
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

MobiIris: Attention-Enhanced Lightweight Iris Recognition with Knowledge Distillation and Quantization
1 Faculty of Information Technology II, Posts and Telecommunications Institute of Technology, Ho Chi Minh City, Vietnam
2 School of Computer Science & Engineering, The Saigon International University, Ho Chi Minh City, Vietnam
3 Institute of Digital Technology, Thu Dau Mot University, Ho Chi Minh City, Vietnam
* Corresponding Author: Trong-Thua Huynh. Email:
(This article belongs to the Special Issue: Deep Learning: Emerging Trends, Applications and Research Challenges for Image Recognition)
Computers, Materials & Continua 2026, 87(3), 19 https://doi.org/10.32604/cmc.2026.076623
Received 23 November 2025; Accepted 06 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This paper introduces MobiIris, a lightweight deep network for mobile iris recognition that enhances attention and specifically addresses the balance between accuracy and efficiency on devices with limited resources. The proposed model is based on the large version of MobileNetV3 and adds more spatial attention blocks and an embedding-based head that was trained using margin-based triplet learning, enabling fine-grained modeling of iris textures in a compact representation. To further improve discriminability, we design a training pipeline that combines dynamic-margin triplet loss, a staged hard/semi-hard negative mining strategy, and feature-level knowledge distillation from a ResNet-50 teacher. Finally, we investigate the use of post-training float16 quantization to reduce memory footprint and latency for deployment on mobile hardware. Experiments on the challenging CASIA-IrisV4-Thousand dataset show that the full-precision MobiIris model requires onlyKeywords
Compared with other biometric features, the unique and stable nature of the iris pattern makes it a reliable and non-invasive means of identification [1]. This capability has proven effective across a wide range of security applications, such as mobile and physical access control, thereby contributing to the expansion of the global iris recognition market. Through miniaturized near-infrared sensors, iris recognition has been deployed on smartphones, which enables contactless authentication in response to the post-pandemic demand for touchless technologies [2]. Reflecting this momentum, Mordor Intelligence projects that this market will grow from USD
However, achieving a balance between accuracy and efficiency remains challenging. This is mainly because widely used state-of-the-art deep learning models are built on large convolutional architectures that demand substantial computational and memory resources. For instance, VGG-16 contains over
Over the years, iris recognition research has steadily progressed, moving from classical image processing and handcrafted machine learning features to deep learning methods [7]. Despite these improvements, the high computational demand of traditional models hinders their deployment on resource-constrained devices, thereby motivating growing interest in lightweight architectures. On the ImageNet dataset, GhostNet, a lightweight architecture with an improved feature generation module, achieved the highest classification accuracy among lightweight models, with competitive computational cost [8]. Similarly, [9] evaluated a set of deep learning models for iris recognition under constrained conditions, showing that MobileNetV3 models reduced parameters by
While lightweight architectures establish a solid foundation for mobile iris recognition, further enhancements in performance can be obtained through optimization techniques. Introduced in [11], knowledge distillation involves transferring knowledge from a larger and more complex teacher model to a smaller and simpler student model. Despite being widely applied in various computer vision tasks, it is less explored in iris recognition. In [12], a comprehensive survey covering a wide range of models and knowledge distillation techniques reported accuracy improvements of over
Despite recent notable progress, several important gaps persist in iris recognition research. First, although lightweight architectures and compression techniques have been widely adopted in other biometric modalities, such as face and fingerprint recognition, their use in iris recognition remains limited. Few studies have investigated their potential, thereby hindering the deployment of compact models in resource-constrained conditions. Second, while knowledge distillation has shown effectiveness in various computer vision tasks, its application combined with compression techniques in iris recognition remains relatively unexplored, limiting the development of compact and accurate models. Third, embedding-based feature learning, which is a common approach in most biometric modalities, has not been fully utilized in iris recognition, as most studies rely on classification-based outputs. Finally, balancing accuracy and efficiency remains challenging, as most prior works focus on one aspect, and few address both within a unified framework.
Motivated by these challenges, this study aims to balance accuracy and efficiency for practical deployment. Specifically, the main objectives are:
For iris recognition tasks, datasets should be carefully prepared to ensure both diversity and consistency. This study employs the CASIA-IrisV4 dataset [15], which contains near-infrared images collected under various acquisition conditions. Specifically, the original data are reorganized into a subject-based directory structure in which each image folder belongs to a single subject. Since the focus of this work is on iris recognition, including feature extraction, encoding, and matching stages, iris segmentation is omitted. Instead, we propose a preprocessing procedure (Algorithm 1) that utilizes Open-Iris library to automatically detect and extract the iris region from each input image for recognition purposes, thereby ensuring that all modules operate solely on the normalized iris area [16].
For our experiments, we conducted tests on all CASIA-IrisV4 subsets. CASIA-IrisV4-Thousand was selected because it yielded the most representative recognition results. This subset also presents challenging acquisition conditions and is widely used in previous iris recognition benchmarks. In detail, it consists of 1000 subjects with a total of 20,000 images, about

Figure 1: Iris images before and after preprocessing.

Algorithm 1 presents the iris-image preprocessing pipeline, providing key operations, starting from loading the input image, extracting the relevant regions to create the region of interest mask, computing the iris bounding box to cropping the iris region, to generating the final output. To ensure uniformity across all samples, additional steps are included to discard improperly processed images and separate left and right eyes of each subject into independent identities, which play a crucial role in model training.
To balance accuracy and efficiency, the large variant of MobileNetV3 is adopted as the backbone for its sufficient representational capacity. Architecturally, an embedding-based module generates compact feature embeddings, while Spatial Attention (SA) complements Squeeze-and-Excitation (SE) to enhance spatial features. As shown in Table 1, SA provides a more efficient alternative to Convolutional Block Attention Module (CBAM) and Non-Local Attention (NLA).

The Spatial Attention, illustrated in Fig. 2, functions similarly to the SE Attention; however, it is designed to focus on spatial features. Given an intermediate feature map F, spatial information is aggregated by applying average pooling and max pooling across the channel dimension, producing two spatial context descriptors,
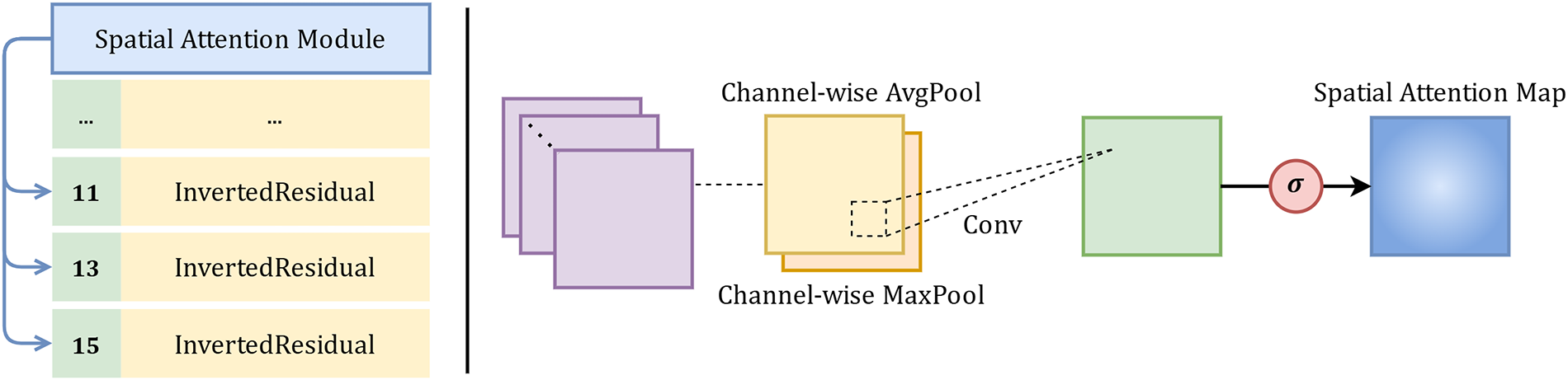
Figure 2: Spatial attention module for discriminative region highlighting.
These context descriptors are then combined to generate the spatial attention map
Instead of relying on closed-set classification, an embedding-based approach suited to the open-set nature of biometric recognition is adopted. As shown in Fig. 3, its design consists of a linear layer followed by batch normalization, producing compact feature embeddings. In related biometric tasks, embedding-based methods outperform classification-based ones: ArcFace achieved state-of-the-art performance, reporting
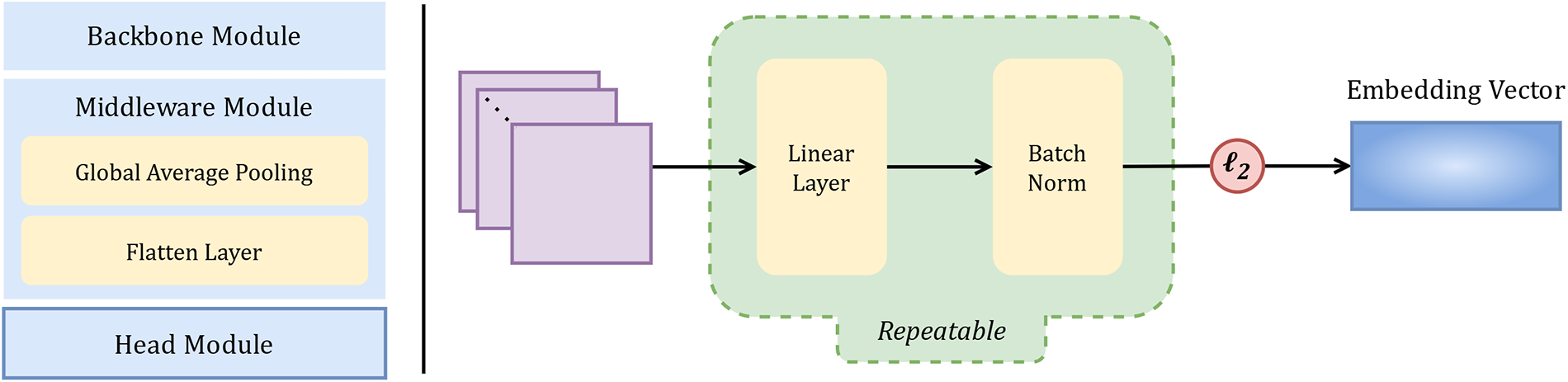
Figure 3: Embedding-based module for feature representation learning.
Let
Together, the lightweight backbone, spatial attention module, and embedding-based head form a cohesive feature extraction and representation framework, which is further reinforced during training through Hard Negative Mining and Knowledge Distillation, enabling the model to focus on challenging samples and to transfer discriminative knowledge from a stronger teacher model.
Algorithm 2 outlines the overall training optimization procedure under the triplet-learning paradigm, including triplet batch sampling and processing. The sampling stage constructs a triplet consisting of an anchor (the reference sample), a positive sample with the same label, and a negative sample with a different label that has not been paired with the selected anchor and positive samples in the current iteration. The processing stage extracts student and teacher embeddings and applies hard negative mining with knowledge distillation, depending on the current phase.

Triplet-based learning is employed to learn discriminative embeddings by enforcing a relative distance constraint among anchor, positive and negative samples. Specifically, the model is trained to minimize the Euclidean distance
To optimize the triplet margin loss, a margin scheduling strategy (5) is adopted, where the margin dynamically changes during training. The margin is initially fixed during a warm-hard phase and then gradually transitions to semi-hard phases using a cosine annealing schedule (4), facilitating effective integration with the hard negative mining strategy. Let
To enhance convergence and embedding discriminability, hard negative mining strategy (6) is applied during training. In the initial warm-up stage,
To strengthen the discriminative capability of the student model, MobileNetV3-L, knowledge distillation is employed using a pretrained teacher model, ResNet-50, trained on the same dataset, as shown in Fig. 4. The student model is optimized with a combined objective
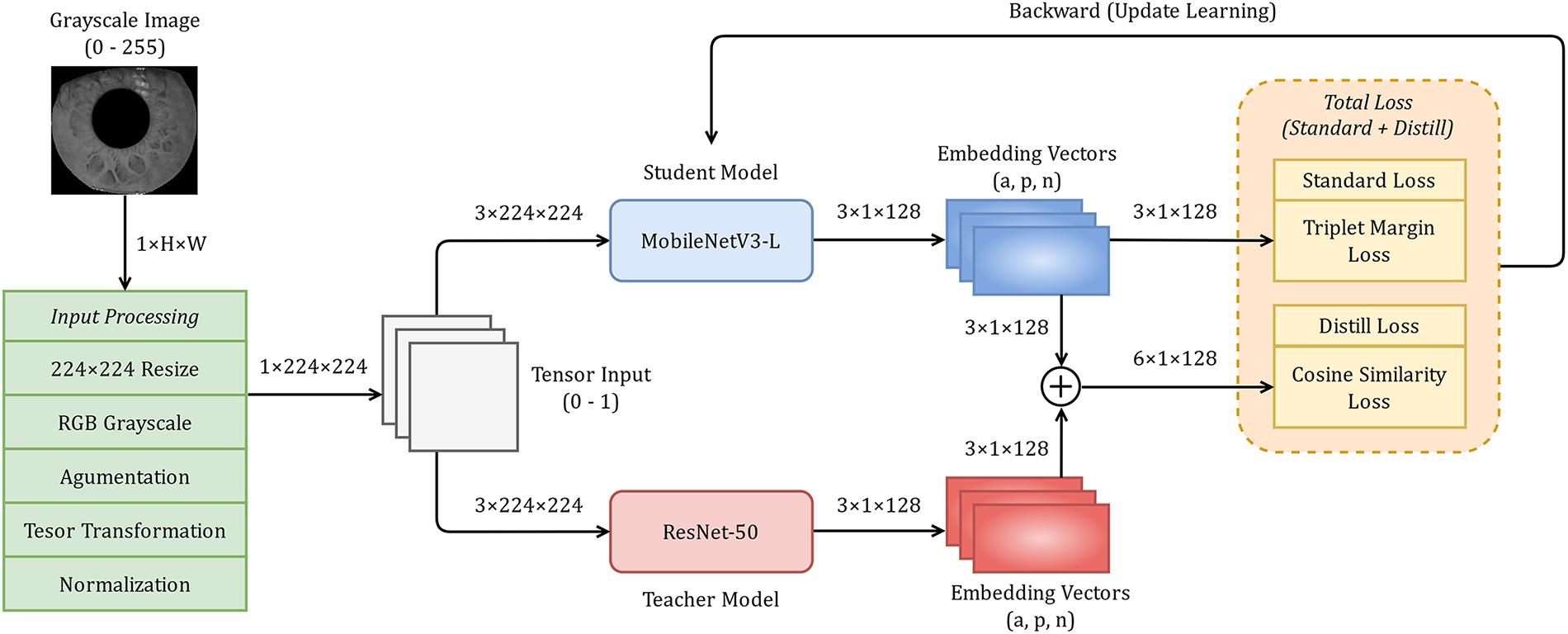
Figure 4: Knowledge Distillation between ResNet-50 teacher and MobileNetV3-L student.
Let
To evaluate recognition performance, two sets of metrics that capture different aspects of the model capabilities are used. These metrics offer a comprehensive assessment of how accurately the model can verify or identify subjects under various conditions. By integrating both threshold-based and ranking-based measures, the evaluation quantifies not only the accuracy but also the robustness of the model in challenging scenarios, such as hard negatives and unseen identities.
A key step in recognition tasks is measuring the similarity between two normalized embedding vectors,
Verification metrics are used to evaluate the model’s ability to determine whether pairs of samples correspond to the same or different identities. Given a similarity score
• False Acceptance Rate, defined as
• False Rejection Rate, defined as
• Equal Error Rate, displayed as
• Verification Rate at a False Acceptance Rate, defined as
Identification metrics are used to evaluate the model’s ability to correctly identify a probe iris image from a gallery of known identities. In contrast to verification, which makes a binary decision, identification ranks all gallery images according to their similarity to the probe.
• Cumulative Matching Characteristic, defined as
Experiments are conducted on the CASIA-IrisV4-Thousand dataset, split into
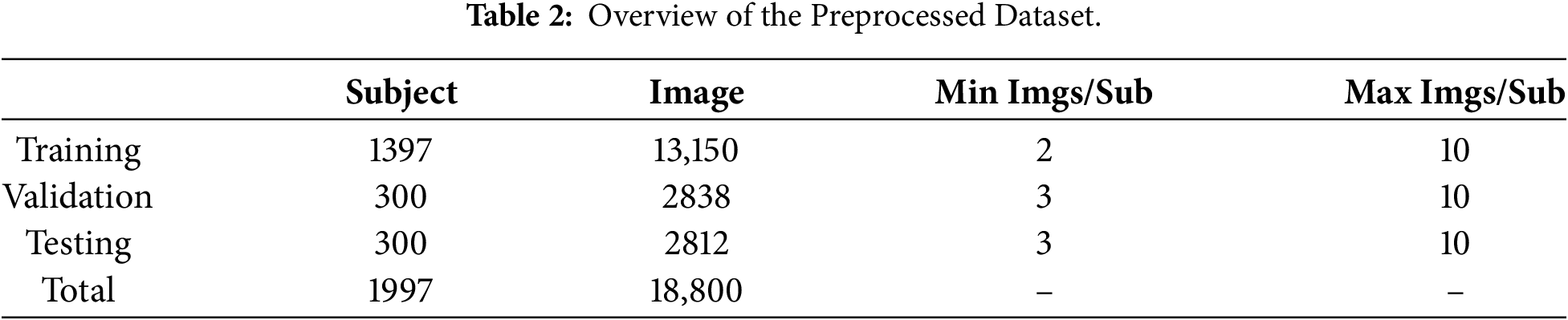
The training process is conducted over
Regarding the hard negative mining strategy, the configuration defines the lower and upper bounds for negative sample selection as scales of the triplet margin. Specifically, these bounds are computed as the product of the margin and generated ratios, as formalized in Eq. (6), thereby selecting negatives according to the current discriminative ability of the model.
In the warm-hard stage, the ratios for the lower and upper bounds,
For the knowledge distillation technique, the configuration specifies a maximum distillation weight
To evaluate the impact of the proposed optimizations, the baseline MobileNetV3-L (BASE) is compared with its optimized variants, and the state-of-the-art ResNet-50 (SOTA). Specifically, attention mechanism and knowledge distillation technique are incorporated into the baseline to create more robust variants. As observed, the individual variants show moderate improvements, whereas their combination (our proposal) yields a more substantial improvement and narrows the performance gap to the state-of-the-art. Table 3 presents a detailed comparison among the baseline, the optimized variants, and the state-of-the-art model.
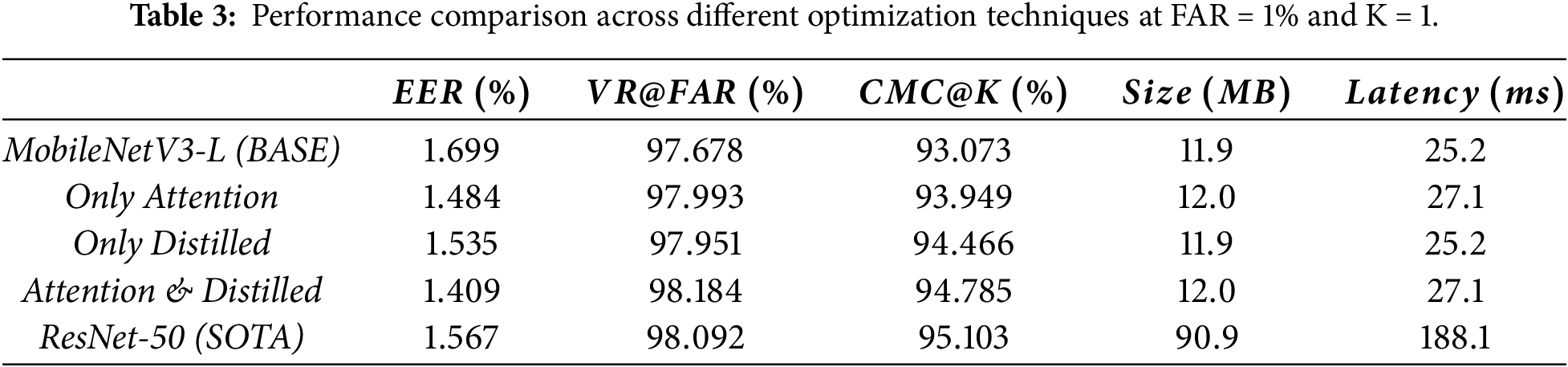
The baseline achieves an EER of
Compared to the baseline, both attention and distillation enhancements achieve consistent accuracy improvements with minimal computational cost. The attention-only variant reduces the EER to
Based on these individual enhancements, combining attention and distillation further improves overall performance. Compared to the baseline, the combined variant slightly increases model size by
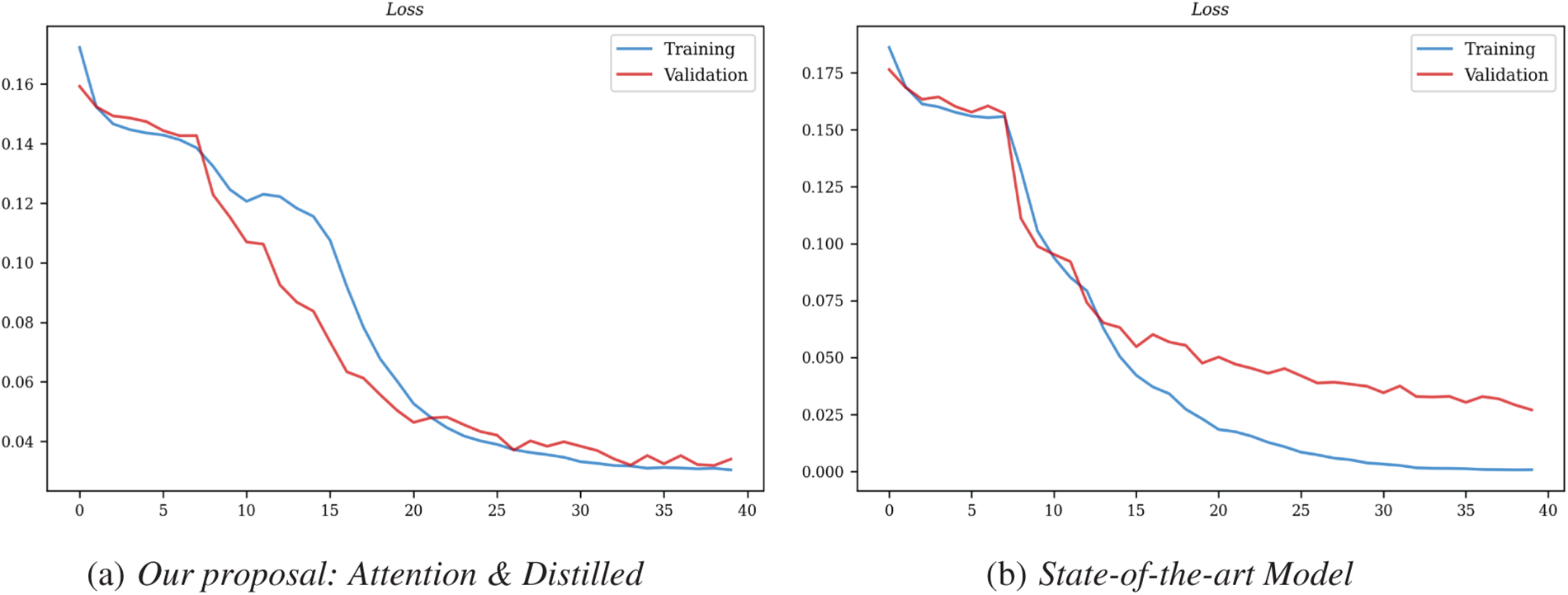
Figure 5: Comparison of training and validation convergence.
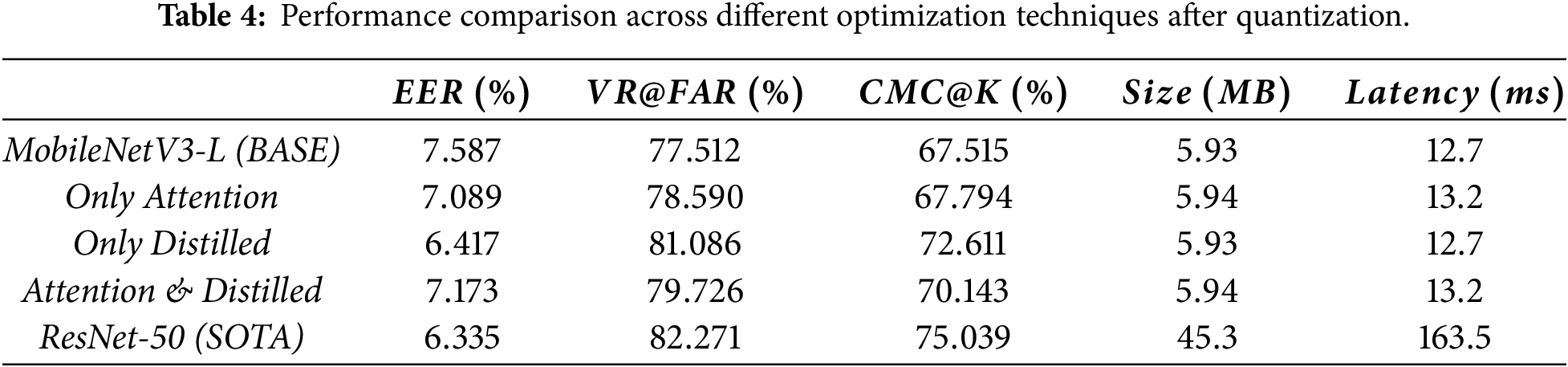
To further examine the practicality of the proposed models for mobile deployment, we assess their performance under post-training quantization. As summarized in Table 4, the results highlight that reduced numerical precision substantially impacts recognition accuracy and computational efficiency. As expected, quantization causes a noticeable degradation in recognition performance across all models.
In this work, post-training quantization is applied to the final models due to its simplicity, compatibility with mobile deployment, and no retraining requirement. Specifically, the weights are converted from float32 to float16, while other tensors remain in full precision due to the model’s sensitivity to numerical precision [20]. As float16 naturally preserves the dynamic range of the weights, converting them to half-precision reasonably reduces memory footprint and computational cost while minimizing precision loss.
The baseline model experiences a substantial accuracy drop after quantization, with an EER increasing from
Meanwhile, the attention-only and distilled-only variants show slight overall improvements compared to the baseline, showing some resilience to quantization. Importantly, the combined variant achieves a balanced performance among all optimized models, with an EER of
In general, the proposed optimizations enhance accuracy and maintain efficiency relative to the baseline; however, all models suffer a noticeable drop in recognition accuracy after quantization, with EER increasing, and VR@FAR and CMC@K decreasing across all variants. To address this, alternative strategies such as quantization-aware training or mixed precision could be considered to reduce the performance drop, though they involve additional training complexity and are left for future work. Consequently, this highlights the need for further development to better preserve accuracy and improve practicality for mobile deployment.
This study presents a lightweight MobileNetV3-L model for mobile iris recognition, optimized through attention mechanism, knowledge distillation, and quantization to achieve a practical balance between accuracy and efficiency. Comprehensive experiments demonstrate that the model achieves a compact size of
Building on these findings, the practical value of this work lies in providing a mobile-ready iris recognition solution that balances recognition accuracy and computational efficiency, improving the overall system architecture to achieve robust and reliable performance, and demonstrating the framework’s practicality through extensive experimental evaluation. By utilizing lightweight architectures and optimization techniques, the proposed framework facilitates deployment across a wide range of practical domains, including smart cities and mobile security. Despite these strengths, current evaluations are limited to standard datasets, and maintaining accuracy under aggressive quantization remains challenging. Consequently, future research built on this work can further expand this work through validation on larger and more diverse datasets, exploration of advanced optimization strategies, extension to multimodal biometric systems, and evaluation across different hardware platforms to enhance robustness, scalability and generalizability.
Acknowledgement: The authors extend their appreciation to the Posts and Telecommunications Institute of Technology (PTIT, Vietnam) for supporting this research.
Funding Statement: Not applicable.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Trong-Thua Huynh and De-Thu Huynh; methodology, Trong-Thua Huynh and Du-Thang Phu; software: Du-Thang Phu and De-Thu Huynh; validation, Quoc H. Nguyen and Hong-Son Nguyen; formal analysis, Trong-Thua Huynh and Quoc H. Nguyen, resources, Du-Thang Phu; data curation, Trong-Thua Huynh; writing—original draft preparation, Du-Thang Phu and De-Thu Huynh; writing—review and editing, Trong-Thua Huynh and Du-Thang Phu; visualization, De-Thu Huynh; supervision, Hong-Son Nguyen; project administration, Trong-Thua Huynh. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the Corresponding Author, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Grother P, Matey J, Tabassi E, Quinn G, Chumakov M. IREX VI: temporal stability of iris recognition accuracy. In: NIST Interagency/Internal Report (NISTIR) 7948. Gaithersburg, MD, USA: National Institute of Standards and Technology; 2013 Jul 11. doi:10.6028/NIST.IR.7948. [Google Scholar] [CrossRef]
2. Emergen Research. Iris recognition market, by component, product, application, end-use, and region, forecast to 2034; 2025 Jul [cited 2025 Oct 15]. Available from: https://www.emergenresearch.com/industry-report/iris-recognition-market. [Google Scholar]
3. Mordor Intelligence Research & Advisory. Iris recognition market size & share analysis: growth trends & forecasts (2025–2030) [Internet]. 2025 Jul [cited 2025 Oct 15]. Available from: https://www.mordorintelligence.com/industry-reports/iris-recognition-market. [Google Scholar]
4. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556. 2014. doi:10.48550/arxiv.1409.1556. [Google Scholar] [CrossRef]
5. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Piscataway, NJ, USA: IEEE; 2016. p. 770–8. doi:10.1109/CVPR.2016.90. [Google Scholar] [CrossRef]
6. Huang G, Liu Z, Van Der Maaten L, Weinberger KQ. Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Piscataway, NJ, USA: IEEE; 2017. p. 4700–8. doi:10.1109/CVPR.2017.243. [Google Scholar] [CrossRef]
7. Nguyen K, Proença H, Alonso-Fernandez F. Deep learning for iris recognition: a survey. ACM Comput Surv. 2024;56(9):223:1–35. doi:10.1145/3651306. [Google Scholar] [CrossRef]
8. Han K, Wang Y, Tian Q, Guo J, Xu C. GhostNet: more features from cheap operations. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 1580–9. doi:10.1109/CVPR42600.2020.00165. [Google Scholar] [CrossRef]
9. Boutros F, Damer N, Raja KB, Ramachandra R, Kirchbuchner F, Kuijper A. On benchmarking iris recognition within a head-mounted display for AR/VR applications. In: Proceedings of the IEEE Int Joint Conference Biometrics (IJCB); 2020 Sep 28–Oct 1; Houston, TX, USA. p. 1–10. doi:10.1109/IJCB48548.2020.9304919. [Google Scholar] [CrossRef]
10. Sumit S, Anavatti S, Tahtali M, Mirjalili S, Turhan U. ResNet-Lite: on improving image classification with a lightweight network. Comput Sci. 2024;246(9):1–10. doi:10.1016/j.procs.2024.09.597. [Google Scholar] [CrossRef]
11. Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. arXiv:1503.02531. 2015. [Google Scholar]
12. Gou J, Yu B, Maybank S, Tao D. Knowledge distillation: a survey. Int J Comput Vis. 2021;129(6):1789–819. doi:10.1007/s11263-021-01453-z. [Google Scholar] [CrossRef]
13. Yin Y, He S, Zhang R, Chang H, Han X, Zhang J. Deep learning for iris recognition: a review. arXiv:2303.08514. 2023. [Google Scholar]
14. Latif SA, Sidek KA, Bakar EA, Hashim AHA. Online multimodal compression using pruning and knowledge distillation for iris recognition. J Adv Res Appl Sci Eng Technol. 2024;37(2):68–81. doi:10.37934/araset.37.2.6881. [Google Scholar] [CrossRef]
15. Institute of Automation, Chinese Academy of Sciences (CASIA). CASIA Iris Image Database, Version 4.0. Beijing, China: Chinese Academy of Sciences; 2010. [Google Scholar]
16. Worldcoin AI. IRIS: iris recognition inference system of the worldcoin project [Computer software]. GitHub. 2023 [cited 2025 Oct 15]. Available from: https://github.com/worldcoin/open-iris. [Google Scholar]
17. Deng J, Guo J, Xue N, Zafeiriou S. ArcFace: additive angular margin loss for deep face recognition. arXiv:1801.07698. 2019. [Google Scholar]
18. Liu W, Wen Y, Yu Z, Li M, Raj B, Song L. SphereFace: deep hypersphere embedding for face recognition. arXiv:1704.08063. 2017. [Google Scholar]
19. Wang H, Wang Y, Zhou Z, Ji X, Gong D, Zhou J, et al. Large margin cosine loss for deep face recognition. arXiv:1801.09414. 2018. [Google Scholar]
20. Jacob B, Kligys S, Chen B, Zhu M, Tang M, Howard A. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); Piscataway, NJ, USA: IEEE; 2018. p. 2704–13. doi:10.1109/CVPR.2018.00286. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools