
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A New Hybrid Approach Using GWO and MFO Algorithms to Detect Network Attack
Department of Computer Engineering, Faculty of Engineering and Architecture, Kırıkkale University, Kırıkkale, 71450, Turkey
* Corresponding Author: Hasan Dalmaz. Email:
Computer Modeling in Engineering & Sciences 2023, 136(2), 1277-1314. https://doi.org/10.32604/cmes.2023.025212
Received 28 June 2022; Accepted 30 September 2022; Issue published 06 February 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This paper addresses the urgent need to detect network security attacks, which have increased significantly in recent years, with high accuracy and avoid the adverse effects of these attacks. The intrusion detection system should respond seamlessly to attack patterns and approaches. The use of metaheuristic algorithms in attack detection can produce near-optimal solutions with low computational costs. To achieve better performance of these algorithms and further improve the results, hybridization of algorithms can be used, which leads to more successful results. Nowadays, many studies are conducted on this topic. In this study, a new hybrid approach using Gray Wolf Optimizer (GWO) and Moth-Flame Optimization (MFO) algorithms was developed and applied to widely used data sets such as NSL-KDD, UNSW-NB15, and CIC IDS 2017, as well as various benchmark functions. The ease of hybridization of the GWO algorithm, its simplicity, its ability to perform global optimal search, and the success of the MFO algorithm in obtaining the best solution suggested that an effective solution would be obtained by combining these two algorithms. For these reasons, the developed hybrid algorithm aims to achieve better results by using the good aspects of both the GWO algorithm and the MFO algorithm. In reviewing the results, it was found that a high level of success was achieved in the benchmark functions. It achieved better results in 12 of the 13 benchmark functions compared. In addition, the success rates obtained according to the evaluation criteria in the different data sets are also remarkable. Comparing the 97.4%, 98.3%, and 99.2% classification accuracy results obtained in the NSL-KDD, UNSW-NB15, and CIC IDS 2017 data sets with the studies in the literature, they seem to be quite successful.Keywords
Nowadays, it has become very popular to use machine learning and related techniques to find solutions to real-world problems. The main feature of machine learning methods is the extraction of characteristics from a large amount of data without human influence [1]. There are many different classification studies that use machine learning methods and apply them to real-world problems. Automated classification of epileptic Electroencephalogram (EEG) signals [2], anomaly detection [3], iris recognition [4] are some of these studies. Network security is also a very important issue. The evolution of technology has increased network security in almost all fields. The continuous increase in network traffic and networked systems, while bringing convenience in implementation, sometimes results in the measures taken for network security being inadequate and creating a vulnerability for possible network attacks. The Internet, which has become an essential part of our daily and working lives, developments in Internet technologies, increasing use of Internet of Things (IoT) technology in many fields, and Internet-based social networks can be considered as one of the main reasons for the increase in network attacks [5]. Various reports on network security state that network attacks have reached a disturbing level of scale and complexity, especially in recent years. Traditional methods such as data encryption, user security, and the use of firewalls are used as initial security measures, but weak passwords or password security breaches do not prevent unauthorized use, and user authentication fails. However, firewalls may also suspect undefined or insecure security policies if there are errors in the configuration [6]. In particular, threats to targets such as commercial, military, and public network systems have made it necessary to increase cybersecurity, and awareness in this area [7].
Intrusion Detection Systems (IDS) aims detect and prevent attacks on the network from inside or outside. In IDS, two types of systems are distinguished: signature-based and anomaly-based. Signature-based systems store known and previously seen attack types in the database, while anomaly-based systems evaluate real-time packets based on their anomalies with regular packets. Various machine learning techniques are used for this evaluation [8]. In addition, IDS has some weaknesses. The main drawback is that events that do not pose a threat are counted as attacks (false positives), while events that pose a threat to the system are not counted as attacks (false negatives). For these reasons, it is important to interpret the information received about the attacks.
Due to the anonymous structure of the Internet and the increasing ease of use, attacks on systems have become relatively easy nowadays. The need for IDS is increasing day by day to protect important and critical data [9]. As computer network attacks and their methods evolve, there are new approaches to prevent these attacks. In particular, the algorithm used is of great importance to find the most appropriate solution for network attack detection, which is considered as an optimization problem. Algorithms for finding the optimal solution are divided into deterministic and stochastic classes. In deterministic algorithms, the solution obtained does not change if the input value does not change. However, structural difficulties may arise in finding the solution, and the desired solution may not be obtained. For these reasons, metaheuristic algorithms, which are a nature-inspired type of stochastic algorithm, are used. They are easy to construct, can be hybridized with metaheuristic algorithms, can be easily applied to different problems, and avoid local optimal values [10,11]. Metaheuristic algorithms are swarm and population-based algorithms. Examples of these algorithms include Salp Swarm Algorithm (SSA), Genetic Algorithm (GA), Moth Flame Optimization (MFO), and Gray Wolf Optimizer (GWO). While these metaheuristic algorithms have advantages, they also have some disadvantages. Their weaknesses are in local search, stuckness, non-repeatable exact solutions, and convergence uncertainties. In order to obtain a better solution, hybrid methods should be developed that combine successful features by using more than one algorithm together [12]. In a developed hybrid algorithm, an attempt is made to eliminate the weaknesses of the existing algorithms and achieve more successful results.
In recent years, the topics of network attack detection and prevention have become very popular. However, there are few studies in the literature on how algorithms can become more efficient in classifying attacks. When developing a hybrid algorithm that uses different algorithms, it is necessary to learn more about how the solution presented using benchmark functions can work more effectively on which types of problems. New studies in this area continue to be of great importance, as network security and the detection and prevention of network attacks is an area that needs constant improvement. Each new study improves on the shortcomings of previous studies and sheds light on future studies. For this reason, our work is significant because it applies not only to network security but also too many problems that machine learning is designed to solve. In this study, a new hybrid algorithm was developed and tested with NSL-KDD, UNSW-NB15, and CIC IDS 2017 data sets. NSL-KDD one of these data sets widely used in the literature is an improved version of the KDD Cup’99 data set. Although this dataset is an improved version of the KDD Cup’99 dataset, it has limitations in handling modern attack types. The UNSW-NB15 and CIC IDS 2017 datasets, which have had these shortcomings further reduced and their suitability for today’s attack types increased, are also datasets that were evaluated as part of this study. To test the generalizability and robustness of the algorithm developed in this study, these datasets, which are widely used in the literature, were examined.
Unlike many similar studies, this study uses a newly introduced hybrid metaheuristic optimization method called GWOMFO to solve benchmark problems and detect network intrusions. GWOMFO contains the best features of GWO and MFO. The study aims to develop a new hybrid algorithm, to show its effectiveness by achieving more successful results than existing algorithms, to introduce a new hybrid algorithm into the literature so that it can be used on various problems in the scientific community, and the study is of the original value in this regard. Briefly, the main contributions of the study are as follows:
• We propose a new structure for network attack detection.
• The proposed hybrid approach is based on GWO and MFO algorithms. A hybrid solution is presented that achieves higher accuracy by eliminating the weaknesses of these algorithms.
• In the development of a new algorithm, the contribution of tests against benchmark functions is presented, and the developed algorithm has proven its success through successful results on these functions.
• The newly developed hybrid algorithm has been tested on 3 different datasets and has achieved successful results. The obtained results were compared with the studies in the literature and showed that it is a successful algorithm with its performance.
The remainder of this paper is arranged as follows. Related works in the literature can be found in Section 2, theoretical background in Section 3, materials and methods used in Section 4, and experimental results in Section 5. Conclusions and future work can be found in the last part of the study.
Data mining and machine learning in network attack detection using various classification methods are now widely used. The main reason for this is to detect different attacks and their types. For effective and successful attack detection, the classification technique used is crucial. So far, several techniques have been proposed to detect attacks and improve existing systems. The use of hybrid methods is one of these techniques.
Researchers continue to develop hybrid IDS to detect network attacks. The most important reason is that a hybrid classifier can improve its ability to detect unknown attacks, its threat detection performance, and its detection speed depending on the underlying algorithms. This section presents some studies in the literature on network attack detection and the limitations of these studies. In addition, some recent studies on network security are mentioned and information about the trend is given.
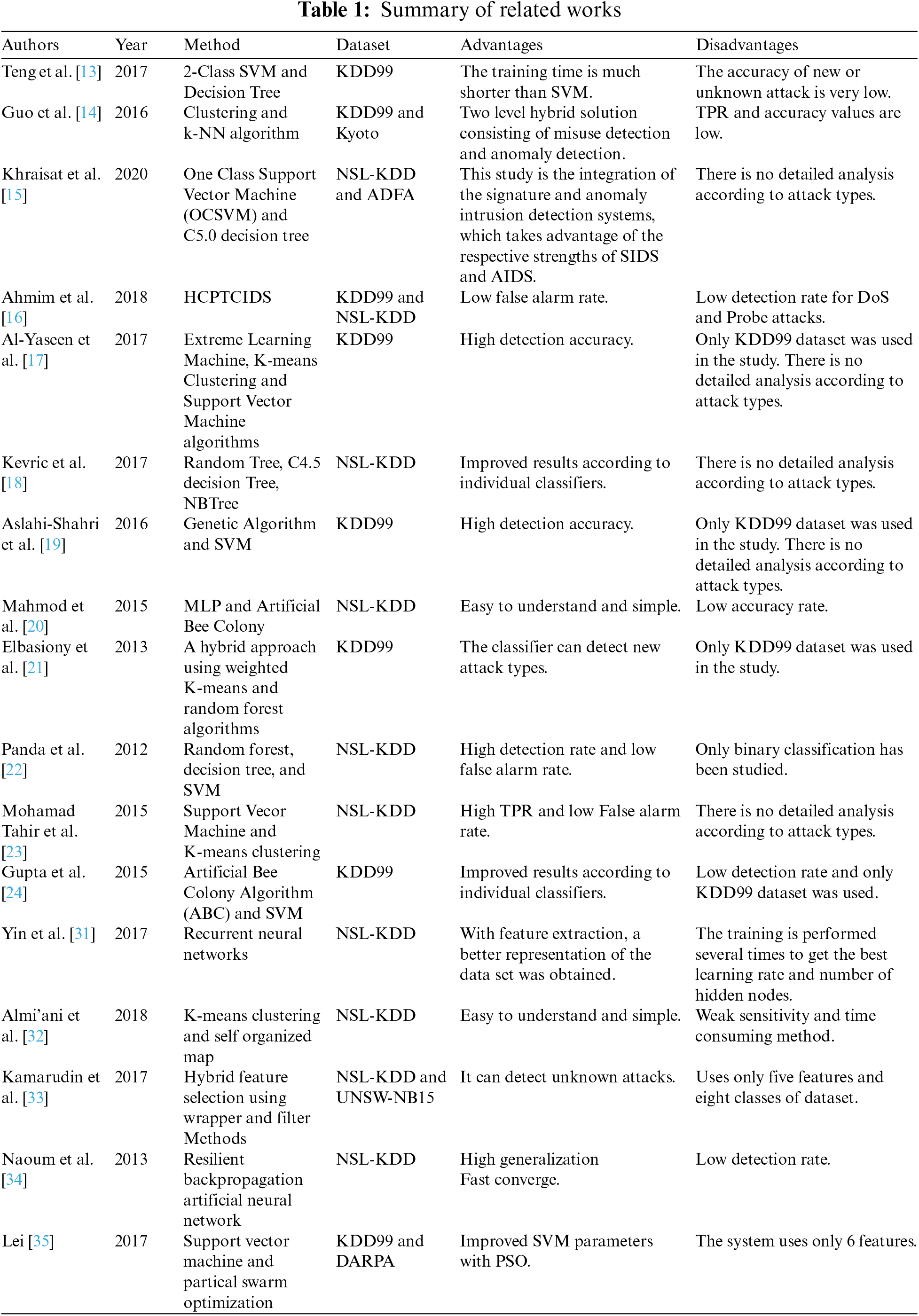
In the first of these studies, Teng et al. [13] proposed a hybrid method created with a 2-class support vector mechanism and a decision tree. In the results obtained, the training time is much shorter than the traditional Support Vector Machine (SVM) algorithm. However, the detection accuracy of unknown or new attacks is quite low. Guo et al. [14] proposed a framework consisting of two stages, anomaly detection and misuse detection. First, network connections pass through stage 1, and if an anomaly is detected, it is forwarded to the anomaly detection component. If it was reported as normal in the first stage, it is forwarded to the misuse detection component. Clustering and k-NN algorithms are used in this structure. In the results obtained, 91.86% TPR and 93.29% accuracy were achieved. Khraisat et al. [15] proposed a hybrid structure using One Class Support Vector Machine (OCSVM) and C5.0 decision tree classifiers. They found that in this study, which aimed at a low false discovery rate and high recognition accuracy, they achieved quite good results compared to existing studies. Ahmim et al. [16] proposed a new IDS called HCPTCIDS that combines the probability estimates of the classification tree. In this structure, which consists of two layers, the first layer contains a tree structure and the second layer contains the final classifier structure of the first layer, which consists of different probability estimates. It was found that the proposed system achieves higher performance than most studies in the literature. Al-Yaseen et al. [17] proposed a new hybrid structure consisting of Extreme Learning Machine, K-means Clustering and SVM algorithms. It was highlighted that this proposed structure significantly improved the network intrusion detection results and they stated that they achieved 95.75% detection accuracy. Kevric et al. [18] proposed a new hybrid structure consisting of the combination of 3 different algorithms. In this study, using C4.5 decision tree, random tree, and Naive Bayes algorithms, it was found that the hybrid structure gave better results than the individual classifiers. Aslahi-Shahri et al. [19] developed a hybrid method consisting of GA and SVM algorithms. They stated that they reached 97.3% True Positive Rate (TPR) in their results.
The main idea in developing a hybrid algorithm, which is also used in this study, is to create a better combined model and obtain more accurate, better, and more reliable results. In another study based on the idea of creating a new model by integrating multiple algorithms, Mahmod et al. [20] proposed a hybrid system based on a multilayer perceptron. In this study, using Multi Layer Perceptron (MLP) and Artificial Bee Colony (ABC) algorithms, it was found that the detection accuracy of new attacks increased with the increase of food sources and colony size, but the success of intrusion detection in multiple classes was low in the NSL-KDD. Elbasiony et al. [21] proposed a new hybrid solution based on K-means and random forest algorithms for network attack detection. Reviewing the obtained results, it was stated that the detection rate and false positive rate were better than many of the compared studies. Panda et al. [22] proposed a hybrid attack detection algorithm consisting of random forest, decision tree, and SVM algorithms to classify network attacks. However, the proposed technique is insufficient to respond to all intrusion attempts. It does not achieve a high detection rate and a low false alarm rate. Mohamad Tahir et al. [23] developed a hybrid intelligent system based on Support Vecor Machine and K-means clustering algorithms for network attack detection. In the results studied, it was found that they achieved 96.24% accuracy and 3.72% false alarm rate. Gupta et al. [24] developed a hybrid algorithm in their study by combining the ABC and SVM algorithm. This study found that the developed hybrid method achieves better average accuracy than both ABC and SVM.
In general, only the accuracy values are given as a result in the studies in the literature. In this study, additional analyzes were made on 3 different data sets according to the attack type. Comparisons were also made with metrics such as accuracy, True Positive Rate (TPR), False Positive Rate (FPR). In addition to these, calculations were made by keeping the number of features low in most studies, which makes the reliability of the obtained result questionable. In addition to these studies, many have appeared in the literature, especially in recent years that address network security and provide solutions to security problems from various aspects. In recent years, many studies have appeared in the literature on popular topics such as IoT and Fog/Cloud Computing that address security issues. Regarding these issues, Kumar et al. [25] proposed a unified IDS for use in IoT environments. Depending on the threshold confidence factor, the rules created from different decision tree models are selected, and the analysis of the data set is performed. In this study, using the UNSW-NB15 data set, they performed better than decision tree models in attack detection rates. Mousavi et al. [26] proposed a hybrid model using ABC, Secure Hash Algorithm 256 (SHA256), and Elliptic Curve Cryptography (ECC) to improve data security in IoT applications. It was found that the efficiency of encryption and decryption operations can be increased by more than 50% and the execution time for encryption is 52.31% lower than the method RSA-AES, when a private key is generated using the algorithm ABC. Al-Qerem et al. [27] studied fog/cloud networks. In their study, they propose concurrency control protocols for this subject. This study, which aims to reduce the communication and computation load in fog and cloud nodes, shows that they succeed in improving network quality. In another study, Bhushan et al. [28] proposed a new approach for flowchart sharing. This proposed method aims to protect Software-Defined Networking (SDN) networks from DDoS attacks with flow table overloading. The increased resilience of the network to the flow table has also been shown to be successful in preventing DDoS attacks. Stergiou et al. [29] discussed the issue of privacy and security in fog environments. They presented a cloud computing-based solution for working with Big Data. In this solution, a security wall was inserted between the cloud server and the Internet to create an architecture to improve network security. Mousavi et al. [30] proposed a study for IoT-based irrigation systems. A cryptographic algorithm is presented to improve the security of these systems. This study highlights that cryptography is one of the most important solutions to protect confidentiality and integrity between nodes. Rivest Cipher (RS4), SHA−256 and ECC are used in this approach. Summary of related works are shown below in Table 1.
3 Theoretical Background of Hybrid Approach
The following subsections provide the necessary background for hybridization. The most prominent feature of the GWO algorithm is its social hierarchy. This hierarchy is also well adapted for solving complex problems. However, to increase the performance of the algorithm, hybridization with the MFO algorithm was considered. In general, the MFO algorithm can achieve good results in finding the best solution, but it is not sufficient to refine the optimal solution in each iteration. For this reason, it is aimed to improve performance by hybridizing with the GWO algorithm. By hybridizing these two algorithms, the goal is to arrive at a precise solution and improve the convergence feature instead of being trapped in local optima. GWO and MFO algorithms are examined in detail in this section.
3.1 Gray Wolf Optimizer (GWO) Algorithm
This algorithm, which considers the social leadership and hunting strategy of gray wolves, was presented in 2014 by Mirjalili [11]. In gray wolves, which generally live in groups, groups consist of 5–12 individuals. Wolves referred to as alpha wolves are defined as leader wolves. There are four main groups: Omega, delta, beta, and alpha wolves. Alpha wolves are the best wolves, while omega wolves are the lowest. Alpha wolves are the decision-makers in managing the other wolves in the group, hunting areas, and sleeping times.
The priority in the hunting strategy of gray wolves is to find the prey. Then the prey is besieged under the leadership of the alpha wolf. Delta, beta, and alpha wolves are used as the three best solutions for updating the location of wolves because they are believed to provide better information about the location of the prey [36,37].
The GWO algorithm is based on the hierarchy of wolves as a model. The best solution found is alpha, the second and third solutions are beta and delta. The remaining solutions are called omegas. In this algorithm, alpha, beta, and delta give commands to omega, and omega searches the solution space for these commands.
In this algorithm, the first step of the hunting process is to encircle the prey. Eqs. (1)–(4) used in the mathematical model and their explanations can be found below.
In Eq. (1),
The value
The 3 best solutions at time t are represented by
The alpha, beta, and delta species of gray wolves have exceptional knowledge of the current location of their prey. Therefore, the three best solutions are recorded, and the other wolves can update their positions relation to the positions of the best search agents. Eqs. (6)–(12) can be used in this context. The pseudocode of the GWO algorithm is shown below in Table 2.

3.2 Moth-Flame Optimization (MFO) Algorithm
This algorithm, presented by Seyedali Mirjalili, was developed by exploiting the particular navigation behavior of moths in nature, called cross-orientation [38]. When the moth moves, it determines a fixed angle to the moon and flies at that angle. This movement enables the moth to fly straight for long distances. However, if you observe moths, you will notice that they make a spiral movement around the light. This situation is caused by artificial light [39]. The extreme proximity to the light source and the attempt to maintain the fixed angle with respect to the light source reveals the spiral trajectory.
In the mathematical model of this algorithm, the moth cluster is represented by the matrix M. The fitness values are stored in an array called AM. At the beginning of the algorithm, a moth population is assigned at a random location based on lower and upper bounds. The flame matrix is updated by calculating the fitness values. It represents the flames and contains the best position each moth has ever reached. The flames are also updated when the moth finds a better solution. Each moth must update its position with only one of the flames. After each iteration, the positions are updated relative to the flame. The position of the moths is updated with Eq. (13). In the equation given in Eq. (13), the positions of the moths in the search space are updated based on the logarithmic spiral function.
Here i’th moth
In the equation, N expresses the maximum number of flames. In other equation expressions, l represents the number of iterations, and T represents the maximum number of iterations. The pseudocode of the MFO algorithm is shown in Table 3.

In this part, the framework of the proposed study, which consists of 5 phases, is presented.
This study used the data sets NSL-KDD, UNSW-NB15, and CIC IDS 2017, which are commonly used for network attack detection. Usually, the data sets contain numerical and categorical data that humans can read and understand. However, some machine learning and deep learning models cannot handle categorical data. Therefore, normalization and transformation processes are performed to clean unnecessary data and improve performance. The result is a more suitable data set.
In the conversion processes, the nominal values in the data set were converted to numeric values. One-to-one digitization of the data used label coding and assigned a numeric value to each categorical value. The result of these processes is a data set consisting of numeric values.
In normalization processes, a linear transformation was made on the data by using min-max normalization, and the data was spread between 0–1. Eq. (15) used for this process is given below.
The min.-max. normalization process examines at how far the field value is from the minimum value and ranks these differences [40].
4.1.2 Hybrid Classification (GWOMFO)
Solutions in the literature for network attack detection systems face many problems such as low detection accuracy, unbalanced detection rates, and difficulty of attack detection in real-time networks. As a result, hybrid algorithms were developed to achieve the best possible accuracy by combining several algorithms to solve these problems. In hybrid techniques, in general, each component has tasks in different phases, such as preprocessing, classification, clustering, and they can also be used together in the same phase. In this study, the hybrid structure obtained by combining the GWO and MFO algorithms was applied and tested in the classification phase. Our aim is to develop a new metaheuristic approach for training artificial neural network (ANN) and to show that the method we have developed is also successful in the network attack detection system using the models trained with the algorithms we have compared. The values in the population of the hybrid algorithm form the weights and biases used in training the ANN. The data we observed and obtained show that the network was well trained and successfully detects attacks compared to studies trained with other algorithms.
In this section, the developed hybrid algorithm is presented. We propose a method to develop a hybrid IDS that combines two machine learning algorithms. In this hybrid model, GWO and MFO are combined to create a hybrid model. Metaheuristic algorithms are algorithms that aim to find global or near-optimal solutions. The ability of the GWO algorithm to find a global optimum and the success of the MFO algorithm in achieving the best result suggest that better performance can be achieved by combining these two algorithms.
In GWO, wolves update their positions according to the food source. During this update, the alpha wolves and the other wolves try to be closest to the food source. Poorly obtained positions are not considered in the GWO calculations. In the MFO algorithm, the best solutions are included in the calculations to obtain the new solution. It is assumed that in this way the best solution is found to reach the food source. The GWOMFO algorithm was developed based on the GWO algorithm, whose pseudocode is given in Table 4. The equations developed for the GWOMFO algorithm, and the explanations of these equations are as follows.

The data set obtained after the data preprocessing described in the previous Section 4.1.1 was used to train and test the proposed system. In this algorithm, the effect of the agents of the GWO algorithm is improved based on the MFO algorithm. This method aims to improve the global convergence, discovery, and exploitation performance instead of running the variant for countless generations without improvement.
The flowchart of the developed hybrid algorithm is shown below in Fig. 1.
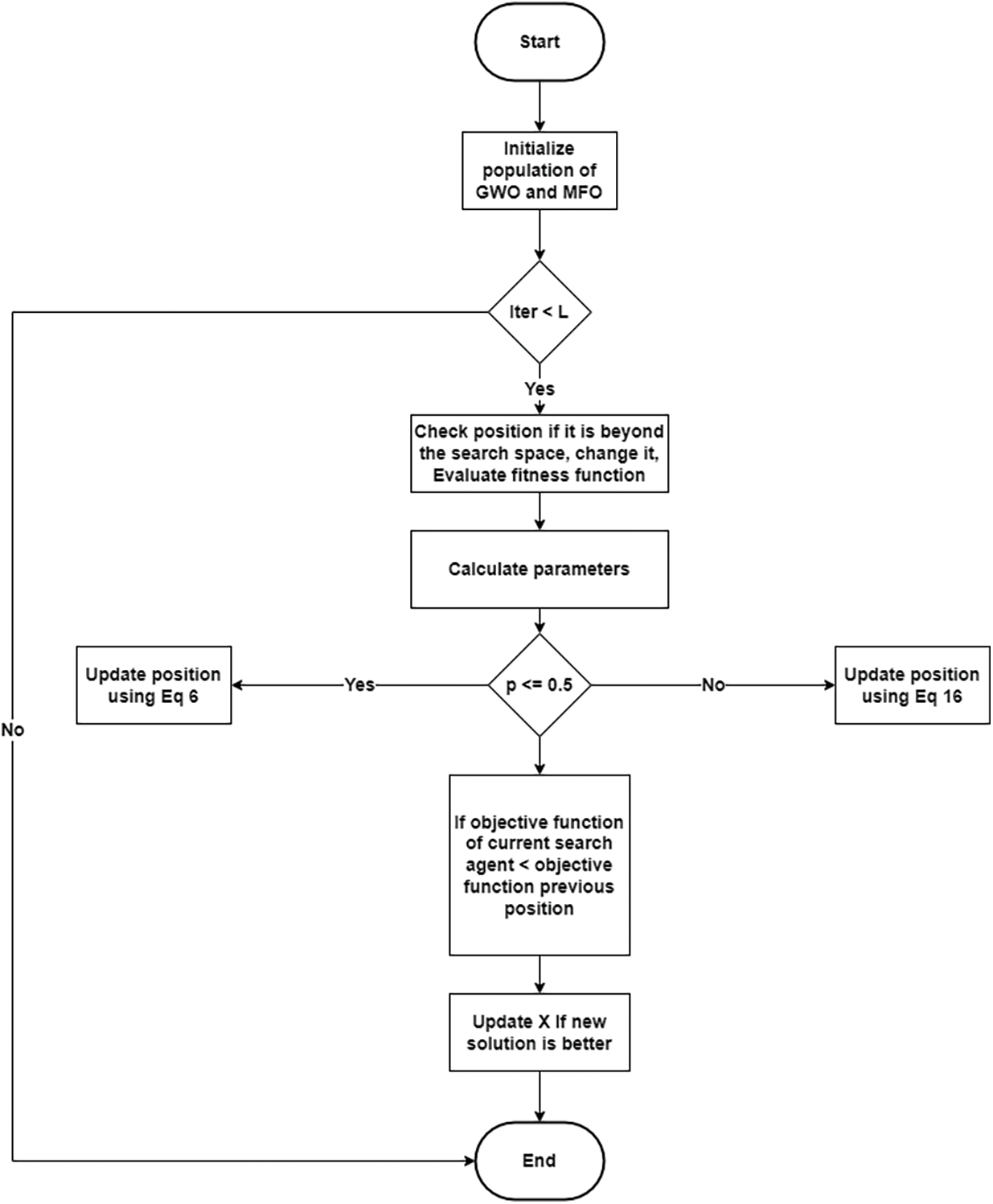
Figure 1: Flowchart of the proposed algorithm (GWOMFO)
In the mathematical model for gray wolf hunting strategy, delta, beta, and alpha wolves are assumed to provide better information about prey location. Therefore, the first three best solutions are used to update the positions of wolves in the GWO algorithm. Moreover, the best solution from the MFO algorithm was evaluated with the found solutions, and a new best solution was created. The equation given by Eq. (16) is used to improve the position in the GWOMFO algorithm. In this equation, the position obtained with the GWO agents is evaluated together with the position from the MFO algorithm. The 4 best solutions at time t are represented by
In this algorithm, hybridization was achieved by interfering with the standard GWO algorithm in 2 stages. First, a condition was added in the exploitation stage to improve hunting performance. Then, Eq. (16) was applied. A new mechanism was added to improve the solution. This improved the hunting mechanism of the GWO. After each iteration, the solution is evolved. Also, the added condition improves the search ability and the exploration phase and increases the quality of the solution.
GWOMFO is started by initializing the population size of both the MFO and GWO search agents. After this process, the fitness value is calculated. After the value assignments for the agents are made, the position updates of the existing search agents are performed using the appropriate equations according to the value of parameter p up to the maximum number of iterations (L) in the loop. After these operations, the fitness value is calculated, and the process continues until a suitable solution is found.
The parameter p is a randomly generated number. If the random value is less than or equal to 0.5, position updates are performed using alpha, beta, and delta position equations. The calculation is performed using Eq. (6) in this condition. The positions are updated if the new position is better than the old one. If it is greater than 0.5, Eq. (16) is used and updated again, comparing it with the old positions. As a result, the fitness value is calculated again. The best fitness value is returned.
In metaheuristic approaches, there are two main components directly related to the search ability of an algorithm: exploration and exploitation. Exploration seeks to find promising solutions by going deep into unknown territory. In other words, exploration aims to increase the diversity of solutions. In contrast, exploitation aims to improve the quality of solutions by searching locally around discoverable and promising solutions. These components conflict with each other and influence each other. Therefore, an optimization algorithm should be designed with a correct and appropriate balance between exploration and exploitation. With this hybrid algorithm, an improvement in exploration and exploitation performance was observed. This is also reflected in the results obtained. The pseudocode of the GWOMFO algorithm is shown in Table 4.
Before modeling or estimation, data sets are separated into training and test data sets. In this separation, the hold-out method was used, and 2/3 of the original data was reserved as the training data set and 1/3 as the test data set [41]. Training of the algorithm was performed using the training sets obtained in this way.
During the testing phase, eight swarm intelligence-based algorithms (GWO, MFO, DE, PSO, MVO, JAYA, SSA, and SCA) and the algorithm developed in this study were applied separately and tested on the NSL-KDD, UNSW-NB15, and CIC IDS 2017 data sets. The results obtained by each algorithm were studied separately.
Several quantitative metrics are used to interpret the results obtained by the testing process performed in the study. These metrics are:
Accuracy: Shows the percentage of correct estimates. It is calculated based on the Confusion Matrix.
Accuracy = TPs + TNs/n
True Positive Rate (TPR): Total number of true positives.
TPR = TPs/(FNs + TPs)
False Positive Rate (FPR): The formula used to calculate this ratio is below.
FPR = FPs/TNs + FPs
Sensitivity (Recall): Shows how well positive situations are predicted.
Sensitivity = TPs/(TPs + FNs)
Precision: It is the criterion that shows the success in positive predictions.
Precision = TPs/(TPs + FPs)
F-measure: Harmonic average of the values for sensitivity and precision.
Studies were assessed and compared using these metrics.
In this study, 3 different data sets were examined. The data sets used in this study are known in the literature as commonly used data sets for network attack detection. These data sets, which differ in terms of attack types and number and type of features, were evaluated in the study to obtain more accurate results about the generalizability and robustness of the developed algorithm. By using these three different data sets, the performance changes and consistency of the algorithm developed in this study will be examined. These data sets are listed below, respectively.
NSL-KDD is a commonly used data set for network attack detection and can also be represented as a model. This data set has been used in many studies in the literature [42–46]. It is an extended version of the data set known as KDD Cup’99. Several problems with the KDD Cup’99 data set have been fixed with the NSL-KDD data set [47]. In particular, biased results should be avoided by removing unnecessary records [48]. The NSL-KDD data set is the result of an evolution of the KDD Cup’99 data set, but has the same characteristics as the KDD Cup’99 data set in terms of features. It contains no unnecessary data, but enough data to train and test. These data sets, defined as attacks, are classified into four main classes. These are DOS, Probe, User to Root (U2R), and Remote to Local (R2L) attacks. The distribution of the data set used is shown in Table 5.
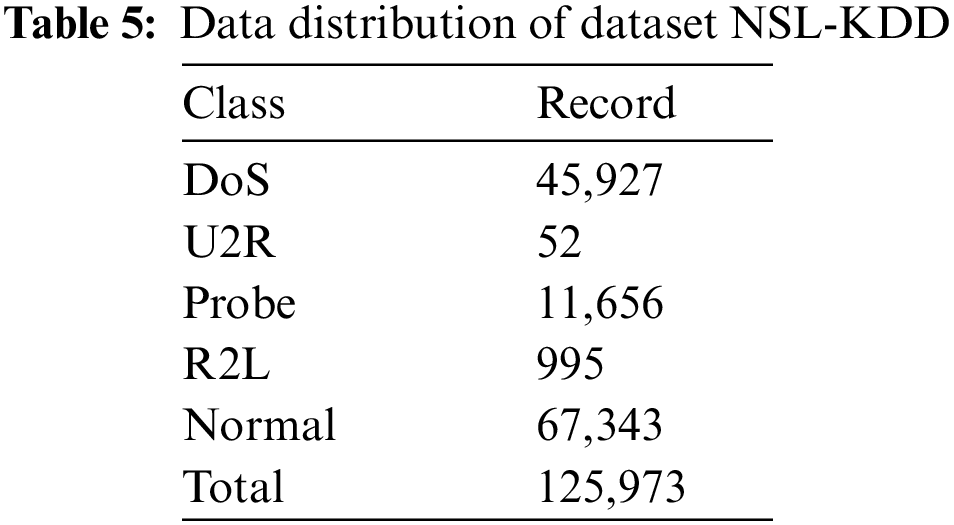
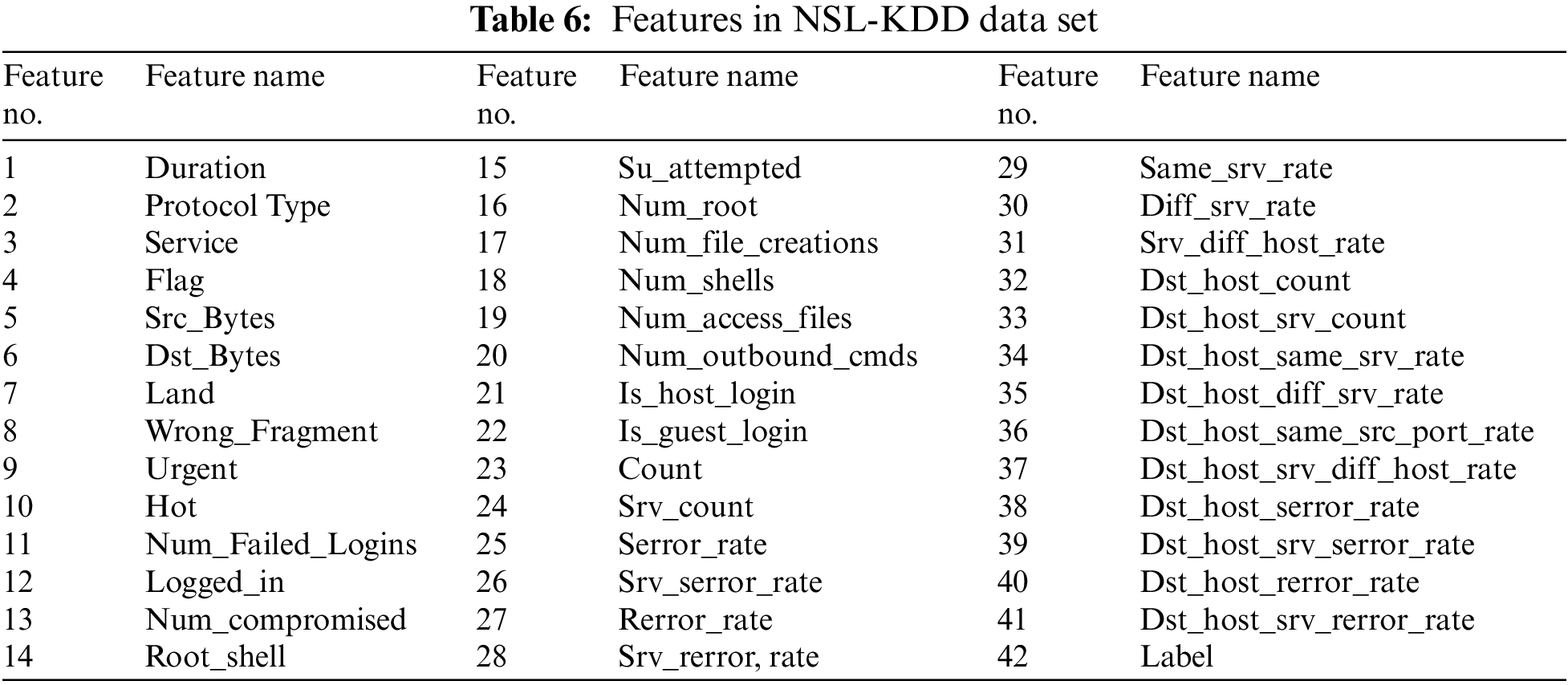
In the NSL-KDD data set, which contains 125,973 records, 67,343 were classified as normal, and 58,630 as attack. With 41 features (32 numeric, six binary, three nominal), this data set contains 24 different attacks and records labeled as normal. Features in NSL-KDD data set shown in Table 6.
One of the most important factors in evaluating the performance of IDS and developing more effective and efficient IDSs is the data sets used [49]. The most commonly used data sets to measure the performance of IDS are KDD99 and NSL-KDD. Data sets are essential for developing IDS and measuring its performance. The data set used should meet the time requirements and include current attack types. The literature’s most commonly used KDD99 and NSLKDD data sets are different from current conditions in terms of attack types and normal traffic scenarios, and the distribution of training and testing data sets is also different. It is now assumed that current data sets should be used in studies. To address these issues, data sets such as UNSW-NB15, CIC IDS 2017 have been developed to capture current and modern attack types [50].
This data set was created using the IXIA PerfectStorm tool at the Australian Cyber Security Center (ACCS) Cyber Range Lab to merge modern, realistic normal network activity and attack behavior from network traffic [50]. This data set has been used in many studies in the literature [51–55]. Unlike NSLKDD, this data set contains original versions of the various identity states that are common today. Attacks in this data set include fuzzer, analytics, backdoor, DoS, exploit, general, reconnaissance, shellcode, and worm attacks. The distribution of the data set used is shown in Table 7.
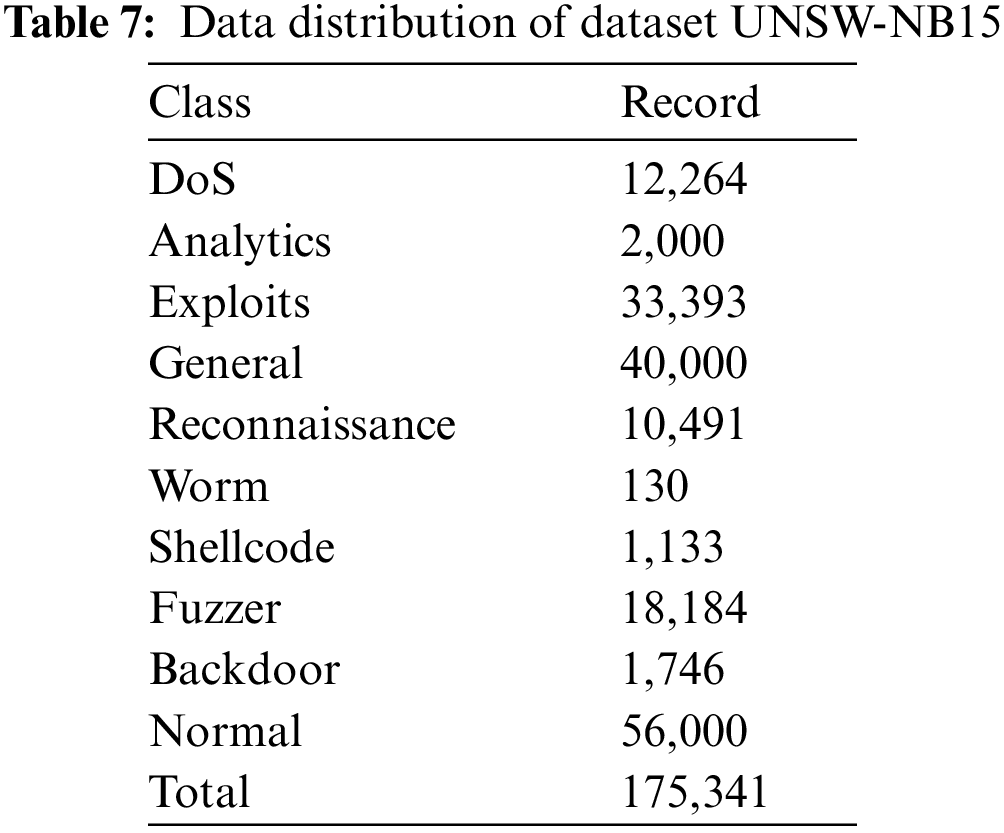
This data set contains 175,341 records and 49 extracted features [56]. Features in UNSW-NB15 data set shown in Table 8.
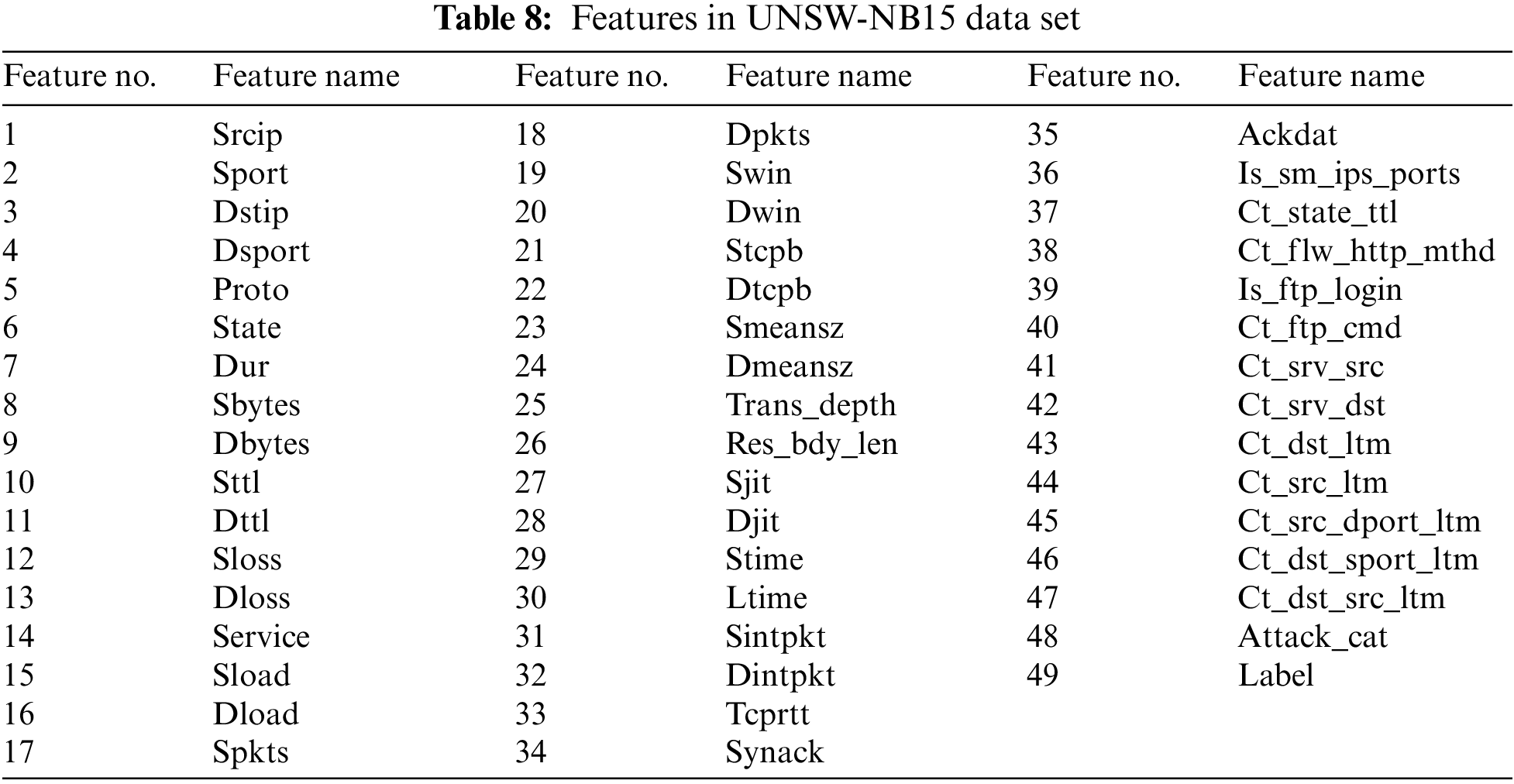
This data set was developed by the University of New Brunswick, School of Computer Science, in 2017. It is an improved version of the ISCX 2012 data set [57]. This data set has been used in many studies in the literature [57–61]. It consists of a generalization of real network traffic. The total number of records in this dataset is 2,829,463. 2,358,036 of these records are normal, and the remaining records are in the attack class. In this dataset, attacks are examined in 7 categories. These are DoS, DDoS, Botnet, Port Scan, Infiltration, Web Attack and HeartBleed attacks. The distribution of the data set used is shown in Table 9.
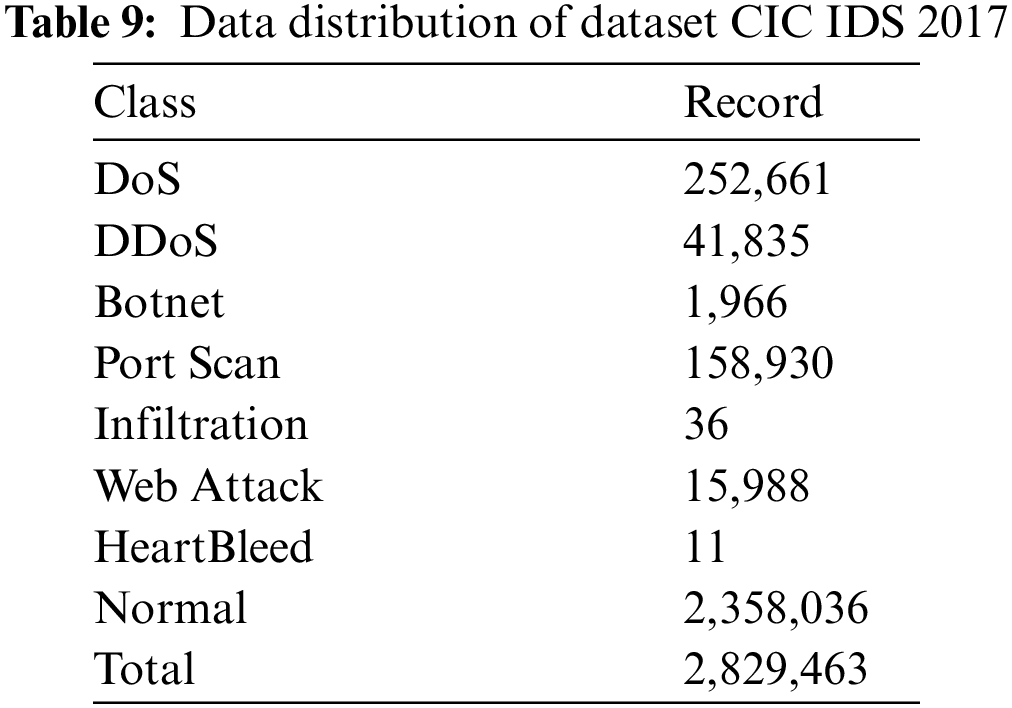
There are more than 80 features in this dataset. Features in CIC IDS 2017 data set shown in Table 10.
In this section, information about the simulation and its environment is given, and the results obtained with the hybrid algorithm are explained and discussed.
To briefly discuss the working environment and the programs used in this study, the computer configurations used for the proposed method are as follows. Two computers are used for development and deployment. The development computer is a home PC with an Intel Core i7-4500U CPU, 16 GB RAM, and a 1 TB SATA HDD. The deployment computer has Intel Xeon E5-2620 v4 2.10 GHz processors (8 cores) server, 64 GB RAM, 512 GB SSD, and 1 TB SATA HDD. In addition, Python version 3.7.6 was used as the programming language and programmed with Spyder IDE.
In all experiments, the values of common parameters such as total number of iterations and population size used in each algorithm are chosen to be the same. Equal search agent, equal run, and equal iteration are set in all run algorithms. The search agent used in all algorithms is set to 30, the number of runs is set to 30, and the number of iterations is set to 100. The developed algorithm was first tested in benchmark functions and its results were examined. Then, it was tested on 3 different data sets that are commonly used in the literature. It is aimed to ensure the consistency and generalizability of the algorithm by running the developed algorithm under the same conditions on 3 different data sets.
In the study, Evolopy framework which developed for ANN training, optimization problem solving, clustering operations and feature selection was used. Each algorithm studied may use its own parameters, may use various constant values, and these may vary according to the applied problems. The values in the Evolopy framework are used in the parameter values of the algorithms [62]. In this study, the method in which the number of hidden neurons is (2 × N + 1) was chosen; N is the number of features in each dataset. For each dataset, all input features values are normalized in the range [0, 1] with normalization technique Eq. (15).
5.2 Benchmark Functions and Results
Benchmark functions to test and validate newly created optimization algorithms with different properties. One of the most important properties of these functions is that they are differentiable, decomposable, scalable, continuous, unimodal, bimodal, continuous, and discontinuous. These properties can determine which problems an algorithm will succeed on.
The hybrid algorithm developed in this study was tested using benchmark functions with different characteristics and compared with various optimization algorithms from the literature. These functions, studied in 2 groups as single-mode and multi-mode, are characterized as single-mode functions containing only one global optimum, and functions with more than one local and global optimum are called multi-mode benchmark functions. Functions F1–F7 are called unimodal functions, which have a single solution. This makes the convergence rate very suitable for testing and applying algorithms. As a result, the GWOMFO exploitation capability can be evaluated by using these unimodal functions. In other functions, such as F8–F13, which are multimodal functions and they are useful to assess our proposed algorithm in terms of exploration. For multimode benchmark functions, there is more than one optimal value, and one of them is the global optimum while the other values are defined as local optima. This is a more complex problem than for single-mode benchmark functions. If the discovery process of an evolved algorithm is poorly designed, no effective wide-angle search can be performed, resulting in the algorithm getting stuck in the local optimum. For this reason, these functions seem to be the most difficult problem for many algorithms.
In this study, 13 functions were investigated as single-mode and multi-mode. These functions provide an important starting point to test the reliability of a developed algorithm. There are many local optimal points in the solution spaces for these functions. As the complexity increases, the number of local optima also increases. In the following, we describe in detail each of the benchmark functions used in this study.
These studied functions are listed in Table 11.
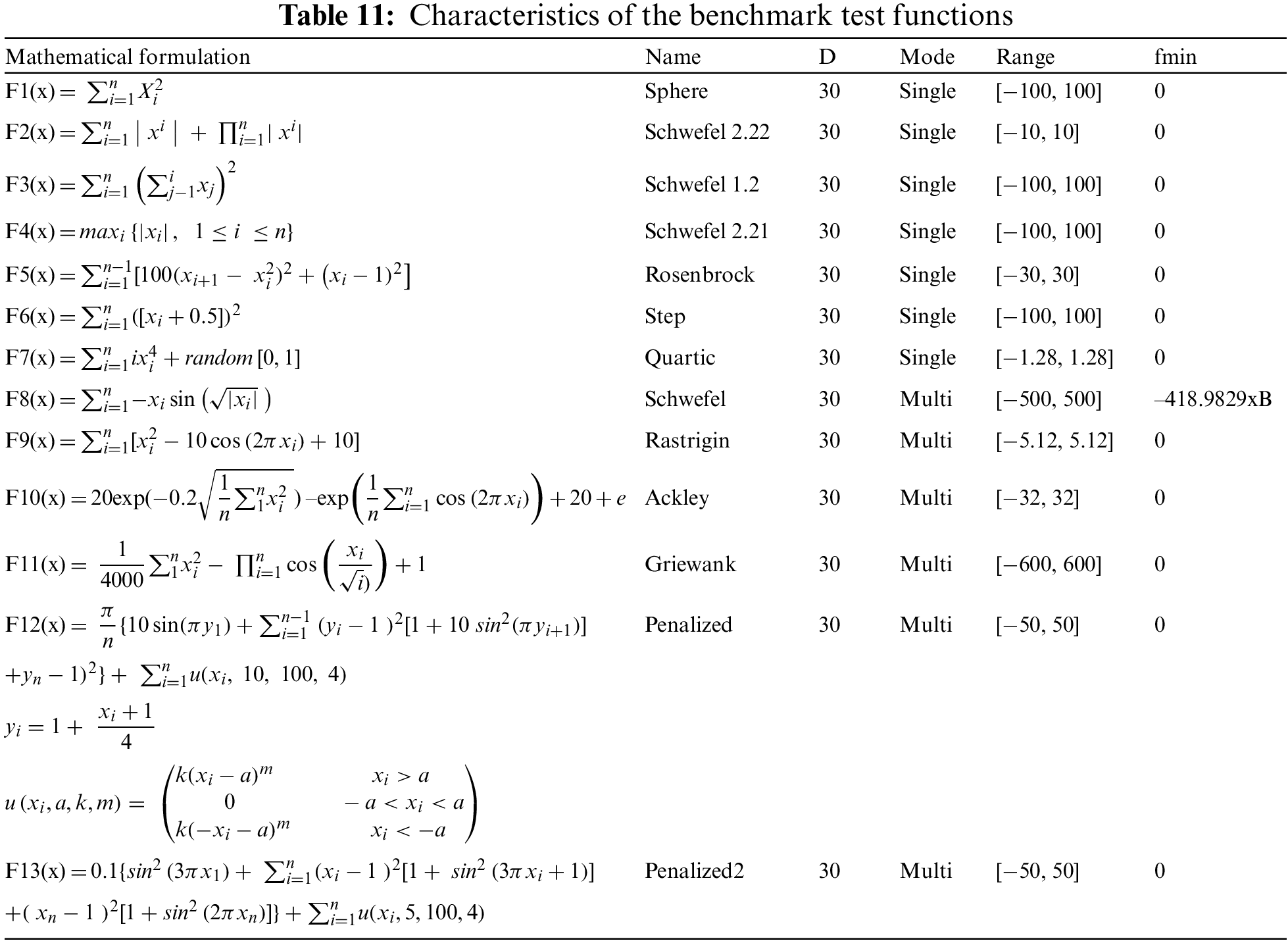
In these functions, F1 is continuous, differentiable, separable and convex. x is a n-dimensional vector located within the range [−100; 100]. The global minimum is located at the origin with a function value of zero. F2 is continuous, differentiable, non-separable and scalable. x is a n-dimensional vector located within the range [−10.0; 10.0]. The global minimum is located at the origin with a function value of zero. F3 is continuous, differentiable, non-separable and scalable. x is a n-dimensional vector located within the range [−100.0; 100.0]. The global minimum is located at the origin with a function value of zero. F4 is continuous, non-differentiable, separable and scalable. x is a n-dimensional vector located within the range [−100.0; 100.0]. The global minimum is located at the origin with a function value of zero. F5 is continuous, differentiable, non-separable and scalable. x is a n-dimensional vector located within the range [−30.0; 30.0]. The global minimum is located at (1, …, 1) with a function value of zero. F6 is discontinuous, non-differentiable, separable and scalable. x is a n-dimensional vector located within the range [−100.0; 100.0]. The global minimum is located at (0.5, …, 0.5) with a function value of zero. F7 is continuous, differentiable, separable and scalable. x is a n-dimensional vector located within the range [−1.28; 1.28]. The global minimum is located at (0, …, 0) with a function value of zero. F8 is continuous, differentiable, separable and scalable. x is a n-dimensional vector located within the range [−500; 500]. The global minimum is located at ±
Each function was run 30 times for the benchmark functions, and the standard deviation and mean were calculated based on the obtained results. The developed hybrid algorithm was applied to benchmark functions, and the results were compared with algorithms based on swarm intelligence such as DE, PSO, MVO, JAYA, SSA, SCA. Table 12 contains the comparison results. This table contains the mean and standard deviation of the algorithms used in the benchmark functions. When examining the means and standard deviations, it was found that GWOMFO generally achieved better means and standard deviations for all benchmark functions.
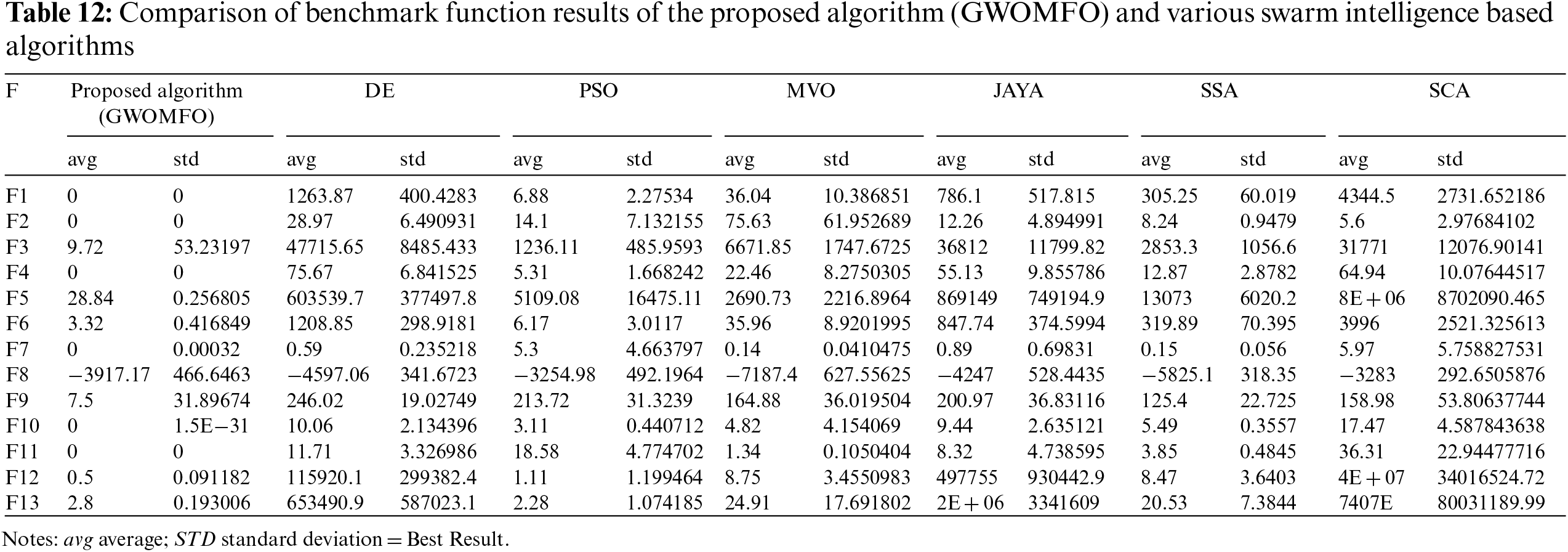
In addition to these results, the average convergence curves of the benchmark functions optimized by GWOMFO are shown in Fig. 2.
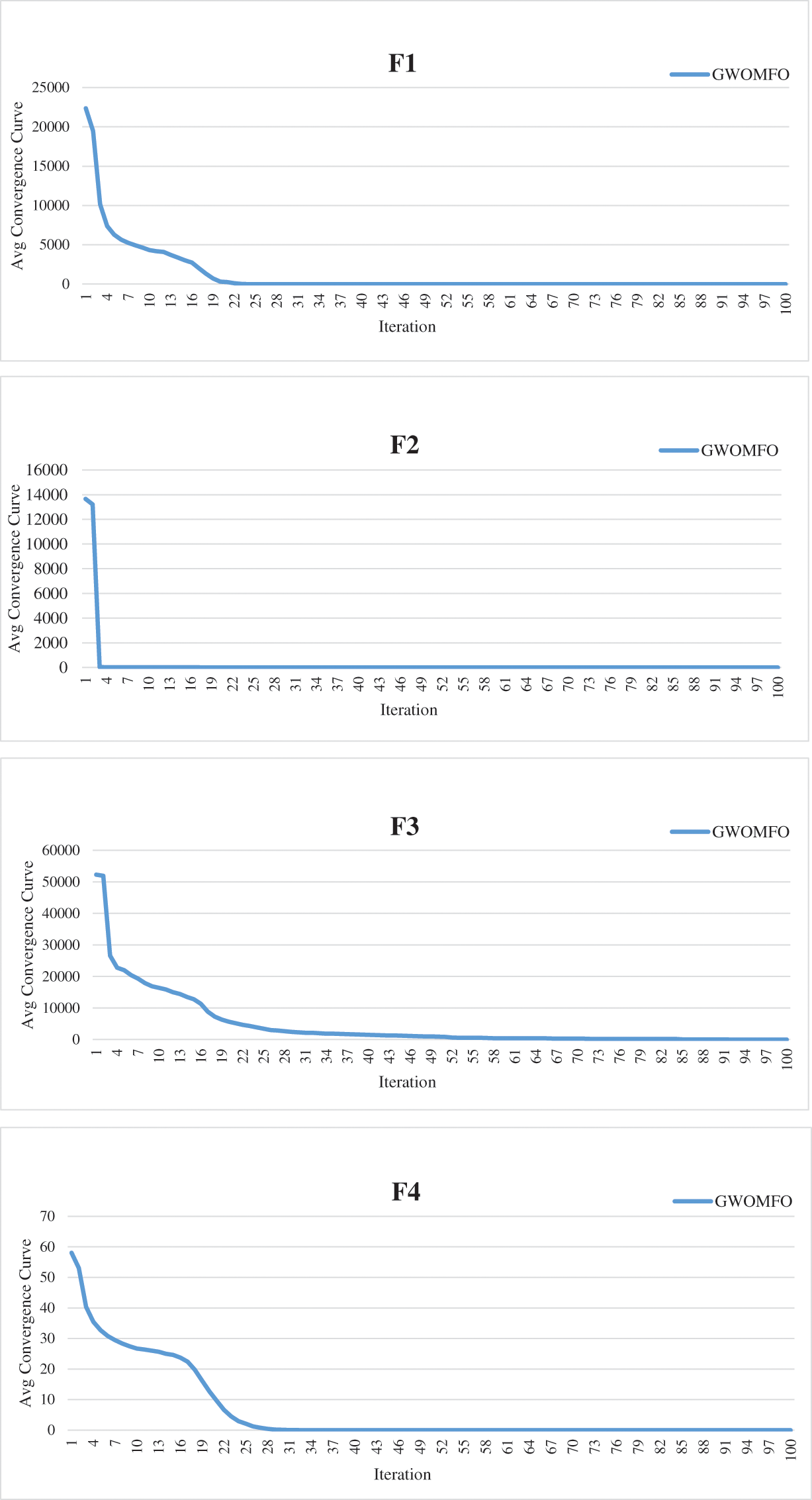
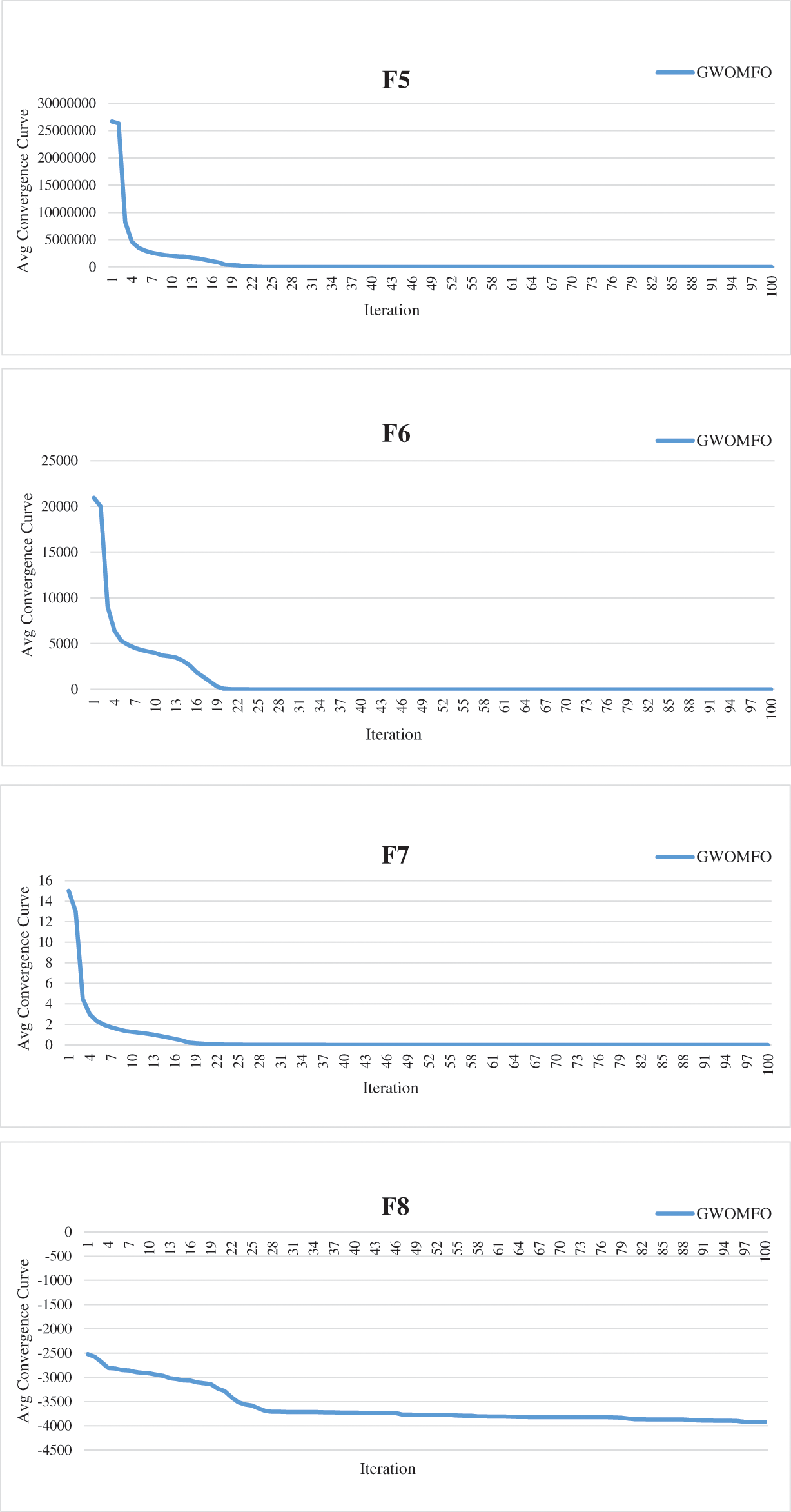
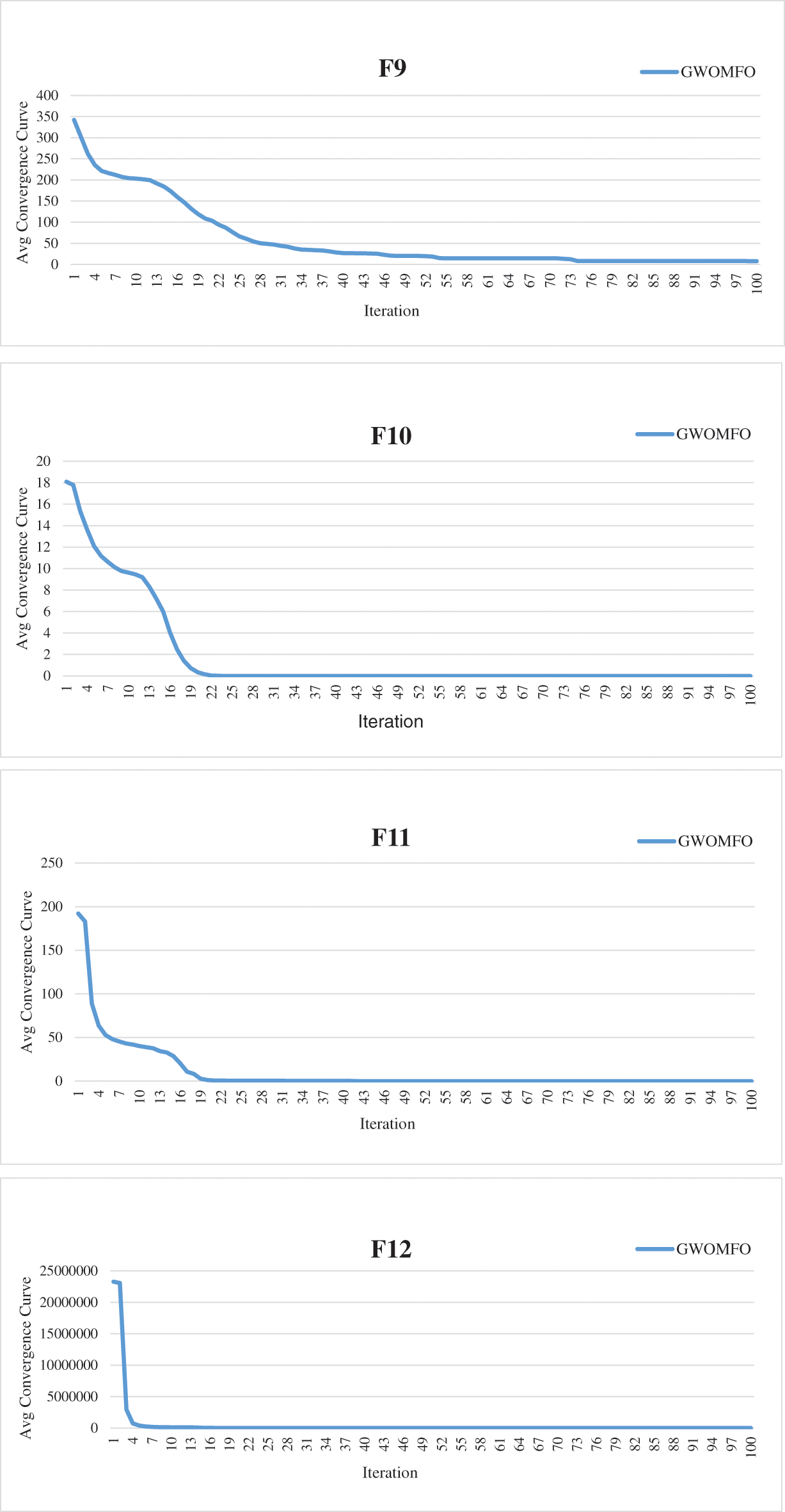
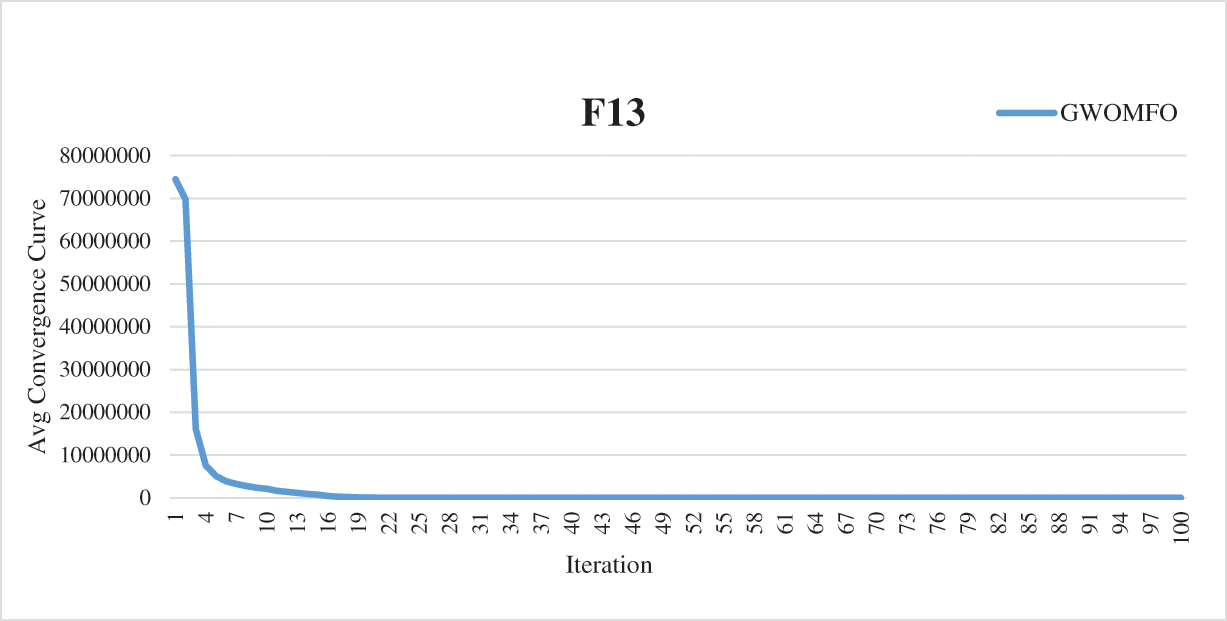
Figure 2: Average convergence curves for benchmark functions optimized with GWOMFO
The graphs in Fig. 2 represent the convergence curves generated for benchmark functions. In these graphs, the horizontal axis represents the index of repetitions, and the vertical axis is the divergence between two consecutive objective function values. The convergence curve shows the value of the objective function compared to the computation time during minimization (model calibration). This testing procedure aims to solve the optimization problems in earlier iterations, reduce the convergence time and obtain a better solution. Thirteen benchmark functions known in the literature were used for the experimental studies. The ultimate goal of optimization is either to reduce the convergence time to obtain the best solution or to increase the efficiency of the algorithm. In this context, the main goal of the developed GWOMFO algorithm focuses on reducing the convergence time, obtaining effective results and improving the local search capability. In this way, the algorithm is designed to reach the solution in fewer iterations. By looking at the change on the y-axis, you can see how fast it converges to the optimal result. In this case, we can say that the most suitable individuals are selected in early iterations to reduce the computational cost of the algorithm.
The GWOMFO algorithm appears to be quite successful in testing benchmark functions. However, the success of the algorithm needs to be demonstrated statistically. For this purpose, Wilcoxon rank sum, a test for data analysis, was applied. It was assumed that the p-value is smaller than 0.05 to express a significant difference. The results obtained are shown in Table 13.
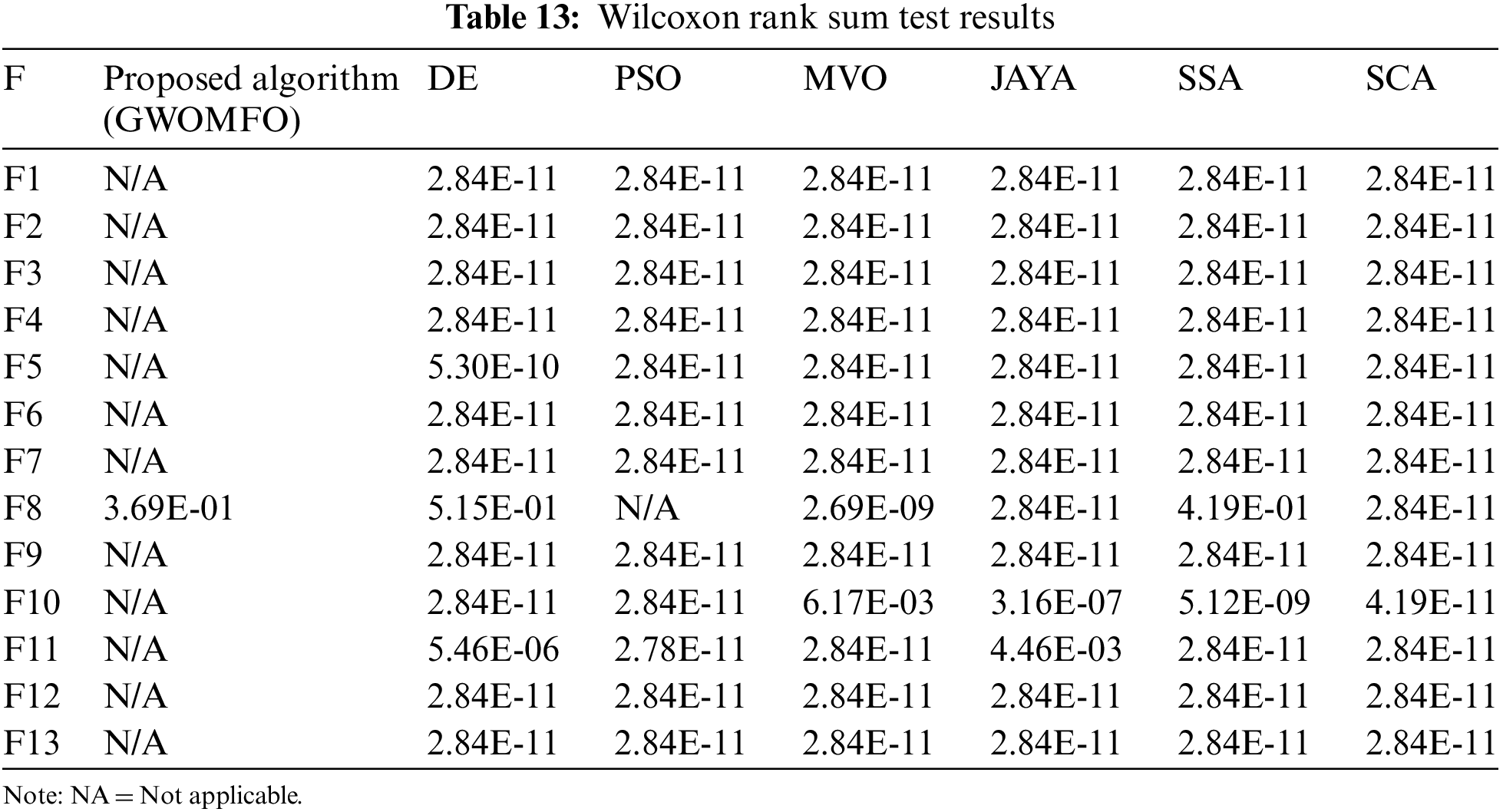
The best algorithm was compared with other algorithms in each statistical test. When examining the results, it was found that the developed algorithm has statistically significant differences. For this reason, it can be concluded that the algorithm is quite successful.
5.3 Network Intrusion Detection Results
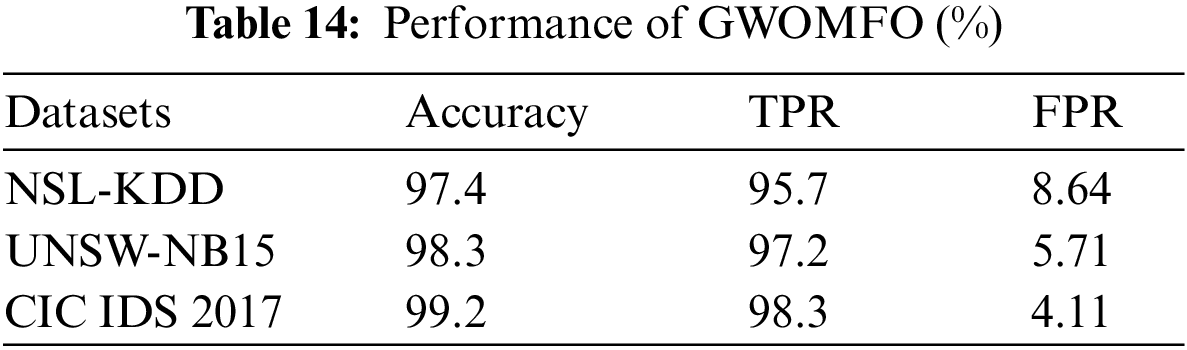
In this section, the results of the hybrid algorithm developed in detecting network attacks are shared. The developed GWOMFO algorithm was applied to 3 different data sets. Confusion matrix was used to evaluate the performance of the proposed technique. The results obtained with 3 different datasets using Accuracy, TPR and FPR metrics are shown in Table 14. The population size was chosen as 30, the number of iterations as 100, and applied.
The developed algorithm was compared with the algorithms on which it is based. The accuracy results obtained are shown in Fig. 3.
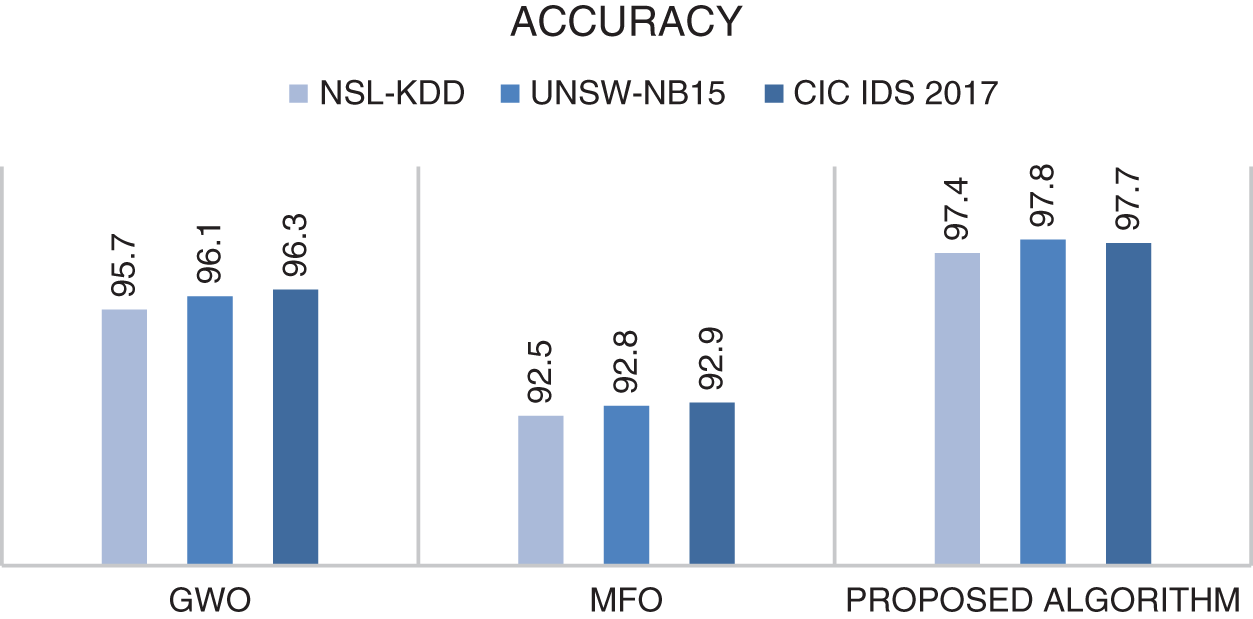
Figure 3: Comparison of accuracy results of GWO, MFO and the proposed algorithm (GWOMFO) on 3 different datasets
It was found that the proposed algorithm achieved the best result in terms of accuracy in all 3 data sets. The proposed algorithm has achieved more successful results than GWO algorithm and MFO algorithm. In other words, better results were obtained by combining GWO and MFO algorithms. However, other criteria within the scope of the study were examined, and the results are shown in Table 15.
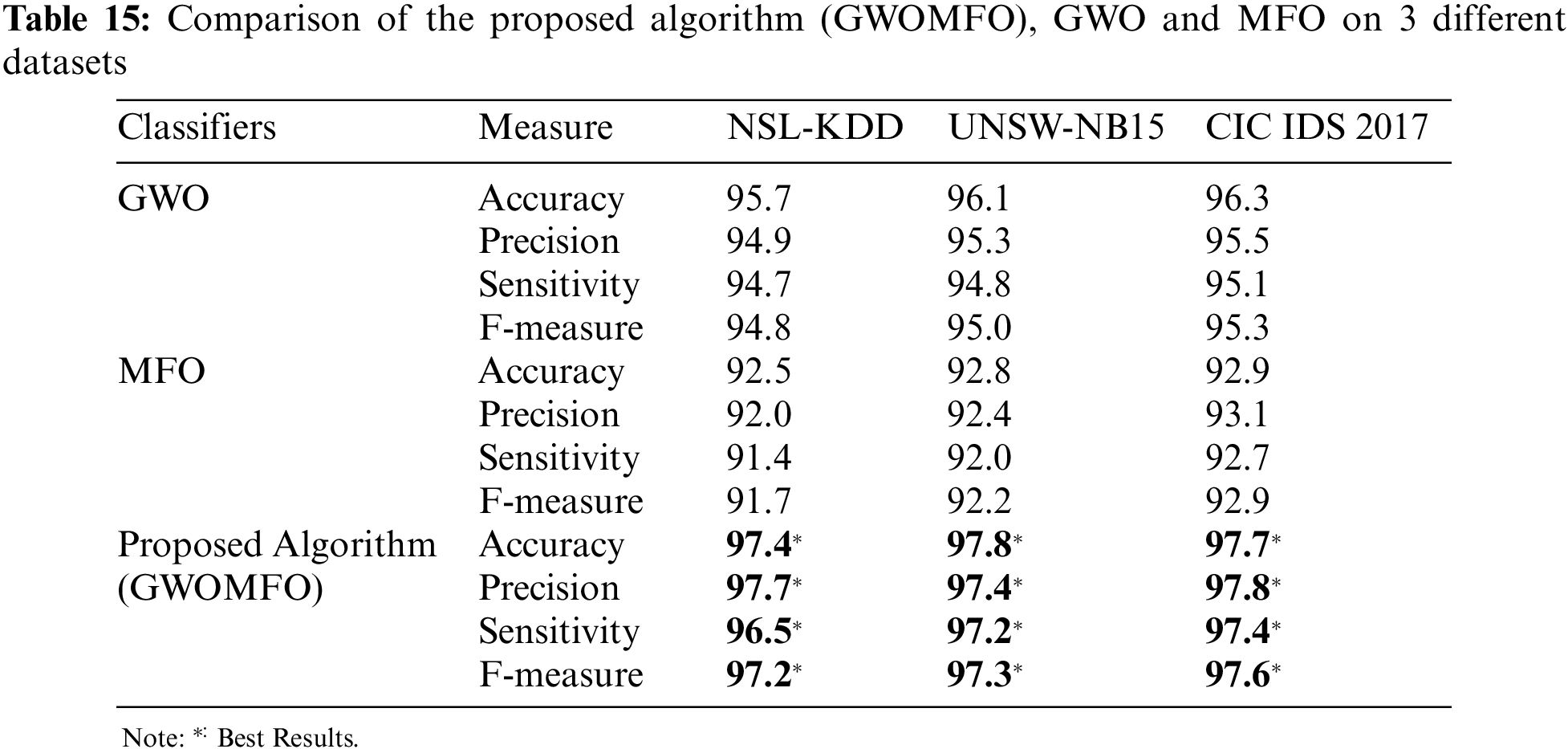
It is found that the developed hybrid algorithm achieves better results in terms of accuracy, precision, sensitivity and F-measure. The successes of various swarm intelligence-based algorithms performing classification processes in the literature are compared to demonstrate the success of the developed hybrid algorithm in network attack detection. For comparison, these swarm intelligence-based algorithms and proposed algorithm were run with the same parameters on 3 datasets. The comparison results considering the accuracy measure are shown in the graph in Fig. 4.
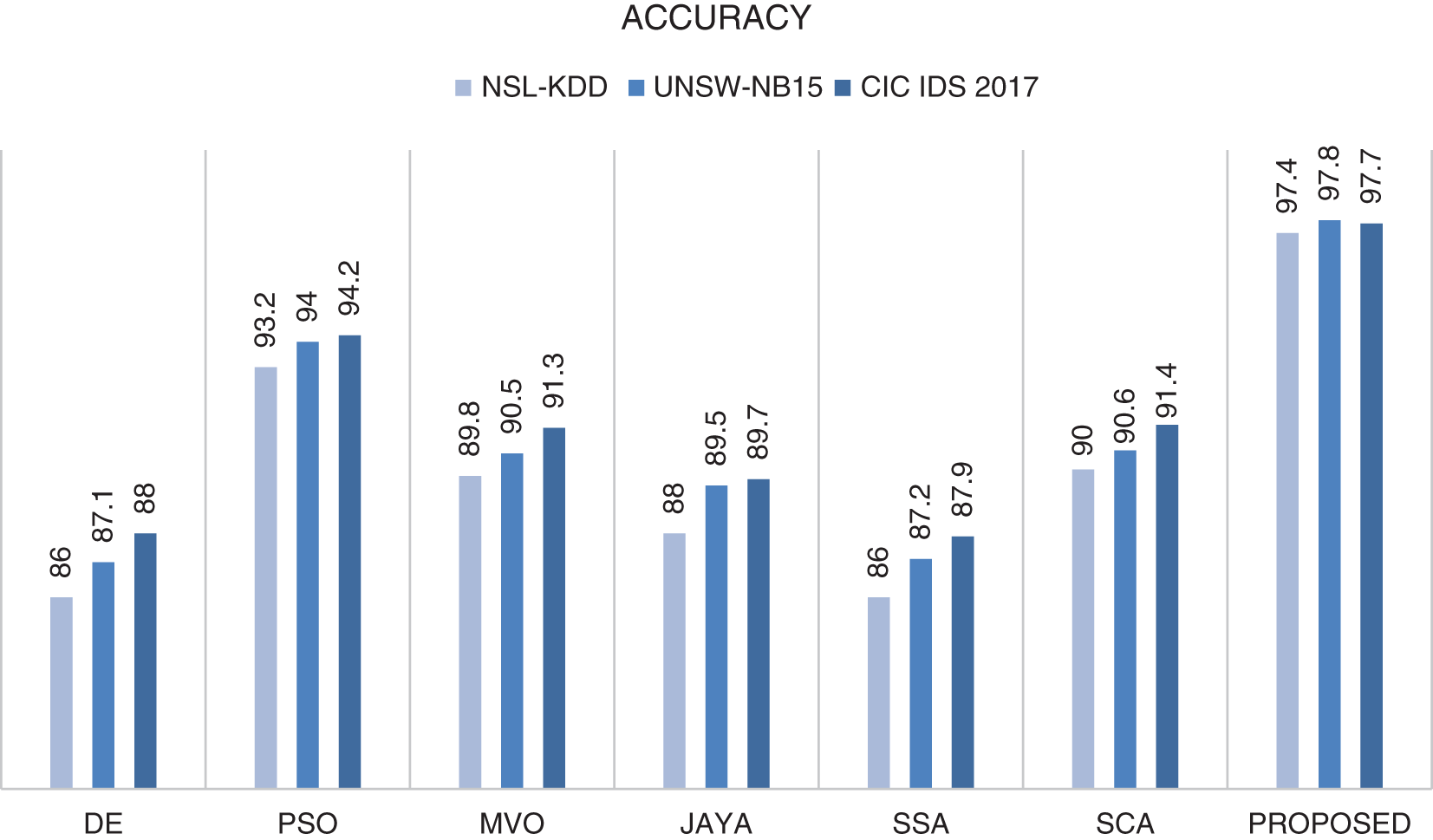
Figure 4: Comparison of the accuracy results of various swarm intelligence based algorithms and proposed algorithm (GWOMFO) on 3 different datasets
It has been shown that the algorithm proposed in the accuracy measurement is the most successful among all the algorithms compared. The results of the comparison considering other metrics are shown in Table 16.
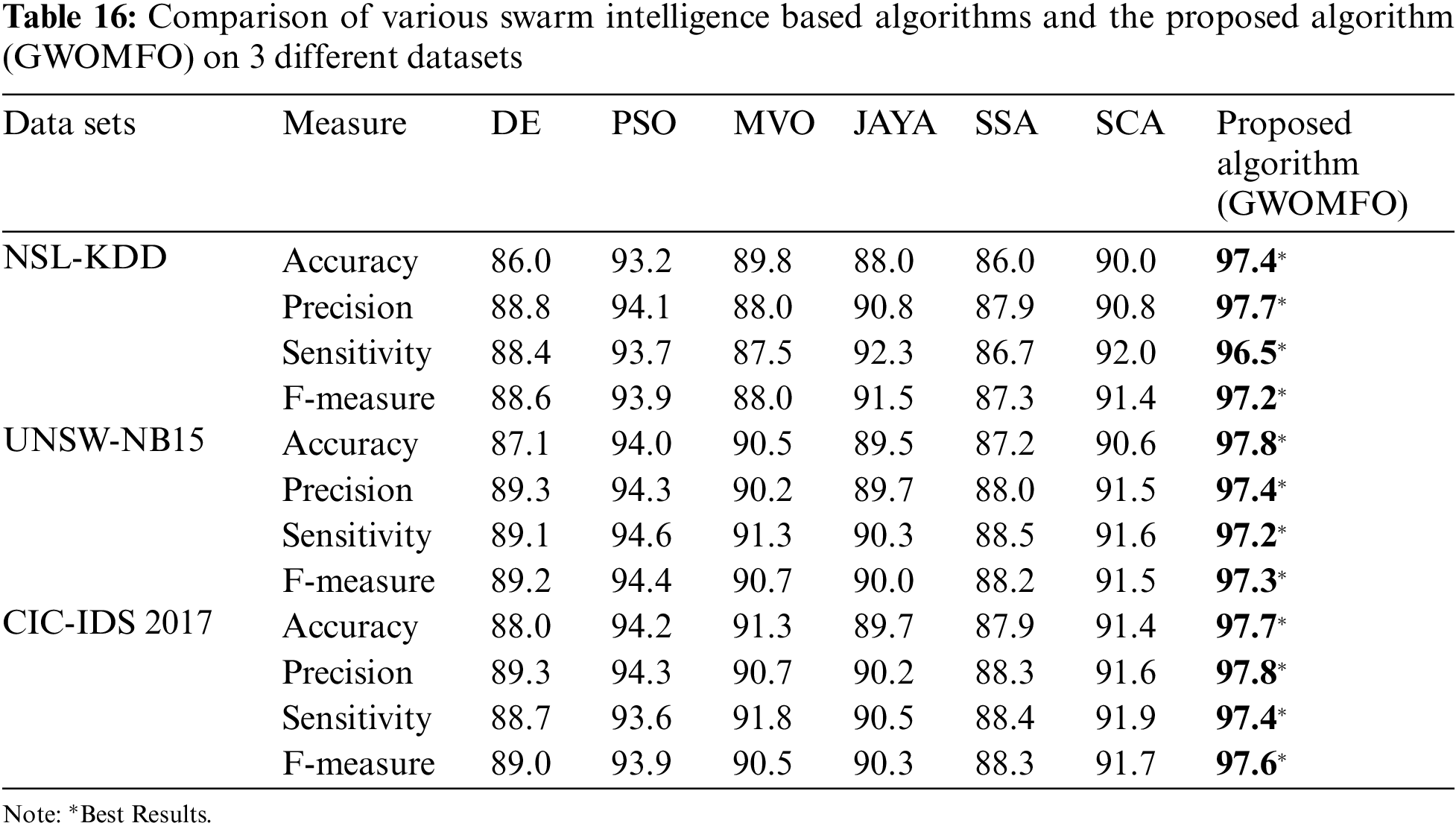
In this study, the performance of the developed algorithm was investigated in three different datasets depending on the type of attack. The obtained results were compared with studies performed on these datasets. Overall, GWOMFO proved to be quite successful and achieved a high detection rate for all types of attacks. The results are shown in Figs. 5–7.
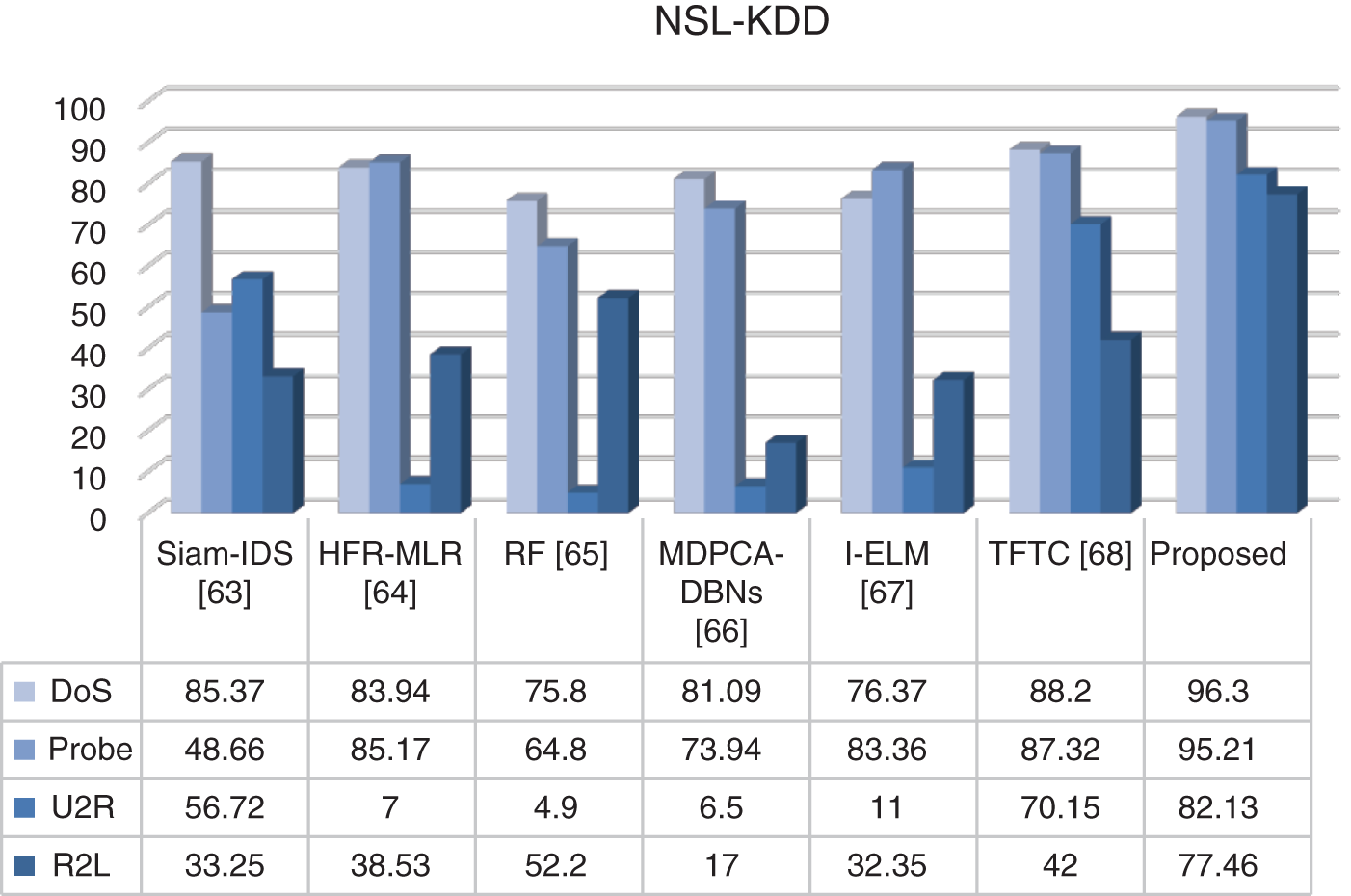
Figure 5: Comparison of TPR results on NSL-KDD dataset
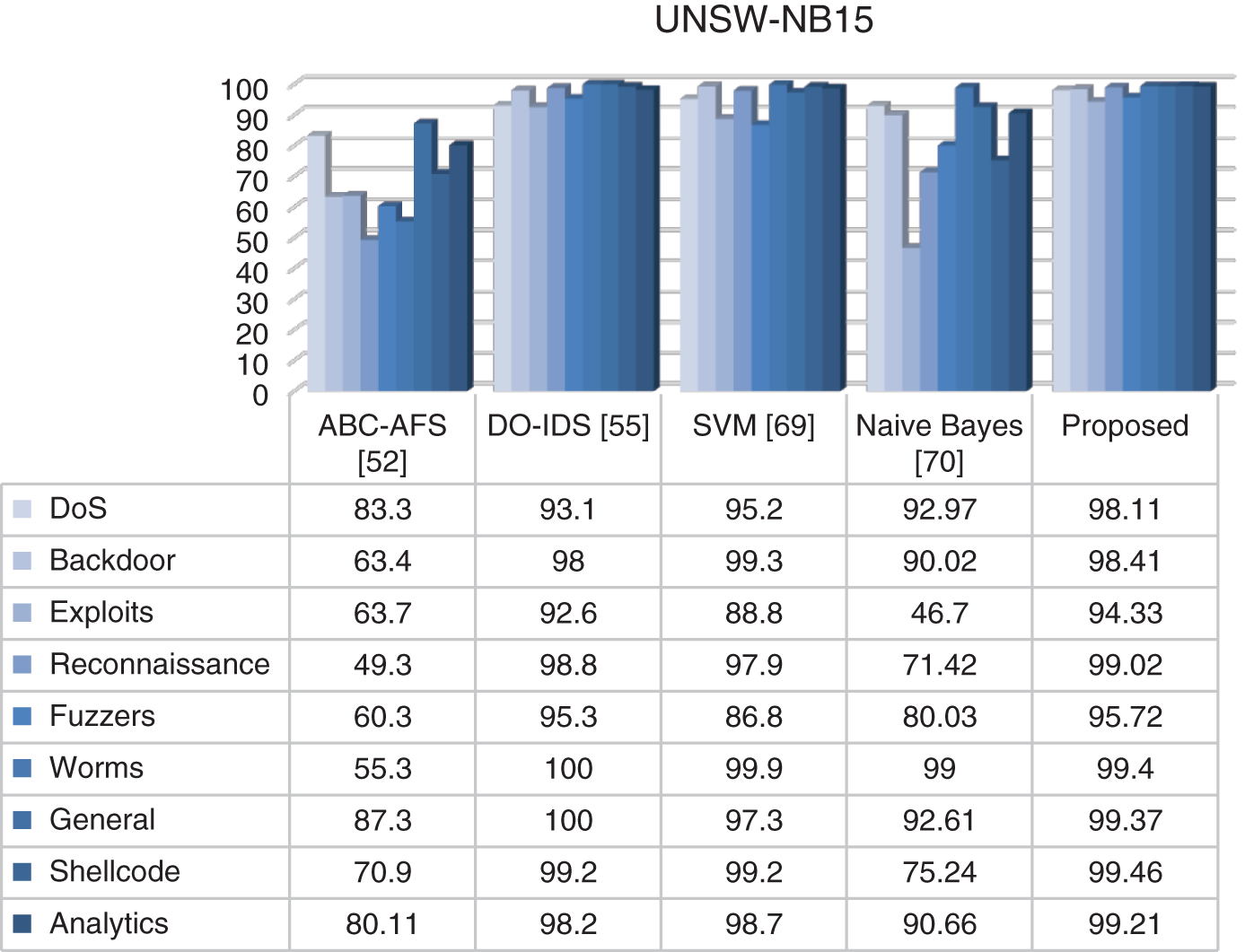
Figure 6: Comparison of TPR results on UNSW-NB15 dataset
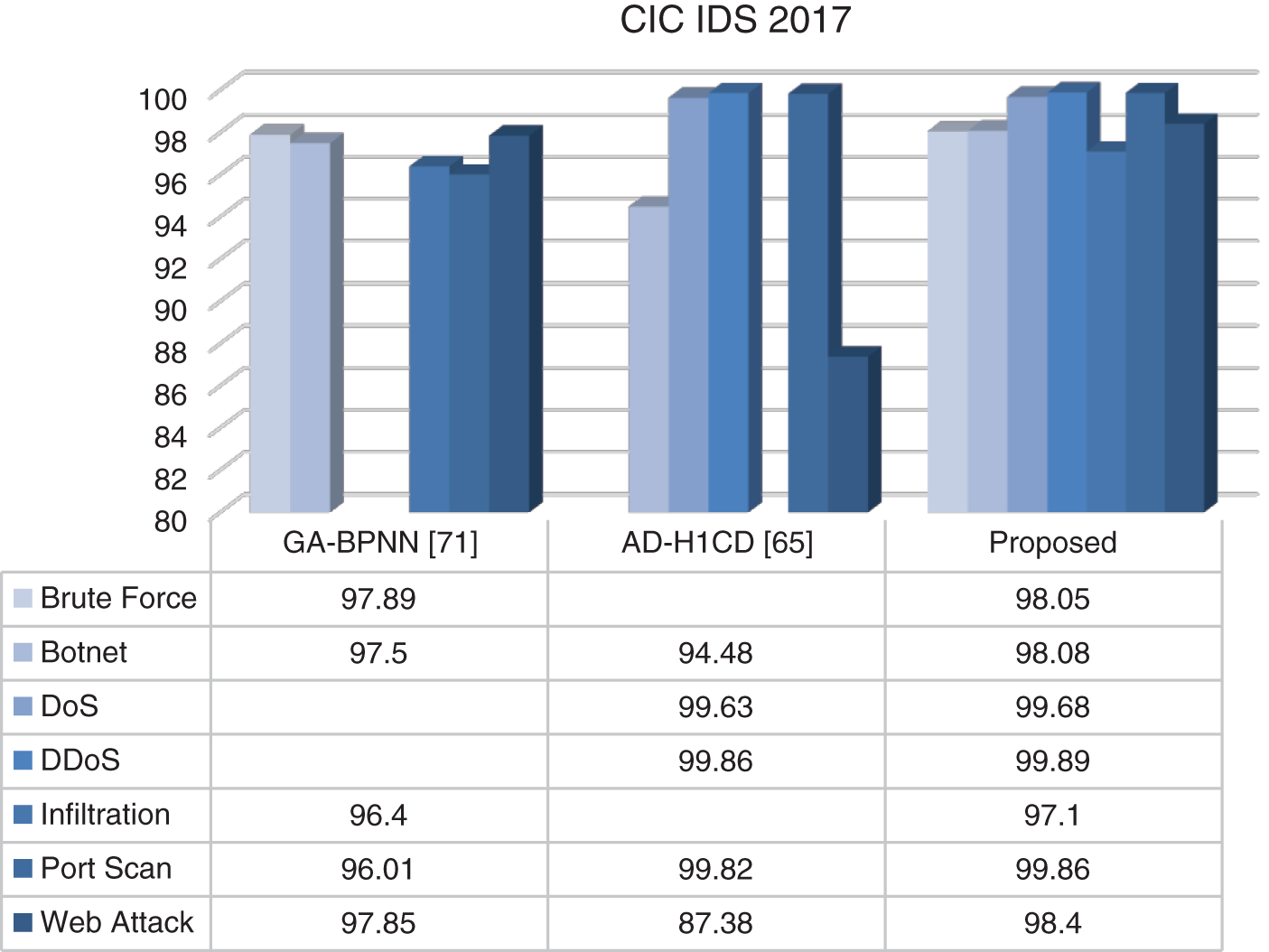
Figure 7: Comparison of TPR results on CIC IDS 2017 dataset
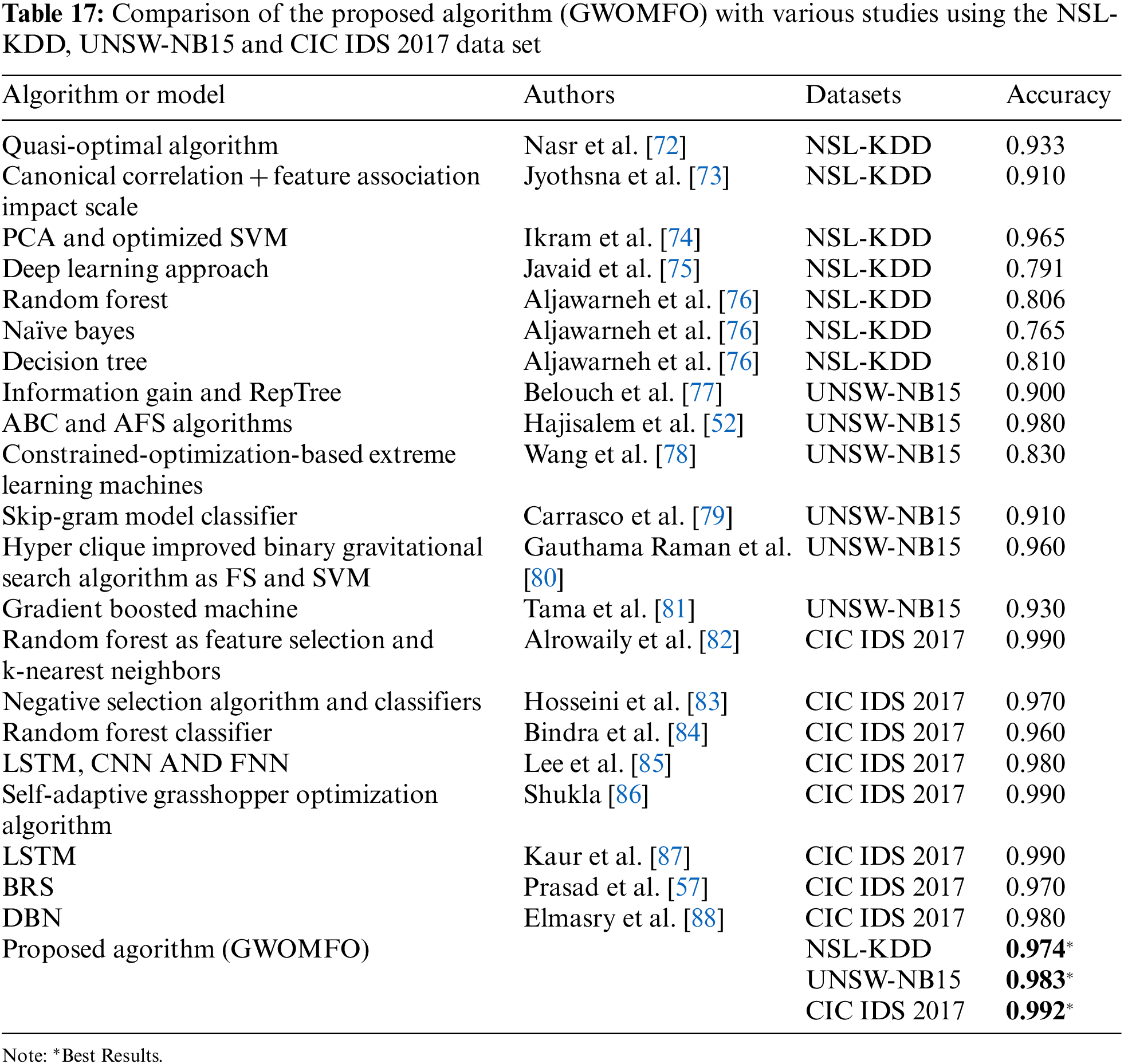
The hybrid algorithm developed in this study was compared with studies using the publicly available data sets NSL-KDD, UNSW-NB15, and CIC IDS 2017. In this study, studies conducted separately on 3 different data sets were examined in detail. The results of these studies were compared using accuracy criteria. The results obtained are presented in Table 17.
In this study, the topic of network attacks and detection is discussed, the data sets commonly used to solve this problem are examined, and the studies in the literature and the results obtained are mentioned. The importance of hybrid solutions to improve the performance of the proposed algorithms for the solution has been highlighted. It has been shown that the use of benchmark functions in the preliminary evaluation of the performance of a developed algorithm provides insight into the performance of the algorithm. This study developed and tested a new hybrid algorithm with NSL-KDD, UNSW-NB15, and CIC IDS 2017 data sets. There is always a need to improve existing methods’ solution quality and develop new methods. Hybrid algorithms can be used to improve the solution quality or performance of the algorithm. In the algorithm developed in this study, the effect of the search agents of the GWO algorithm was improved by hybridizing it with the MFO algorithm. To this algorithm, which was developed based on the GWO algorithm, a new mechanism was added to improve the hunting mechanism of the GWO algorithm. It was observed that the search ability and exploration phase were improved after each iteration, which improved the solution. The obtained results show that the location updates are more successful and efficient depending on the search agents. Unlike studies in the literature, the hybrid algorithm developed in this study was first tested in benchmark functions and then tested on data sets used for network attacks. Performance analyzes were performed by adapting the developed algorithm to 13 benchmark functions. The results obtained were compared with many different studies in this study and the following conclusions were drawn:
i. GWOMFO achieved the best average results on 12 of the 13 benchmark functions compared to other algorithms.
ii. The best classification accuracy was achieved in the NSL-KDD data set with 97.4%.
iii. The best classification accuracy was achieved in the UNSW-NB15 data set with 98.3%.
iv. The best classification accuracy was achieved in the CIC IDS 2017 data set with 99.2%.
v. In general, GWOMFO performed well and achieved high detection rates for all attack types.
The results were compared with the results of different optimization algorithms from the literature. It was found that the developed hybrid model showed a successful result. The success of GWOMFO is due to the newly developed equation, the structure of the algorithm and the parameters used. The obtained results proved that the GWOMFO algorithm is successful in the benchmark functions compared to the algorithms with which it is compared. The successful results obtained on the tested datasets also support the algorithm’s success. By bringing this developed algorithm to the literature, one of the expected goals is to extend techniques that can be adapted to real-world, hard-to-solve problems.
Network security will continue to be a topic that will always be alive. This is because network defense is a necessity. With many recent studies such as [25–28] listed in the related works section of this study, network security is being discussed from many different angles and will continue to be addressed from many different angles and with many new methods. In addition to this study, we are currently working on simultaneous network attack detection, and other possible future work could include the following:
1. Studies may be conducted to further increase the success rates achieved in this study. For this purpose, hybridization with various improved algorithms from the literature can be performed. Also, various improved feature extraction algorithms can achieve better performance.
2. This hybrid approach can be applied to different data sets, and the results can be observed. It can also solve various optimization problems, such as feature selection. To improve network security infrastructure, Deep Learning can be used to develop next-generation intrusion detection systems that detect network threats instantly and with higher accuracy. Developing an IDS model for multi-class data problems using multiple networks in Deep Learning is also possible.
However, a possible limitation of the proposed method is that we tested GWOMFO on only three datasets. It will also be important to test the method on a more recent dataset. We believe that the proposed method can be extended to many domains in the future.
Funding Statement: This work is supported by the Kırıkkale University Department of Scientific Research Projects (2022/022).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Predić, B., Vukić, U., Saračević, M., Karabašević, D., Stanujkić, D. (2022). The possibility of combining and implementing deep neural network compression methods. Axioms, 11(5), 229. DOI 10.3390/axioms11050229. [Google Scholar] [CrossRef]
2. Jukic, S., Saracevic, M., Subasi, A., Kevric, J. (2020). Comparison of ensemble machine learning methods for automated classification of focal and non-focal epileptic EEG signals. Mathematics, 8(9), 1481. DOI 10.3390/math8091481. [Google Scholar] [CrossRef]
3. Ruff, L., Vandermeulen, R., Goernitz, N., Deecke, L., Siddiqui, S. A. et al. (2018). Deep one-class classification. International Conference on Machine Learning, pp. 4393–4402. Stockholm, Sweden, PMLR. [Google Scholar]
4. Adamović, S., Miškovic, V., Maček, N., Milosavljević, M., Šarac, M. et al. (2020). An efficient novel approach for iris recognition based on stylometric features and machine learning techniques. Future Generation Computer Systems, 107, 144–157. DOI 10.1016/j.future.2020.01.056. [Google Scholar] [CrossRef]
5. Resul, D. A. Ş., Bitikçi, B. (2020). Analysis of different types of network attacks on the GNS3 platform. Sakarya University Journal of Computer and Information Sciences, 3(3), 210–230. [Google Scholar]
6. Summers, R. C. (1997). Secure computing: Threats and safeguards. The McGraw-Hill, Inc., New York, U.S.A. [Google Scholar]
7. Baker, S., Filipiak, N., Timlin, K. (2011). In the dark: Crucial industries confront cyberattacks McAfee annual critical infrastructure protection report. 2nd edition, pp. 1–6. Santa Clara, CA: The Center for Strategic and International Studies (CSIS). [Google Scholar]
8. Pehlivanoglu, M. K., Atay, R., Odabaş, D. E. (2019). İki seviyeli hibrit makine Öğrenmesi yöntemi ile saldırı tespiti. Gazi Mühendislik Bilimleri Dergisi, 5(3), 258–272. [Google Scholar]
9. Radoglou-Grammatikis, P. I., Sarigiannidis, P. G. (2019). Securing the smart grid: A comprehensive compilation of intrusion detection and prevention systems. IEEE Access, 7, 46595–46620. DOI 10.1109/Access.6287639. [Google Scholar] [CrossRef]
10. Gupta, D., Gupta, V. (2016). Test suite prioritization using nature inspired meta-heuristic algorithms. International Conference on Intelligent Systems Design and Applications, pp. 216–226. Cham, Porto, Portugal: Springer. [Google Scholar]
11. Mirjalili, S., Mirjalili, S. M., Lewis, A. (2014). Grey wolf optimizer. Advances in Engineering Software, 69, 46–61. DOI 10.1016/j.advengsoft.2013.12.007. [Google Scholar] [CrossRef]
12. Senel, F. A., Gökçe, F., Yüksel, A. S., Yigit, T. (2019). A novel hybrid PSO–GWO algorithm for optimization problems. Engineering with Computers, 35, 1359–1373. [Google Scholar]
13. Teng, S., Wu, N., Zhu, H., Teng, L., Zhang, W. (2017). SVM-DT-based adaptive and collaborative intrusion detection. IEEE/CAA Journal of Automatica Sinica, 5(1), 108–118. DOI 10.1109/JAS.2017.7510730. [Google Scholar] [CrossRef]
14. Guo, C., Ping, Y., Liu, N., Luo, S. S. (2016). A two-level hybrid approach for intrusion detection. Neurocomputing, 214, 391–400. DOI 10.1016/j.neucom.2016.06.021. [Google Scholar] [CrossRef]
15. Khraisat, A., Gondal, I., Vamplew, P., Kamruzzaman, J., Alazab, A. (2020). Hybrid intrusion detection system based on the stacking ensemble of C5 decision tree classifier and one class support vector machine. Electronics, 9(1), 173. DOI 10.3390/electronics9010173. [Google Scholar] [CrossRef]
16. Ahmim, A., Derdour, M., Ferrag, M. A. (2018). An intrusion detection system based on combining probability predictions of a tree of classifiers. International Journal of Communication Systems, 31(9), e3547. DOI 10.1002/dac.3547. [Google Scholar] [CrossRef]
17. Al-Yaseen, W. L., Othman, Z. A., Nazri, M. Z. A. (2017). Multi-level hybrid support vector machine and extreme learning machine based on modified K-means for intrusion detection system. Expert Systems with Applications, 67, 296–303. DOI 10.1016/j.eswa.2016.09.041. [Google Scholar] [CrossRef]
18. Kevric, J., Jukic, S., Subasi, A. (2017). An effective combining classifier approach using tree algorithms for network intrusion detection. Neural Computing and Applications, 28(1), 1051–1058. DOI 10.1007/s00521-016-2418-1. [Google Scholar] [CrossRef]
19. Aslahi-Shahri, B. M., Rahmani, R., Chizari, M., Maralani, A., Eslami, M. et al. (2016). A hybrid method consisting of GA and SVM for intrusion detection system. Neural Computing and Applications, 27(6), 1669–1676. DOI 10.1007/s00521-015-1964-2. [Google Scholar] [CrossRef]
20. Mahmod, M. S., Alnaish, Z. A. H., Al-Hadi, I. A. A. (2015). Hybrid intrusion detection system using artificial bee colony algorithm and multi-layer perceptron. International Journal of Computer Science and Information Security, 13(2), 1. [Google Scholar]
21. Elbasiony, R. M., Sallam, E. A., Eltobely, T. E., Fahmy, M. M. (2013). A hybrid network intrusion detection framework based on random forests and weighted k-means. Ain Shams Engineering Journal, 4(4), 753–762. DOI 10.1016/j.asej.2013.01.003. [Google Scholar] [CrossRef]
22. Panda, M., Abraham, A., Patra, M. R. (2012). A hybrid intelligent approach for network intrusion detection. Procedia Engineering, 30, 1–9. DOI 10.1016/j.proeng.2012.01.827. [Google Scholar] [CrossRef]
23. Mohamad Tahir, H., Hasan, W., Md Said, A., Zakaria, N. H., Katuk, N. et al. (2015). Hybrid machine learning technique for intrusion detection system. 5th International Conference on Computing and Informatics (ICOCI), Istanbul. [Google Scholar]
24. Gupta, M., Shrivastava, S. K. (2015). Intrusion detection system based on SVM and bee colony. International Journal of Computer Applications, 111(10). DOI 10.5120/19576-1377. [Google Scholar] [CrossRef]
25. Kumar, V., Das, A. K., Sinha, D. (2021). UIDS: A unified intrusion detection system for IoT environment. Evolutionary Intelligence, 14(1), 47–59. DOI 10.1007/s12065-019-00291-w. [Google Scholar] [CrossRef]
26. Mousavi, S. K., Ghaffari, A., Besharat, S., Afshari, H. (2021). Improving the security of internet of things using cryptographic algorithms: A case of smart irrigation systems. Journal of Ambient Intelligence and Humanized Computing, 12(2), 2033–2051. DOI 10.1007/s12652-020-02303-5. [Google Scholar] [CrossRef]
27. Al-Qerem, A., Alauthman, M., Almomani, A., Gupta, B. B. (2020). IoT transaction processing through cooperative concurrency control on fog–cloud computing environment. Soft Computing, 24(8), 5695–5711. DOI 10.1007/s00500-019-04220-y. [Google Scholar] [CrossRef]
28. Bhushan, K., Gupta, B. B. (2019). Distributed denial of service (DDoS) attack mitigation in software defined network (SDN)-based cloud computing environment. Journal of Ambient Intelligence and Humanized Computing, 10(5), 1985–1997. DOI 10.1007/s12652-018-0800-9. [Google Scholar] [CrossRef]
29. Stergiou, C., Psannis, K. E., Gupta, B. B., Ishibashi, Y. (2018). Security, privacy & efficiency of sustainable cloud computing for big data & IoT. Sustainable Computing: Informatics and Systems, 19, 174–184. DOI 10.1016/j.suscom.2018.06.003. [Google Scholar] [CrossRef]
30. Mousavi, S. K., Ghaffari, A. (2021). Data cryptography in the internet of things using the artificial bee colony algorithm in a smart irrigation system. Journal of Information Security and Applications, 61, 102945. DOI 10.1016/j.jisa.2021.102945. [Google Scholar] [CrossRef]
31. Yin, C., Zhu, Y., Fei, J., He, X. (2017). A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access, 5, 21954–21961. DOI 10.1109/ACCESS.2017.2762418. [Google Scholar] [CrossRef]
32. Almi’ani, M., Ghazleh, A. A., Al-Rahayfeh, A., Razaque, A. (2018). Intelligent intrusion detection system using clustered self organized map. 2018 Fifth International Conference on Software Defined Systems (SDS), pp. 138–144. Barcelona, Spain, IEEE. [Google Scholar]
33. Kamarudin, M. H., Maple, C., Watson, T., Safa, N. S. (2017). A logitboost-based algorithm for detecting known and unknown web attacks. IEEE Access, 5, 26190–26200. DOI 10.1109/ACCESS.2017.2766844. [Google Scholar] [CrossRef]
34. Naoum, R. S., Abid, N. A., Al-Sultani, Z. N. (2012). An enhanced resilient backpropagation artificial neural network for intrusion detection system. International Journal of Computer Science and Network Security, 12(3), 11. [Google Scholar]
35. Lei, Y. (2017). Network anomaly traffic detection algorithm based on SVM. 2017 International Conference on Robots & Intelligent System (ICRIS), pp. 217–220. Huaian, China, IEEE. [Google Scholar]
36. Mirjalili, S. (2015). The ant lion optimizer. Advances in Engineering Software, 83, 80–98. DOI 10.1016/j.advengsoft.2015.01.010. [Google Scholar] [CrossRef]
37. Doğan, L., Yüzgeç, U. (2018). Robot path planning using gray wolf optimizer. Proceedings of International Conference on Advanced Technologies, Computer Engineering and Science (ICATCES’18), pp. 70. Safranbolu, Turkey. [Google Scholar]
38. Mirjalili, S. (2015). Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowledge-Based Systems, 89, 228–249. DOI 10.1016/j.knosys.2015.07.006. [Google Scholar] [CrossRef]
39. Li, Z., Zhou, Y., Zhang, S., Song, J. (2016). Lévy-flight moth-flame algorithm for function optimization and engineering design problems. Mathematical Problems in Engineering, 2016, 1–22. [Google Scholar]
40. Larose, D. T., Larose, C. D. (2014). Discovering knowledge in data: An introduction to data mining, vol. 4, pp. 411–412. New Jersey, ABD, John Wiley & Sons. [Google Scholar]
41. Omary, Z., Mtenzi, F. (2010). Machine learning approach to identifying the dataset threshold for the performance estimators in supervised learning. International Journal for Infonomics, 3(3), 314–325. DOI 10.20533/iji.1742.4712. [Google Scholar] [CrossRef]
42. Relan, N. G., Patil, D. R. (2015). Implementation of network intrusion detection system using variant of decision tree algorithm. 2015 International Conference on Nascent Technologies in the Engineering Field (ICNTE), pp. 1–5. Navi Mumbai, India, IEEE. [Google Scholar]
43. Chauhan, H., Kumar, V., Pundir, S., Pilli, E. S. (2013). A comparative study of classification techniques for intrusion detection. 2013 International Symposium on Computational and Business Intelligence, pp. 40–43. New Delhi, India, IEEE. [Google Scholar]
44. Bhattacharjee, P. S., Fujail, A. K. M., Begum, S. A. (2017). A comparison of intrusion detection by K-means and fuzzy C-means clustering algorithm over the NSL-KDD dataset. 2017 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), pp. 1–6. Coimbatore, India, IEEE. [Google Scholar]
45. Ullah, I., Mahmoud, Q. H. (2017). A filter-based feature selection model for anomaly-based intrusion detection systems. 2017 IEEE International Conference on Big Data (Big Data), pp. 2151–2159. Boston, USA, IEEE. [Google Scholar]
46. Saleh, A. I., Talaat, F. M., Labib, L. M. (2019). A hybrid intrusion detection system (HIDS) based on prioritized k-nearest neighbors and optimized SVM classifiers. Artificial Intelligence Review, 51(3), 403–443. DOI 10.1007/s10462-017-9567-1. [Google Scholar] [CrossRef]
47. Tavallaee, M., Bagheri, E., Lu, W., Ghorbani, A. A. (2009). A detailed analysis of the KDD CUP 99 data set. 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, pp. 1–6. Ottawa, Canada, IEEE. [Google Scholar]
48. Revathi, S., Malathi, A. (2013). A detailed analysis on NSL-KDD dataset using various machine learning techniques for intrusion detection. International Journal of Engineering Research & Technology (IJERT), 2(12), 1848–1853. [Google Scholar]
49. Tsai, C. F., Hsu, Y. F., Lin, C. Y., Lin, W. Y. (2009). Intrusion detection by machine learning: A review. Expert Systems with Applications, 36(10), 11994–12000. DOI 10.1016/j.eswa.2009.05.029. [Google Scholar] [CrossRef]
50. Moustafa, N., Slay, J. (2016). The evaluation of network anomaly detection systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set. Information Security Journal: A Global Perspective, 25(1–3), 18–31. DOI 10.1080/19393555.2015.1125974. [Google Scholar] [CrossRef]
51. Khammassi, C., Krichen, S. (2017). A GA-LR wrapper approach for feature selection in network intrusion detection. Computers & Security, 70, 255–277. DOI 10.1016/j.cose.2017.06.005. [Google Scholar] [CrossRef]
52. Hajisalem, V., Babaie, S. (2018). A hybrid intrusion detection system based on ABC-AFS algorithm for misuse and anomaly detection. Computer Networks, 136, 37–50. DOI 10.1016/j.comnet.2018.02.028. [Google Scholar] [CrossRef]
53. Boulaiche, A., Adi, K. (2018). An auto-learning approach for network intrusion detection. Telecommunication Systems, 68(2), 277–294. DOI 10.1007/s11235-017-0395-z. [Google Scholar] [CrossRef]
54. Ahmad, U., Asim, H., Hassan, M. T., Naseer, S. (2019). Analysis of classification techniques for intrusion detection. 2019 International Conference on Innovative Computing (ICIC), pp. 1–6. Lahore, Pakistan, IEEE. [Google Scholar]
55. Ren, J., Guo, J., Qian, W., Yuan, H., Hao, X. et al. (2019). Building an effective intrusion detection system by using hybrid data optimization based on machine learning algorithms. Security and Communication Networks, 2019. DOI 10.1155/2019/7130868. [Google Scholar] [CrossRef]
56. Nawir, M., Amir, A., Yaakob, N., Lynn, O. B. (2018). Multi-classi_cation of UNSW-NB15 dataset for network anomaly detection system. Journal of Theoretical and Applied Information Technology, 96(15), 5094–5104. [Google Scholar]
57. Prasad, M., Tripathi, S., Dahal, K. (2020). An efficient feature selection based Bayesian and rough set approach for intrusion detection. Applied Soft Computing, 87, 105980. DOI 10.1016/j.asoc.2019.105980. [Google Scholar] [CrossRef]
58. Panigrahi, R., Borah, S. (2018). A detailed analysis of CICIDS2017 dataset for designing intrusion detection systems. International Journal of Engineering & Technology, 7(3), 479–482. [Google Scholar]
59. D’hooge, L., Wauters, T., Volckaert, B., de Turck, F. (2019). Classification hardness for supervised learners on 20 years of intrusion detection data. IEEE Access, 7, 167455–167469. DOI 10.1109/Access.6287639. [Google Scholar] [CrossRef]
60. Panwar, S. S., Negi, P. S., Panwar, L. S., Raiwani, Y. (2019). Implementation of machine learning algorithms on CICIDS-2017 dataset for intrusion detection using WEKA. International Journal of Recent Technology and Engineering Regular Issue, 8(3), 2195–2207. DOI 10.35940/ijrte.2277-3878. [Google Scholar] [CrossRef]
61. D’hooge, L., Wauters, T., Volckaert, B., de Turck, F. (2019). In-depth comparative evaluation of supervised machine learning approaches for detection of cybersecurity threats. 4th International Conference on Internet of Things, Big Data and Security (IoTBDS), pp. 125–136. Heraklion, Greece. [Google Scholar]
62. Faris, H., Qaddoura, R., Aljarah, I., Bae, J. W., Fouad, M. M. et al. (2016). Evolopy, github. https://github.com/7ossam81/EvoloPy/blob/master/optimizers/. [Google Scholar]
63. Bedi, P., Gupta, N., Jindal, V. (2020). Siam-IDS: Handling class imbalance problem in intrusion detection systems using siamese neural network. Procedia Computer Science, 171, 780–789. DOI 10.1016/j.procs.2020.04.085. [Google Scholar] [CrossRef]
64. Kunang, Y. N., Nurmaini, S., Stiawan, D., Suprapto, B. Y. (2021). Attack classification of an intrusion detection system using deep learning and hyperparameter optimization. Journal of Information Security and Applications, 58, 102804. DOI 10.1016/j.jisa.2021.102804. [Google Scholar] [CrossRef]
65. Ma, C., Du, X., Cao, L. (2019). Analysis of multi-types of flow features based on hybrid neural network for improving network anomaly detection. IEEE Access, 7, 148363–148380. DOI 10.1109/Access.6287639. [Google Scholar] [CrossRef]
66. Yang, Y., Zheng, K., Wu, C., Niu, X., Yang, Y. (2019). Building an effective intrusion detection system using the modified density peak clustering algorithm and deep belief networks. Applied Sciences, 9(2), 238. DOI 10.3390/app9020238. [Google Scholar] [CrossRef]
67. Pajouh, H. H., Dastghaibyfard, G., Hashemi, S. (2017). Two-tier network anomaly detection model: A machine learning approach. Journal of Intelligent Information Systems, 48(1), 61–74. DOI 10.1007/s10844-015-0388-x. [Google Scholar] [CrossRef]
68. Pajouh, H. H., Javidan, R., Khayami, R., Dehghantanha, A., Choo, K. K. R. (2016). A two-layer dimension reduction and two-tier classification model for anomaly-based intrusion detection in IoT backbone networks. IEEE Transactions on Emerging Topics in Computing, 7(2), 314–323. DOI 10.1109/TETC.6245516. [Google Scholar] [CrossRef]
69. Jing, D., Chen, H. B. (2019). SVM based network intrusion detection for the UNSW-NB15 dataset. 2019 IEEE 13th International Conference on ASIC (ASICON), pp. 1–4. Chongqing, China, IEEE. [Google Scholar]
70. Bagui, S., Kalaimannan, E., Bagui, S., Nandi, D., Pinto, A. (2019). Using machine learning techniques to identify rare cyber-attacks on the UNSW-NB15 dataset. Security and Privacy, 2(6), e91. DOI 10.1002/spy2.91. [Google Scholar] [CrossRef]
71. Manimurugan, S., Manimegalai, P., Valsalan, P., Krishnadas, J., Narmatha, C. (2020). Intrusion detection in cloud environment using hybrid genetic algorithm and back propagation neural network. International Journal of Communication Systems, 35(16), e4667. [Google Scholar]
72. Nasr, A. A., Ezz, M. M., Abdulmaged, M. Z. (2016). A learnable anomaly detection system using attributional rules. International Journal of Computer Network and Information Security, 8(11), 58–64. DOI 10.5815/ijcnis.2016.11.07. [Google Scholar] [CrossRef]
73. Jyothsna, V., Prasad, V. R. (2016). FCAAIS: Anomaly based network intrusion detection through feature correlation analysis and association impact scale. ICT Express, 2(3), 103–116. DOI 10.1016/j.icte.2016.08.003. [Google Scholar] [CrossRef]
74. Ikram, S. T., Cherukuri, A. K. (2016). Improving accuracy of intrusion detection model using PCA and optimized SVM. Journal of Computing and Information Technology, 24(2), 133–148. DOI 10.20532/cit.2016.1002701. [Google Scholar] [CrossRef]
75. Javaid, A., Niyaz, Q., Sun, W., Alam, M. (2016). A deep learning approach for network intrusion detection system. Eai Endorsed Transactions on Security and Safety, 3(9), e2. DOI 10.4108/eai.24-5-2016.59124. [Google Scholar] [CrossRef]
76. Aljawarneh, S., Yassein, M. B., Aljundi, M. (2019). An enhanced J48 classification algorithm for the anomaly intrusion detection systems. Cluster Computing, 22(5), 10549–10565. DOI 10.1007/s10586-017-1109-8. [Google Scholar] [CrossRef]
77. Belouch, M., El Hadaj, S., Idhammad, M. (2017). A two-stage classifier approach using reptree algorithm for network intrusion detection. International Journal of Advanced Computer Science and Applications, 8(6), 389–394. DOI 10.14569/issn.2156-5570. [Google Scholar] [CrossRef]
78. Wang, C. R., Xu, R. F., Lee, S. J., Lee, C. H. (2018). Network intrusion detection using equality constrained-optimization-based extreme learning machines. Knowledge-Based Systems, 147, 68–80. DOI 10.1016/j.knosys.2018.02.015. [Google Scholar] [CrossRef]
79. Carrasco, R. S. M., Sicilia, M. A. (2018). Unsupervised intrusion detection through skip-gram models of network behavior. Computers & Security, 78, 187–197. DOI 10.1016/j.cose.2018.07.003. [Google Scholar] [CrossRef]
80. Gauthama Raman, M. R., Somu, N., Jagarapu, S., Manghnani, T., Selvam, T. et al. (2020). An efficient intrusion detection technique based on support vector machine and improved binary gravitational search algorithm. Artificial Intelligence Review, 53(5), 3255–3286. DOI 10.1007/s10462-019-09762-z. [Google Scholar] [CrossRef]
81. Tama, B. A., Rhee, K. H. (2019). An in-depth experimental study of anomaly detection using gradient boosted machine. Neural Computing and Applications, 31(4), 955–965. DOI 10.1007/s00521-017-3128-z. [Google Scholar] [CrossRef]
82. Alrowaily, M., Alenezi, F., Lu, Z. (2019). Effectiveness of machine learning based intrusion detection systems. International Conference on Security, Privacy and Anonymity in Computation, Communication and Storage, pp. 277–288. Cham: Springer. [Google Scholar]
83. Hosseini, S., Seilani, H. (2021). Anomaly process detection using negative selection algorithm and classification techniques. Evolving Systems, 12(3), 769–778. DOI 10.1007/s12530-019-09317-1. [Google Scholar] [CrossRef]
84. Bindra, N., Sood, M. (2019). Detecting DDoS attacks using machine learning techniques and contemporary intrusion detection dataset. Automatic Control and Computer Sciences, 53(5), 419–428. DOI 10.3103/S0146411619050043. [Google Scholar] [CrossRef]
85. Lee, J., Kim, J., Kim, I., Han, K. (2019). Cyber threat detection based on artificial neural networks using event profiles. IEEE Access, 7, 165607–165626. DOI 10.1109/Access.6287639. [Google Scholar] [CrossRef]
86. Shukla, A. K. (2021). Detection of anomaly intrusion utilizing self-adaptive grasshopper optimization algorithm. Neural Computing and Applications, 33(13), 7541–7561. DOI 10.1007/s00521-020-05500-7. [Google Scholar] [CrossRef]
87. Kaur, S., Singh, M. (2020). Hybrid intrusion detection and signature generation using deep recurrent neural networks. Neural Computing & Applications, 32(12). DOI 10.1007/s00521-019-04187-9. [Google Scholar] [CrossRef]
88. Elmasry, W., Akbulut, A., Zaim, A. H. (2020). Evolving deep learning architectures for network intrusion detection using a double PSO metaheuristic. Computer Networks, 168, 107042. DOI 10.1016/j.comnet.2019.107042. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools