
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Enhancing Unsupervised Domain Adaptation for Person Re-Identification with the Minimal Transfer Cost Framework
1 Research Institute of Electronic Science and Technology, University of Electronic Science and Technology of China, Chengdu, 610000, China
2 National Key Laboratory of Optical Field Manipulation Science and Technology, Chinese Academy of Sciences, Chengdu, 610209, China
* Corresponding Author: Qiang Wu. Email:
Computers, Materials & Continua 2024, 80(3), 4197-4218. https://doi.org/10.32604/cmc.2024.055157
Received 19 June 2024; Accepted 05 August 2024; Issue published 12 September 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In Unsupervised Domain Adaptation (UDA) for person re-identification (re-ID), the primary challenge is reducing the distribution discrepancy between the source and target domains. This can be achieved by implicitly or explicitly constructing an appropriate intermediate domain to enhance recognition capability on the target domain. Implicit construction is difficult due to the absence of intermediate state supervision, making smooth knowledge transfer from the source to the target domain a challenge. To explicitly construct the most suitable intermediate domain for the model to gradually adapt to the feature distribution changes from the source to the target domain, we propose the Minimal Transfer Cost Framework (MTCF). MTCF considers all scenarios of the intermediate domain during the transfer process, ensuring smoother and more efficient domain alignment. Our framework mainly includes three modules: Intermediate Domain Generator (IDG), Cross-domain Feature Constraint Module (CFCM), and Residual Channel Space Module (RCSM). First, the IDG Module is introduced to generate all possible intermediate domains, ensuring a smooth transition of knowledge from the source to the target domain. To reduce the cross-domain feature distribution discrepancy, we propose the CFCM Module, which quantifies the difficulty of knowledge transfer and ensures the diversity of intermediate domain features and their semantic relevance, achieving alignment between the source and target domains by incorporating mutual information and maximum mean discrepancy. We also design the RCSM, which utilizes attention mechanism to enhance the model’s focus on personnel features in low-resolution images, improving the accuracy and efficiency of person re-ID. Our proposed method outperforms existing technologies in all common UDA re-ID tasks and improves the Mean Average Precision (mAP) by 2.3% in the Market to Duke task compared to the state-of-the-art (SOTA) methods.Keywords
Person re-identification (re-ID) [1–3] is a computer vision task at matching images of individuals from different camera perspectives. It is widely used in surveillance and security, enabling identification across different times and spaces, with potential value in social analysis and behavior understanding. Traditional re-ID algorithms often rely on handcrafted features such as SIFT [4] and HOG [5], followed by Support Vector Machine (SVM) classifiers [6]. However, these methods face challenges like lighting changes and background occlusions. With advancements in deep learning (DL), DL-based re-ID methods have emerged, categorized into supervised [1,7,8] and unsupervised [9–11] methods. Supervised methods require extensive labeling and often face performance limitations due to domain discrepancies between labeled source and unlabeled target datasets. To address cross-domain differences, researchers focus on unsupervised cross-domain re-ID methods [12,13], which use both source domain labels and target domain data to improve model generalization (see Fig. 1).
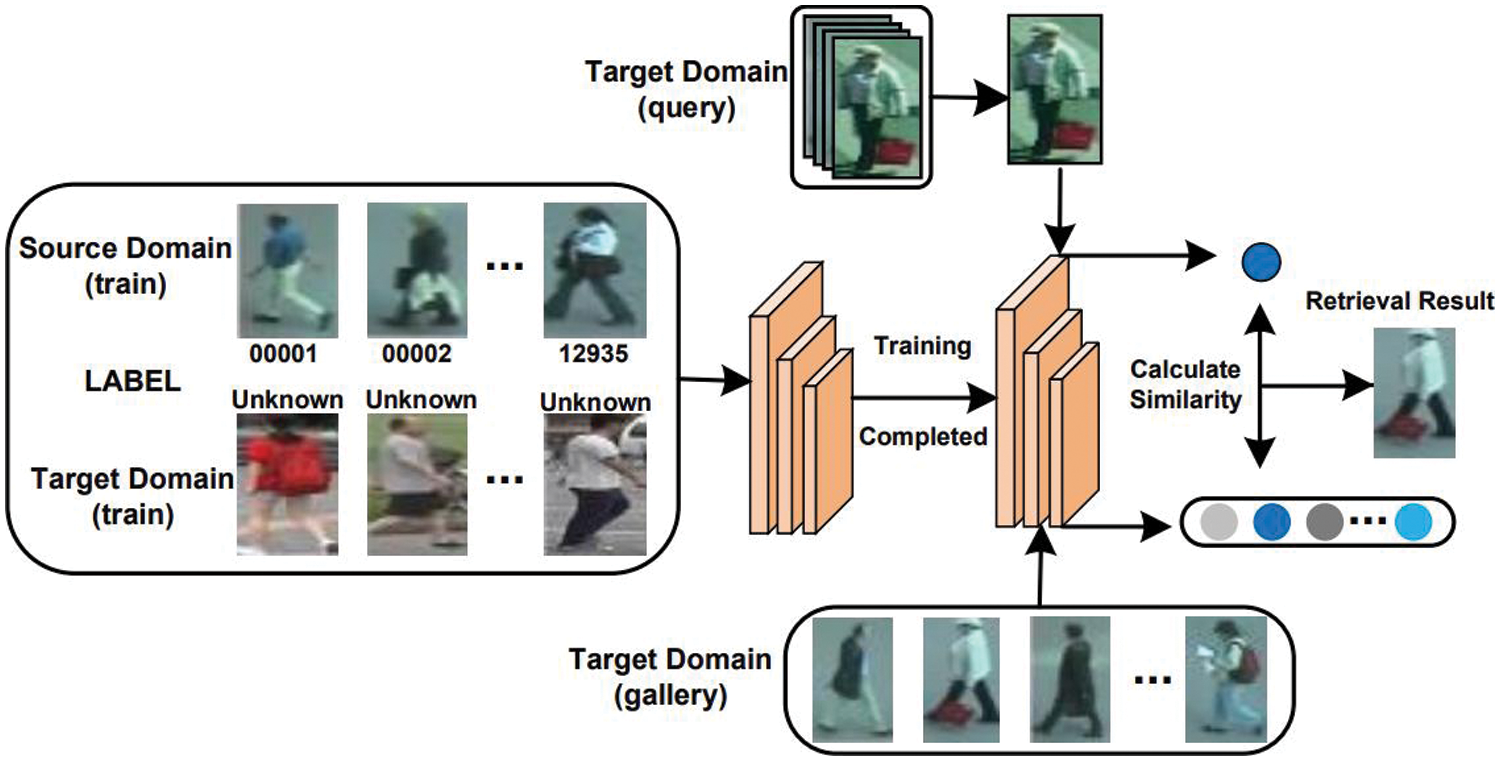
Figure 1: The concept of training and testing models for unsupervised cross-domain person re-ID
Recent studies in unsupervised cross-domain person re-ID have adopted Domain Adaptation (DA) methods to directly align the distributions of the source and target domains. These methods implicitly construct an intermediate domain [14,15], aiming to reduce cross-domain discrepancies by mapping the source and target domains to this intermediate domain. However, due to the lack of supervision for the intermediate state, these methods struggle to provide a stable and smooth transition state, resulting in limited generalization capability. Additionally, guided by the labels of the source domain, direct alignment methods sometimes overfit to the feature distribution of the source domain rather than achieving a more generalized feature representation that encompasses both domains.
In this paper, we propose the Minimal Transfer Cost Framework (MTCF), which adaptively considers all possible intermediate domains during alignment, ensuring feature diversity and smooth knowledge transfer. It comprises three modules: the Intermediate Domain Generator (IDG), the Cross-domain Feature Constraint Module (CFCM), and the Residual Channel Space Module (RCSM). The IDG considers all intermediate domains for knowledge transfer, ensuring computational simplicity. The CFCM uses Maximum Mean Discrepancy (MMD) to balance feature transfer costs, ensuring key feature sharing between domains and utilizing Mutual Information (MI) to maintain intra-domain diversity. The RCSM enhances feature extraction accuracy, improving the model’s focus on key personnel features.
Our contributions are summarized as follows:
• We introduce a novel approach that considers all potential intermediate domains to ensure a smooth transition of knowledge from the source domain to the target domain. This strategy effectively bridges the gap between different domains, facilitating more efficient and accurate person re-identification.
• We design a key feature approach that shares between the source and target domains by accurately quantifying the knowledge transfer cost. This approach maintains the integrity and relevance of features, achieving precise alignment and improving the model’s generalization capabilities.
• We focus on enhancing feature extraction accuracy, particularly in low-resolution images. This improvement boosts the overall effectiveness and efficiency of the person re-identification process, ensuring that key personnel features are accurately captured.
• Extensive experiments show our method achieves state-of-the-art (SOTA) results across various datasets, with a 2.3% improvement in mean Average Precision (mAP) over advanced techniques, enhancing transfer learning performance.
We compare our method with several state-of-the-art approaches to provide a clear context for our contributions. For instance, SPGAN [14] uses GANs for image-to-image translation between source and target domains but struggles with preserving identity information. ECN [15] employs exemplar and camera-invariance constraints to enhance re-ID performance but faces challenges with large domain gaps. Our method differs by explicitly generating intermediate feature representations, avoiding identity mismatch issues. Moreover, methods like MMT [12] focus on mutual mean teaching but lack mechanisms for handling intermediate domain diversity, which our CFCM addresses through mutual information and maximum mean discrepancy.
By addressing these limitations and introducing a comprehensive framework that incorporates intermediate domain generation, feature constraint, and enhanced feature extraction, our method provides a robust solution for cross-domain person re-identification.
In this section, we discuss two key technologies: person re-identification (re-ID) and Domain Adaptation (DA).
Person re-identification (re-ID) aims to match images of individuals captured from different camera perspectives. Traditional techniques relied on manually extracting features [16–18]. However, these methods could only extract shallow features, such as color and texture, and failed to capture high-level semantic information. The advent of deep learning methods has effectively addressed this limitation.
Deep learning methods encompass both supervised and unsupervised approaches. Supervised methods [19,20] are suitable for scenarios where all images are labeled and have similar styles. These methods often employ global/local feature representation learning, attention mechanisms, and semantic feature extraction. Nevertheless, they do not meet the diverse needs of real-world scenarios. Consequently, unsupervised re-ID methods, which do not require identity labels, have gained considerable attention.
Unsupervised methods cluster target domain data to generate pseudo-labels for fine-tuning or training. Fan et al. [9] introduced clustering algorithms within the progressive unsupervised learning method PUL. Additionally, Fu et al. [21] exploited similarities between global and local features to create multiple independent clustering pseudo-labels, thereby improving robustness. Zhao et al. [22] combined pseudo-label clustering with the selection of reliable instances to mitigate label noise. Further advancements were made by Zhai et al. [23], who implemented iterative density clustering, adaptive sample augmentation, and discriminative learning.
Hybrid clustering and sample selection methods have also been investigated. For example, Sun et al. [24] and Jin et al. [25] explored various techniques, while Li et al. [26] introduced a confidence-adaptive method for sample separation. To address pose variations and occlusions, Zhang et al. [27] and Raj et al. [11] developed end-to-end networks, which significantly improved accuracy in complex scenarios.
Domain Adaptation (DA) aims to mitigate the impact of domain shifts on cross-domain re-identification (re-ID) performance by effectively transferring knowledge and constructing implicit or explicit intermediate domains to bridge the gap between the source (labeled) and target (unlabeled) domains. As shown in Fig. 2, (a) represents the typical method of using Generative Adversarial Networks (GANs) to construct implicit intermediate domains (I-Inter), transforming the labeled source domain into an intermediate domain styled after the target domain. In contrast, (b) illustrates our method, which directly constructs explicit intermediate domains (E-Inter) using the source and target domains, serving as a bridge connecting the two.
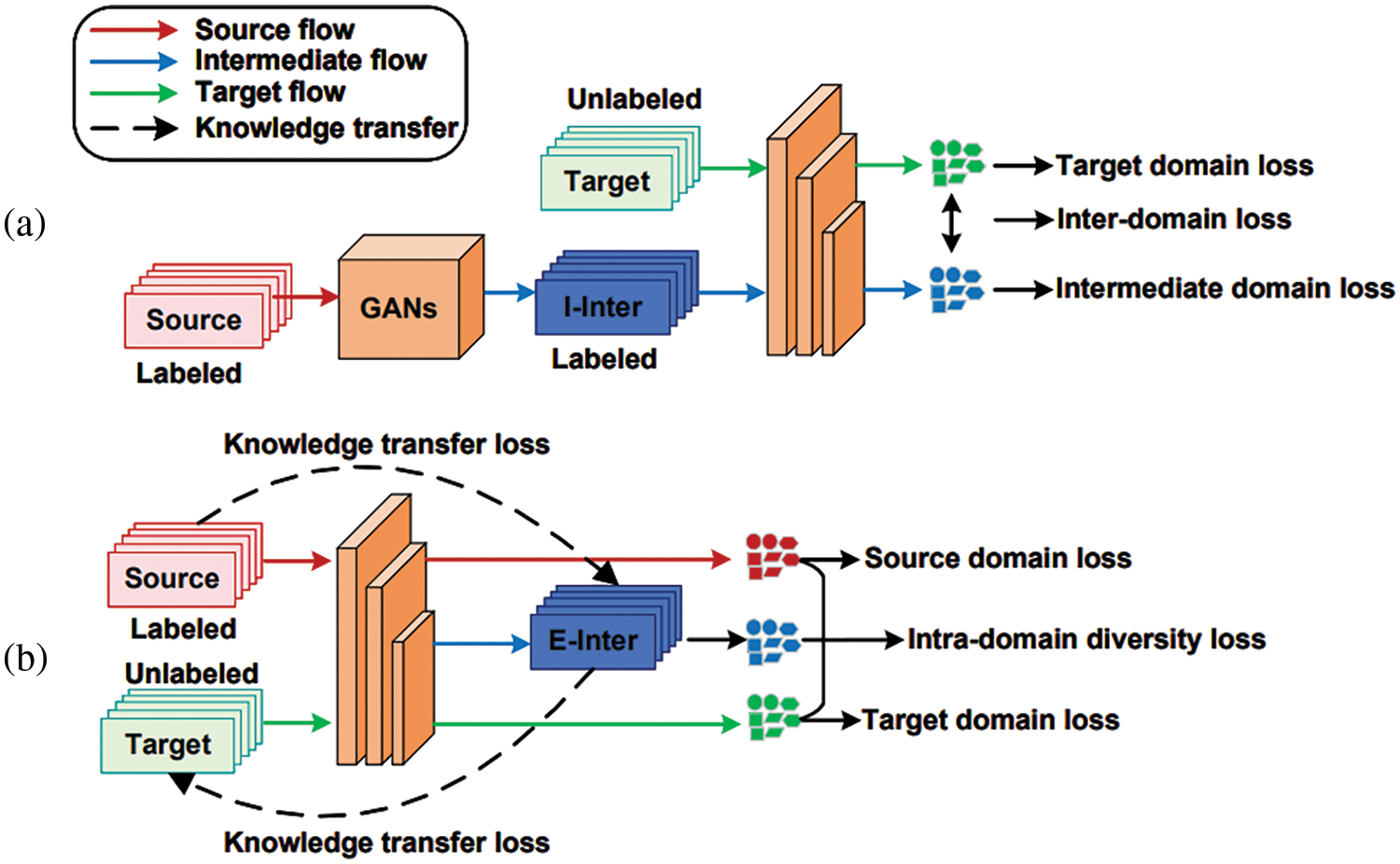
Figure 2: Comparing GAN-based implicit intermediate domains and our explicit intermediate domains for bridging source and target domains
GAN-based methods generate mappings from the source to the target domain, creating implicit intermediate domains. For example, Zheng et al. [28] used GANs to synthesize images with smooth labels. Wei et al. [29] and Deng et al. [30] mapped source images to the target domain style, thereby narrowing the domain gap. Chen et al. [31] combined GANs with contrastive learning modules, enhancing viewpoint invariance and performance. Additionally, Dai et al. [32] introduced a cyclic GAN to select valuable source images for transferring discriminative information to the target domain. Yang et al. [33] employed DPG-GAN [34] and StarGAN [35] to generate and convert images into various camera styles. Zhong et al. [36] aimed to augment datasets by learning invariant features across domains, thus mitigating image style changes caused by camera transformations.
Explicit intermediate domain construction effectively utilizes intermediate representations to bridge domain gaps. For instance, Dai et al. [37] introduced an intermediate domain module to blend hidden representations, reducing disparities. This approach was further advanced by Dai et al. [38], who generated multiple intermediate domains to minimize feature differences while preserving identity information. Moreover, Na et al. [39] addressed the issue of source domain label dominance by segregating the intermediate space into contrastive and consensus areas, thereby enhancing adaptive model performance. Finally, DFDSN-Net [40] diminished style discrepancies through feature fusion and normalization, implicitly introducing intermediate domains within the feature space.
In our section, we propose the Minimal Transfer Cost Framework (MTCF), see Fig. 3, designed for unsupervised domain-adaptive person re-ID. The core of MTCF is identifying an appropriate intermediate domain among all possible intermediate domains, serving as a bridge between the source and target domains. This framework facilitates smooth knowledge transfer, aligning feature distributions and enhancing re-ID performance in the target domain.
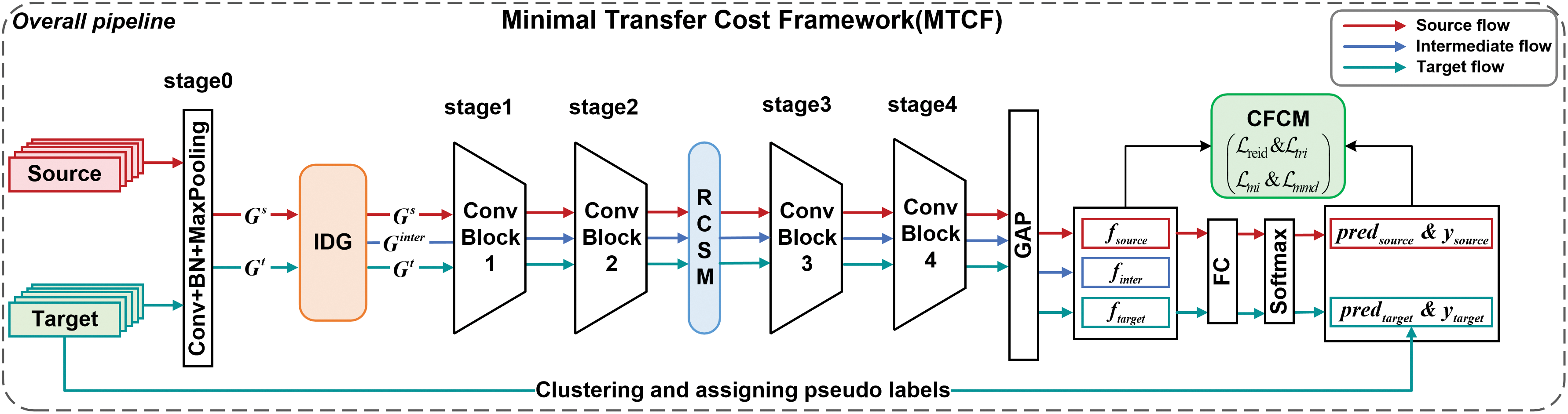
Figure 3: Overall pipeline of our MTCF method
Person re-identification involves two key types of data: source domain data with clear labels and target domain data lacking labels. The backbone network in our study is built upon the IBN-ResNet50 [41], comprising five distinct stages. Initially, data from both the source and target domains pass through stage 0, consisting of Conv+BN+MaxPooling layers, resulting in initial feature representations
Subsequently, these features undergo deeper feature extraction through stage 1 to 4, which consist of ConvBlock1 to ConvBlock4 layers, alongside our specially designed Residual Channel Space Module (RCSM) to enhance feature focus. The feature maps from the three domains then pass through a Global Average Pooling (GAP) layer to generate feature vectors
3.2 Minimal Transfer Cost Framework
The Minimal Transfer Cost Framework (MTCF) is designed to facilitate efficient and effective cross-domain person re-identification by leveraging three synergistic modules: the Residual Channel Space Module (RCSM), the Intermediate Domain Generator (IDG), and the Cross-domain Feature Constraint Module (CFCM). The RCSM enhances feature extraction by integrating spatial and channel attention mechanisms, ensuring key regions are accurately captured. The IDG generates intermediate domain features that blend source and target domain characteristics, ensuring smooth knowledge transfer and minimizing feature distribution discrepancies. The CFCM employs Maximum Mean Discrepancy (MMD) and Mutual Information Neural Estimation (MINE) to align source and target domains while maintaining feature diversity and relevance. Together, these modules optimize the overall performance and generalization capability of the model by balancing classification, triplet, transfer, and intra-domain diversity losses.
3.2.1 Residual Channel Space Module
To more accurately capture key regions within images and enhance the efficiency of capturing essential information across different channels, we propose the Residual Channel Space Module (RCSM), shown in Fig. 4. It integrates spatial attention [42], channel attention, and a residual structure [43].

Figure 4: The internal structure of RCSM and IDG
(1) Channel Attention
Given a feature map
The original feature map
(2) Spatial Attention and Residual Structure
For spatial attention, the average
The spatially adjusted feature map
During the model training process, the attention mechanism dynamically adjusts the channel and spatial responses of the feature map, while the residual structure ensures minimal loss of original information.
3.2.2 Intermediate Domain Generator
For criterion (1), the Intermediate Domain Generator (IDG) facilitates smooth knowledge transfer. In MTCF, as illustrated in Fig. 4, an intermediate domain feature representation
In Eq. (3), the Intermediate Domain Generator (IDG) generates a gradient-based, learnable parameter
By progressively adjusting
We randomly selected 100 pairs of source and target domain images (with each pair having the same person ID) and generated intermediate domain images. The figure presents the PCA projection of the source domain (blue), intermediate domain (green), and target domain (red). As illustrated in Fig. 5, the intermediate domain data points are positioned between the source and target domains in the feature space, indicating that the intermediate domain effectively integrates the characteristics of both the source and target domains. This generation method of the intermediate domain can effectively mitigate the feature distribution discrepancy between the source and target domains, thereby enhancing the model’s generalization capability in cross-domain tasks.
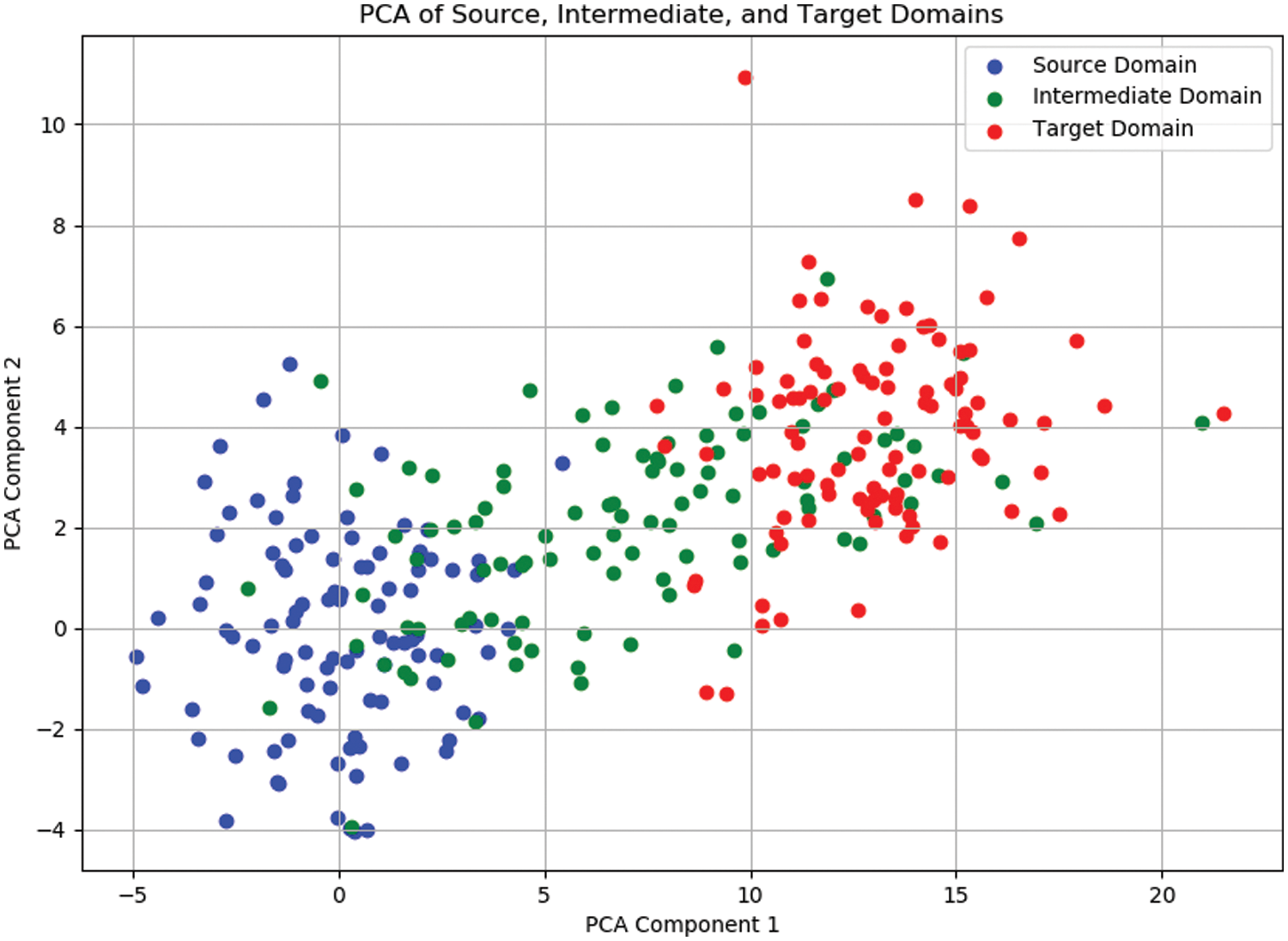
Figure 5: PCA of source, intermediate, and target domains, demonstrating that the intermediate domain (green) effectively integrates characteristics from both the source (blue) and target (red) domains. PCA Component 1 and PCA Component 2 represent the first and second principal components extracted through PCA, capturing the most significant variance in the data
3.2.3 Cross-Domain Feature Constraint Module
The Cross-domain Feature Constraint Module (CFCM) ensures knowledge transfer simplicity using Maximum Mean Discrepancy (MMD) distance loss [44] and maintains feature diversity with Mutual Information (MI) [45].
(1) Quantify Transfer Cost
Maximum Mean Discrepancy (MMD) reduces the distributional discrepancy between domains by minimizing the distance between the mean feature mappings in the RKHS of the source and target domains. Using MMD distance loss, we quantify and minimize knowledge transfer costs, aligning source and target domains. The MMD loss function is formulated as Eq. (4):
where
Minimizing this discrepancy allows the intermediate domain to transition easily to both extremes, enhancing target domain performance. The objective function is formulated as Eq. (5):
(2) Diversification of Intra-Domain Features
Addressing criterion (2), We employ Mutual Information Neural Estimation (MINE) to estimate the mutual information (MI) between two random variables
The estimation of mutual information is based on the following formula:
The objective function to strengthen similarity is Eq. (9):
Here,
In the Minimal Transfer Cost Framework (MTCF), the total loss function
The classification loss
The triplet loss
4.1.1 Datasets and Evaluation Protocol
To evaluate the effectiveness of the MTCF, we conducted experiments on five datasets: Market-1501 [46], DukeMTMC [47], MSMT17 [32], PersonX [48], and Unreal [49]. Detailed dataset information is presented in Table 1.
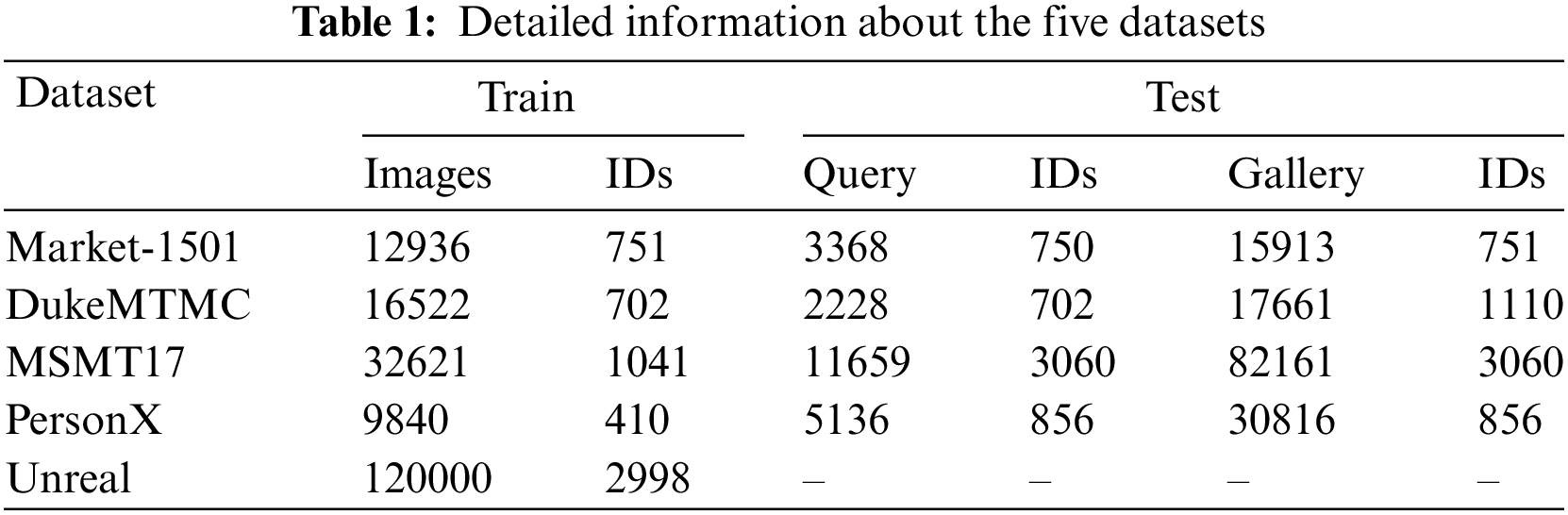
The “Train” subset is used for model training, while the “Query” and “Gallery” subsets are used for model testing. In person re-ID tasks, the trained model matches each “Query” image with the most similar images in the “Gallery” subset. The model’s performance is evaluated using mean Average Precision (mAP) and Cumulative Matching Characteristics at Ranks 1/5/10 (R1/5/10). The mAP measures average retrieval performance across all queries, while R1, R5, and R10 indicate the probability of a correct match in the top 1, 5, and 10 results, respectively. These metrics reflect the precision and recall range of the retrieval.
The proposed MTCF network is implemented using the PyTorch framework and runs on an NVIDIA 4090 GPU. In our experiments, the batch size was set to 16, with image dimensions of 256 × 128 and a feature size of 2048. The Adam optimizer was employed with an initial learning rate of 0.00025 and a weight decay of 0.0005. Training was conducted over 60 epochs, with evaluations performed every 1600 iterations (eval_step = 1). The learning rate was adjusted at the end of each epoch using a step size of 20 and a decay factor of 0.1. To perform unsupervised clustering in the target domain, we utilized the DBSCAN algorithm with eps set to 0.6 and min_samples set to 4. Additionally, we incorporated the XBM module to enhance feature learning, setting the memory size to 8192 and the usage ratio to 1. The hyperparameters for the loss function were configured as follows: mu1 = 0.7, mu2 = 1.0, and mu3 = 0.1. To optimize the selection of convolution algorithms, we enabled cuDNN’s auto-tuner. The initial learning rate of 0.00025 was chosen to balance stability and efficiency, with higher rates causing instability and lower rates slowing convergence. A batch size of 16 optimizes computational resources and training effectiveness, avoiding memory issues from larger sizes while ensuring frequent parameter updates for better generalization. These hyperparameters were tuned to achieve optimal performance.
4.2.1 Comparison with State-of-the-Art Methods
In this section, we compare our MTCF method with recent state-of-the-art person re-ID methods. Based on their training schemes, we categorize UDA person re-ID methods into four types: GAN transferring methods, joint training methods, fine-tuning methods, and intermediate domain methods.
Most methods listed in Table 2 largely overlook the importance of intermediate domains, which can serve as a bridge in domain adaptation between the source and target domains to better transfer the source knowledge to the target domain. While some methods consider explicit intermediate domains, they do not account for all possible intermediate domains. However, our MTCF is capable of identifying the most suitable intermediate domain among all possible options to better improve the performance of UDA re-ID. As shown in Table 2, our method significantly outperforms the best UDA re-ID methods in the Duke to Market task in terms of mAP, as well as in the Market to Duke task in terms of mAP, R1/5/10 accuracy, across all these benchmarks. Notably, in the Market to Duke task, our method shows a 2.3% increase in mAP compared to the best performing methods, CCL+PDA+FA and P2LR.
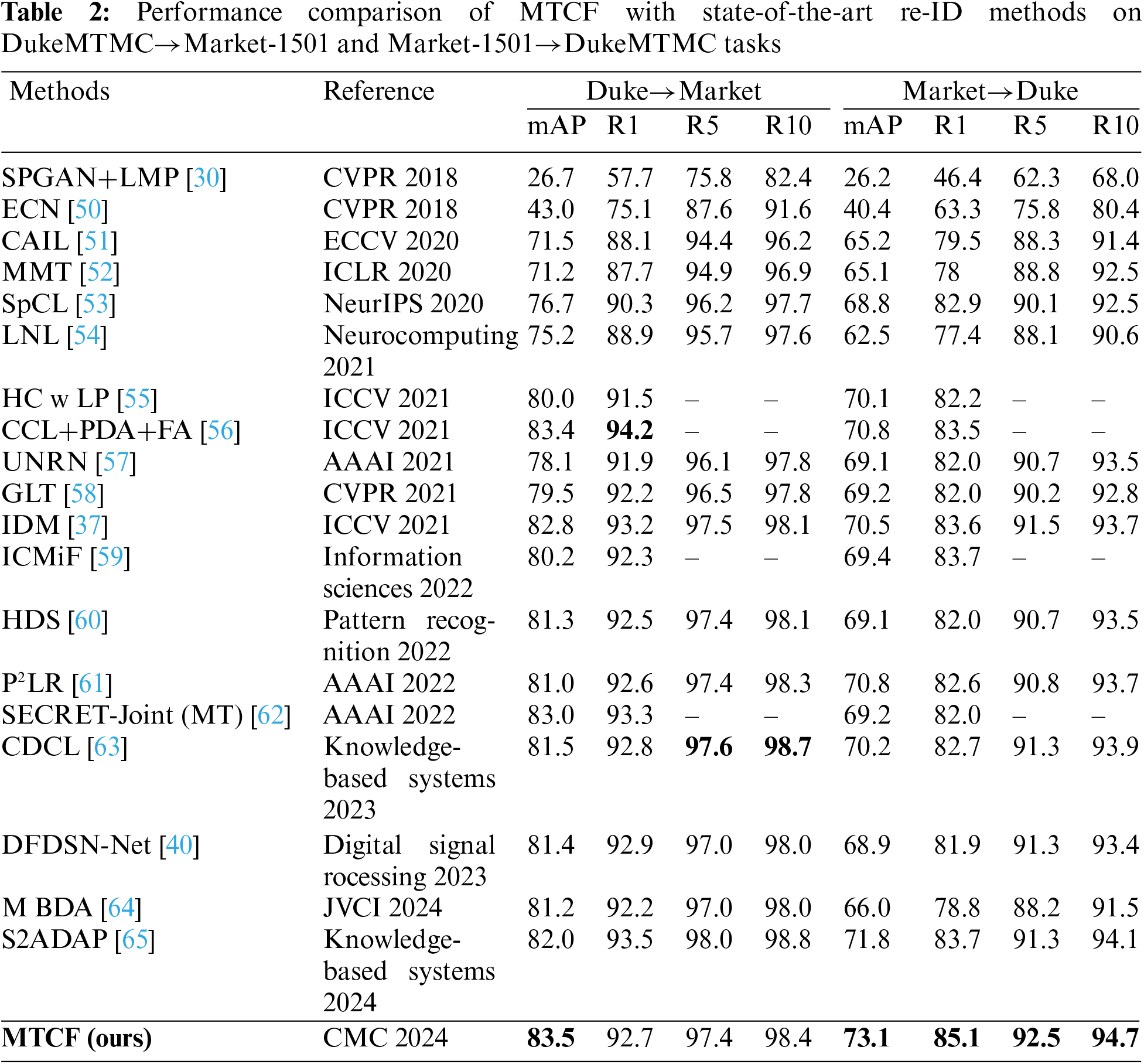
In Table 3, MTCF achieves comparable performance in R5/10 accuracy to leading methods in the Market to MSMT task, ranking third in mAP. In the Duke to MSMT task, it demonstrates superior performance, surpassing the most advanced techniques in mAP and R1/5 accuracy.
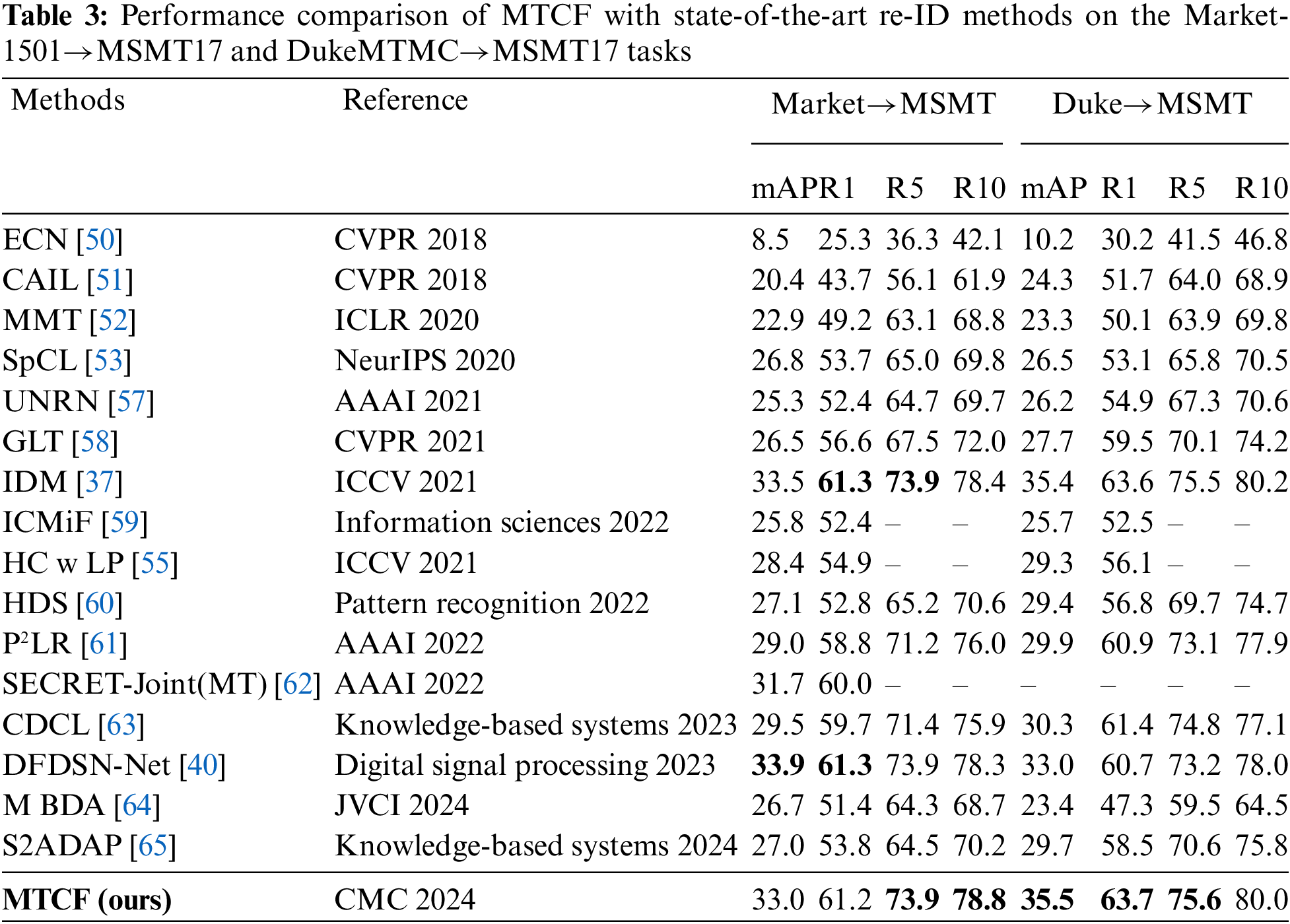
Results from Tables 2 and 3 highlight the exceptional capabilities of our approach in real-to-real re-ID tasks. When compared to recent methods like MBDA and S2ADAP, MTCF excels in multiple metrics, indicating its breakthrough performance in UDA person re-ID tasks.
As shown in Table 4, for the PersonX to Market and PersonX to Duke tasks, our method produced the best results to date in terms of mAP and R1/10 accuracy. In the PersonX to MSMT task, it achieved a mAP of 30.2%, outperforming DFDSN-Net by 1.2%.

Table 5 reveals that in Unreal to Market and Unreal to Duke tasks, MTCF method reached the highest current results in mAP and R1/5/10 accuracy. In the Unreal to MSMT task, MTCF achieved results nearly equal to the top-performing IDM method in various metrics.

Overall, MTCF stands out in synthetic-to-real UDA re-ID tasks. Across benchmarks on both PersonX and Unreal datasets, our approach surpasses front-runners like IDM and DFDSN-Net, particularly in mAP and R1 accuracy. These comparisons emphasize the effectiveness and forefront status of MTCF.
Analyzing Table 6, we integrated the IDG module at different stages of IBN-ResNet50. For Duke to Market, the highest mAP (83.8%) was observed when IDG was inserted after the 1st stage, followed by 83.5% after the 0th stage and 83.4% after the 4th stage. Inserting IDG in the middle stages (2nd and 3rd stages) led to a slight decrease in performance, indicating that integration in the early or late stages is more beneficial. For Market to Duke, early integration of IDG showed better performance, as the mAP value decreased with deeper integration. Our default configuration is to insert IDG after the 0th stage of IBN-ResNet50, which generally produces superior results. We also integrated the RCSM module at different stages. For Duke to Market, inserting RCSM in the early or late stages achieved better results. For Market to Duke, mid-stage integration of RCSM showed better performance. Our default configuration is to insert RCSM after the 2nd stage of IBN-ResNet50.
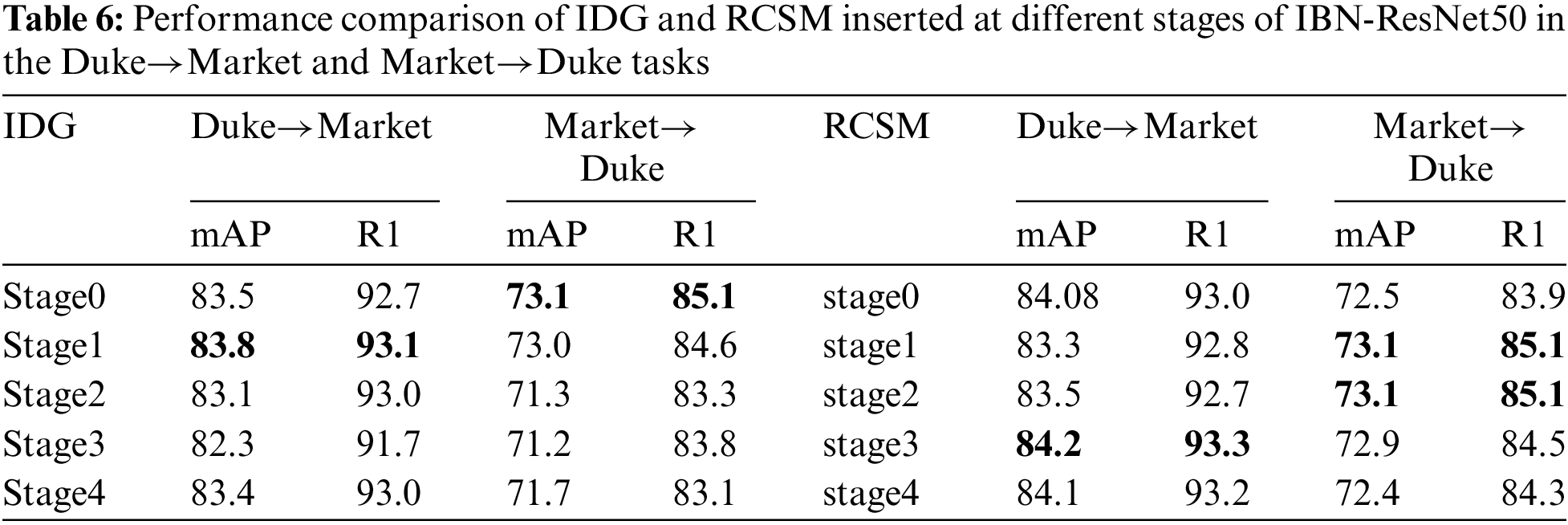
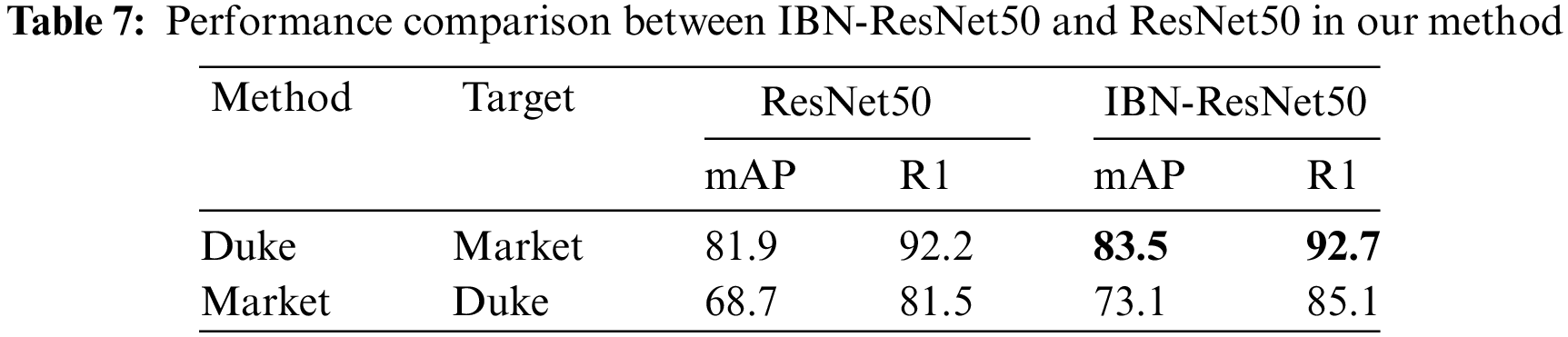
Table 7 compares our method using ResNet50 and IBN-ResNet50 architectures. The performance is generally better on the Duke to Market task than on Market to Duke. This may be attributed to Duke dataset features being more adaptable to Market conditions. IBN-ResNet50 consistently outperforms ResNet50, underscoring its enhanced domain adaptation capabilities.
Our ablation study in Table 8 evaluates the performance of our model on the Market to Duke re-ID task. The Baseline method, IBN-ResNet50+XBM with only

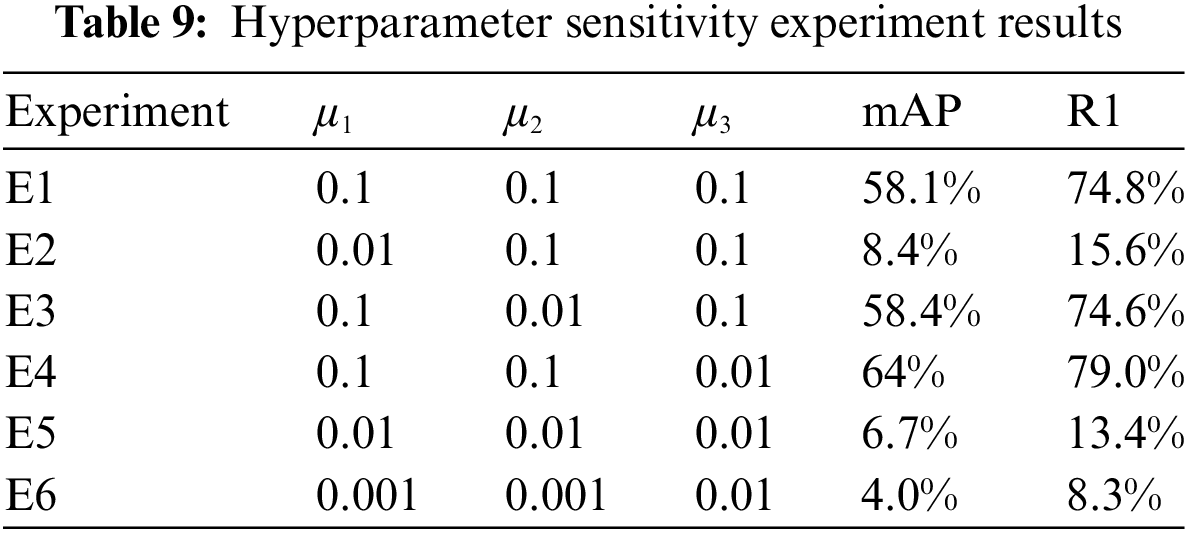
4.2.3 Hyperparameter Sensitivity Analysis
In our person re-ID framework MTCF, the three hyperparameters
4.2.4 Visualization of Model Performance
In the Market to Duke task, our method notably surpasses other models. Fig. 6 illustrates our method’s clear advantage in both mAP and R1 accuracy compared to competing technologies. In the left panel, our method achieves the highest mAP of 73.1%, while the closest competitor (CCL + PDA + FA) reaches 70.8%. In the right panel, our method achieves a Rank-1 accuracy of 85.1%, compared to 83.5% by the same competitor. This significant performance improvement highlights the effectiveness of our approach in cross-domain person re-identification tasks.
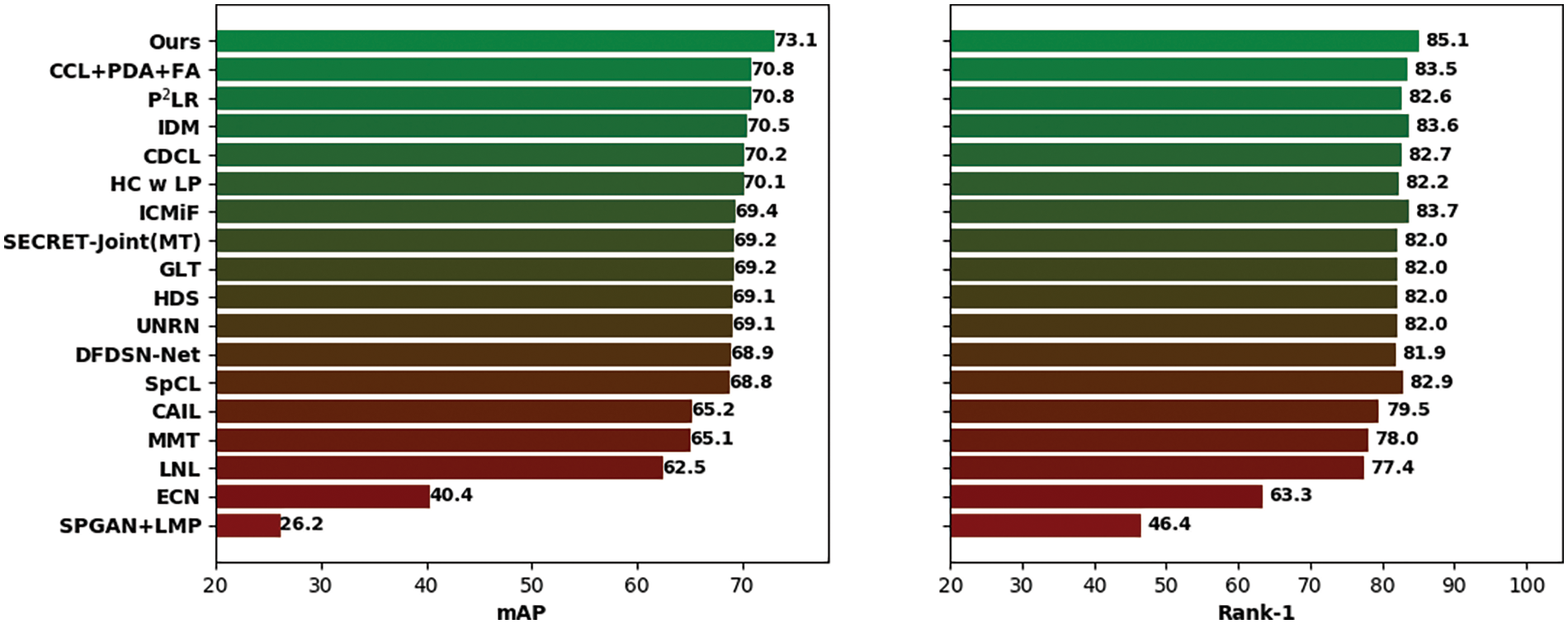
Figure 6: In the Market→Duke task, comparison of our model’s mAP and Rank-1 with baseline models
Furthermore, as shown in Fig. 7, our method consistently outperforms the Baseline in each training iteration in terms of mAP and Rank-1 accuracy, further validating our criteria for intermediate domains. Our model consists of several modules, including the Intermediate Domain Generator (IDG, approximately 0.1 K parameters), the Residual Channel Space Module (RCSM, approximately 0.6 K parameters), and the Cross-domain Feature Constraint Module (CFCM, approximately 13.0 K parameters), with a total parameter count of around 13.7 K. The synergistic operation and parameter optimization of these modules contribute to the superior performance of our method in feature extraction and cross-domain recognition tasks.
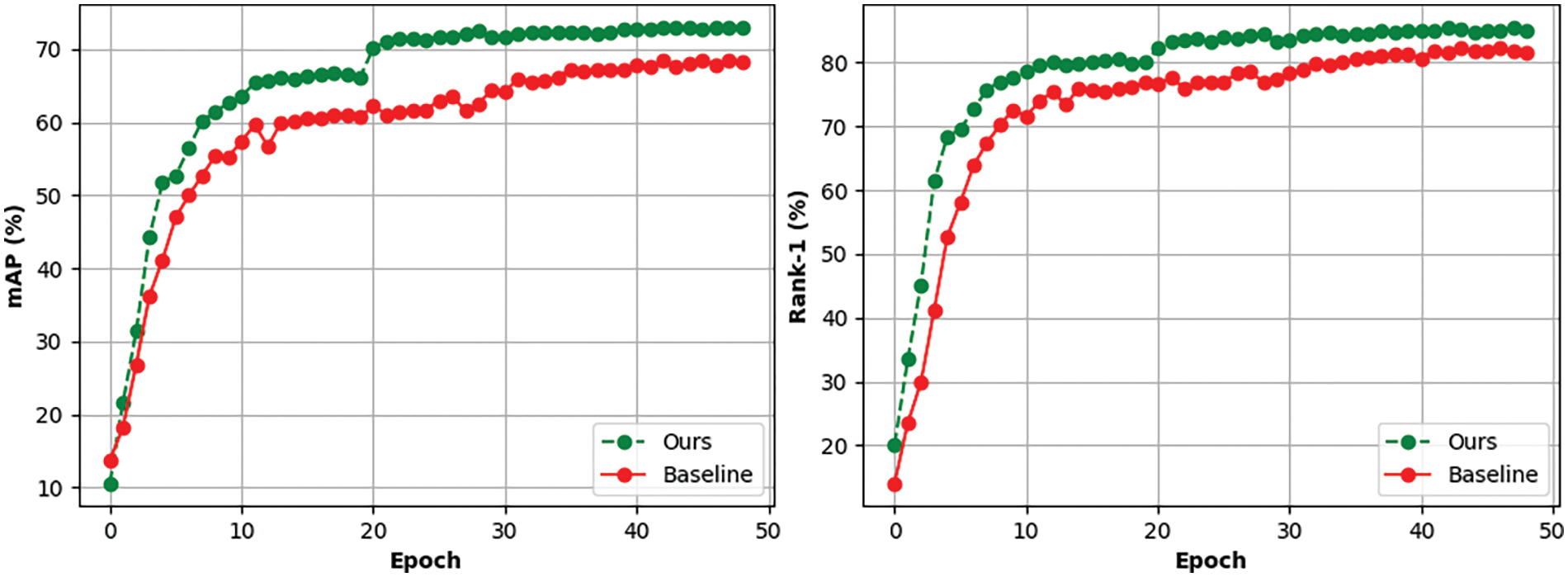
Figure 7: In the Market→Duke task, comparison of each round’s mAP and Rank-1 with baseline method
4.2.5 Visualization of Retrieval Results
For the MTCF trained on adapting from Market to Duke, we tested it using three randomly selected images and compared the retrieval results with the Baseline method, see Fig. 8. In each group, the first image is the Query image, with backbone results on the left and MTCF results on the right. Green marks indicate successful retrieval, while red marks indicate failure. Our method shows significant improvement over the Baseline in Rank-10 accuracy, with increases of 60%, 90%, and 100% in each group, respectively. Particularly, observing the third image, when encountering situations with partial occlusions and low-resolution images, our MTCF method achieves flawless person re-ID, in contrast to the Baseline method.

Figure 8: Examples of randomly selected queries in the Market-1501→DukeMTMC task and their top ten retrieval results (Green and red respectively indicate successful and failed retrieval)
Our method, the Minimal Transfer Cost Framework (MTCF), demonstrates significant advantages over baseline methods, particularly in terms of accuracy and generalization capability. The primary strengths of MTCF include its ability to generate a continuous spectrum of intermediate domains, facilitating smoother knowledge transfer between source and target domains. This is achieved through our Intermediate Domain Generator (IDG), which ensures a stable transition and minimizes feature distribution discrepancies. Additionally, the Residual Channel Spatial Module (RCSM) enhances feature extraction, especially in low-resolution images, while the Cross-domain Feature Constraint Module (CFCM) maintains feature diversity and relevance across domains.
However, MTCF is not without its limitations. One notable challenge is the training stability of GAN-based models, which can affect the overall robustness of the framework. Additionally, while our method integrates existing technologies effectively, this integration might be perceived as lacking novelty.
Our innovation lies in the strategic design of the MTCF architecture, which builds upon existing methods to surpass state-of-the-art (SOTA) results. By designing the MTCF framework, we effectively combine simple methods to achieve superior results. This strategic combination ensures that our method not only enhances performance but also provides a robust and efficient solution for unsupervised domain adaptation in person re-identification.
In our study, we define two key criteria for an appropriate intermediate domain: (1) The ability to smoothly transition to the source or target domain with minimal cost criterion. (2) Diversity within the intermediate domain’s features. We introduce the Minimal Transfer Cost Framework (MTCF) to generate all intermediate domains, ensuring smooth knowledge transfer from the source to the target domain. Within this framework, we firstly propose the Intermediate Domain Generator (IDG), which considers the full spectrum of intermediate domains, serving as both a computational unit and a facilitator of smooth knowledge transfer between the source and target domains. We also introduce the Residual Channel Spatial Module (RCSM), aimed at enhancing the model’s feature extraction capabilities and improving attention to person features in low-resolution images. Subsequently, to reduce the disparity in feature distribution across domains, we propose the Cross-domain Feature Constraint Module (CFCM), which aligns the source and target domains while maintaining feature diversity and semantic relevance. Overall, our method not only aligns with traditional transfer learning theories but also demonstrates its superior performance through extensive experiments on five datasets.
Acknowledgement: We would like to express our gratitude to the creators of the Market-1501, DukeMTMC, MSMT17, PersonX, and Unreal datasets for making these valuable resources available to the research community. These datasets have been crucial for the evaluation of our Minimal Transfer Cost Framework (MTCF). Additionally, we would like to thank the National Key Laboratory of Optical Field Manipulation Science and Technology for their hardware support, which has been instrumental in conducting our experiments.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Sheng Xu and Shixiong Xiang; data collection: Sheng Xu and Feiyu Meng; analysis and interpretation of results: Feiyu Meng and Qiang Wu; draft manuscript preparation: Sheng Xu and Qiang Wu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The additional datasets generated and analyzed during the current study are available from the corresponding author upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Z. Shi, W. Song, J. Shan, and F. Liu, “Augmented deep multi-granularity pose-aware feature fusion network for visible-infrared person re-identification,” Comput. Mater. Contin., vol. 77, no. 3, pp. 3467–3488, 2023. doi: 10.32604/cmc.2023.045849. [Google Scholar] [CrossRef]
2. C. Feng, D. Han, and C. Chen, “DTHN: Dual-transformer head end-to-end person search network,” Comput. Mater. Contin., vol. 77, no. 1, pp. 245–261, 2023. doi: 10.32604/cmc.2023.042765. [Google Scholar] [CrossRef]
3. B. Tang, X. Xu, F. Dai, and S. Wang, “Person re-identification with model-contrastive federated learning in edge-cloud environment,” Intell. Autom. Soft Comput., vol. 38, no. 1, pp. 35–55, 2023. doi: 10.32604/iasc.2023.036715. [Google Scholar] [CrossRef]
4. L. Wu, C. Shen, and A. Van Den Hengel, “Deep linear discriminant analysis on fisher networks: A hybrid architecture for person re-identification,” Pattern Recognit., vol. 65, pp. 238–250, 2017. doi: 10.1016/j.patcog.2016.12.022. [Google Scholar] [CrossRef]
5. N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” presented at the 2005 IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., San Diego, CA, USA, 2005, vol. 1, pp. 886–893. [Google Scholar]
6. X. Liu, H. Wang, Y. Wu, J. Yang, and M. -H. Yang, “An ensemble color model for human re-identification,” presented at the 2015 IEEE Winter Conf. Appl. Comput. Vis., Waikoloa, HI, USA, 2015, pp. 868–875. [Google Scholar]
7. X. Zhu, X. Zhu, M. Li, V. Murino, and S. Gong, “Intra-camera supervised person re-identification: A new benchmark,” presented at the IEEE/CVF Int. Conf. Comput. Vis. Workshops, Seoul, Republic of Korea, 2019. [Google Scholar]
8. Y. Chen, X. Zhu, and S. Gong, “Person re-identification by deep learning multi-scale representations,” presented at the IEEE Int. Conf. Comput. Vis., Venice, Italy, 2017, pp. 2590–2600. [Google Scholar]
9. H. Fan, L. Zheng, C. Yan, and Y. Yang, “Unsupervised person re-identification: Clustering and fine-tuning,” ACM Trans. Multimed. Comput. Commun. Appl., vol. 14, no. 4, pp. 1–18, 2018. doi: 10.1145/3243316. [Google Scholar] [CrossRef]
10. H. -X. Yu, W. -S. Zheng, A. Wu, X. Guo, S. Gong and J. -H. Lai, “Unsupervised person re-identification by soft multilabel learning,” presented at the IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Long Beach, CA, USA, 2019, pp. 2148–2157. [Google Scholar]
11. S. S. Raj, M. V. Prasad, and R. Balakrishnan, “Spatial segment-aware clustering based dynamic reliability threshold determination (SSC-DRTD) for unsupervised person re-identification,” Expert Syst. Appl., vol. 170, 2021, Art. no. 114502. doi: 10.1016/j.eswa.2020.114502. [Google Scholar] [CrossRef]
12. X. Lin, P. Ren, C. -H. Yeh, L. Yao, A. Song, and X. Chang, “Unsupervised person re-identification: A systematic survey of challenges and solutions,” arXiv preprint arXiv:2109.06057, 2021. [Google Scholar]
13. R. Delussu, L. Putzu, and G. Fumera, “Human-in-the-loop cross-domain person re-identification,” Expert Syst. Appl., vol. 226, 2023, Art. no. 120216. doi: 10.1016/j.eswa.2023.120216. [Google Scholar] [CrossRef]
14. L. He and W. Liu, “Guided saliency feature learning for person re-identification in crowded scenes,” presented at the Eur. Conf. Comput. Vis., Glasgow, UK, 2020, vol. 16, pp. 357–373. [Google Scholar]
15. K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Omni-scale feature learning for person re-identification,” presented at the IEEE/CVF Int. Conf. Comput. Vis., Seoul, Republic of Korea, 2019, pp. 3702–3712. [Google Scholar]
16. R. Zhao, W. Ouyang, and X. Wang, “Unsupervised salience learning for person re-identification,” presented at the IEEE Conf. Comput. Vis. Pattern Recognit., Portland, OR, USA, 2013, pp. 3586–3593. [Google Scholar]
17. Y. Yang, J. Yang, J. Yan, S. Liao, D. Yi and S. Z. Li, “Salient color names for person re-identification,” presented at the Eur. Conf. Comput. Vis., Zurich, Switzerland, 2014, vol. 13, pp. 536–551. [Google Scholar]
18. S. Liao, Y. Hu, X. Zhu, and S. Z. Li, “Person re-identification by local maximal occurrence representation and metric learning,” presented at the IEEE Conf. Comput. Vis. Pattern Recognit., Boston, MA, USA, 2015, pp. 2197–2206. [Google Scholar]
19. G. Wu, X. Zhu, and S. Gong, “Learning hybrid ranking representation for person re-identification,” Pattern Recognit., vol. 121, 2022, Art. no. 108239. doi: 10.1016/j.patcog.2021.108239. [Google Scholar] [CrossRef]
20. H. Fu, K. Zhang, and J. Wang, “An adaptive self-correction joint training framework for person re-identification with noisy labels,” Expert Syst. Appl., vol. 238, 2024, Art. no. 121771. doi: 10.1016/j.eswa.2023.121771. [Google Scholar] [CrossRef]
21. Y. Fu, Y. Wei, G. Wang, Y. Zhou, H. Shi and T. S. Huang, “Self-similarity grouping: A simple unsupervised cross domain adaptation approach for person re-identification,” presented at the IEEE/CVF Int. Conf. Comput. Vis., Seoul, Republic of Korea, 2019, pp. 6112–6121. [Google Scholar]
22. F. Zhao, S. Liao, G. -S. Xie, J. Zhao, K. Zhang and L. Shao, “Unsupervised domain adaptation with noise resistible mutual-training for person re-identification,” presented at the Eur. Conf. Comput. Vis., Glasgow, UK, 2020, vol. 16, pp. 526–544. [Google Scholar]
23. Y. Zhai et al., “Ad-cluster: Augmented discriminative clustering for domain adaptive person re-identification,” presented at the IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Seattle, WA, USA, 2020, pp. 9021–9030. [Google Scholar]
24. H. Sun, M. Li, and C. -G. Li, “Hybrid contrastive learning with cluster ensemble for unsupervised person re-identification,” presented at the Asian Conf. Pattern Recognit., New Delhi, India, 2021, pp. 532–546. [Google Scholar]
25. X. Jin et al., “Meta clustering learning for large-scale unsupervised person re-identification,” presented at the 30th ACM Int. Conf. Multimed., Nice, France, 2022, pp. 2163–2172. [Google Scholar]
26. X. Li, Q. Li, W. Xue, Y. Liu, F. Liang and W. Wang, “Confidence-adapted meta-interaction for unsupervised person re-identification,” Appl. Intell., vol. 53, no. 21, pp. 25525–25542, 2023. doi: 10.1007/s10489-023-04863-3. [Google Scholar] [CrossRef]
27. W. Zhang, L. Huang, Z. Wei, and J. Nie, “Appearance feature enhancement for person re-identification,” Expert Syst. Appl., vol. 163, 2021, Art. no. 113771. doi: 10.1016/j.eswa.2020.113771. [Google Scholar] [CrossRef]
28. Z. Zheng, L. Zheng, and Y. Yang, “Unlabeled samples generated by GAN improve the person re-identification baseline in vitro,” presented at the IEEE Int. Conf. Comput. Vis., Venice, Italy, 2017, pp. 3754–3762. [Google Scholar]
29. L. Wei, S. Zhang, W. Gao, and Q. Tian, “Person transfer GAN to bridge domain gap for person re-identification,” presented at the IEEE Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA, 2018, pp. 79–88. [Google Scholar]
30. W. Deng, L. Zheng, Q. Ye, G. Kang, Y. Yang and J. Jiao, “Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification,” presented at the IEEE Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA, 2018, pp. 994–1003. [Google Scholar]
31. H. Chen, Y. Wang, B. Lagadec, A. Dantcheva, and F. Bremond, “Joint generative and contrastive learning for unsupervised person re-identification,” presented at the IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Nashville, TN, USA, 2021, pp. 2004–2013. [Google Scholar]
32. C. Dai, C. Peng, and M. Chen, “Selective transfer cycle GAN for unsupervised person re-identification,” Multimed. Tools Appl., vol. 79, no. 17, pp. 12597–12613, 2020. doi: 10.1007/s11042-019-08604-y. [Google Scholar] [CrossRef]
33. F. Yang, Z. Zhong, Z. Luo, S. Lian, and S. Li, “Leveraging virtual and real person for unsupervised person re-identification,” IEEE Trans. Multimed., vol. 22, no. 9, pp. 2444–2453, 2019. doi: 10.1109/TMM.2019.2957928. [Google Scholar] [CrossRef]
34. L. Ma, Q. Sun, S. Georgoulis, L. Van Gool, B. Schiele and M. Fritz, “Disentangled person image generation,” presented at the IEEE Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA, 2018, pp. 99–108. [Google Scholar]
35. Y. Choi, M. Choi, M. Kim, J. -W. Ha, S. Kim and J. Choo, “StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation,” presented at the IEEE Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA, 2018, pp. 8789–8797. [Google Scholar]
36. Z. Zhong, L. Zheng, Z. Zheng, S. Li, and Y. Yang, “CamStyle: A novel data augmentation method for person re-identification,” IEEE Trans. Image Process., vol. 28, no. 3, pp. 1176–1190, 2018. doi: 10.1109/TIP.2018.2874313. [Google Scholar] [PubMed] [CrossRef]
37. Y. Dai, J. Liu, Y. Sun, Z. Tong, C. Zhang and L. -Y. Duan, “IDM: An intermediate domain module for domain adaptive person re-ID,” presented at the IEEE/CVF Int. Conf. Comput. Vis., Montreal, QC, Canada, 2021, pp. 11864–11874. [Google Scholar]
38. Y. Dai, Y. Sun, J. Liu, Z. Tong, Y. Yang L. -Y. Duan, “Bridging the source-to-target gap for cross-domain person re-identification with intermediate domains,” arXiv preprint arXiv:2203.01682, 2022. [Google Scholar]
39. J. Na, D. Han, H. J. Chang, and W. Hwang, “Contrastive vicinal space for unsupervised domain adaptation,” presented at the Eur. Conf. Comput. Vis., Munich, Germany, 2022, pp. 92–110. [Google Scholar]
40. H. Du, L. He, P. Liu, and X. Hao, “Inter-domain fusion and intra-domain style normalization network for unsupervised domain adaptive person re-identification,” Digit. Signal Process., vol. 133, 2023, Art. no. 103848. doi: 10.1016/j.dsp.2022.103848. [Google Scholar] [CrossRef]
41. K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” presented at the IEEE Conf. Comput. Vis. Pattern Recognit., Las Vegas, NV, USA, 2016, pp. 770–778. [Google Scholar]
42. P. Wei, C. Zhang, Y. Tang, Z. Li, and Z. Wang, “Reinforced domain adaptation with attention and adversarial learning for unsupervised person re-ID,” Appl. Intell., vol. 53, no. 4, pp. 4109–4123, 2023. doi: 10.1007/s10489-022-03640-y. [Google Scholar] [CrossRef]
43. T. Shen and H. Xu, “Facial expression recognition based on multi-channel attention residual network,” Comput. Model. Eng. Sci., vol. 135, no. 1, pp. 539–560, 2023. doi: 10.32604/cmes.2022.022312. [Google Scholar] [CrossRef]
44. P. Chen, T. Jia, P. Wu, J. Wu, and D. Chen, “Learning deep representations by mutual information for person re-identification,” arXiv preprint arXiv:1908.05860, 2019. [Google Scholar]
45. C. Jambigi, R. Rawal, and A. Chakraborty, “MMD-reID: A simple but effective solution for visible-thermal person reid,” arXiv preprint arXiv:2111.05059, 2021. [Google Scholar]
46. L. Zheng, L. Shen, L. Tian, S. Wang, J. Wang and Q. Tian, “Scalable person re-identification: A bench-mark,” in Proc. IEEE Int. Conf. Comput. Vis., 2015, pp. 1116–1124. [Google Scholar]
47. E. Ristani, F. Solera, R. Zou, R. Cucchiara, and C. Tomasi, “Performance measures and a data set for multi-target, multi-camera tracking,” in Eur. Conf. Comput. Vis., Springer, 2016, pp. 17–35. [Google Scholar]
48. X. Sun and L. Zheng, “Dissecting person re-identification from the viewpoint of viewpoint,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2019, pp. 608–617. [Google Scholar]
49. T. Zhang et al., “UnrealPerson: An adaptive pipeline towards costless person re-identification,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 11506–11515. [Google Scholar]
50. Z. Zhong, L. Zheng, Z. Luo, S. Li, and Y. Yang, “Invariance matters: Exemplar memory for domain adaptive person re-identification,” presented at the IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Long Beach, CA, USA, 2019, pp. 598–607. [Google Scholar]
51. C. Luo, C. Song, and Z. Zhang, “Generalizing person re-identification by camera-aware invariance learning and cross-domain mixup,” presented at the Eur. Conf. Comput. Vis., Glasgow, UK, 2020, vol. 16, pp. 224–241. [Google Scholar]
52. Y. Ge, D. Chen, and H. Li, “Mutual mean-teaching: Pseudo label refinery for unsupervised domain adaptation on person re-identification,” arXiv preprint arXiv:2001.01526, 2020. [Google Scholar]
53. Y. Ge et al., “Self-paced contrastive learning with hybrid memory for domain adaptive object re-ID,” Adv. Neural Inf. Process. Syst., vol. 33, pp. 11309–11321, 2020. [Google Scholar]
54. X. Zhu, Y. Li, J. Sun, H. Chen, and J. Zhu, “Learning with noisy labels method for unsupervised domain adaptive person re-identification,” Neurocomputing, vol. 452, pp. 78–88, 2021. doi: 10.1016/j.neucom.2021.04.120. [Google Scholar] [CrossRef]
55. Y. Zheng et al., “Online pseudo label generation by hierarchical cluster dynamics for adaptive person re-identification,” presented at the IEEE/CVF Int. Conf. Comput. Vis., Montreal, QC, Canada, 2021, pp. 8371–8381. [Google Scholar]
56. T. Isobe, D. Li, L. Tian, W. Chen, Y. Shan and S. Wang, “Towards discriminative representation learning for unsupervised person re-identification,” presented at the IEEE/CVF Int. Conf. Comput. Vis., Montreal, QC, Canada, 2021, pp. 8526–8536. [Google Scholar]
57. K. Zheng, C. Lan, W. Zeng, Z. Zhang, and Z. -J. Zha, “Exploiting sample uncertainty for domain adaptive person re-identification,” presented at the AAAI Conf. Artif. Intell., Vancouver, BC, Canada, 2021, vol. 35, pp. 3538–3546. [Google Scholar]
58. K. Zheng, W. Liu, L. He, T. Mei, J. Luo and Z. -J. Zha, “Group-aware label transfer for domain adaptive person re-identification,” presented at the IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Nashville, TN, USA, 2021, pp. 5310–5319. [Google Scholar]
59. J. Huang, H. Ge, L. Sun, Y. Hou, and X. Wang, “ICMiF: Interactive cascade microformers for cross-domain person re-identification,” Inf. Sci., vol. 617, pp. 177–192, 2022. doi: 10.1016/j.ins.2022.10.106. [Google Scholar] [CrossRef]
60. D. Zheng, J. Xiao, Y. Wei, Q. Wang, K. Huang and Y. Zhao, “Unsupervised domain adaptation in homogeneous distance space for person re-identification,” Pattern Recognit., vol. 132, 2022, Art. no. 108941. doi: 10.1016/j.patcog.2022.108941. [Google Scholar] [CrossRef]
61. J. Han, Y. -L. Li, and S. Wang, “Delving into probabilistic uncertainty for unsupervised domain adaptive person re-identification,” presented at the AAAI Conf. Artif. Intell., Vancouver, BC, Canada, 2022, vol. 36, pp. 790–798. [Google Scholar]
62. T. He, L. Shen, Y. Guo, G. Ding, and Z. Guo, “Secret: Self-consistent pseudo label refinement for unsupervised domain adaptive person re-identification,” presented at the AAAI Conf. Artif. Intell., Vancouver, BC, Canada, 2022, vol. 36, pp. 879–887. [Google Scholar]
63. Q. Tian and J. Sun, “Cluster-based dual-branch contrastive learning for unsupervised domain adaptation person re-identification,” Knowl.-Based Syst., vol. 280, 2023, Art. no. 111026. doi: 10.1016/j.knosys.2023.111026. [Google Scholar] [CrossRef]
64. B. Zhang et al., “A domain generalized person re-identification algorithm based on meta-bond domain alignment,” J. Vis. Commun. Image Rep., vol. 98, 2024, Art. no. 104054. doi: 10.1016/j.jvcir.2024.104054. [Google Scholar] [CrossRef]
65. X. Qu, L. Liu, L. Zhu, L. Nie, and H. Zhang, “Source-free style-diversity adversarial domain adaptation with privacy-preservation for person re-identification,” Knowl.-Based Syst., vol. 283, 2024, Art. no. 111150. doi: 10.1016/j.knosys.2023.111150. [Google Scholar] [CrossRef]
66. J. Li and S. Zhang, “Joint visual and temporal consistency for unsupervised domain adaptive person re-identification,” presented at the Eur. Conf. Comput. Vis., Glasgow, UK, 2020, vol. 16, pp. 483–499. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools