
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Recurrent MAPPO for Joint UAV Trajectory and Traffic Offloading in Space-Air-Ground Integrated Networks
1 College of Command & Control Engineering, Army Engineering University of PLA, Nanjing, 210044, China
* Corresponding Author: Fenglin Jin. Email:
Computers, Materials & Continua 2026, 86(1), 1-15. https://doi.org/10.32604/cmc.2025.069128
Received 15 June 2025; Accepted 24 July 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This paper investigates the traffic offloading optimization challenge in Space-Air-Ground Integrated Networks (SAGIN) through a novel Recursive Multi-Agent Proximal Policy Optimization (RMAPPO) algorithm. The exponential growth of mobile devices and data traffic has substantially increased network congestion, particularly in urban areas and regions with limited terrestrial infrastructure. Our approach jointly optimizes unmanned aerial vehicle (UAV) trajectories and satellite-assisted offloading strategies to simultaneously maximize data throughput, minimize energy consumption, and maintain equitable resource distribution. The proposed RMAPPO framework incorporates recurrent neural networks (RNNs) to model temporal dependencies in UAV mobility patterns and utilizes a decentralized multi-agent reinforcement learning architecture to reduce communication overhead while improving system robustness. The proposed RMAPPO algorithm was evaluated through simulation experiments, with the results indicating that it significantly enhances the cumulative traffic offloading rate of nodes and reduces the energy consumption of UAVs.Keywords
SAGIN is an emerging network architecture and a key enabler for future sixth-generation (6G) mobile communication systems, supporting full-area coverage, ultra-high speed, ultra-low latency, high reliability, and intelligent services [1]. By integrating air-based networks (e.g., UAVs and high-altitude platforms), space-based networks (e.g., satellite communication systems) and ground-based networks (e.g., terrestrial base stations), SAGIN establishes a seamless global communication infrastructure [2].
The exponential growth in network devices has led to a dramatic surge in data traffic, particularly in densely populated areas or regions with limited ground communication infrastructure, resulting in significantly increased network load pressures. As a crucial component of SAGIN, UAV networks offer rapid deployment capabilities and exceptional environmental adaptability, serving as effective supplements to ground-based communication nodes. These characteristics not only enhance user experience, but also enable reliable communication services in remote areas. Furthermore, UAV networks contribute to improved overall network performance, supporting the comprehensive coverage and ubiquitous connectivity requirements essential for 6G mobile networks [3].
UAV networks typically comprise one or more UAVs equipped with configurable sensors and communication modules to accommodate diverse mission requirements. This adaptability enables their widespread application in edge computing, traffic offloading, and relay communication systems. Within SAGIN architectures, UAV nodes assume particular significance owing to their rapid deployment capabilities and controllable mobility. Network administrators can further improve overall system performance through dynamic resource allocation and intelligent scheduling of UAV networks.
While UAV networks offer significant advantages and potential for traffic offloading, their implementation presents several challenges [4]. As a novel networking platform, UAVs exhibit high mobility and energy sensitivity, requiring careful consideration of multiple factors including flight duration, coverage range, energy consumption, communication capacity, and compatibility with existing network infrastructure. Although extensive research has addressed optimization problems in UAV networks, such as trajectory planning, deployment location, and resource allocation, relatively few studies have investigated trajectory optimization in SAGIN traffic offloading scenarios that simultaneously account for both energy consumption and data throughput in UAV networks [5].
In response to these issues, this study first formulates a traffic offloading model for SAGIN and defines the problem of offloading efficiency optimization. We then propose a Multi-Agent Proximal Policy Optimization (MAPPO) framework, enhanced with RNNs, to jointly optimize UAV flight trajectories and traffic offloading strategies. This paper makes the following key contributions:
1) We formulate a traffic offloading scenario in SAGIN and propose an efficiency optimization problem for traffic offloading. By jointly optimizing the drone flight trajectories and offloading strategies, we maximize both the user offloading rate and fairness among offloading nodes, while minimizing drone energy consumption.
2) To optimize traffic offloading efficiency, we formulate the problem as a Partially Observable Markov Decision Process (POMDP) and propose an RMAPPO-based algorithm for joint drone trajectory control and traffic offloading decisions. Unlike prior works employing DDPG frameworks, our RMAPPO approach introduces two key innovations: a recurrent architecture that captures temporal dependencies in UAV trajectories, enabling more informed decision-making; a fully decentralized training paradigm that reduces communication overhead while maintaining cooperation. By incorporating RNNs [6], our approach leverages historical observations to improve training efficiency.
3) We designed multiple simulation experiments to evaluate the proposed RMAPPO algorithm. The experimental results show that the algorithm significantly improves the cumulative traffic offloading rate of nodes and reduces the energy consumption of the drones.
In recent years, SAGIN architecture has employed drones and satellites as traffic offloading nodes to mitigate the challenges posed by complex network topologies and resource management. This technology leverages the complementary advantages of heterogeneous networks, improving overall traffic transmission efficiency. However, substantial disparities in communication environments, latency, and coverage among these networks impose strict requirements on traffic offloading techniques.
The intelligentization of traffic offloading algorithms has emerged as a pivotal trend in network technology [7]. Researchers are increasingly using artificial intelligence (AI) to address the complex challenges of air-ground-space networks, optimizing key performance metrics such as throughput, latency, and energy consumption [8]. Depending on the specific offloading problem, different AI techniques are employed. Among existing studies, reinforcement learning (RL) has become the predominant intelligent approach for traffic offloading in such networks.
Recent advances in UAV-assisted wireless networks have seen significant methodological innovations. Hu et al. [9] proposed a two-stage alternating optimization algorithm for simultaneous traffic and computation offloading in UAV-assisted wireless networks. Their approach maximizes user satisfaction through joint optimization of (1) resource allocation (bandwidth and power) and (2) UAV trajectory. For a given trajectory, the resource allocation problem is transformed into a convex optimization via variable substitution, while non-convex trajectory constraints are addressed using successive convex approximation (SCA). Li et al. [10] addressed cellular network congestion caused by exponential data growth through a hierarchical intelligent framework leveraging deep federated learning. This multi-UAV system optimizes nergy-efficient flight paths, deployment locations, and dynamic resource allocation, significantly reducing energy consumption while extending operational endurance. Luo et al. [11] developed a MADRL approach for UAV relay systems serving multiple ground user pairs. Their method simultaneously ensures fairness among users, throughput maximization, and connectivity maintenance, while accounting for UAV payload and energy constraints. In the domain of UAV trajectory optimization, Chapnevis and Bulut [12] investigated a data collection scenario for Internet of Things (IoT) networks employing UAVs. The authors developed both an integer linear programming model and a heuristic algorithm to optimize UAV flight paths. Their approach incorporates the Age of Information (AoI) metric while simultaneously minimizing both mission duration and flight distance. In mobile edge computing, Zhang et al. [13] tackled the challenge of resource-constrained devices handling bandwidth-intensive applications. Their UAV-assisted solution employs a Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm to optimize computational task offloading in edge environments. For space-air-ground integrated networks, An et al. [14] proposed a Deep Deterministic Policy Gradient (DDPG)-based framework that jointly minimizes energy consumption and latency by optimizing UAV trajectories, transmission power, offloading rates, and destination selection.
Current research in UAV network optimization has primarily focused on two key areas: (1) computational offloading strategies [15] and (2) UAV deployment and trajectory optimization [16]. While these approaches effectively address computational capacity and energy efficiency, they often overlook critical requirements for effective traffic offloading. Comprehensive traffic offloading solutions must additionally consider quality-of-service (QoS) guarantees and fair resource allocation. Furthermore, in traffic offloading scenarios, UAV trajectory planning and deployment locations directly impact user experience metrics [17].
Take into account the above questions. First, research on drone networks for traffic offloading must account for their high dynamics. While the dynamic nature of drones enhances node adaptability and network robustness, it also increases network complexity. Consequently, when addressing traffic offloading, it is essential not only to optimize offloading strategies for the existing network topology but also to leverage the drones’ high mobility to improve transmission efficiency and enhance user experience [18].
Second, in scenarios where multiple candidate nodes are available for traffic offloading, the node selection process becomes a critical optimization challenge. This dynamic selection mechanism must account for the rapidly changing network topology while balancing computational overhead with decision accuracy.
As illustrated in Fig. 1, in the SAGIN traffic offloading scenario, satellites and multiple UAVs collaboratively provide network traffic offloading services for ground users. Both UAVs and users can obtain their location information through satellite positioning. Each node can function as an offloading node to alleviate user data transmission pressure. In UAV network traffic offloading, the movement of drones can be controlled to optimize their positions, ensuring optimal offloading service provision. Users can select the most suitable offloading node based on QoS offered by each node. UAVs do not enforce centralized offloading assignments. Instead, they dynamically adjust their trajectories to improve channel conditions, thereby indirectly influencing user decisions. When adjusting their positions, UAVs must consider both the overall network communication efficiency and fairness among offloading nodes.
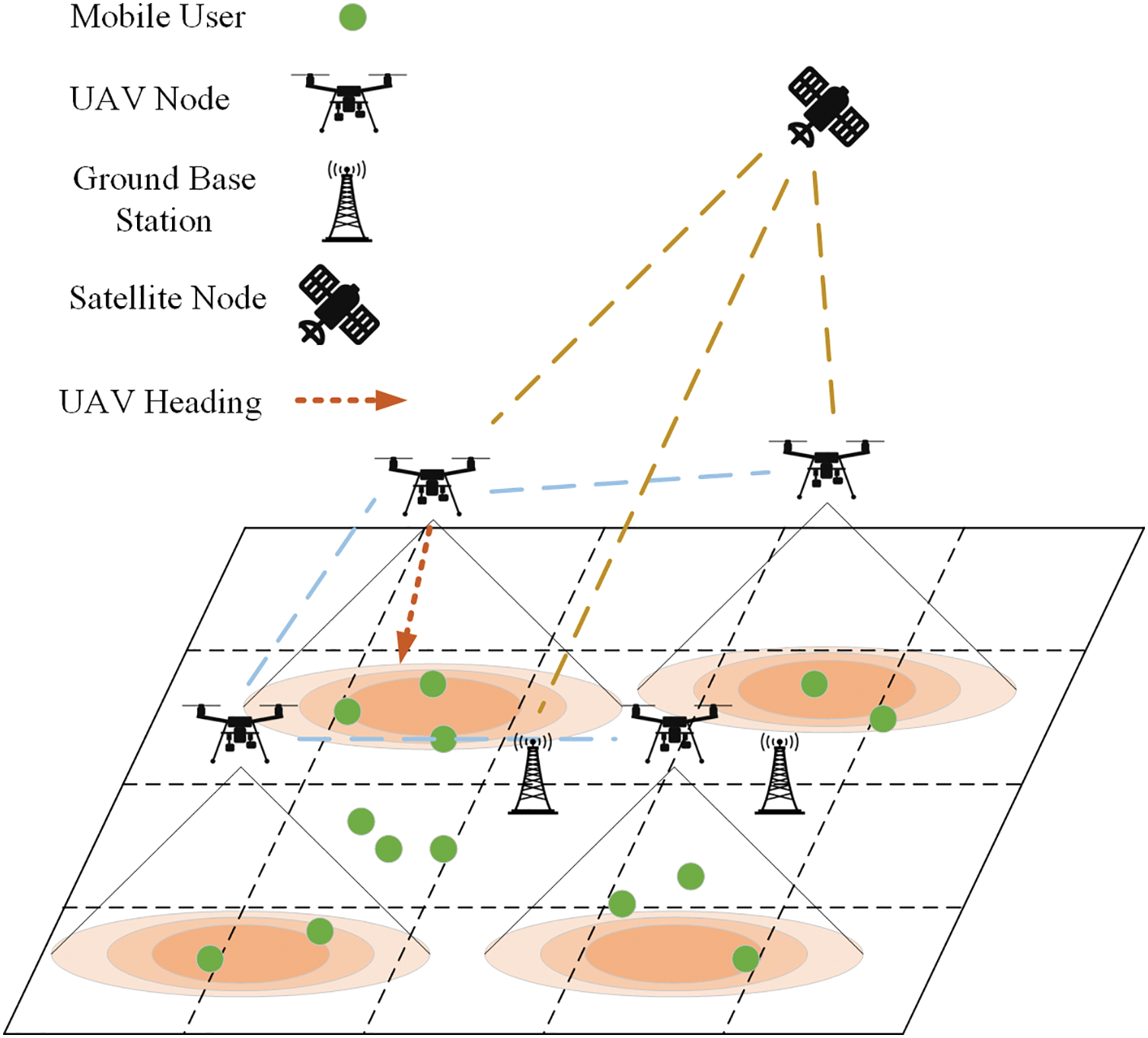
Figure 1: SAGIN architecture
Ground users outside UAV coverage areas or those experiencing poor communication efficiency with UAVs can utilize satellite nodes for traffic offloading. However, given the limited availability of satellite communication resources and their significant propagation delays, ground users preferentially employ UAV networks for traffic offloading when possible.
For the satellite-to-ground communication model, since the satellite altitude significantly exceeds ground users’ movement range, ground nodes can be treated as relatively stationary when analyzing satellite-ground communications. This paper employs a Weibull distribution-based channel model [19] to characterize the satellite-ground communication link, where the channel gain is expressed as:
where
where
The UAV-user communication system employs both uplink and downlink channels. To minimize interference, distinct frequency bands are allocated for uplink and downlink transmission, supplemented by Orthogonal Frequency Division Multiple Access (OFDMA) technology. Given that UAV-ground user communication primarily occurs through line-of-sight (LoS) links while being susceptible to terrestrial obstructions, we adopt a probabilistic LoS channel model [21]. The Los probability between user
where
Path loss for line-of-sight communication
where
In a mission area of
Let
Each ground user has distinct communication demands and traffic offloading requirements. Let
During mission execution, the UAV dynamically adjusts its trajectory within a predefined operational area according to the real-time positions of user nodes, enabling it to identify and navigate toward optimal data offloading points. This study optimizes the UAV’s movement direction and flight path to enhance traffic offloading efficiency while minimizing energy consumption and maintaining fair resource allocation.
At time
Let
To prevent user distribution from becoming overly centralized–-which could lead to multiple users simultaneously selecting the same subset of UAVs as offloading nodes and causing UAV congestion–-we employ the Jain fairness index [23] to define a fairness metric for each UAV. This approach ensures balanced load distribution across all available UAV nodes.
Let
In SAGIN traffic offloading, it is essential to enhance the overall network offloading efficiency while maximizing the user throughput rate. The offloading rate for each user node is derived from the communication model. Throughout the task cycle, it is necessary to maximize optimization target Z, which is expressed as follows:
Let
Let
•
•
•
•
•
To ensure all ground users in the mission area receive high-quality service and enhance the overall data traffic offloading efficiency in SAGIN, the system must not only direct ground users to select optimal UAV or satellite nodes for data offloading based on channel conditions and QoS requirements, but also enable UAV nodes to dynamically adjust their flight trajectories through mobility optimization for deployment at optimal service locations.
There are
Moreover, the target solution for this problem includes not only the UAV’s static deployment locations but also its optimized dynamic trajectory during mission execution, ensuring real-time adaptation to dynamic user distribution for service optimization.
The movement of UAVs is temporally discrete, allowing only one action per time slot. However, its action selection is continuous, and the objective function is a time-varying non-convex optimization problem, which traditional methods struggle to solve. To address this, we employ reinforcement learning (RL) to derive an optimal strategy. Given the cooperative nature of drone networks, a multi-agent reinforcement learning (MARL) approach is adopted. Since the UAV’s action space is continuous, policy-based RL methods are particularly suitable. While Proximal Policy Optimization (PPO) is typically applied in single-agent settings, its core principles can be extended to multi-agent systems.
The basic MAPPO training framework is shown in Fig. 2, and the Clip clipping method used in this paper updates the policy gradient, and the network parameters are updated with the formula [25]:
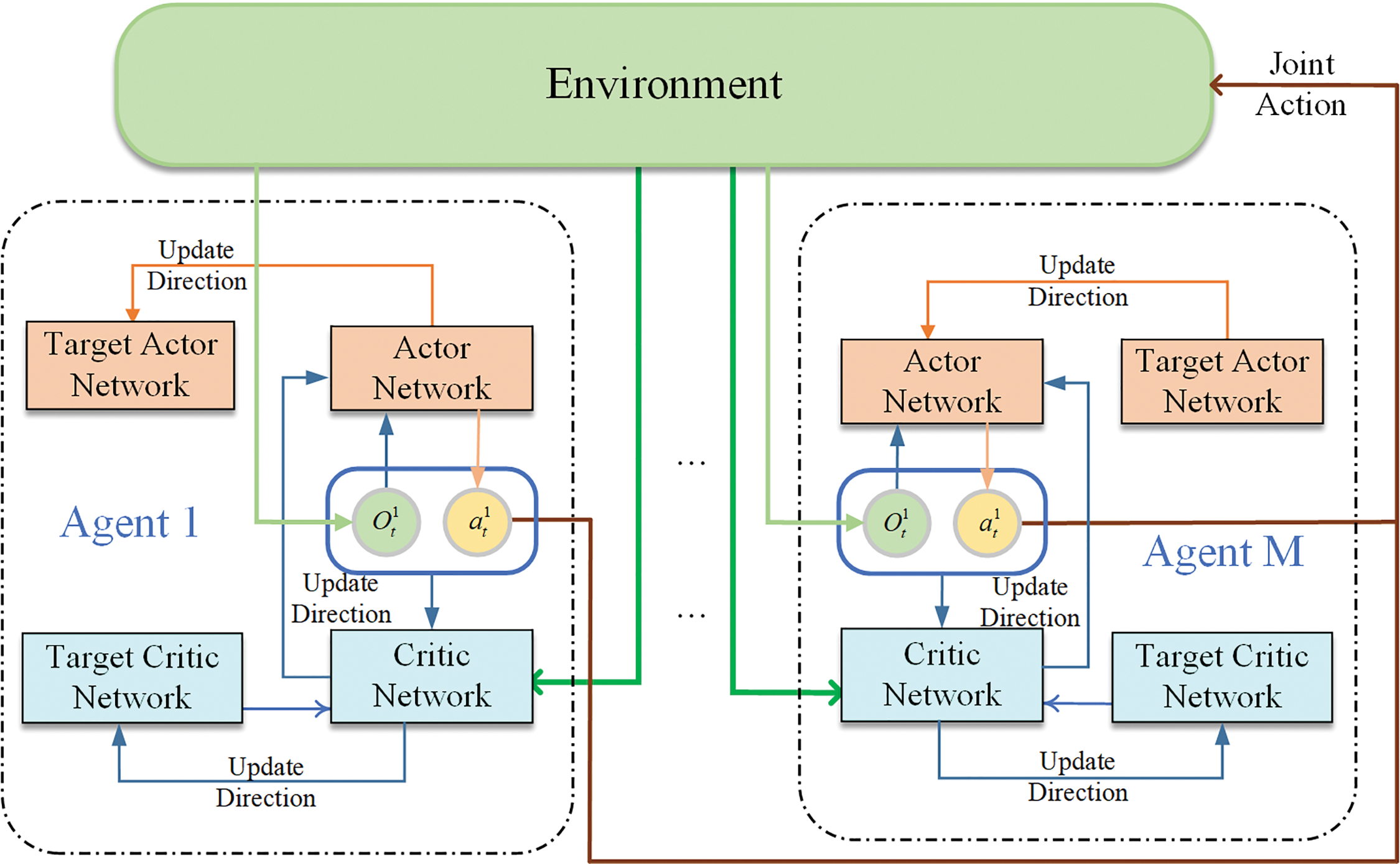
Figure 2: Training framework diagram
Since PPO is designed for single-agent reinforcement learning, it requires centralized training to access global network information. However, in our problem, UAV nodes cannot share all observations, making single-agent PPO unsuitable. To enable effective cooperation among nodes, we adopt a multi-agent architecture.
Traditional MAPPO employs centralized training with decentralized execution (CTDE), where agents share a centralized Critic network that estimates the global value function using the global state and all agents’ actions, while each agent’s Actor network generates actions based on local observations. In contrast, our algorithm uses a fully distributed training approach: each agent maintains its own Critic and Actor networks, updating parameters based solely on local observations. This design reduces reliance on global information, enhancing user privacy and scalability for larger networks.
In path planning problems, trajectories exhibit temporal continuity, where current actions depend on past states and actions. To enable agents to capture these temporal dependencies, we integrate a recurrent neural network (RNN) with reinforcement learning, endowing them with memory capabilities. The architecture of our proposed RMAPPO network is illustrated in Fig. 3.
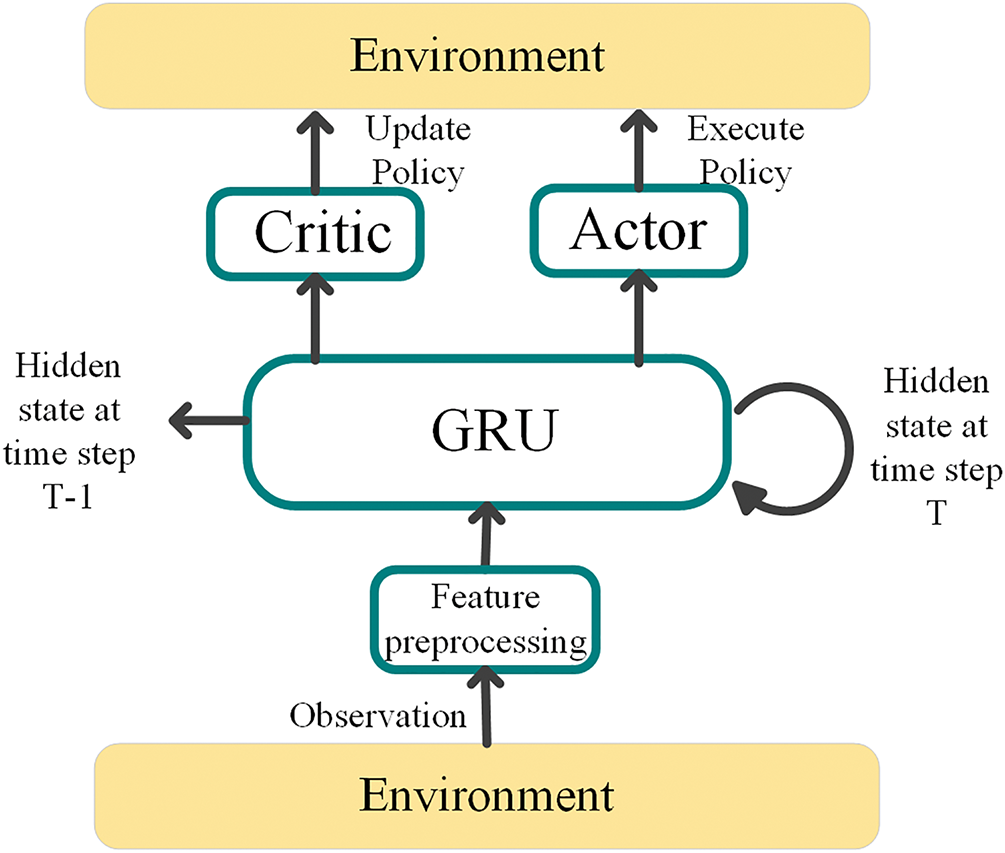
Figure 3: Optimize actor-critic algorithms
Each agent’s state is initially processed by a Gated Recurrent Unit (GRU) layer with 64 hidden units, which maintains historical information through its hidden state mechanism. The processed features are then fed into the Actor network, comprising two fully-connected hidden layers (64 and 32 units, respectively), with actions ultimately generated by an output layer using
Each UAV node has its own observation space, which includes UAV node ID, node position, current user position, node resource consumption. Agent will take appropriate actions according to the local observation of the UAV to guide the UAV to take the best flight trajectory.
The action of the agent includes the flight direction of the UAV
The design of the reward function must consider both the optimization objectives and problem constraints, while carefully scaling different reward components to prevent dominance by large numerical values. For the UAV trajectory optimization problem, we define the following reward and penalty structure:
1. Throughput Reward: The reward is based on the throughput rate achieved by the ground user upon selecting an offloading node, formulated as:
2. Fairness Reward: This reward is determined by the fairness of resource allocation across drone nodes when performing traffic offloading, defined as:
3. Out-of-Bounds Penalty: This penalty constrains the drone’s service range. If drone node
where
where
4. UAV Energy Consumption Penalty: The energy consumption of the UAV directly affects its endurance and serves as a crucial performance metric. To minimize energy waste, we impose a movement penalty proportional to the displacement distance:
The fairness-throughput tradeoff parameter
Algorithm 1 employs a fully distributed training paradigm, wherein each agent maintains its own Critic network and independently updates the network parameters based on local observations. However, agents can share partial observations with each other through communication channels. This design facilitates straightforward implementation for interconnected nodes. The training phase of the algorithm proceeds as follows:

We evaluate the proposed algorithm through comprehensive simulation experiments implemented using the PyTorch framework. Table 1 shows the experimental parameters. The experimental scenario consists of a 5000 m
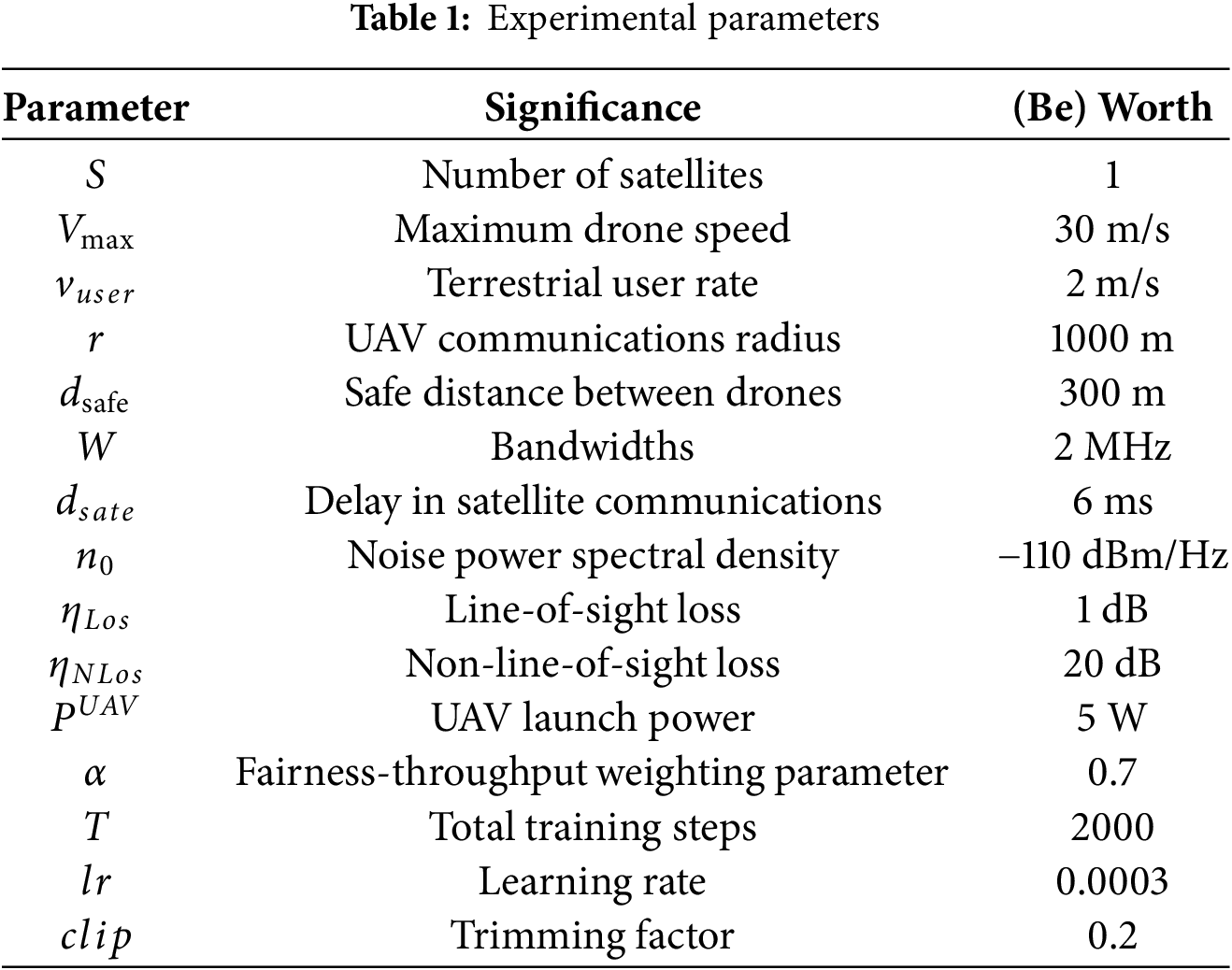
The experiment is conducted in a rectangular task area measuring 5000 m
The first approach implements the IPPO algorithm from [11], which addresses trajectory optimization for multi-UAV transmission services to ground user pairs. Notably, this method does not employ RNN and is also a MARL algorithm. The second approach is a K-means-based heuristic algorithm that: (1) clusters users by location into K groups (where K equals the number of UAVs), (2) directs each UAV toward its cluster centroid, and (3) iteratively updates cluster centroids and UAV trajectories as user positions change. Additionally, we conducted ablation studies to isolate the impact of the GRU layer within the RMAPPO architecture.
As illustrated in Fig. 4, both methods exhibit steadily increasing cumulative rewards with growing iterations, ultimately achieving stable convergence. Notably, the proposed RMAPPO algorithm demonstrates superior performance to IPPO across three key metrics: cumulative reward, throughput, and energy consumption. By integrating recurrent neural networks with reinforcement learning within a distributed multi-agent framework, RMAPPO enhances agents’ perception of local environmental states, thereby facilitating faster policy optimization. Experimental results validate the convergence of RMAPPO and demonstrate its significantly faster convergence rate compared to IPPO under identical iteration counts.
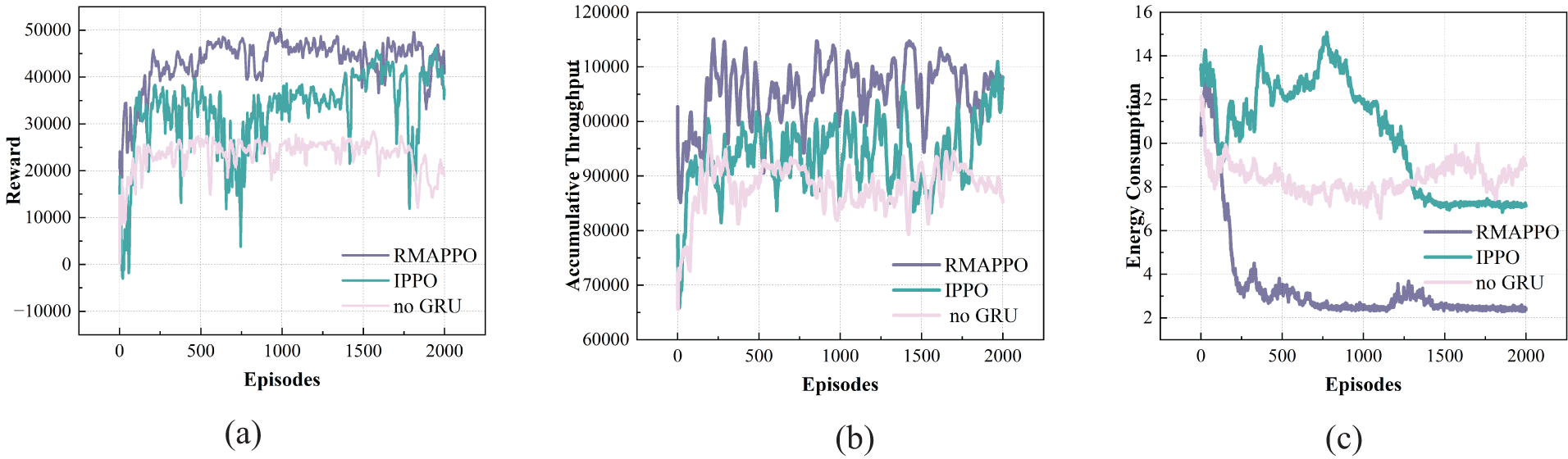
Figure 4: (a) Cumulative reward; (b) Cumulative throughput reward; (c) Cumulative energy penalty
As illustrated in Fig. 5, the scenario comprises four UAVs and 130 ground users. Fig. 5a presents the trajectory generated by the RMAPPO method, demonstrating more comprehensive user coverage compared to other approaches. Fig. 5b displays the trajectory produced by IPPO, revealing that a significant number of users still rely on satellite nodes for traffic offloading during UAV movement. Fig. 5c exhibits the trajectory generated by the K-means algorithm, where substantial offsets between consecutive clustering centers–-caused by ground node mobility–-result in oscillatory UAV movement patterns.
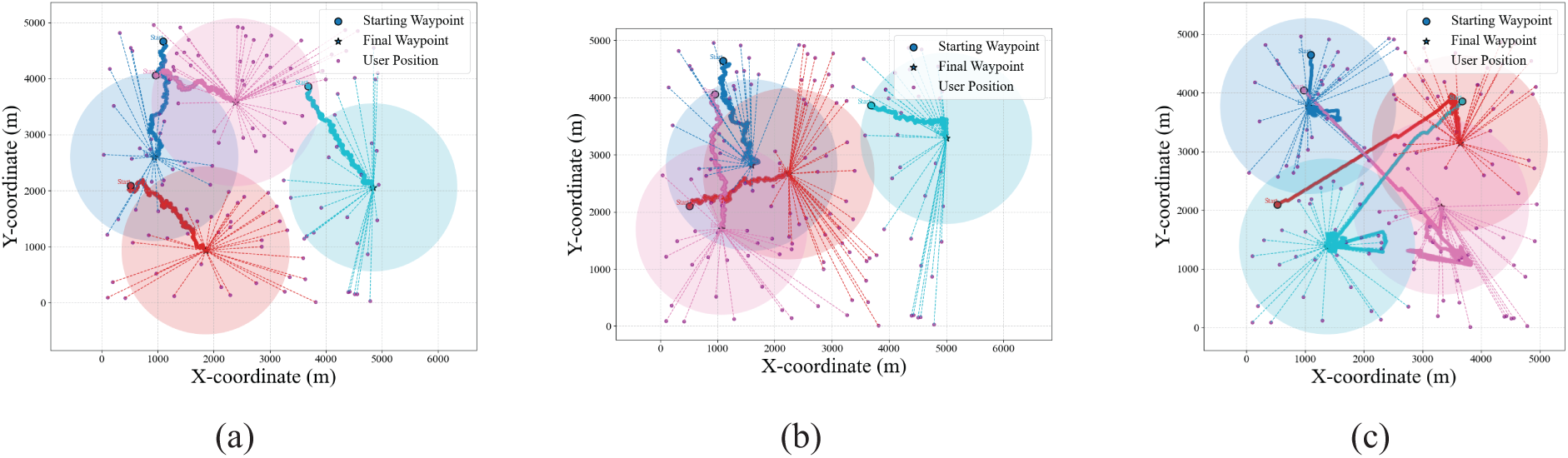
Figure 5: (a) RMAPPO; (b) IPPO; (c) K-means
To further validate the effectiveness of RMAPPO, we evaluated all three methods under varying numbers and spatial distributions of ground users.
As shown in Fig. 6, the RMAPPO algorithm outperforms the other two methods in both fairness metrics and average throughput rate. In contrast, the K-means algorithm fails to account for user mobility, heterogeneous offloading demands, varying satellite-assisted offloading capabilities, and fairness among drone nodes, making it unsuitable for achieving the optimization objective. Furthermore, UAV states exhibit strong temporal dependencies in their continuous position, direction, and velocity, which enables RMAPPO to learn more effective trajectory optimization strategies. However, since RMAPPO incorporates an additional GRU layer compared to IPPO, it exhibits a lower computational efficiency than IPPO. The RMAPPO algorithm exhibits a 10.65% longer execution time compared to IPPO when implemented on identical hardware configurations.
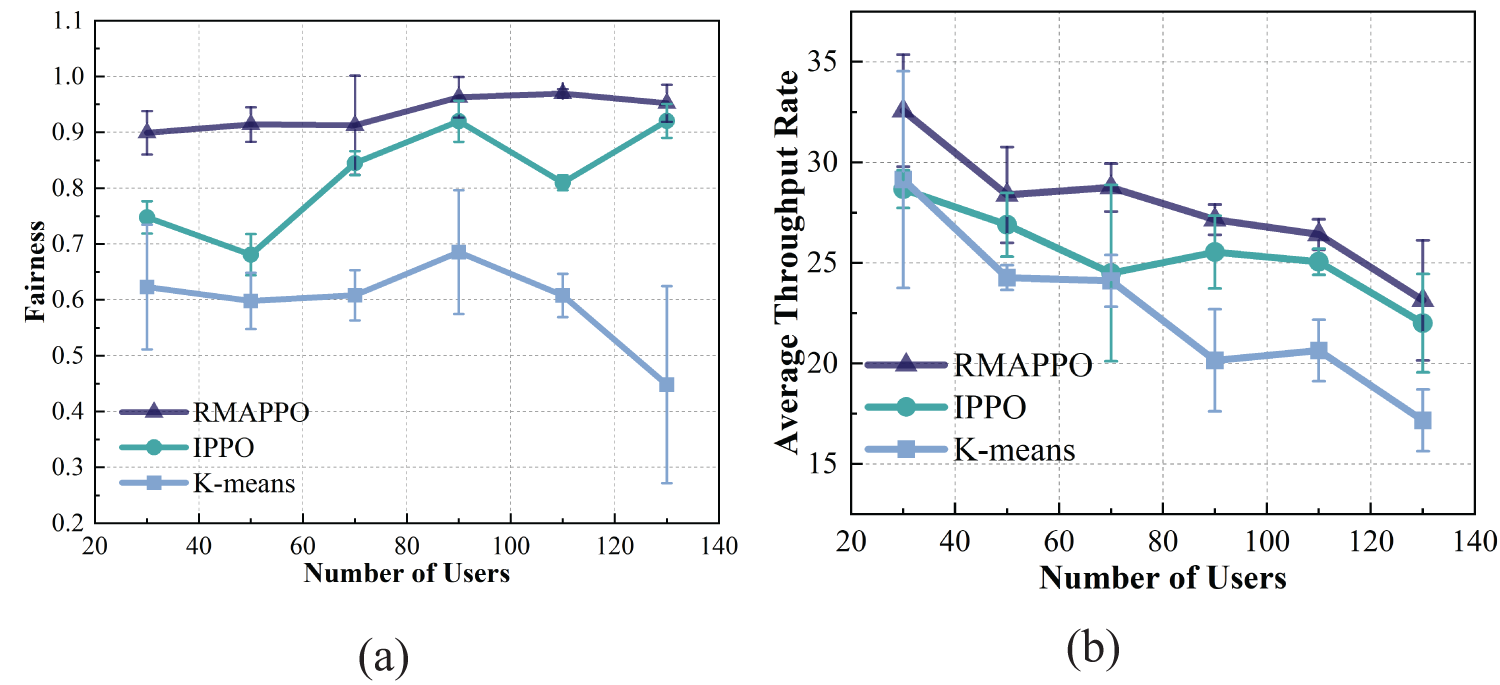
Figure 6: (a) Fairness comparison; (b) Throughput comparison
This paper proposed the RMAPPO algorithm to optimize UAV trajectory and traffic offloading in SAGIN, achieving higher throughput, lower energy consumption, and fairer resource allocation. Key innovations include integrating RNNs for temporal dependency modeling and a decentralized training framework for reduced overhead. Simulations confirmed RMAPPO’s superiority over IPPO and K-means in performance metrics. The work provides a practical solution for dynamic SAGIN environments, paving the way for efficient 6G network offloading. Future research may explore scalability and diverse scenario designs.
Acknowledgement: Not applicable.
Funding Statement: This research was funded by Army Engineering University of PLA.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Zheyuan Jia and Fenglin Jin; analysis and interpretation of results: Jun Xie; draft manuscript preparation: Yuan He. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the Corresponding Author, Fenglin Jin, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Cui H, Zhang J, Geng Y, Xiao Z, Sun T, Zhang N, et al. Space-air-ground integrated network (SAGIN) for 6G: requirements, architecture and challenges. China Commun. 2022;19(2):90–108. doi:10.23919/jcc.2022.02.008. [Google Scholar] [CrossRef]
2. Liu J, Shi Y, Fadlullah ZM, Kato N. Space-Air-ground integrated network: a survey. IEEE Commun Surv Tut. 2018;20(4):2714–41. [Google Scholar]
3. Mahboob S, Liu L. Revolutionizing future connectivity: a contemporary survey on ai-empowered satellite-based non-terrestrial networks in 6G. IEEE Commun Surv Tut. 2024;26(2):1279–321. doi:10.1109/comst.2023.3347145. [Google Scholar] [CrossRef]
4. Lyu J, Zeng Y, Zhang R. UAV-aided offloading for cellular hotspot. IEEE Trans Wireless Commun. 2018;17(6):3988–4001. doi:10.1109/twc.2018.2818734. [Google Scholar] [CrossRef]
5. Owaid SA, Miry AH, Salman TM. A survey on UAV-assistedwireless communications: challenges, technologies, and application. In: 2024 11th International Conference on Electrical and Electronics Engineering (ICEEE). Marmaris, Turkiye; 2024. p. 333–40. [Google Scholar]
6. Zaremba W, Sutskever I, Vinyals O. Recurrent neural network regularization. arXiv:1409.2329. 2014. [Google Scholar]
7. Qin Y, Yang Y, Tang F, Yao X, Zhao M, Kato N. Differentiated federated reinforcement learning based traffic offloading on space-air-ground integrated networks. IEEE Trans Mobile Comput. 2024;23(12):11000–13. doi:10.1109/tmc.2024.3389011. [Google Scholar] [CrossRef]
8. Huang C, Chen P. Mobile traffic offloading with forecasting using deep reinforcement learning. arXiv:1911.07452. 2019. [Google Scholar]
9. Hu X, Zhuang X, Feng G, Lv H, Wang H, Lin J. Joint optimization of traffic and computation offloading in UAV-assistedwireless networks. In: 2018 IEEE 15th International Conference on Mobile Ad Hoc and Sensor Systems (MASS). Chengdu, China; 2018. p. 475–80. [Google Scholar]
10. Li F, Zhang K, Wang J, Li Y, Xu F, Wang Y, et al. Multi-UAV hierarchical intelligent traffic offloading network optimization based on deep federated learning. IEEE Internet of Things J. 2024;11(12):21312–24. doi:10.1109/jiot.2024.3363188. [Google Scholar] [CrossRef]
11. Luo X, Xie J, Xiong L, Wang Z, Liu Y. UAV-assisted fair communications for multi-pair users: a multi-agent deep reinforcement learning method. Comput Netw. 2024;242(3):110277. doi:10.1016/j.comnet.2024.110277. [Google Scholar] [CrossRef]
12. Chapnevis A, Bulut E. AoI-optimal cellular-connected UAV trajectory planning for IoT data collection. In: 2023 IEEE 48th Conference on Local Computer Networks (LCN). Daytona Beach, FL, USA; 2023. p. 1–6. [Google Scholar]
13. Zhang X, Wang J, Wang B, Jiang F. Offloading strategy for UAV-assisted mobile edge computing based on reinforcement learning. In: 2022 IEEE/CIC International Conference on Communications in China (ICCC). Sanshui, China; 2022. p. 702–7. [Google Scholar]
14. An P, Du L, Chen Y. Learning-based task offloading and UAV trajectory optimization in SAGIN. In: 2024 33rd Wireless and Optical Communications Conference (WOCC). Hsinchu, Taiwan; 2024. p. 12–6. [Google Scholar]
15. Gao Y, Ye Z, Yu H. Cost-efficient computation offloading in SAGIN: a deep reinforcement learning and perception-aided approach. IEEE J Selected Areas Commun. 2024;42(12):3462–76. doi:10.1109/jsac.2024.3459073. [Google Scholar] [CrossRef]
16. Lakew DS, Masood A, Cho S. 3D UAV placement and trajectory optimization in UAV assisted wireless networks. In: 2020 International Conference on Information Networking (ICOIN). Barcelona, Spain; 2020. p. 80–2. [Google Scholar]
17. Chapnevis A, Güvenç I, Njilla L, Bulut E. Collaborative trajectory optimization for outage-aware cellular-enabled UAVs. In: 2021 IEEE 93rd Vehicular Technology Conference (VTC2021). Helsinki, Finland; 2021. p. 1–6. [Google Scholar]
18. Fan B, Jiang L, Chen Y, Zhang Y, Wu Y. UAV Assisted traffic offloading in air ground integrated networks with mixed user traffic. IEEE Trans Intell Transp Syst. 2022;23(8):12601–11. doi:10.1109/tits.2021.3115462. [Google Scholar] [CrossRef]
19. Kanellopoulos SA, Kourogiorgas CI, Panagopoulos AD, Livieratos SN, Chatzarakis GE. Channel model for satellite communication links above 10GHz based on weibull distribution. IEEE Commun Lett. 2014;18(4):568–71. doi:10.1109/lcomm.2014.013114.131950. [Google Scholar] [CrossRef]
20. Tan J, Tang F, Zhao M, Kato N. Performance analysis of space-air-ground integrated network (SAGINUAV altitude and position angle. In: 2023 IEEE/CIC International Conference on Communications in China (ICCC). Dalian, China; 2023. p. 1–6. [Google Scholar]
21. Al-Hourani A, Kandeepan S, Lardner S. Optimal LAP altitude for maximum coverage. IEEE Wireless Commun Lett. 2014;3(6):569–72. doi:10.1109/lwc.2014.2342736. [Google Scholar] [CrossRef]
22. Seid AM, Boateng GO, Mareri B, Sun G, Jiang W. Multi-agent DRL for Task offloading and resource allocation in multi-UAV enabled IoT edge network. IEEE Trans Netw Service Manage. 2021;18(4):4531–47. doi:10.1109/tnsm.2021.3096673. [Google Scholar] [CrossRef]
23. Sediq AB, Gohary RH, Schoenen R, Yanikomeroglu H. Optimal tradeoff between sum-rate efficiency and jain’s fairness index in resource allocation. IEEE Trans Wireless Commun. 2013;12(7):3496–509. doi:10.1109/twc.2013.061413.121703. [Google Scholar] [CrossRef]
24. Acharyya R, Basappa M, Das GK. Unit disk cover problem in 2D. In: Murgante B, Misra S, Carlini M, Torre CM, Nguyen HQ, Taniar D, et al., editors. Computational Science and Its Applications-ICCSA 2013. Berlin/Heidelberg, Germany: Springer; 2013. p. 73–85 doi:10.1007/978-3-642-39643-4_6. [Google Scholar] [CrossRef]
25. Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv:1707.06347. 2017. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools