
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

CGMISeg: Context-Guided Multi-Scale Interactive for Efficient Semantic Segmentation
The State Key Laboratory of Public Big Data and College of Computer Science and Technology, Guizhou University, Guiyang, 550025, China
* Corresponding Authors: Chuhua Huang. Email: ; Yongjun Zhang. Email:
(This article belongs to the Special Issue: Novel Methods for Image Classification, Object Detection, and Segmentation)
Computers, Materials & Continua 2025, 84(3), 5811-5829. https://doi.org/10.32604/cmc.2025.064537
Received 18 February 2025; Accepted 19 May 2025; Issue published 30 July 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Semantic segmentation has made significant breakthroughs in various application fields, but achieving both accurate and efficient segmentation with limited computational resources remains a major challenge. To this end, we propose CGMISeg, an efficient semantic segmentation architecture based on a context-guided multi-scale interaction strategy, aiming to significantly reduce computational overhead while maintaining segmentation accuracy. CGMISeg consists of three core components: context-aware attention modulation, feature reconstruction, and cross-information fusion. Context-aware attention modulation is carefully designed to capture key contextual information through channel and spatial attention mechanisms. The feature reconstruction module reconstructs contextual information from different scales, modeling key rectangular areas by capturing critical contextual information in both horizontal and vertical directions, thereby enhancing the focus on foreground features. The cross-information fusion module aims to fuse the reconstructed high-level features with the original low-level features during upsampling, promoting multi-scale interaction and enhancing the model’s ability to handle objects at different scales. We extensively evaluated CGMISeg on ADE20K, Cityscapes, and COCO-Stuff, three widely used datasets benchmarks, and the experimental results show that CGMISeg exhibits significant advantages in segmentation performance, computational efficiency, and inference speed, clearly outperforming several mainstream methods, including SegFormer, Feedformer, and SegNext. Specifically, CGMISeg achieves 42.9% mIoU (Mean Intersection over Union) and 15.7 FPS (Frames Per Second) on the ADE20K dataset with 3.8 GFLOPs (Giga Floating-point Operations Per Second), outperforming Feedformer and SegNeXt by 3.7% and 1.8% in mIoU, respectively, while also offering reduced computational complexity and faster inference. CGMISeg strikes an excellent balance between accuracy and efficiency, significantly enhancing both computational and inference performance while maintaining high precision, showcasing exceptional practical value and strong potential for widespread applications.Keywords
Semantic segmentation is a core task in computer vision and is widely applied in key areas such as autonomous driving, medical image analysis, and remote sensing monitoring. Early methods for semantic segmentation primarily relied on traditional algorithms, including grayscale segmentation, thresholding segmentation, and conditional random fields, among others. However, with ongoing improvements in deep learning techniques, convolutional neural network (CNN)-based approaches, such as FCN [1], DeeplabV3+ [2], and HRNet [3], have made significant progress in segmentation tasks. More recently, the introduction of Transformer-based architectures [4,5] has further boosted segmentation performance. Although progress has been made, most existing approaches still demand considerable computational resources, which hinders their deployment in environments with limited hardware capabilities. Thus, achieving efficient segmentation under such constraints remains a critical challenge.
To address this challenge, recent research has introduced several lightweight, efficient models designed to reduce computational resource consumption while maintaining high segmentation accuracy. These methods typically focus on optimizing model architectures, lowering computational complexity, or employing specific training strategies to enhance inference speed and minimize memory usage. For example, Xu et al. [6] proposed a three-branch architecture that balances speed and performance, allowing real-time semantic segmentation. FeedFormer [7] reengineered the transformer decoder by introducing a feature-enhancing module to replace the self-attention mechanism, achieving high precision and rapid inference. SegNeXt [8] took advantage of multiscale convolutional features to drive spatial attention, demonstrating that simple and efficient convolutional encoders remain highly competitive in both performance and speed.
Although existing lightweight models strike a certain balance between efficiency and accuracy, they fail to fully leverage multi-scale contextual information, limiting their ability to locate foreground objects and optimize boundaries in complex scenes. Furthermore, the lack of effective deep feature synchronization and sharing mechanisms results in an insufficient fusion between low-level details and high-level semantic features, weakening the contextual awareness of multi-scale feature representations and causing boundary-blurring, particularly in the segmentation of complex edges or irregularly shaped objects. In light of these constraints, this paper introduces a Context-Guided Multi-Scale Interaction Semantic Segmentation Network (CGMISeg) to improve segmentation performance while maintaining computational efficiency. CGMISeg incorporates complex contextual relationships and local attention through channel and spatial attention mechanisms, while introducing the designed feature reconstruction and cross-information fusion modules to capture multi-scale contextual dependencies and enable cross-scale interaction. As illustrated in Fig. 1, CGMISeg significantly improves 59 segmentation performance while maintaining low computational complexity, achieving a better 60 trade-off between performance and computational efficiency compared to existing methods. Our main contributions are as follows:
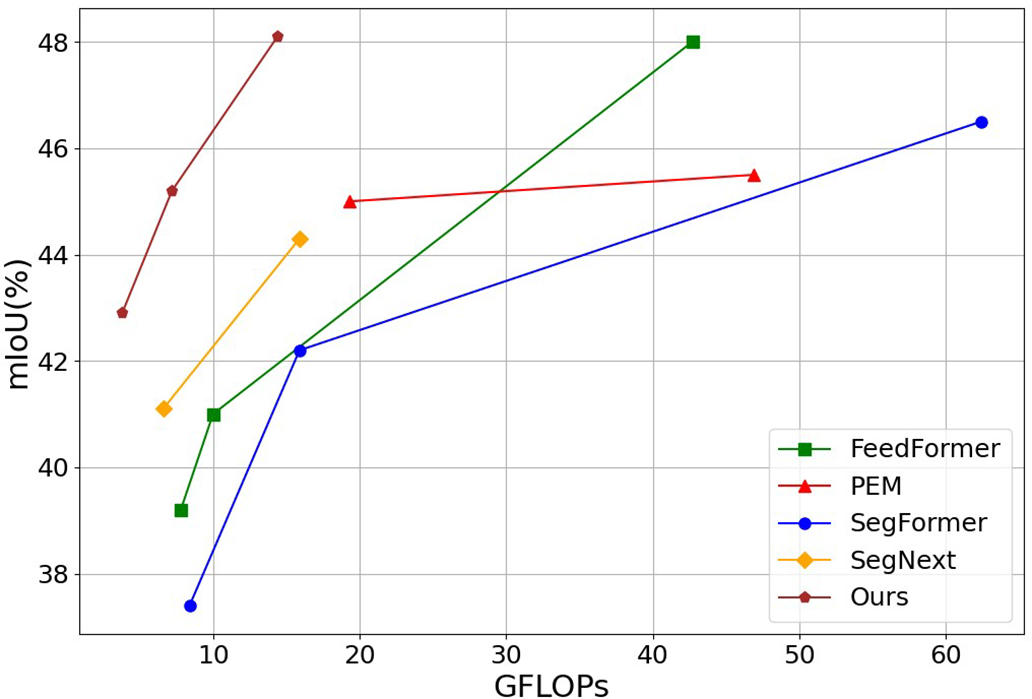
Figure 1: Performance and computational complexity comparison on the ADE20K validation set. Compared to previous methods, our CGMISeg achieves a better balance between performance and computational complexity
1. An efficient context-aware attention modulation is proposed, which dynamically adjusts attention weights in both spatial and channel dimensions. This module captures salient features at different scales, enabling the model to focus more effectively on relevant contexts.
2. A feature reconstruction module is introduced to enhance foreground localization by capturing contextual dependencies across multiple scales.
3. We propose a novel feature fusion method, cross-information fusion, which integrates refined features from the reconstruction module with low-level features from the backbone, enabling effective cross-scale interaction.
4. We construct CGMISeg for 2D semantic segmentation tasks. Compared to current methods, CGMISeg demonstrates superior overall performance, achieving an excellent balance between performance and computational efficiency.
Semantic segmentation is an intensive prediction task in computer vision, aiming to assign a category label to each pixel in an image. The pioneering work of FCN [1] demonstrated that end-to-end pixel-level classification could be achieved using a fully convolutional network, laying the foundation for the application of deep learning in semantic segmentation. Since then, many methods based on convolutional neural network (CNN) have improved FCN from various perspectives. For example, Refs. [3,9] expanded the receptive field by introducing different forms of convolution operations; PSPNet [10] enhanced global scene understanding by collecting multi-scale semantic information; and researchers developed various attention modules [11,12] to improve the model’s focus on key features. Recently, transform-based methods have shown tremendous potential. SETR [13] replaces the traditional FCN encoder-decoder structure with a transformer architecture, learning to efficiently capture contextual information through global self-attention. Mask2Former [14] transforms pixel-wise semantic segmentation into mask classification based on the transformer architecture. RTFormer [15] and HRFormer [16] have made further advances in optimizing encoder structures, improving the overall performance of the model. While these approaches have significantly advanced the field and improved task performance, these methods often come with high computational complexity and large parameter counts, which may become bottlenecks in practical applications, limiting their deployment and use on resource-constrained devices.
2.2 Efficient Semantic Segmentation
Efficient semantic segmentation aims to achieve rapid and accurate pixel-level classification in resource-constrained environments, prioritizing the minimization of computational load, parameter numbers, and inference time. CNN-based approaches have been widely adopted for efficient semantic segmentation. These methods often employ specific architectural designs to balance performance and computational cost. For instance, the BiSeNet series [17,18] utilizes a dual-branch architecture and feature fusion strategies to balance performance and efficiency. STDCNet [19] proposes an enhanced framework by rethinking the BiSeNet structure, removing the complex spatial branch and introducing an STDC-guided module to extract multi-scale information. DFANet [20] reduces parameter numbers through sub-network cascading and multi-scale feature propagation, while maintaining a sufficiently large receptive field. SegNeXt [8] employs efficient convolution operators to capture spatial attention, thereby improving segmentation accuracy and optimizing computational efficiency. In parallel, transformer-based methods have emerged as competitive alternatives in efficient semantic segmentation. SeaFormer [21] constructs an efficient backbone network for segmentation by compressing and enhancing an axial transformer, enhancing its cost-effectiveness. SegFormer [22] integrates a transformer architecture with lightweight multi-layer perceptron (MLP) decoders, avoiding the need for complex decoder designs while generating powerful feature representations. Feedformer [7] optimizes computational efficiency by relocating the encoder module to the position of self-attention modules within the decoder. Furthermore, some approaches [23,24] achieve efficient semantic segmentation by reducing learnable parameters and simplifying the training process through pixel-wise clustering or contrastive learning. However, existing methods still encounter challenges in balancing efficiency and accuracy. These challenges can be categorized into three primary areas: (1) Multi-branch architecture issues: Methods like the BiSeNet series, STDCNet, and DFANet enhance receptive fields through multi-branch designs. While effective in expanding receptive fields, the multi-branch structure introduces computational and memory overhead. This overhead hinders further model compression and improvements in inference speed. Furthermore, feature fusion in these architectures faces challenges of semantic inconsistency and scale variations, potentially leading to redundancy or information loss, thus affecting segmentation performance. (2) Attention mechanism limitations: Approaches such as SegNeXt, SeaFormer, and SegFormer leverage lightweight attention mechanisms or Transformers to improve global context understanding. However, the computational cost associated with these mechanisms remains substantial, especially with high-resolution inputs. (3) Contextual imbalance: Many methods struggle to simultaneously capture fine-grained local details and broad global context, which leads to degraded segmentation performance in complex scenes or with indistinct boundaries. To address these issues, we introduce the Context-Aware Attention Modulation (CAAM) and Feature Refinement Module (FRM) to effectively exploit multi-scale contextual dependencies. Furthermore, we propose the Cross Information Fusion Module (CIFM) for efficient cross-layer information integration. Specifically, addressing the multi-branch structure problem, the CIFM module achieves efficient information fusion between different layers. By integrating these lightweight modules, our CGMISeg achieves a balance between performance and computational overhead without requiring extra paths or complex structures.
Semantic segmentation aims to partition an image into regions with the same semantic features and classify each pixel. Formally, for a given input image
The overall structure of CGMISeg is shown in Fig. 2a. The backbone network first extracts features from each input image, generating feature maps at scales of 1/4, 1/8, 1/16, and 1/32. The feature maps at scales of 1/8, 1/16, and 1/32 are then fed into the Contextual Feature Reconstruction module, which enhances the overall understanding of the scene context through context-aware attention modulation and utilizes a feature reconstruction module to generate reconstructed features that capture multi-scale context as well as axial global context information. The reconstructed features are subsequently fused with shallow features from the backbone via the Cross-Information Fusion module, thereby enhancing the model’s ability to capture fine-grained details and strengthening its overall semantic representation.
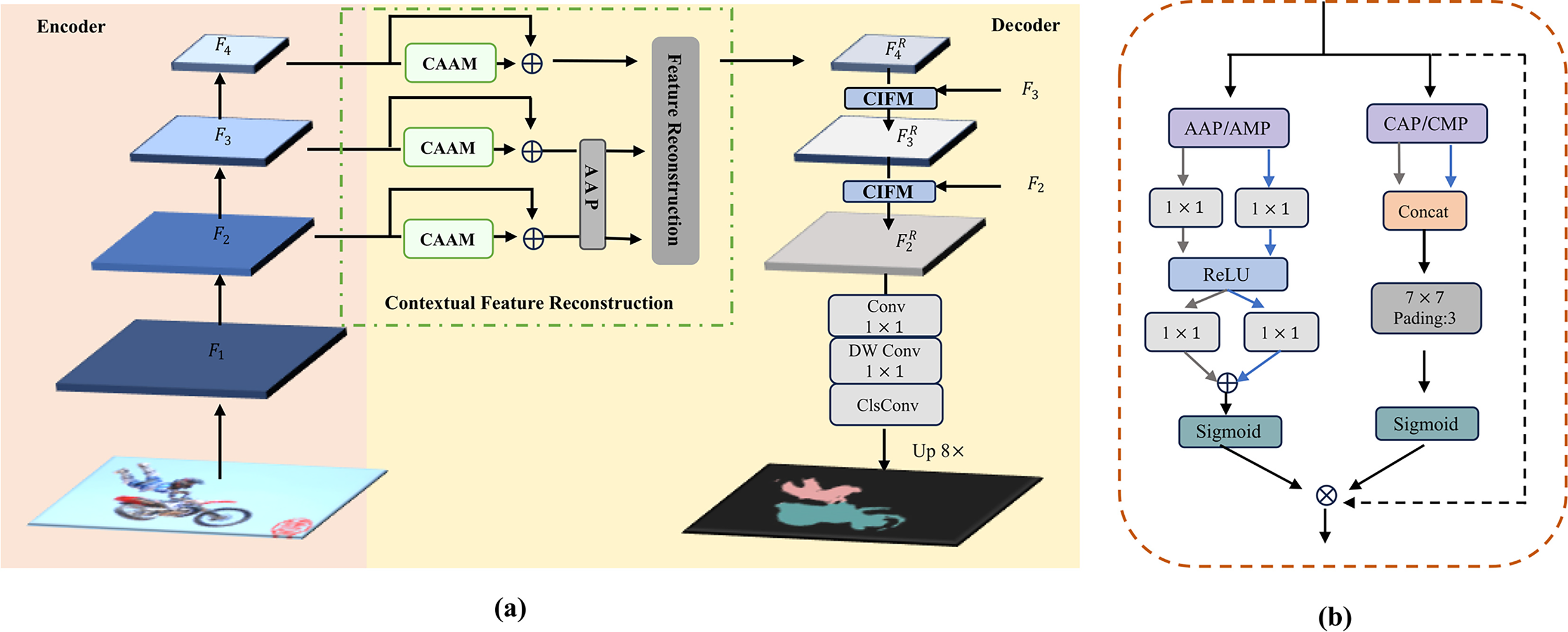
Figure 2: (a) The overall architecture of CGIMSeg. (b) Illustration of the proposed context-aware attention modulation. Features from different stages, denoted as
3.2 Contextual Feature Reconstruction
In semantic segmentation tasks, contextual information always plays a crucial role. Previous studies [25,26] have shown that effectively utilizing contextual information can significantly improve segmentation performance, as it helps the model better understand the scene structure and the relationships between objects, thereby enhancing the accuracy of target object localization and differentiation. In this study, we have designed a contextual feature reconstruction module to capture global contextual information and enhance the focus on foreground features. This module consists of two core components: Context-Aware Attention Modulation (CAAM) and the Feature Reconstruction Module (FRM).
3.2.1 Context-Aware Attention Modulation
Given that the features extracted by the backbone network have strong locality, lack global understanding of the scene context and effective modeling of relationships between local features, we introduce Context-Aware Attention Modulation (CAAM) to enhance feature representation in both channel and spatial dimensions. In Fig. 2b, we present the specific design of CAAM. Specifically, for the four stages of features
where
Subsequently, the features are passed through a ReLU activation function and then restored to the original channel dimension via another
where
In the second branch, global contextual information is extracted by applying both average pooling and max pooling across the channel dimension of the input features. The resulting feature maps are concatenated along the channel dimension and passed through a
where CMP and CAP represent the max and average pooling operations performed along the channel dimension, respectively.
After obtaining the channel attention weight
where
3.2.2 Feature Reconstruction Module
After applying context-aware attention modulation, we obtain the contextual features
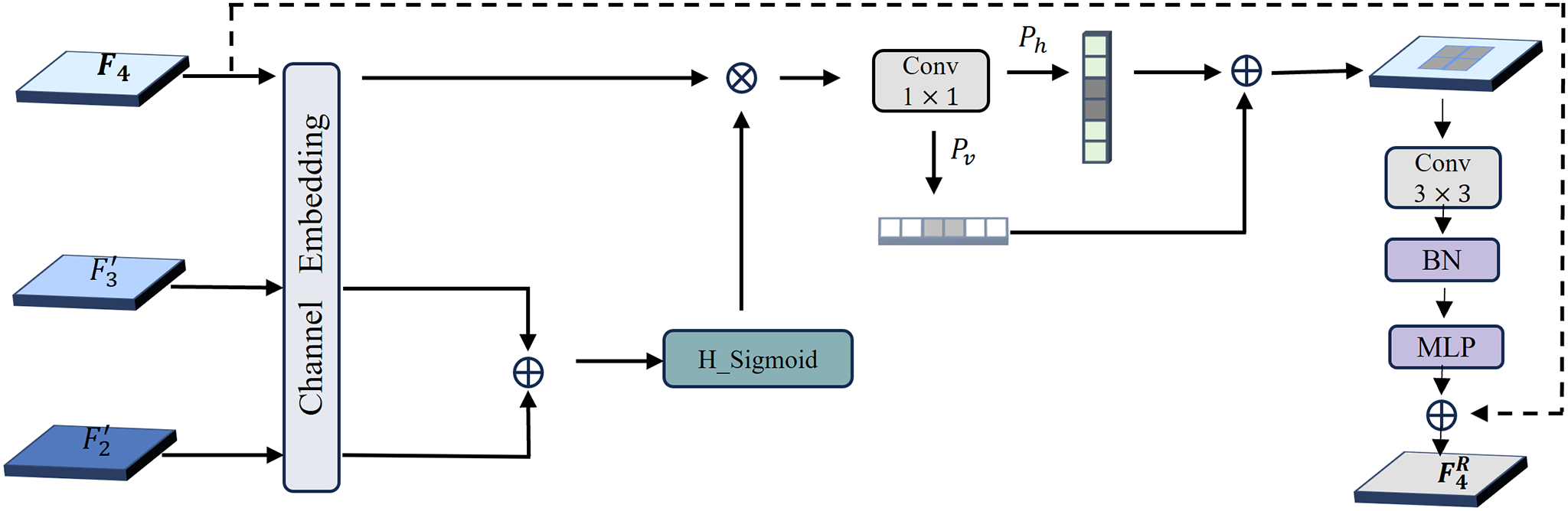
Figure 3: Illustration of the feature reconstruction module (FRM)
Specifically, adaptive average pooling is initially used on the low-level features
where
where
Then,
where
3.3 Multi-Scale Feature Interactive
In the contextual feature reconstruction module, we obtain the reconstructed feature
3.3.1 Cross-Information Fusion Module
The cross-information fusion module is designed to enable effective interaction between features from neighboring stages. As shown in Fig. 4, the module fuses features from high-level and low-level scales. Precisely, we first adjust the high-level features to the same dimensions as the low-level features through convolution and upsampling. Then, the high-level features are directly added to the low-level features for initial feature fusion:
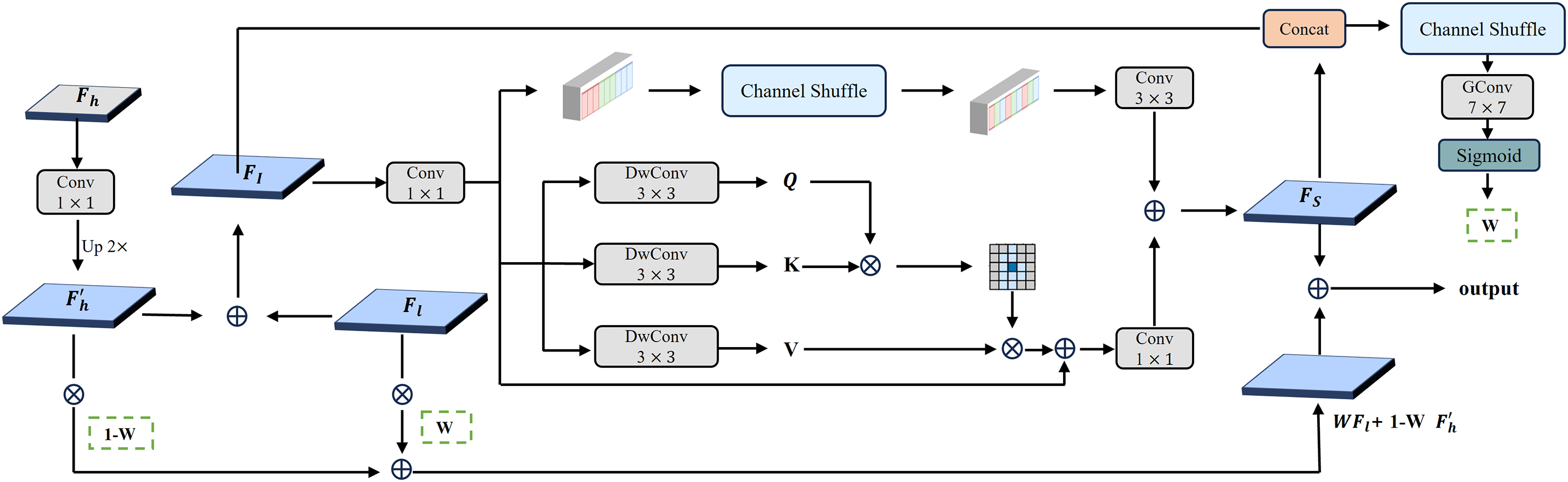
Figure 4: Illustration of the proposed cross-information fusion module (CIFM)
Subsequently, the initial fused feature
In the local branch, the input feature first undergoes a channel shuffle operation, which divides the feature into multiple groups along the channel dimension. Each group is then processed with depthwise separable convolutions to mix and fuse intragroup channel information. After that, a
where
In the global branch, for the input features, three separate
where
After obtaining the outputs from both local and global branches, the two features are summed to obtain the secondary fused feature
where
After obtaining the spatial importance map, we dynamically adjust the contributions of
where
Following the contextual feature reconstruction, the reconstructed deep features
In the upsampling feature aggregation stage, we still do not consider the shallowest feature
where
where B represents the number of images in the training batch,
Datasets. We performed extensive experiments on three widely used segmentation datasets–ADE20K [29], Cityscapes [30], and COCO-Stuff [31]–to assess the performance of our CGMISeg. ADE20K contains over 20,000 images from various environments, covering 150 categories, including 100 object categories and 50 background categories. Cityscapes is a segmentation dataset for urban scenes, containing 5000 finely annotated images across 19 categories. COCO-Stuff is built upon the COCO dataset, with pixel-level annotations for 164K images, and includes 172 categories.
Implementation Details. We implemented the code based on the publicly available mmsegmentation library [32] and used EfficientFormerV2 [33] as the encoder backbone. The model variants CGMISeg-T, CGMISeg-B, and CGMISeg-L correspond to EfficientFormerV2-S1, EfficientFormerV2-S2, and EfficientFormerV2-L, respectively. We employed the AdamW optimizer and a Poly learning rate adjustment strategy during training. The feature embedding dimension for CGMISeg-T is 128, while for CGMISeg-B and CGMISeg-L, it is 256. For training, we adopt dataset-specific hyperparameter configurations. On the ADE20K dataset, the learning rate is set to 0.00012, with input images resized to
4.2 Comparisons with the State-of-the-Art Methods
In this section, we compare our method with various state-of-the-art models on the ADE20K, Cityscapes, and COCO-Stuff. We report the model’s performance in three different variants, namely the tiny model, the base model, and the large model. The results are presented in Table 1. For the tiny model, our proposed CGMISeg-T achieves segmentation performance of 42.9% and 41.7% mIoU on ADE20K and COCO-Stuff, respectively, with only 6.3M parameters and 3.8 GFLOPs of computation. For the base model, CGMISeg-B improves upon the popular PEM-STDC2, achieving a 0.2% improvement on the ADE20K dataset (45.2% vs. 45.0%) and a 0.4% improvement on COCO-Stuff (42.6% vs. 42.2%) compared to SegNeXt-S. Although CGMISeg-B has a slightly lower segmentation performance of 80.7% compared to SegNeXt-S’s 81.3% on the Cityscapes dataset, CGMISeg-B has fewer parameters and only half the computational cost of SegNeXt-S. Furthermore, for the large-scale model, CGMISeg-L outperforms the previous methods on all three datasets, with mIoU scores of 48.1%, 82.3%, and 45.8%, respectively. CGMISeg-L offers better efficiency in terms of both parameter count and computational cost, with only 27M parameters and computational costs of 14.4 and 121.2 GFLOPs for two different input sizes, which is significantly lower than other models of similar scales. These advantages enable CGMISeg-L to achieve high accuracy with improved computational efficiency and reduced resource consumption, making it ideal for resource-limited applications.
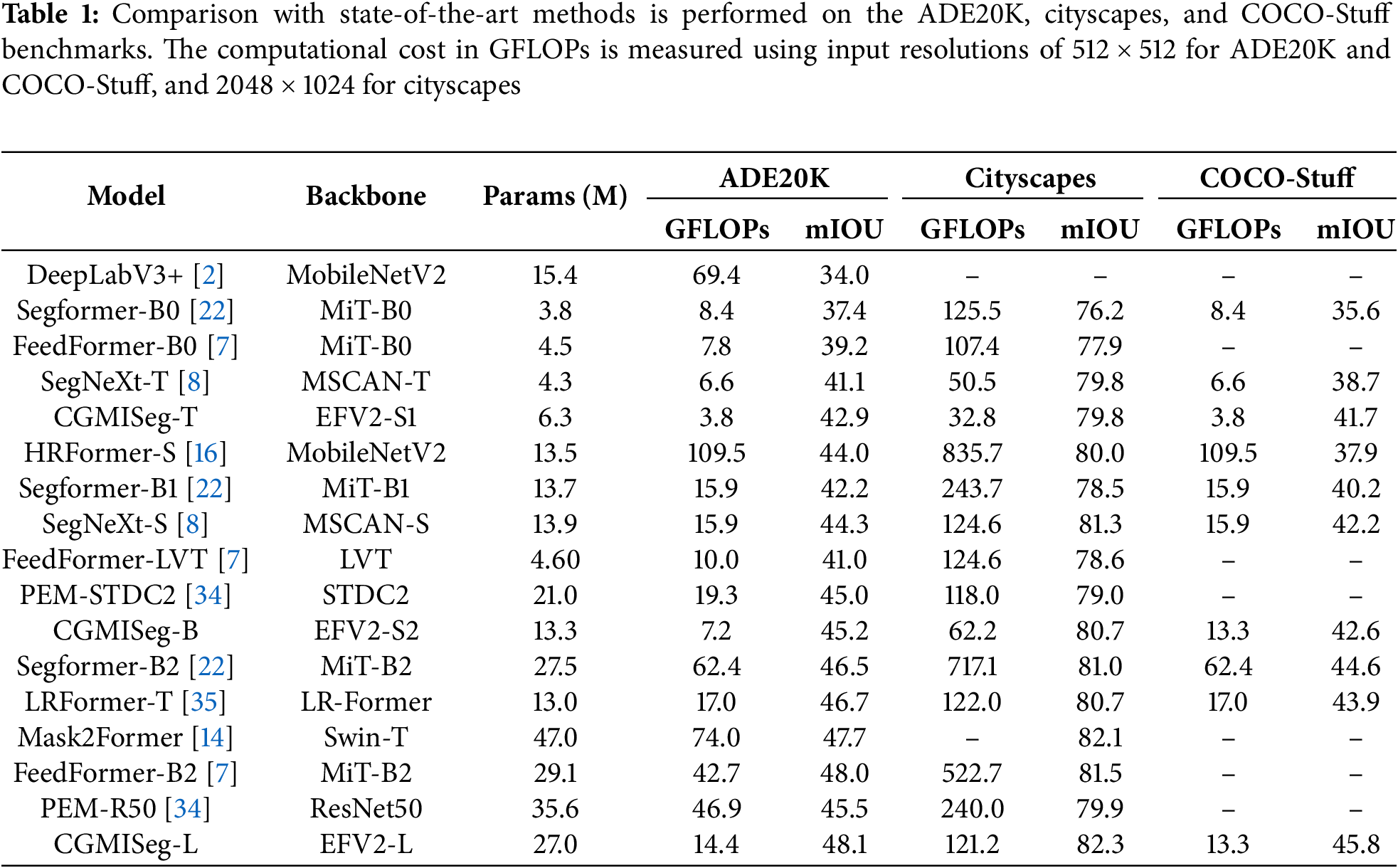
In addition to comparisons in segmentation performance, parameter count, and computational complexity, we also focus on the inference speed and latency of the proposed lightweight model CGMISeg-T to evaluate its practical potential for deployment on resource-constrained devices. As shown in Table 2, without using any dedicated software or hardware acceleration, CGMISeg-T achieves an inference latency of 34.9 ms and an inference speed of 15.7 FPS when processing 512
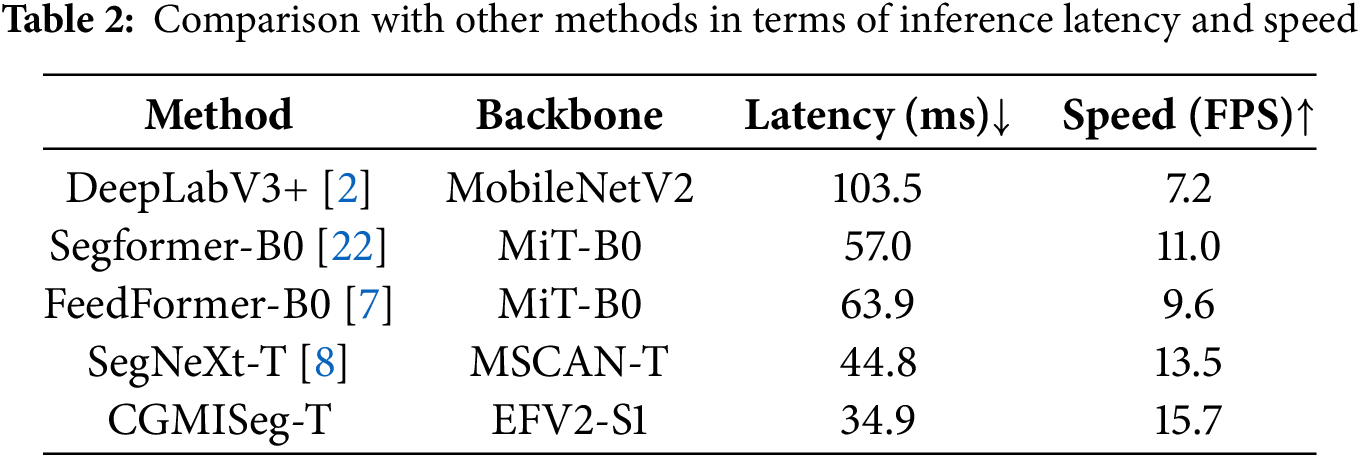
Effectiveness of the proposed modules. In this section, we conducted ablation experiments to evaluate the contributions of each component in the proposed method. Table 3 presents the ablation results for the three main components of CGMISeg: CAAM, FRM, and CIFM. The baseline model, shown in the first row of the table, does not include any additional components. In this baseline, we replaced CIFM with a direct upsampling operation of the deep features, followed by element-wise addition to the shallow features, while omitting both CAAM and FRM. As illustrated in the first row, in the absence of additional modules, the final prediction is generated by directly upsampling the deepest features and merging them with early-layer representations, resulting in a segmentation performance of 39.74% mIoU. The baseline model has 5.80 M parameters and a computational complexity of 3.47 GFLOPs. In the second row, after introducing CAAM for context information extraction, the performance improved by 1.30%. CAAM is lightweight, adding only 0.1 M parameters and less than 0.01 GFLOPs to the baseline model. The third row shows the performance after adding FRM to the baseline model. FRM reconstructs features from three stages of the encoder, and the reconstructed features are used for upsampling. This results in a 2.01% performance improvement over the baseline, demonstrating FRM’s effectiveness in enhancing multi-scale feature fusion and context information capture. FRM adds only 0.3 M parameters and 0.1 GFLOPs to the baseline, highlighting its balance between performance gains and computational cost. When both CAAM and FRM are combined, the performance improves by 2.67% compared to the baseline. Finally, when CAAM, FRM, and CIFM are all introduced, the model achieves 42.94% mIoU, a significant improvement of 3.2% over the baseline, with 6.26 M parameters and 3.84 GFLOPs. The results indicate that the proposed method yields notable performance gains with minimal additional model complexity. By incorporating lightweight modules, it effectively balances accuracy and computational efficiency.
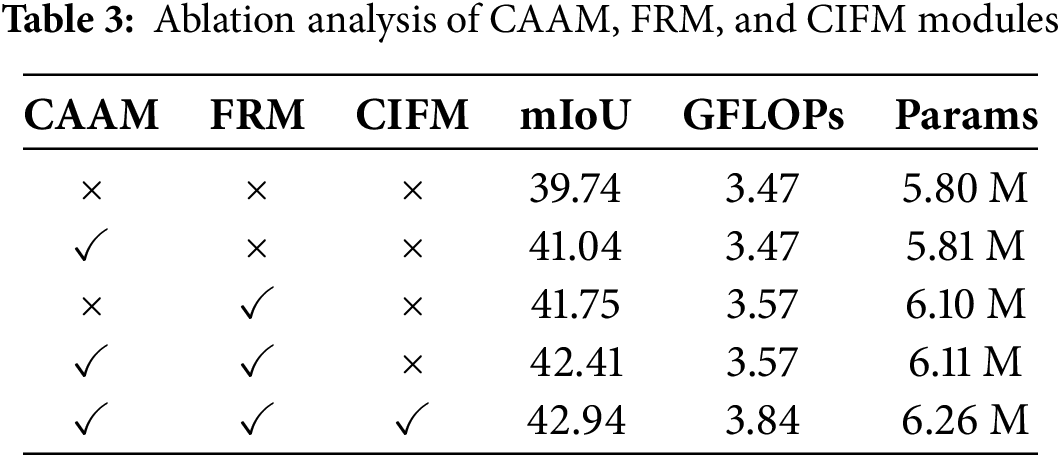
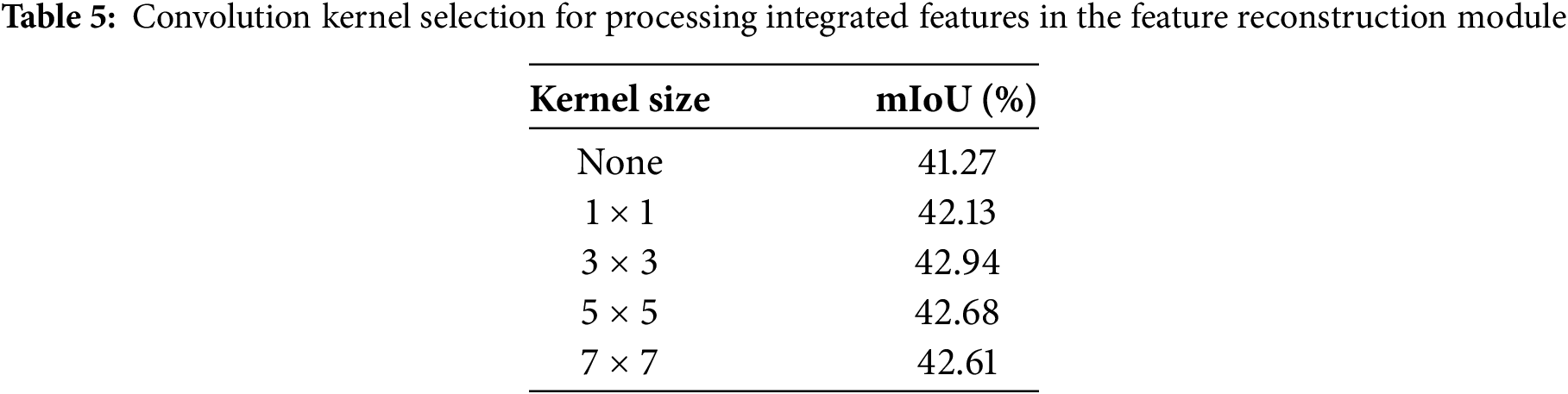
The effectiveness of kernel size in contextual feature reconstruction. To evaluate how kernel size influences contextual feature reconstruction, we conducted a set of experiments exploring its effect on overall model performance. First, we explored different kernel sizes for calculating spatial feature attention weights in the CAAM, as shown in Table 4. Increasing the kernel size initially improved segmentation performance, with the best performance achieved using a 7
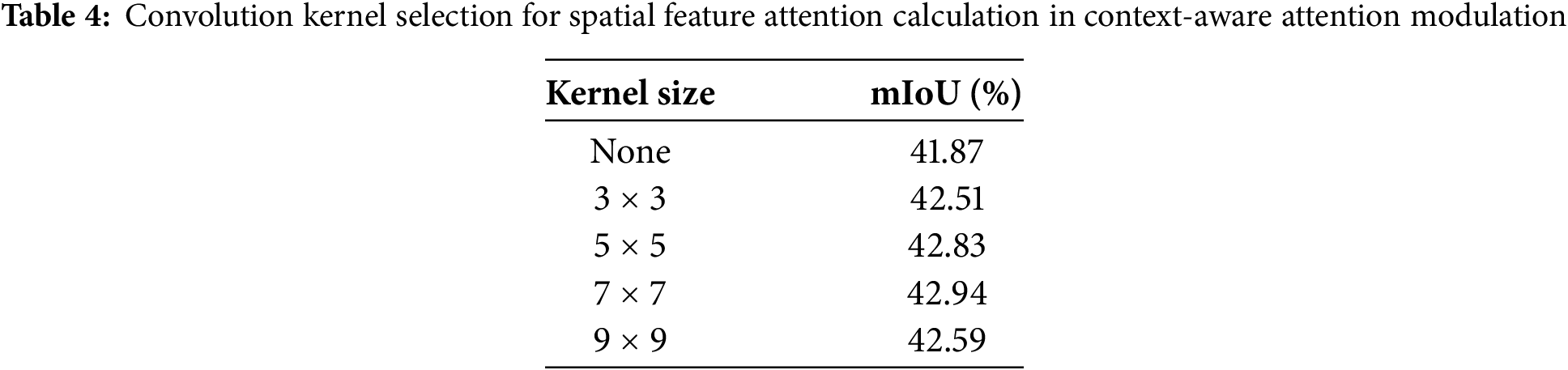
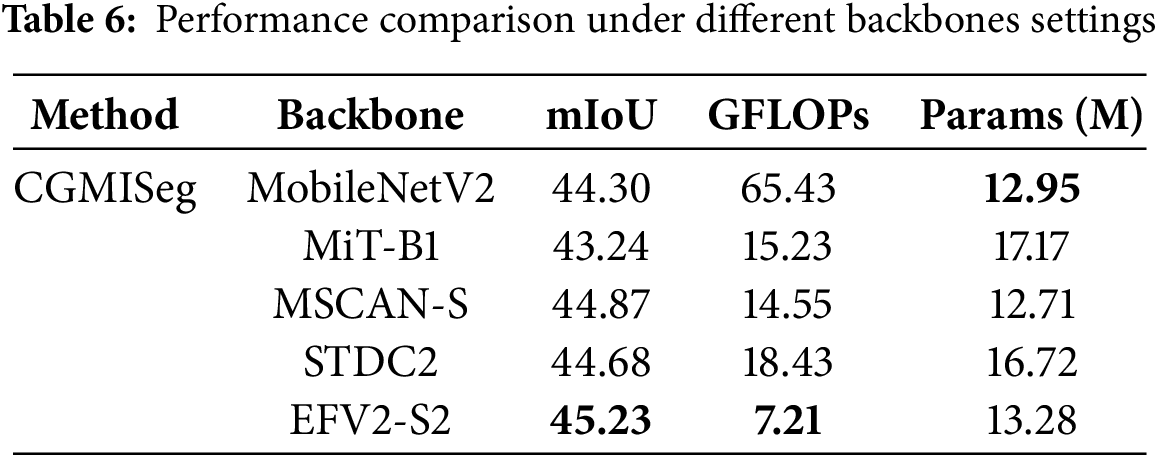
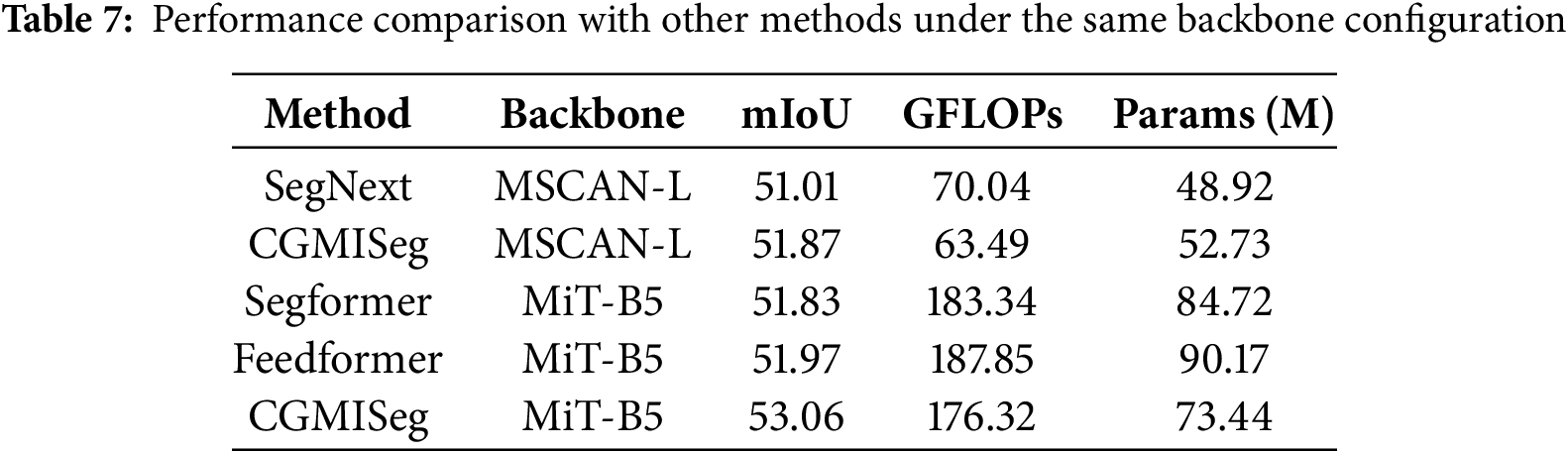
Comparison of performance under different backbones. To validate the performance of our method under different backbone networks, we conducted experiments in two aspects. First, we evaluated the performance of CGMISeg under various lightweight backbone networks to verify the superiority of EfficientFormerV2 as the backbone. As shown in Table 6, we selected backbone networks such as Mix Transformer (MiT) [22], MobileNetV2 [36], MSCAN [8], STDC2 [19], and EfficientFormerV2 (EFV2) [33], all of which have similar computational complexity and parameter scale, ensuring a fair comparison of their impact on the model’s performance. The results show significant differences in segmentation performance under different backbone networks. When using MiT-B1 as the backbone, CGMISeg achieved a segmentation performance of 43.24%. In contrast, when using MobileNetV2 and STDC2 as the backbone networks, the performance of CGMISeg increased to 44.30% and 44.68%, respectively. These results indicate that the choice of backbone network plays a key role in determining the final performance of the model. Notably, EfficientFormerV2-S2 achieved the best performance among the five lightweight backbone networks. Specifically, when EfficientFormerV2-S2 was used as the backbone, CGMISeg achieved a segmentation performance of 45.23% with a complexity of only 7.2 GFLOPs. Compared to the other four backbone networks, EfficientFormerV2-S2 exhibited significant advantages in both performance and computational complexity, demonstrating its superiority among several common lightweight backbone networks. Next, we also compared the performance of CGMISeg with larger-scale backbone networks and further analyzed its advantages compared to other methods. Table 7 compares the’s performance of CGMISeg with MSCAN-L and MiT-B5 backbone networks with other advanced methods. It can be seen that, when MSCAN-L was used as the backbone, CGMISeg outperformed SegNext by 0.86% in terms of performance while reducing computational complexity by 6.55 GFLOPs. When using MiT-B5 as the backbone, CGMISeg also performed better than SegFormer and FeedFormer. Its segmentation performance was improved by 1.23% and 1.09% compared to SegFormer and FeedFormer, respectively, while also having lower parameter counts and computational complexity than these two methods. This indicates that our method improves accuracy and maintains lower computational resource consumption, offering stronger application potential.
To intuitively evaluate the superiority of CGMISeg, visual segmentation results on the ADE20K and Cityscapes test sets are presented in Figs. 5 and 6, respectively, in comparison with two established lightweight semantic segmentation networks, Segformer and SegNext. To facilitate detailed comparison, key regions exhibiting performance variations are highlighted with yellow bounding boxes. Fig. 5 illustrates the segmentation results on the ADE20K dataset. As shown in the first row, Segformer misidentifies pixels on the desktop as part of the adjacent sofa. Similarly, SegNext exhibits category confusion in the highlighted region, misclassifying the floor area. Conversely, CGMISeg avoids these errors, yielding more accurate segmentation boundaries. In the second and third rows, CGMISeg demonstrates enhanced recognition accuracy and superior boundary preservation for objects such as baskets, washing machines, and tables within the highlighted regions, noticeably outperforming Segformer and SegNext. These results underscore its robustness and ability to delineate fine-grained details within complex scenes. To further assess the generalization capabilities of CGMISeg in urban street environments, Fig. 6 presents visual segmentation results on the Cityscapes dataset. Multiple challenging regions are highlighted. As observed, CGMISeg exhibits superior performance on targets such as traffic signs, motorcycles, sidewalks, and fences compared to Segformer and SegNext. For instance, in the first row, Segformer demonstrates misclassification between grass and sidewalks, incorrectly labeling portions of the sidewalk as grass and misidentifying distant motorcycles as cars, leading to category confusion. Concurrently, SegNext exhibits blurry segmentation around the boundaries of traffic signs, failing to accurately capture object contours and compromising the structural integrity of the scene. In contrast, CGMISeg accurately differentiates between sidewalks and grass areas while successfully preserving the contours of motorcycles and traffic signs, showcasing enhanced segmentation precision and improved boundary retention.
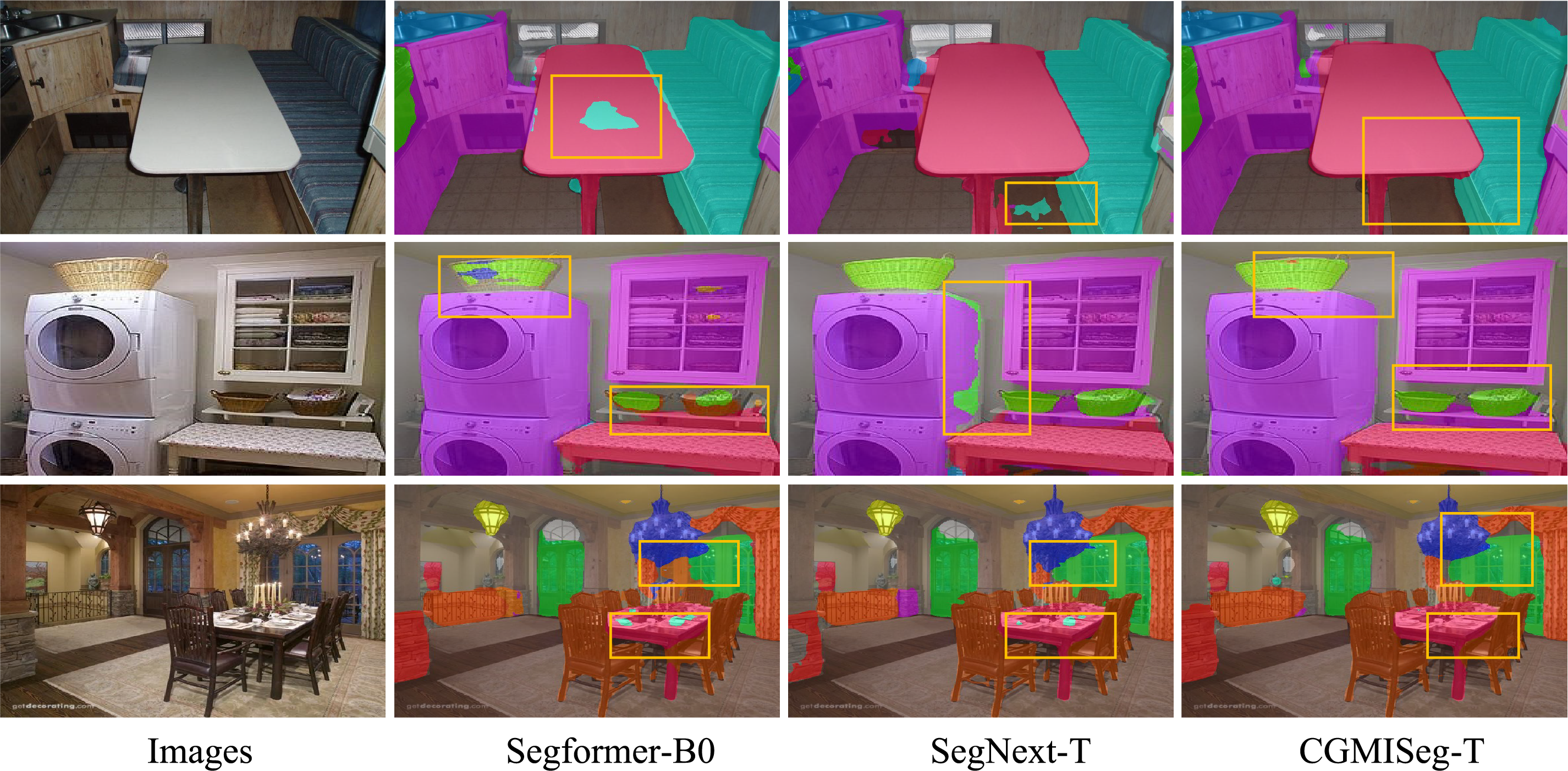
Figure 5: Qualitative comparison of CGMISeg-T on the ADE20K dataset
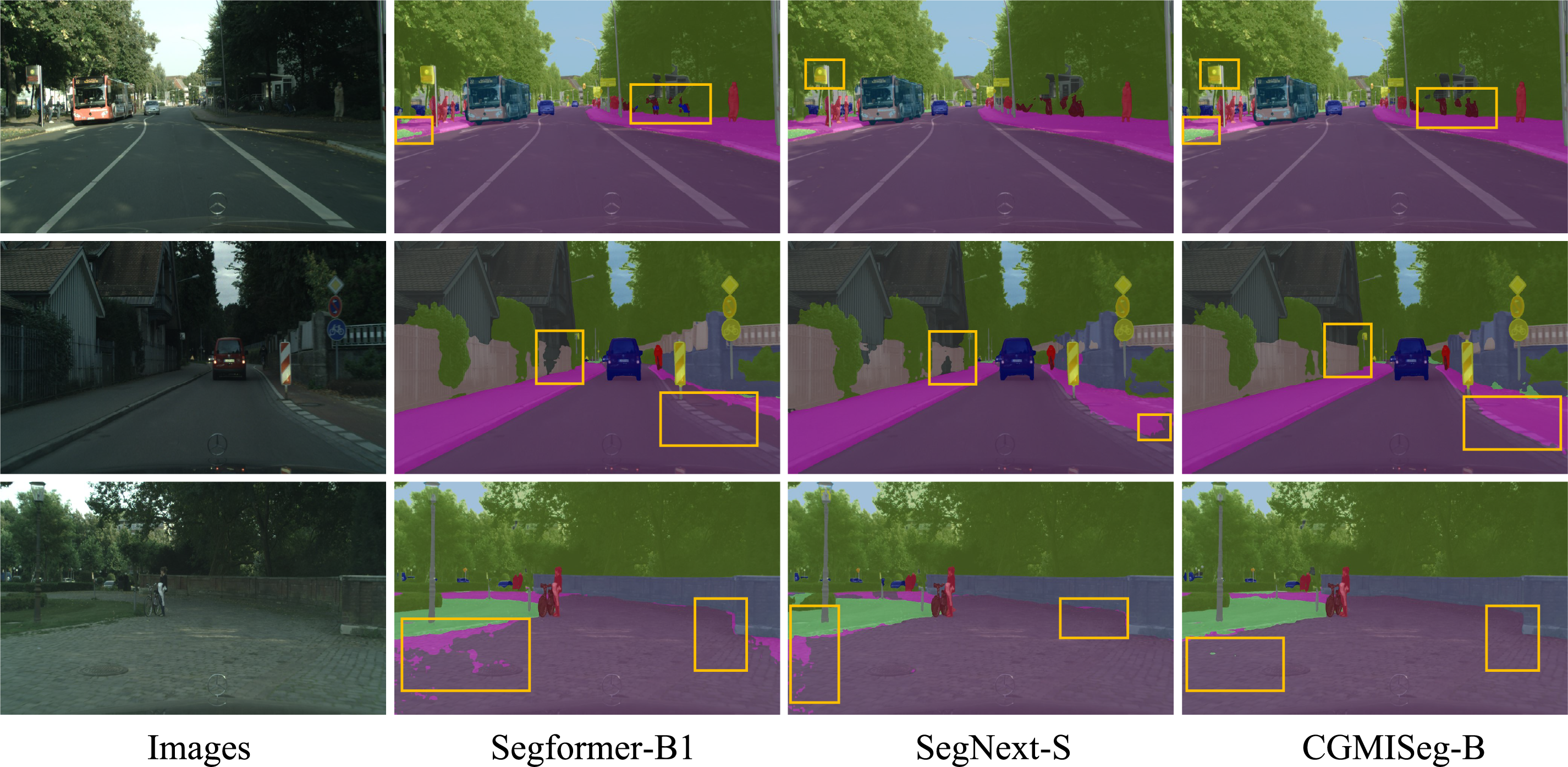
Figure 6: Qualitative comparison of CGMISeg-B on the cityscapes dataset
In addition to evaluations on the standard ADE20K and Cityscapes test sets, we further conducted visual tests of CGMISeg on real-world street view images to assess its generalization capability in complex real-world scenarios. Fig. 7 presents a comparison of segmentation results among CGMISeg, Segformer, and Feedformer on multiple real street view images, using model weights trained on the Cityscapes dataset. As shown in the yellow-highlighted regions, CGMISeg demonstrates higher accuracy and clearer boundary delineation for key targets such as fences, buildings, roads, and sidewalks compared to the other two methods. This further validates CGMISeg’s superior structural awareness and category discrimination ability when faced with realistic and complex environments. Benefiting from its context-aware mechanism and multi-scale feature fusion strategy, CGMISeg effectively mitigates category confusion in regions with overlapping semantics, improves boundary completeness, and preserves fine-grained details, demonstrating strong potential for real-world deployment.

Figure 7: Qualitative comparison of CGMISeg-L on real-world street-view images
Although CGMISeg demonstrates notable advances in computational efficiency and lightweight design, certain limitations warrant further investigation. First, the model’s reliance on GPU (Graphics Processing Unit) inference presents obstacles for real-time deployment on resource-constrained embedded systems. To address this, future research will focus on architectural optimizations, specifically employing more efficient attention mechanisms and post-training quantization methods. Post-training quantization can mitigate the GPU dependency by reducing the model’s memory footprint and computational demands, thereby enabling deployment on devices with limited processing capabilities. Second, experiments focus exclusively on publicly available natural scene datasets. While promising, the model’s generalization capabilities require further validation across cross-domain applications in medical and geospatial imaging. Furthermore, the model’s performance degrades under challenging conditions characterized by high inter-class similarity, significant scale variations, extreme lighting, or heavy occlusions. This is particularly evident in boundary region delineation and small object segmentation, areas where accuracy requires improvement. Future work will also explore dynamic computation allocation and conditional execution mechanisms to improve robustness in these complex scenarios. Finally, while we aim to facilitate real-world deployment, future work is needed to investigate broader hardware compatibility.
In this paper, we propose CGMISeg, a context-guided multi-scale interactive semantic segmentation network that offers excellent performance for semantic segmentation. CGMISeg consists of three key modules: CAAM, FRM, and CIFM. Firstly, the CAAM dynamically adjusts attention weights in both spatial and channel dimensions to capture rich global contextual information. Secondly, FRM enhances the model’s focus on foreground features through multi-scale contextual information fusion and rectangular region modeling. Finally, CIFM facilitates efficient multi-scale feature interaction during the upsampling process, leveraging feature information from each layer of the encoder to optimize boundary details and semantic consistency. Comprehensive evaluations on three benchmark datasets–ADE20K, Cityscapes, and COCO-Stuff–demonstrate that CGMISeg delivers outstanding segmentation performance, achieving an optimal balance between computational cost and segmentation accuracy compared with existing methods.
Acknowledgement: Not applicable.
Funding Statement: This work was supported by the National Natural Science Foundation of China (62162007) and the Guizhou Provincial Basic Research Program (Natural Science) (No. QianKeHeJiChu-ZK[2024]YiBan079).
Author Contributions: Ze Wang: Research design, manuscript drafting. Jin Qin: Data analysis and interpretation, manuscript revision, and methodology. Chuhua Huang: Technical and financial support. Yongjun Zhang: Project supervision and final manuscript revision. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The public datasets used in the research are all available and have been cited in the references.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Long Jonathan, Shelhamer Evan, Darrell Trevor. Fully convolutional networks for semantic segmentation. IEEE Trans Pattern Anal Mach Intell. 2017;39(4):640–51. doi:10.1109/TPAMI.2016.2572683. [Google Scholar] [PubMed] [CrossRef]
2. Chen L, Zhu Y, Papandreou G, Schroff F, Adam H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Computer Vision–ECCV 2018 (ECCV 2018). Cham, Switzerland: Springer; 2018. p. 833–51. doi: 10.1007/978-3-030-01234-2_49. [Google Scholar] [CrossRef]
3. Wang J, Sun K, Cheng T, Jiang B, Deng C, Zhao Y, et al. Deep high-resolution representation learning for visual recognition. IEEE Trans Pattern Anal Mach Intell. 2020;43(10):3349–64. doi:10.1109/TPAMI.2020.2983686. [Google Scholar] [PubMed] [CrossRef]
4. Cheng Bowen, Schwing Alex, Kirillov Alexander. Per-pixel classification is not all you need for semantic segmentation. Adv Neural Inf Process Syst. 2021;34:17864–75. doi:10.5555/3540261.3541628. [Google Scholar] [CrossRef]
5. Thisanke H, Deshan C, Chamith K, Seneviratne S, Vidanaarachchi R, Herath D. Semantic segmentation using vision transformers: a survey. Eng Appl Artif Intell. 2023;126(4):106669. doi:10.1016/j.engappai.2023.106669. [Google Scholar] [CrossRef]
6. Xu JC, Xiong ZX, Bhattacharyya SP. PIDNet: a real-time semantic segmentation network inspired by PID controllers. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023; Vancouver, BC, Canada. p. 19529–39. doi:10.1109/CVPR52729.2023.01871. [Google Scholar] [CrossRef]
7. Shim J, Yu H, Kong K, Kang SJ. FeedFormer: revisiting transformer decoder for efficient semantic segmentation. Proc AAAI Conf Artif Intell. 2023;37(2):2263–71. doi:10.1609/aaai.v37i2.25321. [Google Scholar] [CrossRef]
8. Guo Meng-Hao, Lu C, Hou Q, Liu Z, Cheng M, Hu S. SegNeXt: rethinking convolutional attention design for semantic segmentation. In: NIPS’22: 36th International Conference on Neural Information Processing Systems; 2022 Nov 28–Dec 9; New Orleans, LA, USA. p. 1140–56. doi:10.5555/3600270.3600354. [Google Scholar] [CrossRef]
9. Chen Liang-Chieh. Rethinking atrous convolution for semantic image segmentation. arXiv:1706.05587. 2017. doi:10.48550/arXiv.1706.05587. [Google Scholar] [CrossRef]
10. Zhao H, Shi J, Qi X, Wang X, Jia J. Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2017; Honolulu, HI, USA. p. 6230–9. doi:10.1109/CVPR.2017.660. [Google Scholar] [CrossRef]
11. Zhong Z, Lin Z, Bidart R, Hu X, Daya IB, Li Z, et al. Squeeze-and-attention networks for semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020; Seattle, WA, USA. p. 13062–71. doi:10.1109/CVPR42600.2020.01308. [Google Scholar] [CrossRef]
12. Huang Z, Wang X, Huang L, Huang C, Wei Y, Liu W. CCNet: criss-cross attention for semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2019; Seoul, Republic of Korea. p. 603–12. doi:10.1109/ICCV.2019.00069. [Google Scholar] [CrossRef]
13. Zheng Sixiao, Lu J, Zhao H, Zhu X, Luo Z, Wang Y, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021; Nashville, TN, USA. p. 6877–86. doi:10.1109/CVPR46437.2021.00681. [Google Scholar] [CrossRef]
14. Cheng B, Misra I, Schwing AG, Kirillov A, Girdhar R. Masked-attention mask transformer for universal image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022; New Orleans, LA, USA. p. 1280–9. doi:10.1109/CVPR52688.2022.00135. [Google Scholar] [CrossRef]
15. Wang J, Gou C, Wu Q, Feng H, Han J, Ding E, et al. RTFormer: efficient design for real-time semantic segmentation with transformer. In: NIPS’22: 36th International Conference on Neural Information Processing Systems; 2022 Nov 28–Dec 9; New Orleans, LA, USA. p. 7423–36. doi:10.5555/3600270.3600809. [Google Scholar] [CrossRef]
16. Yuan Y, Fu R, Huang L, Lin W, Zhang C, Chen X, et al. HRFormer: high-resolution vision transformer for dense predict. Adv Neural Inf Process Syst. 2021;34:7281–93. doi:10.5555/3540261.3540818. [Google Scholar] [CrossRef]
17. Yu C, Wang J, Peng C, Gao C, Yu G, Sang N. BiSeNet: bilateral segmentation network for real-time semantic segmentation. In: Computer Vision–ECCV 2018 (ECCV 2018). Cham, Switzerland: Springer; 2018. p. 334–49. doi: 10.1007/978-3-030-01261-8_20. [Google Scholar] [CrossRef]
18. Yu C, Gao C, Wang J, Yu G, Shen C, Sang N. BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation. Int J Comput Vis. 2021;129(11):3051–68. doi:10.1007/s11263-021-01515-2. [Google Scholar] [CrossRef]
19. Fan M, Lai S, Huang J, Wei X, Chai Z, Luo J, et al. Rethinking bisenet for real-time semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021; Nashville, TN, USA. p. 9711–20. doi:10.1109/CVPR46437.2021.00959. [Google Scholar] [CrossRef]
20. Li H, Xiong P, Fan H, Sun J. DFANet: deep feature aggregation for real-time semantic segmentation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019; Long Beach, CA, USA. p. 9514–23. doi:10.1109/CVPR.2019.00975. [Google Scholar] [CrossRef]
21. Wan Q, Huang Z, Lu J, Yu G, Zhang L. SeaFormer: squeeze-enhanced axial transformer for mobile semantic segmentation. In: The Eleventh International Conference on Learning Representations; 2023 May 1–5; Kigali, Rwanda. doi:10.1007/s11263-025-02345-2. [Google Scholar] [CrossRef]
22. Xie E, Wang W, Yu Z, Anandkumar A, Alvarez JM, Luo P. SegFormer: simple and efficient design for semantic segmentation with transformers. Adv Neural Inf Process Syst. 2021;34:12077–90. doi:10.5555/3540261.3541185. [Google Scholar] [CrossRef]
23. Liang J, Zhou T, Liu D, Wang W. Clustseg: clustering for universal segmentation. In: Proceedings of the 40th International Conference on MachineLearning, ICML’23; 2023 Jul 23–29; Honolulu, HI, USA. p. 20787–809. doi:10.5555/3618408.3619265. [Google Scholar] [CrossRef]
24. Wang W, Zhou T, Yu F, Dai J, Konukoglu E, Gool LV. Exploring cross-image pixel contrast for semantic segmentation. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision; 2021; Montreal, QC, Canada. p. 7283–93. doi:10.1109/ICCV48922.2021.00721. [Google Scholar] [CrossRef]
25. Yuan YH, Chen XL, Wang JD. Object-contextual representations for semantic segmentation. In: Computer Vision-ECCV 2020: 16th European Conference; 2020 Aug 23–28; Glasgow, UK. p. 173–90. doi:10.1007/978-3-030-58539-6_11. [Google Scholar] [CrossRef]
26. Shi M, Lin S, Yi Q, Weng J, Luo A, Zhou Y. Lightweight context-aware network using partial-channel transformation for real-time semantic segmentation. IEEE Trans Intell Transp Syst. 2024;25(7):7401–16. doi:10.1109/TITS.2023.3348631. [Google Scholar] [CrossRef]
27. Cao Y, Xu J, Lin S, Wei F, Hu H. Gcnet: non-local networks meet squeeze-excitation networks and beyond. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops; 2019; Seoul, Republic of Korea. p. 1971–80. doi:10.1109/ICCVW.2019.00246. [Google Scholar] [CrossRef]
28. Hou Qibin, Zhou Daquan, Feng Jiashi. Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021; Nashville, TN, USA. p. 13713–22. doi:10.1109/CVPR46437.2021.01350. [Google Scholar] [CrossRef]
29. Zhou B, Zhao H, Puig X, Fidler S, Barriuso A, Torralba A. Scene parsing through ADE20K dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2017; Honolulu, HI, USA. p. 5122–30. doi:10.1109/CVPR.2017.544. [Google Scholar] [CrossRef]
30. Cordts M, Omran M, Ramos S, Rehfeld T, Enzweiler M, Benenson R, et al. The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016; Las Vegas, NV, USA. p. 3213–23. doi:10.1109/CVPR.2016.350. [Google Scholar] [CrossRef]
31. Caesar Holger, Uijlings Jasper, Ferrari Vittorio. Coco-stuff: thing and stuff classes in context. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018; Salt Lake City, UT, USA. p. 1209–18. doi:10.1109/CVPR.2018.00132. [Google Scholar] [CrossRef]
32. Contributors MMS. MMSegmentation: OpenMMLab semantic segmentation toolbox and Benchmark. 2020.” 2023 [Internet] [cited 2025 May 18]. Available from: https://github.com/open-mmlab/mmsegmentation. [Google Scholar]
33. Li Y, Hu J, Wen Y, Evangelidis G, Salahi K, Wang Y, et al. Rethinking vision transformers for mobilenet size and speed. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2023; Paris, France. p. 16843–54. doi:10.1109/ICCV51070.2023.01549. [Google Scholar] [CrossRef]
34. Cavagnero N, Rosi G, Cuttano C, Pistilli F, Ciccone M, Averta G, et al. PEM: prototype-based efficient maskformer for image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2024; Seattle, WA, USA. p. 15804–13. doi:10.1109/CVPR52733.2024.01496. [Google Scholar] [CrossRef]
35. Wu Y, Zhang S, Liu Y, Zhang L, Zhan X, Zhou D, et al. Low-resolution self-attention for semantic segmentation. arXiv:2310.05026. 2023. doi:10.48550/arXiv.2310.05026. [Google Scholar] [CrossRef]
36. Sandler M, Howard A, Zhu M, Zhmoginov A, Chen LC. MobileNetV2: inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018; Salt Lake City, UT, USA. p. 4510–20. doi:10.1109/CVPR.2018.00474. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools