
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Robust Facial Landmark Detection via Transformer-Conv Attention
1 Hefei Institutes of Physical Science, Chinese Academy of Sciences, Hefei, China
2 Science Island Branch, Graduate School of University of Science and Technology of China, Hefei, China
* Corresponding Author: Bingyu Sun. Email:
Computers, Materials & Continua 2026, 87(3), 13 https://doi.org/10.32604/cmc.2026.076236
Received 17 November 2025; Accepted 12 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In facial landmark detection, shape deviations induced by large poses and exaggerated expressions often prevent existing algorithms from simultaneously achieving fine-grained local accuracy and holistic global shape constraints. To address this, we propose a Transformer-Conv Attention-based Method (TCAM). Built upon a hybrid coordinate-heatmap regression backbone, TCAM integrates the long-range dependency modeling of Transformers with the local feature extraction advantages of Depthwise Convolution (DWConv). Specifically, by partitioning feature maps into sub-regions and applying Transformer modeling, the module enforces sparse linear constraints on global information, effectively mitigating the issues caused by discontinuous landmark distributions. Experimental results on the WFLW, COFW, and 300W datasets demonstrate that TCAM significantly outperforms current state-of-the-art methods. Notably, the Normalized Mean Error (NME) is reduced by 0.24% and 0.21Keywords
Facial landmark detection, also known as face alignment, holds a pivotal position in the field of computer vision and has received increasing attention in recent years. As a fundamental task, it serves a crucial pre-localization role in numerous facial applications, such as face recognition [1], face reconstruction [2], and facial expression recognition [3]. With the application of deep learning to facial tasks, popular face alignment methods today are predominantly based on Convolutional Neural Networks (CNNs) and are broadly categorized into two types: coordinate regression and heatmap regression. These methods exhibit distinct algorithmic characteristics, resulting in unique advantages and disadvantages.
The coordinate regression approach directly regresses the positional coordinates of each landmark through a fully connected layer. While this method relies on global features and typically captures the overall shape, it often overlooks the detailed, individual features of landmarks. Conversely, heatmap regression algorithms improve localization accuracy by repeatedly sampling features at different scales. However, maintaining high resolution leads to increased computational volume and longer inference times. Furthermore, because heatmap regression estimates the coordinates of each landmark independently based on a probabilistic heatmap, it lacks global shape constraints, making it susceptible to partial shape collapse and theoretical error lower bounds. Consequently, we adopted a hybrid framework combining both coordinate and heatmap regression as the network’s backbone. This framework leverages the strengths of both methods to better balance global shape constraints with the accuracy of individual landmarks. Despite this integration, the hybrid framework only partially alleviates existing problems. Specifically, current hybrid frameworks still face significant challenges when handling facial images with large poses and exaggerated expressions.
Current localization methods still face significant difficulties in handling images with large poses, exaggerated expressions, and occlusions. Fig. 1 illustrates a comparison between a conventional coordinate-heatmap hybrid model and our proposed model under various challenging conditions. The first three columns show face images with large poses, exaggerated expressions, and a combination of both, respectively, while the last two columns display different degrees of occlusion. The first row of the figure presents the prediction results of the baseline hybrid model [4], and the second row displays the results from our model. As evident from the figure, exaggerated expressions or occlusion cases lead to a significant deviation in the landmark distribution of local details, such as the corners of the mouth, the nose, and the eyebrows. This, in turn, causes large errors in landmark predictions within these detailed regions. The bias in predicting these local parts is often due to the network’s insufficient capacity for processing local features. Furthermore, large poses, such as extreme side profiles, can cause major deviations in predicted face contours due to the lack of holistic shape constraints [5].
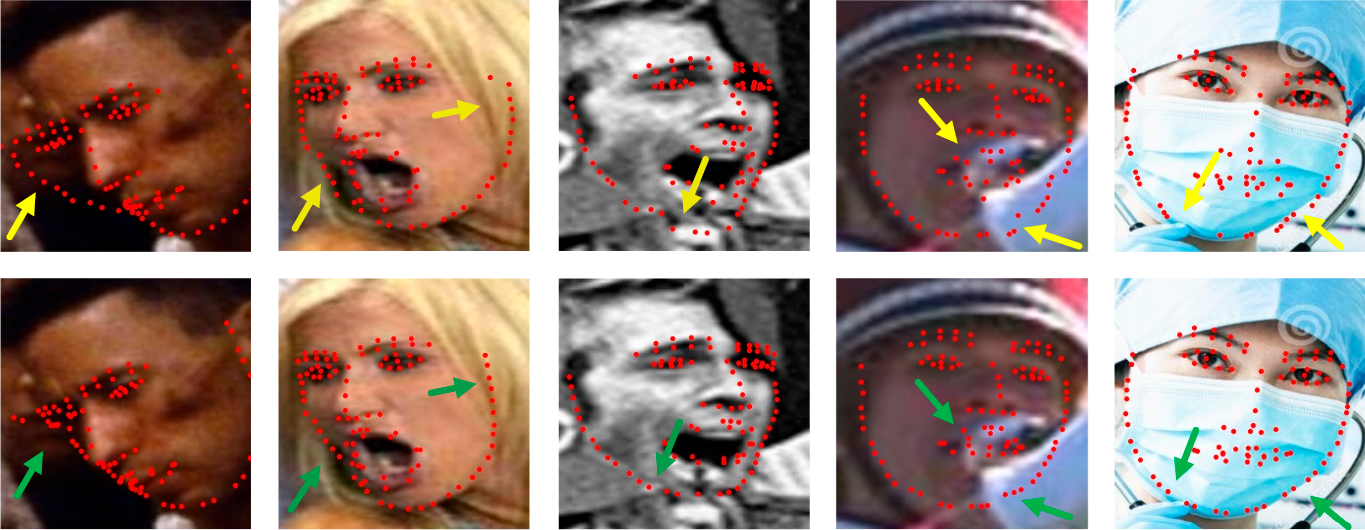
Figure 1: Comparison of the prediction effectiveness between the baseline model and our model on face landmarks under different challenging conditions.
To address these two inherent problems, we propose the integration of a Transformer. In recent years, the Transformer architecture has demonstrated strong performance not only in Natural Language Processing (NLP) but also in computer vision tasks, including classification [6], object detection [7], and segmentation [8]. The self-attention mechanism employed in the Transformer intrinsically exploits the structured relationships among landmarks, which enables the model to acquire superior modeling capabilities for global long-range dependencies. Simultaneously, we incorporate Depthwise Convolution (DWConv), which allows the model to fuse the globally shared weights of convolution with the context-aware weights of the Transformer, thereby achieving stronger local information extraction. This dual approach effectively compensates for the limitations of the backbone framework, enabling better handling of difficult scenarios such as large poses and exaggerated expressions.
The current study presents a Transformer-Conv attention-based facial landmark detection network that constructs contextual spatial relationships between landmarks by leveraging the global modeling capabilities of the Transformer. Prior studies [9] have already validated the feasibility of using the Transformer architecture for face alignment. When the weights from Depthwise Convolution (DWConv) are globally shared, the resulting network exhibits enhanced robustness and accuracy regarding shape constraints and localization precision. As previously mentioned, the coordinate-heatmap regression hybrid framework suffers from two primary issues that impair localization accuracy when dealing with large poses, exaggerated expressions, and occlusions. First, during the heatmap regression stage, certain adjacent landmarks depend on distinct feature blocks, resulting in a lack of neighboring and global feature information and structured relationships; this particularly impacts the localization of face contours in large-pose images. Second, during the coordinate regression stage, the fully connected layer disrupts the spatial structure of local image features, thereby hindering local feature learning for images with exaggerated expressions or occlusions.
To mitigate the impact of these two problems on detection accuracy and model robustness, we introduce T-SGA (Transformer-Sparse Global Attention) and T-DLA (Transformer-DWConv Local Attention) to complement the lost feature information, respectively. In T-SGA, we segment the feature map into different regions and then apply the Transformer’s self-attention mechanism to corresponding pixel points across all regions to learn long-range dependencies, thereby obtaining a globally attentive hybrid interaction. In T-DLA, we utilize a combination of DWConv and the Transformer—specifically, fusing the globally shared weights of DWConv with the context-aware weights of the Transformer. This fusion allows for the extraction of richer local information and better preservation of the local spatial structure compared to simple convolution or a standalone Transformer. Finally, the features are fused using a parallel structure and a convolutional Feed-Forward Network (convFFN). As shown in Fig. 1, our model achieves superior prediction results when handling face images involving large poses, exaggerated expressions, and occlusions.
The current study validates the effectiveness of our method on three publicly available datasets: 300W [10], COFW [11], and WFLW [12]. Based on both subjective and objective experimental results, our detection method outperforms other state-of-the-art methods when processing large poses, exaggerated expressions, and partial occlusions. In summary, the main contributions of this paper are:
• We introduce the T-SGA (Transformer-Sparse Global Attention) module between the layers of the backbone network to obtain a hybrid global interactive attention. By utilizing the global modeling capability of the Transformer, the model is enabled to cross-leverage feature information across different pixel blocks. This mechanism facilitates information sharing within locally occluded regions, compensates for potential shape collapse in heatmap regression, and constrains the overall facial shape.
• To address the lack of refined single-point accuracy often caused by the coordinate regression step, we incorporate the T-DLA (Transformer-DWConv Local Attention) module. T-DLA combines the globally shared weights of convolution with the context-aware weights of the Transformer, thereby focusing on high-frequency local feature information and improving the representation of local details.
• We employ a parallel approach to combine the two attention features and replace the standard Feed-Forward Network (FFN) with a Conv-FFN for enhanced feature fusion. We conducted extensive experiments on three challenging, publicly available datasets to demonstrate the superiority of our model, particularly its effective landmark prediction in facial images with large poses and exaggerated expressions.
The rest of this paper is organized as follows. Section 2 reviews prevailing methodologies in facial landmark detection. Section 3 provides a detailed description of the proposed TCAM framework, focusing specifically on the T-SGA and T-DLA modules, as well as the parallel network architecture. Section 4 presents comprehensive experimental evaluations on three benchmark datasets and includes ablation studies to verify the effectiveness of each component. Finally, Section 5 concludes the paper and discusses potential directions for future research.
2.1 Existing Regression Methods
Facial landmark detection algorithms primarily fall into two categories: coordinate regression and heatmap regression. Coordinate regression methods utilize convolution to extract feature information and subsequently regress all coordinates directly through fully connected layers, which typically results in a reasonable overall shape. The comparative evaluation conducted by Salem et al. [13] across benchmark datasets such as 300W and AFLW reveals that, although state-of-the-art algorithms have made progress, there remains significant room for improvement in detection accuracy and reliability under unconstrained environments. Sun et al. [14] proposed a regression network model with cascaded CNNs, where each cascade layer is used to regress a specific landmark, which are then fused in the final layer to determine the precise locations. Meng et al. [15] introduced a multilevel aggregation network to regress the landmark coordinates of 3D vertices. In this approach, multi-scale features are iteratively and hierarchically fused by combining CNNs and Graph Convolutional Networks (GCNs) for intensive 3D facial alignment and reconstruction. Fan et al. [16] proposed an attention-based adaptive graph convolutional network for face alignment that combines local features and global structural relationships to construct landmark-connected graphs, optimizing these graphs to improve model robustness. Although coordinate regression is fast to train and maintains well-constrained facial shapes due to the network’s reliance on global features, its lack of attention to local details can easily lead to significant offsets at individual points.
On the other hand, the heatmap regression approach generates a probabilistic heatmap, from which the coordinates of the maximum point are derived via the argmax operation to determine landmark positions. Sun et al. [17] first proposed a network structure that preserves high resolution throughout the entire process. By connecting high-resolution and low-resolution sub-networks in parallel, HRNet maintains a richness of feature information through repetitive multi-scale fusion. Yang et al. [18] proposed a hybrid attentional hourglass network to process facial images under large poses, occlusion, and varying lighting conditions. MAttHG utilizes an hourglass network as the backbone, where an attention module extracts features from different levels of the stacked hourglass network to capture rich contextual relationships.
Regarding the utilization of spatial information, Hassaballah et al. [19] developed a two-stage coordinated regression framework (CR-CNN) that employs a heatmap coupling module to transform initial landmark estimates into Gaussian heatmaps, thereby providing prior spatial knowledge for subsequent refinement stages. Xie et al. [20] explored the relationship between facial boundaries and coordinates to obtain boundary-aware landmark location predictions. Their boundary-aware landmark transformation module incorporates boundary features obtained from a self-calibrating boundary estimation module at multiple scales, enabling the construction of a more accurate boundary-to-landmark mapping.
However, although heatmap regression methods can achieve a smaller normalized mean error, repeated up-sampling and down-sampling operations significantly impact the model’s running speed. Furthermore, these methods are highly sensitive to facial shape distortions when processing challenging images exhibiting large poses, exaggerated expressions, or partial occlusions.
Since coordinate regression and heatmap regression possess complementary advantages and disadvantages, it is natural to develop methods that combine the two to achieve superior results. Zhang et al. [21] developed a face alignment model based on a two-stage regression network. The probabilistic heatmap of each landmark is first regressed through an hourglass network, and the initial coordinates are obtained via the argmax function. Simultaneously, an auxiliary network learns the offset of these initial coordinates relative to the ground truth through coordinate regression, combining the two to produce the final landmark coordinates. Jin et al. [4] proposed a new detection head that integrates coordinate and heatmap regression methods. Specifically, after the heatmap regression stage, the coordinate offset is regressed based on the local heatmap. At the same time, a nearest-neighbor regression model was introduced to alleviate the continuity problem of keypoints. Park and Kim [22] proposed an attention combination network, which merges a coordinate regression network and a heatmap regression network using spatial attention. The two networks regress independently and complement each other, compensating for the inaccurate alignment in heatmap regression caused by a lack of local information. It is evident that network models combining both methods can mitigate the inherent disadvantages of each to a certain extent, even if they cannot resolve them entirely. Therefore, we chose a hybrid model integrating both approaches as the backbone of our method.
2.3 Transformer in Computer Vision
The Transformer was initially utilized for Natural Language Processing (NLP) tasks. Due to its superior performance in NLP, it was migrated to the field of computer vision, where it has been applied to tasks such as classification, segmentation, and object detection with excellent results. Dosovitskiy et al. [6] proposed a classification model that does not rely on CNNs but utilizes only the Transformer structure; when sufficient data is available for pre-training, the Transformer, applied directly to sequences of image patches, performs exceptionally well on image classification tasks. Carion et al. [7] introduced DETR, the first application of the Transformer to object detection. This system is based on the Transformer and direct set prediction with bipartite matching loss, which is particularly effective for detecting large objects. Li et al. [23] proposed a cascaded Transformer facial landmark detection method, using the Transformer to intrinsically exploit structured relationships between landmarks and progressively refine coordinates through multiple iterations. Xia et al. [24] proposed a robust face alignment and landmark intrinsic relationship learning framework (SLPT) based on a sparse local patch Transformer. This framework first extracts parallel multi-scale features through HRNet and then inputs the feature maps into the Transformer to learn the intrinsic relationships between landmarks. The final coordinates are obtained through a coarse-to-fine loop framework with continuous iterative optimization. The successful application of the Transformer in the visual domain demonstrates that its superior ability to model long-range dependencies has the potential to provide an effective solution for overall facial and detailed contour constraints. Consequently, we chose the Transformer to optimize our backbone framework.
In this section, we provide a detailed description of our proposed work. We first introduce the overall network architecture in Section 3.1, followed by the description of the Transformer-DWConv local attention (T-DLA) module in Section 3.2, the Transformer-sparse global attention (T-SGA) module in Section 3.3, and finally, the parallel attention architecture in Section 3.4.
3.1 Overall Network Architecture
Our overall network consists of a hybrid backbone and a Transformer-Conv Attention-based Module (TCAM), as illustrated in Fig. 2. We selected PIPNet [4] as the backbone for our algorithm, which is built upon ResNet18 [25] and integrates both coordinate and heatmap regression. This hybrid approach enables the model to maintain accuracy while partially mitigating the theoretical error lower bound problem associated with heatmap regression methods [26]. The input image is first fed into the convolutional network, downsampled to a
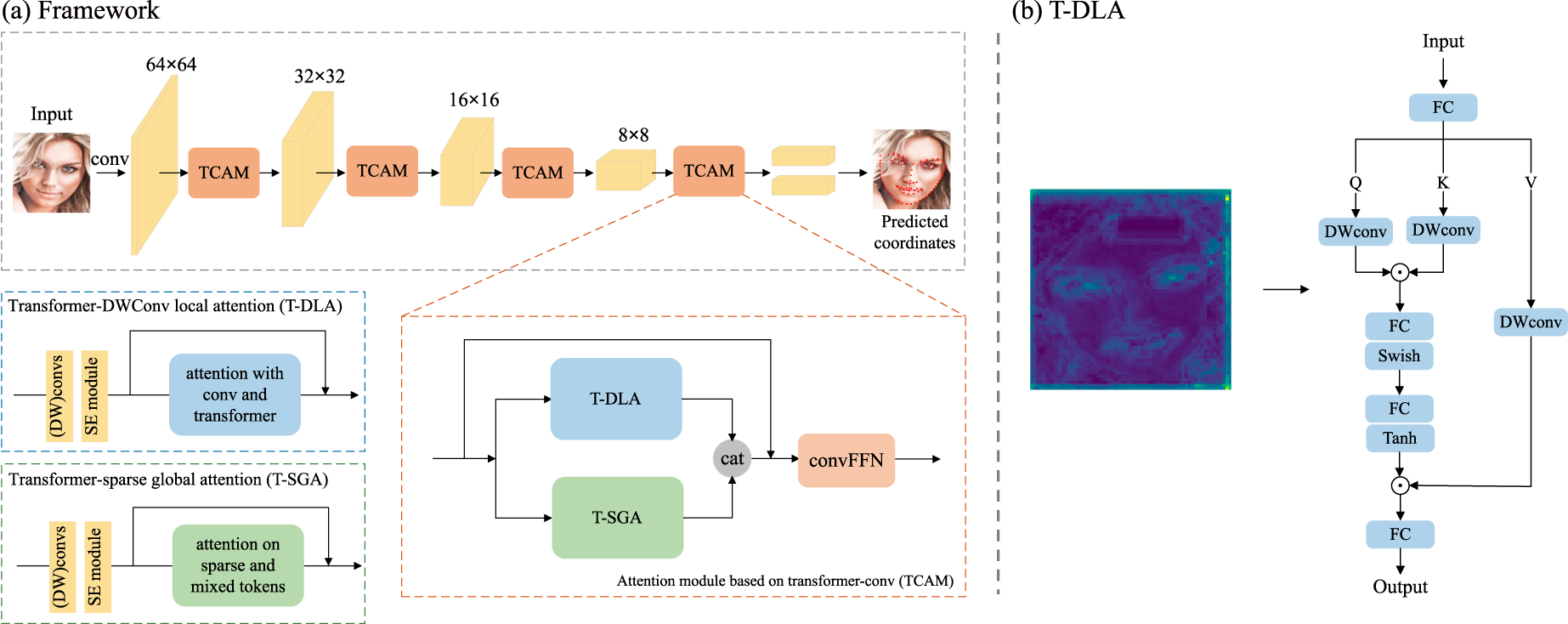
Figure 2: (a) Overview of the TCAM architecture. (b) The structure of T-DLA.
3.2 Transformer-DWConv Local Attention (T-DLA)
To better capture high-frequency localized information, we are inspired by [28] to introduce a local attention module combined with convolution, as shown in Fig. 2b. Unlike traditional Transformer-based local attention, we incorporate convolutional operations both before the Transformer layers and within the Transformer’s attention mechanism itself. This hybrid combination significantly enhances the network’s ability to extract local information compared to approaches that rely solely on convolution or conventional Transformer attention. Fig. 3a illustrates the feature extraction processes of different methods. The first method relies exclusively on the convolution operator to extract local information weights by summing surrounding pixels via the globally shared weights of the convolution kernel. The second method, which relies only on a conventional Transformer, first generates learnable Q (query), K (key), and V (value) vectors through a linear layer. It then computes a similarity matrix by multiplying Q and K, normalizes this matrix using Softmax to derive the weight matrix, and finally multiplies the weight matrix by V to obtain the attention-weighted feature token. This second approach extracts local information using context-aware weights.
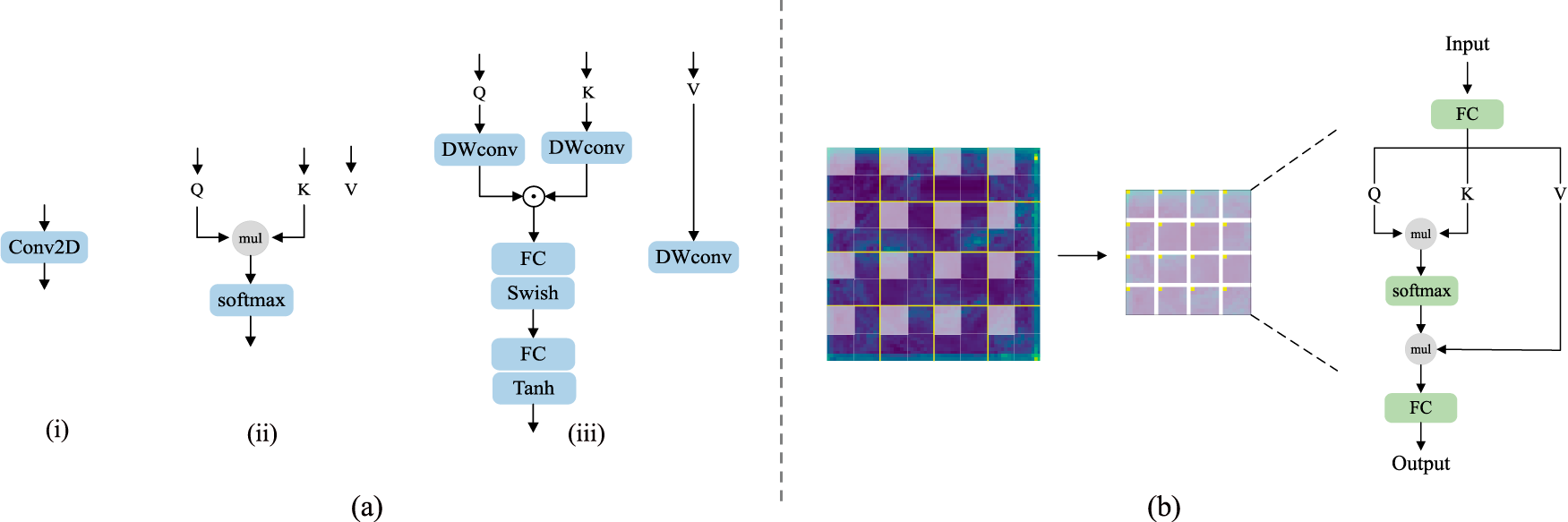
Figure 3: (a) Different processes for extracting feature information by various methods, where (i) represents convolution, (ii) represents a conventional Transformer, and (iii) represents our approach. (b) The structure of T-SGA.
Compared to pure convolution, global interaction is an inherent advantage of self-attention. Our method merges the strengths of both by combining globally shared weights and context-aware weights to better model the relationships between different locations. As depicted in Fig. 3a-iii, the input features are first passed through a Depthwise Convolution (DWConv) to reduce convolutional parameters, and then processed by a Squeeze-Excitation (SE) module [29]. Previous studies have shown that adding convolution and an SE module before the Transformer can enhance the model’s trainability [30]. Subsequently, a linear layer (FC) is used to obtain
where
We compute the element-wise product of
Finally, the context-aware weight matrix
3.3 Transformer-Sparse Global Attention (T-SGA)
Similar to existing methods, we incorporate sparse attention [31,32] to process global information. The overall process for achieving global attention is illustrated in the T-SGA module shown in Fig. 2a. Initially, we perform Depthwise Convolution (DWConv) and Squeeze-Excitation (SE) operations on the input feature maps. As demonstrated in [33], deep convolution can effectively serve as conditional positional encoding for the Transformer. Next, the feature map undergoes segmentation. The process of feature map division and attention enforcement is depicted in Fig. 3b. Feature map segmentation yields
The size of each feature submap is
where
Through experimental comparison, we determined that a parallel connection is superior to a serial connection for combining the T-DLA and T-SGA modules; thus, we adopted a parallel architecture for feature fusion. As illustrated in Fig. 2, the features from the two attention branches are combined using a concatenation (
In this section, we present the subjective and objective experimental results of our proposed method on three publicly available datasets. We also compare these results with the current state-of-the-art methods. The datasets utilized include WFLW [12], COFW [11], and 300W [10]. Furthermore, we provide details regarding the implementation of our method and the evaluation metrics used in the experiments.
We conduct experiments using three benchmark datasets: WFLW, COFW, and 300W. Wider Facial Landmarks in the Wild (WFLW) consists of 10,000 face images, divided into 7500 images for training and 2500 images for testing. The samples are labeled with 98 landmarks. Importantly, WFLW is further partitioned into six challenging subsets based on facial characteristics: large pose, expression, illumination, makeup, occlusion, and blur. These subsets allow for a focused evaluation of the model’s performance on various types of challenging face images.
Caltech Occluded Faces in the Wild (COFW) is a challenging dataset. The training set comprises 1345 color face images, each annotated with 29 landmarks, and the test set contains 507 face images. The COFW dataset features faces captured in complex, real-world scenarios. The face images exhibit a high degree of difficulty due to the large number of different degrees of occlusion and large poses, which complicates accurate detection.
300 Faces In-The-Wild Challenge (300W) is a widely generalized classic face alignment dataset. The 300W training set consists of 3148 face images aggregated from the AFW, HELEN, and LFPW datasets. While there may be multiple faces in each image, only one face is labeled per image, totaling 68 landmarks. The test set contains 689 images sourced from the HELEN, IBUG, and LFPW datasets. The test set is subdivided into two subsets: the COMMON subset (554 images) and the CHALLENGE subset (135 images).
Metrics. We use normalized mean error (NME) and cumulative error distribution (CED) curves to evaluate model performance:
We used the ResNet18 [25] network, pre-trained on ImageNet [34], as the backbone network, and Adam as the optimizer. The learning rate is set to 0.001 and training was carried out for 80 epochs, with a decay of 10 at each of the 40th and 65th epochs.
The proposed model employs ResNet-18 [25], pre-trained on ImageNet [34], as the backbone network. During pre-processing, all input images are cropped and resized to

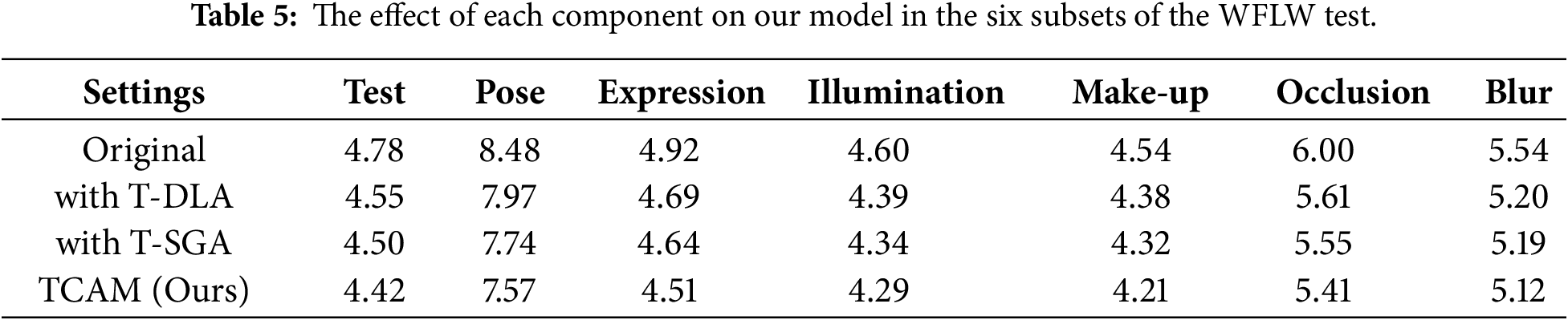
We conducted experiments on the WFLW dataset to evaluate our model’s performance in processing facial images under various challenging conditions. This section presents the Normalized Mean Error (NME) results of our model on the full WFLW test set as well as its six specific subsets, comparing them with other state-of-the-art methods. Additionally, we provide a qualitative assessment through subjective visual results of our model’s detection on the WFLW dataset.
In Table 2, we can see that our method achieves optimal results on the full set of WFLW tests, with NME reaching a much lower 4.42%, which is 0.18% less than MSM, the second-best performer. And in the other six subsets, our model still has a great advantage. Our detection results are the best in the large pose, expression, illumination and makeup subsets. For example, our NME is 0.24%, 0.21%, and 0.26% lower than the second-ranked one in the large pose, expression and makeup subsets. This shows that our method is well suited to dealing with the overall contour collapse and local detail bias brought about by these three cases.
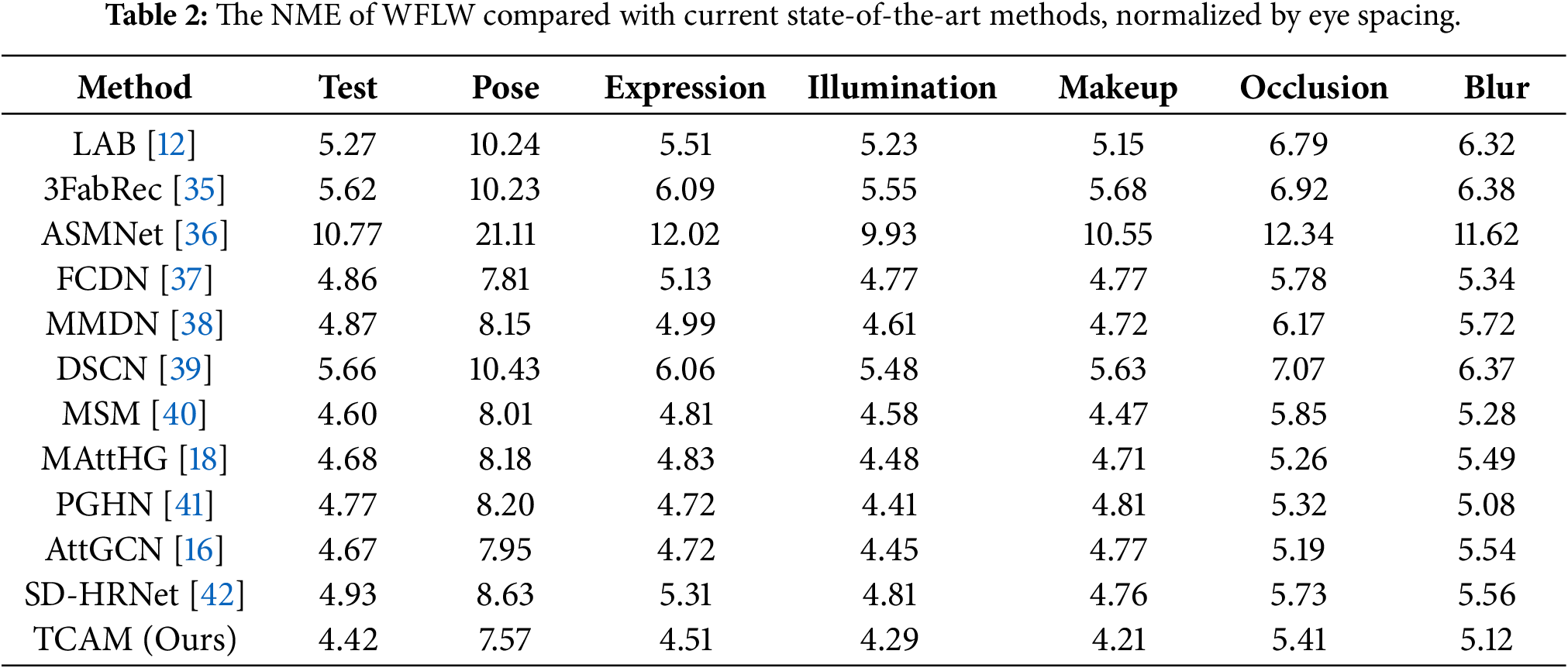
Fig. 4 shows the detection effect of our model on the WFLW dataset. Each column from left to right shows the detection effect graphs affected by the large pose, expression, illumination, makeup, occlusion, and blur cases. The severity of being affected is gradually deepened from top to bottom in each column. The detection effect is very good regardless of the situation or degree of the affected degree. As well as excellent performance in facial boundary constraints and local detail portrayal, we have excellent landmark prediction accuracy and robustness.

Figure 4: Detection results for the six test subsets of the WFLW dataset, with 98 landmarks labeled in total.
To evaluate the robustness of our model against varying degrees of occlusion and extreme poses, we conducted experiments on the COFW dataset. The quantitative results are presented Table 3, where the inter-ocular distance is utilized as the normalization criterion to compare our approach with other recent state-of-the-art methods. As shown in the table, our model achieves the superior performance, obtaining an NME of 4.75% and a failure rate of 0.59%.
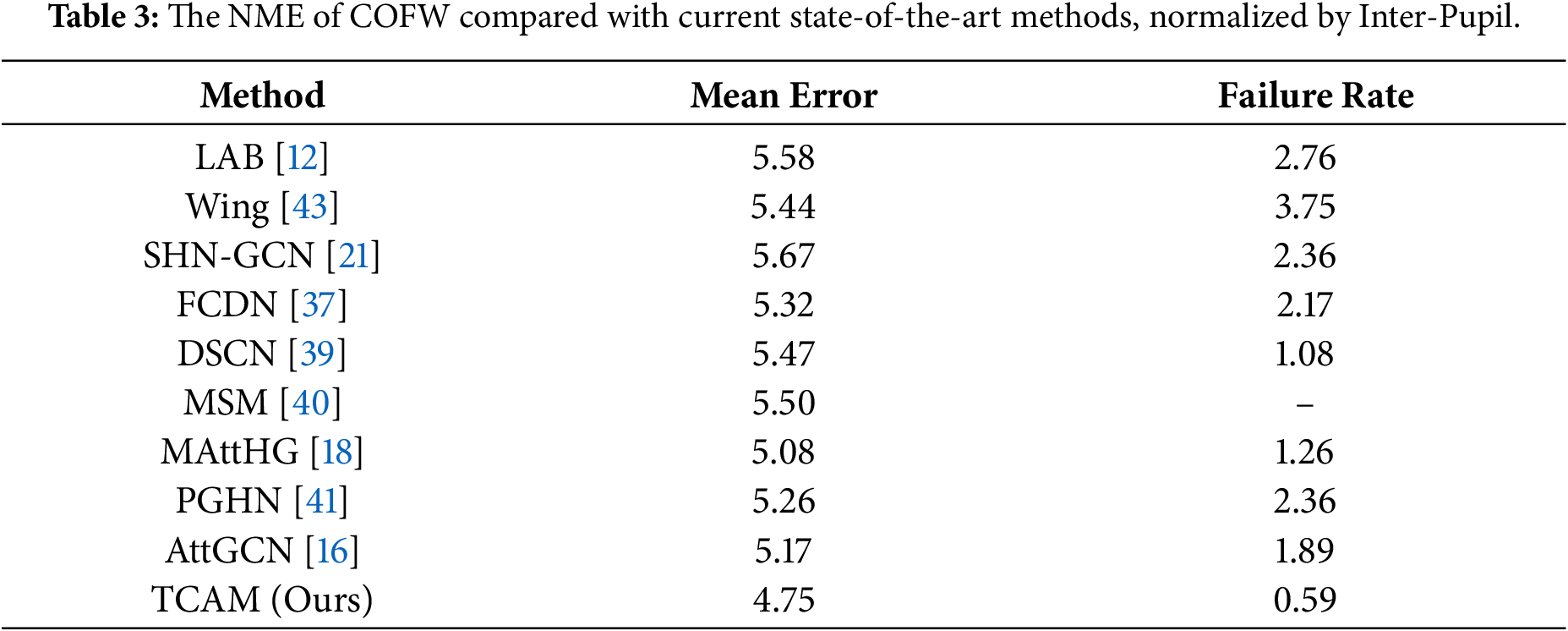
Furthermore, Fig. 5 demonstrates the comparison of Cumulative Error Distribution (CED) curves between our method and existing approaches. Since a larger area under the CED curve indicates a better localization effect, the fact that our method occupies the highest position in the plot further validates its effectiveness. Finally, the qualitative localization results are illustrated in Fig. 6, where the degree of occlusion gradually increases from left to right. It can be observed that our model accurately localizes landmarks even under severe and varying degrees of occlusion.
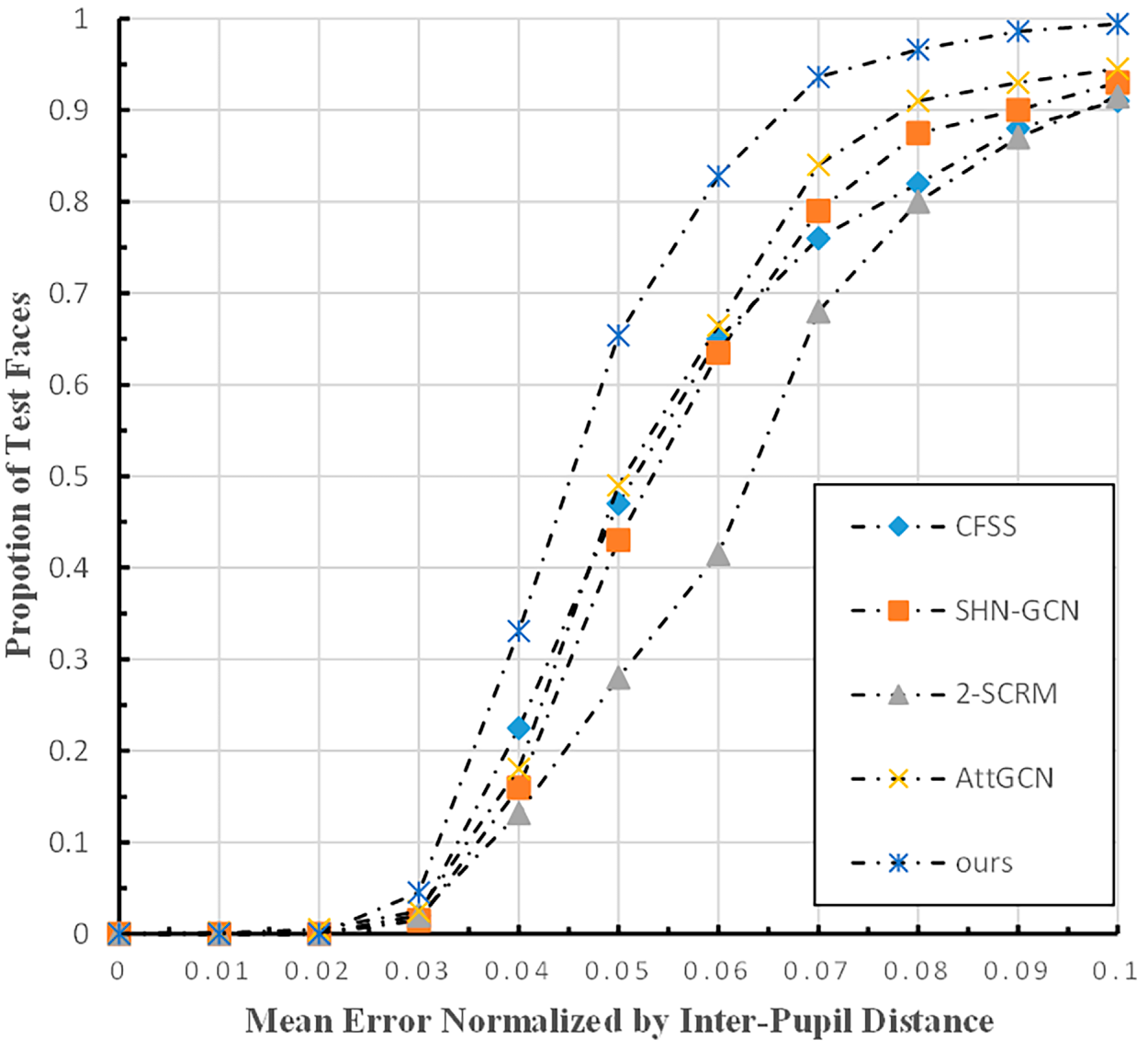
Figure 5: CED curves tested on the COFW dataset by the method in this paper.

Figure 6: Detection results for the COFW test set, with 29 landmarks labeled in total.
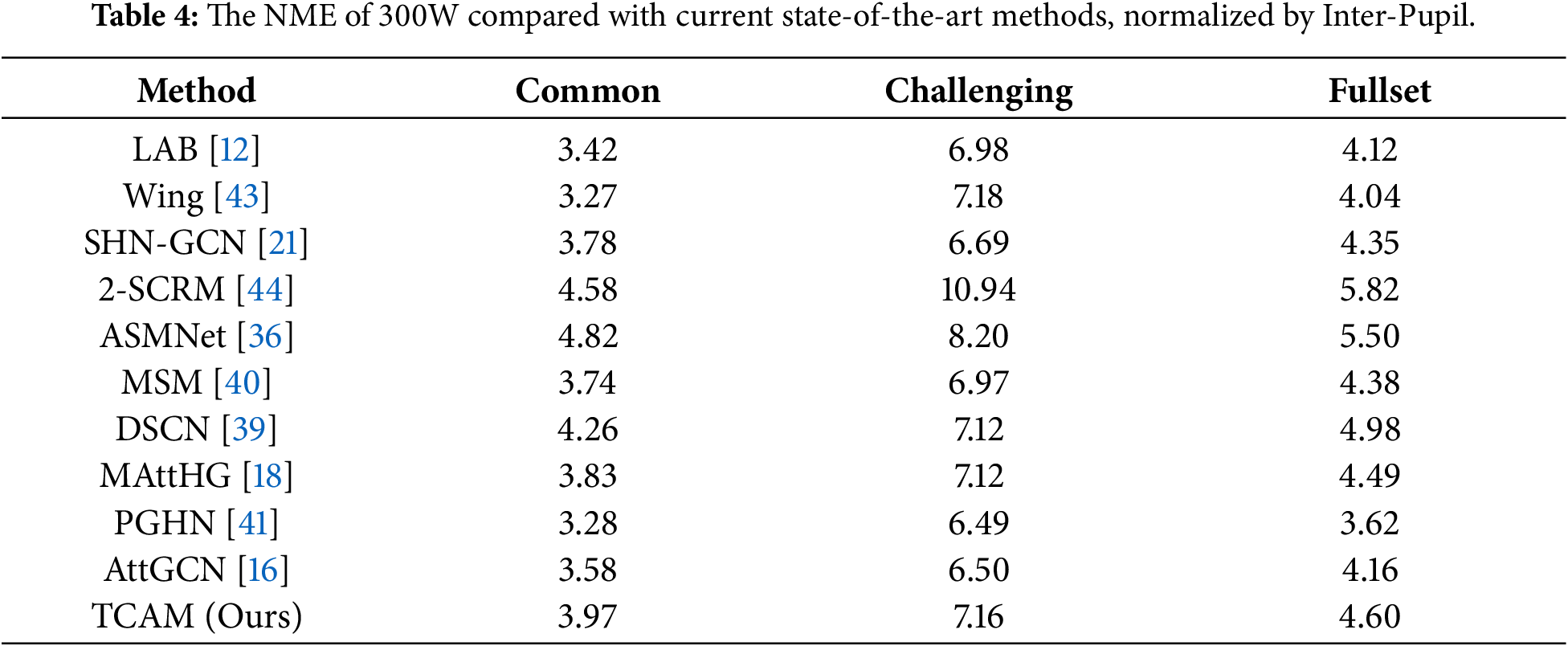
We also evaluated the model’s performance on the classical 300W dataset. Fig. 7 presents a qualitative comparison of detection results between our method and other approaches on this dataset. The first row of the figure displays the ground truth, the second row shows the results of our method, and the third through fifth rows present the results of the other comparison methods. Most of the examples shown involve various degrees of large-pose images. As illustrated, our method’s detection accuracy is high and superior to that of the competing methods. In particular, our approach is more effective at predicting local details and overall contours in the images shown in the final columns. For example, regarding the eye and eyebrow regions in the upper-left corner of the seventh column, our method achieves higher detection accuracy with a landmark distribution that more closely resembles the ground truth. Furthermore, on the facial contours in the eighth column—specifically the left facial contour—our results fit the face more precisely and exhibit better continuity than the other methods.

Figure 7: Our method on the 300 W test set is shown and plotted against other methods, with 68 labeled.
Table 4 demonstrates the objective results of our model compared with other state-of-the-art methods. We compare two normalization approaches, Inter-pupil normalization (IPN). We perform slightly lower under the IPN criterion. This may be because the sample label of the 300W dataset does not label the pupil point, so the coordinate points of the face pupil are averaged by the coordinate points of the surrounding eyes. The entire calculation process is greatly affected by the coordinates of surrounding key points, which may lead to significant errors, so the experimental results perform poorly in the IPN normalization method. In addition, we obtained the second-best performance with 3.27% in the test full set.
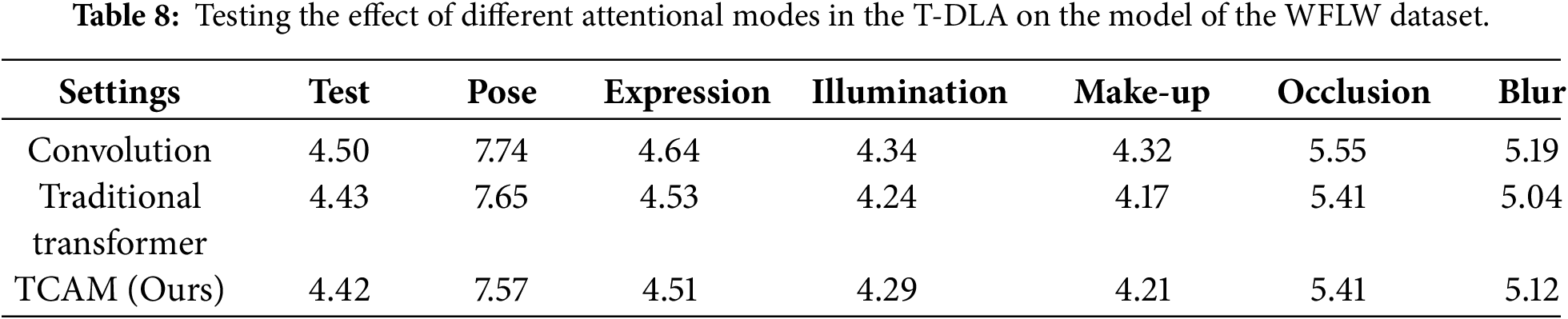
In this section, we evaluate the effectiveness of the parallel architecture and the T-SGA and T-DLA modules through several distinct analyses. First, Table 5 summarizes how each component affects performance when handling various subsets of the complex WFLW dataset, providing a granular view of their robust performance under different conditions. Next, Table 6 compares the performance of the model when fusing features serially vs. parallelly, while Table 7 provides a quantitative comparison of the individual impacts of the T-SGA and T-DLA components across all three datasets. Furthermore, Table 8 presents a comparison of different methods for acquiring local attention, highlighting the specific advantages of our local attention mechanism.


The iterative optimization of landmark localization as each component is added is visually demonstrated in Fig. 8. Additionally, Fig. 9 provides the corresponding qualitative results for the local attention mechanism.

Figure 8: Comparison of performance of the each component and the overall network on the WFLW dataset.

Figure 9: Comparison of different local attention effects.
Impact of the Parallel Structure.
To enable the model to achieve superior localization of both overall shape and local details, we fused the feature information extracted by the local and global attention modules. Consequently, we evaluated the impact of different feature fusion strategies on model performance. We conducted experiments on three datasets using both serial and parallel approaches to integrate features into the model architecture; the results are summarized in Table 6. When attempting to connect T-SGA and T-DLA in a serial manner, our experiments revealed that neither of the two possible module sequences performed as well as the parallel configuration. The results consistently demonstrate that the parallel fusion method yields better performance, with NME values significantly lower than those of the serial structures. Based on these findings, we adopted the parallel structure for feature fusion in our final architecture.
Effectiveness of the T-SGA Module.
We integrated the T-SGA module into the backbone network to address the issues of intermittent landmark distribution and deviations from facial contours, which often occur in heatmap regression due to missing contextual information. We conducted experiments to evaluate the specific contribution of this component to the overall model performance. As shown in Table 7, the inclusion of T-SGA led to a significant improvement in detection accuracy across all benchmarks. The most substantial gains were observed on the WFLW dataset, where the NME decreased by 0.28%, demonstrating the module’s ability to effectively model long-range dependencies and global facial structure.
Additionally, as shown in Table 5, the inclusion of the T-SGA module resulted in the most pronounced improvement within the large-pose subset, where the NME decreased by 0.74%. This improvement is attributed to the Transformer’s exceptional capacity for modeling long-range dependencies, which enables the network to capture spatial relationships between landmarks at distant locations and achieve robust context-awareness. Consequently, the model can more accurately learn facial contour distributions from large-pose images—where standard local features may be occluded or distorted—leading to significantly enhanced localization precision.
As shown in the second, third, fourth, and sixth columns of images in Fig. 8, the localization results with the addition of the T-SGA component (third row) exhibit a substantial improvement in facial contouring compared to the original backbone network (last row). Specifically, facial boundaries that were originally severely deviated or scattered become more continuous and follow a clearly defined geometric structure. This demonstrates the effectiveness of the T-SGA module in imposing global shape constraints and maintaining structural integrity in complex scenarios.
Impact of the T-DLA Module.
To enhance the model’s ability to locate landmarks within fine facial regions, we introduced the T-DLA module. This component integrates the globally shared weights of convolutional layers with the context-aware weights of the Transformer to capture intricate positional relationships within local regions. As demonstrated in Tables 5 and 7, the inclusion of T-DLA significantly improves model accuracy, particularly in the large-pose and occlusion subsets, where the NME decreases by 0.51% and 0.39%, respectively. By strengthening the learning of spatial dependencies among local keypoints, the module can compensate for occluded features using information from surrounding areas and correct the misalignment of local point clusters along facial boundaries. This optimization process is clearly visible in Fig. 8. For instance, in the fourth and sixth columns, a comparison between the original backbone (last row) and the model with the T-DLA component (fourth row) shows superior localization of points in local regions and a marked reduction in the dispersion of point clusters on the facial contours.
Additionally, we evaluated the impact of different local attention mechanisms on the model’s localization performance, as summarized in Table 8. The results clearly indicate that the convolution-only approach is the least effective. While the Transformer-only approach provides a significant improvement, it remains inferior to our proposed hybrid method, particularly in the large-pose and exaggerated-expression subsets, and lags slightly behind on the full WFLW test set. Consequently, we adopted the combination of convolution and Transformer to better handle the complexities of large poses and expressions. Fig. 9 presents the qualitative detection results for these three methods. The superiority of our approach is clearly visible in the second, third, fourth, and sixth columns. Notable examples include the precise localization of the jawline in the second column, the mouth in the third column, the left eyebrow and left jaw in the fourth column, and the right cheek in the sixth column. These results confirm that our hybrid strategy more effectively captures both the high-frequency local details and the structural consistency required for accurate face alignment.
Combining Figs. 8 and 9, we can clearly find that the localization with both T-SGA and T-DLA components is better and most relevant to the ground truth, at which point the model has the best accuracy, and is more robust, especially for dealing with large gestures and pictures with exaggerated expressions.
This paper presents the Transformer-Conv Attention Module (TCAM), a robust framework designed for precise facial landmark localization in complex scenarios. Unlike conventional methods that struggle with extreme spatial variations, our approach synergistically integrates the long-range dependency modeling of Transformers with the local feature extraction of Depthwise Convolutions. The experimental results, validated by objective metrics such as NME, FR, and CED curves, demonstrate the superiority of our model over current state-of-the-art methods. Specifically, the substantial reduction in Failure Rate on the COFW dataset and the high localization accuracy on the WFLW pose subset confirm that the parallel architecture of T-DLA and T-SGA effectively balances global shape constraints with fine-grained local details. These findings underscore the necessity of the TCAM in handling heavy occlusion and exaggerated expressions, providing a highly competitive and robust solution for real-world face alignment tasks.
Acknowledgement: Not applicable.
Funding Statement: This study has no funding support.
Author Contributions: The authors confirm contribution to the paper as follows: Study Conception and Design: Zhi Zhang, Bingyu Sun; Data Collection: Zhi Zhang; Analysis and Interpretation of Results: Zhi Zhang; Draft Manuscript Preparation: Zhi Zhang; Review & Editing: Bingyu Sun; Supervision: Bingyu Sun. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from three benchmark datasets: WFLW [12], COFW [11], and 300W [10].
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Hao M, Liu G, Xie D. Hyperspectral face recognition with a spatial information fusion for local dynamic texture patterns and collaborative representation classifier. IET Image Processing. 2021;15(8):1617–28. doi:10.1049/ipr2.12131. [Google Scholar] [CrossRef]
2. Devi PRS, Baskaran R. SL2E-AFRE : personalized 3D face reconstruction using autoencoder with simultaneous subspace learning and landmark estimation. Appl Intell. 2021;51(4):2253–68. doi:10.1007/s10489-020-02000-y. [Google Scholar] [CrossRef]
3. Li S, Deng W, Du J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 2852–61. [Google Scholar]
4. Jin H, Liao S, Shao L. Pixel-in-pixel net: towards efficient facial landmark detection in the wild. Int J Comput Vis. 2021;129:3174–94. doi:10.1007/s11263-021-01521-4. [Google Scholar] [CrossRef]
5. Wan J, Liu J, Zhou J, Lai Z, Shen L, Sun H, et al. Precise facial landmark detection by reference heatmap transformer. IEEE Trans Image Process. 2023;32(1):1966–77. doi:10.2139/ssrn.4518142. [Google Scholar] [CrossRef]
6. Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16 x 16 words: transformers for image recognition at scale. arXiv:2010.11929. 2020. [Google Scholar]
7. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2020. p. 213–29. [Google Scholar]
8. Yuan Y, Chen X, Chen X, Wang J. Segmentation transformer: object-contextual representations for semantic segmentation. arXiv:1909.11065. 2019. [Google Scholar]
9. Sha Y, Meng W, Zhai X, Xie C, Li K. Accurate facial landmark detector via multi-scale transformer. In: Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Cham, Switzerland: Springer; 2023. p. 278–90. [Google Scholar]
10. Sagonas C, Antonakos E, Tzimiropoulos G, Zafeiriou S, Pantic M. 300 faces in-the-wild challenge: database and results. Image Vis Comput. 2016;47:3–18. doi:10.1016/j.imavis.2016.01.002. [Google Scholar] [CrossRef]
11. Burgos-Artizzu XP, Perona P, Dollár P. Robust face landmark estimation under occlusion. In: Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2013. p. 1513–20. [Google Scholar]
12. Wu W, Qian C, Yang S, Wang Q, Cai Y, Zhou Q. Look at boundary: a boundary-aware face alignment algorithm. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2018. p. 2129–38. [Google Scholar]
13. Salem E, Hassaballah M, Mahmoud MM, Ali AMM. Facial features detection: a comparative study. In: Proceedings of the International Conference on Artificial Intelligence and Computer Vision (AICV 2021). Cham, Switzerland: Springer; 2021. p. 402–12. [Google Scholar]
14. Sun Y, Wang X, Tang X. Deep convolutional network cascade for facial point detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2013. p. 3476–83. [Google Scholar]
15. Meng Y, Chen X, Gao D, Zhao Y, Yang X, Qiao Y, et al. 3D dense face alignment with fused features by aggregating cnns and gcns. arXiv:2203.04643. 2022. [Google Scholar]
16. Fan J, Liang J, Liu H, Huan Z, Hou Z. Robust face alignment via adaptive attention-based graph convolutional network. Neural Comput Applicat. 2023;35(20):15129–42. doi:10.1007/s00521-023-08531-y. [Google Scholar] [CrossRef]
17. Sun K, Xiao B, Liu D, Wang J. Deep high-resolution representation learning for human pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2019. p. 5693–703. [Google Scholar]
18. Yang Z, Shao X, Wan J, Gao R, Lai Z. Mixed attention hourglass network for robust face alignment. Int J Mach Learn Cybernet. 2022;13:869–81. doi:10.1007/s13042-021-01424-3. [Google Scholar] [CrossRef]
19. Hassaballah M, Salem E, Ali AMM, Mahmoud MM. Deep recurrent regression with a heatmap coupling module for facial landmarks detection. Cognit Computat. 2022;16:1964–78. doi:10.1007/s12559-022-10065-9. [Google Scholar] [CrossRef]
20. Xie J, Wan J, Shen L, Lai Z. Think about boundary: fusing multi-level boundary information for landmark heatmap regression. In: 2021 International Joint Conference on Neural Networks (IJCNN). Piscataway, NJ, USA: IEEE; 2021. p. 1–8. [Google Scholar]
21. Zhang J, Hu H, Feng S. Robust facial landmark detection via heatmap-offset regression. IEEE Trans Image Process. 2020;29:5050–64. doi:10.1109/tip.2020.2976765. [Google Scholar] [PubMed] [CrossRef]
22. Park H, Kim D. ACN: occlusion-tolerant face alignment by attentional combination of heterogeneous regression networks. Pattern Recognit. 2021;114(4):107761. doi:10.1016/j.patcog.2020.107761. [Google Scholar] [CrossRef]
23. Li H, Guo Z, Rhee SM, Han S, Han JJ. Towards accurate facial landmark detection via cascaded transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2022. p. 4176–85. [Google Scholar]
24. Xia J, Qu W, Huang W, Zhang J, Wang X, Xu M. Sparse local patch transformer for robust face alignment and landmarks inherent relation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2022. p. 4052–61. [Google Scholar]
25. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2016. p. 770–8. [Google Scholar]
26. Newell A, Yang K, Deng J. Stacked hourglass networks for human pose estimation. In: Computer Vision—ECCV 2016: 14th European Conference. Cham, Switzerland: Springer; 2016. p. 483–99. [Google Scholar]
27. Srinivasu PN, JayaLakshmi G, Narahari SC, de Albuquerque VHC, Khan MA, Cho HC, et al. Super-resolution generative adversarial network with pyramid attention module for face generation. Comput Mat Cont. 2025;85(1):2117–35. doi:10.32604/cmc.2025.065232. [Google Scholar] [CrossRef]
28. Fan Q, Huang H, Guan J, He R. Rethinking local perception in lightweight vision transformer. arXiv:2303.17803. 2023. [Google Scholar]
29. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2018. p. 7132–41. [Google Scholar]
30. Xiao T, Singh M, Mintun E, Darrell T, Dollár P, Girshick R. Early convolutions help transformers see better. Adv Neural Inform Process Syst. 2021;34:30392–400. [Google Scholar]
31. Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al. Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2021. p. 10012–22. [Google Scholar]
32. Tu Z, Talebi H, Zhang H, Yang F, Milanfar P, Bovik A, et al. Maxvit: multi-axis vision transformer. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2022. p. 459–79. [Google Scholar]
33. Chu X, Tian Z, Zhang B, Wang X, Wei X, Xia H, et al. Conditional positional encodings for vision transformers. arXiv:2102.10882. 2021. [Google Scholar]
34. Krizhevsky A, Sutskever I, Hinton G. ImageNet classification with deep convolutional neural networks. In: Advances in neural information processing systems. Red Hook, NY, USA: Curran Associates, Inc.; 2012. doi:10.1145/3065386. [Google Scholar] [CrossRef]
35. Browatzki B, Wallraven C. 3fabrec: fast few-shot face alignment by reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2020. p. 6110–20. [Google Scholar]
36. Fard AP, Abdollahi H, Mahoor M. ASMNet: a lightweight deep neural network for face alignment and pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 1521–30. [Google Scholar]
37. Wan J, Lai Z, Shen L, Zhou J, Gao C, Xiao G, et al. Robust facial landmark detection by cross-order cross-semantic deep network. Neural Networks. 2021;136(2):233–43. doi:10.1016/j.neunet.2020.11.001. [Google Scholar] [PubMed] [CrossRef]
38. Wan J, Lai Z, Li J, Zhou J, Gao C. Robust facial landmark detection by multiorder multiconstraint deep networks. IEEE Trans Neural Netw Learn Syst. 2021;33(5):2181–94. doi:10.1109/tnnls.2020.3044078. [Google Scholar] [PubMed] [CrossRef]
39. Ma J, Li J, Du B, Wu J, Wan J, Xiao Y. Robust face alignment by dual-attentional spatial-aware capsule networks. Pattern Recognit. 2022;122(6):108297. doi:10.1016/j.patcog.2021.108297. [Google Scholar] [CrossRef]
40. Wang H, Cheng R, Zhou J, Tao L, Kwan HK. Multistage model for robust face alignment using deep neural networks. Cognit Comput. 2022;14(3):1123–39. doi:10.1007/s12559-021-09846-5. [Google Scholar] [CrossRef]
41. Fan J, Liang J, Liu H, Huan Z, Hou Z, Zhou X. Robust facial landmark detection by probability-guided hourglass network. IET Image Process. 2023;17(8):2489–502. doi:10.1049/ipr2.12812. [Google Scholar] [CrossRef]
42. Lin X, Zheng H, Zhao P, Liang Y. SD-HRNet: slimming and distilling high-resolution network for efficient face alignment. Sensors. 2023;23(3):1532. doi:10.3390/s23031532. [Google Scholar] [PubMed] [CrossRef]
43. Feng ZH, Kittler J, Awais M, Huber P, Wu XJ. Wing loss for robust facial landmark localisation with convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2018. p. 2235–45. [Google Scholar]
44. Zhang J, Di L, Liang J. Face alignment based on fusion subspace and 3D fitting. IET Image Process. 2021;15(1):16–27. doi:10.1049/ipr2.12002; [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools