
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Unsupervised Satellite Low-Light Image Enhancement Based on the Improved Generative Adversarial Network
1 School of Mathematics and Computer Science, Tongling University, Tongling, 244061, China
2 College of Software Engineering, Zhengzhou University of Light Industry, Zhengzhou, 450000, China
* Corresponding Author: Ming Chen. Email:
Computers, Materials & Continua 2025, 85(3), 5015-5035. https://doi.org/10.32604/cmc.2025.067951
Received 16 May 2025; Accepted 08 August 2025; Issue published 23 October 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This research addresses the critical challenge of enhancing satellite images captured under low-light conditions, which suffer from severely degraded quality, including a lack of detail, poor contrast, and low usability. Overcoming this limitation is essential for maximizing the value of satellite imagery in downstream computer vision tasks (e.g., spacecraft on-orbit connection, spacecraft surface repair, space debris capture) that rely on clear visual information. Our key novelty lies in an unsupervised generative adversarial network featuring two main contributions: (1) an improved U-Net (IU-Net) generator with multi-scale feature fusion in the contracting path for richer semantic feature extraction, and (2) a Global Illumination Attention Module (GIA) at the end of the contracting path to couple local and global information, significantly improving detail recovery and illumination adjustment. The proposed algorithm operates in an unsupervised manner. It is trained and evaluated on our self-constructed, unpaired Spacecraft Dataset for Detection, Enforcement, and Parts Recognition (SDDEP), designed specifically for low-light enhancement tasks. Extensive experiments demonstrate that our method outperforms the baseline EnlightenGAN, achieving improvements of 2.7% in structural similarity (SSIM), 4.7% in peak signal-to-noise ratio (PSNR), 6.3% in learning perceptual image patch similarity (LPIPS), and 53.2% in DeltaE 2000. Qualitatively, the enhanced images exhibit higher overall and local brightness, improved contrast, and more natural visual effects.Keywords
Satellite images captured within planetary shadows suffer from severe low-light conditions, leading to unclear content, low contrast, and excessive noise [1]. This degradation significantly hinders the performance of downstream computer vision tasks that require the high-quality inputs [2], such as object recognition [3], object detection [4], and semantic segmentation [5]. Therefore, enhancing low-light satellite images is essential [6].
Recently, deep learning has made significant progress in the field of low-light image enhancement (LLIE) [7,8]. It is becoming a major driving force in this field. Deep learning approaches significantly improve the performance of LLIE through different learning strategies, network architectures, loss functions, and training data. These methods include utilizing convolutional neural networks (CNN) [9,10] and generative adversarial networks (GAN) [11,12], which are not limited to them, to enhance the brightness, contrast, and color of images while reducing noise and artifacts.
The CNN-based methods usually adopt a supervised learning strategy to learn the mapping relation between input and output images through a multi-layer convolutional network. This method can extract local features of images more robustly, and due to its end-to-end nature, it usually does not require additional processing steps. However, supervised learning depends on paired datasets for training, which is difficult to acquire quickly in practice, and the model generalization capability is limited by the training data [13].
Therefore, GAN-based methods have attracted raising attention. With GANs, generators and discriminators compete to enhance the quality of images. The generator is responsible for extracting enhanced features from low-light images, while the discriminator assesses the quality and authenticity of the generated images. With this method, images are generated more realistically and more advanced features are learned to restore details and information. Among these methods, EnlightenGAN is a typical representative [14]. It adopts an unsupervised learning strategy and does not require paired low- and normal-light images for training. The generator network of EnlightenGAN adopts a U-Net structure [15] guided by an attention mechanism, which emphasizes dark areas through self-attention maps, enhancing dark areas while retaining details. The discriminator network adopts a global-local discriminator structure, in which the global discriminator focuses on the overall illumination distribution, and the local discriminator focuses on image details to ensure a natural enhancement effect. Although EnlightenGAN has achieved remarkable results in LLIE, the reduced feature image extraction capability due to downsampling at the generator end will cause color deviations, compromising color-critical tasks [16]. Meanwhile, detail distortion occurs as deep convolutions homogenize fine textures, blurring edges critical for structural integrity assessment [17].
In addition to the two traditional methods mentioned above, some scholars have considered using attention mechanisms to improve LLIE effects. Zhang et al. [18] proposed a method of stacking visual attention networks for single image super-resolution in response to the problem that most deep learning methods do not fully utilize the advantageous features between feature maps, channels, and pixels. This method effectively improves the utilization of features at different levels and shows good reconstruction performance in 2×, 3×, and 4× reconstruction. In addition, diffusion models have shown great advantages in the field of data generation in recent years. Some scholars have begun to introduce diffusion models to achieve low-light enhancement. Wang et al. [19] proposed a low-light diffusion model (LLDiffusion), which learns degradation representation by jointly learning low-light generation and image enhancement tasks, and introduced a dynamic degradation-aware diffusion module (DDDM) to improve image quality. In the field of remote sensing, Zhang et al. [20] used the fact that multispectral images contain richer spectral features than RGB images to construct a two-stage RGB-to-multispectral reconstruction framework. The model TN was used to generate natural color RGB from true color images through CIE colorimetry, and the model NM was used to reconstruct multispectral images from natural color RGB through a residual network and a channel attention mechanism. In the field of underwater images, Zhang et al. [21] proposed a method based on minimum color loss and locally adaptive contrast enhancement (MLLE), which divides image enhancement into two processes: local adaptive color correction and local adaptive contrast enhancement. This method achieved good results in color, contrast and details. Subsequently, Zhang et al. [22] proposed to solve the problem of underwater image quality degradation by piecewise color correction and dual prior optimization contrast enhancement. This method has good generalization ability for fog and low-light images.
Based on the above analysis, to solve the problems of color deviation resulting from downsampling and information loss in the image details caused by deep convolution in EnlightenGAN, we propose an unsupervised satellite LLIE based on the improved GAN network. The algorithm has the following two advantages:
(1) We introduced IU-Net as the backbone in the feature extraction process. This network could lower the feature extraction loss and more effectively capture the semantic content shared between normal images and low-light images, improving the feature extraction efficiency and solving the color bias problems in the enhanced image.
(2) We introduced GIA at the end of the contraction path, solving the problem of image detail loss and edge distortion caused by continuous convolution. This module improves the algorithm’s processing ability at image details by associating the detail information with the global information.
Experimental outcomes reveal that compared with the baseline EnlightenGAN, the algorithm in this paper has improved by 2.7%, 4.7%, 6.3% and 53.2% in the evaluation metrics SSIM, PSNR, LPIPS and DeltaE 2000, respectively. Compared with the improved EnlightenGAN called LE-GAN [23], the algorithm in this paper has improved 2.5%, 1.0%, 23.5% and 55.7% in the evaluation metrics SSIM, PSNR, LPIPS and DeltaE 2000, respectively.
The rest of this paper is organized as follows: Section 2 summarizes related work; Section 3 details the proposed algorithm, including IU-Net architecture and GIA; Section 4 presents experimental results and analyses (including datasets, parameter settings, evaluation metrics, ablation studies, and comparative evaluations); Section 5 concludes the study and outlines future research directions.
With the advancement of science and technology, human beings’ ability to explore space has developed by leaps and bounds. Various satellites and manned spacecraft have been launched one after another, and space activities have become increasingly frequent. As an important part of space activities, the space on-orbit service of spacecraft is aimed at ensuring the safety and sustainable development of the space environment. Its contents include space assembly tasks (such as on-orbit connection, construction or assembly of spacecraft), space maintenance tasks (such as surface repair and component replacement of spacecraft), and space service tasks (such as recovery of failed spacecraft and capture of space debris). These tasks are inseparable from the detection and identification technology of spacecraft components. For example, in the space assembly mission of spacecraft, space interaction tasks such as on-orbit connection and autonomous rendezvous of spacecraft require accurate data information such as relative position and relative attitude of spacecraft. In the space maintenance mission of spacecraft, problems such as surface damage and component aging of spacecraft can be discovered and solved in time, which increases the safety of spacecraft. With more and more spacecraft put into use, failed spacecraft and space debris are gradually threatening the safety of spacecraft. Therefore, it is necessary to support the completion of tasks such as recovery of failed spacecraft and capture of space debris to keep the space environment clean and safe.
However, in space, when a spacecraft orbits a planet or other celestial body, it may be in a low-light environment due to the spacecraft entering the shadow area cast by the celestial body or being blocked by the celestial body, planet, or large structure. In the low-light environment in space, the image will have lower brightness and contrast than usual. At the same time, the radiation noise contained in space is much greater than the daily radiation noise. Therefore, the spacecraft images captured in this environment often have problems such as unclear content and texture, low contrast, and many noise points. Such low-light images will reduce the detection and recognition capabilities of spacecraft components, thereby affecting the safety of the spacecraft. To avoid this situation, LLIE technology is particularly important.
There are two major types of LLIE algorithms: traditional approaches and deep learning approaches.
Traditional approaches had advantages in simple scenes and limited computing resources, but they had significant limitations in handling complex scenes or improving generalization performance. Traditional methods included histogram equalization algorithms (HE) [24,25] and Retinex algorithms [26,27]. The HE was the simplest and most common LLIE algorithm. It enhanced the global image contrast and brightness by stretching the distribution of the image’s gray-level histogram, making the gray levels more evenly distributed. It was significantly effective when there were many dark pixels in both the foreground and background of the image. However, when the gray-level histogram was stretched abnormally, it could cause local image over-saturation and artifacts. To address this issue, Abdullah-Al-Wadud et al. [28] proposed using local minima to partition the input image histogram. Then specific gray-level ranges were assigned to each sub-histogram and performed equalization separately. To improve brightness preservation and contrast enhancement capabilities, as the first step, Ibrahim and Kong [29] smoothed the input histogram using a one-dimensional Gaussian filter. Then, the smoothed histogram was partitioned according to its local maxima, and the partitions were allocated to a new dynamic range. Finally, histogram equalization was independently applied to the new dynamic ranges. However, the above algorithms based on HE had problems, including blurred details and color distortion. Consequently, the Retinex algorithm was first suggested by Land and McCann [26], which was more aligned with the human visual system. The Retinex algorithm was dependent on the theory of color constancy, adjusting the contrast and brightness of the image without losing image detail information. Subsequently, Jobson et al. [30] proposed a low-pass filter for the SSR model (Single-Scale Retinex Model), which removed the low-frequency components of the original image and left the high-frequency components. Since the human eye is very sensitive to high-frequency components, SSR could better improve the edge information in an image. Nevertheless, SSR employed a Gaussian kernel function for estimating image brightness. The enhanced image could not simultaneously ensure dynamic range compression and contrast enhancement. Especially when there was a large difference in brightness between two regions, halo phenomena would appear in the edge areas. Therefore, Rahman et al. [27] proposed the MSRCR algorithm, solving the color distortion of SSR by introducing a component ratio adjustment factor. Jiang et al. [31] propose a framework called Mutual Retinex, designing a dual-branch structure aimed at characterizing the specific knowledge of reflectance and illumination components while removing perturbations.
Recently, deep learning has shown great application potential in diverse fields. It was increasingly applied to LLIE. According to the differences in methods, there are two general types of learning: supervised and unsupervised. Supervised learning needs a one-to-one pairing in the data set to provide a mapping correlation between normal- and low-light images. For example, Zhang et al. [32] proposed Kind network, inspired by Retinex. The dataset used by this network was paired images captured under different lighting or exposure conditions. At the same time, it provided a mapping function that could flexibly adjust the brightness according to users’ needs to achieve the best visual effect. However, existing methods usually relied on some assumptions that ignored the influence of other factors, such as image noise, so there would be problems such as brightness, contrast, artifacts, and noise. Therefore, Wang et al. [7] suggested a network relying on normalized flow, transforming the complex distribution into a simple distribution through reversible and differentiable mappings. By converting the distribution, its probability density function (PDF) value could be accurately obtained, thereby improving the enhancement effect. However, the above-supervised learning relied on paired datasets, which will often require many costs to obtain. Under specific paired datasets, the generalization performance of the model will be reduced. Hence, unsupervised learning was proposed to solve this problem. EnlightenGAN [14] was the first to introduce unpaired images as datasets into LLIE work, reducing the data acquisition difficulty and improving model generalization. In addition, by introducing a global-local discriminator, EnlightenGAN was able to deal with illumination changes in different spaces in the input image. Furthermore, self-feature preserving loss and self-normalized attention mechanisms were utilized to implement self-supervision learning. However, due to the design of the generator, the model would have color deviations in detail. Afterward, the LE-GAN [23] network used the perceptual attention module to enhance the feature extraction and eliminate the color deviations. Meanwhile, it proposed a new loss function to enhance the visual quality. However, the large amount of calculation in the model leads to poor real-time performance. Yu et al. [33] proposed a new GAN, whose generator contains residual layers, mixed attention layers, and parallel dilated convolutional layers to extract image features. An improved pixel loss function was used to constrain the GAN to learn from low-light images.
2.3 Limitations of Existing Methods
Although the above methods have achieved a series of results, there are still some limitations in the field of satellite images.
First, traditional techniques (e.g., MSRCR, HE variants) lack the representational capacity to recover semantically meaningful features from noise-dominated inputs, often amplifying artifacts.
Second, supervised approaches (e.g., RetinexNet, KinD) require paired low/normal-light images for training. Such data is exceptionally scarce for orbital scenarios due to the dynamic lighting conditions and impossibility of recapturing identical scenes. Consequently, these methods exhibit poor generalization to real unpaired satellite data.
Third, unsupervised GANs like EnlightenGAN circumvent the pairing constraint but introduce color deviations and detail distortion (see Section 1).
To address these challenges, we propose an unsupervised GAN framework with two key innovations:
(1) IU-Net enriches feature extraction via multi-scale fusion in early contraction stages, mitigating color shifts while retaining efficiency for small datasets.
(2) GIA integrates transformer-style self-attention at the bottleneck to adaptively modulate enhancement strength, preserving details and avoiding over-enhancement in mixed-illumination regions.
Through the collaborative work of the generator and discriminator, this algorithm enhances low-light images’ contrast and illumination. Herein, the algorithm core is the generator. Fig. 1 presents the framework of the generator, which mainly comprises two modules: (1) IU-Net: As the backbone of the generator, it is dependent on U-Net, adopting a contraction-extension structure. This structure enables the network to process an image layer by layer and convert it into a more concise representation. Unlike traditional U-Net, IU-Net introduces feature fusion at the contraction end to enhance the feature details. (2) GIA: The downsampling and convolution process of IU-Net may cause the loss of image details and textures, as well as the problem of over-enhancement in different illumination areas. To address these challenges, this study introduced GIA at the end of the contraction path of IU-Net. This module analyzes each area illumination in the image and automatically adjusts the enhancement strength to achieve more accurate and natural image enhancement effects.

Figure 1: The overall generator framework. The core consists of: (1) IU-Net backbone (feature fusion at the contraction end for richer details), and (2) GIA (adaptively adjusts regional enhancement effects to prevent detail loss and over-enhancement)
An overview of the discriminator is shown in Fig. 2. The discriminator adopts the design idea of a global-local discriminator [34], aiming to achieve a more refined image enhancement effect. The focus of the global discriminator is the overall brightness of images, ensuring that the overall visual impact of images can be improved during the enhancement process. The local discriminator focuses on the local area of images. By adaptively adjusting the brightness of different areas, it effectively avoids the overexposure or underexposure problem that may occur in the local area. This combination of global and local processing not only improves the enhancement effect but also ensures the naturalness and authenticity of images.

Figure 2: The overall framework of the discriminator. The discriminator adopts a global-local discriminator. The global discriminator ensures balanced overall brightness, while the local discriminator adaptively adjusts regional illumination to prevent local over/underexposure, enhancing visual impact while preserving naturalness
Given the scarcity of open-source low-light satellite image datasets, there are a limited number of training samples. Consequently, employing large networks as backbone networks tends to exacerbate overfitting issues. To address this challenge, we selected IU-Net as the generator’s backbone. The downsampling process of the standard U-Net extracts semantic features by gradually compressing the spatial resolution. The pixel-level details and color information contained in the shallow layer are weakened in the deep layer, which leads to detail loss and global color shift in the reconstructed image. Compared with the standard U-Net, IU-Net incorporates an additional feature fusion step during the encoding stage, thereby concatenating shallow high-resolution features (containing rich colors/textures) with deep low-resolution features (containing high-level semantics) to avoid dilution of details and color information during downsampling. Characterized by its simplicity and constructability, IU-Net structure is suitable for training small-scale datasets. It not only mitigates the risk of overfitting but also enhances the model’s generalization capabilities. IU-Net, inheriting the U-shaped architecture from U-Net, possesses the encoder-decoder functionality, which is showed in Fig. 3. The convolutional layers are tasked with extracting image features, while the downsampling and upsampling layers dynamically adjust the feature map dimensions to meet the processing demands.

Figure 3: IU-Net architecture. Inheriting the U-shaped encoder-decoder structure from U-Net, IU-Net incorporates cross-layer connections for multi-scale feature fusion and intra-layer connections for the intra-layer feature fusion. Key components include convolutional layers, downsampling/upsampling layers, and feature fusion layers, designed for efficient training and enhanced feature extraction on low-light satellite image datasets
(1) The contraction path includes five stages: C1–C5. Initially, in stage C1, the input image I is merged with the self-normalized attention map A1 to generate X. Subsequently, X is convolved to obtain X1, as shown in Eq. (1). Then, X1 is convolved again, and the convolution result is fused with the original X1 to generate the output. Compared with the standard U-Net, this step incorporates an additional feature fusion step during each downsampling phase, which is
Among them,
After T1 is downsampling, it is used as the input of the C2 stage. After two convolutions, X2 is obtained. Then, the output T2 of the C2 stage can be obtained by Eq. (4). The specific steps are shown in Eqs. (3) and (4):
Among them
After T2 is input into the pooling layer for downsampling, it is used as the input of the C3 stage. According to Eqs. (3) and (4), the output Tj (j = 3, 4, 5) of stages C3, C4, and C5 is obtained in sequence.
(2) The self-normalized attention map A1 is derived by normalizing the three channels of the RGB image to the range [0, 1], converting it to a grayscale image, and then inverting the grayscale image. After multi-level pooling operations are performed on A1, a self-normalized attention map Ak (k = 2, 3, 4, 5) with the same output size as each stage is obtained, which establishes a basis for feature fusion in the extended path stage. The specific steps are shown in Eq. (5):
where
(3) There are five stages in the extension path: E5, E6, E7, E8, and E9. First, the output Ak (k = 1, 2, 3, 4, 5) in step (2) is a dotted product with the output Tk of stages C1–C5 to obtain the enhanced self-normalized attention map Gk. The specific steps are shown in Eq. (6).
Then, in the E5 stage, Gl (l = 5) is convolved and up-sampled to obtain Um (m = 4), and Um (m = 4) is used as the input of E6. The specific steps are shown in Eq. (7).
In the E6 stage, Gl (l = 4) and Um (m = 4) are concatenated, and the output result is convolved twice and then upsampled to obtain Y6, which is used as the input of the next stage E7. The specific steps are shown in Eq. (8).
In E7 and E8, Gl (l = 3, 2) is concatenated with Yn −1 (n = 7, 8) passed from the previous stage in sequence, and the output result is convolved twice and then upsampled as the input Yn of the next stage. This step realizes the skip-layer connection function. The specific steps are shown in Eq. (9).
Finally, in the E9 stage, Yn (n = 8) and G l (l = 1) are concatenated and then subjected to three convolutions to acquire the output. The output is then added to X from step (1) to provide the final output Result. The specific steps are presented in Eq. (10):
Among them,
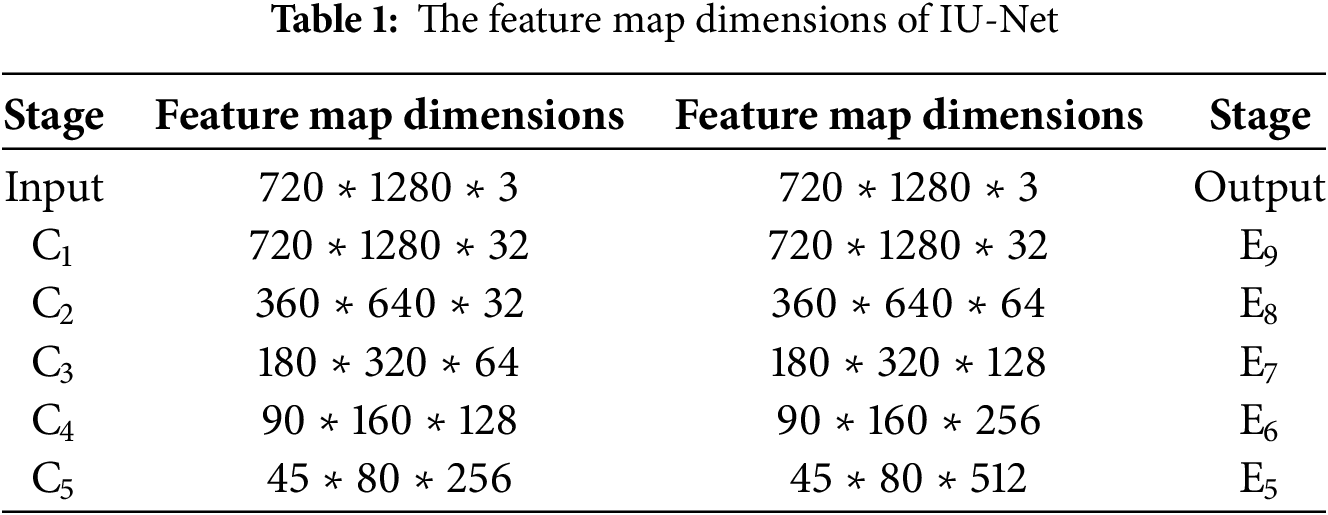
The feature map dimensions of IU-Net are shown in Table 1.
In the contraction path of IU-Net, as the network depth elevates, the continuous convolution operation enables the feature map to show a wider receptive field and deeper essential features. However, in the case of more noise, especially when processing low-light images, due to the characteristics of continuous convolution, the detail information is gradually lost in the layer-by-layer transmission, resulting in image smoothing and blurred details. This problem is particularly evident in the task of LLIE because the enhanced image requires retaining sufficient texture details to ensure its authenticity and naturalness. In addition, when there are adjacent pixels with large illumination differences in the image, continuous convolution will mix the information of these pixels, resulting in blurred edges of the enhanced image and even overexposure in brighter areas, that is, over-enhancement. Over-enhancement destroys the naturalness of the image and may introduce new noise and artifacts, seriously affecting the image quality.
To solve these problems, we suggest GIA. GIA uses a global self-attention mechanism (Eqs. (11) and (12)) to adaptively adjust the enhancement intensity for different illuminated areas, achieving Global Enhancement Balance (GEB). Its core objectives are: (1) Over-enhancement Suppression: Preventing overexposure of brightly lit areas (such as reflections from satellite solar panels). (2) Low-light Details Enhancement: Enhancing the recognizability of shadowed areas (such as seams between spacecraft). Specifically, through the global attention mechanism, GIA calculates the interplay of each position with all other positions based on the feature map received from the deep layer of IU-Net. This calculation considers the information of the entire feature map and can capture global illumination changes and detailed features. Through this mechanism, the module can process adjacent pixels or regions with large differences in illumination separately so that pixels in different illumination areas can be processed more accurately during the enhancement process, avoiding the problem of over- or under-enhancement. At the same time, the introduced global information enables the model to understand better the overall structure and illumination distribution and generate more natural and realistic enhanced images. The GIA architecture is shown in Fig. 1, which adopts the idea of Transformer. For details, the GIA architecture consists of a single-head attention mechanism and a residual connection. It is strategically positioned at the end of the contraction path (bottleneck) where features are highly abstracted but spatially compressed. This helps improve computational efficiency The self-attention calculation is responsible for generating the correlation weights between each position, while the residual connection fuses these weights with the original feature map to obtain the enhanced feature representation. This structural design effectively improves the detail preservation and illumination processing capabilities in image enhancement tasks. Fig. 1 depicts the specific structure.
(1) In the self-attention calculation process, let the output of the contraction path be P (In Fig. 3, P is T5). After performing the convolution operation on P, we get F(x), Y(x), and G(x). After Y(x) is transposed, it is dot-multiplied with G(x) to get the attention weight of R(x). The specific calculation is demonstrated in Eq. (11):
here,
(2) R(x) is processed by the SoftMax function and then dot-multiplied with F(x), to obtain U(x), as shown in Eq. (12):
In the feature fusion process, the enhanced self-normalized attention map G5 obtained in Eq. (6) and U(x) are first convolved, then the convolution outcome is introduced to acquire the enhanced feature representation V(x) as shown in Eq. (13):
The final feature representation, V(x), is used as the input of the extended path part. After V(x) passes through the extended path, the reconstructed image
here,
3.3 Discriminator and Loss Function
In terms of constructing the discriminator, this paper adopts a relative discriminator structure. Unlike traditional discriminators, relative discriminators can evaluate the probability that a real image is more realistic than a randomly sampled fake image. In adversarial training, the network parameters of the generator are optimized by gradually increasing this probability while increasing the loss of the generator. This method not only promotes the generator to produce more realistic data but also reduces the risk of non-convergence during training. The specific calculation formula of the relative discriminator is detailed in Eqs. (15) and (16).
Among them,
We utilized the relative discriminator to construct a local-global dual discriminator structure. The global discriminator is used to improve the brightness of the overall image, while the local discriminator processes the local fragments of the generator’s output images to specifically enhance the local areas of images, effectively reducing the problem of local overexposure.
In the framework of the global discriminator and the generator, the ideal regression target is to be set
here, the values of
In the framework of the local discriminator and generator, batches of images are cropped at random from the enhanced images and the real images as input. Here, the standard least squares loss function is deployed to calculate the loss value. The specific formulas are shown in Eqs. (19) and (20).
here, the parameter values of
For the whole loss function, in the discriminator loss function part, this paper introduces the self-feature preservation loss function (SFPL) to restrict the VGG feature distance between the input low-light image and its enhanced normal-light image. This design emphasizes the self-normalized effect in the model. In order to simplify the calculation, the self-feature preservation loss value
The hardware environment configuration of the experiment was: 16 vCPU Intel(R) Xeon(R) Platinum 8350C CPU @ 2.60 GHz, NVIDIA GeForce RTX 3090 24 GB, 42 GB memory. The software environment configuration was as follows: Ubuntu 5.4.0 operating system, Pycharm 2020.1 Professional Edition. The batch size was 16. The learning rate was 0.0001. The training epochs were 150.
Satellite LLIE was critical for spacecraft on-orbit servicing applications. However, the lack of datasets specifically tailored for satellite low-light environment imaging posed two major challenges:
(1) Domain gaps: Generic low-light datasets lacked domain-specific degradation patterns (e.g., cosmic noise, extreme dynamic range).
(2) Mission alignment: Currently, no dataset supported unpaired training on satellite imagery, which was critical given the inability to capture aligned low-light/normal-light space scenes.
SDDEP addressed these gaps by providing the first unpaired dataset tailored for satellite low-light environment imaging, enabling unsupervised model training that met real-world deployment constraints.
Source: SDDEP was constructed based on the spacecraft dataset for detection, segmentation and parts recognition (SDDSP dataset) [35]. SDDEP was an unpaired dataset, and the image sizes were 720 × 1280.
TrainSet: We constructed the training set by selecting 1199 low-light illumination images from SDDSP as the basis and then adjusted by professional image processing software ACDSee under the guidance of the aerospace analysis software Spacecraft Tracking and Control (STK) to maximize the restoration of the aircraft’s morphology in the low-light environment.
TestSet: we randomly selected 200 normal light images and then processed these images in the environment generated by STK to construct a test set under low light conditions.
Scene coverage: The earth-background (61.1%) and space-background (38.9%) scenes were included to capture diverse illumination conditions (Fig. 4a–c). Fig. 4a showed the low-light image of the spacecraft taken with the earth as the background, Fig. 4b showed the low-light image of the spacecraft with space as the background, and Fig. 4c showed the normal-light image of the spacecraft. Fig. 4a,b showed low-light images, which often had low image quality, low brightness, and contrast, and some areas of the image were severely damaged. At this time, this increased the difficulty of extracting edge, texture, color, and other information from images. Under normal lighting conditions, details, contours, colors, and other information in the image could be clearly observed (Fig. 4c).

Figure 4: Example of dataset. (a) Low-light spacecraft (Earth background), (b) Low-light spacecraft (space background), (c) Normal-light spacecraft. Low-light images exhibited degraded quality (low brightness/contrast, structural damage), while normal-light images preserved clear details
Quality control: We excluded images with motion blur or compression artifacts.
Dataset available address: The address of the SDDEP dataset was https://drive.google.com/file/d/1SycGI1LeeZmq1FDVsoUN8yDfA_hU0Vn4/view?usp=drive_link (accessed on 01 August 2025).
Table 2 showed the detailed distribution of images in SDDEP, where N was the number of images. IEarth or ISpace were the number of images with the earth or space as the background, respectively. So total sample size was 1399 images. In term of brightness histogram statistics, the average pixel value (0–255) of each image was distributed between 60–190, and the standard deviation was between 30–65, indicating that both dim and overexposed scenes were covered.

SSIM [36], LPIPS [37], PSNR [38] and DeltaE 2000 [39] were employed as evaluation metrics. SSIM directly measured how much structural information was preserved in the enhanced image. A higher SSIM meant that the structure of the image was closer to the ideal state, which was critical for spacecraft on-orbit connection, spacecraft surface repair, space debris capture. A higher PSNR meant that the enhancement process introduced less noise and distortion, and better preserved the radiometric properties of the original signal, which was very important for scenarios that required quantitative analysis. LPIPS was based on feature differences learned by deep learning models and was more consistent with human subjective perception. A lower distance value meant that the enhanced image looked more natural and realistic, with fewer artifacts, color casts, or unnatural textures, which was very important for downstream tasks that relied on visual interpretation or required the input image to look “natural”. DeltaE 2000 measured the perceptual color difference between the enhanced image and the reference image. A lower DeltaE value indicated that the color reproduction in the enhanced image was more accurate and faithful to the original scene.
This section described the selection of hyper-parameters and their rationale for algorithmic training model experiments to facilitate the reproducibility of the study.
(1) Feature Fusion Strategy
IU-Net introduced feature fusion in the contraction end to enhance the feature details, as described in Eq. (2). Experiments showed that the effect of introducing feature fusion at different stages varies significantly. Therefore, to achieve the optimal feature fusion effect, feature fusion experiments were conducted at different stages such as C1, C1–C2, C1–C3, C1–C4, and C1–C5, with the effect comparison referred to in Table 3. It could be seen that the best effect was achieved by introducing feature fusion in the C1–C2 stage. This might be because the feature fusion in the first two stages could retain more feature details, while in other stages, as downsampling, the feature details became less and less, which might introduce more interference information. Therefore, we chose to perform feature fusion in the C1–C2 stage.

(2) Learning Rate (LR)
The LR determined the update amplitude of the model parameters in each iteration. A higher LR could speed up the training but might cause the optimal solution to be missed. On the contrary, a lower LR helped the model to converge stably, but it would increase the training time. Therefore, the appropriate selection of the LR was crucial for the model to converge quickly to the optimal solution. To investigate the impact of various LRs on performance, a comparative experiment was conducted. Table 4 showed the training effect of this algorithm under different LRs. The bold numbers represent the optimal solutions, the same as Tables 3–7.


Three various LRs of 0.001, 0.0001, and 0.00001 were used for training (Table 4). When the LR was 0.00001, due to the low LR, the model was prone to fall into the local optimal solution and was difficult to jump out, resulting in poor performance on objective evaluation metrics such as SSIM, LPIPS, and PSNR. When the LR was 0.001, due to the high LR, the loss function value of the model fluctuated around the optimal solution during training, and it was difficult to converge stably, thereby reducing the algorithm performance. Therefore, when the LR was set to 0.0001, the model performed best on evaluation metrics such as SSIM, LPIPS, and PSNR.
(3) Number of Iterations (Epochs)
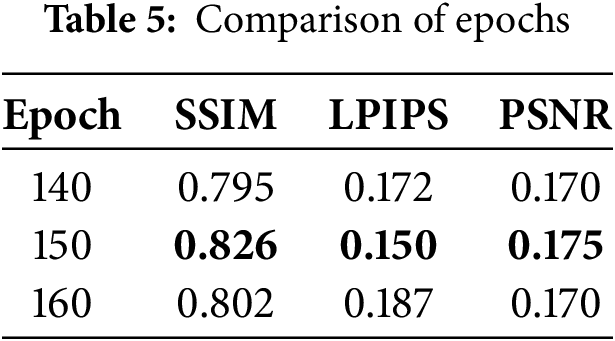
Table 5 presented the training comparison of this algorithm under different numbers of Iterations. With the LR determined to be 0.0001, this paper tested three different epochs to detect the optimal hyper-parameters. The number of iterations (Epochs) had a critical function in avoiding the overfitting and underfitting problems of the model. If there were too many numbers of iterations, the model might over-learn the noise and details in the training data, leading to poor performance on the validation and test sets. On the contrary, if there were not enough number of iterations, the model might fail to fully learn the useful information in the training data. Therefore, choosing an appropriate number of iterations was critical to balancing overfitting and underfitting.
According to the analysis in Table 5, when the iteration number reached 160, the model showed obvious signs of overfitting due to excessive training, leading to a decline in model performance. When the number of iterations was 140, the model had not fully converged, so its performance on the evaluation metrics was also the worst. Therefore, when the number of iterations was set to 150, the model’s performance reached its best state.
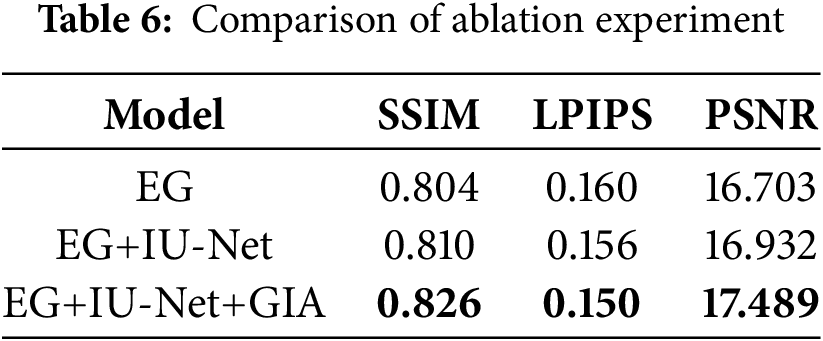
This study aimed to improve algorithm performance by integrating IU-Net and GIA in the EnlightenGAN (EG) framework. This section explored the independent effects of IU-Net and GIA through ablation experiments. After the introduction of IU-Net, it achieved multi-scale feature fusion, retaining more feature details. It significantly improved the visual quality of low-light images, enhanced the contrast and brightness of images, and made image details more distinct (Table 6). Therefore, in the SSIM metrics, the EG algorithm integrated with IU-Net increased by 0.7% compared to the original EG algorithm, reduced by 2.5% in LPIPS, and increased by 1.4% in PSNR.
Further, we introduced GIA after IU-Net. GIA was used to calculate the correlation between each position in the feature map and all other positions, and then automatically identify the noise distribution and detail characteristics of low-light areas. Then a light weight map based on the correlated results was generated. Based on the light weight map, the enhancement level of each area was automatically adjusted to optimize image quality. Therefore, when GIA was integrated into the EG+IU-Net, the overall performance was significantly improved. Compared with EG+IU-Net, SSIM increased by 2.0%, LPIPS reduced by 3.8%, and PSNR increased by 3.2%. Compared with the original EG algorithm, SSIM increased by 2.7%, PSNR increased by 4.7%, and LPIPS reduced by 6.3%.
This study introduced IU-Net and GIA to address the deficiencies in the generator design of EnlightenGAN, comprising insufficient feature extraction capability and image detail loss caused by excessive convolution in the contraction path. To confirm the efficacy of this algorithm, we trained and compared its performance with LIME, LE-GAN, EnlightenGAN, and other algorithms under the same experimental conditions. Tables 7 and 8 displayed the specific findings.
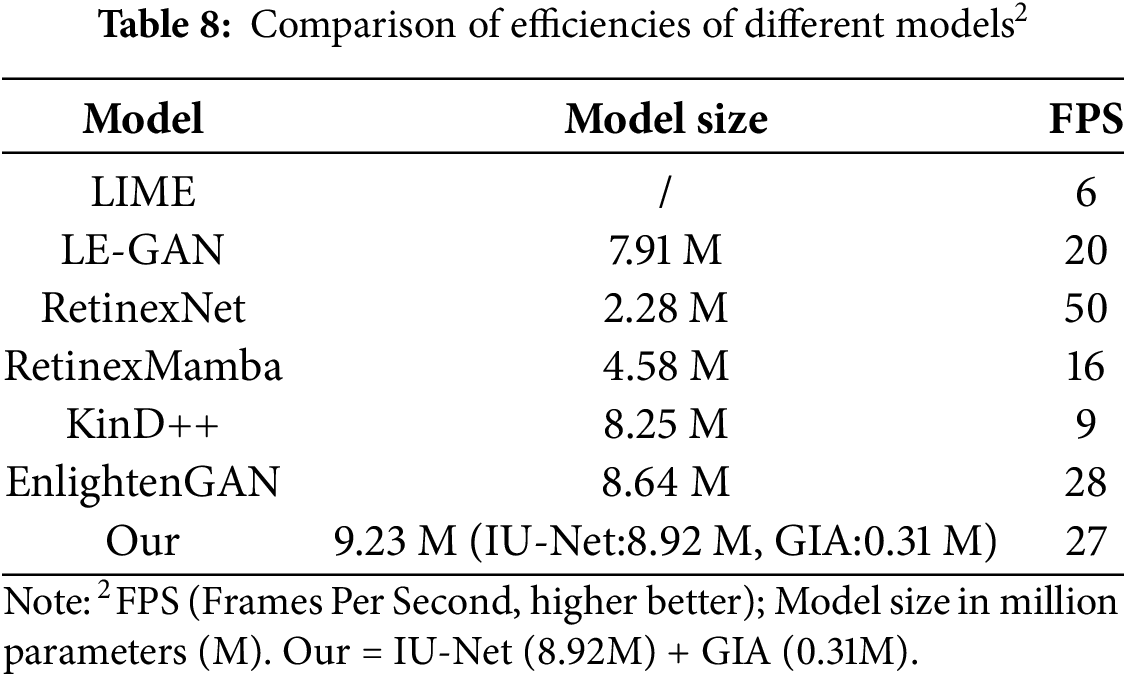
Table 7 revealed that in the SSIM metrics, this algorithm increased by 2.7%, 2.6%, 137.4%, 2.5% and 37.4% compared to EnlightenGAN, KinD++, RetinexMamba [40], RetinexNet, LE-GAN and LIME algorithms, respectively. In the PSNR metrics, it increased by 4.7%, −14.0%, −17.1%, 44.5%, 1.0%, and 10.0%, respectively; And in the LPIPS metrics, it improved by 6.3%, 18.9%, 8.5%, 72.9%, 23.5%, and 53.1%, respectively, significantly improving image quality and demonstrating that this algorithm outperformed other algorithms. As can be seen from Table 7, the proposed method was superior to other algorithms in SSIM and LPIPS in addition to PSNR. After analysis, it could be seen that RetinexMamba effectively eliminated the problem of decomposition error accumulation in traditional methods and significantly improved PSNR by leveraging the global modeling capabilities and end-to-end joint optimization strategy of the Mamba module. And KinD++, as an improved version of RetinexNet, used physical model constraints to make the output closer to the reference image. Although the GAN characteristics of EnlightenGAN could generate more natural textures, the high degree of freedom made it easy to deviate from the pixel values of the reference image. This also affected the effect of our algorithm on PSNR. Among these algorithms, RetinexNet performed the worst enhancement effect, which was mainly due to the lack of noise modeling and insufficient decomposition network capability of the RetinexNet model. Table 7 also showed that our method was 10.757 in DeltaE 2000 metrics, the best among several SOTA algorithms, indicating that the enhanced image generated by our method was closest to the original reference image in color restoration. This meant that the algorithm successfully restored the distorted colors under low light conditions and the output color information was accurate.
As can be seen from Table 8, LIME algorithm used a traditional image processing method and did not involve neural networks, so we filled in “/” in the model size column. Although LIME algorithm was very fast in single operation, it mainly relied on iterative optimization and complex numerical calculations, which made its algorithm efficiency much lower than other algorithms based on deep learning. Compared with LE-GAN and KinD++, due to the innovative architecture design of EnlightenGAN, it could more effectively decouple image enhancement tasks and reduce unnecessary computational cost, so its computational efficiency was also higher than LE-GAN and KinD++. This paper added feature fusion and GIA on the basis of EnlightenGAN, which made the number of parameters of our method slightly higher than EnlightenGAN, but the computational complexity of the feature fusion module was very small, which was just a simple convolution operation, and only the first two stages were performed. And GIA could be executed in parallel. So its computational efficiency was only slightly reduced. Although RetinexMamba performed relatively well in various metrics, the sequence modeling approach of the Mamba module (especially its Selective Scan mechanism) had severe order dependencies and complex memory access patterns, making it difficult to execute efficiently on highly parallelized GPU hardware. Unexpectedly, RetinexNet had the highest execution efficiency among these algorithms. This occurred because RetinexNet decomposed the image into two parts: reflectivity and illumination. Its structure was relatively simple and direct, mainly including decomposition network and adjustment network, and the overall process was linear. As a GAN architecture, EnlightenGAN inherently included adversarial training of generators and discriminators. This structural complexity directly affected the inference speed. However, as could be seen from Table 6, RetinexNet achieved not ideal enhancement effects. Therefore, in practical applications, we needed to weigh the balance between effect and efficiency.
Fig. 5 demonstrated the characteristics of low-light image input (Low), which usually had much noise, blurry, and distorted, with difficult-to-recognize details, low contrast, and unclear object edges. Compared with LIME, the low-light image enhanced by this algorithm had significantly reduced edge distortion and blurring and had higher illumination and clarity. Although LE-GAN also solved the problems of detail distortion, blurring, and low contrast, there was color deviation. Our algorithm had higher saturation and less color deviation. EnlightenGAN, although it used self-normalized attention and U-Net network as a generator and used feature-preserving loss function to avoid overfitting and improve generalization ability, it still had some deficiencies in image details, such as low lighting in local areas and edge blur. RetinexNet algorithm had limited enhancement effect on low-light images, with low contrast and lack of detail information. Although KinD++ had a strong contrast, it produced an overexposure phenomenon and a large number of noise, making it look very unnatural. RetinexMamba appeared Checkerboard artifacts. And the first image has overexposure at the border. Our algorithm introduced IU-Net and GIA to enhance the local area illumination, thus outperforming other algorithms in the subjective evaluation of lighting and image edge details. This proved the feasibility and effectiveness of our algorithm. We used partitioned annotations to more clearly demonstrate the algorithm’s improvements in the core area (foreground) and environmental context (background). Red solid-line boxes (foreground): Label the key spacecraft component areas, highlighting our method’s improvements in edge sharpening and texture detail. Yellow solid-line boxes (background): Label the space/Earth background areas, highlighting our method’s advantages in color naturalness and noise suppression.

Figure 5: Comparison of the effects of diverse models in images. The input image (Low) exhibits noise, blur, distortion, and low contrast. The proposed method, leveraging IU-Net and GIA for local illumination enhancement, significantly reduces noise, distortion, and blur while improving contrast, edge clarity, and saturation with minimal color deviation compared to LIME, LE-GAN, EnlightenGAN, RetinexNet, RetinexMamba and KinD++. Subjective comparison confirms superior performance in lighting and detail preservation
Aiming at the problem of enhancing images captured by satellites under low-light conditions, this study introduces an unsupervised satellite LLIE algorithm based on the improved GAN. By integrating IU-Net and GIA, our algorithm resolves detail loss in deep convolutions and improves feature extraction. Experimental results surpass the mainstream state-of-the-art technologies. However, when this algorithm dealed with adjacent areas with significantly different brightness values, the low-light background part might suffer from overexposure. Future research will explore image segmentation and area processing technology to achieve more precise exposure control by segmenting the image into multiple areas and applying customized enhancement strategies dependent on the brightness features of each area.
Acknowledgement: We would like to express our gratitude to all those who have helped us during the writing of this paper. Special thanks are due to the technical support at Anhui Engineering Research Center of Intelligent Manufacturing of Copper-Based Materials for providing computational resources.
Funding Statement: This research was supported by Anhui Province University Key Science and Technology Project (2024AH053415), Anhui Province University Major Science and Technology Project (2024AH040229).
Author Contributions: Conceptualization, Ping Qi; methodology, Ming Chen; software, Yanfei Niu; investigation, Ping Qi; resources, Yanfei Niu; data curation, Yanfei Niu; writing—original draft preparation, Ming Chen; writing—review and editing, Ming Chen and Fucheng Wang; funding acquisition, Ming Chen and Fucheng Wang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The SDDEP dataset presented in this study are available in https://drive.google.com/file/d/1SycGI1LeeZmq1FDVsoUN8yDfA_hU0Vn4/view?usp=drive_link (accessed on 01 August 2025). The SDDSP dataset were derived from the following resources available in the public domain: https://drive.google.com/drive/folders/1d7sSOHH8eTG6yEA4y7qlI-PvFQ_C-m8s (accessed on 01 August 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Guo X, Li Y, Ling H. LIME: low-light image enhancement via illumination map estimation. IEEE Trans Image Process. 2016;26(2):982–93. doi:10.1109/TIP.2016.2639450. [Google Scholar] [PubMed] [CrossRef]
2. Zhang Z, Zheng H, Hong R, Xu M, Yan S, Wang M. Deep color consistent network for low-light image enhancement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA. p. 1899–908. [Google Scholar]
3. Deng J, Guo J, Xue N, Zafeiriou S. Arcface: additive angular margin loss for deep face recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–21; Long Beach, CA, USA. p. 4690–9. [Google Scholar]
4. Fu J, Liu J, Tian H, Li Y, Bao Y, Fang Z, et al. Dual attention network for scene segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–21; Long Beach, CA, USA. p. 3146–54. [Google Scholar]
5. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39(6):1137–49. doi:10.1109/TPAMI.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
6. Wang W, Wu X, Yuan X, Gao Z. An experiment-based review of low-light image enhancement methods. IEEE Access. 2020;8:87884–917. doi:10.1109/ACCESS.2020.2992749. [Google Scholar] [CrossRef]
7. Wang Y, Wan R, Yang W, Li H, Chau LP, Kot A. Low-light image enhancement with normalizing flow. In: Proceedings of the AAAI Conference on Artificial Intelligence; 2022 Feb 22–Mar 1; Virtual. p. 2604–12. doi:10.1609/aaai.v36i3.20162. [Google Scholar] [CrossRef]
8. Lore KG, Akintayo A, Sarkar S. LLNet: a deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017;61(6):650–62. doi:10.1016/j.patcog.2016.06.008. [Google Scholar] [CrossRef]
9. Jin S, Xu X, Su Z, Tang L, Zheng M, Liang P, et al. MVCT image enhancement using reference-based encoder-decoder convolutional neural network. Expert Syst Appl. 2024;241(2520):122576. doi:10.1016/j.eswa.2023.122576. [Google Scholar] [CrossRef]
10. Wang LW, Liu ZS, Siu WC, Lun DP. Lightening network for low-light image enhancement. IEEE Trans Image Process. 2020;29:7984–96. doi:10.1109/TIP.2020.3008396. [Google Scholar] [CrossRef]
11. Ma Y, Liu J, Liu Y, Fu H, Hu Y, Cheng J, et al. Structure and illumination constrained GAN for medical image enhancement. IEEE Trans Med Imaging. 2021;40(12):3955–67. doi:10.1109/TMI.2021.3101937. [Google Scholar] [PubMed] [CrossRef]
12. Wang R, Jiang B, Yang C, Li Q, Zhang B. MAGAN: unsupervised low-light image enhancement guided by mixed-attention. Big Data Min Anal. 2022;5(2):110–9. doi:10.26599/BDMA.2021.9020020. [Google Scholar] [CrossRef]
13. Anoop PP, Deivanathan R. Advancements in low light image enhancement techniques and recent applications. J Vis Commun Image Represent. 2024;42(1):1–11. doi:10.1016/j.jvcir.2024.104223. [Google Scholar] [CrossRef]
14. Jiang Y, Gong X, Liu D, Cheng Y, Fang C, Shen X, et al. Enlightengan: deep light enhancement without paired supervision. IEEE Trans Image Process. 2021;30:2340–9. doi:10.1109/TIP.2021.3051462. [Google Scholar] [PubMed] [CrossRef]
15. Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. In: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; 2015 Oct 5–9; Munich, Germany. p. 234–41. doi:10.1007/978-3-319-24574-4_28. [Google Scholar] [CrossRef]
16. Lu W, Chen SB, Tang J, Ding CH, Luo B. A robust feature downsampling module for remote-sensing visual tasks. IEEE Trans Geosci Remote Sens. 2023;61:4404312. doi:10.1109/TGRS.2023.3282048. [Google Scholar] [CrossRef]
17. Shen WY, Zhuo ZL. A simple approach to resolve information lost in convolution. Chem J Chin Univ. 1994;15(11):1611. [Google Scholar]
18. Zhang WD, Zhao WY, Li J, Zhuang P, Sun H, Xu Y, et al. CVANet: cascaded visual attention network for single image super-resolution. Neural Netw. 2024;170(2):622–34. doi:10.1016/j.neunet.2023.11.049. [Google Scholar] [PubMed] [CrossRef]
19. Wang T, Zhang K, Luo W, Stenger B, Lu T, Kim TK, et al. LLDiffusion: learning degradation representations in diffusion models for LLIE. Pattern Recognitation. 2025;166(8):1–15. doi:10.1016/j.patcog.2025.111628. [Google Scholar] [CrossRef]
20. Zhang XN, Peng ZY, Wang YF, Fan Ye, Fu TY, Zhang H. A robust multispectral reconstruction network from rgb images trained by diverse satellite data and application in classification and detection tasks. Remote Sens. 2025;17(11):1901. doi:10.3390/rs17111901. [Google Scholar] [CrossRef]
21. Zhang WD, Zhuang PX, Sun HH, Li GH, Kwong S, Li CY. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Trans Image Process. 2022;31:3997–4010. doi:10.1109/TIP.2022.3177129. [Google Scholar] [PubMed] [CrossRef]
22. Zhang WD, Jin SL, Zhuang PX, Liang Z, Li CY. Underwater image enhancement via piecewise color correction and dual prior optimized contrast enhancement. IEEE Signal Process Lett. 2023;30:229–33. doi:10.1109/LSP.2023.3255005. [Google Scholar] [CrossRef]
23. Fu Y, Hong Y, Chen L, You S. LE-GAN: unsupervised low-light image enhancement network using attention module and identity invariant loss. Knowl Based Syst. 2022;240(6):108010. doi:10.1016/j.knosys.2021.108010. [Google Scholar] [CrossRef]
24. Jähne B. Digital image processing. Berlin/Heidelberg, Germany: Springer; 2005. [Google Scholar]
25. Dale-Jones R, Tjahjadi T. A study and modification of the local histogram equalization algorithm. Pattern Recognit. 1993;26(9):1373–81. doi:10.1016/0031-3203(93)90143-k. [Google Scholar] [CrossRef]
26. Land EH, McCann JJ. Lightness and retinex theory. J Opt Soc Am. 1971;61(1):1–11. doi:10.1364/JOSA.61.000001. [Google Scholar] [PubMed] [CrossRef]
27. Rahman Z, Jobson DJ, Woodell GA. Retinex processing for automatic image enhancement. J Electron Imaging. 2004;13(1):1–12. doi:10.1117/1.1636183. [Google Scholar] [CrossRef]
28. Abdullah-Al-Wadud M, Kabir MH, Dewan MAA, Chae O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans Consum Electron. 2007;53(2):593–600. doi:10.1109/TCE.2007.381734. [Google Scholar] [CrossRef]
29. Ibrahim H, Kong NSP. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans Consum Electron. 2007;53(4):1752–8. doi:10.1109/TCE.2007.4429280. [Google Scholar] [CrossRef]
30. Jobson DJ, Rahman Z, Woodell GA. Properties and performance of a center/surround retinex. IEEE Trans Image Process. 1997;6(3):451–62. doi:10.1109/83.557356. [Google Scholar] [PubMed] [CrossRef]
31. Jiang K, Wang Q, An Z, Wang Z, Zhang C, Lin CW. Mutual retinex: combining transformer and CNN for image enhancement. IEEE Trans Emerg Top Comput Intell. 2024;8(3):2240–52. doi:10.1109/TETCI.2024.3369321. [Google Scholar] [CrossRef]
32. Zhang Y, Zhang J, Guo X. Kindling the darkness: a practical low-light image enhancer. In: Proceedings of the 27th ACM International Conference on Multimedia; 2019 Oct 21–25; Nice, France. p. 1632–40. [Google Scholar]
33. Yu WS, Zhao LQ, Zhong T. Unsupervised low-light image enhancement based on generative adversarial network. Entropy. 2023;25(6):932. doi:10.3390/e25060932. [Google Scholar] [PubMed] [CrossRef]
34. Yu J, Lin Z, Yang J. Generative image inpainting with contextual attention. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–22; Salt Lake City, UT, USA. p. 5505–14. [Google Scholar]
35. Dung HA, Chen B, Chin TJ. A spacecraft dataset for detection, segmentation and parts recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021 Jun 13–19; Seattle, WA, USA. p. 2012–9. [Google Scholar]
36. Zhou W, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process. 2004;13(4):600–12. doi:10.1109/TIP.2003.819861. [Google Scholar] [PubMed] [CrossRef]
37. Zhang R, Isola P, Efros AA, Shechtman E, Wang O. The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–22; Salt Lake City, UT, USA. p. 586–95. [Google Scholar]
38. Welstead ST. Fractal and wavelet image compression techniques. Bellingham, WA, USA: Spie Press; 1999. [Google Scholar]
39. Lee YK, Powers JM. Comparison of CIE lab, CIEDE 2000, and DIN 99 color differences between various shades of resin composites. Int J Prosthodont. 2005;18(2):150. [Google Scholar] [PubMed]
40. Bai JS, Yin YH, He QY, Li YX, Zhang XF. Retinexmamba: retinex-based mamba for low-light image enhancement. In: Neural information processing (ICONIP 2024); Singapore: Springer; 2025. p. 427–42. doi:10.1007/978-981-96-6596-9_30. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools