
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Hyperparameter Tuned Deep Hybrid Denoising Autoencoder Breast Cancer Classification on Digital Mammograms
Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Manar Ahmed Hamza. Email:
Intelligent Automation & Soft Computing 2023, 36(3), 2879-2895. https://doi.org/10.32604/iasc.2023.034719
Received 25 July 2022; Accepted 14 November 2022; Issue published 15 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Breast Cancer (BC) is considered the most commonly scrutinized cancer in women worldwide, affecting one in eight women in a lifetime. Mammography screening becomes one such standard method that is helpful in identifying suspicious masses’ malignancy of BC at an initial level. However, the prior identification of masses in mammograms was still challenging for extremely dense and dense breast categories and needs an effective and automatic mechanisms for helping radiotherapists in diagnosis. Deep learning (DL) techniques were broadly utilized for medical imaging applications, particularly breast mass classification. The advancements in the DL field paved the way for highly intellectual and self-reliant computer-aided diagnosis (CAD) systems since the learning capability of Machine Learning (ML) techniques was constantly improving. This paper presents a new Hyperparameter Tuned Deep Hybrid Denoising Autoencoder Breast Cancer Classification (HTDHDAE-BCC) on Digital Mammograms. The presented HTDHDAE-BCC model examines the mammogram images for the identification of BC. In the HTDHDAE-BCC model, the initial stage of image preprocessing is carried out using an average median filter. In addition, the deep convolutional neural network-based Inception v4 model is employed to generate feature vectors. The parameter tuning process uses the binary spider monkey optimization (BSMO) algorithm. The HTDHDAE-BCC model exploits chameleon swarm optimization (CSO) with the DHDAE model for BC classification. The experimental analysis of the HTDHDAE-BCC model is performed using the MIAS database. The experimental outcomes demonstrate the betterments of the HTDHDAE-BCC model over other recent approaches.Keywords
Breast cancer (BC) has become one of the most common cancers among women; as the name defines, it starts in the breast and gradually spreads to other body parts [1]. This cancer ranks second in the list of most common cancer globally, next to lung cancers, and mainly affects the breast glands. BC cells create cancer that can be seen in X-ray images [2]. In 2020, almost 1.8 million cancer cases were identified, representing 30% of those cases. There exist 2 kinds of BC exist: benign and malignant [3]. Cells were categorized based on several features. Identifying BC at an initial stage is critical for reducing the death rate. Medical image analysis considers the effectual methodology for identifying BC [4]. Different imaging modalities were utilized for diagnoses, like magnetic resonance imaging (MRI), digital mammography, infrared thermography, and ultrasound (US). Also, mammography imaging was highly suggested. Mammography generates high-quality images for visualizing the breast’s internal anatomy. There were various pointers of BC from mammograms [5]. Some of them were architectural distortions, masses, and macrocalcifications (MCs). The former 2 indicators were the powerful pointers of cancers in the initial stage, whereas the architectural distortions were less important than the MCs and masses. Radiotherapists cannot simply offer precise manual assessment because of the rising amount of mammograms produced in widespread screening [6]. Thus, computer-aided diagnosis (CAD) systems were advanced for identifying BC’s pointers and enhancing the accuracy of diagnosis. Such a system would simplify the diagnosis procedure and remains a second opinion from the radiologist’s point of view.
For the past few years, several authors have recommended numerous solutions for automated cell classification in BC diagnosis [7]. Because of the complicated nature of classical ML approaches, like feature extraction, pre-processing, and segmentation, the system’s performance reduces accuracy and efficiency. Conventional ML difficulties were addressed by the deep learning (DL) approach, which has occurred currently [8]. This technique can achieve outstanding feature representation for solving object-localization tasks and image classification. A conventional neural network (CNN)-training task mandates a large amount of data lacking in the medical field, particularly in BC [9]. The transfer learning (TL) method from natural-images datasets comes as a solution to this issue, namely ImageNet, and applies a finely tuned method. The TL idea is used for enhancing the performances of different CNN architectures by merging their knowledge. The major benefit of TL was the improvement of classifier accuracy and quickening training procedures [10]. A suitable TL approach was a model transfer; initially, the network parameters were pre-trained utilizing the source data, then such variables were implemented in the target field, and lastly, the network variables were altered for superior performance.
In [11], CNN structure has been devised using simplified feature learning and finely tuned classification method for separating cancer and ordinary mammogram cases. BC was a predominant and mortal illness that seemed resultant the mutation of normal tissues into cancer pathology. Mammograms have become effective and typical tools for BC diagnosis. The presented DL-related method mainly focused on evaluating the pertinence of several feature-learning techniques and improving the learning capability of the DL techniques for an effective BC identification utilizing CNN. Hassan et al. [12] introduce an innovative classifier algorithm for BC masses related to deep CNNs (DCNNs). The author examined the usage of TL from GoogleNet and AlexNet pre-trained techniques, which is suitable for this task. The author, through an experiment, determined the optimal DCNN technique for precise categorization through comparison made with different approaches that vary under the hyper-parameters and design.
Cabrera et al. [13] inquiry depended on this network type for categorizing 3 classes, malignant normal and benign cancer. For this reason, the miniMIAS database employed contains lesser images, and the TL algorithm has been implemented in the Inception v3 pre-trained network. Kavitha et al. [14] provide a novel Optimal Multi-Level Thresholding-related Segmentation with DL-enabled Capsule Network (OMLTS-DLCN) BC diagnosing technique leveraging digital mammogram. The OMLTS-DLCN technique adds an Adaptive Fuzzy related median filtering (AFF) method as a preprocessing stage for eliminating the noise presented in the mammogram images. Further, the presented method includes a CapsNet-related Back Propagation Neural Network (BPNN) classification, and the feature extractor technique was used to identify the BC existence.
Saffari et al. [15] advance a fully automatic digital breast tissue classification and segmentation utilizing advanced DL methods. The Conditional generative adversarial networks (cGAN) network was implemented to segment the tissues dense in mammograms. To take a whole mechanism for breast density classifications, the author modelled a CNN for classifying mammograms related to the standard Breast Imaging-Reporting and Data System (BI-RADS). Zahoor et al. [16] intend to examine a solution for preventing the disease and offer innovative classification techniques to reduce the risk of BC among women. The Modified Entropy Whale Optimization Algorithm (MEWOA) can be projected related to fusion for in-depth feature extracting and executing the classifications. In the presented technique, the effective Nasnet Mobile and MobilenetV2 were implemented for simulation.
This paper presents a new Hyperparameter Tuned Deep Hybrid Denoising Autoencoder Breast Cancer Classification (HTDHDAE-BCC) on Digital Mammograms. The presented HTDHDAE-BCC model examines the mammogram images for the identification of BC. In the HTDHDAE-BCC model, the initial stage of image preprocessing is carried out using an average median filter. In addition, the deep convolutional neural network-based Inception v4 model is employed to generate feature vectors. The parameter tuning process uses the binary spider monkey optimization (BSMO) algorithm. The HTDHDAE-BCC model exploits chameleon swarm optimization (CSO) with the DHDAE model for BC classification. The experimental analysis of the HTDHDAE-BCC model is performed using the MIAS database.
2 The Proposed BC Classification Model
This paper devised a new HTDHDAE-BCC technique for classifying BC on digital mammograms. The HTDHDAE-BCC model encompasses preprocessing, Inception v4 feature extraction, BSMO-based hyperparameter tuning, DHDAE classification, and CSO hyperparameter optimization. Fig. 1 displays the overall process of the HTDHDAE-BCC approach.
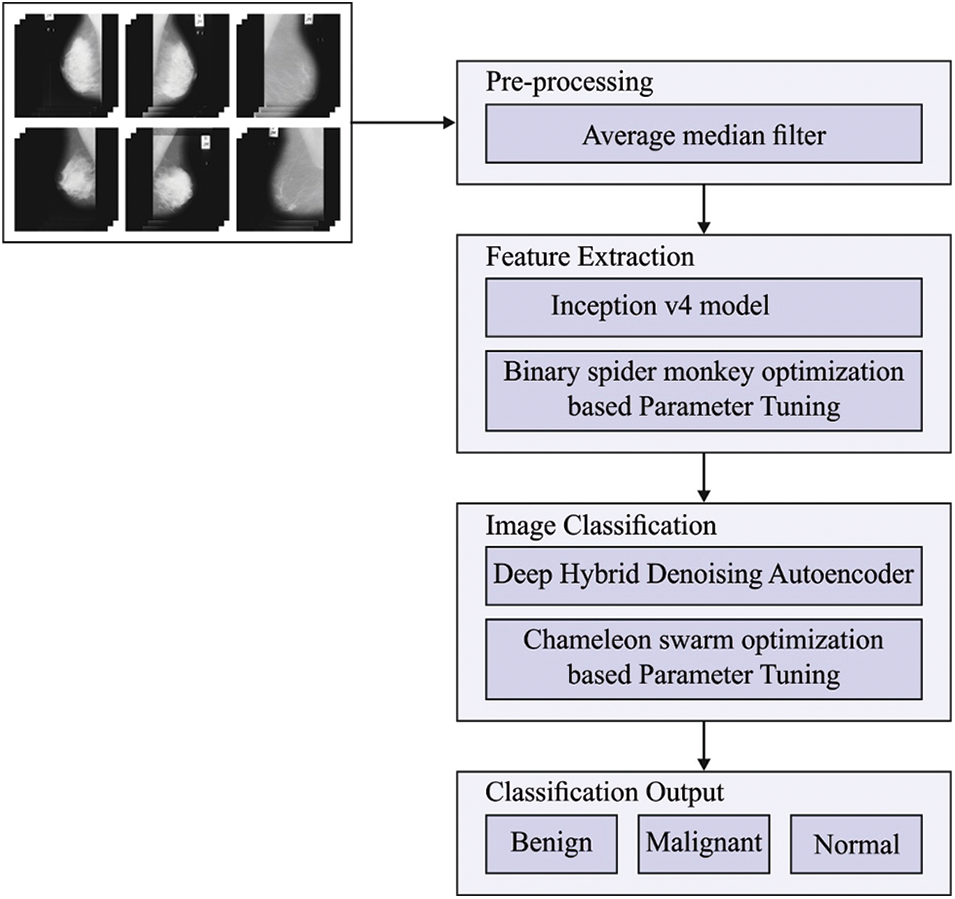
Figure 1: Overall process of HTDHDAE-BCC approach
2.1 Feature Extraction Using Inception v4
In this work, the Inception v4 model is employed to generate feature vectors. CNNs remove the need for manual extraction of features to identify features employed for classifying images. CNN operates through the extraction of features straightforwardly from images. Inception-v4 was a CNN structure constructed on earlier iterations of the Inception family by facilitating the structure and utilizing more inception modules instead of Inception-v3 [17]. The inception module has been initially presented in GoogLeNet and Inception-v1. The input went through 1 × 1, 3 × 3, and 5 × 5 conv, along with the max pooling concurrently and concatenated as output. The inception-v4 presented as a Batch normalization (BN), in which ReLU can be utilized as an activation function for addressing the saturation issue and the resultant vanishing gradients. Moreover, 5 × 5 conv has been replaced by dual 3 × 3 convs for parameter minimization while keeping the receptive field size. Additionally, a factorization idea was presented in the convolution layer to diminish the dimensionality to lessen the overfitting complexity.
2.2 Hyperparameter Tuning Using BSMO Algorithm
To optimally modify the hyperparameters related to the Inception v4 model, the BSMO algorithm is utilized. SMO discovers novel solutions and uses present solutions to accomplish optimum outcomes [18]. The summary of different stages associated with the traditional SMO process is demonstrated for the reader’s rapid reference. The logical operators such as AND (
Initialization phase
Initialization of the arbitrary binary solution is as follows:
In Eq. (7),
Local leader (LL) stage (LLS)
In Eq. (8),
Global leader stage (GLS)
Now,
In Eq. (4),
Local leader decision stage (LLDS)
In Eq. (5),
Global leader decision stage (GLDS)
Once the GL SM value isn’t changed to global leader limit
2.3 BC Classification Using Optimal DHDAE Model
For BC classification, the DHDAE model is exploited in this study. The autoencoder (AE) variants of the Deep Hybrid Boltzmann Machine (DHBM), the DHDAE, Follow the same path as a preceding subsection; however, it starts from the HSDA basis structural design [19]. Also, this borrows the similar structure of DHBM, containing the bi-direction connection required for integrating bottom-up and top-down influences. But, rather than learning through a Boltzmann-based method, we intend to learn a stochastic decoder and encoder procedure over several layers conjointly. The DHDAE might be stacking a strongly incorporated hybrid denoising autoencoder (HdA) with the coupled predictor. An HdA is a single hidden-layer MLP that shares input-to-hidden weight with an encoder-decoder module whose weight is tied (viz., decoding weight is equivalent to the transfer of encoding weight).
A 3-layer form of the joint models (generalized to L layer and determined as the similar variable set as DHBM) is quantified as the encoder
The information flow to collect layer-by-layer statistics is specified as the arrows (that characterize an operation like element-wise non-linearity and matrix multiplication), using the vector at the arrow origin and the suitable layer parameter matrix) that is totalled based on the consecutive computation step taken to evaluate them. Arrows (or operations) in similar computation steps are similar and point to the resultant activation value evaluated. v corresponds to the detection network

Figure 2: Structure of autoencoder
To evaluate layer-by-layer activation value for the DHDAE, one uses the detection model to attain primary guess for
For optimal hyperparameter tuning of the DHDAE, the CSO algorithm is used. CSO algorithm stimulates the hunting and food-searching method [20]. They are many specified classes of species that can change colour to blend with their surroundings. They can live and survive in semi-desert areas, lowlands, mountains, and deserts and usually eat insects. The food hunting procedure includes the following phases: attacking, tracking, and pursuing the prey using their sight. The mathematical steps and models are described in the succeeding subsections.
CSO algorithm was a population-related meta-heuristic that arbitrarily produces an initializing population to begin the optimization procedure. The chameleon population having the size n was generated in a
where
The initialized population is produced according to the problem dimension, and the chameleon count in the searching region is shown below:
In Eq. (10),
The chameleon movement behaviour in searching is represented according to the updated approach of location as follows:
In Eq. (11), t and
Where
Chameleon’s Eyes Rotation able to recognize prey location by rotating their eyes, and that feature assists in spotting the target via 360 degrees steps are given below:
• The initial location was the focal point of gravity;
• The rotation matrix was found out that identifies the prey position;
• The situation is refreshed through a rotation matrix at the focal point of gravity;
• At last, they were resumed to the initial location position
Chameleon assaults its target once it excessively comes closer. The chameleon adjacent to the target is the optimum chameleon and is regarded as the optimum outcome. Such chameleons assault the target through the tongue. The chameleon situation is enhanced since it could prolong the tongue by double the length. It assists the chameleon in exploiting the pursuit space and enables them to catch the target sufficiently. The speed of the tongue, once it is protracted toward the target, is arithmetically given as follows:
In Eq. (12),
The experimental validation of the HTDHDAE-BCC method is tested utilizing the MIAS dataset. It contains 322 images under three class labels, as depicted in Table 1. A few sample images are demonstrated in Fig. 3.


Figure 3: Sample images (a) Normal, (b) Benign, and (c) Malignant
Fig. 4 exhibits the confusion matrices generated by the HTDHDAE-BCC model under five runs. On run-1, the HTDHDAE-BCC model categorized 62 samples into benign, 49 into malignant, and 207 samples into normal. Temporarily, on run-2, the HTDHDAE-BCC approach has categorized 62 samples into benign, 48 samples into malignant, and 207 samples into normal. Meanwhile, on run-3, the HTDHDAE-BCC technique has categorized 62 samples into benign, 48 samples into malignant, and 209 samples into normal. Finally, on run-4, the HTDHDAE-BCC algorithm has categorized 62 samples into benign, 49 samples into malignant, and 206 samples into normal.

Figure 4: Confusion matrices of HTDHDAE-BCC approach (a) Run1, (b) Run2, (c) Run3, (d) Run4, and (e) Run5
Table 2 provides detailed BC classification outcomes of the HTDHDAE-BCC model under five distinct runs.

Fig. 5 provides the overall classifier results of the HTDHDAE-BCC model on run-1. The figure shows that the HTDHDAE-BCC model has enhanced results under all classes. For instance, the HTDHDAE-BCC model has categorized benign images with

Figure 5: Result analysis of HTDHDAE-BCC approach under run-1
Fig. 6 presents the complete classifier results of the HTDHDAE-BCC method on run-2. The figure displayed the HTDHDAE-BCC approach has offered enhanced results under all classes. For example, the HTDHDAE-BCC methodology has categorized benign images with

Figure 6: Result analysis of HTDHDAE-BCC approach under run-2
Fig. 7 illustrates the inclusive classifier results of the HTDHDAE-BCC technique on run-3. The figure represented the HTDHDAE-BCC approach has presented enhanced results under all classes. For example, the HTDHDAE-BCC method has categorized benign images with

Figure 7: Result analysis of HTDHDAE-BCC approach under run-3
Fig. 8 portrays the general classifier results of the HTDHDAE-BCC methodology on run-4. The figure denoted the HTDHDAE-BCC technique has provided enhanced results under all classes. For example, the HTDHDAE-BCC approach has categorized benign images with
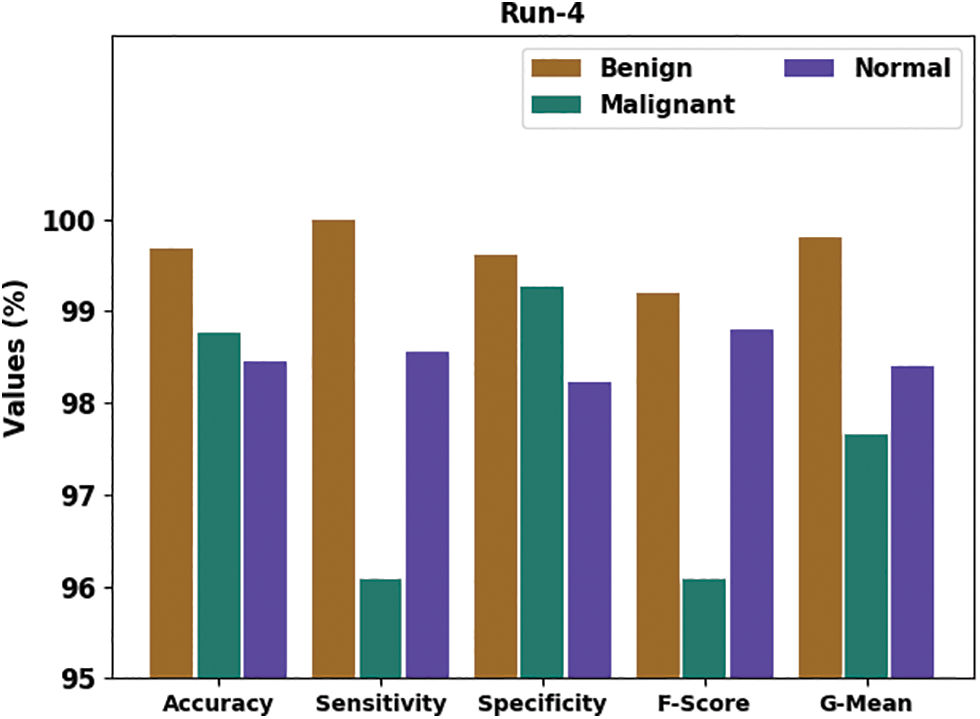
Figure 8: Result analysis of HTDHDAE-BCC approach under run-4
Fig. 9 delivers an overall classifier fallout of the HTDHDAE-BCC approach on run-5. The figure exemplified the HTDHDAE-BCC methodology has rendered enhanced results under all classes. For example, the HTDHDAE-BCC algorithm has categorized benign images with
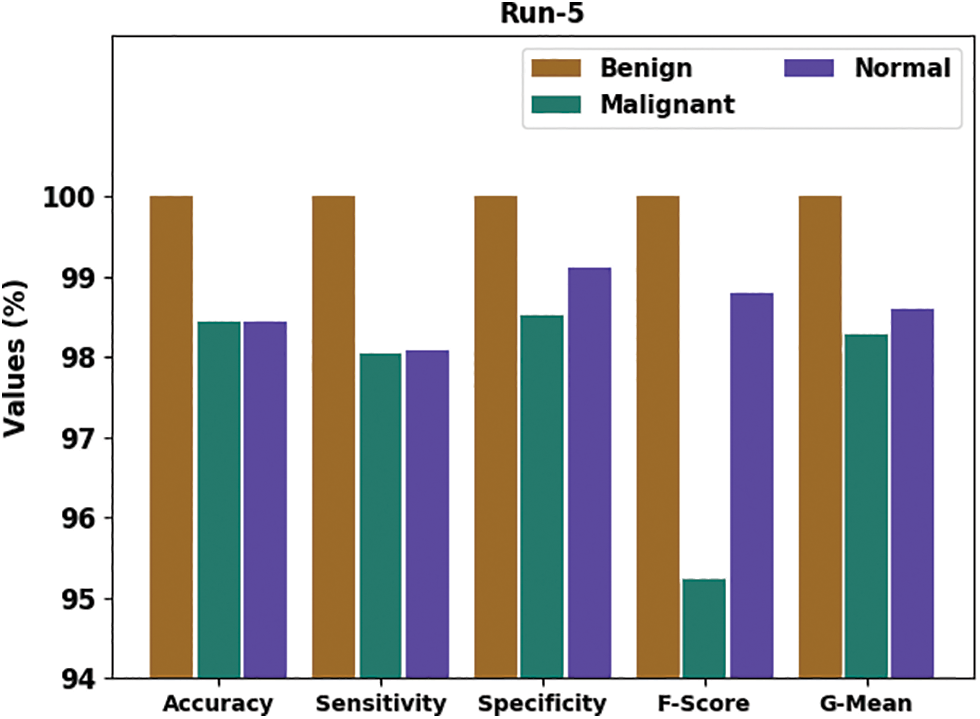
Figure 9: Result analysis of HTDHDAE-BCC approach under run-5
Fig. 10 demonstrates the average classification outcomes of the HTDHDAE-BCC model. On run-1, the HTDHDAE-BCC model has attained average

Figure 10: Average analysis of HTDHDAE-BCC approach (a) Run1, (b) Run2, (c) Run3, (d) Run4, and (e) Run5
The training accuracy (TRA) and validation accuracy (VLA) obtained by the HTDHDAE-BCC method on the test dataset is illustrated in Fig. 11. The experimental outcome inferred that the HTDHDAE-BCC technique had achieved maximal values of TRA and VLA. Particularly the VLA seemed to be higher than TRA.

Figure 11: TRA and VLA analysis of HTDHDAE-BCC approach
The training loss (TRL) and validation loss (VLL) achieved by the HTDHDAE-BCC approach on the test dataset are established in Fig. 12. The experimental outcome implied that the HTDHDAE-BCC algorithm had accomplished the least values of TRL and VLL. In specific, the VLL is lower than TRL.

Figure 12: TRL and VLL analysis of HTDHDAE-BCC approach
A brief ROC analysis of the HTDHDAE-BCC method on the test dataset is depicted in Fig. 13. The results denoted the HTDHDAE-BCC approach has shown its ability to categorize distinct classes on the test dataset.

Figure 13: ROC analysis of HTDHDAE-BCC approach
To ensure the enhanced results of the HTDHDAE-BCC model, a brief comparative examination is offered in Table 3 [21]. The outcomes inferred the improved outcomes of the HTDHDAE-BCC model compared to existing techniques. Based on

Simultaneously, based on
In this paper, a novel HTDHDAE-BCC algorithm was projected for the classification of BC on digital mammograms. In the HTDHDAE-BCC model, the initial stage of image pre-processing is carried out using an average median filter. In addition, the deep convolutional neural network-based Inception v4 model is employed to generate feature vectors. The parameter tuning process can be performed using the binary spider monkey optimization (BSMO) algorithm. The HTDHDAE-BCC model exploits the CSO algorithm with the DHDAE model for BC classification. The experimental analysis of the HTDHDAE-BCC model is performed using the MIAS database. The experimental outcomes demonstrate the betterments of the HTDHDAE-BCC model over other recent approaches. In the upcoming years, the performance of the HTDHDAE-BCC technique can be boosted by a deep instance segmentation model.
Funding Statement: This project was supported by the Deanship of Scientific Research at Prince SattamBin Abdulaziz University under research Project# (PSAU-2022/01/20287).
Conflicts of Interest: The author declares that they have no conflicts of interest to report regarding the present study.
References
1. L. Tsochatzidis, L. Costaridou and I. Pratikakis, “Deep learning for breast cancer diagnosis from mammograms—A comparative study,” Journal of Imaging, vol. 5, no. 3, pp. 37, 2019. [Google Scholar] [PubMed]
2. Y. J. Suh, J. g and B. J. Cho, “Automated breast cancer detection in digital mammograms of various densities via deep learning,” Journal of Personalized Medicine, vol. 10, no. 4, pp. 211, 2020. [Google Scholar] [PubMed]
3. A. Akselrod-Ballin, M. Chorev, Y. Shoshan, A. Spiro, A. Hazan et al., “Predicting breast cancer by applying deep learning to linked health records and mammograms,” Radiology, vol. 292, no. 2, pp. 331–342, 2019. [Google Scholar] [PubMed]
4. L. Shen, L. R. Golies, J. H. Rothstein, E. Fluder, R. McBride et al., “Deep learning to improve breast cancer detection on screening mammography,” Scientific Reports, vol. 9, no. 1, pp. 1–12, 2019. [Google Scholar]
5. A. Kumar, S. Mukherjee and A. K. Luhach, “Deep learning with perspective modeling for early detection of malignancy in mammograms,” Journal of Discrete Mathematical Sciences and Cryptography, vol. 22, no. 4, pp. 627–643, 2019. [Google Scholar]
6. C. D. Lehman, A. Yala, T. Schuster, B. Dontchos, M. Bahl et al., “Mammographic breast density assessment using deep learning: Clinical implementation,” Radiology, vol. 290, no. 1, pp. 52–58, 2019. [Google Scholar] [PubMed]
7. X. Zhu, T. K. Wolfgruber, L. Leong, M. Jensen, C. Scott et al., “Deep learning predicts interval and screening-detected cancer from screening mammograms: A case-case-control study in 6369 women,” Radiology, vol. 301, no. 3, pp. 550–558, 2021. [Google Scholar] [PubMed]
8. D. Arefan, A. A. Mohamed, W. A. Berg, M. L. Zuley, J. H. Sumkin et al., “Deep learning modeling using normal mammograms for predicting breast cancer risk,” Medical Physics, vol. 47, no. 1, pp. 110–118, 2020. [Google Scholar] [PubMed]
9. W. Lotter, A. R. Diab, B. Haslam, J. G. Kim, G. Grisot et al., “Robust breast cancer detection in mammography and digital breast tomosynthesis using an annotation-efficient deep learning approach,” Nature Medicine, vol. 27, no. 2, pp. 244–249, 2021. [Google Scholar] [PubMed]
10. S. S. Chakravarthy and H. Rajaguru, “Automatic detection and classification of mammograms using improved extreme learning machine with deep learning,” IRBM, vol. 43, no. 1, pp. 49–61, 2022. [Google Scholar]
11. G. Altan, “Deep learning-based mammogram classification for breast cancer,” International Journal of Intelligent Systems and Applications in Engineering, vol. 8, no. 4, pp. 171–176, 2020. [Google Scholar]
12. S. A. A. Hassan, M. S. Sayed, M. I. Abdalla and M. A. Rashwan, “Breast cancer masses classification using deep convolutional neural networks and transfer learning,” Multimedia Tools and Applications, vol. 79, no. 41, pp. 30735–30768, 2020. [Google Scholar]
13. J. D. L. Cabrera, L. A. L. Rodríguez and M. P. Díaz, “Classification of breast cancer from digital mammography using deep learning,” Inteligencia Artificial, vol. 23, no. 65, pp. 56–66, 2020. [Google Scholar]
14. T. Kavitha, P. P. Mathai, C. Karthikeyan, M. Ashok, R. Kohar et al., “Deep learning based capsule neural network model for breast cancer diagnosis using mammogram images,” Interdisciplinary Sciences: Computational Life Sciences, vol. 14, no. 1, pp. 113–129, 2022. [Google Scholar] [PubMed]
15. N. Saffari, H. A. Rashwan, M. A. Nasser, V. K. Singh, M. Arenas et al., “Fully automated breast density segmentation and classification using deep learning,” Diagnostics, vol. 10, no. 11, pp. 988, 2020. [Google Scholar] [PubMed]
16. S. Zahoor, U. Shoaib and I. U. Lali, “Breast cancer mammograms classification using deep neural network and entropy-controlled whale optimization algorithm,” Diagnostics, vol. 12, no. 2, pp. 557, 2022. [Google Scholar] [PubMed]
17. M. A. S. Al Husaini, M. H. Habaebi, T. S. Gunawan, M. R. Islam, E. A. Elsheikh et al., “Thermal-based early breast cancer detection using inception V3, inception V4 and modified inception MV4,” Neural Computing and Applications, vol. 34, no. 1, pp. 333–348, 2022. [Google Scholar] [PubMed]
18. N. Khare, P. Devan, C. L. Chowdhary, S. Bhattacharya, G. Singh et al., “Smo-dnn: Spider monkey optimization and deep neural network hybrid classifier model for intrusion detection,” Electronics, vol. 9, no. 4, pp. 692, 2020. [Google Scholar]
19. A. G. Ororbia II, C. L. Giles and D. Reitter, “Online semi-supervised learning with deep hybrid boltzmann machines and denoising autoencoders,” arXiv preprint arXiv:1511.06964, 2015. [Google Scholar]
20. M. Said, A. M. El-Rifaie, M. A. Tolba, E. H. Houssein and S. Deb, “An efficient chameleon swarm algorithm for economic load dispatch problem,” Mathematics, vol. 9, no. 21, pp. 2770, 2021. [Google Scholar]
21. A. Saber, M. Sakr, O. M. Abo-Seida, A. Keshk and H. Chen, “A novel deep-learning model for automatic detection and classification of breast cancer using the transfer-learning technique,” IEEE Access, vol. 9, pp. 71194–71209, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools