
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
A Semantic-Guided State-Space Learning Framework for Low-Light Image Enhancement
Hebei Key Laboratory of Marine Perception Network and Data Processing, School of Computer and Communication Engineering, Northeastern University at Qinhuangdao, Qinhuangdao, 066004, China
* Corresponding Author: Guang Han. Email:
(This article belongs to the Special Issue: Development and Application of Deep Learning and Image Processing)
Computers, Materials & Continua 2026, 87(2), 48 https://doi.org/10.32604/cmc.2026.075756
Received 07 November 2025; Accepted 19 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Low-light image enhancement (LLIE) remains challenging due to underexposure, color distortion, and amplified noise introduced during illumination correction. Existing deep learning–based methods typically apply uniform enhancement across the entire image, which overlooks scene semantics and often leads to texture degradation or unnatural color reproduction. To overcome these limitations, we propose a Semantic-Guided Visual Mamba Network (SGVMNet) that unifies semantic reasoning, state-space modeling, and mixture-of-experts routing for adaptive illumination correction. SGVMNet comprises three key components: (1) a semantic modulation module (SMM) that extracts scene-aware semantic priors from pretrained multimodal models—Large Language and Vision Assistant (LLaVA) and Contrastive Language–Image Pretraining (CLIP)—and injects them hierarchically into the feature stream; (2) a Mixture-of-Experts State-Space Feature Enhancement Module (MoE-SSMFEM) that dynamically selects informative channels and activates specialized state-space experts for efficient global–local illumination modeling; and (3) a Text-Guided Mixture Mamba Block (TGMB) that fuses semantic priors and visual features through bidirectional state propagation. Experimental results demonstrate that on the low-light (LOL) dataset, SGVMNet outperforms other state-of-the-art methods in both quantitative and qualitative evaluations, and it also maintains low computational complexity with fast inference speed. On LOLv2-Syn, SGVMNet achieves 26.512 dB PSNR and 0.935 SSIM, outperforming RetinexFormer by 0.61 dB. On LOLv1, SGVMNet attains 26.50 dB PSNR and 0.863 SSIM. Furthermore, experiments on multiple unpaired real-world datasets further validate the superiority of SGVMNet, showing that the model not only exhibits strong cross-scene generalization ability but also effectively preserves semantic consistency and visual naturalness.Keywords
Low-light imaging suffers from underexposure, noise amplification, and color distortion, which degrade visual quality and hinder downstream computer vision tasks. Consequently, developing robust low-light image enhancement (LLIE) algorithms is crucial for reliable scene understanding under adverse illumination conditions [1–3].
Traditional enhancement algorithms, including histogram equalization, gamma correction, and Retinex-based decomposition, primarily rely on pixel-level transformations in the spatial domain to improve contrast and reveal hidden details. Their handcrafted priors and limited adaptability often lead to overexposure or color imbalance when applied to diverse lighting conditions. With the advent of deep learning, data-driven approaches have achieved remarkable progress by learning complex illumination mappings from large-scale datasets. Existing LLIE models can be broadly divided into Retinex-inspired decomposition networks and end-to-end mapping frameworks. The former decomposes an image into reflectance and illumination components to improve interpretability and physical consistency. For example, RetinexFormer [4] employs Transformer-based attention to capture long-range dependencies and suppress noise. The latter, such as MIRNet-v2 [5] and LLFlow [6], directly learn nonlinear mappings between low-light and normal-light domains, achieving high reconstruction quality through convolutional or Transformer-based architectures.
However, most low-light enhancement models still introduce artifacts such as noise amplification, halo effects, and blocking artifacts during processing. Although additional regularization can partially suppress these artifacts, it often weakens texture details and causes structural blurring, limiting the applicability of these models in complex scenes. Furthermore, existing algorithms still struggle to achieve an effective balance between global modeling capability and computational complexity. Conventional convolutional and Transformer modules typically use a single set of shared parameters to uniformly process all feature channels. This shared-weight structure not only incurs high computational cost but also restricts the adaptability of the model to different illumination regions, semantic scenes, and texture patterns.
Motivated by these observations, we propose a Semantic-Guided Visual Mamba Network (SGVMNet) that simultaneously enhances semantic perception and global modeling capability. Under extremely low-light conditions, the complexity and diversity of illumination degradation make single shared-weight modeling insufficient to characterize illumination distributions and semantic features across different scenes. To address this limitation, we design a Mixture-of-Experts State-Space Feature Enhancement Module (MoE-SSMFEM), which employs sparse expert routing to dynamically model different illumination and semantic subspaces, thereby reducing computational complexity and improving global consistency. In addition, a Semantic Modulation Module (SMM) leverages scene-level semantic information for context-adaptive enhancement, autonomously adjusting illumination distribution and structural restoration for different scenes. This joint design improves the naturalness and color fidelity of the enhanced results and strengthens the generalization capability of SGVMNet across diverse scenes and cross-domain conditions.
The key contributions of our work can be articulated as follows:
1. We propose SGVMNet, a semantic-guided Vision Mamba framework for low-light image enhancement that adaptively adjusts illumination according to scene context, improving color consistency and visual naturalness.
2. We design a lightweight MoE-SSMFEM that balances global modeling and computational efficiency. The module uses sparse expert routing to model different illumination subspaces and simultaneously preserves structural details.
3. We introduce an SMM that utilizes vision–language priors to guide adaptive enhancement for different scenes, leading to better color fidelity and generalization.
In traditional low-light image enhancement, pixel-level adjustment techniques—such as global or local contrast enhancement methods including histogram equalization [7–9], gamma correction [10,11], and CLAHE [12]—aim to improve image visibility by expanding the global dynamic range or constraining local contrast. However, these methods are fundamentally empirical and lack physical modeling; they rely on manually tuned parameters and operate purely in the spatial domain, without jointly modeling the physical attenuation of illumination and the distribution of noise in the frequency domain. As a result, they are unable to establish a physically grounded relationship between illumination degradation and information loss.
Retinex-based enhancement methods attempt to address this by modeling an image as the product of illumination and reflectance components. The Single-Scale Retinex (SSR) [13] applies Gaussian filtering for global illumination estimation, but it often introduces halo artifacts around edges. Guo et al. proposed the LIME model [14], which maximizes illumination using structure-aware regularization to suppress halo effects, though it tends to amplify high-frequency noise in extremely dark regions. Weighted variational models [15] incorporate gradient-domain regularization to improve detail preservation but suffer from high computational cost due to prolonged iterative optimization. To further compensate for the limitations of these Retinex-based methods in illumination estimation and detail preservation, Liu proposed a low-illumination enhancement algorithm that combines homomorphic filtering and Retinex decomposition [16], enhancing color and texture consistency through improved high-pass filtering and wavelet transform. He further introduced an optimized homomorphic filtering algorithm [17] that adaptively compresses illumination components in the frequency domain to enhance contrast and suppress noise, significantly improving visibility and detail perception under complex low-light conditions. These approaches still rely on handcrafted priors and shallow modeling, making them difficult to adapt to dynamic scenes. Fundamentally, they fail to establish a deep correlation between the physics of illumination degradation and semantic scene information, thereby reducing the enhancement process to a numerical optimization problem.
With the rapid advancement of deep neural networks, deep learning–based low-light image enhancement (LLIE) methods have significantly surpassed traditional techniques by learning complex illumination distributions and semantic features directly from data. These methods can generally be categorized into two main paradigms: Retinex-inspired decomposition networks and end-to-end enhancement frameworks.
(1) Retinex-inspired decomposition networks
Inspired by the Retinex theory, early deep models attempted to explicitly decompose images into reflectance and illumination layers for enhancement. RetinexNet [18] pioneered this direction by integrating Retinex decomposition into a trainable CNN framework, enabling joint illumination estimation and reflectance restoration. However, its simplistic smoothness prior caused over-smoothing and residual noise under extreme darkness. KinD [19] and KinD++ [20] improved upon this by incorporating structure-aware loss functions and iterative refinement strategies, achieving better texture preservation and color constancy. More recently, URetinex-Net [21] introduced a learnable uncertainty-aware illumination estimation mechanism to improve robustness against spatially varying light. Although these methods improve interpretability and maintain physical consistency, their pixel-level decomposition is still constrained by local receptive fields. This limitation causes spatial inconsistency and weakens the ability to model global illumination relationships.
(2) End-to-end enhancement frameworks
To overcome the constraints of decomposition-based approaches, end-to-end learning frameworks directly learn the mapping from low-light inputs to normally illuminated outputs without explicit separation. Zero-DCE [22] formulated enhancement as a curve estimation problem, predicting pixel-wise illumination curves in a self-supervised manner. SCI [23] further simplified this formulation using lightweight iterative modules for real-time enhancement. Despite their efficiency, these methods often introduce color shifts and overexposure due to the lack of semantic and structural constraints. To improve perceptual fidelity, recent transformer-based architectures such as LLFlow [6] and LightenDiffusion [24] exploit long-range dependency modeling and diffusion priors to capture global illumination relationships. Although they achieve visually pleasing results, their quadratic complexity and heavy iterative sampling result in high computational costs and limited inference efficiency. Li et al. proposed a semantic-aware Retinex network with spatial-frequency interaction [25], which fuses spatial features with frequency cues to improve illumination correction and detail restoration under low-light conditions. Additionally, PairLIE [26] employs paired supervision and attention-based priors to enhance global-local consistency, but its fixed pixel-level feature alignment restricts adaptability under diverse illumination conditions.
Mamba achieves efficient long-sequence modeling with linear computational complexity by employing a selective state space model and hardware-aware algorithm design. In addition, it maintains Transformer-level performance and simultaneously achieves a significant improvement in computational efficiency, highlighting its potential as a next-generation architecture for sequence modeling tasks.
Recently, the Mamba architecture and its variants have exhibited remarkable adaptability across a wide range of vision tasks. In upstream applications, its selective state-space mechanism effectively captures long-range dependencies with linear complexity, as demonstrated by PixMamba for underwater image enhancement [27], RWKV-SAM for high-resolution segmentation [28], and UVM-Net for single-image denoising [29]. In downstream tasks such as Mamba-YOLO [30] for object detection, MamML for cross-modal re-identification, and Voxel-Mamba [31] for 3D object tracking, hardware-optimized scan operations achieve notable gains in both computational efficiency and model accuracy.
Vision Mamba represents the first adaptation of the Mamba framework to visual processing. Its bidirectional scanning mechanism and parallel computation provide clear advantages in capturing spatial dependencies across high-resolution images. However, its application to low-light image enhancement (LLIE) remains limited. For instance, Retinex-Mamba [32], which combines Mamba’s long-range modeling with Retinex-based illumination decomposition, still suffers from two major drawbacks: (1) its unidirectional feature propagation disrupts spatial consistency across regions, leading to uneven illumination correction; and (2) its fixed enhancement strategy lacks scene adaptability, resulting in degraded performance on unseen conditions and frequent texture loss.3 Methodological Principles.
These limitations indicate that the potential of Vision Mamba for low-light enhancement has not yet been fully explored, highlighting the need for further investigation into semantically guided, state-aware architectures for illumination restoration.
To address the shortcomings of conventional low-light enhancement methods, such as poor generalization and color distortion, we propose SGVMNet, a TGMB-based symmetric encoder–decoder architecture for adaptive low-light enhancement (see Fig. 1a). The overall framework performs enhancement through multi-stage semantic guidance and multi-scale feature fusion, enabling effective illumination correction and detail restoration under diverse lighting conditions.
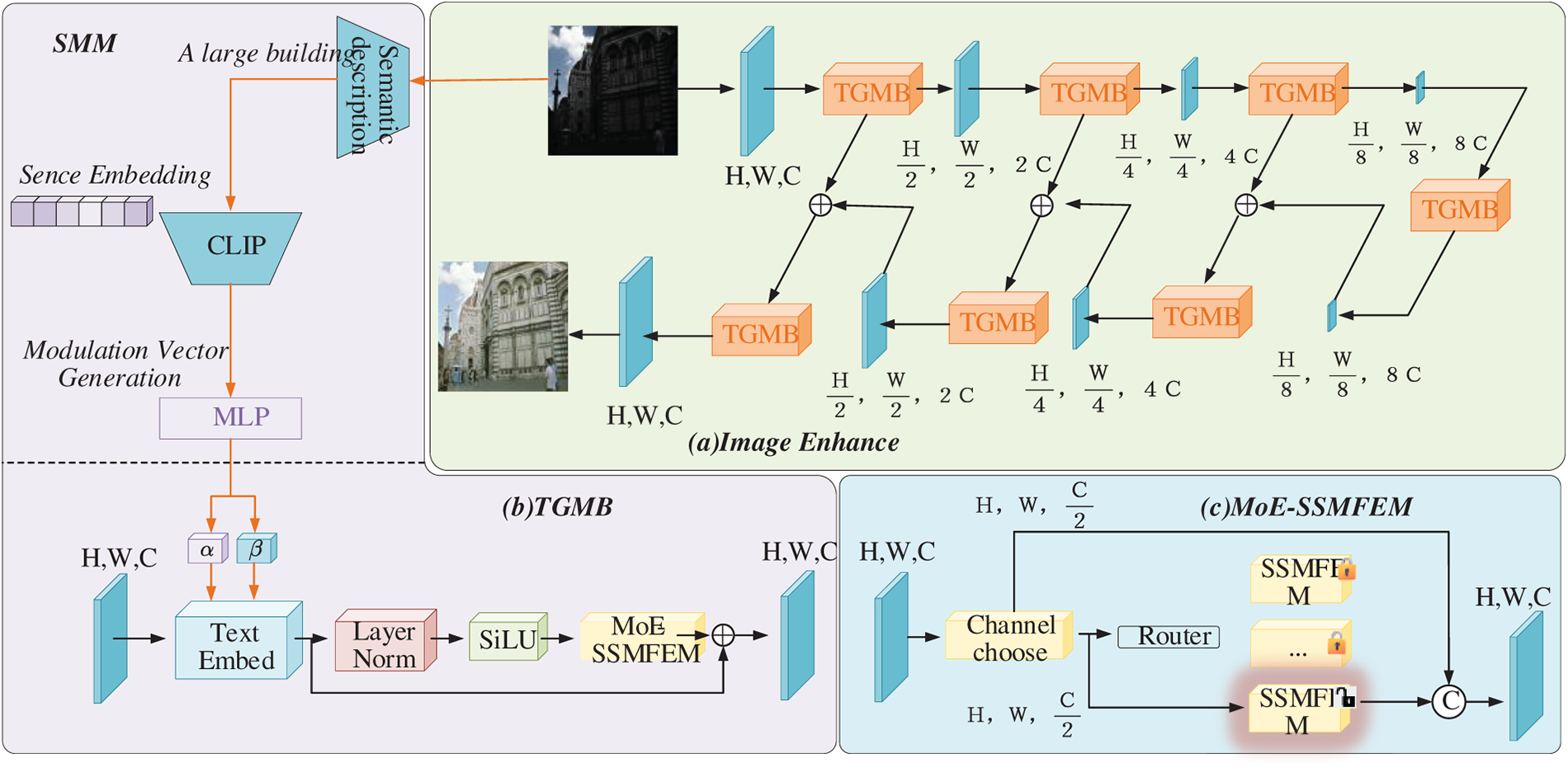
Figure 1: Overall architecture of the proposed SGVMNet. (a) The overall encoder–decoder framework is equipped with TGMBs, guided by semantic features extracted from the semantic description and Contrastive Language–Image Pre-training (CLIP) [33]. (b) The detailed architecture of TGMB consists of a text embedding layer, layer normalization, and the MoE-SSMFEM. (c) The internal structure of MoE-SSMFEM, where input features are first subjected to channel selection, followed by expert routing to activate the most appropriate State-Space Module (SSM) for feature modeling
In the downsampling stage, the input image is sequentially processed by multiple Text-Guided Mixture Mamba Blocks (TGMBs) and 3 × 3 stride-2 convolutions to progressively extract hierarchical features. During this process, the spatial resolution is gradually reduced, and the channel dimension is expanded, enabling hierarchical feature modeling from local details to global semantics. At the bottleneck layer, the TGMB further aggregates global contextual information to infer overall illumination distribution and guide global enhancement.
The decoder mirrors the encoder structure, progressively restoring the spatial resolution of feature maps through upsampling operations. Each decoding stage also embeds a TGMB, which combines skip-connected features from the encoder with continuously injected semantic vectors. This design allows the network to accurately perceive semantic content and simultaneously reconstruct brightness and fine details. The skip connections effectively preserve low-level texture information, leading to improved structural fidelity in the enhanced results.
The proposed TGMB module is illustrated in Fig. 1b. It integrates the Semantic Modulation Module and the Mixture-of-Experts State-Space Feature Enhancement Module (Fig. 1c). This integration enables semantically guided adaptive enhancement and efficient global dependency modeling across diverse scenes, maintaining a lightweight network design.
3.2 Text-Guided Mixture Mamba Block (TGMB)
In SGVMNet, the TGMB module is a core component that performs the task of hierarchical feature modeling from local details to global semantics. TGMB integrates the strengths of semantic modulation and state-space modeling to effectively enhance detail recovery and brightness restoration in low-light images, adapting its enhancement strategy to various illumination conditions and scene contexts. Each TGMB module consists of several cooperative submodules designed to achieve semantically guided and computationally efficient feature transformation.
First, the SMM generates channel-wise modulation parameters (α, β) from scene-aware semantic embeddings. These parameters are injected into the input features through the text embedding layer, dynamically rescaling and shifting their activations. This process aligns the enhancement behavior with high-level semantic priors and global illumination cues.
Next, Layer Normalization stabilizes feature statistics, and the SiLU activation function introduces nonlinearity, capturing subtle texture and luminance variations across complex lighting scenarios.
Finally, the module integrates the MoE-SSMFE to process the features and output them at the same dimensionality as the input. During this stage, feature channels are ranked based on their semantic relevance, and only the most informative subsets are routed through dedicated state-space branches via an adaptive expert selection mechanism. This design activates the most relevant experts, effectively suppressing redundant computations and enabling efficient, context-aware feature refinement.
By combining semantic modulation and expert routing, TGMB achieves semantically conditioned, channel-adaptive reparameterization, which dynamically responds to different illumination conditions. This synergy enables the network to interpret illumination not as pixel-level intensity fluctuations but as scene-dependent semantic cues, leading to consistent color restoration and perceptually coherent brightness enhancement.
3.2.1 Semantic Modulation Module (SMM)
To enhance the naturalness and color fidelity of the enhanced results, we introduce a Semantic Modulation Module into the network. The SMM employs a hierarchical semantic modulation mechanism applied across all TGMB modules to maintain consistent semantic awareness and contextual correlation throughout the encoder–decoder framework. The semantic modulation performs distinct functions at different stages: in the encoding stage, it focuses on guiding low-level texture details and brightness information; in the bottleneck stage, it strengthens global illumination reasoning and semantic fusion; and in the decoding stage, it further enhances structural reconstruction and perceptual consistency.
This hierarchical modulation strategy effectively coordinates the interaction between global semantics and local features, thereby significantly improving scene awareness, brightness stability, and cross-scene generalization under diverse illumination conditions.
As a core component of TGMB, the SMM integrates scene semantics into the feature learning process to achieve semantically guided illumination perception and adaptive enhancement, as illustrated in Fig. 2. The SMM consists of two parts—semantic description generation and modulation vector generation—which operate jointly to extract, aggregate, and inject semantic priors into the visual features effectively.
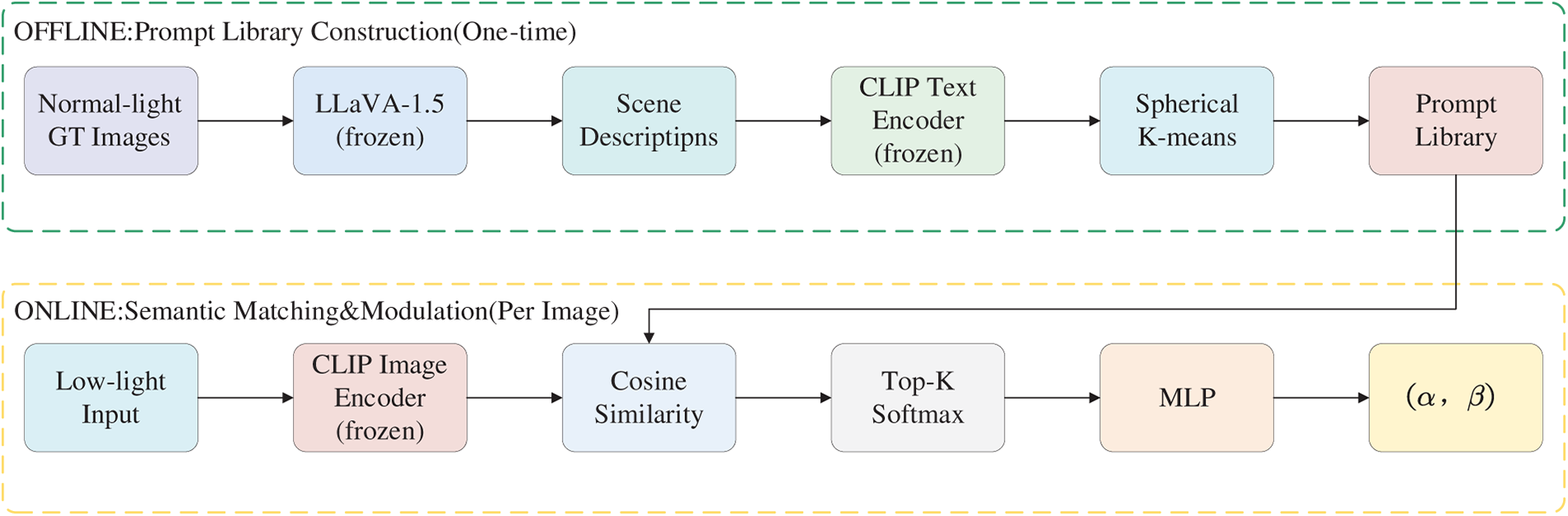
Figure 2: Offline construction of the semantic prompt library and online semantic matching–modulation pipeline for generating modulation parameters
(1) Semantic Description Generation
CLIP has demonstrated impressive zero-shot visual recognition, but its contrastive objective primarily captures coarse image–text alignment, limiting its effectiveness in modeling fine-grained scene attributes that are crucial for low-light enhancement. In our framework, both CLIP (ViT-B/32) and LLaVA-1.5 [34] are kept frozen and are only used to provide semantic priors. To address this, we first employ the large vision–language model LLaVA-1.5 to offline generate one-sentence scene descriptions for all normal-light training images. A critical challenge is that Vision–Language Models (VLMs) tend to describe image quality (e.g., “dark”, “noisy”) rather than scene content when processing low-light images, so we design a task-specific prompt template that explicitly prohibits quality-related descriptions and enforces scene-level content extraction. The generated descriptions thus focus on the semantic characteristics of each scene (e.g., “a bedroom with a bed and nightstand”, “a city street with streetlamps”). We then clean these descriptions to remove irrelevant or erroneous outputs.
To obtain a compact and representative prompt library, all cleaned descriptions are encoded into 512-dimensional embeddings using the frozen CLIP text encoder (ViT-B/32), and spherical K-means clustering is performed in this embedding space, which optimizes cosine similarity and is well-suited to L2-normalized CLIP features. For each cluster, the description closest to the centroid is selected as the representative prompt. The resulting prompt library covers typical low-light scene categories, including indoor residential and office environments, outdoor urban night scenes, portrait scenarios, and general low-light conditions.
After constructing the prompt library, we use it as a set of fixed semantic anchors during training and inference. To avoid the computational overhead of invoking LLaVA for each test image, we adopt an efficient CLIP-based retrieval strategy. Specifically, the frozen CLIP image encoder extracts the visual feature
The top-K most similar prompts are selected, and their text embeddings are averaged with softmax weighting to produce the final semantic vector:
where
This two-stage design ensures the effectiveness of semantic guidance: the training phase acquires rich scene semantic knowledge via LLaVA and distills it into the prompt library, and the inference phase achieves efficient semantic matching through lightweight CLIP retrieval, avoiding the online inference overhead of large vision–language models.
(2) Modulation Vector Generation
After obtaining the semantic vector s ∈ ℝ512, the modulation vector generation module projects it into channel-wise modulation parameters to achieve semantically-aware feature reparameterization. Specifically, the semantic vector s is transformed through a two-layer MLP to generate the modulation parameters (α, β):
where
where the symbol
Here, the semantic vector
3.2.2 Mixture-of-Experts State-Space Feature Extraction Module (MoE-SSMFEM)
As shown in Fig. 3, to achieve efficient illumination reasoning and adaptive feature modeling, we propose a Mixture-of-Experts State-Space Feature Enhancement Module (MoE-SSMFEM) that integrates sparse channel selection, adaptive expert routing, and state-space modeling. This design establishes a flexible illumination-aware representation and maintains computational efficiency.

Figure 3: Structure of the proposed MoE-SSMFEM, which employs channel selection, adaptive expert routing, and state-space modeling to obtain illumination-aware feature representations
(1) Channel Selection Mechanism
To enable the MoE-SSMFEM to focus on illumination-relevant representations, we first introduce a channel selection module that identifies the most informative and illumination-sensitive features for subsequent expert routing. Given an activated feature map
where
A lightweight two-layer MLP estimates the illumination relevance of each channel as
where
Combining Eqs. (5)–(7), the importance score w of each channel is first obtained through global pooling and a lightweight two-layer MLP. Then, channels are ranked according to these scores, and the Top-k channels with the highest illumination sensitivity are retained to form the refined feature representation as shown in Eq. (8).
where
(2) Adaptive Expert Routing and Top-1 Design Rationale
To further enhance illumination reasoning and adaptive feature representation, the selected feature
A lightweight routing network first computes the activation probability for each expert based on the global statistics of
where
The expert with the highest activation probability is then selected through Top-1 routing:
and the corresponding expert
where
During training, we employ a straight-through estimator (STE) for the discrete Top-1 selection [35]: the hard one-hot expert assignment derived from Eq. (11) is used in the forward pass to ensure computational sparsity, and the gradients are computed through the soft softmax probabilities
In our implementation, MoE-SSMFEM employs N = 16 parallel experts organized into four directional groups. Each group adopts a distinct scanning direction for flattening 2D features into 1D sequences: horizontal forward, horizontal backward, vertical forward, and vertical backward. Within each group, four experts with independent parameters enable diverse feature transformations for the same scanning pattern. This Mixture-of-Scans design treats each scanning direction as a specialized pathway, and the Top-1 routing mechanism jointly determines which directional pathway and which expert to activate based on the input’s spatial characteristics.
Each expert adopts a linear State Space Model (SSM) to capture long-range dependencies and illumination dynamics. Specifically, the flattened feature sequence
where
After temporal reasoning, the enhanced output sequence
producing the illumination-adaptive representation
By combining the original and enhanced representations, MoE-SSMFEM preserves both structural fidelity and illumination consistency, providing a robust foundation for subsequent decoding and reconstruction.
4 Experimental Results and Analysis
To comprehensively evaluate the effectiveness and generalization ability of the proposed method, real-scene low-light image datasets are employed during both the training and testing phases.
During the training phase, two versions of the LOL dataset—LOLv1 [18] and LOLv2 [36]—are utilized. Specifically, LOLv1 consists of 500 paired low-/normal-light images, with 485 pairs used for training and 15 pairs for testing. LOLv2 is further divided into a real subset and a synthetic subset. The real subset contains 689 training pairs and 100 testing pairs, and the synthetic subset includes 900 training pairs and 100 testing pairs.
During the testing phase, the model is quantitatively and qualitatively evaluated on three paired datasets—LOLv1, LOLv2, and LSRW [37]—to verify its reconstruction performance and generalization capability on paired data. Furthermore, to comprehensively examine the model’s cross-domain enhancement performance on unpaired real-world images, several public unpaired low-light datasets are employed, including DICM [38], LIME [39], NPE [40], MEF [41], and VV [38]. These datasets encompass diverse low-light environments such as indoor, outdoor, and natural scenes, enabling a systematic assessment of the model’s robustness and adaptability across various real-world conditions.
To comprehensively evaluate the enhancement performance of our proposed method across different scenarios, we employ both full-reference and no-reference image quality assessment metrics on paired datasets (LOLv1, LOLv2, and LSRW) and unpaired datasets (DICM, LIME, NPE, MEF, and VV), respectively.
For the paired datasets, two widely adopted full-reference distortion metrics are utilized: Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). PSNR is a classical objective metric designed to quantify the ratio between the maximum possible signal power and the power of corrupting noise that affects the fidelity of image reconstruction. A higher PSNR value indicates smaller pixel-level errors and higher reconstruction fidelity between the enhanced and reference images. SSIM aims to evaluate perceptual consistency by jointly considering luminance, contrast, and structural similarity between two images, with its value ranging from −1 to 1. Values closer to 1 suggest that the enhanced image preserves structural and perceptual information more faithfully relative to the ground truth.
For unpaired datasets, where corresponding ground-truth images are unavailable, no-reference perceptual metrics are adopted. Specifically, we employ the Natural Image Quality Evaluator (NIQE), a completely blind model that assesses image quality by measuring the deviation between the natural scene statistics extracted from the test image and a statistical model derived from a corpus of pristine natural images. Lower NIQE scores imply that the enhanced image’s statistical characteristics more closely align with those of high-quality natural images, indicating superior perceptual quality and more realistic visual appearance.
The proposed SGVMNet is implemented in PyTorch and trained on two NVIDIA RTX 3090 GPUs. During training, input images are randomly cropped into 128 × 128 patches and augmented with random horizontal flips and 90° rotations. The batch size is set to 8. We use the Adam optimizer with an initial learning rate of 2 × 10−4 and a cosine annealing schedule. Early stopping with a patience of 10 epochs based on validation PSNR is employed to prevent overfitting.
For the MoE-SSMFEM, we adopt a lightweight configuration: the state-space dimension is set to 16. The number of selected channels is fixed at k = 32. To enable gradient flow through the discrete expert selection, we employ a straight-through estimator. An auxiliary load-balancing loss with weight 0.01 is incorporated to encourage balanced expert utilization. Gradient clipping with a maximum L2 norm of 1.0 and dropout with a rate of 0.1 are applied to enhance training stability.
We optimize SGVMNet with a weighted combination of pixel-wise, perceptual, and structural losses. The overall training objective is defined as
where
4.2 Comparison with the State-of-the-Arts
In the experiments on paired datasets, we compare our approach with a range of representative low-light image enhancement methods, including KinD [19], MIRNetv2 [5], RetinexNet [18], SCI [23], Zero-DCE [22], RUAS [44], URetinexNet [21], RetinexFormer [4], and LLFlow [6], along with our proposed model. These methods collectively cover both traditional Retinex-based frameworks and modern deep learning paradigms such as convolutional, attention-based, and flow models, enabling a comprehensive evaluation of reconstruction fidelity and structural consistency on paired data.
For experiments on unpaired real-world datasets, we further include several recent unsupervised or weakly supervised enhancement methods, namely EnlightenGAN [45], KinD++ [20], RUAS, SCI, URetinex-Net, PairLIE [26], and our proposed method. This part of the evaluation focuses on assessing the model’s cross-domain generalization capability and perceptual quality in real low-light scenarios. To ensure fair comparison and reproducibility, all competing models are evaluated using the officially released pre-trained weights and default configurations provided by their authors, without additional fine-tuning.
To comprehensively evaluate the visual enhancement capability of our method, we perform qualitative comparisons on representative samples from the LOLv1, LSRW, and DICM datasets. These datasets collectively cover a wide range of illumination conditions, including paired synthetic data (LOLv1), paired real-world data (LSRW), and unpaired real-scene images (DICM), thus providing a holistic assessment across different domains. For unpaired data, we mainly present qualitative comparisons on the DICM dataset, which contains more diverse low-light scenarios—including indoor, outdoor, and natural environments—than other unpaired datasets such as LIME, NPE, MEF, and VV. Therefore serves as a representative benchmark for visual comparison, and all unpaired datasets are included in the quantitative evaluations.
As illustrated in Fig. 4, a vivid and detail-rich image from LOLv1 is used to evaluate the feature reconstruction capability of each model. RUAS, SCI, and Zero-DCE exhibit noticeable underexposure and incomplete illumination recovery; MIRNetv2 and RetinexNet introduce color distortion and lose fine textures, whereas KinD, LLFlow, and URetinexNet tend to produce overexposed regions with unnatural brightness. To better demonstrate structural fidelity, critical regions are enlarged and highlighted in blue boxes.

Figure 4: Visual comparison of state-of-the-art methods and ours on samples from the LOL dataset
Furthermore, to assess the model’s generalization ability, additional qualitative results on the LSRW dataset (Fig. 5) show that SGVMNet achieves more accurate color reproduction, balanced illumination, and sharper structural details in both indoor and outdoor scenes, consistently outperforming competing methods.

Figure 5: Visual comparison of state-of-the-art methods and ours on samples from the LSRW dataset
On the unpaired DICM dataset (Fig. 6), our method delivers the best balance between brightness restoration and color fidelity compared with EnlightenGAN, KinD++, LightenDiffusion, PairLIE, SCI, and URetinex-Net. Specifically, EnlightenGAN and KinD++ suffer from uneven exposure and amplified artifacts under complex lighting, resulting in over-saturated skin tones; LightenDiffusion enhances global brightness but smooths out local textures, leading to facial detail loss; PairLIE and SCI often cause color shifts and halo artifacts near bright regions; and URetinex-Net exhibits excessive contrast and over-enhanced edges in extremely dark scenes. In contrast, SGVMNet produces visually natural results with well-preserved textures, realistic colors, and evenly distributed illumination across diverse low-light environments.

Figure 6: Visual comparison of state-of-the-art methods and ours on samples from the DICM dataset
To comprehensively evaluate the performance of our approach, we employ both full-reference and no-reference quantitative metrics.
For paired datasets (LOLv1, LOLv2, and LSRW), we report the PSNR and SSIM. For unpaired datasets (DICM, LIME, NPE, MEF, and VV), the no-reference metric NIQE is adopted to evaluate perceptual realism. The quantitative results are summarized in Tables 1 and 2.
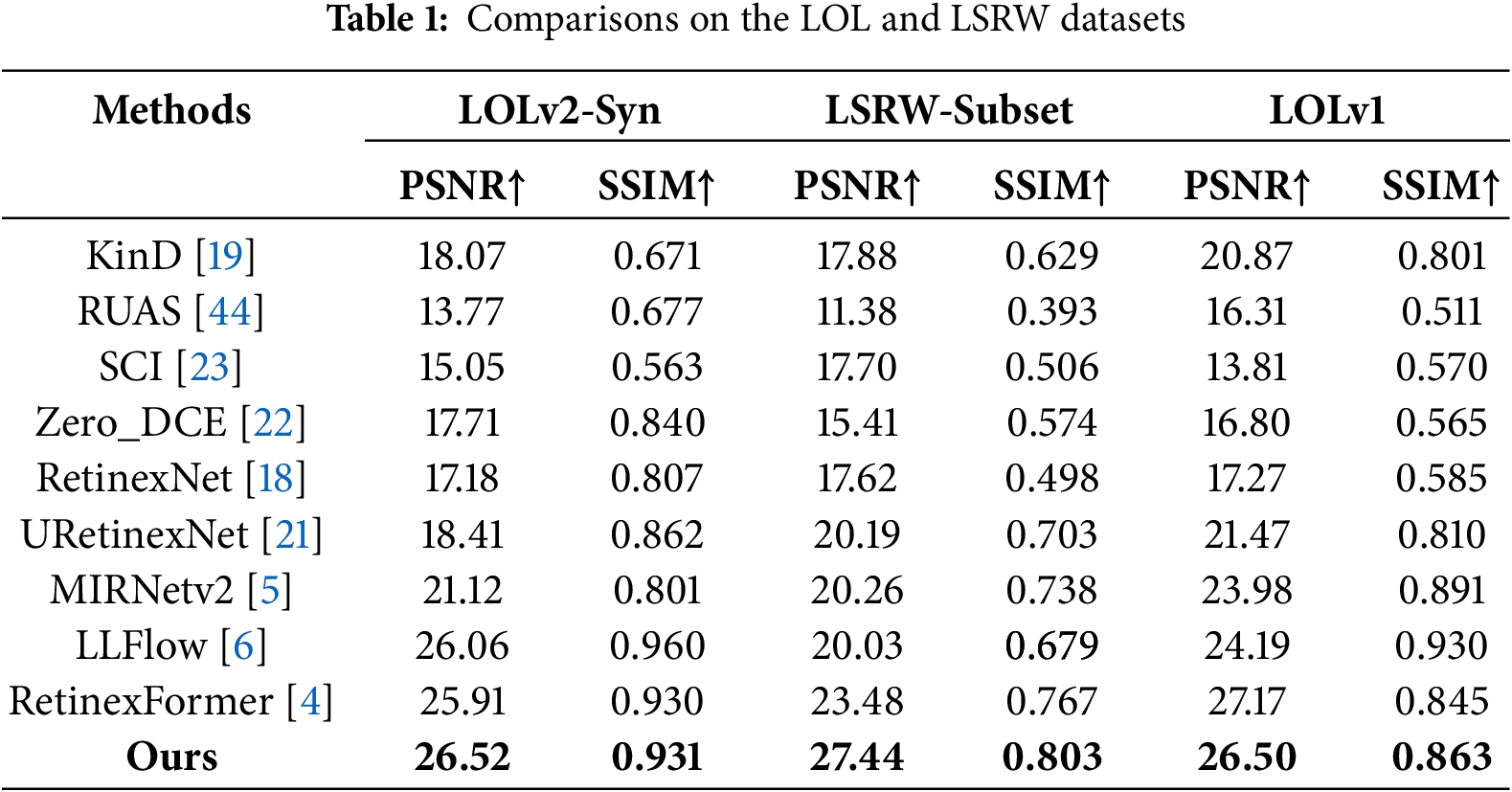
As shown in Table 1, the proposed SGVMNet consistently achieves competitive performance across all three paired datasets. On the LOLv2-Syn subset, our model reaches a PSNR of 26.52 dB and SSIM of 0.931, outperforming RetinexFormer by 0.61 dB in PSNR. On LOLv1, SGVMNet obtains 26.50 dB PSNR and 0.863 SSIM, achieving a favorable balance between reconstruction fidelity and perceptual quality.
On the LSRW subset, which contains more challenging real-world degradations with diverse indoor and outdoor scenes, SGVMNet achieves the highest PSNR of 27.44 dB, surpassing the second-best method, RetinexFormer, by 3.96 dB. We note that on LOLv2-Syn and LOLv1, LLFlow achieves slightly higher SSIM. This is primarily because flow-based methods explicitly model pixel-level bijective mappings, which favors structural similarity metrics on synthetic or well-aligned paired data. In contrast, our semantic-guided approach prioritizes perceptually natural enhancement over strict pixel alignment, which better generalizes to real-world scenarios, as evidenced by our superior performance on LSRW.
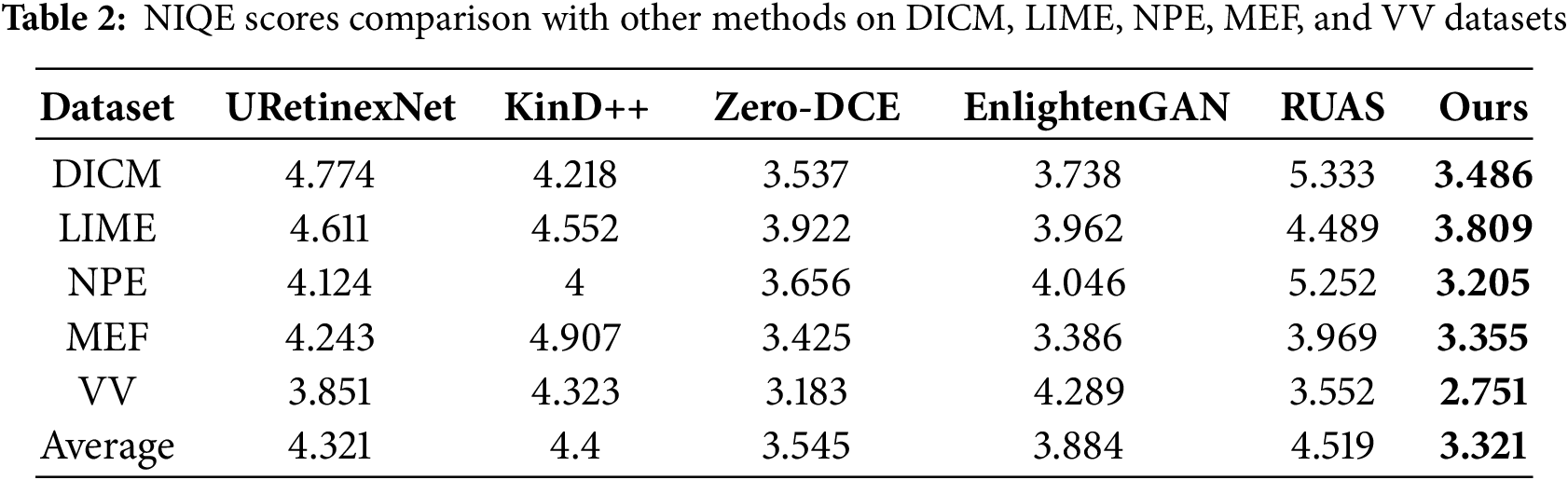
For unpaired datasets, Table 2 shows that SGVMNet achieves the lowest NIQE scores on all test sets, with an average improvement of 0.5–1.5 compared with existing methods. In particular, on the DICM and VV datasets, our model attains NIQE scores of 3.486 and 2.751, respectively, suggesting that the enhanced results are perceptually more natural and free from over-smoothing or color distortions. These quantitative results demonstrate that SGVMNet not only preserves structural and textural details but also enhances perceptual quality under various illumination conditions, verifying its superiority and robustness across diverse low-light scenarios. The best results in each column are highlighted in bold.
As shown in Table 3, we perform ablation experiments on the LOLv2 dataset to analyze the contribution of each component in SGVMNet. All variants share the same Vision-Mamba encoder–decoder backbone described in Section 3.1; only the semantic modulation (SMM), MoE-SSMFEM, and related semantic settings are modified. Baseline denotes this backbone where each TGMB is replaced by a plain Vision-Mamba block, and both SMM and MoE-SSMFEM are disabled, resulting in a pure state-space model. w/o SMM keeps the MoE-SSMFEM experts but removes the SMM, so the expert routing is driven only by low-level visual features without any semantic guidance. w/o MoE preserves the SMM but replaces MoE-SSMFEM with a single state-space expert, which isolates the benefit of dynamic expert routing. Ours corresponds to the full SGVMNet configuration, where both SMM and MoE-SSMFEM are enabled on top of the Vision-Mamba backbone.
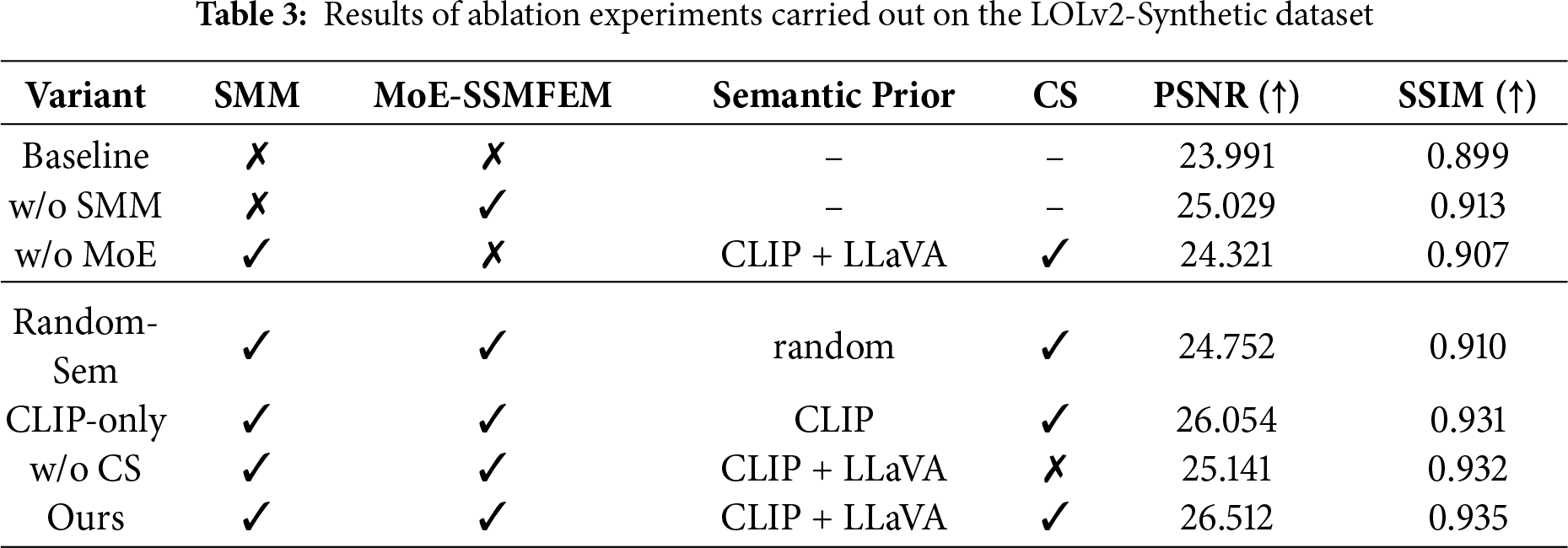
To thoroughly investigate the contribution of semantic guidance, we design additional ablations beyond the basic w/o-SMM configuration. Random-Sem keeps the architecture unchanged but replaces the CLIP + LLaVA semantic embedding with a random Gaussian vector of the same dimension, which significantly degrades performance and thus confirms that the gain comes from meaningful semantic priors rather than extra parameters. CLIP-only removes LLaVA descriptions and relies solely on CLIP text embeddings, yielding lower accuracy than the full model and showing that LLaVA-generated scene descriptions provide complementary cues. The w/o CS variant disables the channel selection module but retains the full semantic prior, leading to a clear drop in performance and highlighting that adaptive channel selection is crucial for effective semantic–visual alignment.
In addition to the quantitative results, qualitative comparisons further support these findings. As illustrated in the ablation visualization (Fig. 7), the baseline model exhibits insufficient brightness recovery and visible noise artifacts. Removing the semantic module leads to unnatural color tones, whereas removing the expert module causes loss of fine details and structural inconsistencies. In contrast, the full SGVMNet restores both global illumination and local texture details more faithfully, producing visually natural and artifact-free enhancement results.

Figure 7: Visual results of the ablation study on the LOLv2 dataset. (a) Original low-light image; (b) Result without the SMM; (c) Result without the Mixture-of-Experts (MoE) module; (d) Result without the channel selection (CS) module; (e) Result of the proposed SGVMNet
4.4 Analysis of Computational Efficiency and Downstream Validation
To verify the real-time applicability of the proposed SGVMNet in practical vision scenarios, both computational efficiency and downstream task performance under extremely low-light conditions are analyzed.
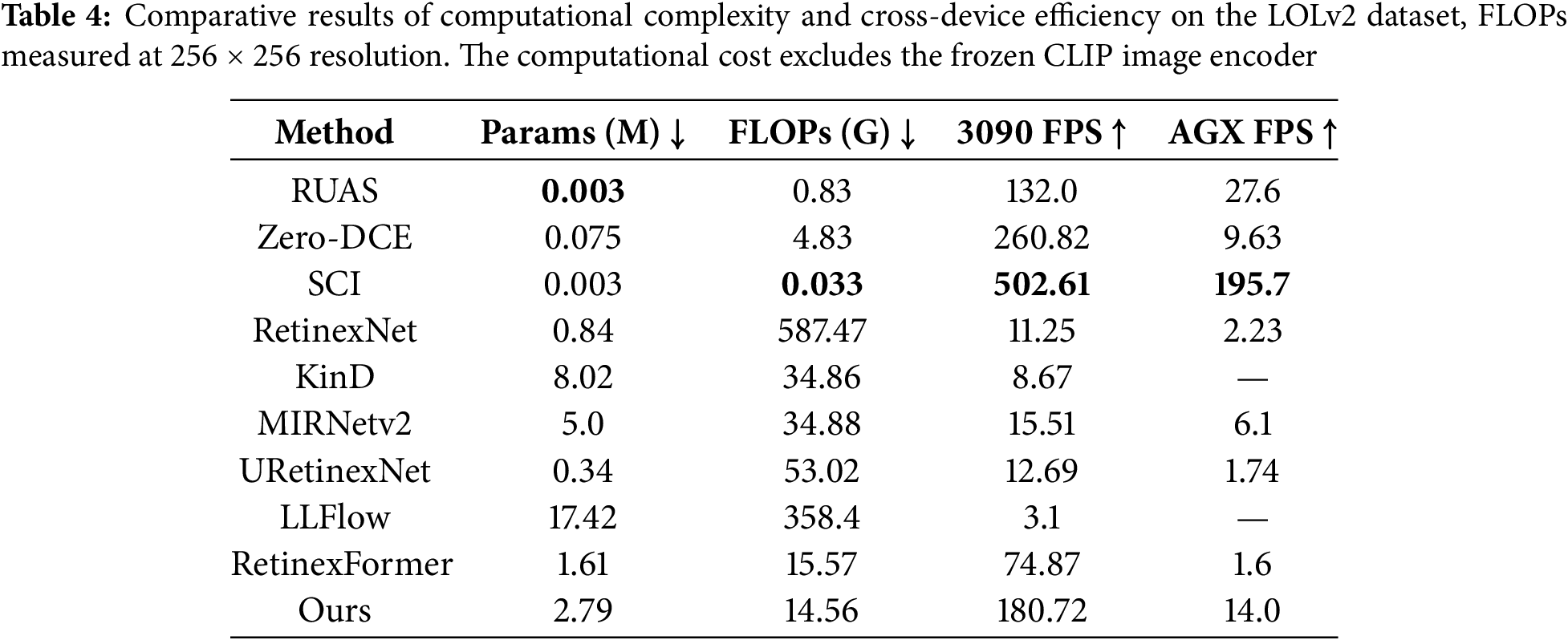
Computational Efficiency: As shown in Table 4, SGVMNet attains an inference speed on RTX 3090 that is approximately 2.4× and 58× higher than RetinexFormer and LLFlow, respectively, and at the same time preserves comparable or even superior perceptual quality. On the Jetson AGX Xavier edge platform, SGVMNet also exhibits a clear speed advantage, enabling real-time or near real-time inference under resource-constrained settings. This efficiency gain stems from the synergy between the sparse expert routing in MoE-SSMFEM and the linear-complexity state-space modeling in Vision Mamba, which together allow SGVMNet to achieve a favorable balance between enhancement quality and computational efficiency.
Complementary to the runtime results in Table 4, Fig. 8 further examines the trade-off between performance and model complexity for a set of representative enhancement methods. Under comparable computational budgets, SGVMNet consistently achieves higher PSNR and thus lies on a more favorable accuracy–efficiency frontier. In particular, our model delivers PSNR comparable to or even surpassing heavy architectures such as RetinexFormer and LLFlow, with substantially fewer parameters and FLOPs.
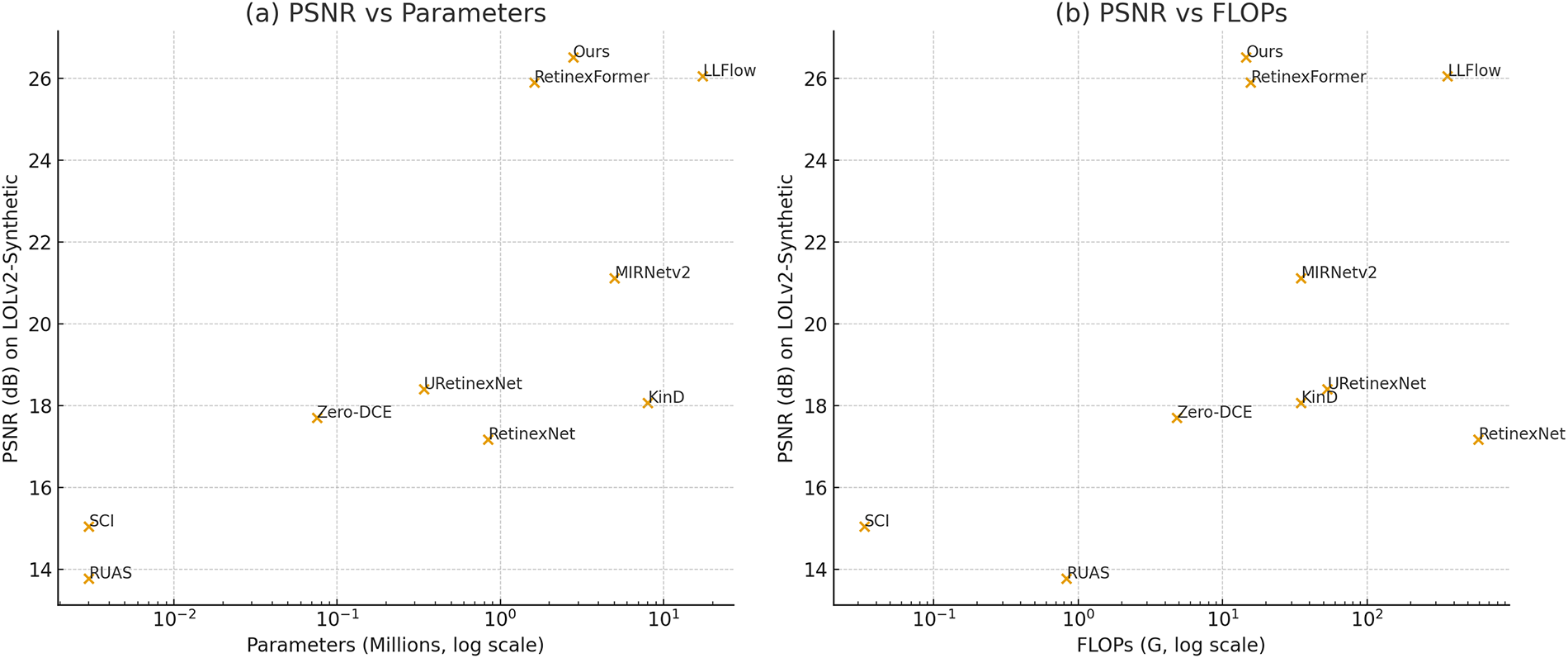
Figure 8: Comparison of representative low-light enhancement methods in terms of PSNR vs. model complexity on the LOLv2-Synthetic dataset. (a) PSNR vs. parameter count (log scale). (b) PSNR vs. FLOPs (log scale). Our SGVMNet consistently lies on a more favorable accuracy–efficiency frontier, achieving top-tier PSNR with substantially fewer parameters and lower computational cost compared to heavy models such as LLFlow and RetinexFormer
Downstream Detection Validation: To evaluate how well the enhancement methods preserve task-relevant semantics for downstream applications, we further conduct an object detection experiment on the Person subset of the ExDark dataset. ExDark contains 7363 real-world low-light images with bounding-box annotations for 12 object categories. We convert the official People annotations into YOLO format, resulting in a test subset with 1865 person instances. A YOLOv8s detector with COCO-pretrained weights is adopted as the fixed backbone, and only the input pre-processing is varied: the detector receives either the raw low-light image (denoted as Original (L)) or its enhanced versions generated by Zero-DCE, SCI, RUAS, RetinexFormer, LLFlow, and our SGVMNet. We compute mAP@0.5, precision, and recall on this subset to quantify the impact of different enhancement methods on detection performance, as summarized in Table 5. The results show that using the raw low-light input already provides a strong baseline, whereas Zero-DCE significantly degrades mAP, precision, and recall, indicating that excessive global brightening and feature flattening are detrimental to detection. In contrast, structure-preserving methods such as SCI, RUAS, RetinexFormer, and LLFlow generally maintain or slightly improve the baseline. Building on this, SGVMNet achieves a better balance between brightness and structural fidelity, producing more natural and visually comfortable illumination and yielding the highest mAP and recall, effectively reducing missed pedestrians under extremely low-light conditions.
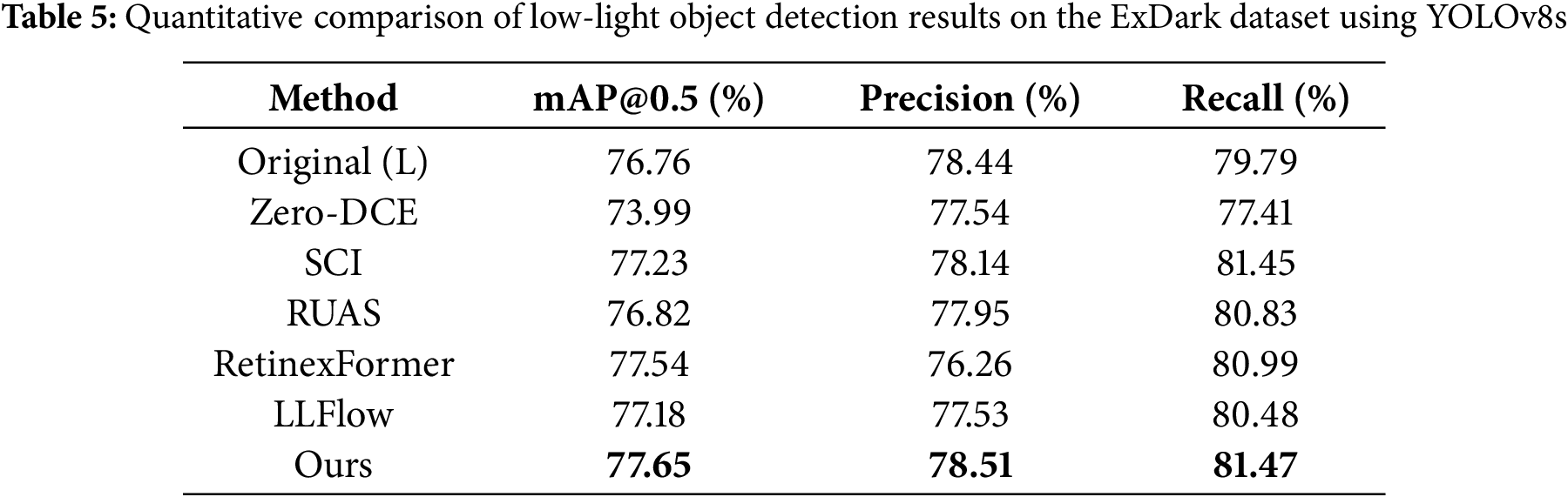
Fig. 9 presents qualitative detection examples under extremely low-light conditions. Lightweight models such as SCI and RUAS tend to produce under-exposed outputs, leading to missed pedestrians. Zero-DCE increases global brightness but heavily flattens features, causing the loss of fine details and failures to detect partially occluded targets. LLFlow and RetinexFormer yield more reasonable exposure, yet over-smoothing and color distortions still introduce false positives and missed detections. In contrast, SGVMNet produces better-balanced illumination and sharper structural boundaries, enabling YOLOv8s to localize more objects with higher confidence and fewer errors. For these real-world scenes, the lack of reliable bounding-box annotations and the domain bias of pre-trained detectors hinder fair quantitative evaluation, so we restrict our comparison to qualitative analysis. The visual results further highlight the semantic fidelity and feature-level consistency of SGVMNet, showing that it not only delivers visually pleasing enhancement but also improves detection interpretability and robustness under extreme illumination.

Figure 9: Qualitative comparison of low-light object detection on the ExDark dataset. The input image is first enhanced by different LLIE methods (SCI, RUAS, Zero-DCE, RetinexFormer, LLFlow, and Ours) and then fed into YOLOv8s for detection. Bounding boxes and confidence scores are shown for each enhancement result
4.5 Failure Cases and Limitations
Besides the aforementioned successful examples, Fig. 10 illustrates two representative failure cases. The images are captured under extremely dark conditions and are illuminated only by a single local light source, which allows us to examine model behavior under semantic mismatch and near-degenerate illumination. We compare SGVMNet with LLFlow, which delivers strong enhancement quality and highly efficient SCI. In these scenes, SCI barely increases brightness or recovers meaningful details; LLFlow produces much stronger exposure but suffers from severe color distortion and noise-blurred textures. SGVMNet achieves a more balanced global brightness and preserves some local structures, yet noticeable noise remains in the background, and the darkest regions still exhibit residual noise and color bias. These cases indicate that SGVMNet still relies on a minimum level of valid signal, and its performance becomes limited when the scene is dominated by a single, highly saturated local light source. Improving robustness under such extreme conditions will be an important direction for future work.

Figure 10: Visual comparison of two extremely low-light scenes. Scene (a) is an almost completely dark outdoor scene illuminated by a small flashlight, and scene (b) is an extremely dark scene lit only by a blue signboard. From left to right: input (a), SCI (a), LLFlow (a), SGVMNet (a), input (b), SCI (b), LLFlow (b), and SGVMNet (b)
This paper introduces SGVMNet, a lightweight semantic-guided Vision Mamba network for low-light image enhancement. The model tackles two major challenges—limited semantic perception and high computational cost—by integrating scene-aware semantic modulation with efficient state-space modeling. A semantic modulation mechanism based on LLaVA and CLIP generates adaptive semantic vectors for illumination correction, and the TGMB, together with the MoE-SSMFEM, jointly improve texture recovery and computational efficiency. Experiments on LOLv1, LOLv2, and LSRW demonstrate that SGVMNet achieves state-of-the-art performance, attaining 26.52 dB PSNR on LOLv2-Syn and 27.44 dB on LSRW, with only 2.79 M parameters and 14.56 G FLOPs, and it also maintains an inference speed of 180.72 FPS on an RTX 3090. These results verify its superior trade-off between enhancement quality and efficiency, enabling practical deployment in real scenarios. However, SGVMNet still faces challenges in extremely dark or spatially non-uniform lighting and under mixed Gaussian–Poisson noise, where global and local cues are not fully balanced. Moreover, applying it directly to night video enhancement requires temporal consistency modeling. Future work will incorporate optical-flow-based temporal alignment and noise–illumination joint learning to improve stability in dynamic and outdoor scenes. In summary, combining semantic reasoning with lightweight state-space modeling provides a scalable and efficient paradigm for high-quality low-light enhancement and lays the groundwork for video and outdoor night-vision applications.
Acknowledgement: We are very grateful to Wei [18] and Yang [36] for creating and sharing the LOL (Low Light Benchmark) dataset, which has provided the foundational data for the research in this paper, allowing us to carry out the related research smoothly.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Study conception and design, analysis and interpretation of results: Xiaoqiang Wang; references collection: Huiying Zhao; draft manuscript preparation: Guang Han, Xi Cai. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data used in this paper can be requested from the corresponding author upon request.
Ethics Approval: This research was carried out in compliance with ethical guidelines.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Wang W, Peng Y, Cao G, Guo X, Kwok N. Low-illumination image enhancement for night-time UAV pedestrian detection. IEEE Trans Ind Inf. 2021;17(8):5208–17. doi:10.1109/tii.2020.3026036. [Google Scholar] [CrossRef]
2. Lin X, Yue J, Ding S, Ren C, Qi L, Yang MH. Dual degradation representation for joint deraining and low-light enhancement in the dark. IEEE Trans Circuits Syst Video Technol. 2025;35(3):2461–73. doi:10.1109/TCSVT.2024.3487849. [Google Scholar] [CrossRef]
3. Zhao Z, Xiong B, Wang L, Ou Q, Yu L, Kuang F. RetinexDIP: a unified deep framework for low-light image enhancement. IEEE Trans Circuits Syst Video Technol. 2022;32(3):1076–88. doi:10.1109/tcsvt.2021.3073371. [Google Scholar] [CrossRef]
4. Cai Y, Bian H, Lin J, Wang H, Timofte R, Zhang Y. Retinexformer: one-stage retinex-based transformer for low-light image enhancement. In: Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV); 2023 Oct 1–6; Paris, France. doi:10.1109/ICCV51070.2023.01149. [Google Scholar] [CrossRef]
5. Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang MH, et al. Learning enriched features for real image restoration and enhancement. In: Computer vision-ECCV 2020. Berlin/Heidelberg, Germany: Springer; 2020. p. 492–511. doi:10.1007/978-3-030-58595-2_30. [Google Scholar] [CrossRef]
6. Wang Y, Wan R, Yang W, Li H, Chau LP, Kot A. Low-light image enhancement with normalizing flow. Proc AAAI Conf Artif Intell. 2022;36(3):2604–12. doi:10.1609/aaai.v36i3.20162. [Google Scholar] [CrossRef]
7. Mu Q, Wang X, Wei Y, Li Z. Low and non-uniform illumination color image enhancement using weighted guided image filtering. Comput Vis Medium. 2021;7(4):529–46. doi:10.1007/s41095-021-0232-x. [Google Scholar] [CrossRef]
8. Zhang F, Shao Y, Sun Y, Gao C, Sang N. Self-supervised low-light image enhancement via histogram equalization prior. In: Proceedings of the 6th Chinese Conference on Pattern Recognition and Computer Vision (PRCV); 2023 Oct 13–15; Xiamen, China. doi:10.1007/978-981-99-8552-4_6. [Google Scholar] [CrossRef]
9. Jebadass JR, Balasubramaniam P. Low light enhancement algorithm for color images using intuitionistic fuzzy sets with histogram equalization. Multimed Tools Appl. 2022;81(6):8093–106. doi:10.1007/s11042-022-12087-9. [Google Scholar] [CrossRef]
10. Jeon JJ, Park JY, Eom IK. Low-light image enhancement using gamma correction prior in mixed color spaces. Pattern Recognit. 2024;146(11):110001. doi:10.1016/j.patcog.2023.110001. [Google Scholar] [CrossRef]
11. Jeong I, Lee C. An optimization-based approach to gamma correction parameter estimation for low-light image enhancement. Multimed Tools Appl. 2021;80(12):18027–42. doi:10.1007/s11042-021-10614-8. [Google Scholar] [CrossRef]
12. Thepade SD, Pardhi PM. Contrast enhancement with brightness preservation of low light images using a blending of CLAHE and BPDHE histogram equalization methods. Int J Inf Technol. 2022;14(6):3047–56. doi:10.1007/s41870-022-01054-0. [Google Scholar] [CrossRef]
13. Rong L, Zhang SH, Yin MF, Wang D, Zhao J, Wang Y, et al. Reconstruction efficiency enhancement of amplitude-type holograms by using Single-Scale Retinex algorithm. Opt Lasers Eng. 2024;176(5):108097. doi:10.1016/j.optlaseng.2024.108097. [Google Scholar] [CrossRef]
14. Li M, Zhao H, Guo X. LIME-eval: rethinking low-light image enhancement evaluation via object detection. arXiv:2410.08810. 2024. doi:10.48550/arXiv.2410.08810. [Google Scholar] [CrossRef]
15. Jia F, Wong HS, Wang T, Zeng T. A reflectance re-weighted Retinex model for non-uniform and low-light image enhancement. Pattern Recognit. 2023;144(12):109823. doi:10.1016/j.patcog.2023.109823. [Google Scholar] [CrossRef]
16. Liu F, Xue Y, Dou X, Li Z. Low illumination image enhancement algorithm combining homomorphic filtering and retinex. In: Proceedings of the 2021 International Conference on Wireless Communications and Smart Grid (ICWCSG); 2021 Aug 13–15; Hangzhou, China. doi:10.1109/ICWCSG53609.2021.00053. [Google Scholar] [CrossRef]
17. He J, Liu J, Chen H, Zhang Y, Wu W. FMR low-light tomato image enhancement algorithm based on optimized homomorphic filter. In: Proceedings of the 2021 7th International Conference on Computer and Communications (ICCC); 2021 Dec 10–13; Chengdu, China. doi:10.1109/ICCC54389.2021.9674365. [Google Scholar] [CrossRef]
18. Wei C, Wang W, Yang W, Liu J. Deep retinex decomposition for low-light enhancement. arXiv: 1808.04560. 2018. [Google Scholar]
19. Zhang Y, Guo X, Ma J, Liu W, Zhang J. KinD: a kindling the darkness network for low-light image enhancement. In: Proceedings of the MM’19: Proceedings of the 27th ACM International Conference on Multimedia; 2019 Oct 21–25; Nice, France. [Google Scholar]
20. Zhang Y, Guo X, Ma J, Liu W, Zhang J. Beyond brightening low-light images. Int J Comput Vis. 2021;129(4):1013–37. doi:10.1007/s11263-020-01407-x. [Google Scholar] [CrossRef]
21. Wu W, Weng J, Zhang P, Wang X, Yang W, Jiang J. URetinex-net: retinex-based deep unfolding network for low-light image enhancement. In: Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. doi:10.1109/CVPR52688.2022.00581. [Google Scholar] [CrossRef]
22. Guo C, Li C, Guo J, Loy CC, Hou J, Kwong S, et al. Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. doi:10.1109/cvpr42600.2020.00185. [Google Scholar] [CrossRef]
23. Ma L, Ma T, Liu R, Fan X, Luo Z. Toward fast, flexible, and robust low-light image enhancement. In: Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. doi:10.1109/CVPR52688.2022.00555. [Google Scholar] [CrossRef]
24. Jiang H, Luo A, Liu X, Han S, Liu S. LightenDiffusion: unsupervised low-light image enhancement with latent-retinex diffusion models. In: Proceedings of the 18th European Conference on Computer Vision (ECCV); 2024 Sep 29–Oct 4; Milan, Italy. doi:10.1007/978-3-031-73195-2_10. [Google Scholar] [CrossRef]
25. Li H, Wang J, Yang H, Tang X, Xu F. Learning semantic-aware retinex network with spatial-frequency interaction for low-light image enhancement. In: Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME); 2024 Jul 15–19; Niagara Falls, ON, Canada. doi:10.1109/ICME57554.2024.10687522. [Google Scholar] [CrossRef]
26. Fu Z, Yang Y, Tu X, Huang Y, Ding X, Ma KK. Learning a simple low-light image enhancer from paired low-light instances. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. doi:10.1109/CVPR52729.2023.02131. [Google Scholar] [CrossRef]
27. Lin WT, Lin YX, Chen JW, Hua KL. PixMamba: leveraging state space models in a dual-level architecture forUnderwater image enhancement. In: Proceedings of the 17th Asian Conference on Computer Vision; 2024 Dec 8–12; Hanoi, Vietnam. doi:10.1007/978-981-96-0911-6_11. [Google Scholar] [CrossRef]
28. Yuan H, Li X, Qi L, Zhang T, Yang MH, Yan S, et al. Mamba or RWKV: exploring high-quality and high-efficiency segment anything model. arXiv:2406.19369. 2024. [Google Scholar]
29. Zheng Z, Wu C. U-shaped vision mamba for single image dehazing. arXiv:2402.04139. 2024. [Google Scholar]
30. Wang Z, Li C, Xu H, Zhu X, Li H. Mamba YOLO: a simple baseline for object detection with state space model. arXiv:2406.05835. 2024. [Google Scholar]
31. Zhang G, Fan L, He C, Lei Z, Zhang Z, Zhang L. Voxel mamba: group-free state space models for point cloud based 3D object detection. arXiv:2406.10700. 2024. [Google Scholar]
32. Bai J, Yin Y, He Q, Li Y, Zhang X. Retinexmamba: retinex-based mamba for low-light image enhancement. In: Neural information processing. Berlin/Heidelberg, Germany: Springer; 2025. p. 427–42. doi:10.1007/978-981-96-6596-9_30. [Google Scholar] [CrossRef]
33. Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning; 2021 Jul 18–24; Virtual. [Google Scholar]
34. Liu H, Li C, Wu Q, Lee YJ. Visual instruction tuning. In: Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023); 2023 Dec 10–16; New Orleans, LA, USA. [Google Scholar]
35. Fedus W, Zoph B, Shazeer N. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity. J Mach Learn Res. 2022;23(1):5232–70. [Google Scholar]
36. Yang W, Wang W, Huang H, Wang S, Liu J. Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE Trans Image Process. 2021;30:2072–86. doi:10.1109/TIP.2021.3050850. [Google Scholar] [PubMed] [CrossRef]
37. Hai J, Xuan Z, Yang R, Hao Y, Zou F, Lin F, et al. R2RNet: low-light image enhancement via real-low to real-normal network. J Vis Commun Image Represent. 2023;90(15):103712. doi:10.1016/j.jvcir.2022.103712. [Google Scholar] [CrossRef]
38. Lee C, Lee C, Kim CS. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans Image Process. 2013;22(12):5372–84. doi:10.1109/TIP.2013.2284059. [Google Scholar] [PubMed] [CrossRef]
39. Guo X, Li Y, Ling H. LIME: low-light image enhancement via illumination map estimation. IEEE Trans Image Process. 2017;26(2):982–93. doi:10.1109/TIP.2016.2639450. [Google Scholar] [PubMed] [CrossRef]
40. Wang S, Zheng J, Hu HM, Li B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans Image Process. 2013;22(9):3538–48. doi:10.1109/TIP.2013.2261309. [Google Scholar] [PubMed] [CrossRef]
41. Ma K, Zeng K, Wang Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans Image Process. 2015;24(11):3345–56. doi:10.1109/TIP.2015.2442920. [Google Scholar] [PubMed] [CrossRef]
42. Zhang R, Isola P, Efros AA, Shechtman E, Wang O. The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. doi:10.1109/CVPR.2018.00068. [Google Scholar] [CrossRef]
43. Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process. 2004;13(4):600–12. doi:10.1109/tip.2003.819861. [Google Scholar] [PubMed] [CrossRef]
44. Liu R, Ma L, Zhang J, Fan X, Luo Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. doi:10.1109/cvpr46437.2021.01042. [Google Scholar] [CrossRef]
45. Jiang Y, Gong X, Liu D, Cheng Y, Fang C, Shen X, et al. EnlightenGAN: deep light enhancement without paired supervision. IEEE Trans Image Process. 2021;30:2340–9. doi:10.1109/TIP.2021.3051462. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools