
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

An Adaptive Imperialist Competitive Algorithm with Cooperation for Flexible Jobshop and Parallel Batch Processing Machine Scheduling
School of Automation, Wuhan University of Technology, Wuhan, China
* Corresponding Author: Deming Lei. Email:
(This article belongs to the Special Issue: Swarm-Based Optimization and its Cross-Disciplinary Applications in Modern Engineering)
Computers, Materials & Continua 2026, 87(3), 79 https://doi.org/10.32604/cmc.2026.076202
Received 16 November 2025; Accepted 29 December 2025; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Both flexible jobshop scheduling and parallel batch processing machine scheduling have been extensively considered; however, the flexible jobshop and parallel batch processing machine scheduling problem (FJPBPMSP) is prevalent in real-life manufacturing processes and is seldom investigated. In this study, FJPBPMSP is examined, where flexible processing and batch processing are performed sequentially. An adaptive imperialist competitive algorithm with cooperation (CAICA) is proposed to minimize makespan and total energy consumption simultaneously. In CAICA, a four-string representation is adopted, and initial empires with novel structures are formed by uniformly dividing the population. An adaptive assimilation and revolution are designed. An adaptive assimilation and revolution are designed. An adaptive imperialist competition with cooperation is provided. Search strategies, imperialists, and colonies are also renewed by new procedures. Computational experiments are conducted on 50 instances. The computational results show that the new strategies of CAICA are effective, and CAICA can provide better results than its comparative algorithms in solving FJPBPMSP.Keywords
Flexible production is often used, and a flexible jobshop consists of M machines, and at least one operation can be processed by more than one machine. Flexible jobshop scheduling problem (FJSP) has been widely applied in many industries such as automobile assembly, textile, chemical material processing, and semiconductor manufacturing, etc., and consists of two main sub-problems: machine assignment and scheduling. In the past decades, FJSP has been considered extensively, and a number of results have been obtained.
Batch processing is a typical production mode and has been widely applied in manufacturing processes of textile, chemical, mineral, pharmaceutical, and semiconductor, etc. Batch processing machines (BPM) can simultaneously process multiple jobs in a batch. Parallel batch and serial batch are often considered; the processing time of the former is the maximum processing time of all jobs in a batch, and the processing time of the latter is the sum of the processing time of all jobs in a batch. The parallel BPM scheduling problem is a typical BPM scheduling problem and has attracted much attention.
As shown above, FJSP and parallel BPM scheduling problems have been studied fully; however, as the combination of FJSP and BPM scheduling, the flexible jobshop and parallel batch processing machine scheduling problem (FJPBPMSP) is seldom considered. In fact, this problem exists in electronic product performance testing [1] and transformer production [2], etc. There are typically two types of FJPBPMSP. The first one is FJSP with some BPMs, and the second consists of a flexible jobshop and parallel BPMs. Single job processing is first done in the flexible jobshop, and then batch processing is executed on parallel BPMs. The second one often occurs in the transformer production process, etc., and is hardly considered.
The imperialist competitive algorithm (ICA) is inspired by the historical phenomena of imperialism and colonialism and has good neighborhood search ability, effective global search property, good convergence rate, and flexible structure. In recent years, ICA has been extensively applied to solve various production scheduling problems, such as FJSP [3,4] and parallel BPM scheduling [5]; however, ICA is not used to solve FJPBPMSP. ICA has successfully been applied to solve FJSP and parallel BPM scheduling, and results revealed that ICA has strong search advantages in solving the above problems. FJPBPMSP is the integration of FJSP and parallel BPM scheduling. The advantages of ICA for FJSP and parallel BPM scheduling show that ICA has potential advantages in handling FJPBPMSP, so ICA is chosen in this study.
The prior research on FJPBPMSP is mainly about the first one, with the minimization of makespan, and multi-objective FJPBPMSP is seldom considered. On the other hand, only one paper [2] is related to the second type of FJPBPMSP, which often exists in transformer production, etc., so it is necessary to handle the second type of FJPBPMSP with multi-objectives.
The main contributions of this paper are summarized as follows:
(1) A multi-objective FJPBPMSP and a mixed-integer linear programming (MILP) model are developed. (2) An adaptive imperialist competitive algorithm with cooperation (CAICA) is proposed to minimize makespan and total energy consumption simultaneously. To produce high quality solutions, a four-string representation is employed to encode the integrated decisions of machine assignment, operation sequencing, batching, and batch scheduling; an empire initialization strategy with uniform division is devised to enhance population diversity; adaptive assimilation and revolution operators are introduced to achieve balanced exploration and exploitation; a cooperative imperialist competition mechanism is constructed to improve convergence stability and solution quality. (3) Computational experiments are conducted on 50 instances. The computational results demonstrate the effectiveness of new strategies and the promising performance of CAICA in solving multi-objective FJPBPMSP.
The previous works on FJSP, parallel BPM scheduling, and FJPBPMSP are shown below.
FJSP has attracted much attention since the pioneering works of Brucker and Schlie [6]. Dauzère-Pérès et al. [7] provided a survey paper, which recalled the related works on FJSP in the past 30 years according to criteria, constraints, configurations, and solution approach. As shown in the survey paper, exact approach [8], heuristic [9,10], and meta-heuristics are often used to solve FJSP. Meta-heuristics are the main method for FJSP because of its high complexity. FJSP has been solved by simulated annealing [11], tabu search (TS, [12]), variable neighborhood search (VNS, [13]), genetic algorithm (GA, [14]), particle swarm optimization (PSO, [15]), ant colony optimization (ACO, [16]), ICA [3], etc.
Reducing energy consumption or environmental impacts has become the main concern of manufacturing companies, and energy-efficient scheduling problems have been investigated fully in the past decade. As a typical energy-efficient scheduling, energy-efficient FJSP has attracted much attention. Luo et al. [17] presented an elaborately-designed multi-objective grey wolf optimization algorithm to solve the problem with variable processing speeds. Ebrahimi et al. [18] introduced four meta-heuristics to solve the problem with three machine states, facility energy cost, and job tardiness penalty. Li et al. [19] solved the problem with setup time and transportation by using an improved Jaya algorithm with problem-specific local search operators. Caldeira et al. [20] dealt with the problem of new job arrivals and turn-on/off strategy and presented an improved backtracking search algorithm.
Akram et al. [21] studied dynamical energy-efficient FJSP with insertion of new jobs and proposed a multi-objective black widow spider algorithm. Jiang et al. [22] solved the problem with two speed-adjustable resources by using a Q-learning-based biology migration algorithm. Zhao et al. [23] developed a double Q-learning-assisted competitive evolutionary algorithm for solving the problem with breakdown and job insertion. Hao et al. [24] presented a hybrid search genetic algorithm (HSGA) to deal with energy-saving FJSP. Xiao et al. [25] studied the production scheduling problem in the aerospace industry and proposed an improved decomposition-based multi-objective evolutionary algorithm (IMOEA/D). Luan et al. [26] presented an enhanced non-dominated sorting genetic algorithm-II (ENSGA-II) to solve energy-saving FJSP. Fan et al. [27] gave a knowledge-enhanced multi-objective memetic algorithm for the problem with a limited multi-load automated guided vehicle. Li and Lei [4] presented an ICA with feedback to solve the problem with transportation and setup times.
The parallel BPM scheduling problem consists of some BPMs and
Uniform parallel BPM scheduling is often solved by mathematical programming [28], heuristic [29], and meta-heuristics such as ACO [30,31], GA [5], ICA [5] and differential evolution [32].
With respect to unrelated parallel BPM scheduling, Lu et al. [33] developed a hybrid artificial bee colony with TS to solve the problem with maintenance and deteriorating jobs. Zhou et al. [34] solved the problem with different capacities and arbitrary job sizes by a random key GA. A shuffled frog-leaping algorithm with VNS is presented for the problem with nonlinear processing time [35]. Xiao et al. [36] proposed a tabu-based adaptive large neighborhood search algorithm. Hu et al. [37] presented a mixed integer linear programming model and an adaptive large neighborhood search for the problem with two-dimensional packing constraints in additive manufacturing.
2.3 Flexible Jobshop and Parallel Batch Processing Machine Scheduling
Two types of FJPBPMSP are often considered. In the first problem, some operations of jobs can be processed on BPMs. For the first problem with all operations processed on BPM, Ham and Cakici [38] proposed an enhanced mixed integer programming (MIP) model, an MIP model with valid inequalities, and a constraint programming model, while Ham [39] formulated an MIP model with priority jobs. Ji et al. [40] proposed a multi-commodity flow model for small-scale problems and constructed an improved adaptive large neighborhood search algorithmic framework with an optimal repair and tabu-based components. Regarding the first problem, where a portion of operations are processed on BPMs, Zhang et al. [1] studied the problem that involves both mandatory and flexible batch processing operations, established an MIP model, and developed a GA enhanced with neighborhood search to minimize makespan. Wang et al. [41] presented an improved scatter search algorithm integrated with a batch job addition algorithm and simulated annealing-based local search. Xue et al. [42] established an MIP model and developed an enhanced multi-population GA with VNS and an immediate predecessor operation-based batching method to minimize makespan.
The second FJPBPMSP is hardly considered, in which
FJPBPMSP is composed of
In a flexible jobshop, there exists at least one operation with two machines in
There are some constraints on jobs and machines.
A job or a batch can be processed on at most one machine at a time.
A machine processes at most one job or one batch at a time.
Processing of the job or batch cannot be interrupted.
A job can only be assigned to one batch.
The problem is composed of five sub-problems, which are machine assignment and scheduling in a flexible jobshop, BPM assignment, batch formation, and batch scheduling on parallel BPM. Machine assignment and BPM assignment are used to select an
The definitions of the mathematical notations are listed in Table 1.

The MILP formulation is detailed below.
s.t.
where
Eqs. (1) and (2) specify two objective functions for minimization: makespan and total energy consumption. Constraint (3) calculates operation completion time. Constraint (4) assigns each operation to exactly one machine. Constraints (5) and (6) prevent operation overlap on the same machine. Constraint (7) considers transportation time between operations. Constraint (8) calculates the arrival time at batch machines. Constraint (9) assigns each job to one batch machine. Constraint (10) assigns jobs to batches. Constraint (11) enforces batch capacity limits. Constraint (12) determines batch processing time. Constraint (13) calculates batch arrival time. Constraint (14) ensures batch start time is after arrival. Constraint (15) sequences batches on the same machine. Constraint (16) calculates batch completion time. Constraint (17) maintains batch sequence continuity. Constraint (18) sets the job completion time as the batch completion time. Eqs. (19), (20), and (21) are the energy consumption of processing, idle time, and transportation, respectively.
Tables 2 and 3 show an example of the problem with 6 jobs, 3 machines for single job processing, and 2 BPMs. “–” means that
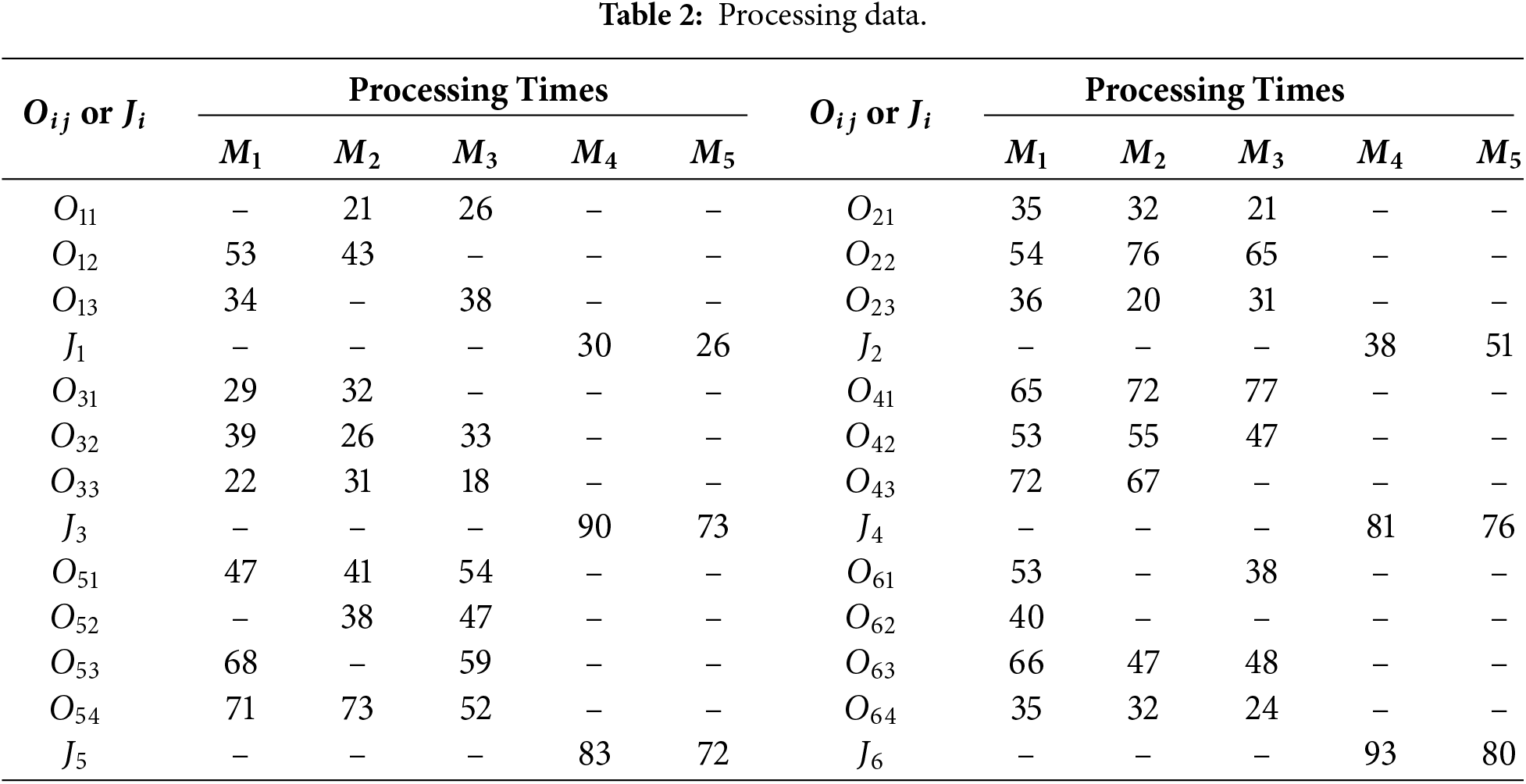
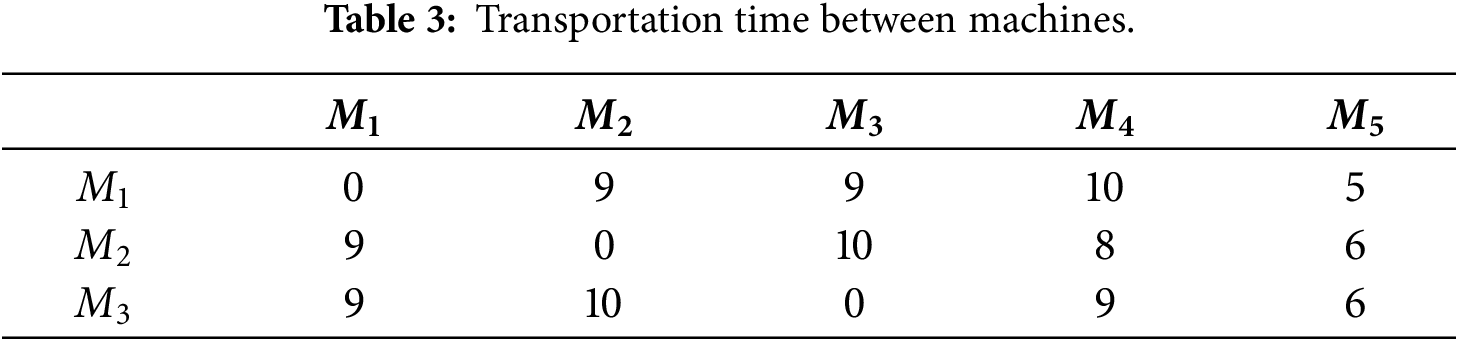
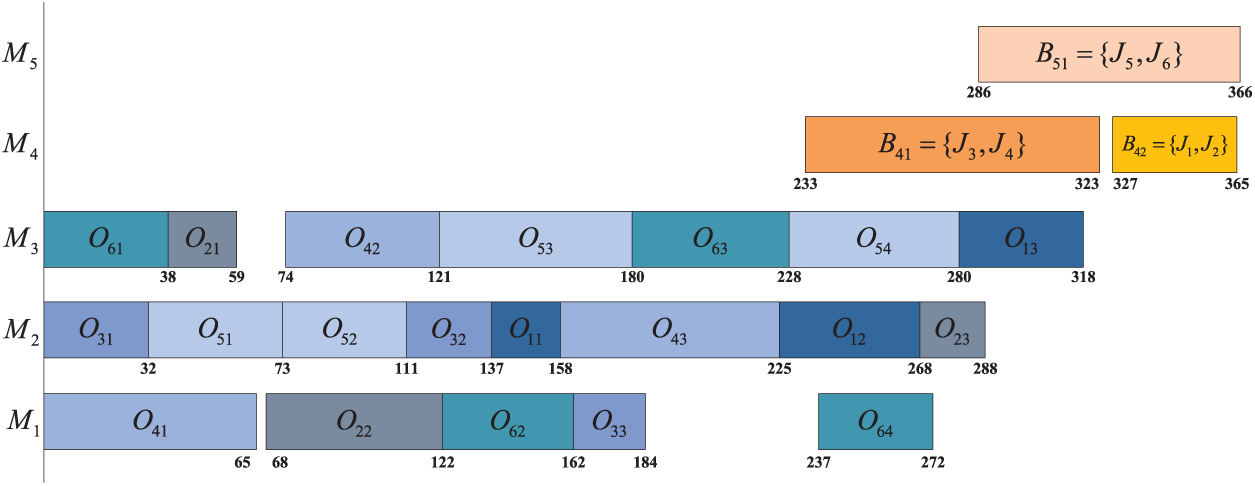
Figure 1: A schedule of the example.
In this scheduling example, the energy consumption process is as follows: Take job
FJPBPMSP has many sub-problems, and each of them is NP-hard. To solve FJPBPMSP, a novel ICA is developed by using new structures of empires, adaptive assimilation, revolution, and the combination of competition and cooperation of empires.
4.1 Initialization and Initial Empires Formation
The problem is the integration of FJSP and the parallel BPM scheduling problem, and it has five sub-problems. Four-string representation is used. For the problem with
The decoding procedure is described as follows.
(1) Convert scheduling string
(2) On each BPM
The first-formed first-processing rule means that the processing sequence of batches is their formation sequence.
Suppose the sub-string of
Batch formation on
(1) Construct batch
(2) For
For the example shown in Tables 2 and 3, a solution is composed of scheduling string [6 3 2 4 4 5 2 5 3 6 1 5 4 6 3 1 5 2 1 6], machine assignment string [2 2 3 3 1 2 2 2 1 1 3 2 2 2 3 3 3 1 3 1], BPM scheduling string [3 4 6 1 5 2] and BPM assignment string [4 4 4 4 5 5]. After the processing in flexible jobshop is finished, jobs
Initial population P consists of N initial solutions and is generated in the following way:
(1) For each
(2) The strategy [44] is used to produce a machine assignment string of all solutions.
With respect to the strategy [44], a machine assignment string of
Initial empires are formed below.
(1) Execute non-dominated sorting and crowding distance computation [45], compute normalized cost
(2) For
where
There are
Two global search operators are given, which are precedence-preserving order-based crossover (POX) [26] and uniform crossover [25]. When POX is performed on solutions
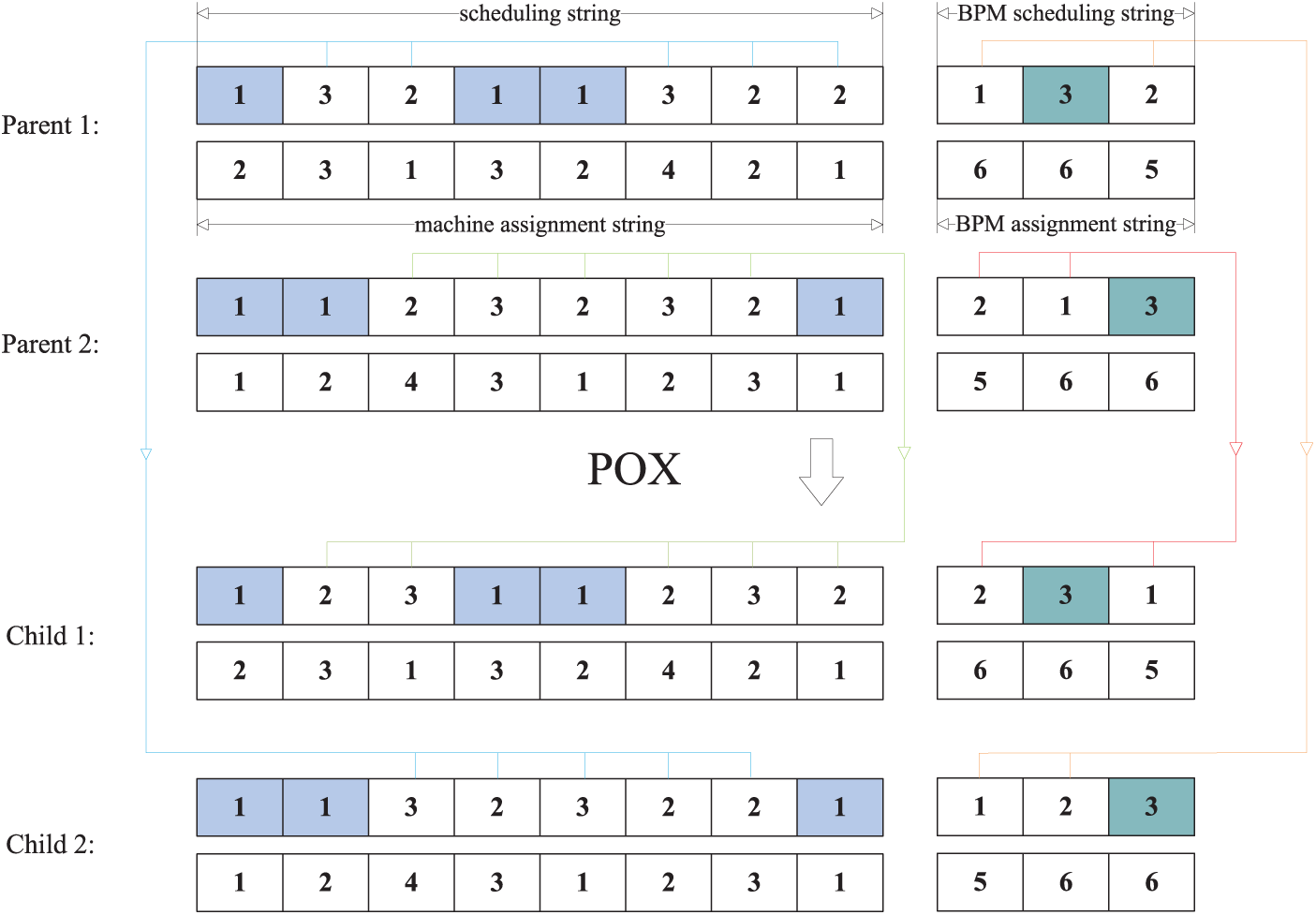
Figure 2: Example of POX.
Six neighborhood structures are denoted as
For each solution
Search process 1 for
Where
For
Search process 2 for
(1) Execute GS of
(2) Perform GS of
4.3 Adaptive Assimilation and Revolution
Assimilation is the main step for producing new solutions. In the assimilation process of empire
In general, only one imperialist as a unique learning object exists in an empire, and each colony moves to its imperialist in the same way. In this study, an adaptive assimilation is given, in which two learning objects of each empire are used adaptively, and the search strategy of each colony is determined dynamically.
Revolution is similar to the mutation of GA and is applied to increase exploration and prevent the early convergence to local optima. Revolution is shown as follows. In each empire
Adaptive assimilation and revolution on generation
(1) Calculate
(2) For each empire
1) Decide
2) For each
(3) For each empire
Where
where
In step (3),
After assimilation and revolution are performed, two imperialists are updated in the following way: in each empire
As shown above,
4.4 Adaptive Imperialist Competition with Cooperation
In ICA, imperialist competition is often implemented as follows: compute total cost and
Adaptive imperialist competition is described as follows.
(1) Calculate
(2) If
(3) If
1) Sort all colonies of empires 1,
2)
3) Perform imperialist competition of step (2) for the remaining
In 2) of step (3), cooperation between the strongest empire 1 and the worst empire
The steps of CAICA are shown below.
(1) Generate initial population P, construct initial
(2) Form initial empires.
(3) Perform adaptive assimilation and revolution.
(4) Renew imperialists of each empire.
(5) Execute adaptive imperialist competition with cooperation.
(6) Update each colony
(7)
Fig. 3 shows the flow chart of CAICA. In each empire
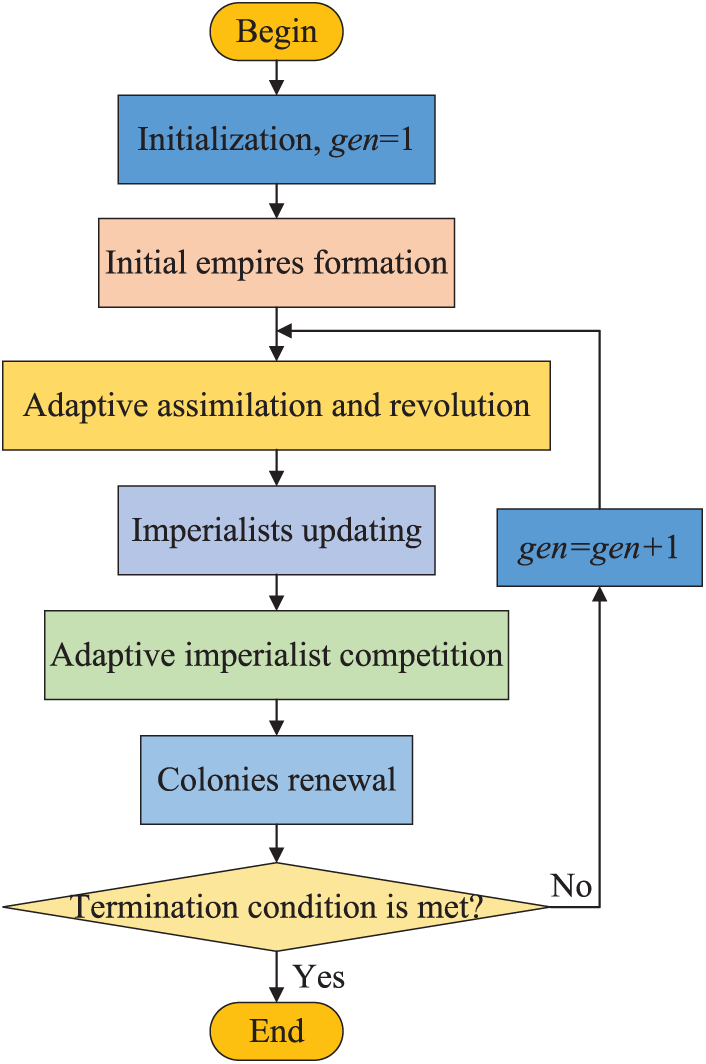
Figure 3: Flow chart of CAICA.
Unlike the previous ICA [47–50], CAICA incorporates several novel features: (1) Each empire is assigned two imperialists; (2) Adaptive assimilation and revolution are introduced, in which colonies adaptively select one for assimilation based on their
Extensive computational experiments are conducted to test the performance of CAICA for FJPBPMSP. All experiments are implemented using Visual Studio 2022 and run on a PC with 8 GB RAM and a 1.8 GHz CPU.
5.1 Instances, Comparative Algorithms and Metrics
FJPBPMSP is seldom considered, and no existing instances can be used. To construct instances for FJPBPMSP, instances Mk01-Mk10 [51], and La01-40 [52] are extended by adding BPMs, and the extended Mk01-Mk10 and La01-La40 are labelled as mMk01-mMk10 and mLa01-mLa40. The added data are shown below:
The coverage metric
Metric HV [54] is used to calculate the hypervolume of the non-dominated solution set
Metric IGD [55] is about the distance of the non-dominated set
where
Three comparative algorithms are chosen. Hao et al. [24] developed HSGA for FJSP, aiming to minimize maximum machine load, total machine load, and makespan. Xiao et al. [25] presented IMOEA/D for FJSP considering makespan, tool number, machine load, and machine energy consumption. Luan et al. [26] proposed ENSGA-II for FJSP with makespan, total delay time, and total energy consumption.
When HSGA is used to solve FJPBPMSP, BPM assignment string, BPM scheduling string, POX, and
For IMOEA/D, when crossover is performed, POX on scheduling string, POX on BPM scheduling string, uniform crossover on machine assignment string and uniform crossover on BPM assignment string are used,
When ENSGA-II is applied, POX and uniform crossover are used on the BPM scheduling string and the BPM assignment string, respectively. When crossover is performed, the corresponding operator is applied sequentially to each of the four strings. Similarly, for mutation, the
To show the effect of new strategies of CAICA, a ICA is constructed, in which initial empires formation and imperialist competition are done in the general ICA. In each empire
Parameters of CAICA are N,
Extensive experiments indicate that CAICA converges well when
The Taguchi method was used to determine the settings of other parameters by using instance mLa25. CAICA, with each parameter combination, randomly runs 20 times for the chosen instance. There are 16 parameter combinations according to the orthogonal array

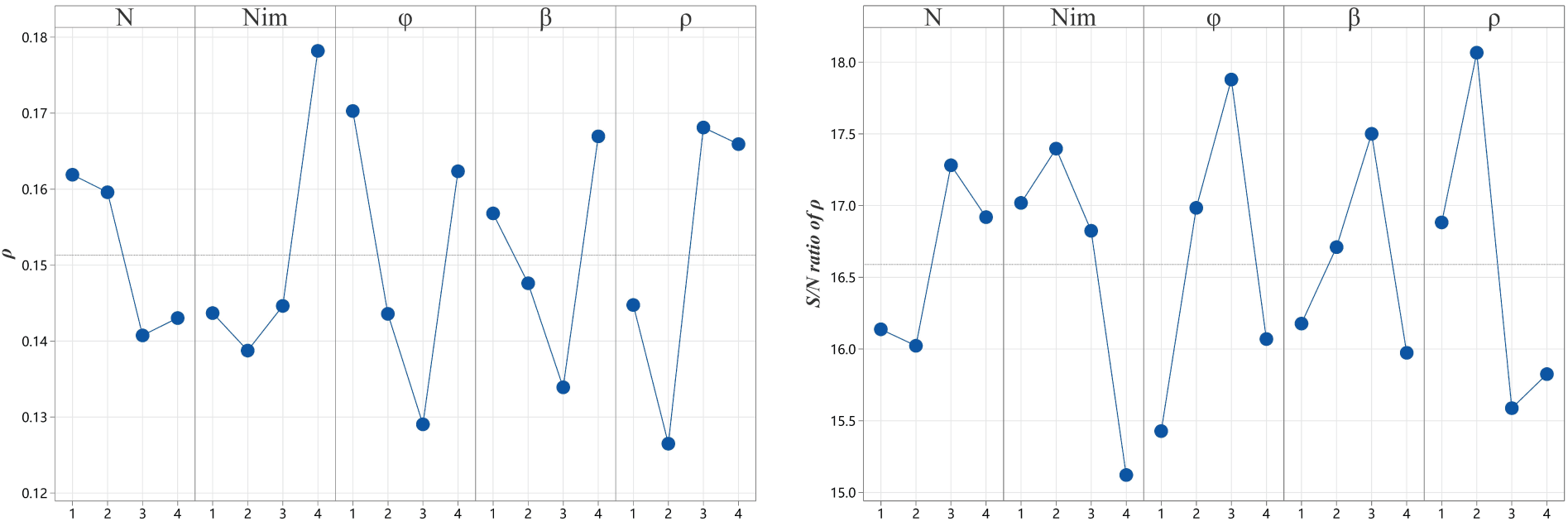
Figure 4: Main effect plot for means and S/N ratios.
For ICA, the parameters besides the stopping condition are N and
CAICA, ICA, HSGA, IMOEAD, and ENSGA-II are independently run 20 times for each instance. Tables 5–8 report the computational results and running time, where C indicates CAICA, I represents ICA, H denotes HSGA, D means IMOEA/D, and E stands for ENSGA-II. Table 9 presents the means and standard deviations of the metrics, computed for each algorithm based on 50 problem instances. Taking IGD as an example, the values for each algorithm are obtained from each instance and then aggregated into the reported statistics. Table 10 describes the results of a paired-sample t-test for the four pairs of compared algorithms on metrics IGD, HV, and
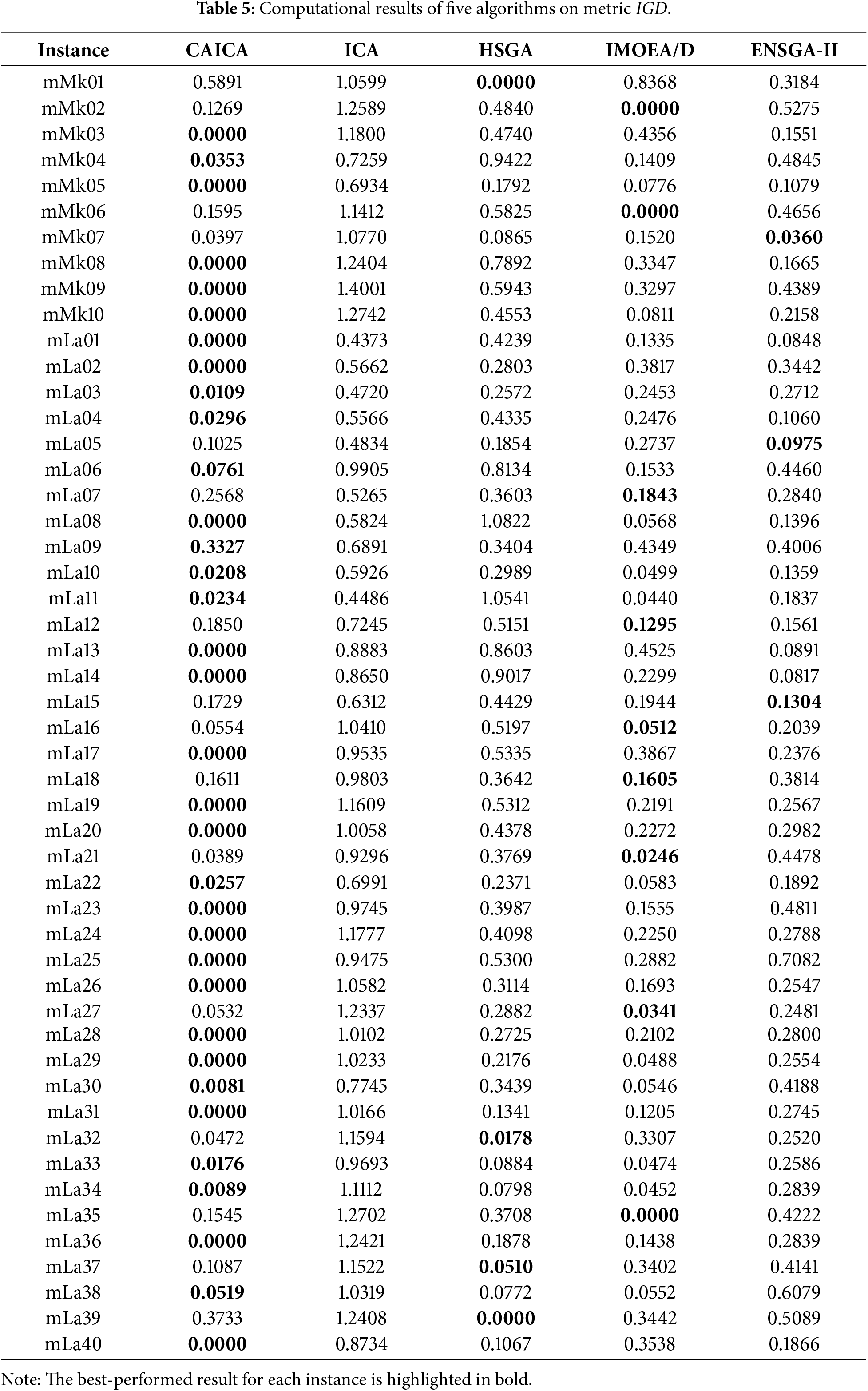
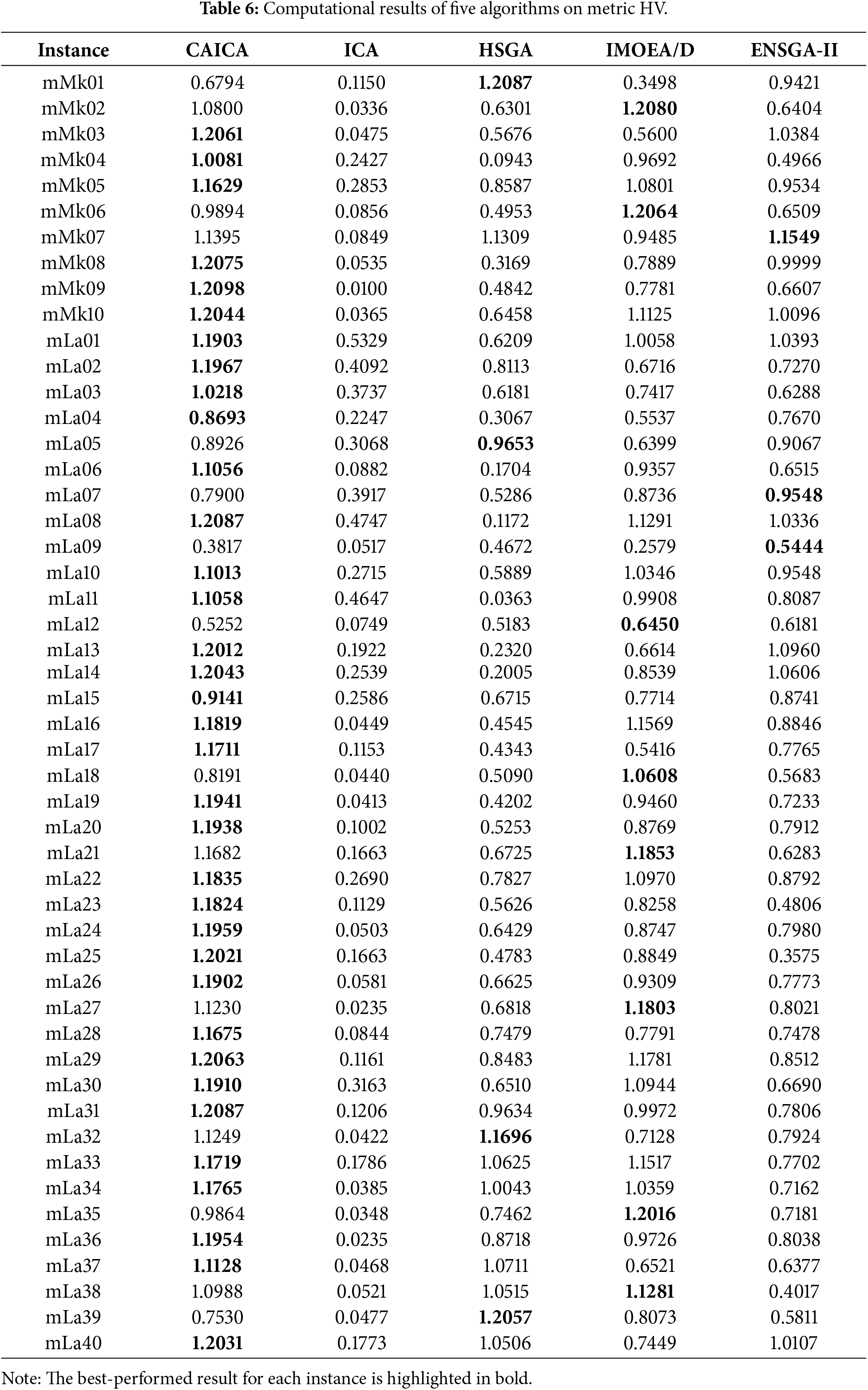
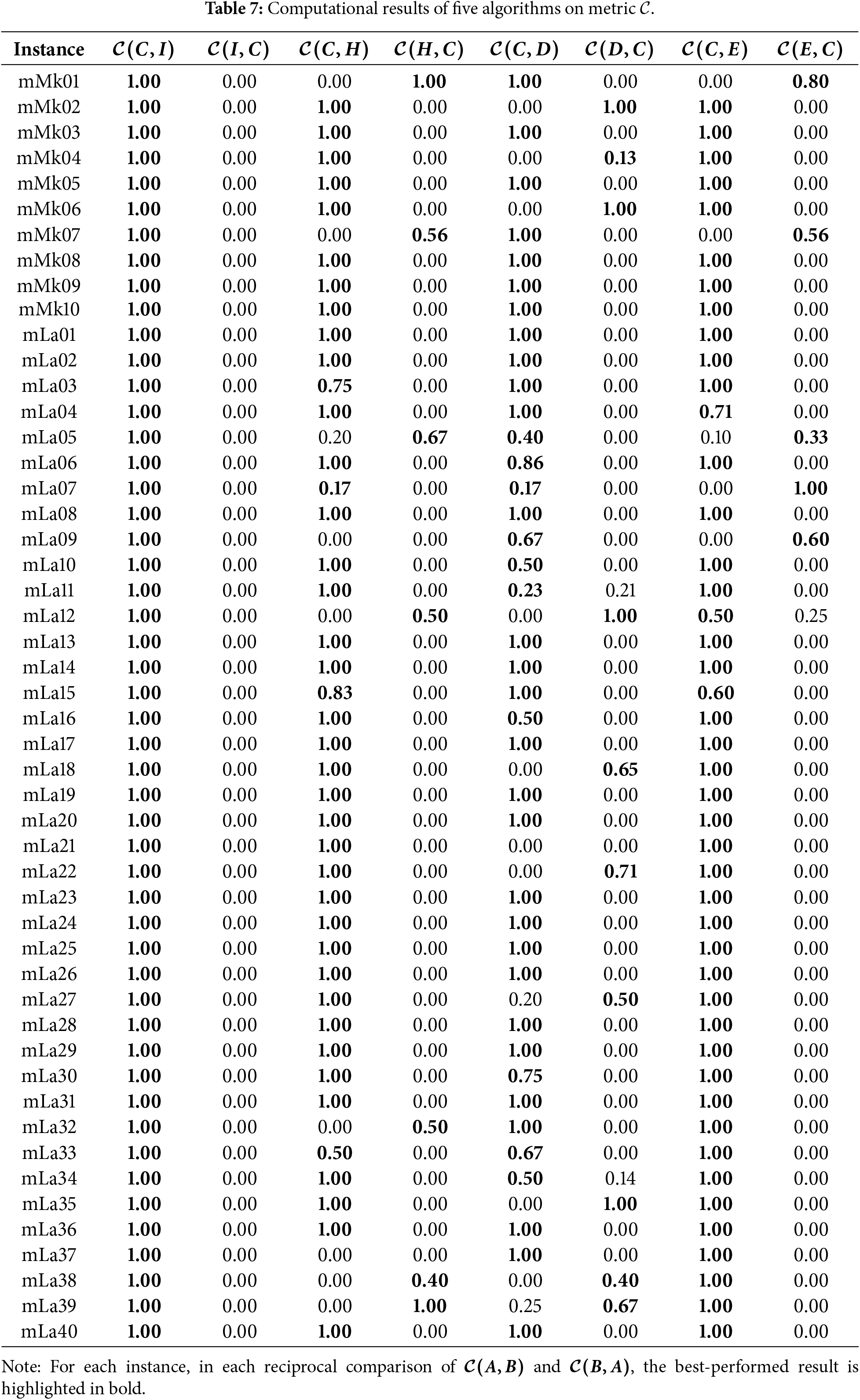
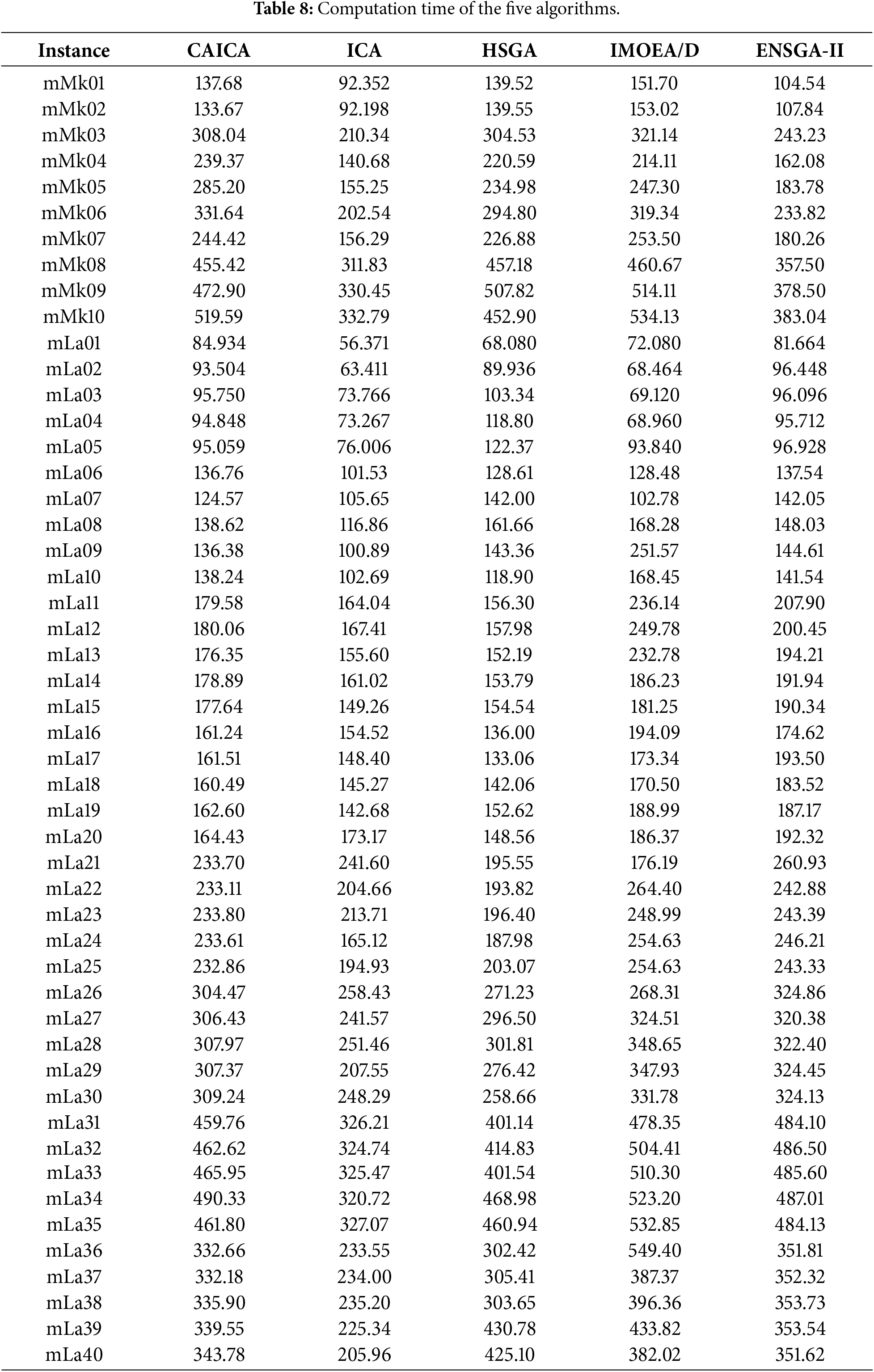
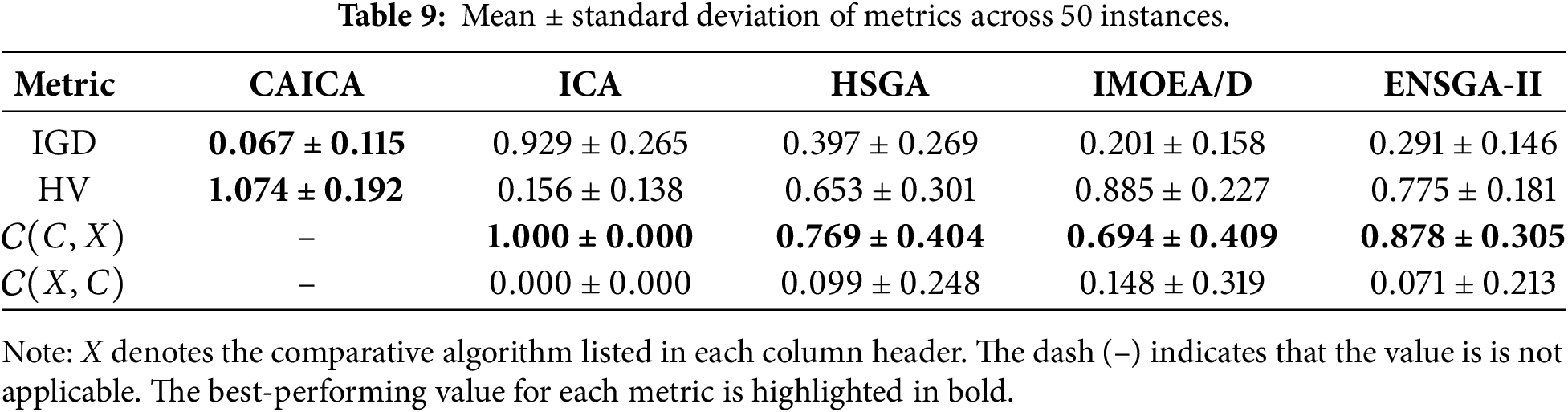
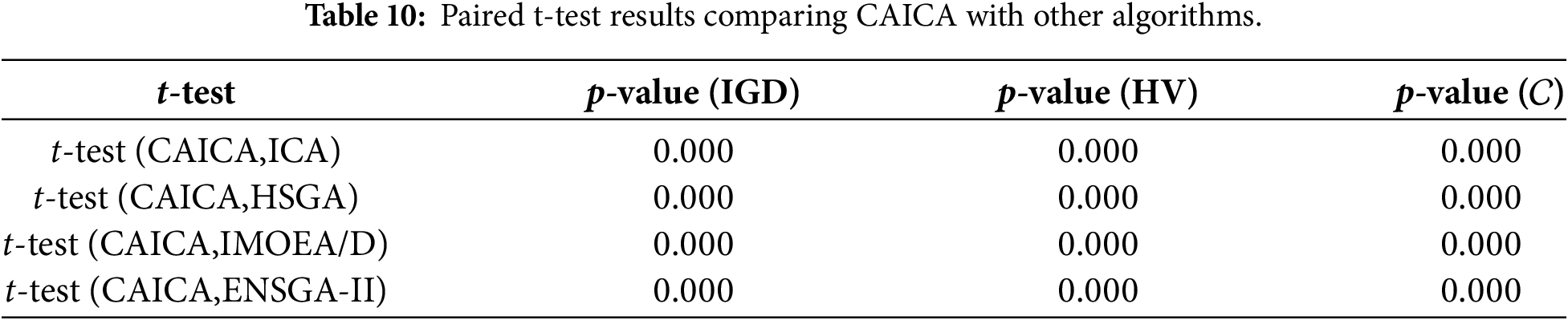
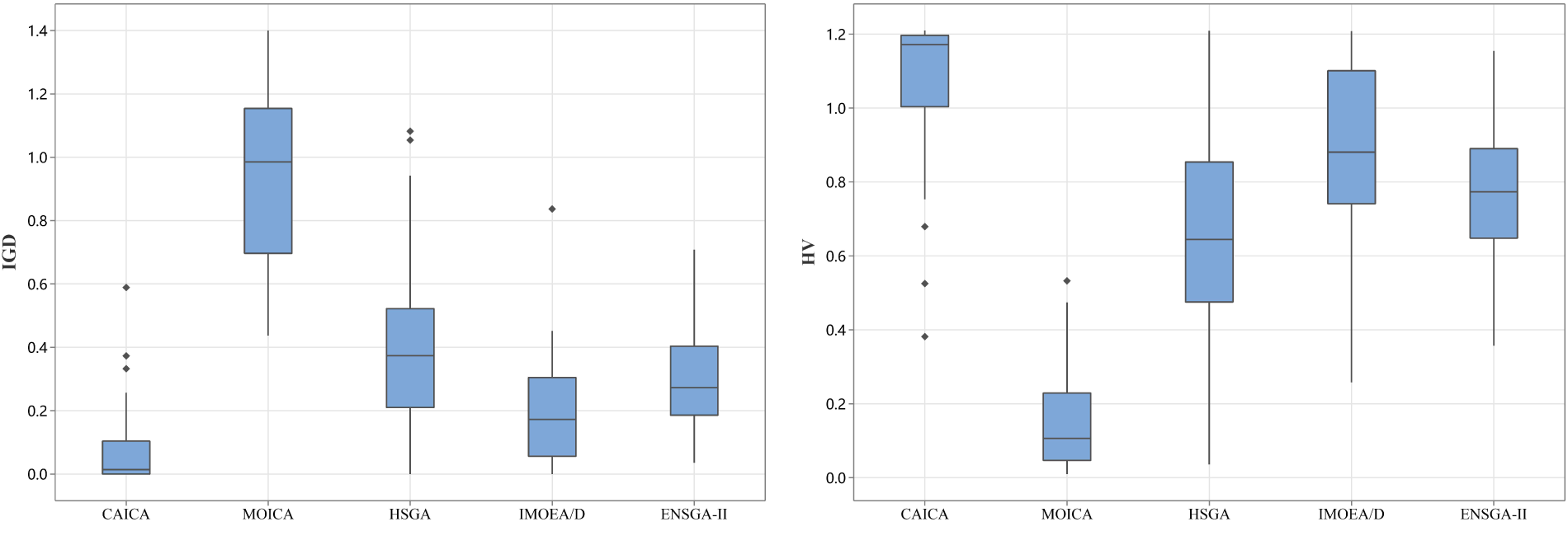
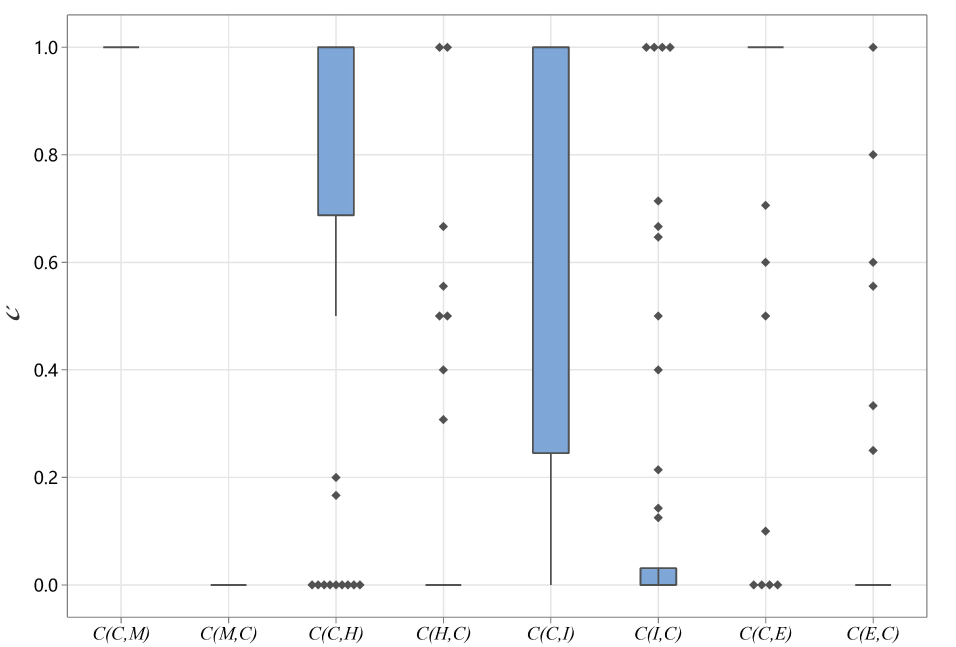
Figure 5: Box plots of five algorithms.
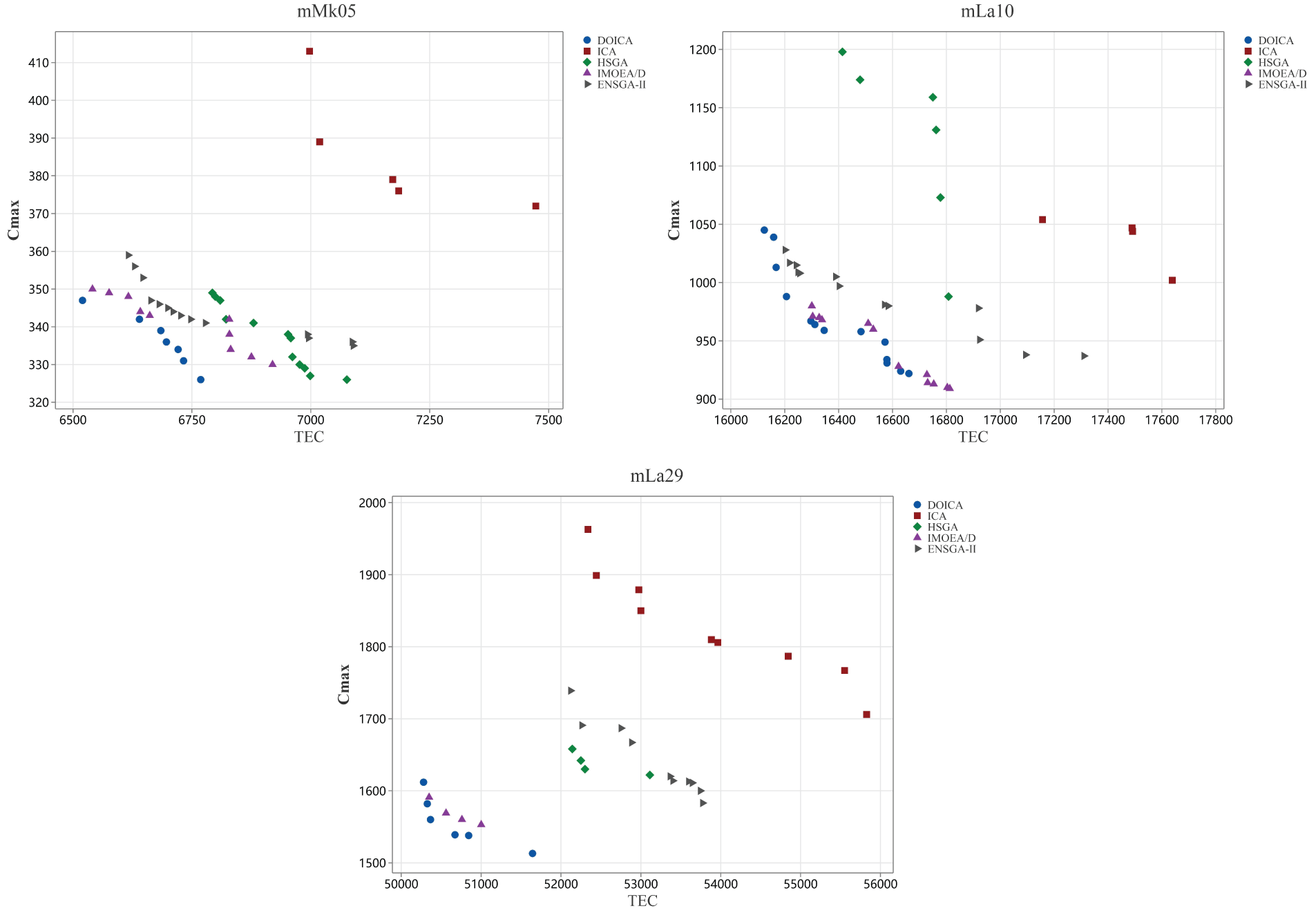
Figure 6: Distribution diagram of non-dominated solutions.
As shown in Table 5, CAICA achieves an IGD of 0 on 22 of 50 instances, and ICA yields significantly larger IGD values than CAICA on most instances. Obviously, removing new strategies from CAICA severely degrades its convergence performance. It can be seen from Table 6 that HV of CAICA is greater than 0.8 on 44 instances and larger than 1.1 on 36 instances, while HV of ICA is less than 0.5 on most instances. Table 7 reveals
When CAICA is compared with HSGA, it can be found from Tables 5–7 that CAICA performs better than HSGA. CAICA obtains a smaller IGD than HSGA on 46 instances and achieves a higher HV than HSGA on 45 instances.
It can also be concluded from Tables 5–7 that CAICA outperforms IMOEA/D. CAICA obtains a smaller IGD than IMOEA/D on 40 instances and achieves a higher HV than IMOEA/D on 40 instances. Table 7 reveals that non-dominated solutions generated by CAICA completely dominate solutions of IMOEA/D on 28 instances. The performance advantages of CAICA can also be seen from Figs. 5 and 6.
As listed in Tables 5–7, CAICA obtains smaller IGD than ENSGA-II on 45 instances and achieves higher HV on 44 instances,
As shown in Table 9, CAICA achieves the best mean values and standard deviations for IGD and HV. The mean and standard deviation of
As analyzed above, CAICA can provide better results than its three comparative algorithms within a similar amount of time, as shown in Table 8. The good performance of CAICA results from its new strategies. Empires have new structures with two imperialists and two learning objects that are used adaptively in assimilation and revolution; all empires have the same number of colonies, and no elimination is applied; moreover, cooperation, adaptive adjustment on search strategies, colonies, and imperialists are also adopted. These things can result in high diversity of population and strong exploration ability; thus, CAICA is a very competitive method for solving FJPBPMSP.
FJPBPMSP is an integration of FJSP and parallel BPM scheduling and is seldom considered. In this study, a new algorithm named CAICA is proposed to minimize makespan and total energy consumption. In CAICA, a four-string representation is adopted, and initial empires with a new structure are formed by uniformly dividing the population. An adaptive assimilation and revolution are given. An adaptive imperialist competition with cooperation is provided. Search strategies, imperialists, and colonies are also updated. Extensive experiments are conducted, and comparisons with peer algorithms validate the rationality and effectiveness of the new strategies and the competitive advantages of CAICA for solving FJPBPMSP.
Distributed FJPBPMSP, as well as the problem with practical constraints such as maintenance and setup time, has seldom been considered. The integration of meta-heuristics with reinforcement learning (RL) presents a promising path to solve FJPBPMSP; thus, the application of RL-based meta-heuristics to various FJPBPMSP will be our primary future research direction. On the other hand, flexible flow shop scheduling problems with BPM extensively exist in real-life manufacturing processes. The problem has high complexity and high research value, so the problem and its optimization algorithms are also our future topics.
Acknowledgement: The authors would like to thank the School of Automation, Wuhan University of Technology, for providing the research platform and technical support.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Study conception and design: Jie Wang; analysis and interpretation of results: Jie Wang; draft manuscript preparation: Jie Wang; review and editing: Deming Lei. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: All standard instances used in this study are publicly available in the open-source toolkit, which can be accessed via the following link: https://github.com/wulijie-coder/FJSP-.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Zhang H, Lv S, Xin D, Jin H. A genetic algorithm enhanced with neighborhood structure for general flexible job shop scheduling with parallel batch processing machine. Expert Syst Appl. 2025;265(4):125888. doi:10.1016/j.eswa.2024.125888. [Google Scholar] [CrossRef]
2. Song L, Liu C, Shi H. Discrete particle swarm algorithm with Q-learning for solving flexible job shop scheduling problem with parallel batch processing machine. J Phys Conf Ser. 2022;2303(1):012022. doi:10.1088/1742-6596/2303/1/012022. [Google Scholar] [CrossRef]
3. Zandieh M, Khatami AR, Rahmati SHA. Flexible job shop scheduling under condition-based maintenance: improved version of imperialist competitive algorithm. Appl Soft Comput. 2017;58(7):449–64. doi:10.1016/j.asoc.2017.04.060. [Google Scholar] [CrossRef]
4. Li M, Lei D. An imperialist competitive algorithm with feedback for energy-efficient flexible job shop scheduling with transportation and sequence-dependent setup times. Eng Appl Artif Intell. 2021;103(1):104307. doi:10.1016/j.engappai.2021.104307. [Google Scholar] [CrossRef]
5. Abedi M, Seidgar H, Fazlollahtabar H, Bijani R. Bi-objective optimisation for scheduling the identical parallel batch-processing machines with arbitrary job sizes, unequal job release times and capacity limits. Int J Prod Res. 2015;53(6):1680–711. doi:10.1080/00207543.2014.952795. [Google Scholar] [CrossRef]
6. Brucker P, Schlie R. Job-shop scheduling with multi-purpose machines. Computing. 1990;45(4):369–75. doi:10.1007/BF02238804. [Google Scholar] [CrossRef]
7. Dauzère-Pérès S, Ding J, Shen L, Tamssaouet K. The flexible job shop scheduling problem: a review. Eur J Oper Res. 2024;314(2):409–32. doi:10.1016/j.ejor.2023.05.017. [Google Scholar] [CrossRef]
8. Soto C, Dorronsoro B, Fraire H, Cruz-Reyes L, Gomez-Santillan C, Rangel N. Solving the multi-objective flexible job shop scheduling problem with a novel parallel branch and bound algorithm. Swarm Evol Comput. 2020;53:100632. doi:10.1016/j.swevo.2019.100632. [Google Scholar] [CrossRef]
9. Gao KZ, Suganthan PN, Tasgetiren MF, Pan QK, Sun QQ. Effective ensembles of heuristics for scheduling flexible job shop problem with new job insertion. Comput Ind Eng. 2015;90:107–17. doi:10.1016/j.cie.2015.09.005. [Google Scholar] [CrossRef]
10. Ozturk G, Bahadir O, Teymourifar A. Extracting priority rules for dynamic multi-objective flexible job shop scheduling problems using gene expression programming. Int J Prod Res. 2019;57(10):3121–37. doi:10.1080/00207543.2018.1543964. [Google Scholar] [CrossRef]
11. Yazdani M, Gholami M, Zandieh M, Mousakhani M. A simulated annealing algorithm for flexible job-shop scheduling problem. J Appl Sci. 2009;9(4):662–70. doi:10.3923/jas.2009.662.670. [Google Scholar] [CrossRef]
12. Shen L, Dauzère-Pérès S, Neufeld JS. Solving the flexible job shop scheduling problem with sequence-dependent setup times. Eur J Oper Res. 2018;265(2):503–16. doi:10.1016/j.ejor.2017.08.021. [Google Scholar] [CrossRef]
13. Yazdani M, Amiri M, Zandieh M. Flexible job-shop scheduling with parallel variable neighborhood search algorithm. Expert Syst Appl. 2010;37(1):678–87. doi:10.1016/j.eswa.2009.06.007. [Google Scholar] [CrossRef]
14. Zhang J, Yang J. Flexible job-shop scheduling with flexible workdays, preemption, overlapping in operations and satisfaction criteria: an industrial application. Int J Prod Res. 2016;54(16):4894–918. doi:10.1080/00207543.2015.1134839. [Google Scholar] [CrossRef]
15. Gu XL, Huang M, Liang X. A discrete particle swarm optimization algorithm with adaptive inertia weight for solving multiobjective flexible job-shop scheduling problem. IEEE Access. 2020;8:33125–36. doi:10.1109/ACCESS.2020.2974014. [Google Scholar] [CrossRef]
16. Huang RH, Yang CL, Cheng WC. Flexible job shop scheduling with due window—a two-pheromone ant colony approach. Int J Prod Econ. 2013;141(2):685–97. doi:10.1016/j.ijpe.2012.10.011. [Google Scholar] [CrossRef]
17. Luo S, Zhang L, Fan Y. Energy-efficient scheduling for multi-objective flexible job shops with variable processing speeds by grey wolf optimization. J Clean Prod. 2019;234(1):1365–84. doi:10.1016/j.jclepro.2019.06.151. [Google Scholar] [CrossRef]
18. Ebrahimi A, Jeon HW, Lee S, Wang C. Minimizing total energy cost and tardiness penalty for a scheduling-layout problem in a flexible job shop system: a comparison of four metaheuristic algorithms. Comput Ind Eng. 2020;141(1):106295. doi:10.1016/j.cie.2020.106295. [Google Scholar] [CrossRef]
19. Jq Li, Jw Deng, Cy Li, Yy Han, Tian J, Zhang B, et al. An improved jaya algorithm for solving the flexible job shop scheduling problem with transportation and setup times. Knowl-Based Syst. 2020;200(3):106032. doi:10.1016/j.knosys.2020.106032. [Google Scholar] [CrossRef]
20. Caldeira RH, Gnanavelbabu A, Vaidyanathan T. An effective backtracking search algorithm for multi-objective flexible job shop scheduling considering new job arrivals and energy consumption. Comput Ind Eng. 2020;149:106863. doi:10.1016/j.cie.2020.106863. [Google Scholar] [CrossRef]
21. Akram K, Bhutta MU, Butt SI, Jaffery SHI, Khan M, Khan AZ, et al. A pareto-optimality based black widow spider algorithm for energy efficient flexible job shop scheduling problem considering new job insertion. Appl Soft Comput. 2024;164:111937. doi:10.1016/j.asoc.2024.111937. [Google Scholar] [CrossRef]
22. Jiang T, Liu L, Zhu H. A Q-learning-based biology migration algorithm for energy-saving flexible job shop scheduling with speed adjustable machines and transporters. Swarm Evol Comput. 2024;90(7):101655. doi:10.1016/j.swevo.2024.101655. [Google Scholar] [CrossRef]
23. Zhao S, Zhou H, Zhao Y, Wang D. DQL-assisted competitive evolutionary algorithm for energy-aware robust flexible job shop scheduling under unexpected disruptions. Swarm Evol Comput. 2024;91(2):101750. doi:10.1016/j.swevo.2024.101750. [Google Scholar] [CrossRef]
24. Hao L, Zou Z, Liang X. Solving multi-objective energy-saving flexible job shop scheduling problem by hybrid search genetic algorithm. Comput Ind Eng. 2025;200(4):110829. doi:10.1016/j.cie.2024.110829. [Google Scholar] [CrossRef]
25. Xiao B, Zhao Z, Wu Y, Zhu X, Peng S, Su H. An improved MOEA/D for multi-objective flexible job shop scheduling by considering efficiency and cost. Comput Oper Res. 2024;167(1):106674. doi:10.1016/j.cor.2024.106674. [Google Scholar] [CrossRef]
26. Luan F, Zhao H, Liu SQ, He Y, Tang B. Enhanced NSGA-II for multi-objective energy-saving flexible job shop scheduling. Sustain Comput Inform Syst. 2023;39:100901. doi:10.1016/j.suscom.2023.100901. [Google Scholar] [CrossRef]
27. Fan L, Lei Q, Song Y, Liu Y, Yang Y. Knowledge-enhanced multi-objective memetic algorithm for energy-efficient flexible job shop scheduling with limited multi-load automated guided vehicles. Eng Appl Artif Intell. 2025;159(3):111771. doi:10.1016/j.engappai.2025.111771. [Google Scholar] [CrossRef]
28. Jula P, Leachman RC. Coordinated multistage scheduling of parallel batch-processing machines under multiresource constraints. Oper Res. 2010;58(4-part-1):933–47. doi:10.1287/opre.1090.0788. [Google Scholar] [CrossRef]
29. Li X, Chen H, Du B, Tan Q. Heuristics to schedule uniform parallel batch processing machines with dynamic job arrivals. Int J Comput Integr Manuf. 2013;26(5):474–86. doi:10.1080/0951192X.2012.731612. [Google Scholar] [CrossRef]
30. Xu R, Chen H, Li X. A bi-objective scheduling problem on batch machines via a pareto-based ant colony system. Int J Prod Econ. 2013;145(1):371–86. doi:10.1016/j.ijpe.2013.04.053. [Google Scholar] [CrossRef]
31. Jia Z, Yan J, Leung JYT, Li K, Chen H. Ant colony optimization algorithm for scheduling jobs with fuzzy processing time on parallel batch machines with different capacities. Appl Soft Comput. 2019;75:548–61. doi:10.1016/j.asoc.2018.11.027. [Google Scholar] [CrossRef]
32. Zhou S, Liu M, Chen H, Li X. An effective discrete differential evolution algorithm for scheduling uniform parallel batch processing machines with non-identical capacities and arbitrary job sizes. Int J Prod Econ. 2016;179(1):1–11. doi:10.1016/j.ijpe.2016.05.014. [Google Scholar] [CrossRef]
33. Lu S, Liu X, Pei J, Thai MT, Pardalos PM. A hybrid ABC-TS algorithm for the unrelated parallel-batching machines scheduling problem with deteriorating jobs and maintenance activity. Appl Soft Comput. 2018;66(2):168–82. doi:10.1016/j.asoc.2018.02.018. [Google Scholar] [CrossRef]
34. Zhou S, Xie J, Du N, Pang Y. A random-keys genetic algorithm for scheduling unrelated parallel batch processing machines with different capacities and arbitrary job sizes. Appl Math Comput. 2018;334(8):254–68. doi:10.1016/j.amc.2018.04.024. [Google Scholar] [CrossRef]
35. Kong M, Liu X, Pei J, Pardalos PM, Mladenovic N. Parallel-batching scheduling with nonlinear processing times on a single and unrelated parallel machines. J Glob Optim. 2020;78(4):693–715. doi:10.1007/s10898-018-0705-3. [Google Scholar] [CrossRef]
36. Xiao X, Ji B, Yu SS, Wu G. A tabu-based adaptive large neighborhood search for scheduling unrelated parallel batch processing machines with non-identical job sizes and dynamic job arrivals. Flex Serv Manuf J. 2024;36(2):409–52. doi:10.1007/s10696-023-09488-9. [Google Scholar] [CrossRef]
37. Hu K, Che Y, Ng TS, Deng J. Unrelated parallel batch processing machine scheduling with time requirements and two-dimensional packing constraints. Comput Oper Res. 2024;162(3):106474. doi:10.1016/j.cor.2023.106474. [Google Scholar] [CrossRef]
38. Ham AM, Cakici E. Flexible job shop scheduling problem with parallel batch processing machines: MIP and CP approaches. Comput Ind Eng. 2016;102(1):160–5. doi:10.1016/j.cie.2016.11.001. [Google Scholar] [CrossRef]
39. Ham A. Flexible job shop scheduling problem for parallel batch processing machine with compatible job families. Appl Math Model. 2017;45(3):551–62. doi:10.1016/j.apm.2016.12.034. [Google Scholar] [CrossRef]
40. Ji B, Zhang S, Yu SS, Xiao X, Chen C, Zheng G. Novel model and solution method for flexible job shop scheduling problem with batch processing machines. Comput Oper Res. 2024;161(1):106442. doi:10.1016/j.cor.2023.106442. [Google Scholar] [CrossRef]
41. Wang H, Xiong H, Zuo W, Shi S. An improved scatter search algorithm for solving job shop scheduling problems with parallel batch processing machine. Sci Rep. 2025;15(1):11872. doi:10.1038/s41598-025-92761-8. [Google Scholar] [PubMed] [CrossRef]
42. Xue L, Zhao S, Mahmoudi A, Feylizadeh MR. Flexible job-shop scheduling problem with parallel batch machines based on an enhanced multi-population genetic algorithm. Complex Intell Syst. 2024;10(3):4083–101. doi:10.1007/s40747-024-01374-7. [Google Scholar] [CrossRef]
43. Lei D, Zheng Y, Guo X. A shuffled frog-leaping algorithm for flexible job shop scheduling with the consideration of energy consumption. Int J Prod Res. 2017;55(11):3126–40. doi:10.1080/00207543.2016.1262082. [Google Scholar] [CrossRef]
44. Zhang G, Gao L, Shi Y. An effective genetic algorithm for the flexible job-shop scheduling problem. Expert Syst Appl. 2011;38(4):3563–73. doi:10.1016/j.eswa.2010.08.145. [Google Scholar] [CrossRef]
45. Deb K, Pratap A, Agarwal S, Meyarivan T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput. 2002;6(2):182–97. doi:10.1109/4235.996017. [Google Scholar] [CrossRef]
46. Nasim Z, Bano Z, Ahmad M. Analysis of efficient random permutations generation for security applications. In: Proceedings of the 2015 International Conference on Advances in Computer Engineering and Applications; 2015 Mar 19–20; Ghaziabad, India. p. 337–41. doi:10.1109/ICACEA.2015.7164726. [Google Scholar] [CrossRef]
47. Lei D, Li H. A cooperated imperialist competitive algorithm for unrelated parallel batch machine scheduling problem. Comput Mater Contin. 2024;79(2):1855–74. doi:10.32604/cmc.2024.049480. [Google Scholar] [CrossRef]
48. Yan B, Liu Y, Huang Y. Improved discrete imperialist competition algorithm for order scheduling of automated warehouses. Comput Ind Eng. 2022;168:108075. doi:10.1016/j.cie.2022.108075. [Google Scholar] [CrossRef]
49. Elyasi M, Selcuk YS, Özener OÖ, Coban E. Imperialist competitive algorithm for unrelated parallel machine scheduling with sequence-and-machine-dependent setups and compatibility and workload constraints. Comput Ind Eng. 2024;190(3):110086. doi:10.1016/j.cie.2024.110086. [Google Scholar] [CrossRef]
50. Luo J, Zhou J, Jiang X. A modification of the imperialist competitive algorithm with hybrid methods for constrained optimization problems. IEEE Access. 2021;9:161745–60. doi:10.1109/ACCESS.2021.3133579. [Google Scholar] [CrossRef]
51. Tay JC, Ho NB. Evolving dispatching rules using genetic programming for solving multi-objective flexible job-shop problems. Comput Ind Eng. 2008;54(3):453–73. doi:10.1016/j.cie.2007.08.008. [Google Scholar] [CrossRef]
52. Hurink J, Jurisch B, Thole M. Tabu search for the job-shop scheduling problem with multi-purpose machines. OR Spektrum. 1994;15(4):205–15. doi:10.1007/BF01719451. [Google Scholar] [CrossRef]
53. Zitzler E, Thiele L. Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach. IEEE Trans Evol Comput. 1999;3(4):257–71. doi:10.1109/4235.797969. [Google Scholar] [CrossRef]
54. While L, Hingston P, Barone L, Huband S. A faster algorithm for calculating hypervolume. IEEE Trans Evol Comput. 2006;10(1):29–38. doi:10.1109/TEVC.2005.851275. [Google Scholar] [CrossRef]
55. Wang Y, Han Y, Wang Y, Pan QK, Wang L. Sustainable scheduling of distributed flow shop group: a collaborative multi-objective evolutionary algorithm driven by indicators. IEEE Trans Evol Comput. 2024;28(6):1794–808. doi:10.1109/TEVC.2023.3339558. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools