
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Task-Specific YOLO Optimization for Railway Tunnel Cracks and Water Leakage: Benchmarking and Lightweight Enhancement
1 Infrastructure Inspection Research Institute, China Academy of Railway Sciences Co., Ltd., Beijing, China
2 National Superior College for Engineers, Beijing University of Aeronautics and Astronautics, Beijing, China
3 State Key Laboratory of Advanced Rail Autonomous Operation, Beijing Jiaotong University, Beijing, China
4 School of Mechanical, Electronic and Control Engineering, Beijing Jiaotong University, Beijing, China
* Corresponding Author: Kangshuo Zhu. Email:
(This article belongs to the Special Issue: Intelligent Transportation System (ITS) Safety and Security)
Computers, Materials & Continua 2026, 87(3), 41 https://doi.org/10.32604/cmc.2026.077314
Received 06 December 2025; Accepted 15 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The safe operation of railway systems necessitates efficient and automated inspection of tunnel defects. While deep learning offers solutions, a clear pathway for selecting and optimizing the latest object detectors for distinct defects under strict speed constraints is lacking. This paper presents a two-stage, task-specific framework for high-speed tunnel defect detection. First, this study conducts a comprehensive comparative analysis of state-of-the-art YOLO models (YOLOv5s, YOLOv8s, YOLOv10s, YOLOv11s) on self-constructed datasets. This systematic comparison identifies YOLOv5s as the optimal model for crack detection, achieving an mAP@0.5 of 0.939 at 77.5 FPS, sufficient for inspection at 50 km/h. Subsequently, for the more complex water leakage detection task, this study proposes a novel lightweight enhancement to the most accurate model, YOLOv11s, by integrating the MobileNetV4 backbone and the Wise-IoU loss function. This optimization reduces computational load by 46.0% and increases speed by 17.4% to 33.97 FPS, theoretically supporting speeds up to 58.6 km/h. The main contributions of this work are twofold. First, this study conducts a systematic comparative analysis of YOLO series (v5 to v11) for distinct tunnel defect types (linear cracks vs. irregular water leakage), providing a clear selection guideline under strict speed constraints. Second, it introduces a novel, task-specific lightweight optimization paradigm, demonstrating that a one-model-fits-all approach is suboptimal for complex inspection tasks. Our study not only provides a practical solution but also establishes a valuable benchmark and optimization paradigm for real-time defect detection in tunnel engineering.Keywords
Abbreviations
| The following abbreviations are used in this manuscript: | |
| CNN | Convolutional Neural Network |
| FPS | Frames Per Second |
| GFLOPs | Giga Floating Point Operations per Second |
| mAP | Mean Average Precision |
| MNv4 | MobileNetV4 |
| UIB | Universal Inverted Bottleneck |
| WIoU | Wise Intersection over Union |
| YOLO | You Only Look Once |
By the end of 2024, the total mileage of operational rail transit in China has reached nearly 12,000 km [1]. As this network continues to expand, the demand for efficient and reliable tunnel maintenance has become increasingly critical. Tunnel structures, under the combined influence of factors such as lining quality defects, varying surrounding loads, and environmental degradation, are prone to developing defects including cracks, water leakage, and lining deterioration [2]. These defects compromise concrete durability, impair the functionality of internal facilities, degrade the tunnel environment, and, most importantly, pose serious threats to operational safety [3].
Traditional detection methods are dominated by manual visual assessment, which suffers from low efficiency, high subjectivity, and stringent requirements for inspector expertise [4,5]. Advances in computer vision and image acquisition technologies have facilitated the application of digital image processing for tunnel surface defect detection, leveraging its capability for image feature extraction and analysis [6–8]. These methods identify and localize defects by applying predefined image processing protocols to extract visual features such as grayscale, texture, and shape. However, the effectiveness of such methods heavily relies on manually tuned filters and parameters, resulting in poor generalization. In the dynamic tunnel environment with fluctuating lighting and complex backgrounds, frequent manual parameter adjustments are required, which increases operational burden and seriously restricts the detection efficiency and feasibility [9].
In recent years, deep learning has garnered extensive attention in tunnel lining detection due to its ability to automatically learn hierarchical features from training data [10,11]. Object detection algorithms can be categorized into two-stage networks (e.g., R-CNN series) and single-stage networks (e.g., SSD, YOLO series) [12–14]. While two-stage networks offer high accuracy, their inference speed is generally inferior to that of single-stage networks, making them less suitable for real-time applications. Recent studies [15,16] comparing object detection frameworks for concrete and rail defects have highlighted that the latency of two-stage models hinders their deployment in high-speed inspection scenarios. Convolutional Neural Network (CNN)-based detectors like Faster R-CNN, Mask R-CNN, and YOLO have been extensively studied for tunnel defect detection [17]. In addition, novel architectures have been proposed; for instance, Zhou et al. integrated Swin Transformer with CNN within a DeepLabv3+ framework, proposing the SCDeepLab hybrid segmentation algorithm [10]; Liu et al. combined U-Net with the Adam optimizer to achieve high accuracy with limited training data [18]. However, regarding high-speed inspection scenarios, adopting lightweight model architectures is a crucial strategy. Employing lightweight backbones such as GhostNet [19], ShuffleNet [20], and SqueezeNet [21], along with model compression techniques like quantization and pruning, can effectively reduce computational complexity and accelerate inference. However, these methods often entail a trade-off with detection accuracy, necessitating careful balancing during optimization.
Despite these advancements, most existing studies either focus on a single model or apply uniform optimization without considering the inherent characteristics of different defects. Critical gaps remain in the current research landscape:
1. Lack of Systematic Benchmarking: A fair and comprehensive performance comparison of mainstream YOLO models (v5 to v11) on distinct tunnel defect types (e.g., linear cracks vs. irregular water leakage) under unified experimental settings is absent.
2. Lack of a Task-Oriented Optimization Pathway: A targeted lightweight optimization strategy that meets the stringent real-time requirement of 50 km/h inspection for each specific defect type has not been established.
To bridge these gaps, this paper proposes a novel two-stage, task-specific framework. The main contributions are summarized as follows:
1. We conduct a systematic comparative analysis of state-of-the-art YOLO models (v5s, v8s, v10s, v11s) on a self-constructed tunnel defect dataset. This establishes a clear performance benchmark, clarifying the trade-offs between newer iterations and established models for crack and water leakage detection.
2. We explore the premise that different defects necessitate different optimal architectural configurations. We demonstrate that while the lightweight YOLOv5s is sufficient for simple linear cracks, the more visually complex water leakage task requires a more advanced architecture to balance accuracy and speed.
3. We propose a novel lightweight enhancement strategy specifically for complex water leakage detection. By integrating the MobileNetV4 backbone and the Wise-IoU loss into YOLOv11s, we achieve a significant reduction in computational load (46.0%) and an increase in inference speed (17.4%) without substantial accuracy loss, establishing an effective task-specific optimization paradigm.
4. Our optimized models demonstrate the feasibility of high-efficiency inspection on resource-constrained hardware. The achieved inference speed theoretically supports inspection speeds exceeding 50 km/h, providing a practical and efficient algorithmic reference for automated railway tunnel inspection.
The remainder of this paper is organized as follows: Section 2 reviews related works and presents our research concept. Section 3 describes the inspection system and dataset construction. Section 4 details the proposed methodology. Experimental results and analysis are presented in Section 5. Finally, Section 6 concludes the paper and suggests future work.
2 Related Works and Research Concept
Automated detection of tunnel surface defects has evolved from traditional image processing to deep learning-based approaches. Early studies primarily relied on digital image processing techniques. Sinha and Fieguth proposed a morphology-based method for automatic segmentation of pipeline defect images [22]. Lei et al. developed an improved segmentation method integrating adaptive partitioning, edge detection, and thresholding to enhance crack identification accuracy [23]. Muduli et al. combined Canny edge detection with HBT filtering to optimize edge feature extraction [24]. While effective in controlled environments, these methods exhibit poor adaptability to complex tunnel conditions (e.g., varying illumination, background clutter) and limited generalization.
To overcome these limitations, CNN-based object detection models have become the mainstream solution for tunnel defect detection due to their powerful feature learning capabilities. Zhou et al. replaced the backbone network of YOLOv4 with EfficientNet and incorporated depthwise separable convolution (DSC), proposing the YOLOv4-ED algorithm for multi-defect detection [17]. Lu et al. introduced a mixed local channel attention (MLCA) module and a bidirectional feature pyramid network to propose the MB-YOLO algorithm, significantly improving both accuracy and speed [25]. Zhou et al. proposed an improved YOLO-LD algorithm by combining an asymptotic feature pyramid network (AFPN) with a convolutional block attention module (CBAM) [26].
As CNNs gain widespread adoption, the demand for real-time execution on resource-constrained hardware continues to grow. Researchers are actively investigating lightweight network designs. Zhou et al. replaced the YOLOX backbone with MobileNetV3, incorporated an Efficient Channel Attention (ECA) module, and used GIoU loss to achieve high-precision real-time crack detection [27]. Zheng et al. designed the DFL-YOLO model, introducing modules like FAPN and LDSC detection head to enhance crack feature extraction efficiency, reducing computational load by 43.8% while maintaining accuracy [28].
In summary, previous research has made significant progress in applying and lightweighting object detection models for tunnel inspection. However, most studies suffer from one or more limitations: (a) a narrow focus on a single or few models, lacking broad systematic comparison; (b) generic optimization strategies not tailored to the distinct visual characteristics of different defect types (e.g., thin linear cracks vs. large irregular water leakage); (c) insufficient validation of real-time performance against concrete high-speed inspection scenarios (e.g., 50 km/h). Our work addresses these limitations by providing a comprehensive benchmark and a task-specific optimization pathway, rigorously evaluated against explicit speed requirements.
3 System Description and Dataset Construction
Deep learning is inherently data-driven; thus, data quality directly impacts model performance. To facilitate effective research on metro tunnel defect detection, this study constructed specialized datasets of cracks and water leakage using a self-developed automatic tunnel image acquisition and detection system.
The system comprises hardware and software components. The hardware system performs high-speed acquisition of tunnel surface images, while the software system implements rapid and accurate defect identification. The overall workflow is illustrated in Fig. 1. During operation, a power supply unit powers the image acquisition module, and a laser source provides synchronized illumination to ensure clear imaging by high-speed line-scan cameras. Captured high-definition images are transmitted to an industrial PC, where the detection process begins. Images are first cropped into patches of specific resolutions tailored to the defect type and then fed into YOLO models for crack and water leakage detection. Results are visualized in real-time via a Graphical User Interface (GUI). Image acquisition was conducted using a dedicated inspection trolley, as shown in Fig. 2.
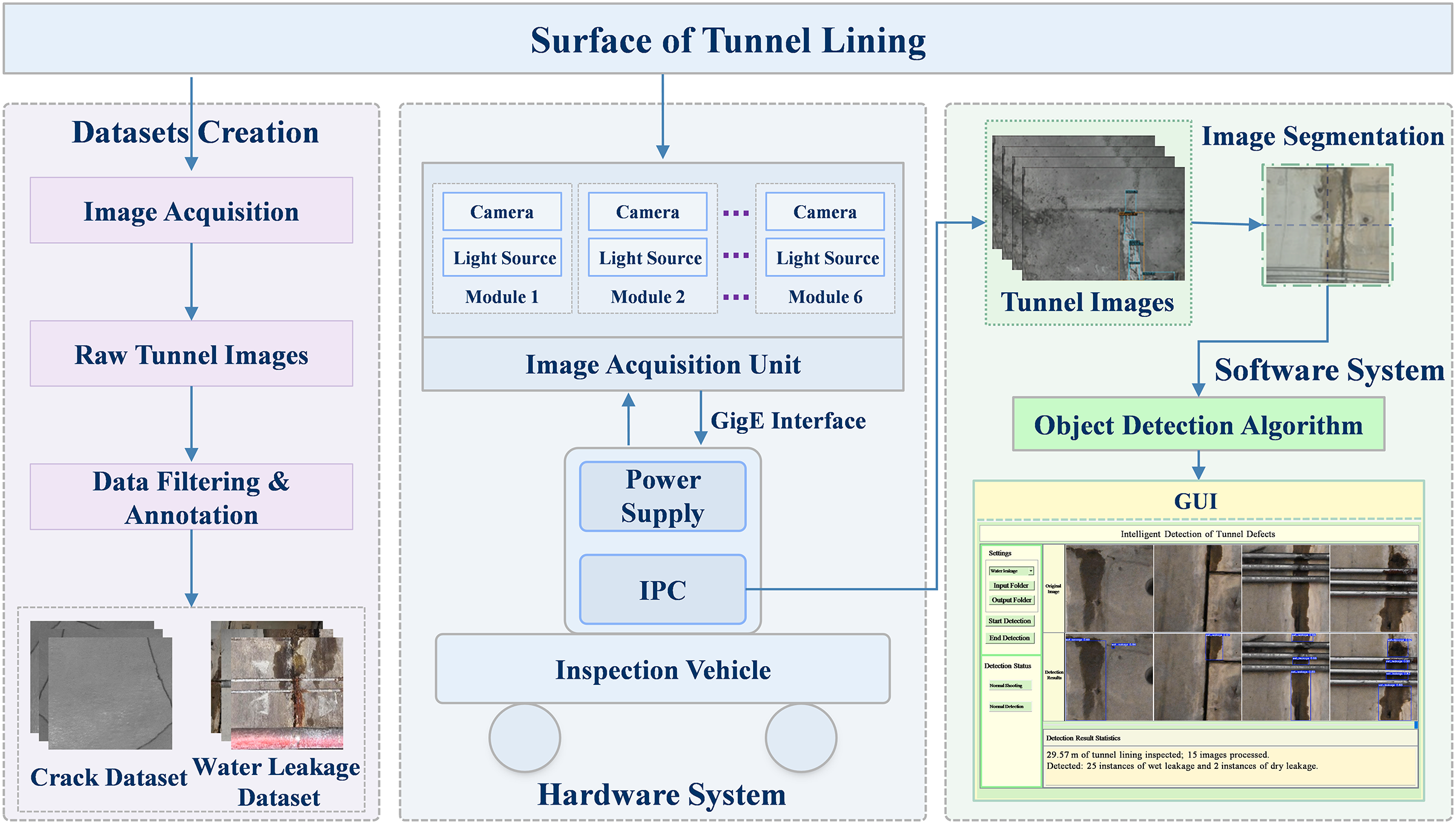
Figure 1: The overall architecture of the tunnel defect inspection system.

Figure 2: Image acquisition system of tunnel lining.
All tunnel images were collected from real-world rail transit tunnels using the aforementioned trolley. Raw images were screened, cropped, and manually annotated using Labelling software to construct the crack and water leakage datasets. Considering that cracks are fine-grained and occupy a small image area, a resolution of
3.1 Crack Dataset Construction
Original crack images were screened and uniformly cropped to


Figure 3: Crack dataset annotation.
3.2 Water Leakage Dataset Construction
Original tunnel images were cropped to


Figure 4: Leakage dataset annotation.
Four standard metrics are adopted: Precision (P), Recall (R), mean Average Precision (mAP), and Frames Per Second (FPS).
Precision and Recall are defined as:
where TP (True Positive) denotes the number of correctly detected defect instances, FP (False Positive) denotes the number of background areas incorrectly identified as defects, and FN (False Negative) represents the number of missed defect instances.
The Average Precision (AP) represents the area under the Precision-Recall (P-R) curve, integrating both precision and recall. The mAP is the mean of the AP values across all K defect categories (in this study,
Frames Per Second (FPS) evaluates the real-time processing capability. It is defined as the inverse of the end-to-end latency (
where
Environment and Hardware: Experiments were conducted on a standard laptop computer equipped with an AMD Ryzen 7 5800H CPU and an NVIDIA GeForce RTX 3050 GPU (4 GB VRAM). The software environment included Python 3.8.20, PyTorch 2.2.2, and CUDA 12.1. All models were implemented using the Ultralytics library (v8.3.0).
Training Configuration: To ensure a fair comparison, identical hyperparameters were used for all models, as detailed in Table 3. The training process lasted 500 epochs with a batch size of 4, utilizing the AdamW optimizer with an initial learning rate of 0.001667 and momentum of 0.9. A cosine warmup strategy was applied for the first 3 epochs, and early stopping was set with a patience of 100 epochs. To further simulate potential variations in illumination and geometry and bridge the domain gap, standard data augmentation strategies (e.g., Mosaic and Mixup) were employed. These strategies were implemented via the unified Ultralytics pipeline to ensure strict consistency across all model families, thereby eliminating potential preprocessing and augmentation discrepancies.

Inference and Test Protocol: To maintain strict consistency between training and inference, defect-specific input sizes were adopted during testing:
This section details the proposed high-speed defect detection algorithm. First, the baseline YOLO models are introduced. Then, two core innovations are elaborated: the lightweight backbone based on MobileNetV4 and the bounding box regression loss using Wise-IoU.
As a representative single-stage detector, YOLO predicts bounding boxes and class probabilities directly in one pass, offering high computational efficiency. We systematically evaluate multiple YOLO iterations for high-speed tunnel inspection.
YOLOv5s: Remains an industrial benchmark due to its robust speed-accuracy balance. Its architecture comprises: an input stage with Mosaic augmentation; a CSPDarknet backbone with cross-stage partial connections; a Neck integrating FPN and PAN for multi-scale fusion; and a Head using GIoU Loss. Its scalable variants (e.g., YOLOv5s) make it suitable for resource-constrained devices, serving as our primary candidate for crack detection.
YOLOv11s: The latest iteration (architecture shown in Fig. 5) serves as the baseline for complex water leakage detection. It introduces key innovations: the C3k2 module with dynamically adjustable kernels for flexibility; the C2PSA component leveraging position-sensitive multi-head attention; a refined path aggregation neck with C3k2 units; and an anchor-free head employing depthwise separable convolutions to reduce parameters. These enhancements grant YOLOv11s superior feature representation for irregular leakage patterns.
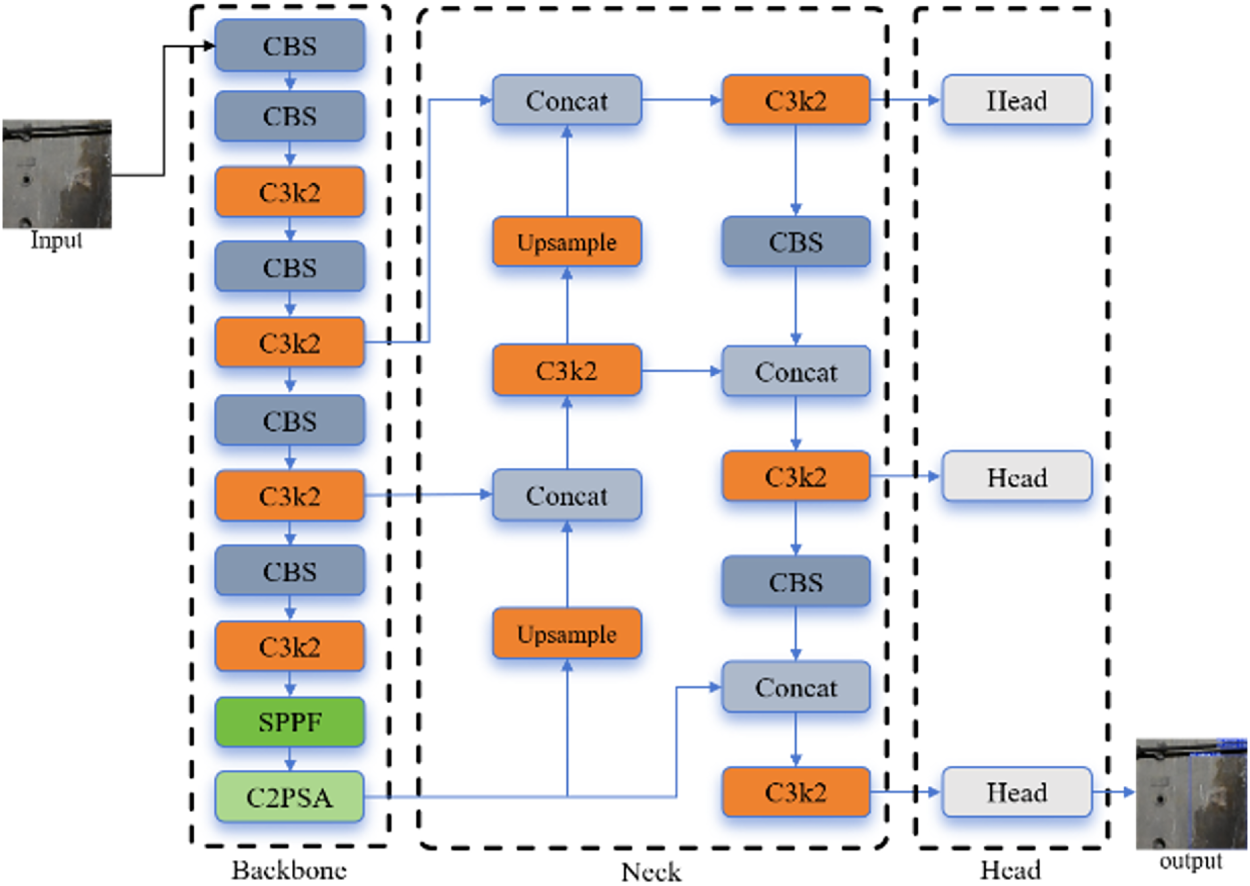
Figure 5: YOLOv11 network structure diagram.
Other Iterations: YOLOv8 introduced an anchor-free paradigm and decoupled head [29]. YOLOv10 proposed an NMS-free end-to-end design [30]. However, preliminary benchmarking (Section 5) revealed they did not offer the optimal trade-off for our specific constraints under the 50 km/h requirement; thus, detailed analysis focuses on YOLOv5 and YOLOv11.
4.2 Model Optimization and Improvements
To meet real-time detection requirements, a balance between efficiency and accuracy is needed. We implement two targeted optimizations for YOLOv11s: integrating the MobileNetV4 backbone to reduce computation and employing the Wise-IoU loss to enhance localization. The improved architecture is shown in Fig. 6.
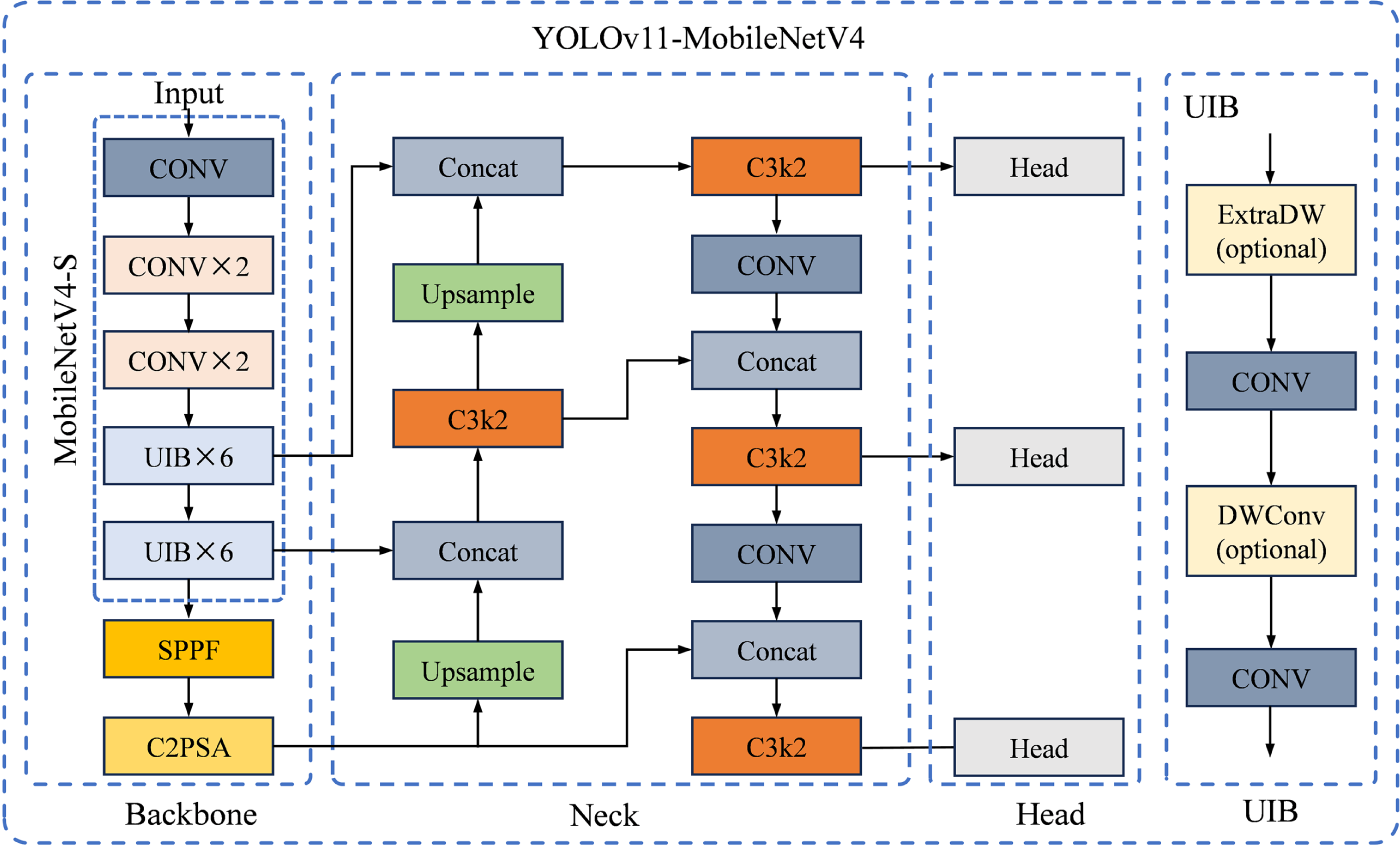
Figure 6: The network structure diagram after the main branch replacement.
4.2.1 Lightweight Backbone Design: MobileNetV4
MobileNetV4 (MNv4) is a state-of-the-art efficient architecture optimized for mobile devices [31]. We integrate its backbone into YOLOv11 to reduce computational redundancy. Its core innovation is the Universal Inverted Bottleneck (UIB) block, derived from Neural Architecture Search (NAS). The UIB extends the classic inverted bottleneck by introducing optional depthwise convolutions, creating four variants to balance capacity and speed: (1) ExtraDW for increased receptive field; (2) ConvNext for spatial mixing; (3) classic Inverted Bottleneck for channel expansion; (4) FFN for pointwise transformation. These blocks are stacked to form a Pareto-optimal backbone, providing robust feature extraction with minimal latency.
4.2.2 Bounding Box Regression Loss Optimization: WIOU
Wise-IoU (WIoU) is an advanced loss function incorporating a dynamic gradient focusing mechanism [32]. Unlike traditional IoU losses, WIoU adjusts gradient contribution based on anchor quality (overlap with ground truth).
We employ its dynamic non-monotonic focusing mechanism to address sample quality imbalance in complex tunnel environments. The strategy involves:
Distance-Based Attention: Constructs an attention term based on the geometric center distance, penalizing predictions far from the target center.
Outlier Suppression: Uses a non-monotonic focusing coefficient that reduces gradient gain for high-quality anchors (preventing overfitting to annotation noise) and applies a bounded penalty to low-quality anchors (e.g., blurred leakage boundaries).
By suppressing harmful gradients from outliers and focusing on medium-quality samples, WIoU enhances generalization and convergence stability. This is particularly beneficial for variable-scale, ambiguous water leakage defects. We adopt the hyperparameters from the original paper [32].
To select the optimal models, comparative experiments were conducted on different YOLO versions. First, the minimum required FPS for 50 km/h inspection is calculated. With a system precision of 0.96 mm/pixel and a speed of 13.899 m/s (50 km/h), the number of pixels scanned per second is
For the minimum frame rate of crack detection: the input image size for detection is
For the minimum frame rate of water leakage detection: the input image size is
In summary, to achieve real-time detection at 50 km/h, the frame rate for crack detection must reach at least 67.64 FPS, and for water leakage detection, at least 28.86 images must be detected per second.
5.1 Experimental Results for Crack Detection
The primary objective of this comparative experiment was to identify the most suitable YOLO architecture for crack detection under the strict 50 km/h speed constraint. This systematic benchmarking across four model families represents a novel contribution, as prior studies often focus on a single model or a narrower range of versions.
For the tunnel crack detection task in this study, lightweight models (small variants) from four YOLO series, namely YOLOv5, YOLOv8, YOLOv10, and YOLOv11, were selected, and comparative experiments were conducted based on the self-constructed crack image dataset. The study focused on analyzing accuracy metrics such as Precision, Recall, mAP@0.5, and mAP@0.5:0.95, while also incorporating computational load (measured by GFLOPs) and inference speed (measured by FPS) to evaluate the accuracy and computational efficiency of models from different series. The quantitative performance results of each model under standardized conditions are presented in Table 4.
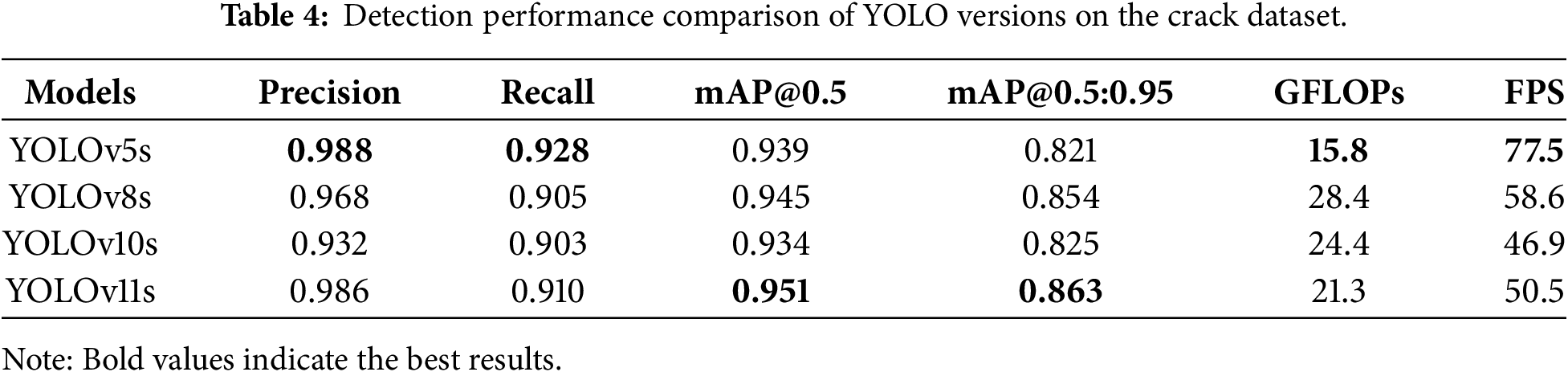
Table 4 and Fig. 7 present the comparative performance of the four models. Although YOLOv11s achieved the highest mAP@0.5 of 0.951, YOLOv5s demonstrated superior overall capability with the highest Precision of 0.988 and Recall of 0.928. These quantitative metrics align directly with the visual results in Fig. 7, where the high recall of YOLOv5s enabled it to detect subtle corner cracks in Fig. 7a and d that were missed by other models. YOLOv11s ranked second in detection completeness, whereas YOLOv8s and YOLOv10s frequently failed to detect obvious defects in Fig. 7a and b. Additionally, YOLOv10s exhibited regression instability by generating redundant overlapping boxes in Fig. 7b and c.

Figure 7: The comparative detection effects of each series of networks on crack images. (a). Top inclined crack under background interference and short inclined crack at bottom-right; (b). Short inclined crack at top-left and inclined crack at bottom-left; (c). Long near-vertical central crack and short inclined crack at top-right; (d). Long near-horizontal central crack and short inclined crack at top-right.
Regarding engineering feasibility, YOLOv5s recorded the lowest GFLOPs of 15.8 and a top speed of 77.5 FPS, making it the only model to exceed the 67.64 FPS threshold required for 50 km/h inspection. In contrast, for YOLOv8s and YOLOv11s, the FPS fell short by 9.04 and 17.14 FPS, respectively, a gap difficult to close without significant accuracy loss. Consequently, YOLOv5s remains the most robust and efficient baseline for real-time crack detection in this scenario.
Discussion: YOLOv5s’s superiority for crack detection stems from its mature, efficient architecture well-suited for small linear features. The fact that newer, more complex models (v10, v11) did not outperform v5 highlights that architectural advances do not always translate to gains for specific tasks. Under strict speed constraints for straightforward defects like cracks, simpler, well-optimized models like YOLOv5s are the most pragmatic choice.
5.2 Experimental Results for Water Leakage Detection
Following the model selection for cracks, we investigated water leakage detection, which presents different challenges due to target size and shape variability. This section aims to determine if the optimal model for cracks is also superior for leakage, or if a task-specific model choice is necessary—a key question not thoroughly explored in previous work.
In practical tunnel engineering, water leakage detection faces numerous challenges such as uneven illumination, water stain interference, and complex environments. Additionally, the collected image data has issues including variable background textures and irregular shapes of water leakage, which impose higher requirements on the adaptability and accuracy of detection algorithms. To explore an efficient water leakage detection solution suitable for complex on-site working conditions, this section conducts detection experiments on different versions of the YOLO series based on the on-site tunnel water leakage dataset. By comparing the performance of each model across various metrics, the optimal detection network is screened out, and the metrics are demonstrated in Table 5.
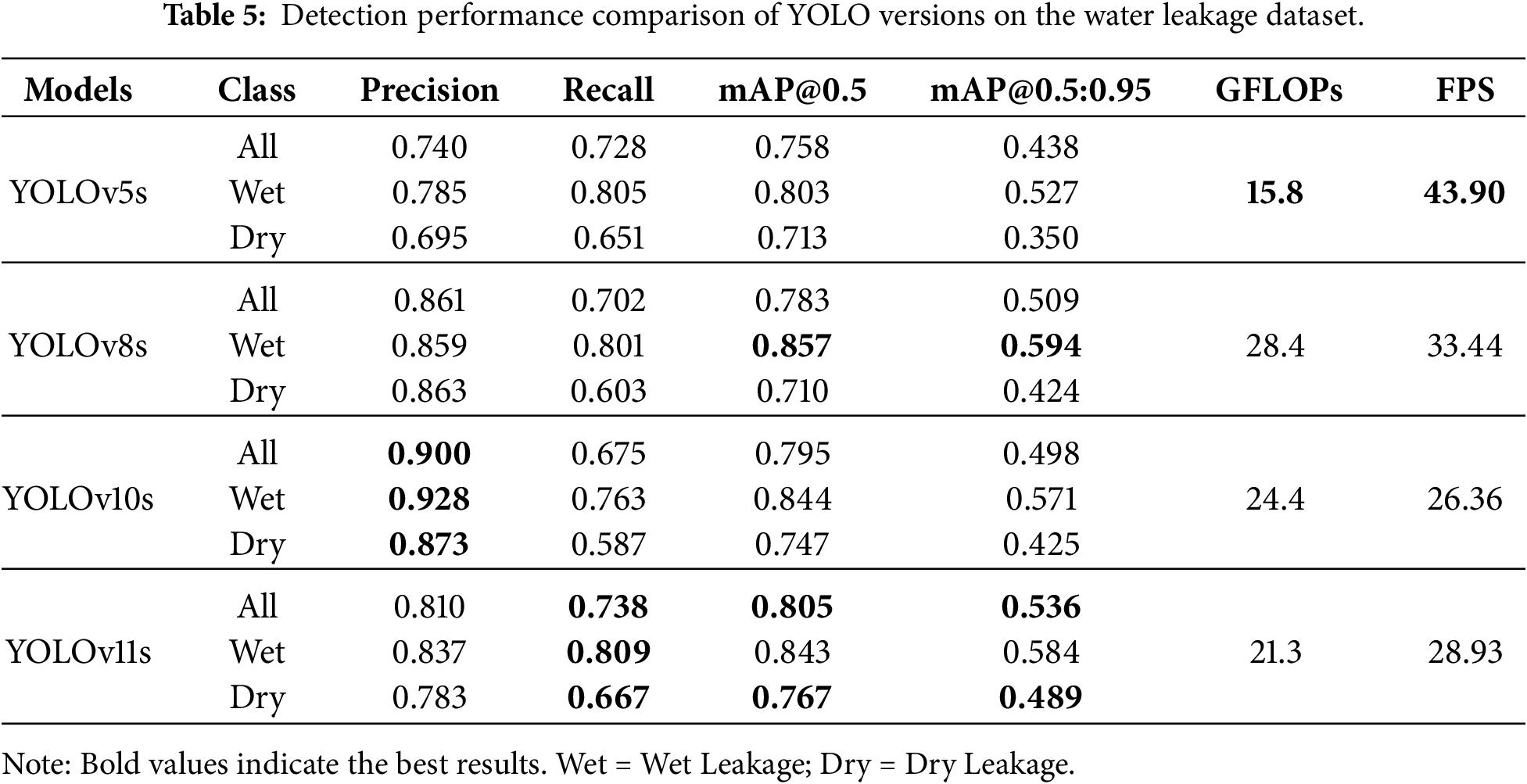
Table 5 and Fig. 8 indicate that dry leakage is much harder to detect than wet leakage. Dry leakage often has low contrast and blends with the tunnel lining. As a result, all models achieve higher accuracy for wet leakage (mAP@0.5 > 0.80) compared to dry leakage (mAP@0.5 ranging from 0.710 to 0.767). Moreover, the models generally assign lower confidence scores to dry leakage predictions.

Figure 8: Comparative detection results of different network series on water leakage images. The dark blue bounding boxes denote wet leakage, and the cyan boxes represent dry leakage. (a). Large-area wet leakage occluded by a pipeline, accompanied by a small patch of wet leakage; (b). Elongated wet leakage at the image edge occluded by pipelines and shadows, with a small patch of wet leakage nestled between a pipeline and its shadow; (c). Dry leakage fragmented by a pipeline and its shadow; (d). Multiple dry leakages under complex background interference.
Performance discrepancies among the tested architectures are evident. Although YOLOv5s is the fastest, its feature extraction is insufficient. It fails to detect the medium-sized wet leakage in Fig. 8a and the small wet leakage in Fig. 8b. YOLOv8s and YOLOv10s also struggle with missed detections. YOLOv8s shows a low Recall for dry leakage (0.603) and misses defects in Fig. 8d. YOLOv10s prioritizes Precision (0.900) at the cost of Recall (0.675). This conservative prediction strategy leads to missed detections of even prominent wet leakage in Fig. 8a.
In contrast, YOLOv11s demonstrates superior comprehensive performance. It achieves the highest mAP@0.5 (0.805) and mAP@0.5:0.95 (0.536). Crucially, it attains the highest Recall for both wet leakage (0.809) and dry leakage (0.667). This robust recall capability is visually confirmed in the detection results. In Fig. 8b, only YOLOv11s detects the small, occluded wet leakage in the center. Furthermore, in Fig. 8c, it successfully identifies the small dry leakage blocked by pipelines and shadows, a target missed by all other models. These results prove that YOLOv11s handles complex backgrounds and occlusions most effectively. Therefore, YOLOv11s is selected as the optimal baseline. However, the need for practical deployment speed still necessitates lightweight optimization.
Discussion: The need for YOLOv11s for water leakage, contrasted with YOLOv5s for cracks, strongly reinforces our core argument for task-specific model selection. More powerful feature representation is required for large, irregular, and texturally complex defects.
5.3 Results of Task-Specific Optimization for Water Leakage
5.3.1 Backbone Replacement with MobileNetV4
Given that water leakage detection requires both maintaining high accuracy to ensure the reliability of detection results and meeting the basic real-time requirements of engineering scenarios, this study conducted improvement experiments on YOLOv11s with the core goals of lightweight design and improved detection speed, striving to enhance model operation efficiency without a significant reduction in detection accuracy.
To explore a lightweight backbone network more suitable for water leakage detection tasks, four sets of comparative experiments were designed. The original YOLOv11s backbone was used as the control, and MobileNetV4 (with depthwise separable convolution as its core), EfficientNetV2 [33] (equipped with a compound scaling strategy), and GhostNetV2 [34] (which reduces computational load through Ghost modules) were introduced. By quantitatively analyzing the differences in parameter count, computational load, inference speed, and detection accuracy among the models, the optimal backbone architecture that balances efficiency and performance was screened out.
As presented in Table 6, the original YOLOv11s remains the accuracy benchmark, achieving the highest comprehensive performance (mAP@0.5: 0.805, mAP@0.5:0.95: 0.536). However, MobileNetV4 demonstrated the superior lightweight characteristics required for the embedded deployment: lowest parameters (5.65 M), lowest GFLOPs (11.5), and the highest inference speed (33.97 FPS), representing a 17.4% speed increase that raises the theoretical maximum inspection speed to 58.6 km/h.
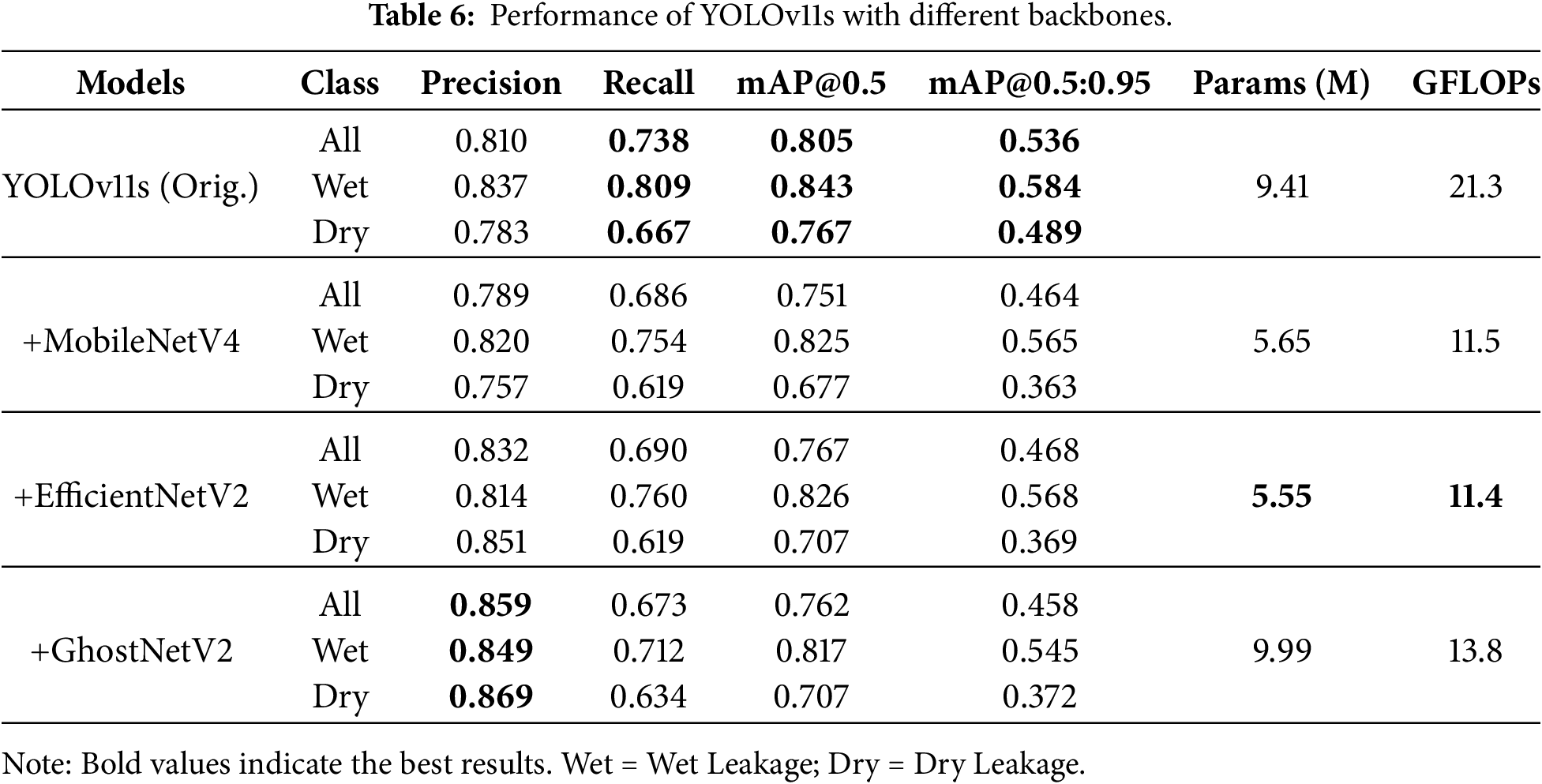
While the substitution resulted in a decrease in overall accuracy (mAP@0.5 dropped to 0.751, mAP@0.5:0.95 to 0.464), the granular class-wise analysis reveals that the model retains robust detection capabilities for Wet Leakage, with an mAP@0.5 of 0.825 and mAP@0.5:0.95 of 0.565, only marginally lower than the baseline. The primary performance degradation is observed in the low-contrast Dry Leakage (mAP@0.5: 0.677, mAP@0.5:0.95: 0.363), where the reduced feature capacity of the lightweight backbone struggles with subtle boundary definitions. Conversely, although EfficientNetV2 and GhostNetV2 exhibited slightly better metrics in specific sub-categories (e.g., EfficientNetV2’s mAP@0.5:0.95 of 0.468), they failed to translate theoretical lightness into actual inference speed gains. Therefore, accepting the trade-off in dry leakage precision to overcome the critical speed bottleneck, MobileNetV4 is selected as the optimal replacement backbone.
5.3.2 Optimization with Wise-IoU Loss
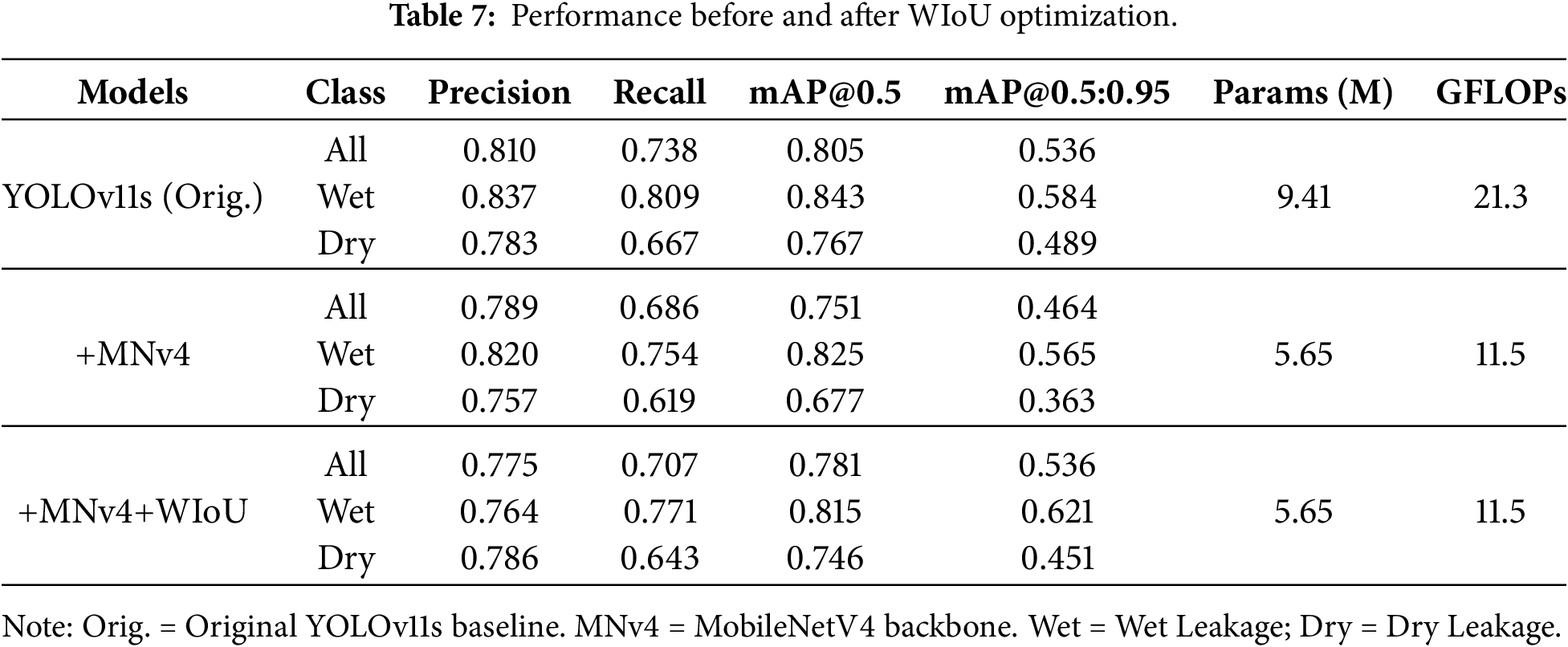
To alleviate the accuracy loss while maintaining the lightweight characteristics of the model, this study replaced the bounding box regression loss function of YOLOv11s with WIOU (Weighted Intersection over Union). By introducing a dynamic weight mechanism, WIOU enhances the gradient attention to hard samples (such as leakage areas with blurred edges and small-scale targets) during the training process, thereby optimizing the gradient allocation efficiency and improving the model’s ability to recognize complex leakage features. This experiment aims to evaluate the improvement effect of the WIOU loss function on detection accuracy while ensuring that no additional parameters or computational burden are introduced, and the experimental results are presented below.
Table 7 quantifies the efficacy of the proposed lightweight optimization strategy. Replacing the backbone with MobileNetV4 initially incurred a performance penalty. The mAP@0.5 dropped from 0.805 to 0.751. However, the integration of the WIoU loss function significantly recovered the discrimination ability of the model. Specifically, WIoU increased the overall mAP@0.5 to 0.781 and improved Recall from 0.686 to 0.707. Furthermore, it restored the overall mAP@0.5:0.95 to the same level as YOLOv11s (0.536), and even achieved a wet leakage mAP@0.5:0.95 of 0.621. This metric surpasses the original YOLOv11s baseline of 0.584. This improvement indicates that the predicted bounding boxes align more tightly with the ground truth.
This enhanced localization accuracy is visually corroborated by the detection results in Fig. 9c and d. In the challenging case of dry leakage, the optimized model achieved a Precision of 0.786. This outperforms the MobileNetV4-only version at 0.757. This enhancement is evident in Fig. 9e. The original YOLOv11s generates redundant and overlapping boxes for a single dry leakage area. In contrast, the optimized model produces a clean and single detection. Furthermore, the model demonstrates superior robustness against false positives. As shown in Fig. 9b, the baseline model misclassifies tunnel lining oil and rust stains as wet leakage. The optimized model correctly ignores this distractor. Crucially, the optimization also addresses missed detections. In Fig. 9a, the baseline model fails to detect the small wet leakage sandwiched between pipes. Similarly, in Fig. 9b, it misses the faint dry leakage in the upper left corner. The optimized model successfully identifies both targets. These improvements are attributed to the dynamic focusing mechanism of WIoU. This mechanism reduces the gradient weights of simple examples and directs attention to hard and low quality anchor boxes. This effectively recovers the feature extraction capability for occluded or blurred leakage during the lightweighting process.

Figure 9: Visual comparison of detection results between the baseline YOLOv11s and the improved model. The dark blue bounding boxes denote wet leakage, and the cyan boxes represent dry leakage. (a). Large elongated wet leakage interrupted by pipelines; (b). Small patches of dry and wet leakage with complex background and oil stain interference; (c). Large wet leakage occluded by rusted pipelines; (d). Elongated wet leakage located at the image boundary (adjacent to the escape platform area); (e). Dry leakage interfered by surface texture patterns.
To further validate the model’s reliability, Fig. 10 presents the training dynamics and classification performance. The smooth convergence of loss and mAP curves in Fig. 10a confirms a stable training process. Furthermore, the confusion matrix (Fig. 10b) demonstrates robust classification, achieving accuracies of 80% for wet leakage and 70% for dry leakage. Crucially, misclassification between leakage types is minimal (
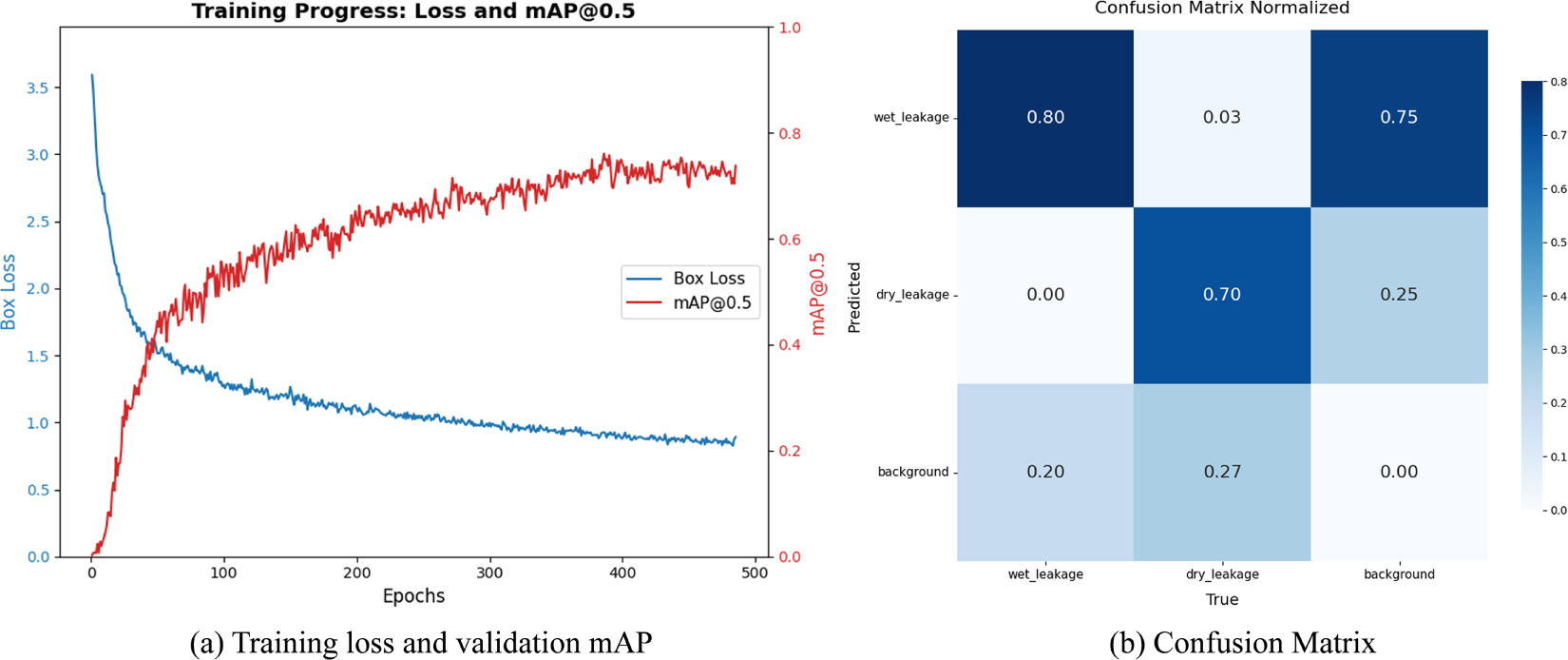
Figure 10: Training dynamics and classification performance of the optimized model: (a) Loss and mAP convergence curves; (b) Confusion matrix.
Final Optimized Model Summary: The task-specific optimization for water leakage yields:
Parameters: Reduced by 40.0% (
GFLOPs: Reduced by 46.0% (from 21.3 GFLOPs to 11.5 GFLOPs).
FPS: Increased by 17.4% (28.93
Accuracy: Maintains a robust mAP@0.5 of 0.781, sufficient for engineering applications.
This optimized model achieves a superior speed-accuracy balance for 50 km/h real-time tunnel inspection.
This study addresses the critical need for high-speed tunnel inspection by introducing a novel, task-oriented framework that moves beyond the conventional one-model-fits-all approach. The framework combines systematic model benchmarking with targeted lightweight optimization, providing a clear pathway for deploying deep learning in real-world railway maintenance.
First, we established a comprehensive benchmark of YOLO models (v5 to v11) for distinct tunnel defects. For crack detection, the lightweight YOLOv5s was optimal, achieving 0.939 mAP@0.5 at 77.5 FPS, sufficient for 50 km/h inspection. For the more challenging water leakage detection, YOLOv11s provided the best accuracy but required optimization to meet speed constraints.
Our second key contribution is a task-specific lightweight optimization paradigm. For water leakage detection, we enhanced YOLOv11s by integrating the MobileNetV4 backbone and the Wise-IoU loss function. The final model reduced computational load by 46.0% and increased inference speed by 17.4% to 33.97 FPS while maintaining a practical mAP@0.5 of 0.781, theoretically supporting inspection speeds up to 58.6 km/h.
The significance of this work extends beyond the specific application. It establishes a generalizable paradigm for selecting and optimizing object detectors in other domain-specific inspection tasks where target characteristics and operational constraints vary. Future work will involve integrating this detection framework into a full-scale inspection vehicle and extending it to other defect types, such as spalling or lining deformation.
Acknowledgement: Not applicable.
Funding Statement: This research was funded by Major Project of Science & Technology Research of China Academy of Railway Sciences, grant number 2024YJ216, and Beijing Natural Science Foundation under Grant L231021.
Author Contributions: For the research, the divisions of labor are as follows: Supervision: Yang Lei, Bo Jiang and Yaodong Wang; Algorithm Research and Writing—Original Draft Preparation: Kangshuo Zhu; Methodology and Resources: Yaodong Wang and Yang Lei; Funding Acquisition: Yang Lei and Bo Jiang; Investigation: Falin Qi; Data Curation: Bo Jiang and Qiming Qu; Formal Analysis: Zhaoning Wang and Feiyu Jia. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The experimental data used in this study are not publicly available, as they are subject to the constraints of a confidentiality agreement and cannot be shared publicly.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Wang F, Liang S, Feng A. Statistical analysis and development of urban rail transit data in China in 2024. Tunnel Construction (Chinese and English Edition). 2025;45(2):425–34. (In Chinese). doi:10.3973/j.issn.2096-4498.2025.02.018. [Google Scholar] [CrossRef]
2. Jiang Y, Pan Z, Zhang X. Tunnel infrastructure health management: a state-of-the-art review on defect development mechanism and robot-aided inspection system. Smart Underground Eng. 2025;1(1):26–39. doi:10.1016/j.sue.2025.05.003. [Google Scholar] [CrossRef]
3. Chen W, Tan XY, Yang J. Review of state-of-the-art in structural health monitoring of tunnel engineering. Smart Underground Eng. 2025;1(1):40–50. doi:10.1016/j.sue.2025.05.004. [Google Scholar] [CrossRef]
4. Huang HW, Li QT, Zhang DM. Deep learning based image recognition for crack and leakage defects of metro shield tunnel. Tunnelling Undergr Space Technol. 2018;77(9):166–76. doi:10.1016/j.tust.2018.04.002. [Google Scholar] [CrossRef]
5. Chun P, Izumi S, Yamane T. Automatic detection method of cracks from concrete surface imagery using two-step light gradient boosting machine. Comput Aided Civ Infrastruct Eng. 2021;36(1):61–72. doi:10.1111/mice.12564. [Google Scholar] [CrossRef]
6. Wang Y, Zhu L, Shi H, Fang E, Yang L. Visual detection technology of tunnel crack based on local image texture calculation. J China Railway Soc. 2018;40(2):82–90. (In Chinese). doi:10.3969/j.issn.1001-8360.2018.02.012. [Google Scholar] [CrossRef]
7. Huang H, Sun Y, Xue Y, Wang F. Inspection equipment study for subway tunnel defects by grey-scale image processing. Adv Eng Inform. 2017;32:188–201. doi:10.1016/j.aei.2017.03.003. [Google Scholar] [CrossRef]
8. Kamaliardakani M, Sun L, Ardakani MK. Sealed-crack detection algorithm using heuristic thresholding approach. J Comput Civ Eng. 2016;30(1):04014110. doi:10.1061/(ASCE)CP.1943-5487.0000447. [Google Scholar] [CrossRef]
9. Li C, Xu P, Niu L, Chen Y, Sheng L, Liu M. Tunnel crack detection using coarse-to-fine region localization and edge detection. Wiley Interdiscip Rev Data Mining Knowl Discov. 2019;9(5):e1308. doi:10.1002/widm.1308. [Google Scholar] [CrossRef]
10. Zhou Z, Zhang J, Gong C. Hybrid semantic segmentation for tunnel lining cracks based on Swin Transformer and convolutional neural network. Comput Aided Civ Infrastruct Eng. 2023;38(17):2491–510. doi:10.1111/mice.13003. [Google Scholar] [CrossRef]
11. Liu R, Zeng W. Automatic detection of structural defects in tunnel lining via network pruning and knowledge distillation in YOLO. Struct Health Monit. 2024;2(8):489. doi:10.1177/14759217241289066. [Google Scholar] [CrossRef]
12. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. Adv Neural Inf Proc Syst. 2015;28:91–9. doi:10.1109/tpami.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
13. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2016. p. 779–788. [Google Scholar]
14. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: single shot multibox detector. In: Leibe B, Matas J, Sebe N, Welling M, editors. Computer Vision—ECCV 2016. Cham, Switzerland: Springer International Publishing; 2016. p. 21–37. doi: 10.1007/978-3-319-46448-0_2. [Google Scholar] [CrossRef]
15. Wang Y, He J. A rapid concrete crack detection method based on improved YOLOv8. IEEE Access. 2025;13:59227–43. doi:10.1109/ACCESS.2025. [Google Scholar] [CrossRef]
16. Wang S, Yan B, Xu X, Wang W, Peng J, Zhang Y, et al. Automated identification and localization of rail internal defects based on object detection networks. Appl Sci. 2024;14(2):805. doi:10.3390/app14020805. [Google Scholar] [CrossRef]
17. Zhou Z, Zhang J, Gong C. Automatic detection method of tunnel lining multi-defects via an enhanced You Only Look Once network. Comput Aided Civ Infrastruct Eng. 2022;37(6):762–80. doi:10.1111/mice.12836. [Google Scholar] [CrossRef]
18. Liu Z, Cao Y, Wang Y, Wang W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom Constr. 2019;104:129–39. doi:10.1016/j.autcon.2019.04.005. [Google Scholar] [CrossRef]
19. Han K, Wang Y, Tian Q, Guo J, Xu C, Xu C. GhostNet: more features from cheap operations. arXiv:1911.11907. 2020. doi:10.48550/arXiv.1911.11907. [Google Scholar] [CrossRef]
20. Zhang X, Zhou X, Lin M, Sun J. ShuffleNet: an extremely efficient convolutional neural network for mobile devices. arXiv:1707.01083. 2017. doi:10.48550/arXiv.1707.01083. [Google Scholar] [CrossRef]
21. Iandola FN, Han S, Moskewicz MW, Ashraf K, Dally WJ, Keutzer K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv:1602.07360. 2016. doi:10.48550/arXiv.1602.07360. [Google Scholar] [CrossRef]
22. Sinha SK, Fieguth PW. Segmentation of buried concrete pipe images. Autom Constr. 2006;15(1):47–57. doi:10.1016/j.autcon.2005.02.007. [Google Scholar] [CrossRef]
23. Lei M, Liu L, Shi C, Tan Y, Lin Y, Wang W. A novel tunnel-lining crack recognition system based on digital image technology. Tunnelling Undergr Space Technol. 2021;108:103724. doi:10.1016/j.tust.2020.103724. [Google Scholar] [CrossRef]
24. Muduli PR, Pati UC. A novel technique for wall crack detection using image fusion. In: 2013 International Conference on Computer Communication and Informatics; 2013 Jan 4–6; Coimbatore, India. doi:10.1109/ICCCI.2013.6466288. [Google Scholar] [CrossRef]
25. Lu G, Kou L, Yan W, Niu P, Liu J. MB-YOLO: a deep learning-based network for detecting cracks in highway tunnel linings. Meas Sci Technol. 2025;36(6):065405. doi:10.1088/1361-6501/addbfd. [Google Scholar] [CrossRef]
26. Zhou Z, Zhou S, Li S, Li H, Yang H. Tunnel lining quality detection based on the YOLO-LD algorithm. Constr Build Mater. 2024;449(11):138240. doi:10.1016/j.conbuildmat.2024.138240. [Google Scholar] [CrossRef]
27. Zhou Z, Yan L, Zhang J, Yang H. Real-time tunnel lining crack detection based on an improved You Only Look Once version X algorithm. Georisk Assess Manage Risk Eng Syst Geohazards. 2023;17(1):181–95. doi:10.1080/17499518.2023.2172187. [Google Scholar] [CrossRef]
28. Zheng X, Mo J, Wang S. DFL-YOLO: a tunnel crack detection algorithm for feature aggregation in complex scenarios. In: Fourth International Conference on Advanced Algorithms and Neural Networks (AANN 2024). Vol. 13416. Cham, Switzerland: Springer; 2024. p. 229–33. doi:10.1117/12.3050023. [Google Scholar] [CrossRef]
29. Sohan M, Sai Ram T, Rami Reddy CV. A review on YOLOv8 and its advancements. In: Jacob IJ, Piramuthu S, Falkowski-Gilski P, editors. Data intelligence and cognitive informatics. Singapore: Springer Nature; 2024. p. 529–45. doi:10.1007/978-981-99-7962-2_39. [Google Scholar] [CrossRef]
30. Wang A, Chen H, Liu L, Chen K, Lin Z, Han J, et al. YOLOv10: real-time end-to-end object detection. Adv Neural Inf Process Syst. 2024;37:107984–8011. doi:10.52202/079017-3429. [Google Scholar] [CrossRef]
31. Qin D, Leichner C, Delakis M, Fornoni M, Luo S, Yang F, et al. MobileNetV4: universal models for the mobile ecosystem. In: Leonardis A, Ricci E, Roth S, Russakovsky O, Sattler T, Varol G, editors. Computer vision—ECCV 2024. Cham, Switzerland: Springer Nature; 2025. p. 78–96. doi:10.1007/978-3-031-73661-2_5. [Google Scholar] [CrossRef]
32. Tong Z, Chen Y, Xu Z, Yu R. Wise-IoU: bounding box regression loss with dynamic focusing mechanism. arXiv:2301.10051. 2023. doi:10.48550/arXiv.2301.10051. [Google Scholar] [CrossRef]
33. Tan M, Le QV. EfficientNetV2: smaller models and faster training. arXiv:2104.00298. 2021. [Google Scholar]
34. Tang Y, Han K, Guo J, Xu C, Xu C, Wang Y. GhostNetV2: enhance cheap operation with long-range attention. Adv Neural Inf Process Syst. 2022;35:9969–82. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools