
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
REVIEW

Generative Adversarial Networks for Image Super-Resolution: A Survey
1 School of Engineering, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
2 School of Software, Northwestern Polytechnical University, Xi’an, China
3 College of Artificial Intelligence, Nanjing University of Aeronautics and Astronautics, Nanjing, China
4 Department of Distributed Systems and IT Devices, Silesian University of Technology, Gliwice, Poland
5 School of Computer Science and Technology, Harbin Institute of Technology, Harbin, China
* Corresponding Author: Chunwei Tian. Email:
Computers, Materials & Continua 2026, 87(3), 3 https://doi.org/10.32604/cmc.2026.078842
Received 09 January 2026; Accepted 05 March 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Image super-resolution is a significant area in the field of image processing, with broad applications across multiple domains. In recent years, advancements in Generative Adversarial Networks (GANs) have led to an increased adoption of GAN-based methods in image super-resolution, yielding remarkable results. However, there is still a limited amount of research that systematically and comprehensively summarizes the various GAN-based techniques for image super-resolution. This paper provides a comparative study that elucidates the application differences of GANs in this field. We begin by reviewing the development of GANs and introducing their popular variants used in image applications. Subsequently, we systematically analyze the theoretical motivations, implementation approaches, and technical distinctions of GAN-based optimization methods and discriminative learning from three perspectives: supervised, semi-supervised, and unsupervised learning. We examine these methods concerning their integration of different network architectures, prior knowledge, loss functions, and multitask strategies. Furthermore, we conduct a systematic comparison of state-of-the-art GAN methods through quantitative and qualitative analyses using publicly available super-resolution datasets. In addition to traditional metrics such as PSNR and SSIM in our quantitative analysis, we also consider complexity and running time as reference standards to better align the evaluation with practical application demands. Finally, we identify several challenges currently faced by GANs in the domain of image super-resolution, including issues related to training stability and the need for improved evaluation metrics. We outline future research directions aimed at enhancing the robustness and efficiency of GAN-based super-resolution techniques, emphasizing the importance of integration with other machine learning frameworks to further advance this exciting field.Keywords
Single image super-resolution (SISR) is an important branch in the field of image processing [1]. It aims to recover a high-resolution (HR) image over a low-resolution (LR) image [2], leading to its wide applications in medical diagnosis [3], video surveillance [4] and disaster relief [5], etc. For instance, in the medical field, obtaining higher-quality images can help doctors accurately detect diseases [6]. Thus, studying SISR is very meaningful to academia and industry [7].
To address the SISR problem, researchers have developed a variety of methods based on degradation models of low-level vision tasks [8,9]. There are three categories for SISR in general, i.e., image itself’s information, prior knowledge and machine learning. In image itself’s information, directly amplifying resolutions of all pixels in an LR image through an interpolation method to obtain a HR image was a simple and efficient method in SISR [10], i.e., nearest neighbor interpolation [11], bilinear interpolation [12] and bicubic interpolation [13], etc. It is noted that in these interpolation methods, high-frequency information is lost in the up-sampling process [10], which may decrease performance in image super-resolution. Alternatively, reconstruction-based methods were developed for SISR, according to optimization methods [14]. That is, mapping a projection into a convex set to estimate the registration parameters can restore more details of SISR [15]. Although the mentioned methods can overcome the drawbacks of image itself’s information methods, they still suffer from the following challenges: a non-unique solution, slow convergence speed and higher computational costs. To prevent this phenomenon, prior knowledge and image itself’s information were integrated into a frame to find an optimal solution to improve the quality of the predicted SR images [16,17]. Besides, machine learning methods can be presented to deal with SISR, according to relation of data distribution [18]. There are also many other SR methods [18,19] that often adopt sophisticated prior knowledge to restrict the possible solution space with the advantage of generating flexible and sharp detail. However, the performance of these methods rapidly degrades when the scale factor is increased, and these methods tend to be time-consuming [20].
To obtain a better and more efficient SR model, a variety of deep learning methods were applied to a large-scale image dataset to solve the super-resolution tasks [21,22]. For instance, Dong et al. proposed a super-resolution convolutional neural network (SRCNN) based pixel mapping that used only three layers to obtain stronger learning ability than those of some popular machine learning methods for image super-resolution [23]. Although the SRCNN had a good SR effect, it still faced problems in terms of shallow architecture and high complexity. To overcome challenges of shallow architectures, Kim et al. [24] designed a deep architecture by stacking some small convolutions to improve the performance of image super-resolution. Tai et al. [25] relied on recursive and residual operations in a deep network to enhance the learning ability of a SR model. To further improve the SR effect, Lim et al. [26] used weights to adjust residual blocks to achieve a better SR performance. To extract robust information, the combination of traditional machine learning methods and deep networks can restore more detailed information for SISR [27]. For instance, Wang et al. [27] embedded a sparse coding method into a deep neural network to make a tradeoff between performance and efficiency in SISR. To reduce the complexity, an up-sampling operation is used in a deep layer in a deep CNN to increase the resolution of low-frequency features and produce high-quality images [28]. For example, Dong et al. [28] directly exploited the given low-resolution images to train a SR model to improve training efficiency, where the SR network used a deconvolution layer to reconstruct HR images. There are also other effective SR methods. HGSRCNN enhances inter- and intra-channel correlations through the parallel utilization of heterogeneous group blocks to obtain richer low-frequency structural information, thereby significantly improving robustness in complex scenes [29]. Lai et al. [30] used the Laplacian pyramid technique with shared parameters in a deep network to accelerate the training speed for SISR. Tian et al. proposed a tree-guided convolutional neural network which leverages a tree architecture to strengthen hierarchical information propagation among key nodes, thereby effectively improving the reconstruction quality [31]. Zhang et al. [32] guided a CNN by attention mechanisms to extract salient features for improving the performance and visual effects in image SISR. Dynamic super resolution network (DSRNet) [33] proposes a dynamic network architecture that utilizes a dynamic gate mechanism to dynamically adjust network parameters to adapt to different scenarios, significantly enhancing the robustness and applicability of the image super-resolution model in complex scenes. Tian et al. [34] proposed a cosine network-based method for SISR, which introduced odd and even enhancement blocks to extract complementary homologous structural information and incorporated a cosine annealing mechanism to optimize the training process, thereby achieving superior performance on multiple public datasets.
With the development of hardware devices, a wider variety of captured images are available [35]. However, the number of available images is insufficient for real applications since scenes in the real world vary. To address this problem, generative methods, such as flow-based models, VAEs, and diffusion models, are developed. Specifically, flow-based models directly calculate the mapping relationship between the normal distribution and the target distribution function to better generate samples similar to the given ones [36]. Although it has better generative effects, it faces the challenge of high computational costs. To solve the unstable training of GANs [37], variational autoencoders (VAEs) use encoders to extract hidden variable distributions to stabilize the training process [38]. Although VAEs can help accelerate training, they are limited by blurry image super-resolution [39]. To enhance the adaptive ability of the generated super-resolution models, diffusion models can use game strategies involving adding and reducing noise to learn an unsupervised super-resolution model. In recent years, diffusion models have increasingly been employed for image super-resolution tasks [40]. While diffusion models can enhance the robustness of generated super-resolution outputs, they often incur higher computational costs and greater resource consumption [41]. Under controlled comparisons of resources—where architecture scale, dataset size, and computational budget are standardized—GANs can compete effectively with diffusion models in the domain of image super-resolution, offering substantial advantages in processing speed. Furthermore, GAN-based upscalers facilitate faster training times and enable single-step inference [42]. Considering the above analysis, GAN-based game strategies are effective tools for generative methods in image super-resolution.
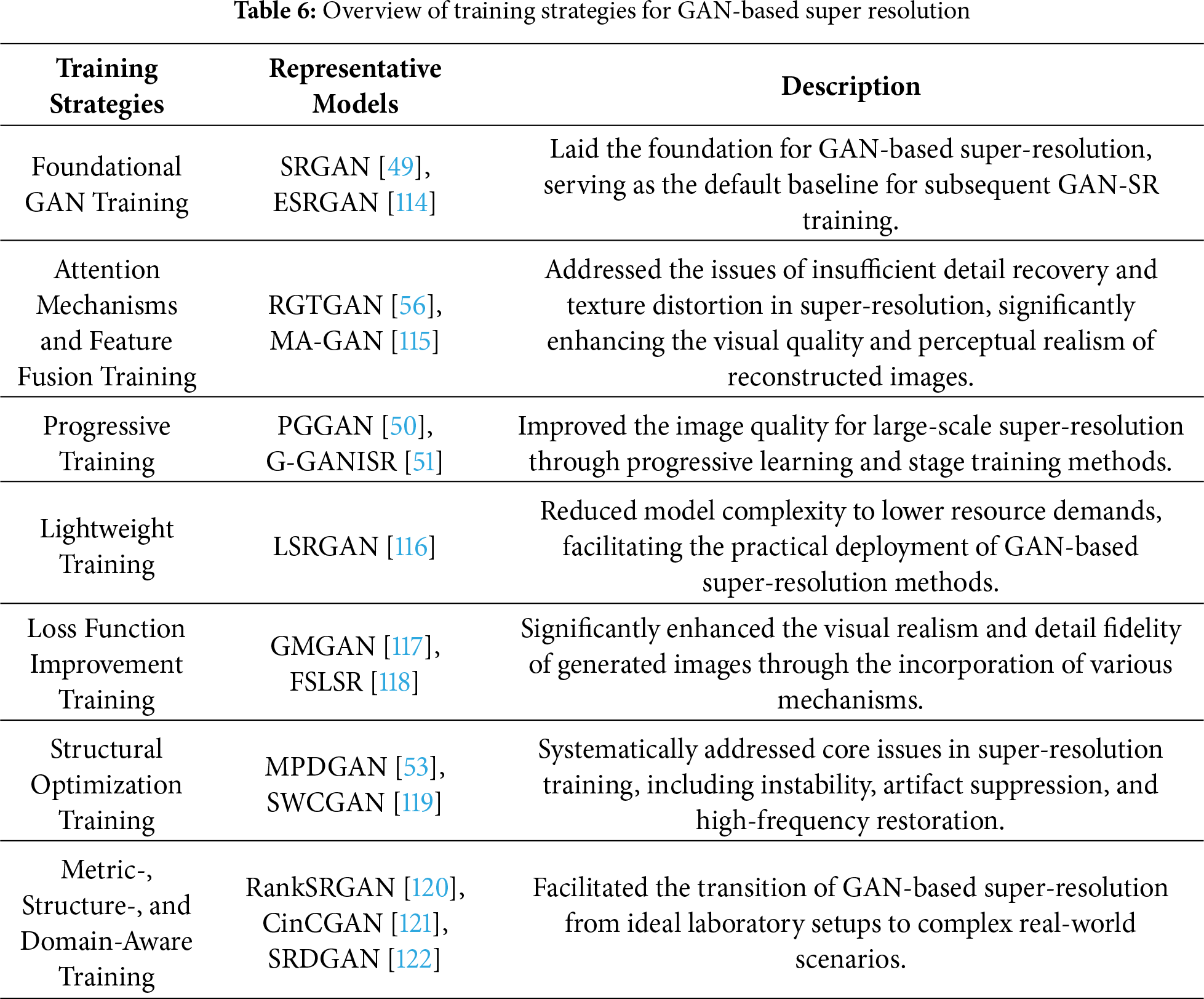
To address the problem of small samples, generative adversarial nets (GANs) were proposed [43–46]. Due to their strong learning abilities, GANs have become popular methods for image super-resolution [47]. For instance, Park et al. [48] combined kernel ideas and GANs to extract more structural information to enhance image sharpness and edge thickness for image super-resolution. When addressing the challenges of super-resolution tasks, GAN-based methods also provide effective solutions. Large-scale scaling requires deeper networks, which in turn demands greater stability. GANs can achieve stability through improved loss functions [49], progressive learning [50,51], and other methods. At the same time, to address common failure modes, GANs enhance sharpness and edge information by introducing residual dense structures and attention mechanisms [52] to avoid distortion of fine details. They eliminate artifacts using multi-discriminators [53] and address color shifts through range-nullspace decomposition [54] and second-order channel attention mechanisms [55]. Additionally, they tackle geometric distortions by employing gradient branching [56] and utilizing bidirectional structural consistency [57]. However, there are few studies summarizing the use of these GANs for SISR.
Prior surveys on GANs [58,59] have continuously emerged, elucidating various technical aspects of GANs, including advancements in performance, related technologies, and their evolutionary trajectories. In recent years, surveys specifically addressing GAN-based super-resolution have also been proposed, such as those in references [60–62]. However, these works exhibit certain limitations: (a) the training paradigms covered are incomplete, particularly lacking in the areas of unsupervised and semi-supervised learning, and (b) the evaluation frameworks deviate from practical deployment requirements, failing to incorporate engineering metrics such as model parameter count, inference time, and memory usage. Differing from previous work based on deep learning techniques for image super-resolution, i.e., Refs. [63,64], we not only refer to the importance of GANs for both low- and high-level tasks in the context of small and large samples but also provide a comprehensive summary of GANs in image super-resolution based on a combination of different training methods (i.e., supervised, semi-supervised, and unsupervised), network architectures, prior knowledge, loss functions, and multiple tasks, which makes it easier for readers to understand the principles, improvements, and the strengths and weaknesses of different GANs for image super-resolution. That is, in this paper, we conduct a comprehensive overview of 258 papers to show their performance, pros, cons, complexity, challenges, and potential research points, etc. First, we demonstrate the effects of GANs in image applications. Second, we present popular architectures for GANs in large and small samples for image applications. Third, we analyze the motivations, implementations, and differences of GAN-based optimization methods and discriminative learning for image super-resolution in terms of supervised, semi-supervised, and unsupervised methods to provide a clearer and more comprehensive overview of the relevant technologies, including the latest advancements, where these GANs operate by combining different network architectures, prior knowledge, loss functions, and multiple tasks for image super-resolution. Fifth, we compare these GANs using experimental settings, quantitative analysis (i.e., PSNR, SSIM, complexity, and running time), and qualitative analysis to make a more practical and complete evaluation. Finally, we report on potential research directions and existing challenges associated with GANs for image super-resolution. The overall architecture of this paper is shown in Fig. 1.
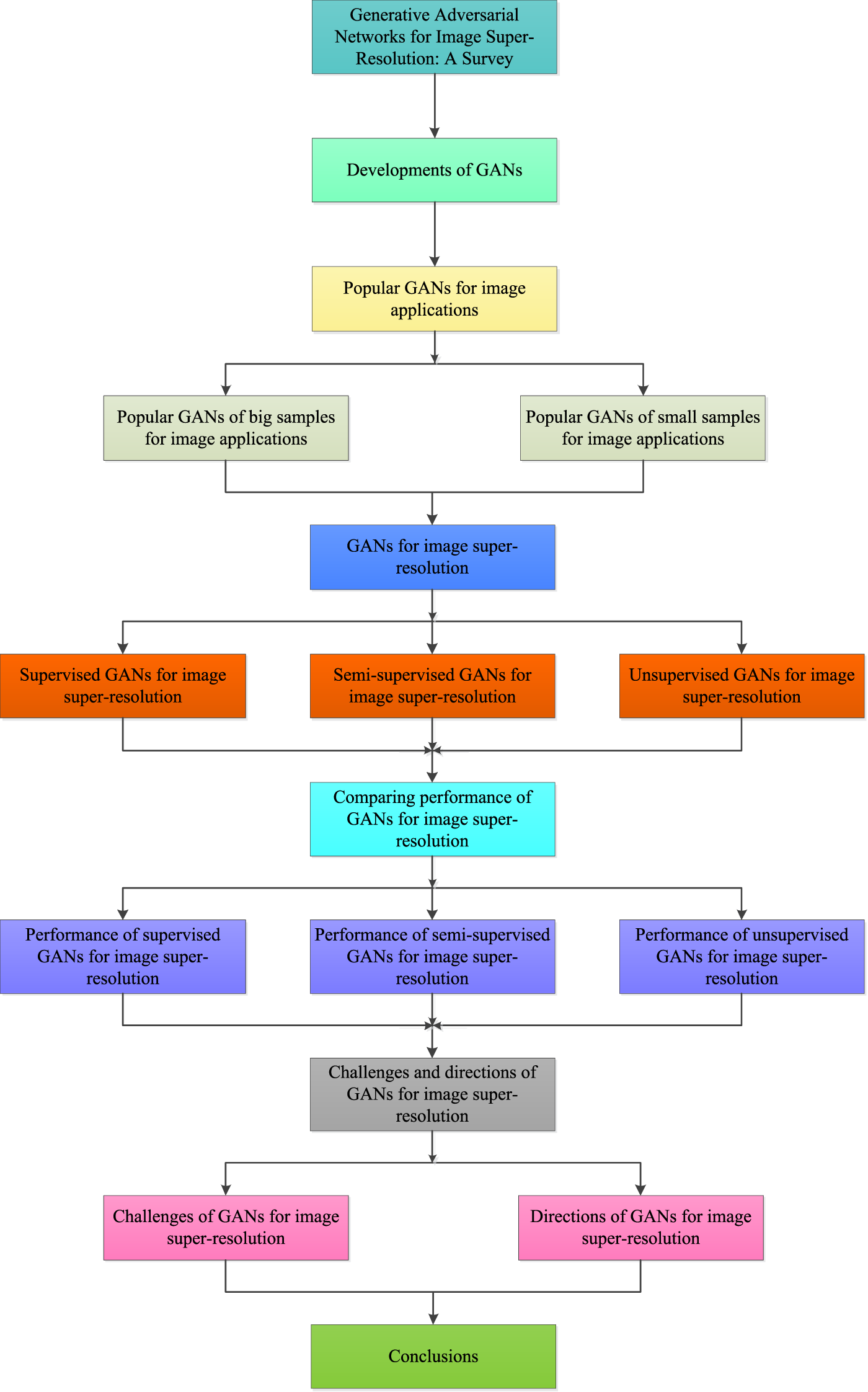
Figure 1: The outline of this overview. It mainly consists of basic frameworks, categories (i.e., supervised, semi-supervised, and unsupervised GANs), performance comparison, challenges, and potential directions.
The remainder of this survey is organized as follows: Section 2 reviews the developments of GANs and surveys popular GANs for image applications; Section 3 focuses on introduction of existing GANs via three ways on SISR; Section 4 compares performance of mentioned GANs from Section 2 for SISR; Section 5 offers potential directions and challenges of GANs in image super-resolution; and Section 6 concludes the overview.
Traditional machine learning methods prefer to use prior knowledge to improve the performance of image processing applications [65]. For instance, Sun et al. [65] proposed a gradient profile to restore more detailed information for improving the performance of image super-resolution. Although machine learning methods based on prior knowledge have fast execution speed, they have some drawbacks. First, they require manually set parameters to achieve better performance on image tasks. Second, they require complex optimization methods to find optimized parameters. To address these challenges, deep learning methods have been developed [66]. Deep learning methods use deep networks, such as CNNs, to automatically learn features instead of manually setting parameters to achieve effective results in image processing tasks, such as image classification [66], image inpainting [67], and image super-resolution [1]. Although these methods are effective for large samples, they are limited for tasks involving small samples [43].
To address the problems mentioned above, GANs are introduced in image processing [43]. GANs consist of a generator network and a discriminator network. The generator network is used to generate new samples according to the given samples. The discriminator network is used to determine the authenticity of the generated new samples. When the generator and discriminator are balanced, the GAN model is complete. The working process of the GAN is shown in Fig. 2, where G and D denote the generator network and the discriminator network, respectively. To better understand GANs, we introduce several basic GANs as follows.
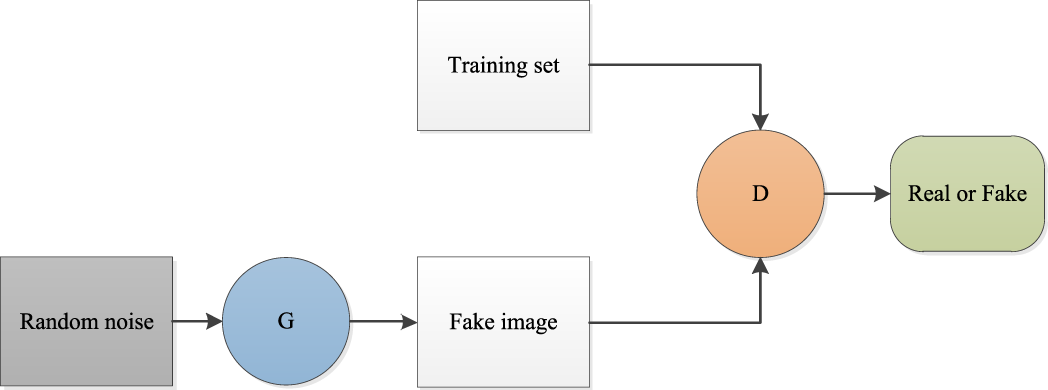
Figure 2: Architecture of generative adversarial network (GAN).
To obtain more realistic effects, conditional information is fused into a GAN (CGAN) to randomly generate images that are closer to real images [68]. CGAN improves GANs to obtain more robust data, which has significant reference value for GANs in computer vision applications. Subsequently, increasing the depth of the GAN instead of using the original multilayer perceptron in a CNN has been developed to improve the expressive ability of GANs for complex vision tasks [69]. To mine more useful information, the bidirectional generative adversarial network (BiGAN) uses dual encoders to collaborate with a generator and a discriminator to obtain richer information for improving performance in anomaly detection, as shown in Fig. 3 [70]. In Fig. 3, x denotes a feature vector, E is an encoder, and y represents an image from the discriminator.
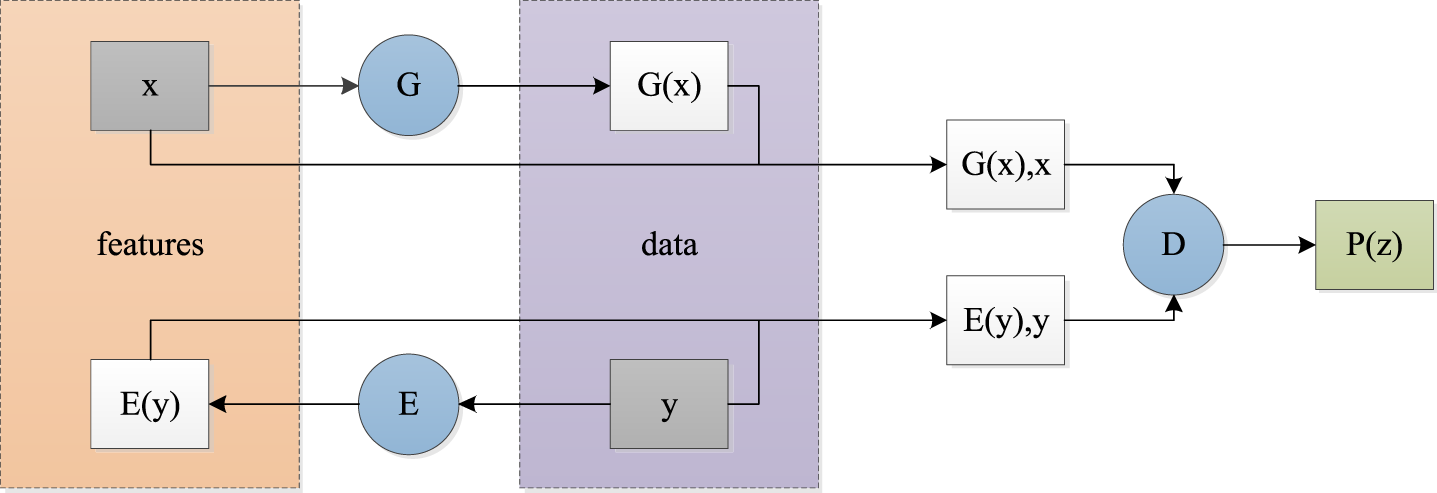
Figure 3: Architecture of bidirectional generative adversarial network (BiGAN).
It is known that pretrained operations can be used to accelerate the training speed of CNNs for image recognition [71]. This idea can be described as an energy-driven process. Inspired by that, Zhao et al. proposed an energy-based generative adversarial network (EBGAN) by incorporating a pretraining operation into the discriminator to improve performance in image recognition [72]. To maintain consistency between the obtained features and the original images, the cycle-consistent adversarial network (CycleGAN) relies on a cyclic architecture to achieve excellent style transfer effects [73], as illustrated in Fig. 4. The implementation and application of CycleGAN are detailed in Section 2.2.1.
Figure 4: Architecture of cycle-consistent adversarial network (CycleGAN).
Although pretrained operations are useful for the training efficiency of network models, they may suffer from mode collapse. To address this problem, Wasserstein GAN (WGAN) used weight clipping to enhance the importance of the Lipschitz constraint to improve the stability of training a GAN [74]. WGAN used weight clipping to perform well. However, it is easier to cause gradient vanishing or gradient exploding [75]. To resolve this issue, WGAN used a gradient penalty (treated as WGAN-GP) to break the limitation of Lipschitz for pursuing good performance in computer vision applications [76]. To further improve the results of image generation, GAN enlarged the batch size and used truncation trick, as well as BIGGAN, which can make a tradeoff between variety and fidelity [76]. To better obtain features of different parts of an image (i.e., freckles and hair), style-based GAN (StyleGAN) uses feature decoupling to control different features and finish style transfer for image generation [77]. The architecture of StyleGAN and its generator are shown in Figs. 5 and 6.
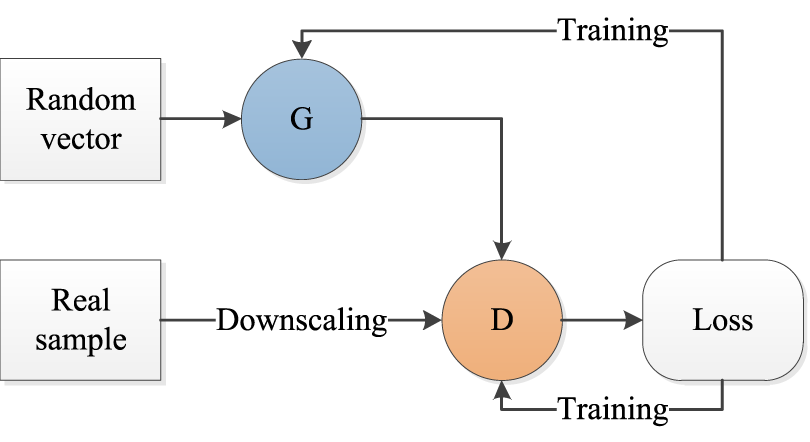
Figure 5: Architecture of StyleGAN.

Figure 6: The structure of generator in the StyleGAN.
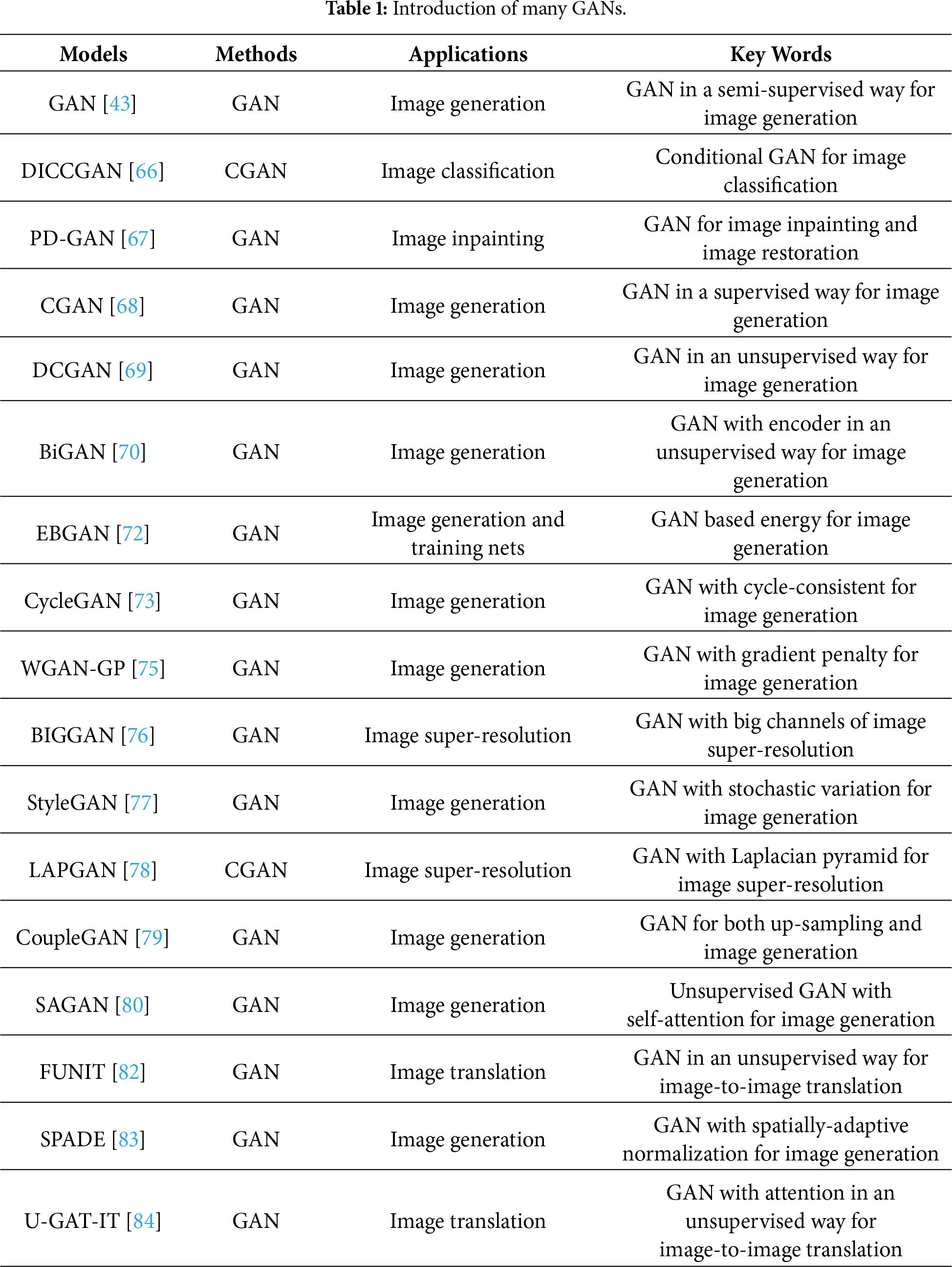
In recent years, GANs with good performance have been applied in the fields of image processing, natural language processing (NLP), and video processing. Also, there are other variants based on GANs for multimedia applications, such as Laplacian pyramid of GAN (LAPGAN) [78], coupled GAN (CoupleGAN) [79], self-attention GAN (SAGAN) [80], and loss-sensitive GAN (LSGAN) [81]. These methods emphasize how to generate high-quality images through various sampling mechanisms. However, researchers have focused on the applications of GANs since 2019, i.e., FUNIT [82], SPADE [83], and U-GAT-IT [84]. Illustrations of more GANs are shown in Table 1.
According to the illustrations mentioned, it is known that variants of GANs have been developed based on the properties of vision tasks in Section 2. To further understand GANs, we present different GANs with training data, i.e., big samples and small samples, for various high- and low-level computer vision tasks, as shown in Fig. 7.
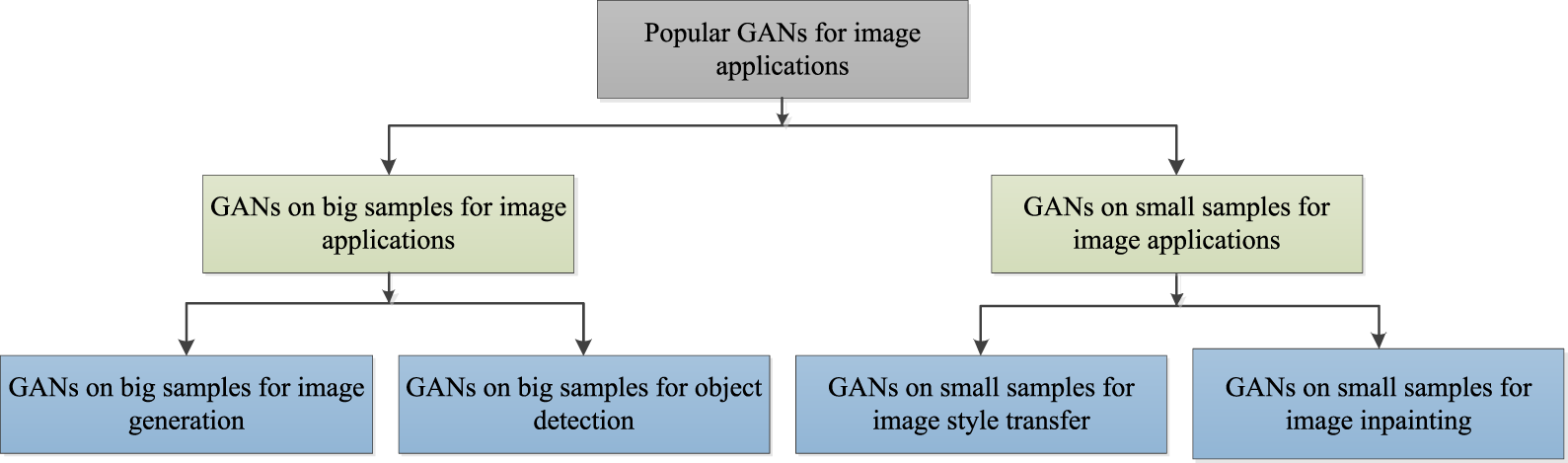
Figure 7: Frame of popular GANs for image applications.
2.1 GANs on Big Samples for Image Applications
2.1.1 GANs on Big Samples for Image Generation
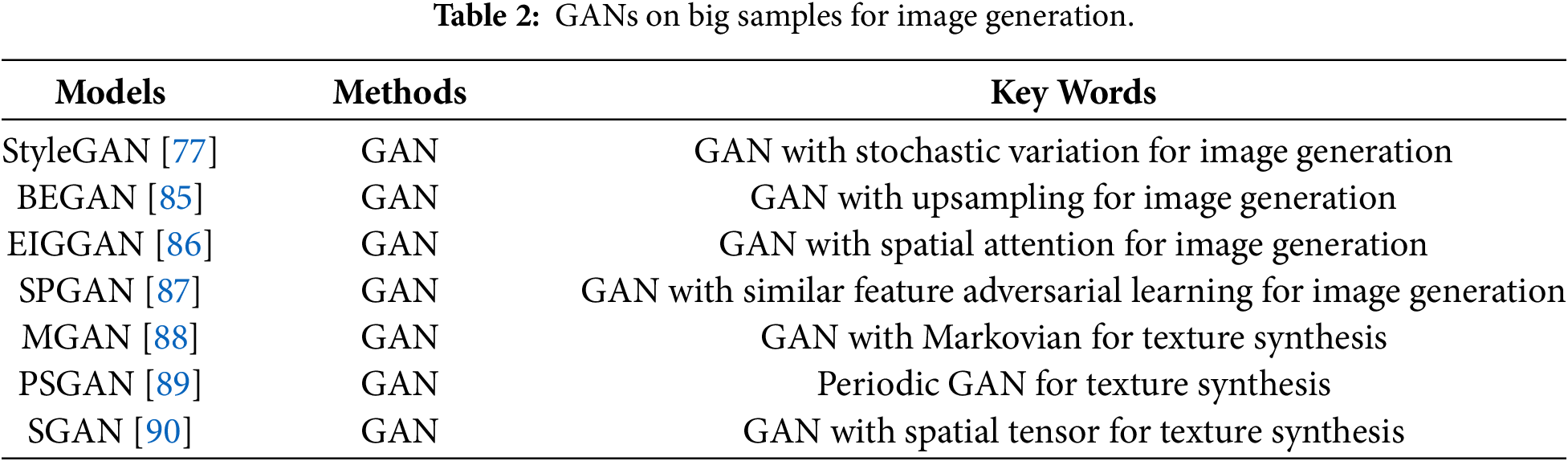
Good performance in image generation depends on rich samples. Inspired by that, GANs have been improved for image generation [45]. That is, GANs use a generator to generate more samples from high-dimensional data to cooperate with the discriminator for promoting the results of image generation. For instance, boundary equilibrium generative adversarial networks (BEGAN) has used the loss obtained from Wasserstein to match the loss of the auto-encoder in the discriminator and achieve a balance between a generator and a discriminator, which can obtain more texture information than common GANs in image generation [85]. To control different parts of a face, StyleGAN decoupled different features to form a feature space to complete the transfer of texture information [77]. Enhanced GAN for image generation (EIGGAN) [86] improves the performance of the generator by incorporating a spatial attention mechanism and parallel residual operations, thereby achieving higher quality and more realistic image generation effects in large-scale image generation tasks. SPGAN leverages a Siamese Projection Network to facilitate adversarial learning of feature similarity; by sharing weights with the discriminator, it reduces parameter complexity, mitigates overfitting, and streamlines the overall model architecture [87]. Besides, texture synthesis is another important application of image generation [88]. For instance, Markovian GANs (MGAN) can quickly capture texture data of Markovian patches to achieve the function of real-time texture synthesis [88], where Markovian patches can be found in Ref. [45]. Periodic spatial GAN (PSGAN) [89] is a variant of spatial GAN (SGAN) [90], which can learn periodic textures of big datasets and a single image. These methods can be summarized in Table 2.
2.1.2 GANs on Big Samples for Object Detection
Object detection has wide applications in the industry, such as smart transportation [91] and medical diagnosis [92], and so on. However, complex environments pose significant challenges to pursuing good performance for object detection methods [93]. Rich data is important for object detection. Existing methods use a data-driven strategy to collect a large-scale dataset, including different object examples under various conditions, to obtain an object detector. However, the obtained dataset does not contain all kinds of deformed and occluded objects, which limits the effectiveness of object detection methods. To resolve this issue, GANs are used for object detection [94,95]. Ehsani et al. used segmentation and generation in GANs of invisible parts of the objects to overcome the challenges of occluded objects [94]. To address the challenge of small object detection on low-resolution and noisy representation, a perceptual GAN (Perceptual GAN) reduced the differences between small objects and large objects to improve performance in small object detection [95]. That is, its generator converts the poorly perceived representations of small objects into high-resolution representations of large objects to fool a discriminator, where the aforementioned large objects resemble real large objects [95]. To obtain sufficient information about objects, an end-to-end multi-task generative adversarial network (SOD-MTGAN) uses a generator to recover detailed information to generate high-quality images to achieve accurate detection [96]. Also, a discriminator transfers classification and regression losses in a back-propagated way into a generator [96]. To address dense small-object detection scenarios, Brais Bosquet et al. proposed Downsampling GAN, wherein the generator synthesizes small-scale object instances from larger targets and the discriminator distinguishes authentic small objects from generated ones; an optical-flow-based spatial selection mechanism is incorporated to ensure the realism and contextual plausibility of the generated samples, thereby improving detector robustness in crowded small-object scenes [97]. Two operations can extract objects from backgrounds to achieve good performance in object detection. More detailed information is shown in Table 3.

2.2 GANs on Small Samples for Image Applications
2.2.1 GANs on Small Samples for Image Style Transfer
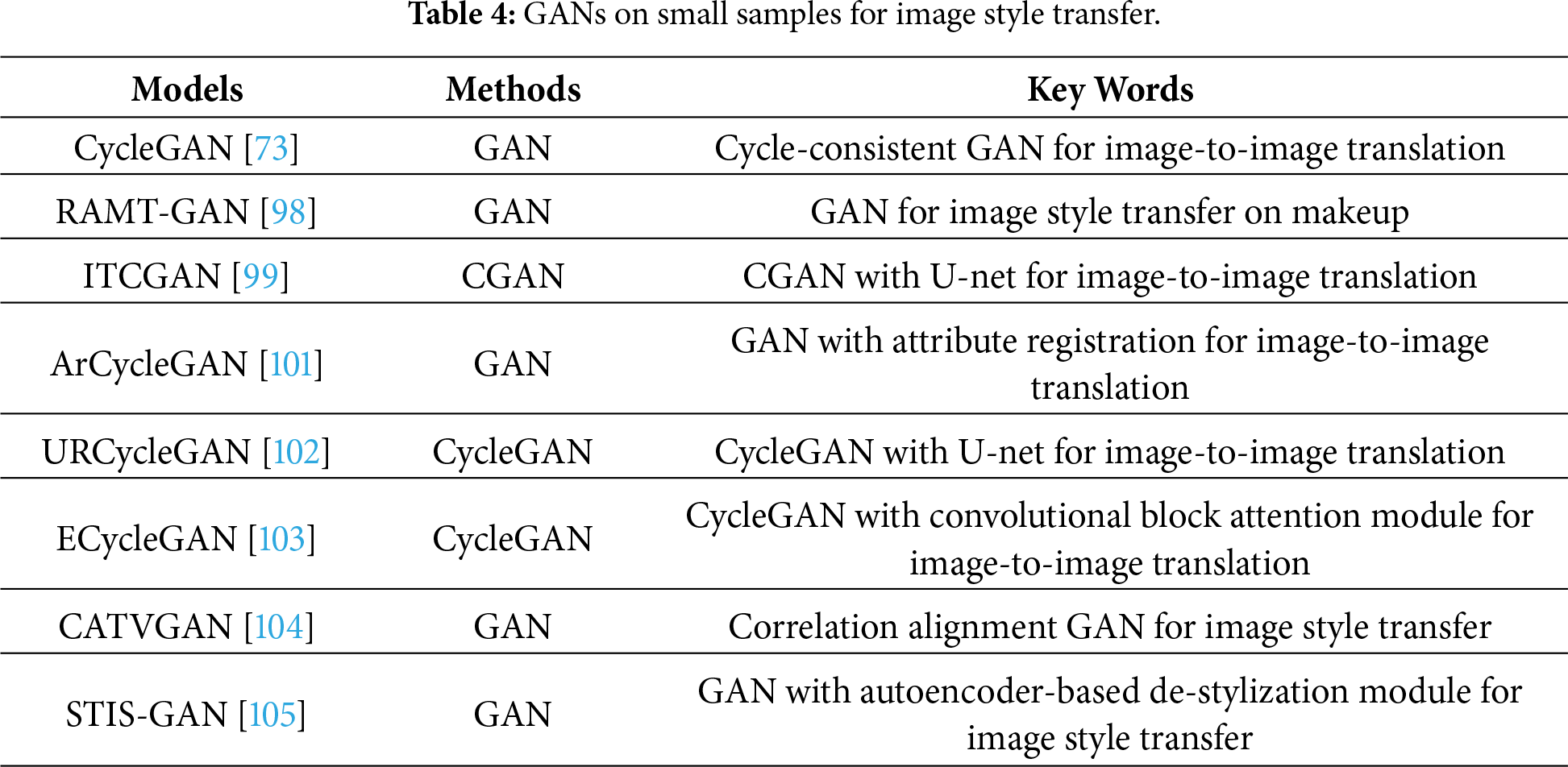
Makeup has important applications in the real world [98]. To save costs, visual makeup software is developed, leading to image style transfer (i.e., image-to-image translation) becoming a research hotspot in the field of computer vision in recent years [45]. GANs are good tools for style transfer on small samples, which can be used for establishing mappings between given images and object images [45]. The obtained mappings are strongly related to aligned image pairs [99]. However, we found that the above mappings do not match the ideal models regarding transfer effects [73]. Motivated by that, CycleGAN used two pairs of a generator and discriminator in a cycle-consistent way to learn two mappings for achieving style transfer [73]. CycleGAN had two phases in style transfer. In the first phase, adversarial loss [83] was used to ensure the quality of generated images. In the second phase, cycle consistency loss [73] was utilized to guarantee that the predicted images fall into the desired domains [100]. CycleGAN had the following merits: it does not require paired training examples [100]. It also does not require the input and output image to share a same low-dimensional embedding space [73]. Due to its excellent properties, many variants of CycleGAN have been conducted for many vision tasks, such as image style transfer [73,101], object transfiguration [102], and image enhancement [103], among others. More GANs on small samples for image style transfer can be found in Table 4.
2.2.2 GANs on Small Samples for Image Inpainting
Images have played important roles in human–computer interaction in the real world [106]. However, they may be damaged when collected by digital cameras, which has a negative impact on high-level computer vision tasks. Thus, image inpainting has significant value in the real world [107]. Due to missing pixels, image inpainting faced enormous challenges [108]. To overcome the above shortcomings, GANs are used to generate useful information for repairing damaged images based on the surrounding pixels in the damaged images [109]. For instance, GANs use a reconstruction loss, two adversarial losses, and a semantic parsing loss to guarantee pixel faithfulness and local-global content consistency for face image inpainting [110]. Although this method can generate useful information, it may cause boundary artifacts, distorted structures, and blurry textures inconsistent with surrounding areas [111,112]. To resolve this issue, Zhang et al. embedded prior knowledge into a GAN to generate more detailed information for achieving good performance in image inpainting [111]. Yu et al. exploit a contextual attention mechanism to enhance a GAN for obtaining excellent visual effects in image inpainting [112]. WSA-GAN constructs long-range dependencies of multi-scale frequency information in the wavelet domain and employs dual parallel-coupled streams to dynamically fuse spatial and channel features, thereby effectively addressing structural distortions and high-frequency detail blurring [113]. Typical GANs on small samples for image inpainting are summarized in Table 5.

3 GANs for Image Super-Resolutions
As stated in the illustrations, it is clear that GANs have many important applications in image processing. Also, image super-resolution is crucial for high-level vision tasks, such as medical image diagnosis and weather forecasting. Thus, GANs for image super-resolution are significant for real-world applications. Few comprehensive reviews exist about GANs for image super-resolution. Inspired by that, we present GANs for image super-resolution, categorized into supervised GANs, semi-supervised GANs, and unsupervised GANs for image super-resolution as shown in Fig. 8. To ensure classification rigor and consistency, the dimension of training paradigms (supervised/semi-supervised/unsupervised) should be determined by data provision formats, with the discriminating criterion being the degree of utilization of collected LR-HR paired data during training. Specifically, supervised GANs for image super-resolution include those based on designed network architectures, prior knowledge, improved loss functions, and multi-tasks for image super-resolution. Semi-supervised GANs for image super-resolution comprise those based on designed network architectures, improved loss functions, and multi-tasks for image super-resolution. Unsupervised GANs for image super-resolution consist of those based on designed network architectures, prior knowledge, improved loss functions, and multi-tasks in image super-resolution. Meanwhile, to more intuitively present the diverse training strategies employed in GAN-based SR, we select several representative approaches and summarize them in Table 6. Further information about GANs for image super-resolution is presented below.
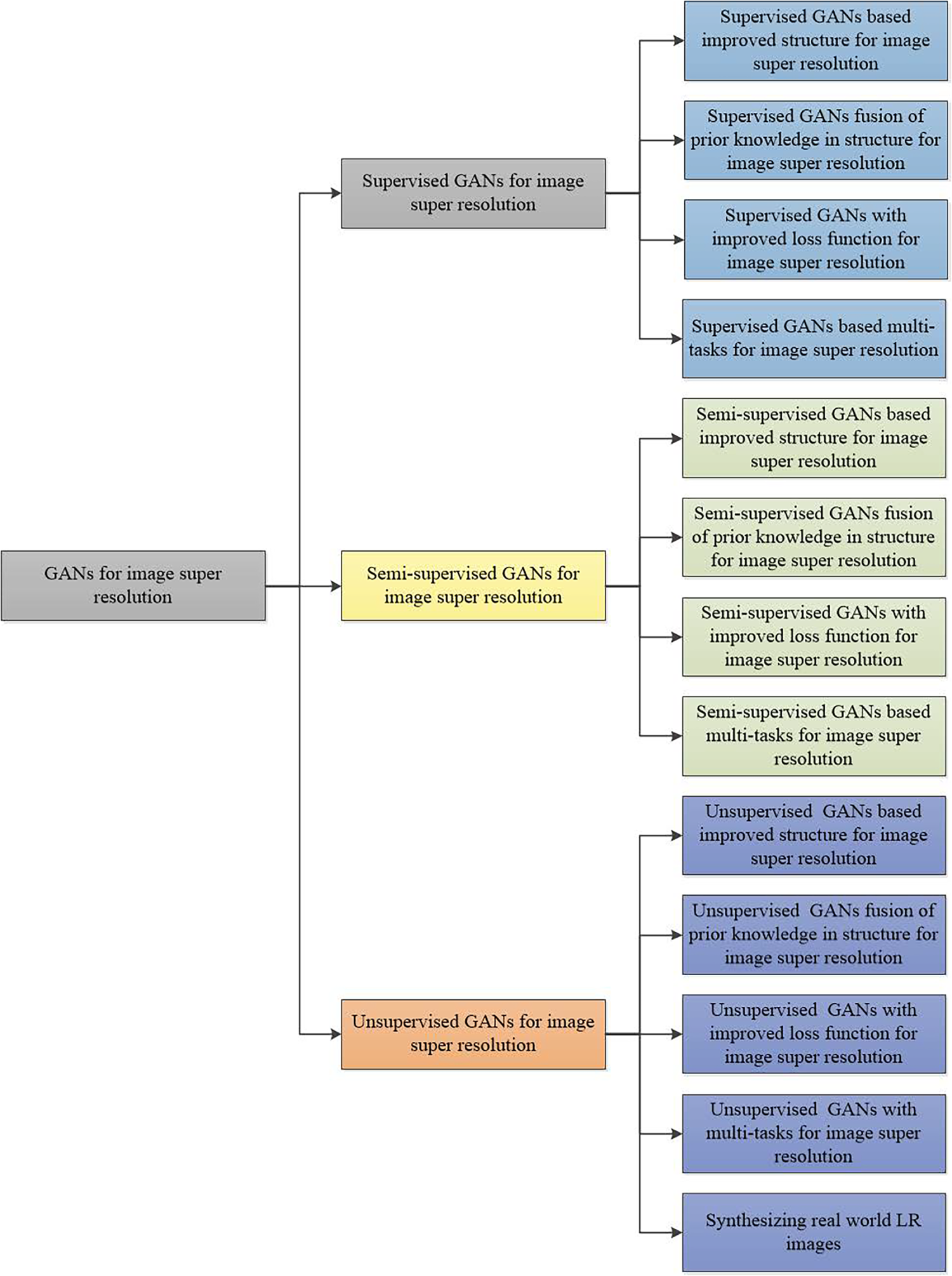
Figure 8: Frame of GANs for image super-resolution.
3.1 Supervised GANs for Image Super-Resolution
3.1.1 Supervised GANs Based Designed Network Architectures for Image Super-Resolution
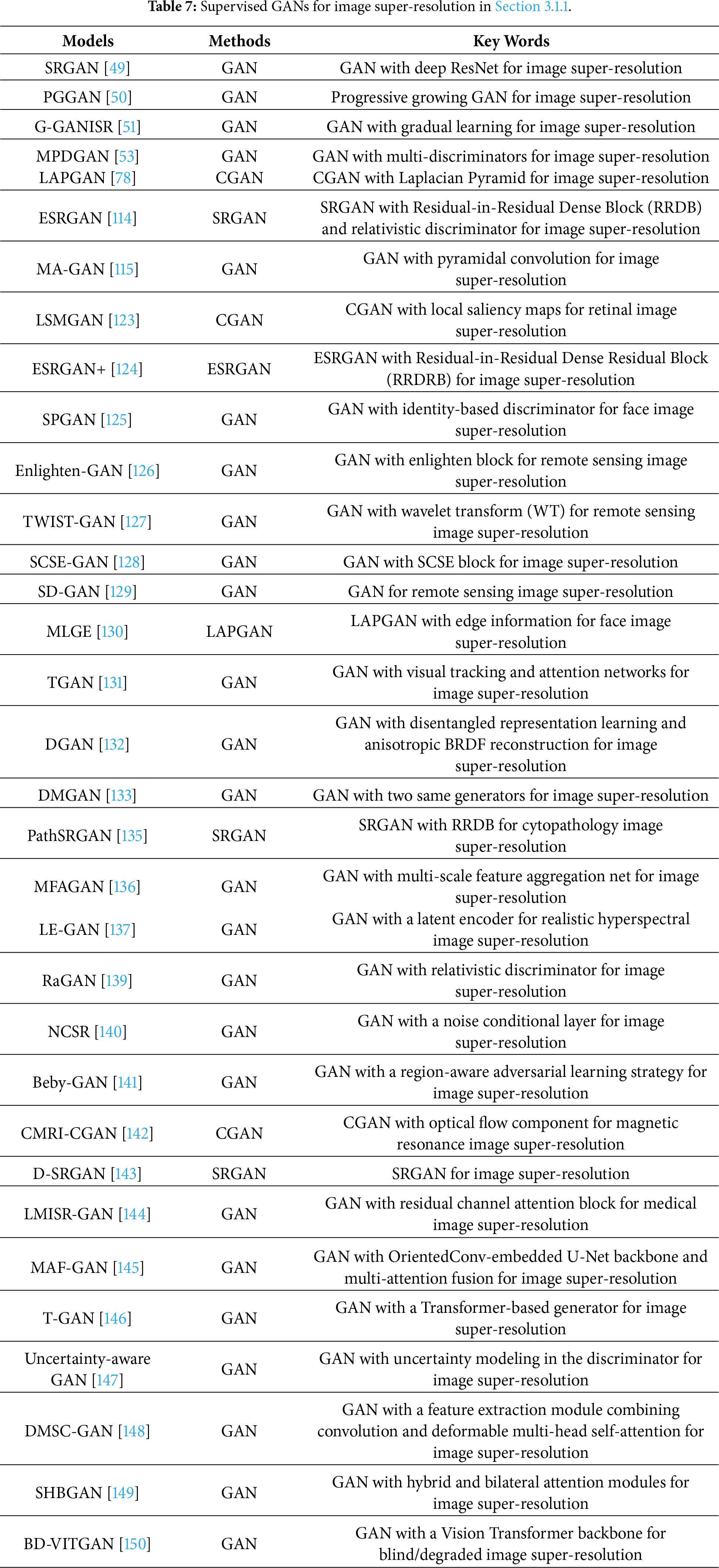
GANs trained in a supervised manner for image super-resolution models are very mainstream. Also, designing GANs via improving network architectures are very novel. Thus, improved GANs in a supervised manner for image super-resolution are very popular. This can improve GANs by designing novel discriminator networks, generator networks, attributes of image super-resolution tasks, complexity, and computational costs. For example, the Laplacian pyramid of adversarial networks (LAPGAN) fused a cascade of convolutional networks into a Laplacian pyramid network in a coarse-to-fine way to obtain high-quality images for assisting image recognition tasks [78]. To overcome the effect of large scales, curvature and highlight compact regions can be used to obtain a local salient map for adapting big scales in image resolution [123]. More research on improving discriminators and generators is presented below.
Regarding the design of novel discriminators and generators, progressive growing generative adversarial networks (PGGAN or ProGAN) utilized different convolutional layers to progressively enlarge low-resolution images to improve image quality for image recognition [50]. To achieve better visual quality with more realistic and natural textures, an enhanced SRGAN (ESRGAN) used residual dense blocks within a generator without batch normalization to extract more detailed information for image super-resolution [114]. To eliminate effects of checkerboard artifacts and unpleasant high frequencies, multi-discriminators were proposed for image super-resolution [53]. That is, a perspective discriminator was used to overcome checkerboard artifacts, and a gradient perspective was utilized to address the issue of unpleasant high frequencies in image super-resolution. To improve the perceptual quality of predicted images, ESRGAN+ fused two adjacent layers in a residual learning manner based on residual dense blocks in a generator to enhance memory abilities and added noise in a generator to achieve stochastic variation and capture more details of high-resolution images [124].
Restoring detailed information may generate artifacts, which can seriously affect the quality of restored images [125]. The methods mentioned in this paragraph effectively alleviate this phenomenon. For face image super-resolution, Zhang and Ling used a supervised pixel-wise GAN (SPGAN) to obtain higher-quality face images via given low-resolution face images of multiple scale factors to remove artifacts in image super-resolution [125]. For remote sensing image super-resolution, Gong et al. used enlighten blocks to make a deep network achieve a reliable point and used self-supervised hierarchical perceptual loss to mitigate the effects of artifacts in remote sensing image super-resolution [126]. Dharejo et al. used Wavelet Transform (WT) characteristics into a transferred GAN to eliminate artifacts and improve the quality of predicted remote sensing images [127]. Moustafa and Sayed embedded squeeze-and-excitation blocks and residual blocks into a generator to obtain enhanced high-frequency details [128]. Additionally, Wasserstein distance enhances the stability of training a remote sensing super-resolution model [128]. To address the pseudo-texture problem, a saliency analysis is fused with a GAN to obtain a salient map that can be used to distinguish the differences between a discriminator and a generator [129].
To obtain more detailed information for image super-resolution, many GANs have been developed [130]. Ko and Dai used the Laplacian idea and edge information in a GAN to obtain more useful information to improve the clarity of predicted face images [130]. Using tensor structures in a GAN can enhance texture information for super-resolution [131]. Using multiple generators in a GAN can obtain more realistic texture details, which is useful to recover high-quality images [132,133]. To achieve better visual effects, a gradually growing GAN used gradual growing factors to improve performance in single image super-resolution (SISR) [51]. The RGTGAN enhance texture fidelity by incorporating a dedicated gradient branch that operates in parallel with an image branch, thereby guiding the generator to produce geometrically consistent and richly detailed textures [56]. SA-GAN employs a second-order channel attention mechanism to fully exploit priors inherent to low-resolution inputs, thereby enabling high-quality reconstructions that combine faithful texture preservation with accurate color reproduction [55]. FEGAN prioritizes salient feature extraction and efficient feature fusion, thereby enabling the generation of high-quality super-resolved thermal images under low computational cost [134].
To reduce computational costs and memory, Ma et al. used a two-stage generator in a supervised manner to extract more effective features from cytopathological images, reducing data acquisition costs and saving expenses [135]. Cheng et al. designed a generator using multi-scale feature aggregation and a discriminator based on PatchGAN to reduce memory consumption in a GAN for super-resolution [136]. Besides, distilling a generator and discriminator can enhance training efficiency of a GAN model for super-resolution [136]. To achieve hyperspectral image super-resolution with enhanced robustness to large upsampling factors and noise, LE-GAN integrates a generator incorporating a short-term spectral–spatial relationship window and a latent encoder, jointly capturing localized spectral–spatial dependencies and compact latent representations to improve reconstruction robustness and fidelity [137]. To enable deep feature extraction, SWCGAN employs a generator composed of interleaved convolutional blocks and Swin Transformer layers to synthesize high-resolution images, and a discriminator built exclusively from Swin Transformer blocks to drive adversarial training [119]. NeXtSRGAN employs a relativistic average discriminator that evaluates relative authenticity by contrasting real and generated samples, enabling combined gradient signals for more realistic SR images [138]. More supervised GANs for image super-resolution are shown in Table 7.
3.1.2 Supervised GANs Based Prior Knowledge for Image Super-Resolution
It is known that the combination of a discriminative method and optimization can create a tradeoff between efficiency and performance [151]. To address the blind distortions in real low-resolution images, Guan et al. utilized a high-resolution to low-resolution image network and a low-resolution to high-resolution image network using the nearest neighbor down-sampling method to learn detailed information and noise priors for image super-resolution [122]. Chan et al. used rich and diverse priors in a given pretrained model to mine latent representative information for generating realistic textures in image super-resolution [152]. Liu et al. incorporated a gradient prior into a GAN to suppress the effects of blur kernel estimation for image super-resolution [153]. Xu et al. proposed the WDDSR, which integrates semantic priors with wavelet-domain priors to enable more accurate image-quality assessment and to provide refined guidance for image generation [154]. In the GAN-prior paradigm, Wang et al. proposed a range–nullspace decomposition for SR to eliminate structural and color inconsistencies [54]. RDL-GAN employs a multi-order degradation simulation framework to model real infrared scene degradation priors, emulating atmospheric, optical, and sensor-induced degradations for enhanced generalization to authentic scenarios [155]. Gram-GAN focuses on the texture similarity of images and overcomes the limitations of spatial location information by leveraging the structural properties of natural images and constructing a Gram matrix [156].
3.1.3 Supervised GANs with Improved Loss Functions for Image Super-Resolution
Loss functions can affect the performance and efficiency of a trained SR model. Thus, we analyze the combination of GANs with various loss functions for image super-resolution [120]. Zhang et al. trained a Ranker to obtain representations of perceptual metrics and used a rank-content loss in a GAN to enhance visual quality in image super-resolution [120]. To eliminate the effects of artifacts, Zhu et al. used an image quality assessment metric to implement a novel loss function to enhance stability in image super-resolution [117]. To decrease the complexity of the GAN model in image super-resolution, Fuoli et al. used a Fourier space supervision loss to recover lost high-frequency information, improve predicted image quality, and accelerate training efficiency in SISR [118]. To enhance the stability of an SR model, using residual blocks and a self-attention layer in a GAN improves the robustness of the trained SR model. Additionally, combining an improved Wasserstein gradient penalty and perceptual loss enhances the stability of an SR model [157]. To extract accurate features, fusing a measurement loss function into a GAN can provide more detailed information for clearer images [158]. Ren et al. imposed an L1 constraint on the edge maps of generated super-resolved and ground-truth high-resolution images to more strongly regularize high-frequency details in the edge domain, thereby producing more realistic reconstructions and better preserving salient edge structures [159].
3.1.4 Supervised GANs Based Multi-Tasks for Image Super-Resolution
Improving image quality is important for high-level vision tasks, such as image recognition [160]. Besides, devices often suffer from the effects of multiple factors, such as device hardware, camera shakes, and shooting distances, which results in collected images being damaged. That may include noise and low-resolution pixels. Thus, addressing the multitasking capabilities of GANs is very necessary [161]. For instance, Adil et al. exploited SRGAN and a denoising module to obtain a clear image. They then used a network to learn unique representative information for person identification [162]. In terms of image super-resolution and object detection, Wang et al. used a multi-class cyclic super-resolution GAN to restore high-quality images and a YOLOv5 detector to complete the object detection task [163]. Zhang et al. used a fully connected network to implement a generator for obtaining high-definition plate images, and a multi-task discriminator was used to enhance super-resolution and recognition tasks [164]. The use of adversarial learning is an effective tool to simultaneously address text recognition and super-resolution [165]. The JDSR-GAN achieves complementarity between the two tasks through joint learning of denoising and super-resolution, thereby improving the overall restoration quality of low-quality faces occluded by masks [166]. DISGAN introduces a 3D Discrete Wavelet Transform-informed discriminator to guide the generator towards minimal noise generation. The model possesses inherent denoising capability while performing super-resolution, enhancing its practicality and generalization [167].
In terms of complex damaged image restoration, GANs are excellent choices [168]. For instance, Li et al. used a multi-scale residual block and an attention mechanism in a GAN to remove noise and restore detailed information in CTA image super-resolution [168]. Nneji et al. improved the VGG19 model to fine-tune two sub-networks with a wavelet technique to simultaneously address COVID-19 image denoising and super-resolution problems [169]. More information can be found in Table 8.
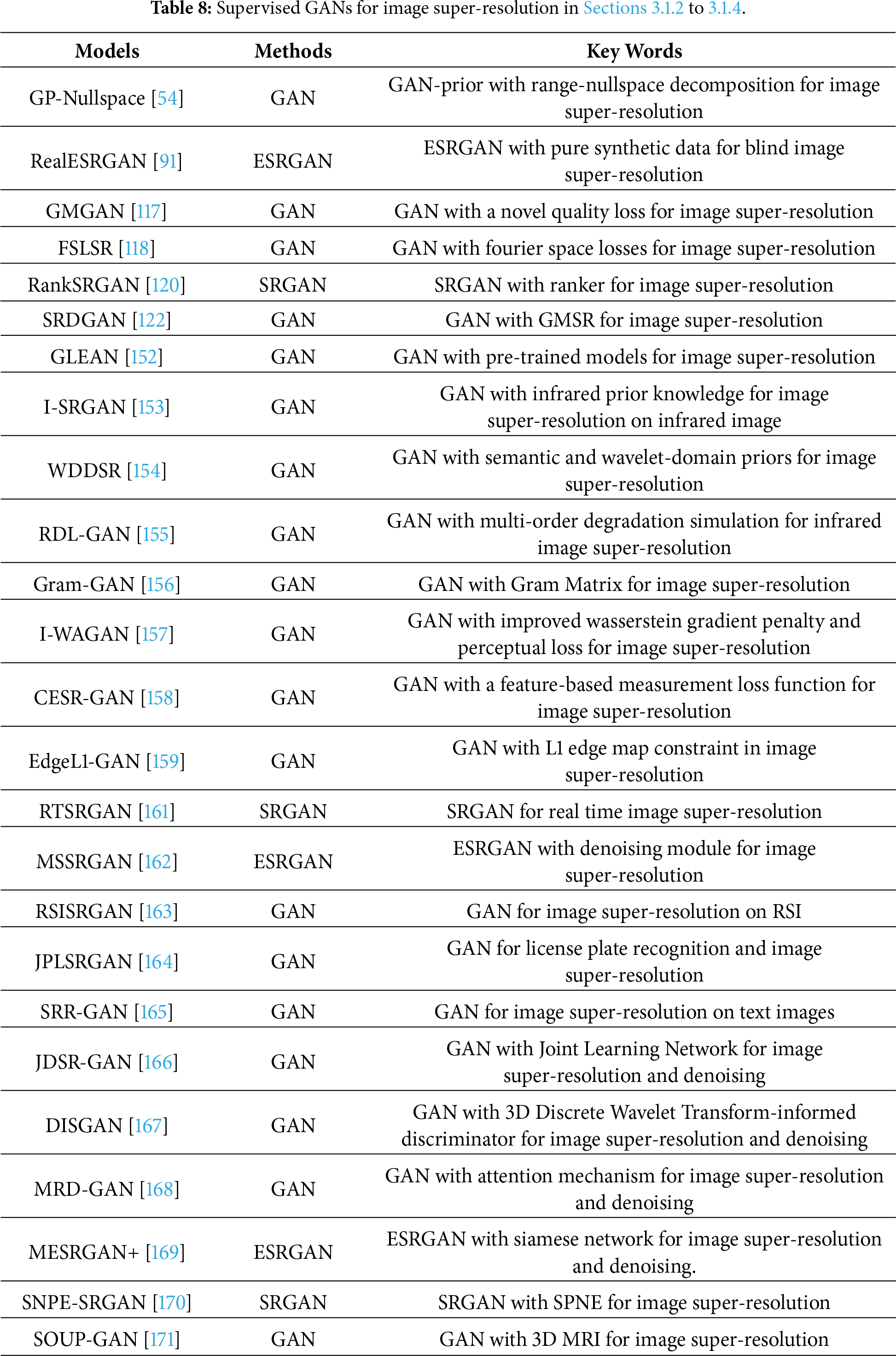
3.2 Semi-Supervised GANs for Image Super-Resolution
3.2.1 Semi-Supervised GANs Based Designed Network Architectures for Image Super-Resolution
For real-world problems with limited data, semi-supervised techniques have been developed. For instance, asking patients to undergo multiple CT scans with additional radiation doses to generate paired CT images for training SR models in clinical practice is unrealistic. Motivated by this, GANs are used in a semi-supervised manner for image super-resolution [172]. For example, You et al. built a mapping from noisy low-resolution images to high-resolution images [172]. Besides, combining a convolutional neural network and residual learning operations in a GAN can facilitate the extraction of more detailed information for image super-resolution [172]. To address super-resolution with limited labeled samples, Xia et al. used soft multi-labels to implement a semi-supervised super-resolution method for person re-identification [173]. That is, first, a GAN is used to conduct an SR model. Second, a graph convolutional network is exploited to construct relationships among the local features of a person. Third, labeled samples are used to train the unlabeled samples via a graph convolutional network.
3.2.2 Semi-Supervised GANs with Improved Loss Functions and Semi-Supervised GANs Based Multi-Tasks for Image Super-Resolution
The combinations of semi-supervised GANs and loss functions are also effective in image super-resolution [174]. For example, Jiang et al. combined an adversarial loss, a cycle-consistency loss, an identity loss, and a joint sparsifying transform loss into a GAN in a semi-supervised way to train a CT image super-resolution model [174]. Although this model made significant progress on some evaluation criteria, it was still disturbed by artifacts and noise.
In terms of multi-tasking, Savioli et al. proposed to use a mixed adversarial Gaussian domain adaptation in a GAN in a semi-supervised way to obtain more useful information for implementing a 3D super-resolution and segmentation [175]. This method achieved better performance on many metrics. More information on semi-supervised GANs in image super-resolution can be illustrated in Table 9.
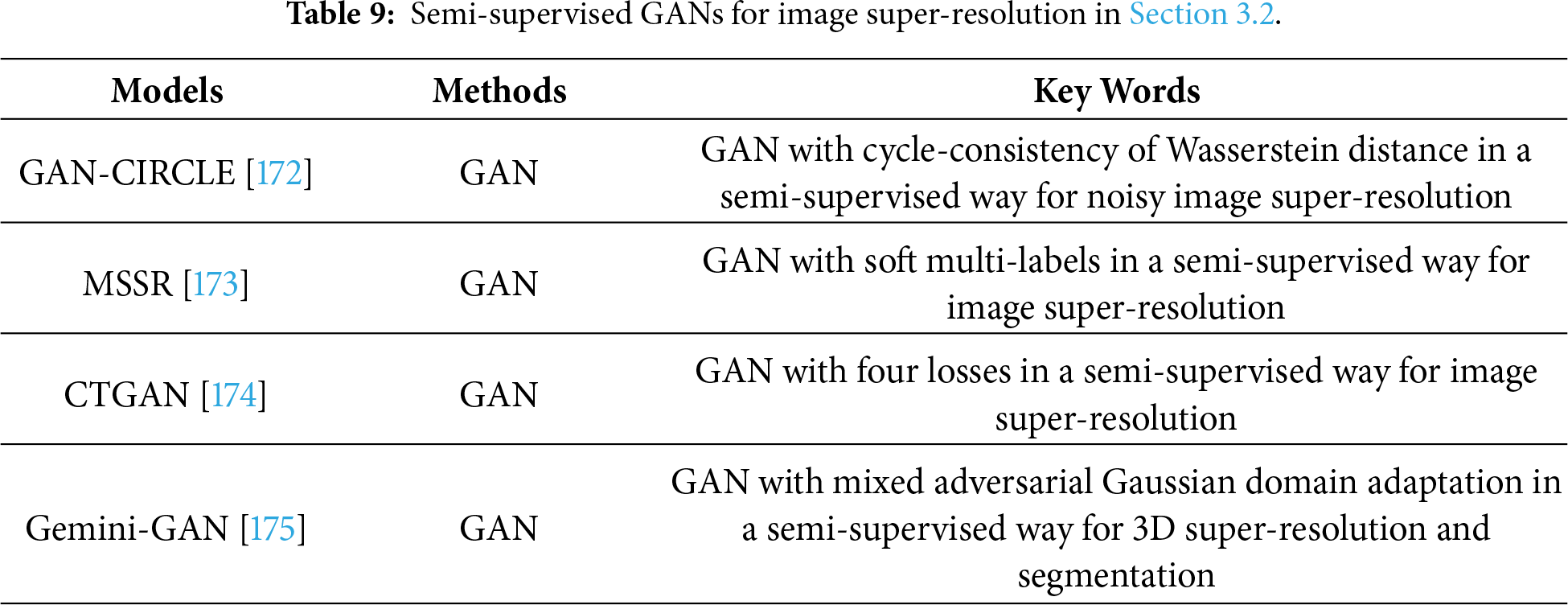
3.3 Unsupervised GANs for Image Super-Resolution
Collected images in the real world have fewer pairs, which poses a challenge for supervised GANs in SISR. To address this phenomenon, unsupervised GANs have been presented [121]. Unsupervised GANs for image super-resolution can be divided into six types: improved architectures, prior knowledge, loss functions, multi-task learning, real image super-resolution, and real-world LR image synthesis in GAN-based unsupervised super-resolution, as follows.
3.3.1 Unsupervised GANs Based Designed Network Architectures for Image Super-Resolution
CycleGANs have obtained success in unsupervised ways in image-to-image translation applications [73]. Accordingly, CycleGANs have been extended into SISR to address unpaired images (i.e., low-resolution and high-resolution) in real-world datasets [121]. Yuan et al. used a CycleGAN for blind super-resolution over the following phases [121]. The first phase removed noise from noisy and low-resolution images. The second phase resorted to an up-sampled operation in a pre-trained deep network to enhance the obtained low-resolution images. The third phase used a fine-tuning mechanism for a GAN to obtain high-resolution images. To address blind super-resolution, bidirectional structural consistency was used in a GAN in an unsupervised way to train a blind SR model and construct high-quality images [57]. Alternatively, Zhang et al. exploited multiple GANs as basis components to implement an improved CycleGAN to train an unsupervised SR model [176]. This method achieves comparable performance with many state-of-the-art supervised models.
There are also other popular methods that use GANs in unsupervised ways for image super-resolution [177]. To improve the learning ability of a SR model in the real world, it combines unsupervised learning and a mean opinion score in a GAN to improve perceptual quality in real-world image super-resolution [177]. To break the fixed downscaling kernel, KernelGAN [47], TVG-KernelGAN [48], and Internal-GAN [178] are used to obtain an internal distribution of patches in the blind image super-resolution. To accelerate the training speed, a guidance module was used in a GAN to quickly seek a correct mapping from a low-resolution domain to a high-resolution domain in unpaired image super-resolution [179]. To improve the accuracy of medical diagnosis, Song et al. used dual GANs in a self-supervised way to mine high-dimensional information for PET image super-resolution [123]. Besides, other SR methods can have an important reference value for unsupervised GANs in terms of image super-resolution. For example, to improve both image synthesis quality and representation learning performance under the unsupervised setting, Wang et al. used an unsupervised method to translate real low-resolution images to real high-resolution images [180]. To achieve better degradation learning and super-resolution performance, Chen et al. resorted to a supervised super-resolution method to convert obtained real low-resolution images into real high-resolution images [181]. In the unsupervised domain, DUS-GAN adopts a dual-discriminator architecture to jointly supervise global content and high-frequency detail generation, thereby improving the fidelity of synthesized images [182]. To promote more stable and reliable training convergence, GF-CWAO-GAN employs the CWAO algorithm to accelerate weight optimization [183]. The FLS-GAN model employs a dual-stream architecture, consisting of an Adaptive Shadow–Highlight Calibration generator and a Near–Far Field Fusion Discriminator, to enable high-fidelity super-resolution reconstruction of deep-sea sonar imagery [184]. The SCGAN model achieves more accurate and robust real-world face super-resolution by establishing a semi-cyclic architecture with two independent degradation branches and a shared restoration branch [185]. More information of mentioned unsupervised GANs for image super-resolution can be shown in Table 10 as follows.
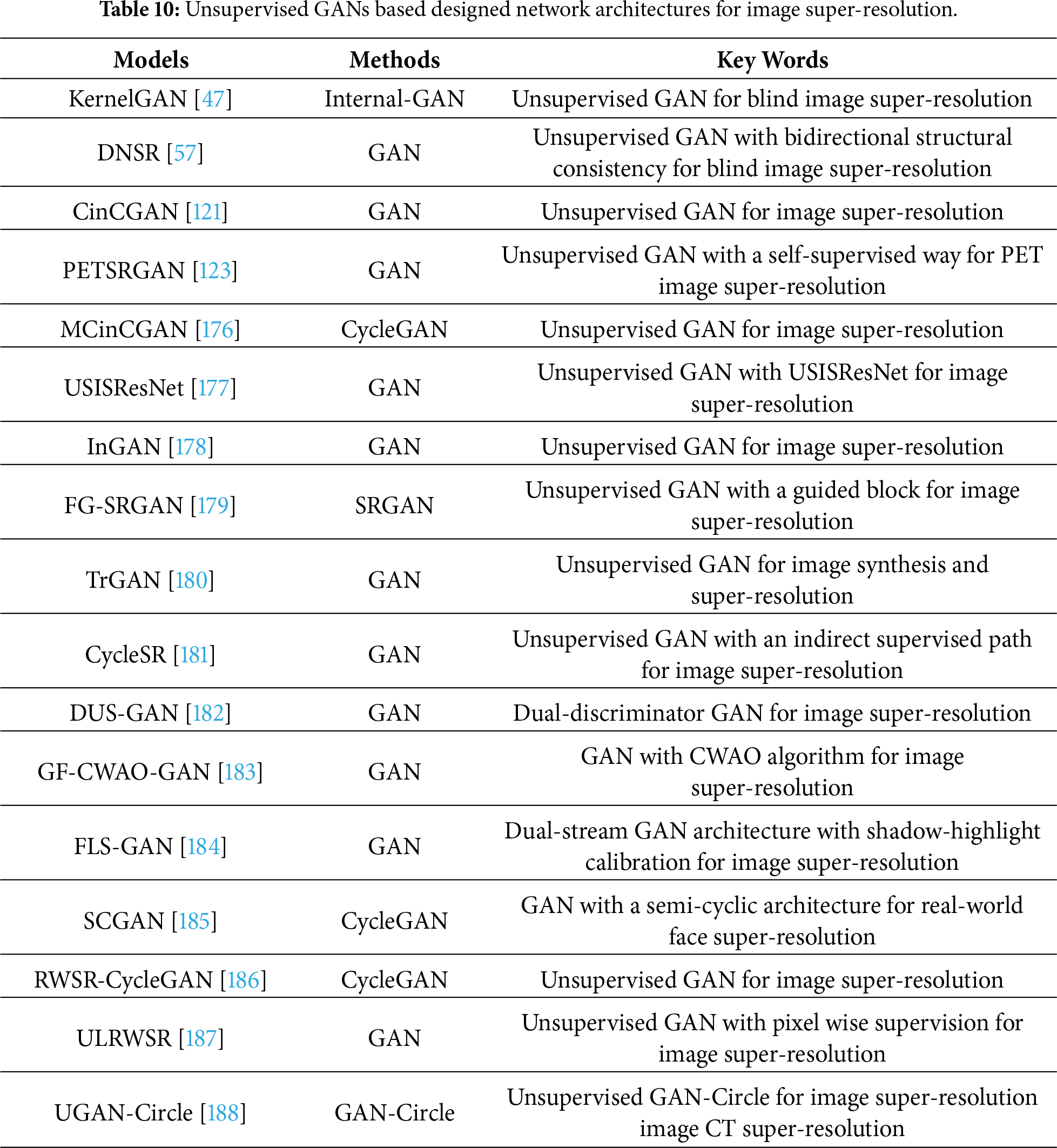
3.3.2 Unsupervised GANs Based Prior Knowledge for Image Super-Resolution
Combining unsupervised GANs and prior knowledge in unsupervised GANs can better address unpaired image super-resolution [189]. Lin et al. combined data error, a regular term, and an adversarial loss to guarantee the consistency of local-global content and pixel faithfulness in a GAN in an unsupervised way to train an image super-resolution model [189]. To better support medical diagnosis, Das et al. combined adversarial learning in a GAN, cycle consistency, and prior knowledge, i.e., identity mapping prior to facilitate more useful information, i.e., spatial correlation, color, and texture information for obtaining cleaner high-quality images [190]. In terms of remote sensing super-resolution, random noise is used in a GAN to reconstruct satellite images [191]. Then, the authors conducted image prior by transforming the reference image into a latent space [191]. Finally, they updated the noise and latent space to transfer the obtained structural information and texture information to improve the resolution of remote sensing images [191].
3.3.3 Unsupervised GANs with Improved Loss Functions for Image Super-Resolution
Combining loss functions and GANs in an unsupervised way is useful for training image super-resolution models in the real world [192]. For instance, Zhang et al. used a novel loss function based on image quality assessment in a GAN to obtain accurate texture information and more visual effects [192]. Besides, an encoder-decoder architecture is embedded in this GAN to mine more structural information for pursuing high-quality images of a generator from this GAN [192]. Han et al. depended on SAGAN and L1 loss in a GAN in an unsupervised manner to analyze multi-sequence structural MRI for detecting brain anomalies [193]. Also, Zhang et al. fused a content loss into a GAN in an unsupervised manner to improve the SR results of hyperspectral images [194]. AOS-GAN incorporates an adaptive weighting network that employs meta-learning to automatically learn dynamic weights for individual loss components, thereby enabling adaptive balancing of objectives and more efficient model optimization [195]. Zhang et al. implemented a frequency-aware adversarial loss and a frequency-aware focal consistency loss to dynamically penalize spectral errors and to place additional emphasis on high-frequency components, thereby enhancing the fidelity of super-resolved images [196]. R2D2-GAN better leverages the information consistency between the two modalities during unsupervised training by adopting a game-theoretic strategy and dynamic adversarial loss [197]. Unsupervised GANs based on prior knowledge and improved loss functions for image super-resolution can be summarized in Table 11.
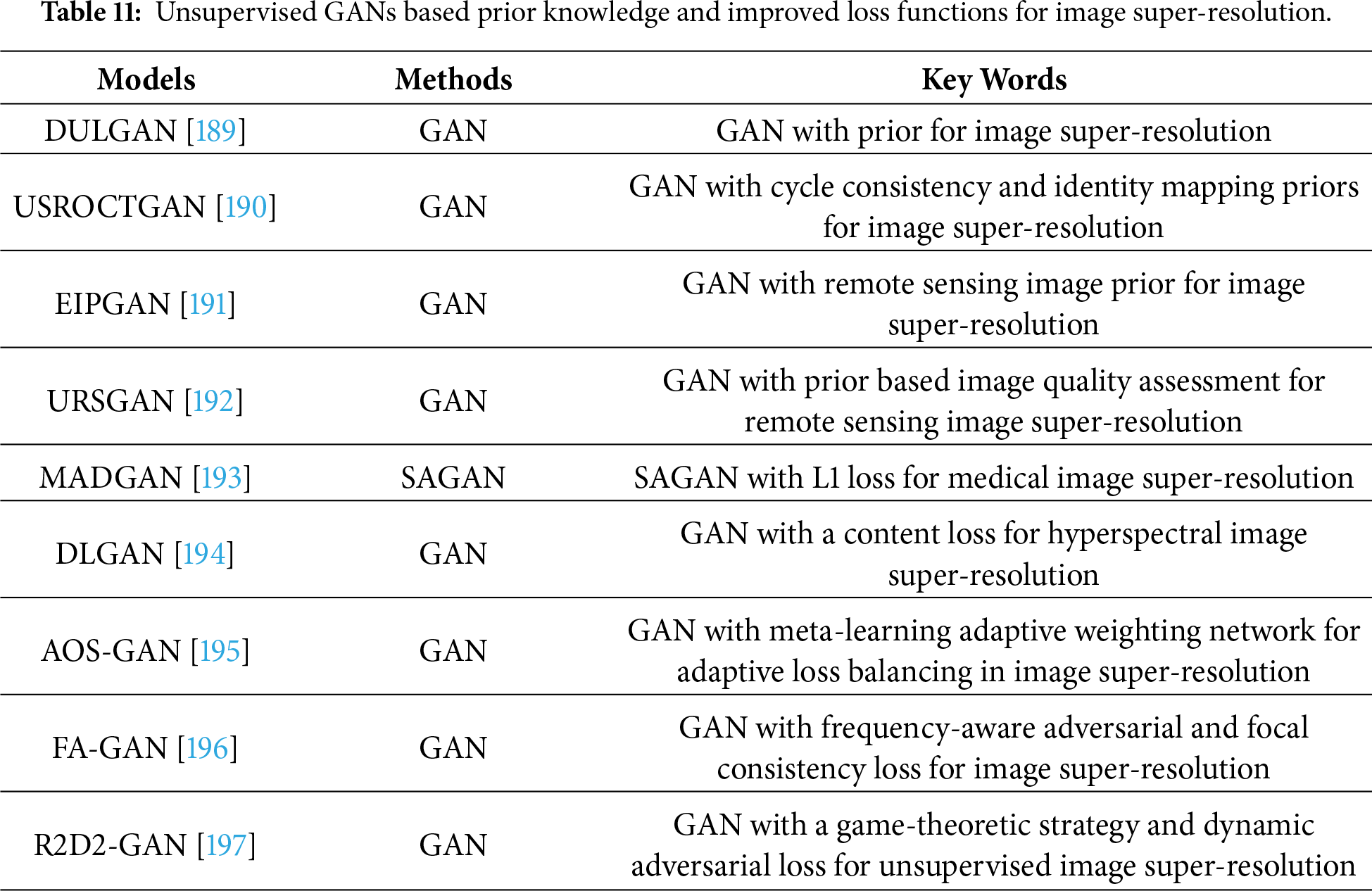
3.3.4 Unsupervised GANs Based Multi-Tasks for Image Super-Resolution
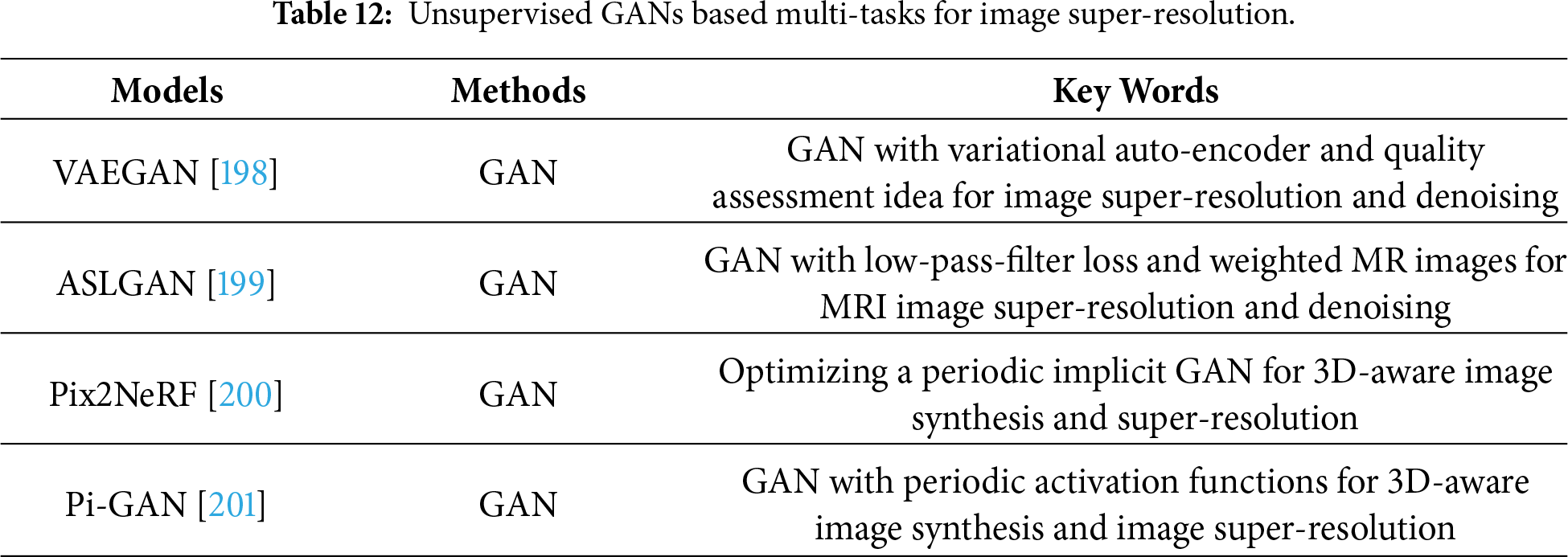
Unsupervised GANs are good tools to address multi-tasking, i.e., noisy low-resolution image super-resolution. For instance, Prajapati et al. transferred a variational auto-encoder and the idea of quality assessment in a GAN to address image denoising and SR tasks [198]. Cui et al. relied on low-pass-filter loss and weighted MR images in an unsupervised GAN to mine texture information for removing noise and recovering the resolution of MRI images [199]. Cai et al. presented a pipeline that optimizes a periodic implicit GAN to obtain neural radiance fields for image synthesis and image super-resolution based on 3D [200]. More unsupervised GANs-based multi-tasking for image super-resolution can be presented in Table 12.
3.3.5 Unsupervised GANs for Real Image Super-Resolution
An important application of GAN-based SR models is dealing with real-world LR images. To eliminate checkerboard artifacts, an upsampling module containing a bilinear interpolation and a transposed convolution was used in an unsupervised CycleGAN to improve the visual effects of restored images in the real world [186]. To recover more natural image characteristics, Lugmayr et al. combined unsupervised and supervised ways for blind image super-resolution [187]. The first step learned to invert the effects of the bicubic downsampling operation in a GAN in an unsupervised way to extract useful information from natural images [187]. To generate image pairs in the real world, the second step used a pixel-wise network in a supervised way to obtain high-resolution images [187]. To remove unpleasing noise and artifacts, Park et al. [202] divided the large and complicated distribution of real-world images into smaller subsets based on similar content. Then, they learned various contents and separable features via multiple discriminators [202]. In terms of computed tomography (CT) images, Li et al. [203] utilized noise injection and a GAN to generate realistic low-resolution images to build training image pairs. This data preprocessing operation enables the proposed KerGAN to generate more precise details and better perceptual quality in medical images [203].
3.3.6 Synthesizing Real World LR Images
An important application of GAN-based SR models is dealing with real-world LR images. So, how to obtain real image pairs with different scale factors to use as training data becomes a problem that we must solve. Starting from SRCNN [23], there are three main ways to prepare super-resolution datasets: synthetic data super-resolution, blind super-resolution, and real image super-resolution. Among them, synthetic data super-resolution is the most common method for data preparation; however, it often exhibits poor generalization due to its inability to account for the complex degradation factors present in real-world scenarios. Therefore, on the basis of the interpolation method, blind super-resolution models add more real-world degradation factors, such as noise, blur, and compression, to the degradation kernel to improve the performance of real-world applications [91,204]. Finally, the best theoretical performance is achieved by directly using a camera to capture real-world images of the same scene at different magnifications. However, in this process, the problem of lens distortion is encountered, which makes image acquisition difficult. Currently, the publicly available real image datasets include RealSR [205] and DRealSR [206].
4 Comparing Performance of GANs for Image Super-Resolution
To make readers understand GANs in image super-resolution more conveniently, we compare the super-resolution performance of these GANs based on datasets and experimental settings, as well as quantitative and qualitative analysis in this section. More information is provided as follows.
The GANs can be divided into three kinds mentioned above for image super-resolution, with datasets correspondingly categorized into three types for both training and testing. These datasets can be summarized as follows.
(1) Supervised GANs for image-resolution
Training datasets: CIFAR10 [207], STL [208], LSUN [209], ImageNet [210], CELEBA [211], DIV2K [212], Flickr2K [213], OST [214], CAT [215] Market-1501 [216], Duke MTMC-reID [217,218], GeoEye-1 satellite dataset [129], Whole slide images (WSIs) [135], MNIST [219] and PASCAL2 [220].
Test datasets: CIFAR10 [207], STL [208], LSUN [209], Set5 [221], Set14 [222], BSD100 [223], CELEBA [211], OST300 [214], CAT [215], PIRM datasets [224], Market-1501 [216], GeoEye-1 satellite dataset [129], WSIs [135] MNIST [219] and PASCAL2 [220].
(2) Semi-supervised GANs for image-resolution
Training datasets: Market-1501 [216], Tibia Dataset [225], Abdominal Dataset [226], CUHK03 [227], MSMT17 [228], LUNA [229], Data Science Bowl 2017 (DSB) [230], UKDHP [231], SG [231] and UKBB [232].
Test datasets: Tibia Dataset [225], Abdominal Dataset [226], CUHK03 [227], Widerface [233], LUNA [229], DSB [230], SG [231] and UKBB [232].
(3) Unsupervised GANs for image-resolution
Training datasets: CIFAR10 [207], ImageNet [210], DIV2K [212], DIV2K random kernel (DIV2KRK) [212], Flickr2K [213], Widerface [233], NTIRE 2020 Real World SR challenge [234], KADID-10K [235], DPED [236], DF2K [114], NTIRE’ 2018 Blind-SR challenge [237], LS3D-W [238], CELEBA-HQ [50], LSUN-BEDROOM [239], ILSVRC2012 [210,240], NTIRE 2020 [234], 91-images [241], Berkeley segmentation [223], BSDS500 [242], Training datasets of USROCTGAN [243,244], SD-OCT dataset [244], UC Merced dataset [245], NWPU-RESIS45 [246] and WHU-RS19 [247].
Test datasets: CIFAR10 [207], ImageNet [210], Set5 [221], Set14 [222], BSD100 [223], DIV2K [212], Urban100 [248], DIV2KRK [212], Widerface [233], NTIRE 2020 [234], NTIRE 2020 Real-world SR Challenge [234], NTIRE 2020 Real World SR challenge [234], DPED [236], CELEBA-HQ [50], LSUN-BEDROOM [239], Test datasets of USROCTGAN [243,244], and Test datasets of USRGAN [192].
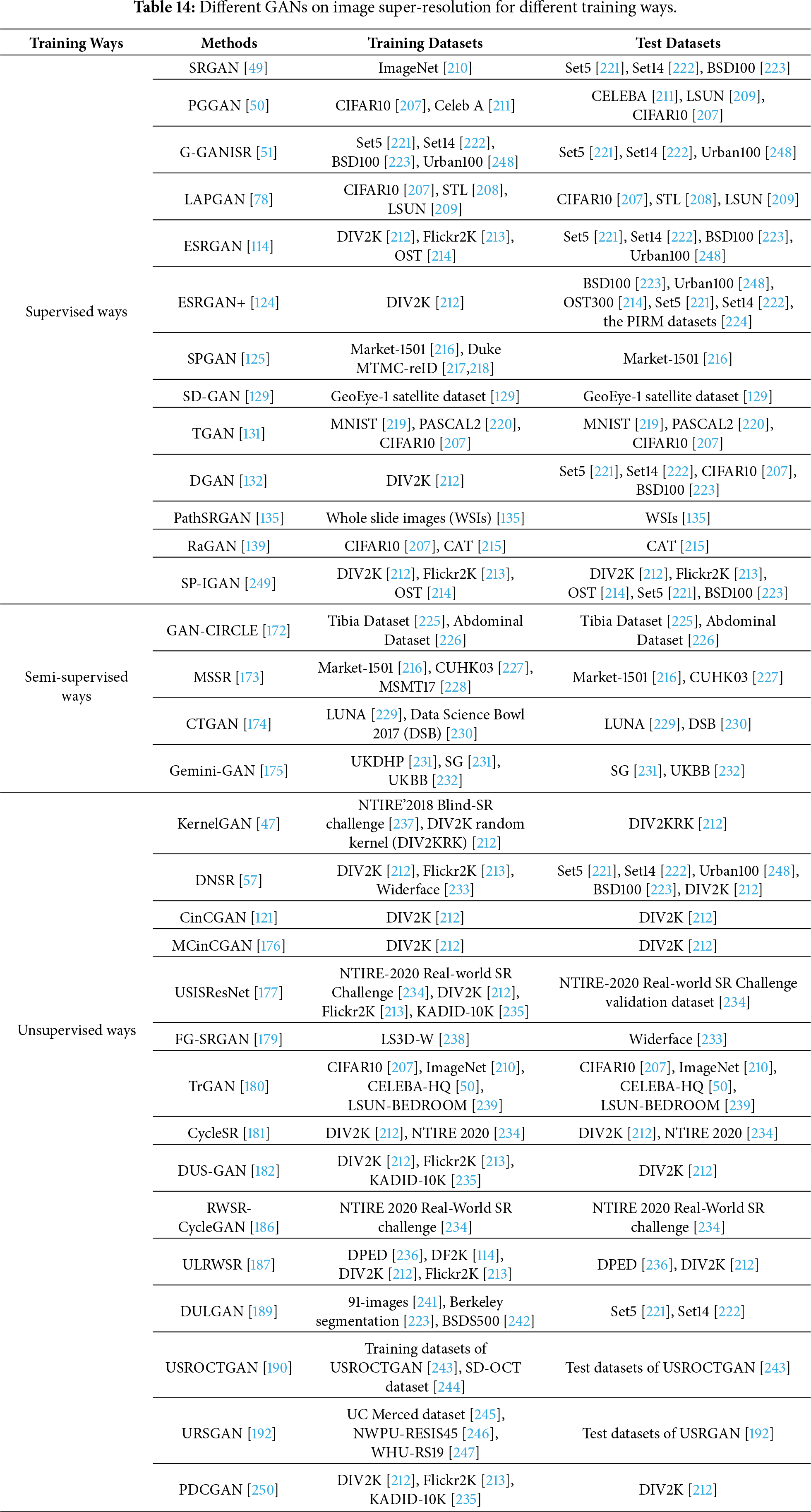
The datasets mentioned regarding GANs for image super-resolution are presented in Table 13. To make readers more easily understand datasets of different methods using various GANs for different training approaches in image super-resolution, we present Table 14 to provide their detailed information.

4.2 Environment Configurations
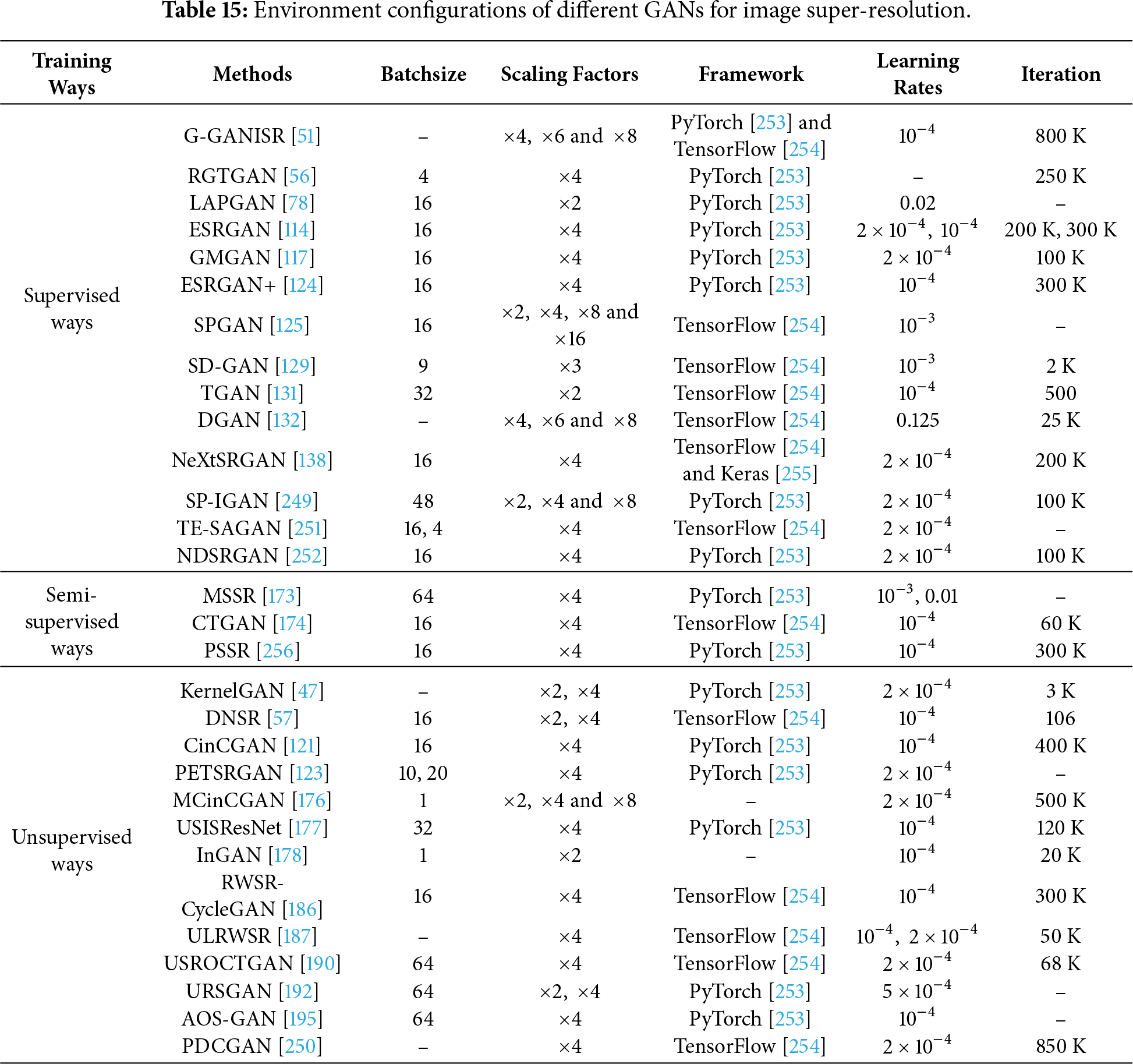
In this section, we compare the differences in environment configurations among different GANs using various training methods (i.e., supervised, semi-supervised, and unsupervised) for image super-resolution, which include batch size, scaling factors, deep learning framework, learning rate, and iterations. This can help readers more easily conduct experiments with GANs for image super-resolution. The information can be summarized as shown in Table 15.
To make readers understand the performance of various GANs in image super-resolution, we use quantitative analysis and qualitative analysis to evaluate the super-resolution effects of these GANs. Quantitative analysis includes PSNR and SSIM of various methods using three training approaches on different datasets for image super-resolution, as well as the running time and complexities of different GANs. Qualitative analysis is used to evaluate the quality of the recovered images.
4.3.1 Quantitative Analysis of Different GANs for Image Super-Resolution
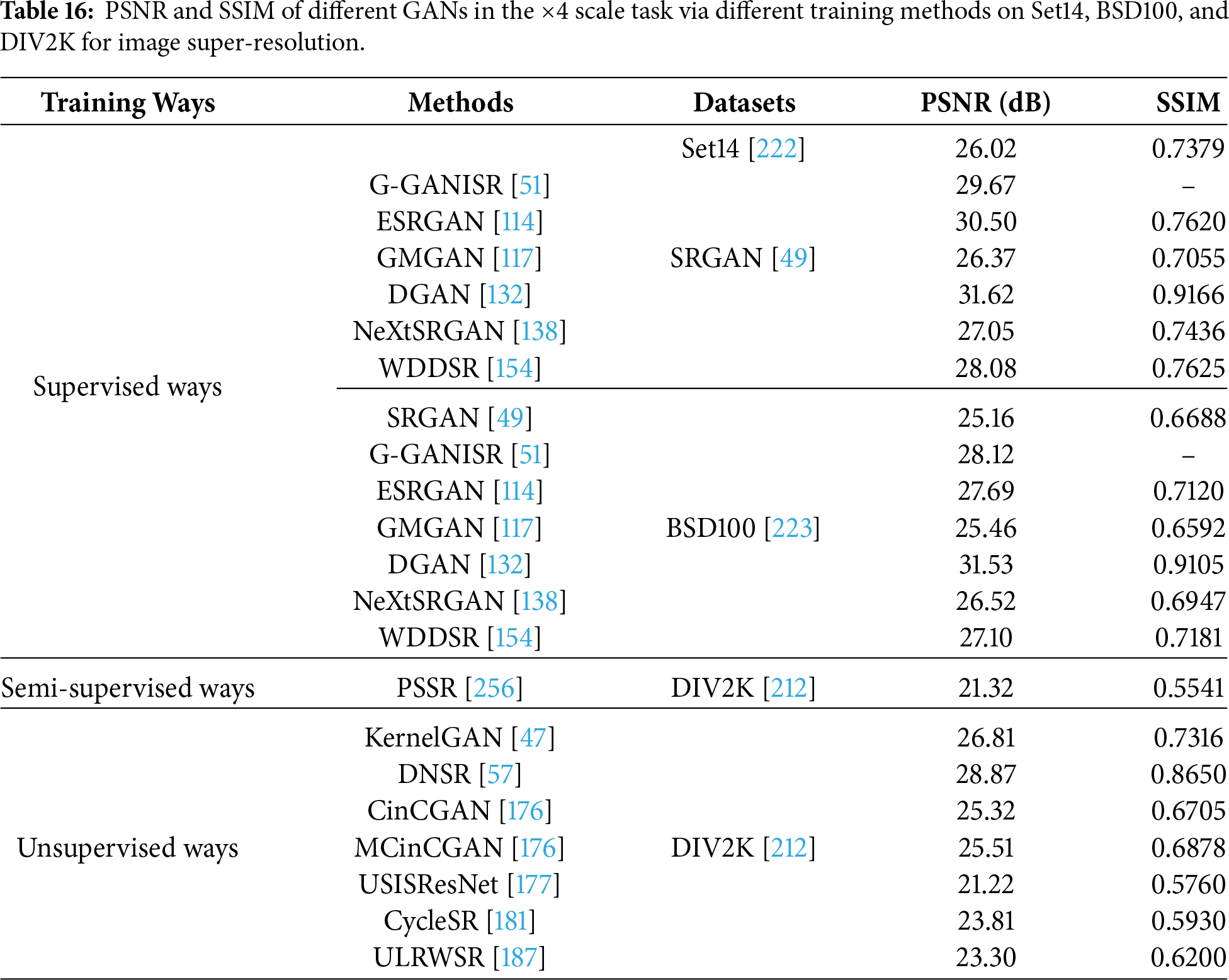
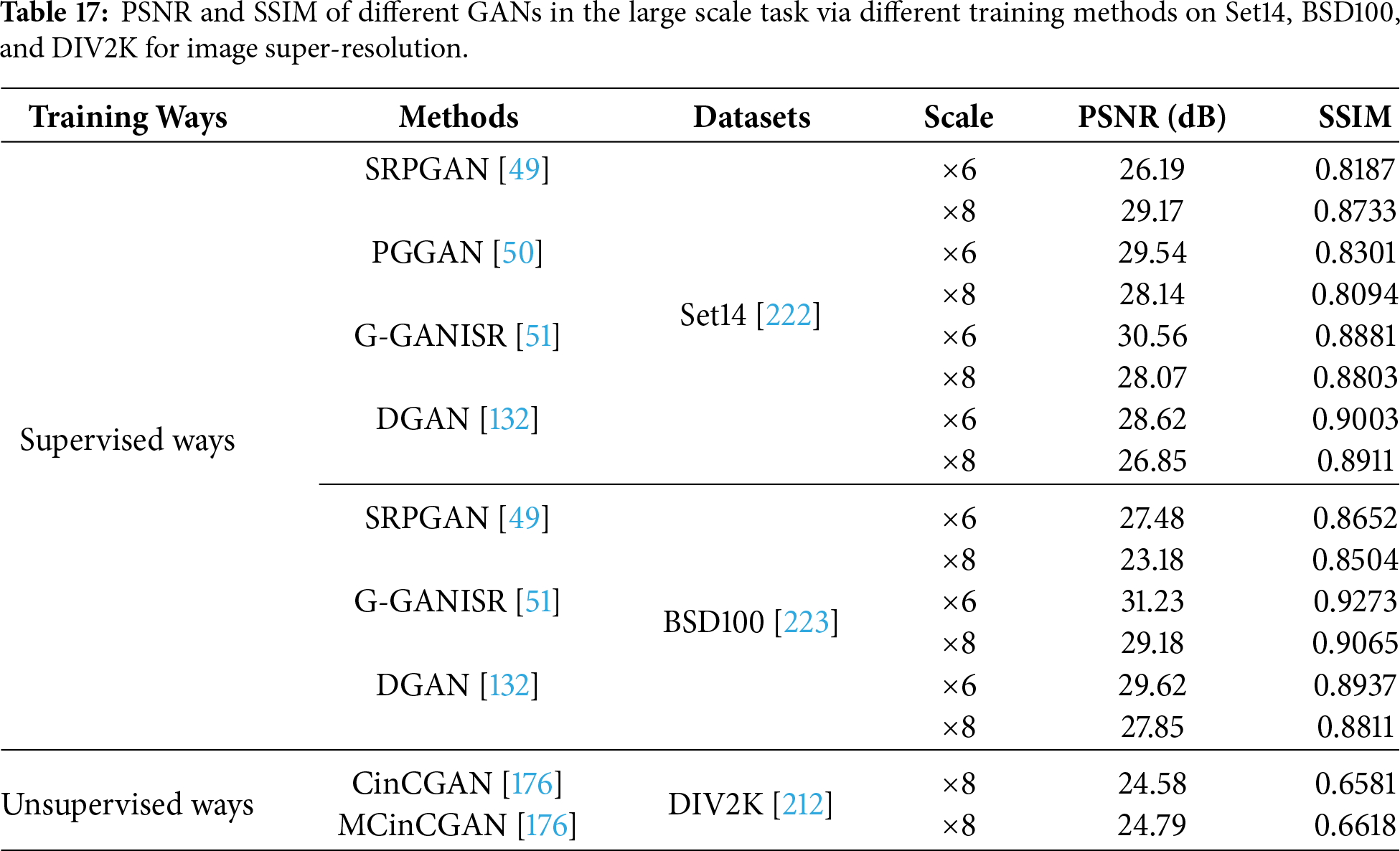
We use SRGAN [49], PGGAN [50], ESRGAN [114], ESRGAN+ [124], DGAN [132], G-GANISR [51], GMGAN [117], SRPGAN [49], DNSR [57], DULGAN [189], CinCGAN [121],MCinCGAN [176], USISResNet [177], ULRWSR [187], KernelGAN [47] and CycleSR [181] in one training way on a public dataset from Set14 [222], BSD100 [223] and DIV2K [212] to test performance for different scales in image super-resolution, as shown in Tables 16 and 17. For instance, ESRGAN [114] outperforms SRGAN [49] in terms of PSNR and SSIM in a supervised manner on Set14 for
Running time and complexity are important indices to evaluate the performance of image super-resolution techniques on real devices [257]. According to that, we conduct experiments with four GANs (i.e., ESRGAN [114], PathSRGAN [135], RankSRGAN [120], and KernelGAN [47]) on two low-resolution images with sizes and for

4.3.2 Qualitative Analysis of Different GANs for Image Super-Resolution
To test the visual effects of different GANs for image super-resolution, we choose Bicubic, ESRGAN [114], RankSRGAN [120], KernelGAN [47], and PathSRGAN [135] to conduct experiments to obtain high-quality images for

Figure 9: Visual images of different GANs on an image of BSD100 for

Figure 10: Visual images of different GANs on an image of Set14 for
5 Challenges and Directions of GANs for Image Super-Resolution
Variations of GANs have achieved excellent performance in image super-resolution. Accordingly, we provide an overview of GANs for image super-resolution to serve as a guide for readers to better understand these methods. In this section, we analyze the challenges faced by current GANs for image super-resolution and provide corresponding solutions to facilitate the development of GANs in image super-resolution.
Although GANs perform well in image super-resolution, they encounter the following challenges:
1) Unstable training. Due to the confrontation between generator and discriminator, GANs are unstable in the training process.
2) Large computational resources and high memory consumption. A GAN is composed of a generator and discriminator, which may increase computational costs and memory consumption. This may lead to a higher demand on digital devices.
3) High-quality images without references. As mentioned in Section 3.3.6, the dependency on paired HR/LR data limits the application of GAN-based super-resolution in real-world scenarios.
4) Complex image super-resolution. Most GANs can deal with a single task, i.e., image super-resolution and synthetic noisy image super-resolution. However, collected images by digital cameras in the real world suffer from drawbacks, i.e., low-resolution and dark-lighting images, complex noisy and low-resolution images. Besides, digital cameras have a higher requirement for the combination of low-resolution images and image recognition. Thus, the existing GANs for image super-resolution cannot effectively repair low-resolution images under the mentioned conditions.
5) Metrics of GANs for image super-resolution. Most of the existing GANs used PSNR and SSIM to test super-resolution performance of GANs. However, PSNR and SSIM cannot fully measure the quality of restored images. Thus, finding effective metrics is very essential for GANs for image super-resolution.
6) GANs are sensitive to hyperparameters and the choice of architecture, which can affect their performance and lead to overfitting.
7) GANs can generate unrealistic artifacts or distortions in the output images, especially in regions with low texture or detail, which can affect the visual quality of the output images.
8) GAN-based image super-resolution methods may not perform well on certain types of images or degradation scenarios.
To address these problems, some potential research points about GANs for image super-resolution are stated below.
1) Enhancing a generator and discriminator extracts salient features to enhance the stability of GANs on image super-resolution. For example, using attention mechanism (i.e., Transformer [258]), residual learning operations, concatenation operations act as the generator and discriminator to extract more effective features to enhance stability, accelerating GAN models in image super-resolution.
2) Designing lightweight GANs for image super-resolution. Reducing convolutional kernels, group convolutions, and combining prior and shallow network architectures can decrease the complexity of GANs for image super-resolution.
3) Using self-supervised methods can obtain high-quality reference images.
4) Combining the attributes of different low-level tasks, along with decomposing complex low-level tasks into a single low-level task via different stages in different GANs, can repair complex low-resolution images, which can help with high-level vision tasks.
5) Using image quality assessment techniques as metrics to evaluate the quality of predicted images from different GANs.
In this paper, we analyze and summarize GANs for image super-resolution. First, we review the development of GANs and popular GANs for image applications; then we give differences of GANs based optimization methods and discriminative learning for image super-resolution in terms of supervised, semi-supervised and unsupervised manners. Next, we compare the performance of these popular GANs on public datasets via quantitative and qualitative analysis in SISR. Then, we highlight challenges of GANs and potential research points on SISR. Finally, we summarize the whole paper.
Acknowledgement: This work was supported in part by the National Natural Science Foundation of China, in part by CAAI-CANN Open Fund developed on OpenI Community, and in part by the Natural Science Foundation of Heilongjiang Province.
Funding Statement: This work was supported in part by the National Natural Science Foundation of China under Grants 62576123, in part by CAAI-CANN Open Fund developed on OpenI Community, and in part by the Natural Science Foundation of Heilongjiang Province under Grant YQ2025F003.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Chunwei Tian; methodology, Ziang Wu and Chunwei Tian; writing—original draft preparation, Ziang Wu, Xuanyu Zhang and Yinbo Yu; writing—review and editing, Qi Zhu, Jerry Chun-Wei Lin and Chunwei Tian. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: All reviewed materials are publicly available and cited, primarily sourced from major academic repositories and publishers including IEEE Xplore, ACM Digital Library, ScienceDirect (Elsevier), SpringerLink, AAAI, Nature, and the arXiv repository.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Wang Z, Chen J, Hoi SC. Deep learning for image super-resolution: a survey. IEEE Trans Pattern Anal Mach Intell. 2020;43(10):3365–87. doi:10.1109/tpami.2020.2982166. [Google Scholar] [PubMed] [CrossRef]
2. Yang W, Zhang X, Tian Y, Wang W, Xue JH, Liao Q. Deep learning for single image super-resolution: a brief review. IEEE Trans Multim. 2019;21(12):3106–21. doi:10.1109/tmm.2019.2919431. [Google Scholar] [CrossRef]
3. Isaac JS, Kulkarni R. Super resolution techniques for medical image processing. In: 2015 International Conference on Technologies for Sustainable Development (ICTSD). Piscataway, NJ, USA: IEEE; 2015. p. 1–6. [Google Scholar]
4. Zhang L, Zhang H, Shen H, Li P. A super-resolution reconstruction algorithm for surveillance images. Signal Process. 2010;90(3):848–59. doi:10.1016/j.sigpro.2009.09.002. [Google Scholar] [CrossRef]
5. Zha Y, Huang Y, Sun Z, Wang Y, Yang J. Bayesian deconvolution for angular super-resolution in forward-looking scanning radar. Sensors. 2015;15(3):6924–46. doi:10.3390/s150306924. [Google Scholar] [PubMed] [CrossRef]
6. Huang Y, Shao L, Frangi AF. Simultaneous super-resolution and cross-modality synthesis of 3D medical images using weakly-supervised joint convolutional sparse coding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 6070–9. [Google Scholar]
7. Cheng T, Bi T, Ji W, Tian C. Graph convolutional network for image restoration: a survey. Mathematics. 2024;12(13):2020. doi:10.3390/math12132020. [Google Scholar] [CrossRef]
8. Tian C, Cheng T, Peng Z, Zuo W, Tian Y, Zhang Q, et al. A survey on deep learning fundamentals. Artif Intell Rev. 2025;58(12):381. doi:10.1007/s10462-025-11368-7. [Google Scholar] [CrossRef]
9. Zhou L, Lu X, Yang L. A local structure adaptive super-resolution reconstruction method based on BTV regularization. Multim Tools Applicat. 2014;71(3):1879–92. doi:10.1007/s11042-012-1311-x. [Google Scholar] [CrossRef]
10. Park SC, Park MK, Kang MG. Super-resolution image reconstruction: a technical overview. IEEE Signal Process Magaz. 2003;20(3):21–36. doi:10.1109/msp.2003.1203207. [Google Scholar] [CrossRef]
11. Rukundo O, Cao H. Nearest neighbor value interpolation. arXiv:1211.1768. 2012. [Google Scholar]
12. Li X, Orchard MT. New edge-directed interpolation. IEEE Trans Image Process. 2001;10(10):1521–7. [Google Scholar] [PubMed]
13. Keys R. Cubic convolution interpolation for digital image processing. IEEE Trans Acoust Speech Signal Process. 1981;29(6):1153–60. doi:10.1109/tassp.1981.1163711. [Google Scholar] [CrossRef]
14. Hardeep P, Swadas PB, Joshi M. A survey on techniques and challenges in image super resolution reconstruction. Int J Comput Sci Mobile Comput. 2013;2(4):317–25. doi:10.32657/10356/58567. [Google Scholar] [CrossRef]
15. Stark H, Oskoui P. High-resolution image recovery from image-plane arrays, using convex projections. JOSA A. 1989;6(11):1715–26. doi:10.1364/srs.1989.wc4. [Google Scholar] [CrossRef]
16. Elad M, Feuer A. Restoration of a single superresolution image from several blurred, noisy, and undersampled measured images. IEEE Trans Image Process. 1997;6(12):1646–58. doi:10.1109/83.650118. [Google Scholar] [PubMed] [CrossRef]
17. Irani M, Peleg S. Improving resolution by image registration. CVGIP Graph Models Image Process. 1991;53(3):231–9. [Google Scholar]
18. Sun J, Xu Z, Shum HY. Image super-resolution using gradient profile prior. In: 2008 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2008. p. 1–8. [Google Scholar]
19. Yan Q, Xu Y, Yang X, Nguyen TQ. Single image superresolution based on gradient profile sharpness. IEEE Trans Image Process. 2015;24(10):3187–202. doi:10.1109/tip.2015.2414877. [Google Scholar] [PubMed] [CrossRef]
20. Nasrollahi K, Moeslund TB. Super-resolution: a comprehensive survey. Mach Vis Appl. 2014;25(6):1423–68. doi:10.1007/s00138-014-0623-4. [Google Scholar] [CrossRef]
21. Guo H, Li J, Gao G, Li Z, Zeng T. PFT-SSR: parallax fusion transformer for stereo image super-resolution. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Piscataway, NJ, USA: IEEE; 2023. p. 1–5. [Google Scholar]
22. Gao G, Xu Z, Li J, Yang J, Zeng T, Qi GJ. CTCNET: a CNN-transformer cooperation network for face image super-resolution. IEEE Trans Image Process. 2023;32:1978–91. [Google Scholar] [PubMed]
23. Dong C, Loy CC, He K, Tang X. Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell. 2015;38(2):295–307. doi:10.1109/tpami.2015.2439281. [Google Scholar] [PubMed] [CrossRef]
24. Kim J, Lee JK, Lee KM. Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2016. p. 1646–54. [Google Scholar]
25. Tai Y, Yang J, Liu X. Image super-resolution via deep recursive residual network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 3147–55. [Google Scholar]
26. Lim B, Son S, Kim H, Nah S, Mu Lee K. Enhanced deep residual networks for single image super-resolution. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2017. p. 136–44. [Google Scholar]
27. Wang Z, Liu D, Yang J, Han W, Huang T. Deep networks for image super-resolution with sparse prior. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2015. p. 370–8. [Google Scholar]
28. Dong C, Loy CC, Tang X. Accelerating the super-resolution convolutional neural network. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2016. p. 391–407. [Google Scholar]
29. Tian C, Zhang Y, Zuo W, Lin CW, Zhang D, Yuan Y. A heterogeneous group CNN for image super-resolution. IEEE Trans Neural Netw Learn Syst. 2024;35(5):6507–19. doi:10.1109/tnnls.2022.3210433. [Google Scholar] [PubMed] [CrossRef]
30. Lai WS, Huang JB, Ahuja N, Yang MH. Deep laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 624–32. [Google Scholar]
31. Tian C, Song M, Fan X, Zheng X, Zhang B, Zhang D. A tree-guided CNN for image super-resolution. IEEE Trans Consumer Electr. 2025;71(2):3631–40. doi:10.1109/tce.2025.3572732. [Google Scholar] [CrossRef]
32. Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y. Image super-resolution using very deep residual channel attention networks. In: Proceedings of the European Conference on Computer Vision (ECCV). Cham, Switzerland: Springer; 2018. p. 286–301. [Google Scholar]
33. Tian C, Zhang X, Zhang Q, Yang M, Ju Z. Image super-resolution via dynamic network. arXiv:2310.10413. 2024. [Google Scholar]
34. Tian C, Zhang C, Zhang B, Li Z, Chen CP, Zhang D. A cosine network for image super-resolution. IEEE Trans Image Proces. 2026;35:305–16. [Google Scholar] [PubMed]
35. Li N, Zhu Z, Wei S, Liu Y. EVASR: edge-based salience-aware super-resolution for enhanced video quality and power efficiency. ACM Trans Multim Comput Commun Appl. 2025;21(9):245. [Google Scholar]
36. Jo Y, Yang S, Kim SJ. Srflow-da: super-resolution using normalizing flow with deep convolutional block. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 364–72. [Google Scholar]
37. Gan Y, Yang C, Ye M, Huang R, Ouyang D. Generative adversarial networks with learnable auxiliary module for image synthesis. ACM Trans Multim Comput Commun Appl. 2025;21(4):1–21. doi:10.1145/3653021. [Google Scholar] [CrossRef]
38. Chira D, Haralampiev I, Winther O, Dittadi A, Liévin V. Image super-resolution with deep variational autoencoders. In: 2022 European Conference on Computer Vision. Cham, Switzerland: Springer; 2022. p. 395–411. [Google Scholar]
39. Dhanusha PB, Muthukumar A, Lakshmi A. Deep feature blend attention: a new frontier in super resolution image generation. Neurocomputing. 2025;618:128989. doi:10.1016/j.neucom.2024.128989. [Google Scholar] [CrossRef]
40. Moser BB, Shanbhag AS, Raue F, Frolov S, Palacio S, Dengel A. Diffusion models, image super-resolution, and everything: a survey. IEEE Trans Neural Netw Learn Syst. 2025;36(7):11793–813. doi:10.1109/tnnls.2024.3476671. [Google Scholar] [PubMed] [CrossRef]
41. Li X, Ren Y, Jin X, Lan C, Wang X, Zeng W, et al. Diffusion models for image restoration and enhancement: a comprehensive survey. Int J Comput Visi. 2025;133(11):8078–108. doi:10.1007/s11263-025-02570-9. [Google Scholar] [CrossRef]
42. Kuznedelev D, Startsev V, Shlenskii D, Kastryulin S. Does diffusion beat GAN in image super resolution? arXiv:2405.17261. 2024. [Google Scholar]
43. Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Advances in neural information processing systems. Red Hook, NY, USA: Curran Associates, Inc.; 2014. 27 p. [Google Scholar]
44. Wang Z, She Q, Ward TE. Generative adversarial networks in computer vision: a survey and taxonomy. ACM Comput Surv (CSUR). 2021;54(2):1–38. doi:10.1145/3439723. [Google Scholar] [CrossRef]
45. Gui J, Sun Z, Wen Y, Tao D, Ye J. A review on generative adversarial networks: algorithms, theory, and applications. IEEE Trans Knowl Data Eng. 2023;35(4):3313–32. doi:10.1109/tkde.2021.3130191. [Google Scholar] [CrossRef]
46. Nayak AA, Venugopala P, Ashwini B. A systematic review on generative adversarial network (GANchallenges and future directions. Arch Computat Meth Eng. 2024;31(8):4739–72. doi:10.1007/s11831-024-10119-1. [Google Scholar] [CrossRef]
47. Bell-Kligler S, Shocher A, Irani M. Blind super-resolution kernel estimation using an internal-GAN. In: Advances in neural information processing systems. Red Hook, NY, USA: Curran Associates, Inc.; 2019. [Google Scholar]
48. Park J, Kim H, Kang MG. Kernel estimation using total variation guided GAN for image super-resolution. Sensors. 2023;23(7):3734. doi:10.3390/s23073734. [Google Scholar] [PubMed] [CrossRef]
49. Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, et al. Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 4681–90. [Google Scholar]
50. Karras T, Aila T, Laine S, Lehtinen J. Progressive growing of GANs for improved quality, stability, and variation. arXiv:1710.10196. 2017. [Google Scholar]
51. Shamsolmoali P, Zareapoor M, Wang R, Jain DK, Yang J. G-GANISR: gradual generative adversarial network for image super resolution. Neurocomputing. 2019;366(4):140–53. doi:10.1016/j.neucom.2019.07.094. [Google Scholar] [CrossRef]
52. Wei Z, Huang Y, Chen Y, Zheng C, Gao J. A-ESRGAN: training real-world blind super-resolution with attention U-Net Discriminators. In: PRICAI 2023: trends in artificial intelligence (PRICAI 2023). Singapore: Springer; 2023. p. 16–27. doi:10.1007/978-981-99-7025-4_2. [Google Scholar] [CrossRef]
53. Lee OY, Shin YH, Kim JO. Multi-perspective discriminators-based generative adversarial network for image super resolution. IEEE Access. 2019;7:136496–510. doi:10.1109/access.2019.2942779. [Google Scholar] [CrossRef]
54. Wang Y, Hu Y, Yu J, Zhang J. GAN prior based null-space learning for consistent super-resolution. arXiv:2211.13524. 2022. [Google Scholar]
55. Zhao J, Ma Y, Chen F, Shang E, Yao W, Zhang S, et al. SA-GAN: a second order attention generator adversarial network with region aware strategy for real satellite images super resolution reconstruction. Remote Sens. 2023;15(5):1391. doi:10.3390/rs15051391. [Google Scholar] [CrossRef]
56. Tu Z, Yang X, He X, Yan J, Xu T. RGTGAN: reference-based gradient-assisted texture-enhancement GAN for remote sensing super-resolution. IEEE Trans Geosci Remote Sens. 2024;62:1–21. [Google Scholar]
57. Zhao T, Ren W, Zhang C, Ren D, Hu Q. Unsupervised degradation learning for single image super-resolution. arXiv:1812.04240. 2018. [Google Scholar]
58. Jabbar A, Li X, Omar B. A survey on generative adversarial networks: variants, applications, and training. ACM Comput Surv. 2022;54(8):1–49. doi:10.1145/3463475. [Google Scholar] [CrossRef]
59. Creswell A, White T, Dumoulin V, Arulkumaran K, Sengupta B, Bharath AA. Generative adversarial networks: an overview. IEEE Signal Proces Magaz. 2018;35(1):53–65. doi:10.1109/msp.2017.2765202. [Google Scholar] [CrossRef]
60. Xue X, Zhang X, Li H, Wang W. Research on GAN-based image super-resolution method. In: 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA). Piscataway, NJ, USA: IEEE; 2020. p. 602–5. [Google Scholar]
61. Wang X, Sun L, Chehri A, Song Y. A review of GAN-based super-resolution reconstruction for optical remote sensing images. Remote Sens. 2023;15(20):5062. doi:10.3390/rs15205062. [Google Scholar] [CrossRef]
62. Feng H. Review of GAN-based image super-resolution techniques. Theoret Natural Sci. 2024;52(1):146–52. doi:10.54254/2753-8818/52/2024ch0134. [Google Scholar] [CrossRef]
63. Jiang J, Wang C, Liu X, Ma J. Deep learning-based face super-resolution: a survey. ACM Comput Surv (CSUR). 2021;55(1):1–36. doi:10.1145/3485132. [Google Scholar] [CrossRef]
64. Anwar S, Khan S, Barnes N. A deep journey into super-resolution: a survey. ACM Comput Surv (CSUR). 2020;53(3):1–34. doi:10.1145/3390462. [Google Scholar] [CrossRef]
65. Sun J, Xu Z, Shum HY. Gradient profile prior and its applications in image super-resolution and enhancement. IEEE Trans Image Process. 2010;20(6):1529–42. doi:10.1109/tip.2010.2095871. [Google Scholar] [PubMed] [CrossRef]
66. Bird JJ, Barnes CM, Manso LJ, Ekárt A, Faria DR. Fruit quality and defect image classification with conditional GAN data augmentation. Sci Hortic. 2022;293(9):110684. doi:10.1016/j.scienta.2021.110684. [Google Scholar] [CrossRef]
67. Liu H, Wan Z, Huang W, Song Y, Han X, Liao J. PD-GAN: probabilistic diverse GAN for image inpainting. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 9371–81. [Google Scholar]
68. Mirza M, Osindero S. Conditional generative adversarial nets. arXiv:1411.1784. 2014. [Google Scholar]
69. Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv:1511.06434. 2015. [Google Scholar]
70. Donahue J, Krähenbühl P, Darrell T. Adversarial feature learning. arXiv:1605.09782. 2016. [Google Scholar]
71. Hinterstoisser S, Lepetit V, Wohlhart P, Konolige K. On pre-trained image features and synthetic images for deep learning. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV) Workshops. Cham, Switzerland: Springer; 2018. p. 682–97. [Google Scholar]
72. Zhao J, Mathieu M, LeCun Y. Energy-based generative adversarial network. arXiv:1609.03126. 2016. [Google Scholar]
73. Zhu JY, Park T, Isola P, Efros AA. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2017. p. 2223–32. [Google Scholar]
74. Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks. In: International Conference on Machine Learning. London, UK: PMLR; 2017. p. 214–23. [Google Scholar]
75. Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville AC. Improved training of wasserstein GANs. In: Advances in neural information processing systems. Red Hook, NY, USA: Curran Associates, Inc.; 2017. [Google Scholar]
76. Brock A, Donahue J, Simonyan K. Large scale GAN training for high fidelity natural image synthesis. arXiv:1809.11096. 2018. [Google Scholar]
77. Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2019. p. 4401–10. [Google Scholar]
78. Denton EL, Chintala S, Fergus R. Deep generative image models using a laplacian pyramid of adversarial networks. In: Advances in neural information processing systems. Red Hook, NY, USA: Curran Associates, Inc.; 2015. [Google Scholar]
79. Liu MY, Tuzel O. Coupled generative adversarial networks. In: Advances in neural information processing systems. Red Hook, NY, USA: Curran Associates, Inc.; 2016. [Google Scholar]
80. Zhang H, Goodfellow I, Metaxas D, Odena A. Self-attention generative adversarial networks. In: International Conference on Machine Learning. London, UK: PMLR; 2019. p. 7354–63. [Google Scholar]
81. Qi GJ. Loss-sensitive generative adversarial networks on lipschitz densities. Int J Comput Vis. 2020;128(5):1118–40. doi:10.1007/s11263-019-01265-2. [Google Scholar] [CrossRef]
82. Liu MY, Huang X, Mallya A, Karras T, Aila T, Lehtinen J, et al. Few-shot unsupervised image-to-image translation. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2019. p. 10551–60. [Google Scholar]
83. Park T, Liu MY, Wang TC, Zhu JY. Semantic image synthesis with spatially-adaptive normalization. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2019. p. 2337–46. [Google Scholar]
84. Kim J, Kim M, Kang H, Lee K. U-GAT-it: unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. arXiv:1907.10830. 2019. [Google Scholar]
85. Berthelot D, Schumm T, Metz L. Began: boundary equilibrium generative adversarial networks. arXiv:1703.10717. 2017. [Google Scholar]
86. Tian C, Gao H, Wang P, Zhang B. An enhanced GAN for image generation. Comput Mater Contin. 2024;80(1):105–18. doi:10.32604/cmc.2024.052097. [Google Scholar] [CrossRef]
87. Gan Y, Xiang T, Ouyang D, Zhou M, Ye M. SPGAN: siamese projection generative adversarial networks. Knowl Based Syst. 2024;285:111353. [Google Scholar]
88. Li C, Wand M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2016. p. 702–16. [Google Scholar]
89. Bergmann U, Jetchev N, Vollgraf R. Learning texture manifolds with the periodic spatial GAN. arXiv:1705.06566. 2017. [Google Scholar]
90. Jetchev N, Bergmann U, Vollgraf R. Texture synthesis with spatial generative adversarial networks. arXiv:1611.08207. 2016. [Google Scholar]
91. Wang X, Xie L, Dong C, Shan Y. Real-ESRGAN: training real-world blind super-resolution with pure synthetic data. arXiv:2107.10833. 2021. [Google Scholar]
92. Gerdprasert T, Mabu S. Object detection for chest X-ray image diagnosis using deep learning with pseudo labeling. In: 2021 IEEE 12th International Workshop on Computational Intelligence and Applications (IWCIA). Piscataway, NJ, USA: IEEE; 2021. p. 1–5. doi:10.1109/iwcia52852.2021.9626027. [Google Scholar] [CrossRef]
93. Zou Z, Shi Z, Guo Y, Ye J. Object detection in 20 years: a survey. arXiv:1905.05055. 2019. [Google Scholar]
94. Ehsani K, Mottaghi R, Farhadi A. Segan: segmenting and generating the invisible. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2018. p. 6144–53. [Google Scholar]
95. Li J, Liang X, Wei Y, Xu T, Feng J, Yan S. Perceptual generative adversarial networks for small object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 1222–30. [Google Scholar]
96. Bai Y, Zhang Y, Ding M, Ghanem B. Sod-MTGAN: small object detection via multi-task generative adversarial network. In: Proceedings of the European Conference on Computer Vision (ECCV). Cham, Switzerland: Springer; 2018. p. 206–21. [Google Scholar]
97. Bosquet B, Cores D, Seidenari L, Brea VM, Mucientes M, Bimbo AD. A full data augmentation pipeline for small object detection based on generative adversarial networks. Pattern Recognit. 2023;133(3):108998. doi:10.1016/j.patcog.2022.108998. [Google Scholar] [CrossRef]
98. Yuan QL, Zhang HL. RAMT-GAN: realistic and accurate makeup transfer with generative adversarial network. Image Vis Comput. 2022;120:104400. [Google Scholar]
99. Isola P, Zhu JY, Zhou T, Efros AA. Image-to-image translation with conditional adversarial networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 1125–34. [Google Scholar]
100. Chang B, Zhang Q, Pan S, Meng L. Generating handwritten Chinese characters using cyclegan. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Piscataway, NJ, USA: IEEE; 2018. p. 199–207. [Google Scholar]
101. Chen H, Guan M, Li H. ArCycleGAN: improved CycleGAN for style transferring of fruit images. IEEE Access. 2021;9:46776–87. [Google Scholar]
102. Kim S, Park KH. U-net and residual-based cycle-GAN for improving object transfiguration performance. J Korea Robot Soc. 2018;13(1):1–7. doi:10.7746/jkros.2018.13.1.001. [Google Scholar] [CrossRef]
103. You Q, Wan C, Sun J, Shen J, Ye H, Yu Q. Fundus image enhancement method based on CycleGAN. In: 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Piscataway, NJ, USA: IEEE; 2019. p. 4500–3. [Google Scholar]
104. Xie B, Wang N, Fan Y. Correlation alignment total variation model and algorithm for style transfer. J Image Graph. 2020;25(2):241–54. doi:10.11834/jig.190199. [Google Scholar] [CrossRef]
105. Luo Y, Chen Z, Lu B, Huang Y, Fu Q, Qin S, et al. Style transfer image steganography based on GANs with frequency domain attention and autoencoder networks. Appl Soft Comput. 2026;188(11):114440. doi:10.1016/j.asoc.2025.114440. [Google Scholar] [CrossRef]
106. Cowie R, Douglas-Cowie E, Tsapatsoulis N, Votsis G, Kollias S, Fellenz W, et al. Emotion recognition in human-computer interaction. IEEE Signal Process Magaz. 2001;18(1):32–80. doi:10.1109/79.911197. [Google Scholar] [CrossRef]
107. Guillemot C, Le Meur O. Image inpainting: overview and recent advances. IEEE Signal Process Magaz. 2013;31(1):127–44. [Google Scholar]
108. Elharrouss O, Almaadeed N, Al-Maadeed S, Akbari Y. Image inpainting: a review. Neural Process Letters. 2020;51(2):2007–28. doi:10.1007/s11063-019-10163-0. [Google Scholar] [CrossRef]
109. Demir U, Unal G. Patch-based image inpainting with generative adversarial networks. arXiv:1803.07422. 2018. [Google Scholar]
110. Li Y, Liu S, Yang J, Yang MH. Generative face completion. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 3911–9. [Google Scholar]
111. Zhang X, Wang X, Shi C, Yan Z, Li X, Kong B, et al. De-GAN: domain embedded GAN for high quality face image inpainting. Pattern Recognit. 2022;124:108415. doi:10.1016/j.patcog.2021.108415. [Google Scholar] [CrossRef]
112. Yu J, Lin Z, Yang J, Shen X, Lu X, Huang TS. Generative image inpainting with contextual attention. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2018. p. 5505–14. [Google Scholar]
113. Shen L, Yan J, Sun X, Li B, Pan Z. Wavelet-based self-attention GAN with collaborative feature fusion for image inpainting. IEEE Trans Emerg Topics Computat Intell. 2023;7(6):1651–64. doi:10.1109/tetci.2023.3263200. [Google Scholar] [CrossRef]
114. Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, et al. ESRGAN: enhanced super-resolution generative adversarial networks. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV) Workshops. Cham, Switzerland: Springer; 2018. p. 63–79. [Google Scholar]
115. Xu M, Wang Z, Zhu J, Jia X, Jia S. Multi-attention generative adversarial network for remote sensing image super-resolution. arXiv:2107.06536. 2021. [Google Scholar]
116. Jiang N, Zhao W, Wang H, Luo H, Chen Z, Zhu J. Lightweight Super-resolution generative adversarial network for SAR images. Remote Sens. 2024;16(10):1788. doi:10.3390/rs16101788. [Google Scholar] [CrossRef]
117. Zhu X, Zhang L, Zhang L, Liu X, Shen Y, Zhao S. GAN-based image super-resolution with a novel quality loss. Math Probl Eng. 2020;2020:5217429. doi:10.1109/ispacs48206.2019.8986250. [Google Scholar] [CrossRef]
118. Fuoli D, Van Gool L, Timofte R. Fourier space losses for efficient perceptual image super-resolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2021. p. 2360–9. [Google Scholar]
119. Tu J, Mei G, Ma Z, Piccialli F. SWCGAN: generative adversarial network combining swin transformer and CNN for remote sensing image super-resolution. IEEE J Select Topics Appl Earth Observat Remote Sens. 2022;15:5662–73. [Google Scholar]
120. Zhang W, Liu Y, Dong C, Qiao Y. Ranksrgan: generative adversarial networks with ranker for image super-resolution. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2019. p. 3096–105. [Google Scholar]
121. Yuan Y, Liu S, Zhang J, Zhang Y, Dong C, Lin L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2018. p. 701–10. [Google Scholar]
122. Guan J, Pan C, Li S, Yu D. SRDGAN: learning the noise prior for super resolution with dual generative adversarial networks. arXiv:1903.11821. 2019. [Google Scholar]
123. Mahapatra D, Bozorgtabar B, Hewavitharanage S, Garnavi R. Image super resolution using generative adversarial networks and local saliency maps for retinal image analysis. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham, Switzerland: Springer; 2017. p. 382–90. [Google Scholar]
124. Rakotonirina NC, Rasoanaivo A. ESRGAN+: further improving enhanced super-resolution generative adversarial network. In: ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Piscataway, NJ, USA: IEEE; 2020. p. 3637–41. [Google Scholar]
125. Zhang M, Ling Q. Supervised pixel-wise GAN for face super-resolution. IEEE Trans Multim. 2020;23:1938–50. doi:10.1109/tmm.2020.3006414. [Google Scholar] [CrossRef]
126. Gong Y, Liao P, Zhang X, Zhang L, Chen G, Zhu K, et al. Enlighten-GAN for super resolution reconstruction in mid-resolution remote sensing images. Remote Sens. 2021;13(6):1104. doi:10.3390/rs13061104. [Google Scholar] [CrossRef]
127. Dharejo FA, Deeba F, Zhou Y, Das B, Jatoi MA, Zawish M, et al. TWIST-GAN: towards wavelet transform and transferred GAN for spatio-temporal single image super resolution. ACM Trans Intell Syst Technol (TIST). 2021;12(6):1–20. [Google Scholar]
128. Moustafa MS, Sayed SA. Satellite imagery super-resolution using squeeze-and-excitation-based GAN. Int J Aeron Space Sci. 2021;22(6):1481–92. doi:10.1007/s42405-021-00396-6. [Google Scholar] [CrossRef]
129. Ma J, Zhang L, Zhang J. SD-GAN: saliency-discriminated GAN for remote sensing image superresolution. IEEE Geosci Remote Sens Letters. 2019;17(11):1973–7. doi:10.1109/lgrs.2019.2956969. [Google Scholar] [CrossRef]
130. Ko S, Dai BR. Multi-laplacian GAN with edge enhancement for face super resolution. In: 2020 25th International Conference on Pattern Recognition (ICPR). Piscataway, NJ, USA: IEEE; 2021. p. 3505–12. [Google Scholar]
131. Ding Z, Liu XY, Yin M, Kong L. TGAN: deep tensor generative adversarial nets for large image generation. arXiv:1901.09953. 2019. [Google Scholar]
132. Zareapoor M, Celebi ME, Yang J. Diverse adversarial network for image super-resolution. Signal Process Image Commun. 2019;74(4):191–200. doi:10.1016/j.image.2019.02.008. [Google Scholar] [CrossRef]
133. Xing H, Bao M, Li Y, Shi L, Xing M. Deep mutual GAN for life-detection radar super resolution. IEEE Geosci Remote Sens Letters. 2021;19:1–5. doi:10.1109/lgrs.2021.3065696. [Google Scholar] [CrossRef]
134. Zhu L, Wu R, Lee BG, Nkenyereye L, Chung WY, Xu G. FEGAN: a feature-oriented enhanced GAN for enhancing thermal image super-resolution. IEEE Signal Process Letters. 2024;31:541–5. [Google Scholar]
135. Ma J, Yu J, Liu S, Chen L, Li X, Feng J, et al. PathSRGAN: multi-supervised super-resolution for cytopathological images using generative adversarial network. IEEE Trans Med Imag. 2020;39(9):2920–30. doi:10.1109/tmi.2020.2980839. [Google Scholar] [PubMed] [CrossRef]
136. Cheng W, Zhao M, Ye Z, Gu S. Mfagan: a compression framework for memory-efficient on-device super-resolution GAN. arXiv:2107.12679. 2021. [Google Scholar]
137. Shi Y, Han L, Han L, Chang S, Hu T, Dancey D. A latent encoder coupled generative adversarial network (LE-GAN) for efficient hyperspectral image super-resolution. IEEE Trans Geosci Remote Sens. 2022;60(12):1–19. doi:10.1109/tgrs.2022.3193441. [Google Scholar] [CrossRef]
138. Park SW, Jung SH, Sim CB. NeXtSRGAN: enhancing super-resolution GAN with ConvNeXt discriminator for superior realism. Visual Comput. 2025;41(10):7141–67. doi:10.1007/s00371-024-03797-2. [Google Scholar] [CrossRef]
139. Jolicoeur-Martineau A. The relativistic discriminator: a key element missing from standard GAN. arXiv:1807.00734. 2018. [Google Scholar]
140. Kim Y, Son D. Noise conditional flow model for learning the super-resolution space. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 424–32. [Google Scholar]
141. Li W, Zhou K, Qi L, Lu L, Jiang N, Lu J, et al. Best-buddy GANs for highly detailed image super-resolution. arXiv:2103.15295. 2021. [Google Scholar]
142. Xia Y, Ravikumar N, Greenwood JP, Neubauer S, Petersen SE, Frangi AF. Super-resolution of cardiac MR cine imaging using conditional GANs and unsupervised transfer learning. Med Image Anal. 2021;71(1):102037. doi:10.1016/j.media.2021.102037. [Google Scholar] [PubMed] [CrossRef]
143. Demiray BZ, Sit M, Demir I. D-SRGAN: DEM super-resolution with generative adversarial networks. SN Comput Sci. 2021;2(1):1–11. [Google Scholar]
144. Ma Y, Liu K, Xiong H, Fang P, Li X, Chen Y, et al. Medical image super-resolution using a relativistic average generative adversarial network. Nuclear Instrum Meth Phys Res Sect A Accelerat Spectrom Detect Assoc Equip. 2021;992(11):165053. doi:10.1016/j.nima.2021.165053. [Google Scholar] [CrossRef]
145. Wang Z, Tan H, Wang Z, Ci J, Zhai H. MAF-GAN: a multi-attention fusion generative adversarial network for remote sensing image super-resolution. Remote Sens. 2025;17(24):3959. doi:10.3390/rs17243959. [Google Scholar] [CrossRef]
146. Du W, Tian S. Transformer and GAN-based super-resolution reconstruction network for medical images. Tsinghua Sci Technol. 2024;29:197–206. [Google Scholar]
147. Ma C. Uncertainty-aware GAN for single image super resolution. In: AAAI’24/IAAI’24/EAAI’24: Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto, CA, USA: AAAI Press; 2024. p. 4071–9. [Google Scholar]
148. Kong Y, Liu S. DMSC-GAN: a c-GAN-based framework for super-resolution reconstruction of SAR images. Remote Sens. 2024;16(1):50. [Google Scholar]
149. Zhong T, Yang F, Dong X, Dong S, Luo Y. SHBGAN: hybrid bilateral attention GAN for seismic image super-resolution reconstruction. IEEE Trans Geosci Remote Sens. 2024;62:5934312. doi:10.1109/tgrs.2024.3492142. [Google Scholar] [CrossRef]
150. Zhang Z, Feng W, Zhong M, Yang M. BD-VITGAN: a blind dense VITGAN for satellite remote sensing images super-resolution reconstruction. Geo-Spat Inf Sci. 2025:1–23. doi:10.1080/10095020.2025.2567568. [Google Scholar] [CrossRef]
151. Zhang K, Zuo W, Gu S, Zhang L. Learning deep CNN denoiser prior for image restoration. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 3929–38. [Google Scholar]
152. Chan KC, Wang X, Xu X, Gu J, Loy CC. Glean: generative latent bank for large-factor image super-resolution. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 14245–54. [Google Scholar]
153. Liu S, Yang Y, Li Q, Feng H, Xu Z, Chen Y, et al. Infrared image super resolution using GAN with infrared image prior. In: 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP). Piscataway, NJ, USA: IEEE; 2019. p. 1004–9. [Google Scholar]
154. Xu Y, Zhou Y, Ma H, Yang H, Wang H, Zhang S, et al. Wavelet-based dual discriminator GAN for image super-resolution. Knowl Based Syst. 2025;317(11):113383. doi:10.1016/j.knosys.2025.113383. [Google Scholar] [CrossRef]
155. Deng F, Wang S, Yang J. Region-aware discriminative learning GAN for super-resolution reconstruction of infrared imagery. Neurocomputing. 2025;639(8):130202. doi:10.2139/ssrn.5038995. [Google Scholar] [CrossRef]
156. Song J, Yi H, Xu W, Li B, Li X. Gram-GAN: image super-resolution based on gram matrix and discriminator perceptual loss. Sensors. 2023;23(4):2098. doi:10.3390/s23042098. [Google Scholar] [PubMed] [CrossRef]
157. Shahidi F. Breast cancer histopathology image super-resolution using wide-attention GAN with improved wasserstein gradient penalty and perceptual loss. IEEE Access. 2021;9:32795–809. doi:10.1109/access.2021.3057497. [Google Scholar] [CrossRef]
158. Shahsavari A, Ranjbari S, Khatibi T. Proposing a novel cascade ensemble super resolution generative adversarial network (CESR-GAN) method for the reconstruction of super-resolution skin lesion images. Inform Med Unlocked. 2021;24(5):100628. doi:10.1016/j.imu.2021.100628. [Google Scholar] [CrossRef]
159. Ren Z, He L, Lu J. Context aware edge-enhanced GAN for remote sensing image super-resolution. IEEE J Select Topics Appl Earth Observat Remote Sens. 2024;17:1363–76. doi:10.1109/jstars.2023.3333271. [Google Scholar] [CrossRef]
160. Talab MA, Awang S, Najim SADM. Super-low resolution face recognition using integrated efficient sub-pixel convolutional neural network (ESPCN) and convolutional neural network (CNN). In: 2019 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS). Piscataway, NJ, USA: IEEE; 2019. p. 331–5. [Google Scholar]
161. Hu X, Liu X, Wang Z, Li X, Peng W, Cheng G. RTSRGAN: real-time super-resolution generative adversarial networks. In: 2019 Seventh International Conference on Advanced Cloud and Big Data (CBD). Piscataway, NJ, USA: IEEE; 2019. p. 321–6. [Google Scholar]
162. Adil M, Mamoon S, Zakir A, Manzoor MA, Lian Z. Multi scale-adaptive super-resolution person re-identification using GAN. IEEE Access. 2020;8:177351–62. doi:10.1109/access.2020.3023594. [Google Scholar] [CrossRef]
163. Wang Y, Bashir SMA, Khan M, Ullah Q, Wang R, Song Y, et al. Remote sensing image super-resolution and object detection: benchmark and state of the art. Expert Syst Appl. 2022;197(3):116793. doi:10.1016/j.eswa.2022.116793. [Google Scholar] [CrossRef]
164. Zhang M, Liu W, Ma H. Joint license plate super-resolution and recognition in one multi-task GAN framework. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Piscataway, NJ, USA: IEEE; 2018. p. 1443–7. [Google Scholar]
165. Xu MC, Yin F, Liu CL. SRR-GAN: super-resolution based recognition with GAN for low-resolved text images. In: 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR). Piscataway, NJ, USA: IEEE; 2020. p. 1–6. [Google Scholar]
166. Gao G, Tang L, Wu F, Lu H, Yang J. JDSR-GAN: constructing an efficient joint learning network for masked face super-resolution. IEEE Trans Multim. 2023;25:1505–12. doi:10.1109/tmm.2023.3240880. [Google Scholar] [CrossRef]
167. Wang Q, Mahler L, Steiglechner J, Birk F, Scheffler K, Lohmann G. DISGAN: wavelet-informed discriminator guides GAN to MRI super-resolution with noise cleaning. In: 2023 IEEE/CVF International Conference on Computer Vision Workshops, ICCVW. IEEE International Conference on Computer Vision Workshops. Piscataway, NJ, USA: IEEE; 2023. p. 2444–53. [Google Scholar]
168. Li P, Li Z, Pang X, Wang H, Lin W, Wu W. Multi-scale residual denoising GAN model for producing super-resolution CTA images. J Ambient Intell Human Comput. 2022;13(3):1515–24. doi:10.1007/s12652-021-03009-y. [Google Scholar] [CrossRef]
169. Nneji GU, Cai J, Monday HN, Hossin MA, Nahar S, Mgbejime GT, et al. Fine-tuned siamese network with modified enhanced super-resolution GAN plus based on low-quality chest X-ray images for COVID-19 identification. Diagnostics. 2022;12(3):717. doi:10.3390/diagnostics12030717. [Google Scholar] [PubMed] [CrossRef]
170. Tampubolon H, Setyoko A, Purnamasari F. SNPE-SRGAN: lightweight generative adversarial networks for single-image super-resolution on mobile using SNPE framework. J Phy Conf Ser. 2021;1898:012038. [Google Scholar]
171. Zhang K, Hu H, Philbrick K, Conte GM, Sobek JD, Rouzrokh P, et al. SOUP-GAN: super-resolution MRI using generative adversarial networks. Tomography. 2022;8(2):905–19. [Google Scholar] [PubMed]
172. You C, Li G, Zhang Y, Zhang X, Shan H, Li M, et al. CT super-resolution GAN constrained by the identical, residual, and cycle learning ensemble (GAN-CIRCLE). IEEE Trans Med Imag. 2019;39(1):188–203. doi:10.1109/tmi.2019.2922960. [Google Scholar] [PubMed] [CrossRef]
173. Xia L, Zhu J, Yu Z. Real-world person re-identification via super-resolution and semi-supervised methods. IEEE Access. 2021;9:35834–45. doi:10.1109/access.2021.3063000. [Google Scholar] [CrossRef]
174. Jiang X, Liu M, Zhao F, Liu X, Zhou H. A novel super-resolution CT image reconstruction via semi-supervised generative adversarial network. Neural Comput Appl. 2020;32(18):14563–78. doi:10.1007/s00521-020-04905-8. [Google Scholar] [CrossRef]
175. Savioli N, de Marvao A, Bai W, Wang S, Cook SA, Chin CW, et al. Joint semi-supervised 3D super-resolution and segmentation with mixed adversarial gaussian domain adaptation. arXiv:2107.07975. 2021. [Google Scholar]
176. Zhang Y, Liu S, Dong C, Zhang X, Yuan Y. Multiple cycle-in-cycle generative adversarial networks for unsupervised image super-resolution. IEEE Trans Image Process. 2019;29:1101–12. doi:10.1109/tip.2019.2938347. [Google Scholar] [PubMed] [CrossRef]
177. Prajapati K, Chudasama V, Patel H, Upla K, Ramachandra R, Raja K, et al. Unsupervised single image super-resolution network (USISResNet) for real-world data using generative adversarial network. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2020. p. 464–5. [Google Scholar]
178. Shocher A, Bagon S, Isola P, Irani M. Ingan: capturing and remapping the “DNA” of a natural image. arXiv:1812.00231. 2018. [Google Scholar]
179. Lian S, Zhou H, Sun Y. FG-SRGAN: a feature-guided super-resolution generative adversarial network for unpaired image super-resolution. In: International Symposium on Neural Networks. Cham, Switzerland: Springer; 2019. p. 151–61. [Google Scholar]
180. Wang J, Zhou W, Qi GJ, Fu Z, Tian Q, Li H. Transformation GAN for unsupervised image synthesis and representation learning. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2020. p. 472–81. [Google Scholar]
181. Chen S, Han Z, Dai E, Jia X, Liu Z, Xing L, et al. Unsupervised image super-resolution with an indirect supervised path. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2020. p. 468–9. [Google Scholar]
182. Prajapati K, Chudasama V, Patel H, Upla K, Raja K, Ramachandra R, et al. Direct unsupervised super-resolution using generative adversarial network (DUS-GAN) for real-world data. IEEE Trans Image Process. 2021;30:8251–64. doi:10.1109/tip.2021.3113783. [Google Scholar] [PubMed] [CrossRef]
183. Deepthi K, Shastry AK, Naresh E. A novel deep unsupervised approach for super-resolution of remote sensing hyperspectral image using gompertz-function convergence war accelerometric-optimization generative adversarial network (GF-CWAO-GAN). Sci Rep. 2024;14(1):29853. doi:10.1038/s41598-024-81163-x. [Google Scholar] [PubMed] [CrossRef]
184. Liu X, Yang J, Xu W, Zhang E, Lu C. FLS-GAN: an end-to-end super-resolution enhancement framework for FLS terrain in deep-sea mining vehicles. Ocean Eng. 2025;332:121369. doi:10.1016/j.oceaneng.2025.121369. [Google Scholar] [CrossRef]
185. Hou H, Xu J, Hou Y, Hu X, Wei B, Shen D. Semi-cycled generative adversarial networks for real-world face super-resolution. IEEE Trans Image Process. 2023;32:1184–99. doi:10.1109/tip.2023.3240845. [Google Scholar] [PubMed] [CrossRef]
186. Kim G, Park J, Lee K, Lee J, Min J, Lee B, et al. Unsupervised real-world super resolution with cycle generative adversarial network and domain discriminator. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2020. p. 456–7. [Google Scholar]
187. Lugmayr A, Danelljan M, Timofte R. Unsupervised learning for real-world super-resolution. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). Piscataway, NJ, USA: IEEE; 2019. p. 3408–16. [Google Scholar]
188. Guha I, Nadeem SA, Zhang X, Levy SM, Torner JC, Saha PK. Unsupervised GAN-CIRCLE for high-resolution reconstruction of bone microstructure from low-resolution CT scans. In: Medical imaging 2021: biomedical applications in molecular, structural, and functional imaging. Vol. 11600. Bellingham, WA, USA: International Society for Optics and Photonics; 2021. doi:10.1117/12.2581068. [Google Scholar] [CrossRef]
189. Lin G, Wu Q, Chen L, Qiu L, Wang X, Liu T, et al. Deep unsupervised learning for image super-resolution with generative adversarial network. Signal Process Image Commun. 2018;68:88–100. doi:10.1016/j.image.2018.07.003. [Google Scholar] [CrossRef]
190. Das V, Dandapat S, Bora PK. Unsupervised super-resolution of OCT images using generative adversarial network for improved age-related macular degeneration diagnosis. IEEE Sens J. 2020;20(15):8746–56. doi:10.1109/jsen.2020.2985131. [Google Scholar] [CrossRef]
191. Wang J, Shao Z, Huang X, Lu T, Zhang R, Ma J. Enhanced image prior for unsupervised remoting sensing super-resolution. Neural Netw. 2021;143(11):400–12. doi:10.1016/j.neunet.2021.06.005. [Google Scholar] [PubMed] [CrossRef]
192. Zhang N, Wang Y, Zhang X, Xu D, Wang X. An unsupervised remote sensing single-image super-resolution method based on generative adversarial network. IEEE Access. 2020;8:29027–39. doi:10.1109/access.2020.2972300. [Google Scholar] [CrossRef]
193. Han C, Rundo L, Murao K, Noguchi T, Shimahara Y, Milacski ZÁ, et al. MADGAN: unsupervised medical anomaly detection GAN using multiple adjacent brain MRI slice reconstruction. BMC Bioinform. 2021;22(2):1–20. [Google Scholar]
194. Zhang S, Fu G, Wang H, Zhao Y. Degradation learning for unsupervised hyperspectral image super-resolution based on generative adversarial network. Signal Image Video Process. 2021;15(8):1695–703. doi:10.1007/s11760-021-01902-9. [Google Scholar] [CrossRef]
195. Shao M, Liu H, Yang J, Cao F. Adaptive one-stage generative adversarial network for unpaired image super-resolution. Neural Comput Appl. 2023;35(28):20909–22. doi:10.1007/s00521-023-08888-0. [Google Scholar] [CrossRef]
196. Zhang W, Yang D, Che H, Ran AR, Cheung CY, Chen H. Unpaired optical coherence tomography angiography image super-resolution via frequency-aware inverse-consistency GAN. IEEE J Biomed Health Inform. 2025;29(4):2695–705. doi:10.1109/jbhi.2024.3506575. [Google Scholar] [PubMed] [CrossRef]
197. Liu J, Zhang H, Tian JH, Su Y, Chen Y, Wang Y. R2D2-GAN: robust dual discriminator generative adversarial network for microscopy hyperspectral image super-resolution. IEEE Trans Med Imag. 2024;43(11):4064–74. [Google Scholar]
198. Prajapati K, Chudasama V, Patel H, Upla K, Raja K, Ramachandra R, et al. Unsupervised real-world super-resolution using variational auto-encoder and generative adversarial network. In: International Conference on Pattern Recognition. Cham, Switzerland: Springer; 2021. p. 703–18. [Google Scholar]
199. Cui J, Gong K, Han P, Liu H, Li Q. Unsupervised arterial spin labeling image superresolution via multiscale generative adversarial network. Med Phys. 2022;49(4):2373–85. doi:10.1002/mp.15468. [Google Scholar] [PubMed] [CrossRef]
200. Cai S, Obukhov A, Dai D, Van Gool L. Pix2NeRF: unsupervised conditional pi-GAN for single image to neural radiance fields translation. arXiv:2202.13162. 2022. [Google Scholar]
201. Chan ER, Monteiro M, Kellnhofer P, Wu J, Wetzstein G. PI-GAN: periodic implicit generative adversarial networks for 3D-aware image synthesis. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 5799–809. [Google Scholar]
202. Park J, Son S, Lee KM. Content-aware local GAN for photo-realistic super-resolution. In: Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2023. p. 10585–94. [Google Scholar]
203. Li Y, Chen L, Li B, Zhao H. 4× Super-resolution of unsupervised CT images based on GAN. IET Image Process. 2023;17(8):2362–74. doi:10.1049/ipr2.12797. [Google Scholar] [CrossRef]
204. Ren H, Kheradmand A, El-Khamy M, Wang S, Bai D, Lee J. Real-world super-resolution using generative adversarial networks. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2020. p. 436–7. [Google Scholar]
205. Cai J, Zeng H, Yong H, Cao Z, Zhang L. Toward real-world single image super-resolution: a new benchmark and a new model. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2019. p. 3086–95. [Google Scholar]
206. Wei P, Xie Z, Lu H, Zhan Z, Ye Q, Zuo W, et al. Component divide-and-conquer for real-world image super-resolution. In: Computer Vision—ECCV 2020: 16th European Conference. Cham, Switzerland: Springer; 2020. p. 101–17. [Google Scholar]
207. Krizhevsky A. Learning multiple layers of features from tiny images; 2009 [cited 2026 Feb 20]. Available from: https://api.semanticscholar.org/CorpusID:18268744. [Google Scholar]
208. Wang D, Tan X. Unsupervised feature learning with C-SVDDNet. Pattern Recognit. 2016;60(11):473–85. doi:10.1016/j.patcog.2016.06.001. [Google Scholar] [CrossRef]
209. Zhang Y, Yu F, Song S, Xu P, Seff A, Xiao J. Large-scale scene understanding challenge: room layout estimation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017); 2017 Jul 21–26; Honolulu, HI, USA. [Google Scholar]
210. Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. Imagenet large scale visual recognition challenge. Int J Comput Visi. 2015;115(3):211–52. doi:10.1007/s11263-015-0816-y. [Google Scholar] [CrossRef]
211. Liu Z, Luo P, Wang X, Tang X. Deep learning face attributes in the wild. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2015. p. 3730–8. [Google Scholar]
212. Agustsson E, Timofte R. Ntire 2017 challenge on single image super-resolution: dataset and study. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2017. p. 126–35. [Google Scholar]
213. Wang Y, Wang L, Yang J, An W, Guo Y. Flickr1024: a large-scale dataset for stereo image super-resolution. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway, NJ, USA: IEEE; 2019. p. 3852–7. [Google Scholar]
214. Wang X, Yu K, Dong C, Loy CC. Recovering realistic texture in image super-resolution by deep spatial feature transform. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2018. p. 606–15. [Google Scholar]
215. Zhang W, Sun J, Tang X. Cat head detection-how to effectively exploit shape and texture features. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2008. p. 802–16. [Google Scholar]
216. Zheng L, Shen L, Tian L, Wang S, Wang J, Tian Q. Scalable person re-identification: a benchmark. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2015. p. 1116–24. [Google Scholar]
217. Ristani E, Solera F, Zou R, Cucchiara R, Tomasi C. Performance measures and a data set for multi-target, multi-camera tracking. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2016. p. 17–35. [Google Scholar]
218. Zheng Z, Zheng L, Yang Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro. In: Proceedings of the 2017 IEEE international Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2017. p. 3754–62. [Google Scholar]
219. LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proc IEEE. 1998;86(11):2278–324. doi:10.1109/5.726791. [Google Scholar] [CrossRef]
220. Everingham M, Van Gool L, Williams CK, Winn J, Zisserman A. The pascal visual object classes (voc) challenge. Int J Comput Visn. 2010;88(2):303–38. doi:10.1007/s11263-009-0275-4. [Google Scholar] [CrossRef]
221. Bevilacqua M, Roumy A, Guillemot C, Alberi-Morel ML. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the British Machine Vision Conference. London, UK: BMVA Press; 2012. p. 135.1–10. [Google Scholar]
222. Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations. In: International Conference on Curves and Surfaces. Cham, Switzerland: Springer; 2010. p. 711–30. [Google Scholar]
223. Martin D, Fowlkes C, Tal D, Malik J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings Eighth IEEE International Conference on Computer Vision, ICCV 2001. Piscataway, NJ, USA: IEEE; 2001. p. 416–23. [Google Scholar]
224. Blau Y, Mechrez R, Timofte R, Michaeli T, Zelnik-Manor L. The 2018 pirm challenge on perceptual image super-resolution. In: Computer Vision—ECCV 2018 Workshops. Cham, Switzerland: Springer; 2018. p. 334–55. [Google Scholar]
225. Chen C, Zhang X, Guo J, Jin D, Letuchy EM, Burns TL, et al. Quantitative imaging of peripheral trabecular bone microarchitecture using MDCT. Med Phys. 2018;45(1):236–49. doi:10.1002/mp.12632. [Google Scholar] [PubMed] [CrossRef]
226. McCollough C, Chen B, Holmes D, Duan X, Yu Z, Xu L, et al. Low dose CT image and projection data [dataset]. Cancer Imag Arch. 2020;48(2):902–11. doi:10.1002/mp.14594. [Google Scholar] [PubMed] [CrossRef]
227. Li W, Zhao R, Xiao T, Wang X. Deepreid: deep filter pairing neural network for person re-identification. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2014. p. 152–9. [Google Scholar]
228. Wei L, Zhang S, Gao W, Tian Q. Person transfer GAN to bridge domain gap for person re-identification. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2018. p. 79–88. [Google Scholar]
229. Setio AAA, Traverso A, De Bel T, Berens MS, Van Den Bogaard C, Cerello P, et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the LUNA16 challenge. Med Image Anal. 2017;42(4):1–13. doi:10.1016/j.media.2017.06.015. [Google Scholar] [PubMed] [CrossRef]
230. Kuan K, Ravaut M, Manek G, Chen H, Lin J, Nazir B, et al. Deep learning for lung cancer detection: tackling the kaggle data science bowl 2017 challenge. arXiv:1705.09435. 2017. [Google Scholar]
231. Woodbridge M, Fagiolo G, O’Regan DP. MRIdb: medical image management for biobank research. J Digit Imag. 2013;26(5):886–90. doi:10.1007/s10278-013-9604-9. [Google Scholar] [PubMed] [CrossRef]
232. Bycroft C, Freeman C, Petkova D, Band G, Elliott LT, Sharp K, et al. The UK Biobank resource with deep phenotyping and genomic data. Nature. 2018;562(7726):203–9. doi:10.1038/s41586-018-0579-z. [Google Scholar] [PubMed] [CrossRef]
233. Yang S, Luo P, Loy CC, Tang X. WIDER FACE: a face detection benchmark. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2016. p. 5525–33. [Google Scholar]
234. Lugmayr A, Danelljan M, Timofte R. Ntire 2020 challenge on real-world image super-resolution: methods and results. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2020. p. 494–5. [Google Scholar]
235. Lin H, Hosu V, Saupe D. KADID-10k: a large-scale artificially distorted IQA database. In: 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX). Piscataway, NJ, USA: IEEE; 2019. p. 1–3. [Google Scholar]
236. Ignatov A, Kobyshev N, Timofte R, Vanhoey K, Van Gool L. DSLR-quality photos on mobile devices with deep convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2017. p. 3277–85. [Google Scholar]
237. Timofte R, Gu S, Wu J, Van Gool L. Ntire 2018 challenge on single image super-resolution: methods and results. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2018. p. 852–63. [Google Scholar]
238. Bulat A, Tzimiropoulos G. How far are we from solving the 2D & 3D face alignment problem? (and a dataset of 230,000 3D facial landmarks). In: Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2017. p. 1021–30. [Google Scholar]
239. Yu F, Seff A, Zhang Y, Song S, Funkhouser T, Xiao J. LSUN: construction of a large-scale image dataset using deep learning with humans in the loop. arXiv:1506.03365. 2015. [Google Scholar]
240. Nguyen A, Clune J, Bengio Y, Dosovitskiy A, Yosinski J. Plug & play generative networks: conditional iterative generation of images in latent space. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 4467–77. [Google Scholar]
241. Yang J, Wright J, Huang TS, Ma Y. Image super-resolution via sparse representation. IEEE Trans Image Process. 2010;19(11):2861–73. doi:10.1109/tip.2010.2050625. [Google Scholar] [PubMed] [CrossRef]
242. Yang J, Price B, Cohen S, Lee H, Yang MH. Object contour detection with a fully convolutional encoder-decoder network. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2016. p. 193–202. [Google Scholar]
243. Fang L, Li S, McNabb RP, Nie Q, Kuo AN, Toth CA, et al. Fast acquisition and reconstruction of optical coherence tomography images via sparse representation. IEEE Trans Med Imag. 2013;32(11):2034–49. doi:10.1109/tmi.2013.2271904. [Google Scholar] [PubMed] [CrossRef]
244. Fang L, Li S, Nie Q, Izatt JA, Toth CA, Farsiu S. Sparsity based denoising of spectral domain optical coherence tomography images. Biomed Optics Exp. 2012;3(5):927–42. doi:10.1364/boe.3.000927. [Google Scholar] [PubMed] [CrossRef]
245. Yang Y, Newsam S. Bag-of-visual-words and spatial extensions for land-use classification. In: Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. New York, NY, USA: ACM; 2010. p. 270–9. [Google Scholar]
246. Cheng G, Han J, Lu X. Remote sensing image scene classification: benchmark and state of the art. Proc IEEE. 2017;105(10):1865–83. [Google Scholar]
247. Dai D, Yang W. Satellite image classification via two-layer sparse coding with biased image representation. IEEE Geosci Remote Sens Letters. 2010;8(1):173–6. doi:10.1109/lgrs.2010.2055033. [Google Scholar] [CrossRef]
248. Huang JB, Singh A, Ahuja N. Single image super-resolution from transformed self-exemplars. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2015. p. 5197–206. [Google Scholar]
249. Wang M, Li Z, Liu H, Chen Z, Cai K. SP-IGAN: an improved GAN framework for effective utilization of semantic priors in real-world image super-resolution. Entropy. 2025;27(4):414. [Google Scholar] [PubMed]
250. Miyato T, Koyama M. cGANs with projection discriminator. arXiv:1802.05637. 2018. [Google Scholar]
251. Xu Y, Luo W, Hu A, Xie Z, Xie X, Tao L. TE-SAGAN: an improved generative adversarial network for remote sensing super-resolution images. Remote Sens. 2022;14(10):2425. doi:10.3390/rs14102425. [Google Scholar] [CrossRef]
252. Guo M, Zhang Z, Liu H, Huang Y. NDSRGAN: a novel dense generative adversarial network for real aerial imagery super-resolution reconstruction. Remote Sens. 2022;14(7):1574. doi:10.3390/rs14071574. [Google Scholar] [CrossRef]
253. Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, et al. Pytorch: an imperative style, high-performance deep learning library. In: Advances in neural information processing systems. Red Hook, NY, USA: Curran Associates, Inc.; 2019. [Google Scholar]
254. Goldsborough P. A tour of tensorflow. arXiv:1610.01178. 2016. [Google Scholar]
255. Keras. GitHub; 2015 [cited 2026 Feb 20]. Available from: https://github.com/fchollet/keras. [Google Scholar]
256. Maeda S. Unpaired image super-resolution using pseudo-supervision. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2020. p. 291–300. [Google Scholar]
257. Tian C, Fei L, Zheng W, Xu Y, Zuo W, Lin CW. Deep learning on image denoising: an overview. Neural Netw. 2020;131(11):251–75. doi:10.1016/j.neunet.2020.07.025. [Google Scholar] [PubMed] [CrossRef]
258. Han K, Xiao A, Wu E, Guo J, Xu C, Wang Y. Transformer in transformer. In: Advances in neural information processing systems. Red Hook, NY, USA: Curran Associates, Inc.; 2021. 34 p. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools