
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Zero-Shot Image Captioning Method Based on the Hamiltonian Monte Carlo
School of Computer and Information Engineering, Shanghai Polytechnic University, Shanghai, China
* Corresponding Author: Hengyang Wu. Email:
(This article belongs to the Special Issue: Advances in Artificial Intelligence for Engineering and Sciences)
Journal on Artificial Intelligence 2026, 8, 169-182. https://doi.org/10.32604/jai.2026.077462
Received 09 December 2025; Accepted 06 February 2026; Issue published 23 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Zero-shot learning as an emerging approach in image captioning techniques, has garnered significant attention from researchers in recent years due to its ability to accomplish tasks without requiring specific category training data. Existing zero-shot image captioning schemes largely rely on traditional language models, which exhibit low efficiency and suboptimal generation quality. To address this issue, this study proposes Hamiltonian Monte Carlo for Image Captioning (HMCIC). This method first models the image captioning task as a probabilistic sampling problem in parameter space, integrating semantic matching and syntactic coherence into an energy function to guide the generation process toward high-quality captions. Secondly, it introduces momentum variables from Hamiltonian dynamics, enabling the sampling process to traverse local optima and achieve smoother, more efficient exploration in parameter space, effectively mitigating the “random walk” phenomenon common in traditional sampling. Finally, by iteratively optimizing the sampling trajectory, the generated descriptions achieve a better balance between semantic accuracy and linguistic fluency. This enables more efficient and accurate zero-shot image captioning without requiring category-specific training. Experimental results on two public datasets demonstrate that compared to other current zero-shot methods, our approach achieves nearly 1.5 times faster average generation speed while also improving word generation accuracy. This indicates the effectiveness of the proposed method.Keywords
With the rapid advancement of deep learning technologies [1], interdisciplinary research at the intersection of computer vision and natural language processing has emerged as a key focus area within artificial intelligence. Image captioning [2], as one of its core tasks, aims to automatically generate accurate and coherent textual descriptions by understanding the content of images. This technology not only requires extracting semantic information from visual data but also transforming it into linguistically coherent expressions, thereby demonstrating broad application potential in fields such as intelligent question-answering, medical assistance, and human-computer interaction.
Early image captioning models were predominantly based on supervised learning frameworks, integrating structures such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs). For instance, the classic “Show and Tell” approach mapped image features to textual descriptions through an encoder-decoder architecture. With the rise of Transformer models and attention mechanisms, multimodal pre-trained models like ViLBERT and OSCAR achieved performance breakthroughs by fusing visual and linguistic features. However, these approaches remain heavily reliant on large-scale labeled datasets and lengthy training processes. In practical applications, scenarios with high annotation costs limit their applicability. To address this challenge, emerging zero-shot [3] methods (e.g., ZeroCap [4] and ConZIC [5]) combine CLIP’s image-text matching capabilities with generative models to generate descriptions without training data. However, these approaches often suffer from excessive generation times due to traversing vast vocabularies, hindering practical deployment.
Although existing zero-shot methods have achieved certain results in generation quality, their inefficient sampling constrains generation speed. ZeroCap pioneered the integration of CLIP’s visual-language alignment capability with GPT-2’s language generation features, iteratively generating words through gradient optimization. While it overcomes reliance on supervised data, its autoregressive generation mechanism [6] requires sequential processing of context for each lexeme, significantly hindering computational efficiency. More critically, ZeroCap’s unidirectional generation mode fails to leverage global semantic information, often resulting in limited lexical diversity and rigid syntactic structures. Addressing this issue, ConZIC proposes a non-autoregressive framework based on Gibbs Sampling. It enhances generation quality through parallel candidate word generation and bidirectional attention mechanisms [7], while introducing controllable signals to boost application flexibility. However, ConZIC still requires traversing a large candidate word list in each iteration to maintain generation quality, resulting in high time complexity and severe speed bottlenecks in long-text scenarios.
The main contributions of this paper can be summarized in two points. First, we propose HMCIC, an image captioning method based on Hamiltonian Monte Carlo sampling, which transforms the energy conservation principle of physical systems into a highly efficient sampling strategy. When paired with a large language model, the number of generated candidate words is reduced, significantly improving generation efficiency. Second, it achieves synergistic optimization of efficiency and performance across mainstream datasets. Experimental results on two public datasets demonstrate a 1.5-fold increase in generation speed compared to ConZIC, while maintaining comparable content accuracy. This lays a solid foundation for the real-time deployment of zero-shot image captioning technology.
Traditional image captioning methods predominantly employ template-based or retrieval-based strategies. With breakthroughs in deep learning technology and the emergence of large-scale annotated datasets, end-to-end deep learning architectures based on supervised training have rapidly become the mainstream paradigm in this field [8]. Traditional deep learning models typically follow an “Encoder-Decoder” framework: pre-trained convolutional neural networks encode input images to extract high-level, semantically meaningful feature vectors or feature maps [9], performing visual feature extraction (Encoder). Recurrent neural networks, primarily Long Short-Term Memory (LSTM) networks and their variants, decode the extracted visual features to generate descriptive text word-by-word (Decoder). To enhance description quality, researchers have integrated multiple techniques: directly optimizing evaluation metrics via reinforcement learning, designing scene graph-based structured representations to facilitate visual relationship inference, and introducing high-level semantic attributes as intermediate steps to assist generation. Overall, traditional supervised deep learning approaches have achieved remarkable success in image captioning tasks through CNN-RNN/Transformer architectures with attention mechanisms, relying on large-scale manually annotated image-text paired datasets. However, the performance of such methods is highly dependent on the scale and quality of annotated data, which is costly to acquire and difficult to generalize to unseen open-domain scenarios [10].
With the advancement of multimodal pre-trained models, image captioning research has expanded from static images to dynamic videos, giving rise to various innovative paradigms aimed at enhancing controllability and adaptability in generation. Within the broader field of image captioning, controllability has emerged as a critical dimension for improving description quality. For instance, in video description tasks, Ma et al. [11] noted that existing end-to-end models are often constrained by the averaging effect of training data, making it challenging to generate descriptions with specific stylistic characteristics (such as level of detail or focus on actions). To address this, they proposed a style-aware two-stage learning framework. By incorporating explicit style vectors and an adaptive video style encoder, this approach enables fine-grained control over generated text length, action complexity, and object granularity. This work underscores the importance of introducing explicit guidance signals in visual generation, aligning with the underlying logic of this paper’s approach—using an energy function to steer text generation—by introducing additional constraints or potential energy to guide the generation process toward a more optimal semantic space.
To address the strong data dependency issue in supervised learning, zero-shot image captioning techniques have emerged. Test-Time Adaptation (TTA) is revolutionizing the landscape of zero-shot image captioning as a technique enabling cross-domain generalization without extensive fine-tuning. The recently proposed Retrieval-Enhanced Test-Time Adaptation (RETTA) [12] framework by Ma et al. bridges frozen visual and language models by introducing learnable tokens. Unlike traditional fine-tuning, RETTA performs rapid gradient optimization (approximately 16 iterations) during inference for each specific video. It leverages retrieved external textual knowledge and CLIP scores as soft targets to achieve efficient zero-shot video description. This “inference-time optimization” strategy demonstrates that significant improvements in generation quality can be achieved solely by adjusting inputs or search paths, without updating model parameters.
The efficiency bottleneck of existing zero-shot methods stems from the limitations of sampling strategies [13]. Monte Carlo methods require extensive iterations to approximate steady-state distributions due to their random walk nature, while Gibbs sampling, though accelerating convergence through conditional probability optimization, remains constrained by local oscillations in high-dimensional spaces [14]. Recent studies have attempted to introduce variational autoencoders or reinforcement learning to optimize search paths, but these methods often introduce additional training overhead, violating the zero-shot premise. Achieving efficient, directed search without relying on fine-tuning has become a critical challenge requiring breakthroughs in this field [15]. Although existing zero-shot image captioning methods have achieved unsupervised generation by incorporating CLIP, they still face challenges in terms of exploration efficiency in latent space and accuracy of semantic localization. To address attention bias and feature misalignment issues in deep models for complex visual tasks, recent research has extensively explored introducing external guidance signals and leveraging advanced semantic paradigms from pre-trained models. In terms of leveraging external prior knowledge, the “Gaze-and-Machine Dual-Driven Attention Fusion Network” proposed by Peng et al. [16] offers significant insights. Addressing the common “shortcut learning” issue in medical image classification, this work innovatively incorporates radiologist gaze data as a supervisory signal. By constructing dual-encoder architecture and designing an attention fusion mechanism, the network forces the model’s focus to align with human experts’ visual cognitive patterns. This effectively filters background noise and precisely locates pathological regions. On the other hand, the application boundaries of CLIP models are continuously expanding, particularly in weakly supervised learning and anomaly detection. The “VPE-WSVAD” framework proposed by Su et al. [17] demonstrates the immense potential of visual prompting in addressing data scarcity issues. Confronting class imbalance and missing labels in video anomaly detection, this approach leverages CLIP’s robust generalization capabilities to design learnable visual prompt exemplars that characterize the semantic prototypes of normal and abnormal events. In summary, whether through explicit attention correction using human gaze data or implicit semantic clustering via visual cues, the core objective remains enhancing the model’s representational robustness in low-resource environments. Inspired by this, HMCIC pioneers the application of Hamiltonian Monte Carlo (HMC) to zero-shot image captioning tasks. It resolves the trade-off between efficiency and diversity through a sampling mechanism inspired by physical dynamics. By introducing momentum variables to construct phase space trajectories in parameter space, HMC transforms random walks into momentum-driven directed exploration, significantly enhancing sampling efficiency [18]. Simultaneously, HMCIC employs adaptive candidate word selection based on a hybrid probability distribution (language model confidence and CLIP matching score), reducing redundant computations by 50% compared to ConZIC’s fixed K-value strategy. This approach enhances zero-shot image captioning speed while preserving diversity.
This paper enhances the Hamiltonian Monte Carlo algorithm by transforming its momentum direction search into a feature search within vector space. Leveraging its “directional” search capability, it achieves efficient candidate word selection and directional iteration. Ultimately, this approach reduces the number of iterations while maintaining candidate word accuracy, thereby improving the overall efficiency of image captioning.
Given an input image I, HMCIC aims to generate text descriptions semantically aligned with the image through a zero-shot approach. Its generation process is modeled as a joint optimization of linguistic fluency (evaluated by a language model) and image relevance (measured by CLIP model) [19]. Compared to traditional approaches, HMCIC’s core innovation lies in abandoning Gibbs Sampling’s random search strategy in favor of introducing Hamiltonian Monte Carlo—a physics-inspired dynamic sampling mechanism. Its generation process comprises several stages. First, a pre-trained language model generates an initial text sequence x0 containing noise, serving as the initial position state of the dynamical system. Next is Hamiltonian dynamic sampling, which is the key component of this method. As shown in the blue module of Fig. 1, we introduce an auxiliary momentum variable
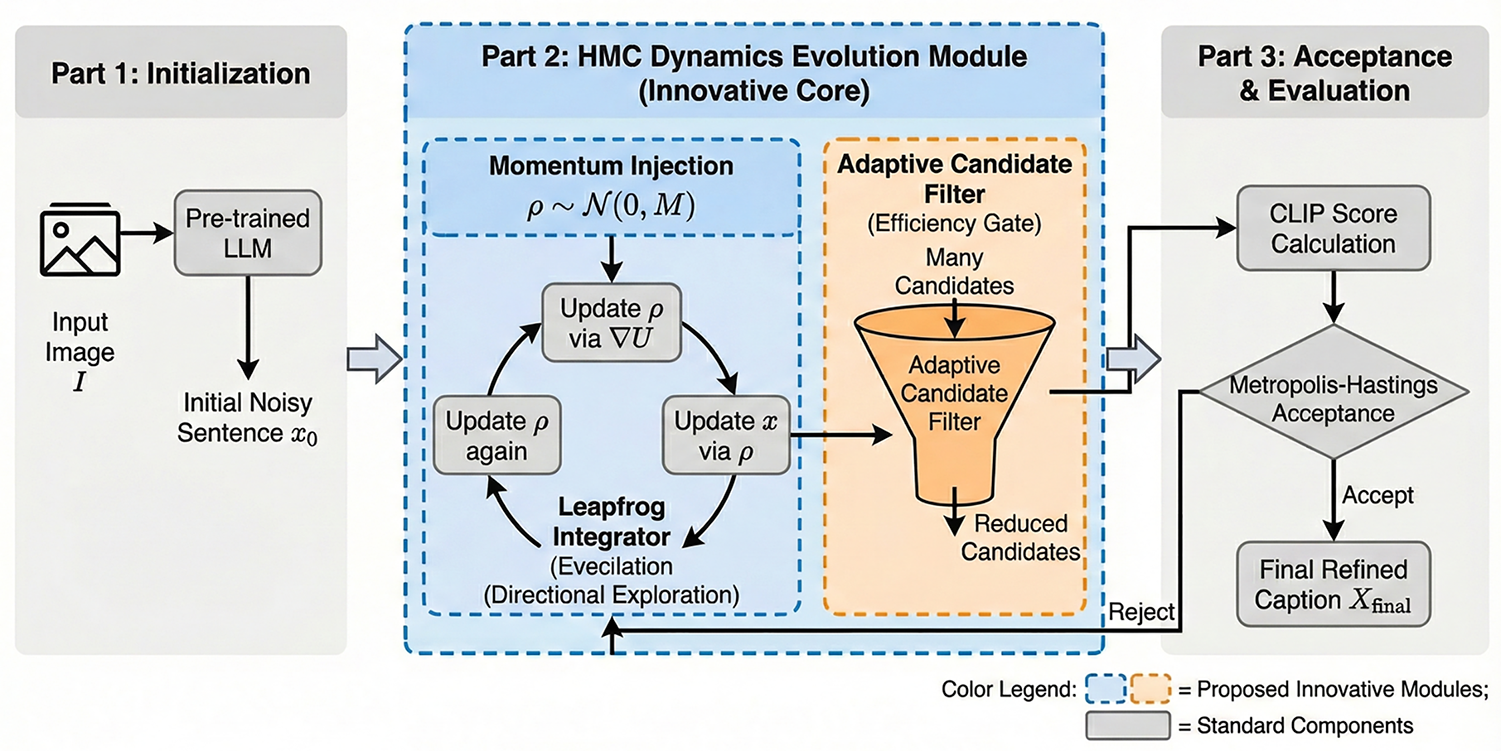
Figure 1: HMCIC generation framework architecture.
3.2 Hamiltonian System Construction
To model the probability of each word, previous zero-shot methods typically employ sequential autoregressive models such as:
However, this autoregressive generation method often leads to issues such as sequential error accumulation and lack of diversity. Gibbs sampling iteratively samples the conditional probability
This flexible sampling order improves the collapse issue in autoregressive text generation [20], thereby enhancing the diversity of generated content. However, as shown in Fig. 2A, Gibbs sampling exhibits a “random walk” behavior in high-dimensional discrete text spaces. Without explicit guidance from gradient directions, the sampling process is prone to “high-frequency oscillations” near local optima, resulting in significant computational resources being wasted on evaluating ineffective candidate words. Simultaneously, this directionless search struggles to overcome energy barriers, often falling into repetitive or generic descriptive patterns, thereby limiting the accuracy of generated text.
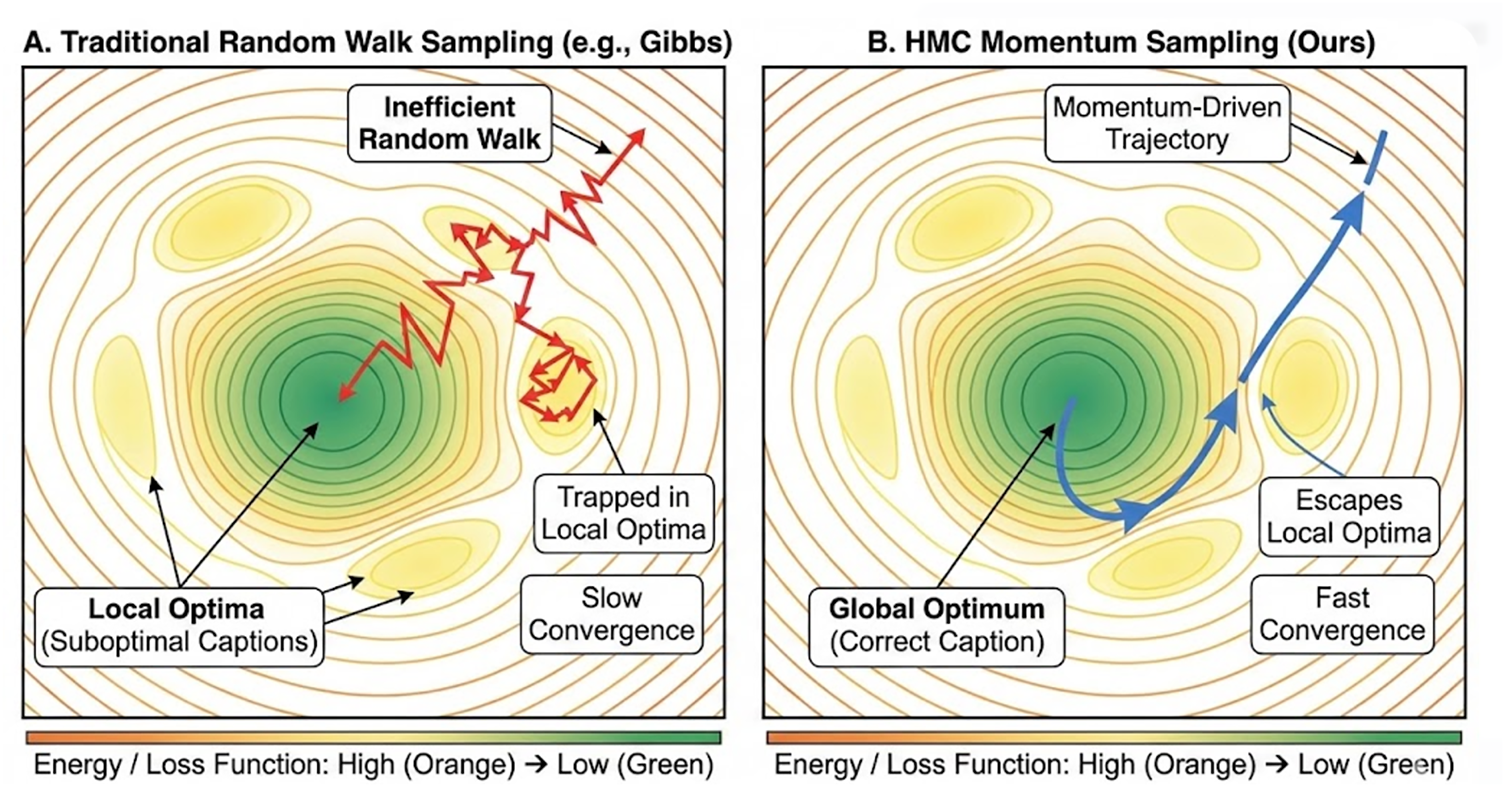
Figure 2: Comparison of exploration trajectories in parameter space.
Therefore, HMCIC equates the text generation process to particle motion in phase space—a concept from physics and dynamical systems theory describing all possible states of a system. This mathematical space represents each point as a specific state of the system. As shown in Fig. 2B, we model text generation as particle motion in phase space. The core distinction of HMC from traditional Markov Chain Monte Carlo (MCMC) methods lies in the introduction of momentum variables. In word sampling tasks, the word embedding space is typically a high-dimensional discrete space (e.g., the vocabulary of BERT/RoBERTa). Traditional methods like Gibbs sampling update words sequentially via random walks, making them prone to local optima or repetitive patterns [21]. HMC, however, models the sampling process as a momentum-driven dynamical system evolution:
To mathematically formalize this process, we define the Hamiltonian
Subsequently, the position variable evolves efficiently in the parameter space driven by the updated momentum:
Finally, the momentum completes the step with another gradient evaluation at the new position. This symplectic integration scheme ensures energy conservation and allows the system to traverse high-probability regions effectively. Upon convergence, the final continuous state
After using HMCIC to guide text generation for word sampling, several candidate words are generated. This process relies solely on text generation based on language models and the Hamiltonian Monte Carlo algorithm. To ensure relevance between the generated content and the given image, similarity detection between images and text is also required. Here, we introduce the CLIP model. Through pre-training on large-scale datasets, it has acquired extensive visual and linguistic knowledge, granting it significant advantages in zero-shot learning [23].
Specifically, when sampling each word, HMCIC first provides several candidate words based on its predicted lexical distribution. These candidates then replace the MASK token at that position, yielding multiple candidate sentences. At this stage, the CLIP model calculates a matching score for each sentence-higher scores indicate better alignment. This process can be summarized as follows:
here, K represents K candidate words that form Sk candidate sentences.
4.1 Datasets and Experimental Details
MSCOCO is a widely used computer vision dataset primarily employed for tasks such as object detection, image segmentation, and image captioning. The dataset comprises a training set of approximately 118,000 images, a validation set of about 5000 images, and a test set of roughly 41,000 images, covering diverse scenarios including daily life, natural landscapes, and urban environments. Each image is accompanied by five manually generated natural language descriptions, providing extensive data support for model training and evaluation.
Visual Genome is a large-scale, multi-task, fine-grained annotated visual understanding dataset. Its annotations are more semantically rich—for example, instead of merely labeling “dog”, it might specify “a brown dog running on the grass”. It provides abundant visual-language pairs suitable for multimodal learning research. While it shares approximately 50,000 images with MSCOCO, its annotations are significantly more detailed.
All experiments were conducted on frozen pre-trained models without any fine-tuning. Specifically, the CLIP-VIT-B/32 image-text matching module was selected, with two distinct language models serving as the Large Language Models (LLM) components: RoBERTa-base and Muppet-RoBERTa-base. During experimentation, the candidate word list length K was set to 200, and the iteration count T was fixed at 10. The improvement in this experiment lies in enhancing both efficiency and accuracy in candidate word processing [24]. Therefore, by altering sentence lengths during experimentation and recording experimental data, the effectiveness of the HMCIC method can be intuitively demonstrated. To ensure consistency in experimental conditions, all experiments were conducted on a single RTX 3090 GPU.
4.2 Accuracy and Diversity Assessment
Since this experiment is based on an improvement to zero-shot learning methods, the primary evaluation focuses on the accuracy of generated content and the diversity of generated words [25]. For evaluation metrics, we selected a subset of supervised metrics requiring human reference, including BLEU-4, METEOR, CIDEr, and SPICE [26]. Additionally, we included one unsupervised metric, CLIPScore [27]. CLIPScore is a reference-free metric measuring similarity between images and their corresponding content, representing the most critical evaluation metric for zero-shot image captioning.
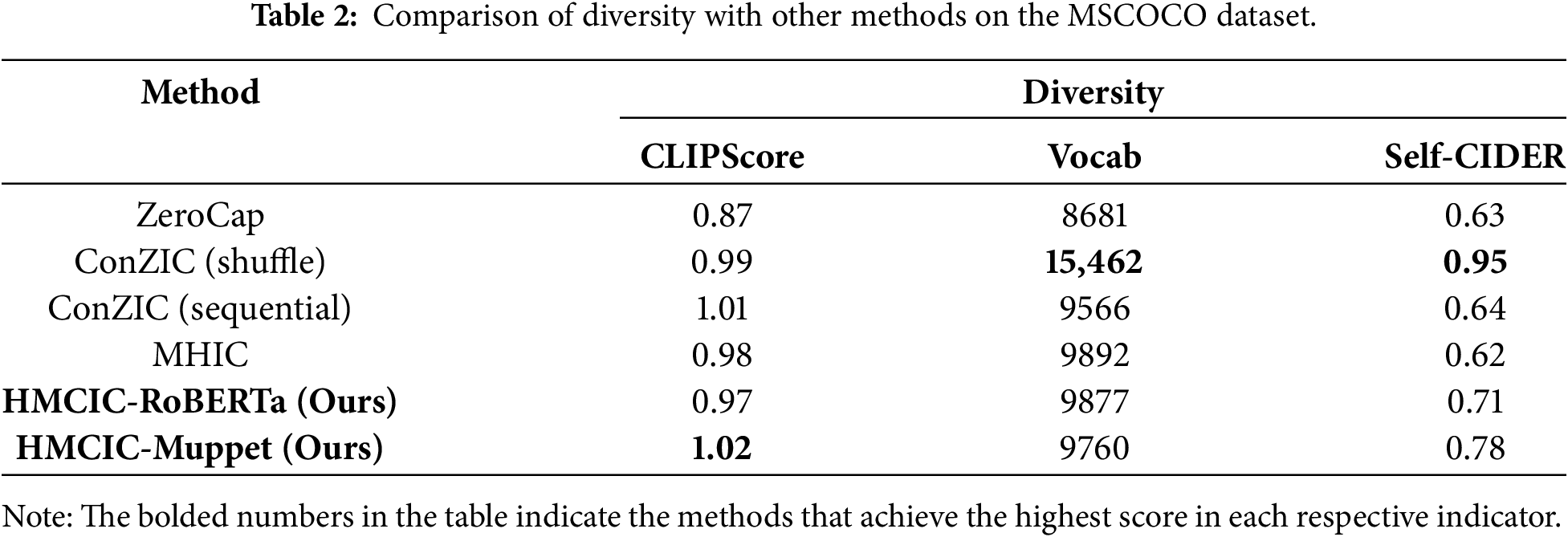
Another vital aspect of image caption generation is evaluating the diversity of generated content. Two metrics are employed here: Vocab and Self-CIDER. Vocab measures the total number of unique words across all generated captions in the test set, reflecting the diversity of outputs from different methods. Self-CIDER is a widely adopted diversity metric based on pairwise similarity between captions. The experimental setup includes several method selections: ZeroCap, ConZIC (shuffle), ConZIC (sequential), and Metropolis-Hastings for Image Captioning (MHIC). Zero-shot image captioning encompasses two subfields: Training-Free and Text-Only Training. Training-Free involves no model parameter updates and no exposure to image description text corpora, relying entirely on the general capabilities of pretrained models. The methods mentioned above fall into this category. Additionally, we introduce MeaCap, a method combining Training-Free with Retrieval-Augmented Generation (RAG). Text-Only Training permits decoder training using pure text from target domains (e.g., COCO). We investigate two such approaches: Image-like retrieval and frequency-based entity filtering for zero-shot captioning (IFCap) and Mining neural composition for zero-shot image captioning via text-only training (MncCap). Experiments were conducted on the classic, widely used MSCOCO dataset, comparing the proposed method with current state-of-the-art approaches.
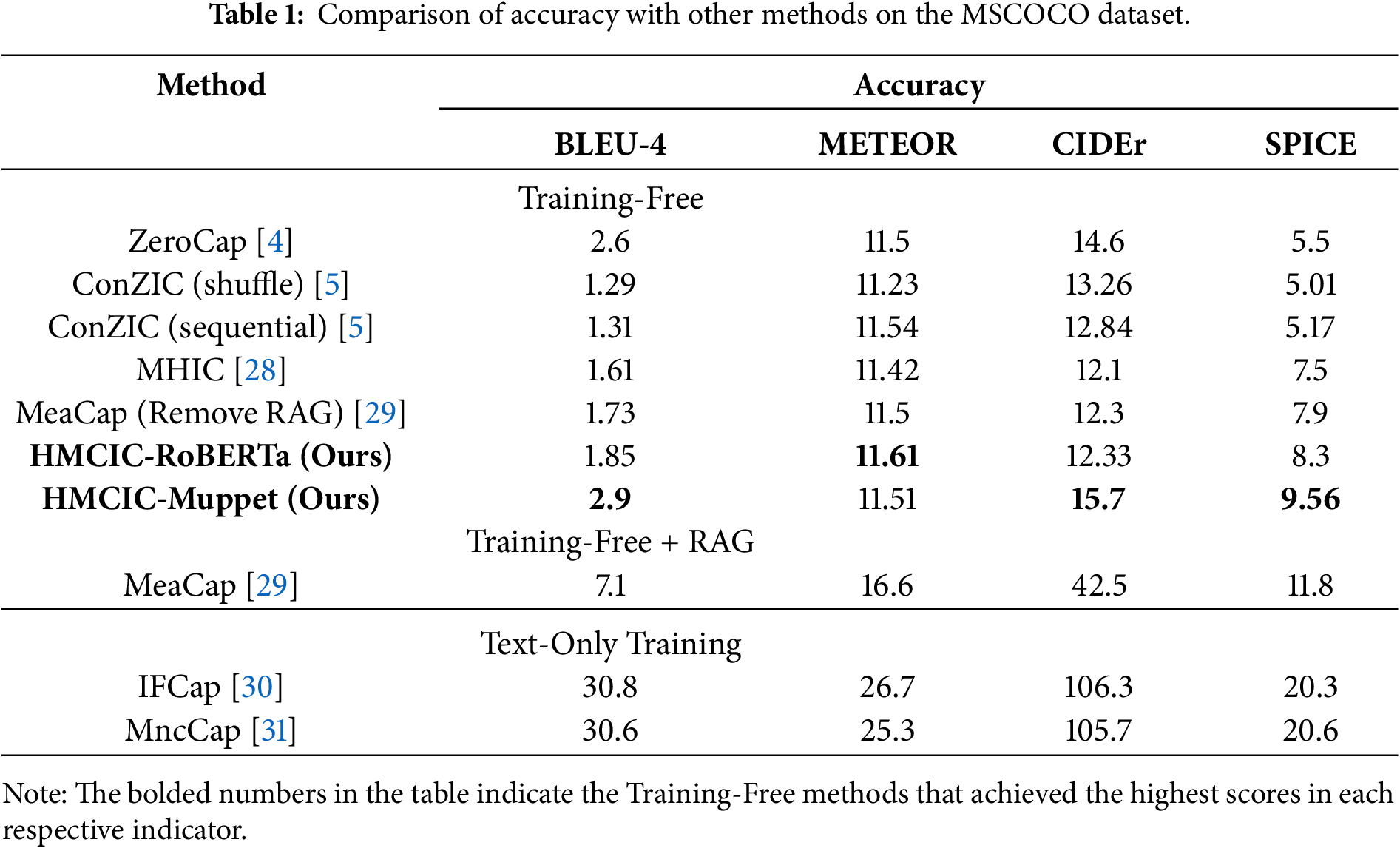
Table 1 presents the performance of state-of-the-art zero-shot methods and our approach on the MSCOCO dataset. HMCIC’s metrics fall significantly below those of IFCap and MncCap, but as a plug-and-play sampling strategy, HMCIC offers flexibility unmatched by Text-Only Training methods. HMCIC does not require retraining the decoder for each new domain, significantly enhancing its versatility. Meanwhile, MeaCap achieves substantial metric improvements through retrieval-augmented techniques, offering valuable reference points for scenarios where external memory repositories can be leveraged. Since the Text-Only Training method employs plain text from the target domain to train the decoder, it has “seen” the text distribution of that domain. Consequently, its linguistic style aligns more closely with human annotations, and its diversity naturally cannot compare to all Training-Free methods. Therefore, it is not included in Table 2 for comparison. It is evident that zero-shot methods achieve relatively low scores on supervised metrics such as BLEU-4, METEOR, CIDEr, and SPICE. This is expected, as supervised methods trained on the MSCOCO dataset can benefit from domain alignment, enabling models to generate content similar to training data. However, this leads to stylistically homogeneous outputs, hindering diversity. The two diversity metrics in Table 2 corroborate this: current state-of-the-art supervised methods generally achieve Vocab scores below 3000 words. ConZIC (shuffle) achieves high diversity metrics by generating content with completely randomized word order. Compared to other zero-shot methods, our approach demonstrates improved accuracy across multiple metrics. Performance across accuracy metrics and both diversity measures further demonstrates HMCIC’s capability to generate both accurate and diverse content. The superiority exhibited by HMCIC opens new possibilities for zero-shot image captioning tasks.
4.3 Effectiveness Assessment of Sampling Strategy
This paper proposes the HMCIC framework to overcome the limitations of traditional Gibbs sampling through a sampling mechanism inspired by physical dynamics. To further validate the effectiveness of the HMCIC framework, we designed a set of orthogonal comparative experiments. This experiment fixes two variables: sampling strategy (using ConZIC, MHIC, and the proposed HMCIC, respectively) and large language model (using RoBERTa and Muppet-RoBERTa, respectively). The goal is to isolate the contributions of the large language model’s capabilities and the algorithmic strategy.
The experimental results are shown in Table 3. Through comparison, we can observe that when the language model is fixed as RoBERTa-base, HMCIC outperforms ConZIC based on Gibbs sampling and MHIC based on Metropolis-Hastings. Similarly, when the large language model is upgraded to Muppet-RoBERTa-base, HMCIC maintains its leading advantage over other sampling strategies. This result strongly demonstrates that the performance improvement primarily stems from the momentum-driven directional search mechanism introduced by HMC, rather than relying solely on the number of parameters or pre-training knowledge of the LLM.
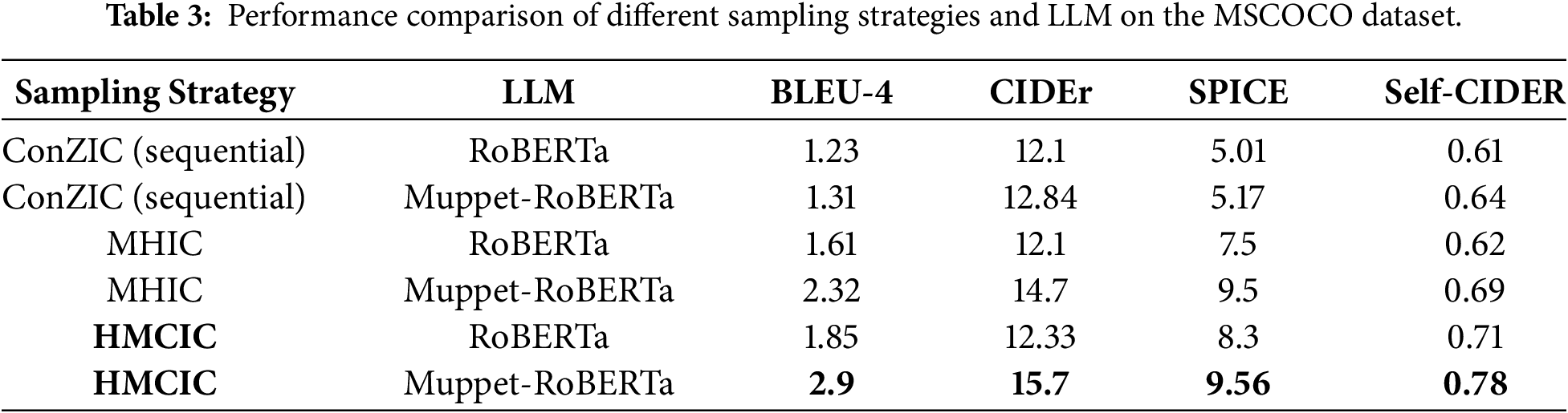
Comparing performance across different large language models, while stronger LLMs (Muppet-RoBERTa) generally improve metrics for all methods, HMCIC achieves optimal accuracy and diversity on both models. Particularly in the HMCIC-RoBERTa combination, certain metrics (e.g., BLEU-4, SPICE) even surpass those achieved by combinations using more powerful language models but weaker sampling strategies (e.g., ConZIC-Muppet-RoBERTa). This further demonstrates that the proposed HMCIC framework serves as a universal, efficient sampling layer capable of functioning independently of the underlying language model, effectively optimizing the parameter space exploration process for zero-shot generation. In summary, HMCIC’s effectiveness stems from its unique Hamiltonian dynamics sampling mechanism, which integrates well with diverse large language models, confirming the robustness and core contribution of this approach.
To visually evaluate the generation quality and speed of different methods, Fig. 3 presents a comparison of generation examples from other methods (ConZIC, MHIC) and the proposed HMCIC method across various scenarios.
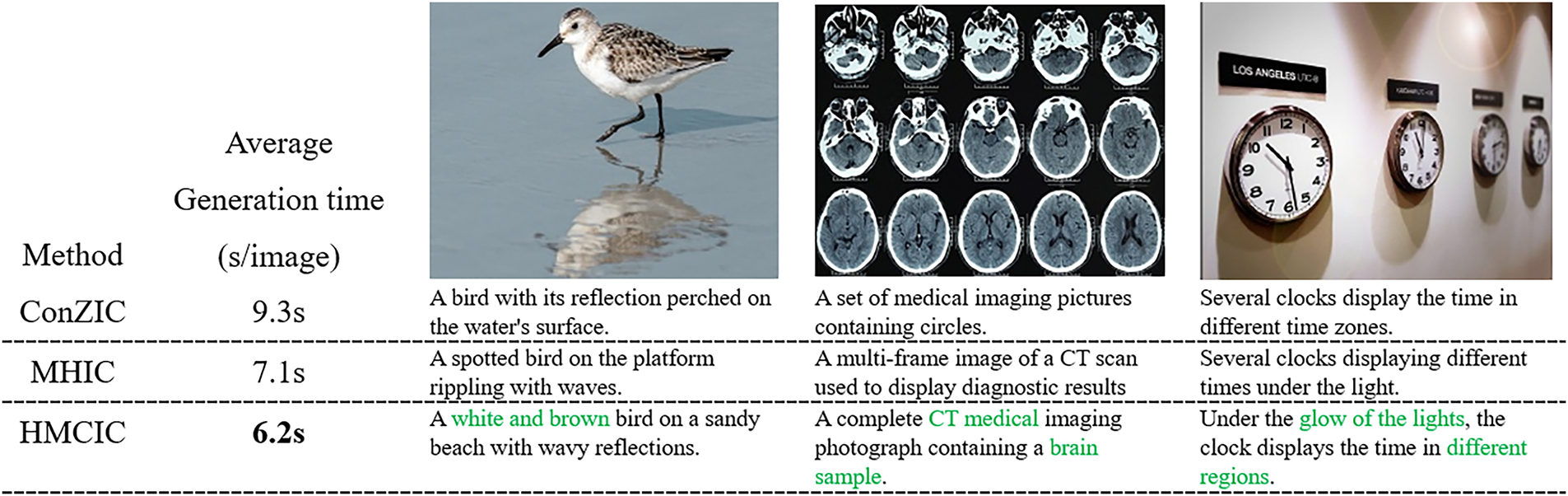
Figure 3: Given an image, the descriptions and average processing times produced by three different methods. The green text highlights HMCIC’s ability to capture image details.
The visualization results demonstrate that HMCIC outperforms the two previously mentioned methods in semantic alignment and linguistic fluency. Specifically, when confronted with complex scenes (such as the second image in Fig. 3), descriptions generated by other methods (e.g., ConZIC) often rely on global features, failing to accurately capture finer details within the image (the brain CT scan depicted). HMCIC-generated captions not only exhibit smoother syntax but also accurately identify fine-grained features in images (e.g., specific object colors or action details), avoiding the “logical discontinuities” commonly observed in Gibbs sampling. Simultaneously, the directed exploration of parameter space by Hamiltonian momentum reduces unnecessary search processes, resulting in a significant overall improvement in generation speed. This further validates that the momentum mechanism effectively enhances generation speed while maintaining accuracy.
4.4 Generation Speed Assessment
Traditional zero-shot image captioning methods typically rely on a global traversal of large-scale candidate word lists, meaning that for each candidate word generated by the language model, its CLIP matching score with the image is directly computed. While this strategy ensures comprehensive search coverage, it incurs significant computational overhead. Particularly when dealing with large vocabularies and generating lengthy texts, the time complexity escalates sharply, severely limiting the method’s practicality and real-time performance. Therefore, the HMCIC method introduces a candidate selection mechanism based on Hamiltonian Momentum Sampling. Through momentum-guided directed search, this approach dynamically evaluates and filters high-potential candidates during each iteration, performing subsequent CLIP matching computations only on this subset. This effectively reduces redundant calculations caused by invalid or low-probability candidates. However, research also reveals that as the generated sentence length increases, the number of potential candidate words the model must process continues to grow accordingly. This leads to an overall increase in the computational burden of sampling and matching, gradually slowing down the generation speed. This phenomenon is visually demonstrated in Fig. 4: Although HMCIC maintains a speed advantage across different sentence lengths, its generation time still gradually increases with length. This indicates that while HMCIC alleviates computational pressure through sampling and filtering, the combinatorial explosion problem in long-text generation remains a critical factor affecting real-time performance.
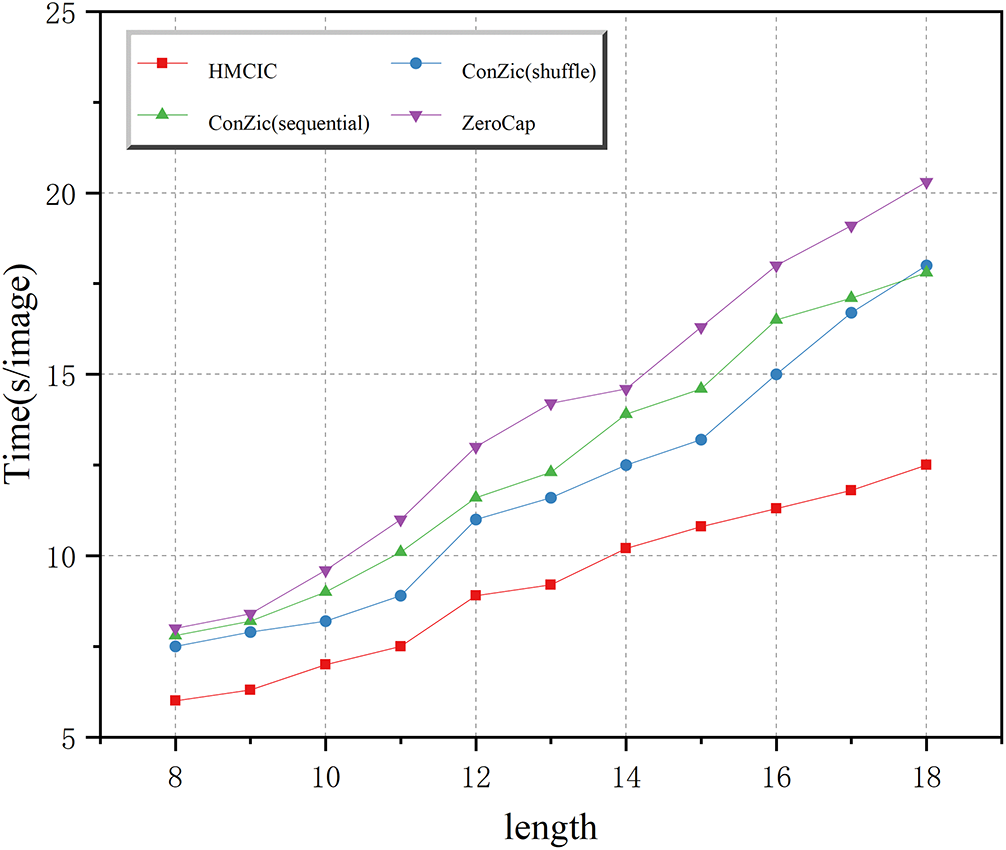
Figure 4: Generation time for different methods.
During the generation process, compared to systems like ConZIC that suffer from inefficient exploration in discrete text spaces, HMCIC provides a certain degree of “directionality”. As shown in Fig. 5, the CLIPScore metric further improves with increasing sentence length and iteration count. When sentence length and iteration count increase, more momentum updates occur, allowing HMCIC’s momentum direction to be better adjusted. This indicates that while enhancing generation speed, it also maintains the quality of generated content.
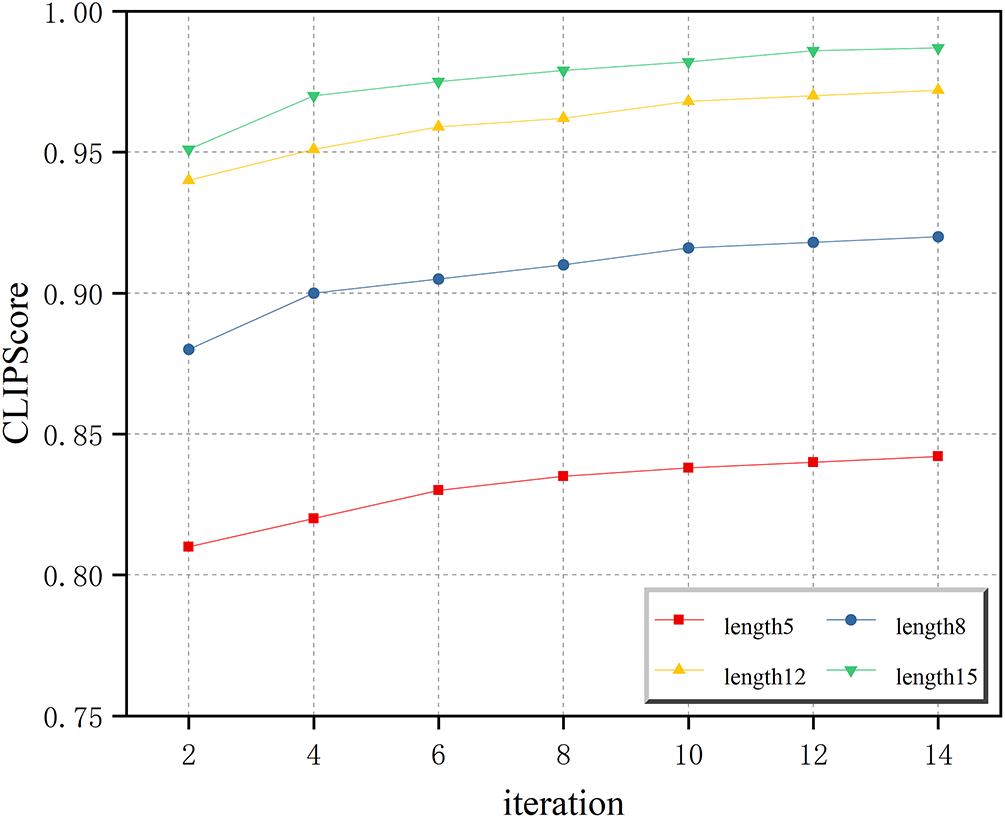
Figure 5: CLIPScore scores for sentences of varying lengths.
This study addresses the issues of inefficient sampling and limited generation quality in existing zero-shot image captioning methods by proposing HMCIC, a zero-shot image captioning method based on Hamiltonian Monte Carlo sampling. By modeling the text generation process as an energy optimization problem in a dynamical system and introducing momentum variables, this method achieves efficient, directional exploration of the parameter space, significantly reducing the random walk behavior and redundant computations inherent in traditional approaches. Experiments demonstrate that HMCIC outperforms current mainstream zero-shot methods across multiple accuracy metrics while achieving significant improvements in generation speed, validating its effectiveness and practicality for high-efficiency cross-modal generation tasks.
Although HMCIC strikes a favorable balance between generation efficiency and quality, this study identifies limitations when generating long texts: beyond a certain sentence length threshold, accumulated momentum may deviate from global semantics, compromising generative coherence. This points to directions for further optimizing the dynamical sampling mechanism and enhancing long-range semantic modeling capabilities.
Looking ahead, the proposed dynamic sampling framework not only provides new methodological support for zero-shot image captioning tasks but also offers insights for broader multimodal generation tasks such as visual question answering, cross-modal retrieval, and video description generation. Future work may focus on the following directions: First, exploring more robust momentum update strategies to enhance the model’s adaptability to long texts and complex semantic structures; Second, integrating curriculum learning or progressive generation mechanisms to further optimize the trade-off between generation efficiency and quality; Third, extending the HMCIC framework to more pre-trained vision-language models to validate its generalization performance across different architectures and tasks. In summary, HMCIC provides an efficient and feasible technical pathway for cross-modal content generation without requiring supervised data, demonstrating strong theoretical significance and practical application potential.
Acknowledgement: We would like to express our gratitude to the teachers and fellow students who provided assistance during the writing of this article.
Funding Statement: This work is supported by the National Natural Science Foundation of China (No. 62162014).
Author Contributions: Long Li was responsible for the primary research execution, including algorithm development, implementation, data analysis, and drafting the manuscript. Hengyang Wu and Na Wang contributed to the manuscript by providing revision suggestions. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The authors confirm that the data supporting the findings of this study are available within the article.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Sharifani K, Amini M. Machine learning and deep learning: a review of methods and applications. World Inf Technol Eng J. 2023;10(7):3897–904. [Google Scholar]
2. Stefanini M, Cornia M, Baraldi L, Cascianelli S, Fiameni G, Cucchiara R. From show to tell: a survey on deep learning-based image captioning. IEEE Trans Pattern Anal Mach Intell. 2023;45(1):539–59. doi:10.1109/TPAMI.2022.3148210. [Google Scholar] [PubMed] [CrossRef]
3. Pourpanah F, Abdar M, Luo Y, Zhou X, Wang R, Lim CP, et al. A review of generalized zero-shot learning methods. IEEE Trans Pattern Anal Mach Intell. 2023;45(4):4051–70. doi:10.1109/TPAMI.2022.3191696. [Google Scholar] [PubMed] [CrossRef]
4. Tewel Y, Shalev Y, Schwartz I, Wolf L. ZeroCap: zero-shot image-to-text generation for visual-semantic arithmetic. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. Piscataway, NJ, USA: IEEE; 2022. p. 17897–907. doi:10.1109/CVPR52688.2022.01739. [Google Scholar] [CrossRef]
5. Zeng Z, Zhang H, Lu R, Wang D, Chen B, Wang Z. ConZIC: controllable zero-shot image captioning by sampling-based polishing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 23465–76. doi:10.1109/CVPR52729.2023.02247. [Google Scholar] [CrossRef]
6. Xie Y, Wen J, Lau KW, Ur Rehman YA, Shen J. What should be equivariant in self-supervised learning. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2022 Jun 19–20; New Orleans, LA, USA. p. 4110–9. doi:10.1109/CVPRW56347.2022.00456. [Google Scholar] [CrossRef]
7. Galassi A, Lippi M, Torroni P. Attention in natural language processing. IEEE Trans Neural Netw Learn Syst. 2021;32(10):4291–308. doi:10.1109/TNNLS.2020.3019893. [Google Scholar] [PubMed] [CrossRef]
8. Ge J, Liu Y, Gui J, Fang L, Lin M, Kwok JT, et al. Learning the relation between similarity loss and clustering loss in self-supervised learning. IEEE Trans Image Process. 2023;32(11):3442–54. doi:10.1109/TIP.2023.3276708. [Google Scholar] [PubMed] [CrossRef]
9. Li MM, Jiang AW, Long YZ, Ning M, Peng H, Wang MW. A visual storytelling algorithm based on fine-grained image features and knowledge graph. J Chin Inf Process. 2022;36(9):139–48. (In Chinese). [Google Scholar]
10. Luo JH, Zhang YL. Evolution and educational application of discipline knowledge graph driven by multimodal large model. Mod Educ Technol. 2023;33(12):76–88. (In Chinese). doi:10.7490/f1000research.1114633.1. [Google Scholar] [CrossRef]
11. Ma Y, Zhu Z, Qi Y, Beheshti A, Li Y, Qing L, et al. Style-aware two-stage learning framework for video captioning. Knowl Based Syst. 2024;301:112258. doi:10.1016/j.knosys.2024.112258. [Google Scholar] [CrossRef]
12. Ma Y, Qing L, Li G, Qi Y, Beheshti A, Sheng QZ, et al. RETTA: retrieval-enhanced test-time adaptation for zero-shot video captioning. Pattern Recognit. 2026;171(8):112170. doi:10.1016/j.patcog.2025.112170. [Google Scholar] [CrossRef]
13. Pan H, Guo Y, Deng Q, Yang H, Chen J, Chen Y. Improving fine-tuning of self-supervised models with Contrastive Initialization. Neural Netw. 2023;159(11):198–207. doi:10.1016/j.neunet.2022.12.012. [Google Scholar] [PubMed] [CrossRef]
14. Qiao C, Zeng Y, Meng Q, Chen X, Chen H, Jiang T, et al. Zero-shot learning enables instant denoising and super-resolution in optical fluorescence microscopy. Nat Commun. 2024;15(1):4180. doi:10.1038/s41467-024-48575-9. [Google Scholar] [PubMed] [CrossRef]
15. Wang FY, Miu QH. Novel paradigm for AI-driven scientific research: from AI4S to intelligent science. Bull Chin Acad Sci. 2023;38(4):536–40. (In Chinese). doi:10.16418/j.issn.1000-3045.20230406002. [Google Scholar] [CrossRef]
16. Peng Q, Zhu S, Su Y, Xing M. Gaze-and-machine dual-driven attention fusion network for medical image classification. In: Proceedings of the International Conference on Intelligent Computing; 2025 Jul 26–29; Ningbo, China. Singapore: Springer Nature; 2025. p. 402–12. doi:10.1007/978-981-95-0036-9_34. [Google Scholar] [CrossRef]
17. Su Y, Tan Y, Xing M, An S. VPE-WSVAD: visual prompt exemplars for weakly-supervised video anomaly detection. Knowl Based Syst. 2024;299(5):111978. doi:10.1016/j.knosys.2024.111978. [Google Scholar] [CrossRef]
18. Lu SS, Chen L, Lu GY, Guan ZY, Xie F. Weakly-supervised contrastive learning framework for few-shot sentiment classification tasks. J Comput Res Dev. 2022;59(9):2003–14. (In Chinese). doi:10.21203/rs.3.rs-2699220/v1. [Google Scholar] [CrossRef]
19. Luo X, Wu H, Zhang J, Gao L, Xu J, Song J. A closer look at few-shot classification again. In: Proceedings of the 40th International Conference on Machine Learning (ICML); 2023 Jul 23–29; Honolulu, HI, USA. p. 23103–23. [Google Scholar]
20. Feng Q, Wu Y, Fan H, Yan C, Xu M, Yang Y. Cascaded revision network for novel object captioning. IEEE Trans Circuits Syst Video Technol. 2020;30(10):3413–21. doi:10.1109/TCSVT.2020.2965966. [Google Scholar] [CrossRef]
21. Liu X, Zhang F, Hou Z, Mian L, Wang Z, Zhang J, et al. Self-supervised learning: generative or contrastive. IEEE Trans Knowl Data Eng. 2023;35(1):857–76. doi:10.1109/TKDE.2021.3090866. [Google Scholar] [CrossRef]
22. Hu X, Yin X, Lin K, Zhang L, Gao J, Wang L, et al. VIVO: visual vocabulary pre-training for novel object captioning. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence; 2021 Feb 2–9; Virtual. p. 1575–83. doi:10.1609/aaai.v35i2.16249. [Google Scholar] [CrossRef]
23. Huang L, Wang W, Chen J, Wei XY. Attention on attention for image captioning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 4633–42. doi:10.1109/iccv.2019.00473. [Google Scholar] [CrossRef]
24. Rahate A, Walambe R, Ramanna S, Kotecha K. Multimodal co-learning: challenges, applications with datasets, recent advances and future directions. Inf Fusion. 2022;81:203–39. doi:10.1016/j.inffus.2021.12.003. [Google Scholar] [CrossRef]
25. Kim DJ, Choi J, Oh TH, Kweon IS. Dense relational captioning: Triple-stream networks for relationship-based captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 6264–73. doi:10.1109/CVPR.2019.00643. [Google Scholar] [CrossRef]
26. Liu M, Zhang C, Bai H, Zhao Y. Part-object progressive refinement network for zero-shot learning. IEEE Trans Image Process. 2024;33(11):2032–43. doi:10.1109/TIP.2024.3374217. [Google Scholar] [PubMed] [CrossRef]
27. Qi Y, Zhao W, Wu X. Relational distant supervision for image captioning without image-text pairs. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI 2024); 2024 Feb 20–27; Vancouver, BC, Canada. p. 4524–32. doi:10.1609/aaai.v38i5.28251. [Google Scholar] [CrossRef]
28. Du D, Wu Y. Improving zero-shot image captioning efficiency with metropolis-hastings. In: Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV); 2024 Oct 18–20; Urumqi, China. Singapore: Springer Nature; 2024. p. 305–18. doi:10.1007/978-981-97-8511-7_22. [Google Scholar] [CrossRef]
29. Zeng Z, Xie Y, Zhang H, Chen C, Chen B, Wang Z. MeaCap: memory-augmented zero-shot image captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 16–22; Seattle, WA, USA. p. 14100–10. doi:10.1109/CVPR52733.2024.01337. [Google Scholar] [CrossRef]
30. Lee S, Kim SW, Kim T, Kim DJ. IFCap: image-like retrieval and frequency-based entity filtering for zero-shot captioning. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing; 2024 Nov 12–16; Miami, FL, USA. p. 20715–27. doi:10.18653/v1/2024.emnlp-main.1153. [Google Scholar] [CrossRef]
31. Liu T, Yang C, Chen G, Gao Q, Song E, Li W. MncCap: Mining neural composition for zero-shot image captioning via text-only training. In: Proceedings of the 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2025 Apr 6–11; Hyderabad, India. p. 1–5. doi:10.1109/ICASSP49660.2025.10889534. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools