
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Intelligent Semantic Segmentation with Vision Transformers for Aerial Vehicle Monitoring
Department of Computer Science, College of Science and Humanities Dawadmi, Shaqra University, Dawadmi, 11911, Saudi Arabia
* Corresponding Author: Moneerah Alotaibi. Email:
Computers, Materials & Continua 2026, 86(1), 1-20. https://doi.org/10.32604/cmc.2025.069195
Received 17 June 2025; Accepted 25 September 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Advanced traffic monitoring systems encounter substantial challenges in vehicle detection and classification due to the limitations of conventional methods, which often demand extensive computational resources and struggle with diverse data acquisition techniques. This research presents a novel approach for vehicle classification and recognition in aerial image sequences, integrating multiple advanced techniques to enhance detection accuracy. The proposed model begins with preprocessing using Multiscale Retinex (MSR) to enhance image quality, followed by Expectation-Maximization (EM) Segmentation for precise foreground object identification. Vehicle detection is performed using the state-of-the-art YOLOv10 framework, while feature extraction incorporates Maximally Stable Extremal Regions (MSER), Dense Scale-Invariant Feature Transform (Dense SIFT), and Zernike Moments Features to capture distinct object characteristics. Feature optimization is further refined through a Hybrid Swarm-based Optimization algorithm, ensuring optimal feature selection for improved classification performance. The final classification is conducted using a Vision Transformer, leveraging its robust learning capabilities for enhanced accuracy. Experimental evaluations on benchmark datasets, including UAVDT and the Unmanned Aerial Vehicle Intruder Dataset (UAVID), demonstrate the superiority of the proposed approach, achieving an accuracy of 94.40% on UAVDT and 93.57% on UAVID. The results highlight the efficacy of the model in significantly enhancing vehicle detection and classification in aerial imagery, outperforming existing methodologies and offering a statistically validated improvement for intelligent traffic monitoring systems compared to existing approaches.Keywords
The rapid urbanization and growing number of vehicles have intensified the need for advanced traffic monitoring systems [1]. Accurate vehicle detection and classification are vital to intelligent transportation systems (ITS), supporting traffic control and security. Traditional methods using handcrafted features and classical machine learning often lack robustness in aerial imagery due to issues like illumination changes, occlusion, and perspective distortion. These approaches also demand high computational resources and struggle with adaptability across diverse platforms like drones and satellites. Recent advancements in deep learning, particularly semantic segmentation and transformer architecture, offer improved solutions. This study proposes a semantic segmentation framework for aerial vehicle monitoring by integrating Vision Transformers (ViTs) with enhanced preprocessing and optimization techniques. Multiscale Retinex (MSR) improves image contrast, while EM segmentation isolates foreground objects. YOLOv10 provides fast and precise vehicle detection [2]. A combination of MSER, Dense SIFT, and Zernike Moments captures detailed features, which are refined using a Hybrid Swarm-based Optimization strategy. ViTs then process spatial dependencies efficiently. Experiments on UAVDT and UAVID datasets demonstrate superior performance over conventional methods [3], confirming the framework’s effectiveness for real-world, scalable traffic surveillance. Unlike prior approaches that either rely solely on handcrafted descriptors or deep learning models, our method uniquely integrates region-, texture-, and shape-based features with a novel PSO–ACO-based optimization and classifies them using a Vision Transformer, enabling a robust and scalable framework for aerial vehicle monitoring.
UAV-based vehicle detection methods fall into two main categories: traditional handcrafted techniques and deep learning frameworks. Handcrafted methods (e.g., SIFT, MSER, HOG) are understandable and lightweight but struggle with aerial challenges like scale, rotation, and illumination changes. Deep learning models such as YOLOv5, YOLOv8, and Faster R-CNN offer higher accuracy but require large datasets, lack interpretability, and generalize poorly without retraining. Vision Transformers (ViTs) have shown promise in capturing spatial dependencies but are rarely combined with handcrafted features in UAV traffic monitoring. Existing fusion methods often neglect intelligent feature selection, leading to redundancy and inefficiency. To overcome these gaps, this study introduces a unified framework that integrates MSER and EM-based segmentation, multi-domain handcrafted feature extraction (MSER, Dense SIFT, and Zernike Moments), hybrid PSO–ACO optimization, and a ViT classifier. This hybrid approach balances interpretability, performance, and efficiency, offering a robust solution for real-time aerial vehicle recognition. The rest of this article is structured as: Section 2 reviews existing aerial vehicle detection and classification methods, highlighting their limitations. Section 3 details the proposed framework, including preprocessing, segmentation, feature extraction, and classification. Section 4 presents experimental analysis, evaluating performance on benchmark datasets against state-of-the-art methods. Finally, Section 5 summarizes contributions and outlines future research directions.
Aerial vehicle monitoring has become increasingly important in transportation, surveillance, and urban planning. Challenges like scale variation, occlusion, and complex backgrounds affect detection accuracy. Traditional methods use handcrafted features, while deep learning offers automated, more effective solutions. This section reviews both approaches, outlining their strengths, limitations, and improvement areas.
2.1 Machine Learning Based Approaches
Ayush Kumar et al. [4] addressed small vehicle detection in aerial imagery using PCA for dimensionality reduction, improving accuracy by reducing misclassifications. Among deep models, ResNet50 outperformed MobileNetv1 (85% vs. 76.25%), emphasizing model selection. However, ambiguity in detecting small objects remained a challenge. Qureshi et al. [5] proposed vehicle detection via channel differencing, blob detection, and shape matching, but the method lacked robustness against varying angles and dataset diversity. Lin et al. [6] introduced the VAID dataset with 6000 aerial images and achieved 88% accuracy using a similar approach, though its performance dropped under non-uniform conditions. Chen et al. [7] combined a Deformable Part Model (DPM) with a CNN to enhance structural feature capture and robustness, especially in occluded or angled views.
2.2 Deep Learning Based Approaches
Zhuang et al. [8] addressed inefficiencies in UAV detection caused by patch-based image splitting and proposed a lightweight multi-task classification (MTC) network to enhance speed. However, its performance in dense scenes and accurate trade-offs remains unexamined. Zuraimi et al. [9] combined YOLOv4 with DeepSORT, achieving 82.08% precision, but lacked solutions for occlusion and lighting issues. Yang et al. [10] introduced BFEN with SLPN and PNW, reaching 88.71% mAP on DETRAC, though it wasn’t tested in rural settings and had unclear complexity. Rani et al. [11] merged Faster R-CNN and SSD, with performance dropping from 85.22% (KITTI) to 64.83% (PASCAL2007), revealing limitations under varied conditions. Basak and Suresh [12] achieved 87.56% on CityCam using CNNs in low-res traffic scenes, but environmental variability was not assessed. Lyu et al. [13] used a CNN-based segmentation model on UAVID, achieving 85% accuracy, though they struggled with small object tracking and temporal consistency.
Unlike these methods, our proposed approach addresses small object detection, occlusions, and scene diversity. It employs MSR for illumination enhancement, EM for accurate segmentation, and YOLOv10 for robust detection. MSER, Dense SIFT, and Zernike Moments ensure rich feature extraction, optimized via Hybrid Swarm-based selection. Finally, the Vision Transformer handles scale variance and background clutter through self-attention, delivering high accuracy and generalization in UAV-based vehicle monitoring. While existing works have explored individual use of descriptors or CNN-based architectures, few have combined handcrafted multi-view features with transformer-based classification. To the best of our knowledge, this is the first approach that fuses MSER, Dense SIFT, and Zernike features; applies a hybrid PSO–ACO optimization for redundancy reduction; and leverages a Vision Transformer for final recognition in UAV-based traffic monitoring.
The proposed framework offers an efficient solution for aerial vehicle detection and classification. It starts with converting image sequences into frames, followed by noise removal and MSR for contrast enhancement. EM segmentation isolates foreground objects, and YOLOv10 performs accurate vehicle detection. Features are extracted using MSER, Dense SIFT, and Zernike Moments, then refined via Hybrid Swarm-Based Optimization. Finally, the Vision Transformer classifies vehicles using its attention mechanism. This streamlined pipeline improves both accuracy and efficiency, as illustrated in Fig. 1.
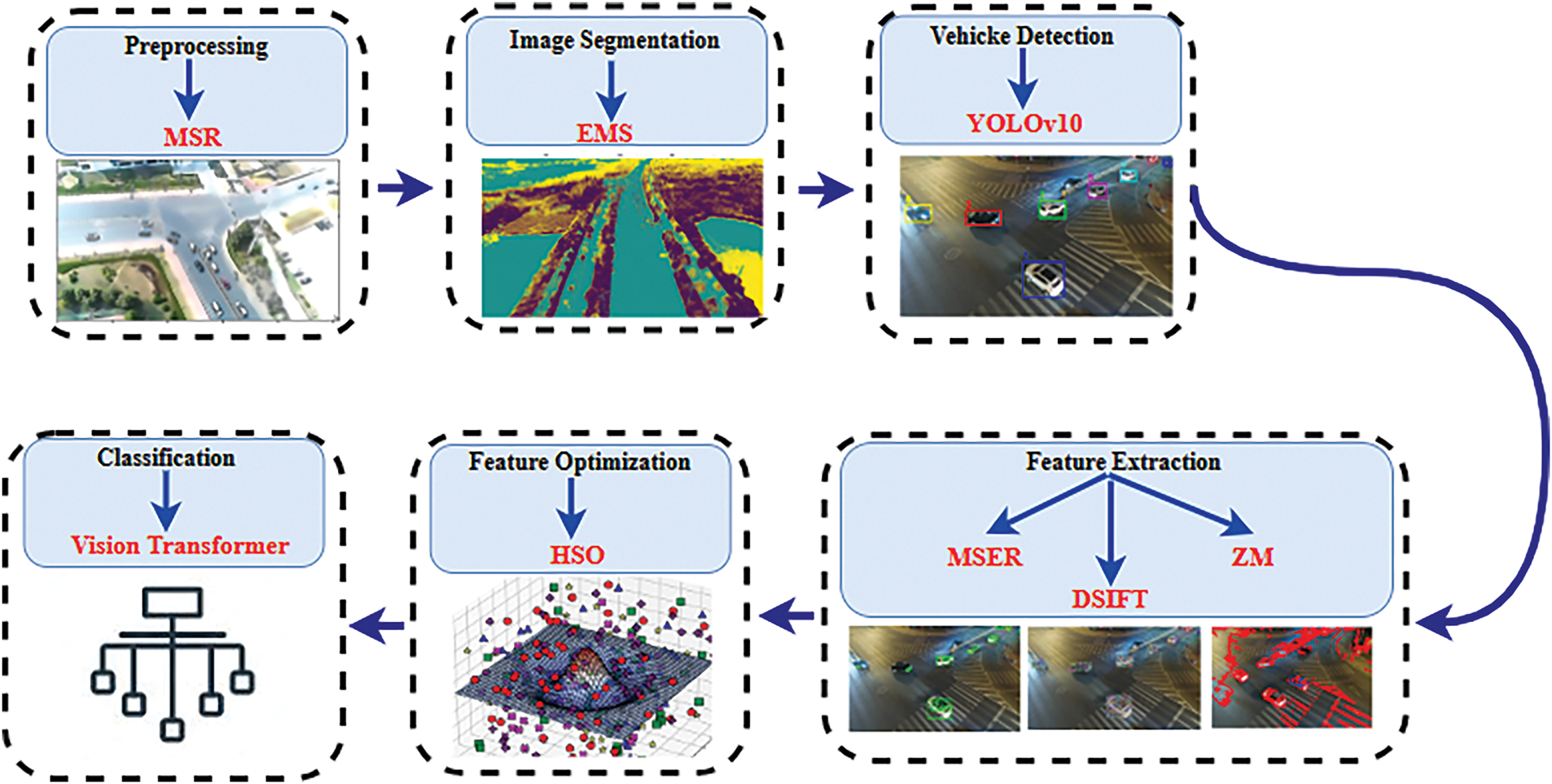
Figure 1: Intelligent traffic monitoring framework integrating preprocessing, segmentation, detection, and classification for accurate real-time analysis
Preprocessing is crucial in aerial vehicle detection due to common issues like illumination variation, shadows, and low contrast from atmospheric or sensor limitations. To address this, Multiscale Retinex (MSR) is applied as an advanced enhancement technique that normalizes illumination while preserving details [14]. Unlike conventional methods, MSR enhances both dark and bright regions by estimating reflectance across multiple Gaussian scales, making vehicles more visible in challenging backgrounds. This makes MSR highly suitable for aerial imagery. The mathematical formulation is shown in Eq. (1):
here, R(x, y) is the enhanced reflectance, I(x, y) is the input image, and
where

Figure 2: Preprocessing via MSR (a) Original frame (b) Preprocessed frame
3.2 Segmentation: Expectation-Maximization (EM)
Segmentation is vital in aerial vehicle detection to separate vehicles from complex backgrounds, enabling accurate feature extraction and classification. Given challenges like lighting variation and occlusions, the Expectation-Maximization (EM) algorithm is applied as a robust probabilistic segmentation method [15]. Unlike traditional thresholding or edge-based techniques, EM uses Gaussian mixtures to model pixel intensities and iteratively refines clusters, ensuring adaptive and precise segmentation, as shown in Eq. (3):
where,
where

Figure 3: Segmentation via EMS (a) Original Image (b) Segmented Output
Comparative Evaluation of Segmentation Methods
To validate the effectiveness of EM segmentation in aerial scenes, we compared it against two commonly used unsupervised segmentation methods: Otsu’s thresholding and K-means clustering. All three methods were evaluated on UAVDT frames, using Intersection over Union (IoU) and Dice Similarity Coefficient (DSC) to measure performance. Table 1 shows the quantative comparison of the segmentation strategies.

The results demonstrate that the EM algorithm consistently provides better foreground object separation, particularly in complex aerial backgrounds with varied lighting and occlusion. This strong performance supports its integration in our proposed vehicle monitoring pipeline.
Accurate vehicle detection is essential for aerial surveillance applications, including traffic monitoring and urban planning. However, challenges such as scale variation, occlusion, and dense traffic complicate the task of aerial detection. This study employs YOLOv10, a cutting-edge model designed for fast and precise detection in complex scenes. Unlike region-based methods, YOLO processes the entire image in one pass, enhancing efficiency for large-scale UAV imagery. YOLOv10 boosts performance through an upgraded backbone, an improved Feature Pyramid Network (FPN), and an anchor-free design, making it particularly effective at detecting small vehicles. The detection pipeline consists of feature extraction, bounding box regression, and classification, utilizing a lightweight convolutional backbone:
where,
where,
where
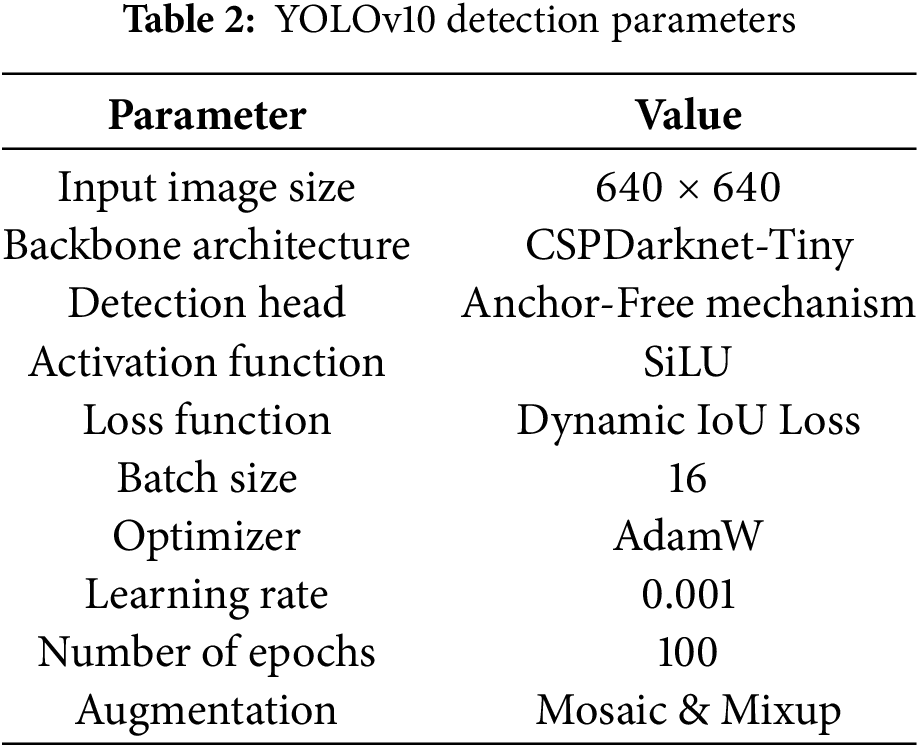

Figure 4: Precise vehicle detection outcomes using YOLOv10 for intelligent traffic monitoring
Feature extraction plays a vital role in vehicle classification by transforming raw images into meaningful representations. This study employs MSER, Dense SIFT, and Zernike Moments to boost detection accuracy. MSER detects stable regions under lighting changes, Dense SIFT captures multi-scale textures, and Zernike Moments offer rotation-invariant shape descriptors. Their integration enhances recognition by addressing scale variation, clutter, and occlusion in aerial imagery.
3.4.1 Maximally Stable Extremal Regions (MSER)
Maximally Stable Extremal Regions (MSER) is a region-based feature extraction method known for its stability under varying conditions, making it valuable for aerial vehicle detection. It identifies consistent regions despite changes in illumination, scale, or viewpoint by analyzing image areas with intensity values significantly different from their surroundings. By selecting stable regions across intensity thresholds, MSER effectively isolates vehicle-like structures in complex aerial scenes. Mathematically, given an intensity function I(x, y), an extremal region R satisfies the condition described in Eq. (8).
The stability of region R is determined by evaluating its area change rate across varying thresholds, given in Eq. (9):
where

Figure 5: MSER based Feature extraction over Vehicles
3.4.2 Dense Scale-Invariant Feature Transform (Dense SIFT)
Dense SIFT enhances vehicle recognition by capturing fine-grained texture and structural details across multiple scales. Unlike traditional SIFT, which operates on keypoints, Dense SIFT applies descriptors uniformly across the image grid [16], ensuring better coverage. This is particularly effective for aerial detection where scales, orientation, and lighting vary. The dense computation yields richer structural representation, boosting classification in cluttered scenes. Mathematically, it begins by constructing a scale-space representation of image I(x, y) using a Gaussian function (
where,
Dense SIFT’s strength lies in its ability to provide a detailed texture description, making it particularly effective in aerial vehicle detection where shape alone may not be sufficient for accurate classification. The results of the SIFT can be depicted in Fig. 6.

Figure 6: Dense SIFT based Feature extraction of vehicles over the Aerial Images
Zernike Moments (ZM) are compact and discriminative shape descriptors that capture global structure while ensuring rotational invariance ideal for UAV-based vehicle detection where objects vary in orientation and scale. They represent image regions using orthogonal Zernike polynomials, reducing redundancy and preserving essential shape features [17]. Mathematically, Zernike Moments of order n and repetition m for an image function I(x, y) are defined as:
where

Figure 7: ZM based feature extraction
Feature optimization improves aerial vehicle detection by selecting relevant features and reducing redundancy. This study uses Hybrid Swarm-Based Optimization (HSO), combining PSO’s global search with ACO’s efficient pathfinding. HSO enhances classification accuracy and avoids premature convergence by refining features from MSER, Dense SIFT, and Zernike Moments. PSO updates positions using personal and global bests to optimize feature subsets:
where
where
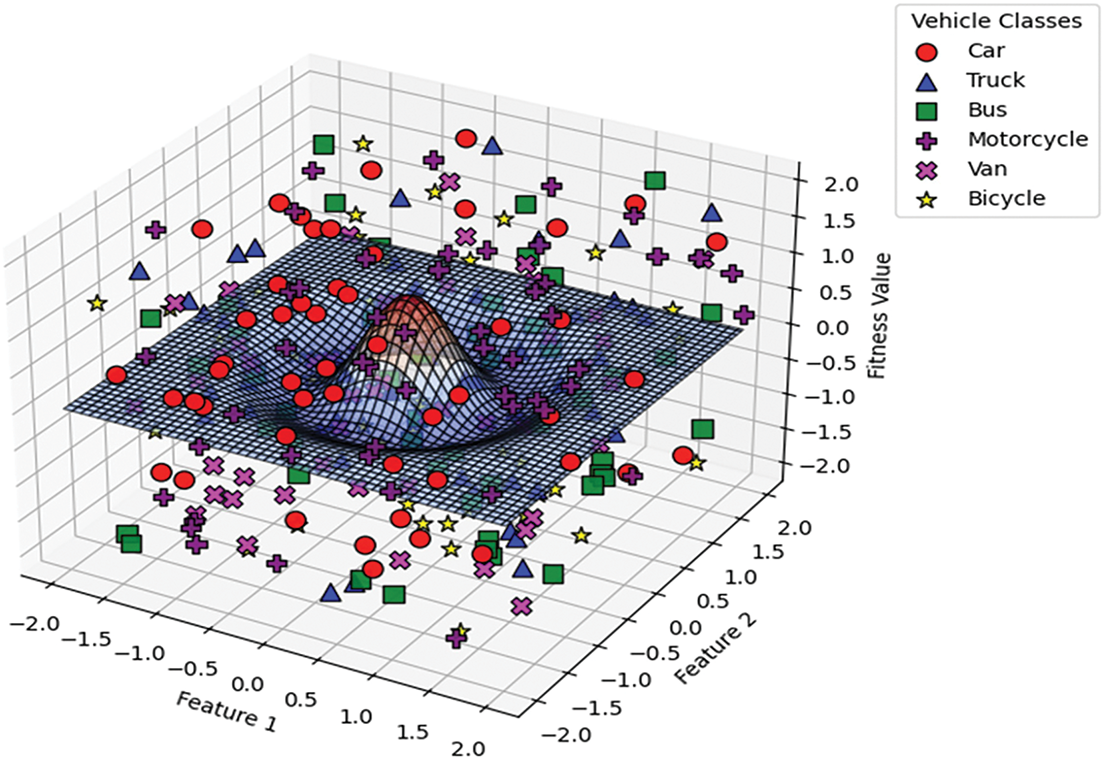
Figure 8: 3D hybrid swarm-based optimized features graph across vehicle classes
Table 3 lists the key parameter values used in the hybrid PSO–ACO optimization process, selected based on experimental tuning and literature guidance.

The optimization terminates when either the maximum number of iterations is reached or no improvement in classification accuracy is observed over 10 consecutive iterations. The final subset is chosen based on the highest validation accuracy achieved using the Vision Transformer classifier. Algorithm 1 shows the flow of Hybrid swarm optimization below.

The Vision Transformer (ViT) is used for classifying detected vehicles in aerial imagery, utilizing self-attention to capture long-range spatial dependencies and patterns. Unlike CNNs, ViT learns global relationships across the entire image, making it effective for handling scale, occlusion, and perspective variations [18]. The process starts by dividing the image into non-overlapping patches, which are linearly embedded and passed, along with a classification token, into the transformer encoder. Multi-head self-attention (MHSA) then models dependencies between all patches, formulated as:
where
where
where
Table 4 provides a structured overview of the critical hyperparameters and configurations used in the Vision Transformer-based vehicle classification model. To train the Vision Transformer classifier, we initialized the model with pretrained weights from the ImageNet-21k dataset. The transformer was then fine-tuned on the optimized feature vectors obtained from our feature extraction and Hybrid Swarm Optimization pipeline. We used the AdamW optimizer with an initial learning rate of 3 × 10−4 and applied a cosine annealing rate schedule to gradually reduce the learning rate to 1 × 10−6 over the training process.

The model was trained for a maximum of 100 epochs with a batch size of 32, and early stopping was implemented with a patience of 10 epochs, monitoring the validation F1-score. Training was conducted using PyTorch 1.12 on an NVIDIA RTX 3060 GPU (6 GB VRAM). The data augmentation included feature-level mixing and standardization. This configuration enabled stable convergence while preventing overfitting and allowed the Vision Transformer to generalize effectively across both UAVDT and UAVID datasets.
Vanishing Gradient Consideration
A potential concern in deep learning models is the vanishing gradient problem, especially in architectures with multiple stacked layers. However, our classification module specifically designs the Vision Transformer (ViT) to mitigate such issues. ViT employs residual connections and layer normalization, which facilitate better gradient flow across layers. Furthermore, the self-attention mechanism in ViT does not rely on deep convolutional stacks, thereby reducing gradient attenuation risks. The use of the AdamW optimizer with adaptive learning rates also helps stabilize training and maintain effective backpropagation. As a result, our approach does not suffer from vanishing gradients during training, and stable convergence was observed across all experiments.
Algorithm 2 presents the full vehicle detection and classification pipeline, integrating all stages from aerial video input through preprocessing, segmentation, detection, feature extraction, optimization, and final classification. This unified approach ensures high accuracy by leveraging advanced techniques at each step. Key advantages include:
• Integrated Pipeline: Combines enhancement, segmentation, detection, feature selection, and classification in one cohesive framework.
• Robust Aerial Performance: MSR and EM segmentation improve visibility under varied lighting and clutter.
• Optimized Features: HSO selects the most relevant features, boosting accuracy and efficiency.
• Transformer-Based Learning: Vision Transformer captures spatial and contextual cues beyond CNNs.
• Scalable Design: Modular architecture allows easy adaptation to other detection tasks or datasets.
This algorithm offers a validated and practical solution for intelligent aerial vehicle monitoring through end-to-end integration and advanced feature optimization. Alogrithm 2 shows the complete proposed methodolgy below.

The proposed approach was implemented and evaluated in the Python 3.9 environment, leveraging advanced deep learning and image processing libraries to ensure efficiency and accuracy. The key dependencies utilized include:
• PyTorch 1.12 (for Vision Transformer-based vehicle classification)
• OpenCV 4.6 (for image preprocessing and feature extraction)
• scikit-learn 1.0 (for feature optimization and selection)
• pymc 4.1 (for Expectation-Maximization-based segmentation)
The experiments were conducted on an Intel Core i7-12700H 2.70 GHz processor with 32 GB RAM and an NVIDIA RTX 3060 GPU (6 GB VRAM) to ensure high computational efficiency. The proposed model was evaluated on UAVDT and UAVID, datasets, demonstrating its effectiveness in aerial vehicle monitoring. A comparative analysis with existing state-of-the-art methods further validates the robustness of the approach.
This subsection introduces the benchmark datasets used to evaluate the proposed framework: UAVDT and UAVID, both widely recognized for aerial object recognition. Sections 4.1.1 and 4.1.2 detail their characteristics and challenges. These datasets validate the robustness and generalization of our approach across diverse conditions.
Introduced by Du et al. [19], UAVDT comprises approximately 10 h of UAV video footage, from which 100 video sequences (~80,000 frames) were selected. A total of ~0.84 million vehicle bounding boxes are annotated, with rich metadata including illumination conditions (daylight, night, fog), flying altitude, camera view, occlusion levels, and vehicle categories. Videos are captured at 30 fps with a resolution of 1080 × 540 pixels. This dataset supports object detection (DET), single-object tracking (SOT), and multi-object tracking (MOT) tasks.
Published by Lyu et al. [13], UAVID consists of 30 high-resolution 4K video sequences (later extended to 42 sequences) captured from oblique angles. A subset of 300 images is densely annotated for eight semantic categories: building, road, tree, low vegetation, static car, moving car, human, and background clutter. This dataset addresses challenges such as scale variation, moving object recognition, and temporal label consistency, and uses mean Intersection-over-Union (mIoU) as the evaluation metric.
4.2 Model Evaluation and Experimental Results
The k-fold cross-validation strategy was used to assess the proposed model’s performance on UAVDT and UAVID datasets, ensuring robust generalization across diverse scenarios. The evaluation demonstrated high effectiveness in vehicle detection and classification, with UAVDT achieving 94.40% accuracy, as shown in Fig. 9, while Precision, Recall, and F1-scores are detailed in Table 5.
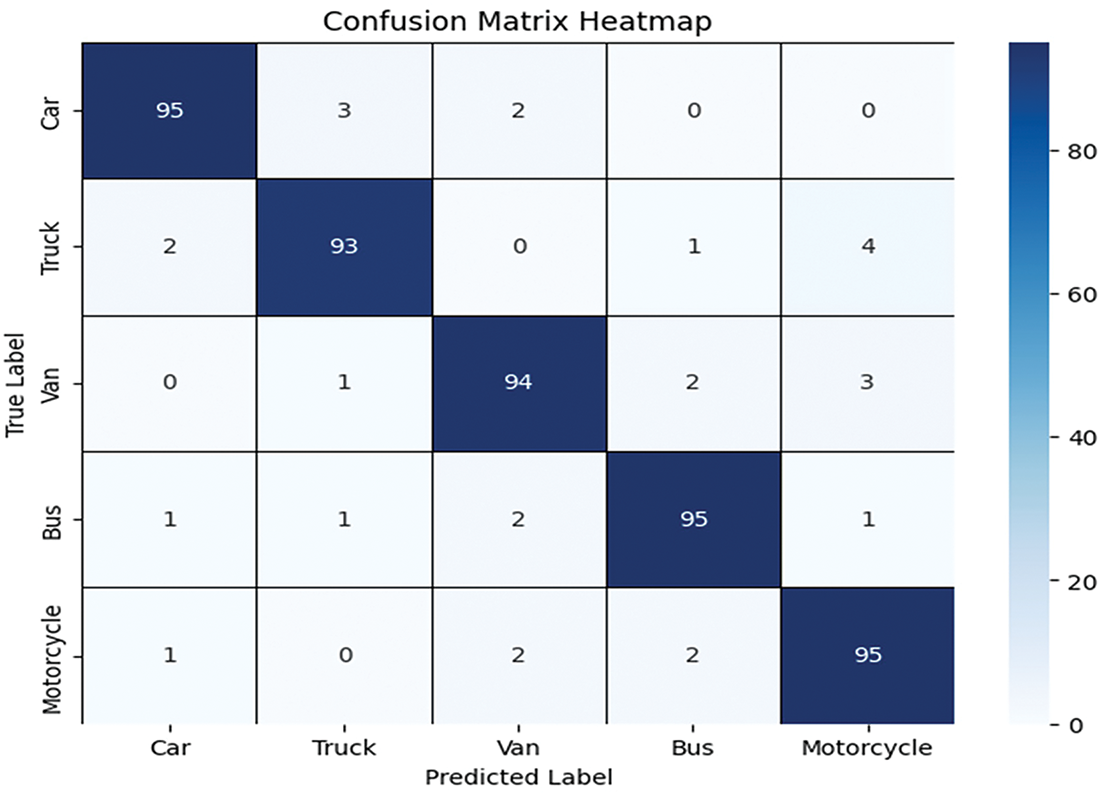
Figure 9: Confusion matric result for the UAVDT dataset

We calculate Precision, Recall, and F1-score (F-measure) using the Vision Transformer. These metrics are then visualized through curves that depict their respective values.
For the UAVID dataset, the confusion matrix results are provided in Fig. 10, showing the confusion matrix, with the Precision, Recall, and F1-scores in Table 6. While Table 7 shows the comparison with SOTA methods.
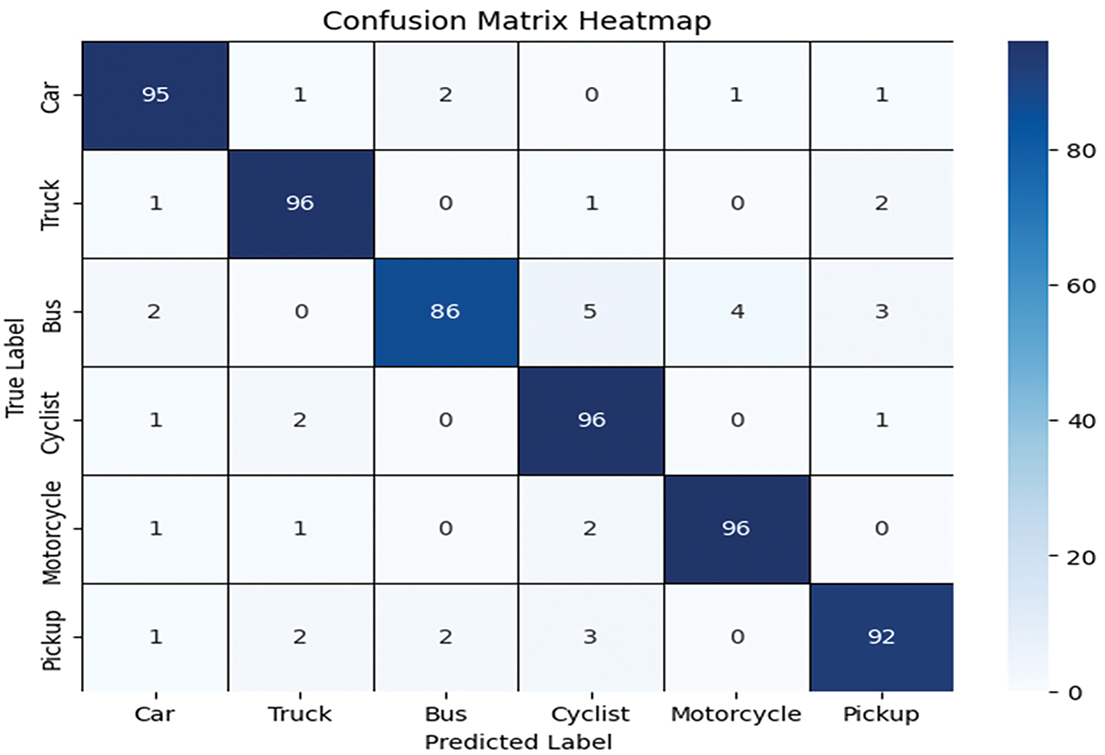
Figure 10: Confusion matrix result for the UAVID dataset


The comparison table highlights that the proposed method achieves the highest accuracy on both UAVDT (94.40%) and UAVID (93.57%) datasets. Prior methods generally show lower performance, with most results ranging between 75%–92%. Several existing works reports results on only one dataset, limiting their generalization.
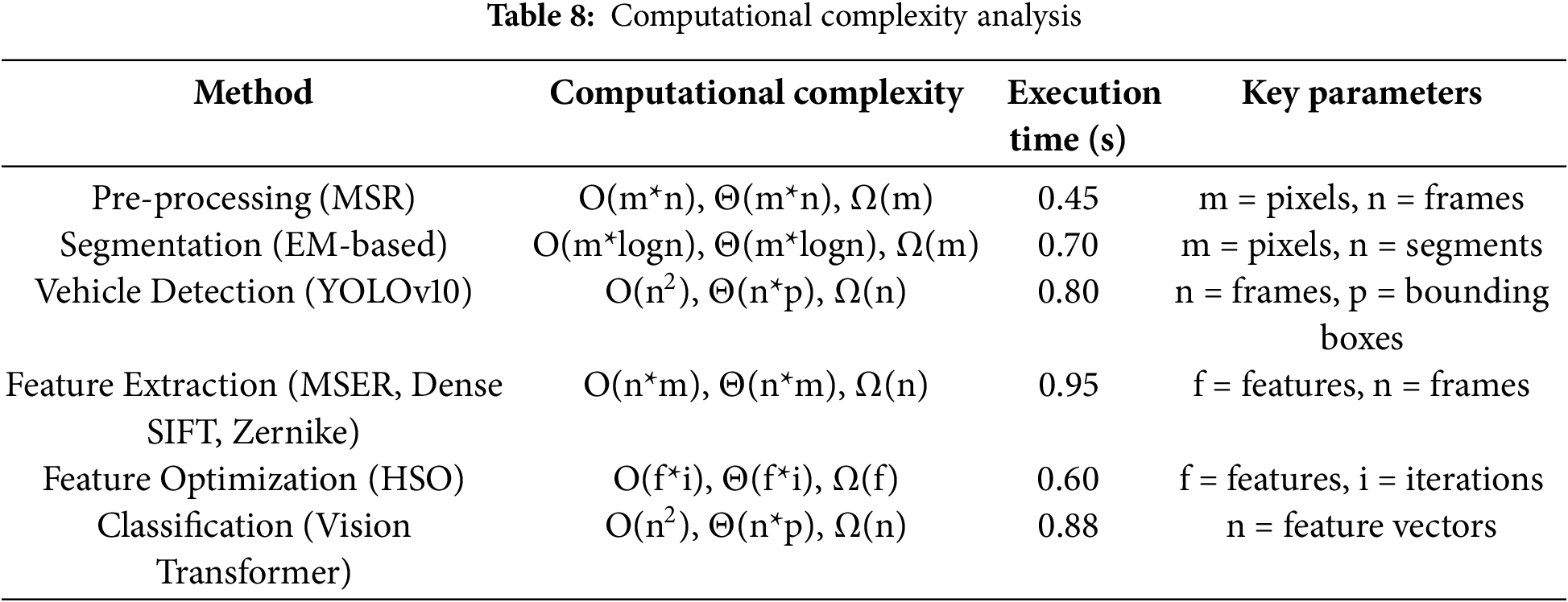
4.3 Computational Complexity Assessment and Justification
The complexity of preprocessing and segmentation depends on pixel count per frame, while YOLOv10 detection scales with frames and bounding boxes, showing quadratic growth. Feature extraction relies on keypoints, and HSO is influenced by feature vectors and iterations. Vision Transformer classification, based on embeddings, generally has cubic complexity. Table 8 summarizes execution times and module-wise efficiency.
Real-Time System Feasibility
To assess the system’s practical usability in real-world traffic monitoring, we evaluated the average processing time of each module on an NVIDIA RTX 3060 GPU (6 GB VRAM). Table 9 presents the breakdown of runtime:

The system achieves an average speed of ~24 FPS, confirming its suitability for real-time traffic monitoring. Since HSO is performed offline, it does not affect inference. Feature extraction supports CPU parallelization, and ViT inference benefits from GPU acceleration and batching, with future deployment feasible on edge devices via model pruning and quantization.
Although the proposed hybrid framework demonstrates promising results in aerial vehicle recognition, there remain several avenues for improvement and further exploration. First, while the current system performs well on UAVDT and UAVID datasets, future work should focus on evaluating the model’s generalizability across additional datasets that cover more extreme variations, such as occlusion-heavy or low-resolution nighttime traffic footage. Second, the computational cost associated with multi-stage feature extraction and optimization, although mitigated through HSO, can be further reduced by exploring lightweight descriptor alternatives or model pruning strategies for real-time edge deployment. Third, integrating a self-adaptive feature selection mechanism or reinforcement learning-based optimization may help further reduce redundancy and dynamically adjust to diverse environments. Lastly, incorporating spatiotemporal information, such as object tracking and temporal attention modules, could expand the system’s capabilities toward video-based behavior analysis and anomaly detection in UAV-based surveillance. Fig. 11 shows some limitation of the proposed system.

Figure 11: Visual examples of failure cases under poor lighting, motion blur, and occlusion
4.5 Ablation Study and Module-Wise Impact Analysis
To evaluate the individual contribution of each module within the proposed framework, an ablation study was conducted by systematically removing or replacing specific components, and the results are summarized in Table 10.

The ablation study evaluates the individual and combined impact of each module in the proposed framework on classification accuracy across UAVDT and UAVID datasets. Removing key components like MSR preprocessing, EM segmentation, or HSO optimization leads to a noticeable performance drop, confirming their contribution. Replacing YOLOv10 or ViT with alternate models (e.g., YOLOv8, ResNet50) also results in decreased accuracy, highlighting the effectiveness of the chosen architecture. The full model achieves the highest accuracy (94.40% on UAVDT), validating the synergy of all components. Overall, the study demonstrates that the integration of all modules is crucial for optimal performance.
In this work, we proposed a multi-stage vehicle detection and classification framework that integrates advanced feature extraction, optimization, and deep learning-based classification. The methodology leverages YOLOv10 for precise detection, with MSER, Dense SIFT, and Zernike Moments for feature extraction, followed by Hybrid Swarm-based Optimization and classification using a Vision Transformer model. Evaluations on benchmark datasets achieved high accuracy, including 94.40% on UAVDT and 93.57% on UAVID, highlighting the robustness and efficiency of the framework in complex aerial imagery complex. Looking ahead, future directions include extending the framework with multi-modal aerial data (e.g., thermal or LiDAR) for enhanced robustness and adopting lightweight Transformer variants for real-time edge deployment. Additionally, incorporating self-supervised strategies and exploring multi-drone collaborative monitoring can broaden its applicability. These advancements position the framework as a promising solution for practical scenarios such as smart city traffic management and large-scale aerial surveillance.
Acknowledgement: The author would like to thank the Deanship of Scientific Research at Shaqra University for supporting this work.
Funding Statement: The author received no specific funding for this study.
Availability of Data and Materials: All publicly available datasets are used in the study.
Ethics Approval: Not applicable.
Conflicts of Interest: The author declares no conflicts of interest to report regarding the present study.
References
1. Zhang Z, Li G. UAV imagery real-time semantic segmentation with global-local information attention. Sensors. 2025;25(6):1786. doi:10.3390/s25061786. [Google Scholar] [PubMed] [CrossRef]
2. Trivedi J, Devi MS, Solanki B. Step towards intelligent transportation system with vehicle classification and recognition using speeded-up robust features. Arch Tech Sci. 2023;28(1):39–56. doi:10.59456/afts.2023.1528.039J. [Google Scholar] [CrossRef]
3. Verdhan A, Saini V, Kukreti DC, Negi R, Bohra M, Kumar I. Real-time vehicle classification using deep neural networks based model. In: Proceedings of the 2024 First International Conference on Technological Innovations and Advance Computing (TIACOMP); 2024 Jun 29–30; Bali, Indonesia. p. 101–6. doi:10.1109/TIACOMP64125.2024.00027. [Google Scholar] [CrossRef]
4. Ayush Kumar CS, Maharana AD, Krishnan SM, Hanuma SS, Sowmya V, Ravi V. Vehicle detection from aerial imagery using principal component analysis and deep learning. In: Proceedings of the 13th International Conference on Innovations in Bio-Inspired Computing and Applications; 2022 Dec 15–17; Seattle, WA, USA. p. 129–40. doi:10.1007/978-3-031-27499-2_12. [Google Scholar] [CrossRef]
5. Qureshi AM, Jalal A. Vehicle detection and tracking using Kalman filter over aerial images. In: Proceedings of the 4th International Conference on Advancements in Computational Sciences (ICACS); 2023 Feb 20–22; Lahore, Pakistan. p. 1–6. doi:10.1109/ICACS55311.2023.10089701. [Google Scholar] [CrossRef]
6. Lin HY, Tu KC, Li CY. VAID: an aerial image dataset for vehicle detection and classification. IEEE Access. 2020;8:212209–19. doi:10.1109/ACCESS.2020.3040290. [Google Scholar] [CrossRef]
7. Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL. Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Access. 2017;40(4):834–48. doi:10.1109/TPAMI.2017.2699184. [Google Scholar] [PubMed] [CrossRef]
8. Zhuang S, Hou Y, Wang D. Towards efficient object detection in large-scale UAV aerial imagery via multi-task classification. Drones. 2025;9(1):29. doi:10.3390/drones9010029. [Google Scholar] [CrossRef]
9. Zuraimi MA, Zaman FH. Vehicle detection and tracking using YOLO and DeepSORT. In: Proceedings of the IEEE 11th IEEE Symposium on Computer Applications & Industrial Electronics (ISCAIE); 2021 Apr 3–4; Penang, Malaysia. p. 23–9. doi:10.1109/ISCAIE51753.2021.9431784. [Google Scholar] [CrossRef]
10. Yang J, Xie X, Wang Z, Zhang P, Zhong W. Bi-directional information guidance network for UAV vehicle detection. Complex Intell Syst. 2024;10(4):5301–16. doi:10.1007/s40747-024-01429-9. [Google Scholar] [CrossRef]
11. Rani S, Dalal S. Comparative analysis of hybrid and deep learning models for vehicle tracking. In: Proceedings of the 2024 Second International Conference on Advanced Computing & Communication Technologies (ICACCTech); 2024 Nov 16–17; Rai, India. p. 835–41. doi:10.1109/ICACCTech65084.2024.00137. [Google Scholar] [CrossRef]
12. Basak S, Suresh S. Vehicle detection and type classification in low resolution congested traffic scenes using image super resolution. Multimed Tools Appl. 2023;83(8):21825–47. doi:10.1007/s11042-023-16337-2. [Google Scholar] [CrossRef]
13. Lyu Y, Vosselman G, Xia GS, Yilmaz A, Yang MY. UAVid: a semantic segmentation dataset for UAV imagery. arXiv:1810.10438. 2018. doi:10.1016/j.isprsjprs.2020.05.009. [Google Scholar] [CrossRef]
14. Pandey P, Saurabh P, Verma B, Tiwari B. A multi-scale retinex with color restoration (MSR-CR) technique for skin cancer detection. In: Soft computing for problem solving. Singapore: Springer; 2019. p. 465–73. doi:10.1007/978-981-13-1595-4_37. [Google Scholar] [CrossRef]
15. Li X, Zhong Z, Wu J, Yang Y, Lin Z, Liu H. Expectation-maximization attention networks for semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision 2019; 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 9167–76. doi:10.1109/ICCV.2019.00926. [Google Scholar] [CrossRef]
16. Li Y, Leong W, Zhang H. YOLOv10-based real-time pedestrian detection for autonomous vehicles. In: Proceedings of the 2024 IEEE 8th International Conference on Signal and Image Processing Applications (ICSIPA); 2024 Sep 3–5; Kuala Lumpur, Malaysia. p. 1–6. doi:10.1109/ICSIPA62061.2024.10686546. [Google Scholar] [CrossRef]
17. Li X, Li X, Li Z, Xiong X, Khyam MO, Sun C. Robust vehicle detection in high-resolution aerial images with imbalanced data. IEEE Trans Artif Intell. 2021;2(3):238–50. doi:10.1109/TAI.2021.3081057. [Google Scholar] [CrossRef]
18. Mandal M, Shah M, Meena P, Devi S, Vipparthi SK. AVDNet: a small-sized vehicle detection network for aerial visual data. IEEE Geosci Remote Sens Lett. 2020;17(3):494–8. doi:10.1109/LGRS.2019.2923564. [Google Scholar] [CrossRef]
19. Du D, Qi Y, Yu H, Yang Y, Duan K, Li G, et al. The unmanned aerial vehicle benchmark: object detection and tracking. In: Proceedings of the 15th European Conference on Computer Vision (ECCV); 2018 Sep 8–14; Munich, Germany. p. 370–86. [Google Scholar]
20. Wang B, Gu Y. An improved FBPN-based detection network for vehicles in aerial images. Sensors. 2020;20(17):4709. doi:10.3390/s20174709. [Google Scholar] [PubMed] [CrossRef]
21. Wang P, Jiao B, Yang L, Yang Y, Zhang S, Wei W, et al. Vehicle re-identification in aerial imagery: dataset and approach. In: Proceedings of the IEEE/CVF International Conference on Computer Vision 2019; 2019 Oct 27–Nov 2. Seoul, Republic of Korea. p. 460–9. doi:10.1109/TCSVT.2023.3298788. [Google Scholar] [CrossRef]
22. Ma B, Liu Z, Jiang F, Yan Y, Yuan J, Bu S. Vehicle detection in aerial images using rotation-invariant cascaded forest. IEEE Access. 2019;7:59613–23. doi:10.1109/ACCESS.2019.2915368. [Google Scholar] [CrossRef]
23. Almujally NA, Qureshi AM, Alazeb A, Rahman H, Sadiq T, Alonazi M. A novel framework for vehicle detection and tracking in night ware surveillance systems. IEEE Access. 2024;12:88075–85. doi:10.1109/ACCESS.2024.3417267. [Google Scholar] [CrossRef]
24. Atik ME, Duran Z, Ipbuker C. Comparative analysis of deep learning-based techniques for UAV image semantic segmentation. In: Proceedings of the 2024 IEEE India Geoscience and Remote Sensing Symposium (InGARSS); 2024 Dec 2–5; Goa, India. p. 828–35. [Google Scholar]
25. Mittal P, Sharma A, Singh R, Sangaiah AK. On the performance evaluation of object classification models in low altitude aerial data. J Supercomput. 2022;78(12):14548–70. doi:10.1007/s11227-022-04469-5. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools