
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Sentiment Analysis and Classification Using Deep Semantic Information and Contextual Knowledge
1 Department of Smart Computing, Kyungdong University 46 4-gil, Bongpo, Gosung, Gangwon-do, 24764, Korea
2 Division of Computer Engineering, Dongseo University, 47 Jurye-ro, Sasang-gu, Busan, 47011, Korea
3 Department of Computer Engineering, Dongseo University, 47 Jurye-ro, Sasang-gu, Busan, 47011, Korea
* Corresponding Author: Dae-Ki Kang. Email:
Computers, Materials & Continua 2023, 74(1), 671-691. https://doi.org/10.32604/cmc.2023.030262
Received 22 March 2022; Accepted 09 June 2022; Issue published 22 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Sentiment analysis (AS) is one of the basic research directions in natural language processing (NLP), it is widely adopted for news, product review, and politics. Aspect-based sentiment analysis (ABSA) aims at identifying the sentiment polarity of a given target context, previous existing model of sentiment analysis possesses the issue of the insufficient exaction of features which results in low accuracy. Hence this research work develops a deep-semantic and contextual knowledge networks (DSCNet). DSCNet tends to exploit the semantic and contextual knowledge to understand the context and enhance the accuracy based on given aspects. At first temporal relationships are established then deep semantic knowledge and contextual knowledge are introduced. Further, a deep integration layer is introduced to measure the importance of features for efficient extraction of different dimensions. Novelty of DSCNet model lies in introducing the deep contextual. DSCNet is evaluated on three datasets i.e., Restaurant, Laptop, and Twitter dataset considering different deep learning (DL) metrics like precision, recall, accuracy, and Macro-F1 score. Also, comparative analysis is carried out with different baseline methods in terms of accuracy and Macro-F1 score. DSCNet achieves 92.59% of accuracy on restaurant dataset, 86.99% of accuracy on laptop dataset and 78.76% of accuracy on Twitter dataset.Keywords
Rapid development in information technology (IT) and the internet has made people not only retrieve the information but express their opinions as well. There is a different platform available for people to express their opinion; opinions like online reviews comprises valuable information for consumers as well as business. A large amount of data is accumulated through these opinions over the internet, opinions, and sentiment can be extracted through NLP and big data analysis [1]. Sentiment analysis is a process of understanding text meaning and analyzing the sentiment hidden in a given text, NLP is one of the popular technology to model disassemble reason extract, and classify. The main aim of sentiment analysis is to identify the attitudes of bipolar views based on targets in sentences [2].
Sentiment analysis is categorized on three distinctive levels that are shown in Fig. 1 and discussed further.
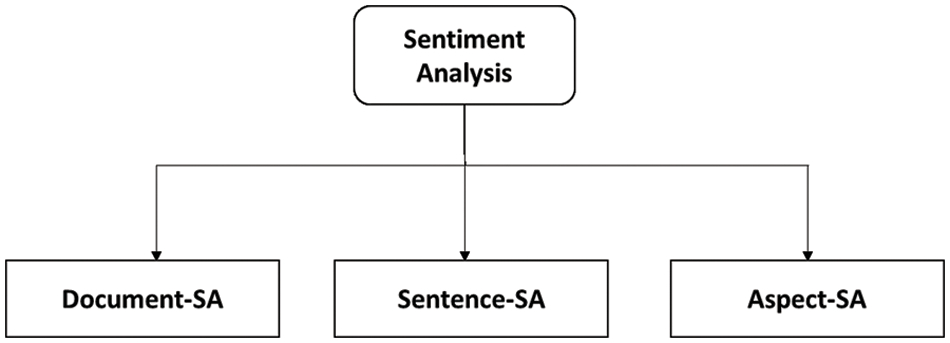
Figure 1: Different categories of sentiment analysis
A.Document-SA: In this type of task, the aim is to determine the positive or negative opinions based on overall documents. It is one of the simplest ways to analyze sentiments. This task considers each document expresses an opinion on a single entity. However, it does not hold for a scenario where multiple views are evaluated in a single document.
B.Sentence-SA: This type of task determines positive, negative, and neutral opinion in a given sentence, it comprises neutral opinion which is not available in document-SA. A neutral opinion is a sentiment that has no effecting opinion i.t. neither positive nor negative. Sentence-SA applies a similar assumption as of document-SA except that it is considered for a single sentence.
C.ABSA (Aspect-SA): Sentence-SA and Document-SA are very effective when there is a sentence or document on a single entity. Further research shows that people talk with different attributes (aspect). In the case of each aspect, there are different opinions. Aspect-based-SA is a fine-grained analysis that usually exists in product reviews for product-based companies such as product review such as phones, cars, and others. It is considered as one of the fine approaches for business development, hence it has become one of the popular and widely available AS.
Aspect-based-SA is referred to as the task of identifying the various aspect in review and distinguishing the sentiment polarities (SP) towards aspects in an individual manner for extracting the fine-grained information. ABSA task possesses wide research value as it enables consumers to an evaluation of product or service from a comprehensive perspective to understand detailed and explicit knowledge of it [2]. Moreover, Neural network-based mechanisms have made a significant impact in comparison with the traditional approach of sentiment analysis. Recent studies on neural networks (NNs) have observed significant growth in Natural Language processing such as text summarization and machine translation, however still ABSA–NN required to be studied in depth [3]. ABSA is categorized into two tasks, mining (aspect mining) and classification (aspect classification); aspect mining tends to extract the aspect words from each sentence, aspect mining has been exploited through unsupervised models, semi-supervised and supervised model whereas aspect classification aims at polarities prediction on the aspect. However, getting accurate sentiment is a major challenge in sentiment classification; for instance, “Food was delicious, but the place was small”. In this sentence, there are two distinctive aspects i.e., food and place and opinion words like “delicious” and “small “corresponds to polarity where “delicious” is positive sentiment polarity towards food and “small” is negative sentiment polarity towards the room.
Fig. 2 shows the general framework followed by the research for classification of aspect-based sentiments, this general framework comprises three-phase namely aspect extraction, aspect sentiment analysis, and sentiment evaluation. Furthermore, apart from these three important blocks it also includes pre-processing steps such as discarding unnecessary information from corpus, tokenization stemming, and so on [4].
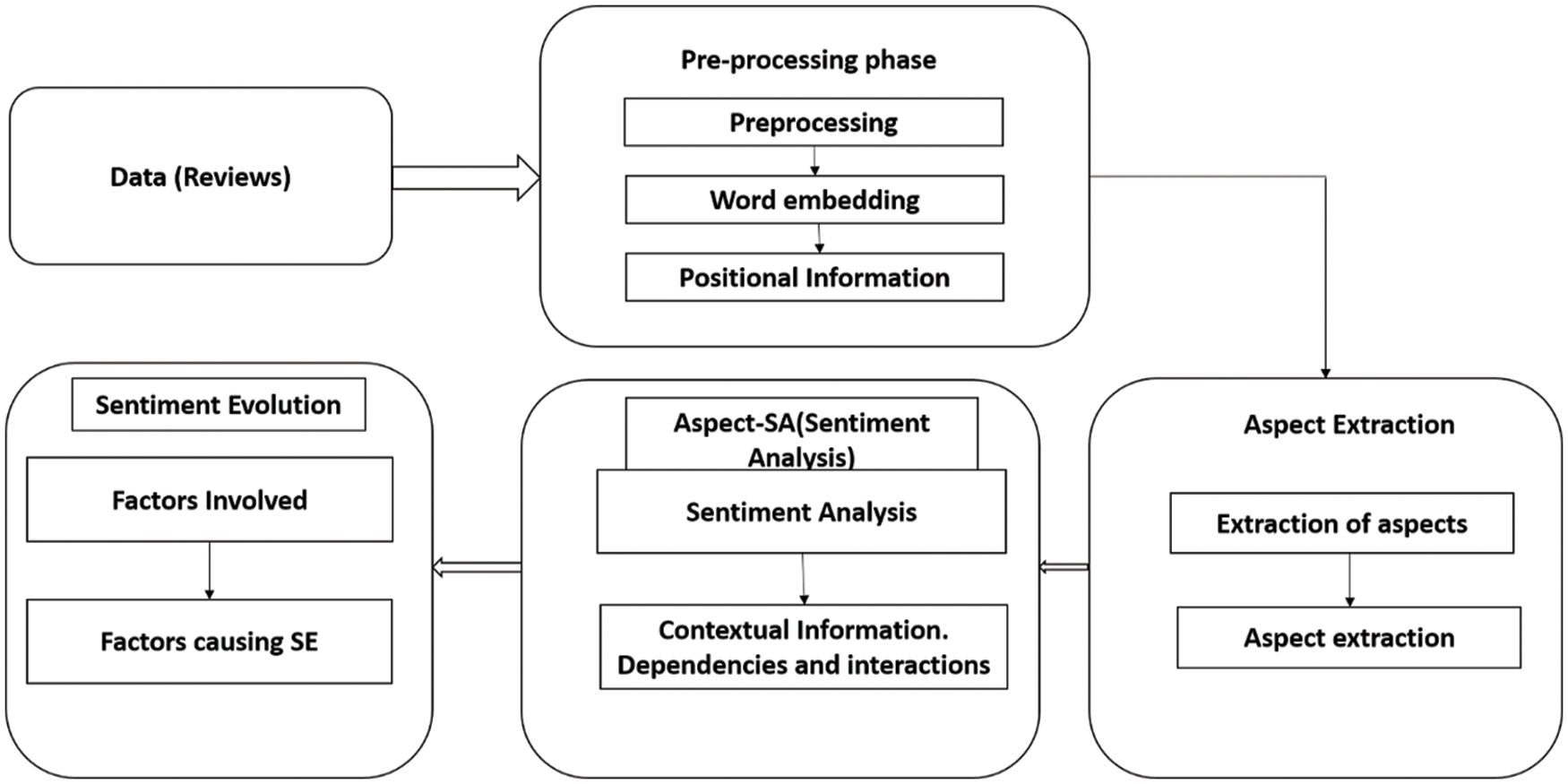
Figure 2: General framework of sentiment analysis
Through research it was observed that conventional sentiment models fail to observe the dynamic polarity recognition due to bilateral information lack, also emotions accompany different emotions. Moreover, in classification, 40% of error occurs when aspects are not considered. In recent years, deep neural networks (DNN) have achieved great success in several applications. Deep learning is classified into convolutional neural networks (CNNs) [5], recurrent neural networks (RNNs) [6], reconvolutional neural networks (ReCNNs) [7], and memory networks (MNs) [8], detailed classification of deep learning is shown in Fig. 3
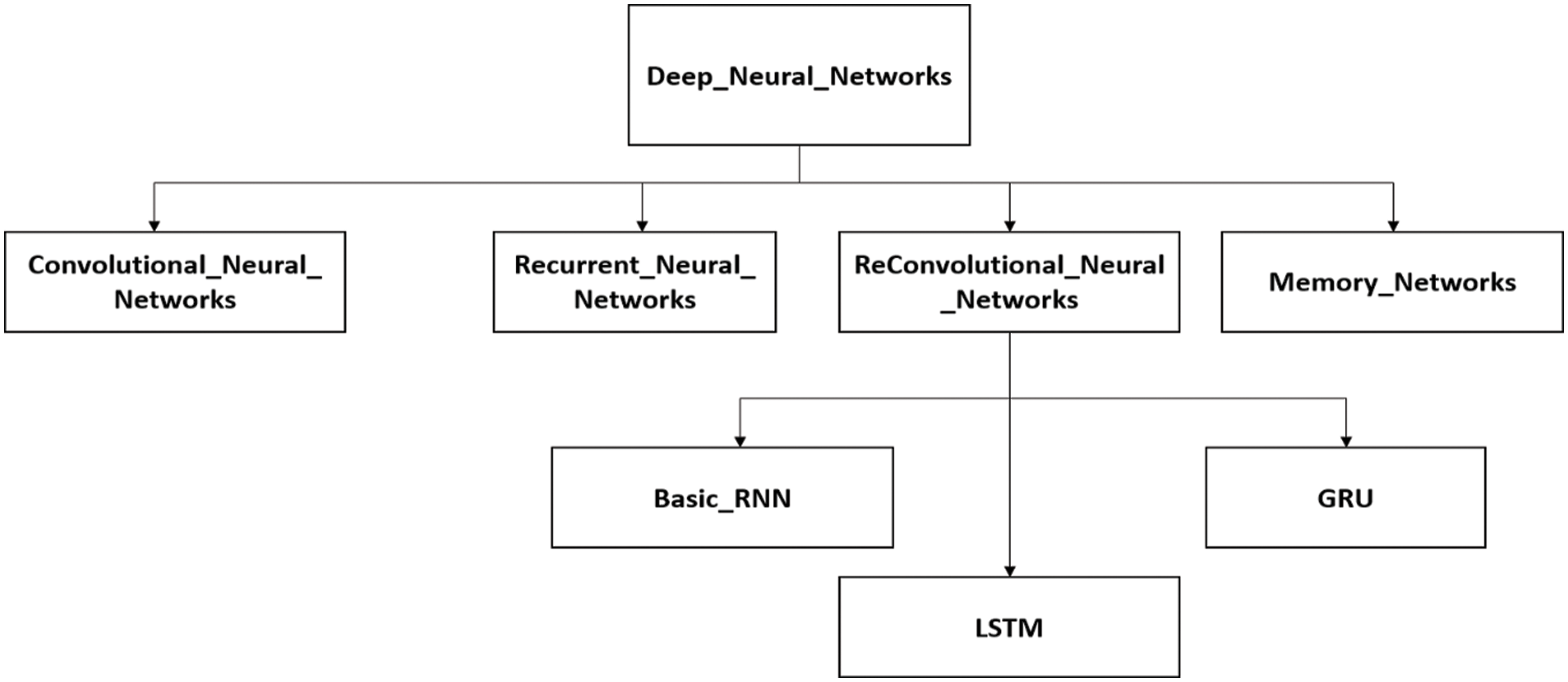
Figure 3: Deep neural network categorization for Aspect-SA
Moreover, Fig. 3 includes the direct deep learning architecture adopted for Aspect-SA, in addition to that attention mechanism has been adopted widely along with the above-mentioned architecture to enhance the feature extraction and context [9]. Other types of Aspect-SA mechanisms include the embedding approach and the transfer learning approach. Furthermore, considering the deep learning architecture, CNN is considered effective and possesses the capability to extract meaningful patterns. However, CNN fails to balance the contextual information and sequential order, this problem can be solved through RNN. Hence recent study on Aspect-SA has focused on RNN, all basic RNN model considers the particular situation, which is formed through many words, however, the target is not restricted to a single word. Thus, attention with long short- term memory (LSTM) is used where targets and context are into LSTM to understand the context, however, it is restricted to single instances [9]. Bidirectional-LSTM is introduced which comprises embedding layer attention layer, contextual layer, and output layer, aspect, and context can be embedded into to get the aspect and contextual output. Hence Bi-LSTM architecture has been exploited widely to exploit the Sentiment analysis, meanwhile, Bi-LSTM based architecture also has a limitation, and considering the review of other research work (discussed in related work), several challenges still exist such as ignoring the other data types such as emoji as it is heavily used by user; also classifying sentiments when there are different targets, pre-processing of data could also improvise accuracy [4]. Other major challenges are deep knowledge of semantic information and context knowledge; thus, this research work focuses on deep semantic information and deep context knowledge [2,10].
Word expresses various sentiments as it holds various semantics in various contexts; for instance, the word “blue” holds different semantics in sentences like “He is so blue that none going to get better” or “I bought blue jeans” or She said it was just a blue. Each sentence conveys different sentiments; moreover, the existing embedding mechanism tends to directly embed the lexicon to word representation this makes no difference in words in different sentences, this fails to provide proposed information of words in various sentences to utilize absolute embedding. Hence motivated by its application and challenges, this research work proposes DSCNet architecture. A further contribution of research work is given below.
• DSCNet architecture incorporates semantic information and contextual knowledge in deep to enhance the aspect extraction and understanding of context.
• Deep semantic knowledge helps in sharing the semantic information of different aspects and focuses on generating optimal features.
• Deep contextual knowledge helps in focusing on the specific words in a more precise way, also a deep integration layer is introduced to integrate the efficiently extracted parts from each dimension.
• DSCNet is developed to remember and provide contextual knowledge for given targeted aspects.
• DSCNet is evaluated on SemEval dataset 2014 task 4 and twitter dataset, evaluation is carried out through on accuracy and Macro-F1
This research work is organized in the following way: the first section starts with an understanding of sentiment analysis, its types, and different challenges and approach used. This section concludes with the motivation and contribution of research work. The second section discusses different related work based on aspect-based sentiment analysis, third section designs and develops a neural network-based mechanism. The fourth section evaluates the proposed methodology considering different online reviews dataset.
Aspect Based Sentiment analysis is a basic task in SA field; it comprises two subtasks i.e., extraction and classification. ABSA considers targets and sentiments both at one time and the aim is for polarity determination of given aspect and sentence. Furthermore, with the development of NLP, SA has been given wide attention by researchers, this section discusses different aspect-based-SA work along with their shortcomings.
In general Aspect based-SA is categorized into the category of lexicon based [11], machine learning (ML) [12] based, and DL-based. A traditional approach such as parts of speech (PoS) [13] and bag of words (BoW) (Bag of Words) [14] focus on utilizing the feature engineering phenomena; also for training machine learning classifiers were used such as NN, support vector machine (SVM) and Naïve Bayesian. Above discussed approach is dependent on handcrafted features and thus it is labor-intensive. Further, the deep learning approach has been an evolutionary phenomenon for sentiment analysis through word embedding, here we discuss some of the recent successful research along with their shortcoming. In [15], Bidirectional gated recurrent unit (GRU) model was developed for complete feature mining for the ABSA task, Bidirectional GRU network is used for acquiring the dependency-based sentence SA along with their corresponding terms. Further, it proposes the learning feature of sentiment polarity in given sentences; despite enhancement in feature mining, accuracy did not improve much, and also it was proven to be time-consuming. Hence [16] developed a novel integration method of CNN and GRU to utilize the local features for efficient processing. Moreover, GRU is used for long-term dependency learning and CNN is used for the generation of local features. However, this model faces the issue of dependency learning which is enhanced in [17], it introduced dependency-related phenomena to identify the dependency-related feature for given aspect term; dependency parse tree is designed and dependency-related feature is integrated into BiLSTM and CNN. Furthermore, this research work observed that sentiment features of a given aspect help in discriminating the sentiment polarity. Designing a tree makes the model too complicated for enhancement in dependency-related phenomena. In [18], a model named effective adaptive transfer network (EATN) was presented, EATN utilized the understanding of the incorporation of correlation between different domains. Furthermore, it proposes domain attention module (DAM) for learning the common feature from a given source domain and further targeting the classification. DAM is designed for two tasks first is the sentiment classification task for sentiment knowledge and the second is domain classification. To reduce the feature dependency multiple kernel mechanism is selected. This mechanism faces an issue with labeling, thus [19] introduces Ecolabels which is a semiautomatic mechanism for the textual ER to provide the large-scale annotation considering English emotion corporate in different generations aiming robust reliability. It comprises two steps, first step includes the automatic process of pre-annotation of the unlabeled sentence along with optimized emotional categories. The second step includes a manual process of refinement where humans determine which is more dominant emotions in given pre-defined possibilities. Further, [20] proposed CNN along with a sentiment module known as SentiCNN, SentiCNN analyses different sentiments in sentences with sentiment and contextual information of words. Contextual words are identified through word embeddings and sentiment information is identified through lexicons. Moreover, a highway network is incorporated for combining the contextual and sentiment information from given sentences through developing the connection among features of sentences and words; also attention mechanism is used based on lexicons to identify the eminent sentiment indicators to make more effective predictions. [21] adopted different mechanism of end-to-end segmentation model named SEGBOT, SEGBOT uses BiRNN for encoding input text sequence, alter another RNN is used along with pointer network to identify the text boundaries in the given input sequence, hence it is not dependent on handcrafted feature and SEGBOT handles variable size issue and sparse boundary tags. To evaluate the model, document level and sentence level analysis are considered.
There have been enormous efforts in the fields of ABSA, however, still there exists research gap analysis that needs to be solved. These gaps include improvisation in the extraction capability of the ABSA model. Hence, in this research work, we used deep semantic and deep contextual knowledge for extraction and contextual understanding. The architecture formulation of DSCNet is designed in the next section of the research work.
The deep learning approach has shown wide application in ABSA task classification as deep learning exploits the aspect and context to classify the sentiment polarity. Hence, this research adopts the deep learning domain and introduces DSCNet. DSCNet exploits the aspect and target sentiment.
Fig. 4 shows DSCNet architecture, it comprises deep features, deep attention layer, DSCNet and Deep Integration layer. DSCNet is primary component of our research model, and it is capable of delivering the contextual knowledge of an aspect that has similar meanings through deep exploration of its features.
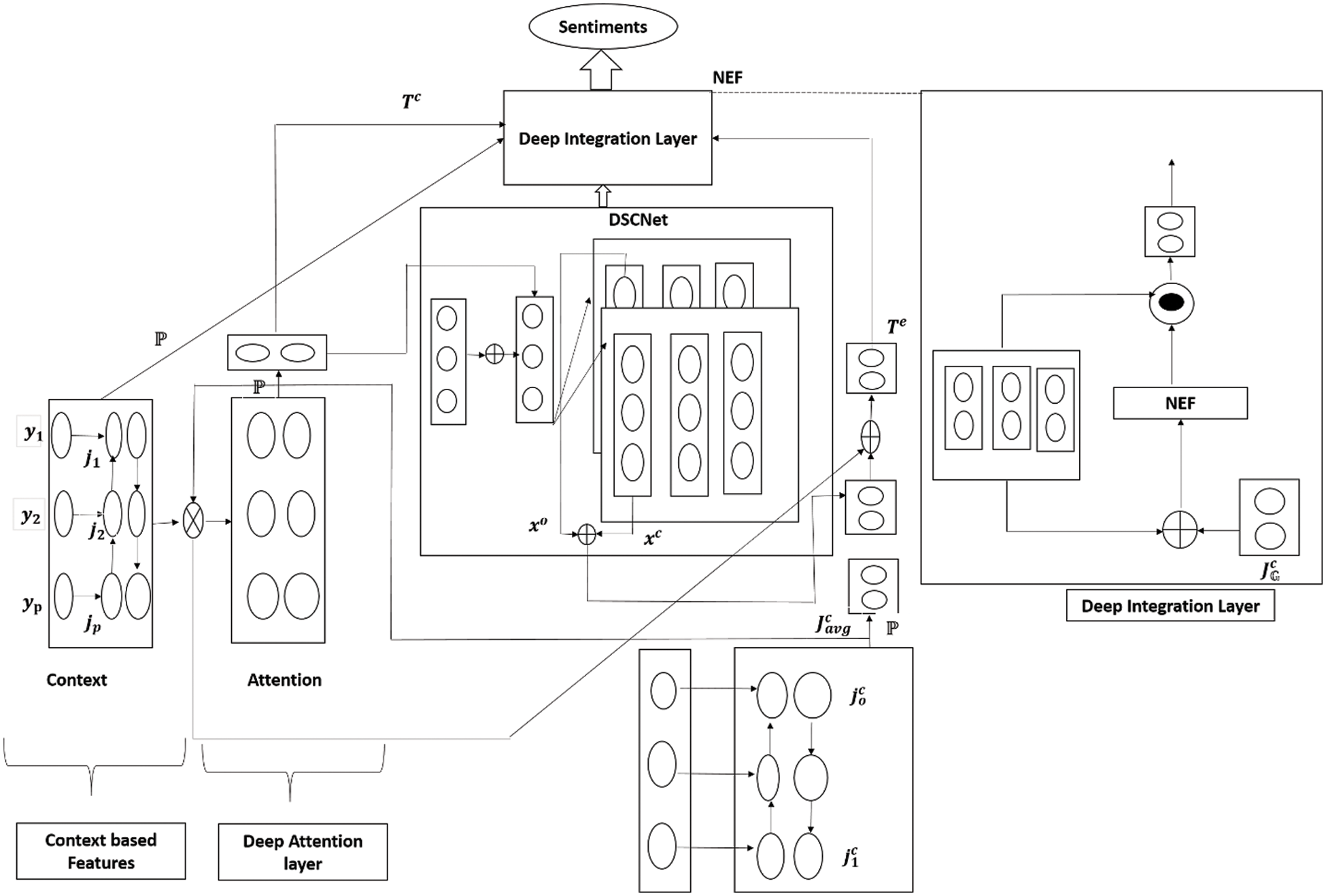
Figure 4: DSCNet architecture
Let’s consider two distinctive entity sentences denoted through
3.2 Word Interpretation and Temporal Relation Analysis
To interpret the words inefficient manner through deep contextual knowledge, a glove model is utilized where each word is mapped into the vector space as
In the above equation,
Matrix is designed for encoding positions for the weights of words and it is denoted as
The above equation comprises bias and weighted matrix denoted by
To understand the aspect considering context, the influence of different aspects on the context has to be measured, hence parameter score is assigned to the words and computed. Attention score helps in getting the aspect-based features. Considering aspect word as
Similarly, considering both context and aspect, attention weights are computed with bias and context words; also
Considering the above two equations, another parameter
Further aspect-based feature with max-pooling and context words are computed through
3.4 Context Based Feature Design with Respect to Aspect
Considering context influence in aspect, aspect is designed and denoted as
Also, the score is computed as:
Moreover, considering the deep contextual knowledge, context-based features is formulated as:
3.5 Deep Semantic Knowledge and Deep Contextual Knowledge
To obtain the optimal semantic information, two embedding metrics are considered concerning domain knowledge and semantic information. These two matrices i.e., memory matrix and aspect alignment matrix are utilized for domain knowledge and semantic information. It comprises three phases extraction, updation, and integration. Furthermore, DSCNet considers two matrix i.e., optimal memory matrix and aspect metrix. Further, exploitation of semantic knowledge and contextual knowledge is carried out as given in Fig. 5.
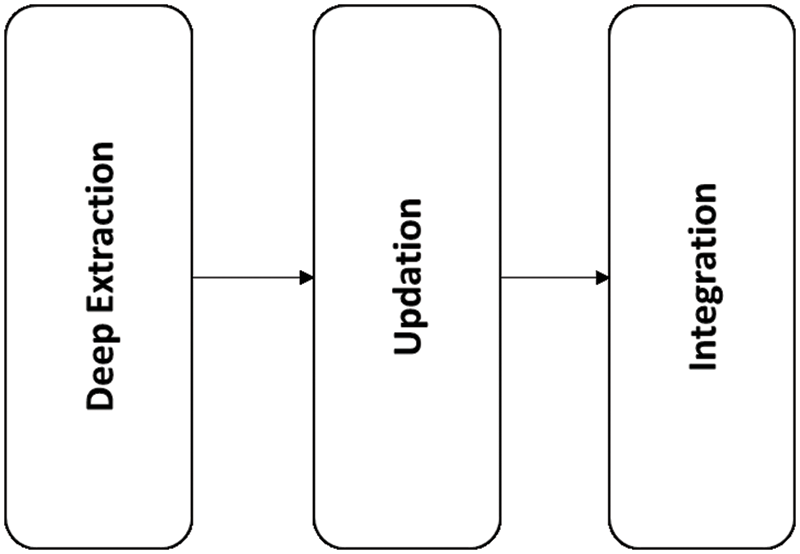
Figure 5: Deep semantic and contextual knowledge exploitation process
As discussed earlier, let’s consider optimal memory matrix that consists of aspect embedding of
Further, mean pooling is carried out on the obtained output (aspect) to represent the aspect in the above equation. The above equation consists of bias and weight matrix denoted as
Another matrix, optimal memory matrix denoted as
Both matrix initialization is performed randomly; the difference between these two is aspect alignment matrix acts as a learnable parameter and the memory matrix acts as a non-learnable parameter. Aspect alignment matrix is further updated using the adjacent aspects embedding and the memory matrix is updated considering the context information.
To compute extracted feature-based information, semantics is given to the network. Aspect based features
In the above equation,
In above equation
In this step, deep semantic knowledge and deep contextual knowledge are integrated, these two are integrated to achieve context based aspect and denoted as
The fine-grained Integration layer is designed to compute the importance of features concerning
In above equation
In above equations
In the above equation, a probability distribution is utilized for polarities;
To distinguish among different aspect embedding, regularization parameter
In the above equation,
Simultaneously, Ground truth denoted as z is considered as a vector, thus loss function n is minimized through the below equation.
In above equation
Sentiment analysis, also known as opinion mining is one of the fundamental tasks in natural language processing; it offers to infer opinions from given text. This research work develops a proposed methodology for Aspect Based Sentiment Analysis. In this section of the research, we evaluate the proposed methodology considering different parameters; evaluation is carried out considering deep learning library PyTorch. The proposed model is designed using python as a programming language and spyder as IDE on the Windows 10 platform packed with 8GB of RAM and 2GB of NVIDIA graphics. DSCNet is evaluated considering precision, recall, accuracy and macro-f1 (these metrics have been discussed later in same section), also comparative analysis is carried out on accuracy and Macro-F1 with other model.
To prove the model efficeincy, three distinctive datasets from SemEVAL 2014 task 4 [22], the dataset comprises Twitter [23], Restaurant and Laptop dataset; dataset statistics are presented in Tab. 1. Each dataset is split into training and dataset into three categories i.e., positive, negative, and neutral. In total there are 2966 reviews of the laptop dataset, 4728 reviews for the Restaurant dataset, and 6728 reviews for the Twitter dataset.

Precision is measure of correct identification of sentiment polarity out of all actual sentiment polarity, it is computed as ratio of true positive to the sum of false positive and true positive.
Recall is measure of all correct identification of sentiments; it can be computed as the correct identification of true positives. Mathematically, it is the ratio of True positive to the sum of false negative and true positive.
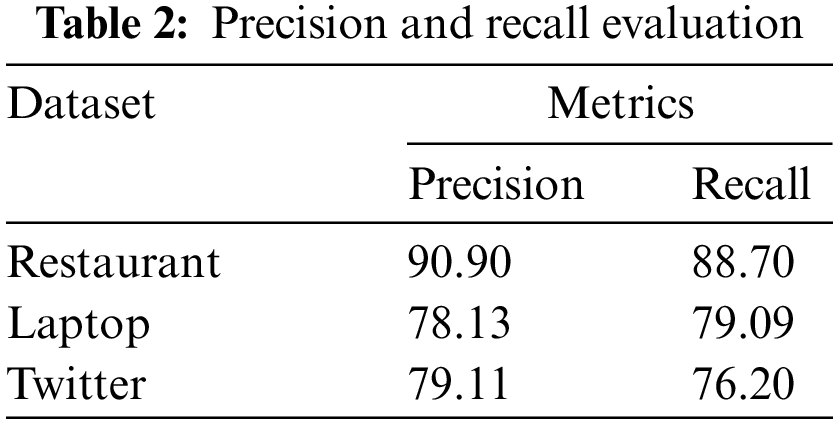
Tab. 2 shows the precision and recall value of all the three dataset through DSCNet mechanism. In case of Restaurant dataset 90.90% of precision was observed and 88.70% of recall value; for Laptop dataset, 78.13% of precision and 79.09% of recall was observed. Considering twitter dataset, 79.11% and 76.20% of precision and recall is achieved.
To prove the model efficiency, the different existing technique is considered. Most of the state-of-art technique is categorized in two categories i.e., with syntactic knowledge and without syntactic knowledge.
SVM [24]: It uses a support vector machine over large features for classification.
IAN [25]: It represents the context and task interactively through an attention mechanism and two LSTMS.
TNet [26]: It transforms BiLSTM to the target-specific embeddings and utilizes Convolutional neural network for encoding.
MGAN [27]: This mechanism utilizes BiLSTM for using multi-grained attention and contextual information to exploit the relationship among context and aspects.
AOA [28]: The attention over attention model is introduced for interaction among context and aspects combined.
AEN [29]: This mechanism adopts the encoder-based attention network for feature modeling and representation to achieve the semantic relations among target and context.
CapsNet [30]: It uses a capsule network for modeling the complicated relationship between the context and target.
BERT-PT [31]: It uses a pre-trained BERT model on post-training for improvisation in target aspect sentiment and reading comprehension.
BERT-SPC [29]: It gives “[SEP]” + sentence + “[CLS]” + target mention into the pre-trained model and further uses pooling-based embedding for classification.
CapsNet-BERT [30]: It utilizes the BERT model and on top of that capsule network is used for sentiment polarities.
AdaRNN [32]: This mechanism learns the sentence representation towards the target through a composition of RNN based semantics over the designed dependency tree.
PhraseRNN [33]: It is an extended version of AdaRNN and improvisation is carried out through integrating two composition functions. This method takes the constituent tree and dependency tree as input.
Synattn [34]: This method integrates syntactic distance to the attention mechanism for modeling the interaction among context and target mention.
CDT [35] and ASGCN [36]: Both mechanisms incorporate dependency with GCN for aspect representation learning; ASGCN applies the attention mechanism for obtaining the final representation.
TD-GAT [37] and TD-GAT-BERT [22] utilize GAT to exploit the syntax structure and improvise with LSTM.
All these methods are compared in existing model RGAT-BERT [38], thus considering RGAT-BERT model, this paper performs comparison on accuracy and macro-f1 in next subsection.
In deep learning, accuracy is major metrics available for classification, it represents the correctly classified model. In general, it is computed through finding ratio of samples correctly identified with total number of samples. Tab. 3 shows the accuracy comparison of different methodologies on restaurant datasets, to achieve more accuracy BERT model has been utilized extensively such as BERT-PT, BERT-SPC, CapsNet-BERT, AEN-BERT, TD-GAT-BERT, out of these methods, BERT-PT achieves the highest accuracy of 84.95. Moreover, the Existing model also adopts BERT based model and achieves an accuracy of 86.68. However, in comparison with these techniques, DSCNet achieves an accuracy of 92.59.

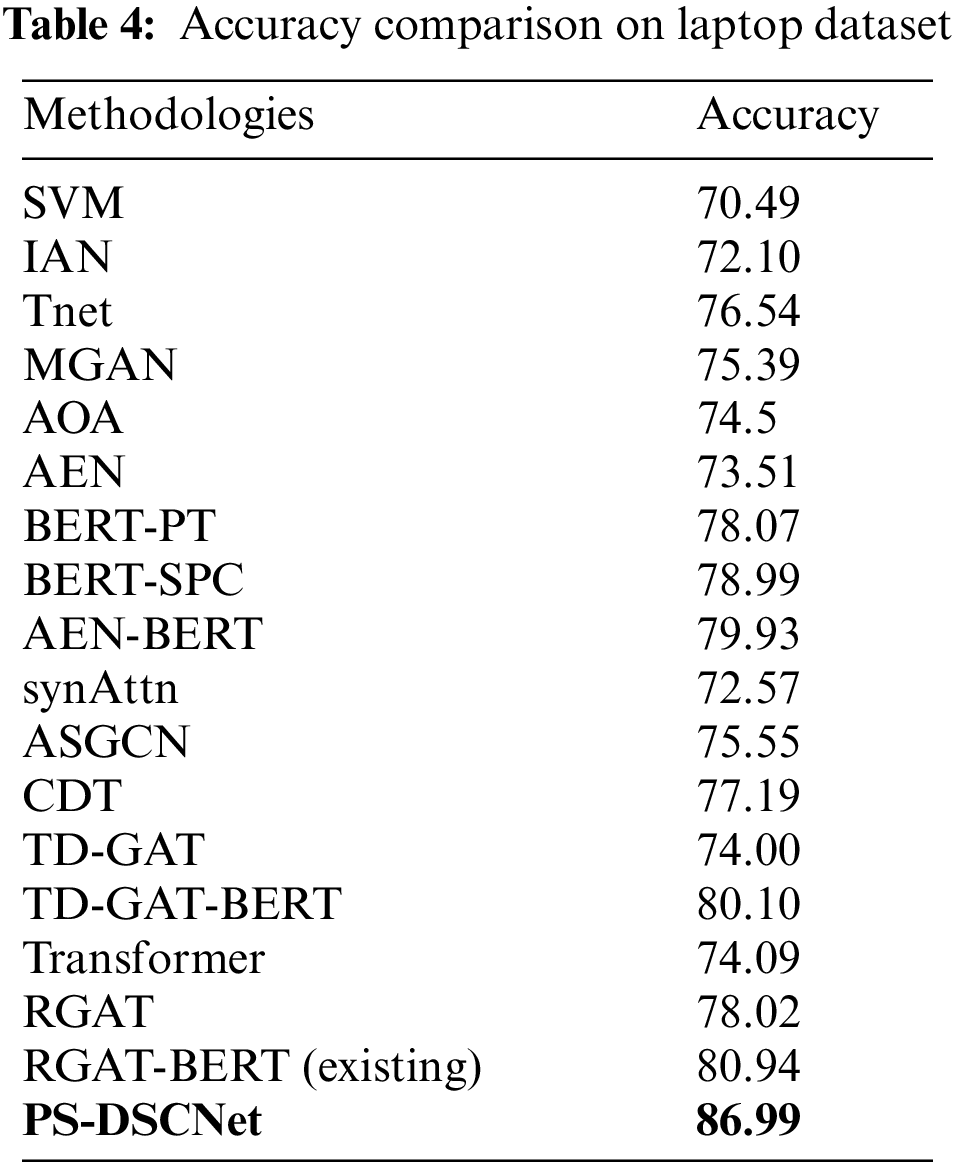
Similarly, on laptop datasets shown in Tab. 4 initial BERT model like BERT-PT and BERT-SPC achieves an accuracy of 78.07 and 78.99 respectively; AEN-BERT achieves an accuracy of 79.93. Other BERT model like TD-GAT-BERT achieves 80.10 and the recent existing BERT model achieves 80.94, in comparison with all these models, DSCNet achieves an accuracy of 86.99.
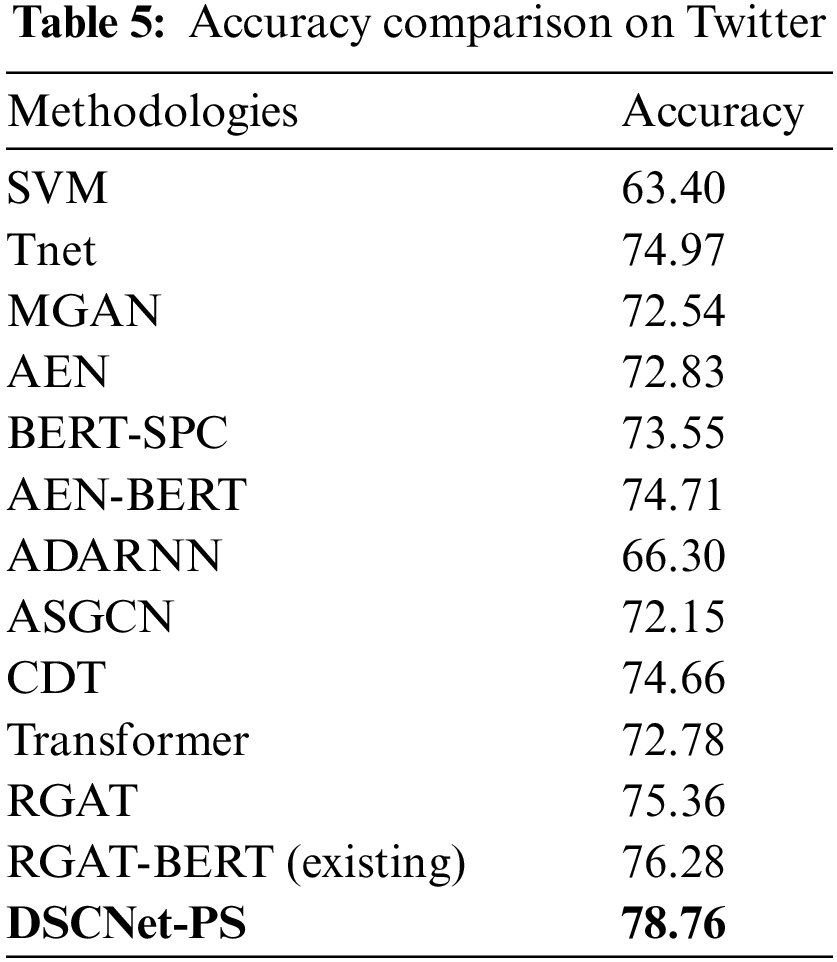
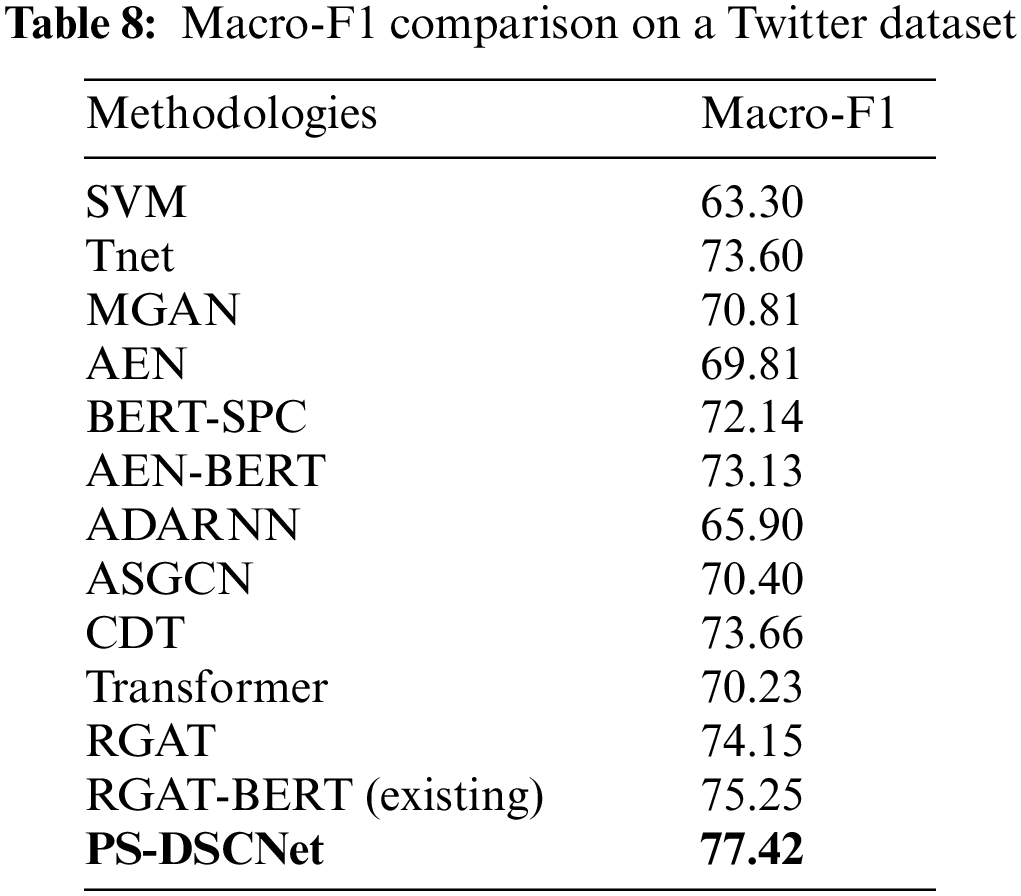
Further, considering the Twitter dataset comparison in Tab. 5, BERT-based model BERT-SPC and AEN-BERT achieve 73.55 and 74.71 respectively; the existing BERT-based model achieves an accuracy of 76.28. In comparison with these methods, DSCNet achieves 78.76% of accuracy.
In classification, the F1 score is a measurement of the test’s accuracy; further F1 measure is computed using precision and recall. In general, we can say that the F1 is harmony mean of recall and precision. Tabs. 6, 7, and 8 shows the Macro-F1 comparison of a restaurant, laptop, and Twitter dataset respectively. Several traditional approaches did not consider macro-F1, however, the BERT model has been considering it as one of the important parameters. considering the restaurant dataset, BERT-PT achieves Macro-F1 of 76.96 and BERT-SPC achieves a Macro-F1 score of 76.98. Furthermore, the existing BERT model i.e., RGAT-BERT achieves a Macro-F1score of 80.92 whereas DSCNet achieves 89.68 of Macro-F1.
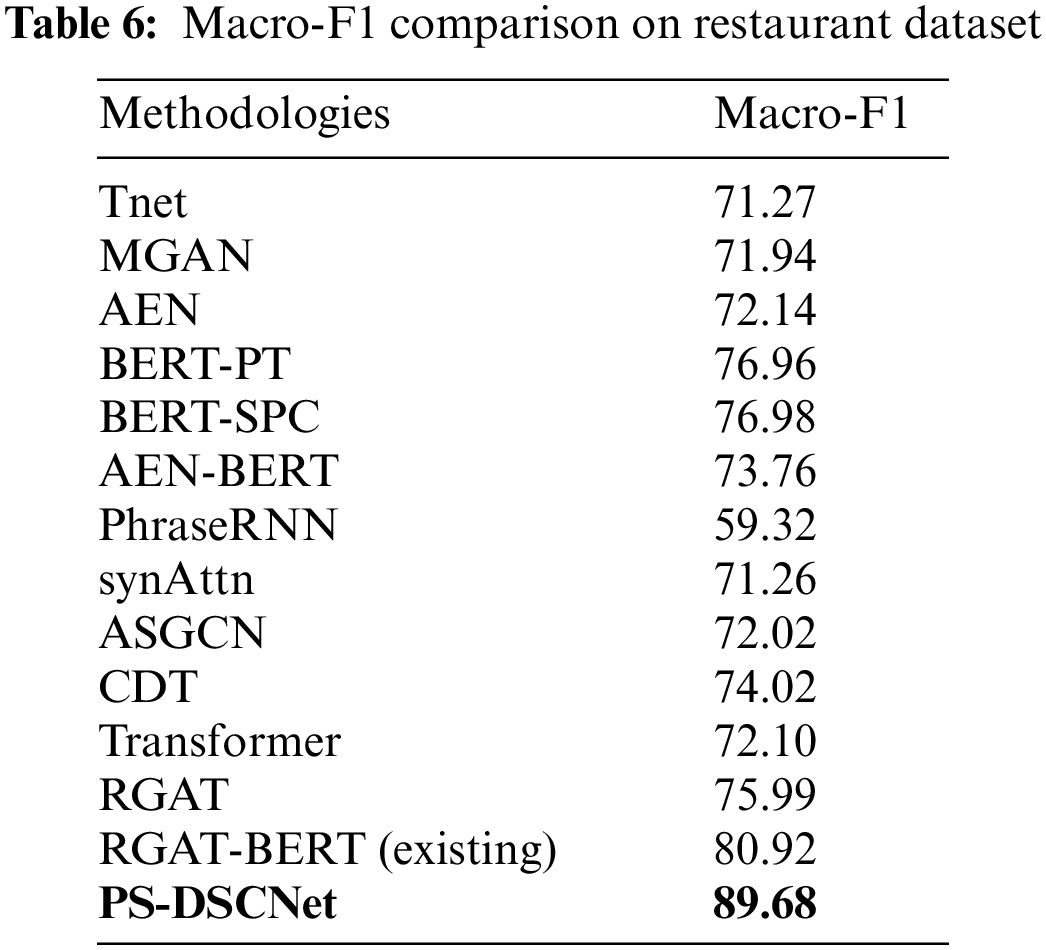
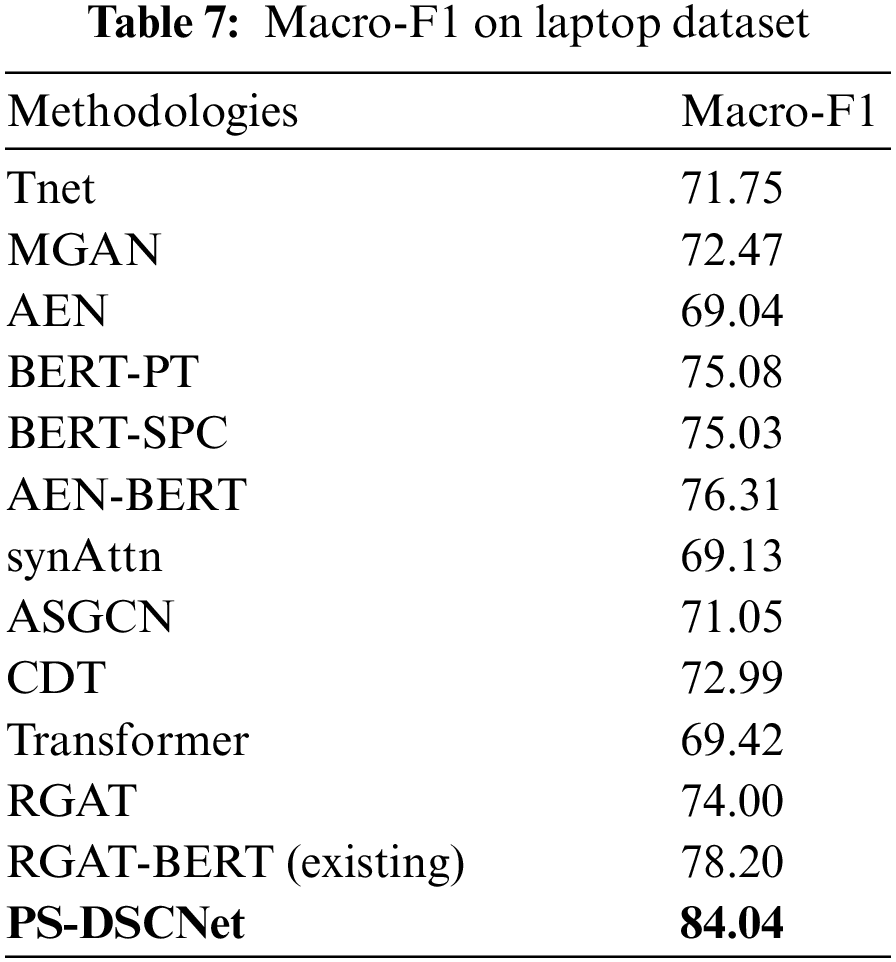
Similarly considering the laptop dataset, the existing BERT model of BERT-PT, BERT-SPC, and AEN-BERT achieve a Macro-F1score of 75.08, 75.03, and 76.31 respectively. Furthermore, the recent existing model i.e., RGAT-BERT model achieves 80.92% and the proposed DSCNet achieves 84.04 of Macro-F1.
Tab. 7 shows the comparison of Macro-F1on a Twitter dataset, existing BERT models like BERT-SPC and AEN-BERT achieve a Macro-F1score of 72.14 and 73.13 respectively. Improvised BERT model i.e., RGAT-BERT model achieves a Macro-F1score of 77.42
4.4 Comparative Analysis and Discussion
Different deep learning architecture has been adopted to enhance the sentiment analysis, this research work tends to exploit the features in deep to understand different contexts of aspect, this section discuss discusses improvisation over the existing model in terms of accuracy and Macro-F1. Considering the laptop dataset, DSCNet improves accuracy by 6.05% and Macro-F1by 5.84%; similarly considering the restaurant dataset DSCNet improves accuracy by 5.91% and a Macro-F1score of 8.76%. At last, considering the Twitter dataset DSCNet improves accuracy by 2.48% and Macro-F1 by 2.17. Further, Figs. 6 and 7 presents the graphical comparison on all the three dataset (Laptop, restaurant and Twitter) accuracy and Macro-F1score.
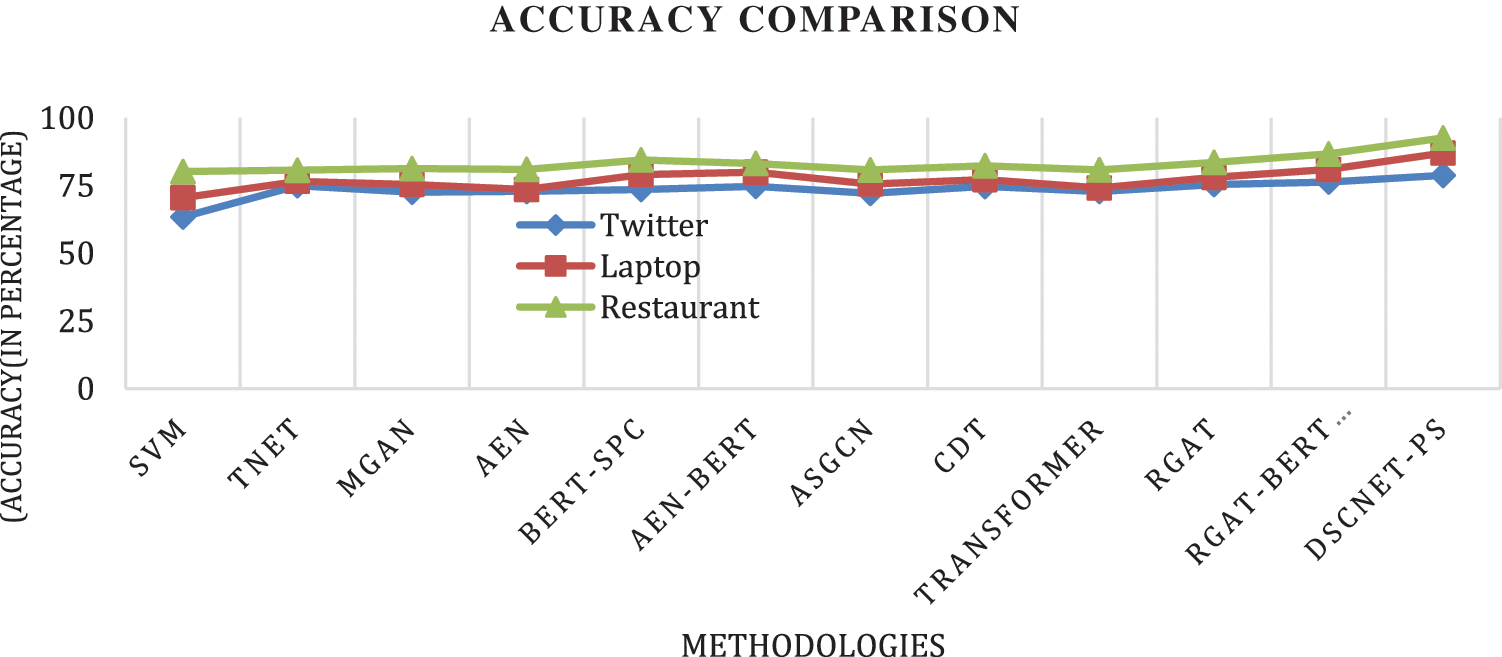
Figure 6: Accuracy comparison on three different dataset
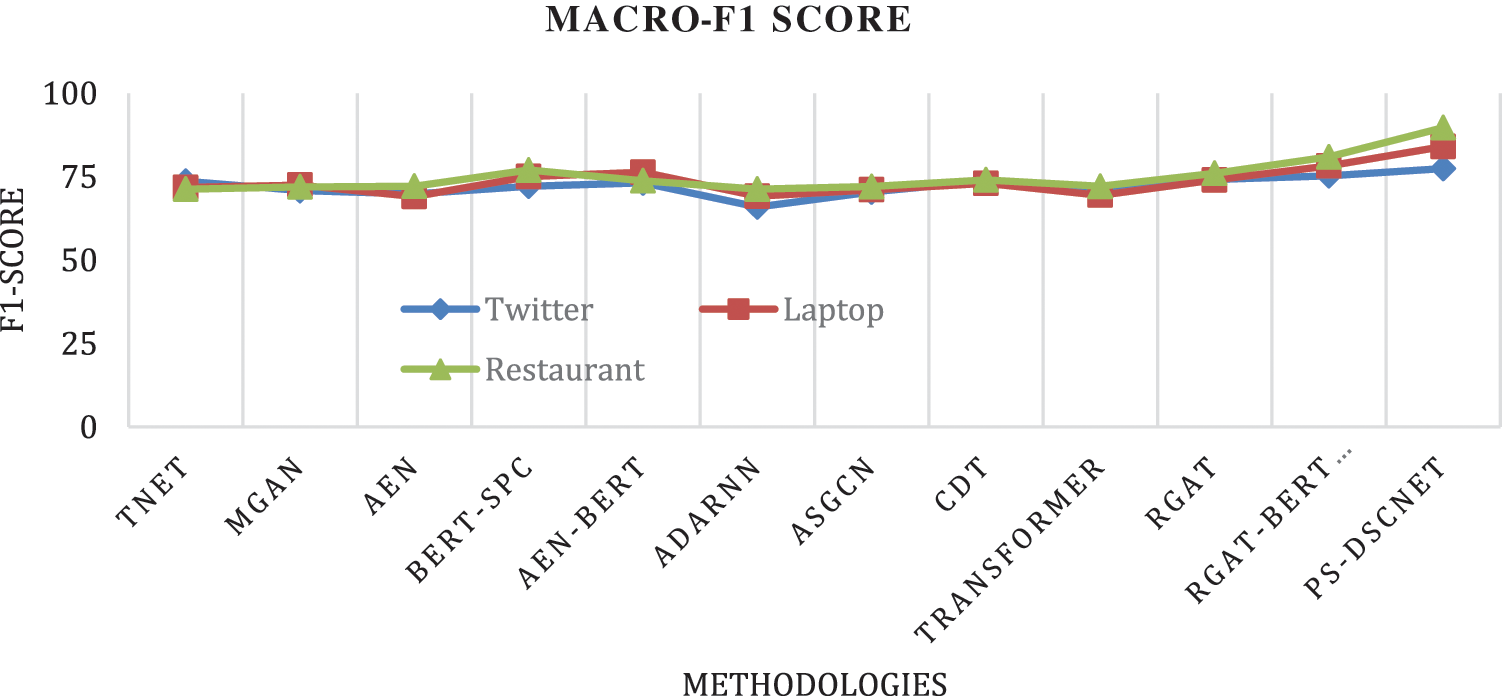
Figure 7: Macro-F1 score comparison on the three dataset
Moreover, considering the deep learning architecture, each metrics plays important role, through analysis it is observed that most of the comparing model ignored precision and recall value and this research did not find suitable mechanism to compare with respect to these two metrics. comparative analysis, it is observed that all these mechanisms did not consider all three datasets, most of the method carried out only on laptop and restaurant; few of them considered Twitter dataset but omitted laptop and restaurant. Furthermore, in past BERT model has been proven to be adopted widely for sentiment analysis; also, existing BERT model like RGAT-BERT has not only considered all three datasets but also achieved better results than other BERT model. However, as discussed earlier BERT model leaves research gap, also most of successful model adopted LSTM and attention based approach, this provided us flexibility to utilize Bi-LSTM in optimal manner. Thus, incorporating with the developed architecture i.e., DSCNet, proposed model achieves better metrics.
Aspect-SA (aspect based sentiment analysis) is an indispensable task in sentiment analysis and subtask in natural language processing. with the development of NLP, research on sentiment analysis has been processed mainly on deep learning from past few years as deep learning architecture provides deep feature extraction, however considering the vulnerabilities of sentiment polarity, existing deep learning architecture fails to understand the context of an aspect which could be solved through deep context knowledge. This research work introduces DSCNet (deep semantic and deep contextual knowledge) architecture, DSCNet architecture incorporates Semantic information and contextual knowledge together in deep to enhance the aspect extraction and understanding. DSCNet have three modules i.e., deep extraction, updation and deep integration which aims for optimal aspect based feautures. DSCNet is evaluated on three customer reviews dataset, two reviews dataset of laptop and restaurant from semeval 2014 task B and ascl Twitter dataset. DSCNet model efficiency is proven through computing deep learning metrics like precision, recall, accuracy and Macro-F1. Furthermore, comparative analysis is carried out with syntax based and syntax free technique along with recent deep learning model and our model is proven to achieve better metrics than these model. Although DSCNet achieves marginal improvisation over the other deep learning architecture, several research areas need to be looked into such as considering dynamic dataset which includes sarcastic comments.
Funding Statement: This research was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science and ICT (NRF-2022R1A2C2012243).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. B. Liu, “Sentiment analysis and opinion mining,” Synthesis Lectures on Human Language Technologies, vol. 5, no. 1, pp. 1–167, 2012. [Google Scholar]
2. E. Cambria, “Affective computing and sentiment analysis,” IEEE Intelligent System, vol. 31, no. 2, pp. 102–107, 2016. [Google Scholar]
3. J. Zhou, S. Jin and X. Huang, “ADeCNN: An improved model for aspect-level sentiment analysis based on deformable CNN and attention,” IEEE Access, vol. 8, pp. 132970–132979, 2020. [Google Scholar]
4. S. Poria, D. Hazarika, N. Majumder and R. Mihalcea, “Beneath the tip of the iceberg: Current challenges and new directions in sentiment analysis research,” IEEE Transactions on Affective Computing, pp. 1--1, 2020. https://doi.org/10.1109/TAFFC.2020.3038167. [Google Scholar]
5. P. Xiang, L. Wang, F. Wu, J. Cheng and M. Zhou, “Single-image deraining with feature-supervised generative adversarial network,” IEEE Signal Process. Letters, vol. 26, no. 5, pp. 650–654, May 2019. [Google Scholar]
6. T. Mikolov, M. Karafiát, L. Burget, J. Cernocký and S. Khudanpur, “Recurrent neural network based language model,” in Proc. of the 11th Annual Conf. of the Int. Speech Communication Association, Makuhari, Japan, pp. 1045–1048, 2010. [Google Scholar]
7. R. Socher, C. C. -Y. Lin, A. Y. Ng and C. D. Manning, “Parsing natural scenes and natural language with recursive neural networks,” in Proc. of the 28th Int. Conf. on Machine Learning. Bellevue Washington, USA, pp. 129–136, 2011. [Google Scholar]
8. J. Weston, S. Chopra and A. Bordes, “Memory networks,” 2014, arXiv:1410.3916. [Online]. Available: http://arxiv.org/abs/1410.3916. [Google Scholar]
9. H. Liu, I. Chatterjee, M. Zhou, X. S. Lu and A. Abusorrah, “Aspect-based sentiment analysis: A survey of deep learning methods,” IEEE Transactions on Computational Social Systems, vol. 7, no. 6, pp. 1358–1375, 2020. [Google Scholar]
10. E. Cambria, “Affective computing and sentiment analysis,” IEEE Intelligent Systems, vol. 31, no. 2, pp. 102–107, 2016. [Google Scholar]
11. B. Zhang, D. Xu, H. Zhang and M. Li, “STCS lexicon: Spectralclustering-based topic-specific Chinese sentiment lexicon construction for social networks,” IEEE Transactions on Computational Social Systems, vol. 6, no. 6, pp. 1180–1189, 2019. [Google Scholar]
12. S. Kiritchenko, X. Zhu, C. Cherry and S. Mohammad, “NRC-Canada2014: Detecting aspects and sentiment in customer reviews,” in Proc. of the 8th Int. Workshop on Semantic Evaluation (SemEval), Dublin, Ireland, pp. 437–442, 2014. [Google Scholar]
13. L. Màrquez and H. Rodríguez, “Part-of-speech tagging using decision trees,” European Conference on Machine Learning (ECML), Chemnitz, Germany, vol. 1398, pp. 25–36, 1998. [Google Scholar]
14. Y. Zhang, R. Jin and Z. -H. Zhou, “Understanding bag-of-words model: A statistical framework,” International Journal of Machine Learning and Cybernetics, vol. 1, no. 1–4, pp. 43–52, 2010. [Google Scholar]
15. W. Ali, Y. Yang, X. Qiu, Y. Ke and Y. Wang, “Aspect-level sentiment analysis based on bidirectional-GRU in SIoT,” IEEE Access, vol. 9, pp. 69938–69950, 2021. [Google Scholar]
16. N. Zhao, H. Gao, X. Wen and H. Li, “Combination of convolutional neural network and gated recurrent unit for aspect-based sentiment analysis,” IEEE Access, vol. 9, pp. 15561–15569, 2021. [Google Scholar]
17. X. Zhang, J. Xu, Y. Cai, X. Tan and C. Zhu, “Detecting dependency-related sentiment features for aspect-level sentiment classification,” in IEEE Transactions on Affective Computing, pp. 1–1, 2021. https://doi.org/10.1109/TAFFC.2021.3063259. [Google Scholar]
18. K. Zhang, Q. Liu, H. Qian, B. Xiang, Q. Cui et al., “EATN: An efficient adaptive transfer network for aspect-level sentiment analysis,” IEEE Transactions on Knowledge and Data Engineering, pp. 1–1, 2021. https://doi.org/10.1109/TKDE.2021.3075238. [Google Scholar]
19. L. Canales, W. Daelemans, E. Boldrini and P. Martínez-Barco, “EmoLabel: Semi-automatic methodology for emotion annotation of social media text,” IEEE Transactions on Affective Computing, vol. 13, no. 2, pp. 579–591, 2022. [Google Scholar]
20. M. Huang, H. Xie, Y. Rao, Y. Liu, L. K. M. Poon et al., “Lexicon-based sentiment convolutional neural networks for online review analysis,” IEEE Transactions on Affective Computing, pp. 1–1, 2020. https://doi.org/10.1109/TAFFC.2020.2997769. [Google Scholar]
21. J. Li, B. Chiu, S. Shang and L. Shao, “Neural text segmentation and its application to sentiment analysis,” IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 2, pp. 828–842, 2022. [Google Scholar]
22. M. Pontiki, D. Galanis, J. Pavlopoulos, H. Papageorgiou, I. Androutsopoulos et al., “Semeval-2014 task 4: Aspect based sentiment analysis,” in Proc. of the 8th Int. Workshop on Semantic Evaluation, Dublin, Ireland, pp. 27–35, 2014. [Google Scholar]
23. L. Dong, F. Wei, C. Tan, D. Tang, M. Zhou et al., “Adaptive recursive neural network for target-dependent twitter sentiment classification,” in Proc. of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, Maryland, USA, pp. 49–54, 2014. [Google Scholar]
24. C. Cortes and V. Vapnik, “Support-vector networks,” Machine Learning, vol. 20, pp. 273–297, 1995. [Google Scholar]
25. D. Ma, S. Li, X. Zhang and H. Wang, “Interactive attention networks for aspect-level sentiment classification,” in Proc. of the 26 Int. Joint Conf. on Artificial Intelligence (IJCAI), Melbourne, Australia, pp. 4068–4074, 2017. [Google Scholar]
26. X. Li, L. Bing, W. Lam and B. Shi, “Transformation networks for targetoriented sentiment classification,” in Proc. of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, pp. 946–9, 2018. [Google Scholar]
27. F. Fan, Y. Feng and D. Zhao, “Multi-grained attention network for aspectlevel sentiment classification,” in Proc. of the 2018 Conf. on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, pp. 3433–3442, 2018. [Google Scholar]
28. B. Huang, Y. Ou and K. M. Carley, “Aspect level sentiment classification with attention-over-attention neural networks,” in Int. Conf. on Social Computing, Behavioral-Cultural Modeling, & Prediction and Behavior Representation in Modeling and Simulation, Washington DC, USA, pp. 197–206, 2018. [Google Scholar]
29. Y. Song, J. Wang, T. Jiang, Z. Liu and Y. Rao, “Attentional encoder network for targeted sentiment classification,” arXiv, vol.abs/1902.09314, 2019. [Google Scholar]
30. Q. Jiang, L. Chen, R. Xu, X. Ao and M. Yang, “A challenge dataset and effective models for aspect-based sentiment analysis,” in Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, pp. 6280–6285, 2019. [Google Scholar]
31. H. Xu, B. Liu, L. Shu and P. Yu, “BERT Post-training for review reading comprehension and aspect-based sentiment analysis,” in Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), Minneapolis, Minnesota, pp. 2324–2335, 2019. [Google Scholar]
32. Y. Du, J. Wang, W. Feng, S. Pan, T. Qin et al., “AdaRNN: Adaptive learning and forecasting of time series, ” in Proc. of the 30th ACM Int. Conf. on Information & Knowledge Management (CIKM), Glod Coast, Australia, pp. 402–411, 2021. [Google Scholar]
33. T. H. Nguyen and K. Shirai, “PhraseRNN: Phrase recursive neural network for aspect-based sentiment analysis,” in Proc. of the 2015 Conf. on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, pp. 2509–2514, 2015. [Google Scholar]
34. R. He, W. S. Lee, H. T. Ng and D. Dahlmeier, “Effective attention modeling for aspect-level sentiment classification,” in Proc. of the 27th Int. Conf. on Computational Linguistics, Santa Fe, New Mexico, USA, pp. 1121–1131, 2018. [Google Scholar]
35. K. Sun, R. Zhang, S. Mensah, Y. Mao and X. Liu, “Aspect-level sentiment analysis via convolution over dependency tree,” in Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, pp. 5678–5687, 2019. [Google Scholar]
36. C. Zhang, Q. Li and D. Song, “Aspect-based sentiment classification with aspect-specific graph convolutional networks,” in Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, pp. 4567–4577, 2019. [Google Scholar]
37. B. Huang and K. Carley, “Syntax-aware aspect level sentiment classification with graph attention networks,” in Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, pp. 5468–5476, 2019. [Google Scholar]
38. X. Bai, P. Liu and Y. Zhang, “Investigating typed syntactic dependencies for targeted sentiment classification using graph attention neural network,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 503–514, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools