
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Virtual Machine Consolidation with Multi-Step Prediction and Affinity-Aware Technique for Energy-Efficient Cloud Data Centers
School of Cyber Science and Engineering, Southeast University, Nanjing, 211189, China
* Corresponding Author: Pingping Li. Email:
Computers, Materials & Continua 2023, 76(1), 81-105. https://doi.org/10.32604/cmc.2023.039076
Received 09 January 2023; Accepted 10 April 2023; Issue published 08 June 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Virtual machine (VM) consolidation is an effective way to improve resource utilization and reduce energy consumption in cloud data centers. Most existing studies have considered VM consolidation as a bin-packing problem, but the current schemes commonly ignore the long-term relationship between VMs and hosts. In addition, there is a lack of long-term consideration for resource optimization in the VM consolidation, which results in unnecessary VM migration and increased energy consumption. To address these limitations, a VM consolidation method based on multi-step prediction and affinity-aware technique for energy-efficient cloud data centers (MPaAFVMC) is proposed. The proposed method uses an improved linear regression prediction algorithm to predict the next-moment resource utilization of hosts and VMs, and obtains the stage demand of resources in the future period through multi-step prediction, which is realized by iterative prediction. Then, based on the multi-step prediction, an affinity model between the VM and host is designed using the first-order correlation coefficient and Euclidean distance. During the VM consolidation, the affinity value is used to select the migration VM and placement host. The proposed method is compared with the existing consolidation algorithms on the PlanetLab and Google cluster real workload data using the CloudSim simulation platform. Experimental results show that the proposed method can achieve significant improvement in reducing energy consumption, VM migration costs, and service level agreement (SLA) violations.Keywords
With the rapid development of global informatization, the energy consumption and CO2 emissions of cloud data centers have increased rapidly [1–3]. Recent studies have shown that cloud data centers account for approximately 7% of the total world’s electricity consumption, and this number is expected to increase to 13% by 2030 [4]. However, the resource utilization of physical hosts in cloud data centers is generally low. Research shows that the average CPU utilization is less than 20%, while an idle host consumes 70% of its peak energy consumption [5]. Inadequate utilization of resources leads to a massive waste of resources and unnecessary energy consumption, which increases the operating costs of cloud service providers and reduces the energy efficiency of the whole society.
In cloud computing, virtualization technology [6] has been used to encapsulate various resources of a cloud data center into virtual machines (VMs) for tenants to use. It should be noted that one physical host can host multiple VMs, so maximizing the number of VMs hosted by each host can maximize the utilization of cloud data center resources and reduce energy consumption. However, when a host hosts too many VMs, it will be overloaded, which will decrease the quality of service (QoS). VM consolidation has been proven to be one of the most effective techniques for optimizing resource utilization and guaranteeing QoS, and it needs to solve three problems [7–9]: 1) host load detection: detect host overloaded or underloaded; 2) migration VM selection: for overloaded hosts, select appropriate VMs to migrate; and 3) VM placement: based on the consideration of QoS and energy consumption, select appropriate hosts to place migration VMs. Through the VM consolidation, resources in the cloud data center can be dynamically adjusted to optimize their allocation.
However, the usage of resources in the cloud data center changes dynamically. For VM consolidation, the dynamically changing characteristics of cloud resources pose a challenge for assessing host load. Related studies use only the current utilization of a single resource (i.e., CPU) when determining host load status [10,11]. In addition, many schemes consider multiple resources (i.e., CPU, memory, disk, and network), but ignore the dynamically changing characteristics of host load [12,13]. The above two solutions fail to accurately describe the host load state, which may lead to unnecessary VM migration, resulting in system performance degradation and additional resource overhead [14]. Second, how to select migration VMs from overloaded hosts and select the optimal placement host for migration VMs is another key problem to be solved. Most of the existing VM consolidation schemes [15–17] do not consider the long-term relationship between VMs and hosts when selecting migration VMs and placement hosts. For a dynamically changing cloud data center, this leads to excessive consolidation and reduces the effective usage of resources, resulting in increased energy consumption and resource waste.
To address the aforementioned challenges encountered in VM consolidation, a VM consolidation algorithm based on multi-step prediction and affinity-aware technique is proposed in this paper. Using the historical data of the cloud data center, an improved linear regression (LR) prediction algorithm is employed to predict the next-moment resource utilization of VMs and hosts. Then, the long-term resource demand in the future period is obtained through multi-step iteration prediction. The current and multi-step prediction values of resources determine the host load state, avoiding aggressive consolidation. In addition, an affinity relationship model between VMs and hosts based on multi-dimensional resources and multi-step prediction values is proposed. Based on the proposed affinity model, affinity-aware VM selection and affinity-aware VM placement methods are designed to improve the utilization of resources, reduce the number of active hosts in a cloud data center, and achieve the purpose of reducing energy consumption.
For the rest of this paper, Section 2 describes the related work, Section 3 introduces the affinity model and multi-step prediction, Section 4 introduces the VM consolidation based on the multi-step prediction and affinity model, Section 5 specifically describes the experimental evaluation, andSection 6 introduces the conclusions.
Energy efficiency and efficient usage of resources have been attracting increasing attention in recent years. VM consolidation has become an effective method to improve resource utilization and energy efficiency in cloud data centers. Relevant research mainly focuses on three aspects, namely, how to determine whether a host is overloaded or underloaded, how to select the appropriate migration VMs from the overloaded host, and how to reselect the appropriate host for migration VMs.
In terms of host load status detection, some recent studies [18–20] used static threshold of CPU as the only criterion. However, in cloud data centers, the usage of resources is constantly changing. Therefore, the static threshold of a single resource cannot accurately assess the load status of a host, resulting in improper resource utilization. Zhou et al. [21] proposed a dynamic threshold method based on the K-Means clustering algorithm, which divided hosts into four types according to the dynamic threshold, improving the detection performance of dynamically changing resources. Beloglazov et al. [11] proposed an adaptive host load threshold algorithm to determine the host load state based on the statistical analysis of historical CPU data, which further improved the performance of adaptive resource dynamic changes. However, these methods only consider the current CPU utilization when performing the host load detection. Therefore, the reliability of overloaded and underload host detection is reduced, resulting in unnecessary migration and energy waste. In addition, the above studies did not consider the effects of other resources on overloaded or underloaded host determination. However, excessive utilization of any resources on a host will affect the performance of the host and reduce its QoS.
Many studies have applied predictive techniques to VM consolidation to perceive dynamic changes in resources. Haghshenas et al. [22] predicted the CPU utilization based on LR and selected underloaded hosts and placement hosts according to the predicted CPU value. Similarly, Farahnakian et al. [23] proposed a combined prediction algorithm based on the LR and K-nearest neighbor algorithm to predict the host CPU utilization, which was used for host overload detection. Moghaddam et al. [24] used machine learning-based methods and neural networks to predict the CPU utilization of a host and designed a dynamic threshold according to the CPU prediction value to determine whether a host was overloaded. By predicting future resource utilization, the VM consolidation can effectively reduce the number of service level agreement violations (SLAv). However, these methods only consider the one-step prediction of current single resource utilization and lack the long-term usage consideration of multi-dimensional resources in the future period. Therefore, it is difficult to obtain long-term optimal management and increase migration times.
In terms of migration VM selection, the random selection (RS) method, minimum migration time (MMT) method, maximum correlation (MC) method, and maximum utilization (MU) method have been widely used [11,25]. In addition, Li et al. [26] used memory page similarity characteristics to select migration VM. They selected VMs with high memory page similarity on different hosts as the VM to be migrated to reduce migration time and data. Masoumzadeh et al. [27] proposed an adaptive VM selection method by integrating multiple VM selection technologies, which dynamically selects the migration VM selection method based on the current host load and the fuzzy Q-learning method. Laili et al. [28] proposed a new iterative budget algorithm for migration VM selection, which established a reverse selection mechanism for randomly selected hosts to find suitable migration VMs. However, the aforementioned studies did not consider the relationship between the future resource usage of VMs and hosts when selecting migration VMs, which not only increases the migration overhead but also brings potential SLAv.
In terms of VM placement, many studies have considered VM placement as a well-known bin-packing problem [29], which is also known as an NP-hard problem. The Best Fit Decreasing (BFD) algorithm, First Fit Decreasing (FFD) algorithm, First Fit (FF) algorithm, and Best Fit (BF) algorithm are widely used heuristic algorithms to solve the VM placement problem [30,31], whose purpose is to reduce energy consumption by reducing the number of running hosts. However, there is much that can be improved on the above widely used heuristics in terms of full utilization of resources, and some researchers have improved them. Beloglazov et al. [11] improved BFD and proposed a power-aware BFD (PABFD) algorithm. PABFD minimizes the increase in power consumption through energy consumption awareness when selecting the placement host for migration VMs. Murtazaev et al. [32] combined the FF and BF algorithms and proposed a Sercon algorithm to minimize the number of hosts and migration costs. Farahnakian et al. [33] used the host load prediction strategy based on the regression model and combined it with the BFD method to determine the placement host. Bobroff et al. [34] proposed a measure-forecast-remap VM placement algorithm by measuring historical workloads and predicting future resource demands to reduce the number of active hosts. However, the aforementioned algorithms do not consider the relationship between the resources required by a migration VM and the remaining resources of a host in the future period. Namely, they optimize only the current usage of resources and only guarantee the optimal current resource allocation after the VM are placed. Since the long-term relationship between multi-dimensional resources in the future period is ignored, a host is prone to overload again in the future, resulting in increased migration costs. Therefore, revealing the relationship between the VM’s resources and the host’s remaining resources in the future period can contribute to the effective utilization of resources and reduce the probability of host overloading in the future period.
In addition, an increasing number of studies have modeled VM consolidation as a single- or multi-objective optimization problem, and various meta-heuristic algorithms have been proposed. Li et al. [35] obtained the optimal mapping relationship between VMs and hosts by simulating the foraging behavior of artificial bees. Besides, Li et al. [36] proposed a differential evolution meta-heuristic algorithm and applied it to VM consolidation. However, the above methods only consider the optimization of energy consumption and ignore the migration cost. Al-Moalmi et al. [37] proposed a grey wolf meta-heuristic algorithm considering the effective utilization of CPU and RAM, which effectively optimized energy consumption and QoS. However, the meta-heuristic algorithms are time-consuming in the evolutionary iteration process. For large-scale data centers, thousands of solution spaces need to be evaluated and compared, resulting in high algorithm complexity.
Existing VM consolidation studies have been mainly focused on reducing cloud data center energy consumption, SLAv, and migration overhead. The core of VM consolidation is to schedule and utilize various resources reasonably, but most studies have ignored the long-term relationship of the resources between VMs and hosts, and lack long-term consideration of resource optimization. To solve this limitation, this paper proposes an efficient and reliable strategy for VM consolidation with full consideration of migration overhead, energy consumption, and QoS. Compared with previous studies, for host load detection, the long-term load changes of the host are considered based on the proposed multi-step prediction, which effectively reduces the overload probability of the host. In addition, based on the proposed multi-step prediction and affinity model, on the one hand, consider the long-term relationship between the overloaded host and the VM when selecting migration VMs, which can quickly and accurately eliminate the overload state of the host with the minimum migration cost, and on the other hand, consider the long-term complementary relationship between the resources of the placement host and the VM when selecting placement hosts, which can make full use of resources.
3 Affinity Model Based on Multi-Step Prediction
As shown in Fig. 1, the local monitor continuously monitors the resource utilization of VMs and hosts. The resource predictor uses the monitoring data to perform prediction. The resource scheduler obtains the current and future utilization of resources through the global monitor and calls the host load detection module, migration VM selection module, and VM placement module to complete the VM consolidation process. The host load detection module is used to determine whether a physical host is overloaded or underloaded. If the physical host is overloaded, the resource scheduler calculates the affinity value between the VM and the host using the migration VM selection module and selects migration VMs. The VM placement module selects the most suitable host in the cluster for the migration VMs.
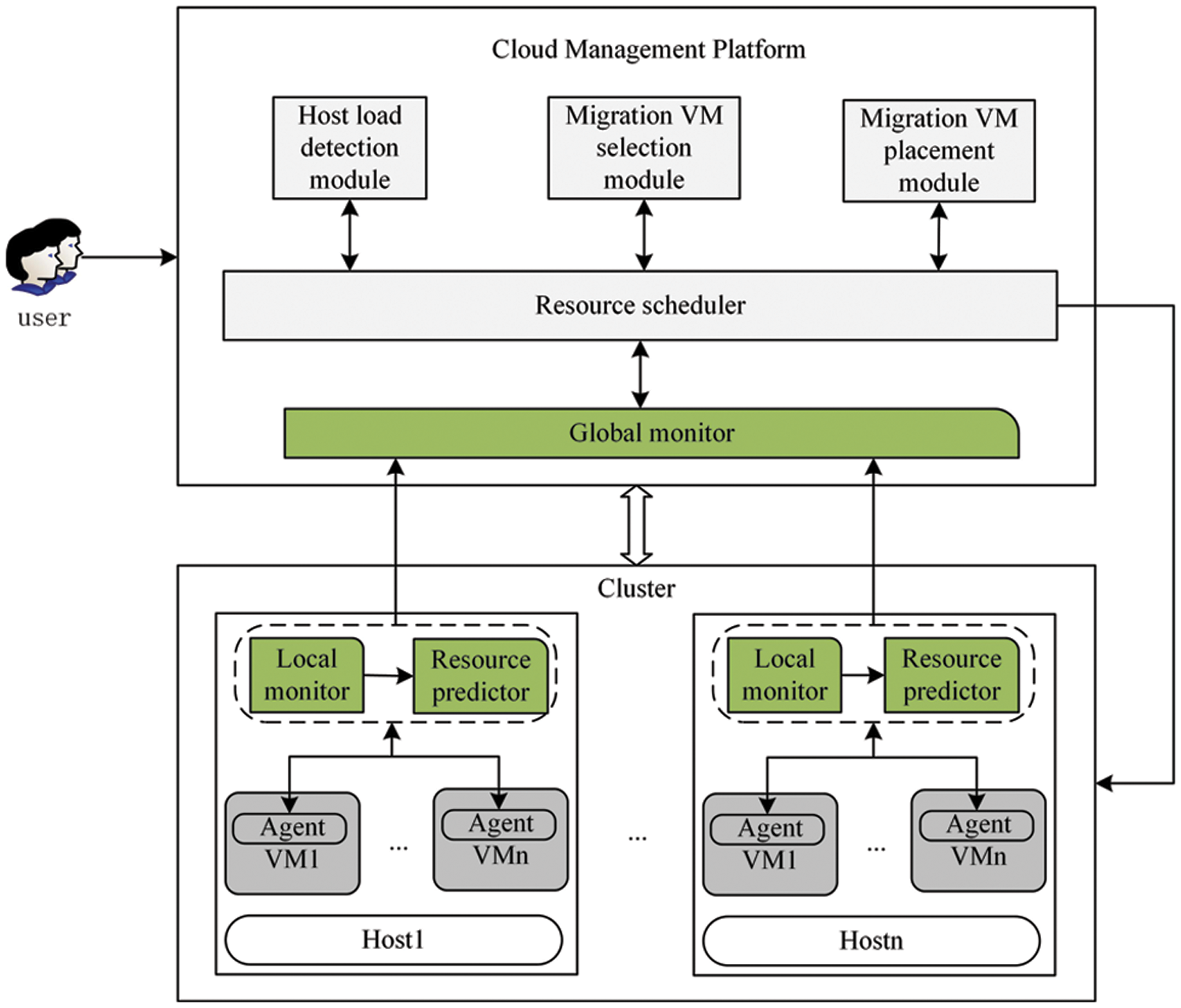
Figure 1: The system framework
In a cloud data center, assume that the number of hosts is
Further, for host
where
3.3 Resource Prediction Based on Improved LR
Assume that the last n utilization of resource
where
where
Previous research has shown that the absolute error of the least square method is not the smallest to solve the LR problem [39]. To improve the prediction accuracy, this study improves the above LR based on the new LR (NLR) model [40]. The basic idea of the NLR is to assume the model to pass through a straight line and a mean point. All sample points are required to be evenly distributed above and below the line. Subtract the slope of the assumed straight line from the slope connected by the sample point and intercept, and make their sum equal to 0. In this way, the slope and intercept can be solved by the simultaneous equation, namely coefficients
There is a common factor
3.4 Multi-Step Prediction Based on Improved LR
The proposed multi-step prediction (MP) aims to predict the long-term usage of resource
where
The MP algorithm is also applicable to the VM resources prediction. Thus, the next
3.5 Affinity Model Based on Multi-Step Prediction
Since multiple VMs are usually running on a host, VMs with different requirements share and compete with each other for the host’s resources. Therefore, each VM has a different effect on host overloading. To determine the key resources that cause host overload and eliminate host overload rapidly and effectively, this section proposes an affinity model by quantifying the relationship between the resources of VMs and hosts.
Assume that at time
where
It should be noted that the larger the value of
When selecting migration VMs from overloaded hosts, selecting the VM with the largest affinity value can rapidly and effectively reduce the overload degree of the host. The value of
4 VM Consolidation Based on Multi-Step Prediction and Affinity-Aware
4.1 Host Load Detection Based on Multi-Step Prediction (MP-HLD)
The MP-HLD pseudo-code is given in algorithm 1. In the MP-HLD algorithm, a data center’s host set
(1) The utilization is larger than
(2) The current utilization is normal, but the utilization in the future period is larger than
Accordingly, a host
(1) The utilization is less than
(2) The current utilization is normal, but the utilization in the future period is less than
The MP-HLD method detects the load status of hosts in advance based on the current and future period resource utilization. For overloaded hosts, it can reduce the SLAv and improve the QoS, and for underloaded hosts, it can reduce the number of running host and energy consumption.

4.2 Affinity-Aware VM Selection Algorithm (AF-VMS)
For overloaded hosts, any type of resource overload can become a bottleneck of the host’s performance. Therefore, potential VMs need to be migrated from overloaded hosts to reduce the load. When selecting migration VMs, if the policy is unreasonable, it will lead to excessive VM migration, which increases energy consumption and affects the VM performance. The pseudo-code of AF-VMS is given in algorithm 2. For host

4.3 Affinity-Aware VM Placement Algorithm (AF-VMP)
Next, the AF-VMP is introduced in detail and the pseudo-code of AF-VMP is given inalgorithm 3. The main objective of the AF-VMP algorithm is to select a host with the maximum affinity from the
where
In addition to the consideration of the affinity value when selecting a placement host, after VM
(1) After a VM is migrated to a host, the resource requirements of all VMs running on the host cannot exceed the configured capacity of the host, namely:
(2) After a VM is migrated to a host, the resource utilization cannot exceed the maximum threshold in the future period, namely:
(3) The affinity value is maximal between migration VM

The detailed process of MPaAF-VMC is shown in algorithm 4. The prediction values

The performance evaluation of the VM consolidation algorithm should be performed on a large-scale cloud data center infrastructure, but it is difficult to perform and repeat experiments in an actual data center to evaluate the proposed algorithm. Therefore, CloudSim [25] simulator was used to evaluate the proposed algorithm. CloudSim is a widely used cloud computing environment simulation software, which can build a virtualized environment and simulate various resources of the cloud data center.
The cloud data center simulated in the experiment included two types of physical hosts HP ProLiant G4 and G5. Detailed information on the host configuration is given in Tables 1, and 2 shows their power consumption characteristics. Table 3 shows the four types of Amazon EC2 VMs used in the experiment [11].



This paper evaluates the performance of the proposed algorithm using several main evaluation metrics of VM consolidation, namely energy consumption, migration cost, and SLAv.
Energy consumption: In this study, it is considered that the energy consumption of a cloud data center is generated by running hosts. Thus, for the same number of VMs, the fewer hosts there are, the lower the energy consumption is. Research has shown that the energy consumption of a host depends on the CPU, memory, network, and storage devices, and it is directly proportional to the CPU utilization [41]. Therefore, CPU utilization is usually used to express the relationship between host energy consumption and resource utilization. In this experiment, the host energy consumption was measured based on the real power consumption data provided by the SPECpower Benchmark results. The energy consumption of HP G4 and G5 servers under different load levels is shown in Table 2.
Migration cost: The performance of the VM will be degraded during the migration, which may lead to the SLAv. Related research [11] has shown that the average performance reduction during the VM migration can be evaluated as 10% of CPU utilization, which is used as an evaluation metric of migration costs in this study. In addition, the number of VM migrations is also used as an evaluation metric of migration costs.
SLA violations: SLA is a conformance agreement between the subscriber and the cloud service provider on services, which is an important metric to comprehensively measure the QoS. SLAv [11] can be measured in two independent aspects: SLA violations due to host overload (SLAVO) and SLA violations due to VM migration (SLAVM). Therefore, the comprehensive SLAv is calculated as follows:
where SLAVO is the duration of the host overload, which is the percentage of time that the host’s resource utilization is close to 100%. SLAVM represents the performance reduction caused by VM migration. Eqs. (23) and (24) are the calculation method of SLAVO and SLAVM, respectively.
In Eq. (23),
This paper evaluates the effectiveness of the proposed methods based on two real-world workload datasets.
PlanetLab Data [42]: PlanetLab collected data from more than 1,000 VMs at more than 500 locations worldwide and tracked the CPU usage every 5 min. During March and April 2011, from the workload traces, we randomly selected 10 days of data, whose statistical characteristics are given in Table 4, showing that the average CPU utilization was much below 50%.

Google Cluster Data (GCD) [43]: GCD tracked the usage of multiple resources for approximately a month in May 2011. Table 5 shows the statistical characteristics of critical resources for 1,600 randomly selected VMs.

5.4.1 Multi-Step Prediction Performance
The GCD was used to evaluate the performance of the proposed MP scheme. The host resource utilization data were collected periodically by capturing the CPU and memory consumed by all tasks when the GCD workload was running. The collected data samples were divided into training and validation datasets. For observation data of a length n, the ratio of training to validation data was 3:2. The mean absolute percentage error (MAPE) and the root mean square error (RMSE) were used to evaluate the accuracy of the prediction model.
The prediction performance of MP for the six-step prediction (corresponding to the predicted value at 30 min) is presented in Fig. 2. Experimental results showed that the predicted value of the MP was close to the real value.
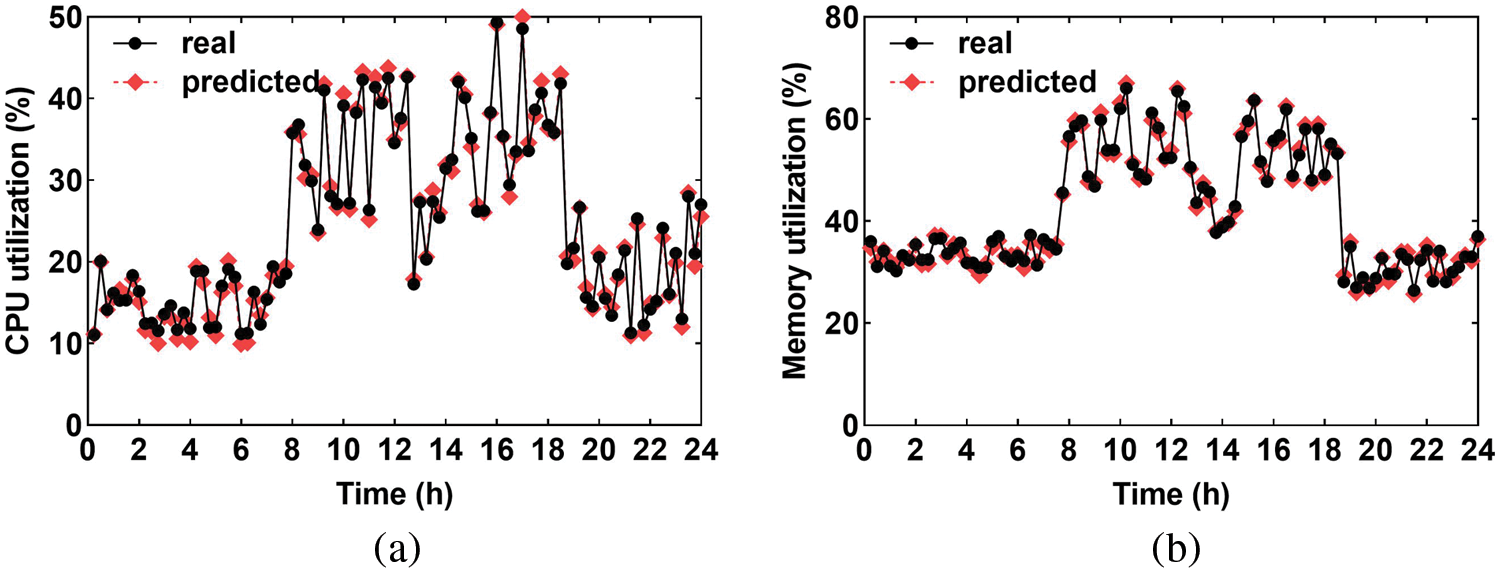
Figure 2: Comparison of the six-step prediction of CPU and memory. (a) CPU. (b) Memory
The results of the multi-step prediction are shown in Fig. 3, which indicates that the MAPE and RMSE values were the smallest for one-step prediction. Then, as the step length increases, the MAPE and RMSE values gradually increased because the error of multi-step prediction accumulated as the step length increases, resulting in a decline in the prediction accuracy. However, the maximum increase in the MAPE value for the CPU and memory was only 0.041 and 0.019, respectively. Therefore, the error values of one- and twelve-step predictions were not very different. This result proved the correctness of the MP algorithm. In other experiments, this paper set the prediction step length to six to ensure the accuracy of the prediction.
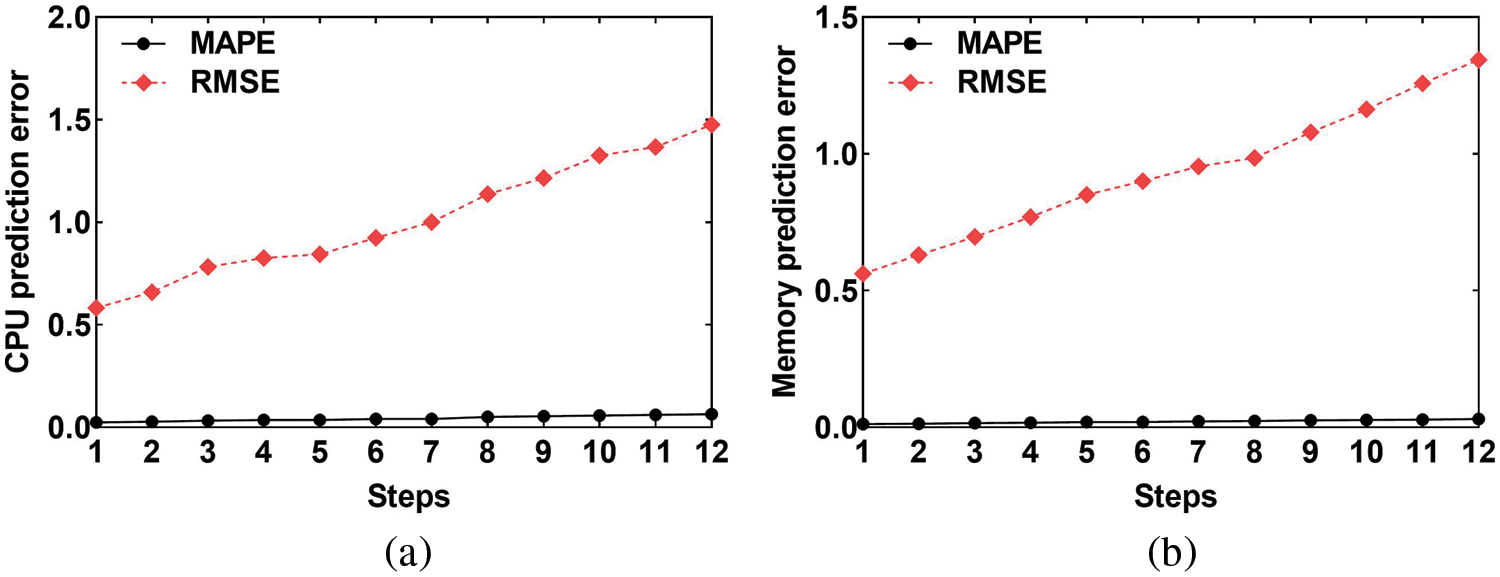
Figure 3: Comparison of the multi-step prediction. (a) CPU prediction error. (b) memory prediction error
The experiment was conducted based on cloud data centers with 100 to 1500 hosts and used the PlanetLab and GCD workloads data to perform VM consolidation every 5 min. We recorded 24 h of data as experimental results. The static detection method and dynamic detection method were used as the benchmark for comparison. For using the static threshold to detect host load (THR-HLD), the host overload threshold was set to 80%, while for using the dynamic threshold to detect host load (LR-HLD), the method of local regression (LR) was used to predict the host resource usage and determine the host load state. The experimental analysis focused on the impact of MP-HLD, THR-HLD, and LR-HLD on the number of overloaded, underloaded, and active hosts under different workloads and cloud data center sizes. The test results are shown in Figs. 4–6.
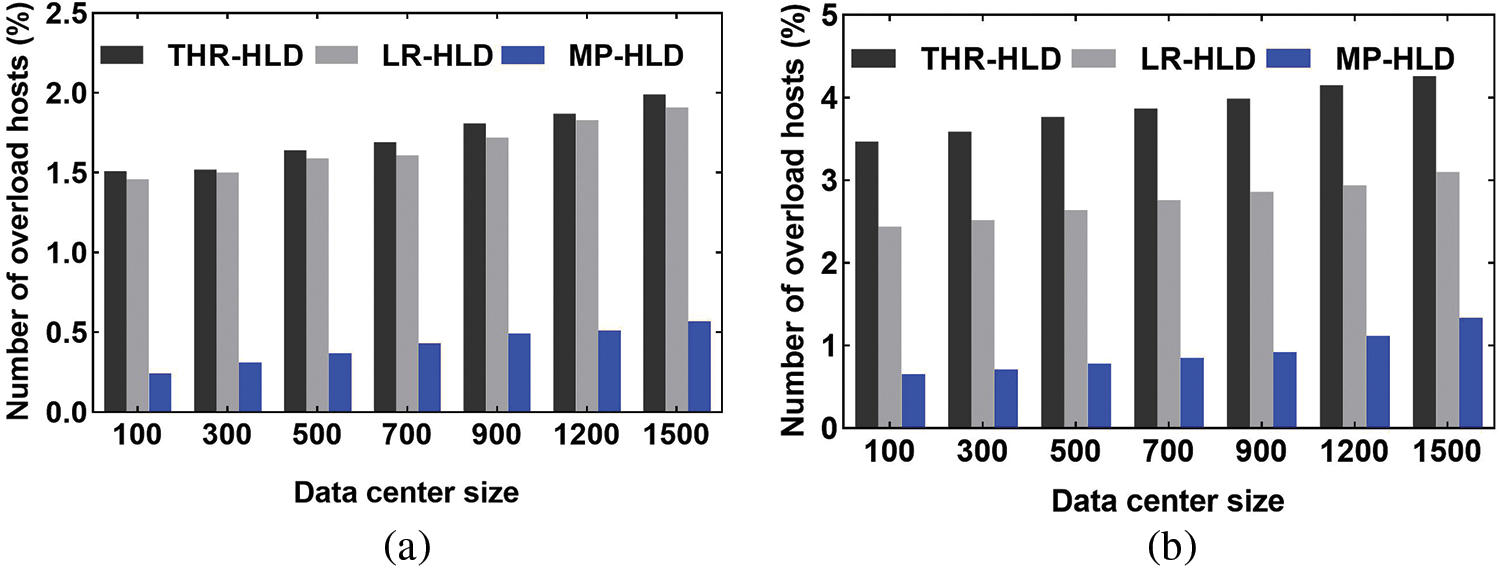
Figure 4: Comparison of the number of overloaded hosts. (a) PlanetLab. (b) GCD
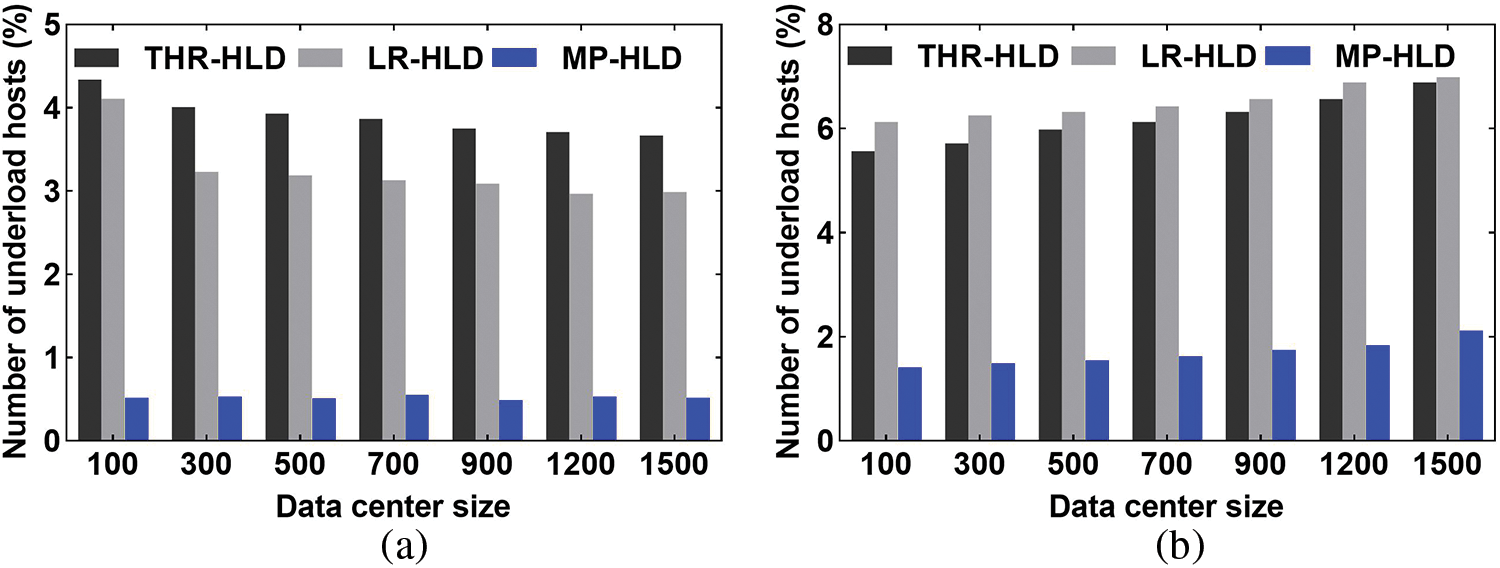
Figure 5: Comparison of the number of underloaded hosts. (a) PlanetLab. (b) GCD
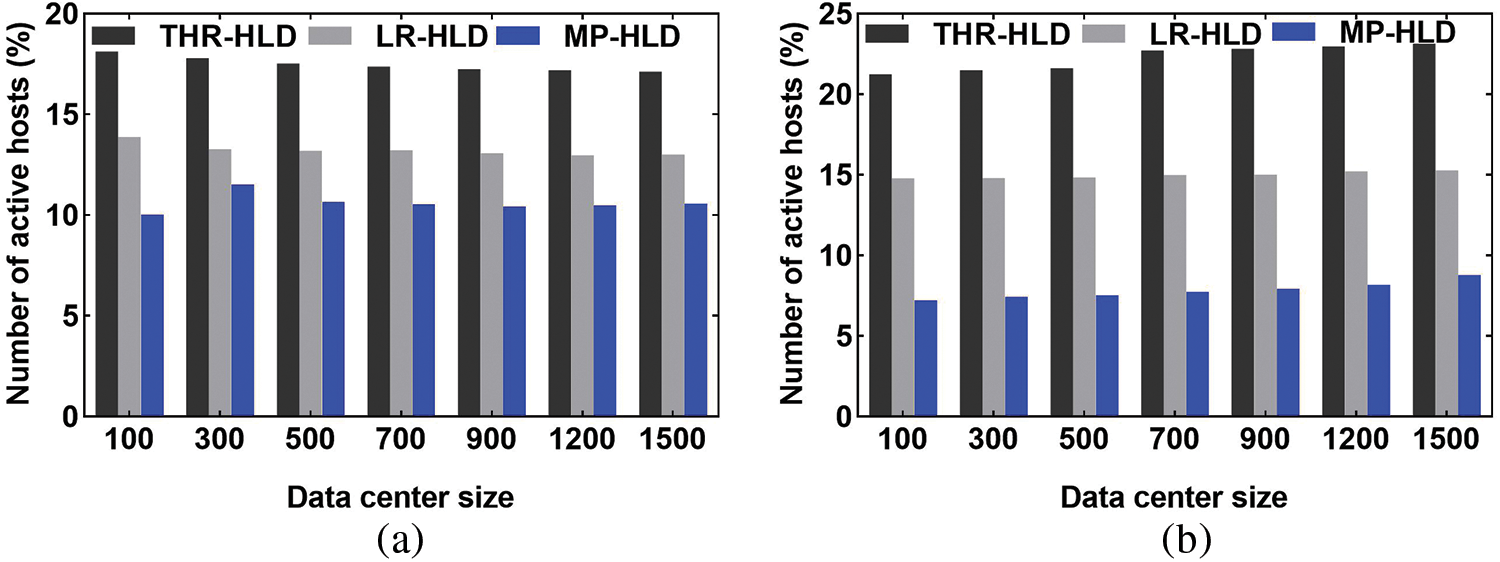
Figure 6: Comparison of the number of active hosts. (a) PlanetLab. (b) GCD
It can be seen from Figs. 4 and 5 that MP-HLD has the least number of hosts in overload and underload host detection. For a data center with 1,500 nodes, compared with static and dynamic threshold schemes, the number of overloaded hosts detected by MP-HLD reduced by 71.4% and 70.2%, respectively, and the number of underloaded hosts detected by MP-HLD reduced by 85.8% and 82.6%, respectively, in PlanetLab workload tests. The static and dynamic threshold algorithms determine the load status of a host only according to the current or short-term resource utilization. Even if the host load fluctuates occasionally or changes in a short time, the host will be judged to be overloaded or underloaded, which leads to misjudgment of the host load status, so more overloaded or underloaded hosts are detected. MP-HLD uses multi-step prediction to predict the host resource usage in the future period. When detecting the host load state, it considers the current and future period of resource usage, which effectively reduces the misjudgment caused by load changes through long-term forecasting of resource usage.
Fig. 6 shows that MP-HLD requires the least number of active hosts. Based on the above analysis, it can be seen that THR-HLD and LR-HLD methods do not fully consider the long-term dynamic changes of cloud data center resources in the future period, so they detect more underloaded or overloaded hosts. During every consolidation, more overloaded and underloaded hosts lead to more VM migrations, and more migration VMs need to activate more hosts to place these VMs.
5.4.3 VM Selection Performance
This section evaluates the performance of the AF-VMS. In addition to using the AF-VMS method, several widely used VM selection algorithms proposed in [25] were used for comparison, namely, the MU, MMT, and MC algorithms. The experiment performed VM consolidation every5 min using PlanetLab and GCD workloads, and the data over 24 h were used as the experimental results. The comparisons of energy consumption and SLAv of different VM selection algorithms under different VM numbers are presented in Figs. 7 and 8. As shown in Figs. 7 and 8, the AF-VMS method had the lowest energy consumption and SLAv among all methods regardless of the number of VMs.
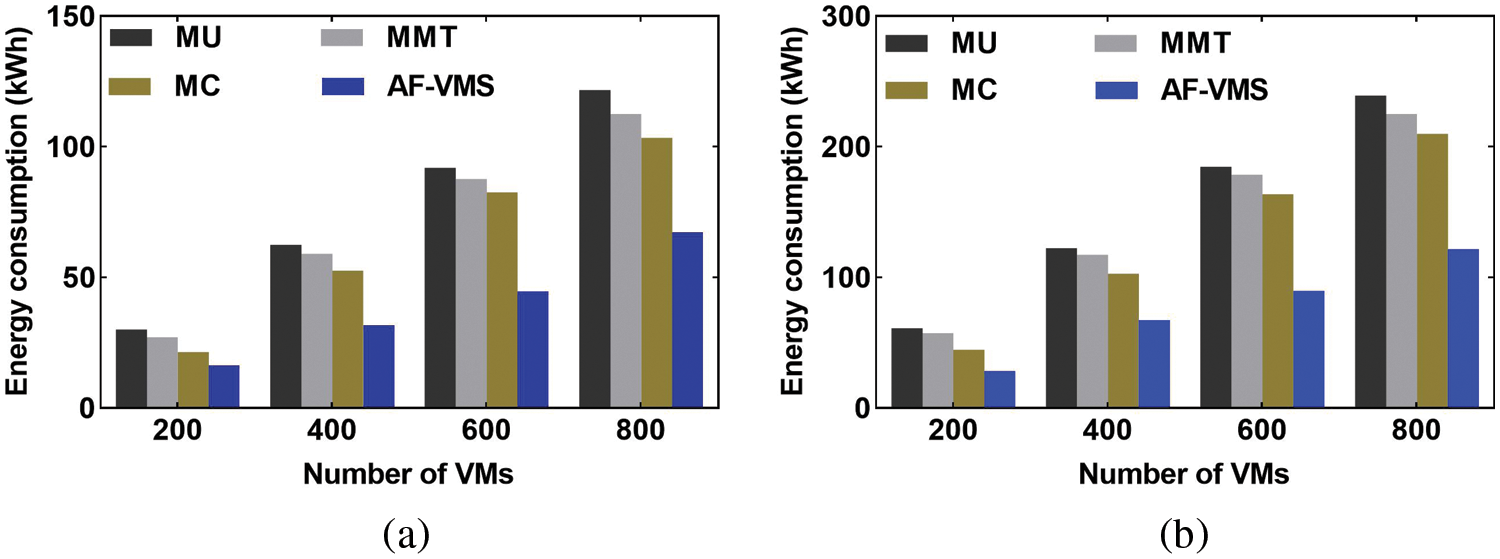
Figure 7: Comparison of energy consumption. (a) PlanetLab. (b) GCD

Figure 8: Comparison of SLAv. (a) PlanetLab data. (b) GCD
Next, the effects of the number of VM migrations and the average number of overloaded hosts per consolidation were analyzed. As shown in Figs. 9 and 10, AF-VMS achieved better performance than the other VM selection strategies. Fig. 9 shows that AF-VMS has the minimum number of migration VMs, achieving reductions of 39.5% and 40.6% on PlanetLab and GCD, respectively, for the cluster with 800 VMs compared to the suboptimal MC scheme. In addition, as presented in Fig. 10, the average number of overloaded hosts per consolidation was reduced by 29.2% and 23.3% on PlanetLab and GCD, respectively, for the cluster with 800 VMs compared to the suboptimal MC scheme.
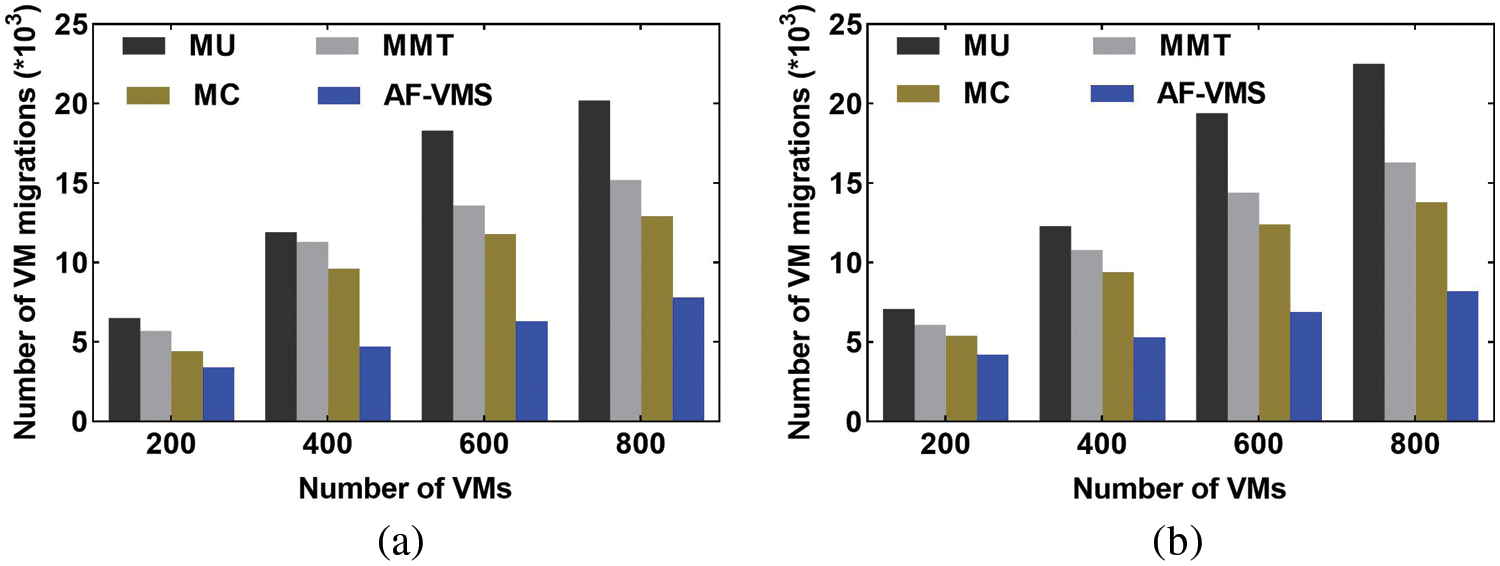
Figure 9: Comparison of the number of VM migrations. (a) PlanetLab data. (b) GCD
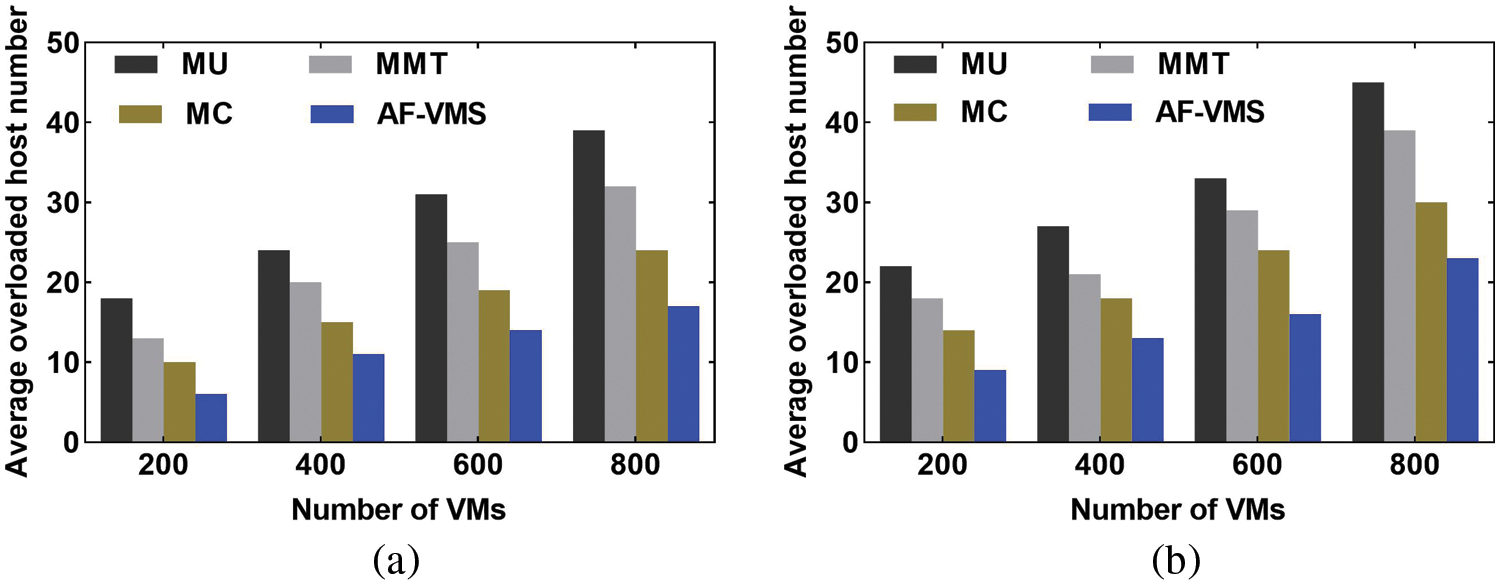
Figure 10: Comparison of the average number of overloaded hosts. (a) PlanetLab. (b) GCD
The above performance improvement was mainly attributable to the affinity model based on the multi-step prediction. The multi-step prediction could correctly predict the resource utilization of the host and VM in the future period. Based on the predicted value, the affinity model calculated the relationship between the VM and the overloaded host, which could accurately select a VM with the greatest impact on the overloaded host. This is because the resource change trend of the selected migration VM and the overloaded host was the closest in the future period, and the resource usage of the selected migration VM and the overloaded host was also the closest in the future period. Consequently, the overloaded host could accurately and rapidly recover to normal load with the minimum number of VM migrations, and it could avoid being overloaded in the future period. This effectively reduces the number of VM migrations and the probability of host overload.
5.4.4 VM Placement Performance
Next, the performance of AF-VMP was evaluated. The host overload detection algorithms THR-HLD, LR-HLD, MP-HLD, the VM selection algorithms MU, MMT, MC, and the widely used heuristic VM placement algorithms FF and PABFD constituted VM consolidation schemes as the comparison benchmarks.
The comparison results of energy consumption, SLAv, and VM migration under different VM selection algorithms and VM placement algorithms are shown in Figs. 11–13. Compared with other schemes, the scheme proposed in this paper significantly reduced power consumption and SLAv with minimal migration cost.
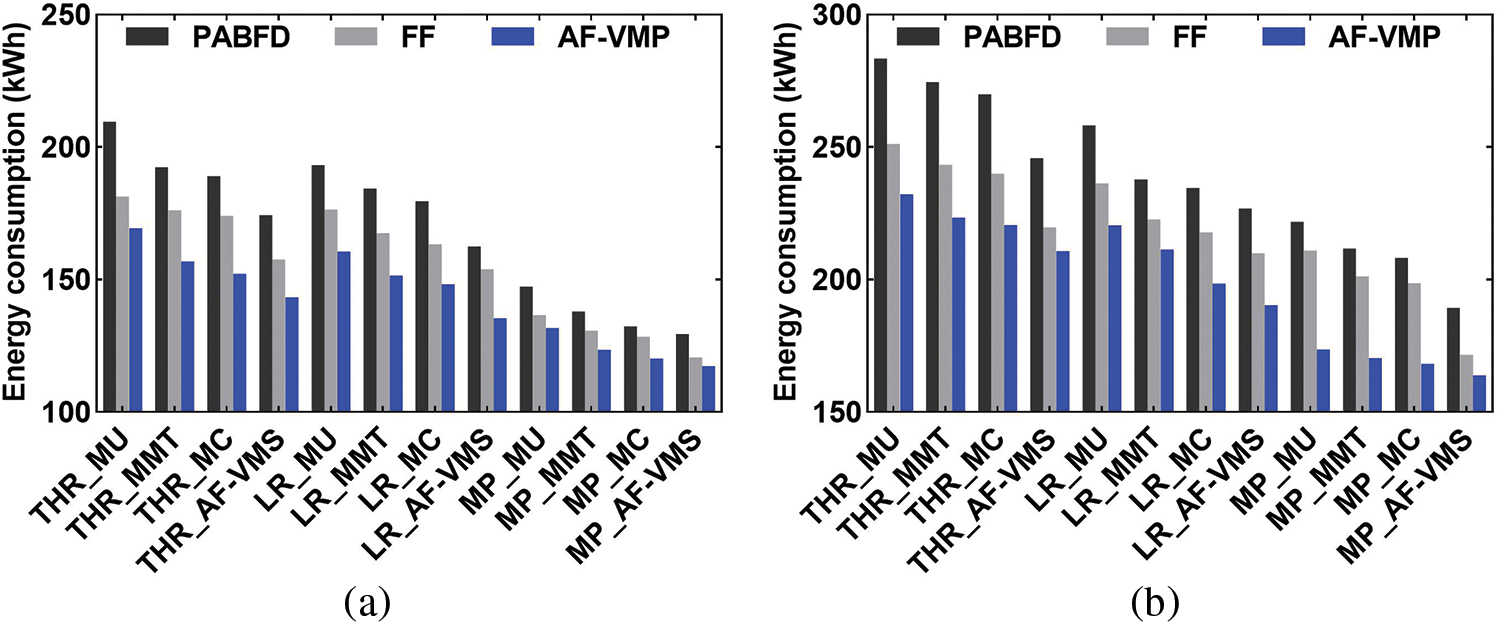
Figure 11: Comparison of energy consumption. (a) PlanetLab. (b) GCD
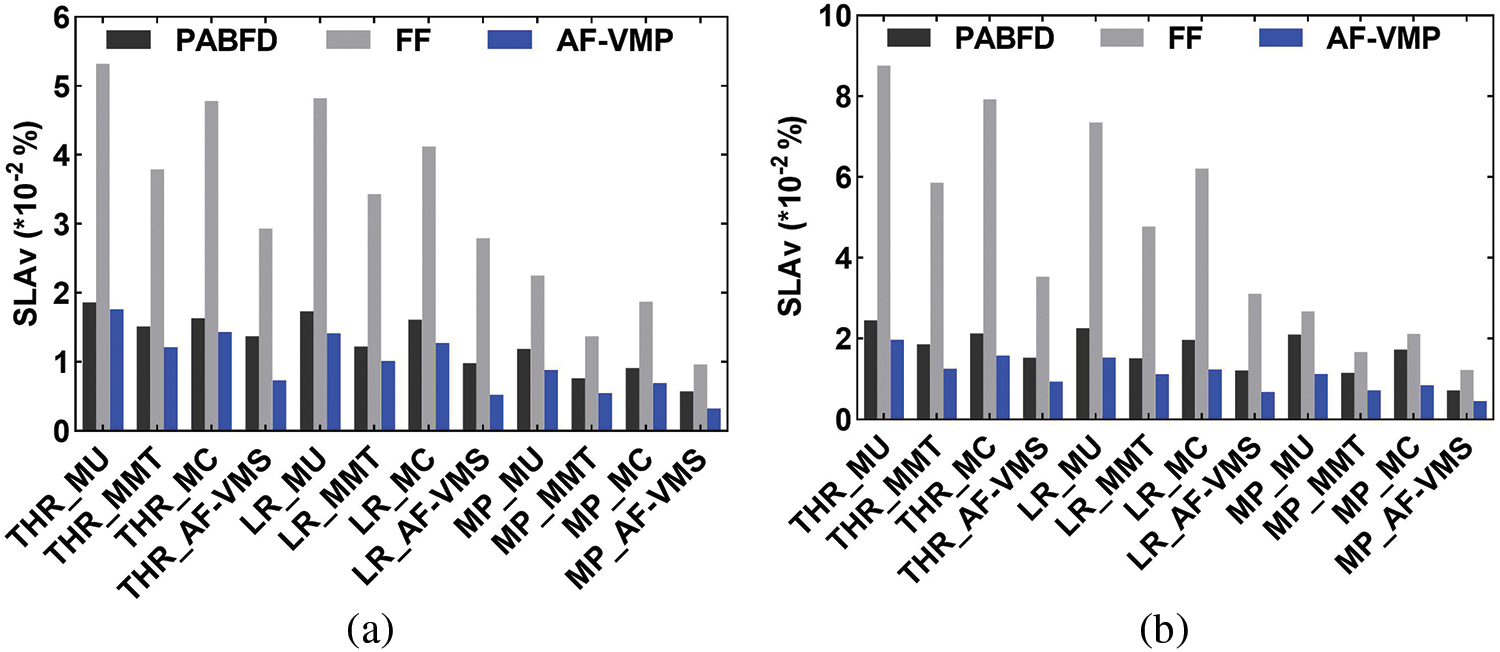
Figure 12: Comparison of SLAv. (a) PlanetLab. (b) GCD
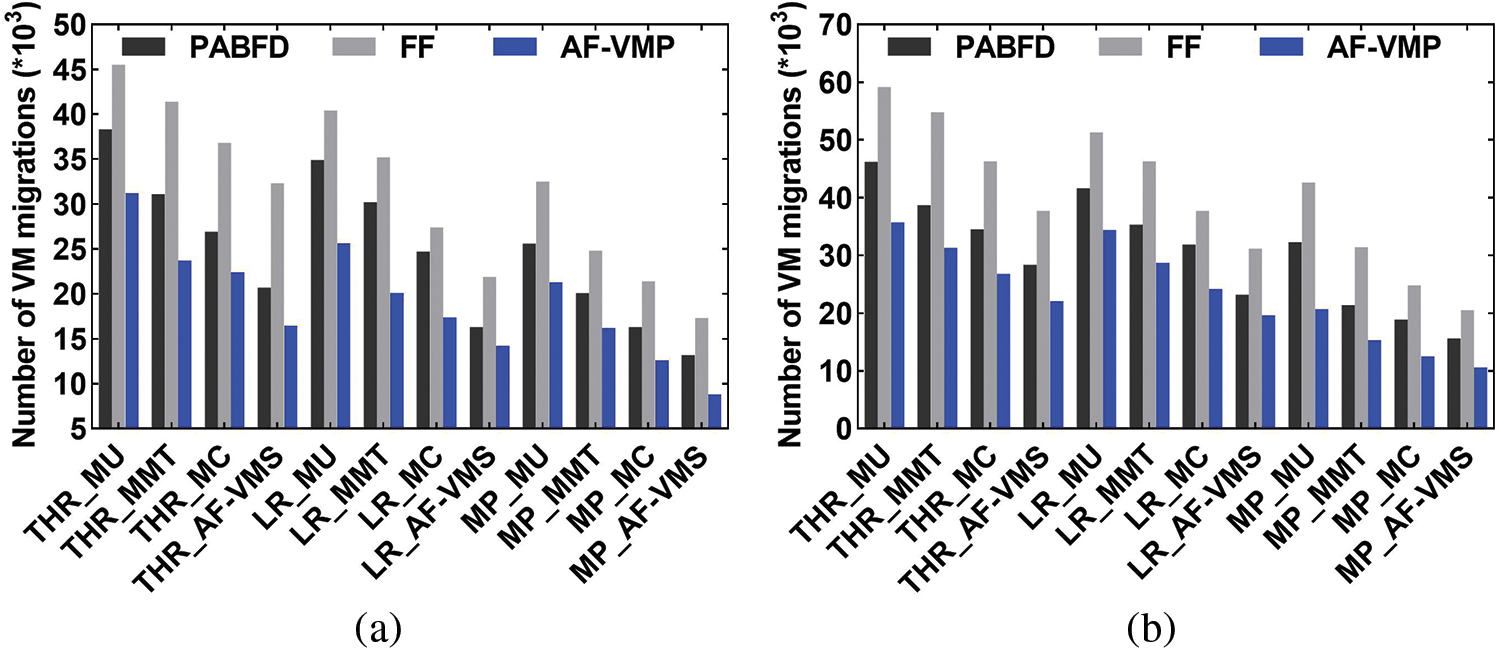
Figure 13: Comparison of the number of VM migrations. (a) PlanetLab. (b) GCD
As shown in Fig. 11, based on the proposed MP, AF-VMS, and AF-VMP VM consolidation scheme, for the data center with 800 hosts and 1000 VMs, the energy consumption per day using the PlanetLab and GCD was 117 kWh and 163 kWh, respectively, and compared with the other algorithms, the maximum reductions were 44% and 42%, respectively. This was because when a VM was relocated, the proposed affinity model considered the complementarity of resources, which maximizes the usage of the host resources. Therefore, the number of running hosts was effectively reduced, thus reducing energy consumption.
Fig. 12 shows that the proposed algorithm had the minimum SLAv, which proved that it achieved a good performance in terms of QoS assurance. The affinity model considered the VM impact on the overloaded host when selecting migration VMs, which could restore overloaded hosts to normal-load hosts with the fastest speed and the smallest migration cost. In addition, AF-VMS and AF-VMP used the resource utilization prediction in the future period as a measurement factor, which effectively reduced the probability of a host being overloaded again in the future period, thus effectively reducing the SLAv. However, the FF algorithm considered only whether the host had sufficient resources when selecting placement hosts, and ignored the effects of SLAv and energy consumption. Therefore, the SLAv generated by the FF algorithm was the highest among all algorithms. The PABFD algorithm mainly focused on the impact on energy consumption and did not consider SLAv.
Similarly, the proposed algorithm had the best performance in terms of migration cost compared with other schemes. As shown in Fig. 13, the FF algorithm migrated the most VMs among all algorithms. This is because the FF algorithm considered only whether the host had sufficient resources at the current moment when migrating VMs, and ignored both the fact of whether the host would be overloaded in the future period and the future dynamic changing trend of host resources. However, based on the affinity model, the proposed algorithm fully considered the impact of these two factors and selected the migration VM that had the greatest impact on the overloaded host which reduced the number of VM migrations. In addition, based on the affinity model, when selecting a host for VM placement, the proposed algorithm not only considered the complementary characteristics of the resources between VM and host but also ensured that the host’s resources were within a normal load range at the current and future periods, thus effectively avoiding the occurrence of host overload and reducing the VM migration number.
Considering the diversity of cloud computing environments, different cluster scales were used to further test the comprehensive performance of the proposed comprehensive algorithm MPaAF-VMC. Table 6 shows the cluster scales. MPaAF-VMC was compared with the LR + MC + PABFD and LR + MC + FF algorithms. In addition, the TVRSM algorithm [44] was used as a comparison benchmark. The TVRSM selected migration VMs from overloaded hosts based on the multiple correlation coefficient (MCC) and selected placement hosts based on the minimum power increasing strategy (MPIS) that selected the host with the smallest power increase.

The performance of different schemes on PlanetLab for various cluster scales is presented in Table 7. The results show that the proposed algorithm has the best performance regarding all metrics among all algorithms. As the cluster scale increased, the energy consumption of each solution increased, but the proposed algorithm had the least energy consumption, VM migrations, and overloaded host number among all methods. The performance improvement was due to the long-term optimization considerations of resources based on the affinity model, which guaranteed long-term optimization and full utilization of resources. In contrast, the other algorithms considered only the current resource utilization, ignoring dynamic changes and the long-term relevance of cloud resources when selecting migration VMs and placement hosts, so they could not guarantee the long-term optimal utilization of resources, which increased energy consumption. Although the TVRSM algorithm selected migration VM based on the MCC strategy that considered the resource correlation between the host and VM, it ignored the long-term correlation of resource usage, which led to more VM migrations and overloaded or underload hosts detection.

To reduce the energy consumption and SLAv of a cloud data center, this paper proposes an MPaAF-VMC algorithm. The MPaAF-VMC uses a multi-step prediction scheme based on the improved LR prediction model to forecast resource demand in the future period. In addition, an affinity model between the host and VM is developed based on the multi-step prediction result. During the VM consolidation, based on the affinity model, for selecting migration VMs, the VM with the maximum affinity value is selected from overloaded hosts, which not only effectively eliminates the overload state of a host but also decreases the number of VM migrations and SLAv, and for selecting placement hosts, the host with the maximum affinity value is selected for migration VMs, which ensures that VMs are deployed on the minimum number of hosts to reduce energy consumption. Finally, many simulation experiments are conducted using PlanetLab and GCD workload data, and the results show that the performance of the MPaAF-VMC algorithm is significantly better than other algorithms. However, as the prediction step length increases, the prediction error will increase, which can be a limitation of this work. This is due to the accumulation of errors with the increase in prediction step length.
With the development of big data and artificial intelligence, higher requirements are put forward for cloud computing systems. In addition to energy consumption challenges, data processing faces new challenges. In future work, during the VM consolidation, the affinity relationship between VMs and between hosts could be analyzed to achieve better energy consumption optimization and data processing performance. In addition, the accuracy of multi-step prediction and the prediction step length could be further explored to perceive potential risks as early as possible and plan resources to meet the challenges.
Acknowledgement: Thanks to our tutors and researchers for their assistance and guidance.
Funding Statement: The project is supported by the National Natural Science Foundation of China (62172089, 61972087, 62172090).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. I. Ahmad, A. Shahnaz, M. Asfand-e-Yar, W. Khalil and Y. Bano, “A service level agreement aware online algorithm for virtual machine migration,” Computers Materials & Continua, vol. 74, no. 1, pp. 279–291, 2023. [Google Scholar]
2. S. S. Panwar, M. M. S. Rauthan and V. A. Barthwal, “A systematic review on effective energy utilization management strategies in cloud data centers,” Journal of Cloud Computing, vol. 11, no. 1, pp. 1–29, 2022. [Google Scholar]
3. S. Bharany, S. Sharma, O. I. Khalaf, G. M. Abdulsahib, A. S. AlHumaimeedy et al., “A systematic survey on energy-efficient techniques in sustainable cloud computing,” Sustainability, vol. 14, no. 10, pp. 6256, 2022. [Google Scholar]
4. M. Avgerinou, P. Bertoldi and L. Castellazzi, “Trends in data centre energy consumption under the European code of conduct for data centre energy efficiency,” Energies, vol. 10, no. 10, pp. 1470, 2017. [Google Scholar]
5. R. Birke, L. Y. Chen and E. Smirni, “Data centers in the cloud: A large scale performance study,” in Proc. of the 5th IEEE Int. Conf. on Cloud Computing, Honolulu, HI, USA, pp. 336–343, 2012. [Google Scholar]
6. J. Wang, H. Gu, J. Yu, Y. Song, X. He et al., “Research on virtual machine consolidation strategy based on combined prediction and energy-aware in cloud computing platform,” Journal of Cloud Computing, vol. 11, no. 25, pp. 1–18, 2022. [Google Scholar]
7. R. Shaw, E. Howley and E. Barrett, “Applying reinforcement learning towards automating energy efficient virtual machine consolidation in cloud data centers,” Information Systems, vol. 107, no. 10, pp. 101722, 2022. [Google Scholar]
8. X. Liu, J. Wu, L. Chen and L. Zhang, “Energy-aware virtual machine consolidation based on evolutionary game theory,” Concurrency and Computation: Practice and Experience, vol. 34, no. 10, pp. 1–16, 2022. [Google Scholar]
9. W. Li, Q. Fan, W. Cui, F. Dang, X. Zhang et al., “Dynamic virtual machine consolidation algorithm based on balancing energy consumption and quality of service,” IEEE Access, vol. 10, pp. 80958–80975, 2022. [Google Scholar]
10. K. Haghshenas, A. Pahlevan, M. Zapater, S. Mohammadi and D. Atienza, “MAGNETIC: Multi-agent machine learning-based approach for energy efficient dynamic consolidation in data centers,” IEEE Transactions on Services Computing, vol. 15, no. 1, pp. 30–44, 2022. [Google Scholar]
11. A. Beloglazov and R. Buyya, “Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in cloud data centers,” Concurrency and Computation: Practice and Experience, vol. 24, no. 13, pp. 1397–1420, 2012. [Google Scholar]
12. A. R. Madireddy and K. Ravindranath, “Dynamic virtual machine relocation system for energy-efficient resource management in the cloud,” Concurrency and Computation: Practice and Experience, vol. 35, no. 3, pp. 1–17, 2022. [Google Scholar]
13. B. M. P. Moura, G. B. Schneider, A. C. Yamin, H. Santos, R. H. S. Reiser et al., “Interval-valued fuzzy logic approach for overloaded hosts in consolidation of virtual machines in cloud computing,” Fuzzy Sets and Systems, vol. 446, no. 4, pp. 144–166, 2022. [Google Scholar]
14. I. Takouna, E. Alzaghoul and C. Meinel, “Robust virtual machine consolidation for efficient energy and performance in virtualized data centers,” in Proc. 2014 IEEE Int. Conf. Green Comput. Commun, Taipei, Taiwan, pp. 470–477, 2014. [Google Scholar]
15. W. Lin, W. Wu and L. He, “An on-line virtual machine consolidation strategy for dual improvement in performance and energy conservation of server clusters in cloud data centers,” IEEE Transactions on Services Computing, vol. 15, no. 2, pp. 766–777, 2022. [Google Scholar]
16. J. Zeng, D. Ding, K. kang, H. Xie and Q. Yin, “Adaptive DRL-based virtual machine consolidation in energy-efficient cloud data center,” IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 11, pp. 2991–3002, 2022. [Google Scholar]
17. P. Li and J. Cao, “A virtual machine consolidation algorithm based on dynamic load mean and multi-objective optimization in cloud computing,” Sensors, vol. 22, no. 23, pp. 9154, 2022. [Google Scholar] [PubMed]
18. C. H. Hsu, K. D. Slagter, S. C. Chen and Y. C. Chung, “Optimizing energy consumption with task consolidation in clouds,” Information Sciences, vol. 258, no. 3, pp. 452–462, 2014. [Google Scholar]
19. Y. Liu, Y. Zhao, J. Dong, L. Li, C. Wang et al., “I-Neat: An intelligent framework for adaptive virtual machine consolidation,” Tsinghua Science and Technology, vol. 27, no. 1, pp. 13–26, 2022. [Google Scholar]
20. C. Mastroianni, M. Meo and G. Papuzzo, “Probabilistic consolidation of virtual machines in self-organizing cloud data centers,” IEEE Transactions on Cloud Computing, vol. 1, no. 2, pp. 125–228, 2013. [Google Scholar]
21. Z. Zhou, J. Abawajy, M. Chowdhury, Z. Hu, K. Li et al., “Minimizing SLA violation and power consumption in cloud data centers using adaptive energy-aware algorithms,” Future Generation Computer Systems, vol. 86, no. 6, pp. 836–850, 2018. [Google Scholar]
22. K. Haghshenas and S. Mohammadi, “Prediction-based underutilized and destination host selection approaches for energy-efficient dynamic VM consolidation in data centers,” Journal of Supercomputing, vol. 76, no. 12, pp. 10240–10257, 2020. [Google Scholar]
23. F. Farahnakian, T. Pahikkala, P. Liljeberg and J. Plosila, “Energy-aware consolidation algorithm based on K-nearest neighbor regression for cloud data centers,” in Proc. IEEE/ACM 6th Int. Conf. Utility Cloud Computing, Dresden, Germany, pp. 256–259, 2013. [Google Scholar]
24. S. M. Moghaddam, M. O’Sullivan, C. G. Walker, S. F. Piraghaj and C. P. Unsworth, “Embedding individualized machine learning prediction models for energy efficient VM consolidation within Cloud data centers,” Future Generation Computer Systems, vol. 106, no. 1, pp. 221–233, 2020. [Google Scholar]
25. R. N. Calheiros, R. Ranjan, A. Beloglazov, C. A. F. D. Rose and R. Buyya, “Cloudsim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms,” Software Practice and Experience, vol. 41, no. 1, pp. 23–50, 2011. [Google Scholar]
26. H. Li, W. Li, H. Wang and J. Wang, “An optimization of virtual machine selection and placement by using memory content similarity for server consolidation in cloud,” Future Generation Computer Systems, vol. 84, no. 5, pp. 98–107, 2018. [Google Scholar]
27. S. S. Masoumzadeh and H. Hlavacs, “Integrating VM selection criteria in distributed dynamic VM consolidation using fuzzy Q-learning,” in Proc. of the 9th Int. Conf. on Network & Service Management, Zurich, Switzerland, pp. 332–338, 2014. [Google Scholar]
28. Y. Laili, F. Tao, F. Wang, L. Zhang and T. Lin, “An iterative budget algorithm for dynamic virtual machine consolidation under cloud computing environment,” IEEE Transactions on Services Computing, vol. 14, no. 1, pp. 30–43, 2021. [Google Scholar]
29. H. Zhao, J. Wang, F. Liu, Q. Wang, W. Zhang et al., “Power-aware and performance-guaranteed virtual machine placement in the cloud,” IEEE Transactions on Parallel and Distributed Systems, vol. 29, no. 6, pp. 1385–1400, 2018. [Google Scholar]
30. B. Speitkamp and M. Bichler, “A mathematical programming approach for server consolidation problems in virtualized data centers,” IEEE Transactions on Services Computing, vol. 3, no. 4, pp. 266–278, 2010. [Google Scholar]
31. A. Beloglazov, J. Abawajy and R. Buyya, “Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing,” Future Generation Computer Systems, vol. 28, no. 5, pp. 755–768, 2012. [Google Scholar]
32. A. Murtazaev and S. Oh, “Sercon: Server consolidation algorithm using live migration of virtual machines for green computing,” IETE Technical Review, vol. 28, no. 3, pp. 212–231, 2011. [Google Scholar]
33. F. Farahnakian, P. Liljeberg and J. Plosila, “LiRCUP: Linear regression based CPU usage prediction algorithm for live migration of virtual machines in data centers,” in Proc. 2013 39th Euromicro Conf. on Software Engineering and Advanced Applications, Santander, Spain, pp. 357–364, 2013. [Google Scholar]
34. N. Bobroff, A. Kochut and K. Beaty, “Dynamic placement of virtual machines for managing sla violations,” in Proc. of 10th IFIP/IEEE Int. Symp. on Integrated Network Management, Munich, Germany, pp. 119–128, 2007. [Google Scholar]
35. Z. Li, C. Yan, L. Yu and X. Yu, “Energy-aware and multi-resource overload probability constraint-based virtual machine dynamic consolidation method,” Future Generation Computer Systems, vol. 80, no. 7, pp. 139–156, 2018. [Google Scholar]
36. Z. Li, X. Yu, L. Yu, S. Guo and V. Chang, “Energy-efficient and quality-aware VM consolidation method,” Future Generation Computer Systems, vol. 102, no. 5, pp. 789–809, 2020. [Google Scholar]
37. A. Al-Moalmi, J. Luo, A. Salah and K. Li, “Optimal virtual machine placement based on grey wolf optimization,” Electronics, vol. 8, no. 3, pp. 283, 2019. [Google Scholar]
38. S. Islam, J. Keung, K. Lee and A. Liu, “Empirical prediction models for adaptive resource provisioning in the cloud,” Future Generation Computing Systems, vol. 28, no. 1, pp. 155–162, 2012. [Google Scholar]
39. R. W. Hawley and N. C. Gallagher, “On Edgeworth’s method for minimum absolute error linear regression,” IEEE Transactions on Signal Processing, vol. 42, no. 8, pp. 2045–2054, 1994. [Google Scholar]
40. Y. Yu, “Research of a new method for solving linear regression,” in Proc. of the 2018 Int. Conf. on Transportation & Logistics, Information & Communication, Smart City (TLICSC 2018), Chengdu, China, pp. 484–488, 2018. [Google Scholar]
41. D. Kusic, J. Kephart, J. Hanson, N. Kandasamy and G. Jiang, “Power and performance management of virtualized computing environments via lookahead control,” Cluster Computing, vol. 12, no. 1, pp. 1–15, 2009. [Google Scholar]
42. K. Park and V. S. Pai, “CoMon: A mostly-scalable monitoring system for planetLab,” ACM SIGOPS Operating Systems Review, vol. 40, no. 1, pp. 65–74, 2006. [Google Scholar]
43. N. Rashid and U. K. Yusof, “Literature survey: Statistical characteristics of google cluster trace,” in Proc. 2018 Fourth International Conf. on Advances in Computing, Communication & Automation (ICACCA), Subang Jaya, Malaysia, pp. 1–5, 2018. [Google Scholar]
44. W. Zhu, Y. Zhuang and L. Zhang, “A three-dimensional virtual resource scheduling method for energy saving in cloud computing,” Future Generation Computer Systems, vol. 69, no. 6, pp. 66–74, 2017. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools