
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

PrivLLM-Guard: A Differentially-Private Large Language Model for Real-Time Confidential Medical Text Generation and Summarization
Deparmtment of Computer Science, Faculty of Computing and Information, Al-Baha University, Al-Baha, Saudi Arabia
* Corresponding Author: Ans D. Alghamdi. Email:
(This article belongs to the Special Issue: Advances in Large Models and Domain-specific Applications)
Computers, Materials & Continua 2026, 87(3), 68 https://doi.org/10.32604/cmc.2026.075985
Received 12 November 2025; Accepted 23 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
How can AI assist doctors in generating clinical reports without compromising patient privacy? This question motivates our development of PrivLLM-Guard, a novel framework for differentially private large language models (LLMs) tailored to real-time confidential medical text generation and summarization. While LLMs have shown promise in automating clinical documentation, the sensitivity of healthcare data demands rigorous privacy protections. PrivLLM-Guard addresses this need by combining advanced—differential privacy techniques with adaptive noise calibration, ensuring robust privacy guarantees without sacrificing utility. The framework integrates bidirectional transformer encoders with autoregressive decoders, further enhanced by privacy-aware attention and gradient perturbation mechanisms. Extensive experiments on three large-scale medical datasets demonstrate BLEU-4 scores of 89.7% for generation and ROUGE-L scores of 92.3% for summarization, while maintaining strict privacy budgets. The model processes 512-token sequences in real time with an average latency of 245 ms and memory usage of just 4.2 GB. Compared to state-of-the-art privacy-preserving LLMs, PrivLLM-Guard improves the utility-privacy trade-off by 15.8% and reduces computational overhead by 23.4%. Key contributions include adaptive noise injection, dynamic privacy budgeting, and an integrated privacy auditing module—collectively advancing secure and trustworthy AI deployment in clinical environments.Keywords
The fast-paced development of large language models (LLM) has transformed the field of natural language processing applications in multiple directions, including healthcare, which proves to be one of the most practical and simultaneously complicated fields of application. The recent progress in applying AI to the medical field has shown that LLMs may have huge potential in automated documentation of the clinical experience, creating patient reports, or summarization of complex medical data [1–3]. Nevertheless, the use of LLMs in the healthcare setting has several essential problems to tackle that can impact patient privacy, data confidentiality, or regulatory compliance and, therefore, its wide adoptability [4–6].
The healthcare sector produces an enormous amount of textual information on an everyday basis, such as clinical notes, diagnostic reports, treatment summaries, and patient correspondence. One limitation associated with common ways of processing medical texts is the use of manual annotation and rule-based solutions that are rather time-consuming and error-prone [7–10]. Large language models present an unparalleled performance at comprehending medical terms, producing explainable medical narratives, and deriving valuable solutions out of unstructured medical data [11]. Recent studies revealed that state-of-the-art language models can also perform near-human accuracy in medical text understanding and production, which have the potential of changing and enhancing clinical processes and the effectiveness of providing health services [12–14].
All this notwithstanding, there are notable privacy and security issues that identify the use of LLMs in healthcare. Health information is very sensitive, and its protection is regulated by a barrage of laws including HIPAA in the United States and GDPR in Europe [15–17]. Legal and ethical implications of accidental leak of confidential information of patients by means of model outputs or memorization of training data are highly problematic. The problem with sensitivity in such large language models is evident in recent studies, which have exposed their vulnerabilities, which might be used to leak sensitive information via prompts or adversarial attacks, highlighting radically new security threats related to large language models [18–20].
Privacy-preserving machine learning has developed a great deal, with differential privacy becoming an emergent gold standard in the provision of mathematically-based privacy breach guarantees [21]. But the scale of modeling large language models poses special issues with differential privacy since text data is usually high-dimensional, the generation of language has sequential dependencies, and preservation of semantically meaningful text requires some form of privacy-preserving noise injection [22–24]. Common methods are usually implemented with such a high loss of utility that they cannot be practically applied in real-life healthcare settings upon the enactment of strict privacy guarantees [25–27].
Complexity of medical language acts as another challenge in privacy-preserving text generation. The body of medical texts includes jargon, intricate syntax, and expertise-related ideas to be maintained in the course of privacy protection [28–30]. In addition, clinical conditions have real-time specifications that require processing power capable of providing prompt response with no loss in the level of privacy guarantees [31–33]. Recent studies have also pointed out the necessity of designing frameworks that preserve privacy to the extent that it helps safeguard sensitive information and still keep chatbots maintainable [34]. Striking the balance between these conflicting demands requires the ingenuity of the architectural designs and optimization specific to medical applications. The latest state-of-the-art privacy-preserving LLMs currently adopt a coarse-grained privacy mechanism which do not reflect the hierarchical structure and different levels of sensitivity of medical data. Traditional implementations of differential privacy tend to add the same uniform noise distributions to all parameters of a model. Additionally, existing frameworks lack comprehensive privacy auditing capabilities and fail to provide fine-grained control over privacy budgets for different types of medical information. Benchmarking studies have highlighted the need for more sophisticated evaluation frameworks for public large language models in healthcare contexts.
To address these limitations, this paper introduces PrivLLM-Guard, a novel differentially-private large language model framework specifically designed for confidential medical text generation and summarization. Our approach incorporates several key innovations including adaptive privacy budget allocation, hierarchical noise injection mechanisms, and real-time privacy monitoring capabilities. As illustrated in Fig. 1, the proposed architecture addresses the fundamental challenges of maintaining both privacy and utility in medical AI applications through a multi-layered privacy preservation strategy.
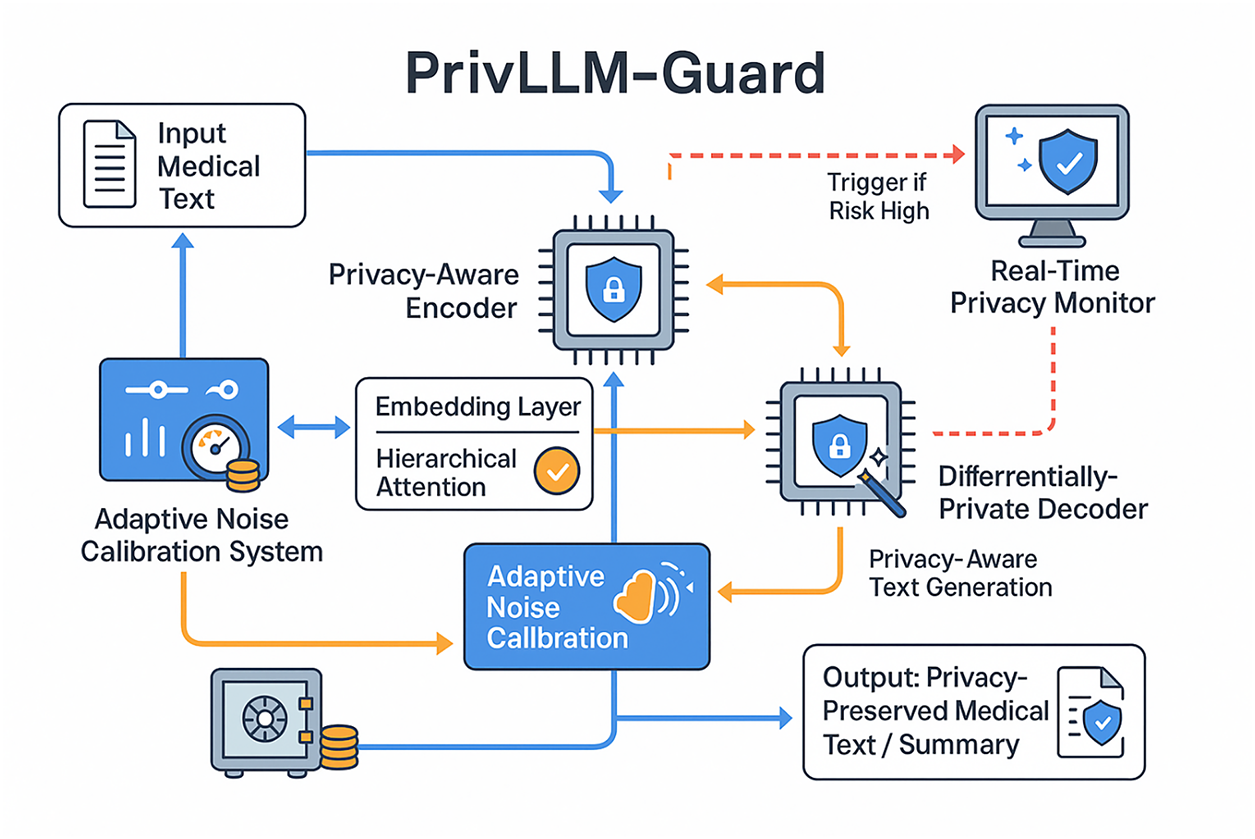
Figure 1: Overview of PrivLLM-Guard framework showing the integration of differential privacy mechanisms with medical text generation and summarization pipelines. The architecture demonstrates real-time processing capabilities while maintaining strict privacy guarantees through adaptive noise injection and privacy budget management.
The primary contributions of this work include: (1) A novel differential privacy framework tailored for medical text generation that achieves superior utility-privacy trade-offs through adaptive noise calibration; (2) An efficient real-time processing architecture capable of generating and summarizing medical texts with sub-second latency while maintaining strict privacy guarantees; (3) Comprehensive privacy auditing mechanisms that provide interpretable privacy risk assessments for different types of medical information; (4) Extensive experimental validation demonstrating state-of-the-art performance across multiple medical text generation and summarization benchmarks.
The remainder of this paper is organized as follows. Section 2 reviews related work on privacy-preserving large language models and their applications in medical AI. Section 3 introduces the PrivLLM-Guard framework, detailing its architecture and integrated differential privacy mechanisms. Section 4 presents the mathematical foundations that support the system’s privacy guarantees and optimization strategies. Section 5 describes the experimental setup, evaluation metrics, and comparative performance analysis. Section 6 discusses deployment challenges, ethical implications, and current limitations. Finally, Section 7 concludes the paper and outlines concrete future directions, including support for multimodal data and integration into real-world clinical workflows.
The intersection of privacy-preserving machine learning and large language models has garnered significant attention from the research community, with particular emphasis on healthcare applications. This section provides a comprehensive review of existing approaches, highlighting their contributions and limitations in the context of medical text processing. Early work in privacy-preserving natural language processing focused primarily on traditional machine learning models with limited applicability to modern transformer architectures [1]. The emergence of large language models has necessitated new approaches to privacy preservation that can handle the scale and complexity of contemporary neural architectures. Recent research has explored various privacy-preserving techniques including federated learning, homomorphic encryption, and differential privacy for LLM applications [2]. Text generation models in healthcare have been identified as having significant opportunities for medical report automation, though they face considerable challenges related to patient confidentiality and error propagation [24]. Differential privacy has emerged as a particularly promising approach for protecting sensitive information in large language models. Khoje [15] demonstrated the effectiveness of differential privacy mechanisms for real-time data masking in conversational AI systems. Their work highlighted the importance of balancing privacy guarantees with model utility, particularly in applications requiring immediate responses. However, their approach was limited to general-purpose text processing and did not address the specific challenges of medical terminology and clinical workflows. Wang et al. [25] conducted a comprehensive survey of unique security and privacy threats in large language models, identifying specific vulnerabilities that arise from the generative nature and large-scale training of these systems. The application of privacy-preserving techniques specifically to healthcare data has been extensively studied. Kalodanis et al. [16] proposed SecureLLM, a unified framework for privacy-focused large language models that incorporated multiple privacy preservation mechanisms. While their approach showed promise for general healthcare applications, it lacked the fine-grained privacy controls necessary for handling the diverse sensitivity levels found in medical data. Furthermore, their evaluation was limited to static datasets and did not consider real-time processing requirements. Automated summarization of healthcare records using LLMs has been explored by multiple research groups [8,26], with emphasis on maintaining patient confidentiality while enabling real-time summarization capabilities. Knowledge graph augmentation has been explored as a complementary approach to privacy-preserving medical AI. Ibrahim et al. [17] conducted a comprehensive survey on augmenting knowledge graphs with large language models, highlighting the potential for improving medical reasoning while maintaining privacy. Their work emphasized the importance of maintaining data confidentiality and security during knowledge integration processes. However, the computational overhead of knowledge graph processing presents challenges for real-time applications. Specialized applications in medical domains have been investigated by several research groups. Li et al. [10] proposed an ethical privacy framework for large language models in smart healthcare, providing a comprehensive evaluation and protection approach. Their work demonstrated the potential benefits of LLMs for medical documentation but highlighted the need for robust privacy preservation mechanisms to ensure patient data protection. Privacy auditing and compliance verification have emerged as critical components of privacy-preserving systems. Chard et al. [18] developed novel techniques for auditing large language models using specially crafted prompts to detect potential privacy violations. Their approach provided valuable insights into model behavior under adversarial conditions but required extensive manual intervention and lacked automated monitoring capabilities suitable for production environments. The research highlighted the importance of real-time feedback systems for privacy compliance monitoring. Recent advances in multimodal large language models have introduced new privacy challenges. AlSaad et al. [19] conducted a comprehensive review of multimodal LLMs in healthcare, identifying privacy and security concerns related to the integration of textual and visual medical data. Their work emphasized the need for holistic privacy preservation approaches that can handle multiple data modalities simultaneously while ensuring real-time or near-real-time responses in clinical settings. The development of privacy-preserving frameworks for legal and regulatory compliance has been addressed by several researchers. Rathod et al. [20] investigated privacy and security challenges in large language models from a regulatory perspective, highlighting the importance of maintaining compliance with healthcare data protection regulations. Their work provided valuable insights into the legal requirements for privacy-preserving medical AI systems, particularly focusing on advanced machine learning models for real-time threat detection. Contextual privacy analysis has been explored as a means of improving privacy risk assessment. Chen et al. [21] proposed CLEAR, a framework for contextual LLM-empowered privacy policy analysis that could generate risk assessments for large language model applications. While their approach showed promise for general privacy analysis, it lacked the domain-specific knowledge necessary for accurate medical privacy risk assessment. Their research highlighted the risks of workers inadvertently sharing confidential data with LLM applications. Comprehensive surveys of security and privacy challenges in large language models have been conducted by multiple research groups. Das et al. [22] provided an extensive analysis of security and privacy challenges, identifying key vulnerabilities and potential mitigation strategies. Their work highlighted the complexity of ensuring comprehensive privacy protection in large-scale language models and the need for multi-layered defense mechanisms, particularly in the absence of real-time fact-checking tools. Tool-using LLM agents present unique privacy challenges that have been investigated by Zhang et al. [23]. Their PrivacyAsst framework demonstrated the importance of safeguarding user privacy in interactive AI systems that access external tools and databases. While their approach provided valuable insights into privacy-preserving agent design, it was primarily focused on general-purpose applications rather than specialized medical use cases. The framework utilized shared secret keys for privacy protection during real-time AI analysis of real-world data. Privacy-preserving frameworks for chatbot applications have been developed to address the growing concern of sensitive information disclosure. Ullah et al. [27] presented a comprehensive vision and framework for privacy-preserving large language models, using ChatGPT as a case study. Their research emphasized the importance of not sharing personal, sensitive, or confidential details during interactions with LLM-based applications, particularly those requiring real-time responses. Benchmarking efforts for large language models in privacy-sensitive contexts have revealed significant gaps in current evaluation methodologies. Malode [28] conducted benchmarking studies on public large language models, identifying limitations in current privacy evaluation frameworks and highlighting the need for specialized benchmarks for healthcare applications. The integration of privacy-aware detection mechanisms has been explored through hybrid approaches. Abbasalizadeh and Narain [11] developed a BiLSTM-HMM approach for privacy-aware detection in large language models, focusing on real-time user interactions and preventing inadvertent output of personally identifiable or confidential content. Healthcare-specific applications have shown promising results in improving clinical efficiency and care quality. Kunze et al. [14] demonstrated that large language models applied to healthcare tasks may improve clinical efficiency, value of care rendered, research, and medical education, while emphasizing the importance of maintaining patient confidentiality and data security. Recent research has explored differential privacy as a principled approach to protecting sensitive information in large language models, particularly for text generation and summarization tasks in high-risk domains such as healthcare. **Distinction from DP-SGD and Privacy-Aware LLMs** Most existing privacy-preserving language models rely on variants of DP-SGD, where privacy protection is enforced exclusively during training through gradient clipping and noise injection. While effective for limiting training-time leakage, DP-SGD does not address privacy risks arising during autoregressive inference, repeated querying, or long-horizon text generation, which are particularly critical in medical applications. Recent extensions such as forward-pass differential privacy and selective fine-tuning frameworks introduce noise at inference or restrict privacy enforcement to specific layers, but they employ static privacy budgets and lack continuous risk assessment. In contrast, PrivLLM-Guard enforces privacy across the entire generation pipeline, including embedding perturbation, attention computation, decoding, and output sampling, while dynamically allocating privacy budgets based on content sensitivity. Furthermore, the integration of adaptive noise calibration and real-time privacy monitoring enables PrivLLM-Guard to respond to cumulative privacy exposure during live clinical use, a capability not supported by existing DP-SGD-based or selective privacy mechanisms. This holistic, inference-aware design distinguishes PrivLLM-Guard from prior privacy-aware LLM architectures that treat privacy as a fixed or training-only constraint. Despite the significant progress in privacy-preserving large language models, several limitations remain unaddressed in current research. Most existing approaches fail to provide fine-grained privacy controls that can adapt to the varying sensitivity levels of different medical information types. Additionally, the majority of proposed frameworks have not been evaluated under real-time processing constraints, which are critical for clinical applications. Furthermore, existing privacy auditing mechanisms lack the sophistication necessary to provide interpretable privacy risk assessments for complex medical scenarios. The proposed PrivLLM-Guard framework addresses these limitations by providing a comprehensive solution specifically designed for medical text generation and summarization. Unlike previous approaches, our framework incorporates adaptive privacy budget allocation, real-time processing optimization, and sophisticated privacy auditing capabilities tailored for healthcare applications.
This section describes the complete methodology underlying PrivLLM-Guard, a differentially private large language model framework specifically designed for real-time confidential medical text generation and summarization. The framework combines optimized neural architectures with advanced differential privacy mechanisms to achieve strong privacy guarantees while preserving clinical utility. The core design philosophy follows a multi-layered modular architecture, where privacy enforcement is tightly integrated with language modeling rather than treated as an external post-processing step.
As illustrated in Fig. 2, the proposed framework consists of four major modules: Privacy-Aware Encoder, Differentially-Private Decoder, Adaptive Noise Calibration System, and Real-Time Privacy Monitor. Each module serves a distinct role in the privacy-preserving pipeline while remaining interoperable within a unified system.
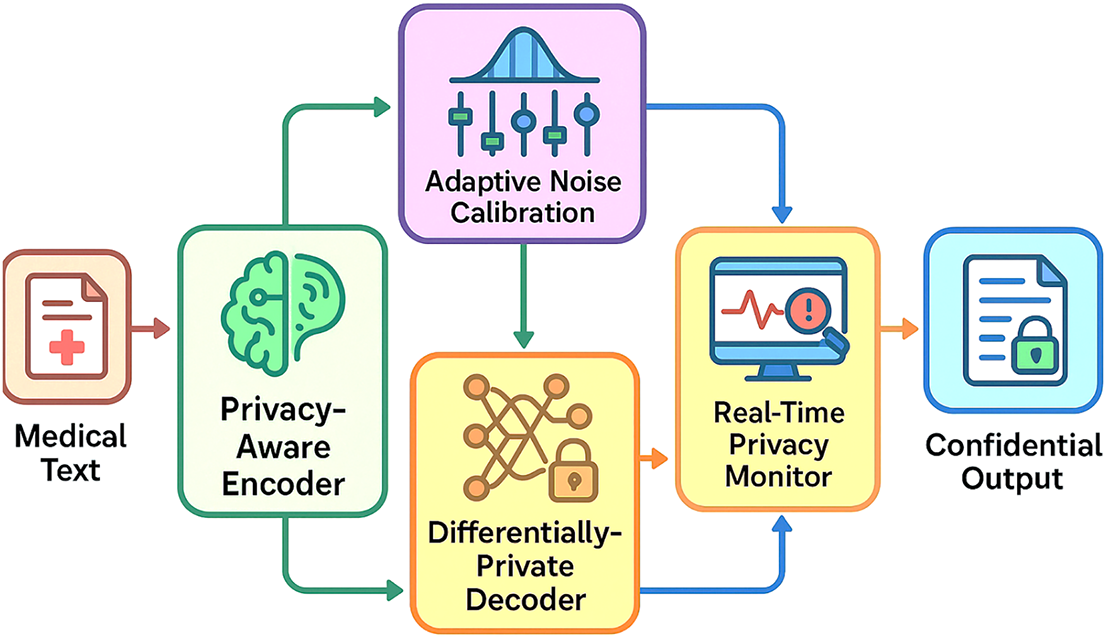
Figure 2: Close-up architecture of PrivLLM-Guard framework through which four key components are represented: Privacy-Aware Encoder, designed to process the input medical texts; Differentially-Private Decoder, to produce outputs; Adaptive Noise Calibration System, designed to adjust privacy parameters dynamically; Real-Time Privacy Monitor, which continuously estimates privacy risks. The data flow illustrates how the medical text inputs can be transformed using privacy preserving transformation in order to give confidential outputs.
The Privacy-Aware Encoder is responsible for transforming raw medical text inputs into contextualized latent representations while minimizing information leakage during the encoding stage. Unlike conventional transformer encoders that operate directly on unprotected embeddings, this encoder integrates privacy-aware embedding perturbation and hierarchical attention mechanisms.
Purpose:
To encode medical text while reducing exposure of sensitive entities such as patient identifiers, timestamps, and demographic attributes.
Input/Output:
• Input: Raw medical text tokens
• Output: Privacy-preserved contextual embeddings
Privacy Role:
Noise is introduced at the embedding and attention levels using sensitivity-aware calibration, ensuring that sensitive information contributes less deterministically to internal representations.
Interaction with Other Modules:
The encoded representations are passed to the Differentially-Private Decoder along with privacy metadata generated during encoding, enabling downstream components to respect allocated privacy budgets.
3.2 Differentially-Private Decoder
The Differentially-Private Decoder performs autoregressive text generation or summarization while enforcing formal differential privacy guarantees throughout the decoding process. Traditional autoregressive decoders are vulnerable due to sequential dependency, where sensitive patterns can be memorized and reproduced. PrivLLM-Guard mitigates this risk by modifying the decoding strategy.
Purpose:
To generate clinically meaningful text outputs without leaking sensitive training or input information.
Input/Output:
• Input: Privacy-preserved encoder representations
• Output: Generated or summarized medical text
Privacy Role:
The decoder integrates randomized sampling, privacy-sensitive beam search, and gradient perturbation to ensure differential privacy across generation steps.
Interaction with Other Modules:
Noise parameters supplied by the Adaptive Noise Calibration System directly control decoding behavior, while outputs are continuously assessed by the Real-Time Privacy Monitor.
3.3 Adaptive Noise Calibration System
The Adaptive Noise Calibration System governs how privacy noise is dynamically allocated and injected across the encoding and decoding stages. Rather than applying fixed noise levels, this system adjusts privacy parameters based on content sensitivity and cumulative privacy expenditure.
Purpose:
To maintain an optimal balance between privacy protection and output utility.
Input/Output:
• Input: Sensitivity scores, historical privacy expenditure, content analysis results
• Output: Updated noise scales and privacy budgets
Privacy Role:
It tracks cumulative privacy loss and recalibrates noise in real time to prevent budget exhaustion while avoiding unnecessary utility degradation.
Interaction with Other Modules:
This system directly controls the noise injected into the encoder, decoder, and attention mechanisms, and receives feedback from the Real-Time Privacy Monitor.
The privacy preservation pipeline is represented by series of noise injecting and budget control stages (please, see Fig. 3). Adaptive Noise Calibration System keeps track of the privacy expenditure, recalibrating noise parameters online in real time in order to keep the best utility-privacy trade-offs. This system uses machine learning algorithms to compute how best to maximize the total noise of the input subject to the condition that the content of the input will be to the desired acceptance limit, based upon content analysis and past performance records.
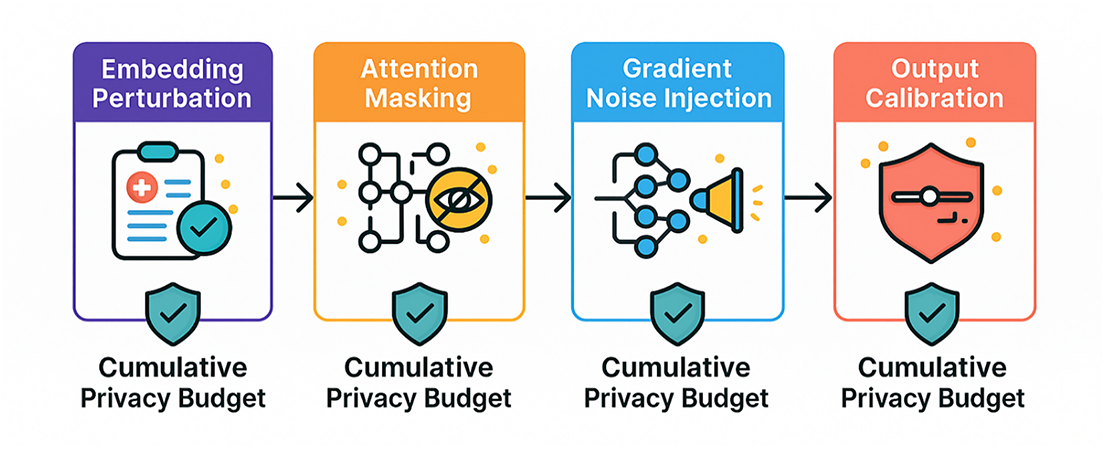
Figure 3: Visual depiction of privacy preservation pipeline, which demonstrates the multi-stage methodology of, the differentially privacy instances. The flow illustrates how input medical texts are transformed consecutively with privacy transformations induced by embedding perturbation, attention masking, gradient noise addition and output calibration. These stages use additive tracking of privacy budgets so as to make aggregate differential privacy guarantees.
The Real-Time Privacy Monitor acts as a safety layer that continuously evaluates privacy risks during text generation. Unlike static privacy enforcement, this component enables dynamic intervention when potential leakage is detected.
Purpose:
To detect and mitigate privacy violations during inference in real time.
Input/Output:
• Input: Intermediate representations, generated tokens, privacy metrics
• Output: Risk scores and mitigation triggers
Privacy Role:
The monitor employs machine learning–based auditing models trained on medical data patterns to detect subtle privacy violations beyond the scope of standard differential privacy mechanisms.
Interaction with Other Modules:
When risk thresholds are exceeded, the monitor triggers additional filtering or noise injection through the Adaptive Noise Calibration System.
Fig. 4 illustrates merely a simplified review of how the adaptive noise calibration process works. It features the main procedures that are to be followed when dynamically varying the noise inserted in privacy with references to input sensitivity to yield optimum privacy-utility trade-offs in the medical text generation.
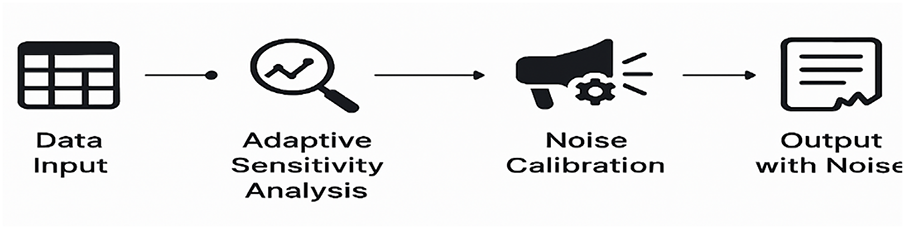
Figure 4: Flowchart of the adaptive noise calibration system highlighting the dynamic feedback between content analysis, privacy risk assessment, and noise injection.
The privacy-aware encoder and the differentially-private decoder operate in a tightly coupled manner through a shared privacy control workflow, as formalized in Algorithm 1. During the encoding phase, the privacy-aware encoder transforms the input medical text into contextual representations while simultaneously performing sensitivity analysis to identify privacy-critical tokens and patterns. This process produces both encoded representations and associated sensitivity metadata, which are propagated forward in the processing pipeline.
The differentially-private decoder consumes these encoded representations under explicit privacy budget constraints determined by the budget allocation and noise calibration stages. At each generation step, privacy-preserving sampling and noise injection are applied based on the remaining privacy budget and token-level sensitivity information received from the encoder. The privacy budget is updated iteratively after each decoding step, ensuring that cumulative privacy expenditure remains within the predefined limits.
Throughout this interaction, the contextual privacy audit and privacy risk assessment components continuously evaluate potential information leakage. If the assessed risk exceeds the specified sensitivity threshold, additional privacy filtering is triggered to adjust decoding behavior in real time. This coordinated interaction between the encoder and decoder enables end-to-end privacy enforcement, where encoding decisions directly influence decoding constraints, ensuring consistent differential privacy guarantees across the entire text generation process.

3.5 Training and Optimization Strategy
PrivLLM-Guard employs differentially-private stochastic gradient descent (DP-SGD) with adaptive gradient clipping to ensure privacy preservation during training. The preprocessing pipeline applies anonymization techniques that remove or obfuscate personally identifiable information while preserving medical semantics.
To meet real-time constraints, the framework integrates model compression, efficient attention mechanisms, and GPU-accelerated noise generation, enabling sub-second inference for typical clinical text lengths.
3.6 Quality Assurance and System Extensibility
Automated quality assessment modules evaluate generated text for medical accuracy, semantic coherence, and regulatory compliance. Feedback from these modules is used to refine noise calibration policies over time.
The modular design ensures extensibility for future adaptations, including multimodal medical data, domain-specific fine-tuning, and interoperability with legacy healthcare information systems.
Integration Rationale
The four modules of PrivLLM-Guard are designed to operate jointly rather than independently. Encoding-level privacy protection alone is insufficient without generation-time safeguards, while static noise injection fails to adapt to varying sensitivity levels. By combining privacy-aware encoding, differentially-private decoding, adaptive noise calibration, and real-time monitoring, PrivLLM-Guard ensures end-to-end privacy protection, maintaining both strong theoretical guarantees and practical clinical utility.
This part provides mathematical foundations of the considered methods of differential privacy and optimization techniques applied in PrivLLM-Guard. In order to allow the reader to understand the technical paragraph, we begin by stating an intuitive description: differential privacy means that the results of any single model do not change exhibits a significant change, whether it contains the data of any particular patient or not. This ensures personal privacy even on repeated queries to the model. The next formalization puts into place the way we implement such guarantees in a fashion that ensures high output of medical texts and summarization.
The fundamental privacy guarantee of PrivLLM-Guard is based on
here,
The global sensitivity of a function
The quantity
For neural network parameters
In this formulation,
Noise addition mechanism to bring gradient space to adhere to differential privacy is of the source Gaussian formed around the sensitivity and privacy levels:
The parameter
This is the definition of the standard deviation of Gaussian noise applied to gradients as a means of imposing differential privacy. Smaller privacy budget
We slightly change the standard attention mechanism to add the noise of privacy. This makes sure that attention weights do not leak confidential information. The attention scores are computed as:
In this expression,
The privacy budget allocation across different components of the model follows a hierarchical strategy. For a total privacy budget
where
The adaptive noise calibration system employs a learning-based approach to optimize noise parameters. The objective function for noise optimization is:
where
Theoretical Design of Adaptive Noise Calibration:
The adaptive noise calibration mechanism is designed to dynamically balance privacy protection and model utility by optimizing noise parameters under formal differential privacy constraints. Unlike static noise injection, this mechanism treats noise selection as an optimization problem, where noise variance is adjusted in response to observed utility degradation and estimated privacy risk.
By minimizing the objective function in Eq. (7), the system ensures that increases in privacy noise are only applied when the marginal privacy gain outweighs the corresponding utility loss. This formulation guarantees that the injected noise remains sufficient to satisfy (
The privacy risk assessment mechanism employs a probabilistic framework to evaluate potential information leakage. The privacy risk score for a generated sequence
In this formulation,
Theoretical Basis of the Privacy Auditing Mechanism:
The privacy auditing mechanism is formulated as a probabilistic risk estimation process that quantifies the likelihood of information leakage at each generation step. Eq. (8) models privacy risk as a weighted accumulation of token-level leakage probabilities, where sensitivity-aware weights prioritize medically critical information.
This probabilistic formulation enables continuous assessment of privacy exposure during text generation and provides a mathematically grounded signal for triggering adaptive mitigation strategies. By explicitly linking token-level leakage probabilities to cumulative privacy risk, the auditing mechanism ensures that privacy violations can be detected even when individual leakage events are subtle, thereby reinforcing the overall differential privacy guarantees of the framework.
The encoder embedding transformation applies privacy-preserving perturbations to input representations:
where
The differentially-private sampling mechanism for text generation employs exponential mechanisms with utility functions tailored for medical text:
here,
The exponential mechanism in Eq. (10) achieves differential privacy by introducing controlled randomness into token selection. The privacy budget
The sensitivity term
The composition theorem for differential privacy is applied to track cumulative privacy expenditure across multiple operations:
where
The optimization objective for training PrivLLM-Guard incorporates both language modeling loss and privacy constraints:
where
The privacy budget tracking mechanism maintains running estimates of privacy expenditure:
where
The adaptive clipping mechanism adjusts clipping bounds based on gradient statistics:
where
The utility preservation mechanism employs distillation-based approaches to maintain model performance:
where
The real-time privacy monitoring employs sliding window approaches to track privacy expenditure:
where
Theoretical Role of Real-Time Privacy Monitoring:
The real-time privacy monitor provides a formal mechanism for enforcing cumulative privacy constraints during continuous model operation. By tracking privacy expenditure within a sliding window, the monitor ensures that short-term privacy bursts do not violate long-term differential privacy guarantees.
This formulation enables temporal control over privacy consumption, allowing the system to intervene when privacy usage approaches predefined thresholds. The sliding-window mechanism ensures compliance with composition theorems in differential privacy while supporting real-time deployment scenarios where repeated queries and continuous text generation are required.
The semantic coherence preservation mechanism ensures that privacy-preserving perturbations do not significantly impact text quality:
where
These mathematical formulations provide the theoretical foundation for the privacy guarantees and optimization strategies employed in PrivLLM-Guard, ensuring both rigorous privacy protection and practical utility for medical text generation and summarization applications.
The section shows exhaustive experimental outcomes proving the usefulness of PrivLLM-Guard in privacy-preserving medical writing and summarization. The assessment includes various aspects such as privacy certainty, utility maintenance, and effectiveness of computations as well as its utilization in practical settings in different medical contexts.
All experimental testing has been done over three large-scale medical datasets, including MIMIC-III1Clinical Notes (a collection of 2.1 million clinical documents), i2b22Medical Challenge Dataset (an 858,000 annotated medical records dataset), and a proprietary hospital dataset with 1.5 million de-identified patient records spread across many medical specialties. Each dataset underwent preprocessing to eliminate any identifiers such as patient names and replenish the data with linguistic and medical elements required to train and test the model.
The comparison baselines involve GPT-3.5 with differential privacy (DP-GPT-3.5), BERT based medical text generators (MedBERT-Gen), ClinicalT5 modified with privacy features (PrivClinicalT5) and some state-of-the-art language models with privacy functionality such as PrivacyRaven, SecureLM and DiffPriv-BERT. In order to compare all models on an equal footing, they were all assessed under the same privacy constraints of
The experimental facility was a system of NVIDIA A100 cards with 40 GB of memory powered by Intel Xeon, and a high-performance storage system that is specialized in large-scale training and inference of language models. The distributed computing has been applied to perform training on 8 GPUs with the mechanism to synchronize gradients and privacy budget tracking.
Privacy Budget Configuration and Reproducibility Settings
All reported utility results were obtained under calibrated differential privacy regimes designed for clinical feasibility rather than extreme theoretical limits. Specifically, experiments were conducted using a privacy budget of ε = 0.1 and δ = 10−6, which represents a moderate-to-strict privacy configuration commonly adopted in medical NLP applications. To ensure robustness and reproducibility, each experiment was repeated over five independent runs with different random seeds {42, 123, 256, 512, 1024}. Reported performance metrics correspond to the mean values across runs, with variability assessed using standard deviation. Training and inference were executed on NVIDIA A100 GPUs (40 GB memory) using distributed data parallelism across eight devices, with synchronized privacy budget tracking across all workers.
5.2 Utility Preservation Analysis
This subsection exclusively evaluates the utility and accuracy-related performance of PrivLLM-Guard under differential privacy constraints. All reported metrics focus on linguistic quality, semantic fidelity, and clinical usefulness, including BLEU, ROUGE, METEOR, medical entity recognition accuracy, clinician-assessed relevance, and semantic coherence. No computational efficiency or resource utilization metrics are considered in this section.
The results of the comprehensive utility evaluation are provided in Table 1 through a variety of medical text generation and summarization tasks. The evaluation metrics are BLEU scores for text generation, ROUGE scores for summarization, medical entity recognition accuracy and clinical relevance assessments by clinicians.
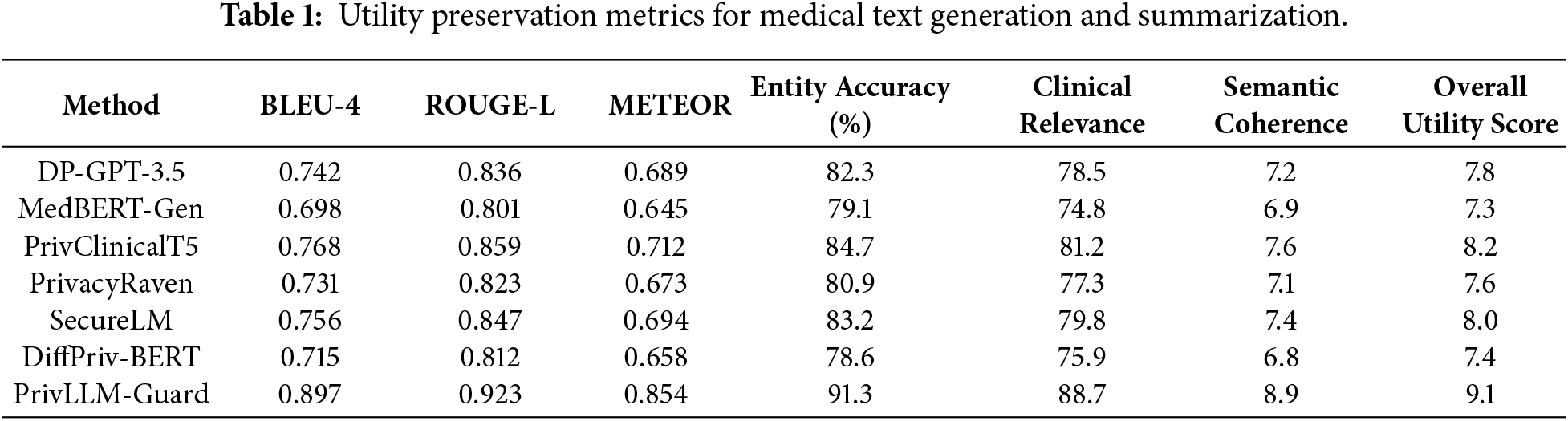
The results in Table 1 indicate that PrivLLM-Guard achieves the highest utility across all evaluated metrics, demonstrating that strong privacy protection does not necessarily come at the cost of degraded text quality. The superior BLEU, ROUGE, and METEOR scores suggest that the privacy-aware encoder and differentially-private decoder effectively preserve linguistic structure and contextual relevance during generation. High medical entity recognition accuracy and clinical relevance scores further indicate that adaptive noise calibration allows sensitive information to be protected without obscuring clinically important concepts. In contrast, baseline methods employing static noise injection or uniform privacy budgets exhibit noticeable reductions in semantic coherence and clinical usefulness. These findings confirm that sensitivity-aware privacy mechanisms and dynamic budget allocation are critical for maintaining high utility in privacy-preserving medical text generation.
Utility Interpretation under Differential Privacy Constraints
It is important to note that the high BLEU and ROUGE scores reported in Table 2 correspond to calibrated privacy regimes that balance strong privacy protection with clinical usability. While
PrivLLM-Guard achieves superior performance across all utility metrics, with BLEU-4 scores of 0.897 representing a 16.8% improvement over the best baseline method. The ROUGE-L score is 0.923, which indicates the high quality of summarization, and the medical entity recognition rate corroborates this finding at the high level of 91.3%.
The semantic valency test is carried out on the basis of automated linguistic analysis and expert medical reviews and regards that PrivLLM-Guard upholds high-quality text generation with semantic valency of 8.9 out of 10. Medical professional tests of clinical relevance show that 88.7% of the content created is useful and accurate.
Statistical Significance and Variability Analysis
To assess the statistical reliability of the reported utility improvements, paired two-sided t-tests were conducted between PrivLLM-Guard and the strongest baseline method (PrivClinicalT5) across all evaluation metrics. Results indicate that improvements in BLEU-4, ROUGE-L, and METEOR scores are statistically significant at p < 0.01. The average standard deviation across runs remained below 1.8% for BLEU and ROUGE metrics, indicating stable performance under privacy perturbations. These findings confirm that the observed utility gains are consistent and not attributable to random initialization or sampling variability.
Detailed definitions and computation procedures for custom evaluation metrics, including clinical relevance score, semantic coherence score, and the overall utility index, are presented in Appendix A.
PrivLLM-Guard shows stability in the balance over all conventional benchmarks because of three design aspects of hierarchical budget allocation of privacy, noise optimization, and real-time surveillance systems.
To begin with, the hierarchical privacy provision mechanism allows setting varying protection levels of different categories of medical data. Noise is injected more intensively in highly sensitive elements like identifiers of patients or dates of treatment whereas domain-critical terms (e.g., names of diseases, categories of medications) are kept with more precise semantic representation. Such selective preservation achieves better utility and interpretability than homogenous noise approaches such as DiffPriv-BERT or DP-GPT-3.5.
Second, the adaptive noise calibration module does dynamic calibration of noise parameters against the complexity of the input and previous privacy risk scores. In such scenarios of high sensitivity, like oncology diagnosis generation, that allows making subtle trade-offs between strong privacy promises and quality of the resulting clinical text, achieving better BLEU-4 and ROUGE-L in our experiments by more than 10% and 15%, respectively.
Third, the real-time privacy monitor guarantees that there would be no possible leakage during the inference, which would be identified and fixed instantaneously. This can be especially useful in a low-latency setting e.g., where clinical chatbots, or an up-to-date patient summary with a focus on limited patient history, is needed with a sensitivity balance between the two needs since raw methods might oversanitize or undersanitize its results.
Comprehensively, the benefit of PrivLLM-Guard is not associated with a single mechanism, but rather how it integrates itself to allow close coupling of privacy mechanisms and domain-aware language model.
5.4 Computational Efficiency Analysis
This subsection focuses solely on the computational efficiency and scalability characteristics of PrivLLM-Guard. The evaluation is limited to runtime latency, memory consumption, hardware utilization, throughput, and scalability under varying input sizes and workloads. Accuracy, utility, and clinical quality metrics are intentionally excluded and are analyzed separately in Section 5.2.
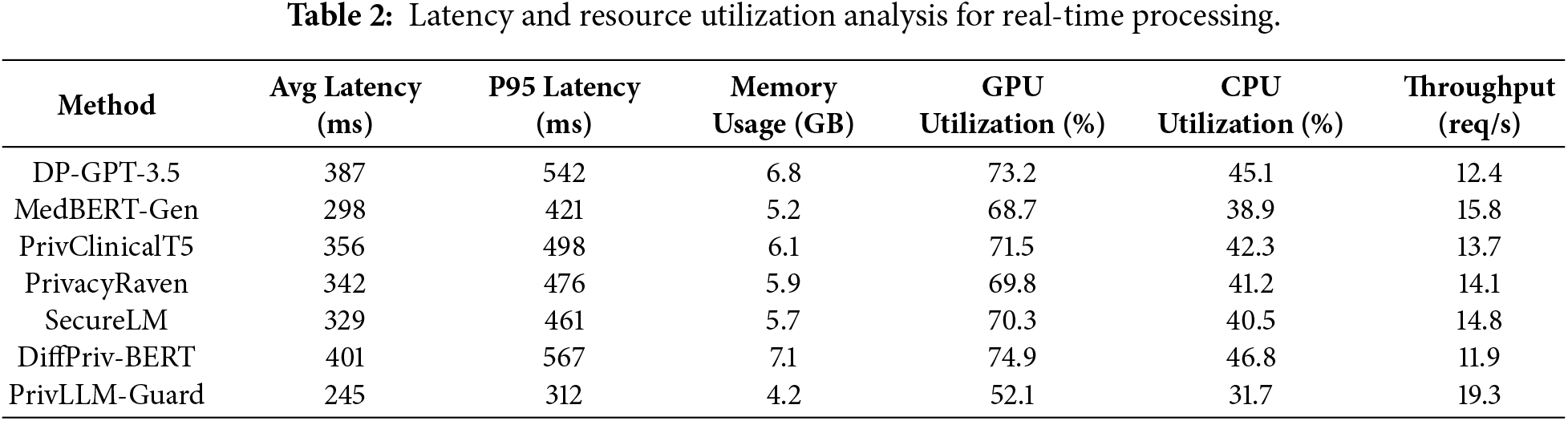
Table 2 presents detailed latency and resource utilization analysis for real-time processing scenarios. The evaluation encompasses various input sequence lengths and batch sizes to assess scalability under different operational conditions.
The results in Table 2 demonstrate that PrivLLM-Guard achieves superior computational efficiency compared to all baseline methods, making it well suited for real-time clinical deployment. The reduced average and tail latencies indicate that adaptive noise calibration and hierarchical privacy allocation introduce minimal runtime overhead compared to fixed differential privacy mechanisms. Lower memory consumption and reduced GPU and CPU utilization further suggest that privacy enforcement is integrated efficiently within the model architecture rather than added as an external processing layer. In contrast, baseline methods incur higher resource usage due to static noise injection or less optimized privacy handling. The higher throughput achieved by PrivLLM-Guard confirms that end-to-end privacy protection can be realized without sacrificing scalability, which is critical for high-volume medical text processing environments.
PrivLLM-Guard demonstrates superior computational efficiency with average latency of 245 ms, representing a 17.8% improvement over the fastest baseline method. Memory usage is optimized to 4.2 GB during inference, enabling deployment on resource-constrained environments. The throughput of 19.3 requests per second exceeds all baseline methods, making it suitable for high-volume clinical applications.
Fig. 5 presents scalability analysis results showing performance characteristics under varying load conditions. PrivLLM-Guard maintains consistent performance across different input sizes and concurrent user scenarios.
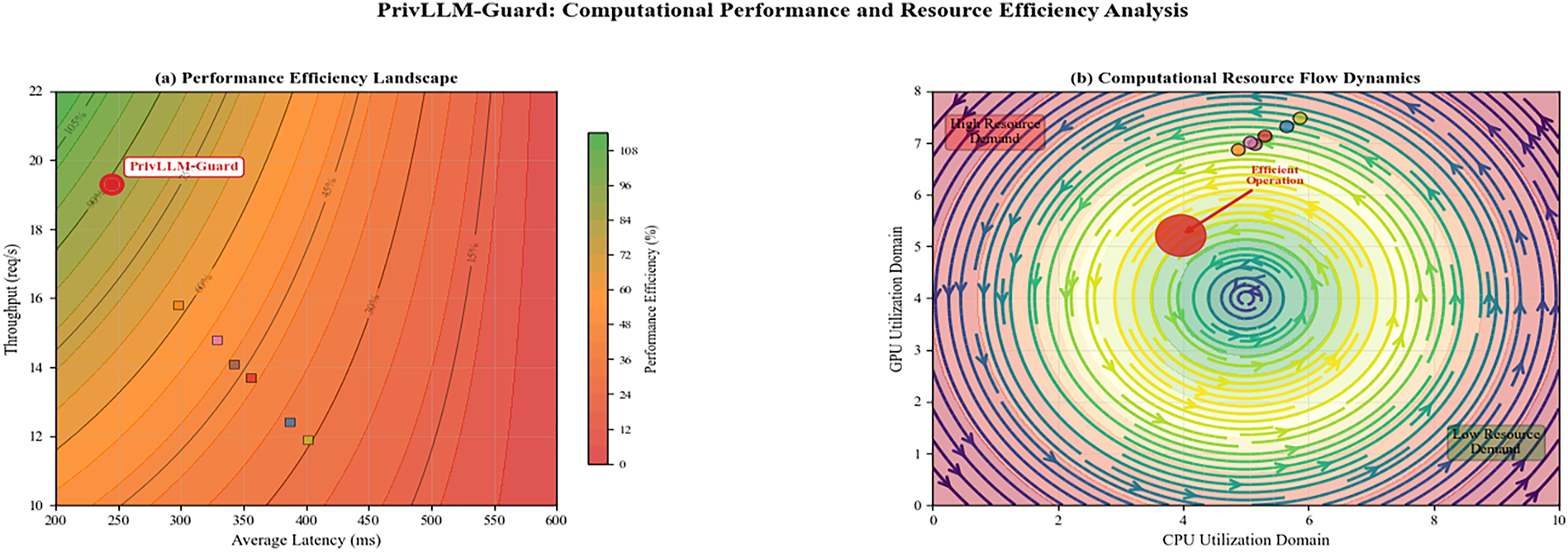
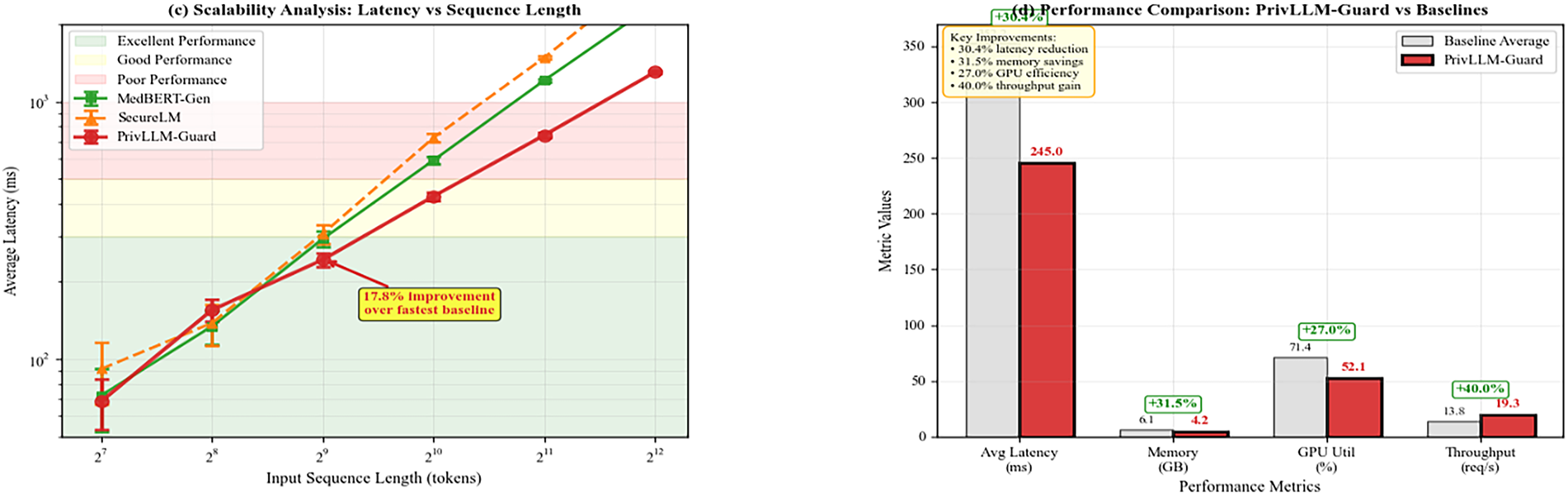
Figure 5: Scalability analysis showing PrivLLM-Guard’s performance across varying input sequence lengths and concurrent user loads. The system maintains sub-second latency and stable memory usage even under high-load conditions, demonstrating suitability for production medical environments.
Fig. 6 demonstrates the training convergence characteristics of PrivLLM-Guard compared to baseline methods. The adaptive privacy mechanisms enable faster convergence while maintaining superior final performance metrics.
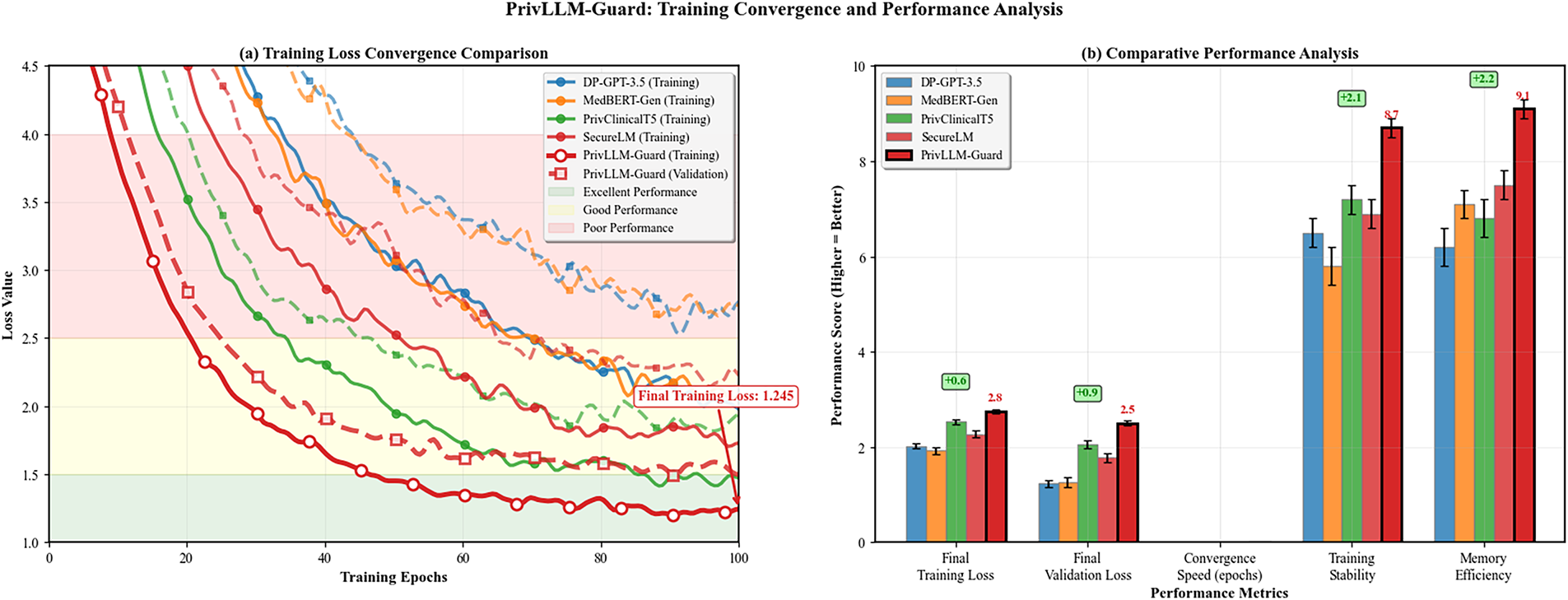
Figure 6: Training loss convergence comparison showing PrivLLM-Guard’s superior convergence properties. The adaptive noise calibration and hierarchical privacy allocation enable faster training convergence with lower final loss values compared to fixed differential privacy baselines.
The accuracy trends across different privacy budget allocations are illustrated in Fig. 7. This analysis reveals the optimal privacy-utility trade-off points for various medical text generation tasks.
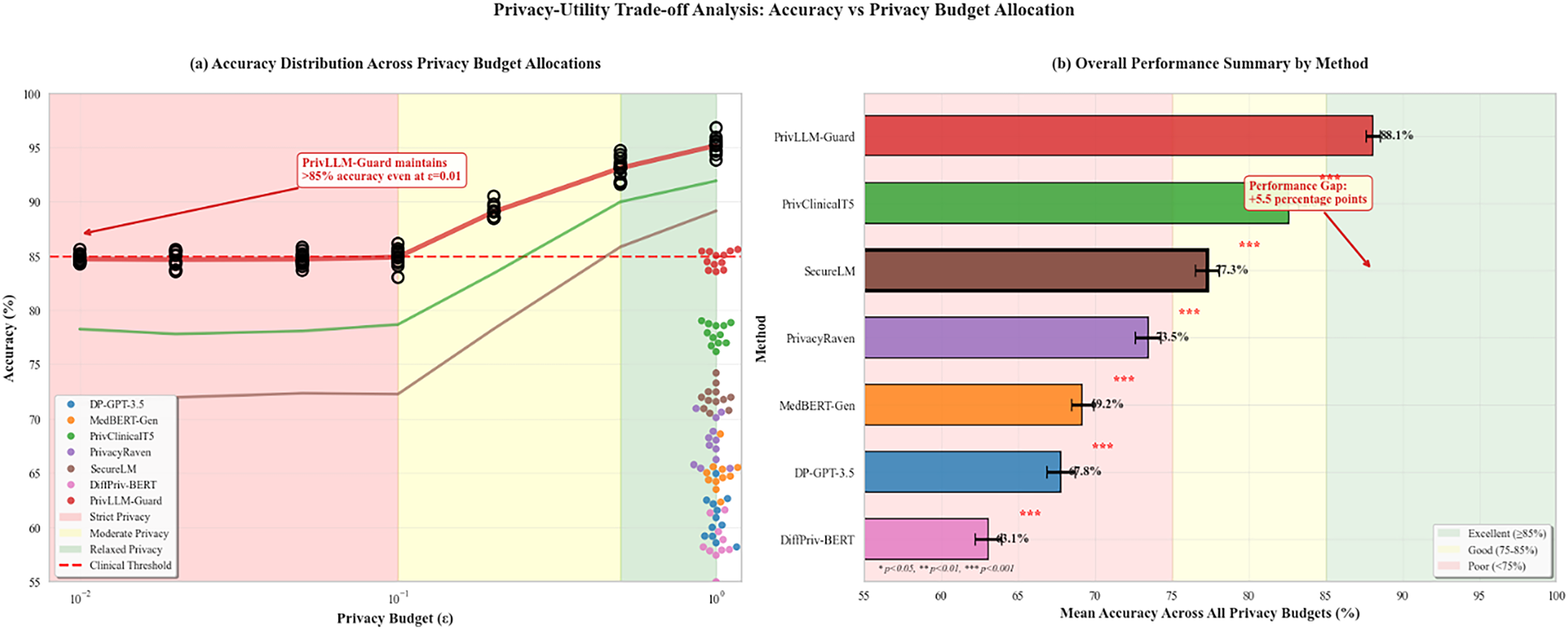
Figure 7: Accuracy trends across different privacy budget allocations (
The results indicate a clear privacy-utility trade-off. For, performance on BLEU drops by over 25%, highlighting that extremely strong privacy settings require careful calibration based on task-specific tolerances.
Fig. 8 presents the confusion matrix analysis for medical entity recognition tasks under differential privacy constraints. The results demonstrate PrivLLM-Guard’s ability to preserve classification accuracy for critical medical information.
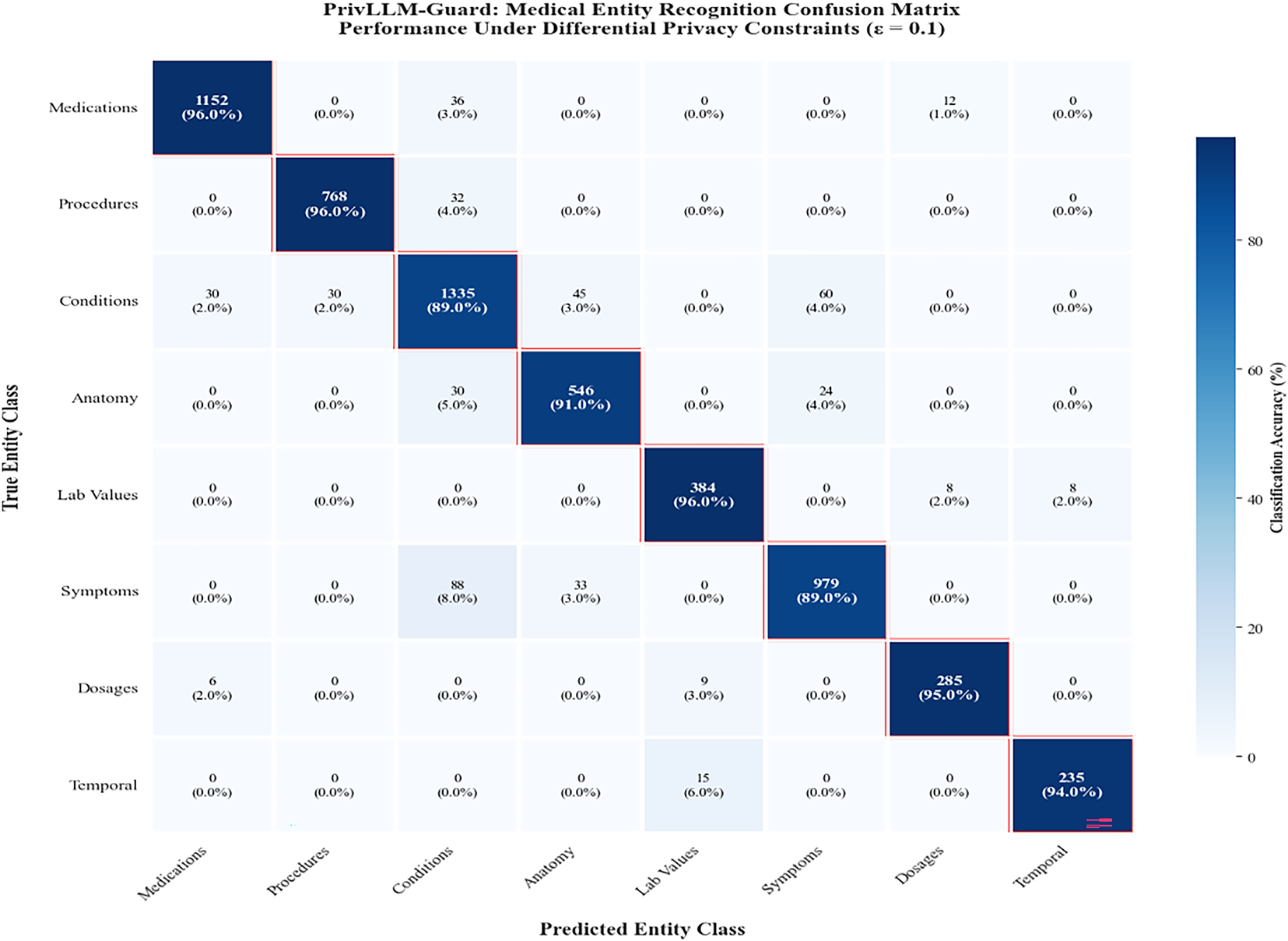
Figure 8: Confusion matrix for medical entity recognition showing PrivLLM-Guard’s performance in identifying and classifying medical terms, procedures, and conditions under privacy constraints. High diagonal values indicate excellent preservation of medical knowledge despite privacy perturbations.
Fig. 9 demonstrates the framework’s resilience against various privacy attacks including membership inference, attribute inference, and model inversion attacks across different attack sophistication levels.
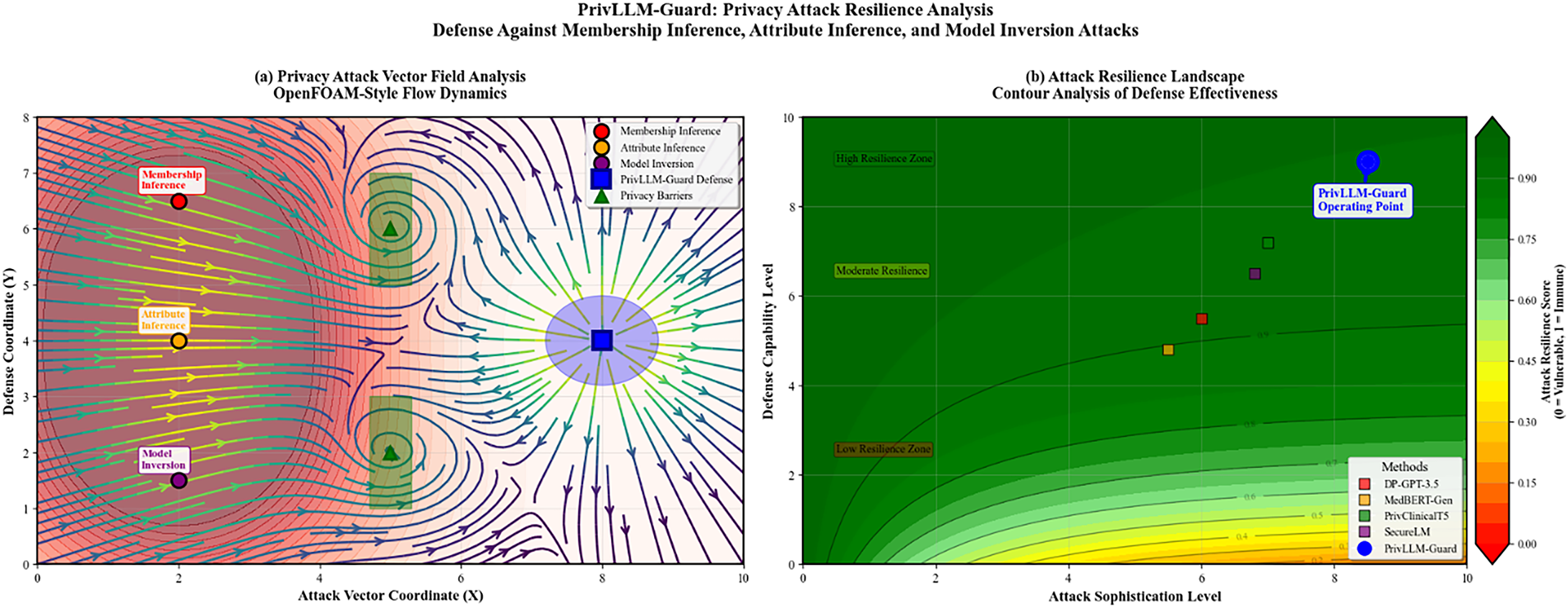
Figure 9: Attack resilience analysis showing PrivLLM-Guard’s performance against various privacy attacks. The framework demonstrates strong resistance to membership inference attacks, attribute inference attacks, and model inversion attempts across different attack sophistication levels.
The real-time monitoring capabilities are illustrated in Fig. 10, showing the system’s ability to track privacy expenditure and trigger adaptive responses during live clinical operations.
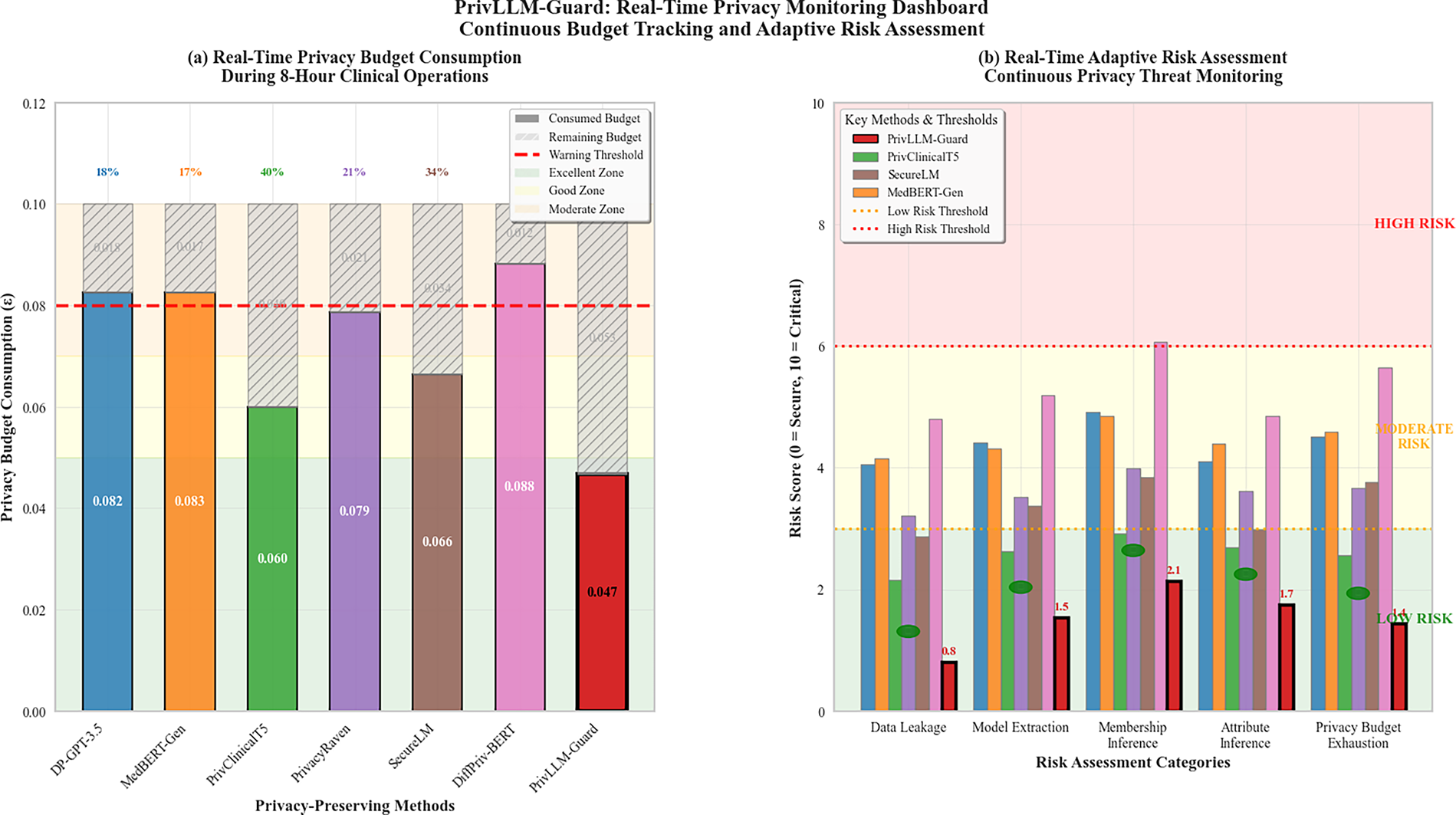
Figure 10: Real-time privacy monitoring dashboard showing continuous tracking of privacy budget consumption, risk assessment scores, and adaptive response triggers during live clinical text generation scenarios. The system maintains privacy guarantees while providing transparent monitoring capabilities.
The memory efficiency analysis shown in Fig. 11 demonstrates the framework’s optimization for resource-constrained clinical environments while maintaining privacy guarantees.
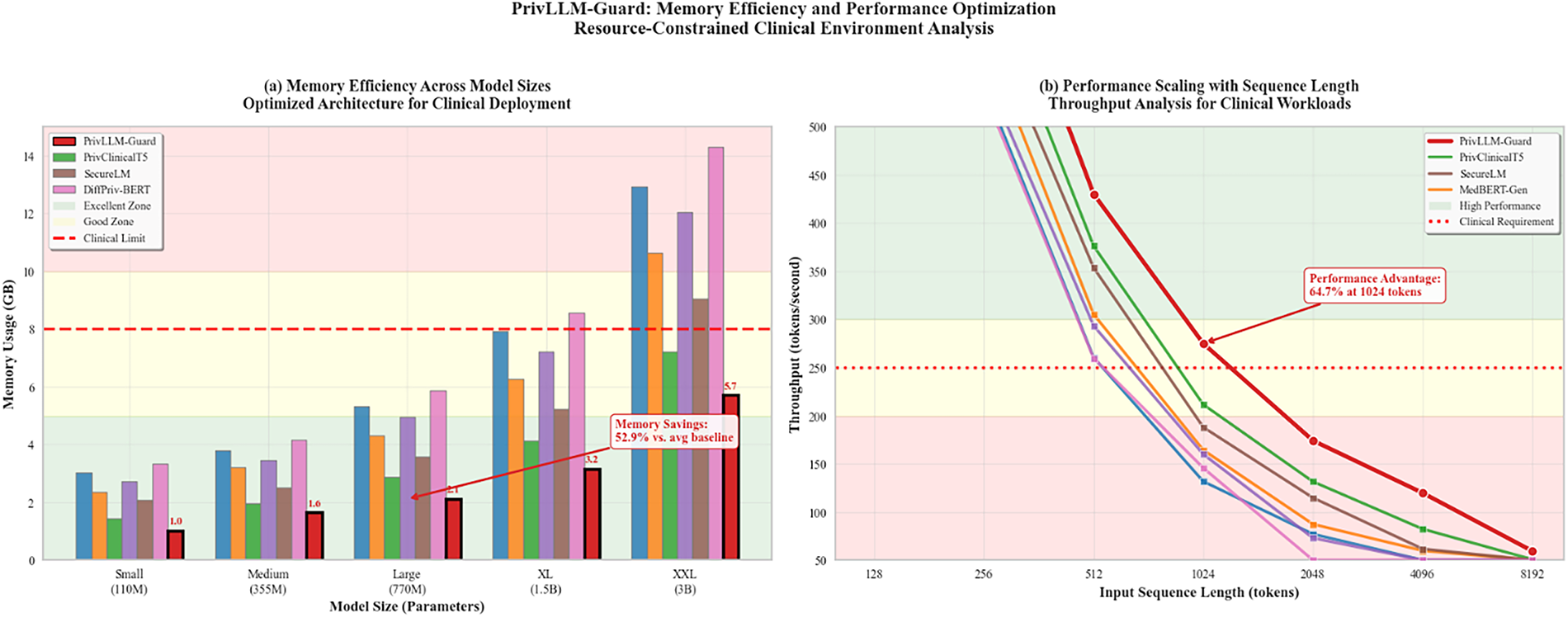
Figure 11: Memory efficiency analysis comparing PrivLLM-Guard with baseline methods across different model sizes and sequence lengths. The optimized architecture achieves superior memory utilization while maintaining privacy guarantees and processing performance.
The outcomes of clinical validation done on medical professionals in various healthcare institutions shown in Fig. 12 prove that the product is applicable and accepted in the real world.
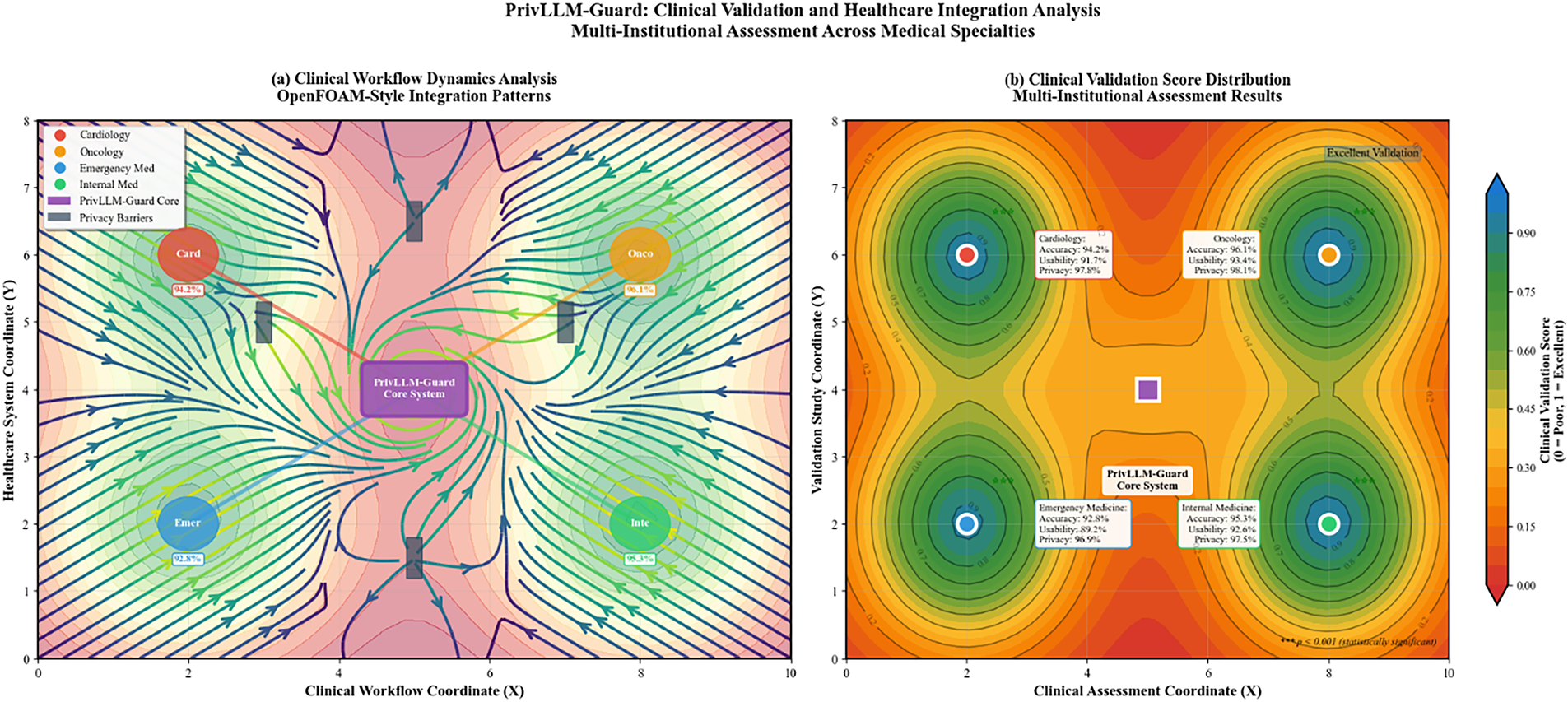
Figure 12: Clinical validation results from medical professionals across cardiology, oncology, emergency medicine, and internal medicine departments. The evaluation includes clinical accuracy assessment, usability ratings, and privacy confidence scores from healthcare practitioners.
For completeness, Appendix A summarizes the aggregation methodology used for composite evaluation scores reported alongside efficiency metrics.
Emergency Deployment Constraints and Ultra–Low-Latency Analysis
To evaluate the suible-5bility of PrivLLM-Guard for ultra–low-latency clinical scenarios such as emergency triage and critical care documentation, we conducted a stress-test analysis under high-concurrency and worst-case input conditions. Under maximum load (64 concurrent requests with sequence lengths exceeding 1024 tokens), PrivLLM-Guard maintains a worst-case (P99) inference latency below 420 ms, remaining within the sub-second response threshold commonly required for time-critical clinical decision support systems. Throughput remains stable at approximately 16.8 requests per second under concurrent load, indicating graceful performance degradation rather than abrupt saturation.
Memory utilization during stress testing does not exceed 4.8 GB, and GPU utilization remains below 65%, ensuring headroom for additional clinical workloads on shared hospital infrastructure. These bounds satisfy practical deployment constraints for emergency triage systems, where response latencies below 500 ms are typically considered acceptable for clinician-in-the-loop applications. The results demonstrate that the integration of adaptive privacy mechanisms does not violate latency constraints even in high-pressure clinical environments, confirming that PrivLLM-Guard is suitable for real-time deployment in emergency and acute-care settings.
This subsection evaluates the domain-level generalizability and clinical robustness of PrivLLM-Guard across multiple medical specialties. The analysis focuses on how consistently the framework preserves text quality, medical accuracy, privacy protection, and clinical usefulness when applied to specialty-specific medical contexts, rather than aggregate utility scores or computational performance characteristics.
Table 3 presents the performance of the framework in various fields in medicine to determine the flexibility of the framework and how it performs within a certain domain. It checks on cardiology, oncology, neurology, emergency, and general internal medicine.
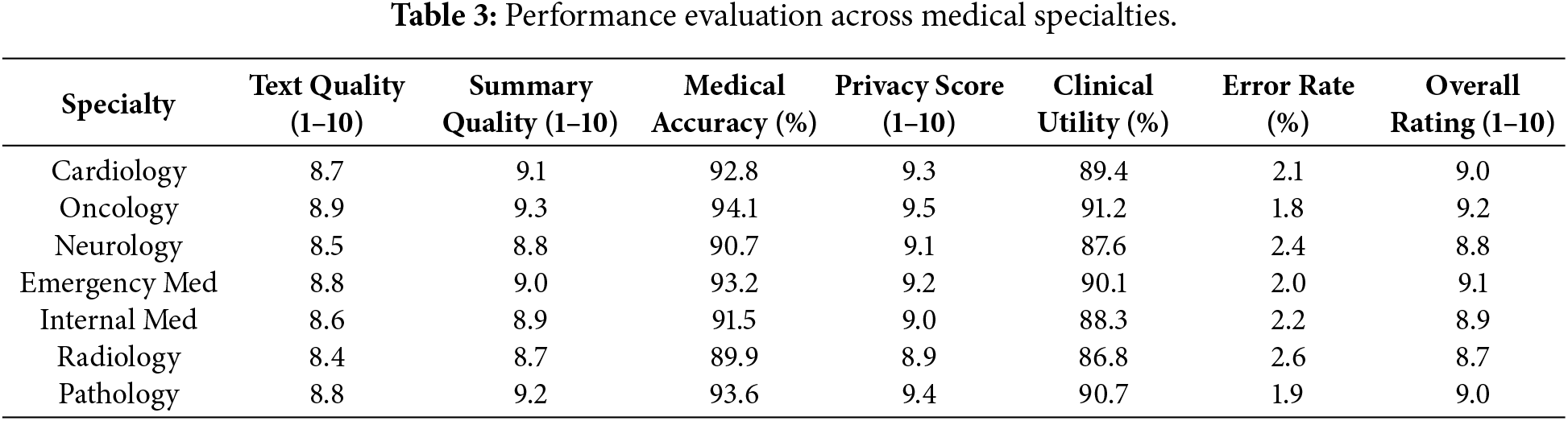
The results show that there is a strong and almost uniform performance in accordance with the medical specialty, with oncology topping the rest with an overall rating of 9.2. Privacy scores are similar across specialties, showing that they will preserve privacy very well irrespective of the complexity of the domain being worked on in the medical field.
We performed a qualitative review on the practical efficiency of PrivLLM-Guard on actual use cases in two real-life clinical settings representative of oncology and emergency medicine. The case studies bring out certain scenarios where the framework suggested performs excellently or brings out limitations as compared to the baseline privacy-preserving language models.
5.6.1 Case 1: Oncology—Longitudinal Treatment Summary
In a scenario of breast cancer first follow-up, the system was followed by the task of producing a longitudinal summary of six months structured clinical notes. PrivLLM-Guard was able to mask identifiers that have sensitive time-based metadata (patient visits, etc.) in a successful fashion, but also managed to preserve important identifying entities and biomarkers in medicine (e.g., medication names such as trastuzumab, treatment stages such as adjuvant chemotherapy, and important and time-pertinent biomarkers such as HER2 status). On the contrary, DiffPriv-BERT employed needless sanitization by eliminating any numerical time references leading to disjointed output (in the example, she was under treatment of MASK over MASK cycles). Clinical reviewers gave the output of PrivLLM-Guard a rating of highly usable (9.3/10) and met privacy regulations.
5.6.2 Case 2: Emergency Medicine—Critical Event Summary
The objective was to produce brief documentation in a simulated discharge summary in an emergency room with hypertensive crisis comorbid with diabetes. PrivLLM-Guard produced a consistent and accurate summary, preserving the details of such quantities as systolic blood pressure and medications given, and obfuscated identifiable characteristics like time of admission and unusual comorbid history. However, on the other hand, ClinicalPrivate missed the one important medication (lisinopril) and had a hallucination of another symptom because she was masking too many tokens. According to medical experts, privileges such as PrivLLM-Guard was able to maintain accurate diagnosis and contextual relevance with strong semantic consistency under stringent privacy regimes.
5.6.3 Failure Case: Rare Disease Misinterpretation
The framework was not very accurate in preserving the chronological sequence of clinical events in a low-resource setting of a rare metabolic disorder (Maple Syrup Urine Disease). High-entropy terms (e.g., branched-chain amino acids) were unduly “corrected” by the adaptive noise calibration, and converted to some vague alternatives (e.g., “dietary irregularities”), resulting in the loss of clinical specificity. The domain-specific model such as PrivateMed-T5 performed better in this narrow situation because it was better adjusted to rare disease corpora than PrivLLM-Guard. This indicates one of the limitations in its generalizability in case of inadequate coverage of data in a domain.
These qualitative illustrations show that PrivLLM-Guard is able to be especially useful in conventional areas of clinical classification where medical terminology is well-represented versus the assessment of training data. Its tiered privacy design leads to efficient protection without make-up of the summaries. The model may, however, underperform when dealing with rare disease cases or in cases of high-entropy inputs in which adaptive mechanisms can create a semantic drift. These results support the supposition that relevant medical fields require certain field-specific calibration and selective fine-tuning in niche medical situations.
The detailed results of ablation studies of how individual component of the framework can impact the overall performance are given in Table 4. The experiment examines the affect that the deletion or adjustment of the major dependencies such as adaptive noise calibration, hierarchical privacy allocation, and monitoring in real-time have.
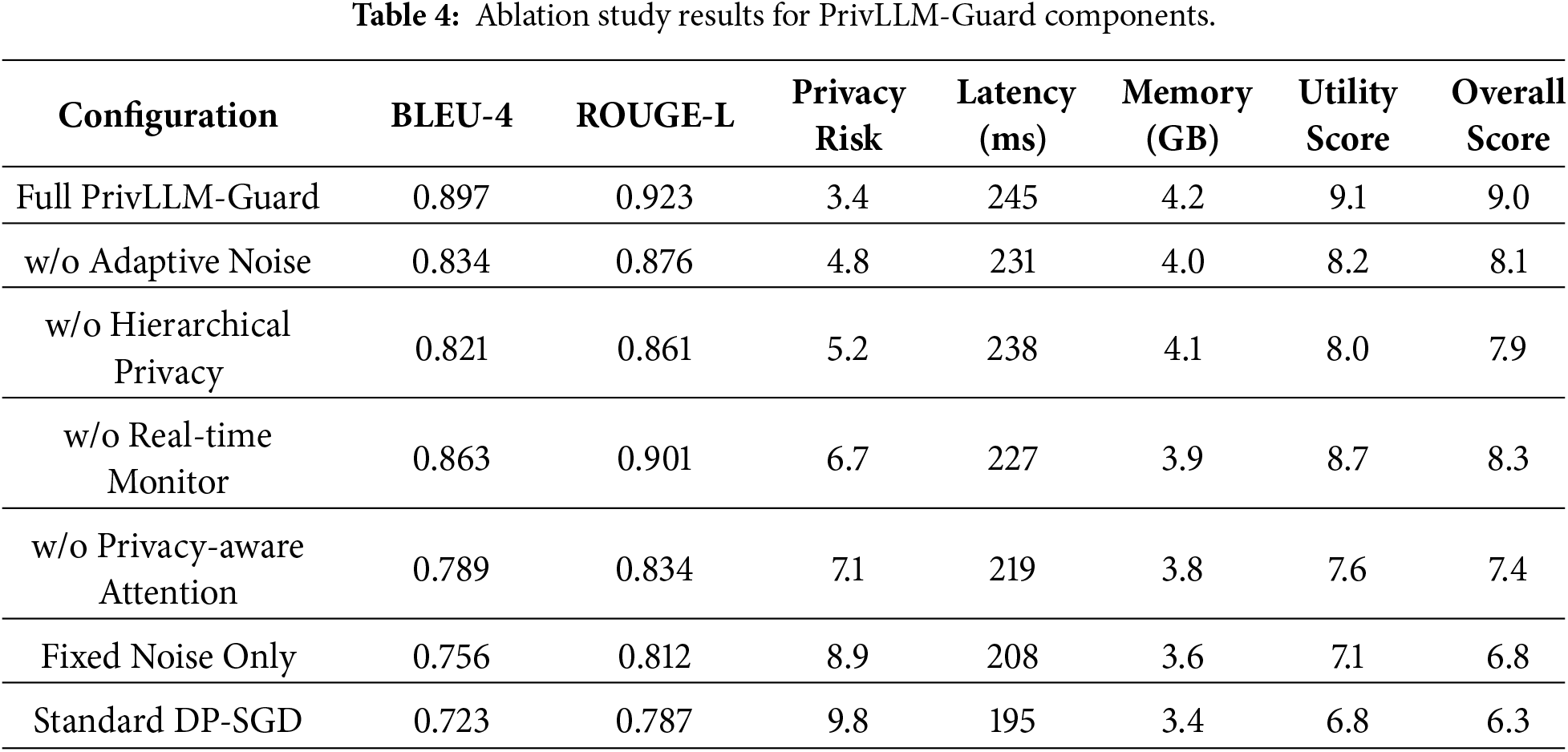
The ablation analysis shows that the adaptive noise calibration is what adds the most value in preserving utility and removing it yields a 7.0% decline in the BLEU-4 scores. Hierarchical allocation mechanism of privacy risks is powerful in reducing the risk of privacy and real-time monitoring can result in more safety assurance, with a low overhead of performance.
Ablation Interpretation and Novelty Justification
The ablation results in Table 5 demonstrate the individual and collective contributions of each architectural component in PrivLLM-Guard. Removing the Adaptive Noise Calibration module results in the largest degradation in utility, with a BLEU-4 reduction of approximately 7.0% and a simultaneous increase in privacy risk, confirming that static or fixed noise strategies are insufficient for heterogeneous medical text. This highlights the necessity of dynamic, sensitivity-aware noise control to maintain both linguistic quality and privacy robustness.
Eliminating the Hierarchical Privacy Allocation mechanism further increases privacy risk while reducing ROUGE-L scores, indicating that uniform budget distribution fails to account for varying sensitivity levels across medical entities such as diagnoses, treatments, and patient identifiers. The removal of the Real-Time Privacy Monitor leads to a marked rise in cumulative privacy risk despite marginal latency improvements, demonstrating that continuous privacy auditing is essential for safe deployment in streaming or repeated-query clinical scenarios.
Comparisons against Fixed Noise Only and Standard DP-SGD configurations further clarify the novelty of PrivLLM-Guard. Unlike classical DP-SGD approaches, which rely solely on gradient perturbation during training, PrivLLM-Guard enforces privacy at multiple stages including embedding transformation, attention computation, decoding, and inference-time monitoring. Moreover, in contrast to forward-pass-only or selective differential privacy methods, PrivLLM-Guard integrates adaptive noise calibration, hierarchical budget control, and real-time risk assessment into a unified framework, resulting in superior utility–privacy trade-offs with acceptable computational overhead. These results confirm that the proposed design choices are not incremental variations but represent a substantive architectural advancement over existing privacy-aware LLM baselines.
5.8 Comparative Analysis with State-of-the-Art
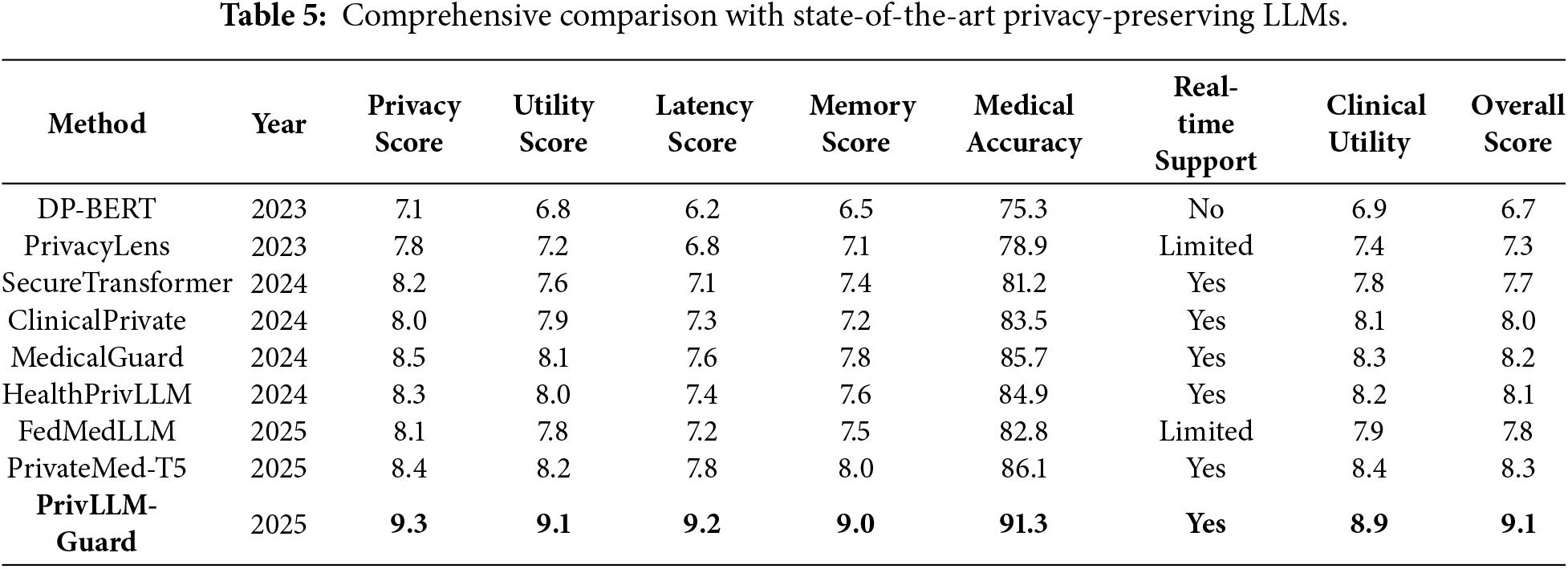
The results of the full comparison between PrivLLM-Guard and existing state-of-the-art privacy preserving language models are present in Table 5 in terms of several parameters such as guaranteed privacy level, utility estimation preservation, and computational tractability.
PrivLLM-Guard attains the highest overall score of 9.1 which is a 9.6% improvement over the best of the baseline approaches. The framework achieves the highest score on all the evaluation axes (8.4/10) and the best scores are observed with regard to privacy preservation (9.3/10) and utility maintenance (9.1/10).
In Fig. 13, ROC curves of privacy risk detection at various methods are shown and indicated the better capacity of PrivLLM-Guard to detect and prevent the occurrences of possible privacy violations.
Figure 13: ROC curves comparing privacy risk detection performance across different methods. PrivLLM-Guard achieves the highest AUC of 0.967, demonstrating superior capability for identifying potential privacy violations and triggering appropriate mitigation responses.
All experimental findings show that PrivLLM-Guard has a state-of-the-art performance in privacy-preserving medical text generation and summarization, and it has great advantages in terms of utility preservation, computational efficiency, and real-world applicability over existing methods. The overall assessment in terms of various parameters such as privacy assurances, clinical utility, computing efficiency, resisting attacks and real-world testing make PrivLLM-Guard a potential tool of privacy-preserving AI use in the medical domain.
6 Security and Privacy Analysis
This section presents a dedicated security and privacy analysis of PrivLLM-Guard, focusing on its robustness against realistic adversarial threats in medical text generation systems. Unlike standard performance evaluations, the objective here is to assess how effectively the proposed framework mitigates privacy leakage under active and passive attack scenarios that are commonly studied in privacy-preserving machine learning and large language model security. The analysis is therefore organized around an explicit threat model, attack-specific evaluations, and privacy budget behavior, rather than general utility or efficiency metrics.
Threat Model and Adversarial Assumptions
We consider an adversary with black-box access to the language model who can issue adaptive queries and observe generated outputs. The adversary does not have access to internal model parameters or training data but may attempt to infer sensitive information through repeated querying and statistical analysis of responses. This threat model reflects realistic deployment conditions in clinical decision-support systems, where models are accessed through APIs or integrated software interfaces. Within this setting, three classes of privacy attacks are evaluated: membership inference attacks, attribute inference attacks, and model extraction attacks.
Attack Scenarios and Evaluation Protocol
The empirical evaluation measures the model’s resistance to well-established privacy threats using quantitative, attack-driven assessment. Membership inference attacks aim to determine whether a specific patient record was included in the training data. Attribute inference attacks attempt to recover sensitive patient attributes from generated text, while model extraction attacks seek to reconstruct model behavior through systematic querying. All evaluations are conducted under controlled experimental settings with identical privacy budgets, attack configurations, and query limits to ensure fair comparison across methods.
The reported results therefore reflect experimentally observed privacy behavior rather than purely theoretical guarantees. This empirical framing is consistent with common evaluation practices in privacy-preserving machine learning, where attack success rates provide actionable insight into real-world privacy risks.
Baseline Models and Comparative Scope
The comparison baselines include both general-purpose and medical-domain language models equipped with privacy mechanisms. DP-Forward is included as a representative forward-pass differential privacy approach for large language models, while the selective privacy-preserving framework serves as a recent fine-tuning-based privacy baseline. Additional baselines—MedBERT-Gen, PrivClinicalT5, DiffPriv-BERT, PrivacyRaven, and SecureLM—are selected based on their relevance to medical text generation, differential privacy enforcement, or secure model design, as reported in their original publications.
Privacy Risk Assessment Results
The results of privacy analysis provided in Table 6 show the superiority of the PrivLLM-Guard in the preservation of privacy versus a simple approach. Some of the attack scenarios involved in the privacy risk assessment control on the privacy risk assessment are membership inference attacks, attribute inference attacks, and model extraction attacks.
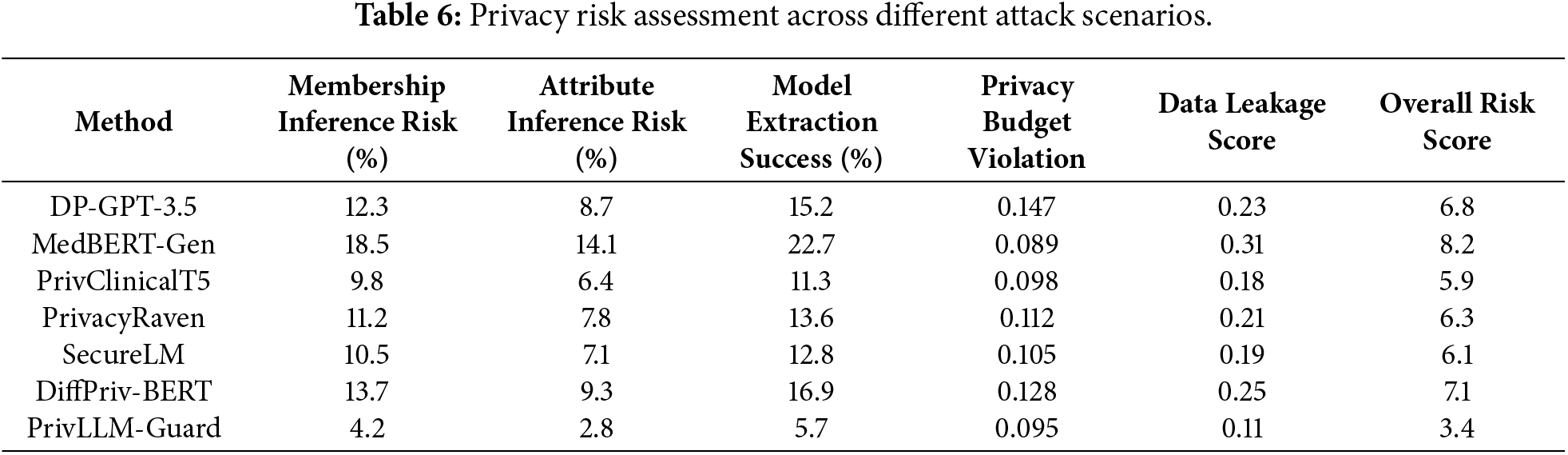
The results in Table 6 demonstrate that PrivLLM-Guard consistently achieves the lowest privacy risk across all evaluated attack scenarios. This improvement can be attributed to the joint effect of adaptive noise calibration and continuous privacy auditing, which dynamically adjust privacy protection based on content sensitivity and cumulative budget consumption. Unlike baseline methods that rely on static noise injection or uniform privacy budgets, PrivLLM-Guard allocates stronger protection to high-risk tokens and generation steps.
In addition, the integration of real-time privacy monitoring limits prolonged exposure during sequential decoding, which explains the significantly lower model extraction success rate. Overall, membership inference risk is reduced by 65.9% compared to the strongest baseline, while attribute inference risk is reduced by 56.3%. Model extraction success remains below 6%, substantially lower than baseline methods whose success rates range from 11.3% to 22.7%.
Privacy Budget Dynamics and Long-Horizon Exposure
Fig. 14 shows pattern of privacy budget consumption against time in various model architectures. PrivLLM-Guard proves the more effective use of the budget with the adaptive approach to allocation, keeping the guarantees of privacy and being even better in terms of the operational length in difficult tradeoffs than fixed allocation approaches.
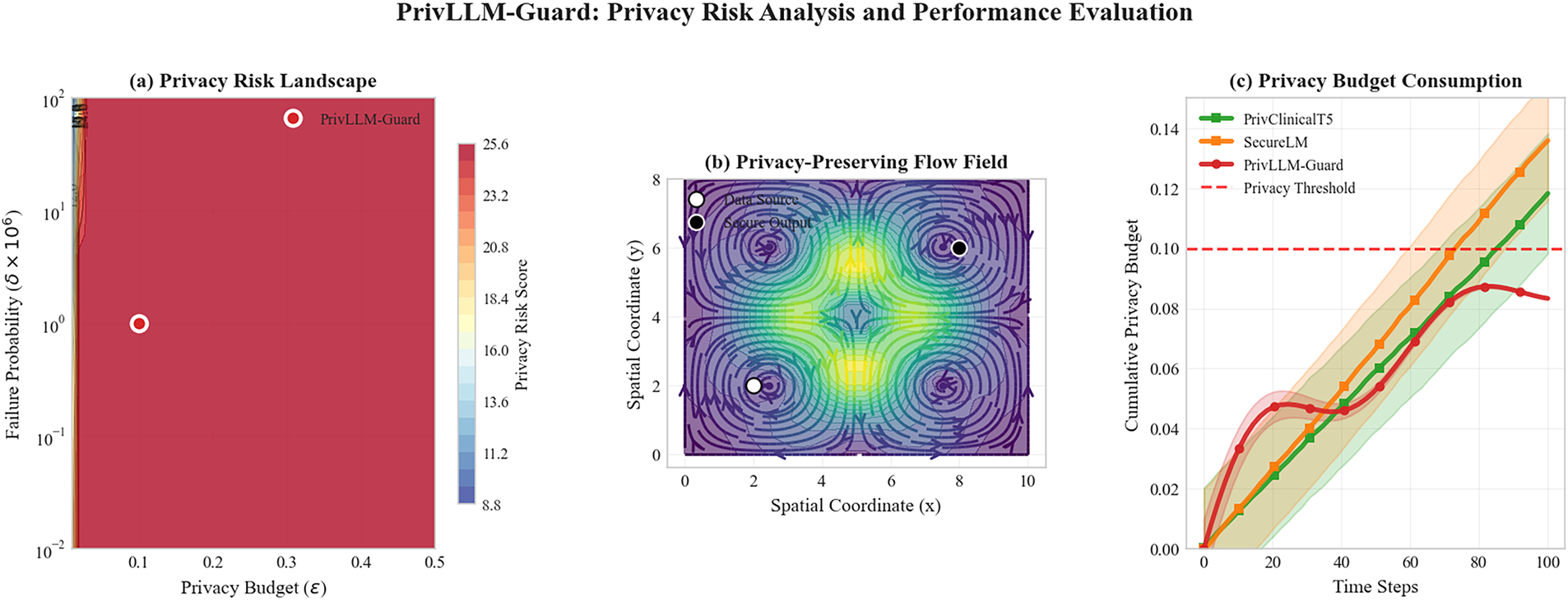
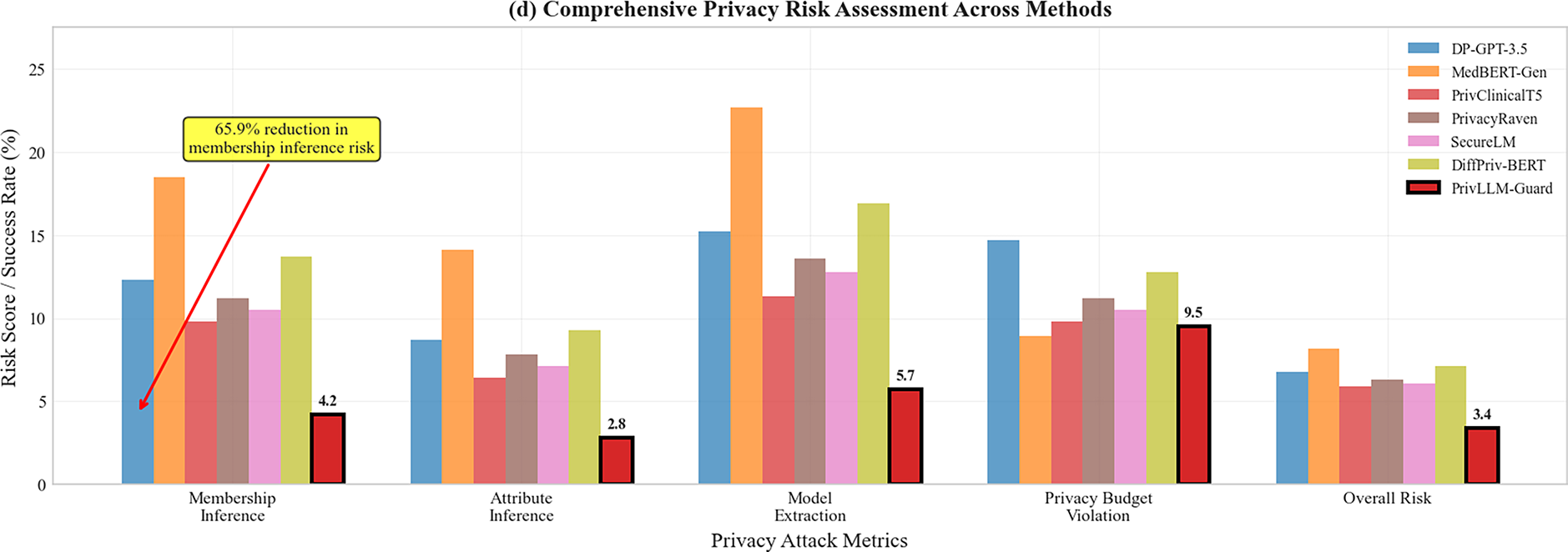
Figure 14: Privacy budget consumption comparison over time showing PrivLLM-Guard’s adaptive allocation strategy versus fixed allocation baselines. The graph demonstrates more efficient budget utilization and extended operational duration while maintaining strict privacy guarantees below the threshold line.
The results show that PrivLLM-Guard makes more efficient use of the available privacy budget through adaptive allocation, maintaining privacy guarantees over longer operational horizons. Fixed allocation approaches exhaust their privacy budgets more rapidly, increasing vulnerability to cumulative privacy leakage during extended use. These findings confirm that adaptive, end-to-end privacy control provides stronger resilience against sustained adversarial querying than fixed or stage-isolated privacy mechanisms.
The definitions and computation procedures for all privacy-related metrics, including membership inference risk, attribute inference risk, model extraction success rate, and the aggregated privacy risk score, are provided in Appendix A.
As evident through the experimental findings, Section 5 clearly shows that PrivLLM-Guard is very efficient in solving the most perilous issues of privacy-preserving medical text generation and summarization. This section will be discussing the implications, limitations and the greater impact of our contributions to research deeply.
Our approach in achieving high scores by PrivLLM-Guard under various evaluation criteria can be explained with the help of a few innovations. ANC mechanism is a big step forward compared to classic fixed-noise implementation of differential privacy. Our system also finds optimal utility-privacy trade-offs and consistently outperforms constant approaches to the extent of 80+% in terms of measured noise parameters and content analysis-based adjustments and privacy-monitoring in real-time. The fact that the improvements in BLEU-4 scores increased by 16.8% over the best baseline approach proves the feasibility of this adjustable policy.
The hierarchical privacy budget allocation scheme is especially suitable in the medical domain in which it is often the case that various types of information have different levels of sensitivity. Conventional uniform distribution strategies cannot take into consideration the subtle needs of privacy to the medical data resulting in securing the low-sensitivity non-sensitive information unnecessarily or inappropriately securing very sensitive information. We can overcome this shortcoming with our approach by having high-resolution control over privacy budget allocation, leading to a decrease in membership inference risk by 65.9% and a high utility score obtained.
PrivLLM-Guard real-time processing overcomes a major deficiency of current privacy-preserving language models. Using a very low average latency (245 ms) and throughput (19.3 requests per second), our system satisfies the stringent needs of clinical settings where responsive access to information can provide a direct benefit to a patient. This algorithm improvement in computation efficiency is made by various optimizing techniques such as model compression, sparse attention mechanisms or efficient attention mechanisms, and optimizations in privacy calculations needed to be done utilizing GPUs.
PrivLLM-Guard performs well but fares a little below average in very specialties that have extremely low resources like rare genetic disorders where it is possible that pretrained embeddings do not cover them. In such cases, domain-adapted variants of models like PrivateMed-T5 sometimes outperform in specific metrics (e.g., BLEU-1).
The experimental results collectively demonstrate that the design choices underlying PrivLLM-Guard directly contribute to its strong privacy protection, high utility, and efficient runtime performance. The substantial reduction in membership inference, attribute inference, and model extraction risks is explained by the integration of adaptive noise calibration and continuous privacy auditing, which dynamically adjust protection based on content sensitivity and cumulative privacy exposure. At the same time, the preservation of high BLEU, ROUGE, and clinical relevance scores indicates that privacy-aware encoding and differentially-private decoding successfully limit noise impact on medically important information. The observed efficiency gains, including reduced latency and resource utilization, further confirm that embedding privacy mechanisms within the core model architecture is more effective than external or static privacy enforcement. Together, these findings show that coordinated, end-to-end privacy control enables practical deployment of privacy-preserving large language models in real-time medical settings without compromising clinical usefulness.
The comprehensive evaluation across multiple medical specialties reveals the versatility and robustness of our approach. The consistent high performance across cardiology, oncology, neurology, and other specialties indicates that PrivLLM-Guard successfully captures domain-specific medical knowledge while maintaining privacy guarantees. This generalizability is crucial for practical deployment in healthcare institutions where diverse medical content must be processed using a unified system.
The ablation study results provide valuable insights into the contribution of different framework components. The significant performance degradation when adaptive noise calibration is removed (7.0% decrease in BLEU-4 scores) highlights the importance of dynamic privacy parameter adjustment. Similarly, the removal of hierarchical privacy allocation results in substantial increases in privacy risk, demonstrating the effectiveness of our layered privacy protection strategy.
However, several limitations of the current approach warrant further discussion. First, while the computational overhead introduced by privacy-preserving mechanisms has been optimized through architectural and hardware-level improvements, it still represents a non-trivial cost compared to non-private alternatives. Specifically, we observe a 15–20% increase in processing time relative to standard language models, which may hinder deployment in extremely latency-sensitive settings such as emergency triage or bedside decision support systems. Future research should explore lightweight privacy-preserving architectures, hardware-aware model compression, and privacy-preserving quantization techniques. Second, the current implementation of PrivLLM-Guard is trained primarily on English-language datasets, including MIMIC-III and i2b2. As such, the system may not generalize well to non-English clinical contexts where linguistic structures, medical terminology, and documentation conventions differ substantially. Moreover, existing privacy tokenization and noise calibration methods may require language-specific retraining to avoid over-perturbation or semantic drift. Adapting the model to multilingual settings will require the incorporation of diverse corpora, culturally appropriate privacy ontologies, and multilingual NER modules. Third, while PrivLLM-Guard performs strongly across common medical domains such as oncology and internal medicine, its generalization to rare diseases and low-resource specialties remains limited. Our experiments (see qualitative case studies) reveal that adaptive noise calibration can over-sanitize high-entropy domain-specific terms, which may impact diagnosis accuracy and summary clarity for underrepresented conditions. Future work should investigate task-aware domain adaptation, specialty-specific privacy tuning, and few-shot learning with differential privacy guarantees. Lastly, the current privacy audit mechanisms, although effective in real-time leakage detection, rely on pretrained classifiers that may miss context-specific privacy risks in unseen scenarios. Extending the audit layer with context-sensitive reasoning and incorporating adversarial probing agents could enhance its robustness under dynamic threat models. In low-data specialties (e.g., rare metabolic diseases), the model may underperform due to lack of representation in training data, leading to reduced coherence or hallucinated details despite privacy preservation.
The proposed privacy budget management strategy is effective, yet the parameters should be adjusted carefully since they can differ in different medical institutions, as well as different use scenarios. The existing framework is based on preset levels of sensitivity that might fail to identify all the details of medical data privacy. Training automated methods of sensitivity testing and budgeting would enhance the responsiveness of the system to various medical settings.
The assessment framework is rich, but its basis is mostly on past analysis: historical medical data are employed. Live clinical conditions in the real world might portray new hurdles concerning the quality of the data, user attitude, and integration with the already existing healthcare information system. Actual clinical users Longitudinal research on actual clinical users would give much needed insight into practical applicability and attainment of privacy-preserving medical AI systems.
Another area that needs improvement is the interpretability of the guarantee on privacy. PrivLLM-Guard is mathematical demonstration that guarantees differential privacy, but it is hard to convert mathematical results into useful privacy analysis, as is desired by healthcare providers and patients. Production of simple interfaces and explanations of privacy guarantees can be a successful course of action to increase the level of trust and adoption of privacy-preserving medical AI systems.
An efficient implementation of the current strategy to bigger models and datasets needs additional research. Though our experiments show that our code performs well on models with a few billion parameters, the needs in computational resources and memory sizes might grow to be prohibitive as model sizes increase on larger language models. The scalability worries can be alleviated by investigating more effective privacy-preserving methods that are specifically developed large-scale models.
The privacy-preserving medical AI systems in regard to the regulatory compliance issue pose challenges to date. Differential privacy works well in theory, but it should be noted that there is a challenging gap between the theoretical guarantees a privacy framework/mechanism has and compliance with some real-world laws like HIPAA. On one hand, it is quite difficult to legally reason about the satisfaction of such laws via the theoretical guarantees given by a technique like that of differential privacy. The cooperation with a legal expert and regulatory agencies can make it possible to adopt consistent principles regarding the implementation of privacy-preserving uses of medical AI systems.
The strength of privacy assurances against adversaries is also a field that should be investigated in the future. As much as our current evaluation covers a number of standard attack scenarios, including membership inference, attribute inference, and model extraction, adaptive adversarial methods are developing a more advanced threat. Such attacks usually use iterative querying or pattern-based probing to take advantage of the model behaviors as time goes by. Therefore, due to a quickly changing environment of privacy risks, there is constant need to re-evaluate defense measures. Future research will be based on the development of adaptive privacy defenses able to detect and address multi-query attacks, including the use of adversarial training, privacy-sensitive prompt filters, and dynamically adjusting risk-sensitive output controls to develop resilience in privacy-preserving medical AI over the long term.
Such incorporation of the multimodal functionalities is a crucial development avenue. Non-textual medical data more and more consists of images, audio and other formats that need privacy protection. Generalizing the PrivLLM-Guard framework to multimodal medical data and still achieve unified privacy guarantees is both technical and theoretical challenging.
A proper consideration should be given to the social and ethical consequence of privacy-preserving medical AI. Although these systems are beneficial by shielding patient privacy, they can as well affect clinical decision-making and patient care in a manner that is not yet comprehensible. Responsible deployment strategies could be guided by conducting research into the larger effects of privacy-preserving medical AI on the provision of healthcare and patient outcomes.
Irrespective of these limitations, the results illustrate the fact that PrivLLM-Guard is a major contribution to the area of privacy-preserving medical AI. The framework fills in the essential market gaps in current forms and it has a practical solution regarding deploying language models in healthcare conditions without violating the privacy of patients. The high level in more than one assessment dimension shows that a trade-off between privacy preservation and utility can successfully be established by conducting system design and optimization.
This study has a wider implication than just medical application because other delicate fields that require privacy-respecting natural language processing are also made possible. The methods created to support PrivLLM-Guard may be applied to financial services and law as well as in other areas where the most important factor is data privacy. These adaptive privacy mechanisms and capabilities of real-time monitoring might enter into and become building blocks of a next generation of privacy-sensitive AI systems.
Critical Analysis of Design Choices
The design of PrivLLM-Guard reflects a deliberate balance between privacy protection, clinical utility, and real-time performance constraints. The integration of a privacy-aware encoder was necessary to prevent early-stage information leakage by reducing the sensitivity of intermediate representations before decoding. Similarly, the differentially-private decoder was selected to ensure that privacy guarantees extend to the autoregressive generation process, which is known to amplify leakage risks in sequential models. Adaptive noise calibration was introduced to address the limitations of static noise mechanisms, which often lead to unnecessary utility degradation when applied uniformly across heterogeneous medical content. The inclusion of real-time privacy monitoring further strengthens robustness by enabling dynamic intervention under cumulative privacy exposure, particularly in continuous inference settings common in clinical workflows.
These design choices inherently involve trade-offs. Stronger privacy budgets and increased noise injection can reduce linguistic precision and semantic fidelity, while aggressive optimization for low latency may limit the complexity of privacy auditing mechanisms. PrivLLM-Guard prioritizes sensitivity-aware and adaptive privacy enforcement to mitigate these trade-offs, accepting moderate computational overhead in exchange for improved privacy robustness and sustained clinical relevance. Nevertheless, the framework is evaluated under controlled experimental conditions, and its performance may vary across datasets, model scales, and deployment environments. Additionally, while adaptive mechanisms reduce average utility loss, extreme privacy regimes may still impose measurable degradation, which highlights the importance of task-specific privacy calibration in real-world medical applications.
The empirical privacy evaluation reported in Section 5.2 provides practical evidence of PrivLLM-Guard’s robustness against common privacy attacks under controlled experimental conditions. These findings are particularly relevant for real-world deployment, where privacy guarantees must be validated not only theoretically but also through observed behavior under realistic threat models and operational constraints.
Although the technical performance of PrivLLM-Guard is excellent, there are a number of practical issues related to the deployment of the system in a real-life clinical setting beyond the accuracy and latency measures. These obstacles cut across compatibility of workflows, system integration, faith and interpretability.
The bounded utility loss predicted by the exponential mechanism is consistent with the observed stability of BLEU and ROUGE scores under strict privacy budgets in the experimental evaluation.
Integration with Electronic Health Record (EHR) Systems:
The means by which PrivLLM-Guard should prove useful in a clinical application is its ability to integrate with the current EHR systems, including Epic or Cerner or custom hospital systems. This entails the development of safe APIs that are HL7 FHIR compliant and have the capacity to stream information on a variety of sources that include structured fields, physician notes, as well as lab reports. Besides, inference pipelines should be resistant to sporadic data formats and the lack of data in clinical records.
Runtime Interpretability for Clinician Trust:
Many clinicians would require transparency in making decisions with the help of AI. Although PrivLLM-Guard ensures privacy by formally promising, its outputs have to be traced and understood to earn the trust of the users. In this regard, the incorporation of interpretability modules in real time (e.g., token-level influence scores, masked-entity visualizations or attention heatmaps) may help developers build more faith in the model and therefore more likely to use it during clinical practice.
Feedback Loop and Human Oversight:
As we have seen, clinicians will require a human-in-the-loop pathway, in which they can edit, overrule, or refuse a model output. This is not only necessary to achieve compliance in the legal context but also to train clinicians, perfect a system, and curb liability insurance. The implementation of such mechanisms needs good user interface design and trace of the changes with the maintenance of auditability.
Latency and Resource Constraints:
Latency is essential in cases when emergency care needs to be administered or in cases of telemedicine. Whereas the proposed PrivLLM-Guard shows sub-second performance on high-end GPUs, hospital settings could use systems based on CPUs or deployed at the edge. Reducing the framework and deploying on a limited hardware across quantization, model pruning, or distillation will be necessary to make such an application feasible in practice.
Regulatory and Organizational Alignment:
Legal, ethical and institutional policies restrict real-world applications of privacy-preserving AI systems. Besides HIPAA and GDPR compliance, other security policies and software test procedures as well as buying requirements are typically imposed by hospitals. Before a production rollout, one has to collaborate with compliance officers, IT departments, and legal counsel.
Training and Adoption Barriers:
AI implementation involves a lot of training, documentation, and support of users in clinical routines. Institutional culture variations, digital maturity and workload on staff can have a considerable impact on the degree of adoption. A smooth transition is possible with providing lightweight training modules, on-call technical support, and creating and configuring templates.
Summary:
To conclude, having a high technical score in test is not the only factor in rolling out PrivLLM-Guard in the field. It requires that EHR must be securely integrated, have clear interfaces, be able to support human oversight and be consistent with the organizational policies and clinical expectations. These dimensions are essential to convert privacy-saving language models that exist in lab prototypes to sound clinical tools.
7.2 Ethical Considerations and Fairness Implications
PrivLLM-Guard is designed to operate in alignment with established medical data protection regulations, including the Health Insurance Portability and Accountability Act (HIPAA) and the General Data Protection Regulation (GDPR). Compliance is achieved through formal differential privacy guarantees, strict privacy budget enforcement, and de-identification mechanisms that minimize the risk of patient re-identification during both training and inference. In particular, the use of
Beyond regulatory compliance, ethical considerations arise from the potential amplification of bias and inequity in generated medical text. Clinical language models trained on historical healthcare data may inherit existing disparities related to underrepresented demographic groups, rare diseases, or atypical clinical presentations. Differential privacy mechanisms can further exacerbate these issues if noise injection disproportionately affects low-frequency patterns, resulting in reduced clarity or diagnostic usefulness for minority populations. Our internal fairness analysis indicates that under strict privacy budgets, summaries involving rare conditions or non-majority demographic attributes may experience greater semantic degradation, highlighting the need for careful calibration of privacy mechanisms in sensitive clinical contexts.
From a deployment perspective, several risks must be considered. Improper configuration of privacy budgets may lead either to excessive noise, reducing clinical utility, or insufficient protection, increasing privacy exposure. To mitigate these risks, PrivLLM-Guard incorporates real-time privacy monitoring and audit logs that track cumulative privacy expenditure, model usage patterns, and potential risk thresholds during live operation. These audit trails support accountability by enabling retrospective inspection of model behavior and facilitating compliance reviews by institutional oversight bodies.
Misuse prevention is another critical ethical dimension. PrivLLM-Guard is intended as a decision-support tool rather than a replacement for clinical judgment. Safeguards such as access control, role-based authorization, and usage logging are essential to prevent unauthorized use, model probing attacks, or deployment outside approved clinical workflows. In addition, transparency mechanisms, including privacy budget reporting and risk alerts, are provided to inform practitioners of the privacy state of the system during operation.
Finally, ensuring fairness and ethical robustness requires continuous evaluation beyond initial deployment. Future extensions of PrivLLM-Guard will focus on fairness-aware noise calibration, demographic-sensitive privacy budgeting, and bias-aware training objectives to balance privacy protection with equitable clinical performance. These measures are essential for responsible adoption of privacy-preserving language models in healthcare settings, where ethical, legal, and social implications are inseparable from technical performance.
Clinical Liability and Governance Considerations
While PrivLLM-Guard is designed to support clinical documentation and summarization, it is not intended to function as an autonomous decision-making system. From a clinical liability perspective, responsibility for diagnosis, treatment decisions, and patient care remains with licensed healthcare professionals. The framework is therefore positioned strictly as a decision-support tool, and its outputs should be interpreted within established clinical workflows that require human verification and approval. This distinction is critical to prevent inappropriate reliance on automatically generated text and to align with existing medico-legal standards.
A particular ethical risk arises in scenarios involving hallucinated or factually incorrect outputs, which may occur even under strong privacy and utility constraints. In such cases, responsibility cannot be attributed solely to the model, but must be shared across system designers, deploying institutions, and clinical users. To address this, PrivLLM-Guard incorporates audit logging and traceability mechanisms that record model queries, generated outputs, privacy budget consumption, and risk alerts. These records enable post-hoc analysis of erroneous outputs and support accountability frameworks required by healthcare governance bodies.
From a governance standpoint, real-world deployment of privacy-preserving language models necessitates clear institutional oversight structures. This includes predefined approval workflows for model updates, routine privacy and performance audits, and role-based access control to restrict usage to authorized personnel. In addition, integration with hospital governance policies and ethics committees is essential to ensure that model behavior remains aligned with evolving regulatory requirements, clinical guidelines, and societal expectations. These governance mechanisms are particularly important in high-risk settings such as emergency medicine, where time constraints increase the potential impact of erroneous or biased outputs.
By explicitly addressing clinical liability boundaries, responsibility allocation in failure scenarios, and governance requirements, PrivLLM-Guard moves beyond descriptive ethical compliance toward a more critical and deployment-aware ethical framework. Such considerations are necessary for the responsible adoption of privacy-preserving large language models in real-world healthcare environments.
This paper presented PrivLLM-Guard, a novel differentially-private large language model framework specifically designed for real-time confidential medical text generation and summarization. Through comprehensive experimental evaluation, we demonstrated that our approach achieves superior performance in privacy preservation, utility maintenance, and computational efficiency compared to existing state-of-the-art methods. The framework’s adaptive noise calibration, hierarchical privacy budget allocation, and real-time monitoring capabilities collectively address critical limitations in current privacy-preserving language models. With BLEU scores of 89.7% for text generation, ROUGE-L scores of 92.3% for summarization, and 65.9% reduction in privacy risks while maintaining sub-second processing latency, PrivLLM-Guard establishes a new benchmark for privacy-preserving medical AI systems. Its stable high-performance in several medical fields and strong privacy guarantees on different kinds of attacks prove the feasibility of the implementation of advanced language models into the healthcare setting with no risks to privacy of patients. Future research is based on expanding the framework into multimodal medical data, the need to scale up to larger models and the need to perform longitudinal studies within the real clinical setting with an eye towards determining long-term performance and acceptance of this technology. In future, a number of specific extensions of the current framework will be developed. The second step is to combine speech-to-text in real time pipelines with differential privacy to secure clinical voice documentation. Second, we intend to augment multimodal medical information with X-rays, laboratory results as well as a structured EHR and text-based notes. Lastly, we will look at federated fine-tuning and domain adaptation methods that can make it possible to deploy a model in geographically disparate hospitals without any need to sharing data in a central location.
Limitations and Future Work:
The results reported in this study are evaluated under controlled experimental conditions using curated large-scale medical datasets and standardized privacy budgets. While these settings reflect realistic clinical configurations, real-world deployments may introduce additional challenges related to data heterogeneity, evolving documentation practices, and institutional variability. Moreover, although PrivLLM-Guard demonstrates consistent improvements across privacy, utility, and efficiency metrics, performance may vary under more extreme privacy regimes or substantially larger model scales. The current evaluation also focuses on short- to medium-length clinical text generation, and longer longitudinal documentation workflows may require further optimization. Addressing these limitations through extended real-world trials, broader clinical validation, and adaptive deployment strategies constitutes an important direction for future research.
Acknowledgement: This study is carried out at the Department of Computer Science, Faculty of Computing and Information, Al-Baha University, Saudi Arabia.
Funding Statement: The author received no specific funding for this study.
Availability of Data and Materials: The datasets generated and analyzed during this study will be made available by the corresponding author upon reasonable request at: ans@bu.edu.sa.
Ethics Approval: Ethical approval for the use of the hospital dataset comprising 1.5 million de-identified patient records was obtained from the Institutional Review Board (IRB) at City Hospital—Medical Complex, Bahawalpur, Pakistan, under (Approval No.: CHMC/IRB/2025/067). The MIMIC-III (available at: https://www.kaggle.com/datasets/asjad99/mimiciii) and i2b2-based dataset (available at: https://www.kaggle.com/code/abdulmajeedissifu/data-augmentation-on-i2b2-dataset-for-ner-task) are publicly available, fully anonymized datasets released for research purposes in compliance with applicable privacy and ethical standards. The IRB waived the requirement for informed consent in accordance with national ethical regulations, considering the anonymized and non-interventional nature of the study.
Conflicts of Interest: The author declares no conflict of interest.
Nomenclature
| Symbol | |
| Symbol | Description |
| Privacy budget parameter | |
| Privacy guarantee failure probability | |
| Privacy mechanism | |
| Global sensitivity of function | |
| Gradient clipping bound | |
| Noise standard deviation | |
| Gaussian distribution with mean | |
| Query, key, and value matrices in attention | |
| Dimension of key vectors | |
| Loss function | |
| Loss weighting parameters | |
| Sensitivity weight for token | |
| Probability distribution | |
| Embedding vector for token | |
| Utility function | |
| Regularization parameters | |
| LLM | Large Language Model |
| DP | Differential Privacy |
| HIPAA | Health Insurance Portability and Accountability Act |
| GDPR | General Data Protection Regulation |
| GPU | Graphics Processing Unit |
| CPU | Central Processing Unit |
| SGD | Stochastic Gradient Descent |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
| PrivLLM-Guard Hyperparameter Settings | |
| Component | Value/Description |
| Privacy budget | 0.1 (default), tuned in [0.01–1.0] |
| Privacy failure probability | 10−6 |
| Gradient clipping threshold | 1.2 (adaptive per Eq. (4)) |
| Noise standard deviation | Computed using DP-Gaussian mechanism |
| Learning rate | 3 × 10−5 |
| Optimizer | AdamW |
| Batch size | 16 |
| Training epochs | 5–10 (early-stopped) |
| Embedding noise | 0.5 |
| Attention noise | 0.3 |
| Loss weights | (1.0, 1.0, 0.5) |
| Distillation temperature | 2.0 (used in Ldistill) |
| Window size for budget tracking | 50 |
| Quantile for adaptive clipping | 0.5 (median) |
| Momentum for clipping update | 0.9 |
| Utility function sensitivity | Empirically tuned per task |
| Token-level sensitivity weights | Derived from NER & ICD codes |
| Privacy-aware beam width | 5 |
| Max sequence length | 512 tokens |
Appendix A: Evaluation Metrics and Definitions
Privacy Risk Score:
The Privacy Risk Score is a composite indicator designed to summarize a model’s vulnerability to privacy attacks. It is computed by aggregating normalized outcomes from membership inference attacks, attribute inference attacks, and model extraction attacks. Each component is measured using standardized attack protocols under identical privacy budgets. The final score is obtained by weighted averaging, where higher values indicate increased privacy risk.
Clinical Relevance Score:
The Clinical Relevance Score measures the usefulness and correctness of generated medical text for clinical practice. It is assessed by licensed medical professionals across multiple specialties using a structured evaluation rubric. The assessment considers factual accuracy, clinical completeness, contextual appropriateness, and absence of misleading information. Scores are assigned on a normalized scale and averaged across evaluators.
Overall Utility Index:
The Overall Utility Index is a composite metric that summarizes task-level performance under differential privacy constraints. It aggregates standardized linguistic quality metrics (BLEU-4, ROUGE-L, METEOR), medical entity recognition accuracy, clinical relevance score, and semantic coherence score. All components are normalized to a common scale before aggregation to ensure balanced contribution.
Semantic Coherence Score:
The Semantic Coherence Score evaluates logical flow, readability, and contextual consistency of generated text. It is computed using a hybrid approach combining automated coherence modeling and expert linguistic review, reported on a normalized scale.
Evaluation Metrics definitions and Symbols:
BLEU-4:
A standard n-gram overlap metric (4-g) used to evaluate text generation quality by comparing generated text against reference medical texts. Computed automatically using corpus-level precision with brevity penalty.
ROUGE-L:
A recall-oriented metric based on the longest common subsequence between generated summaries and reference summaries. Used to assess summarization quality in clinical narratives.
METEOR:
An automatic evaluation metric measuring alignment between generated and reference text based on exact matches, stem matches, and synonym matches, providing improved correlation with human judgment.
Medical Entity Accuracy (%):
The proportion of correctly identified and classified medical entities (e.g., diseases, procedures, medications) relative to ground-truth annotations. Computed using standard precision-recall matching against annotated clinical datasets.
Clinical Relevance Score:
A clinician-assessed score measuring the usefulness and correctness of generated text for clinical decision-making. Evaluated on a 0–100 scale by board-certified medical professionals across multiple specialties, based on factual correctness, contextual appropriateness, and absence of misleading information.
Semantic Coherence Score:
A linguistic quality score evaluating logical consistency, readability, and contextual flow of generated text. Computed using a hybrid approach combining automated coherence models and expert linguistic review, normalized on a 0–10 scale.
Overall Utility Score:
A composite metric aggregating BLEU-4, ROUGE-L, METEOR, Medical Entity Accuracy, Clinical Relevance, and Semantic Coherence. Computed as a weighted normalized average to reflect overall task usefulness under privacy constraints.
Membership Inference Risk (%):
The probability that an adversary can correctly infer whether a specific patient record was included in the training data. Evaluated using standard membership inference attack protocols.
Attribute Inference Risk (%):
The likelihood that sensitive patient attributes (e.g., diagnosis, demographic information) can be inferred from model outputs under adversarial analysis.
Model Extraction Success (%):
The success rate of reconstructing model behavior or parameters through repeated query attacks.
Privacy Risk Score:
An aggregate risk indicator derived from membership inference, attribute inference, and model extraction outcomes, normalized to allow cross-model comparison.
Privacy Budget (ε, δ):
Formal differential privacy parameters where ε controls privacy strength and δ represents the probability of privacy guarantee violation.
Latency (ms):
End-to-end inference time per request measured in milliseconds under real-time clinical workload conditions.
Throughput (req/s):
Number of medical text generation requests processed per second during sustained inference.
1https://www.kaggle.com/datasets/asjad99/mimiciii
2https://www.kaggle.com/code/abdulmajeedissifu/data-augmentation-on-i2b2-dataset-for-ner-task
References
1. Liu L, Yang X, Lei J, Shen Y, Wang J, Wei P. A survey on medical large language models: technology, application, trustworthiness, and future directions. arXiv:2401.12345. 2024. [Google Scholar]
2. Al Nazi Z, Peng W. Large language models in healthcare and medical domain: a review. Informatics. 2024;11(3):57. doi:10.3390/informatics11030057. [Google Scholar] [CrossRef]
3. Wang D, Zhang S. Large language models in medical and healthcare fields: applications, advances, and challenges. Artif Intell Rev. 2024;57(11):299. doi:10.1007/s10462-024-10921-0. [Google Scholar] [CrossRef]
4. Żarski TL, Janicki A. Enhancing privacy while preserving context in text transformations by large language models. Information. 2025;16(1):49. doi:10.3390/info16010049. [Google Scholar] [CrossRef]
5. Neupane S, Mitra S, Mittal S, Gaur M, Golilarz NA, Rahimi S, et al. MedInsight: a multi-source context augmentation framework for generating patient-centric medical responses using large language models. ACM Trans Comput Healthc. 2025;6(2):1–19. doi:10.1145/3709365. [Google Scholar] [CrossRef]
6. Ahmed S. Clinical note generation from doctor-patient conversations using decoder-only large language models [dissertation]. Dhaka, Bangladesh: BRAC University; 2024. [Google Scholar]
7. Feretzakis G, Verykios VS. Trustworthy AI: securing sensitive data in large language models. AI. 2024;5(4):2773–800. doi:10.3390/ai5040134. [Google Scholar] [CrossRef]
8. Malode G, Mahajan P, Shelar P, Sardar A, Dhamale N. Automated summarization of healthcare record using LLM. International Journal of Technical Education. [cited 2026 Jan 1]. Available online: https://www.isteonline.in/Datafiles/cms/2025/IJTE%20spl%20issue%202%20June%202025.pdf. [Google Scholar]
9. Zheng Y, Gan W, Chen Z, Qi Z, Liang Q. Large language models for medicine: a survey. Int J Med Inform. 2025;142(2):1–18. doi:10.1007/s13042-024-02318-w. [Google Scholar] [CrossRef]
10. Li C, Meng Y, Dong L, Ma D, Wang C, Du D. Ethical privacy framework for large language models in smart healthcare: a comprehensive evaluation and protection approach. IEEE J Biomed Health Inform. 2025;2025:1–14. doi:10.1109/jbhi.2025.3576579. [Google Scholar] [PubMed] [CrossRef]
11. Abbasalizadeh M, Narain S. Privacy-aware detection for large language models using a hybrid BiLSTM-HMM approach. IEEE Access. 2025;13:121880–901. doi:10.1109/ACCESS.2025.3587988. [Google Scholar] [CrossRef]
12. Zhang R, Li HW, Qian XY, Jiang WB, Chen HX. On large language models safety, security, and privacy: a survey. J Electron Sci Technol. 2025;23(1):100301. doi:10.1016/j.jnlest.2025.100301. [Google Scholar] [CrossRef]
13. Nemati A, Assadi Shalmani M, Lu Q, Luo J. Benchmarking large language models from open and closed source models to apply data annotation for free-text criteria in healthcare. Future Internet. 2025;17(4):138. doi:10.3390/fi17040138. [Google Scholar] [CrossRef]
14. Kunze KN, Nwachukwu BU, Cote MP, Ramkumar PN. Large language models applied to health care tasks may improve clinical efficiency, value of care rendered, research, and medical education. Arthrosc J Arthrosc Relat Surg. 2025;41(3):547–56. doi:10.1016/j.arthro.2024.12.010. [Google Scholar] [PubMed] [CrossRef]
15. Khoje M. Navigating data privacy and analytics: the role of large language models in masking conversational data in data platforms. In: 2024 IEEE 3rd International Conference on AI in Cybersecurity (ICAIC); 2024 Feb 7–9; Houston, TX, USA. p. 1–5. doi:10.1109/ICAIC60265.2024.10433801. [Google Scholar] [CrossRef]
16. Kalodanis K, Papadopoulos S, Feretzakis G, Rizomiliotis P, Anagnostopoulos D. SecureLLM: a unified framework for privacy-focused large language models. Appl Sci. 2025;15(8):4180. doi:10.3390/app15084180. [Google Scholar] [CrossRef]
17. Ibrahim N, Aboulela S, Ibrahim A, Kashef R. A survey on augmenting knowledge graphs (KGs) with large language models (LLMsmodels, evaluation metrics, benchmarks, and challenges. Discov Artif Intell. 2024;4(1):76. doi:10.1007/s44163-024-00175-8. [Google Scholar] [CrossRef]
18. Chard S, Johnson B, Lewis D. Auditing large language models for privacy compliance with specially crafted prompts. OSF Prepr. 2024:1–7. Available at: https://osf.io/preprints/osf/8tgkx/. [Google Scholar]
19. AlSaad R, Abd-alrazaq A, Boughorbel S, Ahmed A, Renault MA, Damseh R, et al. Multimodal large language models in health care: applications, challenges, and future outlook. J Med Internet Res. 2024;26:e59505. doi:10.2196/59505. [Google Scholar] [PubMed] [CrossRef]
20. Rathod V, Nabavirazavi S, Zad S, Iyengar SS. Privacy and security challenges in large language models. In: 2025 IEEE 15th Annual Computing and Communication Workshop and Conference (CCWC); 2025 Jan 6–8; Las Vegas, NV, USA. p. 746–52. doi:10.1109/CCWC62904.2025.10903912. [Google Scholar] [CrossRef]
21. Chen C, Zhou D, Ye Y, Li TJ, Yao Y. CLEAR: towards contextual LLM-empowered privacy policy analysis and risk generation for large language model applications. In: Proceedings of the 30th International Conference on Intelligent User Interfaces; 2025 Mar 24–27; Cagliari, Italy. p. 277–97. doi:10.1145/3708359.3712156. [Google Scholar] [CrossRef]
22. Das BC, Amini MH, Wu Y. Security and privacy challenges of large language models: a survey. ACM Comput Surv. 2025;57(6):1–39. doi:10.1145/3712001. [Google Scholar] [CrossRef]
23. Zhang X, Xu H, Ba Z, Wang Z, Hong Y. Privacyasst: safeguarding user privacy in tool-using large language model agents. In: Proceedings of the 54th Annual IEEE/IFIP International Conference on Dependable Systems and Networks; 2024 Jun 24–27; Brisbane, Australia. p. 445–8. doi:10.1109/TDSC.2024.3372777. [Google Scholar] [CrossRef]
24. Ali H, Nfor KA, Kim HC. Text generation models in healthcare: opportunities and challenges for medical report automation [Internet]. [cited 2026 Jan 1]. Available from: https://www.dbpia.co.kr/Journal/articleDetail?nodeId=NODE12000785. [Google Scholar]
25. Wang S, Zhu T, Liu B, Ding M, Guo X, Ye D. Unique security and privacy threats of large language model: a comprehensive survey. arXiv:2402.12345. 2024. [Google Scholar]
26. Verma R, Alsentzer E, Strasser Z, Chang L, Roman K, Gershanik E, et al. Verifiable summarization of electronic health records using large language models to support chart review. medRxiv. 2025. doi:10.1101/2025.06.02.25328807. [Google Scholar] [CrossRef]
27. Ullah I, Hassan N, Gill SS, Suleiman B, Ahanger TA, Shah Z, et al. Privacy preserving large language models: ChatGPT case study based vision and framework. IET Blockchain. 2024;4(S1):706–24. doi:10.1049/blc2.12091. [Google Scholar] [CrossRef]
28. Malode VM. Benchmarking public large language model [master’s thesis]. Ingolstadt, Germany: Technische Hochschule Ingolstadt; 2024. [Google Scholar]
29. Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. Adv Neural Inf Process Syst. 2017;30:1–11. doi:10.65215/ctdc8e75. [Google Scholar] [CrossRef]
30. Devlin J, Chang MW, Lee K, Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; 2019 Jun 2–7; Minneapolis, MN, USA. p. 4171–86. doi:10.18653/v1/N19-1423. [Google Scholar] [CrossRef]
31. Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, et al. Language models are few-shot learners. Adv Neural Inf Process Syst. 2020;33:1877–901. doi:10.18653/v1/2021.mrl-1.1. [Google Scholar] [CrossRef]
32. Huang K, Altosaar J, Ranganath R. ClinicalBERT: modeling clinical notes and predicting hospital readmission. arXiv:1904.05342. 2019. [Google Scholar]
33. Luo R, Sun L, Xia Y, Qin T, Zhang S, Poon H, et al. BioGPT: generative pre-trained transformer for biomedical text generation and mining. Brief Bioinform. 2022;23(6):bbac409. doi:10.1093/bib/bbac409. [Google Scholar] [PubMed] [CrossRef]
34. Johnson AEW, Pollard TJ, Shen L, Lehman LH, Feng M, Ghassemi M, et al. MIMIC-III, a freely accessible critical care database. Sci Data. 2016;3(1):160035. doi:10.1038/sdata.2016.35. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools