
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Fuzzy C-Means Clustering-Driven Pooling for Robust and Generalizable Convolutional Neural Networks
1 Department of Computer Engineering, Dong-eui University, Busan, 47340, Republic of Korea
2 Division of Electrical and Electronic Engineering, Korea Maritime & Ocean University, Busan, 49112, Republic of Korea
3 Department of Information Convergence Engineering, Pusan National University, Busan, 46241, Republic of Korea
* Corresponding Author: Jong-Deok Kim. Email:
Computers, Materials & Continua 2026, 87(2), 24 https://doi.org/10.32604/cmc.2025.074033
Received 30 September 2025; Accepted 27 November 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This paper introduces a fuzzy C-means-based pooling layer for convolutional neural networks that explicitly models local uncertainty and ambiguity. Conventional pooling operations, such as max and average, apply rigid aggregation and often discard fine-grained boundary information. In contrast, our method computes soft memberships within each receptive field and aggregates cluster-wise responses through membership-weighted pooling, thereby preserving informative structure while reducing dimensionality. Being differentiable, the proposed layer operates as standard two-dimensional pooling. We evaluate our approach across various CNN backbones and open datasets, including CIFAR-10/100, STL-10, LFW, and ImageNette, and further probe small training set restrictions on MNIST and Fashion-MNIST. In these settings, the proposed pooling consistently improves accuracy and weighted F1 over conventional baselines, with particularly strong gains when training data are scarce. Even with less than 1% of the training set, our method maintains reliable performance, indicating improved sample efficiency and robustness to noisy or ambiguous local patterns. Overall, integrating soft memberships into the pooling operator provides a practical and generalizable inductive bias that enhances robustness and generalization in modern CNN pipelines.Keywords
Deep learning has brought remarkable progress in many fields by learning to extract and organize useful features from data step by step. Within this trend, convolutional neural networks (CNNs) have become the main driving force behind top performance in tasks such as image classification, object detection, and segmentation [1,2]. They are now actively applied to demanding areas like medical imaging and industrial inspection. In real-world applications, however, what matters is not only high accuracy but also predictions that can be reliable. This requires probability estimates that are well-calibrated and models that degrade gracefully when data are noisy or perturbed [3]. Such properties strongly depend on how the intermediate feature representations are formed [4–6]. In short, these trends highlight the need for architectural improvements that prevent information loss when intermediate representations are spatially subsampled [7,8].
CNN is a neural architecture introduced by LeNet-5, proposed by LeCun et al. in 1998, consisting of convolutional layers, downsampling stages, and a subsequent classification head [1] as shown in Fig. 1. Since then, subsampling has served as a key design axis for reducing the spatial dimensionality of inputs at each stage. With the introduction of ImageNet, AlexNet and VGG established max pooling between blocks as the de facto standard for rapidly shrinking per-stage inputs [2,9], while Network in Network popularized global average pooling (GAP) at the head for the final reduction [10]. GoogLeNet combined stride and pooling within multi-scale Inception paths to control per-stage input size, refined in v2/v3 with factorized convolutions and stronger normalization/optimization [11,12]. Inception-v4 and Inception-ResNet fused Inception blocks with residual connections, further strengthening learnable downsampling [13]. The All-CNN family showed that stride-2 convolutions alone can replace fixed pooling with little loss [14], and ResNet made such stride-based transitions standard via identity shortcuts [15]. Under efficiency goals, EfficientNet used depthwise stride-2 operators for spatial reduction [16] and squeeze-and-excitation (SE) and spatial attention modules for channel recalibration and feature refinement [17,18], leaving only a final GAP. More recently, ConvNeXt and ViT minimize or remove local pooling and perform dimensionality reduction via patch embeddings and hierarchical merging [19,20]. In summary, subsampling is a core axis that decides how much to reduce each layer’s input, and its mechanism has shifted from fixed rules to learnable operators.
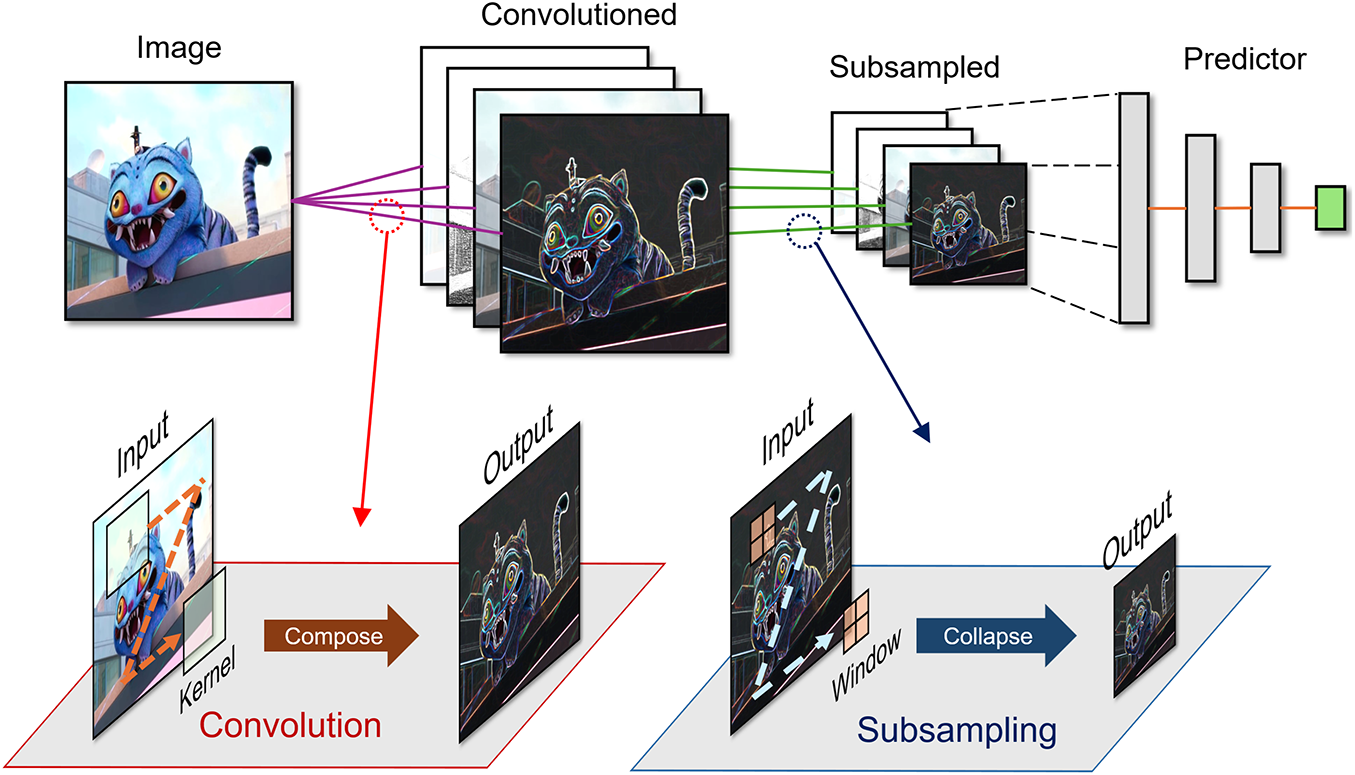
Figure 1: Overview of convolutional neural network and its major components
Among the core components of CNNs, the subsampling stage reduces the spatial size of convolutional feature maps, lowers computational cost, and helps mitigate overfitting [7]. Although many modern backbones now downsample primarily with strided convolutions, the operation that condenses local evidence remains important. Max and average pooling summarize each neighborhood into a single scalar, which can blur boundary details, suppress weak yet informative signals, and miss cues near ambiguous boundaries [8]. To address these issues, adaptive reductions have been proposed. Representative examples include
Nonetheless, important limitations remain. Approaches that learn the pooling exponent or mixing weights, such as
Fuzzy logic provides a principled mathematical framework for quantifying and handling ambiguity and uncertainty [26]. In the view of fuzzy set theory, a sample is not forced into a single category; instead, it is represented by a membership vector whose components lie in [0, 1] and sum to one. Thus, information that conventional pooling would collapse to a single scalar is first decomposed into a compact, multi-aspect code that can capture overlap among feature groups. Among fuzzy clustering methods, fuzzy C-means (FCM) is a widely used soft partitioning scheme: it alternates centroid estimation with membership updates, assigns higher grades to points closer to a centroid, and uses a fuzzifier
This paper proposes a fuzzy pooling layer that estimates per-window soft memberships with FCM and aggregates activations using cluster-specific
Contributions.
1. Uncertainty-aware pooling. Introduces a FCM–driven pooling that encodes per-window soft memberships and aggregates with cluster-specific exponents, explicitly modeling local ambiguity that magnitude-based
2. Drop-in gains across data scarcity. Demonstrates consistent improvements in accuracy and weighted F1 over conventional pooling across backbones and datasets, with the largest margins under limited supervision and subtle class boundaries.
Paper organization. Section 2 reviews pooling methods and related work and discusses their limitations. Section 3 details the design and operation of the proposed fuzzy clustering–based pooling layer. Section 4 evaluates performance across diverse setups, and Section 5 concludes with future directions.
Pooling in CNNs plays a structural role in shaping the feature hierarchy. By summarizing responses within a local window, it reduces spatial resolution, lowers memory footprint and computational burden, and progressively enlarges the effective receptive field. The resulting compact intermediate representations make subsequent layers more tractable and enable stable scaling from early, high-resolution maps to deeper stages [7,29]. In modern architectures, this reduction is realized either by explicit max/average pooling or by strided convolutions; in both cases, the intent is to transform dense neighborhood activations into concise, higher-level features that support efficient learning and inference [14].
2.1 Value-Based Pooling: From Static to Learned Sharpness
Static operators (max/average). For a window
As shown in Fig. 2a, max pooling selects the largest activation in each window, accentuating strong responses and providing limited shift invariance as in Eq. (1), often leading to aliasing artifacts [30]. During backpropagation, the gradient is routed only to the argmax entry, yielding sparse updates but increasing sensitivity to outliers. In contrast, as shown in Fig. 2b, average pooling spreads gradients uniformly across entries and stabilizes optimization, though it can oversmooth edges and lose boundary-level evidence [7,29].
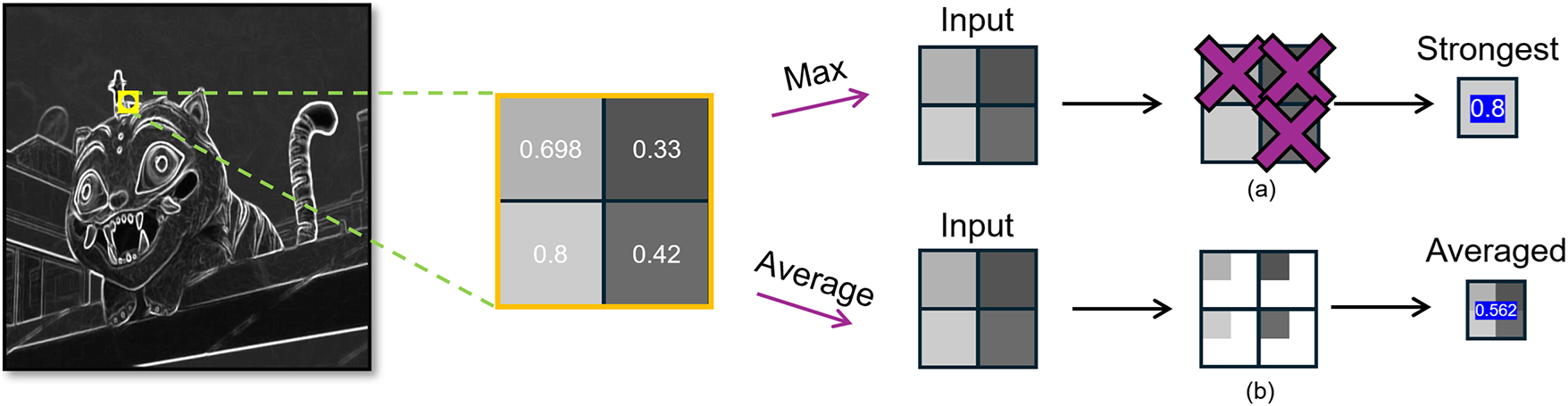
Figure 2: Traditional static pooling. (a) Max pooling keeps only the strongest response; (b) Average pooling takes the mean. Both collapse a local patch to a single scalar
Generalized-mean (Lp) pooling. The generalized mean
controls pooling sharpness with a single parameter
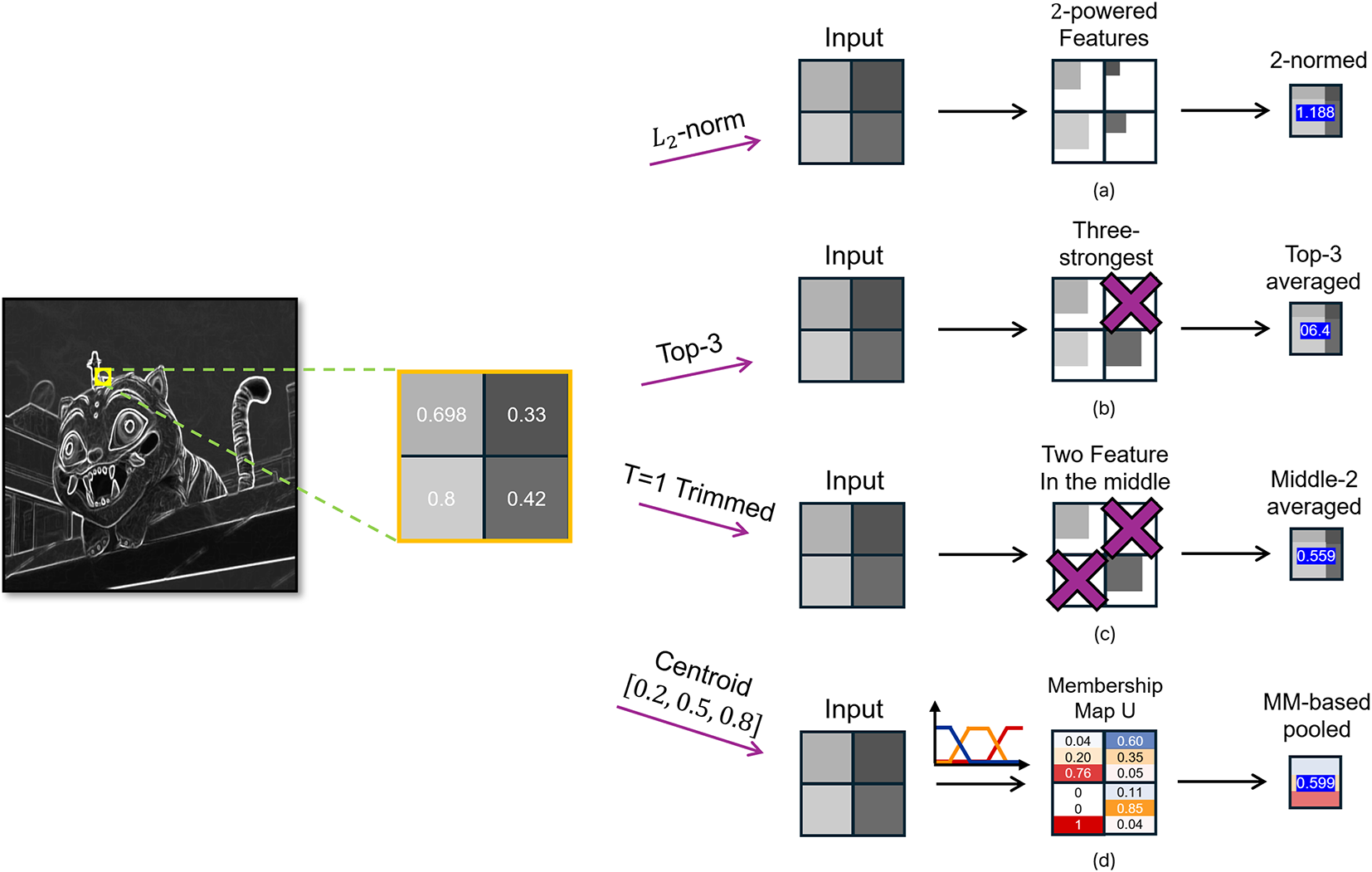
Figure 3: Soft pooling variants on a shared
In practice, power-mean pooling benefits from proper normalization for both accuracy and numerical stability. Prior work on
Order-statistic pooling. This family summarizes responses by rank rather than magnitude. As illustrated in Fig. 3b, Top-K pooling averages the K largest activations (e.g., Top-3 average pooling on a
T-max-avg pooling. This hybrid keeps the maximum if the Top-K responses exceed a threshold T; otherwise, it falls back to the average of Top-K [33]. It balances noise-robustness and peak preservation, though with small windows, it often degenerates to simpler forms.
Unlike value-only reductions, membership-based pooling explicitly represents local ambiguity by assigning each activation a degree of belonging in [0, 1], [26].
Type-1 (membership/rule–driven). Given activations and fixed/learned memberships, pooling is performed as a weighted average. As illustrated in Fig. 3d, learned membership functions (with centers at approximately 0.2, 0.5, and 0.8 in this example) assign weights to entries according to their degrees of belonging before aggregation. This operator is simple and differentiable, but often depends on hand-crafted or task-tuned membership functions, which can limit generality [34,35].
Fuzzy logic has also been integrated into CNN pooling mechanisms and clustering frameworks to enhance feature preservation [36]. FP-CNN [37] introduced a fuzzy pooling operator that adaptively combines max and average pooling through a membership function derived from local feature intensities. Specifically, each pooling region computes a fuzzy membership
Type-2 (uncertain memberships). Here, memberships themselves are uncertain, modeled as intervals with type-reduction prior to defuzzification [38]. It can improve robustness under distribution shifts, but adds complexity and hyperparameters.
Position of this work. Type-1 and Type-2 show the importance of uncertainty-aware pooling, but each faces practical challenges. Our approach addresses these by estimating memberships with FCM and aggregating with cluster-specific exponents, combining adaptability with drop-in compatibility.
3 Fuzzy Clustering–Based Soft Pooling Layer
Design rationale. The analysis in Section 2 suggests three desiderata for a modern pooling operator: (i) avoid collapsing each neighborhood to a single scalar purely by magnitude, so that ambiguous boundary evidence is not discarded; (ii) adapt the sharpness of aggregation to local patterns without the discrete switches of rank-based rules; and (iii) remain numerically stable and efficient, without incurring the overhead of heavy attention mechanisms [17,18] or spectral transforms.
3.1 Overview of the Proposed Layer
Fig. 4 summarizes the workflow of the proposed fuzzy clustering-driven soft pooling layer. Given an input feature map, we compute fuzzy memberships per sample and per location via FCM, using cluster centers shared across the batch. We then realize two pooling variants: (a) Membership Averaging and (b) Membership Maxing. Both variants ultimately perform a normalized generalized-mean (
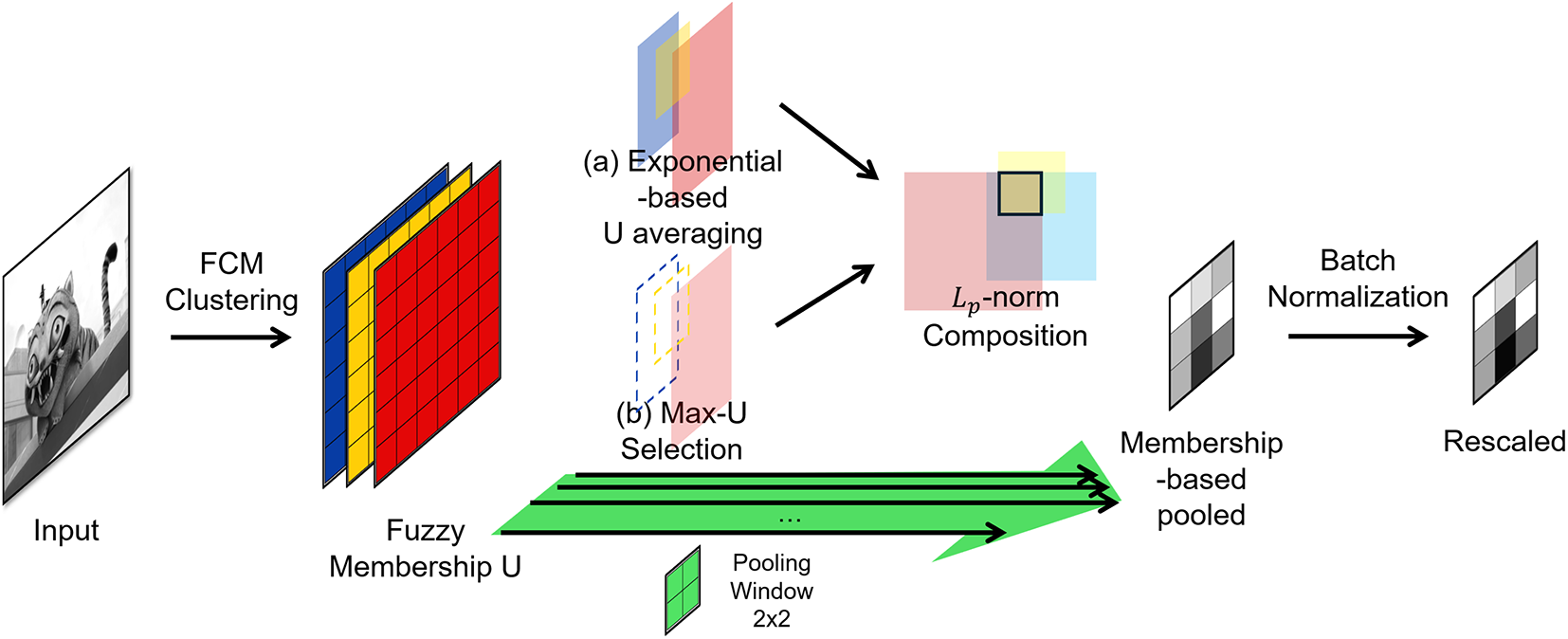
Figure 4: Overview of the proposed fuzzy clustering–based soft pooling layer. FCM yields a per-location membership map U over K latent types. Two branches set the pooling exponent: (a) Membership Averaging and (b) Membership Maxing. The resulting
In practice, the proposed fuzzy pooling layer directly follows each convolutional block, taking its feature map as input without any intermediate transformation. The output retains the same channel dimension and is passed to the next convolution or fully connected layer. Thus, it functions as a drop-in replacement for conventional Max or Average pooling within standard CNN architectures.
3.2 Input Structure and Clustering
Assume a feature tensor
where
yielding a membership tensor
3.3 Computation of the Pooling Exponent
Each cluster
where
Given the memberships
Interpretation of cluster exponents. Implicitly, clusters act as latent pattern types (e.g., edges, textures, flat regions). Learning a distinct
Commonality vs. difference. Both rules rely on the same memberships U and type-wise exponents
Pooling is applied per channel. Let
where
Optionally, a membership-weighted variant replaces the uniform average (
3.5 BN-Inspired Stabilization after the Proposed Fuzzy Pooling
After the proposed fuzzy pooling, a BN-style normalization is appended to stabilize both feature scales and gradient dynamics. In fuzzy clustering-based pooling, the membership distributions
Applying BN immediately after pooling normalizes channel-wise statistics, effectively damping variance propagation and smoothing gradient flow across iterations. From a theoretical perspective, the adaptive
Empirical evidence of this stabilizing effect is presented in Appendix A. Across all architectures (LeNet-5, AlexNet, and VGG-16), the BN-applied variants consistently achieved 3%–8% higher accuracy and weighted F1 scores with reduced variance, demonstrating that BN functions as a structural stabilizer within the proposed fuzzy-adaptive pooling rather than merely as a statistical normalization step. All experiments were conducted with a batch size of 32, providing sufficient samples for reliable batch statistics while avoiding the instability often observed in small-batch BN.
To clarify the computation process of the proposed fuzzy pooling layer, Fig. 5 visualizes the step-by-step operation from clustering to adaptive pooling. An input feature map is clustered by FCM into
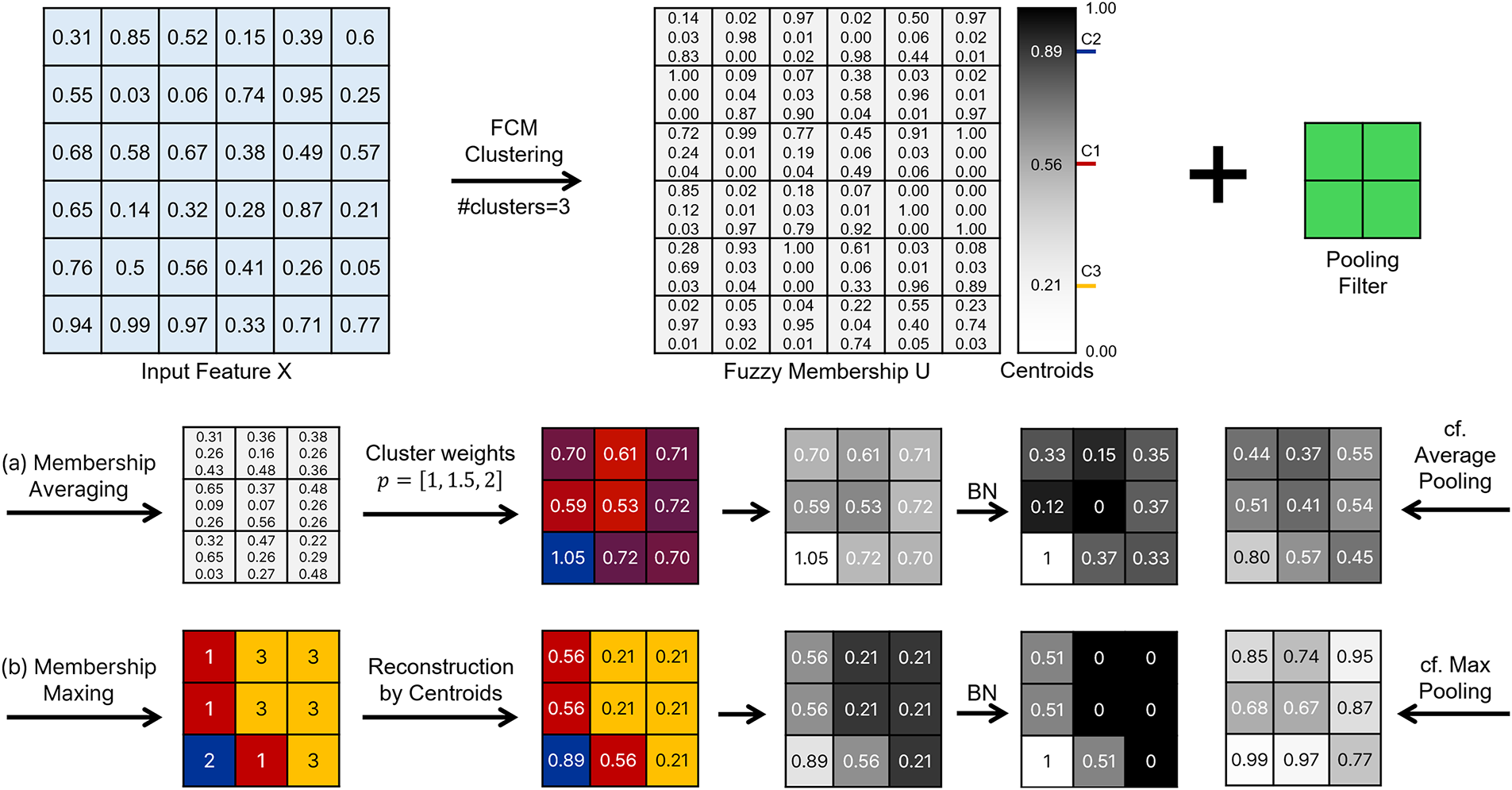
Figure 5: Step-by-step computation of the proposed fuzzy pooling layer. Top: input feature map, FCM memberships, and learned centroids. Bottom: (a) Membership Averaging and (b) Membership Maxing, each followed by BN-style normalization. For comparison, the outputs of conventional average and max pooling are also shown
To further highlight the difference from conventional pooling, Fig. 6 presents the visualized results after the 1st and 2nd pooling stages using various pooling methods. While Average and

Figure 6: Visual comparison of feature maps after the first and second pooling stages across different pooling methods. Average and
This two-step illustration—computation flow followed by visual comparison—clarifies how the proposed fuzzy pooling mechanism translates its adaptive exponent control into perceivable structural differences. The enhanced local contrast observed here provides a visual rationale for the superior discriminative performance demonstrated in Section 4.3 and supports the need for BN stabilization discussed in Section 3.5. For further visualizations concerning the effect of the cluster count K and different integration strategies, please refer to Appendix B.
3.7 Computational Complexity Analysis
The proposed fuzzy pooling layer integrates three computational components: (1) membership estimation based on feature-to-center distances defined in Eq. (3), (2) adaptive
Note that a classical FCM algorithm requires iterative updates with a typical complexity of
Membership computation. Using the distance formulation in Eq. (3), each spatial location computes its distances to K cluster centers and normalizes them according to the membership rule in Eq. (4). This operation requires
Adaptive pooling and normalization. Once the memberships are obtained, the per-location exponent
Overall complexity. Summing these components, the overall computational cost of the proposed layer is
Empirical inference efficiency. To complement the asymptotic analysis, we measured the actual inference time per batch (32 samples) across representative CNNs and pooling methods. Table 1 summarizes the results averaged over five runs.

The inference latency of the proposed fuzzy pooling (Mavg and Mmax) is generally comparable to that of the Type-1 fuzzy baseline (FP) on smaller networks, while being substantially faster on the deeper VGG-16 architecture (e.g.,
4 Implementation and Evaluation
4.1 Experimental Environment and Setup
We evaluate the pooling layers defined in Section 3 in two distinct experimental phases against seven alternatives.
Hardware configuration.
All experiments were conducted on a workstation equipped with an Intel Core i9-13900F CPU (24 cores, 32 threads), an NVIDIA RTX 4090 GPU (24 GB VRAM), and 64 GB of main memory. TensorFlow (ver. 2.12) was used with the NVIDIA-recommended configuration for the RTX 4090, including CUDA 12.x and cuDNN 8.x libraries. The batch size was fixed at 32 across all experiments to ensure consistent batch-normalization statistics and reproducible inference-time comparisons.
Proposed methods. Mavg: Membership-Averaging fuzzy pooling; Mmax: Membership-Maxing fuzzy pooling. Both variants incorporate the BN-style stabilization described in Section 3 (ablation study provided in Appendix A).
Baselines. To validate effectiveness, we compare against seven pooling strategies: Max and Avg pooling (standard);
Backbones and insertion points.
We use three CNN backbones, as illustrated in Fig. 7: (a) LeNet-5 [1], (b) AlexNet [2], and (c) VGG-16 [9]. In all models, the native pooling layers (highlighted in green) are replaced one-for-one by each candidate pooling operator, preserving the original window size, stride, and padding configuration.
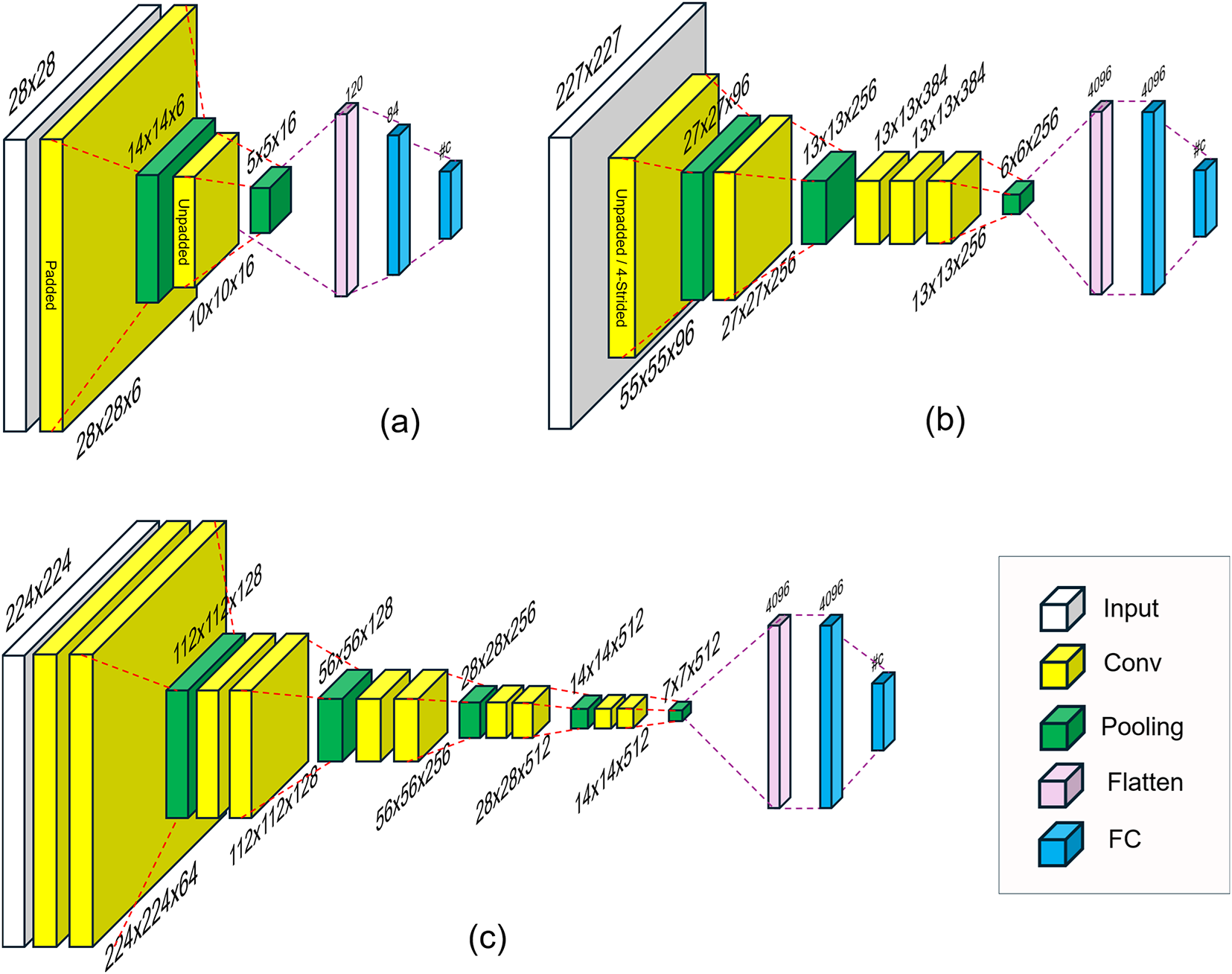
Figure 7: Backbone CNNs and pooling insertion points. (a) LeNet-5-style network for
Why hold-out (HO) instead of
While
Experiment 1 (Multi-backbone comparison).
This phase evaluates general classification performance across diverse domains.
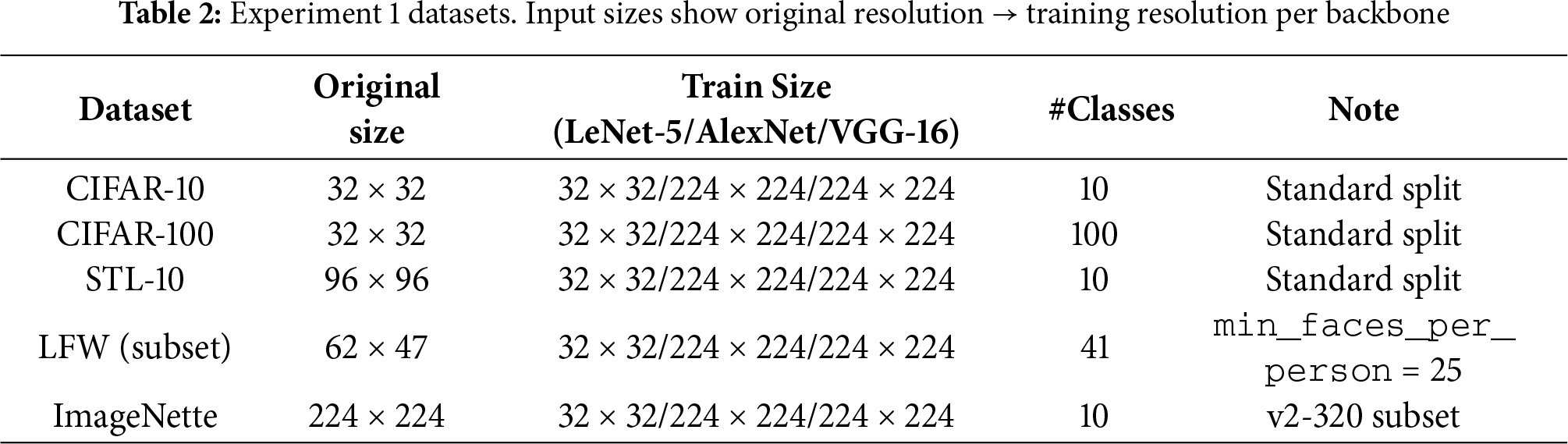
• Datasets: CIFAR-10 and CIFAR-100 [40], LFW (subset) [41], STL-10 [42], and ImageNette (a subset of ImageNet [43]), as summarized in Table 2.
• Split: A single random hold-out (HO) partition with a ratio of train:val:test = 0.6:0.2:0.2.
• Backbones: LeNet-5, AlexNet, and VGG-16.
Experiment 2 (Low-resolution, low-data probe).
This phase probes robustness under data scarcity using lightweight models.
• Backbone: LeNet-5 only (input resized to
• Datasets: MNIST [1] and Fashion-MNIST [44], as summarized in Table 3.
• Split: For each training fraction

Repeated HO with convergence filtering.
For each (dataset, backbone, pooling) configuration, we draw independent random HO partitions and train until obtaining a fixed number of converged runs: 10 runs for Experiment 1 and 5 runs for Experiment 2. Runs that do not converge (e.g., due to divergence or instability) are discarded and retried with a new random seed and split. We report the mean
Preprocessing and training.
Inputs are min-max normalized to
Hyperparameter setting for
The fuzzifier was fixed at
To determine a suitable range for the number of clusters K, we conducted preliminary experiments under conditions similar to the two main setups (Training ratio
In the main experiments, to ensure optimal model selection, K was determined based on the validation loss during the stabilization phase of training—the intermediate stage where training and validation losses oscillate around equilibrium before overfitting begins. This phase, which follows the initial rapid convergence and precedes the divergence between training and validation losses, best reflects the model’s saturated generalization capability. Accordingly, we monitored the validation loss over the last 10 epochs of this phase and selected the K yielding the lowest validation loss. This procedure provides a data-driven and reproducible determination of K, avoiding bias from transient states.
Experiment 1 (Multi-backbone).
Figs. 8–13 present the accuracy and weighted F1 distributions (10 converged hold-out runs) for LeNet-5, AlexNet, and VGG-16. Across all configurations, Mavg and Mmax consistently achieve the highest medians (or tie for the top position) with narrower interquartile ranges (IQRs), indicating robust convergence. Notably, these improvements are statistically significant (Wilcoxon signed-rank test,
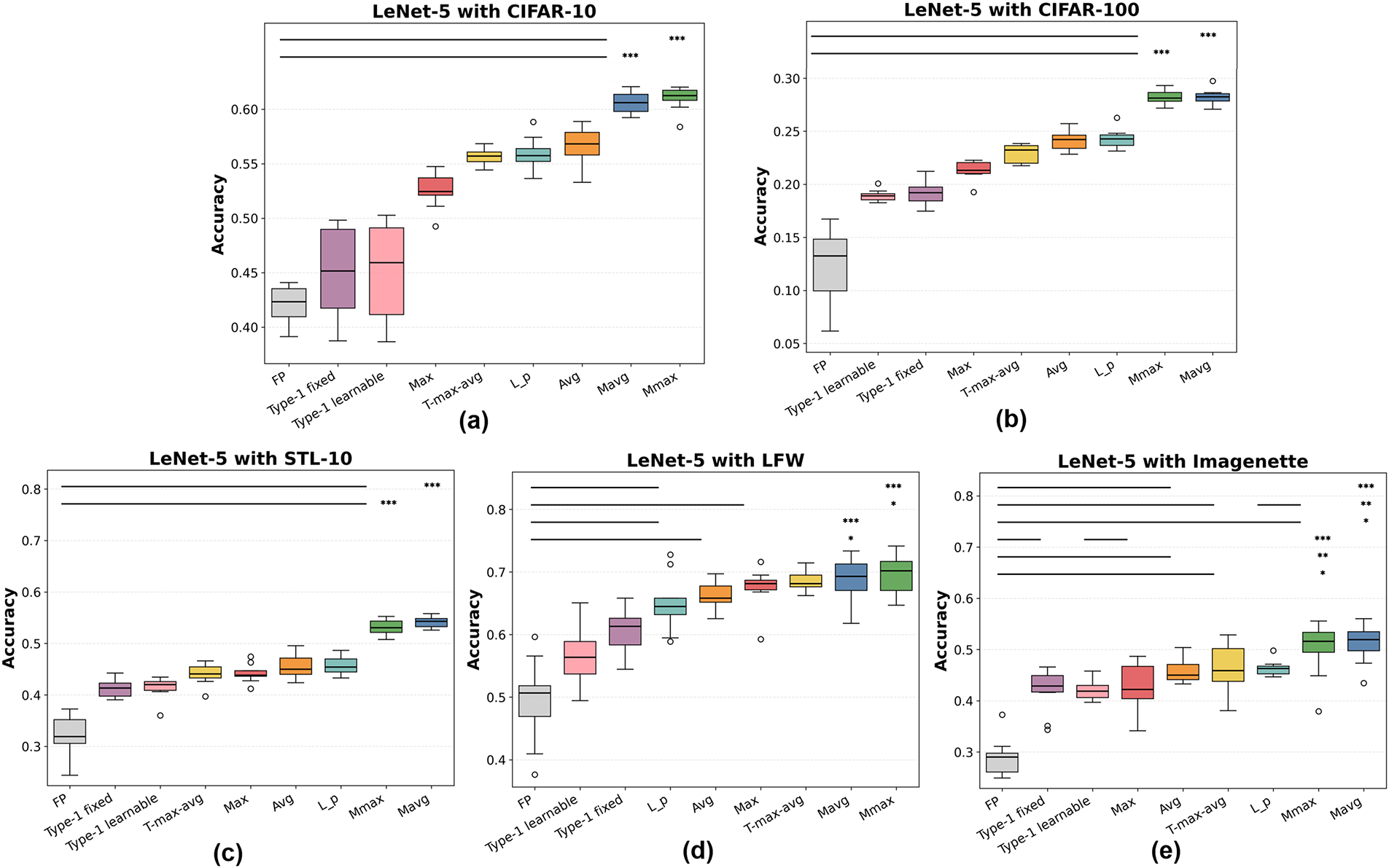
Figure 8: Classification accuracy of pooling methods with LeNet-5 on (a) CIFAR-10, (b) CIFAR-100, (c) STL-10, (d) LFW, and (e) Imagenette. FP denotes the fuzzy-pooling module in FP-CNN [37]. Horizontal bars with asterisks mark paired Wilcoxon signed-rank test results (
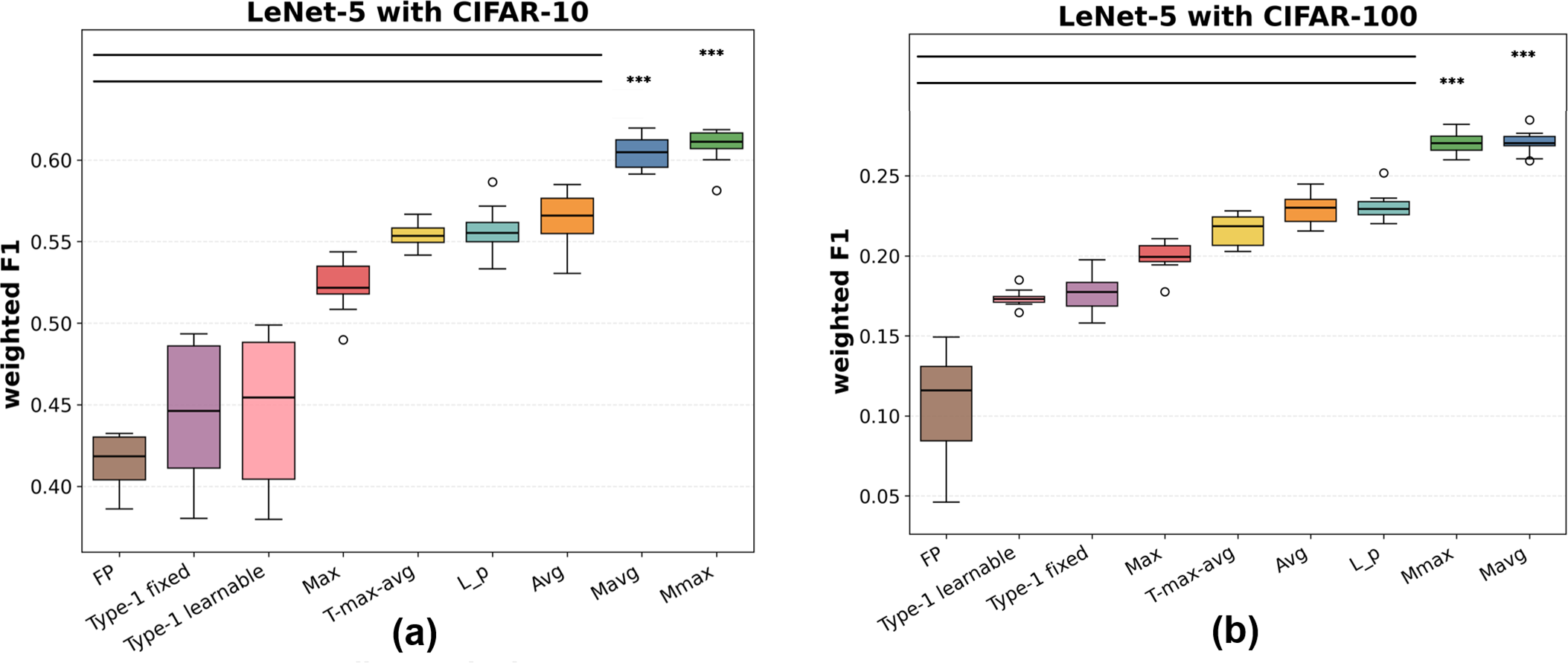
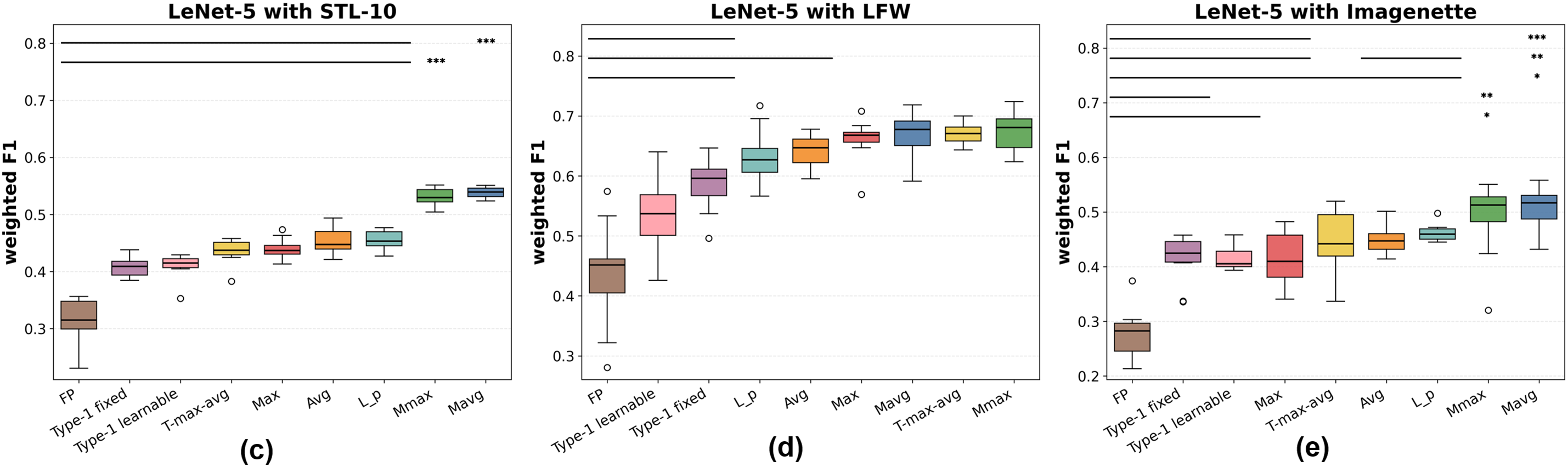
Figure 9: Weighted F1 scores of pooling methods with LeNet-5 on (a) CIFAR-10, (b) CIFAR-100, (c) STL-10, (d) LFW, and (e) Imagenette. Significance notation follows Fig. 8
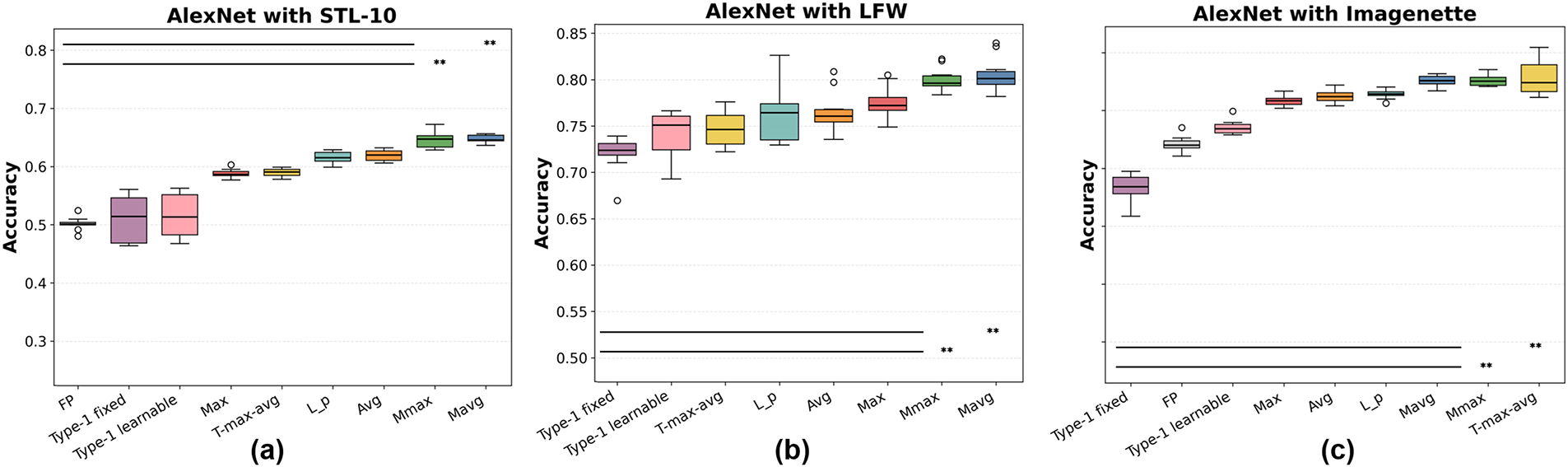
Figure 10: Classification accuracy of pooling methods with AlexNet on (a) STL-10, (b) LFW, and (c) Imagenette. FP denotes FP-CNN. Asterisks indicate significance under paired Wilcoxon tests (∗:
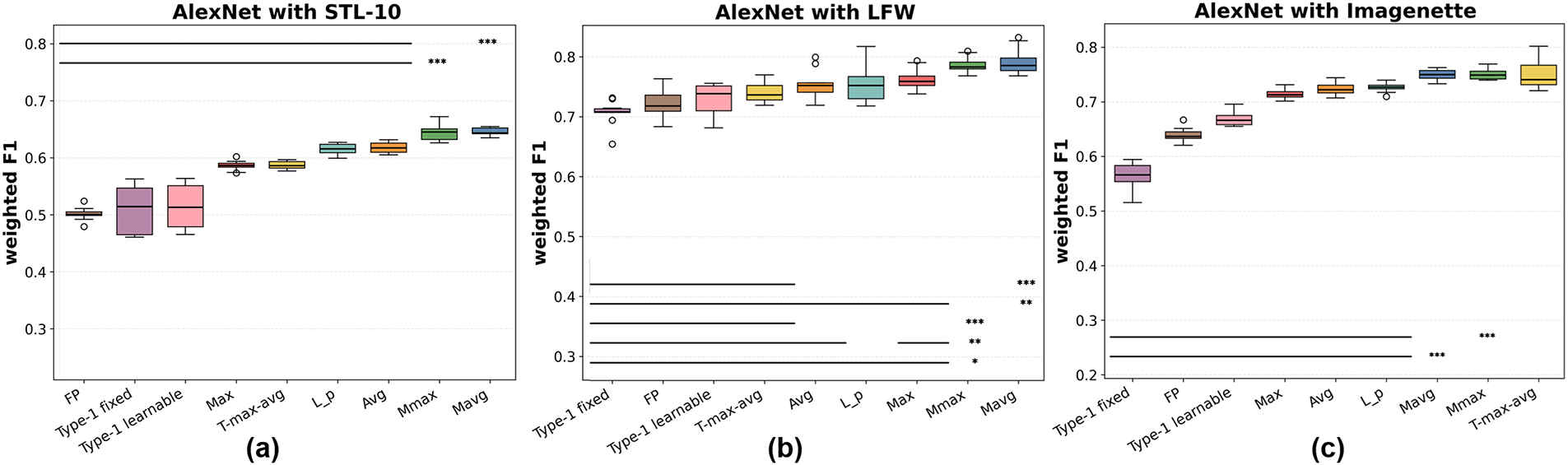
Figure 11: Weighted F1 scores of pooling methods with AlexNet on (a) STL-10, (b) LFW, and (c) Imagenette. Significance notation follows Fig. 10
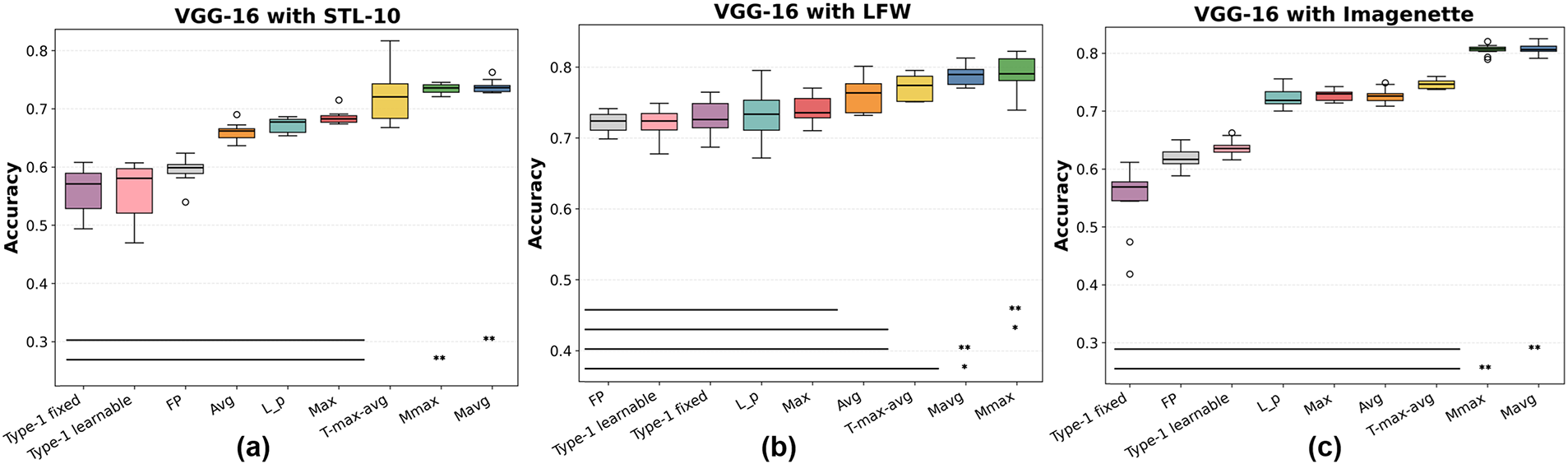
Figure 12: Classification accuracy of pooling methods with VGG-16 on (a) STL-10, (b) LFW, and (c) Imagenette. FP denotes FP-CNN. Significance bars follow the Wilcoxon test conventions in Fig. 8
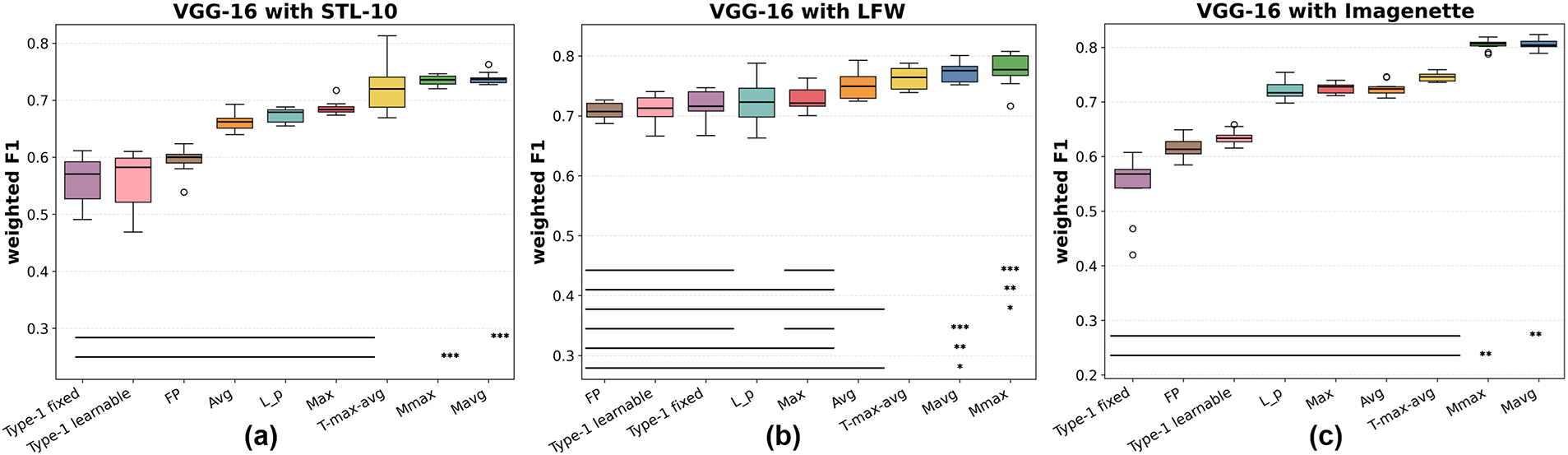
Figure 13: Weighted F1 scores of pooling methods with VGG-16 on (a) STL-10, (b) LFW, and (c) Imagenette. Significance notation follows Fig. 12
As detailed in Figs. 8 and 9, for LeNet-5, Mavg consistently outperforms Max, Avg,
Referring to Figs. 10 and 11, for AlexNet, the superiority of Mavg and Mmax is also evident. On STL-10, Mmax performs best, closely followed by Mavg, both exhibiting small variance. On LFW,
As shown in Figs. 12 and 13, for VGG-16, the deeper backbone raises overall accuracy and F1 relative to LeNet-5 and AlexNet, yet Mavg consistently maintains a performance advantage—most visibly on LFW and Imagenette. While
Comparing accuracy and weighted F1 across all backbones, the relative rankings of pooling methods remain nearly identical. Weighted F1, which better accounts for class imbalance, further highlights the superiority of the proposed methods, especially on CIFAR-100 and Imagenette where the number of classes is large and intra-class variance is substantial. This indicates that membership-based pooling aggregates feature responses more effectively than either extremal selection (Max) or uniform averaging (Avg).
Statistical significance. To confirm that the observed performance gains are not due to random variation, paired two-sided Wilcoxon signed-rank tests were conducted over 10 independent runs per dataset and backbone. Horizontal bars and asterisks in Figs. 8–13 denote significance levels (
In summary, Experiment 1 demonstrates that Mavg is the most consistently strong pooling method, with Mmax providing comparable or complementary benefits. Both converge reliably across diverse datasets and backbones, as evidenced by reduced variance and statistically significant improvements in most cases. While
Experiment 2 (Performance under limited supervision).
We investigate the impact of training-data scarcity by varying the fraction of training samples
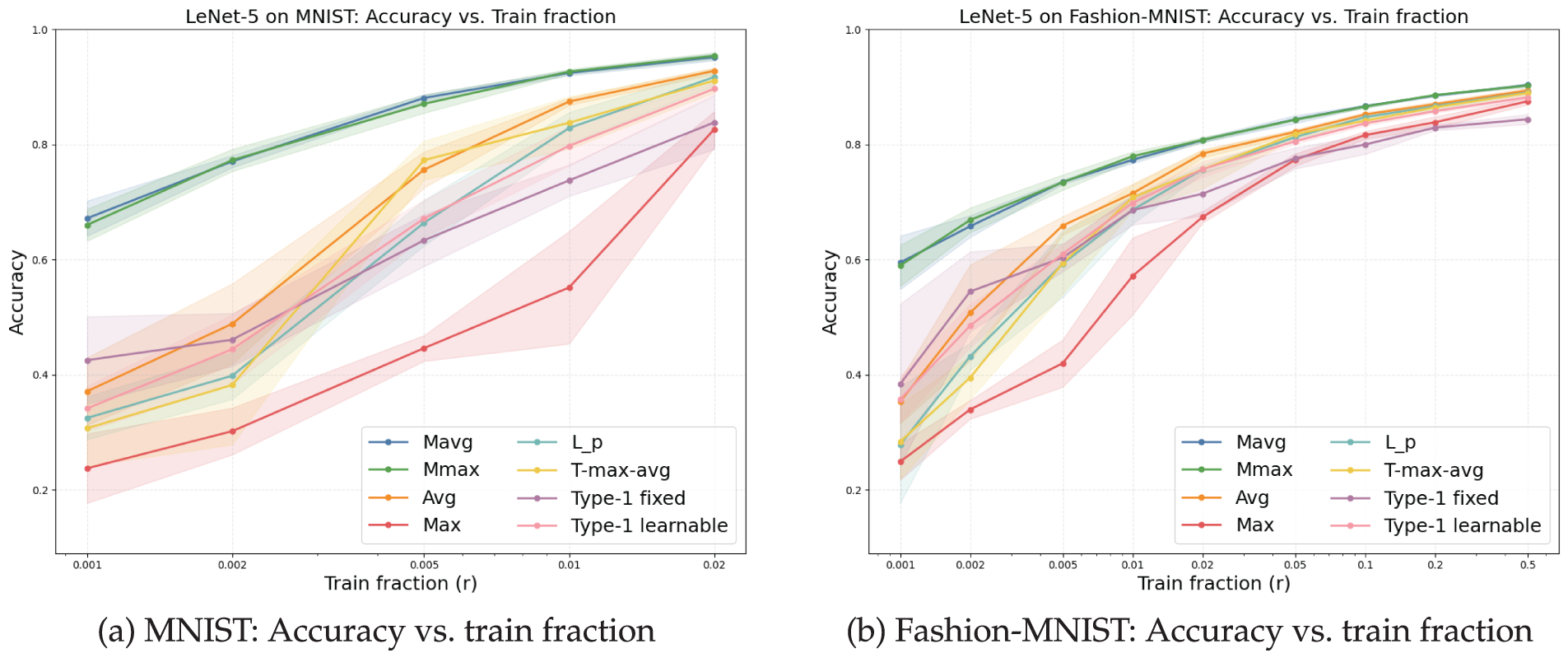
Figure 14: Classification accuracy across training fractions for MNIST and Fashion-MNIST using LeNet-5 (Experiment 2). Shaded bands denote
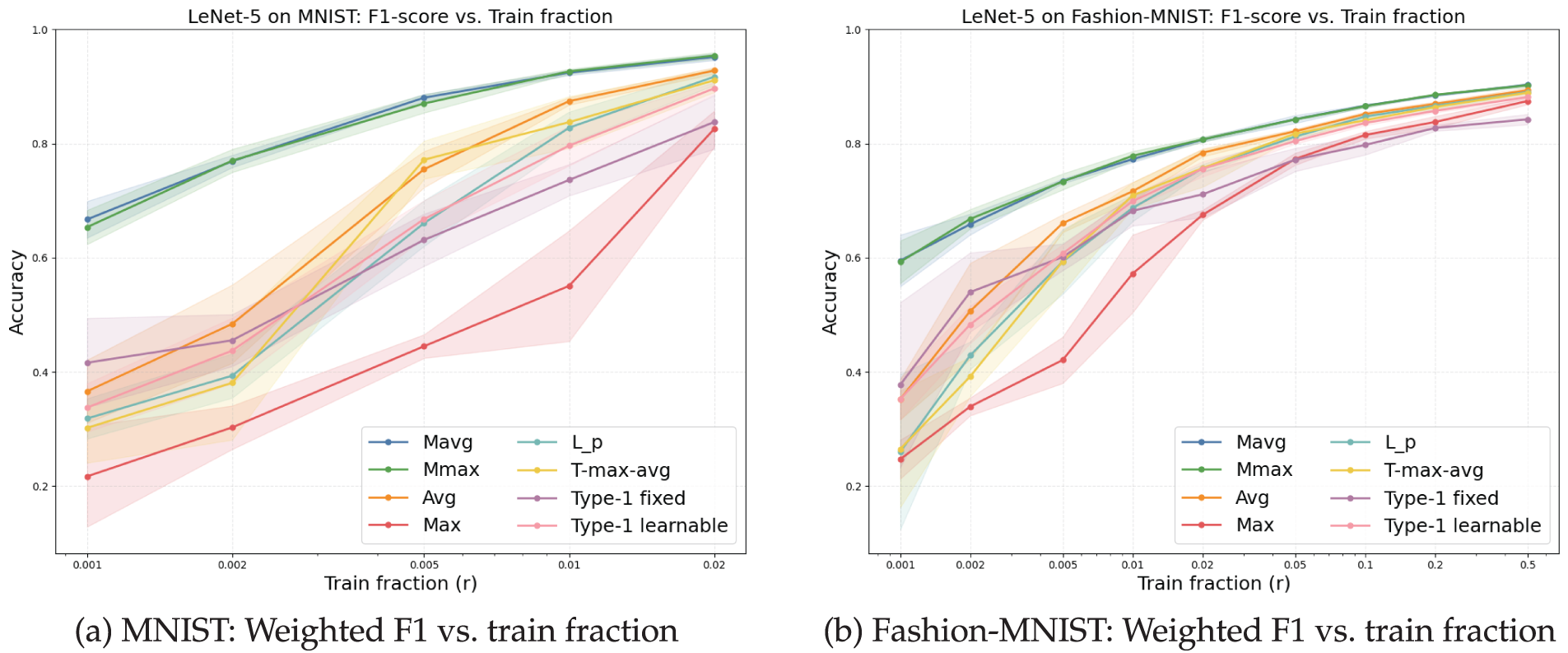
Figure 15: Weighted F1 across training fractions for MNIST and Fashion-MNIST using LeNet-5 (Experiment 2). Shaded bands denote
Overall, membership-based pooling (Mavg/Mmax) consistently outperforms conventional pooling operators on both datasets. On MNIST, the advantage is evident even at extremely small training ratios (
As
On Fashion-MNIST—which is more challenging due to higher intra-class variability—the gaps are even more pronounced at small fractions (
Taken together, Experiment 2 validates the robustness of membership-based pooling under limited supervision, a common real-world scenario where large annotated datasets are unavailable. By aggregating responses via soft memberships—avoiding the pitfalls of both extremal selection (Max) and uniform averaging (Avg)—the proposed pooling family offers a stronger inductive bias that translates into superior generalization, particularly under data scarcity.
Key observations.
(1) Across LeNet-5, AlexNet, and VGG-16, Mavg/Mmax typically achieve higher medians and tighter IQRs than Max/Avg/
(2) On LFW, improvements are present but smaller. With AlexNet, conventional schemes may occasionally tie or slightly outperform the proposed layers. This suggests that when early features are already strongly structured (e.g., by large receptive fields or strong low-level inductive biases) and decision boundaries are subtle, pooling contributes less to overall discriminability.
(3) Type-1 fuzzy pooling (fixed and learnable) consistently shows lower central tendency and higher variance. This aligns with the difficulty of specifying or stably learning crisp membership functions under noisy local statistics. By contrast, our FCM-style soft memberships adapt smoothly within each window, reducing sensitivity to local outliers and improving robustness—consistent with Experiment 2 results under limited supervision.
(4) Weighted F1 mirrors accuracy across all settings, indicating that gains are not artifacts of class-frequency imbalance but reflect genuine improvements in balanced classification.
Overall implications.
Membership-based pooling provides a consistent inductive bias across architectures and datasets, particularly when data are noisy, imbalanced, or scarce. While its relative advantage can diminish under strongly regularized architectures or inherently separable feature spaces (e.g., LFW with AlexNet), the method remains robust and avoids the instability observed in Type-1 fuzzy baselines. These properties make it a practical drop-in replacement for standard pooling in real-world scenarios where dataset conditions are rarely ideal.
This work proposed two fuzzy C-means (FCM)-based pooling layers, Mavg (Membership-Averaging) and Mmax (Membership-Maxing), that bring soft, data-driven aggregation into convolutional neural networks. By leveraging fuzzy memberships computed per pooling region and converting them into a location-adaptive pooling exponent with BN-style stabilization (cf. Section 3), the layers preserve boundary ambiguity and reduce information loss typical of static operators (Max/Avg) while remaining drop-in compatible with standard CNNs.
Empirical findings.
Across Experiment 1 (three backbones: LeNet-5, AlexNet, VGG-16; five datasets: CIFAR-10/100, STL-10, LFW, ImageNette), membership-based pooling attained higher median accuracy and weighted F1 with tighter variability than Max/Avg/
Limitations and scope.
Although the proposed fuzzy pooling layers are lightweight and drop-in compatible with existing CNNs, several limitations and considerations remain.
First, the computation of fuzzy memberships introduces a slight linear overhead proportional to the number of clusters K. This cost is small compared to convolutional operations and involves no iterative optimization. Importantly, unlike rule-based fuzzy systems or conditional pooling strategies, the proposed layer contains no branching operations, which preserves GPU pipelining efficiency and allows highly parallel execution across pooling regions. Consequently, inference speed remains close to that of conventional pooling, as verified in our complexity analysis (Section 3.7).
Second, the method’s performance shows moderate sensitivity to hyperparameters such as the number of clusters K and the fuzzifier
Third, the BN-style normalization effectively stabilizes training but assumes sufficiently large batch sizes for reliable statistics. When batch size is limited or streaming inference is required, alternatives such as Group Normalization or Instance Normalization may provide better stability while retaining the same integration principle.
Finally, our evaluations were based on publicly available image benchmarks to ensure comparability with prior pooling studies. While these datasets provide valuable diversity, future validation on real-world or domain-specific data—such as medical, environmental, or defense applications—would further demonstrate the method’s generalization and reliability under practical conditions.
Practical implications.
Mavg is a strong default due to its smoothness and stable convergence; Mmax can be preferable when preserving high-frequency or edge-dominant responses is critical. Using K close to the number of classes worked reliably across settings, and BN-style post-normalization consistently improved training stability and reproducibility. That said, benefits diminish when early features are already highly separable (e.g., AlexNet on LFW), suggesting that architecture capacity and dataset characteristics should inform the choice of variant and K.
Future work.
• Hyperparameters and rules. Systematic study of K, fuzzifier
• Learning strategies. Regularization/scheduling for the membership map, bilevel objectives for centroids vs. features, and calibration-aware training to improve reliability under shift.
• Architectural/generalization breadth. Extending to modern backbones (ResNets, ConvNeXts, Transformers) and tasks beyond classification (detection/segmentation), including dense prediction where spatial ambiguity is critical.
• Coupled optimization. Joint refinement of memberships and features (e.g., alternating updates, meta-learning of
Summary.
Embedding fuzzy memberships into pooling offers a principled and practical path to more robust, generalizable CNNs. By consistently improving accuracy and balanced metrics across architectures, datasets, and supervision levels—and by retaining a simple drop-in form—Mavg/Mmax illustrate the value of importing fuzzy-set principles into core deep learning operators.
Acknowledgement: The authors would like to express their gratitude to all collaborators who provided constructive feedback during this study.
Funding Statement: This research was supported by the Institute of Information & Communications Technology Planning & Evaluation (IITP)–ITRC (Information Technology Research Center) grant funded by the Korea government (MSIT) (IITP-2025-RS-2023-00260098, 50%), and the Aerospace and ICT Localization & Commercialization Technology Development Project funded by Gyeongsangnam-do and the Gyeongnam Techno park (50%).
Author Contributions: Conceptualization, Seunggyu Byeon, Jung-hun Lee and Jong-Deok Kim; methodology, Seunggyu Byeon; software, Seunggyu Byeon; validation, Seunggyu Byeon and Jung-hun Lee; formal analysis, Seunggyu Byeon; investigation, Seunggyu Byeon and Jung-hun Lee; writing—original draft preparation, Seunggyu Byeon; writing—review and editing, Seunggyu Byeon and Jong-Deok Kim; visualization, Seunggyu Byeon and Jung-hun Lee; supervision, Jong-Deok Kim; project administration, Jong-Deok Kim; funding acquisition, Jong-Deok Kim. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: All datasets used in this study are publicly available: CIFAR-10/100, STL-10, LFW (subset), ImageNette, MNIST, and Fashion-MNIST (see Tables 2 and 3). The implementation of the proposed Mavg/Mmax pooling layers (including training and evaluation scripts) is available at: https://colab.research.google.com/drive/1u8S6Nyp8Ojciy28bMGnZXIoYuehoADCJ?usp=sharing. If any access issues occur, please contact the corresponding author.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
Abbreviations
| Avg | Average pooling |
| BN | Batch normalization |
| CIFAR | Canadian Institute for Advanced Research image datasets (CIFAR-10/100) |
| CNN | Convolutional neural network |
| CV | Cross-validation |
| FC | Fully connected (layer) |
| FCM | Fuzzy C-means clustering |
| FP | Fuzzy pooling (specifically the module in FP-CNN) |
| F1 | F1-score (harmonic mean of precision and recall); “weighted F1” is class-frequency weighted |
| HO | Hold-out (train/validation/test split) |
| IQR | Interquartile range |
| Lp | Generalized-mean pooling with exponent p |
| LFW | Labeled Faces in theWild |
| Mavg | Membership-averaging fuzzy pooling (proposed) |
| Mmax | Membership-maxing fuzzy pooling (proposed) |
| MNIST | Modified National Institute of Standards and Technology dataset |
| RGB | Red–Green–Blue color channels |
| STL-10 | STL-10 image dataset (10 classes, 96 × 96) |
| T-max-avg | Thresholded Top-K max–average hybrid pooling |
| VGG | Visual Geometry Group (e.g., VGG-16) |
Appendix A Ablation Results on BN-Style Normalization
This appendix summarizes the detailed ablation results for BN-style normalization applied after the proposed fuzzy pooling layer. The normalization follows the standard batch normalization formulation described in [31]. The quantitative comparisons across datasets and backbones are presented in Table A1.
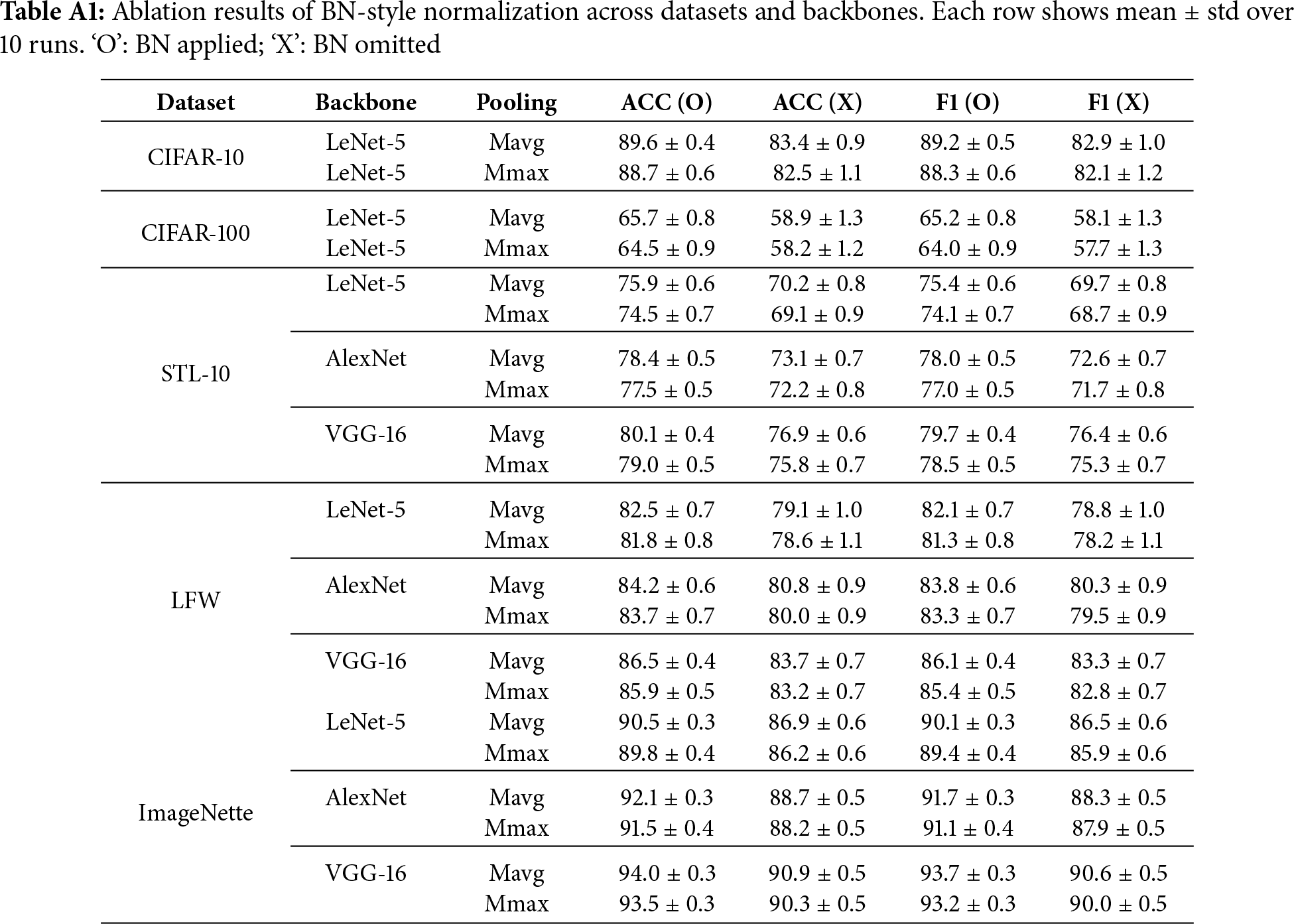
CIFAR-10 and CIFAR-100 were evaluated using LeNet-5, while STL-10, LFW, and ImageNette were tested on LeNet-5, AlexNet, and VGG-16 backbones. Each row reports the mean
BN consistently improves both accuracy and weighted F1 across all datasets. As shown in Table A1, for simpler networks such as LeNet-5 (CIFAR-10/100), the improvement reaches up to 7%–8% absolute, while for deeper networks (AlexNet, VGG-16) on larger datasets, BN contributes steady 3%–5% gains with reduced variance. These results confirm that BN acts as a structural stabilizer against fluctuations induced by fuzzy memberships and adaptive pooling exponents.
Appendix B Visualization of the Proposed Fuzzy Pooling Layer
To provide a qualitative understanding of how the proposed fuzzy pooling operates, we visualize intermediate feature maps and the final pooled responses under different settings. The visualization clarifies how the clustering process, learned pooling exponents, and cluster integration—as detailed in Section 3—jointly determine the spatial saliency pattern produced by the layer.
In all cases, the process proceeds in four stages:
(i) Fuzzy clustering: local features are grouped into K latent types via FCM [28];
(ii) Cluster-wise feature mapping: each cluster yields a distinct feature response map;
(iii) Adaptive modulation: learned exponents
(iv) Integration: the maps are merged using either Membership Averaging (Mavg) or Membership Maxing (Mmax).
Fig. A1a,b illustrates the effect of learned pooling exponents when

Figure A1: Visual comparison of the proposed fuzzy pooling layer. (a,b) show two integration variants derived from identical fuzzy memberships: both start from the same clustering and per-cluster feature maps, modulate local saliency using learned exponents
These qualitative results demonstrate that the proposed fuzzy pooling not only blends average and max pooling behaviors but also adaptively modulates feature intensity through the learned exponents
References
1. Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proc IEEE. 1998;86(11):2278–324. doi:10.1109/5.726791. [Google Scholar] [CrossRef]
2. Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems. Vol. 25. Late Tahoe, NV, USA: Neuro IPS; 2012. [Google Scholar]
3. Hendrycks D, Dietterich T. Benchmarking neural network robustness to common corruptions and perturbations. arXiv:1903.12261. 2019. [Google Scholar]
4. Guo C, Pleiss G, Sun Y, Weinberger KQ. On calibration of modern neural networks. In: Proceedings of the 34th International Conference on Machine Learning; 2017 Aug 6–11; Sydney, NSW, Australia. New Orleans, LA, USA: PMLR; 2017. p. 1321–30. [Google Scholar]
5. Minderer M, Djolonga J, Romijnders R, Hubis F, Zhai X, Houlsby N, et al. Revisiting the calibration of modern neural networks. Adv Neural Inform Process Syst. 2021;34:15682–94. [Google Scholar]
6. Ovadia Y, Fertig E, Ren J, Nado Z, Sculley D, Nowozin S, et al. Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. In: Advances in neural information processing systems. Vol. 32. Vancouver, BC, Canada: Neuro IPS; 2019. [Google Scholar]
7. Zafar A, Aamir M, Mohd Nawi N, Arshad A, Riaz S, Alruban A, et al. A comparison of pooling methods for convolutional neural networks. Appl Sci. 2022;12(17):8643. doi:10.3390/app12178643. [Google Scholar] [CrossRef]
8. Rippel O, Snoek J, Adams RP. Spectral representations for convolutional neural networks. In: Advances in neural information processing systems. Vol. 28. Montreal, QC, Canada: Neuro IPS; 2015. [Google Scholar]
9. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556. 2014. [Google Scholar]
10. Lin M, Chen Q, Yan S. Network in network. arXiv:1312.4400. 2013. [Google Scholar]
11. Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015 Jun 7–12; Boston, MA, USA. p. 1–9. doi:10.1109/CVPR.2015.7298594. [Google Scholar] [CrossRef]
12. Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. p. 2818–26. doi:10.1109/CVPR.2016.308. [Google Scholar] [CrossRef]
13. Szegedy C, Ioffe S, Vanhoucke V, Alemi A. Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the AAAI Conference on Artificial Intelligence; 2017 Feb 11; San Francisco, CA, USA. Vol. 31. p. 4278–84. doi:10.1609/aaai.v31i1.11231. [Google Scholar] [CrossRef]
14. Springenberg JT, Dosovitskiy A, Brox T, Riedmiller M. Striving for simplicity: the all convolutional net. arXiv:1412.6806. 2014. [Google Scholar]
15. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016 Jun 27–30; Las Vegas, NV, USA. p. 770–8. doi:10.1109/CVPR.2016.90. [Google Scholar] [CrossRef]
16. Tan M, Le Q. Efficientnet: rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning; 2019 Jun 9–15; Long Beach, CA, USA. p. 6105–14. [Google Scholar]
17. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 7132–41. doi:10.1109/CVPR.2018.00745. [Google Scholar] [CrossRef]
18. Woo S, Park J, Lee JY, Kweon IS. Cbam: convolutional block attention module. In: Proceedings of the European Conference on Computer Vision. Munich, Germany: ECCV; 2018. p. 3–19. [Google Scholar]
19. Liu Z, Mao H, Wu CY, Feichtenhofer C, Darrell T, Xie S. A convnet for the 2020s. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 18–24; New Orleans, LA, USA. p. 11976–86. doi:10.1109/CVPR52688.2022.01167. [Google Scholar] [CrossRef]
20. Dosovitskiy A. An image is worth 16x16 words: transformers for image recognition at scale. arXiv: 2010.11929. 2020. [Google Scholar]
21. Gulcehre C, Cho K, Pascanu R, Bengio Y. Learned-norm pooling for deep feedforward and recurrent neural networks. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Nancy, France: Berlin/Heidelberg, Germany: Springer; 2014. p. 530–46. doi:10.1007/978-3-662-44848-9_34. [Google Scholar] [CrossRef]
22. Bieder F, Sandkühler R, Cattin P. Comparison of methods generalizing max-and average-pooling. arXiv:2103.01746. 2021. [Google Scholar]
23. Radenović F, Tolias G, Chum O. Fine-tuning CNN image retrieval with no human annotation. IEEE Trans Pattern Anal Mach Intell. 2018;41(7):1655–68. doi:10.1109/TPAMI.2018.2846566. [Google Scholar] [PubMed] [CrossRef]
24. Zeiler MD, Fergus R. Stochastic pooling for regularization of deep convolutional neural networks. arXiv:1301.3557. 2013. [Google Scholar]
25. Zhai S, Wu H, Kumar A, Cheng Y, Lu Y, Zhang Z, et al. S3pool: pooling with stochastic spatial sampling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2017 Jul 21–26; Honolulu, HI, USA. p. 4970–8. [Google Scholar]
26. Zadeh LA. Fuzzy sets. Inform Control. 1965;8(3):338–53. doi:10.1016/S0019-9958(65)90241-X. [Google Scholar] [CrossRef]
27. Dunn JC. A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters. J Cybern. 1973;3(3):32–57. doi:10.1080/01969727308546046. [Google Scholar] [CrossRef]
28. Bezdek JC. Pattern recognition with fuzzy objective function algorithms. New York, NY, USA: Berlin/Heidelberg, Germany: Springer; 1981. [Google Scholar]
29. Goodfellow I. Deep learning. Cambridge, MA, USA: MIT press; 2016. [Google Scholar]
30. Zhang R. Making convolutional networks shift-invariant again. In: International Conference on Machine Learning. Long Beach, CA, USA: PMLR; 2019. p. 7324–34. [Google Scholar]
31. Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd International Conference on Machine Learning; 2015 Jul 7–9; Lille, France. p . 448–56. [Google Scholar]
32. Santurkar S, Tsipras D, Ilyas A, Madry A. How does batch normalization help optimization? In: Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, Garnett R, editors. Advances in Neural Information Processing Systems. Vol. 31. Montréal, QC, Canada: Neuro IPS; 2018. [Google Scholar]
33. Zhao L, Zhang Z. A improved pooling method for convolutional neural networks. Sci Rep. 2024;14(1):1589. [Google Scholar] [PubMed]
34. Sharma T, Singh V, Sudhakaran S, Verma NK. Fuzzy based pooling in convolutional neural network for image classification. In: Proceedings of the 2019 IEEE International Conference on Fuzzy Systems; 2019 Jun 23–26; New Orleans, LA, USA. p. 1–6. doi:10.1109/FUZZ-IEEE.2019.8859010. [Google Scholar] [CrossRef]
35. Diamantis DE, Iakovidis DK. Fuzzy pooling. IEEE Trans Fuzzy Syst. 2020;29(11):3481–8. doi:10.1109/TFUZZ.2020.3024023. [Google Scholar] [CrossRef]
36. Wang Y, Wang Y, Er MJ, Zhu J. Unsupervised fuzzy neural network for image clustering. In: Proceedings of the 2021 IEEE International Conference on Fuzzy Systems; 2021 Jul 11–14; Luxembourg. p. 1–6. doi:10.1109/FUZZ45933.2021.9494601. [Google Scholar] [CrossRef]
37. Hasan MM, Hossain MM, Rahman MM, Azad A, Alyami SA, Moni MA. FP-CNN: a fuzzy pooling-based convolutional neural network for medical image classification. Comput Biol Med. 2023;166(3):107407. doi:10.1016/j.compbiomed.2023.107407. [Google Scholar] [CrossRef]
38. Lin CJ, Chen BH, Lin CH, Jhang JY. Design of a convolutional neural network with Type-2 fuzzy-based pooling for vehicle recognition. Mathematics. 2024;12(24):3885. doi:10.3390/math12243885. [Google Scholar] [CrossRef]
39. Thakur PS, Verma RK, Tiwari R. Analysis of time complexity of K-means and fuzzy C-means clustering algorithm. Eng Math Lett. 2024;2024(4). doi:10.28919/eml/8402. [Google Scholar] [CrossRef]
40. Krizhevsky A. Learning multiple layers of features from tiny images. Toronto, ON, Canada: University of Toronto; 2009. [Google Scholar]
41. Huang GB, Mattar M, Berg T, Learned-Miller E. Labeled faces in the wild: a database forstudying face recognition in unconstrained environments. In: Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition. Marseille, France: HAL; 2008. [Google Scholar]
42. Coates A, Ng A, Lee H. An analysis of single-layer networks in unsupervised feature learning. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics; 2011 Apr 11–13; Fort Lauderdale, FL, USA. p. 215–23. [Google Scholar]
43. Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L. Imagenet: a large-scale hierarchical image database. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition; 2009 Jun 20–25; Miami, FL, USA. p. 248–55. doi:10.1109/CVPR.2009.5206848. [Google Scholar] [CrossRef]
44. Xiao H, Rasul K, Vollgraf R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv:1708.07747. 2017. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools