
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

P&T-Inf: A Result Inference Method for Context-Sensitive Tasks in Crowdsourcing
1 School of Computer Science and Engineering, Central South University, Changsha, 410075, China
2 Glasgow Caledonian University, Glasgow, G4 0BA, UK
* Corresponding Author: Yan Zhang. Email:
Intelligent Automation & Soft Computing 2023, 37(1), 599-618. https://doi.org/10.32604/iasc.2023.036794
Received 12 October 2022; Accepted 06 January 2023; Issue published 29 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Context-Sensitive Task (CST) is a complex task type in crowdsourcing, such as handwriting recognition, route plan, and audio transcription. The current result inference algorithms can perform well in simple crowdsourcing tasks, but cannot obtain high-quality inference results for CSTs. The conventional method to solve CSTs is to divide a CST into multiple independent simple subtasks for crowdsourcing, but this method ignores the context correlation among subtasks and reduces the quality of result inference. To solve this problem, we propose a result inference algorithm based on the Partially ordered set and Tree augmented naive Bayes Infer (P&T-Inf) for CSTs. Firstly, we screen the candidate results of context-sensitive tasks based on the partially ordered set. If there are parallel candidate sets, the conditional mutual information among subtasks containing context information in external knowledge (such as Google n-gram corpus, American Contemporary English corpus, etc.) will be calculated. Combined with the tree augmented naive (TAN) Bayes model, the maximum weighted spanning tree is used to model the dependencies among subtasks in each CST. We collect two crowdsourcing datasets of handwriting recognition tasks and audio transcription tasks from the real crowdsourcing platform. The experimental results show that our approach improves the quality of result inference in CSTs and reduces the time cost compared with the latest methods.Keywords
Crowdsourcing is a process of publishing tasks that are difficult for machines but easy for humans to handle to the Internet, openly recruiting unknown crowds, and leveraging the collective wisdom of crowds to solve similar problems. At present, crowdsourcing has been successfully applied in different fields, such as privacy protection [1], social networks [2], data management [3], software testing [4], etc. The core problem of quality control in crowdsourcing is to infer high-quality results from noisy workers’ answers. In crowdsourcing tasks, Context-Sensitive Task (CST) [5] is a complex task composed of a group of context-related simple subtasks. For example, in handwriting recognition tasks, each handwritten sentence recognition task is composed of many handwritten word recognition subtasks, and words in the sentence are context-related. The current result inference algorithms can be divided into two types according to task granularity: Task-Inf [6] and Subtask-Inf [7]. Task-Inf assigns each task to multiple workers and then infers results by machine learning or group voting [8]. Subtask-Inf divides complex tasks into several subtasks, crowdsources subtasks, infers the results of each subtask by task-level reasoning, and summarizes the optimal results of each subtask to generate the final answer to complex tasks [9].
For crowdsourcing quality control, both types of methods mentioned above are not suitable for CSTs [9]. Firstly, it is quite difficult to answer a complex CST completely and correctly. Therefore, the Task-Inf methods cannot obtain high-quality results by inferring workers’ answer aggregation. Secondly, a CST cannot be directly split into multiple independent subtasks, because subtasks are interrelated in a specific context [5,9–11]. For example, the handwriting recognition task shown in Fig. 1 is to recognize the handwritten sentence “President Kennedy flew from London Airport last night to arrive in Washington this morning”. Individual subtask t9 is difficult to identify, but if workers consider the results of subtasks t3~t5 are “from London Airport”, it is easy to infer the results of subtasks t8~t9 are “to arrive”. Subtask-Inf methods ignore the correlation among subtasks, which will reduce the quality of result inference.

Figure 1: A handwriting recognition task
To solve the above problems in CSTs, we propose a novel algorithm based on the Partially ordered set and Tree augmented naive Bayes Infer (P&T-Inf).
The main contributions of the paper are as follows:
1. We construct a CST dependency tree combined with the context information in external knowledge to model the context correlation of CSTs.
2. We propose a probabilistic model based on tree augmented naive Bayes to describe the crowdsourcing process of CSTs.
3. We design a context-related result inference method P&T-Inf based on the partially ordered set and tree augmented naive (TAN) Bayes for CSTs.
4. We evaluate our method on the crowdsourcing platform Appen. The experimental results demonstrate that compared with the latest methods, our method can effectively improve the quality of CST results with a lower time complexity.
In general, the quality of crowdsourcing mainly depends on the quality of results inferred from the noisy results provided by workers. The result inference algorithms of crowdsourcing tasks can be divided into two types according to task granularity: Task-inf and Subtask-Inf.
Task-Inf algorithms assign each task to multiple workers and then infer the results using machine learning or group voting [12]. For example, Zhang J analyzed the classical algorithms of DS, GLAD [13], RY [14], and ZenRow [15] based on expectation maximization (EM). They analyzed the performance differences of these four algorithms and proposed a non-expectation maximization (non-EM) adaptive weighted majority voting algorithm. It is quite difficult to answer a complex CST completely and correctly, so Task-inf algorithms cannot obtain high-quality results.
Subtask-Inf algorithms divide complex tasks into several subtasks, crowdsource subtasks independently, and then summarize the optimal results of subtasks to generate the final answer to complex tasks [16]. For example, Tran Thanh [17] proposed a Find-Fix-Verify (FFV) workflow for crowdsourcing tasks. The workflow is used to correct and shorten text in a three-step strategy. Different groups of workers are involved in three steps. The ‘Find’ step identified some mistakes in sentences and the ‘Fix’ step fixed these mistakes. Finally, the ‘Verify’ step verified these mistakes and aggregated the results. Because subtasks are interrelated in a specific context, a CST should not be directly divided into multiple independent subtasks, and Subtask-Inf algorithms are not suitable for the result inference in CSTs.
Sun [5] proposed the concept of CST, and the Context-Inf algorithm in the latest study [9] combined Hidden Markov Model (HMM) with Maximum Likelihood Estimation (MLE) algorithm and EM algorithm to infer results. Context-Inf assumes that the ground truth of a CST is a series of unobservable hidden state sequences in HMM, and the collected workers’ answers are HMM observable sequences. The context correlation information among subtasks determines the transition probability of HMM hidden state. The workers’ answer similarity is calculated for the output probability of HMM. HMM assumes that subtasks in CSTs are a series of sequential adjacent correlation, and the probability distribution of the ground truth of the next subtask in the crowdsourcing model can only be determined by the ground truth of the current subtask. However, subtasks in CSTs in reality do not necessarily have sequential adjacent correlation, but more complex correlation models.
Aiming at the problem that subtasks in CSTs do not have necessarily sequential adjacent correlation, which leads to certain defects in the result inference, we propose a context correlation result inference algorithm P&T-Inf. Firstly, we construct worker output matrices and screen the candidate output results based on the partially ordered set. Then we combine the external knowledge and tree augmented naive Bayes to model the context correlation of CSTs. Finally, we infer the results combined with the probabilistic model, which improves the accuracy of result inference and reduces the time cost.
P&T-Inf algorithm flow is shown in Fig. 2, which is divided into four main steps.
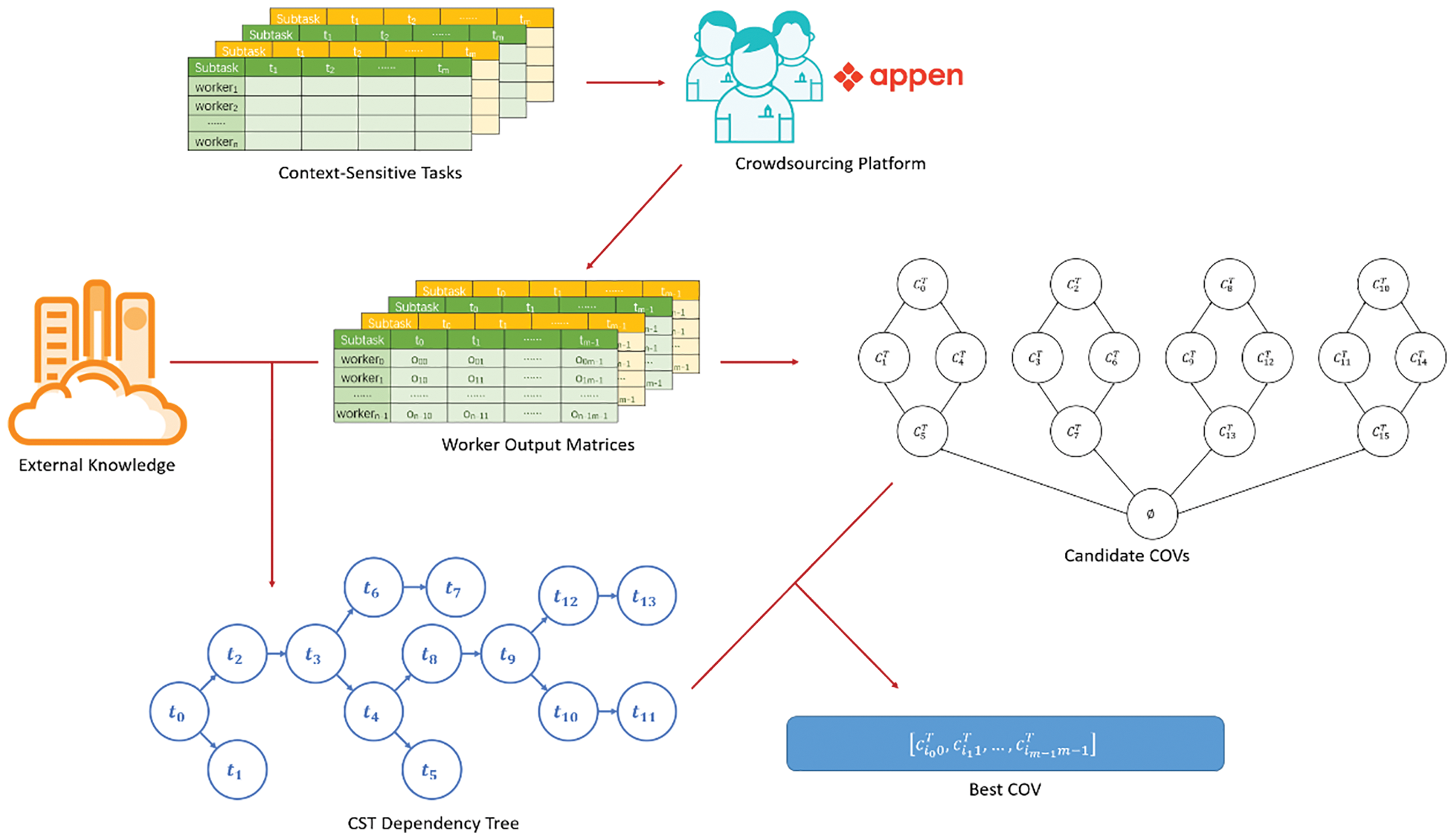
Figure 2: P&T-Inf algorithm flow
Step 1: Publish tasks and collect answers. Independent subtasks lose context-sensitive information, so we publish the CST as a whole to the crowdsourcing platform. Each CST is answered by multiple workers. A CST can be divided into multiple context-related subtasks. For example, we can split the handwriting recognition task into context-related recognition subtasks, workers can selectively identify these subtasks (i.e., certain words in the sentence). The crowdsourcing platform is responsible for issuing CSTs, collecting worker answers, and then constructing worker output matrices according to the division of subtasks.
Step 2: Filter candidate results. The workers’ answers for each subtask are extracted, arranged, and combined without repeated to obtain all possible candidate results, and then the candidate results are filtered based on the partially ordered set.
Step 3: Model context correlation. Based on TAN, each subtask is regarded as an attribute of the CST. Combined with the context information in external knowledge, the conditional mutual information between any two attributes of the CST is calculated. The CST dependency tree is constructed to model the CST context correlation in CSTs.
Step 4: Infer results. A probabilistic model is established to describe the crowdsourcing process of subtasks in CSTs, combined with the CST dependency tree into MLE and EM to infer the results.
3.1 Publish Tasks and Collect Answers
A CST contains multiple subtasks, which are related to each other in a specific context. If these subtasks of a CST are split and crowdsourced separately, the context information will be lost, making it more difficult for workers to identify. We publish the CST as a whole to the crowdsourcing platform. Each CST is answered by multiple workers, and finally, collect the answers of workers. The formulaic definitions of the result inference problem in the P&T-Inf algorithm are as follows:
Definition 1: Worker Output Matrix. As shown in Fig. 3, suppose the CST

Figure 3: Worker output matrix
Definition 2: Candidate Output Vector. As shown in Fig. 3, for output vector
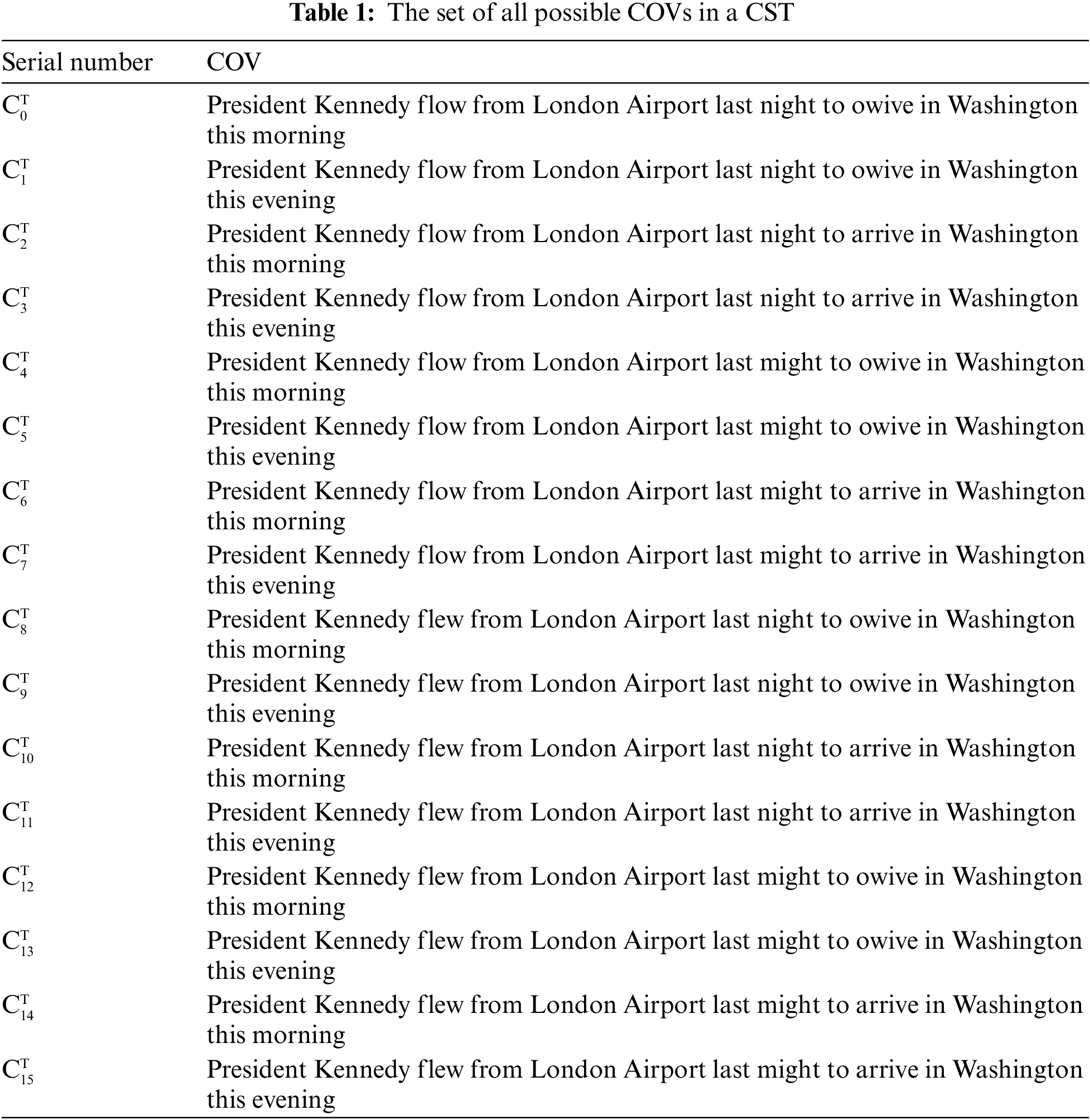
The number of COVs of CST
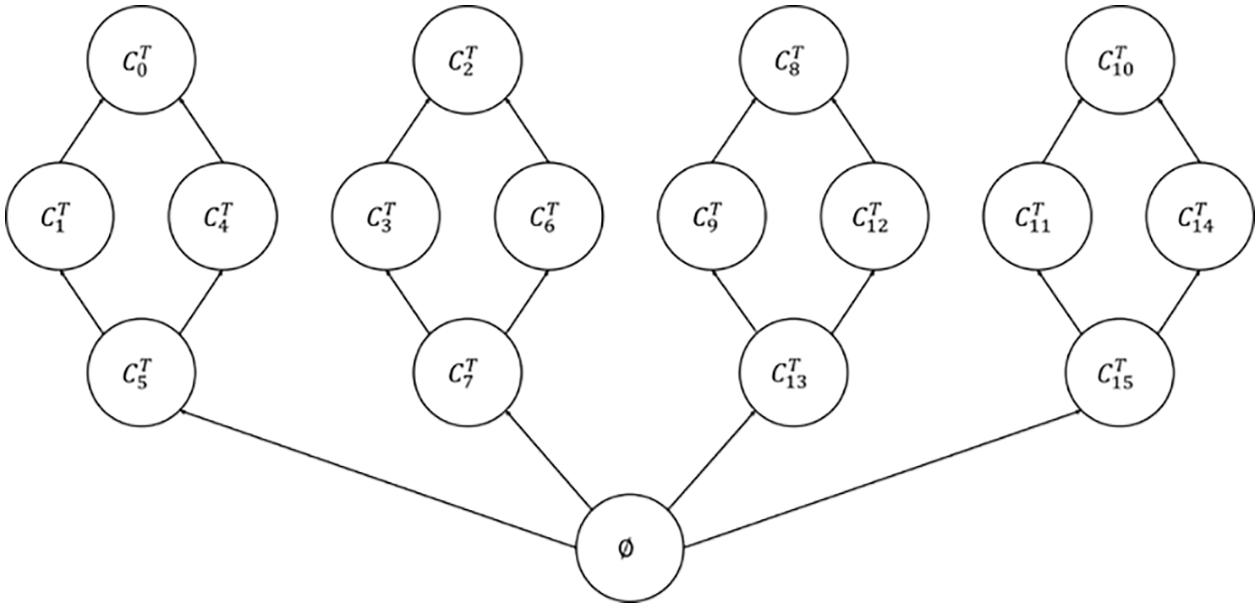
Figure 4: The COV Hasse
The COV partially ordered relationship is sorted from bottom to top and from small to large in Fig. 4. We screen out the four largest COVs,
The TAN Bayes classifier is a semi-naive Bayes classifier of “One-Dependent Estimator” (ODE). TAN is suitable for extracting strong correlation information in the CST context. We regard each subtask as an attribute of the CST, and design a TAN-based context-correlation modeling algorithm for CSTs. The algorithm flow is as follows:
1. For CST T, the formula for calculating the conditional mutual information (CMI) between any two subtasks is as follows:
where
2.
3. A complete graph is constructed with subtasks as nodes, and the weight of edges between any two nodes is set to
4. For each edge
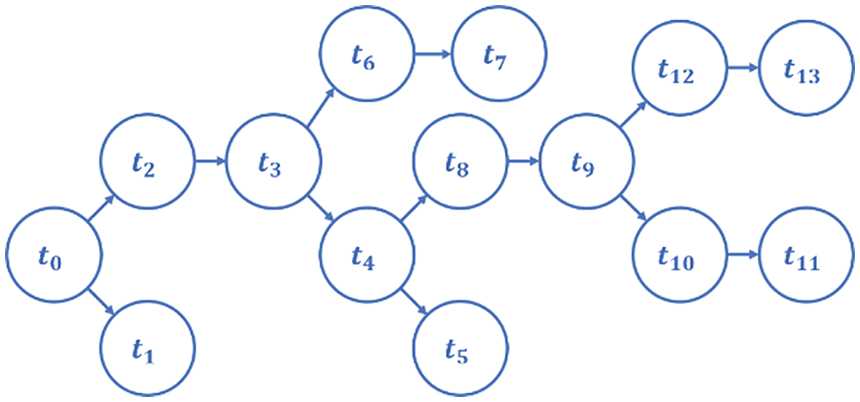
Figure 5: The CST dependency tree
It is easy to find that conditional mutual information
3.4.1 A Crowdsourcing Probabilistic Model for Subtasks
Inspired by Sun et al. [9], we propose a crowdsourcing probabilistic model for subtasks in CSTs. As shown in Fig. 6, for CST T, the output
1.
2.
3.
4.
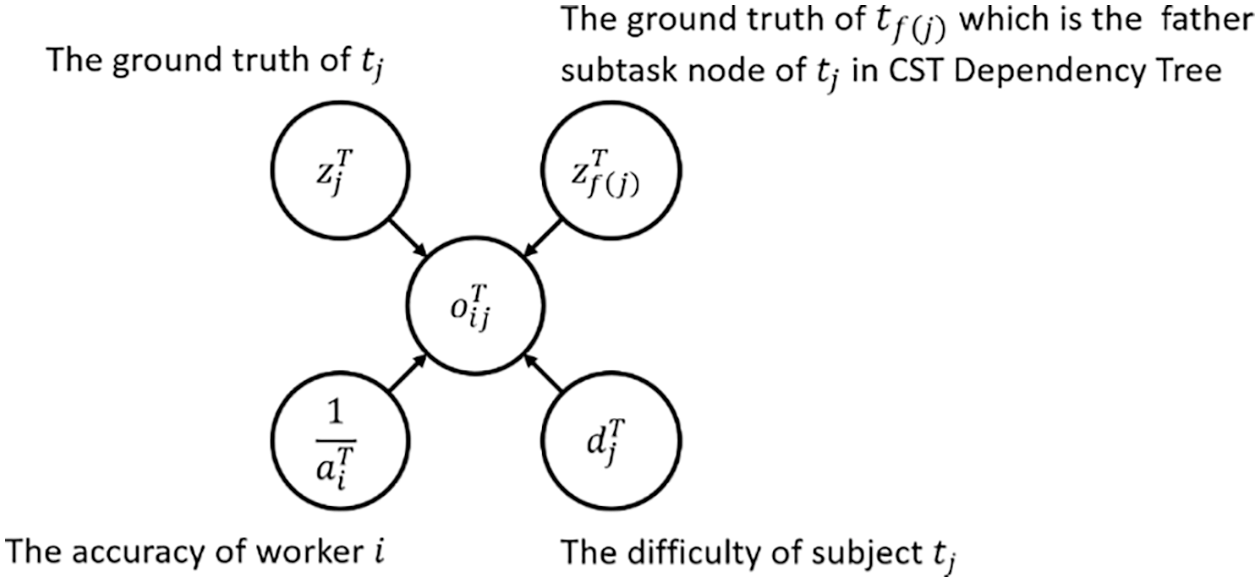
Figure 6: The crowdsourcing probabilistic model for subtask
Assuming that
where
Formula (5) is the normalized correlation degree of
Assuming that
where
Formula (8) represents the normalized error rate of the wrong answer
Define
Formula (9) indicates the conditional probability when
We treat each COV in the largest COV set
The posterior probability that the category of CST
The result inference problem of CSTs has been transformed into the problem of identifying the optimal COV from the set
The TAN inference process includes two parameter sets, namely the reciprocal parameter set of the accuracy of workers
1. Use the MLE algorithm to learn
According to Formula (13), the joint log-likelihood function of all GSTs is:
To maximize
Different from GSTs, the EM algorithm is difficult to learn the real accuracy of workers from general tasks, and the accuracy of workers is relatively stable.
2. Use the EM algorithm to learn
Formula (17) can be derived from Formulas (9)–(11).
M-step (Maximization). We find the parameter to maximize the expected likelihood, namely:
Like the MLE algorithm, we can also use the gradient ascent method to differentiate
We do a two-step alternation calculation until it converges to a locally optimal solution by the EM algorithm.
Through the obtained parameter sets
The experiments contain two datasets, which are described as follows.
Handwriting recognition. The IAM Handwriting English Database [18] was established by the Computer Vision and Artificial Intelligence Research Group of the University of Bern, Switzerland. The handwritten text dataset contains about 1539 pages, 5685 isolated sentences, and 110,000 words samples by 657 authors. The dataset is publicly available for free. This paper randomly selects 150 sentence samples from the IAM handwritten English picture database. We make sure that each sentence contains 15–20 words and then re-cut and splice the new-line sentences in the original image so that each sentence is displayed on one line. We publish these images to be identified as independent crowdsourcing tasks on the crowdsourcing platform Appen. The cost of each task is one cent. There are ten tasks in a group, and each group has at least one GST published to the crowdsourcing workers. Each task is answered by at least 5 workers with level 3 quality, and finally, a crowdsourced dataset of handwriting recognition tasks is obtained.
Audio transcription. LibriSpeech English Speech Corpus [19] is a collection of audiobooks of the LibriVox project [20], suitable for training and evaluating speech recognition systems. LibriSpeech contains 1000 hours of speech sampled at 16 kHz. We cut and sort into audio files of about 10 s each, which have been marked with text. Similar to the handwriting recognition dataset, we randomly select 150 speech samples from the LibriSpeech English Speech Corpus. Each speech contains 15–25 words. Then, we post the transcriptions of these speeches as independent crowdsourcing tasks on Appen. The cost of each task is two cents. Five tasks are a group. Each group has at least one GST released to the crowdsourcing workers. Each task is answered by at least 5 workers with level 3 quality, and finally, the crowdsourced dataset of audio transcription tasks is obtained.
To better evaluate the P&T-Inf algorithm, we select Bayes-Inf and Context-Inf which are the latest result inference algorithms for CSTs [9] and MWK which is the latest result inference algorithm with external knowledge [21] for comparisons. The differences between them are that Bayes-Inf does not introduce context information in the inference process, Context-Inf introduces context information between adjacent subtasks in the inference process, and MWK introduces context information among all subtasks, but the task difficulty is not considered.
Experiments mainly verify the performance of algorithms from the accuracy and the time cost. The evaluation indexes are as follows:
(1) CST Accuracy rate (A):
In Formula (20),
(2) CST Improvement rate (I):
In Formula (21),
(3) Accuracy Effective Improvement of CST (AEI):
In Formula (22),
(4) CST Average Time (AT):
In Formula (23), Time represents the function to calculate the running time for CSTs. The time cost of the same algorithm for different CSTs is roughly the same. AT can evaluate the average time cost of each algorithm for CSTs.
4.3 Experimental Results Analysis
4.3.1 Experiment 1: Comparison of the Accuracy of Algorithms that Introduce Context Information
Experiment 1 verified the effect of introducing context information into result inference algorithms for CSTs. The experiment selected two algorithms P&T-Inf and Bayes-Inf as a comparison. Both Bayes-Inf and P&T-Inf algorithms are EM iterative calculation algorithms, but the latter introduces contextual information in the inference process, while the former does not. Fig. 7 shows the A index curves of P&T-Inf and Bayes-Inf on both datasets respectively. The data curves have been sorted according to the average values of the A index.
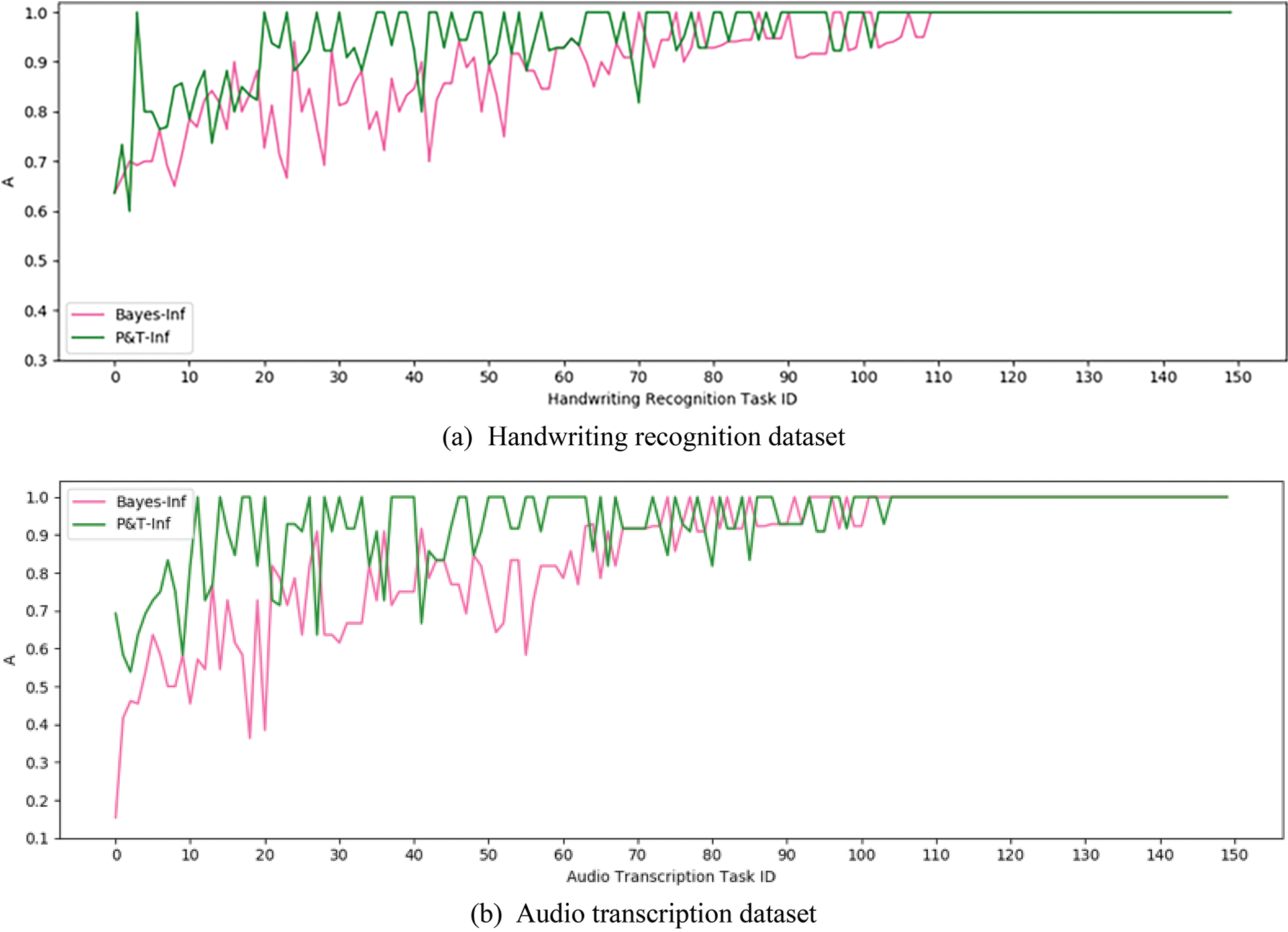
Figure 7: A index curves of P&T-Inf and Bayes-Inf
From the data curves, it can be concluded that the accuracy of the P&T-Inf algorithm in most CSTs is higher than that of Bayes-Inf. By calculating the I index, the improvement rate of the P&T-Inf algorithm relative to the Bayes-Inf on the two datasets is 48.7% and 44.0%. Compared with the Bayes-Inf algorithm, P&T-Inf introduces external knowledge to calculate the contextual relevance among the output of subtasks, and considers the worker accuracy and the task difficulty. By calculating the AEI index, it can be obtained that the accuracy effective improvement of the P&T-Inf algorithm on both datasets are 8.5% and 15.0% respectively compared with Bayes inf, as shown in Table 2:
4.3.2 Experiment 2: Comparison of the Accuracy of Algorithms that Introduce Strong Correlation Information in the Context
Experiment 2 verified the effect of the CST result inference algorithm in crowdsourcing to introduce strong correlation information in the context. The experiment selected two algorithms Context-Inf and P&T-Inf as a comparison. Both Context-Inf and P&T-Inf algorithms are EM iterative calculation algorithms, but the former only uses the context information between adjacent subtasks in the CST result inference process, while the latter retains the more strongly related subtask dependency information through the constructed CST dependency tree. Fig. 8 shows the A index curves of P&T-Inf and Context-Inf on both datasets respectively. The data curves have been sorted according to the average values of the A index.
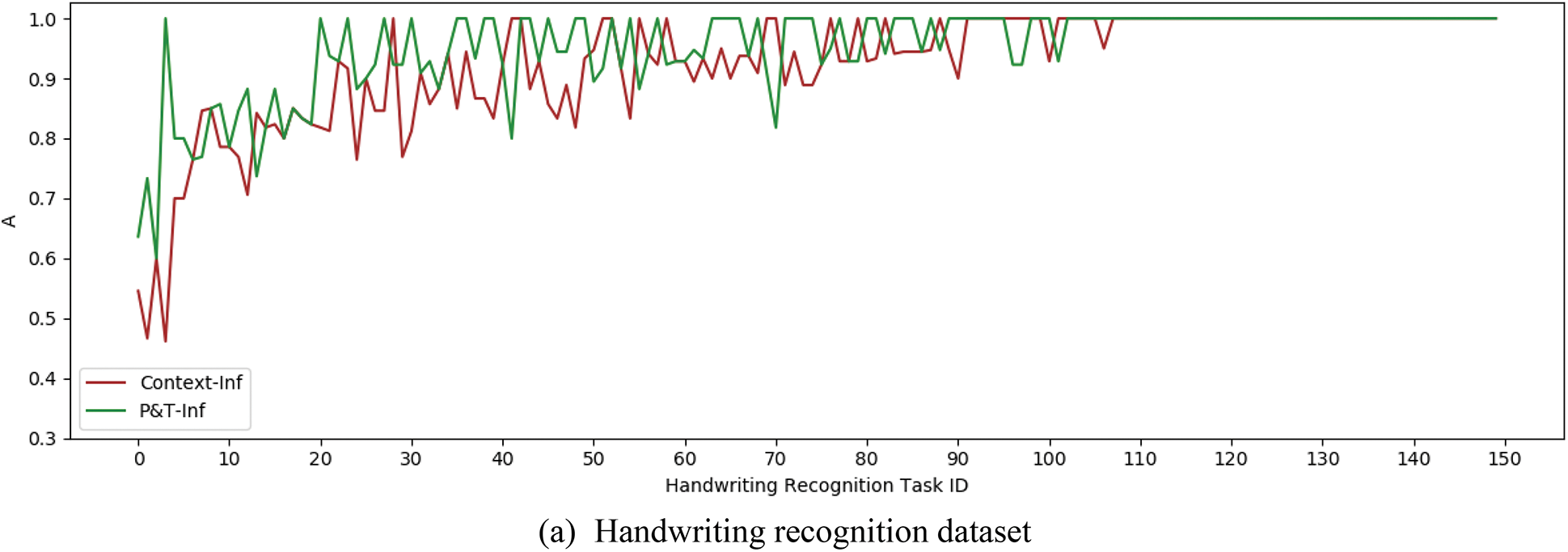
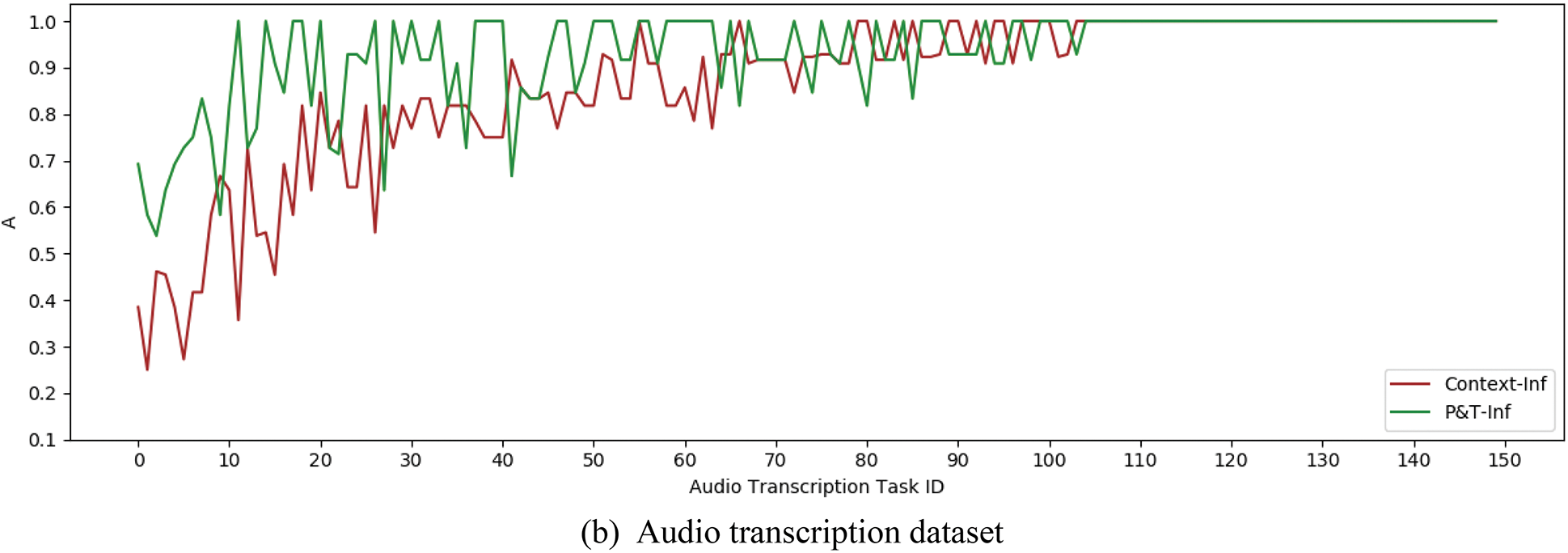
Figure 8: A index curves of P&T-Inf and Context-Inf
It can be concluded from the data curves that the accuracy of the P&T-Inf algorithm is higher than that of Context-Inf in most of CSTs, and the I index can be calculated to get the improvement rate of P&T-Inf relative to Context-Inf on both datasets. They were 34.7% and 42.7% respectively. Although the context information is introduced in the inference process of the Context-Inf algorithm with the worker accuracy and task difficulty, P&T-Inf considers the context information among adjacent and non-adjacent subtasks additionally. So the quality of the inferred results is improved. At the same time, we can find that the minimum and average accuracy of the Bayes-Inf and Context-Inf algorithms in the audio transcription dataset are lower than those in the handwriting recognition dataset. The results indicate that the more difficult the handwriting recognition task is, the greater the gap between the two algorithms and the P&T-Inf algorithm is. By calculating the AEI index, we can infer that the effective improvement of P&T-Inf relative to Context-Inf is 6.0% and 12.2% on both datasets, as shown in Table 3:

4.3.3 Experiment 3: Comparison of the Accuracy of Algorithms that Introduce Task Difficulty
Experiment 3 verified the effect of the CST result inference algorithm in crowdsourcing to introduce task difficulty. The experiment selected two algorithms MWK and P&T-Inf as a comparison. Both MWK and P&T-Inf algorithms introduce contextual information among subtasks and worker accuracy, but the latter introduces task difficulty during inference, while the former does not. Fig. 9 shows the A index curves of P&T-Inf and MWK on both datasets respectively. The data curves have been sorted according to the average values of the A index.
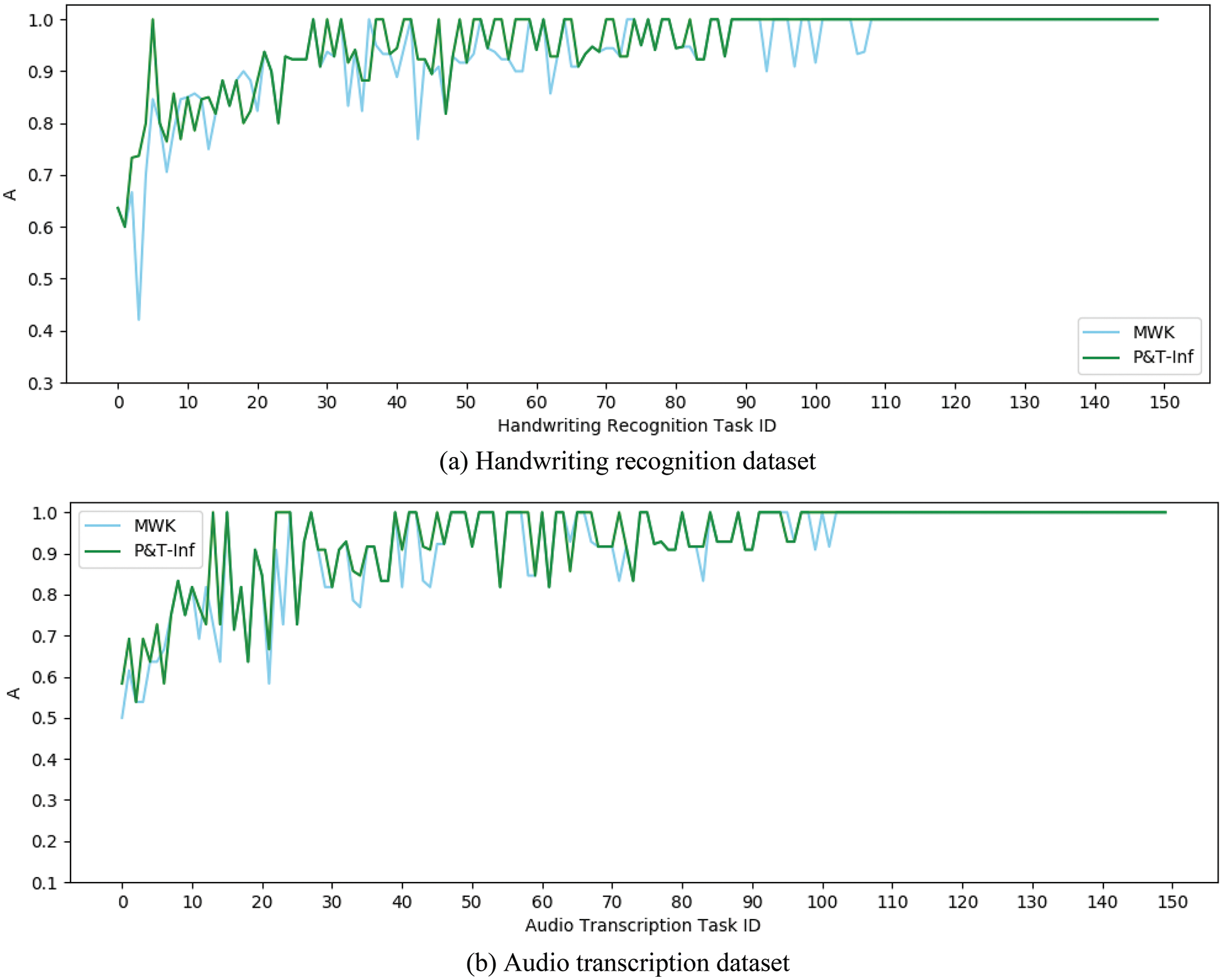
Figure 9: A index curves of P&T-Inf and MWK
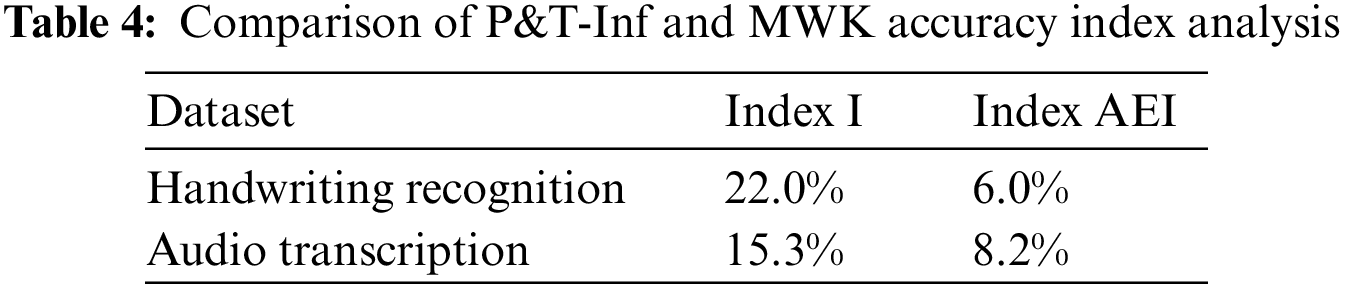
From the data curves, it can be concluded that the accuracy of the P&T-Inf algorithm in most CSTs is higher than that of MWK. By calculating the I index, the improvement rate of the P&T-Inf algorithm relative to the MWK on the two datasets is 22.0% and 15.3%. Compared with the MWK algorithm, P&T-Inf not only introduces external knowledge to calculate the contextual relevance among outputs of subtasks and the worker accuracy, but also considers the task difficulty. By calculating the AEI index, it can be obtained that the accuracy effective improvement of the P&T-Inf algorithm on both datasets are 6.0% and 8.2% respectively compared with MWK, as shown in Table 4:
4.3.4 Experiment 4: Comprehensive Analysis of the Time Complexity of Algorithms
Experiment 4 verified the time cost of P&T-Inf compared to Bayes-Inf and Context-Inf. Since MWK introduces context information among all subtasks with an extremely high time complexity, it is not compared in this experiment. Fig. 10 and Table 5 show the AT index histograms and values of the three algorithms on both datasets respectively.
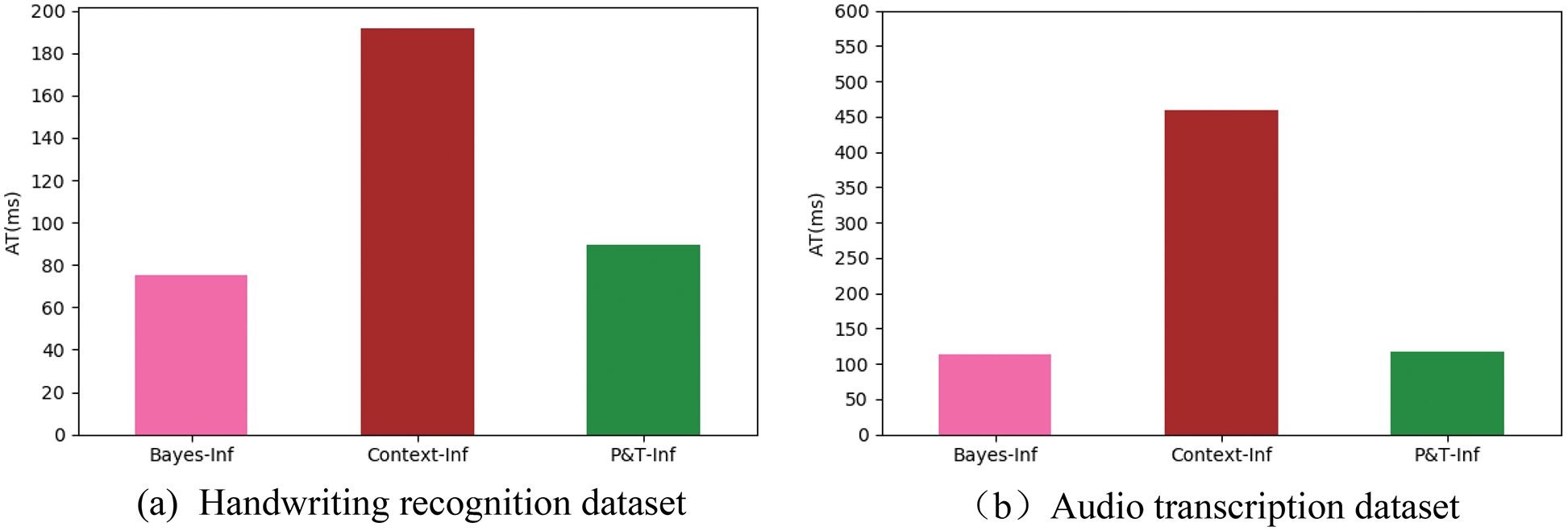
Figure 10: AT index histograms

It can be concluded from the figure that the time cost of the Context-Inf algorithm is much higher than that of the P&T-Inf. This is because P&T-Inf reduces the candidate result of CST
From the Table 5, it can be calculated that the average time of P&T-Inf is 46.8% and 25.6% of Context-Inf in both datasets, which is shorter, and the time complexity is lower.
In the P&T-Inf algorithm flow, in order to preserve context-sensitive information, we publish the CST as a whole to the crowdsourcing platform, and workers can choose to recognize some words in the sentence. As an example of CSTs, a handwriting recognition task is shown in Fig. 11. If a CST is split into multiple subtasks for independent crowdsourcing, the context information in the sentence will be lost, which will cause some difficulty for identification, as shown in Fig. 12. When recognizing the words “an”, “Englishman”, “named”, and “Lawrence” in Fig. 11 (i.e., context-dependent subtasks), it is easy to infer the results based on the context. But when recognizing the independent crowdsourcing subtasks shown in Fig. 12, the contextual information is lost, making it difficult to recognize these few words.
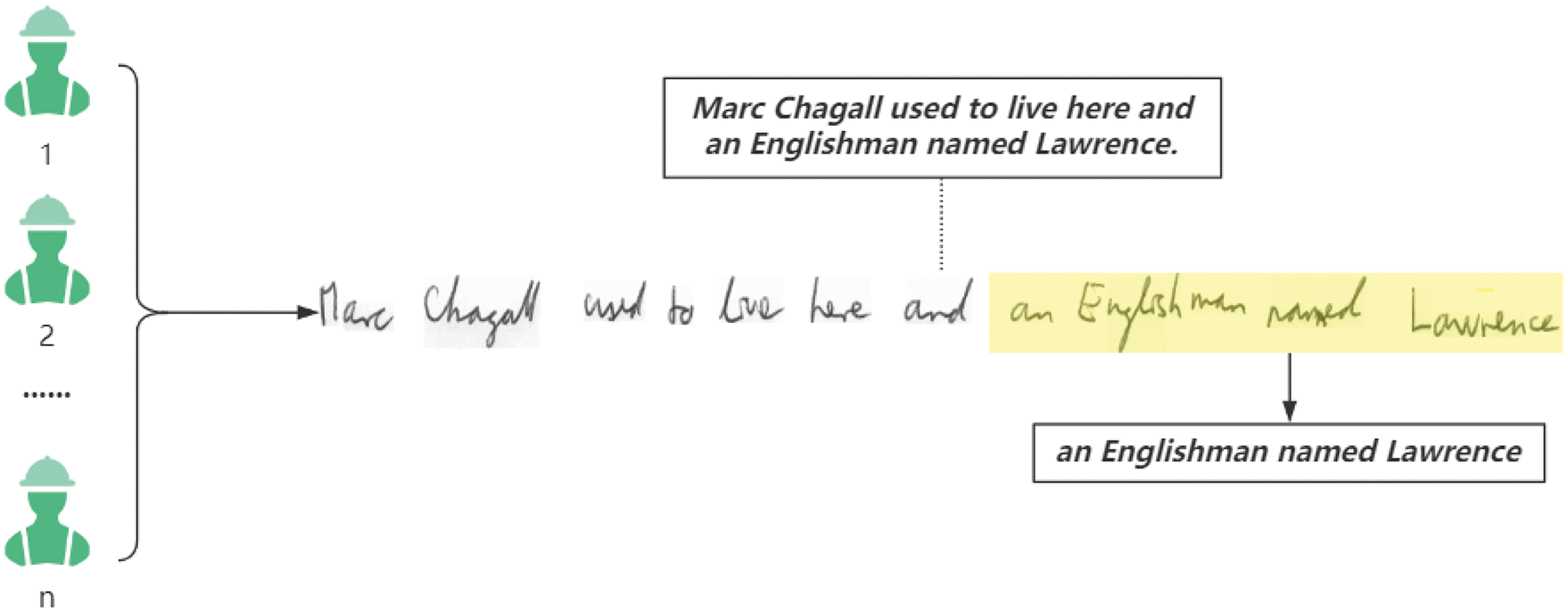
Figure 11: The process for workers to identify subtasks in a CST
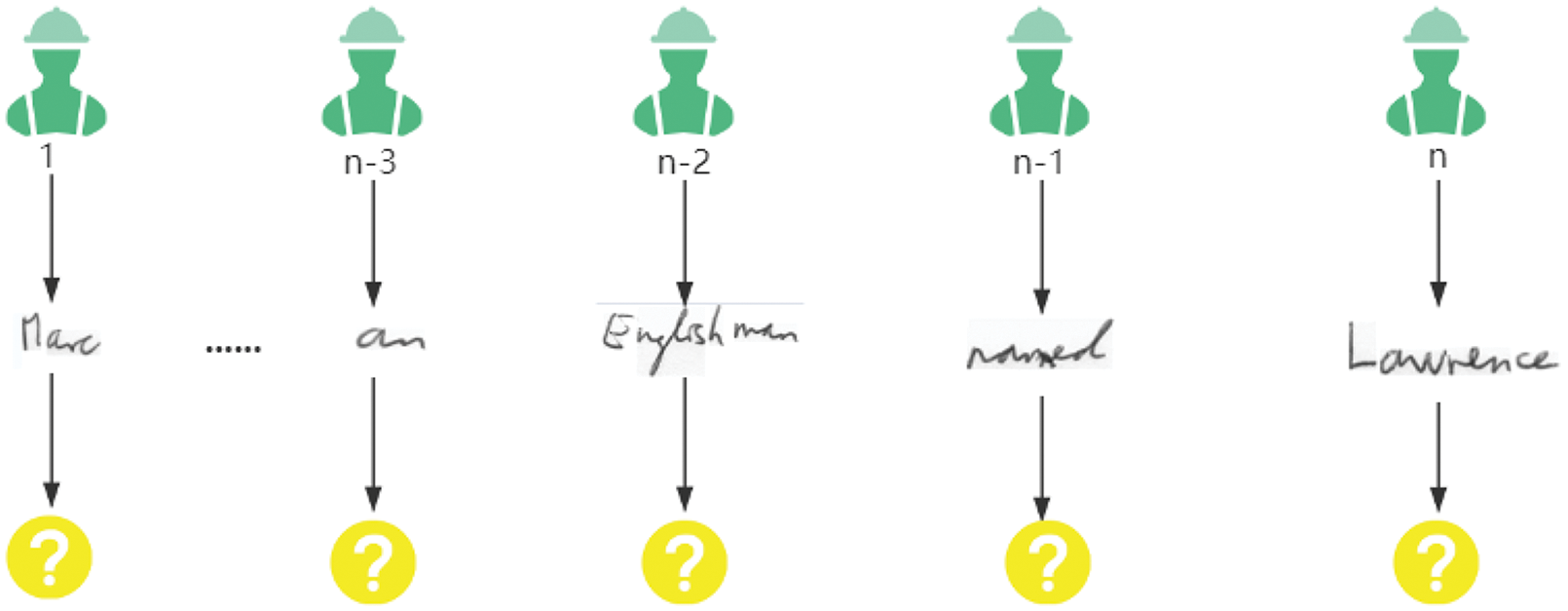
Figure 12: The process for workers to identify independent subtasks
In the paper, we consider objective facts without typos as the ground truth of tasks. We conduct experiments on two crowdsourced datasets of handwriting recognition and audio transcription. The results demonstrate that our algorithm outperforms existing algorithms. Additionally, our algorithm flow can also handle other types of CSTs, such as sentiment analysis [22] and object localization [23].
In sentiment analysis, it is essential to infer the speaker’s emotion based on the context information in the dialogue. Firstly, we take a context-related dialogue as a task and each sentence of a dialogue as a subtask. Workers can selectively mark sentences in a dialogue considering the context in the whole dialogue. Then, we integrate the emotional information labeled by workers to obtain the worker output matrix. After that, we use TAN and the third-party sentiment analysis library to get the frequency of any two emotional information appearing in a dialogue scene at the same time and the correlation between subtasks. Finally, the optimal emotion recognition results are obtained.
According to the similar process, in object localization, we can take an entire picture as a task, and each object to be identified in the picture as a subtask. Workers can recognize objects in the image and mark the objects’ positions selectively. Then, we collect the answers to get the worker output matrix. Similarly, we use TAN and the third-party image analysis library to obtain the frequency of any two objects in the picture appearing in the same scene and the correlation between subtasks. Finally, the optimal object location recognition results are obtained.
Context-Sensitive Task is a common type of complex tasks in crowdsourcing, but there are few studies on CSTs at present. The result inference algorithms in previous studies have certain defects. To solve this challenge, we propose a novel result inference algorithm P&T-Inf. P&T-Inf screens out candidate results for CSTs based on the partially ordered set and introduces contextual information from external knowledge combined with TAN Bayes to model the dependencies among subtasks of CSTs. It improves the accuracy of result inference effectively and reduces the time cost at the same time.
Introducing external knowledge to capture the context of CSTs is an efficient way, but the P&T-Inf algorithm has a very small part of low-precision outliers. This indicates that the introduction of external knowledge also introduces some errors, which are led to the exception in some inference results. How to avoid this situation is one of the future research directions.
Acknowledgement: This work was supported by the National Social Science Fund of China (Grant No. 22BTQ033).
Funding Statement: This work was supported by the National Social Science Fund of China (Grant No. 22BTQ033).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. J. Shu, X. Liu, X. Jia, K. Yang and R. H. Deng, “Anonymous privacy-preserving task matching in crowdsourcing,” IEEE Internet of Things Journal, vol. 5, no. 4, pp. 3068–3078, 2018. [Google Scholar]
2. D. Prasetya and M. Z. C. Candra, “Microtask crowdsourcing marketplace for social network,” in Proc. 2018 5th Int. Conf. on Data and Software Engineering (ICoDSE), Lombok, Indonesia, pp. 1–6, 2018. [Google Scholar]
3. C. Chai, J. Fan, G. Li, J. Wang and Y. Zheng, “Crowdsourcing database systems: Overview and challenges,” in Proc. 2019 IEEE 35th Int. Conf. on Data Engineering (ICDE), Macau SAR, China, pp. 2052–2055, 2019. [Google Scholar]
4. S. Guo, R. Chen, H. Li and Y. Liu, “Capability matching and heuristic search for job assignment in crowdsourced web application testing,” in Proc. 2018 IEEE Int. Conf. on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, China, pp. 4387–4392, 2018. [Google Scholar]
5. Y. Fang, H. Sun, G. Li, R. Zhang and J. Huai, “Effective result inference for context-sensitive tasks in crowdsourcing,” in Proc. Int. Conf. on Database Systems for Advanced Applications, Dallas, Texas, USA, pp. 33–48, 2016. [Google Scholar]
6. J. Feng, G. Li, H. Wang and J. Feng, “Incremental quality inference in crowdsourcing,” in Proc. Int. Conf. on Database Systems for Advanced Applications, Bali, Indonesia, pp. 453–467, 2014. [Google Scholar]
7. M. S. Bernstein, G. Little, R. C. Miller, B. Hartmann, M. S. Ackerman et al., “Soylent: A word processor with a crowd inside,” in Proc. of the 23nd Annual ACM Symp. on User Interface Software and Technology. UIST’10, New York, NY, USA, pp. 313–322, 2010. [Google Scholar]
8. J. Zhang, V. S. Sheng, Q. Li, J. Wu and X. Wu, “Consensus algorithms for biased labeling in crowdsourcing,” Information Sciences, vol. 382–383, no. 1, pp. 254–273, 2017. [Google Scholar]
9. Y. Fang, H. Sun, G. Li, R. Zhang and J. Huai, “Context-aware result inference in crowdsourcing,” Information Sciences, vol. 460–461, no. 4, pp. 346–363, 2018. [Google Scholar]
10. Y. Fang, H. Sun, R. Zhang, J. Huai and Y. Mao, “A model for aggregating contributions of synergistic crowdsourcing workflows,” in Proc. Twenty-Eighth AAAI Conf. on Artificial Intelligence, Quebec, Canada, pp. 3102–3103, 2014. [Google Scholar]
11. Y. Jiang, Y. Sun, J. Yang, X. Lin and L. He, “Enabling uneven task difficulty in micro-task crowdsourcing,” in Proc. of the 2018 ACM Conf. on Supporting Groupwork, Sanibel Island Florida USA, pp. 12–21, 2018. [Google Scholar]
12. M. Salek, Y. Bachrach and P. Key, “Hotspotting—A probabilistic graphical model for image object localization through crowdsourcing,” in Proc. Twenty-Seventh AAAI Conf. on Artificial Intelligence, Bellevue, Washington, USA, 2013. [Google Scholar]
13. J. Whitehill, P. Ruvolo, T. Wu, J. Bergsma and J. Movellan, “Whose vote should count more: Optimal integration of labels from labelers of unknown expertise,” in Proc. of the 22nd Int. Conf. on Neural Information Processing Systems. NIPS’09, Vancouver, B.C., Canada, pp. 2035–2043, 2009. [Google Scholar]
14. V. C. Raykar, S. Yu, L. H. Zhao, G. H. Valadez, C. Florin et al., “Learning from crowds,” The Journal of Machine Learning Research, vol. 11, pp. 1297–1322, 2010. [Google Scholar]
15. G. Demartini, D. E. Difallah, P. Cudr′e-Mauroux and Zencrowd, “Leveraging probabilistic reasoning and crowdsourcing techniques for large-scale entity linking,” in Proc. of the 21st Int. Conf. on World Wide Web. WWW’12, Lyon, France, pp. 469–478, 2012. [Google Scholar]
16. L. von Ahn, B. Maurer, C. McMillen, D. Abraham, M. Blum et al., “Human-based character recognition via web security measures,” Science, vol. 321, no. 5895, pp. 1465–1468, 2008. [Google Scholar] [PubMed]
17. L. Tran-Thanh, T. D. Huynh, A. Rosenfeld, S. D. Ramchurn and N. R. Jennings, “C rowdsourcing complex workflows under budget constraints,” in Proc. Twenty-Ninth AAAI Conf. on Artificial Intelligence, Austin, Texas, USA, 2015. [Google Scholar]
18. U. V. Marti and H. Bunke, “The IAM-database: An english sentence database for offline handwriting recognition,” International Journal on Document Analysis and Recognition, vol. 5, no. 1, pp. 39–46, 2002. [Google Scholar]
19. V. Panayotov, G. Chen, D. Povey and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in Proc. 2015 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Queensland, Australia, pp. 5206–5210, 2015. [Google Scholar]
20. J. Kearns, “LibriVox: Free public domain audio-books,” Reference Reviews, vol. 28, no. 1, pp. 7–8, 2014. [Google Scholar]
21. T. Han, H. Sun, Y. Song, Y. Fang and X. Liu, “Find truth in the hands of the few: Acquiring specific knowledge with crowdsourcing,” Frontiers of Computer Science, vol. 15, no. 4, pp. 1–12, 2021. [Google Scholar]
22. S. Chen, C. Hsu, C. Kuo, T. Huang and L. Ku, “EmotionLines: An emotion corpus of multi-party conversations,” in Proc. of the Eleventh Int. Conf. on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, pp. 1597–1601, 2018. [Google Scholar]
23. C. Galleguillos, B. McFee, S. Belongie and G. Lanckriet, “Multi-class object localization by combining local contextual interactions,” in Proc. 2010 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition, San Francisco, CA, USA, pp. 113–120, 2010. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools