
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Optimal Deep Hybrid Boltzmann Machine Based Arabic Corpus Classification Model
1 Department of Computer Science, College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, Al-Kharj, 16273, Saudi Arabia
2 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Makkah 24211, Saudi Arabia
4 Department of Information Systems, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
5 Department of Digital Media, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11845, Egypt
6 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Mesfer Al Duhayyim. Email:
Computer Systems Science and Engineering 2023, 46(3), 2755-2772. https://doi.org/10.32604/csse.2023.034609
Received 21 July 2022; Accepted 11 October 2022; Issue published 03 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Natural Language Processing (NLP) for the Arabic language has gained much significance in recent years. The most commonly-utilized NLP task is the ‘Text Classification’ process. Its main intention is to apply the Machine Learning (ML) approaches for automatically classifying the textual files into one or more pre-defined categories. In ML approaches, the first and foremost crucial step is identifying an appropriate large dataset to test and train the method. One of the trending ML techniques, i.e., Deep Learning (DL) technique needs huge volumes of different types of datasets for training to yield the best outcomes. The current study designs a new Dice Optimization with a Deep Hybrid Boltzmann Machine-based Arabic Corpus Classification (DODHBM-ACC) model in this background. The presented DODHBM-ACC model primarily relies upon different stages of pre-processing and the word2vec word embedding process. For Arabic text classification, the DHBM technique is utilized. This technique is a hybrid version of the Deep Boltzmann Machine (DBM) and Deep Belief Network (DBN). It has the advantage of learning the decisive intention of the classification process. To adjust the hyperparameters of the DHBM technique, the Dice Optimization Algorithm (DOA) is exploited in this study. The experimental analysis was conducted to establish the superior performance of the proposed DODHBM-ACC model. The outcomes inferred the better performance of the proposed DODHBM-ACC model over other recent approaches.Keywords
With the advancements in Natural Language Processing (NLP), the Arabic Text Categorization (ATC) process has become an active research domain since the Arabic language has several difficulties, such as highly-complicated structure, unique morphological characters and so on [1]. Indeed, the derivational and the inflectional nature of the Arabic language examine highly-complex structures and morphology. The key objective of the ATC approach is to allow pre-defined classes for the Arabic text based on its content. Text representation is a decisive stage that suggestively impacts the performance of the ATC process. In literature, an extensive array of Arabic text representation techniques was reviewed [2]. For example, a conventional text modelling related to the Bag-Of-Words (BOW) representation was attained for the existing acts in the NLP domain. But, this technique suffered from the curse of dimensionality and the non-existence of semantic relations among different text units [3,4]. Text Classification (TC) can be described as a text-mining procedure in which a category or a class is specified for the presented textual file [5]. The productivity of this procedure is measured in terms of class sets, whereas all the class sets contain a set of text files that belong to a particular kind or a topic [6].
The single-label TC presents a single label for every file, whereas the multi-label TC provides different labels for every file [7]. A dynamic classification method is required to handle the huge volumes of text generated on the web every minute. This method should categorize every file under a suitable category and simplify the tasks in other areas like information retrieval and NLP. Unsupervised and supervised Machine Learning (ML) techniques were scrutinized in the domain of TC earlier [8,9]. The unsupervised learning method varies from supervised learning in the labelled dataset. Supervised learning methods utilize labelled datasets to forecast the future, whereas these labelled datasets are known to be the knowledge repository of the models [10]. Precisely, it can be explained as a teaching process in which a method is trained with adequate information and is allowed to perform the predictions after the teaching process is over [11]. In the unsupervised learning approach, the data is not labelled. These methods are unaware of any data or its categories or classes in a dataset; such methods try to find the significant paradigms in a dataset. Both characteristics, as well as the complexities of the Arabic language, make the processing of Arabic texts [12] a challenging process. It is difficult to handle numerous complexities in Arabic like diglossia, ambiguity, etc.; at first, it is challenging to understand and read the Arabic script since the meaning conveyed by the Arabic letters changes according to their position in a word. Secondly, the language has no dedicated letter or capitalization method. Finally, the language has a complex morphology framework, while its alphabet system is not easy to understand [13]. In addition, it is also challenging to normalize the inconsistencies when using a few letters, diacritical marks and dialects. Linguistics researchers and technology developers deal with complexities in NLP tools through morphology analysis, tokenization and stemming from the Arabic language [14].
The current article designs a new Dice Optimization with a Deep Hybrid Boltzmann Machine-based Arabic Corpus Classification (DODHBM-ACC) model. The presented DODHBM-ACC model primarily relies upon different stages of pre-processing and the word2vec word embedding process. For Arabic text classification, the DHBM technique is utilized. It is a hybrid version of the Deep Boltzmann Machine (DBM) and Deep Belief Network (DBN). It has the advantage of learning the decisive intention of a classification process. To fine-tune the hyperparameters involved in the DHBM technique, the Dice Optimization Algorithm (DOA) is exploited in this study. The experimental analysis was conducted to establish the superior performance of the proposed DODHBM-ACC model.
The rest of the paper is organized as follows. Section 2 offers information about the works conducted earlier in this domain, and Section 3 explains the proposed model. Next, Section 4 provides the information on experimental validation, whereas Section 5 concludes the work.
In recent times, Deep Learning (DL) methods are extensively utilized in Sentiment Analysis (SA) research. Few researchers have employed NLP or pre-processing methods to prepare the data for the classification process. El-Alami et al. [15] examined Long Short Term Memory (LSTM), Convolutional Neural Network (CNN) and a combination of these methods to accomplish the ATC process. This work further dealt with the morphological diversity of the Arabic letters by sightseeing the word embedding method using sub-word information and the position weights. This study framed a policy to refine the Arabic vector space representation to ensure an adjacent vector representation for the linked words. It was done with the help of semantic data embedding in lexical sources. The earlier study [16] devised a feature selection algorithm by integrating the Artificial Bee Colony (ABC) technique and the chi-square technique. Chi-square is a filtering technique that can perform calculations simply and rapidly. It can handle a large-dimensional feature and can be utilized as an initial level in feature selection procedures. In this study, the ABC technique, i.e., a wrapper approach, was utilized as another level, after which Naive Base was employed as a Fitness Function (FF).
Al-Anzi et al. [17] developed an innovative text classification technique that neither practised dimensionality reduction nor SA approaches. The presented technique was a space-efficient approach, i.e., it made use of an initial-order Markov method for the hierarchical ATC. A Markov chain method was arranged based on the neighbouring character series for every category and its sub-categories. Then, the preparation methods were utilized to score the files for classification. Alhaj et al. [18] developed a new TC technique to improve the performance of the ATC process utilizing ML approaches. The identification of an appropriate Feature Selection (FS) methodology along with an ideal sum of the features remains the most important step in the ATC process to achieve the finest classification outcomes. Thus, the authors devised an algorithm named Optimal Configuration Determination for ATC (OCATC). It can also be used as a Particle Swarm Optimization (PSO) technique to find the best configuration. The presented algorithm derived and transformed the attributes from the text data into an arithmetic vector with the help of Term Frequency-Inverse Document Frequency (TF–IDF) method.
Alshaer et al. [19] focused on learning the impact of the enhanced Chi (ImpCHI) square method on the performances of the six-renowned classification models. The proposed method was significant enough to enhance Arabic text classification. Further, it was considered a promising basis for the classification of the text due to its contribution in terms of pre-defined classes. Ababneh [20] attempted to find the best dataset that could offer fair evaluation and, importantly, train the method for TC. In this examination, renowned and accurate learning methods were employed. The author provided time measures and emphasized the relevance of training the methods using such datasets to enable the Arabic language authors to choose a suitable dataset and leverage a solid basis for comparison.
3 The Proposed DODHBM-ACC model
The current study has developed a new DODHBM-ACC model for automatic Arabic corpus classification. The presented DODHBM-ACC model primarily relies on four processes: data pre-processing, word embedding, Arabic text classification and hyperparameter tuning. Fig. 1 depicts the overall processes of the DODHBM-ACC technique.
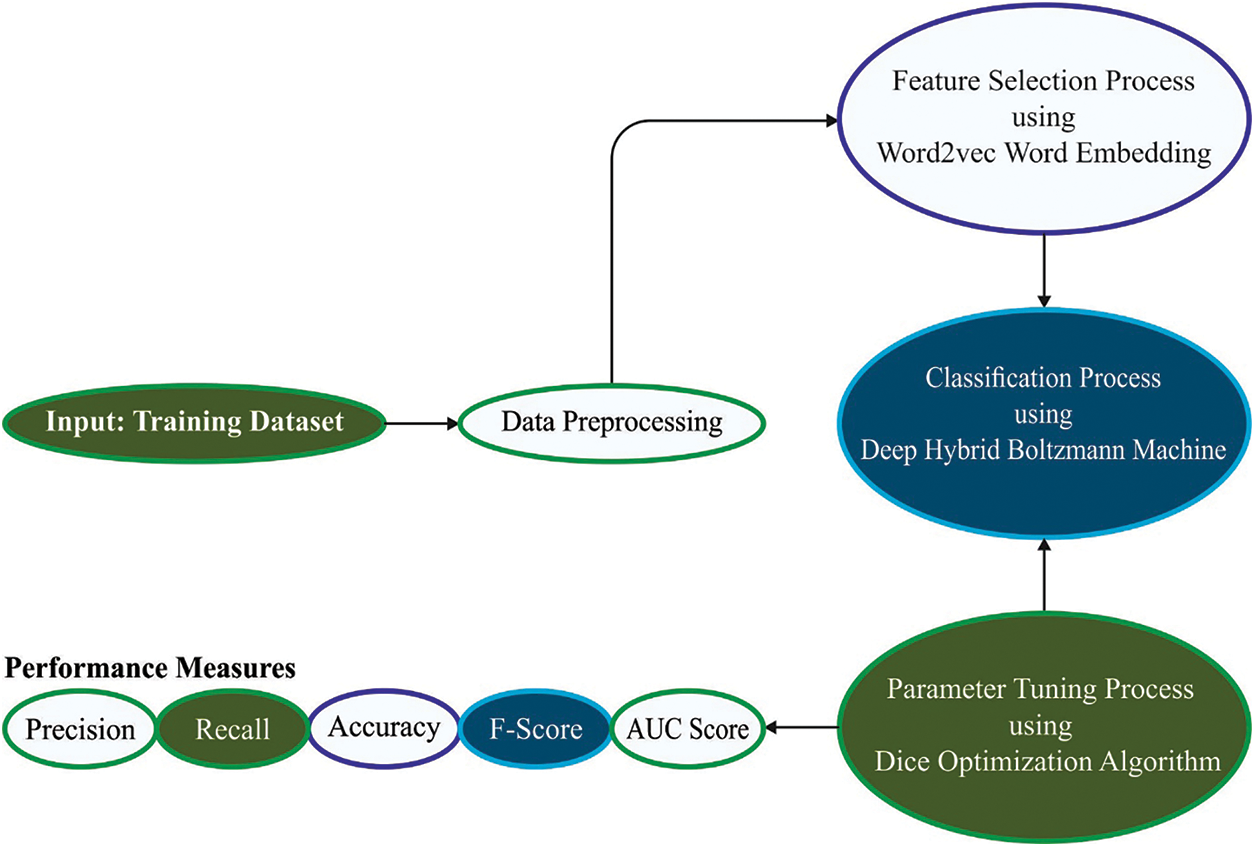
Figure 1: Overall processes of the DODHBM-ACC approach
The overall steps involved in this pre-processing function are briefed herewith.
• Tokenization: This function tokenizes a text and classifies a text as either a token or a word set.
• Stop-words removal: It excludes any type of speech, neither verb nor noun. The list of different stop words in Arabic has more than 400 terminologies.
• Stemming: In this procedure, both suffixes and token prefixes are eliminated. The steaming function is a vital process and positively impacts a model's performance and efficacy.
Word2Vec methodology uses neural network techniques to accomplish word representation [21]. This algorithm considers a large corpus as its input and considers each vocabulary in the corpora. Harris proposed this concept in which a word has the same meaning and is used in the same context. This technique upgrades the vector of a word based on its appearance in the external environment with the help of a pre-determined size window. The comparison amongst those words is higher than the earlier one, and the vector becomes convergent. The Word2Vec process follows two approaches such as the Skip-gram (SG) approach and the Continuous Bag-of-Words (CBOW) approach to generate a word vector. In the SG approach, the vector of an external environment within the window size is transformed based on the centre word. In the CBOW approach, the vector of a word centre is upgraded based on the external environment within the size of the window. In the current study, three dissimilar dimensions have been created for these approaches, such as 100, 200 and 300. Further, a window at 5 is also applied, whereas the minimum word appearance in the corpus is equivalent to 5.
3.3 Arabic Text Classification Using DHBM Technique
For the classification of Arabic texts, the DHBM technique is utilized. This technique is a hybrid version of DBM and DBN and is regarded as an increasingly-complicated variant of both methods [22]. The hybrid structure was created with the intention of conducting the classification process. An alternative method to consider the DHBM approach is to configure a strongly-incorporated Hybrid Restricted Boltzmann Machine (HRBM) instead of an individual module. SBEN is a stack of HRBM in which every model
Eq. (1) notes that
In Eq. (2),
It is to be noted that in the overview of top-down calculation, the hidden as well as the visible layers of the 3-DHBM model are calculated using the executable equations given below.
In this expression, a logistic sigmoid or an activation function is denoted by
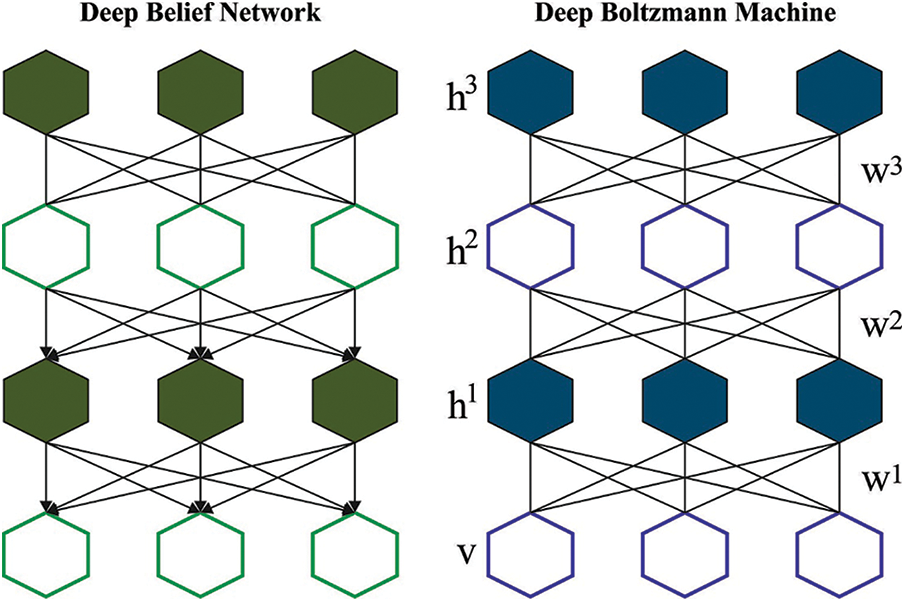
Figure 2: Structure of the DHBM technique
In order to accelerate the prediction process and training time, the DHBM structure is expanded by means of a separate auxiliary network or a co-model that is formerly applied to infer the state of the hidden parameters in the DBM model. Here, the aim is to exploit the individual bottom-up pass. MLP or the detection model, performs a part of the approximation function that is successfully merged with the deep structures of the concentration. Further, it is also trained based on the gradient-descent method. During the fundamental co-training of the detection model, it is anticipated that the mean-field parameter of the target model remains unchanged. Then, an individual learning step is experimentally demonstrated to study the realistic training of the DBM model. Similar principles are claimed for training an in-depth hybrid structure, i.e., DHBM too.
In this detection model, the weight is initialized to DHBM at the beginning of training and is calculated as a completely-factorized element, as given below.
In Eq. (7), the likelihood of
In these expressions, the inference network weight is doubled at all the layers, except the top-most layer, to compensate for the missing top-down feedback. In this hybrid mechanism, especially at the time of prediction, the structure might straightaway produce a suitable calculation for
The detection model can be trained based on Eq. (10):
This shows a minimized Kullback-Leibler (KL) divergence between
3.4 Hyperparameter Tuning Using DOA
In order to fine-tune the hyperparameters involved in the DHBM technique, the DOA approach is exploited in this study. DOA is a game-based optimization approach that simulates the old-age game rules i.e., dice games. In this DOA approach, the primary location of a player is randomly generated on the playing field i.e., problem description space, as expressed in the following equation [23]:
After the formation of the system, the rule is quantified. The players compete in line with the game rules set earlier and determine the winner.
Calculation of each player’s score
A fitness function is applied to simulate the score of all the players. A high score is allocated to the player with the best position, calculated as follows.
In Eq. (12),
Tossing dice for each player
Here, every player tosses a dice. A dice count can be a discrete value between 1 and 6 that signifies the number of players guided by every player and is expressed as follows.
In Eq. (15)
Selection of the Guide’s players for each player
For every player, according to the count of the dice (K), a player guide is arbitrarily chosen amongst the players, as shown below
In Eq. (16),
Update the position of each player.
Here,
Now,
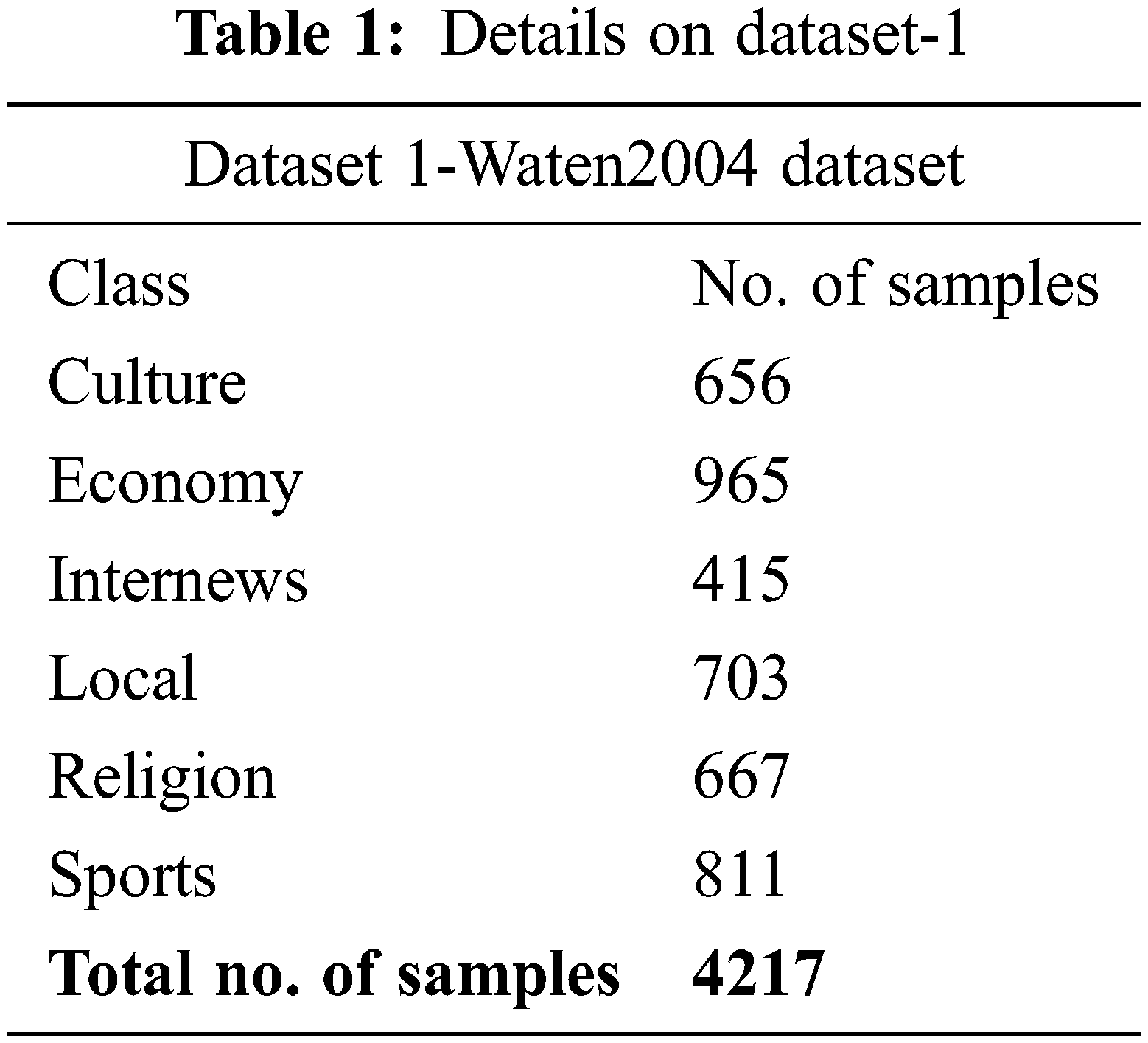
The proposed DODHBM-ACC method was experimentally validated using two data sets such as Waten2004 dataset (dataset 1) and Khaleej2004 dataset (dataset 2). The first dataset has a total of 4,217 samples under six classes as depicted in Table 1. The parameter settings are as follows: learning rate: 0.01, dropout: 0.5, batch size: 5, epoch count: 50, and activation: ReLU.
The confusion matrices generated by the proposed DODHBM-ACC model on dataset-1 are portrayed in Fig. 3. The results indicate that the proposed DODHBM-ACC method achieved improved outcomes under all the aspects. With the entire dataset, the DODHBM-ACC system identified 633 samples as culture class, 941 samples as economy class, 400 samples as Internews class, 689 samples as local class, 635 samples as religion class and 775 samples as sports class. In line with this, with 70% of TR dataset, the proposed DODHBM-ACC approach categorized 435 samples under culture class, 661 samples under economy class, 280 samples under Internews class, 497 samples under local class, 443 samples under religion class and 544 samples under sports class. Similarly, with 30% of TS dataset, the proposed DODHBM-ACC method classified 198 samples under culture class, 280 samples under economy class, 120 samples under Internews class, 192 samples under local class, 192 samples under religion class and 231 samples under sports class respectively.
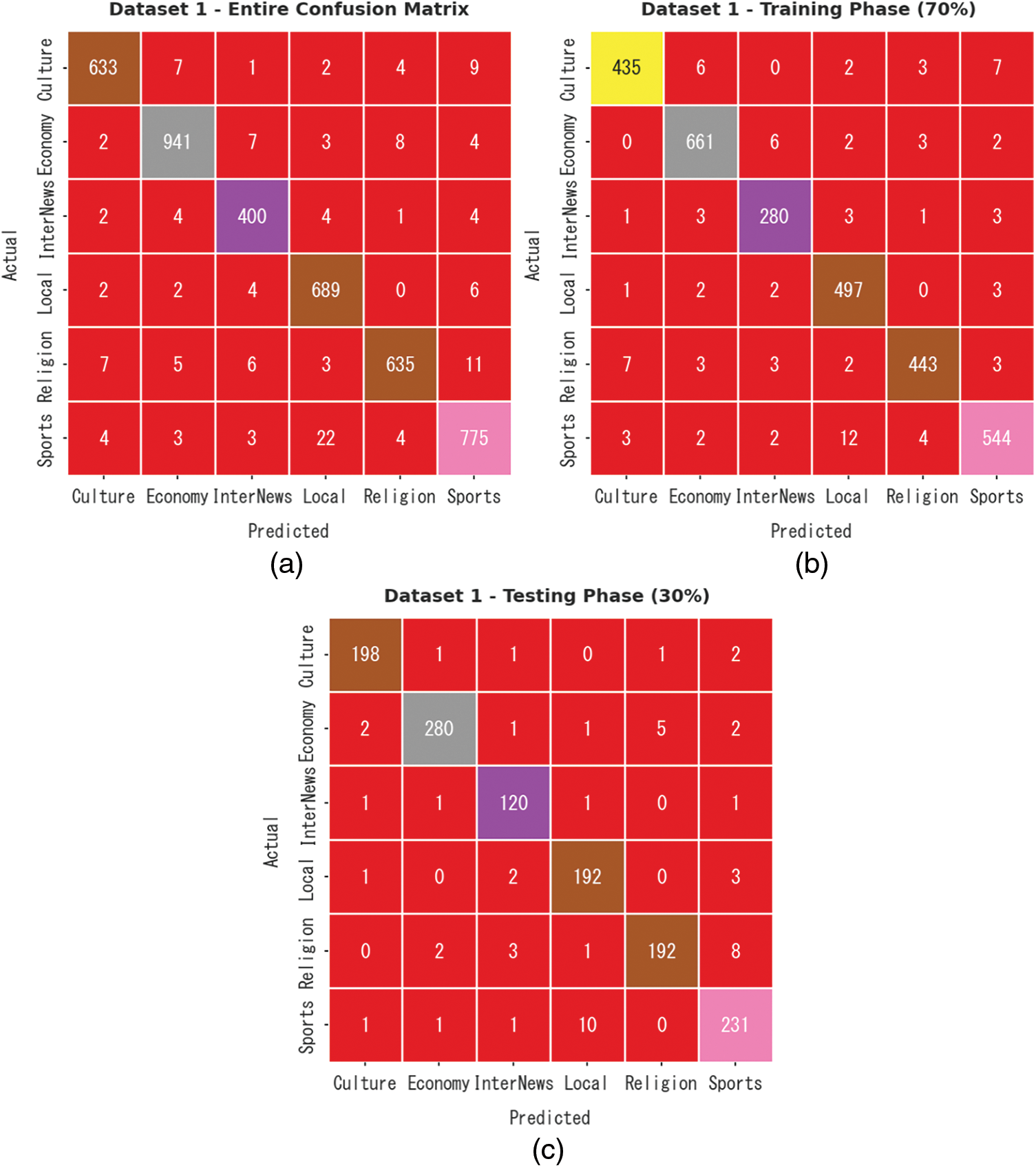
Figure 3: Confusion matrices of the DODHBM-ACC approach under dataset-1 (a) Entire dataset, (b) 70% of TR data, and (c) 30% of TS data
Table 2 demonstrates the overall classification results achieved by the proposed DODHBM-ACC model. With entire dataset, the DODHBM-ACC model reached average
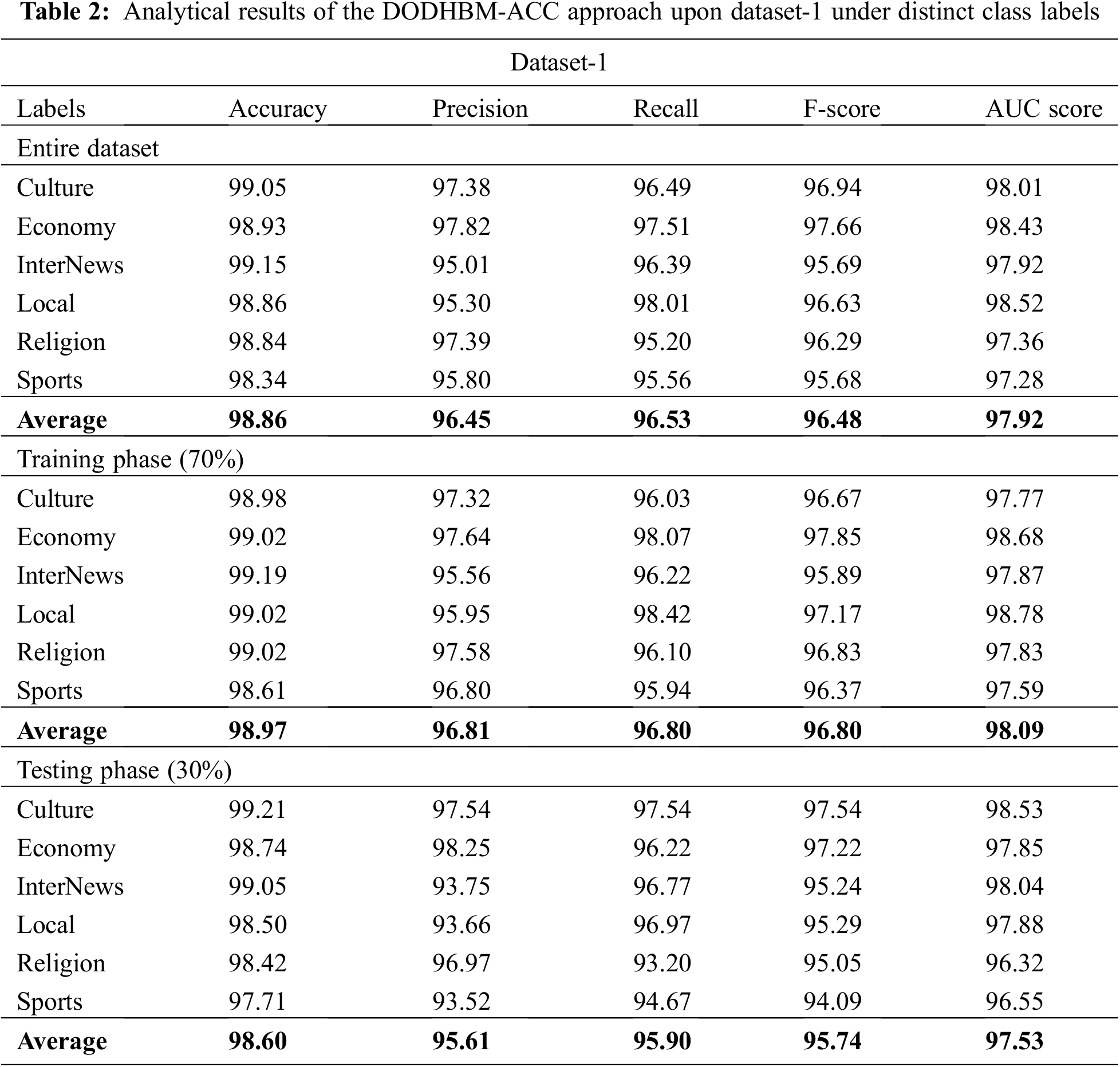
Both Training Accuracy (TRA) and Validation Accuracy (VLA) values, attained by the proposed DODHBM-ACC algorithm on dataset-1, are displayed in Fig. 4. The experimental outcomes denote that the proposed DODHBM-ACC approach obtained the maximal TRA and VLA values while VLA values were higher than the TRA values.
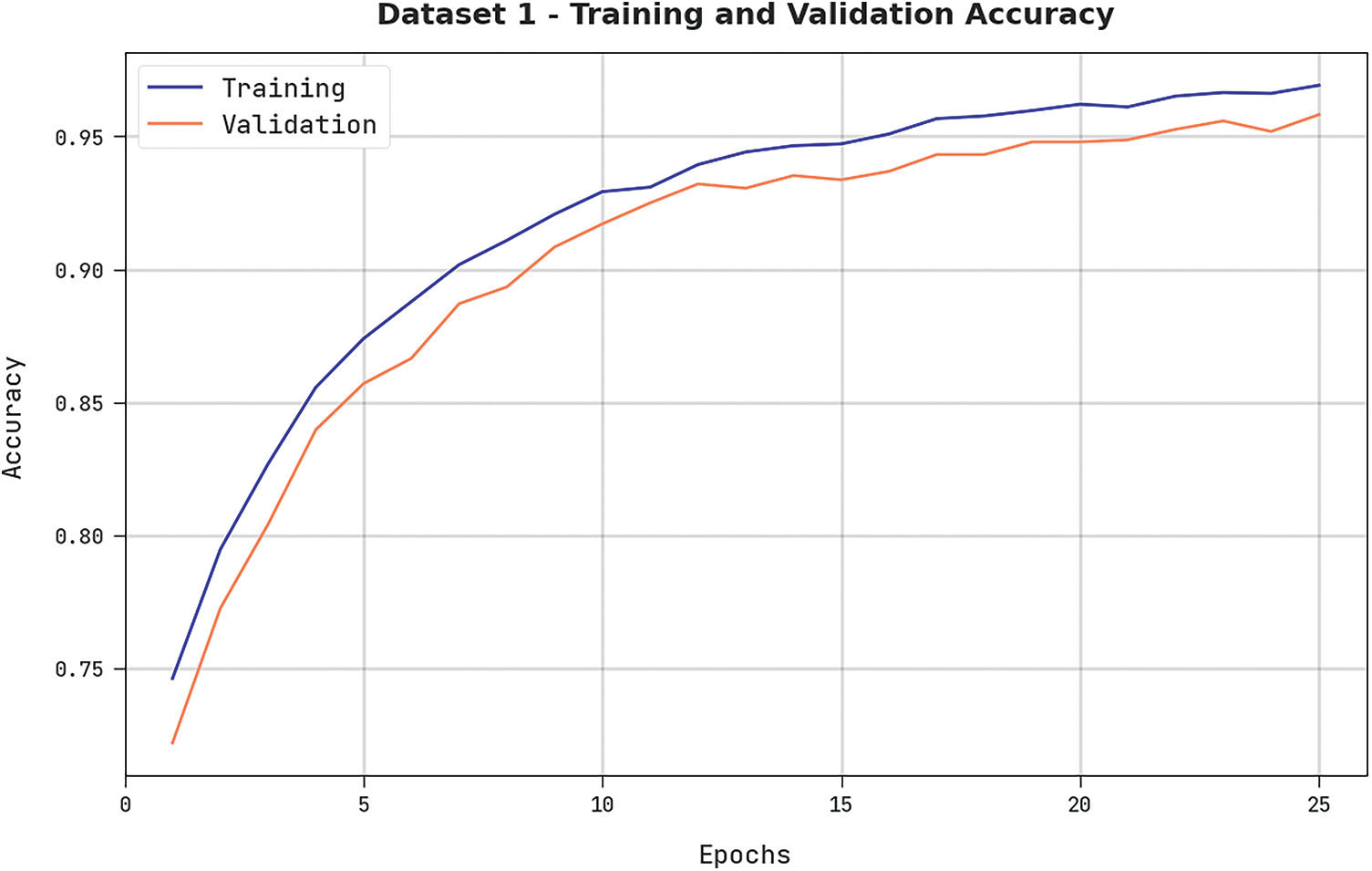
Figure 4: TRA and VLA analyses results of the DODHBM-ACC approach on dataset-1
Both Training Loss (TRL) and Validation Loss (VLL) values, obtained by the proposed DODHBM-ACC technique on dataset-1, are exhibited in Fig. 5. The experimental outcomes represent that the proposed DODHBM-ACC algorithm outperformed other methods with minimal TRL and VLL values whereas the VLL values were lower than the TRL values.
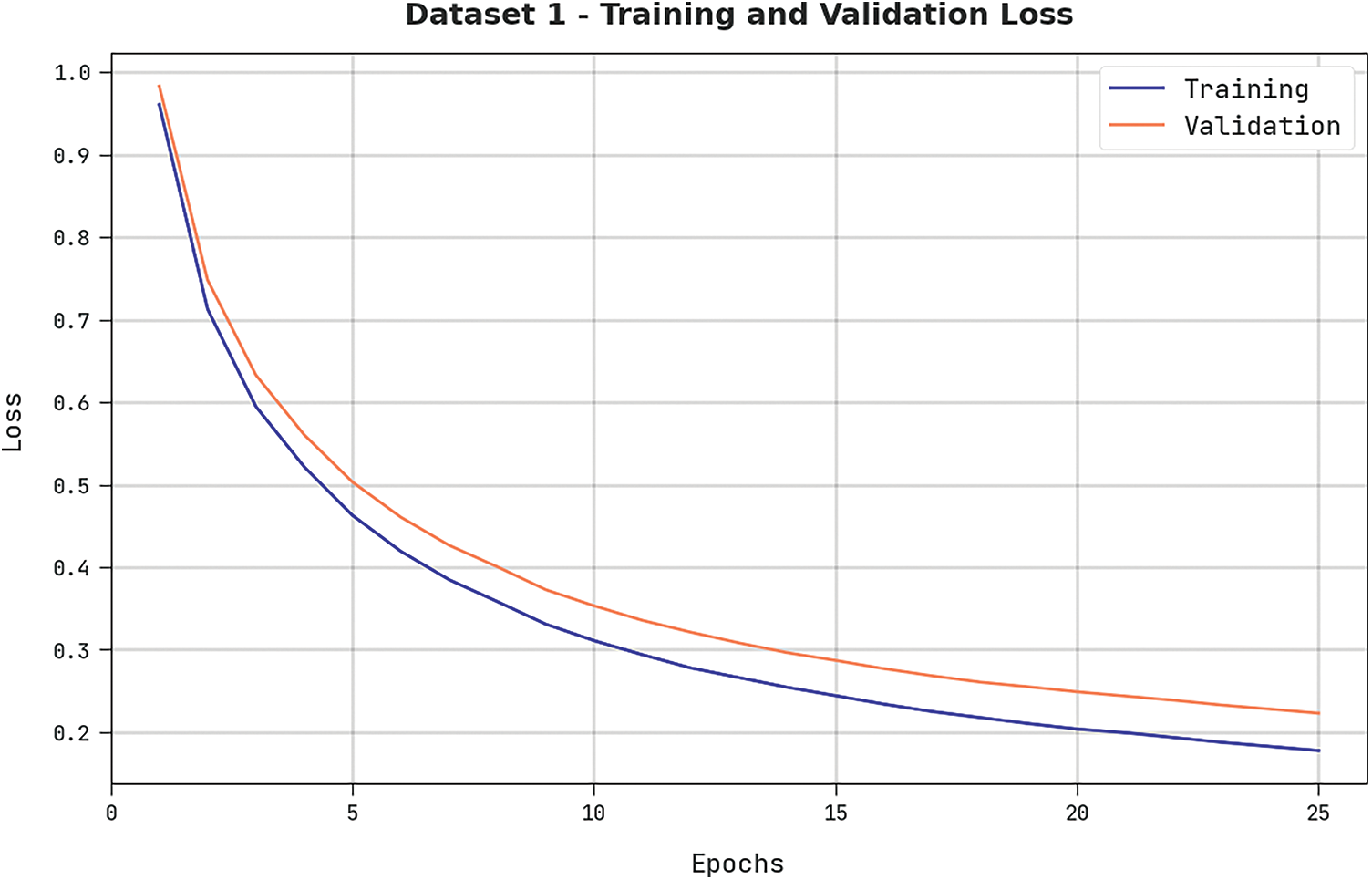
Figure 5: TRL and VLL analyses results of the DODHBM-ACC methodology on dataset-1
A clear precision-recall analysis was conducted upon the proposed DODHBM-ACC methodology using dataset-1, and the results are shown in Fig. 6. The figure signifies that the proposed DODHBM-ACC algorithm produced enhanced precision-recall values under all the classes.
Figure 6: Precision-recall analyses results of the DODHBM-ACC approach on dataset-1
A detailed ROC analysis was conducted upon the presented DODHBM-ACC methodology using dataset-1, and the results are presented in Fig. 7. The results indicate that the proposed DODHBM-ACC technique showcased its ability in categorizing the dataset-1 under distinct classes.
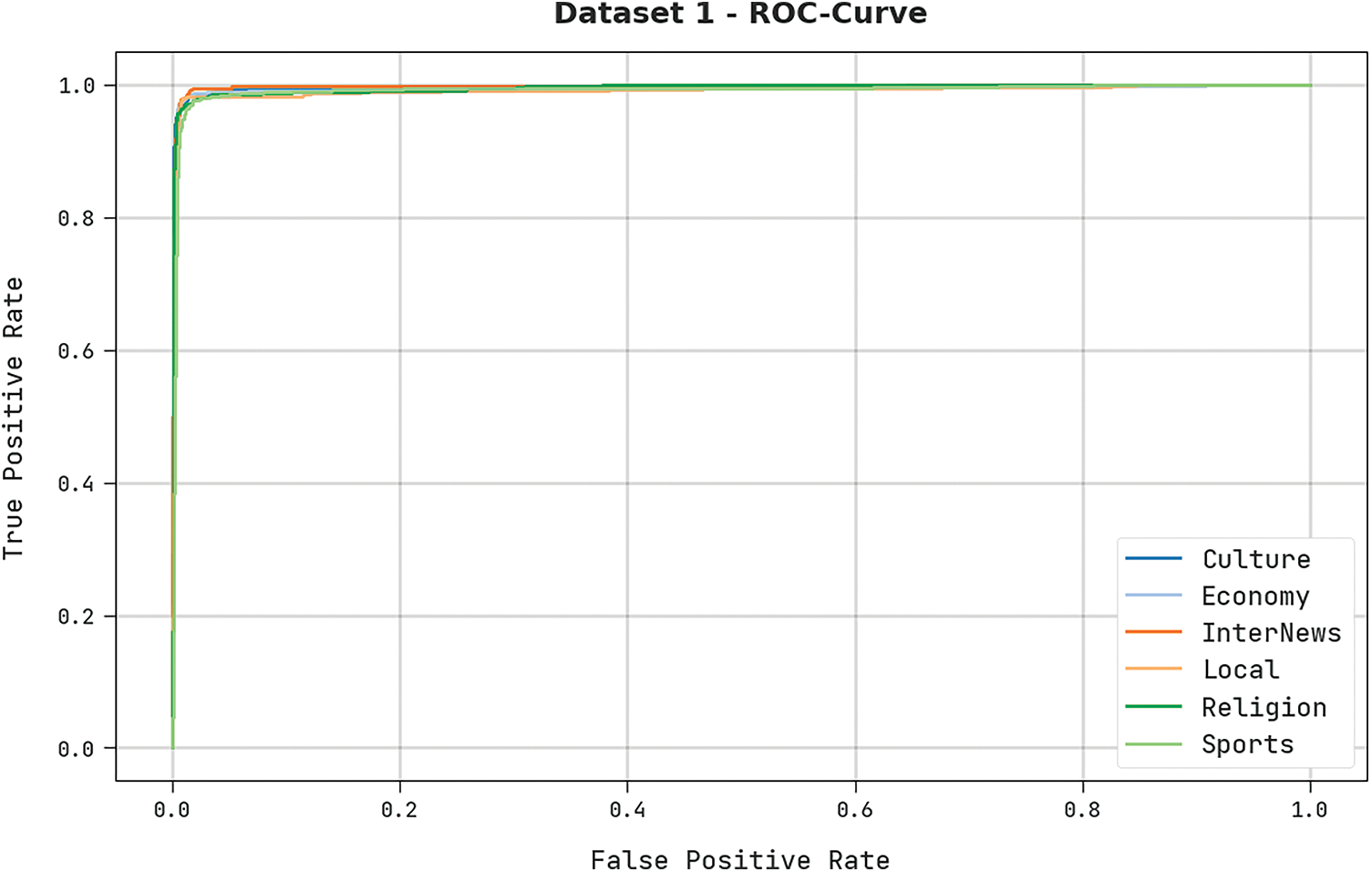
Figure 7: ROC analysis results of the DODHBM-ACC approach on dataset-1
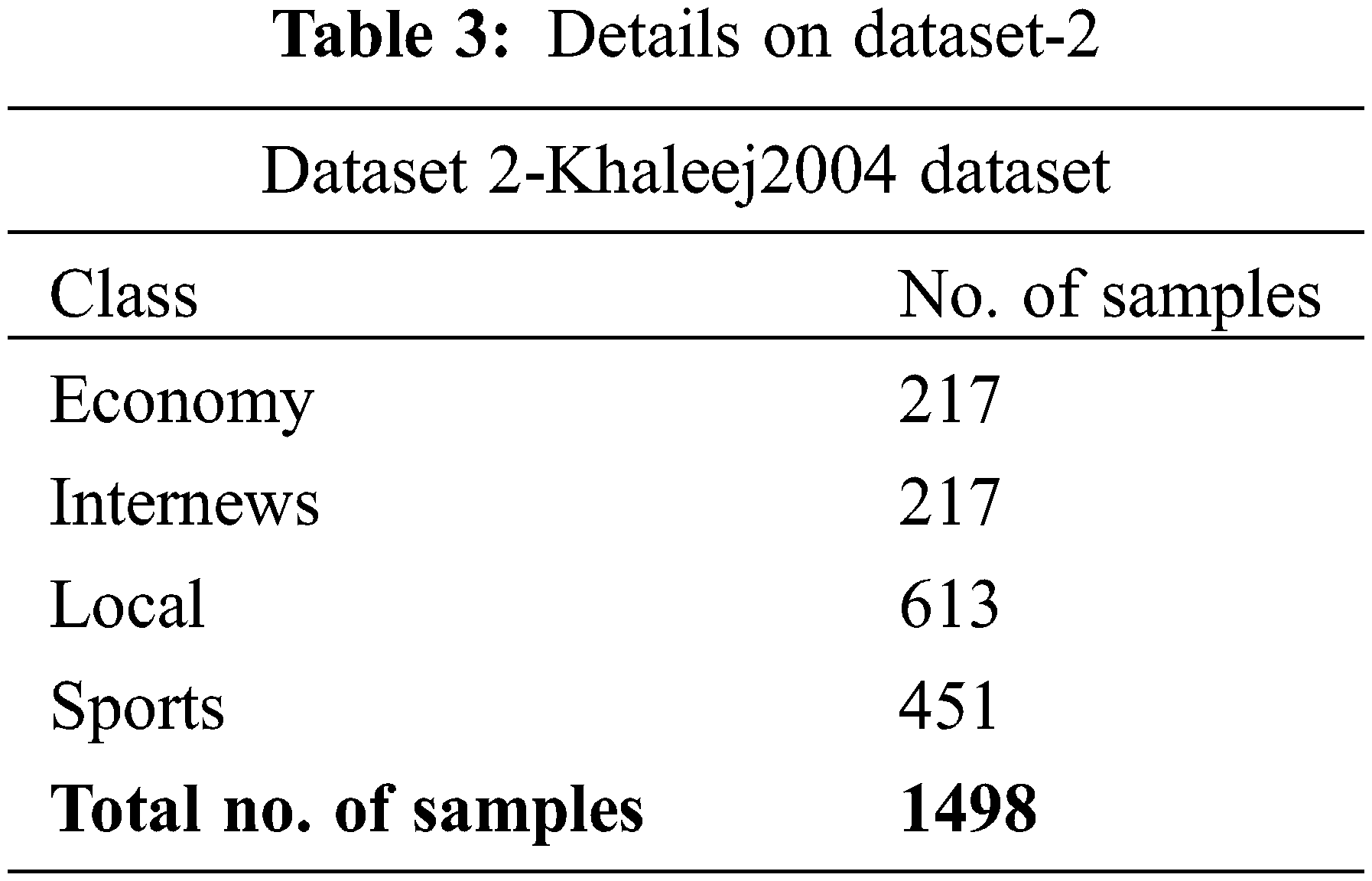
The proposed DODHBM-ACC algorithm was experimentally validated using Khaleej2004 dataset (dataset 2). The dataset holds 1,498 samples under four classes and is depicted in Table 3.
The confusion matrices generated by the proposed DODHBM-ACC method on dataset-2 are shown in Fig. 8. The results indicate that the proposed DODHBM-ACC system displayed improved outcomes under all the aspects. With the entire dataset, the DODHBM-ACC technique identified 214 samples as Economy, 210 samples as Internews, 600 samples as Local class and 438 samples as Sports class respectively. Further, upon 70% of TR dataset, the proposed DODHBM-ACC approach classified 142 samples under Economy, 146 samples under Internews, 430 samples under Local class and 302 samples under Sports class. Meanwhile, with 30% of TS, the presented DODHBM-ACC algorithm categorized 72 samples under Economy, 64 samples under Internews, 170 samples under Local class and 136 samples under Sports class.
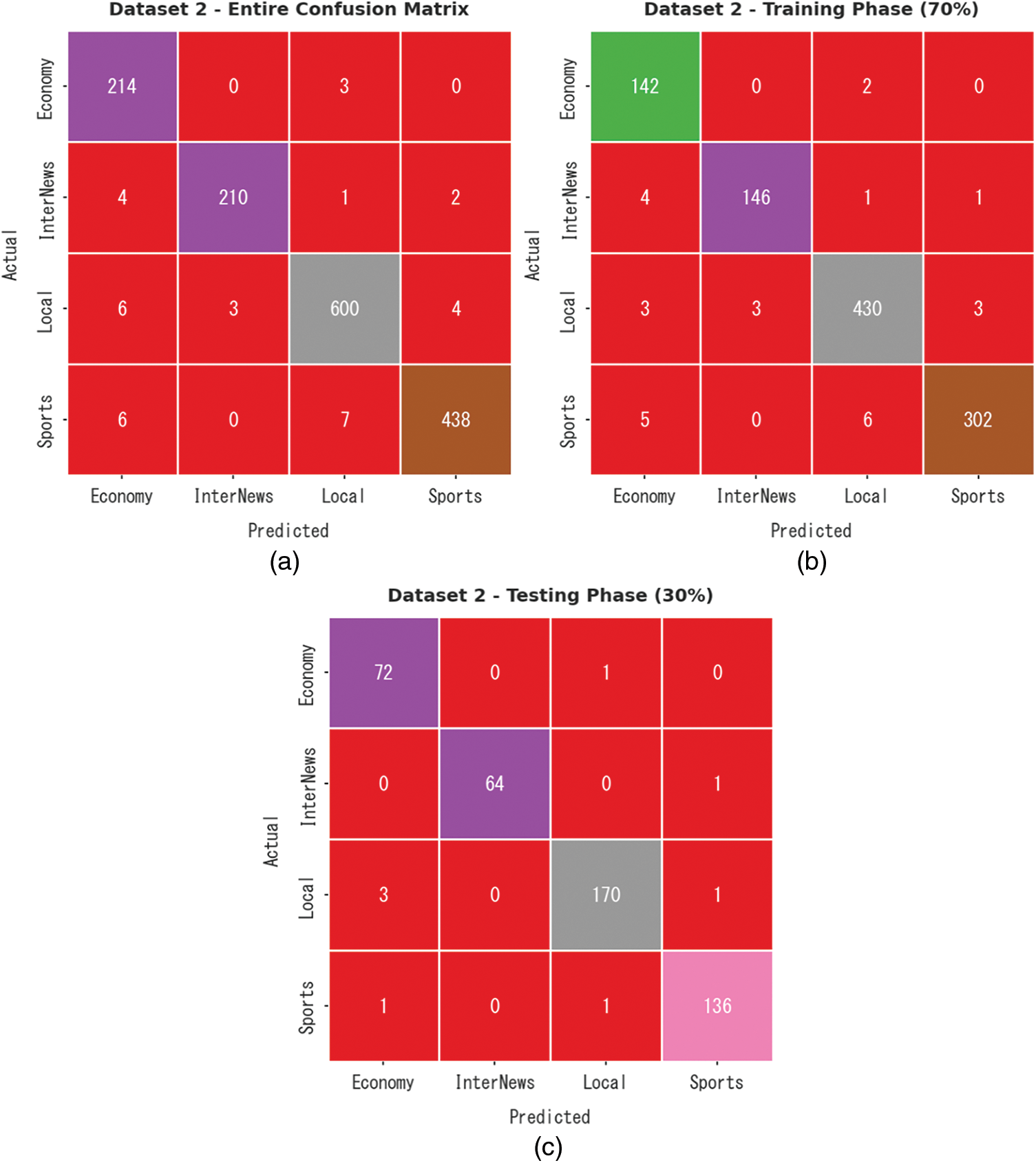
Figure 8: Confusion matrices of the DODHBM-ACC methodology under dataset-2 (a) Entire dataset, (b) 70% of TR data, and (c) 30% of TS dataset
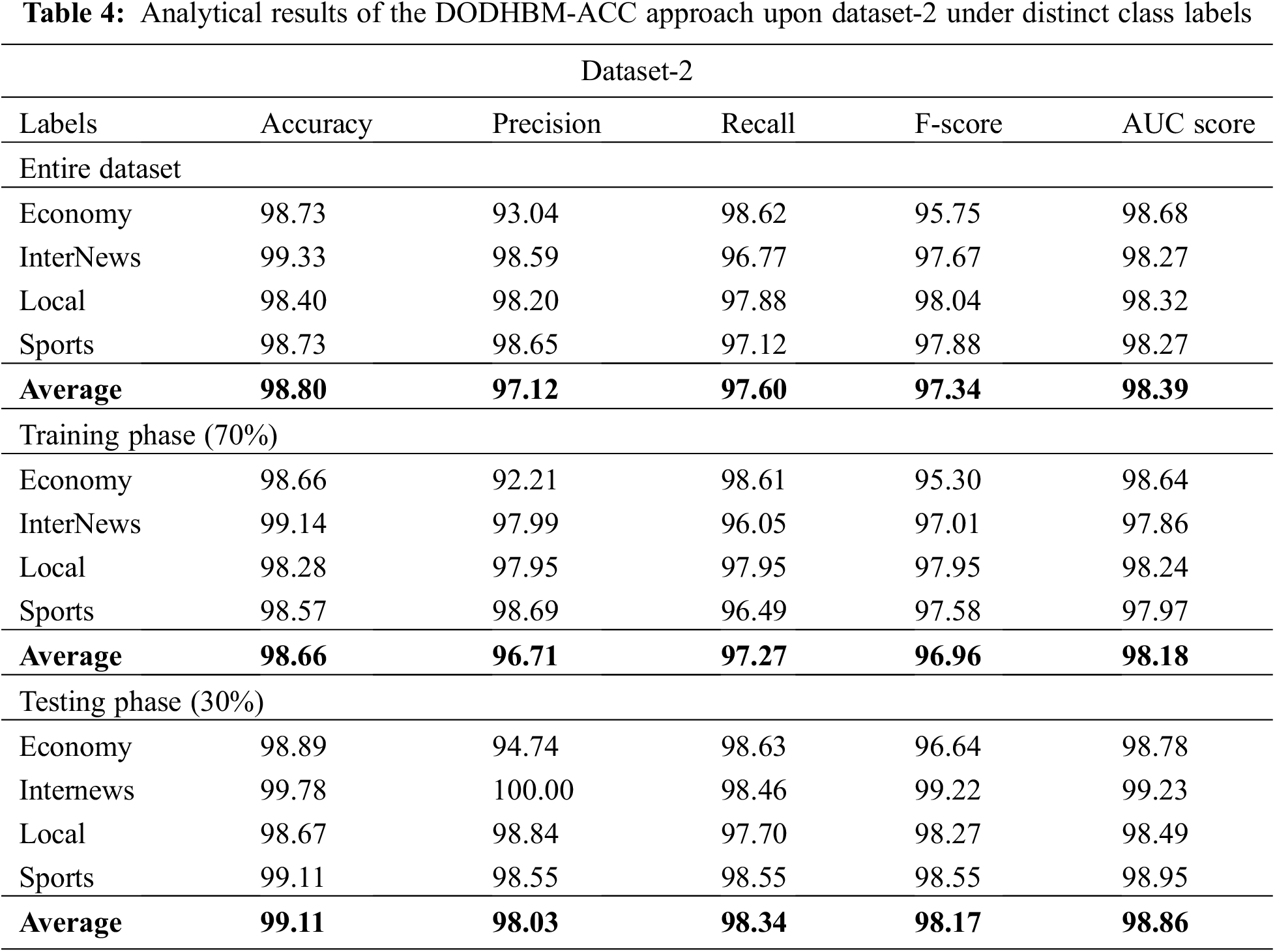
Table 4 demonstrates the overall classification results achieved by the proposed DODHBM-ACC methodology. With entire dataset, the DODHBM-ACC approach produced average
Both TRA and VLA values, acquired by the DODHBM-ACC methodology on dataset-2, are illustrated in Fig. 9. The experimental outcomes denote that the proposed DODHBM-ACC approach gained the maximal TRA and VLA values while the VLA values were higher than the TRA values.
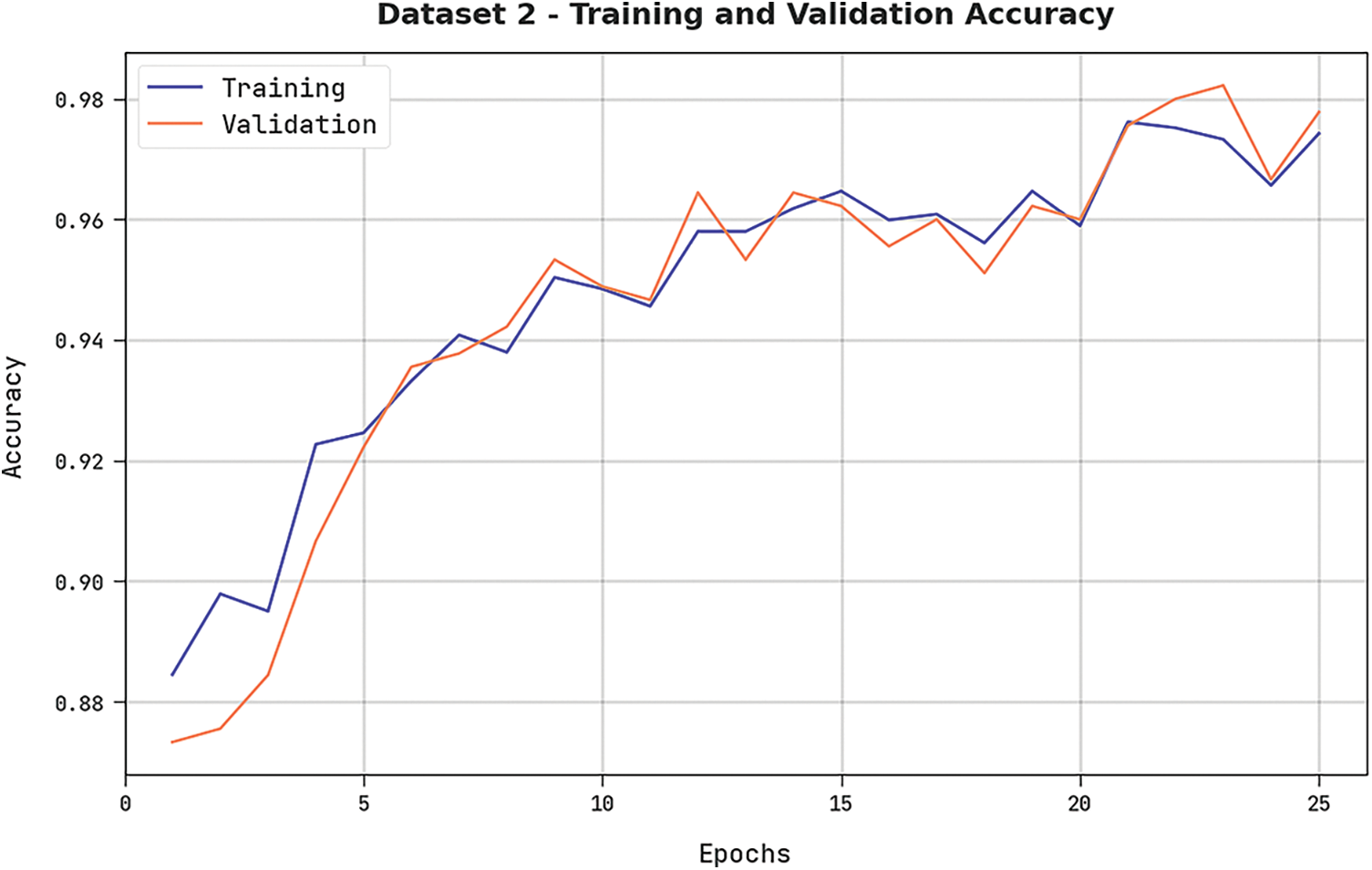
Figure 9: TRA and VLA analyses values of the DODHBM-ACC approach on dataset-2
Both TRL and VLL values, attained by the proposed DODHBM-ACC method on dataset-2, are shown in Fig. 10. The experimental outcomes imply that the proposed DODHBM-ACC technique exhibited the least TRL and VRL values while the VLL values were lesser than the TRL values.
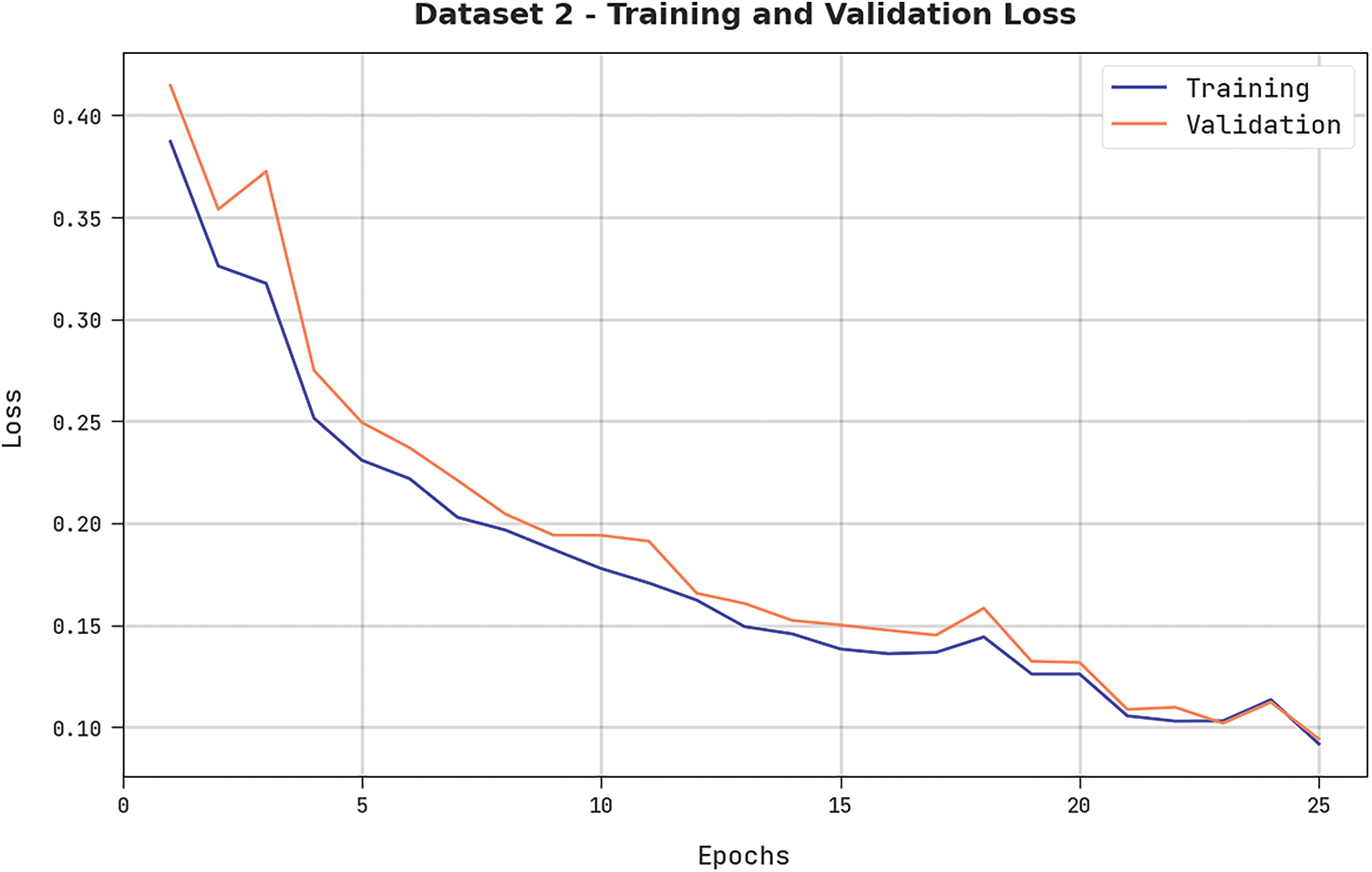
Figure 10: TRL and VLL analyses results of the DODHBM-ACC approach on dataset-2
A clear precision-recall analysis was conducted upon the proposed DODHBM-ACC approach on dataset-2 and the results are portrayed in Fig. 11. The figure represents that the proposed DODHBM-ACC algorithm produced enhanced precision-recall values under all classes.
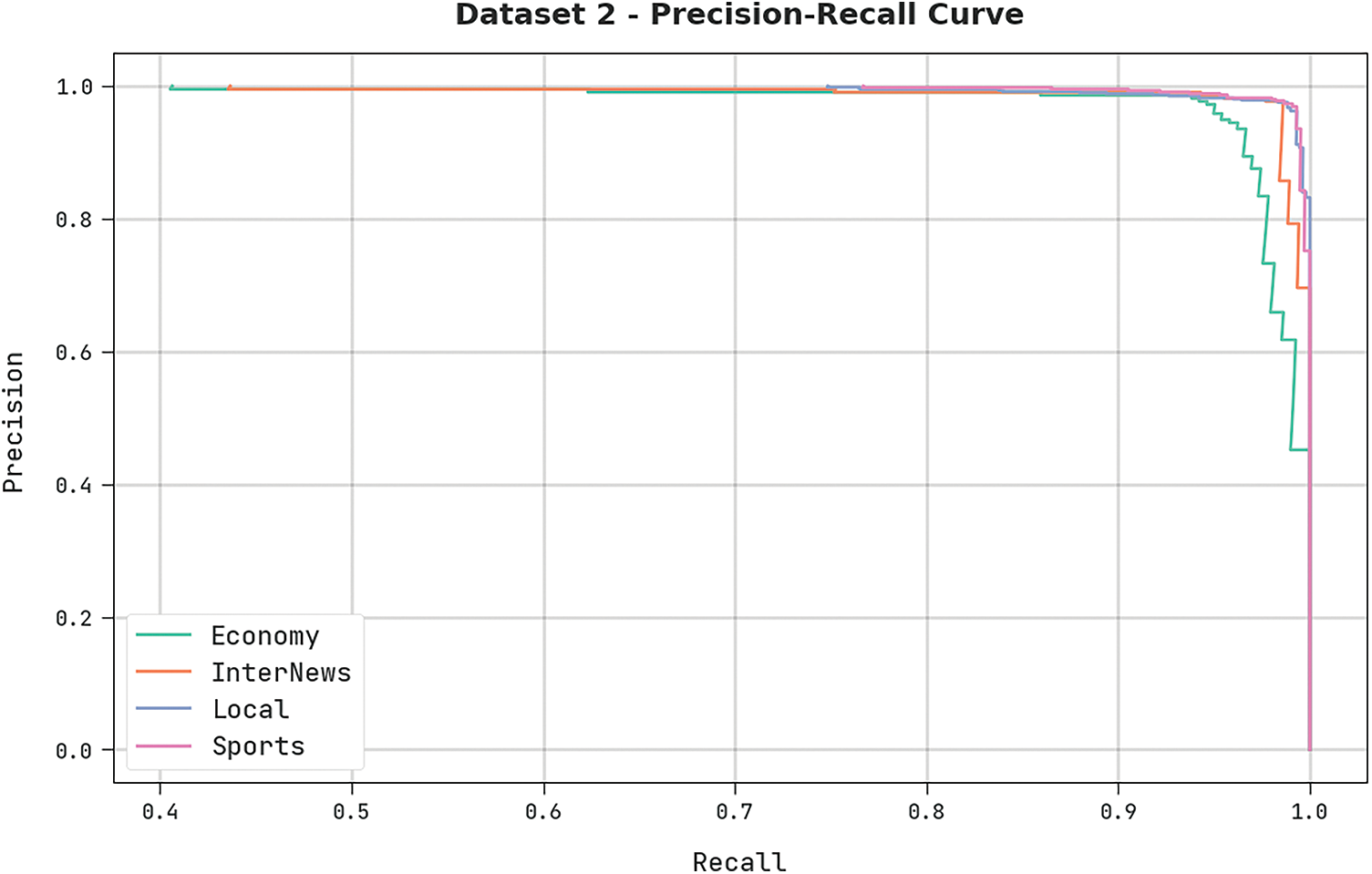
Figure 11: Precision-recall analysis results of the DODHBM-ACC approach on dataset-2
A brief ROC analysis was conducted upon the proposed DODHBM-ACC method using dataset-2, and the results are shown in Fig. 12. The results denote that the proposed DODHBM-ACC methodology established its ability in categorizing the dataset-2 under distinct classes.
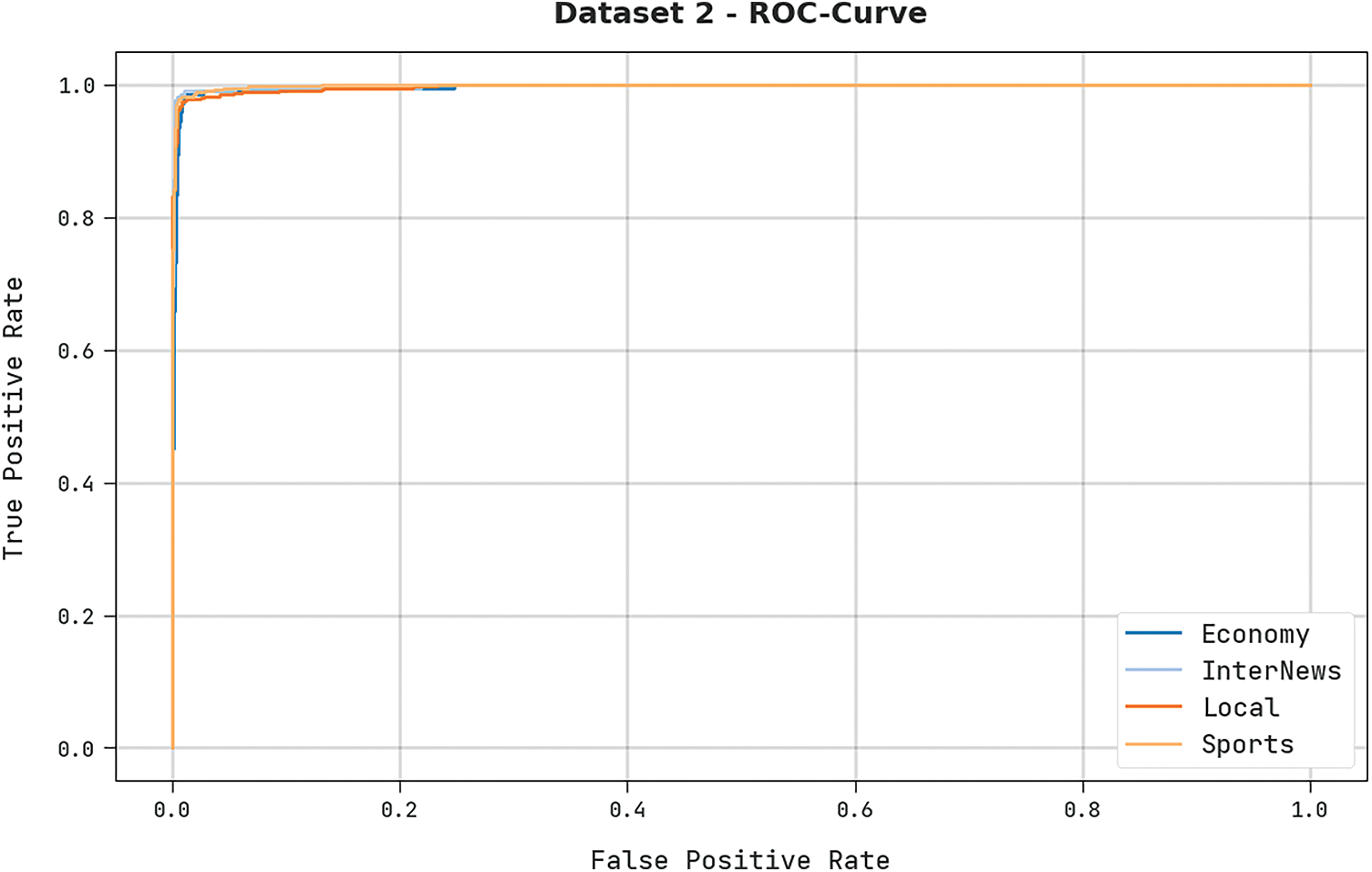
Figure 12: ROC analysis results of the DODHBM-ACC approach under dataset-2
Table 5 highlights the comparative inspection results accomplished by the proposed DODHBM-ACC model on two datasets [16]. The results imply that the DODHBM-ACC model achieved improved performance on both the datasets. For instance, on dataset-1, the proposed DODHBM-ACC model achieved an increased
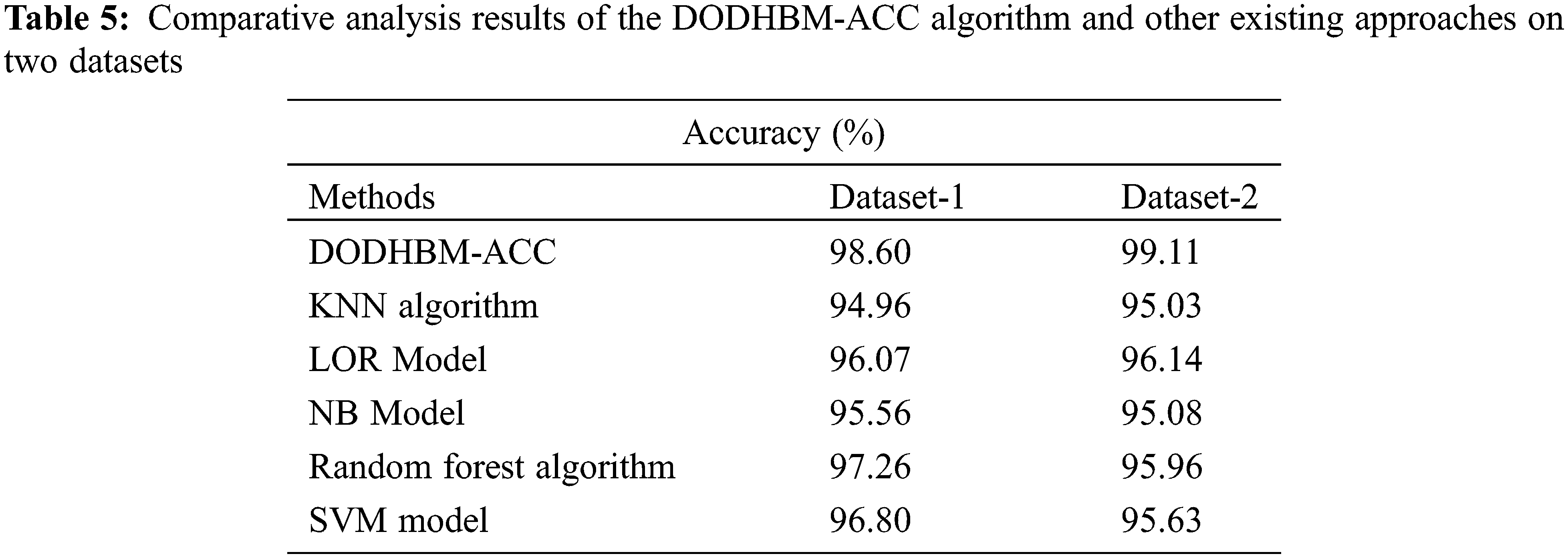
Moreover, on dataset-2, the presented DODHBM-ACC approach offered an increased
In the current study, a new DODHBM-ACC model has been developed for automated Arabic corpus classification. The presented DODHBM-ACC model primarily relies on different stages of pre-processing and word2vec word embedding process. In addition, the presented model uses the DHBM-based classification and DOA-based hyperparameter tuning processes. To adjust the hyperparameters of the DHBM technique, the DOA is exploited in this study. The experimental analysis was conducted to establish the supreme performance of the proposed DODHBM-ACC model. The outcomes confirmed the supremacy of the proposed DODHBM-ACC model over other recent approaches. In the future, the feature selection models can be utilized to reduce the computational complexity of the DODHBM-ACC model.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4310373DSR53).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. Sayed, R. K. Salem and A. E. Khder, “A survey of Arabic text classification approaches,” International Journal of Computer Applications in Technology, vol. 59, no. 3, pp. 236–251, 2019. [Google Scholar]
2. S. L. M. Sainte and N. Alalyani, “Firefly algorithm based feature selection for Arabic text classification,” Journal of King Saud University—Computer and Information Sciences, vol. 32, no. 3, pp. 320–328, 2020. [Google Scholar]
3. A. S. Alammary, “BERT models for Arabic text classification: A systematic review,” Applied Sciences, vol. 12, no. 11, pp. 5720, 2022. [Google Scholar]
4. F. N. Al-Wasabi, “A smart English text zero-watermarking approach based on third-level order and word mechanism of Markov model,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1137–1156, 2020. [Google Scholar]
5. H. Chantar, M. Mafarja, H. Alsawalqah, A. A. Heidari, I. Aljarah et al., “Feature selection using binary grey wolf optimizer with elite-based crossover for Arabic text classification,” Neural Computing and Applications, vol. 32, no. 16, pp. 12201–12220, 2020. [Google Scholar]
6. F. N. Al-Wasabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
7. A. Elnagar, R. Al-Debsi and O. Einea, “Arabic text classification using deep learning models,” Information Processing & Management, vol. 57, no. 1, pp. 102121, 2020. [Google Scholar]
8. F. N. Al-Wasabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
9. S. Bahassine, A. Madani, M. Al-Sarem and M. Kissi, “Feature selection using an improved Chi-square for Arabic text classification,” Journal of King Saud University—Computer and Information Sciences, vol. 32, no. 2, pp. 225–231, 2020. [Google Scholar]
10. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
11. K. A. Wahdan, S. Hantoobi, S. A. Salloum and K. Shaalan, “A systematic review of text classification research based on deep learning models in Arabic language,” International Journal of Electrical and Computer Engineering, vol. 10, no. 6, pp. 6629, 2020. [Google Scholar]
12. A. El Kah and I. Zeroual, “The effects of pre-processing techniques on Arabic text classification,” International Journal of Advanced Trends in Computer Science and Engineering, vol. 10, no. 1, pp. 41–48, 2021. [Google Scholar]
13. N. Aljedani, R. Alotaibi and M. Taileb, “HMATC: Hierarchical multi-label Arabic text classification model using machine learning,” Egyptian Informatics Journal, vol. 22, no. 3, pp. 225–237, 2021. [Google Scholar]
14. M. Hijazi, A. Zeki and A. Ismail, “Arabic text classification based on semantic and relation,” Computer Science, vol. 37, no. 4, pp. 992, 2018. [Google Scholar]
15. F. -Z. El-Alami, S. O. El Alaoui and N. En-Nahnahi, “Deep neural models and retrofitting for Arabic text categorization,” International Journal of Intelligent Information Technologies, vol. 16, no. 2, pp. 74–86, 2020. [Google Scholar]
16. M. Hijazi, A. Zeki and A. Ismail, “Arabic text classification using hybrid feature selection method using chi-square binary artificial bee colony algorithm,” International Journal of Mathematics and Computer Science, vol. 16, no. 1, pp. 213–228, 2021. [Google Scholar]
17. F. S. Al-Anzi and D. AbuZeina, “Beyond vector space model for hierarchical Arabic text classification: A Markov chain approach,” Information Processing & Management, vol. 54, no. 1, pp. 105–115, 2018. [Google Scholar]
18. Y. A. Alhaj, A. Dahou, M. A. Al-qaness, L. Abualigah and A. A. Almaweri, “A novel text classification technique using improved particle swarm optimization: A case study of Arabic language,” Future Internet, vol. 14, no. 7, pp. 194, 2022. [Google Scholar]
19. H. N. Alshaer, M. A. Otair, L. Abualigah, M. Alshinwan and A. M. Khasawneh, “Feature selection method using improved CHI Square on Arabic text classifiers: Analysis and application,” Multimedia Tools and Applications, vol. 80, no. 7, pp. 10373–10390, 2021. [Google Scholar]
20. A. H. Ababneh, “Investigating the relevance of Arabic text classification datasets based on supervised learning,” Journal of Electronic Science and Technology, vol. 20, no. 2, pp. 100160, 2022. [Google Scholar]
21. Y. Yao, X. Li, X. Liu, P. Liu, Z. Liang et al., “Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model,” International Journal of Geographical Information Science, vol. 31, no. 4, pp. 825–848, 2017. [Google Scholar]
22. A. G. Ororbia II, C. L. Giles and D. Reitter, “Online semi-supervised learning with deep hybrid boltzmann machines and denoising autoencoders,” arXiv preprint arXiv:1511.06964, 2015. [Google Scholar]
23. M. Dehghani, Z. Montazeri and O. P. Malik, “DGO: Dice game optimizer,” Gazi University Journal of Science, vol. 32, no. 3, pp. 871–882, 2019. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools