
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

The Research on Low-Light Autonomous Driving Object Detection Method
School of Electronic Information Engineering, Xi’an Technological University, Xi’an, 710021, China
* Corresponding Author: Jianhua Yang. Email:
(This article belongs to the Special Issue: Artificial Intelligence Algorithms and Applications)
Computers, Materials & Continua 2026, 86(1), 1-18. https://doi.org/10.32604/cmc.2025.068442
Received 29 May 2025; Accepted 05 September 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Aiming at the scale adaptation of automatic driving target detection algorithms in low illumination environments and the shortcomings in target occlusion processing, this paper proposes a YOLO-LKSDS automatic driving detection model. Firstly, the Contrast-Limited Adaptive Histogram Equalisation (CLAHE) image enhancement algorithm is improved to increase the image contrast and enhance the detailed features of the target; then, on the basis of the YOLOv5 model, the Kmeans++ clustering algorithm is introduced to obtain a suitable anchor frame, and SPPELAN spatial pyramid pooling is improved to enhance the accuracy and robustness of the model for multi-scale target detection. Finally, an improved SEAM (Separated and Enhancement Attention Module) attention mechanism is combined with the DIOU-NMS algorithm to optimize the model’s performance when dealing with occlusion and dense scenes. Compared with the original model, the improved YOLO-LKSDS model achieves a 13.3% improvement in accuracy, a 1.7% improvement in mAP, and 240,000 fewer parameters on the BDD100K dataset. In order to validate the generalization of the improved algorithm, we selected the KITTI dataset for experimentation, which shows that YOLOv5’s accuracy improves by 21.1%, recall by 36.6%, and mAP50 by 29.5%, respectively, on the KITTI dataset. The deployment of this paper’s algorithm is verified by an edge computing platform, where the average speed of detection reaches 24.4 FPS while power consumption remains below 9 W, demonstrating high real-time capability and energy efficiency.Keywords
With the rapid development of big data, the Internet, and artificial intelligence technology, the degree of automobile intelligence continues to improve, and automatic driving technology is gradually becoming an important development direction of the modern automobile industry [1,2]. One of the core technologies of self-driving vehicles is the target detection system [3], which serves to sense and identify the surrounding environment through various sensors (e.g., camera, millimetre-wave radar, LIDAR, etc.) on the vehicle [4,5], and provides real-time information for the decision-making system. Vision-based deep learning target detection algorithms have attracted much attention due to their rich information and low cost [6]. Most of the existing deep learning target detection algorithms are optimised for situations with good conditions, such as daytime. However, low illumination conditions, such as night time and tunnels, cause colour distortion, low contrast, and low visibility in the images, which affects the performance of the sensors and makes it more difficult to identify targets such as vehicles [7,8].
At present, experts at home and abroad have conducted in-depth research on target detection in the case of low illumination multi-scale dense occlusion. The image enhancement methods for low illumination are traditional histogram-based enhancement algorithms, deep learning-based image enhancement algorithms, and algorithms combining traditional algorithms with deep learning. The histogram-based image enhancement algorithms are HE [9], AHE, and CLAHE [10] algorithms. Veluchamy and Subramani [11] enhanced the contrast by adaptive gamma correction and combined it with a weighted histogram distribution technique in order to preserve the colours and details of the image, improving the contrast of the image while maintaining the natural colours and details Chang et al. [12] improved the contrast of the image while preserving the natural colours and details by automatically setting the block according to its texture degree to set the clipping point of CLAHE and introduced dual gamma correction to enhance brightness, especially in dark regions, while reducing artefacts. Deep learning based image enhancement methods have made significant progress in recent years, such as Jiang et al. [13] proposed an EngtjenGAN network to achieve a better enhancement effect even in the absence of a normal light image, and Jin et al. [14] designed the MEGF method to avoid the problem of overexposure brought about by image enhancement, so that the image extracts more more effective information in the image. Wang et al. [15] proposed a PMRL low-light image enhancement method, which can effectively recover the detailed features of the image by combining a single-scale pipeline and coding and decoding structure. These methods can effectively improve the image quality through deep learning techniques. Methods based on the combination of traditional algorithms and deep learning have made significant progress in recent years, such as Lu et al. [16] combined multi-scale spatial perception with the traditional Retinex image enhancement algorithm to solve the problems of colour distortion and blurred target details; Chen et al. [17] designed an SSNF network architecture using the Retinex method, U-Net, and residual network. Enhancement of low illumination images can reduce the problem of high noise with low visibility. Jiang et al. [18] combined SA and CNN to generate Mutual Retinex based on the Retinex framework and designed a mutual representation module to usher in the improvement of image quality; Latke & Narawade [19] investigated the enhancement of target detection and localisation by combining the Retinex image enhancement technique with the U-Net architecture for accurate segmentation. These methods can effectively improve the image brightness and details, provide higher quality images for the model, and enable the deep learning model to better extract features. Therefore, in this paper, the detection of low illumination images is investigated by combining traditional image enhancement methods with target detection methods.
To optimise and improve the multi-scale dense occlusion problem in target detection [20], a novel task-balanced remote sensing image target detection algorithm MTGS-Yolo based on improved YOLO is proposed, which significantly improves the performance, computational efficiency and generalisation ability of target detection in complex backgrounds by means of a multi-Transformer model, a generalised and efficient aggregation network and a spatial context-aware module; Wei et al. [21] designed a PCBR feature extraction module and a multi-scale perceptual hybrid pool module to improve the yolov5 model so as to enhance its feature extraction ability for multi-scale; Li et al. [22] used a multi-scale detection layer, Swin Transformer module and SOFT-NMS non-maximum suppression to optimise and improve the original model, thus enhancing the model’s detection accuracy for small targets; Zhang et al. [23] proposed the DS-YOLO model, introduced the C2fUIB module to reconstruct the backbone network, improved the PAFPN by using the DO-C2f module, and introduced the SySample up-sampling module to optimise the model’s detection effectiveness for the multi-scale dense occlusion case; Cui & Cao [24] combined dynamic convolution, shallow detection head, C2-Res2Block module and MPDIoU for metrics to optimise the detection performance of multi-scale small and densely-obscured targets; Jiang et al. [25] utilised the MIoP-NMS non-maximal value in the post-processing stage of the YOLOV4 model suppression to improve the model’s detection effect for dense occlusion cases; Zhai et al. [26] proposed a vehicle target tracking method based on YOLOv5s and DeepSort, adding ECA-Net focusing mechanism and using EIOU loss function in YOLOv5 backbone network to improve the detection and tracking accuracy in dense vehicle scenarios. These method studies do not consider the actual situation in the field, so this paper considers the algorithms from the embedded platform.
In order to improve the detection performance in low illumination multi-scale dense occlusion scenarios, a low illumination automatic driving target detection algorithm model, YOLO-LKSDS model, combining traditional augmentation algorithm and deep learning algorithm, is proposed, and the detection performance of the model is validated on BDD100K dataset and KITTI dataset, and the model is deployed on PYNQ-ZU edge computing platform.
Because of its efficient performance, lightweight architecture, and easy deployment, the YOLOv5 model is widely used in practical projects of major enterprises, including industrial manufacturing, autonomous driving, intelligent security, drone detection, and medical imaging. Based on the practical background of autonomous driving in this paper, YOLOV5 is used as the basic model to carry out the research. In this paper, a lightweight low-light multi-scale occlusion target detection is designed based on the original YOLOV5s model. It mainly includes image enhancement, target detection model optimisation and improvement, and final platform validation, and the flow chart is shown in Fig. 1.
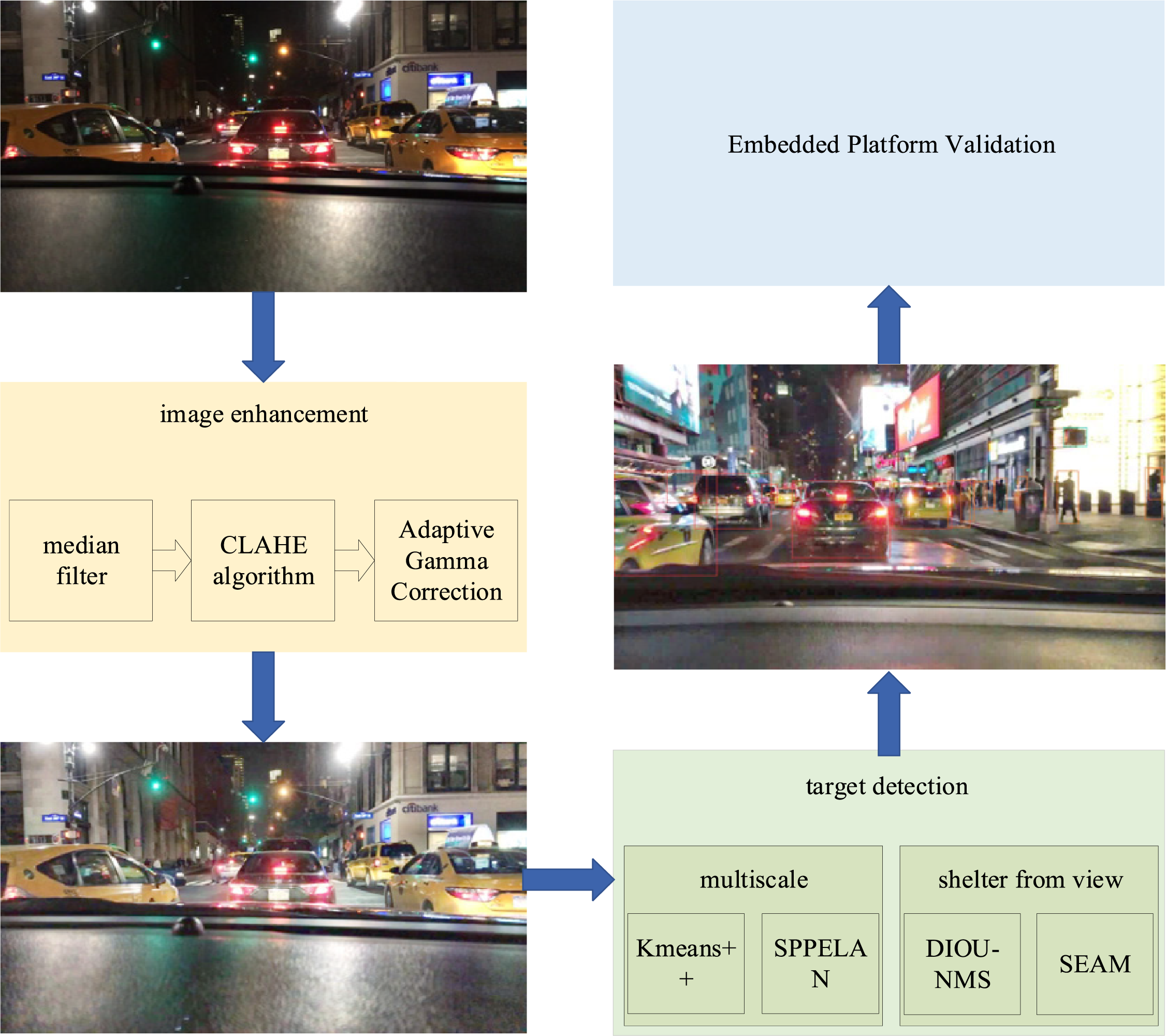
Figure 1: Flowchart of the YOLO-LKSDS algorithm
(1) Image enhancement. For the characteristics of a low illumination environment, combining median filtering and adaptive gamma correction to improve the CLAHE algorithm, adjusting the brightness and contrast of the image, and reducing the noise to provide a high-quality visual image.
(2) Target detection. For the multi-scale and dense occlusion problem, Kmeans++ clustering anchor frame and SPPELAN module are introduced to improve the feature extraction of the model for multi-scale targets; DIOU-NMS and SEAM attention mechanism are introduced to optimise the feature extraction of the model for occluded targets, and to improve the performance and robustness of the model in the case of dense occlusion.
(3) Embedded platform validation. Aiming at the problem that the current target detection algorithms do not consider edge deployment, this paper deploys the improved YOLO-LKSDS target detection algorithm on the PYNQ-ZU embedded board to verify the algorithm’s performance.
2.1 Image Enhancement Algorithm Improvement
2.1.1 Low-Light Autopilot Image Analysis
In low illumination conditions, such as nighttime, the visual camera relies on visible light to work, and the quality of the captured images will be greatly reduced, with blurring and low contrast, which ultimately leads to the degradation of video imaging quality and seriously affects the detection and identification of the surrounding traffic targets by the autopilot system. In this paper, the histogram distribution of 10,000 low illumination automatic driving images is statistically distributed, and the statistical distribution graph is shown in Fig. 2.
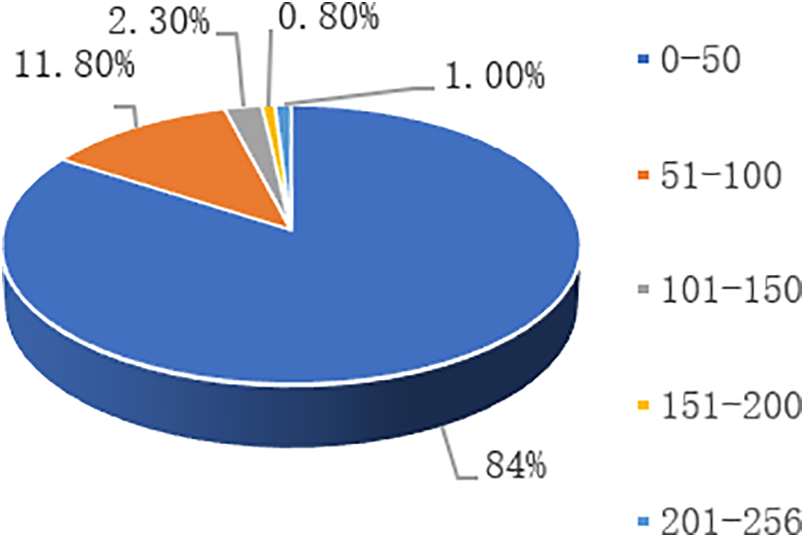
Figure 2: Distribution statistics of 10,000 low-light images
4% of the pixels of the low-light autopilot image are concentrated within the 0–50 pixel interval, and 11.8% are distributed within the 51–100 pixel interval, which proves that most of the values of the pixels of the low-light autopilot image are in the lower interval. The low brightness and contrast of the images will affect the detection accuracy of the model when performing the task of target detection. The histogram of the low-light vision image with its low-light image is shown in Fig. 3.
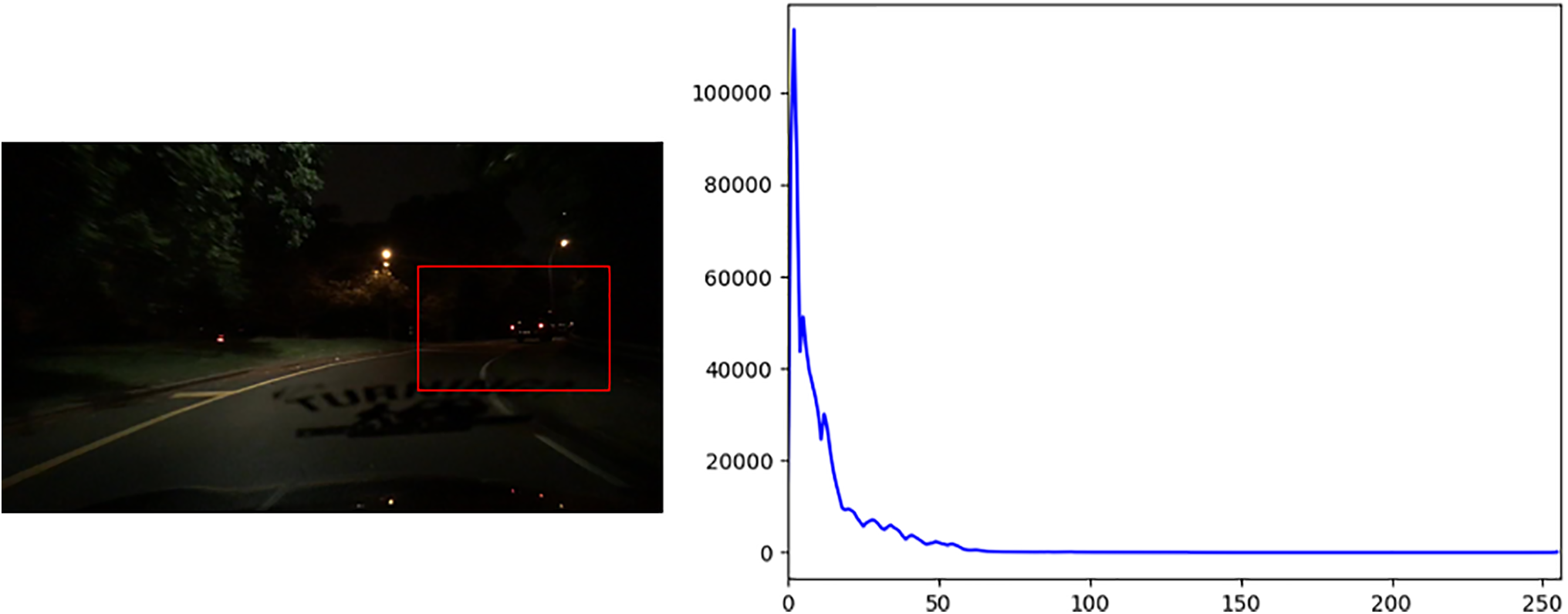
Figure 3: Sample low-light images (left) and their histograms (right) showing pixel concentration in 0–256 range
The low-light visual images and histograms are analysed, and the low-light autopilot images, due to insufficient light lead to uneven luminance distribution, blurred vehicle contours, details are difficult to capture, and the target object contours are poorly defined, which increases the difficulty for subsequent target detection. Therefore, this paper designs an image enhancement algorithm based on CLAHE.
2.1.2 Image Enhancement Algorithm for Low-Light Autonomous Driving
In order to compensate for the original CLAHE algorithm in the enhancement process, the image noise is obvious, the contrast and brightness are still relatively low, and the edge details of the image do not seem to be fully considered. In this paper, the original low-light image is first denoised by median filtering, then the CLAHE algorithm is applied to the de-noised image for image enhancement, and finally, the luminance distribution of the enhanced image is adjusted by using adaptive gamma correction. The algorithm can effectively remove the noise in the image, effectively inhibit the phenomenon of overexposure, and make the detailed features of the target, in the case of low illumination, more clearly displayed. The flowchart of the algorithm is shown in Fig. 4.

Figure 4: Flowchart of image enhancement algorithm
2.1.3 CLAHE Algorithm Image Enhancement
The core of Contrast Limited Adaptive Histogram Equalisation (CLAHE) is to limit the contrast of the local histogram. Histogram statistics are first performed on the original image, and pixel thresholds are set based on the adaptive statistics; when the number of pixels in a certain grey value exceeds the set threshold, it is cropped, and the excess is evenly distributed to each grey level, thus avoiding over-enhancement of the image.
2.1.4 Adaptive Gamma Correction
Adaptive gamma correction applies different gamma values to different parts of an image and is used to process images with uneven brightness and contrast. Its formula is shown in Eqs. (1) and (2).
where
2.2 Optimisation and Improvement of Target Detection Algorithms
2.2.1 Analysis of the Original Model Training Results
In this paper, the original YOLOV5s model is first trained to get its weight file after training is completed, and then the weight file is used to detect the dataset to get the detected graph as shown in Fig. 5a,b.

Figure 5: Original model detection results (a): YOLOv5s fails to detect small-sized targets; (b) YOLOv5s missed the occluded targets
From the effect of the original model in the enhanced target detection task of the autonomous driving scene can be seen in a there is a multi-scale problem in the target detection process of autonomous driving, coupled with the reason that the near-big-far-small slightly farther away from the traffic target will be even smaller, the car, trucks, such as large and medium-sized targets and pedestrians, traffic signs and traffic lights, such as the difference in the scale of such a small-scale targets, the scale of the detection model Insufficient adaptability of the detection model leads to the failure of detecting some small-scale targets, which affects the detection accuracy and robustness. In (b), we can see that in the traffic scene, the targets to be detected are more aggregated, and there is a certain degree of occlusion between each other, and the targets are partially occluded and not detected. Therefore, in this paper, the model is improved for the multi-scale problem and the dense occlusion problem to improve the performance in the detection of traffic targets in multi-scale and dense occlusion situations, and to enhance the detection capability of the model.
2.2.2 YOLO-LKSDS Model Overall Architecture
In this paper, we optimise and improve the multi-scale problem and dense occlusion problem for low illumination autonomous driving scenarios. Firstly, for the multi-scale problem, the Kmeans++ clustering anchor frame algorithm is introduced in the input part of the network, and the SPPF is improved to SPPELAN spatial pyramid pooling in the backbone network part; then, for the dense occlusion problem, the SEAM attention mechanism module is introduced in the head of the network, and its second fully-connected layer activation function is optimised to Hard-Swish, in which the CSMM (Channel and Spatial Mixing Module) structure activation function is optimised as ReLU activation function, and DIOU-NMS is introduced in the post-processing part of the model. Finally, in order to be able to deploy the improved model on the PYNQ-ZU embedded platform, the activation function in the whole model is optimised as LeakyReLU. The overall framework of the YOLO-LKSDS model is shown in Fig. 6.
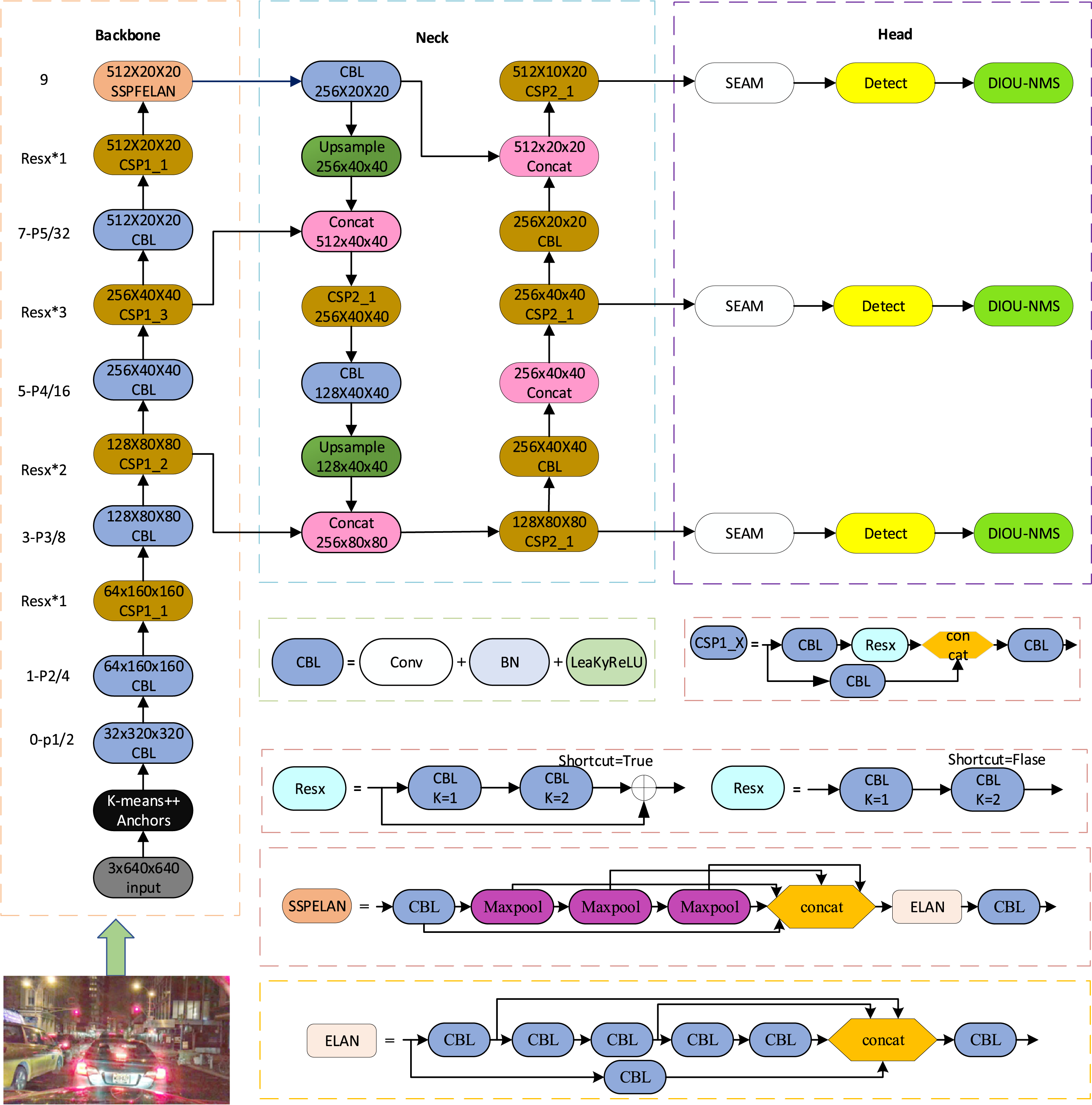
Figure 6: YOLO-LKSDS network structure
2.2.3 Multi-Scale Optimisation Improvements
In this paper, we optimise and improve the multi-scale problem from two points. Firstly, we use the anchor frame algorithm in the input part of the model to generate three different scales of anchor frames applicable to this paper, and secondly, we use SPPELAN in the backbone network part of the model to improve the performance of the model for multi-scale target detection.
(1) Optimisation of the anchor frame algorithm
The default anchor frames used by YOLOv5 are the nine anchor frames generated from the coco dataset at three different scales and are not specific to this dataset. To improve this, YOLOv5 adds Kmeans clustering adaptive anchor frames. The Kmeansclustering algorithm (Kmeans clustering algorithm) iteratively updates the centroids to regroup the objects to the nearest class centroids, and stops iterating when the intraclass distance is minimum and the interclass distance is maximum. The clustering effect depends on the initial selection of the centroids, and it is possible that the global optimal solution cannot be found and will fall into the local optimum. Therefore, in this paper, we use the Kmeans++ algorithm for clustering anchor frames to solve the problem of local optimal solution, and improve the clustering effect and convergence speed by choosing the initial clustering centre more reasonably, and use the average intersection and merger ratio (IOU) as the evaluation criterion of clustering.
(2) SPPELAN spatial pyramid pooling
The YOLOV5s network model uses SPPF, which is an improvement of Spatial Pyramid Pooling (SPP) and is designed to accelerate on the basis of SPP. SPPF performs pooling operations on feature maps at different scales, capturing richer spatial information, which enables better recognition and detection of targets. Although it can avoid the disadvantage of losing part of the spatial information on the image features, its detection accuracy is limited, and it does not carry out fine detail feature extraction, and there are some limitations on the detection accuracy and feature expression ability of the model when dealing with complex scenes such as autopilot as well as multi-scale target detection, especially when dealing with targets with obvious differences in size. Therefore, this paper proposes to use SPPELAN spatial pyramid pooling to improve this shortcoming.
SPPELAN is a combination of the spatial pyramid pooling capability of traditional SPP with the efficient feature aggregation capability of the ELAN structure. The original SPPF performs successive pooling operations after the convolution is completed, and performs a uniform splicing operation after all pooling is completed. SPPELAN spatial pyramid pooling is performed immediately after each pooling, i.e., pooling and splicing operations are performed simultaneously, and after splicing, local features are efficiently aggregated by using the ELAN structure, which enhances the feature extraction capability at its scale. ELAN structure retains the input features and SPP-enhanced features when splicing, which can better increase the diversity of features and significantly improve the detection accuracy of targets of different sizes. In addition, ELAN is also a lightweight network structure, which enables SPPELAN to maintain high computational efficiency, and at the same time, it can better capture multi-scale information, which makes up for the lack of accuracy of SPPF, and it is especially suitable for the task of multi-scale target detection for autonomous driving in this paper.
2.2.4 Dense Masking Optimisation Improvements
YOLOv5 generates candidate frames by feature extraction, target classification, and regression prediction of the target to be detected during the forward propagation process of target detection and removes overlapping frames using NMS (non-maximal suppression), which can lead to missed detection in dense occlusion situations. In order to solve the problem, this paper starts from two points: firstly, introducing the SEAM attention mechanism at the head of the network to enhance feature extraction for occluded targets, and then using the DIOU-NMS non-maximal suppression method in the post-processing stage to improve the detection performance in the case of occlusion.
(1) SEAM attention mechanism
The SEAM (Separated and Enhancement Attention Module) attention mechanism improves the target detection performance under dense occlusion in autonomous driving by combining multi-scale feature enhancement and spatial attention to improve the detection accuracy and robustness of the model.
The SEAM attention mechanism uses average pooling and channel exponential expansion structure to achieve a dynamic weight allocation, which can effectively reduce the impact of missing features in the occluded region on the overall features. The structure of SEAM is shown in Fig. 7.
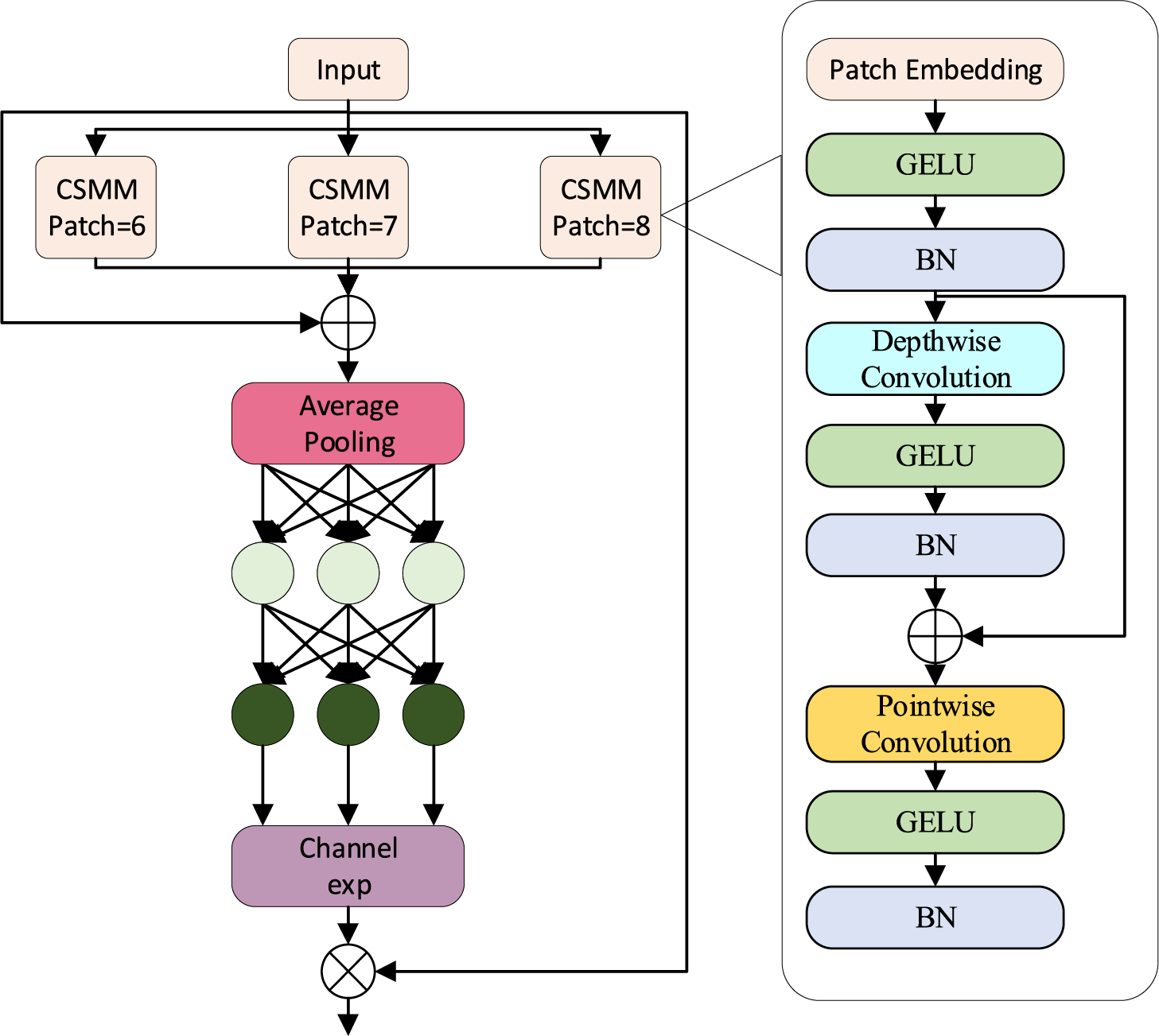
Figure 7: SEAM attention mechanism
Three different scales of CSMM are combined in the SEAM attention mechanism for multi-scale feature extraction to enhance the model’s target detection performance in dense occlusion situations. The output results of the neck network are used as inputs to the SEAM attention mechanism network. Three scales of CSMM are utilised for feature extraction, the small scale CSMM structure focuses on the local detail features of the target and is used to improve the model’s extraction of the features of the unobscured part of the target and the target edge features, the medium scale CSMM structure will balance the features extracted by the small scale CSMM and the large scale CSMM, and the large scale CSMM structure focuses on the extraction of the global features so as to complement the occluded target features, and then the features acquired by the three scales CSMM and the retrograde fusion.
The patches of CSMM are selected as 6, 7, and 8, which will be the three scales that will be able to synthesise the global features for processing the dense occlusion case. The formula for fusion is shown in Eq. (3).
After the completion of feature fusion at different scales, global tie average pooling is performed to extract global feature information, which in turn serves as the basis for subsequent attentional weights. Attention weights are generated by taking the global feature information as input, and then through two fully connected layers, where the first fully connected layer uses the ReLU activation function, and the second fully connected layer uses the Hard-Sigmoid activation function, which ensures that the generated weights are within the range of 0 to 1. Compared with the original Sigmod function, the improved weight generation can avoid the gradient explosion and improve the computational efficiency. The weight generation can avoid gradient explosion and can improve the computational efficiency. The calculation process is shown in Eqs. (4) and (5).
where
Afterwards, the generated attention weights are expanded exponentially so as to enhance their influence on the feature map, and the expanded weights are applied to the input feature map of the module to enhance the input features, and then the weighted ones are added with the original input features through residual connection, so as to be able to enhance the feature expression of the module while retaining the original information, and finally the feature map is generated for output. The calculation process is shown in Eqs. (6)–(8).
(2) DIOU-NMS non-extremely large value suppression
DIOU-NMS not only considers the intersection and concurrency ratio between the two detection frames, but also adds the consideration of the distance between the centroids of the detection frames to improve the model’s performance in detecting dense occlusion in the case of autopilot. The computational procedure of the DIOU-NMS algorithm is shown in Eq. (9).
where IOU denotes the ratio between the predicted frame and the real frame; b is the centre of the predicted frame and
3 Experimental Results and Analysis
BDD100K is a highly comprehensive and large-scale automated driving dataset released by the University of California, Berkeley to promote automated driving research. The main research content of this paper is for automatic driving target detection in low illumination situations, so 100,000 image data in the BDD100K dataset are selected and 10,000 low illumination images containing real scenarios are selected, it covers rain, snow, tunnels, and nighttime image data at different moments, excluding only extreme cases of complete darkness and complete noise. And the training set (8000 pictures) and test set (2000 pictures) are reclassified to contain ten categories, which are car, bus, person, bike, truck, motor, train, rider, traffic sign, and traffic light.
In order to verify the performance of the proposed method, this paper uses precision (P), recall (R), and mean accuracy (mAP) as the main evaluation metrics. The calculation formulas are shown in Eqs. (10)–(12).
where TP denotes the number of positive categories predicted as positive, FN denotes the number of positive categories predicted as negative, FP denotes the number of negative categories predicted as positive, and TN denotes the number of negative categories predicted as negative.
3.3 Evaluation and Analysis of Target Detection Algorithms
To verify the effectiveness of the YOLO-LKSDS algorithm model, this paper conducts ablation experiments using YOLOv5s as the original model, and the results are shown in Table 1. As can be seen from the table, replacing the activation function with LeakyReLU improves the recall rate (R) of the model. LeakyReLU allows negative inputs to retain small gradients, effectively alleviating the “dying” problem of neurons that may be caused by traditional ReLU, and enhancing the model’s ability to extract and express features, especially for some edge or detail features, making them easier to be captured by the model, thereby improving the ability to detect targets and thus increasing the recall rate. The Kmeans++ clustering anchor box algorithm optimizes the selection of anchor boxes. Compared with the traditional Kmeans, Kmeans++ generates an anchor box set that better fits the target size distribution in the dataset through a better initial cluster center selection strategy. Appropriate anchor boxes can more accurately match the actual shape and size of the target, reduce the deviation between the anchor box and the real boundary box of the target, and reduce the probability of false detection and missed detection, which helps to improve the precision (P) of the model’s target detection, with an accuracy improvement of 10.4%. The introduction of the SPPELAN spatial pooling pyramid enhances the model’s ability to understand and locate small targets. SPPELAN extracts features at different scales through multi-scale spatial pooling operations, effectively preserving the detailed information of small targets. For small-sized targets, traditional pooling may lose key features, while SPPELAN can integrate multi-scale features, making it easier for the model to identify small targets, thereby increasing mAP50 by 8.3%. The introduction of DIOU-NMS optimizes the box selection process. Different from the traditional NMS that only considers the intersection over union (IoU), DIOU-NMS combines the distance information between boundary boxes and can more reasonably judge the selection of overlapping boxes. This reduces the repeated detection and missed detection caused by overlapping, increasing the recall rate of the model in target detection by 4.2%, and mAP by 8.4% at the same time. The introduction of the SEAM module further optimizes the model’s feature extraction ability. SEAM uses an attention mechanism to make the model pay more attention to key features and suppress the interference of irrelevant features. It can adaptively adjust the weights of feature channels and highlight the features that are of great significance for target detection, thereby reducing false detection caused by the interference of irrelevant features and increasing the precision by 3.5%. When all modules are added, the precision of the model is improved by 21.5%, and mAP50 is improved by 3.9%. This shows that after adding Kmeans++, SPPELAN module, DIOU-NMS, and SEAM attention mechanism at the same time, the model is synergistically optimized in multiple aspects, such as anchor box selection, feature extraction, box optimization, and attention mechanism, significantly improving the overall detection effect.

The YOLO-LKSDS algorithm model of this paper is compared and analysed with Yolov3-Tiny, Yolov5s (image unenhanced), Yolov5s (image enhanced), Yolov6s, Yolov7, Yolov8n, Yolov8s, Literature [27], and Literature [28], and the comparative table is shown in Table 2. The input size of the images is all 640 ∗ 640.

Compared with the classical target detection algorithms Yolov3-Tiny, Yolov5s, Yolov6s, Yolov7, Yolov8s, the YOLO-LKSDS model proposed in this paper performs better in terms of detection accuracy, mAP50, and the number of parameters of the model. YOLO-LKSDS guarantees a lower number of parameters and computational complexity, while the mAP50 is improved by 17%, 1.3%, 0.9%, 5.5%, 4%, 3% and 2.3% over Yolov3-Tiny, Yolov5s (unenhanced), Yolov5s (enhanced), Yolov6s, Yolov7, Yolov8n, and Yolov8s, respectively, which is a significant rise. Meanwhile, the number of model parameters of YOLO-LKSDS is 6.8M, which is the same as that in reference [27], only slightly higher than that of the lightweight model YOLOv8n and reference [28]. Compared with YOLOv7 (37.2M), which has a larger number of parameters, the number of parameters is reduced by approximately 81.7%, making it more suitable for the deployment of re-source-constrained edge devices. Furthermore, compared with the improved object detection algorithm in reference [27], the detection accuracy and mAP50 of YOLO-LKSDS have increased by 18.3% and 3%, respectively, while the GFLOPs are basically similar, further proving the superiority of the algorithm proposed in this paper. Compared with reference [28], the mAP50 of YO-LO-LKSDS increased by 4.7%. To sum up, the YOLO-LKSDS model in this paper outperforms the comparison models in terms of detection accuracy, model lightweighting, and computational efficiency, and has significant performance advantages in edge deployment.
3.3.3 Generalisation Experiment
To further validate the generalisation performance of YOLO-LKSDS, this paper conducts experiments on the publicly available KITTI dataset. The ratio of the training, test, and validation sets is 8:1:1, and they are reclassified into three classes, cars, pedestrians, and cyclists. The results of the KITTI experiments are shown in Table 3.

The tables are analysed and YOLO-LKSDS outperforms YOLOv5s. The degree of improvement in the evaluation metrics varies due to the differences in the number of targets and the quality of the images in the different datasets. On the KITTI dataset, the accuracy improved by 21.1%, recall by 36.6% as well as mAP50 by 29.3%. These results confirm the generalisation ability of the YOLO-LKSDS algorithm.
3.4 Hardware Implementation of the YOLO-LKSDS Algorithm
In this paper, the model is deployed to the edge computing platform of PYNQ-ZU and model inference is performed on it, and the multi-core heterogeneous platform is shown in Fig. 8. The detection results of the inference are shown in Fig. 9. The resource consumption of the entire system operation and the power consumption of the system are shown in Fig. 10.

Figure 8: Edge computing platform inference runtime diagram

Figure 9: Detection result graph inference of multiple edge computing platforms
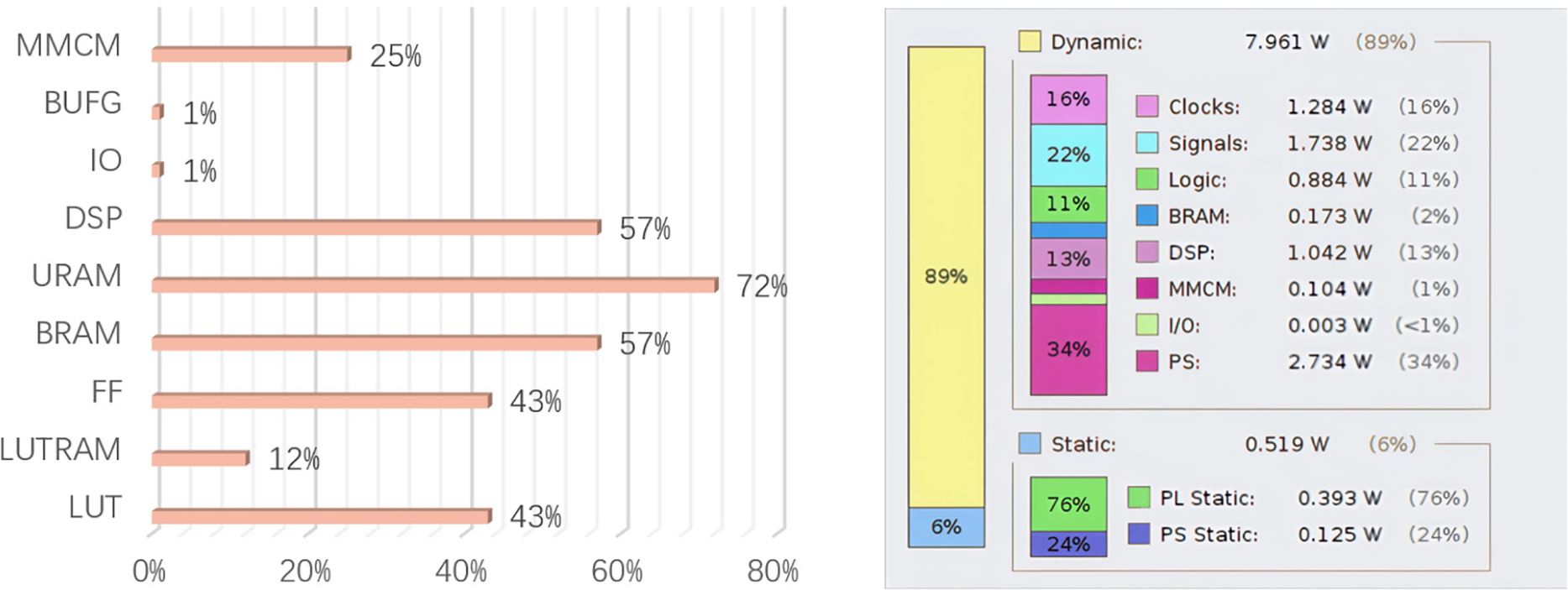
Figure 10: Resource consumption and power consumption of the system
It can be seen that the detection effect of the edge computing platform is intuitively better, the PYNQ-ZU edge computing platform has less resource consumption, and can also be expanded with some functionality, which is conducive to further development, and its power consumption is low, less than 9 W is suitable for deployment in the edge of the actual scene. The inference speed of the deep learning network model from the edge computing platform is estimated for FPS. The speed test results are compared with other models as shown in Table 4.

The FPS of the model in this paper is the inference speed of a single image obtained after inference on 10 groups of images, and then it will be converted into FPS, and the smallest FPS is 24.0, the largest FPS is 24.8, and finally the inference speed of 10 images is averaged, and the average FPS is 24.4. It can be seen from the comparison table that the detection speeds of YOLOv4 and YOLOv6 on the edge computing platform are relatively poor. As a major version of the YOLOv5 series, YOLOv5l has a higher detection efficiency compared to the medium version YOLOv6. The YOLO-LKSDS model in this paper performs best in detecting FPS and is suitable for autonomous driving scenarios.
Power consumption is a key factor in addition to inference speed when deep learning algorithms are deployed on edge computing platforms. Power consumption affects the operational efficiency, heat dissipation, stability and environmental adaptability of the device. Therefore, the power consumption of different models deployed on hardware platforms is compared, and the comparison table is shown in Table 5.

By analysing Table 5, it can be seen that edge computing platforms such as ZCU104, AXU3EG, and PYNQ-ZU exhibit significant power consumption differences when performing deep learning model deployment. Among them, the power consumption of ZCU104 running YOLOV3 is 14.68 W and 25 W, which can be seen that there is a difference in the power consumption of running on the same embedded device under different optimisation improvements; the power consumption of ZCU104 running RetinaNet ResNet-50 is 17.6 W, which is more complex compared to the YOLO model, and the ResNet-50 model is more complicated in design and The AXU3EG consumes 15 W when running YOLOV7, because some of the arithmetic of the DPU is not supported in the inference of the model, and it is necessary to rewrite the arithmetic of the part by itself, so some of the arithmetic written down by itself affects the power consumption of the system; ZCU102 consumes 12.3 W when running YOLOV5, and PYNQ-ZU consumes 12.3 W when running YOLOV5, while PYNQ-ZU consumes 12.3 W when running YOLOV5. The PYNQ-ZU running YOLOV5 consumes 12.3 W, while the PYNQ-ZU running this paper’s customised model consumes the lowest power of 8.98 W. This shows that the PYNQ-ZU combined with this paper’s model has a significant advantage in power consumption control. The PYNQ-ZU edge computing platform in this paper has advantages in both power consumption and speed, so the PYNQ-ZU platform is more suitable for application scenarios such as autonomous driving with low power consumption and high real-time requirements.
In this paper, an improved target detection algorithm, YOLO-LKSDS, is proposed, specifically optimised for target detection in low illumination autonomous driving scenarios. An image enhancement method based on CLAHE algorithm is designed to address the problems of low image quality, insufficient contrast and increased noise under low illumination conditions, and the effect is analysed by subjective and objective evaluation metrics. In order to improve the detection ability of multi-scale targets, Kmeans++ clustering anchor frame algorithm is introduced in the input part of the network model, and SPPEALN spatial pyramid pooling is introduced in the part of the backbone network for improvement, which enhances the feature extraction ability of the model. For the dense occlusion problem in autonomous driving scenarios, the SEAM attention mechanism is added to the detection head of the network model as well as the DIOU-NMS non-maximal suppression is utilised in the post-processing part of the model to enhance the feature extraction of the occluded targets and to improve the performance and robustness of the model. Finally, the activation function of the model is optimised to improve the computational efficiency in order to adapt to the deployment requirements of edge computing platforms. Under the selected BDD100K dataset, the enhanced detection effect of the original model was compared with that of this model. It can be seen that the accuracy and mAP50 of this model have increased by 23.3% and 4.7%, respectively. The accuracy rate, recall rate, and mAP50 of the KITTI dataset have increased by 21.1%, 36.6% and 29.3%, respectively. The FPS of the edge computing platform reaches 24.4, and the power consumption is only 8.98 W. The results show that the YOLO-LKSDS model proposed in this paper can effectively handle the performance and robustness issues of target detection in low-illumination autonomous driving, and has high real-time performance and low power consumption when implemented on the edge platform.
Acknowledgement: This research is carried out under the framework of the research entitled “Research on Key Technologies of Pedestrian Target Detection Based on Multi-Source Information Fusion in Complex Scenarios”.
Funding Statement: This research was supported by the Key R&D Program of Shaanxi Province (No. 2025CY-YBXM-078).
Author Contributions: Jianhua Yang assumed the overall design of this study, was responsible for the design and development of the research protocol, and participated in the writing of some chapters; Zhiwei Lv was responsible for the experimental validation and implementation of the research protocol, as well as assuming the task of writing some chapters; Changling Huo was mainly responsible for the validation and analysis of the experimental data, and completed the correction and optimisation of the thesis diagrams. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The datasets used in this study are the BDD100K public dataset and the KITTI dataset.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Mozaffari S, Al-Jarrah OY, Dianati M, Jennings P, Mouzakitis A. Deep learning-based vehicle behavior prediction for autonomous driving applications: a review. IEEE Trans Intell Transp Syst. 2022;23(1):33–47. doi:10.1109/TITS.2020.3012034. [Google Scholar] [CrossRef]
2. Wang X, Wu Y, Shao K, Xie D, Dong J. Research on autonomous driving multi-object tracking and detection based on improved YOLOv8s. Automot Technol. 2024;12:5–11. (In Chinese). doi:10.19620/j.cnki.1000-3703.20240513. [Google Scholar] [CrossRef]
3. Tan H, Zhang JL, Jia X. Low-light target detection algorithm based on multi-level feature extraction. Comput Eng Appl. 2024;60(24):235–42. (In Chinese). doi:10.3778/j.issn.1002-8331.2308-0093. [Google Scholar] [CrossRef]
4. Zhang YY, Zhang S, Zhang Y, Ji JM, Duan YF, Huang YT, et al. Multi-modality fusion perception and computing in autonomous driving. J Comput Res Dev. 2020;57(9):1781–99. (In Chinese). doi:10.7544/issn1000-1239.2020.20200255. [Google Scholar] [CrossRef]
5. Tang Y, He H, Wang Y, Mao Z, Wang H. Multi-modality 3D object detection in autonomous driving: a review. Neurocomputing. 2023;553(1):126587. doi:10.1016/j.neucom.2023.126587. [Google Scholar] [CrossRef]
6. Wang ML, Zhang H, Zhang CS. A low light target detection algorithm based on deep learning. J Beijing Univ Posts Telecommun. 2024;47(5):59–65. (In Chinese). doi:10.13190/j.jbupt.2023-161. [Google Scholar] [CrossRef]
7. Jiang ZT, Xiao Y, Zhang SQ, Zhu LH, He YT, Zhai FS. Low-illumination object detection method based on dark-YOLO. J Comput Aided Des Comput Graph. (In Chinese). 2023;35(3):441–51. doi:10.3724/SP.J.1089.2023.19354. [Google Scholar] [CrossRef]
8. Wei H, Yu B, Wang W, Zhang C. Adaptive enhanced detection network for low illumination object detection. Mathematics. 2023;11(10):2404. doi:10.3390/math11102404. [Google Scholar] [CrossRef]
9. Abdullah-Al-Wadud M, Kabir MH, Dewan MAA, Chae O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans Consum Electron. 2007;53(2):593–600. doi:10.1109/TCE.2007.381734. [Google Scholar] [CrossRef]
10. Zuiderveld K. Contrast limited adaptive histogram equalization. In: Graphics gems IV. San Diego, CA, USA: Academic Press Professional, Inc.; 1994. p. 474–85. doi:10.5555/180895.180940. [Google Scholar] [CrossRef]
11. Veluchamy M, Subramani B. Image contrast and color enhancement using adaptive gamma correction and histogram equalization. Optik. 2019;183(1):329–37. doi:10.1016/j.ijleo.2019.02.054. [Google Scholar] [CrossRef]
12. Chang Y, Jung C, Ke P, Song H, Hwang J. Automatic contrast-limited adaptive histogram equalization with dual gamma correction. IEEE Access. 2018;6:11782–92. doi:10.1109/ACCESS.2018.2797872. [Google Scholar] [CrossRef]
13. Jiang Y, Gong X, Liu D, Cheng Y, Fang C, Shen X, et al. EnlightenGAN: deep light enhancement without paired supervision. IEEE Trans Image Process. 2021;30:2340–9. doi:10.1109/TIP.2021.3051462. [Google Scholar] [PubMed] [CrossRef]
14. Jin H, Li L, Su H, Zhang Y, Xiao Z, Wang B. Learn to enhance the low-light image via a multi-exposure generation and fusion method. J Vis Commun Image Represent. 2024;100(2):104127. doi:10.1016/j.jvcir.2024.104127. [Google Scholar] [CrossRef]
15. Wang L, Wang X, Li X, Chen X. Parallel multi-scale feature recursive learning for low-light image enhancement. Comput Eng Appl. 2025;16:265–71. [cited 2025 Sep 1]. Available from: https://link.cnki.net/urlid/11.2127.TP.20240925.1212.028. [Google Scholar]
16. Lu Q, Li C, Yin L. Multi-path parallel enhancement of low-light images based on multiscale spatially aware Retinex decomposition. Expert Syst Appl. 2024;252:124301. doi:10.1016/j.eswa.2024.124301. [Google Scholar] [CrossRef]
17. Chen J, Wang Y, Han Y. A semi-supervised network framework for low-light image enhancement. Eng Appl Artif Intell. 2023;126(2):107003. doi:10.1016/j.engappai.2023.107003. [Google Scholar] [CrossRef]
18. Jiang K, Wang Q, An Z, Wang Z, Zhang C, Lin CW. Mutual retinex: combining transformer and CNN for image enhancement. IEEE Trans Emerg Top Comput Intell. 2024;8(3):2240–52. doi:10.1109/TETCI.2024.3369321. [Google Scholar] [CrossRef]
19. Latke V, Narawade V. Detection of dental periapical lesions using retinex based image enhancement and lightweight deep learning model. Image Vis Comput. 2024;146(10):105016. doi:10.1016/j.imavis.2024.105016. [Google Scholar] [CrossRef]
20. Jin Z, Duan J, Qiao L, He T, Shi X, Yan B. MTGS-Yolo: a task-balanced algorithm for object detection in remote sensing images based on improved yolo. J Supercomput. 2025;81(4):542. doi:10.1007/s11227-025-07003-5. [Google Scholar] [CrossRef]
21. Wei LS, Huang SH, Ma LY. MTD-YOLOv5: enhancing marine target detection with multi-scale feature fusion in YOLOv5 model. Heliyon. 2024;10(4):e26145. doi:10.1016/j.heliyon.2024.e26145. [Google Scholar] [PubMed] [CrossRef]
22. Li FP, Rui X, Li ZJ, Song WG. Research on small target fire detection model based on improved YOLOv5. J Tsinghua Univ Sci Technol. 2025;65(4):655–63. doi:10.16511/j.cnki.qhdxxb.2025.27.004. [Google Scholar] [CrossRef]
23. Zhang H, Li G, Wan D, Wang Z, Dong J, Lin S, et al. DS-YOLO: a dense small object detection algorithm based on inverted bottleneck and multi-scale fusion network. Biomim Intell Robot. 2024;4(4):100190. doi:10.1016/j.birob.2024.100190. [Google Scholar] [CrossRef]
24. Cui LQ, Cao HW. Object detection based on improved YOLOv7 for UAV aerial image. Comput Eng Appl. 2024;60(20):189–97. doi:10.3778/j.issn.1002-8331.2312-0100. [Google Scholar] [CrossRef]
25. Jiang Q, Huang Z, Xu G, Su Y. MIoP-NMS: perfecting crops target detection and counting in dense occlusion from high-resolution UAV imagery. Smart Agric Technol. 2023;4(50):100226. doi:10.1016/j.atech.2023.100226. [Google Scholar] [CrossRef]
26. Zhai M, Zhang H, Wang L, Xiao D, Gu Z, Li Z. Special vehicle target detection and tracking based on virtual simulation environment and YOLOv5-Block+DeepSort algorithm. Comput Mater Contin. 2024;81(2):3241–60. doi:10.32604/cmc.2024.056241. [Google Scholar] [CrossRef]
27. Liu H, Zhang Y, Zhou K, Zhang Y, Lv S. Improved YOLOv5-S for traffic sign detection algorithm. J Comput Eng Appl. 2024;60(5):200–9. [cited 2025 Sep 1]. Available from: https://link.cnki.net/urlid/11.2127.TP.20230830.1343. [Google Scholar]
28. Yang B, Hu Z. Improved algorithm based on YOLOv8n for autonomous driving target detection. Control Eng. 2024, 1–7. (In Chinese). doi:10.14107/j.cnki.kzgc.20240494. [Google Scholar] [CrossRef]
29. Bochkovskiy A, Wang CY, Liao HM. YOLOv4: optimal speed and accuracy of object detection. arXiv:2004.10934. 2020. [cited 2025 Sep 1]. Available from: https://arxiv.org/abs/2004.10934. [Google Scholar]
30. Li C, Li L, Jiang H, Weng K, Geng Y, Li L, et al. YOLOv6: a single-stage object detection framework for industrial applications. arXiv:2209.02976. 2022. [cited 2025 Sep 1]. Available from: https://arxiv.org/abs/2209.02976. [Google Scholar]
31. Jocher G, Stoken A, Borovec J, Changyu L, Hogan A, Diaconu L, et al. Ultralytics/yolov5: v3.1-bug fixes and performance improvements. Genève, Switzerland: Zenodo; 2020. doi:10.5281/zenodo.4154370. [Google Scholar] [CrossRef]
32. Tsai TH, Wu PH. Design and implementation of deep learning-based object detection and tracking system. Integration. 2024;99(9):102240. doi:10.1016/j.vlsi.2024.102240. [Google Scholar] [CrossRef]
33. Wang J, Gu S. FPGA implementation of object detection accelerator based on Vitis-AI. In: 2021 11th International Conference on Information Science and Technology (ICIST); 2021 May 21–23;. Chengdu, China. p. 571–7. doi:10.1109/icist52614.2021.9440554. [Google Scholar] [CrossRef]
34. Magalhães SC, dos Santos FN, Machado P, Moreira AP, Dias J. Benchmarking edge computing devices for grape bunches and trunks detection using accelerated object detection single shot multibox deep learning models. Eng Appl Artif Intell. 2023;117(9):105604. doi:10.1016/j.engappai.2022.105604. [Google Scholar] [CrossRef]
35. Li X, Wei Y, Li J, Duan W, Zhang X, Huang Y. Improved YOLOv7 algorithm for small object detection in unmanned aerial vehicle image scenarios. Appl Sci. 2024;14(4):1664. doi:10.3390/app14041664. [Google Scholar] [CrossRef]
36. Yan Z, Zhang B, Wang D. An FPGA-based YOLOv5 accelerator for real-time industrial vision applications. Micromachines. 2024;15(9):1164. doi:10.3390/mi15091164. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools