
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

An Attention-Based 6D Pose Estimation Network for Weakly Textured Industrial Parts
1 School of Smart Manufacturing, Jianghan University, Wuhan, 430056, China
2 State Key Laboratory of Precision Blasting, Jianghan University, Wuhan, 430056, China
* Corresponding Author: Song Xu. Email:
Computers, Materials & Continua 2026, 86(2), 1-19. https://doi.org/10.32604/cmc.2025.070472
Received 17 July 2025; Accepted 27 October 2025; Issue published 09 December 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The 6D pose estimation of objects is of great significance for the intelligent assembly and sorting of industrial parts. In the industrial robot production scenarios, the 6D pose estimation of industrial parts mainly faces two challenges: one is the loss of information and interference caused by occlusion and stacking in the sorting scenario, the other is the difficulty of feature extraction due to the weak texture of industrial parts. To address the above problems, this paper proposes an attention-based pixel-level voting network for 6D pose estimation of weakly textured industrial parts, namely CB-PVNet. On the one hand, the voting scheme can predict the keypoints of affected pixels, which improves the accuracy of keypoint localization even in scenarios such as weak texture and partial occlusion. On the other hand, the attention mechanism can extract interesting features of the object while suppressing useless features of surroundings. Extensive comparative experiments were conducted on both public datasets (including LINEMOD, Occlusion LINEMOD and T-LESS datasets) and self-made datasets. The experimental results indicate that the proposed network CB-PVNet can achieve accuracy of ADD(-s) comparable to state-of-the-art using only RGB images while ensuring real-time performance. Additionally, we also conducted robot grasping experiments in the real world. The balance between accuracy and computational efficiency makes the method well-suited for applications in industrial automation.Keywords
With the development of robotics technology, the automation and intelligence levels in industrial production continue to improve. Automated assembly and sorting based on machine vision have broad application prospects in industrial production [1–3]. Compared with traditional manual operations, automatic production based on industrial robots has significant advantages in terms of efficiency and stability [4]. Accurate pose estimation of parts in industrial scenarios is essential for improving automation and intelligence in tasks such as robotic assembly and sorting.
6D pose estimation refers to calculating an object’s 3-DOF translation and 3-DOF rotation relative to the camera. Accurate pose estimation of objects is significant for various tasks such as industrial sorting, virtual reality, and robotics [5,6]. Generally, current methods of 6D pose estimation can be categorized into two groups: RGB-based methods and RGB-D-based methods. RGB-D-based 6D Pose Estimation methods benefit from depth information, which aids in resolving perceptual ambiguities in complex scenes [7,8]. However, RGB-D-based methods are difficult to ensure real-time performance for pose estimation due to the limitations of hardware requirements and higher costs. Moreover, depth information captured by cameras is often sensitive to environmental factors such as lighting and surface reflectivity. In contrast, RGB-based methods rely only on color images. These methods are not only computationally light and inexpensive but also easy to deploy and suitable for various application scenarios [9–11]. However, due to insufficient information, RGB-based methods are usually difficult to handle occluded and texture-less objects.
The processing of weakly textured objects has always been a key issue in pose estimation. The surface of texture-less objects lacks rich and stable texture details. Feature point-based methods often use local descriptors to solve the 6D pose estimation problem. However, for texture-less objects, feature point-based methods find it difficult to extract enough keypoints in such scenarios, resulting in a reduction in the accuracy of feature matching. In this case, the process of feature matching will be sensitive to noise and environmental changes. In addition, the appearance of texture-less objects is highly similar at different viewing angles and lacks distinctive visual features. As a result, it is difficult to distinguish different poses through visual features.
In recent years, deep learning has been very effective in pose estimation. Some studies have used CNNs to directly regress the 6D pose of an object from an image [12,13]. However, the search space of the 6D pose is too large, resulting in poor generalization. The state-of-the-art works detects the keypoints of the object in the 2D image and then uses PnP to calculate the 6D pose of the object through 2D-3D correspondence. Detecting keypoints in 2D images greatly reduces the search space of the network, and the effect of deep learning methods on 6D pose estimation has also been greatly improved. For instance, PVNet, a pixel-wise voting network, has shown impressive results in handling texture-less objects [14]. PVNet regresses the pixel unit vector pointing to the keypoints by means of a pixel voting mechanism. However, in industrial production scenarios, the 6D pose estimation faces challenges with weak texture and occlusion of industrial parts [15,16]. In this case, due to the reduction of the visible part of the object and the lack of texture features, it is difficult to extract object features, resulting in a lack of accuracy and robustness in 6D pose estimation.
To this end, this paper proposes a pixel-wise voting network CB-PVNet for 6D pose estimation of weakly textured industrial parts, combining an attention mechanism and PVNet [14]. In CB-PVNet, the voting process is adopted to predict the keypoints of affected pixels for 6D pose estimation. The attention mechanism can extract interesting features of the object while suppressing useless features of surroundings. The proposed network performs well even in complex scenarios such as weak texture and occlusion. The major contributions of this paper are summarized as follows:
• An attention-based pixel-level voting network for 6D pose estimation of weakly textured industrial parts is proposed, namely CB-PVNet. On the one hand, to improve the robustness to complex scenes such as occlusion and weak texture, this paper introduces an attention module to focus on the visible part or edge of objects and suppress background interference. On the other hand, this paper replaces the dilated convolution in residual block with a regular 3
• CB-PVNet relies solely on RGB images and does not require depth information or a CAD model of objects. It estimates the 6D pose of objects in complex scenarios with high accuracy while ensuring real-time performance, making it suitable for industrial automation applications.
• The performance of the proposed network is evaluated on both public datasets including LINEMOD, Occlusion LINEMOD and T-LESS datasets and self-made datasets. Additionally, we conduct robot grasping experiments to evaluate the performance of CB-PVNet for robot grasping tasks in the real world.
The remainder of this paper is organized as follows. In Section 2, the related work of 6D pose estimation is presented. In Section 3, we elaborate the proposed 6D pose estimation system. To verify the performance of the proposed 6D pose estimation network, various experiments on public datasets are conducted in Section 4. Then, in Section 5, we construct an industrial parts dataset for 6D pose estimation and conduct experiments on the self-made datasets.
In the field of computer vision and robotics, 6D pose estimation refers to the simultaneous determination of the translation and rotation of an object in 3D space. It is not only widely used in industrial automation scenarios but also plays a key role in various fields such as robot grasping and human-computer interaction [17,18]. In order to improve the accurate perception of the object pose, researchers continue to explore [19–21]. From traditional geometry-based methods to end-to-end solutions driven by deep learning, the research on 6D pose estimation has undergone multiple stages of development and evolution.
Early 6D pose estimation methods mainly rely on feature matching and geometric constraints. Researchers extract features (such as SIFT or ORB) from 2D images and then use RANSAC and PnP algorithms to solve the correspondence between features and the object 3D model to obtain the object pose in 3D space. Although such methods work well in scenarios with rich textures and relatively stable lighting conditions, their performance is often limited in scenarios with missing textures or complex backgrounds. With the rise of deep learning, CNN-based detection frameworks have been introduced into the field of 6D pose estimation [22,23]. Early representative works mainly added a pose regression branch based on a 2D detection model to directly regress the translation and rotation parameters of the object [24]. Among them, the PoseCNN proposed by Xiang et al. [25] achieved better performances when combining semantic segmentation and rotation prediction. Since then, some studies have further combined object detection with keypoint extraction.
Generally, from the perspective of implementation strategy, existing techniques can be classified into four categories: correspondence-based methods, template-based methods, voting-based methods, and regression-based methods.
Correspondence-based methods establish correspondences between 2D visual features and 3D object models. These methods first employ feature descriptors to derive correspondences. Then, a geometric optimization strategy is adopted to estimate the object pose, such as Perspective-n-Point (PnP). Wang et al. [26] proposed a 6-DOF pose estimation method named DenseFusion, which adopted a deep neural network to predict dense correspondences based on RGB-D images. DenseFusion can provide robust performance even in partially cluttered occluded scenarios. However, the computational cost of processing dense data is too high, making it unsuitable for real-time applications. Overall, correspondence-based methods require significant computational resources and careful feature extraction, which can limit their applicability in real-time applications.
Template-based methods estimate the object pose by comparing observed data with pre-rendered templates of 3D objects from multiple viewpoints. Sundermeyer et al. [27] presented a network of object pose estimation by implicitly learning 3D orientations based on RGB images. Instead of relying on explicit viewpoint labels, the network incorporates orientation inference within its detection process. This mechanism can ensure the robustness of the method under clutter and varying viewpoints to a certain extent. This approach unifies object localization and orientation prediction in an end-to-end approach, which it suitable for scenarios where 3D ground truth is difficult to obtain. However, its performance is greatly affected in complex scenarios and extreme lighting conditions, potentially affecting cross-domain adaptability.
Voting-based methods construct multiple hypotheses for potential poses from various candidate features or viewpoints. Then, a voting mechanism is adopted to determine the accurate pose of objects. Voting-based pose estimation methods work better in scenarios with multiple objects or partial occlusions. For the applications of robot operation grasping, Tian et al. [28] presented a 6D pose estimation method based on RGB-D features. They address the challenges of rotation ambiguity for symmetric objects through a discrete-continuous mechanism to predict the rotations of objects. Sampling rotation anchors and predicting deviations from these anchors along with uncertainty scores. In this way, this method effectively resolves local optimization issues. In general, although the voting mechanism tends to be time-intensive, voting-based approaches have shown excellent performance for pose estimation applications in scenarios such as partial occlusion. It is worth noting that our proposed method in this paper belongs to the voting-based method.
Regression-based methods employ machine learning to directly predict the 6D pose from input data. Kleeberger and Huber [29] proposed a novel method for estimating the 6D object pose through a single step, streamlining the traditionally multi-stage process. This method treated pose estimation as a direct regression problem based on RGB-D data. Due to the emphasis on computational efficiency and accuracy, they spatially discretized the input to generate precise pose predictions. This makes it a promising solution for real-time applications such as robotics and augmented reality.
In recent years, pose estimation technology has been increasingly used in the field of industrial automation, enabling robots to recognize, grasp, and assemble objects in 3D space. However, industrial components present unique challenges. Many parts lack distinctive textures, exhibit strong symmetry, or possess reflective metallic surfaces that distort both RGB and depth observations. Such conditions often lead to ambiguity in orientation estimation and incomplete geometric perception. Among the recent advances in 6D pose estimation, several representative works have significantly contributed to improving robustness and generalization for industrial scenarios. Yu et al. [15] proposed a point pair matching-based 6D pose estimation method for robotic grasp detection. They leverages geometric relationships between point pairs to establish rigid correspondences directly in 3D space. By relying on local geometric invariants rather than visual texture, this approach achieves accurate pose alignment even for parts with limited appearance cues, making it well-suited for grasp planning in cluttered industrial environments. PCR-PoseNet [16] focused on texture-less and highly reflective parts by combining RGB and depth features with a point-cloud shape recovery module. This design reconstructs more complete 3D surfaces from partial or noisy depth inputs, enhancing stability and precision in challenging lighting and surface conditions.
Overall, 6D pose estimation technology has gradually moved from traditional geometric feature matching to an end-to-end method driven by deep learning [30–32]. Future development trends will mainly focus on the following aspects: first, further enhance the robustness to complex occlusion scenarios; second, build a more efficient network structure and a more sophisticated geometric modeling method; third, improve the inference speed while ensuring accuracy to meet real-time requirements. With the continuous evolution of deep learning technology and the continuous iteration of hardware, it can be foreseen that 6D pose estimation will become one of the indispensable core technologies in the next generation of intelligent systems.
3.1 The Proposed 6D Pose Estimation System
For occluded or weakly textured objects, it is challenging to extract object features due to the reduction in the visible part of the object and the loss of texture features. In this case, the prediction results of existing methods lack accuracy and robustness. Regarding the above issues, this paper proposes a pixel-wise voting network CB-PVNet for 6D pose estimation. In order to endow the pose estimation algorithm with stronger reasoning ability to accurately estimate the spatial pose of the object in complex scenarios, our proposed network CB-PVNet introduces an attention mechanism to enhance the feature extraction performance. CB-PVNet combines a CBAM attention module and a pose estimation network PVNet based on the Resnet network Resnet-18. The CBAM attention consists of a channel attention module and a spatial attention module. The channel attention module determines which channels are most important for the current task by calculating the mean and maximum values in the channel dimension. The spatial attention module determines which spatial positions are most important for the current task by calculating the correlation between different spatial locations. This strategy can improve the ability to extract key features at the spatial and channel layers, while suppressing useless features to obtain better pose prediction results. Additionally, in order to expand the receptive field, PVNet [14] adopts dilated convolution in residual block. However, for small objects with weak textures, the operation of dilated convolution may miss local information, especially edge details of small objects, local structures, and keypoints. Therefore, we replace the dilated convolution in residual block with a regular 3
The overall network model structure is shown in Fig. 1. The input of CB-PVNet is a single RGB image, and the output is a mask segmentation and direction vector. CB-PVNet focuses on predicting the direction of every pixel rather than directly regressing the location of keypoints from the input image. That is, the network’s main function is to predict vector fields and generate object labels. In this way, the impact of a cluttered background can be reduced by dynamically weighting the feature map’s spatial regions and strengthening the features’ response in the visible region. The pose estimation process of CB-PVNet is as follows. First, the input image is resized by the pooling layer, and the features are extracted by the convolution layer. In this process, the introduced CBAM attention module can extract features of interest and suppress features in the background area. Then, the semantic segmentation of the object and the vector field pointing to the keypoints of the object are output. In this way, the direction of all pixel unit vectors pointing to a certain key point of the detected object can be obtained. Then, RANSAC voting is performed based on the confidence, and the mean and covariance of the spatial probability distribution of each keypoint are evaluated. Finally, the 6D pose of the object is obtained through an EPNP algorithm.
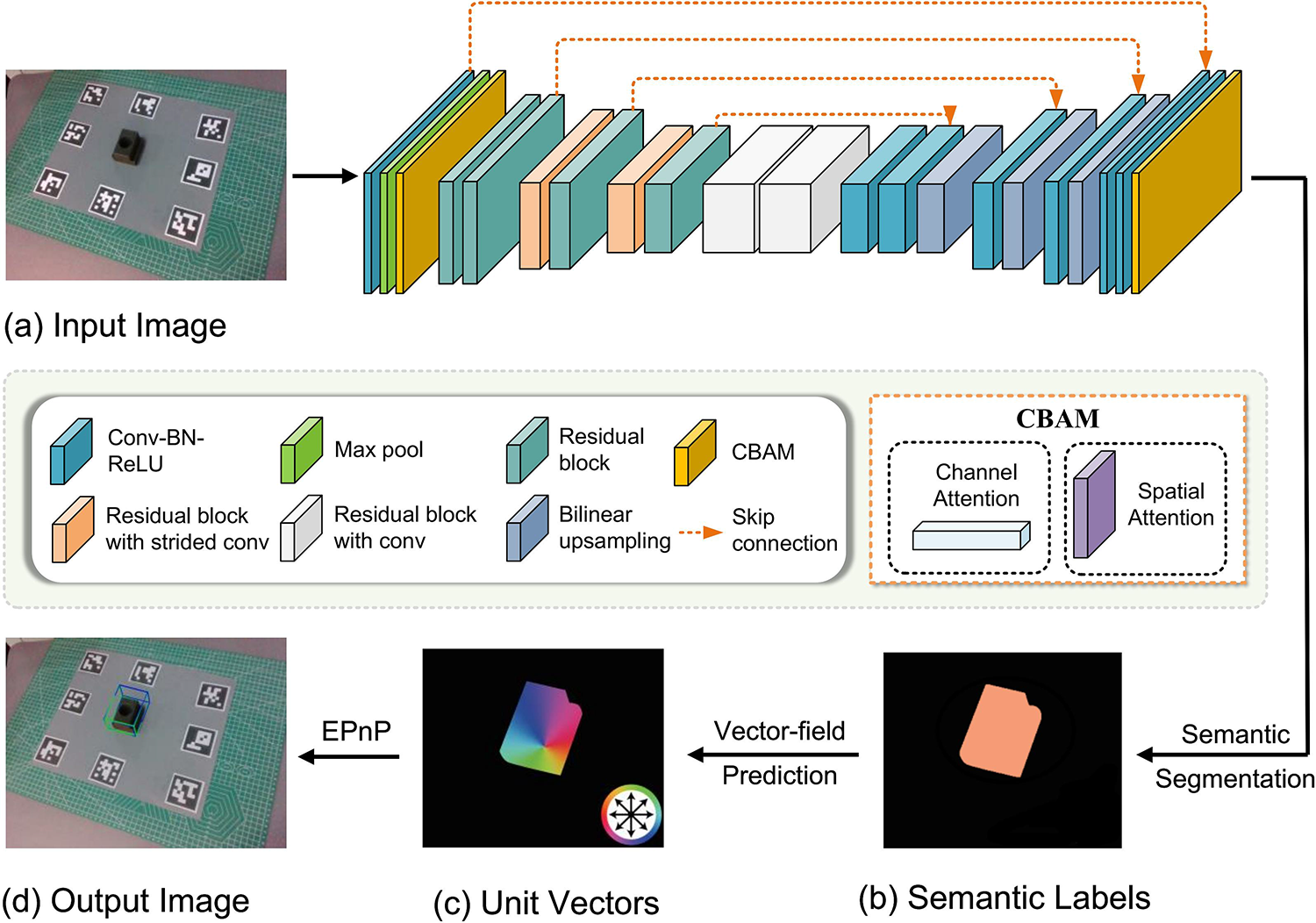
Figure 1: Architecture of the proposed network
3.2 Voting-Based Keypoint Localization
The module of voting-based keypoint localization consists of semantic segmentation and vector field prediction. It mainly achieves two goals: (1) realizes the semantic segmentation of the object and obtains the mask of the object; (2) predicts the vector field of the pixel points in the mask area to each keypoint. In semantic segmentation, after downsampling, feature extraction and upsampling operations, the semantic segmentation results of the input image can be finally achieved to obtain the mask image.
In vector field prediction, after obtaining mask area of the detection image by means of the semantic segmentation, the vector field pointing from the mask area to each keypoint in the image is predicted. The vector pointing from any pixel point in the mask area to the keypoint is:
where
After obtaining the label mask and unit vector of semantic segmentation, the hypothesized keypoints are generated based on the random consistency sampling strategy. First, the corresponding pixels of the object are obtained using the semantic segmentation label. Then, a pair of pixel vectors are randomly selected. The intersection of the two pixels is used as the keypoint hk. Randomly selected N times, a set of keypoints is obtained, which indicates the possible location of the keypoint. Finally, all pixels vote for the keypoint to predict the location of the keypoint. The voting score
where
This hypothesis represents the spatial probability distribution of keypoints. A higher voting score indicates a higher confidence in the hypothesis. Since the confidence of each keypoint in a cluttered scenarios is uncertain, the probability distribution corresponding to each keypoint is obtained through a voting mechanism. The mean
Before estimating the 6D spatial pose of an object, it is necessary to define the keypoints of the object. The commonly used keypoint definition method is the bounding box corner point localization method, which defining the corner points of the bounding box in the 3D model space as keypoints. However, since the keypoints are predicted using the image pixels of the object, the keypoints of some objects are far away from the object at the pixel level. During the training process, the farther the selected keypoints are from the object, the greater the localization error. In order to avoid the keypoints being blocked as much as possible, this paper uses the farthest point sampling algorithm to define the keypoints. When the PnP algorithm is used to solve the object pose, the more dispersed the keypoints are on the object surface, the more accurate the pose estimation is. First, select the center of the object to initialize the keypoint set, and then repeatedly select a point on the object surface that is farthest from the current keypoint set to form a new keypoint set until the threshold of keypoint sets is reached. Selecting too many key points will affect the estimation speed of pose estimation, while selecting too few key points cannot guarantee the robustness of pose estimation. Therefore, based on practical experience, this paper selects a suitable number of keypoints K = 8.
The network loss function includes semantic segmentation loss and vector field prediction loss, the former is classification loss and the latter is regression loss. For semantic segmentation module, we select Softmax as the loss function, which outputs the probability of each class.
where
where
The total loss function of the network is:
where L is the total loss function of the network,
4 Experiments on Public Datasets
4.1 Experimental Dataset and Evaluation Metrics
In order to verify the performance of the proposed 6D pose estimation network in this paper, this section conducts comparative experiments on LINEMOD, Occlusion LINEMOD and T-LESS datasets, which are commonly used in 6D pose estimation. The LINEMOD dataset is a benchmark dataset in the 6D object pose estimation field, which contains 13 different classes of objects. Each object has about 1200 images of a cluttered background but is only slightly obscured. For each image, although other objects appear at the same time, only the annotation information of the target object is provided, including a 6D pose, 3D model, and segmentation mask. The Occlusion LINEMOD dataset is based on the LINEMOD dataset. The Occlusion LINEMOD dataset not only introduces multiple occlusion levels and lighting conditions but also adds the ground-truth pose annotation information, including various cluttered scenarios; for example, objects are severely occluded. The Occlusion LINEMOD dataset has 8 types of objects, and the occlusion scenarios between objects are relatively complex. This is a massive challenge for the pose estimation task. This paper uses 85% of the images in the LINEMOD dataset for training and the remaining 15% for testing, while Occlusion LINEMOD is only used as a test set. This paper uses the adam optimizer for training. The T-LESS dataset is a public benchmark designed for research on 6D object pose estimation. It provides RGB images, depth data, and corresponding 3D object models. The dataset includes 30 categories of industrial components that generally lack distinctive textures, color variations, or reflective properties. These objects exhibit strong geometric symmetry and inter-class similarity, with varying degrees of occlusion and stacking. Each category contains 50 instances captured from multiple viewpoints and poses, along with precise ground-truth pose annotations. During the image dataset training, the batch size is set to 8, the initial learning rate is set to 0.001, and it decays every 20 epochs. The experiments are conducted on a laptop with a Nvidia Geforce RTX 2080 GPU.
For the evaluation metric, we use ADD(-S) metric for 6D pose estimation on the LINEMOD and Occlusion LINEMOD datasets, and adopt the recall under the Visible Surface Discrepancy (VSD) metric with a threshold of 0.3 for 6D pose estimation on the T-LESS dataset.
4.2 Experiments on Public Datasets
In order to analyze the performance of CB-PVNet, we conduct a comparative experiment on LINEMOD, Occlusion LINEMOD and T-LESS datasets respectively in this section. This paper focuses on the performance of the 6D pose estimation network based on RGB images in weak texture, occlusion and other scenarios. Therefore, in order to facilitate comparative analysis, YOLO-6D [34], PVNet [14], ER-Pose [35], RNN-Pose [36] and our proposed network CB-PVNet are respectively adopted for comparative experiments. These methods are well-known for 6D pose estimation based on RGB images.
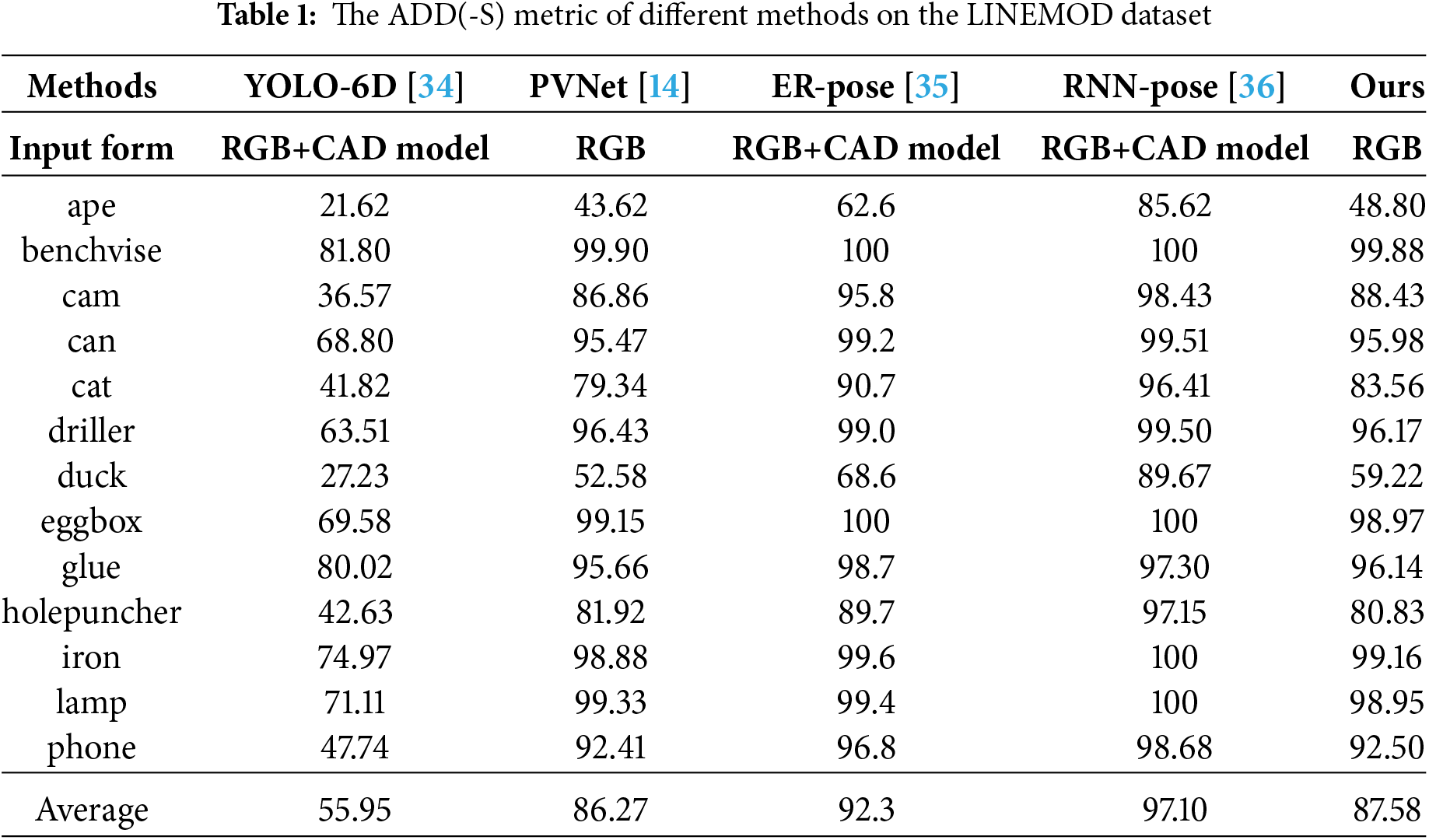
The ADD(-S) metrics of different methods on the LINEMOD Dataset are presented in Table 1. It can be seen that the ADD(-S) metric of our proposed network is better than YOLO-6D [34] and PVNet [14], but lower than ER-Pose [35] and RNN-Pose [36]. It is worth noting that the inputs of YOLO-6D [34], ER-Pose [35] and RNN-Pose [36] are RGB images and CAD model. In constrast, the inputs of PVNet [14] and our proposed network are RGB iamges. In the field of industrial automation, it is difficult to obtain accurate CAD models for some parts. In this case, it is particularly important to estimate the 6D pose of the parts based only on RGB images. Therefore, it is encouraging that the proposed network achieves such performance based only on RGB images.
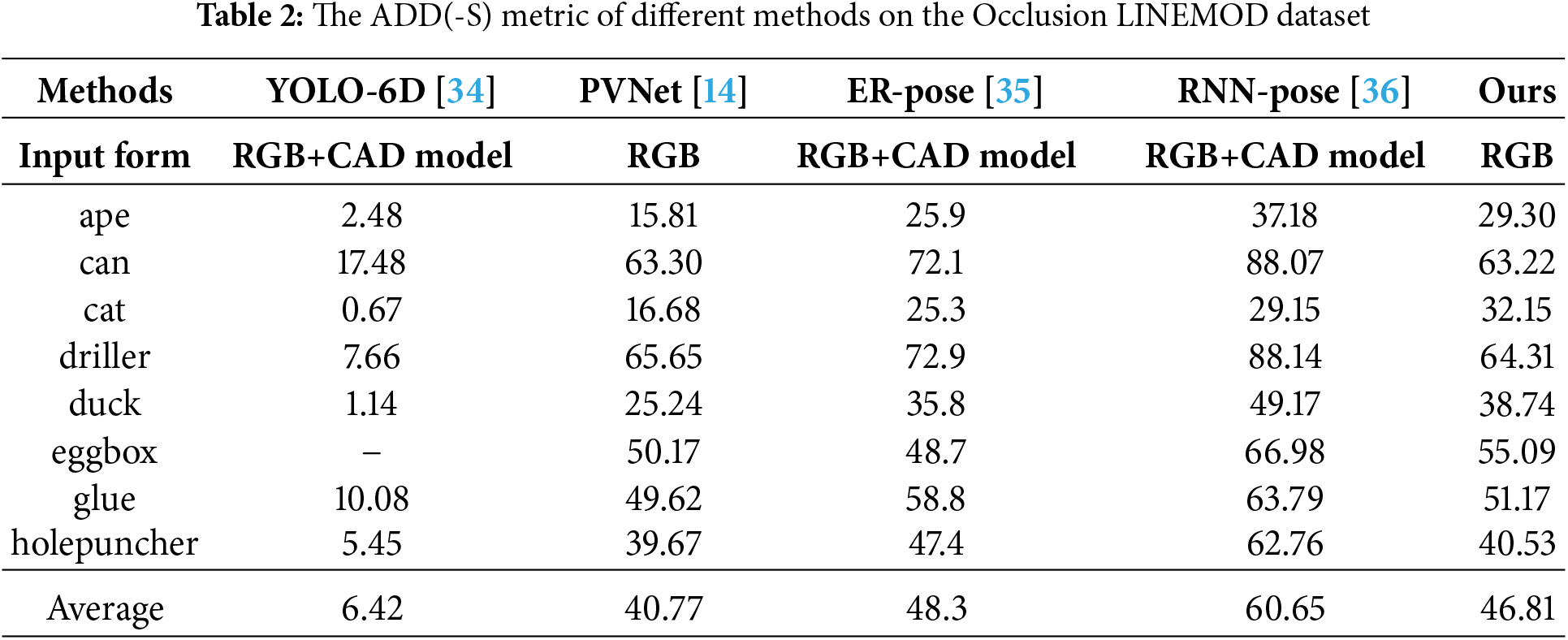
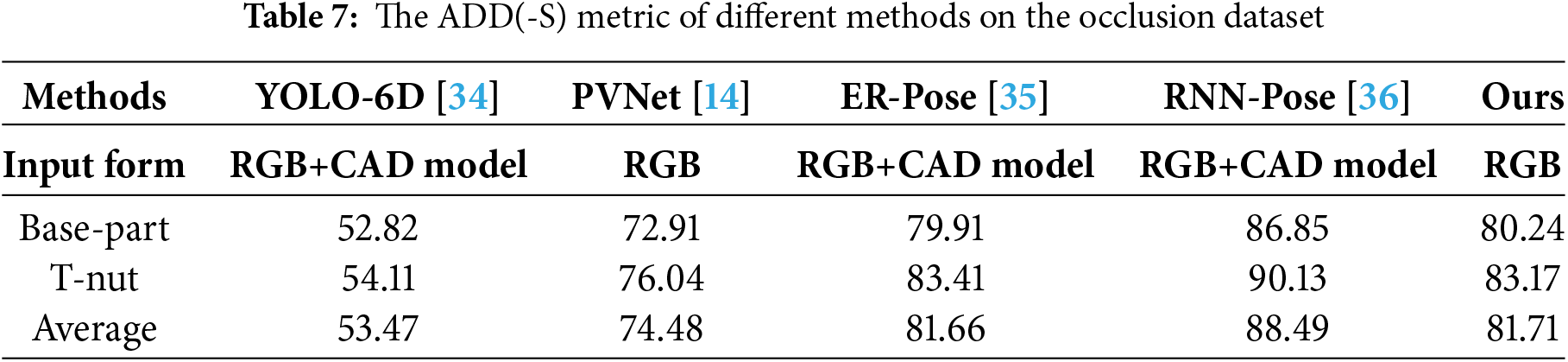
In order to analyze the impact of factors such as occlusion and illumination changes on the object pose estimation, YOLO-6D [34], PVNet [14], ER-Pose [35], RNN-Pose [36] and our proposed network are respectively adopted for comparative experiments on the Occlusion LINEMOD dataset. The ADD(-S) metrics of different methods on the Occlusion LINEMOD dataset are shown in Table 2. It can be seen that in the complex scenarios of Occlusion LINEMOD dataset, the performance of YOLO-6D [34] and PVNet [14] is seriously affected. Although the ADD(-S) metric of our proposed network is lower than RNN-Pose [36], our proposed network achieve performance close to ER-Pose [35] based only on RGB images. In particular, for some small objects such as ape, cat and duck, the performance of our proposed network outperforms ER-Pose [35]. This may be because small objects are prone to losing key information due to occlusion, and the visual features of small objects are easily diluted by the high-dimensional features of deep networks. The attention module in CB-PVNet can strengthen the feature response around small objects and suppress irrelevant background.
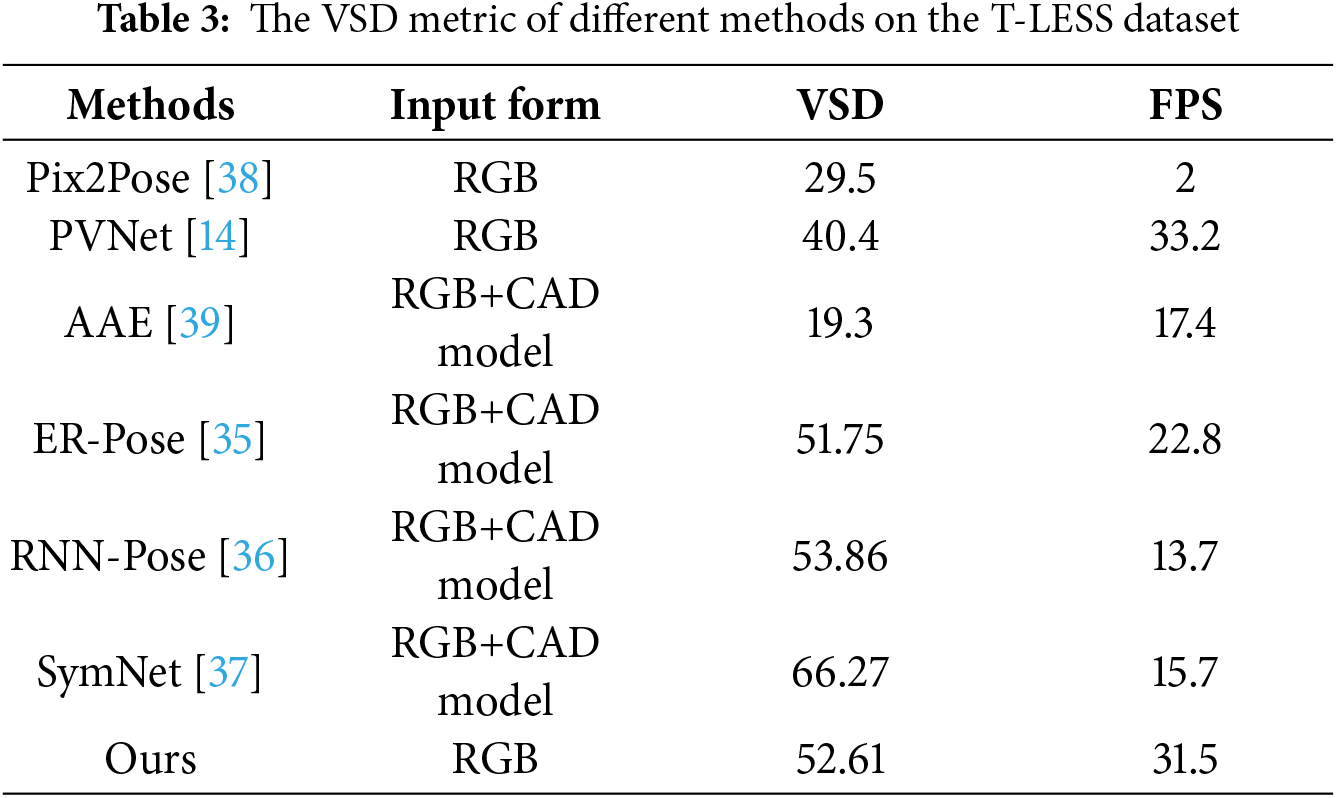
In order to further analyze the 6D pose estimation performance of different methods for weak texture industrial objects, we conduct comparative experiments on the T-LESS dataset. The results of VSD and FPS are shown in Table 3. FPS means Frames Per Second. The works in Table 3 are all RGB-based 6D pose estimation methods. The inputs of YOLO-6D [34], ER-Pose [35], RNN-Pose [36] and SymNet [37] are RGB images and CAD model. In constrast, the inputs of PVNet [14] and our proposed network are only RGB iamges. It can be seen that although the VSD metric of our proposed method is lower than RNN-Pose [36] and SymNet [37], the FPS of our proposed method is higher than that of other methods except PVNet [14]. In the field of industrial automation, real-time performance of part pose estimation is crucial, for example for assembly or sorting operations on automated production lines. Our method can strike a balance between accuracy and computational efficiency, achieving a VSD of 52.61 and an FPS of 31.5.
To analyze the impact of each module in the proposed method, we conducted ablation studies on the T-LESS dataset. The results are shown in Table 4. In the table, the baseline is the original PVNet, without any network modification. AM represents the attention module. RCM represents the modified residual convolution module. It can be seen that after adding AM, the accuracy of the proposed network increased by 7.9 in terms of VSD on the T-LESS dataset. After adding RCM, the accuracy of the proposed network increased by 4.31 in terms of VSD on the T-LESS dataset. The results of the ablation experiment show that the introduction of AM and RCM effectively improves the 6D pose estimation accuracy of proposed network in terms of the VSD metric.

5 Experiments on Self-Made Datasets
Most of the existing object pose estimation models are trained and tested on public datasets such as LineMOD and YCB Video. The objects in public datasets are mostly common daily objects, while there are relatively few datasets for robot grasping objects in industrial production scenarios. To this end, this paper constructs a 6D pose estimation dataset for industrial parts in response to situations such as occlusion and weakly textured objects in industrial production.
The experimental platform for constructing a 6D pose estimation dataset is shown in the Fig. 2. The experimental platform includes an aubo-i5 robot, Aruco code, industrial parts, and an Intel Realsense D435i camera. Among them, the Aruco code consists of an internal ID and an external border. The internal ID is used for error detection, and the external border is used for label localization. Industrial parts include T-nut and Base-part. The experimental configuration for pose estimation in this paper is shown in the Table 5.

Figure 2: The experimental platform
5.1 The Construction of Self-Made Datasets
In order to verify the effectiveness of the proposed method for weak texture or occlusion scenarios, we created two datasets, namely Custom image dataset and Occlusion image dataset. The images in the Custom image dataset are collected from two types of objects, T-nut and Base-part, at different angles and different lighting, as shown in Fig. 3. However, they are mainly concentrated in relatively single scenario, which may contain one or more objects. In contrast, the images in the Occlusion image dataset are mainly collected in complex scenarios, such as occlusion, drastic changes in background. In order to avoid overfitting, data augmentation is performed on the images in the experiment. The Custom image dataset contains two types of objects. Each type of object contains 1362 images. Occlusion image dataset contains two types of objects. Each type of object contains 1386 images. The images are resized as 640

Figure 3: Two types of objects in self-made datasets. (A) T-nut. (B) Base-part
In order to minimize manual intervention, this paper uses the open source toolkit Object Dataset Tools to create an industrial parts image dataset and reconstructs the 3D model of the objects through RGB-D image sequences, as shown in Fig. 4. Firstly, the Aruco codes are pasted in the experimental scenario. It is worth noting that it is necessary to ensure that the Aruco label code is flat, non-repetitive, and has reasonable spacing. The industrial parts are placed in the area surrounded by the Aruco codes. The position of the camera relative to the robot is fixed, and the industrial parts are rotated at a constant speed for recording. During the image capture process, the following requirements must be followed: (1) The viewing angles of each image must overlap to a certain extent and must be captured in multiple layers; (2) It is necessary to avoid capturing images in overly dark or overexposed environments; (3) During image capture process, it is necessary to always ensure that 2 to 3 Aruco code labels are not obstructed in the camera’s field of view. The RGB image and the corresponding depth image of the recorded scene are saved by frame sampling. Then, the point cloud data of all frames are fused to generate the scene point cloud. Secondly, MeshLab is used to segment the entire scene point cloud, remove the background and noise in the point cloud image, generate the PLY model corresponding to each industrial part, and realize the point cloud image segmentation of the object object in complex scenes. Finally, Object Dataset Tools is used to generate the object mask of the RGB-D image sequence for annotation, and a LineMOD format dataset is generated.

Figure 4: The object in object dataset tools
5.2 Experiments on Self-Made Datasets
The proposed network is adopted to perform 6D pose estimation on T-nut and Base-part in the self-made datasets Custom image dataset and Occlusion image dataset. The self-made dataset contains RGB information and depth information. But the depth information is only used to construct the ground-truth of the pose estimation in the image dataset. In the experimental test, only the RGB information in the image dataset is used. In order to intuitively observe the pose estimation performance of the proposed network, the 6D pose estimation visualization results of the Custom image dataset and the Occlusion image dataset are given in Fig. 5. The green bounding box represents the ground-truth of the 6D pose estimation, and the blue bounding box represents the 6D pose estimation result of the proposed network. It can be seen that for the Custom image dataset, the blue bounding box of the 6D pose estimation of the proposed network basically coincides with the green bounding box of the Ground-Truth, which shows that the accuracy of the 6D pose estimation is high. For the Occlusion image dataset, although there are weak textures and occlusions of metal parts, illumination changes, etc., the angle difference between the blue bounding box of the 6D pose estimation of the proposed network and the green bounding box of the ground-truth is relatively small. Overall, the pose estimation results of this network are relatively high and can better adapt to complex scenarios.

Figure 5: Visualizations of results. (A) T-nut on the Custom dataset; (B) Base-part on the Custom dataset; (C) and (D) T-nut on the Occlusion dataset; (E) and (F) Base-part on the Occlusion dataset
In order to further analyze the performance of this network, this section conducts quantitative analysis experiments on two self-made datasets. For the convenience of comparison, this paper conducts experiments using YOLO-6D [34], PVNet [14], ER-Pose [35], RNN-Pose [36] and our proposed CB-PVNet. The used evaluation metric is ADD(-S). Table 6 shows the results of different methods on the Custom image dataset. In terms of ADD-(s) metric, the average value of our proposed network is 93.31. Overall, since the images in the Custom image dataset are mainly collected in experimental scenarios with no occlusion and balanced lighting, the performance of 6D pose estimation is better.
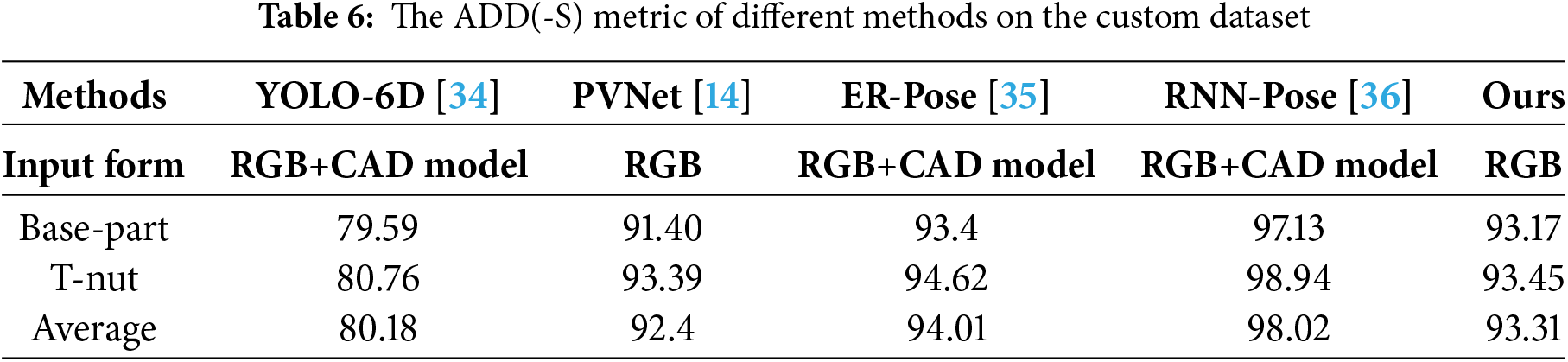
Table 7 shows the results of different methods on the Occlusion image dataset. It can be seen that with the increase in the complexity of the experimental scenarios, the 6D pose estimation performance of Base-part and T-nut is greatly affected. Specifically, the average value of the ADD(-S) metric of our proposed network is 81.71, which is higher than YOLO-6D [34], PVNet [14] and ER-Pose [35] and lower than RNN-Pose [36]. It is worth noting that the input of our network is only RGB images. In the field of industrial automation scenarios, it is difficult to obtain accurate CAD models for some parts. In this case, it is particularly important to estimate the 6D pose of the parts based only on RGB images.
5.3 Robot Grasping Experiments
In this section, to evaluate the performance of CB-PVNet for robot grasping tasks in the real world, the camera realsense D435i installed on the robot is used to capture scenario images, as shown in Fig. 3. After estimating the pose of the grasping object using different methods, a robot grasping experiment is conducted using a robotic arm with a gripper of two fingers. For the convenience of comparison, grasping experiments were conducted on the two objects Base-part and T-nut using different methods.
We use the aruco_ros package in ROS to complete the robot’s hand-eye calibration and obtain the conversion relationship between the camera coordinate system and the robot coordinate system, as shown in the Fig. 6. During the experiment, the end-effector of the robot is moved to the initial pose so that the robot’s field of view is wide enough. In this case, it can ensure that the grasped object is within the field of view of the robot camera, as shown in Fig. 7a. Then, the robot calculates the 6D pose of the grasped object based on the pose estimation method and converts it to the robot coordinate system. After that, the robot’s end-effector is controlled to move above the object, as shown in Fig. 7b. Finally, the robot grasps the object, and the grasping process is shown in Fig. 7c to f.
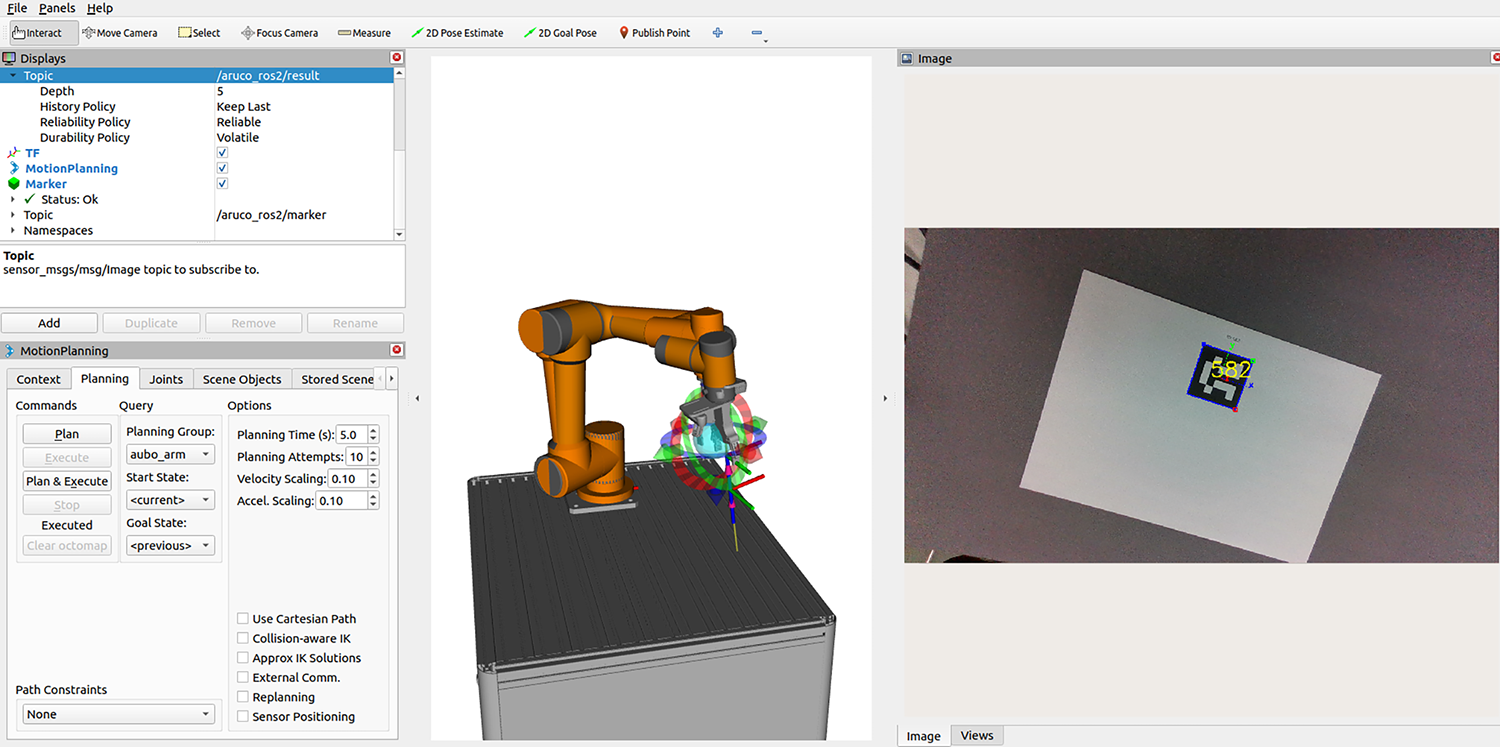
Figure 6: The calibration of the robot experimental platform

Figure 7: The robot grasping process. The order of figures in the grasping process is from left to right and from top to bottom
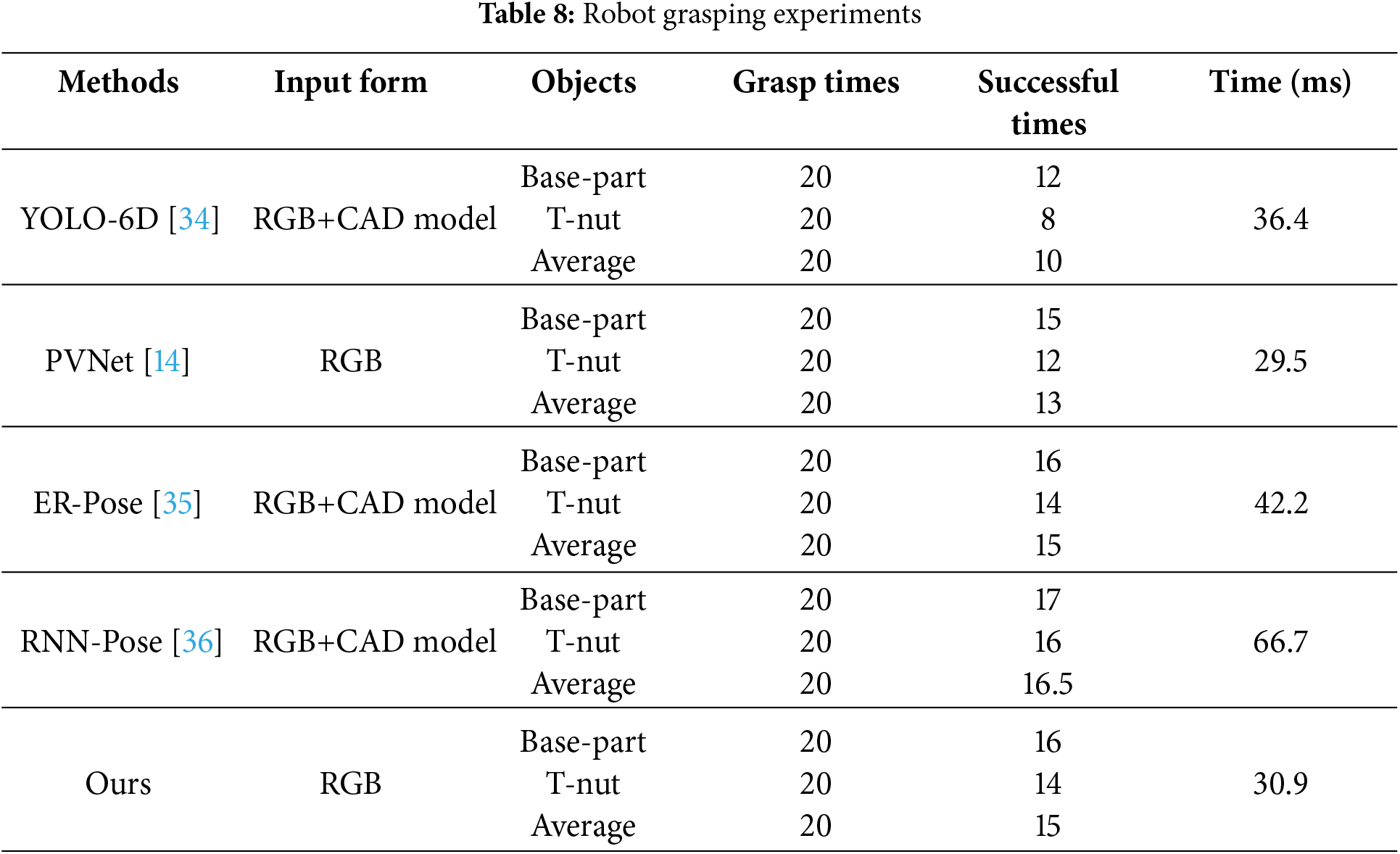
In the robot grasping experiment, we observed that there are two reasons for the failure of object grasping: (1) the spatial pose estimation of the grasped object is inaccurate, which is determined by the 6D pose estimation methods; (2) when the object pose estimation is accurate, the grasping pose of the gripper is unreasonable. When industrial parts are stacked closely together, the gripper will collide and interfere with surrounding non-grasping objects. In this case, even if the 6D pose estimation of the object is accurate, the robot will miss the object or grab the wrong object. This is mainly related to the structure and size of the robot gripper and the dense stacking of industrial parts. The two-finger gripper used in this experiment is large in size and is more prone to interference. Therefore, in order to facilitate the comparative analysis of the performance of different pose estimation methods, we try to avoid serious stacking of workpieces to prevent affecting the operating space of the gripper. During this robot grasping experiment, each type of object is grasped 20 times, and the objects are placed in a different scenario before each grasping. Grasping an object with a robot gripper without it falling is recorded as successful grasping. When an object is grasped by the robot gripper and does not fall off, it is recorded as successful grasping. The results are shown in Table 8. In Table 8, the time represents the time consumed by different methods in a single 6D pose estimation during the robot grasping experiment. As can be seen, the average successful grasping rate of our method is the same as ER-Pose [35], higher than YOLO-6D [34] and PVNet [14], lower than RNN-Pose [36]. The consumed time of our network is 30.9 ms, which is faster than YOLO-6D [34], ER-Pose [35] and RNN-Pose [36], and can ensure the real-time 6D pose estimation of industrial parts. From the experimental results, we can see that our network can achieve a good balance between the accuracy and real-time performance of 6D pose estimation.
In this paper, we propose an attention-based pixel-level voting network CB-PVNet for 6D pose estimation of weakly textured industrial parts. In order to address the challenges with weak texture and occlusion of industrial parts, this paper integrates the attention module CBAM into PVNet, which can extract interesting features of the object while suppressing useless features of the surroundings. The proposed network achieves accurate 6D pose estimation of industrial parts, which is significant for improving automation and intelligence in industrial production, such as robotic assembly and sorting. Extensive experiments were conducted on public datasets and self-made datasets. The results indicate that the proposed network CB-PVNet exhibits great performance of 6D pose estimation for industrial parts in terms of accuracy and real-time performance.
In future work, we plan to evaluate CB-PVNet in more complex scenarios, such as low illumination and severe occlusion, which pose great challenges to keypoint localization. Moreover, we will further optimize the network to better adapt to diverse industrial scenarios.
Acknowledgement: Not applicable.
Funding Statement: This work was supported by the Knowledge Innovation Program of Wuhan-Shuguang Project (Grant No. 2023010201020443), the School-Level Scientific Research Project Funding Program of Jianghan University (Grant No. 2022XKZX33), and the Natural Science Foundation of Hubei Province (Grant No. 2024AFB466).
Author Contributions: Conceptualization, Song Xu and Liang Xuan; methodology, Song Xu; software, Song Xu; validation, Song Xu; formal analysis, Song Xu; investigation, Song Xu, Liang Xuan, Yifeng Li and Qiang Zhang; resources, Song Xu; data curation, Song Xu; writing—original draft preparation, Song Xu; writing—review and editing, Song Xu, Liang Xuan, Yifeng Li and Qiang Zhang; visualization, Song Xu; supervision, Liang Xuan; project administration, Song Xu and Liang Xuan; funding acquisition, Song Xu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Yu L, Wang Y, Wei X, Zeng C. Towards low-carbon development: the role of industrial robots in decarbonization in Chinese cities. J Environ Manag. 2023;330:117216. doi:10.1016/j.jenvman.2023.117216. [Google Scholar] [PubMed] [CrossRef]
2. Li Z, Li S, Luo X. An overview of calibration technology of industrial robots. IEEE/CAA J Autom Sin. 2021;8(1):23–36. doi:10.1109/jas.2020.1003381. [Google Scholar] [CrossRef]
3. Zhang X, Wu Z, Cao C, Luo K, Qin K, Huang Y, et al. Design and operation of a deep-learning-based fresh tea-leaf sorting robot. Comput Electron Agric. 2023;206(4):107664. doi:10.1016/j.compag.2023.107664. [Google Scholar] [CrossRef]
4. Pozna C, Precup RE, Földesi P. A novel pose estimation algorithm for robotic navigation. Robotics Auton Syst. 2015;63:10–21. doi:10.1016/j.robot.2014.09.034. [Google Scholar] [CrossRef]
5. Liu J, Sun W, Yang H, Zeng Z, Liu C, Zheng J, et al. Deep learning-based object pose estimation: a comprehensive survey. arXiv:2405.07801. 2024. [Google Scholar]
6. Liu Y, Wen Y, Peng S, Lin C, Long X, Komura T, et al. Gen6D: generalizable model-free 6-DoF object pose estimation from RGB images. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2022. p. 298–315. [Google Scholar]
7. Li H, Lin J, Jia K. Dcl-net: deep correspondence learning network for 6D pose estimation. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2022. p. 369–85. [Google Scholar]
8. Zhou J, Chen K, Xu L, Dou Q, Qin J. Deep fusion transformer network with weighted vector-wise keypoints voting for robust 6D object pose estimation. In: Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision; 2023 Oct 1–6; Paris, France. p. 13967–77. [Google Scholar]
9. Li Z, Ji X. Pose-guided auto-encoder and feature-based refinement for 6-DoF object pose regression. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). Piscataway, NJ, USA: IEEE; 2020. p. 8397–403. [Google Scholar]
10. Deng X, Mousavian A, Xiang Y, Xia F, Bretl T, Fox D. PoseRBPF: a Rao-Blackwellized particle filter for 6-D object pose tracking. IEEE Trans Robot. 2021;37(5):1328–42. doi:10.1109/tro.2021.3056043. [Google Scholar] [CrossRef]
11. Bengtson SH, Åström H, Moeslund TB, Topp EA, Krueger V. Pose estimation from RGB images of highly symmetric objects using a novel multi-pose loss and differential rendering. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway, NJ, USA: IEEE; 2021. p. 4618–24. [Google Scholar]
12. Lin Z, Ding C, Yao H, Kuang Z, Huang S. Harmonious feature learning for interactive hand-object pose estimation. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2023 Jun 17–24; Vancouver, BC, Canada. p. 12989–98. [Google Scholar]
13. He Y, Huang H, Fan H, Chen Q, Sun J. FFB6D: a full flow bidirectional fusion network for 6D pose estimation. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021 Jun 20–25; Nashville, TN, USA. p. 3003–13. [Google Scholar]
14. Peng S, Liu Y, Huang Q, Zhou X, Bao H. PVNet: pixel-wise voting network for 6DoF pose estimation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–20; Long Beach, CA, USA. p. 4561–70. [Google Scholar]
15. Yu S, Zhai DH, Zhan Y, Wang W, Guan Y, Xia Y. 6-D object pose estimation based on point pair matching for robotic grasp detection. IEEE Trans Neural Netw Learn Syst. 2025;36(7):11902–16. doi:10.1109/tnnls.2024.3442433. [Google Scholar] [PubMed] [CrossRef]
16. Han Z, Chen L, Zha Y, Wu S. PCR-PoseNet: a 6D pose estimation method for texture-less and highly refle ctive industrial parts with point cloud shape recovery. Vis Comput. 2025;41(11):8745–60. doi:10.1007/s00371-025-03896-8. [Google Scholar] [CrossRef]
17. Wang H, Sridhar S, Huang J, Valentin J, Song S, Guibas LJ. Normalized object coordinate space for category-level 6d object pose and size estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–20; Long Beach, CA, USA. p. 2642–51. [Google Scholar]
18. Lin J, Liu L, Lu D, Jia K. SAM-6D: segment anything model meets zero-shot 6D object pose estimation. In: Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2024 Jun 16–22; Seattle, WA, USA. p. 27906–16. [Google Scholar]
19. Lin M, Murali V, Karaman S. 6D object pose estimation with pairwise compatible geometric features. In: 2021 IEEE International Conference on Robotics and Automation (ICRA). Piscataway, NJ, USA: IEEE; 2021. p. 10966–73. [Google Scholar]
20. Gao G, Lauri M, Wang Y, Hu X, Zhang J, Frintrop S. 6D object pose regression via supervised learning on point clouds. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). Piscataway, NJ, USA: IEEE; 2020. p. 3643–9. [Google Scholar]
21. Yuan S, Ge Z, Yang L. Single-camera multi-view 6DoF pose estimation for robotic grasping. Front Neurorobot. 2023;17:1136882. doi:10.3389/fnbot.2023.1136882. [Google Scholar] [PubMed] [CrossRef]
22. Tan T, Dong Q. SMOC-Net: leveraging camera pose for self-supervised monocular object pose estimation. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2023 Jun 17–24; Vancouver, BC, Canada. p. 21307–16. [Google Scholar]
23. Josifovski J, Kerzel M, Pregizer C, Posniak L, Wermter S. Object detection and pose estimation based on convolutional neural networks trained with synthetic data. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway, NJ, USA: IEEE; 2018. p. 6269–76. [Google Scholar]
24. Kehl W, Manhardt F, Tombari F, Ilic S, Navab N. SSD-6D: Making rgb-based 3D detection and 6D pose estimation great again. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. p. 1521–9. [Google Scholar]
25. Xiang Y, Schmidt T, Narayanan V, Fox D. Posecnn: a convolutional neural network for 6D object pose estimation in cluttered scenes. arXiv:1711.00199. 2017. [Google Scholar]
26. Wang C, Xu D, Zhu Y, Martín-Martín R, Lu C, Fei-Fei L, et al. Densefusion: 6D object pose estimation by iterative dense fusion. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–20; Long Beach, CA, USA. p. 3343–52. [Google Scholar]
27. Sundermeyer M, Marton ZC, Durner M, Brucker M, Triebel R. Implicit 3D orientation learning for 6D object detection from rgb images. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV); Cham, Switzerland: Springer; 2018. p. 699–715. [Google Scholar]
28. Tian M, Pan L, Ang MH, Lee GH. Robust 6D object pose estimation by learning RGB-D features. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). Piscataway, NJ, USA: IEEE; 2020. p. 6218–24. [Google Scholar]
29. Kleeberger K, Huber MF. Single shot 6D object pose estimation. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). Piscataway, NJ, USA: IEEE; 2020. p. 6239–45. [Google Scholar]
30. Park J, Cho NI. Dprost: dynamic projective spatial transformer network for 6D pose estimation. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2022. p. 363–79. [Google Scholar]
31. Feng G, Xu TB, Liu F, Liu M, Wei Z. NVR-net: normal vector guided regression network for disentangled 6D pose estimation. IEEE Trans Circ Syst Video Tech. 2023;34(2):1098–113. doi:10.1109/tcsvt.2023.3290617. [Google Scholar] [CrossRef]
32. Liang G, Chen F, Liang Y, Feng Y, Wang C, Wu X. A manufacturing-oriented intelligent vision system based on deep neural network for object recognition and 6D pose estimation. Front Neurorobot. 2021;14:616775. doi:10.3389/fnbot.2020.616775. [Google Scholar] [PubMed] [CrossRef]
33. Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision; 2015 Dec 7–13; Santiago, Chile. p. 1440–8. [Google Scholar]
34. Tekin B, Sinha SN, Fua P. Real-time seamless single shot 6d object pose prediction. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 292–301. [Google Scholar]
35. Yang X, Li K, Wang J, Fan X. ER-pose: learning edge representation for 6D pose estimation of texture-less objects. Neurocomputing. 2023;515(2):13–25. doi:10.1016/j.neucom.2022.09.151. [Google Scholar] [CrossRef]
36. Xu Y, Lin KY, Zhang G, Wang X, Li H. Rnnpose: 6-DoF object pose estimation via recurrent correspondence field estimation and pose optimization. IEEE Trans Pattern Anal Mach Intell. 2024;46(7):4669–83. doi:10.1109/cvpr52688.2022.01446. [Google Scholar] [CrossRef]
37. Lin Y, Su Y, Inuganti S, Di Y, Ajilforoushan N, Yang H, et al. Resolving symmetry ambiguity in correspondence-based methods for instance-level object pose estimation. IEEE Trans Image Process. 2025;34:1700–11. doi:10.1109/tip.2025.3544142. [Google Scholar] [PubMed] [CrossRef]
38. Park K, Patten T, Vincze M. Pix2Pose: pixel-wise coordinate regression of objects for 6D pose estimation. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 7667–76. [Google Scholar]
39. Sundermeyer M, Marton ZC, Durner M, Triebel R. Augmented autoencoders: implicit 3D orientation learning for 6D object detection. Int J Comput Vis. 2020;128(3):714–29. doi:10.1007/s11263-019-01243-8. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools