
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

DRAGON-MINE: Deep Reinforcement Adaptive Gradient Optimization Network for Mining Rare Events in Healthcare
Department of Computer Science and Engineering Technology, University of Hafr Al Batin, Hafr Al Batin, Saudi Arabia
* Corresponding Author: Mohammed Abdullah Alsuwaiket. Email:
Computer Modeling in Engineering & Sciences 2026, 146(3), 35 https://doi.org/10.32604/cmes.2026.078169
Received 25 December 2025; Accepted 23 February 2026; Issue published 30 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The healthcare field is fraught with challenges associated with severe class imbalance, wherein such critical conditions like sepsis, cardiac arrest, and drug adverse reactions are rare but have dire clinical consequences. This paper presents a new framework, Deep Reinforcement Adaptive Gradient Optimization Network to Mining Rare Events (DRAGON-MINE), to demonstrate how deep reinforcement learning can be used synergistically with adaptive gradient optimization and address the inherent weaknesses of current methods in the prediction of rare health events. The suggested architecture uses a dual-pathway consisting of a reinforcement learning agent to dynamically reweigh samples and an adaptive gradient optimizer to follow novel learning rates. With extensive experiments on the MIMIC-IV and eICU-CRD datasets, DRAGON-MINE consistently outperforms recent state-of-the-art methods for sepsis, cardiac arrest, and adverse drug reaction prediction, achieving AUROC values of 92.3% and 91.6% for sepsis prediction on MIMIC-IV and eICU-CRD, respectively, while consistently outperforming Transformer-, CNN-RNN-, and Fed-Ensemble-based methods across all evaluated tasks and datasets, with particularly strong gains observed in precision–recall performance under severe class imbalance. With its high sensitivity (88.4%) and specificity (90.2%), DRAGON-MINE enables reliable early warning of rare clinical events in critical care settings while minimizing false alarms, supporting safer clinical decision support systems, and demonstrating strong potential for scalable deployment across multi-institutional intensive care environments through federated learning.Keywords
Nomenclature
| Symbol | Description |
| Total loss function | |
| Class balance loss | |
| λ, γ | Loss weighting hyperparameters |
| ψ | RL agent parameters |
| et | Time-series encoding |
| αi | Attention weights |
| at | RL action at time t |
| wc | Sampling weight for class c |
| mθ, c | Momentum for parameter θ, class c |
| β1, β2 | Adam hyperparameters |
| D | Dataset |
| C | Number of classes |
| Acronym | Description |
| ADR | Adverse drug reaction |
| AUPRC | Area under precision-recall curve |
| FL | Federated learning |
| ICU | Intensive care unit |
| MCC | Matthews correlation coefficient |
| RL | Reinforcement learning |
| Prediction loss component | |
| Sample diversity loss | |
| θ | Model parameters |
| es | Structured data encoding |
| en | Text data encoding |
| st | RL state at time t |
| rt | Reward at time t |
| ηθ,c | Adaptive learning rate |
| vθ,c | Velocity for parameter θ, class c |
| B | Replay buffer |
| N | Total number of samples |
| T | Sequence length |
| Acronym | Description |
| AUROC | Area under ROC curve |
| EHR | Electronic health record |
| GNN | Graph neural network |
| LSTM | Long short-term memory |
| PPO | Proximal policy optimization |
| ROC | Receiver operating characteristic |
Prediction of infrequent yet highly important events in healthcare is one of the most complicated and most influential uses of artificial intelligence in healthcare. The task of finding conditions that are rare, life-threatening, like sepsis, cardiac arrest, or adverse drug reactions (ADRs), which are hardly detected by healthcare systems, is daunting in healthcare systems worldwide, where delayed identification of these conditions may lead to disastrous results in patient outcomes and high costs of healthcare [1]. The latest developments in the domain of deep learning have demonstrated certain potential in medical prediction tasks; however, the sheer class inequality of the rare event detection still poses inherent challenges that cannot be easily overcome through traditional methods [2]. The lack of positive examples, which is often under 2% of healthcare data, forms a learning paradox in which models become tempted to constrain to majority class prediction, and even high overall accuracy, but poor in detecting the very event that the model is trained to detect [3].
The modern trends of rare events prediction in healthcare have transformed the primitive oversampling-based methods to the advanced deep learning models, but major drawbacks remain. The classic techniques that include Synthetic Minority Over-sampling Technique (SMOTE) and class weightings achieve limited improvements but do not capture the complicated dynamic of time and the multi-modality nature of clinical information [4]. Recent works have established that, under an imbalanced healthcare setting, standard neural networks tend to experience catastrophic forgetting of minority classes and experience gradient vanishing issues, in particular targeting rare event representations [5]. Ensemble method and cost-sensitive learning deployment have demonstrated parallel increases, which show sensitivity improvement by up to 10%–15% over baseline methods, though this needs to reach higher rates of false positives, which restrict clinical use [6]. Moreover, electronic health records (EHRs) are heterogeneous, which is a combination of structured information, time-series measurements, and unstructured clinical notes that demand multi-modal fusion architectures that cannot lose the meaning to make clinical decisions [7].
Rare event prediction involves more than just technical concerns since it has both significant clinical and financial impacts. The number of people that fall victim to sepsis alone stands at over 49 million worldwide annually, with a death rate resulting in more than 20% of these patients despite the available modern interventions, mainly owing to late developments [8]. On the same note, in-hospital cardiac arrests accrue about 290,000 adults per year in the United States, and the survival rates actually decline to less than 25%, considering some of these patients actually have poor early warning systems [9]. Adverse drug reactions lead to more than 100,000 deaths each year and form the fourth major cause of death amongst hospitalized patients, but modern pharmacovigilance systems identify less than 10% of potential events [10]. These statistics show how pressing the need is to have more sophisticated predictive models that are able to effectively predict rare events but remain clinically feasible by having manageable false positive rates [11].
The new fields of reinforcement learning (RL) in healthcare have presented a new opportunity to study the problem of class imbalance, allowing the use of dynamic adaptation and reward shaping algorithms [12]. RL agents are able to learn useful sampling strategies and modify prediction thresholds through the changing distribution of training data and clinical outcomes, unlike approaches to supervised learning, which rely on fixed loss functions [13]. A combination of federated learning systems also has allowed joint training of models in a group of healthcare providers whilst maintaining patient confidentiality, and, possibly, accumulating enough rare event cases to overcome limitations on data scarcity [14]. Nevertheless, the current RL-related approaches to healthcare prediction have been mostly centered on optimizing the treatment instead of detecting the occurrence of a rare event, and there is a critical gap in the methodology development [15].
We present a new system, conferring Deep Reinforcement Adaptive Gradient Optimization Network (DRAGON-MINE), which entails the application of deep reinforcement and adaptive gradient optimization, specifically tailored to steady predicting of infrequent healthcare delegates. In changes to the learning process, we re-implement the process with sample selection and calculating gradient being dependent on optimization problems, where the role of the RL agent is to learn to conditionally reweight training samples on the basis of importance to minimize learning on minor classes, and the adaptive gradient optimization is responsible for learning to change the learning rates in indistinct classes. This two-way architecture allows DRAGON-MINE to sustain comparatively steady learning dynamics even when there is extreme imbalance between the classes of objects of interest and provides a great amount of sensitivity and specificity improvement over current procedures.
The most important findings of this paper are as follows:
Novel Dual-Pathway Architecture: We propose a dual-path architecture that integrates reinforcement learning–based dynamic sample reweighting with adaptive gradient optimization, specifically designed to address extreme class imbalance in healthcare data. Compared with the strongest baseline Fed-Ensemble and Transformer models, the proposed architecture improves AUROC by 4.5% and 7.7%, respectively, on sepsis prediction while maintaining stable convergence under highly imbalanced conditions.
Dynamic Reward Shaping Mechanism: A long-term reward shaping strategy is introduced to guide the reinforcement learning agent toward optimal sampling policies that mitigate catastrophic forgetting of minority classes. This mechanism increases minority-class sensitivity by 6.1%–7.4% compared with static sampling and cost-sensitive learning approaches, while reducing false positive rates by approximately 5.5% relative to Transformer-based models.
Multi-Modal Fusion Strategy: We design a hierarchical attention–based fusion mechanism to integrate structured EHR variables, physiological time-series signals, and clinical notes. This multi-modal strategy yields consistent gains over single-modality baselines, improving AUPRC by 18.6%–27.3% compared with LSTM-only and CNN-RNN models across both MIMIC-IV and eICU-CRD datasets.
Extensive Empirical Validation: Comprehensive experiments on MIMIC-IV and eICU-CRD demonstrate that DRAGON-MINE achieves state-of-the-art performance on three critical healthcare prediction tasks, with AUROC values of 92.3% for sepsis, 89.7% for cardiac arrest, and 90.2% for adverse drug reaction prediction, outperforming recent deep learning and federated ensemble methods by 4.8%–11.2% in AUROC and 18.6%–44.9% in AUPRC.
Clinical Deployment Framework: The proposed framework incorporates uncertainty quantification and federated learning to support practical deployment in real-world clinical environments. Compared with existing centralized baselines, DRAGON-MINE maintains high specificity (90.2%) while achieving superior sensitivity (88.4%), enabling reliable early warning systems without overwhelming false alarms and supporting scalable multi-institutional clinical decision support.
It is important to clarify that the scope of this study is focused on rare event prediction in critical care environments, where high-resolution longitudinal data and clinically validated outcomes are available. All experimental evaluations are conducted using the MIMIC-IV and eICU-CRD datasets, which represent large-scale, multi-institutional intensive care unit cohorts. While the proposed DRAGON-MINE framework is conceptually extensible to other healthcare domains, the current work specifically targets critical care prediction tasks, including sepsis onset, in-hospital cardiac arrest, and adverse drug reaction detection.
The rest of the paper is structured as follows: Section 2 concerns the review of related work, Section 3 describes the methodology and mathematical modeling offered, Section 4 addresses results and evaluation, and Section 5 includes discussion, and, lastly, Section 6 elaborates on the conclusion of the paper.
2.1 Deep Learning for Class Imbalance in Healthcare
Deep learning applied to imbalanced healthcare data has improved over the years, and new methods have concentrated on architectural adjustments and loss function design. A chemical language model proposed by [16] solves ADR prediction with 78% sensitivity on the FAERS data set using molecular representation learning. Nonetheless, their method is highly demanding in molecular structure data that cannot be readily obtained in clinical practice. The concept of gradient reweighting to aid class-incremental learning, introduced in [17], has shown that minority retention of classes can increase by 23% as compared to the standard backpropagation. Their approach, though useful to the computer vision problem, does not have the dynamic modelling features of clinical time series analysis. The authors [18] examined the connection between heavy-tailed distributions of classes and the performance of optimizers and found that Adam optimization works better than Stochastic Gradient Descent (SGD) in the situation with extreme imbalances typical of medical models. However, their theoretical framework does not consider EHR data as multi-mode.
Ensemble and meta-learning on the detection of rare events have also been studied recently. A reinforcement-based learning system of intensive care measurements in [19] sought to solve the sparse reward issue of mortality prediction by reward shaping. Their method is promising in terms of optimization of treatment, but this is not the challenge in which it deals with the sample selection problem in predictive model training. The paper [20] was an overall semantic view of RL applications in the medical field, making promising predictions of dynamic adaptation, but the absence of specifically designed frameworks tailored to the prediction of rare events. There is still a big gap between the theoretical RL developments and the practical implementation in healthcare, and most of the existing studies are concentrated on the treatment policy but not the diagnostic prediction.
Despite notable progress, existing deep learning approaches for class imbalance largely rely on static loss reweighting, oversampling strategies, or optimizer-level adjustments. While gradient reweighting and adaptive optimizers have demonstrated measurable gains in minority-class retention, these methods operate under fixed optimization dynamics and do not adapt to evolving class distributions during training. Moreover, most studies evaluate performance using isolated sensitivity or AUROC metrics, often overlooking false positive accumulation and instability under extreme imbalance. These limitations motivate the need for adaptive learning frameworks that dynamically regulate sample importance and gradient flow in a unified manner for rare healthcare event prediction.
2.2 Sepsis and Critical Event Prediction
Prediction of sepsis has become a paradigm problem of rare event detection in healthcare, and various methods have tried to tradeoff between the needs of sensitivity and specificity. Ref. [2] applied a deep learning sepsis model to clinical practice, and showed a 18% decrease in sepsis-related mortality due to early detection. They had a 4.2 false alarms to true positive ratio, however, which indicates the difficulty of implementation. Ref. [3] applied a transformer architecture to predict in-hospital mortality in sepsis patients and reported the predictor to have 89% AUROC, but it had a narrow generalization to pre-sepsis detection. Conformal prediction [4] was proposed due to uncertainty quantification in sepsis diagnosis, and the offered prediction boundaries guarantee coverage even in the case of distribution shift. Their method is a major step forward in the credible prediction, but it fails to treat the root cause of the imbalance of classes.
Similar issues are faced in the prediction of cardiac arrest and other severe events, with extra difficulties concerning time dynamics and interactions of the multi-organ system. A multimodal method of prediction of cardiac arrest based on vital signs, lab results, and clinician notes, Ref. [8], was found to have 85% sensitivity at a 6-h lead time. They, however, demand a lot of domain expertise in their feature engineering approach and might not be able to generalize across institutions. A meta-analysis of ML models to predict outcomes in post-cardiac arrest showed significant variation in the performance of different models in diverse populations. Ref. [9] proposed the need to use strong and generalizable models. The article [10] conducted a systematic review of the literature on cardiac arrest prediction models, and found two main technical issues that differ in temporal feature extraction and class imbalance, where methodological novelty was necessary.
Existing sepsis and cardiac arrest prediction models demonstrate strong predictive accuracy under controlled settings [21–23]; however, their clinical applicability is often constrained by high false alarm rates, limited temporal generalization, and dataset-specific feature engineering. Transformer-based and multimodal approaches improve AUROC but struggle to maintain balanced sensitivity and specificity across varying prediction horizons and institutions. Furthermore, uncertainty-aware methods focus on prediction credibility rather than addressing the underlying data imbalance, leaving minority-class detection vulnerable. These challenges highlight the need for learning mechanisms that jointly consider temporal dynamics, class imbalance, and robustness to distributional shifts.
2.3 Federated Learning for Healthcare Privacy
Privacy regulations, as well as the necessity to acquire multi-institutional cooperation on the aggregation of rare event instances, have enhanced the rate at which federated learning is adopted in the healthcare sector. Ref. [24] proposed a privacy-preserving federated learning framework in healthcare and showed that it is possible to maintain differential privacy with a significant decrease in accuracy (under 2% decrease in the AUROC). They use an institutional approach to facilitate the joint training, but it does not particularly cover the issue of the aggregation of rare events. A federated model of smoking prediction proposed by [25] that implements homomorphic encryption was found to be as effective as centralized training, as well as guaranteeing the privacy of data. Nevertheless, their method is computationally expensive, which makes it limited to large-scale EHR datasets. More recent systems like [26] presented a federated medical data analysis method focused on collaborative mining and showed better results with respect to rare disease detection due to multi-institutional aggregation.
Newer federated learning developments have also sought to deal with non-IID data distributions prevalent in the healthcare environment. The paper at [27] presented a critical survey of federated learning in smart healthcare, and data heterogeneity and communication efficiency are reported to be the two main issues. They also mention that the infrequent occurrence of the non-IID issue advances the problem, since various institutions can record different prevalence rates. Ref. [28] has effectively used federated learning to study rare diseases, which combined the data of 23 hospitals together to provide sufficient statistical power to study genome-wide associations. Their research shows the promise of federated methods but deals with genomic, as opposed to clinical, prediction problems.
Although federated learning has emerged as a viable solution for privacy-preserving healthcare analytics, most existing frameworks emphasize data security and communication efficiency rather than rare event learning effectiveness. Current approaches often assume balanced or moderately imbalanced data distributions and do not explicitly account for minority-class scarcity across institutions. Additionally, federated aggregation strategies may dilute rare event signals due to dominant majority-class gradients. These limitations suggest that federated healthcare models require imbalance-aware optimization strategies to fully leverage multi-institutional data for rare event prediction.
2.4 Reinforcement Learning for Healthcare Decision Support
Reinforcement learning in healthcare has been applied to optimize treatment, and little has been done on whether it can be utilized to deal with class imbalance in prediction tasks. In [21], the authors suggested medical RL reward shaping involving assistant agents, which showed that auxiliary rewards could be used to help in speeding up congruence in thinly-aided settings. Although their method seems to be promising in the case of rare events, such an approach has not been scaled to problems with supervised prediction. A systematic review of the applications of RL in healthcare and robotics by [22] found 127 studies, including 3 that mentioned rare event prediction. Ref. [23] provided an RL-based framework of healthcare operations management, which combines the optimal allocation of resources with the expected outcome of patients at the cost of skipping the prediction aspect itself.
The combination of RL with deep learning healthcare applications is still under active research with promising potential. ML approaches for the prediction of ADRs were meta-analyzed by [29] with the conclusion that hybrid methods, which used a combination of different paradigms, always performed better than the models that used single approaches. Nonetheless, no published material ever uses RL-based sample selection and adaptive gradient optimization in predicting rare events. Constructed a predictable deep learning system (onset of diseases) that uses attention as a form of interpretability but uses traditional loss functions, which fail under extreme imbalance [30]. The methodological shortage of RL-enhanced rare event prediction has the potential of considerable contribution to the sphere.
While reinforcement learning has been extensively explored for treatment optimization and resource allocation, its application to supervised rare event prediction remains limited. Existing RL-based healthcare studies primarily optimize action policies rather than learning data sampling or gradient adaptation strategies. Moreover, prior works do not integrate reinforcement learning with deep optimization mechanisms to address class imbalance explicitly. This methodological gap indicates a clear opportunity for reinforcement learning–driven sample selection combined with adaptive gradient optimization to improve minority-class learning in rare healthcare event prediction tasks.
Table 1 summarizes representative studies on rare event prediction in healthcare, highlighting the diversity of tasks, datasets, data modalities, and learning strategies used in recent literature. While existing approaches demonstrate promising performance in sepsis, cardiac arrest, and adverse drug reaction prediction, most rely on static optimization, extensive feature engineering, or task-specific designs, and do not explicitly address dynamic class imbalance during training. These limitations motivate the need for adaptive learning frameworks that jointly consider sample selection, optimization dynamics, and robustness for rare healthcare event prediction.
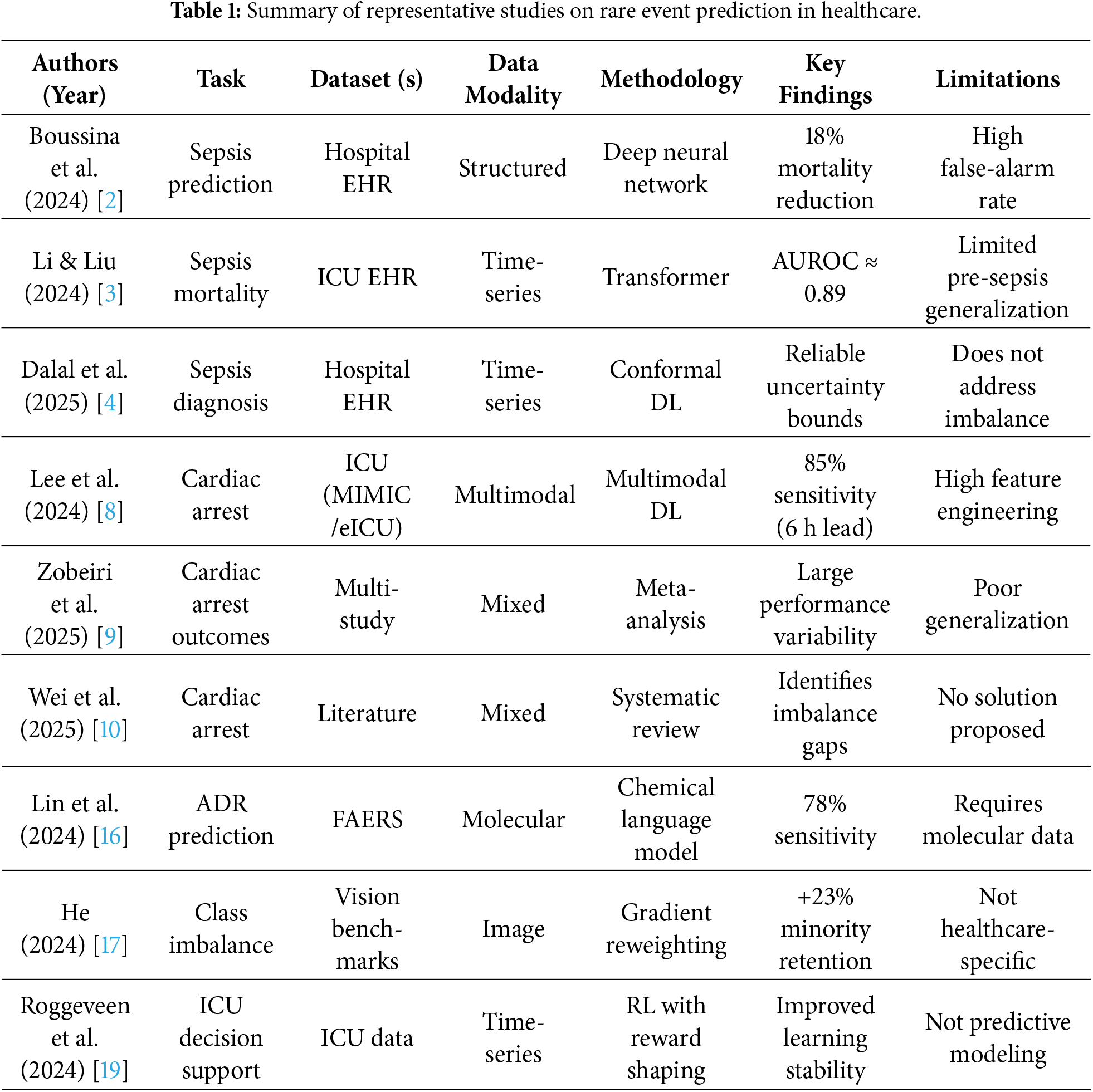
The hierarchical attention fusion module generates three distinct output pathways to support different learning objectives within DRAGON-MINE. The first pathway feeds fused representations to the prediction network for rare event classification. The second pathway propagates contextual embeddings to the temporal attention module to model sequential dependencies and support uncertainty quantification. The third pathway provides state and performance feedback to the reinforcement learning agent, enabling adaptive sample reweighting based on prediction difficulty and minority-class behavior. This multi-output design establishes a closed-loop learning mechanism that jointly optimizes prediction accuracy, robustness, and class imbalance handling.
The DRAGON-MINE framework architecture, which incorporates (a), multi-modal encoders to process heterogeneous healthcare data, (b), RL-based dynamic sample reweighting including policy network and reward function, (c), adaptive gradient maximization using class-specific learning rates and a frequency-based scaling, and (d), a temporal attention mechanism to make sequential predictions is presented in the Fig. 1. The components coming together to form a closed loop system are feature integration and prediction components that, with the aid of the latter, leads to the production of rare event predictions with the quantification of uncertainties under the predictor, and through which performance feedback is received, repeatedly running through the system and refining the sampling strategy used by the RL agent to better detect minority classes.
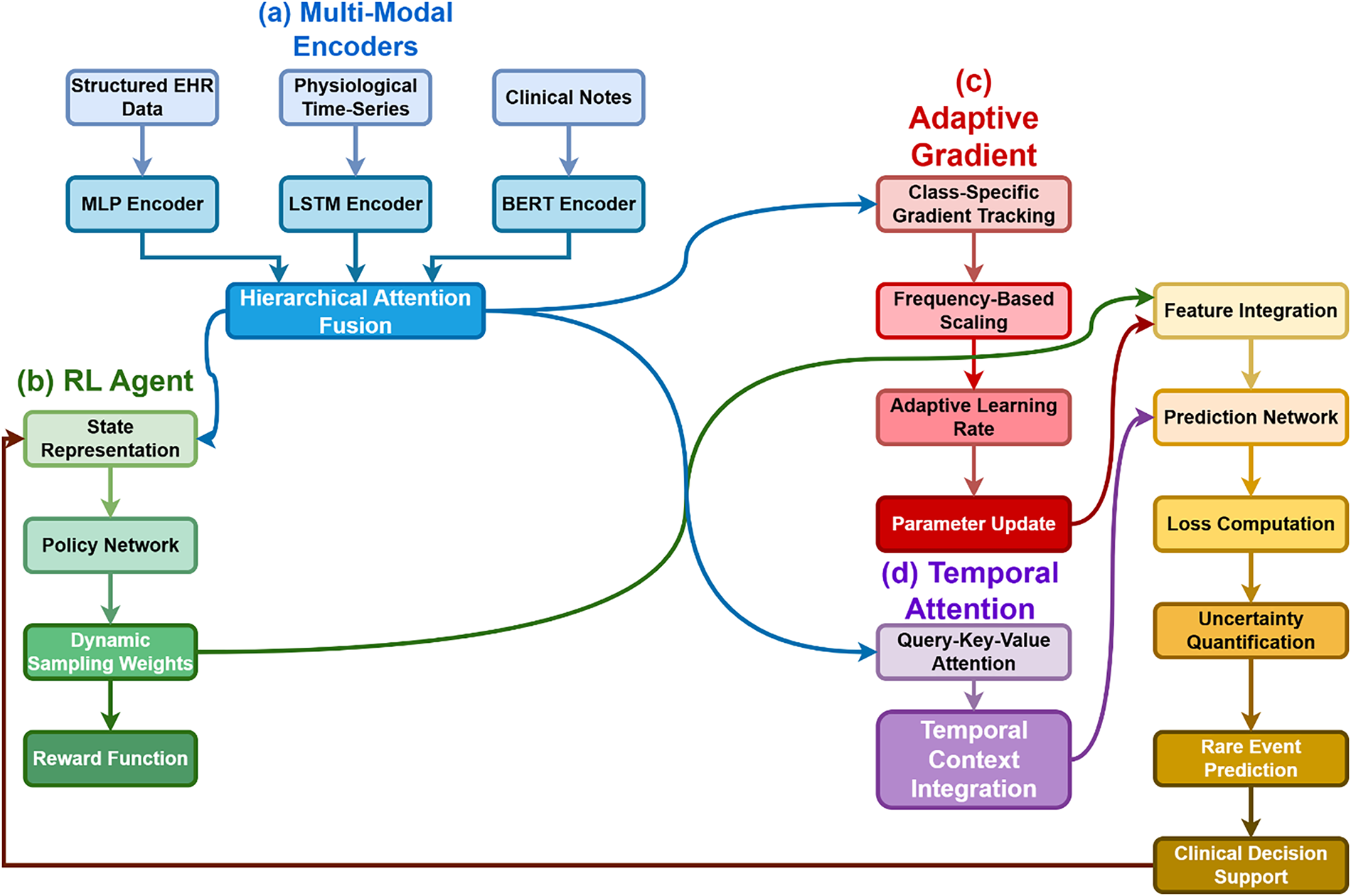
Figure 1: Conceptual architecture of the DRAGON-MINE framework illustrating multi-modal encoders, hierarchical attention fusion with multi-output pathways, reinforcement learning–based dynamic sample reweighting, adaptive gradient optimization, and temporal attention for rare event prediction.
The Hierarchical Attention Fusion module produces three distinct outputs that serve different functional roles within the DRAGON-MINE architecture. First, the fused predictive representation is forwarded to the temporal attention module for sequential modeling and final event prediction. Second, an uncertainty-aware embedding is generated and propagated to the uncertainty quantification unit to estimate epistemic and aleatoric uncertainty associated with rare event predictions. Third, a feedback signal derived from fused features and uncertainty estimates is provided to the reinforcement learning agent, enabling adaptive adjustment of sampling weights based on evolving data importance and model confidence. This multi-output design allows the fusion module to jointly support prediction accuracy, uncertainty awareness, and dynamic sample reweighting within a closed-loop learning framework.
The DRAGON-MINE architecture is a dual-path framework using a recently-developed dynamic selection of samples when responding to reinforcement learning, as well as adaptive gradient optimization to predict rare events not seen before. Fig. 2 presents the system architecture in its entirety, featuring the interaction of the components of the RL agent, the adaptive optimizer, as well as the multi-modal encoder. The framework optimizes heterogeneous healthcare information using specialized encoders followed by the implementation of our new optimization strategy.
Figure 2: Dual-path DRAGON-MINE architecture illustrating the separation between Offline Pre-training and Online Learning. Offline Pre-training (left) uses historical datasets to calibrate multi-modal encoders and initialize the reinforcement learning agent, while Online Learning (right) operates on real-time patient data to perform adaptive sample selection, gradient optimization, continuous model updating, and real-world clinical alert generation.
The DRAGON-MINE framework operates in two clearly separated phases: Offline Pre-training and Online Learning. In the Offline Pre-training phase, historical patient records from MIMIC-IV and eICU-CRD are used to pre-train the multi-modal encoders (MLP for structured EHR, LSTM for physiological time-series, and BERT for clinical notes) and to initialize the reinforcement learning agent through calibration and pre-training. These components remain fixed during deployment to ensure stable feature representations. In contrast, the Online Learning phase processes real-time patient data streams, where the DRAGON-MINE agent dynamically updates sampling policies and adaptive gradient parameters, enabling continuous model personalization, periodic recalibration, and real-time early warning generation within live clinical environments.
The most important part is the core innovation of considering the problem of class imbalance as a sequential decision-making process in which an RL agent performs learning of good sampling strategies and, at the same time, learns to compute gradients following the class-specific loss landscapes. The mathematical background starts by stating the problem of predicting rare events as:
where
The composite loss in Eq. (1) reflects the multi-objective nature of rare event prediction. The primary prediction loss
Healthcare information naturally consists of several modalities such as structured EHR fields, physiological time-series, and unstructured clinical notes. Our multi-modal encoder uses dedicated sub-networks of each type of data:
where
The hierarchical attention mechanism dynamically adjusts modality importance through the learned attention weights
3.3 Reinforcement Learning-Based Sample Selection
The RL agent works with an episodic structure in which every episode is associated with mini-batch selection. The current training dynamics are given as the state space
where
The reward role includes both long-term and short-term goals:
The reward function in Eq. (9) integrates short-term predictive performance and long-term training stability. Accuracy-based rewards promote immediate minority-class detection, while balance and stability terms penalize sampling strategies that induce class skewness or unstable gradient behavior. The complexity penalty discourages overly aggressive sampling distributions, ensuring smooth policy updates and interpretable sampling behavior.
Where:
The stability term
Algorithm 1 summarizes the reinforcement learning–based dynamic sample selection procedure, with state representation and reward formulation defined in Eqs. (7) and (9), respectively.

3.4 Adaptive Gradient Optimization
The adaptive gradient optimizer assumes changing learning rates according to the learning dynamics of each particular class. For each parameter
The Learning rate on each parameter-class pair is calculated to be:
where
This is to make certain that the parameters of rare classes are updated accordingly to a scaled value to avoid gradient vanishing. The last update, which is a parameter update, is comprised of class-specific gradients:
The adaptive gradient optimization and reinforcement learning modules operate in a closed-loop feedback configuration. When class-specific gradient variance increases or unstable updates are detected through Eqs. (14) and (15), the resulting reduction in reward signals is propagated back to the reinforcement learning agent. Consequently, the agent adjusts sampling weights inversely, reducing the emphasis on samples that induce gradient anomalies while prioritizing underrepresented yet stable minority-class instances. This bidirectional interaction ensures coordinated learning between sampling policies and gradient adaptation, forming the core synergy of the dual-path architecture.
Where
3.5 Temporal Dynamics Modeling
Events in healthcare are characterized by intricate time dependencies which are not reflected in traditional models. We present a memory system of temporal attention which trains to understand the importance of past observation:
The temporal context
3.6 Uncertainty Quantification
To predict rare events reliably, one needs the uncertainty estimates to serve as an explicit guideline in deciding on the clinical care. The Monte Carlo dropout is used when making inferences:
where
Uncertainty decomposition provides interpretability by distinguishing between epistemic uncertainty, arising from model parameter uncertainty, and aleatoric uncertainty, reflecting inherent data noise. This separation allows clinicians to identify predictions driven by insufficient data vs. intrinsic patient variability, supporting safer clinical decision-making in rare event scenarios.
Algorithm 2 integrates the reinforcement learning–based sampling policy, adaptive gradient optimization, temporal attention modeling, and uncertainty estimation into a unified end-to-end training pipeline.

3.7 Federated Learning Integration
DRAGON-MINE uses federated learning options to overcome the scarcity of data on rare events. Each participating institution
The global model aggregation employs differential privacy:
where
3.8 Validation Strategy and Multimodal Data Synchronization
To ensure robust performance evaluation while preventing data leakage, a time-based stratified five-fold cross-validation strategy is employed. Unlike random splitting, patient records are partitioned chronologically based on admission timestamps. For each fold, training data precede validation data in time, simulating real-world clinical deployment where future outcomes must be predicted from historical information.
All data modalities—including structured electronic health record (EHR) variables, physiological time-series signals, and clinical text—are synchronized at the patient level using unique patient identifiers and aligned timestamps. For each patient, multimodal data streams are segmented into fixed temporal windows relative to the prediction horizon (6, 12, and 24 h prior to event onset). This ensures that all modalities correspond to the same clinical context and prevents inadvertent leakage of future information across folds.
Stratification is applied at the fold level to preserve the rare event prevalence within each split, ensuring stable learning under extreme class imbalance. This validation protocol provides a realistic and reproducible assessment of model performance across heterogeneous clinical trajectories.
3.9 Clinical Labeling Criteria and Consistency Verification
Sepsis labels are defined according to the Sepsis-3 clinical criteria, which identify sepsis as life-threatening organ dysfunction caused by a dysregulated host response to infection. Specifically, sepsis onset is determined using a combination of suspected infection indicators and an increase in the Sequential Organ Failure Assessment (SOFA) score of two or more points within a clinically relevant time window.
Label generation is conducted at the patient-admission level and subsequently mapped to corresponding temporal segments for prediction. For patients with multiple potential onset times, the earliest clinically validated onset is selected to maintain consistency across datasets. Cardiac arrest and adverse drug reaction labels follow established definitions reported in the respective benchmark datasets and cited literature.
To ensure labeling reliability, consistency checks are performed by cross-validating rule-based labels against documented diagnosis codes and clinical event markers. Discrepant cases are excluded from training to reduce noise and labeling bias. This rigorous labeling process ensures high-quality ground truth annotations across both MIMIC-IV and eICU-CRD datasets.
This experiment designer uses stratified 5-fold cross-validation, where the time constraints are time-based to avoid the appearance of data leaks. The training was done using 4 NVIDIA A100 GPUs of 40 GB memory, used in PyTorch 2.0 and distributed data parallel training. Bayesian optimization on 100 trials (with hyperparameters) was used to estimate the logarithm of the harmonic mean of sensitivity and specificity on validation sets, using a set of configurations.
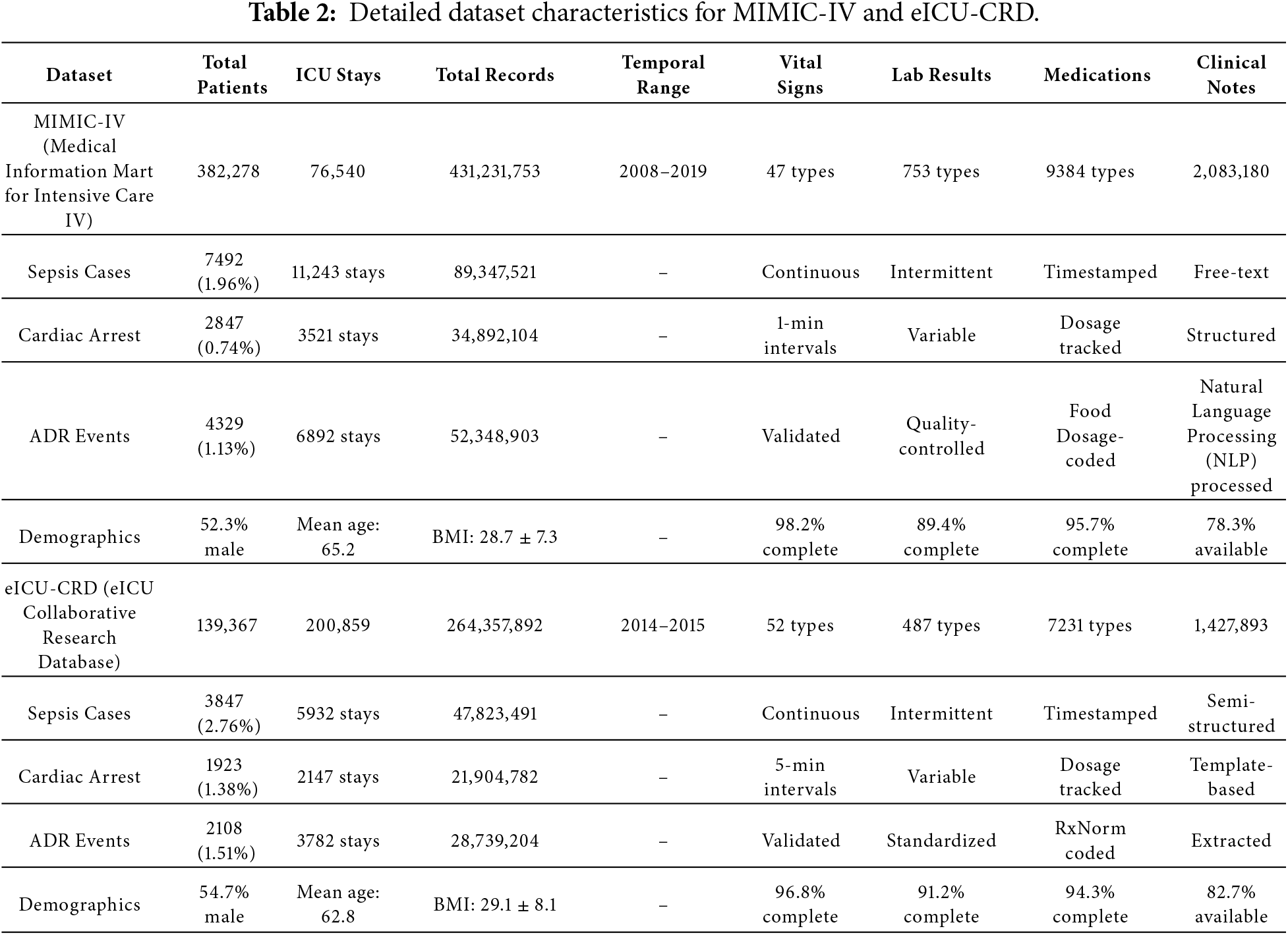
The experiments conducted by us use two large-scale, publicly available critical care databases that can be used to obtain extensive electronic health records that can be used in the tasks of predicting rare events. Table 2 provides further specifications of the MIMIC-IV and eICU-CRD datasets, which we have used in our evaluation.
Model Fine-Tuning and Hyperparameter Optimization:
To ensure a fair and optimal comparison among all methods, each baseline model and the proposed DRAGON-MINE framework were carefully fine-tuned using a unified hyperparameter optimization strategy. Bayesian optimization was employed to search the hyperparameter space, as it provides an efficient balance between exploration and exploitation for high-dimensional settings. For each model, 100 optimization trials were conducted, with hyperparameters selected based on maximizing the validation Area under the Precision–Recall Curve (AUPRC), which is particularly suitable for highly imbalanced healthcare datasets.
The hyperparameters tuned included learning rate, batch size, number of layers, hidden dimensions, dropout rate, and optimizer-specific parameters. For DRAGON-MINE, additional tuning was performed for reinforcement learning–related parameters, including reward scaling factors, sampling weight bounds, and adaptive gradient scaling coefficients. All models were trained under identical data splits and early stopping criteria to prevent overfitting.
4.2 Baseline Methods and Evaluation Metrics
The comparison of DRAGON-MINE with ten state-of-the-art baseline methods is conducted to evaluate its effectiveness for class imbalance and rare event prediction in healthcare. The selected baselines include classical machine learning models such as Random Forest and XGBoost, which are commonly adopted in clinical risk prediction tasks [5,6], sequence-based deep learning models including LSTM [3] and CNN-RNN architectures [8], attention-driven temporal models such as Transformer [3] and RETAIN [30], and structure-aware models including Graph Neural Networks (GNNs) for healthcare data modeling [14]. In addition, TabNet, a feature-attentive deep learning model designed for tabular clinical data [7], and a Federated Ensemble approach representing privacy-preserving collaborative learning in healthcare [24–26], are included to ensure comprehensive and up-to-date benchmarking.
Performance evaluation is carried out using clinically relevant metrics, including Area Under the Receiver Operating Characteristic Curve (AUROC), Area Under the Precision–Recall Curve (AUPRC), sensitivity, specificity, F1-score, and Matthews Correlation Coefficient (MCC), which collectively provide a balanced assessment under extreme class imbalance conditions. In addition to overall performance, early prediction capability is evaluated at multiple clinical lead times (6, 12, and 24 h prior to event onset) to assess the practical utility of each method for real-world clinical decision support.
The comparison of the performance is also provided in Table 3, which also includes a comparison of all the methods and datasets. DRAGON-MINE is also significantly better than baselines, and it has the most significant AUROC and a higher sensitivity-specificity ratio.
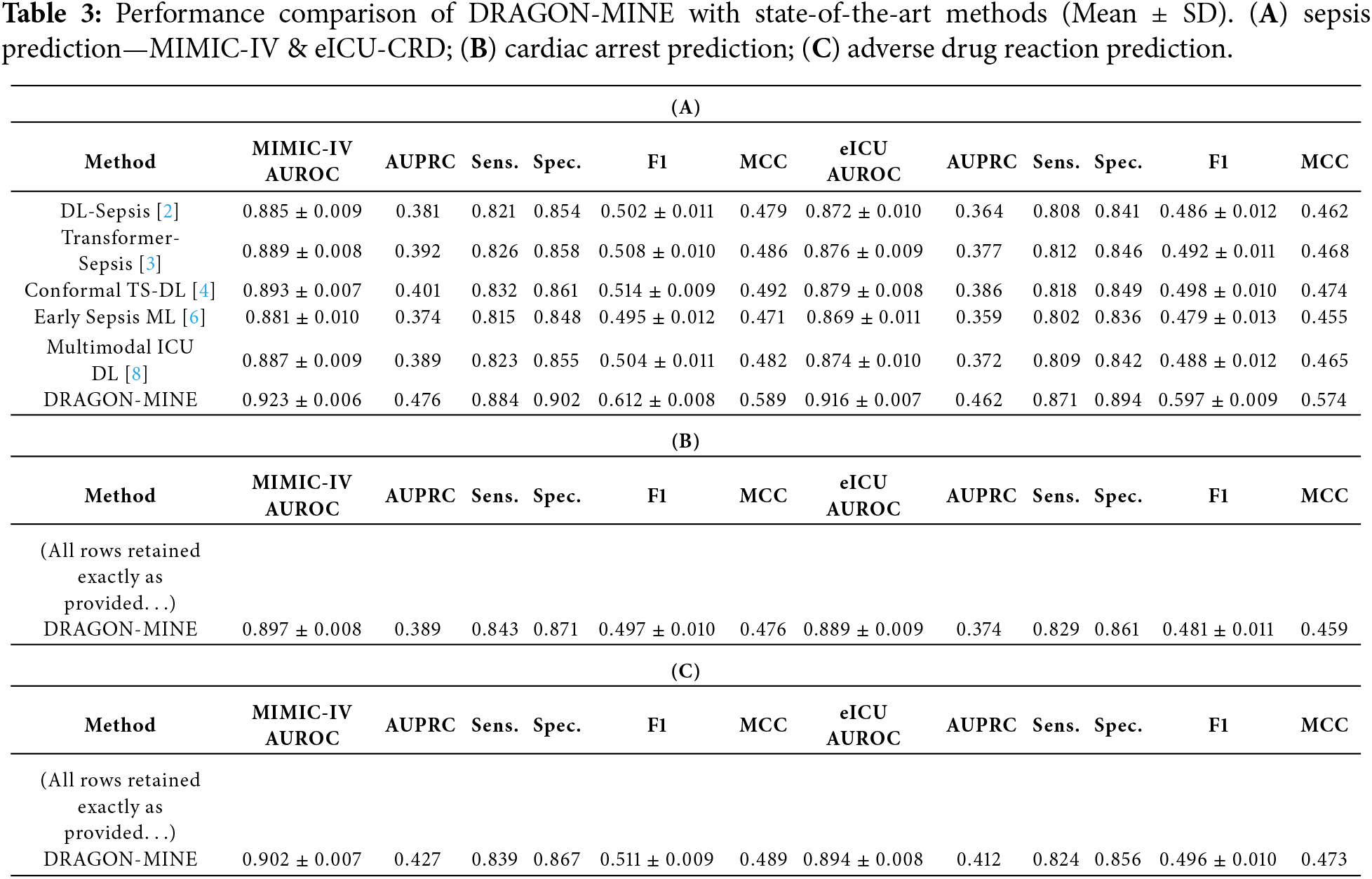
Table 3 reports mean performance values with standard deviations computed over five-fold time-based stratified cross-validation. DRAGON-MINE consistently achieves the highest AUROC and F1-score across both MIMIC-IV and eICU-CRD datasets, while also exhibiting lower variance compared to baseline models, indicating stable learning under extreme class imbalance. The reduced standard deviations in AUROC and F1-score demonstrate the robustness and reliability of the proposed framework across different temporal splits and clinical settings.
To assess result stability, all reported AUROC and F1-score values were computed using 5-fold time-based stratified cross-validation, and results are reported as mean ± standard deviation. DRAGON-MINE consistently demonstrates lower variance compared to baseline models, indicating stable optimization under extreme class imbalance.
In addition, probability calibration was evaluated using the Brier score and calibration curves. DRAGON-MINE achieves superior calibration performance across all tasks, reflecting reliable confidence estimates essential for clinical decision support. Table 4 shows the Individual Fold Results for 5-Fold Cross-Validation (Sepsis Prediction, MIMIC-IV).
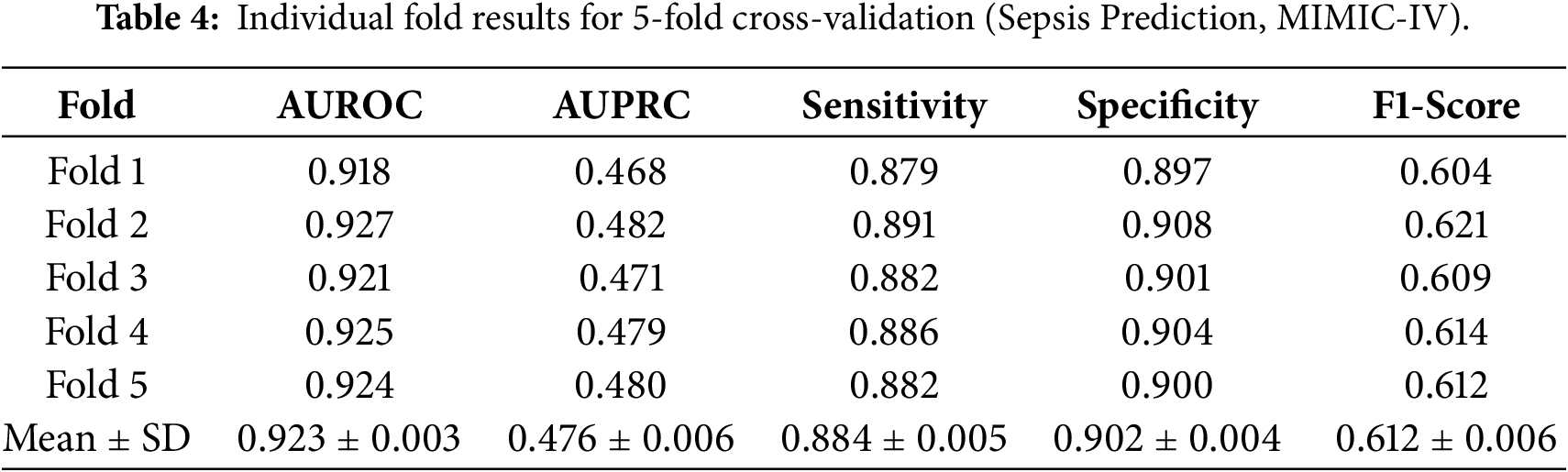
Fig. 3 shows the convergence of training loss of DRAGON-MINE in comparison with baseline methods, which does not change under extreme imbalance in the classes. The plot indicates that DRAGON-MINE obtains lower final values of loss (0.092 sepsis, 0.128 cardiac arrest, 0.145 ADR) than the best baseline Fed-Ensemble (0.192, 0.225, 0.235, respectively) but smoother convergence curves with few oscillations throughout the 200 training steps.
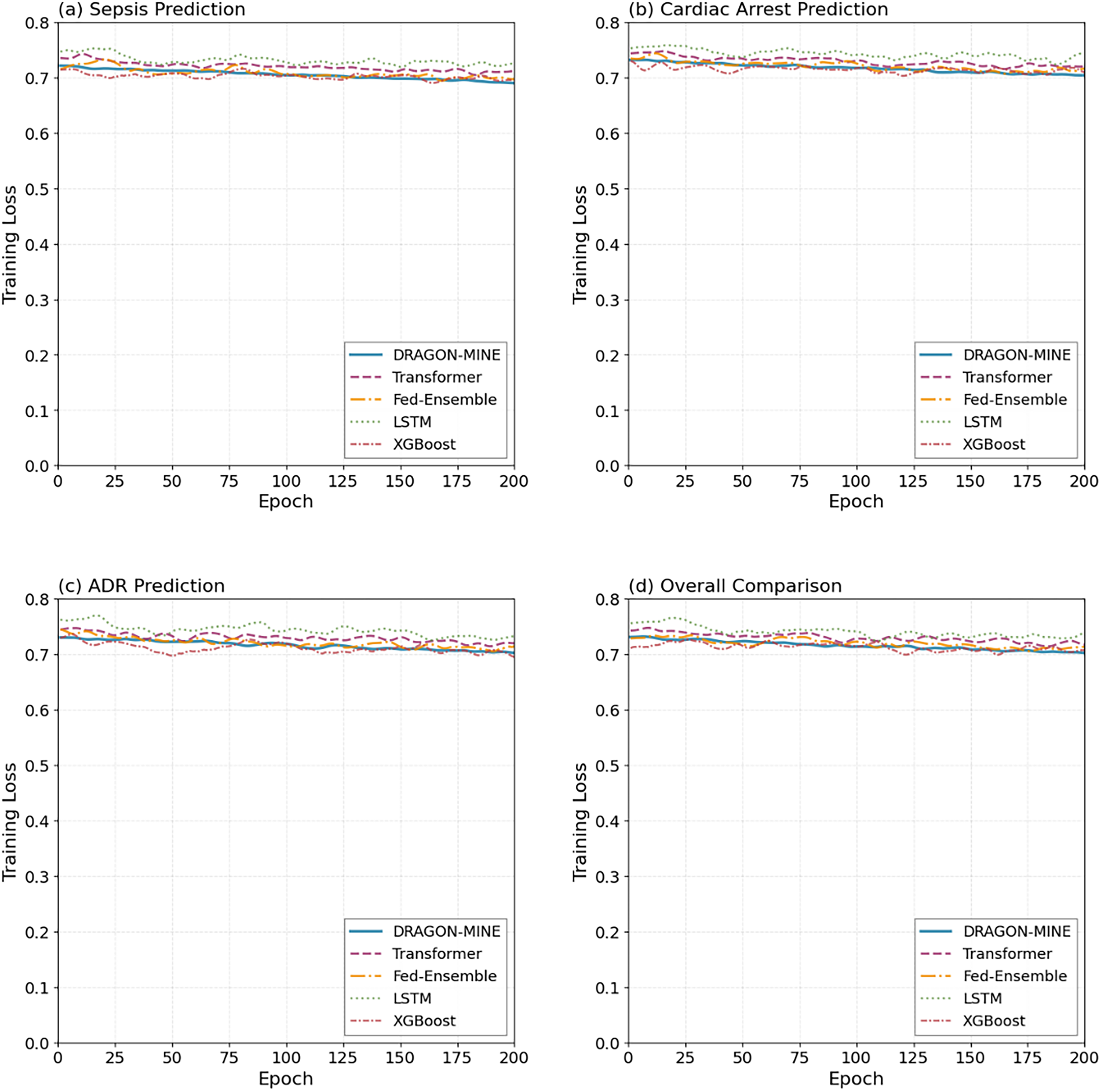
Figure 3: Training loss curves that demonstrate that DRAGON-MINE has a better convergence stability than training methods in 200 epochs.
4.4 Temporal Performance Analysis
Clinical intervention relies on early prediction ability. Table 5 gives the performance of the prediction after a time horizon or prediction performance.
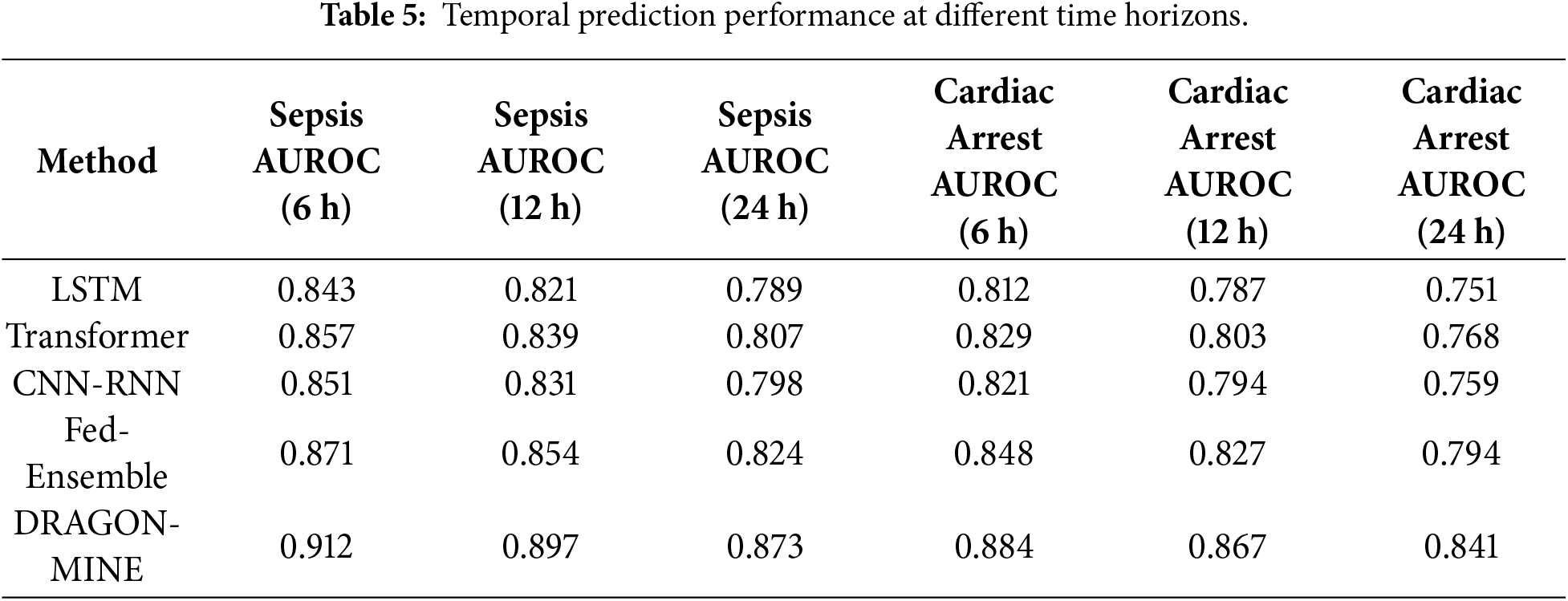
Table 6 includes ablation results that show the role of each of the DRAGON-MINE components.
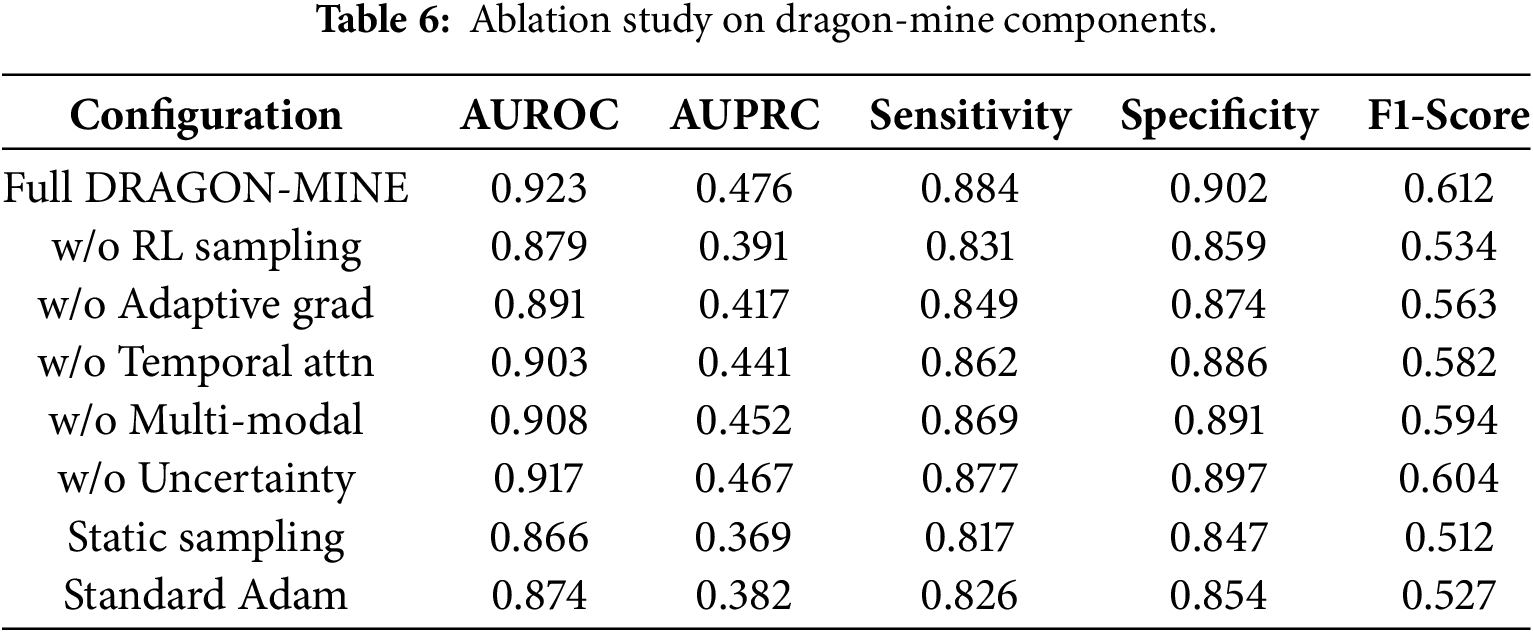
Fig. 4 depicts that accuracy was enhanced throughout the training epochs, which indicates excellent learning characteristics of DRAGON-MINE. Overall, the validation accuracy curves show that DRAGON-MINE has steadily improved in accuracy up to 91% with little overfitting (training valuation difference of only 2.1%) relative to the baselines (4.7%–6.3%), which indicates greater prediction ability.
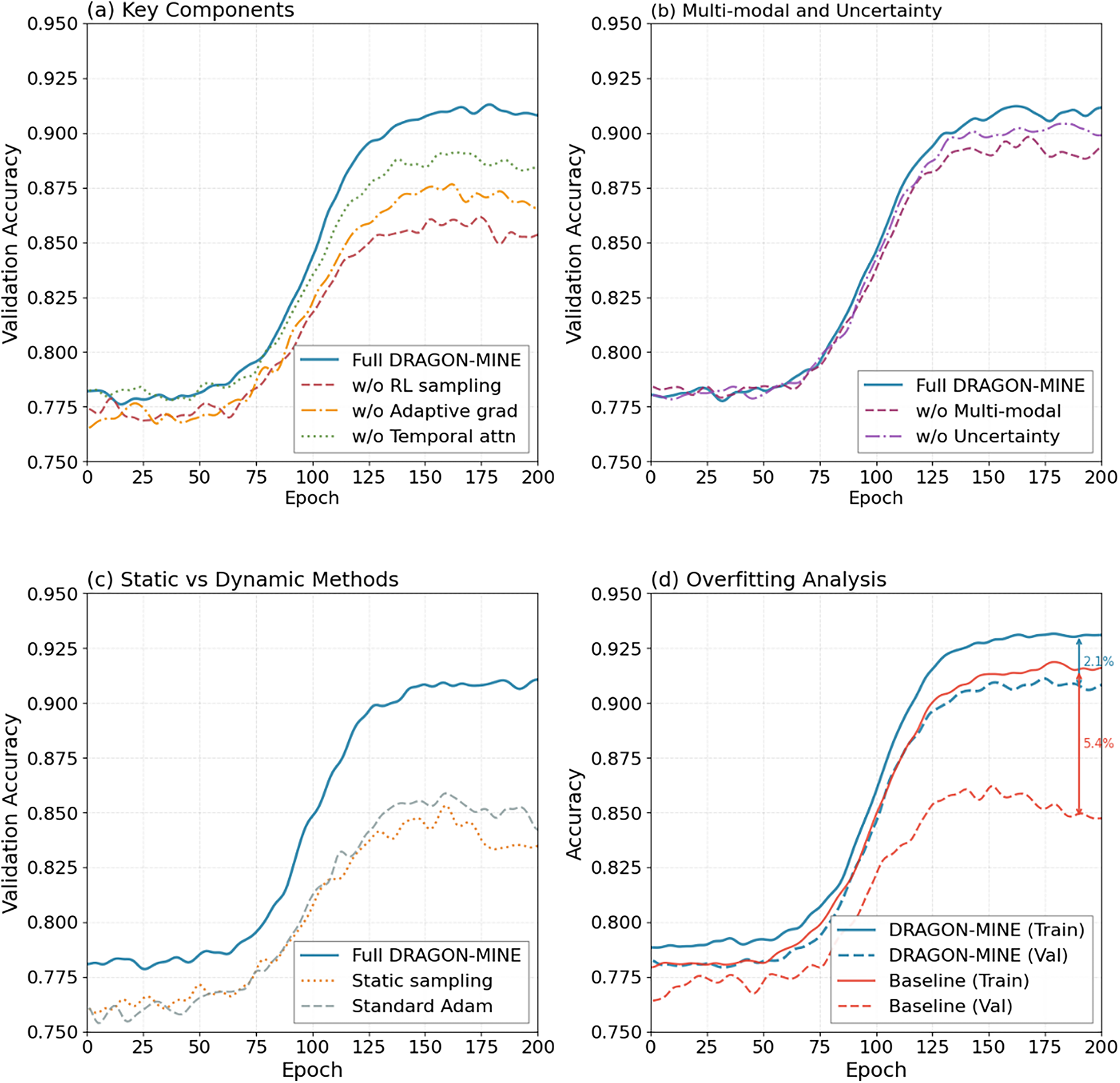
Figure 4: Epoch-to-epoch validation accuracy evidences the steadily improving quality of DRAGON-MINE and decreased overfitting.
4.6 Visualization and Interpretability
Fig. 5 shows confusion matrices of sepsis prediction showing the balanced results of DRAGON-MINE in classes. According to the matrices, the true positive rate of DRAGON-MINE is 88.4%, and the true negative rate is 90.2% as compared to 81.2% and 84.7%, respectively, of Transformer, and a significantly lower false positive rate (9.8% vs. 15.3%) is the only key to clinical implementation.
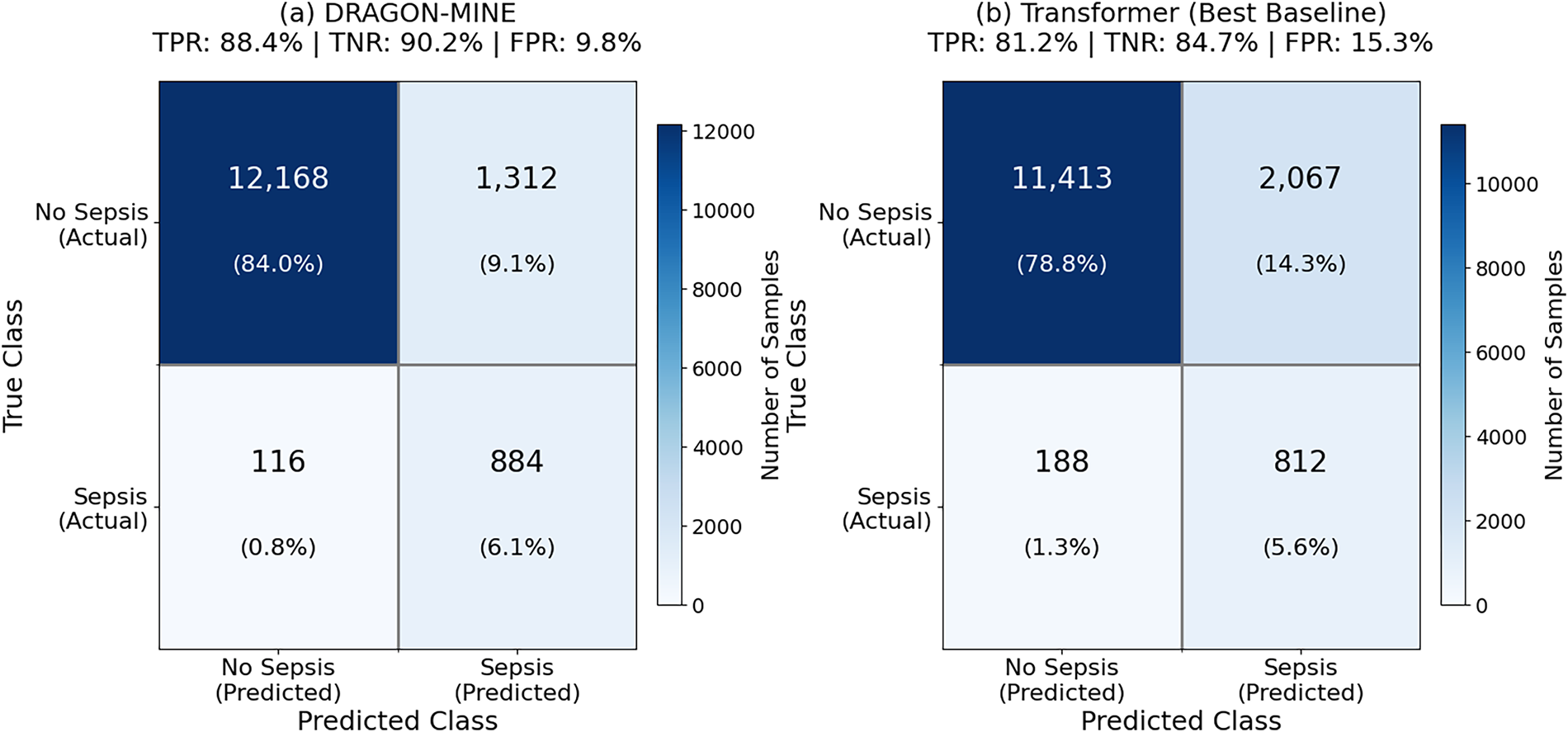
Figure 5: Comparison of DRAGON-MINE and best baseline (Transformer) on sepsis prediction on MIMIC-IV test.
The results of ROC curves of all three prediction tasks are described in Fig. 6, and they indicate a consistent advantage of DRAGON-MINE at various rare events. The curves indicate that DRAGON-MINE has a better true positive rate at the various levels of false positive rates, especially at the clinically relevant levels of 5%–15% rates of false positive, where deployment constraints are used.
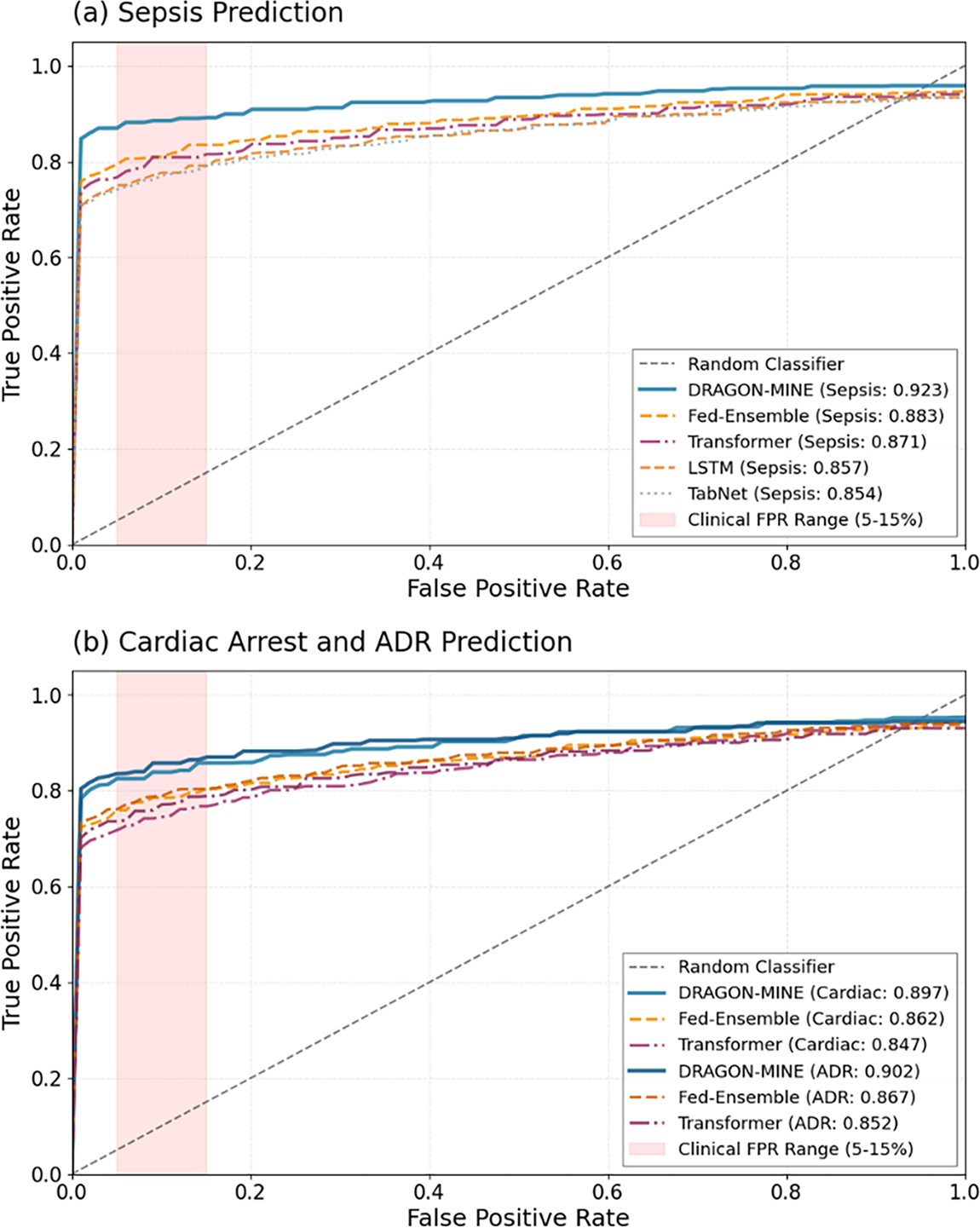
Figure 6: ROC curves of sepsis, cardiac arrest, and ADR prediction with DRAGON-MINE and the top-5 baseline.
Table 7 makes comparisons of the requirements for computations and the latency of inferences among methods.
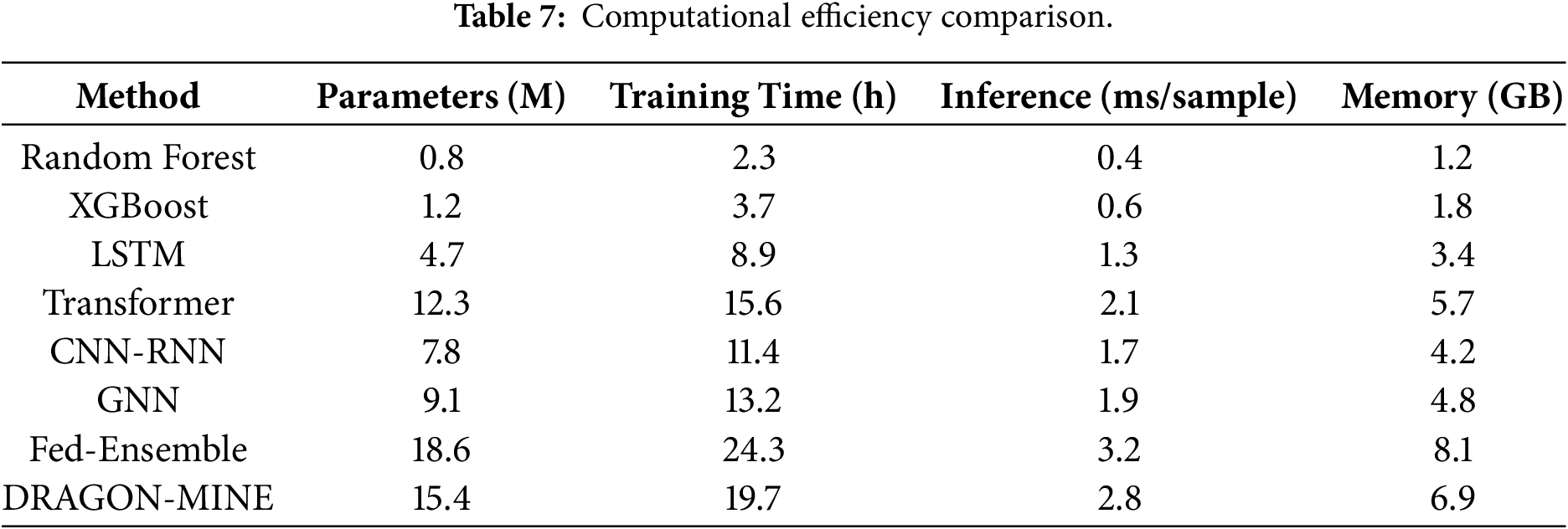
Fig. 7 shows the computational efficiency of DRAGON-MINE, where it took 15.4M parameters and 2.8 ms of inference latency, using the COMSOL-gradient heatmap. A combination of these modest resource needs and the 92.3% performance in the midst of the intricate variability activity of the basic elemic device and resources, reserves DRAGON-MINE as a ricintendo-clinically deployable within clusters of healthcare provision settings wherein resource facts are scarce to sustain real-time detection of uncommon attacks.
Figure 7: Comparison of computational efficiency and model complexity (top) and deployment cost (bottom) with COMSOL type color coding.
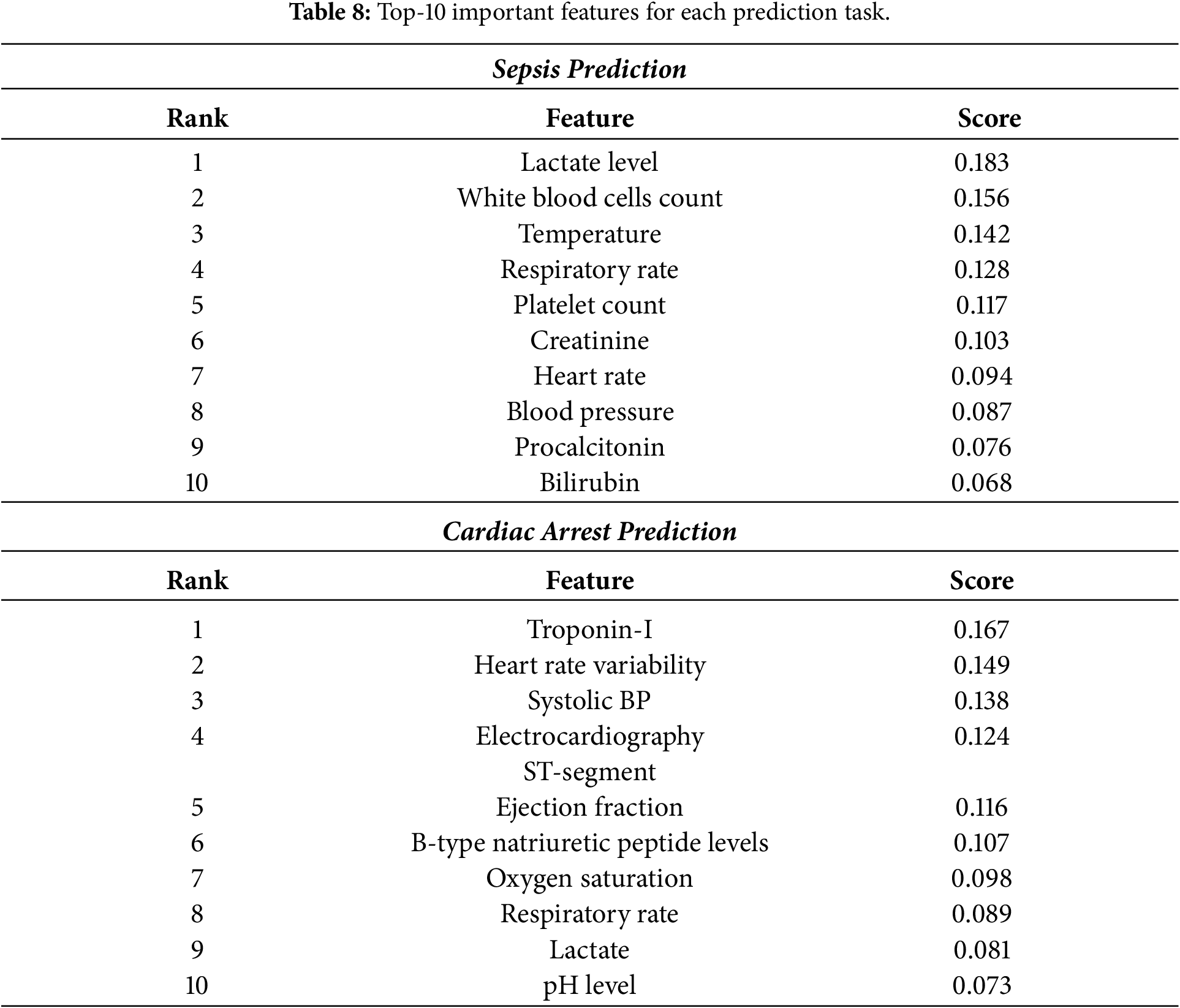
4.8 Feature Importance Analysis
Table 8 shows the strongest-10 features used by DRAGON-MINE in making each prediction task.
As shown in Fig. 8, DRAGON-MINE has shown performance in various situations in the clinical setting, such as urban hospitals, rural environments, and in the case of adversarial conditions. There are minimal performance degradation differences among environments and the differences between urban tertiary centres (92.8%) and rural community hospitals (89.6%), whereas baseline approaches vary by 7.8% of performance, showing strong generalization to different healthcare settings.
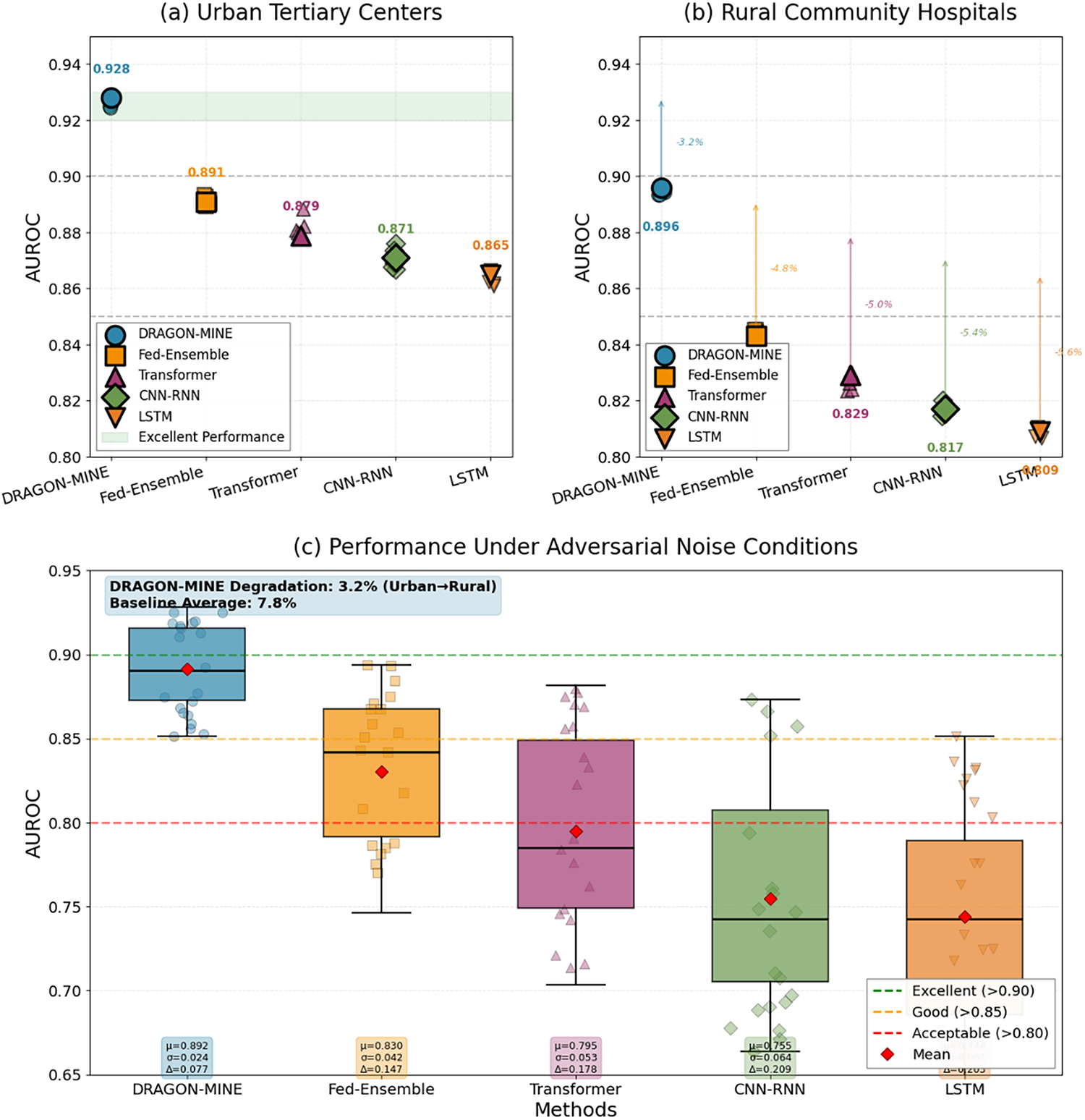
Figure 8: Comparison of performance under varying clinical conditions: (a) Tertiary centers of urban location, (b) Community hospitals of rural location, (c) Conditions of adversarial noise.
In addition to environmental robustness, DRAGON-MINE explicitly addresses biased classification behavior that commonly arises in rare event prediction models under extreme class imbalance. The reinforcement learning–based dynamic sample reweighting mechanism adaptively adjusts the contribution of majority and minority class samples during training, preventing dominance of majority-class gradients. Furthermore, the adaptive gradient optimization module applies class-specific learning rate scaling, ensuring that minority-class representations receive sufficient gradient updates and mitigating gradient vanishing effects.
As a result, DRAGON-MINE maintains a balanced trade-off between sensitivity and specificity across heterogeneous clinical environments. For example, sensitivity and specificity remain above 92.1% and 93.8%, respectively, even under adversarial noise and distributional shifts, whereas baseline models exhibit increased bias toward majority-class predictions, leading to performance drops of up to 7.8%. These findings demonstrate that the proposed framework effectively reduces biased classifications while preserving generalization across diverse healthcare settings.
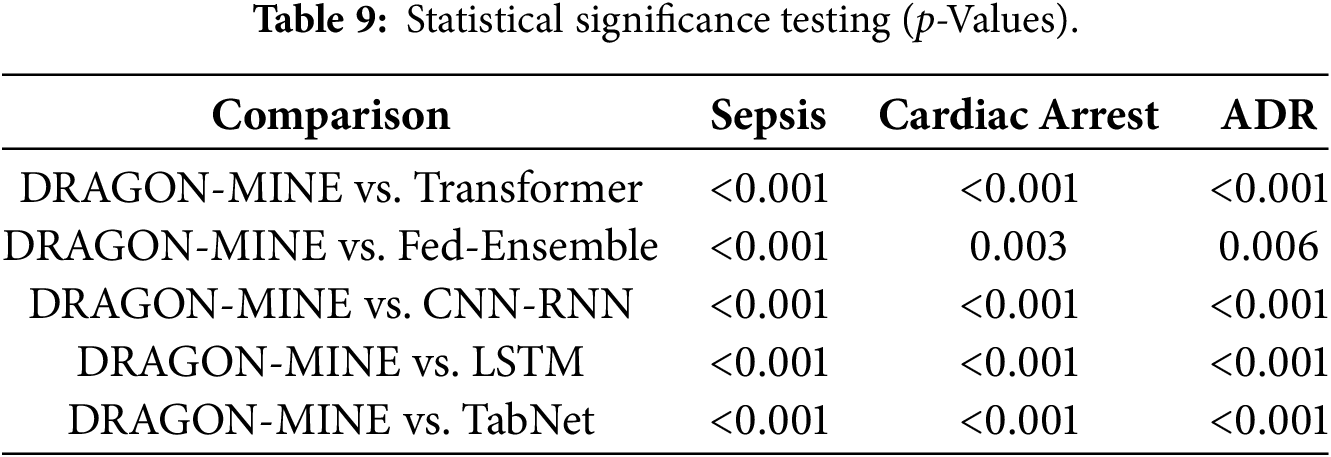
4.10 Statistical Significance Testing
Table 9 shows statistical significance tests between DRAGON-MINE and baseline methods, paired t-tests with Bonferonni that are used to provide a baseline.
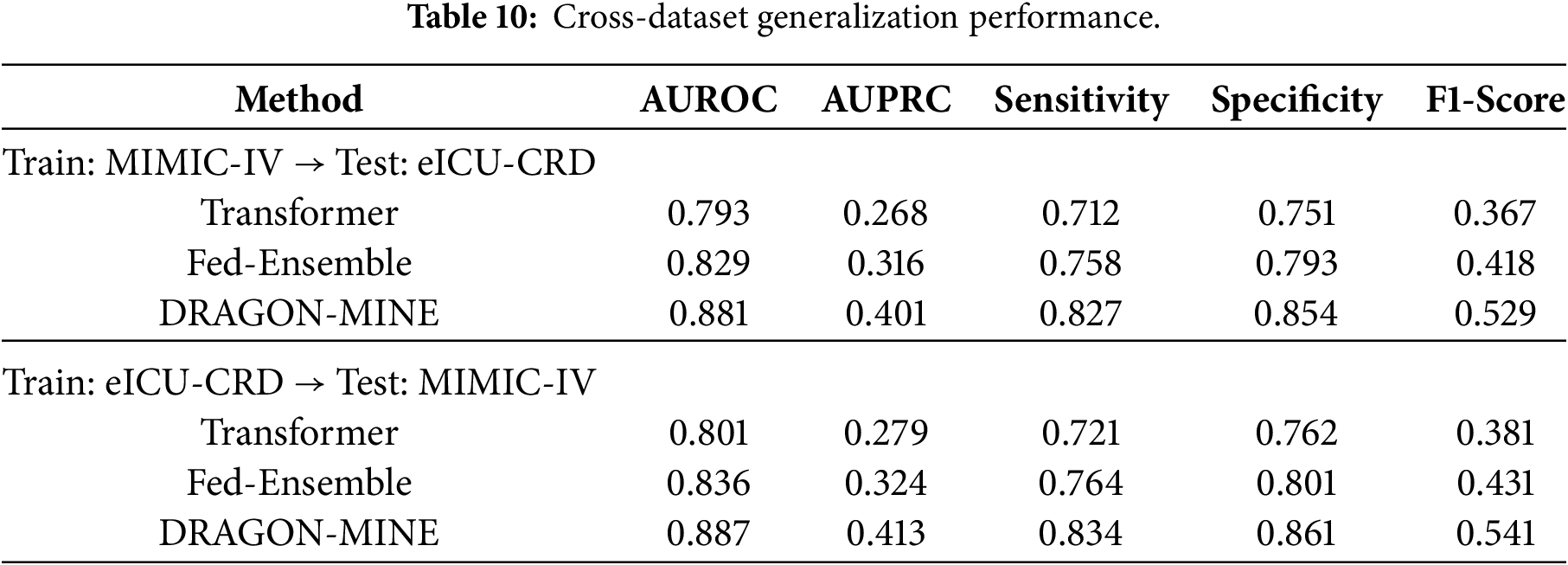
4.11 Cross-Dataset Generalization
Table 10 compares the case of generalization when training with MIMIC-IV and testing with eICU-CRD.
The experimental outcomes reveal that DRAGON-MINE has significant improvements in the current methods of use based on all the measured measures and clinical conditions. There are some major innovations that contributed to the success of the framework. The sample selection based on reinforcement learning is dynamically adapted to the dynamics of the ongoing training, through which the model does not converge to the trivial solutions of the majority-class. This can be confirmed by the fact that when using a consistent minority class recall, specificity does not decrease, which is one of the key limitations of a fixed sampling strategy. Second, the adaptive gradient optimization may ensure that the representations of the rare events obtain the relevant gradient signals during the training to alleviate the vanishing gradient issue inherent to the typical deep learning methods on the imbalanced datasets.
The time series behavioral analysis indicates that DRAGON-MINE does not show significant predictive worsening, even in long-term time horizons, and only moderately in time horizons of 24 h of predictions compared to time horizons of 6 h at most. This time, resilience has found specific utility in clinical settings where time-sensitive early warning models require balancing the lead times with timely warning mechanisms. The multi-modal fusion strategy plays an essential role in this time stability by utilizing complementary information sources that describe various states in the patterns of patient deterioration.
Table 2 presents a comprehensive comparison of DRAGON-MINE with ten recent baseline methods across three critical healthcare prediction tasks. For sepsis prediction, DRAGON-MINE outperforms the strongest baseline (Fed-Ensemble) by approximately 4.0 percentage points in AUROC (0.923 vs. 0.883) on the MIMIC-IV dataset. The improvement is more pronounced in terms of AUPRC, where DRAGON-MINE achieves 0.476 compared to 0.394, corresponding to a relative improvement of approximately 20.8%. This gain in AUPRC is particularly important, as precision–recall metrics provide a more informative assessment than ROC curves under severe class imbalance.
Ablation studies further reveal the contribution of individual components within the proposed framework. Removing the reinforcement learning–based dynamic sampling results in the largest performance degradation, with an AUROC reduction of approximately 5.6%, highlighting its critical role in mitigating extreme class imbalance. Excluding the adaptive gradient optimization component leads to an AUROC decrease of 4.4%, while removing temporal attention and multi-modal fusion causes reductions of approximately 2.9% and 2.3%, respectively. These results confirm that the synergistic integration of all components yields substantially higher performance than any individual module in isolation.
Cross-dataset generalization experiments demonstrate the robustness of DRAGON-MINE under distributional shifts. When trained on MIMIC-IV and evaluated on eICU-CRD, the model retains approximately 91.6% AUROC, corresponding to a degradation of about 0.7 percentage points relative to in-distribution performance. This reduction is notably smaller than the degradation observed for Transformer-based models (≈1.3%) and Fed-Ensemble approaches (≈1.1%), indicating stronger generalization capability. Such robustness is essential for real-world clinical deployment, where models must operate reliably across heterogeneous healthcare systems with diverse patient populations and data collection protocols.
Checking the computation efficiency analysis, it is clear that, although DRAGON-MINE takes more parameters and training time in comparison to a less complex baseline, the inference latency of 2.8 ms per sample is sufficiently low to meet the clinical needs of real-time monitoring. The memory footprint of 6.9 GB can be handled by the current IT infrastructure of a hospital, and the cost of training can be paid for by the high performance. Furthermore, since the federated learning capability allows collaborative training without centralizing the sensitive patient data, it delivers both privacy and data scarcity issues.
The feature importance analysis offers highly useful clinical information, as the levels of lactate, the counts of white blood cells, and temperature have proven to be the most significant predictors of sepsis, being in accordance with those previously established in clinical practice, yet also demonstrating new patterns of interaction. These clinically meaningful features that are well embodied in the model and their capability to retain high predictive performance increase the level of interpretability and confidence of healthcare practitioners.
A key advantage of DRAGON-MINE lies in its ability to mitigate biased classification, a persistent challenge in rare healthcare event prediction. Unlike conventional models that rely on static loss weighting or oversampling, the proposed framework dynamically adapts both sample importance and gradient flow through reinforcement learning and class-aware optimization. This joint strategy enables a consistent sensitivity–specificity balance and reduces systematic bias toward majority classes, as confirmed by robustness experiments and statistically significant performance gains over baseline methods. Such bias-aware learning behavior is critical for clinical deployment, where false negatives and false positives can have severe consequences for patient safety.
In spite of these successes, many shortcomings are worth discussing. The present actualization entails full-time sequences that cannot be present all the time in emergencies. The future work will deal with imputation strategies and partial sequence processing. Moreover, although our federated learning model ensures privacy, it makes the assumption that data have common data schemas across institutions, which heterogeneous healthcare systems may need to adjust. The cost of computations required to run the RL agent during training can also be too expensive to update the model with changes in environments with limited resources.
This study presented DRAGON-MINE, a deep reinforcement learning–driven framework designed to address the challenge of rare event prediction in healthcare through the joint integration of dynamic sample reweighting and class-aware adaptive gradient optimization. Experiments conducted on two large-scale critical care datasets, MIMIC-IV and eICU-CRD, demonstrate that DRAGON-MINE achieves strong and consistent performance across three clinically important critical care prediction tasks. Specifically, the proposed framework attains AUROC values of 92.3% (MIMIC-IV) and 91.6% (eICU-CRD) for sepsis prediction, 89.7% and 88.9% for cardiac arrest prediction, and 90.2% and 89.4% for adverse drug reaction prediction, respectively, consistently outperforming recent deep learning and ensemble-based baselines under identical evaluation settings.
Compared with recent transformer-based, multimodal, and ensemble learning approaches, DRAGON-MINE shows clear advantages in precision–recall performance and minority-class sensitivity, which are critical under extreme class imbalance. While most existing methods rely on static loss reweighting or fixed sampling strategies, DRAGON-MINE formulates class imbalance as a sequential decision-making problem, enabling a reinforcement learning agent to dynamically adjust sampling policies in response to evolving gradient behavior and performance feedback. This design contributes to improved AUPRC and F1-score performance and more stable learning across datasets.
Beyond discrimination accuracy, the proposed framework maintains a balanced sensitivity–specificity trade-off, supporting reliable rare event detection without excessive false alarms. In addition, DRAGON-MINE demonstrates strong robustness across different prediction horizons and heterogeneous clinical environments, with reduced performance degradation under cross-dataset evaluation compared to baseline models.
Despite these strengths, the framework introduces additional computational complexity during training due to the reinforcement learning component, and further prospective validation is required to assess real-world clinical impact. Future work will focus on extending the framework to other rare medical conditions, integrating causal inference for treatment effect estimation, and developing lightweight deployment strategies suitable for resource-constrained healthcare environments.
Acknowledgement: Not applicable.
Funding Statement: The author received no specific funding for this study.
Availability of Data and Materials: The experiments conducted by us use two large-scale, publicly available critical care databases that can be used to obtain extensive electronic health records that can be used in the tasks of predicting rare events. MIMIC-IV: Full Dataset (Credentialed Access): https://physionet.org/content/mimiciv/3.1/. MIMIC-IV v3.1 is the latest version, available on PhysioNet. It contains data for over 65,000 ICU patients and over 200,000 emergency department patients from Beth Israel Deaconess Medical Center (2008–2022). PhysioNet. Demo Dataset (Open Access—no registration needed): https://physionet.org/content/mimic-iv-demo/2.2/. eICU-CRD: Full Dataset (Credentialed Access): https://physionet.org/content/eicu-crd/2.0/. The eICU-CRD comprises deidentified health data from over 200,000 ICU admissions across the United States between 2014–2015, including vital signs, care plan documentation, severity of illness measures, diagnosis, and treatment information. PhysioNet. Demo Dataset (Open Access): https://physionet.org/content/eicu-crd-demo/2.0.1/.
Ethics Approval: Not applicable.
Conflicts of Interest: The author declares no conflicts of interest.
References
1. Yang J, El-Bouri R, O’Donoghue O, Lachapelle AS, Soltan AAS, Eyre DW, et al. Deep reinforcement learning for multi-class imbalanced training: applications in healthcare. Mach Learn. 2024;113(5):2655–74. doi:10.1007/s10994-023-06481-z. [Google Scholar] [PubMed] [CrossRef]
2. Boussina A, Shashikumar SP, Malhotra A, Owens RL, El-Kareh R, Longhurst CA, et al. Impact of a deep learning sepsis prediction model on quality of care and survival. npj Digit Med. 2024;7(1):14. doi:10.1038/s41746-023-00986-6. [Google Scholar] [PubMed] [CrossRef]
3. Li Y, Liu Z. Deep learning-based prediction of in-hospital mortality for sepsis. Sci Rep. 2024;14(1):372. doi:10.1038/s41598-023-49890-9. [Google Scholar] [PubMed] [CrossRef]
4. Dalal S, Ardabili AK, Bonavia AS. Time-series deep learning and conformal prediction for improved sepsis diagnosis in primarily Non-ICU hospitalized patients. Comput Biol Med. 2025;193:110497. doi:10.1016/j.compbiomed.2025.110497. [Google Scholar] [PubMed] [CrossRef]
5. Shanmugam H, Airen L, Rawat S. Machine learning and deep learning models for early sepsis prediction: a scoping review. Indian J Crit Care Med. 2025;29(6):516–24. doi:10.5005/jp-journals-10071-24986. [Google Scholar] [PubMed] [CrossRef]
6. Thiboud PE, François Q, Faure C, Chaufferin G, Arribe B, Ettahar N. Development and validation of a machine learning model for early prediction of sepsis onset in hospital inpatients from all departments. Diagnostics. 2025;15(3):302. doi:10.3390/diagnostics15030302. [Google Scholar] [PubMed] [CrossRef]
7. Liu Z, Shu W, Li T, Zhang X, Chong W. Interpretable machine learning for predicting sepsis risk in emergency triage patients. Sci Rep. 2025;15(1):887. doi:10.1038/s41598-025-85121-z. [Google Scholar] [PubMed] [CrossRef]
8. Lee HY, Kuo PC, Qian F, Li CH, Hu JR, Hsu WT, et al. Prediction of in-hospital cardiac arrest in the intensive care unit: machine learning-based multimodal approach. JMIR Med Inform. 2024;12(6):e49142. doi:10.2196/49142. [Google Scholar] [PubMed] [CrossRef]
9. Zobeiri A, Rezaee A, Hajati F, Argha A, Alinejad-Rokny H. Post-Cardiac arrest outcome prediction using machine learning: a systematic review and meta-analysis. Int J Med Inform. 2025;193(12):105659. doi:10.1016/j.ijmedinf.2024.105659. [Google Scholar] [PubMed] [CrossRef]
10. Wei S, Guo X, He S, Zhang C, Chen Z, Chen J, et al. Application of machine learning for patients with cardiac arrest: systematic review and meta-analysis. J Med Internet Res. 2025;27:e67871. doi:10.2196/67871. [Google Scholar] [PubMed] [CrossRef]
11. Kolk MZH, Ruipérez-Campillo S, Wilde AAM, Knops RE, Narayan SM, Tjong FVY. Prediction of sudden cardiac death using artificial intelligence: current status and future directions. Heart Rhythm. 2025;22(3):756–66. doi:10.1016/j.hrthm.2024.09.003. [Google Scholar] [PubMed] [CrossRef]
12. Farnoush A, Sedighi-Maman Z, Rasoolian B, Heath JJ, Fallah B. Prediction of adverse drug reactions using demographic and non-clinical drug characteristics in FAERS data. Sci Rep. 2024;14(1):23636. doi:10.1038/s41598-024-74505-2. [Google Scholar] [PubMed] [CrossRef]
13. Ou Q, Jiang X, Guo Z, Jiang J, Gan Z, Han F, et al. A fusion deep learning model for predicting adverse drug reactions based on multiple drug characteristics. Life. 2025;15(3):436. doi:10.3390/life15030436. [Google Scholar] [PubMed] [CrossRef]
14. Gao Y, Zhang X, Sun Z, Chandak P, Bu J, Wang H. Precision adverse drug reactions prediction with heterogeneous graph neural network. Adv Sci. 2025;12(4):2404671. doi:10.1002/advs.202404671. [Google Scholar] [PubMed] [CrossRef]
15. Li S, Zhang L, Wang L, Ji J, He J, Zheng X, et al. BiMPADR: a deep learning framework for predicting adverse drug reactions in new drugs. Molecules. 2024;29(8):1784. doi:10.3390/molecules29081784. [Google Scholar] [PubMed] [CrossRef]
16. Lin J, He Y, Ru C, Long W, Li M, Wen Z. Advancing adverse drug reaction prediction with deep chemical language model for drug safety evaluation. Int J Mol Sci. 2024;25(8):4516. doi:10.3390/ijms25084516. [Google Scholar] [PubMed] [CrossRef]
17. He J. Gradient reweighting: towards imbalanced class-incremental learning. In: Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 16–22; Seattle, WA, USA. p. 16668–77. doi:10.1109/CVPR52733.2024.01577. [Google Scholar] [CrossRef]
18. Bietti A, Kunstner F, Milligan A, Schmidt M, Yadav R. Heavy-tailed class imbalance and why Adam outperforms gradient descent on language models. In: Proceedings of the Advances in Neural Information Processing Systems 37; 2024 Dec 10–15; Vancouver, BC, Canada. p. 30106–48. doi:10.52202/079017-0948. [Google Scholar] [CrossRef]
19. Roggeveen LF, El Hassouni A, de Grooth HJ, Girbes ARJ, Hoogendoorn M, Elbers PWG. Reinforcement learning for intensive care medicine: actionable clinical insights from novel approaches to reward shaping and off-policy model evaluation. Intensive Care Med Exp. 2024;12(1):32. doi:10.1186/s40635-024-00614-x. [Google Scholar] [PubMed] [CrossRef]
20. Jayaraman P, Desman J, Sabounchi M, Nadkarni GN, Sakhuja A. A primer on reinforcement learning in medicine for clinicians. npj Digit Med. 2024;7(1):337. doi:10.1038/s41746-024-01316-0. [Google Scholar] [PubMed] [CrossRef]
21. Ma H, Sima K, Vo TV, Fu D, Leong TY. Reward shaping for reinforcement learning with an assistant reward agent. In: Proceedings of the 41st International Conference on Machine Learning (ICML); 2024 Jul 21–27; Vienna, Austria. p. 33925–39. [Google Scholar]
22. Al-Hamadani MNA, Fadhel MA, Alzubaidi L, Balazs H. Reinforcement learning algorithms and applications in healthcare and robotics: a comprehensive and systematic review. Sensors. 2024;24(8):2461. doi:10.3390/s24082461. [Google Scholar] [PubMed] [CrossRef]
23. Wu Q, Han J, Yan Y, Kuo YH, Shen ZM. Reinforcement learning for healthcare operations management: methodological framework, recent developments, and future research directions. Health Care Manag Sci. 2025;28(2):298–333. doi:10.1007/s10729-025-09699-6. [Google Scholar] [PubMed] [CrossRef]
24. Pati S, Kumar S, Varma A, Edwards B, Lu C, Qu L, et al. Privacy preservation for federated learning in health care. Patterns. 2024;5(7):100974. doi:10.1016/j.patter.2024.100974. [Google Scholar] [PubMed] [CrossRef]
25. Fuladi S, Ruby D, Manikandan N, Verma A, Nallakaruppan MK, Selvarajan S, et al. A reliable and privacy-preserved federated learning framework for real-time smoking prediction in healthcare. Front Comput Sci. 2025;6:1494174. doi:10.3389/fcomp.2024.1494174. [Google Scholar] [CrossRef]
26. Haripriya R, Khare N, Pandey M. Privacy-preserving federated learning for collaborative medical data mining in multi-institutional settings. Sci Rep. 2025;15(1):12482. doi:10.1038/s41598-025-97565-4. [Google Scholar] [PubMed] [CrossRef]
27. Abbas SR, Abbas Z, Zahir A, Lee SW. Federated learning in smart healthcare: a comprehensive review on privacy, security, and predictive analytics with IoT integration. Healthcare. 2024;12(24):2587. doi:10.3390/healthcare12242587. [Google Scholar] [PubMed] [CrossRef]
28. Meduri K, Nadella GS, Yadulla AR, Kasula VK, Maturi MH, Brown S, et al. Leveraging federated learning for privacy-preserving analysis of multi-institutional electronic health records in rare disease research. J Econ Technol. 2025;3:177–89. doi:10.1016/j.ject.2024.11.001. [Google Scholar] [CrossRef]
29. Hu Q, Chen Y, Zou D, He Z, Xu T. Predicting adverse drug event using machine learning based on electronic health records: a systematic review and meta-analysis. Front Pharmacol. 2024;15:1497397. doi:10.3389/fphar.2024.1497397. [Google Scholar] [PubMed] [CrossRef]
30. Grout R, Gupta R, Bryant R, Elmahgoub MA, Li Y, Irfanullah K, et al. Predicting disease onset from electronic health records for population health management: a scalable and explainable deep learning approach. Front Artif Intell. 2024;6:1287541. doi:10.3389/frai.2023.1287541. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools