
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
YOLO-Drive: Robust Driver Distraction Recognition under Fine-Grained and Overlapping Behaviors
1 Department of Computer and Information Science, Faculty of Science and Technology, University of Macau, Macau SAR, 999078, China
2 Faculty of Digital Science and Technology, Macau Millennium College, Macau SAR, 999078, China
* Corresponding Author: Simon James Fong. Email:
Computers, Materials & Continua 2026, 87(2), 26 https://doi.org/10.32604/cmc.2025.074899
Received 21 October 2025; Accepted 12 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Accurately recognizing driver distraction is critical for preventing traffic accidents, yet current detection models face two persistent challenges. First, distractions are often fine-grained, involving subtle cues such as brief eye closures or partial yawns, which are easily missed by conventional detectors. Second, in real-world scenarios, drivers frequently exhibit overlapping behaviors, such as simultaneously holding a cup, closing their eyes, and yawning, leading to multiple detection boxes and degraded model performance. Existing approaches fail to robustly address these complexities, resulting in limited reliability in safety critical applications. To overcome these pain points, we propose YOLO-Drive, a novel framework that enhances YOLO-based driver monitoring with EfficientViM and Polarized Spectral–Spatial Attention (PSSA) modules. EfficientViM provides lightweight yet powerful global–local feature extraction, enabling accurate recognition of subtle driver states. PSSA further amplifies discriminative features across spatial and spectral domains, ensuring robust separation of concurrent distraction cues. By explicitly modeling fine-grained and overlapping behaviors, our approach delivers significant improvements in both precision and robustness. Extensive experiments on benchmark driver distraction datasets demonstrate that YOLO-Drive consistently out-performs state-of-the-art models, achieving higher detection accuracy while maintaining real-time efficiency. These results validate YOLO-Drive as a practical and reliable solution for advanced driver monitoring systems, addressing long-standing challenges of subtle cue recognition and multi-cue distraction detection.Keywords
Safe driving increasingly depends on real-time monitoring of driver behavior to detect distractions before they lead to accidents. Distracted driving remains one of the leading causes of collisions, especially as secondary in-vehicle tasks such as phone use, eating, or adjusting controls become more common [1]. In response, many computer-vision systems have been developed for driver distraction detection in intelligent transportation systems (ITS).
However, two persistent challenges continue to limit their reliability in real-world driving settings:
1. Fine-grained cue recognition: Distraction behaviors often manifest through subtle changes—eye blinking, eyelid closure, partial yawning, hand movement—which are difficult to detect with standard detectors that emphasize coarse features. Traditional convolutional or spatial attention modules struggle to distinguish these high-frequency or directional textures [2].
2. Overlapping and multi-cue distractions: In real-world driving, a driver may perform multiple actions simultaneously, such as holding a cup while glancing away, or yawning while tilting their head. Conventional single-label or single-region detectors may miss one of the cues or misclassify overlapping ones, thus reducing detection robustness [3].
In this article, coarse distraction behaviors refer to easily observable actions such as drinking or phone use, whereas fine distraction behaviors denote subtle cues such as eye closure or slight yawning. As illustrated in Fig. 1, even within a single frame, multiple YOLO detection boxes frequently overlap across closely located facial regions such as the eyes and mouth. These composite annotations highlight the difficulty of distinguishing concurrent fine-grained behaviors, underscoring the importance of modeling overlapping distractions. Moreover, the in-cabin environment introduces additional complexity: varying lighting, occlusions from steering wheel or accessories, passenger presence, and background clutter. These factors perturb spatial features, increasing false positives and false negatives.

Figure 1: Examples of real-world driver distraction scenarios with composite YOLO annotations. Each frame contains multiple overlapping detection boxes capturing fine-grained and concurrent cues (e.g., eye closure with yawning, drinking while glancing away). The spatial proximity of facial regions (eyes and mouth) highlights the difficulty of distinguishing overlapping behaviors, motivating the development of YOLO-Drive
Existing methods in driver distraction detection tend to fall short across three respects:
• Many approaches rely on convolutional backbones that lack long-range context modeling, limiting sensitivity to distributed cues [4].
• Attention mechanisms are often purely spatial or channel-based, lacking frequency- or directional selectivity that can emphasize discriminative textures (e.g., eye edges) [5].
• Multi-behavior or overlapping cue detection is typically not addressed; most works assume a single dominant distraction per frame [6].
Recent surveys emphasize the need for models that can jointly reason about manual, visual, and cognitive distractions in realistic driving conditions [7]. Other works improve distraction detection using hybrid deep learning approaches [8] or adapt YOLO architectures for driver behavior recognition [9], but they do not fully tackle overlapping cues or fine-grained texture distinctions.
To address these gaps, we introduce YOLO-Drive, a driver distraction detection architecture built on YOLOv12 but enhanced with two core innovations:
• EfficientViMBlock, which fuses efficient state-space modeling with light convolution to jointly capture global dependencies and local structural detail—allowing the network to detect distributed cues across head, hands, and posture more effectively.
• Polarized Spectral–Spatial Attention (PSSA), a novel attention module that combines frequency-domain selective enhancement (via learnable radial Gaussians and angular von Mises distributions) with multi-dilated spatial aggregation. This yields directional and frequency-aware feature weighting that emphasizes fine-grained textures (eye edges, directional hand contours) while suppressing irrelevant noise.
Importantly, our design explicitly supports multi-cue overlapping detection: by coupling global-local modeling and selective attention, YOLO-Drive can detect multiple concurrent distraction behaviors in a single frame, rather than forcing an exclusive dominant label. For breaking through the current limitations, our contributions are:
1. Identification of overlapping cue distraction as a critical yet under-addressed pain point in driver monitoring, exemplified in Fig. 1 where multiple fine-grained cues occur within overlapping facial regions.
2. A hybrid EfficientViMBlock that alleviates the trade-off between locality and global context under real-time constraints.
3. A spectral–spatial attention module (PSSA) that adaptively tunes frequency and directional emphasis to highlight fine-grained discriminative signals.
4. Extensive experiments demonstrating significant improvements over baseline (YOLOv12) and state-of-the-art methods in recall, mAP@50, and mAP@50:95, especially under multi-behavior conditions.
The remainder of this paper is structured as follows: Section 2 reviews related work on distraction detection and vision-based recognition models; Section 3 details the architecture of YOLO-Drive, including the EfficientViMBlock and PSSA modules; Section 4 presents experimental results and ablation studies; discusses limitations and deployment considerations; and Section 5 concludes the study. By explicitly addressing the overlapping and fine-grained distraction challenges illustrated in Fig. 1, YO-LO-Drive advances beyond existing methods to provide a more reliable foundation for real-world intelligent transportation systems.
Driver distraction detection has become a central research area in intelligent transportation systems, supported by advances in deep learning and computer vision. Several categories of approaches have been explored, each with distinct advantages and shortcomings.
2.1 CNN-Based and Ensemble Approaches
Early works adopted convolutional neural networks (CNNs) for posture and behavior classification. Tran et al. [10] applied VGG-16, AlexNet, GoogleNet, and ResNet for real-time distracted driving detection, demonstrating good performance but struggling to capture subtle cues such as eyelid closure and partial yawns [11]. Kumar et al. introduced a genetic algorithm-based ensemble of VGG-16, Inception, and DenseNet, achieving high accuracy on benchmark datasets. However, ensembles incur high inference cost and typically assume a single dominant distraction, limiting their robustness to overlapping behaviors [12]. Similarly, Ezzouhri et al. proposed a CNN-based framework with a segmentation module for driver body parts, improving accuracy but still treating distraction categories as mutually exclusive [13].
2.2 Transformer-Based and Attention-Driven Methods
With the rise of transformers, several works have incorporated attention mechanisms into distraction detection. A multi-task Vision Transformer (ViT-DD) was proposed to jointly model distraction and driver emotion, providing stronger contextual reasoning than pure CNNs but with increased computational complexity [14]. DSDFormer, an innovative mamba-transformer structure, further improved robustness with state-space inspired attention but did not explicitly address fine-grained local cues or overlapping multi-cue distractions [15].
2.3 Lightweight Real-Time Detector Modifications
To ensure real-time efficiency, some studies adapted YOLO backbones. For example, a YOLOv8-based detector combined with GhostC2f and SimAM was introduced for driver behavior detection, significantly reducing model size and inference latency [16]. While promising for deployment, such lightweight detectors generally sacrifice sensitivity to fine-grained cues and lack frequency-domain awareness. Other works in edge-oriented optimization focus on pruning, quantization, or channel reduction [17]. Although computationally efficient, they seldom model multi-cue distraction behaviors.
CNN and ensemble-based approaches demonstrate high accuracy in detecting dominant distraction cues and are relatively simple in architecture [18,19]; however, they often miss fine-grained behavioral indicators, provide limited global contextual understanding, and lack mechanisms for multi-cue modeling. Transformer- and attention-based methods, on the other hand, effectively capture long-range dependencies and enable stronger contextual reasoning [20,21], but they are computationally heavy, do not explicitly incorporate frequency- or direction-aware modeling, and frequently overlook overlapping distractions. Lightweight YOLO-based and edge-optimized models offer real-time performance with a smaller computational footprint [22], yet they typically compromise on detection sensitivity and do not explicitly address scenarios involving multiple overlapping distraction cues.
2.5 Research Gap and Motivation
Despite considerable progress, none of the existing methods address all critical challenges simultaneously: (1) detection of subtle, fine-grained cues [23,24]; (2) robust recognition of overlapping, multi-cue distractions [25]; (3) balanced integration of local and global features [26]; and (4) frequency- and direction-aware attention [27]. Existing approaches typically solve only a subset of these issues, leaving significant gaps in performance under real-world driving conditions.
Therefore, a new solution is demanded. To this end, we propose YOLO-Drive, which integrates EfficientViM for global–local modeling and Polarized Spectral–Spatial Attention (PSSA) for fine-grained cue emphasis, enabling reliable recognition of overlapping distractions while maintaining real-time performance.
This section presents the proposed YOLO-Drive framework, which builds upon YOLOv12 [28] by introducing two novel modules designed to address the limitations of conventional spatial attention under real-world driving conditions. The baseline YOLOv12 model is chosen due to its strong balance of accuracy and real-time inference. However, its reliance on standard attention restricts its ability to capture fine-grained textures (e.g., subtle eye closure) and overlapping multi-cue behaviors (e.g., yawning while tilting the head). To overcome these challenges, we propose two core modifications:
1. EfficientViMBlock, an efficient hybrid backbone unit that integrates local convolutional structure modeling with global state-space sequence modeling, enabling fine-grained feature extraction while maintaining long-range contextual reasoning.
2. Polarized Spectral–Spatial Attention (PSSA), a dual-branch attention module that selectively enhances discriminative cues in both the spatial and frequency domains, with directional awareness that emphasizes subtle and overlapping driver distraction behaviors.
The overall architecture of YOLO-Drive is illustrated in Fig. 2, while detailed structures of EfficientViMBlock and PSSA are provided in Figs. 3 and 4, respectively.
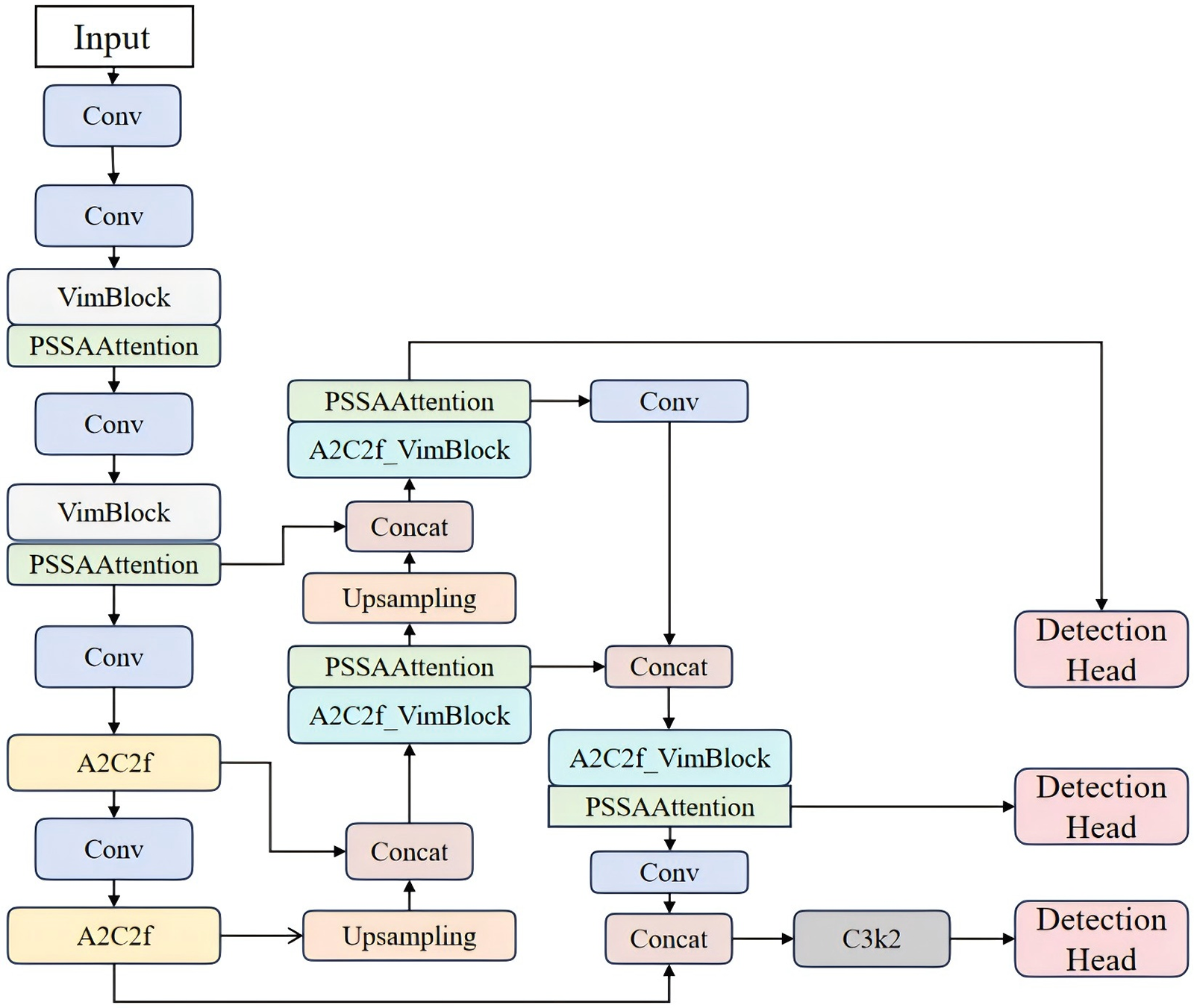
Figure 2: Overall architecture of the proposed YOLO-Drive framework. The baseline YOLOv12 detector is enhanced with two key components: (1) EfficientViM Blocks, which fuse local convolutional structure modeling with global state-space dependency aggregation, and (2) the Polarized Spectral–Spatial Attention (PSSA) module, which selectively emphasizes fine-grained frequency- and direction-aware features. Together, these modules enable robust detection of overlapping and subtle distraction cues under real-world in-cabin driving scenarios
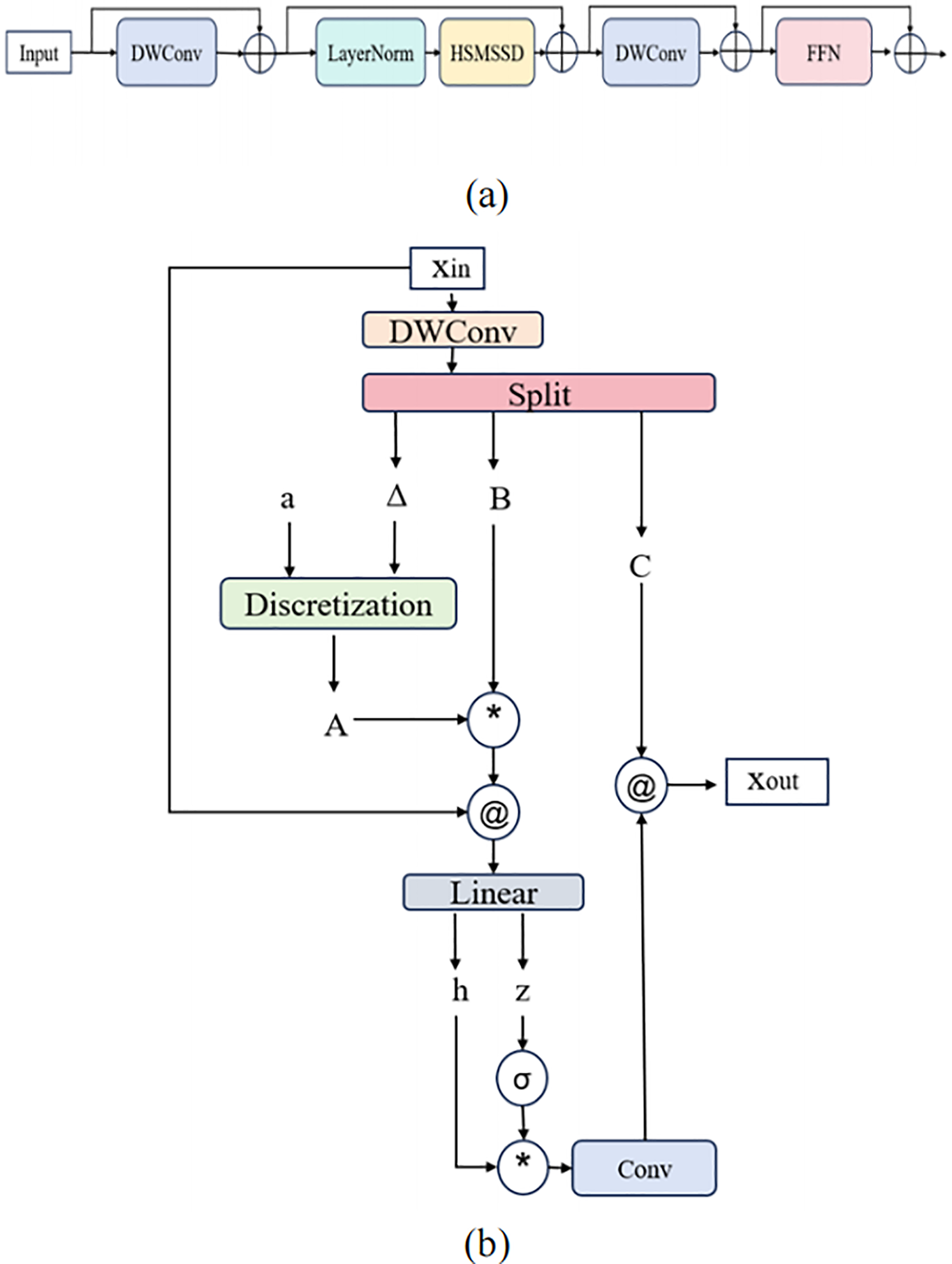
Figure 3: Structure of the EfficientViM Block. (a) Workflow of the full block, comprising depthwise convolution (DWConv), layer normalization (LayerNorm), Hidden State Mixer–based Structured State-Space Dynamics (HSM-SSD), and a feedforward neural network (FFN). (b) Internal structure of HSM-SSD, which adaptively aggregates global contextual information using a stable state kernel
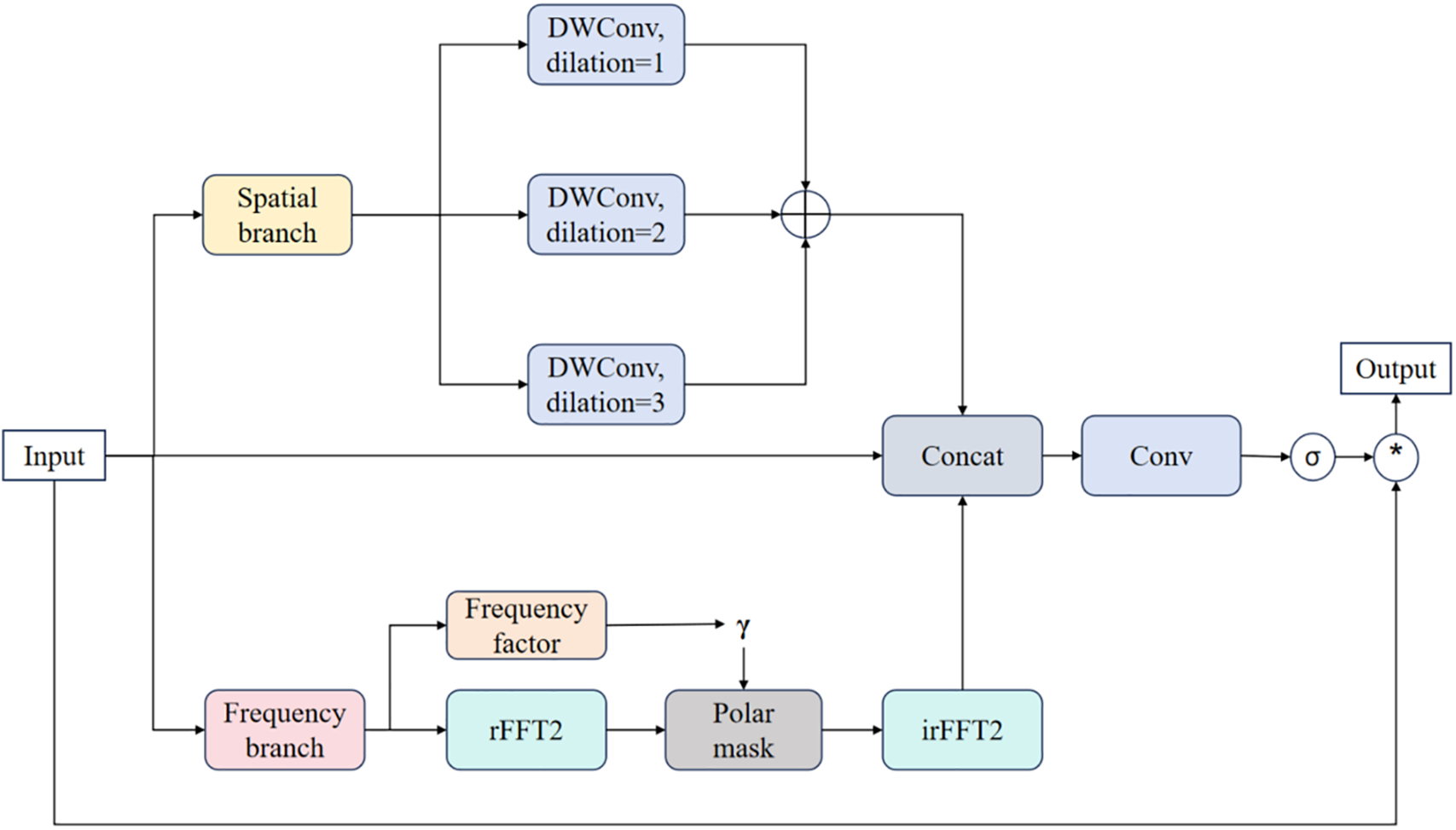
Figure 4: Structure of the proposed Polarized Spectral–Spatial Attention (PSSA) module. The module integrates (i) a spatial branch with multi-dilated depthwise convolutions for multi-scale local feature aggregation, and (ii) a frequency branch with learnable radial Gaussian and angular von-Mises functions applied in the Fourier spectrum to achieve selective frequency–directional enhancement. The outputs are fused with channel-adaptive residual gating to stabilize feature injections and improve discriminability of fine-grained driver cues
3.1 EfficientViMBlock: Hybrid Global–Local Modeling
Driver distraction cues often involve fine-grained local variations (eye opening/closure, lip movement, hand position) that occur in conjunction with cross-regional dependencies (head–hand coordination steering wheel interaction). Convolutional operations capture local details but cannot model long-range dependencies. Transformer-based attention provides global interactions but incurs quadratic complexity, making it unsuitable for real-time deployment.
To resolve this trade-off, we adopt the EfficientViMBlock [29], which fuses convolution with the Hidden State Mixer State-Space Dynamics (HSM-SSD) for lightweight global modeling. Here, the state-space formulation provides an efficient way to capture long-range dependencies with linear complexity, enabling global–local interaction without sacrificing real-time performance.
Let the input feature be
1. Local refinement: Apply a 3 × 3 depthwise separable convolution to refine local textures, producing x1.
2. Global modeling (HSM-SSD): Flatten x1 along the spatial dimension, apply LayerNorm, and project into the HSM-SSD block. Feature maps are convolved and aggregated to generate
This avoids the quadratic complexity of self-attention while retaining global dependency modeling.
3. Aggregation and projection: Weighted global aggregation yields
Which is projected, gated, and passed through linear and convolutional layers to obtain the final
4. Post-processing: Another 3 × 3 depthwise convolution ensures local consistency after global fusion, followed by a two-layer 1 × 1 feedforward network for channel reorganization.
Intuitively, EfficientViMBlock balances local and global representations by combining two complementary mechanisms. Lightweight 3 × 3 depthwise convolutions preserve fine spatial structures, such as eyelid boundaries, lip contours, and finger edges, crucial for distinguishing subtle interfering cues. Simultaneously, the HSM-SSD branch processes flattened global sequences, enabling long-range dependency modeling of faces, hands, and overall pose with linear complexity. This joint design allows the module to aggregate cross-regional behavioral context while maintaining sensitivity to local texture variations, essential for reliably detecting overlapping cues in realistic driving scenarios.
Integration into YOLOv12 is achieved by replacing C3k2 and A2C2f blocks with EfficientViM-enhanced variants (VimBlock and A2C2f_VimBlock), while retaining the ELAN and R-ELAN structures for stability. Fig. 3 illustrates the full workflow of EfficientViMBlock, including the HSM-SSD design, with the pseudo-code provided in Algorithm 1.

3.2 Polarized Spectral–Spatial Attention (PSSA)
Even with improved global–local modeling, subtle distractions such as eyelid micro-movements or partial yawns remain difficult to distinguish, especially under over-lapping conditions where eye and mouth regions interfere. Standard spatial or channel attention lacks the ability to differentiate between frequency bands and directional textures, which are crucial for modeling fine-grained driver behaviors.
To address this, we propose PSSA, a dual-domain selective attention module (see Fig. 4).
1. Spatial branch (multi-dilation aggregation): Parallel depthwise separable convolutions with dilation rates {1, 2, 3} capture features across near, medium, and far receptive fields:
2. Frequency branch (polar spectrum modeling): Apply 2D real-valued Fourier transform:
where
where
where
where
where
The enhanced frequency-domain representation is denoted by
where
3. Fusion and residual gating: The outputs of the spatial branch, frequency branch, and original feature are fused via 1 × 1 convolution, gated, and scaled:
where
Our model enhances orientation awareness through a frequency branch design of PSSA. By transforming the feature map to the Fourier domain and converting the frequency grid to polar coordinates, PSSA can independently enhance both the radial frequency components and angular orientation. A learnable radial Gaussian function selectively amplifies high-frequency textures, such as eyelid edges or subtle mouth openings, while an angular von Mises function highlights patterns consistent with specific orientations. This polar-frequency modeling allows PSSA to selectively enhance subtle and orientation-sensitive cues and suppress irrelevant background noise, even when multiple interfering behaviors coexist in spatially overlapping regions. The pesudo-code of PSSA has present in Algorithm 2.

These two modules are integrated into YOLO-Drive in a complementary and task-oriented manner. Efficient ViMBlocks are embedded into the backbone network, replacing the original C3k2 and A2C2f components, enabling the detector to capture fine local structures and long-range global dependencies at an early feature extraction stage. The PSSA module is integrated into the neck area, and its spectral orientation enhancement function is applied before multi-scale feature fusion, selectively amplifying frequency-sensitive and orientation-aware cues related to driver distraction. By combining hybrid global-local modeling and polar coordinate spectral-spatial attention mechanisms, YOLO-Drive significantly improves its ability to identify subtle, nuanced, and overlapping distraction behaviors.
4 Experimental Results and Discussion
4.1 Experimental Environment and Datasets
Experiments were conducted on the Distracted-Driving Dataset provided by Roboflow [30], which is widely adopted for in-cabin distraction recognition tasks. The dataset contains 8864 labeled images across 12 driver behavior categories, including safe driving, texting, talking on the phone, operating the radio, drinking, reaching behind, hair and makeup, talking to passengers, eyes closed, yawning, nodding off, and eyes open. It is divided into 6860 training, 1000 validation, and 1004 testing samples.
The hardware environment consisted of a server equipped with an Intel Xeon Gold 6248R processor (20 vCPUs), two NVIDIA A100-PCIE GPUs (40 GB VRAM each), and 144 GB RAM. The software environment was Ubuntu 20.04 LTS (64-bit) with PyTorch 2.3.0 as the deep learning framework.
We used three widely used metrics for measuring detection accuracy to comprehensively evaluate model performance:
1. Recall—measures detection coverage of ground-truth objects.
2. mAP@0.5—mean average precision at IoU threshold 0.5, evaluating bounding-box accuracy and classification correctness.
3. mAP@0.5:0.95—stricter mAP averaged over IoU thresholds [0.5:0.95], assessing robustness under varying localization and classification requirements.
Table 1 reports the performance comparison with existing approaches. The proposed YOLO-Drive outperforms all baselines across all metrics. Specifically, recall reaches 73.3%, outperforming Khanam’s method [31] (62.7%) and RT-DETR [32] (60.3%) by 10.6% and 13.0%, respectively. This indicates a stronger capability in reducing missed detections.
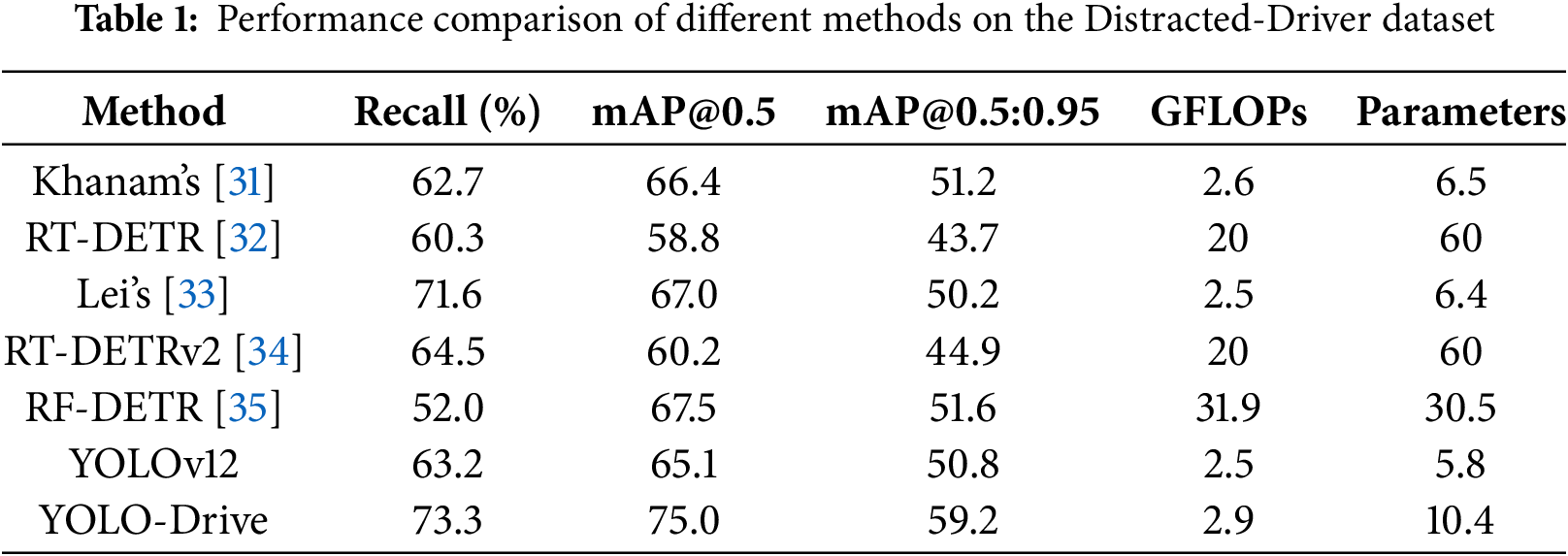
In terms of mAP@0.5, YOLO-Drive achieves 75.0%, surpassing the previous result by Lei et al. [33] (67.0%) and improving nearly 10 percentage points over baseline YOLOv12 (65.1%). Under the stricter mAP@0.5:0.95 metric, YOLO-Drive attains 59.2%, markedly higher than RF-DETR [35] (51.6%) and YOLOv12 (50.8%). These gains demonstrate that YOLO-Drive maintains consistent accuracy under diverse IoU thresholds, validating its robustness and generalization.
Despite these improvements, YOLO-Drive’s computational complexity increases only slightly (2.9 GFLOPs and 10.4M parameters), remaining within the lightweight range, and is significantly more efficient during training than Transformer-based detectors such as RT-DETR and RT-DETRv2. This highlights the advantages of the proposed architecture in balancing accuracy and computational cost.
Fig. 5 illustrates visual comparisons between YOLO-Drive and YOLOv12. In the first example, YOLOv12 fails to recognize subtle facial cues when the driver’s eyes are partially visible, whereas YOLO-Drive accurately detects “eyes open”. In the second case, YOLOv12 misclassifies “normal driving” as “talking to passenger” due to slight head movement, while YOLO-Drive makes the correct distinction. These qualitative observations align with the quantitative gains in Table 1, confirming that the proposed model captures fine-grained details and reduces category confusion in complex cabin scenarios.

Figure 5: Visual comparison of detection results between YOLO-Drive and baseline (YOLOv12)
Table 2 presents ablation results evaluating the contribution of each module. The baseline YOLOv12 achieves 63.2% recall, 65.1% mAP@0.5, and 50.8% mAP@0.5:0.95. Introducing only EfficientViMBlock improves global-local modeling but lowers recall (59.3%), showing insufficient robustness when used in isolation. Replacing with only A2C2f_VimBlock further degrades performance (56.2% recall, 63.2% mAP@0.5). When both modules are combined, performance improves significantly (68.4% recall, 72.6% mAP@0.5). Finally, integrating the PSSA module yields optimal results (73.3% recall, 75.0% mAP@0.5, 59.2% mAP@0.5:0.95), validating the complementary contributions of EfficientViM and PSSA.
From the ablation results in Table 2, we can observe that using EfficientViM alone improves global-local context modeling but reduces recall, indicating that long-range interactions alone are insufficient to distinguish subtle, overlapping cues. Conversely, PSSA focuses on frequency- and orientation-sensitive details, but due to the lack of global semantic structure provided by EfficientViM, the enhanced fine cues are more susceptible to cross-region interference. When used in combination, EfficientViM provides stable region-level separation, while PSSA further sharpens fine and directional textures within each region. This combined effect improves both spatial ambiguity resolution and texture-level discriminability. The final model achieves the highest recall and mAP, confirming that overlapping distraction behavior requires both global structural modeling and frequency domain cue enhancement for reliable detection.
4.6 Attention Heatmaps Qualitative Analysis
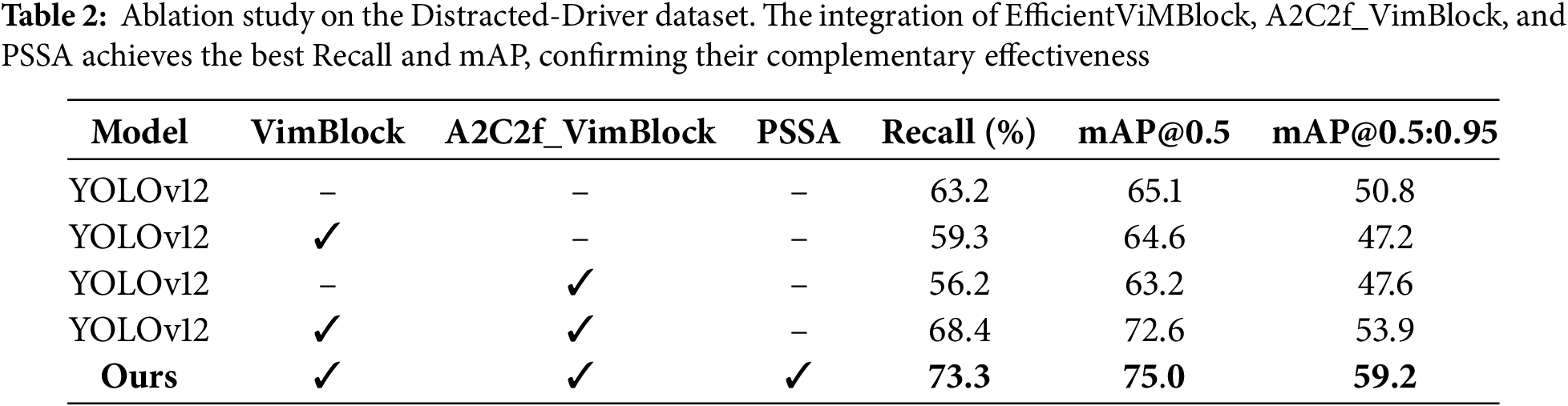
The effectiveness of the proposed YOLO-Drive framework is further demonstrated from the generated attention heatmaps. As shown in Fig. 6, when the driver exhibits overlapping states of “eyes open” and “safe driving” as well as “eyes closed” and “drowsy”, the attention maps simultaneously focus on the eye, mouth, and body regions, confirming that the model is able to correctly localize these two fine-grained cues without confusing them. In addition to the face, the heatmaps also extend to the arm and body positions in both safe and distracted states, demonstrating that the network is able to reliably attend to the driver’s overall posture. These visualizations confirm that our model not only achieves higher classification accuracy but also bases its predictions on the correct anatomical regions, thus addressing the challenges of overlapping and fine-grained distractions that existing methods cannot address.
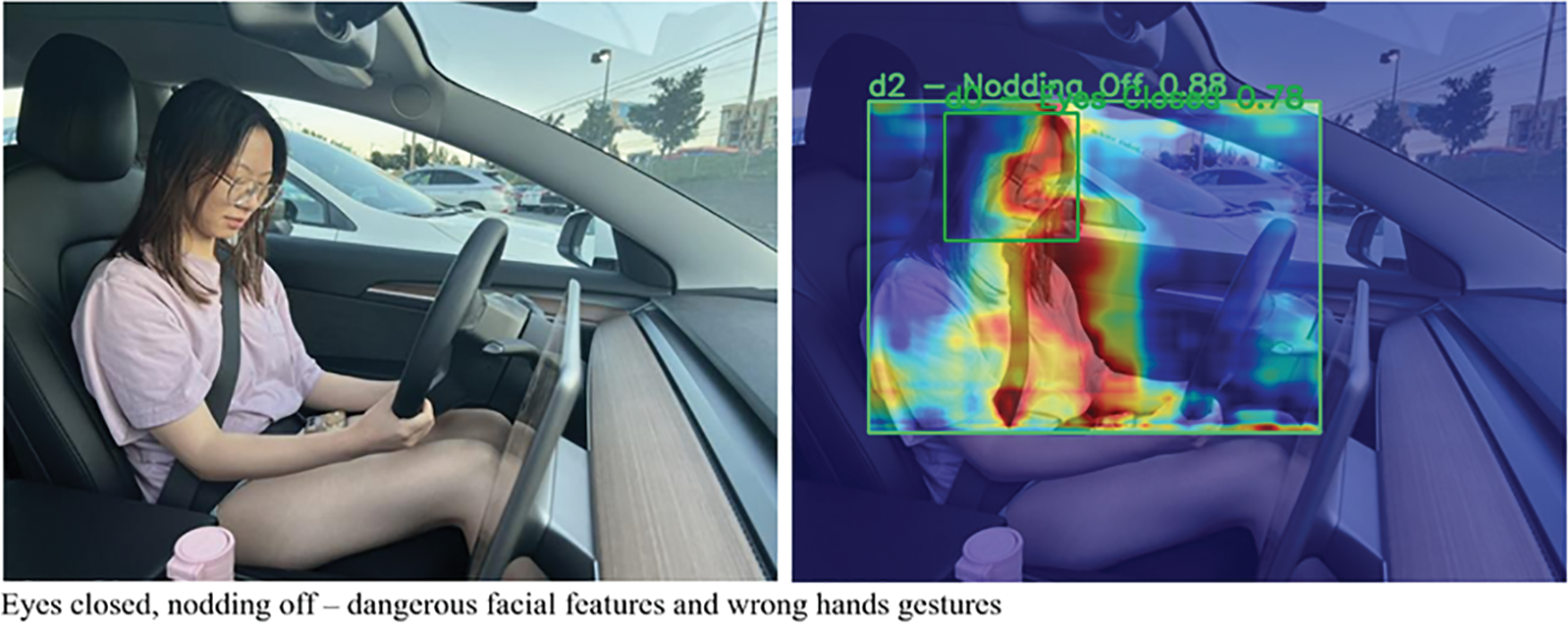
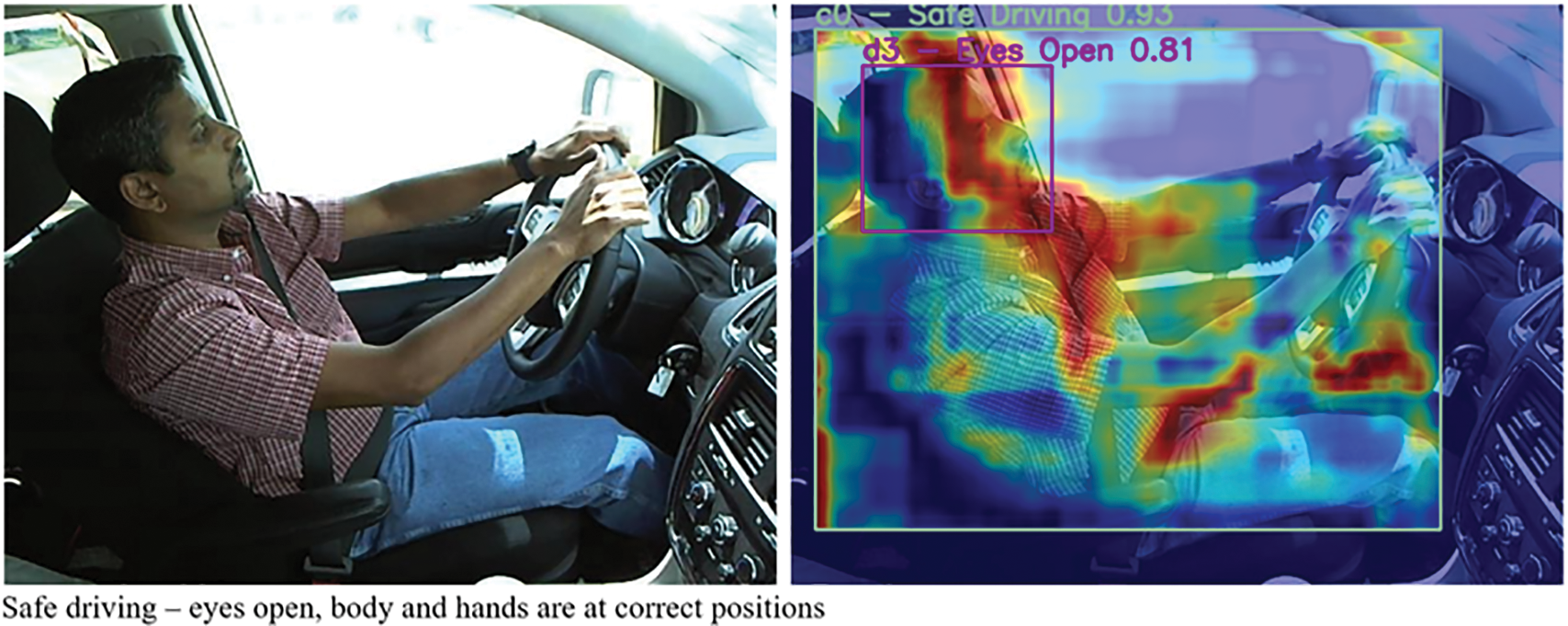
Figure 6: Attention heatmap for overlapping cues of eyes open (or closed) and driving safely, (or nodding off) highlighting simultaneous focus on ocular and oral regions
Fig. 7 shows the attention visualization results of YOLO-Drive in two typical challenging scenarios: the top example shows “yawning with eyes open” and the bottom example shows “yawning with eyes closed”, both accompanied by a more complex background and facial occlusion. As can be seen in both cases, the model’s attention is primarily focused on the eyes and mouth, which are key features for distinguishing fine-grained sleepiness-related behaviors. This demonstrates that the proposed PSSAttention module effectively highlights fine-grained facial texture, enabling it to distinguish between categories with some overlapping features, such as “eyes closed” and “yawning”.
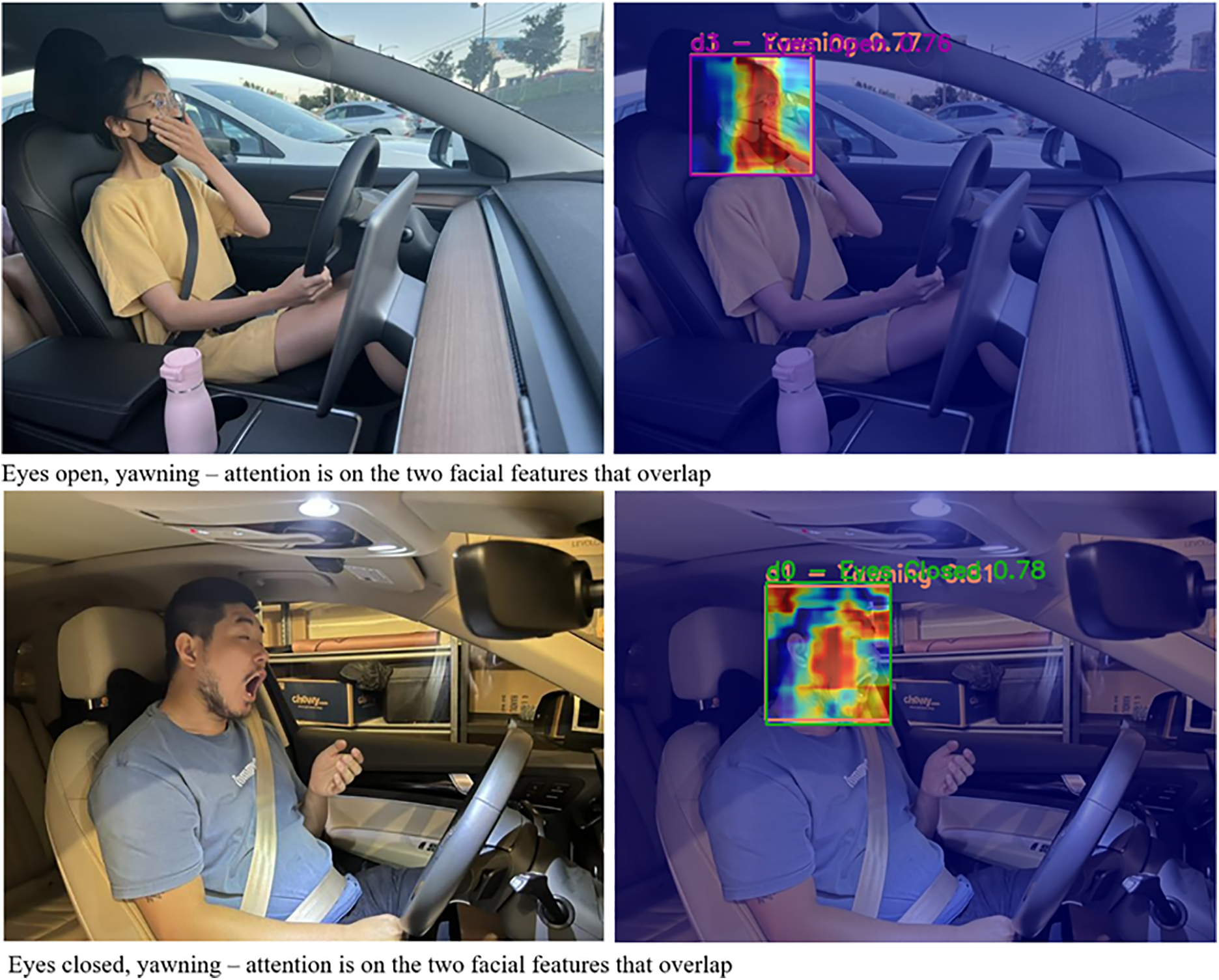
Figure 7: Attention visualization of YOLO-Drive for yawning behaviors under two different facial states: (top) eyes open and yawning, (bottom) eyes closed and yawning with more complex obstructions and backgrounds
4.7 Attention Heatmaps Quantitative Interpretability Analysis
To reduce the subjectivity of Grad-CAM visualizations and provide a more principled assessment of interpretability, we further introduce two quantitative significance metrics: Attention Dispersion (AD) and Frequency-Energy Ratio (FER). These metrics have been widely used in recent CAM-based interpretability studies to characterize the concentration and stability of model attention.
AD measures the spatial concentration of the normalized saliency map
To quantify interpretability, we randomly sampled 100 test images from the Distracted-Driver dataset and computed AD and FER for both the YOLOv12 baseline and our YOLO-Drive model. As shown in Table 3, YOLOv12 obtains an AD of 0.1057 and an FER of

4.8 Potential Failure Case Analysis
Fig. 8 illustrates a typical test conducted under extremely dark nighttime conditions. In the left image, YOLO-Drive successfully detects the yawning event even in low light, demonstrating the robustness of the PSSA-enhanced fine-grained features. However, in the right image, the model fails to recognize the driver’s behavior. Under such low illumination, key high-frequency textures are almost indistinguishable. Therefore, the feature branches in PSSA that perceive frequency and orientation fail to extract reliable features, leading to misclassification. This failure mode reflects a common limitation in real-world driver monitoring systems: insufficient cabin lighting fundamentally reduces discriminative visual cues. Future work will combine temporal consistency and illumination robustness modeling to mitigate this situation.

Figure 8: Model performance under insufficient cabin illumination showing a correct and an incorrect prediction
This paper introduced YOLO-Drive, a novel driver distraction detection framework that integrates EfficientViM for global–local feature fusion and Polarized Spectral–Spatial Attention (PSSA) for fine-grained cue enhancement. Through extensive experiments on the Distracted-Driver dataset, YOLO-Drive demonstrated substantial improvements over state-of-the-art baselines, achieving higher Recall, mAP@0.5, and mAP@0.5:0.95. The ablation study confirmed the complementary effectiveness of EfficientViM and PSSA in addressing the long-standing limitations of conventional detectors, such as difficulty in modeling subtle eye and hand cues, misclassification under overlapping behaviors, and robustness in cluttered in-car environments.
The results show that YOLO-Drive not only improves raw detection accuracy but also enhances the reliability of classifying both coarse and fine-grained distraction behaviors. Its ability to distinguish visually similar actions and capture micro-expressions such as eyelid closure or yawning underscores its practical relevance for real-world driver monitoring. Future work will extend this framework to video-based temporal modeling and multi-sensor fusion, aiming to further strengthen real-time detection robustness in diverse driving conditions.
Acknowledgement: Not applicable.
Funding Statement: This research was funded by the Guangzhou Development Zone Science and Technology Project (2023GH02), the University of Macau (MYRG2022-00271-FST) and research grants by the Sci-ence and Technology Development Fund of Macau (0032/2022/A) and (0019/2025/RIB1).
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Zhichao Yu and Jiahui Yu; methodology, Zhichao Yu; software, Zhichao Yu; validation, Zhichao Yu, Jiahui Yu and Simon James Fong; formal analysis, Jiahui Yu and Yaoyang Wu; writing—original draft preparation, Zhichao Yu; writing—review and editing, Jiahui Yu and Simon James Fong; visualization, Jiahui Yu and Yaoyang Wu; supervision, Simon James Fong; project administration, Simon James Fong; funding acquisition, Simon James Fong. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in Roboflow at https://universe.roboflow.com/ipylot-project/distracted-driving-v2wk5.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Dong Y, Hu Z, Uchimura K, Murayama N. Driver inattention monitoring system for intelligent vehicles: a review. IEEE Trans Intell Transp Syst. 2011;12(2):596–614. doi:10.1109/TITS.2010.2092770. [Google Scholar] [CrossRef]
2. Chen J, Jiang Y, Huang Z, Guo X, Wu B, Sun L, et al. Fine-grained detection of driver distraction based on neural architecture search. IEEE Trans Intell Transp Syst. 2021;22(9):5783–801. doi:10.1109/TITS.2021.3055545. [Google Scholar] [CrossRef]
3. Huang T, Fu R. Driver distraction detection based on the true driver’s focus of attention. IEEE Trans Intell Transp Syst. 2022;23(10):19374–86. doi:10.1109/TITS.2022.3166208. [Google Scholar] [CrossRef]
4. Tawari A, Trivedi MM. Robust and continuous estimation of driver gaze zone by dynamic analysis of multiple face videos. In: Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings; 2014 Jun 8–11; Dearborn, MI, USA. p. 344–9. doi:10.1109/IVS.2014.6856607. [Google Scholar] [CrossRef]
5. Woo S, Park J, Lee JY, Kweon IS. CBAM: convolutional block attention module. In: Computer vision—ECCV 2018. Cham, Switzerland: Springer; 2018. p. 3–19. doi:10.1007/978-3-030-01234-2_1. [Google Scholar] [CrossRef]
6. Abouelnaga Y, Eraqi HM, Moustafa MN. Real-time distracted driver posture classification. arXiv:1706.09498. 2017. doi; 10.48550/arxiv.1706.09498. [Google Scholar] [CrossRef]
7. Doshi A, Trivedi MM. On the roles of eye gaze and head dynamics in predicting driver’s intent to change lanes. IEEE Trans Intell Transp Syst. 2009;10(3):453–62. doi:10.1109/TITS.2009.2026675. [Google Scholar] [CrossRef]
8. Vora S, Rangesh A, Trivedi MM. Driver gaze zone estimation using convolutional neural networks: a general framework and ablative analysis. IEEE Trans Intell Veh. 2018;3(3):254–65. doi:10.1109/TIV.2018.2843120. [Google Scholar] [CrossRef]
9. Eraqi HM, Abouelnaga Y, Saad MH, Moustafa MN. Driver distraction identification with an ensemble of convolutional neural networks. J Adv Transp. 2019;2019:4125865. doi:10.1155/2019/4125865. [Google Scholar] [CrossRef]
10. Tran D, Do HM, Sheng W, Bai H, Chowdhary G. Real-time detection of distracted driving based on deep learning. IET Intell Transp Syst. 2018;12(10):1210–9. doi:10.1049/iet-its.2018.5172. [Google Scholar] [CrossRef]
11. Xing Y, Lv C, Wang H, Cao D, Velenis E, Wang FY. Driver activity recognition for intelligent vehicles: a deep learning approach. IEEE Trans Veh Technol. 2019;68(6):5379–90. doi:10.1109/TVT.2019.2908425. [Google Scholar] [CrossRef]
12. Aljasim M, Kashef R. E2DR: a deep learning ensemble-based driver distraction detection with recommendations model. Sensors. 2022;22(5):1858. doi:10.3390/s22051858. [Google Scholar] [PubMed] [CrossRef]
13. Ezzouhri A, Charouh Z, Ghogho M, Guennoun Z. Robust deep learning-based driver distraction detection and classification. IEEE Access. 2021;9:168080–92. doi:10.21227/f9z3-0438. [Google Scholar] [CrossRef]
14. Li Z, Zhao X, Wu F, Chen D, Wang C. A lightweight and efficient distracted driver detection model fusing convolutional neural network and vision transformer. IEEE Trans Intell Transp Syst. 2024;25(12):19962–78. doi:10.1109/TITS.2024.3447041. [Google Scholar] [CrossRef]
15. Chen J, Zhang Z, Yu J, Huang H, Zhang R, Xu X, et al. DSDFormer: an innovative transformer-mamba framework for robust high-precision driver distraction identification. arXiv:2409.05587. 2024. [Google Scholar]
16. Du Y, Liu X, Yi Y, Wei K. Optimizing road safety: advancements in lightweight YOLOv8 models and GhostC2f design for real-time distracted driving detection. Sensors. 2023;23(21):8844. doi:10.3390/s23218844. [Google Scholar] [PubMed] [CrossRef]
17. Liu S, Wang Y, Yu Q, Liu H, Peng Z. CEAM-YOLOv7: improved YOLOv7 based on channel expansion and attention mechanism for driver distraction behavior detection. IEEE Access. 2022;10:129116–24. doi:10.1109/ACCESS.2022.3228331. [Google Scholar] [CrossRef]
18. Sheikh AA, Khan IZ. Enhancing road safety: real-time detection of driver distraction through convolutional neural networks. arXiv:2405.17788. 2024. doi:10.48550/arxiv.2405.17788. [Google Scholar] [CrossRef]
19. Khan T, Choi G, Lee S. EFFNet-CA: an efficient driver distraction detection based on multiscale features extractions and channel attention mechanism. Sensors. 2023;23(8):3835. doi:10.3390/s23083835. [Google Scholar] [PubMed] [CrossRef]
20. Yang H, Liu H, Hu Z, Nguyen AT, Guerra TM, Lv C. Quantitative identification of driver distraction: a weakly supervised contrastive learning approach. IEEE Trans Intell Transp Syst. 2024;25(2):2034–45. doi:10.1109/TITS.2023.3316203. [Google Scholar] [CrossRef]
21. Li G, Wang G, Guo Z, Liu Q, Luo X, Yuan B, et al. Domain adaptive driver distraction detection based on partial feature alignment and confusion-minimized classification. IEEE Trans Intell Transp Syst. 2024;25(9):11227–40. doi:10.1109/TITS.2024.3367665. [Google Scholar] [CrossRef]
22. Elshamy MR, Emara HM, Shoaib MR, Badawy AA. P-YOLOv8: efficient and accurate real-time detection of distracted driving. In: Proceedings of the 2024 IEEE High Performance Extreme Computing Conference (HPEC); 2024 Sep 23–27; Wakefield, MA, USA. p. 1–6. doi:10.1109/HPEC62836.2024.10938429. [Google Scholar] [CrossRef]
23. Li B, Chen J, Huang Z, Wang H, Lv J, Xi J, et al. A new unsupervised deep learning algorithm for fine-grained detection of driver distraction. IEEE Trans Intell Transp Syst. 2022;23(10):19272–84. doi:10.1109/TITS.2022.3166275. [Google Scholar] [CrossRef]
24. Fu S, Yang Z, Ma Y, Li Z, Xu L, Zhou H. Advancements in the intelligent detection of driver fatigue and distraction: a comprehensive review. Appl Sci. 2024;14(7):3016. doi:10.3390/app14073016. [Google Scholar] [CrossRef]
25. Siddharth S, Trivedi MM. On assessing driver awareness of situational criticalities: multi-modal bio-sensing and vision-based analysis, evaluations, and insights. Brain Sci. 2020;10(1):46. doi:10.3390/brainsci10010046. [Google Scholar] [PubMed] [CrossRef]
26. Chen J, Zhang Q, Chen J, Wang J, Fang Z, Liu Y, et al. A driving risk assessment framework considering driver’s fatigue state and distraction behavior. IEEE Trans Intell Transp Syst. 2024;25(12):20120–36. doi:10.1109/TITS.2024.3446832. [Google Scholar] [CrossRef]
27. Wang H, Chen J, Huang Z, Li B, Lv J, Xi J, et al. FPT: fine-grained detection of driver distraction based on the feature pyramid vision transformer. IEEE Trans Intell Transp Syst. 2023;24(2):1594–608. doi:10.1109/TITS.2022.3219676. [Google Scholar] [CrossRef]
28. Tian Y, Ye Q, Doermann D. YOLOv12: attention-centric real-time object detectors. arXiv:2502.12524. 2025. doi:10.48550/arxiv.2502.12524. [Google Scholar] [CrossRef]
29. Lee S, Choi J, Kim HJ. EfficientViM: efficient vision mamba with hidden state mixer based state space duality. In: Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2025 Jun 10–17; Nashville, TN, USA. p. 14923–33. doi:10.1109/CVPR52734.2025.01390. [Google Scholar] [CrossRef]
30. Ipylot Project. Distracted driving dataset (Roboflow Universe). Roboflow [Internet]; 2022 [cited 2025 Oct 15]. Available from: https://universe.roboflow.com/ipylot-project/distracted-driving-v2wk5. [Google Scholar]
31. Khanam R, Hussain M. YOLOv11: an overview of the key architectural enhancements. arXiv:2410.17725. 2024. doi: 10.48550/arXiv.2410.17725. [Google Scholar] [CrossRef]
32. Zhao Y, Lv W, Xu S, Wei J, Wang G, Dang Q, et al. DETRs beat YOLOs on real-time object detection. In: Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 16–22; Seattle, WA, USA. p. 16965–74. doi:10.1109/CVPR52733.2024.01605. [Google Scholar] [CrossRef]
33. Lei M, Li S, Wu Y, Hu H, Zhou Y, Zheng X, et al. YOLOv13: real-time object detection with hypergraph-enhanced adaptive visual perception. arXiv:2506.17733. 2025. doi:10.48550/arxiv.2506.17733. [Google Scholar] [CrossRef]
34. Lv W, Zhao Y, Chang Q, Huang K, Wang G, Liu Y. RT-DETRv2: improved baseline with bag-of-freebies for real-time detection transformer. arXiv:2407.17140. 2024. doi:10.48550/arxiv.2407.17140. [Google Scholar] [CrossRef]
35. Robinson I, Robicheaux P, Popov M, Ramanan D, Peri N. RF-DETR: neural architecture search for real-time detection transformers. arXiv:2511.09554. 2025. doi:10.48550/arXiv.2511.09554. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools