
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Causal Representation Enhances Cross-Domain Named Entity Recognition in Large Language Models
1 School of Artificial Intelligence, Zhongyuan University of Technology, Zhengzhou, 450007, China
2 School of Computer Science, Zhongyuan University of Technology, Zhengzhou, 450007, China
3 Zhengzhou Key Laboratory of Text Processing and Image Understanding, Zhengzhou, 450007, China
4 School of Information Science and Technology, North China University of Technology, Beijing, 100144, China
* Corresponding Author: Xiaoming Liu. Email:
Computers, Materials & Continua 2025, 83(2), 2809-2828. https://doi.org/10.32604/cmc.2025.061359
Received 22 November 2024; Accepted 17 February 2025; Issue published 16 April 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Large language models cross-domain named entity recognition task in the face of the scarcity of large language labeled data in a specific domain, due to the entity bias arising from the variation of entity information between different domains, which makes large language models prone to spurious correlations problems when dealing with specific domains and entities. In order to solve this problem, this paper proposes a cross-domain named entity recognition method based on causal graph structure enhancement, which captures the cross-domain invariant causal structural representations between feature representations of text sequences and annotation sequences by establishing a causal learning and intervention module, so as to improve the utilization of causal structural features by the large language models in the target domains, and thus effectively alleviate the false entity bias triggered by the false relevance problem; meanwhile, through the semantic feature fusion module, the semantic information of the source and target domains is effectively combined. The results show an improvement of 2.47% and 4.12% in the political and medical domains, respectively, compared with the benchmark model, and an excellent performance in small-sample scenarios, which proves the effectiveness of causal graph structural enhancement in improving the accuracy of cross-domain entity recognition and reducing false correlations.Keywords
Nomenclature
| LLMs | Large Language Models |
| CD-NER | Cross-Domain Named Entity Recognition |
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| EB | Entity Boundaries |
| LB | Label Boundaries |
| IE | Information Extraction |
| GCN | Graph Convolutional Network |
| CD-LM | Cross-Domain Language Model |
| BCE | Binary Cross Entropy |
In recent years, LLMs such as GPT-3 [1] have demonstrated remarkable performance in zero-shot and few-shot tasks, advancing the research on CD-NER [2]. However, CD-NER still faces the challenge of scarcity of large scale annotated data in specific domains. This scarcity limits the model’s ability to learn features relevant to the target domain, leading to reduced accuracy in entity recognition. Additionally, it exacerbates issues related to causal and spurious correlations within NER tasks, which traditional methods struggle to effectively address. The emergence of LLMs has significantly alleviated this dependency. Although LLMs have exhibited excellent generalization capabilities in NLP tasks through contextual learning [1] and chain-of-thought [3] techniques, their performance in cross-domain NER tasks still requires improvement. Current research on cross-domain tasks primarily models the interaction between domains using two methods: domain adaptation based on pre-trained language models and prompt-based approaches leveraging LLMS. Domain adaptation methods enhance target domain performance by sharing source domain knowledge and domain-invariant features, but their generalization ability relies on the similarity between the source and target domains. When there is a significant disparity, model performance tends to decline markedly. Prompt-based methods, on the other hand, improve target domain performance by designing domain-specific prompts to activate the latent capabilities of LLMs [4]. However, their effectiveness depends on the choice and design of prompts, and they have limited generalization capacity to new domains.
Furthermore, selective biases induced by label and contextual correlations across domains can lead to model overfitting to non-representative features, ignoring the true causal relationships and thereby constraining the model’s generalization capability and prediction accuracy. As illustrated in Fig. 1, “John Preskill” should be recognized as a “scientist” rather than merely a “Person”, and the reason for this problem is that LLMs will incorrectly learn the correlation between “John Preskill” and the “person” during the pre-training process, but this correlation is a spurious correlation problem. Therefore, in complex cross-domain tasks, causal and spurious correlations are critical issues [5]. Causal correlations are stable and interpretable, whereas spurious correlations fluctuate with changes in the environment. Recent studies have attempted to mitigate the impact of spurious correlations using causal inference methods [6–8], optimizing the model’s predictive capabilities, reducing the negative effects of confounding factors, and enhancing performance in cross-domain tasks.

Figure 1: Causal learning helps models alleviate entity bias
Despite the effectiveness of these methods in reducing the over-prediction issues in cross-domain tasks, they still face several challenges. Firstly, there is a lack of thorough exploration of causal relationship consistency across domains. Traditional approaches are often applied to model training in specific scenarios and fail to fully leverage underlying structured knowledge [9]. Secondly, the issue of entity bias [10] is difficult to effectively filter out. The variation in entity information across different domains can affect LLMs, leading them to rely on biased parameters and make unreliable predictions [11]. Additionally, LLMs parameters are not accessible and their logical structure is uncalibrated, which hampers the capture of causal relationships in cross-domain tasks, resulting in inadequate adaptability to diverse domain data.
To address the aforementioned challenges, this paper proposes a CD-NER method based on the enhancement of causal graph structure. The model is designed to meet the different requirements of different domains. The model generates fused semantic features by migrating the original semantic information and domain invariant feature knowledge from the source domain model to the target domain and combining them with the target domain. In addition, the fusion semantic features are then used to build a causal graph with the target domain labels to capture the causal semantic features between the fusion semantic features and the target domain labels, so as to explain the causal relationship between them. After that causal intervention and counterfactual strategies are used to generate cross-domain invariant causal structure predictions, which enhances the ability of LLM to recognize causal relationships and improves its performance in cross-domain entity information detection. The main contributions are as follows:
1. This paper proposes a method that fuses multiple domains to identify and leverage causal relationships, enhancing large language model performance by mitigating semantic interference, causal inconsistency, and entity bias in cross-domain tasks.
2. Experimental results on several domain-specific NER datasets validate the effectiveness of this approach.
This section will introduce related works in the areas of cross-domain NER, large language models, and causal invariant learning.
2.1 Cross-Domain Named Entity Recognition
Current CD-NER models primarily employ two approaches: domain adaptation and contrastive learning. Mou et al. [12] introduced the basic concepts and ideas of domain transfer, leveraging shared knowledge from the source domain to enhance the performance in the target domain. However, Tang et al. [13] pointed out that previous methods neglected domain-specific information, leading to conflicts in entity types. To address this, they built upon the work of Li et al. [14] by employing entity discrimination tasks and entity-aware training settings to mitigate the negative impacts of domain-specific entity type dependencies. Wang et al. [15] explored multi-domain adaptation by setting up linear and layers for each domain. Nevertheless, with an increase in the number of domains, the model tends to become more complex and difficult to train.
In the context of contrastive learning methods, Das et al. [16] suggested using Gaussian embeddings and contrastive learning to improve the accuracy of few-shot NER. However, this approach overlooked the integrity of entities. Xu et al. [17] proposed guided momentum contrastive learning, which improves the accuracy of cross-domain NER by guiding the learning process through EB and LB.
In comparison, previous methods have failed to adequately leverage the causal relationship between features and labels to optimize predictive performance. This shortfall has resulted in suboptimal handling of entity bias issues. Moreover, these methods have not fully explored the rich knowledge embedded in LLMs.
Recent research has increasingly explored the use of LLMs for IE tasks [1]. LLMs have demonstrated excellent performance across a wide range of NLP tasks, particularly in zero-shot environments. By leveraging instruction tuning, they have significantly enhanced performance, showcasing their great potential in IE tasks [1]. However, recent studies indicate that LLMs still face challenges when dealing with complex cross-domain tasks [18]. Qin et al. [19] found that ChatGPT shows limited performance in zero-shot sequence labeling tasks. Fei et al. [20] suggested that the choice and order of examples in context learning may lead to prediction biases. Wang et al. [21] argued that entity bias significantly affects large models, causing these LLMs to rely on biased parameters, resulting in unreliable predictions. Ye et al. [22] proposed using data augmentation techniques to improve LLMs’ capabilities in few-shot NER by enhancing original data with context and entity-level augmentations to utilize the unique characteristics of NER tasks. Bernal et al. [23] pointed out that LLMs perform worse than traditional pre-trained language models in few-shot biomedical relation extraction tasks. Zhang et al. [24] observed that even with instruction tuning, LLMs’ performance in certain IE tasks still struggles to surpass that of pre-trained language models.
Causal invariant learning is a common approach used to address domain adaptation and domain generalization problems in cross-domain transfer learning. Domain generalization is crucial for learning domain-invariant causal knowledge. Tang et al. [25] proposed a scene graph generation framework based on causal reasoning. By constructing causal graphs, they extracted counterfactual causal relationships to eliminate the impact of biases. However, this method did not consider the biases implied by cross-cultural differences. Lin et al. [26] categorized biases into intra-domain and cross-domain types. They proposed constructing causal models using a hierarchical Bayesian deep model to calculate causal effects and eliminate both intra-domain and cross-domain biases through causal intervention. To address selection bias and distributional bias in data, Ren et al. [8] developed a framework for covariance and variance optimization to learn the causal relationships between features and targets, minimizing covariance to obtain causal effects and resolve data bias issues between NER and relation extraction. Yang et al. [10] replaced contextual information with causal intervention to uncover the primary causal relationships in data from a causal reasoning perspective. Cao et al. [27] suggested using structural causal models as analytical tools to identify hidden potential risks in exploratory tasks, thus reducing data biases.
Assuming an input sequence
CD-LM based on causal graph structures. The method constructs causal graphs to capture cross-domain invariant causal representations between the feature representations of text sequences and the labeled sequences, thereby improving the performance of LLMS in target domain entity recognition. As shown in Fig. 2, the model first introduces a feature fusion module to obtain label structure information between the source domain and the target domain. By employing GCN alignment techniques, the model acquires cross-domain invariant structural information. Subsequently, the model utilizes causal learning to capture potential causal relationship features within text sequences and enhances them into cross-domain invariant causal graph representations. Through counterfactual strategies, the model proactively adjusts and evaluates the causal effects among features, eliminating the confounding factors caused by entity bias, and ensuring the reliability and consistency of causal relationships. This approach allows the model to accurately capture the causal structures within text sequences. Finally, using prompts and LLMs, the model enhances its ability to represent cross-domain invariant features, thereby improving the learning and prediction of causal relationships in text. This enhancement boosts the detection accuracy of entity information across different domains.
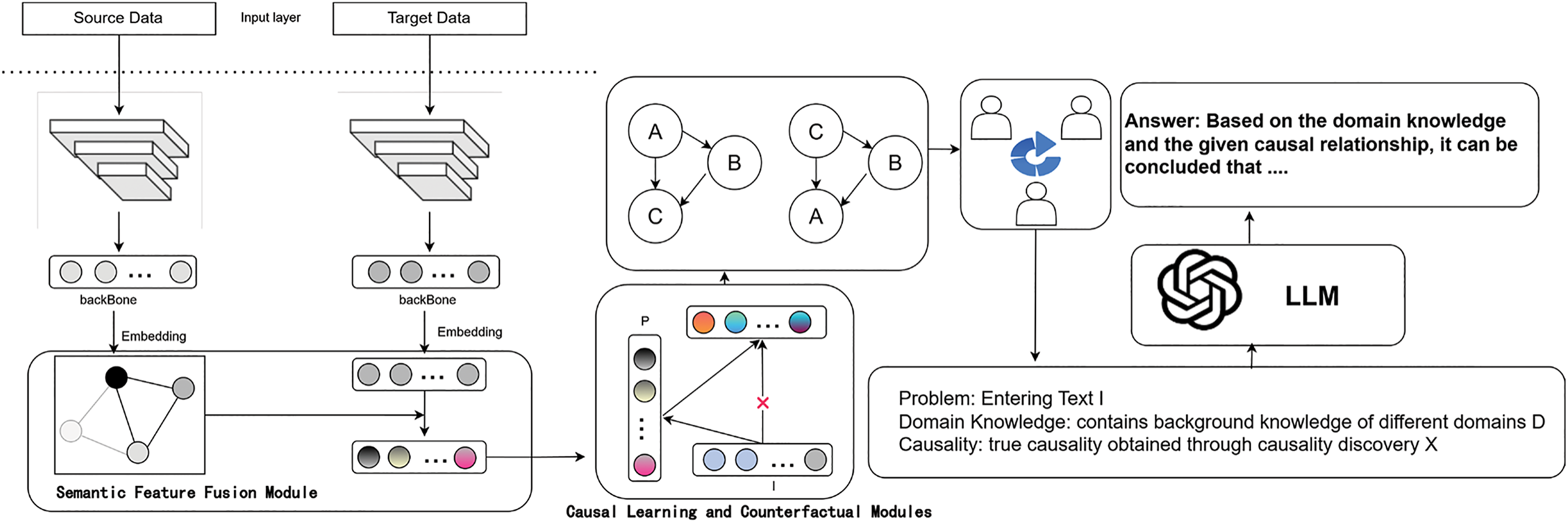
Figure 2: Overall framework of CDLM
4.1 Semantic Feature Fusion Module
Due to potential mismatches between the labels in the source domain and the target domain datasets, models trained on the source domain cannot be directly applied to the target domain. The differences in label distribution necessitate adjustments and adaptations in the target domain. The method need to calculate the probability distribution of mapping the target domain labels to the source domain labels
Here,
where,
where
where
where
where [;] represents the concatenation operation, Y represents the ground truth label of the sentence. Through the loss calculation this approach not only accurately learns the relevant entity information from both the source and target domains but also effectively integrates the entity information from both domains.
4.2 Causal Learning and Counterfactual Modules
This paper constructs a structural causal model to describe the causal learning module within the CDLM. In NER tasks, a causal graph can be used to represent the causal relationships among different variables. This graph is represented by a Directed Acyclic Graph, where node I represents the fused semantic features generated by the text sequence in the target domain, which is composed by fusing together the semantic features output from the target domain and the graph structure constructed in the source domain. Node E represents focusing only on entity semantic features in the target domain, node C represents focusing only on confounding factors in the target domain, node P represents representing prior knowledge in the target domain, node D represents domain information in the target domain, and node Y represents the output of labeling. Specifically, the causal graph is illustrated in Fig. 3: where Fig. 3a represents shows an example of entity bias, Fig. 3b depicts the causal relationship between the variables and Fig. 3c shows a counterfactual operation. Specifically, (a) illustrates an example of entity bias. The name “Ludwig van Beethoven” is easily associated with a “concert hall”, but not all musicians are related to a “concert hall”, and not every instance of “Ludwig van Beethoven” should be identified as a Musician; it could also be classified as a Person. In the causal graph illustrated in (b), domain information D (such as the entity type musician rather than person), prior knowledge P represents the fused semantic features from the previous step, entity information E (such as Ludwig van Beethoven), predicted label Y (such as the type musician), and confounding factor C represents the confounding factor introduced by entity bias. Specifically, as shown in Fig. 3a, the name “Ludwig van Beethoven” can be easily associated with “concert hall”, but not all musicians are associated with “concert hall” is associated with “concert hall” and not every instance of “Ludwig van Beethoven” should be recognized as a musician, and therein lies the influence of confounding factors.
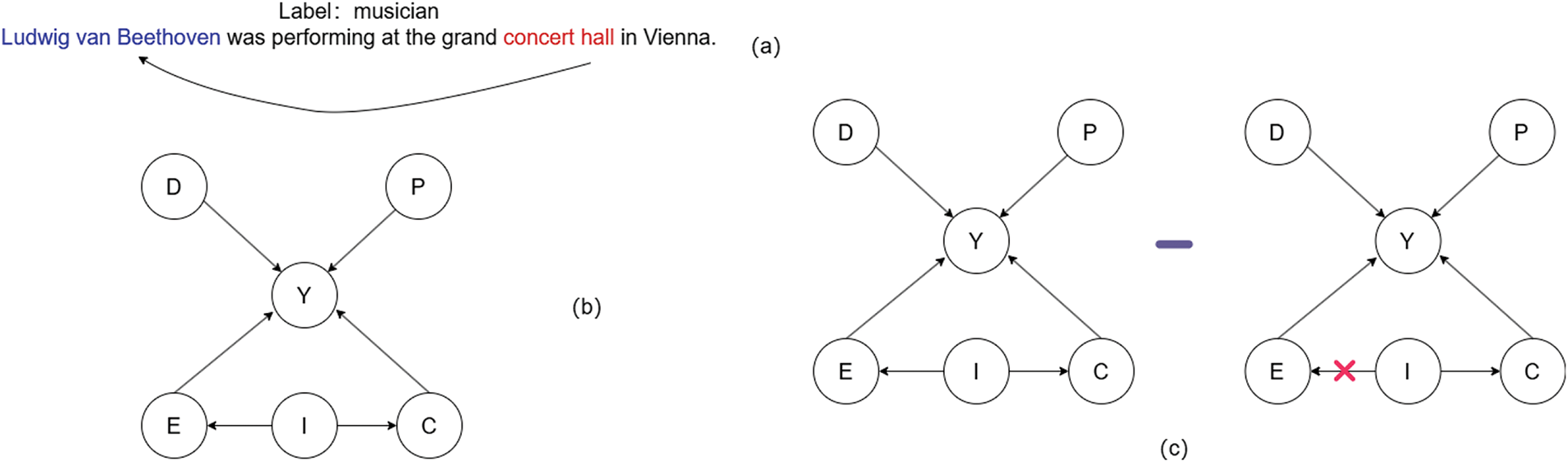
Figure 3: Causal model diagram
Since the input text I consists of entity information E and confounding factors C, it includes causal paths
where the do-operator is the back-door criterion. To more accurately calculate the direct causal effect of entity information E on the output Y, a method of controlling variables is employed. First, the total direct causal effect after counterfactual reasoning is calculated. This is represented using the English letters directly:
Here,
By controlling the variable
This difference represents the effect of entity feature E on Y when R, P and D are held constant, considering only the impact of E on Y. This allows for the direct calculation of the causal effect of E on Y, excluding the potential confounding effects introduced by
As shown in Fig. 3c, a counterfactual operation is demonstrated, which directly calculates the direct causal effect of entity feature E on
where
Explicit Counterfactuals: Explicit counterfactuals involve direct intervention or control operations to transform specific variables into counterfactual scenarios, thereby evaluating the direct effect of particular features on dependent variables. To clearly ascertain the impact of specific entity information, a masking operation is performed on feature vectors. By observing the changes in the model’s prediction results after masking out real entity information, the effect can be evaluated. The masking operation involves creating a mask vector M, and then using the Hadamard Product (element-wise multiplication) to obtain the feature vector
This method focuses on masking entity information to more clearly observe changes in the model output in the absence of such information. The specific processing workflow can be represented by the following calculation formula:
where
Implicit Counterfactuals: Implicit counterfactuals utilize latent variable models or generative models to simulate hypothetical scenarios and capture potential causal relationships. Specifically, in each understanding module, the cross-attention mechanism dynamically divides the input into two disjoint parts (i.e., real entity information u and other information including
To ensure that the generative model reduces dependence on important labels, the method introduce a consistency loss:
where y represents the predicted result of the entity, is used to increase the probability of generating labels when focusing on unrelated tags:
This section proposes a causality extraction module for LLMs consisting of three components: causality discovery, voting discussion iteration, and counterfactual reasoning. The following is the specific design:
Given a set of causal variables
Given a text I and a set of dependent variables X, LLMs based on a full understanding of the set of dependent variables X, combine information from multiple domains D to analyze and find the direct causal relationship between the set of dependent variables X, without the need to look for indirect causality, which can be directly inferred from the direct. The part of the prompt is: Read carefully for possible causal relationships between this text and the one I’ve provided, extracting words or phrases with direct causal relationships based on your expertise and making sure that each causal chain accurately represents a direct causal relationship between the two variables, rather than an indirect association.
where
With the multiple constraints M derived from the current causality discovery phase, multiple rounds of expert voting are conducted to go through to verify the reasonableness of the direct causality, and in case of conflict, multiple rounds of expert discussion are conducted, where the experts will vote individually on the issue and give specific opinions until all the experts’ opinions are agreed upon. The part of the prompt is: Read this text carefully and score the results, evaluating the results in terms of accuracy, relevance, and domain adaptation, each on a scale ranging from 1 to 5 (1 being the worst and 5 being the best), with specific explanations. Specifically, the output of the LLMs is combined with the scoring-based approach in each round of discussion:
Finally, model integrates background knowledge with the final causal structure and uses counterfactual reasoning to validate its response, avoiding hallucination. Counterfactual reasoning involves generating an alternative answer, comparing it to the original, and checking for contradictions. If inconsistencies are found, the model evaluates the alternative and refines its response; otherwise, it outputs the original answer.
4.4 Objective Optimization and Optimization Algorithms
Finally, the overall loss of the model can be expressed as:
where
To demonstrate the effectiveness of the method proposed in this paper, the method conducted tests on five English datasets as well as a dedicated cross-domain dataset. The experimental results were analyzed from five different perspectives, including ablation studies, parameter testing, case studies, LLMs model analysis, and further extended experiments.
This study utilizes six publicly available datasets, including CoNLL-2003 [29], BioNLP13PC [30], BioNLP13CG [30], MIT-Restaurant [31], MIT-Movie [31], and Cross-NER [32]. The CoNLL-2003 English dataset is derived from the Reuters corpus. The BioNLP13PC dataset originates from the BioNLP 2013 Shared Task, focusing on extracting pathway information from biomedical literature, while the BioNLP13CG dataset is dedicated to extracting information related to cancer genetics. The MIT-Movie dataset serves as a benchmark for enhancing text processing capabilities in the movie domain, and the MIT-Restaurant dataset is a training and testing corpus for semantic labeling in the restaurant domain. The Cross-NER dataset includes five distinct domains (politics, natural science, music, literature, and artificial intelligence), each featuring unique entity types. For ease of understanding, in the following we replace the dataset with a more concise form, shortening BioNLP13PC to PC, BioNLP13CG to CG, MIT-Restaurant to Res, and MIT-Movie to Mov. In addition, the different domains of Cross-NER will be abbreviated differently: the politics domain will be abbreviated as Pol, natural science as Sci, music as Mus, literature as Lit, and artificial intelligence as AI.
For this study, the adopted approach is based on the pre-trained language modeling framework on BERT [33]. The adopted LLM is based on LLaMA3.1-8B and GPT-3.5-Turbo-0125. After several iterations of parameter tuning, the following optimal experimental parameters are selected: stochastic gradient descent is chosen as the optimizer, the learning rate is set to 0.0001. The batch size is set to 8, and the hidden layer size is set to 768. To prevent overfitting, the dropout rate is set to 0.5. The evaluation metrics used are consistent with those used in previous studies, and the micro-F1-score is adopted as the main evaluation metric. This metric combined precision and recall across all categories to provide a more comprehensive assessment of model performance. The final result is the average of five independent runs to ensure robustness and reliability. Given the diverse characteristics of these datasets, this study designs the experiments to validate the proposed method’s effectiveness in two main parts. In the first part, the CoNLL-03 dataset is used as the baseline dataset for CD-NER, with experiments conducted on the PC, CG, and Cross-NER target datasets. The second part of the experiment aims to explore the few-shot cross-domain transfer capabilities based on the CoNLL-03 dataset, selecting Cross-NER, Res and Mov as the target datasets to test the transferability.
To validate the effectiveness of the proposed model, comparative experiments were conducted against related models on different datasets. Coach [34]: Liu et al. first detect whether tokens are slot entities to learn general patterns and then classify the slot entities, which improves the prediction accuracy in specific domains. LANER [9]: Hu et al. enhance the relationship between labels and tokens through multi-task learning, improving the transferability of label information and facilitating mutual promotion of NER tasks between source and target domains. NNShot [35]: Yang et al. train an NER model on the source domain as a feature extractor and then classify features using nearest neighbors. StructShot [35]: Building on NNShot, this method introduces structured information to enhance the model’s recognition capability. LST-NER [28]: Zhang et al. model label relationships as probability distributions, constructing a label graph for cross-domain NER tasks in scenarios where the label sets of the source and target domains differ. LightNER [36]: Chen et al. improve the overall performance of NER tasks in resource-constrained environments by incorporating prompts during model training. TemplateNER [37]: Ma et al. transform NER into a large language model task through template-free prompt tuning techniques, enhancing NER performance in few-shot scenarios. CP-NER [38]: Chen et al. propose using frozen pre-trained language model parameters and cross-domain prompt techniques to integrate knowledge from multiple domains, enhancing NER performance in the target domain and preventing performance degradation due to insufficient data from a single domain.
The experimental results on various commonly used cross-domain datasets are presented in Tables 1–3, where CDLM(LLaMa) in the table represents LLM using the LLaMA3.1-8B model and CDLM(GPT) represents LLM using the GPT-3.5-Turbo-0125 model. The bold font indicates the top performance in the comparative experiments, the italicized font_indicates the second-best results, and a dash—indicates the absence of experimental results. Overall, the proposed CDLM outperforms the baseline models in both resource-rich and resource-scarce domains. Compared to state-of-the-art models, it also demonstrates significant improvements across multiple datasets and domains. The method adopted a model architecture similar to LST-NER as the foundational framework. Although LST-NER is based on a single-task framework and its performance is inferior to the multi-task LANER in several aspects, as well as showing a significant gap when compared to prompt-based models like LightNER and CP-NER, the modified CDLM demonstrates significant improvements across various dimensions.
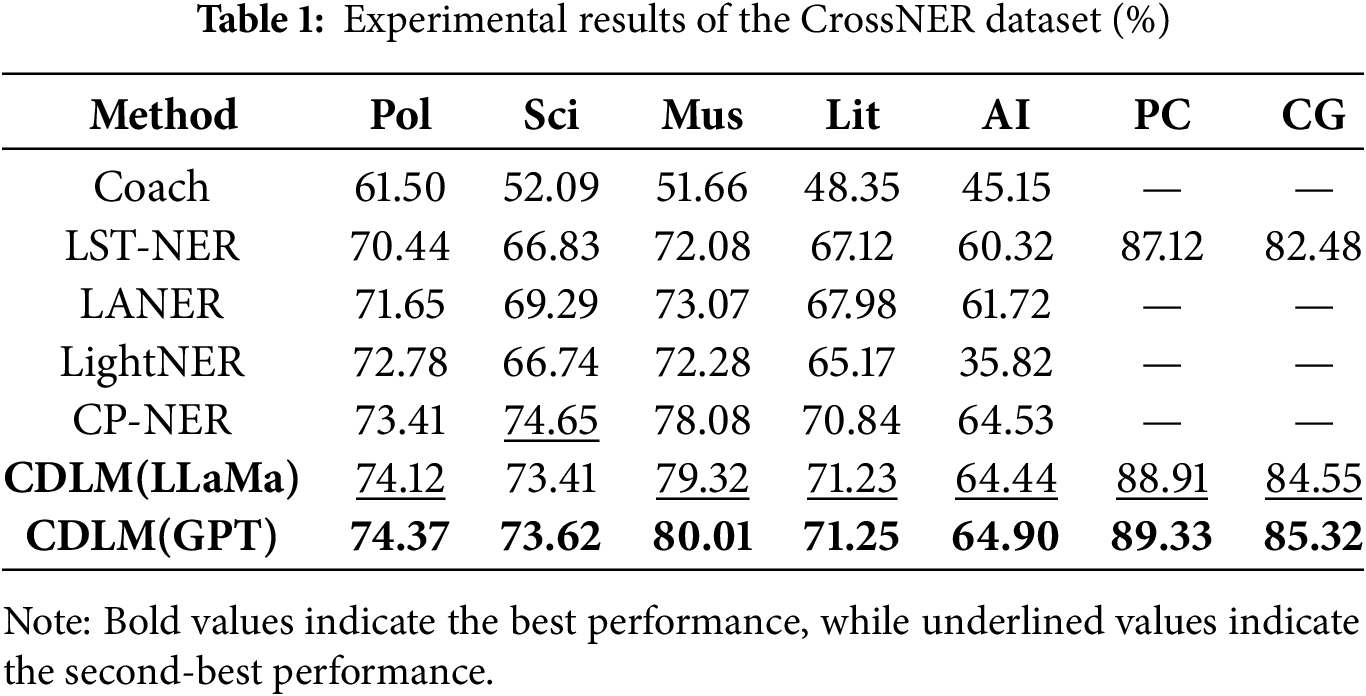
Notably, when compared to the multi-task LANER, the CDLM exhibits substantial enhancements across the five domains of the CrossNER dataset. For instance, it achieves an increase of 2.47% in the Pol domain and 4.12% in the Sci domain, which effectively validates the efficacy of the proposed method. This method leverages the pre-trained language model’s capability to effectively identify causal relationships between entities and contexts. It also utilizes the extensive corpora within the LLM to provide contextual support and deepen understanding, addressing potential limitations of LLMs in comprehending and generating content based on causal relationships. Furthermore, the proposed method does not require additional training for the LLM, thereby fully harnessing the LLM’s inherent capabilities. It is adaptable to various types of LLMs and can optimize their performance across different datasets without altering the model architecture or parameters. In terms of training time and resource consumption, the method significantly underperforms CP-NER, yet achieves comparable results and exhibits notable improvements in certain domains, such as a 0.71% increase in the Pol domain and a 0.68% increase in the Mus domain. Moreover, in entirely different medical and biological datasets, the results are promising. For instance, on the medical PC dataset, the method shows a 1.79% improvement over the baseline framework, and a 2.07% improvement on the biological CG dataset. Hence, the experimental comparison results indicate that the proposed method demonstrates significant advantages in multiple dimensions. Additionally, the method also shows remarkable advantages in terms of resource consumption and training time.
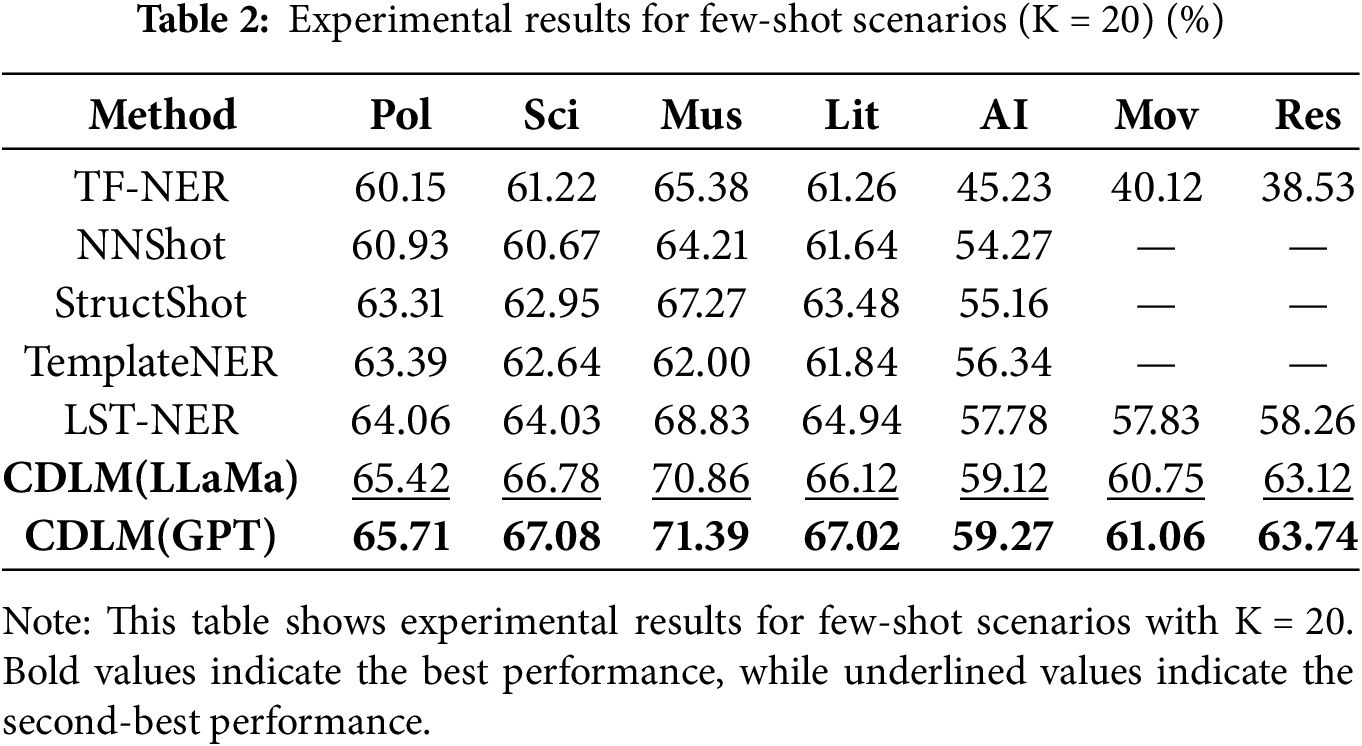
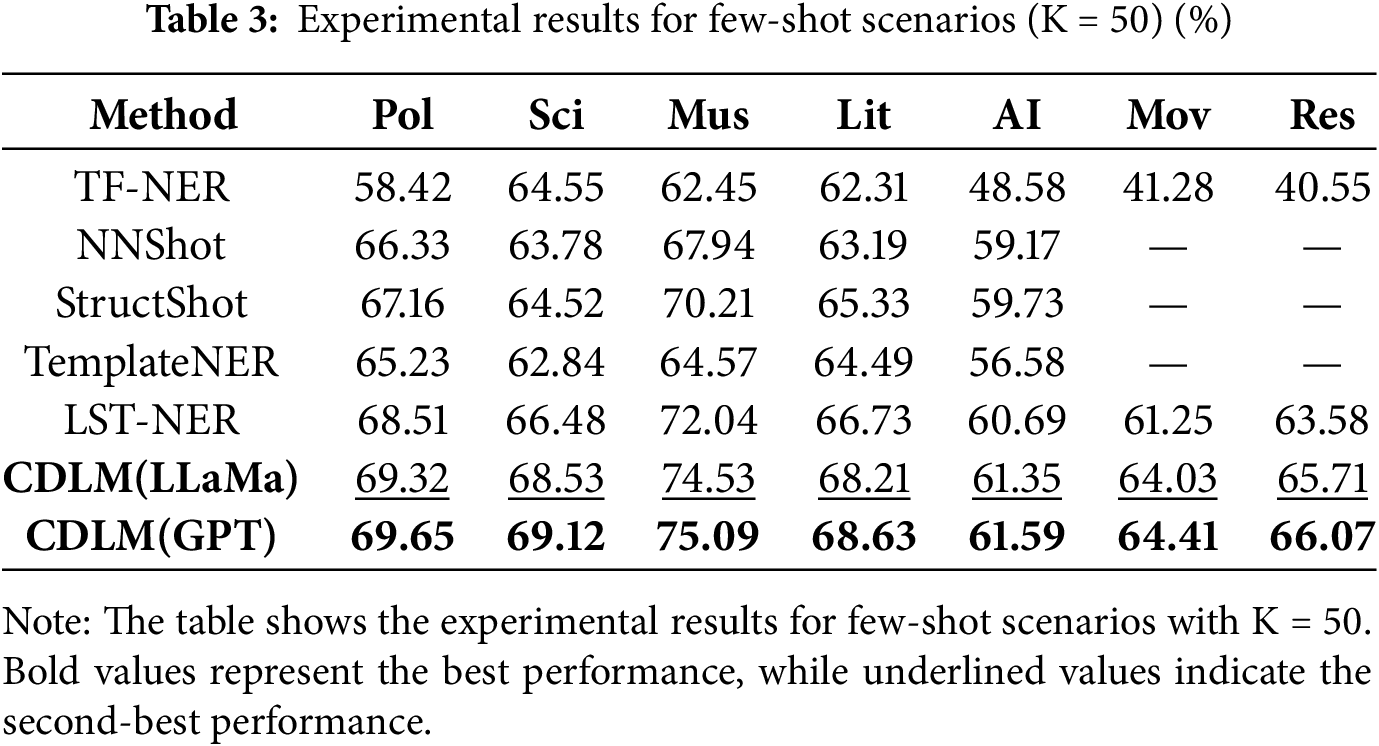
To further validate the effectiveness and robustness of the proposed method, few-shot experiments were conducted on specific CrossNER, Res and Mov datasets in low-resource environments. The experimental results are presented in Tables 2 and 3.
The experimental results demonstrate that the proposed model consistently outperforms the baseline models in a small sample environment, with significant improvements observed under settings of K = 20 and K = 50. The method presented in this paper not only effectively leverages the rich semantic knowledge of LLMs but also addresses the issue of spurious correlations in LLMs through causal semantic relationships. This approach yields substantial improvements not only on the CrossNER dataset but also in scenarios where the source and target domains are entirely different. Specifically, compared to the best experimental results, the model achieves an average increase in F1-score by 1.73% and 1.50% under K = 20 and K = 50 sample settings, respectively. Furthermore, in the source and target domains (Res and Mov), where there are significant differences in domain and labels, the F1-scores for Res and Mov increase by 2.92% and 4. 83% at K = 20, and by 2.78% and 2.13% at K = 50, respectively. These results clearly indicate that the model effectively utilizes semantic features derived from causal relationships to enhance the rich semantic knowledge of LLMs. By integrating features from both the source and target domains and identifying causal relationships between features, the model effectively mitigates the issue of spurious correlations between entities and context. This approach enhances the accuracy and reliability of the model in handling complex semantic tasks.
In this subsection, the method selected the
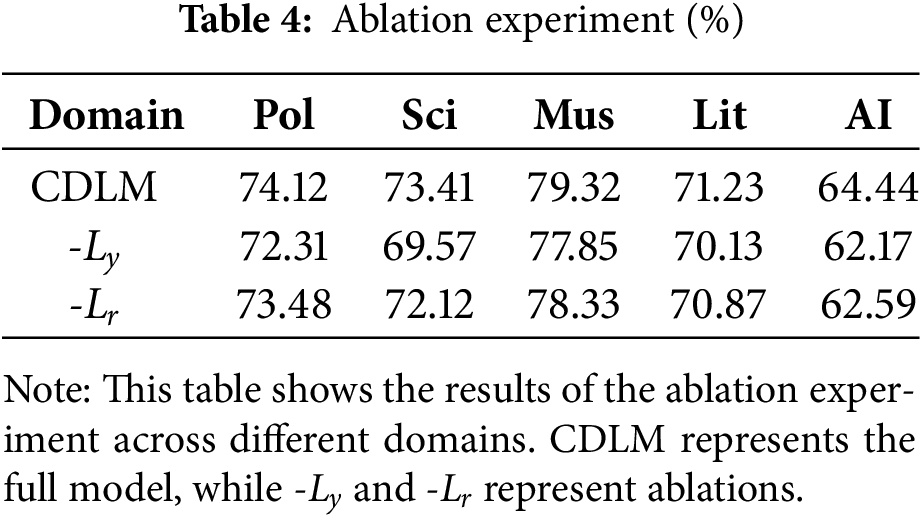
To validate the effectiveness of each module, ablation experiments were conducted on the
To investigate the impact of the parameters
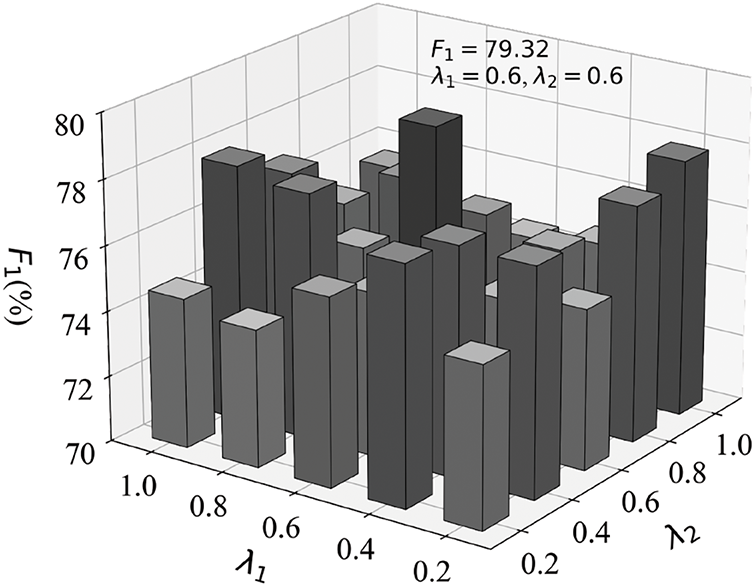
Figure 4: The values corresponding to different
This study presents an in-depth case analysis by selecting representative sentences from various fields within the CrossNER dataset to elucidate the challenges and countermeasures in cross-domain tasks. The uniqueness of cross-domain tasks lies in the uncertainty and diversity of terminologies and labels across different domains. For instance, as demonstrated in Table 5, the term “Experts” might be labeled as “Person” in certain fields, while in others, it could be labeled as “Scientist”. Such label uncertainties exacerbate the complexity of model processing and contribute to significant domain bias issues.

In order to further analyze the predictive effectiveness of the model for different entity types, we performed a fine-grained analysis of the PC dataset, in which the main entity types in the PC dataset are Simple-chemical (CHEM), Gene-or-gene-product (GGP), Cellular-component (CCP) and Complex, respectively.
Table 6 shows the main experimental results, and it can be seen that compared with the LLM-based CP-NER method, CDLM improves its performance on several entity types, which once again validates the effectiveness of this paper’s method. In addition, CDLM still achieves good performance even on CCP entity types with less data volume, which further proves that CDLM has greater improvement even when facing the long-tail problem of data distribution.

Existing models often struggle with effectively identifying and distinguishing information from various unknown domains in cross-domain tasks. Although these models can accurately identify entity information, they exhibit a high degree of domain specificity in determining entity types, making generalization to unseen domains challenging. The method proposed in this paper leverages the extensive corpus of LLMs to integrate information from both source and target domains by exploiting cross-domain invariances. By incorporating causal learning, the model’s capability to adapt to new domain entity information is further enhanced, resulting in more accurate predictions and entity type classifications. The model undergoes training and validation on multi-domain data, showcasing its robustness and effectiveness in CD-NER.
To evaluate the generalization capability of the LLMs, commonly used few-shot NER datasets were employed for testing, including ConLL-2003 and FewNERD. In Fig. 5, the main experimental results are summarized. Due to the high costs associated with using the ChatGPT API, Ma et al. [39]’s research was referenced for a comparative analysis of ChatGPT and InstructGPT results. The experimental findings indicate that in few-shot scenarios, the LLM performs exceptionally well in both 1-shot and 5-shot settings, significantly outperforming methods based on pre-trained language models. This superior performance is attributed to the LLM’s extensive corpus and powerful generalization capabilities. However, as the number of samples increases, the performance curve gradually declines. This demonstrates the LLM’s high sensitivity to small sample sizes and complex label information, indicating a challenge in fully leveraging limited training data to achieve accurate NER.
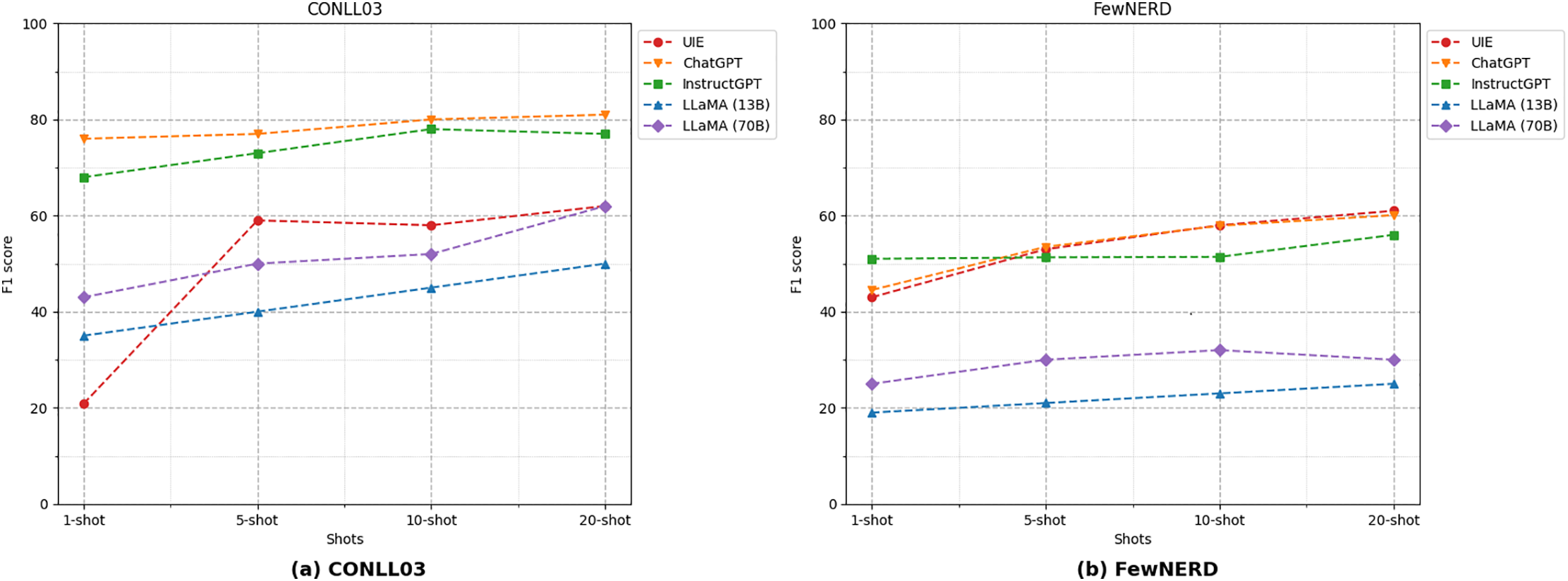
Figure 5: LLM experiment
7.2 Why LLM’s Performance in Sequence Annotation Tasks Is Not Satisfactory
Through the above experiments, the performance deficiencies of LLM in sequence labeling tasks were analyzed, focusing on the following three key aspects: 1. Insufficient Utilization of Annotations: Compared to domain-specific models, LLMs gain limited benefits from increased training samples and label types, manifesting in two main constraints: (1). Effective Sample Capacity: The effective sample capacity is restricted by the model’s maximum input length, leading to performance saturation before reaching the sample capacity limit. (2). Label Type Increase: An increase in label types results in fewer examples per label, limiting the LLM’s ability to understand complex label interactions. This reduces the efficacy of annotations, as the LLM cannot leverage the expanded training data as effectively as domain-specific models. 2. Unfamiliarity with Task Format: LLMs are not sufficiently familiar with the highly flexible task formats typical in sequence labeling tasks, which impacts their contextual learning ability. The complex format of sequence labeling tasks, combined with a lack of relevant tasks in instruction-tuning datasets, makes it difficult for LLMs to accurately understand and execute these tasks. This unfamiliarity hampers the LLM’s ability to handle diverse and intricate task structures. 3. Inadequate Contextual Understanding: LLMs exhibit limitations in handling complex contextual relationships and long-distance dependencies, affecting their performance in sequence labeling tasks. The model struggles to fully comprehend subtle contextual cues within the text, leading to insufficient labeling accuracy. These limitations hinder the LLM’s ability to parse and understand nuanced information, which is crucial for precise sequence labeling.
In this paper, we propose leveraging causal relationships to enhance the CD-NER capability of LLMs. This approach mitigates domain-specific biases and enhances the model’s adaptability to diverse tasks. Specifically, cross-domain feature fusion representations are improved by effectively incorporating causal relationships between entities and their contexts. Experimental results validate the model’s effectiveness, demonstrating superior performance across various domains and providing novel insights for future research. Despite its robust performance, the model still has some limitations. Future work will focus on enhancing rapid adaptation to new domains by optimizing cross-domain feature integration, and optimizing model algorithms by analyzing information such as the computational complexity of the model. There is also significant value in introducing simpler baseline methods that provide models with more flexible adaptability and higher computational efficiency. At the same time, exploring how to effectively fine-tune the causality of techniques using parameters is critical to better capture and utilize domain-specific features, which will further enhance the ability of models to handle a variety of complex tasks.
Acknowledgement: None.
Funding Statement: This research was supported by National Natural Science Foundation of China Joint Fund for Enterprise Innovation Development (U23B2029), National Natural Science Foundation of China (62076167, 61772020), Key Scientific Research Project of Higher Education Institutions in Henan Province (24A520058, 24A520060, 23A520022) and Postgraduate Education Reform and Quality Improvement Project of Henan Province (YJS2024AL053).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Jiahao Wu, Jinzhong Xu, Xiaoming Liu, Jie Liu; data collection: Jiahao Wu, Guan Yang; analysis and interpretation of results: Jiahao Wu, Jinzhong Xu; draft manuscript preparation: Jiahao Wu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in CrossNER at https://github.com/zliucr/CrossNER (accessed on 16 February 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Brown TB, Mann B, Ryder N. Language models are few-shot learners. arXiv:2005.14165. 2020. [Google Scholar]
2. Alqaaidi SK, Bozorgi E. A survey on recent named entity recognition and relation classification methods with focus on few-shot learning approaches. arXiv:2310.19055. 2023. [Google Scholar]
3. Wei J, Wang X. Chain of thought prompting elicits reasoning in large language models. arXiv:2201.11903. 2022. [Google Scholar]
4. Chen Z, Xu L, Zheng H, Chen L, Tolba A, Zhao L, et al. Evolution and prospects of foundation models: from large language models to large multimodal models. Comput Mater Contin. 2024;80(2):1753–808. doi:10.32604/cmc.2024.052618. [Google Scholar] [CrossRef]
5. Kuang K. Causal inspired trustworthy machine learning. In: Proceedings of the ACM Turing Award Celebration Conference—China 2023. ACM TURC ’23; 2023; New York, NY, USA: Association for Computing Machinery. p. 3–4. doi:10.1145/3603165.3607365. [Google Scholar] [CrossRef]
6. Tao Z, Jin Z, Bai X. SEAG: structure-aware event causality generation. In: Findings of the Association for Computational Linguistics: ACL 2023; 2023; Toronto, ON, Canada: Association for Computational Linguistics. p. 4631–44. [Google Scholar]
7. Lin J, Zhou J, Chen Q. Causal intervention-based prompt debiasing for event argument extraction. arXiv:2210.01561. 2022. [Google Scholar]
8. Ren L, Liu Y, Cao Y, Ouyang C. CoVariance-based causal debiasing for entity and relation extraction. In: Bouamor H, Pino J, Bali K, editors. Findings of the association for computational linguistics: EMNLP 2023. Singapore: Association for Computational Linguistics; 2023. p. 2627–40. [Google Scholar]
9. Hu J, Zhao H, Guo D. A label-aware autoregressive framework for cross-domain NER. In: Findings of the Association for Computational Linguistics: NAACL 2022; 2022; Seattle, WA, USA: Association for Computational Linguistics. p. 2222–32. [Google Scholar]
10. Yang Z, Liu Y, Ouyang C. Causal intervention-based few-shot named entity recognition. In: Findings of the Association for Computational Linguistics: EMNLP 2023; 2023; Singapore: Association for Computational Linguistics. p. 15635–46. [Google Scholar]
11. Kalyan KS. A survey of GPT-3 family large language models including ChatGPT and GPT-4. arXiv:2310.12321. 2023. [Google Scholar]
12. Mou L, Meng Z, Yan R. How transferable are neural networks in NLP applications? In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; 2016; Austin, TX, USA: Association for Computational Linguistics. p. 479–89. [Google Scholar]
13. Tang M, Zhang P. DoSEA: a domain-specific entity-aware framework for cross-domain named entity recogition. In: Proceedings of the 29th International Conference on Computational Linguistics; 2022; Gyeongju, Republic of Korea: International Committee on Computational Linguistics. p. 2147–56. [Google Scholar]
14. Li X, Feng J. A unified MRC framework for named entity recognition. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; 2020; Online, Association for Computational Linguistics. p. 5849–59. [Google Scholar]
15. Wang J, Kulkarni M. Multi-domain named entity recognition with genre-aware and agnostic inference. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; 2020; Association for Computational Linguistics. p. 8476–88. [Google Scholar]
16. Das SSS, Katiyar A. CONTaiNER: few-shot named entity recognition via contrastive learning. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); 2022; Dublin, Ireland: Association for Computational Linguistics. p. 6338–53. [Google Scholar]
17. Xu J, Zheng C, Cai Y. Improving named entity recognition via bridge-based domain adaptation. In: Findings of the Association for Computational Linguistics: ACL 2023; 2023; Toronto, ON, Canada: Association for Computational Linguistics. p. 3869–82. [Google Scholar]
18. Han R, Yang C, Peng T. An empirical study on information extraction using large language models. arXiv:2305.14450. 2024. [Google Scholar]
19. Qin C, Zhang A, Zhang Z. Is ChatGPT a general-purpose natural language processing task solver? arXiv:2302.06476. 2023. [Google Scholar]
20. Fei Y, Hou Y, Chen Z. Mitigating label biases for in-context learning. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); 2023; Toronto, ON, Canada: Association for Computational Linguistics. p. 14014–31. [Google Scholar]
21. Wang F, Mo W, Wang Y. A causal view of entity bias in (Large) language models. In: Findings of the Association for Computational Linguistics: EMNLP 2023; 2023; Singapore: Association for Computational Linguistics. p. 15173–84. [Google Scholar]
22. Ye J, Xu N, Wang Y, Zhou J, Zhang Q, Gui T, et al. LLM-DA: data augmentation via large language models for few-shot named entity recognition. arXiv:2402.14568. 2024. [Google Scholar]
23. Jimenez Gutierrez B, McNeal N, Washington C. Thinking about GPT-3 In-context learning for biomedical IE? Think again. In: Findings of the Association for Computational Linguistics: EMNLP 2022; 2022; United Arab Emirates: Abu Dhabi. p. 4497–512. [Google Scholar]
24. Zhang K, Jimenez Gutierrez B, Su Y. Aligning instruction tasks unlocks large language models as zero-shot relation extractors. In: Findings of the Association for Computational Linguistics: ACL 2023; 2023; Toronto, Canada: Association for Computational Linguistics. p. 794–812. [Google Scholar]
25. Tang K, Niu Y, Huang J. Unbiased scene graph generation from biased training. arXiv:2002.11949. 2020. [Google Scholar]
26. Lin Z, Ding H, Hoang NT. Pre-trained recommender systems: a causal debiasing perspective. arXiv:2310.19251. 2024. [Google Scholar]
27. Cao B, Lin H, Han X. Can prompt probe pretrained language models? Understanding the invisible risks from a causal view. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); 2022; Dublin, Ireland: Association for Computational Linguistics. p. 5796–808. [Google Scholar]
28. Zheng J, Chen H, Ma Q. Cross-domain Named entity recognition via graph matching. In: Findings of the Association for Computational Linguistics: ACL 2022; 2022; Dublin, Ireland: Association for Computational Linguistics. p. 2670–80. [Google Scholar]
29. Tjong Kim Sang EF, De Meulder F. Introduction to the CoNLL-2003 Shared Task: language-Independent Named Entity Recognition. In: Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003; 2003. p. 142–7. [Google Scholar]
30. Bossy R, Kim JD, Kim JJ. Overview of BioNLP shared task 2013. In: Proceedings of the BioNLP Shared Task 2013 Workshop; 2013; Sofia, Bulgaria: Association for Computational Linguistics. p. 1–7. [Google Scholar]
31. Liu J, Pasupat P, Cyphers S, Glass J. Asgard: a portable architecture for multilingual dialogue systems. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing; 2013; Vancouver, BC, Canada. p. 8386–90. [Google Scholar]
32. Liu Z, Xu Y, Yu T, Dai W, Ji Z, Cahyawijaya S, et al. CrossNER: evaluating cross-domain named entity recognition. arXiv:2012.04373. 2020. [Google Scholar]
33. Devlin J, Chang MW, Lee K. BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); 2019; Minneapolis, MN, USA: Association for Computational Linguistics. p. 4171–86. [Google Scholar]
34. Liu Z, Winata GI. Coach: a coarse-to-fine approach for cross-domain slot filling. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; 2020; Association for Computational Linguistics. p. 19–25. [Google Scholar]
35. Yang Y, Katiyar A. Simple and effective few-shot named entity recognition with structured nearest neighbor learning. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); 2020; Association for Computational Linguistics. p. 6365–75. [Google Scholar]
36. Chen X, Li L, Deng S. LightNER: a lightweight tuning paradigm for low-resource NER via pluggable prompting. In: Proceedings of the 29th International Conference on Computational Linguistics; 2022; Gyeongju, Republic of Korea: International Committee on Computational Linguistics. p. 2374–87. [Google Scholar]
37. Ma R, Zhou X, Gui T, Tan Y. Template-free prompt tuning for few-shot NER. In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; 2022; Seattle, WA, USA: Association for Computational Linguistics. p. 5721–32. [Google Scholar]
38. Chen X, Li L, Qiao S. One model for all domains: collaborative domain-prefix tuning for cross-domain NER. arXiv:2301.10410. 2023. [Google Scholar]
39. Ma Y, Cao Y, Hong Y. Large language model is not a good few-shot information extractor, but a good reranker for hard samples! In: Findings of the Association for Computational Linguistics: EMNLP 2023; 2023; Singapore: Association for Computational Linguistics. p. 10572–601. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools