
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Two-Branch Intrusion Detection Method Based on Fusion of Deep Semantic and Statistical Features
State Key Laboratory of Public Big Data, College of Computer Science and Technology, Guizhou University, Guiyang, China
* Corresponding Author: Liang Wan. Email:
(This article belongs to the Special Issue: Advances in Machine Learning and Artificial Intelligence for Intrusion Detection Systems)
Computers, Materials & Continua 2026, 87(3), 18 https://doi.org/10.32604/cmc.2026.076986
Received 30 November 2025; Accepted 08 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The semantic complexity of large-scale malicious payloads in modern network traffic severely limits the robustness and generalization of existing Intrusion Detection Systems (IDS). This limitation presents a major challenge to network security. This paper proposes a dual-branch intrusion detection method called CPS-IDS. This method fuses deep semantic features with statistical features. The first branch uses the DeBERTav2 module. It performs deep semantic modeling on the session payload. This branch also incorporates a Time Encoder. The Time Encoder models the temporal behavior of the packet arrival interval time series. A Cross-Attention mechanism achieves the joint modeling of payload semantics and temporal behavior. This joint modeling accurately characterizes the potential attack intent and its temporal-coordinate dependency. The second branch utilizes a Transformer-LiteFF structure. It performs global dependency modeling on the flow statistical features. This process extracts the non-redundant representation of the statistical sequence. Finally, the design includes a Gated Fusion Mechanism. This mechanism efficiently integrates the multi-dimensional features. It then completes the intrusion classification. The paper validates the proposed CPS-IDS on three public datasets: CICIDS2017, UNSW-NB15 and CICIoT23. The method achieves accuracies of 99.92%, 94.54% and 97.91%, respectively, in multi-classification tasks. The experimental results demonstrate that CPS-IDS surpasses existing mainstream models in both accuracy and generalization. The system thus provides an effective solution for improving intrusion detection performance in complex network environments.Keywords
Malicious network traffic presents substantial challenges to intrusion detection due to its high concealment, heterogeneity, and rapid evolution. The widespread deployment of Transport Layer Security (TLS/SSL) has resulted in a large proportion of encrypted traffic, rendering traditional detection mechanisms incapable of directly interpreting payload contents. In addition, the behavioral differences between benign and malicious traffic have become increasingly subtle, while contemporary attack strategies exhibit enhanced stealthiness and polymorphism. These factors collectively constrain the accuracy, stability, and generalization capability of existing intrusion detection systems.
To overcome these limitations, this paper introduces CPS-IDS, a Transformer-based [1] intrusion detection framework that integrates deep semantic features with statistical representations. The framework adopts the network session as the fundamental analysis unit. To address the pronounced class imbalance in intrusion datasets, an Auxiliary Classifier Generative Adversarial Network (AC-GAN [2]) is incorporated to synthesize additional samples for minority attack categories. For feature representation, the DeBERTav2 [3] module is employed to extract deep semantic information from payload sequences, the global dependency relationships in the statistical flow features are extracted using Transformer-LiteFF. These two complementary feature branches are subsequently fused to enhance the comprehensiveness and discriminative power of the learned representations, thereby enabling efficient and robust intrusion classification.
The main contributions of this article are summarized as follows: (1) A multi-modal feature fusion mechanism based on Cross-Attention has been proposed. Unlike existing IDS models that merely fuse features through simple vector concatenation, CPS-IDS is the first to achieve forced alignment modeling of payload semantics and inter-arrival time of packets. Through the cross-attention mechanism, the model can capture the nonlinear correlations of attack intentions in the payload content and temporal distribution, significantly enhancing the perception ability for low-frequency and covert attack behaviors. (2) An innovative dual-branch heterogeneous architecture was constructed to mine multi-dimensional features. In the semantic branch, the decoupled attention mechanism of DeBERTav2 was utilized to deeply analyze the complex semantic dependencies among payload bytes. Compared with traditional models that extract shallow syntactic features, this architecture possesses stronger feature depth. In the statistical branch, the Transformer with the Lite-FF structure was integrated to model multi-dimensional statistical features, effectively addressing the dimension redundancy issue in traditional feature extraction and extracting more discriminative high-order representations. (3) To address the severe class imbalance issue in network traffic, the AC-GAN was introduced. This strategy not only can generate high-quality samples of the minority class but also ensures the consistency of labels of the generated samples through the auxiliary classification loss. Experiments show that this method effectively alleviates the overfitting caused by the long-tail distribution of data and enhances the detection robustness of the model in real non-balanced environments.
The remainder of this paper is organized as follows. Section 2 reviews related studies. Section 3 details the architecture and core modules of CPS-IDS. Section 4 presents the datasets and experimental configurations. Section 5 reports the evaluation results and comparisons with baseline models. Section 6 concludes the work and outlines potential directions for future research.
Machine learning (ML) and deep learning (DL)–based approaches for malicious traffic detection have undergone significant development over the past decades. Network Intrusion Detection Systems (NIDS) incorporating DL architectures, such as Convolutional Neural Networks (CNN) [4], Recurrent Neural Networks (RNN) [5], Autoencoders [6], and Long Short-Term Memory networks (LSTM) [7], have demonstrated strong performance in detecting large volumes of anomalous data and novel network attacks [8,9].
Traditional NIDS primarily rely on conventional ML models, such as Support Vector Machines (SVM) and Decision Trees, which classify traffic based on statistical features including session duration and packet counts. Fu et al. [10] reported that methods leveraging statistical and temporal features can achieve accurate detection of known malicious traffic and exhibit certain generalization capability; however, their performance is limited against previously unseen attacks. To improve detection, Liu et al. [11] proposed FS-Net, which learns feature representations from packet length sequences using a GRU-based autoencoder and reconstruction mechanism. Hu et al. [12] modeled packet sequences as graphs and applied Graph2Vec to obtain session-level embeddings. Zhang et al. [13] developed a real-time detection framework based on Online Isolation Forest for SD-WAN environments, enabling low-latency anomaly detection via packet-level and sequence-level modeling. Xie et al. [14] further combined TCP protocol awareness and traffic augmentation to extract packet sequence features from TLS-encrypted traffic for classification.
Compared with traditional ML methods, DL-based models offer stronger capabilities in automated feature extraction and complex traffic modeling. Yu et al. [15] designed a dual-CNN network to capture packet-level and session-level features in parallel, enhancing detection performance for minor classes through few-shot learning. Bader et al. [16] combined CNN and LSTM to learn spatiotemporal representations from raw byte streams while incorporating statistical features to improve detection efficacy. Zhu et al. [17] proposed CMTSNN, employing a cascaded CNN-LSTM structure for feature fusion, and Lin et al. [18]’s TSCRNN optimized temporal and spatial feature modeling. With the introduction of Transformer models, Han et al. [19] applied them to traffic classification, jointly considering packet headers and payloads. Wang et al. [20] proposed a Transformer-based NIDS that combines unsupervised learning with self-supervised masked reconstruction to enhance anomaly representation. Han et al. [21]’s ECNet further integrated multi-view features using gated feature fusion and a confidence mechanism, improving both representation capacity and detection robustness.
In terms of enhancing the transparency and adaptability of the detection system, Farooqui et al. [22] proposed the AutoSHARC framework. This research combines SHAP interpretive analysis with a feedback-driven re-training mechanism. By identifying the key features that cause a decline in QoS, it guides the re-training of the model, effectively solving the problem of performance degradation of detection models in the IoT environment due to network dynamic changes. Regarding the deployment challenge of deep learning models on resource-constrained devices, Umair et al. [23] explored the application of knowledge distillation (Knowledge Distillation) technology. They transferred the knowledge of the complex teacher model to the lightweight student model, maintaining high detection accuracy while significantly reducing inference time and memory usage, providing a feasible solution for real-time anomaly detection in consumer IoT devices.
In summary, DL-based methods integrating architectures such as Transformer, CNN, and GRU can substantially improve feature extraction efficiency and intrusion detection accuracy. Nevertheless, these approaches still face limitations in fully capturing spatial, temporal, and inter-packet dependencies in network traffic, resulting in incomplete feature representations and reduced robustness of classification. Therefore, enhancing the robustness and generalization of DL-based NIDS in complex and dynamic network environments remains a critical and urgent research challenge.
This section presents a detailed description of the proposed Transformer-based intrusion detection framework, CPS-IDS, which integrates deep semantic features, temporal behaviors, and statistical representations. The model consists of three primary components: a data processing module, a feature learning module, and a feature fusion module. The overall architecture is illustrated in Fig. 1. CPS-IDS can be deployed at Local Area Network (LAN) boundaries or on edge nodes to enable real-time monitoring and analysis of communications between the internal LAN and the external Internet.
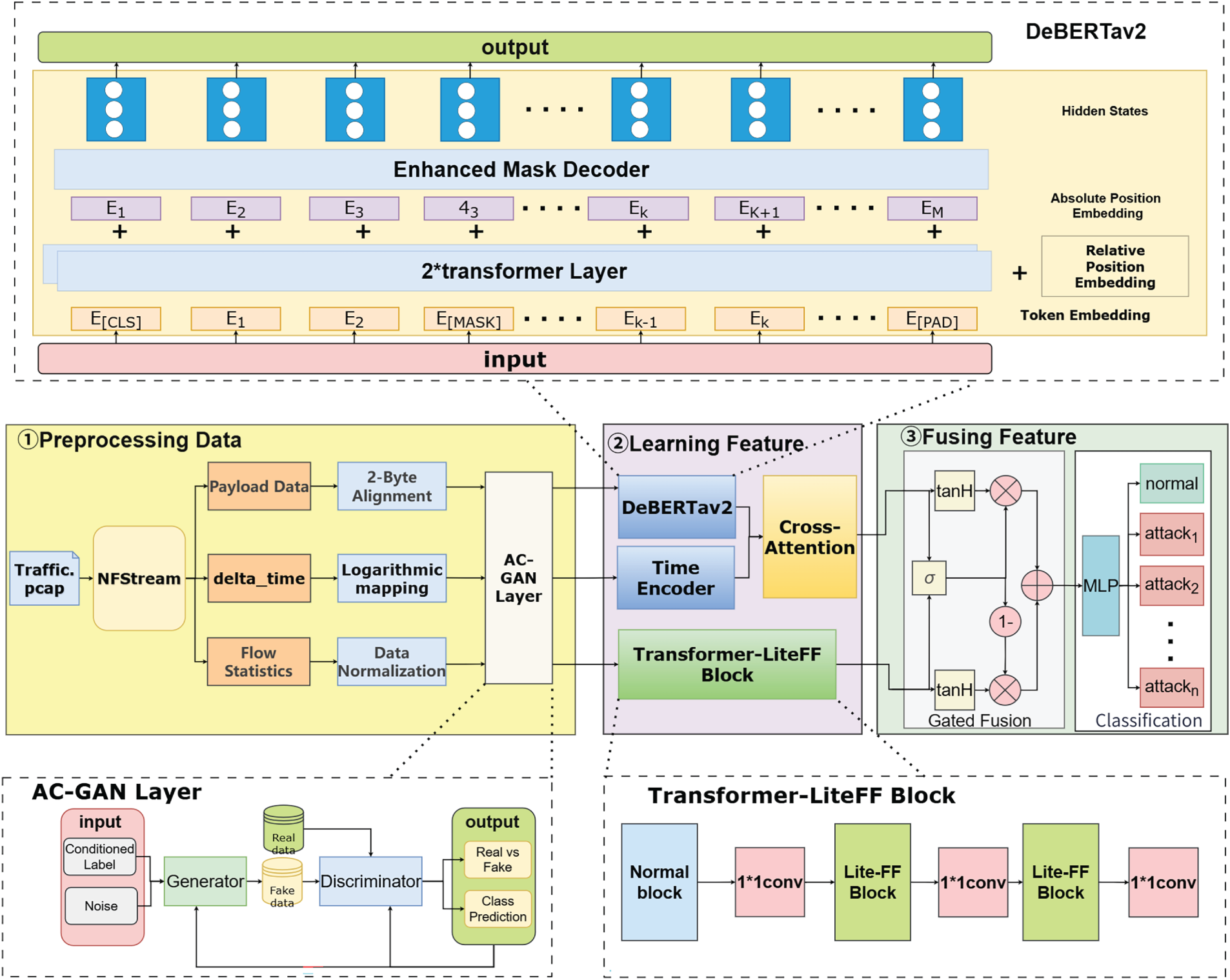
Figure 1: Overall architecture diagram.
The detection workflow of CPS-IDS is summarized in Algorithm 1. During training, an AC-GAN is employed to generate synthetic samples for minority-class attack traffic. This approach addresses the class imbalance problem and enhances the model’s ability to recognize rare attack types.

The network traffic analysis framework NFStream [24] was employed to process raw PCAP files, systematically capturing both standard flow metrics and packet payload contents for each flow. During extraction, relevant statistical and protocol features were stored as structured CSV files for subsequent modeling. In the feature selection phase, dimensions highly correlated with network protocol behavior were retained from multiple time windows, including communication frequency, packet direction, flow duration, port usage, and TCP control flags. To mitigate the impact of differing magnitudes among statistical features and to improve training convergence and model stability, all numerical features were standardized using the Z-score method.
To convert raw network byte streams into structured representations suitable for deep learning, a hierarchical payload processing and serialization mechanism is adopted. Considering that discriminative semantic cues of network attacks (e.g., malicious signatures and protocol negotiation fields) are primarily concentrated at the early stage of a session, a two-level truncation strategy is employed. At the flow level, for each flow defined by a 5-tuple, only the first
Following ET-BERT [25] and PEAN [26], bigram tokenization is adopted instead of single-byte tokenization. Bigram tokenization expands the vocabulary from
yielding a fixed-length sequence of 256 tokens per flow. This design aligns with protocol field structures and maintains strict byte consistency, making it more suitable for network traffic than adaptive subword schemes such as BPE.
The sequence length of 256 tokens is selected as a trade-off between semantic coverage and computational efficiency, effectively controlling the
To comprehensively capture temporal traffic behavior, the inter-packet arrival time series was included as a third feature type during preprocessing. This time series, which reflects connection activity and protocol interaction rates, is computed as the difference between arrival times of consecutive packets within the same flow. Consequently, the preprocessing stage produces three distinct feature types: (1) inter-packet arrival time series, (2) payload token sequences, and (3) flow statistical features. Each feature type is subsequently processed by its corresponding modeling module and integrated during the feature fusion phase.
During the sample preparation stage, in response to the highly unbalanced distribution of the number of normal traffic and attack traffic in different network traffic data sets, this paper adopts a hybrid sample balancing strategy. Specifically, for the majority class samples (normal traffic) that account for a significantly higher proportion, they are randomly downsampled by 5% of their original size to effectively control the sample size; at the same time, all attack category samples are completely retained, thereby achieving an initial category balance of the training data without introducing any synthetic samples.
To verify the rationality of this sampling strategy, this paper conducted a comparative analysis of the category distribution before and after sampling on three public datasets with different distribution characteristics, namely CICIDS2017, UNSW-NB15, and CICIoT2023. The results are shown in Fig. 2.
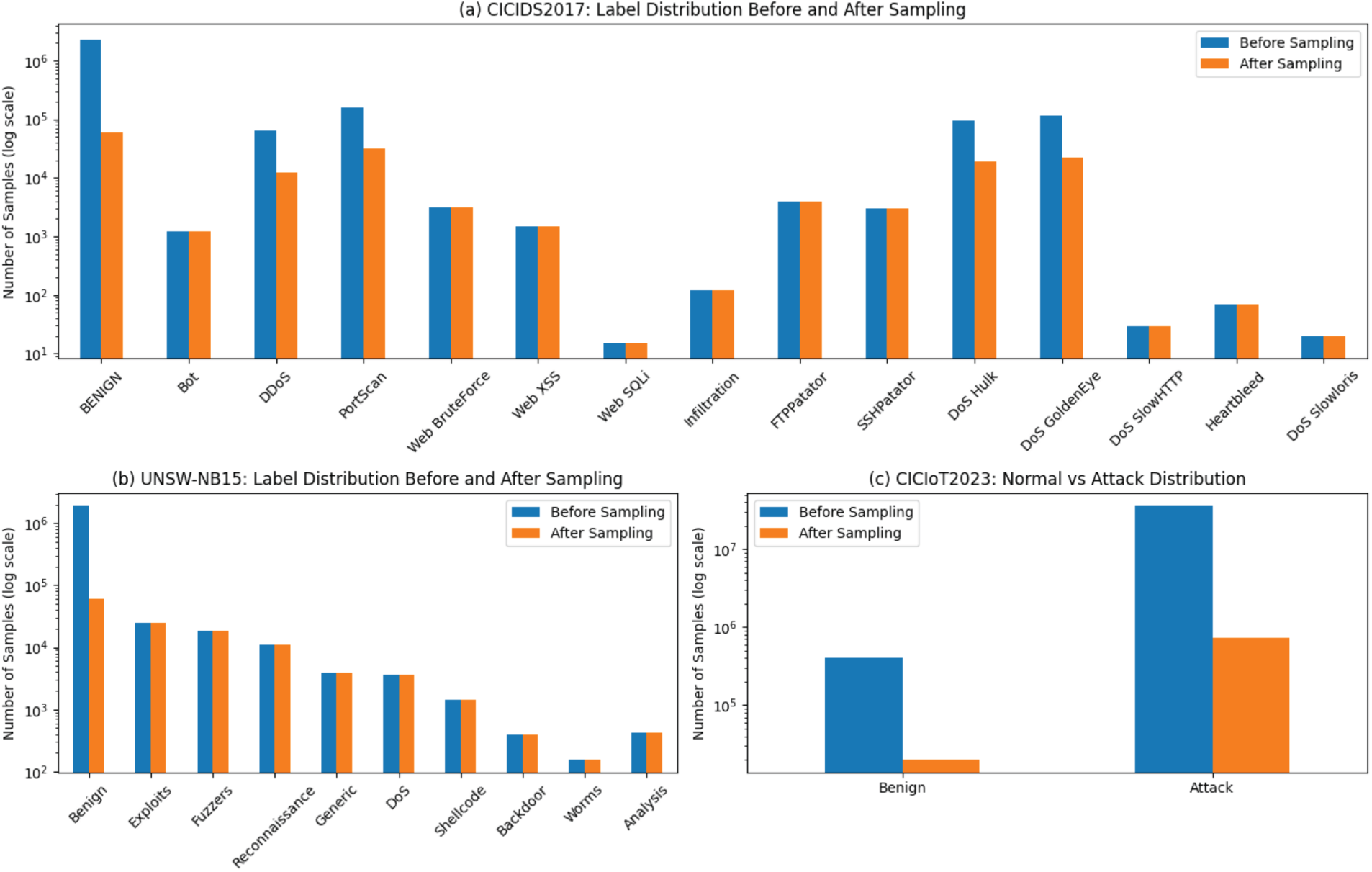
Figure 2: Comparison of label distributions before and after sampling on different datasets.
In the CICIDS2017 dataset, the number of normal traffic samples before sampling was much higher than that of various attack traffic samples, resulting in a severely imbalanced data distribution. After 5% random down-sampling, the scale of normal traffic was significantly reduced, while the sample quantities of Bot, Web Attack, Infiltration, and Heartbleed attack categories remained unchanged. The attack categories such as DoS, DDoS, and PortScan, although their quantities decreased, still maintained their relative proportion relationships, indicating that the internal structure of the attack traffic was not disrupted.
In the UNSW-NB15 dataset, the sampling strategy also significantly reduced the proportion of normal traffic in the training set. At the same time, all attack category samples were completely retained, including samples of attack types with relatively small quantities such as Worms, Backdoor, and Shellcode. The distribution of attack categories before and after sampling was completely consistent, further verifying the effectiveness of this strategy in maintaining the stability of the attack distribution. Given the extremely large scale of attack traffic in the CICIoT2023 dataset, this paper conducts a comparative analysis of normal traffic and attack traffic from a macro perspective. The results show that the sampling operation effectively controlled the scale of attack traffic, making it suitable for model training. Meanwhile, various types of DDoS, DoS, and Mirai attacks still retain sufficient sample quantities, ensuring the diversity and representativeness of attack types.
The adopted hybrid downsampling strategy can effectively alleviate the class imbalance problem on different datasets. While significantly reducing the training cost, it maintains the original distribution structure of attack traffic and does not introduce additional noise, providing a reliable data foundation for subsequent model training and performance evaluation.
3.2.2 Minority Class Sample Generation and Augmentation Module
To mitigate the class imbalance arising from the predominance of normal traffic and the scarcity of attack samples, this study employs an AC-GAN for data augmentation following the initial preprocessing stage. As an extension of the GAN, AC-GAN incorporates conditional information, such as class labels, into both the generator and the discriminator. The generated pseudo-samples consist of three types of traffic features: the payload vector, the inter-packet arrival time series vector, and the statistical feature vector. The model structure of AC-GAN is shown in Table 1.
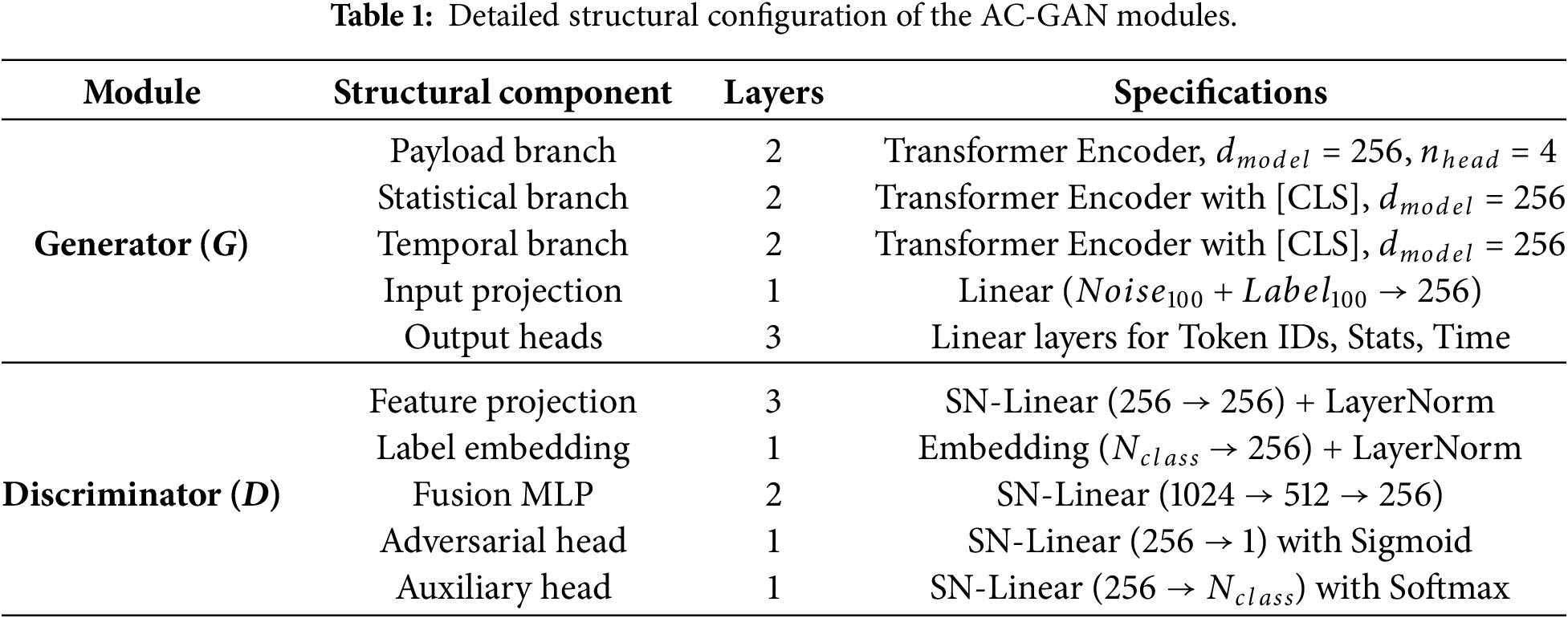
The generator employs a joint architecture comprising three parallel sub-networks, which take a low-dimensional latent noise vector
The discriminator D takes the feature triplet
The adversarial loss
The auxiliary classification loss
The comprehensive objectives for the discriminator and generator are formulated as:
where
During training, the model is optimized using the Adam optimizer, with the learning rates for the generator (
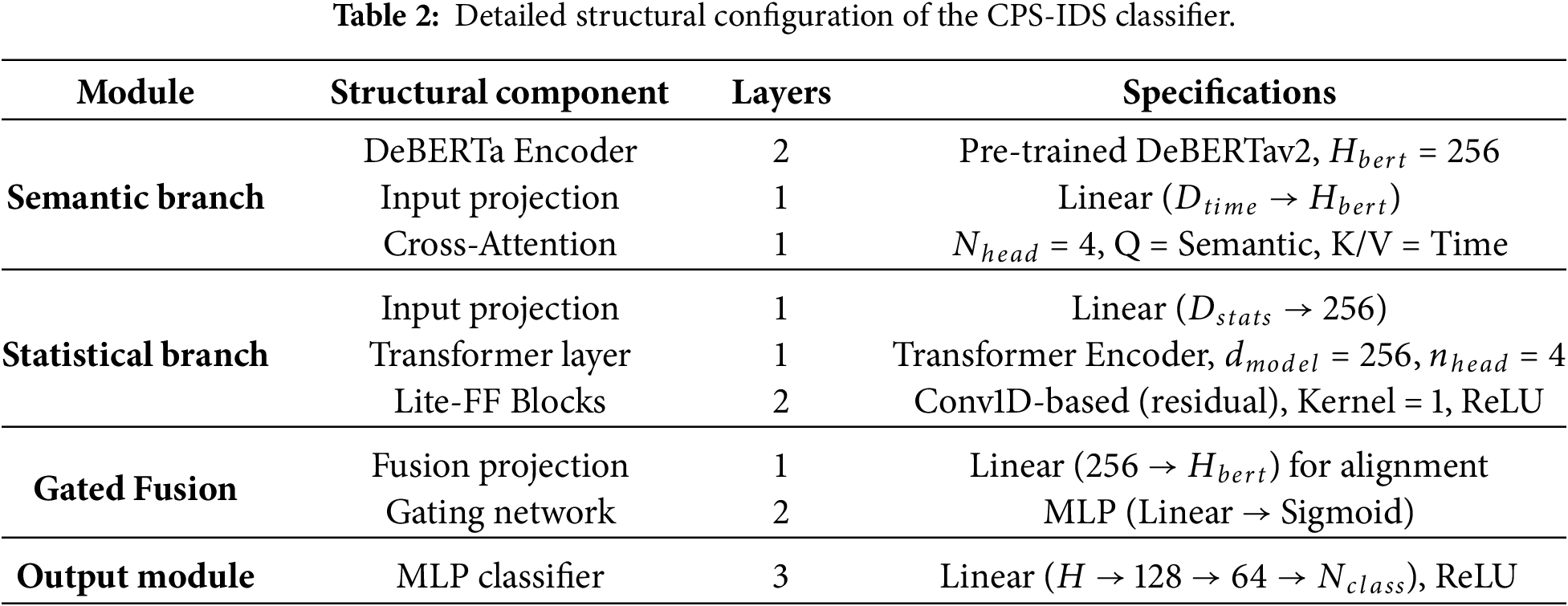
To balance the detection accuracy and inference efficiency, CPS-IDS adopts a lightweight parameter configuration. As shown in Table 2, the semantic branch uses a 2-layer DeBERTav2 structure, with the hidden layer dimension set to 256, extracting byte-level features through decoupled attention mechanisms; meanwhile, the temporal encoder and the statistical branch maintain the same dimensional space, facilitating multimodal feature integration through a gated fusion mechanism.
3.3.1 Payload Semantic Modeling
The payload segment of network traffic contains specific communication content, such as HTTP requests, DNS queries, and fragments of attack commands. These sequences often include potential attack patterns, command signatures, and characteristic strings, which are valuable for intrusion detection. In this study, DeBERTav2 is employed as the feature representation learner for payload data. Compared with the standard BERT model [27], DeBERTav2 introduces architectural innovations that better capture complex semantic dependencies in non-natural language sequences, such as hexadecimal byte streams.
The raw payload is first converted into a hexadecimal byte sequence:
where L denotes the payload length. A Bigram tokenization strategy is then applied, combining two adjacent bytes into a single token:
where V represents the 16-bit vocabulary and N is the token sequence length. Sequences shorter than N are padded with the [PAD] token, while longer sequences are truncated to ensure uniform input dimensions.
In DeBERTav2, each token is mapped into a content embedding and a position embedding:
where
where
During pre-training, DeBERTav2 employs traditional Masked Language Modeling (MLM) and introduces the Enhanced Mask Decoder (EMD) to improve context representation. For a masked sequence, the EMD objective is:
where
After multi-layer decoupled Transformer encoding and EMD pre-training, the payload sequence representation is:
The [CLS] token embedding is taken as the global payload semantic representation:
which serves as the feature embedding for the network traffic payload.
3.3.2 Temporal Behavior Modeling
To capture the temporal dynamics of network flows, packet interarrival time series are utilized as input features. The sequence
To integrate temporal information with payload semantics, the payload representation
Here,
3.3.3 Global Dependency Modeling of Statistical Features
Statistical features
To overcome this limitation, we propose the Transformer-LiteFF block for global dependency modeling of the statistical feature sequence
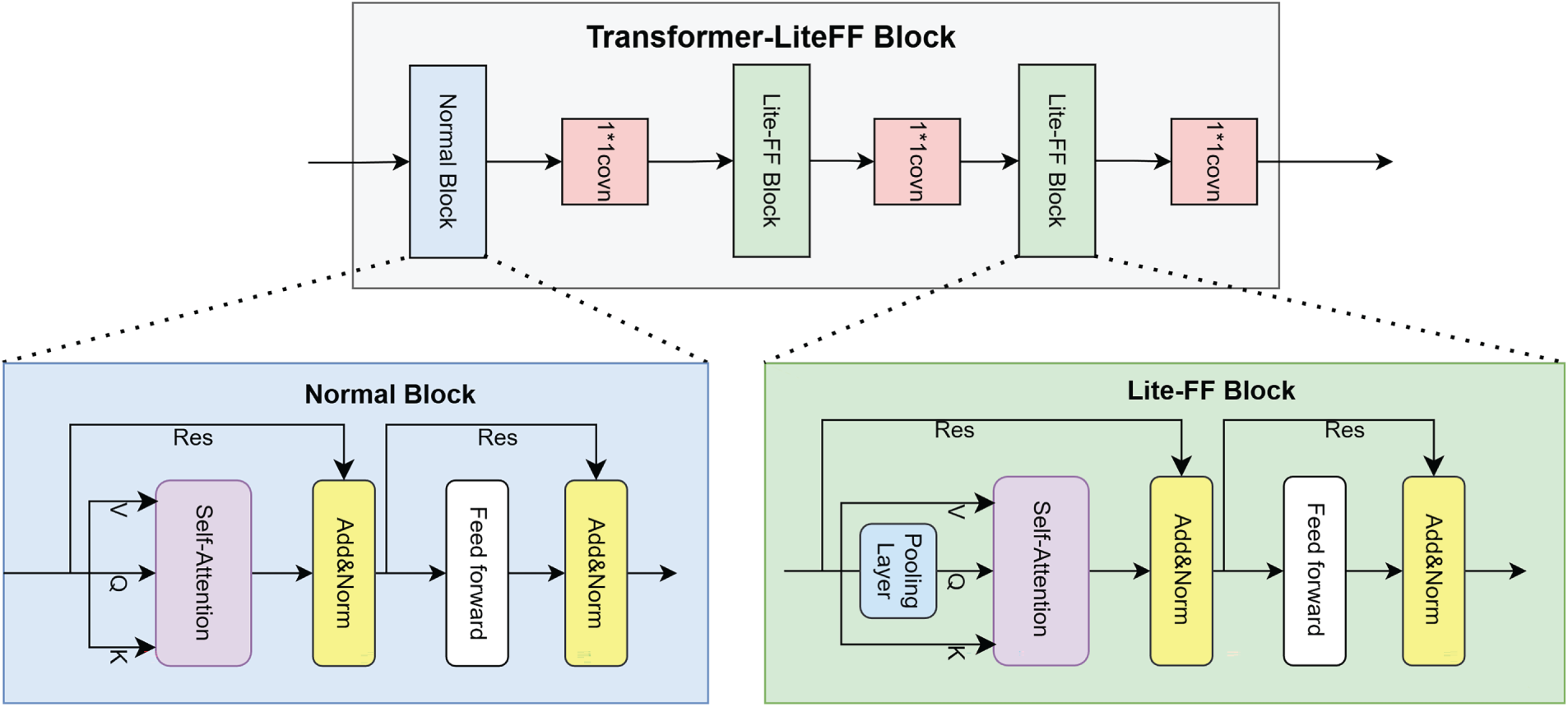
Figure 3: Transformer-LiteFF block.
The embedded sequence
To obtain a compact, non-redundant representation, we incorporate the Lite-FF Structure (Lite FlowFormer Block) [28]. This structure integrates a bottleneck layer into the Transformer’s feed-forward network, forcing feature compression while preserving critical information, thereby enhancing efficiency and reducing redundancy.
Finally, the processed statistical feature sequence
The resulting vector
The Feature Fusion Module is designed to integrate the outputs of the dual-branch feature learning module, namely the joint semantic-temporal representation
To address this, a Gated Fusion Mechanism is employed for adaptive and efficient feature combination. A gating vector
where
The fused feature vector F is then computed as a gated weighted sum:
where
4 Datasets and Experimental Setup
This study employs three authoritative datasets representing diverse network scenarios: traditional networks (CICIDS2017 [29]), hybrid modern networks (UNSW-NB15 [30]), and IoT edge networks (CICIoT23 [31]). Common attack types such as DDoS, Brute Force, and Botnet are present across these datasets, enabling the extraction of shared attack patterns in protocol payloads, connection frequency, packet size distribution, traffic rate, mean and variance of packet lengths, and flow duration. The diversity of attacks provides complementary differentiation for the model: CICIDS2017 emphasizes session-level features for Web attacks (e.g., XSS), UNSW-NB15 supplements payload features for Shellcode attacks, and CICIoT23 includes resource-exhaustion attacks specific to IoT devices.
To evaluate the generalization and detection performance of the proposed method, experiments were conducted on the three datasets mentioned above. Key experimental configurations, hardware environment, and training strategies are detailed as follows.
Experiments were performed on a system equipped with an NVIDIA GeForce RTX 3070 GPU (8 GB VRAM), a 12th Gen Intel Core i5-12400 CPU, and 16 GB RAM. The operating system was [Placeholder for OS, e.g., Ubuntu 20.04], the deep learning framework was PyTorch 2.0, and Python version 3.10.
During training, the parameter configuration is shown in Table 3. The Cross-Entropy loss was used as the primary classification objective, with class-weighted samples applied to mitigate data imbalance. Model parameters were optimized using the AdamW optimizer, combined with a learning rate warm-up and decay schedule. To rigorously evaluate the generalization performance of the proposed CPS-IDS and prevent potential data leakage, a strict flow-level data separation strategy was adopted. The dataset was partitioned into training and testing sets with an 8:2 ratio. Unlike conventional packet-level random splitting, network packets were first aggregated into discrete flows according to their 5-tuple information (source IP, destination IP, source port, destination port, and protocol). Each flow, uniquely identified by its Flow ID, was assigned exclusively to either the training or testing set, ensuring that no packets from the same flow appeared in both subsets. Furthermore, highly identifiable fields such as IP addresses and timestamps were excluded during feature extraction to prevent the model from memorizing host-specific patterns. This design forces the framework to learn intrinsic semantic signatures and statistical dynamics of attack behaviors rather than dataset-specific artifacts. During training, the optimal model was selected based on validation performance, and the final results—including Accuracy, Precision, Recall, and F1-score—were reported on the independent test set to ensure the reliability and transparency of the experimental evaluation.

To comprehensively assess the performance of the proposed CPS-IDS, four widely-used metrics are employed: Accuracy, Precision, Recall, and F1-score. These metrics are standard in multi-class intrusion detection and effectively quantify the model’s classification performance across different categories.
Multi-classification experiments were conducted on the CICIDS2017, UNSW-NB15, and CICIoT2023 datasets using the proposed method.
As presented in Table 4 and Fig. 4, CPS-IDS achieves a weighted-average F1-score of 0.9992. Notably, despite the high performance on majority classes, the recall for Infiltration remains relatively lower at 0.8947. This is primarily due to the feature manifold overlap; infiltration attacks often involve legitimate-looking internal-to-internal communications, which share high statistical and semantic similarity with Benign traffic. The AC-GAN helps bridge the quantity gap (from a support of only 38 samples), but the inherent ‘mimicking’ nature of such attacks poses a persistent challenge for absolute separation.
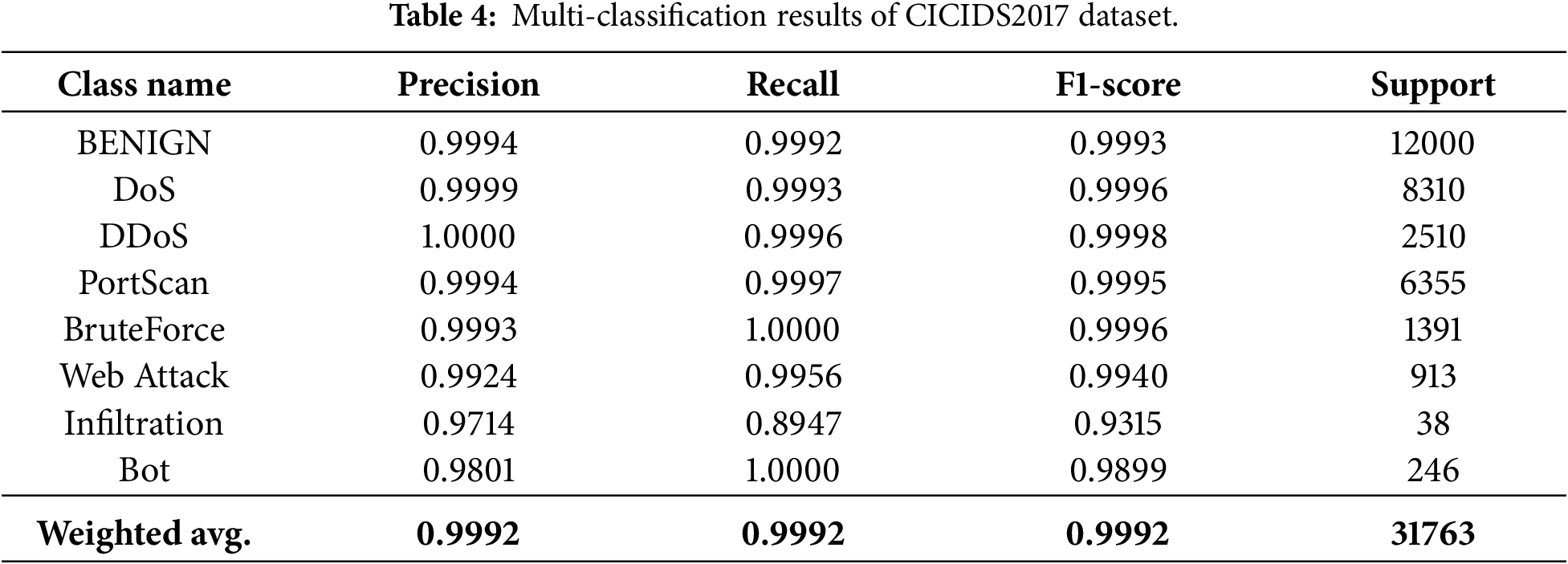
Figure 4: CICIDS2017 confusion matrix.
Table 5 and Fig. 5 illustrate the framework’s performance on the more complex UNSW-NB15 dataset. While the weighted-average F1-score reaches 0.9440, the recall rates for Analysis (0.3415) and DoS (0.3874) are noticeably constrained. We attribute this to two factors: extreme initial scarcity and high intra-class variance. Although AC-GAN balances the class distribution, the initial information available for the ‘Analysis’ category is insufficient to capture all its diverse sub-attack vectors, potentially leading to a partial mode collapse where the generator synthesizes only a subset of attack patterns. Furthermore, the overlapping feature space between low-intensity DoS and Benign bursts limits the classifier’s ability to draw a sharp decision boundary.
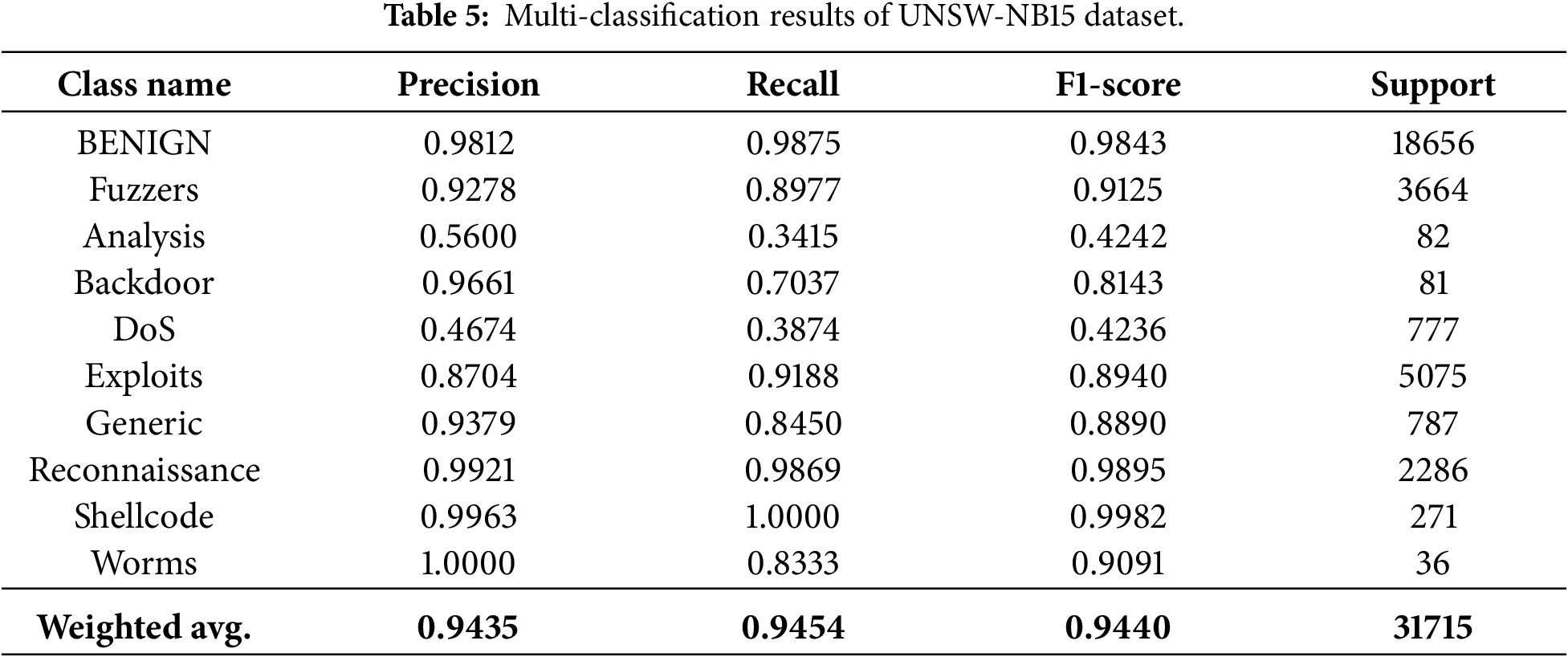
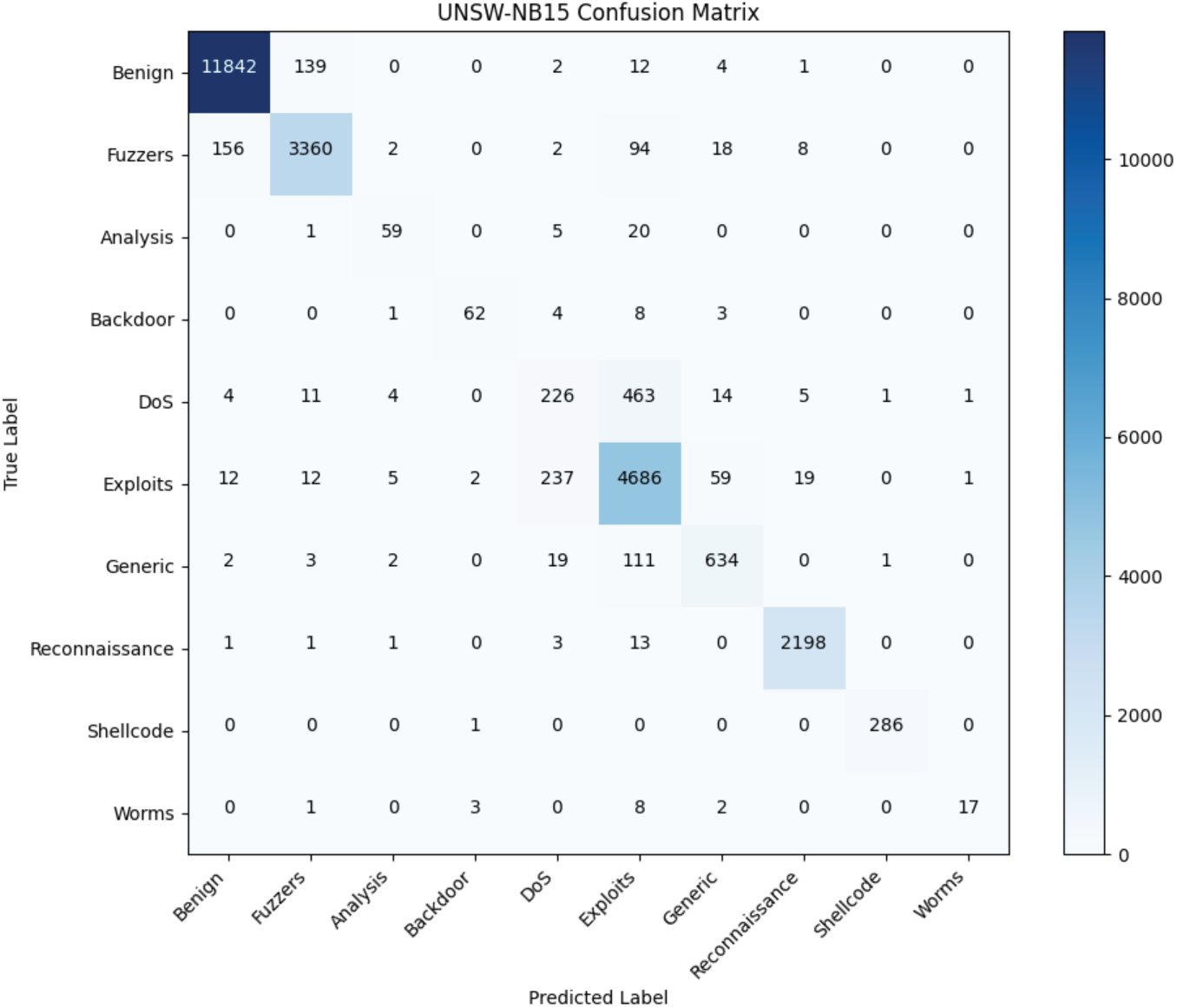
Figure 5: UNSW-NB15 confusion matrix.
The results in Table 6 and Fig. 6 indicate that CPS-IDS performs excellently on the CICIoT2023 dataset. However, WebAttack shows a recall of 0.7885. In IoT environments, Web-based attacks often utilize simplified protocols that can be statistically indistinguishable from legitimate device-to-cloud management traffic. This suggests that while multimodal fusion (Payload + Time + Stats) significantly improves detection compared to single-modality baselines, the dynamic nature of IoT traffic requires even more granular temporal modeling to fully isolate these stealthy intrusions.
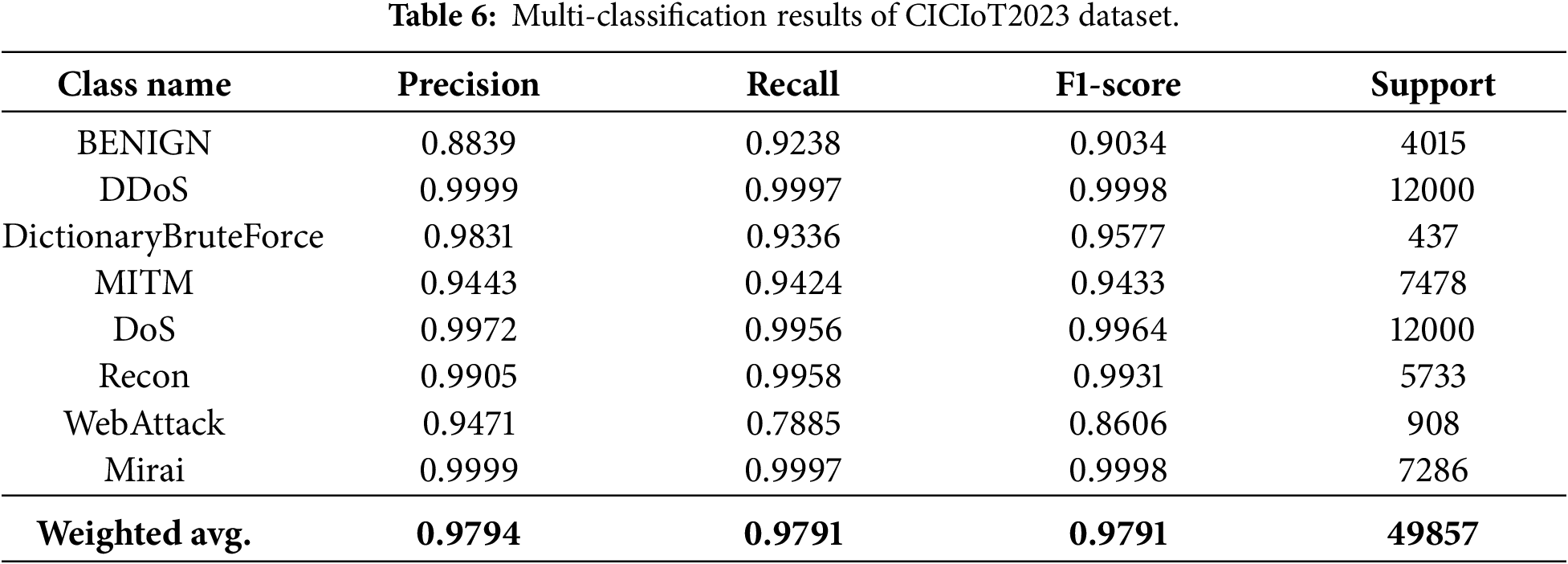
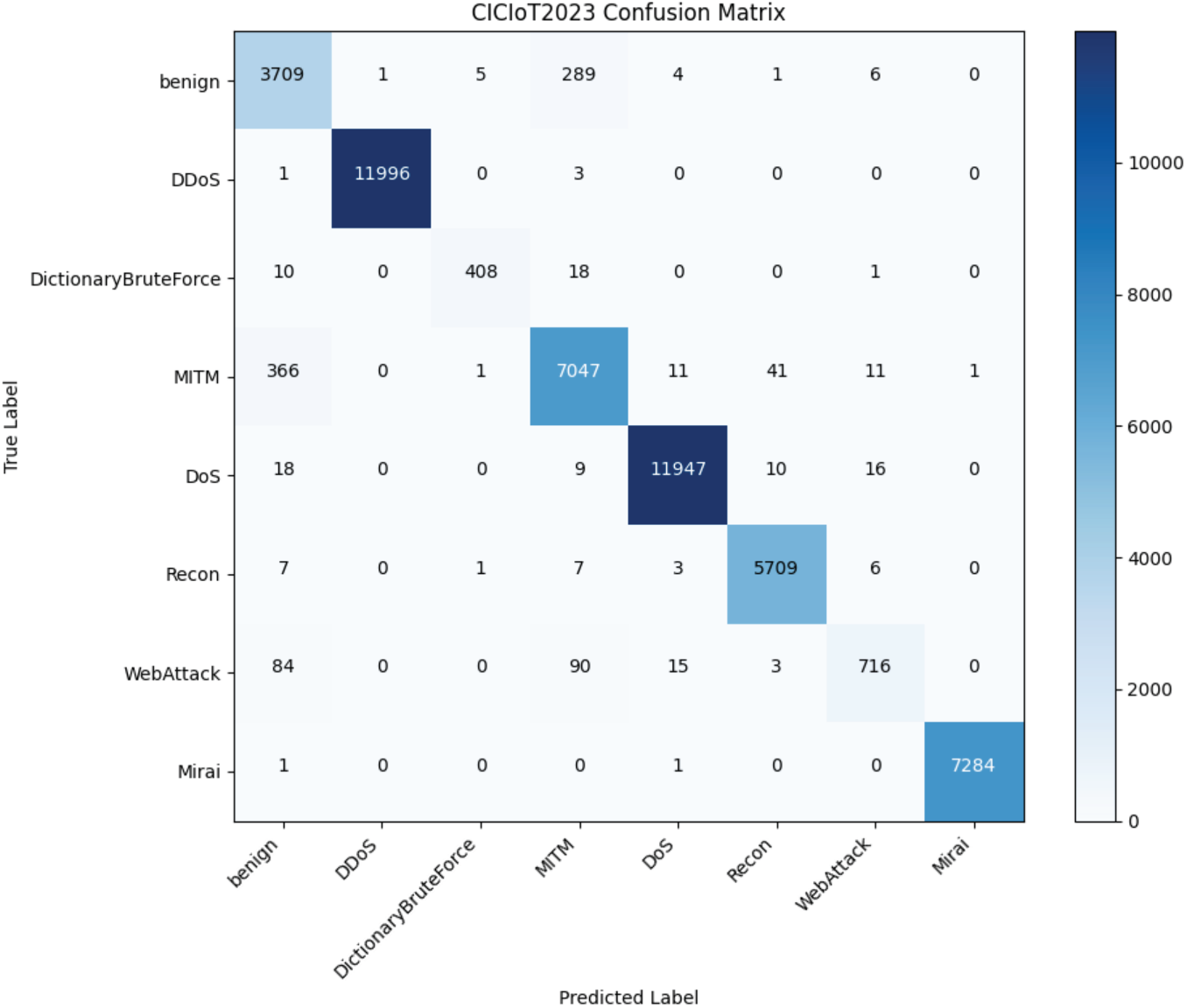
Figure 6: CICIoT2023 confusion matrix.
Overall, the results across three benchmark datasets validate that the AC-GAN effectively mitigates class imbalance by populating underrepresented regions of the feature space. However, as noted in the persistent challenges for ‘Infiltration’ and ‘Analysis’, generative augmentation alone cannot fully resolve cases where malicious features are inherently similar to benign patterns. This underscores the necessity of our Cross-Attention mechanism, which attempts to leverage temporal-semantic dependencies to provide the additional discriminative power required for these challenging cases.
To comprehensively assess the effectiveness of the proposed method, in the multi-classification experiment, I selected some intrusion detection methods from the past three years, such as Et-bert [25], Transformer [32], Graph2vec+RF [12], GTID [19], DeepCLG [33] and CTWA [34], and compared them with my method. The comparison indicators included Accuracy, Precision, Recall and F1-score. The specific experimental results are shown in Table 7.
As shown in Table 7 and Fig. 7, the proposed method consistently outperforms the comparative approaches across all three datasets. It achieves the highest Accuracy, Precision, Recall, and F1-score in every case. These results confirm the method’s effectiveness and superiority in multi-class intrusion detection, demonstrating stronger feature representation, enhanced anomaly detection capability, and robust generalization across diverse network scenarios.
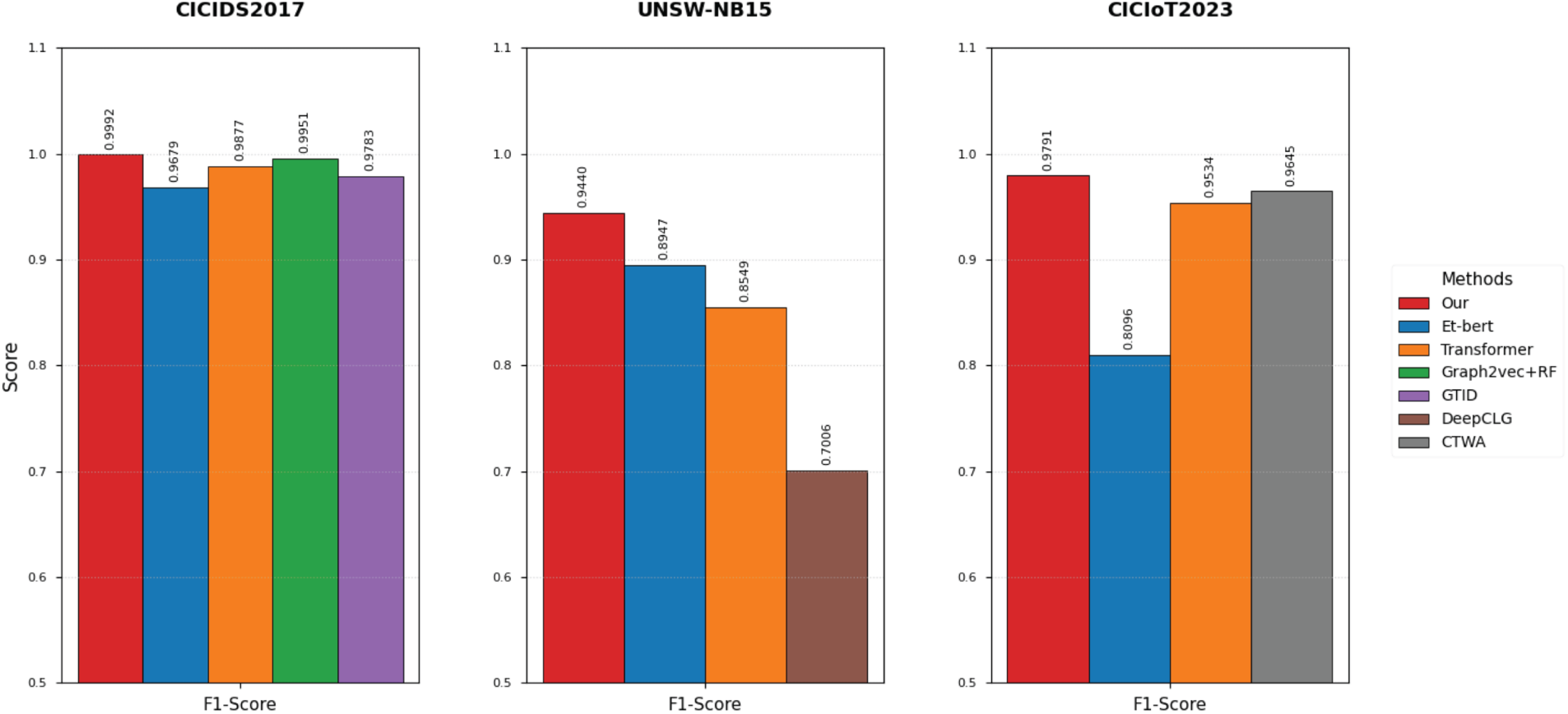
Figure 7: Bar chart of the comparison experiment.
5.3 Generation of Sample Quality Assessment
To intuitively verify the effectiveness of the minority sample augmentation module in the CPS-IDS model, t-SNE (t-Distributed Stochastic Neighbor Embedding) is employed to project the high-dimensional fusion embeddings onto a 2D plane for visual analysis. For each of the three datasets—UNSW-NB15, CIC-IDS2017, and CIC-IoT23—800 real samples were randomly selected from the test sets, while 800 synthetic samples were generated for the corresponding classes using the trained conditional generator. The feature extraction point is situated at the multimodal feature fusion layer of the classifier, which captures a joint representation of payload semantics, flow statistics, and temporal characteristics. Fig. 8 illustrates the distribution comparison, where blue dots represent real traffic samples and red dots represent synthetic samples.
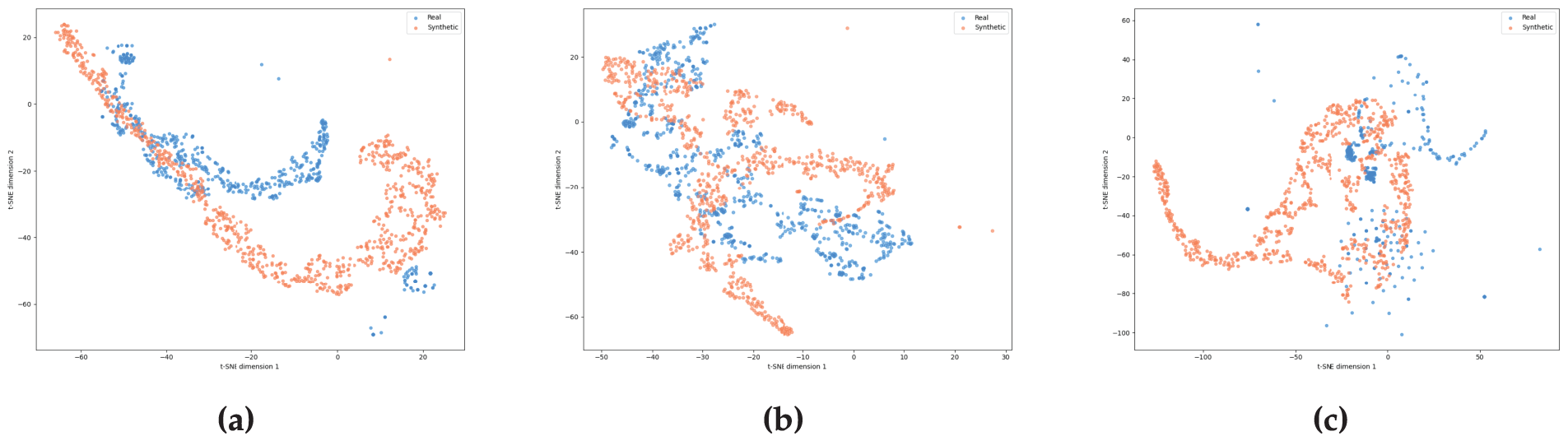
Figure 8: The t-SNE visualization display of the deep semantic features of the real and synthetic samples in CIC-IDS2017 (a), UNSW-NB15 (b), and CIC-IoT23 (c).
As shown in Fig. 8c, the red synthetic samples exhibit a high degree of overlap and intertwining with the blue real samples in the feature space. This demonstrates that the proposed generator accurately captures the intrinsic correlations between multimodal features, ensuring that the generated samples not only approximate the real distribution numerically but also maintain consistency in deep semantic logic. In Fig. 8a,b, real samples form several distinct, discrete clusters corresponding to various attack subcategories or behavioral patterns. Rather than being concentrated at a single point, the synthetic samples are distributed within and around the boundaries of these real clusters. This confirms the robust manifold coverage of the generation module, which effectively fills sparse regions in the feature space originally occupied by minority samples. In conclusion, the t-SNE visualization confirms that CPS-IDS is capable of generating minority samples with high fidelity and diversity.
Through a systematic ablation study, we evaluate the contribution of four critical components—AC-GAN Sample Augmentation, DeBERTav2 Representation Learning, Statistical Feature Modeling, and Temporal Behavior Features with their Fusion—to the overall detection performance of the proposed model. Experiments were conducted on three public datasets: CICIDS2017, UNSW-NB15, and CICIoT2023. The results are summarized in Table 8 and Fig. 9.
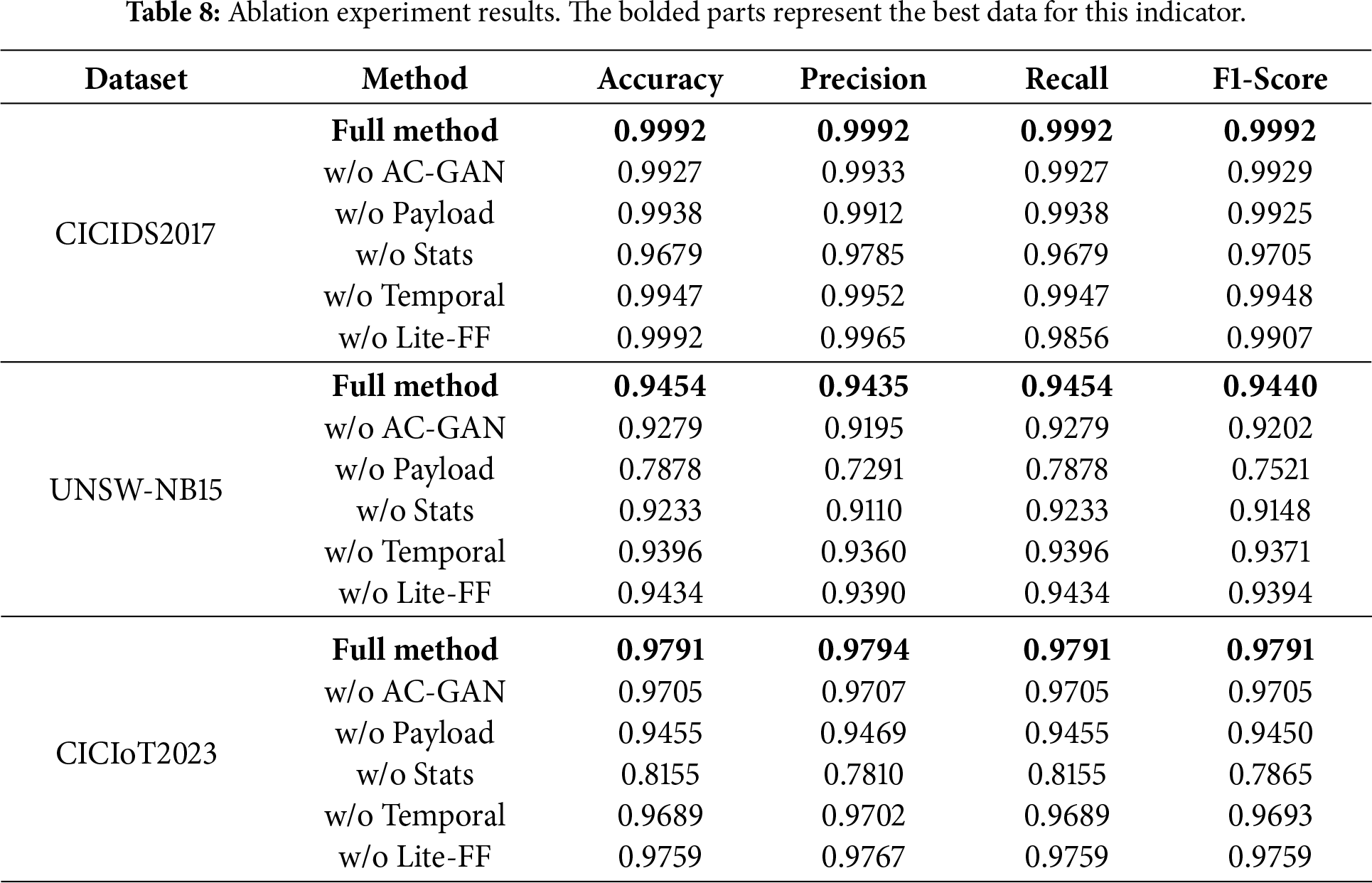
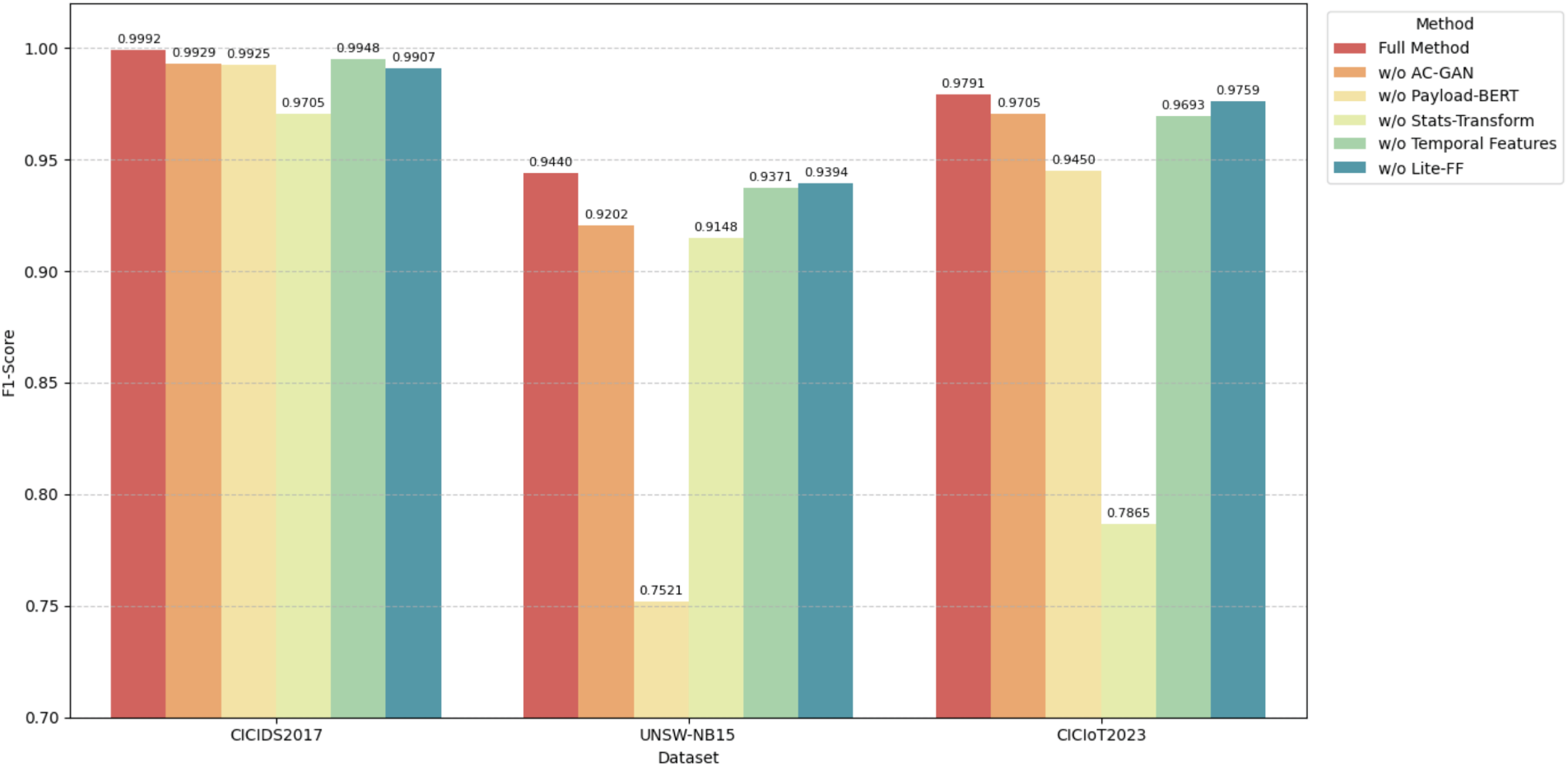
Figure 9: Bar graph of the ablation experiment.
The results in Table 8 and Fig. 9 confirm that the Full Method achieves the best performance across all three datasets, demonstrating the effective synergy among all proposed modules. Removing any component leads to notable performance degradation, highlighting the necessity of multi-modal fusion and augmentation.
Key observations from the ablation study are as follows:
1. AC-GAN Augmentation (w/o AC-GAN): Beyond the F1-Score drop on UNSW-NB15 (−0.0238), the removal of AC-GAN leads to a sparse and biased feature space. Without synthesized minority samples, the classifier’s decision boundary collapses toward the majority class. AC-GAN improves feature quality by “filling” the underrepresented regions of the manifold with high-fidelity synthetic samples, ensuring the model learns a more continuous and robust class-separation boundary.
2. DeBERTav2 Semantic Learning (w/o Payload): The massive decline in UNSW-NB15 (F1-Score −0.1919) indicates that omitting payload semantics deprives the model of contextual discriminators. DeBERTav2’s disentangled attention improves feature quality by isolating the relative positions of bytes from their content, allowing the model to distinguish between similar byte sequences that serve different malicious functions. Without it, the model relies on shallow statistical signatures, failing to capture the “intent” of the attack.
3. Transform-Conv Statistical Modeling (w/o Stats): The sharp reduction on CICIoT2023 (−0.1926) highlights the loss of global flow-level descriptors. Statistical features provide a macroscopic view of the traffic (e.g., total volume, flow duration). Removing this module lowers feature quality by limiting the model to localized byte-level patterns, making it blind to high-volume flooding attacks (e.g., DDoS) that are characterized by their statistical frequency rather than their payload content.
4. Temporal Feature Fusion (w/o Temporal): Excluding the Time Encoder leads to a loss of dynamic behavioral signatures. Network attacks often exhibit specific “rhythms” (e.g., periodic heartbeat in C&C traffic or rapid bursts in scanning). Joint temporal-payload modeling ensures that semantic tokens are weighted by their arrival patterns. Removing this component degrades feature quality into a “static” representation, losing the ability to differentiate between legitimate high-speed communication and rapid automated attack bursts.
5. Lite-FF Structure (w/o Lite-FF): The impact of removing Lite-FF varies across datasets, which explains the observed inconsistency in the ablation trends. Lite-FF is not designed as a standalone discriminative module but rather as a lightweight refinement component for statistical feature representations. Its effectiveness therefore depends on the relative importance of statistical features within the overall feature hierarchy. In IoT-oriented datasets such as CICIoT2023, where payload information is limited or weakly informative, statistical features constitute the primary source of behavioral evidence. Under this condition, Lite-FF significantly improves representation compactness by suppressing redundancy and noise in high-dimensional statistical inputs, leading to more stable and discriminative flow-level representations. Consequently, its removal results in a noticeable performance degradation. In contrast, for CICIDS2017 and UNSW-NB15, payload semantic representations dominate the decision process, while statistical features mainly play a complementary role. In such scenarios, the refinement provided by Lite-FF yields a smaller marginal benefit, resulting in less consistent performance changes across datasets. This observation highlights that Lite-FF contributes adaptively depending on the dominance of statistical features in the target traffic domain.
5.5 Model Performance Analysis
In order to further evaluate the deployment feasibility of CPS-IDS in the actual network environment, this section quantitatively analyzes the number of model Parameters (Parameters), computational complexity (FLOPs), inference Latency (Latency) and training efficiency. Since ET-BERT is the representative Transformer model in this field and provides an open source implementation, it is used as the main comparison benchmark in this experiment. The comparison results are shown in Table 9.
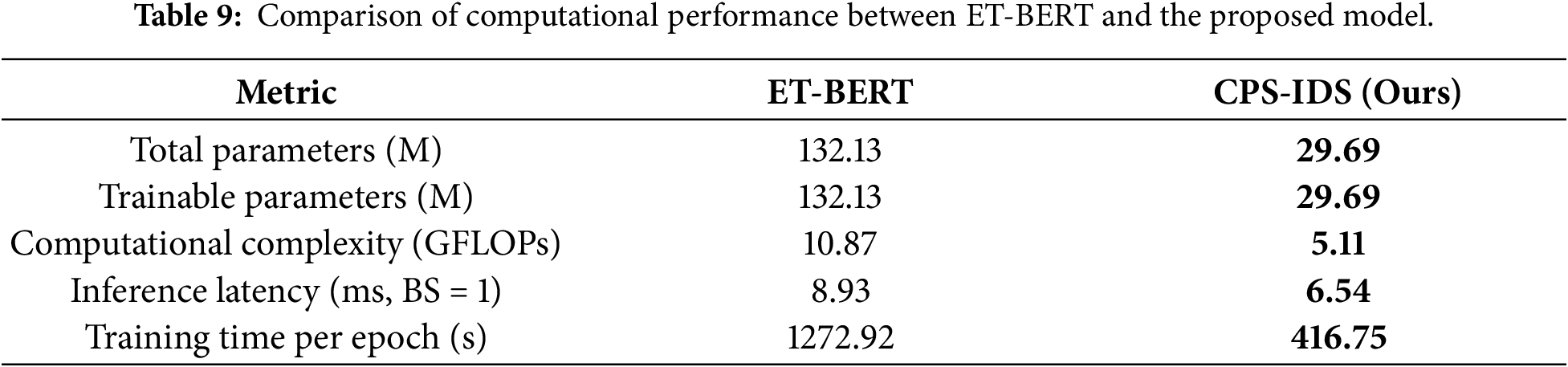
The total parameter count of CPS-IDS is only 29.69 M, which is approximately 77.5% less than that of ET-BERT. This is mainly attributed to the introduction of the Lite-FF structure in the statistical dependency branch and the adoption of a more streamlined heterogeneous dual-branch design in this paper. While maintaining high detection accuracy, it significantly reduces the model’s occupation of storage resources, making it more conducive to the deployment of edge computing devices. In terms of computational complexity, the FLOPs of CPS-IDS is 5.11 GFLOPs, which is only about half of that of ET-BERT. This indicates that when processing the same scale of traffic data, the model proposed in this paper consumes less computing resources. In the single-sample inference scenario (Batch Size = 1), the average delay of CPS-IDS is 6.54 ms, which is approximately 2.39 ms shorter than that of ET-BERT. In a high-speed network environment, the reduction of milliseconds-level delay is crucial for preventing the spread of malicious attacks. In conclusion, CPS-IDS not only performs exceptionally well in detection accuracy, but also has significant advantages in model lightweighting and execution efficiency, achieving a good balance between performance and efficiency.
To address the increasingly complex and covert intrusion behaviors in modern networks, this paper proposes a deep intrusion detection system that combines an AC-GAN enhancement mechanism with Transformer-based modeling. The model integrates two complementary traffic features: semantic representations of payloads extracted via the DeBERTav2 module, and packet interarrival time series. These are fused through a Cross-Attention mechanism, effectively capturing both the temporal dynamics of network flows and their semantic dependencies on payload content, providing a fine-grained basis for intrusion detection.
Additionally, statistical behavior is modeled using the Transformer-LiteFF block, while the AC-GAN is employed to augment minority-class attack traffic. This approach is designed to alleviate data scarcity and enhance the model’s robustness againstimbalanced attack samples.
Experimental results on multiple mainstream datasets suggest that the proposed system achieves highly competitive detection performance, particularly in improving the recognition of minority attack classes. While the optimized DeBERTav2 and Transform-Conv designs aim to control computational cost, further validation is required to ensure their real-time performance in high-throughput production environments or on resource-constrained edge devices. Future research will focus on enhancing the model’s transferability to diverse real-world network settings and optimizing inference latency for line-rate detection.
Acknowledgement: State Key Laboratory of Public Big Data, College of Computer Science and Technology, Guizhou University, Guiyang.
Funding Statement: This work was supported in part by the National Natural Science Foundation of China under Grant 62262004 (http://www.nsfc.gov.cn).
Author Contributions: Conceptualization: Lan Xiong, Liang Wan and Jingxia Ren; methodology: Lan Xiong; software: Lan Xiong; validation: Lan Xiong, Liang Wan and Jingxia Ren; formal analysis: Lan Xiong; investigation: Lan Xiong; resources: Lan Xiong; data curation: Lan Xiong; writing—original draft preparation: Lan Xiong; writing—review and editing: Lan Xiong, Liang Wan and Jingxia Ren; visualization: Jingxia Ren; supervision: Liang Wan; project administration: Liang Wan; funding acquisition: Liang Wan. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The datasets used in this study—CICIDS2017, UNSW-NB15, and CICIoT2023—are publicly available. They can be accessed from their respective sources: CICIDS2017 (https://www.unb.ca/cic/datasets/ids-2017.html), UNSW-NB15 (https://www.unsw.adfa.edu.au/unsw-canberra-cyber/cybersecurity/ADFA-NB15-Datasets/), and CICIoT2023 (https://www.unb.ca/cic/datasets/iot-2023.html).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017); 2017 Dec 4–9; Long Beach, CA, USA. p. 5998–6008. [Google Scholar]
2. Mirza M, Osindero S. Conditional generative adversarial nets. arXiv:1411.1784. 2014. [Google Scholar]
3. He P, Gao J, Chen W. DeBERTaV3: improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing. arXiv:2111.09543. 2021. [Google Scholar]
4. Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. Proc Neural Inf Process Syst. 2012;25:1097–105. doi:10.1145/3065386. [Google Scholar] [CrossRef]
5. Zhang A, Lipton ZC, Li M, Smola AJ. Dive into deep learning. Cambridge, UK: Cambridge University Press; 2023. [Google Scholar]
6. Michelucci U. An introduction to autoencoders. arXiv:2201.03898. 2022. [Google Scholar]
7. Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9:1735–80. doi:10.1162/neco.1997.9.8.1735. [Google Scholar] [PubMed] [CrossRef]
8. Ferrag MA, Maglaras L, Moschoyiannis S, Komninos N. Deep learning for cyber security intrusion detection: approaches, datasets, and comparative study. J Inf Secur Appl. 2020;50:102419. doi:10.1016/j.jisa.2019.102419. [Google Scholar] [CrossRef]
9. Lee SW, Mohammadi M, Rashidi S, Patoary MKA, Abbasi A. Towards secure intrusion detection systems using deep learning techniques: comprehensive analysis and review. J Netw Comput Appl. 2021;187:103111. doi:10.1016/j.jnca.2021.103111. [Google Scholar] [CrossRef]
10. Fu Z, Liu M, Qin Y, Gu G, Fan J, Wei M. Encrypted malware traffic detection via graph-based network analysis. In: Proceedings of the 25th International Symposium on Research in Attacks, Intrusions and Defens; 2022 Oct 26–28; New York, NY, USA. p. 495–509. doi:10.1145/3545948.3545983. [Google Scholar] [CrossRef]
11. Liu C, He L, Xiong G, Zhao B, Liu Z, Xie K, et al. FS-Net: a flow sequence network for encrypted traffic classification. In: Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications; 2019 Apr 29–May 2; Paris, France. p. 1495–503. doi:10.1109/INFOCOM.2019.8737507. [Google Scholar] [CrossRef]
12. Hu X, Gao W, Cheng G, Li J, Zhang G. Towards early and accurate network intrusion detection using graph embedding. IEEE Trans Inf Forensics Secur. 2023;18:5817–31. doi:10.1109/TIFS.2023.3318960. [Google Scholar] [CrossRef]
13. Zhang P, He F, Zhang H, Zhang W, He Z, Li Z, et al. Real-time malicious traffic detection with online isolation forest over SD-WAN. IEEE Trans Inf Forensics Secur. 2023;18:2076–90. doi:10.1109/TIFS.2023.3262121. [Google Scholar] [CrossRef]
14. Xie R, Wang Y, Cao J, Ma Y, Liu B, Li Z, et al. Rosetta: enabling robust TLS encrypted traffic classification in diverse network environments with TCP-aware traffic augmentation. In: Proceedings of the ACM Turing Award Celebration Conference; 2023 Jul 28–30; Wuhan, China. p. 131–2. doi:10.1145/3603165.3607437. [Google Scholar] [CrossRef]
15. Yu L, Dong J, Chen L, Xie R, Guo M, Zhou X. PBCNN: packet bytes-based convolutional neural network for network intrusion detection. Comput Netw. 2021;194:108117. doi:10.1016/j.comnet.2021.108117. [Google Scholar] [CrossRef]
16. Bader O, Lichy A, Hajaj C, Alghazi B. MalDIST: from encrypted traffic classification to malware traffic detection and classification. In: Proceedings of the 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC); 2022 Jan 8–11; Las Vegas, NV, USA. p. 527–33. doi:10.1109/CCNC49033.2022.9700625. [Google Scholar] [CrossRef]
17. Zhu S, Xu X, Gao H, Lin J, Chen J, Liu S. CMTSNN: a deep learning model for multiclassification of abnormal and encrypted traffic of Internet of Things. IEEE Internet Things J. 2023;10:11773–91. doi:10.1109/JIOT.2023.3244544. [Google Scholar] [CrossRef]
18. Lin K, Xu X, Gao H. TSCRNN: a novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT. Comput Netw. 2021;190:107974. doi:10.1016/j.comnet.2021.107974. [Google Scholar] [CrossRef]
19. Han X, Cui S, Liu S, Liu J, Jiang S. Network intrusion detection based on n-gram frequency and time-aware transformer. Comput Secur. 2023;128:103171. doi:10.1016/j.cose.2023.103171. [Google Scholar] [CrossRef]
20. Wang W, Jian S, Tan Y, Peng Y, Liu J. Robust unsupervised network intrusion detection with self-supervised masked context reconstruction. Comput Secur. 2023;128:103131. doi:10.1016/j.cose.2023.103131. [Google Scholar] [CrossRef]
21. Han X, Liu S, Liu J, Cui S, Jiang S. ECNet: robust malicious network traffic detection with multi-view feature and confidence mechanism. IEEE Trans Inf Forensics Secur. 2024;19:6871–85. doi:10.1109/TIFS.2024.3426304. [Google Scholar] [CrossRef]
22. Farooqui MS, Khattak AA, Awaji BH, Alturki N, Alnazzawi N, Hanif M, et al. AutoSHARC: feedback driven explainable intrusion detection with SHAP-Guided Post-Hoc retraining for QoS sensitive IoT networks. Comput Model Eng Sci. 2025;145(3):4395–439. doi:10.32604/cmes.2025.072023. [Google Scholar] [CrossRef]
23. Umair M, Khan MS, Al Malwi W, Asiri F, Nafea I, Saeed F, et al. Knowledge distillation for lightweight and explainable intrusion detection in resource-constrained consumer devices. IEEE Trans Consumer Electron. 2025;71(4):12157–65. doi:10.1109/TCE.2025.3601183. [Google Scholar] [CrossRef]
24. Aouini Z, Pekar A. NFStream: a flexible network data analysis framework. Comput Netw. 2022;204:108719. doi:10.1016/j.comnet.2021.108719. [Google Scholar] [CrossRef]
25. Lin X, Xiong G, Gou G, Li Z, Shi J, Yu J. ET-BERT: a contextualized datagram representation with pre-training transformers for encrypted traffic classification. In: Proceedings of the WWW ’22: Proceedings of the ACM Web Conference 2022; 2022 Apr 25–29; Lyon, France. p. 633–42. doi:10.1145/3485447.3512217. [Google Scholar] [CrossRef]
26. Lin P, Ye K, Hu Y, Lin Y, Xu CZ. A novel multimodal deep learning framework for encrypted traffic classification. IEEE/ACM Trans Netw. 2023;31(3):1369–84. doi:10.1109/TNET.2022.3215507. [Google Scholar] [CrossRef]
27. Devlin J, Chang MW, Lee K, Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); 2019 Jun 2–7; Minneapolis, MA, USA. p. 4171–86. doi:10.18653/v1/N19-1423. [Google Scholar] [CrossRef]
28. Zhao R, Deng X, Yan Z, Ma J, Xue Z, Wang Y. MT-FlowFormer: a semi-supervised flow transformer for encrypted traffic classification. In: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22); 2022 Aug 14–18; Washington, DC, USA. p. 2576–84. doi:10.1145/3534678.3539314. [Google Scholar] [CrossRef]
29. Sharafaldin I, Lashkari AH, Ghorbani AA. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In: Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018); 2018 Jan 22–24; Funchal, Madeira, Portugal. p. 108–16. doi:10.5220/0006639801080116. [Google Scholar] [CrossRef]
30. Moustafa N, Slay J. UNSW-NB15: a comprehensive dataset for network intrusion detection systems. In: Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS); 2015 Nov 10–12; Canberra, ACT, Australia. p. 1–6. doi:10.1109/MilCIS.2015.7348942. [Google Scholar] [CrossRef]
31. Neto ECP, Dadkhah S, Ferreira R, Zohourian A, Lu R, Ghorbani AA. CICIoT2023: a real-time dataset and benchmark for large-scale attacks in IoT environment. Sensors. 2023;23(13):5941. doi:10.3390/s23135941. [Google Scholar] [PubMed] [CrossRef]
32. Akuthota UC, Bhargava L. Transformer based intrusion detection for IoT networks. IEEE Internet Things J. 2025;12(5):6062–7. doi:10.1109/JIOT.2025.3525494. [Google Scholar] [CrossRef]
33. Gulzar Q, Mustafa K. Enhancing network security in industrial IoT environments: a DeepCLG hybrid learning model for cyberattack detection. Int J Mach Learn Cybern. 2025;16:4797–815. doi:10.1007/s13042-025-02544-w. [Google Scholar] [CrossRef]
34. Wang H, Yang Y, Tan P. CTWA: a novel incremental deep learning-based intrusion detection method for the Internet of Things. Artif Intell Rev. 2025;58:374. doi:10.1007/s10462-025-11358-9. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools