
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Improving Robustness for Tag Recommendation via Self-Paced Adversarial Metric Learning
1 School of Automation and Electrical Engineering, Zhejiang University of Science and Technology, Hangzhou, 310023, China
2 Bingwu (Ningbo) Intelligent Equipment Co., Ltd., Ningbo, 315600, China
* Corresponding Authors: Zhengshun Fei. Email: ; Xinjian Xiang. Email:
Computers, Materials & Continua 2025, 82(3), 4237-4261. https://doi.org/10.32604/cmc.2025.059262
Received 01 October 2024; Accepted 09 December 2024; Issue published 06 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Tag recommendation systems can significantly improve the accuracy of information retrieval by recommending relevant tag sets that align with user preferences and resource characteristics. However, metric learning methods often suffer from high sensitivity, leading to unstable recommendation results when facing adversarial samples generated through malicious user behavior. Adversarial training is considered to be an effective method for improving the robustness of tag recommendation systems and addressing adversarial samples. However, it still faces the challenge of overfitting. Although curriculum learning-based adversarial training somewhat mitigates this issue, challenges still exist, such as the lack of a quantitative standard for attack intensity and catastrophic forgetting. To address these challenges, we propose a Self-Paced Adversarial Metric Learning (SPAML) method. First, we employ a metric learning model to capture the deep distance relationships between normal samples. Then, we incorporate a self-paced adversarial training model, which dynamically adjusts the weights of adversarial samples, allowing the model to progressively learn from simpler to more complex adversarial samples. Finally, we jointly optimize the metric learning loss and self-paced adversarial training loss in an adversarial manner, enhancing the robustness and performance of tag recommendation tasks. Extensive experiments on the MovieLens and LastFm datasets demonstrate that SPAML achieves F1@3 and NDCG@3 scores of 22% and 32.7% on the MovieLens dataset, and 19.4% and 29% on the LastFm dataset, respectively, outperforming the most competitive baselines. Specifically, F1@3 improves by 4.7% and 6.8%, and NDCG@3 improves by 5.0% and 6.9%, respectively.Keywords
The explosive growth of internet data has made the challenge of information overload increasingly pronounced. As a result, it has become more difficult for users to efficiently access relevant information. Recommendation systems [1,2] analyze user preferences and behaviors to provide personalized information filtering. They have become essential technologies in fields such as e-commerce, social media, and online streaming. Traditional recommendation systems mainly focus on modeling the two-dimensional relationship between users and items, utilizing collaborative filtering (CF) [3] methods to predict user interest in items to deliver personalized recommendations. To explore more complex recommendation scenarios and meet practical needs, tag recommendation systems [4,5] introduce tag data into the interactions between users and items. This creates a three-dimensional relationship among users, items, and tags. By leveraging tags to represent diverse types of content, such as products, audio, video, and images. These systems better capture the intrinsic connections between content and user preferences. This enables more personalized and efficient recommendations, especially in more complex recommendation scenarios.
Currently, most tag recommendation systems rely on tensor factorization to process high-dimensional interaction data. This technique decomposes the complex relationships among users, items, and tags into a product of multiple low-dimensional matrices, capturing latent associations and enabling personalized tag predictions. Examples of such methods include pairwise interaction tensor factorization (PITF) [6], nonlinear tensor factorization (NITF) [7], and attention-based neural tag recommendation (ABNT) [8]. In recent years, various deep learning techniques have been combined to more effectively learn and process the relationships between different entities. Graph neural network (GNN) has been successfully integrated with tensor factorization methods to extract higher-order collaborative signals among users, items, and tags. Notable examples include metapath and multi-interest aggregated graph neural network (M2GNN) [9] and attention learning tag-aware recommendation (TRAL) [10]. Tag recommendation also effectively captures diverse data structures by leveraging content features such as text, code, and sentiment information, enabling more accurate tag predictions. Representative methods include sentiment analysis matrix factorization (SAMF) [11], retrieval augmented cross-modal tag recommendation (RACM) [12], and Code-mixed representation learning for tag recommendation (CDR4Tag) [13]. Despite the success of tensor factorization in tag recommendation, its reliance on inner product for recommendation presents inherent limitations. While the inner product reduces computational complexity, it fails to satisfy the triangle inequality [14]. This leads to an inability to accurately measure the true distance among users, items, and tags. For instance, two similar users may be mapped to distant locations in the inner product space, resulting in suboptimal recommendation accuracy.
Metric learning has been widely applied in areas including image classification [15] and person re-identification [16]. In tag recommendation, to address the limitations of tensor factorization, researchers have introduced metric learning methods based on the triangle inequality principle. Metric learning computes the distance differences between entities to quantify their proximity. This ensures that the distances between users, items, and tags accurately reflect their similarity. However, metric learning in geometric space struggles with flexibility, particularly when representing highly similar samples. This can lead to overly close positioning of similar items, failing to accurately reflect user preferences. To address this limitation, methods such as latent relational metric learning (LRML) [17], hyperbolic space metric learning (HyperML) [18], multimodal attentive metric learning (MAML) [19], and collaborative residual metric learning (CoRML) [20] have been proposed. These approaches optimize the distance metrics among users, items, and tags. This allows the model to handle similar items more flexibly and reduces the occurrence of recommendation errors. The fixed margin problem in metric learning limits the model’s performance when handling complex data distributions. A small fixed margin struggles to capture intricate interactions, whereas a larger margin creates convergence difficulties. To address this issue, methods such as symmetric metric learning (SML) [21] and probabilistic metric learning with adaptive margin (PMLAM) [22] have been introduced. Metric learning excels at capturing the similarity between entities but is highly sensitive to noise. Even minor noise or perturbations can cause inaccuracies in distance calculations, affecting recommendation accuracy and limiting the robustness of metric learning in tag recommendation systems.
Metric learning models are highly vulnerable to adversarial attacks [23,24], where even minor input perturbations can lead to high-confidence mispredictions. To address this issue, various defense strategies have been proposed in recent years to improve model robustness. Adversarial training methods aim to improve model robustness by incorporating adversarial examples into the training process. These methods enhance resistance to adversarial attacks either by adding regularization terms to constrain parameter updates or by optimizing feature representations. However, a common issue in adversarial training arises when high-intensity adversarial perturbations significantly alter a sample’s features, pushing them across the model’s decision boundary. This results in the model being unable to correctly classify normal samples and adversarial samples, leading to overfitting. To address this, researchers have proposed curriculum learning-based adversarial training methods [25], where the attack intensity is gradually increased from weak to strong. This progression helps prevent high-intensity samples from crossing the decision boundary prematurely. Notable examples include curriculum adversarial training (CAT) [26], dynamic adversarial training (DAT) [27], and friendly adversarial training (FAT) [28]. Despite its potential, curriculum learning faces two significant challenges: catastrophic forgetting and the lack of a quantitative standard for adversarial sample intensity. Catastrophic forgetting occurs when models trained with high-intensity attacks fail to retain the adversarial features learned from low-intensity attacks. Additionally, the lack of a standardized way to quantify adversarial sample intensity poses a challenge. It complicates the accurate measurement of their impact during model training and evaluation.
Self-paced learning (SPL) is a learning paradigm that simulates the human cognitive process, gradually mastering sample features from simple to complex. SPL has demonstrated success in fields including fault diagnosis [29] and image clustering [30]. Building on this foundation, we propose a novel tag recommendation method, SPAML, to address the limitations of curriculum learning and enhance model robustness. SPAML leverages metric learning to precisely model the relationships among users, items, and tags. In addition to the standard metric model, we introduce a self-paced adversarial training model that quantifies the difficulty of adversarial samples based on their loss function values and dynamically adjusts their weights during training. The core of our method lies in progressively incorporating adversarial samples during training. Samples with lower loss values are prioritized, while those with higher losses are gradually introduced, ensuring that the model consistently retains knowledge from low-intensity adversarial samples, thereby mitigating the issue of catastrophic forgetting. The adversarial process involves jointly optimizing the metric learning loss and the self-paced adversarial training loss. Furthermore, we propose two weighting strategies: hard weighting scheme and soft weighting scheme, leading to two model variants: SPAML-H and SPAML-S. Experimental results demonstrate that SPAML consistently outperforms the most competitive baselines in tag recommendation tasks, validating the effectiveness of our method. In summary, our key contributions are as follows:
• SPAML introduces a novel method by combining metric learning and self-paced adversarial training. Metric learning accurately captures the distance relationships among users, items, and tags, while self-paced adversarial training effectively addresses catastrophic forgetting and compensates for the lack of a quantitative standard for attack intensity in curriculum learning-based adversarial training.
• We designed a self-paced adversarial training model that dynamically adjusts the weight of adversarial samples during training. Unlike traditional fixed adversarial training strategies, SPAML employs both hard weighting scheme and soft weighting scheme to effectively prevent overfitting to adversarial samples, thereby improving recommendation accuracy in complex environments.
• Comprehensive experiments were conducted on the MovieLens and LastFm datasets to evaluate SPAML’s performance in tag recommendation tasks. Additionally, ablation studies were performed to quantify the contribution of each component to SPAML’s overall performance. The results demonstrate that self-paced adversarial training significantly enhances the model’s adversarial robustness, particularly on the larger and more complex LastFm dataset.
Tag recommendation systems leverage tensor factorization methods to predict tag lists by utilizing interaction data among users, items, and tags. PITF [6] adopts a pairwise interaction approach, learning from both users-tags and items-tags interaction, achieving strong recommendation performance. Building on PITF, NITF [7] extends the feature space’s capacity by using gaussian radial basis functions, enhancing the model’s ability to capture nonlinear features. In contrast, ABNT [8] integrates a multilayer perceptron with an attention mechanism, enabling nonlinear modeling of entities. Additionally, SAMF [11] utilizes generating topic distributions from user and item reviews, creating user and item feature matrices, and quantifying sentiment information in reviews, which are then integrated into the users-items rating matrix to address data sparsity and trustworthiness issues. RACM [12] enhances the representation of titles, descriptions, and code by retrieving information from external knowledge sources and applying a cross-modal, context-aware mechanism for fine-grained feature extraction, thereby enhancing cross-modal retrieval and tag recommendation performance. CDR4Tag [13] employs a dual interaction strategy through code mixing to incorporate the deep semantic associations between software objects and tags into a joint representation space, enriching the semantics of software objects. M2GNN [9] constructs a heterogeneous information network using graph neural network to capture the semantic relationships among users, items, and tags, and uses a hierarchical aggregation framework to filter out irrelevant tags and interests, solving the issue of data sparsity in cross-domain recommendation. TRAL [10] generates dense tag feature vectors for users and items, and employs an attention pooling layer to automatically assign feature weights, learning nonlinear high-order interaction features to improve recommendation accuracy. While current tag recommendation methods have achieved some success in improving recommendation performance, they primarily focus on the correlations among users, items, and tags. However, these methods perform less effectively when dealing with adversarial disturbances such as malicious user inputs and noise. Therefore, enhancing the robustness of tag recommendation systems is a key focus of our research.
Metric learning methods have been extensively researched and applied in recommendation systems, effectively capturing the similarity between different entities, which provide more accurate recommendations. Among these methods, collaborative metric learning (CML) [31] was the first to apply metric learning to recommendation systems, addressing the issue that matrix factorization did not satisfy the triangle inequality. It achieves this by mapping users and items into a low-dimensional metric space, where distances represent user preferences for items. LRML [17] pointed out that CML tended to cluster similar users and items into the same point, exacerbating geometric inflexibility and limiting model performance. To solve this, LRML generates latent relation vectors using a memory attention mechanism to improve flexibility when handling similar users and items. HyperML [18] adopts hyperbolic metric learning in the Mobius rotation space to better capture the hierarchical and complex structure of users-items relationships. MAML [19] leverages the multimodal features of items and uses an attention mechanism to estimate user attention on different aspects of the item, overcoming the inflexibility limitations of CML. Moreover, CML is constrained by the fixed-margin impact on performance, particularly in highly sparse recommendation scenarios. Assigning a learnable margin hyperparameter for each user and item can improve model performance, but at a high computational cost and with a risk of overfitting. SML [21] highlighted that CML’s use of a fixed margin leads to user conflict problems, where it only considers users-items relationships and may drag negative sample items toward positive sample items, contradicting the basic assumptions of metric learning. SML addresses this by assigning different adaptive margins for each user and item, thereby learning distinct vector representations. PMLAM [22] parameterizes users and items using Gaussian distributions and generates adaptive margins for different training samples, modeling distances between users and items with the Wasserstein distance. CoRML [20] models the users-items distance residuals to learn generalized users-items distance metrics, capturing user preferences based on interaction signals. Despite the improvements in the performance of metric learning models through enhanced geometric structures and flexible margin adjustments, the robustness of these models remains limited. Our work enhances metric learning model robustness through self-paced adversarial training, ensuring the accuracy of recommendation results.
Adversarial training [23,32,33] is a critical method for mitigating the inherent vulnerabilities of deep learning models. By introducing carefully constructed, imperceptible adversarial examples into the training process, this technique significantly improves the model’s robustness. There are two main branches of adversarial training. The first introduces regularization terms into the objective function to constrain changes in model parameters, thereby enhancing robustness. For example, adversarial model perturbation (AMP) [34] minimizes loss under the worst norm constraint instead of directly minimizing empirical risk, encouraging the model to favor flatter local minima, thereby improving generalization ability. Fast adversarial training via law (FGSM-LAW) [35] combines Lipschitz regularization with automatic weight averaging to improve model robustness and prevent catastrophic overfitting. The second focuses on optimizing feature representation by adjusting the structure of the feature space to increase resistance to adversarial attacks. Feature separation and recalibration (FSR) [36] separates input feature maps into robust and non-robust features, recovering potentially useful information and significantly improving the robustness of adversarial training methods, while maintaining low computational cost. Maximum mean discrepancy adversarial autoencoder (MMD-AAE) [37] introduces maximum mean discrepancy to align distributions from different domains and matches adversarial autoencoder learning to an arbitrary prior distribution, enabling generalizable feature representation that can adapt to unseen target domains. Adversarial feature desensitization (AFD) [38] learns adversarially robust features from a domain adaptation perspective, making the learned features both predictive and robust to adversarial attacks. In addition, CAT [26] trains the model by gradually increasing the difficulty of adversarial samples, starting with weaker adversarial samples and then progressing to stronger ones, thereby reducing the overfitting problem. DAT [27] introduces a first-order stability condition to evaluate model convergence quality and dynamically adjusts the training process based on the strength of the current adversarial attack. FAT [39] employs an early-stopping mechanism to recycle gradient information during model updates, thus eliminating the computational cost of generating adversarial samples while preventing overtraining. Despite the promise of curriculum learning, it suffers from catastrophic forgetting” and the lack of a quantitative standard for attack intensity. To tackle this issue, our work introduces an adaptive pacing strategy to adjust the training process, mitigating the limitations of curriculum learning and effectively defending against diverse adversarial attacks, thereby further enhancing model robustness.
In this section, we will provide a detailed explanation of the proposed model.
As illustrated in the Fig. 1, we demonstrate the process from embedding to joint optimization using the metric learning model and the self-paced adversarial training model. The input data consisting of users, items, and tags is mapped through the embedding layer to generate low-dimensional embedding representations. In the metric learning model, we use Euclidean distance to measure the similarity between users, items, and their associated tags. By optimizing the loss function, we maximize the distance between positive and negative samples, ensuring the model accurately distinguishes the semantic relationships represented by different tags. In the self-paced adversarial training model, we apply small perturbations to the input samples using projected gradient descent (PGD) to generate adversarial samples. By calculating the distances of these adversarial samples in the embedding space, the model learns to effectively distinguish between similar yet challenging samples. The self-paced adversarial training module determines the difficulty level of adversarial samples based on their loss values and dynamically adjusts the weights of difficult samples. The model begins by training on simple adversarial samples that are easier to distinguish and gradually introduces more complex adversarial samples. This self-paced learning model, which progressively increases sample difficulty, enables the model to steadily improve its ability to fit complex adversarial samples while retaining knowledge of “simple” adversarial samples. Finally, the losses from both metric learning and self-paced adversarial training are jointly optimized in an adversarial manner, enhancing the model’s robustness and its generalization ability to unseen data.

Figure 1: The proposed framework for SPLMA
Tag recommendation aims to accurately predict the possibility of a user selecting a certain tag for an item. It includes three types of entities: the set of users
In tag recommendation, user IDs, item IDs, and tag IDs typically exist in a sparse ID format. Since these IDs do not contain numerical value information, they are not directly suitable for computations. To transform these sparse IDs into numerical representations suitable for the model, we employ an embedding technique. Specifically, the model assigns each ID a low-dimensional dense embedding vector, stored in embedding matrices. For a given user
where
The task of tag recommendation involves establishing a scoring function Y that captures the implicit feedback of users selecting tags for items. Specifically,
During the tag recommendation process, the system calculates relevance scores for all potential tags based on users-items interaction
where N represents the length of tag recommendation list.
3.1.1 Tag Recommendation Based on Metric Learning
In the specific task of tag recommendation, metric learning methods model the users-items-tags distance by calculating the distances between embedding representations to assess the relevance of tags to users and items, quantifying the similarity or dissimilarity between the two embedding representations. Therefore, the distance among users, items, and tags
At the same time, we aim to enforce the separation of the distance among users, items, and negative tags, thereby ensuring that the relationship between negative tags and users-items pairs is weaker than that of positive tags. Thus, the distance relationship
Triplet loss is a widely used metric learning method. Our goal is to ensure that in the embedding space, the distance between users and positive tags is less than that between users and negative tags, thereby enabling the model to correctly distinguish positive tags from negative tags. The objective function for triplet loss can be formulated as follows:
where
Although metric learning can effectively utilize the embedding distances among users, items, and tags to achieve good recommendation performance, solely relying on these distance relationships may lead to weak generalization of the model. The model has two main limitations:
1. Duan et al. [40] and Chen et al. [41] point out that metric learning models are highly sensitive to small perturbations or noise, which can undermine their robustness in real-world scenarios. Furthermore, Wang et al. [42] emphasized that minor fluctuations in user preferences during tag recommendation tasks can lead to variations in behavioral data, thereby impacting the embedding representations of items and tags.
2. Mao et al. [43] pointed out that metric learning models are prone to overfitting the training data. Li et al. [44] further noted that in the embedding space, if the models focuses solely on bringing the positive tags close to the users and items in the training set, while ignoring noise or outliers, their performance on the test set or new data may deteriorate.
To strengthen the robustness and generalization ability of metric learning, we introduce adversarial training into the metric learning model. By adding targeted adversarial perturbations, the model can still make accurate predictions in the presence of such perturbations. Specifically, we use the PGD method, which iteratively generates adversarial perturbations through repeated updates, ensuring that the magnitude of the perturbations remains within a limited range. This process continuously adjusts the perturbations to generate adversarial samples with higher attack strength. To improve the robustness of metric learning in modeling the relationships among users, items, and tags, we design targeted adversarial perturbations for the metric learning model. Specifically, adversarial perturbations are added to the embedding representations. After
where
After obtaining the adversarial samples, we integrate them into the metric learning model for adversarial training. The model demonstrates greater stability when exposed to adversarial inputs, thereby improving its robustness and generalization ability. To achieve this, we designed a loss function that incorporates adversarial perturbations, as described below:
where
Although adversarial training has made significant progress in enhancing the robustness of models, it still has two main limitations:
1. Cai et al. [26] and Wang et al. [45] pointed out that adversarial training often focuses on high-intensity adversarial samples, which are closer to the model’s decision boundary and more likely to contain noise. The model’s excessive attention to these high-noise samples can cause it to deviate from the normal decision boundary, negatively impacting its performance on real-world data. This phenomenon is referred to as overfitting to adversarial samples. Additionally, Cai et al. [26] noted that curriculum learning-based adversarial training alleviates overfitting to some extent, but it also introduces new challenges.
2. He et al. [46] highlighted the lack of a quantitative measure for attack intensity. Specifically, the number of iterations in the PGD directly affects the strength of the generated adversarial samples. Too few iterations result in weak perturbations that fail to adequately test the model’s robustness, whereas too many iterations increase computational costs and reduce training efficiency.
3. Cai et al. [26] further noted that adversarial training starts directly with high-intensity adversarial samples, which may lead the model to overlook simpler adversarial samples. As training progresses, the model tends to focus on more high-intensity adversarial examples, forgetting the features learned from simpler ones. This could weaken the model’s defense mechanisms when encountering low-intensity adversarial attacks.
3.2.1 Self-Paced Adversarial Training
To overcome the challenges faced by curriculum learning-based adversarial training, we propose a novel method called self-paced adversarial training [46]. This method tackles the lack of a quantitative measure for attack intensity by evaluating the difficulty of adversarial samples and dynamically adjusting weights using soft and hard weighting schemes [25], based on the adversarial training loss. This indirectly achieves a quantification of attack intensity. By assigning higher weights to simpler adversarial samples, the model initially focuses on learning from these samples, which are farther from the decision boundary and contain less noise. This facilitates the stable optimization of the decision boundary. As training progresses, more complex adversarial samples are gradually incorporated. The dynamic weight adjustment prevents the model from exclusively focusing on complex adversarial samples, thus avoiding the forgetting of features learned from simpler ones and enhancing the model’s robustness.
where M is the number of triples,
Soft weighting scheme is a continuous weighting method where the model learns from all adversarial samples while adjusts the weight of each sample based on the adversarial training loss. The soft weighting scheme formula is as follows:
where
Hard weighting scheme is a binary adversarial sample selection method where the model only trains on adversarial samples with loss values below a predefined threshold, ignoring those that do not meet the criteria. This approach is simple and efficient by enabling the model to prioritize training on easily learnable adversarial samples through an initial filtering process. The hard weighting formula is as follows:
where
The metric learning model optimizes the distances between users, items, and tags, while the self-paced adversarial training model enhances the model’s robustness by progressively increasing the difficulty of adversarial samples. To achieve this goal, we designed a joint training loss function, enabling the model to optimize both objectives during training. The joint training loss function integrates the adversarial training loss with the original metric learning loss, enhancing the model’s robustness ability and improving stability of prediction results. Therefore, the final loss function is as follows:
where
The computational complexity of the SPAML model is composed of two parts: the metric learning loss
Metric learning loss
Self-paced adversarial training loss
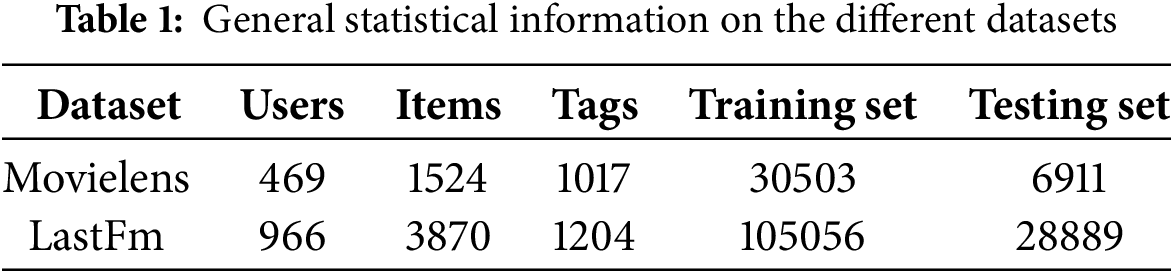
We conducted experiments using two publicly available datasets, MovieLens and LastFM, to evaluate the baselines and the proposed method. Table 1 presents the general statistical information for the different datasets.
MovieLens: A typical dataset for movie recommendation. In this dataset, users’ tagging behavior towards movies reveals users’ interests and preferences for movies, which is valuable for researching and evaluating recommendation methods in the movie recommendation field.
LastFM: A dataset in the domain of music recommendation and music information retrieval. By analyzing the tags assigned to music by users, it helps to understand users’ interests and preferences, providing valuable information for music recommendation.
The MovieLens dataset can be downloaded from https://grouplens.org (accessed on 08 December 2024), and the LastFM dataset from http://www.last.fm (accessed on 08 December 2024). Given the differences in scale and sparsity between these two datasets, we performed preprocessing to extract a core subset of interaction data, specifically obtaining a p-core for each dataset. In both MovieLens and LastFM, interaction data among users, items, and tags is typically sparse. To ensure sufficient interactions between users, items, and tags, we adopted the 10-core dataset, where each user, item, and tag must appear at least 10 times. For testing, the last interaction of each user with an item using a tag was used as the testing set, while the remaining interactions served as the training set. This preprocessing step ensures a fair and consistent evaluation of different methods under the same conditions. In comparison, 5-core or 3-core datasets result in sparser user-item-tag interactions, which limits the model’s ability to capture meaningful relationships. Similarly, the original datasets are even more sparse, containing a large proportion of low-quality interactions that degrade model training and increase computational overhead. Therefore, the 10-core dataset strikes a balance between data density and volume, facilitating effective and reliable evaluations. We employed F1@N and NDCG@N as evaluation metrics to assess performance of various baseline methods and our proposed approach.
We evaluated the effectiveness of our proposed method by comparing it with the following baseline methods:
CF [3]: Utilizes matrix factorization to convert the users-tags interactions into low-rank vector inner products for similarity prediction.
PITF [6]: Models the interaction between users-tags and items-tags relationships, predicting scores through inner product operations.
NITF [7]: Introduces the Gaussian radial basis function, expanding the feature space capacity and enhancing the model’s ability to capture nonlinear features.
ABNT [8]: Leverages fully connected networks and attention mechanisms to capture complex nonlinear relationships among users, items, and tags, thus providing the model with stronger feature extraction capabilities.
CML [31]: Adopts metric learning to model the distance relationships between user-tags and item-tags.
SML [21]: Introduces adaptive margin to dynamically adjust the distances between entities, improving the model’s flexibility and robustness.
LRML [17]: Generates latent relation vectors through memory attention mechanisms, enhancing the model’s ability to capture deep relationships.
AML [41]: Enhances model robustness by adding adversarial perturbations and optimizes model parameters to reduce overfitting.
ATHN [47]: Improves model stability and prediction accuracy in diverse datasets by generating hard samples and adopting the adversarial learning method.
We assess the recommendation quality of all methods in the experiment using F1@N and NDCG@N, which are standard metrics commonly employed in the recommendation field.
where
All baseline methods are implemented on the Tensorflow 1.15 framework using NVIDIA GeForce RTX 3090 GPU, The hyperparameters are set according to the best-reported values in the respective literature. The learning rate is set to 0.001, and the embedding dimension
The experimental results on the LastFm and Movielens datasets are presented in Tables 2 and 3.


The CF method, which predicts similarities by converting the users-tags matrices into low-rank vector inner products, shows relatively weak performance. Compared to tensor decomposition-based methods (PITF, NITF, and ABNT), PITF calculates similarities between users-tags and items-tags through inner products. However, it does not satisfy the triangular inequality and neglects distance metrics, limiting its effectiveness. NITF improves over PITF by expanding the feature space using Gaussian radial basis functions. ABNT further enhances this by utilizing fully connected networks and attention mechanisms to model nonlinear relationships between users and items. Nevertheless, due to its reliance on a large number of parameters, ABNT’s performance in recommendation tasks remains suboptimal. In comparison, the proposed SPMLA-H and SPMLA-S methods exhibit superior results. Specifically, on the Movielens dataset, SPMLA-H improves F1@3 and NDCG@3 by 2.1% and 3.0% over PITF, respectively, while SPMLA-S shows even greater improvements, with 3.1% and 2.9% increases in the same metrics. Compared to the tensor decomposition-based optimal baseline method (NIFT), the F1@3 scores increased by 5.7% and 11.7%, respectively. SPMLA also demonstrates remarkable performance on the LastFm dataset. These results indicate that the proposed method significantly enhances recommendation accuracy by more effectively capturing the similarity relationships among users, items, and tags.
Compared to metric learning-based methods (CML, LRML, and SML), CML models the relationships between users-tags and items-tags through distance metrics. LRML enhances CML by introducing a memory attention mechanism to generate latent relation vectors, while SMT establishes adaptive margins to adjust entity distances. metric learning methods effectively address the limitations of PITF by using distance metrics, thereby improving recommendation accuracy. SPMLA-H improved by 4.8% and 4.2% in F1@3 and NDCG@3, respectively, over CML on the Movielens dataset, while SPMLA-S improved by 5.7% and 4.2%. Compared to metric learning-based optimal baseline method (CML), the F1@3 scores increased by 5.7% and 6.9%, respectively. The proposed method incorporates an adversarial training mechanism into metric learning models, generating adversarial samples to improve the model’s robustness and generalization ability in noisy data and adversarial attack scenarios. Experimental results demonstrate that traditional metric learning methods, lacking adversarial training, perform poorly in complex environments. Experiments on the LastFM dataset further validate that adversarial training significantly enhances the model’s robustness and adaptability, particularly in handling noisy data and adversarial scenarios, showing clear advantages in managing complex data environments.
Compared to adversarial learning-based methods (AML and ATHN), AML enhances model robustness by introducing adversarial perturbations, which force the model to strengthen its defense mechanisms. However, its adversarial training strategy remains relatively simplistic. ATHN focuses on improving feature extraction through adversarial training by generating hard negative samples, though it primarily emphasizes feature extraction rather than broader adversarial methods. On the LastFm and Movielens datasets, compared to adversarial learning-based method (ATHN), the F1@3 scores increased by 2.9% and 1.6%, respectively. The proposed method employs self-paced adversarial training strategy that dynamically adjusts the weight distribution of adversarial samples during training, achieving quantitative control over attack intensity. This strategy progressively adapts to adversarial samples of varying difficulty, effectively preventing the model from forgetting the features of simpler adversarial samples while focusing solely on complex ones. It also enhances the model’s robustness against strong adversarial attacks and reduces the risk of overfitting. Consequently, SPAML demonstrates outstanding recommendation performance and stability when handling diverse and challenging adversarial samples. Furthermore, a comparison between the two weighting schemes, SPAML-H and SPAML-S, indicates that the soft weighting scheme in SPAML-S considers additional factors during training, enabling more refined and efficient adaptability.
This section analyzes the effect of hyperparameters on model performance, with a focus on the parameters
For the soft weighting scheme, we fine-tuned two key parameters:

Figure 2: Effect of

Figure 3: Effect of
For the hard weighting scheme, the primary optimized parameter is

Figure 4: Effect of
Compared with the soft weighting scheme and hard weighting scheme, we observed that the soft weighting scheme allowed the model to achieve a better balance between exploring diverse samples and focusing on more complex ones. This smooth transition from simple to complex samples helped enhance final recommendation accuracy. On the other hand, the hard weighting scheme, with its more aggressive sample selection, facilitated faster model convergence.
To verify the effectiveness of the proposed method, we conducted ablation experiments to evaluate the effect of different components of SPAML-H and SPAML-S on model performance as shown in Table 4, focusing particularly on the role of the self-paced adversarial training module.

The ablation study shows the effectiveness of each component of the proposed method and its contributions to recommendation performance. Relying solely on metric learning to compute the distances between users, items, and tags is insufficient for handling adversarial samples due to its lack of robustness against perturbations. The introduction of adversarial training significantly enhances the model’s robustness, allowing it to maintain high recommendation quality under complex scenarios. Furthermore, SPAML-H and SPAML-S, which integrate the self-paced adversarial training strategy, further improve the model’s ability to handle both simple and complex adversarial samples. Notably, SPAML-S, employing a soft weighting scheme, achieves the best performance, underscoring the effectiveness of dynamic weight adjustment during training. These findings confirm that the self-paced adversarial training strategy is critical for improving both the robustness and the effectiveness of the proposed method.
4.8 Effectiveness in Adversarial Training
To evaluate the performance of the proposed method under varying types of attacks and attack parameters. Systematic experiments were conducted on the MovieLens and LastFm datasets using SPAML-H and SPAML-S. The best-performing metrics are highlighted in bold, while the second-best metrics are underlined in Table 5.

The experimental results demonstrate the effectiveness of the proposed method in enhancing model performance under various adversarial attack types and parameters. On the MovieLens and LastFm datasets, the PGD adversarial training method achieves outstanding results in terms of F1@3 and NDCG@3 metrics, showcasing its ability to counter complex adversarial samples. In comparison, the FGSM adversarial training method delivers relatively average performance, indicating its limited capability in handling high-intensity attacks. FreeLB and MIM adversarial training methods exhibit consistently stable performance across diverse settings, further validating their general adaptability. Notably, SPAML-S consistently outperforms SPAML-H across all attack methods and parameter configurations. This result highlights the effectiveness of the soft weighting strategy in SPAML-S, enabling it to adapt dynamically to adversarial sample maintaining superior performance. Overall, these findings confirm that the proposed adaptive adversarial training strategy significantly enhances both the robustness of the model in diverse and challenging scenarios.
4.9 Effect of Different Embedding Dimensions
We explored the effect of different embedding dimensions
Figure 5: Effect of embedding dimensions on recommendation performance
We further analyzed the sensitivity of the SPMLA-H and SPMLA-S models to different embedding dimensions. The results clearly indicate that as
4.10 Effect of Different Iterations
To evaluate the robustness of the proposed SPAML-H and SPAML-S methods during training, we tested the performance of all methods across different iteration cycles while keeping other parameters at their optimal values. The results are presented in Fig. 6.
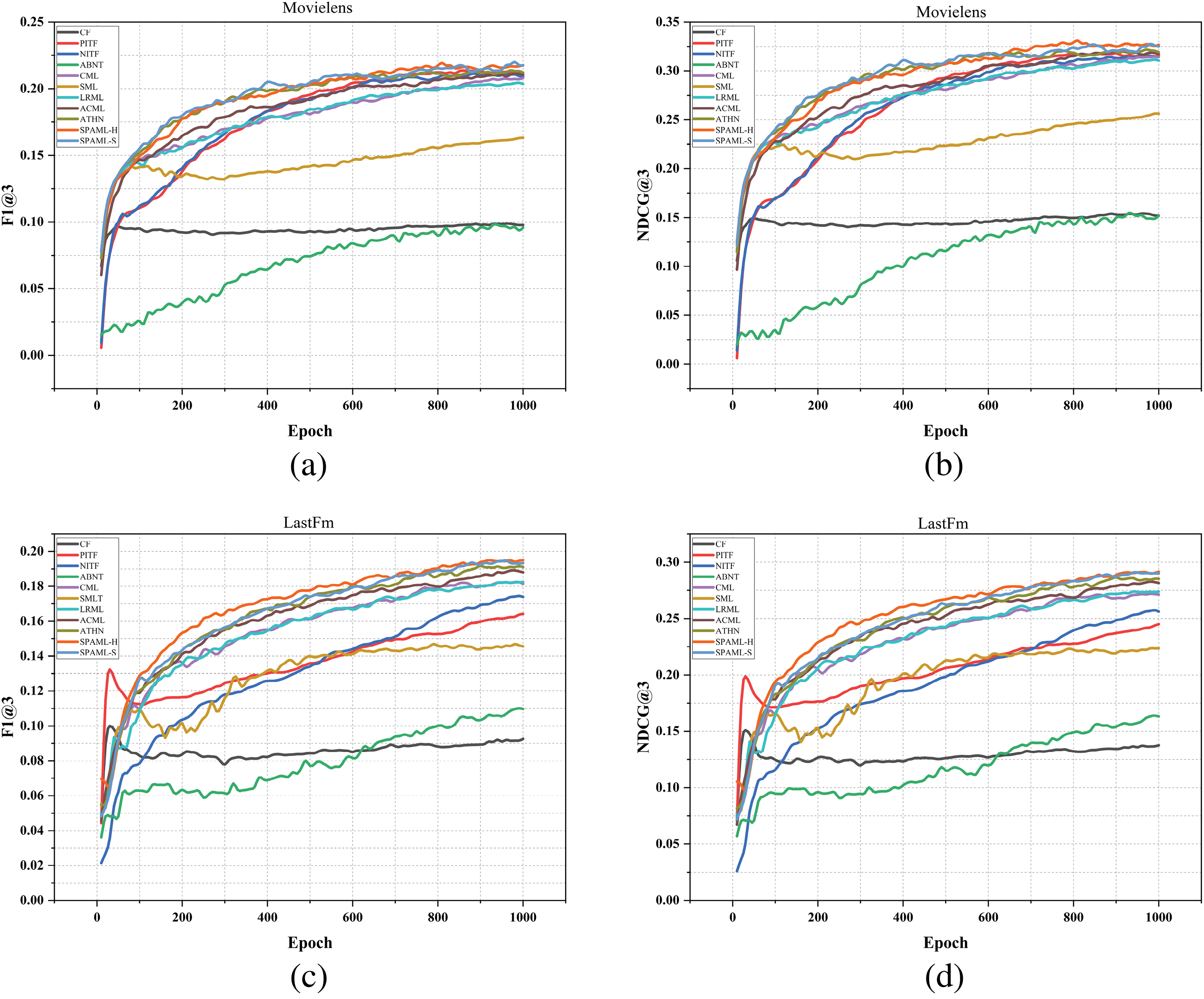
Figure 6: Effect of different iterations on recommendation performance
Compared to other baseline methods, SPAML-H and SPAML-S consistently demonstrate superior performance across each iteration. On both datasets, the training process for F1@3 and NDCG@3 metrics is notably more stable, which suggests that self-paced adversarial training significantly enhances the robustness of the metric learning model. By continually optimizing the model through adversarial training, more stable and reliable prediction results are achieved, even as iterations increase.
4.11 Evaluation of Model Robustness with and without Attacks
Tag recommendation systems in real-world applications often encounter unpredictable noise and adversarial perturbations. To evaluate the robustness of the proposed method, experiments were conducted under two scenarios: no-attack and attack. In the no-attack scenario, the dataset remains unchanged. In the attack scenario, random tag replacements simulate adversarial or noisy conditions with three levels of attack intensity: low (10% perturbed), medium (20%), and high (30%).
The experimental results in Table 6 provide a comprehensive evaluation of the model’s robustness under no-attack and varying attack scenarios. On the original dataset, the model achieves high F1 and NDCG scores on both MovieLens and LastFm datasets, showcasing its ability to capture intrinsic data features and provide reliable recommendations without external disturbances. Under low-intensity attacks, the model’s performance slightly decreases but remains robust, demonstrating strong resistance to minor adversarial perturbations. For medium-intensity attacks, the model shows moderate performance degradation, yet it continues to deliver satisfactory recommendations. Notably, under high-intensity attacks, the model maintains a stable performance, particularly with the SPAML-S variant outperforming SPAML-H, indicating its enhanced resistance in highly challenging scenarios. These results confirm the critical role of the proposed adaptive adversarial training strategy in mitigating the impact of adversarial perturbations, thereby enhancing both robustness and stability across diverse scenarios.

The traditional tag recommendation methods primarily rely on inner product to model the similarity relationships between users, items, and tags. However, the inner product does not satisfy the triangle inequality, leading to suboptimal recommendation performance. In contrast, SPAML improves recommendation quality and accuracy by using distance metrics, replacing the inner product with distance to model the relationships between users, items, and tags. While metric learning-based tag recommendation methods perform well in capturing the distance similarity between items and users, they are vulnerable to noisy data. These methods often struggle to extract deep information from the data, resulting in poor generalization ability and robustness. In contrast, SPAML combines self-paced adversarial training, which enhances the method’s robustness in handling noisy data and adversarial attacks. Adversarially trained tag recommendation methods typically use a fixed adversarial training strategy, which may lead to overfitting or difficulty in adapting to diverse adversarial perturbations. In contrast, SPAML’s self-paced adversarial training mechanism dynamically adjusts the weight of adversarial samples, effectively handling adversarial examples of varying complexity.
The practical significance of SPAML lies in its benefits for users, businesses, and recommendation systems. For users, the proposed method reduces the errors in recommendations caused by highly similar tags, thereby improving recommendation accuracy and enhancing user satisfaction and experience. For businesses, the method effectively mitigates the impact of malicious inputs or noise, providing reliable product-related tags to users and ensuring the stability and reliability of recommendation results. This, in turn, increases user retention and revenue. For recommendation systems, the method offers new insights into handling recommendation scenarios with noisy data and adversarial attacks. The proposed algorithm demonstrates a certain level of generalizability and can be effectively applied to the Delicious dataset. Delicious is a social bookmarking dataset containing users’ tag annotations for web. Its structure is highly similar to that of the MovieLens and LastFM datasets, as all three include interaction information among users, items, and tags. Future research could focus on optimizing the model’s computational efficiency, developing lightweight adversarial training mechanisms, or more efficient adversarial sample selection strategies to accommodate real-time deployment in large-scale systems.
In this paper, we propose SPAML, a self-paced adversarial metric learning method. SPAML captures deep distance relationships between normal samples and dynamically adjusts the weights of adversarial samples using hard and soft weighting schemes, enabling a gradual progression from simple to complex adversarial examples. The joint optimization of the metric learning and self-paced adversarial training loss functions fosters robust defenses and stable predictions, enhancing performance in tag recommendation tasks. Compared to traditional adversarial training methods, SPAML not only improves adversarial robustness but also enhances generalization, reducing overfitting. However, it has certain limitations in terms of training complexity and stability. The generation and selection of adversarial samples introduce additional complexity during training. Furthermore, adversarial training increases computational overhead, especially on high-dimensional and sparse datasets typical of recommendation systems, resulting in longer training times and higher computational costs.
Future research could focus on optimizing adversarial sample generation mechanisms, improving training efficiency, and exploring the model’s performance in more complex scenarios. The application of hyperbolic space in recommendation systems has shown significant potential. Constructing hyperbolic distance models among users, items, and tags, and investigating the application of adaptive adversarial training in this geometric structure could further enhance model performance and adaptability.
Acknowledgement: The authors would like to thank all the reviewers who participated in the review.
Funding Statement: This work was partially supported by the Key Research and Development Program of Zhejiang Province (No. 2024C01071), the Natural Science Foundation of Zhejiang Province (No. LQ15F030006).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Zhengshun Fei, Jianxin Chen; data collection: Gui Chen; analysis and interpretation of results: Xinjian Xiang; draft manuscript preparation: Zhengshun Fei, Jianxin Chen, Gui Chen, Xinjian Xiang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: All data and code generated and used in this study are available upon reasonable request from the corresponding author. Our study is clearly documented and accessible for replication by others.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Ko H, Lee S, Park Y, Choi A. A survey of recommendation systems: recommendation models, techniques, and application fields. Electronics. 2022;11(1):141. doi:10.3390/electronics11010141. [Google Scholar] [CrossRef]
2. Chen J, Dong H, Wang X, Feng F, Wang M, He X. Bias and debias in recommender system: a survey and future directions. ACM Trans Inf Syst. 2023 Feb;41(3):1–39. doi:10.1145/3564284. [Google Scholar] [CrossRef]
3. Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems. Computer. 2009;42(8):30–7. [Google Scholar]
4. Wu L, He X, Wang X, Zhang K, Wang M. A survey on accuracy-oriented neural recommendation: from collaborative filtering to information-rich recommendation. IEEE Trans Knowl Data Eng. 2023;35(5):4425–45. doi:10.1109/TKDE.2022.3145690. [Google Scholar] [CrossRef]
5. Zang T, Zhu Y, Liu H, Zhang R, Yu J. A survey on cross-domain recommendation: taxonomies, methods, and future directions. ACM Trans Inf Syst. 2022 Dec;41(2):1–39. doi:10.1145/3548455. [Google Scholar] [CrossRef]
6. Rendle S, Schmidt-Thieme L. Pairwise interaction tensor factorization for personalized tag recommendation. In: Proceedings of the Third ACM International Conference on Web Search and Data Mining, ser. WSDM ’10; 2010; New York, NY, USA: Association for Computing Machinery. p. 81–90. doi:10.1145/1718487.1718498. [Google Scholar] [CrossRef]
7. Fang X, Pan R, Cao G, He X, Dai W. Personalized tag recommendation through nonlinear tensor factorization using gaussian kernel. Proc AAAI Conf Artif Intell. 2015 Feb;29(1):1. doi:10.1609/aaai.v29i1.9214. [Google Scholar] [CrossRef]
8. Yuan J, Jin Y, Liu W, Wang X. Attention-based neural tag recommendation. In: Li G, Yang J, Gama J, Natwichai J, Tong Y, editors. Database systems for advanced applications. Cham: Springer International Publishing; 2019. p. 350–65. doi:10.1007/978-3-030-18579-4_21. [Google Scholar] [CrossRef]
9. Huai Z, Yang Y, Zhang M, Zhang Z, Li Y, Wu W. M2GNN: metapath and multi-interest aggregated graph neural network for tag-based cross-domain recommendation. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’23; 2023; New York, NY, USA: Association for Computing Machinery. p. 1468–77. doi:10.1145/3539618.3591720. [Google Scholar] [CrossRef]
10. Zuo Y, Liu S, Zhou Y, Liu H. Tral: a tag-aware recommendation algorithm based on attention learning. Appl Sci. 2023;13(2):814. doi:10.3390/app13020814. [Google Scholar] [CrossRef]
11. Liu N, Zhao J. Recommendation system based on deep sentiment analysis and matrix factorization. IEEE Access. 2023;11(6):16994–17001. doi:10.1109/ACCESS.2023.3246060. [Google Scholar] [CrossRef]
12. Lu S, Xu P, Liu B, Sun H, Jing L, Yu J. Retrieval augmented cross-modal tag recommendation in software Q&A sites. arXiv:2402.03635. 2024. [Google Scholar]
13. Li L, Wang P, Zheng X, Xie Q, Tao X, Velásquez JD. Dual-interactive fusion for code-mixed deep representation learning in tag recommendation. Inf Fusion. 2023;99:101862. doi:10.1016/j.inffus.2023.101862. [Google Scholar] [CrossRef]
14. Shrivastava A, Li P. Asymmetric LSH (ALSH) for sublinear time maximum inner product search (MIPS). In: Advances in neural information processing systems. Montreal, Canada: Curran Associates, Inc.; 2014. Vol. 3, p. 2321–9. [Google Scholar]
15. Ge Y, Chen D, Li H. Mutual mean-teaching pseudo label refinery for unsupervised domain adaptation on person re-identification. arXiv:2001.01526. 2020. [Google Scholar]
16. Ye M, Shen J, Lin G, Xiang T, Shao L, Hoi SC. Deep learning for person re-identification: a survey and outlook. IEEE Trans Pattern Anal Mach Intell. 2021;44(6):2872–93. [Google Scholar]
17. Tay Y, Anh Tuan L, Hui SC. Latent relational metric learning via memory-based attention for collaborative ranking. In: Proceedings of the 2018 World Wide Web Conference, ser. WWW ’18; 2018; Republic and Canton of Geneva, Switzerland: International World Wide Web Conferences Steering Committee. p. 729–39. doi:10.1145/3178876.3186154. [Google Scholar] [CrossRef]
18. Vinh Tran L, Tay Y, Zhang S, Cong G, Li X. HyperML: a boosting metric learning approach in hyperbolic space for recommender systems. In: Proceedings of the 13th International Conference on Web Search and Data Mining, ser. WSDM ’20; 2020; New York, NY, USA: Association for Computing Machinery. p. 609–17. doi:10.1145/3336191.3371850. [Google Scholar] [CrossRef]
19. Liu F, Cheng Z, Sun C, Wang Y, Nie L, Kankanhalli M. User diverse preference modeling by multimodal attentive metric learning. In: Proceedings of the 27th ACM International Conference on Multimedia, ser. MM ’19; 2019; New York, NY, USA: Association for Computing Machinery. p. 1526–34. doi:10.1145/3343031.3350953. [Google Scholar] [CrossRef]
20. Wei T, Ma J, Chow TW. Collaborative residual metric learning. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’23; 2023; New York, NY, USA: Association for Computing Machinery. p. 1107–16. doi:10.1145/3539618.3591649. [Google Scholar] [CrossRef]
21. Li M, Zhang S, Zhu F, Qian W, Zang L, Han J, et al. Symmetric metric learning with adaptive margin for recommendation. Proc AAAI Conf Artif Intell. 2020 Apr;34(4):4634–41. doi:10.1609/aaai.v34i04.5894. [Google Scholar] [CrossRef]
22. Ma C, Ma L, Zhang Y, Tang R, Liu X, Coates M. Probabilistic metric learning with adaptive margin for top-k recommendation. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD'20; 2020; New York, NY, USA. pp. 1036–44. [Google Scholar]
23. Goodfellow IJ, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. arXiv:1412.6572.2015. 2025. [Google Scholar]
24. Wong E, Rice L, Kolter JZ. Fast is better than free: revisiting adversarial training. arXiv:2001.03994.2020. 2020. [Google Scholar]
25. Wang X, Chen Y, Zhu W. A survey on curriculum learning. IEEE Trans Pattern Anal Mach Intell. 2022;44(9):4555–76. doi:10.1109/TPAMI.2021.3069908. [Google Scholar] [PubMed] [CrossRef]
26. Cai Q-Z, Du M, Liu C, Song D. Curriculum adversarial training. arXiv:1805.04807. 2018. [Google Scholar]
27. Wang Y, Ma X, Bailey J, Yi J, Zhou B, Gu Q. On the convergence and robustness of adversarial training. arXiv:2112.08304. 2022. [Google Scholar]
28. Zhang J, Xu X, Han B, Niu G, Cui L, Sugiyama M, et al. Attacks which do not kill training make adversarial learning stronger. In: III HD, Singh A, editors. In: Proceedings of the 37th International Conference on Machine Learning, PMLR; 2020 Jul 13–18; Vienna, Austria. p. 11278–87. [Google Scholar]
29. Zhao K, Liu Z, Li J, Zhao B, Jia Z, Shao H. Self-paced decentralized federated transfer framework for rotating machinery fault diagnosis with multiple domains. Mech Syst Signal Process. 2024;211:111258. doi:10.1016/j.ymssp.2024.111258. [Google Scholar] [CrossRef]
30. Yanming L, Jinglei L. Leveraging self-paced learning and deep sparse embedding for image clustering. Neural Comput Appl. 2024;36:5135–51. doi:10.1007/s00521-023-09335-w. [Google Scholar] [CrossRef]
31. Hsieh C-K, Yang L, Cui Y, Lin T-Y, Belongie S, Estrin D. Collaborative metric learning. In: Proceedings of the 26th International Conference on World Wide Web, WWW ’17; 2017; Republic and Canton of Geneva, Switzerland: International World Wide Web Conferences Steering Committee. p. 193–201. doi:10.1145/3038912.3052639. [Google Scholar] [CrossRef]
32. Ma̧dry A, Makelov A, Schmidt L, Tsipras D, Vladu A. Towards deep learning models resistant to adversarial attacks. Statistics. 2017;1050(9):1205–32. [Google Scholar]
33. Ruijin Xue QW, Feng S. Improving diversity with multi-loss adversarial training in personalized news recommendation. Comput Mater Contin. 2024;80(2):3107–22. doi:10.32604/cmc.2024.052600. [Google Scholar] [CrossRef]
34. Zheng Y, Zhang R, Mao Y. Regularizing neural networks via adversarial model perturbation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun; Nashville, TN, USA. p. 8156–65. [Google Scholar]
35. Jia X, Chen Y, Mao X, Duan R, Gu J, Zhang R, et al. Revisiting and exploring efficient fast adversarial training via law: lipschitz regularization and auto weight averaging. IEEE Trans Inf Forensics Secur. 2024:1. doi:10.1109/TIFS.2024.3420128. [Google Scholar] [CrossRef]
36. Kim WJ, Cho Y, Jung J, Yoon S-E. Feature separation and recalibration for adversarial robustness. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun; Vancouver, BC, Canada. p. 8183–92. [Google Scholar]
37. Li H, Pan SJ, Wang S, Kot AC. Domain generalization with adversarial feature learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2018 Jun; Salt Lake City, UT, USA. [Google Scholar]
38. Bashivan P, Bayat R, Ibrahim A, Ahuja K, Faramarzi M, Laleh T, et al. Adversarial feature desensitization. In: Ranzato M, Beygelzimer A, Dauphin Y, Liang P, Vaughan JW, editors. Advances in neural information processing systems. Vancouver, BC, Canada: Curran Associates, Inc.; 2021. Vol. 34, p. 10665–77. [Google Scholar]
39. Shafahi A, Najibi M, Ghiasi MA, Xu Z, Dickerson J, Studer C, et al. Adversarial training for free!. In: Wallach H, Larochelle H, Beygelzimer A, d’ Alché-Buc F, Fox E, Garnett R, editors. Advances in neural information processing systems. Vancouver Convention Center, Vancouver, BC, Canada: Curran Associates, Inc.; 2019. Vol. 32. [Google Scholar]
40. Duan Y, Zheng W, Lin X, Lu J, Zhou J. Deep adversarial metric learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2018 Jun; Salt Lake City, UT, USA. [Google Scholar]
41. Chen S, Gong C, Yang J, Li X, Wei Y, Li J. Adversarial metric learning. arXiv:1802.03170. 2018. [Google Scholar]
42. Wang Z, Wang Y, Dong B, Pracheta S, Hamlen K, Khan L. Adaptive margin based deep adversarial metric learning. In: 2020 IEEE 6th International Conference on Big Data Security on Cloud (BigDataSecurityIEEE International Conference on High Performance and Smart Computing, (HPSC) and IEEE International Conference on Intelligent Data and Security (IDS); 2020; Baltimore, MD, USA. p. 100–8. doi:10.1109/BigDataSecurity-HPSC-IDS49724.2020.00028. [Google Scholar] [CrossRef]
43. Mao C, Zhong Z, Yang J, Vondrick C, Ray B. Metric learning for adversarial robustness. In: Wallach H, Larochelle H, Beygelzimer A, d’ Alché-Buc F, Fox E, Garnett R, editors. Advances in neural information processing systems. Vancouver Convention Center, Vancouver, BC, Canada: Curran Associates, Inc.; 2019. Vol. 32. [Google Scholar]
44. Li P, Brost B, Tuzhilin A. Adversarial learning for cross domain recommendations. ACM Trans Intell Syst Technol. 2022 Nov;14(1):1–25. doi:10.1145/3548776. [Google Scholar] [CrossRef]
45. Wang Y, Zou D, Yi J, Bailey J, Ma X, Gu Q. Improving adversarial robustness requires revisiting misclassified examples. International Conference on Learning Representations. New Orleans, LA, USA; 2019. [Google Scholar]
46. He L, Ai Q, Yang X, Ren Y, Wang Q, Xu Z. Boosting adversarial robustness via self-paced adversarial training. Neural Netw. 2023;167(1):706–14. doi:10.1016/j.neunet.2023.08.063. [Google Scholar] [PubMed] [CrossRef]
47. Wang J, Chen G, Xin K, Fei Z. Metric learning with adversarial hard negative samples for tag recommendation. J Supercomput. 2024;80(14):21475–507. doi:10.1007/s11227-024-06274-8. [Google Scholar] [CrossRef]
48. Zhu C, Cheng Y, Gan Z, Sun S, Goldstein T, Liu J. FreeLB: enhanced adversarial training for natural language understanding. 2020. doi:10.48550/arXiv.1909.11764. [Google Scholar] [CrossRef]
49. Dong Y, Liao F, Pang T, Su H, Zhu J, Hu X, et al. Boosting adversarial attacks with momentum. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018; Salt Lake City, UT, USA. p. 9185–93. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools