
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
DL-YOLO: A Multi-Scale Feature Fusion Detection Algorithm for Low-Light Environments
School of Science, Dalian Minzu University, Dalian, China
* Corresponding Author: Hongmei Liu. Email:
Computers, Materials & Continua 2026, 87(2), 81 https://doi.org/10.32604/cmc.2026.074204
Received 05 October 2025; Accepted 13 January 2026; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Driven by rapid advances in deep learning, object detection has been widely adopted across diverse application scenarios. However, in low-light conditions, critical visual cues of target objects are severely degraded, posing a significant challenge for accurate low-light object detection. Existing methods struggle to preserve discriminative features while maintaining semantic consistency between low-light and normal-light images. For this purpose, this study proposes a DL-YOLO model specially tailored for low-light detection. To mitigate target feature attenuation introduced by repeated downsampling, we design a Multi-Scale Feature Convolution (MSF-Conv) module that captures rich, multi-level details via multi-scale feature learning, thereby reducing model complexity and computational cost. For feature fusion, we integrated the C3k2-DWR module by embedding the Dilation-wise Residual (DWR) mechanism into the 2-core optimized Cross Stage Partial (C3) framework, achieving efficient feature integration. In addition, we replace conventional localization losses with WIoU (Weighted Intersection over Union), which dynamically adjusts gradient gain according to sample quality, thereby improving localization robustness and precision. Experiments on the ExDark dataset demonstrate that DL-YOLO delivers strong low-light detection performance. The relevant code is published at https://github.com/cym0997/DL-YOLO.Keywords
Object detection is a key task in computer vision, aiming to identify and localize objects within images. Deep learning has revolutionized this field, driving its application across diverse scenarios. Especially under low-light conditions, object detection demonstrates significant application potential in scenarios such as Nighttime security surveillance [1], nighttime autonomous driving systems [2], nighttime military reconnaissance [3], and low-light industrial quality inspection [4].
However, low-light detection faces numerous formidable challenges. Under low illumination (<10 lux), the image signal-to-noise ratio plummets, causing details such as target textures and edges to blend into the dark background. Traditional convolutional networks’ fixed receptive fields struggle to effectively distinguish targets from noise. Furthermore, a “semantic gap” exists: models trained on images under normal lighting fail to recognize targets in low-light environments. Existing approaches either rely on pixel-level brightness enhancement techniques (e.g., histogram equalization [5], Retinex) without optimizing the feature distribution required for detection tasks; or depend on large-scale annotated datasets while neglecting the severe loss of target features during low-light image processing [6]. To address these issues and significantly improve low-light detection accuracy, we propose three key innovations: (1) The MSF-Conv module employs multi-scale convolutional feature fusion operations to capture both fine-grained and global features simultaneously. By replacing traditional convolutional modules, it enhances the model’s multi-modal recognition capabilities for input features and enriches feature representations. (2) The C3K2_DWR module expands network width through parallel convolutions and adaptive receptive fields, improving feature extraction efficiency without significantly increasing complexity. (3) The WIoU loss function incorporates a dynamic focus mechanism that optimizes the model’s attention to varying sample sizes by flexibly adjusting gradient gain. This enables the model to allocate attention more evenly across low-light images of differing quality. In general, the specific contributions of this paper are as follows:
• To address the limitation of image enhancement failing to meet object detection requirements, this paper proposes the DL-YOLO model, which enhances the accuracy and reliability of detection models in identifying targets under low-light conditions by enhancing feature extraction and object localization capabilities.
• In terms of feature extraction, we replace the original convolutions with the MSF-Conv module to prevent target-dark background fusion during convolution, thereby preserving deep-level information and meeting the complex feature extraction demands of low-light scenarios. Additionally, the C3k2_DWR module is embedded at the model’s neck to optimize multi-scale feature fusion through parallel convolutions, enhancing low-light detection performance. The WIoU loss function is introduced to refine localization accuracy, effectively addressing target blurring issues under low illumination.
• Experiments demonstrate that our model achieves outstanding performance on the ExDark dataset, making significant contributions to low-light object detection research.
Enhancing object detection capabilities in challenging environments is essential, particularly in low-light situations. However, dim lighting typically results in overall image darkness and reduced contrast, introducing noise that causes detail loss and makes key visual features of targets difficult to identify [7], as shown in Fig. 1. These elements substantially increase the challenge of detection, and existing object detection algorithms have not been fully tested under low-light conditions, leading to performance degradation when directly applied to such environments.

Figure 1: The left side shows a city street during the day, the middle depicts a dimly lit city street at night, and the right displays an overexposed image.
Furthermore, current research primarily focuses on the field of image enhancement. Traditional image enhancement methods (e.g., histogram equalization [8]) can improve brightness and contrast but yield only limited gains in detection accuracy. Wang et al. [9] proposed a Retinex framework that considers decoupling, leveraging synergistic enhancement techniques to improve both light and noise issues in dimly lit photos. Zhu et al. [10] constructed an efficient collaborative reflection and illumination learning framework, enabling efficient low-light image enhancement. However, a fundamental disconnect persists between image enhancement and object detection [11]: Supervised learning-based augmentation methods yield high visual metrics but offer limited improvement in detection mAP (Mean Average Precision). Conversely, zero-shot methods with lower visual scores significantly enhance mAP. This contradiction stems from human vision prioritizing natural brightness and noise suppression, while machine vision relies on discriminative features like sharp edges. Excessive smoothing erases minute details and distorts semantic structures, making it difficult for detectors to distinguish objects against dark backgrounds. Therefore, enhancement strategies must preserve or strengthen semantic and structural features relevant to downstream tasks, rather than merely optimizing overall visual quality.
To overcome the limitations of image enhancement techniques, researchers have designed various deep learning-based detection algorithms, encompassing both single-stage and two-stage approaches. Two-stage approaches like Faster R-CNN [12] and Cascade R-CNN [13] achieve high-precision detection through a “region-first, classification-second” workflow. However, the complex structure and high computational demands of two-stage algorithms limit their real-time applications.
Unlike two-stage methods, single-stage algorithms such as SSD [14], RetinaNet [15], and the YOLO (You Only Look Once) series skip candidate region generation and directly output bounding boxes during image processing, making them computationally more efficient and better suited for real-time processing demands. With advances in YOLO technology, some end-to-end models have incorporated image enhancement and object detection into a unified framework. For example, PE-YOLO [16] combines image enhancement techniques with the YOLOv3 detection framework, decomposing images through the Laplacian pyramid and enhancing details and low-frequency information. However, single-feature extractors perform poorly when handling multi-scale objects, prompting some studies to focus on optimizing multi-scale feature extraction and fusion mechanisms. For instance, LLD-YOLO [17] integrates the C3k2-RA with the Con-AM module to enhance multi-scale feature fusion, improving its low-light vehicle detection performance.
Although the aforementioned methods have improved low-light detection performance to some extent, inherent limitations remain: while image enhancement techniques can improve visual effects, they fail to enhance semantic performance and may even introduce noise; Existing deep learning approaches, while showing progress, struggle to balance accuracy, efficiency, and low-light adaptability, particularly lacking specialized designs for low-illumination features; these methods generally overlook the issues of feature fragility and background confusion in low-light environments. Therefore, addressing the limitations of existing methods, this study proposes an improved DL-YOLO model. By optimizing the architecture to enhance feature extraction and object localization capabilities, it better adapts to object detection tasks under low-illumination conditions.
This study adopts the high-performance and efficient YOLOv11s as the baseline model. It consists of three key components: Backbone, Neck, and Head [18]. The backbone adopts an enhanced CSPDarknet53, integrating C3k2, SPPF, and C2PSA modules to fuse deep separable convolutions with parallel spatial attention mechanisms, thereby improving feature quality and computational efficiency. The neck employs the PANet (Path Aggregation Network) architecture, effectively merging multi-resolution features to optimize feature utilization and enhance multi-scale object detection. The head network adopts a decoupled design, splitting classification and localization tasks into independent branches [19] to improve multi-scale detection performance. This study selects the high-performance, efficient YOLOv11s as the baseline model.
We propose an improved DL-YOLO that aims to balance resource efficiency and detection accuracy to address low-light object detection challenges. The specific improvements are as follows: first, replacing traditional convolutional modules with the Multi-Scale Feature Fusion Convolution (MSF-Conv) module to delve deeper into multi-layer image details and enhance complex feature capture capabilities; Second, an extensible residual attention expansion (DWR) module is introduced and embedded into the C3K2_DWR architecture in the neck. Through the design of a parallel convolution layer, it effectively adapts to the complex feature extraction requirements under low-light conditions, enhancing low-light detection performance. The DL-YOLO network architecture is illustrated in Fig. 2.
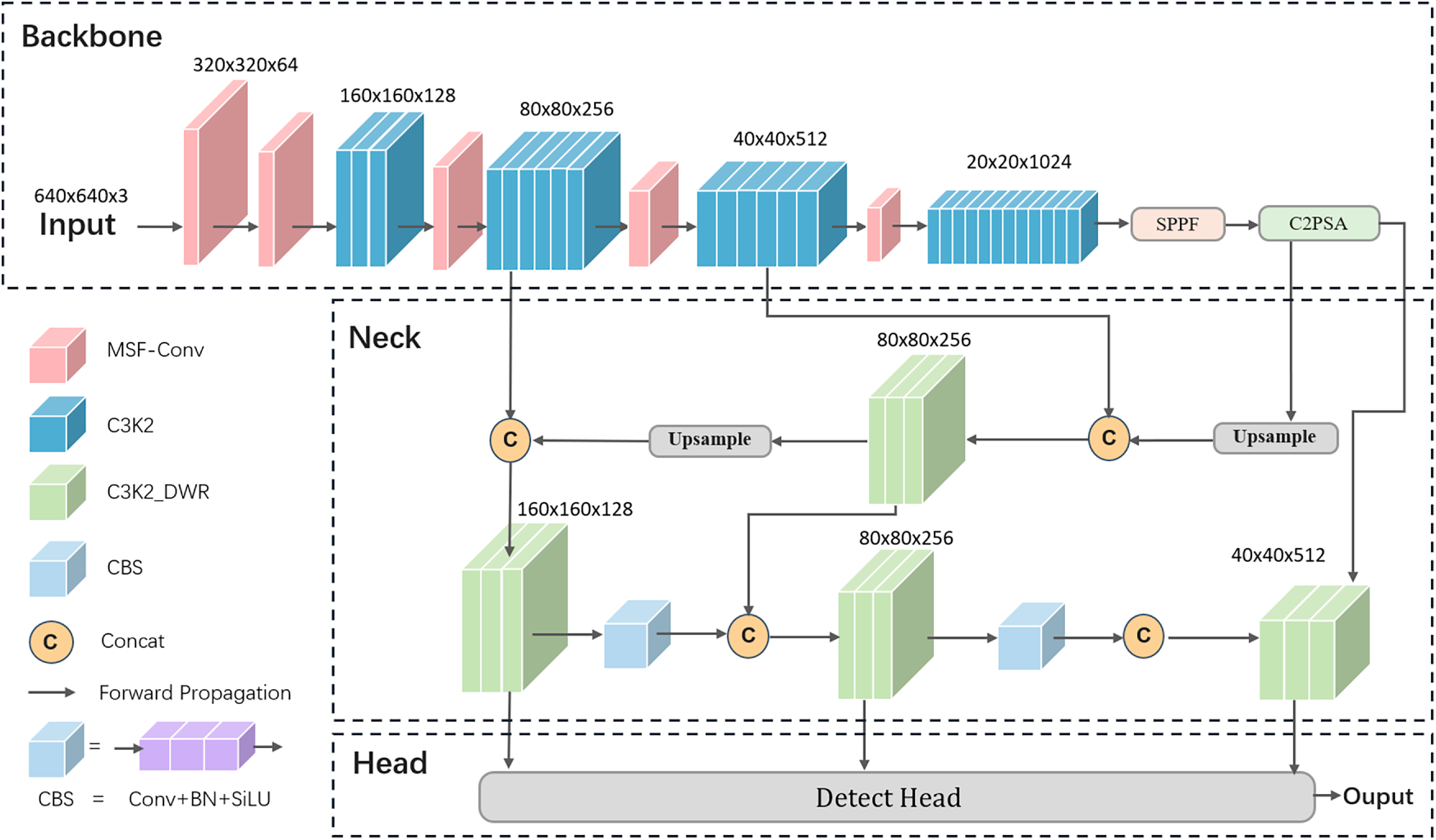
Figure 2: DL-YOLO architecture figure.
Traditional object detection models enhance feature extraction capabilities by adding convolutional layers. Although this enriches semantic information, it may sacrifice details and reduce detection precision. Particularly in low-light scenarios, the visible details of targets are already scarce, while fine-grained features such as textures, edges, and shapes are particularly crucial for distinguishing similar targets from the background in low-light environments or complex backgrounds. However, with the progress of downsampling, the reduction in feature map resolution, and the limitations of receptive fields may result in the disappearance of these crucial details, consequently diminishing detection efficacy.
To deal with these issues, we developed the Multi-Scale Feature Fusion Convolution module (MSF-Conv), with its structure shown in Fig. 3. Considering the limited receptive field of standard convolutions, which struggles to capture complex feature interactions under low-light conditions, MSF-Conv first performs preliminary feature extraction using 3
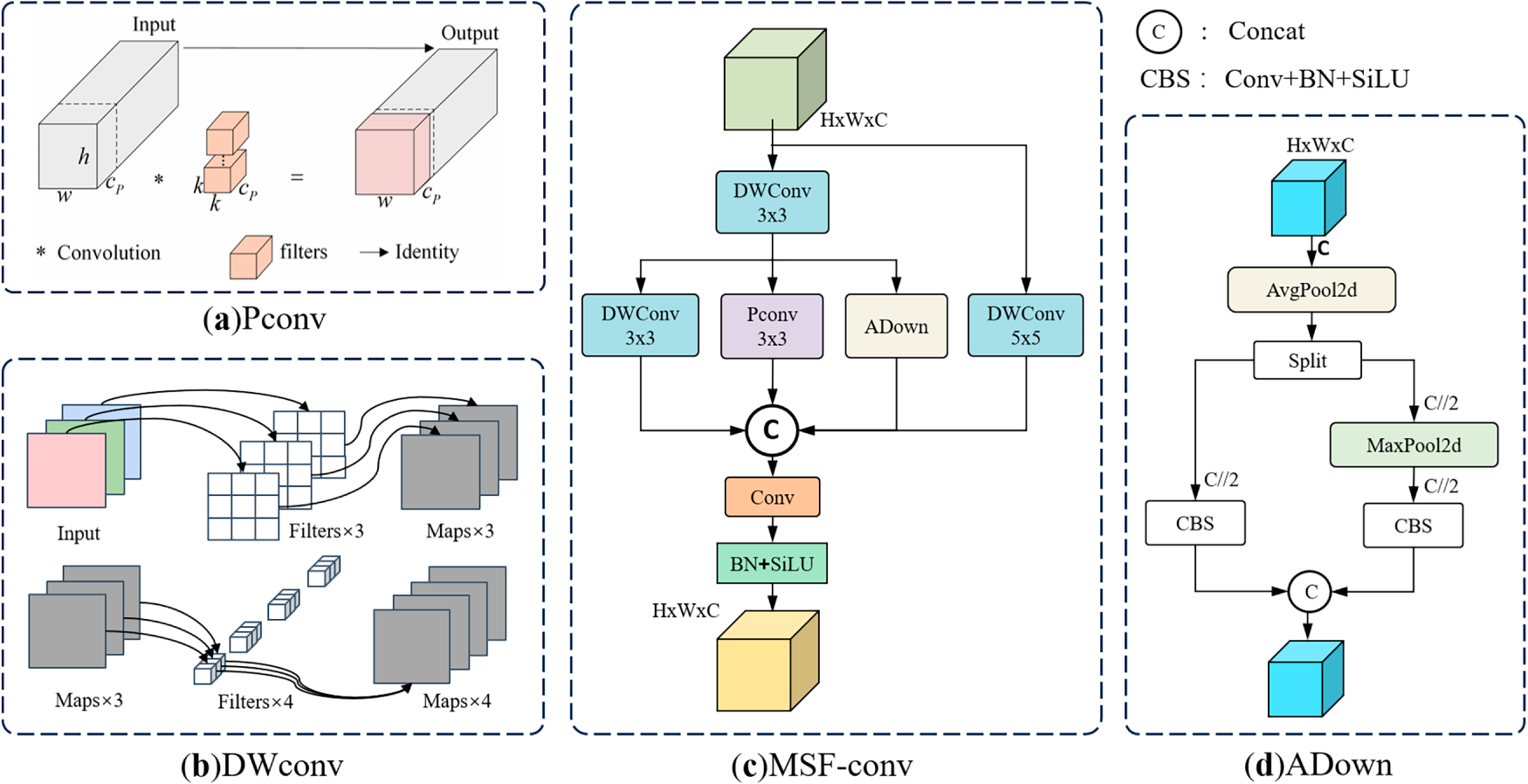
Figure 3: MSF-Conv model diagram. MSF-Conv performs multi-scale feature extraction by concurrently applying convolutional kernels of varying sizes alongside adaptive downsampling.
Compared to traditional convolutions that filter all channels, partial convolutions (PConv) leverage inherent similarities and feature map redundancy across channels. They apply standard convolutions only to selected channels, reducing computational cost and GFLOPs. As shown in Fig. 3a, when input and output feature maps are aligned by channel count, the GFLOPs calculation for PConv is:
Where
Among them, the ADown [20] convolution block is selected to perform adaptive downsampling on low-light features, reducing spatial resolution while preserving key information and avoiding information loss caused by downsampling. Its multi-branch structure enhances the network’s flexibility in processing features across various scales, as depicted in Fig. 3c. The adaptive learning capability of the ADown module allows it to dynamically adjust according to illumination changes and target characteristics dynamically, precisely meeting the complex demands of low-light target detection. Meanwhile, the MSF-Conv module incorporates a residual structure with a large 5

3.3 Improved C3K2 Module—C3K2_DWR
The DWRseg [21] network’s Dilated Residual (DWR) module is an efficient two-step residual feature extraction method (Fig. 4). By dividing convolutions into two stages: Regional Residualization (RR) and Semantic Residualization (SR), it enhances features extracted from the network’s higher-level scalable receptive fields. This approach effectively captures and integrates multi-scale contextual information, enabling cross-scale information encapsulation while simplifying the feature processing workflow.
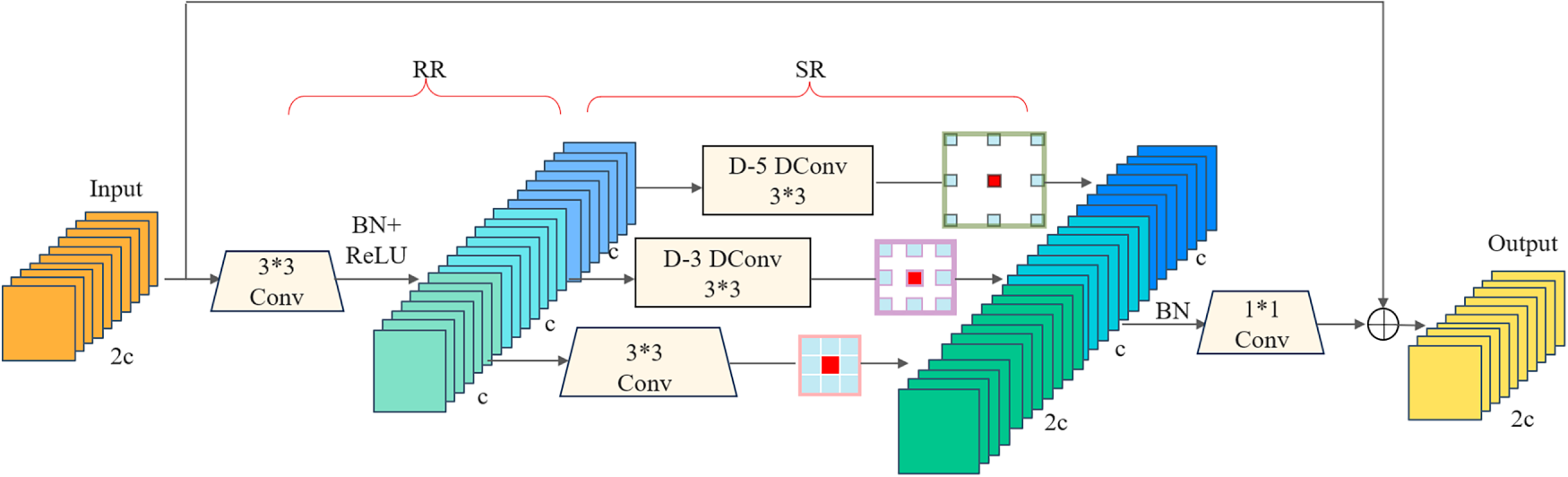
Figure 4: DWR model figure.
Step 1: Regional Residualization (RR): This step generates concise regional feature maps through residual connections and convolutional operations, enhancing the model’s perception of local details and providing clear input for subsequent semantic extraction.
Step 2: Semantic Residualization (SR): Employing a multi-branch design, this approach utilizes convolutions with varying dilation rates to expand the receptive field, thereby capturing multi-scale contextual information without increasing parameters [22]. By flexibly adjusting the dilation rate, the SR module dynamically adapts to the receptive field requirements at each stage, efficiently extracting and integrating features.
Building upon this foundation, we embedded the DWR module within the C3K module framework to construct the C3K2_DWR module, deploying it at the network bottleneck. This module adopts a multi-layer parallel convolutional architecture, where some features undergo direct processing via standard convolutions, while others are processed through multiple C3K_DWR modules (when the parameter is set to True) or the DWR structure, as shown in Fig. 5. By combining channel separation strategies with variable convolution kernels (e.g., 3 × 3, 5 × 5), C3K2_DWR delivers enhanced feature extraction capabilities, particularly suited for complex scenes and deep feature extraction tasks. Through semantic-level residual learning and dynamic receptive field adjustment, this module effectively fuses feature maps of different resolutions from the backbone network. This enables the model to grasp both overall object features and category-specific details, providing robust data support for subsequent detection tasks.
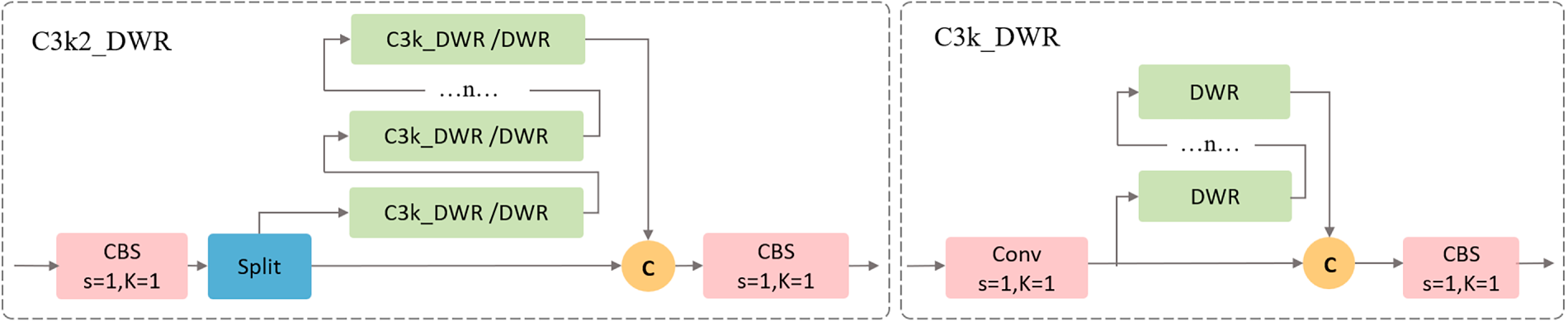
Figure 5: C3K2_DWR and C3K_DWR model diagram. The model employs multiple parallel convolutional layers to achieve efficient feature integration.
The CIoU (Complete Intersection over Union) loss function used by YOLOv11 comprehensively considers overlap, center distance, and aspect ratio, but ignores variations in sample quality. When processing low-light images, blindly performing bounding box regression on low-quality samples actually reduces localization accuracy. The DL-YOLO model replaces CIoU with the WIoU loss function. Unlike monotonic focusing mechanisms such as CIoU, WIoU fully taps into the potential of non-monotonic focusing mechanisms, dynamically adjusting gradient gain based on anchor quality. This approach undermines the competitiveness of high-quality anchors while lessening the impact of gradients from poor samples, enhancing the model’s generalization capability.
Define the bounding box as
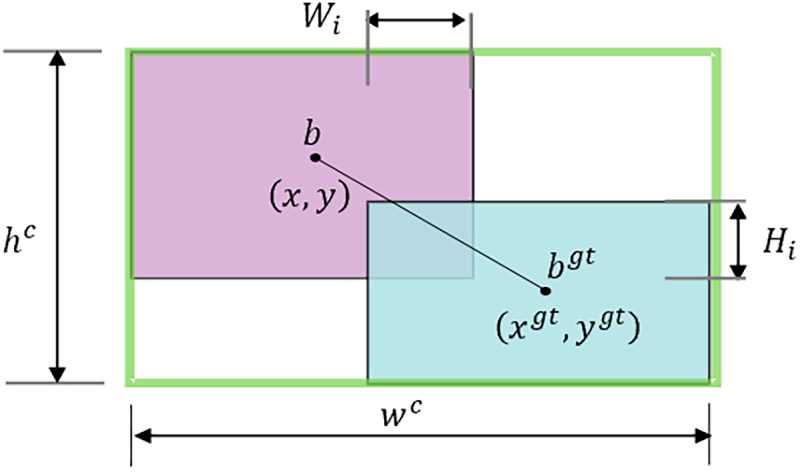
Figure 6: The rectangular schematic diagram of the predicted box and the real box.
IoU denotes the intersection-over-union ratio between predicted and ground-truth bounding boxes, while
We can construct distance attention based on distance metrics, yielding the two-layer attention mechanism WIoUv1:
Among them,
WIoU v1 reduces the IoU value of high-quality anchor boxes through
Applying the non-monotonic focus coefficient
where
The WIoU loss function achieves faster runtime efficiency by omitting aspect ratio calculations. In low-light datasets containing numerous low-quality samples, WIoU outperforms other loss functions, rendering it the optimal selection for such object detection scenarios.
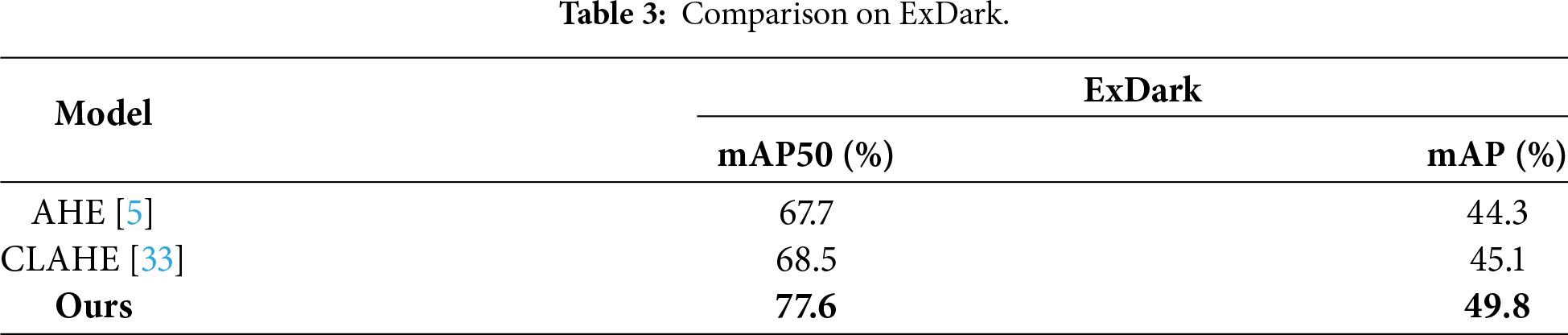
This study evaluates low-light detection performance using the ExDark dataset [23] released by the University of Malaya in 2018. It encompasses ten illumination scenarios ranging from extreme darkness to twilight, comprising 7363 real-world images (Fig. 7), covering diverse settings such as streets, interiors, and natural landscapes. Specific specifications are detailed in Table 1. Compared to traditional datasets, ExDark focuses on low-light challenges such as insufficient brightness, contrast decay, significant noise, and detail loss. This enhances model generalization capabilities and better meets the practical demands of applications like autonomous driving and security surveillance. To comprehensively evaluate cross-domain adaptability, we conducted supplementary experiments on the DARK FACE monitoring dataset and the NightOwls [24] vehicle-mounted night vision dataset to validate the model’s low-light detection generalization capabilities.

Figure 7: ExDark Dataset Example: Includes images from four real-world low-light scenarios: streets, indoor environments, outdoor settings, and natural landscapes.

This table provides a detailed summary of the 12 object categories within the ExDark dataset.
In our study, we employed PyTorch [25] for model construction and utilized the SGD (Stochastic Gradient Descent) optimizer for model training. The experimental framework was aligned with YOLOv11. The primary hyperparameters were initialized with a learning rate (lr0) of 0.01, a momentum for SGD of 0.937, and a weight decay of 0.0005. The Training was set for 200 epochs, with a learning rate modified using cosine annealing. The dimensions for training and testing images were standardized to 640
This research employs metrics such as Precision, Recall, and mAP to evaluate low-light detection performance.
(1)
(2)
(3)
(4)
(5)
where TP, FP, and FN indicating correct positive predictions, incorrect positives, and incorrect negatives, respectively. K denotes the number of classes. To evaluate a model’s computational efficiency, we introduce three metrics: Params (number of parameters), GFLOPs (Giga Floating-point Operations Per Second), and FPS (Frames Per Second). These metrics collectively establish a multidimensional evaluation framework for computational performance.
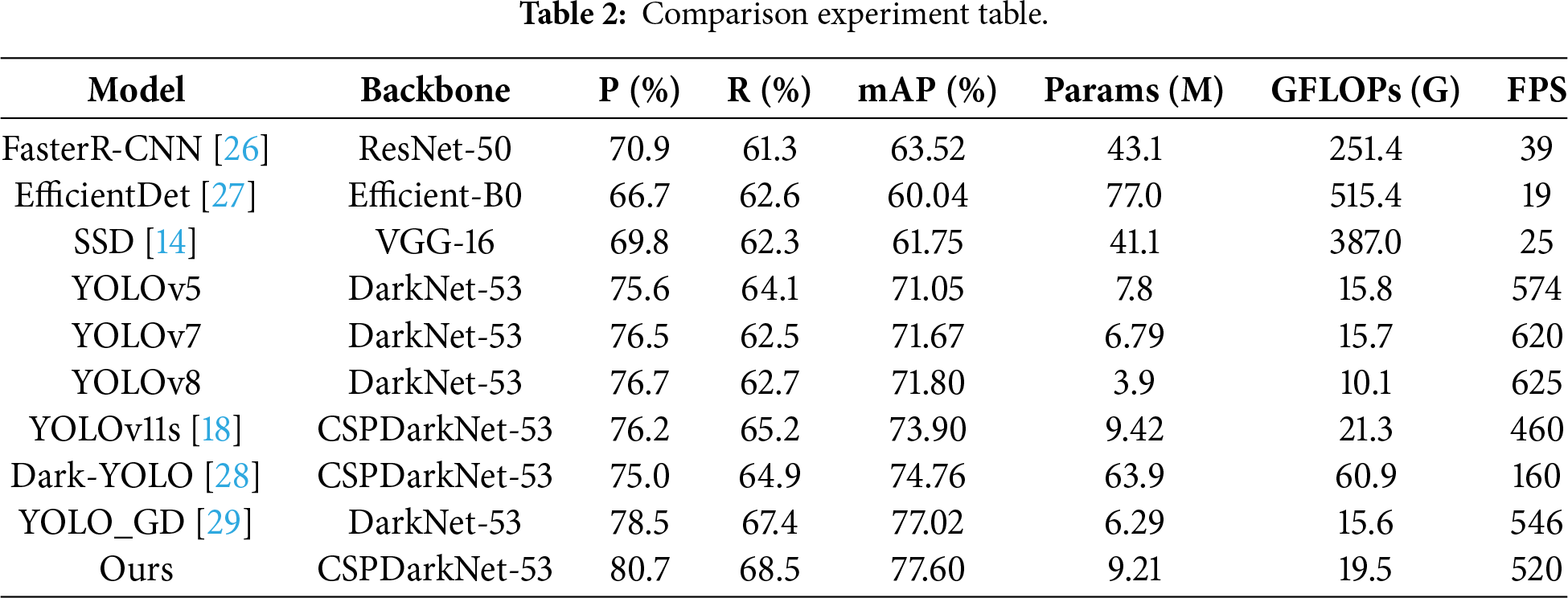
To evaluate DL-YOLO’s performance, we systematically compared it with several mainstream algorithms (see Table 2). Results demonstrate that DL-YOLO achieves dual improvements in accuracy and speed. Its mAP reaches 77.6%, significantly outperforming two-stage algorithms like Faster R-CNN, and surpassing YOLOv8 and YOLOv7 by 5.8% and 5.93%, respectively. Compared to the baseline YOLOv11s, DL-YOLO achieves a 4.1% and 4.5% improvement in mAP and accuracy, respectively, while boosting FPS by approximately 13%, demonstrating the exceptional efficiency of its enhanced that of the latest YOLO_GD, DL-YOLO achieves a 0.54% increase in mAP and a 2.2% improvement in accuracy. Experimental results confirm that DL-YOLO achieves a remarkable balance between accuracy and efficiency while attaining state-of-the-art performance. We also compared three non-AI (Artificial Intelligence) augmentation paradigms(AHE, CLAHE; see Table 3). Traditional enhancement methods show limited effectiveness in boosting detection performance and often cause side effects like color distortion and noise amplification. By contrast, DL-YOLO’s end-to-end design outperforms in both mAP50 and mAP metrics, fully validating its effectiveness.
The visualization results in Fig. 8 demonstrate DL-YOLO’s exceptional capability in handling dense objects, occlusions, and low-contrast scenes. In the first row, due to the dense distribution of objects, the YOLOv8, YOLOv11, and YOLO_GD models all missed some small vehicles and mislocalized roadside features. In the second row, affected by occlusions and edge separation between targets, Fig. 8a,c failed to detect individuals isolated by edges. Fig. 8b was unable to detect pedestrians inside the vehicle. In the third row, due to the low contrast between objects and the background, other models misclassified chairs as tables, whereas DL-YOLO accurately detected and localized the targets. These results confirm DL-YOLO’s superior generalization capability, effectively addressing false negatives and false positives while improving target recognition and localization accuracy.

Figure 8: Experimental comparison figures.
We further conducted reference-free IQA (image quality assessment) on the ExDark test set. As shown in Table 4, DL-YOLO achieved the lowest NIQE [30], PIQE [31] and BRISQUE [32] scores, reflecting sharper edges, reduced noise and better perceived quality. This result confirms that multi-scale feature fusion and the WIoU training strategy enhance mAP without sacrificing visual naturalness, instead enabling clearer and more robust reconstruction of textures in dark regions.

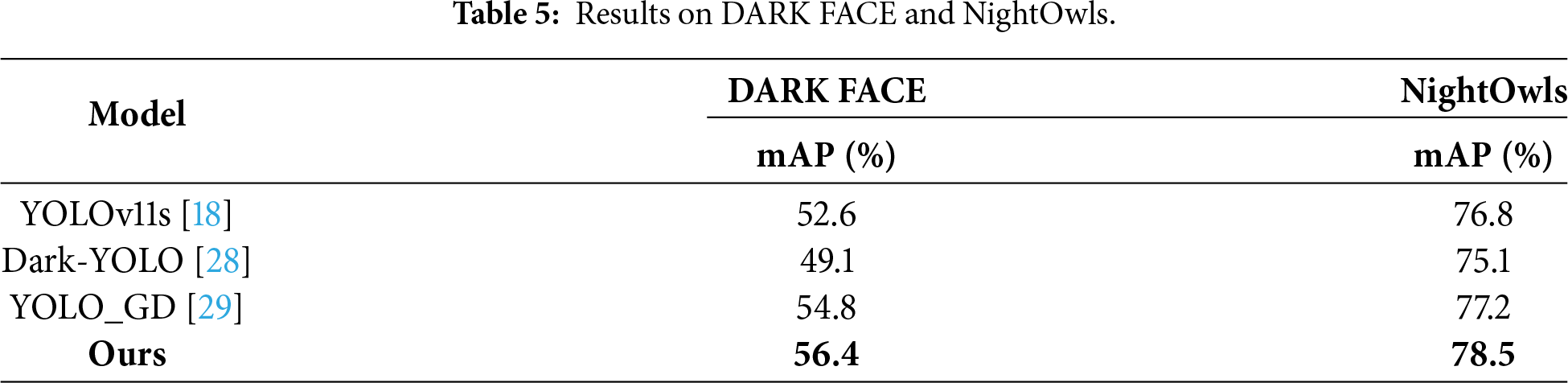
Experimental results confirm the model’s outstanding performance on the DARK FACE and NightOwls datasets, attaining 56.4% and 78.5% mAP, respectively (see Table 5). These results surpass the methods, validating its effectiveness in detecting faces and pedestrians under complex low-light conditions and highlighting its strong cross-scenario generalization capability.
As illustrated in Fig. 9, we conducted systematic ablation experiments for each module. The results, visualized across multiple metrics, demonstrate that both the independent embedding and the combined introduction of the new method significantly optimize the final prediction map.
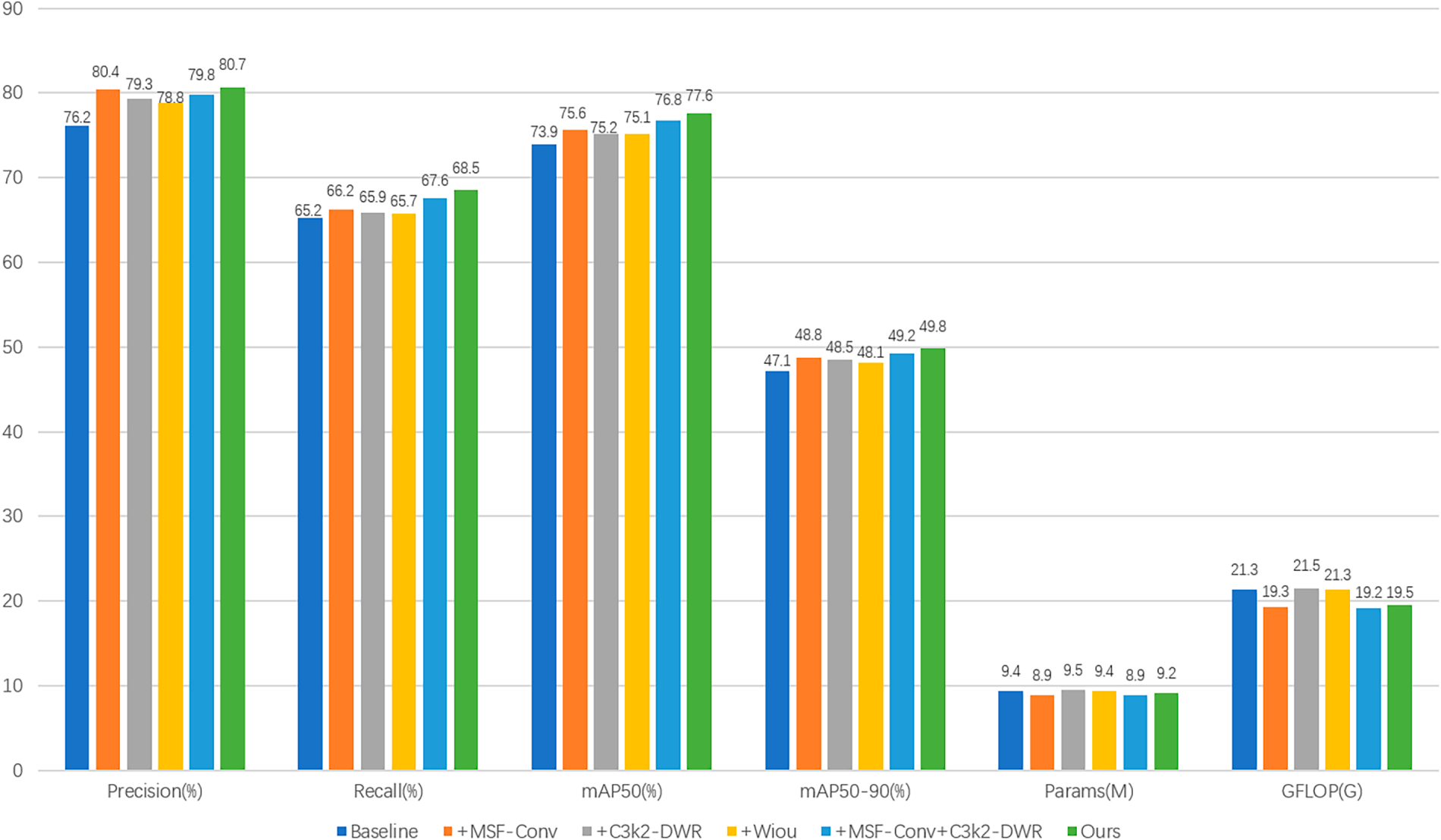
Figure 9: Dissolution results.
(1) After introducing the MSF-Conv module, the map, precision, and recall metrics all showed a marked upward trend. Concurrently, the number of parameters in the model reduced from 9.42 to 8.92 M, reducing nearly 500,000 parameters, lowering computational complexity while substantially enhancing its capacity to extract key object features under low-illumination conditions.
(2) Integrating the C3k2_DWR module into the model neck demonstrated a clear upward trend in recall and mAP metrics. This module intelligently learns feature maps in accordance with the size of the receptive field, identifying the appropriate receptive fields in reverse to accommodate the diverse demands of feature extraction. In the three comparative experiments shown above, our model outperformed the baseline model across all scenes, significantly improving the recognition accuracy for objects with diverse dimensions.
(3) Final testing demonstrates that the combined approach of “feature enhancement, structure optimization, loss calibration” employed in this work significantly outperforms individual modules. The MSF-Conv module addresses feature scarcity in low-light conditions, C3K2_DWR enhances multi-scale fusion efficiency, and WIoU suppresses noise propagation during training. These components form a closed-loop system rather than a simple stack: WIoU’s gradient feedback dynamically guides MSF-Conv to focus on high-quality, discriminative regions. This enables the model to identify objects more accurately under low-light and dark background conditions, better aligning with practical application requirements.
However, due to the use of 5

Figure 10: Fault case figure.
In our work, we introduce an innovative multi-scale convolution module (MSF-Conv) designed explicitly for image downsampling in low-light environments. This module simultaneously captures image details and global features through multi-scale convolution feature fusion operations. Meanwhile, multiple parallel convolutional layers are employed, and the Dynamic Weighted Resampling Convolution module (DWR) is integrated into the C3K2_DWR Module Architecture, thereby forming a more efficient feature extraction mechanism. The introduction of the WIoU loss function effectively addresses the negative impact of low-quality instances on model performance and resolves the challenge of object localization under low-illumination conditions. Our model has demonstrated superior performance over baseline models in testing and has also outperformed other existing algorithms. Looking ahead, we plan to further refine the model architecture, investigate more efficient multi-scale feature extraction techniques and lightweight network designs, and extend its application to various vision tasks such as autonomous driving, security surveillance, image segmentation, and object tracking.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Data organization and technical details: Yuanmeng Chang; result validation and initial draft writing: Yuanmeng Chang; manuscript review: Hongmei Liu. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The ExDark dataset supporting this research is openly accessible at [github.com/cs-chan/Exclusively-Dark-Image-Dataset].
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Bijoor S, Alugubelly M, Aggarwal S. Light weight real-time burglary detection and inspection in low light surveillance videos. In: 2023 16th International Conference on Developments in eSystems Engineering (DeSE); 2023 Jan 10–13; Istanbul, Turkiye. p. 317–24. doi:10.1109/DeSE60595.2023.10469491. [Google Scholar] [CrossRef]
2. Wu H, Zhang R, Chen J, Lyu N, Hu H, Guo Y et al. WTEFNet: real-time low-light object detection for advanced driver assistance systems. IEEE Trans Instrum Meas. 2026;75:1–16. [Google Scholar]
3. Li Y, Luo Y, Zheng Y, Liu G, Gong J. Research on target image classification in low-light night vision. Entropy. 2024;26(10):882. doi:10.3390/e26100882. [Google Scholar] [PubMed] [CrossRef]
4. Li Y, Niu Y, Xu R, Chen Y. Zero-referenced low-light image enhancement with adaptive filter network. Eng Appl Artif Intell. 2023;124(1):106611. doi:10.1016/j.engappai.2023.106611. [Google Scholar] [CrossRef]
5. Pizer SM, Amburn EP, Austin JD, Cromartie R, Geselowitz A, Greer T, et al. Adaptive histogram equalization and its variations. Comput Vis Graph, Image Process. 1987;39(3):355–68. doi:10.1016/s0734-189x(87)80186-x. [Google Scholar] [CrossRef]
6. Xiao Y, Jiang A, Ye J, Wang MW. Making of night vision: object detection under low-illumination. IEEE Access. 2020;8:123075–86. doi:10.1109/ACCESS.2020.3007610. [Google Scholar] [CrossRef]
7. Shang X, Li N, Li D, Lv J, Zhao W, Zhang R, et al. CCLDet: a cross-modality and cross-domain low-light detector. IEEE Trans Intell Transp Syst. 2025;26(3):3284–94. doi:10.1109/tits.2024.3522086. [Google Scholar] [CrossRef]
8. Zhu X, Xiao X, Tjahjadi T, Wu Z, Tang J. Image enhancement using fuzzy intensity measure and adaptive clipping histogram equalization. IAENG Int J Comput Sci. 2019;46(3):395–408. doi:10.18535/ijecs/v5i6.30. [Google Scholar] [CrossRef]
9. Wang Y, Cao Y, Zha ZJ, Zhang J, Xiong Z, Zhang W, et al. Progressive retinex: mutually reinforced illumination-noise perception network for low-light image enhancement. In: Proceedings of the 27th ACM International Conference on Multimedia. New York, NY, USA: ACM; 2019. p. 2015–23. doi:10.1145/3343031.3351047. [Google Scholar] [CrossRef]
10. Zhu G, Ma L, Liu R, Fan X, Luo Z. Collaborative reflectance-and-illumination learning for high-efficient low-light image enhancement. In: 2021 IEEE International Conference on Multimedia and Expo (ICME). Piscataway, NJ, USA: IEEE; 2021. p. 1–6. doi:10.1109/ICME49332.2021.9481248. [Google Scholar] [CrossRef]
11. Liu F, Fan L. A review of advancements in low-light image enhancement using deep learning. arXiv:2505.05759. 2025. [Google Scholar]
12. Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2014. p. 580–7. [Google Scholar]
13. Cai Z, Vasconcelos N. Cascade R-CNN: high quality object detection and instance segmentation. IEEE Trans Pattern Anal Mach Intell. 2019;43(5):1483–98. doi:10.1109/tpami.2019.2956516. [Google Scholar] [PubMed] [CrossRef]
14. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: single shot multibox detector. In: European conference on computer vision. Cham, Switzerland: Springer; 2016. p. 21–37. doi:10.1007/978-3-319-46448-0-2. [Google Scholar] [CrossRef]
15. Lin TY, Goyal P, Girshick R, He K, Dollár P. Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2017. p. 2980–8. doi:10.1109/ICCV.2017.323. [Google Scholar] [CrossRef]
16. Yin X, Yu Z, Fei Z, Lv W, Gao X. PE-YOLO: pyramid enhancement network for dark object detection. In: International Conference on Artificial Neural Networks. Cham, Switzerland: Springer; 2023. p. 163–74. doi:10.1007/978-3-031-26224-4-12. [Google Scholar] [CrossRef]
17. Zhang Q, Guo W, Lin M. LLD-YOLO: a multi-module network for robust vehicle detection in low-light conditions. Signal Image Video Process. 2025;19(4):271. doi:10.1007/s11760-024-02480-7. [Google Scholar] [CrossRef]
18. Zhuo S, Bai H, Jiang L, Zhou X, Duan X, Ma Y, et al. SCL-YOLOv11: a lightweight object detection network for low-illumination environments. IEEE Access. 2025;13:47653–62. doi:10.1109/access.2025.3550947. [Google Scholar] [CrossRef]
19. Weng T, Niu X. Enhancing UAV object detection in low-light conditions with ELS-YOLO: a lightweight model based on improved YOLOv11. Sensors. 2025;25(14):4463. doi:10.3390/s25144463. [Google Scholar] [PubMed] [CrossRef]
20. Wang CY, Yeh IH, Mark Liao HY. YOLOv9: learning what you want to learn using programmable gradient information. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2024. p. 1–21. [Google Scholar]
21. Wei H, Liu X, Xu S, Dai Z, Dai Y, Xu X. DWRSeg: rethinking efficient acquisition of multi-scale contextual information for real-time semantic segmentation. arXiv:2212.01173. 2022. [Google Scholar]
22. Zhang X, Di X, Liu M. DBLDNet: dual branch low light object detector based on feature localization and multi-scale feature enhancement. Multimed Syst. 2025;31(4):288. doi:10.1007/s00530-025-01873-8. [Google Scholar] [CrossRef]
23. Loh YP, Chan CS. Getting to know low-light images with the exclusively dark dataset. Comput Vis Image Underst. 2019;178:30–42. doi:10.1016/j.cviu.2018.10.010. [Google Scholar] [CrossRef]
24. Neumann L, Karg M, Zhang S, Scharfenberger C, Piegert E, Mistr S, et al. Nightowls: a pedestrians at night dataset. In: Asian Conference on Computer Vision. Cham, Switzerland: Springer; 2018. p. 691–705. [Google Scholar]
25. Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, et al. Pytorch: an imperative style, high-performance deep learning library. In: Advances in neural information processing systems. London, UK: PMLR; 2019. [Google Scholar]
26. Ren S, He K, Girshick R, Sun J. Towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2016;39(6):1137–49. doi:10.1109/tpami.2016.2577031. [Google Scholar] [CrossRef]
27. Tan M, Pang R, Le QV. Efficientdet: scalable and efficient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2020. p. 10781–90. [Google Scholar]
28. Liu Y, Li S, Zhou L, Liu H, Li Z. Dark-YOLO: a low-light object detection algorithm integrating multiple attention mechanisms. Appl Sci. 2025;15(9):5170. doi:10.3390/app15095170. [Google Scholar] [CrossRef]
29. Li J, Wang X, Chang Q, Wang Y, Chen H. Research on low-light environment object detection algorithm based on YOLO_GD. Electronics. 2024;13(17):3527. doi:10.3390/electronics13173527. [Google Scholar] [CrossRef]
30. Mittal A, Soundararajan R, Bovik AC. Making a “completely blind” image quality analyzer. IEEE Signal Process Lett. 2012;20(3):209–12. doi:10.1109/lsp.2012.2227726. [Google Scholar] [CrossRef]
31. Venkatanath N, Praneeth D, Sumohana SC, Swarup SM. Blind image quality evaluation using perception based features. In: 2015 Twenty First National Conference on Communications (NCC). Piscataway, NJ, USA: IEEE; 2015. p. 1–6. [Google Scholar]
32. Mittal A, Moorthy AK, Bovik AC. No-reference image quality assessment in the spatial domain. IEEE Trans Image Process. 2012;21(12):4695–708. doi:10.1109/tip.2012.2214050. [Google Scholar] [PubMed] [CrossRef]
33. Zuiderveld K. Contrast limited adaptive histogram equalization. In: Graphics gems IV. San Diego, CA, USA: Academic Press; 1994. p. 474–85. doi:10.1016/b978-0-12-336156-1.50061-6. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools