
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Fake News Classification: Past, Current, and Future
1 Department of Computer Science, University of Engineering and Technology, Lahore, 54890, Pakistan
2 Department of Computer Science & Information Technology, Abu Dhabi University, Abu Dhabi, 59911, United Arab Emirates
3 Department of Software Engineering, Faculty of Engineering and Architecture, Nisantasi University, Istanbul, Turkey
* Corresponding Author: Shehzad Ashraf Chaudhry. Email:
Computers, Materials & Continua 2023, 77(2), 2225-2249. https://doi.org/10.32604/cmc.2023.038303
Received 07 December 2022; Accepted 17 April 2023; Issue published 29 November 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The proliferation of deluding data such as fake news and phony audits on news web journals, online publications, and internet business apps has been aided by the availability of the web, cell phones, and social media. Individuals can quickly fabricate comments and news on social media. The most difficult challenge is determining which news is real or fake. Accordingly, tracking down programmed techniques to recognize fake news online is imperative. With an emphasis on false news, this study presents the evolution of artificial intelligence techniques for detecting spurious social media content. This study shows past, current, and possible methods that can be used in the future for fake news classification. Two different publicly available datasets containing political news are utilized for performing experiments. Sixteen supervised learning algorithms are used, and their results show that conventional Machine Learning (ML) algorithms that were used in the past perform better on shorter text classification. In contrast, the currently used Recurrent Neural Network (RNN) and transformer-based algorithms perform better on longer text. Additionally, a brief comparison of all these techniques is provided, and it concluded that transformers have the potential to revolutionize Natural Language Processing (NLP) methods in the near future.Keywords
Recent internet advancements have had a considerable impact on social communications and interactions. Social media platforms are being used more and more frequently to obtain information. Additionally, people express themselves through a variety of social media sites. Speedy access to information, low cost, and quick information transmission are just a few of social media’s many advantages. These advantages have led many people to choose social media over more conventional news sources, including television or newspapers, as their preferred method of news consumption. Therefore, social media is replacing traditional news sources quickly. However, social media’s nature can be changed to accomplish different goals [1]. One of the reasons that social networks are favored for news access is that it allows for easy commenting and sharing of material with other social media users. Low cost and ease of access are the primary reasons numerous people use social network platforms with rapid access to conventional news sources such as the internet, newsletter, and telecasting. The large volume of internet news data necessitates the development of automated analysis technologies.
Moreover, recently, during the coronavirus breakdown, the spread of fake news on social networking sites has increased, causing a terrible epidemic worldwide. Fig. 1 shows some of the fake news stories circulated on social media during the lockdown1,2,3,4,5. Emissions from Chinese crematoriums could be visible from space. 500 lions are released into the streets of Russia to keep people indoors. In London, doctors are being mugged. The condition can be cured with snake oils or vitamins. How about inhaling a hairdryer’s heated air? Or gargling with garlic water that’s been warmed up?
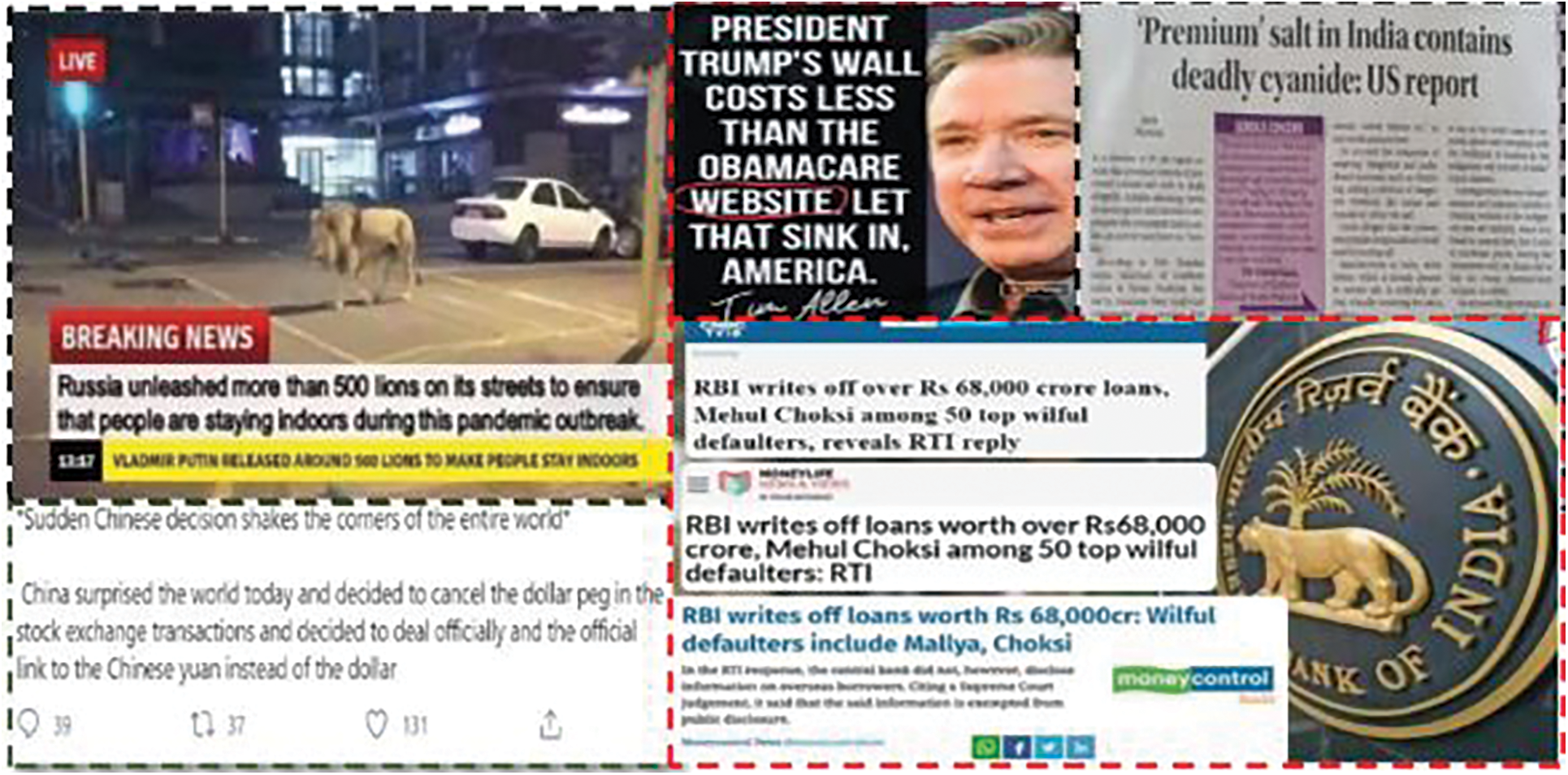
Figure 1: Examples of fake news spread on social media
False information harms people, society, corporations, and governments. The spread of fake news, particularly low-quality news, negatively affects personal and societal beliefs. Spammers or malicious users may distribute false and misleading information that could be very harmful. As a result, identifying fake news has become an essential area of study. Manually identifying and removing fake news or fraudulent reviews from social media takes more effort, money, and time. According to certain prior studies, people perform worse than automated systems when it comes to distinguishing real news from fake news [2].
ML technologies have been focusing on automatically distinguishing between fake and authentic news for the last few years. Following the 2015 presidential election in the United States, several important social media platforms, including Twitter, Facebook, and Google, focused on developing ML and NLP-based methods to identify and prevent fake news. The extraordinary progress of supervised ML models cleared the path for developing expert systems to detect fake news in English, Portuguese, and other languages [2]. Different ML models can have different results on the same classification problem, which is a serious issue [3]. Their performance can be affected by corpus features like the size of the corpus and the distribution of instances into classes [3]. The performance of the K-Nearby Neighbor (KNN), for example, is determined by the value of (k). Similarly, when handling optimization issues, the Support Vector Machine (SVM) experiences numerical instability [4].
Various ML algorithms have been utilized in the past to classify fake news. These algorithms are compared against state-of-the-art techniques such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), which are currently being used. Transformer models are also experimented with as they are expected to be employed in future fake news classification tasks. This approach enables the evaluation of past techniques. It allows for understanding the current trends in fake news classification and a glimpse into potential future developments in the field. A detection algorithm with two phases has been suggested in this study to detect fake and bogus news on social networking sites. The proposed model is a hybrid of ML algorithms and NLP techniques. Text mining methods are used on the internet news data set in the initial part of this project. Text analysis tools and procedures are designed to extract structured information from raw news data. In the second step, supervised learning algorithms (BayesNet, Logistic Model Tree (LMT), Stochastic Gradient Descent (SGD), decision stump, linear SVM, kernel SVM, Logistic Regression, Decision Tree and Gaussian Discriminant Analysis have been applied to two publicly available Random and Buzzfeed Political News datasets [5]. Individual studies employing only a few of these algorithms have been published in the literature.
Furthermore, they are primarily implemented on a single dataset. In contrast to previous papers, the challenge of detecting fake and fraudulent news has been dealt with and regarded as a classification issue. A wide range of supervised learning algorithms has opted for all two publicly available data sets comprising titles and bodies. The contributions of this research paper are:
• We compared the performance of sixteen supervised learning algorithms.
• A pipeline for the utilization of transformers on two different datasets.
• Analyzed and presented the past, current and future trends of NLP techniques.
The following is a breakdown of the paper’s structure. The related work is briefly described in Section 2. Details of some of the ML and DL algorithms are described in Section 3. Section 4 contains the details of the methodology and how text preprocessing techniques are applied before utilizing artificial intelligence methods. Section 5 covers datasets and experimental evaluations produced from sixteen supervised artificial intelligence algorithms for two different datasets. Section 5 also describes the results and discussion part. In Section 6, conclusions and future research directions have been examined.
In recent years, detecting rumors and fake news, evaluating web content trustworthiness, and developing fact-checking systems have all been hot subjects. Preprocessing of data can be utilized for the estimation and recovery of various text forms. This includes pre-handling the text utilizing NLP, for example, stemming or lemmatization, standardization, tokenization, and afterward utilization of Term Frequency-Inverse Document Frequency (TF-IDF) [6] for forming words into vectors, Honnibal et al. [7] utilized Spacy for changing words into vectors. Similarly, Mikolov et al. [8] and Pennington et al. [9] used word2vec and Glove for word embeddings.
Even though the fake news identification problem is only established, it has drawn much attention. Different researchers proposed different methodologies to distinguish fake news in many data types. Reference [10] divided the difficulty of detecting fake news into three categories, i.e., severe fabrication, comical fake news, and massive scope deception. In [11], Conroy et al. utilized a hybrid technique and proposed a novel detector for fake news. Their proposed methodology [11] incorporates different linguistic cueing and network analysis techniques. In addition to this, they used the vector space model to confirm news [12]. In [13] methodology, TF-IDF and SVM were used to categorize news into different groups. In [14], humorous cues were employed to detect false or deceptive news. The authors proposed an SVM-based model and used 360 news articles to evaluate it. To verify the stories, reference [15] found different perspectives on social media. Then, they tested their model against actual data sets. Reference [16] employed ML classifiers such as Decision Tree, K-Nearest Neighbor, Naive Bayes, SVM, and Logistic Regression to classify fake news from online media sources. An ensemble categorization model is suggested in the article [17] for identifying fake news that outperformed the state-of-the-art in terms of accuracy. The recommended approach identified vital characteristics from the datasets. The retrieved characteristics were then categorized using an ensemble model of three well-known ML models: Decision Tree, Random Forest, and Extra Tree Classifier.
Two categorization models were presented in [18] to address the problem of identifying fake news. One is a Boolean crowd-sourcing approach, while the other is a Logistic Regression model. Aside from this, the preprocessing methods for the problem of false news detection and the creation of assessment measures for data sets have been thoroughly documented [19]. Reference [20] employed ML classification techniques and n-gram analysis for classifying spam and fake news. On publicly accessible datasets, the authors assessed their study methods throughout. Gradient boosting, SGD, Random Forests, SVM, and limited Decision Trees were used as classification methods [21]. Reference [22] have developed CSI, an algorithm comprises of different characteristics for classifying fake news. Three characteristics were merged in their strategy for a more accurate forecast. Capture, score, and integrate were the three attributes. Reference [23] introduced a tri-relationship false news detection model that considers news attitude, publisher bias, and interactions of users. They evaluated their approach using public datasets for detecting fake news. To classify fake news, the author of [24] suggested a novel hybrid DL model that integrated CNN and RNN. The algorithm was evaluated effectively on two false news datasets, and detection performance was notably superior to previous non-hybrid baseline techniques.
Reference [25] developed a novel hybrid algorithm based on attention-based LSTM networks for the fake news identification challenge. Evaluation of the method’s performance is conducted on benchmark sets of false news detection data. In early 2017, reference [26] investigated the current state of fake news, provided a remedy for fake news, and described two opposing approaches. Janze et al. [27] developed a detection technique for spotting fake news. The authors of this study evaluated their models on Facebook News during the 2016 presidential election in the United States. Reference [28] developed another automated algorithm. This paper’s authors provided a categorization model based on semantic, syntactic, and lexical information. Reference [29] offered an automated technique for detecting false news in popular Twitter discussions. This approach was tested on three existing data sets. Reference [30] researched the statistical features of misinformation, fraud, and unverified assertions in online social networks.
Reference [31] developed a competitive model to mitigate the impact of misleading information. The author mainly focused on the interaction between original erroneous and updated information. Reference [32] developed a new algorithm for detecting fake news that considers consumer trust. Reference [33] solved the problem by using a crowded signal. As a result, the authors have presented a novel detective method that uses Bayesian inference and learns the accuracy of users’ flagging over time. Reference [34] suggested a content-based false news detection approach. The authors developed a semi-supervised approach for detecting fake news. Reference [35] looked at the different types of social networks and advocated using them to identify and counteract false news on social media. Reference [36] created a model that can identify the truthfulness of Arabic news or claims using a Deep Neural Network (DNN) approach, specifically Convolutional Neural Networks (CNN). The aim was to tackle the fact-checking problem, determining whether a news text claim is authentic or fake. The model achieved an accuracy of 91%, surpassing the performance of previous methods when applied to the same Arabic dataset. Reference [37] discussed the use of Deep Learning (DL) models to detect fake news written in Slovak, using a dataset collected from various local online news sources associated with the COVID-19 epidemic. The DL models were trained and evaluated using this dataset. A bidirectional LSTM network combined with one-dimensional convolutional layers resulted in an average macro F1-score of 94% on an independent test set.
For accurately identifying misleading information using text sentiment analysis [38] presented “emoratio,” a sentiment scoring algorithm that employs the Linguistic Inquiry Word Count (LIWC) tool’s psychological and linguistic skills. Reference [39] proposed a thorough comparative examination of different DL algorithms, including ensemble methods, CNN, LSTM, and attention mechanisms for fake news identification. The CNN ensembled with bidirectional LSTM using the attention mechanism was found to have the most remarkable accuracy of 88.75%. Another tricky topic of false news classification is the circulation of intentionally generated phony photographs and altered images on social media platforms. The examination was directed by [40] on a dataset of 36, 302 picture answers by utilizing both traditional and deep picture forgery techniques for distinguishing fraudulent pictures produced using picture-to-picture transformation based on the Generative Adversarial Networks (GAN) model, a DNN for identifying fake news in its early stages. Reference [41] utilized time and assault for veracity classification [42], style examination of hyperpartisan news [43], are worth focusing on spearheading research in believability investigation on informal organizations.
Bidirectional Encoder Representations Transformer (BERT) and VGG19, based on a multi-modal supervised framework, namely ‘Spotfake’ [44], classify the genuine and fictitious articles by utilizing the capacities of encoders and decoders. Moreover, reference [45] used Adversarial training to classify news articles. The purpose of [46] was to develop a model for identifying fake news using the content-based classification approach and focusing on news titles. The model employed a BERT model combined with an LSTM layer. The proposed model was compared to other base classification models, and a standard BERT model was also trained on the same dataset to compare the impact of using an LSTM layer. Results indicated that the proposed model slightly improved accuracy on the datasets compared to the standard BERT model. References [47,48] utilized linear discriminant analysis and KNN for the detection of fake news, even in a vehicular network. The summary of the related work is shown in Table 1.
Several datasets have been used for fake news detection research. Some of the datasets that have been used in the past are LIAR, FNC-1, and FakeNewsNet datasets. On the other hand, the GossipCop, PolitiFact, and the Fake News Challenge (FNC) datasets are widely used in the current era. It is important to note that many datasets are created to serve a specific research problem; therefore, they might not be generalizable to other scenarios and might not have the same size, type of data, quality, and time coverage. Thus, it is essential to consider these factors when selecting the dataset for a specific task.
This work uses transformers, RNN, and conventional ML algorithms to classify fake news and provide an in-depth comparison of all these models. Results depict that ML algorithms perform better than complex DL-based models on shorter text. While for longer text, transformers outperform other algorithms.
3 Machine Learning and Deep Learning
This section briefly describes the algorithms used in this study’s experiments. Moreover, it is further divided into ML and DL methods.
One of the most well-known supervised learning methods, SVM, is used to tackle classification and regression problems. “Linear separable data” refers to information that can be split into two groups by a single straight line. Linear SVM is used to classify such information, and the classifier employed is referred to as a linear SVM classifier.
When the collection of samples cannot be divided linearly, SVM can be expanded to address nonlinear classification challenges. The data are mapped onto a high-dimensional feature space by applying kernel functions, where linear grouping is conceivable.
In contrast to Linear Regression, Logistic Regression is used as a classification technique. Logistic regression predicts the outcome by utilizing values of different independent variables. It is undoubtedly one of the most utilized ML techniques. Rather than giving a constant value, it provides the result as a binary, i.e., valid or invalid, fake and real, yes or no, etc. Its probabilistic value ranges between 0 and 1.
It is a supervised ML algorithm based on the Bayesian theorem for classification tasks. This classifier posits that features in a class are independent of each other. This type of classifier is relatively easy to construct and is especially good for massive datasets. Naive Bayes outperforms even the most advanced classification systems due to its simplicity.
One of the supervised algorithms based on rules is the Decision Tree. The Decision Tree is used for classification and regression and is a non-parametric method. In the Decision Tree, every node has one of the rules and gives output that is passed to another node, and then another rule-based testing is applied.
Random Forest is a supervised algorithm that combines Decision Trees for the different samples and gives results by giving an average from each Decision Tree. It is one of the flexible algorithms that can produce a good result for classification even without tuning.
3.1.7 Gaussian Discriminant Analysis-Linear
ML algorithms that directly predict the class from the training set are known as discriminant algorithms. One of the discriminative algorithms applied in our study is Gaussian Discriminant Analysis. Gaussian Discriminant Analysis fits a Gaussian distribution to each class of data separately to capture the distribution of each class. The probability will be high if the predicted value lies at the center of the contour of one of the classes in the training dataset. Linear Discriminant Analysis is a particular type of Quadratic Discriminant Analysis with linear boundaries.
3.1.8 Gaussian Discriminant Analysis-Quadratic
ML algorithms that directly predict the class from the training set are known as discriminant algorithms. One of the discriminative algorithms applied in our study is Gaussian Discriminant Analysis. Gaussian Discriminant Analysis fits a Gaussian distribution to each class of data separately to capture the distribution of each class. The probability will be high if the predicted value lies at the center of the contour of one of the classes in the training dataset.
KNN is one of the most well-known and widely utilized supervised learning methods. It works by finding the distance between new data points and comparing it with the number of K points provided as input. The data point is allocated to the class where the distance is minimum. Euclidean distance is one of the distance functions used in KNN.
It is a specially modified version of KNN. In contrast to traditional KNN, it assigns the highest weight to the points which are near and less weight to those which are far away. Its performance varies with the change in the hyperparameter K. Weighted KNN may produce outliers if the value of K is too small.
3.2.1 Gated Recurrent Units (GRU)
GRU comprises two gates, i.e., the update gate and the reset gate. An update gate combines the features of an input gate and a forget gate. A forget gate makes decisions about which data will be discarded and which will be stored. On the other hand, reset gates prevent gradient explosions by erasing previous information. It regulates how much past data must be discarded.
3.2.2 Long Short-Term Memory (LSTM)
Each LSTM network has three gates that govern data flow and cells storing data. The data is transmitted from the beginning to the end of the time step by the Cell States. In LSTM, the forget gate determines whether data must be pushed forward or omitted. While in the input gate, upon deciding on the relevant data, the data is sent to the input gate, which carries the data onto the cell states, causing them to be updated. It is as simple as storing and changing the weight. An output gate is triggered when the information has been transferred via the input gate. The output gate produces the hidden phases, and the current condition of the cells is carried forward to the next step.
3.3.1 Bidirectional Encoder Representations from Transformers (BERT)
BERT is an excellent addition to the Transformers community, especially for dealing with longer text. It is a bidirectional encoder-based transformer proposed by Google. BERT currently consists of two versions BERT base and BERT large. For the input, BERT took 512 tokens sequence at once. BERT can take three input embedding types: position embeddings, segment embeddings, and token embeddings.
ALBERT is a particularly lite variant of BERT with efficient training speed and fewer parameters as compared to BERT. Because ALBERT uses absolute position embeddings, it is best to pad the right side of the inputs rather than the left. Moreover, the computation cost remains the same as BERT because it has the same number of hidden layers as BERT.
A neural language model based on Transformer called Decoding enhanced BERT with disentangled attention (DeBERTa) trains on enormous amounts of raw text corpora using self-supervised learning. To do numerous NLP jobs in the future, DeBERTa is built to accumulate universal language representations. By utilizing three unique strategies, DeBERTa trumps the previous state-of-the-art BERT. The strategies are as follows:
• A precise attention mechanism.
• Mask decoder improvement.
• A technique for virtual adversarial training that can be fine-tuned.
The architecture of RoBERTa is similar to that of BERT, but it employs a different pre-training strategy and a byte-level BPE as a tokenizer. It extends BERT by changing crucial hyperparameters, such as deleting the following sentence pre-training goal and training with considerably bigger mini-batches and learning rates.
This section provides the detail of our methodology for fake news classification. Each step is discussed in sequence. First, duplicated words and unwanted characters, such as numbers, stopwords, dates, time, etc., are removed from the dataset. Then, feature extraction was performed on the fake news dataset to reduce the feature space. Each word frequency is calculated for the construction of a document term matrix. Sixteen supervised algorithms are applied to the two political news datasets in the final step. Fig. 2 shows the whole methodology, and Table 2 shows the specifications of the dataset being utilized in it.
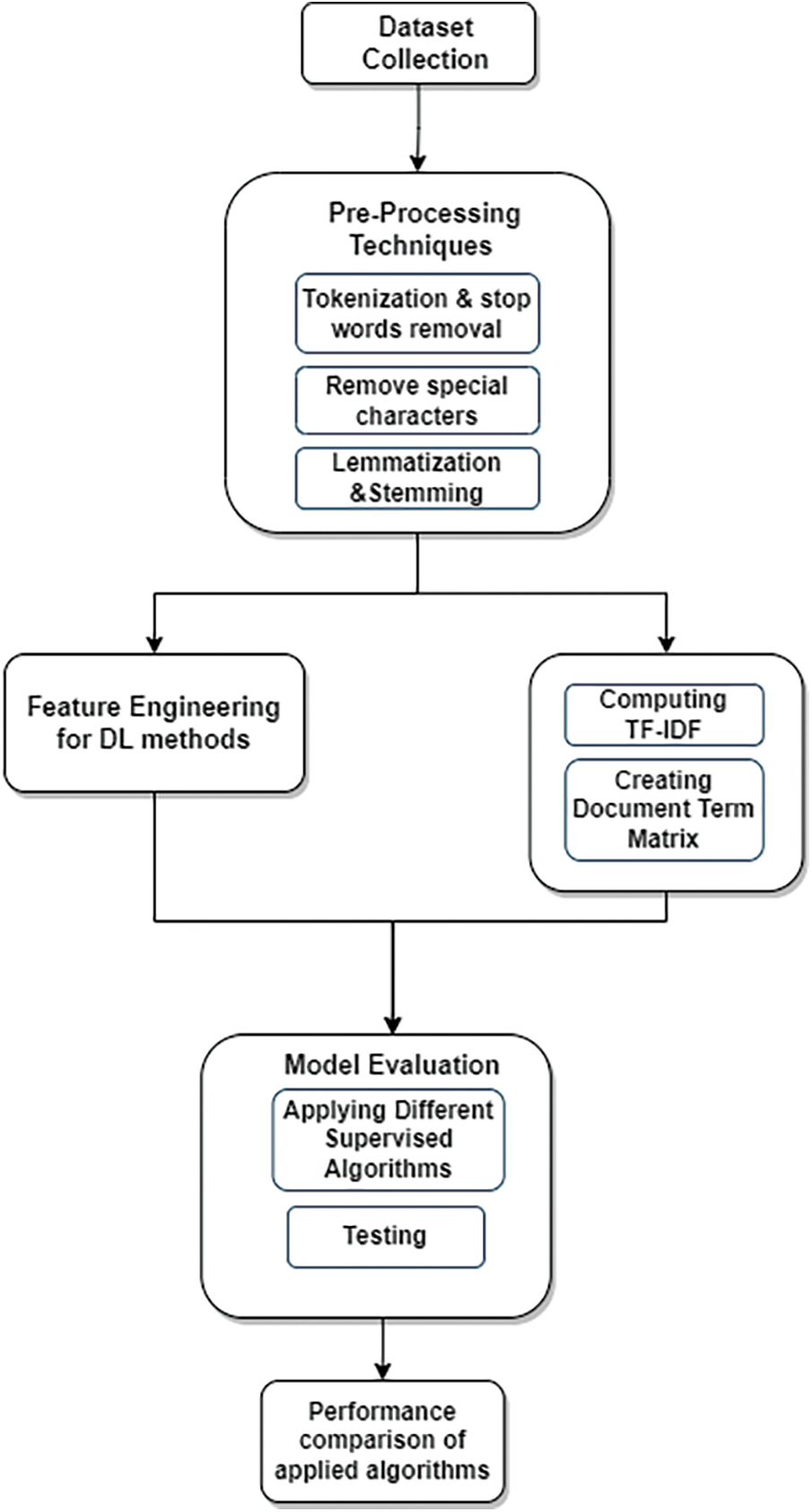
Figure 2: The overall process flow of methodology
4.1 Preprocessing for ML Algorithms
• Tokenization
From the word tokenization, it is clear that it is used to make tokens of text by dividing the text into smaller chunks. Punctuation marks are also eradicated from the corpus. Moreover, a number filter has been used to remove those words that contain numeric values, followed by a case converter filter for converting all text from upper to lower case. Lastly, in this step, a filter is used to remove DateTime from the textual data.
• Stopwords and line removal
Stopwords, usually little, are used to join phrases and finish sentences. These are regional language terms that do not transmit knowledge. Pronouns, prepositions, and conjunctions are all examples of stop words. The number of stopwords in the English language is between 400 and 500 [49]. Stop words include that, does, a, an, so on, where on, too, above, I until, but, again, what, all, and when.
• Stemming
Stemming is a technique to identify the fundamental forms of words with similar semantics but diverse word forms. This process converts grammatical structures such as a word’s verb, adjective, noun, adverb, and so on into their root form. The words “collect,” “collections,” and “collecting,” for example, all come from the word “collect.”
The specifics of the preprocessing processes are displayed in Table 3.

Managing high-dimensional information is the most challenging part of text mining. To increase performance, unrelated and inconsequential qualities should be disposed of from the model. The means of information preprocessing include extracting features from high-layered unstructured data. In this work, stem phrases in informational collections with a recurrence over the edge are tracked down utilizing a feature selection method. Following this technique, each record was changed into a vector of term loads by weighing the terms in its informational index. The Vector Space Model (VSM) is the most direct essential portrayal. VSM assigns a value to each word that indicates the word’s weight in the text. Term frequency is one approach for calculating these weigh. Inverse Document Frequency (IDF) and Term Frequency Inverse Document Frequency (TF-IDF) are the two most well-known of these methods. In this paper, the TF-IDF approach is applied. The TF-IDF approach is used to weigh a phrase in any piece of information and assign value based on the number of times it appears in the document. It also looks at the keyword’s significance across the internet, a technique known as corpus.
The performance of our model is evaluated using precision, accuracy, F1-score, and recall, represented in Eqs. (1)–(4), respectively.
whereas TPN stands for True Positive News—news that is real and anticipated by the model to be real. TNN stands for True Negative News—fake news projected to be fake by the model. FPN stands for False Positive News or the real fake news that the model incorrectly anticipated to be true. FNN stands for False Negative News; the actual real news projected to be fake by the model.
In this section, dataset and training details are provided. Moreover, the comparison results of RNN, transformers, and ML-based algorithms are also discussed.
In this work, two publicly available datasets from the political domain [5] are used. As discussed above, sixteen (RNN, transformers, and conventional ML) algorithms are applied to the title and body text of the dataset. Before applying the algorithms, the dataset is split with a ratio of 70% to 30%, respectively, for training and testing. The TF-IDF is used to form the word-weighted matrix for feature extraction for the conventional ML algorithms. While for the RNN-based algorithm, GloVe vectors are utilized.
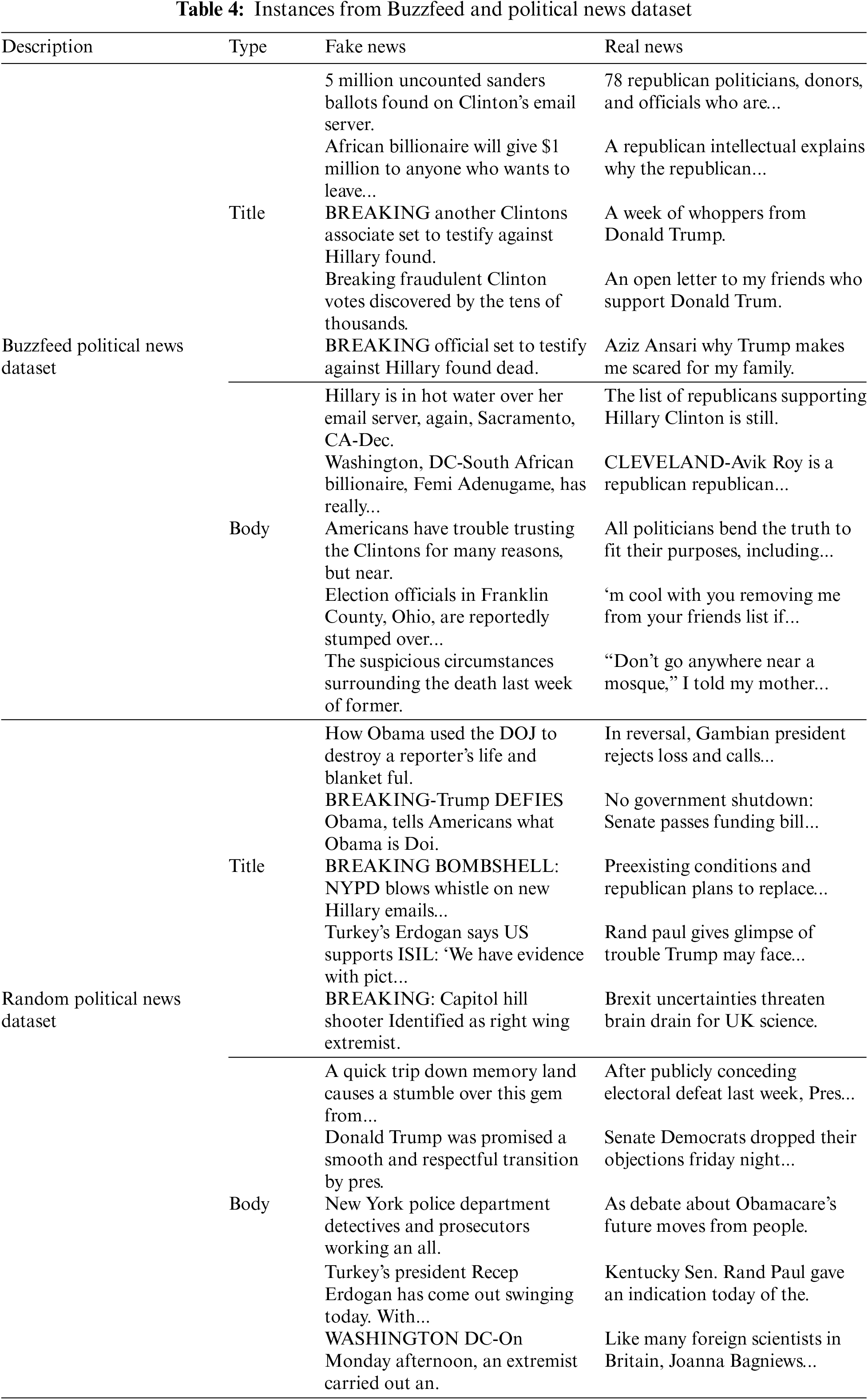
The dataset [5] described in Table 2 is used for the tests. “Buzzfeed News Data and Random News Data” are just two news datasets that are included. 48 examples of false news and 53 instances of actual news are included in” Buzzfeed News Data.” On the other hand, the “Random News Data” collection contains 75 instances of satire, true news, and false news. Real news and false news data are both used in this study. Both datasets include the headline and the story’s content, which are utilized separately to classify the dataset. A few examples of these datasets are shown in Table 4.
For the DL-based method, i.e., RNN and GRU, a glove matrix of 300 embedding dimensions and 60 epochs with a batch size of 16 are used. The hidden units are set to 256, which is the number of neurons in the hidden layer. The number of hidden units is chosen based on the task’s complexity and the dataset’s size. A dropout rate of 0.3 is used during the training of the model. This rate is chosen to strike a balance between preventing overfitting and maintaining the model’s ability to capture the relevant information from the data. The optimization algorithm used for training the model is Stochastic Gradient Descent (SGD), a widely used optimization algorithm for training neural networks. To further prevent overfitting, an early stopping strategy is implemented. Moreover, the learning rate is set to 0.0001, which determines the optimization algorithm’s step size in finding the model’s optimal parameters.
For both datasets, experiments are run 10 times for conventional ML algorithms because there is a massive distinction between the outcomes due to random data selection. After running each traditional algorithm of ML 10 times, the mean value of evaluation measures, i.e., accuracy, precision, recall, andF1-score, is taken.
These hyperparameters were chosen through a combination of literature review and experimental tuning, demonstrating that they provided optimal performance for the task. Finally, in addition to the RNNs, the transformers model is trained using BERT embeddings with a dropout rate of 0.2. The dropout rate of 0.2 is used on the BERT embeddings during the fine-tuning process to prevent overfitting.
5.2 Dataset 1: Buzzfeed Political News Dataset
The Buzzfeed Political News dataset has been subjected to the recently mentioned supervised ML, RNN, and transformer-based algorithms to determine whether the news is accurate. The features are disengaged from the dataset using TF-IDF. On the dataset for Buzzfeed Political News, Tables 5 and 6 compare the effectiveness of various supervised ML algorithms on the title and body of the Buzzfeed Political News dataset, respectively. Tables 5 and 6 show that in terms of precision, kernel SVM and quadratic Gradient Discriminant Analysis (GDA) perform worst on the title and body of the Buzzfeed Political News dataset, respectively. On the other hand, linear GDA and Random Forest perform best in terms of precision on the title and body text of the Buzzfeed News dataset. Tables 5 and 6 depict that kernel SVM has the worst performance regarding the recall and F1-score linear GDA, Logistic Regression, and Random Forest on title and body text, respectively. It seems that kernel SVM and BERT perform best in terms of recall and F1-score on the title, while kernel SVM and RoBERTa perform best on body text. Regarding accuracy, kernel SVM performs worst on both title and body, while BERT and RoBERTa perform best on the title and body text. Figs. 3 and 4 depict a graphical illustration of the algorithm’s performance in terms of accuracy, precision, recall, and F-measure metrics. While Fig. 5 shows the comparison of loss on the title and body of the Buzzfeed Political News dataset.
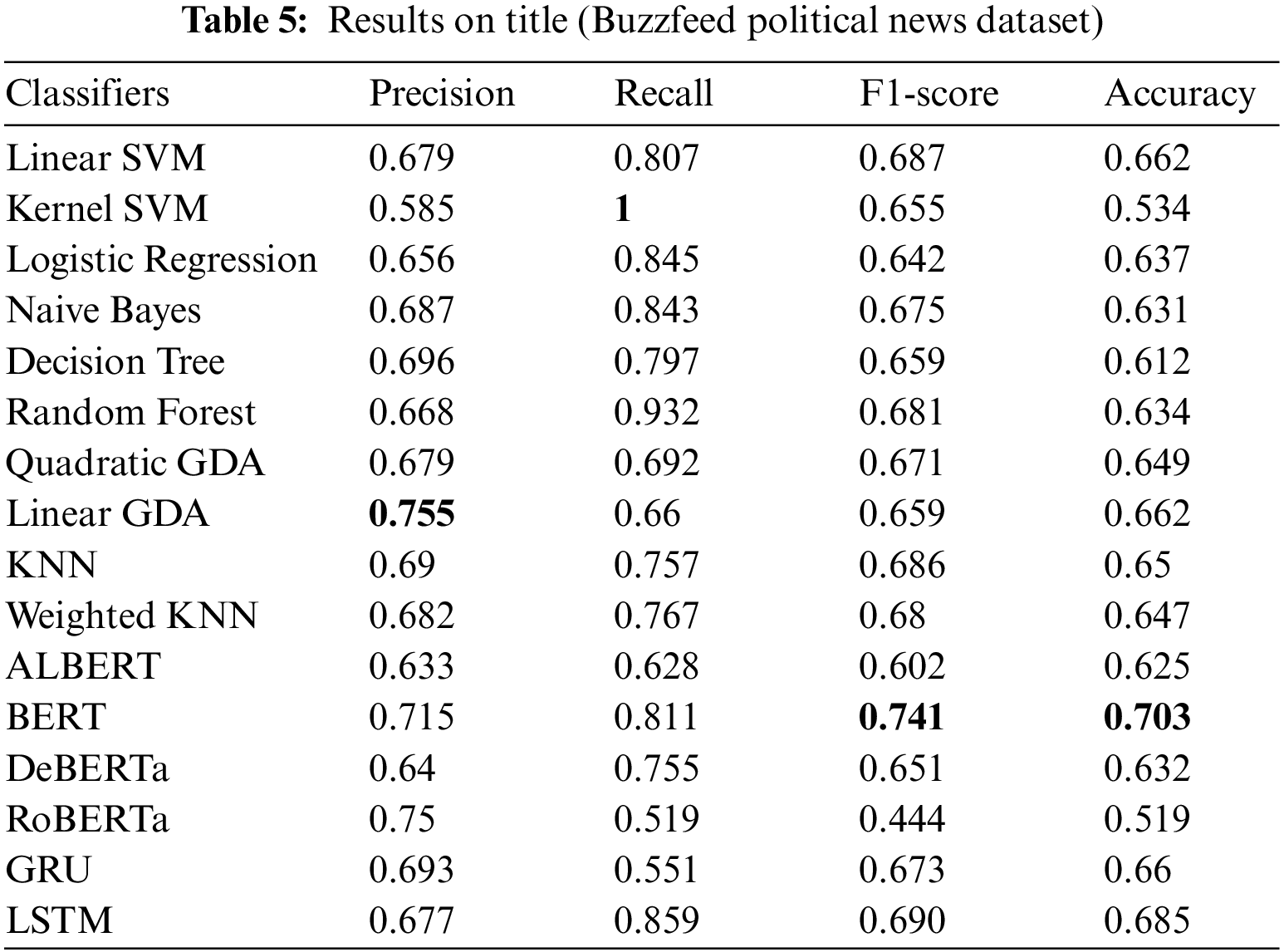
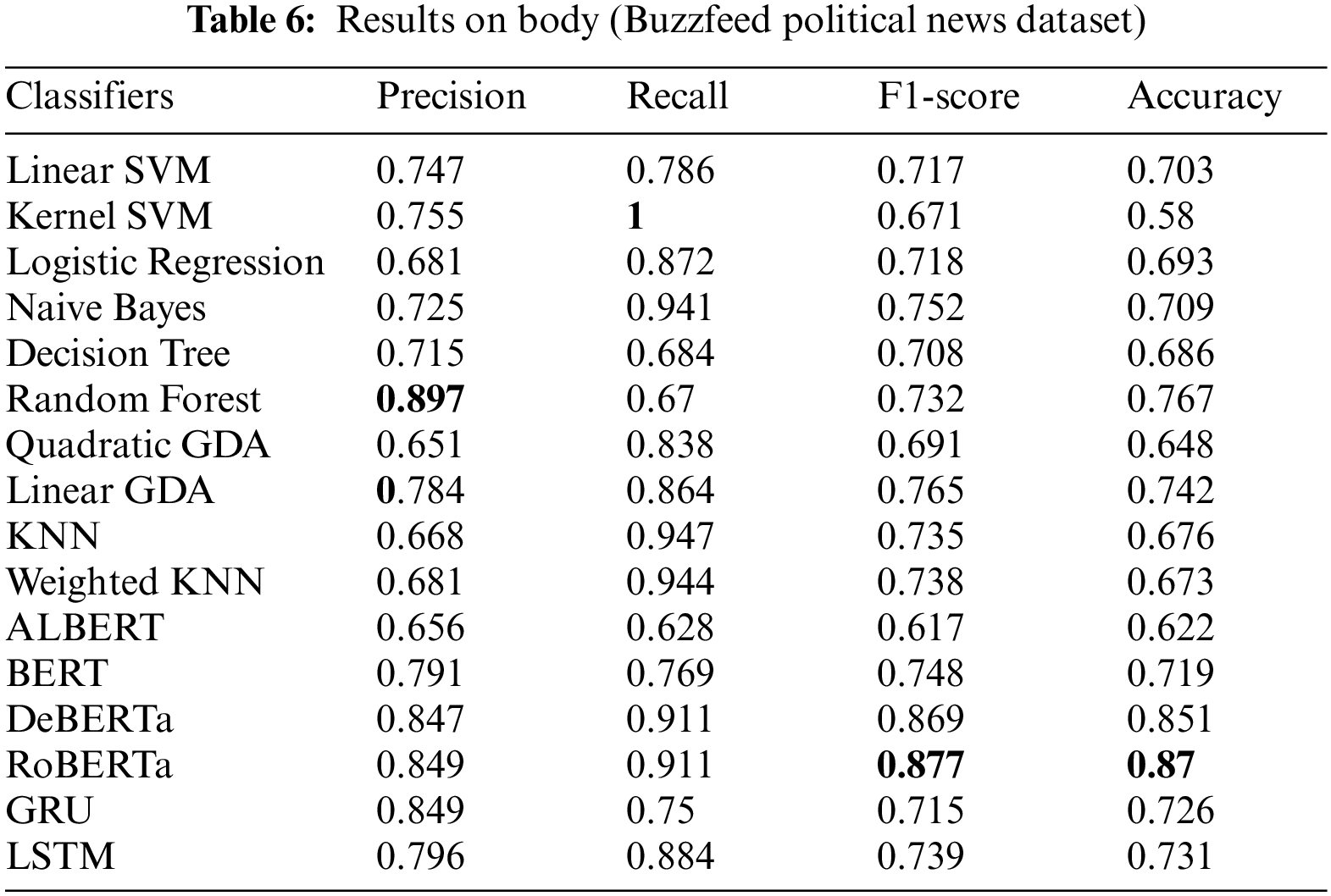
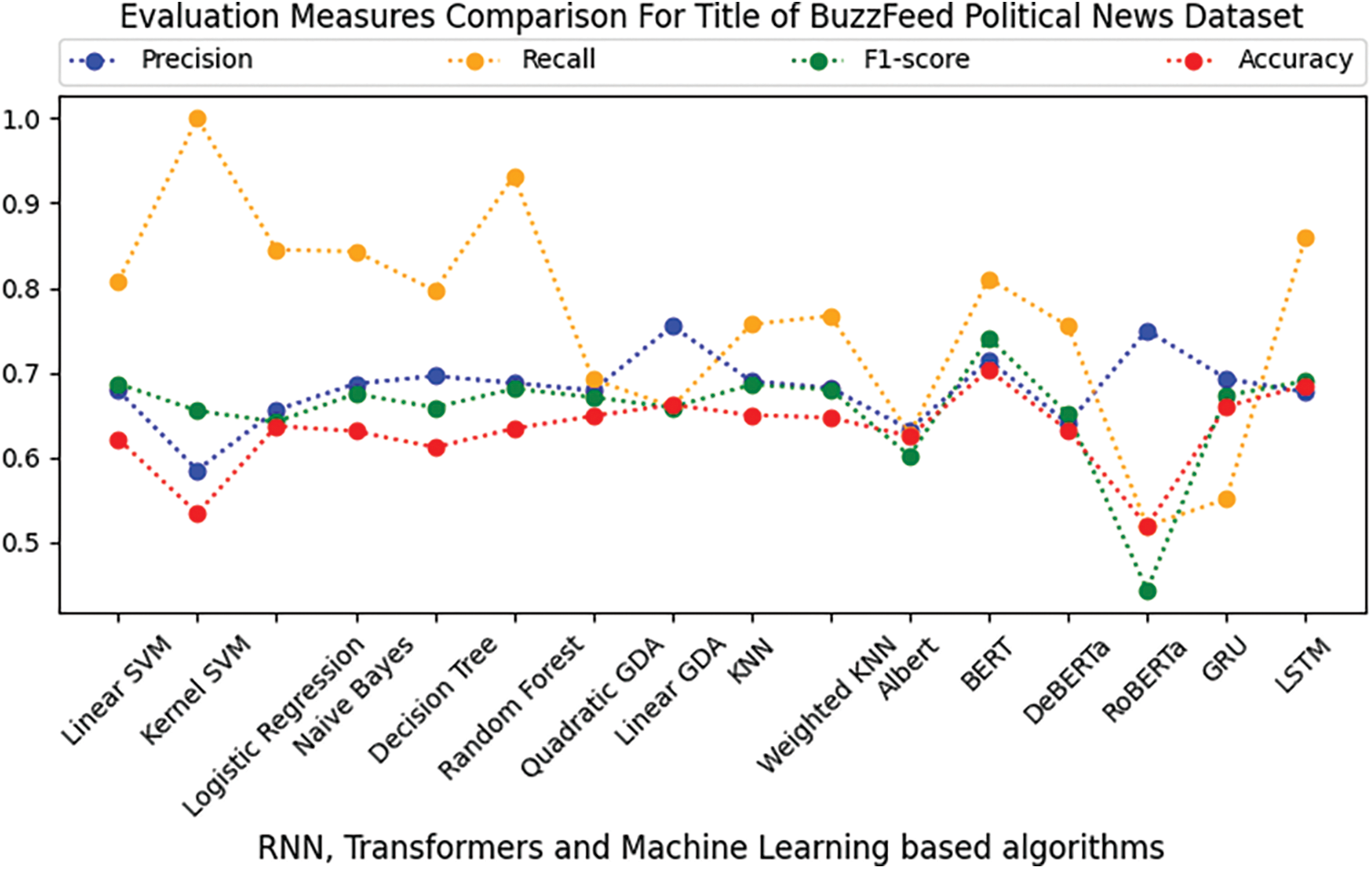
Figure 3: Comparison of RNN, transformers, and ML-based algorithms on the title text of Buzzfeed political news dataset
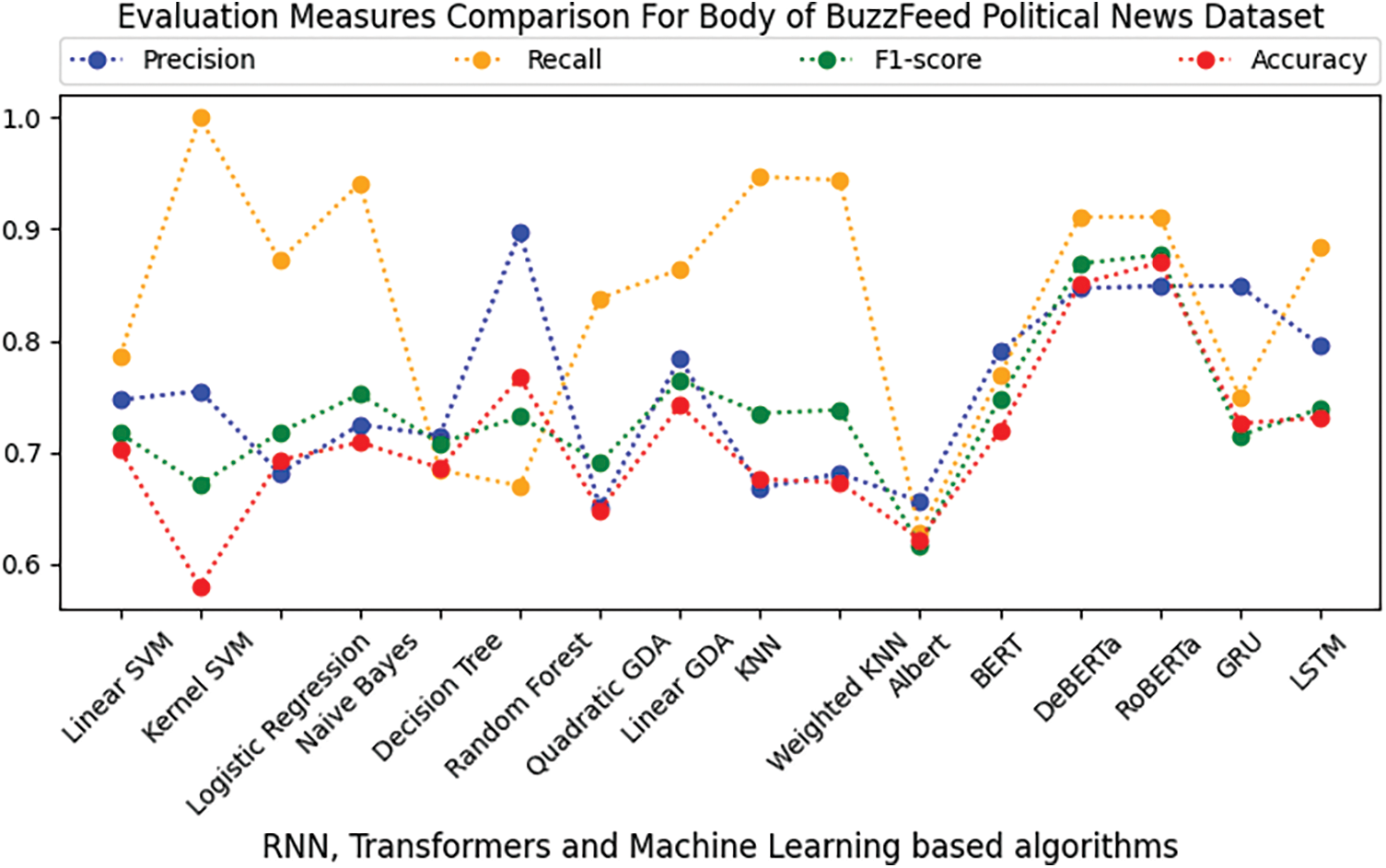
Figure 4: Comparison of RNN, transformers, and ML-based algorithms on the body text of Buzzfeed political news dataset
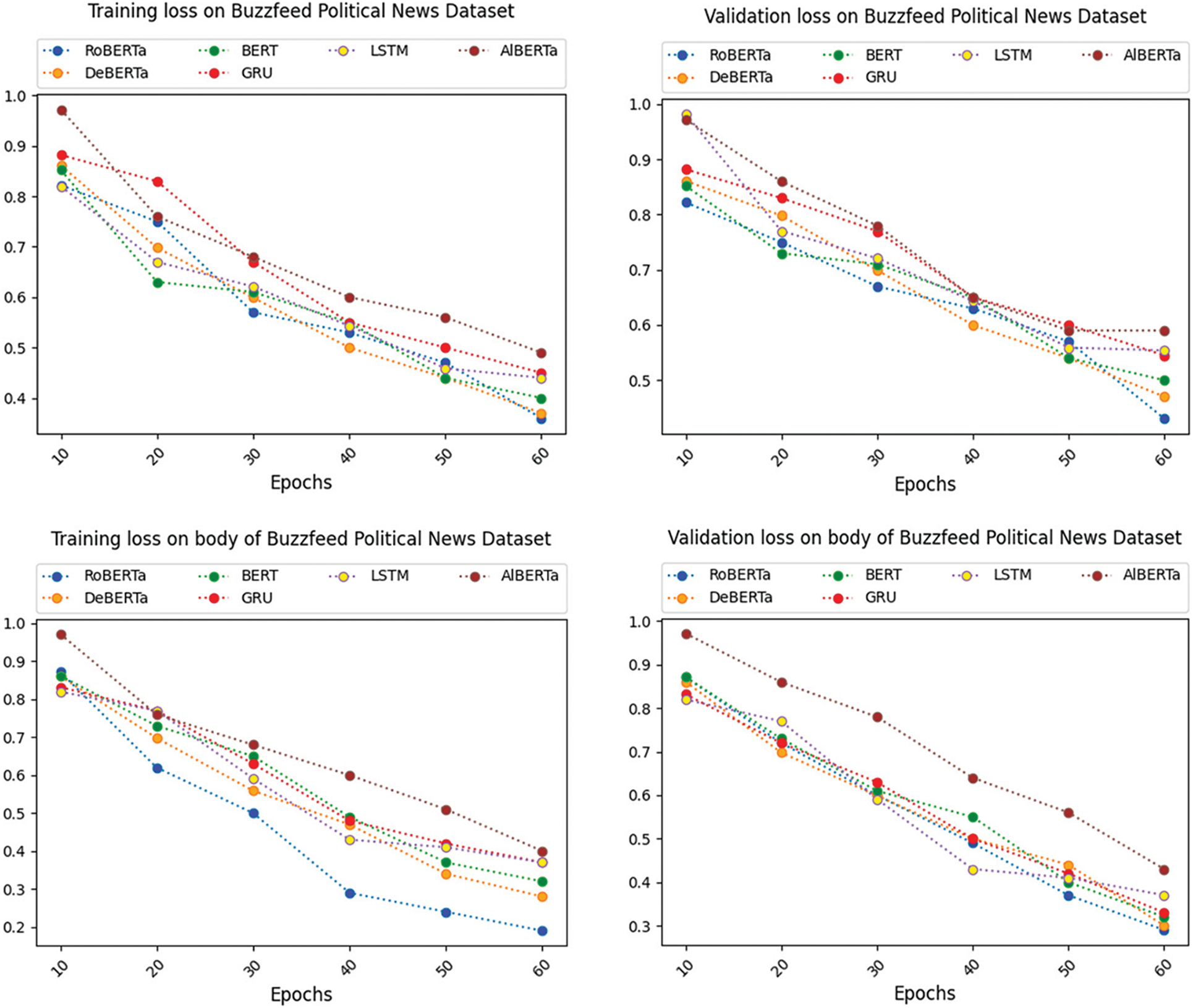
Figure 5: Comparison of loss on title and body of Buzzfeed political news dataset
5.3 Dataset 2: Random Political News Dataset
This section provides the results of the applied artificial intelligence algorithms with respect to their evaluation measures on both datasets. On the title and body of the Random Political News dataset, Tables 7 and 8 show the outcomes of the various supervised ML algorithms. Figs. 6 and 7 visually represent a comparison of sixteen supervised learning algorithms’ outputs. In addition to this, Fig. 8 shows the comparison of loss on the title and body of the Random Political News dataset.
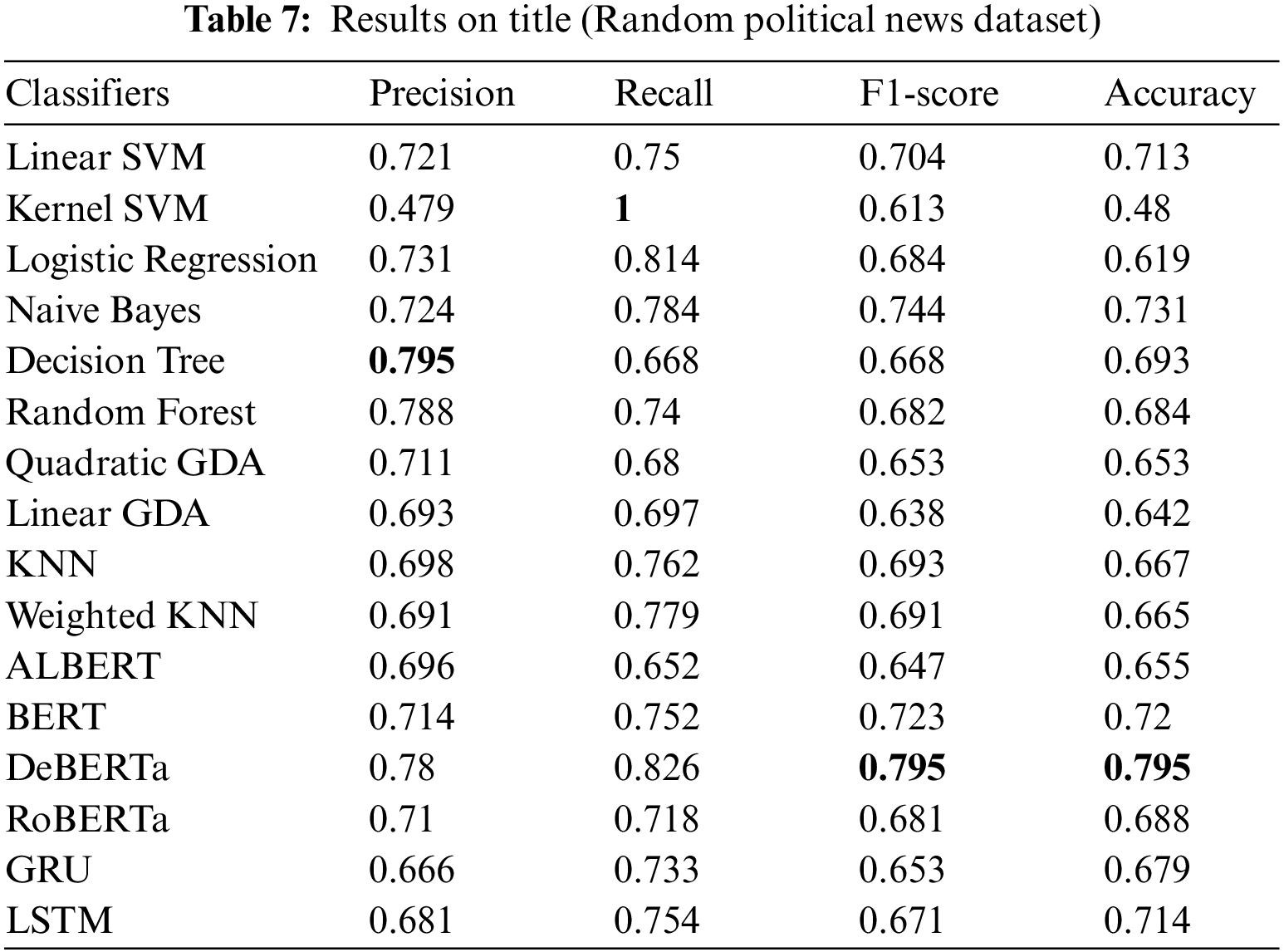
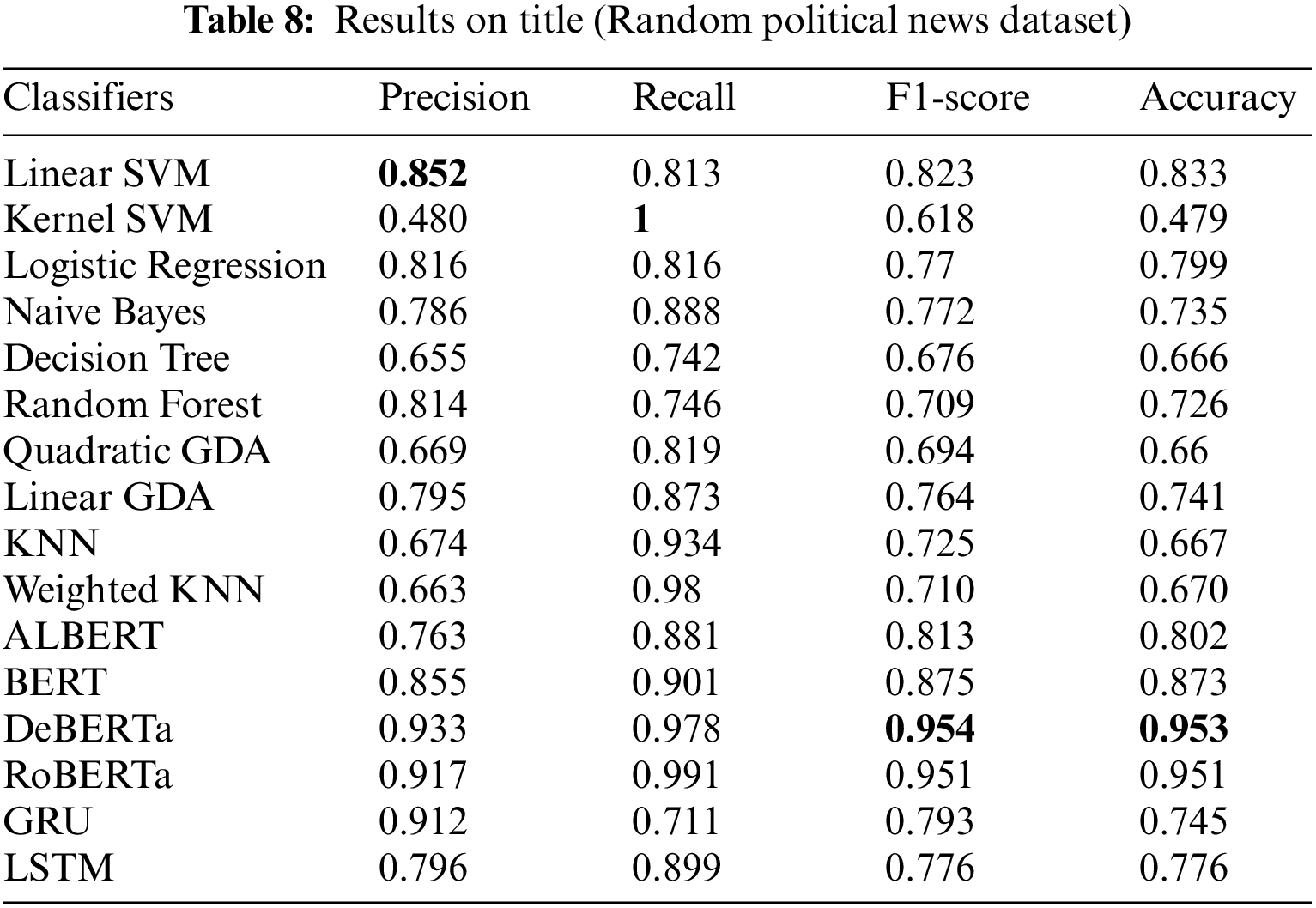
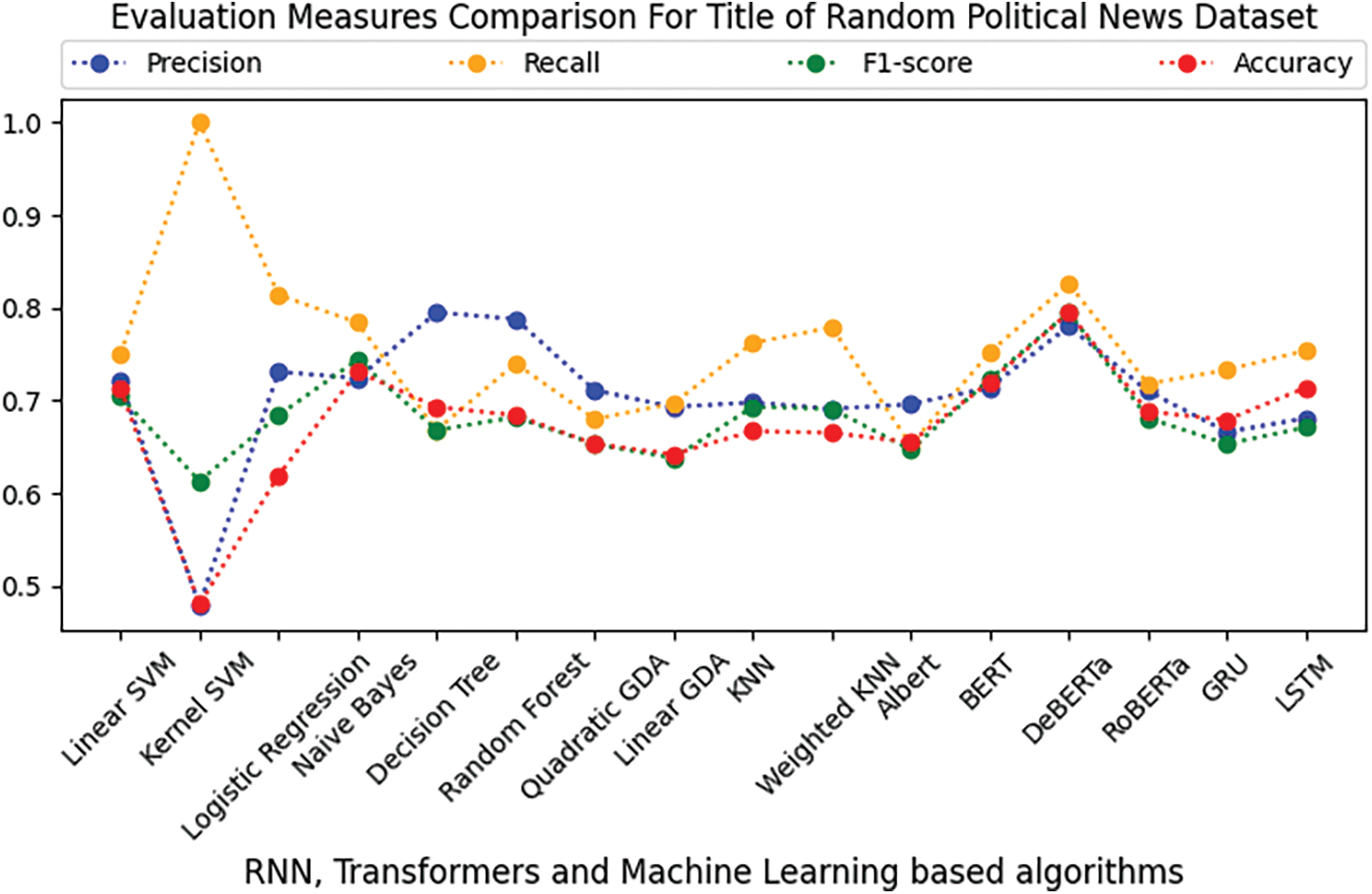
Figure 6: Comparison of RNN, transformers, and ML-based algorithms on the title text of the random political news dataset
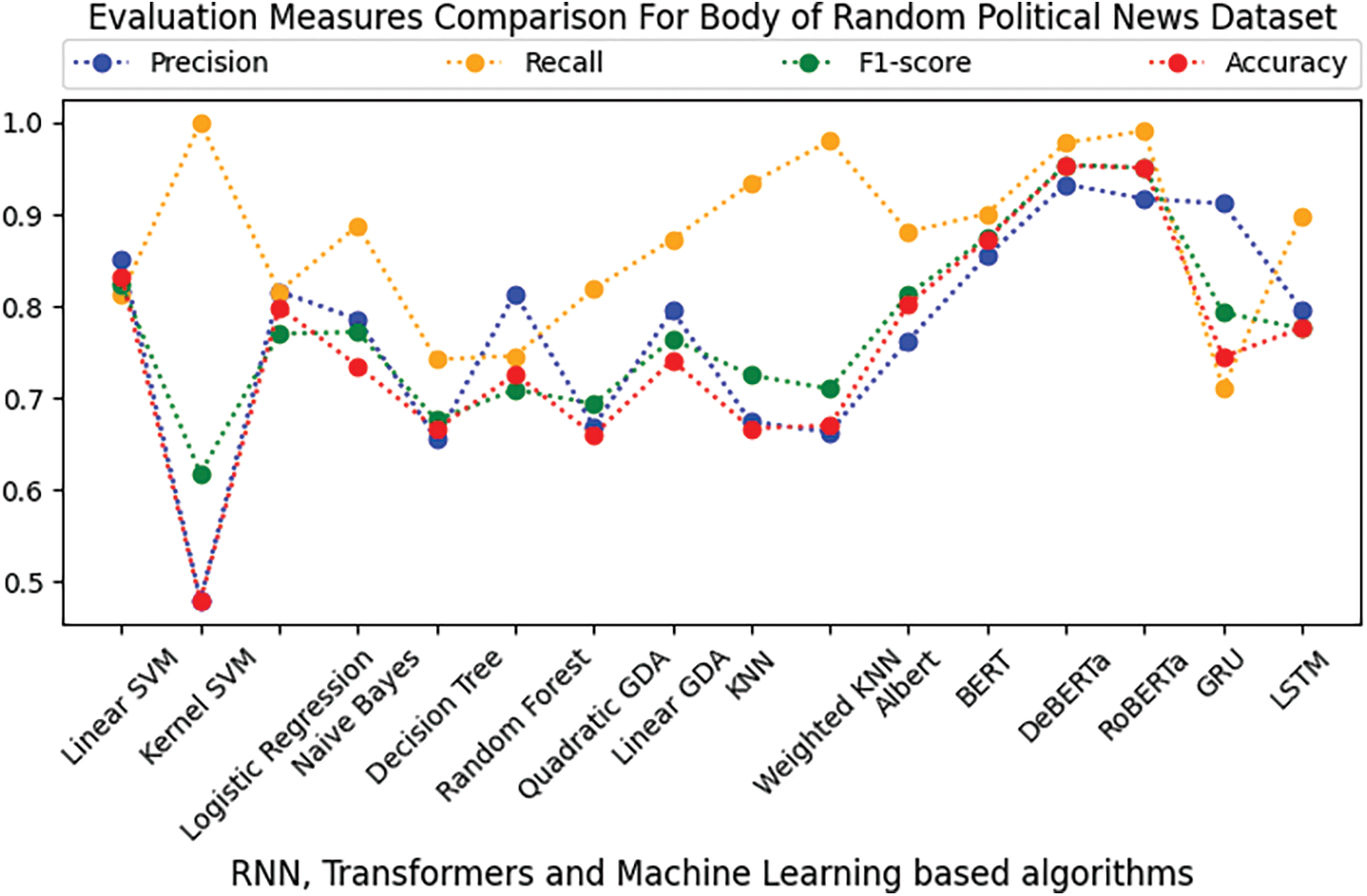
Figure 7: Comparison of RNN, transformers, and ML-based algorithms on the body text of the random political news dataset
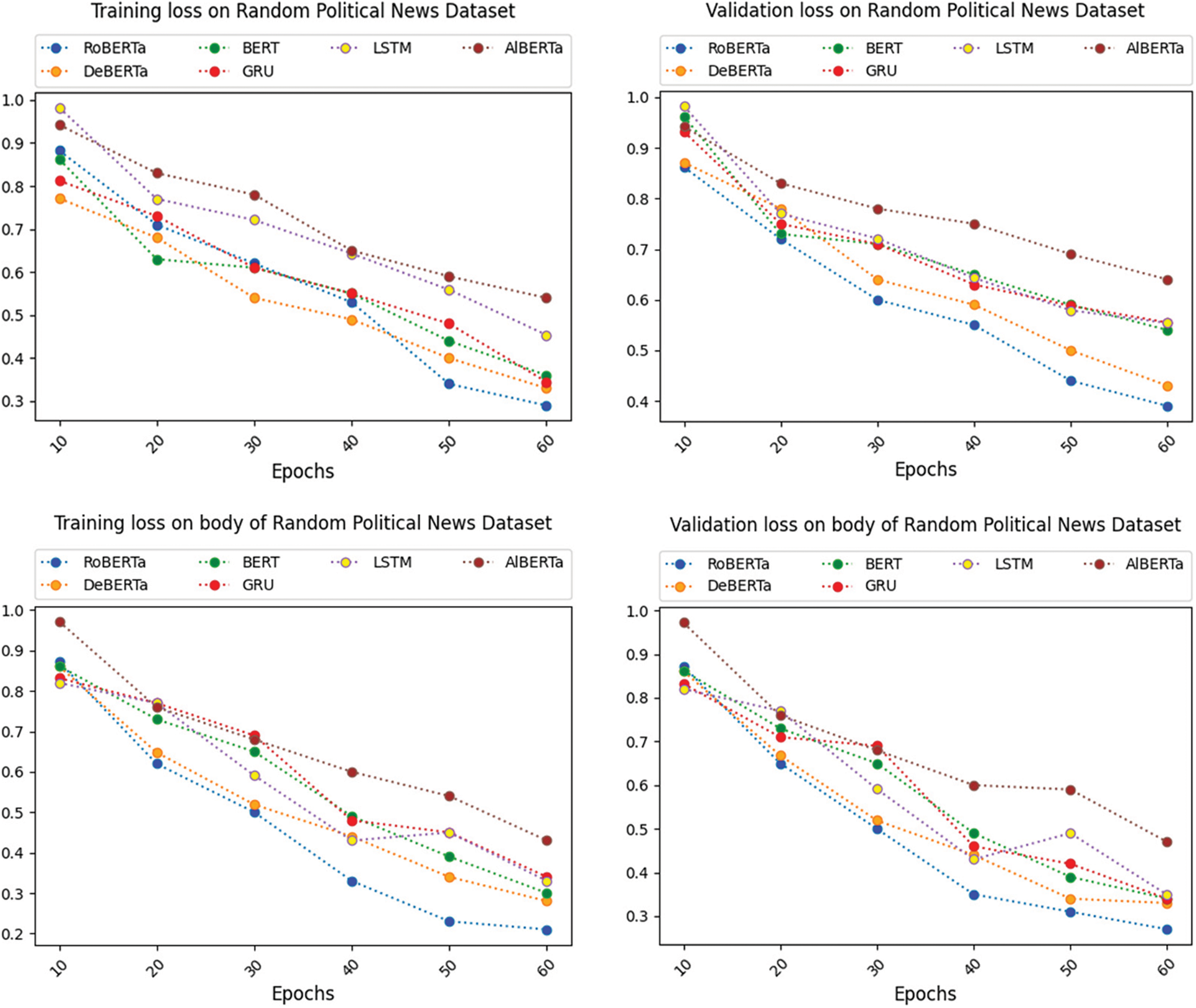
Figure 8: Comparison of loss on title and body of random political news dataset
In Tables 7 and 8 for the Random Political News dataset, kernel SVM performs worst in terms of precision on both title and body text. While on precision, Decision Tree and linear SVM performance are best of all others. For recall, Decision Tree performance is worst on both title and body. On the other hand, kernel SVM performs best in terms of recall.
For F1-score and accuracy, kernel SVM remains on the lowest performance for title and body text, while DeBERTa performs best on title and body, respectively.
From the above results and analysis, it is depicted that in the title text of both datasets, the performance of conventional ML algorithms is better than RNN and transformer-based algorithms in terms of computation and evaluation measures. For the longer text, i.e., transformers outperform the remaining applied algorithms for the body of both datasets.
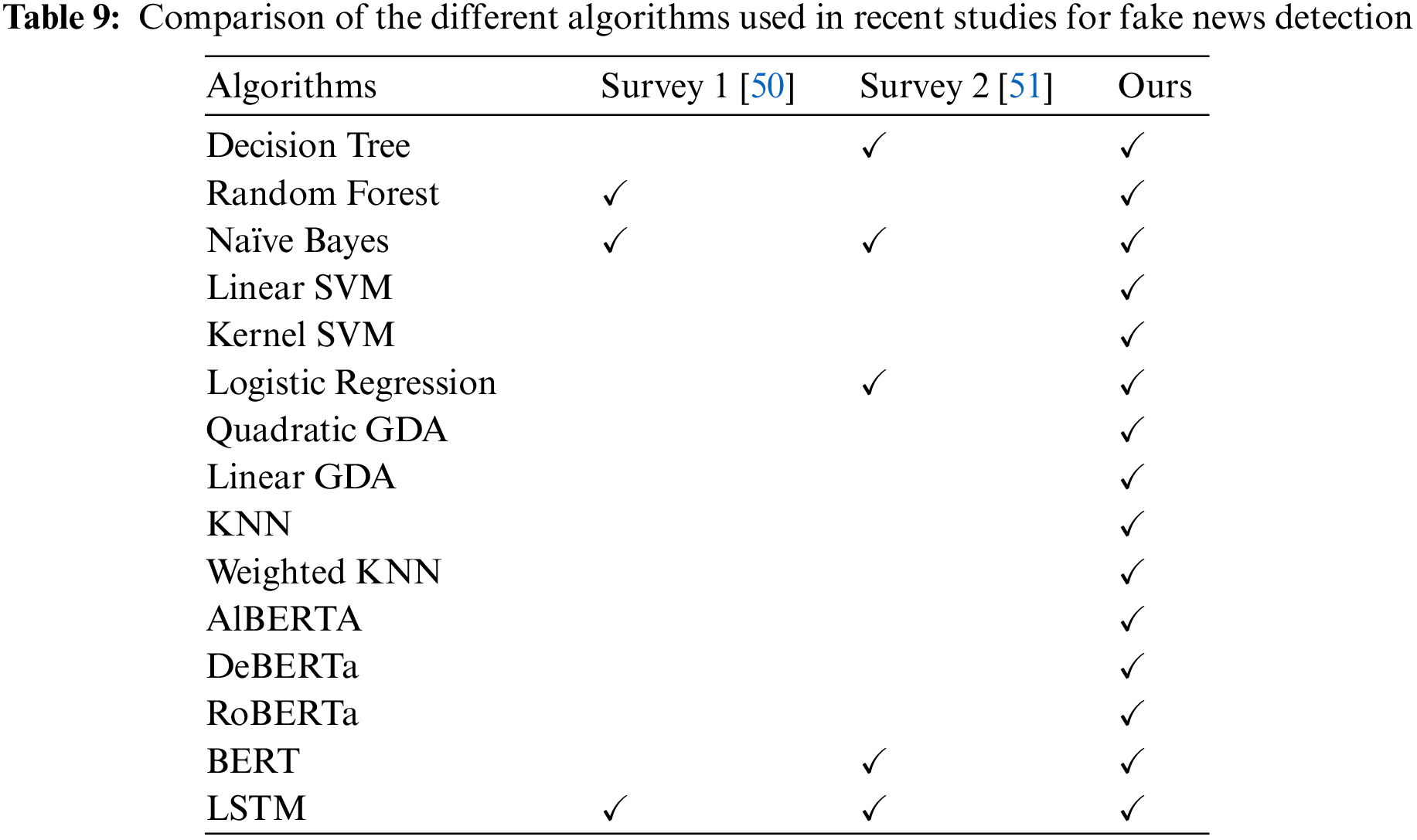
Other than this, Table 9 shows the comparison of different algorithms used for the detection of fake news in recent surveys.
This paper compares supervised learning models for detecting fake news on social media based on NLP techniques and supervised RNN, transformers, and conventional ML algorithms. The accuracy, recall, precision, and F1-measure values for supervised artificial intelligence algorithms are examined. Two datasets are used to determine the average performance of all supervised AI algorithms. From our obtained results, it is clear that ML algorithms perform better on short text classification. It depicts that it is better to use an ML algorithm when the text is one or two lines, and also ML algorithms are efficient in computation. In contrast, longer text transformers outperform the other algorithms.
In the future, this work could be improved with the advancement in transformers, existing hybridizing techniques, and intelligent optimization algorithms. In addition, we will be looking for multi-modal data (images, videos, audio) to detect fake news. The experiments will be undertaken on a multi-modal dataset to understand better the aspects of fake news identification and how to employ ML algorithms better.
Acknowledgement: ADU authors acknowledge financial support from Abu Dhabi University’s Office of Research and Grant programs.
Funding Statement: Abu Dhabi University’s Office of sponsored programs in the United Arab Emirates (Grant Number: 19300752) funded this endeavor.
Author Contributions: All the authors contributed equally.
Availability of Data and Materials: https://github.com/rpitrust/fakenewsdata1.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1https://timesofindia.indiatimes.com/times-fact-check/news/fake-alert-no-russia-does-not-have-lions-roaming-the-streets-to-keep-people-indoors/articleshow/74768135.cms
2https://www.boomlive.in/fake-news/rbi-denies-reports-of-writing-off-loans-worth-rs-68000-crore-7864
3https://factcheck.afp.com/no-comedian-tim-allen-did-not-write-pro-trump-post
4https://www.thehindu.com/sci-tech/science/fact-check-no-potassium-ferrocyanide-in-some-salt-brands-is-not-at-toxic-levels/article28263022.ece
5https://smhoaxslayer.com/china-did-not-cancel-the-dollar-peg-in-its-stock-exchange-transactions/
References
1. H. Allcott and M. Gentzkow, “Social media and fake news in the 2016 election,” Journal of Economic Perspectives, vol. 31, no. 2, pp. 211–36, 2017. [Google Scholar]
2. R. A. Monteiro, R. L. Santos, T. A. Pardo, T. A. D. Almeida, E. E. Ruiz et al., “Contributions to the study of fake news in Portuguese: New corpus and automatic detection results,” in Proc. of Int. Conf. on Computational Processing of the Portuguese Language, Canela, Brazil, pp. 324–334, 2018. [Google Scholar]
3. K. Pham, D. Kim, S. Park and H. Choi, “Ensemble learning-based classification models for slope stability analysis,” Catena, vol. 196, pp. 196, 2021. [Google Scholar]
4. J. Xiao, “SVM and KNN ensemble learning for traffic incident detection,” Physica A: Statistical Mechanics and its Applications, vol. 517, pp. 29–35, 2019. [Google Scholar]
5. B. Horne and S. Adali, “This just in: Fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news,” in Proc. of Int. AAAI Conf. on Web and Social Media, Atlanta, Georgia, USA, vol. 11, pp. 759–766, 2017. [Google Scholar]
6. K. S. Jones, “A statistical interpretation of term specificity and its application in retrieval,” Journal of Documentation, vol. 28, no. 1, pp. 11–21, 1972. [Google Scholar]
7. M. Honnibal and I. Montani, “spaCy 2: Natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing,” Sentometrics Research, vol. 7, no. 1, pp. 411–420, 2017. [Google Scholar]
8. T. Mikolov, K. Chen, G. Corrado and J. Dean, “Efficient estimation of word representations in vector space,” arXiv:1301.3781, 2013. [Google Scholar]
9. J. Pennington, R. Socher and C. D. Manning, “Glove: Global vectors for word representation,” in 2014 Conf. on Empirical Methods in Natural Language Processing (EMNLP), Abu Dhabi, United Arab Emirates, pp. 1532–1543, 2014. [Google Scholar]
10. V. L. Rubin, Y. Chen and N. K. Conroy, “Deception detection for news: Three types of fakes,” Proceedings Association for Information Science and Technology, vol. 52, no. 1, pp. 1–4, 2015. [Google Scholar]
11. N. K. Conroy, V. L. Rubin and Y. Chen, “Automatic deception detection: Methods for finding fake news,” in Proc. of the Association for Information Science and Technology, vol. 52, no. 1, pp. 1–4, 2015. [Google Scholar]
12. V. L. Rubin, N. J. Conroy and Y. Chen, “Towards news verification: Deception detection methods for news discourse,” in Proc. of Hawaii Int. on System Sciences, Hawaii, USA, pp. 5–8, 2015. [Google Scholar]
13. S. M. H. Dadgar, M. S. Araghi and M. M. Farahani, “A novel text mining approach based on TF-IDF and support vector machine for news classification,” in Proc. of 2016 IEEE Int. Conf. on Engineering and Technology, Coimbatore, India, pp. 112–116, 2016. [Google Scholar]
14. V. L. Rubin, N. Conroy, Y. Chen and S. Cornwell, “Fake news or truth? using satirical cues to detect potentially misleading news,” in Proc. of the Second Workshop on Computational Approaches to Deception Detection, California, USA, pp. 7–17, 2016. [Google Scholar]
15. Z. Jin, J. Cao, Y. Zhang and J. Luo, “News verification by exploiting conflicting social viewpoints in microblogs,” in Proc. of the AAAI Conf. on Artificial Intelligence, Phoenix, Arizona, USA, vol. 30, pp. 2972–2978, 2016. [Google Scholar]
16. S. Pandey, S. Prabhakaran, N. S. Reddy and D. Acharya, “Fake news detection from online media using machine learning classifiers,” Journal of Physics: Conference Series, vol. 2161, no. 1, pp. 012027, 2022. [Google Scholar]
17. S. Hakak, M. Alazab, S. Khan, T. R. Gadekallu, P. K. R. Maddikunta et al., “An ensemble machine learning approach through effective feature extraction to classify fake news,” Future Generation Computer Systems, vol. 117, pp. 47–58, 2021. [Google Scholar]
18. E. Tacchini, G. Ballarin, M. L. Della Vedova, S. Moret and L. de Alfaro, “Some like it hoax: Automated fake news detection in social networks,” arXiv:1704.07506, 2017. [Google Scholar]
19. K. Shu, A. Sliva, S. Wang, J. Tang and H. Liu, “Fake news detection on social media: A data mining perspective,” ACM SIGKDD Explorations Newsletter, vol. 19, no. 1, pp. 22–36, 2017. [Google Scholar]
20. H. Ahmed, I. Traore and S. Saad, “Detecting opinion spams and fake news using text classification,” Security and Privacy, vol. 1, no. 1, pp. 9, 2018. [Google Scholar]
21. S. Gilda, “Notice of violation of ieee publication principles: Evaluating machine learning algorithms for fake news detection,” in Proc. 2017 IEEE 15th Student Conf. on Research and Development, Putrajaya, Malaysia, pp. 110–115, 2017. [Google Scholar]
22. N. Ruchansky, S. Seo and Y. Liu, “CSI: A hybrid deep model for fake news detection,” in Proc. of the 2017 ACM on Conf. on Information and Knowledge Management, Singapore, pp. 797–806, 2017. [Google Scholar]
23. K. Shu, S. Wang and H. Liu, “Exploiting tri-relationship for fake news detection,” arXiv:1712.07709, 2017. [Google Scholar]
24. J. A. Nasir, O. S. Khan and I. Varlamis, “Fake news detection: A hybrid cnnrnn based deep learning approach,” International Journal of Information Management Data Insights, vol. 1, no. 1, pp. 100007, 2021. [Google Scholar]
25. Y. Long, “Fake news detection through multi-perspective speaker profiles,” in Proc. of the Eighth Int. Joint Conf. on Natural Language Processing, vol. 2, pp. 252–256, 2017. [Google Scholar]
26. A. Figueira and L. Oliveira, “The current state of fake news: Challenges and ‘opportunities,” Proceedings Computer Science, vol. 121, pp. 817–825, 2017. [Google Scholar]
27. C. Janze and M. Risius, “Automatic detection of fake news on social media platforms,” 2017. [Online]. Available: https://www.ttcenter.ir/ArticleFiles/ENARTICLE/3884.pdf [Google Scholar]
28. V. P’erez-Rosas, B. Kleinberg, A. Lefevre and R. Mihalcea, “Automatic detection of fake news,” arXiv:1708.07104, 2017. [Google Scholar]
29. C. Buntain and J. Golbeck, “Automatically identifying fake news in popular twitter threads,” in Proc. of 2017 IEEE Int. Conf. on Smart Cloud (SmartCloud), New York, USA, pp. 208–215, 2017. [Google Scholar]
30. A. Bessi, “On the statistical properties of viral misinformation in online social media,” Physica A: Statistical Mechanics and its Applications, vol. 469, pp. 459–470, 2017. [Google Scholar]
31. H. Zhu, H. Wu, J. Cao, G. Fu and H. Li, “Information dissemination model for social media with constant updates,” Physica A: Statistical Mechanics and its Applications, vol. 502, pp. 469–482, 2018. [Google Scholar]
32. K. Shu, S. Wang and H. Liu, “Understanding user profiles on social media for fake news detection,” in Proc. of 2018 IEEE Conf. on Multimedia Information Processing and Retrieval, Miami, Florida, USA, pp. 430–435, 2018. [Google Scholar]
33. S. Tschiatschek, A. Singla, M. Gomez Rodriguez, A. Merchant and A. Krause, “Fake news detection in social networks via crowd signals,” in WWW’18: Companion Proc. of the the Web Conf. 2018, Lyon, France, pp. 517–524, 2018. [Google Scholar]
34. G. B. Guacho, S. Abdali and E. E. Papalexakis, “Semi-supervised contentbased fake news detection using tensor embeddings and label propagation,” in Proc. of SoCal NLP Symp., California, USA, pp. 3–5, 2018. [Google Scholar]
35. K. Shu, H. R. Bernard and H. Liu, “Studying fake news via network analysis: Detection and mitigation,” in Emerging Research Challenges and Opportunities in Computational Social Network Analysis and Mining. Cham, Switzerland: Springer, pp. 43–65, 2019. [Google Scholar]
36. F. Harrag and M. K. Djahli, “Arabic fake news detection: A fact checking based deep learning approach,” Transactions on Asian and Low-Resource Language Information Processing, vol. 21, no. 4, pp. 1–34, 2022. [Google Scholar]
37. M. Sarnovský, V. Maslej-Krešňáková and K. Ivancová, “Fake news detection related to the COVID-19 in Slovak language using deep learning methods,” Acta Polytechnica Hungarica, vol. 19, no. 2, pp. 43–57, 2022. [Google Scholar]
38. O. Ajao, D. Bhowmik and S. Zargari, “Sentiment aware fake news detection on online social networks,” in 2019 IEEE Int. Conf. on Acoustics, Speech and Signal Processing, Brighton, England, pp. 2507–2511, 2019. [Google Scholar]
39. S. Kumar, R. Asthana, S. Upadhyay, N. Upreti and M. Akbar, “Fake news detection using deep learning models: A novel approach,” Transactions on Emerging Telecommunications Technologies, vol. 31, no. 2, pp. 3767, 2020. [Google Scholar]
40. F. Marra, D. Gragnaniello, D. Cozzolino and L. Verdoliva, “Detection of gan-generated fake images over social networks,” in Proc. of 2018 IEEE Conf. on Multimedia Information Processing and Retrieval, Miami, Florida, USA, pp. 384–389, 2018. [Google Scholar]
41. Y. Liu and Y. F. B. Wu, “FNED: A deep network for fake news early detection on social media,” ACM Transactions on Information Systems, vol. 38, no. 3, pp. 1–33, 2020. [Google Scholar]
42. B. D. Horne, J. Nørregaard and S. Adali, “Robust fake news detection over time and attack,” ACM Transactions on Intelligent Systems and Technology, vol. 11, no. 1, pp. 1–23, 2019. [Google Scholar]
43. M. Potthast, J. Kiesel, K. Reinartz, J. Bevendorff and B. Stein, “A stylometric inquiry into hyperpartisan and fake news,” arXiv:1702.05638, 2017. [Google Scholar]
44. S. Singhal, R. R. Shah, T. Chakraborty, P. Kumaraguru and S. Satoh, “Spotfake: A multi-modal framework for fake news detection,” in Proc. of 2019 IEEE Fifth Int. Conf. on Multimedia Big Data, Singapore, pp. 39–47, 2019. [Google Scholar]
45. A. Tariq, A. Mehmood, M. Elhadef and M. U. G. Khan, “Adversarial training for fake news classification,” IEEE Access, vol. 10, pp. 82706–82715, 2022. [Google Scholar]
46. N. Rai, D. Kumar, N. Kaushik, C. Raj and A. Ali, “Fake news classification using transformer based enhanced lstm and bert,” International Journal of Cognitive Computing in Engineering, vol. 3, pp. 98–105, 2022. [Google Scholar]
47. A. Gaurav, B. B. Gupta, A. Castiglione, K. Psannis and C. Choi, “A novel approach for fake news detection in vehicular ad-hoc network (VANET),” in Computational Data and Social Networks: 9th Int. Conf., CSoNet 2020, Dallas, TX, USA, pp. 386–397, 2020. [Google Scholar]
48. M. Casillo, F. Colace, B. B. Gupta, D. Santaniello and C. Valentino, “Fake news detection using LDA topic modelling and k-nearest neighbor classifier,” in Computational Data and Social Networks: 10th Int. Conf., CSoNet 2021, Virtual Event, pp. 330–339, 2021. [Google Scholar]
49. D. Sharma and S. Jain, “Evaluation of stemming and stop word techniques on text classification problem,” International Journal of Scientific Research in Computer Science and Engineering, vol. 3, no. 2, pp. 1–4, 2015. [Google Scholar]
50. R. Dhiren, H. Shethna, K. Patel, U. Thakker, S. Tanwar et al., “A taxonomy of fake news classification techniques: Survey and implementation aspects,” IEEE Access, vol. 10, pp. 30367–30394, 2022. [Google Scholar]
51. P. Aishika and M. Pradhan, “Survey of fake news detection using machine intelligence approach,” Data & Knowledge Engineering, vol. 144, pp. 102118, 2023. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools