
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Automatic Clustering of User Behaviour Profiles for Web Recommendation System
1 Department of Computer Science and Engineering, Velalar College of Engineering and Technology, Erode, 638 012, Tamil Nadu, India
2 Al-Nahrain Nanorenewable Energy Research Center, Al-Nahrain University, Baghdad, 64074, Iraq
3 Department of Computer Science, College of Computers and Information Technology, Taif University, P.O. Box 11099, Taif 21944, Saudi Arabia
4 Department of Computer Science and Engineering, Kongu Engineering College, Perundurai, 638060, Tamil Nadu, India
5 School of Digital Science, University Brunei Darussalam, Jln Tungku Link, Gadong BE1410, Brunei Darussalam
* Corresponding Author: S. Sadesh. Email:
Intelligent Automation & Soft Computing 2023, 35(3), 3365-3384. https://doi.org/10.32604/iasc.2023.030751
Received 01 April 2022; Accepted 26 May 2022; Issue published 17 August 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Web usage mining, content mining, and structure mining comprise the web mining process. Web-Page Recommendation (WPR) development by incorporating Data Mining Techniques (DMT) did not include end-users with improved performance in the obtained filtering results. The cluster user profile-based clustering process is delayed when it has a low precision rate. Markov Chain Monte Carlo-Dynamic Clustering (MC2-DC) is based on the User Behavior Profile (UBP) model group’s similar user behavior on a dynamic update of UBP. The Reversible-Jump Concept (RJC) reviews the history with updated UBP and moves to appropriate clusters. Hamilton’s Filtering Framework (HFF) is designed to filter user data based on personalised information on automatically updated UBP through the Search Engine (SE). The Hamilton Filtered Regime Switching User Query Probability (HFRSUQP) works forward the updated UBP for easy and accurate filtering of users’ interests and improves WPR. A Probabilistic User Result Feature Ranking based on Gaussian Distribution (PURFR-GD) has been developed to user rank results in a web mining process. PURFR-GD decreases the delay time in the end-to-end workflow for SE personalization in various methods by using the Gaussian Distribution Function (GDF). The theoretical analysis and experiment results of the proposed MC2-DC method automatically increase the updated UBP accuracy by 18.78%. HFRSUQP enabled extensive Maximize Log-Likelihood (ML-L) increases to 15.28% of User Personalized Information Search Retrieval Rate (UPISRT). For feature ranking, the PURFR-GD model defines higher Classification Accuracy (CA) and Precision Ratio (PR) while utilising minimum Execution Time (ET). Furthermore, UPISRT's ranking performance has improved by 20%.Keywords
Web Data Mining (WDM) is a method of extracting information from the World Wide Web (WWW) using UBP relevant information. It is also used to fetch the desired outcome from web information retrieval for the user [1]. WDM is a significant area of data mining that handles the removal of knowledge from the WWW. Web mining denotes the utilization of DMT to recover, remove, and observe information for knowledge discovery from web documents and services. Web content mining, structure mining, and usage mining are three different types. A user profile is an aggregation of user-expected data which determines the user's working state. Ontology is the technique for knowledge explanation and formalization that symbolises user profiles in web information gathering.
Personalized search is focused on addressing the challenges in the web search community depending on the individual users’ preferences. But similar preferences of users are not collected efficiently, and they adversely change the results of online search results. So, the retrieval of information depends on the user’s behavior and remains a demanding task to be attempted. The rapid growth of WPR by the users retrieves results using DMT. However, it did not offer a higher performance filtering rate of results to the end-users. These DMT were not carried out efficiently to filter the user’s results. In an online context, conventional methods accurately predict user search ranking. However, it does not produce excellent reinforced service for a general user’s requirements and preferences. There are also issues connected with the automatic updating of UBPs. Keyword Advertising Campaign using Gender Search Query (KAC-GSQ) efficiently examines the connection between brand and gender by utilizing hypothesis testing [2,3]. Significant analysis and ranking of documents based on the importance of a query specified by the user is the major problem to be addressed for personalized search on the web. The proposed work aims to develop an efficient ranking system for user results on web-based SEs such as Yahoo, Facebook, and Microsoft’s SE Company platform. The main objective is to investigate how these SEs rank their users. The proposed work contributes to the following phases: (a) MC2-DC based on the UBP; (b) HFRSUQP applied for Probabilistic User Result Feature Ranking (PURFR) based on GDF; (c) PURFR-GD model that recognizes the result features and examines them with modernized user profiles.
• To collect similar UBP and perform automatic update operations using the clustering method, review the history with updated UBP and move to appropriate clusters by removing the Replica Information (RI) from browsing search history or visiting our SE.
• To progress the user query output rate on WPR using an automatic User Query (UQ) probability function.
• Using GDF, evaluate the rank rate for User Query Results (UQR), with the top-ranked result given by the height of the curved peak.
While conducting online research, and Amount of invested mental effort(AIME) [4] was expended. AIME is examined via a pre-and post-search questionnaire, as well as a question-and-answer session. It also uses the demerits of mental effort on an end user’s search knowledge and skills. Wikipedia Miner is an open-source toolkit for mining Wikipedia. The toolkit generates databases of short versions of Wikipedia’s content and structure. It incorporates a Java Application Programming Interface to access articles and categories. Parallel processing of Wikipedia that possesses semantic relatedness metrics based on machine learning is essential. Part-of-Speech (POS) sequence information can identify the critical information in spite of rare n-grams. According to the researcher, an English POS tagger uses two different POS tagsets and an unsupervised POS induction method, particularly adjusted for queries. The idea of mixed-script IR and analysis of the query logs of Bing SE calculate the occurrence. The Mixed-Script space is a monolingual or multi-lingual space with more than one script [5,6].
A user’s location information plays a significant part in web search. It manages them into ontologies to generate an ontology-based profile. In personalized search systems, the search results are graded consistently with the user’s interest, and the searchable documents contain organizational user-defined ideas—the authors’ designed user search personalization in Semantic Web (SW) mining. Non-SW sites employ the SW personalization system. They were prearranged, a new technique for improving the quality of recommendations depending on the essential structure. Authors designed personalized SW retrieval and summarization of web-based documents. They opine that text summarization in a designed system depends on removing appropriate sentences from the original document to form a WordNet summary [7,8]. A model for manipulating semantic queries and providing personalized nutrition and health data has been developed. The UBP ontology is based on cultural, linguistic, and health-related considerations. Users’ natural language queries are mapped into ontology-based queries using query templates.
The work uses the log analyzer tool as a weblog expert to determine users’ actions and access an astrology website. Web mining utilizes the DMT and interprets constructive information from web data. A conceptual weighting method is designed for query expansion using UBP. The terms containing higher weight and terms from previous searches with a better threshold weight are chosen to gain ideas in the network linked to the query phrases. Suitable query terms involve the results of information retrieval systems. WPR is based on web usage and domain knowledge [9–11]. Two new models are designed to symbolize domain knowledge and web-page information. The conceptual prediction model creates a semantic network of web usage knowledge. The author presented the quality of web service composition in a semantic dimension. It designs a new model matching the new dimension of semantic quality with a Quality-of-Service (QoS) metric utilizing ranking and optimisation criteria. SW services allow for automated reasoning over web service composition [12].
Record matching problems occur when the information from multiple databases is linked. The author has suggested a new algorithm for SW service matching. To overcome some of the limitations of semantic distance and degree of overlap in a specified object-oriented web service, the novel service matching technique calculates the height factor of the ontology tree and the local density factor. Unsupervised duplicate detection is designed for a particular query. It also recognizes the duplicated query result records from multiple web databases and removes them from dynamic results. The gender of key phrases is critical in calculating sponsored search results and behaviour [13,14]. It has significant alterations in UBP as calculated by sponsored search metrics between the gender categories. The main objective is to study the efficiency of increased personalization of SE advertising. An algorithm combines product information from multiple websites to organize it for search, comparison, or WPR systems’ applications. The algorithm employs word sense disambiguation methods to tackle differing values between different taxonomies. It is carried out while dealing with product taxonomy-specific characteristics such as composite categories. To calculate the destination competitiveness score for each content item in technologically advanced online learning, the provided state vector models are adapted. A new dynamic pairwise learning technique has been developed for the purpose of optimising Web portal content. This technique uses dynamic user preferences that are eliminated based on the user’s input on portal services to determine attribute scores for content items. SW technologies are used in expert systems for decision support. Many interrelated data sources are symbolised using the Resource Description Framework (RDF). The primary process of such engines is to optimize the order in which partial results of queries are connected. The researcher implemented Ant Colony Optimization for RDF chain queries [15–17].
3.1 MC2-DC for Effective Search On Web Using Personalized User Behaviours
The information on the web is increased increases day-by-day by comparing the efforts of the people with two different methods. Web-based information is more beneficial for multimedia technology. The information system delivers the information to other information systems’ applications or other users. AIME is a non-automatic mental clarification with additional information applied to a material unit. Data are collected through search transaction logs, pre-search and post-search background questionnaires, and interviews. AIME uses two different information retrieval systems named web SE and library system. In the following sections [18–20], the two ways that can be used to find out information about a user are explained. Web Knowledge Database gets information about the user and uses the taxonomical information to update UBPs. The MC2-DC method is used to group similar UBP files even on dynamic updating with the help of a UBP analysing process diagram. The set of processes works together on the web to group similar users’ behavior even on the dynamic updation of the UBP. One widely used method in modelling the UBP-based clustering is the Markov chain. The MC2-DC method is put in place so that the system can be used by more people and produce results related to UQ search. It has Dynamic Clustering (DC) built in to make it easier to work with user profiles that are automatically updated [21–25].
As illustrated in Fig. 1, the user queries are provided to the SE, which fetches the query result from a web knowledge database. The WWW includes all the web pages with the title names of each content. The browser analyzes the user’s behavior based on each UBP and Request (REQ) Query. The UBP includes storing UBP information and queries on a web browser. Then, the personalized web search results are recommended through the browser [26–30]. The browser keeps track of all the users’ data using the MC2-DC method to collect the updated data. The collection of UBP in the web knowledge database produces the relevant search results using the MC2-DC method. The architecture diagram of the MC2-DC method is illustrated in Fig. 2.
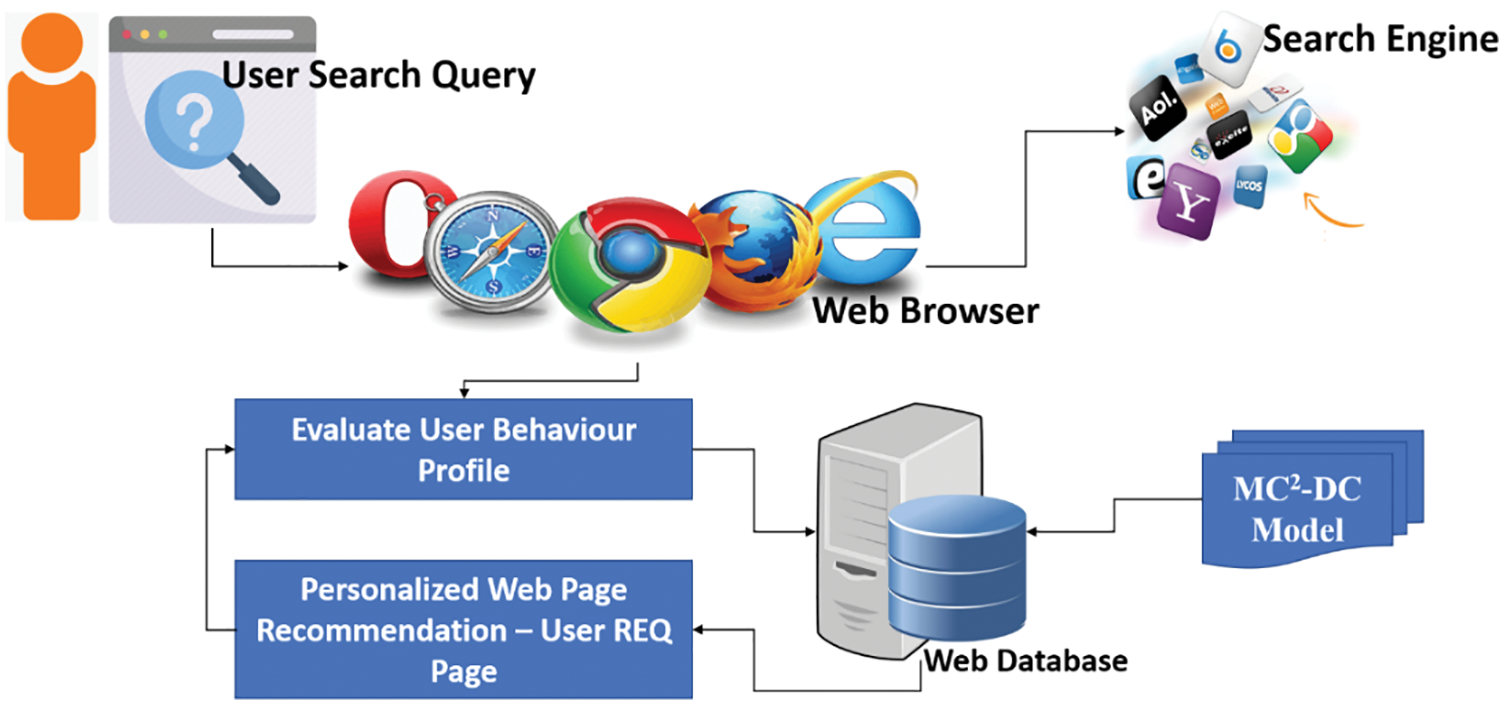
Figure 1: Active process flow of UBP
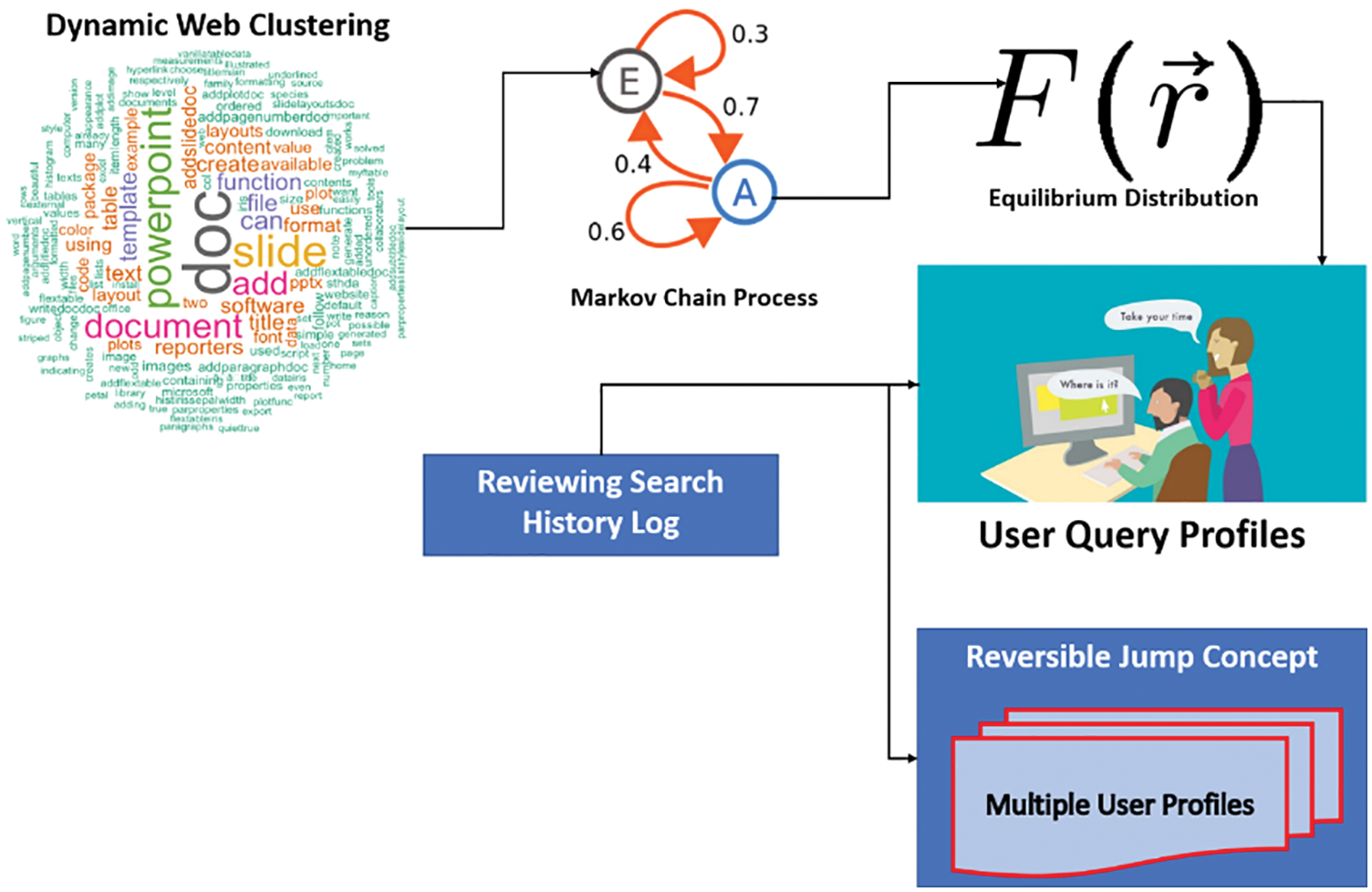
Figure 2: Proposed model of MC2-DC
The Markov chain process on the web contains the collection of user web REQ routing sessions. The Markov chain adopts Equilibrium Distribution (ED) to handle a mixture of UBPs with similar information. The MC2-DC ED combines different UBP with similar search queries. The Markov chain converges with the ED to balance the UBPs with a similar query search. Higher-order transitional probabilities are used to identify the user’s RI accurately. The removal of RI reduces the memory consumption rate and also the running time. The DC carries the Cluster Head (CH) operation on each group to automatically update and maximize the use of the proposed model for personalized query search based on UBP. Next, DC operation is carried out on an automatically updated UBP to balance the accuracy rate even in the dynamic web page environment [31–35]. The search history is reviewed periodically to improve the automatic update of UBP. Finally, the main goal of the RJC in MC2-DC is to review the history with updated UBPs and forward it to the appropriate clusters. MC2-DC with RJC helps to work on a mixture of different UBP on WDM. Moreover, the RJC includes higher-order transitional probabilities to remove the replica from the updated UBP [23]. As a result, the MC2-DC method successfully clusters UBP based on users’ different sets of test relationships. The MC2-DC processing of chain queries is formularized as Eq. (1)
The possible chain query ‘CQ’ for a different set of UBP is acquired through the web browser. Here, the user ‘UR’ requests either single/multiple queries repeatedly to fetch the result based on the personalized UBP.
From Eq. (2), the query search is obtained at ‘Timei’ for different UBP ‘U’. The limit of ED using the MC2-DC method is reserved as infinity ‘
In Eq. (3), the ‘U’ carries the ‘n’ UBP, whereas ‘k’ represents the updated UBP. The updated UBP is the same, and the MC2-DC method removes ‘k’ duplicates from the “n” UBP.
In Eq. (4), User1, User2, User3 ….Userk is different from UBP. The DC of web UBP uses the replica operation to remove the repeated UBP information on the same profile. A DC technique is an efficient way to cluster similar queries on the updated UBP. The MC2-DC method aims to update the UBP while controlling the replica factor automatically. The algorithmic of MC2-DC is assumed below:
3.2 Algorithm for Markov Chain Monte Carlo-Dynamic Clustering
Step 1. Input: ‘k’ web UBP with ‘n’ UBP
Step 2. Repeat
Step 3. For Each ‘k’ UBP
Step 4. For Each ‘Q’ query fetched
Step 5. Cluster identical queries on personalized UBP
Step 6. End For
Step 7. End For
Step 8. For Each Cluster ‘C’
Step 9. Form CH
Step 10. Update the cluster as per the updated UBP
Step 11. Review of history and update UBP ‘k’
Step 12. End For
Step 13. If replica on update UBP, Then Remove RI
Step 14. Else
Step 15. Append UBP to appropriate Cluster ‘C
Step16. End If
Step 17. Until (all ‘k’ web UBP processed)
Step 18. Output: Dynamic Cluster ‘C’ with automatically updated UBP
The algorithmic step in the MC2-DC method for automatic updation of UBP is the reversible jump approach. Its main goal is to remove the RI and update the UBP with minimal running time. It helps to work on a mixture of different UBP information and cluster web data by avoiding replicas [36–40]. For each Cluster ‘C,’ the CH forms ‘CH’ for easier updation of personalized UBP. With this, similar preferences of users are clustered effectively to improve the online searching results for UBP. Finally, to review the history with updated UBP, the process of RJC is introduced in the MC2-DC method. The flow diagram of RJC using MC2-DC is clearly illustrated in Fig. 3.
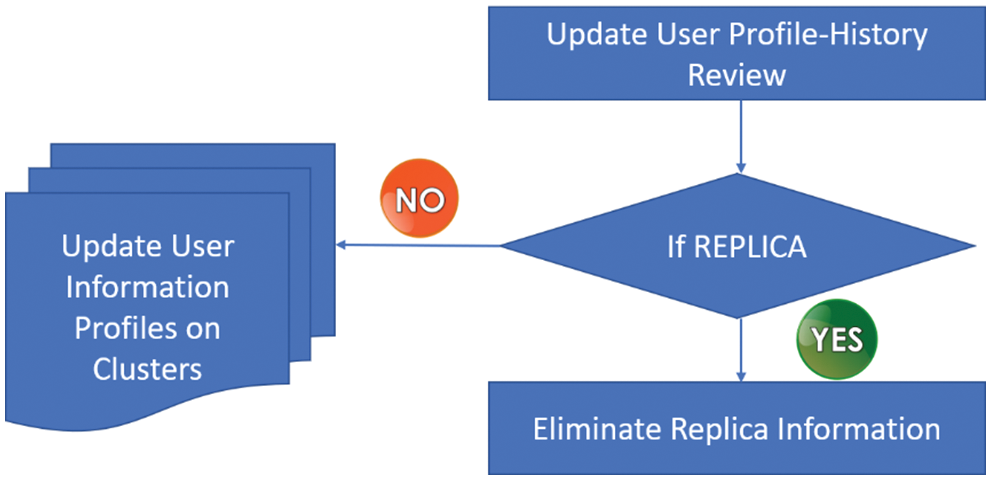
Figure 3: Process of RJC information
The main goal of RJC is to review the history with updated UBP and move to the appropriate clusters by removing the RI. The UQRs are again altered as per the automatic updation of UBP using the MC2-DC method [41–45]. The MC2-DC process of using the reversible jump concept establishes the web search after the UBP update. The automatic UBP update is as given below.
With the help of the reversible jump, one transition ‘1TRANS’, two transitions ‘2TRANS’, and up to four transitions ‘NTRANS’ are noted on the updating web UBP automatically through RJC. In Eq. (5), “Web user” stands for the web users for whom the jump is done backward in order to search for query results according to the updated UBP.
4 An Effective Filtering of Query Based On Updated User Behavioral Profiles in Web Mining
The HFRSUQP model is developed to filter query results effectively and is divided into sub-processes based on UQ and regime-switching procedures [46–50].
According to the automatic up-gradation of UBP through SE and switching personalised interests by web clients, impactful query outcome filtering is frequently used to filter user findings. The following is a mapping function ‘θ’ that can be used to formulate the problem of the study of efficiently filtering database queries:
In Eq. (6), ‘Webuser’ represents web users, “user request” represents the ‘REQ’ sent to the browser by many web users, and ‘WPR’ stands for “Web Pages Recommendation”. The following sections demonstrate how to filter based on a user query and how to design a regime-changing technique.
In Eq. (7), sample ‘SQRY’, User Query ‘UserQRY’ is selected from the database at a time ‘DBTime’. The database contains different result sets for the query. Then, the result sets are represented as DBx, DBx+1, up to DBx+n. User Query ‘UserQ’ is selected from the database at ‘Database’ in Eq. (7) sample ‘Sq’. The necessary consequence sets are then defined by ‘DBx, DBx+1’, and so on, up to ‘DBx+n’. The linear temporal has a range of outcomes in the database.
Only the ‘DBx, DBx+2’ result set provided in Eq. (8) is acceptable by the ‘Userq’ outcome fetched on ‘Squery’ after filtering in the HFRS-UQP model.
Using the maximum likelihood of an outcome based on static and dynamic UBP, queries with the precise dataset are retrieved for sample ‘Squer’ using Eq. (9). The presented Log-likelihood function is applied to achieve the most precise results.
With the maximisation operation, log-likelihood achieves the output from Eq. (10). The viewed result allows consideration of allocation with the conditional user probability. The conditional method fetches high-accuracy query outcomes on the web using the user profile data. ‘DBx’ and series ‘DBx+2’ are results accumulated on the webserver database to obtain a more precise outcome.
From Eq. (11), the GDF ‘DBj’ of database server ‘DB’ estimates the procedure with accurate results. The filtering of a query result is achieved successfully with GDF regime probability ‘P’.
Using a DMT, the WPR can be mined to connect weblogs and provide users with valuable data. As a result of usage mining, users can get an accurate and efficient filtering method. Using DMT, the proposed research finds patterns that provide phenomenally accurate results. Submission of queries on SE is always the first step in the process. The SE sends a database schema to a database for accurate results. A simple filtering process can be carried out here in order to successfully remove the negative effects of the environment from the query. Fig. 4 illustrates the query results achieved via DMT. There is an end-to-end collection of database queries for several web clients in WebC1, WebC2, etc.,WebCn’, where their REQs are placed on the internet browser. To improve the ‘Userquery’ result rate, the browser requests an operational DMT with effective filtering and switching functions. The network-based mining of ‘Userquery’ results through the web browser generates high accuracy. Web mining is used in order to get the most accurate results depending on the number of ‘user queries'.
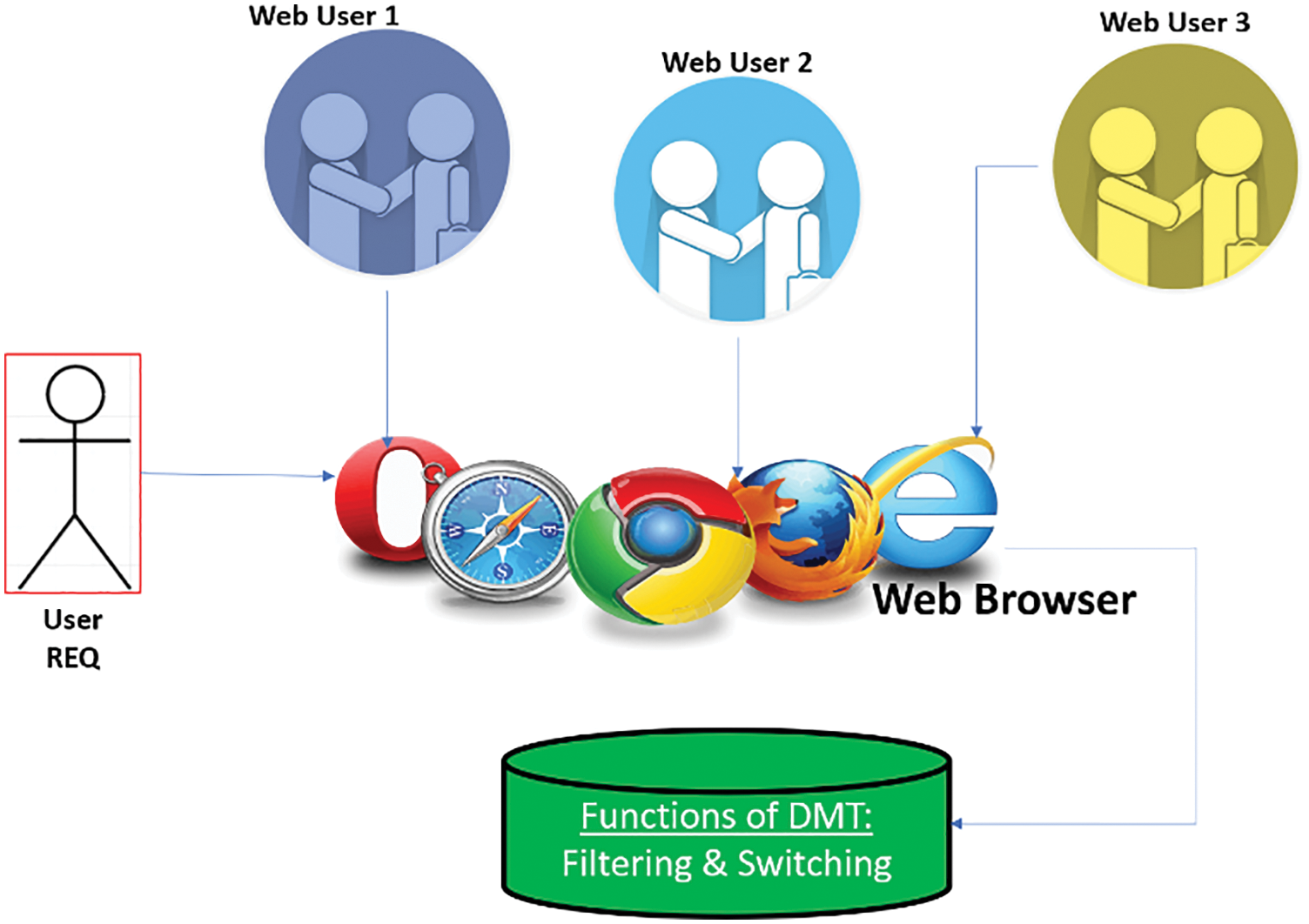
Figure 4: Process of end-to-end query fetching by DM
As shown in Fig. 5, the HFRS-UQP model’s overall design is displayed. It filters the server information that can be mined by web mining. Using the proposed methodology, the UQRs are retrieved, and DMT is carried out. Updated UBP is used to filter ‘Userquery’ results effectively based on profiles. With the ‘Maximum_Likelihood_Function’, the query-related result is filtered out, and the irrelevant results are removed. Unrelated object terms are removed from the database using the HFF method. Using regime-switching, personalised information is retrieved from the updated UBP. SEs use a combination of DMT to send results on time without giving up the accuracy of the research to users. People use the HFRSUQP model to search the web for information and only get precise findings when they submit a clear query to the SE. To get accurate query results, the WPR system effectively uses static and dynamic change-based UBP information [51–59].
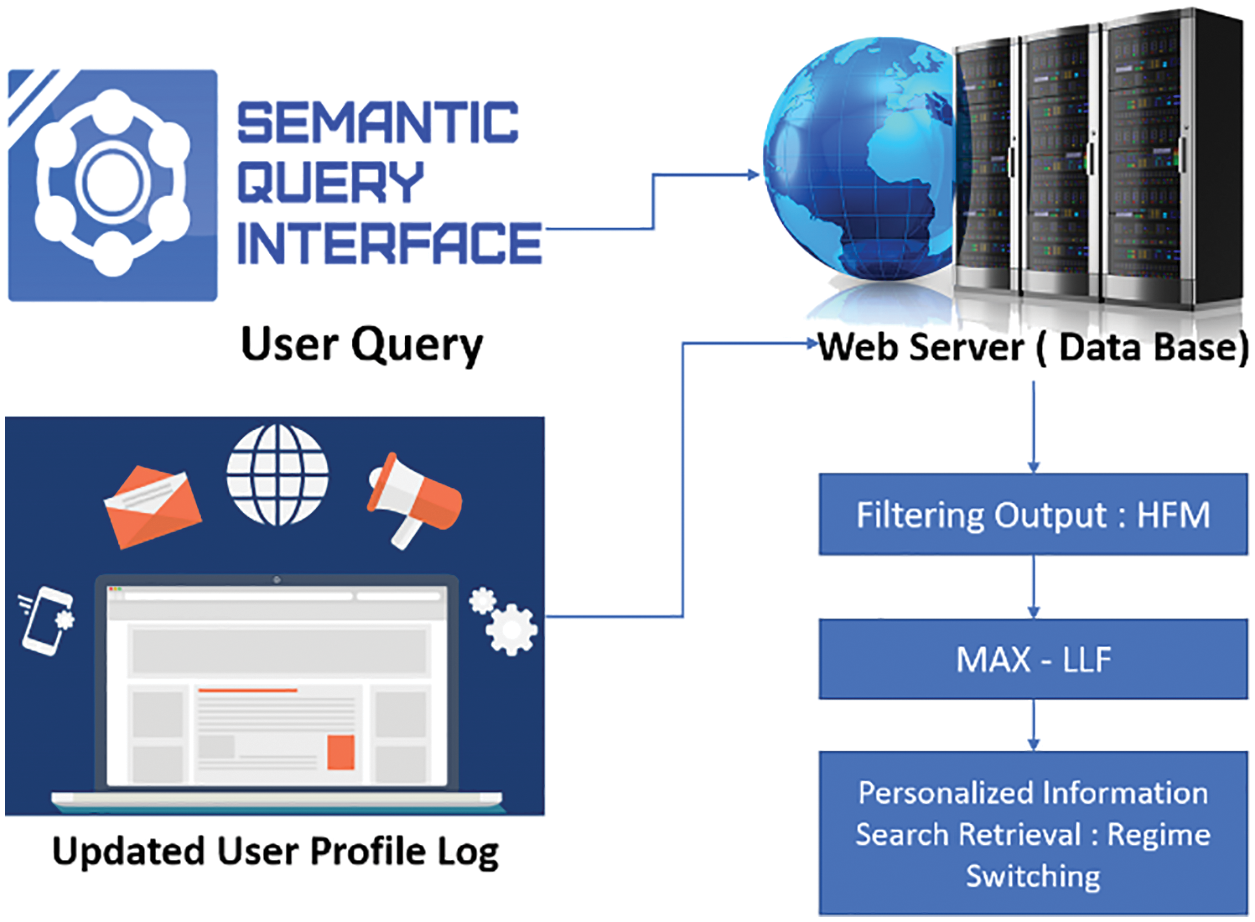
Figure 5: Proposed model of HFRS-UQP
4.2 Algorithm for Regime Switching
Step 1: Input: S = {S1,S2,…,Sn}; Uq = {UW1,Uq2,…,Uqn}; D = {DBx,DBx+1,DBx+2…,DBx+n}
Step 2: Output: Use of a updated UBP for a more accurate ‘Userquery’
Step 3: CASE I: UBP information status with static mode
Step 4: For Each ‘Sq’
Step 5: For Each UBP Data
Step 6: Perform probability function
Step 7: Sq(Userquery/DBTime) = Uquery[DBx, DBx+1, DBx+2, DBx+3,…. DBx+n]
Step 8: Execute Filtering Function
Step 9: Filtering of ‘S’ result Uquery [DBx, DBx+2]
Step 10: Perform MLL-GDF
Step 11: End For
Step 12: End For
Step 13: CASE I: UBP status with dynamic mode
Step 14: Goto: Step 2
5 Probabilistic Feature Ranking Based On Gaussian Distribution Function In Web Mining
The proposed PURFR-GD model is presented for the effective ranking of UQ. The PURFR-GD are: (a) Features ID, (b) Classification of features, and (c) PURFR. The overall design of PURFR based on GDF is presented in Fig. 6. The UBP is characterized based on the REQs made by the users on SEs. The SE mines data available in databases using different DMT. However, more attention is required to the automatic updation of UBP to improve the personalization of different SEs. Automatic updating of UBP for effective UQ search is the fundamental part of the proposed work. Given the reviews provided by the users related to a product or service, the first step is the efficient identification of features from the reviews and then analyzing the user’s opinions on the features through effective classification. Lastly, a dynamic diversity re-ranking algorithm determines how important each feature is by looking at how often it appears and how much each user's opinion on that feature affects their overall opinion.
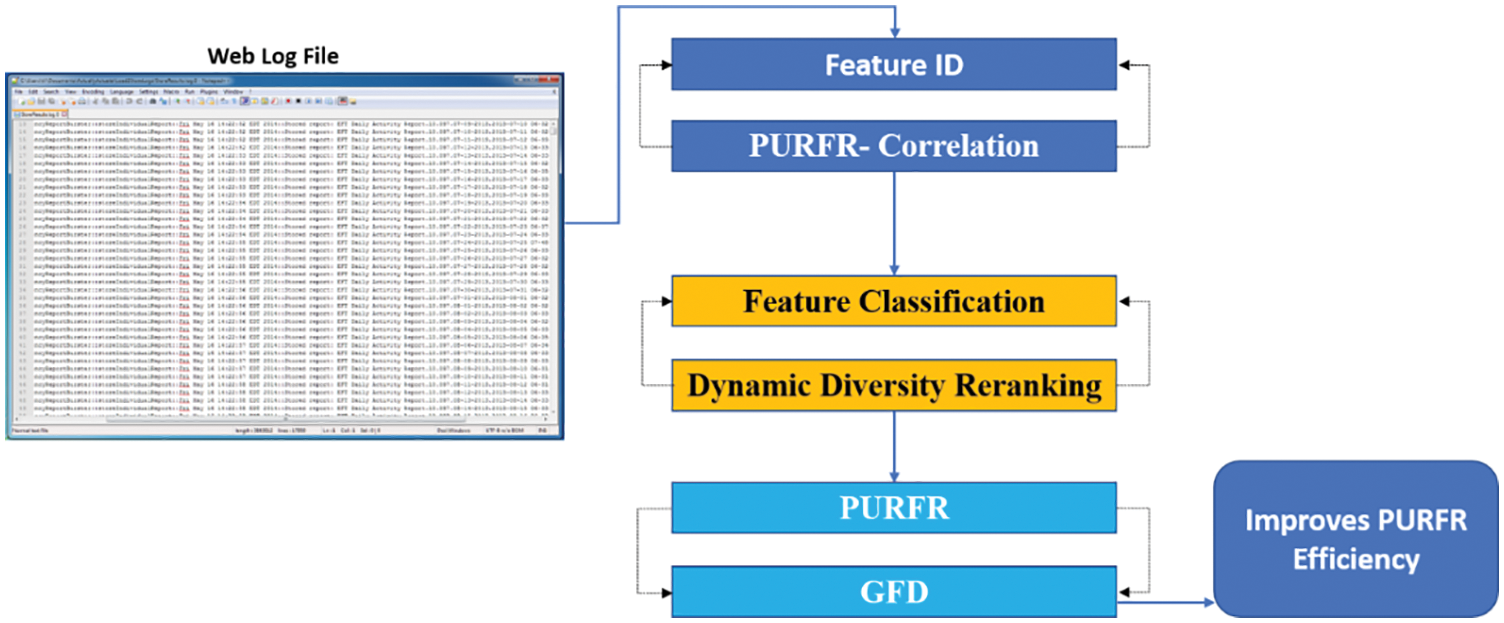
Figure 6: Overview of PURFR-GD design
5.1 Probabilistic User Result Feature Correlation
The PURFR correlation model is used to efficiently identify features in the first step of designing PURFR based on GDF. While it produces more accurate results, the computational cost makes it inefficient for personalised web searches involving vast amounts of data. Traditional web personalization methods must rely on subset evaluation, which exclusively maintains feature redundancy with feature relevance, in order to eliminate features of redundant appearances. As a result, the proposed feature selection model, as shown in Fig. 7, provides a better method for removing feature redundancy by explicitly handling the PURFR correlation model.
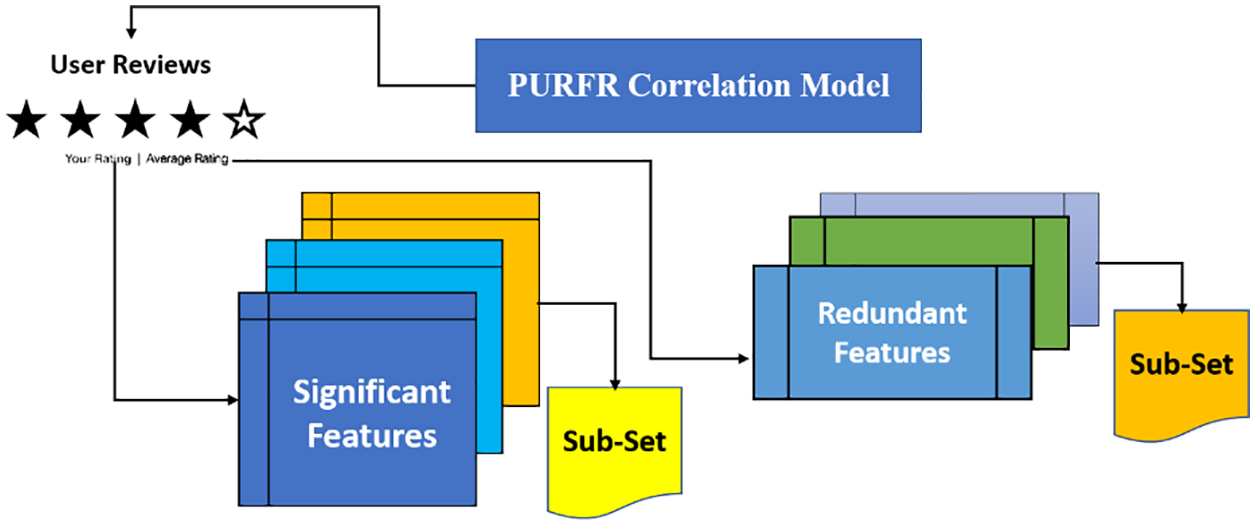
Figure 7: PURFR correlation model
The significant PURFR User Correlation model is then given as below,
From Eqs. (12) and (13), the significant PURFR is obtained and then used to identify if redundant appearances occur or not. Similarly, the redundant appearances are then obtained using the Probabilistic User Correlation model through the correlation coefficient (CC) ‘ε’. The CC value ‘ε’ is then formalized as given below, Eq. (14)
The CC value ‘ε’ is then formalized as given below,
where ‘aj’ means ‘xi/yi’, and the value of ‘ε’ is amongst ‘−1/1’. If ‘x/y’ are associated, Then ‘ε’ set ‘1’, IF ‘x’ and ‘y’ are separate values, Then ‘ε’ set 0’.
The complete ranking is then classified into ‘peak/least’ and is represented below.
From Eq. (15), ‘ORpeak/ORleast’ denotes the overall ranking with peak and most minor analyses, respectively.
The Data Distribution Ratio (DDR) finds the change in similar appearance between the feature set and UBP from Eq. (16).
The parameters that entirely comprise the GDF are collectively represented by,
As stated earlier, the features frequently commented on and reviewed by users are of greater importance. Hence, the feature frequency is used as the prior knowledge while applying “GDF”. Here, the GDF is close to the distribution where the mean vector represents the frequency of the same feature with the covariance matrices representing different UBP for an exact item. The GDF shown is normalized, and hence the overall ranking values of ‘ORi’ give a probability of ‘1’. From Eq. (18), PURFR is obtained from the importance rankings ‘ORi’ where j = 1, 2, 3,…, n. The height of the curve peak in the GDF denotes the highest rank value, and the lower value denotes the lower priority range. The algorithm of PURFR is given below.
5.2 Algorithm for Probabilistic User Result Feature Ranking
Step 1: Input: CR={CR1,CR2,…, CRn}; D={Dx, Dx+, Dx+2.., Dx+n}
Step 2: Output: Resourceful PURFR
Step 3: For Each UBP information D
Step 4: For Each User Review, UR
Step 5: Perform feature ID
Step 6: Get substantial and redundant information
Step 7: Apply PURFR Correlation model
Step 8: Get correlation coefficient value
Step 9: Classify significant information
Step 10: Execute feature classification
Step 11: Apply dynamic diversity re-ordering
Step 12: Classify complete ordering into ‘peak/least’
Step 13: Perform PURFR
Step 14: Implement GDF for finding the complete ordering
Step 15: End For
Step 16: End For
Experiments are carried out in the Java platform for the MC2-DC, HFRSUQP, and PURFR-GD models with an existing Keyword Advertising Campaign with Gender Search Query (KAC-GSQ). Some of the parameters like similar UBP Clustering Rate (CR), UPISRT, CA, updated UBP accuracy, Precision Ratio (PR), Execution Time (ET), and Ranking Efficiency (RE) are measured to demonstrate the real-time procedure in practice.
6.1 Analysis of User Profile Clustering Rate
The measurement of similar UBP CR of MC2-DC, HFRSUQP, and PURFR-GD designs used ED. ED is given by the ratio of response web data to the REQ web data in percentage as in Eq. (19). The similar UBP clustering rate efficiency of the proposed MC2-DC, HFRSUQP, and PURFR-GD methods are compared with the existing KAC-GSQ scheme.
The proposed MC2-DC method incorporated a Markov chain that applies ED to handle a mixture of UBP with similar UBP information, resulting in an increased similar UBP CR of 20.129% when compared to KAC-GSQ. In addition, the MC2-DC method increases the similar UBP CR. Similarly, the proposed HFRSUQP method improves the CR by 6.78% when compared to KAC-GSQ, and the PURFR-GD method improves the CR by 12.45% when compared to KAC-GSQ. Therefore, the proposed MC2-DC method attains a high CR among other proposed methods. The targeting results of similar UBP CR using MC2-DC, HFRSUQP, and PURFR-GD models with existing schemes, namely KAC-GSQ in Fig. 8, are projected for graphical comparison based on the varied size of clusters.
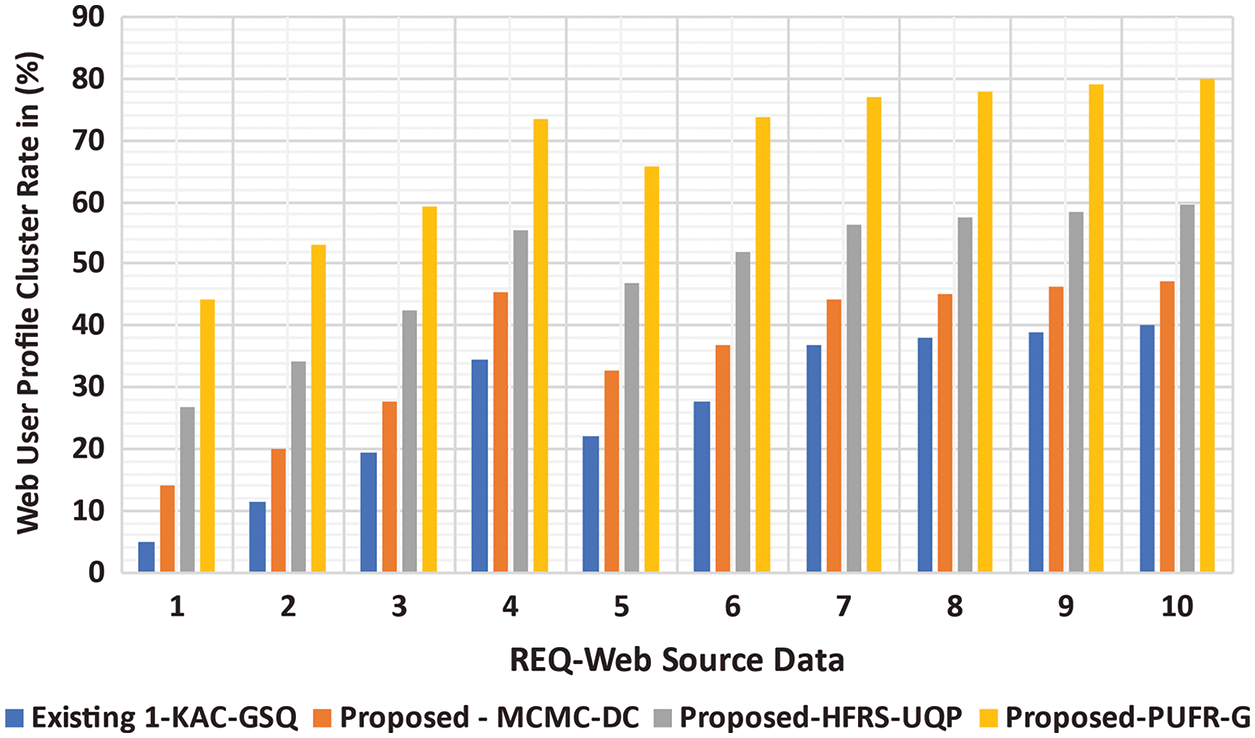
Figure 8: Analysis of web UBP CR vs. QueryRE web source data
6.2 Analysis of User Personalized Information Search Retrieval Rate
The UPISRT denotes the accuracy of user REQ retrieval. The Retrieval Rate (RR) is the accurate user REQ retrieved, and ‘Tn’ is the number of REQs completed in the testing data set. The UPISRT depends on the size of the user’s REQ. Eq. (20). As illustrated in Fig. 9, the proposed MC2-DC, HFRSUQP, and PURFR-GD models perform better than the KAC-GSQ method. The UPISRT using the HFRSUQP model is improved with the application of HFF, where ML-L outcome is fetched in web mining. The UPISRT in web mining for numerous UQ- REQ is performed at different time intervals. The UPISRT in the HFRSUQP model is increased along with other proposed methods and existing methods by creating a filtering method whose services classify the best method of quickly fetching the ‘UserQuery’ output. Hence, the HFRSUQP model is improved by a search RR of 23.49% when compared to KAC-GSQ. The proposed MC2-DC with PURFR-GD methods increased the RR by 11.34% and 18.12% when compared to KAC-GSQ. Therefore, among the three proposed methods, the HFRSUQP model shows an increased UPISRT.
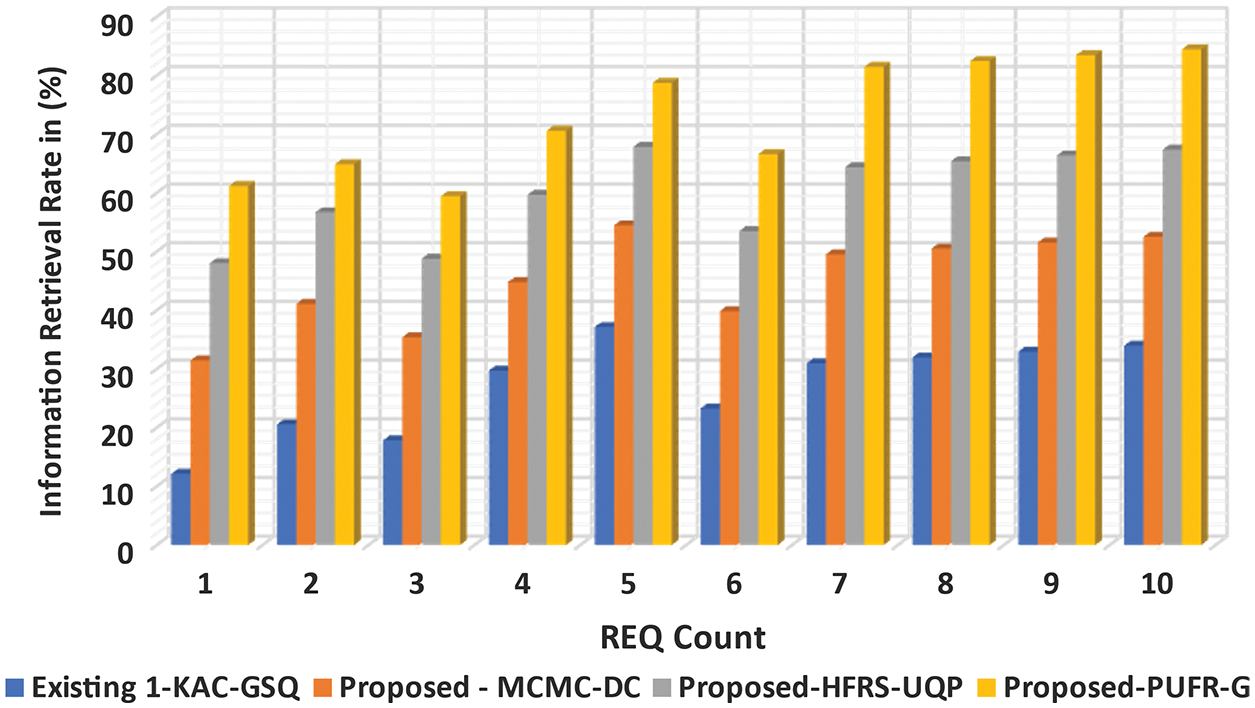
Figure 9: Analysis of information RR vs. QueryREQ
6.3 Analysis of Classification Accuracy
The CA is a measure of correctly classifying the UserQuery when applied to the total UQ, Eq. (21). The comparison of three proposed MC2-DC, HFRSUQP, and PURFR-GD models and one existing KAC-GSQ is shown in Fig. 10. The CA of the conceptual model PURFR-GD is better than the existing method. The result can be attributed to PURFR-efficient GD’s feature classification on the web using dynamic diversity re-ranking. Therefore, the improvement of CA in the PURFR-GD model is 37.81% when compared to the existing KAC-GSQ, and it has obtained a lower CA of 29.19% and 20.19% when compared to the proposed MC2-DC HFRSUQP, respectively.
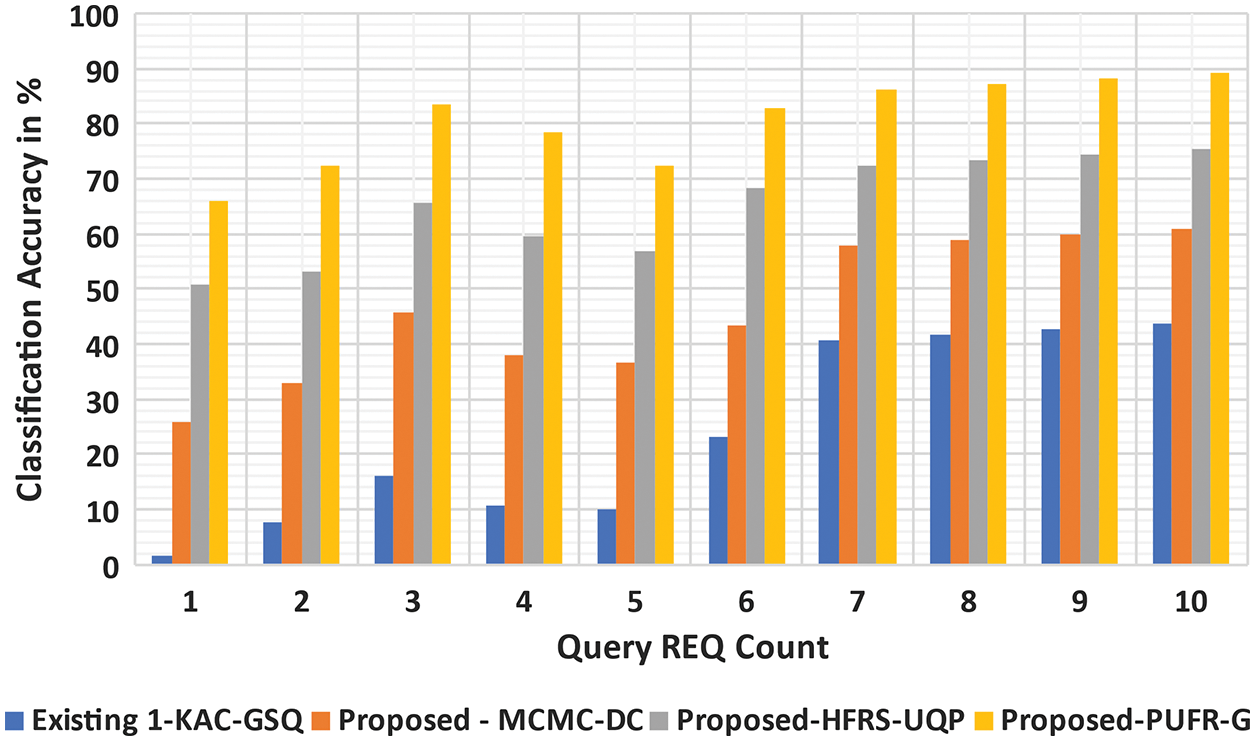
Figure 10: Analysis of CA vs. QueryREQ
6.4 Analysis of Updated User Profile Accuracy
The accuracy of working with the automatically updated UBP method is the ratio of accuracy from the WPR database to the complete evolutions on WPR, Eq. (22).
Fig. 11 illustrates the accuracy of automatic updated UBP. From the experimental results, the proposed MC2-DC method achieves better automatic updated UBP accuracy than other proposed methods. When compared to two other proposed methods and one existing method, the MC2-DC method succeeds. The rate of accuracy using the proposed MC2-DC method increases with the application of DC operation that efficiently carries out CH operation on each group, resulting in an increased accuracy of 25.6% when compared to KAC-GSQ. In addition, the proposed HFRSUQP method increases the updated UBP accuracy by 15.67% when compared to the existing KAC-GSQ. Similarly, the proposed PURFR-GD model’s accuracy is 19.15% higher than KAC-GSQ.
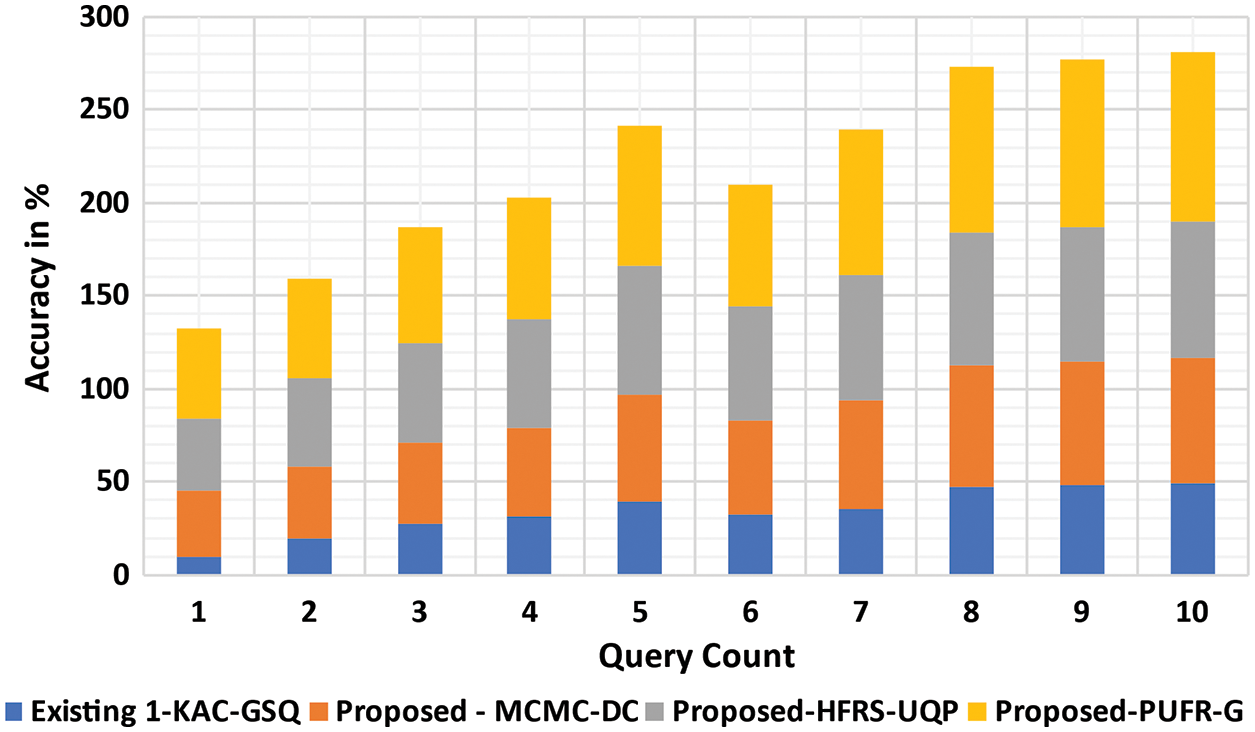
Figure 11: Analysis of accuracy vs. query count
6.5 Analysis of Precision Ratio (PR)
PR stands for true feature retrieval probability. PR is also called the “positive predictive value”. The measurement of PR of the proposed model PURFR-GD is made with the existing Keyword Advertising Campaign using Gender Search Queries (KAC-GSQ), Personalized Ontology Model (POM), and Web-page Recommendation Through Semantic Enhancement Model (WRT-SEM), Eq. (23). Fig. 12 illustrates the performance comparison of PR results, and the proposed model PURFR-GD provides better PR performance than POM, WRT-SEM, and KAC-GSQ. Applying the PURFR correlation model in the proposed model, PURFR-GD eliminates feature redundancy, and significant non-redundant features are further considered, improving the PR by 24.15% when compared to POM. The proposed model also incorporates feature extraction redundancy, improving the PR by 15.6%, particularly in comparison with WRT-SEM and 8.911%, similar to KAC-GSQ.
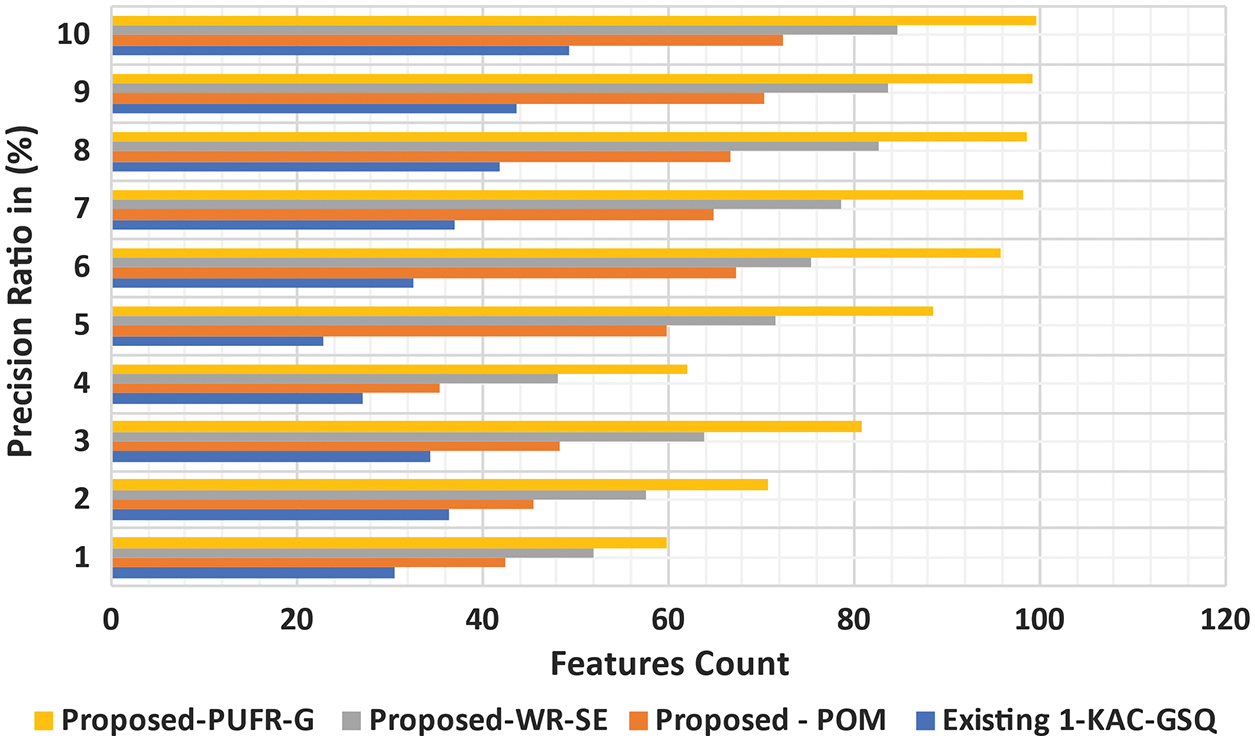
Figure 12: Analysis of PR vs. Features
6.6 Analysis of Query Execution Time
ET for feature ranking is considered to execute feature ranking by PURFR, Eq. (24). Fig. 13 illustrates the performance of ET for the proposed PURFR-GD and existing KAC-GSQ, POM, and WRT-SEM, respectively. On average, the proposed model PURFR-GD significantly reduces the ‘UserQuery’ processing time. The ‘UserQuery’ results of different personalizations are obtained using GDF. The GDF produces the mean vector and covariance matrix to describe the rank rate of the UQR and decrease completion time. To identify the rank rate of the UQR, the GDF produces the mean vector and covariance matrix result. As a result, the ET of ‘UserQuery’ processing is significantly reduced by 17% compared to POM. In addition, the ‘UserQuery’ ET is also reduced by 31% when compared to WRT-SEM and 41% when compared to KAC-GSQ.
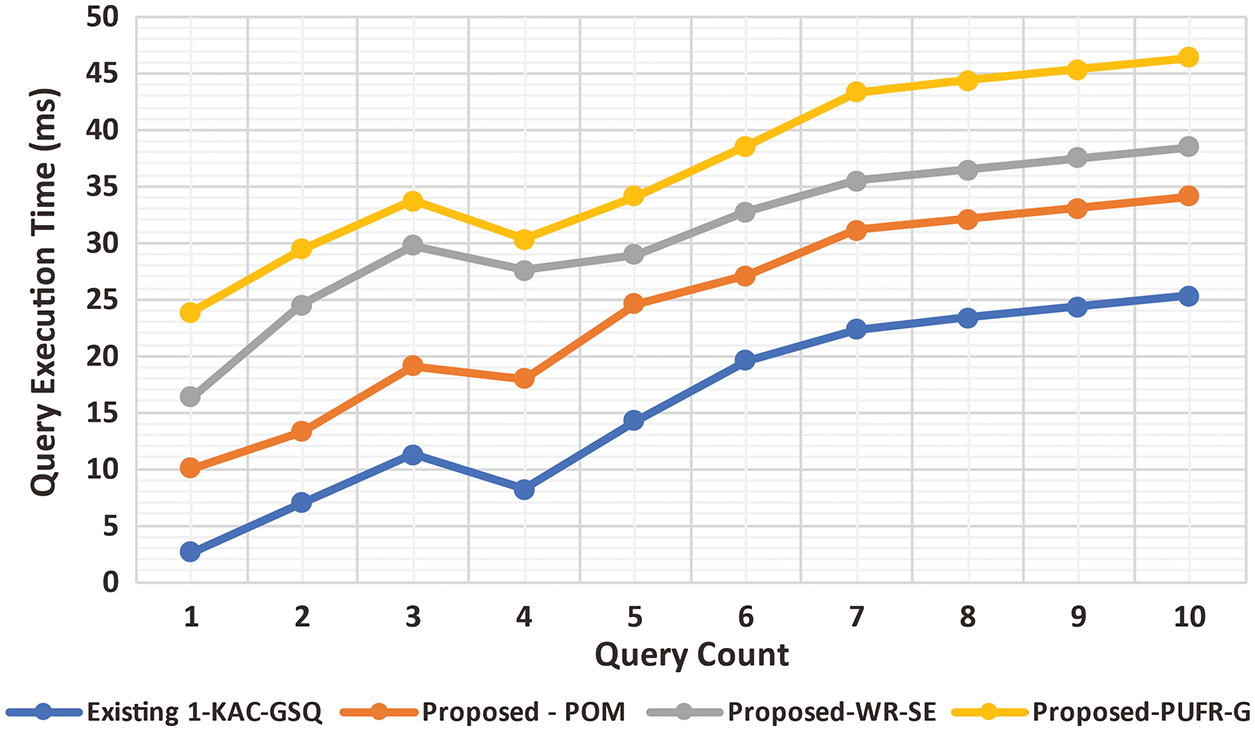
Figure 13: Analysis of Query ET vs. QueryREQ
6.7 Analysis of Ranking Efficiency
A ranking efficiency is the number of the relevant features retrieved from the input features, Eq. (25). When a ranking model is used to personalise the web, the method’s RE is measured in terms of its ability to have an overall impact. The ranking efficiency of the proposed PURFR-GD method is compared with existing KAC-GSQ, POM, and WRT-SEM methods. Fig. 14 shows how the RE of the new PURFR-GD and the existing KAC-GSQ, POM, and WRT-SEM were measured. The application of the PURFR algorithm achieves RE. This algorithm significantly improves and minimises redundant features with improved feature classification. As a result, UPISRT’s RE has improved. This improvement is 27% better than POM and 19% better than WRT-SEM. Finally, the retrieval rate is improved by 11% compared to the KAC-GSQ method.
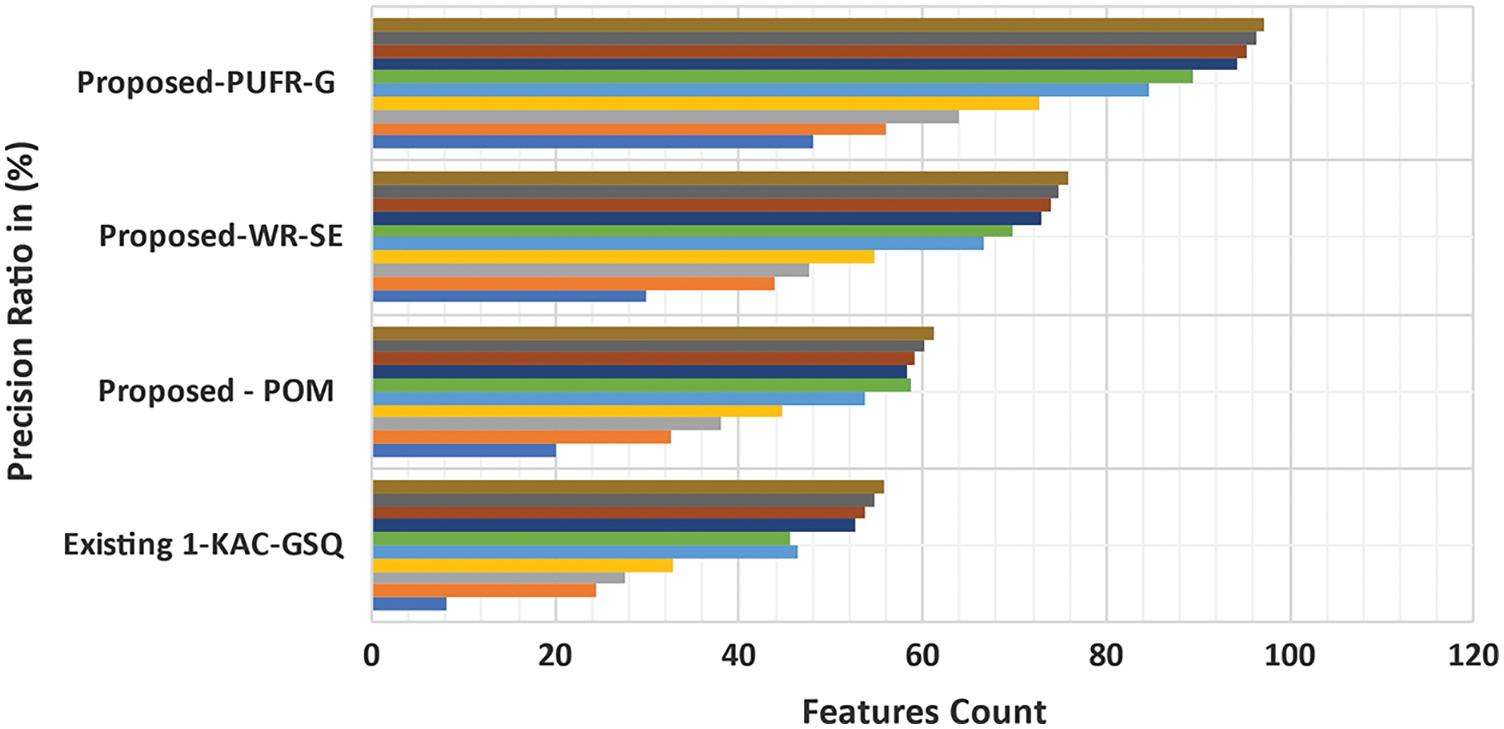
Figure 14: Analysis of PR vs. Features
The PURFR-GD model was developed with the aim of efficient ranking for ‘Userquery’ results on a web mining system. The proposed model consists of feature ID, classification of features, and PURFR. The HFRSUQP model improves the ‘Userquery’ result on WPR. The initial step of HFF is developed to filter the user output based on personalized information on automatic updated UBP through SE. An HFRSUQP model improves the ‘Userquery’ result rate on WPR in web mining. It involves two different operations, such as filtering and switching data mining. The MC2-DC method efficiently utilizes the MC2-DC function to derive various UBP with a similar ‘Userquery’ search. It also applies the DC process to minimize the update and running time with the help of the ED function for each UBP's data. Theoretical analysis and the experiment results demonstrate that the PURFR-GD model provides higher CA, efficiency, and PR. The RE for UPISRT improved by 16%. HFF using extensive ML-L increases the UPISRT by 11%.
Moreover, MC2-DC increases the automatically updated UBP accuracy by 15% with a DC operation that efficiently performs CH operation on each group. Future work will focus on a fuzzy system based on online data streams. This fuzzy system can significantly improve the UBP update process and provide effective personalized results for user-related queries. It needs to balance the complexity of web-based applications with less complexity in real-time usage.
Funding Statement: We deeply acknowledge Taif University for Supporting this study through Taif University Researchers Supporting Project number (TURSP-2020/115), Taif University, Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. E. Saleh, A. Alhammadi, I. Shayea, N. Alsharif, N. M. Alzahrani et al., “Measuring and assessing performance of mobile broadband networks and future 5G trends,” Sustainability, vol. 14, no. 2, pp. 1–20, 2022. [Google Scholar]
2. A. Mehbodniya, S. Bhatia, A. Mashat, E. Mohanraj and S. Sudhakar, “Proportional fairness based energy-efficient routing in wireless sensor network,” Computer Systems Science and Engineering, vol. 41, no. 3, pp. 1071–1082, 2022. [Google Scholar]
3. A. R. Khaparde, F. Alassery, A. Kumar, Y. Alotaibi, O. I. Khalaf et al., “Differential evolution algorithm with hierarchical fair competition model,” Intelligent Automation & Soft Computing, vol. 33, no. 2, pp. 1045–1062, 2022. [Google Scholar]
4. A. Revathy, C. S. Boopathi, O. I. Khalaf and C. A. T. Romero, “Investigation of AlGaN channel HEMTs on β-Ga2O3 substrate for high-power electronics,” Electronics, vol. 11, no. 2, pp. 1–12, 2022. [Google Scholar]
5. A. T. Hoang, X. P. Nguyen, O. I. Khalaf, T. X. Tran, M. Q. Chau et al., “Thermodynamic simulation on the change in phase for carburizing process,” Computers, Materials & Continua, vol. 68, no. 1, pp. 1129–1145, 2021. [Google Scholar]
6. A. U. Priyadarshni and S. Sudhakar, “Cluster-based certificate revocation by cluster head in mobile ad-hoc network,” International Journal of Applied Engineering Research, vol. 10, no. 20, pp. 16014–16018, 2015. [Google Scholar]
7. C. A. Tavera, H. J. Ortiz, O. I. Khalaf, D. F. Saavedra and T. H. H. Aldhyani, “Wearable wireless body area networks for medical applications,” Computational and Mathematical Methods in Medicine, vol. 2021, no. 5574376, pp. 1–9, 2021. [Google Scholar]
8. C. He, Y. Tang, Z. Yang, K. Zheng and G. Chen, “SRSH: A social recommender system based on Hadoop,” International Journal of Multimedia and Ubiquitous Engineering, vol. 9, no. 6, pp. 141–152, 2014. [Google Scholar]
9. D. Stalin David, M. Anam, K. Chandraprabha, S. Arun Mozhi Selvi, D. K. Sharma et al., “Cloud security service for identifying unauthorized user behaviour,” Computers, Materials & Continua, vol. 70, no. 2, pp. 2581–2600, 2022. [Google Scholar]
10. D. Stalin David, S. Arun Mozhi Selvi, S. Sivaprakash, P. Vishnu Raja, D. K. Sharma et al., “Enhanced detection of glaucoma on ensemble convolutional neural network for clinical informatics,” Computers, Materials & Continua, vol. 70, no. 2, pp. 2563–2579, 2022. [Google Scholar]
11. F. Moawad, H. Talha, E. Hosny and M. Hashim, “Agent-based web search personalization approach using dynamic user profile,” Egyptian Informatics Journal, vol. 13, no. 3, pp. 191–198, 2012. [Google Scholar]
12. G. Li, F. Liu, A. Sharma, O. I. Khalaf, Y. Alotaibi et al., “Research on the natural language recognition method based on cluster analysis using neural network,” Mathematical Problems in Engineering, vol. 2021, no. 9982305, pp. 1–13, 2021. [Google Scholar]
13. G. Suryanarayana, K. Chandran, O. I. Khalaf, Y. Alotaibi, A. Alsufyani et al., “Accurate magnetic resonance image super-resolution using deep networks and Gaussian filtering in the stationary wavelet domain,” IEEE Access, vol. 9, pp. 71406–71417, 2021. [Google Scholar]
14. H. S. Gill, O. I. Khalaf, Y. Alotaibi, S. Alghamdi and F. Alassery, “Multi-model CNN-RNN-LSTM based fruit recognition and classification,” Intelligent Automation & Soft Computing, vol. 33, no. 1, pp. 637–650, 2022. [Google Scholar]
15. H. S. Gill, O. I. Khalaf, Y. Alotaibiand, S. Alghamdi and F. Alassery, “Fruit image classification using deep learning,” Computers, Materials & Continua, vol. 71, no. 3, pp. 5135–5150, 2022. [Google Scholar]
16. H. Zhao, P. L. Chen, S. Khan and O. I. Khalafe, “Research on the optimization of the management process on internet of things (IoT) for electronic market,” The Electronic Library, vol. 39, no. 4, pp. 526–538, 2021. [Google Scholar]
17. J. J. P. M. Y. Alotaibi, O. I. Khalaf and S. Alghamdi, “Heap bucketization anonymity-an efficient privacy-preserving data publishing model for multiple sensitive attributes,” IEEE Access, vol. 10, pp. 28773–28791, 2022. [Google Scholar]
18. L. Jiang, Y. Cheng, L. Yang, J. Li, H. Yan et al., “A trust-based collaborative filtering algorithm for E-commerce recommendation system,” Journal of Ambient Intelligence and Humanized Computing, vol. 10, no. 8, pp. 3023–3034, 2019. [Google Scholar]
19. M. Chau, D. Zeng, H. Chen, M. Huang and D. Hendriawan, “Design and evaluation of a multi-agent collaborative web mining system,” Decision Support Systems, vol. 35, no. 1, pp. 167–183, 2003. [Google Scholar]
20. M. Diaby, E. Viennet and T. Launay, “Exploration of methodologies to improve job recommender systems on social networks,” Social Network Analysis and Mining, vol. 4, no. 1, pp. 227, 2014. [Google Scholar]
21. M. J. Pazzani, “Framework for collaborative, content-based and demographic filtering,” Artificial Intelligence Review, vol. 13, no. 5, pp. 393–408, 1999. [Google Scholar]
22. M. N. Nikiforos, M. Malakopoulou, A. Stylidou and A. G. Alvanou, “Enhancing collaborative filtering recommendations for web-based learning platforms with genetic algorithms,” in 15th Int. Workshop on Semantic and Social Media Adaptation and Personalization, Zakynthos, Greece, pp. 1–6, 2020. [Google Scholar]
23. M. Rajalakshmi, V. Saravanan, V. Arunprasad, C. A. T. Romero, O. I. Khalaf et al., “Machine learning for modeling and control of industrial clarifier process,” Intelligent Automation & Soft Computing, vol. 32, no. 1, pp. 339–359, 2022. [Google Scholar]
24. M. Vinodhini Mani, M. Prakash, A. Youseef, A. Saleh and O. I. Khalaf, “Hyperledger health chain: Patient-centric IPFS-based storage of health records,” Electronics, vol. 10, no. 23, pp. 1–23, 2021. [Google Scholar]
25. N. A. Khan, O. I. Khalaf, C. A. T. Romero, M. Sulaiman and M. A. Bakar, “Application of intelligent paradigm through neural networks for numerical solution of multiorder fractional differential equations,” Computational Intelligence and Neuroscience, vol. 2022, no. 2710576, pp. 1–16, 2022. [Google Scholar]
26. N. O. García, M. F. D. Velásquez, C. A. T. Romero, J. H. O. Monedero and O. I. Khalaf, “Remote academic platforms in times of a pandemic,” International Journal of Emerging Technologies in Learning, vol. 16, no. 21, pp. 121–131, 2021. [Google Scholar]
27. N. Subramani, P. Mohan, Y. Alotaibi, S. Alghamdi and O. I. Khalaf, “An efficient metaheuristic-based clustering with routing protocol for underwater wireless sensor networks,” Sensors, vol. 22, no. 415, pp. 1–16, 2022. [Google Scholar]
28. O. I. Khalaf and G. M. Abdulsahib, “Design and performance analysis of wireless IPv6 for data exchange,” Journal of Information Science and Engineering, vol. 37, no. 6, pp. 1335–1340, 2021. [Google Scholar]
29. O. I. Khalaf, “Preface: Smart solutions in mathematical engineering and sciences theory,” Mathematics in Engineering, Science and Aerospace, vol. 12, no. 1, pp. 1–4, 2021. [Google Scholar]
30. O. I. Khalaf, C. A. T. Romero, S. Hassan and M. T. Iqbal, “Mitigating hotspot issues in heterogeneous wireless sensor networks,” Journal of Sensors, vol. 2022, no. 7909472, pp. 1–14, 2022. [Google Scholar]
31. O. I. Khalaf, M. Sokiyna, Y. Alotaibi, A. Alsufyani and S. Alghamdi, “Web attack detection using the input validation method: DPDA theory,” Computers, Materials & Continua, vol. 68, no. 3, pp. 3167–3184, 2021. [Google Scholar]
32. O. Wisesa, A. Andriansyah and O. I. Khalaf, “Prediction analysis for business to business (B2B) sales of telecommunication services using machine learning techniques,” Majlesi Journal of Electrical Engineering, vol. 14, no. 4, pp. 145–153, 2020. [Google Scholar]
33. P. Martinez, L. G. Perez and M. Barranco, “A multi granular linguistic content-based recommendation model,” International Journal of Intelligent Systems, vol. 22, no. 5, pp. 4192–4434, 2007. [Google Scholar]
34. P. Mohan, N. Subramani, Y. Alotaibi, S. Alghamdi, O. I. Khalaf et al., “Improved metaheuristics-based clustering with multihop routing protocol for underwater wireless sensor networks,” Sensors, vol. 22, no. 4, pp. 1–16, 2022. [Google Scholar]
35. Q. Yang, J. Sun, J. Wang and Z. Jin, “Semantic web-based personalized recommendation system of courses knowledge research,” in Int. Conf. on Intelligent Computing and Cognitive Informatics, Kuala Lumpur, pp. 214–217, 2010. [Google Scholar]
36. R. Khaparde, F. Alassery, A. Kumar, Y. Alotaibi, O. I. Khalaf et al., “Differential evolution algorithm with hierarchical fair competition model,” Intelligent Automation & Soft Computing, vol. 33, no. 2, pp. 1045–1062, 2022. [Google Scholar]
37. R. Vasanthi, O. I. Khalaf, C. A. T. Romero, S. Sudhakar and D. K. Sharma, “Interactive middleware services for heterogeneous systems,” Computer Systems Science and Engineering, vol. 41, no. 3, pp. 1241–1253, 2022. [Google Scholar]
38. S. Dalal and O. I. Khalaf, “Prediction of occupation stress by implementing convolutional neural network techniques,” Journal of Cases on Information Technology, vol. 23, no. 3, pp. 27–42, 2021. [Google Scholar]
39. S. N. Alsubari, S. N. Deshmukh, A. A. Alqarni, N. Alsharif, T. H. H. Aldhyani et al., “Data analytics for the identification of fake reviews using supervised learning,” Computers, Materials & Continua, vol. 70, no. 2, pp. 3189–3204, 2022. [Google Scholar]
40. S. R. Hemavathi Akhila, Y. Alotaibi, O. I. Khalaf and S. Alghamdi, “Authentication and resource allocation strategies during handoff for 5G IoVs using deep learning,” Energies, vol. 15, no. 6, pp. 1–27, 2022. [Google Scholar]
41. S. Rajendran, O. I. Khalaf and Y. Alotaibi, “MapReduce-based big data classification model using feature subset selection and hyperparameter tuned deep belief network,” Scientific Reports, vol. 11, no. 24138, pp. 1–10, 2021. [Google Scholar]
42. S. S. Rawat, S. Alghamdi, G. Kumar, Y. Alotaibi, O. I. Khalaf et al., “Infrared small target detection based on partial sum minimization and total variation,” Mathematics, vol. 10, no. 4, pp. 1–19, 2022. [Google Scholar]
43. S. Sudhakar and S. Chenthur Pandian, “Secure packet encryption and key exchange system in mobile ad hoc network,” Journal of Computer Science, vol. 8, no. 6, pp. 908–912, 2012. [Google Scholar]
44. S. Sudhakar and S. Chenthur Pandian, “A trust and co-operative nodes with affects of malicious attacks and measure the performance degradation on geographic aided routing in mobile ad hoc network,” Life Science Journal, vol. 10, no. 4s, pp. 158–163, 2013. [Google Scholar]
45. S. Sudhakar and S. Chenthur Pandian, “An efficient agent-based intrusion detection system for detecting malicious nodes in MANET routing,” International Review on Computers and Software (I.RE.CO.S.), vol. 7, no. 6, pp. 3037–3304, 2012. [Google Scholar]
46. S. Sudhakar and S. Chenthur Pandian, “Authorized node detection and accuracy in position-based information for MANET,” European Journal of Scientific Research, vol. 70, no. 2, pp. 253–265, 2012. [Google Scholar]
47. S. Sudhakar and S. Chenthur Pandian, “Hybrid cluster-based geographical routing protocol to mitigate malicious nodes in mobile ad hoc network,” International Journal of Ad Hoc and Ubiquitous Computing, vol. 21, no. 4, pp. 224–236, 2016. [Google Scholar]
48. S. Sudhakar and S. Chenthur Pandian, “Investigation of attribute aided data aggregation over dynamic routing in wireless sensor,” Journal of Engineering Science and Technology, vol. 10, no. 11, pp. 1465–1476, 2015. [Google Scholar]
49. S. Sudhakar and S. Chenthur Pandian, “Trustworthy position-based routing to mitigate against the malicious attacks to signifies secured data packet using geographic routing protocol in MANET,” WSEAS Transactions on Communications, vol. 12, no. 11, pp. 584–603, 2013. [Google Scholar]
50. S. Sudhakar, G. R. K. Rao, O. I. Khalaf and M. Rajesh Babu, “Markov mathematical analysis for comprehensive real-time data-driven in healthcare,” Mathematics in Engineering Science and Aerospace, vol. 12, no. 1, pp. 77–94, 2021. [Google Scholar]
51. S. Sudhakar, O. I. Khalaf, G. R. K. Rao, D. K. Sharma, K. Amarendra et al., “Security-aware routing on wireless communication for e-health records monitoring using machine learning,” International Journal of Reliable and Quality E-Healthcare, vol. 11, no. 3, pp. 1–10, 2022. [Google Scholar]
52. S. Sudhakar, O. I. Khalaf, P. Vidya Sagar, D. K. Sharma, L. Arokia Jesu Prabhu et al., “Secured and privacy-based IDS for healthcare systems on e-medical data using machine learning approach,” International Journal of Reliable and Quality E-Healthcare, vol. 11, no. 3, pp. 1–11, 2022. [Google Scholar]
53. S. Sudhakar, O. I. Khalaf, S. Priyadarsini, D. K. Sharma, K. Amarendra et al., “Smart healthcare security device on medical IoT using Raspberry Pi,” International Journal of Reliable and Quality E-Healthcare, vol. 11, no. 3, pp. 1–11, 2022. [Google Scholar]
54. S. Sudhakar, P. Vidya Sagar, R. Ramesh, O. I. Khalaf and R. Dhanapal, “The optimization of reconfigured real-time datasets for improving classification performance of machine learning algorithms,” Mathematics in Engineering Science and Aerospace, vol. 12, no. 1, pp. 43–54, 2021. [Google Scholar]
55. S. Sudhakar, V. Subramaniyaswamy, R. H. Jhaveri, V. Vijayakumar, S. Roy et al., “A secure recommendation system for providing context-aware physical activity classification for users,” Security and Communication Networks, vol. 2021, no. 4136909, pp. 1–15, 2021. [Google Scholar]
56. T. Puri, M. Soni, G. Dhiman, O. I. Khalaf, M. Alazzam et al., “Detection of emotion of speech for RAVDESS audio using hybrid convolution neural network,” Journal of Healthcare Engineering, vol. 2022, no. 8472947, pp. 1–9, 2022. [Google Scholar]
57. U. Srilakshmi, N. Veeraiah, Y. Alotaibi, S. Alghamdi, O. I. Khalaf et al., “An improved hybrid secure multipath routing protocol for MANET,” IEEE Access, vol. 9, pp. 163043–163053, 2021. [Google Scholar]
58. X. L. Zheng, C. C. Chen, J. L. Hung, W. He, F. X. Hong et al., “A hybrid trust-based recommender system for online communities of practice,” IEEE Transactions on Learning Technologies, vol. 8, no. 4, pp. 345–356, 2015. [Google Scholar]
59. Y. Yun, D. Hooshyar, J. Jo and H. Lim, “Developing a hybrid collaborative filtering recommendation system with opinion mining on purchase review,” Journal of Information Science, vol. 44, no. 3, pp. 331–344, 2018. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools