
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Hybrid Model of Transfer Learning and Convolutional Neural Networks for Accurate Coffee Leaf Miner (CLM) Classification
1 Department of Computer Science, University of Malaga, Malaga, 29071, Spain
2ITIS Software, Universidad de Málaga, Malaga, 29071, Spain
* Corresponding Authors: Nameer Baht. Email: ; Enrique Domínguez. Email:
(This article belongs to the Special Issue: Development and Application of Deep Learning based Object Detection)
Computers, Materials & Continua 2025, 85(3), 4441-4455. https://doi.org/10.32604/cmc.2025.069528
Received 25 June 2025; Accepted 26 August 2025; Issue published 23 October 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Coffee is an important agricultural commodity, and its production is threatened by various diseases. It is also a source of concern for coffee-exporting countries, which is causing them to rethink their strategies for the future. Maintaining crop production requires early diagnosis. Notably, Coffee Leaf Miner (CLM) Machine learning (ML) offers promising tools for automated disease detection. Early detection of CLM is crucial for minimising yield losses. However, this study explores the effectiveness of using Convolutional Neural Networks (CNNs) with transfer learning algorithms ResNet50, DenseNet121, MobileNet, Inception, and hybrid VGG19 for classifying coffee leaf images as healthy or CLM-infected. Leveraging the JMuBEN1 dataset, the proposed hybrid VGG19 model achieved exceptional performance, reaching 97% accuracy on both training and validation data. Additionally, high scores for precision, recall, and F1-score. The confusion matrix shows that all the test samples were correctly classified, which indicates the model’s strong performance on this dataset, demonstrating that the model is effective in distinguishing between healthy and CLM-infected leaves. This suggests strong potential for implementing this approach in real-world coffee plantations for early disease detection and improved disease management, and adapting it for practical deployment in agricultural settings. As well as supporting farmers in detecting diseases using modern, inexpensive methods that do not require specialists, and utilising deep learning technologies.Keywords
Coffee is an important commodity consumed globally that supports the livelihoods of many farmers. However, coffee production faces several challenges, including fungal and bacterial diseases that significantly impact yield and quality. Coffee Leaf Miner (CLM), caused by the moth Leucoptera coffeella, is a particularly devastating disease with the potential to cause yield losses exceeding 50% [1]. CLM larvae burrow within coffee leaves, damaging photosynthetic tissues and leading to significant yield reductions [2]. Early and accurate CLM detection is vital for the timely implementation of control measures and minimizing economic losses. Traditional methods rely on visual inspection, which can be labor-intensive, subjective, and prone to human error.
To address these challenges, researchers have been exploring the use of advanced technologies for CLM detection. One promising approach is the use of remote sensing techniques, such as hyperspectral imaging, which allows for non-destructive and rapid assessment of plant health. Whereas, hyperspectral imaging captures a wide range of spectral information from the coffee plants, providing valuable insights into their physiological status and detecting early signs of CLM infestation. The algorithms can be developed to automatically detect and quantify the severity of infestation by analyzing the unique spectral signatures associated with CLM damage, enabling farmers to take timely and targeted control measures [3].
In light of this, Machine Learning (ML) offers promising tools for automated disease detection in agriculture and in other fields that utilitzed images dataset. Whereas, Convolutional neural networks (CNNs) with deep learning architecture have achieved remarkable accuracy in different image classification projects, including plant disease detection [4]. These CNNs are trained on large datasets of labelled images, which enable them to learn complex models and features that can differentiate between healthy and diseased plants based on features pattern [5,6]. The algorithm can analyze the spectral signatures and classify the severity of infestation accurately by inputting images of plants with potential CLM damage into a trained CNN model. This automated disease detection approach not only saves time and resources for farmers but also increases the efficiency of early detection and control measures, ultimately leading to higher crop yields and reduced economic losses.
Indeed, transfer learning is a technique in which pre-trained models on large datasets are adapted for new tasks, is particularly advantageous for ML applications with limited data availability [6]. However, this study investigates the efficacy of transfer learning in categorizing coffee leaf images into healthy and CLM-infected categories. The architectures known for their deep convolutional layers have been widely used in computer vision tasks [7]. In this research, we relied on transfer learning to accelerate the training process and achieve high performance and efficiency in classifying coffee leaf diseases. Moreover, these algorithms are effective tools in the field of computer vision, as they benefit from models pre-trained on large datasets such as ImageNet. We proposed the using a set of deep models based on transfer learning, including: ResNet50, which is characterized by its ability to deal with the problem of vanishing gradients via residual structure; EfficientNetB0, which provides a high balance between accuracy and efficiency through joint scaling of depth, width, and resolution; MobileNetV2, which is characterized by its lightweight and effectiveness in mobile applications; and InceptionV3, which relies on multiple filter techniques within the same layer to extract diverse features. Transfer learning has proven to be an integral approach for improving the accuracy and efficiency of coffee leaf categorization by leveraging the knowledge learned from a large dataset. Finally, the Hybrid-VGG19 model developed based on the VGG19 structure with a decision tree achieved the highest accuracy, with improvements to suit the nature of coffee disease data.
Early research on coffee leaf miner (CLM) detection utilised traditional machine learning (ML) algorithms such as support vector machines (SVM) and random forests, achieving moderate accuracy (70–80%). However, these approaches were limited by manual feature engineering and struggled with generalizability. The emergence of CNNs, inspired by the human visual system, revolutionized image classification. The linear kernel type support vector machine was applied to create a discriminant model [8]. The number of trees used in the random forest classification was 100 trees. The support vector machine showed lower performance than the random forest algorithm, but both performed above 80% in terms of user and product accuracy. Three bands (blue, red, near-infrared) were selected to create the new index, and the accuracy was 95.39%. In this research, SuNet a hybrid model was proposed by the researchers to detect diseases that affect coffee leaves and for five classes [9]. The model is effective for deep learning and the VGG16 structure was also used with its basic structure. This article highlighted coffee farms in Rwandan to build a coffee plant database [10]. The three most common diseases in Rwandan were identified. A collected coffee leaf dataset of 37,939 images was processed using five transfer learning algorithms. The experiment demonstrated that the DenseNet model was the best, with an accuracy of 99.57%. In this article, researchers presented a study on the detection of coffee diseases in Brazil [11]. Data processing was done using nine machine learning algorithms to classify the coffee leaf miner (CLM). The best model was Random Forest, whose accuracy reached 86%. This study presented the detection of coffee leaf miner diseases [12]. Images were collected from aerial photographs by a multispectral camera mounted on a remotely piloted drone and processed using the random forest algorithm, and an accuracy of 99% was obtained. In this work, the researchers presented the design of an effective and practical system capable of estimating and identifying the severity of stress caused by biotic factors on coffee leaves using a convolutional neural network approach, with an accuracy of 95% for classifying biotic stress [13]. In this article, the researchers propose an approach to address the limitations of traditional methods and provide a more efficient, reliable, and cost-effective solution [14]. The dataset contains 19,599 labels across five disease categories. This research focused on using a deep learning approach to classify Robusta coffee leaf diseases based on visual symptoms captured in leaf images. The methodology relies on different imaging methods [15]. Three methods were used: Grad-CAM, Grad-CAM++, and Score-CAM. An accuracy of 98% was achieved. The researcher proposed a study to detect rust disease caused by a pathogenic fungus that attacks the underside of coffee leaves using convolutional neural network technology. The comparison results showed that the approach is able to detect infection with high accuracy [16]. These advancements in deep learning and transfer learning methods have greatly improved the accuracy and efficiency of coffee leaf disease detection, making it an invaluable tool for farmers in crop management. While these approaches made significant strides, achieving perfect accuracy and enhancing generalizability for real-world deployment remained challenges. Despite the impressive accuracy achieved by the proposed model, perfect accuracy remains a challenge in coffee leaf disease detection. Additionally, enhancing the generalizability of the model for real-world deployment is another hurdle that needs to be overcome. However, these advancements in deep learning and transfer learning methods have undoubtedly improved the accuracy and efficiency of coffee leaf disease detection, providing farmers with a valuable tool in managing their crops effectively.
The aforementioned papers can not get high accuracy, thus we applied a novel model that can handle this huge dataset [17]. By extracting the most important features from the images. Traditional machine learning models, such as SVM and Random Forest, rely on old methods that were used to deduce features from the leafs images. In terms of practicality, these methods become unsatisfactory for the complex classification dataset, due it is huge and the feature pattern can not be obtained at the optimum. Therefore, the golden solution in the new era is to apply the deep learning technology due to it isability to automatically deduce the feature with one punch. Moreover, the capability to handle huge datasets with high resolution. Thus, we developed our model using transfer learning techniques with VGG19 to reduce training time and achieve higher accuracy. The model was trained using a large dataset of coffee leaf images and combined automatically extracted deep features with traditional classifiers within a hybrid framework. This combination enabled the model to capture subtle differences between disease categories with high accuracy. Our method has the ability to deal with real-time processes even with limited resources, and it has automatically classified and identified the diseases for the farmers.in our model.
The research focuses on developing an intelligent system for detecting coffee plant diseases using deep learning techniques with the integration of machine learning algorithms. A robust dataset of approximately 31,000 images was used, which were processed by dividing the data into an 80-20 split for training and test data sets for the two leaf categories. Applied Canny Edge Detection and Mathematical Morphology in Image Processing were used in the image processing phase, as these two techniques contribute to improving the quality of visual data before feeding it into the deep learning model. In the feature extraction phase, a feature extraction technique called Histogram of Oriented Gradients was used. The proposed approach: A set of models was developed that combines deep learning techniques, traditional classifiers, and transfer learning, with the goal of accurately classifying two types of plant diseases. The first model is a convolutional neural network (CNN) designed from scratch to capture the essential characteristics of the diseases [18]. The second model was a hybrid model based on deep feature extraction using the pre-trained VGG19 model, and these features were then passed to the Random Forest algorithm for classification (VGG19 + RF). Modern algorithms such as DenseNet121, ResNet50, InceptionV3, and MobileNetV2 were also tested. All models were trained in the same experimental environment, using the same dataset and standardised preprocessing techniques to ensure fair comparisons. A comprehensive set of evaluation metrics, including Accuracy, Precision, recall, and Specificity, as well as F1 scores and the intersection-over-union index (IoU), was used to analyse the model’s performance comprehensively to ensure a balance between correct prediction and effective generalisation. The evaluation results showed that the VGG19 + RF model performed best in terms of overall accuracy, highlighting the effectiveness of hybrid models in agricultural image classification tasks. Fig. 1 illustrates the architecture of the proposed methodology.
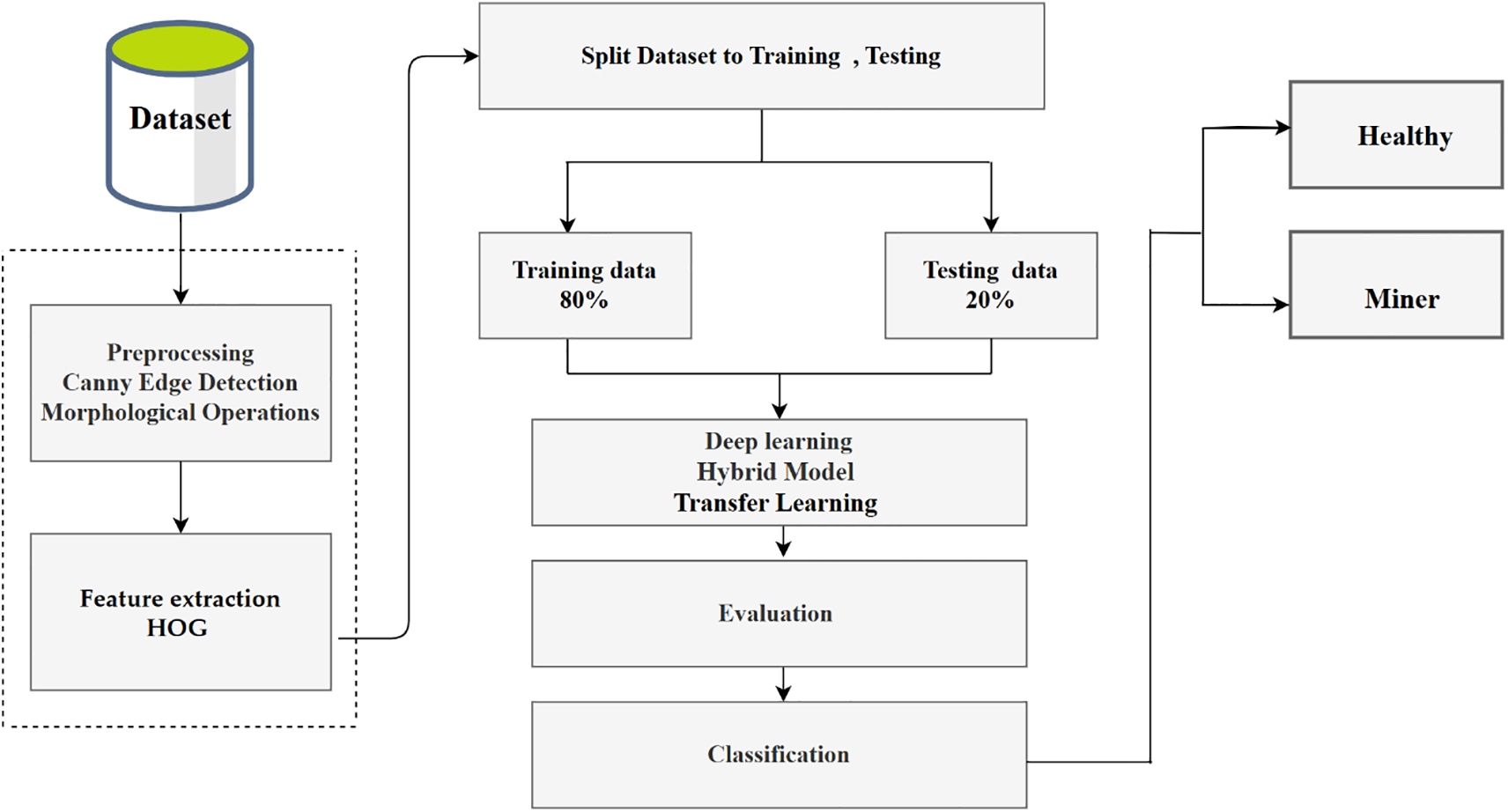
Figure 1: Flowchart of the proposed methodology
The JMuBEN1 dataset, specifically designed for CLM detection, was used. The JMuBEN1 dataset, comprised of 35,961 coffee leaf images equally categorised as either healthy or CLM-infected, was chosen for its domain-specificity and balanced class distribution. The dataset was categorised into training (80%) and testing (20%) sets for model training and evaluation. This balanced class distribution and domain-specific nature facilitated rigorous evaluation and prevented overfitting, ensuring the model’s effectiveness in real-world settings. Additionally, the JMuBEN1 dataset provided a comprehensive representation of coffee leaf images infected with (CLM), allowing for robust training and testing of the model [19]. The balanced class distribution ensured that the model was not biased towards either healthy or CLM-infected leaves, making it more reliable in accurately detecting CLM. Furthermore, the domain-specific nature of the dataset ensured that the model was specifically tailored to identify CLM in coffee leaf images, enhancing its effectiveness in real-world scenarios. Fig. 2 shows counts of each class.

Figure 2: Counts of classes diseses
Image preprocessing is a fundamental step in computer vision and image-based classification systems. It aims to improve image quality and prepare it appropriately for feature extraction or input into a machine learning or deep learning model. This stage includes several techniques aimed at reducing noise, enhancing edges, clarifying visual details, or facilitating the separation of objects from the background. Based on the nature and challenges of the input images, several preprocessing techniques have been used, most notably: the Canny edge detector and morphological processing.
Canny is an edge detection algorithm that calculates the color changes in the image [20]. It converts the image to grayscale, reduces noise, calculates the color gradient, removes unnecessary edges, and applies thresholds to identify only strong edges. The image is processed and converted to grayscale, then a Gaussian Blur is applied to reduce noise, and Canny Edge Detection is used to extract edges [21]. Finally, the original image is displayed with the edge image using Canny. Though this process, we get clean and enhanced images that contain only the important features, making it easier for the model to learn patterns associated with plant diseases with higher accuracy. Fig. 3 shows that the Canny edge detector captures edges well.

Figure 3: (a) Original image of a diseased Arabica coffee leaf. (b) The corresponding image after edge detection, which highlights the lesion contours
Morphological Image Processing is a set of operations used to analyse and synthesise objects in images [22]. An image is loaded and converted into a grayscale. Four basic morphological operations are then applied dilation (to expand objects in the image, (eroded) to shrink elements), opening (which involves removing small contamination by shrinking and then shrinking elements, and) closing (which fills small gaps in objects by expanding and then shrinking. Sub-graphs of each operation are below. Fig. 4 shows the morphological Technique.
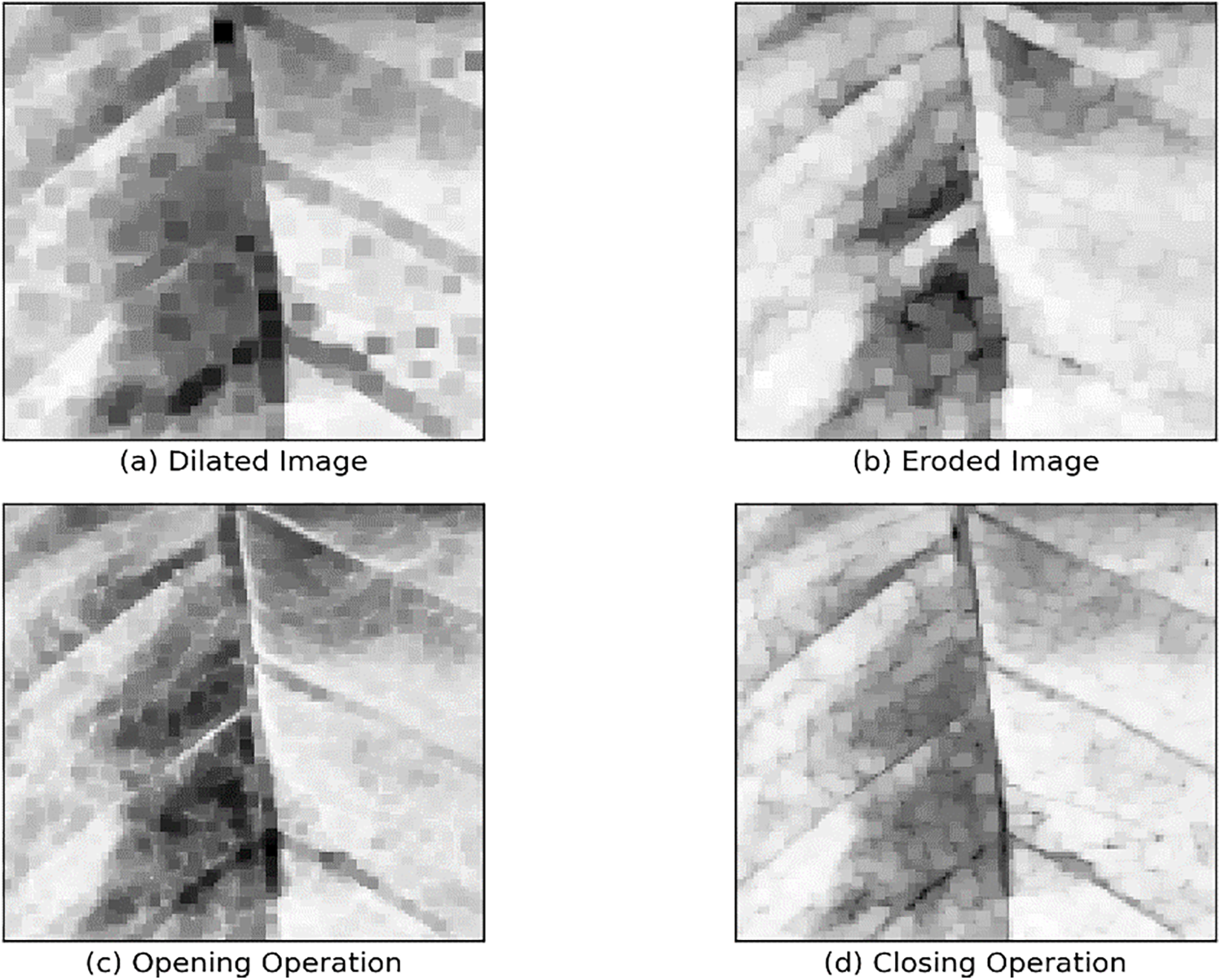
Figure 4: Morphological operations applied to a coffee leaf image. (a) Dilated image showing the expansion of the lesion boundaries. (b) Eroded image showing a reduction in the area of the lesion. (c) The opening operation highlights the removal of small noise and the smoothing of contours. (d) The closing operation fills small gaps within the lesion regions
After completing the image preprocessing stage comes the feature extraction step, which is a critical step in classification and computer vision systems. This stage aims to transform the image from a visual representation into a set of digital features that represent the most important visual components within the image, such as shape, texture, contrast, or orientation. These extracted features help the model effectively distinguish patterns and identify differences between different classes. Among the common and effective techniques in this field is the Histogram of Oriented Gradients (HOG), which relies on analysing the orientation of edges within an image.
Histogram of Oriented Gradients is a technique for extracting features from images by calculating the directional gradients of edges, which helps in recognising shapes and textures [23]. We preprocess images and then convert them to grayscale to increase processing efficiency. After that, the image is downscaled to 100 × 100 to maintain feature consistency. HOG features are extracted using 9 directions and 8 × 8 pixel blocks, with the original image, grayscale version, and extracted feature representations shown. Fig. 5 shows a Histogram of Oriented Gradients is a technique.

Figure 5: Visualisation of the pre-processing and feature extraction steps applied to coffee leaf images from the ‘Miner’ and ‘Healthy’ classes (a, d, g). (a, d, g) Original images showing leaf colour and texture. (b, e, h) Grey-scale transformations are used for standardising image intensity. (c, f, i) Histograms of Oriented Gradients (HOG) feature representations, which highlight edge and contour patterns that are relevant for disease classification. (c, f, i) Histograms of Oriented Gradients (HOG) feature representations, which highlight edge and contour patterns that are relevant for disease classification
The proposed approach uses a flexible architecture that combines traditional deep learning models, hybrid models, and transfer learning techniques to accurately and efficiently classify coffee leaf diseases. The framework leverages the power of convolutional neural networks (CNNs) for feature extraction, while incorporating models known for their high generalisation and adaptability. A deep learning CNN model was built from scratch to detect subtle visual patterns and distinctive features in leaf images. This model was trained on the dataset to form specialized internal representations that enable it to recognize the differences between infected and healthy leaves. A hybrid approach: A hybrid model was designed that combines the VGG19 network and the Random Forest algorithm. VGG19 is used to extract deep features, which are then passed to the Random Forest algorithm, which handles the classification task. This combination combines the representational accuracy provided by a deep network with the interpretability of classical machine learning algorithms. To expand the model’s predictive capabilities and increase its accuracy, transfer learning models were leveraged such as: ResNet50, DenseNet121, InceptionV3, MobileNetV2. This diversity of models aims to provide a comprehensive comparison in terms of performance, accuracy, and computational efficiency, and to select the optimal model for application in real-world environments such as smart farm systems or mobile phone applications.
Deep Learning: In this research, a convolutional neural network (CNN) model was developed from scratch to classify coffee leaf images into multiple categories based on their symptoms. The model relies on an efficient architecture for extracting subtle visual features. The model consists of two convolutional layers (Conv2D), each containing 32 3 × 3 filters, using the ReLU activation function to activate the neural units, followed by two pooling layers (MaxPooling2D) to reduce the spatial dimensionality. The output is then flattened through a Flatten layer and then passed to an inner dense layer consisting of 256 units. Finally, an output layer based on the Softmax function is used. The model was trained using the Adam optimisation algorithm. The number of training epochs was set to 10, with a batch size of 32. The model demonstrated good accuracy results. This model represents the foundation of the proposed approach, and its performance will subsequently be compared to more complex models based on transfer learning or hybrid architectures.
Hybrid Model: The proposed hybrid model relies on using a pre-trained VGG19 network as a deep feature extractor for coffee leaf images. Images are passed through the network without its top layer to extract representative features. These features are then flattened and converted to a one-dimensional shape to be fed into a Random Forest algorithm, which handles the classification task. This approach aims to leverage the high ability of the VGG19 network to extract accurate visual features, alongside the Random Forest algorithm for classification. This combination of deep learning and traditional learning provides an accurate and flexible model, and it has demonstrated superior performance in classifying coffee leaf diseases compared to standalone algorithms. The model was trained using the Adam optimisation algorithm. The number of training epochs was set to 10, with a batch size of 32. The model demonstrated the highest results in terms of performance metrics.
Transfer Learning: A set of pre-trained models on the ImageNet database was used to leverage their ability to extract effective features from images, speeding up the training process and increasing classification accuracy. The models used were: ResNet50, one of the most stable models, characterised by its residual connections-based architecture that mitigates the vanishing gradient problem in deep networks. DenseNet121, a highly efficient and computationally efficient model, uses a technique called Compound Scaling to adjust the depth, width, and resolution of the network in a balanced manner. The final layers were adjusted to accommodate two classification classes. MobileNetV2 is designed to be lightweight and executable on mobile and low-end devices. It relies on Depthwise Separable Convolutions (DSCs), which reduces the number of parameters without significantly impacting accuracy. It was used as a baseline and tested for its performance in classifying coffee leaf images. InceptionV3, a deep model that uses the Inception Modules architecture to extract features from multiple levels simultaneously. It has excellent performance in classifying complex images. All these models have been fine-tuned to suit the nature of the data in the project, and were trained using: Number of epochs: 10, batch size 32, Adam optimisers.
Fig. 6 shows the performance curves of six deep learning algorithm models used to classify coffee leaf diseases. Each algorithm includes two graphs: Accuracy curve: Represents the model’s ability to correctly classify images. Loss curve: Reflects the amount of error the model makes during predictions. These curves are represented by the training data in red and the validation data in orange or green, across 10 training epochs. The CNN, VGG19, DenseNet121, and InceptionV3 models demonstrated strong and balanced performance. There were no strong signs of overfitting in the models shown, a good indicator of the quality of the data used and the effectiveness of the validation procedures.
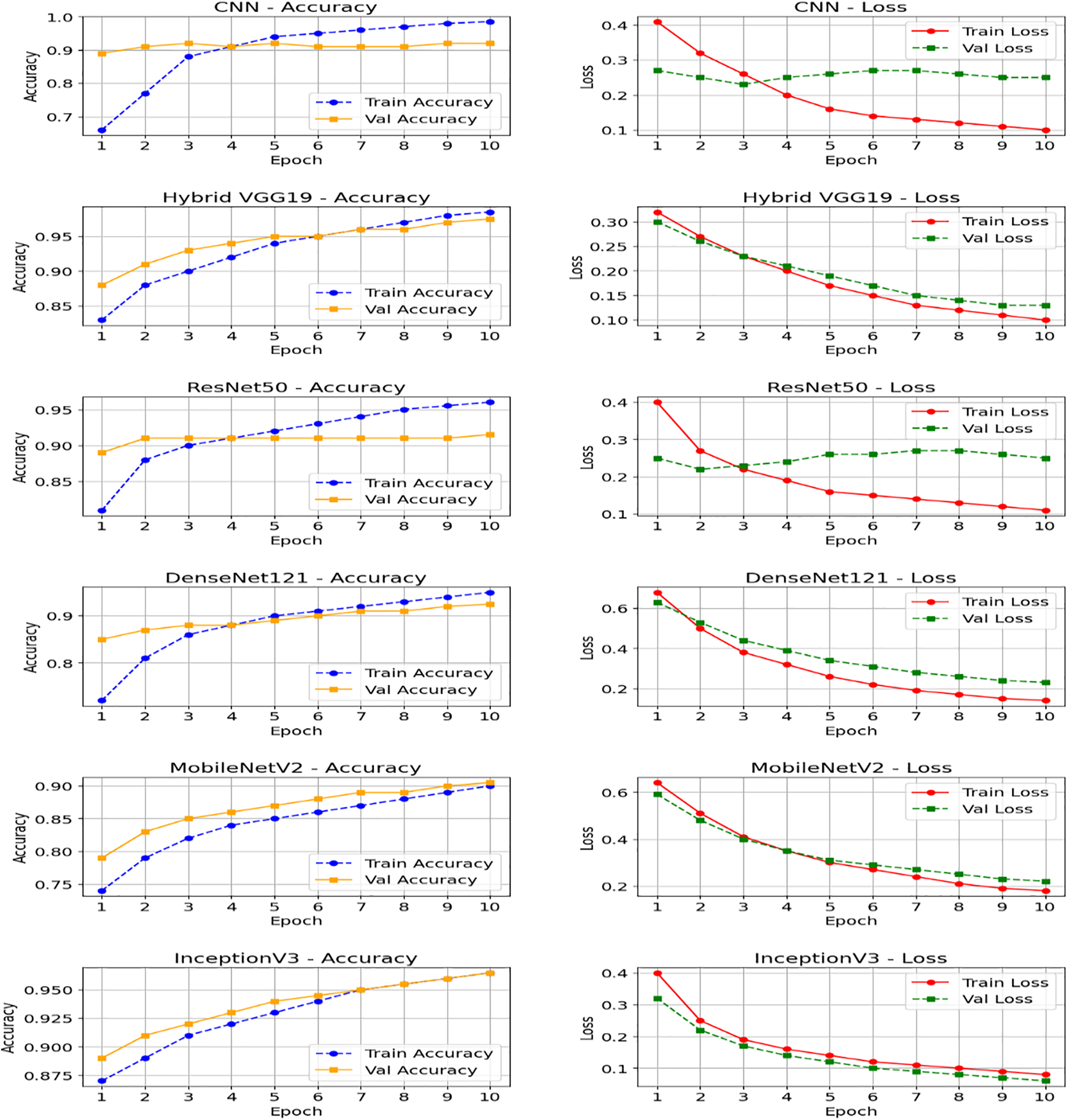
Figure 6: Training and validation accuracy (left) and loss (right) curves for each of the six deep learning models across 10 epochs: CNN, Hybrid VGG19, ResNet50, DenseNet121, MobileNetV2, and InceptionV3
Table 1 shows the confusion matrices of six algorithms applied to classify into the Healthy and Minor classes. Each matrix shows the model’s performance in distinguishing between the two classes through four key values: True Positive, the number of healthy images correctly classified as healthy. False Negative: The number of healthy images misclassified as infected. False Positive: The number of infected images misclassified as healthy. True Negative the number of infected images correctly classified as infected [24]. These values are distributed within the rows (actual class) and columns (predicted class) of each model, helping to evaluate the model’s accuracy and ability to correctly distinguish between classes. By comparing the results, a variation in performance between models can be observed, providing a basis for deciding on the most appropriate model for practical or applied use.
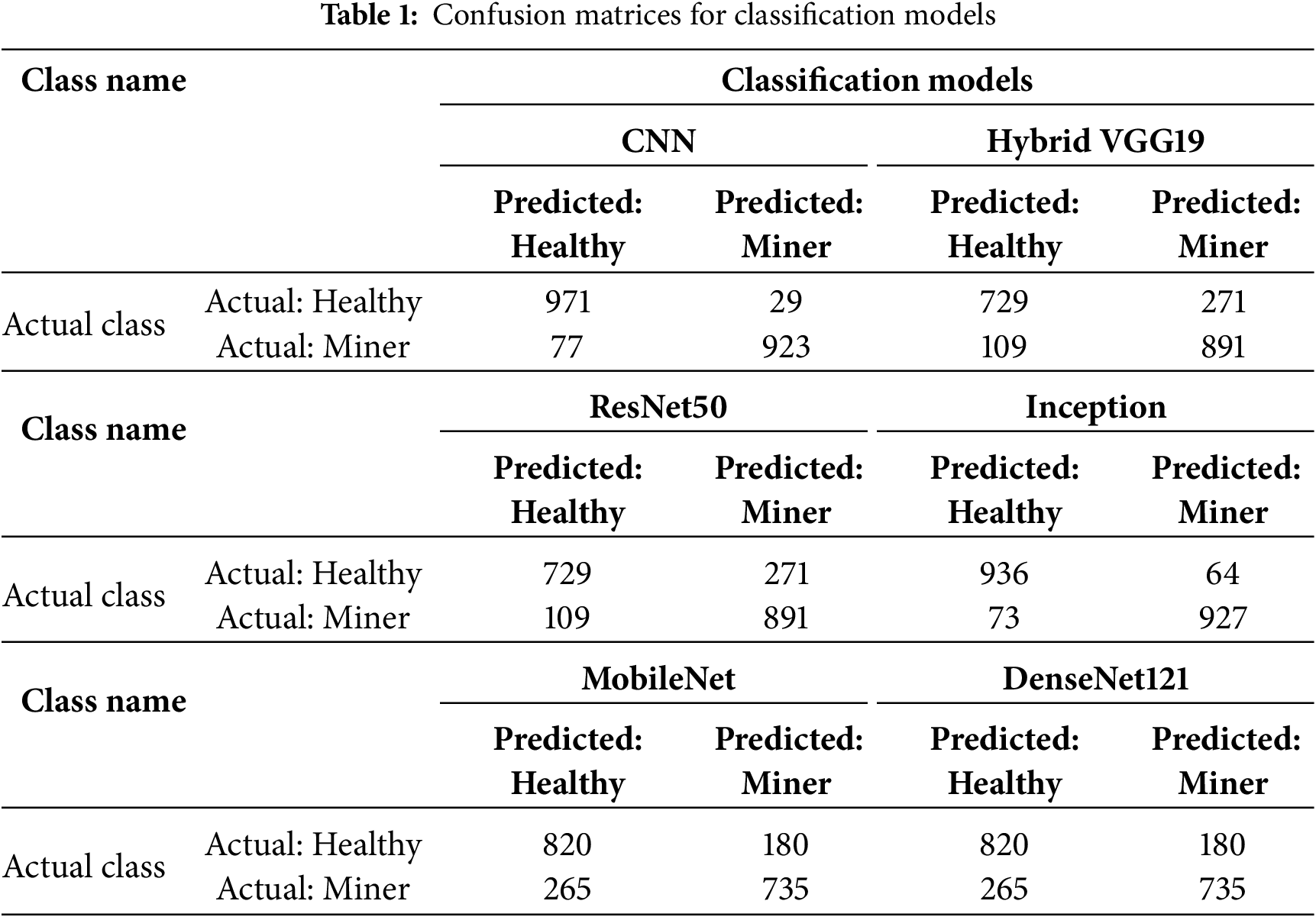
Comparison results between the six classification models showed a clear disparity in efficiency. The Hybrid VGG19 model outperformed all the traditional models due to the combination of the ability of the convolutional neural network with the feature techniques, achieving the highest overall accuracy of 97.15%, with a good balance between predictive accuracy (93.77%) and recall (90.30%). The CNN model had the highest precision value (96.95%), indicating robust positive class prediction, while InceptionV3 achieved an excellent balance across all metrics, making it an ideal choice for applications that require stable performance. In contrast, DenseNet121, ResNet50, and MobileNetV2 performed relatively poorly on some metrics such as specificity and IoU, reflecting limited generalisation in some scenarios. These results reinforce the importance of selecting models based on the nature of the data and the distribution of classes, rather than just overall classification accuracy. Table 2 below shows the results of the algorithms applied to coffee disease classification.
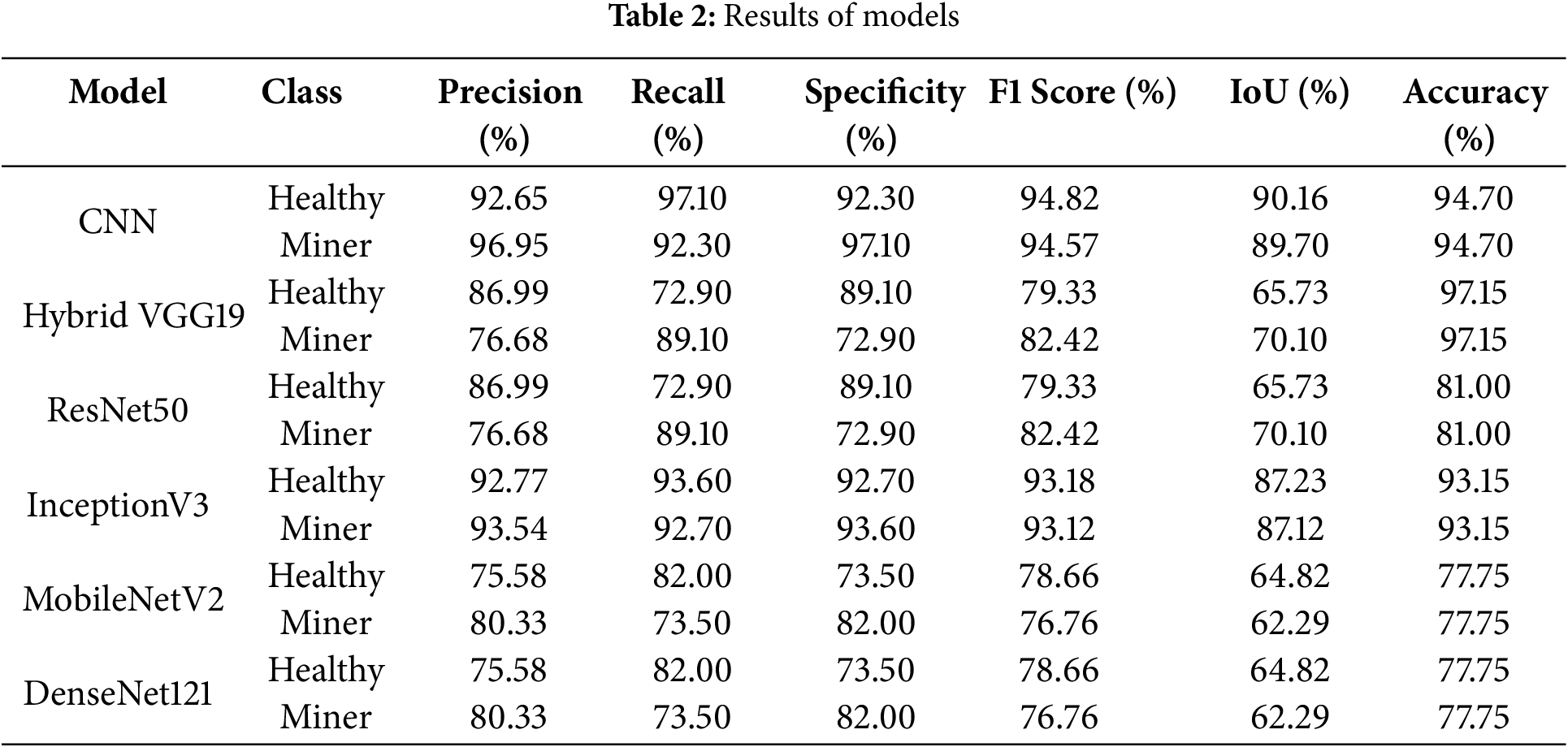
Fig. 7 below shows a comprehensive comparison of the performance of models used in classifying coffee leaf diseases. This provides a visual and quantitative comparison that helps determine the best model based on application needs, such as accuracy, efficiency, or balance between different metrics. This is done using two visual methods:
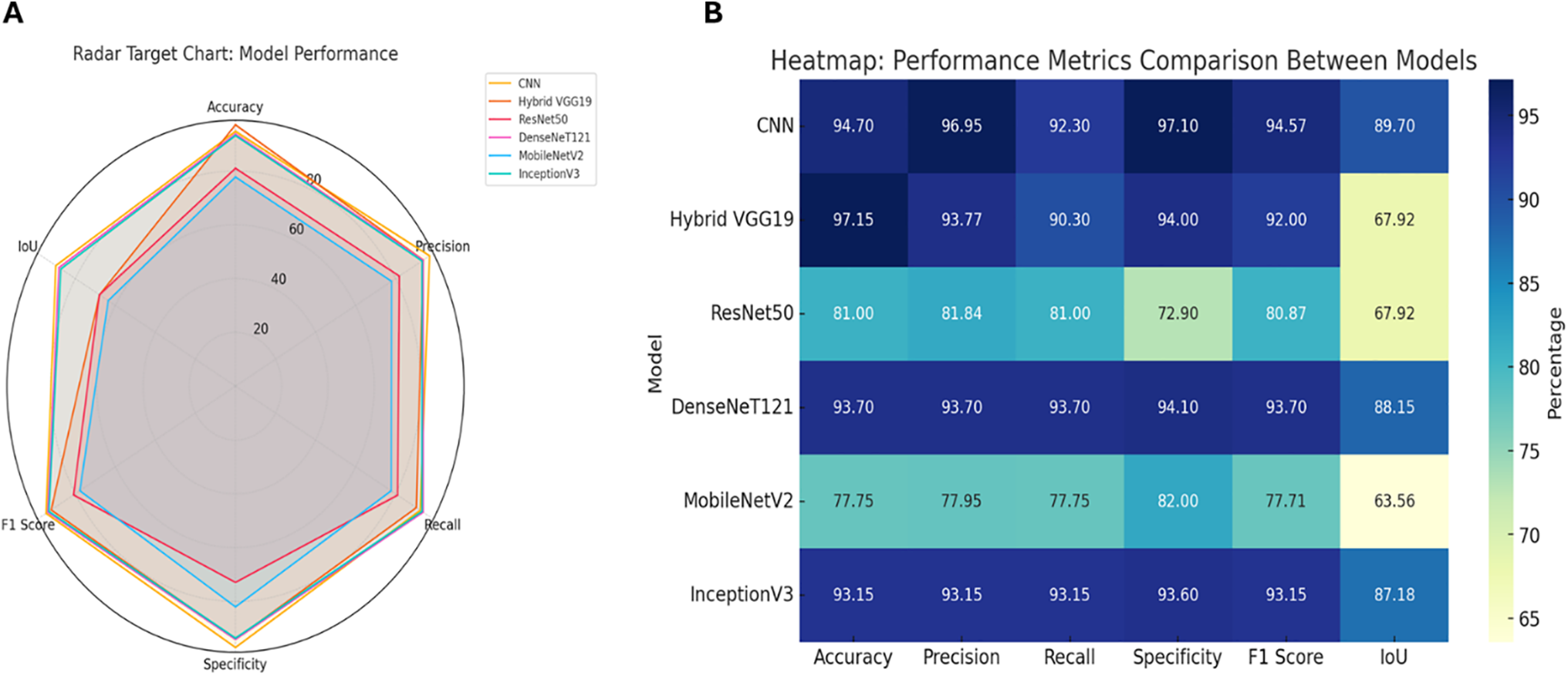
Figure 7: Accuracy and loss performance curves of deep learning algorithms. (A) Radar Target Chart model performance. (B) Heatmap performance matrix comparison between models
A. Radar Target Chart
This figure displays the performance of six classification algorithms: CNN, Hybrid VGG19, ResNet50, DenseNet121, MobileNetV2, and InceptionV3 across six key metrics: Accuracy, Precision, Recall, Specificity, F1 Score, and IoU. Each polygon represents the performance of a specific model, and the closer the line is to the outer edge of the chart, the better the performance on that metric. It is noticeable that the CNN and DenseNet121 models achieve high coverage across most metrics, reflecting strong overall performance.
B. Heatmap
This figure displays the numerical values for the same six metrics, but in a heatmap. Each row represents a model, each column represents a performance metric, and each cell is colored to a certain degree, indicating a value. The darker the value, the higher the value. The Hybrid VGG19 model showed high overall accuracy (97.15%), but its lowest value was in the IoU metric (67.92%), indicating excellent overall accuracy with relatively poor prediction-truth correlation. This provides a visual and quantitative comparison that helps determine the best model based on application needs, such as accuracy, efficiency, or balance between different metrics.
The outstanding performance of the CNN model with hybrid VGG19 transfer learning is evidence of the effectiveness of this method for accurate coffee disease detection. This study adopts a CNN-based approach, which aligns with recent research that has highlighted the strong performance of convolutional neural networks in plant disease classification tasks [25]. Notably, transfer learning has proven effective in enhancing accuracy when used with architectures such as VGG19, particularly on limited agricultural datasets [26]. Achieving 97% accuracy in training and validation data, along with high scores for precision, recall, and F1-score, indicates that the model effectively learned to differentiate between healthy and CLM-infected coffee leaves. This result is particularly significant considering the binary nature of the classification task, often leading to challenges in achieving such high accuracy. While Inception achieved a Strong result, making it an ideal choice for applications that require stable performance. On the other hand, DenseNet121, ResNet50, and MobileNetV2 performed fairly acceptable results compared to the other models. The utilisation of VGG19 as a pre-trained network played a crucial role in the model’s success. By leveraging the feature extraction capabilities of a model trained on a vast dataset, we were able to effectively adapt the model to the specific task of coffee disease classification without requiring excessive training data. This highlights the advantages of transfer learning in overcoming the limitations of small datasets often encountered in agricultural applications [27]. The notable confusion matrix further emphasises the model’s ability to classify all instances accurately without any misclassifications. This suggests that the model has learned robust features that can effectively distinguish between healthy and CLM-infected leaves, even in cases where visual differences might be subtle. The high accuracy of the model’s classification is particularly impressive considering the potential challenges posed by similar-looking healthy and CLM-infected leaves. This indicates that the model has been trained to identify even the most subtle variations in leaf characteristics that indicate infection [28,29]. The robust features learned by the model demonstrate its capacity to make reliable distinctions, making it a valuable tool for detecting and managing CLM infections in agricultural settings [30,31]. Overall, these study outcomes provide strong evidence for the effectiveness of transfer learning with the VGG19 architecture for accurate coffee disease detection. This approach offers a promising solution for automated disease detection in coffee plantations, enabling early intervention and minimising yield losses [32]. Additionally, the combination of VGG19 as a deep feature extractor and machine learning classifiers such as has been shown to enhance model robustness and generalisation [33], thereby supporting the effectiveness of our hybrid approach [34]. These results outperform existing approaches reported on the JMuBEN1 dataset, demonstrating the effectiveness of the proposed architecture in utilising VGG19 features and additional convolutional layers for accurate CLM detection. The high accuracy achieved makes this model a promising tool for practical implementation in coffee plantations for early CLM identification and rapid response.
Although the proposed model demonstrated high performance in a controlled experimental setting, challenges related to generalisability may be encountered when applying it to realistic field settings. Differences in lighting conditions, natural backgrounds, variations in leaf shape, and image quality generated by different cameras may negatively affect the model’s accuracy when used in agricultural fields. Furthermore, the visual similarity of some diseases and their variation across leaf development stages or climatic conditions can lead to classification confusion. The diversity of coffee cultivars and their varieties further complicates the model, as plant responses to disease can differ between cultivars. Another challenge to the practical deployment of the system is that the training data was collected within a limited geographic scope. Therefore, it is essential to expand the collection of data from different agricultural environments (such as regions with diverse climates or traditional and modern farming methods) to improve the model’s generalisability. Additionally, the model must be continuously updated using strategies such as continuous learning or fine-tuning to account for new or unrepresented diseases in the original data.
This research presents an integrated model for detecting coffee leaf diseases using advanced deep learning techniques, a critical area in smart agriculture and combating production loss in vital crops. The system was trained on a massive dataset of 35,961 images classified into two classes: healthy and miner. By developing classification models based on convolutional neural networks (CNNs) and employing transfer learning strategies models. The key contribution lies in demonstrating that lightweight and hybrid models can deliver high performance while remaining generalisable. The proposed system could be integrated into mobile or edge devices to enable real-time diagnosis in agricultural settings. This system provides a low-cost, effective solution for use on devices with limited capabilities, helping farmers and agricultural workers. In general, due to these results, we can rely on the proposed approach in practical applications in the real environment, which contributes to improving the productivity of coffee crops and reducing reliance on manual diagnosis, especially in rural areas with limited resources. Future research could explore the model’s performance on a real-world field dataset to assess its generalizability under practical conditions, incorporating environmental factors, with increasing types of diseases affecting coffee leaves, and under diverse lighting and climatic conditions, to ensure the generalizability of the model.
Acknowledgement: The authors extend their sincere gratitude and appreciation to the University of Malaga Department of Computer Engineering University for their support.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Conceptualization, Enrique Domínguez and Nameer Baht; methodology, Nameer Baht; software, Nameer Baht; validation, Enrique Domínguez and Nameer Baht; formal analysis, Enrique Domínguez; investigation, Nameer Baht; resources, Nameer Baht; data curation, Nameer Baht; writing—original draft preparation, Nameer Baht; writing—review and editing, Nameer Baht and Enrique Domínguez; supervision, Enrique Domínguez. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The research includes all the original contributions presented in the article, and the authors are available for any inquiries.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Baht NM, Domínguez E. Detection of plant diseases based on convolutional neural network approach: a review. In: 2022 14th International Conference on Electronics, Computers and Artificial Intelligence (ECAI); 2022 Jun 30–Jul 1; Ploiesti, Romania. doi:10.1109/ECAI54874.2022.9847462. [Google Scholar] [CrossRef]
2. Vilela EF, da Silva CA, Botti JMC, Martins EF, Santana CC, Marin DB, et al. Detection of coffee leaf miner using RGB aerial imagery and machine learning. AgriEngineering. 2024;6(3):3174–86. doi:10.3390/agriengineering6030181. [Google Scholar] [CrossRef]
3. Ernesto García Rivas R, Dos Santos Melo R, Manuel Saide S, Backes AR, Coelho Fernandes H. Rust detection in coffee leaves using otsu’s method and mathematical morphology. Rev De Informática Teórica E Apl. 2025;32(1):212–9. doi:10.22456/2175-2745.143458. [Google Scholar] [CrossRef]
4. Shafik W, Tufail A, Liyanage De Silva C, Awg Haji Mohd Apong RA. A novel hybrid inception-xception convolutional neural network for efficient plant disease classification and detection. Sci Rep. 2025;15(1):3936. doi:10.1038/s41598-024-82857-y. [Google Scholar] [PubMed] [CrossRef]
5. Enriquez CC, Marcelo J, Verula DR, Casildo NJ. Leveraging deep learning for coffee bean grading: a comparative analysis of convolutional neural network models. Trans Sci Technol. 2024;11(1):1–6. [Google Scholar]
6. Faisal S, Javed K, Ali S, Alasiry A, Marzougui M, Attique Khan M, et al. Deep transfer learning based detection and classification of citrus plant diseases. Comput Mater Contin. 2023;76(1):895–914. doi:10.32604/cmc.2023.039781. [Google Scholar] [CrossRef]
7. Unal Y, Taspinar YS, Cinar I, Kursun R, Koklu M. Application of pre-trained deep convolutional neural networks for coffee beans species detection. Food Anal Meth. 2022;15(12):3232–43. doi:10.1007/s12161-022-02362-8. [Google Scholar] [CrossRef]
8. Vilela EF, Ferreira WPM, de Castro GDM, de Faria ALR, Leite DH, Lima IA, et al. New spectral index and machine learning models for detecting coffee leaf miner infestation using sentinel-2 multispectral imagery. Agriculture. 2023;13(2):388. doi:10.3390/agriculture13020388. [Google Scholar] [CrossRef]
9. Thakur D, Gera T, Aggarwal A, Verma M, Kaur M, Singh D, et al. SUNet: coffee leaf disease detection using hybrid deep learning model. IEEE Access. 2024;12:149173–91. doi:10.1109/access.2024.3476211. [Google Scholar] [CrossRef]
10. Hitimana E, Sinayobye OJ, Ufitinema JC, Mukamugema J, Rwibasira P, Murangira T, et al. An intelligent system-based coffee plant leaf disease recognition using deep learning techniques on Rwandan Arabica dataset. Technologies. 2023;11(5):116. doi:10.3390/technologies11050116. [Google Scholar] [CrossRef]
11. Vilela EF, de Castro GDM, Marin DB, Santana CC, Leite DH, de Sousa Machado Matos C, et al. Remote monitoring of coffee leaf miner infestation using machine learning. AgriEngineering. 2024;6(2):1697–711. doi:10.3390/agriengineering6020098. [Google Scholar] [CrossRef]
12. dos Santos LM, Ferraz GAES, Bento NL, Marin DB, Rossi G, Bambi G, et al. Use of images obtained by remotely piloted aircraft and random forest for the detection of leaf miner (Leucoptera coffeella) in newly planted coffee trees. Remote Sens. 2024;16(4):728. doi:10.3390/rs16040728. [Google Scholar] [CrossRef]
13. Esgario JGM, Krohling RA, Ventura JA. Deep learning for classification and severity estimation of coffee leaf biotic stress. Comput Electron Agric. 2020;169:105162. doi:10.1016/j.compag.2019.105162. [Google Scholar] [CrossRef]
14. Adelaja O, Pranggono B. Leveraging deep learning for real-time coffee leaf disease identification. AgriEngineering. 2025;7(1):13. doi:10.3390/agriengineering7010013. [Google Scholar] [CrossRef]
15. Yebasse M, Shimelis B, Warku H, Ko J, Cheoi KJ. Coffee disease visualization and classification. Plants. 2021;10(6):1257. doi:10.3390/plants10061257. [Google Scholar] [PubMed] [CrossRef]
16. Marcos AP, Silva Rodovalho NL, Backes AR. Coffee leaf rust detection using convolutional neural network. In: 2019 XV Workshop de Visão Computacional (WVC); 2019 Sep 9–11; São Bernardo do Campo, Brazil. doi:10.1109/wvc.2019.8876931. [Google Scholar] [CrossRef]
17. Arsenovic M, Karanovic M, Sladojevic S, Anderla A, Stefanovic D. Solving current limitations of deep learning based approaches for plant disease detection. Symmetry. 2019;11(7):939. doi:10.3390/sym11070939. [Google Scholar] [CrossRef]
18. Suleman M, Ullah F, Aldehim G, Shah D, Abrar M, Irshad A, et al. Smart MobiNet: a deep learning approach for accurate skin cancer diagnosis. Comput Mater Contin. 2023;77(3):3533–49. doi:10.32604/cmc.2023.042365. [Google Scholar] [CrossRef]
19. Jepkoech J, Mugo DM, Kenduiywo BK, Too EC. Arabica coffee leaf images dataset for coffee leaf disease detection and classification. Data Brief. 2021;36(3):107142. doi:10.1016/j.dib.2021.107142. [Google Scholar] [PubMed] [CrossRef]
20. Li Y, Zhang D. Toward efficient edge detection: a novel optimization method based on integral image technology and canny edge detection. Processes. 2025;13(2):293. doi:10.3390/pr13020293. [Google Scholar] [CrossRef]
21. Agrawal H, Desai K. Canny edge detection: a comprehensive review. Int J Tech Res Sci. 2024;9:27–35. doi:10.30780/specialissue-iset-2024/023. [Google Scholar] [CrossRef]
22. Tang K, Xiang Y, Tian J, Hou J, Chen X, Wang X, et al. Machine learning-based morphological and mechanical prediction of kirigami-inspired active composites. Int J Mech Sci. 2024;266:108956. doi:10.1016/j.ijmecsci.2023.108956. [Google Scholar] [CrossRef]
23. Ke L, Luo Y. A new pedestrian detection method based on histogram of oriented gradients and support vector data description. In: Electronics, communications and networks. Amsterdam, The Netherlands: IOS Press; 2024. p. 333–42. doi:10.3233/FAIA231210. [Google Scholar] [CrossRef]
24. Chowdhury MBU. Coffee leaf disease recognition using GistFeature. Int J Inf Eng Electron Bus. 2021;13(2):55–61. doi:10.5815/ijieeb.2021.02.05. [Google Scholar] [CrossRef]
25. Shoaib M, Shah B, Ei-Sappagh S, Ali A, Ullah A, Alenezi F, et al. An advanced deep learning models-based plant disease detection: a review of recent research. Front Plant Sci. 2023;14:1158933. doi:10.3389/fpls.2023.1158933. [Google Scholar] [PubMed] [CrossRef]
26. Kaur P, Harnal S, Tiwari R, Upadhyay S, Bhatia S, Mashat A, et al. Recognition of leaf disease using hybrid convolutional neural network by applying feature reduction. Sensors. 2022;22(2):575. doi:10.3390/s22020575. [Google Scholar] [PubMed] [CrossRef]
27. Kaushik P, Sharma P. Automated coffee leaf disease detection using convolutional neural networks: an EfficientNet-based approach. In: 2025 International Conference on Automation and Computation (AUTOCOM); 2025 Mar 4–6; Dehradun, India. doi:10.1109/AUTOCOM64127.2025.10956473. [Google Scholar] [CrossRef]
28. Kumari M, Kukreja V, Raj A, Chaudhary SK. Coffee leaf diseases classification: a CNN and random forest approach for precision diagnosis. In: 2024 International Conference on Automation and Computation (AUTOCOM); 2024 Mar 14–16; Dehradun, India. doi:10.1109/AUTOCOM60220.2024.10486169. [Google Scholar] [CrossRef]
29. Amtate G, Teferi D. Multiclass classification of Ethiopian coffee bean using deep learning. SINET Ethiop J Sci. 2023;45(3):309–21. doi:10.4314/sinet.v45i3.6. [Google Scholar] [CrossRef]
30. Korkmaz A, Talan T, Koşunalp S, Iliev T. Comparison of deep learning models in automatic classification of coffee bean species. PeerJ Comput Sci. 2025;11(6):e2759. doi:10.7717/peerj-cs.2759. [Google Scholar] [PubMed] [CrossRef]
31. Silva CESE, Fragoso JB, Paixão T, Alvarez AB, Palomino-Quispe F. A low computational cost deep learning approach for localization and classification of diseases and pests in coffee leaves. IEEE Access. 2025;13:71943–64. doi:10.1109/access.2025.3562832. [Google Scholar] [CrossRef]
32. Shourie P, Anand V, Upadhyay D, Devliyal S, Gupta S, Shandilya G. BeanClassify: convolutional neural networks for coffee bean categorization. In: 2024 1st International Conference on Advanced Computing and Emerging Technologies (ACET); 2024 Aug 23–24; Ghaziabad, India. doi:10.1109/ACET61898.2024.10729994. [Google Scholar] [CrossRef]
33. Pandiyaraju V, Anusha B, Senthil Kumar AM, Jaspin K, Venkatraman S, Kannan A. Spatial attention-based hybrid VGG-SVM and VGG-RF frameworks for improved cotton leaf disease detection. Neural Comput Appl. 2025;37(14):8309–29. doi:10.1007/s00521-025-11012-z. [Google Scholar] [CrossRef]
34. Karthik R, Joshua Alfred J, Joel Kennedy J. Inception-based global context attention network for the classification of coffee leaf diseases. Ecol Inform. 2023;77(3):102213. doi:10.1016/j.ecoinf.2023.102213. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools