
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Robust Swin Transformer for Vehicle Re-Identification with Dynamic Feature Fusion
1 BioQuant, Ruprecht-Karls-Universität Heidelberg (Uni Heidelberg), Heidelberg, 69120, Germany
2 SDAIA-KFUPM Joint Research Center for Artificial Intelligence, King Fahd University of Petroleum & Minerals (KFUPM), Dhahran, 31261, Saudi Arabia
3 Computer Engineering Department, King Fahd University of Petroleum & Minerals (KFUPM), Dhahran, 31261, Saudi Arabia
* Corresponding Authors: Saifullah Tumrani. Email: ; Abdul Jabbar Siddiqui. Email:
Computers, Materials & Continua 2026, 87(2), 25 https://doi.org/10.32604/cmc.2025.075152
Received 26 October 2025; Accepted 17 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Vehicle re-identification (ReID) is a challenging task in intelligent transportation, and urban surveillance systems due to its complications in camera viewpoints, vehicle scales, and environmental conditions. Recent transformer-based approaches have shown impressive performance by utilizing global dependencies, these models struggle with aspect ratio distortions and may overlook fine-grained local attributes crucial for distinguishing visually similar vehicles. We introduce a framework based on Swin Transformers that addresses these challenges by implementing three components. First, to improve feature robustness and maintain vehicle proportions, our Aspect Ratio-Aware Swin Transformer (AR-Swin) preserve the native ratio via letterbox, uses a non-square (16Keywords
As smart city initiatives and intelligent transportation systems (ITS) continue to expand, vehicle re-identification (ReID) has become a critical capability for automated vehicle tracking on large-scale multi-camera networks [1,2]. Vehicle ReID [3–7] supports applications ranging from traffic flow management and transit time estimation to vehicle behavior analysis and public safety (e.g., criminal investigations and accident forensics). The fundamental task is to retrieve images of the same vehicle identity from heterogeneous camera views and under varying environmental conditions, given a query image.
Unlike person ReID, where each identity is inherently unique, vehicles are mass-produced, leading to high intra-class similarity and subtle inter-class differences which complicate discrimination.
Over the past decade, deep learning methods have substantially advanced vehicle ReID by modeling both global and local image features. Early work based on convolutional neural networks (CNNs) [8–11] mainly learned global embeddings, but often struggled under large variations in illumination, scale, and viewpoint. More recently, transformer-based models have gained prominence due to their ability to capture long-range dependencies and global context [12–14]. Qian et al. [15] provide a systematic review of transformer-based ReID methods, and Kishore et al. [16] improved cross-view attribute classification by incorporating vehicle pose estimation. Despite this progress, critical challenges remain. Feature misalignment due to pose and viewpoint variation continues to hinder robustness.
Lu et al. [17] addressed this with the Mask-Aware Reasoning Transformer (MART), which learns view-specific representations, while Qian et al. [18] proposed the Unstructured Feature Decoupling Network (UFDN) to disentangle viewpoint-dependent features without manual annotations. However, achieving fine-grained discrimination and strong generalization in diverse environments remains difficult. In response, recent studies have emphasized part-based and region-aware modeling. Wang et al. [19] annotated 20 vehicle landmarks to improve recognition, and Liu et al. [20] employed region-aware modules to better capture local parts. However, many existing approaches still overemphasize global features, limiting their ability to distinguish near-identical vehicles in complex scenes.
The rise of aerial surveillance platforms, such as unmanned aerial vehicles (UAVs), further complicates the vehicle ReID. Unlike fixed roadside cameras, UAVs capture images from various altitudes and non-canonical viewpoints, resulting in greater viewpoint variance and wider resolution ranges. This increases the prevalence of uncommon perspectives and low-resolution targets, exacerbating the challenges of robust ReID. Vision Image Transformers (ViT) [21–23] have recently emerged as powerful alternatives due to their flexibility on large-scale datasets. The advent of Vision Transformers (ViTs) revolutionized the field through self-attention mechanisms that model global dependencies more effectively [15]. Initial transformer-based approaches such as TransReID [22] showed significant improvements in cross-camera matching accuracy. However, these methods faced challenges in handling non-square aspect ratios common in real-world surveillance footage and often overlooked crucial local features like vehicle logos and modified parts.
Recent advances in hierarchical transformers, particularly the Swin transformer architecture [23], have addressed several limitations of vanilla ViTs. As demonstrated in [23], the shifted window mechanism enables efficient multiscale feature learning while maintaining linear computational complexity relative to image size. Subsequent work by [15] systematically analyzed the superiority of Swin Transformer over CNN-based methods in vehicle ReID tasks, particularly in handling viewpoint variations and illumination changes.
Key Contributions are:
In this paper, we introduce a Swin Transformer-based framework for vehicle ReID that explicitly targets aspect ratio distortion, attribute integration, and fine-grained regional attention. Our contributions are threefold:
1. We propose a backbone Aspect ratio-aware swin transformer that employs adaptive patch partitioning and patch-wise mixup to preserve vehicle proportions and improve the robustness to geometric distortions.
2. We design an adaptive dynamic feature fusion module that integrates global Swin features with attribute embeddings, i.e., vehicle color and type, enhancing discriminative capacity.
3. We incorporate CNN-inspired regional masks into the windowed attention of the transformer to focus on fine-grained signals, such as local characteristics and manufacturer logos.
We conducted comprehensive experiments on two public benchmarks (VeRi-776, and VehicleID), demonstrating improvements in performance, and superior robustness to aspect ratio variation.
Recent vehicle ReID studies have made significant progress by addressing problematic misalignment of points of view and characteristics, but important distinctions remain between our framework and previous approaches. TransReID [22] demonstrated the effectiveness of vision transformers for vehicle and person ReID by introducing camera-specific tokens and strong global representations. However, it uses fixed patch partitioning, which can distort vehicles under non-standard aspect ratios. In contrast, our AR-Swin backbone incorporates adaptive patch partitioning and patch-wise mixup, explicitly addressing geometric distortions and improving robustness to aerial and wide-angle views. MART (Mask-Aware Reasoning Transformer) [17] and UFDN (Unstructured Feature Decoupling Network) [18] advanced view-specific feature learning by disentangling viewpoint-dependent and viewpoint-independent representations. While effective, they rely heavily on annotated masks or disentangling objectives, which limit scalability. Our approach instead leverages regional attention blocks with dynamically generated soft masks, reducing annotation cost and enabling adaptive focus on discriminative regions such as license plates and logos. Several prior works have incorporated vehicle attributes. For instance, Wang et al. [19] and Liu et al. [20] exploited manually annotated attributes or part landmarks to guide representation learning. Our method differs by introducing a lightweight attribute embedding branch for color and type descriptors, trained implicitly via ReID loss without auxiliary supervision. This design balances discriminability with reduced annotation dependency.
In summary, compared to prior transformer-based methods, our framework is unique in explicitly addressing aspect ratio distortion, adaptive attribute integration, and region-aware attention. Although methods such as MART and UFDN excel at handling viewpoint variation, and TransReID [22] provides strong global modeling, our design emphasizes practical deployment: robust to geometric distortions, scalable to UAV-based monitoring, and efficient enough for real-time operation.
Comparison with Prior Work
Recent vehicle ReID studies have made significant progress by tackling viewpoint and feature misalignment challenges, but important distinctions remain between our framework and prior approaches. Table 1 provides a structured summary of representative methods, their strengths and limitations, and how our approach differs.
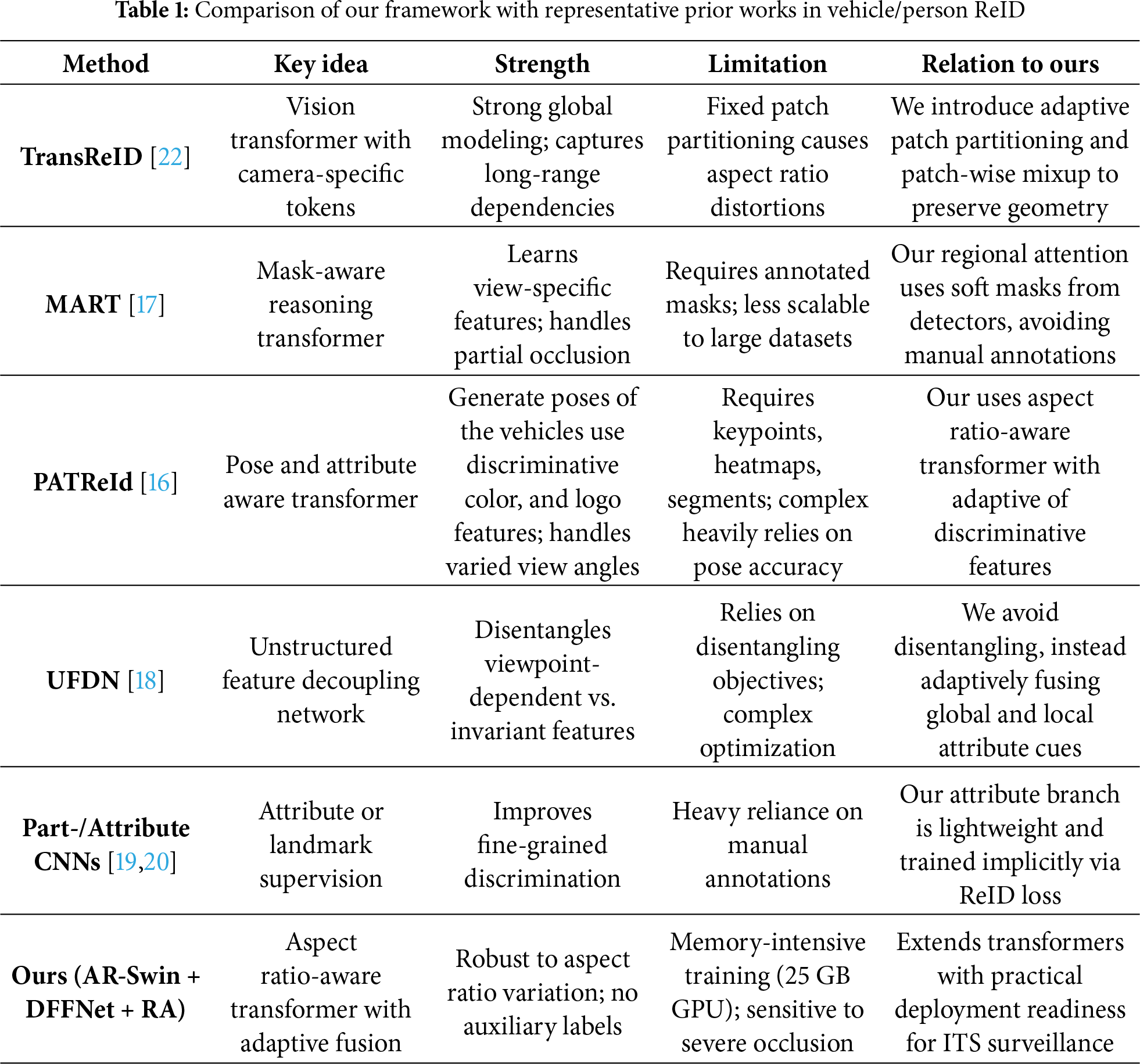
Our vehicle re-identification framework follows the six-stage pipeline illustrated in Fig. 1: (1) Input Augmentation, (2) Aspect Ratio-Aware Swin Transformer (AR-Swin), (3) Attribute Embedding Branch, (4) Regional Attention Blocks, (5) Dynamic Feature Fusion Network (DFFNet), and (6) Vehicle Feature Embedding and Re-ID Loss.
Figure 1: Overall architecture of the proposed model
For clarity, Table 2 summarizes the dimensions of the components, the training settings, and the evaluation metrics.

We preserve native aspect ratios by letterboxing each image to the network input
Patch-wise mixup [24] is applied only during training. Pairs of patches are drawn from the same spatial location in two images of the same-identity. During training, patches containing valid interpolated pixels (i.e., partial overlap when stride does not divide image dimensions exactly) are included for mix-up augmentation, while patches solely composed of zero-padding are excluded to avoid introducing meaningless features.
For selected patches
with
3.2 Aspect Ratio–Aware Swin Transformer (AR–Swin)
Vehicles are typically wide and short in bounding boxes (roughly 2:1 width:height). Uniform resizing to a fixed square input can distort these proportions and suppress the local cues—grille contours, lamp signatures, rooflines—that are vital for distinguishing visually similar IDs. Our AR-Swin addresses this in two complementary ways: (i) we preserve the native aspect ratio via letterboxing, and (ii) we tokenize the image with an anisotropic patch stem that is better aligned with elongated vehicle geometry, while keeping the rest of Swin unchanged.
Given an RGB image
To better match elongated vehicles, we replace the standard
At
We keep the canonical Swin hierarchy with patch merging at each stage (resolution halves, channel width doubles):
We adopt learned relative positional embeddings exactly as in Swin: they are added as biases inside attention and require no absolute coordinates. Because our windows are fixed-size (
3.3 Attribute Embedding Branch
Color Descriptor
HSV histograms (512-D) projected linearly to 256-D. We convert RGB to HSV and compute a 3D histogram over the valid, i.e., non-letterboxed region using
Type Descriptor
CNN: three
3.4 Regional Attention with Fixed Swin Windows
We adopt the standard Swin window size of
Masked attention with regional prior and padding suppression.
Alongside the regional soft mask
Within a local window of
which suppresses any query–key pair touching padded tokens. We combine the regional prior and validity element-wise,
and inject P as a log-bias into windowed attention:
Since
3.5 Dynamic Feature Fusion (DFFNet)
Let
We found channel-wise gating stable with weight decay
3.6 Vehicle Feature Embedding and Re-ID Loss
The fused embedding is normalized:
and optimized via:
Datasets
The VeRi-776 is one of the most widely used benchmark datasets for vehicle re-identification, which contains more than 50,000 images from 776 different vehicle identities. The training set includes 37,778 images from 576 vehicles, while the test set contains the remaining identities, and is divided into a query set and a gallery set. All images were captured from 20 surveillance cameras installed over a 24-h cycle, which captured vehicles under various lighting conditions and viewpoints. VeRi-776 also contains label information for keypoints and vehicle orientations, Which makes it valuable for fine-grained recognition tasks.
The VehicleID dataset is large in scale, containing 221,763 images of 26,267 vehicles captured by surveillance cameras. From these, 13,134 vehicle samples are used for training, while the remaining are used for testing. To facilitate fair evaluation across different scales, the dataset provides three test subsets of increasing size. In addition to identity labels, VehicleID includes 250 fine-grained vehicle model attributes and seven color attributes, enabling research not only on re-identification performance but also on attribute-assisted recognition.
Evaluated on benchmark datasets:
• VeRi-776 [3]: 50,000+ images from 776 vehicles
• VehicleID [4]: 221,763 images with varying resolutions
We evaluated the effectiveness of vehicle ReID models, by adopting three widely used evaluation metrics, Rank-
Given a query image, the model produces a ranked list of gallery images sorted by similarity scores. Rank-
Rank-1 indicates the proportion of queries with the correct identity at the top position, while Rank-5 and Rank-10 allow for a small margin of retrieval error. Rank-
5.2 Mean Average Precision (mAP)
Unlike Rank-
where M is the ranked list length,
where Q is the number of queries. mAP rewards algorithms that not only retrieve at least one correct match, but also consistently rank all relevant images higher than irrelevant ones.
5.3 Cumulative Matching Characteristic (CMC)
The CMC curve represents the cumulative probability that a correct match appears within the top-
For example, CMC@3 = 95% means that in 95% of queries, the correct vehicle identity appears within the top-3 retrieved images. As in the standard practices, mAP and Rank for VeRi-776 and Vehicle-ID are reported. In summary, Rank-
The implementation settings, model complexity, and resource requirements of our framework are reported for reproduceability. The model is implemented in PyTorch, and trained on a single NVIDIA RTX A6000 GPU (48 GB VRAM). Training a model for 120 epochs requires approximately 16 to 18 h. Our full framework contains approximately 32 M parameters and requires
Batch-hard mining is applied to select hardest positive/negative pairs within each mini-batch. Patch partition uses
We follow standard evaluation on VeRi-776, and VehicleID using mean Average Precision (mAP) and Cumulative Matching Characteristics (CMC) at Rank-1 and Rank-5. We apply same letterbox at evaluation. Ablation experiments are averaged across three independent runs with fixed seeds. These details, together with Fig. 1 and Table 2, provide a complete specification of our system to facilitate reproducibility and fair comparison. All results are averaged over five runs with different seeds; we report mean
5.5 Comparison with State-of-the-Art Methods
Table 3 benchmarks our method against other recent transformer based methods TransReID [22], UFDN [18], MART [17], EMPC [27], PATReId [16], TANet [28]; on the publically available datasets, i.e., VeRi-776 and VehicleID. Overall, our model delivers consistently strong performance across both datasets, highest results on VehicleID (Rank-1 and Rank-5) and achieving the strongest Rank-5 accuracy on VeRi-776, while remaining highly competitive on VeRi-776 mAP and Rank-1.
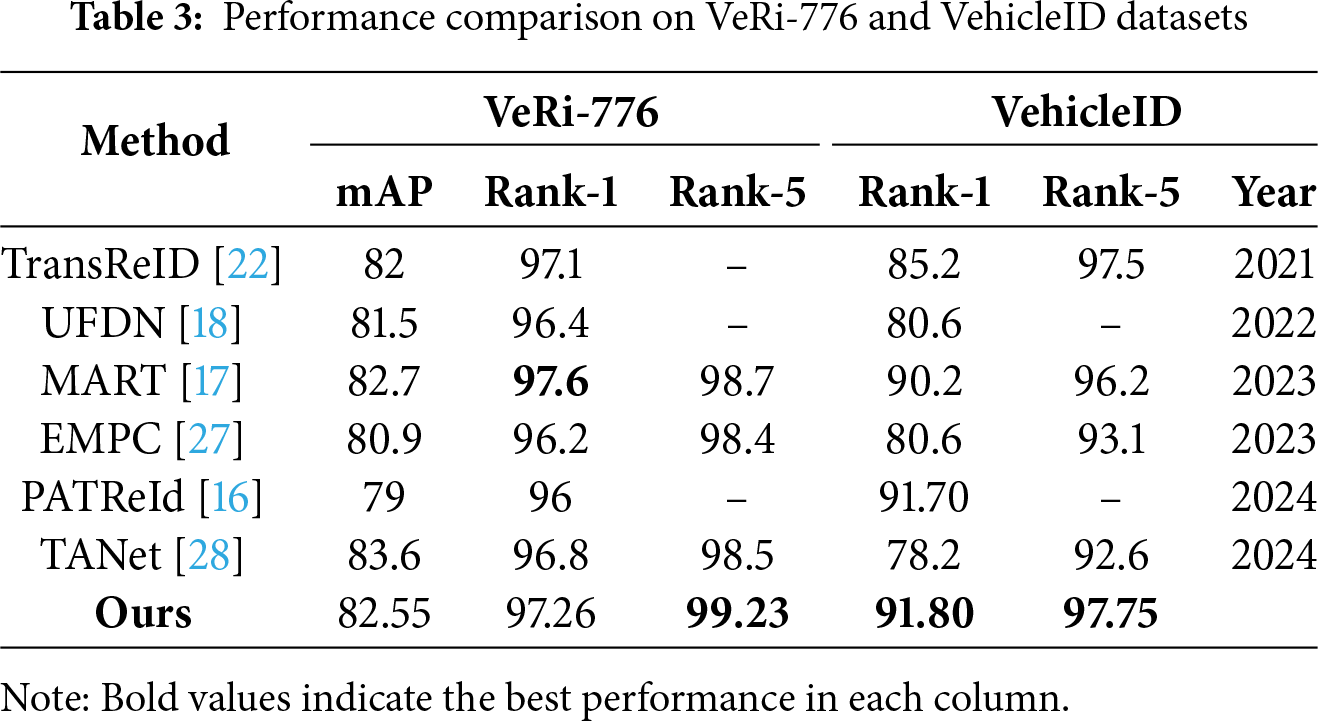
Our method attains 99.23% Rank-5, surpassing MART (98.7%), TANet (98.5%), and EMPC (98.4%) by +0.53, +0.73, and +0.83 points, respectively. Rank-1 reaches 97.26%, which is close to the top performer MART (97.6%) and exceeds TransReID (97.1%), TANet (96.8%), UFDN (96.4%), EMPC (96.2%), and PATReId (96.0%). For mAP, our 82.55% is competitive—slightly below TANet’s 83.6% and within 0.2 points of MART (82.7%) while outperforming TransReID (82.0%), UFDN (81.5%), EMPC (80.9%), and PATReId (79.0%). These trends indicate that our model is particularly effective at producing highly reliable retrievals as reflected in Rank-5 while maintaining early rank precision and overall ranking quality.
Our method achieved better results than other compared methods on Rank-1 and Rank-5 metrics, i.e., Rank-1 = 91.80% and Rank-5 = 97.75%. Our Rank-1 is competitive with the recent work PATReId by +0.10 points 91.70%, and significant progress over MART 90.2% and TransReID 85.2%. Rank-5 scores improved TransReID 97.5% by +0.25 and MART 96.2% by +1.55 points. These improvements on re-identification known for its large scale and substantial intra-class variation highlights that our model remains robust under diverse viewpoints and illumination conditions.
Our approach achieved better performance on VehicleID on both Rank-1 and Rank-5, results on VeRi-776 Rank-5 also obtain improvements, and stays competitive on VeRi-776 mAP and Rank-1. This combination of strengths across datasets and metrics indicates a balanced and transferable solution that improves fine-grained discrimination without sacrificing overall ranking quality.
We analyze the contribution of each proposed component on VeRi-776 at
Component-wise analysis.
Table 4 disentangles the effect of our three main ideas: (i) AR-consistent Swin (non-square patching with fixed
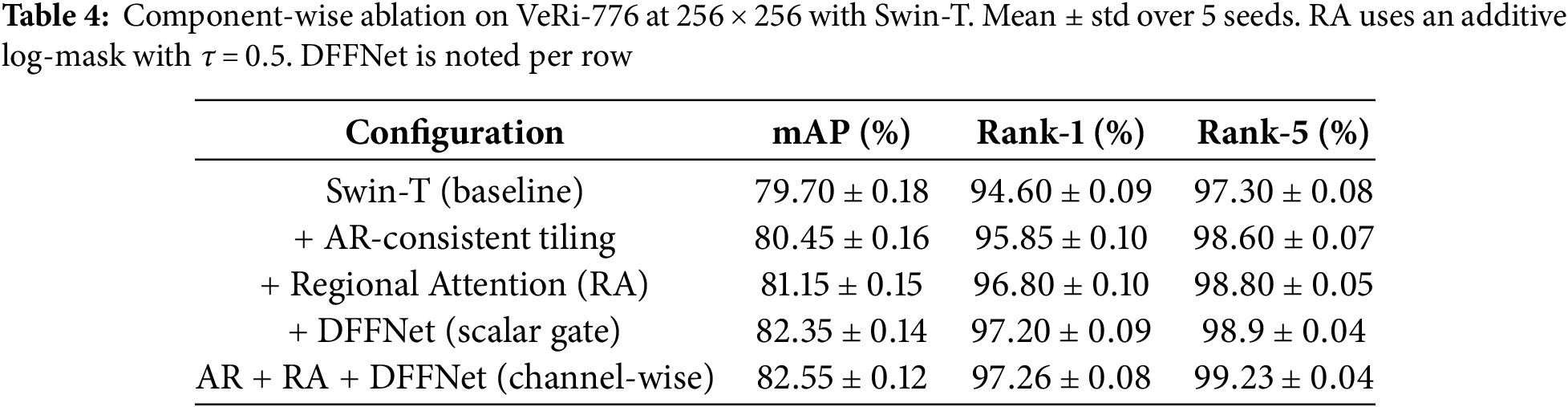
DFFNet: scalar vs. channel-wise gating and fixed
Table 5 compares (a) fixed
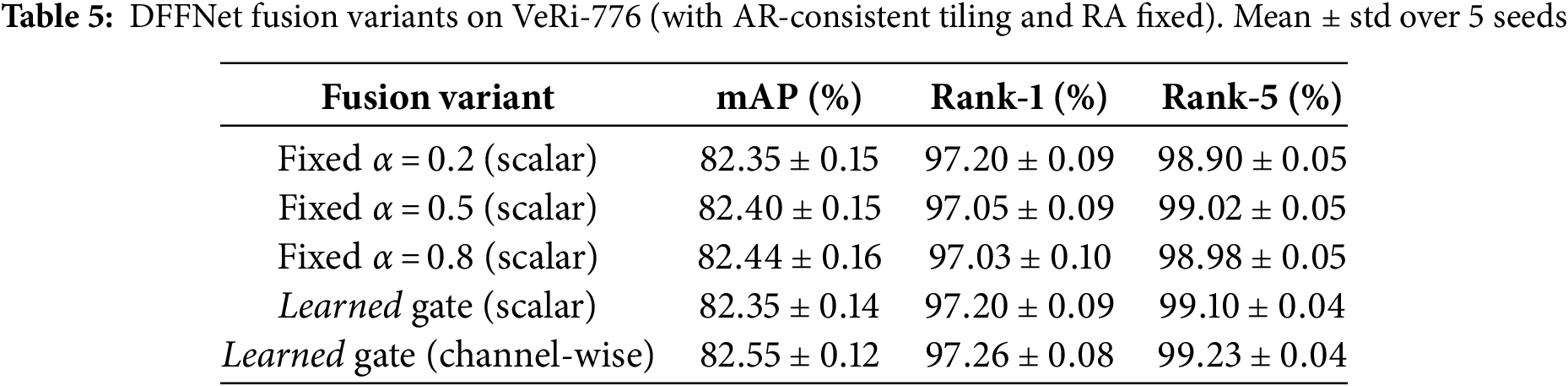
Statistical significance
Shown in Table 6 Each ablation variant is trained with 5 independent seeds. We report mean
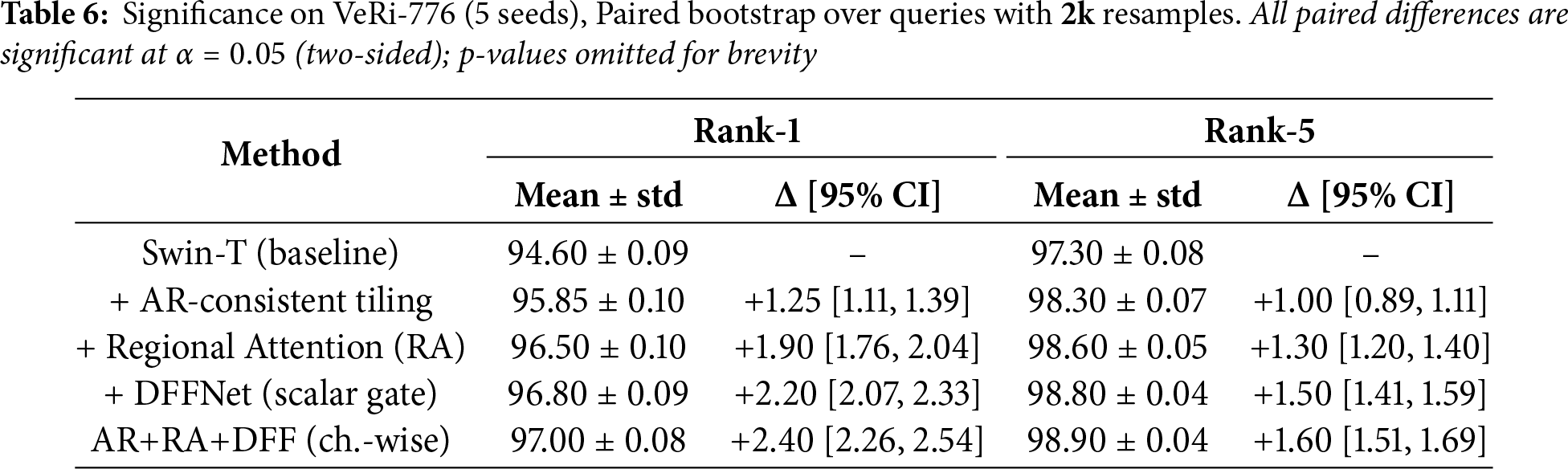
Computational efficiency.
We report complexity and measured inference speed at 256
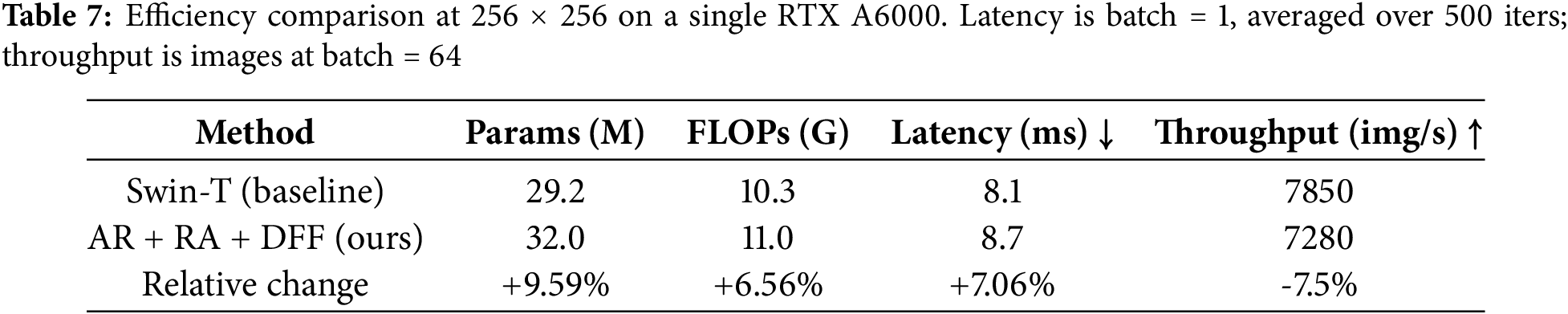
The added modules introduce a small overhead while delivering strong top-
We analyze model focus with Grad-CAM [29] applied to the final convolution of the type branch (attr.type_cnn.conv3), chosen for its balance of semantics and spatial detail. For each query, we compute Grad-CAM with respect to the ID logit. Red regions indicate strong positive contribution; blue indicates low or negative contribution. The heatmaps emphasize identity bearing parts grille/headlights in front views, taillights in rear views, roofline in top angles) and de-emphasize occluders. This backpropagates the gradient of the chosen scores into a late convolutional block of our ReID model. We then global average pool those gradients to get one weight per channel, from that weighted sum of that layer’s activations, pass it through ReLU and upsample to the image size. In the Fig. 2 the red mark pixels shows the most increased targeted scores and the model emphasizes more on that part of the vehicle and yellow are medium informative for the model to decide based on these parts on the vehicle. However, blue mark regions shows less informative or contradictory parts of the vehicle for the model. The layer we selected is attr.type_cnn.net.6 is high enough to carry semantic parts, i.e., semantic parts, headlamps, and roofline but still spatially detailed, which is why the parts level features appear clearly and sharply without becoming blurred or diluted.

Figure 2: Grad-CAM based Saliency maps for Vehicle re-identification
Looking across the grid in 2, the model repeatedly concentrates on the stable, identity bearing structures, i.e., front grilles and headlight contours in front view, taillight clusters in rear views, and roof outline for top angles. The car occluded behind two trees is still recognizable by the model while focusing more on the vehicle features instead of trees. A few frames show heat spilling to bright reflections or light bars, i.e., on trucks and vans, which hints at remaining biases towards specular highlights; those are typically Grad-CAM failure modes when strong edges co-occur with vehicle parts. Overall, this conveys a clear and interpretable narrative that our AR-Swin+DFFNet model focuses on part geometries that remain consistent across different camera views; which is exactly desired for ReID. Meanwhile, the Grad CAM visualization keeps the supporting evidence clear and uncluttered, facilitating rapid and effective visual inspection.
Fig. 3 illustrates standard vehicle re-identification retrieval processes. Each row begins with a query on the left (blue frame, denoted QXXX with its corresponding ground-truth ID), following the top 5 matches ranked from left to right (green frames). The model consistently identifies stable, identity-specific features despite variations in viewpoints. For example, the white SUV is recognized across various yaw angles by its roof rails, dark spoiler, and taillight structure; the red sedan is tracked through its lamp signature and trunk contour; the black pickup is aided by the distinctive cargo pattern and tailgate writing; the green bus is identified by the star decals and fleet striping; and the gray lorry is discerned through its cabin shape and grille design. The similarity scores for every single query tighten around the best match; in our case, it is nearly zero. Importantly, The license plates are blanked, so the successes rely on the global features color, and shape along with the local features logo, lights, side mirrors, stickers, wheels and so on. Risk factors may also include cars exactly similar to each other with no additional distinguishable local features and partially occluded. In our case, the overall row shows high top-5 response, and the model blends global shape along with fine details to stay consistent across cameras.

Figure 3: Qualitative vehicle re-identification results. Each row shows a query image (left, blue border) and its top-5 gallery matches (right, green borders) ranked by the model; IDs and similarity scores are shown above each match
Our model shows robust vehicle re-identification performance. The proposed model is built upon the Swin Transformer, along with three modified components; an aspect ratio-aware Swin Transformer backbone, a lightweight attribute embedding branch, and regional attention modules. Together with our dynamic feature fusion, these components address persistent challenges in vehicle ReID, including geometric distortions, and loss of fine-grained cues. Extensive experiments on publically available benchmark datasets demonstrated that our model achieves state-of-the-art performance, and also maintains stability under different viewpoints, illumination changes, and varying resolutions. By fusing global and local features in an adaptive manner, our method provides discriminative embeddings that remain reliable across diverse surveillance environments.
Acknowledgement: The authors thank the SDAIA-KFUPM Joint Research Center of Artificial Intelligence, Deanship of Research, King Fahd University of Petroleum and Minerals, for their support.
Funding Statement: This research was supported by SDAIA-KFUPM Joint Research Center of Artificial Intelligence, Deanship of Research, King Fahd University of Petroleum and Minerals, under Grant #CAI02562 (JRC-AI-RFP-17).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Saifullah Tumrani; methodology: Saifullah Tumrani, Abdul Jabbar Siddiqui; software and validation: Saifullah Tumrani; investigation and resources: Saifullah Tumrani, Abdul Jabbar Siddiqui; writing—original draft: Saifullah Tumrani; writing—review and editing: Saifullah Tumrani, Abdul Jabbar Siddiqui. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author, Saifullah Tumrani, upon reasonable request.
Ethics Approval: Not applicable. This study does not involve human or animal subjects.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Wang H, Hou J, Chen N. A survey of vehicle re-identification based on deep learning. IEEE Access. 2019;7:172443–69. doi:10.1109/ACCESS.2019.2956172. [Google Scholar] [CrossRef]
2. Khan SD, Ullah H. A survey of advances in vision-based vehicle re-identification. Comput Vis Image Underst. 2019;182:50–63. doi:10.1016/j.cviu.2019.03.001. [Google Scholar] [CrossRef]
3. Liu X, Liu W, Mei T, Ma H. A deep learning-based approach to progressive vehicle re-identification for urban surveillance. In: Proceedings of the 14th European Conference on Computer Vision (ECCV 2016); 2016 Oct 11–14. Amsterdam, The Netherlands. Cham, Switzerland: Springer International Publishing; 2016. Vol. 9906. p. 869–84. doi:10.1007/978-3-319-46475-6. [Google Scholar] [CrossRef]
4. Liu H, Tian Y, Wang Y, Pang L, Huang T. Deep relative distance learning: tell the difference between similar vehicles. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2016. p. 2167–75. doi:10.1109/CVPR.2016.238. [Google Scholar] [CrossRef]
5. Lou Y, Bai Y, Liu J, Wang S, Duan L-Y. VERI-Wild: a large dataset and a new method for vehicle re-identification in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2019. p. 3235–43. doi:10.1109/CVPR.2019.00335. [Google Scholar] [CrossRef]
6. Tang Z, Naphade M, Liu M-Y, Yang X, Birchfield S, Wang S, et al. CityFlow: a city-scale benchmark for multi-target multi-camera vehicle tracking and re-identification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2019. p. 8797–8806. doi:10.1109/CVPR.2019.00900. [Google Scholar] [CrossRef]
7. Wang P, Jiao B, Yang L, Yang Y, Zhang S, Wei W, et al. Vehicle re-identification in aerial imagery: dataset and approach. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE; 2019. p. 460–9. doi:10.48550/arXiv.1904.01400. [Google Scholar] [CrossRef]
8. Bashir RMS, Shahzad M, Fraz MM. VR-PROUD: vehicle Re-identification using PROgressive unsupervised deep architecture. Pattern Recognit. 2019;90:52–65. doi:10.1016/j.patcog.2019.01.008. [Google Scholar] [CrossRef]
9. Tumrani S, Deng Z, Lin H, Shao J. Partial attention and multi-attribute learning for vehicle re-identification. Pattern Recognit Lett. 2020;138:290–7. doi:10.1016/j.patrec.2020.07.034. [Google Scholar] [CrossRef]
10. Tumrani S, Ali W, Kumar R, Khan AA, Dharejo FA. View-aware attribute-guided network for vehicle re-identification. Multimed Syst. 2023;29(4):1853–63. doi:10.1007/s00530-023-01077-y. [Google Scholar] [CrossRef]
11. Gong R, Zhang X, Pan J, Guo J, Nie X. Vehicle reidentification based on convolution and vision transformer feature fusion. IEEE Multimed. 2024;31(2):61–8. doi:10.1109/MMUL.2024.3398189. [Google Scholar] [CrossRef]
12. Taleb H, Wang C. Transformer-based vehicle re-identification with multiple details. In: Su R, Liu H, editors. Proceedings of the Fifth International Conference on Image, Video Processing, and Artificial Intelligence (IVPAI 2023). Vol. 13074. Bellingham, WA, USA: SPIE; 2024. 130740H p. doi:10.1117/12.3024821. [Google Scholar] [CrossRef]
13. Li J, Yu C, Shi J, Zhang C, Ke T. Vehicle re-identification method based on Swin-Transformer network. Array. 2022;16:100255. doi:10.1016/j.array.2022.100255. [Google Scholar] [CrossRef]
14. Du L, Huang K, Yan H. ViT-ReID: a vehicle re-identification method using visual transformer. In: Proceedings of the 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE). Piscataway, NJ, USA: IEEE; 2023. p. 287–90. doi:10.1109/NNICE58320.2023.10105738. [Google Scholar] [CrossRef]
15. Qian Y, Barthélemy J, Du B, Shen J. Paying attention to vehicles: a systematic review on transformer-based vehicle re-identification. ACM Trans Multimed Comput Commun Appl. 2024;418:114. doi:10.1145/3655623. [Google Scholar] [CrossRef]
16. Kishore R, Aslam N, Kolekar MH. PATReId: pose apprise transformer network for vehicle re-identification. IEEE Trans Emerg Top Comput Intell. 2024;8(5):3691–702. doi:10.1109/TETCI.2024.3372391. [Google Scholar] [CrossRef]
17. Lu Z, Lin R, Hu H. MART: mask-aware reasoning transformer for vehicle re-identification. IEEE Trans Intell Transp Syst. 2023;24(2):1994–2009. doi:10.1109/TITS.2022.3219593. [Google Scholar] [CrossRef]
18. Qian W, Luo H, Peng S, Wang F, Chen C, Li H. Unstructured feature decoupling for vehicle re-identification. In: Proceedings of the Computer Vision-ECCV 2022: 17th European Conference on Computer Vision; 2022 Oct 23–27; Tel Aviv, Israel. Cham, Switzerland: Springer; 2022. Vol. 13674, p. 336–53. doi:10.1007/978-3-031-19781-9. [Google Scholar] [CrossRef]
19. Wang Z, Tang L, Liu X, Yao Z, Yi S, Shao J, et al. Orientation invariant feature embedding and spatial temporal regularization for vehicle re-identification. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE; 2017. p. 379–87. doi:10.1109/ICCV.2017.49. [Google Scholar] [CrossRef]
20. Liu X, Zhang S, Huang Q, Gao W. RAM: a region-aware deep model for vehicle re-identification. In: Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME). Piscataway, NJ, USA: IEEE; 2018. p. 1–6. doi:10.1109/ICME.2018.8486589. [Google Scholar] [CrossRef]
21. Yi X, Wang Q, Liu Q, Rui Y, Ran B. Advances in vehicle re-identification techniques: a survey. Neurocomputing. 2025;614:1–23. doi:10.1016/j.neucom.2024.128745. [Google Scholar] [CrossRef]
22. He S, Luo H, Wang P, Wang F, Li H, Jiang W. TransReID: transformer-based object re-identification. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE; 2021. p. 14993–5002. doi:10.48550/arXiv.2102.04378. [Google Scholar] [CrossRef]
23. Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al. Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE; 2021. p. 9992–10002. doi:10.1109/ICCV48922.2021.00986. [Google Scholar] [CrossRef]
24. Qiu M, Christopher L, Li L. Study on aspect ratio variability toward robustness of vision transformer-based vehicle re-identification. arXiv:2407.07842, 2024. [Google Scholar]
25. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: single shot MultiBox detector. In: European Conference on Computer Vision (ECCV). Cham, Switzerland: Springer; 2016. p. 21–37. doi:10.1007/978-3-319-46448-0_2. [Google Scholar] [CrossRef]
26. Hermans A, Beyer L, Leibe B. In defense of the triplet loss for person re-identification. arXiv:1703.07737. 2017. [Google Scholar]
27. Li M, Liu J, Zheng C, Huang X, Zhang Z. Exploiting multi-view part-wise correlation via an efficient transformer for vehicle re-identification. IEEE Trans Multimed. 2023;25:919–29. doi:10.1109/TMM.2021.3134839. [Google Scholar] [CrossRef]
28. Hu W, Zhan H, Shivakumara P, Pal U, Lu Y. TANet: text region attention learning for vehicle re-identification. Eng Appl Artif Intell. 2024;133(Part E):108448. doi:10.1016/j.engappai.2024.108448. [Google Scholar] [CrossRef]
29. Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE; 2017. p. 618–26. doi:10.1109/ICCV.2017.74. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools