
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
VitSeg-Det & TransTra-Count: Networks for Robust Crack Detection and Measurement in Dynamic Video Scenes
1 College of Computer Science, Weinan Normal University, Weinan, 714000, China
2 College of Electronic and Information Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing, 210000, China
3 College of Information Engineering, Yangzhou University, Yangzhou, 225127, China
* Corresponding Authors: Yubin Yuan. Email: ; Yiquan Wu. Email:
Computers, Materials & Continua 2026, 87(1), 82 https://doi.org/10.32604/cmc.2025.070563
Received 18 July 2025; Accepted 22 October 2025; Issue published 10 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Regular detection of pavement cracks is essential for infrastructure maintenance. However, existing methods often ignore the challenges such as the continuous evolution of crack features between video frames and the difficulty of defect quantification. To this end, this paper proposes an integrated framework for pavement crack detection, segmentation, tracking and counting based on Transformer. Firstly, we design the VitSeg-Det network, which is an integrated detection and segmentation network that can accurately locate and segment tiny cracks in complex scenes. Second, the TransTra-Count system is developed to automatically count the number of defects by combining defect tracking with width estimation. Finally, we conduct experimental verification on three datasets. The results show that the proposed method is superior to the existing deep learning methods in detection accuracy. In addition, the actual scene video test shows that the framework can accurately label the defect location and output the number of defects in real time.Keywords
Cracks are a critical form of damage in civil engineering and are commonly found in various infrastructures, including bridges, pavements, buildings, dams, and tunnels. These cracks not only impair the functionality of structural components but also pose significant safety hazards, potentially leading to catastrophic consequences. Thus, early crack detection is vital for pavement safety. However, identifying cracks, particularly microcracks, is challenging due to complex backgrounds, uneven illumination, and obstructions. While conventional manual inspection is tedious and error-prone, computer vision advancements now enable automated crack detection.
Current mainstream detection algorithms, such as Faster R-CNN [1], the YOLO series [2], and DETR [3], have achieved efficient localization and classification on single-frame images. However, they still face several limitations: (1) Lack of Dynamic Continuity Modeling: These models process individual frames independently, ignoring the continuous evolution of cracks across video sequences. As a result, the same crack may be repeatedly detected in real world scenarios, leading to duplicate counting or trajectory drift. (2) Inability to Track Crack Identity: Most existing detectors lack an object tracking mechanism, making it difficult to determine whether cracks detected in consecutive frames belong to the same entity. This hinders consistent identity maintenance over time. (3) Unpredictable Object Counts: While detection models can localize objects with bounding boxes, they cannot directly output the total number of defects. In video sequences, defect counting often relies on additional post processing logic, increasing system complexity. (4) Limited Performance on Small Objects: Traditional convolution based detection networks struggle with small or texture blurred cracks due to restricted receptive fields and resolution reduction. (5) Absence of Robust Counting Mechanisms: Most industrial inspection systems either lack integrated counting functionality or rely on heuristic threshold matching rules, missing end-to-end learnable and robust counting solutions.
In practical engineering applications, such as road condition assessment [4], pipeline crack monitoring [5], weld defect inspection [6] and other scenarios, defect detection systems must process continuous video streams rather than performing single frame image analysis. Under such dynamic conditions, defect manifestations across temporal frames are susceptible to multiple interference factors, such as camera perspectives, illumination changes, sensor vibration, or occlusion. Defect morphology may dynamically evolve (e.g., crack propagation/lateral widening), while appearance features may suffer from blurring or distortion. Consequently, static detectors alone are incapable of achieving accurate defect identification and quantification, let alone fulfilling the demands for automated diagnosis and early warning systems in engineering practice.
In view of the above problems, we propose a dynamic crack defect integrated measurement framework based on Transformer from the perspective of visual measurement system design. The framework is structurally integrated with tasks such as detection and segmentation, tracking and counting, and gives consideration to recognition accuracy and quantitative analysis capability. By introducing a fine feature sampling mechanism and cross frame identity matching technology, the system can realize continuous identification and quantitative statistics of cracks in the video stream and has the measurement capability of high automation, strong robustness and low delay. The main contributions of this chapter are as follows:
(1) A multi task integrated visual inspection system for dynamic scenes is proposed, integrating the tasks of detection, segmentation, tracking and counting in the same architecture to achieve continuous recognition, status tracking and quantity statistics of defect objects in the video stream. In view of the significant characteristics of crack like defects in dynamic scenes, mechanisms such as multi scale dilated convolution, channel spatial attention fusion, and dynamic feature sampling are adopted, enabling the system to maintain stable recognition capabilities in complex environments such as dynamics, occlusion, and non-rigid changes.
(2) The integrated network of VitSeg-Det detection and segmentation is designed, and the multi scale feature expression system is built with EfficientNet-b5 as the backbone. The micro scale feature scoring module and macro scale perception module are integrated to achieve high precision positioning and mask generation of microcracks. Among them, the scoring module combines the channel and spatial attention mechanism, selects the high information entropy area through dynamic sampling and inputs it into the Transformer encoder to improve the response ability of the model to fine-grained defects; Macro scale branching uses dilated convolution to model the global topological structure of cracks, which enhances the system’s perception of long range irregular cracks.
(3) The TransTra-Count object tracking and counting module is proposed. Based on the self attention mechanism of Transformer, Spatial Feature Dual Modal Data Association and Long Term Memory Update Trade off Model (CrackDSF-LMe) is constructed to maintain the stable identity of crack objects under occlusion, blurring and illumination disturbance. The system integrates an unsupervised mask skeleton width estimation algorithm, combines a width smoothing mechanism and a change rate constraint, effectively solves the problem of “sudden change of the same crack width”, and realizes dynamic quantitative assessment and robust statistics of crack defect.
(4) A high resolution, sequential and self-built video dataset of cracks, RoadDefect-MT, was constructed, covering a variety of complex scenes such as pavement disease types, occlusion and illumination changes, to comprehensively verify the performance of the system in terms of measurement accuracy, tracking consistency and statistical stability. This dataset fills the gap in the existing public data set that lacks dynamic features and measurement annotation, and provides basic resources and experimental platform support for subsequent crack identification and visual measurement research.
In addition, the system in this paper fully considers the project deployment requirements in the design, supports the operation on edge equipment, and is suitable for industrial measurement scenarios such as road inspection, weld quality assessment, pipeline crack monitoring, and it has good popularization and practical value. This work not only improves the crack detection accuracy, but also improves the “defect recognition” to “quantifiable measurement”, providing a design paradigm for future video intelligent measurement systems.
Recent advances in computer vision have revolutionized infrastructure monitoring, enabling automated, precise measurement for structural health assessment. Key applications include pavement condition evaluation [7], bridge structural analysis [8], and concrete crack detection [9], where vision-based systems now play a pivotal role in operational decision-making. Particularly in metrology, the integration of computer vision with quantitative measurement techniques has emerged as a critical research focus, addressing the fundamental challenge of achieving automated defect identification with parametric precision and repeatability.
2.1 CNN-Based Crack Detection Method
The rise of deep learning has provided new technological pathways for automatic crack detection and measurement [10], particularly within the CNN framework. Through end-to-end training methods, deep learning enables automatic learning of multi-level semantic features, significantly improving detection accuracy and scene adaptability. Research in this field can be broadly categorized into two main types: image segmentation and object detection.
Segmentation Methods. The goal of image segmentation tasks is to achieve pixel-level localization of crack areas. Common approaches include architectures such as FCN [11], DeepLab [12], and U-Net [13]. In the field of crack segmentation, Sun et al. developed a multi-scale attention module based on Deeplabv3+ to guide the decoder in extracting more fine-grained crack edge information [14]. Kang et al. integrated Faster-RCNN with tubular flow field and distance transformation modules to achieve segmentation and parametric measurement under complex backgrounds [15]. Ali and Cha introduced adversarial training mechanisms to alleviate the issue of scarce annotations while enhancing segmentation performance on concrete structures [16]. Kang and Cha designed a semantic transformation network combining multi-head attention mechanisms and compression modules, significantly improving segmentation accuracy and computational efficiency [17].
Detection Methods. Object detection methods focus on rapidly localizing crack targets through bounding box regression and classification models, which can be divided into two stage and single stage detection approaches. Two stage detectors like the R-CNN series algorithms [18] in accuracy, with innovations such as illumination robust Gaussian mixture integration [19] and morphology enhanced bounding box optimization [20]. Meanwhile, single stage models (YOLO, SSD [21]) prioritize speed, with recent improvements including deformable SSD for complex cracks [22], lightweight MobileNet variants [23], and attention-augmented YOLOv3 [24]. Hybrid approaches like YOLO-MF [25] further bridge speed and functionality by incorporating flow based defect counting.
Although CNN-based methods have demonstrated strong capabilities in static image analysis, they still face three major limitations: The restricted receptive field hinders the modeling of long range structural dependencies, thereby limiting the accurate identification of elongated or discontinuous cracks. The inability to maintain interframe consistency complicates the achievement of temporally coherent structural measurements. Detection results often require additional modules for tasks such as object counting, which undermines system integration and operational automation.
2.2 Transformer-Based Crack Detection Method
The Transformer architecture has demonstrated remarkable advantages in recent visual tasks, owing to its global modeling capacity and powerful self attention mechanism. Since the initial application of Vision Transformer (ViT) in image classification, related approaches have rapidly expanded to domains such as semantic segmentation, object detection, and video modeling.
Segmentation Methods. The application of Vision Transformer (ViT) in segmentation tasks primarily revolves around two types of architectures: pure Transformer models (e.g., SETR [26], SegFormer [27]) and hybrid CNN-Transformer models (e.g., Swin-UNet [28]). In the context of crack segmentation: Wang et al.’s efficient depthwise separable convolution (88.08% mIoU with 20% data) [29] and Zhou et al.’s SCDeepLab (inverted residuals + SwinTransformer), which outperforms CNNs [30]. These advances demonstrate transformers’ superiority in accuracy and robustness for crack analysis.
Detection Methods. Transformers have revolutionized crack detection through their self-attention mechanisms, with several key advancements: Swin Transformers [31] enhance noise robustness via window-based attention, Linformer [32] reduces complexity to O(n) using low rank approximations [33], and Crack-DETR [34] combines high/low frequency features for noise resistant detection. Additional innovations include attention fused encoder decoders [34] for improved accuracy and NMS-free contrastive learning [35] for pavement defects. These developments demonstrate Transformers’ superiority in handling complex crack detection scenarios while addressing computational challenges.
The Transformer architecture effectively addresses three critical challenges in crack measurement: global context modeling, cross frame identity consistency, and morphological parameter quantification. Recent advances demonstrate its dual capability in both enhancing structural recognition accuracy and enabling automated measurement of defect characteristics (location, width, evolution trends) through superior sequence modeling. While successful in static image analysis, current Transformer applications largely neglect dynamic video requirements, particularly in modeling temporal patterns and quantifiable metrics like width variation trends and target consistency across frames. This highlights a crucial research gap in developing video oriented Transformer architectures for structural measurement tasks.
This paper proposes an integrated framework for the detection, segmentation, tracking, and counting of pavement crack defects in video sequences. As illustrated in Fig. 1, the system is designed to achieve continuous identification of crack objects across spatial temporal dimensions and automate the quantification of structural parameters. Built upon a Transformer based architecture, the method integrates spatial structure modeling and temporal state maintenance mechanisms to overcome limitations of conventional image level approaches, such as poor cross frame correlation and repeated counting. The system consists of a front end crack perception module and a back end structural measurement module. The former employs a VitSeg-Det network to perform high precision object detection and pixel level mask segmentation, while the latter fuses segmentation results with multi frame features and incorporates a TransTra-Count module to establish object level tracking chains for identity preservation and quantity statistics. Additionally, the system integrates mask skeleton extraction and width estimation algorithms, enabling the extraction of crack geometric parameters without manual annotation. Ultimately, the system can stably output structured measurement results under continuous video input, offering an efficient and reliable vision based solution for intelligent assessment of surface defects in infrastructure.
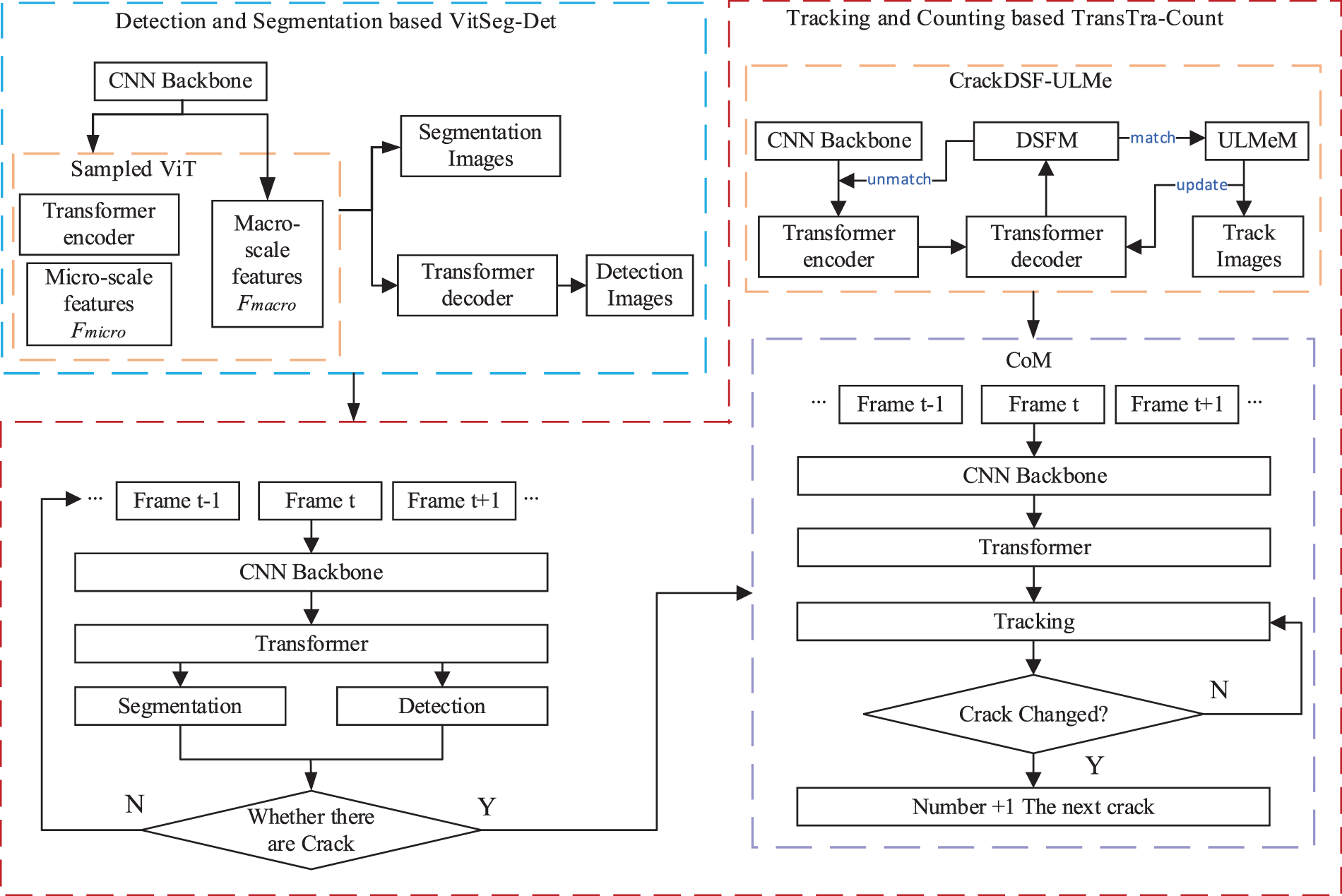
Figure 1: Framework of the Transformer-based detection, segmentation, tracking and counting algorithm
3.1 Detection and Segmentation Model: VitSeg-Det
VitSeg-Det is an integrated visual modeling structure for pavement crack detection and segmentation proposed by us, which aims to achieve high-precision crack area recognition and structural parameter extraction, and provide accurate and detailed input for follow-up tracking and measurement modules. The network takes EfficientNet-b5 as the backbone feature extraction structure, and uses its compound expansion mechanism in width, depth and resolution to achieve efficient multi scale receptive field modeling. On this basis, VitSeg-Det introduces the refined feature refinement module Sampled ViT and the macro scale structure modeling module. The former combines the channel attention and spatial attention mechanisms to build a scoring network, dynamically samples the areas with rich fracture morphology information, and leads the Transformer encoder to capture the changes of fracture details through the lightweight embedding mechanism; the latter uses dilated convolution to expand the receptive field and extract topological continuity and irregular distribution pattern of cracks in the global space. The above two types of features jointly construct the segmentation branch and detection branch through abstract fusion to achieve the unified modeling of pixel level crack mask generation and target box positioning. While maintaining lightweight and deployability, the entire architecture significantly improves the model’s ability to identify tiny cracks, branching structures and defects in complex backgrounds, laying an accurate perceptual foundation for highly robust defect measurement and dynamic structure modeling in video sequences. Its structure is shown in Fig. 2.
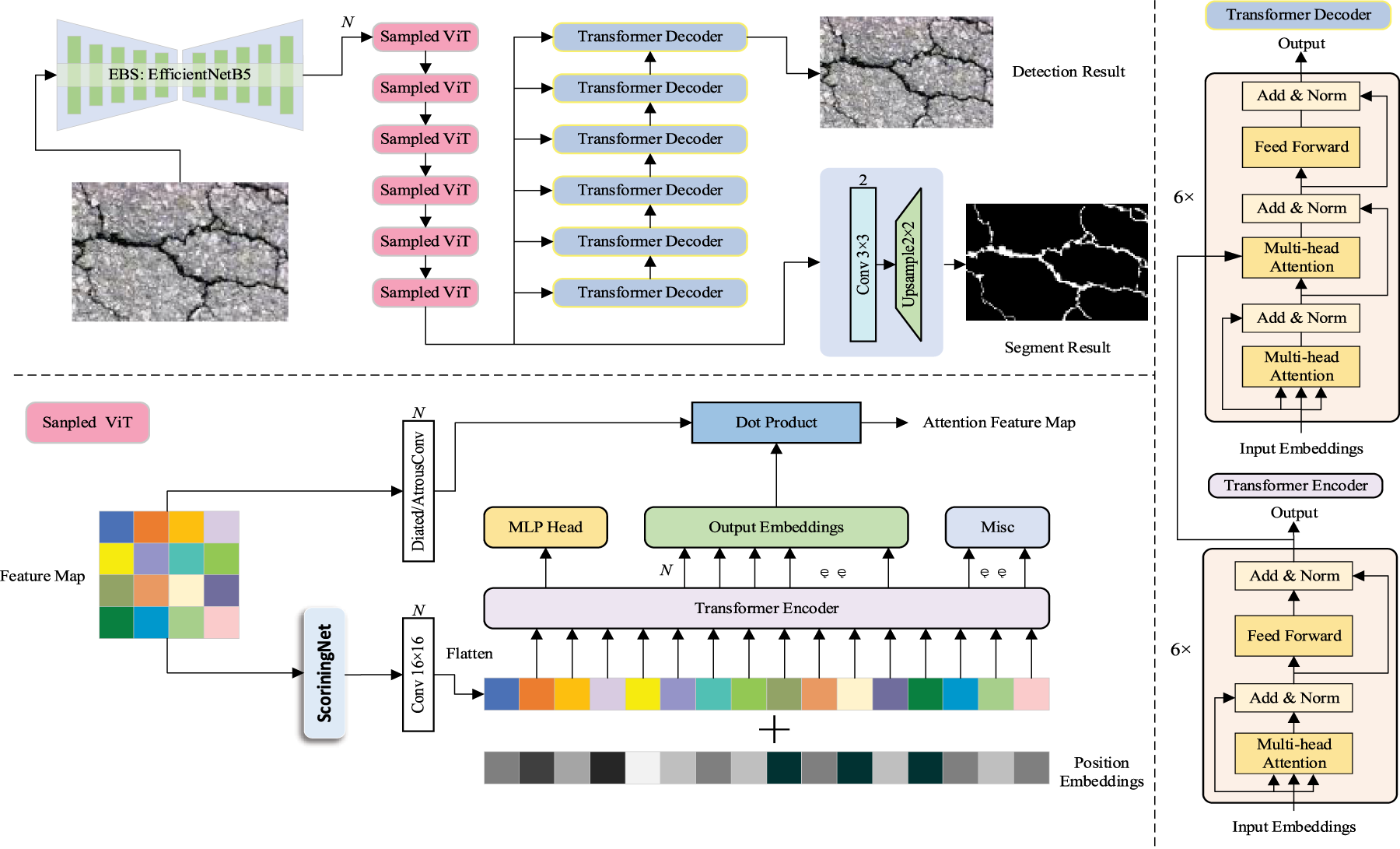
Figure 2: The detailed network of the Transformer-based pavement crack segmentation and detection (VitSeg-Det)
After feature extraction, we abstract feature F into micro scale features
3.1.2 Fine Feature Refinement Module: Sampled-ViT
In VitSeg-Det, there is a Sample-ViT module, which is mainly used to refine features.
The lightweight scoring network adopts the method of combining channel attention and spatial attention, in which the spatial attention part uses the depth separable convolution to further reduce the number of parameters. In specific implementation, channel attention generates channel weight through global average pooling and a full connection layer, while a spatial attention calculates spatial importance score through a deeply separable convolution (first channel by channel 3 × 3 convolution, then a 1 × 1 convolution dimension reduction), and finally multiplies the two to get the fused feature score. While maintaining the sensitivity to the crack area, this design significantly reduces the computational complexity and is more suitable for edge equipment deployment. The information score S of each spatial feature position is:
PE for position embeddings,
Refine feature
Macro scale feature
As shown in Fig. 2, the
The detection network is shown in Fig. 2. After the feature passes through the 6-layer encoder, it is input into the decoder together with the location code and the learned query. The output of each layer of the decoder predicts the type and location of defects, similar to the feature pyramid network.
3.2 Tracking and Counting Model: TransTra-Count
The technology of using traditional CNN based networks to detect defects has become very mature, but when it comes to defect counting, these detection networks can’t distinguish whether defects are detected in the same way, which leads to the problem of multiple counting. Therefore, we have developed a Transformer based defect tracking and counting method, TransTra-Count.
The tracking network is shown in Fig. 3. In this paper, we propose a pavement crack tracking method, CrackDSF-ULMe. The model is based on the DETR. Our core contribution is to establish a data association model that includes the appearance feature similarity and spatial similarity of cracks according to the characteristics of pavement cracks. It can not only deal with the small displacement between consecutive frames but also adapt to the feature fluctuations caused by illumination changes, and can also solve the occlusion and ambiguity problems. In the long term memory update module, we introduce the change of illumination as the control signal to suppress shadow interference, and propose an adaptive aggregation algorithm to fuse the output of two adjacent frames to alleviate the occlusion problem. At the same time, the unsupervised method is used to monitor the crack width according to the segmentation mask, and the width loss will be increased in the loss function to restrict the width change rate, so as to avoid the unreasonable situation that “the same crack has a sudden change in the width of adjacent frames”; The trajectory management module automatically initializes and terminates the trajectory according to the match configuration reliability and historical activity to ensure that the life cycle of each crack ID is consistent with the physical reality. Through the closed-loop process of feature enhancement → detection → association → long-term memory update → track management, the whole system has realized the whole process of structured automatic measurement and output of crack object number, location, size and damage level, as shown in Fig. 4, providing a quantitative basis with space-time continuity for pavement disease diagnosis.
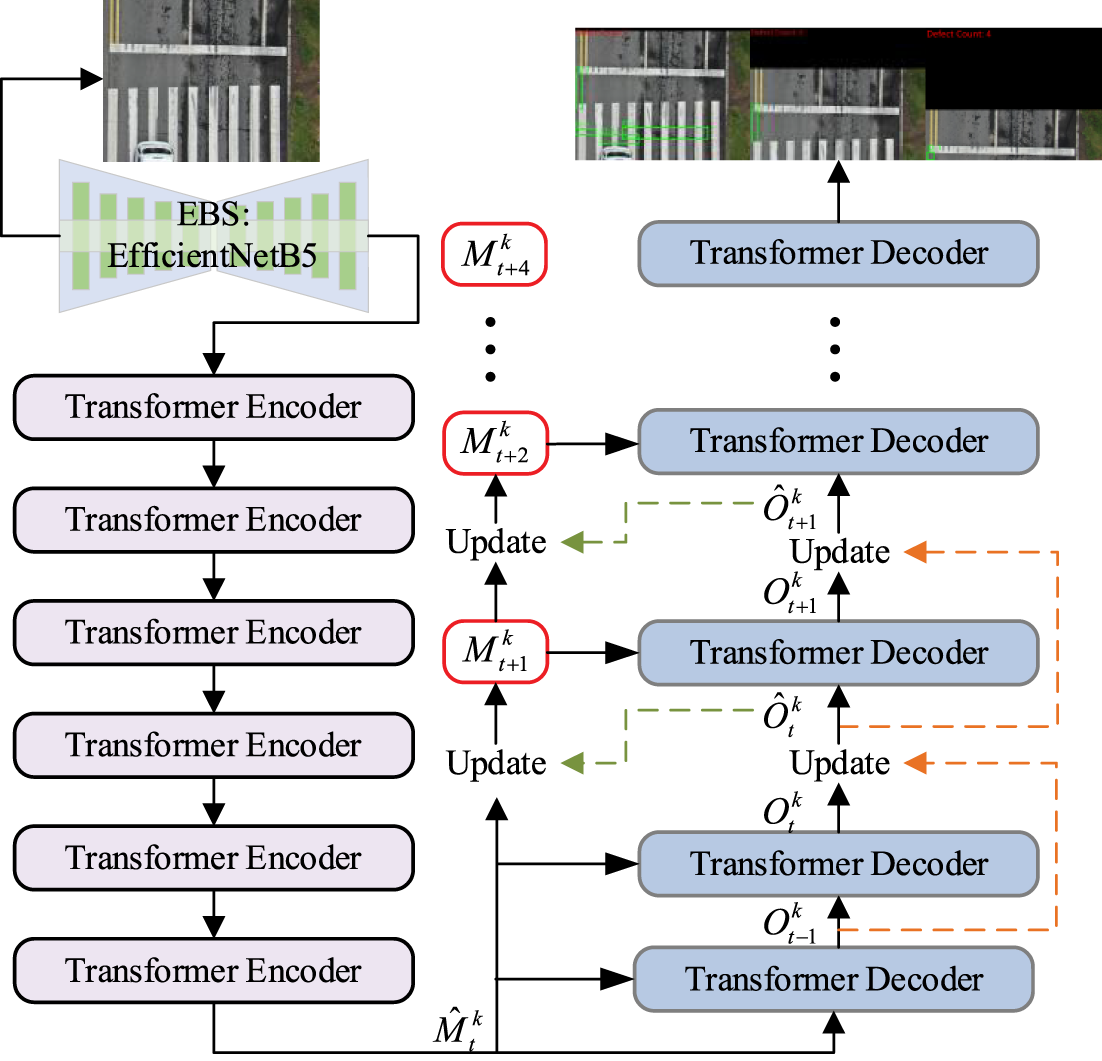
Figure 3: The detailed network of transformer-based spatial-feature dual-modal joint enhancement long-term memory method for pavement crack tracking (CrackDSF-LMe)

Figure 4: The closed-loop flowchart of CrackDSF-LMe
We input the results of VitSeg-Det into the tracking model, because the pavement cracks in the video may have different appearances due to changes in light, rain cover or shooting angles, and the same crack looks like different objects in different frames. Therefore, we use VitSeg-Det to obtain the multi scale characteristics of the cracks, as well as the segmentation mask, to improve the robustness of the network.
3.2.1 Spatial-Feature Dual-Modal Data Association: DSFM
In the data association phase, the algorithm combines spatial IoU measurement and feature similarity calculation based on the attention mechanism, and dynamically balances their contributions through learnable weight parameters. The cost matrix is shown in Eq. (7):
The association decision
where
When
If the matching score
3.2.2 Adaptive Appearance Aggregation-Long-Term Memory Update Trade Off Model: ULMeM
Different from most existing methods in CrackDSF-ULMe, our core contribution is to establish a long-term memory, maintain the long-term time characteristics of each crack, and effectively inject time information into the follow-up tracking process, so that some extremely long cracks will not be identified repeatedly.
Generally, in the video stream, the object changes and moves very little in consecutive frames, so we have designed a Long-term Memory Retention Update Trade off Module (ULMeM), as shown in Fig. 4. Initially, we send the
Problems such as blurring or occlusion often occur in video streams. An intuitive way to solve this problem is to use multi frame features to enhance single frame representation. We use adaptive aggregation algorithm in ULMeM to fuse the output of two adjacent frames. Due to occlusion and blurring, the output embedded signal of the current frame may not be reliable. Therefore, as shown in Fig. 5, we generate a channel weighted
wherein,
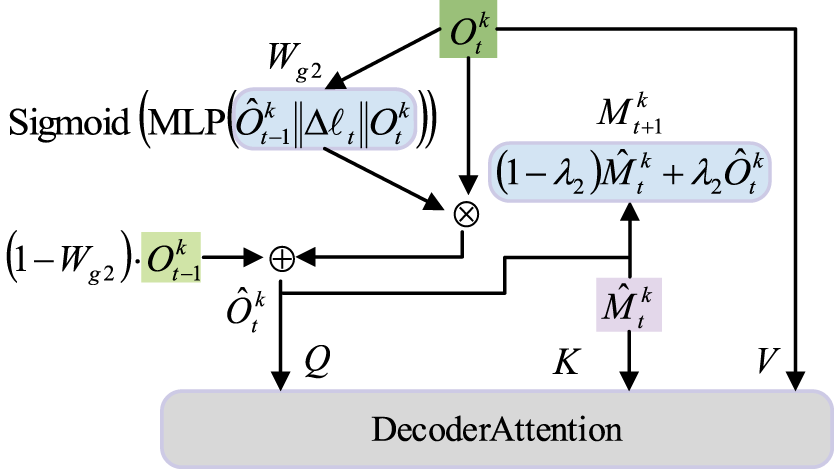
Figure 5: The structure diagram of Memory Retention-Update Trade-off Module (ULMeM)
At last, we design a combination of detection, tracking and width loss. The detection loss dominated initial training is used to quickly locate the crack, and the tracking and width loss dominated in the later stage for fine tracking. Before calculating the loss, we first design an unsupervised crack width calculation method, which interacts with the width loss.
According to the standard for rating technical conditions of highways, the damage degree of cracks is judged by the average width of cracks, so we use an unsupervised method to calculate the average width of cracks in this paper. The process is shown in Algorithm 1. Firstly, the input binary mask is skeletonized to extract the central skeleton of the object; Then calculate the Euclidean distance transformation of the mask (that is, the distance from each foreground pixel to the nearest background pixel). At this time, the distance value of the skeleton pixel represents the maximum inscribed circle radius (that is, half width) from the position to the edge; Finally, take the average value of twice the distance of all skeleton pixels (that is, the full width) as the average width of the object.
In order to make the width curve smoother and suppress the measurement noise, the width is gradually updated, as shown in the following formula:
where,
The specific formula of the loss function is shown in (17).

In this paper,
where, P is the successfully associated detection tracking pair, and
3.2.4 Count Evaluation Module: CoM
In the TransTra-Count system, the counting module plays a critical role in the statistical analysis of crack targets and the evaluation of damage levels. Its core function is to achieve real-time, unique, and non-repetitive counting of crack objects in video streams while outputting structured measurement results. Deeply integrated with the detection, segmentation, and tracking branches, the module forms a closed-loop automated measurement framework tailored for surface defect quantification. The overall workflow is illustrated in Fig. 6.
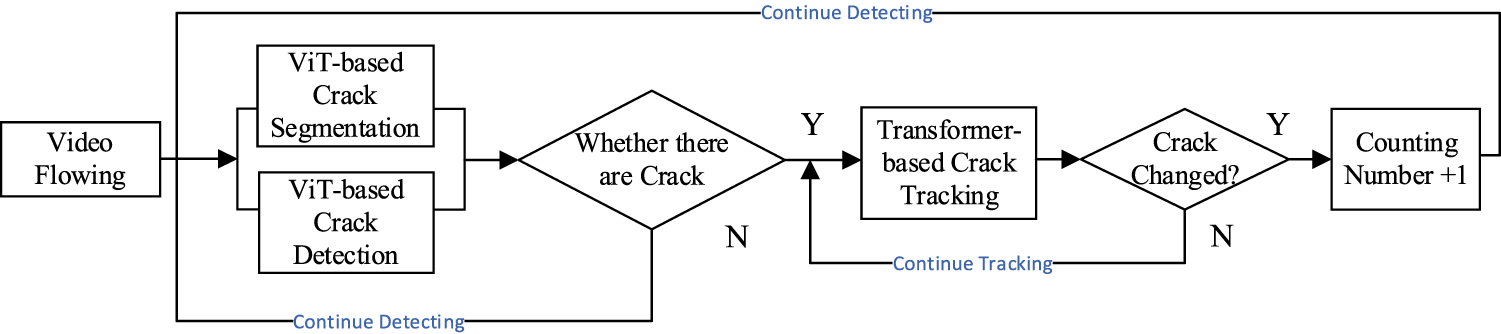
Figure 6: The closed-loop flowchart of TransTra-Count
First, the system determines whether structural crack targets exist in the current frame based on results from the front-end detection and segmentation subnetworks. If no valid defect region is detected, the system skips to the next frame to avoid unnecessary computation, forming a sparse, efficient, and low-redundancy frame-level processing pipeline. Once a potential crack region is identified, the counting module immediately invokes a multi-object tracking mechanism to perform real-time matching between the current detection and historical trajectories. This matching process relies on multimodal similarity measures incorporating spatial location, segmentation mask, and appearance features. A matching control strategy is then applied to determine the temporal continuity of the target: if it is a new crack instance, the system assigns a unique ID and updates the global defect counter; if it corresponds to an existing target tracked across frames, the original ID and counting state are retained to ensure temporal consistency and avoid duplicate counting.
Ultimately, the counting module outputs structured statistical results-including crack quantities and identifiers-providing quantitative, traceable, and engineering-ready decision support for pavement condition management, maintenance prioritization, and lifecycle assessment. By establishing a closed-loop feedback mechanism integrating detection, tracking, and measurement, the module not only enhances counting accuracy and system responsiveness but also embodies an industrial intelligent inspection philosophy oriented toward “structured measurement”. The system demonstrates strong generalization capability and deployment feasibility in practical applications, particularly in use cases such as road crack maintenance, bridge structural diagnosis, and condition assessment of transportation infrastructure.
Our work relies on two public datasets, DeepCrack [36] (general crack segmentation dataset), UVA-PDD2023 [37] (pavement disease detection dataset) and UAPD [38]. And independently collected the RoadDefect-MT data set to form a multi-source, multi scene pavement disease database. The specific composition is as follows:
DeepCrack: provides high-resolution (up to 2592 × 1944) fine crack annotation, covering various scenes such as walls and floors, and is used for the generalized learning of slender crack characteristics by the model.
UVA-PDD2023: including the annotation data of common pavement diseases such as cracks, with low resolution (640 × 480), which is suitable for the training of small target detection ability of the model.
UAPD: comprises 3151 images with an original resolution of 7952 × 5304 pixels. It includes six types of road defects with diverse sizes and morphological characteristics: longitudinal cracks (LC), transverse cracks (TC), alligator cracks (AC), oblique cracks (OC), repair marks, and potholes.
4.2 Self-Built RoadDefect-MT Dataset
The Dajiang Mini 3 Pro UAV (equipped with a 4K/60 fps camera) is used to fly at a height of 2–5 m to ensure that pixel level diseases are visible. The 4K resolution video capture is carried out on the roads in Jiangning District of Nanjing and the campus of Nanjing University of Aeronautics and Astronautics for asphalt roads. Through systematic inspection, it covers different lighting conditions (sunny and cloudy) and shooting angles (overhead and squint) to ensure data diversity.
The constructed RoadDefect-MT (Measurement & Tracking) dataset consists of 33 video clips (each lasting 2–18 s, with a resolution of 3840 × 2160 and a frame rate of 30 fps), totaling 3390 frames, each of which has been meticulously annotated. The dataset covers four typical types of road defects: transverse cracks, longitudinal cracks, mesh cracks, and crack patches. The distribution of these defects is not uniform, with crack patches being the most prevalent. The remaining three categories are roughly evenly distributed, with an overall ratio of approximately 1 (transverse): 1 (longitudinal): 1 (mesh): 2 (patches). This distribution reflects the real-world scenario where repaired areas are more commonly encountered in road networks. In order to adapt to the dynamic detection task, the annotation follows the MOT (Multi Object Tracking) format, and the annotation objects include defect categories, bounding boxes, and motion tracks. The video capture mode covers five UAV motion states: forward shooting, in situ rotation, forward rotation, and horizontal/vertical screen switching to better meet the needs of different scenes. Fig. 7 is an example of dataset annotation.

Figure 7: Some samples of RoadDefect-MT dataset
The RoadDefect MT dataset has high resolution, which can provide pixel level defect details and support the accurate positioning of small targets (such as fine cracks); and multi-mode UAV motion simulation of a real patrol scene can reduce the dependence of the model on a fixed shooting angle.
In this study, we use high-performance computing equipment to train the deep learning model. In terms of hardware configuration, a computer equipped with the 12-th generation Intel® Core™ I9-12900K central processor, NVIDIA GeForce RTX 3090 graphics processor and 64 GB memory computer. The software environment is based on Python 3.8 programming language, and the PyTorch framework is used for model development. At the same time, CUDA 11.1 acceleration library is used to optimize the GPU computing performance.
A phased training strategy was adopted in this systems to ensure stable and efficient learning. The entire process consists of two core stages:
In the first stage, the focus is on training the VitSeg-Det integrated detection and segmentation network. This network employs an end-to-end joint training approach, with a backbone shared by both detection and segmentation tasks. During training, the model simultaneously receives sample data annotated with bounding boxes and segmentation masks. In the forward pass, the network computes both detection loss and segmentation loss in parallel. These two losses are combined into a total loss function via weighted summation, and then the weights of the shared backbone and the two task-specific heads are updated synchronously through backpropagation. This design enables the detection and segmentation tasks to optimize collaboratively and mutually reinforce each other, allowing the shared backbone to learn more general and robust feature representations.
In the second stage, after the VitSeg-Det network is fully trained, all its weights are frozen, and the TransTra-Count tracking and counting network is trained on this basis. Specifically, consecutive video frames are fed into the frozen VitSeg-Det network to obtain precise bounding boxes, category confidence scores, and corresponding deep appearance features of all cracks in each frame. This information (boxes + features), along with the tracking trajectories from the previous frame, forms training sample pairs that are input into the TransTra-Count network. The core task of this network is to learn data association-i.e., determining which target in the current frame corresponds to which track in the previous frame for the same crack entity-and to develop the ability to maintain consistent target identity IDs in complex scenarios through training.
In terms of model performance evaluation, this research has constructed a set of multi-dimensional comprehensive evaluation system to comprehensively measure the performance of the algorithm in the crack segmentation, detection and tracking tasks. For the crack segmentation task, we use the average intersection and union ratio (mIoU) as the core index, and evaluate the pixel level positioning accuracy by calculating the overlap ratio of predicted and real labeled regions. In the crack detection task, we take the average accuracy (mAP) as the main indicator, combined with the detection performance under different IoU thresholds (such as AP50), supplemented by the Precision, Recall rate, F1 score, Floating Point Operations Per Second (FLOPS), Frame Per Second (FPS) and other indicators, to conduct a comprehensive evaluation from the two dimensions of detection accuracy and integrity. For more challenging crack tracking tasks, we introduce higher-order evaluation indicators: HOTA (Higher Order Tracking Accuracy) is used to comprehensively measure the overall performance of detection and correlation, DetA (Detection Accuracy) and AssA (Association Accuracy) are used to quantify the pure detection accuracy and pure correlation accuracy respectively, and IDF1 scores are used to evaluate identity retention capability. In addition, in order to comprehensively analyze the tracking quality, we also introduced the area under the curve (AUC) to evaluate the tracking stability, used the P-norm to calculate the trajectory prediction error, and combined it with the accuracy index to verify the reliability of the tracking results.
5.1 Sampled-ViT Ablation Experiment
In Section 3.1.2, we designed a lightweight scoring network to obtain
where
where, α and β are learnable parameters, μ(S) is the mean score, and std(S) is the standard deviation of the score.
In Table 1, the performance of two dynamic ω generation methods in the pavement crack segmentation task is verified. It can be seen from the table that Stat-ω is slightly better than MLP-ω (+0.59% mIoU), because the statistics are more stable, and MLP overfitting noise can be avoided. And the FPS of Stat-ω is close to fixed ω, because it only needs simple tensor operation without additional trainable parameters, while MLP-ω requires additional forward calculation and parameter update, increasing delay and memory occupation, and FPS decreases by 23%; The omega range of MLP-ω is larger, but some extreme values (such as ω < 0.3) will lead to missed detection.
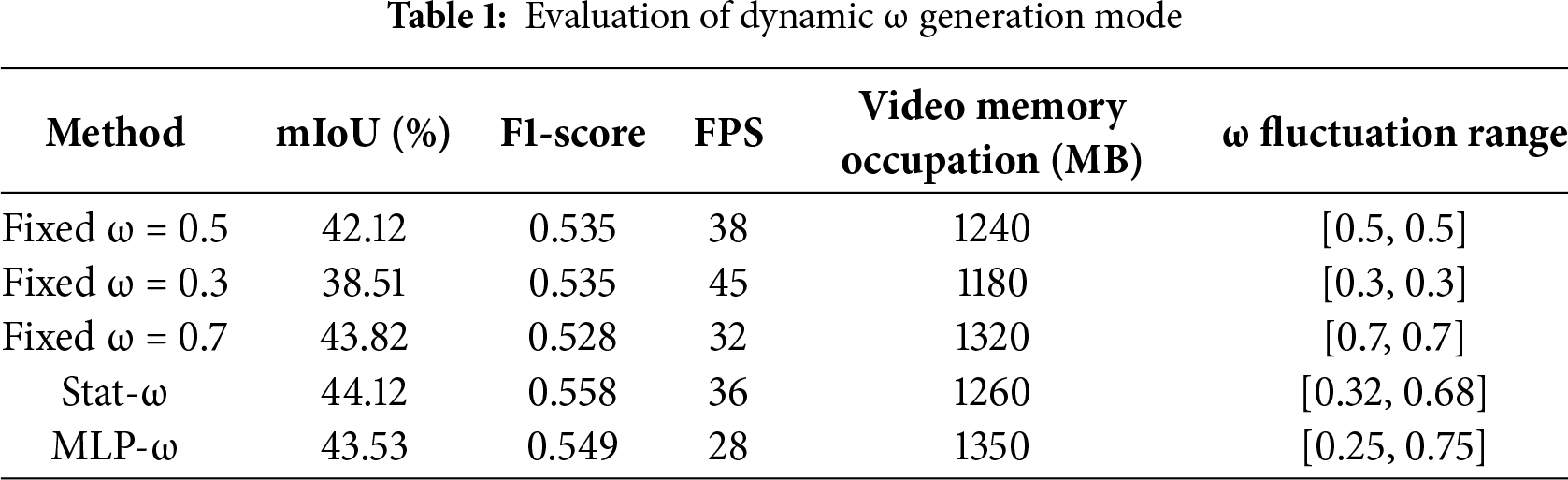
In this study, the dynamic ω generating function based on statistics is used to achieve optimal performance. When deploying edge devices, in order to balance the calculation efficiency and accuracy, a fixed ω value can be selected according to the characteristics of the scene: ω = 0.5 is recommended for conventional scenarios; ω = 0.3 can be selected for sparse crack scenes (such as expressways) to improve calculation efficiency; it is recommended to adopt ω = 0.7 to enhance robustness in areas with dense cracks (such as old pavement). The server retains the dynamic ω mechanism to ensure the highest detection accuracy. This hierarchical strategy achieves an adaptive balance between computing resources and detection accuracy.
As shown in Table 2, the statistical approach demonstrates greater stability and effectively prevents the MLP from overfitting to noise. Specifically, different levels of Gaussian noise (with noise variances σ2 = 0.01, 0.02, and 0.03) were added to the test set images, and the performance of three methods Fixed-ω(0.5), Stat-ω, and MLP-ω was evaluated accordingly.
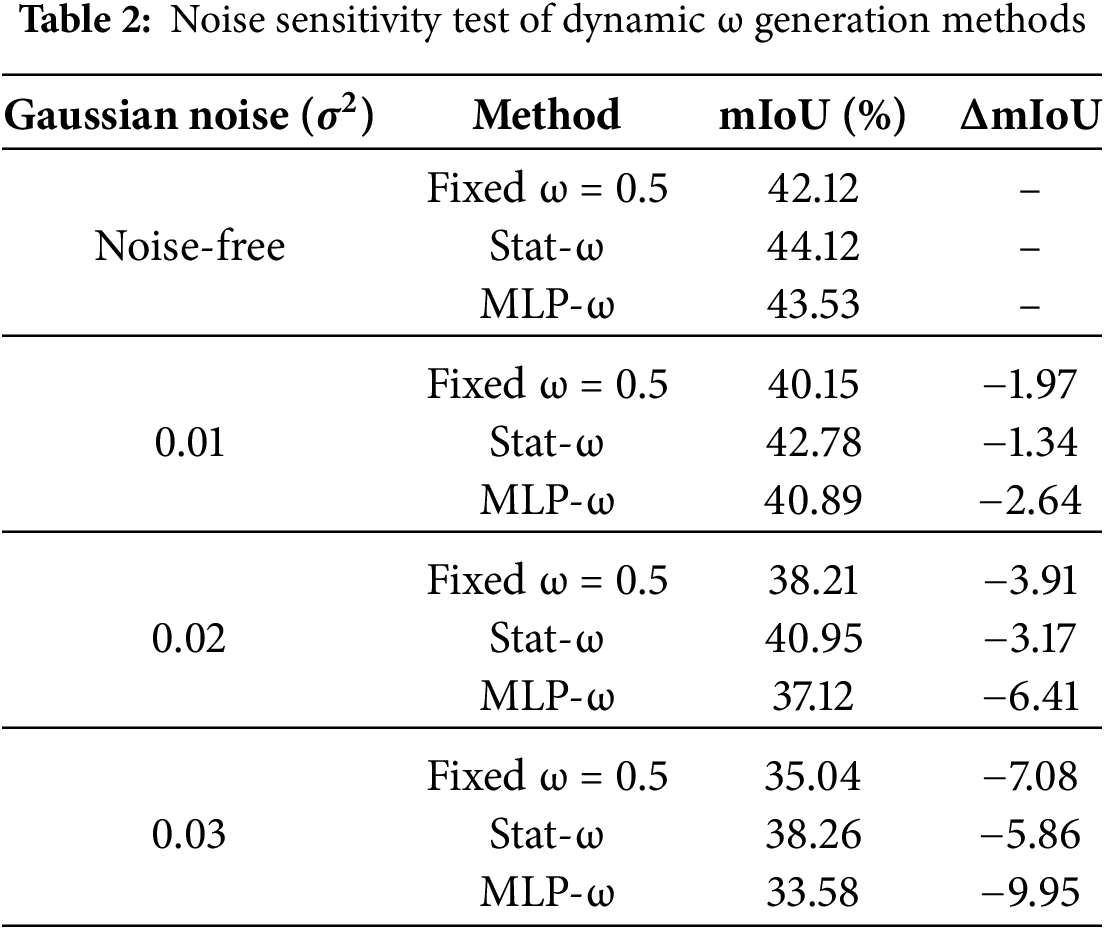
The results in Table 2, under different noise levels, show that the decrease in mIoU (ΔmIoU) of Stat-ω is consistently smaller than that of MLP-ω. For example, at σ2 = 0.03, the performance of Stat-ω declines by 5.86%, while MLP-ω exhibits a decrease of nearly 10%. This quantitatively demonstrates that MLP-ω, due to its learnable parameters, is more prone to learning and amplifying noise present in the training data (i.e., overfitting), leading to a sharp performance degradation on noisy inputs. In contrast, Stat-ω relies on simple statistical measures and lacks learning capacity, making it insensitive to noise and thus exhibiting stronger generalization robustness.
The results in Table 3 show that μ(S) and std(S) have significant synergistic effects in the Stat-ω method. When μ(S) is used only, mIoU is 43.1%, which indicates that single dependence on global features will lead to insufficient local saliency perception; When std(S) is used only, the mIoU is 42.8%, which reflects that simply focusing on local changes will reduce the sensitivity to the overall structure. When μ(S) + std(S) are used together, mIoU increases to 44.12%, which proves that the combination of the two can effectively balance the perception of global features and local details.

To systematically evaluate the contribution of key modules in the proposed VitSeg-Det framework to model performance, a series of ablation studies were conducted on the UAPD and UVA-PDD2023 datasets. The experiments were designed to incrementally incorporate each submodule for analysis, with results summarized in Table 4. All experiments consistently employed EfficientNet-b5 as the backbone network and maintained identical training parameter settings to ensure fairness and reliability in the comparisons. In the experimental design, the fusion of fine-grained and macro scale features was implemented using the joint μ(S) + std(S) method from the statistical approach.
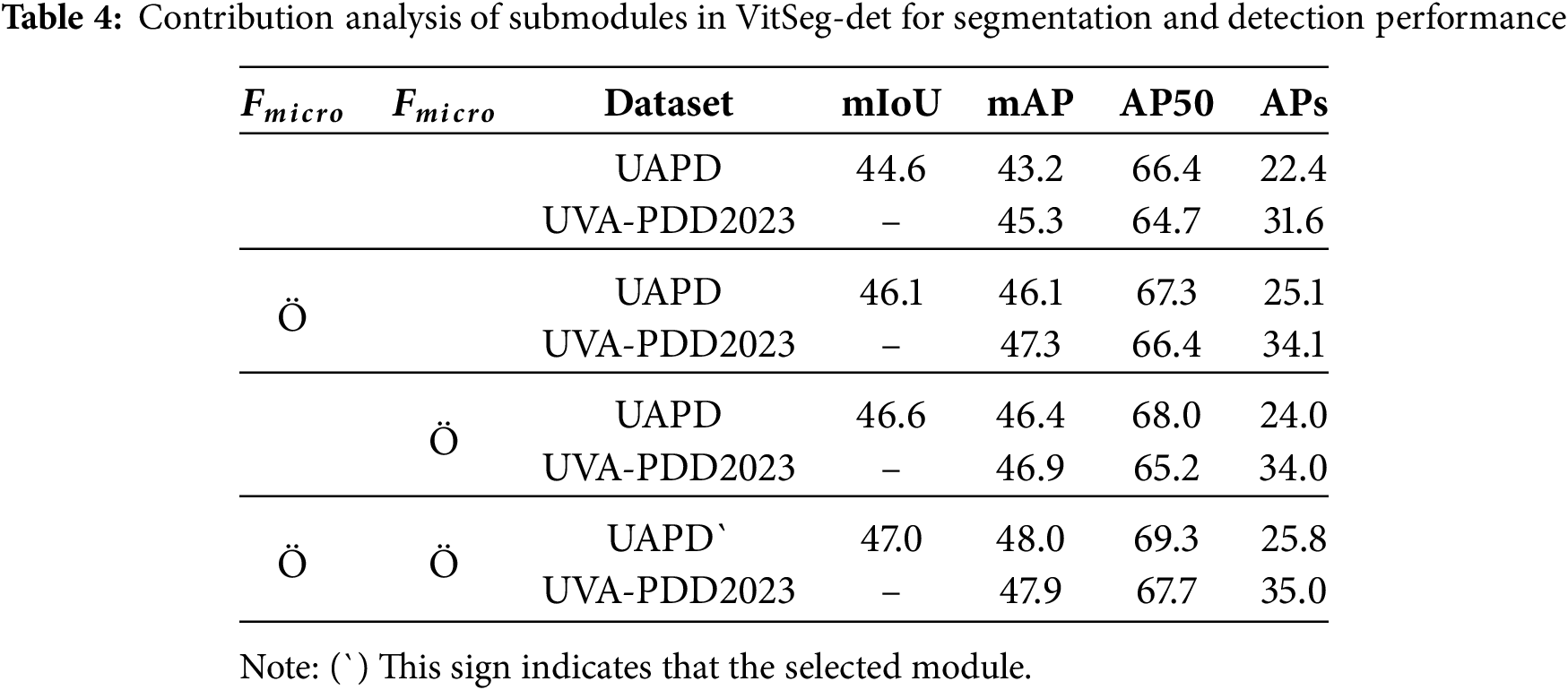
The experimental results demonstrate that both the fine grained feature module and the macro scale feature module in the VitSeg-Det model contribute significantly to performance improvement. When used in combination, the model achieves its best overall performance, with the segmentation mIoU increasing to 47.0 and the detection mAP reaching 48.0 on the UAPD dataset. The fine grained feature module notably enhances the detection capability for small targets (reflected by a significant improvement in APs), while the macro scale feature module more substantially improves segmentation accuracy and detection performance for regular sized objects. The two modules exhibit complementary characteristics, and their synergistic effect leads to optimal results across all evaluation metrics. This consistent trend is observed on both the UAPD and UVA-PDD2023 datasets.
5.2 CrackDSF-LMe Ablation Experiment
In this section, we studied several components of the model, such as spatial feature double joint data association, adaptive appearance aggregation, light gating, and long-term memory. Our main contribution is that we can accurately identify the cracks in the video stream and avoid the problem of repeated counting.
In this paper, we propose a data association method DSFM, and control the fusion ratio between IoU measurement and feature similarity calculation based on the attention mechanism by introducing the adjustable parameter
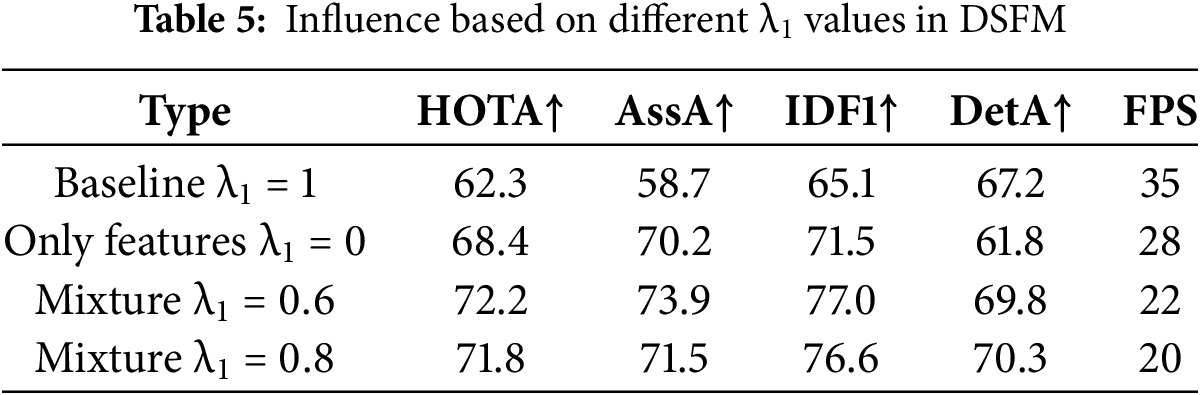
In Section 3.2.2, we designed a ULMeM module, which can dynamically fuse the object features from adjacent frames, and integrate the interframe lighting changes to avoid the impact of sharp changes in light. We decompose this structure in Table 4. The first result only uses single frame features as the comparison benchmark, the second group uses fixed weights instead of adaptive weights, the third group removes illumination compensation, and the last group is the complete model. As shown in Table 6, compared with Wg2 = 0.5, the adaptive weight increases about 12.3% (65.7 → 73.8) in HOTA, which indicates that it is necessary to dynamically adjust the memory retention ratio for occluded/blurred scenes. IDF1 increases significantly (71.8 → 78.7), which verifies that adjusting the memory weight through dynamic response appearance difference significantly reduces ID switching errors; Compared with the fourth group, the removal led to a 2.9% decrease in DetA (71.4 → 68.5), indicating that the false detection rate increased when the illumination suddenly changed, and the histogram moment matching effectively improved the tracking stability; In the fourth group, compared with baseline, the FPS is reduced from 36 to 28, because the introduction of multi frame computing increases the time consumption, but significantly improves the accuracy (HOTA + 11.5), which is suitable for high-precision demand scenarios. It can be seen that all indicators of the complete model are optimal, indicating that the joint modeling of illumination, adaptive appearance aggregation and memory update can comprehensively solve the problems of fuzziness, occlusion and brightness change.
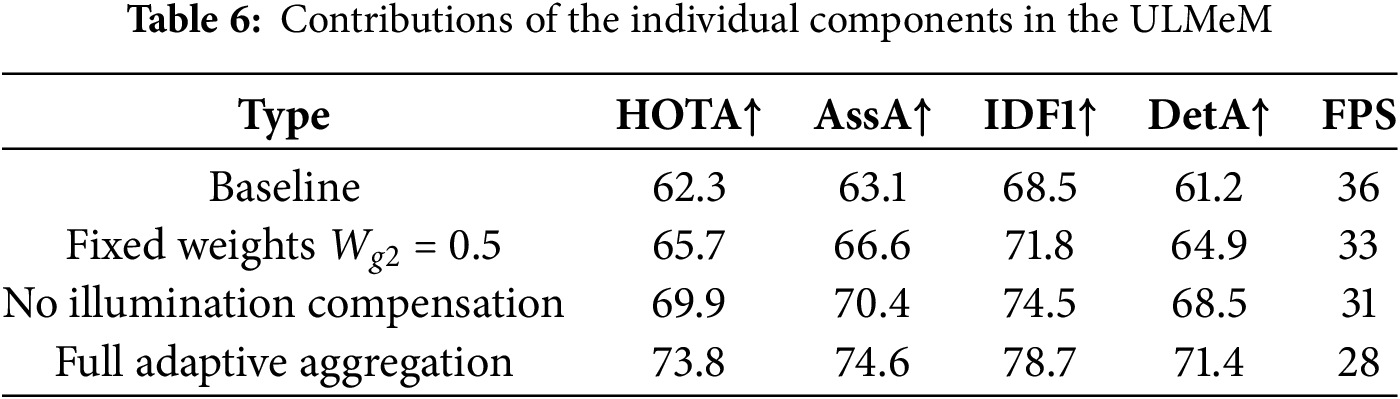
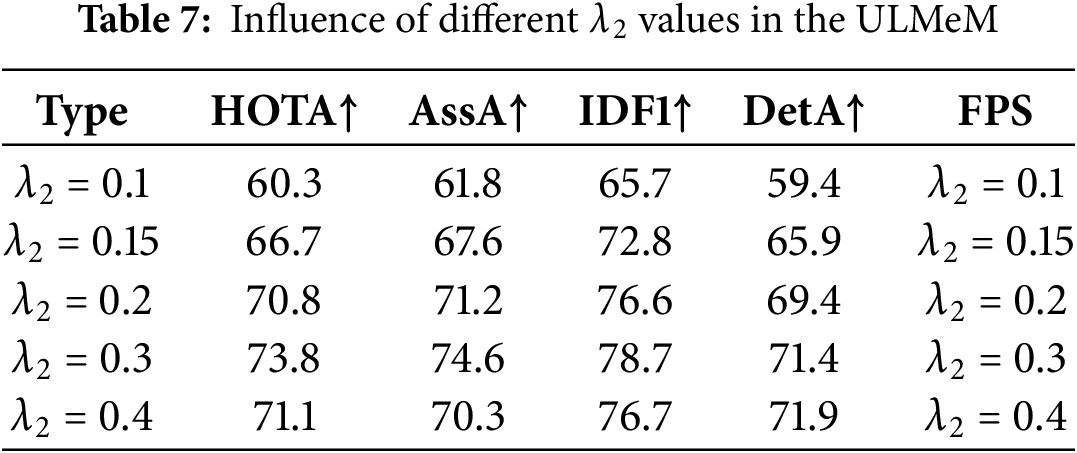
The long-term memory we proposed in Section 3.2.2 is to use the longer time information and further inject it into the subsequent track embedding to enhance the object characteristics. We have studied the performance of long memory. As shown in Table 7, when
5.3 Detection and Segmentation Qualitative and Quantitative Analysis
Since our segmentation detection model is a multi task model, and Sampled-ViT is used as a shared encoder to extract global features, we have carried out unified processing on the dataset to adapt to the multi task model training. First, the training set and verification set of the DeepCrack dataset are integrated to generate the detection frame annotation, and each image is expanded to 30 video sequences through translation transformation to synchronously generate frame by frame segmentation tags and detection frame annotation. At the same time, we manually segment and annotate 100 crack images in the UVA-PDD2023 dataset, and generate 30 frames of video data and their corresponding multitask annotations using translation scaling transformation. In the test phase, the UVA-PDD2023 test set is selected to comprehensively evaluate the generalization performance of the model.
For the performance analysis of Sample-ViT, we conducted systematic comparative experiments on all test images, as illustrated in Fig. 8. In the comparative experiments of this study, we selected representative benchmark models based on the following principles: (1) Task relevance. The selected models (e.g., Mask2Former, DPT) are advanced representatives dedicated to semantic segmentation or general segmentation tasks, and their design objectives are highly relevant to our crack segmentation task. (2) Architectural comparability. We specifically included Transformer-based models (e.g., SegGPT, DPT) to enable fair comparisons of efficiency (parameter count, FLOPs) and accuracy on the basis of similar architectures. (3) Industry influence and versatility. As a pioneering work in context-aware segmentation, SegGPT provides an important performance reference. The results show that Sample-ViT with the EfficientNetB5 backbone network exhibits the most excellent fine-grained segmentation capability in the road crack detection task. It can generate finer and more continuous crack segments, significantly improving the detection rate of microcracks.
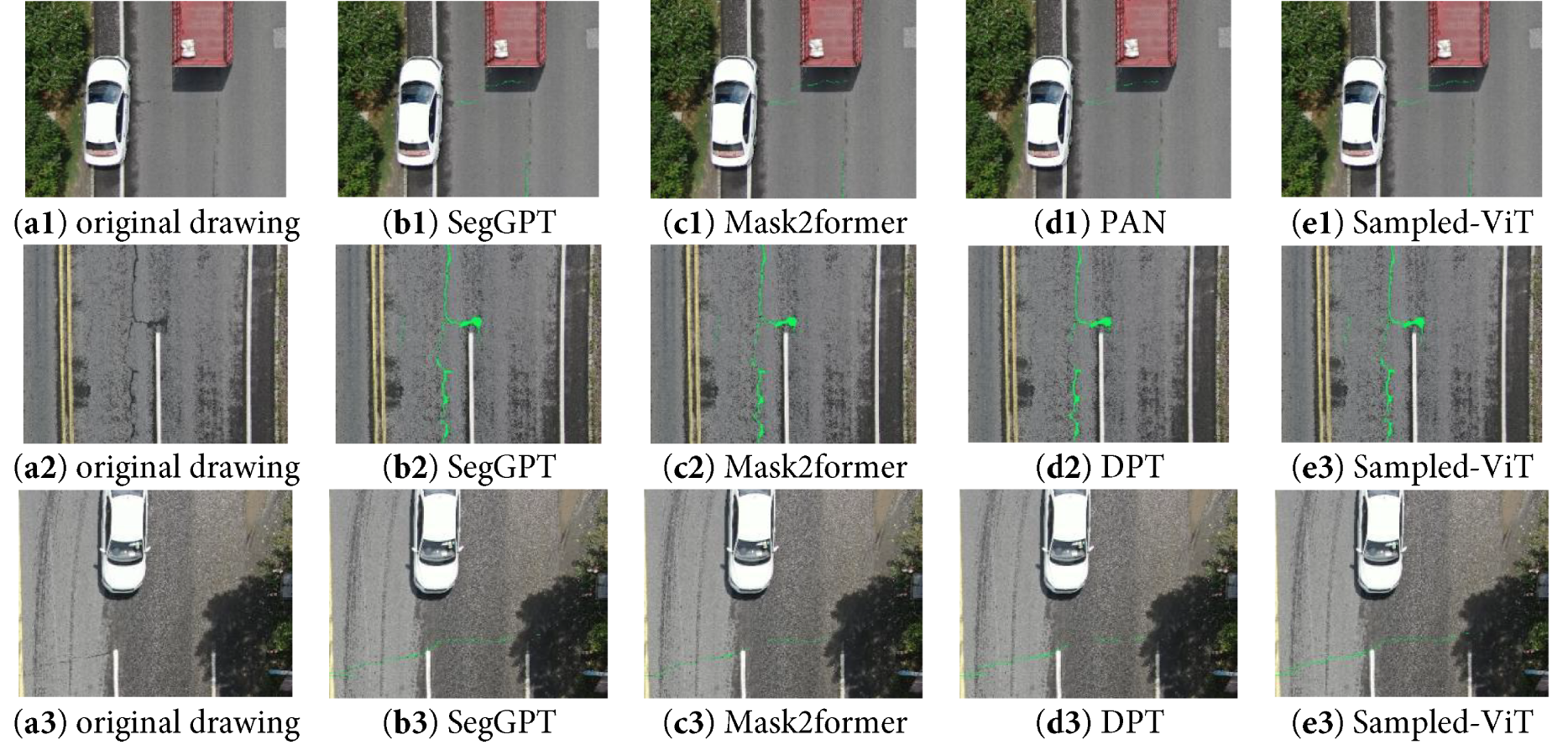
Figure 8: The results of segment: From left to right, they are original image, SegGPT, Mask2former, DPT and ours in sequence
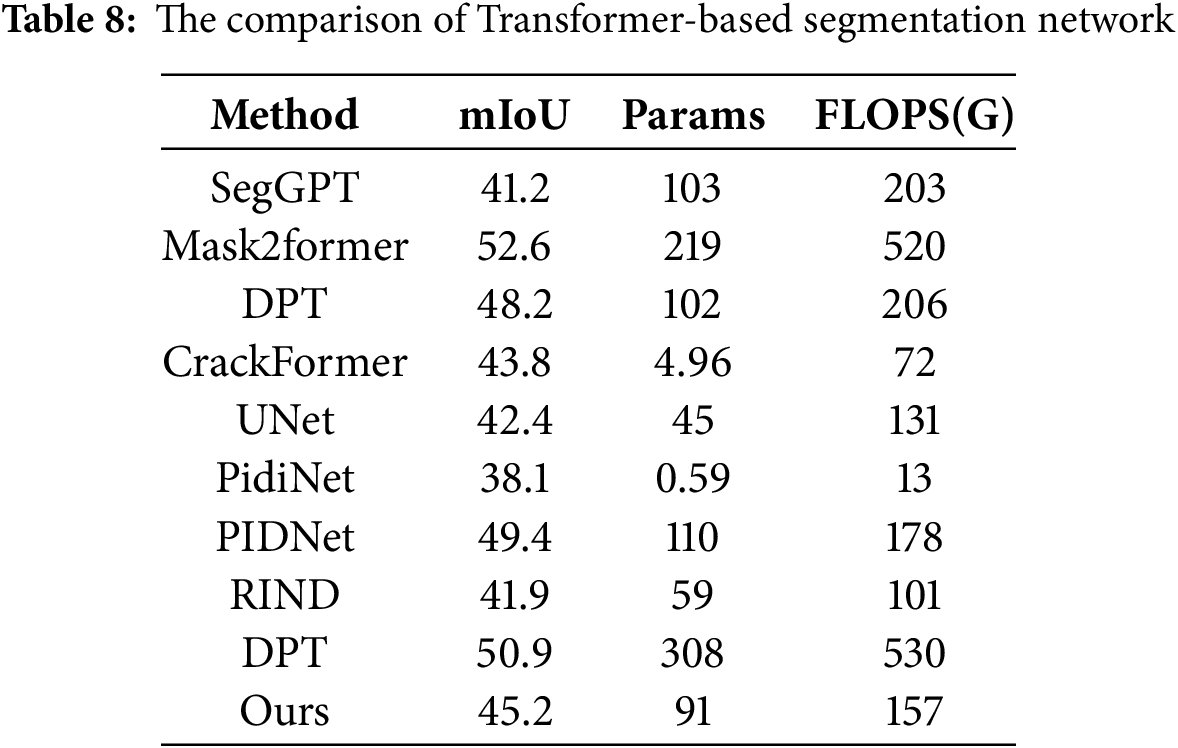
As shown in Table 8, the methods proposed in this study show excellent performance balance in video segmentation tasks. Compared with the mainstream model, our method achieves 45.12% mIoU with only 91M parameters (based on ViT base), which is superior to SegGPT (41.2%) in accuracy. At the same time, the calculation amount (157 G FLOPS) is significantly lower than DPT and SegGPT of similar ViT base architectures. Although Mask2Former (Swin Transformer) performs best with 52.6% mIoU, its 219 M parameters and 520 G FLOPS have significantly higher computing costs. Experimental results show that the proposed method has lightweight advantages while maintaining competitive segmentation accuracy, and is particularly suitable for real-time video analysis scenes with limited computing resources.
When testing model validation, this study conducted a comprehensive performance evaluation of the trained model on the standard test set, and used indicators such as accuracy, precision, recall and F1 score to compare with the CNN based method. The experimental results show that the detection network optimized by Transformer has achieved significant improvement: as shown in Table 9, our method’s F1 score reached 74.13, with an accuracy rate of 70.20%, 23.4% and 9.6% higher than the optimal CNN model (Yolo v8) respectively. From the performance comparison of each algorithm listed in Table 10, we can see that under the same input size (31,333,800), our method performs well in detection accuracy while maintaining a real-time processing speed of more than 16 fps. Although the number of model parameters (41.55 M) is slightly higher than some of the comparison methods, the computational efficiency (81.63 G FLOPs) is better than that of DETR (86.93 G FLOPs) and is significantly higher than the computational complexity of the traditional CNN method (Faster RCNN 0.178 T FLOPs). As shown in Fig. 9, our method and DETR show stable detection capability for various defect types, while SSD and Yolo series have faster detection speed, but their performance in this dataset is poor, and Faster RCNN has obvious problems of false detection and missing detection. These results confirm the advantages of the proposed method in accuracy and efficiency. In the future, we will further improve the real-time performance through code optimization to meet the application requirements of high-precision real-time detection.
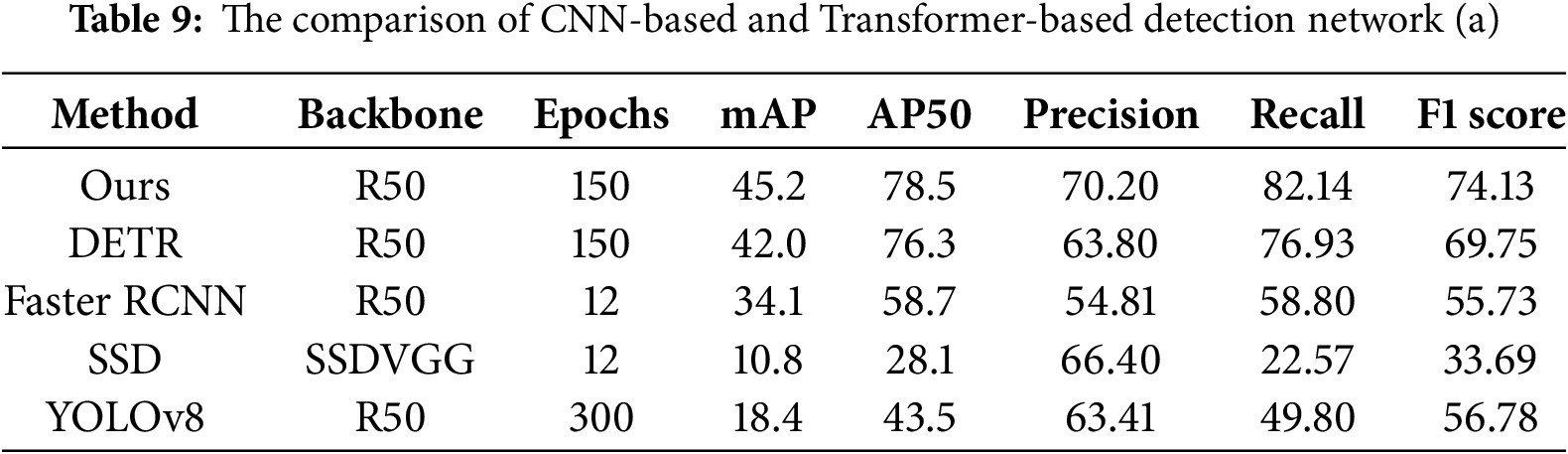
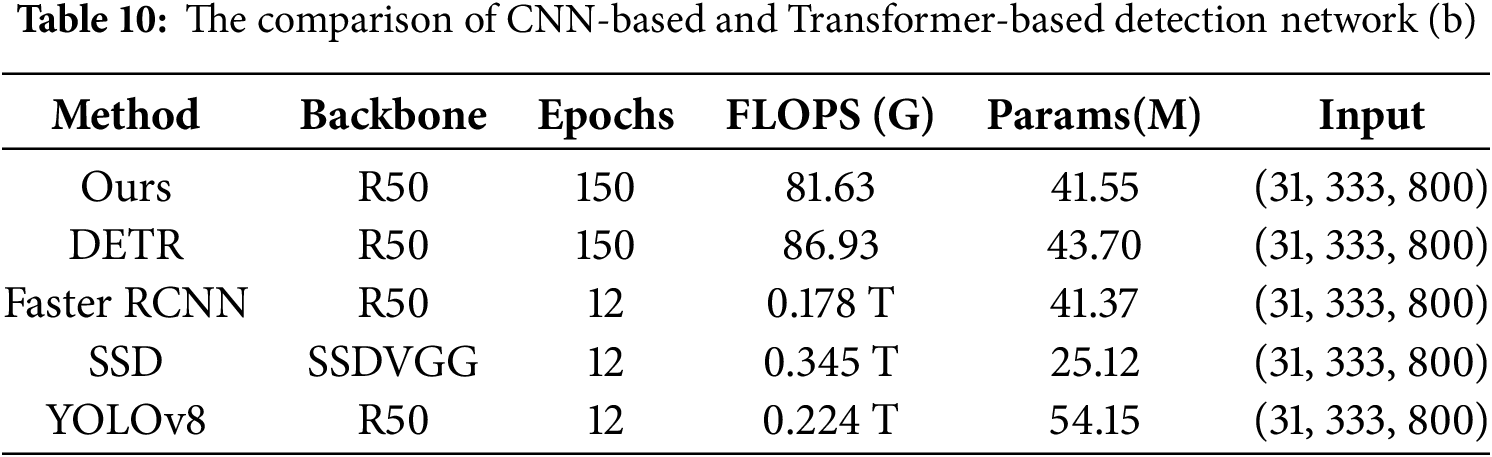

Figure 9: Visual comparison of test results
5.4 Tracking Segmentation Qualitative and Quantitative Analysis
To verify the performance of the tracking model, we use the UVA-PDD dataset to generate analog video sequences, and expand each image to 30 frames through translation transformation to simulate continuous frame input in the real scene. In the test phase, the RoadDefct MT dataset is used for generalization evaluation. Experimental results show that the proposed tracking network achieves an average accuracy of 97.1% and an F1 score of 0.84 on the test set. As shown in Fig. 10, the Precision Recall (PR) curve of pavement defect detection is close to the upper right corner of the coordinate system, indicating that the network can track crack targets stably and accurately.
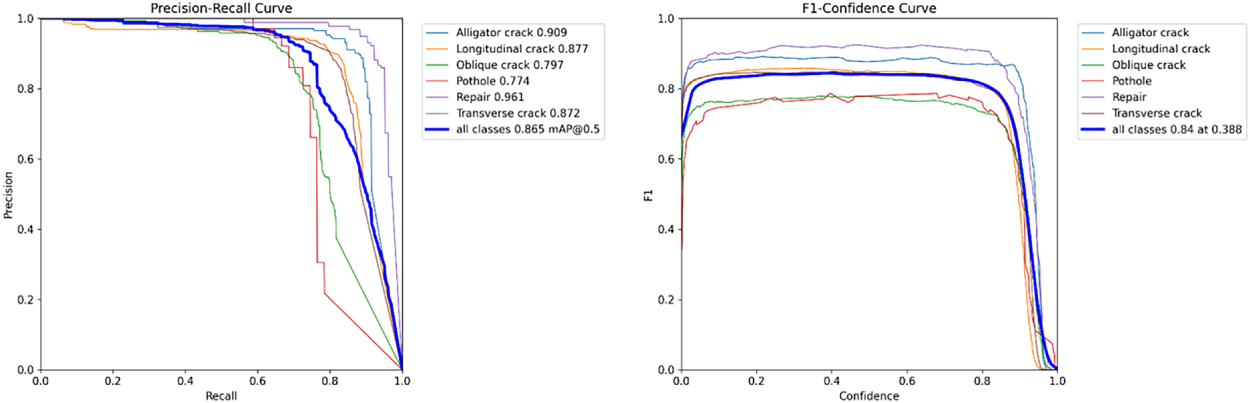
Figure 10: Precision recall (PR) curve and F1 score performance analysis
To verify the advancement of the proposed TransTra-Count method, we conducted a comprehensive comparison between it and current mainstream multi-object tracking algorithms on the RoadDefect-MT dataset. As a classic paradigm, DeepSORT integrates motion models and appearance features, serving as the foundation for many subsequent studies and thus adopted here as a performance baseline. ByteTrack focuses on motion models as its core and significantly enhances association robustness by effectively utilizing low-score detection boxes, representing the advanced level of the current technical route in this field. BoT-SORT and OC-SORT, respectively, introduce camera motion compensation and trajectory smoothing optimization based on ByteTrack, together forming a collection of various advanced online tracking strategies. All the aforementioned trackers have open-source and stable implementations, facilitating reproducible and fair comparisons. The experimental results are presented in Table 11.
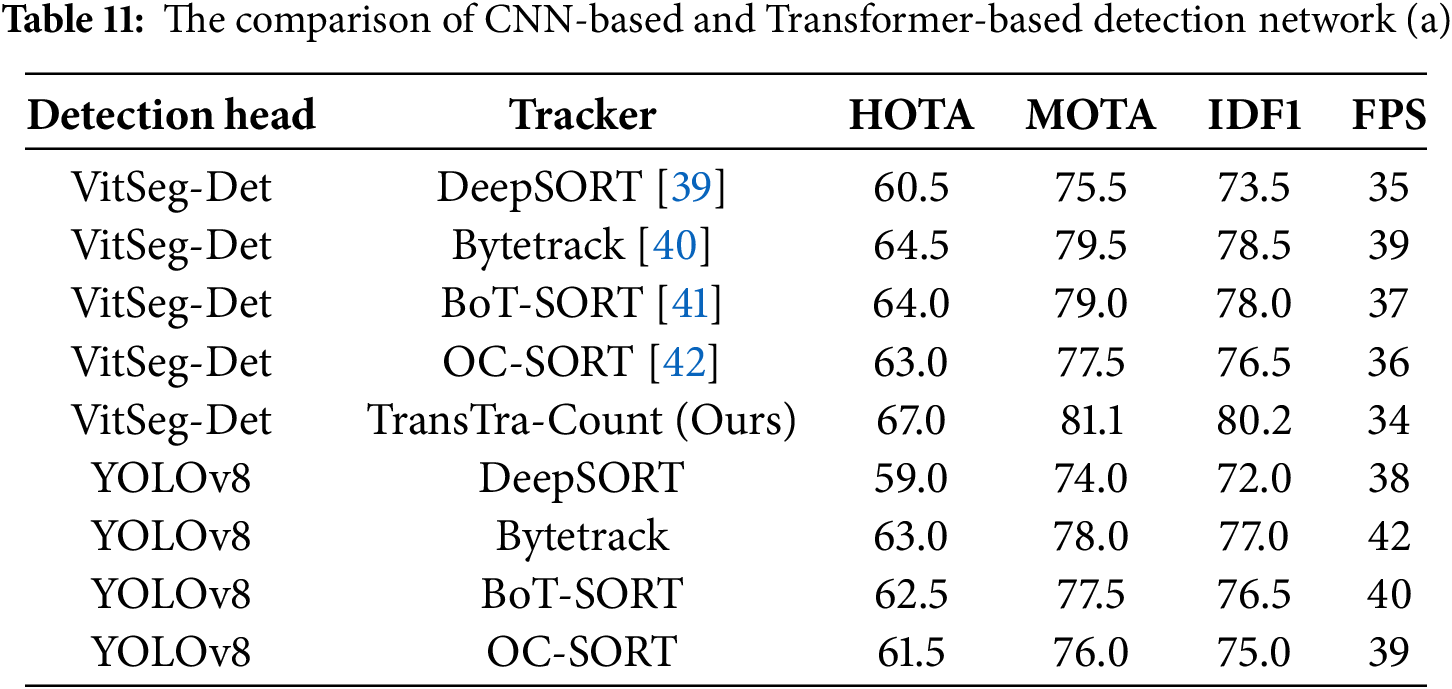
A controlled variable approach was adopted, where two detectors-the proposed VitSeg-Det and the widely used YOLOv8-were fixed and paired with each of the five tracking methods to evaluate the performance of different combinations in multi-object tracking tasks.
First, in terms of detector performance comparison, the proposed VitSeg-Det in this paper demonstrates significant advantages. When paired with the same tracker, VitSeg-Det consistently and stably outperforms YOLOv8 in all core tracking metrics (HOTA, MOTA, IDF1). Taking the combination with Bytetracker as an example, VitSeg-Det achieves a 1.5% performance improvement in HOTA (64.5 vs. 63.0), MOTA (79.5 vs. 78.0), and IDF1 (78.5 vs. 77.0), fully demonstrating its higher accuracy and robustness as a detection module.
Second, in the horizontal comparison of trackers, it was observed that for the same detector, Bytetrack and BoT-SORT delivered the best and closely matched performance, followed by OC-SORT, while the classic DeepSORT algorithm performed relatively weakly. This trend reflects the continuous progress in multi-object tracking technology regarding the robustness of data association. Notably, the proposed TransTra-Count tracker achieved the best performance among all combinations. When paired with VitSeg-Det, this combination reached the highest tracking performance (HOTA: 67.0, MOTA: 81.1, IDF1: 80.2), significantly outperforming other compared algorithms and strongly validating the effectiveness of TransTra-Count’s innovative design.
Finally, in terms of computational efficiency, combinations using YOLOv8 achieved the highest frame rates (ranging from 38 to 42 FPS), benefiting from the computational efficiency of its CNN architecture. Although the Transformer-based VitSeg-Det combinations resulted in slightly lower frame rates (ranging from 34 to 39 FPS), they offered a favorable trade-off between accuracy and efficiency due to their superior precision. It is particularly noteworthy that the proposed TransTra-Count method maintained a real-time processing speed of 34 FPS while achieving leading accuracy metrics, successfully balancing precision and efficiency.
In conclusion, the experimental results demonstrate that both VitSeg-Det as a detection module and TransTra-Count as a tracking module deliver outstanding performance. Their combination forms a powerful and efficient solution for road defect detection and tracking.
To comprehensively evaluate the overall performance of the proposed method, we conducted a comparative analysis from a more macroscopic method paradigm perspective. The experimental results are shown in Table 12.
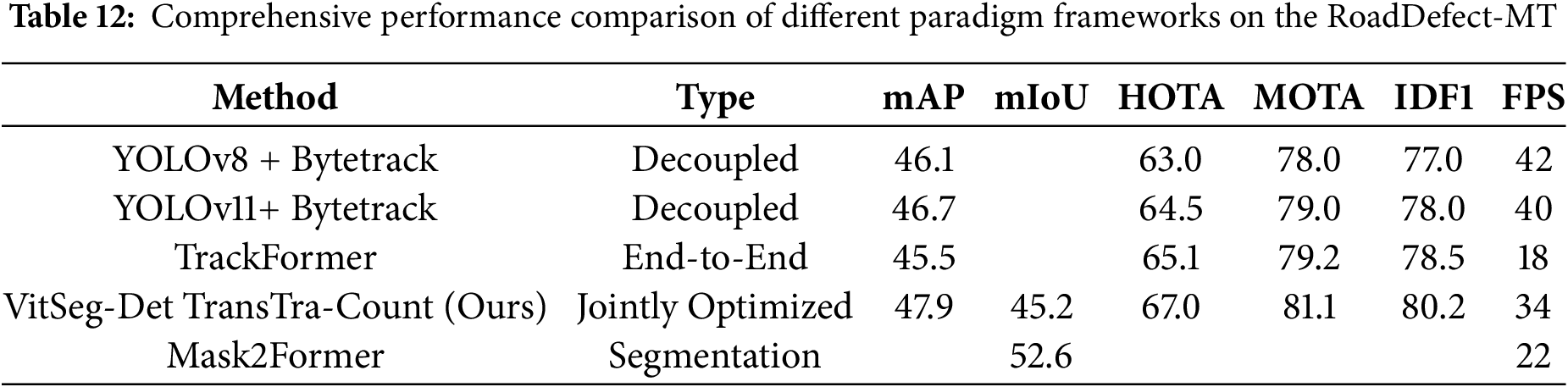
The experimental results show that the proposed joint optimization framework in this paper achieves the best performance across all key indicators and leads comprehensively. Specifically, this method achieves an mAP of 47.9% in the detection task, an mIoU of 50.1% in the segmentation task, and significantly outperforms other frameworks in multi-object tracking, with HOTA of 67.0, MOTA of 81.1, and IDF1 of 80.2. This result indicates that the joint optimization mechanism can effectively promote the collaboration and information complementation between detection and tracking tasks, thereby achieving global performance optimization.
By comparing different paradigms, it can be observed that the end-to-end paradigm (TrackFormer) outperforms the decoupled method in tracking metrics, demonstrating certain potential of end-to-end learning. However, its detection accuracy (mAP 45.5) is relatively low, and its inference speed is the slowest (18 FPS), reflecting the limitations of this paradigm in terms of efficiency and flexibility. The decoupled paradigm, leveraging its architectural advantages, performs best in terms of speed (40–42 FPS) and has become a widely adopted efficient solution in practical applications. However, its accuracy ceiling still falls short of the joint optimization method.
The reference pure segmentation model Mask2Former achieved an mIoU of 52.6% in semantic segmentation tasks, but it lacks tracking capabilities and cannot output multi-object tracking metrics. Moreover, its inference speed (22 FPS) is lower than that of most detection and tracking models.
To verify the effectiveness of the Transformer-based pavement defect detection and counting model, we conducted comprehensive tests on multiple datasets, including: (1) a publicly available benchmark dataset enhanced with translation augmentation; (2) our self-built 840 × 2160@30 fps. During the experiment, we strictly maintained the original resolution of each dataset to ensure the authenticity of the test conditions. The experimental results are shown in Figs. 11 and 12.
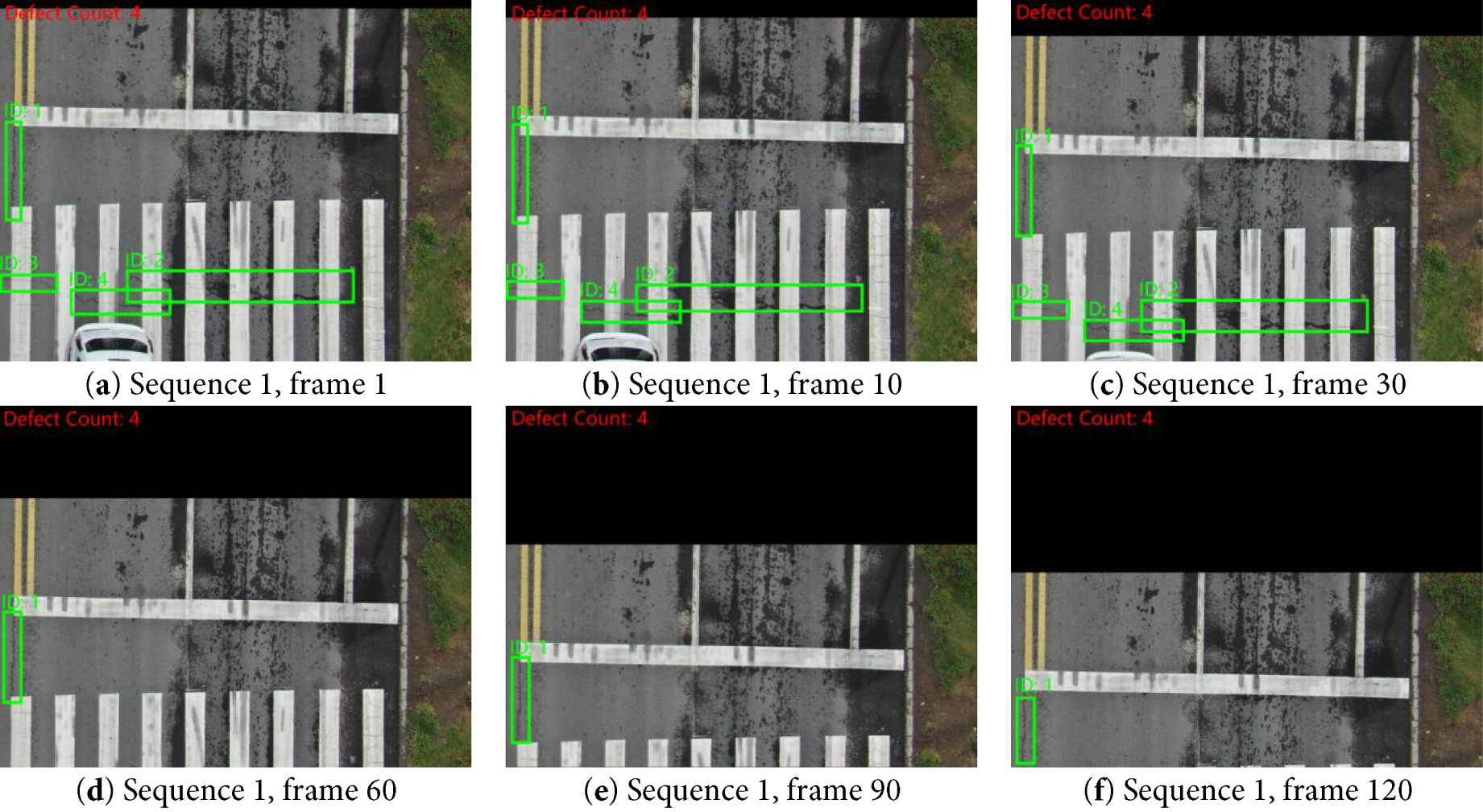
Figure 11: Defect tracking count (sequence 1)
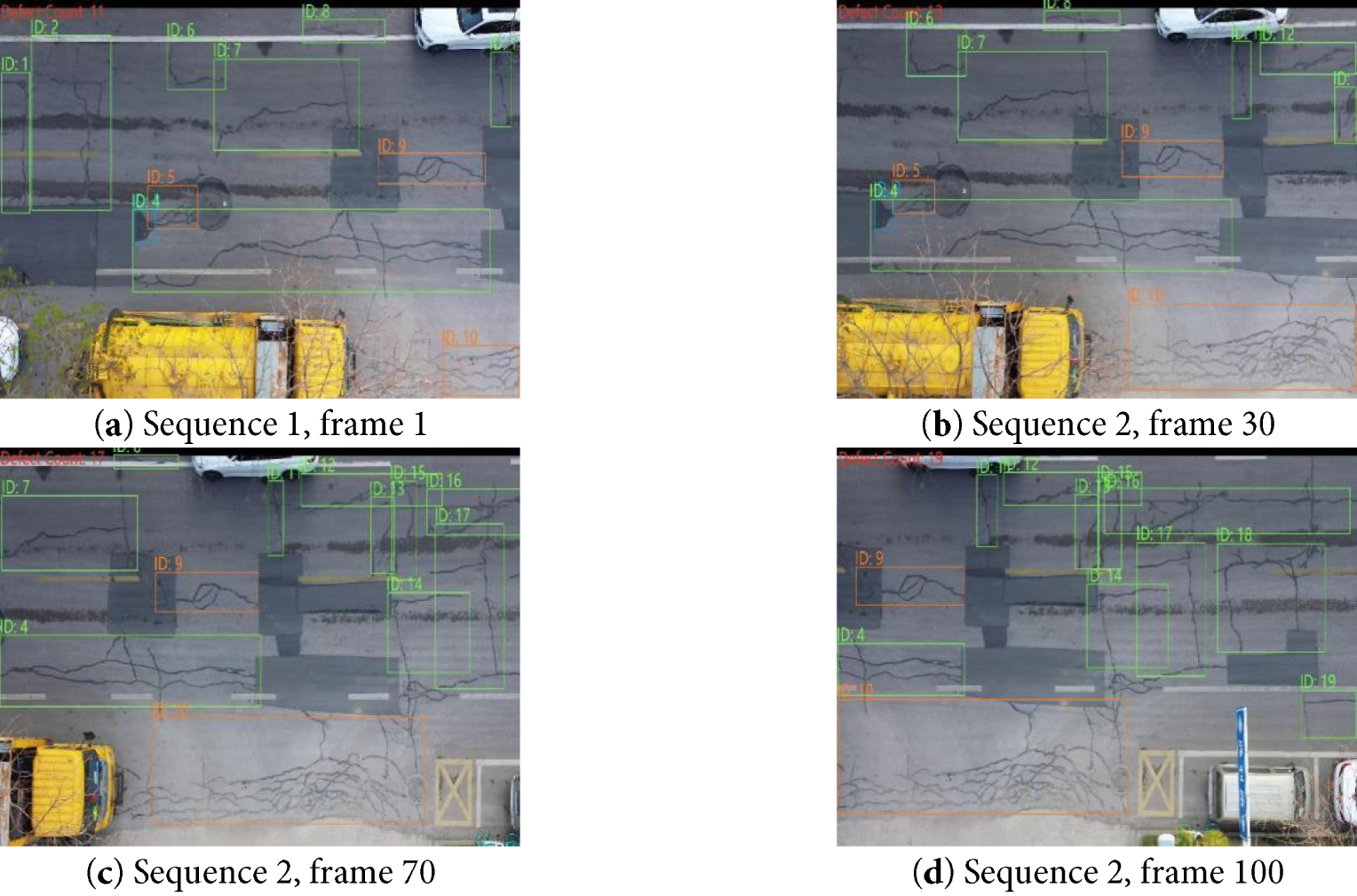
Figure 12: Defect tracking count (sequence 2)
As shown in Fig. 10, our system achieved accurate defect detection and stable tracking on the aforementioned datasets. The experimental results demonstrate that our method performs excellently on test data with different resolutions and frame rates. It not only accurately detects various types of pavement defects but also achieves stable target tracking and precise quantity counting. Notably, in the 4K high-definition video tests, despite a significant increase in the volume of input data, our model still maintained stable detection accuracy and counting precision. This preliminarily proves the algorithm’s adaptability to high-resolution scenarios.
At the same time, we fully recognize a limitation of the current research: the self-collected dataset relied on for primary validation is insufficient in terms of scale (only 33 videos) and scene diversity (sourced from a single collection location). This may affect the model’s generalization ability in broader and more complex real-world environments. Although supplementary experiments on public datasets such as DeepCrack and UVA-PDD further support the effectiveness of the method, we acknowledge that these datasets constructed from static images cannot fully replicate the challenges posed by real dynamic video scenarios. Therefore, the conclusions of this paper should be regarded as a strong validation of the effectiveness of the proposed TransTra-Count model within the scope of our existing datasets. These results provide valuable references and a foundation for practical engineering applications, but the universality of the model still needs further verification in the future through larger-scale and more diverse real-world video datasets.
5.6 Embedded Device Verification
To comprehensively evaluate the deployment feasibility and resource adaptability of the proposed method in actual industrial scenarios, this section focuses on the edge inference platform and systematically analyzes the performance of this method under lightweight deployment conditions.
The experiment was conducted on the embedded edge device Jetson AGX Orin 32 GB. Before deployment, the FP16 precision optimization processing was carried out using the Tensor RT toolchain to closely align with the acceleration scheme in actual embedded scenarios; the input image size was uniformly set to 1024 × 1024, and the batch size was set to 1 to simulate the continuous single-frame image processing flow, ensuring the consistency and reusability of the evaluation.
The performance tests cover four key indicators: model size (MB), maximum frame rate (FPS), peak memory usage (MB), and single-frame latency (ms). As shown in Table 13, the experimental results show that the proposed method, while integrating detection and segmentation, still maintains low resource usage and high inference efficiency. The maximum frame rate reaches 20 FPS, and the single-frame processing latency is 49.8 ms. This performance demonstrates the excellent engineering applicability of this method in high-frequency industrial defect detection and quality monitoring tasks, providing a feasible lightweight solution for actual industrial applications.

6 Conclusion and Limitations Discussion
Focusing on the requirements of automatic identification of road crack defects and quantification of structural parameters, this research has constructed a multi task integrated crack measurement system based on the Transformer architecture, which focuses on breaking through the problems of repeated counting errors, structural information loss and measurement output inexplicability faced by existing methods in complex dynamic scenes. The system as a whole has realized end-to-end closed-loop modeling from detection, segmentation, tracking to counting, and promoted the transformation of the crack recognition task from “image level classification” to “structured measurement”. Its innovative contributions in visual perception and quantitative analysis are mainly reflected in the following four aspects:
First of all, to solve the problem that microcracks are difficult to segment in the low contrast background, a VitSeg-Det integrated detection and segmentation network is designed. Combining the channel space attention fusion scoring mechanism and the macro scale dilated convolution feature modeling, the edge structure and global topology information of cracks are accurately extracted, which effectively supports the measurement and calculation of subsequent structural parameters.
Secondly, to solve the problem of recognition drift and repeated counting of the same crack object in dynamic video due to changes in illumination and perspective, a TransTra-Count module is proposed, which is based on the space feature bimodal association and long-term memory update mechanism, and realizes the identity maintenance and life cycle management of the crack object. In many actual videos, the system achieves accurate and non repetitive object counting output, and maintains measurement stability under interference conditions such as occlusion and blurring.
Thirdly, in terms of crack structure measurement, this paper proposes an unsupervised width estimation method based on mask skeleton, and designs a smooth update mechanism and a width change rate constraint loss function to ensure the continuity and physical rationality of the estimation results in the time dimension.
Fourthly, to provide more comprehensive experimental support for system verification and measurement evaluation, this paper constructs a self built high resolution dynamic crack dataset, RoadDefect-MT, which covers a variety of typical pavement disease patterns, different illumination and occlusion conditions, and is supplemented by average width marking and track numbering, making up for the gaps in time sequence consistency and measurement marking in existing public datasets. The experimental results show that the method in this paper is significantly better than the existing mainstream methods on the dataset, showing stronger measurement stability, statistical accuracy and engineering adaptability.
Overall, this paper has made several key breakthroughs in visual measurement modeling, dynamic target statistics, and structural parameter extraction, verifying the effectiveness and scalability of the Transformer architecture in multi-task visual measurement systems. However, there are still several limitations that need to be further explored:
Firstly, the current validation mainly focuses on road surface scenarios. The applicability of this method in vertical or elevated surfaces such as bridges and tunnels remains an open question. This is mainly due to the differences in crack morphology under different perspectives and the influence of gravity, as well as the challenges of shadow and perspective distortion in imaging of vertical surfaces. Secondly, existing research also has limitations such as a single target type and limited measurement granularity. The current system focuses on the measurement of linear cracks, and the generalization ability for other common disease types such as potholes and network cracks has not been verified. At the same time, the parameter measurement is still concentrated on macroscopic indicators such as average width, and the quantitative ability for three-dimensional attributes such as depth and volume needs to be expanded. Additionally, the system faces challenges in extreme environments such as heavy rain, severe stains, and intense vibrations during actual deployment. Although this method performs robustly under common interference conditions, its generalization ability in unseen extreme scenarios still needs to be verified through more extensive datasets.
In response to these limitations, future work will focus on the following aspects: Firstly, extend the detection range from road surfaces to bridge facades, tunnel walls, and other vertical surfaces to verify and enhance the model’s generalization ability in different scenarios and perspectives; Secondly, develop a universal measurement framework that can be applied to potholes, network cracks, and various structural diseases; Thirdly, construct a new generation of three-dimensional bridge and road disease data sets that integrate multi-view imaging, depth information, and calibration parameters to support fine-scale structural measurement at spatial scales; At the same time, explore segment-based structural modeling methods based on Transformer to achieve differentiated measurement and evaluation of cracks and other diseases, providing more precise data support for road and bridge maintenance decisions. Finally, further research will focus on robustness enhancement methods that integrate physical priors and adaptive learning mechanisms to improve the performance stability of the system in extreme conditions, promoting the effective transformation of research results into practical engineering applications.
Acknowledgement: We would like to express our gratitude to all those who contributed to the completion of this research. Their insights, discussions, and support greatly enhanced the quality and depth of this work.
Funding Statement: This work was supported in part by the Natural Science Foundation of Shaanxi Province of China under Grant 2024JC-YBQN-0695.
Author Contributions: The authors confirm contribution to the paper as follows: methodology, Langyue Zhao; software, Langyue Zhao and Yubin Yuan; validation, Langyue Zhao, Yubin Yuan and Yiquan Wu; formal analysis, Langyue Zhao and Yubin Yuan; investigation, Langyue Zhao; resources, Langyue Zhao; data curation, Langyue Zhao; writing—original draft preparation, Langyue Zhao and Yubin Yuan; writing—review and editing, Langyue Zhao and Yubin Yuan; visualization, Langyue Zhao and Yubin Yuan; project administration, Langyue Zhao and Yubin Yuan. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data sharing not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39(6):1137–49. doi:10.1109/TPAMI.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
2. Redmon J, Farhadi A. YOLOv3: an incremental improvement. arXiv:1804.02767. 2018. [Google Scholar]
3. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. In: Proceedings of the European Conference on Computer Vision; 2020 Aug 23–28; Glasgow, UK. p. 213–29. doi:10.1007/978-3-030-58452-8_13. [Google Scholar] [CrossRef]
4. Fan L, Wang D, Wang J, Li Y, Cao Y, Liu Y, et al. Pavement defect detection with deep learning: a comprehensive survey. IEEE Trans Intell Veh. 2024;9(3):4292–311. doi:10.1109/tiv.2023.3326136. [Google Scholar] [CrossRef]
5. Ma D, Fang H, Wang N, Lu H, Matthews J, Zhang C. Transformer-optimized generation, detection, and tracking network for images with drainage pipeline defects. Comput Aided Civil Eng. 2023;38(15):2109–27. doi:10.1111/mice.12970. [Google Scholar] [CrossRef]
6. Vasan V, Sridharan NV, Balasundaram RJ, Vaithiyanathan S. Ensemble-based deep learning model for welding defect detection and classification. Eng Appl Artif Intell. 2024;136:108961. doi:10.1016/j.engappai.2024.108961. [Google Scholar] [CrossRef]
7. Zhao K, Xu S, Loney J, Visentin A, Li Z. Road pavement health monitoring system using smartphone sensing with a two-stage machine learning model. Autom Constr. 2024;167:105664. doi:10.1016/j.autcon.2024.105664. [Google Scholar] [CrossRef]
8. Peng X, Wang P, Zhou K, Yan Z, Zhong X, Zhao C. Bridge defect detection using small sample data with deep learning and Hyperspectral imaging. Autom Constr. 2025;170:105900. doi:10.1016/j.autcon.2024.105900. [Google Scholar] [CrossRef]
9. Dung CV, Anh LD. Autonomous concrete crack detection using deep fully convolutional neural network. Autom Constr. 2019;99(4):52–8. doi:10.1016/j.autcon.2018.11.028. [Google Scholar] [CrossRef]
10. Li S, Zhao X. Automatic crack detection and measurement of concrete structure using convolutional encoder-decoder network. IEEE Access. 2020;8:134602–18. doi:10.1109/ACCESS.2020.3011106. [Google Scholar] [CrossRef]
11. Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2015 Jun 7–12; Boston, MA, USA. p. 3431–40. doi:10.1109/CVPR.2015.7298965. [Google Scholar] [CrossRef]
12. Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv:1412.7062. 2014. [Google Scholar]
13. Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. In: Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; 2015 Oct 5–9; Munich, Germany. p. 234–41. doi:10.1007/978-3-319-24574-4_28. [Google Scholar] [CrossRef]
14. Sun X, Xie Y, Jiang L, Cao Y, Liu B. DMA-net: deepLab with multi-scale attention for pavement crack segmentation. IEEE Trans Intell Transp Syst. 2022;23(10):18392–403. doi:10.1109/TITS.2022.3158670. [Google Scholar] [CrossRef]
15. Kang D, Benipal SS, Gopal DL, Cha YJ. Hybrid pixel-level concrete crack segmentation and quantification across complex backgrounds using deep learning. Autom Constr. 2020;118(4):103291. doi:10.1016/j.autcon.2020.103291. [Google Scholar] [CrossRef]
16. Ali R, Cha YJ. Attention-based generative adversarial network with internal damage segmentation using thermography. Autom Constr. 2022;141:104412. doi:10.1016/j.autcon.2022.104412. [Google Scholar] [CrossRef]
17. Kang DH, Cha YJ. Efficient attention-based deep encoder and decoder for automatic crack segmentation. Struct Health Monit. 2022;21(5):2190–205. doi:10.1177/14759217211053776. [Google Scholar] [PubMed] [CrossRef]
18. He K, Gkioxari G, Dollár P, Girshick R. Mask R-CNN. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV); 2017 Oct 22–29; Venice, Italy. p. 2980–8. doi:10.1109/ICCV.2017.322. [Google Scholar] [CrossRef]
19. Chen DR, Chiu WM. Road crack detection using Gaussian mixture model for diverse illumination images. In: Proceedings of the 2020 30th International Telecommunication Networks and Applications Conference (ITNAC); 2020 Nov 25–27; Melbourne, VIC, Australia. p. 1–6. doi:10.1109/ITNAC50341.2020.9315113. [Google Scholar] [CrossRef]
20. Yan BF, Xu GY, Luan J, Lin D, Deng L. Pavement distress detection based on faster R-CNN and morphological operations. China J Highw Transp. 2021;34(9):181–93. doi:10.19721/j.cnki.1001-7372.2021.09.015. [Google Scholar] [CrossRef]
21. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: single shot multiBox detector. In: Proceedings of the Computer Vision—ECCV 2016; 2016 Oct 11–14; Amsterdam, The Netherlands. p. 21–37. doi:10.1007/978-3-319-46448-0_2. [Google Scholar] [CrossRef]
22. Yan K, Zhang Z. Automated asphalt highway pavement crack detection based on deformable single shot multi-box detector under a complex environment. IEEE Access. 2021;9:150925–38. doi:10.1109/ACCESS.2021.3125703. [Google Scholar] [CrossRef]
23. Hou Y, Shi H, Chen N, Liu Z, Wei H, Han Q. Vision image monitoring on transportation infrastructures: a lightweight transfer learning approach. IEEE Trans Intell Transport Syst. 2023;24(11):12888–99. doi:10.1109/tits.2022.3150536. [Google Scholar] [CrossRef]
24. Zhang Y, Zuo Z, Xu X, Wu J, Zhu J, Zhang H, et al. Road damage detection using UAV images based on multi-level attention mechanism. Autom Constr. 2022;144:104613. doi:10.1016/j.autcon.2022.104613. [Google Scholar] [CrossRef]
25. Ma D, Fang H, Wang N, Zhang C, Dong J, Hu H. Automatic detection and counting system for pavement cracks based on PCGAN and YOLO-MF. IEEE Trans Intell Transport Syst. 2022;23(11):22166–78. doi:10.1109/tits.2022.3161960. [Google Scholar] [CrossRef]
26. Zheng S, Lu J, Zhao H, Zhu X, Luo Z, Wang Y, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 6877–86. doi:10.1109/CVPR46437.2021.00681. [Google Scholar] [CrossRef]
27. Xie E, Wang W, Yu Z, Anandkumar A, Alvarez JM, Luo P. SegFormer: simple and efficient design for semantic segmentation with transformers. Adv Neural Inf Process Syst. 2021;34:12077–90. [Google Scholar]
28. Cao H, Wang Y, Chen J, Jiang D, Zhang X, Tian Q, et al. Swin-Unet: Unet-like pure transformer for medical image segmentation. In: Proceedings of the Computer Vision—ECCV 2022; 2022 Oct 23–27; Tel Aviv, Israel. p. 205–18. doi:10.1007/978-3-031-25066-8_9. [Google Scholar] [CrossRef]
29. Wang W, Su C. Automatic concrete crack segmentation model based on transformer. Autom Constr. 2022;139:104275. doi:10.1016/j.autcon.2022.104275. [Google Scholar] [CrossRef]
30. Zhou Z, Zhang J, Gong C. Hybrid semantic segmentation for tunnel lining cracks based on Swin Transformer and convolutional neural network. Comput Aided Civ Infrastruct Eng. 2023;38(17):2491–510. doi:10.1111/mice.13003. [Google Scholar] [CrossRef]
31. Guo F, Qian Y, Liu J, Yu H. Pavement crack detection based on transformer network. Autom Constr. 2023;145:104646. doi:10.1016/j.autcon.2022.104646. [Google Scholar] [CrossRef]
32. Wang S, Li BZ, Khabsa M, Fang H, Ma H. Linformer: self-attention with linear complexity. arXiv:2006.04768. 2020. [Google Scholar]
33. Wan H, Gao L, Su M, Sun Q, Huang L. Attention-based convolutional neural network for pavement crack detection. Adv Mater Sci Eng. 2021;2021:5520515. doi:10.1155/2021/5520515. [Google Scholar] [CrossRef]
34. Liu G, Liu G, Chai X, Li L, Dai F, Huang B. Crack-DETR: complex pavement crack detection by multifrequency feature extraction and fusion. IEEE Sens J. 2025;25(9):16349–60. doi:10.1109/jsen.2025.3549121. [Google Scholar] [CrossRef]
35. Dong R, Xia J, Zhao J, Hong L. CL-PSDD: contrastive learning for adaptive generalized pavement surface distress detection. IEEE Trans Intell Transp Syst. 2025;26(4):5211–24. doi:10.1109/TITS.2024.3525193. [Google Scholar] [CrossRef]
36. Zou Q, Zhang Z, Li Q, Qi X, Wang Q, Wang S. DeepCrack: learning hierarchical convolutional features for crack detection. IEEE Trans Image Process. 2019;28(3):1498–512. doi:10.1109/TIP.2018.2878966. [Google Scholar] [PubMed] [CrossRef]
37. Yan H, Zhang J. UAV-PDD2023: a benchmark dataset for pavement distress detection based on UAV images. Data Brief. 2023;51:109692. doi:10.1016/j.dib.2023.109692. [Google Scholar] [PubMed] [CrossRef]
38. Zhu J, Zhong J, Ma T, Huang X, Zhang W, Zhou Y. Pavement distress detection using convolutional neural networks with images captured via UAV. Autom Constr. 2022;133:103991. doi:10.1016/j.autcon.2021.103991. [Google Scholar] [CrossRef]
39. Pujara A, Bhamare M. DeepSORT: real time & multi-object detection and tracking with YOLO and TensorFlow. In: Proceedings of the 2022 International Conference on Augmented Intelligence and Sustainable Systems (ICAISS); 2022 Nov 24–26; Trichy, India. p. 456–60. doi:10.1109/ICAISS55157.2022.10011018. [Google Scholar] [CrossRef]
40. Zhang Y, Sun P, Jiang Y, Yu D, Weng F, Yuan Z, et al. ByteTrack: multi-object tracking by associating every detection box. In: Proceedings of the Computer Vision—ECCV 2022; 2022 Oct 23–27; Tel Aviv, Israel. p. 1–21. doi:10.1007/978-3-031-20047-2_1. [Google Scholar] [CrossRef]
41. Aharon N, Orfaig R, Bobrovsky BZ. BoT-SORT: robust associations multi-pedestrian tracking. arXiv:2206.14651. 2022. [Google Scholar]
42. Cao J, Pang J, Weng X, Khirodkar R, Kitani K. Observation-centric SORT: rethinking SORT for robust multi-object tracking. arXiv:2203.14360. 2022. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools