
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Multi-Firmware Comparison Based on Evolutionary Algorithm and Trusted Base Point
College of Software Engineering, Zhengzhou University of Light Industry, Zhengzhou, 450000, China
* Corresponding Author: Wenbing Wang. Email:
Computers, Materials & Continua 2025, 84(1), 763-790. https://doi.org/10.32604/cmc.2025.065179
Received 05 March 2025; Accepted 24 April 2025; Issue published 09 June 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Multi-firmware comparison techniques can improve efficiency when auditing firmwares in bulk. However, the problem of matching functions between multiple firmwares has not been studied before. This paper proposes a multi-firmware comparison method based on evolutionary algorithms and trusted base points. We first model the multi-firmware comparison as a multi-sequence matching problem. Then, we propose an adaptation function and a population generation method based on trusted base points. Finally, we apply an evolutionary algorithm to find the optimal result. At the same time, we design the similarity of matching results as an evaluation metric to measure the effect of multi-firmware comparison. The experiments show that the proposed method outperforms Bindiff and the string-based method. Precisely, the similarity between the matching results of the proposed method and Bindiff matching results is 61%, and the similarity between the matching results of the proposed method and the string-based method is 62.8%. By sampling and manual verification, the accuracy of the matching results of the proposed method can be about 66.4%.Keywords
As embedded systems evolve toward intelligentization, firmware has transitioned from simple single-function control programs (e.g., 1980s microcontroller firmware [1]) to become a core software component in complex systems. Modern firmware, such as that used in Cisco networking devices and industrial control systems (ICS), integrates advanced features like network protocol stacks, security encryption modules, and multi-architecture compatibility (ARM/X86/RISC-V). This technological advancement has caused firmware complexity to grow exponentially, introducing new security challenges such as heterogeneous compatibility verification and the detection of hidden vulnerabilities [2,3]. To address these challenges, rigorous auditing and analysis of firmware have become essential.
In recent years, binary code similarity detection [4–7] has emerged as a versatile tool for security analysis, playing a critical role in addressing the aforementioned challenges. This technology identifies function correspondences by comparing binary executables to determine their similarity. Its applications are extensive, including malware detection [8–11], plagiarism identification [12–14], vulnerability searching [15–17], and patch analysis [18–21]. In the firmware domain, binary code comparison has been further applied to firmware comparison [22], analyzing the correlation of functions between different firmware versions. As firmware continues to evolve, this capability for comparison and analysis has become indispensable for effective firmware auditing and security analysis.
While binary code comparison techniques have advanced significantly in recent years, they predominantly address one-to-one (O2O) or one-to-many (O2M) scenarios. In O2O methods, tools like BinDiff [23] analyzes pairwise structural or semantic similarities between functions in two programs using control flow graphs (CFGs) or heuristic hashing, establishing a one-to-one correspondence. DEEPBINDIFF [24] leverages machine learning and natural language processing. It combines assembly instructions with CFG structures to generate embedding vectors for each basic block in two binary programs and then iteratively searches for matching basic blocks to achieve more precise one-to-one comparisons. And in O2M methods, Genius [25] converts control flow graphs (CFGs) into high-dimensional numerical feature vectors, uses clustering algorithms to generate a set of feature vectors (i.e., codebook), and combines Locality-Sensitive Hashing (LSH) to quickly filter out candidate functions similar to the query function from a large pool. CEBin [17] integrates embedding-based and comparison-based approaches. It first uses an embedding-based method to efficiently filter out the top K candidate functions from a large-scale function pool, and then employs a comparison-based method to perform precise matching on these candidates. Currently, the study of many-to-many (M2M) comparisons between programs is relatively rare. While some works attempt multi-program analysis, they often reduce the problem to aggregated pairwise comparisons. For example, early works like Kruegel et al. [26] applied CFG graph coloring to detect worm variants, but their dataset (less than 20 MB executables) and pairwise logic limit scalability. Hu et al. [27] employed N-gram opcode features to cluster malware, whereas Farhadi et al. [28] integrated instruction-level clones. However, both approaches simplified M2M comparisons to localized pairwise matching. Even recent innovations like JTrans [29] (transformer-based function matching) and VulHawk [30] (microcode-driven cross-architecture search) extend O2M paradigms without true M2M optimization. To the best of our knowledge, no prior work explicitly addresses M2M firmware function comparison, which requires simultaneous analysis of inter-version dependencies, cross-architecture compatibility, and evolutionary code changes across multiple firmware binaries.
This paper’s main objective is to establish function correspondences between multiple firmwares. To improve the efficacy, we should construct the correspondence between firmware functions as much as possible (called matching or comparison in this paper). To perform the multi-firmware comparison, we first model the multi-firmware matching as a multi-sequence matching problem. Then we propose a fitness function and a population generation and updating method based on trusted base points and local optimal solutions. Finally, we apply an evolutionary algorithm to find the optimal result. At the same time, we design the similarity of matching results as an evaluation metric to measure the effect of multi-firmware comparison.
We evaluate the performance of the proposed method with real-world firmwares of routers. The experiments show that the similarity of matching results between the proposed method and Bindiff is 61%, and the similarity of the matching results between our solution and the string-based method is 62.8%. The accuracy of the matching results of the proposed method is about 66.4% by manual verification through sampling.
In summary, we make the following contributions:
• To the best of our knowledge, we are the first to propose a multi-firmware comparison method based on an evolutionary algorithm. It can be used for the function correspondence construction of multi-firmware.
• We depict the multi-firmware comparison problem with the multi-sequence comparison model and design a fitness function for the evolutionary algorithm.
• We propose a population generation and updating method based on trusted base points and local optimal solutions for multi-firmware comparison.
• We implement our proposed approach and verify the feasibility of our solution on real-world firmwares. The experiments illustrate that our solution outperforms Bindiff [23] (Version 5) and the string-based method.
This section defines the multi-firmware comparison problem and then illustrates the observation with a motivation example.
Inspired by bioinformatics, where conserved regions in gene sequences are identified despite mutations, our model assumes core firmware functions retain logical consistency across versions. Evolutionary algorithms search for globally optimal alignments, avoiding local optima traps inherent in syntax-based methods. To address these challenges, we model multi-firmware comparison as a multi-sequence matching problem.
Given a sequence set
•
• The sequence
• The matrix does not contain columns whose values are all
For N firmwares, we define the results of the multi-firmware comparison in the above way. In this paper,
Fig. 1 shows an example of a function matching matrix corresponding to a multi-firmware comparison. The functions

Figure 1: Example of multi-firmware sequence comparison
Since we focus on firmwares, there is an assumption that there is no randomization of function addresses. Namely, functions in firmware are generally placed in order. To facilitate the subsequent analysis, we add a condition to the above representation, if
This paper uses the optimized evolutionary algorithm to find the best matching result of multi-firmware. Fig. 2 shows the workflow of the optimized evolutionary algorithm.
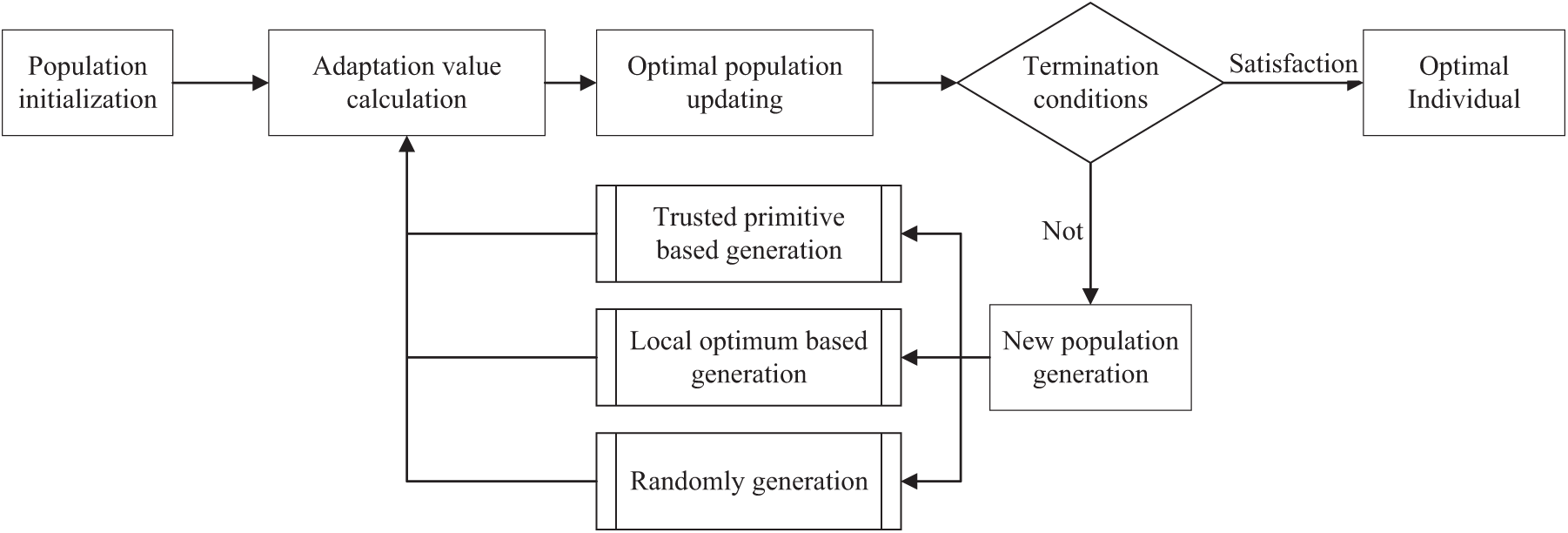
Figure 2: Workflow of optimized evolutionary algorithm
3.1 Workflow of Optimized Evolutionary Algorithm
3.1.1 Population Initialization
The initialization of the population is to provide several initial solutions (seeds). Compared with the completely random generation of function matching matrix, some relatively reliable initial solutions can be provided based on string matching and other methods for multi-firmware matching. To verify the proposed method’s effectiveness, we randomly generate the initial population.
3.1.2 Optimal Population Update
The optimal population is the optimal result accumulated over iterations. The measure of the merit of individuals in a population relies on the fitness function. Since the design of the fitness function also involves the elaboration related to the generation of new populations, we illustrate it in detail in Section 3.2. A proportional selection method and the best individual preservation strategy can update the optimal population. In the former, individuals are selected randomly according to their adaptation value, and their probability is proportional to their adaptation value. The latter is a simple selection of the individual with the highest adaptation value. For the optimal population size (i.e., the number of individuals in the optimal population, denoted as
3.1.3 New Population Generation
The primary purpose of new population generation is to generate several individuals using various methods to provide a basis for updating the optimal population. The prerequisite for new population generation is to determine that there is still a chance to optimize the optimal population. If there is no chance for optimization, the optimal individuals are output directly. Generally, we determine the conditions for termination (i.e., no more updates of the optimal population) in three ways: (1) the adaptation value of the optimal individual reaches a specified size; (2) the number of population updates is more significant than a threshold; (3) the average increase in adaptation value of the optimal population after several updates is less than a threshold. In this paper, since the change of adaptation value at the beginning of the population update is small, we only rely on the number of population updates and the adaptation value of the best individual to determine the termination.
This paper adopts three methods to generate new populations: generation based on trusted base points, local optima, and random generation. The first two methods will be described in Sections 4 and 5. Random generation generates new individuals randomly according to the function matching matrix A. Random generation aims to obtain as many different matching possibilities as possible for each function, which is particularly important for population optimization, especially for generating new populations based on trusted base points.
The fitness function provides a metric for evaluating individuals in a population, also referred to as the “objective function” in some studies. In this paper, the fitness function reflects the similarity of a function matching scheme between firmwares (a function matching matrix as a matching scheme). The fitness function consists of three components: feature similarity
For a multi-firmware comparison, there is a function matching matrix
where
The similarity calculation of the matching function for a single column should also sum the mean values after accumulation, as shown in Eq. (3).
where
Therefore, we designs the scoring function
To determine the
In the case of unequal eigenvectors, since each dimension of the eigenvector of the function is a non-negative integer, the Euclidean distance of the eigenvectors of the function must be a number greater than
In multi-sequence matching, each sequence is not identical. Therefore, it is necessary to form a function matching matrix by inserting empty bits. Theoretically, a large number of empty bits can be inserted. In that case, any number of sequences that are not identical can form a multi-sequence matching scheme and find the corresponding multi-sequence correspondence matrix A. However, the function matching matrix formed in this scenario has no guiding meaning. Therefore, we should limit the number of empty bits. In this paper, we follow the strategy of empty penalty score, and the formula for calculating the empty penalty score of matrixA is shown in Eq. (7).
where
In the traditional scoring for multiple sequence matching, the empty penalty consists of two parts: one is called the starting empty penalty, which is shown as Eq. (7); and the other is called the extended empty penalty. The starting empty penalty affects the number of inserted spaces, while the extended empty penalty affects the continuity of the inserted spaces, i.e., the number of consecutive spaces. In this paper, the formula for calculating the consecutive score is designed based on the idea of extending the empty space, as shown in Eq. (9).
where A is a function matching matrix of N firmwares if the number of columns is L, the sequence that can calculate the consecutive score is only
The strategy of taking positive values for the continuity scores instead of penalty scores is based on the following considerations. The mismatch of functions in different firmwares is often because different firmwares have other functional modules, which will bring continuous missing or changing. In this case, the correct match is destined to bring penalty points due to the presence of empty spaces. At the same time, any two mismatched functions can also calculate the similarity score, and the correct match solution will likely have a lower score than the other solution. Since there are few cases where large segments of consecutive mismatch functions have correspondence between firmwares, there are even fewer cases where a high score can be guaranteed. Therefore, the consecutive scores can positively offset the empty space penalties caused by the overall missing functional modules between different firmwares to reduce mismatches.
In practice, the consecutive score is not integrated into the similarity calculation of each column like the empty penalty score but is calculated and applied separately.
The non-empty similarity is mainly to calculate the function similarity of non-empty terms in a multiple sequence matching column. Only Eq. (3) needs to be modified, as shown in Eq. (10).
If
4 Population Generation Methods Based on Trusted Base Points
In traditional bioinformatics, multiple sequence comparisons often exist conserved locations. Several stable gene fragments remain unchanged for specific functionality during biological evolution, even if the species differ. In multiple sequence comparisons, such similarities are generally conserved locations.
In this paper, the scenario of firmware matching is similar to the case of conserved location, i.e., for a function matching matrix A, column
Each generated seed (i.e., function matching matrix) has at least one individual function of the particular firmware that has found the correct correspondence (even if it is a randomly generated seed). After all, the probability that any firmware function does not find a valid counterpart is extremely low for each seed.
For case ❶, we use it to guide the generation of initial populations. However, not every firmware can find a function with correct correspondence before multiple sequence comparisons. Therefore, we do not discuss it in this paper. For case ❷, we reduce the difficulty of optimal population generation by accumulating columns with high similarity for each seed. Our approach is based on this (i.e., case ❷).
Fig. 3 shows an example of seed generation based on trusted base points. The 3 firmwares
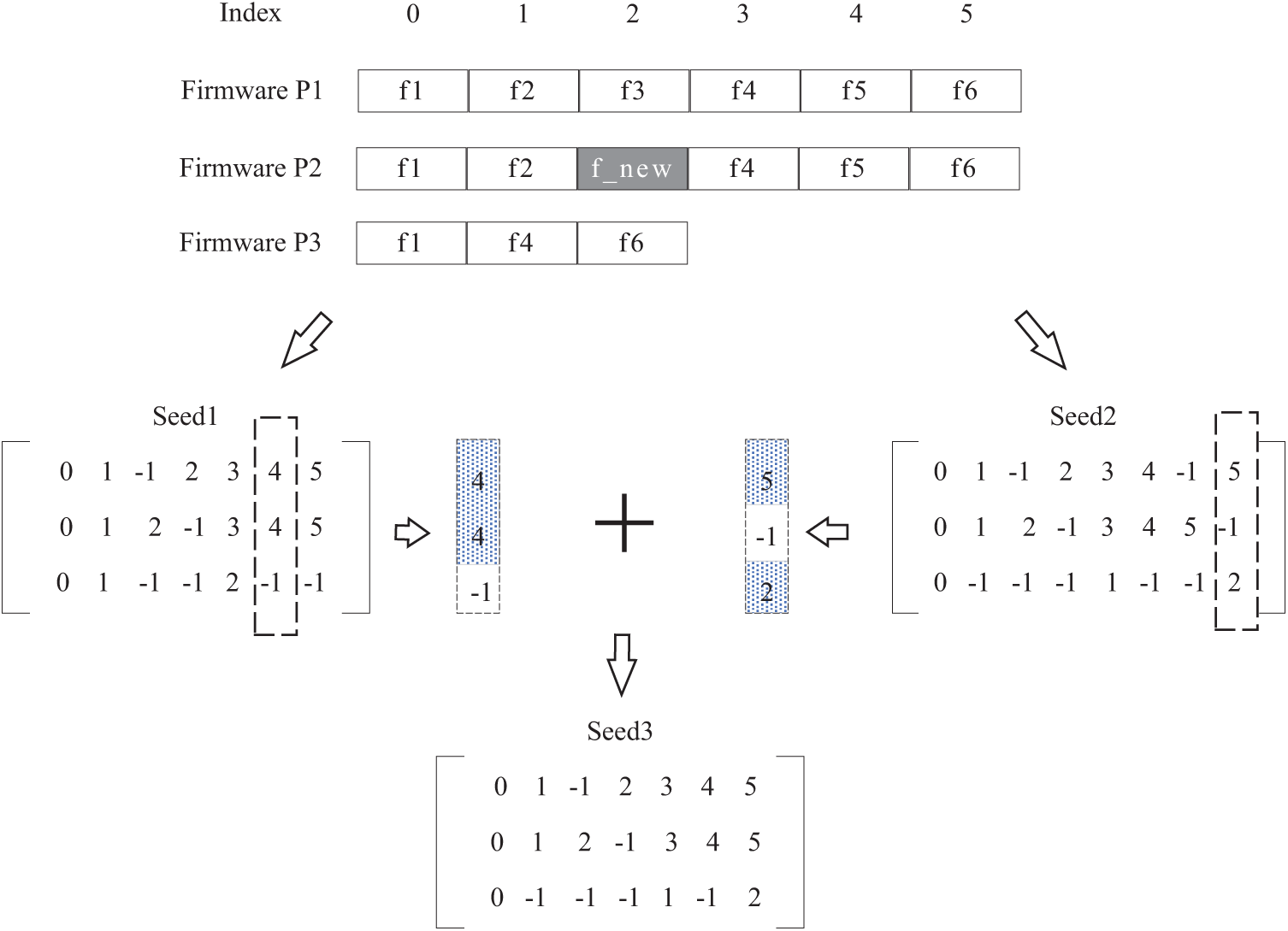
Figure 3: Seed generation based on trusted base point
4.2 Trusted Base Point Management
Since selecting trusted base points filters the columns with high similarity in the function matching matrix, each generated seed can extract trusted base points. Given that both feature similarity
4.2.1 Confident Trusted Base Points
For a function matching matrix A with a column
(1) Its feature similarity satisfies
(2) For any column
(3) For any column
In this paper, the maximum feature similarity is 1, and considering the slight difference of floating-point numbers in operation,
4.2.2 Stable Trusted Base Points
The similarity of stable trusted base points is lower than that of confident trusted base points and higher than that of suspected trusted base points. Stable trusted base points include two main cases:
• In the process of adding confident trusted base points, if a column
• For a column
In this paper, the maximum non-empty similarity is 1, considering the slight difference of floating-point numbers in the operation process. Therefore,
4.2.3 Suspected Trusted Base Points
For a column
4.2.4 Trusted Base Points Updating
Since each seed can generate a trusted base point, the number of trusted base points will increase as the number of population optimization rounds increases. Therefore, the stored trusted base points need to be updated. The update strategies are different for the three types of trusted base points.
• Confident Trusted Base Points. Make sure that no function of any firmware belongs to more than one confident trusted base point at the same time, and if this happens, change the corresponding confident trusted base point to a stable trusted base point.
• Stable Trusted Base Point. There is no restriction on the stable trusted base point for a function. A function can belong to more than one stable trusted base point simultaneously. However, considering the efficiency of implementation, a function that belongs to a different stable trusted base point only retains the highest feature similarity of several. This paper takes the value of 5.
• Suspected Trusted Base Points. The suspected trusted base point themselves contain a large number of false matches due to the high probability of conflict between suspected trusted base points (see Section 4.3.2 for details). The saved results should be discarded periodically. For the suspected trusted base point, the selection strategy in this paper is to discard the suspected trusted base point with feature similarity lower than 0.8 every 3 rounds.
4.3 Seed Construction Methodology
The essence of population generation is to repeat the seed generation. As long as the seed generation method is straightforward, population generation can be completed. The seed construction based on trusted bases consists of three parts: trusted base point selection, ranking, and seed generation.
4.3.1 Trusted Base Point Selection
Due to the large number of three types of trusted base points stored, it is necessary to select the base points in the process of use. Trusted base point selection is to control the number of selected base points. We randomly choose all of the confident trusted base points at each seed generation, 50% of the stable trusted base points, and 1% of the suspected trusted base points to guide the seed construction.
4.3.2 Trusted Base Point Ranking
After completing the initial filtering of trusted base points, it is necessary to rank them to reduce the difficulty of subsequent seed construction. For two trusted base points
Based on the above criteria, the selected trusted base points can be ranked. However, there are still two cases that need to be handled: Case (1), No order relation. For two trusted base points
For the case of no sequential relationship, since the two basis points are not divided into sizes, the size of the two basis points is determined randomly in the sorting process. For the case of contradictory ranking, we eliminate one of the conflicting basis points, and the principle of elimination is as follows:
• If the two bases are both confident trusted base points or suspected trusted base points, one base point is retained, and the other is deleted based on the similarity of the two bases.
• If both base points are stable trusted base points, one base point is retained, and the other one is deleted based on the similarity of the non-null features of both base points.
• If two base points are not of the same type, and one of them is a confident trusted base point, keep the confident trusted base point and delete the other one.
• If two base points are not of the same type, and one of them does not exist, one is retained, and the other is deleted based on the similarity of the two bases.
Based on the above principle, the selected trusted base point are eliminated and sorted to form an ordered sequence of trusted base points from smallest to largest.
After obtaining the ordered sequence of trusted base points, we transform the generating the seeds (i.e., function matching matrix) into filling the index values segment by segment. For any two adjacent trusted base points in the ordered sequence of trusted base points, take
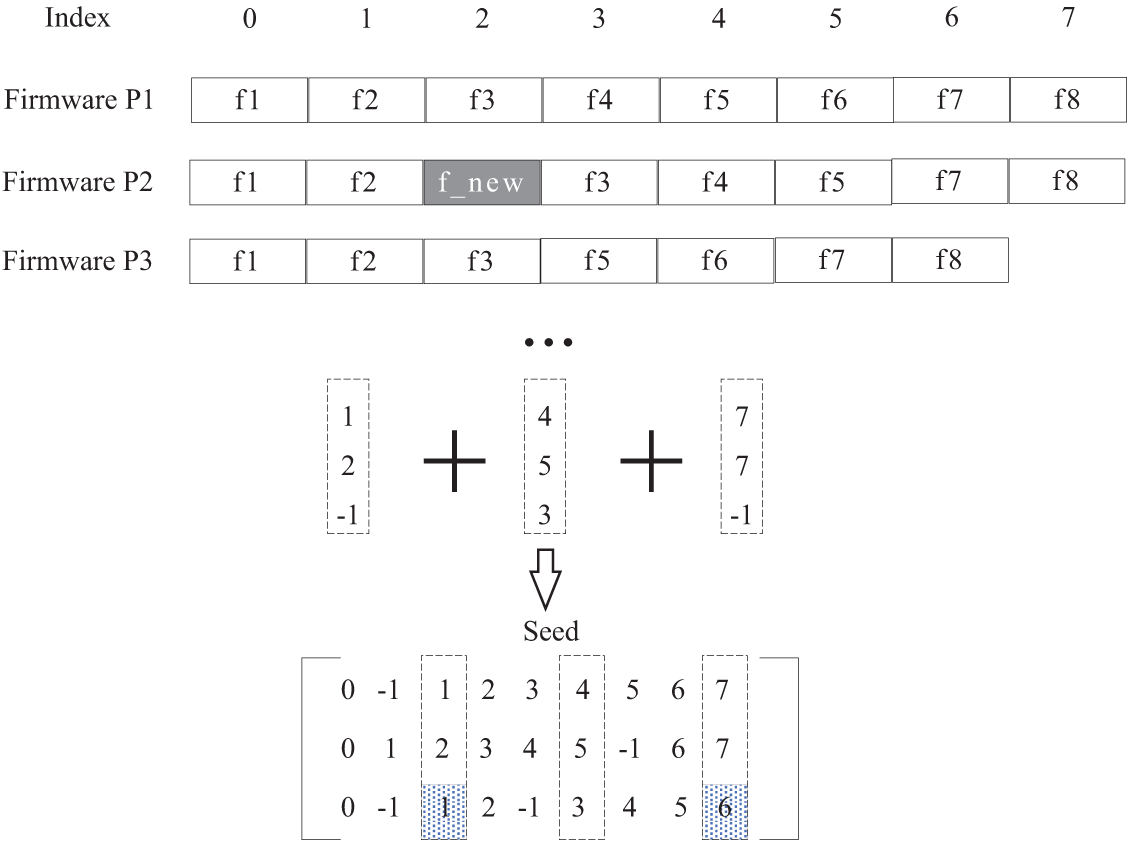
Figure 4: Example of interval filling between bases
Suppose there are three firmwares
5 Population Generation Method Based on Local Optimal Solution
We cut each seed of the existing population into several intervals according to the same criteria and combine the optimal solutions of each seed in each interval to form a new population. As shown in Fig. 5, two seeds
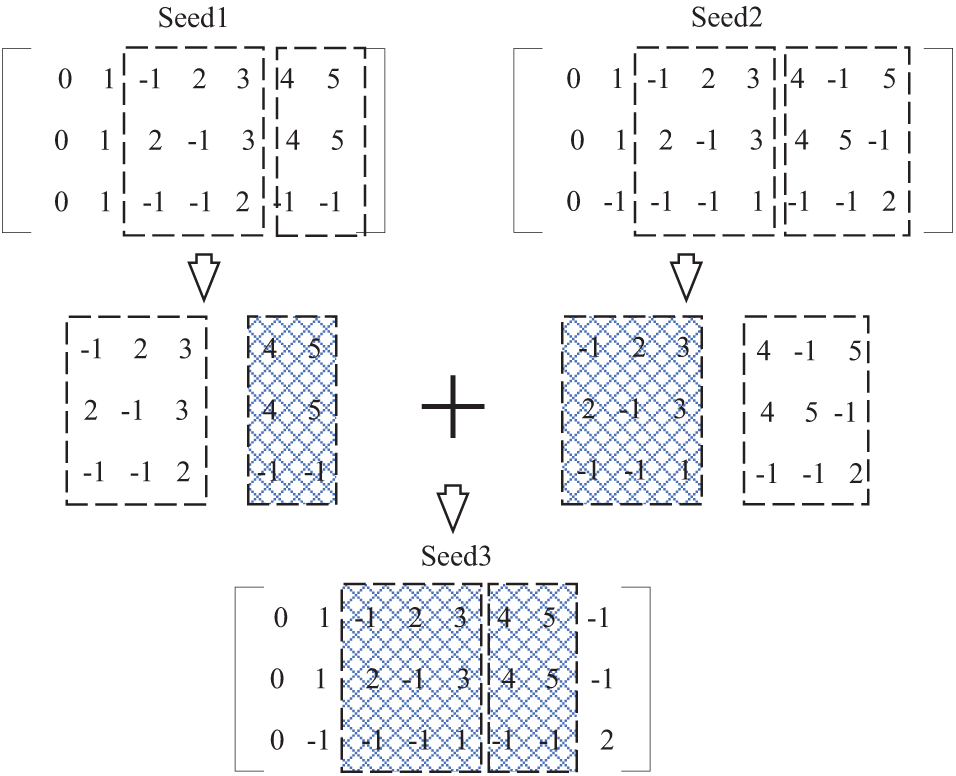
Figure 5: Example of seed generation based on local optimal
The purpose of interval segmentation is to provide uniform criteria for selecting local optimal solutions among different seeds and provide a crossover between seeds. With interval segmentation, the function matching matrix can be partitioned into several small matrices representing the local function correspondence of the firmware.
For several function matching matrices (i.e., populations) formed by N firmwares, one firmware is first selected as the benchmark from among N firmwares for partitioning the interval, assuming that the
For each function matching matrix in the population (take an N ∗ L matrix A as an example), A can be cut into M small matrices
Based on the above conditions, we can continue adding the requirements to limit the sequence
An example of interval segmentation is shown in Fig. 6. The two examples of interval segmentation are based on row 2, which represent the two cases of random interval segmentation (i.e., the number of functions in each interval of the base file is random) and equidistant interval segmentation (i.e., the number of functions in each interval of the base file is equal except for the first and last intervals). In this paper, we chose the method of isometric interval division in the experiment, and the interval size was set as 5.
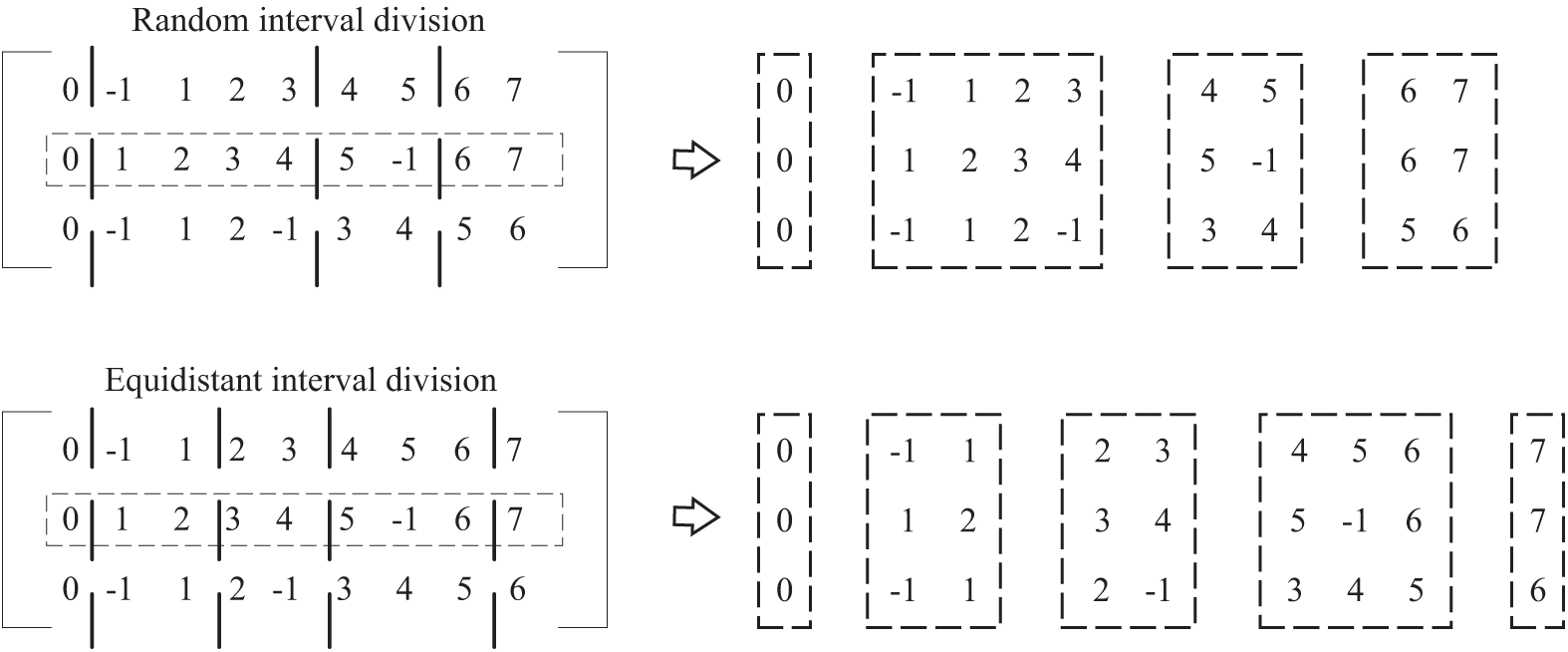
Figure 6: Example of interval division
With interval segmentation, several intervals can be formed based on a specific firmware, and any seed in the population can create a corresponding small matrix (local solution of multiple sequences) based on a specified interval. Ideally, a local optimal solution can be selected among the small matrices obeying the same interval. The local optimal solution in each interval can be spliced to generate a better new seed. As shown in Fig. 5, the first row of the seed is the base, and the second interval is
5.2.1 Local Optimal Solution Selection
When picking small matrices within the same interval, whether a small matrix is ideal as a local solution can be evaluated by following the fitness function in Section 3.2. However, the local solution with the highest adaptation score is not guaranteed to match the functions between firmwares because the function between firmwares is often deformed due to the upgrade. Therefore, in practice, one of the local solutions with the highest adaptation score should be selected for subsequent seeding instead of just selecting the solution with the highest adaptation value. By doing so, we can increase the possibility of finding the actual matching result of the deformation function. In general, the top 5% to 10% of the local solutions are selected based on their adaptation scores, and the selection is proportional to the adaptation scores of the local solutions. The local solutions chosen by the above method are referred to as local optimal solutions in the following. The proportion of 5%–10% is chosen because the number of individuals in the optimal population is above 100 (usually 130), and there will not be less than one local solution to choose from.
5.2.2 Local Optimal Solution Splicing
After the local optimal solutions are selected for each interval, each local optimal solution is sorted according to the order of the intervals. Then the local optimal solutions are stitched together to form a new seed. However, two cases (i.e., interval interruption and interval overlap) cannot be directly spliced between the local optimal solutions. Fig. 7 shows the local optimal solutions of the three intervals with the firmware in row 2 as the base, and the shaded area shows the interval interruption and interval overlap. Interval interruption is where a function of a firmware line is not included in any of the local optimal solutions. It is common for functions that are unique to that firmwares and functions that fail to match. For example, as shown in Fig. 7, the first line of firmware is missing the function with index 4. In this case, it is straightforward to fill the interval between two adjacent locally optimal solutions by analogy with the filling method in Section 5.2. The interval overlap is when the functions of a firmware line appear in the adjacent local optimal solutions simultaneously. In Fig. 7, the function with the firmware index 6 in the first row appears twice. There are two ways to deal with interval overlap:
• row-by-row random discarding. Two local optimal solutions of a row of overlapping function index interval
• overall random discarding. The fitness value of the two local optimal solutions is calculated, and one of them is selected randomly according to the fitness value. The other is discarded and does not participate in the local optimal solution splicing. The interval interruptions caused by discarding the local optimal solution are treated as interval interruptions.
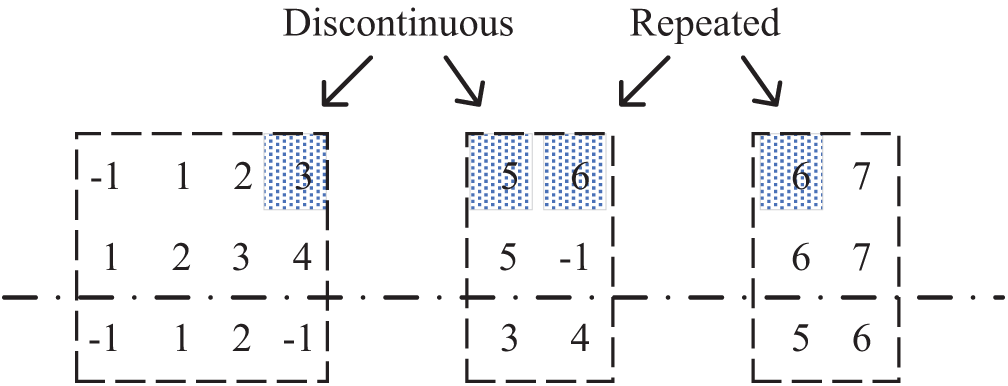
Figure 7: Discontinuous interval and repeated interval
In practical experiments, the overall random discarding method has good experimental results. See Section 6.4.2 for details.
In this Section, we first introduce the experiment environment, dataset, and evaluation metrics and baseline. Then, we study the effect of trusted base points on multi-firmware comparison and the effect of the local optimal solution splicing method on the multi-firmware comparison. Finally, we compare our solution with Bindiff (version 5) and the string-based method, and we manually verify the multi-firmware comparison effect of our approach. Specifically, our evaluation aims to answer the following research questions (RQ).
• RQ1: Whether the trusted base point is effective for multi-firmware comparison?
• RQ2: Whether the local optimal solution splicing is effective for multi-firmware comparison?
• RQ3: How effective is our solution compared with state-of-the-art works for multi-firmware comparison?
The experimental environment consists of an Intel Xeon Gold 6150 CPU @2.70 GHz processor, 128 GB RAM, Samsung T5 SSD 2 TB hard disk. We use the IDA Pro to preprocess the firmware and implement the proposed method with Python 3.7.
To demonstrate the effect of our solution. we select the Cisco C2600, C1800 series firmwares as our dataset. The two series of firmwares have different instruction sets. The number of functions in the firmware is large, and the firmware is monolithic executables rather than multiple files packaged and compressed, which has the value of analysis. Specifically, to study the effect of trusted base points on the multi-firmware comparison, we select four firmware, i.e., c1841-advipservicesk9-mz.124-17, c1841-advipservicesk9-mz.124-22.t, c1841-advipservicesk9-mz.124-22.t, c1841 advsecurityk9-mz.124-24.t5, and c1841-broadband-mz.124-16. The number of seeds for the optimal population is set to 130, and the number of seeds generated by each of the three population update methods is 70 (210 in total). The number of iterations in this experiment was set to 20.
In addition, we select four other firmwares to study the effect of local optimal solution splicing and compare with baseline works, including c2600-ipbase-mz.123-6f, c2600-ipbase-mz.123-25, c2600-ipbase-mz.124-19, and c2600-ipbase-mz.124-25c. The number of seeds for the optimal population is set to 130, and the number of seeds generated by each of the three population update methods is 70 (210 in total). The number of iterations in this experiment was set to 200 rounds.
Due to the difficulty of multiple sequences matching itself, the fact that some of the firmware functions in the matching results are set to correspond to empty bits does not mean that the function does not correspond to the matching function but may not find the actual matching result. Based on this consideration, only the non-empty matches in each row of the function matching matrix are considered when designing the similarity of matching results.
The seed with the highest adaptation (function matching matrix) needs to be analyzed to verify the correctness of the function correspondence in the function matching matrix. Since we do not have the source code for these firmwares, we cannot build ground truth, so we use the following evaluation methods to evaluate our approach.
Metric I: Similarity of matching results. The similarity of matching results. N firmwares using method X for multiple sequence matching formed a function matching matrix A, the size of matrix A is
where
Metric II: Precision. As shown in Eq. (12), where TP is a true positive result, and FP is a false-positive result.
In this paper, we do not use the precision directly for evaluation mainly based on the following considerations: without the source code of firmware, it is not possible to determine whether the function matches are correct or not, and due to a large number of firmware functions and the significant time cost of manual analysis, it is not reliable to use the precision of the sampled results as the precision rate of the multi-firmware comparison results, and the value can only be used as a reference. Therefore, the precision of the analysis results can be compared with previous dual-firmware comparison methods or tools with high precision. If the similarity of the matching results is high, the accuracy of the analysis results is considered close to that method.
Baseline. In this paper, we choose Bindiff and string-based method as the baseline. The similarity between the proposed method and Bindiff is evaluated by using the similarity of matching results, supplemented by the precision analysis, obtained by sampling the results of multi-firmware matching and then manually verifying them.
The string-based matching is a classical method for constructing function correspondence by extracting the strings referenced by functions within the firmware to establish the function correspondence between firmwares. Although the similarity of matching results can be used to measure the degree of approximation between the proposed method and Bindiff, Bindiff itself has miss-matching cases. Meanwhile, string-based matching is less likely to have miss-matching instances, so the similarity of matching results with strings can be used as a supplement to measuring the operation effect of our solution. Therefore, the similarity of string-based method can be used as a supplement to measuring the effectiveness of our solution.
6.4.1 Effect of Trusted Base Points on Multi-Firmware Comparison
To answer the RQ1, we study the effect of the number of trusted base points and the number of empty spaces on the multi-firmware comparison. The experiment is performed in 7 groups. Each group is pre-selected with a certain number of trusted base points (the number of trusted base points is from manual analysis, more than 10,000) to simulate the effect of our solution in Section 4.
Since it is a 4-firmware comparison, there are three cases of trusted base point according to the number of nulls: no null, 1 null and 2 nulls. The sets of trusted base points provided by the 7 sets of experiments are as follows: (TB1) randomly select 10 non-empty trusted base points. (TB2) randomly select 100 trusted base points, where the ratio of no null, 1 null and 2 null trusted base points is 1:1:1. (TB3) randomly select 100 trusted base points, among which the ratio of no null, 1 null and 2 nulls trusted base points is 1:1:2. (TB4) randomly select 100 trusted base points, among which the ratio of no null, 1 null and 2 null trusted base points is 2:1:1. (TB5) randomly select 1000 trusted base points, among which the ratio of no null, 1 null and 2 null trusted base points is 1:1:1. (TB6) randomly select 1000 trusted base points, among which the ratio of no null, 1 null and 2 null trusted base points is 1:1:2. (TB7) randomly select 1000 trusted base points, among which the ratio of no null, 1 null and 2 null trusted base points is 2:1:1.
The experimental results are shown in Fig. 8. As shown in Fig. 8, both the fitness values and similarities increase with the number of iterations. Increasing the number of trusted base points also leads to better results: for fitness, increasing the number of trusted base points leads to higher fitness values, while for both similarities, increasing the number of trusted base points leads to more minor fluctuations in similarity values. For the proportion of trusted base points of different null types, the fitness value is higher when the ratio of null-free trusted base points is higher. As for the similarity, the experiment is at the early stage of training, and the similarity fluctuates a lot, so we can only see that the trend of the mean increase is the same as a whole, and we cannot determine which ratio has a more significant effect on the similarity.
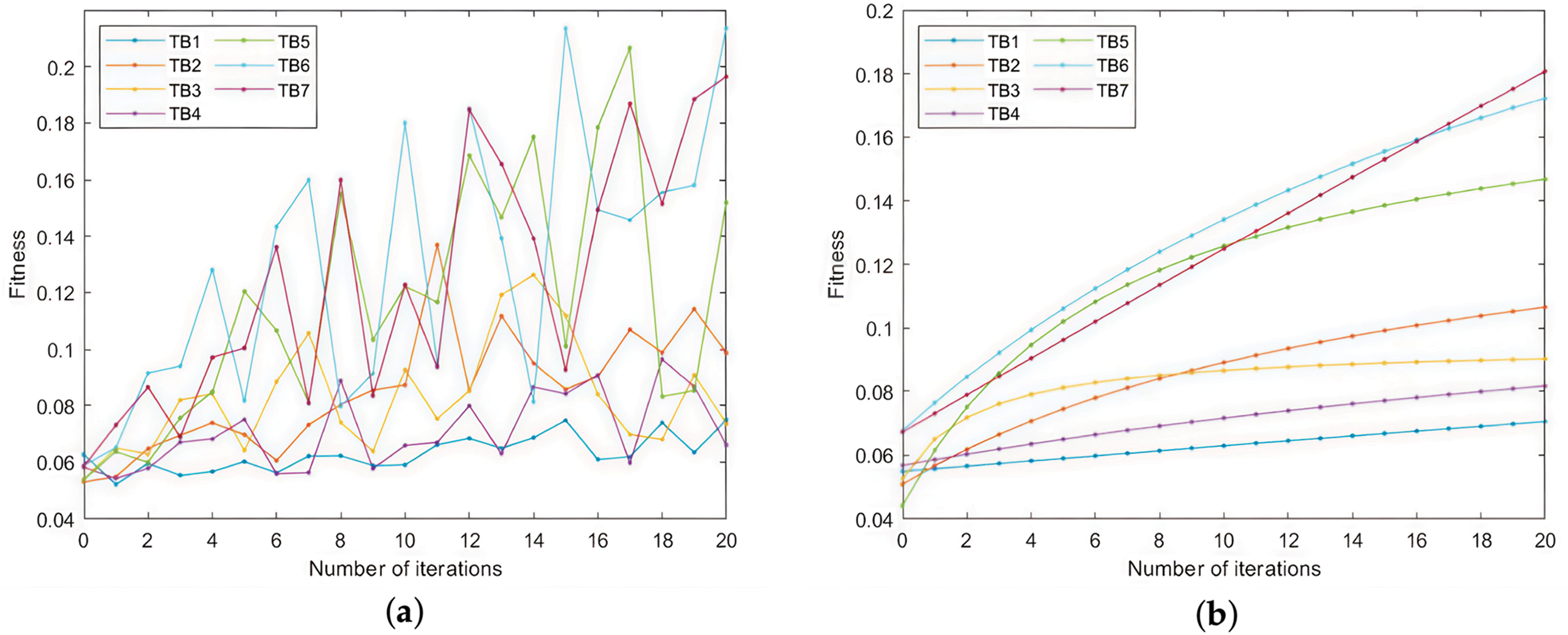
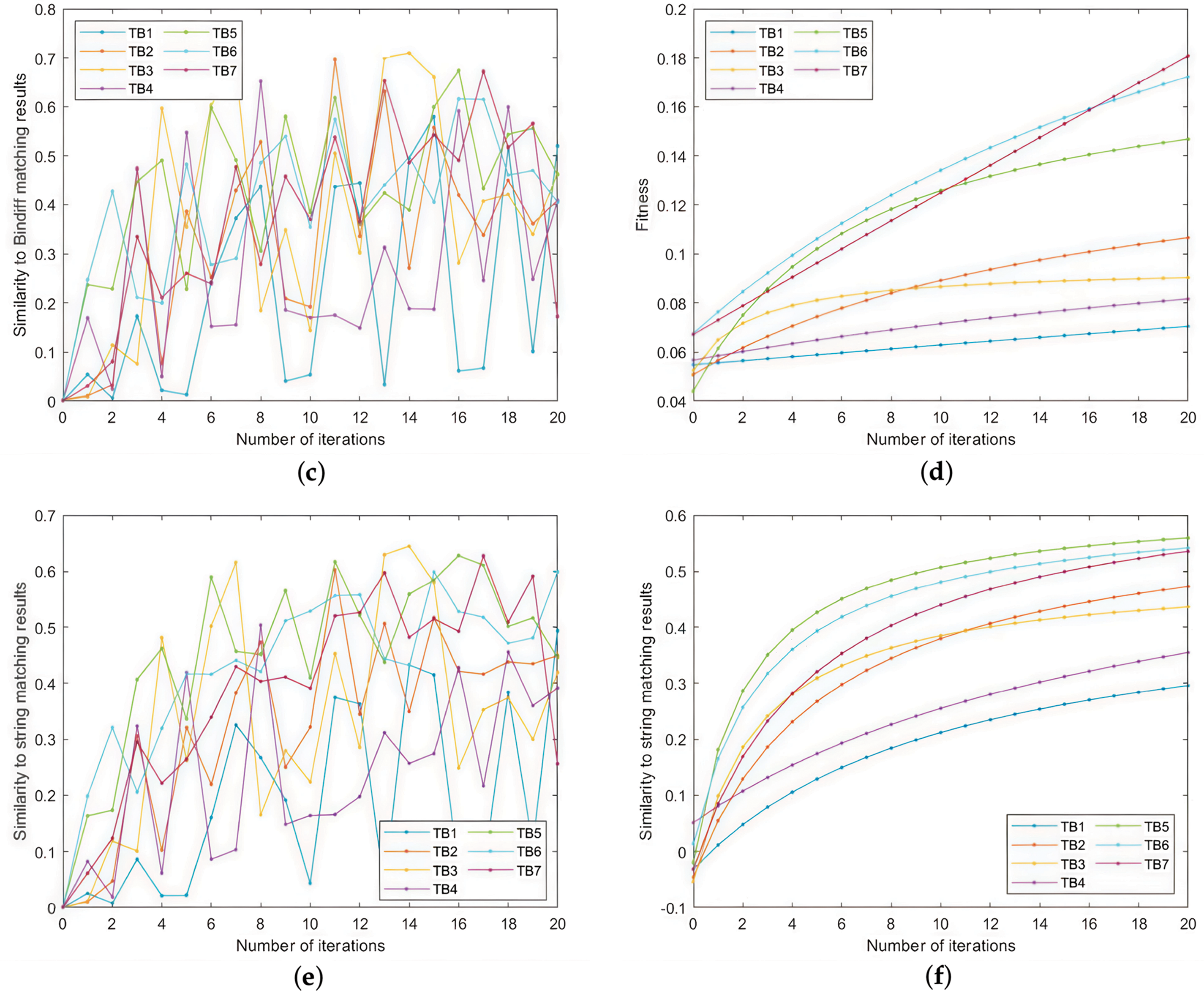
Figure 8: The influence of trusted base points on the multi-firmware comparison. (a) The mean fold of fitness for each round of seeds during 20 iterations; (b) The mean of fitness; (c) The mean fold of similarity to Bindiff for each round of seeds during 20 iterations; (d) The mean of fitness; (e) The mean fold of the similarity between the seeds and the string-based matching results for each of the 20 iterations; (f) The mean of fitness
6.4.2 Effect of Local Optimal Solution Splicing Method on Multiple Sequence Comparison
In this part, we try to answer the RQ2. Section 5.2 proposes two local optimal solution splicing methods for the case of overlapping intervals: row-by-row random discarding and overall random discarding. The result is shown in Fig. 9. Fig. 9a shows the fitness scatter plot of the optimal population. Each column of the scatter represents the fitness value of each individual in the optimal population after that round of iteration. The orange nodes indicate the overall random discarding. The blue nodes indicate the row-by-row random discarding. Fig. 9b shows the mean values of the fitness of the optimal population in each iteration. The red line indicating the overall random discarding and the blue line indicating the row-by-row random discarding.
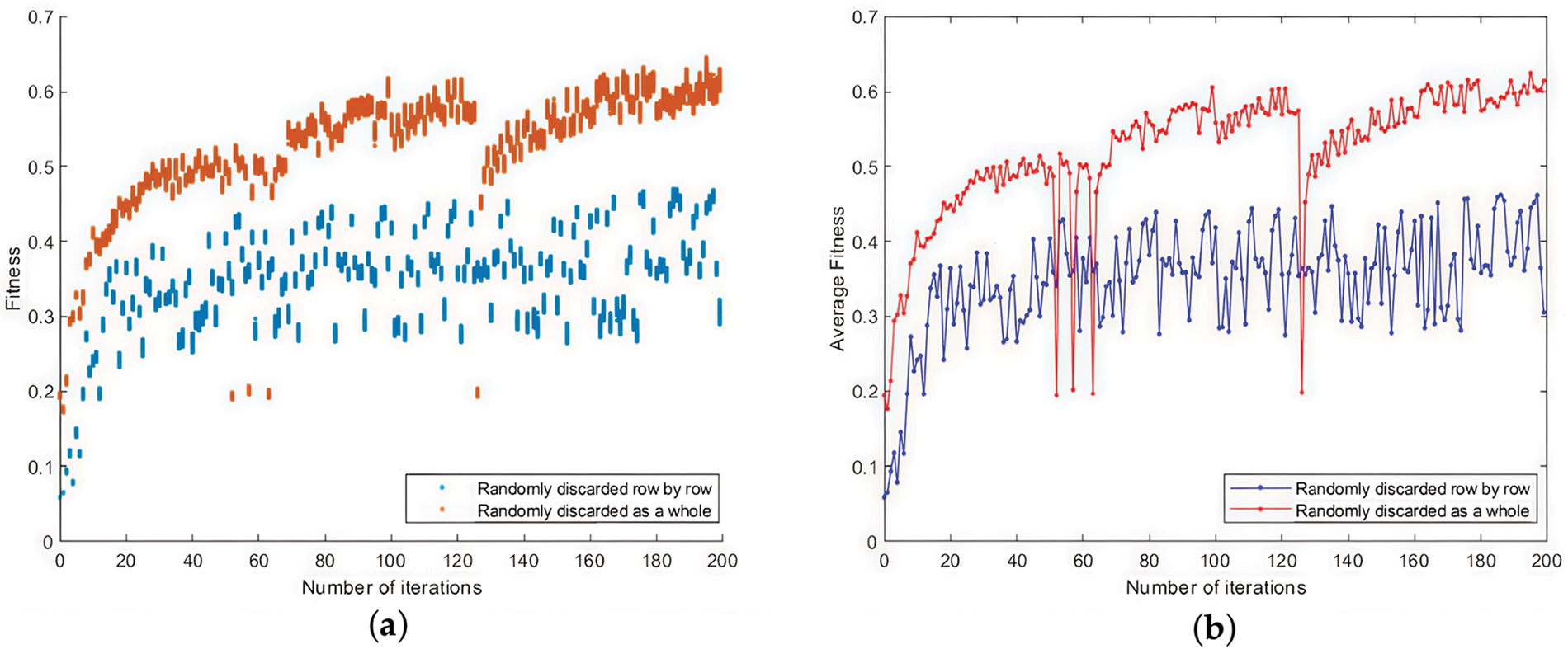
Figure 9: Comparison of local optimal solution combining methods: (a) The fitness scatter plot of the optimal population; (b) The mean values of the fitness of the optimal population in each iteration
The experiments show that the overall random discarding is more effective than the row-by-row random discarding. The former has a significantly larger fitness value than the latter, with less fluctuation. There are several reasons for this result. One of the main reasons is that the row-by-row random discarding is likely to destroy the correct function correspondence in the local optimal solution because the overlapping of the local optimal solution is randomly replaced, which leads to the decrease of the similarity of the local optimal solution after splicing. In contrast, the overall random discarding does not cause such damage. The above situation may arise only from a few mismatched functions with high similarity. If the frequency of interval overlap between local optimal solutions and the size of the overlap can be controlled, then the row-by-row random discarding should also be effective. Therefore, the row-by-row random discarding can be tried to deal with the overlap problem at a later stage of the multi-sequence matching, i.e., after most of the correspondences between the firmware functions have been correctly constructed.
6.4.3 Adaptation and Similarity of Matching Results
To answer the RQ3, we compare our solution with Bindiff (version 5) and string-based method.
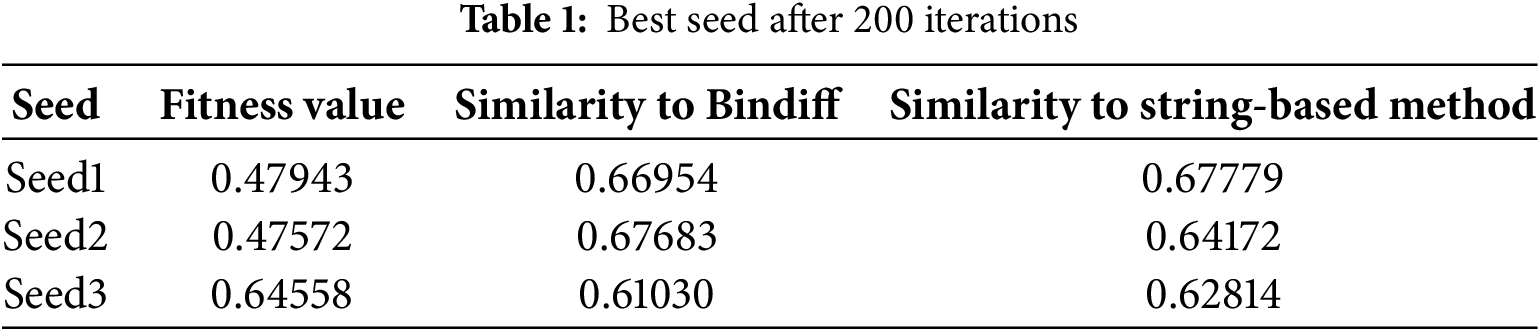
Fig. 10 shows the evolution of the optimal population for the 200 iterations of the 4-firmware. Fig. 10a shows the scatter plot of the optimal population. The scatter points in each column represent each individual in the optimal population after that iteration. The yellow nodes indicate the fitness values. The blue nodes indicate the similarity of the seeds with Bindiff matching results. The orange nodes indicate the similarity of the seeds with string-based matching results. Fig. 10b shows the mean values of the best populations in each iteration, the black line shows the mean value of fitness, the red line shows the mean value of similarity with Bindiff matching results, and the blue line indicates the mean value of similarity with string-based matching results. As shown in Fig. 10, with the increase of the number of iterations, the best populations are continuously updated. The overall trends of fitness, similarity with Bindiff matching results, and similarity with string-based matching results are consistent. The values reach above 0.5 and stabilize after about 70 iterations. It should be noted that there are four large fluctuations in Fig. 10 because the experiment was not completed in one time, and the program had to be rerun based on the results at that time due to the interruption of the experiment caused by the power failure. In fact, from the perspective of smoothing the data, it is sufficient to exclude the data of these 4 times, even if keeping or excluding the data of these 4 times does not affect the effectiveness of the argument of this paper. However, we realize that the evolutionary algorithm has some robustness in the iterative process itself, and therefore, we choose to keep such original data. After 200 iterations, the optimal population has three seeds with the largest of the three taken values, as shown in Table 1. It can be seen that it is a reasonable choice to use the fitness value of the proposed method to measure the seeds, and the seeds with the higher values of all the three kinds of values (i.e., Seed3) can be obtained. The experiment shows that the similarity of matching result between our solution and the Bindiff is above 60%.
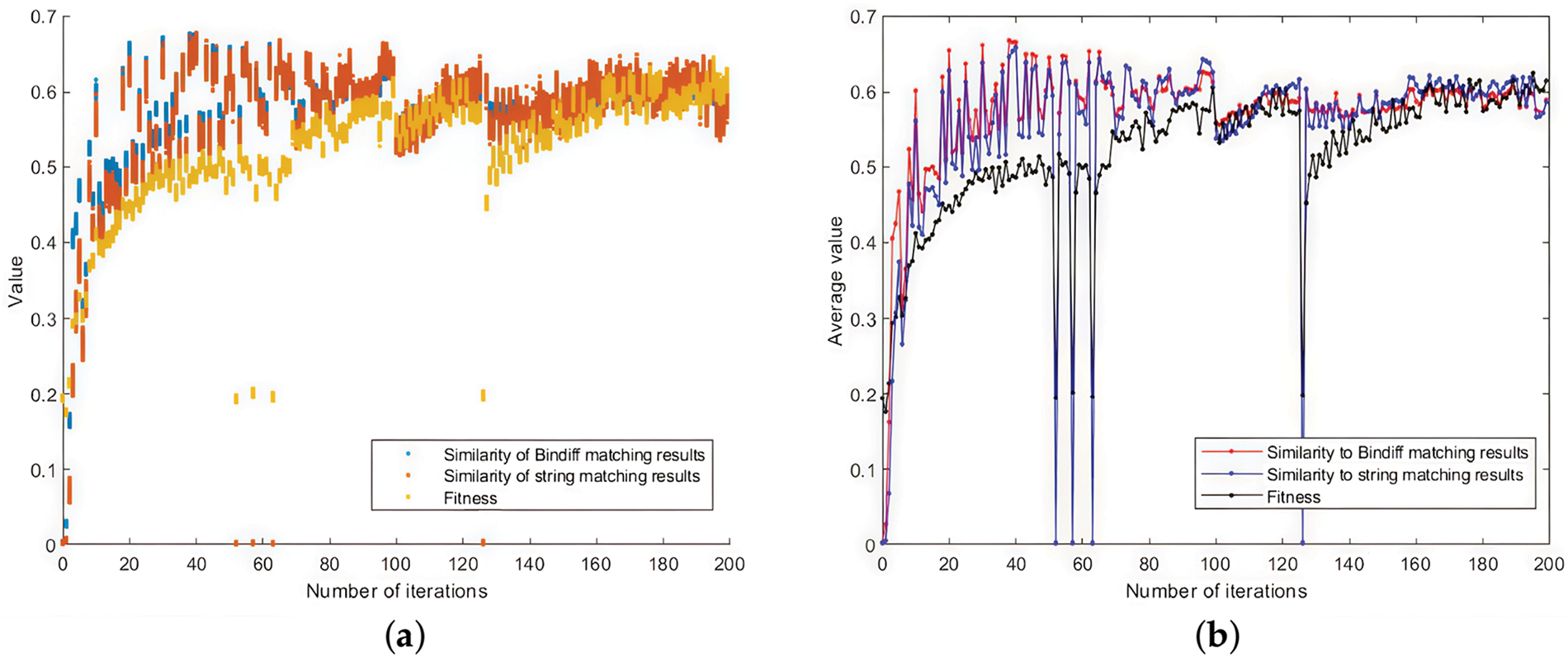
Figure 10: P4 Sequence comparison effect: (a) The evolution of the optimal population for the 200 iterations of the 4-firmware; (b) The mean values of the best populations in each iteration
6.4.4 Sampling and Manual Verification
To determine the effectiveness of the proposed method, the results of the 4-firmware comparison are sampled and manually checked.
The sampling consists of four cases, which are: (Case 1) the method of this paper is consistent with Bindiff; (Case 2) the method is not compatible with Bindiff; (Case 3) the method is consistent with the string-based matching result; (Case 4) the method is not consistent with the string-based matching result.
For each case, 50 cases were selected and 200 cases in total. For Case 1 and Case 3, the results of the manual verification are shown in Table 2. It can be seen that the sampling accuracy of this method is at least 96% when it agrees with the Bindiff matching result or the string-based matching result. The similarity of the matching results proposed in this paper is a measure of the similarity between this method and other methods in the matching results.
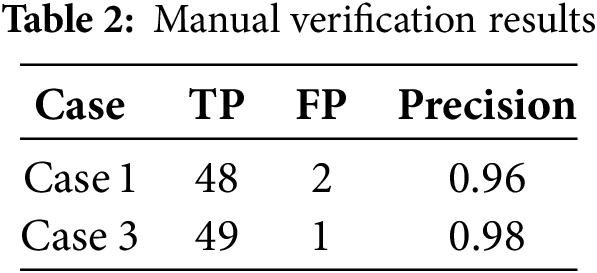
For Case 2 and Case 4, the manual verification results are shown in Table 3. It can be seen that the results of the proposed method are not satisfactory when they are not consistent with Bindiff matching results or string-based matching results. The main reason is that this method is multi-sequence matching, while the other method is dual-sequence matching, and the difficulty of matching is different. In terms of string comparison, not all functions have strings, and not all functions with strings are sampled, so the sample coverage is not wide enough. Therefore, to evaluate the overall accuracy, Bindiff is preferred as a reference, and the matching result of this method can reach 66.4% accuracy under this condition (Table 1, Seed3, 0.6103 * 0.96 + 0.3897 * 0.2).

Based on the present results, it can be seen that increasing the similarity of matching results of our solution can indeed achieve higher accuracy. In addition, it is reasonable to use the similarity of matching results as the evaluation index at this stage, which can make up for the shortage of manual verification.
7.1 The Analysis of Time-Space Overhead
Our solution solves the problem of constructing function correspondence between multiple firmwares, which requires an analysis of its time-space overhead.
Assuming that there are N firmwares for multi-firmware comparison and
Now we have the assumption that the average number of functions of firmware is
For the time complexity, since this paper adopts Eq. (3) to calculate the single column similarity, the time overhead of one column function in the matrix is
7.2 The Importance of Trusted Base Points in Firmware Security
Trusted base points are critical in firmware security, providing stable reference points for function matching across different firmware versions. This stability is essential for detecting security vulnerabilities and malicious code, as security analysis often requires comparing multiple firmware versions. For example, in cross-version comparisons, trusted base points ensure consistent function matching even when firmware undergoes updates or modifications. This consistency is vital for identifying subtle changes that may indicate malicious code insertion or vulnerability exploitation. Moreover, trusted base points help reduce false positives and false negatives in security assessments. By offering a stable reference, they enhance the reliability of automated security tools, making them more effective in detecting both known and unknown threats. This is particularly important in environments where firmware updates are frequent. Trusted base points also support complex matching scenarios, such as cross-version and cross-architecture comparisons. These scenarios are crucial for identifying sophisticated attack patterns that may span multiple firmware releases or target different hardware platforms. For instance, attackers might exploit vulnerabilities in older firmware versions and propagate them to newer versions. Therefore, cross-version analysis is indispensable for comprehensive security auditing.
In summary, the proposed method not only reduces the time and space overhead compared to traditional dual firmware matching methods but also integrates trusted base points to enhance the robustness and efficiency of firmware security analysis. This combination of performance optimization and security reliability makes our approach particularly suitable for real-world firmware ecosystems where both efficiency and security are paramount.
Binary matching techniques have been studied extensively in the past, and this section summarizes the research related to many-to-many comparisons between programs.
In program analysis, the literature [26] is the earliest study found to compare the similarity of many-to-many programs. This paper extracted the program’s control flow graph (CFG) and combined it with graph coloring techniques to detect the variant worms. The experimental dataset consists of less than 20 MB executable files. Saebjornsen et al. [31] used disassembly instructions as input. After instruction transformation and normalization, it uses a clustering algorithm to evaluate the similarity of instruction sequences, thus realizing binary code similarity evaluation. Although the input is multiple binary code regions, the comparison results are to find the most matching clone instruction sequence to score the similarity rather than construct a functional correspondence. Santos et al. [32] proposed a detection method based on opcode sequence frequency for unknown malware variants. Also, a way is provided to mine the correlation of each opcode to weigh its sequence frequency. The literature [33] aims to perform malicious family categorization of malware; by performing master block extraction of functions to reduce the time overhead of similarity analysis. Although the comparison is many-to-many, the object of the comparison is multiple master blocks of two files, which is essentially a one-to-one comparison of programs. The study in [34] compares at the CFG level obtain semantic meaning to the binary code through dynamic execution behavior to observe changes in the behavior of the underlying malware functionality over time. Jin et al. [35] designed a hashing method that can map the semantic information of functions into corresponding feature vectors and perform function clustering based on the feature vectors to guide finding semantically similar functions in many binary programs. However, to improve identification accuracy, it is necessary to simulate the execution of the basic block to extract the basic block input and output for hashing. Hu et al. [27] extracted the disassembly opcodes of malicious programs used N-gram opcode short sequence features to represent malicious programs, and then used Euclidean distance to calculate the similarity of different programs and used a clustering algorithm to categorize malicious programs. Jang et al. [36] proposed a method for measuring software evolution relationships and two software evolution types. Farhadi et al. [28] mainly detected code clones in malware, including both exact clone detection and imprecise clone detection, defines clones by judging the similarity of consecutive assembly instructions and integrates small clone intervals into large clone intervals by clone fusion. This study mainly focuses on the similarity analysis at the assembly instruction level, which is still a comparison between the two files. Ruttenberg et al. [37] aimed to find the standard function modules (set of functions) among different malware. Through two stages of clustering, the primary function modules in the samples are first clustered into several clusters of basic function modules. Then each sample is carved based on the clusters, and then inter-sample clustering is performed to determine the correlation between samples. Wang et al. [29] propose a jump-aware Transformer-based model, jTrans, which integrates control-flow information into the Transformer architecture to conduct function similarity detection. Their method focuses on one-to-many tasks in this study but can be extended to many-to-many problems by treating each function in the pool as a source function and solving multiple one-to-many problems. Luo et al. [30] propose an intermediate representation function model that lifts binary code into microcode, preserving the main semantics of binary functions through instruction simplification. This approach is designed to facilitate cross-architecture binary code search. Although their method supports many-to-many function similarity analysis, it primarily focuses on measuring the similarity between two given binaries at the function level.
The above study found that previous studies, except for the method [35], could not be used to construct function correspondence between multiple firmwares. This study [35] focused on finding function hash methods, which are relatively expensive to maintain for constantly updated firmware; in particular, the technique requires simulation execution to obtain essential block input-output pairs, which is too much overhead due to a large number of firmware functions (up to hundreds of thousands) and is less feasible for firmware.
Our approach fills the research gap of multi-firmware comparison, reduces the time overhead of using the dual-firmware matching method in the multi-firmware matching scenario, and avoids the contradiction of non-closed matching result transfer based on the transferability of dual-firmware matching result in the multi-firmware matching scenario. In addition, our solution is mainly based on the evolutionary algorithm to adjust the function matching scheme and obtain the optimal matching results of multi-firmware functions. It does not conflict with the method of using function hash to calculate function similarity in the literature [35] and can be used in combination.
In this paper, we propose an evolutionary algorithm-based multi-firmware comparison method. First, we transform the multi-firmware comparison problem into a multi-sequence comparison problem and design a fitness function for firmware comparison. Then, we propose a population generation and updating method based on the trusted base point and local optimal solution for firmware and combine the two ways to optimize the optimal population. Finally, we compare our solution with Bindiff and the string-based method. The experiments show that the proposed method outperforms Bindiff and the string-based method. Besides, the more trusted base points, the more nodes are matched without empty space and the best result of the multi-firmware comparison. Our solution is feasible and effective.
While our proposed evolutionary algorithm-based method for multi-firmware comparison has demonstrated significant improvements over existing approaches, several avenues for future enhancement remain. In future research, we will further analyze the characteristics of firmware updates, such as changes in the relative positions of code, to optimize the comparison process.
Acknowledgement: The authors would like to express their gratitude to the editors and reviewers for their detailed review and insightful advice.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Conceptualization: Wenbing Wang, Yongwen Liu; Investigation: Wenbing Wang; Methodology: Wenbing Wang, Yongwen Liu; Validation: Wenbing Wang; Writing—original draft preparation: Wenbing Wang; Writing—review and editing: Yongwen Liu; Supervision: Yongwen Liu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data available on request from the authors.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Raghunathan K. History of microcontrollers: first 50 years. IEEE Micro. 2021;41(6):97–104. doi:10.1109/MM.2021.3114754. [Google Scholar] [CrossRef]
2. Nino N, Lu R, Zhou W, Lee KH, Zhao Z, Guan L. Unveiling IoT security in reality: a firmware-centric journey. In: 33rd USENIX Security Symposium (USENIX Security 24); 2024; Philadelphia, PA. Berkeley, CA, USA: USENIX Association; 2024. p. 5609–26. [cited 2025 Mar 5]. Available from: https://www.usenix.org/conference/usenixsecurity24/presentation/nino. [Google Scholar]
3. Wu Y, Wang J, Wang Y, Zhai S, Li Z, He Y, et al. Your firmware has arrived: a study of firmware update vulnerabilities. In: 33rd USENIX Security Symposium (USENIX Security 24); 2024; Philadelphia, PA. Berkeley, CA, USA: USENIX Association; 2024. p. 5627–44. [cited 2025 Mar 5]. Available from: https://www.usenix.org/conference/usenixsecurity24/presentation/wu-yuhao. [Google Scholar]
4. Wang J, Zhang C, Chen L, Rong Y, Wu Y, Wang H, et al. Improving ML-based binary function similarity detection by assessing and deprioritizing control flow graph features. In: 33rd USENIX Security Symposium (USENIX Security 24); 2024; Philadelphia, PA. Berkeley, CA, USA: USENIX Association; 2024. p. 4265–82. [cited 2025 Mar 5]. Available from: https://www.usenix.org/conference/usenixsecurity24/presentation/wang-jialai. [Google Scholar]
5. He H, Lin X, Weng Z, Zhao R, Gan S, Chen L, et al. Code is not natural language: unlock the power of semantics-oriented graph representation for binary code similarity detection. In: 33rd USENIX Security Symposium (USENIX Security 24); 2024; Philadelphia, PA. Berkeley, CA, USA: USENIX Association; 2024. p. 1759–76. [cited 2025 Mar 5]. Available from: https://www.usenix.org/conference/usenixsecurity24/presentation/he-haojie. [Google Scholar]
6. Collyer J, Watson T, Phillips I. Faser: binary code similarity search through the use of intermediate representations. arXiv:2310.03605. 2023. [Google Scholar]
7. Wang H, Gao Z, Zhang C, Sha Z, Sun M, Zhou Y, et al. Learning transferable binary code representations with natural language supervision. In: Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis; 2024; Vienna, Austria. New York, NY, USA: Association for Computing Machinery; 2024. p. 503–15. doi:10.1145/3650212.3652145. [Google Scholar] [CrossRef]
8. Li T, Shou P, Wan X, Li Q, Wang R, Jia C, et al. A fast malware detection model based on heterogeneous graph similarity search. Comput Netw. 2024;254(27):110799. doi:10.1016/j.comnet.2024.110799. [Google Scholar] [CrossRef]
9. Novak P, Oujezsky V, Kaura P, Horvath T, Holik M. Multistage malware detection method for backup systems. Technologies. 2024;12(2):23. doi:10.3390/technologies12020023. [Google Scholar] [CrossRef]
10. Jia L, Yang Y, Li J, Ding H, Li J, Yuan T, et al. MTMG: a framework for generating adversarial examples targeting multiple learning-based malware detection systems. In: Pacific Rim International Conference on Artificial Intelligence; 2023; Jakarta, Indonesia. Berlin/Heidelberg: Springer-Verlag; 2023. p. 249–61. doi:10.1007/978-981-99-7019-3_24. [Google Scholar] [CrossRef]
11. Jia L, Yang Y, Tang B, Jiang Z. ERMDS: a obfuscation dataset for evaluating robustness of learning-based malware detection system. BenchCouncil Transact Benchmarks Stand Evaluat. 2023;3(1):100106. doi:10.1016/j.tbench.2023.100106. [Google Scholar] [CrossRef]
12. Zhang P, Wu C, Peng M, Zeng K, Yu D, Lai Y, et al. The impact of inter-procedural code obfuscation on binary diffing techniques. In: Proceedings of the 21st ACM/IEEE International Symposium on Code Generation and Optimization; 2023; Montréal, QC, Canada. New York, NY, USA: Association for Computing Machinery; 2023. p. 55–67. doi:10.1145/3579990.3580007. [Google Scholar] [CrossRef]
13. Walker A, Cerny T, Song E. Open-source tools and benchmarks for code-clone detection: past, present, and future trends. SIGAPP Appl Comput Rev. 2020;19(4):28–39. doi:10.1145/3381307.3381310. [Google Scholar] [CrossRef]
14. Luo L, Ming J, Wu D, Liu P, Zhu S. Semantics-based obfuscation-resilient binary code similarity comparison with applications to software and algorithm plagiarism detection. IEEE Trans Softw Eng. 2017;43(12):1157–77. doi:10.1109/TSE.2017.2655046. [Google Scholar] [CrossRef]
15. Pewny J, Garmany B, Gawlik R, Rossow C, Holz T. Cross-architecture bug search in binary executables. In: 2015 IEEE Symposium on Security and Privacy; 2015; San Jose, CA, USA. Los Alamitos, CA, USA: IEEE Computer Society; 2015. p. 709–24. [cited 2025 Mar 5]. Available from: https://ieeexplore.ieee.org/document/7163056. [Google Scholar]
16. Feng Q, Wang M, Zhang M, Zhou R, Henderson A, Yin H. Extracting conditional formulas for cross-platform bug search. In: ASIA CCS, 2017-Proceedings of the 2017 ACM Asia Conference on Computer and Communications Security; 2017; Abu Dhabi, United Arab Emirates. New York, NY, USA: Association for Computing Machinery; 2017. p. 346–59. doi:10.1145/3052973.3052995. [Google Scholar] [CrossRef]
17. Wang H, Gao Z, Zhang C, Sun M, Zhou Y, Qiu H, et al. CEBin: a cost-effective framework for large-scale binary code similarity detection. In: Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis; 2024; Vienna, Austria. New York, NY, USA: Association for Computing Machinery; 2024. p. 149–61. doi:10.1145/3650212.3652117. [Google Scholar] [CrossRef]
18. Zhang H, Qian Z. Precise and accurate patch presence test for binaries. In: Proceedings of the 27th USENIX Security Symposium; 2018; Baltimore, MD. Berkeley, CA, USA: USENIX Association; 2018. p. 887–902. [cited 2025 Mar 5]. Available from: https://www.usenix.org/conference/usenixsecurity18/presentation/zhang-hang. [Google Scholar]
19. Xu Z, Chen B, Chandramohan M, Liu Y, Song F. SPAIN: security patch analysis for binaries towards understanding the pain and pills. In: 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE); 2017 May 20–28; Buenos Aires, Argentina. Los Alamitos, CA, USA: IEEE Computer Society; 2017. p. 462–72. [cited 2025 Mar 5]. Available from: https://ieeexplore.ieee.org/document/7985685. [Google Scholar]
20. Liu X, Wu Y, Yu Q, Song S, Liu Y, Zhou Q, et al. PG-VulNet: detect supply chain vulnerabilities in IoT devices using pseudo-code and graphs. In: Proceedings of the 16th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement; 2022; Helsinki, Finland. New York, NY, USA: Association for Computing Machinery; 2022. p. 205–15. doi:10.1145/3544902.3546240. [Google Scholar] [CrossRef]
21. Jiang Z, Zhang Y, Xu J, Wen Q, Wang Z, Zhang X, et al. Semantic-based patch presence testing for downstream kernels. In: Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security; 2020; Virtual Event, USA. New York, NY, USA: Association for Computing Machinery; 2020. p. 1149–63. doi:10.1145/3372297.3417240. [Google Scholar] [CrossRef]
22. Haq IU, Caballero J. A survey of binary code similarity. ACM Comput Surv. 2021;54(3):1–38. doi:10.1145/3446371. [Google Scholar] [CrossRef]
23. BinDiff [Internet]. Zynamics; 2021. [cited 2024 Mar 5]. Available from: https://www.zynamics.com/bindiff.html. [Google Scholar]
24. Duan Y, Li X, Wang J, Yin H. DeepBinDiff: learning program-wide code representations for binary diffing. In: Proceedings 2020 Network and Distributed System Security Symposium; 2020; San Diego, CA, USA. Available from: https://www.ndss-symposium.org/ndss-paper/deepbindiff-learning-program-wide-code-representations-for-binary-diffing/. [Google Scholar]
25. Feng Q, Zhou R, Xu C, Cheng Y, Testa B, Yin H. Scalable graph-based bug search for firmware images. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security; 2016; Vienna, Austria. New York, NY, USA: Association for Computing Machinery. doi:10.1145/2976749.2978370. [Google Scholar] [CrossRef]
26. Kruegel C, Kirda E, Mutz D, Robertson W, Vigna G. Polymorphic worm detection using structural information of executables. In: International Workshop on Recent Advances in Intrusion Detection; 2005; Seattle, WA, USA. Berlin/Heidelberg: Springer; 2005. p. 207–26. [cited 2025 Mar 5]. Available from: https://link.springer.com/chapter/10.1007/11663812_11. [Google Scholar]
27. Hu X, Shin KG, Bhatkar S, Griffin K. Mutantx-s: scalable malware clustering based on static features. In: 2013 USENIX Annual Technical Conference (USENIX ATC 13); 2013; San Jose, CA. Berkeley, CA, USA: USENIX Association; 2013. p. 187–98. [cited 2025 Mar 5]. Available from: https://www.usenix.org/system/files/conference/atc13/atc13-hu.pdf. [Google Scholar]
28. Farhadi MR, Fung BCM, Charland P, Debbabi M. Binclone: detecting code clones in malware. In: 2014 Eighth International Conference on Software Security and Reliability (SERE); 2014; San Francisco, CA, USA. Los Alamitos, CA, USA: IEEE Computer Society; 2014. p. 78–87. [cited 2025 Mar 5]. Available from: https://ieeexplore.ieee.org/document/6895418. [Google Scholar]
29. Wang H, Qu W, Katz G, Zhu W, Gao Z, Qiu H, et al. Jump-aware transformer for binary code similarity detection. In: Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis; 2022; Virtual, Republic of Korea. New York, NY, USA: Association for Computing Machinery; 2022. p. 1–13. doi:10.1145/3533767.3534367. [Google Scholar] [CrossRef]
30. Luo Z, Wang P, Wang B, Tang Y, Xie W, Zhou X, et al. VulHawk: cross-architecture vulnerability detection with entropy-based binary code search. In: Proceedings 2023 Network and Distributed System Security Symposium; 2023; San Diego, CA, USA. [cited 2025 Mar 5]. Available from: https://www.ndss-symposium.org/ndss-paper/vulhawk-cross-architecture-vulnerability-detection-with-entropy-based-binary-code-search/. [Google Scholar]
31. Sæbjørnsen A, Willcock J, Panas T, Quinlan D, Su Z. Detecting code clones in binary executables. In: Proceedings of the Eighteenth International Symposium on Software Testing and Analysis; 2009; Chicago, IL, USA. New York, NY, USA: Association for Computing Machinery; 2009. p. 117–28. doi:10.1145/1572272.1572287. [Google Scholar] [CrossRef]
32. Santos I, Brezo F, Nieves J, Penya YK, Sanz B, Laorden C, et al. Idea: opcode-sequence-based malware detection. In: International Symposium on Engineering Secure Software and Systems; 2010; Pisa, Italy. Berlin/Heidelberg: Springer-Verlag; 2010. p. 35–43. [cited 2025 Mar 5]. Available from: https://link.springer.com/chapter/10.1007/978-3-642-11747-3_3. [Google Scholar]
33. Kang B, Kim T, Kwon H, Choi Y, Im EG. Malware classification method via binary content comparison. In: Proceedings of the 2012 ACM Research in Applied Computation Symposium; 2012; San Antonio, TX. New York, NY, USA: Association for Computing Machinery; 2012. p. 316–21. doi:10.1145/2401603.2401672. [Google Scholar] [CrossRef]
34. Lindorfer M, Di Federico A, Maggi F, Comparetti PM, Zanero S. Lines of malicious code: insights into the malicious software industry. In: Proceedings of the 28th Annual Computer Security Applications Conference 2012; 2012; Orlando, FL, USA. New York, NY, USA: Association for Computing Machinery; 2012. p. 349–58. doi:10.1145/2420950.2421001. [Google Scholar] [CrossRef]
35. Jin W, Chaki S, Cohen C, Gurfinkel A, Havrilla J, Hines C, et al. Binary function clustering using semantic hashes. In: 2012 11th International Conference on Machine Learning and Applications; 2012; Boca Raton, FL, USA. Los Alamitos, CA, USA: IEEE Computer Society; 2012. p. 386–91. [cited 2025 Mar 5]. Available from: https://ieeexplore.ieee.org/document/6406693. [Google Scholar]
36. Jang J, Woo M, Brumley D. Towards automatic software lineage inference. In: 22nd USENIX Security Symposium (USENIX Security 13); 2013; Washington, DC. Berkeley, CA, USA: USENIX Association; 2013. p. 81–96. doi:10.5555/2534766.2534774. [Google Scholar] [CrossRef]
37. Ruttenberg B, Miles C, Kellogg L, Notani V, Howard M, LeDoux C, et al. Identifying shared software components to support malware forensics. In: International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment; 2014; Egham, UK. Cham: Springer; 2014. p. 21–40. [cited 2025 Mar 5]. Available from: https://link.springer.com/chapter/10.1007/978-3-319-08509-8_2. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools