
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Context Encoding Deep Neural Network Driven Spectral Domain 3D-Optical Coherence Tomography Imaging in Purtscher Retinopathy Diagnosis
1 Department of Computer Science, College of Computer Science, King Khalid University, Abha, 61421, Saudi Arabia
2 Division of Artificial Intelligence and Machine Learning, Karunya Institute of Technology and Sciences, Coimbatore, 641114, India
3 Department of Computer Science and Engineering, Anna University, Chennai, 600025, India
* Corresponding Author: Prasanalakshmi Balaji. Email:
(This article belongs to the Special Issue: Medical Imaging Based Disease Diagnosis Using AI)
Computers, Materials & Continua 2025, 84(1), 1101-1122. https://doi.org/10.32604/cmc.2025.062278
Received 14 December 2024; Accepted 02 April 2025; Issue published 09 June 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Optical Coherence Tomography (OCT) provides cross-sectional and three-dimensional reconstructions of the target tissue, allowing precise imaging and quantitative analysis of individual retinal layers. These images, based on optical inhomogeneities, reveal intricate cellular structures and are vital for tasks like retinal segmentation. The proposed study uses OCT images to identify significant differences in peripapillary retinal nerve fiber layer thickness. Incorporating spectral-domain analysis of OCT images significantly enhances the evaluation of Purtcher Retinopathy. To streamline this process, the study introduces a Context Encoding Deep Neural Network (CEDNN), which eliminates the time-consuming manual segmentation process while improving the accuracy of retinal layer thickness measurements. Despite the excellent performance of deep learning-based Convolutional Neural Networks (CNNs) in multiclass ocular fluid segmentation and lesion identification, certain challenges remain. Specifically, segmentation accuracy declines in regions with very tiny patches of subretinal fluid, often due to limited training data. The proposed CEDNN addresses these limitations by reducing processing time and enhancing accuracy. The approach incorporates advanced diffusion techniques in the 2D segmentation process using a gradient convergence field that accounts for the anisotropic nature of image features. Experimental results on public datasets and clinical OCT images demonstrate that the CEDNN approach achieves remarkable performance, with an accuracy of 99.3%, sensitivity of 99.4%, and specificity of 99%. Furthermore, the use of 3D representations of surface data outperforms traditional 2D surface estimates, enhancing segmentation quality. The system also incorporates temporal dimension estimation, making it feasible to forecast rapid disease progression. This advanced approach holds significant potential for improving retinal disease detection and analysis, setting a new benchmark in automated OCT-based diagnostics.Keywords
Fundus Fluorescein Angiography (FA), which allows physicians to examine retinal capillary flow and spot regions of ischemia, has been essential in evaluating retinal vascular health for the past few decades. However, FA is still an intrusive treatment that involves injecting a fluorescein dye into the movement, which may result in complications, including allergic responses. By providing high-resolution cross-sectional images without the need for dye injection, optical coherence tomography (OCT), on the other hand, has significantly improved retinal diagnostics since its inception in the 1990s. OCT technology provides quick, precise images of the retina’s microscopic structure, significantly altered retinal imaging. Advances in OCT have made it possible to distinguish between static and dynamic signals in the retina, improving the imaging of microvascular structures [1]. A five-degree-of-freedom mechanical arm for OCT retinal imaging is presented. The gadget offers a fresh approach to enhancing OCT imaging, but its scalability and usefulness are constrained. The complex nature of combining OCT technology with a mechanical arm makes the device challenging to operate in standard clinical settings where user-friendliness and setup speed are vital. Furthermore, the problems with maintenance and training needed for physicians to utilize the system efficiently could not be adequately covered.
In contrast to ultrasonic imaging, OCT uses low-coherence light to produce images with a resolution of micrometers, enabling light to enter the retina as deep as 1 to 2 mm and offering fine-grained views of the layers under the surface. The techniques described could be computationally intensive, limiting their use for point-of-care or quick diagnostics [2]. The suitability for various neuropathy kinds or phases has not been well-tested on various patient populations. Furthermore, the limits of adaptive optics in individuals with specific eye problems, including cataracts or retinal illnesses that impact the optical qualities of the eye, could not be adequately addressed in the research [3]. Ophthalmologists now utilize OCT to test the retinal layer and identify a range of retinal disorders. Depending on the doctor’s instructions, patients must maintain their heads still while the equipment scans their eyes, either with or without dilatation. It takes five to ten minutes to complete this operation. Although the process is painless, the eyes may remain sensitive for a few hours after dilatation. OCT provides accurate structural images of the retina, particularly the nerve fiber layer, which are helpful in diagnosing diseases including glaucoma and macular degeneration. The inflammation and retinal layers in schizophrenia have limitations because they only look at one particular mental illness. Although helpful in comprehending retinal anatomy and mental health.
Furthermore, it does not take into consideration of wider variety of retinal alterations across various phases or kinds of schizophrenia, and the relationship between retinal characteristics and symptoms in schizophrenia may not be entirely definitive [4]. OCT has also been used in biopsies to get fine-grained images of tissues without requiring the acquisition of invasive samples. OCT allows for a thorough structural investigation of the retina, including the anterior region, because it is a non-contact imaging technique. To diagnose retinal illnesses including Diabetic Retinopathy (DR) and age-related macular degeneration, it has been shown useful in identifying situations like neovascularization and non-perfusion regions. OCT scans wider regions of the retina and allows doctors to evaluate structural and functional aspects during diagnosis through continuous software developments [5,6].
The difficulties of putting OCT into practice in healthcare settings with limited resources like exorbitant expenses, a lack of infrastructure, or the requirement for specialized training are not addressed. The study could not include thorough comparisons with alternative imaging modalities or diagnostic instruments about neglected illnesses [5]. Despite machine learning’s enormous promise, one major disadvantage would be its need for sizable, well-selected datasets for model training. Furthermore, the models may encounter difficulties with interpretability, generalizability, or overfitting, which are typical issues when integrating machine learning with medical imaging. Additionally, the study could not adequately address the ethical issues around protecting patient data and incorporating AI-based technologies into clinical processes [6].
OCT imaging segmentation algorithms are constantly being improved to reduce artifacts caused by elements like blood vessel damage. Recent studies have attempted to enhance OCT’s segmentation capabilities to improve the analysis of retinal characteristics. Deep learning-based OCT image denoising is the main topic of this comprehensive study [7]. This research ignores the difficulties of training deep learning models with little or no noisy datasets, which might result in poor generalization in real-world situations, even while it emphasizes the advantages of deep learning. Furthermore, the computing resources needed for deep learning models might be a major obstacle in clinical settings where speed and cost-effectiveness are critical. Additionally, the study might not have addressed the trade-off between denoising and maintaining crucial diagnostic features, or the possible dangers of overfitting. Motion estimation and subpixel motion artifact reduction for 3D-OCT are covered [8]. Although it tackles a significant problem in OCT imaging, one possible drawback is that the correction methods could not generally apply to all motion artifacts, particularly in patients with certain medical problems or who move involuntarily. The quality and resolution of the OCT system being utilized may also have an impact on how successful these techniques are. Additionally, the study could not have properly taken into account the trade-offs between the accuracy of artifact removal and processing performance, which could affect real-time clinical application.
To improve diagnostic speed and accuracy, this study proposes an improved OCT system that aims to increase the rate of detection during OCT volume acquisition, particularly in clinical settings. The proposed method tackles the difficulties of reconstructing high-resolution images, reducing overheads while preserving axial and spatial resolution comparable to more costly equipment. The technology also reduces motion-related artifacts frequently brought on by patient movement or physiological variables during the scan by significantly reducing the acquisition time.
Motivation
While there have been significant advancements in purtscher retinopathy detection through image processing and machine learning techniques, notable challenges still hinder their widespread clinical implementation. Ongoing research is focusing on improving model accuracy, generalizability, and interpretability, as well as addressing the data limitations to develop more robust and reliable systems for purtscher retinopathy detection. Continued efforts are essential to ensure that these technologies can be effectively integrated into clinical workflows and provide real-world benefits in the early detection and management of purtscher retinopathy. The novel contribution of the proposed research is as follows.
1. The Context Encoding Deep Neural Network (CEDNN) encodes spatial and contextual features to automate retinal layer thickness measurement, replacing manual segmentation.
2. Advanced diffusion techniques are used in the 3D segmentation process, leveraging a gradient convergence field to model the anisotropic characteristics of OCT image features.
3. Addressed challenges in segmenting regions with small subretinal fluid patches by enhancing the robustness of the network despite limited training data.
4. Enhanced the evaluation of purtscher retinopathy by integrating spectral-domain analysis, allowing for precise identification of changes in retinal nerve fiber layer thickness.
5. Improved segmentation quality using 3D surface data representations demonstrated superior performance compared to traditional 2D surface estimates.
6. Integrated temporal dimension analysis to predict rapid disease progression, adding a dynamic forecasting capability to the diagnostic process.
7. Validated the CEDNN approach on public datasets and clinical OCT images, setting a new benchmark for automated OCT-based retinal disease detection and analysis diagnostics.
OCT provides more comprehensive information on the primary retinal structures. It provides detailed information on the morphology of eye funds, indicating the existence of many pathological symptoms in intraretinal layers. Therefore, in recent years, computerized diagnostic systems have developed and analyzed this imaging modality. Traditionally, retinal vascular occlusions were characterized by dye-based angiography. It requires considerable intravenous access and a transit eye to choose, constraining the interpretation of non-transit eye arterial perfusion [6].
Traditional image processing methods concentrate on detecting anomalies in retinal images, and have been applied for purtscher retinopathy detection. These methods include thresholding, edge detection, and segmentation AlMohimeed et al. [9] proposed SPORG-RBVS to overcome limitations detected in other retinal vessel segmentation. It involved the tuning process done using Sandpiper optimization and then accompanied by a growing method-based segmentation process. Coric et al. [10] proposed a technique where the retinal thickness measurements get updated through the pRNFL (peripapillary Retinal Nerve Finer Layer) segmentation software. This study mainly focused on longitudinal atrophy and retinal atrophy. The experiments were carried out on multiple sclerosis (MS) patients, where their nerves are damaged or may affect the nervous system of the brain and the whole body. The scans have small deviations in segmenting the tiny blood vessels. This bias can be corrected through further study of segmentation techniques. Regarding this comparison, the older version results of segmentation are subtracted from the latest version. The results of the latest version achieved 95% accuracy.
The severity of glaucoma is analyzed through 3D neural network filtering techniques. The research is mainly focusing on the macula and optic nerve analysis. After an in-vivo percutaneous coronary intervention, a system for evaluating the quantitative and qualitative elements in patient-vessel and lesion components of tumor cells is described. The technique of collecting vascular architecture and performing morphological evaluations from OCT data was automated in this work. The geographical distribution of superficial calcium is linked to several processes and long-term consequences. The complication of this scenario arises from the clinical finding that calcifications are frequently eccentric, resulting in an inhomogeneous rigidity distribution inside the arterial wall. The structural setup is needed during high-pressure dilatations to prevent vascular segmentation and deformity [8,11]. The PLEX Elite 9000 was used to obtain two horizontal 15 mm × 9 mm OCT scans of the upper and lower retina, with the macula at the center of the horizontal axis. For assessment, 15 mm × 15 mm wide-field OCT images were employed, and these two scans were mounted using the built-in function. The study has massive flaws, including the constraints of a small cohort retrospective analysis. To explore the possibility, a more significant number of patients with non-proliferative DR are needed. However, the OCT could not identify all areas of neovascularization. Despite this, more than 95% of neovascularization was visible within 6 optical nerve disc diameters, a distance even wide-field SS-OCT images couldn’t cover [12].
The unique findings were nearly impossible to overlook. Therefore, the anterior vitreous region of high OCT intensity was puzzled by the posterior aspect [13,14]. Before considering the initialization, more pathological attributes are required for the system to learn a pathological shape and the model to identify the most likely shape [15,16]. The presence of blood compresses the exterior nuclear layer when an affected diabetic retinopathy patient is histologically screened. In the structural OCT, the blood is usually more hyperreflective. For this reason, the system cannot exclude that the structural OCT detected subretinal pseudocyst may constitute blood concentrations that compress the external nuclear layer during imaging [17,18]. The coarse identification of vessel shades might be improved for more precise findings and applied to additional layers. Over images of varying resolutions, a coherent comparison of the techniques is not verified [19,20]. A physical OCT system was created for tri-dimensional shearlet decomposition. Continuous trajectories were also described in combination with rasterization technology but were conceived for the operation of offline image data [21]. In many scans, the compactness is suspected of being an artifact instead of the genuine structure of the vessel linked. The vessel density calculations do not exclude certain areas; it is necessary to consider this issue [22–25]. The highest inner-limiting membrane (ILM) area, which is associated with vascular darkening, and the outer plexiform layer (OPL) area are evaluated for vascular structure identification. However, the method has not detected the presence of pathological entities, such as hard exudates and drusens, that potentially cause vascular shadows in OCT images [26]. The layers limit the search space in the outside retinal area of diffuse retinal thickened edemas. The heterogeneous collection of 307 characteristics has been extracted inside defined-size windows in this narrow area. In the event of malignant, the external region is not concentrated. This requires a large-scale feature collection. This makes the search process more challenging [27]. Manual mining is unsustainable and offers complicated results in determining the density of the Foveal Vascular Zone. Furthermore, this extraction would be carried out without repeatability [28]. Contrasts and the submucosal gland’s inhomogeneous tissue require adequate parameters to maximize segmentation accuracy [29]. It is also noted that if features from various frequencies are added, the number of trained parameters will rise. A compromise between the accuracy of the classification and the processing load is, therefore, necessary. The computing effort may be reduced and reliably classified [30,31]. In contrast, in certain circumstances, the vector field convolution does well; in the event of significant artifacts at bifurcation points, it has enormous difficulty [32].
Support Vector Machines (SVM) with feature selection were used by Bilal et al. [33] for DR classification. This method shows the potential to differentiate between standard and DR images. However, the kernel function and feature selection significantly impact SVM performance, and if not correctly adjusted, they may provide less-than-ideal results. Furthermore, SVM needs a lot of labeled data for training, which isn’t always possible, particularly in areas with little access to medical professionals. Because late stages of DR are less common in the general population, it is challenging for SVM to detect severe instances reliably. This is another issue with the approach when dealing with unbalanced datasets.
DR detection has witnessed notable increases in automation and accuracy with the advent of deep learning methods, especially Convolutional Neural Networks (CNNs). Manual feature extraction is no longer necessary since CNNs can automatically learn hierarchical features from retinal images. A significant advancement in diagnosing diabetic retinopathy was made to identify DR from retinal fundus images. Wong et al. [34] presented a deep-learning technique called CNN. In numerous instances, CNN surpassed human specialists and conventional techniques, exhibiting remarkable accuracy. However, the need for large, high-quality labeled datasets, which may be expensive and time-consuming, is a significant drawback of deep learning models. Other deep learning models, such as DenseNet [35] and ResNet (Residual Networks) [36], have been investigated for DR detection in addition to CNNs. These models expand on the CNN architecture by adding deeper layers or more effective connections to identify intricate patterns in the retinal images. For instance, DenseNet’s dense connection pattern in which each layer gets input from every layer before it has produced encouraging results. This method may result in better speed and feature reuse, especially when identifying minor features in DR images. Even while these models have outperformed more conventional machine learning techniques, they still have issues with overfitting, computational expense, and the requirement for large labeled datasets.
A lightweight CNN was developed to identify Macular Edema (ME) in OCT images [37]. The model provides visual explanations using feature activation maps and uses a Block Matching and 3D filtering (BM3D) method to standardize retinal layer analysis, making it easier for physicians to comprehend. Its lightweight design makes faster training and real-time application possible, which offers a dependable and consistent ME detection technique. However, due to its dependence on a single dataset, there are questions about its generalizability across various demographics and imaging circumstances.
As shown in Fig. 1, different approaches have been published for retinal blood vessels and lesion segmentation to diagnose purtscher retinopathy. Everyone has a few things in common to produce terms based on intensity or gradient information. In addition to this regularization, predictions are more robust for blood vessels’ noise or shadowing. The proposed method chooses to differentiate them with the technique to review this wide range of methods comprehensively.
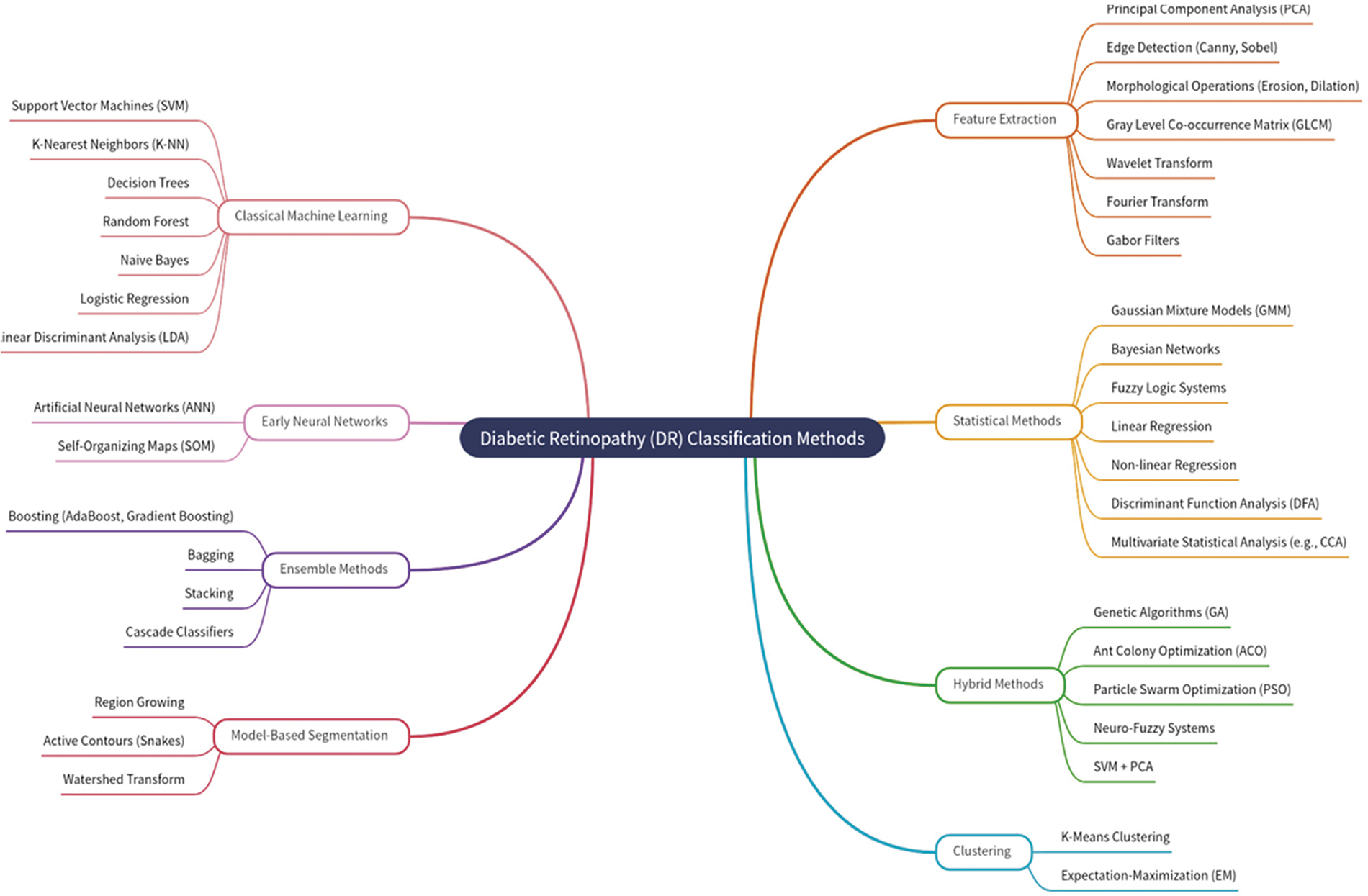
Figure 1: Purtscher retinopathy classification methods based on literature review
Explainable AI (XAI) was investigated by Vasireddi et al. [38] about DR detection to give deep learning models interpretability. Although integrating XAI into DR detection shows promise, balancing explainability and model performance is difficult. The accuracy of sophisticated models, such as CNNs, can occasionally be decreased by adding explainability layers. Furthermore, the confidence that physicians require when utilizing the models for decision-making may be compromised because techniques like saliency maps, which are intended to visualize the results of deep learning, don’t always offer adequate or clear explanations. Additionally, XAI methods are constantly developing, and there are still issues with their generalizability across different datasets and clinical settings.
In a 3D-CNN, there are two key disadvantages. Firstly, the quantities entered are aggressively compressed, which might lead to a loss of crime. Secondly, because of the shallow network topology, its generalization potential is extremely restricted [39]. The Atreus spatial pyramid pooling comprises most of the subretinal fluid lesions, apart from the exact segmentation of the abnormal borders generated mainly by the integrated transformation ability in the deep convolutional neural network [40]. Despite the overall sound performance of deep learning-based CNN for multi-class retinal fluid detection technique, there were certain volumes for which the approach demonstrated less precision in segmentation [41]. One of the key causes of the preceding iterative technique’s significant positive border placement errors was the presence of an outwardly oblique border tissue [42–44]. For proper extraction of features, previous knowledge regarding the thickness of the layer and attenuation coefficient values is needed. This limitation is the reason for the variations in the attenuation of the retinal blood vessel layer coefficients between normal and diseased eyes [2,45].
OCT’s micrometer resolution and millimeter depth of penetration into the retinal tissue make it excellent for ophthalmic imaging. No other noninvasive imaging technology could provide such a high level of resolution. OCT is now standardized in clinical imaging and offers cross-sectional and 3D images of the target tissue. The spectral-domain OCT is better than the time-domain OCT. It shows high resolution with improved features of the retina. Images are organized as Normal, Choroidal Neovascularization (CNV) with neovascular membrane and associated subretinal fluid, Diabetic Macular Edema (DME) with retinal-thickening-associated intraretinal fluid, Multiple drusen present in early age-related macular degeneration. The public dataset used for the experimental setup in this proposed method contains 84,495 OCT images. Table 1 outlines the configuration setup of the experimental environment.

To reduce risks due to high OCT intensity in the vitreous, a physician should pay much attention to the intraoperative OCT images amidst the normal appearance and the accurate identification of tissues in the anterior chamber. Comparison with measurements of preoperative biometrics prevents the complicated tissues in the anterior chamber from being misaligned. The following methods were first created in the proposed approach:
• Segmentation in the deep optic nerve images of big shadows.
• Aims to avoid false vessels and to get an accurate map of vessels
• The way to provide size distribution of vessels in various geometric areas.
• Segmentation of different types of lesions and grade of the disease.
Fig. 2 shows the anatomical retinal image structure of a 3D-OCT image. The gradient convergence field uses the more advanced diffusion in the 2D segmentation process, which considers the anisotropic nature of the image features.
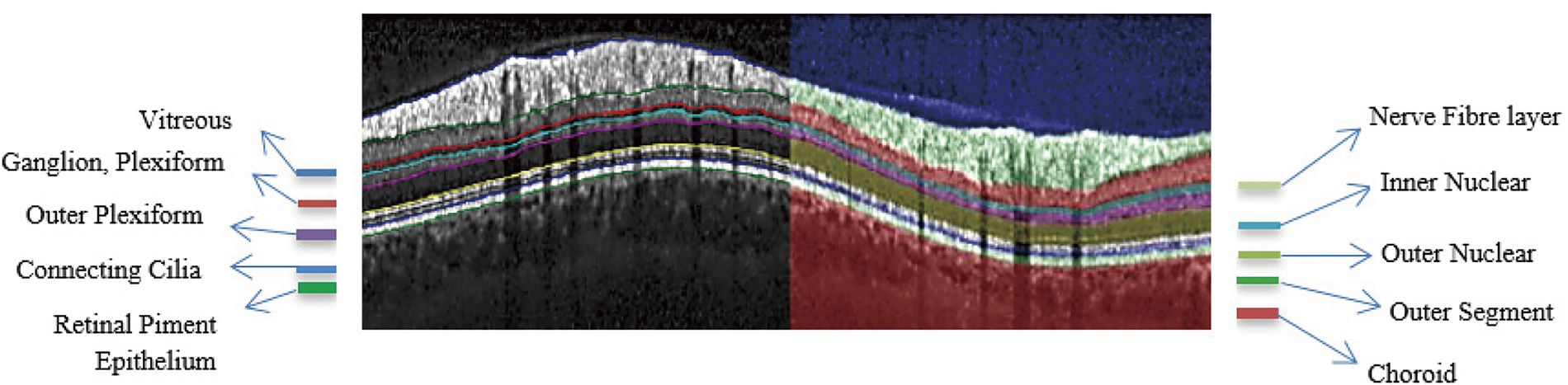
Figure 2: Segmented anatomical structure of retinal layers of an OCT image
Extending 2D work to 3D space for vessel segmentation ensures precise 3D geometry of vessels and longitudinal analysis to enhance disease detection. As shown in Fig. 3, the preprocessing system improves the gradient convolution field, enabling it to handle excessive artifact images inside OCT.

Figure 3: The proposed methodology for OCT image analysis
The input images represented by the 3D matrix are considered for segmentation. The volumetric data with errors due to the shadow effects are rearranged from z-x-y directional coordinates to x-y-z coordinates. Here, the blood vessels’ shape and intensity values are considered in this rearrangement. The foreground blood vessels are detected through the algorithm. The histogram equalization techniques reduce the noise and inhomogeneity. Where each tile image is considered, and the nearby intensity pixels are matched by their histogram equalization. The intensity of the nearby pixels is adjusted to the highest-intensity pixel values.
As shown in Fig. 4, the preprocessed technique increases the fundus image segmentation outcome. Compared with existing algorithms, the Contrast Limited Adaptive Histogram Equalization (CLAHE), technique improves the contrast between images. It increases vascular structures and removes the structure of non-vascular pixels. Moreover, when the image contrast is improved, further enhanced image stretching is not essential; thus, distortion of the blood vessels is avoided.
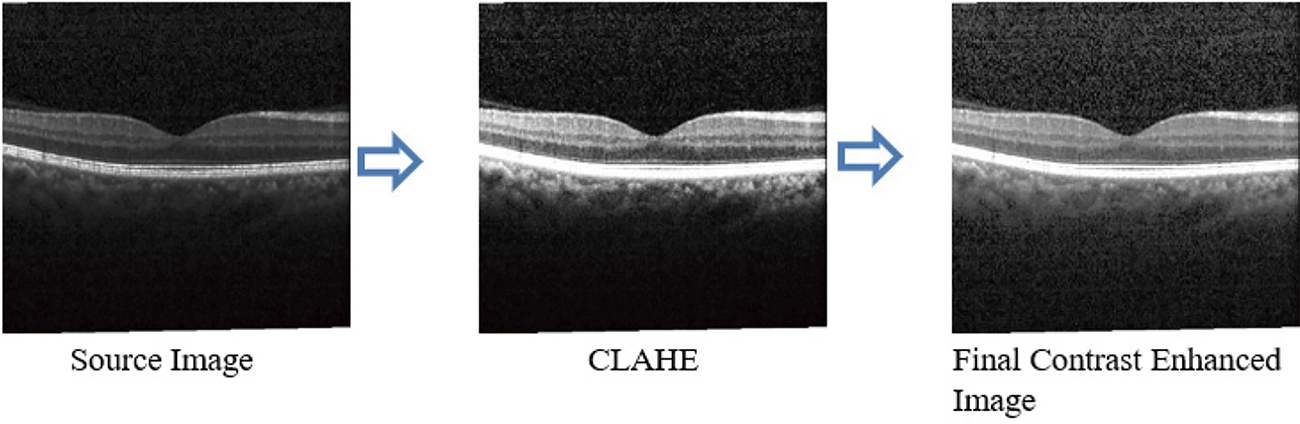
Figure 4: Preprocessed OCT image
In Fig. 5, each pixel value is adjusted to the same level; all OCT images are processed similarly. This is necessary because some images may have large pixel ranges, which might result in more significant loss, while others may have lower pixels, which could result in less loss. High pixel ranges will receive many representatives when choosing to update weights. This might reduce the gap between the high and low pixel ranges if the intensities are adjusted to minimize discrepancies in image processing caused by various pixel ranges. The noise reduction process helps to achieve the best performance metrics.
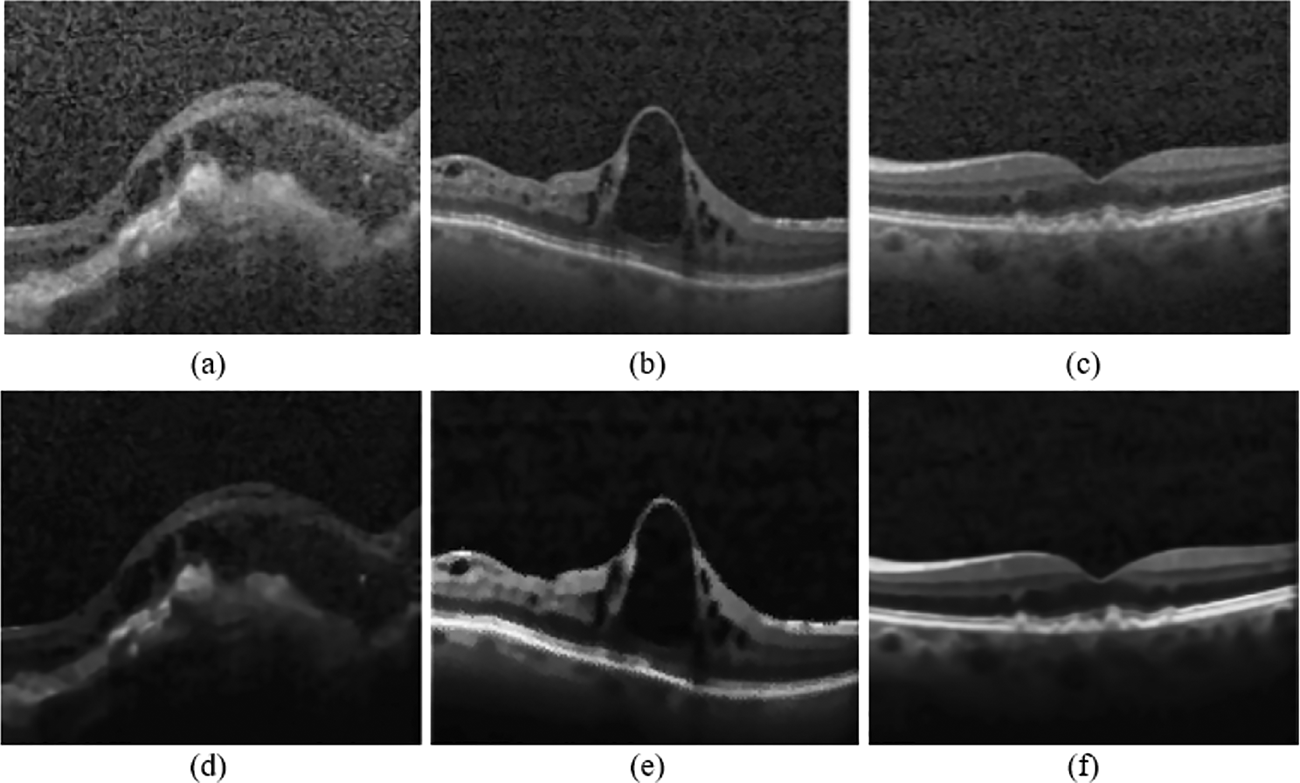
Figure 5: (a–c): Input OCT images, (d–f) Preprocessed images using the proposed technique
4.2 Segmentation Using Context Encoding Deep Neural Network (CEDNN)
The network is used to capture the information present in the retinal image. It is based on the Residual Neural Network (ResNet). The features are given as input to the contextual encoder layer, which generates class-dependent feature maps. The contextual information required for the top layer is learned from the scaling factor. The fully connected layer learns features from the generated feature maps. The training module of semantic encoding loss calculations has been executed parallelly, and it avoids pixel-wise loss. The object class contains details of the pixel-wise loss for non-blood vessel pixels, which are omitted by this segmentation technique. The convolution process optimizes the output context encoder module. It reduces the losses of the semantic encoder and other pixel-wise losses.
The input image is collected and pre-trained by CNN, as illustrated in Fig. 6. Hence, the input feature maps are obtained from the source image. Then, the context encoder generates the encoding semantics and predicts the scaling factors required for the network. The generated semantics are given as an input for pixel-wise prediction. At last, the decoder generates the final output of segmented feature maps at a high level. The feature encoder consists of the information on pre-trained feature vectors of the corresponding image in the form of a feature map.
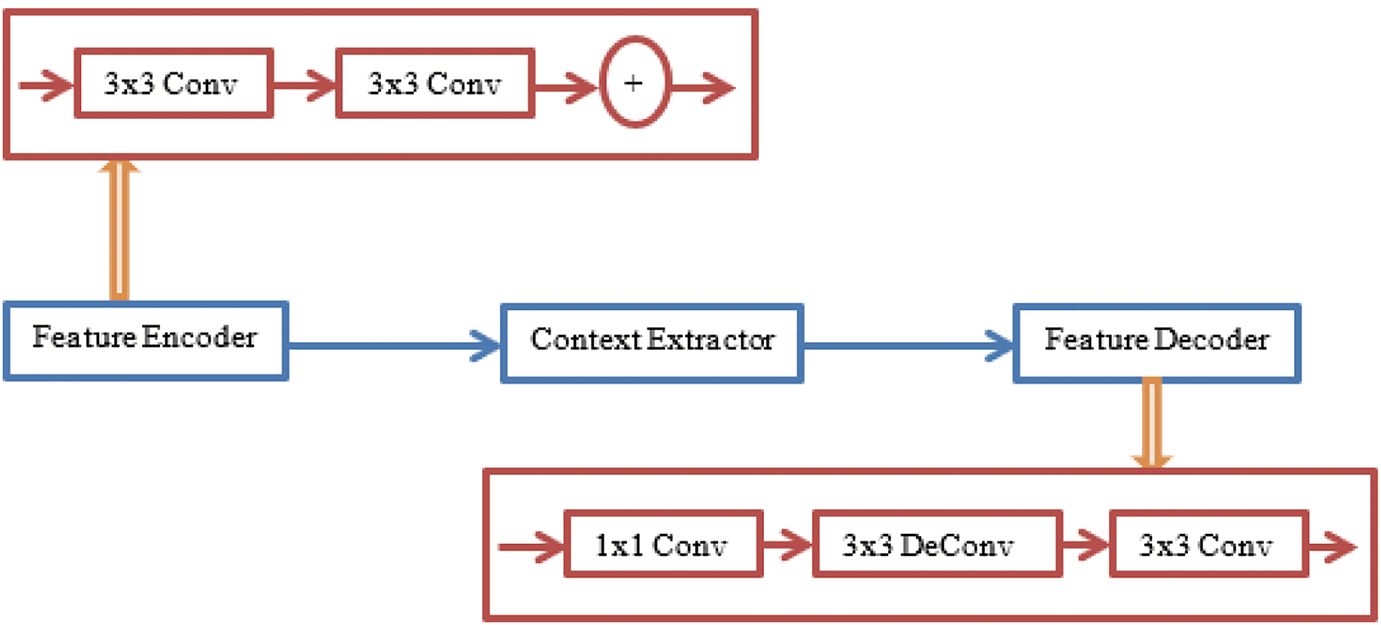
Figure 6: The proposed Context Encoding Deep Neural Network (CEDNN) for OCT image segmentation
The feature map is represented by
The 3D volumetric data generates features in the 3D feature space. The spatial decomposition of the image leads to efficient parameter determination and produces non-linear volumetric data. The 3D convolutional operation applied to the image is represented in Eq. (3).
The size of the 3D kernel
The outer product operation of the 3D kernel is represented as a one-dimensional vector as follows.
The Eq. (3) is rewritten as follows.
where
The multi-kernel pooling layer contains feature maps of various sizes. The dimension of the feature map is reduced to 1/N of the original input image’s feature dimension. The context extractor extracts the information of blood vessel pixels and ignores other non-blood vessel pixels. In the end, it generates vascular feature maps. In the receptive field, 1 × 1 convolution is applied with the linear activation function. The other training features are added with the original features in the receptive field. So that the sizeable receptive field could extract more high-level abstract features from these large objects. The segmentation loss is tested by applying different weights. The segmentation value of 0.2 yields the best performance. The decoder consists of 1 × 1 and 3 × 3 convolution filters and performs the convolution operations. The decoder generates the segmentation result of the vascular map.
The proposed system significantly influenced size measurements of correct anatomical slab segmentation. The failure to adjust segmentation boundaries is a substantial cause of error for the measurement area. Although this is not necessary for experimental data comparing many scans from a single individual, these flaws restrict the capacity to compare or combine field data in all investigations and OCT devices. Fig. 6 depicts the 3D-data cube of the optic nerve head area captured from an OCT image. The layer boundary includes the cartesian coordinates. The black lines on this image indicate voxels, even though they were made up of 200 × 200 B-scans. A notable aspect of deep learning is its performance. As a result of their perceived invisibility, deep learning systems are often referred to as black boxes. This phase involves the generation of activation maps for each class. As shown in Fig. 7, the activation maps’ focus regions were used to derive most CNN characteristics.
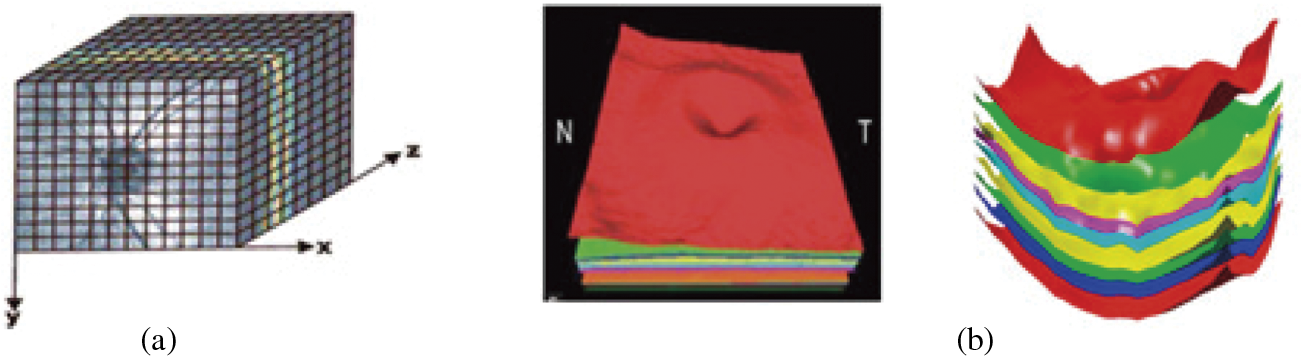
Figure 7: (a) 3D rendering of 11 layers of an OCT image obtained through B-scans; (b) Boundaries are detected through the proposed method
The layers are segmented, and Fig. 7 shows the sample image in the experimental dataset. This model utilizes single-slice segmentation on a 3D OCT image, segmenting the entire macular layer.
The shape-prior approach has prior information on the shape of different voxel locations. The OCT B-Scan propagates the segmentation labels into a region and identifies its reflectivity values. Beginning at the mid-slice, the scan advances to the cross-section. The acquired OCT image scan captures voxels of the images at 1024 × 1024 × 5 dimensions. The 3D representation of these images is visualized using the activation map, as shown in Fig. 8. The 3D blood vessel view is obtained through OCT images.
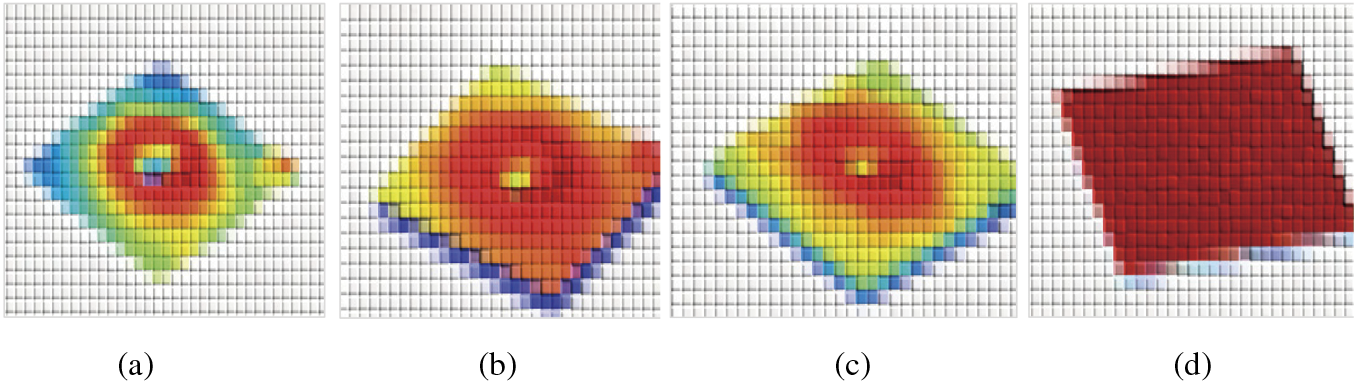
Figure 8: The segmented 3D-OCT layers. (a) surface of layer 1; (b) surface of layer 7; (c) surface of layers 8 to 11; (d) surface of layers 2 to 6
The vessel segmentation algorithm provides details about vessel density, diameter, and vessel vasculature. The proposed method is tested over the public dataset. This technique plays an efficient role in quantifying results in Ophthalmology for the diagnosis of eye disease. Using the non-contact imaging technique, OCT provides structure information on blood vessel components through light backscattering. The choroidal veins have a higher intensity than the neighboring background tissues.
The 3D-OCT image contains 11 layers, and these layers are segmented in an n-iteration as shown in Algorithm 1.

3D blood perfusion maps are obtained through the OCT speckle-signal induced by the blood vessels. The artifacts of the OCT technique appear as a tail artifact at the bifurcation point, which has changed shape into a line instead of a circular shape. Since the signals are highly scattered by red blood cells while they receive the speckle signal below the vessels, shadow-like artifacts are induced on the captured image. The proposed techniques improve the most failed algorithms in this area. The generated feature maps are visualized by activation mapping.
Convolutional layer 6 generates 256 feature maps. This is resized into an input size of 512 × 512 from the averaged feature map. Fig. 9 shows the results of the iterative segmentation technique, while Fig. 10 shows the segmented malignant of the OCT image. The acquired results are compared to the corresponding ground truth images. The results reveal that the segmentation results are consistent with ground truth. The proposed technique monitors the changes in the diameter of blood vessels, lesions, and vasculature.
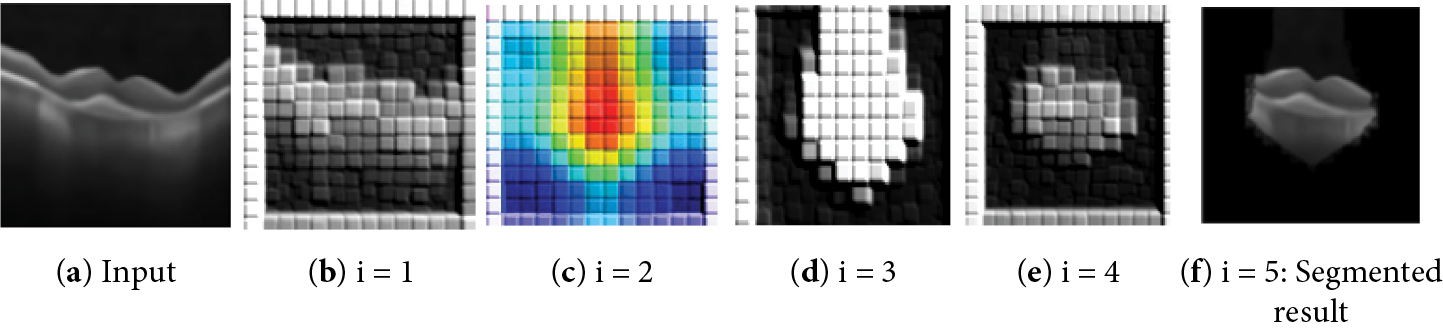
Figure 9: The results of the segmentation process of the input image
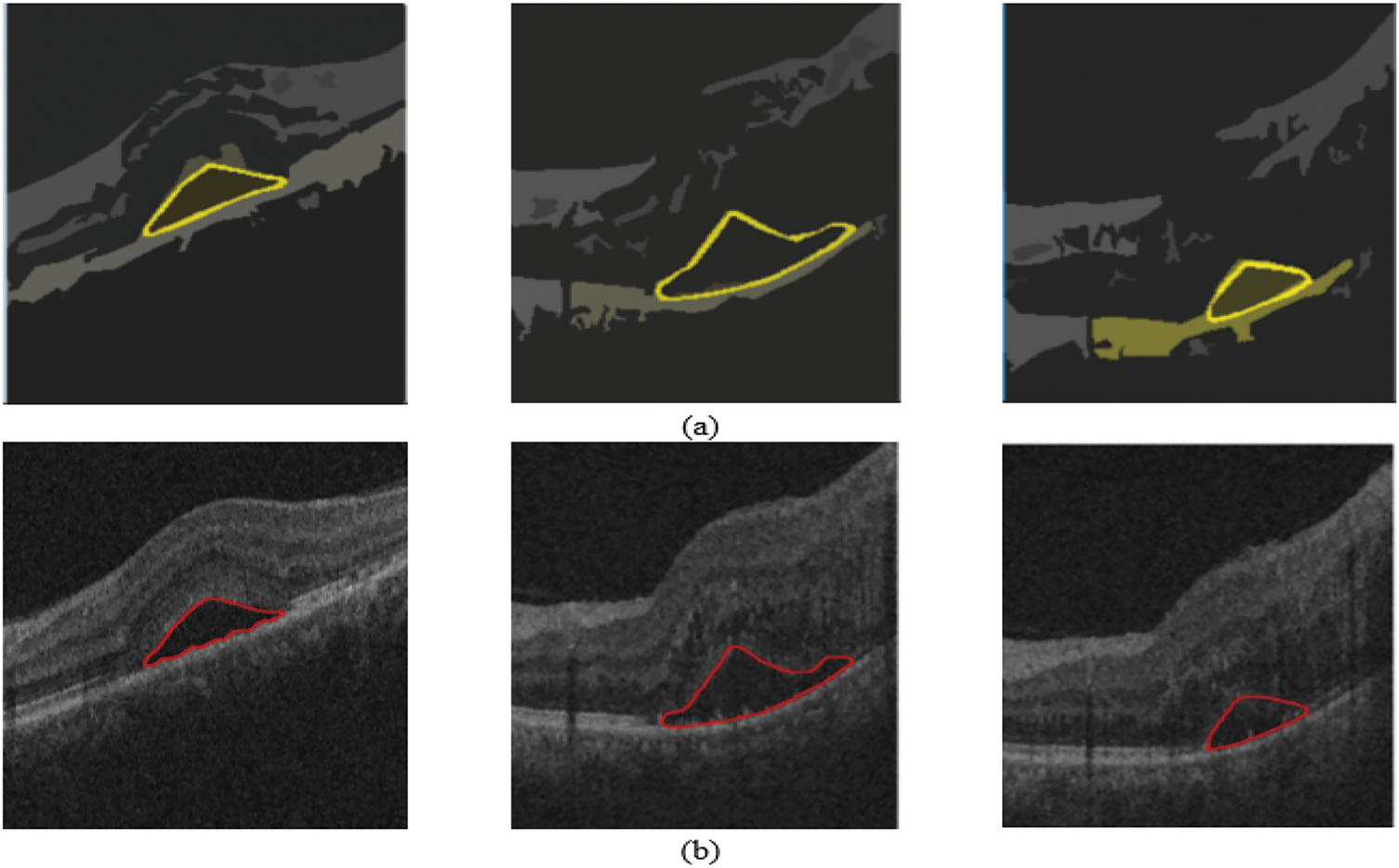
Figure 10: Results on 3D OCT image: (a) Ground Truth; (b) Obtained segmented tumors
The proposed research quantifies the diameter of the newly formed vessels in the retina. The segmentation findings concerning the ground truth images are examined. The experts use their manual skills to identify these ground truth.
As shown in Fig. 11, the model focuses on important regions of the retina, as shown by Grad-CAM representations for retinal disorders. The Choroidal Neovascularization (CNV) heatmap shows aberrant blood vessel development under the retina, usually close to the macula. The model focuses on areas that exhibit retinal thickening or swelling, frequently near the macula, which is a sign of fluid buildup in Diabetic Macular Edema (DME). The heatmap in Drusen highlights the yellowish deposits that indicate age-related macular degeneration beneath the retina, usually close to the optic disc or macula. The heatmap displays a more diffuse pattern for normal retinal images, on the other hand, which reflects the absence of diseases and the model’s emphasis on the retina’s general structure. The model learns and concentrates on these visuals, which makes them an invaluable clinical validation tool.
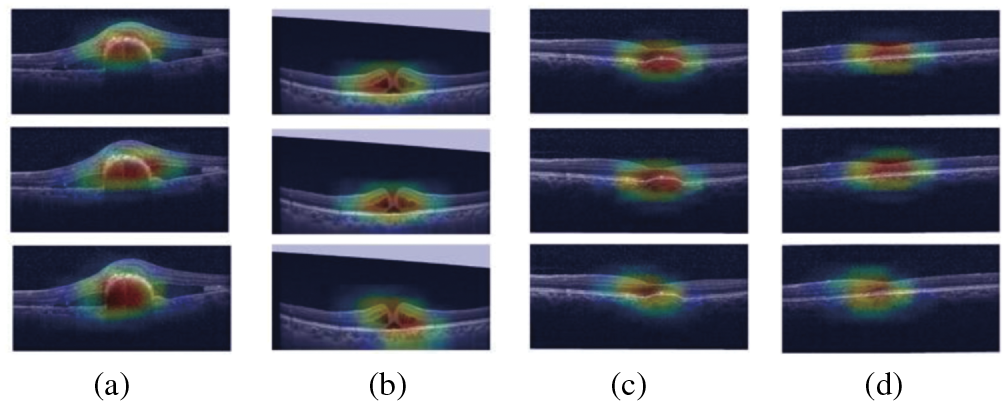
Figure 11: GradCam visualization maps of (a) CN; (b) DME; (c) Drusen; (d) Normal image
The proposed algorithm’s performance is measured using the following metrics.
i. The algorithm’s sensitivity (recall) indicates how well the algorithm can identify blood vessels.
ii. Specificity refers to the algorithm’s ability to identify non-blood vessels accurately.
iii. The ratio of the total number of pixels that are successfully recognized to the number of image fields of vision is known as accuracy.
iv. Out of all projected positive instances, precision is the percentage of accurately predicted positive cases.
v. The F1-score balances accuracy and recall by taking the harmonic mean of the two measures.
vi. The Confidence Interval (CI) for a performance metric such as accuracy may be computed using the formula in Eq. (15).
where:
•
• Z = preferred degree of confidence
•
The proposed Context Encoding Deep Neural Network technique improves the accuracy to 99.3%, sensitivity (recall) to 99.4%, specificity to 99%, precision to 98.91%, and F1-score to 99.2%. The proposed technique outperformed the competitive methods on both the public dataset and clinical images. Considering the findings of this assessment, it is concluded that this technique precisely separates the distinct layers from patients affected by upgraded stages of purtscher retinopathy for a wide variety of images. There is no over-segmentation or under-segmentation during the observation.
Fig. 12 indicates the model’s strong performance in classifying 84,495 images. As shown in Table 2, with a high sensitivity of 99.4%, it successfully identifies 41,993 true positives while only misclassifying 254 cases as false negatives. Specificity of 99% shows the model’s reliability in identifying true negatives, with 41,824 correct predictions and 423 false positives, reflecting minimal misclassification of negative cases as positive. Overall, the model’s accuracy of 99.3% highlights small fraction of errors in the overall dataset.
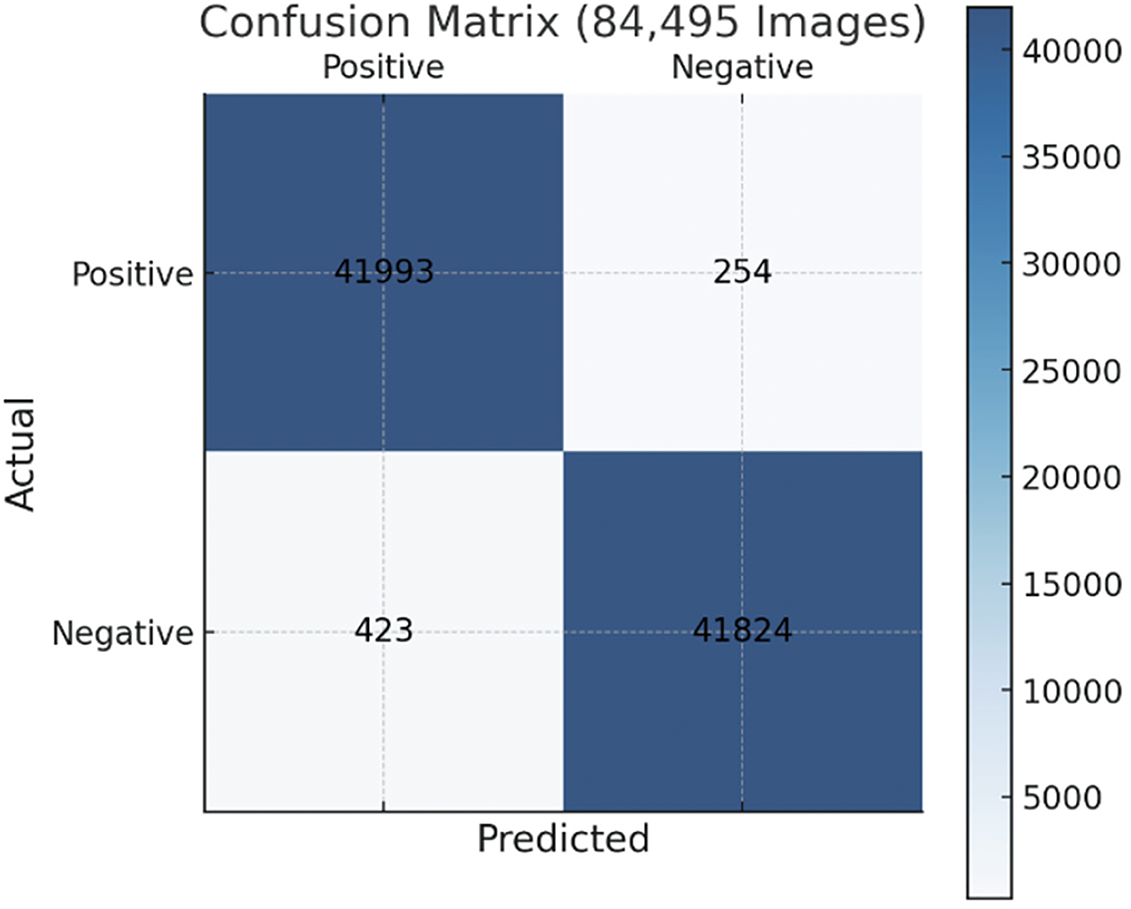
Figure 12: Confusion matrix of the proposed method’s performance

In the proposed purtscher retinopathy classification, an accuracy of 99.3% with a 95% confidence interval of (99.12% and 99.48%) implies that the model performs exceptionally well in correctly classifying purtscher retinopathy images, such as OCT scans, as either positive or negative for the presence of the disease. The proposed Context-Encoding Deep Neural Network technique improves accuracy to 99.3%, sensitivity to 99.4%, and specificity to 99%.
As shown in Table 2, Sensitivity 99.40% lies between 99.32% and 99.48%, so the margin of error is ±0.08%; Specificity 99% lies between 98.88% and 99.12%, so the margin of error is ±0.12%; Accuracy 99.30% lies between 99.12% and 99.48%, so the margin of error is ±0.18%.
The algorithm never compromises its quality at any cost. The proposed technique outperformed the competitive methods on the public dataset and clinical images. Considering the findings of this assessment, it is concluded that this technique precisely separates the distinct layers from patients affected by upgraded stages of purtscher retinopathy for a wide variety of images. There is no over-segmentation or under-segmentation during the observation.
Fig. 13 demonstrates the ROC values for the proposed method. The training dataset helps stabilize the proposed technique’s performance. The AUC of the ROC curve on the training dataset is 98.2%, while on the test data set, it is 98.9%. In terms of sensitivity, specificity, and accuracy, the suggested model performs better than the state-of-the-art model.
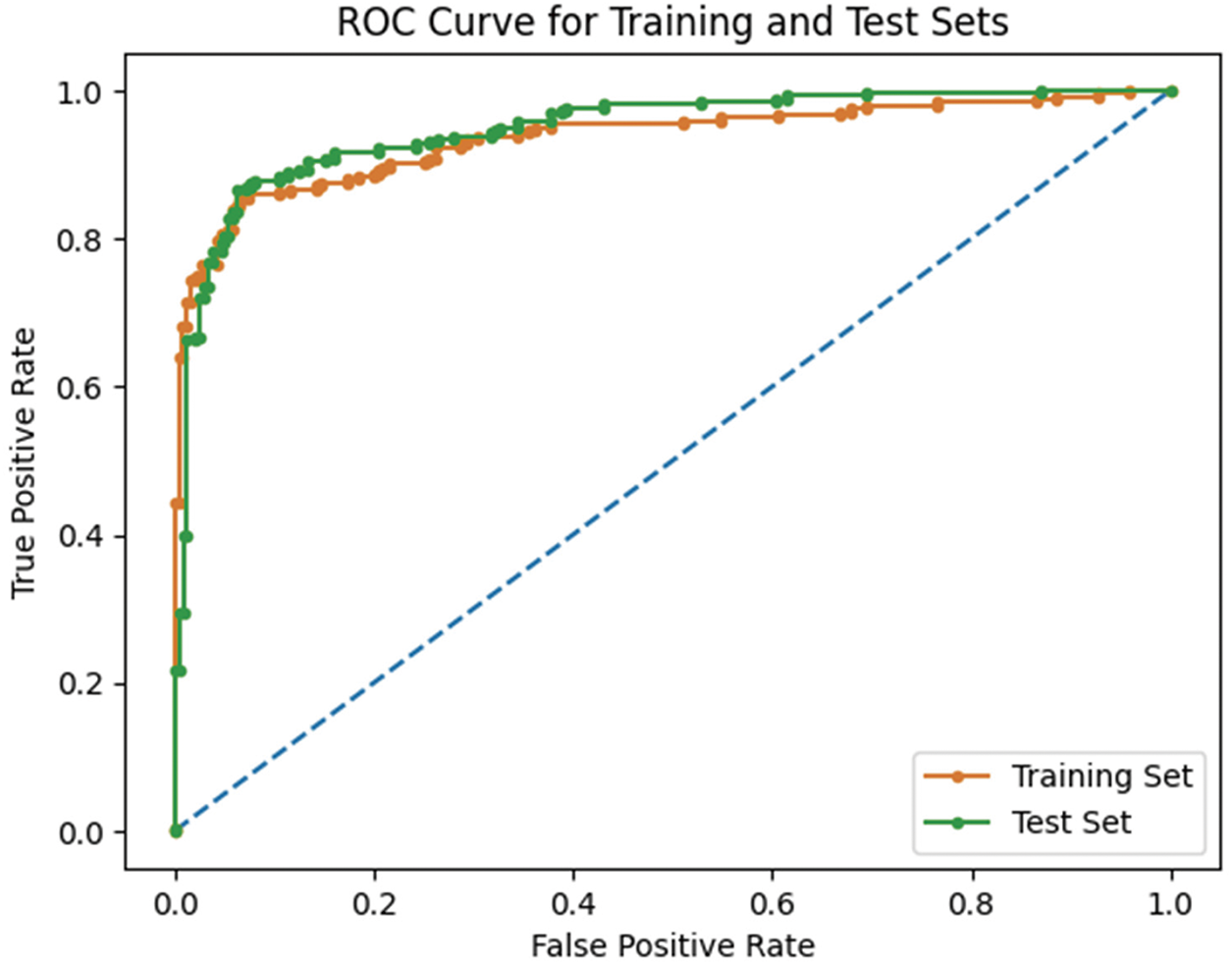
Figure 13: The ROC of the proposed approach on the test and training dataset
Table 3 shows the computational complexity and Floating-Point Operations (FLOPs) for the various phases of a 3D imaging process. Segmentation is the most computationally demanding step, needing 87.9 G FLOPs, while pre-processing is the least demanding, costing 0.15 G FLOPs. The classification step needs 13.3 G FLOPs, but feature aggregation is relatively low, requiring just 0.000512 G FLOPs.

Table 4 outlines key hyperparameters for the Context Encoding Deep Neural Network (CEDNN) used in retinal image segmentation and analysis. It includes values for learning rate, optimizer choice, batch size, and other parameters like dropout rate, convolutional layers, and kernel size. These settings are vital for optimizing the network’s performance in retinal layer segmentation and purtscher retinopathy analysis using OCT images. The values provided serve as starting points, which may require fine-tuning based on the specific dataset and application.

The proposed Context Encoding Deep Neural Network (CEDNN) model, combining hyperparameter tuning, OCT pre-processing, and deep learning optimization, has significant clinical potential. Its high accuracy and sensitivity make it suitable for early detection of purtscher retinopathy. By automating OCT scan analysis, the model can ease the workload of ophthalmologists, ensuring faster and more efficient diagnoses, particularly in high-volume or resource-limited settings. Its objective and constant performance guarantees dependable outcomes, making it an invaluable tool in clinical settings.
The ophthalmologist analyzed and tested the proposed technique using the segmentation findings of OCT images acquired from public databases and real-time clinical images. The dataset contains both normal and abnormal images. The vessel depigments are proactively removed from the model, and the system traces all small blood vessels. Fig. 14 shows the results acquired in real-time OCT clinical images.
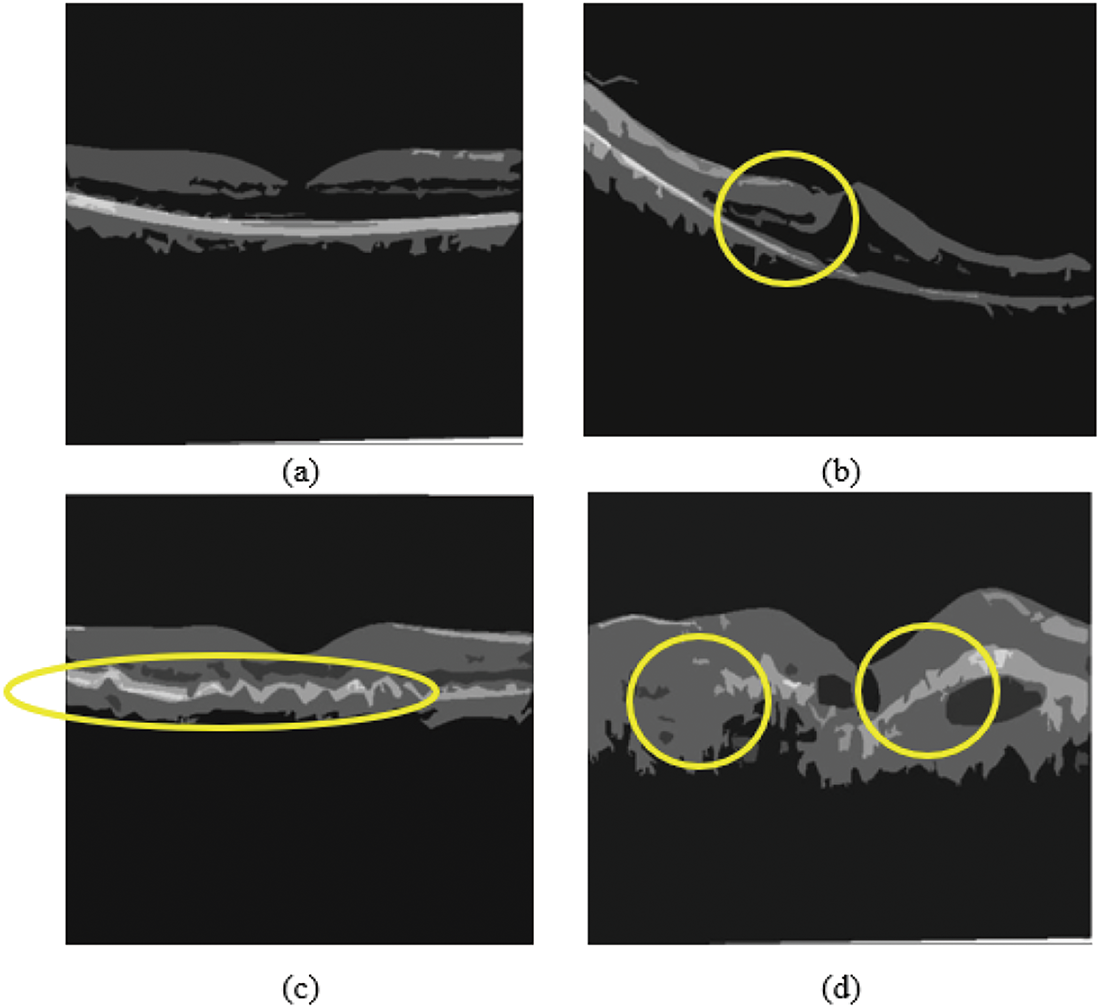
Figure 14: Real-time clinical OCT image classification obtained from hospital: (a) Normal OCT, (b) Macular edema, (c) Drusen, (d) Choroidal Neovascularization
The experts used various criteria to evaluate the segmentation outcomes of the methods presented. Flagging, information signal distortion, and visibility darken the images near the corners. This model proves the significance of an application in medical imaging for segmenting retinal layers in OCT images.
The spectral OCT image was sufficient to diagnose multifocal retinal occlusions if dye-based an-giography is unavailable. Because of the repeatability of OCT, the proposed system tracks the disease’s dynamic progress. The imagery and analysis strategies are applied to various occlusive vascular retinal and choroidal disorders. In addition, 3D representations of surface data led to superior performance compared to 2D representations. The proposed Context Encoding Deep Neural Network (CEDNN) outperforms the competitive methods in segmenting the different layers and classifying the pathologies. The identified pathological features are used to classify the severity of purtscher retinopathy disease. The proposed method segments the complex retinal structures with notable curvatures and other pathological anomalies. Numerous ground truth numerical data point to the effectiveness of the proposed approach in segmenting normal and diseased OCT images. Finally, the proposed system considered that it is beneficial to estimate the temporal dimension, and forecasting of quick impact is also practicable. Extension to different types of diseases is planned for future studies and additional clinical research.
Acknowledgement: The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work.
Funding Statement: This research was funded by the Deanship of Research and Graduate Studies at King Khalid University through small group research under grant number RGP1/180/46.
Author Contributions: Conceptualization, Anand Deva Durai Chelladurai; Data curation, Theena Jemima Jebaseeli; Formal analysis, Omar Alqahtani; Funding acquisition, Prasanalakshmi Balaji; Investigation, Omar Alqahtani; Project administration, Anand Deva Durai Chelladurai and Prasanalakshmi Balaji; Resources, Jeniffer John Simon Christopher; Software, Prasanalakshmi Balaji; Supervision, Theena Jemima Jebaseeli; Visualization, Jeniffer John Simon Christopher; Writing—original draft, Anand Deva Durai Chelladurai; Writing—review & editing, Prasanalakshmi Balaji. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in OCT Dataset: 10.17632/rscbjbr9sj.3.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
Nomenclature
| OCT | Optical Coherence Tomography |
| CEDNN | Context Encoding Deep Neural Network |
| pRNFL | peripapillary Retinal Nerve Fiber Layer |
| ILM | Inner-Limiting Membrane |
| OPL | Outer Plexiform Layer |
| CNN | Convolutional Neural Network |
| DME | Diabetic Macular Edema |
| DR | Diabetic Retinopathy |
| CNV | Choroidal Neovascularization |
| CLAHE | Contrast Limited Adaptive Histogram Equalization |
| ROC | Receiver Operating Characteristic Curve |
| AUC | Area Under Curve |
| OCT | Optical Coherence Tomography |
References
1. Ahronovich E, Shen JH, Vadakkan TJ, Prasad R, Joos KM, Simaan N. Five degrees-of-freedom mechanical arm with remote center of motion (RCM) device for volumetric optical coherence tomography (OCT) retinal imaging. Biomed Opt Express. 2024;15(2):1150–62. doi:10.1364/BOE.505294. [Google Scholar] [PubMed] [CrossRef]
2. Koyazo JT, Lay-Ekuakille A, Ugwiri MA, Trabacca A, De Santis R, Urooj S, et al. Optical coherence tomography sensing: image post processing for neuropathy detection. Measurement. 2024;236(3):115037. doi:10.1016/j.measurement.2024.115037. [Google Scholar] [CrossRef]
3. Kurokawa K, Nemeth M. Multifunctional adaptive optics optical coherence tomography allows cellular scale reflectometry, polarimetry, and angiography in the living human eye. Biomed Opt Express. 2024;15(2):1331–54. doi:10.1364/BOE.505395. [Google Scholar] [PubMed] [CrossRef]
4. Carriello MA, Costa DFB, Alvim PHP, Pestana MC, Bicudo DDS, Gomes EMP, et al. Retinal layers and symptoms and inflammation in schizophrenia. Eur Arch Psychiatry Clin Neurosci. 2024;274(5):1115–24. doi:10.1007/s00406-023-01583-0. [Google Scholar] [PubMed] [CrossRef]
5. Mahendradas P, Acharya I, Rana V, Bansal R, Ben Amor H, Khairallah M. Optical coherence tomography and optical coherence tomography angiography in neglected diseases. Ocul Immunol Inflamm. 2024;32(7):1427–34. doi:10.1080/09273948.2023.2211161. [Google Scholar] [PubMed] [CrossRef]
6. Bansal P, Harjai N, Saif M, Mugloo SH, Kaur P. Utilization of big data classification models in digitally enhanced optical coherence tomography for medical diagnostics. Neural Comput Appl. 2024;36(1):225–39. doi:10.1007/s00521-022-07973-0. [Google Scholar] [CrossRef]
7. Ahmed H, Zhang Q, Donnan R, Alomainy A. Denoising of optical coherence tomography images in ophthalmology using deep learning: a systematic review. J Imaging. 2024;10(4):86. doi:10.3390/jimaging10040086. [Google Scholar] [PubMed] [CrossRef]
8. Zhang X, Zhong H, Wang S, He B, Cao L, Li M, et al. Subpixel motion artifacts correction and motion estimation for 3D-OCT. J Biophotonics. 2024;17(9):e202400104. doi:10.1002/jbio.202400104. [Google Scholar] [PubMed] [CrossRef]
9. AlMohimeed I, Sikkandar MY, Mohanarathinam A, Parvathy VS, Ishak MK, Karim FK, et al. Sandpiper optimization algorithm with region growing based robust retinal blood vessel segmentation approach. IEEE Access. 2024;12:28612–20. doi:10.1109/ACCESS.2024.3365273. [Google Scholar] [CrossRef]
10. Coric D, Balk LJ, Verrijp M, Eijlers A, Schoonheim MM, Killestein J, et al. Cognitive impairment in patients with multiple sclerosis is associated with atrophy of the inner retinal layers. Mult Scler. 2018;24(2):158–66. doi:10.1177/1352458517694090. [Google Scholar] [PubMed] [CrossRef]
11. Hogg RE, Wright DM, Dolz-Marco R, Gray C, Waheed N, Teussink MM, et al. Quantitative parameters from OCT angiography in patients with diabetic retinopathy and in those with only peripheral retinopathy compared with control participants. Ophthalmol Sci. 2021;1(2):100030. doi:10.1016/j.xops.2021.100030. [Google Scholar] [PubMed] [CrossRef]
12. Hirano T, Hoshiyama T, Hirabayashi K, Wakabayashi M, Toriyama Y, Tokimitsu M, et al. Vitreoretinal interface slab in OCT angiography for detecting diabetic retinal neovascularization. Ophthalmol Retin. 2020;4(6):588–94. doi:10.1016/j.oret.2020.01.004. [Google Scholar] [PubMed] [CrossRef]
13. Horiguchi H, Kurosawa M, Shiba T. Posterior capsule rupture with FLACS due to erroneous interpretation of a high OCT intensity area in anterior vitreous. Am J Ophthalmol Case Rep. 2020;19:100811. doi:10.1016/j.ajoc.2020.100811. [Google Scholar] [PubMed] [CrossRef]
14. Mehta NS, Lee JG, Gupta L, Zhou DB, Andrade Romo JS, Castanos MV, et al. Correlation of OCT angiography vessel densities and the early treatment diabetic retinopathy study grading scale. Ophthalmol Retin. 2021;5(7):714–5. doi:10.1016/j.oret.2020.11.009. [Google Scholar] [PubMed] [CrossRef]
15. Rathke F, Schmidt S, Schnorr C. Probabilistic intra-retinal layer segmentation in 3-D OCT images using global shape regularization. Med Image Anal. 2014;18(5):781–94. doi:10.1016/j.media.2014.03.004. [Google Scholar] [PubMed] [CrossRef]
16. Guo YK, Hormel TT, Gao LQ, You QS, Wang BJ, Flaxel CJ, et al. Quantification of nonperfusion area in montaged widefield OCT angiography using deep learning in diabetic retinopathy. Ophthalmol Sci. 2021;1(2):100027. doi:10.1016/j.xops.2021.100027. [Google Scholar] [PubMed] [CrossRef]
17. Sacconi R, Lutty GA, Mullins RF, Borrelli E, Bandello F, Querques G. Subretinal pseudocysts: a novel OCT finding in diabetic macular edema. Am J Ophthalmol Case Rep. 2019;16(10):100567. doi:10.1016/j.ajoc.2019.100567. [Google Scholar] [PubMed] [CrossRef]
18. Arya M, Filho MB, Rebhun CB, Moult EM, Lee BK, Alibhai Y, et al. Analyzing relative flow speeds in diabetic retinopathy using variable interscan time analysis OCT Angiography. Ophthalmol Retin. 2021;5(1):49–59. doi:10.1016/j.oret.2020.06.024. [Google Scholar] [PubMed] [CrossRef]
19. Gonzalez-Lopez A, deMoura J, Novo J, Ortega M, Penedo MG. Robust segmentation of retinal layers in optical coherence tomography images based on a multistage active contour model. Heliyon. 2019;5(2):e01271. doi:10.1016/j.heliyon.2019.e01271. [Google Scholar] [PubMed] [CrossRef]
20. Shiraki A, Sakimoto S, Eguchi M, Kanai M, Hara C, Fukushima Y, et al. Analysis of progressive neovascularization in diabetic retinopathy using widefield OCT angiography. Ophthalmol Retin. 2021;6(2):153–60. doi:10.1016/j.oret.2021.05.011. [Google Scholar] [PubMed] [CrossRef]
21. Haydar B, Chretien S, Bartoli A, Tamadazte B. Three-dimensional OCT compressed sensing using the shearlet transform under continuous trajectories sampling. Inform Med Unlocked. 2020;19:100287. doi:10.1016/j.imu.2019.100287. [Google Scholar] [CrossRef]
22. Hojati S, Kafieh R, Fardafshari P, Fard MA. A MATLAB package for automatic extraction of flow index in OCT-A images by intelligent vessel manipulation. SoftwareX. 2020;12(12):100510. doi:10.1016/j.softx.2020.100510. [Google Scholar] [CrossRef]
23. Sanborn GE, Wroblewski JJ. Evaluation of a combination digital retinal camera with spectral-domain optical coherence tomography (SD-OCT) that might be used for the screening of diabetic retinopathy with telemedicine: a pilot study. J Diabetes Its Complicat. 2018;32(11):1046–50. doi:10.1016/j.jdiacomp.2018.08.010. [Google Scholar] [PubMed] [CrossRef]
24. Wang FP, Saraf SS, Zhang QQ, Wang RK, Rezaei KA. Ultra-widefield protocol enhances automated classification of diabetic retinopathy severity with OCT Angiography. Ophthalmol Retin. 2020;4(4):415–24. doi:10.1016/j.oret.2019.10.018. [Google Scholar] [PubMed] [CrossRef]
25. Schwartz R, Khalid H, Sivaprasad S, Nicholson L, Anikina E, Sullivan P, et al. Objective evaluation of proliferative diabetic retinopathy using OCT. Ophthalmol Retin. 2020;4(2):164–74. doi:10.1016/j.oret.2019.09.004. [Google Scholar] [PubMed] [CrossRef]
26. de Moura J, Novo J, Charlon P, Fernandez MI, Ortega M. Retinal vascular analysis in a fully automated method for the segmentation of DRT edemas using OCT images. Procedia Comput Sci. 2019;159:600–9. doi:10.1016/j.procs.2019.09.215. [Google Scholar] [CrossRef]
27. Samagaio G, de Moura J, Novo J, Orteg M. Automatic segmentation of diffuse retinal thickening edemas using optical coherence tomography images. Procedia Comput Sci. 2018;126:472–81. doi:10.1016/j.procs.2018.07.281. [Google Scholar] [CrossRef]
28. Diaz M, Novo J, Penedo MG, Orteg M. Automatic extraction of vascularity measurements using OCT-A images. Procedia Comput Sci. 2018;126:273–81. doi:10.1016/j.procs.2018.07.261. [Google Scholar] [CrossRef]
29. Xie J, Chen S, Wang NS, Wang LL, Bob E, Liu LB. Automatic differentiation of non keratinized stratified squamous epithelia and columnar epithelia through feature structure extraction using OCT. Biomed Signal Process Control. 2020;60(2):101919. doi:10.1016/j.bspc.2020.101919. [Google Scholar] [CrossRef]
30. Das V, Dandapat S, Bora PK. Multi-scale deep feature fusion for automated classification of macular pathologies from OCT images. Biomed Signal Process Control. 2019;54:101605. doi:10.1016/j.bspc.2019.101605. [Google Scholar] [CrossRef]
31. Gonzalez-Lopez A, Ortega M, Penedo MG, Charlon P. A web-based framework for anatomical assessment of the retina using OCT. Biosyst Eng. 2015;138(10):44–58. doi:10.1016/j.biosystemseng.2015.04.001. [Google Scholar] [CrossRef]
32. Zhang HZ, Essa E, Xie XH. Automatic vessel lumen segmentation in optical coherence tomography (OCT) images. Appl Soft Comput J. 2020;88(2):106042. doi:10.1016/j.asoc.2019.106042. [Google Scholar] [CrossRef]
33. Bilal A, Imran A, Baig TI, Liu X, Long H, Alzahrani A, et al. Improved support vector machine based on CNN-SVD for vision-threatening diabetic retinopathy detection and classification. PLoS One. 2024;19(1):e0295951. doi:10.1371/journal.pone.0295951. [Google Scholar] [PubMed] [CrossRef]
34. Wong CYT, Liu T, Wong TL, Tong JMK, Lau HHW, Keane PA. Development and validation of an automated machine learning model for the multi-class classification of diabetic retinopathy, central retinal vein occlusion and branch retinal vein occlusion based on color fundus photographs. JFO Open Ophthalmol. 2024;7:100117. doi:10.1016/j.jfop.2024.100117. [Google Scholar] [CrossRef]
35. Albahli S, Nazir T, Irtaza A, Javed A. Recognition and detection of diabetic retinopathy using Densenet-65 based Faster-RCNN. Comput Mater Contin. 2021;67(2):014691. doi:10.32604/cmc.2021.014691. [Google Scholar] [CrossRef]
36. Lin CL, Wu KC. Development of revised ResNet-50 for diabetic retinopathy detection. BMC Bioinform. 2023;24(1):157. doi:10.1186/s12859-023-05293-1. [Google Scholar] [PubMed] [CrossRef]
37. Altan G. DeepOCT: an explainable deep learning architecture to analyze macular edema on OCT images. Eng Sci Technol Int J. 2022;34(23):101091. doi:10.1016/j.jestch.2021.101091. [Google Scholar] [CrossRef]
38. Vasireddi HK, Devi KS, Reddy GR. DR-XAI: explainable deep learning model for accurate diabetic retinopathy severity assessment. Arab J Sci Eng. 2024;49(9):12899–917. doi:10.1007/s13369-024-08836-7. [Google Scholar] [CrossRef]
39. Wang X, Chen H, Ran AR, Luo LY, Chan PP, Tham CC, et al. Towards multi-center glaucoma OCT image screening with semi-supervised joint structure and function multi-task learning. Med Image Anal. 2020;63(1):101695. doi:10.1016/j.media.2020.101695. [Google Scholar] [PubMed] [CrossRef]
40. Hu JJ, Chen YY, Yi Z. Automated segmentation of macular edema in OCT using deep neural networks. Med Image Anal. 2019;55(2):216–27. doi:10.1016/j.media.2019.05.002. [Google Scholar] [PubMed] [CrossRef]
41. Lu DH, Heisler M, Lee S, Ding GWG, Navajas E, Sarunic MV, et al. Deep-learning based multi-class retinal fluid segmentation and detection in optical coherence tomography images using a fully convolutional neural network. Med Image Anal. 2019;54(13):100–10. doi:10.1016/j.media.2019.02.011. [Google Scholar] [PubMed] [CrossRef]
42. Miri MS, Abràmoff MD, Kwon YH, Sonka M, Garvin MK. A machine-learning graph-based approach for 3D segmentation of Bruch’s membrane opening from glaucomatous SD-OCT volumes. Med Image Anal. 2017;39(4):206–17. doi:10.1016/j.media.2017.04.007. [Google Scholar] [PubMed] [CrossRef]
43. Sun ZH, Tang FY, Wong R, Lok J, Szeto SKH, Chan JCK, et al. OCT angiography metrics predict progression of diabetic retinopathy and development of diabetic macular edema: a prospective study. Ophthalmology. 2019;126(12):1675–84. doi:10.1016/j.ophtha.2019.06.016. [Google Scholar] [PubMed] [CrossRef]
44. Liu GD, Xu D, Wang F. New insights into diabetic retinopathy by OCT angiography. Diabetes Res Clin Pract. 2018;142(1):243–53. doi:10.1016/j.diabres.2018.05.043. [Google Scholar] [PubMed] [CrossRef]
45. Novosel J, Thepass G, Lemij HG, de Boer JF, Vermeer KA, van Vliet LJ. Loosely coupled level sets for simultaneous 3D retinal layer segmentation in optical coherence tomography. Med Image Anal. 2015;26(1):146–58. doi:10.1016/j.media.2015.08.008. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools