
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Simultaneous Depth and Heading Control for Autonomous Underwater Vehicle Docking Maneuvers Using Deep Reinforcement Learning within a Digital Twin System
Department of Systems & Naval Mechatronic Engineering, National Cheng Kung University, Tainan City, 70101, Taiwan
* Corresponding Author: Yu-Hsien Lin. Email:
(This article belongs to the Special Issue: Reinforcement Learning: Algorithms, Challenges, and Applications)
Computers, Materials & Continua 2025, 84(3), 4907-4948. https://doi.org/10.32604/cmc.2025.065995
Received 27 March 2025; Accepted 18 June 2025; Issue published 30 July 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This study proposes an automatic control system for Autonomous Underwater Vehicle (AUV) docking, utilizing a digital twin (DT) environment based on the HoloOcean platform, which integrates six-degree-of-freedom (6-DOF) motion equations and hydrodynamic coefficients to create a realistic simulation. Although conventional model-based and visual servoing approaches often struggle in dynamic underwater environments due to limited adaptability and extensive parameter tuning requirements, deep reinforcement learning (DRL) offers a promising alternative. In the positioning stage, the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm is employed for synchronized depth and heading control, which offers stable training, reduced overestimation bias, and superior handling of continuous control compared to other DRL methods. During the searching stage, zig-zag heading motion combined with a state-of-the-art object detection algorithm facilitates docking station localization. For the docking stage, this study proposes an innovative Image-based DDPG (I-DDPG), enhanced and trained in a Unity-MATLAB simulation environment, to achieve visual target tracking. Furthermore, integrating a DT environment enables efficient and safe policy training, reduces dependence on costly real-world tests, and improves sim-to-real transfer performance. Both simulation and real-world experiments were conducted, demonstrating the effectiveness of the system in improving AUV control strategies and supporting the transition from simulation to real-world operations in underwater environments. The results highlight the scalability and robustness of the proposed system, as evidenced by the TD3 controller achieving 25% less oscillation than the adaptive fuzzy controller when reaching the target depth, thereby demonstrating superior stability, accuracy, and potential for broader and more complex autonomous underwater tasks.Keywords
The ocean, covering over 70% of the Earth’s surface, offers valuable resources that have driven the increasing deployment of Autonomous Underwater Vehicles (AUVs) for safe and efficient exploration and development. AUVs are widely utilized for a variety of tasks, including seabed resource exploration, marine habitat monitoring, and deep-sea structure inspections [1,2]. Their high safety, reliability, and controllability make them indispensable in missions such as seabed mapping [3], underwater equipment inspection [4], and mine detection [5]. As underwater missions become more complex and prolonged, long-term endurance has become a critical requirement for AUV operations. To meet this demand, underwater docking stations have been developed to provide power recharging and data transmission capabilities, which are essential for extending mission duration and enhancing autonomy. However, achieving reliable docking remains a significant challenge. Environmental uncertainties such as ocean currents, limited visibility, and posture deviations between the AUV and docking station introduce substantial difficulties for precise motion control during docking maneuvers [6,7]. Although vision-based guidance systems, such as the one proposed by Li et al. [8], have improved docking accuracy and achieved up to 80% success rates, many early studies were limited by controlled test environments and simplified motion models. These constraints have restricted the applicability of such methods to fully autonomous and precise docking operations in more dynamic and unpredictable underwater settings.
With the development of hardware like cameras, visual information has become a crucial source for decision-making and judgment in AUV monitoring and identification tasks. DL has improved image processing, making image recognition for docking missions widely adopted. Singh et al. [9] used YOLO (short for You Only Look Once) to identify the LED light rings of target docking stations for positioning. Sans-Muntadas et al. [10] employed a Convolutional Neural Network (CNN) to map camera inputs to error signals for controlling the docking of AUVs, demonstrating the feasibility of autonomous docking using only camera lenses as sensors.
The AUV docking process comprises the return and docking phases, with a reliable return control system crucial for successful docking. Li et al. [6] developed a hybrid method integrating ultra-short baseline and computer vision to enhance accuracy and stability during final docking. Standard controllers, such as PID and fuzzy controllers, are capable of controlling a stable, fast and accuracy performance. However, with the nonlinear nature of underwater environments, the performance of fixed parameters can be limited [11]. In this case, machine learning (ML) is increasingly applied to AUV control strategies. Reinforcement Learning (RL) has gained prominence for its ability to learn through environmental interactions and feedback, improving performance over traditional methods. Yu et al. [12] demonstrated that DRL offers superior accuracy in AUV trajectory tracking compared to PID methods.
To overcome the inherent limitations of conventional PID methods in dealing with nonlinear and uncertain underwater environments, the sigmoid PID controller incorporates nonlinear modulation through a sigmoid function, which significantly improves control adaptability and stability [13]. BELBIC PID controllers, inspired by brain emotional learning, have been employed to manage dynamic behaviors in AUVs more effectively [14]. Neuroendocrine PID controllers, integrating neural networks with endocrine mechanisms, have also demonstrated robustness under uncertain conditions [15]. Although these intelligent PID controllers improve adaptability and control precision, they still require extensive parameter tuning and exhibit limited generalization across diverse scenarios. Their ability to handle highly dynamic, unstructured environments, such as those encountered in autonomous docking, remains constrained.
In recent years, deep reinforcement learning (DRL) has attracted significant attention in the field of AUV control, offering promising solutions for complex and dynamic underwater environments. The Deep Deterministic Policy Gradient (DDPG) algorithm, which combines Deep Q-Network (DQN) techniques with an Actor-Critic architecture to output deterministic actions, has demonstrated its ability to handle continuous state and action spaces effectively [16]. Carlucho et al. [17] applied DDPG to address AUV path navigation, while Yao and Ge [18] further enhanced the method by incorporating an adaptive multi-restrictive reward function, achieving better results in three-dimensional path tracking and obstacle avoidance. Despite its advantages, DDPG presents limitations such as instability in policy updates and overestimation of action-value functions, which hinder its reliability in more challenging scenarios. To overcome these issues, Fujimoto et al. [19] proposed the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm, introducing twin critics, delayed policy updates, and target policy smoothing to stabilize learning and improve control accuracy. Li and Yu [20] later applied TD3 for real-time trajectory planning in multi-AUV charging navigation, ensuring timely and collision-free arrival at charging stations. Beyond DRL approaches, recent studies have explored hybrid control strategies. For instance, an adaptive PID controller based on Soft Actor–Critic (SAC) has been proposed to enhance interpretability and performance in AUV path following tasks [21]. Additionally, the integration of fuzzy logic with PID control has been investigated to address nonlinearities and uncertainties in AUV dynamics [22]. Model Predictive Control (MPC) methods have also been advanced, with recent work incorporating Gaussian Processes to improve trajectory tracking and obstacle avoidance capabilities in dynamic ocean environments [23]. These developments underscore the rapid evolution of control techniques for AUVs. However, while these methods perform well in simulated settings, further integration with digital twin (DT) systems remains necessary to ensure robust and reliable transfer to real-world docking operations.
In addition to DRL, several advanced tuning algorithms have been proposed to optimize controllers in nonlinear systems. The Memorizable Smoothed Functional Algorithm (MSFA) enhances convergence and reduces computational cost through memory-based search [24], while Norm-Limited Simultaneous Perturbation Stochastic Approximation (NL-SPSA) stabilizes gradient estimates for systems with nonlinearities [25]. Smoothed functional variants have also improved reinforcement learning convergence in off-policy tasks [26]. However, these methods mainly target static or simplified scenarios and remain limited in handling sequential decision-making and sim-to-real transfer, which are essential for AUV docking. Compared to these approaches, DRL algorithms offer distinct advantages in addressing sequential decision-making and sim-to-real transfer challenges, which are critical for AUV docking in dynamic underwater environments.
Underwater vehicle performance is affected by payload and environmental changes, complicating parameter design and accurate mathematical modeling. Additionally, advancements in image recognition have outpaced simple numerical simulations, leading to increased focus on developing high-fidelity simulation environments. Manhães et al. [27] proposed an Unmanned Underwater Vehicle (UUV) simulator based on the open-source robot simulation platform Gazebo. This simulator allows for collaborative task simulations for multiple AUVs and simulates underwater operation interaction tasks using robotic arms. However, the visual quality of UUV Simulator is relatively low, makes it lacks authenticity when processing image. Henriksen et al. [28] proposed an open-source simulator for underwater vehicles, MORSE. This simulator supports ROS and Python, making it suitable for academic research and sensor simulation. However, it has relatively simple graphics, and its underwater physics engine lacks accuracy. Potokar et al. [29] proposed HoloOcean, an open-source underwater vehicle simulator based on Unreal Engine 4 (UE4). This simulator can be easily installed through simple steps and quickly execute simulations through the Python interface, with reliable physics engine and visual quality. It also allows easy construction of the required underwater environment within the UE4 software.
This study establishes a DT system characterized by synchronized interaction between the physical and virtual environments and the transfer of control algorithms from simulation to real-world applications (sim-to-real transfer). The digital twin system in this study is defined based on the triad architecture proposed by Grieves [30]. Sharma et al. [31] noted that DT technology offers advantages such as real-time monitoring, simulation, optimization, and accurate prediction, but its theoretical framework and practical applications have not yet been widely realized. Liu et al. [32] established a DT system for a physical robot using DT technology to transfer DRL algorithms to real-world robots. Their experimental results confirmed the effectiveness of intelligent grasping algorithms and the virtual-to-real transfer methods and mechanisms based on digital twins.
Recently, DT technology has been increasingly applied in various fields [33], further demonstrating its potential to bridge virtual models with real-world systems. Additionally, several studies have made notable progress in advancing DT technologies and reinforcement learning methods for underwater robotics. Chu et al. [34] proposed an adaptive reward shaping strategy to enhance DRL for AUV docking, addressing the challenges of complex environmental dynamics. Patil et al. [35] systematically benchmarked several DRL algorithms for underwater docking, confirming the effectiveness of TD3 in achieving high success rates, yet their work remained limited to simulation environments without full sim-to-real validation. Chu et al. [36] introduced MarineGym, a reinforcement learning benchmark platform designed for underwater tasks, which emphasized training efficiency and reproducibility, but did not focus on docking or transfer to real-world applications. Yang et al. [37] integrated DT technology with reinforcement learning for autonomous underwater grasping, demonstrating the potential of sim-to-real transfer, albeit in tasks other than docking. Havenstrøm et al. [38] investigated DRL-based control for AUV path following and obstacle avoidance, yet without incorporating DT systems or addressing docking scenarios.
This study aims to build an asynchronous AUV digital twin simulation system as an initial step toward a complete DT system, addressing limitations in real-time underwater communication. After evaluating various open-source platforms, HoloOcean was selected to develop the 3D AUV simulation system, using the UE4 engine to simulate 6-DOF motion and visualize vehicle movement. Experimental hydrodynamic coefficients were integrated into the model to ensure realistic simulation results. Although DRL and simulation platforms have been widely adopted in AUV control studies, most remain limited to purely simulated environments without addressing the gap to real-world operations. To overcome this limitation, this study proposes a DT system that integrates the physics-based simulation platform and DRL algorithms, enabling not only control strategy training but also seamless sim-to-real transfer. The developed controllers were successfully validated in real AUV docking experiments, demonstrating the practicality and reliability of our approach. Thus, the system serves both as a DRL training environment and as a bridge to real-world deployment. This research not only enhances AUV control but also provides insights for future AUV digital twin development.
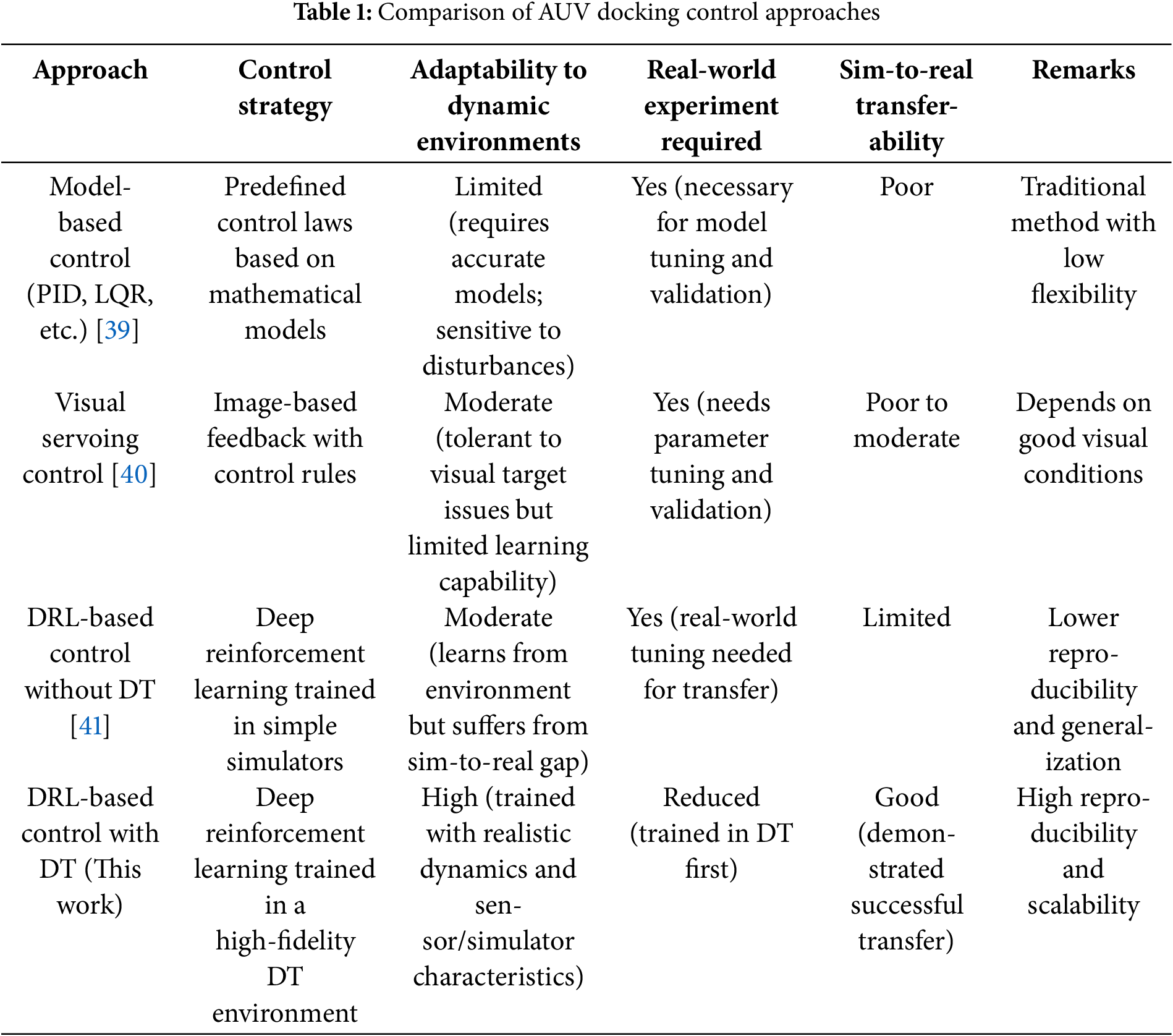
Table 1 summarizes the differences between the proposed method and other state-of-the-art approaches for AUV docking control. Compared to conventional methods relying on hand-crafted control laws or visual servoing techniques, our DT-based DRL control system offers improved adaptability, reduced dependency on real-world trials, and demonstrated robustness through successful sim-to-real transfer. This comparative analysis highlights the potential of the proposed approach as a scalable and efficient solution for autonomous underwater docking missions.
This study proposes a DT system integrated with DRL to achieve adaptive and transferable AUV docking control. A hybrid control strategy combining TD3 and a novel image-based I-DDPG is developed and successfully validated through both simulation and real-world experiments, demonstrating robust sim-to-real transfer. Furthermore, comprehensive quantitative evaluations confirm the reliability and effectiveness of the proposed method in handling nonlinear and uncertain underwater environments. The remainder of this study is organized as follows: Section 2 elaborates on the methodologies related to AUVs, docking devices, and DRL-based continuous motion control. Section 3 outlines the framework of the 3D AUV maneuvering system. In Section 4, the control methods and experimental design are introduced. Section 5 validates the feasibility of the simulation and experimental results, along with the data analysis. Finally, Section 6 concludes the study and discusses future work.
To accurately describe the motion of the AUV, it is necessary to define coordinate systems, including the earth-fixed coordinate system and the body-fixed coordinate system, as shown in Fig. 1.
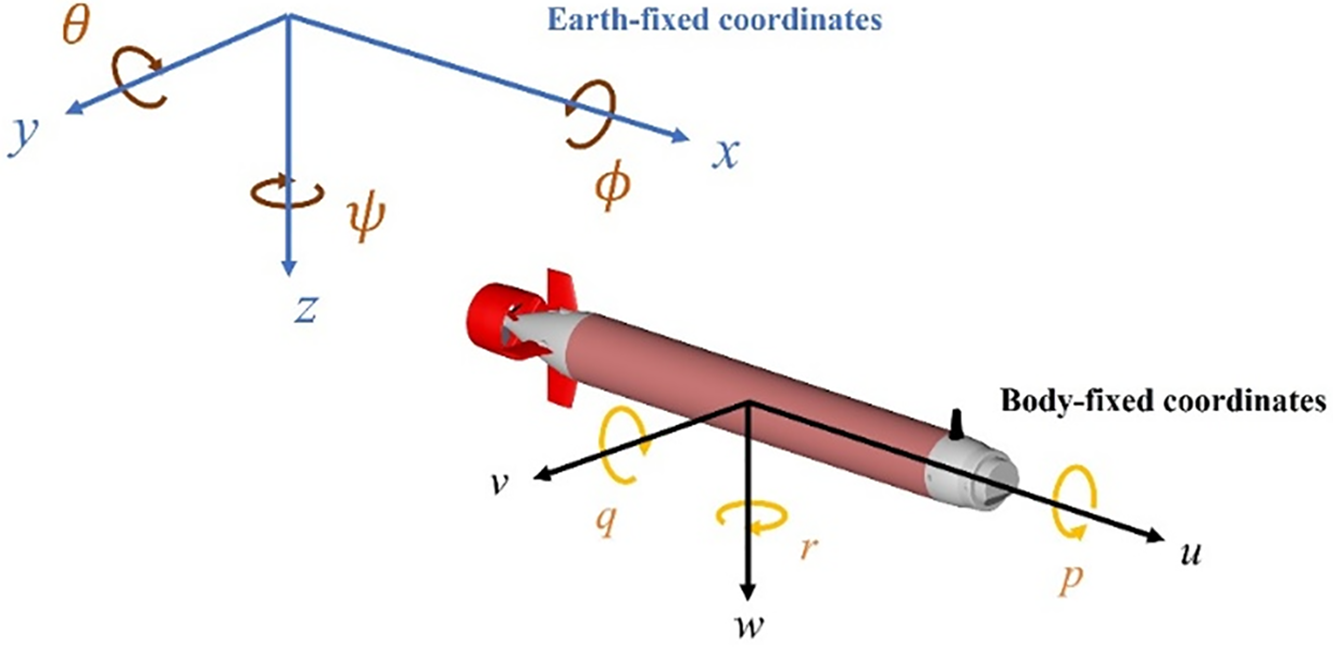
Figure 1: The schematic of the earth-fixed and body-fixed coordinate systems
The MateLab AUV features capabilities such as image identification, 6-DOF motion control, depth-keeping, and heading stabilities. The AUV’s hull design is based on the model proposed by Myring [42], with a total length of 1.7 m and a diameter of 0.17 m, resembling a torpedo shape, as shown in Fig. 2a. It weighs 40 kg, with positive buoyancy adjusted to 0.15 kg to ensure it can float to the surface in case of a system shutdown. The AUV is composed of three sections: the bow compartment, the control compartment, and the stern compartment. The bow compartment is equipped with a wide-angle camera, a stereo camera module, LED lights, and a pressure sensor module; the control compartment houses a mini-industrial computer, batteries, and various control modules; the stern compartment features propulsion provided by a DC brushless motor paired with a four-blade propeller and includes four independent servos for rudder operation, with each rudder’s axis control range being ±30°. Detailed configurations are illustrated in Fig. 2b. In this study, the mini-industrial computer integrates several key modules through serial communication methods such as RS232. These modules include the depth measurement module, the attitude and heading reference system (AHRS), the imaging module, the Bluetooth module, the propulsion control system, and the power management system, as shown in Fig. 2c.
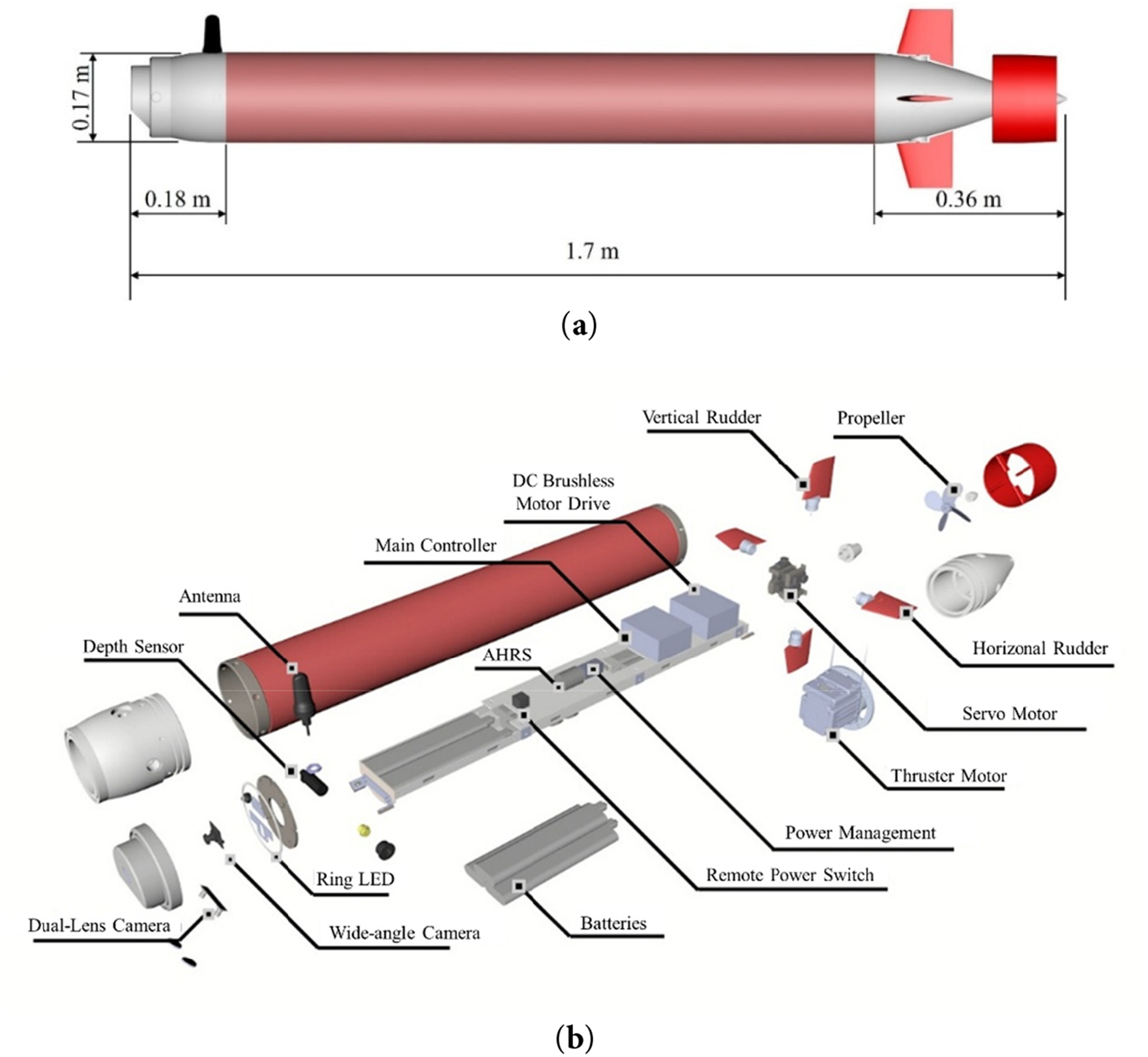
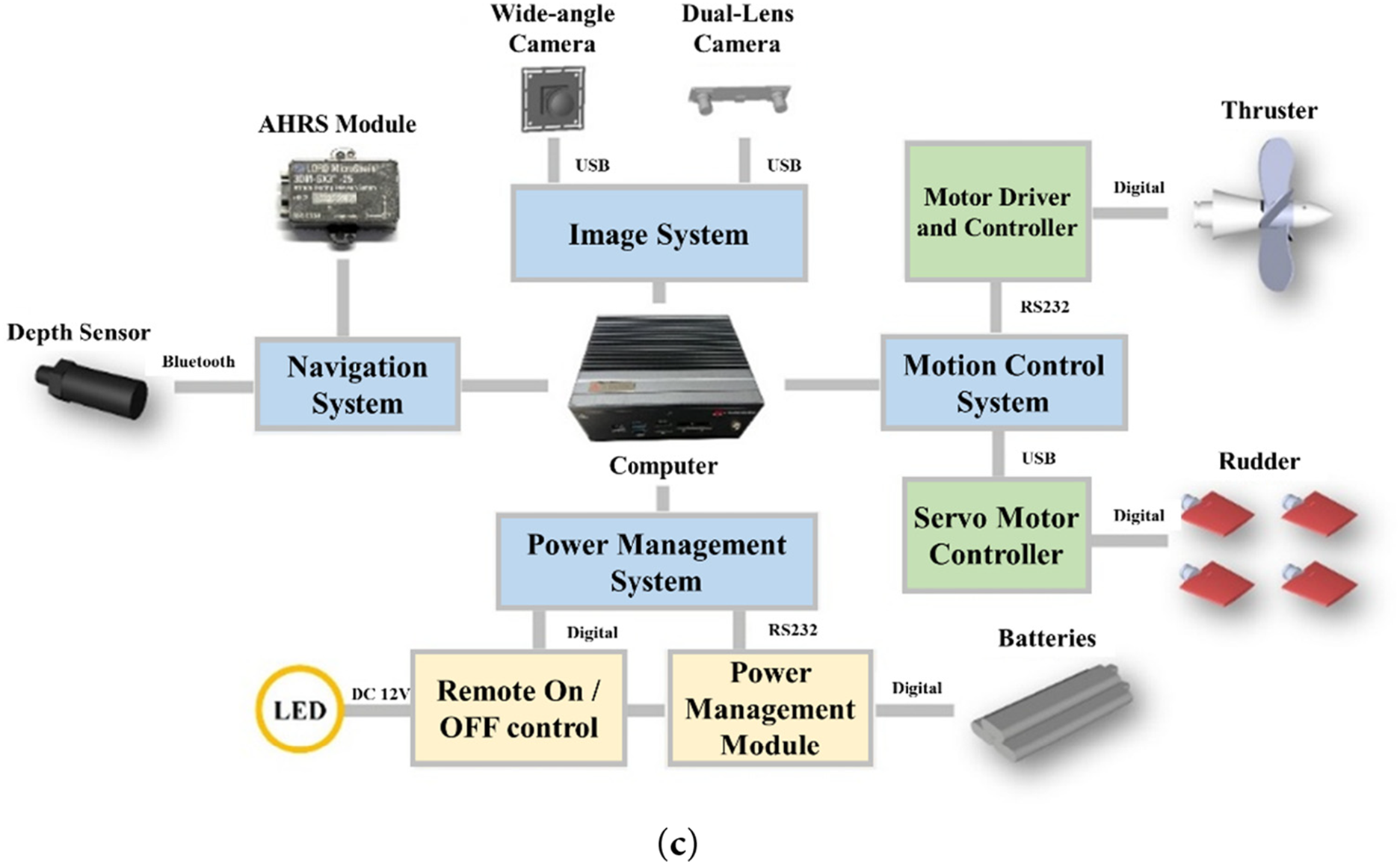
Figure 2: MateLab AUV: (a) geometric appearance; (b) internal configuration diagram; (c) comprehensive system block diagram
2.2 Equation of Motion for AUV
The motion model of an AUV integrates rigid-body dynamics with kinematic equations, typically expressed using hydrodynamic coefficients. The vehicle’s motion is primarily influenced by factors such as body inertia, hydrodynamic forces, propeller thrust, and rudder forces. The hydrodynamic coefficients vary depending on hull type and operational conditions, and their selection is often based on empirical determination. This study employs the six-degree-of-freedom motion equation model proposed by Fossen [43], as represented in Eq. (1).
where
(1) System inertia matrix
The system inertia matrix M is defined in Eq. (2). Assuming the AUV is fully submerged, M is positive definite and constant.
The matrix
where
(2) Coriolis-centripetal matrix
The Coriolis-centripetal matrix
The matrix
(3) Damping matrix
The fluid dynamic damping in an AUV is inherently nonlinear and coupled. To approximate the damping matrix
(4) Restoring force and moment matrix
The matrix
(5) Control input vector
In this study, the AUV regulates its attitude using two vertical and two horizontal control fins, complemented by a thruster. Establishing a mapping between the vehicle control inputs and the resulting forces and moments is therefore essential. This research adopts the control input model proposed by Harris and Whitcomb [44]. The position of the
where
(6) AUV Hydrodynamics
By substituting Eqs. (2) and (5) into Eqs. (1), (10) is obtained:
where the left-hand side represents the inertial forces and moments acting on the AUV, while the right-hand side comprises external forces, including hydrodynamic forces, restoring forces, and control inputs. The hydrodynamic forces and moments acting on the AUV, denoted by
The hydrodynamic force components along six degrees of freedom are expanded in terms of dimensionless hydrodynamic coefficients, as presented in Eqs. (12)–(17). These equations enable the calculation of hydrodynamic forces and moments acting on the AUV across six degrees of freedom.
Surge:
Sway:
Heave:
Roll:
Pitch:
Yaw:
The right-hand sides of the equations present the expanded forms of the hydrodynamic forces expressed in terms of dimensionless hydrodynamic coefficients. ρ denotes the fluid density, and L represents the vehicle length. The hydrodynamic coefficients adopted in this study are based on our previous study [45], which established the coefficients through towing tank experiments and validated the model’s accuracy in reproducing real AUV motion responses. The details of these coefficients are provided in Appendix A.
The docking system offers an effective solution to recovering the AUV to the mother ship, providing greater flexibility and ease of repositioning compared to more expensive fixed docking systems. The movable docking system is illustrated in Fig. 3. This study utilizes our developed docking device featuring a rectangular frame as its main structure. The conical docking entrance is constructed from aluminum alloy bars, with an opening at the top to accommodate an antenna or sail. The rear end is equipped with an adjustable support bracket, allowing it to accommodate AUVs of various lengths. The entrance is equipped with LED ring lights to serve as targets for AUV visual recognition and positioning tracking. Additionally, a fixed bracket for a variable information light disc is positioned above the entrance, though this study focuses on using the LED ring for docking information.
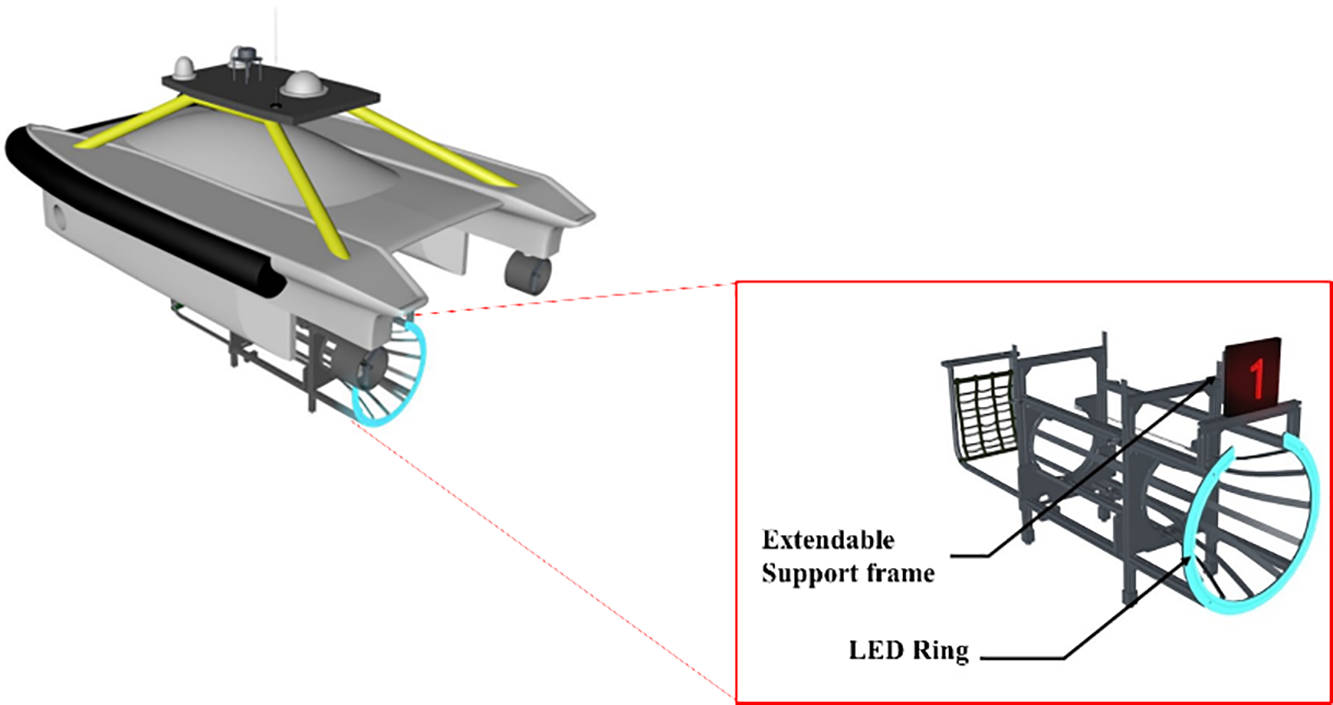
Figure 3: The schematic of the movable docking system
2.4 YOLOv7 Deep Learning Object Recognition Algorithm
YOLO [46] differs from traditional object detection models by framing the object detection problem as a single regression task, combining all aspects of object detection into one unified neural network. This approach enables YOLO to detect and locate all objects in an image in a single pass, offering faster and more comprehensive inferences on the entire image while predicting both the categories and locations of objects. Building upon YOLOv4, Wang et al. [47] introduced the YOLOv7 algorithm with several enhancements and optimizations. YOLOv7 adopts a different CNN structure, incorporating extended efficient layer aggregation networks (ELAN) and model scaling techniques to improve both inference speed and accuracy. The processing flow of the YOLO algorithm is illustrated in Fig. 4.

Figure 4: Illustration of the YOLO processing flow
To adapt the YOLOv7 model for underwater docking scenarios, a domain-specific dataset was created using synthetic images from the UE4-based digital twin environment and real-world images from basin experiments. The dataset included various perspectives and lighting conditions of the docking station’s LED light ring. The YOLOv7 model, initialized with COCO-pretrained weights, was subsequently fine-tuned on this dataset. Through transfer learning and hyperparameter tuning, the model achieved a balance between detection accuracy and real-time performance, enabling robust target localization during the docking maneuvers. This study applies the YOLOv7 object detection method to achieve target recognition and localization in docking missions, serving as the perception module within the I-DDPG control system.
2.5 DRL-Based Continuous Motion Control
DRL utilizes deep neural networks to approximate value functions or control policies, improving learning accuracy and enabling applications in more complex interactive environments. This study employs two DRL algorithms, DDPG and TD3, for docking control and depth-heading control in docking tasks.
2.5.1 The Architecture and Algorithm of DDPG
The DDPG algorithm is a DRL method specifically designed for continuous control problems. Based on the Actor-Critic framework, DDPG utilizes deep neural networks and policy gradient methods to output deterministic actions, making it well-suited for continuous action spaces and high-dimensional state spaces. The architecture of the DDPG network is illustrated in Fig. 5, where the temporal difference error (TD-error) represents the discrepancy between the predicted and target values.
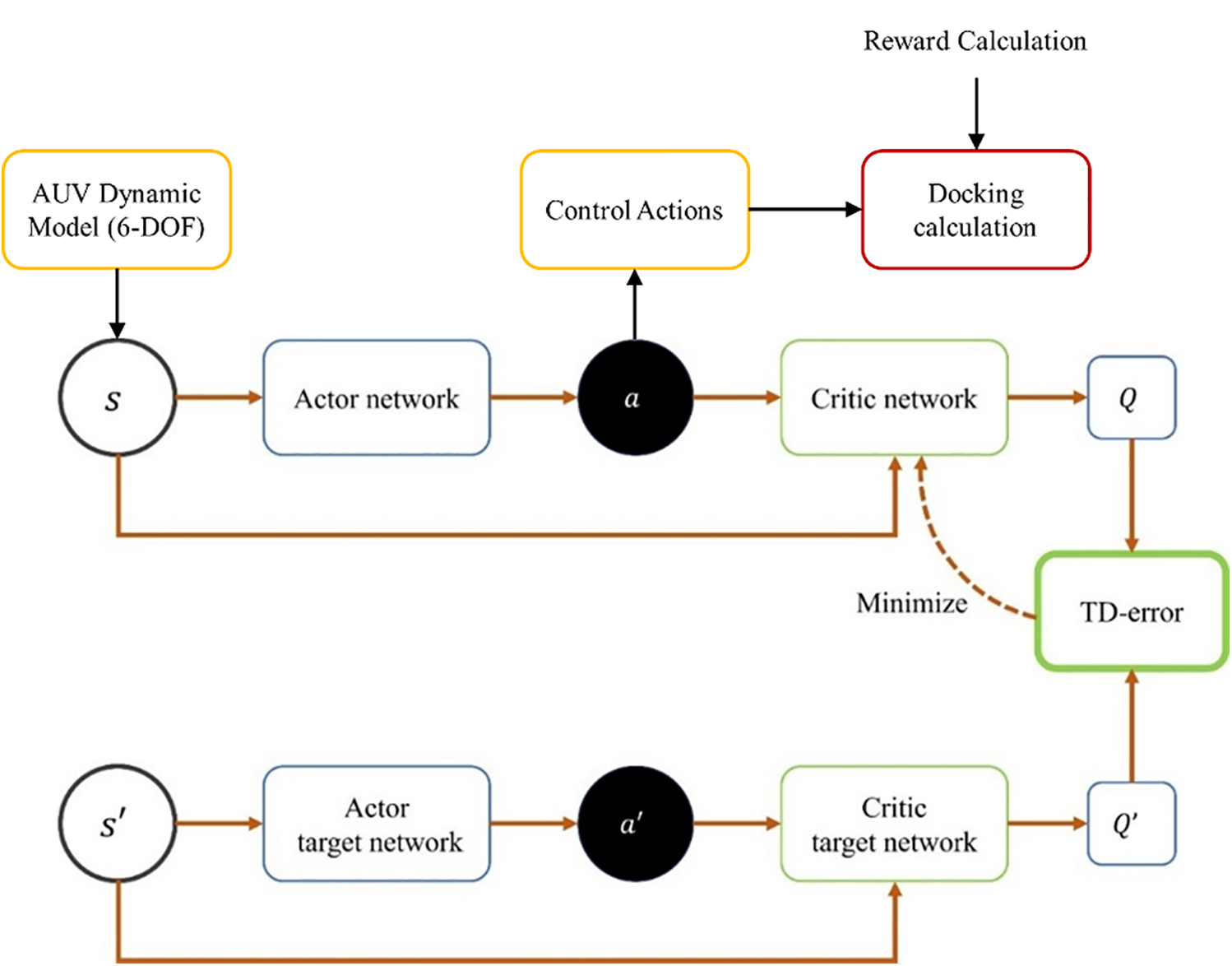
Figure 5: The architecture of the DDPG network
2.5.2 The Architecture and Algorithm of TD3
DDPG has been successfully applied to many continuous control problems. However, it faces challenges such as unstable policy updates and overestimation of Q-values. To address these issues, Fujimoto et al. [19] proposed the TD3 algorithm. TD3 is an optimized version of DDPG, incorporating three key improvements: target policy smoothing, clipped double-Q Learning, and delayed policy updates. Target policy smoothing enhances algorithm stability by smoothing the target Q-values, clipped double-Q learning prevents overly optimistic value estimates, improving policy reliability, and delayed policy updates reduce fluctuations in the policy network, enhancing learning stability. These enhancements enable TD3 to demonstrate superior performance across various control tasks, particularly in applications such as robotics control, autonomous driving, and game AI.
As shown in Fig. 6, the TD3 agent in this study follows a similar framework to DDPG for continuous AUV control, where AUV motion states serve as input to the Actor-Critic networks. The agent outputs control actions that directly command the rudder and thruster, forming the control inputs to the AUV dynamic model. The closed-loop interaction is reinforced through reward feedback, enabling the DRL agent to learn effective control policies suited for underwater docking tasks.

Figure 6: The network architecture of TD3
3 AUV Simulation and Control System Architecture
In this study, an integrated 3D AUV simulation and control system was developed using the open-source underwater robot simulator HoloOcean, which is based on the reinforcement learning simulator Holodeck [48] and Unreal Engine 4 (UE4). UE4 offers a robust platform that provides accurate physics simulation, high-fidelity visual rendering, and flexible environment customization through its C++ and Blueprint interfaces. By using these capabilities, the proposed simulation system integrates the AUV motion model as the core simulation component and serves as the virtual environment for DRL training and control validation, as illustrated in Fig. 7. In this system architecture, the AUV receives control commands, rudder deflection angles

Figure 7: Architectural diagram of the digital twin system environment
3.1 Motion Simulation in HoloOcean
The numerical integration method commonly used in physics engines to approximate these results is the semi-implicit Euler method. It combines the simplicity of the explicit Euler method with the stability of the implicit Euler method, providing a balance of low computational cost and stability. Therefore, in HoloOcean, external forces such as buoyancy, gravity, and propeller thrust are applied to the AUV model in each frame, as shown in Fig. 8. The physics engine then computes the AUV’s position and attitude based on these applied forces, simulating the AUV’s motion through this process.

Figure 8: Schematic of the HoloOcean simulation method
3.2 UE4 Visualization and AUV Simulation Setup
First, the 3D model of the AUV needs to be imported into UE4, and its surface materials must be configured (as shown in Fig. 9a) to closely match its real-world appearance. The sensor modules, including the forward-looking camera, depth sensor, and INS, are then positioned according to the actual AUV system architecture. By utilizing UE4’s terrain tools and water plugins, a realistic underwater environment can be created. This study employs the capabilities of the UE4 game development platform to construct the virtual underwater environment used in the simulation system, as shown in Fig. 9b.

Figure 9: (a) 3D model of the AUV in UE4; (b) the virtual underwater environment
After importing the model into UE4, interaction functionalities can be implemented either by editing character blueprints or using C++. In this study, the AUV model is developed using C++ code. The initial step involves setting the basic specification parameters of the AUV, including the center of gravity, center of buoyancy, weight, and volume. Additionally, the positions of the propeller and rudder need to be set, as they will be used to apply propeller thrust and rudder forces, respectively. The positions of the center of buoyancy and center of gravity are defined relative to the vehicle’s coordinate center.
This study employs the numerical simulation method [49] for the AUV, using hydrodynamic equations to compute the hydrodynamic forces
3.3 Simulation System Interface and Workflow
The Python interface of HoloOcean in this study emulates the design of OpenAI Gym [50], enabling simulations to be executed with only a few lines of code. This environment facilitates parameter adjustment, data collection and integration, simulation control, DRL training, and result output. Action commands are transmitted from Python to the simulation system, which subsequently computes the AUV’s state information for the next time step. The computed state information is returned to Python, serving as input for the DRL model during training. Furthermore, data displayed on the simulation window provides real-time feedback on the current simulation status of the AUV. The simulation process is illustrated in Fig. 10.

Figure 10: Simulation process of the Python interface
4 Control Methods and Experimental Design
The AUV’s docking process is divided into three stages: positioning (surface sailing and diving states), searching (depth-keeping and searching states), and docking (object-tracking state), enabling the AUV to locate the docking device and complete the docking task. This study focuses on evaluating the control performance of the DT system during this planned docking process and its virtual-to-real conversion. For the positioning and searching stages, the TD3 algorithm is implemented to control both the depth and heading of the AUV. The input states include real-time depth, pitch, and yaw angles, while the actions consist of horizontal and vertical rudder commands. The reward function is designed to minimize depth and heading errors while maintaining smooth control. Except for the docking stage, TD3 is employed for horizontal plane heading control and vertical plane depth control, as illustrated in Fig. 11a. During the docking stage, the I-DDPG algorithm is applied, using the bounding box coordinates of the detected target object as input states to generate rudder control commands. The reward structure focuses on target alignment accuracy while penalizing abrupt actions to ensure stable docking maneuvers. The overall control process and transition among the stages are depicted in Fig. 11b.

Figure 11: (a) Diagram of AUV control stages; (b) process of the docking task
TD3 adopts two critic networks to mitigate Q-value overestimation by averaging the outputs, thereby enhancing stability and accuracy. In contrast, DDPG uses a single critic network, which may lead to overestimation and less stable learning. This structural difference allows TD3 to outperform DDPG, particularly in complex environments. During the searching stage, both the thruster and rudder require high-precision control, whereas in the docking stage, only the rudder is needed once the AUV is sufficiently close to the dock. Detailed discussions on each method are presented in the following sections.
4.1 TD3 Depth and Heading Control Method
In the positioning stage, when the target is out of visibility range and cannot be tracked, specifically during the surface sailing and diving states, this study uses depth information
To achieve stable depth and heading control during the positioning stage, this study utilizes the proposed maneuvering simulation system to train TD3 to control the AUV during this phase. In the simulation environment, the AUV’s initial position is set at the origin of the world coordinates with the bow oriented at a heading angle of
The training process of interacting TD3 with the AUV 3D maneuvering simulation system is illustrated in Fig. 12. In each step, the agent generates a set of horizontal and vertical rudder angle actions
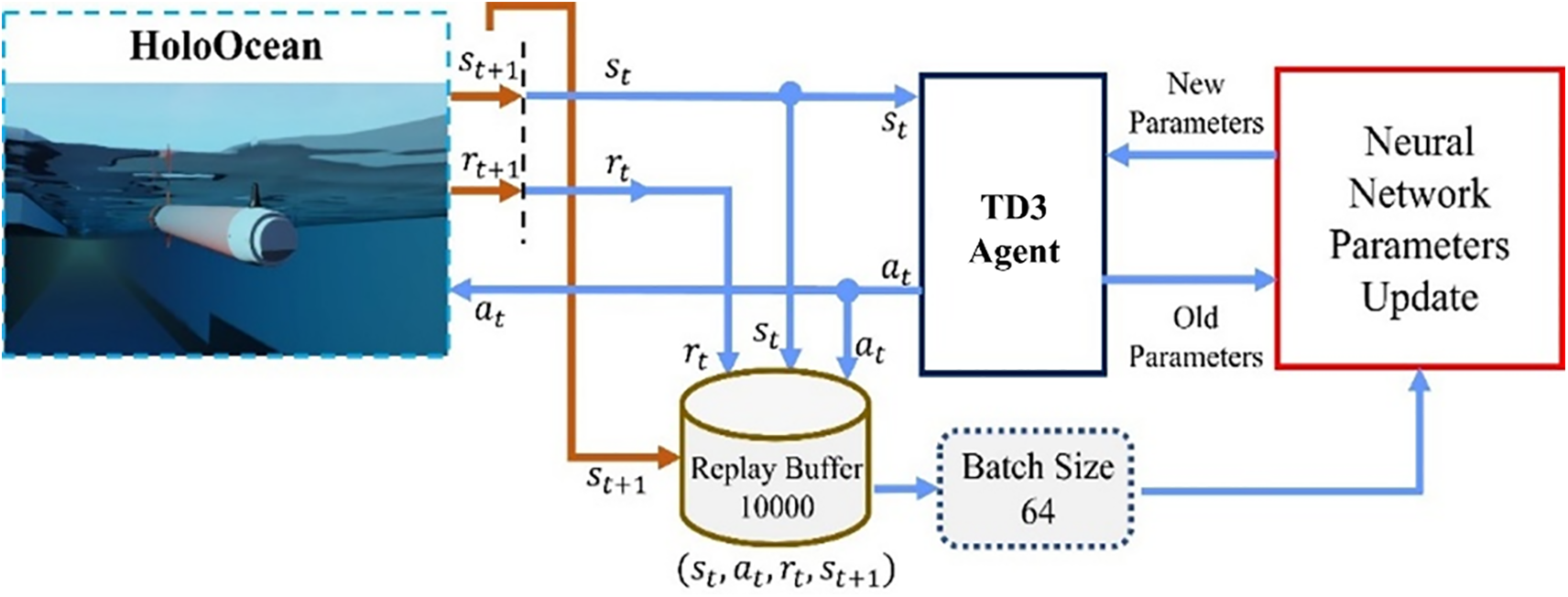
Figure 12: TD3 training process
During the TD3 training process, the environmental states consist of the AUV’s current depth information
where
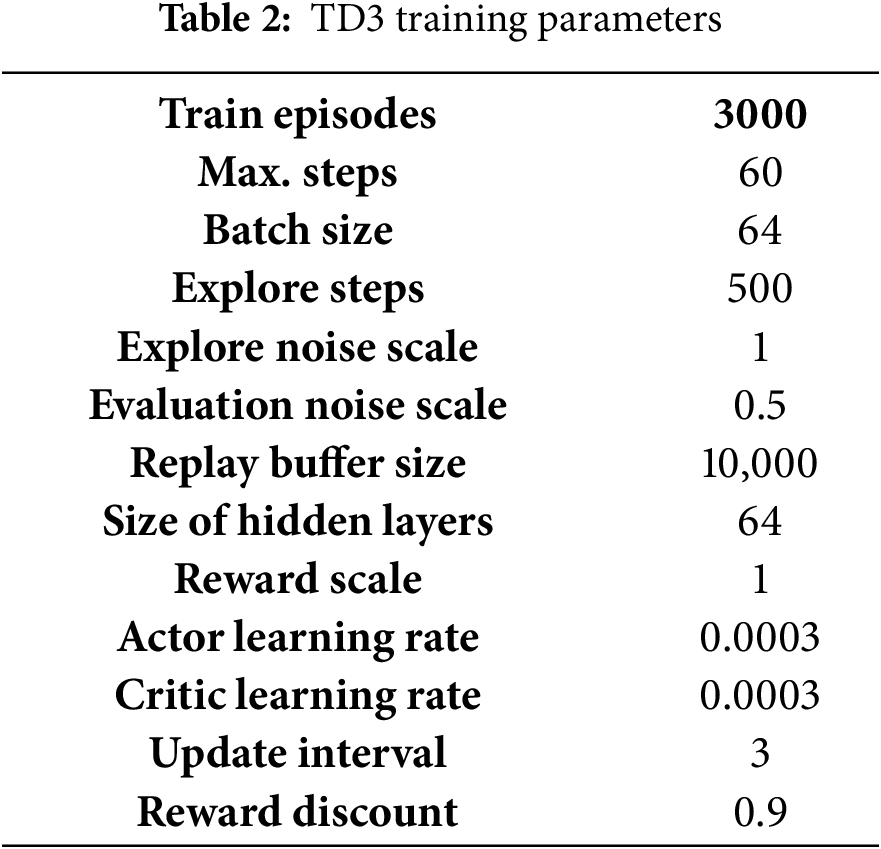
The training parameters are listed in Table 2. The model is trained for 3000 episodes, which is deemed sufficient for learning various environmental features based on the complexity of the task. Each episode has a maximum of 60 steps, which is appropriate for the target docking task. The batch size for updates is set to 64, striking a balance between training stability and computational efficiency. The reward discount factor,
4.2 I-DDPG Image Target Tracking Control Method
This study employs the I-DDPG method as the docking control approach during the docking stage. I-DDPG is a DRL algorithm based on DDPG, which integrates Image-based Visual Servoing (IBVS) object detection as the target input. In this study, the YOLO algorithm is employed for detecting the target LED ring. The tracking process of the I-DDPG control is illustrated in Fig. 13a. After the camera captures images of the target, YOLO is used for identification and localization, obtaining target information, including the bounding box center coordinates and dimensions

Figure 13: (a) Process of I-DDPG image-object-tracking control; (b) illustration of the target located within the AUV’s field of view

To ensure the successful docking of the AUV with the target dock, the goal is to keep the target object as close to the center of the AUV’s camera frame as possible by controlling
where

Figure 14: Illustration of the reward based on the target object’s position
I-DDPG is built upon the DDPG algorithm and is trained within the visualization simulation environment combining Unity and MATLAB. At each step, the model determines the angles for the horizontal and vertical rudders, denoted as

Figure 15: Interactive illustration of I-DDPG and digital twin
The training parameters for I-DDPG are presented in Table 4. The complexity of the environment states and the high-dimensional action space in the target tracking task necessitate long training times for convergence. Consequently, the number of training episodes was set to 3000. As illustrated in Fig. 16, which depicts the relationship between reward values and the number of episodes, the reward value begins to increase toward a local maximum only after approximately 500 episodes. Subsequently, the reward values continue to fluctuate before stabilizing at around 2500 episodes. To alleviate convergence difficulties arising from this complexity, the size of the experience replay buffer was reduced, enabling more frequent updates to the network parameters and thereby accelerating the convergence rate.
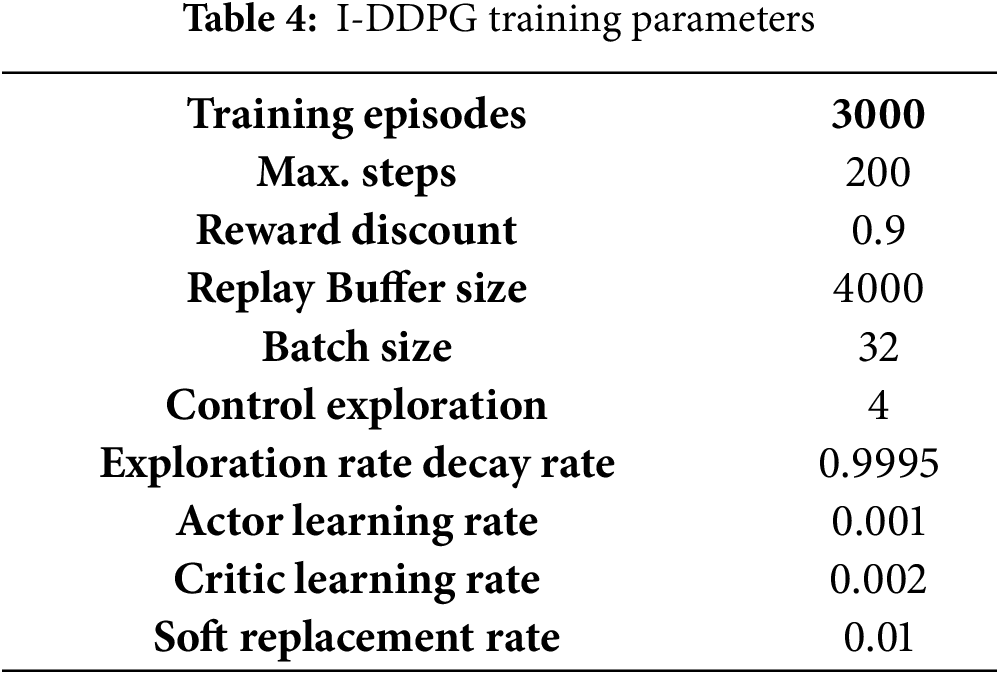

Figure 16: Variation in the reward during the I-DDPG training process
4.3 Design of the Underwater Docking Experiment
To validate the control effectiveness of the TD3 controller, which was trained using the developed 3D AUV maneuvering simulation system for tracking target depth and heading control, and to assess its impact on the subsequent docking stage, this study conducted both simulations and practical experiments on an AUV underwater docking task. The practical experiments were carried out in a water basin at National Cheng Kung University, measuring 50 m in length, 25 m in width, and with a water depth of 2 m.
The equipment setup for the underwater docking task in this study is as follows: The center of the docking device’s entrance was submerged to a depth of 1 m below the water surface, with the initial distance for the task set at 50 m. Both the simulation and experimental environments were configured according to these parameters. The simulation environment was based on the maneuvering simulation system, as shown in Fig. 17a. The key difference between the actual experiment and the simulation is that the experimental environment does not include a movable platform. As a result, only the docking device was placed in the water during the experiment. The docking device remained afloat due to its buoyancy, provided by the attached floats. By adjusting the position of these floats, the center of the docking device’s entrance was maintained at a depth of 1 m below the water surface. The experimental environment setup is illustrated in Fig. 17b.

Figure 17: The equipment setup in (a) the simulation environment, and (b) the experimental environment
In the underwater docking task, TD3 is applied to control the depth and heading during the positioning stage, enabling the AUV to stably descend to a position suitable for searching the docking device. During the searching stage, zig-zag heading motion control is used in combination with YOLOv7 to capture the position of the docking device. In the final docking process, the I-DDPG image target control system is used to navigate the AUV toward the docking device and adjust its posture to align with the target device. Subsequently, the feasibility of TD3 is validated by comparing simulation and experimental results. Eventually, the total performance and stability of the docking task will be evaluated via automatic docking experiments and data analysis.
5.1 Training Results of TD3 for Synchronous Control of Depth and Heading
This study utilizes a maneuvering simulation system to train TD3 for simultaneous depth and heading control. This training process optimizes the controller for horizontal and vertical rudder adjustments during the positioning stage of the subsequent underwater docking task. Fig. 18 illustrates the variation in reward values throughout the training process. Due to the complexity of achieving simultaneous control in both horizontal and vertical planes, this continuous control task presents significant challenges for the convergence of the reward function. It is not until after 1500 episodes that the reward values increase significantly and converge to a higher value range. Despite this, significant fluctuations remain in the later stages of training.

Figure 18: Variation in the reward during the TD3 training process
After 3000 training episodes, the TD3 model demonstrates effective performance in controlling both depth and heading in a real-world system experiment. Fig. 19a–c illustrates the time series for depth

Figure 19: Training results for TD3 depth and heading control: (a) AUV’s depth; (b) pitch angle; (c) horizontal rudder angle; (d) XY plane position; (e) yaw angle; (f) vertical rudder angle
The depth control performance of the TD3 model can be compared with that of other studies. Lin et al. [51] conducted an AUV depth-keeping study using an adaptive fuzzy controller, which demonstrated AUV depth-keeping performance with a target depth of 1 m. The red line in Fig. 20 represents the depth-keeping performance of the TD3 controller, while the blue line represents that of the adaptive fuzzy controller. The presented data is normalized with respect to the target depth. The results clearly show that the TD3 controller enables the AUV to reach the target depth faster and maintain stability more effectively than the adaptive fuzzy controller.

Figure 20: Comparison between the TD3 controller and the adaptive fuzzy controller (
It should be noted that the response of the TD3 controller is displayed over a 60-s period, which corresponds to the typical duration of the positioning and searching stages. Within this time frame, the controller’s transient response, convergence speed, and steady-state accuracy can be sufficiently demonstrated. Furthermore, this duration reflects practical constraints imposed by the physical dimensions of the test environments, including the towing tank and plane water basin. Additionally, a zoom-in subplot has been added to highlight the transient response within the first 60 s, where performance differences are most pronounced. In general, Fig. 20 indicates the superior performance of the TD3 controller in terms of response speed and depth-keeping stability, achieving 25% less oscillation than the adaptive fuzzy controller when reaching the target depth, which highlights its enhanced stability, accuracy, and potential scalability for more complex autonomous underwater tasks.
In addition to the qualitative comparison illustrated in Fig. 20, a quantitative analysis has been conducted to further evaluate the performance of the TD3 controller. Table 5 summarizes key time response specifications, including rise time and settling time, calculated from the depth control experiments. These indicators provide a more detailed assessment of the controller’s dynamic performance and stability. Moreover, as shown in the experimental results, the TD3-based control method achieves faster convergence and better steady-state accuracy compared to the conventional adaptive fuzzy controller. This clearly demonstrates the superiority of the proposed method in handling complex underwater docking tasks.

5.2 Simulation and Experimental Results of AUV Underwater Docking
Prior to conducting the actual underwater docking experiments, this study first designed and simulated the entire docking control process using a maneuvering simulation system. The subsequent underwater docking experiments were conducted following this planned process to validate both the TD3 model’s control capability in real underwater environments and the feasibility of the planned task flow in simulation, as illustrated in Fig. 21a,b. The docking process was divided into the following stages: 0–15 s for positioning, 15–50 s for searching (transitioning earlier to docking if the target is detected), and 50 s onward for docking.

Figure 21: The recodes of (a) simulation, and (b) experiments
Fig. 22a–g presents the recorded data from the underwater docking task simulation and actual experiments, including yaw angle
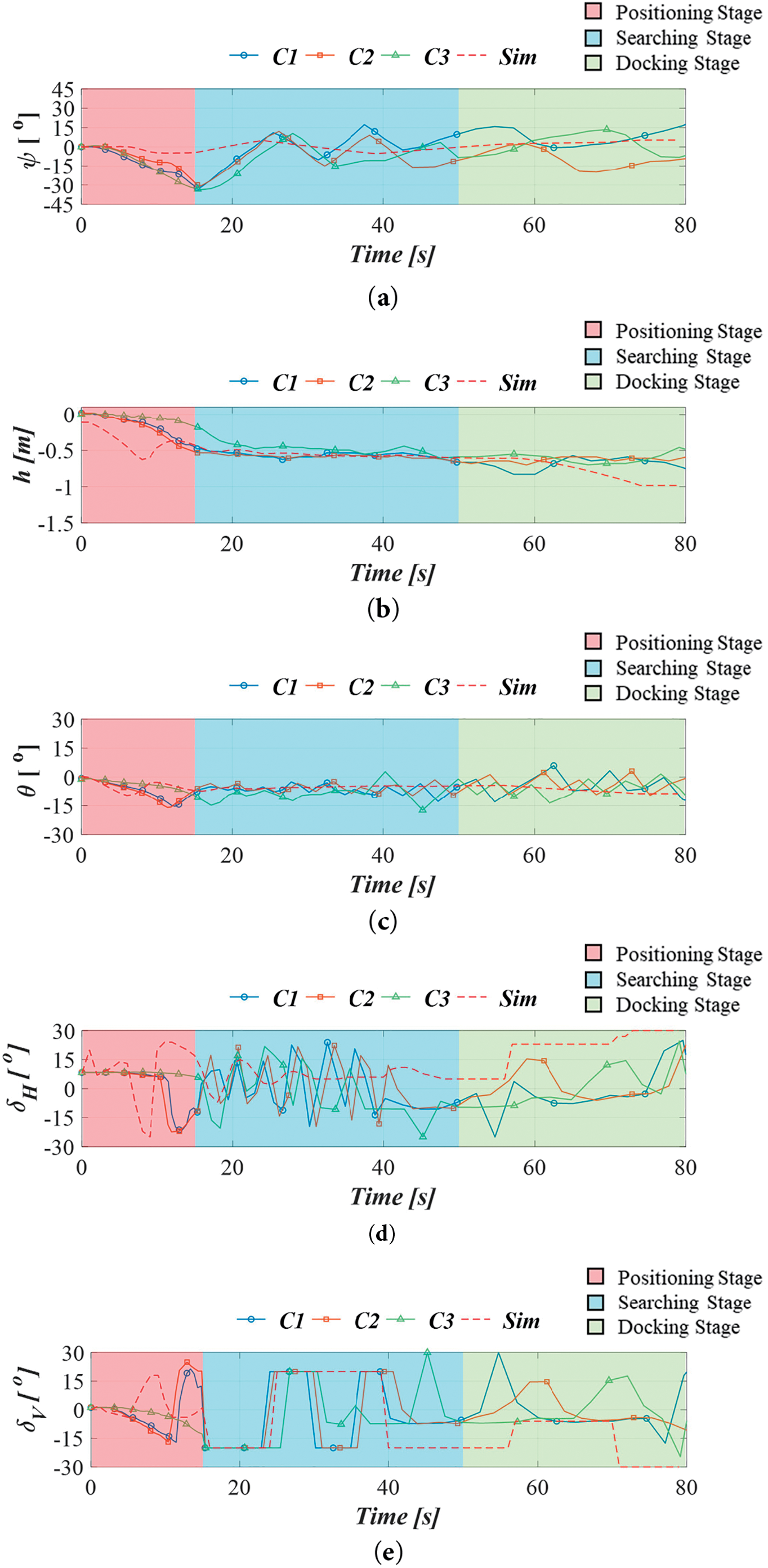
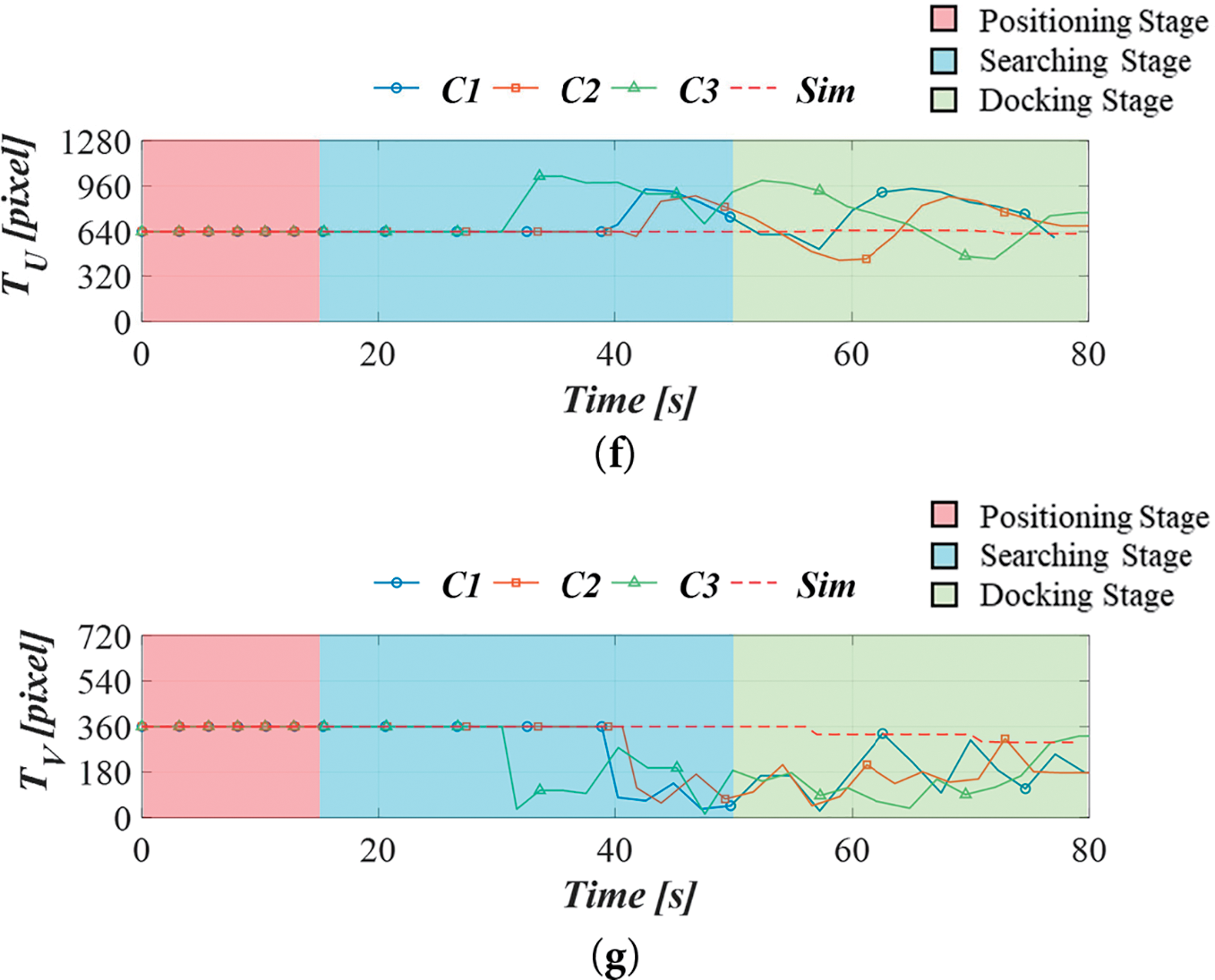
Figure 22: Time series of AUV’s docking tasks: (a) yaw angle; (b) depth; (c) pitch angle; (d) horizontal rudder angle; (e) vertical rudder angle; (f) horizontal image coordinate of the target; (g) vertical image coordinate of the target
In this study, TD3 was employed for the synchronous control of depth and heading angle during the positioning stage. In the searching stage, TD3 continued to control depth, while heading control was switched to the zig-zag method. The effectiveness of these control strategies was evaluated by plotting the depth and heading angle distributions in the visual coordinate system for both the simulation and all experimental cases during the positioning and searching stages, as shown in Fig. 23a–d. The horizontal axis represents the AUV’s heading angle (
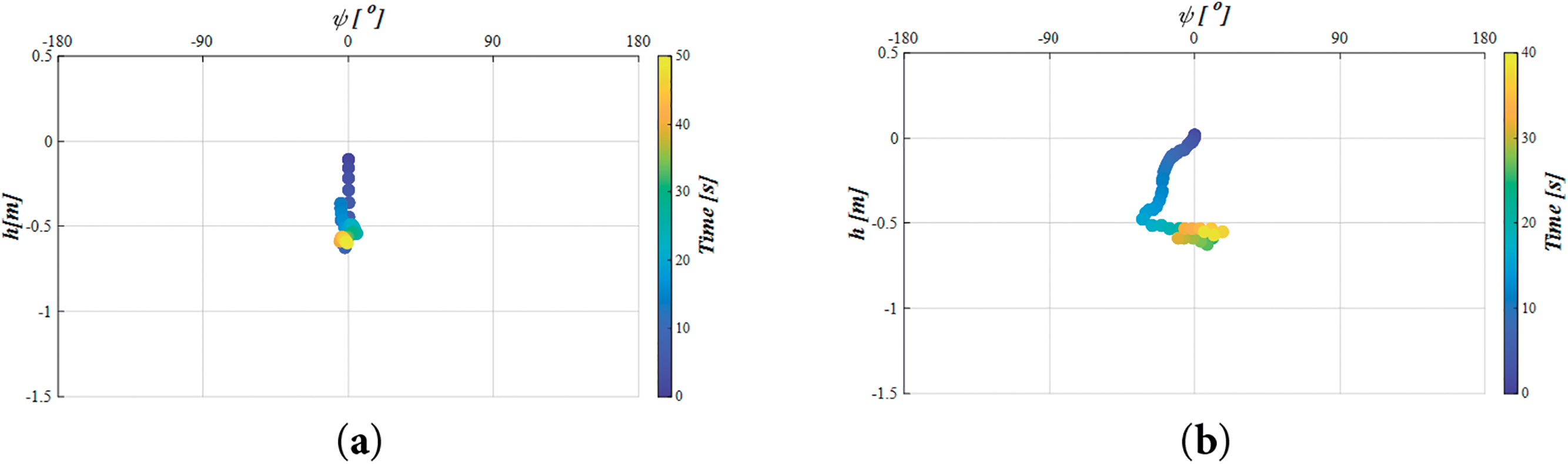
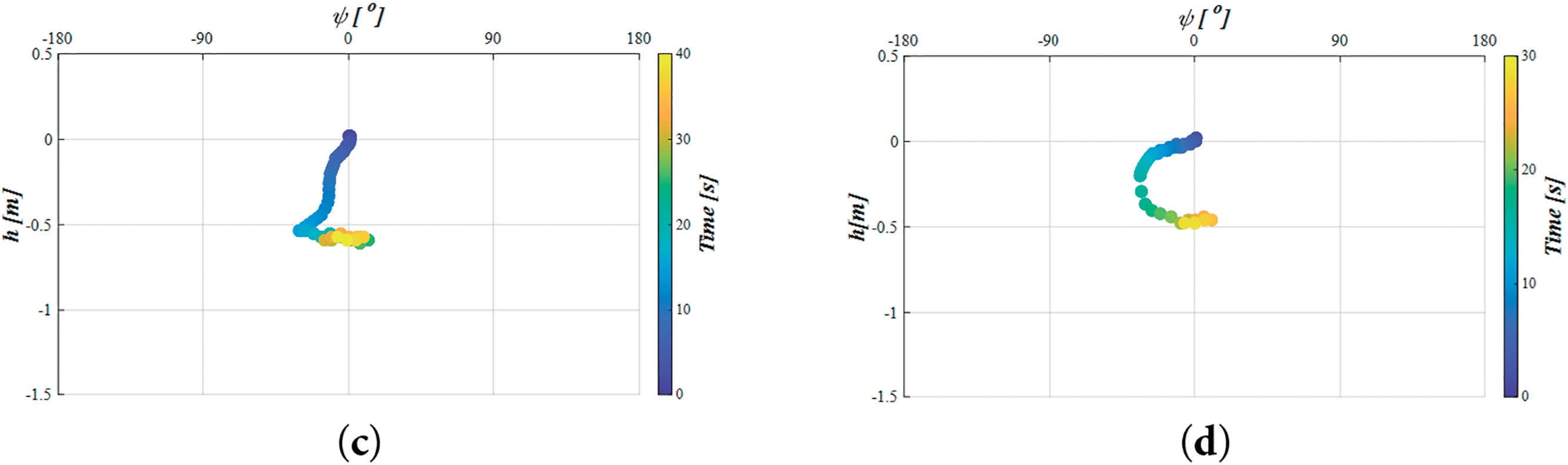
Figure 23: Distributions of depth
In this study, image coordinates were used as the main control parameters during the docking stage. The tracking results were evaluated based on the distribution of the target image center on visual coordinates for both the simulation and all experimental cases during the docking stages, as shown in Fig. 24a–d. The horizontal axis represents the image’s horizontal coordinate (
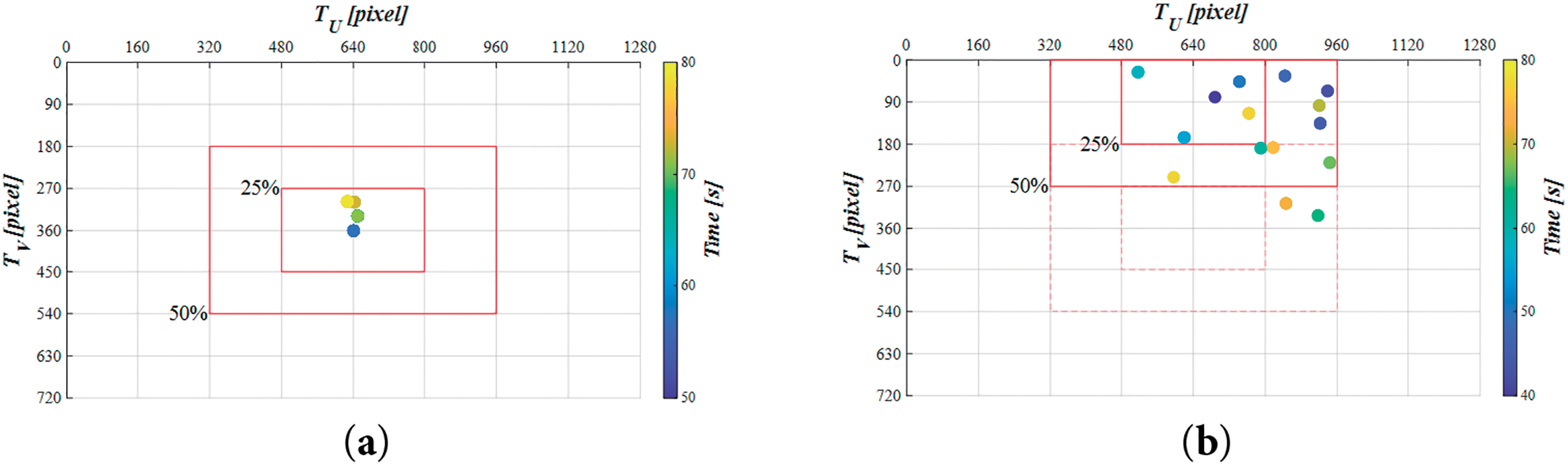
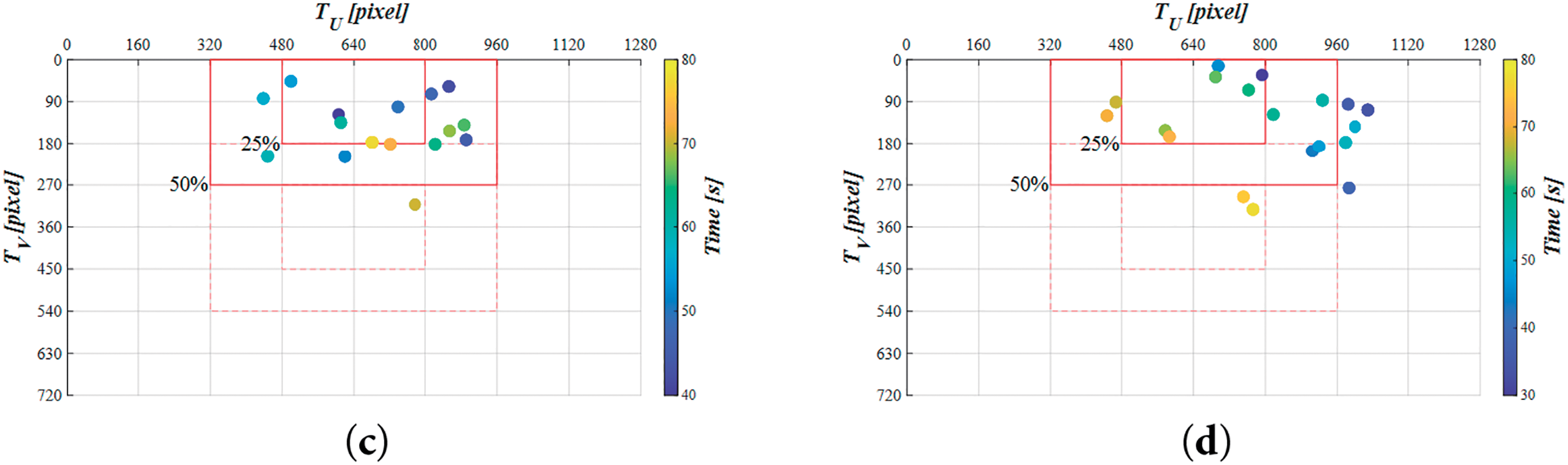
Figure 24: Trajectory of the dock’s image center in the image coordinate system during the docking stage in (a) the simulation, (b) C1, (c) C2, and (d) C3
The docking initiation times in the simulation and all experimental cases varied due to differences in image recognition results. Therefore, only the first 15 s of the docking task, where the duration was identical, were analyzed and compared to assess TD3’s control performance during the positioning stage. This study followed the method proposed by Herlambang et al. [52], employing the integral of absolute error (IAE) and mean absolute error (MAE) to quantify the results. Data on depth, pitch angle, and yaw angle from the positioning stage were analyzed to evaluate TD3’s control performance in both the simulation and actual experiments, as shown in Eqs. (20)–(25).
where
Additionally, this study converts the IAE and MAE of the pitch and yaw angles into the arc length traversed by the AUV and integrates them with the depth IAE and MAE to compute the overall IAE (
where
The results of

Figure 25: (a) Total IAE values; (b) total MAE values for different cases in the docking task
Although the TD3 controller demonstrated commendable performance in stabilizing the AUV’s depth and heading in both simulation and experimental tests, the results also revealed several limitations, particularly when operating in the more unpredictable conditions of real-world environments. A critical discussion of these challenges offers valuable insights into the current system’s capabilities and areas where further refinement is necessary.
One of the most evident challenges arose from environmental disturbances inherent to real-world operations. Unlike the controlled simulation scenarios, actual underwater environments introduced additional complexities such as surface waves, ambient currents, and turbulent flows. These factors occasionally perturbed the AUV’s trajectory, resulting in minor deviations from the planned path and affecting response stability, especially during transitions between maneuvering states.
In addition to external disturbances, sensor noise and latency emerged as significant factors influencing control precision. When sensor models in the simulation could approximate idealized conditions, real-world measurements inevitably suffered from noise and delays. These imperfections were particularly noticeable in yaw control, where small but persistent fluctuations in heading were observed, underscoring the sensitivity of the TD3 controller to measurement uncertainties.
Another issue relates to the smoothness of control actions. Although the reward function was explicitly designed to promote stable and gradual rudder adjustments, the controller occasionally issued abrupt control commands, particularly when reacting to sudden changes in the environment. While such instances did not compromise the docking mission, they suggest that the policy could be further optimized to enhance control stability under dynamically changing conditions.
In general, these observations indicate that when the TD3 controller effectively manages the primary control objectives in relatively stable scenarios, its robustness in highly dynamic or uncertain environments remains an area for improvement. Future work should therefore consider strategies such as incorporating disturbance observers, refining reward structures, or exploring more advanced reinforcement learning algorithms to further improve adaptability and resilience. Addressing these issues will be essential to advance the DT system towards practical deployment in complex real-world underwater missions.
This study presents a control system that integrates DT technology and DRL to advance AUV docking from simulation toward practical application. The approach involves training the TD3 DRL controller in a realistic simulation environment and validating its performance through actual underwater docking experiments. Results demonstrate that the control strategy is effective and exhibits strong reproducibility across both virtual and physical conditions, offering a promising direction for underwater robotics.
The control system monitors real-time motion states of the AUV and makes decisions for operating the vertical and horizontal rudders, particularly during the positioning stage of the docking process. The entire docking sequence is pre-planned within the simulation platform, and then executed in physical environments following the same procedure. This method addresses the challenge of transferring algorithms from simulation to field application and reduces the need for trial-and-error experimentation. During the operational phases, TD3 is responsible for depth and heading control, YOLOv7 assists in detecting the docking station through visual cues during the searching phase, and the I-DDPG algorithm adjusts the final approach and alignment to complete the docking task.
Some real-world issues were also encountered, such as the AUV’s forward-tilted bow caused by buoyancy, which limited its field of view. This required an adjustment to the control algorithm’s visual reference point. In addition, differences in dynamic behavior between the simulated and physical environments, possibly due to unexpected rudder force or unmodeled hydrodynamic inertia, were observed. Despite these challenges, all test cases successfully completed the docking process, and reliable navigation data including depth, attitude, and image tracking was collected.
Although discrepancies were observed between simulation and real-world results based on IAE and MAE indicators, the consistency observed through correlation analysis confirms that the trained control policy performs reliably in practical environments. Furthermore, the modular structure of the proposed control system allows for flexible adaptation to different AUV configurations and complex underwater conditions. With the ability to update model parameters and retrain policies in the simulation, the system can be extended to accommodate diverse docking scenarios. Future work will explore more advanced learning algorithms and adaptive training techniques to improve performance under dynamic marine conditions and expand its applicability to a broader range of autonomous underwater missions.
Acknowledgement: This research was sponsored in part by Higher Education Sprout Project, Ministry of Education to the Headquarters of University Advancement at National Cheng Kung University (NCKU).
Funding Statement: This work was supported by the National Science and Technology Council, Taiwan [Grant NSTC 111-2628-E-006-005-MY3]. This research was partially supported by the Ocean Affairs Council, Taiwan. This research was sponsored in part by Higher Education Sprout Project, Ministry of Education to the Headquarters of University Advancement at National Cheng Kung University (NCKU).
Author Contributions: Yu-Hsien Lin: Project administration, Funding acquisition, Writing—reviewing and editing, Conceptualization, Methodology. Po-Cheng Chuang: Formal analysis, Writing—original draft preparation, Software. Joyce Yi-Tzu Huang: Data analysis, Writing—reviewing and editing. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
| Surge velocity | |
| Sway velocity | |
| Heave velocity | |
| Roll rate | |
| Pitch rate | |
| Yaw rate | |
| AUV’s global | |
| AUV’s global | |
| AUV’s global | |
| Roll angle | |
| Pitch angle | |
| Yaw angle | |
| System inertia matrix of the AUV | |
| Coriolis-centripetal matrix | |
| Damping matrix of the AUV | |
| Restoring force and moment matrix | |
| Vector of control input | |
| Position and orientation state vector in the Earth-fixed coordinate system | |
| Rigid-body system inertia matrix | |
| Added mass system inertia matrix | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Hydrodynamic added mass force along the | |
| Coupling effects around the roll axis due to angular acceleration | |
| Coupling effects around the roll axis due to angular acceleration | |
| Coupling effects around the roll axis due to angular acceleration | |
| Added moment of inertia due to angular acceleration | |
| Added moment of inertia due to angular acceleration | |
| Added moment of inertia around the yaw axis due to angular acceleration | |
| Rigid-body Coriolis-centripetal matrix | |
| Fluid forces induced by the rigid body’s motion | |
| Position of the | |
| Vector from the vehicle’s center to the | |
| Angular position of the | |
| Hydrodynamic forces and moments acting on the AUV | |
| Environment state | |
| Agent action | |
| Bounds of the action | |
| Parameters of the Actor network | |
| Parameters of the DDPG Critic network | |
| Parameters of the TD3 Critic network | |
| Parameters of the target Actor network | |
| Parameters of the DDPG target Critic network | |
| Parameters of the TD3 target Critic network | |
| Action chosen by the Actor network | |
| Q-value evaluated by the Critic network | |
| Update target value | |
| Update ratio constant used for soft update | |
| Total reward | |
| Reward for depth | |
| Punishment for | |
| Reward for yaw angle | |
| Reward lateral distance | |
| AUV’s horizontal rudders | |
| AUV’s vertical rudders | |
| AUV’s depth | |
| Distance between the bow and the center of gravity | |
| Center coordinate of recognition bounding box | |
| Width and height of recognition bounding box | |
| I-DDPG input state | |
| I-DDPG output action | |
| Reward for target object position | |
| Reward for target detection | |
| Reward for vertical rudder angle | |
| Reward for horizontal rudder angle | |
| Reward for boundary condition | |
| Reward for distance to the target object | |
| the depth result after 3000 training episodes | |
| the pitch angle result after 3000 training episodes | |
| the yaw angle result after 3000 training episodes | |
| Integral of the absolute depth error for the AUV | |
| Integral of the absolute pitch angle error for the AUV | |
| Integral of the absolute yaw angle error for the AUV | |
| Total integral of the absolute total error for the AUV | |
| Mean absolute error of the AUV depth | |
| Mean absolute error of the AUV pitch angle | |
| Mean absolute error of the AUV yaw angle | |
| Total mean absolute error of the AUV | |
| Bouyancy | |
| Gravity | |
| AUV’s length | |
| AUV’s mass | |
| Center of Gravity in the | |
| Center of Gravity in the | |
| Center of Gravity in the | |
| Buoyancy Center in the | |
| Buoyancy Center in the | |
| Buoyancy Center in the | |
| Mass Moment of Inertia about the | |
| Mass Moment of Inertia about the | |
| Mass Moment of Inertia about the | |
| Inertia Moment on the | |
| Inertia Moment on the | |
| Inertia Moment on the |
Dimensionless hydrodynamics coefficients.

References
1. Ignacio LC, Victor RR, Del Rio R, Pascoal A. Optimized design of an autonomous underwater vehicle, for exploration in the Caribbean Sea. Ocean Eng. 2019;187(8):106184. doi:10.1016/j.oceaneng.2019.106184. [Google Scholar] [CrossRef]
2. Paim PK, Jouvencel B, Lapierre L, editors. A reactive control approach for pipeline inspection with an AUV. In: Proceedings of OCEANS 2005 MTS/IEEE; 2005 Sep 17–23; Washington, DC, USA. [Google Scholar]
3. Blidberg DR, editor. The development of autonomous underwater vehicles (AUVa brief summary. IEEE ICRA. 2001;4:122–9. [Google Scholar]
4. Zhao S, Yuh J. Experimental study on advanced underwater robot control. IEEE Trans Robot. 2005;21(4):695–703. doi:10.1109/tro.2005.844682. [Google Scholar] [CrossRef]
5. Zeng Z, Lian L, Sammut K, He F, Tang Y, Lammas A. A survey on path planning for persistent autonomy of autonomous underwater vehicles. Ocean Eng. 2015;110(3):303–13. doi:10.1016/j.oceaneng.2015.10.007. [Google Scholar] [CrossRef]
6. Li DJ, Chen YH, Shi JG, Yang CJ. Autonomous underwater vehicle docking system for cabled ocean observatory network. Ocean Eng. 2015;109(2):127–34. doi:10.1016/j.oceaneng.2015.08.029. [Google Scholar] [CrossRef]
7. Yazdani AM, Sammut K, Yakimenko O, Lammas A. A survey of underwater docking guidance systems. Robot Auton Syst. 2020;124(1):103382. doi:10.1016/j.robot.2019.103382. [Google Scholar] [CrossRef]
8. Li Y, Jiang Y, Cao J, Wang B, Li Y. AUV docking experiments based on vision positioning using two cameras. Ocean Eng. 2015;110(2009):163–73. doi:10.1016/j.oceaneng.2015.10.015. [Google Scholar] [CrossRef]
9. Singh P, Gregson E, Ross J, Seto M, Kaminski C, editors. Vision-based AUV docking to an underway dock using convolutional neural networks. In: 2020 IEEE/OES Autonomous Underwater Vehicles Symposium (AUV); 2020 Sep 30–Oct 2. Johns, NL, Canada. [Google Scholar]
10. Sans-Muntadas A, Kelasidi E, Pettersen KY, Brekke E. Learning an AUV docking maneuver with a convolutional neural network. IFAC J Syst Control. 2019;8(4):100049. doi:10.1016/j.ifacsc.2019.100049. [Google Scholar] [CrossRef]
11. Lawrence NP, Forbes MG, Loewen PD, McClement DG, Backström JU, Gopaluni RB. Deep reinforcement learning with shallow controllers: an experimental application to PID tuning. Control Eng Pract. 2022;121(5):105046. doi:10.1016/j.conengprac.2021.105046. [Google Scholar] [CrossRef]
12. Yu R, Shi Z, Huang C, Li T, Ma Q. Deep reinforcement learning based optimal trajectory tracking control of autonomous underwater vehicle. In: 2017 36th Chinese Control Conference (CCC); 2017 Jul 26–28; Dalian, China. [Google Scholar]
13. Ateş A, Alagöz BB, Yeroğlu C, Alisoy H, editors. Sigmoid based PID controller implementation for rotor control. In: 2015 European Control Conference (ECC); 2015 Jul 15–17; Linz, Austria. [Google Scholar]
14. Lucas C, Shahmirzadi D, Sheikholeslami N. Introducing BELBIC: brain emotional learning based intelligent controller. Intell Autom Soft Comput. 2004;10(1):11–21. doi:10.1080/10798587.2004.10642862. [Google Scholar] [CrossRef]
15. Liu B, Ren L, Ding Y, editors. A novel intelligent controller based on modulation of neuroendocrine system. In: International Symposium on Neural Networks; 2005 May 30–Jun 1; Chongqing, China. Berlin/Heidelberg, Germany: Springer; 2005. [Google Scholar]
16. Lillicrap TP, Hunt JJ, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. arXiv: 1509.02971. 2015. [Google Scholar]
17. Carlucho I, De Paula M, Wang S, Menna BV, Petillot YR, Acosta GG, editors. AUV position tracking control using end-to-end deep reinforcement learning. In: OCEANS 2018 MTS/IEEE Charleston; 2018 Oct 22–25; Charleston, SC, USA. [Google Scholar]
18. Yao J, Ge Z. Path-tracking control strategy of unmanned vehicle based on DDPG algorithm. Sensors. 2022;22(20):7881. doi:10.3390/s22207881. [Google Scholar] [PubMed] [CrossRef]
19. Fujimoto S, Hoof H, Meger D, editors. Addressing function approximation error in actor-critic methods. In: International Conference on Machine Learning; 2018 Jul 10–15; Stockholm, Sweden. [Google Scholar]
20. Li X, Yu S. Obstacle avoidance path planning for AUVs in a three-dimensional unknown environment based on the C-APF-TD3 algorithm. Ocean Eng. 2025;315(1):119886. doi:10.1016/j.oceaneng.2024.119886. [Google Scholar] [CrossRef]
21. Wang Y, Hou Y, Lai Z, Cao L, Hong W, Wu D. An adaptive PID controller for path following of autonomous underwater vehicle based on soft actor-critic. Ocean Eng. 2024;307(4):118171. doi:10.1016/j.oceaneng.2024.118171. [Google Scholar] [CrossRef]
22. Khodayari MH, Balochian S. Design of adaptive fuzzy fractional order PID controller for autonomous underwater vehicle (AUV) in heading and depth attitudes. Int J Marit Eng. 2016;158(A1):30–48. doi:10.5750/ijme.v158ia1.1156. [Google Scholar] [CrossRef]
23. Liu T, Zhao J, Huang J. A gaussian-process-based model predictive control approach for trajectory tracking and obstacle avoidance in autonomous underwater vehicles. J Mar Sci Eng. 2024;12(4):676. doi:10.3390/jmse12040676. [Google Scholar] [CrossRef]
24. Mok R, Ahmad MA. Fast and optimal tuning of fractional order PID controller for AVR system based on memorizable-smoothed functional algorithm. Eng Sci Technol. 2022;35(9):101264. doi:10.1016/j.jestch.2022.101264. [Google Scholar] [CrossRef]
25. Yonezawa H, Yonezawa A, Kajiwara I. Experimental verification of active oscillation controller for vehicle drivetrain with backlash nonlinearity based on norm-limited SPSA. Proc Inst Mech Eng Part K J Multi-Body Dyn. 2024;238(1):134–49. doi:10.1177/14644193241243158. [Google Scholar] [CrossRef]
26. Vijayan N, Prashanth L. Smoothed functional-based gradient algorithms for off-policy reinforcement learning: a non-asymptotic viewpoint. Syst Control Lett. 2021;155(2):104988. doi:10.1016/j.sysconle.2021.104988. [Google Scholar] [CrossRef]
27. Manhães MMM, Scherer SA, Voss M, Douat LR, Rauschenbach T, editors. UUV simulator: a gazebo-based package for underwater intervention and multi-robot simulation. In: Oceans 2016 MTS/IEEE Monterey; 2016 Sep 19–23; Monterey, CA, USA. [Google Scholar]
28. Henriksen EH, Schjølberg I, Gjersvik TB, editors. UW morse: the underwater modular open robot simulation engine. In: 2016 IEEE/OES Autonomous Underwater Vehicles (AUV); 2016 Nov 6–9 Tokyo, Japan. [Google Scholar]
29. Potokar E, Ashford S, Kaess M, Mangelson JG, editors. HoloOcean: an underwater robotics simulator. In: 2022 International Conference on Robotics and Automation (ICRA); 2022 May 23–27;Philadelphia, PA, USA. [Google Scholar]
30. Grieves M. Digital twin: manufacturing excellence through virtual factory replication. In: White paper; 2014. p. 1–7. [Google Scholar]
31. Sharma A, Kosasih E, Zhang J, Brintrup A, Calinescu A. Digital twins: state of the art theory and practice, challenges, and open research questions. J Ind Inf Integr. 2022;30(1):100383. doi:10.1016/j.jii.2022.100383. [Google Scholar] [CrossRef]
32. Liu Y, Xu H, Liu D, Wang L. A digital twin-based sim-to-real transfer for deep reinforcement learning-enabled industrial robot grasping. Robot Comput-Integr Manuf. 2022;78(12):102365. doi:10.1016/j.rcim.2022.102365. [Google Scholar] [CrossRef]
33. Hu C, Zhang Z, Li C, Leng M, Wang Z, Wan X, et al. A state of the art in digital twin for intelligent fault diagnosis. Adv Eng Inform. 2025;63(6):102963. doi:10.1016/j.aei.2024.102963. [Google Scholar] [CrossRef]
34. Chu S, Lin M, Li D, Lin R, Xiao S. Adaptive reward shaping based reinforcement learning for docking control of autonomous underwater vehicles. Ocean Eng. 2025;318(17):120139. doi:10.1016/j.oceaneng.2024.120139. [Google Scholar] [CrossRef]
35. Patil M, Wehbe B, Valdenegro-Toro M, editors. Deep reinforcement learning for continuous docking control of autonomous underwater vehicles: a benchmarking study. In: OCEANS 2021: San Diego-Porto; 2021 Sep 20–23; San Diego, CA, USA. [Google Scholar]
36. Chu S, Huang Z, Li Y, Lin M, Carlucho I, Petillot YR, et al. MarineGym: a high-performance reinforcement learning platform for underwater robotics. arXiv:2503.09203. 2025. [Google Scholar]
37. Yang X, Gao J, Wang P, Li Y, Wang S, Li J. Digital twin-based stress prediction for autonomous grasping of underwater robots with reinforcement learning. Expert Syst Appl. 2025;267(3):126164. doi:10.1016/j.eswa.2024.126164. [Google Scholar] [CrossRef]
38. Havenstrøm ST, Rasheed A, San O. Deep reinforcement learning controller for 3D path following and collision avoidance by autonomous underwater vehicles. Front Robot AI. 2021;7:566037. doi:10.3389/frobt.2020.566037. [Google Scholar] [PubMed] [CrossRef]
39. Lyu H, Zheng R, Guo J, Wei A, editors. AUV docking experiment and improvement on tracking control algorithm. In: 2018 IEEE International Conference on Information and Automation (ICIA); 2018 Aug 11–13; Wuyishan, China. [Google Scholar]
40. Lee P-M, Jeon B-H, Kim S-M, editors. Visual servoing for underwater docking of an autonomous underwater vehicle with one camera. In: Oceans 2003 Celebrating the Past Teaming Toward the Future (IEEE Cat. No. 03CH37492); 2003 Sep 22–26; San Diego, CA, USA. [Google Scholar]
41. Zhang T, Miao X, Li Y, Jia L, Wei Z, Gong Q, et al. AUV 3D docking control using deep reinforcement learning. Ocean Eng. 2023;283(17):115021. doi:10.1016/j.oceaneng.2023.115021. [Google Scholar] [CrossRef]
42. Myring D. A theoretical study of body drag in subcritical axisymmetric flow. Aeronaut Q. 1976;27(3):186–94. doi:10.1017/s000192590000768x. [Google Scholar] [CrossRef]
43. Fossen TI. Handbook of marine craft hydrodynamics and motion control. Hoboken, NJ, USA: John Wiley & Sons; 2011. [Google Scholar]
44. Harris ZJ, Whitcomb LL, editors. Preliminary evaluation of cooperative navigation of underwater vehicles without a DVL utilizing a dynamic process model. In: 2018 IEEE International Conference on Robotics and Automation (ICRA); 2018 May 21–25; Brisbane, QLD, Australia. [Google Scholar]
45. Lin Y-H, Chiu Y-C. The estimation of hydrodynamic coefficients of an autonomous underwater vehicle by comparing a dynamic mesh model with a horizontal planar motion mechanism experiment. Ocean Eng. 2022;249(4):110847. doi:10.1016/j.oceaneng.2022.110847. [Google Scholar] [CrossRef]
46. Redmon J, Divvala S, Girshick R, Farhadi A, editors. You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016 Jun 27–30; Las Vegas, NV, USA. [Google Scholar]
47. Wang C-Y, Bochkovskiy A, Liao HYM, editors. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2023 Jun 17–24; Vancouver, BC, Canada. [Google Scholar]
48. Greaves J, Robinson M, Walton N, Mortensen M, Pottorff R, Christopherson C, et al. Holodeck: a high fidelity simulator. San Francisco, CA, USA: GitHub; 2018. [Google Scholar]
49. Prestero T, editor. Development of a six-degree of freedom simulation model for the REMUS autonomous underwater vehicle. In: MTS/IEEE Oceans 2001 An Ocean Odyssey Conference Proceedings (IEEE Cat. No. 01CH37295); 2001 Nov 5–8; Honolulu, HI, USA. [Google Scholar]
50. Brockman G, Cheung V, Pettersson L, Schneider J, Schulman J, Tang J, et al. OpenAI Gym. arXiv:1606.01540. 2016. [Google Scholar]
51. Lin Y-H, Yu C-M, Wu I-C, Wu C-Y. The depth-keeping performance of autonomous underwater vehicle advancing in waves integrating the diving control system with the adaptive fuzzy controller. Ocean Eng. 2023;268(14):113609. doi:10.1016/j.oceaneng.2022.113609. [Google Scholar] [CrossRef]
52. Herlambang T, Rahmalia D, Yulianto T, editors. Particle swarm optimization (PSO) and ant colony optimization (ACO) for optimizing pid parameters on autonomous underwater vehicle (AUV) control system. J Phys Conf Ser. 2019;1211(1):012039. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools