
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Modified Sine Cosine Optimization with Adaptive Deep Belief Network for Movie Review Classification
1 Department of Applied Linguistics, College of Languages, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Saudi Arabia
3 Department of English, College of Science & Art at Mahayil, King Khalid University, Muhayel Aseer, 63311, Saudi Arabia
4 Department of Computer Science, College of Sciences and Humanities-Aflaj, Prince Sattam bin Abdulaziz University, Al-Aflaj, 16828, Saudi Arabia
5 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
6 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Mesfer Al Duhayyim. Email:
Intelligent Automation & Soft Computing 2023, 37(1), 283-300. https://doi.org/10.32604/iasc.2023.035334
Received 16 August 2022; Accepted 23 November 2022; Issue published 29 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Sentiment analysis (SA) is a growing field at the intersection of computer science and computational linguistics that endeavors to automatically identify the sentiment presented in text. Computational linguistics aims to describe the fundamental methods utilized in the formation of computer methods for understanding natural language. Sentiment is classified as a negative or positive assessment articulated through language. SA can be commonly used for the movie review classification that involves the automatic determination that a review posted online (of a movie) can be negative or positive toward the thing that has been reviewed. Deep learning (DL) is becoming a powerful machine learning (ML) method for dealing with the increasing demand for precise SA. With this motivation, this study designs a computational intelligence enabled modified sine cosine optimization with a adaptive deep belief network for movie review classification (MSCADBN-MVC) technique. The major intention of the MSCADBN-MVC technique is focused on the identification of sentiments that exist in the movie review data. Primarily, the MSCADBN-MVC model follows data pre-processing and the word2vec word embedding process. For the classification of sentiments that exist in the movie reviews, the ADBN model is utilized in this work. At last, the hyperparameter tuning of the ADBN model is carried out using the MSCA technique, which integrates the Levy flight concepts into the standard sine cosine algorithm (SCA). In order to demonstrate the significant performance of the MSCADBN-MVC model, a wide-ranging experimental analysis is performed on three different datasets. The comprehensive study highlighted the enhancements of the MSCADBN-MVC model in the movie review classification process with maximum accuracy of 88.93%.Keywords
Computational linguists create resources and tools for significant practical tasks like information extraction from text, machine translation, speech synthesis, text mining, grammar checking, and speech recognition. Computational linguistics refers to the study of computer systems to understand Natural language generation [1]. Tools that operate in computational linguistics utilize artificial intelligence (AI), that is, formal methods, Algorithms, data structures to express knowledge, methods for inference process, etc. Recent advancement in the web has impacted the everyday life of humans, and the necessity of user view analysis has seen exponential growth [2]. The flow of massive volumes of data can affect the decision-making process in organizations. Analyzing emotions, aspects, and reactions of people with regard to entities like issues, services, events, products, and their attributes by the feedback from Web pages is known as opinion mining [3]. The improvement in the domain of web technology made changes in the way of expressing people’s opinions. People depend on the user perspective information to analyze the substances for online purchases or booking movie tickets to watch movies [4]. The users will interface by tweets on Twitter, posts on Facebook, and so on. The measure of data can be huge to highlight that it becomes a burden for a common man to examine and come to a conclusion.
Sentiment analysis (SA) can be broadly organized into 2 types they are classification methods and information-oriented method. An information-oriented method needs an extensive database of predefined feelings and an effective information portrayal to recognize sentiments [5]. There exists a massive volume of opinionated data accessible in digital formats, for example, microblogs, reviews, social networks, Twitter forum discussions, and blogs [6]. Therefore, studying SA has an overwhelming effect on economics, natural language processing (NLP), political science, social sciences, and management sciences since they are influenced by people’s opinions. A sentiment can be a negative or positive emotion, opinion, feeling, or valuation regarding a term, feature, or attribute from a sentiment holder. Neutral, Positive, and negative views are known as sentiment orientations (also termed semantic polarities, orientations, or opinion orientations) [7].
Owing to the evolution of massive data and the volume of data that has been produced and exchanged every minute, analyzing, mining, and comprehending this data has increased remarkably [8]. And then, the regular Neural Networks (NN) and machine learning (ML) methods are inadequate to gain big data; deep learning (DL) has become the key to the big data period. DL refers to a subfield of ML and an alternative to NNs. Simply, regular NN was a single network having output and input layers along with the hidden layers simultaneously performing computation. Deep Neural Networks (DNN) have many NNs in which the output of a single network was input to the next network, and so on [9]. This has overcome the limitation of the number of hidden layers in NNs and works with big data feasibly. DL networks will learn the attributes on their own, i.e.,; it is a robust ML method that studies multiple layers of features and induces outcomes of prediction [10]. DL is currently utilized in several applications in the domain of information processing and signal, particularly with the development of big data. Moreover, DL networks were utilized in opinion mining and SA.
This study develops a computational intelligence-enabled modified sine cosine optimization with adaptive deep belief network for movie review classification (MSCADBN-MVC) technique. The major intention of the MSCADBN-MVC technique is focused on the identification of sentiments thatthat exist in the movie review data. Primarily, the MSCADBN-MVC model follows data pre-processing and word2vec word embedding process. For the classification of sentiments exist in the movie reviews, the ADBN model is utilized in this work. At last, the hyperparameter tuning of the ADBN model is carried out using the MSCA technique. In order to demonstrate the significant performance of the MSCADBN-MVC model, a wide-ranging experimental analysis is performed on three different datasets.
Rehman et al. [11] project a hybrid method utilizing long short-term memory (LSTM) and deep convolutional neural network (CNN) method called Hybrid CNN-LSTM technique to address the SA problem. Firstly, the author employs the Word to Vector (Word2Vec) technique for training primary word embedding. The Word2Vec will translate the text strings to a vector of numerical values, calculates the distance in words, and creates groups of comparable words related to their meanings. And then, embedding can be executed where the presented method integrates a group of features that can be derived by global max-pooling, and convolution layers have long-term dependences. Abidin et al. [12] intend to categorize the SA of movie reviews gained from the IMDb website. The support vector machine (SVM) technique has been used for classifying the movie review’s sentiments. At the same time, the information gain (IG) and radial basis function (RBF) kernel are utilized for enhancing classification. Feature selection has been made through the removal of unrelated attributes and choosing attributes with a strong correlation for classifying purposes. The IG method has been employed for selecting features.
In [13], the author makes use of LSTMs, a variant of recurrent neural network (RNN) for predicting the SA for the mission of movie review analysis. LSTMs seem to be excellent in devising very long sequential data. The issue was imposed as a binary classifier task in which the review is negative or positive. Sentence vectorizing techniques were utilized to deal with the variability of the sentence length. In this study, the author tries to examine the effect of hyperparameters such as activation functions, dropout, and the number of layers. Ullah et al. [14] devises a DNN having 7 layers for movie reviews’ SA. The method comprises input layers named an embedding layer that denotes the data as a number of sequences named vectors and 2 consecutive layers of 1D-CNN (1-dimensional CNN) to extract features. A global max-pooling layer can be used for dimension reduction. A dense layer for classifying purposes and a dropout layer were utilized to reduce overfitting and enhance generalization error in the NN. An FC layer was the final layer for predicting 2 classes.
Ramadhan et al. [15] focused on analyzing the sentiment of opinions from numerous comments from IMDB site users utilizing the star rating aspect and categorized utilizing the SVM method. SA was a classifying process for understanding the emotions, opinions, and interactions of a text or document. SVM can be fruitful for several applications in engineering and science, particularly for classification (pattern identification) issues. Along with the SVM technique, the term frequency-inverse document frequency (TF-IDF) method was utilized for changing the document shape into numerous words. In [16], the LSTM classifier can be utilized to analyze the sentiments of the IMDb movie reviews. It depends on the RNN method. The data can be efficiently pre-processed and divided to enhance the post-classifier performance. In [17], the author performs SA in 2 different movie review datasets utilizing several ML approaches. The author devises some structures of sentiment classification utilizing these methods on the given dataset.
In this study, a new MSCADBN-MVC technique has been developed for the identification and classification of movie reviews on social media. The major intention of the MSCADBN-MVC technique is focused on the identification of sentiments that exist in the movie review data. Fig. 1 demonstrates the overall process of the MSCADBN-MVC approach.

Figure 1: Overall process of MSCADBN-MVC approach
3.1 Data Pre-Processing and Word Embedding
Primarily, the MSCADBN-MVC model follows data pre-processing and the word2vec word embedding process. The pre-processing not only focus on cleaning the text but is also helpful in extracting the text features such as numerous words, symbols, and URLs which is not helpful for classifying purposes [18]. In the pre-processing stage, it involves various tasks for converting unstructured text files into a word vector as listed below:
• Stemming
• Tokenization
• Short-word removal
• Stop-word removal
Stemming: it aims to discover the root word through the removal of suffixes. In the feature space, various tokens which share a similar root-word are recognized as the same token.
Tokenization will chunk text sentences as meaningful words named tokens. With the help of the whitespaces, the text documents were chunked out of a long paragraph. Additionally, the special characters, HTML tags, punctuation, and XML scripts presented in text documents have not affected the performance. So, eliminating them will be helpful in reducing the feature count in the classification stage.
Short-word Removal: A short word with a length of 1 to 2 characters can be removed to reduce the feature or number count. Such short words were often extracted from short-form words, like ‘ok’ (read: okay) and ‘tq’ (thank you). It can be taken as noise due to the spelling and grammatical errors that are repeated in an informal text. Therefore, to reduce the feature count, it has to be eliminated from the text documents.
Stop-word Removal intends to omit terms or tokens in the text files which were commonly known as ‘functional words’ because it does not have any meaning, for example ‘but’, ‘this’, and ‘is’. The stop-words were repetitive, and it does not affect the classifying process; conversely, it minimizes computational difficulty.
Word2Vec was an open-source tool related to DL. In recent times, it is gaining more popularity due to its maximum accuracy in examining semantic similarities between 2 words and has a less computational cost. It comprises 2 modes they are Skip-Gram and Continuous bag of words (CBOW), which is applied quickly to study word embedding out of the original text and captures word relations with the built vector representing method (NN method). In this study, the Skip-Gram method has been chosen for training word embedding. Then in the text pre-processing stage, the Skip-Gram model learns the word vector representations of every word in the document and extracts the vector representation for every word encountered in the input. After that, the representation of every sentence is got through the average on the vectors of all its encompassing words. During the sentiment prediction stage, the vector representation of the novel document can be derived in the same way.
3.2 Movie Review Sentiment Classification
At this stage, the ADBN model is used for the classification of sentiments that exist in movie reviews. DBN is a model made up of more than one Restricted Boltzmann Machine (RBM) [19]. The feature extracted using the initial RBM is transferred to the upper RBM, whereas the features extracted by the latter layer of RBM are transferred to the backpropagation neural network (BPNN). According to the structural properties of multilayer, it is simple to achieve the compression coding of the data, therefore accomplishing the best feature depiction.
RBM is a building block of DBN, and it is extensively employed in pattern recognition, data reconstruction, and classification. RBM is an undirected graph mechanism that involves hidden and visible layers without linking among nodes in a similar layer, and different layers are connected. The architecture is the same as the two-layer fully convolutional network (FCN) while considering each visible and hidden layers are binary distributed. RBM is an energy mechanism where the energy function is utilized originally. At the same time, the neural network uses RBM, with a vector v and h signifying neuron in the visible and hidden units as follows:
Now
The marginal distribution of RBM is:
Here
Assume that the amount of instances is I and the present instance is i. The variable
To attain the optimum value
Now,
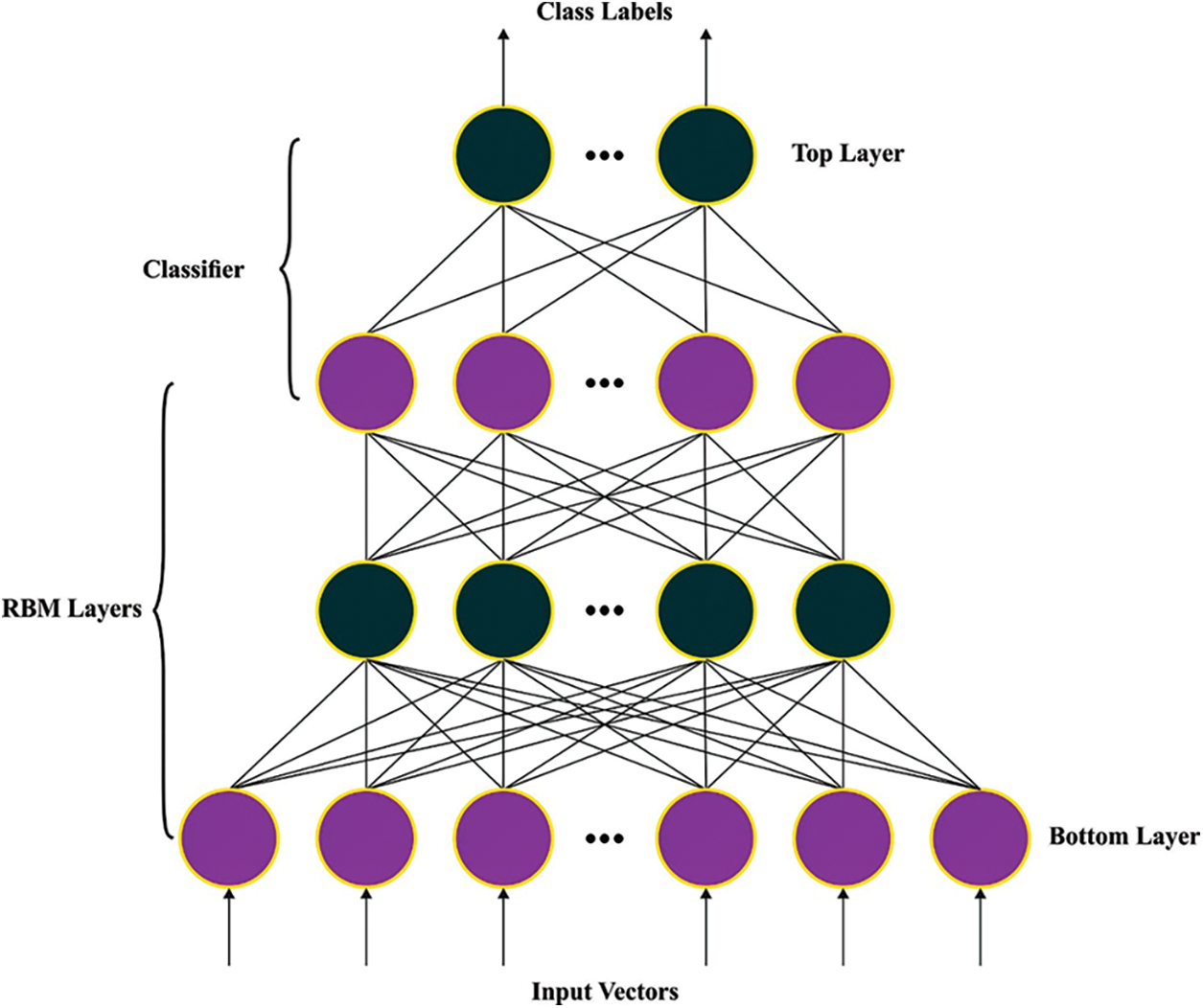
Figure 2: Structure of DBN
By utilizing the Contrastive Divergence (CD) approach for training RBM and different from Gibbs sampling, the CD approach needs k steps of Gibbs sampling to retrieve a better fit. The CD method comprises a recursive step of Gibbs sampling that estimates the data distribution and model by means of a larger amount of continuous updates, which improves the computation speed of learning and ensures the computation performance.
Stochastic gradient descent (SGD) and variant might be the increasingly common optimization algorithm in ML; however, the learning method is sometimes slower, and the update direction is dependent wholly on the current batch. Therefore, its update is extremely unstable.
The momentum model, known as classical momentum (CM), is a method to go faster gradient descent that collects velocity vector in the direction wherein the objective lens continues to reduce during the procedure of iteration. CM updates the direction of the previous renewal and exploits the gradient of the current batch to finetune the last update direction. Therefore, stability is improved to a range such that learning is faster, and it is evaluated in the following:
In Eq. (5),
The stochastic gradient descent (SGD) optimizer with momentum causes the gradient in a similar direction to accumulate, as different directions cancel one another, which might accelerate the method to the optimum point. Nevertheless, the momentum gradient is sightless. The gradient drops faster; however, it could judge where the parameter will fall. Consequently, the variable still drops faster once it is nearer the optimum solution that it might miss it. In such cases, Nelder mead (NM) could be a possible solution. The dissimilarity between momentum and NM is considered in the gradient computation. In NM, the gradient is computed afterwards the existing speed is employed. Consequently, NM is described by adding a correction factor to the momentum model that evaluates the gradient of
But sometimes, the NM approach is very conservative. For the RBM training to accomplish adequate training speed and classification, an independent adaptive learning rate is presented.
In Eq. (7),
3.3 Design of MSCA for Hyperparameter Optimization
Finally, the hyperparameter tuning of the ADBN model is carried out using the MSCA technique. SCA draws motivation from the mathematical modelling of the sine and cosine trigonometric functions [20]. The solution position in the population is upgraded according to the sine and cosine functions output, which makes them oscillate near the optimum solution. The return value of a function is
The location updating method is accomplished in all the iterations through Eqs. (9) and (10),
The abovementioned two formulas are utilized as control parameter
In Eq. (11),
The search procedure can be controlled using four arbitrary variables, and they affect the existing and the optimal solution position. The balance between solutions is required for the optimal global convergence. It can be accomplished by altering the range of based functions in the adhoc method. Exploitation is assured through the fact that the sine and cosine function exhibits a cyclic pattern that allows for relocation nearby the solution. Change in the range of sine and cosine functions allows the procedure to search the outer of the respective destination. Moreover, the solution needs the location not to overlap with the area of another solution.
For good quality of randomness, the value for variable
In Eq. (12), t indicates the present iteration, T characterizes the maximal amount of iterations in a run, and a shows a constant.
The MSCA technique integrates the Levy flight (LF) concepts into the standard SCA. LF is a type of chaotic system, whereas the magnitude of the leap has defined by the possibility function [21]. If the higher fly recognizes a prey area, Aquila defines the land and then strikes. It is recognized as a contour flight with rapid glide invasion. During this work, Aquila optimized a detailed examination of the target prey in certain areas from the arranging for the assault. This performance was formulated properly as follows.
whereas
In which s represents the constant fixed to 0.01, u signifies the randomized value between zero and one, and r denotes the randomized number between
whereas
In order to provide the number of search iterations,
The MSCA method will derive a fitness function (FF) for achieving enhanced classifier outcomes. It specifies a positive value for denoting superior outcomes of the candidate solutions. In this article, the reduction of the classifier error rate can be regarded as the FF, which is presented below in Eq. (17).
The proposed model is simulated using Python 3.6.5 tool on PC i5-8600 k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1 TB HDD. The parameter settings are given as follows: learning rate: 0.01, dropout: 0.5, batch size: 5, epoch count: 50, and activation: ReLU.
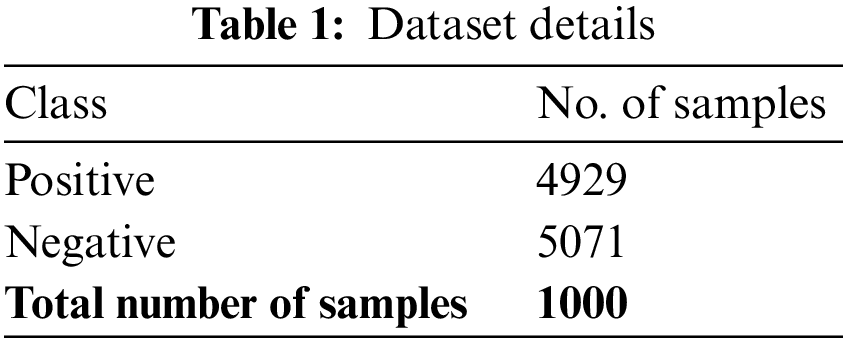
The experimental validation of the presented MSCADBN-MVC model takes place. The dataset comprises 4929 samples in the positive class and 5071 samples into the negative class, as illustrated in Table 1.
The confusion matrices of the MSCADBN-MVC model on the movie review classification process are given in Fig. 3. On run-1, the MSCADBN-MVC model has recognized 4814 samples into positive class and 3955 samples into negative class. In the meantime, on run-2, the MSCADBN-MVC approach has recognized 3696 samples into the positive class and 5040 samples into negative class. In parallel, on run-3, the MSCADBN-MVC method has recognized 3952 samples into positive class and 4383 samples into negative class. Also, on run-4, the MSCADBN-MVC algorithm has recognized 4534 samples into positive class and 4359 samples into negative class. Finally, on run-5, the MSCADBN-MVC methodology has recognized 3589 samples into positive class and 4785 samples into negative class.
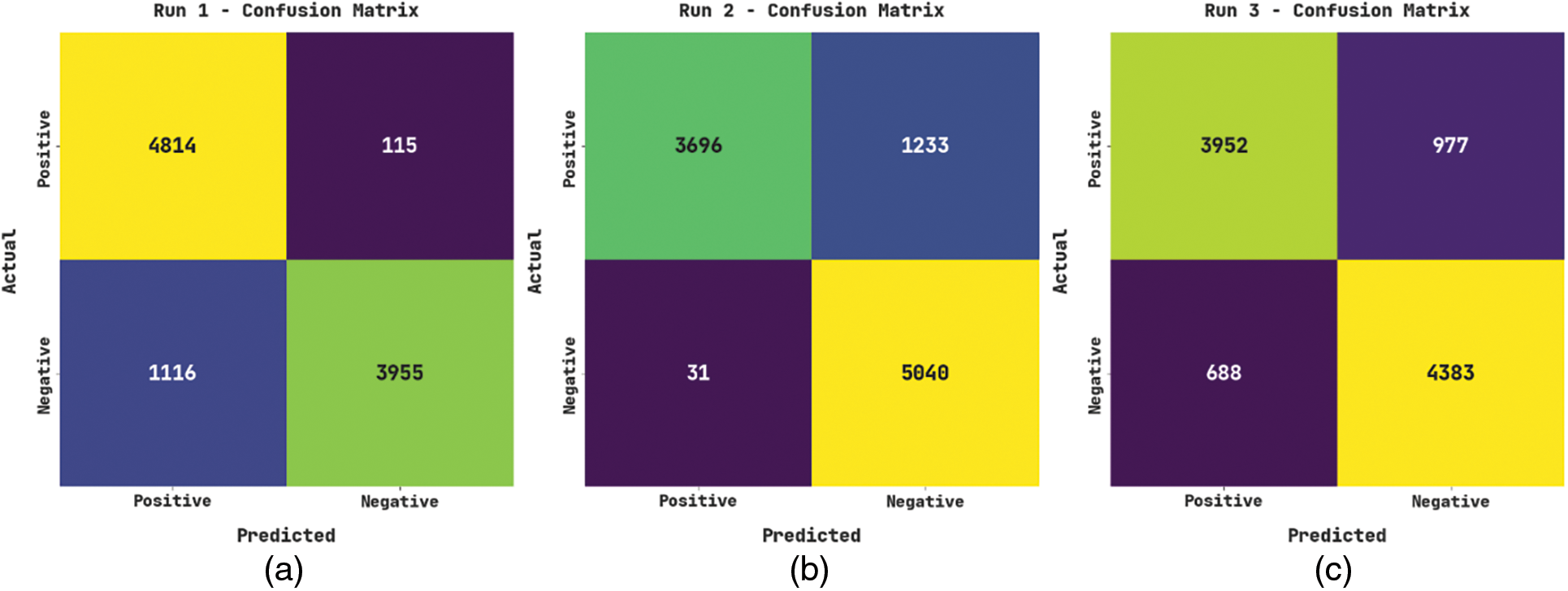
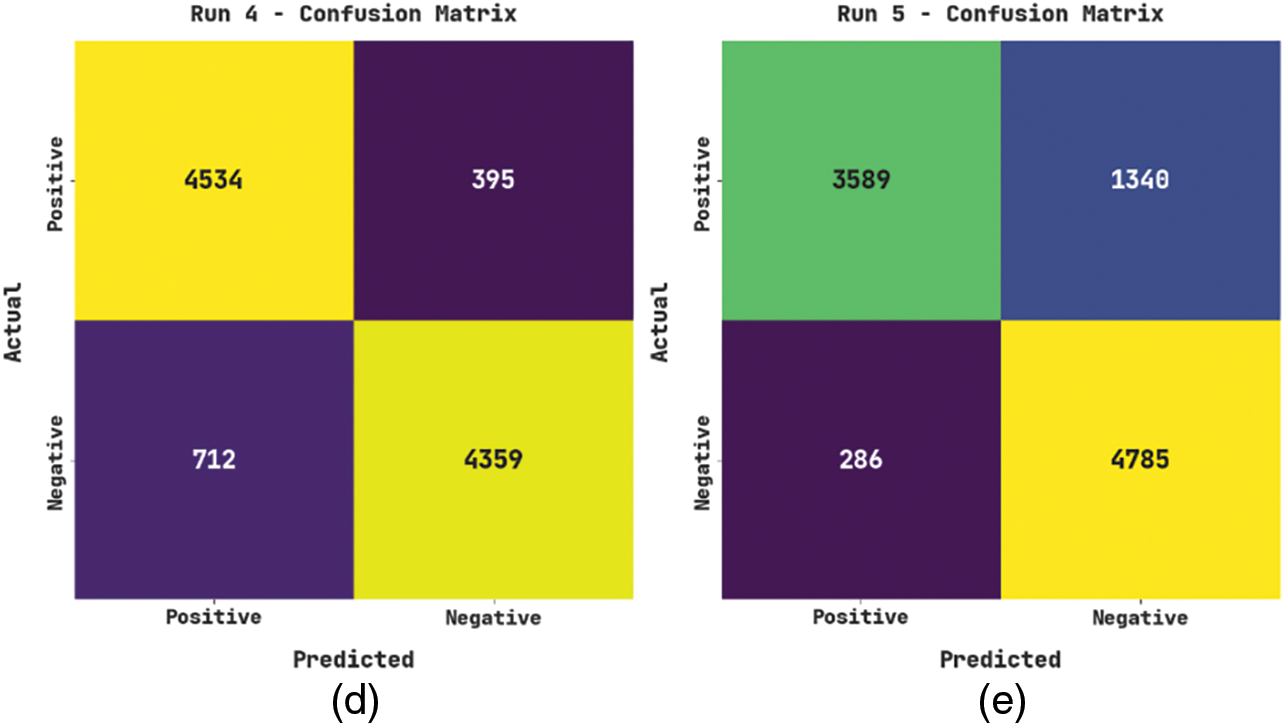
Figure 3: Confusion matrices of MSCADBN-MVC approach (a) Run1, (b) Run2, (c) Run3, (d) Run4, and (e) Run5
Table 2 provides overall classification outcomes of the MSCADBN-MVC model under five distinct runs. Fig. 4 reports a brief movie review classification results of the MSCADBN-MVC model under test run-1. The presented MSCADBN-MVC model has categorized positive movie reviews with
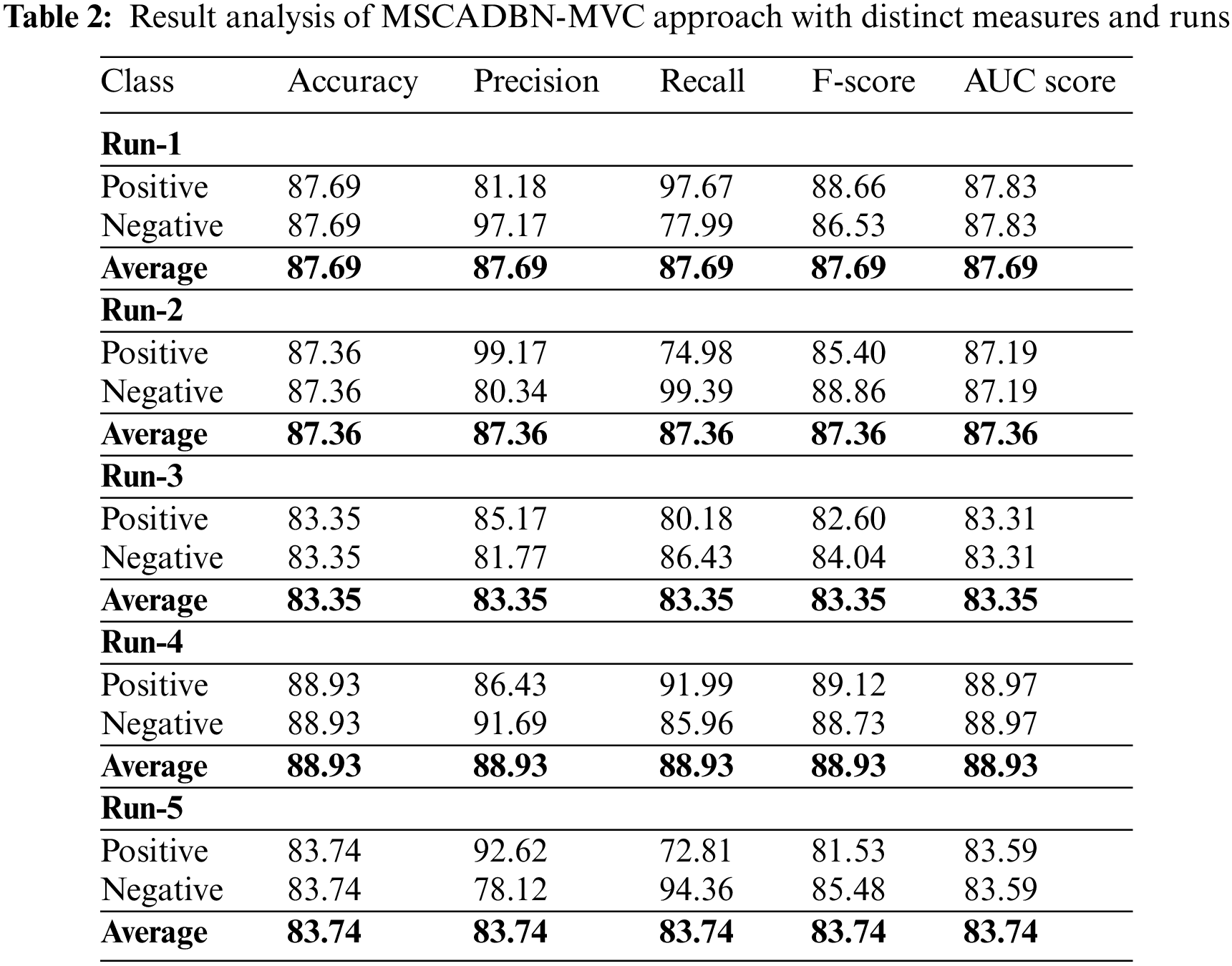
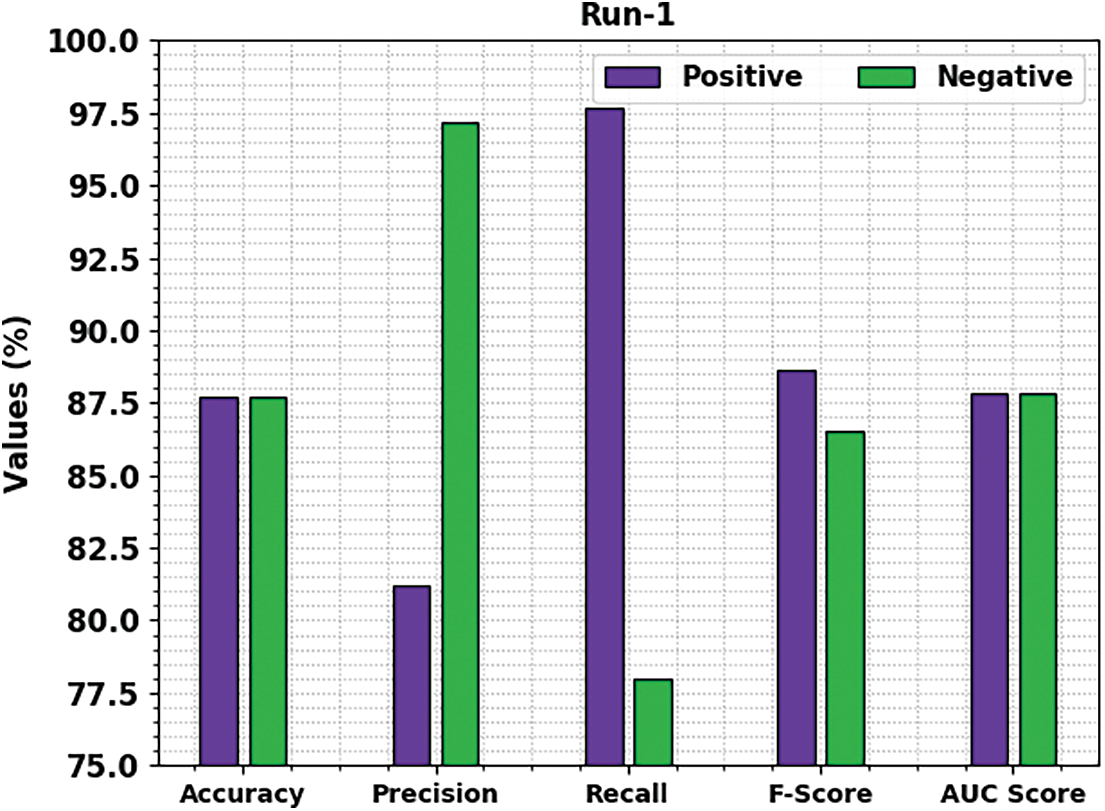
Figure 4: Result analysis of MSCADBN-MVC approach under Run-1
Fig. 5 reports a brief movie review classification results of the MSCADBN-MVC model under test run-2. The presented MSCADBN-MVC model has categorized positive movie reviews with
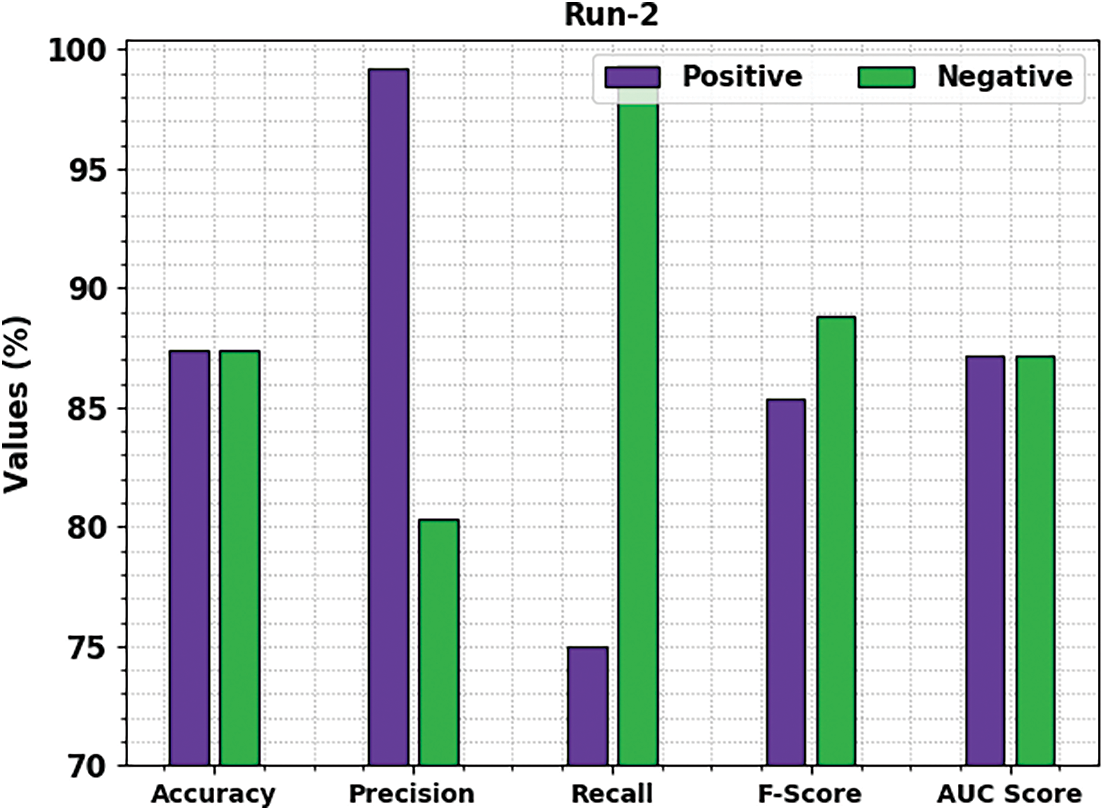
Figure 5: Result analysis of MSCADBN-MVC approach under Run-2
Fig. 6 reports a brief movie review classification results of the MSCADBN-MVC model under test run-3. The presented MSCADBN-MVC model has categorized positive movie reviews with
Figure 6: Result analysis of MSCADBN-MVC approach under Run-3
Fig. 7 reports a brief movie review classification results of the MSCADBN-MVC model under test run-4. The presented MSCADBN-MVC model has categorized positive movie reviews with
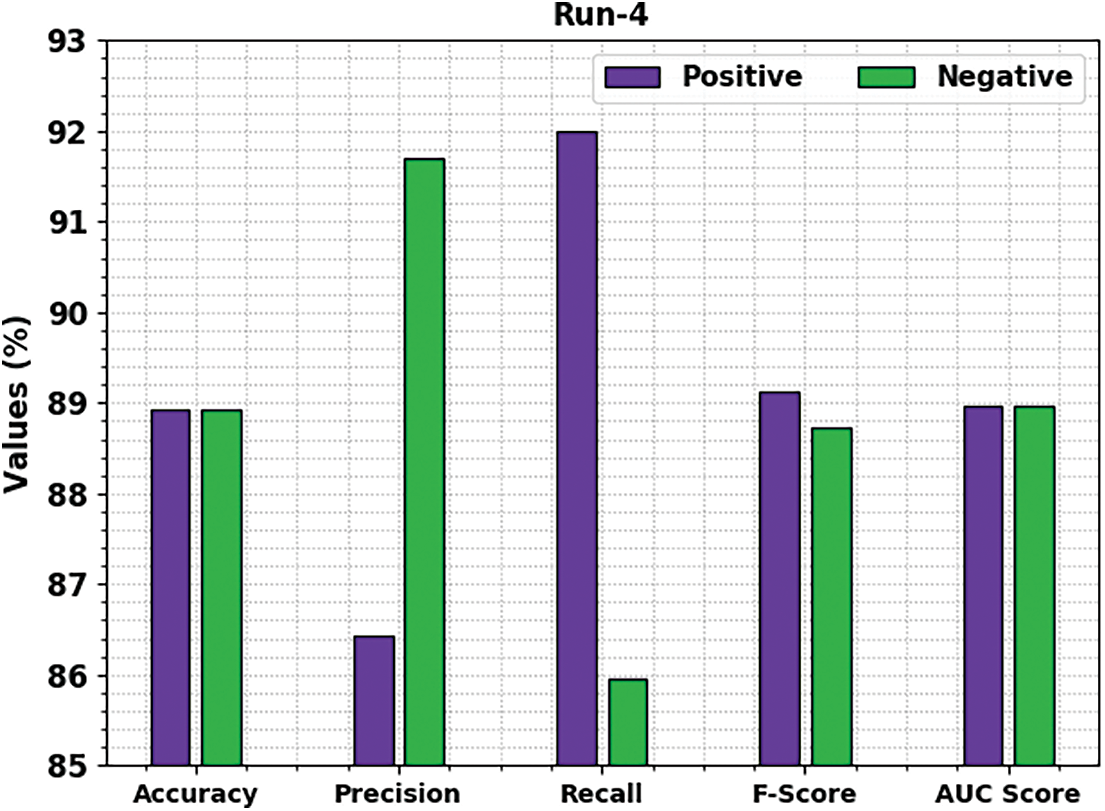
Figure 7: Result analysis of MSCADBN-MVC approach under Run-4
Fig. 8 reports a brief movie review classification results of the MSCADBN-MVC model under test run-5. The presented MSCADBN-MVC model has categorized positive movie reviews with
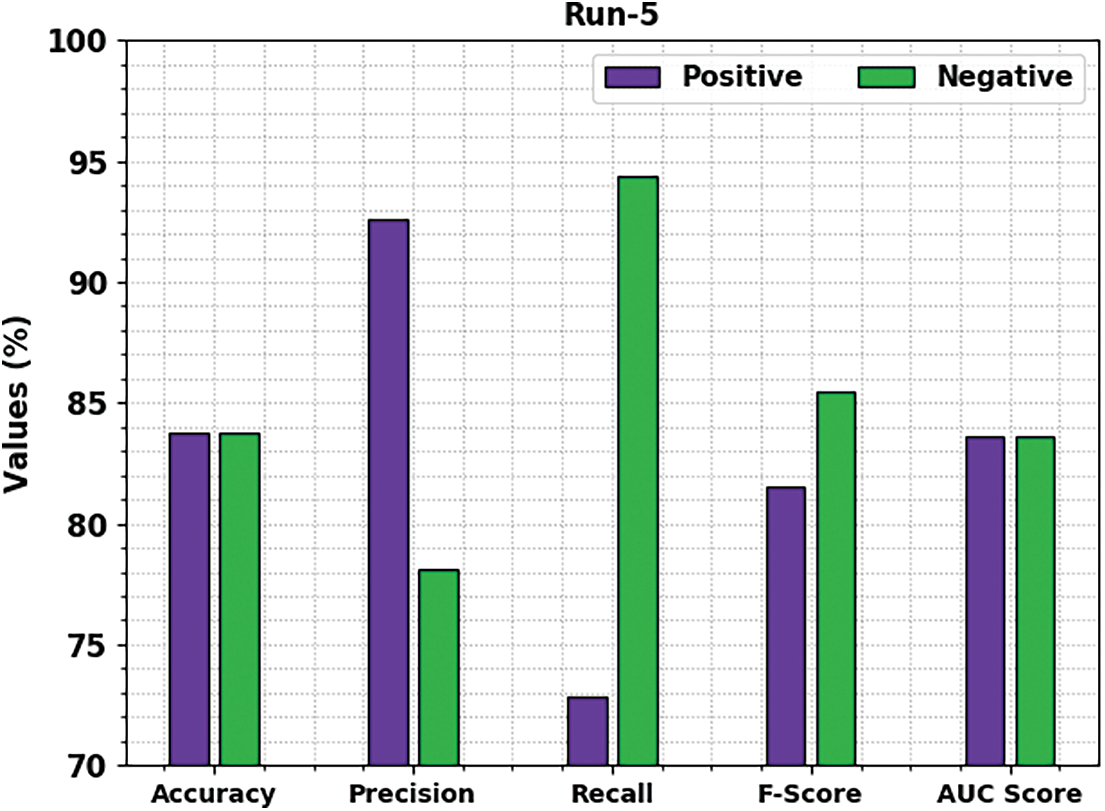
Figure 8: Result analysis of MSCADBN-MVC approach under Run-5
The training accuracy (TRA) and validation accuracy (VLA) acquired by the MSCADBN-MVC technique on test dataset is shown in Fig. 9. The experimental outcome implicit the MSCADBN-MVC algorithm has gained maximal values of TRA and VLA. Seemingly, the VLA is greater than TRA.
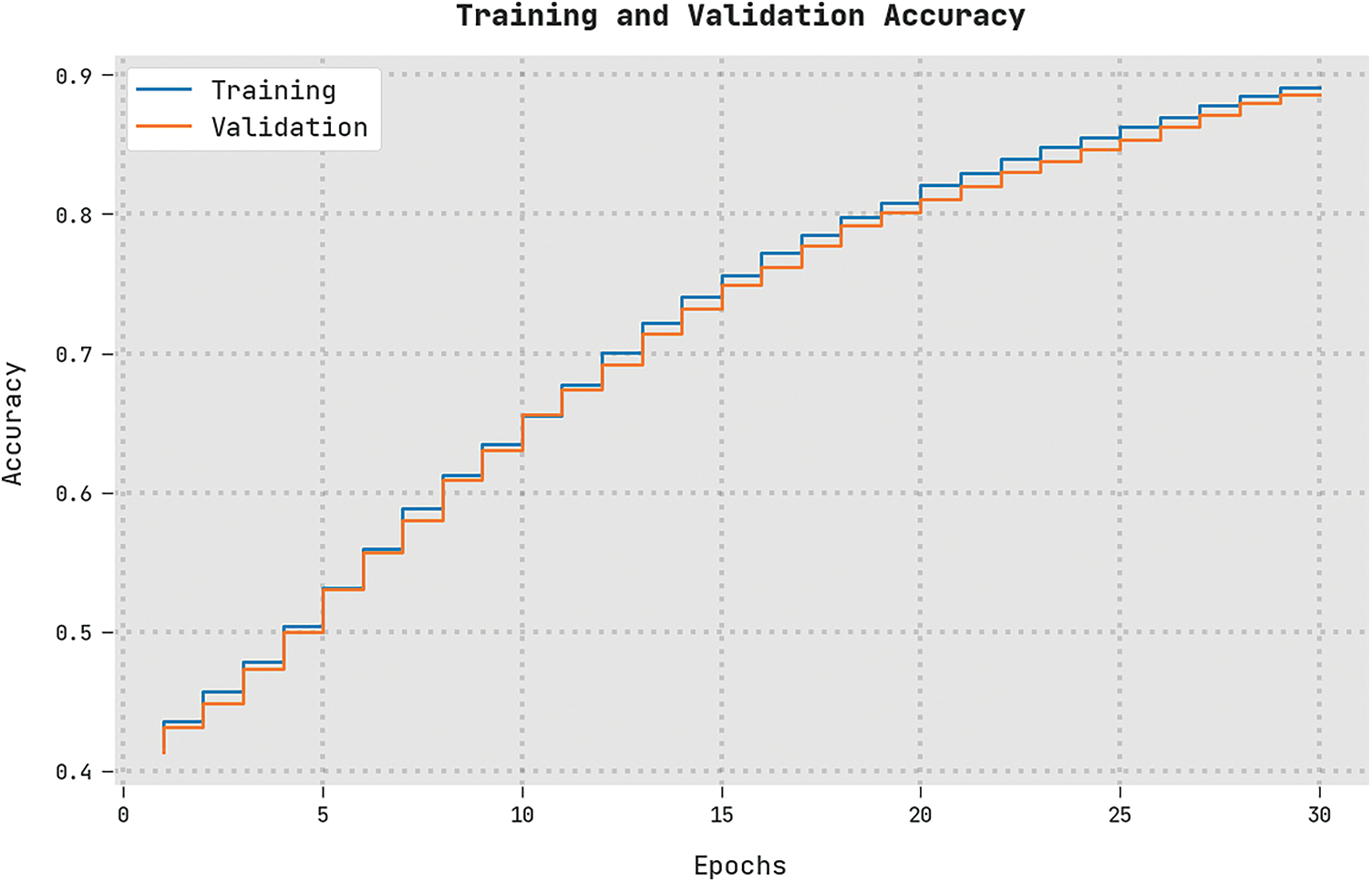
Figure 9: TRA and VLA analysis of MSCADBN-MVC approach
The training loss (TRL) and validation loss (VLL) gained by the MSCADBN-MVC technique on test dataset are exhibited in Fig. 10. The experimental outcome denoted the MSCADBN-MVC method has displayed least values of TRL and VLL. Particularly, the VLL is lesser than TRL.
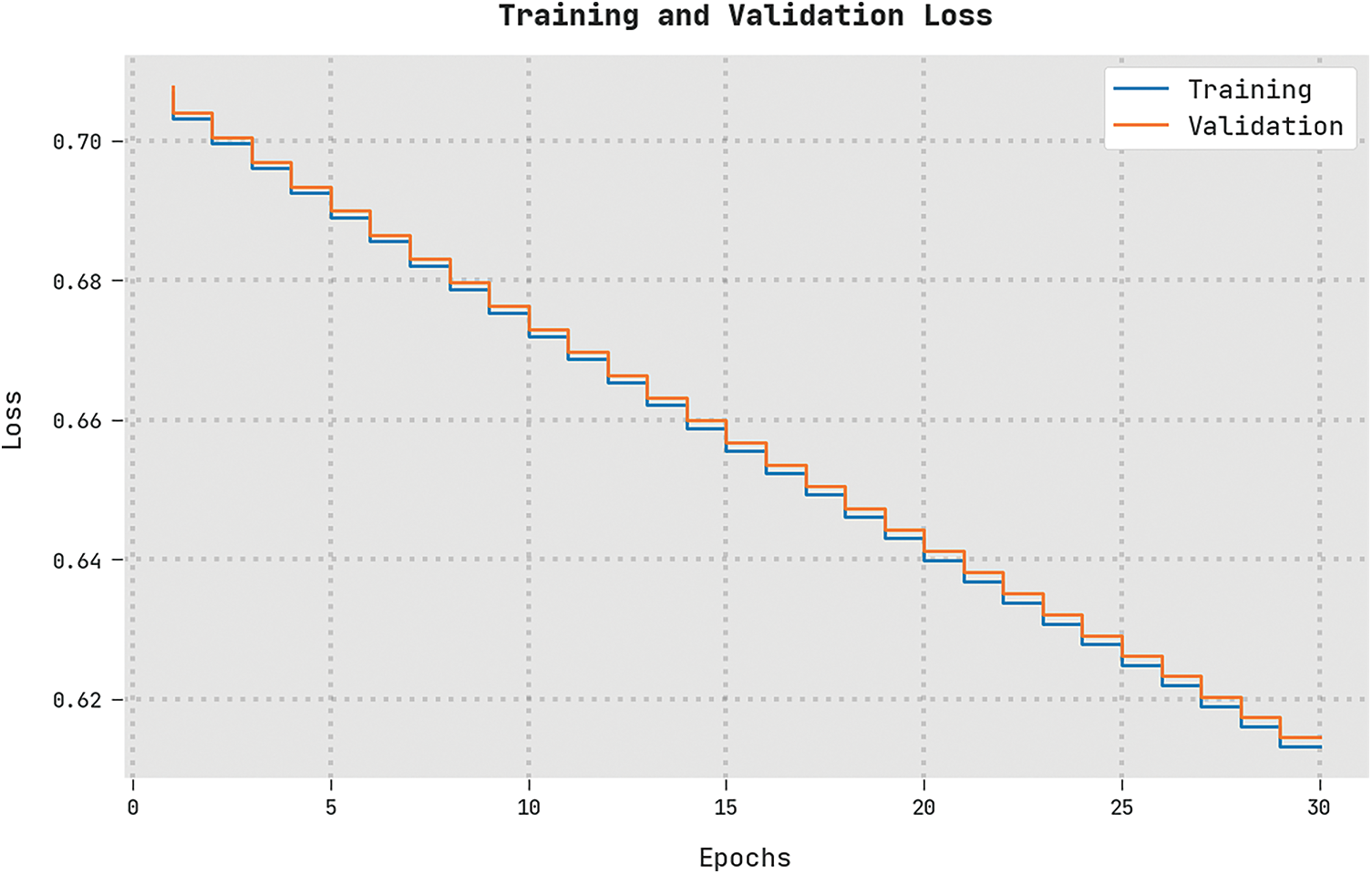
Figure 10: TRL and VLL analysis of MSCADBN-MVC approach
A clear precision-recall investigation of the MSCADBN-MVC algorithm on test dataset is represented in Fig. 11. The figure represented the MSCADBN-MVC approach has resulted in enhanced values of precision-recall values under all classes.
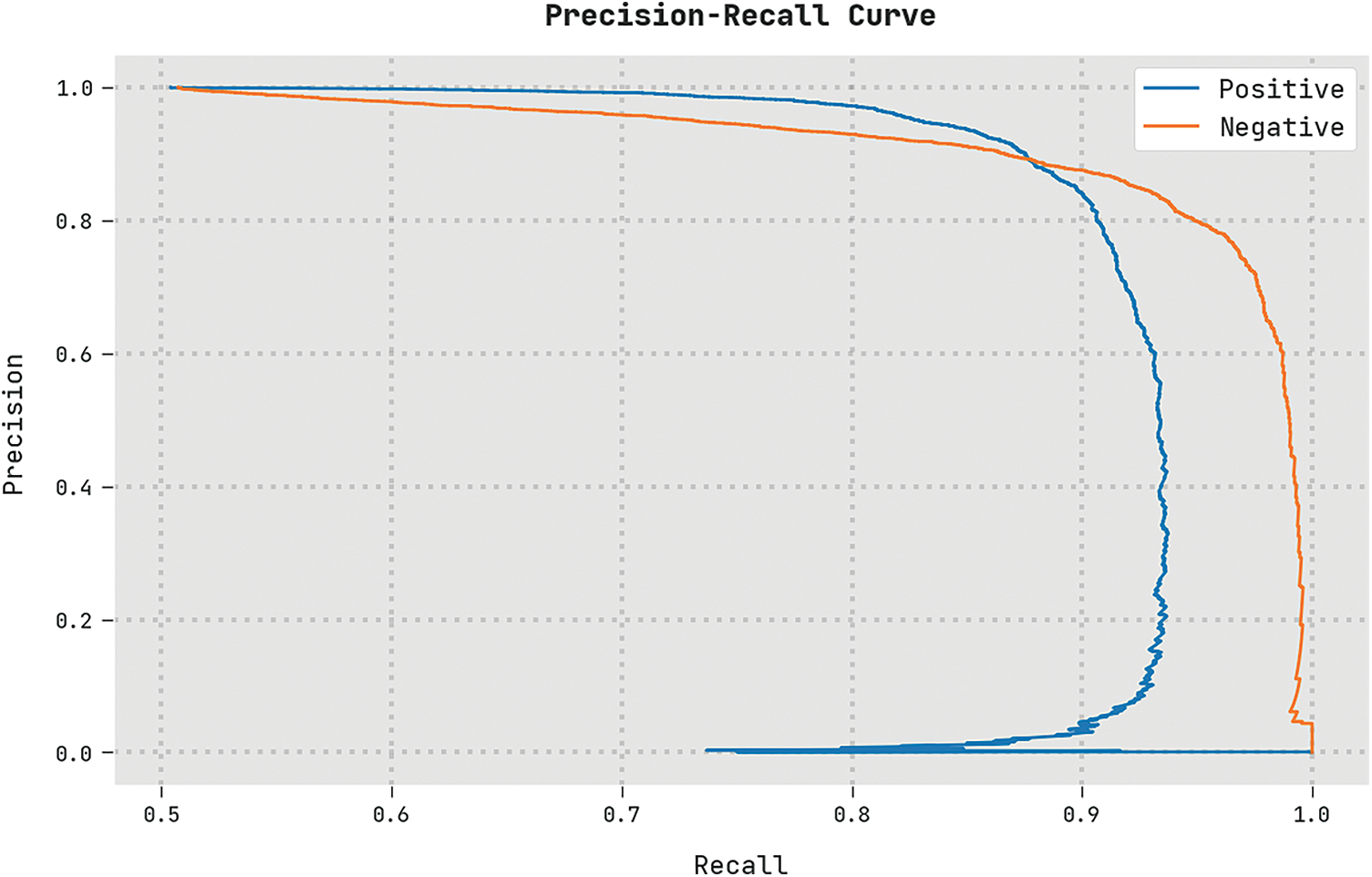
Figure 11: Precision-recall analysis of MSCADBN-MVC approach
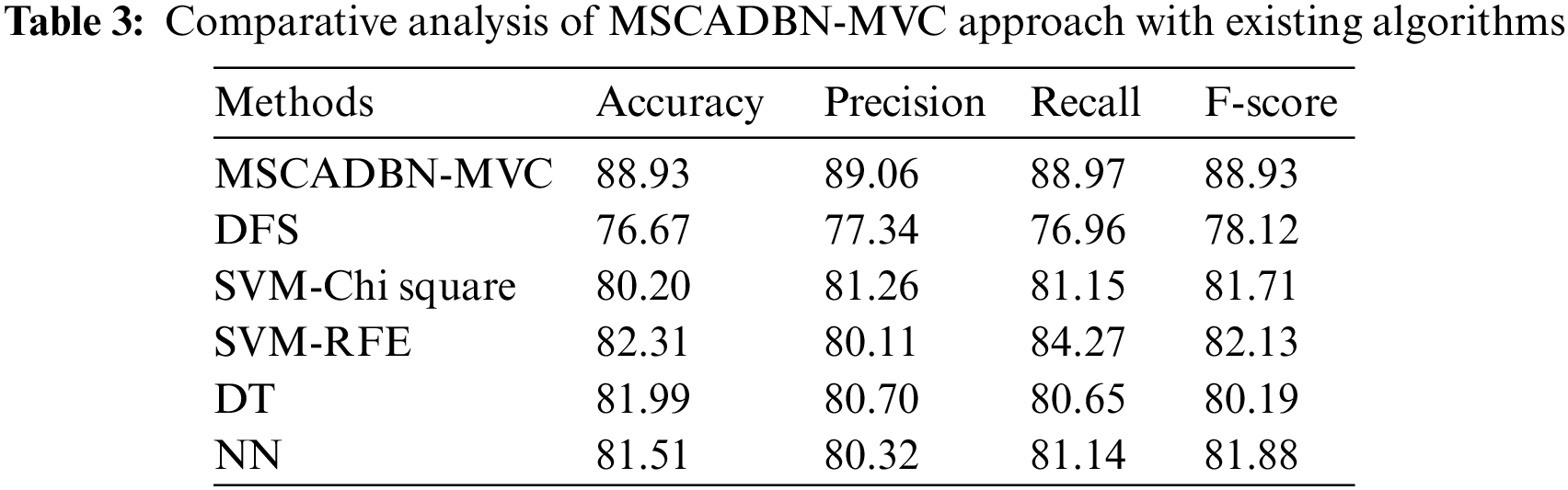
The movie review classification results of the MSCADBN-MVC model are compared with existing ML models in Table 3 [22]. The results implied that the MSCADBN-MVC model has shown enhanced outcomes over other models. Based on
In this study, a new MSCADBN-MVC technique has been developed for the identification and classification of movie reviews on social media. The major intention of the MSCADBN-MVC technique is focused on the identification of sentiments that exist in the movie review data. Primarily, the MSCADBN-MVC model follows data pre-processing and word2vec word embedding process. For the classification of sentiments exist in the movie reviews, the ADBN model is utilized in this work. At last, the hyperparameter tuning of the ADBN model is carried out using the MSCA technique, which integrates the LF concepts into the standard SCA. In order to demonstrate the significant performance of the MSCADBN-MVC model, a wide ranging experimental analysis is performed on three different datasets. The comprehensive study highlighted the enhancements of the MSCADBN-MVC model in movie review classification process. In future, the performance of the MSCADBN-MVC model can be boosted using advanced DL models.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R281), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4320484DSR08).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. B. L. Devi, V. V. Bai, S. Ramasubbareddy and K. Govinda, “Sentiment analysis on movie reviews,” in Emerging Research in Data Engineering Systems and Computer Communications, Advances in Intelligent Systems and Computing, vol. 1054, Singapore: Springer, pp. 321–328, 2020. [Google Scholar]
2. M. Y. A. Salmony and A. R. Faridi, “Bert distillation to enhance the performance of machine learning models for sentiment analysis on movie review data,” in 2022 9th Int. Conf. on Computing for Sustainable Global Development (INDIACom), New Delhi, India, pp. 400–405, 2022. [Google Scholar]
3. A. S. Abdullah, K. Akash, J. S. Thres and S. Selvakumar, “Sentiment analysis of movie reviews using support vector machine classifier with linear kernel function,” in Evolution in Computational Intelligence, Advances in Intelligent Systems and Computing Book Series, vol. 1176, Singapore: Springer, pp. 345–354, 2021. [Google Scholar]
4. M. Yasen and S. Tedmori, “Movies reviews sentiment analysis and classification,” in 2019 IEEE Jordan Int. Joint Conf. on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, pp. 860–865, 2019. [Google Scholar]
5. R. Maulana, P. A. Rahayuningsih, W. Irmayani, D. Saputra and W. E. Jayanti, “Improved accuracy of sentiment analysis movie review using support vector machine based information gain,” Journal of Physics: Conference Series, vol. 1641, no. 1, pp. 012060, 2020. [Google Scholar]
6. M. Hossen and N. R. Dev, “An improved lexicon based model for efficient sentiment analysis on movie review data,” Wireless Personal Communications, vol. 120, no. 1, pp. 535–544, 2021. [Google Scholar]
7. N. O. F. Daeli and A. Adiwijaya, “Sentiment analysis on movie reviews using information gain and K-nearest neighbor,” Journal of Data Science and Its Applications, vol. 3, no. 1, pp. 1–7, 2020. [Google Scholar]
8. N. M. Ali, M. M. A. E. Hamid and A. Youssif, “Sentiment analysis for movies reviews dataset using deep learning models,” International Journal of Data Mining & Knowledge Management Process, vol. 9, no. 2/3, pp. 21–27, 2019. [Google Scholar]
9. R. S. Kumar, A. F. S. Devaraj, M. Rajeswari, E. G. Julie, Y. H. Robinson et al., “Exploration of sentiment analysis and legitimate artistry for opinion mining,” Multimedia Tools and Applications, vol. 81, no. 9, pp. 11989–12004, 2022. [Google Scholar]
10. S. Onalaja, E. Romero and B. Yun, “Aspect-based sentiment analysis of movie reviews,” SMU Data Science Review, vol. 5, no. 3, pp. 10, 2021. [Google Scholar]
11. A. U. Rehman, A. K. Malik, B. Raza and W. Ali, “A hybrid CNN-LSTM model for improving accuracy of movie reviews sentiment analysis,” Multimedia Tools and Applications, vol. 78, no. 18, pp. 26597–26613, 2019. [Google Scholar]
12. Z. Abidin, W. Destian and R. Umer, “Combining support vector machine with radial basis function kernel and information gain for sentiment analysis of movie reviews,” Journal of Physics: Conference Series, vol. 1918, no. 4, pp. 042157, 2021. [Google Scholar]
13. J. D. Bodapati, N. Veeranjaneyulu and S. Shaik, “Sentiment analysis from movie reviews using lstms,” Ingenierie des Systemes D’Information, vol. 24, no. 1, pp. 125–129, 2019. [Google Scholar]
14. K. K. Ullah, A. Rashad, M. Khan, Y. Ghadi, H. Aljuaid et al. “A deep neural network-based approach for sentiment analysis of movie reviews,” Complexity, vol. 2022, pp. 1–9, 2022. [Google Scholar]
15. N. G. Ramadhan and T. I. Ramadhan, “Analysis sentiment based on imdb aspects from movie reviews using svm,” Sinkron: Jurnal dan Penelitian Teknik Informatika, vol. 7, no. 1, pp. 39–45, 2022. [Google Scholar]
16. S. M. Qaisar, “Sentiment analysis of imdb movie reviews using long short-term memory,” in 2nd Int. Conf. on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, pp. 1–4, 2020. [Google Scholar]
17. D. D. Tran, T. T. S. Nguyen and T. H. C. Dao, “Sentiment analysis of movie reviews using machine learning techniques,” in Proc. of Sixth Int. Congress on Information and Communication Technology, Lecture Notes in Networks and Systems Book Series, Singapore, Springer, vol. 235, pp. 361–369, 2022. [Google Scholar]
18. S. H. Kumhar, M. M. Kirmani, J. Sheetlani and M. Hassan, “Word embedding generation for Urdu language using word2vec model,” Materials Today: Proceedings, pp. S2214785320394426, 2021. https://doi.org/10.1016/j.matpr.2020.11.766 [Google Scholar] [CrossRef]
19. J. Xie, G. Du, C. Shen, N. Chen, L. Chen et al., “An end-to-end model based on improved adaptive deep belief network and its application to bearing fault diagnosis,” IEEE Access, vol. 6, pp. 63584–63596, 2018. [Google Scholar]
20. A. B. S. Yıldız, N. Pholdee, S. Bureerat, A. R. Yıldız and S. M. Sait, “Sine-cosine optimization algorithm for the conceptual design of automobile components,” Materials Testing, vol. 62, no. 7, pp. 744–748, 2020. [Google Scholar]
21. M. A. Elaziz, A. Mabrouk, A. Dahou and S. A. Chelloug, “Medical image classification utilizing ensemble learning and levy flight-based honey badger algorithm on 6G-enabled internet of things,” Computational Intelligence and Neuroscience, vol. 2022, pp. 1–17, 2022. [Google Scholar]
22. N. S. M. Nafis and S. Awang, “An enhanced hybrid feature selection technique using term frequency-inverse document frequency and support vector machine-recursive feature elimination for sentiment classification,” IEEE Access, vol. 9, pp. 52177–52192, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools