
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

RetinexWT: Retinex-Based Low-Light Enhancement Method Combining Wavelet Transform
College of Computer Science and Engineering, Chongqing University of Technology, Chongqing, 400054, China
* Corresponding Author: Jianxun Zhang. Email:
(This article belongs to the Special Issue: Computer Vision and Image Processing: Feature Selection, Image Enhancement and Recognition)
Computers, Materials & Continua 2026, 86(2), 1-20. https://doi.org/10.32604/cmc.2025.067041
Received 23 April 2025; Accepted 15 October 2025; Issue published 09 December 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Low-light image enhancement aims to improve the visibility of severely degraded images captured under insufficient illumination, alleviating the adverse effects of illumination degradation on image quality. Traditional Retinex-based approaches, inspired by human visual perception of brightness and color, decompose an image into illumination and reflectance components to restore fine details. However, their limited capacity for handling noise and complex lighting conditions often leads to distortions and artifacts in the enhanced results, particularly under extreme low-light scenarios. Although deep learning methods built upon Retinex theory have recently advanced the field, most still suffer from insufficient interpretability and sub-optimal enhancement performance. This paper presents RetinexWT, a novel framework that tightly integrates classical Retinex theory with modern deep learning. Following Retinex principles, RetinexWT employs wavelet transforms to estimate illumination maps for brightness adjustment. A detail-recovery module that synergistically combines Vision Transformer (ViT) and wavelet transforms is then introduced to guide the restoration of lost details, thereby improving overall image quality. Within the framework, wavelet decomposition splits input features into high-frequency and low-frequency components, enabling scale-specific processing of global illumination/color cues and fine textures. Furthermore, a gating mechanism selectively fuses down-sampled and up-sampled features, while an attention-based fusion strategy enhances model interpretability. Extensive experiments on the LOL dataset demonstrate that RetinexWT surpasses existing Retinex-oriented deep-learning methods, achieving an average Peak Signal-to-Noise Ratio (PSNR) improvement of 0.22 dB over the current State Of The Art (SOTA), thereby confirming its superiority in low-light image enhancement. Code is available at https:// github.com/CHEN-hJ516/RetinexWT (accessed on 14 October 2025).Keywords
As technology progresses, the need for clear, accurate information extraction from images continues to expand. Environmental factors, however, often obstruct the capture of high-quality images. Nighttime or low-light images typically suffer from issues such as noise, uneven illumination, and blurred details, all of which degrade visual quality and result in incomplete information. These limitations not only impair visual perception but also have cascading effects on advanced computer vision tasks, such as object recognition, autonomous driving, and image classification, ultimately reducing the accuracy of downstream processing tasks.
To address these challenges, a variety of low-light image enhancement algorithms have been proposed, including basic methods like gamma correction and histogram equalization. However, these approaches frequently lead to over-enhancement and image distortion, as their success depends heavily on the accuracy of manually set priors. In real-world scenarios, the complexity of lighting conditions complicates the determination of low-light factors.
Traditional cognitive methods, like the Retinex theory [1], inspired by the human visual system, decompose an image into two components—illumination and reflectance—to emulate how human perception interprets color and brightness across varying lighting conditions. According to Retinex theory, the objective of low-light enhancement is to mitigate illumination effects, amplify the reflectance component, and recover details and color. However, traditional Retinex approaches require complex parameter tuning and often introduce significant noise and artifacts, especially under low-light conditions.
With advancements in deep learning, convolutional neural networks (CNNs) and Transformer-based models have set new benchmarks for low-light image enhancement. CNNs effectively capture local image features, such as edges and textures, which are essential for detail restoration and noise suppression in low-light settings. However, under low-light conditions, image details and textures are frequently lost, while accurate separation of illumination information remains essential. Conventional convolution operations struggle to balance detail preservation with precise illumination estimation. Furthermore, traditional convolutional upsampling and downsampling mechanisms can degrade details, as texture and edge occlusion or blurring is common in low-light images. Direct convolutional downsampling can exacerbate this issue by conflating noise with detail, especially in dim and degraded regions, where noise is often erroneously amplified.
In feature fusion during upsampling and downsampling, standard channel-wise concatenation is typically used. This technique, which concatenates features along the channel dimension, lacks the ability to selectively emphasize relevant features, often leading to an accumulation of redundant information that dilutes key details and hampers the model’s ability to capture critical features effectively. Additionally, because CNNs primarily capture local features, relying on these features alone may be insufficient to address global illumination deficiencies in low-light images. While Transformer models, with their self-attention mechanism, enable a global perspective and model long-range dependencies more effectively, they enhance detail and structure restoration in low-light images. However, applying the original Transformer architecture is computationally intensive and involves a complex training process, making it challenging to adopt in real-time low-light image enhancement tasks.
To overcome these limitations, we propose RetinexWT, a unified low-light image enhancement framework that tightly integrates physical Retinex modeling with modern deep architectures in both spatial and frequency domains. Building upon the traditional Retinex theory, we augment the reflectance and illumination components with perturbation terms to explicitly characterize complex low-light degradations. The framework comprises two main modules: an Illumination Estimator and a Corruption Restorer. The Illumination Estimator, enhanced by a Wavelet Transform Feature Decomposer, exploits low-frequency illumination priors and high-frequency structural details to generate accurate illumination maps while adaptively attenuating noise. The Corruption Restorer employs an Illumination-Guided Transformer with Wavelet (IGTW), in which self-attention is explicitly guided by illumination features and reinforced through a Gated Fusion Mechanism, enabling selective feature integration from downsampling and upsampling paths. This design not only preserves fine details and suppresses noise but also mitigates overexposure artifacts and reduces the computational burden commonly observed in vanilla Transformers. Collectively, RetinexWT forms a cohesive and interpretable enhancement pipeline that achieves robust brightness enhancement, effective degradation suppression, and superior visual fidelity across diverse low-light conditions.
In summary, our main contributions can be summarized as follows:
• We propose a Transformer-based hybrid attention network for low-light image enhancement, ensuring effective modeling of long-range dependencies during the enhancement process. Our method leverages frequency domain information obtained from wavelet transform in combination with the Retinex model to obtain more accurate illumination information.
• We avoid traditional downsampling and instead introduce a Haar wavelet decomposer to preserve information. The input features are decomposed into high-frequency and low-frequency components through wavelet transform, allowing the structural and detail information of the image to be retained and separated during downsampling, thereby improving enhancement performance. Additionally, by providing frequency domain features, the model can utilize this rich information during reconstruction to perform more targeted operations in noise suppression, edge refinement, and noise removal based on frequency domain characteristics.
• We introduce a gating mechanism to selectively fuse the features from upsampling and downsampling. Compared to direct channel concatenation, this mechanism can adaptively determine which features are more important. By controlling the contribution of different channel features, it better balances noise suppression and detail preservation. During feature fusion, convolution and activation operations are applied to further refine and enhance information flow, reducing the risk of information loss during upsampling and downsampling.
• Qualitative and quantitative experiments demonstrate that our RetinexWT outperforms all previous Retinex-based deep learning methods and achieves superior results over state-of-the-art (SOTA) methods across multiple datasets.
In conclusion, Our innovative use of a Haar wavelet decomposer for downsampling ensures the retention of important structural and textural features across multiple frequency components, providing a superior enhancement performance. Additionally, the introduction of a gating mechanism for feature fusion offers an adaptive method for balancing noise suppression and detail preservation, a crucial improvement over traditional concatenation methods. By incorporating the Transformer’s self-attention mechanism, we also enhance the model’s ability to capture global dependencies, further improving the quality of the enhanced images.
2.1 Low-Light Image Enhancement
Traditional methods: Traditional methods generally employ mathematical models to enhance low-light images, such as Histogram Equalization (HE) [2–5] and Gamma Correction (GC) [6–8]. The core idea of these methods is to map the distribution of low-light input images by enhancing smaller values (usually representing darker regions) to achieve an enhancement effect. These methods are intuitive, easy to use, and computationally efficient. However, methods based on HE and GC often struggle to effectively handle color information, which may result in color distortion or artifacts in the image. Additionally, in certain cases (such as extremely dark or bright images), it is challenging to obtain reliable information from the environment, leading to information loss or poor enhancement results. Unlike the aforementioned methods, the Retinex theory [9] is a framework used to explain and simulate how the human visual system perceives object colors. This theory decomposes low-light images into reflectance and illumination components, thereby recovering an underlying normally lit image. It enables a better balance between brightness enhancement and noise suppression. Jobson [10,11] and others conducted studies based on the Retinex model, gradually recognizing through exploratory research that estimating the illumination layer is key to achieving brightness enhancement. However, as these methods [12–14] rely on manually designed priors, they often require meticulous parameter tuning. Inaccurate priors or regularization can lead to artifacts and color shifts in the enhanced images, significantly limiting their generalization capability, and the optimization process is usually time-consuming. Additionally, these studies often overlook the presence of noise, resulting in noise retention or amplification in the enhanced images.
Deep Learning Methods: In recent years, deep learning has achieved widespread success across various fields of computer vision tasks, such as object detection, scene segmentation, and low-light image enhancement. Based on Retinex theory, many methods utilize convolutional neural networks (CNNs) [15–18] for low-light image enhancement. For example, RetinexNet, proposed by Wei et al. [19], combines Retinex theory with deep convolutional networks to estimate and adjust illumination maps, achieving image contrast enhancement, and uses BM3D [20] denoising as a post-processing step. Zhang et al. [21] developed a self-supervised CNN to address low-light enhancement tasks. RetinexDIP [22] leverages the implicit prior information inherent in neural network structures to transform the low-light image enhancement problem into a generation problem. Reference [23] combine Retinex decomposition with deep learning. However, many deep learning methods [24,25] involve cumbersome multi-stage training pipelines and perform poorly when addressing image contamination factors, often resulting in amplified noise and color distortion. Moreover, CNN-based methods have limitations in capturing long-range dependencies across different regions of the image. Star [26] applied the Transformer architecture to the low-light enhancement domain, successfully addressing the challenge of capturing long-range dependencies. Later, reference [27]proposed the IAGC model, designing a novel Transformer block that fully models pixel dependencies through a hierarchical attention mechanism from local to global, allowing poorly illuminated regions to effectively utilize information from distant regions. However, Transformer-based models frequently encounter issues with overexposure in illuminated areas. In addition, the self-attention mechanism of Transformers introduces significant computational burden and complexity when handling long sequences, which remains a major challenge.
2.2 Wavelet Transforms in Image Processing
Wavelet Transforms have recently gained significant attention in image processing as a new technique that provides multi-resolution representation while capturing both low-frequency and high-frequency components of signals or images, which helps in better understanding their structure and characteristics (Fig. 1). Given that wavelet transforms are reversible and capable of preserving all information, they have been utilized within CNN architectures to improve performance across various computer vision tasks. For instance, Bae et al. [28] demonstrated that learning CNN representations on wavelet subbands could benefit image restoration tasks. DWSR [29] uses low-resolution wavelet subbands as input to recover lost details in image super-resolution tasks. Wavelet-SRNet [30], a wavelet-based CNN, was introduced for multi-scale face super-resolution. Haar wavelet transforms are integrated with multi-resolution analysis within [31] for texture classification and image annotation. In low-light image enhancement tasks, the application of Wavelet Transforms enables targeted brightness enhancement and detail improvement by separating low-frequency luminance information from high-frequency detail information. For example, reference [32] decomposing an image into low-frequency and high-frequency components allows for enhancing the low-frequency part to improve brightness while utilizing low-frequency information to adjust high-frequency details, ensuring accuracy in details. Another approach [33] uses low-frequency restoration and high-frequency reconstruction subnetworks to enhance brightness and detail information separately, achieving a more natural low-light enhanced image. These examples show that incorporating wavelet transforms into low-light enhancement tasks holds great potential for future applications.
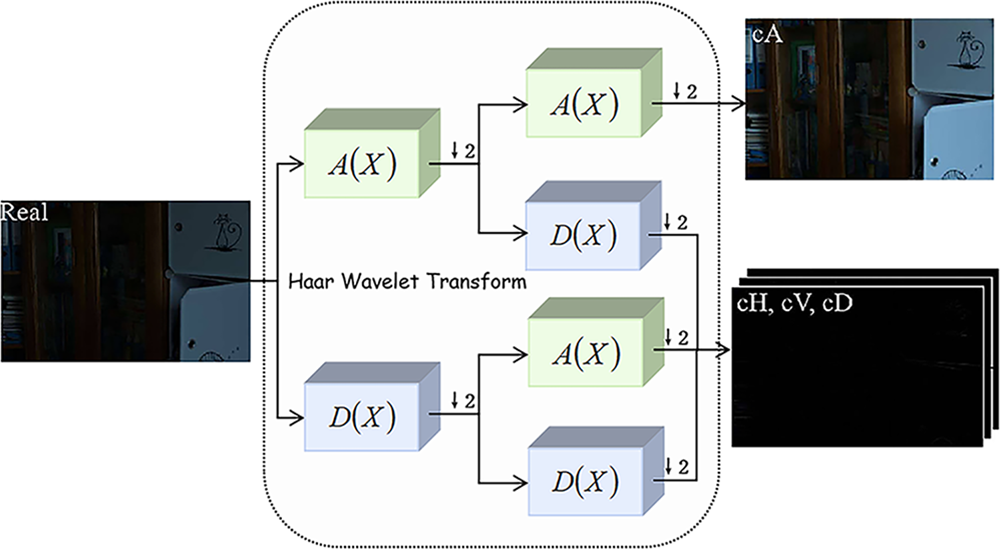
Figure 1: A schematic diagram of feature decomposition using Haar wavelet transform. Here,
Fig. 2 illustrates the overall architecture of our proposed RetinexWT method. As shown in Fig. 2a, RetinexWT primarily consists of two components: the Illumination Estimator and the Corruption Restorer. The Illumination Estimator is inspired by the traditional Retinex model, with enhancements that introduce perturbation terms combined with frequency-domain information. To further refine the illumination feature estimation, the design integrates wavelet transform. The Corruption Restorer is based on the Illumination Guided Transformer with Wavelet (IGTW), as shown in Fig. 2b. The core unit of IGTW is the Enhanced Illumination-Guided Attention Model (EIGAM), which comprises the Illumination-Guided Attention (IGA), Nonlinear Activation-Free (NAF) Block, Layer Normalization (LN), and Feed-Forward Network (FFN). The details of IGTW are depicted in Fig. 3a.
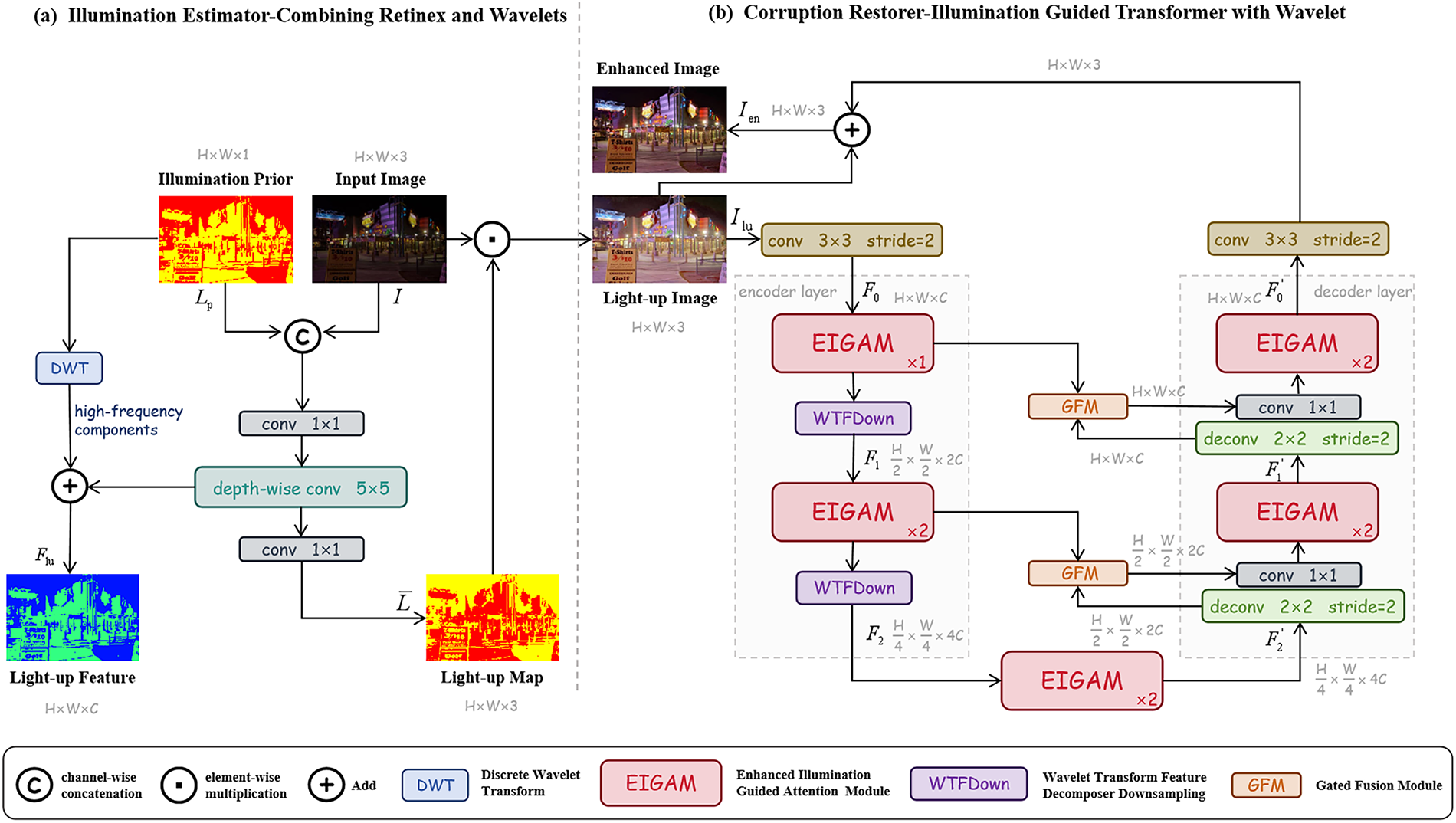
Figure 2: Overview of our method. RetinexWT consists of an Illumination Estimator (a) and an Illumination Guided Transformer with Wavelet (IGTW) (b)
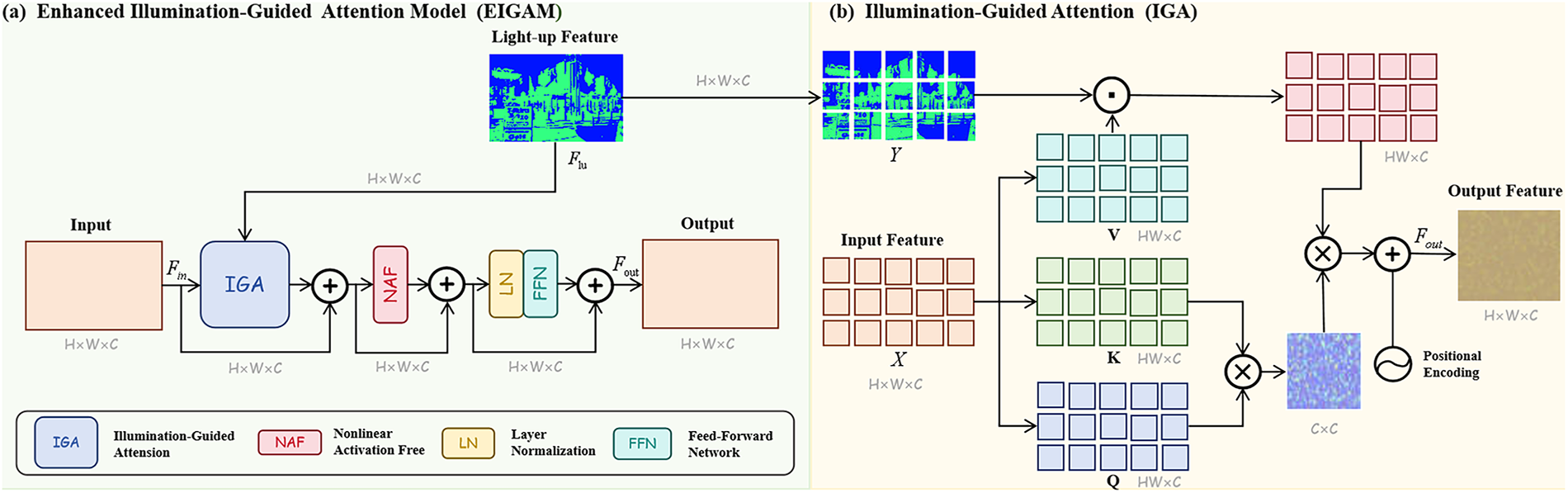
Figure 3: (a) The Enhanced Illumination-Guided Attention Model (EIGAM) incorporates illumination guidance through IGA mechanism, followed by a NAF module to reduce computational complexity. LN and a FFN are applied with residual connections to enhance feature extraction and maintain the integrity of original details. (b) In the Illumination-Guided Attention (IGA) module, the illumination feature captured by the IE is used as the
In the domain of low-light image enhancement, Retinex theory is commonly applied to simulate the human visual system’s perception of brightness and color. Traditional Retinex algorithms decompose an input image
where
here,
which can be simplified as:
where
In this formulation, IE represents the Illumination Estimator, and CR denotes the Corruption Restorer. The Illumination Estimator (IE) takes I and
As shown in Fig. 2a, the Illumination Estimator (IE) combines the original low-light image I with the illumination prior
It is well-known that the low-frequency components in wavelet transforms predominantly capture the overall illumination and structural information of an image. The illumination prior
Finally, another
3.3 Illumination Guided Transformer with Wavelet
In the RetinexWT framework, the Corruption Restorer (IGTW) module consists of an encoder and a decoder, both based on an Illumination-Guided Transformer with Wavelet architecture and incorporating a Gated Fusion Mechanism. The encoder handles the downsampling process, while the decoder manages upsampling, as illustrated in Fig. 2b. Both the downsampling and upsampling processes are divided into two stages. Initially, the Illumination Estimator (IE) generates an illumination map
EIGAM. The structure of the Enhanced Illumination-Guided Attention Model (EIGAM) is depicted in Fig. 3a. Within EIGAM, the input feature
here,
where
GFM. The Gated Fusion Module (GFM) in the Illumination Guided Transformer with Wavelet (IGTW) is designed to fuse features from the downsampling and upsampling paths, as shown in Fig. 4a. GFM first concatenates the upsampling feature
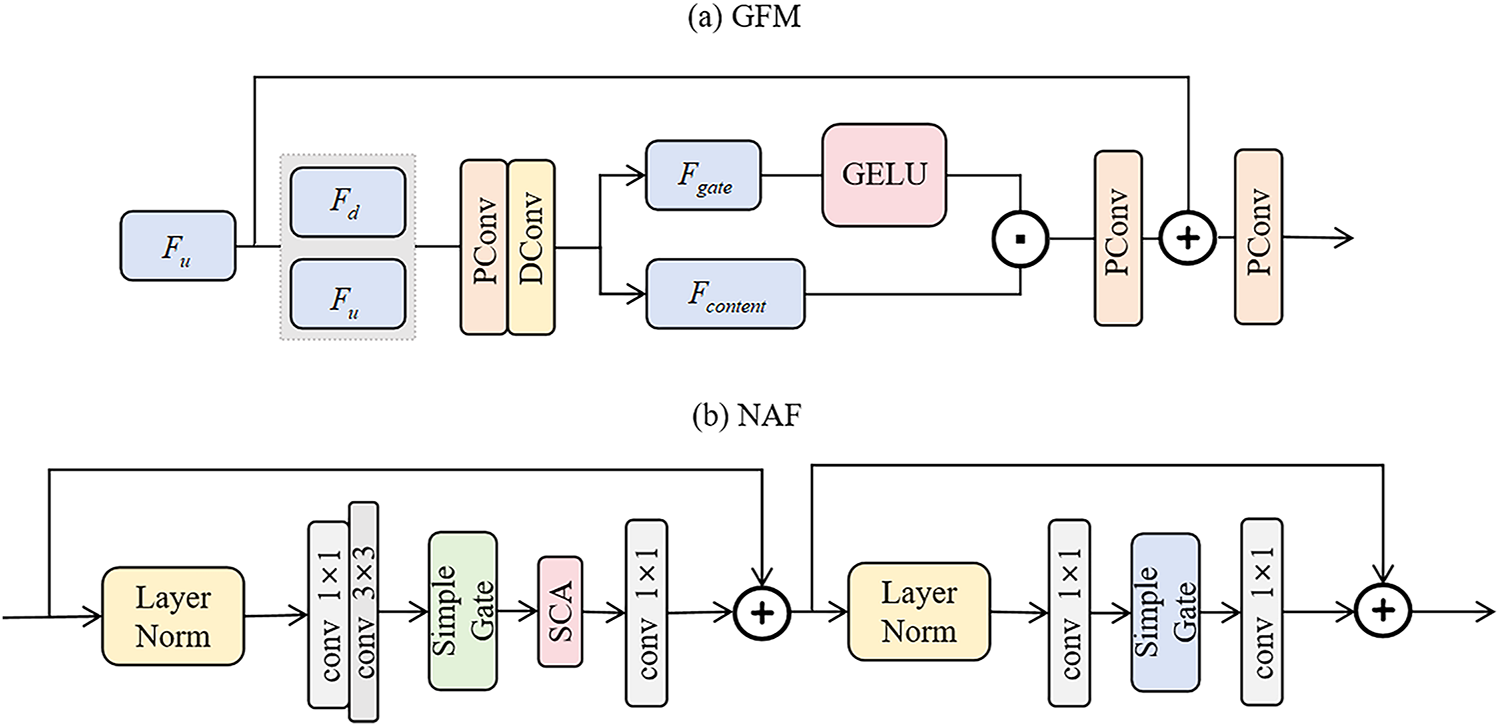
Figure 4: (a) Gated Fusion Module (GFM), (b) Nonlinear Activation Free (NAF)
The
NAF. We employ a module called the Nonlinear Activation Free (NAF), which eliminates traditional nonlinear activation functions to reduce computational complexity and enchance performance. As illustrated in Fig. 4b, the NAF module begins by applying a
3.4 Wavelet Transform Feature Decomposer Downsampling
Wavelet Transform is a signal processing technique that decomposes a signal into sub-signals of different frequency bands, enabling simultaneous analysis in the time and frequency domains. In the context of image processing, Wavelet Transform is employed to decompose an image into multiple sub-bands, consisting of low-frequency and high-frequency components. The low-frequency components capture the overall brightness and structural information of the image, making them suitable for global brightness enhancement. Conversely, the high-frequency components encode details such as edges and textures, while also containing noise. In low-light image enhancement tasks, separately processing the low- and high-frequency components can improve image brightness while preserving fine details, such as textures and edges. However, traditional approaches often directly apply Wavelet Transform in the downsampling layers of neural networks, substituting spatial domain features with frequency domain features. While effective in certain aspects, this substitution can lead to the loss of critical spatial information, resulting in blurry or distorted enhanced images. To address this limitation, we propose a method that integrates both frequency and spatial domain information: the Wavelet Transform Feature Decomposer Downsampling (WTFDown). This approach incorporates frequency domain feature mapping into the downsampling process within low-light enhancement networks. By combining the strengths of frequency and spatial domain representations, WTFDown aims to preserve both structural integrity and fine details in the enhanced images. The architecture of WTFDown is illustrated in Fig. 5.
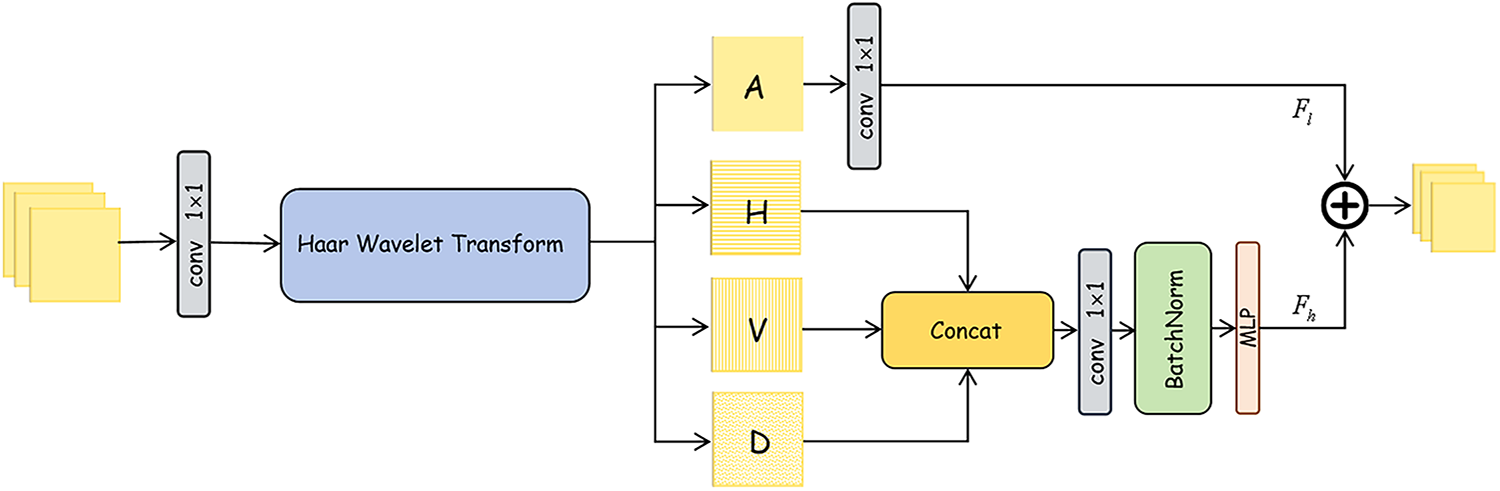
Figure 5: The WTFDown module introduces frequency domain feature mapping into the network for downsampling. This structure uses the Haar wavelet transform to decompose the original features into high-frequency and low-frequency components, processes them separately, and then adds them together to obtain a composite of global and local features. Finally, it combines these with spatial features, allowing the model to consider features in a new representation domain
In WTFDown, the input features are first passed through a
Specifically, the input feature
where
here, the
where
This section begins by outlining the implementation details, datasets, and evaluation metrics used in the study. Subsequently, it presents both quantitative and qualitative results, comparing the proposed approach with state-of-the-art methods for low-light image enhancement. Finally, an ablation study is conducted to evaluate the contribution and effectiveness of each component within the proposed model.
Implementation Detail. Our RetinexWT is implemented in PyTorch and trained on an NVIDIA RTX A6000 GPU (CUDA 11.8, Python 3.9, PyTorch 2.0) using the Adam optimizer [35] with
Datasets and Metrics. We evaluated our method on the LOL dataset, which is divided into two versions: LOL-v1 [19] and LOL-v2 [37]. In LOL-v1, the dataset contains 485 training image pairs and 15 test image pairs, with each pair comprising a low-light input image and a corresponding high-quality reference image. The LOL-v2 dataset is further categorized into two subsets: LOL-v2-real and LOL-v2-synthetic. The training-to-test data ratios in LOL-v2-real and LOL-v2-synthetic are 689:100 and 900:100, respectively. The distribution of training and test pairs within these subsets mirrors the structure of LOL-v1. In addition to the paired LOL datasets, we utilized several unpaired datasets to evaluate the model’s generalization capabilities. These datasets include LIME [38] (10 images), DICM [39] (64 images), MEF [40] (17 images), VV [41] (24 images), and ExDark [42] (7358 images). These datasets provide diverse visual conditions, facilitating a comprehensive assessment of the model. For performance evaluation, we employed two full-reference metrics—PSNR, SSIM [43]—to quantitatively assess the quality of the enhanced images compared to the reference images in the paired datasets.
4.2 Comparison with the State-of-the-Art
We compared the proposed method with various deep learning-based SOTA methods listed in Table 1, including SID [44], 3DLUT [45], DeepUPE [46], SCI [47], RetinexNet [19], and others. The datasets used for comparison include synthetic data from LOL-v1 [19] and both real and synthetic data from LOL-v2 [37]. For a fair comparison, we utilized the official pre-trained models of each method and their publicly available code to obtain the quantitative results.
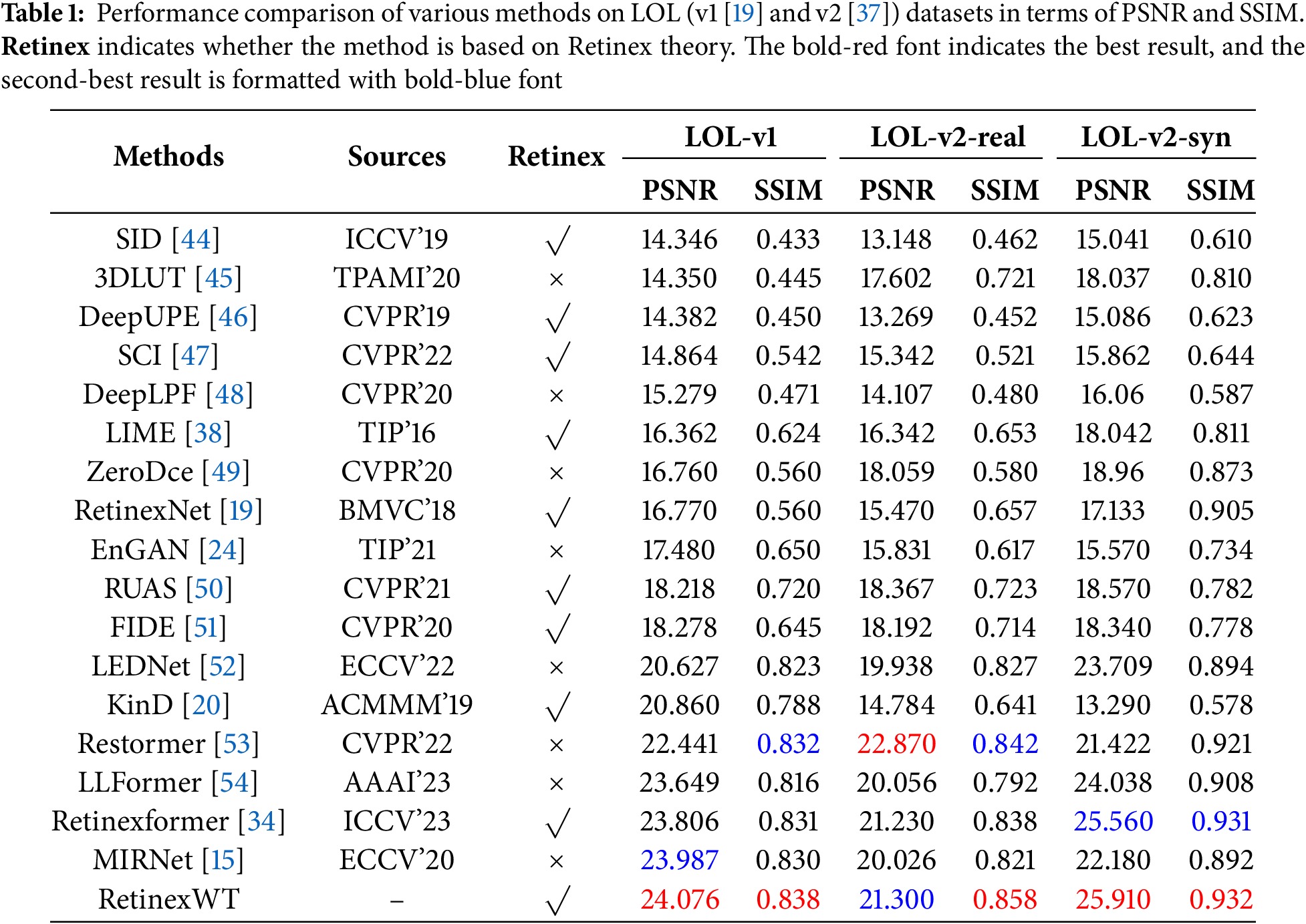
Quantitative analysis. The evaluation metrics used for comparison are Peak Signal-to-Noise Ratio (PSNR) and Structure Similarity Index Measure (SSIM), where PSNR reflects the overall enhancement quality, with higher values indicating better performance, and SSIM measures the preservation of high-frequency details and structural information, with higher values signifying superior retention of image content. Our proposed RetinexWT method demonstrates a significant performance advantage over the aforementioned SOTA methods on the LOL dataset.
Specifically, when compared to other Retinex-based deep learning SOTA methods, including SID [44], DeepUPE [46], SCI [47], LIME [38], RetinexNet [19], RUAS [50], FIDE [51], KinD [20], and Retinexformer [34], our method achieves notable improvements in both PSNR and SSIM across the LOL-v1 and LOL-v2 datasets. In terms of PSNR, RetinexWT achieves enhancements of 0.27 dB, 0.07 dB, and 0.35 dB on LOL-v1, LOL-v2-real, and LOL-v2-synthetic datasets, respectively. Similarly, SSIM improvements of 0.007 dB, 0.02 dB, and 0.001 dB are observed on the same datasets, underscoring the superior capability of our method to balance enhancement quality and detail preservation. As shown in Table 1, further highlighting the efficacy of our approach. Furthermore, RetinexWT attains these improvements with a computational cost of only 16.83 G FLOPs and 2.11 M parameters, which is among the lowest in all compared methods. Notably, when compared to models of similar complexity, such as Retinexformer, our approach achieves higher PSNR and SSIM scores across all datasets, underscoring its favorable performance-efficiency trade-off.
Quantitative analysis. To provide a more comprehensive and intuitive comparison, we conducted a visual evaluation of our RetinexWT method against other state-of-the-art (SOTA) approaches. Fig. 6 and Fig. 7 are drawn from the LOL dataset (LOL-v1 [19] and LOL-v2 [37]), where the input consists of severely degraded low-light images. The results reveal several limitations of existing methods: noise amplification (e.g., RetinexNet in Fig. 7), underexposure or overexposure (e.g., LEDNet and RUAS in Fig. 6), color distortion (e.g., Restormer in Fig. 7), and the introduction of black spots and artifacts (e.g., EnGAN and Kind in Fig. 7).

Figure 6: The qualitative experimental results of our method and SOTA approaches on the LOL-v1 [19] and LOL-v2 [37] datasets demonstrate clear advantages. Upon closer examination with magnification, our method achieves superior visual effects

Figure 7: The qualitative experimental results of our method and SOTA approaches on the LOL-v2 [38] datasets demonstrate clear advantages. Upon closer examination with magnification, our method achieves superior visual effects
In contrast, our method demonstrates notable improvements in both global and local enhancement. It effectively manages exposure levels, significantly improves visibility and contrast, and minimizes noise, thereby delivering superior visual quality. Additionally, we present unpaired benchmark results in Fig. 8, where our method exhibits precise exposure control and vibrant color restoration. In particular, Fig. 8 deliberately includes challenging cases such as extremely low-light, high-noise, and overexposure-prone scenes, demonstrating not only the strong generalization capability of our approach across diverse low-light conditions, but also its robustness against severe degradations.

Figure 8: Visual results on LIME [38], DICM [39], MEF [40], VV [41], ExDark [42], and we selected one “hard-sample” image from each dataset and compared it against the other methods, our method achieves superior visual effects
4.3 Low-Light Object Detection
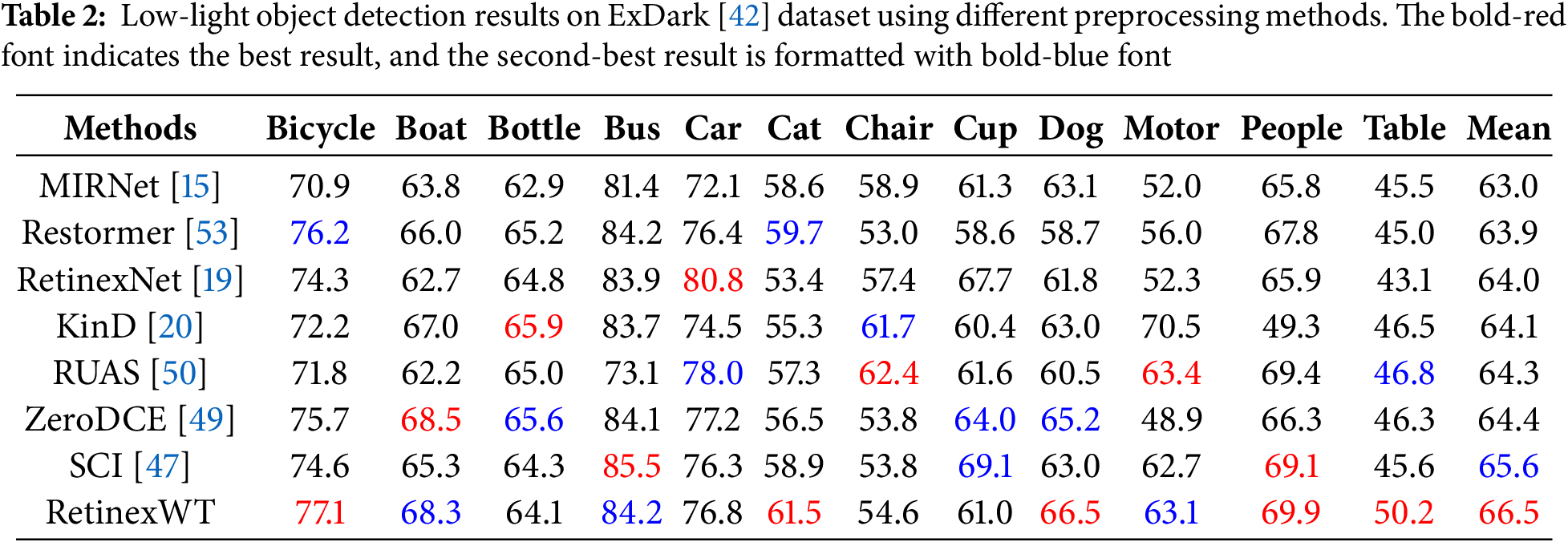
In this section, we examine the effect of various preprocessing methods on the efficiency of object detection under low-light conditions. Specifically, we perform experiments on the ExDark [42] dataset, which comprises 7363 real-world nighttime images spanning 12 object categories. To evaluate the impact of preprocessing, we first apply our proposed RetinexWT method along with several comparative approaches, and subsequently employ YOLO-v3 [55] as the object detection model to assess the detection performance.
Quantitative analysis. In Table 2, we present the average precision (AP) scores achieved by different methods used as preprocessing steps for object detection. RetinexWT stands out by not only achieving the highest overall average AP score but also securing the highest AP in five specific categories: Bicycle, Cat, Dog, People, and Table. Furthermore, it demonstrates strong performance by achieving the second-highest AP in the categories of Boat, Bus, and Motor. These results highlight the effectiveness and robustness of RetinexWT in enhancing object detection performance across diverse categories.
Quantitative analysis. We performed a visual comparison of object detection results on the original low-light images and those enhanced by RetinexWT, as illustrated in Fig. 9. In the detection results on the original low-light images, some categories were missed, and the overall detection accuracy was significantly limited. In contrast, the enhanced images processed by RetinexWT demonstrated comprehensive category detection with noticeable improvements in detection accuracy.

Figure 9: Visual comparison of the impact of our method on low-light object detection
In this section, we conduct an ablation study by progressively integrating the proposed components into the framework and analyzing their coupling mechanisms. All experiments are performed on the LOL-v1 and LOL-v2-syn datasets. As shown in Table 3, when the IGA, WTFDown, GFM, and NAF components are excluded, the model achieves PSNR values of 22.748 and 24.572 dB, and SSIM values of 0.823 and 0.887, respectively, indicating the limitations of the baseline framework.
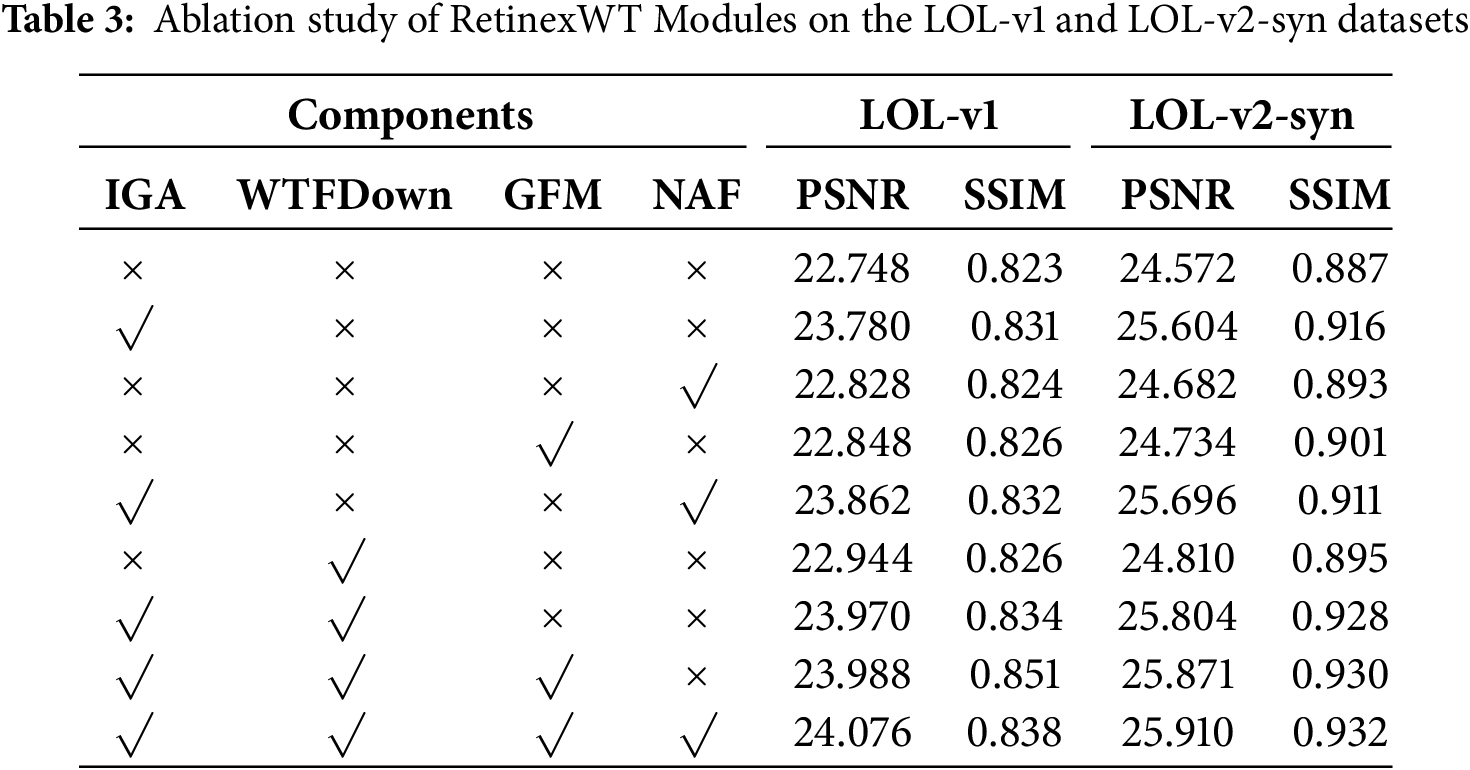
The improvements brought by each component are closely tied to their roles and interactions in the processing pipeline. Specifically, the IGA exploits illumination priors from the Illumination Estimator to guide global context modeling, increasing the PSNR by 1.032 dB on both datasets. The WTFDown enhances this process by providing frequency-domain decomposition, enabling the network to jointly utilize low-frequency illumination and high-frequency detail information, contributing an additional 0.196 and 0.238 dB. When combined, IGA and WTFDown exhibit a synergistic effect, raising the PSNR gains to 1.222 and 1.232 dB, as the attention mechanism can better leverage the decomposed multi-scale features.
The GFM further strengthens this synergy by selectively integrating upsampled and downsampled features, thereby preserving edge and texture details while suppressing noise, yielding improvements of 0.100 dB and 0.162 dB. The NAF block reduces computational complexity while maintaining feature integrity, providing an additional 0.080 and 0.110 dB gain. When IGA, WTFDown, and GFM are combined, the PSNR is further improved by 0.018 and 0.067 dB compared to the preceding configuration.
Ultimately, the complete RetinexWT framework, integrating all four components, achieves the highest PSNR and SSIM values among all configurations, with improvements of 1.328 and 1.338 dB in PSNR, and 0.015 and 0.045 in SSIM, compared to the baseline. This confirms that the proposed components are not independent “stacked” modules, but rather interdependent mechanisms in which illumination guidance, frequency-domain decomposition, gated spatial fusion, and efficient feature refinement operate in a cohesive manner to enhance low-light image restoration performance.
This paper presented a novel deep learning model for low-light image enhancement, which integrated Retinex theory with wavelet transform. The model introduced a perturbation term into the traditional Retinex framework and leveraged wavelet transform to estimate illumination information for initial enhancement. To address detail loss, a Corruption Restorer module was developed, which combined wavelet transform with an illumination-guided transformer to effectively recover lost details. Extensive experiments validated the superiority of the proposed approach in handling low-light image enhancement tasks. Both quantitative evaluations and qualitative visual comparisons demonstrated that the method consistently outperformed state-of-the-art techniques, achieving remarkable improvements in both metrics and visual fidelity.
Our future research will focus on three key aspects: computational efficiency, robustness in extreme scenarios, and cross-domain generalization. First, we will reduce inference latency through model compression, quantization, and operator-level optimization to achieve real-time enhancement, particularly in application domains such as autonomous driving and security monitoring where low-latency and high reliability are critical. Second, for extremely dark and high-noise conditions, we will introduce learnable noise modeling and degradation-consistent regularization to further improve detail recovery and noise suppression capabilities. Additionally, leveraging large-scale unlabeled data, we will explore self-supervised paradigms based on contrastive learning or masked reconstruction to reduce reliance on paired training data and enhance cross-scene generalization. Finally, we will jointly optimize the enhancement network with downstream tasks such as object detection and semantic segmentation, enabling mutual reinforcement between low-light enhancement and high-level perception objectives. This approach aims to achieve simultaneous improvements in perceptual quality, task accuracy, and computational feasibility under hardware-constrained scenarios.
Acknowledgement: Thanks for the support from my teachers and friends during the writing of this thesis.
Funding Statement: This work is supported in part by the National Natural Science Foundation of China [Grant number 62471075], the Major Science and Technology Project Grant of the Chongqing Municipal Education Commission [Grant number KJZD-M202301901].
Author Contributions: The authors confirm contribution to the paper as follows: Methodologies, coding, and thesis writing, Hongji Chen; experimental guidance, thesis writing revision, Jianxun Zhang; dataset processing, Tianze Yu and Yingzhu Zeng; experimental data organization, Huan Zeng. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Land EH, McCann JJ. Lightness and retinex theory. J Opt Soc Am. 1971;61(1):1–11. doi:10.1364/josa.61.000001. [Google Scholar] [PubMed] [CrossRef]
2. Roy S, Bhalla K, Patel R. Mathematical analysis of histogram equalization techniques for medical image enhancement: a tutorial from the perspective of data loss. Multimed Tools Appl. 2024;83(5):14363–92. doi:10.1007/s11042-023-15799-8. [Google Scholar] [CrossRef]
3. Dhal KG, Das A, Ray S, Gálvez J, Das S. Histogram equalization variants as optimization problems: a review. Arch Comput Methods Eng. 2021;28(3):1471–96. doi:10.1007/s11831-020-09425-1. [Google Scholar] [CrossRef]
4. Dyke RM, Hormann K. Histogram equalization using a selective filter. Vis Comput. 2023;39(12):6221–35. doi:10.1007/s00371-022-02723-8. [Google Scholar] [PubMed] [CrossRef]
5. Jha K, Sakhare A, Chavhan N, Lokulwar PP. A review on image enhancement techniques using histogram equalization.grenze. Int J Eng Technol (GIJET). 2024;10(1):923–8. [Google Scholar]
6. Sun X, Fang H, Yang Y, Zhu D, Wang L, Liu J, et al. Robust retinal vessel segmentation from a data augmentation perspective. In: Ophthalmic Medical Image Analysis: 8th International Workshop, OMIA 2021. Cham, Switzerland: Springer International Publishing; 2021. p. 189–98. [Google Scholar]
7. Zhu Z, Wei H, Hu G, Li Y, Qi G, Mazur N. A novel fast single image dehazing algorithm based on artificial multiexposure image fusion. IEEE Trans Instrum Meas. 2020;70:1–23. doi:10.1109/tim.2020.3024335. [Google Scholar] [CrossRef]
8. Rahman S, Rahman MM, Abdullah-Al-Wadud M, Al-Quaderi GD, Shoyaib M. An adaptive gamma correction for image enhancement. EURASIP J Image Video Process. 2016;2016(1):35. doi:10.1186/s13640-016-0138-1. [Google Scholar] [CrossRef]
9. Provenzi E, De Carli L, Rizzi A, Marini D. Mathematical definition and analysis of the Retinex algorithm. J Opt Soc Am A. 2005;22(12):2613–21. doi:10.1364/josaa.22.002613. [Google Scholar] [PubMed] [CrossRef]
10. Jobson DJ, Rahman ZU, Woodell GA. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans Image Process. 1997;6(7):965–76. doi:10.1109/83.597272. [Google Scholar] [PubMed] [CrossRef]
11. Jobson DJ, Rahman ZU, Woodell GA. Properties and performance of a center/surround retinex. IEEE Trans Image Process. 1997;6(3):451–62. doi:10.1109/83.557356. [Google Scholar] [PubMed] [CrossRef]
12. Rahman ZU, Jobson DJ, Woodell GA. Retinex processing for automatic image enhancement. J Electron Imaging. 2004;13(1):100–10. doi:10.1117/1.1636183. [Google Scholar] [CrossRef]
13. Wang S, Zheng J, Hu HM, Li B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans Image Process. 2013;22(9):3538–48. doi:10.1109/tip.2013.2261309. [Google Scholar] [PubMed] [CrossRef]
14. Wu W, Weng J, Zhang P, Wang X, Yang W, Jiang J. Uretinex-net: retinex-based deep unfolding network for low-light image enhancement. In: Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. [Google Scholar]
15. Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang MH, et al. Learning enriched features for real image restoration and enhancement. In: Computer Vision—ECCV 2020 (ECCV 2020). Cham, Switzerland: Springer; 2020. p. 492–511. [Google Scholar]
16. Lv F, Lu F, Wu J, Lim C. Mbllen: low-light image/video enhancement using CNNs. In: British Machine Vision Conference (BMVC); 2018 Sep 2–6; Newcastle, UK. [Google Scholar]
17. Lore KG, Akintayo A, Sarkar S. Llnet: a deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017;61(6):482–95. doi:10.1016/j.patcog.2016.06.008. [Google Scholar] [CrossRef]
18. Xu X, Wang R, Fu CW, Jia J. SNR-aware low-light image enhancement. In: Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. p. 17714–24. [Google Scholar]
19. Wei C, Wang W, Yang W, Liu J. Deep retinex decomposition for low-light enhancement. In: Proceedings of the British Machine Vision Conference (BMVC); 2018 Sep 2–6; Newcastle, UK. [Google Scholar]
20. Dabov K, Foi A, Katkovnik V, Egiazarian K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans Image Process. 2007;16(8):2080–95. doi:10.1109/tip.2007.901238. [Google Scholar] [PubMed] [CrossRef]
21. Zhang Y, Zhang J, Guo X. Kindling the darkness: a practical low-light image enhancer. In: MM ’19: Proceedings of the 27th ACM International Conference on Multimedia; 2019 Oct 21–25; Nice France. p. 1632–40. [Google Scholar]
22. Zhao Z, Xiong B, Wang L, Ou Q, Yu L, Kuang F. RetinexDIP: a unified deep framework for low-light image enhancement. IEEE Trans Circuits Syst Video Technol. 2022;32(3):1076–88. doi:10.1109/tcsvt.2021.3073371. [Google Scholar] [CrossRef]
23. Zhang Y, Guo X, Ma J, Liu W, Zhang J. Beyond brightening low-light images. Int J Comput Vis. 2021;129(4):1013–37. doi:10.1007/s11263-020-01407-x. [Google Scholar] [CrossRef]
24. Jiang Y, Gong X, Liu D, Cheng Y, Fang C, Shen X, et al. EnlightenGAN: deep light enhancement without paired supervision. IEEE Trans Image Process. 2021;30:2340–9. doi:10.1109/tip.2021.3051462. [Google Scholar] [PubMed] [CrossRef]
25. Mi A, Luo W, Qiao Y, Huo Z. Rethinking Zero-DCE for low-light image enhancement. Neural Process Lett. 2024;56(2):93. doi:10.1007/s11063-024-11565-5. [Google Scholar] [CrossRef]
26. Zhang Z, Jiang Y, Jiang J, Wang X, Luo P, Gu J. STAR: a structure-aware lightweight transformer for real-time image enhancement. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision; 2021 Oct 11–17; Montreal, QC, Canada. p. 4106–15. [Google Scholar]
27. Wang Y, Liu Z, Liu J, Xu S, Liu S. Low-light image enhancement with illumination-aware gamma correction and complete image modelling network. In: Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision; 2023 Oct 1–6; Paris, France. p. 13128–37. [Google Scholar]
28. Bae W, Yoo J, Ye JC. Beyond deep residual learning for image restoration: persistent homology-guided manifold simplification. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW2017 Jul 21–26; Honolulu, HI, USA. p. 1141–9. [Google Scholar]
29. Guo T, Mousavi HS, Vu TH, Monga V. Deep wavelet prediction for image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops; 2017 Jul 21–26; Honolulu, HI, USA. p. 1100–9. [Google Scholar]
30. Huang H, He R, Sun Z, Tan T. Wavelet-SRNet: a wavelet-based CNN for multi-scale face super resolution. In: Proceedings of the 2017 IEEE International Conference on Computer Vision; 2017 Oct 22–29; Venice, Italy. p. 1689–97. [Google Scholar]
31. Fujieda S, Takayama K, Hachisuka T. Wavelet convolutional neural networks. arXiv:1805.08620. 2018. [Google Scholar]
32. Zou W, Gao H, Yang W, Liu T. Wave-Mamba: wavelet state space model for ultra-high-definition low-light image enhancement. In: Proceedings of the 32nd ACM International Conference on Multimedia; 2024 Oct 28–Nov 1; Melbourne, VIC, Australia. p. 1534–43. [Google Scholar]
33. Xiang Y, Hu G, Chen M, Emam M. WMANet: wavelet-based multi-scale attention network for low-light image enhancement. IEEE Access. 2024;12(6):105674–85. doi:10.1109/access.2024.3434531. [Google Scholar] [CrossRef]
34. Cai Y, Bian H, Lin J, Wang H, Timofte R, Zhang Y. Retinexformer: one-stage retinex-based transformer for low-light image enhancement. In: Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision; 2023 Oct 1–6; Paris, France. p. 12504–13. [Google Scholar]
35. Kingma DP, Ba J. Adam: a method for stochastic optimization. arXiv:1412.6980. 2014. [Google Scholar]
36. Loshchilov I, Hutter F. SGDR: stochastic gradient descent with warm restarts. arXiv:1608.03983. 2016. [Google Scholar]
37. Yang W, Wang W, Huang H, Wang S, Liu J. Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE Trans Image Process. 2021;30:2072–86. doi:10.1109/tip.2021.3050850. [Google Scholar] [PubMed] [CrossRef]
38. Guo X, Li Y, Ling H. LIME: low-light image enhancement via illumination map estimation. IEEE Trans Image Process. 2017;26(2):982–93. doi:10.1109/tip.2016.2639450. [Google Scholar] [PubMed] [CrossRef]
39. Lee C, Lee C, Kim CS. Contrast enhancement based on layered difference representation. In: Proceedings of the 19th IEEE International Conference on Image Processing (ICIP); 2012 Sep 30–Oct 3; Orlando, FL, USA. p. 965–8. [Google Scholar]
40. Ma K, Zeng K, Wang Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans Image Process. 2015;24(11):3345–56. doi:10.1109/tip.2015.2442920. [Google Scholar] [PubMed] [CrossRef]
41. Vonikakis V, Kouskouridas R, Gasteratos A. On the evaluation of illumination compensation algorithms. Multimed Tools Appl 2018;77(7):9211–33. doi:10.1007/s11042-017-4783-x. [Google Scholar] [CrossRef]
42. Loh YP, Chan CS. Getting to know low-light images with the exclusively dark dataset. Comput Vis Image Underst. 2019;178:30–42. doi:10.1016/j.cviu.2018.10.010. [Google Scholar] [CrossRef]
43. Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process. 2004;13(4):600–12. doi:10.1109/tip.2003.819861. [Google Scholar] [PubMed] [CrossRef]
44. Chen C, Chen Q, Do MN, Koltun V. Seeing motion in the dark. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 3184–93. [Google Scholar]
45. Zeng H, Cai J, Li L, Cao Z, Zhang L. Learning image-adaptive 3D lookup tables for high performance photo enhancement in real-time. IEEE Trans Pattern Anal Mach Intell. 2020;42(12):3158–72. doi:10.1109/tpami.2020.3026740. [Google Scholar] [PubMed] [CrossRef]
46. Wang R, Zhang Q, Fu CW, Shen X, Zheng WS, Jia J. Underexposed photo enhancement using deep illumination estimation. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2019 Jun 15–20; Long Beach, CA, USA. p. 6842–50. [Google Scholar]
47. Ma L, Ma T, Liu R, Fan X, Luo Z. Toward fast, flexible, and robust low-light image enhancement. arXiv:2203.07911. 2022. [Google Scholar]
48. Moran S, Marza P, McDonagh S, Parisot S, Slabaugh G. DeepLPF: deep local parametric filters for image enhancement. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 12826–35. [Google Scholar]
49. Guo C, Li C, Guo J, Loy CC, Hou J, Kwong S, et al. Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA. p. 1780–9. [Google Scholar]
50. Liu R, Ma L, Zhang J, Fan X, Luo Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 10556–65. [Google Scholar]
51. Xu K, Yang X, Yin B, Lau RWH. Learning to restore low-light images via decomposition-and-enhancement. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 14–19; Seattle, WA, USA. p. 2278–87. [Google Scholar]
52. Zhou S, Li C, Loy CC. LEDNet: joint low-light enhancement and deblurring in the dark. In: Computer Vision—ECCV 2022: 17th European Conference. Cham, Switzerland: Springer; 2022. p. 573–89. [Google Scholar]
53. Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang MH. Restormer: efficient transformer for high-resolution image restoration. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. p. 5718–29. [Google Scholar]
54. Wang T, Zhang K, Shen T, Luo W, Stenger B, Lu T. Ultra-high-definition low-light image enhancement: a benchmark and transformer-based method. In: AAAI’23/IAAI’23/EAAI’23: Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence. Washington, DC, USA: AAAI Press; 2023. p. 2654–62. [Google Scholar]
55. Zhao L, Li S. Object detection algorithm based on improved YOLOv3. Electronics. 2020;9(3):537. doi:10.3390/electronics9030537. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools