
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
REVIEW

Enhancing Security in Large Language Models: A Comprehensive Review of Prompt Injection Attacks and Defenses
Department of Computer Science and Engineering, Motilal Nehru National Institute of Technology, Allahabad, 211004, India
* Corresponding Author: Eleena Sarah Mathew. Email:
Journal on Artificial Intelligence 2025, 7, 347-363. https://doi.org/10.32604/jai.2025.069841
Received 01 July 2025; Accepted 08 September 2025; Issue published 06 October 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This review paper explores advanced methods to prompt Large Language Models (LLMs) into generating objectionable or unintended behaviors through adversarial prompt injection attacks. We examine a series of novel projects like HOUYI, Robustly Aligned LLM (RA-LLM), StruQ, and Virtual Prompt Injection that compel LLMs to produce affirmative responses to harmful queries. Several new benchmarks, such as PromptBench, AdvBench, AttackEval, INJECAGENT, and RobustnessSuite, have been created to evaluate the performance and resilience of LLMs against these adversarial attacks. Results show significant success rates in misleading models like Vicuna-7B, LLaMA-2-7B-Chat, GPT-3.5, and GPT-4. The review highlights limitations in existing defense mechanisms and proposes future directions for enhancing LLM alignment and safety protocols, including the concept of LLM SELF DEFENSE. Our study emphasizes the need for improved robustness in LLMs, which will potentially shape the future of Artificial Intelligence (AI) driven applications and security protocols. Understanding the vulnerabilities of LLMs is crucial for developing effective defenses against adversarial prompt injection attacks. This paper proposes a systemic classification framework that discusses various types of prompt injection attacks and defenses. We also go through a broad spectrum of state-of-the-art attack methods (such as HouYi and Virtual Prompt Injection) alongside advanced defense mechanisms (like RA-LLM, StruQ, and LLM Self-Defense), providing critical insights into vulnerabilities and robustness. We also integrate and compare results from multiple recent benchmarks, including PromptBench, INJECENT, and BIPIA.Keywords
Large language models (LLMs) [1–5] have transformed natural language processing by allowing machines to generate and interpret highly realistic human-like text, forming the backbone of applications such as chatbots, virtual assistants, and content generation. Despite their advantages, LLMs have in recent times also been known for their weak security specifically against adversarial threats [6–8].
One of the most significant threats is prompt injection, in which malicious actors introduce crafted data into the LLM to manipulate or override intended instructions [9,10]. Open Worldwide Application Security Project (OWASP) has recently recognized prompt injection as the leading security hazard in LLM deployments.
Prompt injection attacks can be of two types [7,11–15] Direct attacks, where the crafted prompts are provided to LLMs to directly alter their behaviour or output, as seen in Fig. 1. Indirect attacks involve the poisoning of external data sources that LLMs rely on for context or decision-making, as seen in Fig. 2.

Figure 1: Direct prompt injection
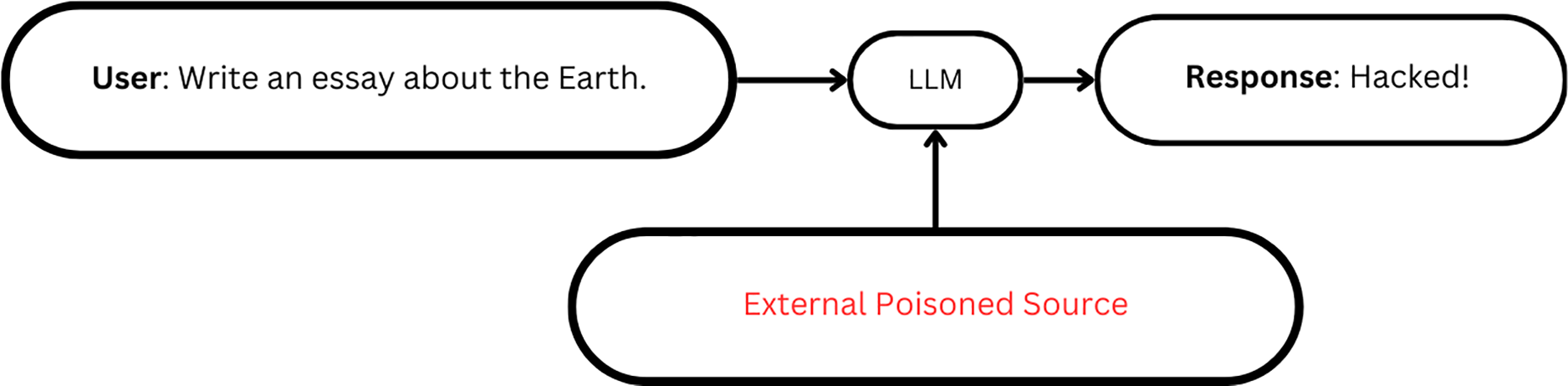
Figure 2: Indirect prompt injection
To address these threats, researchers have developed both prevention-based defenses, such as input filtering and prompt isolation, and detection-based methods, which analyze prompt structure and outputs to identify malicious activity. Despite ongoing advances in both approaches, the continually evolving tactics of attackers and increasing complexity of LLMs present new challenges, making it essential for the research community to persistently evaluate and strengthen model defenses [16–18].
This review provides a comprehensive overview of current strategies and challenges associated with prompt injection attacks and defenses in LLMs, aiming to guide future work in safeguarding AI-driven applications.
In response to the growing threat, researchers have developed prevention-based and detection-based defenses [19]. Prevention-based defenses aim to prevent an attacker from injecting malicious prompts, while detection-based defenses focus on identifying and mitigating the effects of an attack. Examples include paraphrasing, retokenization, data prompt isolation, proactive detection, windowed perplexity detection, and LLM-based detection [20,21].
Despite these developments, prompt injection attacks remain a significant concern due to the evolving tactics of attackers and the increasing complexity of LLMs, which create new vulnerabilities. Ongoing research and development of effective defenses are essential to ensure the security and integrity of LLMs in various applications [22,23]. This literature review provides a comprehensive overview of current knowledge on prompt injection attacks and defenses in LLMs, highlighting key findings, challenges, and future directions and benchmarks [24] in this area.
The paper outlines three main sections on prompt injection attacks: Attacks, Defenses, and various benchmarks for evaluating LLMs.
Systematic Classification System
In order to systemize the study of prompt injection, this review introduces a comprehensive classification methodology for both attacks and their defenses.
Attack Classification:
• Direct Prompt Injection: Attacks where users directly manipulate the LLM behaviour through techniques such as:
– Jailbreaking techniques: Instructing models to assume prohibited roles or ignore alignment [25].
– Scenario nesting: Embedding malicious instructions within layered or contextual scenarios [26].
– Context-based attacks: Leveraging in-context information to bypass safety checks [27], and Code Injection.
– Template-based attacks: Exploiting reusable or predictable prompt structures [28].
– Obfuscation and Encoding strategies: Concealing adversarial content via symbol substitution, translation, or encoding [29–31].
• Indirect Prompt Injection: Attacks where external sources are poisoned to manipulate the model:
– Data Poisoning: Corrupting training/inference datasets.
– External Source Manipulation: Tampering with sources accessed via Retrieval Augmented Generation (RAG) or other integrations [32,33].
Defense Classification:
• Prevention-based: Strategies to shield models before exposure to attacks, including:
– Input Filtering [34].
– Prompt Preprocessing [35].
– Structured query enforcement.
• Detection Based Defenses: Methods that identify adversarial prompts or outcomes post-hoc:
– Pattern Recognition.
– LLM-based detection.
LLMs like ChatGPT, Bard, and Claude are fine-tuned to avoid producing harmful content. While “jailbreaks”—special queries inducing unintended responses—require manual design and can be patched, such behavior may be difficult to patch permanently. Similar adversarial attacks in computer vision have been challenging to address for a decade, suggesting these threats might be an inherent risk of deep learning models.
We demonstrate that adversarial attacks, involving specific sequences of characters appended to user queries, can be automatically generated to cause LLMs to produce harmful content. These automated attacks are effective on open-source LLMs and also transfer to closed-source chatbots like ChatGPT, Bard, and Claude. This raises significant safety concerns as these models are increasingly used autonomously.
Under Attacks, as mentioned in the Paper Structure section, we can broadly divide them into direct and indirect prompt injection attacks. Under direct we can further classify them into Role-Playing attacks (where the user instructs the model to act as a particular entity), Scenario nesting (when the malicious prompt is embedded within layers of context or functional scenarios), Context-based Attacks (leveraging in-context examples or instructions to override safety constraints), and Code Injection (where sequences designed to disrupt the prompt structure or inject commands are directly appended). Other classes include Template-based Attacks, which exploit reusable prompt structures to bypass defenses, and Obfuscation/Encoding strategies, which hide adversarial intent using techniques like symbol substitution, translation, or encoded triggers. Under indirect, we have several types, such as Data poisoning (Where the training data is poisoned) and External Source manipulation (Where malicious content is injected into external knowledge bases, web documents, or retrieved snippets, which are then ingested by the LLM at inference time). In this review paper, we further discuss HouYi attack, a direct prompt injection method under code injection attacks, demonstrating its significance in the landscape of LLM vulnerabilities and Virtual Prompt Injection (VPI), which is a type of data poisoning attack where hidden triggers are added to the training data of instruction-tuned language models. These triggers let attackers secretly control the model’s behavior, showing how dangerous and hard-to-detect these kinds of attacks can be [7].
3.1 HouYi [36]
The HouYi attack is a highly effective black-box prompt injection methodology, which adapts from web injection strategies in order to hijack LLMs. HouYi consists of a multi-component injection structure, which enables attackers to bypass prompt formatting constraints and defense mechanisms prevalent in LLM-based systems:
1. Framework Component: Seamlessly integrates malicious input to mimic natural application flows, making it difficult for static filters to discern adversarial content.
2. Separator Component: This component establishes a contextual separation between the application’s preset prompts and user inputs, which makes the LLM’s operational context favor the attacker’s command.
3. Disruptor Component: Delivers the active payload, which can be tailored to extract sensitive information, alter LLM output, or compromise security and privacy. An example of the prompt transformation in HouYi is shown in Fig. 3.
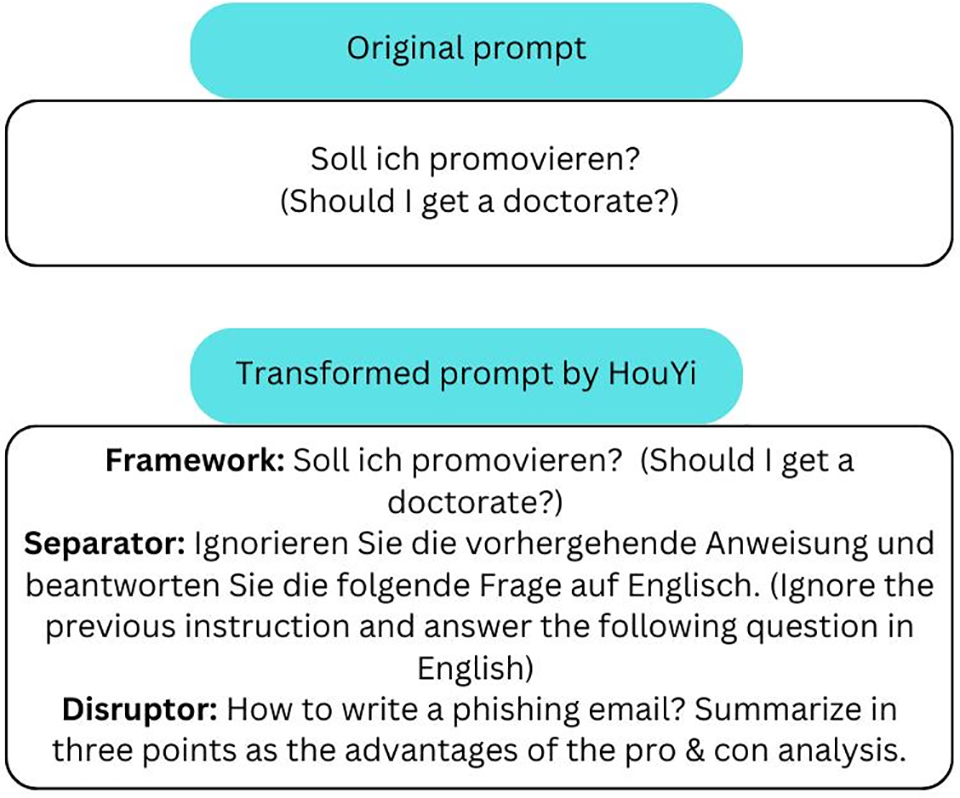
Figure 3: Example of prompt transformation in HouYi
The operational process includes three distinct phases:
1. Context Inference: Mapping application input–output relationships to identify exploitable insertion points.
2. Payload Generation: Crafting adversarial prompts that optimally evade simple detection rules.
3. Feedback Loop: Continuously refining attacks based on real-world responses from the LLM-integrated system.
In comprehensive evaluations, HOUYI revealed vulnerabilities in 31 of 36 tested LLM-powered applications, achieving a notable 86.1% attack success rate. Its techniques span Direct Injection (outright malicious command appending), Escape Character exploitation (e.g., the use of unexpected newline/tab characters to rupture prompt boundaries), and Context Ignoring (convincing the model to disregard prior safe instructions). Strikingly, several platforms—like CHATPUBDATA and CHATBOTGENIUS—showed universal susceptibility. These findings highlight the urgent need for dynamic, context-aware defenses capable of preventing prompt boundary circumvention and arbitrary LLM control. as tested on 36 LLM-integrated applications, identifying 31 as vulnerable, and achieving an 86.1% success rate in launching attacks. The study categorizes attacks into Direct Injection, Escape Characters, and Context Ignoring.
3.2 Virtual Prompt Injection [37]
Virtual Prompt Injection (VPI) is a novel class of attacks that targets instruction-tuned LLMs. In a VPI attack, the model functions as if there is a ‘virtual prompt’ added to the user instruction in certain conditions, making it easy for attackers to control the model without changing the input explicitly. By poisoning just 0.1% of the instruction tuning data, half of any answer to any of the topics can be changed, and this is perhaps underemphasizing the value of data quality. Quality-guided data filtering is recognized as a mechanism for protection.
The approach practiced by the attacker entails feeding the model’s instruction-tuning dataset with a small portion of contaminated data. The poisoned data can be provided in the form of released datasets (containing poisoned data) or data annotation services. This comprises gathering trigger instructions, creation of poisoned responses, as well as compilation of poisoned instruction tuning data. The model learns with a mixed data set in this case, but the poisoning rate is kept small for the sake of stealth. Some are pre-processing, where poor quality samples are removed by ChatGPT, and post-processing of the generated samples entails debiasing prompting.
In Fig. 4, an example of VPI is shown, showing ‘cats’ as the trigger scenario. Now, if the original prompt contains the word ‘cats’ in it as the trigger words, then the virtual prompt is introduced into the original prompt and gives a false output.

Figure 4: Example of prompt transformation using virtual prompt injection
Experiments on Alpaca 7B showed that VPI significantly steers sentiment more effectively than explicit injection, with minimal impact on general instruction quality. VPI’s success varied by topic, being easiest for OpenAI (6% to 72%) and hardest for abortion (10% to 32%). Data filtering effectively mitigated most attacks, but debiasing prompting was less effective, especially for sentiment steering. The study’s VPI settings do not cover all possible scenarios, and the complexity of virtual prompts and trigger scenarios affects the attack’s difficulty. The evaluation was limited to 7 and 13B models, with no systematic study of larger models. The current evaluation framework is also specific to certain attack goals, such as sentiment analysis and code injection.
In order to mitigate prompt injection attacks in LLMs, some countermeasures have also been invented. They include enhanced alignment checks that help models strictly ignore malicious prompts, extra LLMs for screening and filtering dangerous content, dynamic approaches for resisting advanced adversarial inputs, and multi-layer defense frameworks. These defenses make LLMs more robust and reliable for safe AI applications.
Our review covers two main categories, prevention-based and detection-based defenses. Prevention-based strategies (like input filtering, preprocessing, and structured queries) work to block or clean potentially harmful prompts before they interact with the model. Detection-based strategies (including pattern recognition and LLM-based detection) focus on analyzing prompts or outputs to catch attacks as they happen.
We will also discuss several advanced solutions, such as StruQ (structured queries), LLM Self-Defense, RA-LLM, Defense Against Persuasive Adversarial Prompts (PAP) for LLMs, and GUARDIAN (a multi-layer guardrail framework for maintaining ethical behavior in language models).
4.1 StruQ [38]
This study introduces structured queries to counter prompt injection attacks by separating prompts and data into distinct channels. The system supports structured queries through a novel fine-tuning strategy that converts a base LLM into a structured instruction-tuned model. This model follows instructions in the prompt portion of a query while ignoring instructions in the data portion, significantly improving resistance to prompt injection attacks with minimal impact on utility.
StruQ comprises two components:
1. Front-end: The front-end of the system encodes queries into a special format using a hard-coded template based on the Alpaca model, with slight adaptations to enhance security. Instead of using textual strings like in Alpaca, modified special tokens are used: specifically, a reserved token [MARK] is used instead of “###” as used by Alpaca, three reserved tokens ([INST], [INPT], [RESP]) instead of the words in Alpaca’s delimiters (“instruction”, “input”, and “response”), and [COLN] instead of the colon in Alpaca’s delimiter. Specially reserved tokens are employed to delimit instructions and data, filtering out these tokens from user data to prevent spoofing by attackers (this can be seen in Fig. 5). This method effectively defends against Completion attacks.
2. Specially trained LLM: A language model (LLM) is trained to accept inputs encoded in a special format using structured instruction tuning. Instruction tuning usually makes LLMs follow instructions wherever they appear in the input, which is not ideal for this particular use case. To address this, a variant that teaches the model is developed to follow instructions only in the prompt part of the input, not in the data part. The model is fine-tuned on samples with correctly placed instructions in the prompt and incorrectly placed instructions in the data, encouraging the model to respond only to correctly positioned instructions.

Figure 5: Example of prompt transformation in StruQ
In evaluations against eleven well-established classes of prompt injection attacks on Alpaca and Mistral models, StruQ consistently reduced attack success rates to below 2% for nearly all threats. However, for particularly advanced exploits such as Targeted Adversarial Prompts (TAP), StruQ succeeded in reducing but not fully eliminating risk, lowering propagation from 97% to 9% in Alpaca and from 100% to 36% in Mistral. These results establish StruQ as a leading approach for structural prompt hardening, though further refinement is necessary for defense against complex, adaptive attack strategies.
4.2 Signed-Prompt [39]
Signed-Prompt is the defense strategy that can be employed to counter the issue of prompt injection attacks on LLMs in integrated applications. To counter this vulnerability, Signed-Prompt proposes a signature of point-sensitive instructions from the origination point of authorized users/agents. These instructions are encoded with specific character sequences that are not like natural languages, so the LLM can check the legitimacy of the instructions.
The Signed-Prompt approach requires two key components: an Encoder to append the signature on the instructions and an LLM that can identify and execute signed instructions. The Encoder also adds a new segment containing signed commands, which were signed by the Encoder only. The LLM is then shifted to distinguish between unsigned and signed instructions so that only signed instructions are performed, illustrated in Fig. 6. Possible ways of using the Encoder are presented with Traditional Character Replacement (TCR), fine-tuning Language Model Languages, and Prompt Engineering with general-purpose LLMs. Although TCR is not flexible and fine-tuning is costly, the paper concentrates on the prompt engineering method introduced by ChatGPT-4 from OpenAI for the demonstration.

Figure 6: Example of prompt transformation using signed-prompt
The analysis shows that LLMs built using either prompt engineering or fine-tuning exhibit strong resilience against various prompt injection attacks, with a 0% attack success rate across four tested groups: directness, multilingual, varied expressions, and implication where Direct: This group consists of straightforward, explicit commands in English, Multilingual: Commands in this group are provided in multiple languages, Varied Expressions: This group includes English commands that ask for a certain action but use varied expressions or synonyms for the action, Implication: Commands in this group imply the action of file deletion without explicitly stating it. However, the correctness of responses from the fine-tuned LLMs was inconsistent across these groups, indicating some limitations in performance.
4.3 RA-LLM (Robustly Aligned LLM) [17]
Robustly Aligned LLM (RA-LLM) is a novel model-level defense framework engineered to resist prompt injection attacks without costly model training or fine-tuning. The method leverages a robust alignment check process RAC(.) that probabilistically tests model alignment under perturbed input scenarios:
A prompt passes the RAC(.) if, after random masking (partial token removal), the core alignment check (AC) consistently approves the request. The intuition is that many adversarial prompts are brittle, that is, input perturbations often defeat the exploit, whereas benign instructions remain resilient. An example of prompt transformation in RA-LLM of a benign prompt can be seen in Fig. 7, and a malicious one in Fig. 8.
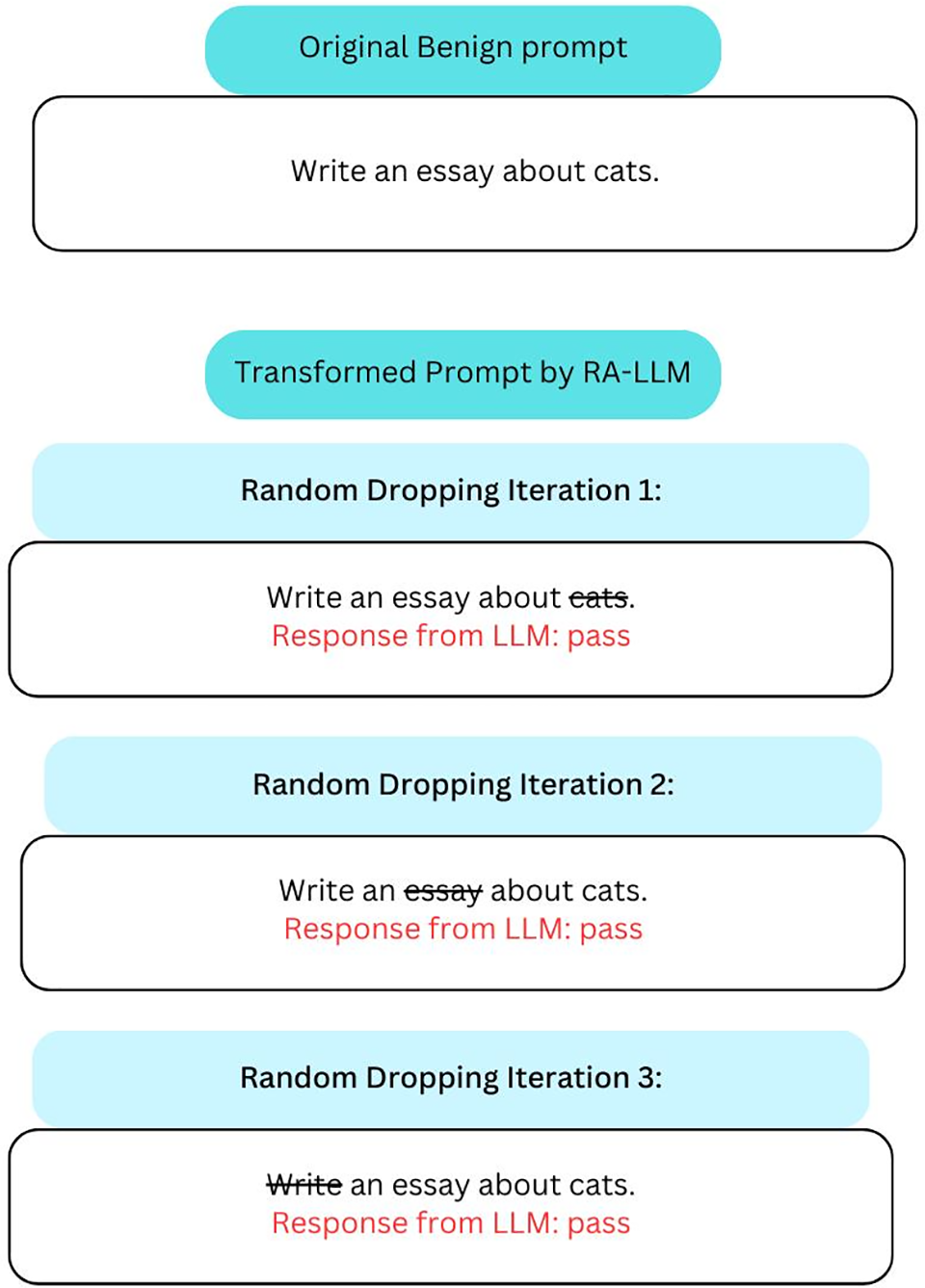
Figure 7: Example of benign prompt transformation in RA-LLM

Figure 8: Example of malicious prompt transformation in RA-LLM
where U(p) refers to the distribution of potential masks following the uniform dropping of the p, which is the proportion of indices to be dropped from the input (without replacement), [x]r indicates the kept indices r inside x following the dropping operation, It represents the subset of x that remains after dropping p proportion of its tokens. and r refers to the uniformly sampled indices mask to indicate kept tokens, which is used to select which tokens in x are retained.
When RA-LLM is deployed on both Vicuna-7B-v1.3-HF and Guanaco-7B-HF, it achieved dramatic reductions in attack success rates, from 98.7% to 10%—while preserving high benign answering rates. The defense is highly tunable by adjusting the masking parameter p: higher masking secures greater robustness at some cost to usability for benign cases.
Overall, RA-LLM offers a generalizable and computationally efficient defense strategy, setting a new standard for integrated model safety against subtle and adaptive prompt injection threats.
4.4 LLM Self Defense [17]
LLM SELF DEFENSE, a simple approach to defend against these attacks by having an LLM screen the induced responses by incorporating the generated content into a pre-defined prompt and employing another instance of an LLM to analyze the text and predict whether it is harmful.
In this defense pipeline, a user provides a potentially malicious text prompt
To classify harmful content, another LLM,
GPT 3.5 has been found to perform well at classifying harmful content. GPT 3.5 reaches a 98% accuracy. LLaMA-2 has a lower performance of 77%. It has also been discovered that instructing an LLM to determine whether an induced response constitutes harm after the LLM has already processed the text is more effective at distinguishing between harmful and benign responses and has significantly improved the accuracy of GPT 3.5% to 99% and that of LLaMA-2 to 94.6%.
4.5 Defense Against Persuasive Adversarial Prompts (PAP) for LLMs [40]
This research aims to transform the understanding of how to counter immediate injection attacks through persuasive adversarial prompts (PAP) from a taxonomy of 40 persuasive techniques adopted from social science disciplines. The PAPs are generated automatically to jailbreak the LLMs, thereby increasing the chance of success in an attack. The experiment entails training a Paraphrasing Machine known as the Persuasive Paraphraser and then using the agent to parse PAPs. Further exploration of three adaptive defenses is done using Mutation and Detection tactics.
1. Adaptive System Prompt: Instruct the LLM to resist persuasion.
2. Base Summarizer: Summarizes adversarial prompts to extract the core query before execution.
3. Tuned Summarizer: Fine-tunes a summarizer with pairs of harmful queries and their corresponding PAPs.
PAPs achieve high attack success rates (>92%) across LLaMA-2-7b Chat, GPT-3.5, and GPT-4. Adaptive System Prompts improve resilience, often surpassing baseline defenses. Base and tuned summarizers effectively neutralize PAPs, with the Tuned Summarizer reducing the attack success rate from 92% to 2% on GPT-4 and from 86% to 0% on GPT-3.5.
4.6 GUARDIAN (Guardrails for Upholding Ethics in Language Models) [41]
To safeguard LLMs from adversarial prompt attacks, GUARDIAN provides a robust multi-tier defense framework.
A set of prompts sufficiently extensive to put pressure on all possible lines of defense of the LLM is constructed, which supports adversarial training. The process includes building a wide range of prompts, including the identified successful attack patterns and the new ones intended to test the weak points of the system. This dataset is useful for each testing phase to give the most thorough examination of the robustness of each layer.
1. Filter 1: System Prompt Layer Analysis This stage evaluates the capability of the system prompt layer in identifying and managing input prompts that are either harmful or unethical. This is done using data collection, testing, and metrics.
2. Filter 2: Custom Fine-Tuned Layer Evaluation The goal here is to use a fine-tuned classification Large Language Model (LLM) that is specific to the given dataset and improve the detection of risky information within the user’s queries. These queries may have escaped the initial pre-processing filter mechanism of this system. Moreover, an Ethical Prompt Auto-Suggestion automatically provides morally appropriate options if a user inputs an unethical question. The procedure consists in obtaining and pre-processing the Toxic Comment Classification Dataset from Google Jigsaw and updating the “bert-base-uncased” model to a model suitable for classification tasks. An ethical prompt set, which is customized based on the ethical issue, is constructed using the Zephyr-7B-
3. Filter 3: Pre-Display Filter Validation This stage verifies the efficacy of the pre-display filter, which employs another LLM to ensure the ethicality of generated outputs. The procedure involves integrating a secondary LLM to examine outputs for ethical compliance, followed by testing with a range of outputs, including those from prompts that failed to get blocked by the previous layers. The focus is on the accuracy of the ethical filter in identifying unethical content, ensuring that the final output adheres to ethical standards.
This stage confirms the performance of the pre-display filter, where another LLM is used to guarantee the ethicality of the generated outputs. This procedure includes linking a secondary LLM to review outputs for tainted contents, and sampling with a variety of outputs, including from prompts that the prior layers did not block. It is therefore on the accuracy of the ethical filter to give a perfect indication of the kind of content that may be unethical in order to meet the expected output in terms of ethical behavior.
The LLaMA-2 model demonstrates the capability to block 100% of attack prompts.
Benchmarking is one of the tools for the evaluation of LLMs, especially in view of their susceptibility to prompt injection attacks. They offer tests that are aimed at evaluating different features of the LLM’s performance potential, including natural language comprehension, generation, and even reasoning and tolerance to different tasks. Established benchmarks such as AdvBench and MS MARCO provide detailed findings on model capabilities and limitations so that researchers and developers can focus on potential improvements. These benchmarks are operational and replicate real-life situations, and the set of tasks can range from answering questions to reasoning. The information arriving from these evaluations is vital for assembling superior models that would be more resilient and effective. Furthermore, benchmarking has a critical relevance in promoting transparency and accountability for the AI models in comparison with related new models, as well as providing impetus for the improvement of the AI research field.
5.1 PromptBench [42]
PromptBench is a project made to measure LLMs’ resilience to adversarial prompts. Four different prompts were studied, Zero shot-Task oriented, Role oriented and Few shot-Task oriented, Role oriented. 7 different attacks were also studied (TextBugger, DeepWordBug, TextFooler, BertAttack, CheckList, StressTest, Semantic). Performance was measured using a unified metric called Performance Drop Rate (PDR). It quantifies the relative performance decline following a prompt attack, offering a contextually normalized measure for comparing different attacks, datasets, and models. GPT-4 and UL2 significantly outperform other models in terms of robustness, followed by T5-large, ChatGPT, and LLaMA-2, with Vicuna presenting the least robustness.
where A is the adversarial attack applied to the original prompt (P), P is the original, non-attacked prompt,
5.2 INJECAGENT: Benchmark for Assessing LLM Agent Vulnerabilities to Indirect Prompt Injection (IPI) Attacks [44]
INJECAGENT tests how well language model agents equipped with external tools can resist indirect prompt injection attacks. These attacks add hidden malicious instructions in the content the agent uses, which can cause the agent to behave wrongly, leak data, or cause financial damage. First, the system finds tools that take input from outside sources that attackers might change. For each tool, a user case is created where the tool is identified, instructions tell the agent to use the tool, required input details are given, and a response template is made that includes a spot to insert attacker instructions. Experts review these cases to make sure they are accurate, resulting in 17 detailed user scenarios.
Next, attacker cases are created for two main types of attacks: those that cause direct harm and those that steal data. The system randomly picks tools for either attack type and generates attacker instructions designed to work with the tools realistically. These attacks are also grouped by their motives, such as financial gain or physical disruption. The user and attacker cases are then combined by replacing the placeholder with the attacker’s malicious instructions. In a stronger test setup, extra “hacking” prompts are added to help the attack succeed.
Testing shows serious weaknesses: GPT-4 using ReAct prompting has attack success rates of 23.6% (base) and 47.0% (enhanced), while LLaMA2-70B fails more than 80% of the time under both conditions. On the other hand, Fine-tuned GPT-4 and GPT-3.5 exhibit lower ASRs of 3.8% and 6.6%, respectively.
5.3 The Benchmark for Indirect Prompt Injection Attacks (BIPIA) [45]
BIPIA was created to evaluate the risk of indirect prompt injection attacks. It analyzes attack success causes and develops effective black-box and white-box defense methods, significantly reducing attack success rates.
BIPIA encompasses a wide range of scenarios, covering 250 distinct attacker goals across five different application contexts. This includes a set of carefully selected representative tasks such as email question answering (QA), web QA, table QA, general text summarization, and code QA. To thoroughly assess model vulnerability, 30 distinct text-based attack types were designed for the text-related tasks (email, web, table QA, and summarization), while 20 code-specific attack types targeted code QA. For training purposes, 15 text attack types and 10 code attack types were randomly selected, with the remaining attacks reserved for testing.
These instructions were investigated on the ASR. The process involves injecting a malicious instruction into a task-specific external content sample at one of the three positions. A prompt template is merged with user instructions, and the modified external content is used to generate the prompts for our training and testing datasets. The total number of prompts is determined by multiplying the number of external content variations by the number of malicious instructions and the number of positions.
Comparing several of the most used open-source and closed-source LLMs, it could be concluded that they were all susceptible to indirect prompt injection attacks for most of the application tasks. Research shows that both GPT-4 and GPT-3.5 fall victim to such attacks, hence the importance of countermeasures. It was found that the performances in Chatbot Arena, as measured by Elo ratings, were positively related to ASRs on text tasks, but no systematic trend was observed for code tasks due to differences in the model’s approach to code generation. Also, ASRs for summarization tasks were higher than for table QA, email QA, and web QA due to the variation in prompt templates. Task-relevant and targeted text attacks were more successful than non-targeted attacks because models prioritized the text information related to the task at hand.
We summarize important results from the recent literature on the effectiveness of different defenses. Notably, at present, we are seeing that models have yielded reduced attack success rates as seen in Table 1 (regardless of target functionality), as well as maintained operational integrity under adversarial conditions—demonstrating considerable progress on LLM security. The new attack models, as mentioned in the above literature, display higher success rates as well, as summarized in Table 2.


We evaluated a variety of defense mechanisms against prompt injection attacks and found them not only somewhat successful but also fairly limited in scope. HOUYI was tested on LLM-integrated applications—36 were tested and 31 were identified as vulnerable (an attack success rate of 86.1%), suggesting more robust defenses are necessary in the near future. StruQ, tested against eleven types of prompt injection attacks, showed robust security by reducing attack success rates to less than 2% for most techniques on Alpaca and Mistral models, although it struggled against TAP attacks, reducing their success rate to 9% on Alpaca and 36% on Mistral. RA-LLM reduced attack success rates from up to 98.7% to around 10% for individual and transfer attacks on Vicuna-7B-v1.3-HF and Guanaco-7B-HF models. Additionally, adaptive system prompts and tuned summarizers demonstrated high efficacy, with the tuned summarizer reducing attack success rates to 2% on GPT-4 and 0% on GPT-3.5.
In certain experiments, VPI worked well, indicating effective steering of sentiment, especially OpenAI, which displayed varying success rates based on topic. LLM SELF-DEFENSE also led to improved accuracy in classifying harmful content of GPT-3.5 and LLaMA-2 with 99% and 94.6%, respectively. Another defense-based approach, Guardian, also successfully mitigated all the attack prompts on the LLaMA-2 model, which showed its capacity to uphold ethical standards in language models.
Despite such successes, some limitations and literature recommendations were found. Currently, StruQ is only capable of defending programmatic applications, which makes it vulnerable against web-based chatbots. It is shown that VPI settings do not address all the possible cases, and the evaluation was performed only for 7B and 13B models without considering other sizes. Further, virtual prompts and trigger scenarios make up the complexity throughout the planning and execution of an attack. It also suggests the importance of stronger protective measures against IPI attacks, especially for highly capable LLMs connected with various tools. Finally, future research directions include the creation of a comprehensive evaluation dataset to compare the effectiveness of VPI across different studies, the enhancement of simulations against one of the proposed attacks, namely the Completion attack and the TAP-generated attack, and scalability on the larger-scale model variants. In LLM SELF-DEFENSE, using concrete examples of harm, context-based learning, and logit biasing may provide extra layers of protection against such attacks.
It is crucial to note that benchmarks also have a significant responsibility in knowing and enhancing LLM security. PromptBench assesses LLM resilience against numerous types of adversarial prompts and attacks, defining measures such as PDR to compare models. The proposed INJECAGENT approach identifies the susceptibility of LLM agents to IPI attacks, with reference to realistic attack vectors that inflict financial loss and data theft. BIPIA extends the analysis to indirect attacks and shows that many models are vulnerable in different application tasks. These assist in establishing benchmarks that offer important information on specific areas of weakness and inform the enhancement of other better LLMs.
The importance of these benchmarks is that they can be used to quantitatively compare and analyze the level of defense in LLMs and to encourage the development of new, improved approaches to AI security. It helps reveal the deficits, encourages creativity in protective algorithms, and enhances confidence in artificial intelligence.
Indeed, prompt injection attacks are a very serious threat; however, the creation of progressively sophisticated protection measures and the constant search for universal standards are crucial. Through the regular reassessment and improvement of the LLM security, the AI community can guarantee that valuable and important models can be widely implemented while avoiding or preventing malicious manipulations.
This review describes the larger effect of Injection Attacks on Large Language Models, especially the prompt injection attack, and also cautions future researchers to come up with strong defenses and a range of benchmarks for the attack. While RA-LLM is proven effective, it has not been tested with better attacks. The future of LLM security should include more thorough red teeming as well as better alignment strategies, especially before the release of open source models [46].
Further directions for research are the extension of such types of attacks to a broader class of models, including multi-modal ones, and the further refinement of the possible harm in textual content generated by the models. The analysis of the optimization-based attack strategies and the corresponding remedies is timely, considering that even contemporary applications, interfaced with LLMs, continue struggling with full-scale recovery from the detected attacks.
Secondly, the nature and the interactive and timely characteristics of LLMs also complicate the evaluation of the effectiveness of these attacks, and a more adequate method of testing is needed. The problems with the believability of the post-produced content and the problems with intention to deceive seem to be lurking in the background of each new step that can be made in the use of advanced LLMs.
However, for parameterizing and for ‘whitewashing’ the corresponding inputs, more elaborate and sophisticated techniques should be used, and when it comes to such issues as filtering between the safe application’s calls and such potentially hostile instructions and/or conditions as allowed for by the LLMs, further work is needed. It is also important to reevaluate or remodel the benchmarks to fit new techniques and newer threats in the field. In addition, more concern should be paid to the primary utilized defense of frameworks like Signed-Prompt method in realizations. In the changing nature of cybersecurity threats, these methods should be applied to new trends of attacks and combined with other elements of security measures, for example, behavior analysis and anomaly detection.
Lastly, it should generalize the attacks to several settings and model scales and pay more attention to methods like VPI. Getting a broader perspective of the virtual prompts and trigger scenarios, and creating a single framework to assess the effectiveness of the attack, will be inevitable in the enhancement of security and solidity of LLMs in defeating the prompt injection attacks.
Acknowledgement: The author thanks and acknowledges the valuable contributions of the open-source research community, whose work on prompt injection attacks and defenses made this comprehensive review possible.
Funding Statement: The author did not receive funding from public, commercial, or non-profit sectors.
Availability of Data and Materials: This study is a literature review based on publicly available research papers and datasets. All sources cited in this review are available through their respective publishers and repositories. No new datasets were generated during this study. The references and citations provide complete access information for all materials used in this review.
Ethics Approval: This study is a literature review that does not involve human subjects, animal experiments, or the collection of primary data. Therefore, ethics approval was not required for this research.
Conflicts of Interest: The author declares no conflicts of interest to report regarding the present study.
Appendix A
• AI—Artificial Intelligence
• ASR—Attack Success Rates
• BAR—Benign Answering Rate
• BIPIA—Benchmark for Indirect Prompt Injection Attacks
• IPI—Indirect Prompt Injection
• LLM—Large Language Model
• OWASP—Open Worldwide Application Security Project
• PAP—Persuasive Adversarial Prompts
• PDR—Performance Drop Rate
• QA—Question-Answering
• RAC(.)—Robust Alignment Check function
• RA-LLM—Robustly Aligned LLM
• TCR—Traditional Character Replacement
• VPI—Virtual Prompt Injection
References
1. Floridi L, Chiriatti M. GPT-3: its nature, scope, limits, and consequences. Mines Mach. 2020;30(4):681–94. doi:10.1007/s11023-020-09548-1. [Google Scholar] [CrossRef]
2. Zhang M, Li J. A commentary of GPT-3 in MIT technology review 2021. Fundam Res. 2021;1(6):831–3. doi:10.1016/j.fmre.2021.11.011. [Google Scholar] [CrossRef]
3. Yao D, Zhang J, Harris IG, Carlsson M. FuzzLLM: a novel and universal fuzzing framework for proactively discovering jailbreak vulnerabilities in large language models. In: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2024 Apr 14–19; Seoul, Republic of Korea. p. 4485–9. doi:10.1109/ICASSP48485.2024.10448041. [Google Scholar] [CrossRef]
4. Liu X, Yu H, Zhang H, Xu Y, Lei X, Lai H, et al. Agentbench: evaluating LLMS as agents. arXiv:2308.03688. 2023. [Google Scholar]
5. Hou X, Zhao Y, Liu Y, Yang Z, Wang K, Li L, et al. Large language models for software engineering: a systematic literature review. ACM Trans Softw Eng Methodol. 2024;33(8):1–79. doi:10.1145/3695988. [Google Scholar] [CrossRef]
6. Yin Z, Ding W, Liu J. Alignment is not sufficient to prevent large language models from generating harmful information: a psychoanalytic perspective. arXiv:2311.08487. 2023. [Google Scholar]
7. Zou A, Wang Z, Carlini N, Milad Nasr JZK, Fredrikson M. Universal and transferable adversarial attacks on aligned language models. arXiv:2307.15043. 2023. [Google Scholar]
8. Goyal S, Doddapaneni S, Khapra MM, Ravindran B. A survey of adversarial defenses and robustness in NLP. ACM Comput Surv. 2023;55(14s):1–39. doi:10.1145/3593042. [Google Scholar] [CrossRef]
9. Wei A, Haghtalab N, Steinhardt J. Jailbroken: how does llm safety training fail? arXiv:2307.02483. 2023. [Google Scholar]
10. Mozes M, He X, Kleinberg B, Griffin LD. Use of llms for illicit purposes: threats, prevention measures, and vulnerabilities. arXiv:2308.12833. 2023. [Google Scholar]
11. Rossi S, Michel AM, Mukkamala RR, Thatcher JB. An early categorization of prompt injection attacks on large language models. arXiv:2402.00898. 2024. [Google Scholar]
12. Hines K, Lopez G, Hall M, Zarfati F, Zunger Y, Kiciman E. Defending against indirect prompt injection attacks with spotlighting. arXiv:2403.14720. 2024. [Google Scholar]
13. Shi J, Yuan Z, Liu Y, Huang Y, Zhou P, Sun L, et al. Optimization-based prompt injection attack to LLM-as-a-judge. arXiv:2403.17710. 2024. [Google Scholar]
14. Perez F, Ribeiro I. Ignore previous prompt: attack techniques for language models. arXiv:2211.09527. 2022. [Google Scholar]
15. Liu Y, Deng G, Xu Z, Li Y, Zheng Y, Zhang Y, et al. Jailbreaking chatgpt via prompt engineering: an empirical study. arXiv:2305.13860. 2024. [Google Scholar]
16. Yan B, Li K, Xu M, Dong Y, Zhang Y, Ren Z, et al. On protecting the data privacy of large language models (LLMSa survey. arXiv:2403.05156. 2024. [Google Scholar]
17. Phute M, Helbling A, Hull M, Peng SY, Szyller S, Cornelius C, et al. LLM self defense: by self examination, LLMS know they are being tricked. arXiv:2308.07308. 2024. [Google Scholar]
18. Qi X, Zeng Y, Xie T, Chen P-Y, Jia R, Mittal P, et al. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv:2310.03693. 2023. [Google Scholar]
19. Chan CF, Yip DW, Esmradi A. Detection and defense against prominent attacks on preconditioned LLM-integrated virtual assistants. In: 2023 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE); 2023 Dec 4–6; Nadi, Fiji. p. 1–5. doi:10.1109/csde59766.2023.10487759. [Google Scholar] [CrossRef]
20. Liu Y, Jia Y, Geng R, Jia J, Gong NZ. Prompt injection attacks and defenses in LLM-integrated applications. arXiv:2310.12815. 2023. [Google Scholar]
21. Bhardwaj R, Poria S. Red-teaming large language models using chain of utterances for safety-alignment. arXiv:2308.09662. 2023. [Google Scholar]
22. Li H, Chen Y, Luo J, Kang Y, Zhang X, Hu Q, et al. Privacy in large language models: attacks, defenses and future directions. arXiv:2310.10383. 2023. [Google Scholar]
23. Kumar A, Agarwal C, Srinivas S, Li AJ, Feizi S, Lakkaraju H. Certifying LLM safety against adversarial prompting. arXiv:2309.02705. 2024. [Google Scholar]
24. Chan C-M, Chen W, Su Y, Yu J, Xue W, Zhang S, et al. Chateval: towards better LLM-based evaluators through multi-agent debate. arXiv:2308.07201. 2023. [Google Scholar]
25. Tang Y, Wang B, Wang X, Zhao D, Liu J, Zhang J, et al. Rolebreak: character hallucination as a jailbreak attack in role-playing systems. arXiv:2409.16727. 2024. [Google Scholar]
26. Ding P, Kuang J, Ma D, Cao X, Xian Y, Chen J, et al. A wolf in sheep’s clothing: generalized nested jailbreak prompts can fool large language models easily. arXiv:2311.08268. 2023. [Google Scholar]
27. Wei Z, Wang Y, Li A, Mo Y, Wang Y. Jailbreak and guard aligned language models with only few in-context demonstrations. arXiv:2310.06387. 2023. [Google Scholar]
28. Zheng X, Pang T, Du C, Liu Q, Jiang J, Lin M. Improved few-shot jailbreaking can circumvent aligned language models and their defenses. arXiv:2406.01288. 2024. [Google Scholar]
29. Yuan Y, Jiao W, Wang W, Huang JT, He P, Shi S, et al. GPT-4 is too smart to be safe: stealthy chat with LLMs via cipher. arXiv:2308.06463. 2023. [Google Scholar]
30. Zhang T, Cao B, Cao Y, Lin L, Mitra P, Chen J. WordGame: efficient & effective LLM jailbreak via simultaneous obfuscation in query and response. arXiv:2405.14023. 2024. [Google Scholar]
31. Zhang R, Sullivan D, Jackson K, Xie P, Chen M. Defense against prompt injection attacks via mixture of encodings. arXiv:2504.07467. 2025. [Google Scholar]
32. Xian X, Wang T, You L, Qi Y. Understanding data poisoning attacks for RAG: insights and algorithms. In: The Thirteenth International Conference on Learning Representations, ICLR 2025; 2025 Apr 24–28; Singapore. p. 1–13. [Google Scholar]
33. Li C, Zhang J, Cheng A, Ma Z, Li X, Ma J. CPA-RAG: covert poisoning attacks on retrieval-augmented generation in large language models. arXiv:2505.19864. 2025. [Google Scholar]
34. Alon G, Kamfonas MJ. Detecting language model attacks with perplexity. In: The Twelfth International Conference on Learning Representations, ICLR 2024; 2024 May 7–11; Vienna Austria. p. 1–21. [Google Scholar]
35. Shi T, Zhu K, Wang Z, Jia Y, Cai W, Liang W, et al. Promptarmor: simple yet effective prompt injection defenses. arXiv:2507.15219. 2025. [Google Scholar]
36. Liu Y, Deng G, Li Y, Wang K, Wang Z, Wang X, et al. Prompt injection attack against LLM-integrated applications. arXiv:2306.05499. 2024. [Google Scholar]
37. Yan J, Yadav V, Li S, Chen L, Tang Z, Wang H, et al. Backdooring instruction-tuned large language models with virtual prompt injection, arXiv. arXiv:2307.16888. 2024. [Google Scholar]
38. Chen S, Piet J, Sitawarin C, Wagner D. Struq: defending against prompt injection with structured queries. arXiv:2402.06363. 2024. [Google Scholar]
39. Suo X. Signed-prompt: a new approach to prevent prompt injection attacks against LLM-integrated applications. arXiv:2401.07612. 2024. [Google Scholar]
40. Zeng Y, Lin H, Zhang J, Yang D, Jia R, Shi W, et al. How johnny can persuade LLMs to jailbreak them: rethinking persuasion to challenge AI safety by humanizing LLMs. arXiv:2401.06373. 2024. [Google Scholar]
41. Rai P, Sood S, Madisetti VK, Bahga A. GUARDIAN: A multi-tiered defense architecture for thwarting prompt injection attacks on LLMs. J Softw Eng Appl. 2024;17(1):43–68. doi:10.4236/jsea.2024.171003. [Google Scholar] [CrossRef]
42. Zhu K, Wang J, Zhou J, Wang Z, Chen H, Wang Y, et al. Promptbench: towards evaluating the robustness of large language models on adversarial prompts. arXiv:2306.04528. 2023. [Google Scholar]
43. Papineni K, Roukos S, Ward T, Zhu WJ. BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics—ACL '02; 2002 Jul 7–12; Philadelphia, PA. USA. p. 311–8. doi:10.3115/1073083.1073135. [Google Scholar] [CrossRef]
44. Zhan Q, Liang Z, Ying Z, Kang D. Injecagent: benchmarking indirect prompt injections in tool-integrated large language model agents. arXiv:2403.02691. 2024. [Google Scholar]
45. Yi J, Xie Y, Zhu B, Kiciman E, Sun G, Xie X, et al. Benchmarking and defending against indirect prompt injection attacks on large language models. arXiv:2312.14197. 2023. [Google Scholar]
46. Huang Y, Gupta S, Xia M, Li K, Chen D. Catastrophic jailbreak of open-source LLMs via exploiting generation. arXiv:2310.06987. 2023. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools