
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Steel Surface Defect Detection via the Multiscale Edge Enhancement Method
1 College of Computer and Software Engineering, Huaiyin Institute of Technology, Huai’an, 223003, China
2 China Mobile Group Jiangsu Co., Ltd., Huai’an, 223003, China
* Corresponding Author: Yuanyuan Wang. Email:
Computers, Materials & Continua 2026, 86(3), 40 https://doi.org/10.32604/cmc.2025.072404
Received 26 August 2025; Accepted 17 October 2025; Issue published 12 January 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
To solve the false detection and missed detection problems caused by various types and sizes of defects in the detection of steel surface defects, similar defects and background features, and similarities between different defects, this paper proposes a lightweight detection model named multiscale edge and squeeze-and-excitation attention detection network (MSESE), which is built upon the You Only Look Once version 11 nano (YOLOv11n). To address the difficulty of locating defect edges, we first propose an edge enhancement module (EEM), apply it to the process of multiscale feature extraction, and then propose a multiscale edge enhancement module (MSEEM). By obtaining defect features from different scales and enhancing their edge contours, the module uses the dual-domain selection mechanism to effectively focus on the important areas in the image to ensure that the feature images have richer information and clearer contour features. By fusing the squeeze-and-excitation attention mechanism with the EEM, we obtain a lighter module that can enhance the representation of edge features, which is named the edge enhancement module with squeeze-and-excitation attention (EEMSE). This module was subsequently integrated into the detection head. The enhanced detection head achieves improved edge feature enhancement with reduced computational overhead, while effectively adjusting channel-wise importance and further refining feature representation. Experiments on the NEU-DET dataset show that, compared with the original YOLOv11n, the improved model achieves improvements of 4.1% and 2.2% in terms of mAP@0.5 and mAP@0.5:0.95, respectively, and the GFLOPs value decreases from the original value of 6.4 to 6.2. Furthermore, when compared to current mainstream models, Mamba-YOLOT and RTDETR-R34, our method achieves superior performance with 6.5% and 8.9% higher mAP@0.5, respectively, while maintaining a more compact parameter footprint. These results collectively validate the effectiveness and efficiency of our proposed approach.Keywords
As the cornerstone of modern industry, steel is indispensable in construction, automobile manufacturing, and many other fields. However, its production, transportation, and storage processes are susceptible to complex conditions, often resulting in defects such as cracks and dents on surfaces. These defects not only affect appearance but also deteriorate mechanical properties, bury safety hazards, and even cause major accidents [1]. Therefore, it is particularly important to detect steel surface defects and ensure the quality of the steel surface, which not only speeds up the entire production inspection process but also ensures the quality of the steel itself and long-term safety in construction and use.
In the early stage, the steel defect detection method, which relies on manual judgement of defect information, had low detection efficiency, and the false detection and missed detection problems caused by subjective factors occurred frequently, which made it difficult to meet the needs of large-scale detection. However, although the infrared detection and magnetic flux leakage detection methods reduce the judgment error caused by subjective factors, the scope of application is small, and stringent requirements exist for the detection environment and equipment maintenance [2].
With the development of technology, object detection technology based on deep learning has gradually become mainstream, and this method has also been used in the detection of steel defects. The two-stage algorithm, represented by the Faster-RCNN [3] and Mask R-CNN [4], divides the detection process into two parts: candidate box generation and classification regression. Although this type of algorithm has a good detection effect, the detection accuracy increases at the expense of the overall detection speed, so it is not convenient for practical deployment and application. The core idea of the one-stage algorithm, represented by SSD [5] and YOLO [6] series algorithms, is to extract features directly from different regions of the input image and use convolutional neural networks to regress and classify the feature images. This type of algorithm has a higher detection speed, but the detection accuracy for small objects may be slightly lower than that of the two-stage algorithm [7].
In the current methods for detecting steel surface defects, the types of defects are diverse, the sizes of the defects are usually different, small defects may occupy only a small part of the ratio of pixels in the image, and the texture of the defects themselves is more complex. Therefore, in the detection process, it is often difficult to extract the edge features of defects, which leads to difficulty in distinguishing defects from background images and makes it difficult to locate small defects accurately.
In recent years, deep learning-based detection methods have achieved remarkable progress in this research domain. Multiscale feature fusion design and lightweight architecture represent crucial approaches for balancing model detection accuracy and efficiency. Liu et al. [8] proposed a lightweight detection model, FDFNet, for steel defect detection tasks. The Differentiated Fusion module, specifically designed for the neck network, effectively enhances the consistency and heterogeneity of feature maps across different scales. FDFNet has demonstrated competitive performance on the NEU-DET dataset. Based on YOLOv8, Zhu et al. [9] enhanced the model’s multi-scale feature representation by integrating C2f-MB and FocalModulation mechanisms, and introduced the Normalized Wasserstein Distance (NWD) loss to improve small defect detection. However, their approach still suffers from relatively low detection accuracy for certain defect categories.
Considering that the fine edge and contour features of steel defects are susceptible to degradation within complex industrial environments, a phenomenon that poses challenges to defect detection, this paper proposes a novel multiscale edge enhancement module (MSEEM). Also, we propose an edge enhancement module with squeeze-and-excitation attention (EEMSE) that can be used to improve the detection head section in combination with the squeeze-and-excitation (SE) attention mechanism. Specifically, we have made the following improvements:
First, we design an edge enhancement module (EEM), which suppresses the high-frequency information in the image without changing the size of the input image through the average pooling operation, and then extracts the high-frequency part in the original image, that is, the defect edge part information, by subtracting the low-frequency features from the original features. The processed enhanced edge information is added to the original feature so that the final output feature has more prominent edge feature information while retaining the original information.
Second, we design a multiscale edge enhancement module (MSEEM), on the basis of the EEM. By using the EEM to extract features from the input image at different scales, we can obtain the image data after multiscale edge enhancement so that the ability to express defect features can be effectively improved. By further processing the data, we can obtain clearer information about the target edge profile.
Finally, by introducing the squeeze-and-excitation (SE) attention mechanism [10] into the EEM, the importance of each channel can be dynamically adjusted while enhancing the target edge contour to increase the model’s attention to channels with important information and improve the ability to express features. We name the module edge enhancement module with squeeze-and-excitation attention (EEMSE), which can be applied adaptively to the detection head. By integrating the proposed module into the detection head of YOLOv11n, we obtain a more lightweight detection head module, termed Detect-EdgeEnhancerSE. Compared to the original detection head structure, EdgeEnhancerSE features a reduced parameter count. The resulting YOLOv11n model integrated with EdgeEnhancerSE achieves a 1.3% improvement in mAP@0.5 over the baseline model, while simultaneously reducing computational complexity by 0.6 GFLOPs.
By combining the multiscale edge enhancement module and edge enhancement module with squeeze-and-excitation attention, we propose a multiscale edge and SE attention network (MSESE) based on YOLOv11. By obtaining multiscale edge enhancement images, the detection effect of the network model can be effectively improved, and the lighter detection head module can reduce the detection time while ensuring the detection performance of the model. Compared to the baseline model, the improved version achieves a 4.1% increase in mAP@0.5 along with a reduction in parameter count. It demonstrates superior detection performance across all six common defect categories, including crazing, pitted surface, inclusion, scratches, patches, and rolled-in scale, when compared to the original model. These results suggest that the modified model offers enhanced suitability for practical applications.
Deep learning has evolved in recent years and has sparked profound changes in object detection. With the advantages of completing feature extraction through the model itself to obtain features with better representation ability and then completing feature selection and classification, CNNs have been favoured by the majority of researchers and have been applied by researchers to steel surface defect detection with good results.
Fu et al. [11] selected SqueezeNet as the backbone architecture and designed a compact and efficient convolutional neural network model. By training the underlying features and fusing multiple receptive fields, they achieved accurate and efficient identification of defect targets. He et al. [12] proposed a multigroup convolutional neural network (MG-CNN) to classify and extract defect features and achieved good detection results on a hot-rolled strip dataset.
As technology continues to mature, an increasing number of deep learning methods have been applied to steel defect detection research. As one of the representative algorithms of two-stage target detection, Faster-RCNN is usually one of the commonly used algorithms steel in defect detection research. It adheres to the design idea of region proposal + CNN + support vector machine (SVM). Features are extracted from the image through the CNN, and the region recommendation algorithm is used to generate candidate regions and correct the coordinates. The extracted features are processed by the fully connected layer, and the final classification and positioning results are obtained with the classifier. In the study of this algorithm, Yin and Yang [13] added the FPN to Faster R-CNN to promote the fusion of high-level and low-level feature information, reduced the quantization error by using RolAlign, enhanced network convergence by using CycleGAN, and introduced multilayer RolAlign for the extreme aspect ratio in the data to improve the detection effect.
In addition, as representatives of one-stage target detection algorithms, algorithms such as SSD, YOLO and RetinaNet can obtain target category and location information directly without adjusting the candidate box. They are also widely used in steel defect detection research. For example, Yan et al. [14] proposed the use of the transformer multihead attention mechanism to improve the SSD algorithm and introduced the involution operator to improve the algorithm’s ability to detect small target defects while controlling the number of computational parameters. Siddiqui and Ahn [15] focused on the detection of small defect features on a steel surface and proposed optimizing YOLOv5 by using a deep separable convolution and channel shuffling mechanism, and weighting and fusing the feature values output by a feature pyramid network to improve feature propagation and network expression ability. Zhang et al. [16] integrated a self-designed multiscale feature enhancement module into YOLOv8 to enhance the detection layer of small targets by fusing multiscale features. To balance the detection accuracy and detection speed, Wang et al. [17] improved the lightweight feature of RetinaNet and proposed a spatial pyramid pooling mechanism based on a cross-stage local structure to ensure good detection accuracy.
In the context of target detection research incorporating edge features, Dong et al. [18] proposed an Edge-aware Interactive Refinement Network (EAIRNet) based on ResNet34. This network enhances the perception capability of defect boundaries and, combined with region attention guidance, achieves precise localization of steel strip defect boundaries. This method directly modifies ResNet-34 to extract multi-scale features. While effective, this approach exhibits limited transferability. Furthermore, the substantial parameter count of EAIRNet presents challenges for real-time detection applications. Based on YOLOv8, Shen and Huang [19] proposed the ESE-YOLO detection model, which utilizes an ELEStem module to extract edge features and employs shifted convolutions to enhance the receptive field. Additionally, they further optimized the parameter count by refining the feature pyramid network. However, although this method achieves rapid detection of defect targets with relatively low computational complexity, its detection accuracy still requires further improvement.
Furthermore, although transformer technology can effectively increase detection accuracy, its computational complexity is high, so the detection time is relatively long [20]. Most current studies do not focus on the edge contour information of defects, and it is difficult to recover edge details; thus, defect localization needs to be further improved [21]. Considering that the application of steel surface defect detection technology in practical applications puts forward high requirements for the balance between detection accuracy and real-time performance, we selected the YOLOv11 algorithm as the basis and made improvements on this basis, proposed the MSEEM and EEMSE modules. Both MSEEM and EEMSE exhibit transferable characteristics, allowing for their adaptive integration into various model architectures. MSEEM preserves the original features of the input image while incorporating defect edge features extracted at different scales. This integration enhances the model’s focus on defect boundary information, thereby improving defect localization. EEMSE exhibits a lightweight design, characterized by a lower parameter count compared to the detection head of the baseline YOLOv11 model. This reduction in parameters contributes to enhanced computational efficiency. Ultimately, by integrating both modules, we proposed the MSESE network so that the model can pay more attention to the edge information of defects and achieves detection effects with higher reasoning speed.
In the process of steel surface defect detection, different types of defects have their own characteristics in terms of shape, size and texture. Typically, the defect itself occupies only a small fraction of the pixel ratio of the image data, so it contains relatively limited feature information. The surface texture features of steel are relatively complex. Affected by external factors such as light, the edge texture features of small defects are more easily confused with background features, thus increasing the difficulty of distinguishing defects from the background and resulting in difficulty in defect detection. To solve the defect edge feature extraction and defect detection problems, this paper first designs an edge feature enhancement module named the EEM and then proposes a multiscale edge enhancement module named the MSEEM. Additionally, we propose the edge enhancement module with squeeze-and-excitation attention module (EEMSE) to enhance the performance of detection head. And finally, an MSESE network based on YOLOv11 is constructed to achieve accurate detection of steel surface defects. We introduce the EEM and MSEEM module in detail in Section 3.1 and the EEMSE in Section 3.2.
3.1 Multiscale Edge Enhancement Module
During the detection process, steel surface defects often occupy only a small part of the image to be detected, and the shape of the defects themselves is not fixed; thus, false detections and missed detections occur frequently during the recognition process. The image data in the steel surface defect dataset are all grayscale images, and the defects have a certain degree of similarity with the background in terms of texture and colour. Therefore, in the process of extracting the characteristics of steel surface defects, the effective extraction of defect edge contour information plays a vital role in improving the subsequent detection accuracy and efficiency. To better extract and use the edge information of defects and ensure the accuracy and efficiency of subsequent defect detection, we propose and design the MSEEM. This module processes the input image through a series of operations, such as multiscale feature extraction, edge enhancement, the dual-domain selection mechanism (DSM) [22] and feature fusion, to enhance the image’s feature expression ability, especially the ability to express defect target edge information, without changing the image shape and size. Its structure is shown in Fig. 1.
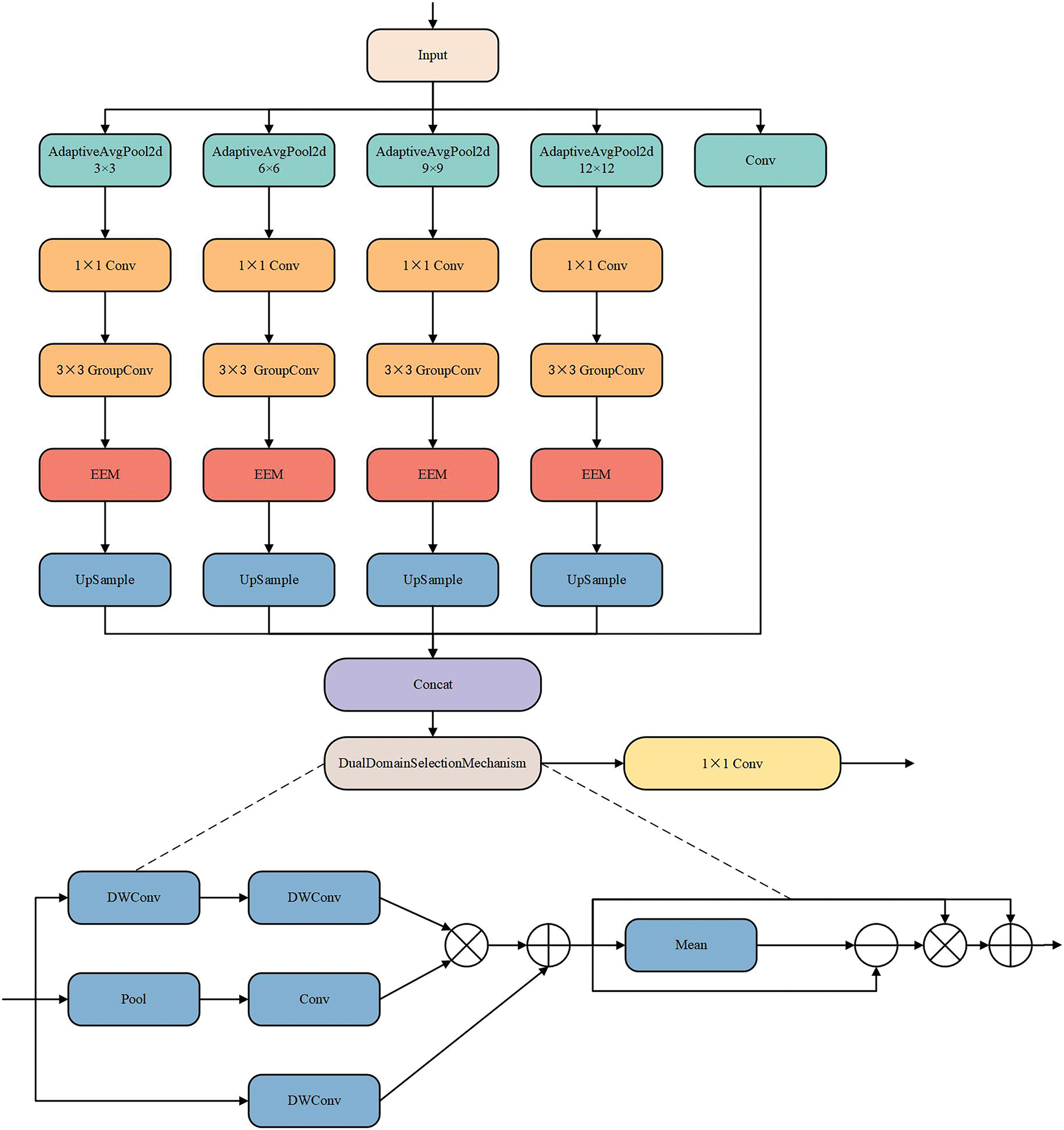
Figure 1: MSEEM (The input feature maps will be edge-enhanced at different scales, and the enhanced feature images will be further processed through a dual-domain selection mechanism to enhance key information and make the features clearer)
Specifically, the MSEEM divides the task into len(bins) +1 branches according to the length of the multiscale feature extraction list bins. The task is divided into multiple multiscale feature extraction branches and one local feature extraction branch. For the input feature map, the size of the value stored in the bin list represents the size of the pooling target applied on the feature map. The smaller feature image often contains the global information of the whole image, which is more conducive to the acquisition of global features [23], and the pooled larger feature image can be used to capture more detailed features in the image; that is, local information can be acquired. On the basis of the number of target sizes defined in the list, the MSEEM assigns a corresponding branch for each scale to be processed to pool the feature map to the specified scale for feature extraction. Specifically, we configure the multi-scale pooling hyperparameter as bins = [3, 6, 9, 12] to construct a five-branch parallel feature extraction architecture. This structure comprises four branches generated via adaptive average pooling, producing spatial grid scales of 3 × 3, 6 × 6, 9 × 9, and 12 × 12, along with an additional local branch that preserves the original spatial dimensions of the input. This design is intended to systematically capture cross-scale information ranging from local details to global context.
Specifically, the local branch is responsible for retaining the feature information of the original feature map. The 3 × 3 grid branch captures global semantic information from the image. Serving as intermediate levels, the 6 × 6 and 9 × 9 grid branches extract structured contextual information at different granularities and model spatial relationships between defect components. The 12 × 12 grid branch preserves richer spatial details at a relatively larger grid scale, thereby providing more precise cues for defect localization.
Finally, feature maps from all branches are resized to a consistent spatial dimension, then concatenated and fused along the channel dimension. This design facilitates cross-scale feature complementarity, ultimately enhancing the model’s detection capability for steel surface defects ranging from fine-scale to larger anomalies.
In the multiscale feature extraction branch, according to the different sizes of the output target, the MSEEM first uses adaptive average pooling to dynamically adjust the feature image to the specified size, extracts the information of the feature image, enhances the edge information through convolution operation and EEM processing, and finally restores the enhanced feature image to the original size through the upsampling operation. Thus, we can obtain feature images with edge information enhancement at different scales. The EEM is the edge enhancement module we designed, which we introduce in detail in Section 3.1.1.
In the local feature extraction branch, the MSEEM performs only simple feature extraction operations on the input feature image. Finally, the feature maps in all branches are fused in the channel dimension. Owing to the capture of local and global feature information, the enhanced feature image has better expression ability while highlighting the edge features of the target to better adapt to the detection task.
To further enhance the key information of the detected target in the feature image, the useless information is suppressed. The processed feature map is passed to the dual-domain selection mechanism for further processing, and finally, the feature map optimized by both space and frequency is output to improve the model’s ability to perceive the detected target and optimized the detection accuracy.
Typically, the edges of defects such as scratches and cracks appear as rapidly changing areas of pixel intensity in steel surface images. This area changes dramatically and is the high-frequency information part of the image [24], which is also the core feature of edge information. By extracting this high-frequency information, the contour and shape characteristics of the defect can be effectively highlighted, providing an effective basis for subsequent detection.
To effectively obtain the high-frequency information of the defect image, we propose and design an edge feature enhancement module, named the EEM, which can enhance the extraction of the edges of defect features without changing the size of the input image. Unlike the fixed linear kernels of Sobel operators, the EEM adopts a parameterized design where its weights are optimized through training, thereby achieving enhanced edge feature extraction. Its structure is shown in Fig. 2.
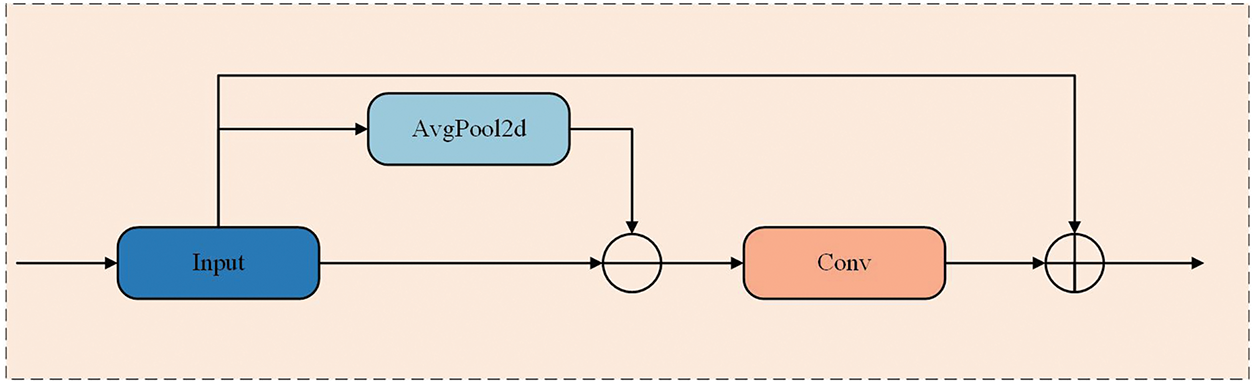
Figure 2: Structure of the EEM module
Specifically, the module extracts high-frequency edge information through pooling and convolution operations. For the input feature map, the EEM initially employs a 3 × 3 local average pooling operation to blur the high-frequency edge information in the image, thereby preserving the low-frequency information component of the entire image. Then, by subtracting the pooled feature map from the original feature map, we quickly obtain a difference, which is the high-frequency information we expect to obtain, that is, the edge information. The edge information processed by the convolutional layer is added to the original feature map, and the edge features are enhanced while retaining the original feature map information through feature fusion. The specific structure of the convolutional layer is shown in Fig. 3.
Figure 3: Conv structure
The output feature image after EEM processing is effectively enhanced at the edge of the defect, and the size and dimension of the feature image before and after processing by the EEM do not change, and can be directly applied to the subsequent processing, feature extraction, and selection.
3.1.2 Dual-Domain Selection Mechanism
To reduce the interference caused by factors such as poor image quality and noise information, the target should be presented more clearly, and the edge information of the defective target should be highlighted. We introduce a dual domain selection mechanism (DSM) in the MSEEM to further process the feature image. By combining the differences in the spatial and spectral domains, the DSM enables the model to focus more on the critical regions in the image, thereby helping the model achieve more accurate detection. Specifically, the DSM is composed of two main parts: the space selection module (SSM) and the frequency selection module (FSM). The SSM can effectively locate the key areas in the input features, and the FSM can enhance the image based on the initial position information provided by the SSM, thereby suppressing noise and enhancing the image feature expression capability.
The main role of the SSM is to help the network focus on key areas, such as degraded areas in the space domain, and provide the initial locations of these areas for the FSM. For the input feature map
where F is the input feature map and where AvgPool(F) and MaxPool(F) represent average pooling and maximum pooling, respectively. Conv3 represents a convolution operation with a convolution kernel size of 3 × 3. The final result F′ is the output feature map and F′ ∈ R(H×W×1), which contains the degeneration location information. In addition, the SSM uses deep convolution to generate channel-level representations on the input feature map, and the process is shown in Eq. (2).
where
On the basis of the feature map information provided by the SSM, the FSM obtains the high-frequency features of the feature map by removing the low-frequency signals so that the key information in the feature map, including the blurred area and edge information, can be presented more clearly. The processing procedure can be formulated as Eq. (3):
where
To address the fact that the grayscale image data in the steel defect dataset may have low image contrast and the weak defect texture features may be affected by lighting and other factors, through further processing by the DSM, the final feature map output by the MSEEM can maintain clarity while having more prominent edge information to effectively cope with the subsequent detection needs.
3.2 Edge Enhancement Module with Squeeze-and-Excitation Attention
In the detection of steel surface defects, multiple defect targets may appear in the same detection image. The textures of these defects are similar to the background, and the defects also have a certain degree of similarity. In addition, owing to changes in factors such as lighting conditions in the production environment, the grayscale value of the defect image may fluctuate, which introduces new requirements for detection. Therefore, we propose a new improved module for the YOLOv11 detection head structure. By introducing the SE attention mechanism into the EEM we designed, we form a new edge enhancement module called EEMSE, which can be combined with the existing detection head to improve our detection task.
In computer vision tasks, attention mechanisms are commonly employed to guide models in focusing on salient features within feature maps. Several established attention mechanisms are commonly adopted to enhance detection models. These include the Convolutional Block Attention Module (CBAM) [25], Efficient Channel Attention (ECA) [26], and the Squeeze-and-Excitation (SE) module, all of which are widely integrated for performance improvement.
The structure of the CBAM attention mechanism is illustrated in Fig. 4. Its core design lies in the sequential connection of two submodules: a channel attention module and a spatial attention module. This architecture enhances feature responses from both channel and spatial dimensions, enabling the module to adaptively focus on the most informative features in the input image.
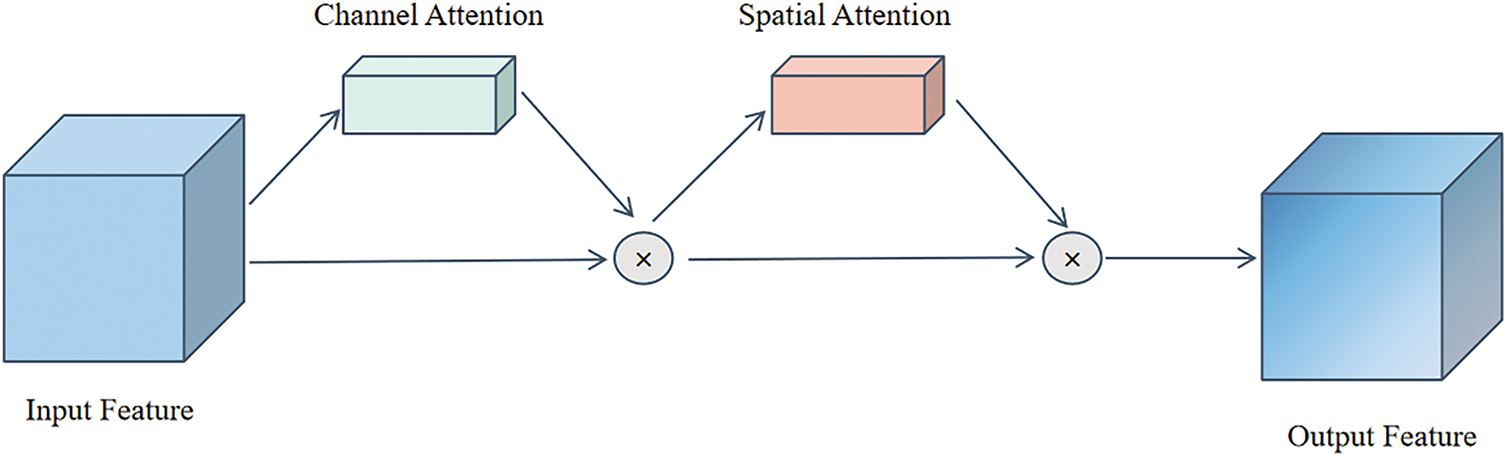
Figure 4: Structure of the convolutional block attention module
The ECA module exemplifies an efficient, lightweight design, as depicted in Fig. 5. It employs a one-dimensional global average pooling layer to compute average values for each channel, generating attention factors that represent channel-wise importance. These factors are then refined through a one-dimensional convolutional layer, ultimately implementing an effective channel attention mechanism.
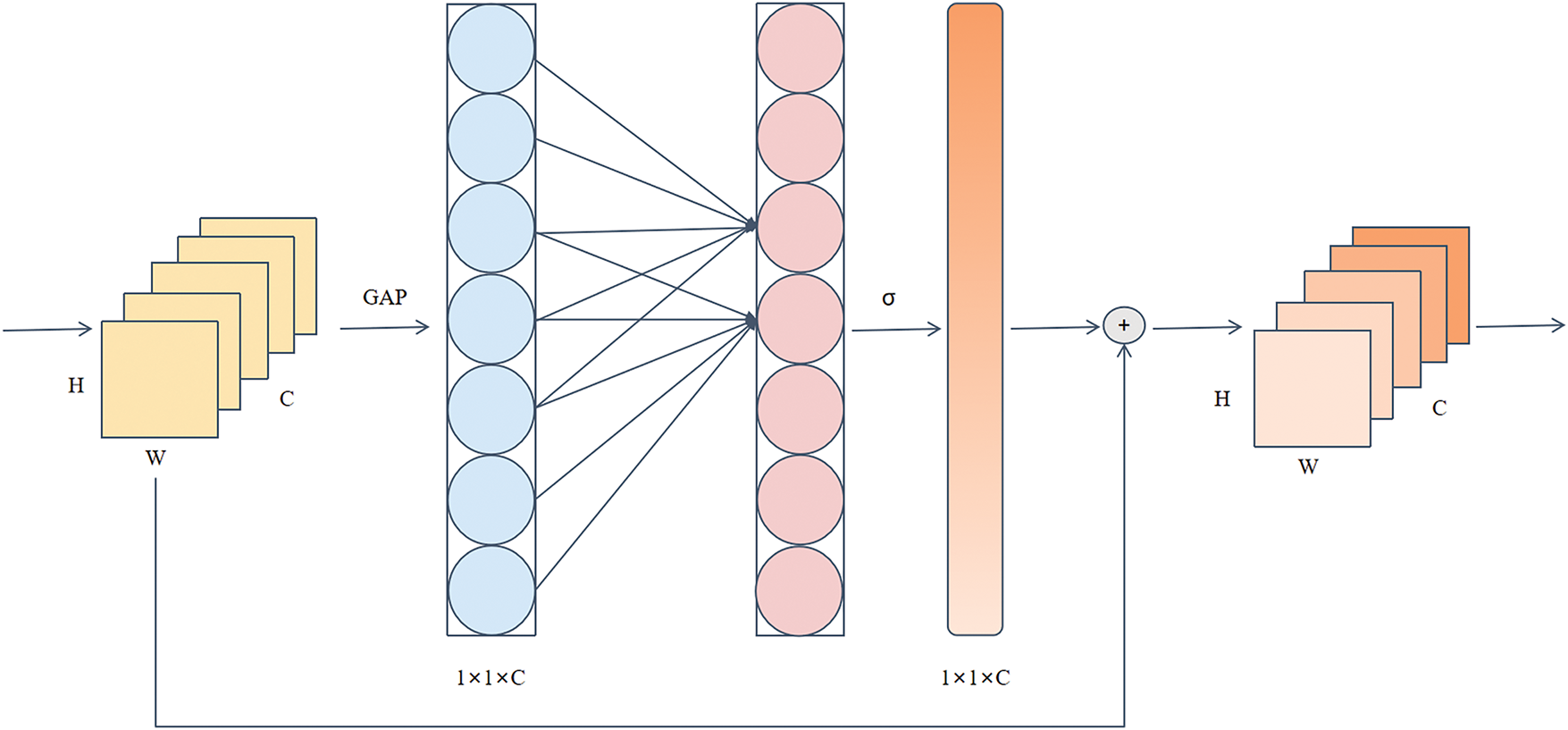
Figure 5: Structure of the efficient channel attention module
However, the CBAM module itself has a considerable number of parameters. Simultaneously, it must be considered that our Edge Enhancement Module (EEM) has already performed preliminary processing on the input image, highlighting high-frequency information such as edges and contours. Therefore, directly reintroducing CBAM, which possesses its own spatial attention mechanism, would inevitably lead to bloating of the module architecture and increase the computational burden on the model. The local cross-channel interaction strategy employed by ECA, while highly efficient, may fall short of SE in constructing complex channel-wise nonlinear relationships when confronted with intricate detection tasks. Consequently, we ultimately selected the SE attention mechanism to construct the EEMSE module.
Among them, the SE attention mechanism is a general channel attention mechanism that plays an important role in enhancing the feature expression ability. By dynamically adjusting the importance of different feature channels, features that are important for the current task receive more attention. The SE attention mechanism enhances the model expression capability by performing two operations, squeeze and excitation, on the input feature image, as shown in Fig. 6.
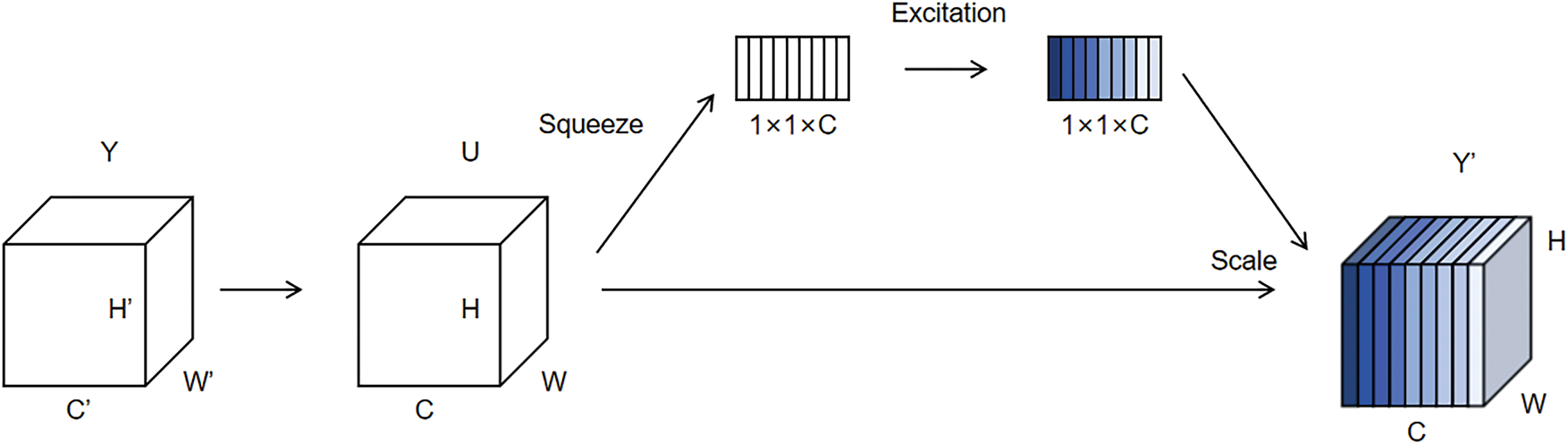
Figure 6: Structure of the squeeze-and-excitation attention mechanism
For the feature map with an input size of H × W × C, the squeeze operation compresses the spatial information of each channel into a single value through global average pooling to form a vector of 1 × 1 × C, which can retain the global information of each channel. In the excitation operation, the obtained vector is subsequently further processed through two fully connected layers to obtain the channel weights. The obtained weight coefficients are used to adjust the feature intensity of each channel in the original feature map to obtain the weighted feature image. With the help of the SE attention mechanism, the important features of the input image are further strengthened, while the non-important features are effectively suppressed.
In the design of the EEMSE module, we introduce the SE attention mechanism into the EEM to form the EEMSE module, the structure of which is shown in Fig. 7. The input feature map is first passed to the EEM for edge enhancement processing. The EEM is responsible for extracting edge information from the feature image and enhancing it, thereby highlighting the edge contour information in the feature map. The enhanced feature image is fed into the SE module to dynamically adjust the importance of each channel so that the model can pay more attention to the channel with important information and improve the feature representation effect. Notably, the EEMSE module we designed is also a plug-and-play module. Moreover, the module has a relatively small number of parameters, so it is more effective in increasing the detection speed. This module can be adaptively introduced into different versions of the detection head for improvement to achieve accurate detection of the target at a higher detection speed.
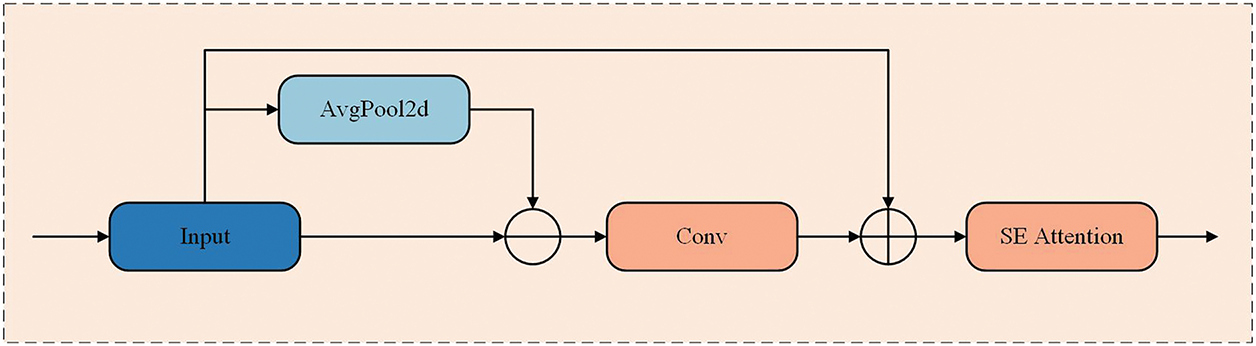
Figure 7: Structure of the EEMSE module
3.3 Multiscale Edge and SE Attention Detection Network
In response to the accuracy and detection speed requirements for steel surface defect detection, we use self-designed modules to further construct the MSESE feature extraction network on the basis of the YOLOv11 network structure, and its structure is shown in Fig. 8. First, we use the MSEEM to improve the original C3k2 module, the result of which is called C3k2 Multiscale Edge Information Select, so that the network can focus on and extract the edge information of the feature image in combination with multiscale features. We then incorporate EEMSE into the detection head structure to achieve more accurate identification of steel surface defects, thereby making the detection of steel defects possible in different environments.
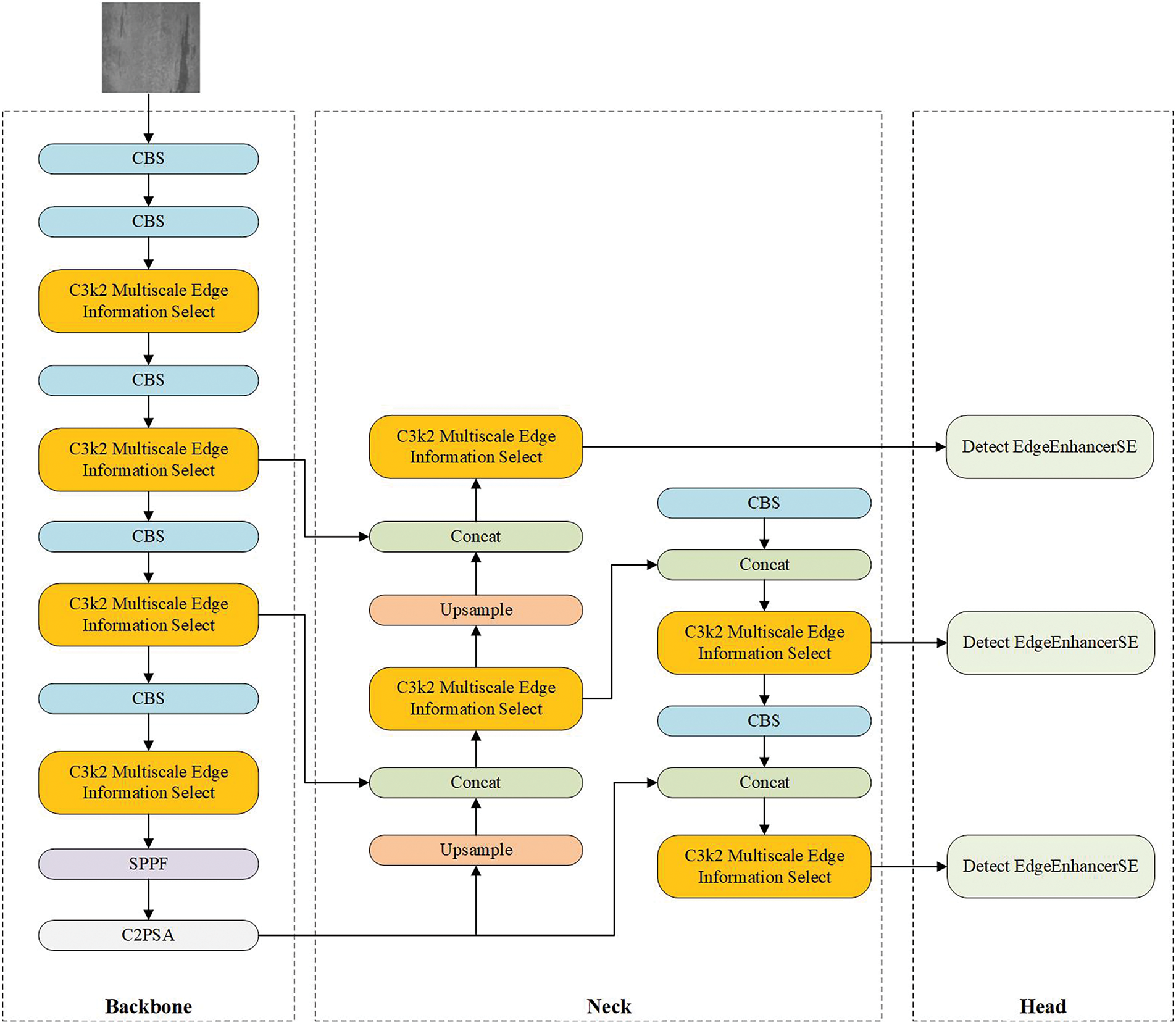
Figure 8: Structure of the MSESE network
In the design of the MSESE network, we retain the original SPPF and C2PSA modules in the YOLOv11 network without making any changes. The SPPF module can perform maximum pooling operations at different scales and then concatenate the results to obtain features at multiple spatial scales. The C2PSA module is a new module proposed in YOLOv11 that can guide the model to focus on more important areas in the image and improve the spatial attention ability of the model. Their structures are shown in Fig. 9.
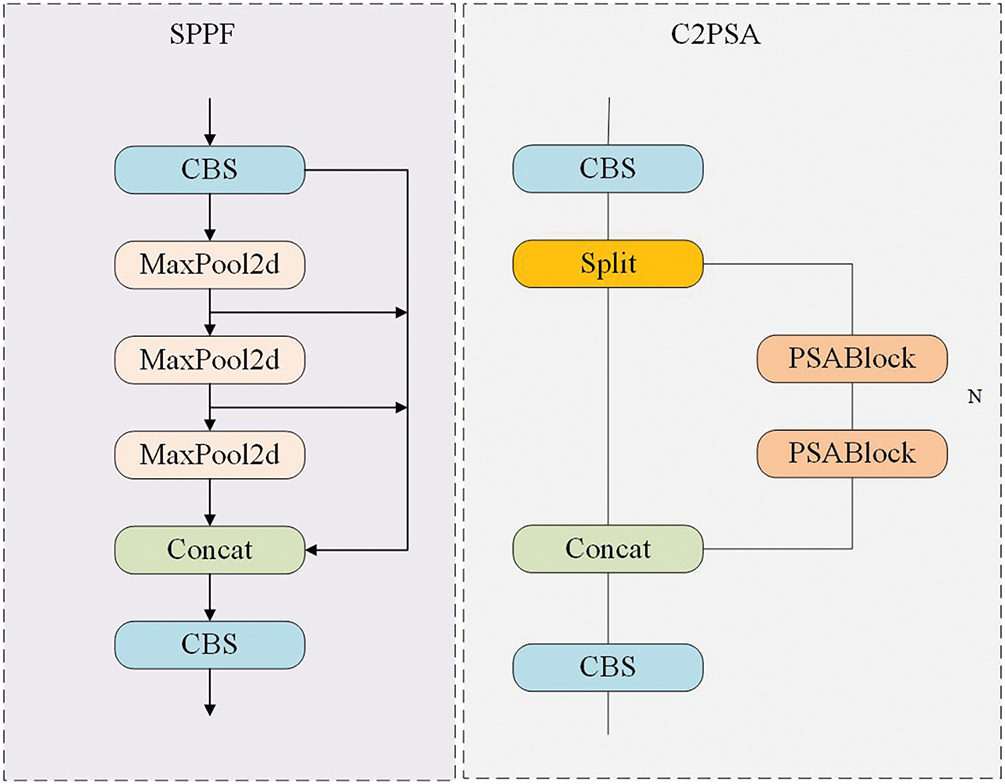
Figure 9: Structure of SPPF (left) and C2PSA (right)
3.3.1 C3k2 Multiscale Edge Information Select
YOLOv11 innovatively proposes the C3k2 module and applies it to the network, which enhances the flexibility of feature extraction by introducing a variable convolutional kernel size. Specifically, the C3k2 module contains two branches, and the branch route can be flexibly selected by setting the parameters of C3k to true or false. In a shallow network, the bottleneck module can usually be used to extract features directly, whereas in a deep network, by setting the parameter to true, the corresponding bottleneck module is replaced by the C3k module to process the deep features. This design has certain advantages in large-scale target feature extraction. However, in the face of small defects, especially when dealing with small defects on the surface of steel, the feature extraction ability of C3k2 still needs to be further optimized. Therefore, we introduce the MSEEM based on C3k2 to improve the feature extraction ability. The improved module is called C3k2 Multiscale Edge Information Select. The structures of the original C3k2 module and the improved C3k2 Multiscale Edge Information Select module are shown in Fig. 10.
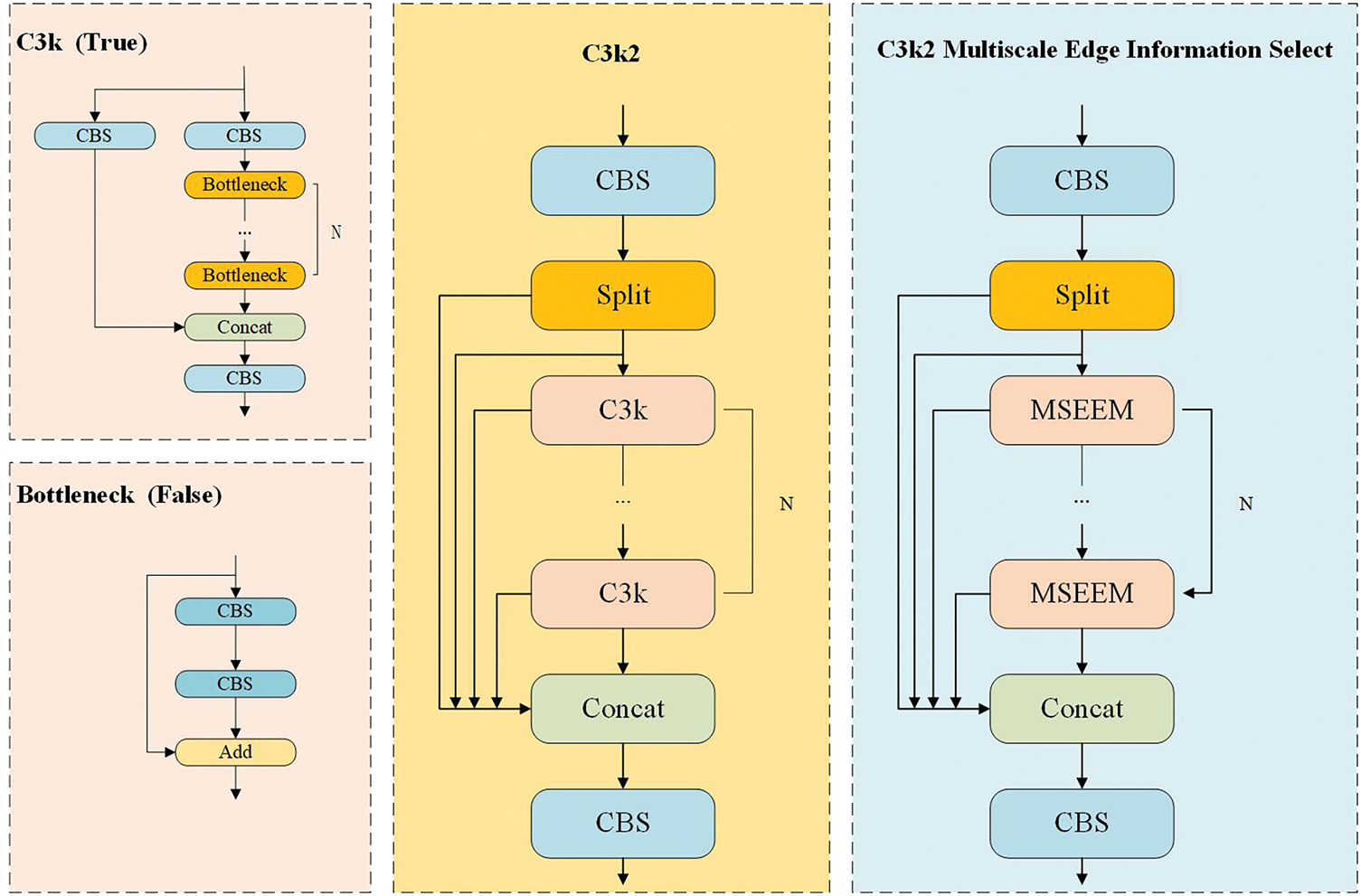
Figure 10: C3k2 module and C3k2 multiscale edge information select module
Specifically, we replace the bottleneck in the branch where the C3k parameter is false with the previously proposed MSEEM while retaining the C3k module in the other branch. Therefore, when the C3k parameter is set to false, the feature extraction operation can no longer be simply implemented by using the bottleneck, and instead, the MSEEM is used to strengthen the edge of the small feature at multiple scales. Compared with the original C3k2 module, this design can obtain a better receptive field to more accurately capture the edge contours and detailed features of various target defects.
In the design of the detection head, YOLOv11 adopts an anchor-free detection mechanism that can directly predict [27] the position of the target center point. This design simplifies the detection process and optimizes the speed of nonmaximum suppression, thereby improving the overall detection efficiency. However, it is still difficult for existing detection heads to present accurate positioning effects in complex background environments, and the different sizes and shapes of targets, unfixed positions, and low discrimination between targets and the background environment all increase the difficulty of target recognition, which has a certain impact on the detection performance, especially for the detection of steel surface defects. Therefore, we introduce the previously proposed EEMSE module into the original detection head of YOLOv11 to form a new detection head module, called Detect Edge Enhancer SE, which can enhance edge features and dynamically adjust channel importance while further strengthening feature representation, thereby improving detection accuracy. The improved detection head structure is shown in Fig. 11.
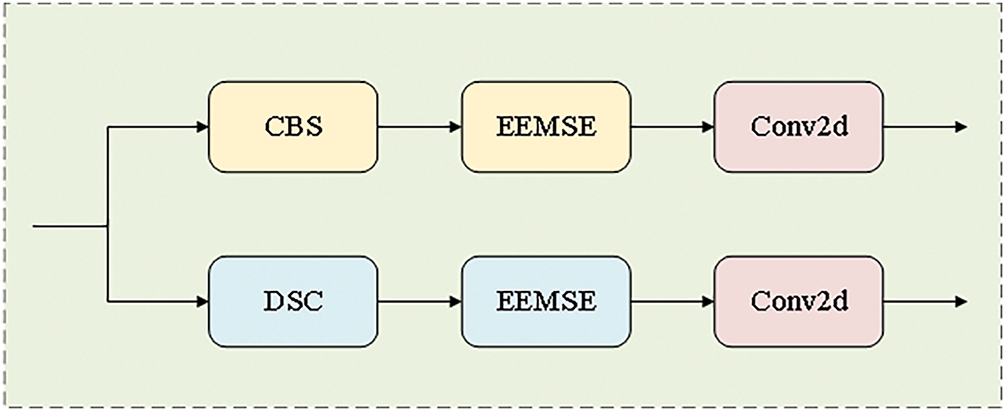
Figure 11: Structure of detect edge enhancer SE (Replace the original CBS and DSC modules with the self-designed module EEMSE)
In the improved Detect Edge Enhancer SE, the EEMSE module can further enhance and extract edge contour information from the image of small steel defects and improve the feature expression ability. Moreover, Detect Edge Enhancer SE has fewer parameters than the original detection head does, which means that we can obtain effective defect detection results with higher inference speed.
To verify the effectiveness of the MSEEM and EEMSE module designed for model improvement, we selected various versions of Hyper-YOLO [28], YOLOv10 [29], and YOLOv8 [30], in addition to YOLOv11, for ablation comparison experiments. The datasets used in the experiments are all NEU-DET datasets. Experiments show that our improvement has a positive effect on the detection task.
The dataset selected for the experiment is the steel defect detection dataset NEU-DET, which originates from Northeastern University. It covers six common types of steel surface defects: crazing, pitted surfaces, inclusions, scratches, patches, and rolled-in scales [31]. The dataset comprises a total of 1800 defect images. Each image is annotated with one or multiple defect label instances. In total, the dataset includes 689 instances of crazing, 432 of pitted surface, 1011 of inclusion, 548 of scratches, 881 of patches, and 628 of rolled-in scale. All images have a uniform spatial resolution of 200 × 200 pixels. A sample image is shown in Fig. 12. The image data are all grayscale images. The figure shows that the defect image data are similar to the background in colour and texture, and some defects have certain similarities and are usually difficult for the human eye to distinguish intuitively. In addition, such defects usually occupy only a small space on the surface of the steel and are affected by the testing environment, such as the lighting, making them difficult to detect during the actual process. Currently, the NEU-DET dataset has become a widely used benchmark dataset. In the experiment, we divided the training set, the validation set and the test set at a ratio of 8:1:1.

Figure 12: Image of steel surface defects
The programming language used in this experiment was Python 3.8. The experimental environment configuration used CUDA 11.8, and an RTX 4090 GPU was used for accelerated computing. To ensure the fairness of the results, all subsequent experiments were conducted in this environment. In the training phase, we standardized the parameters to ensure efficient training and performance optimization of the model. The number of training iterations used in the experiment was 300, and the batch size was 16.
4.3 Experimental Evaluation Indicators
To effectively evaluate the impact of the improved design on model performance, we comprehensively considered the detection performance and model complexity and then selected six mainstream evaluation indicators to measure the improvement effect.
The indicators used to measure model performance include precision, recall, and mean average precision (mAP). The precision reflects the proportion of samples predicted by the model to be positive and the samples that are actually positive. Recall is used to provide feedback on the model’s ability to correctly predict positive samples. The mAP can measure the average detection performance of the model for all categories at different confidence thresholds. According to different IoU threshold ranges, the mAP can be further subdivided into two types: mAP@0.5 and mAP@0.5:0.95. The former represents only the mAP value when the IoU threshold is 0.5, whereas the latter reflects the average mAP calculated between the IoU thresholds of 0.5 and 0.95, which is relatively more comprehensive. The indicators used to measure the complexity of the model are parameters and GFLOPs. The parameters represent the sum of the trainable parameters in the model, whereas the GFLOPs represent the number of floating-point operations performed by the model during the inference process. They effectively reflect the overall computational complexity and resource consumption of the model.
To ensure the effectiveness of the improved model, we added the MSEEM and EEMSE modules to YOLOv8n/s/m, YOLOv11n/s/m, and YOLOv11n/s/m and added the MSEEM to Hyper-YOLO to verify their effectiveness. Through the ablation experiment in this part, we verified the effectiveness of the MSEEM and EEMSE module. The experimental results are shown in Table 1.
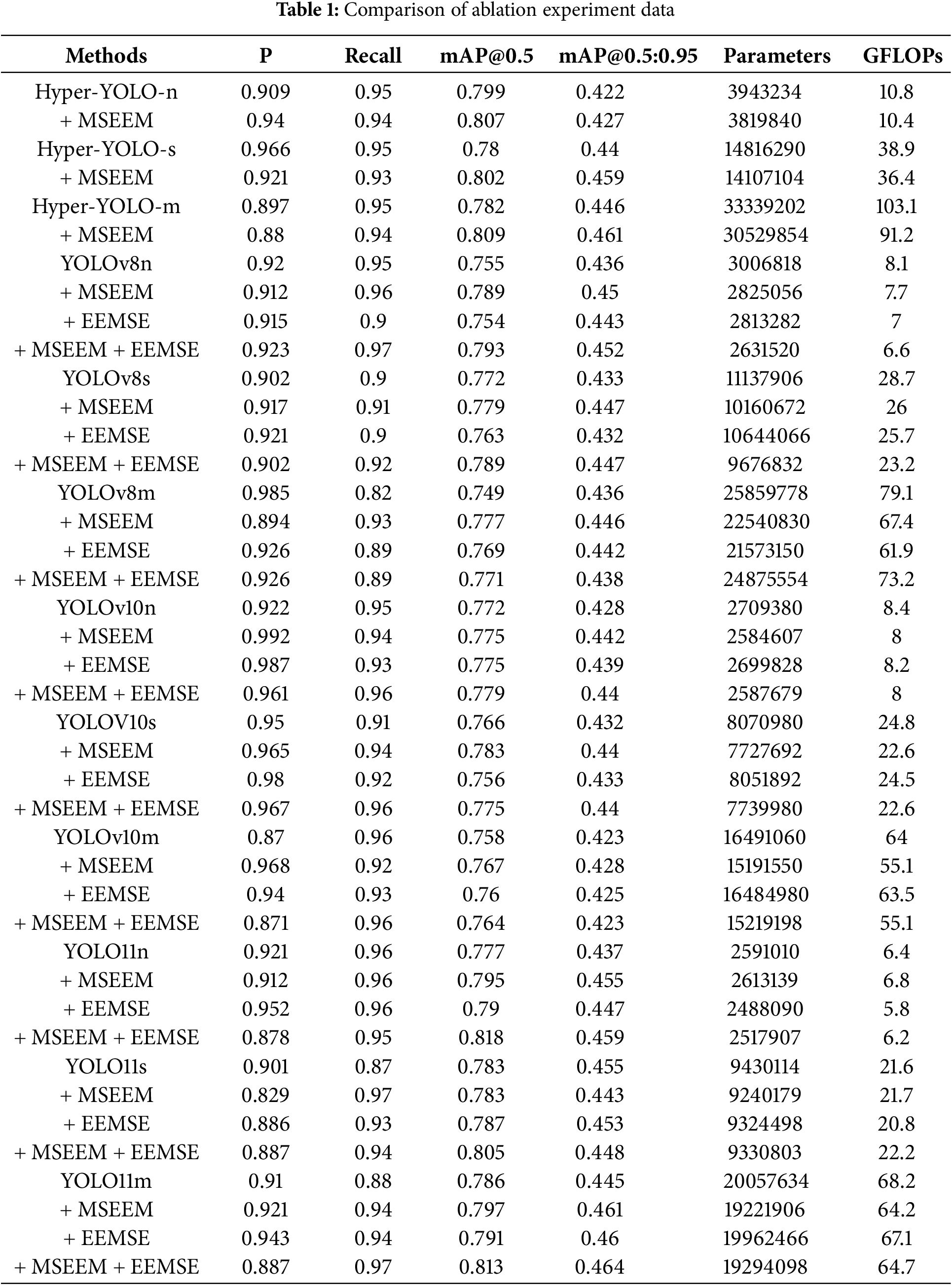
First, the MSEEM enhances the high-frequency information and suppresses the low-frequency information of the feature image at different scales so that the original feature image obtains more significant defect edge feature information. By adding the MSEEM to the model, except for YOLOV11s, whose mAP@0.5 result remains unchanged before and after the improvement and whose mAP@0.5:0.95 decreases by 1.2%, the other algorithms all achieve increases in mAP@0.5 and mAP@0.5:0.95 after the MSEEM is introduced, especially YOLOv8n, whose mAP@0.5 increases by 3.4% after the use of the MSEEM, and whose mAP@0.5:0.95 increases by 1.4%. This shows that the MSEEM is effective in improving detection accuracy.
Second, the EEMSE module incorporates the SE attention mechanism based on the EEM, which enables EEMSE to further adjust the feature information according to the channel importance after enhancing the edge information of the defect feature and improves the feature expression ability. Moreover, the EEMSE module has fewer parameters and is more friendly in terms of computing speed. By introducing the EEMSE module into the algorithm, YOLOv11n/s/m, YOLOv10 n/s/m, and YOLPOv8 n/s/m achieve a reduction in the number of parameters while ensuring detection accuracy, and the GFLOPs value is lower. In particular, the GFLOPs value of YOLOv8m decreased by 17.2 after the EEMSE module was used, whereas its mAP@0.5 and mAP@0.5:0.95 did not decrease but increased by 2% and 0.6%, respectively, indicating that EEMSE has the advantage of being lighter while improving model accuracy.
Overall, when both the MSEEM and EEMSE module are available, compared with the initial algorithms, the other algorithms achieve different degrees of improvement in mAP@0.5 and mAP@0.5:0.95, except for YOLOv11s, which has a slight decrease in mAP@0.5:0.95 of 0.7% after two modules are introduced at the same time, and the number of parameters of all the algorithms is effectively reduced. This means that the overall performance of the trained model at different IoU thresholds is enhanced and that greater computational efficiency is achieved. This design can achieve better detection effects with less computational effort.
To verify that the improved MSESE network based on the MSEEM and EEMSE module has certain advantages in detection, we select a variety of mainstream detection network models for comparative experiments, and the experimental results are shown in Table 2. The data in the table indicate that the mAP@0.5 values of the current mainstream models are all below 80%, but when the MSESE network is used to improve YOLOv11n/s/m, the mAP of the final model reaches 81.8%, 80.5% and 81.3%, which is a significant improvement. The mAP value of 0.5:0.95 is also better than that of most models, and the detection speed is better. The optimal detection model can be obtained by using the MSESE network on the basis of YOLOv11n, and the precision of the model is 87.8%, the recall is 95%, the mAP@0.5 is 81.8%, the mAP@0.5:0.95 is 45.9%, and the GFLOPs value is only 6.2. The comparison shows that although the model is slightly inferior to the other models in terms of precision and recall, it obtains the optimal mAP@0.5 value while having fewer parameters and higher inference speed, indicating significant advantages. Compared with the current popular models Mamba-YOLOT and RTDETR-R34, the mAP@0.5 of MSESE is increased by 6.5% and 8.9%, respectively, whereas the number of parameters of MSESE is only approximately 42% of that of Mamba-YOLOT and only 8% of that of RTDETR-R34, and the corresponding GFLOPs values are reduced by 7 and 82.6, respectively. The results show that our MSESE network can achieve excellent detection results with less computational overhead during the detection process and has a clear advantage over similar network models.
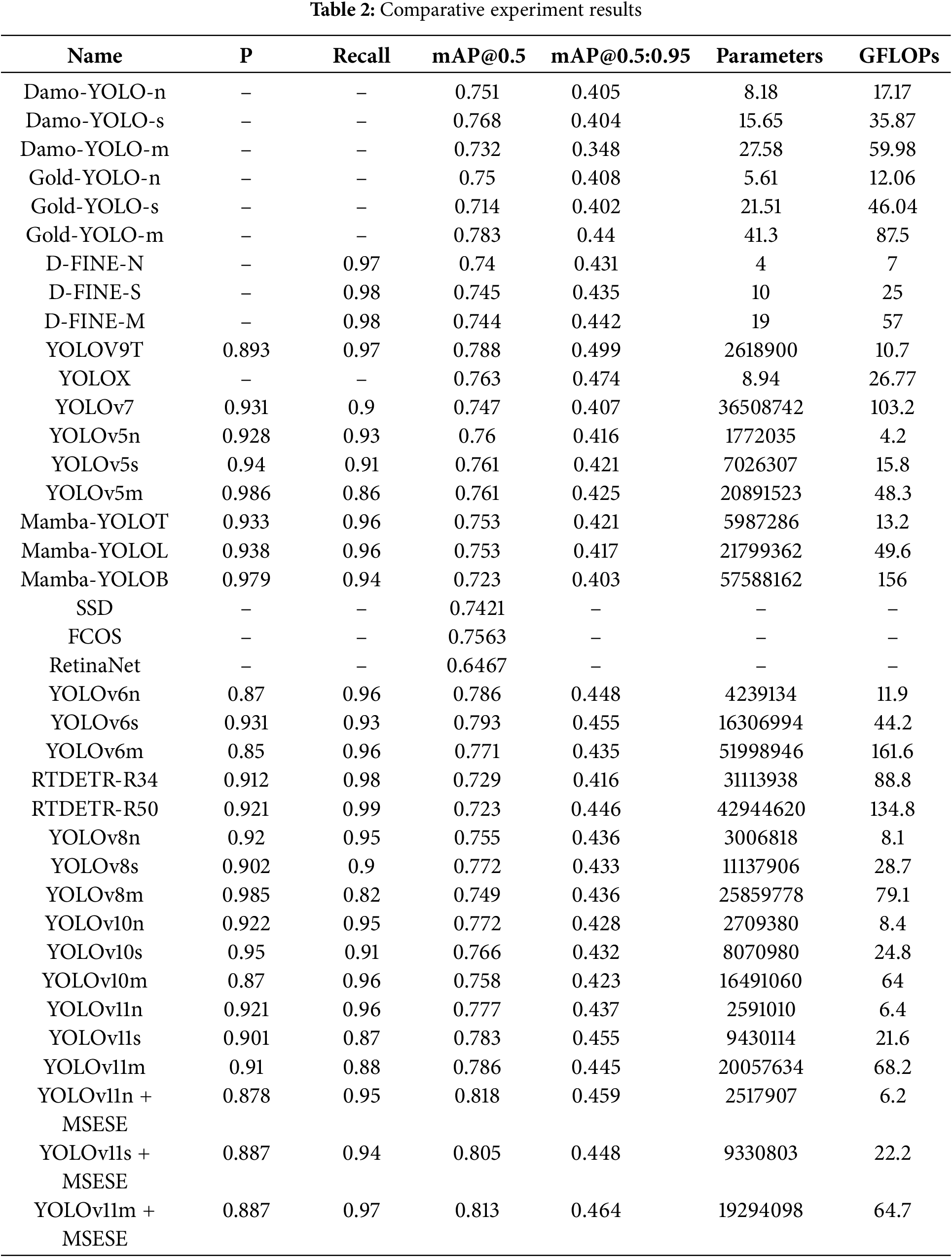
To intuitively present the effects of the MSEEM and EEMSE module, on the basis of the training results of the YOLOv11n/s/m detection model before and after improvement in the actual training process, we plotted the fluctuations in the mAP values before and after model improvement with increasing number of training iterations, as shown in Fig. 13. The lighter lines represent the training changes of the original model, whereas the darker lines correspond to the training process of the improved model. As shown in the figure, the mAP values of each model in the early stage fluctuated with increasing number of training iterations, whereas the improved model was more stable than it was before the improvement. When the number of epochs in the training process reaches 200, the fluctuation in the mAP value of the model begins to stabilize. At this time, the model using the MSESE network is significantly better than the original model. Finally, the mAP value of the improved model is significantly greater than that before the improvement in the steady state, which also confirms that our improvement has a good effect on the improvement in model detection performance.
Figure 13: Epoch-mAP diagram
To evaluate the generalization capability of the MSESE, we conducted generalization validation on the Severstal dataset, which covers four common types of steel surface defects. The dataset comprises a total of 6666 images, each with a resolution of 800 × 128 pixels. The dataset was partitioned into training, validation, and test sets at an 8:1:1 ratio. All experiments were performed under identical environments as described in Section 4.2. The results are presented in Table 3.

By using YOLOv11n-MSESE for training on the Severstal dataset, we observe that the improved model demonstrates measurable improvements across all evaluation metrics compared to the baseline YOLOv11n. The experimental results indicate that MSESE exhibits robust generalization capability, enabling more efficient and accurate defect detection.
4.7 Module Improvements Validated across Multiple Algorithms
To further compare the improvement effects of the MSESE network applied to different versions of YOLO, we add it to several types of current popular algorithms for detailed comparison, and the experimental results are shown in Table 4. Since the MSEEM can combine feature images with edge enhancement at different scales to achieve effective extraction and positioning of target edge contours, EEMSE can reduce the number of calculation parameters while enhancing edge contour information. Therefore, when the MSESE network is used to improve the n, s, and m models of YOLOv11, YOLOv10, and YOLOv8, the remaining algorithms achieve varying degrees of improvement in mAP@0.5 and mAP@0.5:0.95, except for YOLOv11s, which has a slight decrease in mAP@0.5:0.95 of 0.7% after the two modules are introduced at the same time, and the number of parameters of all algorithms is effectively reduced. The experiments show that our improvements can achieve better detection effects with less computational effort.
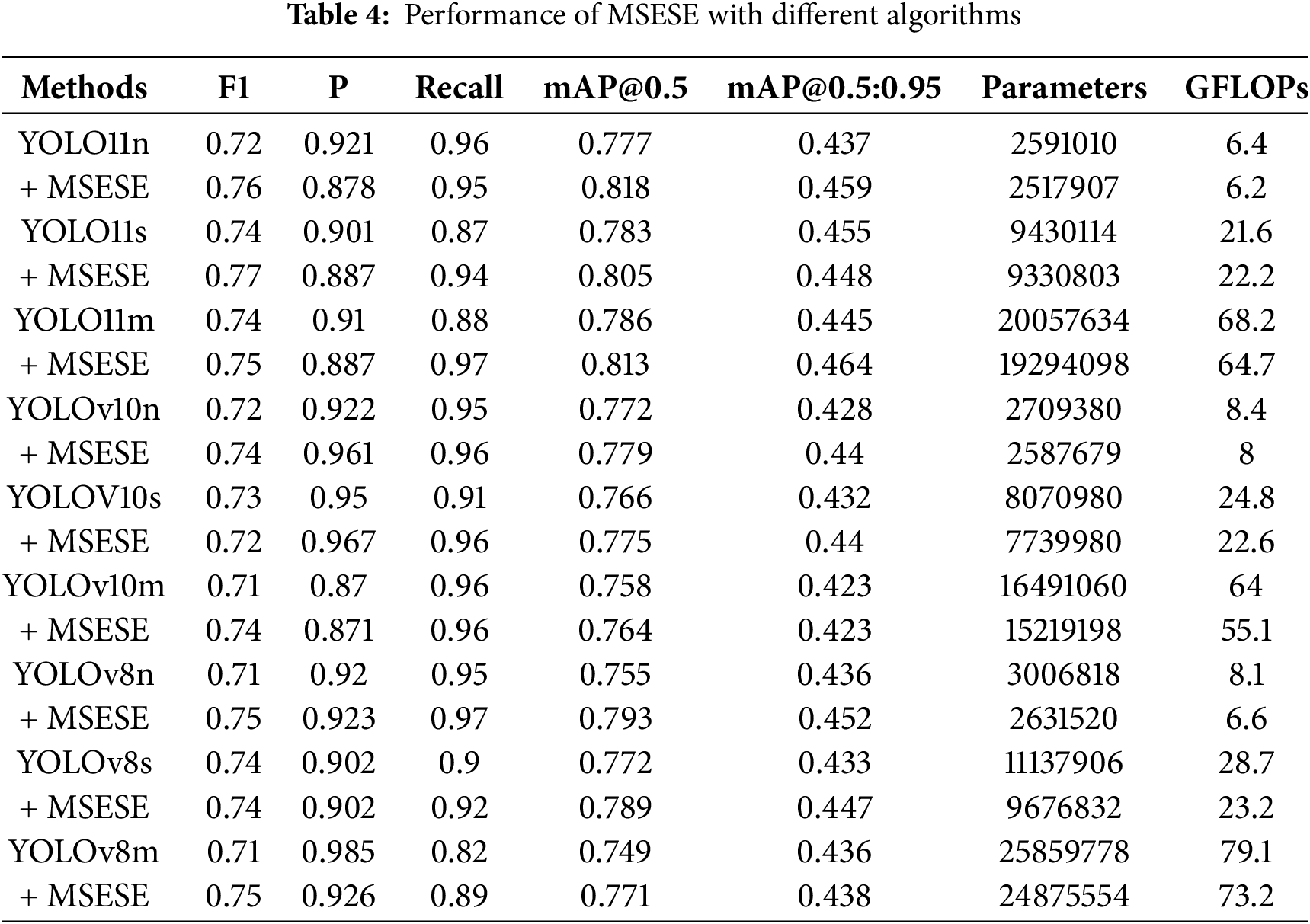
4.8 Analysis of the Experimental Results
Section 3 shows that the MSEEM can enhance high-frequency edge information, suppress low-frequency information, and combine multiscale images to enhance the contours of steel surface defects. The EEMSE module can enhance the edge information of feature images with fewer parameters. Therefore, the improved MSESE network can excellently complete the defect detection task at a higher speed.
To intuitively demonstrate the performance improvements brought by MSEEM and EEMSE, we conducted a visual analysis of defect detection results before and after integrating each module, as shown in Fig. 14. The results clearly show that both modules contribute to enhancing the detection performance. The detection of crazing defects is challenging. In our evaluation, the input image contained two instances of this defect; however, the original model successfully identified only one while missing the other. The integration of MSEEM enabled the model to identify this previously overlooked defect. Through the combined effect of EEMSE, the final improved model achieved complete detection of both defect instances with higher accuracy than the baseline.

Figure 14: Detection results with and without the MSEEM and EEMSE modules
We selected the detection results of YOLOv11n/s/m before and after improvement, as well as the original YOLOv8n and YOLOv10n for the same defect for comparison. The detection results of these models are shown in Fig. 15. As shown in the figure, among the crazing defects, YOLOv8n, YOLOv10n, and the unimproved YOLOv11s and YOLOv11m all miss detections, whereas the model using the MSESE network effectively identify each defect. In the detection of pitted surfaces, inclusions, and scratches, all the models can detect the target completely, but the improved models often have better detection accuracy. In addition, when both patches and inclusion defects appear in the image, YOLOv11n and YOLOv11s can detect only patch defects but miss inclusion defects. When MSESE is used to improve YOLOv11n and YOLOv11s, both types of defects can be effectively identified. For rolled-in scale defects, YOLOv11s does not provide any feedback, but the improved model can effectively locate defects with higher accuracy. This effect occurs because the EEM can initially enhance the target edge contour information, whereas the MSEEM further processes the enhanced edge feature information at different scales, enabling the model to obtain richer defect edge contour information, thereby accurately locating and effectively identifying defects.

Figure 15: Comparison of the detection effects of each model
Heatmaps can usually intuitively reflect the model’s attention to different areas in the detection image. The warm highlighted areas are the areas that the model focuses on, whereas the cold areas, such as the blue part in the figure, indicate that the model pays less attention to this area. Fig. 16 shows the heatmap of the detection effect of the model before and after improvement on the same type of steel defects. As shown in the figure, under the action of the MSEEM, the model focuses on the edge information of the defects in the image. The highlighted part of the figure reflects the location and edge information of the defects.

Figure 16: Comparison of the heatmap effects of various defect detection methods before and after improvement
Observation of the original image data in the dataset reveals that for different categories of defects, there are certain similarities. For example, the crazing and rolled-in scale defects are very similar. For steels with the same type of defect, the defects themselves may be quite different; for example, scratches are not fixed in any direction [32]. Therefore, to further judge the ability of the improved MSESE network to detect various defects, we select more mainstream models to compare the detection results for various defects with the detection results of the MSESE network. The comparison results are shown in Fig. 17. As shown in the figure, the MSESE network is slightly inferior to YOLOv6n and YOLOv11n in terms of patches. For pitted surfaces, inclusions, and scratches, the detection effect of MSESE is comparable to that of YOLOv6n, but MSESE is still significantly better than the other models are. In the detection of the other two types of defects, MSESE achieves the best detection effect. Even though some defects have certain similarities in steel surface defect detection, which makes detection difficult, MSESE still stably achieves better detection results, which also confirms that our improvements have indeed improved the ability to detect small defects on steel surfaces.
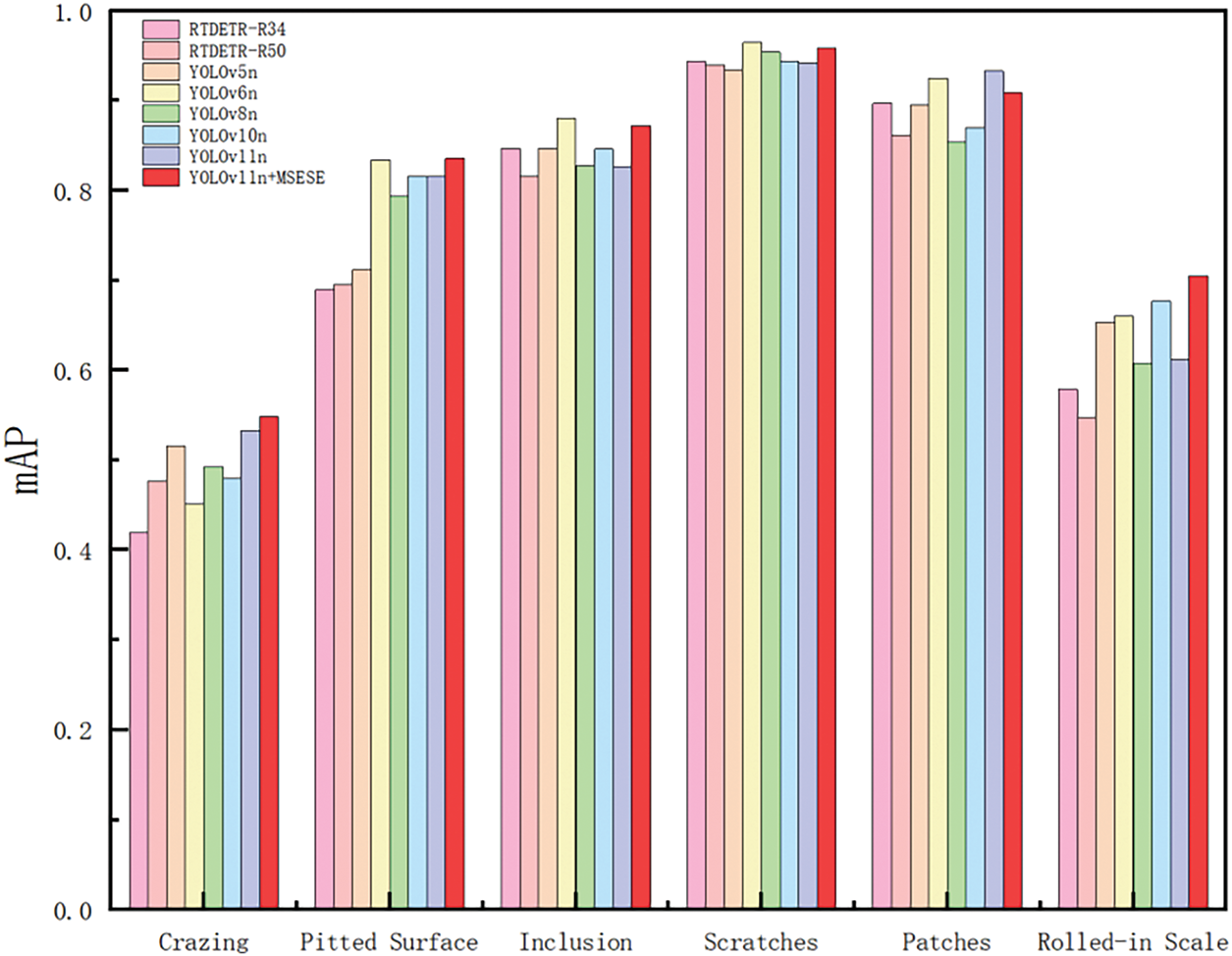
Figure 17: The detection effect of different models for each type of defect
To better present the impact of the MSESE network on detection efficiency, we further plot the relationship between model accuracy and inference speed for comparison, as shown in Fig. 18. When the node is farther from the X axis and closer to the Y axis, the model has a greater detection effect and better inference speed, and the model performance is better. The figure shows that each node of the improved model is located above the node before improvement, which means that the improvement operation makes the model more reliable. In particular, the YOLOv11 model shows the highest accuracy after the MSESE network is used. This is due mainly to our MSEEM module, which enables the model to pay more attention to the edge information of the defect target, thereby achieving accurate positioning of the defect. For the same model, its reasoning speed improved after the improvement. There is a significant gap between the reasoning speeds of YOLOv8 and YOLOv10 before and after the MSESE network is used. The reasoning speed of the model using the MSESE network is significantly better than that of the original model. Our EEMSE module has the advantage of higher detection speed because of its smaller number of parameters. The comparison proves that the MSEEM and EEMSE module we designed and the MSESE network they constitute can effectively reduce the inference time while having better detection effects, which is more in line with the balance in model accuracy and computing speed required in actual detection.
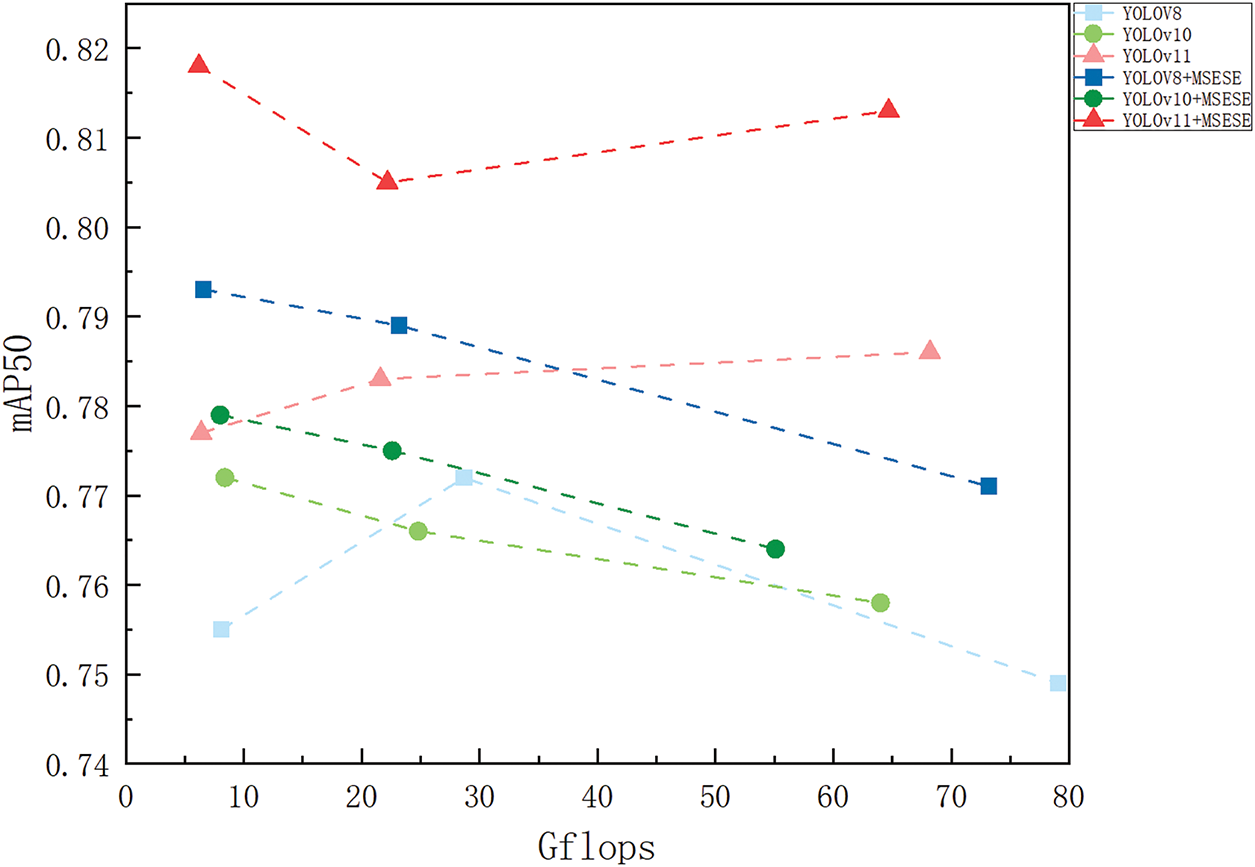
Figure 18: Relationship between model accuracy and inference speed (Each point from left to right represents the n/s/m version of the current model)
To address the detection difficulties caused by the small proportion of defects on the steel surface and the similarities between defects, this paper first proposes a multiscale edge enhancement module, the MSEEM, to learn and enhance the contour features of the defect edges from different scales. The module can be added to the network adaptively to enhance the expressive ability of feature images without changing the output size. Subsequently, we propose an EEMSE module combined with an attention mechanism, and the module is adaptively added to the detection head part of YOLOv11 for improvement. This design allows the model to enhance the edge contour of the defect while paying more attention to the important information in this part to improve the detection effect. At the same time, by employing this module to refine the detection head architecture, we effectively reduce parameter count while achieving better detection accuracy at significantly accelerated speeds. On the basis of YOLOv11, we use the MSEEM and EEMSE module to improve the network as a whole and then propose the EEMSE network. Experiments show that this improvement can enhance the performance of the model at different IoU thresholds and reduce the computational cost. The improved model can obtain excellent detection results with less calculation time, so it can better balance the detection accuracy and real-time performance required in practical applications.
In addition, our improved MSESE network can improve the ability to detect various defects, but for crazing defects, the detection performance of all networks is generally not as good as that for other defects. However, for the detection of defects such as patches, our improved model has not yet stood out among other models. We will pay more attention to this aspect and continue to improve it in the future.
Acknowledgement: Thank you to our researchers for their collaboration and technical assistance.
Funding Statement: This research was funded by Ministry of Education Humanities and Social Science Research Project, grant number 23YJAZH034, The Postgraduate Research and Practice Innovation Program of Jiangsu Province, grant number SJCX25_17 and National Computer Basic Education Research Project in Higher Education Institutions, grant number 2024-AFCEC-056, 2024-AFCEC-057.
Author Contributions: Conceptualization, Yuanyuan Wang, Yemeng Zhu and Xiuchuan Chen; methodology, Yuanyuan Wang, Yemeng Zhu and Xiuchuan Chen; software, Yuanyuan Wang, Yemeng Zhu and Xiuchuan Chen; validation, Yuanyuan Wang, Yemeng Zhu and Xiuchuan Chen; formal analysis, Tongtong Yin; investigation, Shiwei Su; resources, Yuanyuan Wang; data curation, Shiwei Su and Tongtong Yin; writing—original draft preparation, Yuanyuan Wang, Yemeng Zhu and Xiuchuan Chen; writing—review and editing, Yuanyuan Wang, Yemeng Zhu, Xiuchuan Chen, Shiwei Su and Tongtong Yin; visualization, Yemeng Zhu; supervision, Yuanyuan Wang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in Github at https://github.com/YM-Zhu/MSESE (accessed on 01 August 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Wen X, Shan J, He Y, Song K. Steel surface defect recognition: a survey. Coatings. 2023;13(1):17. doi:10.3390/coatings13010017. [Google Scholar] [CrossRef]
2. Li L. The UAV intelligent inspection of transmission lines. In: Proceedings of the 2015 International Conference on Advances in Mechanical Engineering and Industrial Informatics; 2025 Apr 11–12; Zhengzhou, China. p. 1542–5. [Google Scholar]
3. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39(6):1137–49. doi:10.1109/TPAMI.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
4. He K, Gkioxari G, Dollár P, Girshick R. Mask R-CNN. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV); 2017 Oct 22–29; Venice, Italy. p. 2980–8. doi:10.1109/ICCV.2017.322. [Google Scholar] [CrossRef]
5. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: single shot MultiBox detector. In: Proceedings of the Computer Vision—ECCV 2016: 14th European Conference; 2016 Oct 11–14; Amsterdam, The Netherlands. p. 21–37. doi:10.1007/978-3-319-46448-0_2. [Google Scholar] [CrossRef]
6. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. p. 779–88. doi:10.1109/CVPR.2016.91. [Google Scholar] [CrossRef]
7. Wang CC, Gao SB, Cai CX, Chen HL. Vehicle-road visual cooperative driving safety early warning algorithm for expressway scenes. J Image Graph. 2022;27(10):3058–67. (In Chinese). doi:10.11834/jig.210290. [Google Scholar] [CrossRef]
8. Liu J, Zhang Z, Kawsar Alam MD, Cai Q, Xia C, Tang Y. FDFNet: an efficient detection network for small-size surface defect based on feature differentiated fusion. Digit Signal Process. 2025;167(5):105432. doi:10.1016/j.dsp.2025.105432. [Google Scholar] [CrossRef]
9. Zhu CJ, Liu LL, Zhu HB. Surface defect detection algorithm for strip steel based on YOLOv8-NFMC. Foreign Electron Meas Technol. 2024;43(7):97–104. [Google Scholar]
10. Hu J, Shen L, Albanie S, Sun G, Wu E. Squeeze-and-excitation networks. IEEE Trans Pattern Anal Mach Intell. 2020;42(8):2011–23. doi:10.1109/TPAMI.2019.2913372. [Google Scholar] [PubMed] [CrossRef]
11. Fu G, Sun P, Zhu W, Yang J, Cao Y, Yang MY, et al. A deep-learning-based approach for fast and robust steel surface defects classification. Opt Lasers Eng. 2019;121:397–405. doi:10.1016/j.optlaseng.2019.05.005. [Google Scholar] [CrossRef]
12. He D, Xu K, Zhou P. Defect detection of hot rolled steels with a new object detection framework called classification priority network. Comput Ind Eng. 2019;128:290–7. doi:10.1016/j.cie.2018.12.043. [Google Scholar] [CrossRef]
13. Yin T, Yang J. Detection of steel surface defect based on faster R-CNN and FPN. In: Proceedings of the 7th International Conference on Computing and Artificial Intelligence; 2021 Apr 23–26; Tianjin, China. p. 15–20. doi:10.1145/3467707.3467710. [Google Scholar] [CrossRef]
14. Yan X, Yang Y, Tu N. Steel surface defect detection based on improved SSD. Mod Manuf Eng. 2023;5:112–20. (In Chinese). [Google Scholar]
15. Siddiqui MY, Ahn H. Faster metallic surface defect detection using deep learning with channel shuffling. Comput Mater Contin. 2023;75(1):1847–61. doi:10.32604/cmc.2023.035698. [Google Scholar] [CrossRef]
16. Zhang T, Pang H, Jiang C. GDM-YOLO: a model for steel surface defect detection based on YOLOv8s. IEEE Access. 2024;12:148817–25. doi:10.1109/ACCESS.2024.3476908. [Google Scholar] [CrossRef]
17. Wang WJ, Zhang Y, Wang JH, Xu Y. Lightweight steel surface defect detection algorithm based on improved RetinaNet. Pattern Recognit Artif Intell. 2024;37(8):692–702. (In Chinese). doi:10.16451/j.cnki.issn1003-6059.202408003. [Google Scholar] [CrossRef]
18. Dong X, Li Y, Fu L, Liu J. Edge-aware interactive refinement network for strip steel surface defects detection. Meas Sci Technol. 2025;36(1):016222. doi:10.1088/1361-6501/ad9856. [Google Scholar] [CrossRef]
19. Shen BX, Huang HQ. Research on surface defect detection of steel strip based on ESE-YOLO. J Electron Meas Instrum. 2025;1–12. (In Chinese). [Google Scholar]
20. Hu K, Shen C, Wang T, Xu K, Xia Q, Xia M, et al. Overview of temporal action detection based on deep learning. Artif Intell Rev. 2024;57(2):26. doi:10.1007/s10462-023-10650-w. [Google Scholar] [CrossRef]
21. Hu K, Zhang E, Xia M, Wang H, Ye X, Lin H. Cross-dimensional feature attention aggregation network for cloud and snow recognition of high satellite images. Neural Comput Appl. 2024;36(14):7779–98. doi:10.1007/s00521-024-09477-5. [Google Scholar] [CrossRef]
22. Cui Y, Ren W, Cao X, Knoll A. Focal network for image restoration. In: Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV); 2023 Oct 1–6; Paris, France. p. 12955–65. doi:10.1109/ICCV51070.2023.01195. [Google Scholar] [CrossRef]
23. Li SF, Gao SB, Zhang YY. Pose-guided instance-aware learning for driver distraction recognition. J Image Graph. 2023;28(11):3550–61. (In Chinese). [Google Scholar]
24. Chen L, Gu L, Zheng D, Fu Y. Frequency-adaptive dilated convolution for semantic segmentation. In: Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 16–22; Seattle, WA, USA. p. 3414–25. doi:10.1109/CVPR52733.2024.00328. [Google Scholar] [CrossRef]
25. Woo S, Park J, Lee JY, Kweon IS. CBAM: convolutional block attention module. In: Computer Vision—ECCV 2018. Cham, Switzerland: Springer; 2018. p. 3–19. doi:10.1007/978-3-030-01234-2_1. [Google Scholar] [CrossRef]
26. Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q. ECA-Net: efficient channel attention for deep convolutional neural networks. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 11531–9. doi:10.1109/cvpr42600.2020.01155. [Google Scholar] [CrossRef]
27. Li B, Li SL. Improved YOLOv11n small object detection algorithm in UAV view. Comput Eng Appl. 2025;61(7):96–104. (In Chinese). [Google Scholar]
28. Feng Y, Huang J, Du S, Ying S, Yong JH, Li Y, et al. Hyper-YOLO: when visual object detection meets hypergraph computation. IEEE Trans Pattern Anal Mach Intell. 2025;47(4):2388–401. doi:10.1109/TPAMI.2024.3524377. [Google Scholar] [PubMed] [CrossRef]
29. Wang A, Chen H, Liu L, Chen K, Lin Z, Han J, et al. YOLOv10: real-time end-to-end object detection. arXiv:2405.14458. 2024. [Google Scholar]
30. Terven J, Córdova-Esparza DM, Romero-González JA. A comprehensive review of YOLO architectures in computer vision: from YOLOv1 to YOLOv8 and YOLO-NAS. Mach Learn Knowl Extr. 2023;5(4):1680–716. doi:10.3390/make5040083. [Google Scholar] [CrossRef]
31. He Y, Song K, Meng Q, Yan Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans Instrum Meas. 2020;69(4):1493–504. doi:10.1109/TIM.2019.2915404. [Google Scholar] [CrossRef]
32. Song K, Yan Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl Surf Sci. 2013;285:858–64. doi:10.1016/j.apsusc.2013.09.002. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools