
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Robust Audio-Visual Fusion for Emotion Recognition Based on Cross-Modal Learning under Noisy Conditions
1 Department of Artificial Intelligence, Chung-Ang University, Seoul, 06974, Republic of Korea
2 Department of Electrical, Electronic and Systems Engineering, Universiti Kebangsaan, Bangi, 43600, Malaysia
3 School of Computer Science and Engineering, Chung-Ang University, Seoul, 06974, Republic of Korea
* Corresponding Authors: Bong-Soo Sohn. Email: ; Jaesung Lee. Email:
Computers, Materials & Continua 2025, 85(2), 2851-2872. https://doi.org/10.32604/cmc.2025.067103
Received 25 April 2025; Accepted 19 August 2025; Issue published 23 September 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
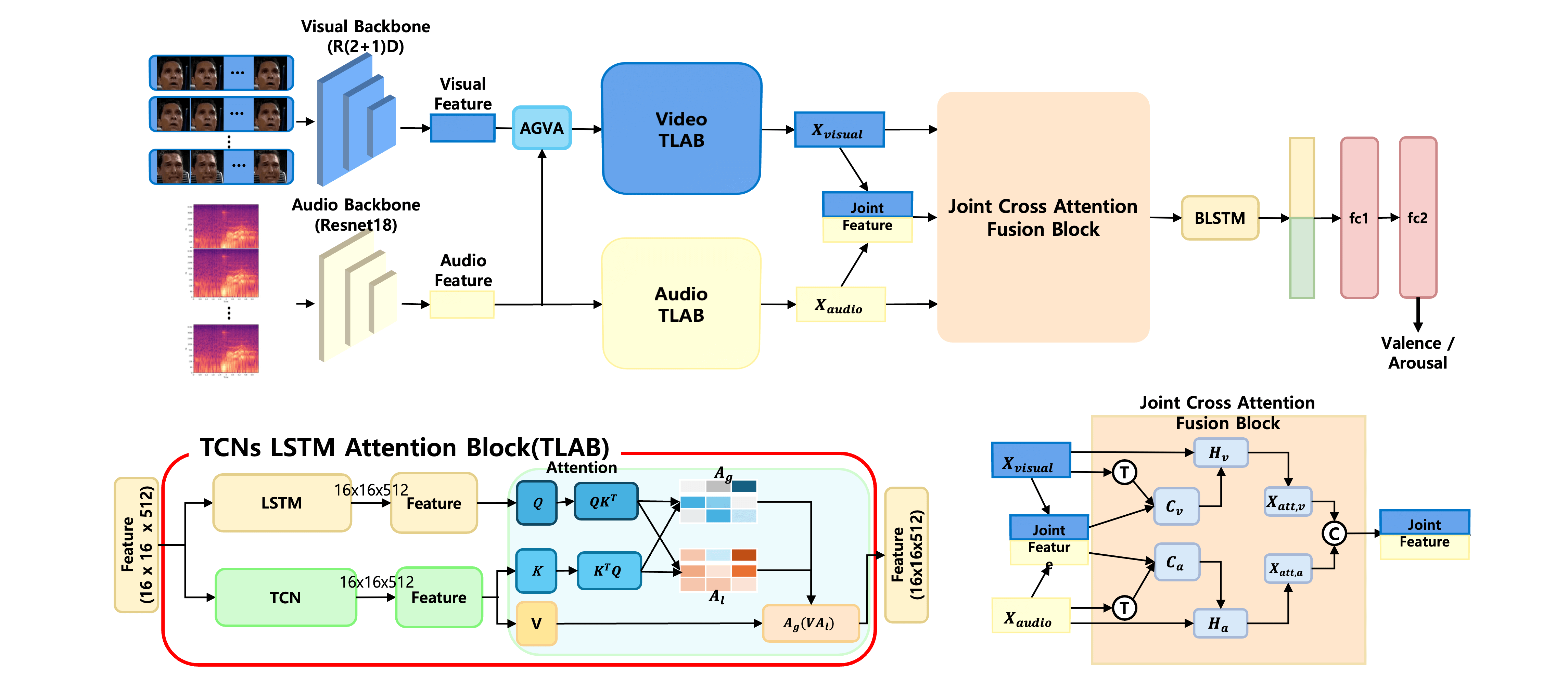
Emotion recognition under uncontrolled and noisy environments presents persistent challenges in the design of emotionally responsive systems. The current study introduces an audio-visual recognition framework designed to address performance degradation caused by environmental interference, such as background noise, overlapping speech, and visual obstructions. The proposed framework employs a structured fusion approach, combining early-stage feature-level integration with decision-level coordination guided by temporal attention mechanisms. Audio data are transformed into mel-spectrogram representations, and visual data are represented as raw frame sequences. Spatial and temporal features are extracted through convolutional and transformer-based encoders, allowing the framework to capture complementary and hierarchical information from both sources. A cross-modal attention module enables selective emphasis on relevant signals while suppressing modality-specific noise. Performance is validated on a modified version of the AFEW dataset, in which controlled noise is introduced to emulate realistic conditions. The framework achieves higher classification accuracy than comparative baselines, confirming increased robustness under conditions of cross-modal disruption. This result demonstrates the suitability of the proposed method for deployment in practical emotion-aware technologies operating outside controlled environments. The study also contributes a systematic approach to fusion design and supports further exploration in the direction of resilient multimodal emotion analysis frameworks. The source code is publicly available at (accessed on 18 August 2025).Graphic Abstract
Keywords
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools