
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Federated Learning for Malicious Domain Detection via Privacy-Preserving DNS Traffic Analysis
1 Institute of Computer Science, Shah Abdul Latif University Khairpur, Khairpur, Pakistan
2 Department of Computer Science and Information Technology, College of Engineering, Abu Dhabi University, Abu Dhabi, United Arab Emirates
3 Department of Software Engineering, Nisantasi University, Istanbul, Türkiye
* Corresponding Author: Samar Abbas Mangi. Email:
Computers, Materials & Continua 2026, 87(3), 88 https://doi.org/10.32604/cmc.2026.077337
Received 07 December 2025; Accepted 09 February 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Malicious domain detection (MDD) from DNS telemetry enables early threat hunting but is constrained by privacy and data-sharing barriers across organizations. We present a deployable federated learning (FL) pipeline that trains a compact deep neural network (DNN; 64-32-16 with ReLU and dropout 0.3) locally at each client and exchanges only masked model updates. Privacy is enforced via secure aggregation (the server observes only an aggregate of masked updates) and optional server-side differential privacy (DP) via clipping and Gaussian noise. Our feature schema combines DNS-specific lexical cues (characterKeywords
Domain Name System (DNS) telemetry is a first responder for network defense: almost every malicious campaign-from phishing and command & control (C2) to domain-generation algorithms (DGAs) and fast-flux infrastructure-ultimately surfaces as resolvers translating hostnames to IPs. Learning discriminative patterns from DNS logs can therefore identify malicious domains early, complementing endpoint and flow-based analytics. However, DNS data is privacy-sensitive (e.g., reveals user intent, enterprise asset names) and often siloed by policy, regulation, or business constraints. Centralizing raw logs across organizations is thus impractical or outright prohibited, leaving most detection models data-starved and biased to single-tenant environments.
Federated learning (FL) offers a pragmatic alternative: clients (enterprises, ISPs, campuses) train locally on their own DNS events and share only model updates with a coordinating server. In principle, FL preserves data locality while unlocking cross-organization generalization. In practice, however, several challenges remain under-explored for the DNS malicious domain detection (MDD) setting: (i) feature realism, where lexical signals (e.g., character n-grams, entropy) must be combined with temporal/query-behavior cues (e.g., TTL dispersion, burstiness) without leaking raw queries; (ii) non-IID heterogeneity, as clients differ in user populations, resolvers, time-zones, and threat exposure, leading to skewed label/base-rate distributions and drift; (iii) privacy–utility trade-offs, since secure aggregation and differential privacy (DP) introduce noise or constraints that may hinder convergence; and (iv) robustness, where adversarial clients can poison model updates (label-flip, sign-flip, backdoors) unless the aggregation stack includes integrity checks or robust estimators.
Prior FL-for-security efforts (e.g., CO-DEFEND, FedMSE) demonstrate the promise of distributed training but typically evaluate on flow records or generic security telemetry, use one FL optimizer (FedAvg), and limit privacy/robustness analysis or DNS-specific features. Moreover, DNS-focused studies frequently evaluate centralized models on curated feeds, which overestimate generalization and ignore cross-tenant heterogeneity. Consequently, the community lacks a deployable, privacy-preserving, and robustness-aware FL pipeline tailored to DNS MDD with comprehensive baselines and statistical rigor.
Let
1.2 Threat Model and Privacy Scope
We assume an honest-but-curious server that executes the protocol but tries to infer client information from messages, and clients that can be benign or adversarial. We employ (a) secure aggregation so the server observes only the sum of masked updates, and (b) DP at the server via clipping and Gaussian noise to bound information leakage over rounds. We analyze poisoning pressure via simple label-flip/sign-flip stress tests and discuss robust aggregation options (median/trimmed-mean).
Our pipeline prioritizes: (1) deployability via a compact DNN (64–32–16 with ReLU and dropout 0.3) that fits typical enterprise clients; (2) realism via DNS-specific lexical and temporal features engineered to avoid raw-log exfiltration; (3) coverage of FL baselines (FedAvg, FedProx, FedNova) under controlled non-IID regimes; and (4) statistical transparency using 95% confidence intervals (CIs) and paired significance tests against a centralized reference.
• C1: DNS-specific FL pipeline. We present an end-to-end, privacy-preserving pipeline for malicious domain detection that combines lexical (e.g., n-gram profiles, entropy, TLD indicators) and temporal/behavioral features (e.g., TTL spread, query cadence) within a deployable lightweight DNN appropriate for bandwidth- and compute-constrained clients.
• C2: Comprehensive FL baselines under non-IID. Beyond FedAvg, we evaluate FedProx (proximal regularization for client drift) and FedNova (normalization for heterogeneous local steps) across mild/medium/severe label and feature skew, reporting both accuracy metrics and communication rounds/bytes to a target AUC.
• C3: Statistical rigor. We report 95% bootstrap CIs and paired significance tests (DeLong for ROC-AUC; McNemar for accuracy) vs. centralized and local-only baselines, and we characterize per-client variance to expose heterogeneity effects.
• C4: Privacy & robustness analysis. We give a concrete, step-by-step secure aggregation example (masking and cancellation), apply server-side DP (clipping+Gaussian noise), and examine poisoning awareness via anomaly screening and robust aggregation discussion, quantifying utility impact where feasible.
• C5: Reproducible artifacts. We outline feature schemas, FL hyperparameters, and non-IID partition recipes to facilitate replication and extension in real-world pilots.
RQ1: How close can privacy-preserving FL get to a centralized upper bound on DNS MDD while outperforming local-only training?
RQ2: Which FL optimizer (FedAvg, FedProx, FedNova) best tolerates DNS-style non-IID skew when factoring in communication cost?
RQ3: What is the empirical cost of secure aggregation and server-side DP on utility and convergence?
RQ4: Under simple poisoning stress (label/sign flip), which lightweight mitigations stabilize performance without heavy server overhead?
Section 2 positions our work against recent FL-for-security literature and DNS detection studies. Section 3 details datasets, feature design, client partitions, and non-IID generators. Section 4 describes the lightweight DNN and the FL training protocol (FedAvg/FedProx/FedNova). Section 5 formalizes secure aggregation and server-side DP and outlines poisoning-aware screening. Section 6 presents results with CIs/significance, ablations on model choice and non-IID severity, and a communication-cost audit. Section 7 discusses deployment, limitations, and ethical considerations; Section 8 concludes.
Centralized DNS malicious domain detection. Malicious domain detection (MDD) using DNS telemetry has traditionally been studied in centralized settings where resolver logs are aggregated and models are trained using lexical statistics (e.g., length distributions, character
Federated learning for security and intrusion detection. Federated learning (FL) addresses this constraint by exchanging model updates rather than raw data; FedAvg remains the canonical baseline for cross-silo deployments [3]. Empirical evidence from privacy-sensitive domains (e.g., cross-institutional healthcare) further supports the feasibility of training competitive models without sharing sensitive records [4]. Building on these foundations, a growing body of work adapts FL to intrusion detection and network/IoT security. Recent surveys and systematic reviews emphasize recurring challenges such as non-IID client distributions, participation heterogeneity, and communication overhead, and provide taxonomies of design choices and threat models [5–8]. Representative systems explore diverse datasets and architectures, including decentralized approaches for encrypted-DNS-related detection, representation learning for IoT IDS, and federated deep architectures for wireless IDS, as well as coordination mechanisms (e.g., blockchain-backed auditing) aimed at improving provenance and integrity [9–13].
Threat-specific FL applications and privacy-aware DNS analytics. Beyond generic IDS, threat- and topology-specific studies broaden the landscape. Adaptive FL has been investigated for DDoS detection under workload variation [14], and hybrid deep models combined with FL have been evaluated in SDN contexts [15]. Privacy-preserving FL formulations have also been explored for content-layer threats such as phishing [16]. In parallel, encrypted DNS and privacy-aware DNS analytics underscore the tension between visibility and confidentiality, reinforcing the need for feature engineering and release constraints that avoid exposing raw resolver logs [17]. From a systems perspective, decentralized and 6G-oriented analyses further study how topology and transport interact with FL reliability, bandwidth budgets, and privacy [18].
Robustness and privacy enforcement in federated security. Robustness and privacy enforcement are active research directions in FL-based security. Reviews catalog defenses against malicious or faulty clients, including update screening and robust aggregation, and discuss how these mechanisms interact with client skew and operational constraints [19]. Complementary work investigates combining FL with differential privacy (DP) and related privacy mechanisms in security/IoT settings to improve confidentiality while maintaining detection performance [20]. Additional trends explore orthogonal directions such as privacy-enhanced botnet detection, hierarchical federated generative modeling in smart environments, and broader cyber-physical settings that benefit from privacy-preserving learning patterns [21–23]. Early position and working papers also discuss next-generation AI for DNS-over-HTTPS and forensics-oriented anomaly detection, reflecting continuing interest in secure and privacy-aware DNS analytics [24,25].
Gap and positioning. Despite steady progress on FL for IDS, comparatively fewer studies provide a DNS-specific, end-to-end FL pipeline that jointly (i) uses privacy-compatible DNS feature representations (to avoid raw-log sharing), (ii) evaluates multiple FL optimizers under controlled non-IID regimes with rigorous uncertainty reporting, and (iii) integrates secure aggregation and optional DP with explicit communication accounting while examining practical robustness stabilizers. Our work targets this gap by designing DNS-specific lexical and temporal features suitable for cross-silo deployment, systematically comparing FL optimizers under varying heterogeneity, and incorporating secure aggregation and optional server-side DP alongside lightweight screening and robust aggregation mechanisms.
3 Datasets and Federation Setup
This section describes how domains are sourced and labeled, how per–client DNS datasets are constructed under privacy constraints, and how federation parameters (client sampling, non–IID partitions, and training protocol) are instantiated.
3.1 Source Domains and Labeling Pipeline
Benign and malicious candidates are collected from multiple feeds and then normalized into a common schema to avoid raw–log sharing.
Benign domains are drawn from popularity lists (e.g., top sites by category and geography) and curated enterprise allowlists. To reduce popularity bias and near–duplicate leakage, we (i) stratify by category (news, commerce, cloud, social) and region, (ii) deduplicate at the registered domain level using the public suffix list, and (iii) remove ephemeral tracking subdomains via rule–based filters.
Malicious candidates are aggregated from multiple threat–intelligence sources, with emphasis on DGAs and fast–flux infrastructure. To cover families unseen in a single feed, we (i) merge across feeds and time windows, (ii) include synthetically generated DGA samples using public DGA seeds (placed only in training unless otherwise noted), and (iii) apply retrospective labels for domains later confirmed by incident reports. Conflicts are resolved with a precedence order malicious > benign > unknown, with unknown subsequently discarded.
Each domain
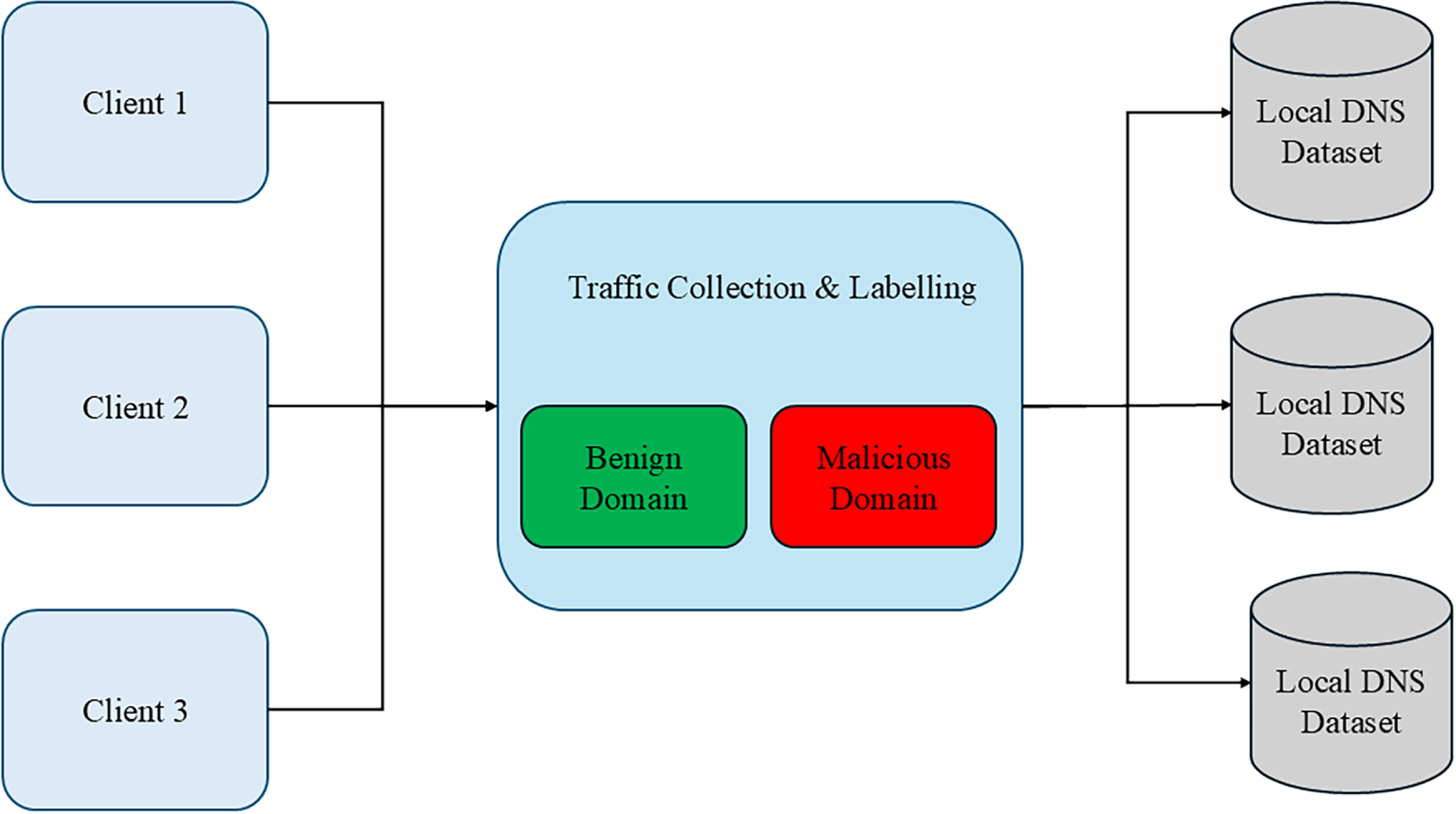
Figure 1: Per–client DNS dataset creation from a central labeling pipeline. Centralized labeling is performed on feed identifiers and privacy–compatible heuristics; only feature vectors and labels are retained per client.
3.2 Feature Schema (Privacy–Compatible)
For each domain we compute features locally from DNS resolver summaries to avoid raw queries or PII. Let
• Lexical (computed on the registered domain and subdomain tokens): length, vowel/consonant ratios, Shannon entropy,
• Behavioral/temporal (aggregated over a window
• Infrastructure hints (if available without leaking PII): AS number histogram (coarsened), IP geodiversity counts (bucketized), passive DNS co–occurrence degree (k–anonymized).
Client-side overhead. Behavioral features are computed from window-level counters (streaming aggregates) rather than per-packet processing; the dominant cost is maintaining per-registered-domain counts within each window. This scales with the number of distinct domains observed in the window and is practical for high-throughput resolvers when implemented as incremental counters (e.g., hash maps with periodic compaction).
All features are standardized per client using training–fold statistics only. Fields that could reveal users or hostnames are never exported.
3.3 Train/Validation/Test Protocol
Datasets are split temporally to reduce leakage from future into past. For each client
A representative choice is
To emulate realistic heterogeneity across organizations, we generate per–client label/feature skews by sampling client–specific class mixtures and temporal slices. A common construction uses a Dirichlet prior:
where K is the number of classes (here,
3.5 Client Privacy, Sanitization, and Governance
Before feature extraction, resolvers apply on–premises sanitization: strip query names to registered domains, hash auxiliary fields with keyed hashing where needed, and aggregate per window
3.6 Federation Topology and Participation
We adopt a standard cross–silo FL topology with a central aggregator and N long–lived clients. At each round
and broadcasts the current global weights
3.7 Secure Aggregation and Differential Privacy
Clients mask their updates using pairwise or PRG–derived masks so that the server can only compute the sum:
The aggregator computes
with privacy accounting over R rounds reported as
3.8 Optimizers and Hyperparameters
We compare three FL variants:
• FedAvg: standard weighted averaging of client updates.
• FedProx: proximal regularization with coefficient
• FedNova: normalization to correct bias from variable local steps.
Unless noted, we use
3.9 Cross–Time Generalization and Leakage Controls
To evaluate robustness to temporal shift, we hold out a future slice for testing and prevent leakage by (i) forbidding duplicated registered domains across splits, (ii) excluding synthetic DGA samples from test unless explicitly stated, and (iii) recomputing feature standardization statistics only on the training fold. Model selection uses validation AUC and early stopping with patience
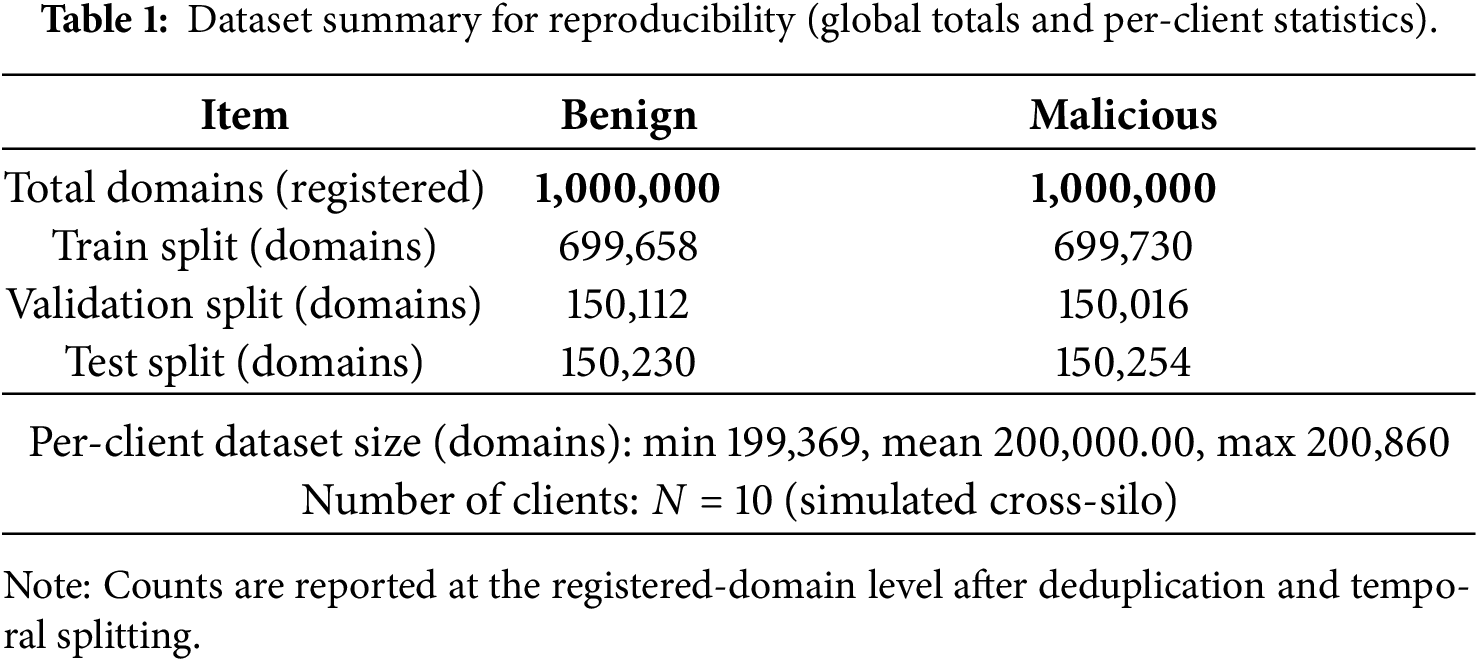
Table 1 summarizes the dataset composition used in our experiments (global totals and per-client statistics) for reproducibility.
3.10 Simulation Realism and Bias
Synthetic query generation and replay can under–approximate resolver–specific caching, TTL handling, and burstiness. We therefore (i) evaluate cross–time generalization by training on
This section specifies the lightweight classifier architecture, the supervised learning objective and regularization, the calibration and thresholding strategy for deployment, and the federated optimization protocols (FedAvg, FedProx, FedNova). We also describe client participation, early stopping, and communication/computation accounting.
The local model is a compact feed-forward DNN designed for modest client hardware. Let
with layer widths
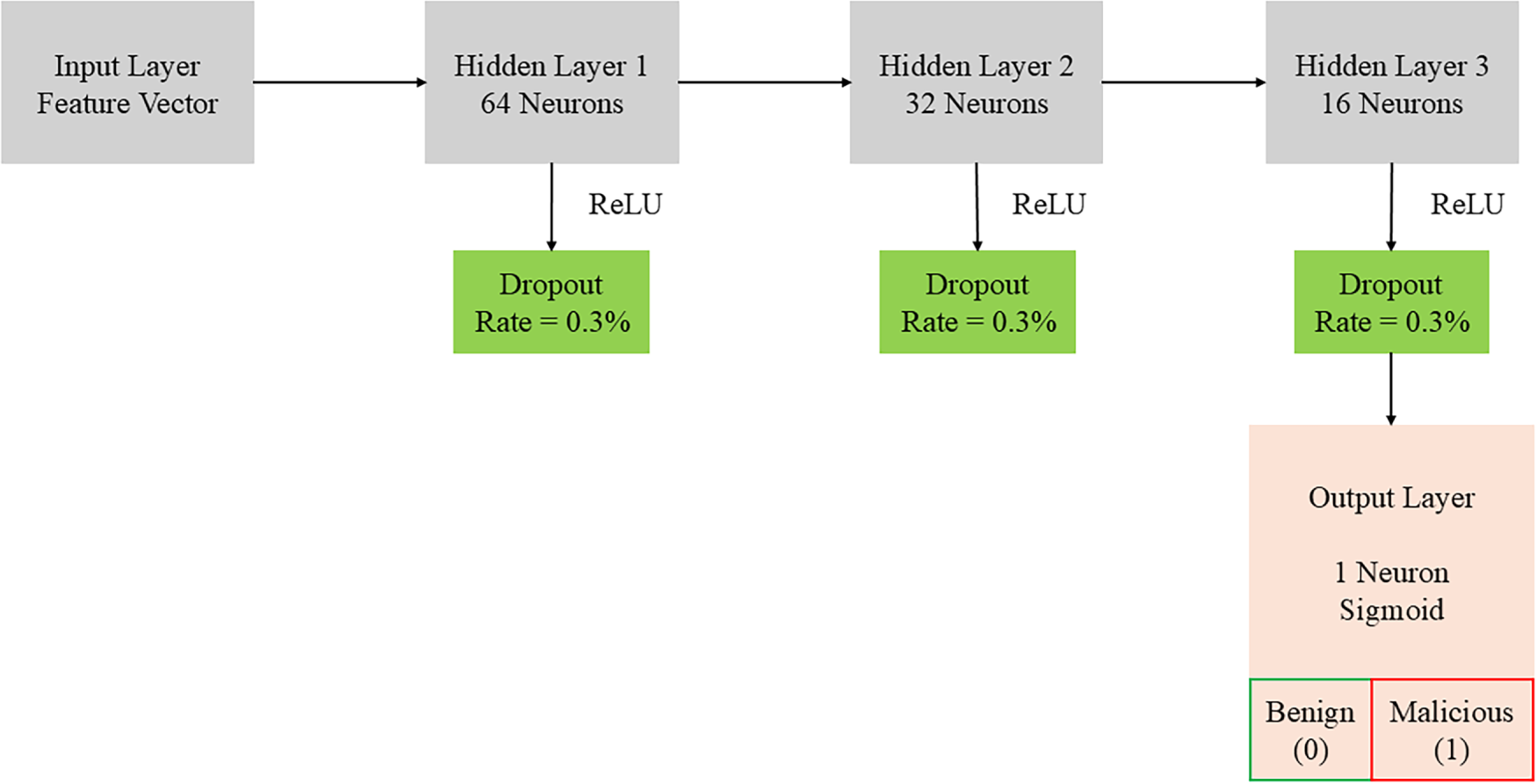
Figure 2: Lightweight DNN used for binary domain classification (benign vs. malicious).
4.2 Objective, Class Imbalance, and Regularization
Binary cross-entropy with class weights addresses imbalance:
where
4.3 Optimization and Scheduling (Local)
Each client trains with mini-batch SGD or Adam. Default settings are Adam (
4.4 Calibration and Thresholding
For deployment, we calibrate probabilities on the validation set using temperature scaling:
Let
Clients compute local minimizers (or E-epoch solutions)
Clients solve a proximal subproblem that stabilizes training under heterogeneous objectives and non-IID data:
where
To correct bias from variable local steps and partial participation, FedNova normalizes client contributions by their effective local step counts
with
4.6 Client Sampling, Early Stopping, and Rounds
At round
4.7 Ablations: Architecture and Loss
Ablations compare the DNN against (i) a 1D-CNN over character-level embeddings of the domain string and (ii) a GRU sequence model over tokenized subdomains. For each model we record parameter count, client-side latency (ms) on a reference CPU (Intel Xeon Silver), ROC-AUC/PR-AUC on the test split, and rounds to a target AUC
4.8 Communication and Computation Accounting
Let P be the number of parameters. Per round, each selected client uploads P floating-point values (or a compressed/quantized representation if enabled) and downloads P values:
where
4.9 Implementation Details and Defaults
Unless stated, training uses Adam with learning rate
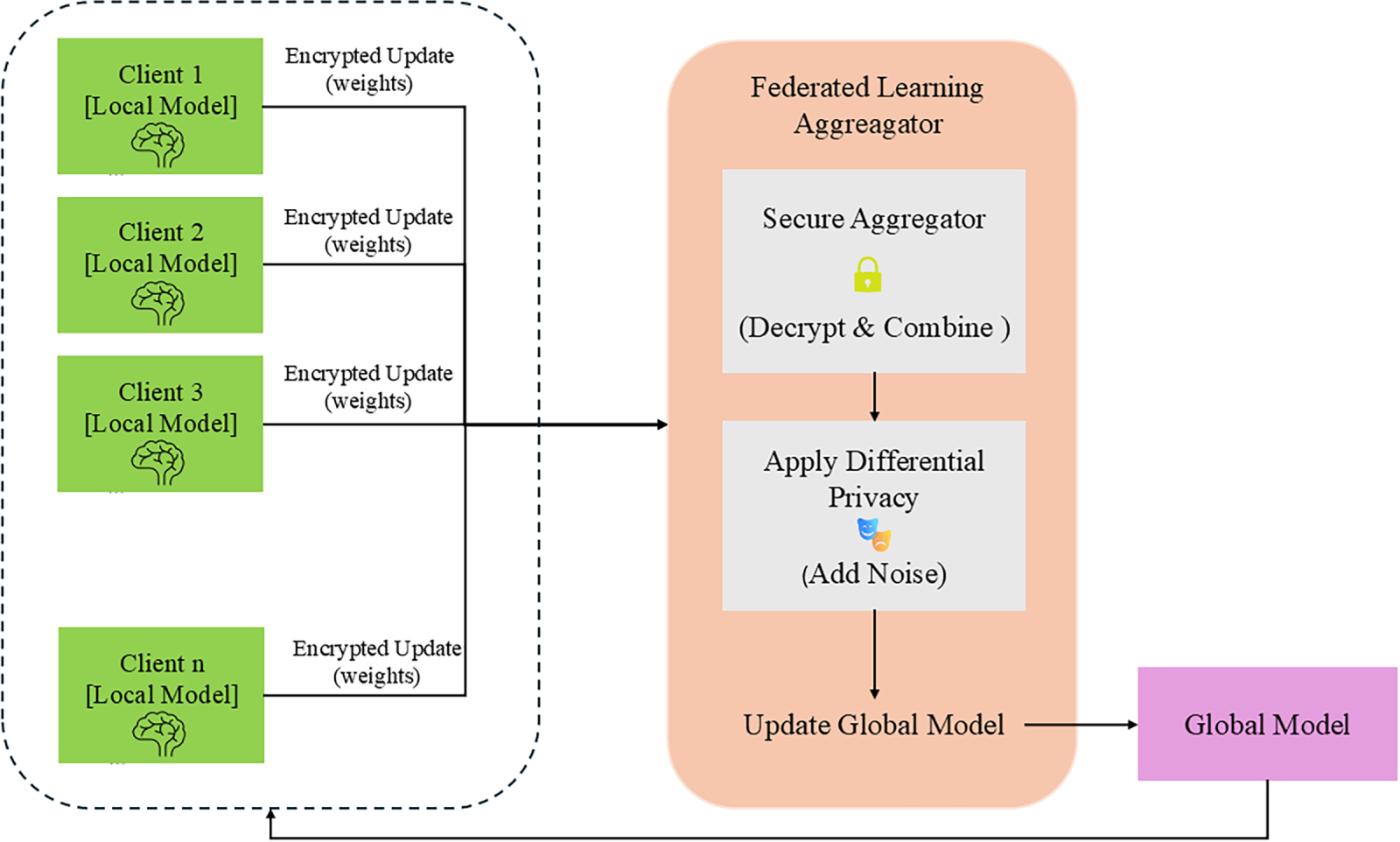
Figure 3: High-level FL system overview with broadcast.
5 Privacy and Robustness Mechanisms
Each client masks its local update so that the server can only recover an aggregate over participating clients. Client
The server aggregates
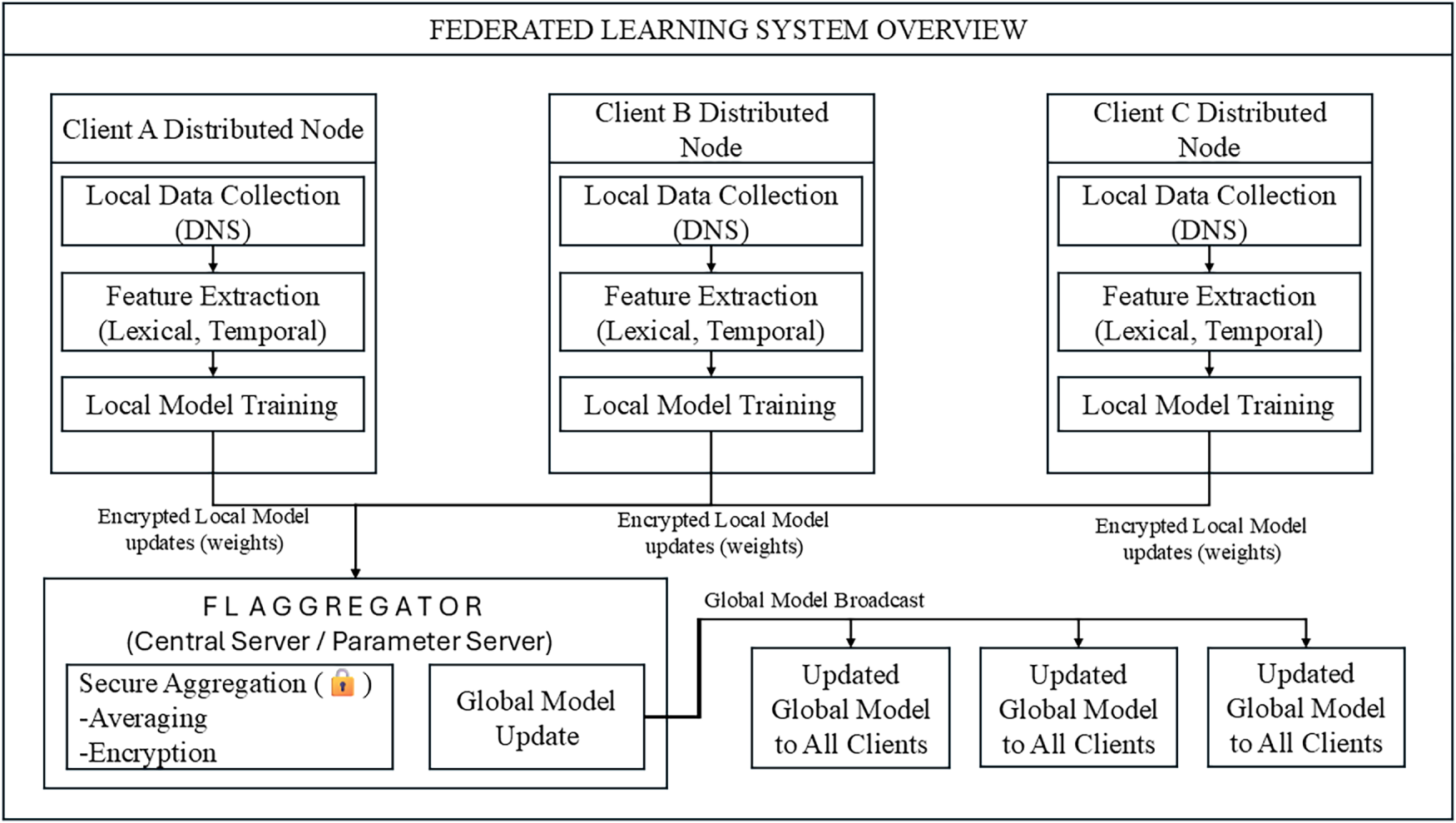
Figure 4: Secure aggregation with DP noise; the server has no access to individual client updates.
5.1.1 Worked Example (Explicit Numeric)
Consider three clients with 2D updates
which equals the true sum of unmasked updates
We apply server-side DP by clipping the aggregated update and adding Gaussian noise (Section 3). Across repeated model refresh cycles in long-term DNS monitoring, privacy loss composes over time; therefore, deployments should track a privacy budget per model/version and account for cumulative
5.3 Poisoning Awareness and Robustness
We screen updates with lightweight anomaly checks (e.g., norm caps and cosine-similarity outliers) and evaluate simple poisoning stress tests (label-flip/sign-flip). Robust aggregation options (median/trimmed-mean) are discussed and included in ablations in Section 6.
This section details the evaluation setup, non-IID regimes, metrics and statistical methodology, hyperparameters, and results. We also report ablations (model choice), privacy/robustness stress tests, and communication accounting.
6.1 Evaluation Setup and Baselines
We compare centralized training, local-only training (per-client models), and three federated optimizers: FedAvg, FedProx, and FedNova. Unless stated, we use the dataset partitions and privacy-compatible features from Section 3. Centralized training pools all training partitions only (no test leakage). Local-only trains a separate model for each client and averages metrics across clients on their own test slice. Federated runs use the same validation policy and early stopping across methods.
6.2 Non-IID Regimes and Client Participation
We evaluate three heterogeneity regimes using a Dirichlet label skew with concentration
• Mild:
• Medium:
• Severe:
For all federated runs we train for
6.3 Metrics and Statistical Methodology
We report threshold-free utility (ROC-AUC, PR-AUC) and thresholded metrics (Accuracy, Precision, Recall, F1). The operating threshold is set on the validation set by maximizing F1 or achieving a target recall
6.3.1 Confidence Intervals (CIs)
For each metric
where
For ROC-AUC we use DeLong’s paired test against the centralized baseline; for Accuracy we use McNemar’s test on paired predictions:
where
6.4 Hyperparameters and Implementation
Local optimization uses Adam with learning rate
6.5 Learning Curves and Convergence Behavior
Fig. 5 shows representative client-side training loss trajectories; Fig. 6 plots global accuracy vs. federated rounds under FedAvg. Convergence speed is reported as rounds to reach target ROC-AUC
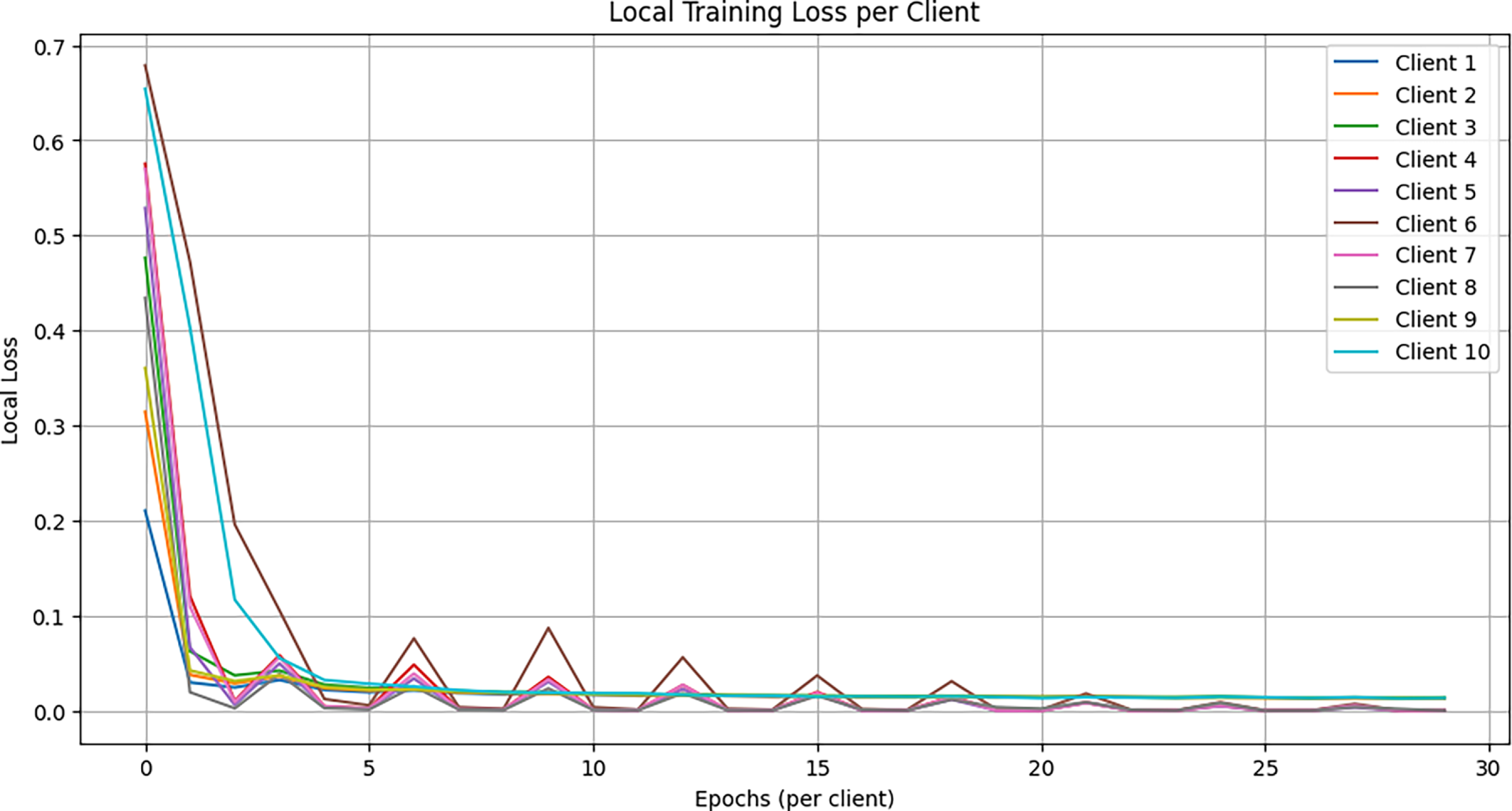
Figure 5: Local training loss per client over epochs (mild non-IID). Shaded regions indicate the interquartile range across clients.
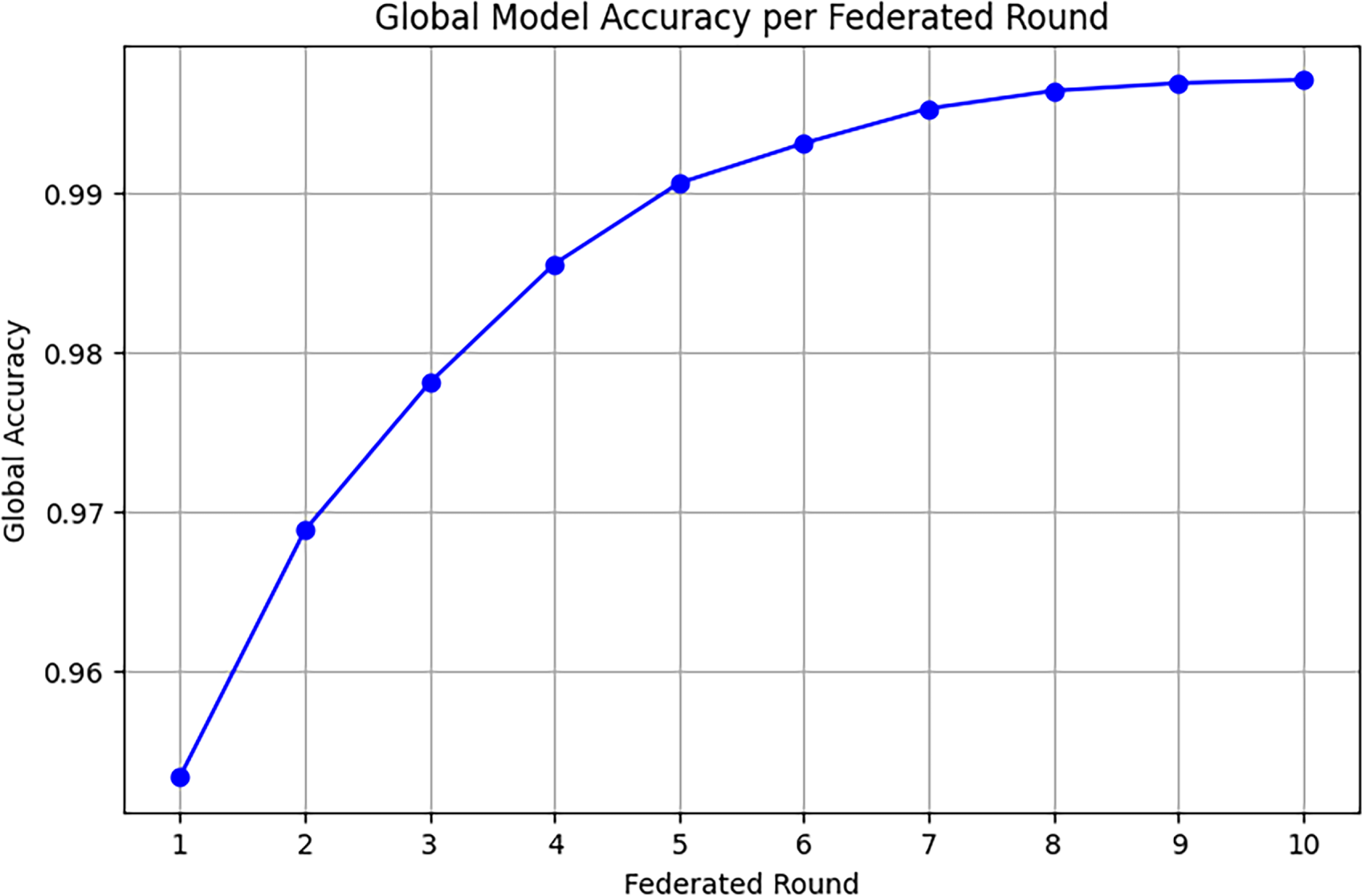
Figure 6: Global accuracy vs. federated rounds (FedAvg) with participation
Table 2 summarizes global ROC-AUC and DeLong

6.7 Ablations: Architecture and Loss
Table 3 reports parameter count, client-side latency on a reference CPU, and accuracy metrics for the DNN, a 1D-CNN over character embeddings, and a GRU over tokenized subdomains. The compact DNN typically offers the best accuracy–latency trade–off, while CNN/GRU provide marginal gains at higher cost.

6.8 Privacy Accounting and Utility Trade-Offs
We evaluate server-side DP with clipping
We simulate (i) label-flip on a fraction
6.10 Communication and Computation Accounting
Let P be the number of model parameters and
We also report total traffic to the target AUC and the number of rounds saved by optimizer choice. Table 4 summarizes communication for each federated variant.

6.11 Reporting Protocol and Reproducibility
We fix random seeds
Across non-IID regimes, federated variants approach the centralized upper bound while significantly outperforming local-only training. Under medium/severe skew, FedProx or FedNova reduce rounds-to-target with similar or slightly better AUC/F1. DP at
This section discusses deployability and operational trade-offs observed in our study, then enumerates explicit limitations and directions for future work. While our federated approach narrows the gap to a centralized upper bound and preserves data locality, several practical hurdles remain before large-scale production adoption.
Cross-silo deployments involve long-lived clients (enterprises, ISPs, campuses) with heterogeneous resources, policies, and participation rates. In a realistic DNS workflow, each organization runs a local feature-extraction and training service adjacent to its resolver or DNS analytics pipeline. Resolver events are sanitized on-premises (e.g., reducing QNAMEs to registered domains, aggregating to window-level counters, and removing direct identifiers), after which privacy-compatible lexical and behavioral features are computed locally. At an operational cadence aligned with change-control windows (e.g., nightly or weekly), clients download the current global model, train locally for a small number of epochs, and upload masked updates for aggregation. Operators can monitor per-round utility and drift indicators and, when necessary, roll back to a prior global checkpoint using standard MLOps practices.
Although cross-silo participants are more stable than cross-device FL, dropouts and stragglers still occur due to maintenance windows, connectivity limits, or policy constraints. We therefore view partial participation (
Our design keeps raw DNS data on-premises and uses secure aggregation (SecAgg) together with optional server-side differential privacy (DP). SecAgg prevents the server from inspecting individual client updates under an honest-but-curious threat model, while DP bounds information leakage from the aggregated update across rounds under a specified
We also emphasize the practical privacy-utility trade-off: stronger clipping and noise improve privacy guarantees but may reduce detection utility, especially under severe class imbalance and non-IID skews. For deployment, we recommend selecting privacy budgets via policy requirements first and then validating operating points empirically, reporting both utility metrics and the corresponding accounting parameters (e.g., clipping threshold C, noise scale
7.3 Robustness and Security Posture
We considered simple label-flip and sign-flip attacks and evaluated lightweight defenses appropriate for cross-silo operations. The primary attack surface arises from malicious or compromised participants that can manipulate labels, craft poisoned updates, or attempt backdoor behaviors; the risk is amplified in DNS MDD because positives are sparse and client data are non-IID, so a small adversarial fraction may disproportionately affect rare families. As mitigations, we found that screening mechanisms (e.g., norm caps and cosine-similarity outlier filtering) and robust aggregation variants (e.g., median or trimmed-mean) can reduce attack impact with minimal coordination. These defenses primarily add server-side computation rather than bandwidth overhead and can be combined with SecAgg via pre-aggregation screening on client-side statistics or post-aggregation checks on the summed update. Stronger Byzantine-resilient protocols, verifiable computation, or attested execution are promising directions when adversarial participation is higher, but they introduce additional complexity and operational cost.
Cross-time generalization was evaluated via temporal splits, yet real deployments face seasonal effects, vendor migrations, and emergent DGA families. In practice, shifts in TLD popularity or resolver behavior can reduce precision, so periodic re-federation and drift monitoring are important. We recommend combining routine re-training with distribution-shift alarms based on summary statistics (e.g., population stability index (PSI) and Jensen-Shannon (JS) divergence on key features) to detect when the feature or label prior has moved outside the training regime.
Open-set dynamics remain challenging because newly emerging DGAs and domain-registration patterns are not fully captured by historical engineered features. Incorporating representation learning (e.g., subword/domain embeddings) may improve out-of-distribution tolerance, but it increases model size and may require careful client-side compute and privacy considerations.
7.5 Communication and Compute Trade-Offs
Federation replaces raw-log transfer with parameter exchange. For a model with P parameters and payload precision
Operational realism. The communication analysis above uses FP32 as a baseline and full participation in the default setting. In practice, deployments often use partial participation (
The present study has several limitations that temper external validity. First, portions of the dataset rely on synthetic queries and public threat feeds; although we used temporal holds and cross-time tests, passive-capture coverage is limited and may not reflect resolver-specific caching and TTL behavior. Second, our experiments emulate a modest number of clients with controlled non-IID, so results may change with dozens to hundreds of heterogeneous participants, intermittent connectivity, or highly variable participation schedules. Third, robustness evaluation focused on simple poisoning patterns and lightweight defenses; we did not study adaptive adversaries, stealthy backdoors, collusion among clients, or privacy attacks that combine side information with repeated model snapshots. Finally, we emphasized FedAvg, FedProx, and FedNova; other approaches such as control-variate methods (e.g., SCAFFOLD) and personalization strategies could further improve non-IID performance but introduce additional system complexity. While our feature set was designed to be privacy-compatible, certain aggregations (e.g., IP geodiversity) may still be sensitive in strict environments and could require further coarsening or alternative encodings.
Several extensions can strengthen practicality and scientific value. A key next step is to validate the approach in larger cross-silo pilots with more organizations, longer time horizons, and real resolver logs governed by appropriate data-use agreements. Methodologically, personalization and adaptive weighting (e.g., client-specific heads or meta-learning) may address persistent non-IID while preserving privacy guarantees. From a systems perspective, compression-aware training that combines quantization or sparsification with optimizer choices can reduce bandwidth and rounds-to-target, but should be evaluated jointly with stability and privacy accounting. On the security side, stronger robustness evaluations–including Byzantine-resilient aggregation, integrity mechanisms via secure enclaves/attestation, and defenses tailored to backdoor threats–remain important for adversarial environments. Finally, tighter privacy accounting (e.g., RDP/moment accountants) and representation learning for open-set DGAs are promising, provided client-side compute and governance constraints are satisfied.
In summary, federated DNS malicious-domain detection is feasible with a compact model and a lightweight privacy stack, offering utility close to centralized training while keeping data local. Real-world deployment will benefit from expanded pilots, stronger robustness guarantees, and compression-aware protocols that align with organizational privacy and operational constraints.
Eployment will benefit from expanded pilots, stronger robustness guarantees, and compression-aware protocols that align with organizational privacy and operational constraints.
This work investigated federated learning (FL) for malicious domain detection (MDD) from privacy-compatible DNS features across multiple organizations. We developed a compact pipeline in which clients train a lightweight DNN locally and share only masked model updates for secure aggregation, with optional server-side differential privacy (DP) applied to the aggregated update. Across mild to severe non-IID client regimes, federated models approached the centralized upper bound and consistently outperformed local-only training, while preserving data locality and supporting realistic cross-silo participation patterns.
We further observed that optimizer choice provides a practical lever under stronger heterogeneity: FedProx and FedNova generally reduced rounds-to-target under medium/severe skew with comparable (and in some settings slightly improved) final utility relative to FedAvg. Adding DP at moderate noise levels incurred a modest, measurable cost in ROC-AUC/PR-AUC and F1 that can be controlled through standard accounting parameters (e.g., clipping threshold, noise scale, participation rate, and number of rounds). Finally, lightweight poisoning defenses such as norm caps and cosine-based outlier filtering improved resilience against simple label-flip and sign-flip attacks without increasing communication overhead.
Overall, the results indicate that privacy-preserving FL is a viable alternative to centralized training for DNS-based MDD, delivering near-centralized accuracy while keeping sensitive resolver data on-premises. At the same time, external validity will benefit from larger cross-silo pilots with real resolver logs and longer time horizons, and robustness should be strengthened against adaptive/backdoor attacks and higher adversarial participation. Personalization, control-variate methods, and compression-aware optimization are natural extensions to further balance utility, privacy, and cost at scale.
Acknowledgement: The authors gratefully acknowledge the guidance and support of their supervisor during the completion of this study.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contributions to the paper as follows: study conception and design: Samar Abbas Mangi, Samina Rajper; data collection: Samar Abbas Mangi, Noor Ahmed Shaikh; analysis and interpretation of results: Samar Abbas Mangi, Shehzad Ashraf Chaudhry; draft manuscript preparation: Samar Abbas Mangi, Samina Rajper; manuscript review and editing: Samina Rajper, Noor Ahmed Shaikh, Shehzad Ashraf Chaudhry. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The dataset used in this study is publicly available on Kaggle at: https://www.kaggle.com/datasets/nizamuddinmaitlo/malicious-domain-detection-dataset.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Sahoo D, Liu C, Hoi SCH. Malicious URL detection using machine learning: a survey. arXiv:1701.07179. 2017. [Google Scholar]
2. Zhauniarovich Y, Khalil I, Yu T, Dacier M. A survey on malicious domains detection through DNS data analysis. arXiv:1805.08426. 2018. [Google Scholar]
3. McMahan HB, Moore E, Ramage D, Hampson S, Arcas BA. Communication-efficient learning of deep networks from decentralized data. arXiv:1602.05629. 2017. [Google Scholar]
4. Sheller MJ, Reina GA, Edwards B, Martin J, Bakas S. Multi-institutional deep learning modeling without sharing patient data: a federated learning approach for computational pathology. Sci Rep. 2020;10(1):1–12. [Google Scholar]
5. Hernandez-Ramos JL, Karopoulos G, Chatzoglou E, Kouliaridis V, Marmol E, Gonzalez-Vidal A, et al. Intrusion detection based on federated learning: a systematic review. arXiv:2308.09522. 2023. [Google Scholar]
6. Belenguer L, Navaridas J, Pascual JA. A review of federated learning in intrusion detection systems for IoT. arXiv:2204.12443. 2022. [Google Scholar]
7. Hamad NA, Abu Bakar KA, Qamar F, Jubair AM, Mohamed RR, Mohamed MA. Systematic analysis of federated learning approaches for intrusion detection in the Internet of Things environment. IEEE Access. 2025;13:95410–44. doi:10.1109/access.2025.3574672. [Google Scholar] [CrossRef]
8. Agrawal S, Sarkar S, Aouedi O, Yenduri G, Piamrat K, Bhattacharya S, et al. Federated learning for intrusion detection system: concepts, challenges and future directions. arXiv:2106.09527. 2021. [Google Scholar]
9. Nguyen VT, Beuran R. FedMSE: federated learning for IoT network intrusion detection. arXiv:2410.14121. 2024. [Google Scholar]
10. Nivaashini M, Suganya E, Sountharrajan S, Prabu M, Bavirisetti DP. FEDDBN-IDS: federated deep belief network-based wireless network intrusion detection system. EURASIP J Inf Secur. 2024;2024(1):8. doi:10.1186/s13635-024-00156-5. [Google Scholar] [CrossRef]
11. Cajaraville-Aboy D, Moure-Garrido M, Beis-Penedo C, Garcia-Rubio C, Díaz-Redondo RP, Campo C, et al. CO-DEFEND: continuous decentralized federated learning for secure DoH-based threat detection. arXiv:2504.01882. 2025. [Google Scholar]
12. Chaurasia N, Ram M, Verma P, Mehta N, Bharot N. A federated learning approach to network intrusion detection using residual networks in industrial IoT networks. J Supercomput. 2024;80(13):18325–46. doi:10.1007/s11227-024-06153-2. [Google Scholar] [CrossRef]
13. Almaghthawi A, Ghaleb EAA, Akbar NA, Asiri L, Alrehaili M, Altalidi A. Federated-learning intrusion detection system based blockchain technology. Int J Onl Eng. 2024;20(11):16–30. doi:10.3991/ijoe.v20i11.49949. [Google Scholar] [CrossRef]
14. Doriguzzi-Corin R, Siracusa D. FLAD: adaptive federated learning for DDoS attack detection. Comput Secur. 2024;137(4):103597. doi:10.1016/j.cose.2023.103597. [Google Scholar] [CrossRef]
15. Zhou Q, Mao X, Chen Y. A DDoS attack detection method combining federated learning and hybrid deep learning in software-defined networking. Comput J. 2025;68(10):1463–75. doi:10.1093/comjnl/bxaf049. [Google Scholar] [CrossRef]
16. Elkhawas AI, Chen TM, Gashi I. Privacy-preserving federated learning for phishing detection. IEEE Technol Soc Mag. 2025;44(2):77–84. doi:10.1109/mts.2025.3558971. [Google Scholar] [CrossRef]
17. Qin Z, Yan H, Zhang B, Wang P, Li Y. Real-time identification technology for encrypted DNS traffic with privacy protection. Comput Mater Continua. 2025;83(3):5811–29. doi:10.32604/cmc.2025.063308. [Google Scholar] [CrossRef]
18. Teixeira R, Baldoni G, Antunes M, Gomes D, Aguiar RL. Leveraging decentralized communication for privacy-preserving federated learning in 6G Networks. Comput Commun. 2025;233(4):108072. doi:10.1016/j.comcom.2025.108072. [Google Scholar] [CrossRef]
19. Latif N, Ma W, Ahmad HB. Advancements in securing federated learning with IDS: a comprehensive review of neural networks and feature engineering techniques for malicious client detection. Artif Intell Rev. 2025;58(3):91. doi:10.1007/s10462-024-11082-w. [Google Scholar] [CrossRef]
20. Nkoom M, Hounsinou SG, Crosby GV. Securing the Internet of robotic things (IoRT) against DDoS attacks: a federated learning with differential privacy clustering approach. Comput Secur. 2025;155(4):104493. doi:10.1016/j.cose.2025.104493. [Google Scholar] [CrossRef]
21. Drefahl P, Kostage K, Peppers S, Guo W, Mazzola L, Qu C. Design of a hierarchical federated generative learning based smart home system. In: Digital human modeling and applications in health, safety, ergonomics and risk management. Cham, Switzerland: Springer Nature; 2025. p. 160–77. doi:10.1007/978-3-031-93502-2_11. [Google Scholar] [CrossRef]
22. Zhang Q, Liu M, Li P, Yuan J, Zhu H. Multidomain secure communication and intelligent traffic detection model in VANETs. Int J Intell Syst. 2025;2025(1):2539516. doi:10.1155/int/2539516. [Google Scholar] [CrossRef]
23. Wu G, Wang X. A privacy-enhanced framework with deep learning for botnet detection. Cybersecurity. 2025;8(1):9. doi:10.1186/s42400-024-00307-8. [Google Scholar] [CrossRef]
24. Ndibe OS. AI-driven forensic systems for real-time anomaly detection and threat mitigation in cybersecurity infrastructures. Int J Res Publ Rev. 2025;6(5):389–411. doi:10.55248/gengpi.6.0525.1991. [Google Scholar] [CrossRef]
25. Ali B, Chen G. Next-generation AI for advanced threat detection and security enhancement in DNS over HTTPS. J Netw Comput Appl. 2025;244(3):104326. doi:10.1016/j.jnca.2025.104326. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools