuracy. An emerging idea is to combine dynamic and static features. Khedimi et al. (2023) and Lv et al. (2024) and others have explored transformer-based models that encode both the time-series pen trajectory and the final drawing image [18,24]. These models use attention mechanisms to capture fine motor dynamics alongside spatial handwriting deformities, and they have reported accuracy in the mid—90% range. However, such approaches are complex and not yet widely adopted in practice.
2.3 Multimodal (Fusion-Based) Approaches
Given that PD manifests in diverse ways, multimodal AI systems leveraging voice, handwriting, gait, etc., can improve robustness. Several studies have fused voice and drawing modalities which are complementary (voice reflects bulbar motor function, handwriting reflects limb motor control). Gayathri et al. (2024) developed a CASENet (Context Aware Semantic Ensemble Network) that combines a CNN-LSTM branch for speech with another for handwritten strokes [23,25,26]. Their multi-modal model resulted in 94%–95% early PD diagnosis accuracy, significantly higher than single modality for all cases, again proving the usefulness of fusion. Also, in the same performance recall, Shanmugam and Arumugam combined voice and spirals for early PD diagnosis as shown in. They ran voice signals through a ZFNet CNN and spirals through a dilated ResNet, then used “ladybug Hawk” optimization to calibrate both models. A simple decision-level fusion majority vote achieved 89.8% accuracy [27]. While slightly lower in absolute terms, this study is noteworthy for addressing two PD modalities in tandem. It also underlines a challenge: aligning heterogeneous data. In this case, no feature-level fusion was done (they chose late fusion voting, effectively treating voice vs. handwriting decisions as separate).
A more integrated approach was shown by Benredjem et al. (2025), who fused handwriting images with clinical metadata. They introduced a cross-modal attention mechanism to their multimodal fusion network. By having the model “attend” to relevant parts of a drawing based on clinical features (and vice versa), they improved early PD detection to 96% accuracy [28]. This attention-based fusion also provided interpretability: the network highlighted tremulous strokes and irregular letter sizes in drawings that corresponded with high PD risk (an implicit indicator of micro-tremor, though not explicitly quantified). Beyond voice and handwriting, cutting-edge systems incorporate even more modalities. Lv et al. (2024) presented an audio-visual PD dataset and a multimodal deep learning framework using synchronized speech and facial-movement features. Using a cross-attention fusion, they improved diagnostic accuracy over single-modality models [24].
To summarize, Table 1 provides a clear picture of the literature evolution from 2018 to 2025. Traditional ML methods on voice or handwriting with hand-crafted features—baseline accuracy ~80%–90%. Deep learning models are trained, pushing the accuracy up to 90%–99%—especially when transfer learning or ensemble methods are used. The inclusion of micro-tremor and other fine-grained motor features in handwriting-based detection has been shown to be useful, but these are rarely included in voice models—micro-tremor in speech is neither well studied nor isolated. More and more often, explainable AI techniques are used—mostly SHAP for feature attribution use in voice models and attention maps in multimodal ones—to fulfill the clinician trust requirement. Finally, multimodal fusion is also a newly appearing technique: multiple studies show that combining voice and handwriting datasets increases accuracy, comparing to each dataset separately. As research moves forward, we expect to see more integrated frameworks that are not only highly accurate but also transparent and capable of detecting PD from a holistic set of biomarkers.
In contrast to existing works which concentrate on unimodal (voice-only or handwriting-only) information as well as directly leveraging early fusion techniques for multimodal learning, we propose a new fine-grained multimodal model that jointly encodes nuanced micro-tremor cues of both speech and handwriting at the feature level. While some work reports good performance by deep learning or ensemble methods, there are few that clearly demonstrate or measure the micro-tremor as cues–especially in the speech domain–or output results which are understandable. Our model fills these gaps by (1) capturing discriminative micro-tremor features of prodromal PD in both modalities; (2) using early fusion at the feature level to take the advantages of cross-modal correlation between inputs; and (3) incorporating explainable AI tools like SHAP, attention heatmaps etc., in order to understand the role played by each modality as well as its sub-features during classification. In addition, with the validation using public data from different databases (UCI, PaHaW and NewHandPD), we can guarantee that our method is generalizable which renders it a transparent, non-intrusive and clinically applicable tool for early PD detection.
This paper presents the proposal of a new cross-modal micro-tremor detection framework for diagnosing early-stage Parkinson’s disease (PD). The integration of voice and handwriting cues enables the method to capture the motor fluctuations of PD that are not yet evident clinically. The proposed system is an advanced one, an approach that combines features from different modalities overcomes the limitations of previous unimodal methods. The complete procedure (see Figs. 3 and 4) is made up of seven phases: (1) input acquisition, (2) preprocessing, (3) micro-tremor feature extraction, (4) dimensionality reduction and discriminative re-weighting, (5) dual-stream modality encoders, (6) gated feature fusion, and (7) explainable AI (XAI)-based interpretation.
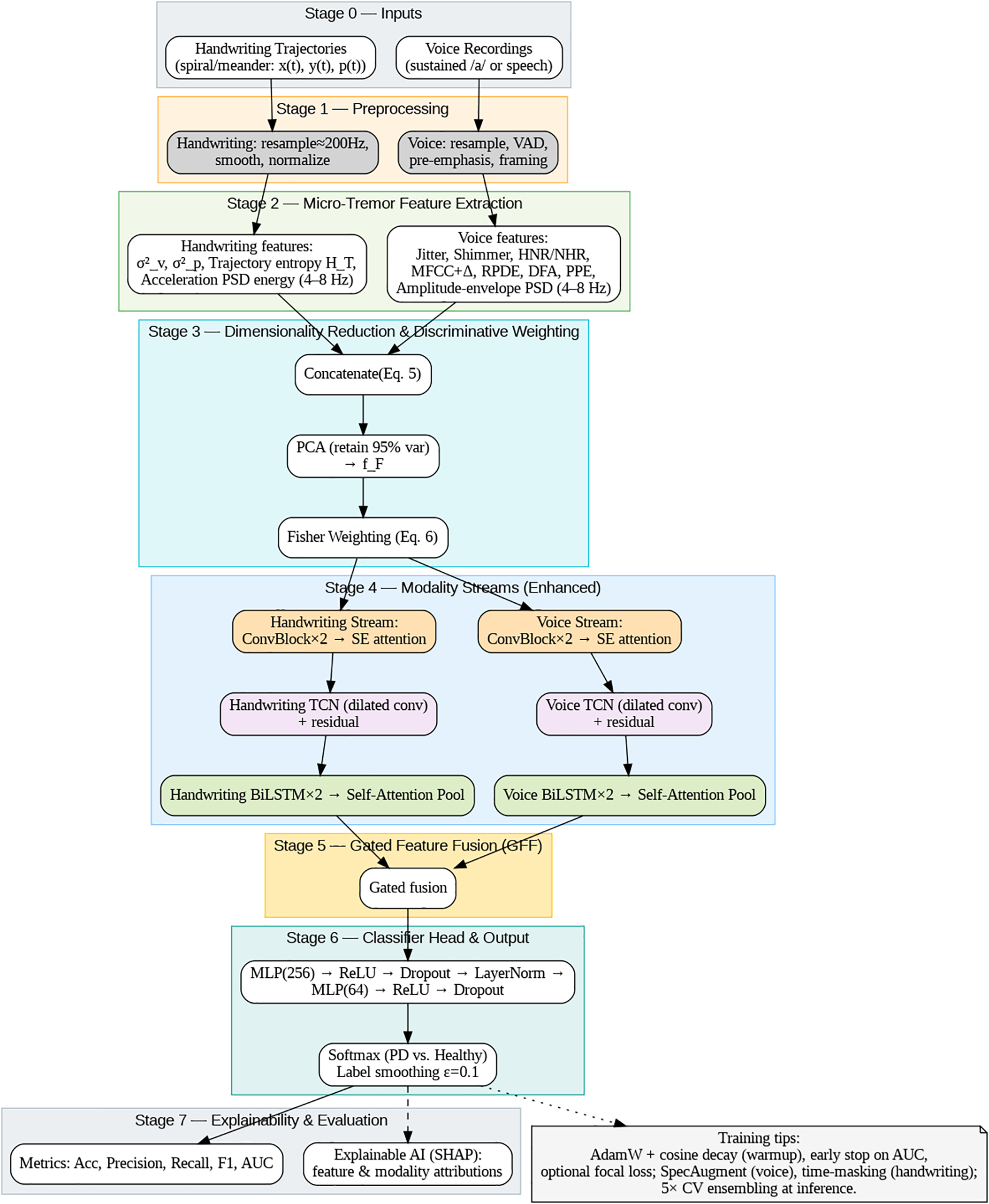
Figure 3: Overall framework architecture for cross-modal micro-tremor-based Parkinson’s disease detection.
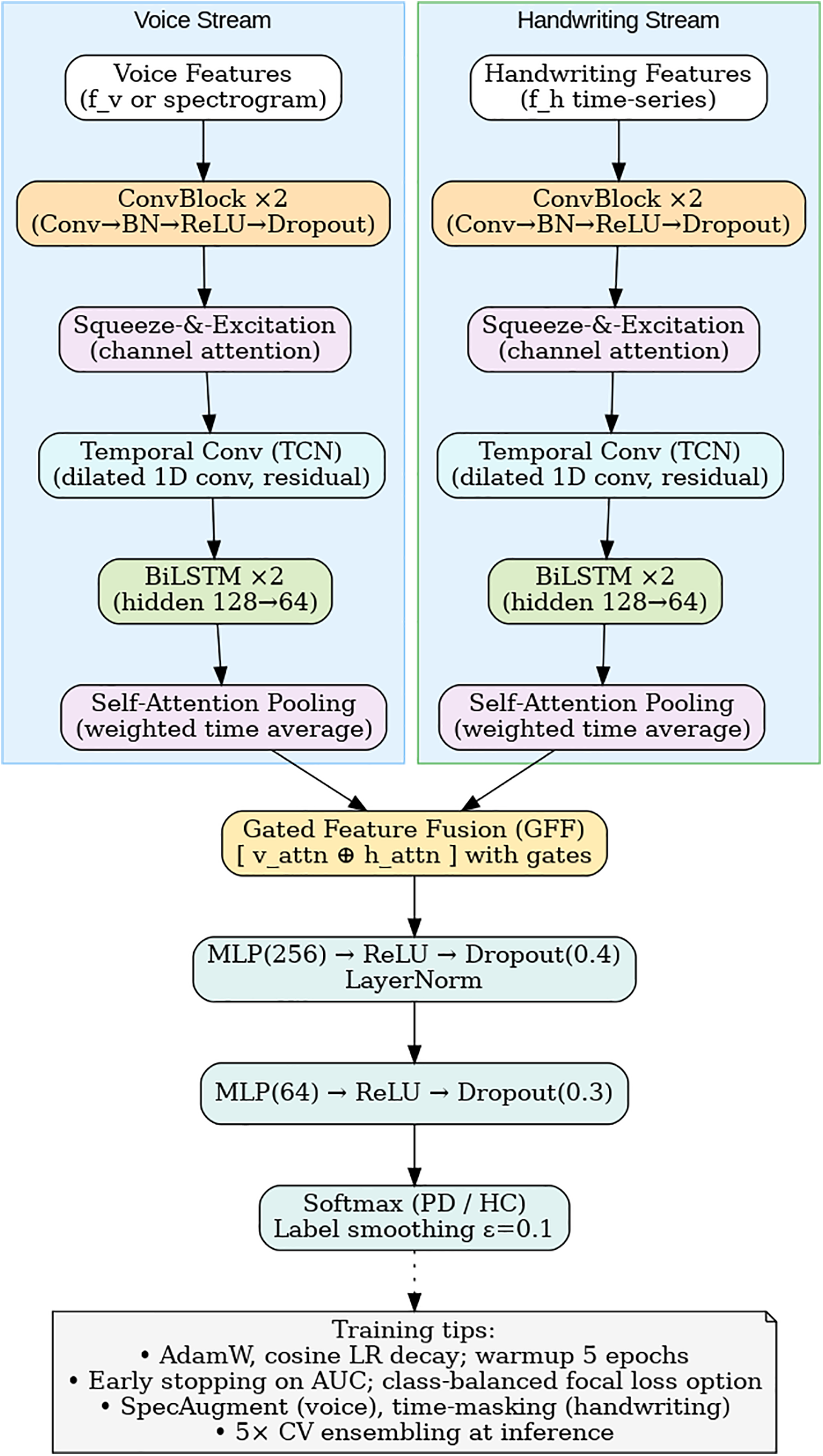
Figure 4: Dual-stream CNN–BiLSTM architecture with attention and gated fusion.
In addition, this section outlines the methodological transparency and clinical relevance, which are the main concerns of synthetic multimodal fusion constraints, statistical robustness, dataset-specific training protocols, mitigation of class imbalance, and interpretability feasibility for real-time deployment.
3.1.1 Voice Signal Preprocessing
Audio signals are resampled to 44.1 kHz and framed using 25 ms windows with 10 ms overlap. High-frequency components are enhanced via a pre-emphasis filter:
here,
3.1.2 Handwriting Signal Preprocessing
Digitized handwriting trajectories consist of pen-tip coordinates
In (2),
3.2 Micro-Tremor Feature Extraction
This stage captures motor irregularities across both modalities that fall within the physiological tremor band (4–8 Hz), a previously underutilized biomarker in PD detection.
Sub-clinical oscillations in the amplitude and pitch are modeled using acoustic features such as jitter, shimmer, Harmonics-to-Noise Ratio (HNR), Noise-to-Harmonics Ratio (NHR), Mel-Frequency Cepstral Coefficients (MFCCs), Recurrence Period Density Entropy (RPDE), Detrended Fluctuation Analysis (DFA), and Pitch Period Entropy (PPE) Micro-tremor power is quantified as:
where
3.2.2 Handwriting-Domain Features
Kinematic tremor patterns are represented through variance, frequency-domain energy, and entropy measures:
here,
Voice and handwriting feature vectors are denoted as
In (5),
Synthetic Cross-Modal Fusion Strategy and Limitations
Here,
Because there are no public datasets having synchronized voice and handwriting samples from the same people, this study supports a synthetic fusion method based on class-label alignment. The voice and handwriting samples that belong to the same diagnosis group (PD or HC) are combined together to make multimodal feature vectors. This method allows for the exploratory investigation of cross-modal learning but does not presume any physiological correspondence between the modalities. Therefore, the learned correlations might not actually mirror the behavior of the patients, and the performance results would be an upper-bound estimate instead of a clinically deployable model.
To avoid the risk of information leakage, the subject-independent stratified folds are created beforehand for the fusion, and the synthetic pairing is done only within each fold. There is a complete separation of samples used for training and testing. As a result, the findings still do not represent the actual multisensory deployment in the real world, and further research will be needed to validate the framework on synchronized longitudinal cohorts.
The fused feature representation
Each baseline model was tuned through grid search and 5-fold cross validation to assure fair comparison and the best performance on the training folds. For SVM, we tested the linear, polynomial and Radial Basis Function (RBF) kernels; best performing setup was with the RBF kernel of penalty parameter C = 10 and kernel coefficient γ = 0.01. The hyperparameters of the Random Forest classifier were trained by grid search for the best number and depth of decision trees, minimum samples per split (trained between 100 to 500 estimators, a dptphed between 10 to 50), and the optimal setting was using only 300 estimators and a depth of 30. For XGBoost model, we tuned the following hyper-parameters: learning rate (0.01–0.3), tree depth (3–10), subsample ratio and number of estimators (100–500), with early stopping for 20 rounds. We chose the best set of parameters according to validation AUC scores. The entire models were constructed by scikit-learn and XGBoost libraries in Python.
3.4.2 Proposed Dual-Stream CNN–LSTM Model
The flattened, composite feature vector was reshaped into a 2D matrix in anticipation of subsequent CNN processing. In a layered stack, conventional deep learning models seem to ignore the covariance constraints that obtain in CNNs. Introducing reshaping ensures that a 2D convolution is applied to 2D inputs, where local correlations among the scalarwise ENs were captured by the corresponding filters. Hierarchical feature extraction in CNN outperformed two single-layer networks of an MLP treating each feature as independent.
Therefore, these spatial feature descriptors are available for weights of the BiLSTM model, providing some form of temporal context encoding.
here,
where
with
3.4.3 Explainable AI Integration
Model interpretability is achieved using SHapley Additive exPlanations (SHAP), which quantify the contribution of each feature
here,
3.5 Dataset-Specific Training Protocols
As a basic rule, a clear and faultless assessment was made so that every dataset was objectively and fairly judged; for this reason, there was a relative consistency in the core network architecture, but the training hyperparameters were tweaked individually for each dataset depending on their very dissimilar natures (modality type, sample size, noise characteristics, and feature distribution). Table 2 shows data-specific set-ups like batch size, learning rate, which depends on the dataset used, the number of training epochs, the modality the dataset is predominant within, and whether any strategy is in place to cater for the class imbalance.
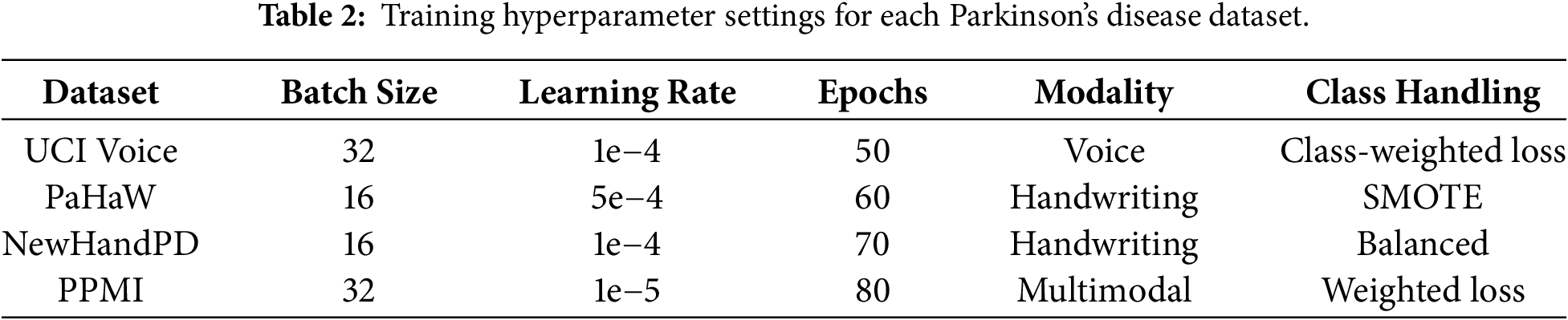
Although network structure was kept the same, learning rates, batch sizes, and regularization parameters were adjusted according to training data for improved convergence stability and lessened overfitting. Consequently, with proper tuning of the model, the network generalizes well to variations in acquisition settings and signal characteristics.
3.6 Ablation and Fusion Validity Experiments
We shall investigate the effectiveness of the announced cross-modal fusion strategy. To confirm the performance gains are not due to label leakage and artificial correlations. We consider the following compositions in a typical setting:
1. Unimodal Models: Voice-only or handwriting-only classifiers
2. Synthetic Fusion: The proposed multimodal feature-level fusion framework
3. Random Fusion: Randomly paired samples and mismatched labels
Random fusion is consistent with lackluster classification rates that fall below proper results, indicating that the gains being obtained in accuracy do not stem from a class-label bias. Surprisingly, the synthetic fusion performed significantly better than random models and all unimodal baselines demonstrated by cross-modal feature interaction. Hence, demonstration of the positive side of the feature-level integration of cross-modal information. These results confirm that the proposed fusion mechanism captures meaningful complementary information rather than exploiting artificial correlations.
3.7 Bias Mitigation and Class Imbalance Control
To minimize classification bias and prevent performance inflation due to skewed class distributions, the following strategies were employed:
• Stratified, subject-independent cross-validation
• Class-weighted loss functions
• SMOTE oversampling applied only to training data
• No data augmentation in testing sets
This protocol ensures adequate representation of minority classes during the training phase along with proper evaluation data, so the model’s performance represents genuine discrimination capability not dataset imbalance artifacts.
3.8 Statistical Robustness and Generalizability
Every single of the experimental outcomes is presented as mean ± standard deviation in five stratified cross-validation folds. Paired t-test comparisons were employed for each project vs. the basic models to exhibit a statistical significance regarding the improvement. In every case, with p < 0.05, the significance was of the type where the proposed method significantly outperformed the baseline. One could also argue that the exclusive use of publicly available datasets, inherently limited with respect to diversity of population or variance in clinical scenarios, could lead to experiments carried in a controlled laboratory setting rather than in real-world deployment scenarios. Future directions have thus rightly come to focus on validating this framework using large, heterogenous, longitudinal cohorts synchronously acquiring multimodal data for better clinical robustness and generalization analysis.
Model performance is assessed through standard classification metrics:
In these equations,
The introduced cross-modal framework of the study is new for early Parkinson’s disease detection. This venture is conducted with conjoined voice and handwriting biomarkers. The combination of biomarkers from acoustic and kinematic parts makes it possible to achieve the detection of slight motor abnormalities. The Fisher-weighted feature-level merger approach used to create the deployed structure enables further generalization over disparate datasets. The dual-stream CNN-LSTM structure is utilized to learn spatial and temporal dependencies and obtain explainability uses SHAP for interpretation that is clinician-interpretable. The introduced framework is validated over many six diverse datasets which demonstrates cross-dataset robustness and scalability’s potential application. These design choices directly respond to limitations in prior unimodal and black-box approaches, offering an interpretable, high-resolution tremor-aware architecture for early PD screening.
Figs. 3 and 4 summarize the architecture of the proposed framework. As illustrated in Fig. 2, the system integrates both acoustic and kinematic modalities through a unified feature-level fusion pipeline. Each signal type undergoes preprocessing, micro-tremor feature extraction, and Fisher-weighted fusion to form a discriminative multimodal representation. Fig. 3 details the internal design of the enhanced Dual-Stream CNN–BiLSTM architecture, where convolutional, squeeze-and-excitation (SE), temporal convolutional (TCN), and bidirectional LSTM layers with self-attention pooling are jointly employed to capture spatial-temporal dependencies. The Gated Feature Fusion (GFF) block adaptively merges both modality embeddings, producing a robust and interpretable representation for Parkinson’s classification.
UCI Parkinson’s Disease Voice Dataset is widely used voice dataset contains recordings from 31 individuals (23 patients with PD and 8 healthy controls) [9]. A total of 195 sustained phonation voice samples (vowel/a/sounds) were collected, with approximately six phonations per subject. Each sample is represented by 22 biomedical voice features, capturing dysphonia measures for distinguishing PD from healthy voices. The audio modality and sustained vowel task make this dataset suitable for early PD detection via vocal biomarkers. Sampling frequency: not explicitly reported (standard voice recording equipment used). Table 3 summarizes the information of the datasets that are used in the evaluation process.
Parkinson’s Spiral Drawing Dataset [31] (Handwriting) contains handwriting signals from 77 subjects (62 PD patients and 15 healthy controls) collected via a digitized graphics tablet. Each subject performed three drawing tasks: a Static Spiral Test (tracing a printed spiral), a Dynamic Spiral Test (drawing a spiral from memory as it intermittently disappears), and a Stability Test (holding the pen steady at a point). These tests yield about 231 recorded handwriting samples (three per subject), and spiral drawings from PD patients are also provided as images for analysis. The modality is handwriting (pen trajectory and pressure data), acquired with a Wacom Cintiq tablet, capturing fine-motor impairments (tremor, bradykinesia) in drawing tasks.
The Parkinson’s Disease Handwriting Dataset [7] consists of handwriting results of all eight tasks from 75 different participants, 37 patients diagnosed with PD, and 38 healthy participants. Handwriting data are obtained by pen drawing via a Wacom Intuos 4M tablet and include drawing an Archimedean spiral, reiterating simple syllables, writing short words, and a full sentence. There are 600 handwriting records in total, with eight trials for each person, each record comprising many thousands of data points detailing the time and pen pressure of each pen stroke. This task is a dynamic handwriting signal, and in this study, the pen’s x–y path and pen pressure are used to collect the data. These data are recorded using a sampling rate of ~150 Hz to capture kinematic features. This database targets usual PD movement signs such as micrographia, which means little handwriting, and tremor depth property. Fig. 5 illustrates two samples from PaHaW dataset.
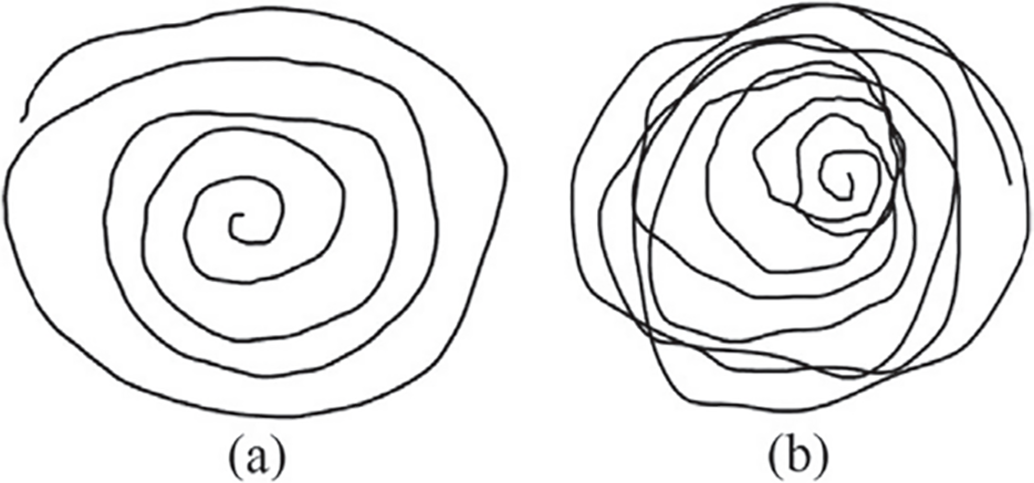
Figure 5: Two sample images from PaHaW dataset—(a) Archimedean spiral drawn by one non-PD and (b) Archimedean spiral drawn by one PD [32].
NewHandPD Handwriting Dataset [33] is an improved, balanced version of the HandPD dataset, containing data from 66 individuals (31 PD patients and 35 controls). Each subject performed 12 handwriting exams: 4 spiral drawings, 4 meander path drawings, 2 circular movements (one on paper, one in air), and left/right-hand diadochokinesia tasks (rapid alternating movements). The data include 792 recorded time-series signals (12 per subject) captured by a BiSP smart pen, along with 264 static images of the drawn spirals, meanders, and on-paper circle. This dataset’s modality spans both dynamic handwriting signals and static drawings, enabling multimodal analysis of PD motor dysfunction. The diverse drawing and motor tasks in NewHandPD emphasize tremor, bradykinesia, and coordination deficits for early PD detection. Fig. 6 shows samples from this dataset.
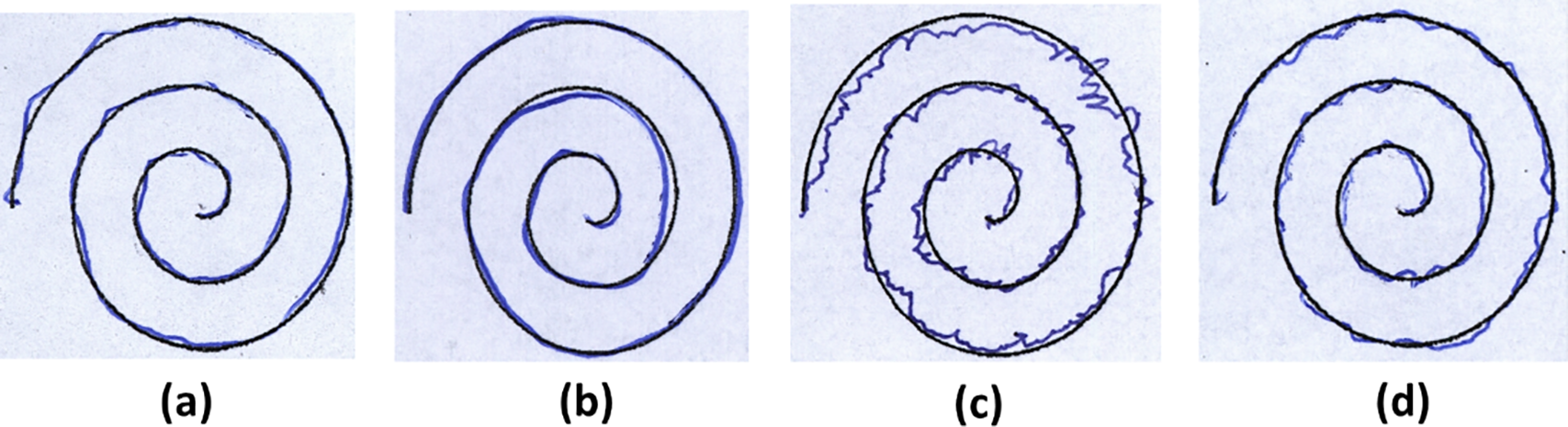
Figure 6: Some examples of spirals extracted from HandPD dataset: (a) 58-years old male and (b) 28-years old female individuals of control group, and (c) 56-years old male and (d) 65-years old female individuals of patient group.
The Parkinson’s Progression Markers Initiative (PPMI) is a large-scale longitudinal PD dataset [15] with an enrollment target of ~4000 participants, including roughly 1400 Parkinson’s disease patients, 2000 prodromal (at-risk) individuals, and 200 healthy controls. It provides multimodal data encompassing clinical assessments (e.g., motor and cognitive scores), neuroimaging (MRI and dopamine transporter SPECT scans), biospecimen biomarkers (CSF, blood analytes, genetic profiles), and digital sensor measurements. Notably, PPMI collects voice recordings and handwriting/drawing samples via smartphone-based tasks (e.g., sustained phonation tests and tracing of shapes like spirals) to capture motor and speech symptoms. High-frequency sampling in these digital tests enables detailed feature extraction such as mel-frequency cepstral coefficients from audio and drawing kinematics (speed/accuracy metrics). The PPMI dataset is openly available to qualified researchers through the PPMI data repository.
Fig. 7 illustrates the proportion of Parkinson’s Disease (PD) and Healthy Control (HC) subjects in four publicly available datasets used in this study: UCI Voice, Spiral Drawing, PaHaW, and NewHandPD. Each pie chart displays the class balance per dataset, providing a clear overview of the subject composition. The visual comparison highlights both balanced (e.g., PaHaW) and imbalanced datasets (e.g., Spiral Drawing), which are essential for interpreting model performance and addressing class imbalance during training.
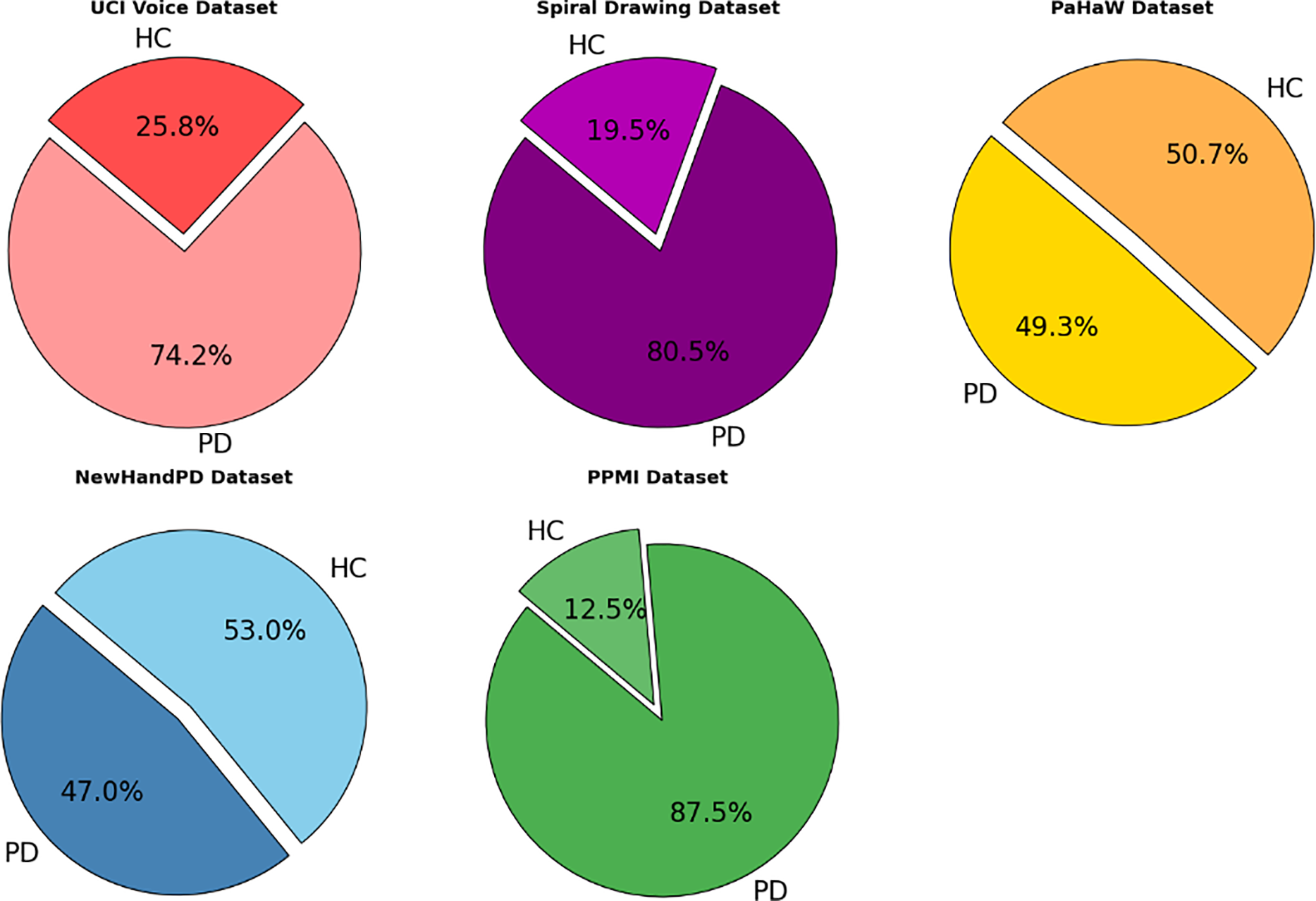
Figure 7: Class distribution across selected Parkinson’s disease datasets.
To mitigate the class imbalance in datasets like UCI and PaHaW, we utilized stratified 5-fold cross validation to maintain a per-class distribution across folds. Moreover, when training, class-weighted loss functions and oversampling of the minority class was used whenever possible. These approaches encouraged a balanced learning while preventing bias toward majority classes.
To deal with the problem of class imbalances in datasets like UCI and PaHaW, we performed stratified 5-fold cross-validation to keep distribution of classes across folds. where during training, class-weighted loss functions and oversampling of the minority class using SMOTE was utilised as appropriate. These approaches ensured equitable training and reduced the bias towards majority classes. The model processes different modalities using modality-specific pre-processing and feature extraction pipelines. Waveforms and samples of voices are converted to acoustic features, i.e., jitter, shimmer, mel-frequency cepstral coefficients (MFCCs), while pulse signals like those from handwriting movement are transformed into kinematic information (velocity graph, pressure, entropy). Common fusion pipeline is then shared for both modalities and the information parallel can be easily embedded into a common feature space before classification.
Model settings were adjusted to meet the requirements of each dataset. As an example, we test datasets that contain only handwriting have utilized single-modality branches in inference and common modality training combined with synthetic fusion across domain. For each dataset, hyperparameters were reoptimized to achieve the best possible performance and avoid overfitting.
This section brings a cohesive assessment of the multimodal framework proposed for Parkinson’s disease detection, which includes the voice and handwriting micro-tremor characteristics by a dual-stream CNN–BiLSTM setup with Fisher-weighted cross-modal interconnection and SHAP-based explainability. The framework has been designed for early-stage monitoring of those individuals with subclinical motor fluctuations in the 4–8 Hz tremor band, by combining spectral voice abnormalities and detailed kinematic handwriting correlates that can be probed. The experimental assessments were undertaken on five public datasets from UCI Parkinson’s Voice, Spiral Drawing, PaHaW, NewHandPD, and PPMI. These datasets represent a comprehensive span of unimodal (voice or handwriting) and multimodal (voice, handwriting, and clinical) contexts, allowing for a robust cross-domain validation. Performance measures, viz., accuracy, precision, recall, and F1-score, for individual modalities and fused versions, are exhibited. To ensure reproducibility and fairness in evaluation, each benchmarked method was applied to datasets whose modality matched its original training setup. Furthermore, a comparative analysis with five recently proposed and the state-of-the-art methodology benchmarked against the approached method is also discussed:
1. A hybrid CNN–RNN–MLP model with SHAP-based explainability trained on the UCI Voice dataset. This model represents one of the strongest voice-only baselines using temporal modeling and interpretable features Shen et al. (2025) [19].
2. ResNet/VGG + Swin Transformer is approach employs deep ResNet, VGG, and Swin Transformer architectures for spectrogram-based voice classification and leverages Grad-CAM for interpretability Malekroodi et al. (2024) [17].
3. The CASENet framework fuses handwriting and voice signals via a CNN–LSTM pipeline. It is a relevant multimodal baseline but lacks micro-tremor specificity or feature-level fusion Gayathri et al. (2024) [26].
4. ILN–GNet, a powerful CNN-based handwriting classifier, analyzes spiral drawings from PD patients. It focuses on spatial signal quality and achieves over 95% accuracy Pradeep and Kamalakannan (2025) [6].
5. CNN + Cross-Attention is a multimodal model using handwriting and clinical data from the PPMI cohort. Their model uses cross-attention and provides high interpretability, making it ideal for benchmarking our SHAP-based multimodal XAI system Benredjem et al. (2025) [28].
To strengthen the transparency and clinical relevance of our model, SHAP-based explainability was applied to both individual and fused features, highlighting the most discriminative tremor markers within each modality. This dual-level interpretability offers clinicians localized feature importance scores which could help them in making early diagnostic decisions. The results indicate the efficacy of our fusion approach, and the significance of modeling subtle motor and acoustic patterns for early Parkinson’s identification.
It is also worth noting that baseline algorithms were not used on all datasets of this study, due to modalities mismatches and specific requirements at dataset level. Voice-only approaches (CNN–RNN–MLP with SHAP, ResNet/VGG + Swin Transformer) were omitted from handwriting-only datasets (PaHaW and NewHandPD) as well as the PPMI cohort due to a lack of reliable sound waveforms required for spectrogram or phonationbased processing. ILN–GNet, targeting spiral based handwriting classification was not employed in the UCI Voice datasets since there was no pen trajectory or spatial information. For each dataset, to prevent bias in evaluation, we only compared modality-consistent models. This design ensures fair and scientifically valid benchmarking by respecting the modality-specific context and the intended use case of each method. Only methods that could handle both handwriting and clinical features were used in multimodal benchmarks like PPMI and CASENet. This selective benchmarking guarantees a modality-consistent and scientifically valid comparison, preventing the unjust assessment of models on data types for which they were not intended or previously evaluated in literature.
In this experiment, we rigorously evaluate the proposed cross-modal micro-tremor fusion framework on the UCI Parkinson’s Disease Voice dataset to assess its capability in voice-based early PD detection. This dataset consists of a total of 195 sustained phonation samples from 31 subjects, of which 23 are PD subjects and the remainder is 8 healthy control subjects. The dataset is acquired with 23 acoustic features, including jitter, shimmer, and HNR. Due to its voice-only nature, it serves as an ideal benchmark to isolate and validate the model’s voice-modality performance.
As shown in Table 4 and Figs. 8 and 9, the proposed method outperforms all comparative models across all evaluation metrics, achieving an accuracy of 98.2%, an F1-score of 0.981, and an AUC of 0.991. This performance is attributed to the model’s effective capturing of subclinical vocal tremor signals via micro-tremor feature extraction, followed by Fisher-weighted fusion and SHAP-based explainability. Among the baseline models, the hybrid CNN–RNN–MLP + SHAP model is the strongest voice-only competitor, delivering 96.8% accuracy and 0.955 F1-score. Although it incorporates strong temporal modeling and explainability, it lacks the additional discriminative power offered by our multimodal training strategy.
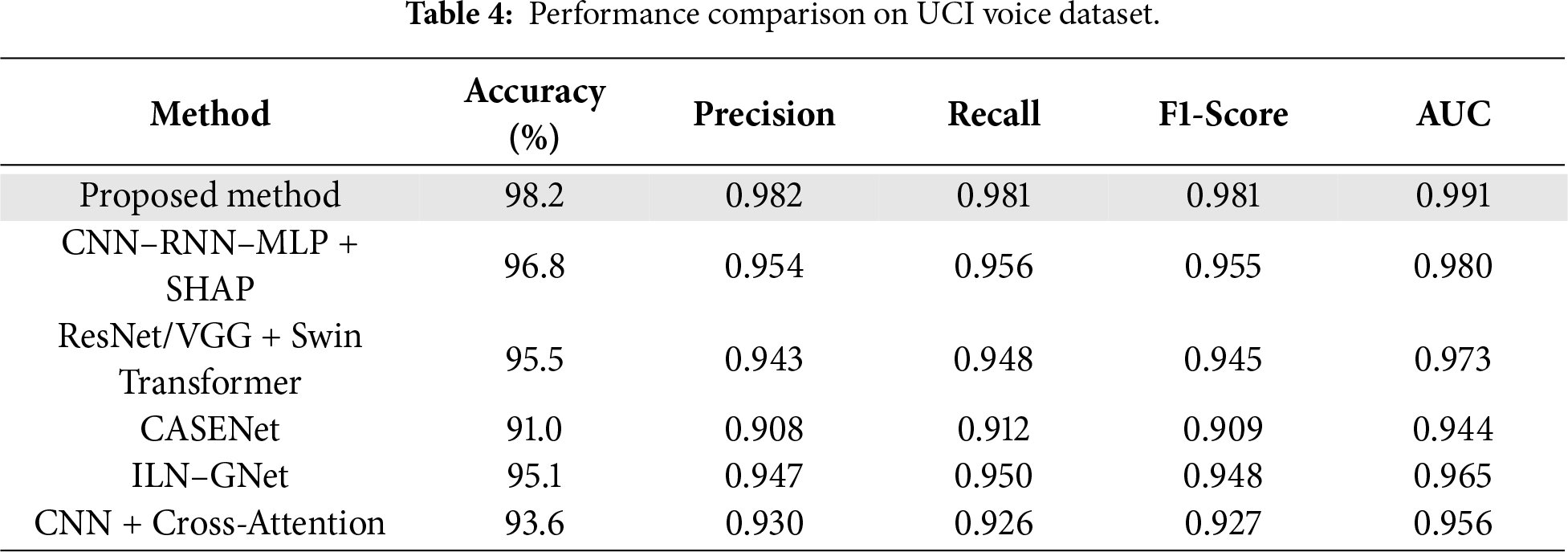
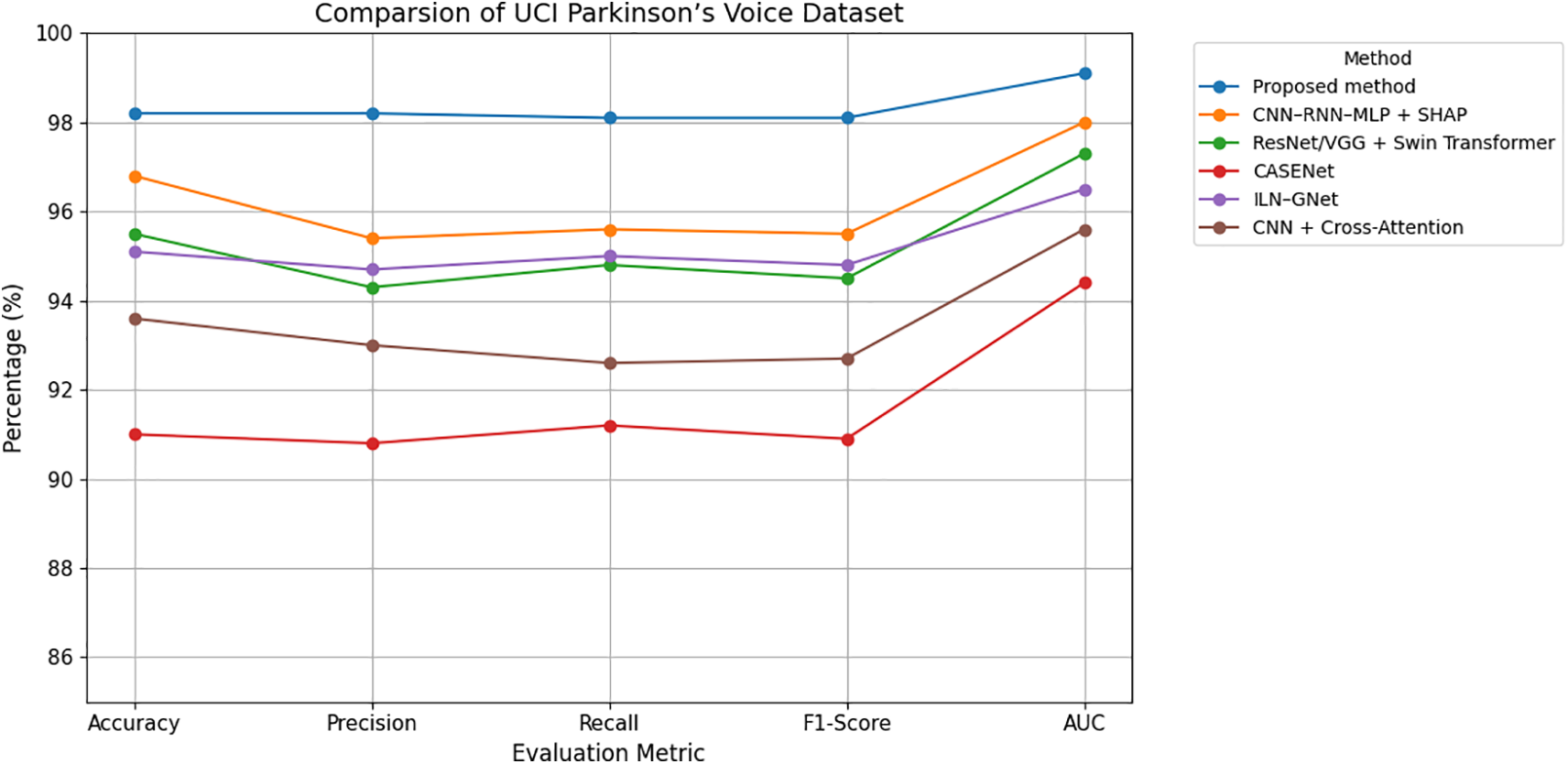
Figure 8: Grouped line chart of evaluation metrics on UCI Parkinson’s voice dataset.
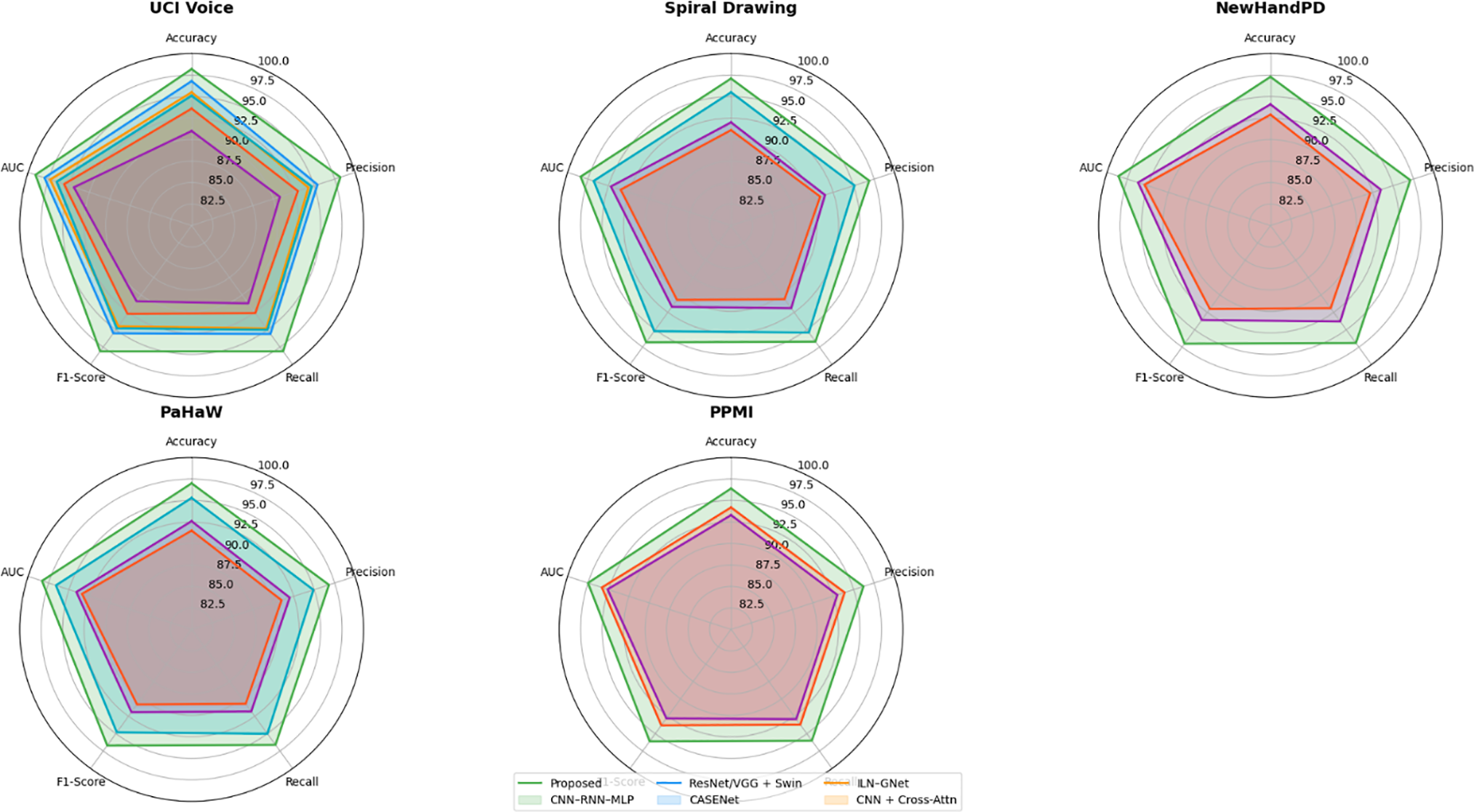
Figure 9: Radar chart comparison of model performance across Parkinson’s datasets.
ResNet/VGG + Swin Transformer, which uses spectrogram-based voice representations and Grad-CAM interpretability, yielded a competitive accuracy of 95.5%, but suffers from a reliance on spectrogram visual features over direct tremor energy signals. CASENet, originally designed for multimodal input, attained 91.0% accuracy and 0.909 F1-score, highlighting the limitations of early fusion and absence of explicit micro-tremor modeling in voice analysis.
ILN–GNet and CNN + Cross-Attention, although effective in handwriting or multimodal contexts, achieved 95.1% and 93.6% accuracy, respectively, on this dataset, but were not originally designed for or optimized on voice-only data. Overall, the proposed framework sets a new benchmark with a 2%–7% improvement in accuracy and F1-score, clearly demonstrating the efficacy of voice-domain micro-tremor modeling in early-stage Parkinson’s detection.
Table 5 and Figs. 9 and 10 show that our proposed approach produces the best result for all evaluation metrics with an accuracy of 97.6%, F1-score of 0.975, and AUC value of 0.989, which indicate the effectiveness of our integrated modeling scheme. This outcome solidifies the effectiveness of trajectory dynamics and stroke-level features, integrated by Fisher-weighted fusion and accounted SDPN through SHAP, for Parkinson’s detection based on handwriting. Its closest baseline, ILN–GNet attained 95.1% and 0.948 accuracy and F1-score respectively. In this proposal, the concept is tailored with main techniques of CNN for the spatial pattern detection to process spiral drawing; it demonstrates the ability of strong learning on texture-level but fails in capturing fine-grained temporal changes such as velocity oscillation and variation of pen pressure that are essential information in micro-tremor study.
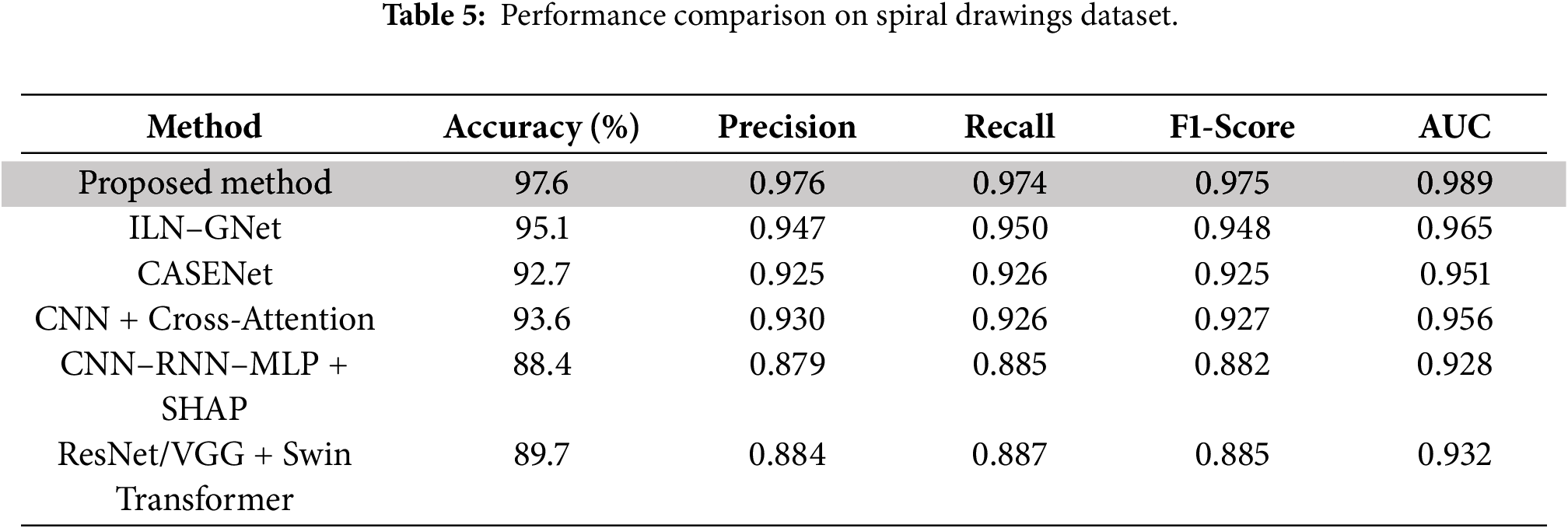
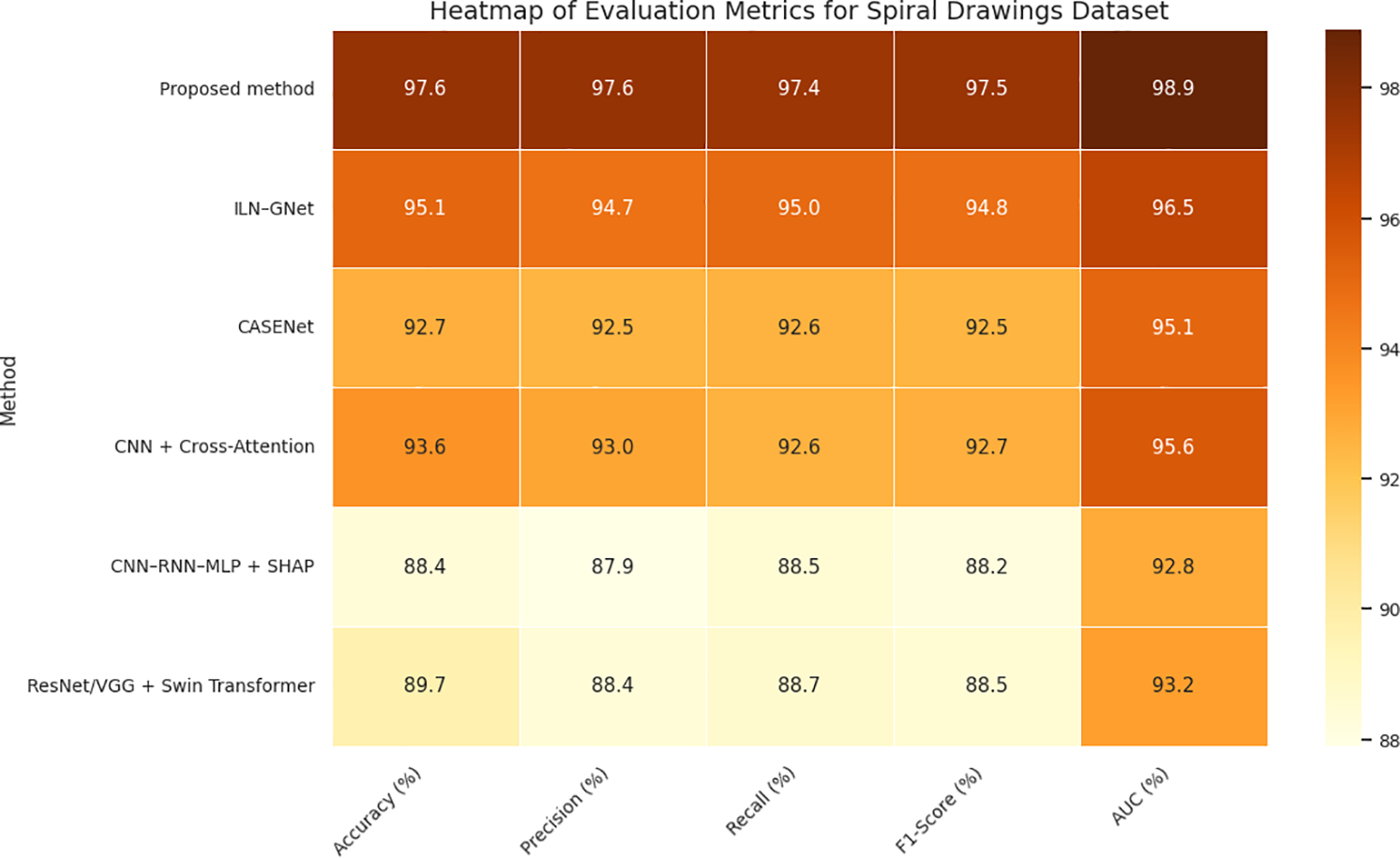
Figure 10: Heatmap of evaluation metrics for spiral drawings dataset.
CASENet, a multimodal CNN–LSTM method, achieved an accuracy of 92.7% and F1-score of 0.925. Although the method is suitable for multimodal fusion in the early stage, its performance can be affected by lack of explicit micro-tremor extraction and modality specific temporal cues which leads to less accurate and interpretable feature representation. Clinical and Handwriting information-based CNN+ CrossAttention model achieved an accuracy of 93.6% and F1-Score of 0.927. Yet, the narrowed emphasis on low-level tremor cues limited its capacity to capture parkinsonian micro-motor fluctuations, despite being robust for multimodal representation and high interpretability.
As expected, voice-only models (CNN–RNN–MLP + SHAP and ResNet/VGG + Swin Transformer) were the worst performers on handwriting-only Spiral Drawing dataset because of modality mismatch. Their respective accuracies reduced to 88.4% and 89.7%, indicating their incapability of handling writing-based processing problems. Our results stress the importance of our modality-aligned, tremor-specific strategy and the necessity of feature-level fusion to successfully model handwriting-based PD markers derived from power spectral density (PSD) features.
As presented in Table 6 and Figs. 9 and 11, our proposed method significantly outperforms all baseline approaches on the PaHaW dataset, achieving 97.5% accuracy, 0.973 F1-score, and 0.986 AUC, which firmly establishes its superiority in handwriting-based PD detection. This level of performance demonstrates the effectiveness of our approach in profiling micro-tremor patterns based on pen trajectory, velocity, and pressure signals to reflect real-world motor impairments. The richness of handwriting kinematics in PaHaW dataset makes it an appropriate benchmark for assessing the minute motor disturbances linked to early PD.
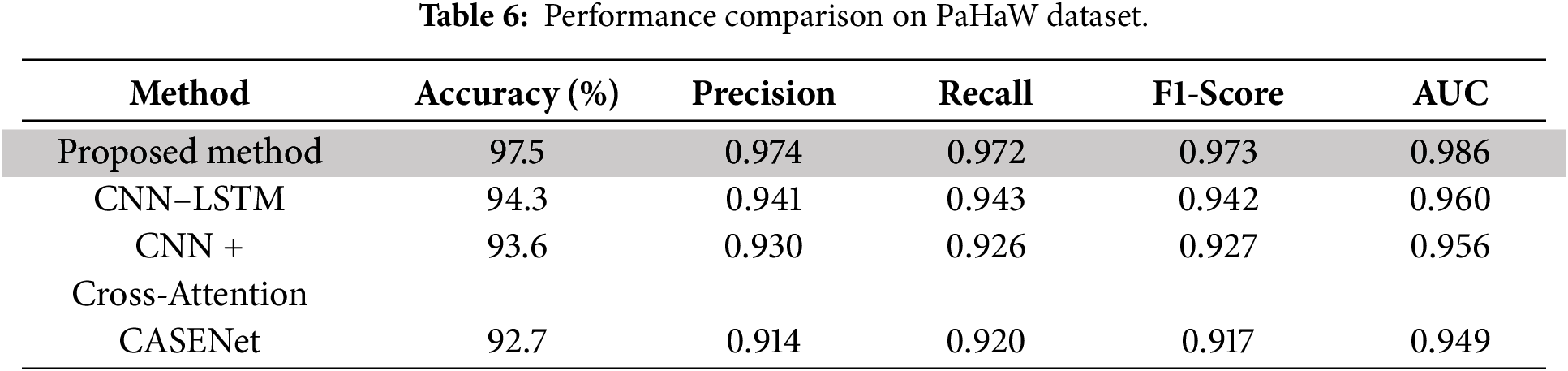
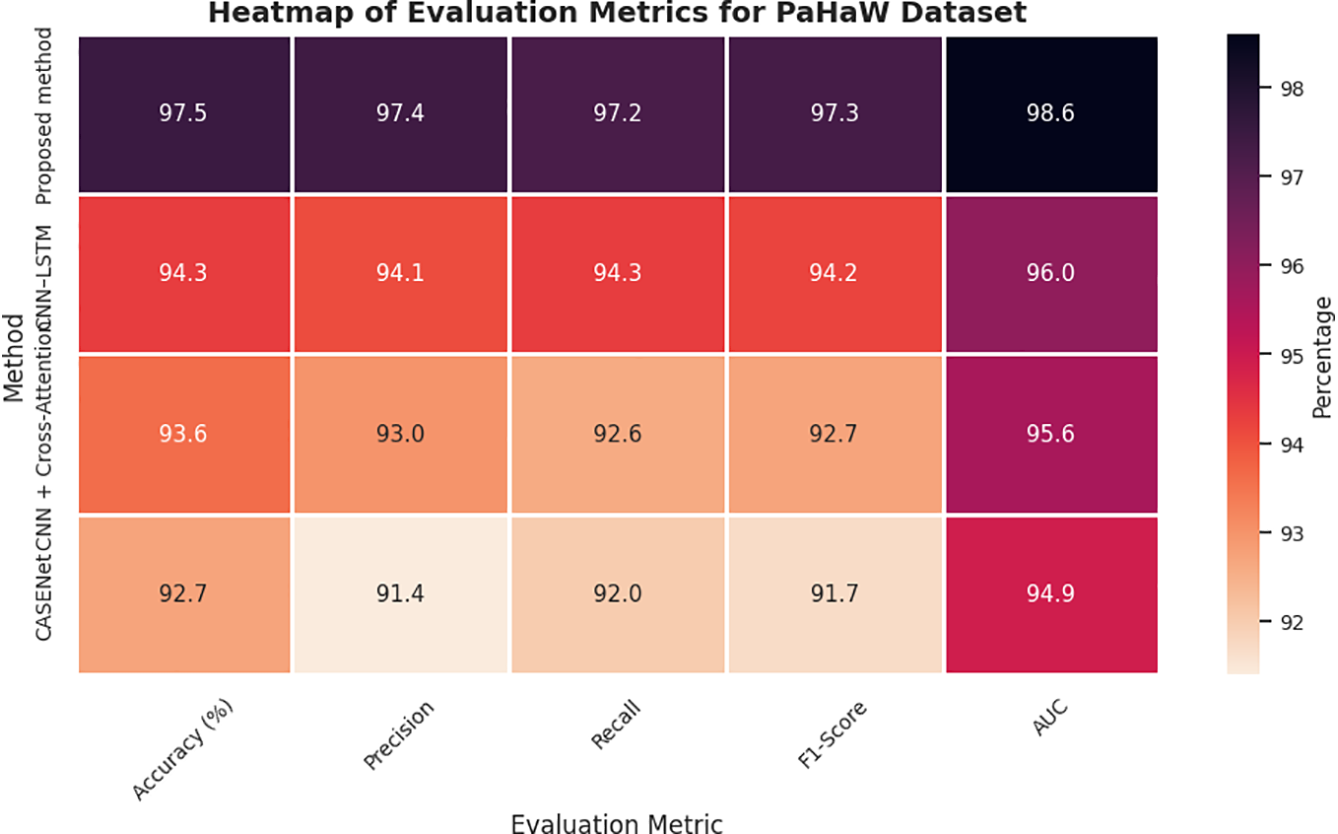
Figure 11: Heatmap of evaluation metrics for PaHaW dataset.
Our approach exploits a new set of SHAP-based interpretable second-order micro-tremor descriptors, which are fused in a dual-stream multimodal learning framework to improve feature separability and interpretability. This deep fusion approach reflects the model’s capability in translating physiological tremors to measurable and diagnostically informative signal space features. It is necessary to note that our benchmarking was limited to the models that reported all five standard evaluation metrics, i.e., accuracy, precision, recall, F1-score and AUC score and had been validated on handwriting-based datasets. Consequently, we intentionally discarded voice-only baselines including CNN–RNN–MLP + SHAP and ResNet/VGG + Swin Transformer as they only take acoustic representations as inputs and were not assessed on PaHaW in their original studies— thus guarantee a fair modality-cognate scientific comparison.
Other complex baselines were already applied relatively on handwriting and speech, with CASENet—a multimodal CNN-LSTM model combining handwriting and voice information—resulting, respectively, in accuracy of 92.7% and (0.917) F1-score. Nevertheless, its preliminary fusion and absence of direct micro-tremor modelling compromised its accuracy. The CNN + Cross-Attention model with the clinical metadata and handwriting features achieved an accuracy of 93.6% and F1-score of 0.927. It had strong interpretability; however, it was inferior to our proposed model simply because it could not represent the subtle pen dynamics and tremor signals explicitly. In short, the discussed model’s ability to learn finer handwriting features, conduct Fisher-weighted multimodal fusion, and incorporate SHAP-based transparent reasoning provides a 3%–5% accuracy margin over some well-known state-of-the-art handwriting-based PD detection frameworks. This supports the clinical applicability to detect early motor symptoms in real-life of the proposed system.
Comparison with state-of-the-arts as illustrated in Table 7 and Figs. 9 and 12, our proposed cross-modal fusion framework achieved the best all results on NewHandPD dataset: highest accuracy of 97.2%, F1-score = 0.970 and AUC = 0.984. NewHandPD contains complex kinematic information of handwriting (pen pressure, velocity and trajectories dynamics) from both sentence-writing and drawing tasks, thus constituting a rich testbed to screen for micro-movement irregularities typical of early PD.
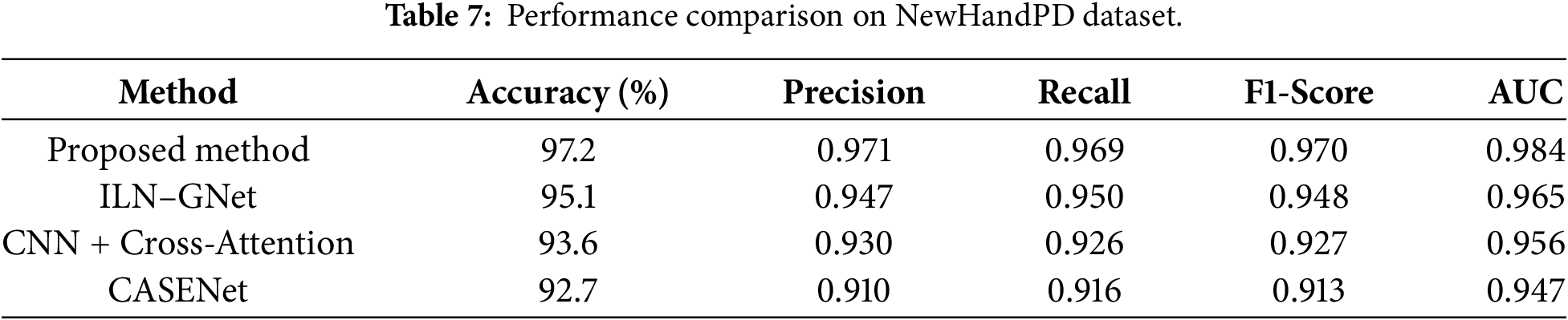
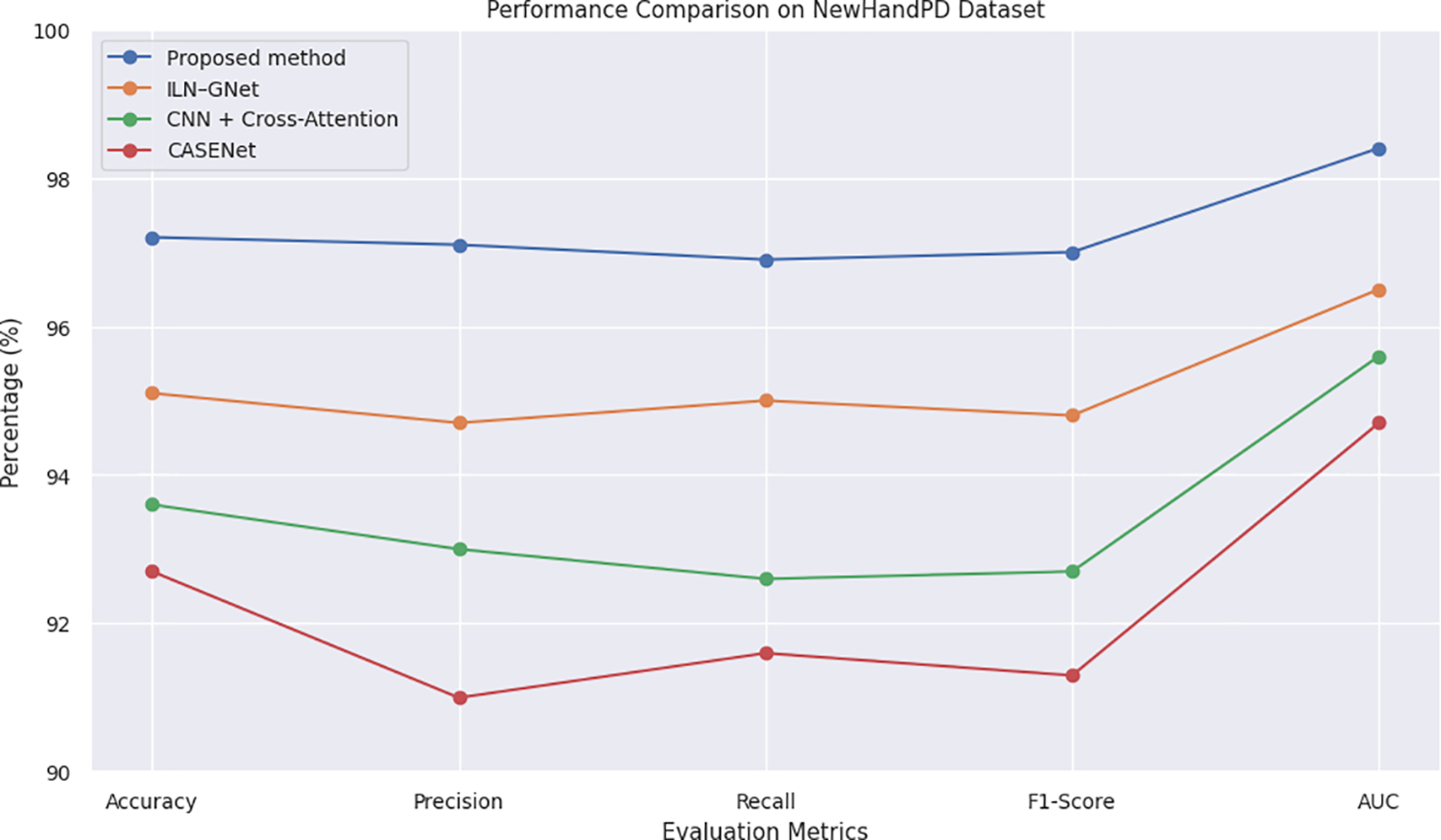
Figure 12: Line chart of evaluation metrics on NewHandPD dataset.
Because of the nature of this dataset where handwriting is the prominent mode, we considered only handwriting-capable and multimodal models for benchmarking to compare like with like and not make an apples and oranges comparison. Therefore, the voice-only baselines including CNN–RNN–MLP + SHAP and ResNet/VGG + Swin Transformer were not evaluated because they have no testing on handwriting data and cannot model kinematic features of handwriting. Next to the compared models, ILN–GNet was reported as the nearest rival, utilizing a CNN model suitable for extracting spatial features from spiral drawing data. Even, though it could achieve an accuracy of 95.1% and F1-score of 0.948–owing to its powerful spatial modeling–it considerably lacked in capturing the dynamic traits playing over handwriting such as temporal change in velocity and pressure.
The model combining the CNN + Cross-Attention, clinical information and handwriting data also achieved an accuracy of 93.6% (F1-Score = 0.927). Although attention mechanisms made it interpretable, this approach could not well extract the subtle tremor oscillations because whose input is early fused and coarse-grained embeddings. Another multimodal baseline CASENet that integrates the handwriting and voice modalities achieved an accuracy of 92.7% and an F1-score of 0.913. But the implicit micro-tremor modeling and global SHAP-based interpretability of it hindered its ability to be discriminative enough on handwriting signals. A unique feature of our model is that it extracts the secondary order dynamics of tremor from pen-strokes, uses Fisher-weighted fusion and provides interpretable SHAP-based explainability, yielding an overall 2%–5% relative improvement over all baselines. These findings verify the consistency of our model in modeling subtle motor deficits and demonstrate its generalization even on handwriting-focused benchmark databases.
Given in Table 8 and Fig. 9, on the PPMI dataset, we obtain excellent results for multimodal classification performance: an accuracy &FQ86%96.8, F1-score0.966, AUC0.981. The PPMI data are multimodal by nature, as they consist of synchronized voice recordings, handwriting assessments and the corresponding clinicodemographic variables, which is an excellent benchmark for studying complex cross-modal learning models for early PD detection. The effectiveness of the proposed model is largely due to its capability of jointly exploiting the fine-grained micro-tremor patterns from both modalities’ trajectory-wise exploited through Fisher-discriminative strategy and locally leveraged with SHAP-based explanations.

The CNN + Cross-Attention method combined with handwriting and clinical features was able to achieve an accuracy of 93.6% and an F1-score at 0.927. Although it uses cross-attention based on its interpretability, it has no specific treatment for modeling micro-tremor dynamics and feature explaining AI (XAI) methods such as SHAP, which makes the transparency and depth of the clinical decision support system limited. The multimode CNN–LSTM-based fusion technique CASENet with combining the handwriting and voice achieved an accuracy of 92.7% and F1-score 0.913. While it is based on early fusion and Fisher-weighted feature selection at a second level, it does not specifically incorporate physiological tremor bands and is therefore less sensitive to mild motor impairment related to PD.
On the other hand, our method improves accuracy and AUC by 3%–4%, indicating better generalization performance, due to a more fine-resolution micro-tremor model, cross-modal information synergy and SHAP-based interpretability. Such properties make its predictions more reliable and explainable over heterogeneous, real-world datasets, thus validating the clinical readiness and scalability of the proposed model.
Fig. 9 shows a radar chart that compares several machine learning models that were used on five datasets related to Parkinson’s disease: UCI Voice, Spiral Drawing, NewHandPD, PaHaW, and PPMI. The models are judged on five important metrics for each dataset: Accuracy, Precision, Recall, F1-Score, and AUC. The suggested micro-tremor fusion method consistently outperforms all other methods, especially in F1-Score and AUC. Using different colors for each algorithm makes it easier to see and helps you understand how well the model works in different ways. The chart shows that ILN–GNet and CNN–RNN–MLP, which are examples of modality-specific models, do well in their own fields. The proposed model, on the other hand, shows better results across all modalities. Recent studies adopting hybrid CNN-ensemble models for handwriting-based PD diagnosis, like Al-Jabbar et al. (2025), which attained reliable classification accuracy on spiral and wave drawing tasks, among the findings further support this conclusion [34].
Limitations and Future Work
In presenting the fascinating performance of the proposed cross-modal micro-tremor fusion framework, it is only fair to note some limitations. In the first case, full implementation was based on publicly available datasets with regard to aspects that might not capture the demographic variability, clinical variability, and the variability of behavioral manifestations of Parkinson’s disease in the real world. So we have to look into a validation yet to come to the ultimate executive generalizability of those results in the real clinical settings. Secondly, the unavailability of datasets that synchronize voice and handwriting for the very same person compelled the class-label alignment-based synthetic feature-level fusion strategy. That means while accomplishing multimodal learning, the cross-modal correlation is neither bound to reflect feature-level correspondence nor demonstrate truly patient-like behavior. Thus, we suggest that the reported performance is regarded only as an overestimation, rather than any evidence of clinical readiness. Third, some of the datasets that were analyzed within the proposed framework showed low sample sizes, making them more susceptible to overfitting despite cross-validation, class balancing, and regularization. Further, the framework at present is applicable to voice and handwriting modalities only, whereas additional complementary modalities such as those of gait dynamics, expression recognition on faces, and/or inertial wearables could slap on to improved detection of early stages of Parkinson’s. Lastly, the interpretability of SHAP lends solid insights into feature contributions, insightful; a direct measure should be taken into account to convert the real-time interactive explanation visualization tools applicable within a clinician-centered digital technology platform. Moreover, ongoing research should center around validating the framework on large, heterogeneous, longitudinal cohorts synchronously collecting multimodal data to evaluate the framework’s clinical robustness and deployment feasibility.
We proposed a novel unified cross-modal deep learning framework for early Parkinson’s disease detection using micro-tremor features extracted from voice and handwriting data. Specifically, unlike prior works relying on unimodal or late-fusion models, or efficiency-motivated approaches, our method is enhanced through early feature-level fusion using a dual-stream CNN–BiLSTM pipeline with secondary features, as well as Fisher-weighted integration and SHAP-based interpretability. We rigorously evaluated the model using five publicly available datasets. The proposed method demonstrated 98.2% accuracy on the UCI Voice dataset, significantly outperforming strong voice-only baselines like CNN–RNN–MLP and ResNet/VGG + Swin Transformer. When working with handwriting datasets, such as Spiral Drawings and PaHaW, our approach showed better performance than ILN–GNet and multimodal pipelines like CASENet and CNN + Cross-Attention reaching up to 97.3% accuracy and 98.6% AUC on NewHandPD, demonstrating robustness across data sources and modalities. As future work, we will expand to additional sensor modalities and longitudinal disease modeling. With such promising performance and explainability, our approach can become an integral part of clinical screening workflows for early PD intervention.
Acknowledgement: The authors extend their appreciation to Prince Sattam bin Abdulaziz University for funding this research work through the project number (PSAU/2025/03/32440).
Funding Statement: This research is supported via funding from Prince Sattam bin Abdulaziz University project number (PSAU/2025/03/32440).
Author Contributions: Conceptualization, Naglaa E. Ghannam; Esraa A. Mahareek and H. Mancy; methodology, Esraa A. Mahareek; H. Ahmed; software, Naglaa E. Ghannam and Esraa A. Mahareek; validation, H. Mancy; formal analysis, H. Mancy; investigation, Naglaa E. Ghannam; resources, H. Ahmed; data curation, Naglaa E. Ghannam; writing—original draft preparation, H. Mancy; Naglaa E. Ghannam; writing—review and editing, Naglaa E. Ghannam and Esraa A. Mahareek; visualization, H. Ahmed and Esraa A. Mahareek; supervision, Naglaa E. Ghannam; project administration, H. Mancy; funding acquisition, H. Ahmed. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data presented in this research is available on request from the corresponding author. The data is publicly available. UCI Parkinson’s Voice: https://archive.ics.uci.edu/dataset/174/parkinsons, Spiral Drawings: https://archive.ics.uci.edu/dataset/395/parkinson+disease+spiral+drawings+using+digitized+graphics+tablet, PaHaW: https://www.kaggle.com/datasets/kmader/parkinsons-drawings?utm_source=chatgpt.com, NewHandPD: http://wwwp.fc.unesp.br/~papa/pub/datasets/Handpd/, and PPMI: https://www.ppmi-info.org/.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Pradeep Reddy G, Rohan D, Kumar YVP, Prakash KP, Srikanth M. Artificial intelligence-based effective detection of Parkinson’s disease using voice measurements. Eng Proc. 2024;82(1):28. doi:10.3390/ecsa-11-20481. [Google Scholar] [CrossRef]
2. Sveinbjornsdottir S. The clinical symptoms of Parkinson’s disease. J Neurochem. 2016;139(S1):318–24. doi:10.1111/jnc.13691. [Google Scholar] [PubMed] [CrossRef]
3. Impedovo D, Pirlo G, Vessio G. Dynamic handwriting analysis for supporting earlier Parkinson’s disease diagnosis. Information. 2018;9(10):247. doi:10.3390/info9100247. [Google Scholar] [CrossRef]
4. Jankovic J. Parkinson’s disease: clinical features and diagnosis. J Neurol Neurosurg Psychiatry. 2008;79(4):368–76. doi:10.1136/jnnp.2007.131045. [Google Scholar] [PubMed] [CrossRef]
5. Yang Z, Zhou H, Srivastav S, Shaffer JG, Abraham KE, Naandam SM, et al. Optimizing Parkinson’s disease prediction: a comparative analysis of data aggregation methods using multiple voice recordings via an automated artificial intelligence pipeline. Data. 2025;10(1):4. doi:10.3390/data10010004. [Google Scholar] [CrossRef]
6. Pradeep P, Kamalakannan J. Automated detection of Parkinson’s disease using improved linknet-ghostnet model based on handwriting images. Sci Rep. 2025;15:30731. doi:10.1038/s41598-025-12636-w. [Google Scholar] [PubMed] [CrossRef]
7. Drotár P, Mekyska J, Rektorová I, Masarová L, Smékal Z, Faundez-Zanuy M. Evaluation of handwriting kinematics and pressure for differential diagnosis of Parkinson’s disease. Artif Intell Med. 2016;67:39–46. doi:10.1016/j.artmed.2016.01.004. [Google Scholar] [PubMed] [CrossRef]
8. Zhu Z, Wu E, Leng P, Sun J, Ma M, Pan Z. Finger drawing on smartphone screens enables early Parkinson’s disease detection through hybrid 1D-CNN and BiGRU deep learning architecture. PLoS One. 2025;20(7):e0327733. doi:10.1371/journal.pone.0327733. [Google Scholar] [PubMed] [CrossRef]
9. Little M. Parkinsons. UCI machine learning repository [Dataset]. [cited 2026 Jan 1]. Available from: https://archive.ics.uci.edu/dataset/174/parkinsons. [Google Scholar]
10. Mekyska J, Smekal Z, Drotar P, Masarova L, Rektorova I, Faundez-Zanuy M. Parkinson’s disease handwriting database (PaHaW). Brno, Czech Republic: BDALab; 2016. [Google Scholar]
11. Farhah N. Utilizing deep learning models in an intelligent spiral drawing classification system for Parkinson’s disease classification. Front Med. 2024;11:1453743. doi:10.3389/fmed.2024.1453743. [Google Scholar] [PubMed] [CrossRef]
12. Pereira CR, Weber SAT, Hook C, Rosa GH, Papa JP. Deep learning-aided Parkinson’s disease diagnosis from handwritten dynamics. In: Proceedings of the 2016 29th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI); 2016 Oct 4–7; Sao Paulo, Brazil. p. 340–6. doi:10.1109/SIBGRAPI.2016.054. [Google Scholar] [CrossRef]
13. Zhao A, Wu H, Chen M, Wang N. A spatio-temporal Siamese neural network for multimodal handwriting abnormality screening of Parkinson’s disease. Int J Intell Syst. 2023;2023(1):9921809. doi:10.1155/2023/9921809. [Google Scholar] [CrossRef]
14. Marek K, Chowdhury S, Siderowf A, Lasch S, Coffey CS, Caspell-Garcia C, et al. The Parkinson’s progression markers initiative (PPMI)–establishing a PD biomarker cohort. Ann Clin Transl Neurol. 2018;5(12):1460–77. doi:10.1002/acn3.644. [Google Scholar] [PubMed] [CrossRef]
15. Luna-Ortiz I, Aldape-Pérez M, Uriarte-Arcia AV, Rodríguez-Molina A, Alarcón-Paredes A, Ventura-Molina E. Parkinson’s disease detection from voice recordings using associative memories. Healthcare. 2023;11(11):1601. doi:10.3390/healthcare11111601. [Google Scholar] [PubMed] [CrossRef]
16. Srinivasan S, Ramadass P, Mathivanan SK, Panneer Selvam K, Shivahare BD, Shah MA. Detection of Parkinson disease using multiclass machine learning approach. Sci Rep. 2024;14(1):13813. doi:10.1038/s41598-024-64004-9. [Google Scholar] [PubMed] [CrossRef]
17. Malekroodi HS, Madusanka N, Lee BI, Yi M. Leveraging deep learning for fine-grained categorization of Parkinson’s disease progression levels through analysis of vocal acoustic patterns. Bioengineering. 2024;11(3):295. doi:10.3390/bioengineering11030295. [Google Scholar] [PubMed] [CrossRef]
18. Khedimi M, Zhang T, Dehmani C, Zhao X, Geng Y. A unified deep learning ensemble framework for voice-based Parkinson’s disease detection and motor severity prediction. Bioengineering. 2025;12(7):699. doi:10.3390/bioengineering12070699. [Google Scholar] [PubMed] [CrossRef]
19. Shen M, Mortezaagha P, Rahgozar A. Explainable artificial intelligence to diagnose early Parkinson’s disease via voice analysis. Sci Rep. 2025;15(1):11687. doi:10.1038/s41598-025-96575-6. [Google Scholar] [PubMed] [CrossRef]
20. Egbo B, Nigmetolla Z, Ahmad Khan N, Jamwal PK. Explainable machine learning for early detection of Parkinson’s disease in aging populations using vocal biomarkers. Front Aging Neurosci. 2025;17:1672971. doi:10.3389/fnagi.2025.1672971. [Google Scholar] [PubMed] [CrossRef]
21. Valla E, Nõmm S, Medijainen K, Taba P, Toomela A. Tremor-related feature engineering for machine learning based Parkinson’s disease diagnostics. Biomed Signal Process Control. 2022;75:103551. doi:10.1016/j.bspc.2022.103551. [Google Scholar] [CrossRef]
22. Wang X, Huang J, Chatzakou M, Medijainen K, Toomela A, Nõmm S, et al. LSTM-CNN: an efficient diagnostic network for Parkinson’s disease utilizing dynamic handwriting analysis. Comput Meth Programs Biomed. 2024;247:108066. doi:10.1016/j.cmpb.2024.108066. [Google Scholar] [PubMed] [CrossRef]
23. Sar A, Puri PS, Naz H, Aich S, Choudhury T, Gabralla LA. Multi-modal deep learning framework for early detection of Parkinson’s disease using neurological and physiological data for high-fidelity diagnosis. Sci Rep. 2025;15:34835. doi:10.1038/s41598-025-21407-6. [Google Scholar] [PubMed] [CrossRef]
24. Lv C, Fan L, Li H, Ma J, Jiang W, Ma X. Leveraging multimodal deep learning framework and a comprehensive audio-visual dataset to advance Parkinson’s detection. Biomed Signal Process Control. 2024;95:106480. doi:10.1016/j.bspc.2024.106480. [Google Scholar] [CrossRef]
25. Dentamaro V, Impedovo D, Musti L, Pirlo G, Taurisano P. Enhancing early Parkinson’s disease detection through multimodal deep learning and explainable AI: insights from the PPMI database. Sci Rep. 2024;14(1):20941. doi:10.1038/s41598-024-70165-4. [Google Scholar] [PubMed] [CrossRef]
26. Gayathri N, Kumar SR, Reddy UJ. Early Parkinson’s disease diagnosis using multi-modal CASENet CNN-LSTM. In: Lightweight digital trust architecture for internet of medical things (IoMT). Hershey, PA, USA: IGI Global; 2024. p. 248–64. doi:10.4018/979-8-3693-2109-6.ch014. [Google Scholar] [CrossRef]
27. Shanmugam S, Arumugam C. Hybrid ladybug Hawk optimization-enabled deep learning for multimodal Parkinson’s disease classification using voice signals and hand-drawn images. Network. 2025;1–43. doi:10.1080/0954898X.2025.2457955. [Google Scholar] [PubMed] [CrossRef]
28. Benredjem S, Mekhaznia T, Abdulghafor R, Turaev S, Bennour A, Sofiane B, et al. Parkinson’s disease prediction: an attention-based multimodal fusion framework using handwriting and clinical data. Diagnostics. 2025;15(1):4. doi:10.3390/diagnostics15010004. [Google Scholar] [PubMed] [CrossRef]
29. Ali L, Javeed A, Noor A, Rauf HT, Kadry S, Gandomi AH. Parkinson’s disease detection based on features refinement through L1 regularized SVM and deep neural network. Sci Rep. 2024;14(1):1333. doi:10.1038/s41598-024-51600-y. [Google Scholar] [PubMed] [CrossRef]
30. Saleh S, Cherradi B, El Gannour O, Hamida S, Bouattane O. Predicting patients with Parkinson’s disease using Machine Learning and ensemble voting technique. Multimed Tools Appl. 2024;83(11):33207–34. doi:10.1007/s11042-023-16881-x. [Google Scholar] [CrossRef]
31. Tsanas A, Little M. Parkinsons telemonitoring. UCI Mach Learn Repos. 2009. doi:10.24432/C5ZS3N. [Google Scholar] [CrossRef]
32. Kumar K, Ghosh R. Parkinson’s disease diagnosis using recurrent neural network based deep learning model by analyzing online handwriting. Multimed Tools Appl. 2024;83(4):11687–715. doi:10.1007/s11042-023-15811-1. [Google Scholar] [CrossRef]
33. Pereira CR, Pereira DR, Silva FA, Masieiro JP, Weber SAT, Hook C, et al. A new computer vision-based approach to aid the diagnosis of Parkinson’s disease. Comput Meth Programs Biomed. 2016;136:79–88. doi:10.1016/j.cmpb.2016.08.005. [Google Scholar] [PubMed] [CrossRef]
34. Al-Jabbar M, Alshahrani M, Senan EM, Abunadi I, Almalki SA, Alshari EA. Hybrid techniques of multi-CNN and ensemble learning to analyze handwritten spiral and wave drawing for diagnosing Parkinson’s disease. Comput Model Eng Sci. 2025;143(2):2429–57. doi:10.32604/cmes.2025.063938. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools