
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Pavement Crack Detection Based on Star-YOLO11
1 Digital Research Center, Jiangxi Jiaotou Maintenance Technology Group Co., Ltd., Nanchang, 330200, China
2 School of Software, Nanchang Hangkong University, Nanchang, 330063, China
* Corresponding Author: Pengliu Tan. Email:
Computers, Materials & Continua 2026, 86(1), 1-22. https://doi.org/10.32604/cmc.2025.069348
Received 20 June 2025; Accepted 18 August 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In response to the challenges in highway pavement distress detection, such as multiple defect categories, difficulties in feature extraction for different damage types, and slow identification speeds, this paper proposes an enhanced pavement crack detection model named Star-YOLO11. This improved algorithm modifies the YOLO11 architecture by substituting the original C3k2 backbone network with a Star-s50 feature extraction network. The enhanced structure adjusts the number of stacked layers in the StarBlock module to optimize detection accuracy and improve model efficiency. To enhance the accuracy of pavement crack detection and improve model efficiency, three key modifications to the YOLO11 architecture are proposed. Firstly, the original C3k2 backbone is replaced with a StarBlock-based structure, forming the Star-s50 feature extraction backbone network. This lightweight redesign reduces computational complexity while maintaining detection precision. Secondly, to address the inefficiency of the original Partial Self-attention (PSA) mechanism in capturing localized crack features, the convolutional prior-aware Channel Prior Convolutional Attention (CPCA) mechanism is integrated into the channel dimension, creating a hybrid CPC-C2PSA attention structure. Thirdly, the original neck structure is upgraded to a Star Multi-Branch Auxiliary Feature Pyramid Network (SMAFPN) based on the Multi-Branch Auxiliary Feature Pyramid Network architecture, which adaptively fuses high-level semantic and low-level spatial information through Star-s50 connections and C3k2 extraction blocks. Additionally, a composite dataset augmentation strategy combining traditional and advanced augmentation techniques is developed. This strategy is validated on a specialized pavement dataset containing five distinct crack categories for comprehensive training and evaluation. Experimental results indicate that the proposed Star-YOLO11 achieves an accuracy of 89.9% (3.5% higher than the baseline), a mean average precision (mAP) of 90.3% (+2.6%), and an F1-score of 85.8% (+0.5%), while reducing the model size by 18.8% and reaching a frame rate of 225.73 frames per second (FPS) for real-time detection. It shows potential for lightweight deployment in pavement crack detection tasks.Keywords
At the end of 2023, the China highway mileage has reached 5,436,800 km. The rapid expansion of transportation infrastructure has intensified pavement damage caused by freight overloading, particularly at bypass routes near overload inspection stations, where non-weighing checkpoints frequently develop crack defects. These structural deteriorations pose escalating threats to highway safety, demanding urgent maintenance interventions. Current practices predominantly rely on manual inspection methods, which suffer from three key limitations: (1) Low automation leads to subjective bias and misjudgment, potentially resulting in error rates as high as 20%, (2) Impaired reliability in defect quantification and inefficiency, typically increasing inspection time by 1.5–2 h per kilometer compared to automated methods, (3) Delayed maintenance response due to time-consuming verification processes, which may extend the response time by 3–7 days.
In recent years, deep learning-based detection technology has advanced and matured significantly. Particularly in the domain of image processing and recognition, this technology has demonstrated exceptional capabilities in handling and analyzing vast datasets. Its sophisticated architecture enables the identification and learning of shared features across diverse image datasets. Through extensive training, these models can automatically apply learned feature representations to achieve accurate recognition of previously unseen images. Currently, algorithm research in the field of deep learning object detection mainly includes three types: multi-stage detection algorithms based on Region-based Convolutional Neural Networks (R-CNN), single-stage detection algorithms based on You Only Look Once (YOLO), and detection algorithms based on Transformer. Many scholars have made significant contributions to this field. Xu and Ma [1] proposed a crack detection method for asphalt pavement based on the improved Faster-RCNN model, which effectively improves the accuracy of crack detection, especially the ability to detect fine cracks, through the use of the ResNet50 network combined with the Convolutional Block Attention Module (CBAM). Xiao et al. [2] implemented an improved Mask R-CNN model for pavement crack recognition by adjusting the aspect ratio of anchor points and introducing a cascaded multi-threshold detector, which improves the high-precision localization and pixel-level segmentation of the cracks. The fragmented nature of multi-stage detection algorithms means that their detection speed can never break through the bottleneck, making rapid detection impossible in actual crack detection applications. In research on detection algorithms based on Transformer, Wei et al. [3] proposed an enhanced vision combining the sensory field attentional convolution (RFAConv) and contextual broadcast median (CBM) modules. Transformer model (RFAConv-CBM-ViT), which improves the accuracy of metal surface defect detection by optimizing the global feature capture and attention density. Hu et al. [4] proposed a dual backbone complex crack detection network called CCDFormer, which, by combining the strengths of the Transformer and the Convolutional Neural Network (CNN), uses a parallel branch structure to extract global and local features respectively, and designs a feature fusion module to integrate the two. Although Transformer-related models have great potential for development in the field of detection, their enormous number of parameters remains a significant limitation that is difficult to resolve, making them unsuitable for practical application in real-time crack detection. The YOLO algorithm is a single-stage target detection network framework, which, compared with the traditional multi-stage detection algorithms, including Faster R-CNN, Mask R-CNN, etc., does all the computation in a single forward propagation. This makes YOLO very advantageous in real-time detection and ensures that the accuracy is not much lower than that of multi-stage detection algorithms while keeping the speed fast. Since its introduction, it has been enthusiastically received by a wide range of researchers, and after several iterations, YOLO continues to optimize its detection accuracy and detection speed, making great contributions to the field of target detection. Xing et al. [5] proposed an improved YOLOv5 algorithm called EMG-YOLO for road crack detection on edge computing devices, which improved the accuracy and efficiency of crack detection by optimizing the model structure and loss function. Youwai et al. [6] proposed YOLO9tr, incoarporating the partial attention mechanism to achieve fast reasoning while maintaining high accuracy in pavement damage detection despite the small number of model parameters. Mulyanto et al. [7] proposed a lightweight YOLOv8-based method for fast ground crack detection, which improved the accuracy, F1 score, and FPS while the model parameters were reduced. Pei et al. [8] proposed a pavement defect detection model, YOLO-RDD, based on YOLOv8 by introducing a new feature extraction and fusion method, a dynamic serpentine convolution (DSC-C2f) module, and a coordinate attention mechanism, which improves the accuracy and real-time detection of defects such as pavement cracks. Table 1 below summarizes recent deep learning-based methods for detecting pavement cracks.

In conclusion, the application of deep-learning technology to pavement crack detection holds significant value. Existing research primarily centers on the detection accuracy of single-pavement diseases, overlooking the crack detection accuracy in the context of co-existing multiple cracks. Moreover, with the continuous increase in model parameters, numerous models cannot be deployed on lightweight mobile devices for real-time detection. To enhance the real-time and accurate detection of multiple cracks and other pavement diseases, this paper makes the following contributions: By integrating pavement crack detection scenarios, the Star-YOLO11 model is designed based on YOLO11n for lightweight mobile devices. In the backbone network, the StarBlock feature extraction structure is employed. In the feature refinement layer, the CPCA mechanism is introduced to adaptively aggregate feature information. In the Neck, feature information is designed by leveraging CPCA channel feature information and the SMAFPN structure. To expand the model’s learning scope, data augmentation is carried out on the pavement crack disease dataset, and a novel dataset augmentation strategy is formulated. This effectively improves the efficiency and accuracy of pavement crack detection and supports equipment deployment and practical pavement detection applications.
2.1 YOLO11 Algorithm Principle and Structure
Since the YOLO series started, its models and improved variants have shown excellent performance in computer vision and created many classic architectures. Compared to YOLOv8 and YOLOv10, YOLO11 improves both detection accuracy and inference speed. It’s categorized into five variants (X, L, M, S, and N) by architectural scale. Among them, YOLO11n has the smallest network size and fewest model parameters, so it’s especially suitable for deployment on lightweight mobile devices.
The network architecture of YOLO11 comprises four main components: the feature extraction backbone network (Backbone), feature refinement layer, feature fusion neck (Neck), and detection head (Head). Inheriting the C2fDarknet53 structure from YOLOv8, the backbone employs the C3k2 module as a replacement for the C2f module while incorporating hierarchical connections to enhance inter-layer information flow within the feature extraction backbone. Integration of the Batch Normalization (BN) normalization method with the Sigmoid Linear Unit (SiLU) activation function in the downsampling convolution module stabilizes the training process and improves model representational capability. The feature refinement layer integrates both the Spatial Pyramid Pooling-Fusion (SPPF) module and the C2PSA module, where the latter evolves from YOLOv10’s PSA mechanism through dual-layer nesting. This design aims to strengthen feature extraction via both multi-head attention mechanisms and feed-forward neural networks. The neck partially follows the PAFPN structure, combining Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) formed by YOLOv8. FPN [9] is designed to enhance the feature extraction capability by combining the low-level detail information and high-level semantic information, which can effectively improve the network’s recognition ability for targets at different scales, and PANet [10] enhances the fusion of features at different scales through bottom-up path aggregation, which makes the model better able to handle the detection tasks of both small and large objects. The head part compares to YOLOv8 in the original decoupling of the head of the category detection head depthwise separable convolution is introduced, which greatly reduces the number of parameters and computation, as shown in Fig. 1 below.
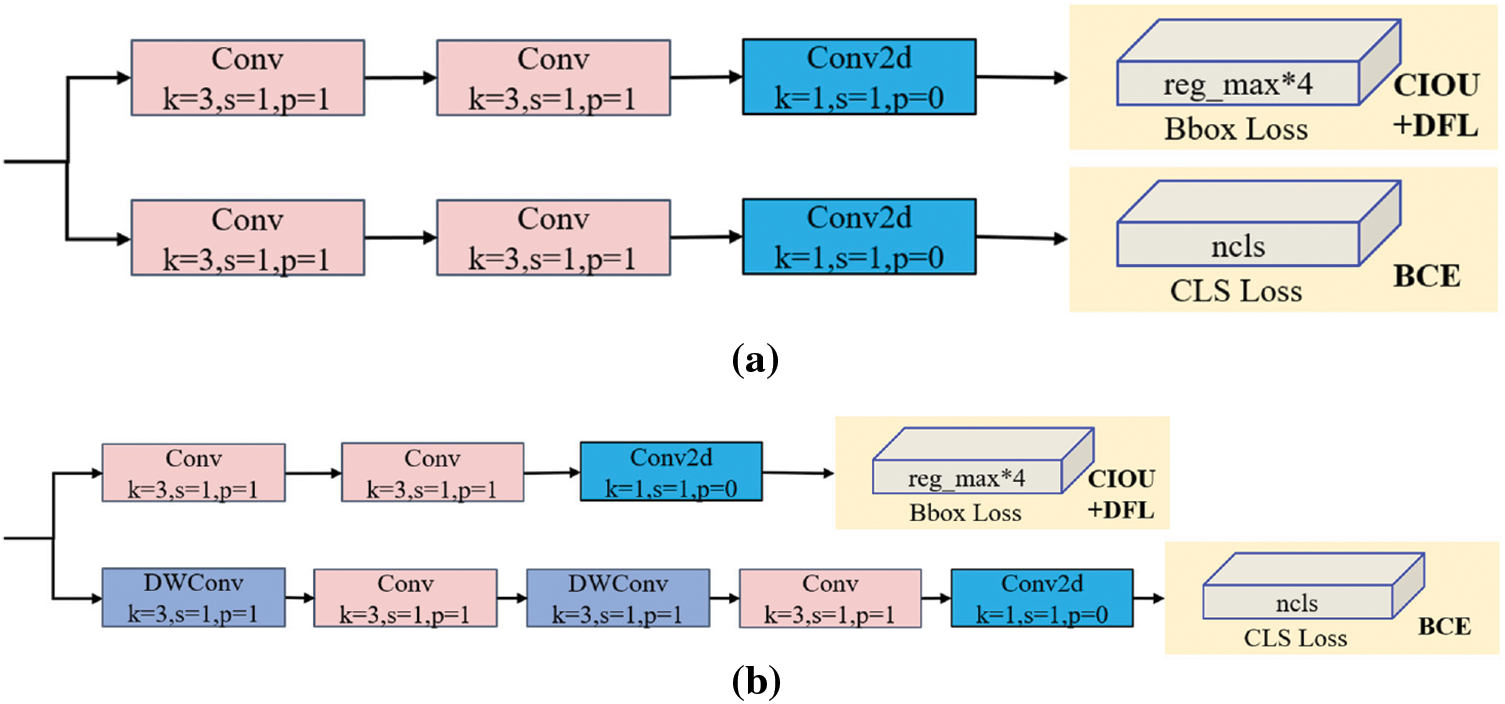
Figure 1: Comparison of head structures. (a) YOLOv8 head structure; (b) YOLO11 head structure
In the loss computation framework of YOLO11, the loss function comprises localization loss and classification loss. The localization loss quantifies the discrepancy between predicted and ground-truth bounding boxes, ensuring precise target localization, while the classification loss measures the divergence between predicted class probabilities and true annotations. For localization optimization, YOLO11 employs the Complete Intersection over Union (CIoU) loss combined with Distribution Focal Loss (DFL), whereas the classification component is implemented through Binary Cross-Entropy (BCE) loss. The final total loss is determined by the weighted summation of these two components.
2.2 Algorithm Improvement Analysis
In outdoor pavement crack detection tasks, the operational requirements typically demand real-time processing, lightweight deployment, and strong generalization capabilities. However, in practical crack category detection applications, the YOLO11 algorithm struggles to maintain stable detection accuracy, frequently demonstrating rapid inference speeds at the expense of insufficient detection precision. Dong et al. [11] indicate that YOLO11 performs poorly when dealing with narrow and elongated cracks, which is highly relevant to the common morphology of road surface cracks. This limitation may stem from the model’s insufficient ability to extract features from small targets.
Secondly, in the scenario of dynamic equipment detection, the differences in road surface conditions and target shape and size require the algorithm to have a sufficient field of view and target detection feature extraction capabilities. The YOLO11 algorithm is prone to false positives when performing this task. Therefore, we considered improving the information capture and feature extraction capabilities of the original model, while also optimizing the model’s feature fusion structure.
To optimize pavement crack detection performance, the Star-YOLO11 architecture is developed. Observing that excessive C3k2 modules in the backbone network lead to mediocre detection efficacy and inflated parameter count, we propose replacing these modules with StarBlocks through a StarStage block design. This configuration combines downsampling convolutions with element-wise multiplication, achieving enhanced feature extraction while maintaining parameter efficiency. Addressing the pixel dominance of pavement cracks and environmental backgrounds, we integrate a third-tier CPCA mechanism following the dual-layer Partial Self-attention (PSA) in the feature refinement layer, specifically enhancing detection of subtle and low-contrast cracks. Furthermore, the proposed SMAFPN incorporates dual C3k2 modules and establishes multi-branch auxiliary connections between the Neck and StarBlock-enhanced backbone, enabling adaptive fusion of high-level semantics and low-level spatial features. The Star-YOLO11 model structure is shown in Fig. 2.
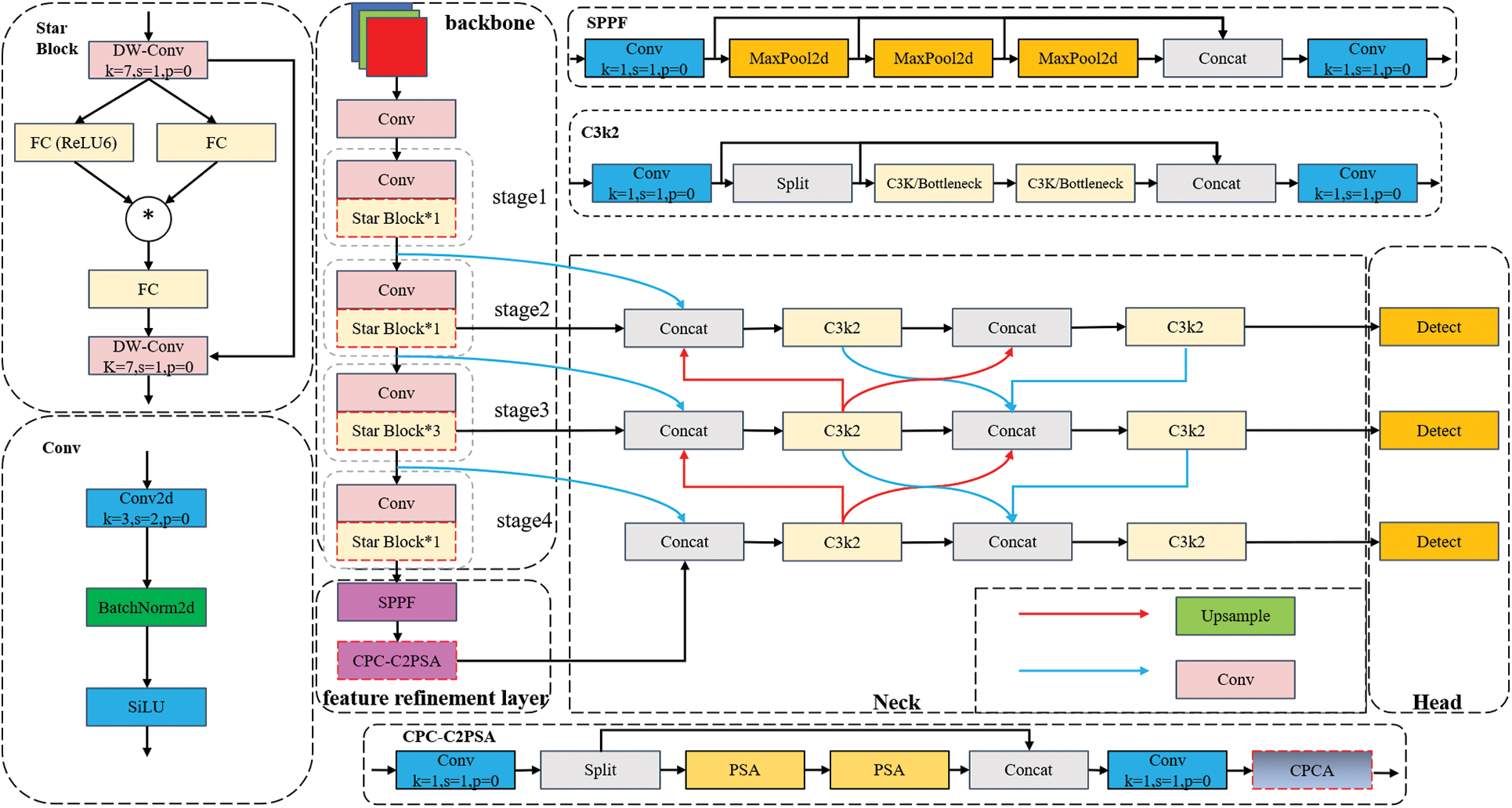
Figure 2: Structure of star-YOLO11
3.1 DataSet Augmentation Strategies
To effectively simulate real-world environments, a comprehensive data augmentation strategy is implemented for enhanced model generalization, which requires high-quality datasets with adequate samples. Data augmentation technology reduces manual annotation and expands training data through geometric transformations. Conventionally, augmentation methods are divided into traditional and complex ones, but existing approaches usually use them separately without synergy. This study proposes an integrated strategy combining basic geometric operations with advanced environmental simulations. Besides conventional additives, we incorporate weather-robustness factors, resulting in 12 augmentation methods. hrough combinatorial permutations, this framework generates up to 27 distinct augmentation strategies, as shown in Fig. 3, each image must undergo both traditional and complex data augmentations, ensuring every dataset sample exhibits multiple complexities. This approach further enriches the dataset diversity while improving model generalization capabilities.
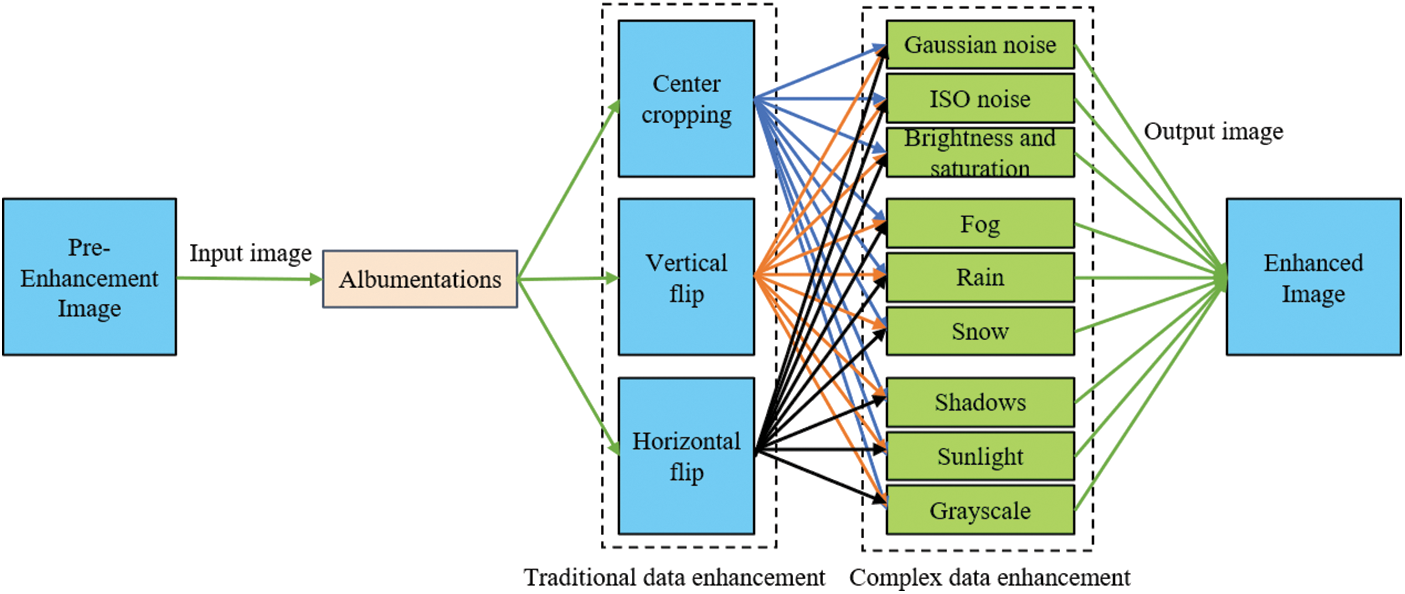
Figure 3: Dataset augmentation strategy
3.2 Improved Feature Extraction Backbone Network
The feature extraction backbone network, as a critical stage in YOLO11, progressively aggregates low-level information into high-level representations. While maximizing feature abstraction generally improves subsequent detection performance, the original YOLO11’s C3k2 feature extraction blocks inherently struggle to capture sufficient discriminative features under strict model size constraints, therefore, based on StarBlock [12] the idea of element-wise multiplication, the structure of StarBlock stacking is used to replace the original C3k2 module to increase the accuracy of model detection, and the depthwise separable convolution is used before and after the multiplication instead of the ordinary 1 × 1 convolution to reduce the number of computational parameters in the backbone network.
The structure of StarBlock is very simple and efficient, and its core idea of element-wise multiplication is usually written as
where i and j are used as channel subscripts and
Having rewritten this, a combination of
In this study, the StarBlock stacking configuration of the backbone network is designed and named Star-s50. Comparative analysis shows that compared to YOLO11’s original architecture and prior StarNet-s1/s2 configurations, Star-s50 has better architectural compactness and enhanced multi-scale feature representation capacity. Specifically, in the third extraction block for pavement crack feature emphasis, Star-s50 has three stacked StarBlocks, while single StarBlocks are used in other stages. This hierarchical design maintains large receptive fields during feature map derivation, and experiments show significant improvements in both backbone observational ability and model parametric efficiency. The model is more lightweight, as shown in Fig. 4.
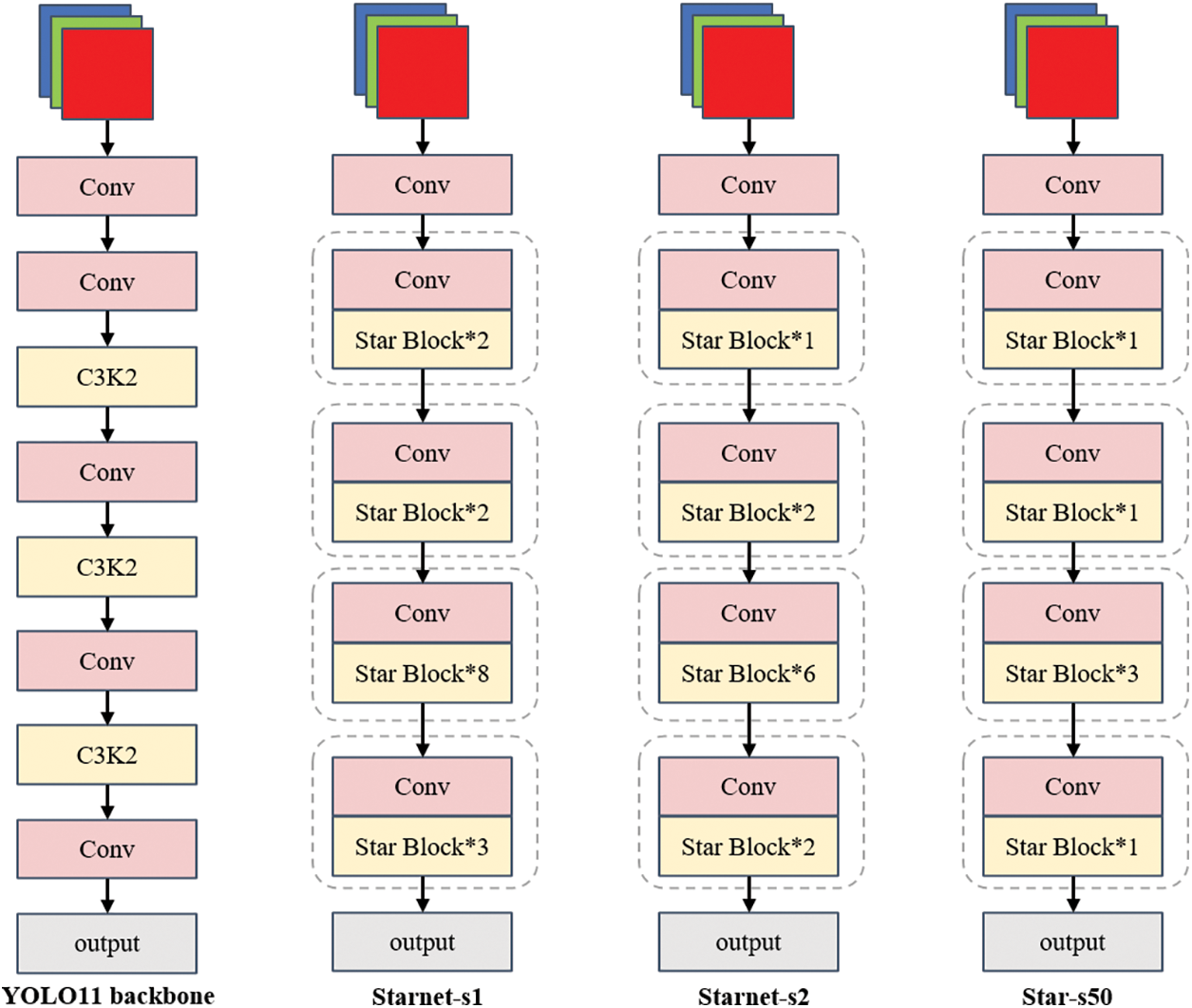
Figure 4: Comparison of different backbone network architectures
3.3 Integration of CPCA Attention Mechanisms
The Channel Prior Convolutional Attention (CPCA) [13] attention mechanism is a new type of attention that combines channel and spatial attention, compared to SE [14] attention, which focuses only on the channel dimension and completely ignores spatial dimension information, and CBAM [15] attention, which generates only a single piece of spatial information in the spatial dimension, CPCA adopts multi-scale depthwise separable convolutional modules to constitute spatial attention, which can dynamically assign attention weights on channel and spatial dimensions, effectively extract spatial relations while preserving the channel prior, and has a good ability to focus on information channels and important regions, and its structure is shown in Fig. 5.
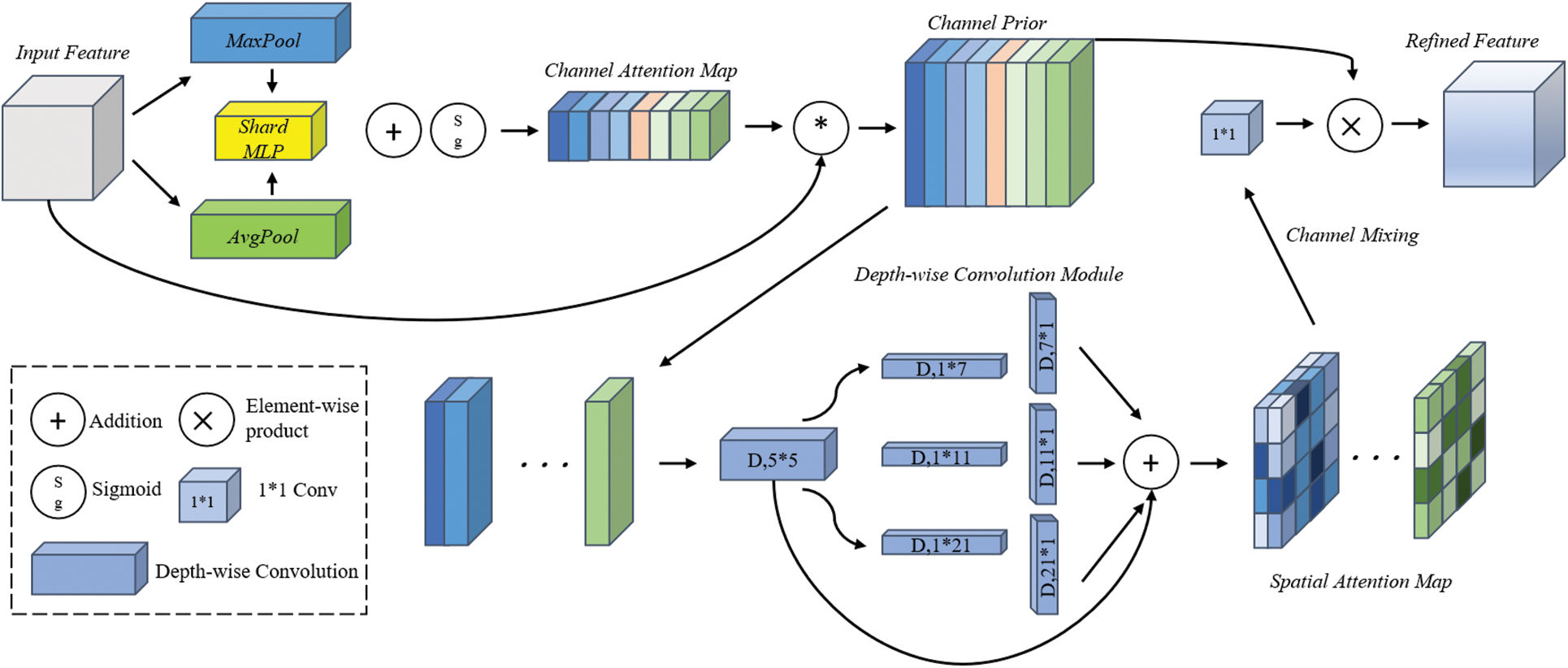
Figure 5: Working principle and structure of CPC-attention
The proposed attention mechanism uses a sequential channel-spatial architecture (Eqs. (6) and (7)). In the channel attention phase, spatial context is aggregated by concurrent average and max pooling across feature maps. The pooled features are processed by a shared MLP, and the outputs are summed element-wise to get channel attention weights (Eq. (8)). Channel-refined features are obtained by element-wise multiplying input features and the channel attention map. Then, spatial attention processing uses a depthwise convolution module with a triple-branch architecture. Multi-scale features from parallel branches are aggregated to compute spatial attention weights (Eq. (9)), where:
F = Original feature map
CA (·) = Channel attention operation
SA (·) = Spatial attention operation
The final feature refinement is achieved via element-wise multiplication between channel-refined features and spatial attention weights.
The original YOLO11 architecture has a C2PSA structure with dual-layer nesting of the PSA mechanism from YOLOv10 [16], showing strong global contextual modeling. But conventional self-attention mechanisms lack local structural awareness, leading to poor focus on locally intensive features such as pavement cracks. To solve this, we add a CPCA mechanism to the terminal of the baseline C2PSA structure, creating the CPC-C2PSA architecture. This addition enhances information propagation at the most vulnerable feature integration stage of the network, as shown in Fig. 6.

Figure 6: CPC-C2PSA fusion attention module
3.4 SMAFPN Feature Pyramid Structure
The original YOLO11’s neck employing PAFPN exhibits limitations in multi-scale feature integration, primarily merging features at equivalent scales while lacking comprehensive multi-scale integration across divergent resolution layers. Crucially, this architecture fails to adaptively synthesize high-level semantics with low-level spatial cues. To address these shortcomings, we propose the Star Multi-Branch Auxiliary Feature Pyramid Network (SMAFPN), which establishes enhanced connectivity between MAFPN [17] and the backbone’s StarBlock. Departing from MAFPN’s RepHELAN module, SMAFPN integrates YOLO11-native C3k2 modules for architectural compatibility. The connectivity framework adopts a dual-component architecture: Surface Assisted Fusion (SAF) orchestrates backbone-to-neck feature transmission Advanced Assisted Fusion (AAF) facilitates intra-neck cross-scale feature blending. Fig. 7 comparatively illustrates the enhanced architecture against baseline PAFPN and prevalent YOLO-series BiFPN [18] implementations. BiFPN enhances PAFPN by incorporating a P3-level feature extraction module, enabling intra-level feature propagation from the backbone network to preceding detection head stages. In contrast, SMAFPN innovates through dual PAFPN-derived connection blocks and multi-branch pathways. This architecture facilitates shallow feature preservation from StarBlock and hierarchical fusion with deep neck features, specifically optimizing small-target pavement crack detection accuracy.
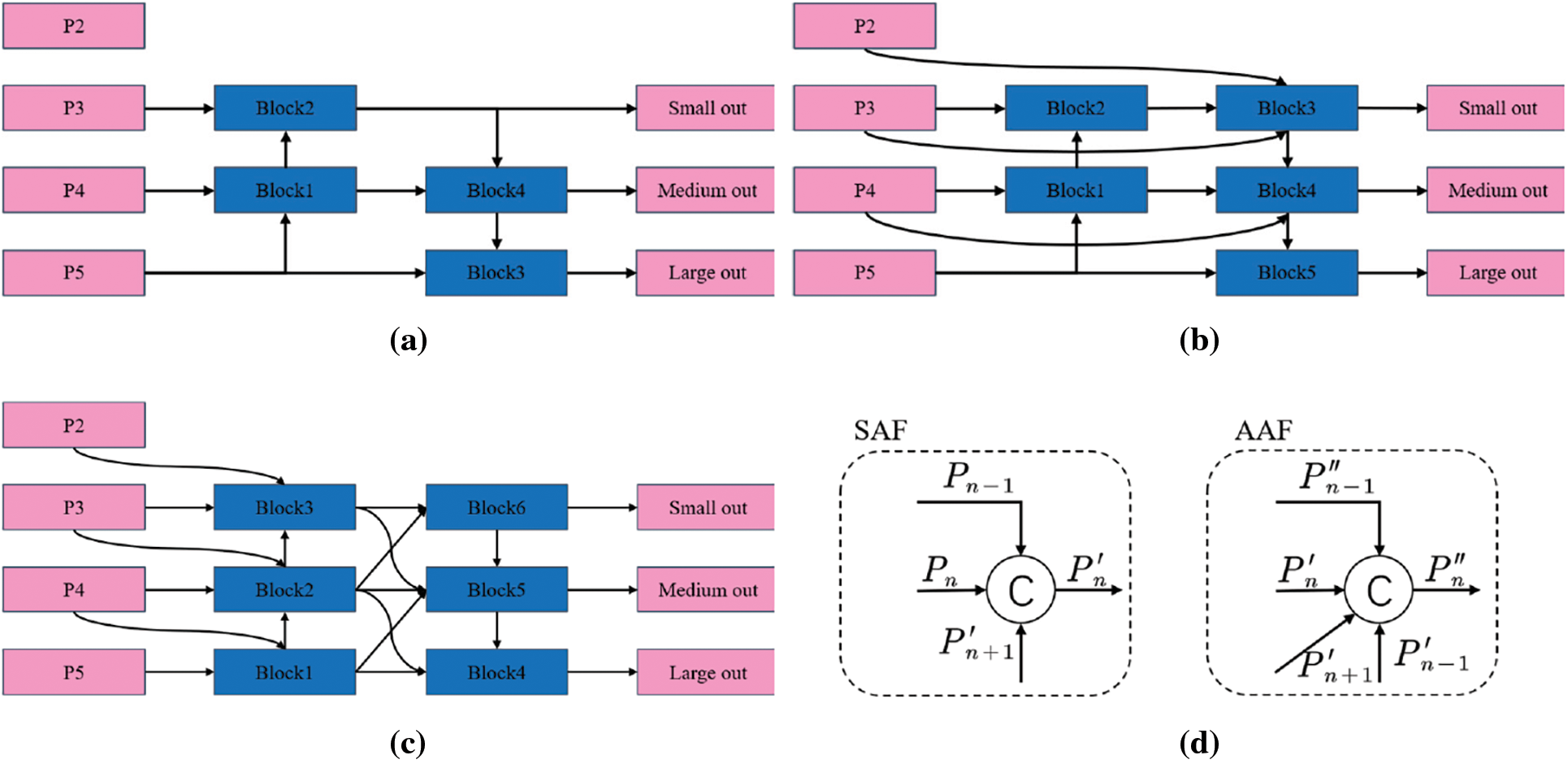
Figure 7: PAFPN, BiFPN, SMAFPN network architecture. (a) PAFPN structure; (b) BiFPN structure; (c) SMAFPN structure; (d) SAF and AAF structures
The connection of SAF mainly consists of four parts, in addition to the current input feature map
AAF further enhances the interactive utilization of feature layer information by integrating multi-scale information in the neck, which consists of five main parts, adding a shallow high-resolution layer
The experiment uses the publicly available dataset RDD2022 China regional dataset [19], which contains five types of pavement crack datasets captured by UAVs and non-motorized vehicles carrying smart cameras, including Longitudinal Crack, Transverse Crack, Alligator Crack, Pothole, and Repair, as shown in Fig. 8.

Figure 8: Example diagram of 5 categories in a dataset. (a) Longitudinal Crack; (b) Transverse Crack; (c) Alligator Crack; (d) Pothole; (e) Repair
The dataset is partitioned into training, validation, and test sets at an 8:1:1 ratio, with 3502 training, 437 validation, and 439 test images. Then, the data augmentation strategy from Section 2.1 is applied to the training set. Each image goes through sequential augmentations, including mandatory center cropping and vertical flipping, combined with one randomly chosen operation from: horizontal flipping with Gaussian noise, ISO noise, brightness/saturation adjustment, environmental simulations (rainy, foggy, snowy, shadows, sunlight, grayscale). The effect of the partial augmentation is shown in Fig. 9.

Figure 9: Partial augmentation effect schematic. (a) Original image; (b) Vertical flip + Shadow; (c) Vertical flip + Snow; (d) Horizontal flip + Brightness; (e) Center cropping + Gaussian noise
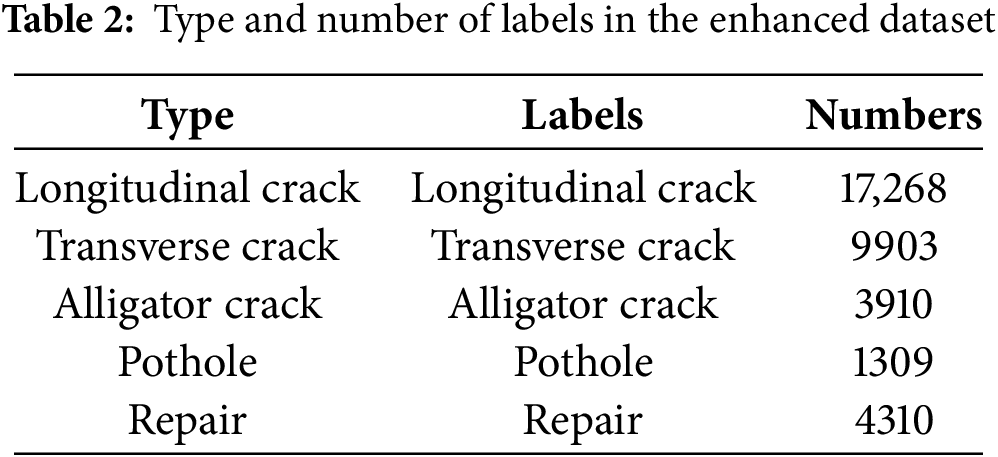
The augmented training set comprises 17,494 images, enhancing both the quantity and quality of annotated samples across categories, thereby improving the model’s generalization capability, as shown in Table 2.
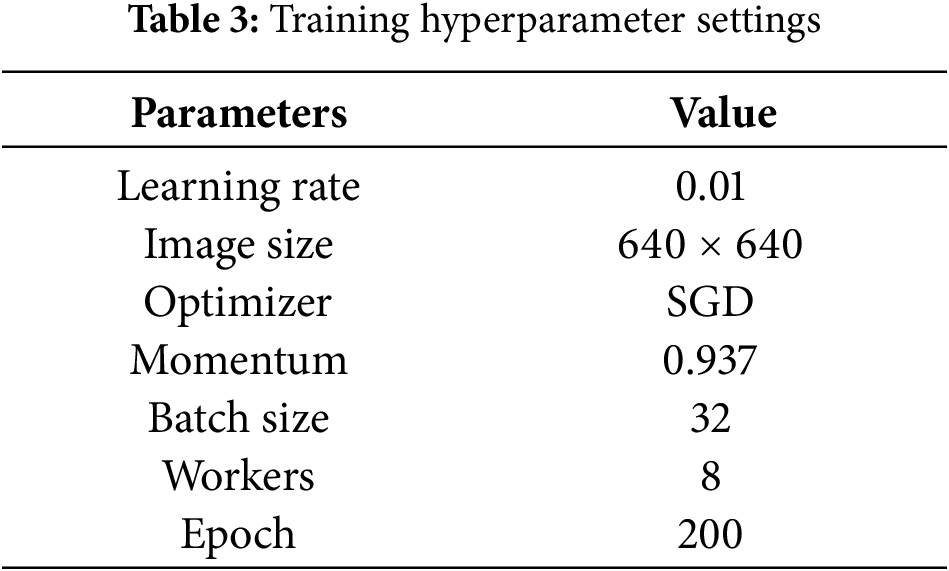
To verify the proposed algorithm’s effectiveness, PyCharm was chosen as the programming environment. With the Windows 10 operating system, Python 3.10 was the programming language, PyTorch 2.3.0 was the deep-learning framework, and CUDA version 11.8 was used. The hardware test environment for model training had an 11th Gen Intel(R) Core(TM) i7-11700 @ 2.50 GHz processor with 16 GB of RAM, and an NVIDIA RTX 4060Ti (16 GB of VRAM) GPU. The specific training hyperparameter settings are shown in Table 3.
To comprehensively evaluate the model, the used evaluation metrics include precision (P) reflecting the model’s ability to differentiate negative samples, Recall (R) reflecting its ability to recognize positive samples, mAP measuring the model’s accuracy, mAP50 indicating correct prediction when the intersection and concurrency ratio of the true and predicted frames is over 50, F1-score measuring the model’s comprehensive performance and stability, parameter count measuring the model’s size and complexity, and computation volume (GFLOPs) indicating the number of billions of floating-point operations per second and measuring the computational device’s floating-point operation performance. The specific calculation formula is shown in Eqs. (12)–(15).
4.4 Analysis of the Training Process
The training dynamics of deep learning models are monitored through two core metrics: the loss function and mean Average Precision (mAP), where decreasing loss values and increasing mAP scores indicate improved model performance. As illustrated in the loss curves of training and validation in Figs. 10 and 11, the 200-epoch training process exhibits three distinct phases: rapid reduction, gradual convergence, and steady-state stabilization. During the initial phase, elevated loss values originate from the model’s inability to accurately fit the prediction box probability distributions. Through iterative optimization, these distributions progressively refine, manifesting as: (1) exponential decay in loss during early epochs, (2) decelerated improvement during gradual convergence, and (3) asymptotic stabilization indicating model convergence. This phased evolution validates the model’s progressive adaptation to the target data distribution.
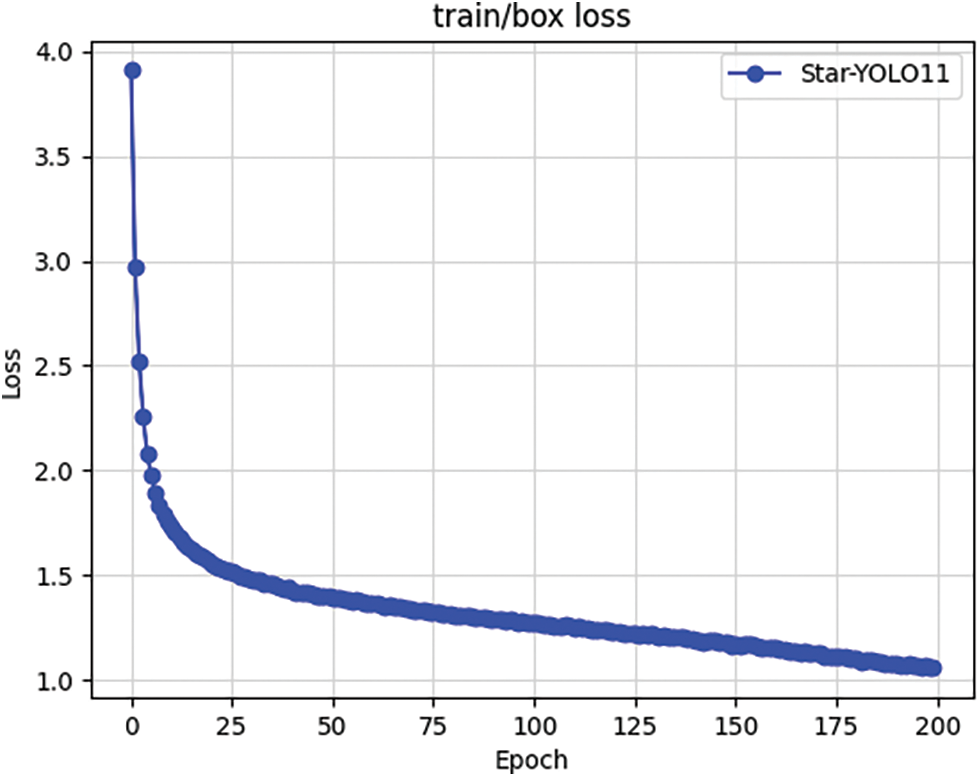
Figure 10: Curve of training loss value dynamics
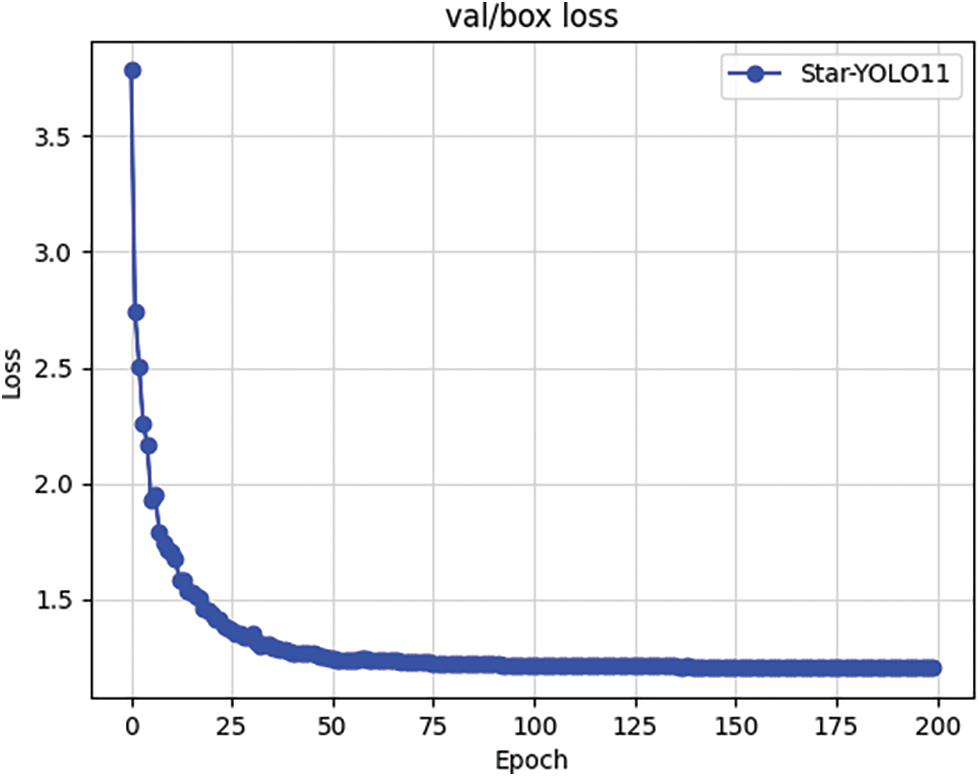
Figure 11: Validation set loss value dynamic change curve
Fig. 12 illustrates the mean Average Precision (mAP) validation curve during model training. The trajectory exhibits minimal fluctuations, maintaining a smooth progression that validates the algorithmic structural effectiveness and dataset reliability. With the mAP50 metric ultimately stabilizing at convergence, this progression demonstrates successful model convergence, confirming training completion.
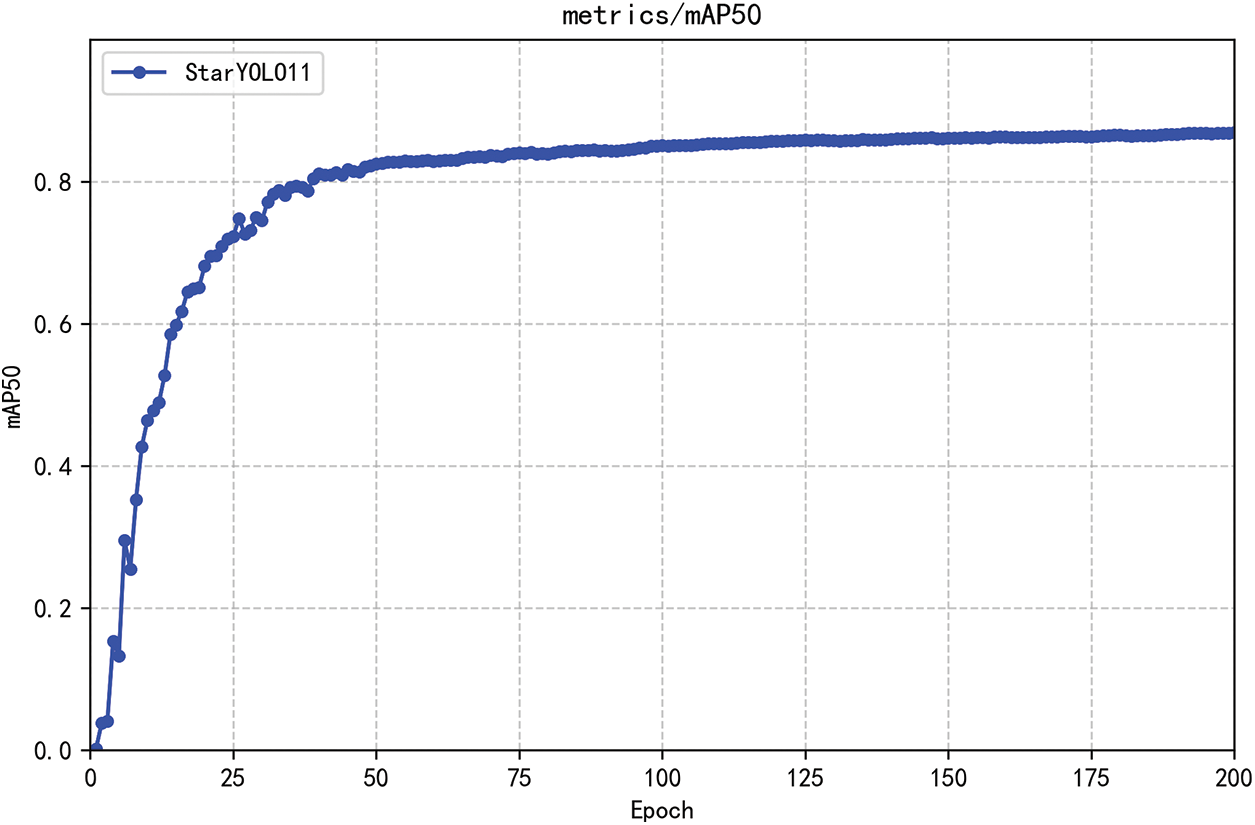
Figure 12: Dynamic curve of mean average precision
4.5.1 Effectiveness of Data Set Augmentation Strategies
To validate the effectiveness of the data augmentation strategy designed in Section 2.1 of this paper, we trained the original YOLO11n model using both the unaugmented training set and the augmented training set, and then tested them on the same test set. The test results are shown in Table 4.
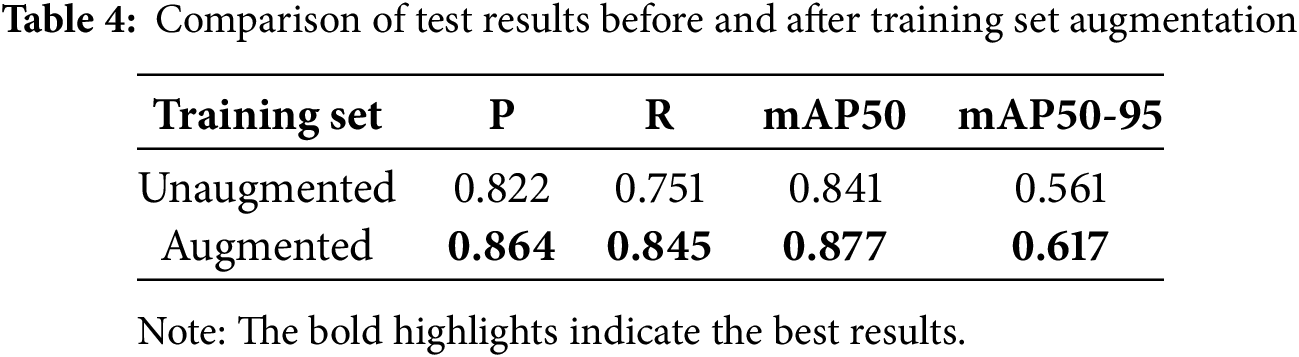
As can be seen from the table above, after using the data augmentation strategy proposed in this paper, all metrics of the test results have been improved, significantly enhancing the model’s generalization ability and demonstrating high robustness, thereby validating the effectiveness of the data augmentation strategy proposed in this paper.
4.5.2 Effectiveness of Star-s50
To verify the effectiveness of the Star-s50 backbone network, an experimental comparison of backbone network replacement is carried out based on YOLO11n, both of which are trained using the enhanced training set and tested using the same test set, and the test results are shown in Table 5.

Although Starnet-s1 has slightly higher accuracy and Starnet-s2 has slightly higher recall, Star-s50 achieves the best performance with 88.3% mAP50, indicating that it strikes a better overall balance between accuracy and recall across all categories. Additionally, the architectural design of Star-s50 (such as the strategically stacked StarBlock strategy detailed in Section 3.2) enhances the model’s parameter efficiency and training stability, making it a more balanced and robust choice for lightweight deployment in real-world road crack detection scenarios. This balance between detection accuracy, model size, and computational efficiency makes Star-s50 the most suitable backbone network for the proposed Star-YOLO11.
4.5.3 Effectiveness of CPC-C2PSA
Subsequently, experiments were conducted to compare different attention mechanism fusions based on the use of Star-s50’s YOLO11n to demonstrate the superiority of the CPC-C2PSA attention structure fused in this paper. The test results after the control variable experiment are shown in Table 6.

As can be seen from the table, the model incorporating the CPCA attention mechanism achieved an mAP50 of 90%, far exceeding the other attention mechanisms. Although the recall rate decreased, the accuracy rate was significantly improved, achieving a better overall balance between accuracy and recall rates across all categories.
The table shows that the model incorporating the CPCA attentional mechanism has an mAP50 of 90%, which far exceeds the rest of the attention. To verify the effectiveness of the control variable experimental comparison of SMAFPN with PAFPN and BiFPN, it was conducted based on YOLO11n using Star-s50 and CPC-C2PSA, and the test results are shown in Table 7.

As can be seen in the table, the structure of feature fusion of SMAFPN can effectively improve the accuracy of the model to 90.3%, and the accuracy is only slightly better than that of PAFPN when using BiFPN, which is far behind the SMAFPN structure used in this paper.
4.5.5 Ablation Experiments and Comparative Experiments of Star-YOLO11
Finally, to verify the effectiveness of Star-YOLO11, ablation experiments are carried out based on YOLO11n; “✔” represents the use of this module, and the experimental test results are shown in Table 8. The precision, recall, and average detection accuracy of the method proposed in this paper in all categories of detection results are shown in Fig. 13.


Figure 13: Star-YOLO11 test result indicators by category
As shown in the table, all three modules effectively improve the model’s detection accuracy. The Star-s50 backbone network significantly reduces the number of model parameters in YOLO11 and achieves a substantial improvement in mAP50, outperforming the original YOLO11 backbone network. The introduction of the CPCA attention mechanism effectively improves the model’s accuracy, enhancing focus on small and less prominent cracks. When combined with Star-s50, it achieves an mAP50 of 90% and still improves by nearly one point on mAP50-95. The introduction of SMAFPN enables the model to focus on the interaction between shallow-layer and deep-layer information. Although it does not offer a significant advantage when combined with the other two models, the combination of all three achieves a p value of 89.9%, an mAP of 90.3%, and an mAP50-95 of 62.7%. Although the improved recall rate is slightly lower, the change is acceptable. This may be due to false negatives caused by the difficulty of detecting extremely small or early-stage cracks in road surfaces, or challenges posed by variations in lighting, shadows, debris, and inconsistent crack appearances in actual images. Future improvements could involve adding more datasets containing more challenging negative samples or subtle crack variations to enhance recall rates. Star-YOLO11’s high mAP50 and mAP50-95 indicate that, despite the slightly lower recall rate, the overall detection quality is good.
At the same time, to verify the superiority of the improved model compared with other mainstream algorithms, Star-YOLO11 is compared with other classical algorithms on the same dataset, and the results of the different algorithm comparison tests are shown in Fig. 14.

Figure 14: Comparative testing of different models
It can be seen that Star-YOLO11 has high performance in all the main metrics in the same scale network model, where all the metrics are at the optimum, except the recall. In addition, Star-YOLO11 has an advantage over the original YOLO11 in terms of algorithm model size and real-time computing speed, in addition to the improvement of detection performance, as shown in Table 9.

After comparing the data during model testing, it was found that the improved Star-YOLO11 model has reduced its model size, with the total number of parameters decreasing by 18.8%. This theoretically demonstrates its suitability for lightweight deployment on mobile device algorithms, and the model’s F1 score has also seen a slight improvement. Although its FPS is lower than the original model, it remains above 200, which is the highest among current models. The detection speed is at the forefront, theoretically capable of effectively meeting practical detection requirements.
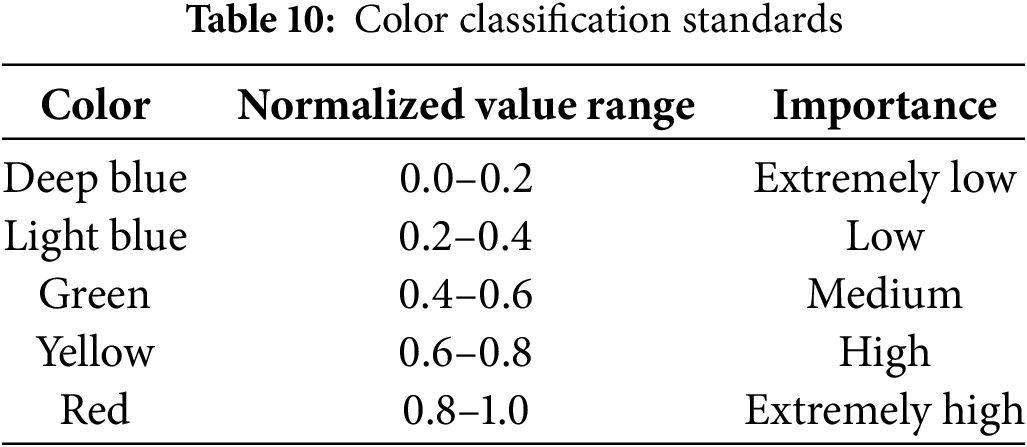
Heatmaps were generated for the YOLO11 and Star-YOLO11 models using the Gradient-Weighted Class Activation Map (Grad-CAM) technique. These heatmaps visually illustrate the specific regions of interest within the feature maps that the models focus on. Grad-CAM is a visualization technique used to explain the decision-making process of convolutional neural networks (CNNs). It generates a heatmap by leveraging gradient information from the model’s output, highlighting the regions in the input image that contribute most significantly to the prediction. After normalization of the original Grad-CAM activation maps, the normalized values are divided into different colors. Pixels with higher gradients in the feature maps are represented by darker red in the heatmap, while pixels with lower gradients are represented by darker blue. The specific color meanings are detailed in Table 10.
After the analysis of experimental data, to visualize the improvement effect of the method proposed in this paper as well as to observe the optimization degree of each part of the improvement on the model, a visual analysis of the key aspects of the experiment is made. To verify the information capturing ability and feature extraction ability of the model, as well as the optimization of the channel prior convolutional attention on the sensory field, the comparison of the heat map between the model before improvement and the model after improvement is carried out, as shown in Fig. 15.

Figure 15: Comparison of the heat map of the algorithm. (a) Original image; (b) YOLO11 heat map; (c) Star-YOLO11 heat map
The disparities in color intensity among diverse regions in the figure explicitly indicate the substantial difference in the model’s emphasis on road cracks prior to and subsequent to improvement. As depicted in the figure, the red and yellow regions on the overall crack skeleton in Star-YOLO11 are notably more abundant than those in YOLO11 and are distributed in closer proximity to the crack skeleton. The Star-YOLO11 model exhibits a higher level of global coverage in crack perception and a significantly enhanced focus on crack targets. To verify the detection effect of the model in real engineering applications, the detection performance of the model on the test set before and after the improvement is compared, and the detection results are shown in Fig. 16, which shows that the improved algorithm significantly improves the problems of leakage detection and detection accuracy of the original YOLO11 model.

Figure 16: Comparison of the detection of the algorithm. (a) Original image; (b) YOLO11 detection result; (c) Star-YOLO11 detection result
To accomplish the pavement crack detection task and address the issues in highway pavement disease detection, including the presence of diverse disease types, the challenge of feature extraction for different diseases, and the slow speed of disease identification, a novel pavement crack detection method using Star-YOLO11 is proposed. In the backbone network of feature extraction, this method expands the implicit dimensional space of features by substituting the C3k2 module with a multi-layered StarBlock. This enables the capture of more effective information. Subsequently, in the feature refinement layer, the channel a priori convolutional attention mechanism is introduced and combined with the PSA mechanism to form the CPC-C2PSA structure. This structure enhances the attention towards crack damage with a small pixel proportion in the image at the end of the weakest information. Finally, based on the concept of a multi-assisted branching feature pyramid structure, the connection between the deep and shallow layers of the neck is constructed. This ensures that feature fusion can simultaneously acquire deeper and shallower information, thereby improving the model’s detection effect on small and medium-sized target cracks. Experimental results indicate that on large datasets, the accuracy, mAP50, mAP50-95, and F1 scores of the tests can reach 89.9%, 90.3%, 62.7%, and 85.4%, respectively. These values are significantly improved compared to the original model. Moreover, the model’s parameter count size is reduced by 18.8% compared to the original model. Theoretically, the algorithm can be deployed on lightweight mobile devices, meeting the requirements of actual pavement crack detection tasks and providing strong support for pavement inspection. Future research can focus on deploying the model on mobile devices such as cell phones or drones for pavement crack detection tasks.
Acknowledgement: None.
Funding Statement: This research was funded by the Jiangxi SASAC Science and Technology Innovation Special Project and the Key Technology Research and Application Promotion of Highway Overload Digital Solution.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization and resources, Jiang Mi; investigation and funding acquisition, Zhijian Gan; methodology and writing—original draft preparation, Xin Chang; software, Zhi Wang; validation, Pengliu Tan and Jiang Mi; formal analysis, Haisheng Xie; data curation, Xin Chang; writing—review and editing, Pengliu Tan and Xin Chang; supervision and project administration, Pengliu Tan. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data are contained within the article.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Xu K, Ma RG. Crack detection of asphalt pavement based on improved faster-RCNN. Comput Syst Appl. 2022;31(7):341–8. (In Chinese). doi:10.15888/j.cnki.csa.008594. [Google Scholar] [CrossRef]
2. Xiao LY, Li W, Yuan B, Cui YQ, Gao R, Wang WQ. A pavement crack identification method based on improved instance segmentation model. Geomat Inf Sci Wuhan Univ. 2023;48(5):765–76. (In Chinese). doi:10.13203/j.whugis20210279. [Google Scholar] [CrossRef]
3. Wei H, Zhao L, Li R, Zhang M. RFAConv-CBM-ViT: enhanced vision transformer for metal surface defect detection. J Supercomput. 2024;81(1):155. doi:10.1007/s11227-024-06662-0. [Google Scholar] [CrossRef]
4. Hu X, Li H, Feng Y, Qian S, Li J, Li S. CCDFormer: a dual-backbone complex crack detection network with transformer. Pattern Recognit. 2025;161(4):111251. doi:10.1016/j.patcog.2024.111251. [Google Scholar] [CrossRef]
5. Xing Y, Han X, Pan X, An D, Liu W, Bai Y. EMG-YOLO: road crack detection algorithm for edge computing devices. Front Neurorobot. 2024;18:1423738. doi:10.3389/fnbot.2024.1423738. [Google Scholar] [PubMed] [CrossRef]
6. Youwai S, Chaiyaphat A, Chaipetch P. YOLO9tr: a lightweight model for pavement damage detection utilizing a generalized efficient layer aggregation network and attention mechanism. J Real Time Image Process. 2024;21(5):163. doi:10.1007/s11554-024-01545-2. [Google Scholar] [CrossRef]
7. Mulyanto A, Sari RF, Muis A. Road damage dataset evaluation using YOLOv8 for road inspection system. In: 2024 16th International Conference on Computer and Automation Engineering (ICCAE); 2024 Mar 14–16; Melbourne, Australia. Piscataway, NJ, USA: IEEE; 2024. p. 403–7. doi:10.1109/ICCAE59995.2024.10569208. [Google Scholar] [CrossRef]
8. Pei J, Wu X, Liu X. YOLO-RDD: a road defect detection algorithm based on YOLO. In: 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD); 2024 May 8–10; Tianjin, China. Piscataway, NJ, USA: IEEE; 2024. p. 1695–703. doi:10.1109/CSCWD61410.2024.10580137. [Google Scholar] [CrossRef]
9. Lin TY, Dollár P, Girshick R, He K, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017 Jul 21–26; Honolulu, HI, USA. Piscataway, NJ, USA: IEEE; 2017. p. 936–44. doi:10.1109/CVPR.2017.106. [Google Scholar] [CrossRef]
10. Liu S, Qi L, Qin H, Shi J, Jia J. Path aggregation network for instance segmentation. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. Piscataway, NJ, USA: IEEE; 2018. p. 8759–68. doi:10.1109/CVPR.2018.00913. [Google Scholar] [CrossRef]
11. Dong X, Yuan J, Dai J. Study on lightweight bridge crack detection algorithm based on YOLO11. Sensors. 2025;25(11):3276. doi:10.3390/s25113276. [Google Scholar] [CrossRef]
12. Ma X, Dai X, Bai Y, Wang Y, Fu Y. Rewrite the stars. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 16–22; Seattle, WA, USA. Piscataway, NJ, USA: IEEE; 2024. p. 5694–703. doi:10.1109/CVPR52733.2024.00544. [Google Scholar] [CrossRef]
13. Huang H, Chen Z, Zou Y, Lu M, Chen C, Song Y, et al. Channel prior convolutional attention for medical image segmentation. Comput Biol Med. 2024;178(27):108784. doi:10.1016/j.compbiomed.2024.108784. [Google Scholar] [PubMed] [CrossRef]
14. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. Piscataway, NJ, USA: IEEE; 2018. p. 7132–41. doi:10.1109/CVPR.2018.00745. [Google Scholar] [CrossRef]
15. Woo S, Park J, Lee JY, Kweon IS. CBAM: convolutional block attention module. In: Computer vision—ECCV 2018. Amsterdam, The Netherlands: Elsevier; 2018. p. 3–19. doi:10.1007/978-3-030-01234-2_1. [Google Scholar] [CrossRef]
16. Wang A, Chen H, Liu L. YOLOv10: real-time end-to-end object detection. In: Globerson A, Mackey L, Belgrave D et al., editors. Advances in neural information processing systems. Vol. 37. Red Hook, NY, USA: Curran Associates, Inc.; 2024. p. 107984–8011. [Google Scholar]
17. Yang Z, Guan Q, Zhao K, Yang J, Xu X, Long H, et al. Multi-branch auxiliary Fusi on YOLO with re-parameterization heterogeneous convolutional for accurate object detection. In: Pattern recognition and computer vision. Singapore: Springer Nature; 2024. p. 492–505. doi:10.1007/978-981-97-8858-3_34. [Google Scholar] [CrossRef]
18. Tan M, Pang R, Le QV. EfficientDet: scalable and efficient object detection. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. Piscataway, NJ, USA: IEEE; 2020. p. 10778–87. doi:10.1109/cvpr42600.2020.01079. [Google Scholar] [CrossRef]
19. Arya D, Maeda H, Ghosh SK, Toshniwal D, Sekimoto Y. RDD2022: a multi-national image dataset for automatic road damage detection. Geosci Data J. 2024;11(4):846–62. doi:10.1002/gdj3.260. [Google Scholar] [CrossRef]
20. Ouyang D, He S, Zhang G, Luo M, Guo H, Zhan J, et al. Efficient multi-scale attention module with cross-spatial learning. In: ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2023 Jun 4–10; Rhodes Island, Greece. Piscataway, NJ, USA: IEEE; 2023. p. 1–5. doi:10.1109/ICASSP49357.2023.10096516. [Google Scholar] [CrossRef]
21. Yang L, Zhang R-Y, Li L. SimAM: a simple, parameter-free attention module for convolutional neural networks. In: Meila M, Zhang T, editors. Proceedings of the 38th International Conference on Machine Learning. Vol. 139. Milton Keynes, UK: PMLR; 2021. p. 11863–74. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools