
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Computational Linguistics Based Arabic Poem Classification and Dictarization Model
1 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
2 Department of Applied Linguistics, College of Languages, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Prince Saud AlFaisal Institute for Diplomatic Studies, Riyadh, Saudi Arabia
4 Department of Computer Science, College of Computing and Information System, Umm Al-Qura University, Makkah, Saudi Arabia
5 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
6 Department of Information System, College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Manar Ahmed Hamza. Email:
Computer Systems Science and Engineering 2024, 48(1), 97-114. https://doi.org/10.32604/csse.2023.034520
Received 19 July 2022; Accepted 13 November 2022; Issue published 26 January 2024
A correction of this article was approved in:
Correction: Computational Linguistics Based Arabic Poem Classification and Dictarization Model
Read correction
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Computational linguistics is the scientific and engineering discipline related to comprehending written and spoken language from a computational perspective and building artefacts that effectively process and produce language, either in bulk or in a dialogue setting. This paper develops a Chaotic Bird Swarm Optimization with deep ensemble learning based Arabic poem classification and dictarization (CBSOEDL-APCD) technique. The presented CBSOEDL-APCD technique involves the classification and dictarization of Arabic text into Arabic poetries and prose. Primarily, the CBSOEDL-APCD technique carries out data pre-processing to convert it into a useful format. Besides, the ensemble deep learning (EDL) model comprising deep belief network (DBN), gated recurrent unit (GRU), and probabilistic neural network (PNN) are exploited. At last, the CBSO algorithm is employed for the optimal hyperparameter tuning of the deep learning (DL) models to enhance the overall classification performance. A wide range of experiments was performed to establish the enhanced outcomes of the CBSOEDL-APCD technique. Comparative experimental analysis indicates the better outcomes of the CBSOEDL-APCD technique over other recent approaches.Keywords
Poetry frames a huge body of literature from several renowned languages. Counties, even predating literacy, utilized poetry as an interaction and communication means [1]. Arabic poetry is a thriving, conventional literature which has an origin dating to prior the 6th century. Arab people will pay more attention to their art and celebrates gifted poets. Arabic writers compose poems to explain ideas, express emotions, give wisdom, pride and ridicule, motivate, flirt, record events, and praise and defame. Traditional Arabic poetry contains 16 m that varies in rhythm and target purposes. Chanting a poem articulately needs knowledge of the poem’s meter and acquiring a discretized version of its verses (letters engraved with short vowels); diacritics were repeatedly not engraved in Arabic texts. The Arabic language was not an exception in terms of poetry. Many findings regarding the early Islamic and pre-Islamic Arabs were found via their poetry [2,3]. Arabs employed poetry to exhibit all detail of their life. Poetry is so valuable to them that they bring 7 legendary poems on ‘Al Kaaba’ curtains, their holiest location. It is even employed to collect on periodical festivals for reciting and promulgating their poems [4,5]. The Arabic language was the 6th most spoken language across many counties.
Arabic script orientation will be from right to left [6]. It contains twenty-eight letters, which include twenty-five consonants and three long vowels. Moreover, it involves certain special glyphs named diacritics. The diacritics in Arabic are split into 4 categories respective to their functionalities [7,8]. The initial category of diacritics involves a short vowel after every letter. The second category attaches a constant letter at the word end [9]. The ‘Shadda’ diacritic formed the third category and was employed for producing stressed letters. The 4th category was the diacritic ‘Sukun’, which can be utilized for indicating vowel absence [10].
The majority of the solutions for the automatic identification of Poem classifiers depend on Natural Language Processing (NLP) techniques [11]; there has recently been a leaning against using pure machine learning (ML) approaches such as neural networks for that task [12,13]. NLP methods contain the disadvantage of their complexity and, to a greater extent, rely on the language utilized in the text. It offers a robust motivation to use other ML methods for classifier tasks [14]. Additionally, the prevailing automatic techniques rely upon employing pre-trained vectors (e.g., Word2Vec, Glove) as word embedding for better performance from the classifier method. That makes identifying hatred content impracticable in cases where users deliberately obfuscate their offensive terminologies with short slang words [15].
In [16], a Deep Belief Network (DBN) can be leveraged as a diacritizers for Arabic text. DBN refers to one deep learning (DL) method that seems highly effective for several ML complexes. The author assesses the usage of DBN as a classifier in automated Arabic text discretizations. The DBN is well-trained to categorize every input letter with the respective diacritized versions separately. Madhfar et al. [17] offered three deep learning (DL) techniques for recovering Arabic text diacritics concerning this study in a text-to-speech synthesis mechanism utilizing DL. The primary method was a baseline method for testing how a simple DL executes over the corpora. The next method was related to an encoder-decoder structure that looks like this text-to-speech synthesis method having several alterations to suit this issue. The latest method was related to the encoder share of the text-to-speech method that attains exciting performance in diacritic error rate metrics and word error rates.
Fadel et al. [18] provided numerous DL approaches for the automated discretization of Arabic text. This technique was constructed utilizing 2 key techniques, viz. embeddings, recurrent neural network (RNN) and Feed-Forward Neural Network (FFNN), and has numerous improvements like Conditional Random Field (CRF), Block-Normalized Gradient (BNG), and 100-hot encoding. The techniques were tested on the only easily accessible benchmark data, and the outcomes exhibit that these techniques are either on par or better with others, even those demanding human-crafted language-dependent postprocessing stages dissimilar to ours. In [19], the long short term memory (LSTM) method was employed to investigate the efficacy of neural network (NN) in Arabic NLP. The method was explicitly practical for recognizing part-of-speech (POS) tags for morphemes and Arabic words taken from the Quranic Arabic Corpus (QAC) data. QAC becomes a renowned gold standard dataset organized by authors from Leeds varsity. In [20], the researchers employed a Gated Recurrent Unit (GRU) and recurrent neural network (RNN), applying a simple gating system to improve Arabic discretization processes. Assessment of GRU for discretization can be executed compared to the exiting outcomes acquired with LSTM, an influential RNN structure receiving the familiar fallouts in discretization.
This paper develops a Chaotic Bird Swarm Optimization with deep ensemble learning based Arabic poem classification and dictarization (CBSOEDL-APCD) technique. The presented CBSOEDL-APCD technique involves the classification and dictarization of Arabic text into Arabic poetries and prose. Primarily, the CBSOEDL-APCD technique carries out data pre-processing to convert it into a useful format. Besides, the EDL model comprising deep belief network (DBN), gated recurrent unit (GRU), and probabilistic neural network (PNN) are exploited. At last, the CBSO algorithm is employed for the optimal hyperparameter tuning of the DL models to enhance the overall classification performance. A wide range of experiments were performed to demonstrate the enhanced outcomes of the CBSOEDL-APCD technique.
The rest of the paper is organized as follows. Section 2 introduces the proposed model, and Section 3 offers the performance validation. Lastly, Section 4 concludes the study.
2 Design of CBSOEDL-APCD Technique
In this study, a new CBSOEDL-APCD algorithm was introduced for classifying and dictarization of Arabic text into Arabic poetries and prose. The presented CBSOEDL-APCD technique includes data pre-processing, fusion process, and parameter optimization. It can clean social media posts during data pre-processing to remove unwanted symbols and noise. Fig. 1 showcases the overall process of the CBSOEDL-APCD approach. This step aims to maximize the count of words whose embedded was defined in the pre-trained word embedded technique.
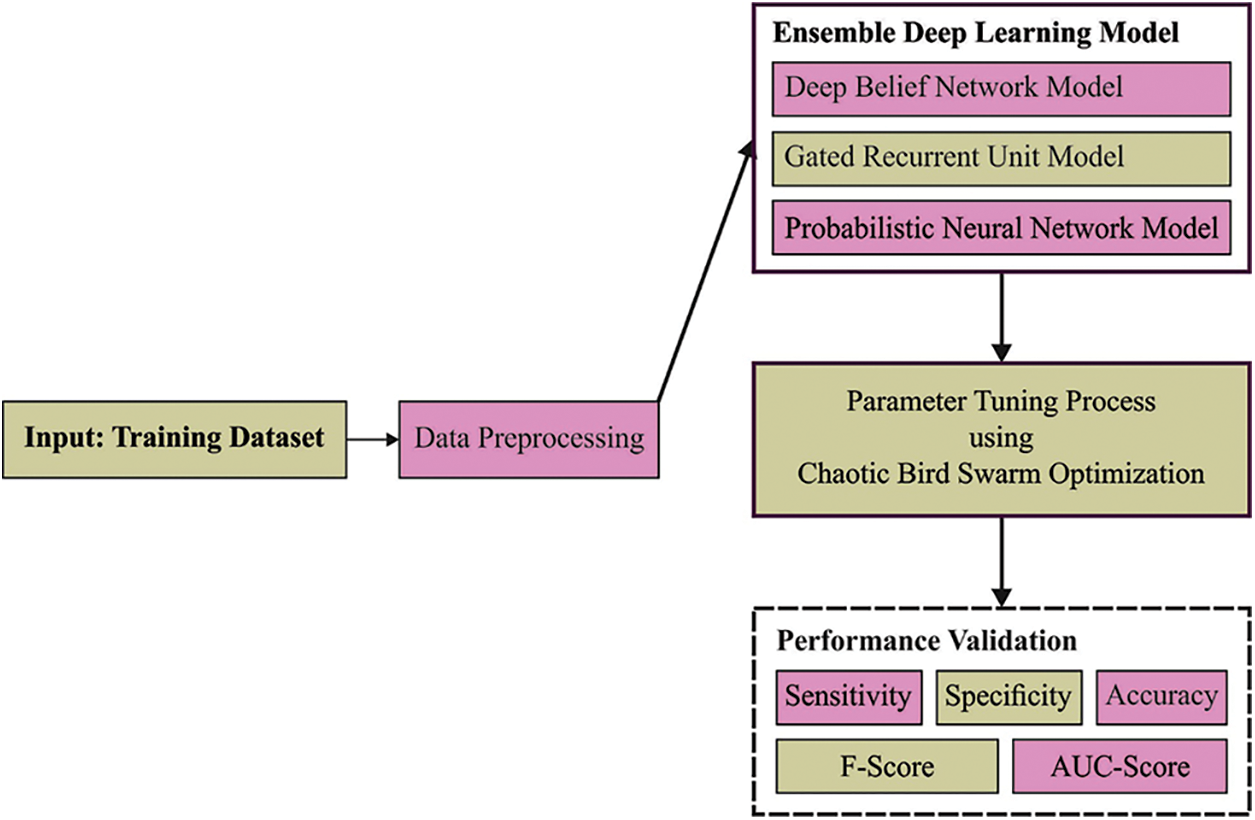
Figure 1: Overall process of CBSOEDL-APCD approach
The steps followed to clean the Arabic comments are as follows:
• Eliminating the stop words with a list of stop words including MSA and Dialect Arabic, i.e., ( like), (
like), (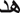 this), and)
this), and)  until).
until).
• Normalize the words and eliminate unwanted punctuation marks and symbols.
• Eliminating elongation and utilizing a single event in its place.
Concerning step 2, as the word embedded method does not comprise representation for emoticons, it can be established a mapping amongst known emoticons to their equivalent emojis. This approach cannot fail the sentiment stated by individuals’ emoticons. Emojis were tokenized by assigning spaces among them; all the emojis are looked upon individually from the word-embedded method, which supports that once a set of emojis, without spaces between, perform in a comment, this integration may not have an equivalent word embedded.
2.1 Process Involved in EDL Model
This study’s EDL model encompasses DBN, GRU, and PNN models. A fusion of three models helps in accomplishing enhanced Arabic poetry classification performance.
DBNs can learn several layers of nonlinear features in unlabeled information. The high-order feature learned with the upper layer is extracting the hidden unit from the lower layer that is recognized with trained Restricted Boltzmann Machines (RBMs) from a greedy layer-wise approach by Contrastive Divergence technique and stacking them all over each other [21]. A generative DBN was capable of performing image in-painting and reconstruction.
Assume it takes an
whereas
And the conditional probability is
In which
and
It can be complex to perform Gibbs sampling by conditional distribution

Like the LSTM model, GRU is intended for adoptively updating or resetting the memory contents with
To evaluate the state
In Eq. (3),
To evaluate the update gate
The new memory content
Now
GRU is fast than LSTM in training because GRU has a simple structure using lesser parameters and thus employs lesser memory. Fig. 2 depicts the infrastructure of the GRU approach.
Figure 2: Structure of GRU
Consider an input vector
In real-time data classification problems, dataset distribution is generally unknown, and a calculation of probability density function
Now,
Eq. (7) describes the architecture and the process of PNN. Then, assume a Gaussian function as an activation for the probability density function and consider that this function can be evaluated for class g as follows:
In Eq. (8),
In Eq. (9),
Here, a single smoothing variable for every class and attribute is employed. The selection of variation of
2.2 Hyperparameter Optimization
For optimal hyperparameter tuning of the DL models, the CBSO algorithm is exploited in this work. The BSO algorithm is a robust optimization procedure with the features of the simplest technique, better expandability, etc. Deliberate N virtual birds fly and forage for food [23]. Supposing
1. Foraging behaviour can be defined by Eq. (10):
2. Vigilance behaviour can be defined by Eq. (11):
which
3. Flight behaviour is defined below:
Now,
In this section, the Arabic poetry classification outcomes of the CBSOEDL-APCD model are tested using an Arabic poetry dataset comprising 34000 samples under 17 class labels, as depicted in Table 1.
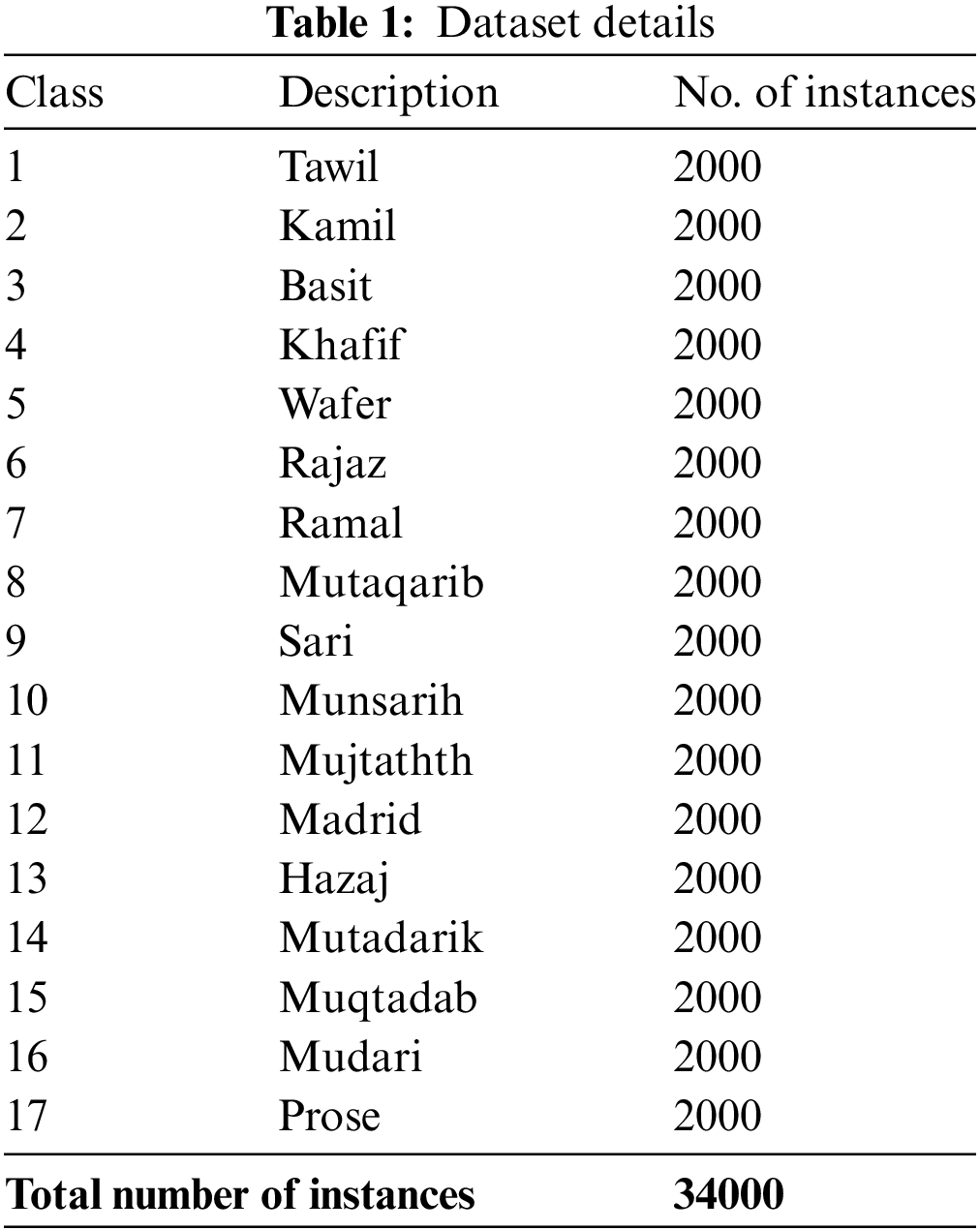
Fig. 3 reports the confusion matrix generated by the CBSOEDL-APCD model on the entire dataset. The figure indicated that the CBSOEDL-APCD model had recognized 1887 samples into class 1, 1928 samples into class 2, 1911 samples into class 3, 1885 samples into class 4, 1917 samples into class 5, 1893 samples into class 6, 1911 samples into class 7, and so on.
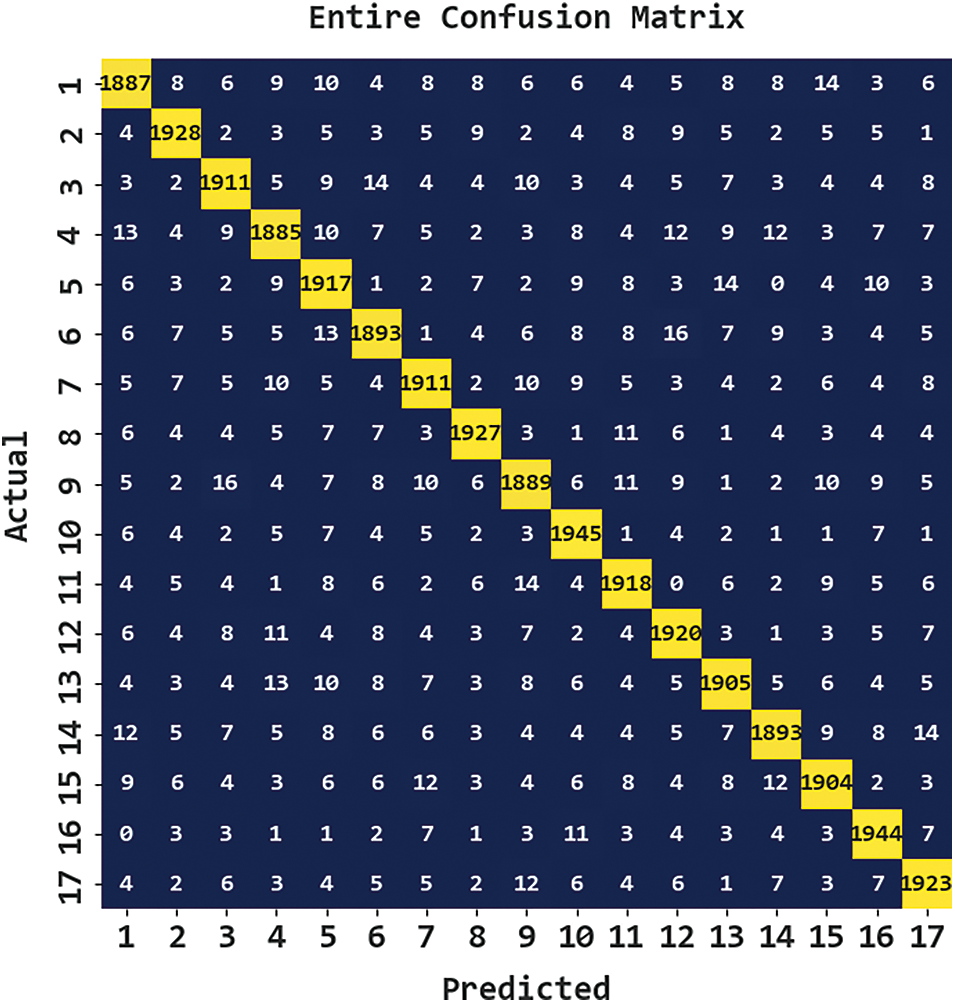
Figure 3: Confusion matrix of CBSOEDL-APCD approach under the entire dataset
A detailed poetry classification outcome of the CBSOEDL-APCD model under the entire dataset is represented in Table 2 and Fig. 4. The results reported that the CBSOEDL-APCD model had enhanced outcomes under all class labels. For instance, the CBSOEDL-APCD model has identified class 1 samples with
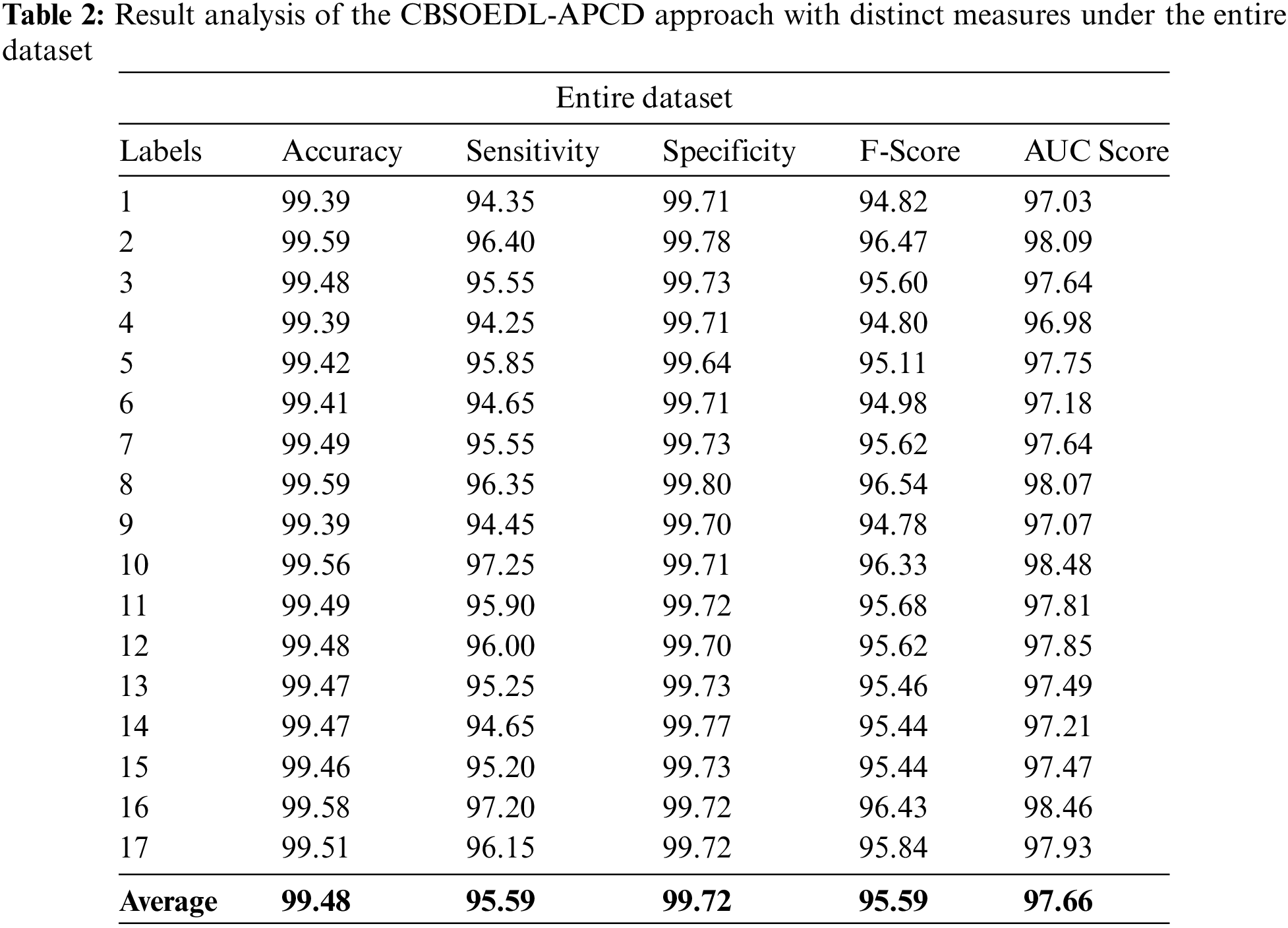
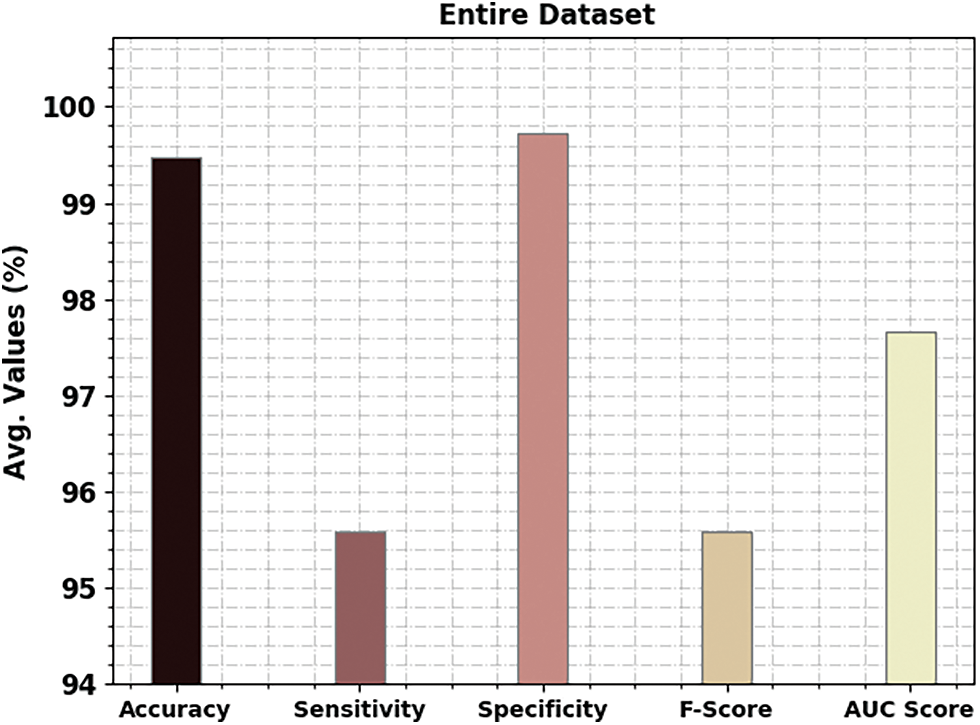
Figure 4: Average analysis of the CBSOEDL-APCD approach under the entire dataset
Fig. 5 portrays the confusion matrix generated by the CBSOEDL-APCD algorithm on 70% of training (TR) data. The figure represented the CBSOEDL-APCD approach has recognized 1272 samples into class 1, 1341 samples into class 2, 1336 samples into class 3, 1346 samples into class 4, 1306 samples into class 5, 1324 samples into class 6, 1392 samples into class 7, and so on.
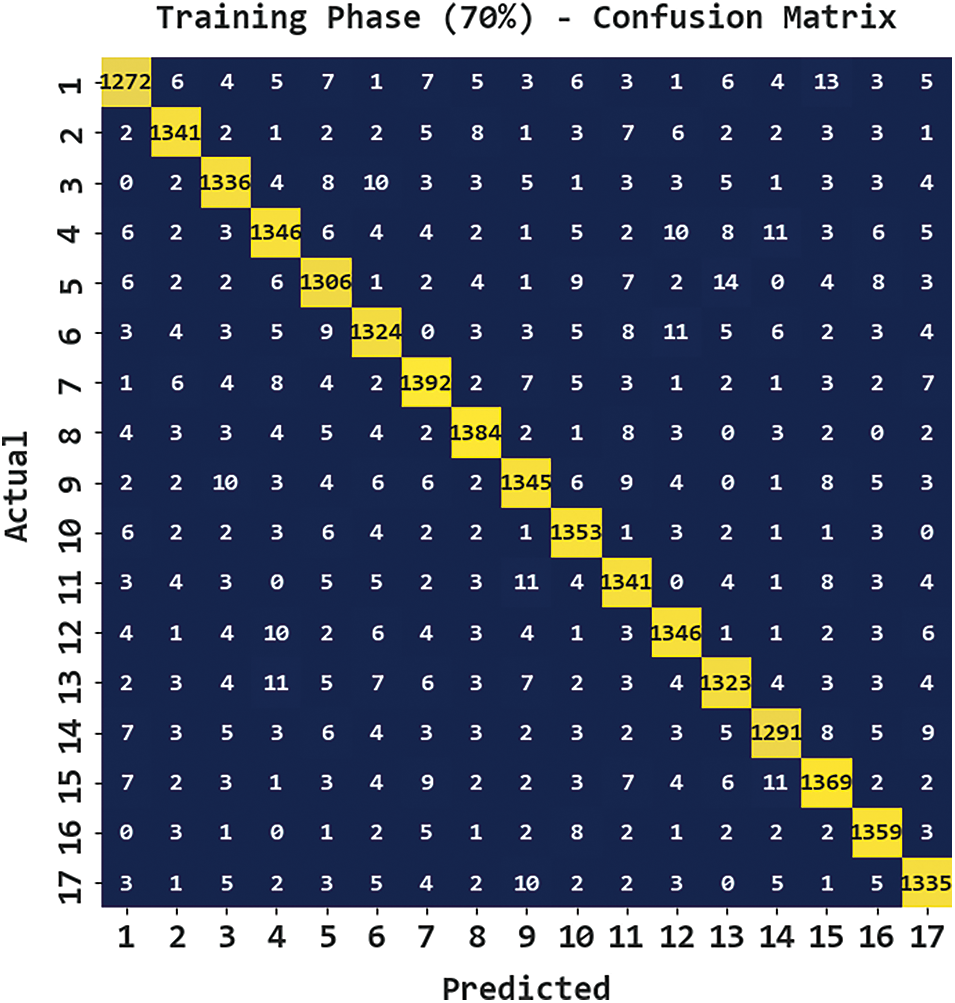
Figure 5: Confusion matrix of CBSOEDL-APCD approach under 70% of TR data
A brief poetry classification outcome of the CBSOEDL-APCD approach under 70% of training (TR) is represented in Table 3 and Fig. 6. The results reported that the CBSOEDL-APCD algorithm had exhibited enhanced outcomes under all class labels. For example, the CBSOEDL-APCD approach has identified class 1 samples with
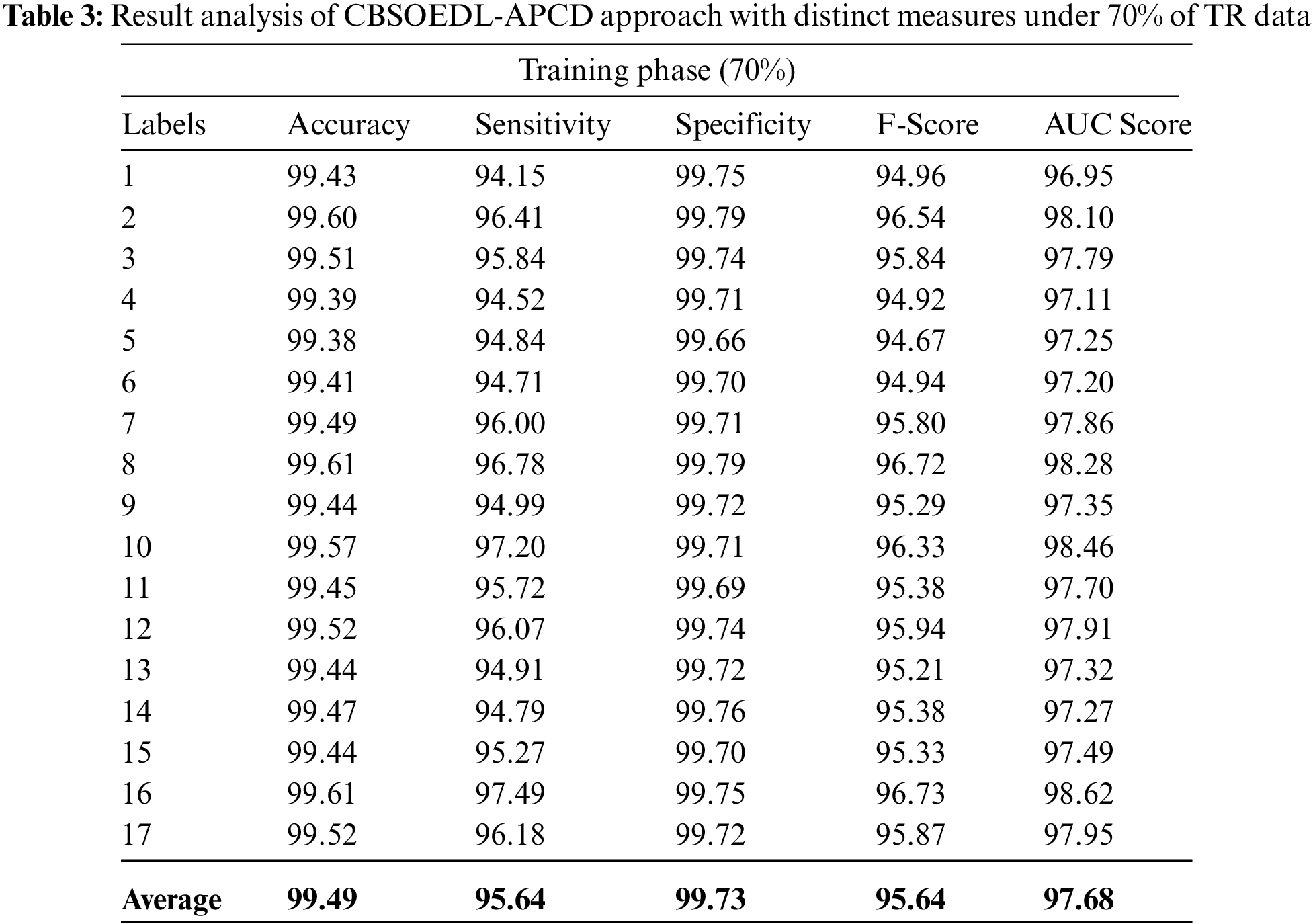
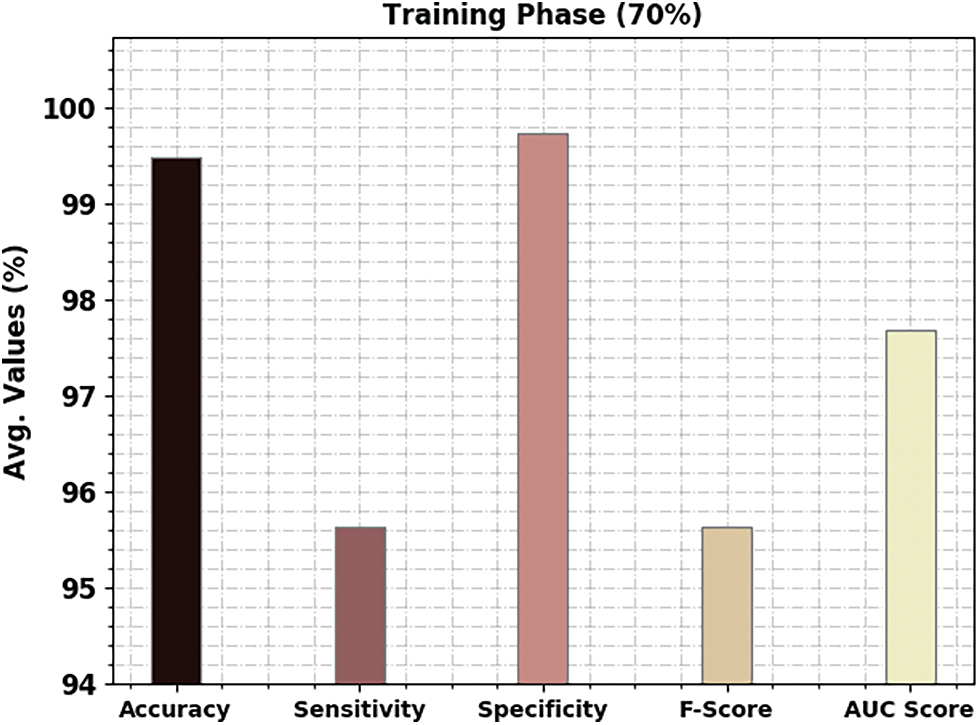
Figure 6: Average analysis of CBSOEDL-APCD approach under 70% of TR data
Fig. 7 presents the confusion matrix generated by the CBSOEDL-APCD algorithm on 30% of testing (TS) data. The figure denoted the CBSOEDL-APCD approach has recognized 615 samples into class 1, 587 samples into class 2, 575 samples into class 3, 539 samples into class 4, 611 samples into class 5, 569 samples into class 6, 519 samples into class 7, and so on.
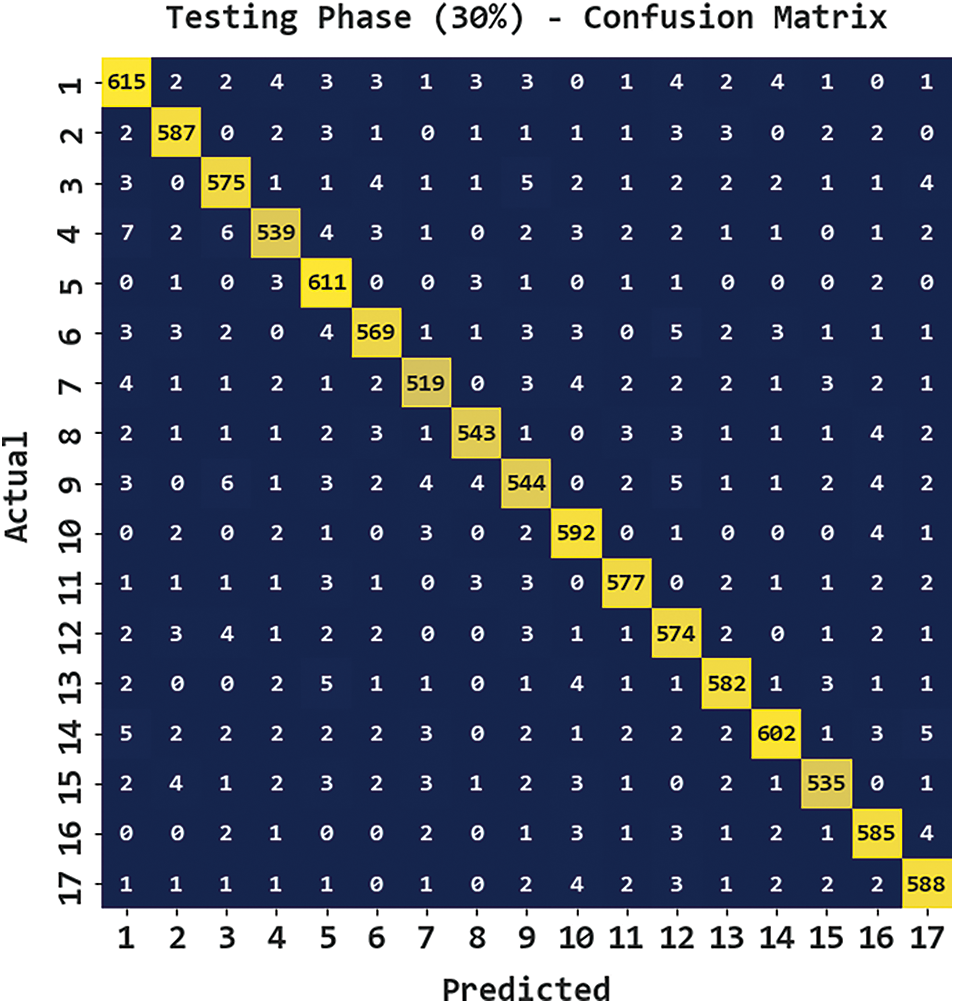
Figure 7: Confusion matrix of CBSOEDL-APCD approach under 30% of TS data
A brief poetry classification outcome of the CBSOEDL-APCD approach under 30% of TS is depicted in Table 4 and Fig. 8. The results reported that the CBSOEDL-APCD approach had outperformed enhanced outcomes under all class labels. For example, the CBSOEDL-APCD technique has identified class 1 samples with an
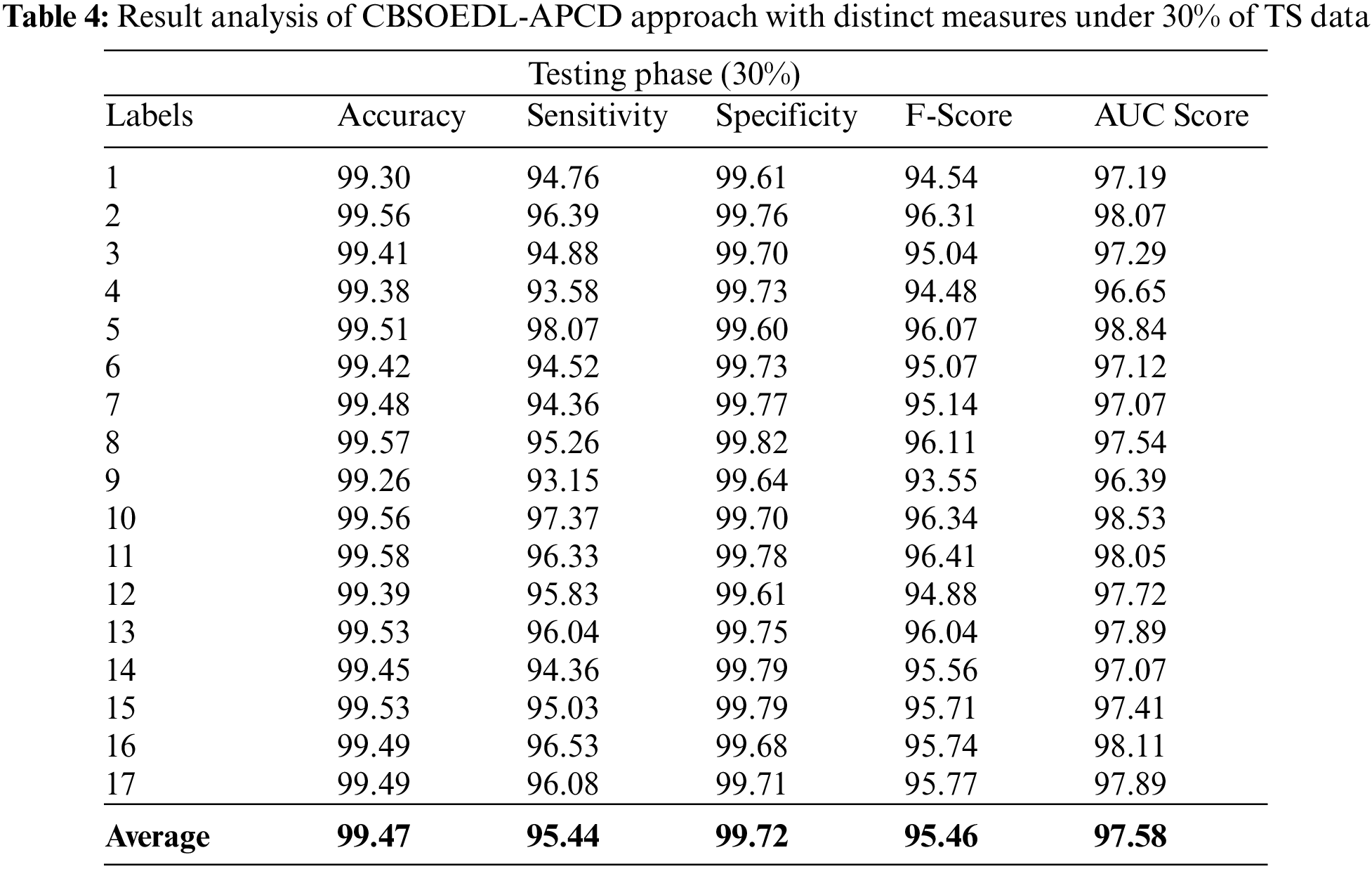
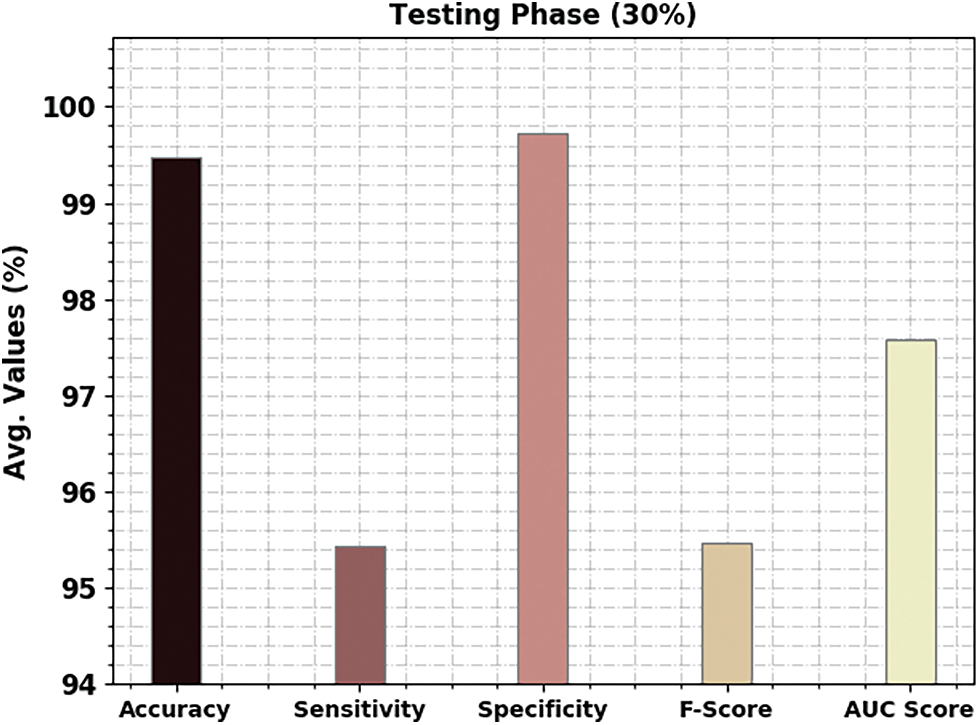
Figure 8: Average analysis of CBSOEDL-APCD approach under 30% of TS data
The training accuracy (TRA) and validation accuracy (VLA) gained by the CBSOEDL-APCD method on the test dataset is shown in Fig. 9. The experimental outcome represented the CBSOEDL-APCD algorithm has attained maximum values of TRA and VLA. In Particular, the VLA is greater than TRA.
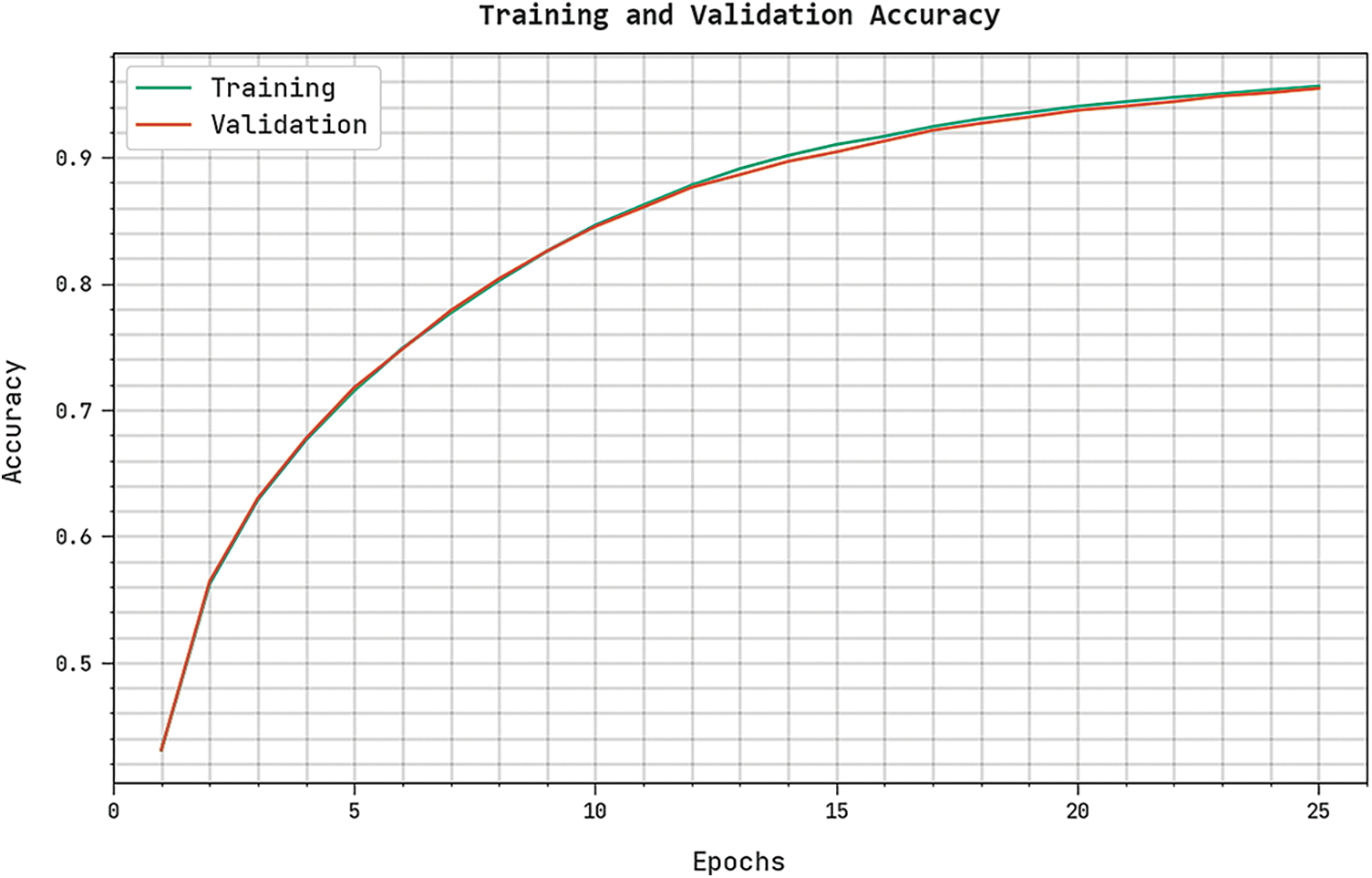
Figure 9: TRA and VLA analysis of the CBSOEDL-APCD approach
The training loss (TRL) and validation loss (VLL) gained by the CBSOEDL-APCD algorithm on the test dataset were exhibited in Fig. 10. The experimental outcome indicates the CBSOEDL-APCD approach has accomplished least values of TRL and VLL. Seemingly, the VLL is lesser than TRL. A clear precision-recall analysis of the CBSOEDL-APCD methodology on the test dataset is given in Fig. 11. The figure specified that the CBSOEDL-APCD algorithm has resulted in enhanced values of precision-recall values under all classes. A detailed ROC analysis of the CBSOEDL-APCD technique on the test dataset is portrayed in Fig. 12. The results implicit that the CBSOEDL-APCD algorithm has outperformed its ability to categorise distinct classes on the test dataset. For assuring the enhancements of the CBSOEDL-APCD model, a comparative
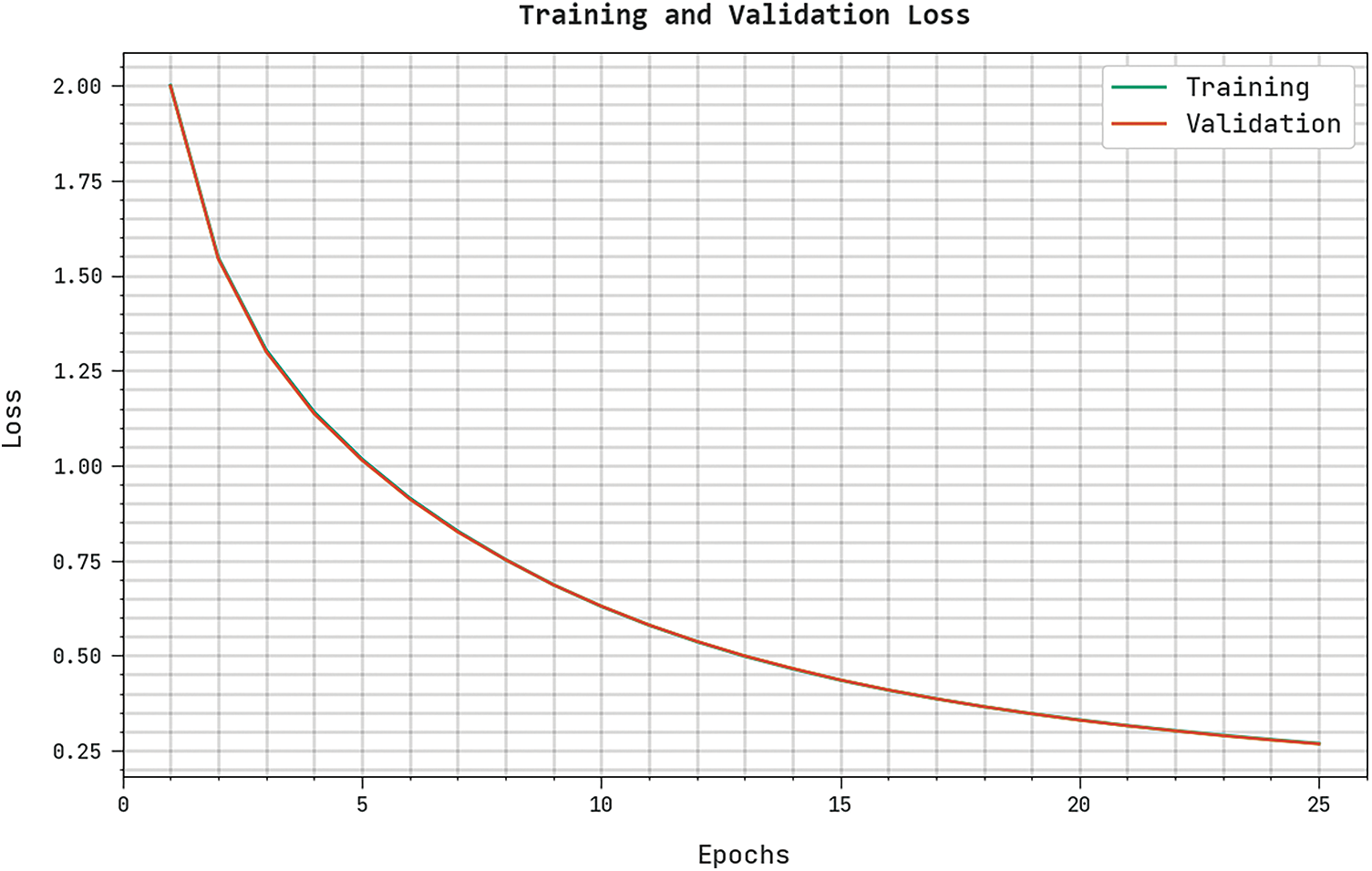
Figure 10: TRL and VLL analysis of the CBSOEDL-APCD approach
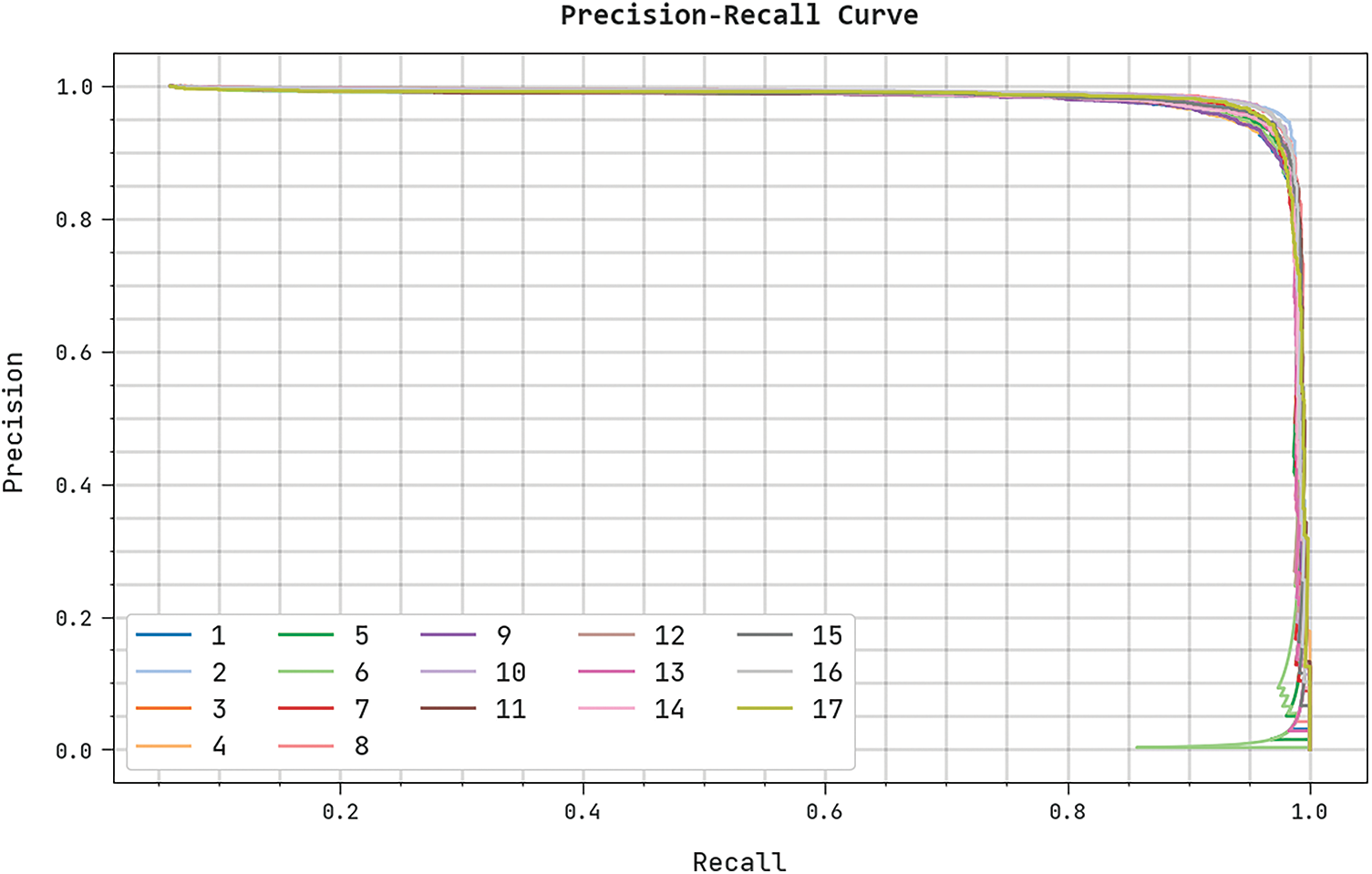
Figure 11: Precision-recall analysis of the CBSOEDL-APCD approach
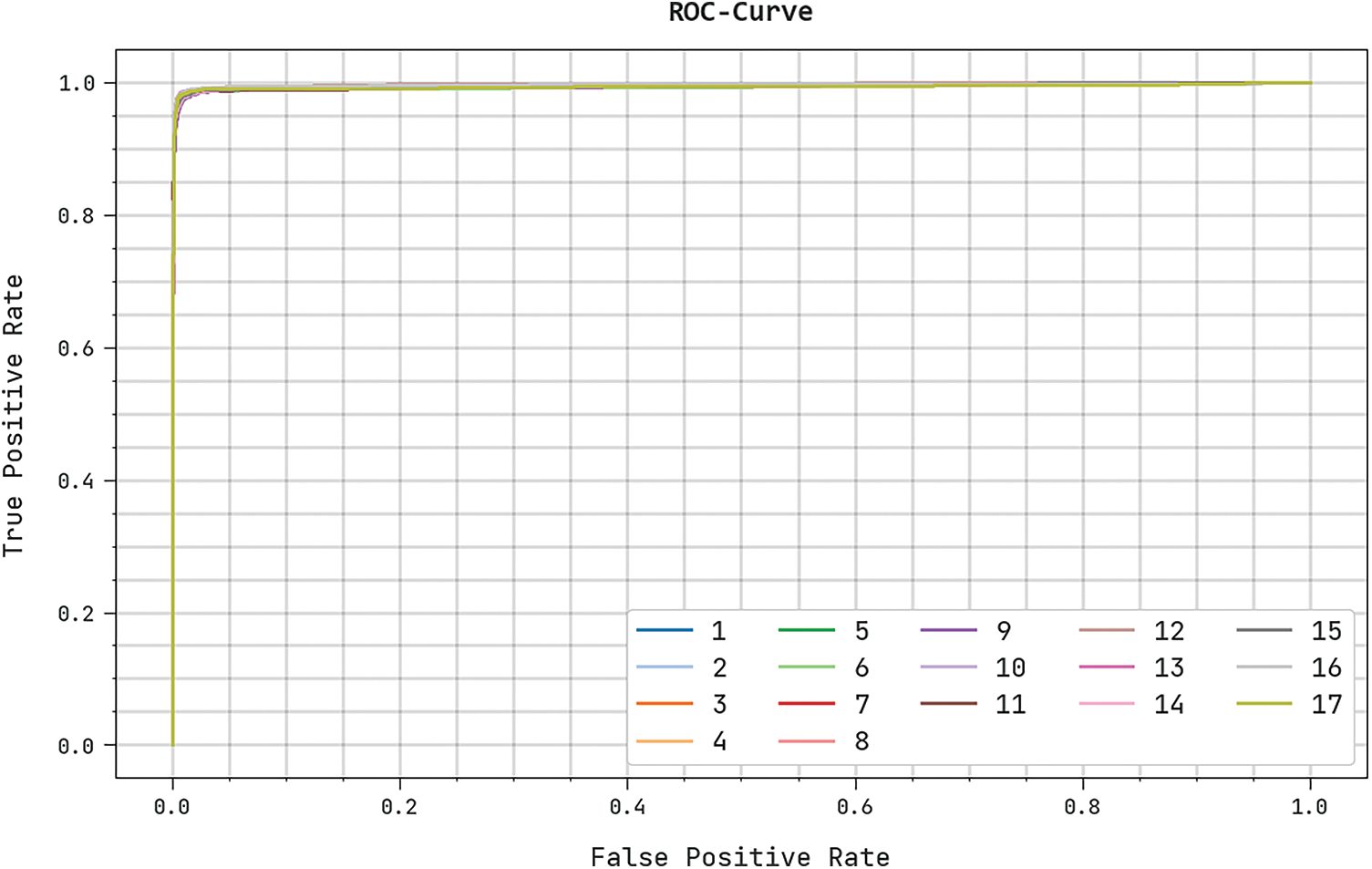
Figure 12: ROC analysis of the CBSOEDL-APCD approach
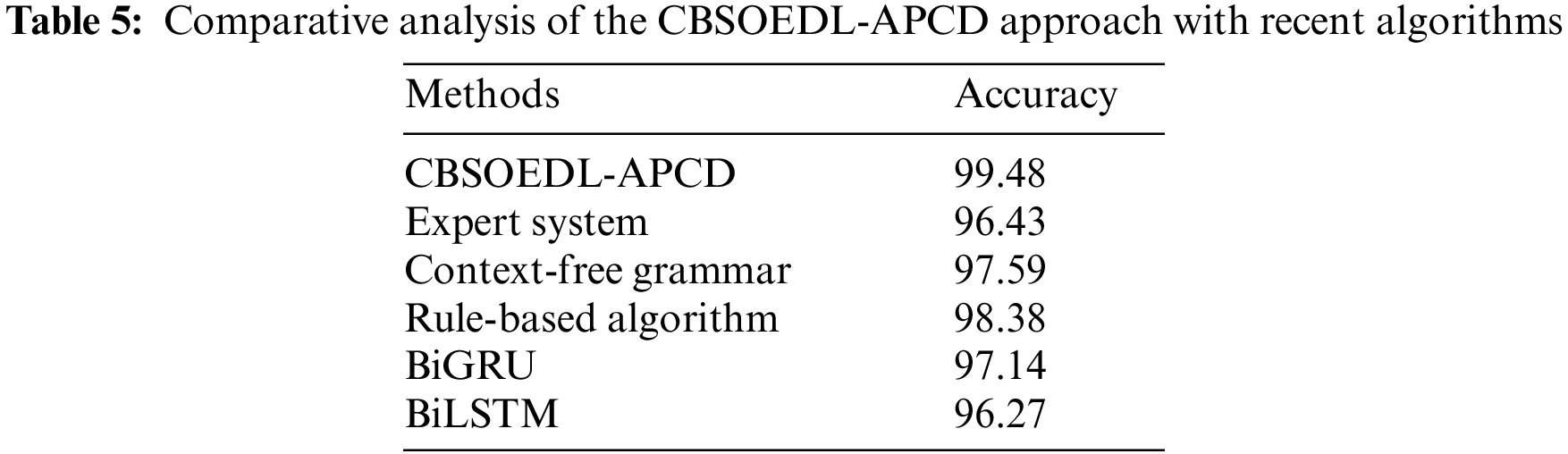
Next, the bidirectional gated recurrent unit (BiGRU) and Context free grammar models have obtained slightly enhanced
This study introduced a new CBSOEDL-APCD algorithm for classifying and dictarization of Arabic text into Arabic poetries and prose. Primarily, the CBSOEDL-APCD technique carries out data pre-processing to convert it into a useful format. Besides, the EDL model encompasses DBN, GRU, and PNN models. At last, the CBSO algorithm is employed for the optimal hyperparameter tuning of the DL models to enhance the overall classification performance. An extensive range of experiments was performed to demonstrate the enhanced outcomes of the CBSOEDL-APCD technique. A wide-ranging experimental analysis indicates the better outcomes of the CBSOEDL-APCD approach over other recent ones. Thus, the CBSOEDL-APCD technique can be employed to classify Arabic poems.
Acknowledgement: The authors express their gratitude to Princess Nourah bint Abdulrahman University Researchers Supporting Project, Princess Nourah bint Abdulrahman University Riyadh Saudi Arabia.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R281), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4310373DSR42.
Author Contributions: Conceptualization, Hala J. Alshahrani; Methodology, Hala J. Alshahrani; Najm Alotaibi, Software, Mohamed K. Nour; Validation, Mahmoud Othman and Manar Ahmed Hamza Investigation, Hala J. Alshahrani; Data curation, Gouse Pasha Mohammed; Writing – original draft, Manar Ahmed Hamza, Hala J. Alshahrani, Najm Alotaibi, Mohamed K. Nour, Mahmoud Othman, Gouse Pasha Mohammed, Mohammed Rizwanullah and Mohamed I. Eldesouki; Writing – review & editing, Manar Ahmed Hamza, Mahmoud Othman, Gouse Pasha Mohammed, Mohammed Rizwanullah; Visualization, Mohamed I. Eldesouki; Project administration, Manar Ahmed Hamza; Funding acquisition, Hala J. Alshahrani. All authors have read and agreed to the published version of the manuscript.
Availability of Data and Materials: Data sharing not applicable to this article as no datasets were generated during the current study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. Masmoudi, C. Aloulou, A. Abdellahi and L. Belguith, “Automatic discretization of Tunisian dialect text using SMT model,” International Journal of Speech Technology, vol. 25, no. 1, pp. 89–104, 2021. [Google Scholar]
2. M. A. A. Rashwan, A. A. Al Sallab, H. M. Raafat and A. Rafea, “Deep learning framework with confused sub-set resolution architecture for automatic Arabic discretization,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 3, pp. 505–516, 2015. [Google Scholar]
3. G. Abandah and A. Karim, “Accurate and fast recurrent neural network solution for the automatic discretization of Arabic text,” Jordanian Journal of Computers and Information Technology, vol. 6, no. 2, pp. 103–121, 2020. [Google Scholar]
4. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
5. O. Hamed, “Automatic discretization as prerequisite towards the automatic generation of Arabic lexical recognition tests,” in Proc. of the 3rd Int. Conf. on Natural Language and Speech Processing, Trento, Italy, pp. 100–106, 2019. [Google Scholar]
6. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
7. M. S. Al-shaibani, Z. Alyafeai and I. Ahmad, “Meter classification of Arabic poems using deep bidirectional recurrent neural networks,” Pattern Recognition Letters, vol. 136, pp. 1–7, 2020. [Google Scholar]
8. F. N. Al-Wesabi, “A smart English text zero-watermarking approach based on third-level order and word mechanism of markov model,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1137–1156, 2020. [Google Scholar]
9. A. Fadel, I. Tuffaha, B. Al-Jawarneh and M. Al-Ayyoub, “Arabic text discretization using deep neural networks,” in 2nd Int. Conf. on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, pp. 1–7, 2019. [Google Scholar]
10. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
11. G. A. Abandah, A. Graves, B. Al-Shagoor, A. Arabiyat, F. Jamour et al., “Automatic discretization of Arabic text using recurrent neural networks,” International Journal on Document Analysis and Recognition (IJDAR), vol. 18, no. 2, pp. 183–197, 2015. [Google Scholar]
12. A. A. Karim and G. Abandah, “On the training of deep neural networks for automatic Arabic-text discretization,” International Journal of Advanced Computer Science and Applications, vol. 12, no. 8, pp. 276–286, 2021. [Google Scholar]
13. F. N. Al-Wesabi, A. Abdelmaboud, A. A. Zain, M. M. Almazah and A. Zahary, “Tampering detection approach of Arabic-text based on contents interrelationship,” Intelligent Automation & Soft Computing, vol. 27, no. 2, pp. 483–498, 2021. [Google Scholar]
14. A. Shahrour, S. Khalifa and N. Habash, “Improving Arabic discretization through syntactic analysis,” in Proc. of the Conf. on Empirical Methods in Natural Language Processing, Lisbon, Portu, pp. 1309–1315, 2015. [Google Scholar]
15. I. H. Ali, Z. Mnasri and Z. Laachri, “Gemination prediction using DNN for Arabic text-to-speech synthesis,” in 16th Int. Multi-Conf. on Systems, Signals & Devices (SSD), Istanbul, Turkey, pp. 366–370, 2019. [Google Scholar]
16. W. Almanaseer, M. Alshraideh and O. Alkadi, “A deep belief network classification approach for automatic discretization of Arabic text,” Applied Sciences, vol. 11, no. 11, pp. 5228, 2021. [Google Scholar]
17. M. A. H. Madhfar and A. M. Qamar, “Effective deep learning models for automatic discretization of Arabic text,” IEEE Access, vol. 9, pp. 273–288, 2021. [Google Scholar]
18. A. Fadel, I. Tuffaha and M. Al-Ayyoub, “Neural Arabic text discretization: State-of-the-art results and a novel approach for Arabic nlp downstream tasks,” ACM Transactions on Asian and Low-Resource Language Information Processing, vol. 21, no. 1, pp. 1–25, 2022. [Google Scholar]
19. A. Alharbi, M. Taleb and M. Kalkatawi, “Deep learning in Arabic sentiment analysis: An overview,” Journal of Information Science, vol. 47, no. 1, pp. 129–140, 2019. [Google Scholar]
20. R. Moumen, R. Chiheb, R. Faizi and A. El, “Evaluation of gated recurrent unit in Arabic discretization,” International Journal of Advanced Computer Science and Applications, vol. 9, no. 11, pp. 360–3664, 2018. [Google Scholar]
21. W. Deng, H. Liu, J. Xu, H. Zhao and Y. Song, “An improved quantum-inspired differential evolution algorithm for deep belief network,” IEEE Transactions on Instrumentation and Measurement, vol. 69, no. 10, pp. 7319–7327, 2020. [Google Scholar]
22. G. Capizzi, G. L. Sciuto, C. Napoli, D. Polap and M. Wozniak, “Small lung nodules detection based on fuzzy-logic and probabilistic neural network with bioinspired reinforcement learning,” IEEE Transactions on Fuzzy Systems, vol. 28, no. 6, pp. 1178–1189, 2020. [Google Scholar]
23. K. Mishra and S. K. Majhi, “A binary bird swarm optimization based load balancing algorithm for cloud computing environment,” Open Computer Science, vol. 11, no. 1, pp. 146–160, 2021. [Google Scholar]
24. G. A. Abandah, M. Z. Khedher, M. R. A. Majeed, H. M. Mansour, S. F. Hulliel et al., “Classifying and diacritizing Arabic poems using deep recurrent neural networks,” Journal of King Saud University-Computer and Information Sciences, vol. 34, no. 6, pp. 3775–3788, 2022. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools