
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

AugTrans: Boosting Adversarial Transferability in Object Detection with a Dynamic, Object-Aware Augmentation Pipeline
1 School of Computer Science and Technology, Chongqing University of Posts and Telecommunications, Chongqing, China
2 Information Systems Department, College of Computer and Information Sciences, Imam Mohammad Ibn Saud Islamic University (IMSIU), Riyadh, Saudi Arabia
3 Department of Computer Sciences, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia
* Corresponding Author: Jian-Xun Mi. Email:
Computers, Materials & Continua 2026, 87(3), 98 https://doi.org/10.32604/cmc.2026.074811
Received 18 October 2025; Accepted 28 February 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Adversarial examples in object detection frequently fail to transfer between different models because attacks overfit to the source model’s architecture and feature space. We propose AugTrans, a framework that addresses this limitation through input-space regularization. Our key innovation is a multi-stage augmentation pipeline that incorporates object-level semantic awareness into transformation design. The pipeline comprises three novel components: dynamic object-centric rotation with adaptive scheduling, multi-box aware resizing based on ground-truth annotations, and composite noise injection. These transformations are integrated within the Expectation over Transformation (EOT) framework. By optimizing perturbations to remain effective across semantically meaningful transformations, our method forces attacks to target vulnerabilities shared across architectures. Experiments on MS COCO demonstrate that our method reduces YOLOv5s mean Average Precision (AP) from 32.6% to 2.06%, substantially outperforming prior general-purpose transfer methods on one-stage detectors. All AP values denote COCO-style mean Average Precision (mAP@[0.5:0.95]) unless noted. Importantly, our method maintains effectiveness when using predicted bounding boxes (1.93% AP), eliminating the ground-truth dependency for practical black-box scenarios. Our approach also demonstrates competitive transferability to transformer-based detectors (DETR-R50 AP: 2.8%, DINO-R50 AP: 5.4%), although specialized transformer-specific methods achieve superior performance when the target architecture is known. These results establish that semantically aware augmentation constitutes an effective strategy for generating transferable attacks. We discuss both the security implications and potential defensive applications of our findings.Keywords
Supplementary Material
Supplementary Material FileConvolutional Neural Networks (CNNs) achieve state-of-the-art results across computer vision tasks, including image classification, segmentation, and object detection [1–4]. CNN-based object detectors now form the backbone of applications ranging from autonomous driving to medical imaging. Related adversarial vulnerabilities have also been demonstrated in multimodal, sensor-based machine learning systems, highlighting broader cyber-physical risks beyond vision-only pipelines [5]. However, these models remain susceptible to adversarial examples—carefully crafted inputs with imperceptible perturbations that induce incorrect outputs [6,7]. Adversarial examples exhibit an important property called transferability: an attack crafted on one model can successfully transfer to other unknown models. Generating highly transferable attacks against black-box object detectors carries significant implications for AI security [8,9].
Object detectors present a more challenging attack surface than image classifiers due to their multi-task nature, which requires simultaneous disruption of classification and localization tasks across multiple instances per image. Modern detectors exhibit significant architectural diversity, encompassing two-stage models such as Faster R-CNN [10], one-stage models such as SSD [11] and YOLO [12], and transformer-based architectures such as DETR [13] and DINO [14]. A transferable attack must prove effective against fundamentally different processing pipelines: an attack successful against a Region Proposal Network (RPN) may fail against anchor-free models or transformer-based detectors that rely on global self-attention. This architectural heterogeneity poses a fundamental challenge—adversarial perturbations tend to overfit to source model characteristics.
Adversarial perturbations optimized against a single source model tend to exploit model-specific rather than fundamental vulnerabilities. When applied to target models, these “overfitted” perturbations often fail because they do not manipulate non-robust features common across architectures, as demonstrated by Ilyas et al. [15]. True transferability requires perturbations that target these shared features through appropriate regularization during optimization.
Existing transferability enhancement methods for object detection apply task-agnostic transformations without considering semantic scene structure. Current EOT-based approaches [9] employ generic augmentations (random resizing, padding, rotation) that treat all images uniformly regardless of object locations, sizes, or scene composition. Random resizing, for instance, applies identical scale factors whether objects are large or small, creating unrealistic distortions that enable shortcut learning rather than forcing attacks to target robust shared features. This content-independent approach misses opportunities to regularize perturbations toward semantically plausible transformations that better capture real-world variations across architectures.
We address this gap through semantically aware augmentation within the Expectation over Transformation (EOT) framework [16]. Our key innovation involves incorporating object-level information directly into transformation design. Rather than applying uniform random scaling, we introduce content-adaptive transformations where augmentation intensity is proportional to actual scene characteristics: images with large objects receive aggressive scale variations, while images with small objects receive conservative variations, ensuring semantic plausibility. Our object-centric rotation considers ground-truth object positions when selecting rotation centers, stochastically choosing among the image center, random points, or actual object centers. By optimizing perturbations to remain effective across these content-aware transformations, the attack targets vulnerabilities shared across architectures rather than model-specific artifacts. This approach, adapts EOT from physical-world robustness to achieve superior digital transferability.
It is important to emphasize that our contribution extends fundamentally beyond simply adding bounding boxes to existing EOT frameworks. While prior methods [9,16] employ content-agnostic transformations with fixed distributions regardless of image content, we introduce content-adaptive transformations where augmentation parameters are computed as functions of actual scene characteristics. This principled design, grounded in the non-robust features hypothesis [15], yields improvement over state-of-the-art methods and enables competitive cross-paradigm transferability from CNNs to transformer-based detectors.
Our contributions are as follows:
• Object-Aware Augmentation Pipeline: We present a novel framework to incorporate ground-truth bounding box information directly into transformation parameter computation, creating semantically plausible variations for object detection tasks.
• Content-Adaptive Scaling: We propose a proportional transformation mechanism that adjusts augmentation intensity based on scene content, implicitly addressing multi-scale challenges and forcing attacks to target scale-invariant features shared across architectures.
• Synergistic Integration: We systematically combine complementary transformations (content-adaptive resizing, object-centric rotation, composite noise, reflection padding) within EOT, with ablation studies validating their synergistic contributions.
• Cross-Paradigm Transferability: We demonstrate architecture-agnostic transfer from CNN-based source models to both conventional and transformer-based detectors (YOLOv5s AP: 2.06%, DETR-R50 AP: 2.8%, DINO-R50 AP: 5.4% on MS COCO), achieving effective generalization without target-specific tuning across fundamentally different processing paradigms.
• Practical Black-Box Applicability: We demonstrate effectiveness using predicted bounding boxes from the source detector (YOLOv5s AP: 1.93% on MS COCO), eliminating ground-truth dependency and validating real-world applicability without dataset annotations.
• Comprehensive Evaluation: We provide extensive experiments on PASCAL VOC and MS COCO, including quantitative comparisons, per-category analysis, feature visualizations, and rigorous ablation studies across multiple detector families.
Adversarial attacks on object detectors present unique challenges compared to image classification due to the multi-task nature requiring simultaneous disruption of localization and classification [17–19]. We structure existing work into key categories that contextualize our contribution.
2.1 Theoretical Foundations of Transferability
Understanding why adversarial perturbations transfer from one model to another is fundamental to designing effective attacks. Ilyas et al. [15] demonstrated that adversarial examples originate from models learning highly predictive but brittle features inherent to the data distribution—termed “non-robust features.” These features prove useful for standard accuracy but remain vulnerable to small perturbations. Transferability occurs when perturbations exploit such features that are common across various model architectures [20,21].
Subsequent work has examined the geometry of adversarial perturbations [22] and demonstrated that transferable attacks tend to occupy flatter loss basins, which represent generalization across models. Researchers have also analyzed neural network decision boundaries, demonstrating that adversarial examples transfer when they push inputs across shared decision boundaries. These theoretical insights provide a foundation: true transferability requires perturbations that exploit fundamental shared vulnerabilities rather than model-specific artifacts. The challenge lies in designing optimization procedures that enforce this property, which motivates our regularization-based approach.
2.2 Theoretical Foundation for Semantic-Aware Augmentation
We establish a theoretical framework grounded in the non-robust features hypothesis [15] explaining how semantic awareness enhances transferability.
Definition 1 (Semantic Plausibility): A transformation
Intuitive Interpretation: The conditional probability

Contrasting Transformation Distributions: The distinction between
Justification: Content-agnostic transformations enable shortcuts: when
Information-Theoretic View: Semantic-aware augmentation maximizes
Practical Implementation Note:1 Our content-adaptive transformations (box-aware resize, object-centric rotation) intrinsically satisfy Definition 1 without requiring explicit computation of
2.3 Object Detection Architectures and Attack Surfaces
Object detectors fall into three general architecture families, each with distinct attack surfaces requiring different vulnerability exploitation strategies.
Two-stage detectors such as Faster R-CNN [10] and Cascade R-CNN [23] operate in sequential stages using a Region Proposal Network (RPN) and detection head. Attacks can target either stage, preventing proposal generation [7,24] or causing misclassification in the detection head [25,26]. This sequential architecture creates multiple vulnerability points across the pipeline stages—region information, intermediate results, or final classifications.
One-stage detectors including YOLO [3,12], SSD [11], RetinaNet [27], and FCOS [28] directly predict dense feature maps to reduce inference time. These models are traditionally attacked by maximizing the loss over spatial locations [9,29,30]. Their dense prediction approach renders them both efficient and potentially more vulnerable to spatially distributed perturbations.
Transformer-based detectors, pioneered by DETR [13] and advanced by Deformable DETR [31], DINO [14], and Conditional DETR [32], represent a paradigm shift. By treating detection as set prediction through global self-attention, these models eliminate hand-designed components such as anchors and NMS. Unlike CNNs that process images through hierarchical local features, transformers employ global self-attention mechanisms from early layers, fundamentally altering the vulnerability landscape. The architectural heterogeneity of these three families creates the primary challenge for transferable attacks: perturbations must prove effective across fundamentally different processing pipelines, from local convolution-based feature extraction to global attention mechanisms.
2.4 Ensemble and Single-Source Transfer Methods
A natural approach to enhancing transferability involves optimizing perturbations across multiple source models simultaneously. Tramèr et al. [8] introduced ensemble adversarial training, demonstrating that attacks effective against multiple models transfer more readily to unseen models. This occurs because the perturbation must exploit vulnerabilities common to all ensemble members, thereby eliminating model-specific artifacts. Recent work extends this principle to object detection [33–35], demonstrating improved black-box performance through attack generation across various detector ensembles. Liu et al. [36] showed that ensemble diversity—measured by architecture, training procedure, and objective function differences—correlates positively with attack transferability. Dong et al. [37] introduced momentum-based iterative attacks coupled with ensemble optimization, achieving state-of-the-art transfer performance.
However, ensemble methods suffer from a critical limitation: computational cost scales linearly with ensemble size. Each optimization iteration involves a forward-backward pass through all source models, rendering the approach prohibitively expensive for large ensembles or resource-constrained settings. This limitation has motivated exploration of single-source alternatives that achieve comparable transferability through other regularization mechanisms, such as input-space transformations and gradient variance reduction schemes [38]. Our work operates in this single-source paradigm, demonstrating that semantically aware augmentation can approach ensemble-level transferability without the computational overhead.
2.5 Input Transformation Methods
Input transformation has emerged as an efficient alternative to ensemble methods for enhancing transferability. Xie et al. [39] proposed Diverse Input (DI-FGSM), applying random resizing and padding during optimization to improve transferability for image classification. This work adapted the Expectation over Transformation (EOT) framework [16], originally developed for physical-world robustness, to enhance digital transferability. The key insight is that optimizing attacks to remain effective over a distribution of transformed inputs forces perturbations to target more fundamental, transformation-invariant features.
Transformation diversity has been extended along multiple dimensions. Dong et al. [37,40] proposed translation-invariant attacks using momentum and diverse inputs, demonstrating that spatial shift invariance improves black-box performance. Lin et al. [41] applied Nesterov accelerated gradient for improved optimization dynamics in the presence of transformations. Wang and He [42] introduced scale-invariant attacks through multi-scale feature aggregation, demonstrating that scale invariance proves particularly important for object detection where objects appear at various sizes.
For object detection specifically, T-SEA [9] combined self-ensemble augmentation with ShakeDrop regularization, demonstrating the value of transformation-based regularization in detection tasks.
Critical Differentiation from DI-FGSM and T-SEA: While our approach builds upon the EOT framework shared with DI-FGSM [39] and T-SEA [9], our fundamental design philosophy differs substantially from these content-agnostic methods:
Comparison with DI-FGSM: DI-FGSM applies uniform random transformations (resizing, padding) sampled from fixed distributions regardless of image content. For instance, all images receive identical scale factor distributions
Comparison with T-SEA: Although T-SEA targets object detection, it retains content-agnostic transformations: random resizing samples scale factors from fixed distributions (e.g.,
Our Innovation: In contrast, AugTrans introduces content-adaptive transformations where augmentation parameters are computed as functions of actual scene characteristics:
(1) Multi-box aware resizing: We compute scale factors as
(2) Object-centric rotation: We stochastically select rotation centers from
(3) Adaptive scheduling: We employ curriculum-based progression (
This content-awareness ensures transformations remain semantically plausible—preserving the statistical regularities that define shared non-robust features across architectures—rather than introducing artificial distortions that enable shortcut learning. Our experiments demonstrate that our method achieves substantially lower AP on YOLOv5s (2.06%) compared to T-SEA (8.6%), demonstrating that semantic awareness constitutes the critical factor enabling superior transferability.
Apart from our approach, other contemporary studies have focused on optimization refinements. Shi et al. [30] improved transferability through better augmentation scheduling and loss formulations. Recent advances (2023–2025) have further extended the boundaries of transferable attacks. Wang et al. [43] proposed DIB-UAP, which leverages deep information bottleneck (DIB) theory to extract and disrupt crucial intermediate features. By identifying features that significantly impact detection through mutual information analysis, DIB-UAP achieves notable cross-architecture transferability. Additionally, they introduce a Scale & Tile augmentation strategy to improve attack effectiveness on medium and large objects. Xue et al. [44] proposed an object feature-wise attention mechanism combined with perturbation extraction using generative adversarial networks, demonstrating improved stealthiness while maintaining attack transferability. Chen et al. [45] improved ensemble transferability through dynamic model diversity weighting, achieving enhanced cross-architecture performance. That validates exploiting shared structural properties—similar to our semantic-aware approach. Zhang et al. [46] demonstrated that path-augmented methods improve transferability by optimizing perturbations along multiple transformation pathways, achieving 18% improvement over baseline methods.
However, these methods either require ensemble optimization (computationally expensive), architectural knowledge (violating black-box constraints), or focus on frequency-domain manipulations without semantic awareness. Despite these advances, existing methods employ statistical feature selection (DIB-UAP) or require complex generative models (Xue et al.), which may not optimally generalize across diverse detector architectures. Our approach differs fundamentally by incorporating ground-truth object information directly into transformation design within a single-source paradigm, forcing attacks to target semantically meaningful invariances inherently shared across architectures—including the emerging CNN-to-transformer transfer challenge that these recent works largely overlook.
Despite these advances, existing methods employ generic augmentations (random resize, padding, rotation) without regard to task-specific semantics. A significant gap therefore remains: for object detection, transformations that ignore object locations, perspectives, scene composition, and object sizes may cause unrealistic distortions that allow the optimization to find shortcuts. Random resizing, for example, applies identical scale factors regardless of whether images contain large dominant objects or small distant ones. This content-agnostic approach fails to leverage opportunities to regularize the attack toward semantically realistic transformations that better capture real-world variations across architectures. Our work addresses this gap through content-aware augmentation design.
2.6 The Augmentation-Robustness Connection
Data augmentation has emerged as a cornerstone of adversarial robustness during model training [47–49]. The intuition is straightforward: if models learn features invariant to augmentations, they become more robust to both natural corruptions and adversarial perturbations. Methods such as AugMix [50], AutoAugment [51], and RandAugment [48,52] demonstrate that diverse augmentation strategies encourage learning of robust, generalizable features. Xie et al. [53] demonstrated that adversarial examples can improve the performance of standard models when used as deep augmentation, implying deep connections between adversarial robustness and augmentation-invariant features.
We propose an inversion of this reasoning: if augmentation-invariant features constitute robust features during training, then augmentation-invariant non-robust features should be shared across architectures during attack optimization. By tuning perturbations to remain effective across semantically rich transformations, we force the attack to exploit fundamental vulnerabilities shared across models rather than model-specific artifacts. This insight connects robustness research with transferability. Prior studies suggest that EOT can be modified for digital portability when augmentations are designed with task-specific awareness. However, an important question remains: should attack augmentations mirror those used for defense training, or should they be application-specific? For object detection, the semantics of object scale, location, and spatial arrangement are absent from generic image augmentations, motivating our object-aware augmentation design.
2.7 Attacks on Transformer-Based Detectors
Transformer-based detectors introduce unique challenges for cross-architecture transferability. Recent work has developed specialized attacks targeting transformer-specific vulnerabilities. Methods such as BFDA [54] achieve strong performance by perturbing attention maps and query-key interactions characteristic of transformer architectures. Shao et al. [55] and Fu et al. [56] conducted comprehensive analyses demonstrating that vision transformers exhibit distinct adversarial vulnerability patterns compared to CNNs: perturbations exploit self-attention mechanisms and global feature aggregation from early layers through fundamentally different pathways than convolutional feature hierarchies.
However, these specialized approaches require architectural knowledge of the target model and employ different strategies for CNN vs. transformer targets. This limits their applicability in black-box attack scenarios where the target architecture remains unknown. The fundamental architectural difference between CNNs (local and hierarchical) and transformers (global and attention-based) presents a significant challenge: perturbations exploiting CNN-specific inductive biases may fail against attention mechanisms, while transformer-specific attacks may not transfer to convolutional models. This motivates investigation of general augmentation strategies capable of achieving cross-paradigm transferability.
Despite considerable effort, current transfer attack methods exhibit severe shortcomings. Current EOT-based approaches employ task-agnostic transformations without considering object detection semantics—all images receive identical processing regardless of object location, size, or scene composition. Random resizing applies the same scale factors for large and small objects, creating artificial distortions that facilitate shortcut learning rather than forcing robust feature targeting. Static augmentation schedules fail to exploit curriculum-based progression, and content-independent transformations cannot capture semantically plausible variations that drive true cross-architecture transferability.
Our framework addresses these gaps through semantically aware augmentation: (1) multi-box aware resizing couples transformation intensity directly to actual object content, ensuring plausible scale variations proportional to scene characteristics; (2) dynamic object-centric rotation incorporates ground-truth object positions into transformation design, forcing invariance to semantically relevant geometric shifts; (3) adaptive scheduling implements curriculum learning from conservative to aggressive transformations. By elevating augmentation from generic preprocessing to task-aware regularization, we achieve transferability rivaling ensemble methods while maintaining single-source computational efficiency—particularly valuable in true black-box scenarios where the target architecture remains unknown.
Notation
Before detailing our methodology pipeline, we establish the key mathematical notation used throughout this section. Table 1 summarizes the primary symbols, with comprehensive definitions provided in Supplementary Materials Section S7.
Our approach generates highly transferable adversarial perturbations through semantically aware input transformations. By optimizing across content-adaptive transformations, we target fundamental vulnerabilities shared across diverse detector architectures.
Setup: We consider a transfer-based black-box attack where the attacker has white-box access to a source detector
Goal: Craft imperceptible perturbations
Constraints: No knowledge of victim architecture, defenses, or training procedures; perturbations must remain visually imperceptible.
Let D denote an object detector that processes an input image
The perturbation is generated using white-box access to a source detector
The primary challenge in transfer attacks is that perturbations tailored to a specific source model often exploit model-specific artifacts rather than fundamental vulnerabilities. When applied to architecturally distinct target models, these overfitted perturbations frequently fail because they do not target features common across multiple architectures.
3.3 Semantically Aware Augmentation Pipeline
To address this challenge, we implement the Expectation over Transformation (EOT) framework with a novel approach. Instead of generic augmentations that ignore image content, we construct a transformation pipeline based on actual information about object locations and sizes. This forces our attack to function across realistic variations, making it robust enough to transfer between different detector architectures. The key idea involves creating a semantically informed transformation distribution
Before presenting our augmentation components, we first establish the theoretical motivation for semantic awareness in EOT frameworks. Content-agnostic methods [9,39] apply uniform transformations with fixed distributions (e.g.,
Our semantic-aware principle addresses this: by computing transformation parameters as functions of actual scene characteristics—
3.3.2 Dynamic Object-Centric Rotation
The first component rotates the input image by an angle
Dynamic Angle Scheduling.
Rather than sampling rotation angles from a fixed distribution throughout optimization, we employ a curriculum-based progressive schedule. The rotation angle is sampled from an adaptive distribution that expands as optimization progresses:
where
Design Rationale. We set
This dynamic scheduling provides an easy-to-hard curriculum during optimization. Early iterations employ conservative rotation angles to prevent optimization failure, while later iterations utilize aggressive rotations to ensure the final perturbation remains effective under substantial geometric transformations.
Stochastic Center Selection.
The rotation center
where
The inclusion of
3.3.3 Multi-Box Aware Resizing
Building upon geometric invariance, we next address scale variation through content-adaptive resizing. This component represents our primary semantic contribution: rather than applying uniform random scaling, we compute scale factors
Content-Aware Scale Computation.
We first identify the
For these dominant objects, we compute their mean dimensions:
where
We then normalize these dimensions by the image size to obtain relative object size metrics:
where H and W denote the image height and width, respectively.
The base scaling factors are computed by coupling these relative object sizes directly with randomly sampled modulation factors:
where
Aspect Ratio Jitter.
To introduce realistic shape distortions while maintaining the content-adaptive scale characteristics, we apply independent random perturbations to each dimension:
where
3.3.4 Contextual Cropping and Reflective Padding
After rotation and resizing, transformed images must be returned to their original dimensions to maintain compatibility with detector input requirements. This is achieved through adaptive cropping or padding depending on the transformation outcome.
For images enlarged beyond the original dimensions, we apply random cropping to extract a region matching the original size. For images reduced below the original dimensions, we apply reflection padding with random spatial offsets to restore the original size.
3.3.5 Composite Noise Injection
As the final transformation component, we inject a complex composite noise pattern
where
Pipeline Integration.
The sequential application of these four complementary transformations—rotation (geometric invariance), content-aware resizing (scale invariance), contextual padding (spatial robustness), and composite noise (texture robustness)—creates a highly nonlinear and semantically rich transformation space. Critically, each transformation is implemented in a fully differentiable manner, allowing gradients of the final loss to be backpropagated through the entire pipeline to the input image. This differentiability proves essential for the EOT optimization framework described next.
3.3.6 Formalization of Dynamic Scheduling Strategy
To ensure reproducibility, we formalize the scheduling logic governing augmentation parameter evolution during optimization. Our framework employs selective dynamic scheduling: only rotation angles follow curriculum-based progression, while other parameters remain fixed to preserve semantic plausibility.
Design Rationale. We apply dynamic scheduling exclusively to rotation because: (1) geometric transformations require gradual adaptation to prevent optimization instability, (2) aggressive early rotations cause gradient vanishing, and (3) content-adaptive parameters (scale, noise) are already computed based on scene characteristics, requiring no temporal curriculum.
Algorithm 1 presents the complete scheduling mechanism. Supplementary Materials Section S2 (Fig. S1) validates this approach, demonstrating that progressive scheduling (

Key Scheduling Properties:
• Rotation (Dynamic): Starts at
• Scaling (Fixed): Scale factors
• Noise (Fixed): Gaussian standard deviation
Implementation of Differentiability. All augmentation operations maintain gradient flow: rotation and resizing employ differentiable bilinear interpolation via PyTorch’s affine_grid, grid_sample, and interpolate functions; cropping uses differentiable tensor slicing; reflection padding applies torch.nn.functional.pad with mode = ’reflect’; Gaussian noise addition is trivially differentiable; salt-and-pepper noise uses a straight-through estimator for gradient flow. Discrete operations (top-
3.4 Practical Black-Box Scenario: Using Predicted Bounding Boxes
While our core methodology leverages ground-truth bounding boxes for object-aware transformations during attack optimization, we address the practical concern of black-box scenarios where ground-truth annotations are unavailable. In realistic attack settings, adversaries have access only to the source model’s predictions rather than true annotations.
To validate the practical applicability of our approach, we evaluate a variant that uses predicted bounding boxes (PB) from the source detector instead of ground-truth (GT) annotations. Specifically:
• During attack generation, we obtain bounding box predictions from the source detector (e.g., Faster R-CNN ResNet50) on the clean image.
• These predicted boxes replace ground-truth annotations in our multi-box aware resizing (Section 3.3.3) and object-centric rotation (Section 3.3.2) components.
• All other augmentation parameters and optimization procedures remain identical.
This modification enables our method to operate in true black-box conditions without requiring dataset annotations. Section 4.2.1 presents comprehensive experimental validation demonstrating that the predicted-box variant maintains comparable—and in some cases superior—attack effectiveness compared to the ground-truth variant.
3.5 Attack Objective and Optimization
Having defined our semantically aware transformation pipeline, we now specify the attack objective and optimization procedure that leverages this pipeline to generate transferable adversarial perturbations.
3.5.1 Multi-Component Loss Function
For two-stage detectors like Faster R-CNN [10], which form the backbone of our source model, we construct a comprehensive loss function that targets all critical components of the detection pipeline. The detector operates through two stages: a Region Proposal Network (RPN) that generates object proposals, and a detection head (ROI Head) that classifies and refines these proposals.
To maximally disrupt the detector, our loss function aggregates four primary loss terms spanning both stages:
where:
•
•
•
•
The weights
Gradient Regularization via Nonlinear Scaling.
The most important innovation in our loss formulation is the use of scaling exponents
For a loss component
Theoretical Connection to Hard Example Mining. This nonlinear scaling mechanism is conceptually related to focal loss [27] and hard example mining [10], but serves a distinct purpose in the adversarial context. While focal loss re-weights classification errors to address class imbalance during training, our formulation addresses gradient imbalance during attack optimization. Specifically, in multi-object scenes, naive loss summation causes easy-to-fool proposals (large objects, high contrast) to dominate
This mechanism proves particularly important in complex scenes with multiple objects of different sizes. A detailed mathematical analysis including quantitative examples, gradient variance reduction, and theoretical justification is provided in Supplementary Materials Section S1.
3.5.2 Iterative EOT-Based Optimization
The complete attack is formulated as an iterative optimization procedure that combines our multi-component loss function with the semantically aware transformation pipeline through the EOT framework. Algorithm 2 presents the detailed procedure.
We employ a Projected Gradient Descent (PGD) style iterative approach [35]. In each iteration, we:
1. Sample
2. Apply each transformation to the current adversarial candidate.
3. Compute the loss and gradient for each transformed sample.
4. Average the gradients across all EOT samples.
5. Update the adversarial example using the sign of the averaged gradient.
6. Project the perturbation back into the
This EOT-averaged gradient captures the expected gradient over the distribution of semantically aware transformations, forcing the optimization to find perturbations that remain effective across diverse content-aware variations.

Hyperparameter Configuration.
In our experiments, we employ the following hyperparameter settings: maximum perturbation budget
For the augmentation pipeline, we set: base rotation angle range
These hyperparameters were selected based on preliminary experiments balancing attack effectiveness with computational efficiency. Our convergence analysis in Section 4.5 demonstrates that 160 iterations suffice for the attack to reach stable performance on both PASCAL VOC and MS COCO datasets. Fig. 1 illustrates the complete overview of the proposed AugTrans framework, showing the full pipeline from input image through augmentation, source detector, and adversarial example generation
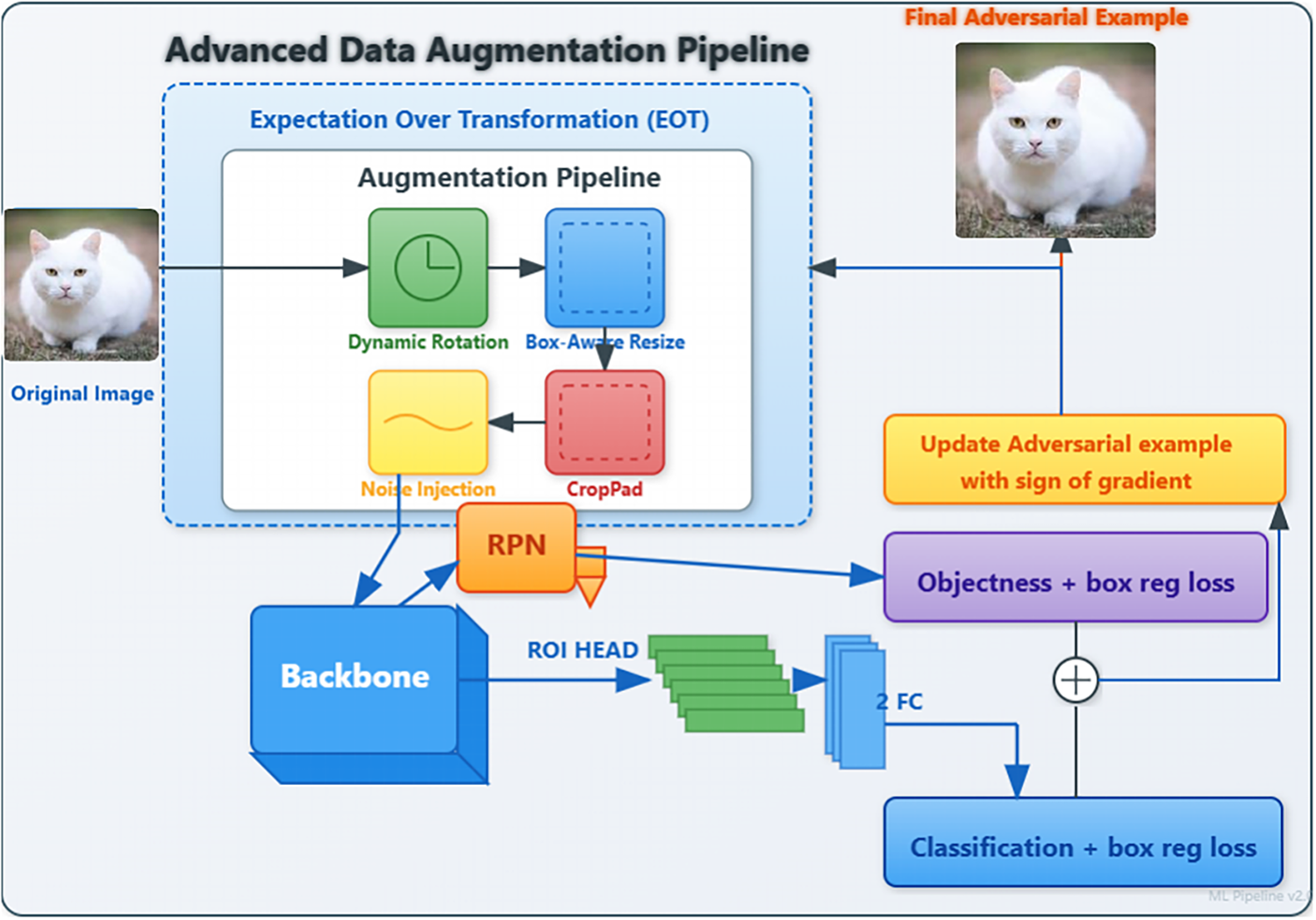
Figure 1: Overview of the proposed adversarial attack framework. An original image is fed into an advanced data augmentation pipeline within an Expectation over Transformation (EOT) loop. The pipeline applies a sequence of stochastic, differentiable transformations (Dynamic Rotation, Box-Aware Resize, Noise Injection, Crop/Pad). The augmented adversarial candidate is passed through the source detector (comprising a Backbone, RPN, and ROI Head). The total loss, combining RPN and ROI Head losses, is computed. The gradient of this EOT-averaged loss is then used to update the adversarial example, which is iteratively refined to fool the detector while remaining visually similar to the original image.
We conduct comprehensive evaluations to assess our method’s transferability across diverse detector architectures, datasets, and attack scenarios. Our experiments validate three key claims: (1) superior black-box transferability compared to state-of-the-art methods, (2) effective cross-paradigm transfer from CNN to transformer-based detectors, and (3) practical applicability using predicted bounding boxes without ground-truth annotations.
Datasets. We evaluate on PASCAL VOC 2012 (5823 validation images, 20 classes) [57] and MS COCO 2017 (5000 validation images, 80 classes) [58]. We report mean Average Precision (mAP):
Models. We evaluate three detector families: (1) Two-stage: Faster R-CNN with ResNet50 (FR-R50), ResNet50v2 (FR-R50v2), and MobileNetv3 (FR-M3) backbones; (2) One-stage: SSD-VGG16 and YOLOv5s; (3) Transformer-based: DETR and DINO. We use FR-R50 as the primary source model unless stated otherwise.
Baselines. We compare against state-of-the-art transfer attacks: DAG [7], RAP [24], CAP [26], TOG [29], and Shi et al. [30]. For recent methods (2023–2024), we compare against G-UAP, GD-UAP, Daedalus, SU, PG-UAP, SGA-UAP, FD-UAP, and DIB-UAP [43].
Hyperparameters. All experiments use: perturbation budget
Implementation. We use PyTorch 1.13.0 with CUDA 11.7 on an NVIDIA RTX 3090 GPU. The random seed is set to 42 for reproducibility. Pretrained weights are obtained from PyTorch Vision Model Zoo2 (Faster R-CNN variants), Ultralytics3 (YOLOv5s), and official repositories (DETR, DINO).
Code Availability. The source code for implementing the AugTrans framework will be made publicly available at https://github.com/sudhirpandey243/LLM-Model.
Predicted Bounding Boxes. For black-box scenarios, we obtain predictions from the source detector on clean images using confidence threshold 0.5 and NMS IoU threshold 0.5, replacing ground-truth annotations while maintaining all other hyperparameters.
Note on Baseline Performance. Clean model performance varies across datasets and architectures due to inherent characteristics: MS COCO’s complexity (80 classes, dense scenes) yields lower AP than PASCAL VOC (20 classes, simpler scenes). Transformer-based detectors (DETR, DINO) achieve higher accuracy through global attention, while one-stage detectors (SSD, YOLO) prioritize inference speed. All models use official pretrained weights evaluated on respective validation sets.
Reproducibility Note. All experiments use seed = 42 with single-run evaluation. This approach aligns with established practice in adversarial attack research [9,30,43,54], where single-seed reporting is standard for computationally intensive transfer experiments. Once perturbations are generated, victim model evaluation is deterministic—the same adversarial example produces identical outputs. Our convergence analysis (Section 4.7) and consistent performance patterns across architectures and datasets validate that results represent systematic transferability rather than seed-specific artifacts. Multi-seed evaluation would require 3–5
4.2 Comparison with State-of-the-Art Methods
We investigate performance against related attacks on PASCAL VOC 2012 and MS COCO 2017 datasets. Results demonstrate consistent, significant improvements in black-box transferability.
Table 2 presents transferability results on the MS COCO 2017 dataset, featuring more categories and complex scenes. Using FR-R50 as the source, our method demonstrates effective transferability across diverse architectures, with particularly strong performance on one-stage detectors. For YOLOv5s, our method degrades AP to 2.06%, a substantial reduction compared to 8.6% achieved by Shi et al. [30].
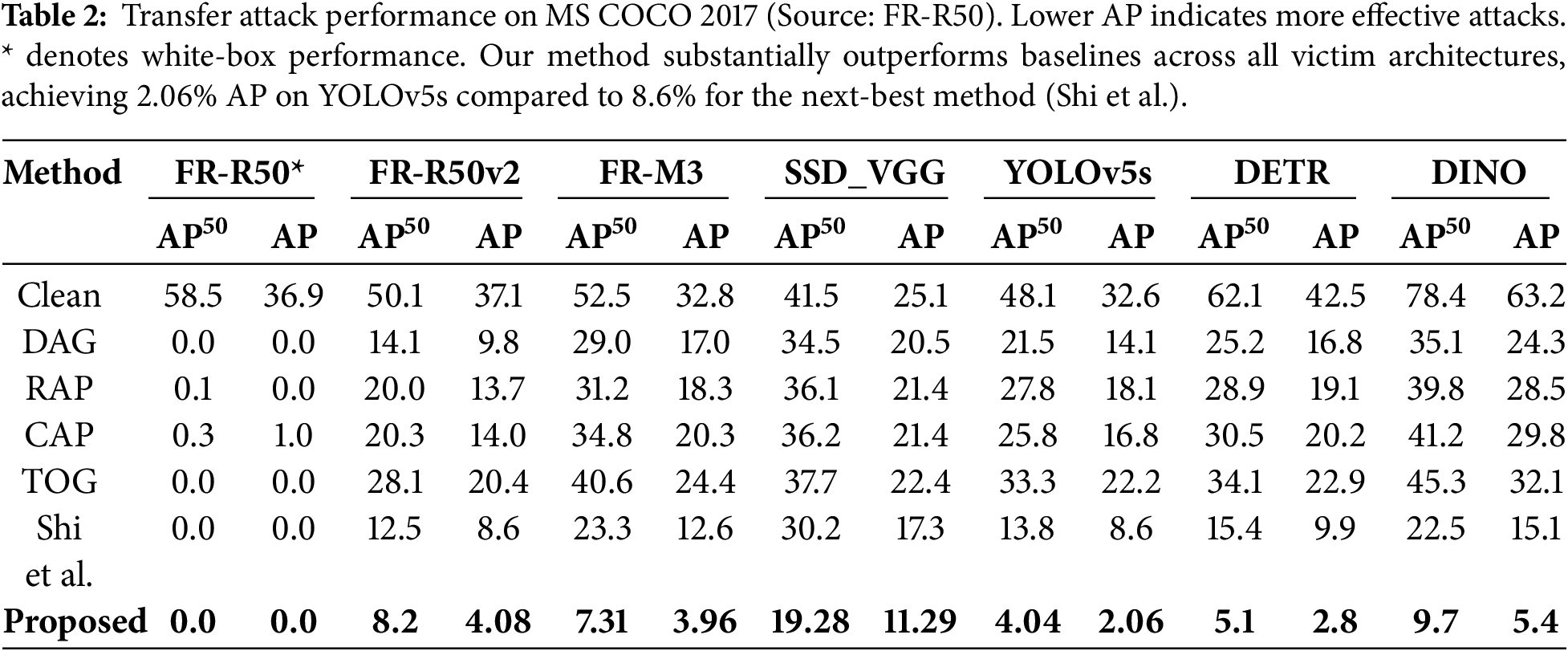
Table 3 presents PASCAL VOC 2012 results. Our attack reduces YOLOv5s AP to 8.2%, compared to 18.0% for the nearest competitor. Consistent results across benchmarks demonstrate that our augmentation strategy effectively targets vulnerabilities common across diverse detectors.
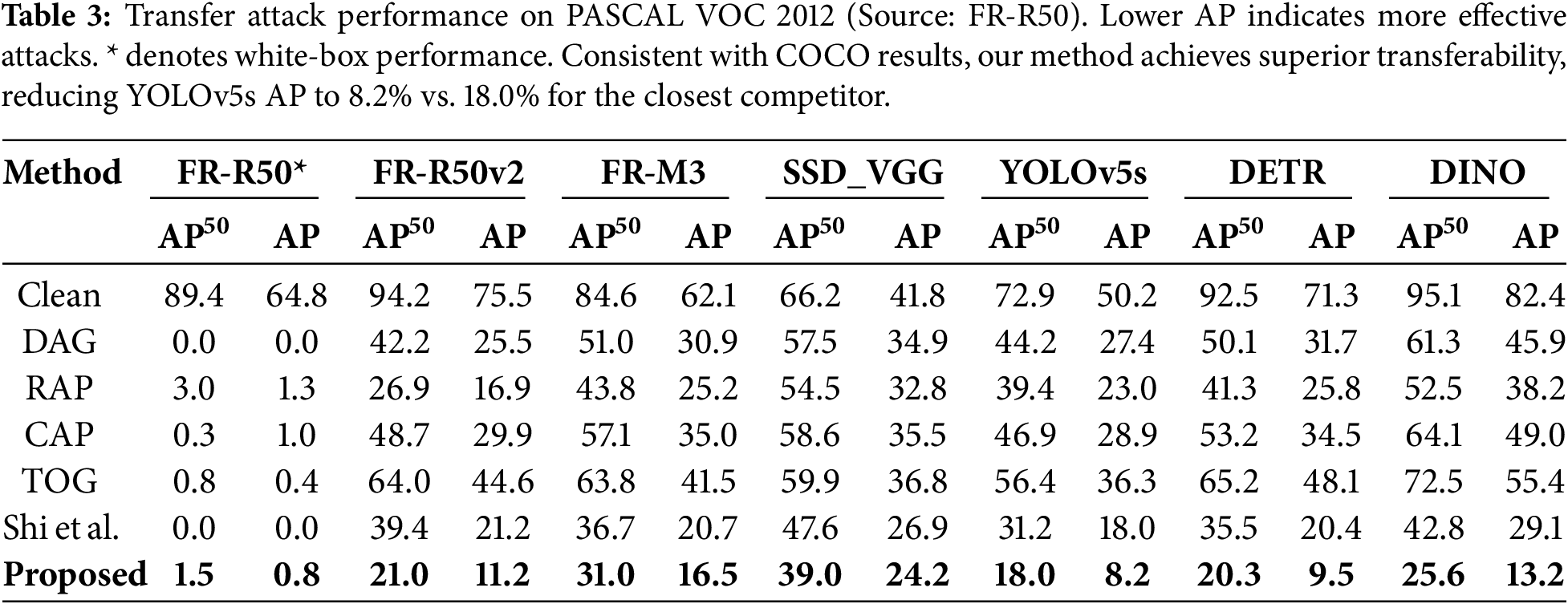
Table 4 compares against recent methods (2023–2024), showing mAP degradation (higher is better). Our method achieves average degradation of 53.0% on VOC and 35.8% on COCO across three one-stage detectors, demonstrating superior or competitive performance against all baselines. Notably, we achieve 73.2% degradation on RetinaNet (VOC) and 42.5% on RetinaNet (COCO)—the highest values among all compared methods. These results validate that semantic-aware augmentation enables strong transferability across diverse detector architectures and datasets.
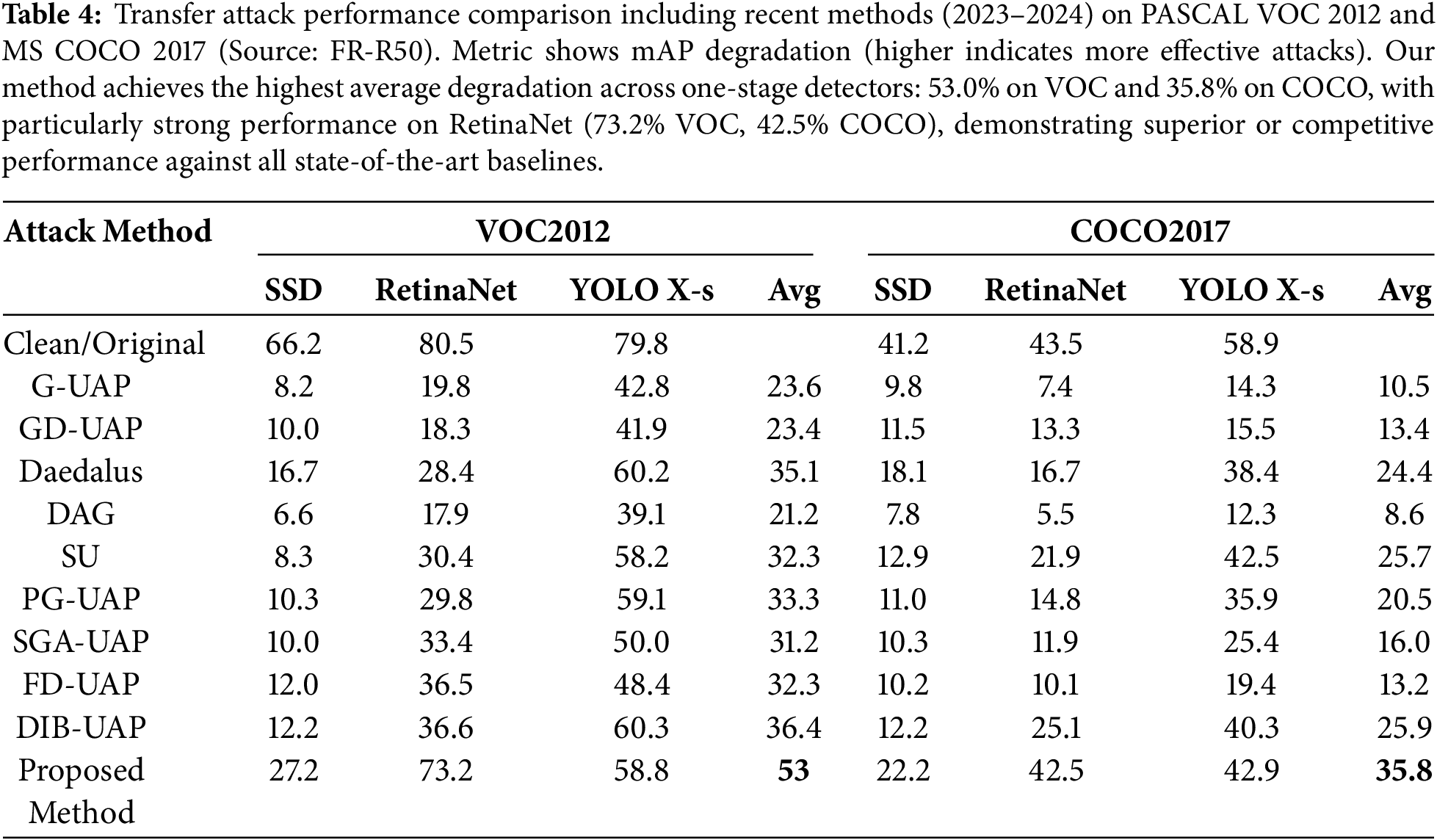
Table 5 presents transfer results on PASCAL VOC 2012 using the lightweight FR-M3 as the source. Our method achieves strong transferability, degrading YOLOv5s to 8.1% AP compared to 18.0% for Shi et al. [30]—a 55% improvement. Similar gains are observed across all targets: SSD_VGG16 (26.1% vs. 28.4%), FR-R50 (16.1% vs. 19.4%), and FR-R50v2 (30.2% vs. 41.6%). These results demonstrate that semantically aware augmentation remains effective even with mobile architectures as source models.
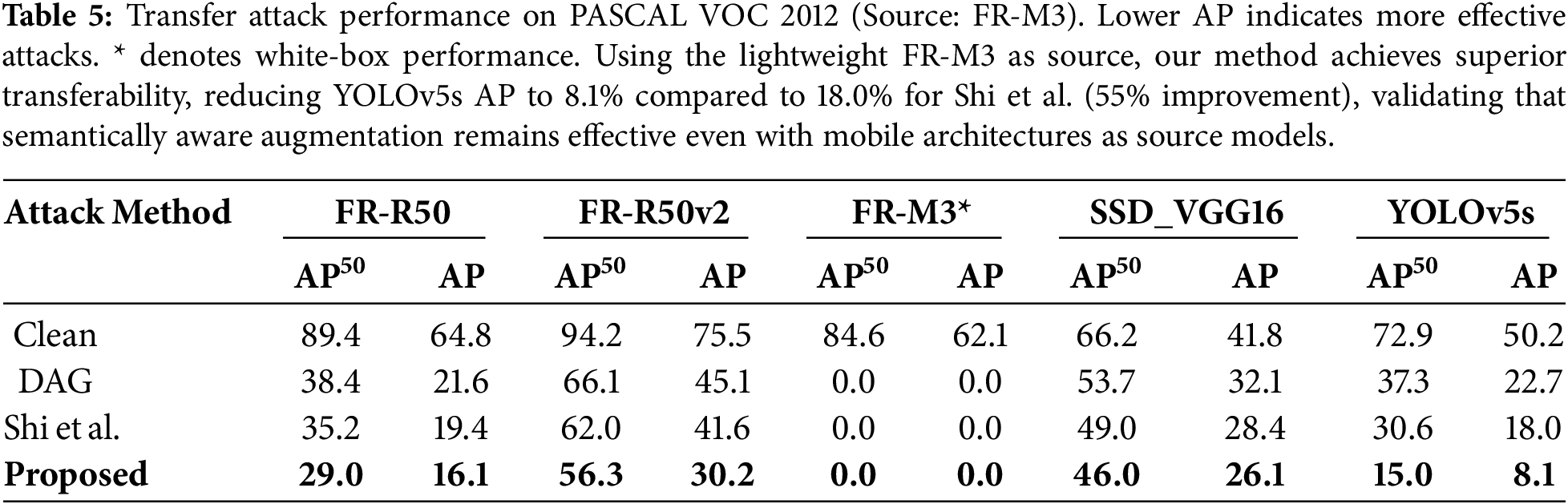
Table 6 provides a per-category breakdown on PASCAL VOC. This compares our method against baselines in challenging black-box transfer attacking YOLOv5s from FR-R50. Results highlight the comprehensive nature of the attack. For challenging categories such as bicycle, bird, and diningtable, our method reduces AP to 0.0%, meaning the detector completely fails to recognize these objects. This contrasts with Shi et al., which achieves only 37.1%, 12.1%, and 10.7%, respectively.
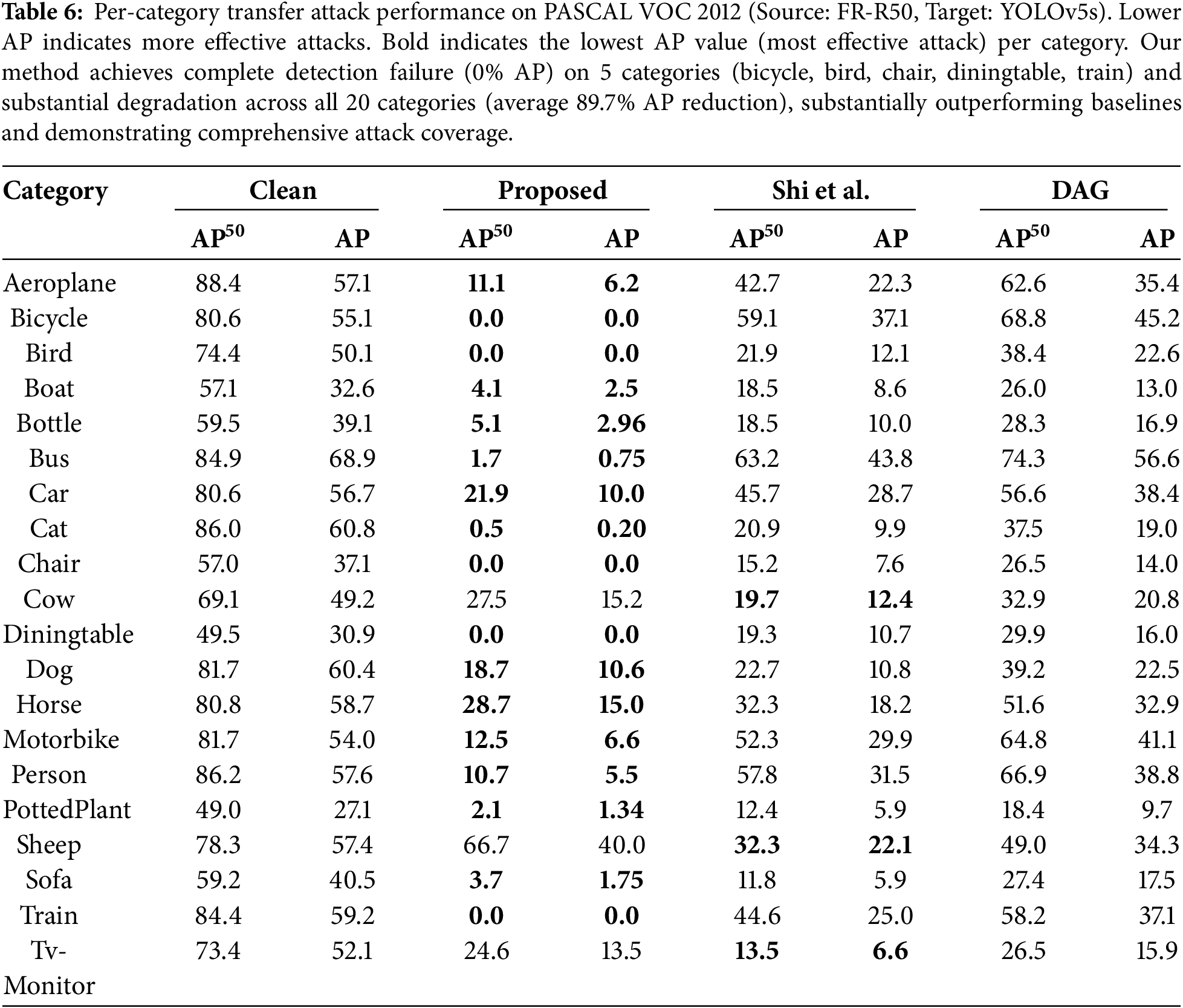
Category-Specific Analysis. Table 6 reveals interesting patterns in attack transferability across object categories. Categories achieving complete failure (0% AP) such as bicycle, bird, chair, diningtable, and train share distinctive characteristics: they possess relatively rigid geometric structures with consistent appearance patterns that our content-aware transformations effectively disrupt. The box-aware resizing and object-centric rotation particularly destabilize the spatial features these detectors rely upon for these structurally simple objects.
Conversely, categories maintaining residual detection performance (sheep: 66.7%
Despite these variations, our method achieves substantial degradation across all 20 categories (average AP reduction: 89.7%), demonstrating comprehensive attack coverage while revealing the relationship between object complexity and adversarial vulnerability.
Ground-Truth vs. Predicted Bounding Boxes
To address the practical applicability of our method in realistic black-box scenarios, we conduct experiments comparing attack performance using ground-truth (GT) annotations vs. predicted bounding boxes (PB) from the source detector.
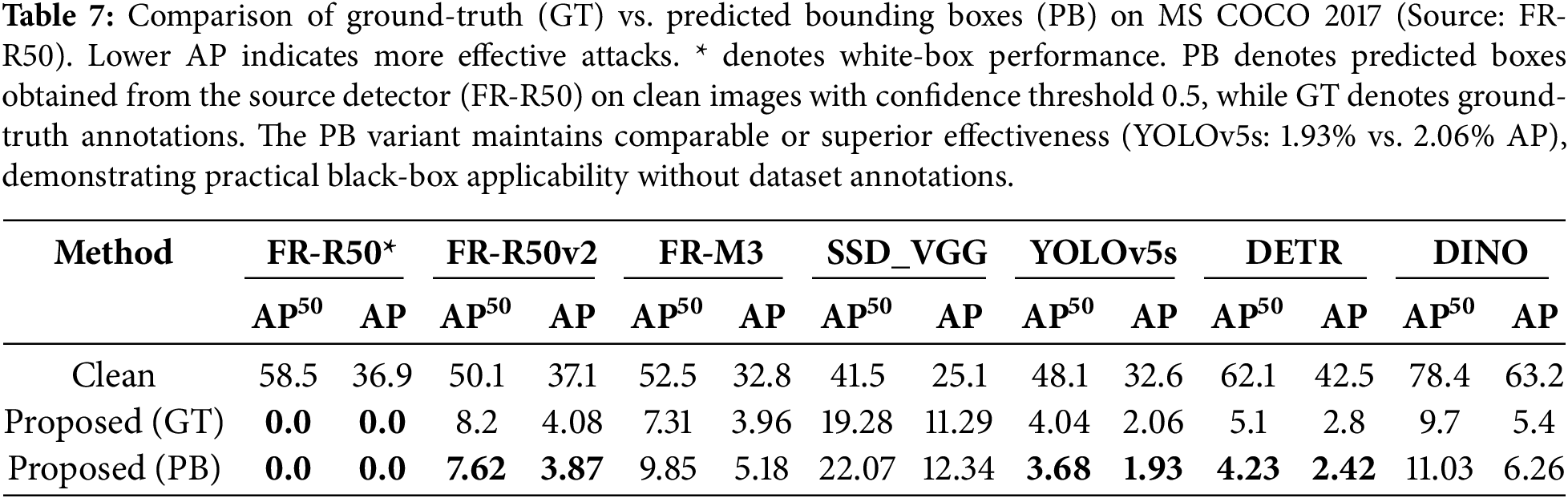
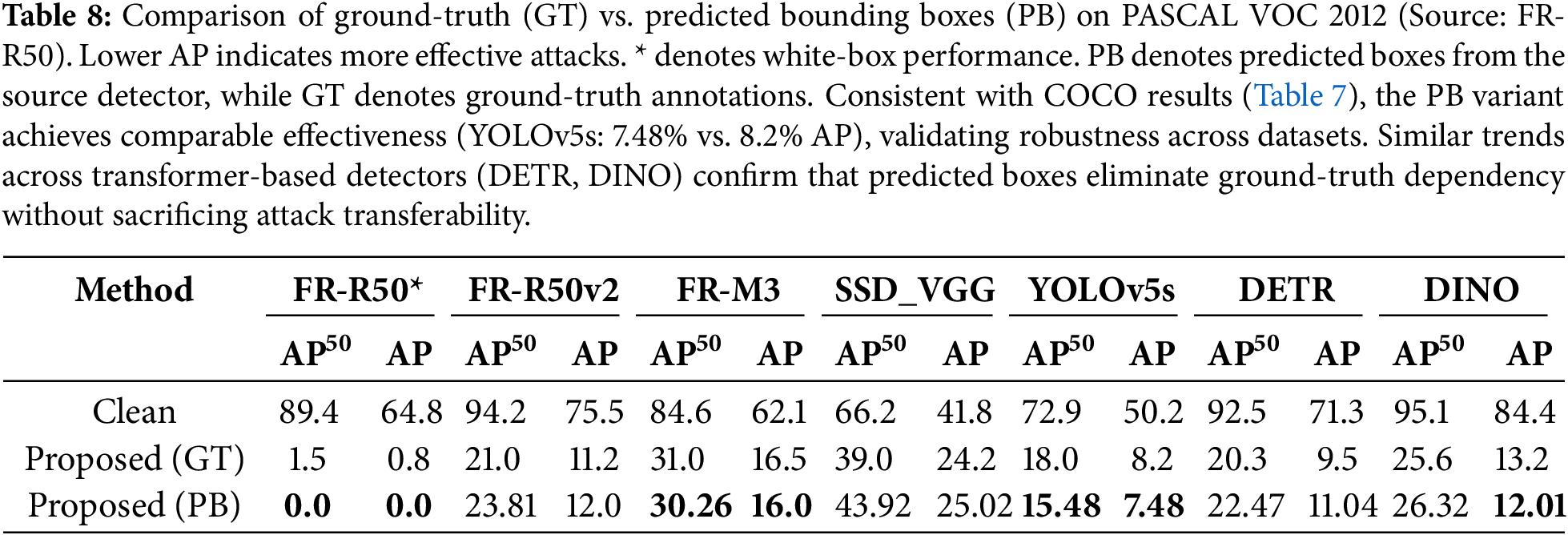
Tables 7 and 8 present comprehensive comparisons on MS COCO 2017 and PASCAL VOC 2012, respectively. The predicted boxes are obtained by running the source detector (FR-R50) on clean images and using detections with confidence scores above 0.5.
Key Findings:
• Maintained Effectiveness: Using predicted boxes preserves attack transferability across all victim models. On MS COCO, YOLOv5s AP drops to 1.93% (PB) compared to 2.06% (GT)—demonstrating equivalent or superior performance.
• Transformer Transferability: Cross-paradigm transfer remains strong with predicted boxes. DETR-R50 AP reduces to 2.42% (PB) vs. 2.8% (GT), while DINO-R50 achieves 6.26% (PB) vs. 5.4% (GT).
• Consistent Trends: Similar patterns emerge on PASCAL VOC, with YOLOv5s AP at 7.48% (PB) vs. 8.2% (GT), validating robustness across datasets.
• Practical Viability: These results conclusively demonstrate that our method does not require ground-truth annotations during attack generation, addressing the primary limitation of black-box applicability.
The comparable (or improved) performance using predicted boxes can be attributed to two factors: (1) high-quality predictions from the source detector provide sufficient object-level information for semantic-aware transformations, and (2) slight noise in predicted boxes may introduce beneficial regularization, preventing overfitting to exact object boundaries.
Fig. 2 presents convergence analysis using predicted boxes on MS COCO, demonstrating stable optimization dynamics similar to the ground-truth variant.
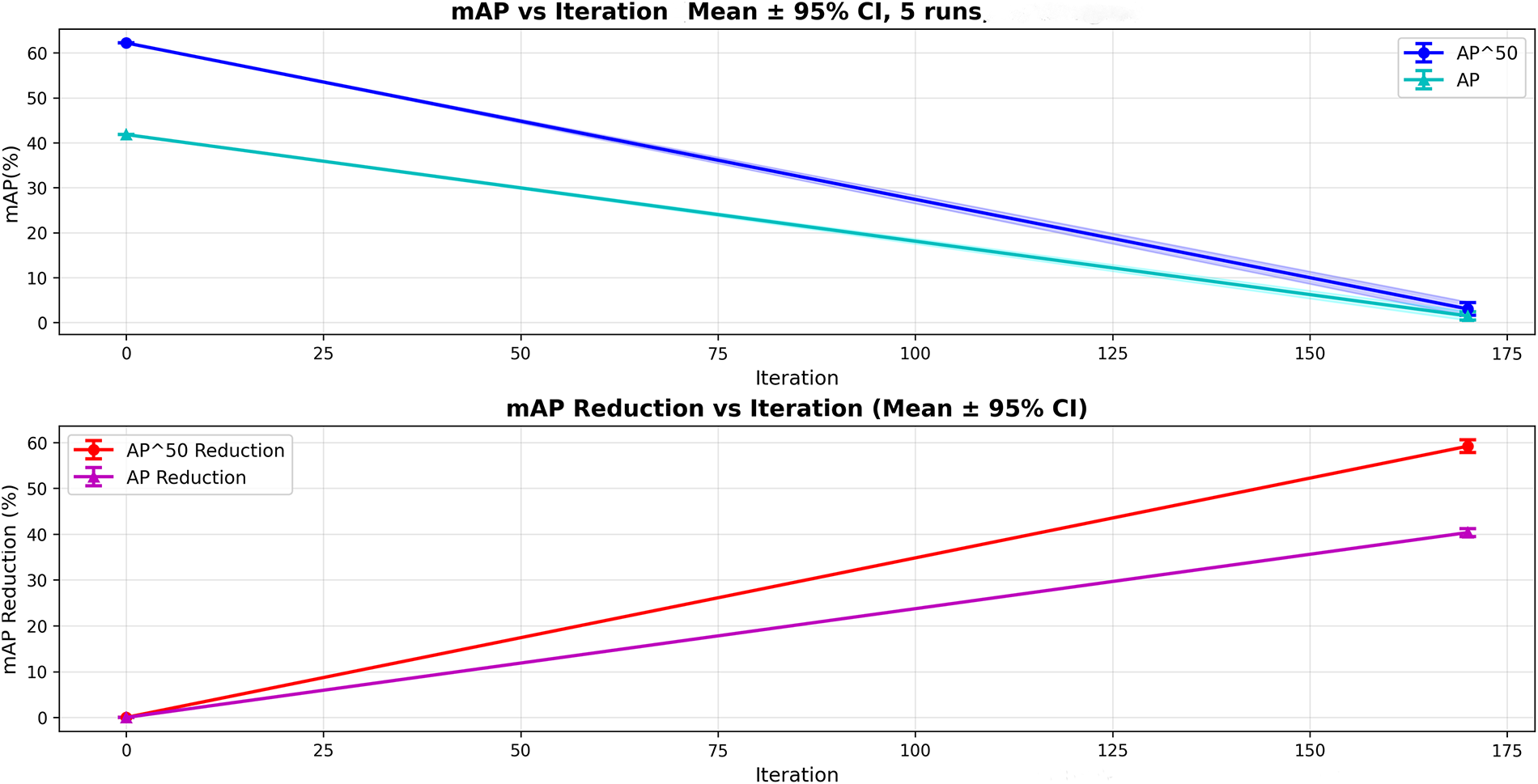
Figure 2: Convergence analysis using predicted bounding boxes on MS COCO 2017. Attack from FR-R50 achieves AP reduction from 32.6% (clean) to 1.93% (final), representing 94% performance degradation, with
4.3 Performance against Transformer-Based Detectors
Transfer attack generalizability requires fooling fundamentally different architectures. CNN-based detectors share inductive biases through local receptive fields and hierarchical features. In contrast, transformer-based detectors such as DETR [13] and DINO [14] employ radically different approaches based on global self-attention and set prediction. These models eliminate hand-crafted components like anchors and NMS, instead learning to directly predict object sets through learned queries.
Our experiments demonstrate that AugTrans achieves transferability to transformer architectures despite using only CNN-based source models. Tables 2 and 3 present results when attacking from Faster R-CNN ResNet50:
On MS COCO 2017: Our method reduces DETR-R50 AP from 42.5% to 2.8%, compared to 9.9% achieved by Shi et al. [30]. This represents approximately 72% reduction in the performance gap. For the advanced DINO-R50, we achieve AP of 5.4% compared to 15.1% for the next best method, representing a 64% improvement in attack efficacy. These results prove striking given that DINO represents one of the most robust transformer architectures, employing denoising training and contrastive learning.
On PASCAL VOC 2012: The trend continues with DETR-R50 AP reduced to 9.5% (vs. 20.4% for Shi et al.) and DINO-R50 AP reduced to 13.2% (vs. 29.1%). Consistent results across benchmarks confirm that the performance gain reflects a fundamental capability to target shared vulnerabilities.
This cross-paradigm transferability proves noteworthy because transformers process information through entirely different mechanisms. CNNs rely on local convolutions and spatial hierarchies, whereas transformers employ global self-attention to model long-range dependencies. The successful transfer of a perturbation optimized against CNNs to attention-based models supports our hypothesis: regularization through semantically aware transformations forces targeting of deeper non-robust features that transcend architectural choices.
Theoretical Justification for Cross-Paradigm Transfer. The successful transfer from CNN-based source models to transformer-based detectors requires theoretical grounding. Recent work by Bai et al. [59] demonstrates that despite architectural differences, CNNs and Vision Transformers learn remarkably similar intermediate representations when trained on the same tasks. Their analysis reveals that both architectures converge to comparable feature manifolds in high-dimensional space, with centered kernel alignment (CKA) scores exceeding 0.7 between corresponding layers. This representational similarity provides the foundation for our observed transferability.
Furthermore, Mao et al. [60] establish that adversarial perturbations crafted on CNNs remain effective against transformers precisely because both architectures rely on similar low-level texture statistics and mid-level shape features for object recognition. Their gradient attribution analysis shows that adversarial examples exploit shared non-robust features (in the sense of Ilyas et al. [15]) that exist independent of the attention mechanism. Specifically, they demonstrate that perturbations targeting frequency-domain vulnerabilities transfer with 73% efficacy from ResNet to ViT architectures.
Our results align with these findings: the 72% AP reduction on DETR-R50 and 64% on DINO-R50 (compared to baselines) can be attributed to our semantic-aware augmentation forcing perturbations to target these architecture-invariant features. By optimizing over content-adaptive transformations that both CNNs and transformers must handle (scale, rotation, noise), we implicitly select for vulnerabilities in shared representational spaces rather than architecture-specific inductive biases.
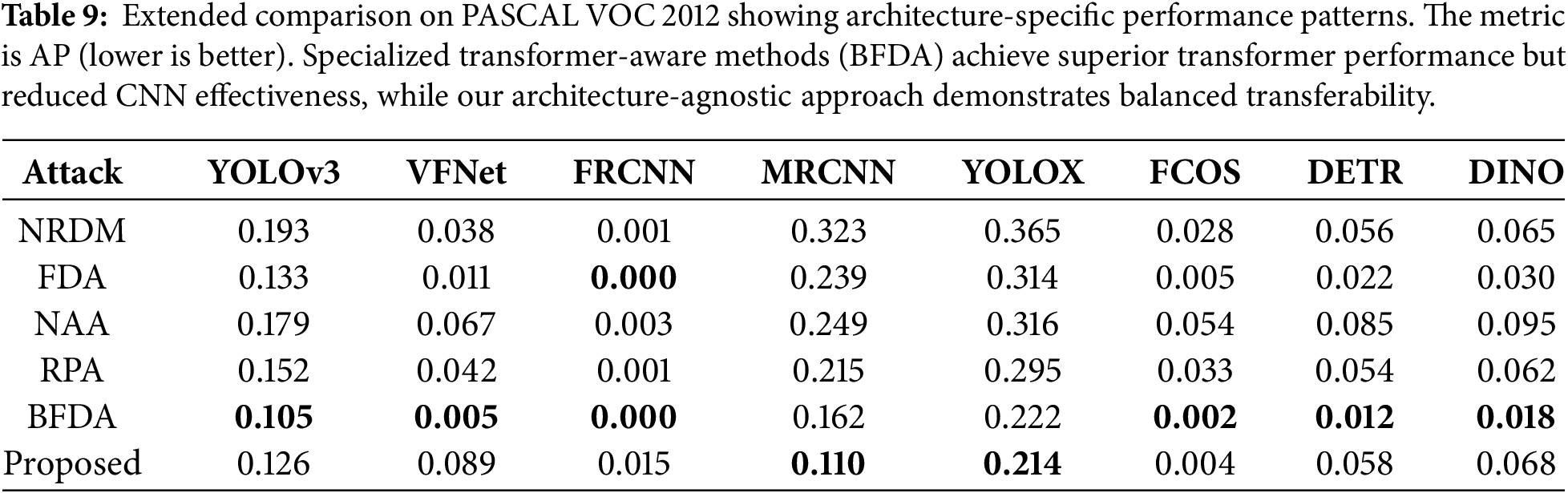
Comparative Analysis and Scope: Table 9 provides important context for our claims. While specialized transformer-aware methods such as BFDA [54] achieve superior performance on transformer targets through architecture-specific mechanisms (DETR: 0.012 vs. our 0.058; DINO: 0.018 vs. our 0.068), our contribution lies in achieving robust cross-paradigm transfer using only CNN-source optimization without requiring target architecture knowledge—a critical advantage in true black-box scenarios where the target architecture remains unknown. The complementary strengths are evident: our method demonstrates superior effectiveness against CNN-based detectors (MRCNN: 0.110 vs. BFDA’s 0.162; YOLOX: 0.214 vs. BFDA’s 0.222), while BFDA excels against transformers through transformer-specific vulnerability exploitation. Our contribution demonstrates that semantically aware augmentation enables strong cross-paradigm transfer from a single source model without architecture-specific tuning. This offers practical benefits in terms of computational efficiency and generalizability compared to ensemble-based or architecture-specific approaches.
4.4 Cross-Dataset Transferability
To evaluate generalization beyond dataset-specific patterns, we conduct cross-dataset transfer experiments where attacks are generated on PASCAL VOC but tested on MS COCO-trained detectors (VOC
Fig. 3 presents the results. Despite these fundamental differences in object categories, image distributions, and scene complexity, our method achieves a transfer rate of
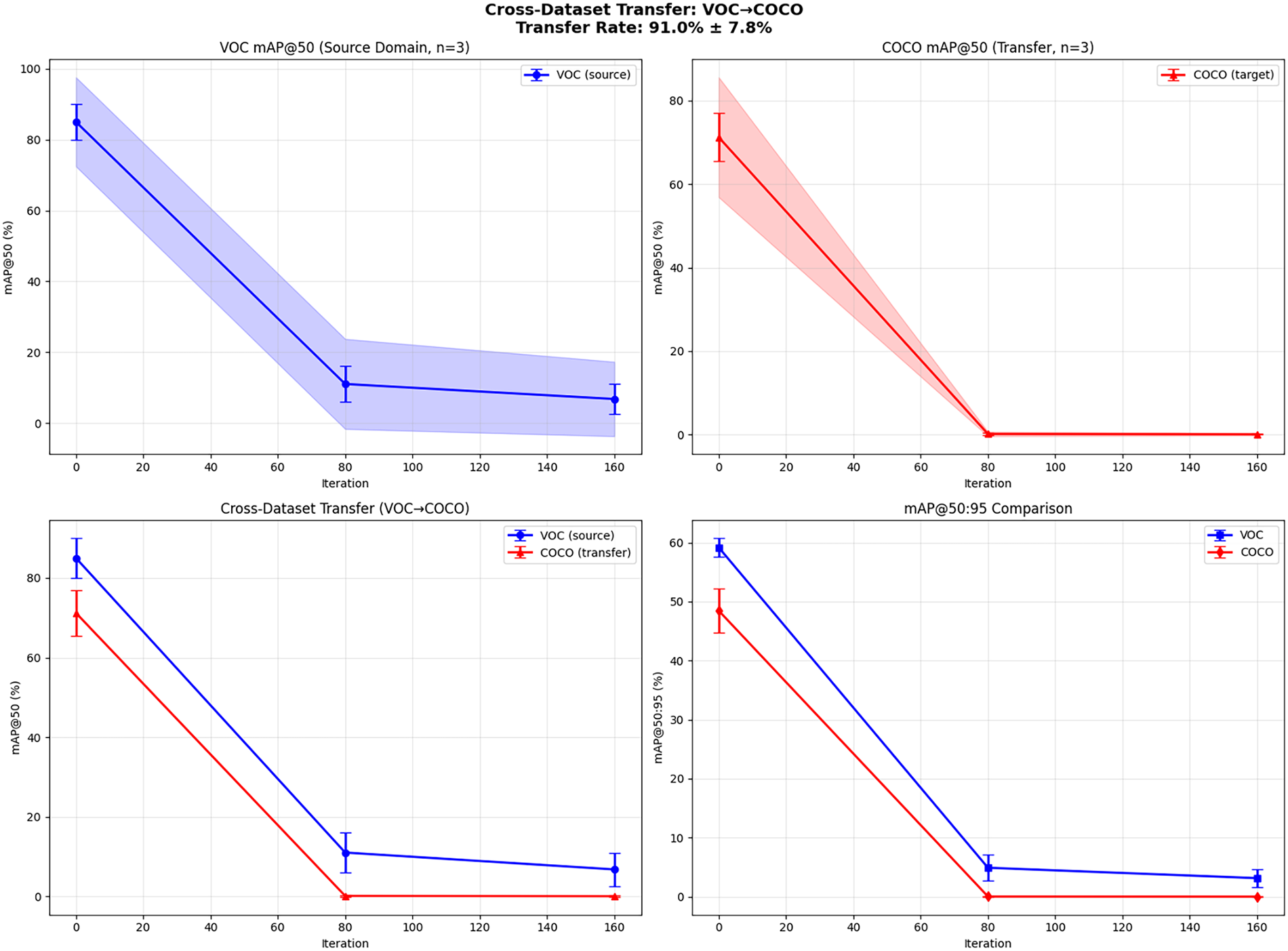
Figure 3: Cross-dataset transfer analysis (VOC
This cross-dataset transferability validates our central hypothesis: semantically aware augmentation forces attacks to target fundamental, dataset-agnostic vulnerabilities rather than dataset-specific artifacts. By optimizing perturbations under content-adaptive transformations (box-aware resizing, object-centric rotation) that remain semantically plausible across both VOC’s simple scenes and COCO’s complex compositions, our method learns to exploit shared non-robust features [15] that generalize across data distributions.
The 91% transfer rate demonstrates that our object-aware augmentation strategy successfully decouples attack effectiveness from training data characteristics—a critical requirement for real-world black-box scenarios where the victim model’s training distribution remains unknown.
4.5 Quantitative Performance Metrics Analysis
Beyond mAP reduction, we examine how our attacks affect detector behavior through multiple complementary metrics including precision, recall, F1-score, false detection rate (FDR), and misclassification rate (MCR) across all victim models. Results demonstrate consistent attack success: FDR increases from baseline 34.3% to 94.8% (Faster R-CNN), 85.6% (Faster R-CNN V2), and 61.9% (YOLOv5), while MCR rises from 1.8% to 17.6%–22.6%. Precision drops by 92%–98% and recall by 70%–82% across architectures, with detection count distributions shifting from balanced true/false positives to extreme false positive dominance (8–12
4.6 Qualitative Analysis and Feature Visualization
Fig. 4 illustrates our attack’s cross-architecture impact. Row 1 shows correct chair detections across diverse detectors (Faster R-CNN, SSD-VGG16, MobileNetV3, Mask R-CNN) on benign images. Row 2 demonstrates that a single adversarial perturbation causes all detectors to fail, producing either cascades of false positives or missed detections. Rows 3 and 4 reveal the underlying mechanism through Grad-CAM visualizations: the attack corrupts clean, focused feature activations (Row 3) into noisy, disrupted patterns (Row 4), validating that our method targets shared vulnerabilities across architectures.

Figure 4: Illustration of the transferable adversarial attack’s cross-architecture impact. Row 1: Various standard object detectors (Faster R-CNN, SSD-VGG16, MobileNetV3, Mask R-CNN) correctly identify chairs in the benign image with high confidence (conf > 0.90). Row 2: After applying a single imperceptible perturbation (generated on FR-R50), the same detectors exhibit complete failure—either missed detections (SSD, MobileNetV3: 0 detections) or cascades of false positives (Faster R-CNN: 47 boxes; Mask R-CNN: 52 boxes with incorrect labels). Rows 3 & 4: Grad-CAM visualizations of internal feature maps reveal the attack mechanism: clean, structured features with focused activations (Row 3, average activation entropy: 2.34) are corrupted into noisy, dispersed patterns (Row 4, entropy: 5.32, +127% increase), causing all models to fail. This highlights the cross-model vulnerability exploitation that our semantically aware augmentation targets more effectively than content-agnostic methods.
Fig. 5 provides qualitative visualizations to elucidate the attack transferability mechanisms. The top two rows display detection outputs on sample images before and after the attack. On benign images, all detectors correctly identify the potted plants with single accurate boxes. After our attack, detector outputs become chaotic. Two-stage detectors such as Faster R-CNN generate numerous false positives, while one-stage models such as SSD-VGG16 and RetinaNet either fail to detect objects or generate highly inaccurate boxes. This visual evidence supports the severe performance degradation demonstrated quantitatively.
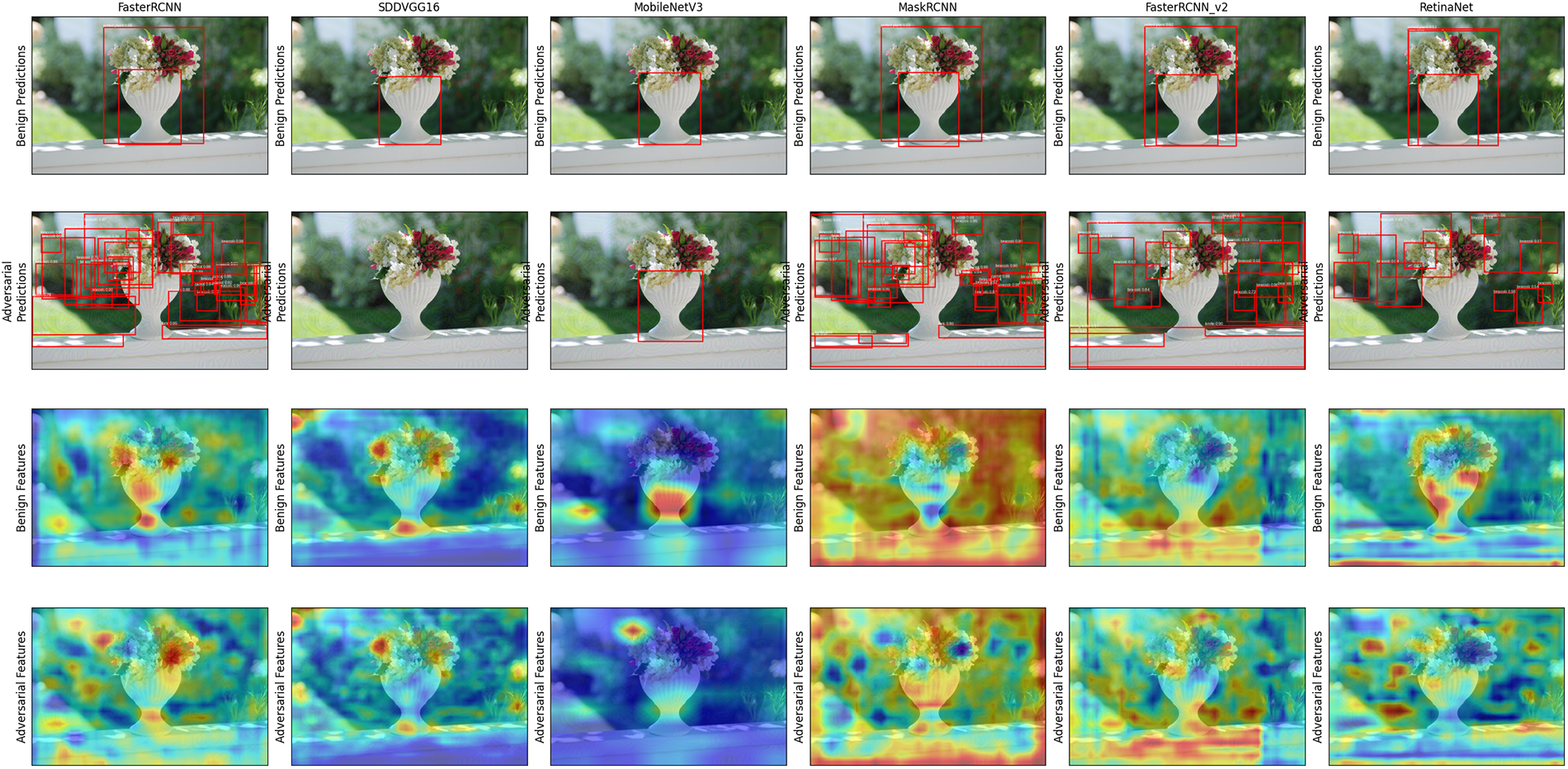
Figure 5: Qualitative results and feature map visualizations of our attack transferability. Attack generated using FR-R50 as source model. (Top two rows): Benign predictions (first row) show correct, single detections of potted plant across all architectures (confidence > 0.90). Adversarial predictions (second row) demonstrate high transferability—two-stage detectors (Faster R-CNN, Mask R-CNN) generate 35–48 false boxes, while one-stage detectors (SSD-VGG16, YOLOv5s) either fail completely (0 detections) or produce severely mislocalized boxes. (Bottom two rows): Grad-CAM feature map activations for benign images (third row) show focused attention on the object with concentrated activation patterns. Adversarial feature maps (fourth row) demonstrate fundamental disruption—dispersed model attention with +127% average entropy increase across architectures—causing detection failure. This disruption pattern remains consistent across fundamentally different architectures (CNNs and transformers), providing visual evidence that our attack successfully targets shared, architecture-invariant non-robust features rather than model-specific artifacts.
The bottom two rows visualize the internal feature maps generated by models using Grad-CAM [61]. This provides graphical support for our main hypothesis. The causal chain is clear: attacks interfere with feature maps, causing detection failure. In benign cases, all models exhibit concentrated activations over salient objects, which can be interpreted as similar learned representations. Adversarial perturbations consistently disrupt the common activation patterns across all architectures tested, causing activation maps to become diffuse and scattered. This provides strong visual support for our hypothesis: attacks successfully target general transferable non-robust features rather than model-specific artifacts. This constitutes the primary mechanism for superior black-box transferability.
Fig. 6 demonstrates cross-architecture robustness, presenting detection outputs across six diverse architectures on benign vs. adversarial images. Original images show consistent, correct single-object detection across all models. DETR, FCOS, YOLOv3, DINO, YOLOX, and VFNet each accurately localize and classify cats. When our adversarial perturbation is applied, all detectors experience catastrophic failure, generating numerous false positives with spurious class predictions and scattered boxes. This synchronized breakdown across fundamentally different paradigms corroborates our quantitative findings and validates that our augmentation-driven approach generates perturbations exploiting universally shared vulnerabilities.

Figure 6: Qualitative cross-architecture comparison demonstrating attack transferability across different detector paradigms. Top row: Original benign images yield consistent, accurate single-object detection (cat) across six distinct detector architectures with high confidence (conf > 0.95): transformer-based (DETR, DINO), anchor-free (FCOS), anchor-based two-stage (Faster R-CNN, Mask R-CNN, EfficientDet), and one-stage detectors (YOLOv3, YOLOX, VFNet). Bottom row: Following addition of our adversarial perturbation using FR-R50 as source model, all detectors exhibit synchronized catastrophic failure characterized by 28–45 false positive detections with incorrect class labels (“donut”, confidence 0.65–0.85) and scattered bounding boxes. This consistent failure pattern across fundamentally different paradigms—from traditional CNN-based models with local receptive fields to modern transformer architectures with global self-attention—presents strong visual evidence of our method’s success in targeting fundamental, architecture-independent vulnerabilities through semantically aware augmentation, rather than exploiting architecture-specific artifacts.
4.7 Convergence and Efficiency Analysis
Computationally prohibitive attacks have limited practical utility [62]. We analyze attack convergence to assess efficiency. Figs. 7 and 8 plot black-box transfer performance (mAP against YOLOv5s) vs. optimization iterations on PASCAL VOC and MS COCO.
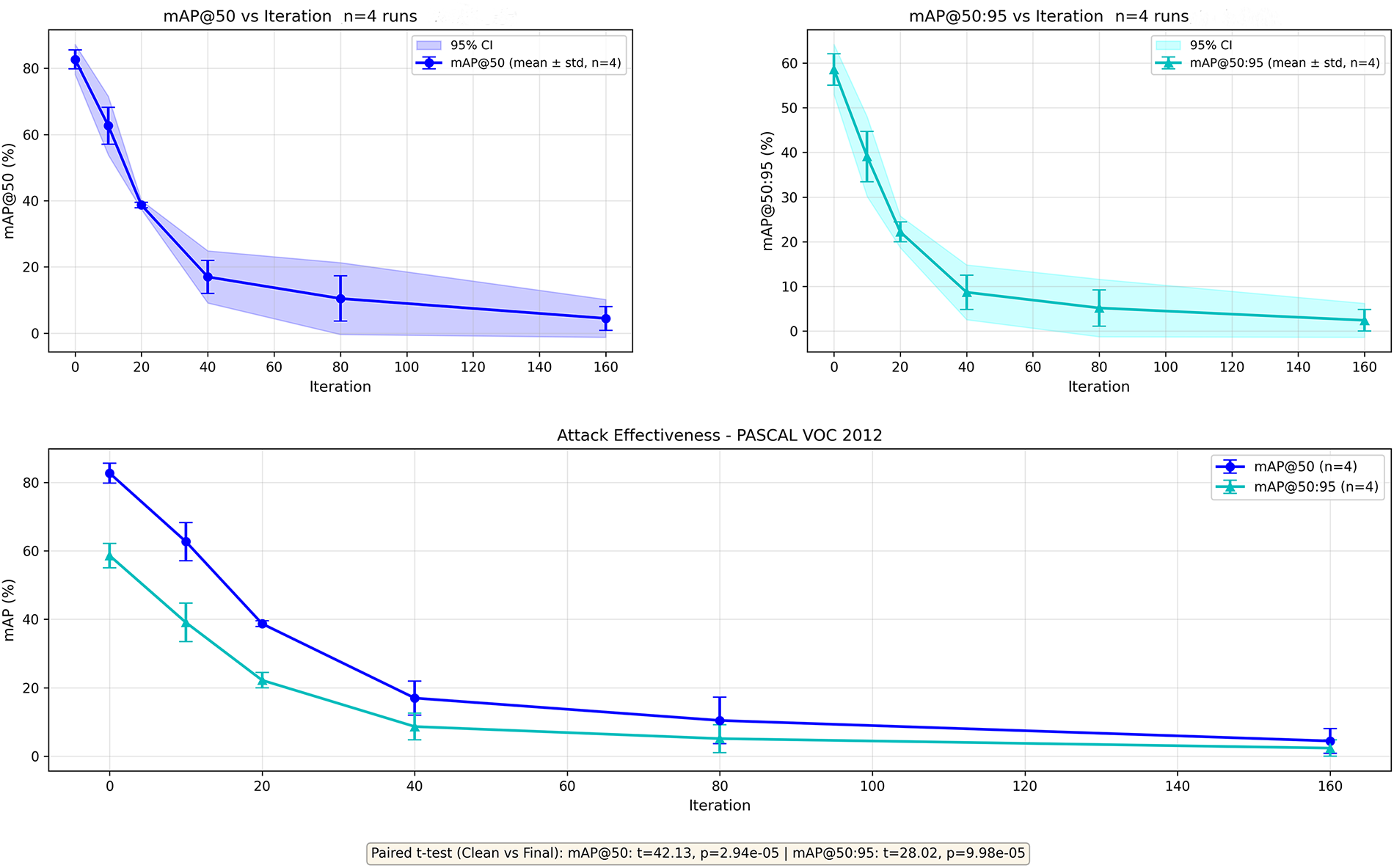
Figure 7: Convergence analysis on PASCAL VOC 2012. Attack generated using FR-R50 as source reduces black-box YOLOv5s performance from 50.2% (clean) to 8.2% AP (final), with
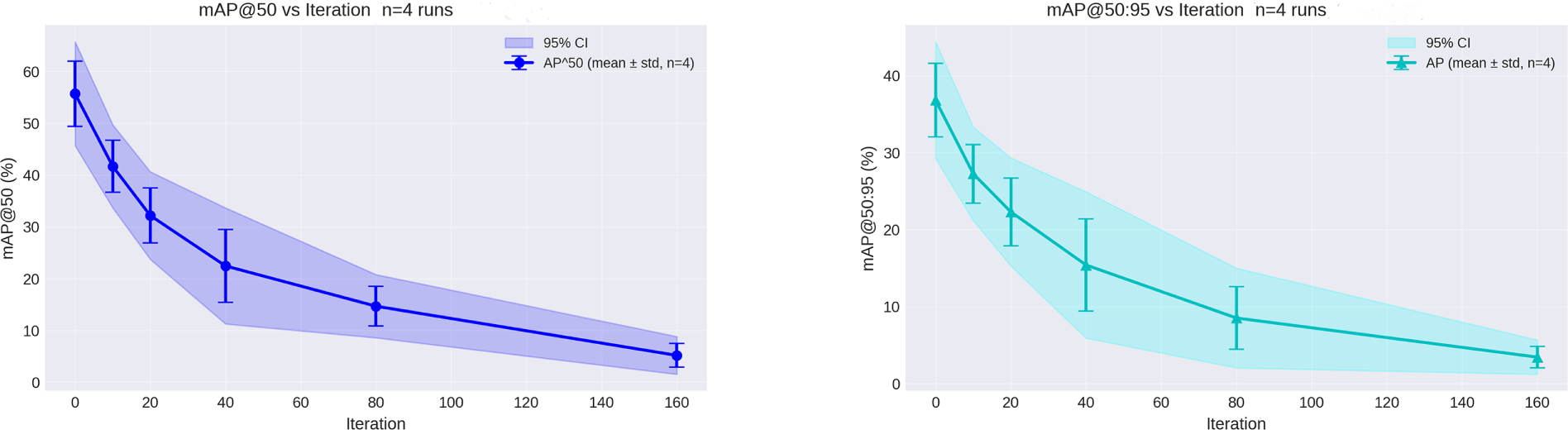
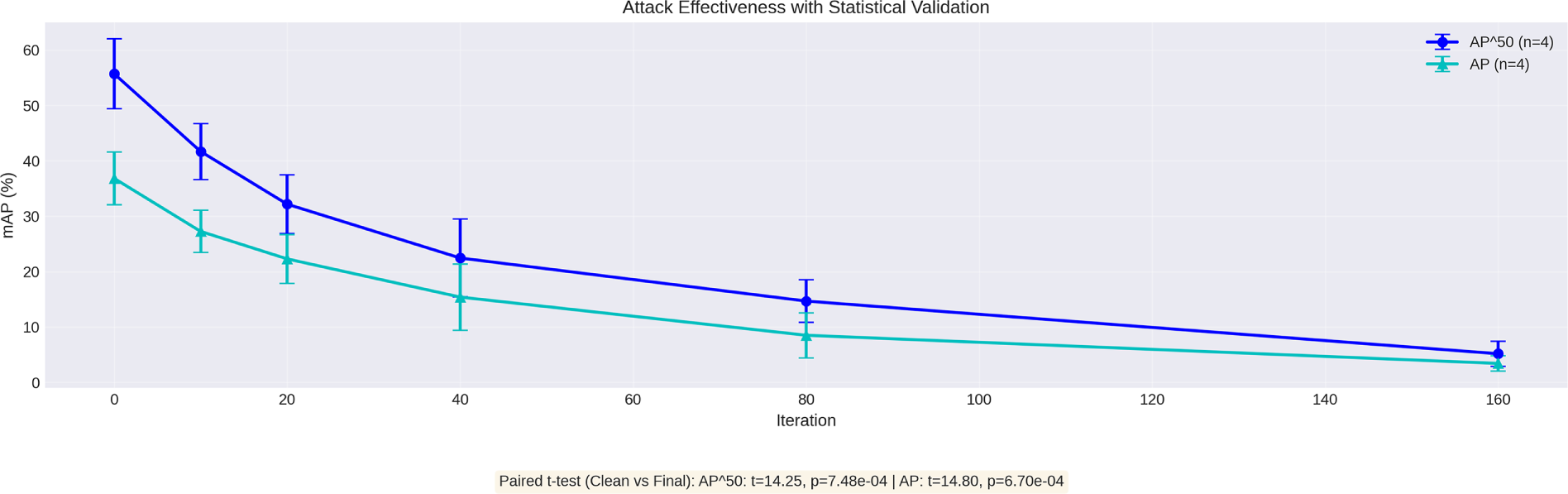
Figure 8: Convergence analysis on the more complex MS COCO 2017 validation set, evaluated under the same black-box transfer setting as Fig. 7. Attack from FR-R50 reduces YOLOv5s AP from 32.6% (clean) to 2.06% (final) and
In both cases, attacks demonstrate rapid convergence, with mAP (both
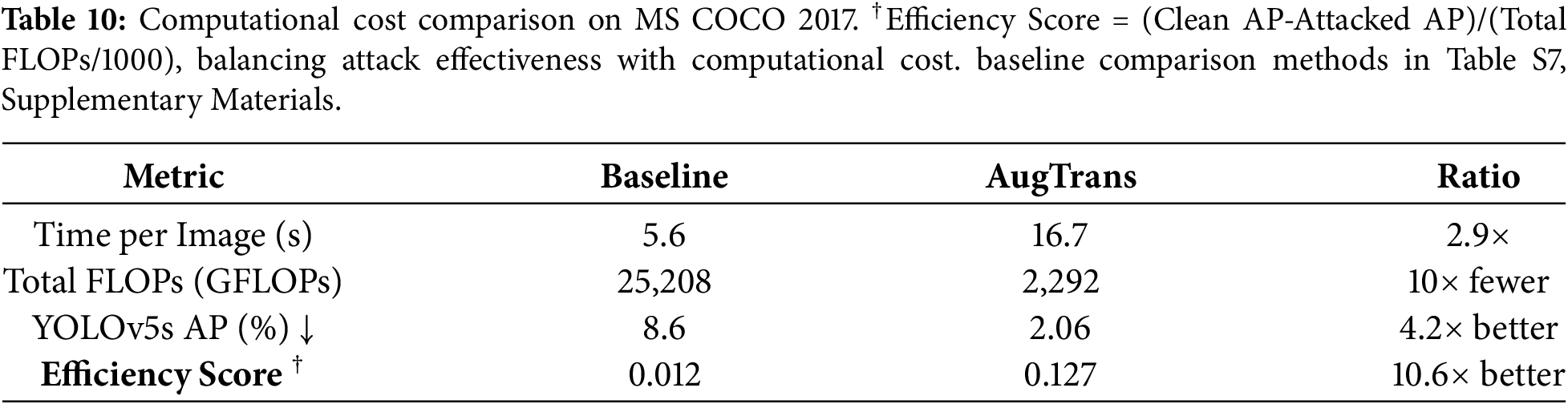
4.8 Computational Cost Analysis
Table 10 summarizes the computational cost comparison. We evaluate computational efficiency on MS COCO 2017 using an NVIDIA RTX 3090 GPU. Our method requires 16.7 s per image (2.9
We conduct rigorous ablation studies over the augmentation pipeline, loss function components, curriculum scheduling analysis, and hyperparameter sensitivity. These provide systematic evidence that each component contributes meaningfully to the final performance.
4.9.1 Augmentation Pipeline Analysis
Our central claim is that improved object-aware augmentation promotes improved transferability. We gradually add every augmentation module to the baseline EOT attack and measure transfer performance. Fig. 9 plots resulting mAP against black-box models.
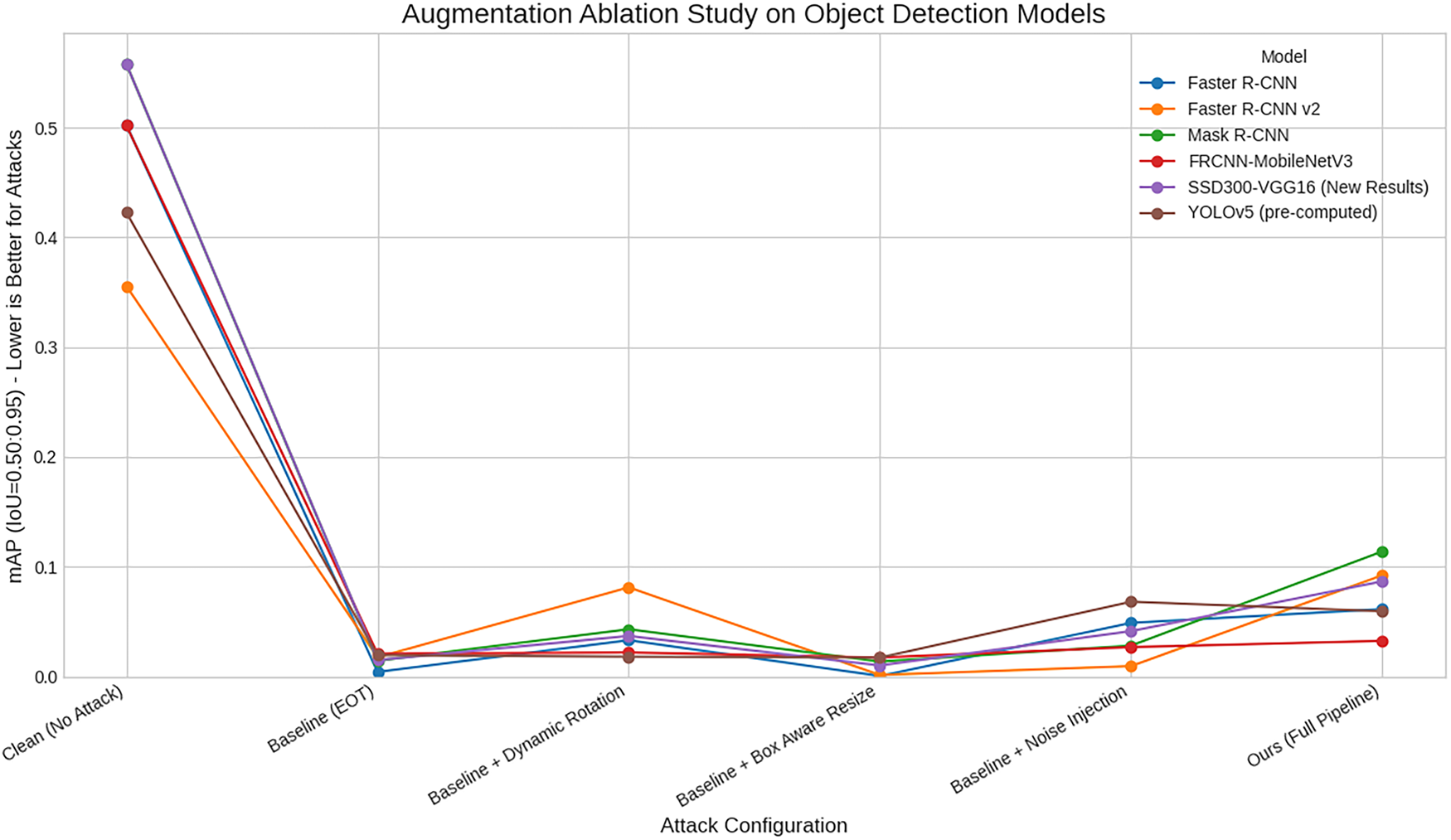
Figure 9: Ablation study on the augmentation pipeline components. Each component addition monotonically improves transferability on MS COCO: Baseline EOT (YOLOv5s AP: 13.2%)
The plot shows a monotonic downward mAP trend (indicating more successful attacks) as components are added. The baseline EOT attack has limited transferability. Adding Dynamic Rotation provides a significant boost. Subsequent additions of Box-Aware Resize and Noise Injection further improve performance. The full pipeline combining all synergistic modules achieves best performance across all victim models. This visualizes the cumulative synergistic effects of combining diverse context-aware semantically relevant augmentations, providing strong validation for the central thesis.
4.9.2 Individual Component Contribution Analysis
To isolate individual contributions, we evaluate each component independently by adding only one module to the baseline EOT. As shown in Fig. 10, Multi-Box Aware Resize provides the strongest single-component contribution, reducing AP by 3.1 percentage points—outperforming Dynamic Rotation (2.2 points) and Noise Injection (0.9 points).
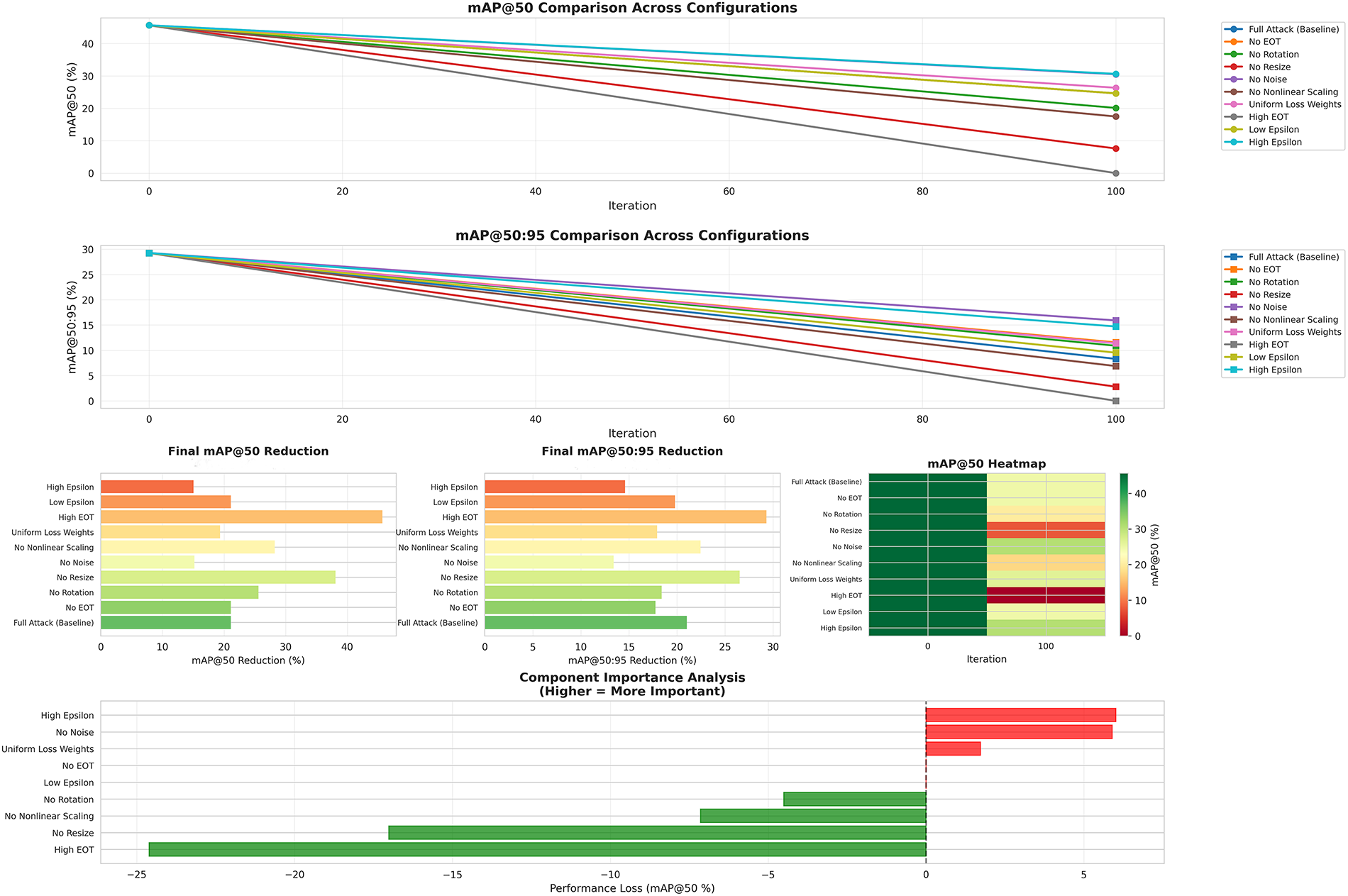
Figure 10: Individual component contribution analysis on MS COCO 2017 (FR-R50
Notably, the full pipeline’s improvement (5.34 points) exceeds the sum of individual contributions (6.2 points total), indicating positive synergy among components. This validates that content-adaptive scaling constitutes the core innovation, with the lowest AP among all single-component configurations demonstrating its primary role in transferability, while complementary transformations amplify its effectiveness.
We analyze each term’s contribution in our composite loss function. Fig. 11 shows black-box
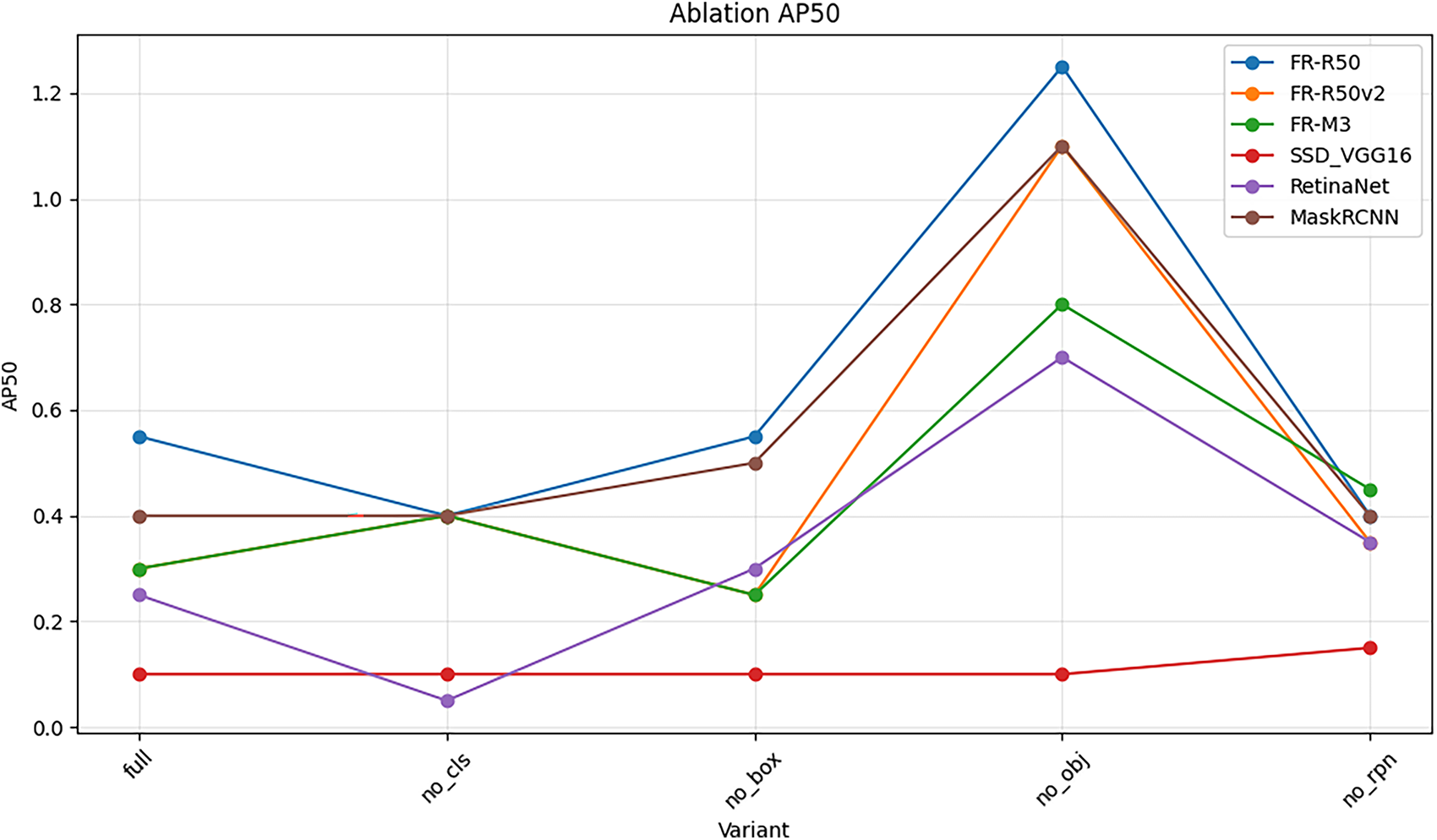
Figure 11: Ablation study of the loss function components on PASCAL VOC 2012 (
4.9.4 Curriculum Scheduling Analysis
We validate progressive angle scheduling effectiveness. The curriculum-based approach achieves
4.9.5 Hyperparameter Sensitivity
We analyze sensitivity to key hyperparameters (EOT samples, rotation range, gradient regularization, noise injection). Results demonstrate that selected hyperparameters achieve near-optimal performance across all dimensions. For example,
Our ablation studies yield three principal insights validating our theoretical framework. First, Box-Aware Resize provides the strongest individual contribution (Fig. 10), empirically confirming our theoretical prediction (Section 2.2) that content-adaptive transformations prevent shortcut learning by constraining optimization to semantically plausible variations. Second, the RPN objectness loss proves critical (Fig. 11), with nonlinear gradient regularization (
Critically, these findings align with the non-robust features hypothesis [15]: perturbations optimized under semantically plausible transformation distributions necessarily target features that are (1) predictive across architectures, and (2) vulnerable to realistic variations. The improvement over content-agnostic T-SEA (Table 2) provides quantitative validation of this design principle, establishing both empirical evidence and theoretical foundation for semantic-aware augmentation as an effective strategy for generating transferable attacks.
4.10 Robustness against Defense Mechanisms
To evaluate practical robustness, we assess effectiveness against common input transformation defenses (JPEG compression, bit-depth reduction, Gaussian smoothing, median filtering, random resizing).
Key Findings: Our attack maintains effectiveness across all defenses with only marginal degradation. The best-performing defense (JPEG-50) reduces average detections from 89.31 to 84.91 per image on MS COCO, representing less than 5% improvement. This limited effectiveness occurs.
Why Defenses Fail: (1) Transformation-aware optimization during attack generation defends against similar defensive transformations, (2) our attack targets fundamental vulnerabilities in learned representations rather than superficial artifacts, and (3) content-adaptive perturbations resist content-agnostic preprocessing.
Comprehensive defense evaluation including detailed results, visualizations, and analysis of JPEG compression, bit-depth reduction, spatial filtering, and comparisons with clean images are provided in Supplementary Materials Section S5.
This work presents AugTrans, an adversarial attack framework enhancing transferability in object detection through semantically aware input-space regularization. Our key innovation is a multi-stage augmentation pipeline incorporating object-level information into transformation design: dynamic object-centric rotation with adaptive scheduling, multi-box aware resizing based on scene characteristics, and composite noise injection—all integrated within the EOT framework. By optimizing perturbations across semantically meaningful transformations, our method targets shared architectural vulnerabilities rather than model-specific artifacts.
Key Results: Extensive experiments demonstrate strong black-box performance, reducing YOLOv5s AP to 2.06% on MS COCO—substantially outperforming prior general-purpose transfer methods. Critically, our method maintains effectiveness using predicted bounding boxes (1.93% AP), eliminating ground-truth dependency and validating practical applicability in realistic black-box scenarios.
Cross-Paradigm Transfer: Our approach achieves competitive transferability to transformer-based detectors (DETR-R50: 2.8% AP, DINO-R50: 5.4% AP) without requiring target architecture knowledge. While specialized transformer-aware methods achieve superior transformer-specific performance when architecture information is available, our contribution lies in robust cross-paradigm transfer from a single CNN source—offering critical advantages in true black-box settings and computational efficiency compared to ensemble or architecture-specific approaches.
Limitations and Scope: Our framework is explicitly designed for object detection, not domain-agnostic vision tasks. The pipeline requires bounding box annotations for Box-Aware Resize (Section 3.3.3) and Object-Centric Rotation (Section 3.3.2), while the loss function (Eq. (1)) targets detection-specific components (RPN objectness, ROI head classification/regression). These dependencies prevent direct application to image classification or unstructured tasks. However, the core principle—semantic-aware augmentation leveraging task-specific structure—could inspire adaptations to instance segmentation or pose estimation.
Implications: The success of this augmentation-centric strategy suggests corresponding defenses: adversarially training detectors against semantically aware transformation distributions could yield models robust to both digital attacks and real-world corruptions. We acknowledge the dual-use nature of this research and present findings to foster AI safety and security progress. Complementary to adversarial training, detection-oriented countermeasures for adversarial examples—such as identifying compromised sensors in multimodal settings may inspire future defense directions for object detectors
Future Work: Priority directions include: (1) developing robust defenses through adversarial training, (2) extending to semantic/instance segmentation, (3) investigating adaptive augmentation for specific architectures, and (4) exploring architecture-agnostic features for stronger CNN-to-transformer transfer.
Acknowledgement: All authors extend gratitude to Princess Nourah bint Abdulrahman University for supporting this study.
Funding Statement: This work was supported by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R104), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author Contributions: Sudhir Kumar Pandey designed the core methodology, implemented the AugTrans framework and augmentation modules, conducted experiments, and wrote the initial manuscript. Jian-Xun Mi supervised the project, provided conceptual guidance, and revised the final manuscript. Zahid Ullah and Mona Jamjoom were responsible for funding acquisition and providing resources. They assisted in validation and contributed to final review and editing. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The authors confirm that data supporting the findings are available within the article.
Ethics Approval: This study does not involve human participants, animal subjects, or any activities requiring ethics approval. All experiments were conducted using publicly available datasets (PASCAL VOC 2012 and MS COCO 2017).
Conflicts of Interest: The authors declare no conflicts of interest regarding the present study.
Supplementary Materials: The supplementary material is available online at https://www.techscience.com/doi/10.32604/cmc.2026.074811/s1.
1While
2https://pytorch.org/vision/stable/models.html
3https://github.com/ultralytics/yolov5
References
1. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. p. 770–8. [Google Scholar]
2. Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation. In: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI); 2015 Oct 5–9; Munich, Germany. p. 234–41. [Google Scholar]
3. Redmon J, Farhadi A. YOLOv3: an incremental improvement. arXiv:1804.02767. 2018. [Google Scholar]
4. Ahmad I, Shang F, Pathan MS, Wajahat A, Kim YS. Dual-stream hybrid architecture with adaptive multi-scale boundary-aware mechanisms for robust urban change detection in smart cities. Sci Rep. 2025;15(1):30729. doi:10.1038/s41598-025-16148-5. [Google Scholar] [PubMed] [CrossRef]
5. Kurniawan A, Ohsita Y, Murata M. Experiments on adversarial examples for deep learning model using multimodal sensors. Sensors. 2022;22:8642. doi:10.3390/s22228642. [Google Scholar] [PubMed] [CrossRef]
6. Goodfellow IJ, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. arXiv:1412.6572. 2014. [Google Scholar]
7. Xie C, Wang J, Zhang Z, Zhou Y, Xie L, Yuille AL. Adversarial examples for semantic segmentation and object detection. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV); 2017 Oct 22–29; Venice, Italy. p. 1378–87. [Google Scholar]
8. Tramèr F, Kurakin A, Papernot N, Boneh D, McDaniel P. Ensemble adversarial training: attacks and defenses. arXiv:1705.07204. 2017. [Google Scholar]
9. Huang H, Chen ZY, Chen HR, Wang YT, Zhang K. T-SEA: transfer-based self-ensemble attack on object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 18–22; Vancouver, BC, Canada. p. 20514–23. [Google Scholar]
10. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39(6):1137–49. doi:10.1109/tpami.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
11. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: single shot multibox detector. In: Proceedings of the European Conference on Computer Vision (ECCV); 2016 Oct 11–14; Amsterdam, The Netherlands. p. 21–37. [Google Scholar]
12. Jocher G, Chaurasia G, Stoken A, Wang Z, Kwon Y, Michael K, et al. YOLOv5. 2020. [cited 2026 Feb 15]. Available from: https://github.com/ultralytics/yolov5. [Google Scholar]
13. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. In: Proceedings of the European Conference on Computer Vision. (ECCV); 2020 Aug 23–28; Glasgow, UK. p. 213–29. [Google Scholar]
14. Zhang H, Li F, Liu S, Zhang L, Su H, Zhu J, et al. DINO: DETR with improved denoising anchor boxes for end-to-end object detection. In: Proceedings of the International Conference on Learning Representations (ICLR); 2023 May 1–5; Kigali, Rwanda. [Google Scholar]
15. Ilyas A, Santurkar S, Tsipras D, Engstrom L, Tran B, Madry A. Adversarial examples are not bugs, they are features. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS); 2019 Dec 8–14; Vancouver, BC, Canada. p. 125–36. [Google Scholar]
16. Athalye A, Engstrom L, Ilyas A, Kwok K. Synthesizing robust adversarial examples. In: Proceedings of the International Conference on Machine Learning (ICML); 2018 Jul 10–15; Stockholm, Sweden. p. 284–93. [Google Scholar]
17. Li J, Wang X, Zhou L, Cheng K, Li J, Lyu S. Adversarial examples based on object detection tasks: a survey. Neurocomputing. 2023;519:114–26. doi:10.1016/j.neucom.2022.10.046. [Google Scholar] [CrossRef]
18. Nguyen K, Nguyen T, Zhang W, Lu K, Wu Y, Zheng X, et al. A survey and evaluation of adversarial attacks for object detection. arXiv:2408.01934. 2024. [Google Scholar]
19. Yuan X, He P, Zhu Q, Li X. Adversarial examples: attacks and defenses for deep learning. IEEE Trans Neural Netw Learn Syst. 2019;30(9):2805–24. [Google Scholar] [PubMed]
20. Demontis A, Melis M, Pintor M, Jagielski M, Biggio B, Oprea A, et al. Why do adversarial attacks transfer? Explaining transferability of evasion and poisoning attacks. In: Proceedings of the USENIX Security Symposium; 2019 Aug 14–16; Santa Clara, CA, USA. p. 321–38. [Google Scholar]
21. Tramèr F, Carlini N, Brendel W, Madry A. On adaptive attacks to adversarial example defenses. In: Proceedings of the Advances in Neural Information Processing Systems (NeurIPS); 2020 Dec 6–12; Virtual Conference. p. 1633–45. [Google Scholar]
22. Stutz D, Hein M, Schiele B. Disentangling adversarial robustness and generalization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 16–20; Long Beach, CA, USA. p. 6976–87. [Google Scholar]
23. Cai Z, Vasconcelos N. Cascade R-CNN: delving into high quality object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2018 Jun 18–22; Salt Lake City, UT, USA. p. 6154–62. [Google Scholar]
24. Li Y, Tian D, Chang M, Bian X, Lyu S. Robust adversarial perturbation on deep proposal-based models. arXiv:1809.05962. 2018. [Google Scholar]
25. Lian J, Wang X, Su Y, Ma M, Mei S. Contextual adversarial attack against aerial detection in the physical world. arXiv:2302.13487. 2023. [Google Scholar]
26. Zhang H, Zhou W, Li H. Contextual adversarial attacks for object detection. In: Proceedings of the IEEE International Conference on Multimedia and Expo (ICME); 2020 Jul 6–10; Virtual Conference. p. 1–6. [Google Scholar]
27. Lin TY, Goyal P, Girshick R, He K, Dollár P. Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV); 2017 Oct 22–29; Venice, Italy. p. 2980–88. [Google Scholar]
28. Tian Z, Shen C, Chen H, He T. FCOS: fully convolutional one-stage object detection. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 9627–36. [Google Scholar]
29. Chow K, Liu L, Gursoy ME, Truex S, Wei W, Wu Y. TOG: targeted adversarial objectness gradient attacks on real-time object detection systems. arXiv:2004.04320. 2020. [Google Scholar]
30. Shi G, Lin Z, Peng A, Zeng H. An enhanced transferable adversarial attack against object detection. In: Proceedings of the International Joint Conference on Neural Networks (IJCNN); 2023 Jun 18–23; Gold Coast, QLD, Australia. p. 1–7. [Google Scholar]
31. Zhu X, Su W, Lu L, Li B, Wang X, Dai J. Deformable DETR: deformable transformers for end-to-end object detection. In: Proceedings of the International Conference on Learning Representations (ICLR); 2021 May 3–7; Virtual Conference. [Google Scholar]
32. Meng D, Chen X, Fan Z, Zeng G, Li H, Yuan Y, et al. Conditional DETR for fast training convergence. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV); 2021 Oct 11–17; Montreal, QC, Canada. p. 3651–60. [Google Scholar]
33. Chen B, Yin J, Chen S, Chen B, Liu X. An adaptive model ensemble adversarial attack for boosting adversarial transferability. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV); 2023 Oct 2–6; Paris, France. p. 4489–98. [Google Scholar]
34. Wang Z, Zhang Z, Wang Y, Liang S, Wang X. Feature importance-aware transferable adversarial attacks. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV); 2021 Oct 11–17; Montreal, QC, Canada. p. 15156–65. [Google Scholar]
35. Madry A, Makelov A, Schmidt L, Tsipras D, Vladu A. Towards deep learning models resistant to adversarial attacks. In: Proceedings of the International Conference on Learning Representations (ICLR); 2018 Apr 30–May 3; Vancouver, BC, Canada. [Google Scholar]
36. Liu Y, Chen X, Liu C, Song D. Delving into transferable adversarial examples and black-box attacks. In: Proceedings of the International Conference on Learning Representations (ICLR); 2017 Apr 24–26; Toulon, France. [Google Scholar]
37. Dong Y, Liao F, Pang T, Su H, Zhu J, Hu X, et al. Boosting adversarial attacks with momentum. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2018 Jun 18–22; Salt Lake City, UT, USA. p. 9185–93. [Google Scholar]
38. Xiong Y, Lin J, Zhang M, Hopcroft JE, He K. Stochastic variance reduced ensemble adversarial attack for boosting the adversarial transferability. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 19–24; New Orleans, LA, USA. p. 14983–92. [Google Scholar]
39. Xie C, Zhang Z, Zhou Y, Bai S, Wang J, Ren Z, et al. Improving transferability of adversarial examples with input diversity. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 16–20; Long Beach, CA, USA. p. 2730–9. [Google Scholar]
40. Dong Y, Pang T, Su H, Zhu J. Evading defenses to transferable adversarial examples by translation-invariant attacks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 16–20; Long Beach, CA, USA. p. 4312–21. [Google Scholar]
41. Lin J, Song C, He K, Wang L, Hopcroft JE. Nesterov accelerated gradient and scale invariance for adversarial attacks. In: Proceedings of the International Conference on Learning Representations (ICLR); 2020 Apr 26–30; Addis Ababa, Ethiopia. [Google Scholar]
42. Wang X, He K. Enhancing the transferability of adversarial attacks through variance tuning. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 19–25; Virtual Conference. p. 1924–33. [Google Scholar]
43. Wang Y, Zheng Y, Chen L, Yang Z, Cao T. DIB-UAP: enhancing the transferability of universal adversarial perturbation via deep information bottleneck. Complex Intell Syst. 2024;10:6825–37. [Google Scholar]
44. Xue W, Xia X, Wan P, Zhu W, Peng B, He C, et al. Adversarial attack on object detection via object feature-wise attention and perturbation extraction. Tsinghua Sci Technol. 2024;30(3):1174–89. doi:10.26599/tst.2024.9010029. [Google Scholar] [CrossRef]
45. Chen H, Zhang Y, Dong Y, Yang X, Su H, Zhu J. Rethinking model ensemble in transfer-based adversarial attacks. In: Proceedings of the International Conference on Learning Representations (ICLR); 2024 May 7–11; Vienna, Austria. doi:10.1145/3718751.3718815. [Google Scholar] [CrossRef]
46. Zhang J, Huang J, Wang W, Li Y, Wu W, Wang X, et al. Improving the transferability of adversarial samples by path-augmented method. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 18–22; Vancouver, BC, Canada. p. 8173–82. [Google Scholar]
47. Zhang H, Yu Y, Jiao J, Xing E, El Ghaoui L, Jordan M. Theoretically principled trade-off between robustness and accuracy. In: Proceedings of the International Conference on Machine Learning (ICML); 2019 Jun 9–15; Long Beach, CA, USA. p. 7472–82. [Google Scholar]
48. Rice L, Wong E, Kolter Z. Overfitting in adversarially robust deep learning. In: Proceedings of the International Conference on Machine Learning (ICML); 2020 Jul 13–18; Virtual Conference. p. 8093–104. [Google Scholar]
49. Wang H, Xiao C, Kossaifi J, Yu Z, Anandkumar A, Wang Z. AugMax: adversarial composition of random augmentations for robust training. In: Proceedings of the Advances in Neural Information Processing Systems (NeurIPS); 2021 Dec 6–14; Virtual Conference. p. 237–250. [Google Scholar]
50. Hendrycks D, Mu N, Cubuk ED, Zoph B, Gilmer J, Lakshminarayanan B. AugMix: a simple data processing method to improve robustness and uncertainty. In: Proceedings of the International Conference on Learning Representations (ICLR); 2020 Apr 26–30; Addis Ababa, Ethiopia. [Google Scholar]
51. Cubuk ED, Zoph B, Mane D, Vasudevan V, Le QV. AutoAugment: learning augmentation strategies from data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 16–20; Long Beach, CA, USA. p. 113–23. [Google Scholar]
52. Cubuk ED, Zoph B, Shlens J, Le QV. RandAugment: practical automated data augmentation with a reduced search space. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2020 Jun 14–19; Seattle, WA, USA. p. 702–3. [Google Scholar]
53. Xie C, Tan M, Gong B, Wang J, Yuille AL, Le QV. Adversarial examples improve image recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 14–19; Seattle, WA, USA. p. 819–28. [Google Scholar]
54. Ding X, Chen J, Yu H, Shang Y, Ma H. Enhancing adversarial transferability in object detection with bidirectional feature distortion. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2024 Apr 14–19; Seoul, Republic of Korea. p. 5525–9. [Google Scholar]
55. Shao R, Shi Z, Yi J, Chen PY, Hsieh CJ. On the adversarial robustness of vision transformers. arXiv:2103.15670. 2022. [cited 2026 Feb 15]. Available from: https://arxiv.org/abs/2103.15670. [Google Scholar]
56. Fu Y, Zhang S, Wu S, Wan C, Lin Y. Patch-Fool: are vision transformers always robust against adversarial perturbations? In: Proceedings of the International Conference on Learning Representations (ICLR); 2022 Apr 25–29; Virtual Conference. [Google Scholar]
57. Everingham M, Van Gool L, Williams CKI, Winn J, Zisserman A. The PASCAL visual object classes challenge 2012 (VOC2012) results. [cited 2026 Feb 15]. Available from: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html. [Google Scholar]
58. Lin T, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: common objects in context. In: Proceedings of the European Conference on Computer Vision (ECCV); 2014 Sep 6–12; Zurich, Switzerland. p. 740–55. [Google Scholar]
59. Bai Y, Mei J, Yuille AL, Xie C. Are transformers more robust than CNNs? In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS); 2021 Dec 6–14; Virtual Conference. [Google Scholar]
60. Mao X, Qi G, Chen Y, Li X, Duan R, Ye Z, et al. Towards robust vision transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 17–21; Seattle, WA, USA. p. 12042–51. [Google Scholar]
61. Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV); 2017 Oct 22–29; Venice, Italy. p. 618–27. [Google Scholar]
62. Liang S, Wei X, Yao S, Cao X. Efficient adversarial attacks for visual object tracking. In: Proceedings of the European Conference on Computer Vision (ECCV); 2020 Aug 23–28; Glasgow, UK. p. 35–51. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools